VDC là Trung tâm Phát triển công nghệ số 1 tại Thành phố Hồ Chí Minh, được thành lập bởi sự hợp tác từ NAB – Ngân hàng kinh doanh lớn nhất của Úc với 160 năm kinh nghiệm và PYCOGroup, công ty tư vấn và phát triển kỹ thuật số toàn cầu đến từ Bỉ.
Lý do khiến VDC trở thành “điểm đến” lý tưởng cho các tài năng công nghệ tỏa sáng sự nghiệp
“Cập bến” tại Việt Nam, NAB mang đến làn gió mới cho lĩnh vực phần mềm và fintech với sự xuất hiện của Trung tâm VDC, hoạt động với nhiệm vụ xây dựng nhóm kỹ thuật số và cho ra đời những giải pháp tối ưu, đáp ứng yêu cầu ngày càng cao từ người dùng.
VDC là Trung tâm Phát triển công nghệ số 1 tại Thành phố Hồ Chí Minh, được thành lập bởi sự hợp tác từ NAB – Ngân hàng kinh doanh lớn nhất của Úc với 160 năm kinh nghiệm và PYCOGroup, công ty tư vấn và phát triển kỹ thuật số toàn cầu đến từ Bỉ.
VDC là sự kết hợp mạnh mẽ của các dịch vụ tài chính cùng với các nhà công nghệ, kỹ sư phát triển phần mềm, nhà xây dựng và người kiểm tra, cung cấp đầy đủ các dịch vụ qua ngân hàng doanh nghiệp, ngân hàng cá nhân và tài sản.VDC đang tận dụng các công cụ và kỹ thuật mới nhất được sử dụng bởi các công ty công nghệ và kỹ thuật số hàng đầu trên toàn cầu để trải qua quá trình chuyển đổi công nghệ số “Cloud First”.
Không chỉ quan tâm đến công nghệ, VDC còn chú trọng đầu tư vào sự phát triển của từng cá nhân trong công ty, là cơ hội cho các nhân tài công nghệ phát triển sự nghiệp và từng bước gặt hái thành công.
Nếu bạn là một lập trình viên hay kỹ sư IT mong muốn học hỏi, nâng tầm sự nghiệp và đã sẵn sàng bước và “cuộc chơi” công nghệ thì VDC chính là nơi phù hợp cho tài năng của bạn thăng hoa.
3 lý do khiến bạn không muốn bỏ lỡ cơ hội trở thành một phần của VDC
Môi trường làm việc tuyệt vời
Cùng nhau và phát triển và lớn mạnh, mỗi thành viên của VDC là một “mảnh ghép” tài năng, là phần tử quan trọng tạo nên đội ngũ VDC thống nhất. Tại đây, điều bạn nhận được không chỉ là công việc, mà còn cả những cơ hội và cánh cửa tương lại rộng mở phía trước. Tin tưởng và những người có ý tưởng và ước mơ, VDC mong muốn bạn đạt được nguyện vọng của chính mình và sẵn sàng tạo mọi điều kiện để bạn thực hiện mong ước đó.
Bạn luôn được sát cánh bên những đồng nghiệp có cùng chí hướng, những con người không kém phần đam mê học hỏi và nõ lực cải thiện bản thân. Bất kể trong công việc hoặc cuộc sống, trong hoạt động nhóm hay các buổi đi chơi, bạn luôn có những thời khắc vui vẻ cùng đồng nghiệp và không thiếu sự hứng khởi kích hoạt niềm hăng say công việc của bạn.
Cơ hội phát triển không giới hạn
Mỗi thành viên của VDC làm việc dựa trên niềm đam mê trong việc tạo ra giá trị, những sản phẩm vượt tốt nhất. Sự vượt xa những mong đợi của khách hàng cũng chính là sự nỗ lực không ngừng của VDC và cũng chính là thời cơ cho mỗi “chiến binh” tỏa sáng tài năng của chính mình.
Ngoài ra, mỗi tài năng còn được định hướng đi trên con đường đào tạo chuyên nghiệp và bài bản, mở ra con đường sự nghiệp đầy hứa hẹn.
Loạt đãi ngộ tạo động lực, kích hoạt tiềm năng
VDC hiểu rằng, sự phát triển của đội ngũ nhân viên chính là mấu chốt cho sự hưng thịnh của công ty. Tại VDC, bạn chỉ cần thoải mái lan tỏa năng lượng và yên tâm “chiến việc”, mọi đãi ngộ xứng đáng đã có công ty lo với:
Chế độ lương, thưởng cạnh tranh và xứng đáng với mọi nỗ lực của bạn;
Văn phòng Agile mới toanh và hiện đại với các trang thiết bị tốt nhất đã sẵn sàng chờ sự xuất hiện của những tài năng công nghệ;
Chế độ chăm sóc sức khỏe cực tốt cho bạn và thành viên trong gia đình;
Được tham gia các lớp học tiếng Anh với giáo viên bản ngữ, tạo nền tảng cho còn đường phát triển của bạn;
Được tiếp xúc với các công nghệ mới nhất và làm việc với các đối tác trong nước và quốc tế. Và nếu bạn đã sẵn sàng đương đầu với những dự án đầy thách thức cùng VDC?
