Freelancer IT là nghề không những đòi hỏi kinh nghiệm, kỹ năng mà còn sự tâm huyết với nghề. Tuy nhiên, liệu bạn có biết được sự tự do của nghề freelancer IT thật sự có tồn tại hay không? Cùng TopDev tìm ra câu trả lời thông qua bài viết sau.
Nếu là một freelancer IT uy tín, bạn dễ dàng nhận được những hợp đồng lớn. Đồng thời, bạn sẽ kiếm được thu nhập “khủng” trong thời gian ngắn.
Freelancer IT có thể thỏa sức tung hoành theo nhịp độ làm việc của bản thân. Bạn không bị chi phối bởi thời gian như làm việc inhouse; môi trường được thoải mái lựa chọn. Song, mỗi freelancer it cần đảm bảo tiến độ và hiệu suất công việc theo hợp đồng công việc.
Thế nhưng, tính tự do của nghề freelancer IT liệu có tồn tại thực sự? Thực tế cho thấy, những rủi ro của nghề này thật sự là một vấn đề lớn đấy!
Freelancer IT chịu trách nhiệm toàn bộ quá trình
Nếu làm teamwork trong một dự án, bạn phải cộng tác với nhiều đối tượng khác nhau; chia sẻ các nhiệm vụ để cùng nhau thực hiện thì freelancer IT lại khác.
Bạn là một nhân tố làm việc độc lập dựa trên nguyên liệu là các nguồn dữ liệu được các khách hàng cung cấp. Đó là lý do khiến các áp lực trở nên lớn hơn.
Bạn phải chịu trách nhiệm trực tiếp cho những chiến lược, kế hoạch, từng bước đi thực hiện nhiệm vụ. Nếu thiếu tính kỷ luật và chuyên nghiệp sẽ dẫn đến những hậu quả nghiêm trọng.
Những rủi ro tiềm ẩn
Trách nhiệm luôn đi kèm với những rủi ro tồn đọng. Chúng có thể phát sinh bất cứ lúc nào. Và bạn không thể trốn chạy hay bỏ cuộc mà chỉ có các đối diện và giải quyết chúng.
Hãy nhìn vào thực tế để bình tĩnh giải quyết các sự cố có thể xảy ra trong nghề IT tự do. đơn xin nghỉ việc
Freelancer IT but NoFree – Tự do nhưng ràng buộc
Ưu điểm lớn nhất dễ nhận thấy khi nhắc đến freelancer là tự do. Thế nhưng, bề nổi ấy không thể khỏa lấp được những nỗi niềm riêng của các freelancer it. Bạn quên mất tính áp lực của một người làm IT tự do.
Nếu xét trên phương diện về tự do, những người làm việc it tự do dường như luôn phải chật vật trong mê cung deadline cùng những đòi hỏi từ khách hàng. Nhiều lúc nó đáng sợ đến mức các freelancer it quyết định thay đổi vị trí freelancer hoặc thực hiện các dự án phát triển nghề nghiệp khác.
Tính khốc liệt và sự cạnh tranh ngầm giữa các Freelancer IT
Rất ít người thành công với nghề freelancer. Không phải ai cũng đáp ứng được những đòi hỏi của nghề này. Ngay cả những freelancer dày dạn kinh nghiệm; nhiều khi cũng cảm thấy mệt mỏi sau quãng thời gian “lăn lộn” với nghề được cho là “tay làm hàm nhai, tay quai miệng trễ”.
Không những thế, khi freelancer it trở thành xu hướng, thì môi trường làm việc trở nên cạnh tranh và khắc nghiệt hơn. Do vậy, nhiều người làm IT tự do dù có thâm niên lâu năm vẫn luôn tìm kiếm một công việc khác. Điều này giúp họ phải cân bằng công việc này với một công việc khác. Yêu thích, đam mê nhưng mọi thứ phải an toàn, cơ hội phát triển tốt thì mới có thể tiến xa.
Quay trở lại với chuỗi bài “How to” – làm như thế nào, bên cạnh các bài viết liên quan đến Selenium và những thứ linh tinh trong đời sống thường ngày của mình, mình bổ sung chuỗi bài viết này để luyện tập các kỹ năng của bản thân liên quan đến chuyên môn kiểm thử, rèn luyện lối tư duy, dịch và diễn giải cho dễ hiểu nhất từ các bài toán cụ thể trong thực tế.
Những bài toán thực tế – có thể là bạn sẽ gặp rất nhiều nhưng như mình đã nói đâu đó trong các bài viết trước đây, gặp nhiều thậm chí cảm thấy rất quen thuộc, tuy nhiên nếu chỉ nghĩ mà không ghi lại hoặc lưu trữ đâu đó thì trước sau gì cũng bị gió thổi bay, không thì cũng tự bốc hơi mà thôi, chưa kể đến việc thiếu sót mà trong suy nghĩ bạn khó có thể nhận ra. Rồi kể cả việc có kiến thức kỹ năng, nhưng không được luyện tập nó cũng sẽ tự mai một đi.
Chứng minh dễ thấy nhất là việc các anh chàng tay chân cơ bắp, bụng sáu múi vô cùng hấp dẫn, nhưng nếu không tập tành đều đặn thì cái việc cơ bị xịt đi là điều hết sức bình thường nha=)) muốn to thì lại phải tập tiếp. Nói chung, làm gì cũng cần phải có sự luyện tập kiên trì và đều đặn nhá. Quá chuẩn luôn không cần nhiều dẫn chứng nữa.
Ùi, lại lan man rồi, hôm nay mình sẽ đưa ra bài toán về OTP, và cùng nhau suy nghĩ các trường hợp có thể dùng để kiểm thử cái tính năng này nhé!
Nói lại sơ qua về OTP trước đã.
OTP là gì?
OTP là viết tắt của từ One Time Password dịch nôm na sang tiếng Việt là mật khẩu sử dụng một lần. Mã OTP được ra đời để đảm bảo bạn là “người thật” đang thực hiện giao dịch tại thời gian thực. Nó thường dùng được dùng làm lớp thứ 2 để xác minh giao dịch trong giao dịch ngân hàng, xác minh đăng nhập trên tài khoản email, mạng xã hội,…
Ví dụ đơn giản như việc bạn thực hiện chuyển khoản tài khoản ngân hàng, đến bước xác nhận thực hiện giao dịch, phía ngân hàng sẽ gửi cho bạn 1 mã về tin nhắn theo số điện thoại bạn đăng ký, bạn phải nhập đúng mã trong tin nhắn đó thì việc chuyển khoản mới được thực hiện. Việc này để đảm bảo rằng “chính bản thân bạn” là người chuyển tiền đi chứ không phải là một kẻ giả mạo nào đó vô tình hay cố ý tấn công tài khoản của bạn (trừ việc bạn làm lộ hết tất tật các thông tin -.-). Hay ví vụ khác khi bạn thay đổi mật khẩu của Gmail, Facebook bạn cũng sẽ nhận được một mã yêu cầu xác thực trước khi đổi được mật khẩu. OK. Hiểu OTP rồi nhé.
Thông tin thêm quan trọng, bạn có thể nhận được mã xác thực này thông qua tin nhắn SMS, qua cuộc gọi tự động, qua ứng dụng được cài đặt trên smartphone như Smart OTP, Smart Token, hay qua các thiết bị cứng như Token Card…
Chi tiết hơn về OTP các bạn có thể search thêm Google nhé, nói ngắn gọn thế thôi. bây giờ đi vào tiết mục chính.
Các trường hợp kiểm thử OTP
* Quá trình sinh mã OTP
1. Kiểm tra các OTP cần phải được sinh ra và gửi đi sau một khoảng thời gian nhất định nào đó – khoảng thời gian này cần phải đáp ứng yêu cầu nha. Chứ lâu quá phiên đăng nhập hết hạn rồi mới gửi được thì toi! Hoặc thời gian từ khi có yêu cầu cho đến lúc nhận được mã quá lâu thì cần xem xét đến độ trễ của đường truyền để tìm giải pháp thích hợp, tránh để hacker xấu lợi dụng bắt ngang tín hiệu
2. Trong một phiên xác thực, kiểm tra xem số lượng OTP tối đa được sinh ra và gửi đi là bao nhiêu? – Cái này để tránh trường hợp spam hệ thống, vét cạn.
3. Kiểm tra xem các loại ký tự mà OTP hỗ trợ là dạng nào: có loại OTP chỉ là một dãy các số, hoặc chỉ là một cụm chữ cái ngẫu nhiên hay có thể bao gồm cả số lẫn chữ tùy theo yêu cầu thiết kế hệ thống.
4. Kiểm tra để xem xem các mẫu OTP được gửi có dễ đoán hay không? – Cái này cũng tùy thuộc vào việc sử dụng thuật toán nào để sinh mã OTP, nhưng mình cũng có thể kiểm tra liên tục nhiều lần để xem có thể đoán được quy luật sinh mã của hệ thống, mã sinh ra các dãy số có quá đơn giản, dễ suy luận mã tiếp theo hay có vấn đề gì khác hay không?
* Chức năng gửi mã OTP
5. Kiểm tra để đảm bảo được chỉ có điện thoại hoặc email được đăng ký của giao dịch mới nhận được OTP này. Ví dụ ông A thực hiện giao dịch nhưng mà ông B nhận được tin nhắn thì có phải là chết không! :v
6. Kiểm tra chức năng gửi lại OTP xem hoạt động của nó như thế nào? Có đáp ứng được yêu cầu chức năng hay không? Khi nhấn gửi lại liên tục thì hệ thống có đáp ứng hay xử lý như thế nào?
* Việc kích hoạt, sử dụng mã OTP
7. Kiểm tra xem thời gian hết hạn của một OTP là bao lâu? Thường thì sẽ là 30s hoặc 60s gì đó đó. – Nếu như OTP tồn tại quá lâu, cộng với độ trễ khi dữ liệu đồng bộ tới máy chủ các hacker có thể lợi dụng điểm này để giải mã thuật toán OTP và đánh cắp thông tin.
8. Kiểm tra với trường hợp có một OTP đã bị hết hạn cho phiên giao dịch, thì nó có thể sử dụng để xác thực được nữa hay không? Nếu có thì nhất định là fail rồi :)) – Mật khẩu sử dụng 1 lần mà sử dụng nhiều lần vẫn được thì đúng là có gì đó sai sai :v
9. Kiểm tra với trường hợp OTP đã được sử dụng, thì nó có sử dụng được sử dụng được cho lần sau nữa hay không? – Thường thì sẽ không thể sử dụng cho lần sau được. Vì mình đã gặp trường hợp có 1 OTP thì trong ngày đó mình có thể sử dụng đăng nhập và sử dụng nhiều lần được. -.- không biết có phải lỗi hay là cố tình thế
10. Kiểm tra trong trường hợp khi yêu cầu gửi lại mã OTP mới, thì OTP cũ – dù chưa sử dụng để kích hoạt thì có sử dụng được nữa hay không? Tất nhiên phải không sử dụng được nữa thì mới đúng.
11. Kiểm tra trường hợp khi nhập chưa đủ số lượng ký tự yêu cầu của OTP, người dùng có thể thực hiện thao tác tiếp theo không? Ví dụ nhập được 3 ký tự thì nhấn nút Thực hiện/Next, thao tác có được thực thi không?
12. Kiểm tra xem người dùng có thể nhập vào sai OTP tối đa bao nhiêu lần?
13. Kiểm tra với trường hợp nhập sai, hoặc nhập sai OTP quá nhiều lần thì hệ thống sẽ xử lý như thế nào? Hệ thống khoá tạm thời tài khoản người dùng hay hủy giao dịch đang thực hiện hay không? Hay có thông báo xử lý nào đến người dùng hay không?
14. Kiểm tra sau khi giao dịch trước đó bị hủy, hay tài khoản bị khóa tạm thời, sau đó người dùng có thể gửi yêu cầu để hệ thống gửi OTP tiếp nữa hay không?
15. Kiểm tra với trường hợp người dùng cung cấp số điện thoại và email không hợp lệ, sau đó gửi yêu cầu cung cấp OTP, thì hệ thống có phản hồi hay không? và nếu có sẽ phản hồi như thế nào? Nếu không thì làm sao để nhận biết được?
16. Kiểm tra đường dẫn của các hướng dẫn và trợ giúp cho người dùng về OTP của hệ thống có hoạt động bình thường và đúng hay không?
17. Kiểm tra đối với trường hợp người dùng không nhận được thông tin mã OTP, hoặc quá hạn thời gian sử dụng mã OTP đó thì sẽ có hướng dẫn hoặc chỉ dẫn nào để lấy được mã khác hay không?. Nếu có thì kiểm tra xem hoạt động của nó như thế nào? Thường thì sẽ có chức năng cho phép người dùng gửi yêu cầu lấy mã khác khi mã hết hạn hoặc vì một lý do nào đó mà không nhận được mã OTP tương ứng.
Trên đây là 17 ý tất tần tật mà mình nghiên cứu tìm hiểu được, các bạn có ý kiến hay bổ sung gì thì đừng ngần ngại để lại bình luận phía dưới cho mình nhé! Cũng đừng quên chăm chỉ luyện tập nữa nha!
Chia sẻ của bạn Nguyễn Dương Hải về quá trình trở thành một BA từ QC.
Trong một năm trở lại đây, nó là câu hỏi mà mình luôn tìm kiếm và khám phá. Mình có background 6 năm là QC, và chuyển từ QC sang BA dường như là một thách thức rất lớn, không chỉ đơn giản vì nó khó khăn cho bạn, mà còn là cách đánh giá của người khác về bạn nữa. QC có những lợi điểm khi chuyển thành BA, nhưng cũng có không ít nhược điểm, đặc biệt là về mặt mindset, thậm chí là so với một fresher. Hôm nay, mình viết bài này để chia sẻ về việc mình đã rèn luyện những skill cần thiết cho một BA khi vẫn còn là một QC như thế nào. Khi đã có được skill và mindset, vấn để chỉ còn là bạn có muốn follow theo con đường đó hay không.
Như là một QC, mình ngày ngày có nhiệm vụ là dựa vào requirement để viết ra test case bao phủ nó, để đảm bảo sản phẩm làm ra đạt ‘chất lượng’. Như là QC, mình từng coi requirement là tuyệt đối, sản phẩm sẽ hoàn hảo nếu làm giống requirement. Nhưng sự thật là, kể cả mình khi dùng product mình làm ra cũng gặp vấn đề, đừng nói gì end user. Hơn nữa, có những feature mình làm mà chẳng User nào dùng, hoặc được một thời gian thì client nói nên đập đi làm lại!! Mình bắt đầu đặt câu hỏi “Tại sao chúng ta lại làm ra flow này?”, “Nó giúp ích gì cho user?”. Ngắn gọn hơn, mình bắt đầu muốn tham gia vào việc làm ra requirement.
Cách đây hơn 6 năm, ở công ty cũ của mình, khi mình nói là muốn join vào meeting của BA và client, đã có người cười vào mặt mình ^^. Sau đó, mình cứ đợi đến khi BA và team meeting với client là mình mở cửa phòng họp đi vô. Mọi người khá ngạc nhiên nhưng không nói gì vì nói thì client sẽ nghe ^^. Sau đó, mình nhận nhiều feedback về việc tự tiện này và khuyên mình nên quay lại với task của mình. Mình vẫn phải đảm bảo task QC được hoàn thành trong khi spend extra time cho việc này. Ngoài ra, bạn cũng phải vô cùng ý tứ. Thời gian đầu, mình chỉ ngồi im và nghe, rồi dùng kiến thức đó để hỏi BA sau này. Sau này, mình mạnh dạn hơn, khi mình chắc chắn cái mình nói sẽ có value thì hãy nói, và đó là tiền đề để team chấp nhận mình hơn trong những buổi nghe và discuss về requirement.
Những meeting này là kinh nghiệm vô giá. Bạn được nghe ý tưởng từ đầu, cũng giống như bạn là Developer và bạn nhìn thấy những dòng code system đầu tiên vậy. Nó sẽ giúp bạn hiểu về requirement rất nhiều. Không! Không phải là requirement, mà là nhu cầu của khác hàng. Bạn cũng sẽ học được cách nói chuyện và giải thích khách hàng của BA. Tuy nhiên, hãy để ý vị trí của bạn. BA sẽ là người mặc định được nói chuyện với client và đề ra giải pháp. Đừng có thái độ lấn quyền khi bạn chưa chắc bạn đang nói gì. Mình từng NHIỀU lần sai phạm và nó sẽ trả giá đắt đó!
Với khả năng gà vịt của bạn lúc đầu, chắc chắn là sẽ không hiểu hết. Hãy đem thắc mắc của mình, suy nghĩ câu chữ và ý tưởng cho thật kỹ, và đem tới hỏi BA. Lúc đầu, sẽ có rất nhiều câu hỏi stupid và những câu không đáng hỏi ( quá chi tiết, đợi document ra sẽ có). Hãy nhận lỗi và improve. Mình cũng phải cám ơn 2 chị BA ở Pyco Group đã rất kiên nhẫn với mình.
Chưa hết, hãy theo dõi calendar và lịch trình trao đổi với client của BA. Một trong những điều quan trọng nhất của BA là phải biết lấy requirement từ đúng người, đúng thời điểm. Bằng việc tìm hiểu BA lấy được requirement, confirmation này từ ai sẽ là một điều quan trọng sau này cho bạn.
Dần dà, bạn sẽ biết cách nghe và hiểu được cái client muốn là gì. Bạn cũng sẽ biết cách và thời điểm để đặt câu hỏi. Đó sẽ là tiền đề cho những phát triển sau này trong BA skill set.
2/ Nói chuyện với End User
Đây là cái mình học được ở Atlassian Viet Nam. NIHITO – Nothing Important Happen Inside The Office. Mặc dù theo mình thì có rất nhiều cái thú vị ở office, nhưng ngoài kia, khi bạn nói chuyện với end user, sẽ là một trải nghiệm hoàn toàn khác. Chỉ khi bạn thật sự ra ngoài và lắng nghe end user kể về pain point của họ, bạn mới hiểu là product của bạn cần làm gì, để giải quyết điều gì. Việc tìm đúng end user, người sẽ là target của bạn cũng sẽ là một challenge thú vị. Nó sẽ giải quyết rất nhiều yếu điểm trong giải pháp của chúng ta. Có bao giờ bạn ngồi trong phòng họp, bạn, BA, PM,… tranh cãi rất nhiều về việc nên làm feature này thế nào cho tốt, nhưng chưa có ai thực sự có evidence nào để back up cho ý kiến của họ. Đã có ai từng tới để hỏi end user về vấn đề này?
Ở một số công ty lớn, việc làm những buổi UX testing hay UX research/ interview sẽ được handled bởi PO, hoặc 1 role riêng là UX researcher. Tuy nhiên, QC sẽ là một assistant tốt. Lý do là vì:
Bạn có good knowledge về product. Bạn có thể giúp cho test user nắm được một số điểm chính trong hệ thống nếu họ bị stuck. Một mình PO sẽ không làm xuể chuyện này
Như là QC, bạn có con mắt quan sát tốt. Bạn sẽ dễ nhận ra user nào đang cảm thấy thích feature và user nào đang khó chịu với nó. PO thường mang QC vào phòng quan sát để theo dõi và discuss reason với họ về hành vi của end user.
Bạn có những góc nhìn rất thú vị về product. Thường thì PO, hay BA sẽ nhìn product dựa trên happy case là chủ yếu. Còn bạn, với thâm niên của QC, bạn sẽ có khuynh hướng focus vào unhappy case hơn. Tuy nhiên, hãy nhớ chỉ raise lên unhappy case khi mà bạn tin rằng use case này sẽ có ảnh hưởng lớn đến user khi gặp lỗi, làm họ muốn leave. Hãy tập control và loại bỏ những case không quá quan trọng đi
Ở công ty nhỏ, làm product nhỏ, bạn có thể chỉ đơn giản là mang product của bạn, khéo léo hỏi 1 vài đồng nghiệp không làm product này xem họ thấy thế nào về product? Mình từng tổ chức rất nhiều session như vậy, chỉ cần mời được khoảng 5 người là bạn đã có những feedback giá trị về feature của bạn rồi.
Hãy tập lắng nghe complain của mọi người nhiều hơn, và try your best để advice họ ^^, kể cả trong văn phòng và ngoài đời. Bạn sẽ dễ dàng nhận ra là sau này, khi bạn nói chuyện, lời nói của bạn sẽ có xu hướng tập trung để giải quyết vấn đề nhiều hơn là than vãn ^^. Những kinh nghiệm ngoài đời sống cũng sẽ giúp ích rất nhiều. Đừng tự thu mình lại chỉ trong văn phòng làm việc, và cũng đừng suy nghĩ theo hướng ‘mọi việc đã vậy rồi, không sửa dược đâu’
Nói tóm lại, gặp mặt và nói chuyện với end user sẽ giúp bạn có những thông tin và kinh nghiệm vô cùng giá trị để tư vấn, làm cho sản phẩm tốt hơn. Nó cũng sẽ giúp bạn rèn luyện thói quen “speak with evidences”, điều rất quan trọng sau này khi bạn muốn thuyết phục client hay team member của bạn về một feature.
3/ Nâng cao việc communicate với member trong team
Đây là cái mà QC chúng ta thường hay làm, và thường hay làm sai. Mình không biết các bạn thế nào, nhưng có một thời gian mình chỉ đem process, requirement, và rule để đi nói chuyện với bộ phận khác, đặc biệt là với developer. “Bug! Nó sai với requirement!”, “Bản build này fail rồi! Nó có 3 lỗi critical nè!”,…. Như là QC, mình sẽ không bàn đúng sai ở đây. Tuy nhiên, cách tiếp cận đó bạn sẽ không còn dùng được nữa khi là BA. Requirement có thể nói là do bạn tạo ra (hoặc bạn và PO), nhiệm vụ của bạn là thuyết phục client và team member tin rằng đó là approach đúng bằng bằng chứng và lý lẽ. Get được user’s feedback sẽ là một backup quan trọng cho bạn. Chuyển tư duy và cách communicate là một việc quan trọng để trở thành BA.
Hơn thế nữa, dù là QC hay BA, bạn cần phải biết về technical. Đặc biệt là BA, vì giải pháp phải khả thi mới là giải pháp tốt. Giải pháp là vô nghĩa nếu team bạn không thể làm ra nó được, hoặc nó không phù hợp với system hiện tại được. Bạn cần làm việc kỹ hơn với Developer để hiểu rõ system và công nghệ của chúng ta có yếu điểm gì, có thể làm được gì. Hơn thế nữa, sẽ luôn luôn có những thắc mắc từ client về cách làm của Developer và ngược lại. Bạn sẽ là người đứng giữa để giải quyết những khúc mắc đó. Hãy join với Developer khi họ nói về building system, database,… để thu thập thêm kiến thức và học cách chuyển tải nó thành ngôn ngữ cho non-tech member
4/ Quality không phải là quan trọng nhất nữa. Hãy làm quen!
Như mình có đề cập một chút ở phần 2/. Khi là QC, bạn chỉ cần quan tâm về quality. Tuy nhiên, nếu muốn trở thành BA, bạn phải hiểu rằng một product tốt là một product balance được về Cost, Scope và Quality. Đôi khi BA sẽ đi đến quyết định release một feature với những flow chính đảm bảo chỉ để bắt kịp với xu thế thị trường, hoặc bạn chưa biết là User phản ứng thế nào nên bạn chỉ release ra với mục đích lấy thêm feedback. Bạn sẽ phải tập làm quen và chấp nhận với những mindset đó.
Sẽ rất fun, mình hứa với bạn đấy ^^! Đây là những công việc hồi đó mình chịu làm extra cho team:
Update requirement: Tới hỏi BA “Cái flow này thì sao chị?”, thì BA nói “Uh, em nghĩ đúng rồi đó. Chị bận quá! Em giúp chị update được không?”. Hãy cố gắng nhận những task nhỏ, đã có ví dụ về structure từ trước để add vào requirement. Thường là requirement cho Edge cases. Nó sẽ giúp bạn hiểu hơn về cách làm ra document.
Làm culi hỏi việc cho Developer: Developer hay có suy nghĩ là mình làm gì cũng được, miễn sao thằng QC này cho mình pass là được, nên thay vì là làm đúng theo cái BA muốn, thì chuyển nó thành làm đúng theo cái QC muốn. Điều này dẫn đến việc Dev sẽ hỏi bạn về expect của bạn, thay vì là BA. Đương nhiên, như là QC bạn sẽ cần hỏi BA về những quyết định của mình. Dần dà, thậm chí có một số những quyết định nhỏ bạn có thể tự quyết định, và nói lại với BA update document sau
Tập vẽ User flow: Theo mình thấy, User flow là thứ ngôn ngữ đơn giản và chung nhất mà tech và non-tech có thể hiểu được. Mình hay dùng cái này để nói chuyện với mấy anh Dev. Rồi về sau nó có thể được add vào text requirement luôn. Đôi khi chỉ đơn giản là người ta chụp cái hình bạn vẽ nguệch ngoạc trên bảng thôi ^^.
Handle một số job về database: Database testing sẽ tốt. Ngoài ra, hồi xưa, client của mình thỉnh thoảng còn có nhu cầu kêu team mình export ra data cho người ta theo kiểu “Trong tuần này có bao nhiêu thằng User tăng 10 fan vậy?” Nếu không quá bận, QC có thể làm nó được. Hiểu về database system sẽ là một điều rất tốt cho vị trí BA sau này.
Sau này, bạn sẽ thấy có những công ty yêu cầu bạn biết vẽ rất nhiều loại diagram, và có hiểu biết về cả database structure nữa. Những công việc kia sẽ là hành trang quý báu cho bạn khi bước tiếp như là BA.
Lời kết
Mình hy vọng qua bài viết này các bạn QC nói riêng cũng như các bạn đang muốn chập chững bắt đầu công việc BA nói chung sẽ có những bước đi đầu tiên hiệu quả cho việc trở thành BA của bạn. Đương nhiên, để trở thành một BA thực thụ và chuyên nghiệp sau này sẽ còn nhiều điều bạn phải học, và tất cả những điều mình nói ở trên bạn sẽ phải làm cho thật nhuần nhuyễn. Chúc bạn thành công trên con đường trở thành BA!
Bài viết được sự cho phép của tác giả Edward Thiên Hoàng
Cùng với Algorithm thì System Design là một phần rất quan trọng trong phỏng vấn và tuyển dụng, nhất là bạn ứng tuyển với vị trí từ Senior trở lên. Và để cùng tôi chuyển bị tốt cho đợt phỏng vấn tuyển dụng sắp tới, ta hãy cùng nhau tìm hiểu về những điều cơ bản và sơ lược nhất về thiết kế hệ thống nhé. Nói trước đây là một bài viết siêu dài, mời các bạnhãy ngồi xuống thư giãn và làm ly trà sữa cho tăng mood và bật nhạc thư giãn trước khi đọc bài nhé.
Hệ thống phân tán (distributed system) là hệ thống phần mềm mà các thành phần cấu tạo nên nó nằm ở trên các máy tính khác nhau được kết nối thành mạng lưới (network). Các máy tính này phối hợp hoạt động với nhau để hoàn thành một nhiệm vụ chung bằng cách trao đổi qua lại các thông điệp (message)
Nói nôm na là hệ thống phân tán là việc hệ thống bạn có nhiều quá trình xử lý độc lập trên nhiều nhiều server vật lý khác nhau.
Với các hệ thống doanh nghiệp lớn (enterprise) đòi hỏi sự linh hoạt trong mở rộng bảo trì thì distributed system là một lựa chọn hoàn hảo.Và các tính chất chính để hình thành một hệ thống phân tán là: Khả năng mở rộng(Scalability), Độ tin cậy (Reliability), Tính khả dụng (Availability), Hiệu suất (Efficiency) và Tình mở rộng và khả năng bảo trì (Manageability).
1. KHẢ NĂNG MỞ RỘNG (SCALABILITY)
Scalability là khả năng mở rộng (scaling) của hệ thống (system), quy trình (process) hay mạng lưới (network), với nhu cầu gia tăng về số lượng công việc tăng theo thời gian của mô hình kinh doanh (business model).
Mô hình kinh doanh có thể mở rộng quy mô vì nhiều lý do như gia tăng khối lượng dữ liệu lưu trữ (data storage) hay khối lượng công việc (process/request) , ví dụ: số lượng truy cập hay đặt hàng của một hệ thống thương mại điện tử. Và yêu cầu của sự mở rộng phải đạt được nhu cầu này mà không làm giảm hiệu suất, nói chung Scalability là đáp ứng được sử mở rộng hay giảm theo kích thước của hệ thống theo thời gian.
Có hai dạng scaling là mở rộng theo chiều ngang (vertical scaling) và mở rộng theo chiều dọc (horizontal scaling).
– Vertical scaling: là cách mở rộng server hiện tại bằng cách nâng cấp độ mạnh (power) bằng cách nâng cấp CPU, Ram, Storage, v.V… Vertical-scaling thường bị giới hạn bởi vượt quá khả năng về cấu hình vật lý hiện đại hay độ trễ khi “chẳng may” Server bị downtime để nâng cấp hay deploy hệ thống.
– Horizontal scaling: là cách mở rộng bằng cách thêm nhiều Node/Server vào một mạng lưới đang có, làm tăng khả năng chịu tải có hệ thống. Cách làm này rẻ và dễ làm hơn so với Vertical-scaling, đặc biệt là rất dễ dàng downsize cũng như upsize hệ thống
– Horizontal scaling: là cách mở rộng bằng cách thêm nhiều Node/Server vào một mạng lưới đang có, làm tăng khả năng chịu tải có hệ thống. Cách làm này rẻ và dễ làm hơn so với Vertical-scaling, đặc biệt là rất dễ dàng downsize cũng như upsize hệ thống
Một ví dụ của Horizontal-scaling là MongoDB và Cassandra, cả hai đều cung cấp sẵn những phương pháp để scale hệ thống bằng cách thêm nhiều node vào hoặc xóa bớt các node mà không hề có độ trễ (zero downtime). Và một ví dụ khác về Vertical-scaling là MySQL, nó có thể dễ dàng chuyển đổi một Server đang chạy sang một Server mới lớn hơn khỏe hơn, nhưng quá trình có downtime.
2. ĐỘ TIN CẬY (RELIABILITY)
Reliability có thể giải thích dân dã rằng đó là độ “lì” của hệ thống có nghĩa là hệ thống sẽ tiếp tục cung cấp dịch vụ của mình ngay khi có một hoặc nhiều thành phần (phần mềm/phần cứng) của hệ thống bị lỗi. Reliability là thành phần chính trong bất cứ một hệ thống phân tán (distributed system) nào, bởi vì trong một hệ thống như vậy, mọi hỏng hóc của một thành phần nào đó sẽ được thay thế một thành phần đang khỏe mạnh khác, đảm bảo luôn hoàn thành nhiệm vụ yêu cầu.
Ví dụ của độ tin cậy là, một trang thương mại điện tử hay hệ thống ngân hàng (banking) mọi thông tin về giao dịch (transaction) của người dùng sẽ không bao giờ bị hủy do lỗi server đang chạy giao dịch đó, mỗi server bị lỗi sẽ phải được thay thế ngay bởi một bản sao chứa đầy đủ thông tin của server đó.
Để đạt được độ tin cậy, hệ thống phải có chế độ back-up real time của từng thành phần trong hệ thống, đây cũng là một thách thức về mặt kỹ thuật cũng như chi phí của dự án.
3. TÍNH SẴN SÀNG (AVAILABILITY)
Tính sẵn sàng là thời gian một hệ thống vẫn hoạt động bình thường trong một khoảng thời gian cụ thể, đây là thước đo đơn giản về tỷ lệ phần trăm thời gian mà hệ thống hoạt động liên tục trong một khoảng thời gian bình thường. Ví dụ như một chiếc xe hơi có thể chạy trong nhiều tháng mà không cần bảo trì bảo dưỡng, thì có thể nói là chiếc xe đó có tính availability cao. Nếu chiếc xe hơi đó ngừng hoạt động để đem tới gara để bảo trì, nó được coi là không availability trong thời gian đó.
Sự khác nhau của độ tin cậy (reliability) và tính sẵn sàng (availability):
Nếu hệ thống có tính reliability thì nó chắc chắn sẽ có availability, tuy nhiên hệ thống có tính availability không có nghĩa là nó có tính reliability. Nói một cách khác thì reliability có nghĩa là nó có tính high availability, tuy nhiên vẫn có thể đạt được tính availability với một hệ thống không có tính reliability bằng cách giảm thiểu tối đa thời gian bảo trì, sửa chữa. Hãy lấy một ví dụ, một hệ thống eCommerce có tỷ lệ availability lên đến 99,99% trong hai năm đầu tiên nó bắt đầu, nhưng hệ thống có một lỗi tiềm ẩn về bảo mật mà trong quá trình kiểm thử (testing) không phát hiện ra, khách hàng không hề biết về điều đó và họ vẫn rất hạnh phúc (happy) với hệ thống, cho đến một ngày đẹp trời vào bỗng nhiên lỗi tiềm ẩn đó bị khai thác dẫn đến hệ thống giảm tính sẵn sàng trong một thời gian dài hơn bình thường cho đến khi lỗi được “hot fix” ngay lập tức.
Kỳ thực mà nói một hệ thống có độ tin cậy cao (high reliability) gần như rất khó đạt được trong thực tế, mà hầu như chúng ta chỉ hướng tới một hệ thống có tính sẵn sàng cao (high availability) mà thôi.
4. HIỆU SUẤT (EFFICIENCY)
Hiệu suất của một hệ thống phân tán là khả năng chịu tải (high load) và thời gian phản hồi (low latency). Có nghĩa là một hệ thống có khả năng chịu được nhiều request đồng thời với độ trễ thấp là một hệ thống có hiệu suất cao. Thông thường nó được đo đếm bằng số lượng request nó nhận được và phản hồi trong một khoảng thời gian, thường được tính bằng giây. Ví dụ một hệ thống eCommerce có hiệu suất là chịu được 5k lượt đặt hàng trên một giây — 5k order / second, hay 500k lượt người cùng truy cập vào cùng một thời điểm.
5. TÍNH MỞ RỘNG VÀ KHẢ NĂNG BẢO TRÌ (MANAGEABILITY)
Một tính chất quan trọng khác của một distributed system đó là khả năng dễ dàng mở rộng và bảo trì của hệ thống, nói cách khác là tốc độ của hệ thống khi thực hiện sửa chữa (repair) hay bảo trì (maintain) khi cần, nếu thời gian trên càng cao thì tính availability càng thấp. Để đạt được điều này, hệ thống cần phải dễ dàng phát hiện lỗi hoặc lỗi tiềm tàng nếu có, khả năng hiểu nhanh được nguyên nhân lỗi (root cause), dễ dàng thực hiện các thay đổi cần thiết để điều chỉnh, hoặc đơn giản chỉ là dễ dàng mở rộng khi cần.
Việc sớm phát hiện cũng như giải quyết vấn đề sớm sẽ làm giảm downtime từ đó tăng tính sẵn sàng của hệ thống đi lên. Ví dụ những ứng dụng doanh nghiệp (enterprise system) có khả năng tự phát hiện lỗi sau đó cô lập và báo cáo nhanh cho người vận hành hệ thống.
Chúng ta sẽ học từ từ, từng câu chữ tôi sẽ cố gắng làm sáng tỏ vấn đề cho bạn. Những phần nào bạn cảm thấy bối rối, hãy ngừng lại, hít một hơi dài, ra ban công ngắm em hàng xóm đang phơi đồ và vào đây ta lại tiếp tục. Nào let go!
1. Thế nào là window, linux?
Hẳn có bạn sẽ chưa biết nhiều về linux đâu, còn window thì có thể bạn biết nhiều rồi. Cái thời mới dùng máy tính để chơi LOL, bạn đã xài win xp, window 7, window 8 chứ chắc hẳn có bạn chưa chơi LOL trên linux đâu nhỉ :))
Mình chém thế thôi chứ Linux không support game nhiều, mà nó chủ yếu hỗ trợ việc học tập là chính. Nếu bạn muốn có một môi trường trong lành, không game(vì muốn chơi cũng lằng nhằng mới cài được), dùng toàn dòng lệnh hại não hơn thằng window, thì hãy dùng linux và lập trình. Đặc biệt lập trình C mà chơi với linux thì giống như là nằm ngủ mà có gấu ôm ấy, phê cực kỳ!
Bạn có 2 chọn lựa để chơi với linux, 1 là bạn cài thẳng hệ điều hành của nó lên. Tôi nói linux là nhân hệ điều hành, giống như 1 bộ não vậy. Có nhiều hệ điều hành nhân linux, bạn có thể cài ubuntu, kali linux… Còn nếu bạn ghét phải cài nhiều hệ điều hành trên 1 máy, tôi sẽ giúp bạn cài môi trường hao hao linux trên window cho bạn để bạn code C. Bạn sẽ dùng dòng lệnh để build chương trình, mới đầu thì hơi hoảng khi phải làm quen với em C trên linux. Nhưng không sao, bạn đẹp trai bạn có quyền tán!
OK vậy là bạn đã hiểu láng máng về linux rồi, bây giờ tôi sẽ giới thiệu môi trường build C trên linux và window khác nhau như nào. Tưởng tượng từng đoạn text bạn code ra, nó giống như con bò bạn cho vào cái máy, thì cái máy đó nó sẽ nhào trộn, cho mắm muối, gia vị, nén lại thành từng thỏi xúc xích cho bạn ăn. Xúc xích bò thì ngon lắm :)) Cái máy đó nó sản xuất cho các bạn thích ăn xúc xích to bằng ngón tay thì khác, còn bạn nào muốn thỏi xúc xích to bằng quả chuối nó lại khác. Việc bạn chế biến bằng máy cũng giống như bạn dùng hệ biên dịch để build vậy. Tôi chém rồi :)) Rõ ràng window ví như muốn ăn to bằng ngón tay còn linux bạn muốn nó to bằng quả chuối. Vậy ở 2 môi trường này cần 2 hệ biên dịch code C khác nhau đúng không nào? Vậy window dùng gì để build code C, còn linux dùng gì để build code C? Bạn sẽ biết ngay sau đây.
2. Biên dịch code C trên Linux khác với Window như nào?
GNU C/C++ compiler là cái máy chế biến C/C++ cho linux, còn MinGW thì là cái máy chế biến C/C++ cho window. Cái xúc xích thành phẩm của bạn ở đây có thể là 1 file exe thực thi như các bạn hay thấy. Hoặc có thể là file dll, file .o, file .lib… Nhiều thể loại lắm, bạn cứ từ từ mà xem em C của chúng ta có rất nhiều tài năng, toàn thứ hay ho không. Bạn sẽ tán em C bằng cách tán từ trong ruột tán ra, đảm bảo chén sạch từ trên xuống dưới nhé. OK, vậy bây giờ chúng ta cần tải cái máy MinGW này về và cài vào máy window của chúng ta. Bạn thích dùng win 7, win 8 hay 10 đều thoải mái nhé. Chúng ta chỉ quan tâm hệ điều hành của bạn đang ở dạng x64 hay x86 mà thôi. Thế 2 thằng này là cái gì? Ồ bạn chỉ hiểu nôm na thằng x64 nhiều thanh ghi hơn nên tốc độ nhanh hơn, còn x86 thì chậm hơn xíu, kiến trúc khác nhau nên bộ cài cũng khác nhau nốt. Vậy để kiểm tra hệ điều hành của bạn đang ở 64 hay 86 thì làm như nào? Đơn giản lắm, bạn hãy ngó xuống bàn phím máy tính, tìm cái nút hình cửa sổ, ghì chặt nút đó và nhấn thêm nút R, bạn sẽ thấy 1 ô hiển thị lên, bạn nhập cmd và nhấn ENTER cái tạch! Như 1 hacker, màn hình đen sì console nổi lên. Bạn gõ tiếp systeminfo vào và ENTER tạch cái tiếp.
Bạn sẽ thấy thông tin na ná như sau:
Máy của mình nó hiện lên x64 thì mình là hệ 64bit. Còn máy bạn có thể x86 thì là 32 bit lắm :))
Rồi mời bạn nhổ 1 sợi lông chân và tiếp tục đọc cho tỉnh táo!
Nãy giờ tôi hù bạn tí thôi. Tôi đã chuẩn bị 1 bộ build để bạn chả cần quan tâm máy bạn là x86 hay x64 nữa, nó hỗ trợ cho cả 2 luôn. Bạn chọn vào link sau để tải về:
Các bạn tạo mới cho mình một file .editorConfig, File này các bạn tạo theo template của mình như hình bên dưới.
Và bây giờ bạn tìm đến dòng có chữ file_header_templatevà chúng ta sẽ thêm thông tin copyright của mình ở đây như hình bên dưới:
[*.{cs,vb}]
file_header_template = Copyright (c) ThaoMeo 2000. All rights reserved.\nLicensed under the laptrinhvb.net license.\nEmail: nguyenthao.laptrinhvb@gmail.com.\nTel:0933.913.122
C#
Các bạn xuống dòng bằng dấu “\n” nhé.
Bây giờ, các bạn lưu lại là xong.
Và bây giờ khi các bạn tạo mới file .cs nào thì thông tin copyright header này đều có xuất hiện.
Còn ở class nào chưa có thêm thông tin, các bạn chọn ngay dòng đầu tiên và nhấn phím (Ctrl + .) => chọn Add header file như hình dưới đây.
Bài viết được sự cho phép của BBT Tạp chí Lập trình
Giới thiệu
Chất lượng công việc là một trong những yếu tố quan trọng xác định thành công của bạn tại nơi làm việc. Có nhiều cách để làm điều này trong lĩnh vực công nghệ phần mềm. Nhưng có một cách dễ dàng và hiệu quả là áp dụng kiểm thử. Lý do đơn giản là khả năng viết mã đạt chất lượng thường quan trọng hơn nhiều so với việc viết một khối lượng lớn mã khó bảo trì và tồn tại nhiều lỗi.
Unit Test (Kiểm thử đơn vị) là kỹ thuật kiểm thử những khối thành phần nhỏ nhất trong phần mềm (thường là các hàm hoặc phương thức). Đây là một trong những cấp độ kiểm thử đơn giản và có thể bắt đầu sớm trong vòng đời phát triển phần mềm. Thậm chí, bạn có thể viết unit test trước khi viết mã. Tuy nhiên, đây không phải là một thuật ngữ mới trong lĩnh vực phần mềm. Khái niệm unit test xuất hiện lần đầu trong ngôn ngữ lập trình Smalltalk vào những năm 1970. Đến nay, unit test gần như đã trở thành một chuẩn mực trong ngành bởi mục đích của nó là phục vụ yêu cầu nâng cao chất lượng sản phẩm phần mềm.
“Hành trình vạn dặm bắt đầu từ một bước chân.” – Lão Tử
Với nhiều lập trình viên, dù mới vào nghề hay đã gạo cội, thì unit test là một trong những kỹ năng không thể thiếu khi làm việc. Nếu bạn chưa từng nghe qua hoặc chưa có điều kiện thực hành thì cùng bước những bước chân đầu tiên qua bài viết này nhé!