Đừng chần chờ thêm nữa, lựa chọn vị trí phù hợp với bạn ngay hôm nay:
Đây là hai vai trò thường xuất hiện trong cơ cấu của các doanh nghiệp làm công nghệ lớn. Các doanh nghiệp sẽ có bảng mô tả công việc không giống nhau cho cùng một vị trí, kể cả Solution Architect và Software Architect, ở một góc nhìn tổng thể từ các doanh nghiệp thì cải hai vai trò này có một số điểm khác biệt lớn.
Solution Architect thường tham gia cùng với đội kinh doanh (giai đoạn dự án chưa được hình thành) để nắm được các vấn đề kinh doanh của khách hàng, hoặc các cơ hội kinh doanh và đề xuất các giải pháp thiết kế hệ thống để loại bỏ các ràng buộc trong hoạt động kinh doanh.
Software Architect được hình thành với mục đích biến giải pháp kiến trúc đề xuất từ Solution Architect thành thành sản phẩm kiến trúc thực tiễn.
Cả hai vai trò cùng tham gia sẽ đảm bảo sản phẩm thực tế đến người dùng cuối được chính xác hơn với những gì được mô tả trong giải pháp đề xuất. Và sản phẩm thực tế được thiết kế chi tiết, triển khai với các nhà phát triển, những người có giới hạn về tầm nhìn về giải pháp tổng thể.
Dưới đây là mô tả công việc chung của hai vai trò này.
1. Solution Architect
Thường không trực tiếp thiết kế phần mềm, Solution Architect thường tập trung vào làm việc trên tính năng lớn với các giải pháp công nghệ, đề xuất thiết kế.
Đưa ra cách tiếp cận toàn diện để hiểu được ràng buộc trong kinh doanh, vấn đề của khách hàng để đưa ra giải pháp tổng thể để giúp khách hàng loại bỏ những ràng buộc đó.
Là người sử dụng công nghệ để giải quyết bài toán kinh doanh của khách hàng.
Am hiểu về mảng kiến thức nghiệm vụ của khách hàng, các giải pháp công nghệ có trên thị trường, giới hạn của mỗi công nghệ, xu hướng phát triển nền tảng công nghệ, và cả khả năng phát triển giải pháp thành hiện thực bằng phần mềm.
Biết được các giới hạn của giải pháp, khả năng mở rộng, khả năng bảo trì trong tương lai.
Có trách nhiệm đưa ra độ ưu tiên cho giải pháp cần được triển khai.
Tuỳ theo khu vực địa lý khác nhau mà công việc của vai trò này được đảm nhận một phần bởi các vai trò Product Manager hoặc Senior Business Analyst.
Thông thường các Solution Architect có sự đòi hỏi khác nhau tuỳ theo ngành công nghiệp đặc thù. Là một người bạn đáng tin cậy trong giới công nghệ và thấy được niềm vui khi sản phẩm phần mềm thực tế giải quyết triệt để nhu cầu của khách hàng.
Là người phải tìm hiểu hết các tính năng được đề xuất trong giải pháp và thiết kế ra kiến trúc phần mềm thực tế.
Thực hiện thiết kế kiến trúc hệ thống
Đưa ra cách tiếp cận về mặt kỹ thuật để phát triển phẩn mềm giải quyết các tính năng nghiệp vụ, viết các tài liệu kiến trúc tổng quan, coding convention, và hướng dẫn các developer phát triển bản thiết kế chi tiết cho từng chức năng.
Chịu trách nhiệm đánh giá các công nghệ, các components, kỹ thuật phát triển, phương thức phát triển, tích hợp hệ thống, và hướng dẫn các developer thực hiện công việc hàng ngày một cách hiệu quả.
Ví dụ về Distributed Systems được phát triển và sử dụng trong thực tế bao gồm hệ thống Database (SQL, NoSQL), hệ thống Cache (Redis, Memcached), hệ thống Message-Queue hay Publish/Subscribe (Kafka, RabbitMQ …). Những hệ thống này tuy có những tính năng khác nhau, tuy nhiên phần cốt lõi của chúng đều phải giải quyết một vấn đề cơ bản, đó là bài toán đồng thuận.
Như đã đề cập ở phần 1, một trông những tính chất của Distributed System là khả năng hoạt động như một thực thể thống nhất đối với người sử dụng. Để đạt được mục đích này thì trong quá trình hoạt động, các process trong hệ thống cần có được sự nhất trí về trạng thái dữ liệu (state) cũng như các bước vận hành tiếp theo (action). Do các process có thể không nằm cùng trên một máy tính vật lý nên chúng buộc phải giao tiếp qua network để đạt được sự nhất trí này. Tuy nhiên, cả máy tính lẫn network đều có thể gặp phải các sự cố, khiến cho việc giao tiếp để đảm bảo sự đồng nhất giữa các process trở nên không đơn giản.
Cách đạt được sự nhất trí giữa các process trong Distributed Systems, kể cả khi gặp sự cố, được gọi là bài toán đồng thuận (Distributed Consensus). Để hiểu rõ hơn bài toán này, trong bài viết này chúng ta sẽ bàn về hai ví dụ mang tính minh họa.
Bài toán hai vị tướng (Two generals problem)
Bài toán được phát biểu như sau: Có 2 vị tướng chỉ huy 2 đạo quân đóng ở các địa điểm khác nhau và cùng đối đầu với một đội quân đối phương. Hai vị tướng này cần đi đến một quyết định: cùng tấn công đối phương, hoặc cùng rút lui. Nếu họ cùng tấn công đối phương thì sẽ giành thắng lợi, nếu họ cùng rút lui thì sẽ bảo toàn được lực lượng. Ngược lại nếu hai vị tướng ra quyết định trái ngược (1 tấn công, 1 rút lui) thì họ sẽ bị đối phương đánh bại. Hai vị tướng có thể dùng giao liên để gửi thư cho nhau, tuy nhiên mỗi giao liên đều có khả năng bị đối thử bắt giữ, dẫn đến việc lá thư sẽ không được vận chuyển. Vậy 2 vị tướng trên cần dùng giao thức nào để có thể đi đến hành động thống nhất?
Trước khi tiếp tục bài viết, mình khuyến khích các bạn hãy thử tự tìm cách giải cho bài toán này. Về cơ bản, bài toán yêu cầu một trong hai vị tướng phải đề xuất ra hành động và gửi thư cho vị tướng còn lại để yêu cầu sự nhất trí. Tuy nhiên, làm cách nào để vị tướng đề xuất đó biết được rằng thông tin đã đến được tay vị tướng kia hay chưa?
Đối với những bạn có hiểu biết về mảng Computer Networking, có thể bạn sẽ nhận thấy bài toán này có nhiều điểm tương đồng với giao thức TCP/IP, là giao thức mạng được phát triển nhằm cho phép người gửi tin có thể đảm bảo rằng thông tin đã đến được phía người nhận. Chúng ta có thể áp dụng cách tiếp cận tương tự cho bài toán này, dựa trên giao thức DATA/ACK của TCP/IP. Một vị tướng (G1) sẽ đề xuất phương án và gửi thông tin cho người còn lại (G2). Khi nhận được thư, G2 sẽ thực hiện theo phương án được đề xuất và gửi thư xác nhận (ACK) cho G1. Nếu G1 nhận được thư xác nhận, G1 cũng sẽ thực hiện phương án đó.
Tuy nhiên, những mẩu thư liên lạc kể trên đều có thể bị mất dọc đường, theo như điều kiện của bài toán. Nếu thư G1->G2 bị mất, G2 sẽ không nhận được đề xuất. Tệ hơn nữa, nếu thư ACK bị mất, G2 sẽ tấn công trong khi G1 vẫn chưa quyết định được hành động. Vậy chúng ta giải quyết trường hợp này ra sao? Câu trả lời ngắn gọn ở đây là, bài toán không có lời giải hoàn hảo. Thật vậy, đối phương trên lý thuyết có khả năng chặn được tất cả liên lạc giữa 2 vị tướng, và trong trường hợp đó sẽ không có cách nào đạt được sự đồng thuận cả.
Ý nghĩa chính của bài toán 2 vị tướng có nhằm minh họa một điều, đó là không có lời giải “hoàn hảo” cho bài toán đồng thuận. Tuy nhiên, chúng ta có thể đưa ra một phương án mang tính “thực tế” hơn, bằng việc giả thiết rằng đối phương không phải lúc nào cũng có thể bắt được tất cả các thư liên lạc được gửi đi giữa 2 vị tướng. Theo đó, ta có thể cho G1 gửi lại đề xuất nếu không nhận được ACK sau một thời gian nào đó, cho đến khi nhận được ACK từ G2 (tương tự như cơ chế retransmission của TCP/IP).