Bài viết này có gì
Với bài viết này, bạn học được những nội dung sau:
Một số khái niệm cơ bản trong hoạt động testing và unit testing
Sử dụng JUnit trong dự án Java nói chung
Kết hợp Mockito và JUnit để thực hiện việc kiểm thử trong một số tình huống thực tế
Case Study và những bài học khi thực hiện kiểm thử
Lợi ích của Unit Testing
Tách rời việc kiểm thử với mã nguồn; không cần viết mã vào phương thức main() để có thể kiểm tra phương thức có hoạt động đúng đắn hay không.
Duy trì một bộ kiểm thử liên tục được cập nhật.
Đảm bảo mã mới không ảnh hưởng và gây lỗi tới những chức năng hiện có (qua việc thực hiện chạy lại toàn bộ bộ test đã viết từ trước).
Thuật ngữ
Để đọc hiểu nội dung hướng dẫn này, bạn cần biết đến một số thuật ngữ thường được sử dụng trong các hoạt động kiểm thử.
Test case
Test case là các trường hợp cần kiểm thử với đầu vào và đầu ra được xác định cụ thể. Một test case thường có hai thành phần dưới đây:
Expected value: Giá trị mà chúng ta mong đợi khối lệnh trả về
Actual value: Giá trị thực tế mà khối lệnh trả về
Sau khi thực hiện khối lệnh cần kiểm thử, chúng ta sẽ nhận được actual value. Lấy giá trị đó so sánh với expected value. Nếu hai giá trị này trùng khớp nhau thì kết quả của test case là PASS. Ngược lại, kết quả là FAIL.
Application (hoặc Code) Under Test
Application Under Test (AUT) là thuật ngữ thường được dùng để chỉ đến hệ thống/ứng dụng đang được kiểm thử. Với hoạt động unit test, các đơn vị kiểm thử của chúng ta là những thành phần nhỏ nhất trong hệ thống nên có thể dùng các thuật ngữ khác phù hợp hơn như Code Under Test (CUT).
Mock và Stub
Đây là các thành phần bên ngoài được mô phỏng hoặc giả lập trong ngữ cảnh của hoạt động kiểm thử. Thông thường, để AUT hoạt động đúng chức năng thì sẽ cần đến những thành phần bên ngoài như Web Service, Database,… Ở cấp độ unit test, chúng ta cần phải tách rời các thành phần phụ thuộc này để có thể dễ dàng thực thi test case. Phần này sẽ được giải thích rõ hơn trong mục Sử dụng Mockito (Mocking framework).
Lưu ý: Ngoài thuật ngữ mock và stub, thỉnh thoảng bạn sẽ gặp các từ khác như Spy và Fake.
Thiết kế test case
Trong phần này, chúng ta sẽ tìm hiểu các loại test case, cấu trúc thường gặp ở một test case và xem xét một số yếu tố tạo nên một test case tốt. Dựa vào các đặc tính đó, chúng ta sẽ tìm hiểu những nguyên tắc để có thể thiết kế và thực hiện được các test case tốt.
Phân loại test case
Positive test case: Là những trường hợp kiểm thử đảm bảo người dùng có thể thực hiện được thao tác với dữ liệu hợp lệ.
Negative test case: Là những trường hợp kiểm thử tìm cách gây lỗi cho ứng dụng bằng cách sử dụng các dữ liệu không hợp lệ.
Hãy làm rõ các loại test case trên qua một ví dụ đơn giản như sau. Giả sử, chúng ta đang thiết kế ứng dụng đặt phòng khách sạn và có một yêu cầu là:
Hệ thống cho phép khách hàng có thể đặt phòng mới với thời gian xác định.
Với yêu cầu trên, chúng ta có một số trường hợp cần kiểm thử như sau:
Trường hợp positive là đảm bảo có thể thêm phòng với các dữ liệu hợp lệ như mã phòng cần đặt, thời gian hợp lệ, mã khách hàng hợp lệ, giá tiền được tính với số ngày đặt,…
Còn các trường hợp negative sẽ cố gắng thực hiện thao tác đặt phòng với những dữ liệu không hợp lệ như:
Đặt phòng mới mà không có mã phòng
Đặt phòng mới với thời gian không hợp lệ (thời gian ở quá khứ)
Đặt phòng mới với mã khách hàng không tồn tại trong cơ sở dữ liệu
Đặt phòng mới với giá tiền âm (nhỏ hơn 0).
… và nhiều trường hợp khác
Hy vọng qua ví dụ trên, bạn có thể phân loại được các test case và tự xác định được các test case cho yêu cầu phần mềm mà bạn đang thực hiện.
Cấu trúc một test case
Các trúc mã mà chúng ta nên tuân thủ trong một test case là cấu trúc AAA. Cấu trúc này gồm 3 thành phần:
Arrange – Chuẩn bị dữ liệu đầu vào và các điều kiện khác để thực thi test case.
Act – Thực hiện việc gọi phương thức/hàm với đầu vào đã được chuẩn bị ở Arrange và nhận về kết quả thực tế.
Assert – So sánh giá trị mong đợi và giá trị thực tế nhận được ở bước Act. Kết quả của test case sẽ là một trong hai trạng thái sau:
PASS: nếu kết quả mong đợi và kết quả thực tế khớp nhau
FAIL: nếu kết quả mong đợi khác với kết quả thực tế
Đôi khi bạn sẽ bắt gặp một số bài viết dùng từ cấu trúc Given-When-Then. Về bản chất, cũng chính là cấu trúc AAA như trên.
Thành phần cố định (Fixtures)
Là những thành phần được lặp đi lặp lại qua mỗi test case và có thể chia sẻ các thao tác chung giữa các test case. Ví dụ: thiết lập cấu hình hoặc chuẩn bị dữ liệu trước khi bộ test được thực thi, và dọn dẹp bộ nhớ sau khi hoàn thành. Thành phần cố định phải được đặt lên trên cùng của bộ kiểm thử.
Có bốn loại thành phần cố định chính:
Setup
Là thành phần được thực thi trước khi test case thực thi. Trong một số thư viện xUnit (công cụ hỗ trợ viết và thực thi unit test), chúng ta thường gặp những phương thức/hàm, hoặc annotion có tên là BeforeEach. Thành phần này chính là Setup.
One-Time Setup
Là thành phần được thực thi đầu tiên (trước cả khi cả setup và test case được thực thi). Trong một số thư viện xUnit (công cụ hỗ trợ viết và thực thi unit test), chúng ta thưsờng gặp những phương thức/hàm, hoặc annotion có tên là BeforeAll. Thành phần này chính là One-Time Setup.
Teardown
Là thành phần được thực thi sau khi test case được thực thi. Trong một số thư viện xUnit (công cụ hỗ trợ viết và thực thi unit test), chúng ta thường gặp những phương thức/hàm, hoặc annotion có tên là AfterEach. Thành phần này chính là Teardown.
One-Time Teardown
Là thành phần được thực thi sau cùng (sau khi tất cả test case và teardown được thực thi). Trong một số thư viện xUnit (công cụ hỗ trợ viết và thực thi unit test), chúng ta thường gặp những phương thức/hàm, hoặc annotion có tên là AfterAll. Thành phần này chính là One-Time Teardown.
Đặc tính của một unit test tốt
Một ca kiểm thử tốt sẽ có những đặc tính sau đây:
Dễ viết – Có thể bao quát được nhiều trường hợp kiểm thử mà không mất quá nhiều công sức.
Dễ đọc – Có thể mô tả được chính xác hành vi hoặc chức năng được kiểm thử.
Tự động hoá – Có thể thực thi lặp lại nhiều lần.
Dễ thực thi và thực thi nhanh.
Đồng nhất – Luôn trả về cùng kết quả sau mỗi lần chạy (nếu không thay đổi mã nguồn bên trong).
Cô lập – Có thể thực thi độc lập mà không phụ thuộc vào các thành phần khác trong hệ thống. Bạn có thể tham khảo mục “Sử dụng Mockito” để làm rõ hơn ý này.
Khi kết quả kiểm thử thất bại (FAILED), có thể dễ dàng tìm ra giá trị mong đợi và nhanh chóng xác định được vấn đề.
Quy ước đặt tên
Tên lớp chứa mã kiểm thử
Tên lớp chứa mã kiểm thử thường sử dụng hậu tố “Tests” sau tên lớp được kiểm thử. Ví dụ: tên lớp là StockService thì tên lớp chứa mã kiểm thử sẽ là StockServiceTests.
Tên phương thức kiểm thử (test case)
Theo nguyên tắc, tên phương thức kiểm thử phải giải thích nhiệm vụ rõ ràng. Có thể tham khảo một số quy ướt đặt tên cho phương thức như sau:
Sử dụng từ should. Ví dụ: favouriteStocksShouldbeSaved, todayPriceShouldBeShowed.
@Test
public void favouriteStocksShouldbeSaved() {}
Viết theo mẫu Given[Đầu-Vào]When[Hành-Vi]Then[Kết-Quả-Mong-Đợi]. Ví dụ:
@Test
public void GivenNullUsernameWhenCreateStudentThenShouldThrowException() {}
Viết theo mẫu when[hành-vi]_then[Kết-quả]
@Test
public void whenEnterValidUsernameAndPassword_thenLoginSuccessfully() {}
Gợi ý viết kiểm thử tốt
Mỗi test case nên là một phương thức độc lập, có thể thực thi mà không phụ thuộc vào bất kỳ test case nào khác.
Thứ tự thực hiện của mỗi test case không nên ảnh hưởng đến kết quả thực thi (mặc dù có thể).
Khi phát hiện bug trong chương trình, hãy viết ngay kiểm thử cho trường hợp xảy ra bug đó để có thể kiểm tra lại sau này.
Tên phương thức kiểm thử phải rõ ràng. Vì vậy không phải do dự nếu tên phương thức quá dài. Ví dụ TestDivisionWhenNumPositiveDenomNegative tốt hơn DivisionTest3.
Hãy kiểm thử những trường hợp ném ra ngoại lệ (nếu có). Ví dụ WhenDivisionByZeroShouldThrowException.
Hãy kiểm thử các trường hợp negative để làm rõ hình thức phản hồi khi đầu vào là dữ liệu không hợp lệ.
Sử dụng JUnit
Hiện nay, JUnit được tích hợp và hỗ trợ ở phần lớn các IDE hiện tại cho Java (như Eclipse, IntelliJ, NetBeans,…). Việc sử dụng JUnit trong các dự án Java không khó. Các bạn có thể tìm hiểu cách cài đặt thư viện cho dự án của mình qua những hướng dẫn trên mạng.
Trong mục này, chúng ta sẽ cùng lượt qua những tính năng được hỗ trợ trong JUnit 5 – phiên bản mới nhất hiện nay.
Ví dụ đầu tiên
Dưới đây là ví dụ giúp bạn có cái nhìn tổng quan về một kiểm thử được viết với JUnit5:
import com.codegym.Calculator;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertEquals;
class CalculatorTests {
private final Calculator calculator = new Calculator();
@Test
void shouldReturn2When1Plus1() {
assertEquals(2, calculator.add(1, 1));
}
}
Giải thích ví dụ:
@Test là annotation đánh dấu phương thức shouldReturn2When1Plus1() là một test case. Hãy chú ý rằng tên của phương thức test được viết rất rõ là nên trả về kết quả 2 khi 1 cộng 1.
Ở phần thân của phương thức chứa một dòng mã kiểm tra kết quả của phương thức add() với đầu vào là hai số có giá trị lần lượt là 1 và 1.
So sánh giá trị thực tế trả về của phương add() với giá trị mong đợi là 2.
Sau khi chạy test case này, kết quả sẽ là PASS nếu phương thức add(1, 1)) trả về kết quả đúng bằng 2.
Các mục tiếp theo sẽ cung cấp thêm chi tiết về một số tính năng cơ bản được hỗ trợ trong JUnit5.
Các annotation trong JUnit
Sơ đồ dưới đây thể hiện thứ tự thực hiện các phương thức khi được đánh dấu với annotion tương ứng:
Các annotaion @BeforeAll, @BeforeEach,@AfterEach, @AfterAll là những thành phần cố định, thực hiện các chức năng lặp đi lặp lại. Annotation @Test được dùng để xác định một test case.
Assertions
Assertions là lớp chứa các phương thức hỗ trợ đánh giá các điều kiện trong kiểm thử.
So với phiên bản trước, JUnit 5 vẫn giữ các phương thức cũ và thêm một số phương thức mới tận dụng những tích năng của Java 8.
Dưới đây là danh sách những phương thức assertion có trong JUnit5.
assertTrue và assertFalse
Phương thức assertTrue được dùng để kiểm tra kết quả của điều kiện có bằng true hay không. Ví dụ:
@Test
public void whenAssertingConditions_thenVerified() {
assertTrue(10 > 5, "10 lớn hơn 5");
}
Ngược lại, phương thức assertFalse được dùng để kiểm tra kết quả của điều kiện có bằng false hay không.
@Test
public void whenAssertingConditions_thenVerified() {
assertTrue(5 > 10, "5 không lớn hơn 10");
}
assertEquals và assertNotEquals
Phương thức assertEquals được dùng để kiểm tra giá trị mong đợi và thực tế có bằng nhau hay không. Ví dụ:
assertEquals và assertNotEquals
Phương thức assertEquals được dùng để kiểm tra giá trị mong đợi và thực tế có bằng nhau hay không. Ví dụ:
Ngược lại, Phương thức assertNotEquals được dùng để kiểm tra giá trị mong đợi và thực tế có bằng nhau hay không. Chúng ta cập nhật lại ví dụ ở trên:
@Test
public void whenAssertingConditions_thenVerified() {
// thay thế phương thức toUpperCase() thành toLowerCase()
String actual = new String("CodeGym").toLowerCase();
String expected = "CODEGYM";
assertNotEquals(expected, actual);
}
Với trường hợp các giá trị chúng ta đang so sánh thuộc kiểu Object, assertEquals và assertNotEquals sẽ gọi phương thức equals để so sánh giá trị.
Có một điểm cần lưu ý nếu giá trị là kiểu số thực (float hoặc double). Trên thực tế, có nhiều trường hợp mà giá trị số thực mong đợi và thực tế có thể chênh lệch với nhau trong khoảng chấp nhận được. Với tình huống này, phương thức assertEquals và assertNotEquals hỗ trợ tham số thứ ba là delta (bên cạnh expected và actual). Chúng ta cùng xem qua ví dụ dưới đây:
@Test
public void whenAssertingConditions_thenVerified() {
float actual = 12 / 3.0001f;
float expected = 4;
assertEquals(expected, actual, 0.001f);
}
Kết quả của phép chia 12 cho 3.001 thì sẽ là một số thực 3.9998667. Kết quả của ca kiểm thử ví dụ trên là PASSED vì chúng ta đã cho phép mức chênh lệch tối đa là 0.001.
assertArrayEquals
Phương thức assertArrayEquals có thể xác nhận mảng mong đợi và thực tế có bằng nhau hay không. Chúng ta cùng xem xét ví dụ dưới đây:
public void whenAssertingArraysEquality_thenEqual() {
char[] expected = { 'C', 'o', 'd', 'e', 'G', 'y', 'm' };
char[] actual = "CodeGym".toCharArray();
assertArrayEquals(expected, actual, "Mảng phải giống nhau");
}
assertSame và assertNotSame
Khu chúng ta muốn xác nhận giá trị mong đợi và thực tế tham chiếu đến cùng một đối tượng hay không, chúng ta phải dùng assertSame hoặc assertNotSame:
@Test
public void whenAssertingSameObject_thenVerified() {
String actual = new String("CodeGym");
String expected = "CodeGym";
assertSame(expected, actual);
}
Kết quả của phương thức test trên là FAILED vì hai biến actual và expected đang tham chiếu đến hai đối tượng khác nhau trong bộ nhớ.
Chúng ta nên lưu ý về sự khác nhau giữa assertSame và assertEquals (đã tìm hiểu ở ví dụ trước):
assertEquals chỉ quan tâm đến giá trị có bằng nhau không (thông qua phương thức equals) mà không cần biết hai giá trị được so sánh có phải cùng là một đối tượng hay không.
assertSame sẽ trả về PASSED chỉ khi cả hai biến cùng tham chiếu đến một đối tượng.
assertIterableEquals
assertIterableEquals so sánh các giá trị được chứa bên trong hai đối tượng kiểu Iterable. Để trả về kết quả PASSED, hai iterable phải trả về bằng số phân tử, giá trị của các phần tử đó và cả vị trí của các phần tử. Hãy cùng xem ví dụ dưới đây:
@Test
public void givenTwoLists_whenAssertingIterables_thenEquals() {
Iterable<String> al = new ArrayList<>(asList("CodeGym", "Coding", "Bootcamp", "Java"));
Iterable<String> ll = new LinkedList<>(asList("CodeGym", "Coding", "Bootcamp", "Java"));
assertIterableEquals(al, ll);
}
Kết quả của test case trên là PASSED. Phương thức assertIterableEquals chỉ so sánh giá trị các phần tử bên trong mà không quan tâm đến việc các phần tử này đang được lưu trữ tại hai biến thuộc kiểu khác nhau (ArrayList và LinkedList).
assertThrows
Để có thể xác nhận được phương thức đang kiểm thử có ném ra một ngoại lệ hay không, chúng ta có thể sử dụng assertThrows. Giả sử chúng ta có một phương thức như sau:
static void throwAnException() {
throw new IllegalArgumentException("Tham số không hợp lệ");
}
Dùng cách thức dưới đây để kiểm tra xem phương thức throwAnExcepiont() có ném ra một ngoại lệ hay không, và ngoại lệ đó có phải là IllegalArgumentException hay không:
@Test
void whenAssertingException_thenThrown() {
Exception e = assertThrows(IllegalArgumentException.class, () -> throwAnException());
assertEquals("Tham số không hợp lệ", e.getMessage());
}
Các assertion khác
assertLinesMatch
fail
assertNotNull và assertNull
assertAll
assertTimeout và assertTimeoutPreemptively
Sử dụng Mockito (Mocking framework)
Khi xây dựng phần mềm, AUT sẽ phụ thuộc vào các thành phần bên ngoài như cơ sở dữ liệu, API, hệ thống file,… Các thành phần phụ thuộc này có thể chưa sẵn sàng hoặc thậm chí chưa tồn tại ở thời điểm chúng ta viết Unit Test. Ngay cả khi những thành phần này đã được chuẩn bị sẵn sàng thì việc thực thi một test case có phụ thuộc sẽ chậm hơn vì phải cần thời gian đợi và tương tác với thành phần bên ngoài.
Cô lập AUT là một trong những kỹ thuật giúp giải quyết vấn đề trên. Và lúc này, chúng ta sẽ phải cần đến các mocking framework (tạm dịch là khung mô phỏng) để giả lập các thành phần bên ngoài, nhờ đó có thể cô lập và kiểm thử AUT dễ dàng hơn. Đối tượng mô phỏng này sẽ không gây phá vỡ cấu trúc mã nguồn khi đối tượng thật được thiết kế và triển khai. Hình dưới đây thể hiện việc tạo hai đối tượng mô phỏng là Mock WS và Mock DB để thay thế sự phụ thuộc vào WebService và Database.
Việc tìm hiểu cách thiết lập và sử dụng các mocking framework này là bước quan trọng giúp mở rộng Unit Test cho các hệ thống lớn và phức tạp. Với lập trì viên Java, Mockito là một công cụ không thể thiếu.
Tạo đối tượng mô phỏng
Phương thức mock() cho phép chúng ta tạo đối tượng mô phỏng từ một class hoặc interface. Phương thức này không yêu cầu thêm gì khi sử dụng. Và nó có thể tạo các thuộc tính class mô phỏng hoặc các đối tượng mô phỏng cần dùng trong phương thức. Ví dụ dưới đây thể hiện cách tạo một đối tượng mô phỏng kiểu UserRepository (đã được định nghĩa trước):
verify(stockRepository).count();
Mô phỏng hành vi
Sử dụng phương thức when() để mô phỏng hành vi của đối tượng. Để xác định kết quả thực hiện, chúng ta có thể sử dụng thenReturn() hoặc thenThrow().
thenReturn() trả về kết quả
thenThrow() sẽ ném ra một ngoại lệ
verify(stockRepository).count();
Nếu muốn trả về nhiều kết quả cho nhiều lần gọi, chúng ta sử dụng thenReturn() nhiều lần như sau;
when(stockRepository.count())
.thenReturn(50)
.thenReturn(100)
.thenReturn(200);
// Kết quả in ra màn hình sẽ là:
System.out.println(stockRepository.count()); // 50
System.out.println(stockRepository.count()); // 100
System.out.println(stockRepository.count()); // 200
Kiểm chứng
Chúng ta có thể kiểm tra xem phương thức/hàm có được gọi hay không qua phương thức verify().
verify(stockRepository).count();
Mockito hỗ trợ những tham số giúp chúng ta có thể mở rộng khả năng kiểm chứng việc gọi phương thức như:
Số lần gọi với times()
Thời gian thực hiện với timeout(), giúp kiểm chứng thời gian thực hiện thuật toán có đảm bảo yêu cầu
Ví dụ:
verify(stockRepository, times(2)).count(); // gọi 2 lần
verify(stockRepository, timeout(10)).count(); // 10 mili giây
Kết hợp JUnit
Đây là đoạn mã ví dụ cách kết hợp Mockito và JUnit để viết mã kiểm thử đơn vị:
@Test
public void tryMockitoMock() {
verify(stockRepository).count();
when(stockRepository.count())
.thenReturn(10);
long stockCount = stockRepository.count();
Assertions.assertEquals(10, stockCount);
verify(stockRepository).count();
}
Ở phương thức trên, chúng ta mô phỏng hành vi lấy số lượng user thông qua phương thức count() được định nghĩa trong UserRepository. Khi count() được gọi, đối tượng mô phỏng sẽ trả về kết quả là 111 thay vì phải truy vấn vào cơ sở dữ liệu để lấy thông tin.