Bài toán các vị tướng Byzantine (Byzantine General’s problem)
Viết tắt là BGP, bài toán này được phát biểu như sau: Có n vị tướng đến từ Byzantine (tên một đế quốc thời trung cổ nằm tại vùng Thổ Nhĩ Kỳ và đông nam châu Âu ngày nay), mỗi người chỉ huy một đội quân, cùng bao vây một thành trì của đối phương. Họ cần đạt được sự nhất trí về phương án hành động: hoặc tấn công (A), hoặc rút lui (R). Các vị tướng có thể liên lạc với nhau bằng cách gửi thư qua giao liên một cách an toàn (thông tin liên lạc không bị mất hay đánh tráo). Tuy nhiên, một vài trong số n vị tướng này là gián điệp của đối phương, và có khả năng gửi những mẩu tin bất kì, nhằm ngăn cản việc nhất trí của các đội quân còn lại. Yêu cầu bài toán đặt ra là: 1) tìm ra một giao thức để các vị tướng (không phải gián điệp) có thể nhất trí về hành động (A hoặc R), 2) tìm hiểu xem số lượng gián điệp ảnh hưởng đến giao thức trên như thế nào?
Bài toán này được nêu ra bởi nhà khoa học máy tính Leslie Lamport trong bài báo “The Byzantine Generals Problem“, và tên gọi của kiểu sự cố “Byzantine” (xem lại phần 1) được đặt theo tên bài toán này. Có nhiều người hay nhầm lẫn giữa bài toán này và bài toán 2 vị tướng (2GP) được nêu ở phần trước. Hai bài toán có một vài điểm khác biệt. Thứ nhất, BGP có một số lượng đội quân bất kì (thay vì chỉ 2 như 2GP). Thứ nhì, cả 2 vị tướng trong 2GP đều “trung thành”, trong khi BGP có một hoặc nhiều vị tướng là gián điệp. Thứ ba, ở 2GP, việc liên lạc giữa 2 đạo quân có thể bị gián đoạn, trong khi ở BGP chúng ta coi như liên lạc giữa các vị tướng là hoàn hảo.
Để đi đến lời giải, chúng ta hay thử bắt đầu lý luận từ một vài trường hợp đơn giản. Với n=1, bài toán trở nên tối giản, không có sự đồng thuận nào ở đây cả. Với n=2, ta có một lời giải tương đối đơn giản: một vị tướng sẽ đề xuất phương án v và gửi thư cho vị tướng còn lại, và cả 2 sẽ cùng thực hiện v. Do liên lạc giữa 2 vị tướng được đảm bảo, chắc chắn họ sẽ đạt được sự đồng thuận. Trong trường hợp một trong hai vị tướng là gián điệp, bất kì hành động nào của người còn lại đều hợp lệ.
Bài toán trở nên phức tạp hơn khi n=3. Trong tình huống đơn giản nhất với m=0 gián điệp, lời giải của chúng ta tương tự như trường hợp n=2. Một vị tướng G1 sẽ đề xuất phương án hành động v và gửi thông tin cho các vị tướng còn lại. Các vị tướng còn lại khi nhận được tin sẽ thực hiện theo v. Vậy nếu m=1 thì sao? Trong trường hợp này, người để xuất (G1) có thể là gián điệp và sẽ gửi những thông tin trái ngược nhau cho 2 vị tướng còn lại (G2 và G3). Chúng ta có thể thử dùng liên lạc giữa G2 và G3 để xác nhận lại thông tin. Kể cả vậy, nếu G1 là gián điệp, G2 và G3 vẫn sẽ nhận được những thông tin không thống nhất về phương án hành động v. Thật vậy, nếu G1 gửi A cho G2 và R cho G3, G2 và G3 sẽ nhận nhìn thấy những thông tin như sau:
// G2, G3 là các vector chứa thông tin phương án nhận được từ G1. Phần tử [0] là thông tin nhận được từ G1, [1] là thông tin nhận được từ vị tướng còn lại.
G2: [A R]
G3: [R A]
Điều tương tự xảy ra khi G2 hay G3 là gián điệp. Điều này dẫn đến việc G2 hoặc G3 không xác định được gián điệp là ai, và không thể thống nhất được phương án v. Một cách tổng quát hơn, BGP không có lời giải cho trường hợp n vị tướng và m gián điệp nếu 3m >=n .
Nói cách khác, BGP chỉ có thể giải được khi số gián điệp nhỏ hơn 1/3 số vị tướng (3m < n). Thuật toán để giải bài toán này được gọi tên là Byzantine Fault Tolerance (BFT). Chi tiết về thuật toán (và cách chứng minh) tương đối phức tạp nên mình sẽ không trình bày ở đây (khuyến khích các bạn đọc thuật toán này trong bài báo của Lamport). Tuy nhiên mình sẽ tóm tắt một vài ý chính:
Ý tưởng: Các vị tướng được chia thành 2 vai trò: 1 vị tướng đóng vai trò chỉ huy (C), những người còn lại là các phó tướng (L). Chỉ huy sẽ đề xuất phương án v và các phó tướng sẽ làm theo. Để đạt được yêu cầu bài toán kể cả khi chỉ huy C là gián điệp, các phó tướng sẽ thông tin cho nhau biết xem phương án v mà mình nhận được là gì. VD, phó tướng L3 sẽ gửi v3 (nhận được từ C) cho các phó tướng còn lại. Sau khi quá trình này kết thúc, mỗi phó tướng L sẽ có được một vector các giá trị mà các phó tướng nhận được từ chỉ huy: L = [v1 v2 ... v_(n-1)], và sẽ chọn giá trị nào chiếm đa số.