Case Study
Dự án mà chúng ta sẽ thực hiện là một trang cửa hàng trực tuyến đơn giản hỗ trợ duyệt danh sách sản phẩm và thông tin chi tiết của từng mặt hàng. Khách hàng có thể chọn sản phẩm và lưu vào giỏ hàng để thanh toán.
Trước khi thực sự viết mã, hãy thiết kế chi tiết bao gồm những interface, class và các phương thức có thể cần để thực hiện được ứng dụng này. Dựa vào bản thiết kế, hãy viết các unit test case cho ứng dụng.
Chặng đường tiếp theo
Cảm ơn bạn đã đồng hành cùng bài viết đến đây. Hy vọng những bước chân đầu tiên này sẽ mang lại nhiều ý nghĩa cho chặng đường học hỏi tiếp theo của bạn. Hãy tìm tòi và thực hành nhiều hơn để có thể làm chủ được kỹ năng Unit Test nói riêng và automation testing nói chung. Tới đây, chúng ta nên làm gì để học và thực hành hiệu quả hơn ở kỹ năng này?
Câu châm ngôn của mình là “Thế giới này thật là rộng lớn.. và có quá nhiều sách để đọc”. Nên gợi ý đầu tiên luôn là đọc những đầu sách hay về Unit Test, Test-Driven Development và những chủ đề liên quan. Các bạn xem qua các gợi ý sách và website bên dưới nhé!
Sách nên tham khảo
Test Driven Development: By Example – Tác giả: Kent Beck
The Art of Unit Testing – Roy Osherove (Các ví dụ trong sách được viết vớt .NET nhưng vẫn có thể tham khảo để phát triển ứng dụng trên Java)
Sau khi kết thúc hai phần trước, chúng ta đã có những kiến thức cơ bản về chiếc bàn phím cơ, không để các bạn đợi lâu, ở phần này chúng ta sẽ thực sự bắt tay vào làm một chiếc bàn phím hoàn chỉnh.
Tham khảo thật nhiều layout, thiết kế của cộng đồng
Thiết kế cho mình một layout hợp lý
Đặt mua linh kiện, keycaps, switches, cắt plate nếu cần thiết
Hàn mạch bằng tay, hoặc thiết kế mạch in rồi mới hàn
Hàn controller, viết firmware hoặc modify từ các firmware có sẵn như QMK hay TMK
Done
Trước khi bắt đầu thì các bạn hãy để mình khoe hàng tí đã, chiếc bàn phím bốn chấm không, à nhầm 40% mang tên SnackyMini Keyboard một sản phẩm kết tinh của tinh thần bốn chấm không, của trí tuệ Việt và nền công nghệ tiên tiến của Đế quốc Tư bản Huê Kỳ, cộng với nguồn cung cấp thiết bị kĩ thuật, linh kiện bán dẫn phong phú của người anh lớn Trung Hoa, một sản phẩm của người Việt, dành cho cả người Việt lẫn người không Việt, được nghiên cứu, thiết kế và tối ưu dành riêng cho các software developer, một… ấy ấy ấy, thôi các bạn đừng tắt mà, ở lại đọc tiếp đi mà, mình im rồi đây
Bài viết sẽ mang tính chất ghi chép lại quá trình mình thực hiện chiếc bàn phím, một số yếu tố kĩ thuật sẽ được lượt bỏ hoặc tối giản, phun ra mà không có giải thích hay chú thích, nên có thể bài viết sẽ có những đoạn khó hiểu. Nếu sau khi đọc xong series bài viết này và các bạn có ý định tự mình làm một chiếc bàn phím cơ, và có thắc mắc, xin đừng ngại comment hoặc để lại lời nhắn, mình sẽ cố gắng trả lời trong phạm vi hiểu biết của bản thân.
Thiết kế layout
Việc đầu tiên cần làm khi bắt đầu bất kì một dự án nào đó là thiết kế. Chúng ta cần phải thiết kế bố cục (layout) Làm phần cứng không giống như phần mềm, chỉ cần một sai sót nhỏ trong bố cục hoặc một điểm bất hợp lý trong thiết kế thì chúng ta phải trả giá bằng cả thời gian lẫn tiền bạc và công sức, các sai lầm thường rất khó hoặc là không thể sửa chữa, làm lại.của chiếc bàn phím, bước này rất quan trọng và đòi hỏi bạn phải tham khảo thật nhiều, suy nghĩ một cách thật kĩ lưỡng để chọn được một bố cục và thiết kế ưng ý.
Nếu chưa biết mình muốn gì, thì các bạn có thể tham khảo qua các mẫu bàn phím khác nhau trên các cộng đồng dân chơi phím cơ như Reddit /r/MechanicalKeyboards, Geekhack, Deskthority, trên những cộng đồng này cũng thường xuyên có những thảo luận về việc tự build bàn phím, rất hữu ích. Ngoài ra thì còn nhiều cộng đồng khác, ví dụ như VietnamMechKey.
Ý tưởng của mình là thiết kế bộ chiếc bàn phím có layout 40% nên cũng đã tham khảo nhiều từ trang 40percent.club. Một số yêu cầu thiết kế của mình tự đặt ra là như sau:
Sau một thời gian xài layout 60% thì mình thấy dù sao bàn phím có hàng phím mũi tên vẫn tiện hơn cả, vì thế chiếc bàn phím nhỏ gọn sắp build cũng phải có 4 phím mũi tên.
Tiếp theo, vì công việc chính của mình là code, nên để có thể sử dụng chiếc bàn phím này hằng ngày, thì mình vẫn phải giữ lại các phím cơ bản hay dùng như [ ] ( ) { } ; : < > , ., hoặc Tab.
Sau một thời gian sử dụng Emacs thì mình sử dụng phím Ctrl khá thường xuyên, vì thế phím này cần phải đặt ở một vị trí nào đó cho tiện bấm nhất.
Cụm phím Cmd, Alt, Shift bên phía tay phải mình chưa một lần nào phải đụng tới trong suốt bao nhiêu năm xài máy tính, nên tốt nhất là vứt nó đi.
Layout vừa nhỏ nên sẽ không đủ chỗ để đặt hàng phím số vào, cho nên tốt hơn cả là giấu nó vào hàng phím QWERTY thông qua một phím Fn, khi nhấn phím này thì bàn phím sẽ chuyển qua layout phím số.
Bàn phím mặc định ở trên, và bàn phím khi nhấn nút Fn ở dưới:
Sau khi kết thúc bước này, các bạn có thể export layout này ra định dạng JSON và đưa qua http://builder.swillkb.com/ để thiết kế plate và case, nếu các bạn có ý định làm bàn phím plate mount. Ở đây mình chỉ xài PCB mount nên bỏ qua bước này.
Ngoài ra, bạn còn có thể vào tab Summary để xem danh sách và số lượng các phím cần dùng, ví dụ đây là danh sách các phím cần dùng cho layout của mình:
Thiết kế mạch in
Đến đây, chúng ta đã có layout, bước tiếp theo là thiết kế mạch in (PCB) để hàn các linh kiện vào. Thực ra việc này đối với nhiều người khó hơn là hàn mạch bằng tay (handwired), với mình thì… trước đây mình cũng đã làm một bản prototype handwired, tuy nhiên nhờ kĩ năng hàn mạch thần sầu, mình nướng chín luôn hầu hết diode trên mạch và cuối cùng thì bản này bị vứt xó.
Sau khi xem xét nhiều phương án, thì việc tự thiết kế PCB là khả thi nhất, vì như thế đến công đoạn hàn linh kiện vào đỡ vất vả hơn, và giảm thiểu được tối đa nguy cơ xảy ra lỗi. Mỗi tội tốn tiền nhiều hơn.
Để thiết kế PCB thì mình dùng phần mềm KiCad vì nó trực quan, đầy đủ nhiều chức năng, có khả năng render ra board mạch hoàn chỉnh trông rất đẹp, open source và miễn phí, và quan trọng nhất là đa số các cơ sở sản xuất mạch đều hỗ trợ định dạng file của KiCad.
Cái khó nhất khi dùng KiCad là giao diện của nó không được thông minh cho lắm, hay nói thẳng ra nó luôn là giao diện ngu như . Đặc biệt là trên macOS. Đó là chưa kể cơ chế quản lý thư viện footprint và component của nó khá rối. Trước khi bắt tay vào làm thì các bạn nên đọc qua bài hướng dẫn sử dụng của Deskthority, đây là bài viết dễ hiểu nhất mà mình có thể tìm thấy, mặc dù hơi cũ.
Cái khó thứ hai, là bắt đầu như thế nào? một cái switch có những chân nào, cần đục những lỗ nào? khoảng cách giữa các switch là bao xa? để nắm được các thông tin này thì bạn cần phải bới tung các wiki và các diễn đàn về phím cơ lên. Ở đây mình sẽ nói sơ qua, vì các bạn có đọc trước cũng không thể nhớ được cho tới khi các bạn bắt tay vô làm và tự mình đụng phải các vấn đề đó
Về khoảng cách giữa các chân switch, thì theo tài liệu của hãng Cherry, mỗi switch có kích thước 15.6mm x 15.6mm, keycaps có kích thước tầm 18mm x 18mm nữa, theo matt3o, khi kết hợp lại thì mỗi một switch 1u nên chiếm một ô có kích thước 19.05mm x 19.05mm.
Một hình vuông màu đen như trên là footprint cho một phím/switch đã kèm cả key caps (1u). Hai phím 1u kề nhau sẽ có footprint kề cạnh nhau, và khoảng cách giữa hai phím như thế này đủ để đặt vào một con diode (kí hiệu D39 như trong hình).
À, cũng phải nói thêm, mình sử dụng Teensy 3.2 làm controller cho chiếc bàn phím này, vì lý do nó dễ mua, dễ lập trình, hỗ trợ giao tiếp với máy tính như là một thiết bị USB, và có sẵn bộ thư viện Teensyduino xài khá tiện.
Sau vài ngày hì hục với KiCad thì đây là thành quả, nhìn rối như tơ vò, nhưng là một cái PCB 2 mặt:
Ngày xưa mình từng có thời gian tự làm PCB trên miếng đồng bằng máy in laser, giấy màu, bàn ủi, bàn chải đánh răng và thuốc sắt FeCl3, chưa bao giờ mình dám mơ tới chuyện làm một cái PCB có đường mạch mỏng hơn 2mm, chứ đừng nói tới một cái PCB 2 mặt.
Quên nói, 4 cái lỗ ở 4 góc board có đường kính 2.5mm, vừa đủ cho một con M2 standoff cắm vào.
Sau khi hoàn thành, thì mình hí hửng xuất file ra và gửi cho nhà in, đây là một công ty ở Trung Quốc, sở dĩ chọn Trung Quốc là vì hôm đó ngày lễ ở Mỹ, không có nhà in nào của Mỹ làm việc cả.
Có bạn hỏi muốn biết thêm chi tiết về công đoạn này, thì như thế này: Khi làm việc với các công ty in mạch, bạn sẽ phải gửi file cho họ, bạn có thể nén và gửi toàn bộ project KiCad cho họ, hoặc đơn giản hơn thì có thể xuất project ra thành nhiều file gerber (mỗi một file gerber sẽ là một layer của board, ví dụ layer mạch đồng, layer khoan lỗ, layer hình vẽ trên mạch,…) rồi nén tất cả lại thành một file zip để gửi. Trong repo Github ở cuối bài, mình có để sẵn file snackymini-manufacturing-submission.zip trong thư mục hardware, chứa các file gerber này, có thể gửi trực tiếp file này tới nhà in. Còn dịch vụ mình sử dụng là công ty JLCPCB, họ có đội ngũ support rất tận tình, trao đổi và confirm qua mail liên tục, mỗi tội tiếng Anh của các bạn này hơi bị dỏm, được cái giá cả khá ổn và thời gian gia công khá nhanh.
Vì nôn nóng nên mình chọn in gấp, chỉ tốn 2 ngày gia công và 3 ngày để mấy cái mạch bơi từ bên đó qua bên đây, tầm 50 USD ra đi cho 10 cái board mạch đen cóng ngầu xì dầu:
Trong thời gian chờ in mạch thì mình cũng đặt mua luôn các linh kiện cần thiết, bao gồm:
1 board mạch Teensy 3.2 loại có hàn sẵn header
50 switch Cherry MX Black
100 diode 1N4148
Keycaps thì đã có sẵn, gom góp lại cũng đủ quân số, mặc dù lố nhố
Hầu hết các phím mình dùng đều không quá 2.5u, và cũng quên không đục lỗ cắm stabilizer, nên mình bỏ qua nó luôn, gõ thấy cũng hơi kì kì nhưng kệ đi.
Việc tiếp theo là lôi switches và diodes ra hàn, mình dùng Cherry Black, ban đầu gõ thấy khá nặng vì đã quen xài Brown, nhưng dần cũng quen.
Hàn controller vô mặt sau, ở đây thì có một vấn đề, đó là vì sợ Teensy sẽ đụng vào switch, mình phải dùng header để tạo ra khoảng cách, và hàn ngược con Teensy lại cho phần chân cắm vào phần bụng của PCB, điều này sai với thiết kế ban đầu. Rất may lỗi này có thể khắc phục được bằng phần mềm:
Hàn xong đâu ra đấy thì mới thấy khi thiết kế mạch, mình quá cẩn thận khi đã dành ra một phần diện tích khá lớn cho viền ngoài của board, về sau khi xem mạch thực tế và xem các bản thiết kế khác thì khá tiếc, vì đáng ra không có phần viền, bàn phím trông sẽ gọn gàng hơn.
Đâu ra đấy xong thì lắp key caps vào:
Thế là xong phần cứng. Tiếp theo là đến firmware.
Viết Firmware
Nếu các bạn không đọc các bài trước, thì lý do mình quyết định tự viết firmware chỉ đơn giản là vì mình không compile được các firmware có sẵn như QMK hay TMK cho Teensy 3.2 nếu các bạn sử dụng controller khác, có thể các bạn sẽ compile được và không cần phải đâm đầu vào con đường đen tối này. Suy cho cùng, tự viết firmware cũng có cái hay của nó, và mình học được rất nhiều từ việc này. Dưới đây là một vài ghi chép của mình trong quá trình viết, nếu không thực sự quan tâm, các bạn có thể bỏ qua cũng được.
Mãi cho đến khi hoàn thành xong phần hardware thì mình mới bắt tay vào viết firmware hoàn chỉnh (chứ không phải là cái firmware điều khiển 4 nút như trong bài trước). Về cơ bản thì không khác nhiều mấy so với trong bài trước, mình dùng một mảng kiểu unit8_t để lưu thông tin về layout bàn phím, đây là một mảng 3 chiều, nó gồm có 2 mảng 2 chiều, mỗi một mảng 2 chiều là một layout:
Một thay đổi nữa so với bài viết trước, đó là thuật toán debounce, sau khi thử nghiệm và tham khảo từ các firmware khác, thì mình quyết định làm đơn giản hơn, giống với các firmware phổ biến như QMK/TMK, là quét từng đợt sau mỗi 15 milli giây, đơn giản đến không đỡ được:
Khi compile và upload firmware vào bàn phím, ban đầu thì mọi thứ có vẻ hoạt động rất trơn tru, nhưng khi mình thử gõ một đoạn nội dung dài vào, thì xảy ra tình trạng mất phím, ví dụ gõ:
Hello I am Huy
thì lại thành ra:
Helo I m Hy
Thế là tốn thêm 1 ngày để debug, nguyên nhân thì hết sức ngớ ngẩn vì trong lúc viết firmware, mình lười và chỉ làm cho cái bàn phím đọc mỗi một phím duy nhất ở một thời điểm, và khi gõ nhanh, ở một thời điểm có thể sẽ có rất nhiều phím được nhấn xuống. Cũng nhờ thế mà lại biết thêm được khái niệm NKRO (n-key roll over), một chức năng giúp cho bàn phím có thể ghi nhận được nhiều phím trong một thời điểm. Đối với các bàn phím sử dụng cổng USB, thì tối đa chi ghi nhận được 6 phím, trong khi đó bàn phím dùng cổng PS/2 thì xả láng.
Việc implement chức năng này cũng không mấy khó khăn, nhờ các hàm Keyboard.set_key1, Keyboard.set_key2, Keyboard.set_key3,… của Teensyduino. Về ý tưởng thì ở mỗi lần quét, mình tạo một mảng gồm 6 phần tử để lưu lần lượt giá trị các phím nhận được:
#define MAXIMUM_STROKES 6struct Key* readKey(){
structKey* result = (Key*)malloc(MAXIMUM_STROKES * sizeof(structKey));int currentFinger = 0;
for (int row = 0; row < ROWS; row++) {
for (int col = 0; col < COLS; col++) {
if (keyPressedAt(row, col)) {
result[currentFinger].row = row;
result[currentFinger].col = col;
if (currentFinger < MAXIMUM_STROKES) currentFinger++;
}
}
}
return result;
}
Rồi sau đó lần lượt sử dụng các hàm Keyboard.set_key<x> để gán giá trị cho từng phím, và gửi đi một lần bằng hàm Keyboard.send_now():
voidsubmitLayout(struct Key* keys, uint8_t layout[ROWS][COLS]){
int currentFinger = 0;
...
for (int i = 0; i < SUPPORTED_STROKES; i++) {
int c = layout[pos.r][pos.c];
if (c != NULL_KEY) {
setKey(currentFinger, c);
currentFinger++;
}
}
...
Keyboard.send_now();
}
Một số bàn phím còn cho phép người dùng tự cấu hình layout bằng phần mềm trên máy tính, xét ở góc độ firmware, điều này không quá khó, chỉ việc chuyển mảng keyLayout về một cấu trúc khác có thể lưu được vào bộ nhớ của Teensy, từ đó ta có thể load ra mỗi khi bàn phím được khởi động. Ví dụ lưu vào EEPROM thông qua hàm EEPROM.read() và EEPROM.write(), tuy nhiên cần lưu ý, EEPROM của Teensy 3.2 chỉ có 2KB, hơi ít, nhưng chắc vừa đủ xài. Nhưng nếu đã tự build được firmware, thì chả cần làm vậy cho mất công, chỉ cần customize layout bằng cách customize luôn source code
Mấy hôm nay ngồi xem kĩ lại firmware QMK, thấy nó có vài features khá thú vị, như Grave Escape Key, Key Lock, Tap Dance hay Mouse Key,… hôm nào có thời gian mình sẽ ngồi clone lại và viết thêm về chủ đề này.
Chỉ cần chừng đó thứ thì bạn đã có thể tự mình viết được firmware cho chiếc bàn phím của mình rồi. Nếu quan tâm, các bạn có thể tham khảo mã nguồn đầy đủ của firmware lẫn hardware cho bàn phím này tại đây https://github.com/huytd/snackymini-keyboard/
Xin cảm ơn các bạn đã kiên nhẫn đọc đến tận đây (tui nói vậy thôi chứ tui biết bạn scroll xuống đây từ đầu trang, chỉ tốn có 3 giây). Nếu bạn cũng là dân chơi mech, hy vọng bài viết này giúp các bạn hiểu thêm về những chiếc bàn phím tiền triệu mà mình đã mua. Nếu bạn chưa phải là dân chơi, hy vọng bài viết này làm nhụt chí và ngăn bạn lao vào con đường tốn kém này. Nếu đã đọc hết mà vẫn quyết định sẽ mua hoặc tự làm một chiếc bàn phím cơ, thì mình xin chúc mừng và chúc các bạn may mắn luôn.
P/S: Nếu bạn nào đang ở US, thì mình còn dư vài cái PCB, nếu có hứng thú thì cứ PM mình qua Facebook, mình sẽ gửi tặng.
Bài viết này được gõ bằng bàn phím SnackyMini Keyboard
Bài viết được sự cho phép của tác giả Nguyễn Trần Chung
WSL là gì
WSL (Windows Subsystem for Linux) là một tính năng có trên Windows x64 (từ Windows 10, bản 1607 và trên Windows Server 2019), nó cho phép chạy hệ điều hành Linux (GNU/Linux) trên Windows. Với WSL bạn có thể chạy các lệnh, các ứng dụng trực tiếp từ dòng lệnh Windows mà không phải bận tâm về việc tạo / quản lý máy ảo như trước đây. Cụ thể, một số lưu ý mà Microsoft liệt kê có thể làm với WSL
Bạn có thể làm gì với WSL
Chạy được từ dòng lệnh các lệnh linux như ls, grep, sed … hoặc bất kỳ chương trình nhị phân 64 bit (ELF-64) nào của Linux
Chạy được các công cụ như: vim, emacs …; các ngôn ngữ lập trình như NodeJS, JavaScript, C/C++, C# …, các dịch vụ như PHP, Nginx, MySQL, Apache, …
Có thể thực hiện cài đặt các gói từ trình quản lý gói của Distro đó (như lệnh apt trên Ubuntu, yum trên CentOS)
Từ Windows có thể chạy các ứng dụng Linux thông qua command line
Từ Linux có thể gọi ứng dụng của Windows
Yêu cầu
WSL1: Windows 10 1607 (window + R -> winver)
WSL2: Kích hoạt chế độ hỗ trợ ảo hóa của CPU (CPU Virtualization), bạn kích hoạt bằng cách truy cập vào BIOS của máy, tùy loại mainboard mà nơi kích hoạt khác nhau
Bài viết được sự cho phép của BBT Tạp chí Lập trình
Nhanh chóng phát hành một sản phẩm mới hoặc tính năng mới ra thị trường là nhiệm vụ đầy thử thách với mọi công ty trên thế giới. Việc hóc búa nhất là làm sao để các nhóm riêng biệt: phát triển, QA và vận hành IT làm việc cùng nhau để hoàn thành công việc và phát hành sản phẩm nhanh nhất có thể.
Các qui trình và kĩ thuật đã trải qua một quá trình tiến hóa để giải quyết thử thách này. Một thập kỉ trước không ai biết đến từ DevOps, nhưng vào năm 2009, một phương pháp đã tổng hợp các qui trình để phối hợp và giao tiếp giữa nhóm phát triển, QA và vận hành IT giúp rút ngắn đáng kể thời gian đưa sản phẩm ra thị trường bắt đầu phổ biến với tên gọi DevOps.
Phương pháp DevOps là một tập hợp các kĩ thuật được thiết kế để giải quyết vấn đề rời rạc giữa nhóm phát triển, QA và vận hành thông qua hợp tác và giao tiếp hiệu quả, kết hợp chặt chẽ qui trình tích hợp liên tục với triển khai tự động.Giúp tạo ra một môi trường để phát triển, QA và phát hành phần mềm ra thị trường nhanh chóng và ổn định.
Phương pháp Truyền thống vs DevOps
Theo phương pháp thác nước truyền thống, nhà phát triển viết mã cho các yêu cầu trên môi trường local. Khi phần mềm được build, đội QA kiểm thử phần mềm trên một môi trường tương tự như môi trường production. Cuối cùng, khi đã đáp ứng các yêu cầu, phần mềm được phát hành cho bên vận hành. Quá trình từ khi thu thập yêu cầu đến khi triển khai sản phẩm vào vận hành mất nhiều thời gian. Do hai bên phát triển và vận hành làm việc độc lập, khả năng cao là sản phẩm cuối cùng sẽ mất thêm nhiều thời gian nữa để đưa vào vận hành. Ngoài ra, sản phẩm có thể không chạy đúng như mong đợi hay gặp những trục trặc khác.
Khi đó, qui trình DevOps có một phương pháp tốt hơn để giải quyết những vấn đề trên. DevOps nhấn mạnh vào việc phối hợp và giao tiếp giữa nhóm phát triển, nhóm QA và nhóm vận hành để thực hiện việc phát triển liên tục, tích hợp liên tục, chuyển giao liên tục và giám sát các qui trình liên tục bằng cách dùng các công cụ kết nối các nhóm giúp đẩy nhanh tốc độ phát hành. Nhờ đó công ty có thể nhanh chóng thích ứng với những thay đổi từ yêu cầu kinh doanh.
DevOps ra đời một phần dựa trên khả năng phát hành sản phẩm nhanh khi công ty áp dụng Agile. Nhưng có thêm những qui trình khiến DevOps khác biệt với Agile.
Các nguyên lý của Agile chỉ áp dụng cho qui trình phát triển và QA, Agile tin tưởng vào việc tạo ra các nhóm nhỏ phát triển và phát hành phầm mềm chạy tốt trong một khoảng thời gian ngắn, được gọi là Sprint. Nhóm chỉ tập trung vào Sprint và không giao tiếp với bên vận hành.
Còn DevOps lại chú trọng hơn vào việc phối hợp suôn sẻ giữa các nhóm phát triển, QA và vận hành trong suốt chu trình phát triển. Nhóm Vận hành liên tục tham gia thảo luận cùng nhóm phát triển về các mục tiêu của dự án, lộ trình phát hành và các yêu cầu kinh doanh khác. Từ ngày đầu, nhóm vận hành nên đưa ra các yêu cầu liên quan đến vận hành cho nhóm phát triển, sau đó kiểm tra lại chúng. Việc giám sát dự án liên tục cùng với giao tiếp hiệu quả và thường xuyên giúp công ty có thể nhanh chóng phát hành.
Hãy xem xét vài lợi ích có thể nhận được từ qui trình và văn hóa DevOps.
Lợi ích đầu tiên ta sẽ nhận được là DevOps giúp giảm đáng kể thời gian đưa sản phẩm ra thị trường nhờ kết nối giữa các nhóm làm việc và làm theo qui trình phát triển liên tục.
Nhờ các nhóm đồng bộ tốt hơn, các thành viên có được tầm nhìn rõ ràng về các công việc đang làm, do đó họ có thể thấy các vấn đề hoặc các khó khăn trước khi chúng thực sự xảy ra. Nhờ vậy thành viên nhóm có kế hoạch tốt hơn để vượt qua các vấn đề đó.
Nhờ sự minh bạch trong qui trình, những người phát triển sản phẩm sẽ cảm thấy mình là chủ sản phẩm. Họ thực sự sở hữu mã từ khi bắt đầu đến lúc vận hành.
Viện triển khai tự động sản phẩm bằng các công cụ tự động hóa trong nhiều môi trường cho phép bạn nhanh chóng thấy được các vấn đề liên quan đến môi trường. Với những phương pháp khác thì thường tốn rất nhiều thời gian để phát hiện được các vấn đề này.
Những công cụ cho DevOps
Vì DevOps là sự cộng tác của Phát triển, QA và Vận hành, không thể có một công cụ duy nhất đáp ứng được tất cả các nhu cầu. Vì vậy cần nhiều công cụ để thực hiện thành công mỗi giai đoạn.
Hãy xem thử một vài công cụ cho mỗi giai đoạn ở dưới đây.
Monitoring: Nagios, NewRelic, Graphite …
Virtualization và Containerization: Vagrant, VMware, Xen, Docker …
Công cụ để build, test and deployment: Jenkins, Maven, Ant, Travis, Bamboo, Teamcity…
Dù DevOps đã ra đời hàng thập kỉ, nhưng nó vẫn rất mới mẻ với nhiều người. Do đó, vẫn còn nhiều hiểu nhầm.
Vài người nghĩ rằng triển khai DevOps cho phép nhà phát triển làm luôn công việc của bên vận hành. Điều này hoàn toàn không đúng. DevOps nhấn mạnh vào việc cộng tác từ cả hai nhóm, do vậy những nhà phát triển có các kĩ năng vận hành sẽ có lợi thế trong chu kỳ kinh doanh nhanh chóng hiện nay.
Cũng có rất nhiều người tin rằng có thể triển khai DevOps bằng cách dùng một bộ các công cụ cho tất cả phần việc. Điều đó không đúng; dùng vài công cụ không giúp ta đạt được DevOps, mà ta chỉ có thể đạt được các giá trị cốt lõi của nó thông qua thực sự triển khai qui trình DevOps và khôn ngoan chọn dùng các công cụ.
DevOps ngày càng trở lên phổ biến nhờ văn hóa phát triển liên tục, tích hợp liên tục, chuyển giao liên tục và qui trình giám sát liên tục thông qua việc cộng tác giữa Phát triển và Vận hành giúp giảm đáng kể thời gian đưa sản phẩm ra thị trường.
Xin chào các bạn, bài viết hôm nay mình sẻ hướng dẫn các bạn cách sử dụng thư viện FluentValidation để kiểm tra dữ liệu Form nhập liệu trên Winform C#.
[C#] Using Fluent Validation Form
Bất kỳ, khi các bạn thiết kế Form nào để nhập liệu, các bạn đều phải kiểm tra xem form đó người dùng nhập liệu vào có hợp liệu hay không.
HR – Nghề nhân sự tuyen dung it da nang như một sứ mệnh đặc biệt. Bạn muốn giúp bản thân mình tạo ra sự khác biệt trong phạm vi nghề nghiệp? Tạo động lực và niềm cảm hứng cho các nhân viên của mình? Sau đây là 3 hướng dẫn để giúp bạn sẵn sàng chinh chiến ở level cao hơn trong lĩnh vực nhân sự.
1. Xác định rõ ràng, cụ thể về giá trị mà bạn sẽ cung cấp cho khách hàng và gắn bó với nó
Phân tích từ một ví dụ từ thực tiễn. Bạn cung cấp dịch vụ nhân sự cho các công ty về tuyen dung it da nang thuộc chủ sở hữu theo mô hình ứng dụng công nghệ thực tiễn với nguồn lao động trẻ.
Thực tế cho thấy khi khởi nghiệp, chúng ta có xu hướng tập trung vào những thị trường quá rộng. Từ suy nghĩ ấy, khiến bạn có những định hướng chưa đúng đắn vì sự cung cấp nhầm đối tượng (rộng và lẫn lộn) sẽ khiến các khách hàng càng xa bạn hơn.
Bạn cần tìm ra những giá trị cụ thể mà bạn mong muốn mang đến cho khách hàng. Xây dựng nó thành một hệ thống; lập kế hoạch định hướng có mục tiêu.
Hãy lưu ý rằng dịch vụ nhân sự cần được đảm bảo kỹ lưỡng về nguyên tắc chuyên môn. Nếu quá rời rạc và có quá nhiều sự khác nhau về dịch vụ sẽ thiếu điểm nhấn với khách hàng.
2. Áp dụng cách thức: Mở rộng quan hệ nhân sự với nhiều người – nhưng xin lời khuyên chỉ một vài người
Hiểu đơn giản tức là bạn chỉ nên tìm kiếm sự tư vấn khôn ngoan từ một vài người có kinh nghiệm. Đó là điều bạn nên thực hiện khi quyết định những gì bạn sẽ làm.
Chúng ta luôn có xu hướng tìm kiếm lời khuyên từ những người thân thiết. Đó không phải là việc làm sai. Nhưng nó sẽ khiến bạn mất đi nhiều thời gian để tìm ra được những người thật sự muốn lắng nghe bạn.
Vì thế, hãy linh đông và nhận ra ai là người bạn cần hỏi. Các tiêu chi bạn có thể xét là: kinh nghiệm sống, kiến thức và kỹ năng.
2 – tuyen dung it da nang
Điều quan trọng nhất bạn cần nhớ là bạn có thể xin ý kiến từ nhiều nguồn; nhiều đối tượng ở các lĩnh vực khác nhau với điều kiện là dự án. Chiến lược của bạn cần được hoàn thành, chỉn chu được 90%. Và phải chắc chắn khả năng chiến lược ấy phải được tiến hành. đơn xin nghỉ việc
3. Đầu tư cho chính mình: Tìm điểm mạnh mẽ để phát triển sâu và tự cân đối cuộc sống
Bạn có thể là nhân sự giỏi trong khi làm việc cho người khác. Nhưng lại ít giỏi khi làm việc đó cho chính mình.
Điểm mạnh là thứ quan trọng bạn cần tìm kiếm. Hãy suy nghĩ về những câu hỏi cho bản thân như: Bạn thích làm điều gì, bạn muốn trở thành người thế nào,.. Thế mạnh là điều bạn phải bắt buộc tìm ra.
Đừng xem thường việc này nhé! Vì việc nhận ra thế mạnh bản thân có thể thay đổi bạn một cách tốt hơn. Thế mạnh còn là một cơ sở nền tảng quan trọng. Từ đó, các nhà quản trị tuyen dung it da nang có thể phát triển vấn đề chuyên môn cho nhân viên mình dựa trên tiềm lực thế mạnh sẵn có.
3 – tuyen dung it da nang
Một điều quan trọng nữa, đó là nếu bạn muốn thành công, bạn phải cân bằng cuộc sống của mình. Điều này khá dễ dàng để nắm bắt nhưng nhiều người không làm được điều đó, đặc biệt là khi họ mới bắt đầu.
Không ai có thể duy trì một lịch trình điên rồ kín đặc và họ cần có sự hỗ trợ của gia đình vô thời hạn. Hãy luôn đảm bảo sự cân bằng với gia đình ngay cả khi điều đó là khó khăn để làm như vậy.
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Product Manager nên từ chối như thế nào để “được lòng người” nhất!
Tác giả: Maddy Kirsch
Cách từ chối hay ho cho Product Manager là gì?
Công việc của Product Manager là gì? Họ phải đưa ra được những lựa chọn tốt nhất. Vậy để đưa ra những lựa chọn tốt nhất, một Product Manager thường phải nói không với những đề xuất, ý tưởng, yêu cầu hay thậm chí là sự đòi hỏi từ các bên liên quan. Tuy nhiên, trên thực tế để được lòng mọi người cũng như công việc được suôn sẻ hơn, bạn nên biết cách từ chối khéo léo, hãy làm sao để đối phương có thể hiểu được vấn đề và tôn trọng quyết định của bạn.
Từ chối khéo léo giúp PM làm việc hiệu quả hơn
6 mẹo các Product Manager có thể sử dụng để nói “không”
Dành thời gian để thảo luận với các bên liên quan về yêu cầu của họ
Lý do cho việc này rất đơn giản, tất cả mọi người đều muốn được lắng nghe. Trong những khóa đào tạo trước khi nhận việc của các công ty lớn, như với chương trình KMS Technology tuyển dụng, Product Manager sẽ được hướng dẫn về cách lắng nghe những yêu cầu và khiếu nại của khách hàng, sau đó nói chuyện với họ như thế nào để họ hiểu và thông cảm với vấn đề hiện tại.
Khi một bên liên quan trong nội bộ công ty hoặc một khách hàng đến gặp bạn với yêu cầu thêm một tính năng hay một yêu cầu mà bạn không thể hỗ trợ, ít nhất là không phải ngay lập tức, bạn đừng vội vàng nói lời từ chối với họ.
Bạn không nên nói những câu nói đại loại như “Điều đó có vẻ không phải là ưu tiên cho sản phẩm này” hoặc, “Chúng tôi không có điều đó trong lộ trình.” Tại sao? Có hai nguyên do:
Đầu tiên, khi bạn từ chối mà không đưa ra những lý do thích hợp cho yêu cầu của bên liên quan, bạn sẽ khiến họ có cảm giác không hề được lắng nghe hay suy xét đến quan điểm của họ. Thay vào đó, Product Manager hãy dành thời gian ghi nhận yêu cầu, giải thích cho người đó hiểu rằng bạn hiểu tại sao họ muốn hoặc cần nó, tuy nhiên để thực hiện yêu cầu này ngay bây giờ thì rất khó.
Thứ hai, Product Manager có thể nói rằng “Đó không phải là ưu tiên của chúng tôi”. Trong trường hợp này dù bạn không giải thích quá nhiều về lý do từ chối nhưng ít ra vẫn tốt hơn so với việc bị từ chối mà không biết lý do là gì.
Vậy nên lời khuyên của tôi ở đây là, khi bạn phải từ chối ai đó, hãy chứng minh rằng bạn hiểu rõ công việc của mình và có lý do chính đáng để làm như vậy.
Hiểu rõ nội dung công việc để đưa ra những lập luận hợp lý
Năng lực của Product Manager là gì? Để có năng lực làm việc xuất sắc, bạn cần dành nhiều thời gian để nghiên cứu và nghiền ngẫm về dự án của mình. Điều này bao gồm sự hiểu biết cặn kẽ về thị trường, nguồn nhân lực và năng lực nội bộ của công ty, bối cảnh cạnh tranh và các yếu tố cạnh tranh thị trường ảnh hưởng đến các quyết định chung như thế nào. Lúc này, bạn có thể đưa ra nhiều lý do thuyết phục hơn cho sự từ chối của mình.
Hiểu rõ dự án giúp PM thuyết phục được đối phương
Do đó, trước tiên Product Manager nên dành thời gian thảo luận với người yêu cầu. Điều này sẽ chứng tỏ rằng bạn có thiện chí và muốn hiểu nhu cầu của họ, đánh giá cao gợi ý của họ. Sau đó, khi giải thích lý do tại sao bạn không thể đáp ứng yêu cầu, bạn có thể cung cấp bối cảnh lớn hơn – như các dự án cạnh tranh hoặc duy trì tính đơn giản và khả năng sử dụng của sản phẩm – mà người yêu cầu có thể không xem xét đến.
Nếu có thể, hãy chứng minh ý kiến này chỉ có giá trị nhất thời mà thôi
Giá trị nhất thời cần sự giải thích của Product Manager là gì? Giả sử trong trường hợp Product Manager phải từ chối yêu cầu từ nhóm bán hàng hoặc tiếp thị dù nó thật sự là quyết định hay ho. Hoặc một ý kiến mà bạn đơn giản là chưa từng gặp phải và có thể đáng được đưa vào kế hoạch sản phẩm nhưng trước tiên cần được kiểm tra. Câu trả lời của bạn lúc này có thể không phải là “không” – mà thay vào đó là “không phải lúc này”.
Ý tưởng thứ hai để các bên liên quan thấy rằng Product Manager dự định đánh giá các yêu cầu của họ và bạn không từ chối chúng, mà là đặt những yêu cầu này trong một diễn đàn cộng đồng, lý tưởng là một diễn đàn có thể truy cập được cho cả nhóm nội bộ của bạn cũng như khách hàng bên ngoài và thậm chí triển vọng, nơi bất kỳ bên quan tâm nào có thể bỏ phiếu hoặc bình luận về các ý tưởng mới.
Sự rõ ràng trong lựa chọn của Product Manager là gì?
Nhất là khi làm việc với các giám đốc trong công ty, bạn nên trình bày rõ ràng về lộ trình làm việc sản phẩm, bạn sẽ áp dụng những phương pháp nào, chủ đề, tính năng nào cho dự án này. Nếu bạn có thể chứng minh rõ ràng thông qua bản trình bày về cách làm việc của mình, rằng giai đoạn nước rút tiếp theo hoặc chu kỳ phát triển dài hạn hơn cần tập trung vào X, với lý do vững chắc đằng sau quyết định đó. Chắc chắn lúc này các bên liên quan sẽ thấy hợp lý và thông cảm với hành động rằng bạn không thể đáp ứng yêu cầu của họ với đề xuất Y.
Khả năng giao tiếp tốt của Product Manager là gì? Hãy hạn chế dùng chủ từ “tôi” khi nói không
Với tư cách là một Product Manager, bạn là người mà các bên liên quan sẽ đưa ra ý tưởng hoặc yêu cầu cho lộ trình phát triển sản phẩm. Nhưng điều đó không đồng nghĩa với việc bạn đang đưa ra quyết định mang tính cá nhân khi từ chối yêu cầu đó. Một cách hữu hiệu để nhấn mạnh điều này và giúp các bên liên quan hiểu rõ hơn về lý do tại sao bạn phải từ chối họ, đó là không đề cập đến bản thân bạn trong cuộc trò chuyện. Chẳng hạn thay vì nói “Tôi không nghĩ chúng ta nên tập trung vào ý kiến đó bây giờ”, bạn hãy nói rằng “Nghiên cứu của chúng tôi đã cho chúng tôi biết điều đó…”.
Cố gắng đừng dùng từ “không” dù bạn đang nói không
Đây là một cách rất hay để Product Managervừa thể hiện sự tôn trọng với đối phương vừa có cơ hội tận dụng được những ý tưởng tốt cho thời điểm khác. Bạn có thể nói mình sẽ dành ý kiến này cho kế hoạch sắp tới,… Bạn không cam kết bất cứ điều gì, nhưng việc bạn ghi nhận ý kiến đó khiến người nói có cảm giác được tôn trọng và ý tưởng của họ dường như cũng có giá trị nào đó trong chiến lược sản phẩm của bạn.
Những mẹo nhỏ trên đây dù không phải là tất cả nhưng cũng sẽ phần nào quyết định được sự khéo léo và khả năng giao tiếp chuyên nghiệp của một Product Manager. Bạn vừa giữ nguyên được bản kế hoạch mà mình cho là tốt nhất, lại vừa không khiến người khác cảm thấy tức giận mà được tôn trọng hơn rất nhiều.
Cách tạo một portfolio ấn tượng cho Product Manager
Tác giả: Dr. Nancy Li
Portfolio của Product Manager là gì?
Hầu hết công việc của các Product Manager đều yêu cầu về kinh nghiệm làm quản lý sản phẩm, nhưng làm thế nào để thể hiện được những dự án mà trước đây bạn đã làm trong portfolio? Bài viết dưới đây chia sẻ với các bạn cách để tạo một portfolio thể hiện những kỹ năng bạn đã có trong các công việc trước và thông qua vòng phỏng vấn một cách trơn tru nhất.
Portfolio là một phần cực kỳ quan trọng vì nó thể hiện những sản phẩm bạn đã hoàn thành trong công việc trước đó của mình. Gần đây, có một sinh viên của tôi nhận được công việc Product Manager trong lĩnh vực thương mại điện tử. Có được kết quả này là nhờ trước đây cô ấy đã làm một portfolio rất ấn tượng để được tuyển vào vị trí này.
Portfolio của Product Manager được yêu cầu rất cao
Product Manager Portfolio cần thể hiện những gì?
Portfolio của Product Manager là gì? Những phần nào cần có trong portfolio?
Portfolio chứa danh sách các sản phẩm mà bạn đã làm việc trước đây, cách bạn sử dụng các phương pháp để quản lý sản phẩm. Từ đó nhà tuyển dụng phân tích xem bạn đã có kinh nghiệm làm việc ở vị trí này trước đây chưa, cũng như nắm được cách bạn làm việc, những thành phần quan trọng trong việc build một sản phẩm.
Tôi tin rằng ở đây có nhiều bạn nghĩ rằng một portfolio ấn tượng cần có thiết kế đẹp nhưng điều này không thật sự cần thiết với công việc Product Manager. Portfolio của một Product Manager cần tập trung vào kinh nghiệm làm việc với khách hàng, trải nghiệm khách hàng và các yêu cầu có liên quan đến việc phát triển sản phẩm và phát hành nó ra thị trường. Đây cũng chính là 3 phần chính cần có của một product portfolio.
Tính cách khách hàng và trải nghiệm với họ trong portfolio sẽ thể hiện cách bạn tận dụng nó trong khi làm việc ra sao. Và thông thường thì bạn sẽ có nhiều hơn một loại tính cách khách hàng trong portfolio của mình. Chẳng hạn sẽ có 5 yêu cầu khác nhau về sản phẩm trước đây cần được đề cập đến.