Tuy nhiên, L3 nói trên có thể là gián điệp và có thể gửi các giá trị v3 khác nhau cho các phó tướng còn lại. Vậy trường hợp này giải quyết ra sao? Nếu L3 là gián điệp thì v3 thực tế vô nghĩa. Điều quan trọng duy nhất ở đây là các phó tướng (không phải gián điệp) đồng thuận với nhau về v3. Ta có thể đạt được sự đồng thuận này bằng cách giải một bài toán đồng thuận “con”, tương tự như bài toán gốc nhưng loại bỏ đi chỉ huy C. Thay vào đó, L3 giờ đóng vai trò chỉ huy, nhằm mục đích thống nhất về giá trị v3 giữa các phó tướng còn lại. Đây là lời giải theo kiểu đệ quy. Do lời giải này chỉ có ý nghĩa khi C là gián điệp, nên số gián điệp trong hệ thống “con” này là m-1. Quá trình đệ quy này được lặp lại m lần đối với mỗi phó tướng, cho đến trường hợp m=0 (là trường hợp đơn giản đã bàn ở trên).
Performance của lời giải: Độ phức tạp (complexity) xét về mặt số lượng thông tin cần gửi đi của lời giải này là O(n^m), do kết quả của quá trình đệ quy. Điều này có nghĩa là với lời giải trên có tính thực tế không cao trong các hệ thống lớn gồm nhiều process (do số thông tin cần gửi ở đây tăng theo cấp số nhân). Đã có nhiều nghiên cứu cải tiến lời giải nhằm cải thiện hiệu năng của bài toán này, như pBFT, Speculative Byzantine Fault Tolerance…
Ứng dụng thực tế của thuật toán BFT
Thuật toán BFT (và các biến thể) nhằm giải quyết vấn đề consensus cho các hệ thống mà có thể sẽ gặp phải kiểu sự cố Byzantine (mời xem lại định nghĩa về kiểu sự cố này ở phần 1). Ví dụ về các hệ thống này bao gồm Blockchain, các hệ thống hàng không vũ trụ của NASA hay SpaceX…
Tuy nhiên, trong hầu hết các ứng dụng Internet thực tế, kiểu sự cố Byzantine hiếm khi xảy ra (so với các kiểu sự cố khác như fail-stop, fail-recover). Lý do là vì: 1) các hệ thống DS như Database, Message Queue … thường được triển khai ở trong một môi trường an toàn (thường là trong các data center có sự kiểm soát tốt về mặt kết nối mạng thông qua tường lửa…), tách biệt với các cá thể có ý định tấn công từ bên ngoài; 2) kết nối của hệ thống với môi trường Internet bên ngoài thường được mã hóa dựa trên những giao thức bảo mật như SSL. VD như, khi bạn đọc blog này với đường link bao gồm “https“, bạn được đảm bảo rằng nội dung của blog thực sự đến từ người viết chứ không bị đánh tráo; 3) các giao thức được chuẩn hóa như TCP/IP, HTTP… cũng giúp bảo vệ cho hệ thống khỏi những lỗi Byzantine được gây ra do trục trặc từ phần cứng.
Nói thế để thấy rằng, tuy thuật toán BFT tương đối phức tạp và có hiệu năng thấp, chúng ta cũng không cần phải lo đến việc áp dụng thuật toán này cho dự án của mình. Trong các phần sau, chúng ta sẽ bàn thêm về các thuật toán Consensus cho các hệ thống được coi như “miễn dịch” với kiểu sự cố Byzantine.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Trong bài viết trước, mình đã giới thiệu với các bạn những ý tưởng cơ bản của Clean Architecture. Trong bài viết này, mình sẽ đi vào chi tiết cách hiện thực Clean Architecture với một ứng dụng Java sẽ như thế nào, các bạn nhé!
Module use-cases thì để đơn giản, mình chỉ định nghĩa một use case duy nhất là tìm kiếm thông tin sinh viên bằng tên:
package com.huongdanjava.cleanarchitecture.usecases.student;
import com.huongdanjava.cleanarchitecture.entities.Student;
import com.huongdanjava.cleanarchitecture.usecases.adapter.StudentAdapter;
public class FindStudentByNameUseCase {
private StudentAdapter adapter;
public FindStudentByNameUseCase(StudentAdapter adapter) {
this.adapter = adapter;
}
public Student find(String name) {
return adapter.findByName(name);
}
}
Ở đây, như các bạn thấy, mình có định nghĩa thêm một package là adapter. Trong idea của Clean Architecture thì lớp adapter sẽ nằm bên ngoài lớp use-cases nhưng ở đây, chúng ta có thể gộp lớp adapter này nằm trong module use-cases cũng được, không cần phải thêm một module adapter để định nghĩa các interface, không cần thiết lắm. Nhưng nếu các bạn muốn follow chặt chẽ idea của Clean Architecture thì có thể introduce thêm module adapter nữa cũng được.