Còn với MVP, có rất nhiều loại MVP nhưng MVP phổ biến nhất là Mockups và videos. Nếu bạn có thể trực tiếp cho khách hàng xem các loại mockups và videos của sản phẩm thì những phản hồi từ khách hàng chắc chắn sẽ giúp bạn cải thiện sản phẩm sau đó tốt hơn rất nhiều.
Tạo một portfolio để thể hiện những kinh nghiệm mình có trước đây
Đối với công việc Product Manager, kinh nghiệm là một yếu tố cực kỳ quan trọng. Do đó những dự án mà bạn thể hiện trong portfolio khi tham gia chương trình Product Manager tuyển dụng sẽ giúp nhà tuyển dụng nắm bắt và xác định chính xác những kỹ năng mà bạn sở hữu. Lời khuyên của tôi là tất cả các bạn sinh viên nên dành ra ít nhất 20 tiếng để tạo cho mình một product portfolio. Vì làm như vậy sẽ giúp bạn hiểu rõ hơn công việc của một Product Manager là gì, để sau khi nhận việc bạn có thể bắt đầu vào guồng công việc nhanh nhất.
Kinh nghiệm làm việc rất cần với vị trí quản lý sản phẩm
Trong trường hợp bạn chưa từng làm công việc nào liên quan đến quản lý sản phẩm trước đó thì ngay bây giờ bạn hãy bắt đầu bằng cách làm những dự án phụ. Thông thường các công ty startup sẽ có khá nhiều các dự án như thế cho bạn làm việc, và nhờ đó bạn cũng sẽ tích lũy thêm được kinh nghiệm cho bản thân mình.
Tôi dám khẳng định rằng nếu bạn đã đầu tư thời gian và công sức cho một chiếc product portfolio ấn tượng thì bạn sẽ được mời phỏng vấn dựa theo những gì bạn đã cung cấp trên mạng. Tôi đã từng hỏi các học viên của tôi rằng bạn có biết làm cách nào mà chúng ta có thể trở thành Product Manager dù không hề apply trước. Theo đó, các mối quan hệ xã hội sẽ giúp bạn làm điều này.
Khi bạn đăng tải các thông tin này của mình lên mạng xã hội hay các nền tảng tuyển dụng, những công ty nào đang cần tuyển Product Manager sẽ chú ý hơn đến portfolio của bạn, nhất là portfolio có nhiều kinh nghiệm làm việc.
Hãy đính kèm portfolio trong resume và đơn xin việc của bạn
Trong resume của mỗi người sẽ có một phần gọi là Product Manager Project, nơi bạn có thể tập hợp mọi dự án mà mình đã thực hiện. Trong đó bạn có thể chia sẻ về những lần làm việc với khách hàng trước của mình và những yêu cầu bạn đã vạch ra cho lộ trình làm việc của mình.
Trong suốt buổi phỏng vấn, nhà tuyển dụng sẽ liên tục hỏi bạn các câu hỏi liên quan đến công việc như khi nào thì bạn có thể cho phát hành một sản phẩm,… Các câu hỏi có thể sẽ được dựa trên portfolio của bạn, do đó nếu mang theo nó trong cuộc phỏng vấn trực tiếp, bạn không chỉ gây ấn tượng tốt hơn với người phỏng vấn mà còn giúp chính mình thoải mái hơn khi trả lời phỏng vấn.
Là dân IT hẳn mọi người không còn xa lạ với cụm từ Software Architect (SA) – ở đây tôi tạm dịch là kiến trúc sư phần mềm. Tuy nhiên không phải ai cũng hiểu được vai trò, trách nhiệm, công việc thực sự và con đường sự nghiệp của một SA. Đây là những câu hỏi mà tôi đã từng đặt ra khi bước vào những nấc thang đầu tiên của vị trí này. Tôi tự đi tìm lời giải đáp cho mình.
PHÂN LOẠI KIẾN TRÚC SƯ PHẦN MỀM
Thật ra có nhiều cách để phân loại kiến trúc sư phần mềm. Tuy nhiên, ở đây tôi sử dụng cách phân loại của Microsoft. Đây cũng là một cách thức phân chia khá phổ biến trong ngành phần mềm hiện nay.
Là cầu nối giữa chủ sở hữu sản phẩm và đội ngũ kĩ thuật. Họ là những người có kinh nghiệm chiều sâu trong lĩnh vực mà sản phẩm đang xây dựng.
Chịu trách nhiệm trong việc xây dựng và phát triển yêu cầu – thiết lập viễn cảnh, bộ khung của môi trường IT trong sản phẩm.
Kiến trúc sư hạ tầng (infrastructure architect)
Là người chịu trách nhiệm trong việc thiết lập, xây dựng giải pháp về cơ sở hạ tầng IT (ví dụ: mạng, các vấn đề bảo mật, thiết bị/ phương thức lưu trữ, ..) trong sản phẩm để đáp ứng nhu cầu của doanh nghiệp.
Kiến trúc sư giải pháp (solution architect)
Là người chịu trách nhiệm trong việc thiết kế, xây dựng giải pháp cho những yêu cầu của sản phẩm.
Kiến trúc sư kĩ thuật (Technology-specific architect)
Là người chịu trách nhiệm về một hoặc một số lĩnh vực kĩ thuật cụ thể.
Trong một số công ty hiện tại ở Việt Nam, có một vị trí gọi là Technical Architect (kiến trúc sư kĩ thuật) trong tổ chức. Vị trí này chịu trách nhiệm cho việc phân tích, đánh giá giải pháp, xây dựng kiến trúc hệ thống. Nếu ánh xạ với cách phân loại trên thì TA chính là Solution Architect.
NHỮNG TÍNH CÁCH CẦN THIẾT CỦA MỘT KIẾN TRÚC SƯ PHẦN MỀM GIỎI
Cho dù bạn có là kiến trúc sư phần mềm nào, thì dưới đây là những tính cách bắt buộc phải có để đạt được đỉnh cao của nghề này:
1. Nhạy bén về kinh tế: mọi kiến trúc sư khi đưa ra giải pháp cho bất cứ bài toán nào cũng đều phải cân nhắc chi phí, lợi ích tương quan của doanh nghiệp. Đây là yếu tố then chốt đánh giá hiệu quả của một giải pháp.
2. Có tầm nhìn xa: khi tham gia vào một dự án, kiến trúc sư phải cân nhắc những giải pháp, công nghệ sắp xuất hiện, xem xét những thay đổi gần đây trong lĩnh vực công nghiệp đang phát triển… và làm cách nào để tận dụng tối đa giải pháp hiện tại trong tương lai.
3. Nghiên cứu kĩ thuật mới: một kiến trúc sư phải luôn luôn nghiên cứu những hướng kĩ thuật mới, từ kiến trúc IT cho đến những ứng dụng và xu hướng phát triển ứng dụng
4. Hiểu và có khả năng ứng dụng những framework,kiến trúc hệ thống, phương pháp luận trong quá trình phát triển phần mềm
6. Có thể làm việc trên những thông tin còn chưa rõ ràng.
7. Khả năng truyền đạt và giao tiếp
LÀM SAO ĐỂ TÔI CÓ THỂ TRỞ THÀNH MỘT KIẾN TRÚC SƯ PHẦN MỀM
Kiến trúc sư phần mềm là đỉnh cao của thang nghề nghiệp khi bạn chọn đi theo con đường kĩ thuật. Để trở thành một kiến trúc sư phần mềm, bạn nên theo những bước sau:
1. Định hướng rõ ràng về loại kiến trúc sư phần mềm bạn muốn trở thành
2. Xác định và xây dựng những kĩ năng cần thiết. Liên tục bổ sung kiến thức phù hợp cho loại hình kiến trúc sư mà bạn chọn
3. Không ngừng phấn đấu và khẳng định vai trò của một kiến trúc sư trong chính những dự án mà bạn đang tham gia.
4. Cố gắng rèn luyện và lấy những chứng chỉ quốc tế về kiến trúc sư kĩ thuật của những tập đoàn công nghệ lớn (Microsoft hoặc Sun). Microsoft bạn cần lấy được MCA (Microsoft Certificate Architect). Đối với Sun, bạn cần lấy được chứng chỉ: SCEA (Sun Certificate Enterprise Architect)
Con đường để trở thành một kiến trúc sư phần mềm đỉnh cao và chuyên nghiệp vẫn còn ở rất xa. Và có một điều tôi luôn tâm niệm là: dù ở bất kì ngành nghề nào, vị trí nào – việc phấn đấu để đạt được đỉnh cao trong sự nghiệp cũng đều đem lại những lợi ích như nhau so với những vị trí hoặc ngành nghề khác.
CHỈ LÀ MỘT VÀI THỨ TÔI MONG CHỜ Ở MỘT KIẾN TRÚC SƯ PHẦN MỀM (KTSPM).
KTSPM, trước hết, phải thấy xa hơn những gì mà một kĩ sư bình thường thấy và thực sự hiểu rõ về hệ thống. Có một chuyện khá là kì cục là các dự án hay bắt đầu bằng cách cho KTSPM viết ngày viết đêm ra một cái gọi là framework (framework ở đâu ra mà lắm thế), sau đó lui ra, và các kĩ sư bình thường sẽ nhào vô viết thêm tính năng, và chúng ta có một phần mềm. Sau đó có thể có chút trục trặc, chậm chạp thì các KSTPM này lại quay trở lại để dọn rác.
Nhưng hãy để tôi kể câu chuyện về dự án mà tôi đang làm đã. Đầu tiên chúng tôi có một KTSPM. Người này chuẩn bị mọi thứ, từ hệ thống build, database, Spring, Hibernate này kia, và cũng viết một ít làm mẫu. Và vì chỉ là làm giúp nên rời dự án nhanh chóng. Sau đó chúng tôi bỏ một thời gian dài loay hoay vừa muốn giữ cái nền này vừa muốn đập bỏ. Khi yêu cầu phần mềm thay đổi và vấn đề nảy sinh thì cái nền rõ ràng là không phù hợp. Nhưng cái nền là do KTS viết ra mà. Sự thiếu dứt khoát khiến cho mọi thứ trong hệ thống mà chúng tôi xây dựng vẫn còn khá là vá víu và không linh hoạt. Trong giai đoạn này có hai người nữa, một người là KTS và một người gần được KTS. Nhưng họ cũng chỉ viết mã cho một vài phần. Có thể là những phần khó hơn, nhưng nó chỉ là một phần nhỏ của toàn bộ bức tranh. Và nó cũng chứa những sai lầm tiềm ẩn như những nhiều phần khác. Và nó cũng có thể được hoàn thành bởi những kĩ sư khác trong dự án, mặc dù có thể là phải có một chút hướng dẫn. Nói tóm lại, những KTSPM đang làm những việc mà kĩ sư làm, chỉ là (có thể) ở một trình độ tốt hơn.
Vậy những sai lầm mà dự án tôi gặp phải và mắc kẹt là gì. Có thể kể ra những thứ khá cơ bản, như bỏ qua các bước an ninh cơ bản (chống XSS, CSRF), không xây dựng một dạng protocol (hay interface) thống nhất cho các request, bỏ lơ vấn đề cache và performance (cache phía server, cache phía client), không có hệ thống build tự động, không có phương pháp chung để xử lí vấn đề cross-browser, v.v. Đây là những vấn đề có tác động quan trọng tới thiết kế của phần mềm, nên không thể giải quyết một sớm một chiều được. Dĩ nhiên, phần mềm là một hệ thống phức tạp mà khi đã đầy đủ các bộ phận thì việc thay đổi sẽ tốn kém. Vì vậy, không thể ngày hôm nay nghĩ về vấn đề này thì xây dựng nó một kiểu, rồi mai gặp hay chợt nghĩ về vấn đề khác thì sửa đối nó theo kiểu khác.
Tất nhiên KTS vẫn nên là người viết những thành phần quan trọng, để góp phần tạo ra một phần mềm có chất lượng tốt. Nhưng kĩ sư giỏi thì cũng có thể viết được những phần khó, họ cũng có thể đọc sách, tìm hiểu, suy nghĩ. Vậy thì giá trị đặc biệt của KTSPM nằm ở chỗ nào, tại sao họ đứng trên một cấp, và lương cao hơn? Theo tôi nghĩ đấy là vì kĩ sư giỏi là những người chỉ giải quyết được những vấn đề cục bộ, riêng rẽ, chứ không thể quan sát hệ thống một cách tổng thể. KTSPM phải là người định hướng. Họ phải liệt kê ra được những yêu cầu, vấn đề, hoặc thử thách mà dự án sẽ đối mặt, trước mắt và tương lai. Họ phải xây dựng được những quy tắc chung để kĩ sư có thể tuân theo nhằm hạn chế sai sót. Họ phải biết phân bổ nhân lực cho hợp lí với từng phần việc. Và họ phải nắm tình trạng phát triển hiện tại của phần mềm để nhận ra những bài toán hay cải tiến cần được thực hiện một cách thực sự đúng đắn và dứt khoát.
(Bạn nghỉ ngơi một xíu trả lời câu này xem. Nếu bối rối thì chắc chưa phải KSTPM rồi.)
Không chỉ nhìn xa hơn những kĩ sư, KTSPM còn phải cố gắng nhìn xa hơn những gì ông chủ nghĩ. Không phải là về kinh doanh, mà là về chức năng của phần mềm. Họ phải biết trừu tượng hóa các yêu cầu cụ thể để có cái nhìn bao quát cho chức năng mà trong đó yêu cầu của những người phân tích nghiệp vụ chỉ là một lựa chọn, một hướng hiện thực cụ thể. Ý định của con người luôn thay đổi rất nhanh, và yêu cầu cũng vậy, nên không có lí do gì lập trình viên đặt niềm tin là những thứ họ phải làm hiện tại sẽ giống vậy mãi mãi. Chuẩn bị tốt cho những lựa chọn chưa xảy ra sẽ giúp phần mềm linh động với những nhu cầu, đòi hỏi từ thị trường. Và điều quan trọng là thấy trước thay đổi của hệ thống là nhiệm vụ của KSTPM, không cần ai khác phải nói ra, và họ sẽ không thể đổ lỗi đi đâu đó như người phân tích nghiệp vụ, hay người dùng nếu không thực hiện tốt nhiệm vụ này.
Chẳng hạn, hãy nói việc hỗ trợ bookmark cho những web application dùng AJAX nhiều. Nếu một trang web mà trạng thái của nó, như đang mở tab nào, đang hiện nội dung gì, không được thể hiện trên địa chỉ thì người dùng sẽ không thể bookmark để quay lại trạng thái đó một cách nhanh chóng được. Tuy nhiên, yêu cầu phần mềm thường quên mất chuyện này, trong khi nếu không được thiết kế ngay từ đầu thì việc chỉnh sửa thiết kế của ứng dụng để hỗ trợ chức năng này sẽ khá rắc rối. Do nên KTSPM phải biết tự thấy trước và đáp ứng chức năng ngay khi chưa có yêu cầu.
Có thể tóm lại là KSTPM trước hết phải biết nhìn xa, nhìn trừu tượng, không chỉ xây nên framework mà còn những tiêu chuẩn, quy định, và đường lối cho dự án.
Điều thứ ba, liên quan đến cách mà một KTSPM làm việc với nhân viên (và sẽ không viết ở đây).
Khi tìm hiểu và làm việc với Distributed Systems, chúng ta có thể sẽ hay bắt gặp những cụm từ như: Replicated State machine, Log replication hay Event-driven, Event-sourcing. Về bản chất, những khái niệm này đều được xây dựng xung quanh mô hình “Máy trạng thái” (State machine). Bài viết này sẽ mô tả mô hình này và lý do tại sao State machine lại được áp dụng rộng rãi trong Distributed Systems.
Trạng thái (state) của một process có thể hiểu là tập hợp các giá trị của các biến (variable) trong process đó. VD, nếu process p1 có thể có state S1 = {x=1, y=2}. Thường trong thực tế, một process sẽ có cả dữ liệu trong RAM lẫn trên đĩa cứng, chúng ta coi tất cả các dữ liệu này là state của process đó.
State machine trong tin học là một mô hình tính toán, trong đó một máy tính (machine) thay đổi trạng thái (state) dựa theo chuỗi input mà nó được cung cấp. Ta hãy lấy ví dụ một bài toán: xác định xem trong một dãy số nhị phân (VD: 110100101), số chữ số 0 là chẵn hay lẻ. Bài toán này có thể giải bằng cấu trúc State machine, trong đó chuỗi input là chuỗi các chữ số nhị phân, và “state” có thể là “chẵn” (S1) hay “lẻ” (S2). State machine này bắt đầu từ trạng thái S1 (có 0 chữ số 0), và với mỗi giá trị chữ số, nó thay đổi trạng thái theo như hình minh họa bên dưới. Trạng thái cuối cùng cũng là kết quả (output) của bài toán.
Về thứ tự của các phần tử trong một tật hợp. Giả sử ta có một tập hợp S={x1,x2,x3,x4}. Nếu tất cả các phần tử của tập hợp này có thể được sắp xếp theo một thứ tự cố định (VD: x1 < x2 < x3 < x4), bao gồm cả tính bắc cầu (x1 < x2, x2 < x3 => x1 < x3) và phản đối xứng (x1 <= x2 & x2 <= x1 => x1 = x2), thì tập hợp này được gọi là có thứ tự toàn phần (total order). Nếu không thỏa mãn điều kiện trên thì tập hợp này có thứ tự một phần (partial order). Khái niệm này quan trọng trong việc xác định thứ tự các sự kiện trong Distributed Systems. Bạn có thể tham khảo kĩ hơn về lý thuyết thứ tự của tập hợp tại đây.
Bắt đầu từ một cấu trúc quen thuộc: log
Hầu như ai làm dev cũng đều phải quen làm việc với log. Nói đơn giản thì log là một chuỗi các dữ kiện giúp lưu lại thông tin về những sự kiện đã xảy ra trong quá trình phần mềm vận hành. Mỗi dữ kiện được gọi là một entry. Ví dụ, đây là một đoạn log của dpkg trên Ubuntu:
$ tail -f /var/log/dpkg.log
2020-09-21 01:51:20 status installed man-db:amd64 2.9.1-1
2020-09-21 01:51:21 trigproc dbus:amd64 1.12.16-2ubuntu2.1 <none>
2020-09-21 01:51:22 status half-configured dbus:amd64 1.12.16-2ubuntu2.1
2020-09-21 01:51:23 status installed dbus:amd64 1.12.16-2ubuntu2.1
2020-09-21 01:51:24 trigproc mime-support:all 3.64ubuntu1 <none>
2020-09-21 01:51:25 status half-configured mime-support:all 3.64ubuntu1
2020-09-21 01:51:26 status installed mime-support:all 3.64ubuntu1
2020-09-21 01:51:27 trigproc initramfs-tools:all 0.136ubuntu6.3 <none>
2020-09-21 01:51:28 status half-configured initramfs-tools:all 0.136ubuntu6.3
2020-09-21 01:51:29 status installed initramfs-tools:all 0.136ubuntu6.3
Một log entry trong ví dụ trên bao gồm hai thông tin: một là mô tả về sự kiện, hai là thời điểm (timestamp) xảy ra của sự kiện. Loại log quen thuộc này thường được gọi là Application log, mục đích chính của nó là giúp chúng ta truy tìm thông tin khi cần thiết (ví dụ như để truy vết bug chẳng hạn). Lưu ý là, các entry trong log luôn có thứ tự toàn phần (total order). Đối với log kể trên thì giá trị của timestamp là yếu tố xác định thứ tự của các entry. Log entry chỉ có thể được thêm vào log, chứ không thể bị xóa đi hay thay đổi. Thuật ngữ mô tả quy tắc này là “append-only”.
Trong lý thuyết về Distributed Systems, hai thành phần thông tin kể trên của log (nội dung và thứ tự của sự kiện) đóng vai trò quan trọng. Các hệ thống Distributed Systems hiện nay đều được xây dựng xung quanh việc đồng thuận về nội dung của chuỗi log. Hệ quả này dựa trên nguyên lý (tạm gọi là nguyên lý nhân bản trạng thái) như sau:
Nếu ta có hai process tất định (deterministic) như nhau và chúng xử lý cùng chuỗi dữ liệu đầu vào (input) như nhau, thì chúng sẽ có đầu ra (output) và trạng thái cuối cùng (state) như nhau.
Deterministic process ở đây được hiểu là process chỉ vận hành dựa trên việc xử lý input chứ không phụ thuộc vào các yếu tố bên ngoài (VD như yếu tố thời gian, yếu tố ngẫu nhiên…). Hiển nhiên là hai hệ thống deterministic như nhau nếu cùng nhận một chuỗi input sẽ cho ra kết quả như nhau. Do đó, chúng ta có thể lưu trữ hoàn toàn lịch sử trạng thái của một hệ thống bằng việc lưu trữ chuỗi input dưới dạng log.
Đến đây thì chúng ta có thể nhận thấy được sự liên quan giữa “log” và “State machine”. Nếu ta có một deterministic process được cấu trúc theo dạng State machine và một log lưu lại các input của process này, ta có được toàn bộ thông tin về quá trình hoạt động của process. Lấy ví dụ, một hệ thống ngân hàng cần lưu trữ thông tin tài khoản của khách hàng. Ta có thể lưu những yêu cầu xử lý của khách hàng dưới dạng input log như sau:
1. Tài khoản X được khởi tạo.
2. Tài khoản X nạp 100.000 VND.
3. Tài khoản Y được khởi tạo.
4. Tài khoản X chuyển cho tài khoản Y 50.000 VND.
5. Tài khoản Y rút ra 20.000 VND.
Từ log trên ta có thể dễ dàng tính ra trạng thái cuối cùng của hệ thống này (sau sự kiện 5) là {X=50.000, Y=30.000}. Tuy nhiên, ngoài ra, cấu trúc input log này có một vài ưu điểm như sau:
Thứ nhất, cấu trúc này lưu trữ được nhiều thông tin hơn là việc lưu trạng thái thông thường. Ở đây ta mặc nhiên có được một lịch sử giao dịch cho tài khoản X và Y. Điều này cho phép ta có thể xác định được trạng thái của hệ thống trong bất kì thời điểm nào.