Như các bạn thấy, mình cũng khai báo thêm Hibernate dependency cho phần implementation của JPA và thư viện Lombok để việc định nghĩa các entity đơn giản hơn!
Ở đây, như các bạn thấy, mình có thêm một class là StudentMapper để convert data từ database sang entity và sau đó, nếu entity này được sử dụng ở đâu đó, ví dụ như module rest, chúng ta sẽ có một class Mapper khác để convert từ entity sang dto của rest để trả về cho người dùng.
Việc sử dụng class Mapper này sẽ giúp chúng ta giảm sự phụ thuộc giữa các module với nhau, chúng ta có thể dễ dàng thêm mới hoặc loại bỏ bớt module mà chúng ta sẽ dùng cho ứng dụng, với ít sự thay đổi code nhất.
Module rest
Sau khi đã lấy được data từ database, bây giờ là lúc chúng ta hiện thực module rest, đảm nhận vai trò expose API cho người dùng sử dụng.
Tập tin pom.xml của module rest có nội dung như sau:
Mình sử dụng spring-web dependency để định nghĩa các RESTful API, use-cases dependency để gọi tới các use cases của ứng dung và thư viện lombok chỉ để đơn giản cho việc định nghĩa các dto.
Ở đây, mình đang autowired FindStudentByNameUseCase là do mình đang tận dụng benifit của ứng dụng này với Spring framework, chúng ta sẽ định nghĩa các use cases trong Spring container. Nếu ứng dụng của các bạn sử dụng những framework khác thì việc sử dụng use cases sẽ phụ thuộc vào các framework đó.
Module configuration
Như mình nói, để ứng dụng có thể chạy được, chúng ta cần có module configuration.
Nếu các bạn để ý, mình đã định nghĩa các module rest và db generic nhất có thể, và việc cấu hình ứng dụng trong module configuration sẽ quyết định ứng dụng của chúng ta chạy như thế nào! Ví dụ ở đây, mình đang sử dụng MySQL để chạy ứng dụng, sau này nếu mình muốn chuyển sang một database system khác như PostgreSQL chẳng hạn, việc mình cần làm là chỉ cần thay đổi ở module configuration này mà thôi, …
Tập tin pom.xml của parent project có nội dung như sau:
Đến đây thì chúng ta đã hoàn thành ứng dụng ví dụ của mình.
Giả sử mình có table student và data được tạo trong database server MySQL như sau:
CREATE TABLE`student`(`id`bigint(20)NOTNULLAUTO_INCREMENT,`name`varchar(50)NOTNULL,`age`bigint(2)NOTNULL,PRIMARY KEY(`id`))ENGINE=InnoDB DEFAULTCHARSET=latin1;INSERT INTO student SET name='Khanh',age=33;
thì khi chạy ứng dụng và request tới http://localhost:9090/student/find?name=Khanh, các bạn sẽ thấy kết quả như sau:
Điều đầu tiên mình phải khẳng định luôn Kano không phải là một design pattern, nó cũng không phải là tên một framework hay bất kỳ một khái niệm công nghệ nào. Mà nó là một mô hình cho kỹ thuật phân loại tính năng từ góc nhìn của khách hàng.
Tại sao lại vậy? Mô hình này thì có liên quan gì tới code? Thì mời các bạn hãy theo dõi bài viết này nhé.
Kano là một mô hình dùng để phân loại tính năng từ góc nhìn của khách hàng. Mô hình này được giáo sư Noriaki Kano ứng dụng vào thập niên 80 để giúp đội ngũ thiết kế hiểu được yêu cầu và tầm quan trọng của sản phẩm xét từ góc độ của khách hàng.
1.2 Mô hình Kano hoạt động như thế nào?
Kano phân loại thuộc tính (tính năng) của sản phẩm thành 3 nhóm chính
Nhóm 1: Nhóm tính năng cơ bản
Đây là nhóm tính năng sản phẩm cần phải có, nhất định phải có. Nếu không có nhóm tính năng này thì sản phẩm sẽ mất đi cái bản chất, mất đi cái giá trị cốt lõi. Ví dụ điện thoại thì dùng để nghe – gọi, đồng hồ dùng để xem giờ, đèn dùng để chiếu sáng,…
Đây là nhóm tính năng cần phải đầu tư để thực hiện, nếu sản phẩm tạo ra mà không có các tính năng nằm trong nhóm này thì người sử dụng sẽ không thể dùng nổi và cảm thấy bực bội.
Đây là nhóm tính năng cần phải ưu tiên làm trước. Tuy nhiên có một lưu ý là dù bạn có làm tốt nhóm tính năng này đến mấy thì khách hàng cũng không cảm thấy thỏa mãn hơn là bao. Bởi nghiêm nhiên điện thoại là phải nghe gọi được, đồng hồ phải xem giờ được,…
Chốt: Đây là nhóm tính năng mà sản phẩm nhất định phải có, không có không được. Độ ưu tiên là 1.
Nhóm 2: Nhóm tính năng mong đợi
Đây là nhóm tính năng thiên về hiệu suất của sản phẩm, là các tính năng mà càng có thì càng tốt. Ví dụ điện thoại ngoài nghe gọi thì có thể kết nối internet, nghe nhạc, chụp hình; Đồng hồ ngoài xem giờ thì có thể đo được nhịp tim, đo số bước chân; Máy tính thì càng xử lý nhanh thì càng tốt,…
Đây là nhóm tính năng mà khách hàng không thật sự cần, tuy nhiên sản phẩm càng có nhiều thì khách hàng càng hài lòng. Nhưng cũng cần phải lưu ý, việc triển khai các tính năng nằm ở nhóm này sẽ kéo giá thành của sản phẩm tăng lên. Vì vậy bạn cần phải cân bằng sao cho vừa đảm bảo được sự hài lòng của khách, vừa đảm bảo được giá thành sản phẩm.
Chốt: Đây là nhóm tính năng mà sản phẩm càng có nhiều thì khách hàng càng hài lòng. Độ ưu tiên là 2.
Nhóm 3: Nhóm tính năng vượt qua kỳ vọng của khách hàng, gây phấn khích khi sử dụng
Đây là nhóm tính năng rất bá đạo, rất ưu việt, rất độc đáo mà khi khách hàng trải nghiệm sẽ cảm thấy phấn khích, thích thú. Ví dụ như smartphone có các trợ lý ảo có thể giao tiếp bằng giọng nói với người sử dụng; Công nghệ sạc không dây,…
Vì đây là những tính năng mà khách hàng không ngờ tới, nên khi phát hiển ra họ sẽ cảm thấy vô cùng sung sướng, trầm trồ trước tính năng của sản phẩm. Tuy nhiên đây là nhóm tính năng mà cho dù không có cũng không làm giảm sự thỏa mãn của khách hàng, vì ngay từ đầu họ không nghĩ rằng là sản phẩm của bạn sẽ có.
Chốt: Đây là nhóm tính năng nếu có thì sẽ gây sự phấn kích cho người sử dụng, còn không có cũng không sao. Độ ưu tiên là 3.
II. ÁP DỤNG KANO VÀO VIỆC PHÁT TRIỂN SẢN PHẨM NHƯ THẾ NÀO?
Vậy là bạn đã hiểu về mô hình Kano là gì cũng như cách nó hoạt động rồi chứ. Vậy áp dụng vào code của bạn như thế nào đây.
2.1 Phân tích rõ ràng các nhóm tính năng
Trước khi bắt đầu code, bạn hãy dành thời gian để phân tích yêu cầu bài toán (requirements) thành 3 nhóm như của phương pháp Kano. Làm tốt bước này, bạn sẽ biết rõ đâu là cái ưu tiên phải làm trước, đâu là cái là cái có thể làm sau, để tránh trường hợp cứ tập trung làm những cái đâu đâu trong khi cái quan trọng thì lại bỏ qua.
2.2 Release phiên bản đầu tiên sau khi code xong các tính năng cơ bản
Theo mô hình Kano, các tính năng cơ bản là các tính năng cần phải có. Vì vậy nếu đã hoàn thiện các tính năng cơ bản thì đồng nghĩa với việc sản phẩm cũng phần nào sẵn sàng tới tay người sử dụng. Bạn nên release phiên bản đầu tiên tại giai đoạn này để có thể đón nhận feedback từ người dùng càng sớm càng tốt.
2.3 Release các tính năng mong đợi, tính năng gây “phấn khích” thông qua các phiên bản tiếp theo
Lúc này sản phẩm của bạn đã đáp ứng được yêu cầu chạy đúng, đáp ứng được những nhu cầu cơ bản của người dùng. Từ giờ trở đi, tùy thuộc vào yêu cầu mà bạn sẽ tung ra các bản cập nhật tính năng mới, mục đích giúp người sử dụng có trải nghiệm tốt hơn.
Trong một số trường hợp, nếu bạn cảm thấy việc nâng cấp, cải tiến, bổ sung tính năng mới mà không khiến người dùng cảm thấy thỏa mãn hơn là bao thì bạn có thể dừng luôn tại đây. Coi như nhiệm vụ đã hoàn thành.
III. KẾT LUẬN
Đây là một phương pháp phát triển sản phẩm rất hay mà mình học được kể từ khi đi làm thực tế.