Thứ hai, cấu trúc này hỗ trợ khả năng đối phó sự cố (fault tolerant) của hệ thống. Nếu như một server bị crash trong quá trình hoạt động, thì khi phục hồi, ta có thể tái thiết lại trạng thái cho server đó bằng cách “chạy” lại input log này (đây còn được gọi là ‘log replay’).
Kết cấu này cũng mang tính đàn hồi (scalable) cao. Dữ liệu log kể trên có thể được nhân bản hay chuyển hóa thành các dạng dữ liệu khác nhằm phục vụ cho các mục đích khác nhau. Ta sẽ bàn về điều này nhiều hơn trong phần Event sourcing.
Log replication và Replicated State machine.
Ở phần 2, chúng ta đã nói sơ qua về tầm quan trọng của bài toán đồng thuận (consensus) trong DS. Bài toán này thực ra là phiên bản đơn giản hóa, vì yêu cầu đặt ra chỉ là giúp các server đồng thuận 1 giá trị. Trên thực tế, các hệ thống khi vận hành phải tiếp nhận yêu cầu của người dùng và thay đổi trạng thái liên tục, do đó bài toán ở đây là các server phải đồng thuận một chuỗi giá trị thay đổi theo thời gian. Các server cũng có thể bị mất kết nối hoặc crash, khiến cho việc đồng bộ thông tin giữa các máy càng trở nên phức tạp. Lấy ví dụ, nếu một server crash và sau đó phục hồi, khi đó trạng thái của server này đã khác biệt so với các server khác. Làm thế nào để ta biết được trạng thái nào mới là trạng thái đúng?
Mô hình Replicated State machine (các máy trạng thái nhân bản), hay Log replication, được phát triển nhằm giải quyết vấn đề này. Trong mô hình này, mỗi server trong hệ thống được cấu trúc dưới dạng State machine, tương đồng với Deterministic process được nêu ở phần trên. Log trong trường hợp này là chuỗi các input mà hệ thống nhận được từ người dùng (client), sắp xếp theo thứ tự thời gian (total order). State machine và log này được nhân bản ra tất cả các server trong hệ thống nhằm giúp các máy đồng thuận với nhau. Có nhiều cơ chế để thực hiện thao tác nhân bản này, ví dụ như leader/follower (thuật toán Raft), hay atomic broadcast (thuật toán ZAB). Chúng ta sẽ tìm hiểu sâu hơn về các thuật toán này trong các bài sau.
Điểm ưu việt của cơ chế này là, trong trường hợp một server nào đó fail, server này có thể phục hồi trạng thái bằng cách replay lại log. Các server cũng có thể so sánh phiên bản log của mình và xác định được phiên bản nào là phiên bản được cập nhật mới nhất (dựa trên thứ tự các entry trong log). Ngoài ra, nếu một server mới được thêm vào hệ thống, server này cũng có thể đồng thuận với các server còn lại thông qua cơ chế tương tự.
Mối liên hệ đến Event-sourcing
Replicated State machine (RSM) và Event-sourcing (ES) là hai khái niệm khác nhau. RSM chỉ về mô hình consensus trong Distributed Systems nói chung, trong khi đó ES nói về cách tổ chức và sắp đặt dữ liệu của một ứng dụng cụ thể. Tuy nhiên, hai khái niệm này dựa trên cùng một nguyên lý nhân bản trạng thái nêu trên, nên ta hãy bàn sơ qua về ES ở đây một chút.
Event-sourcing hoạt động dựa trên việc lưu lại dữ liệu của một hệ thống dưới dạng một chuỗi các sự kiện (event) theo thứ tự thời gian trong một cấu trúc Event Log. Event log này là dữ liệu duy nhất mô tả trạng thái của hệ thống, tại thời điểm hiện tại cũng như trong quá khứ. Kiến trúc ES hoạt động khác biệt so với kiểu trên trúc phổ thông thêm-sửa-xóa (CRUD). Thử ví dụ về hệ thống ngân hàng ở phần trước: một hệ thống theo kiểu CRUD có thể lưu mỗi tài khoản ở một dòng trong bảng SQL, trong khi đó, với ES, ta lưu tất cả các sự kiện trong hệ thống trong một chuỗi event duy nhất (xem VD ở trên). Cũng giống như input log, Event log cho phép tái tạo lại dữ liệu của hệ thống ở bất kì thời điểm nào.
Điểm cộng lớn nhất của cách bố trí dữ liệu kiểu này nằm ở sự đơn giản: một chuỗi sự kiện duy nhất chứa đầy đủ các thông tin của hệ thống, từ số tiền hiện tại đến lịch sử giao dịch của một tài khoản. Theo kiểu CRUD, ta sẽ phải có một bảng riêng biệt để lưu lịch sử các giao dịch của các tài khoản, và sử dụng JOIN khi cần truy cập dữ liệu ở nhiều bảng khác nhau. Với ES, ta chỉ có một chuỗi duy nhất (thường được gọi là single source of truth).
Sự đơn giản này giúp các hệ thống ES có tính đàn hồi (scalability) cao. Với kiểu CRUD, thường thì ta sẽ phải thiết kế Database nhằm tối ưu cho cả việc đọc và ghi dữ liệu. Tuy nhiên không phải dữ liệu nào cũng có thể tối ưu được một cách tuyệt đối. Hầu hết các hệ thống đều phải hy sinh hiệu năng cho việc đọc (hoặc ghi) để tối ưu cho hoạt động còn lại. Hơn nữa, các ứng dụng trên thực tế đều phải thay đổi theo thời gian để liên tục đáp ứng yêu cầu mới, do đó, việc tối ưu database ngay từ đầu gần như là bất khả thi.
Với ES thì dữ liệu được tổ chức theo kiểu hoàn toàn khác biệt. Tất cả tiến trình ghi (write) đều có hiệu năng cao, do chỉ phải thêm (append) event (do event không được phép sửa/xóa). Các event này sau đó được chuyển hóa thành các dạng dữ liệu được tối ưu cho việc đọc (có thể là trong một bảng SQL hoặc các database khác). Quy trình này được gọi là projection (Xem hình minh họa ở trên), trong đó Event log tại từng thời điểm nhất định được chuyển hóa thành các snapshot nhằm tối ưu việc truy cập dữ liệu. Điều này giúp cho hệ thống không bị bó buộc bởi cấu trúc quan hệ – thực thể (entity-relationship) trong các kiểu dữ liệu truyền thống.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Search trên Google các bạn có thể tìm thấy hàng đống bài viết về cái chủ đề này, mỗi người một kiểu trình bày khác nhau. Có thể có bạn sẽ lĩnh hội rất nhanh, cũng có thể không nên mình xin tổng hợp lại và cố gắng viết lại nó theo một kiểu dễ hiểu nhất (sẽ cố gắng hết sức ).
Ý tưởng chính của Dependency Injection đó là bạn không phụ thuộc vào ai cả và người khác cũng không phụ thuộc vào bạn. Khi cần mình sẽ gọi bạn và bạn cũng vậy.
Giả sử bạn có một đối tượng là Circle, đối tượng này có một phương thức là draw()như sau:
public class Circle {
public void draw() {
System.out.println("Drawing circle ...");
}
}
Giờ mình muốn sử dụng đối tượng này để vẽ hình tròn, mình sẽ khởi tạo đối tượng Circle ngay trong constructor và mình sẽ code như sau:
public class Drawing {
public Circle circle;
public Drawing() {
circle = new Cirle();
}
public void preparing() {
System.out.println("Preparing ...");
}
public void draw() {
circle.draw();
}
public static void main(String[] args) {
Drawing drawing = new Drawing();
drawing.draw();
}
}
Rõ ràng bạn thấy đối tượng Drawing của mình đang phụ thuộc vào đối tượng Circle của bạn (nghĩa là mình đang phụ thuộc vào bạn đấy), bởi vì mỗi khi chạy ứng dụng, đối tượng Drawing lại phải giữ luôn thông tin của đối tượng Circle. Đây là nhược điểm thứ nhất của cách code này.
Nhược điểm thứ hai đó là nếu sau này mình muốn vẽ một tam giác, mình lại phải đi khai báo lại đối tượng khác để đáp ứng nhu cầu của mình. Đối tượng Drawing của mình vì thế cứ phải thay đổi liên tục theo nhu cầu.
Vậy giờ làm sao để giải quyết hai nhược điểm này?
Nhược điểm thứ hai chúng ta có thể giải quyết dễ dàng bằng cách sử dụng interface. Đối tượng Circle của bạn giờ sẽ hiện thực một interface tên là Shape, cụ thể như sau:
public interface Shape {
public void draw();
}
public class Circle implement Shape {
public void draw() {
System.out.println("Drawing circle ...");
}
}
Sau này mình muốn vẽ tam giác thì chỉ cần viết thêm một lớp mới và hiện thực interface Shape là được.
Đối với nhược điểm thứ nhất, Dependency Injection sinh ra để giải quyết nó.
Hãy xem Dependency Injection giải quyết như thế nào nhé, mình xin sửa lại đối tượng Drawing như sau:
public class Drawing {
private Shape shape;
public Drawing(Shape shape) {
this.shape = shape;
}
public void setShape(Shape shape) {
this.shape = shape;
}
public void preparing() {
System.out.println("Preparing ...");
}
public void draw() {
shape.draw();
}
}
Các bạn thấy đó, nếu bây giờ mình chỉ muốn đối tượng Drawing của mình chỉ chuẩn bị các dụng cụ để vẽ mà thôi, mình sẽ không cần gọi đến đối tượng Circle của bạn, code sẽ như sau:
Drawing drawing = new Drawing(null);
drawing.preparing();
Và giờ sau khi chuẩn bị xong, mình sẽ cần bạn để vẽ một hình tròn, mình sẽ gọi đến bạn:
Drawing drawing = new Drawing(null);
drawing.preparing();
Shape shape = new Circle();
drawing.setShape(shape);
drawing.draw();
Thật ra, những code này nhiều bạn đã làm rồi nhưng không biết nó là Dependency Injection thôi.
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
1. Khái niệm đầu tiên
Chuyện đặt tên thì chả ai dạy ở trường DH cả, toàn hứng như nào thì đặt như vậy thôi. Nếu ông nào nói với tôi trường ông dạy cách đặt tên, quy tắc các kiểu thì chúc mừng ông thế thôi.
Tên thì bất cứ đâu trong code của bạn. Tên biến, tên hàm, tên lớp, packages… Vậy thì đặt tên như nào cho chuẩn? Hồi mới đi làm, sếp nói 1 câu nhớ tới bây giờ: Em cứ đặt tên dài cũng được, miễn là nó giải thích luôn tên đó để làm cái gì, còn hơn là đặt abc i hay j mà chả biết mục đích nó là gì cả. Càng đơn giản càng tốt. Ví dụ bây giờ ta đặt tên ngày tháng năm trong C++:
int a, b, c;
Tôi tự hiểu a là ngày, b là tháng, c là năm! Đem code cho thầy đọc méo hiểu đúng không? Vậy đấy là cái ngu nhiều ông dễ mắc phải.
Sửa lại: int ngay, thang, nam;
Ít nhất 3 cái biến kiểu nguyên trên cũng đã giải thích luôn nó để lưu cái gì.
Sách gốc đặt:
int elapsedTimeInDays;
int daysSinceCreation;
int daysSinceModification;
int fileAgeInDays;
Trông nó clear chưa? Vậy quy tắc đầu tiên tôi muốn nhét vào mũi bạn là đặt tên thì đặt cho dễ hiểu vào, không sau thằng đọc code bạn nó lại “dm thằng lol cái méo gì thế này”
Bây giờ thử đọc đoạn code sau:
std::vector<int> getThem() {std::vector<int> list1;for (int i = 0; i < theList.size(); i++)if (theList[0] == 4)list1.push_back(theList[i]);return list1;}
Các ông hiểu mẹ gì không? theList là cái méo gì? Tại sao lại so sánh với 4?
Rồi méo hiểu đúng không. Thế nên bây giờ đọc đoạn code sau xem thế nào:
#define FLAGGED 4std::vector<int> getFlaggedCells() {std::vector<int> flaggedCells;for (int i = 0; i < gameBoards.size(); i++)if (theList[0] == FLAGGED)flaggedCells.push_back(theList[i]);return flaggedCells;}
Đọc từng dòng: Đầu tiên là định nghĩa 4 có nghĩa là FLAGGED. Sau đó đổi tên hàm thành getFlaggedCell. Hàm này trả về danh sách cell flagged. Cái flggedCell là cái cần trả về. Lấy từng phần tử tỏng gameBoard so sánh với FLAGGED để xem nó có phải là flagged hay không. Đấy, cùng 1 logic máy hiểu như nhau, nhưng rõ ràng với người thì chỉ hiểu được cái hàm khi ông ta đã đặt lại các thứ 1 cách clean!
2. Tiền tố trong tên
Trước mới vào nghề IT, tôi thường hay thêm cái prefix ở đầu. Ví dụ:
class Date {
int day;
};
Tôi sửa thành:
class Date {
int mDay;
};
Nói chung đây là 1 quy tắc hay áp dụng ngay cả java nữa. Nhưng bạn thích đặt hay không tuỳ bạn, miễn phải ghi nhớ như sau:
Giả sử trung C++ ta có hàm setDay:
void Date::setDay (int day) {
mDay = day;
}
Giả sử bạn muốn dùng biến day trong class Date trên thì bạn sẽ phải dùng con trỏ this như này:
void Date::setDay (int day) {
this.day = day;
}
để phân biệt day ở trong là day của class Date, còn day kia là tham số truyền vào.
Nếu bạn quên không dùng this thì coi như tự gán nó vào nó. Kết quả là sai! May mắn bây giờ các IDE có màu sắc phân biệt cho dev đỡ nhầm rồi. Tuy nhiên các newbie mới vào nghề thì vẫn hay lơ mơ mà nhầm lắm.
Chốt lại bạn muốn dùng tiền tố cũng được, không dùng cũng được nhưng phải tỉnh. Sách nói là bạn không nên dùng, đừng cố làm nó phức tạp. Nhưng tôi nghĩ dự án ông sếp yêu cầu thì vẫn phải dùng thôi. CLingme tụi tôi chẳng hạn, có 1 lô lốc yêu cầu đặt prefix luôn :))
ví dụ tôi thường thêm m_o cho object, m_i cho biến integer, m_c cho biến char,…
3. Interface và implementation
Interface là cái mẽ gì? Đơn giản tôi hay dùng nó trong C++ như này:
class TheFunyFuck;
class ITheFuckAllDelegate {
public:
virtual void onFuck(TheFunyFuck* sender) = 0;
};
Thì cái lớp IFuckAllDelegate được gọi là lớp interface – giao diện =)) sao lại là giao diện? Giao diện là cái bạn trông thấy tên hàm mà méo thấy phần code của hàm. Hàm virutal ảo thì làm gì có code, ông nào kế thừa lại lớp IFuckAllDelegate thì mới bắt buộc phải viết code. Ở đây quy tắc là nếu như lớp đó là Interface thì bắt đầu bằng I.
Implementation là việc xử lý lại interface đó. Tôi cũng chưa gặp bao giờ việc viết code cho nó nên cũng chưa rõ cách đặt tên thế nào cho chuẩn. Ví dụ trong sách, anh em tự nghiên cứu:
ShapeFactoryImp
4. Tên lớp
Tên lớp là danh từ hay cụm danh từ và bắt đầu bằng chữ cái viết hoa. Ví dụ: class Sinhvien;
class Giaovien;
Méo ai đặt tên là:
class Lambaitap;
class Daysinhvien;
class cailogithon;
5. Tên phương thức
Tên phương thức là động từ hay cụm động từ, bắt đầu bằng chữ cái thường. Ví dụ các bạn hay thấy hàm set và get:
void setName(string name);
string getName();
Méo ai lại đặt như này:
void SetName(string name);
Còn trường hợp hàm tạo và quá tải hàm thì làm như nào? Ví dụ bạn có hàm tạo phân số như này:
Các bài kiểm tra năng lựccoding là được xem là cách thức hiệu quả trong việc đánh giá kỹ năng ứng viên. Điều này có nghĩa ý lớn trong tuyen dung it, freelancer it. Tuy nhiên, để tối ưu hóa thông qua những ảnh hưởng cụ thể, nhà tuyen dung it cần nắm bắt được 2 yếu tố sau đây:
(1) Khi nào
(2) Bằng cách nào ứng dụng được nó vào quy trình tuyển dụng hiện tại.
Tuyển được đúng người luôn là mục tiêu của các nhân sự viên IT. Thế nhưng, những thách thức về bài toán đánh giá ứng viên chưa bao giờ là dễ dàng. Mỗi quy trình trong tuyen dung it đều có tính quan trọng. Nó sẽ đảm bảo việc ứng viên phải làm bài test theo đúng tâm lý và nguyện vọng của họ một cách tự nguyện, không phải thiên cưỡng. Từ đó mới được tỉ lệ ứng tuyển cao hơn, và candidate engagement tốt hơn.
Trước khi đi vào đánh giá ứng viên trong tuyen dung IT
Xét riêng về khía cạnh sàng lọc ứng viên (screening) đầu vào để tiến vào các bước trong quy trình tuyen dung it, hiện tại vẫn còn không ít những hiểu lầm; hiểu sai về số năm kinh nghiệm cũng như level đầu vào của ứng viên.
Để tiến vào khâu đánh giá ứng viên, trước hết nhân sự IT cần hiểu rõ các mức kinh nghiệm của ứng viên Lập trình, freelancer it hiện nay:
* Tính đến thời điểm năm 2020
Số năm kinh nghiệm
Năm sinh ứng viên
Entry-level
Mới ra trường
1998
1 năm KN
1997
2 năm KN
1996
Mid-level
3 năm KN
1995
4+ năm KN
Từ 1994 về trước
Trong thời điểm chuyển giao tuyển dụng sang thế hệ Gen Z, các ứng viên có độ tuổi khoảng từ năm 1994-1996 thường vẫn bị hiểu lầm là cấp “Mới ra trường” – “Graduated”.
Song trên thực tế, đây là các ứng viên đều đã có tối thiểu 2 năm kinh nghiệm nếu làm việc đúng ngành từ khi tốt nghiệp. Các nhà tuyển tuyen dung it cần tránh hiểu lầm tai hại này để không bỏ lỡ các hồ sơ có năng lực và phù hợp nhưng bị đánh giá là “thiếu kinh nghiệm”.
Bài test đánh giá ứng viên ảnh hưởng như thế nào đến candidate engagement?
Bài đánh giá năng lực có thể ảnh hưởng rất lớn đến hiệu quả tuyển dụng của bạn từ trước đến nay. Tuy nhiên, vẫn chưa có cách tối ưu hiệu quả nhất cho nó.
Các công ty công nghệ lớn nhất trên thế giới, dù tập đoàn hùng mạnh hay công ty khởi nghiệp mới đều có chung một ưu tiên: thứ tự sắp xếp test năng lực. Thông thường, họ đều sẽ sắp xếp bài test vào giai đoạn phỏng vấn technical thông thường (manual tech screen).
Điểm đặc biệt của test coding là đòi hỏi không ít công sức và quan trọng là sự đồng thuận của ứng viên. Không phải ứng viên nào cũng sẽ bằng lòng và sẵn sàng thực hiện đánh giá năng lực này. Nói cách khác, khi ứng viên nghe về đánh giá năng lực, một bộ phận nhỏ “leave the chat”. Mặt khác, vẫn có nhiều bạn rất sẵn lòng tham gia kiểm tra đánh giá. Chính thứ tự và cách sắp xếp bài đánh giá của bạn sẽ ảnh hưởng đến sự sẵn lòng của ứng viên với bài test.
Vậy mục tiêu tìm kiếm là gì?
Mục tiêu là tìm được sự cân bằng: vừa tối ưu hóa sự tham gia của ứng viên. Đồng thời lại vừa tối thiểu hoá áp lực lên team bạn. Khi nói đến đánh giá mã hóa, điều đó có nghĩa là xem xét 3 yếu tố chính:
Số lượng ứng viên ứng tuyển (nhiều hay ít)
Nguồn ứng viên (nhà tự tuyển hay outsource)
Level kinh nghiệm của vị trí và ứng viên (mới ra trường hay có kinh nghiệm)
Việc phác thảo nên một quy trình tuyen dung it chi tiết hướng đến sự thay đổi mang tính hợp lý, có hiệu quả. Đồng thời, tạo nguồn ứng viên tốt nhất mà không đè áp lực đánh giá lên team mình.
Điều đó đồng nghĩa rằng các ứng viên chất lượng sẽ tiếp tục stay engaged. Song, tỉ lệ tham gia sẽ tăng cao; Tech talent brand của bạn sẽ để lại những ấn tượng tốt trong giới Lập trình viên nói chung, và giới IT tìm việc nói riêng.
03 nhân tố chính ảnh hưởng lên quy trình tuyen dung IT
Những nhân tố nào ảnh hướng đến ứng viên IT?
Liệt kê ra sẽ có vẻ hơi quá rõ ràng. Nhưng chính 3 nhân tố này sẽ giúp bạn quyết định được đâu là thời điểm phù hợp đánh giá ứng viên hợp lý và đúng với mức độ sẵn lòng của ứng viên.
1. Số lượng cao vs. thấp
Bạn có đang tuyển dụng trong mùa cao điểm (ví dụ: mùa tốt nghiệp giữa năm)? Hoặc bạn đang có quá nhiều đơn ứng tuyển mà không có thời gian để review? Nếu như team tuyển dụng của bạn đang phải sử dụng nhiều cách shortcut hoặc loại trừ để hoàn thiện quy trình (ví dụ: chỉ chấp nhận các CV có tiêu chí nào đó nhất định), nó có nghĩa là bạn đang xử lý một lượng ứng viên lớn.
Mặt khác, nếu việc tuyen dung IT đang ở mức ổn định. Tức là team có thể chọn lọc các các đơn ứng tuyển mà không phải skip quá nhiều tiêu chí. Điều này chứng tỏ bạn đang có lượng ứng viên thấp vừa.
Nhìn chung, các vị trí phát triển phần mềm, thiết kế đều sẽ có số lượng ứng tuyển cao. Mặt khác, các vị trí như tuyển dụng Data Scientist thì có xu hướng ít lượng ứng tuyển hơn.
2. Nguồn ứng viên tự tuyển (Inbound) vs. Nguồn ứng tuyển bên ngoài (Sourced)
Có một nguyên tắc như sau: Nếu nguồn CV của bạn chủ yếu đến từ tin đăng nội bộ, tức là nguồn thiên inbound. Mặt khác, nếu như bạn phải tận dụng các nguồn khác để fill CV (ví dụ thông qua LinkedIn, referral hoặc cách khác) thì có nghĩa là nguồn thiên source.
Nguồn ứng cử viên cũng có mối quan hệ chặt chẽ với vị trí tuyen dung it. Ở mức “mới ra trường” thì nguồn CV sẽ dễ đến từ nguồn nội bộ – inbound hơn. Ví dụ qua trang Tuyển dụng – Career của công ty bạn. Ngược lại, ở mức yêu cầu kinh nghiệm, bạn đơn giản chỉ cần thường sẽ phải cần đến các nguồn tuyển dụng ngoài. Và tất nhiên, cần nhiều công tìm CV hơn để kéo ứng viên apply vào.
3. Entry-Level vs. Mid-Level
Vị trí bạn đang tuyển có yêu cầu không, và bao nhiêu năm nếu có? Bạn có thể tập trung vào các vị trí bạn hay tuyen dung it nhất. Mặc dù mọi tổ chức đều có định nghĩa – yêu cầu riêng. Nhưng chúng ta thường thấy các công ty sẽ sắp xếp level như sau:
Entry-level sẽ dành cho nhóm từ 0-3 năm (ứng viên có năm sinh khoảng từ 1995-1998) kinh nghiệm.
Mid-level được xác định từ 4-8 (ứng viên có năm sinh từ 1994 trở lên) năm kinh nghiệm.
Xác định quy trình tuyen dung it ứng viên phù hợp nhất cho doanh nghiệp
Tùy thuộc vào cách bạn sắp xếp các tiêu chí của mình sau 3 yếu tố, quy trình tiếp cận ứng viên của bạn sẽ khác nhau. Sử dụng biểu đồ dưới đây để xác định quy trình công việc phù hợp cho bạn.
tuyen dung it
Lưu ý: Đối với các doanh nghiệp quy mô hơn, một quy trình không phải chỉ gói gọn trong 1 workflow. Đừng dừng lại ở chỉ một workflow. Hãy xác định nó cho riêng mỗi nhóm department/vị trí riêng.
Ví dụ: Nếu bạn tuyển dụng vào mùa tốt nghiệp đại học (số lượng lớn, level entry), lượng ứng tuyển chủ yếu đến từ tin đăng nội bộ (inbound). Vậy sẽ rơi vào Workflow 1.
Workflow 1
W1 – tuyen dung it
Cách hoạt động W1
Trong quy trình làm việc này, bạn gửi bài đánh giá cho ứng viên ngay khi họ nộp đơn. Bài code này sẽ tạo ra một phần drop-off (bỏ đơn) nhỏ. Nhưng trong trường hợp này thì không sao cả.
Số lượng ứng viên của bạn từ nguồn inbound cao hoàn toàn có thể giúp bạn cân bằng được. Ngay cả khi có những rủi ro xảy ra trong quy trình, bạn vẫn sẽ có rất nhiều ứng cử viên chất lượng để vượt qua phần còn lại của quy trình.
Tại sao?
Workflow này hợp lý vì nó sẽ sàng lọc ứng viên ngay từ những khâu đầu tiên.
Bằng cách đưa bài test ngay từ lúc nhận đơn, ứng viên sẽ thể hiện mức độ quan tâm – đầu tư của họ cho vị trí và công ty bạn hay không. Nó cũng giúp các ứng viên không hứng thú tự sàng lọc ngay từ những bước đầu. Các bộ phận technical không cao cũng có thể thích ứng nhanh chóng, tạo nên talent pool dễ quản lý hơn cho recruiter để gọi điện phỏng vấn.
Workflow 2
W2 – tuyen dung it
Cách hoạt động W2
Trong trường hợp này, bài test coding sẽ được chèn vào ở giai đoạn thứ 3. Vì số lượng ứng tuyển đã ít hơn, bạn không nên chèn bài test vào ngay đầu quy trình nữa. Vì nó sẽ tạo phần drop-off (bỏ đơn) mà số lượng đơn ứng tuyển có thể không bù lại kịp thời.
Nhìn nhận dưới góc độ tích cực, việc tiến hành phone screen – phỏng vấn qua điện thoại trước giúp bạn có cái nhìn tổng quát về ứng viên trước khi yêu cầu họ tiến hành thêm các bước khác (gồm cả bài đánh giá).
Tại sao?
Tạo điều kiện bộc lộ những ưu thế về khả năng và kết nối với những người khác. Việc ưu tiên dành thời gian sẽ giúp bạn duy trí hình ảnh Nhà tuyen dung it tốt. Đồng thời duy trì mối quan hệ ứng viên trong các bước sau của quy trình.
Workflow 3
W3 – tuyen ung it
Cách hoạt động W3
Trong trường hợp này, tất cả các tiêu chí đều khá áp lực cho bạn. Bạn có khối lượng ứng viên thấp, rất ít application từ inbound và yêu cầu nhiều kinh nghiệm.
Với tình hình này, bài đánh giá năng lực nên được đưa vào bước cuối quy trình tuyen dung it, tuyển dụng Data Scientist. Đối với một ứng viên thụ động (passive candidate), nhân sự thậm chí có thể xem xét thay bài đánh giá năng lực với nhiều hình thức có tương tác khác. Bởi vì ở giai đoạn này, việc tương tác và kết nối với ứng viên cần một người có kinh nghiệm dày dặn và có insight rõ ràng.
Tại sao?
Trong tình thế này, bạn giống như người “bán job” cho ứng viên vậy. Quan trọng là bạn có truyền tải nhiều giá trị đến họ hay không? Một hành động cc trực tiếp vào luồng mail của họ sẽ cho thấy bạn thật sự quan tâm đến họ.
Lưu ý: Việc tuyển người cho riêng trường hợp này có nhiều thử thách.
Tối ưu hiệu quả của bài đánh giá năng lực coding trong tuyen dung
Điều quan trọng là phải sử dụng chúng theo cách phù hợp với công ty của bạn – không có một cách tiếp cận nào áp dụng được với tất cả mọi người. Các bài coding assessment này thì không khả thi khi áp dụng chỉ 1 bài cho nhiều vị trí. Nếu xây dựng nhiều bài test phù hợp cho từng vị trí, bạn cũng sẽ phải tốn không ít thời gian và công sức để hoàn thiện được một bộ Assessment hoàn thiện và đầy đủ.
Hiện nay có không ít các đơn vị chuyên cho ra Coding Assessment ra đời, cung cấp cho bạn đa dạng các bộ challenges hỗ trợ trực tiếp cho công tác tìm kỹ sư và lập trình viên của doanh nghiệp.
Nền tảng tuyển dụng ứng viên IT
Điển hình như TopDev x HackerRank – Nền tảng kết hợp tuyen dung it và đánh giá ứng viên IT chuẩn quốc tế đầu tiên tại Việt Nam. TopDev x HackerRank mang lại lợi ích giải phóng Tech Lead/ Manager khỏi công việc đánh giá ứng viên; trợ giúp các HR/ IT Recruiter không có background công nghệ trong việc tuyen dung it.
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products









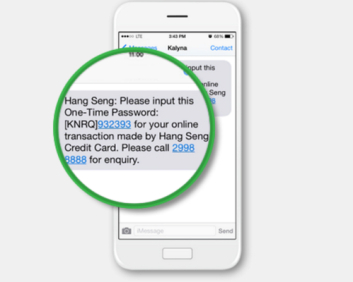
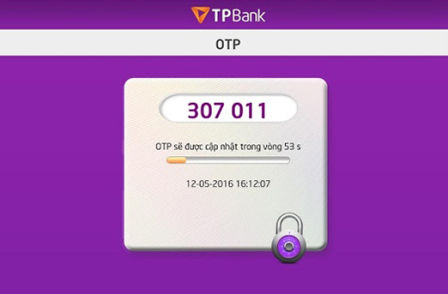
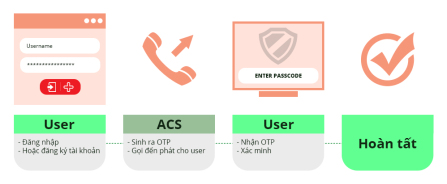
 bây giờ đi vào tiết mục chính.
bây giờ đi vào tiết mục chính.


 và bật nhạc thư giãn
và bật nhạc thư giãn  trước khi đọc bài nhé.
trước khi đọc bài nhé.
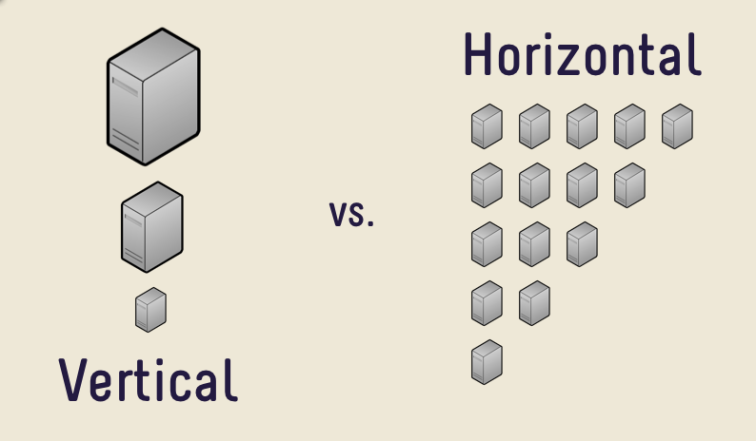
 của hệ thống có nghĩa là hệ thống sẽ tiếp tục cung cấp dịch vụ của mình ngay khi có một hoặc nhiều thành phần (phần mềm/phần cứng) của hệ thống bị lỗi. Reliability là thành phần chính trong bất cứ một hệ thống phân tán (distributed system) nào, bởi vì trong một hệ thống như vậy, mọi hỏng hóc của một thành phần nào đó sẽ được thay thế một thành phần đang khỏe mạnh khác, đảm bảo luôn hoàn thành nhiệm vụ yêu cầu.
của hệ thống có nghĩa là hệ thống sẽ tiếp tục cung cấp dịch vụ của mình ngay khi có một hoặc nhiều thành phần (phần mềm/phần cứng) của hệ thống bị lỗi. Reliability là thành phần chính trong bất cứ một hệ thống phân tán (distributed system) nào, bởi vì trong một hệ thống như vậy, mọi hỏng hóc của một thành phần nào đó sẽ được thay thế một thành phần đang khỏe mạnh khác, đảm bảo luôn hoàn thành nhiệm vụ yêu cầu.
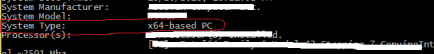

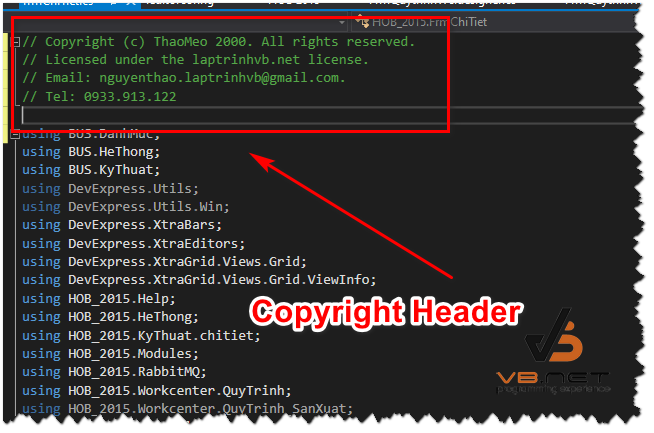
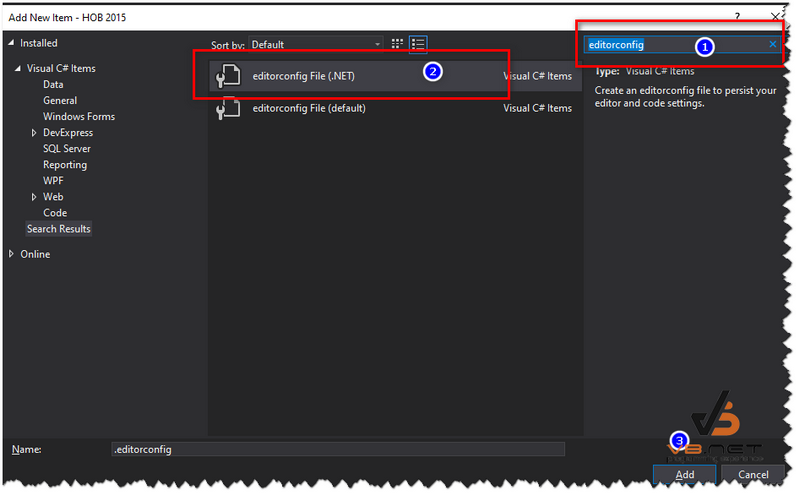
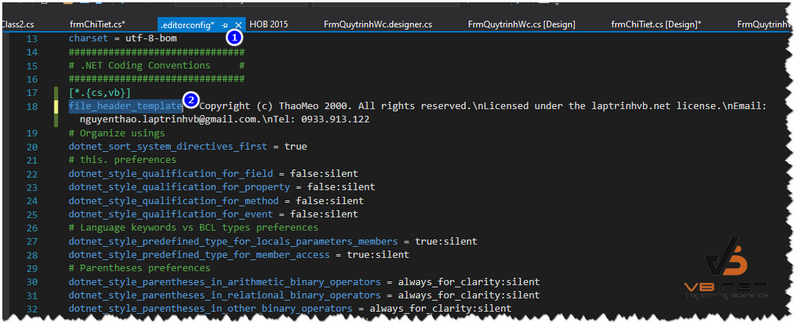
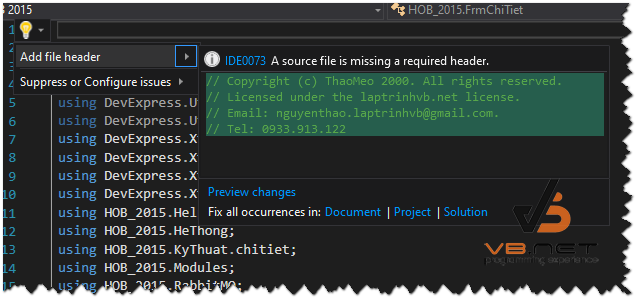


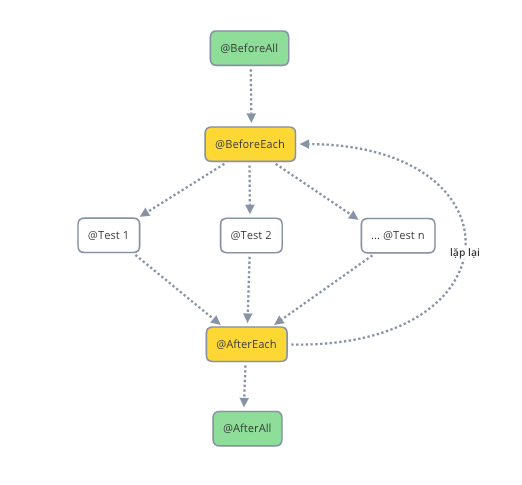
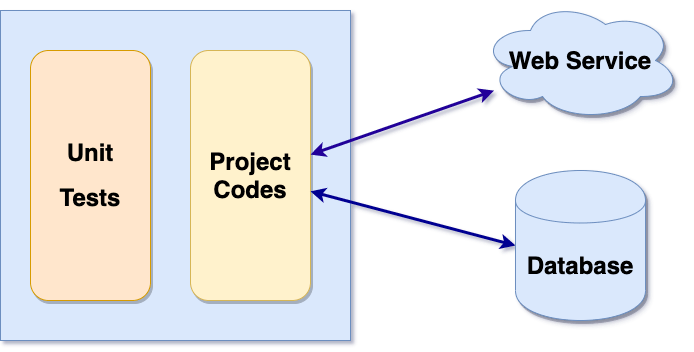
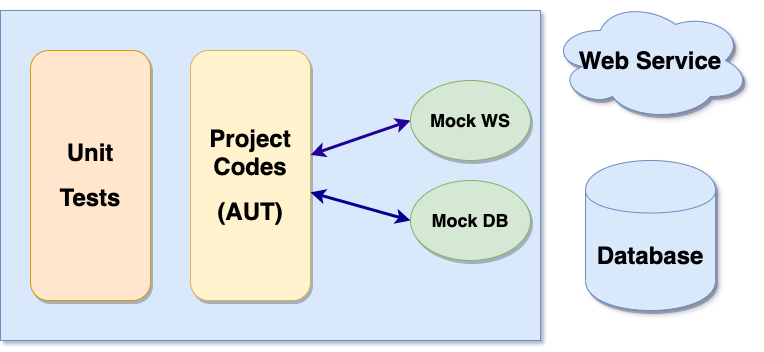




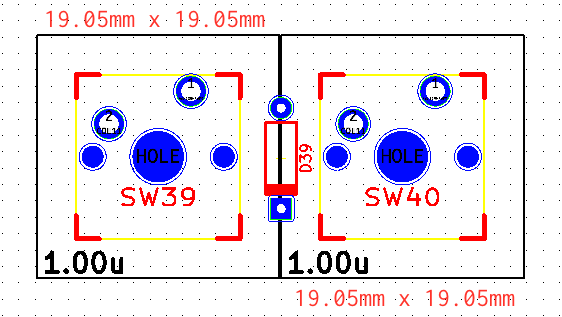
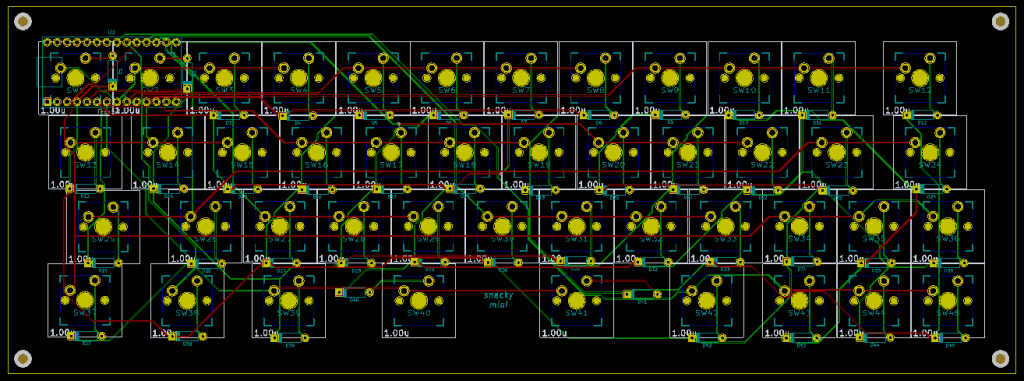








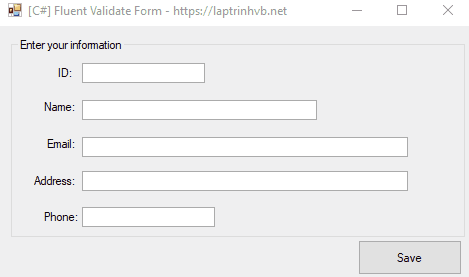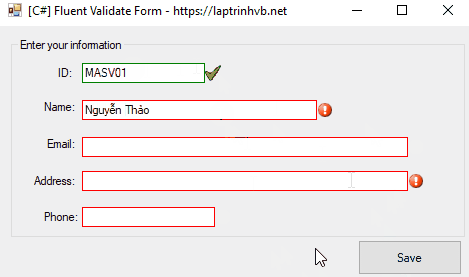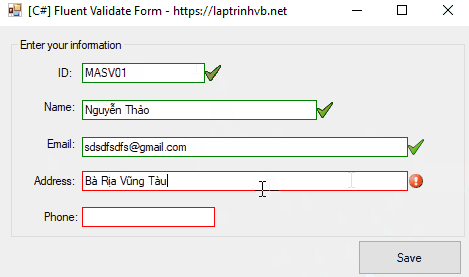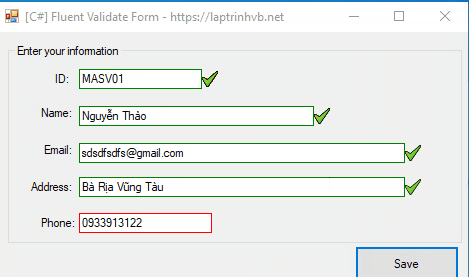

















 ).
).