Mình tin rằng đây không phải là một cách làm mới. Trước khi đọc bài viết này, rất có thể bạn đã từng thực hiện một phương pháp tương tự, có điều nó không có tên cụ thể hoặc đơn giản là bạn chỉ làm dựa trên kinh nghiệm mà không thể phát biểu ra thành lời. Thì hy vọng với bài viết này, mình đã giúp bạn cụ thể hóa phương pháp, cũng như giúp bạn biết rằng trên đời này có một mô hình được gọi là Kano.
Cảm ơn bạn đã đọc hết bài viết. Hẹn gặp lại trong những bài viết lần sau.
CV English ITcủa bạn liệu đã được hoàn thiện chưa? Đâu là cách thức viết CV IT English hiệu quả nhất. Cùng TopDev điểm qua 7 bước viết CV chuẩn giúp chinh phục nhà tuyển dụng IT.
1. Tạo mẫu format chuẩn cho CV English IT
CV cần đạt chuẩn format và đảm bảo bố cục nội dung
Hãy lựa chọn một định dạng CV mang đậm cá tính của bạn. Bạn nên lưu ý, dù bạn là Freelancer IT, Senior Developer thì CV IT tiếng Anh của bạn cần phải chuẩn format – đủ nội dung. Tìm kiếm một cách truyền tải sao cho bố cục hợp lý, được thiết chuyên nghiệp nhất để gia tăng cơ hội ghi điểm nhà tuyển dụng.
2. Một ảnh đại diện chuyên nghiệp bên cạnh thông tin cá nhân
Nhà tuyển dụng chỉ cần 3-5s hoặc chưa đến 30s để đọc hết thông tin trên CV của bạn.
viết CV English IT quá dài. Hãy thêm vào CV IT tiếng Anh một hình ảnh đại diện chuyên nghiệp, ấn tượng.
Thế nào là định dạng chuẩn?
Tên của bạn sẽ được đặt nổi bật, kích thước lớn ngay đầu trang cạnh ảnh đại diện.
Địa chỉ nhà của bạn nên được liệt kê ở định dạng khối ở bên trái của tờ giấy. Đặt số điện thoại và email của bạn dưới địa chỉ nhà của bạn.
3. Những dòng mô tả mang đậm cá tính và chuyên môn của bạn
Phần mô tả được đặt ngay dưới tên của bạn, cạnh ảnh đại diện và để kích cỡ chữ nhỏ. Ý nghĩa của phần mô tả trong CV English IT là phản ánh một phần bạn là ai. Nó thể hiện các khía cạnh kỹ năng và thế mạnh của bạn. Tất nhiên, chúng có liên quan đến lĩnh vực công việc hoặc mục tiêu nghề nghiệp của bạn
Lưu ý đáng nhớ
+ Mô tả ngắn gọn, không dài dòng
+ Trong tâm có liên qua đến vị trí bạn ứng tuyển
+ Có liên quan đến công việc bạn đang ứng tuyển
+ Chứa một số minh chứng thực tế
4. Chia sẻ về quá trình học tập và chuyên môn của bạn
Phần này có thể ở đầu CV IT tiếng Anh hoặc bạn có thể chọn liệt kê nó sau các phần khác. Thứ tự của các phần tùy thuộc vào bạn. Bạn có thể linh động để liệt kê thêm các khóa học nâng cao bên cạnh tên trường/cơ sở học tập của bạn
Những thông tin kế đến là: niên khóa, ngày nhập học, chuyên ngành chính và điểm GPA.
5. Thể hiện những kinh nghiệm của bạn
Đây là một phần quan trọng. Bạn cần liệt kê các kinh nghiệm mính có liên quan đến công việc trong CV English IT. Dù đó là kinh nghiệm về Freelancer IT, tuyển dụng Data Scientist bạn vẫn có thể tự tin đưa nó vào CV.
Lựa chọn kinh nghiệm như thế nào cho CV IT English?
Lựa chọn và chia sẻ về các thành quả mà trải nghiệm mang lại.
bài học thực tế mà bạn đang được. Đồng thời chỉ ra các thiếu sót bạn nhận thấy. Chính điều này sẽ giúp nhà tuyển dụng đánh giá cao kỹ năng phân tích của bạn.
6. Quan tâm đến kỹ năng và thành tích của bạn
Phần này là nơi bạn liệt kê những điều bạn đã hoàn thành trong công việc trước đây và các kỹ năng bạn đã phát triển thông qua kinh nghiệm của mình. Đây cũng là phần mà bạn liệt kê bất kỳ những thành tích trong quá khứ: những giải thưởng, công nhận của một cộng đồng hoặc tổ chức dành cho bạn.
7. Sở thích, sở trường, người tham khảo
Đây là những phần thông tin không quá quan trọng. Tùy vào vị trí lập trình bạn ứng tuyển, bạn sẽ bổ sung vào CV English IT của mình sao cho phù hợp.
Trong bài viết này, tôi sẽ chia sẻ với các bạn cách để trả lời phỏng vấn tuyển dụng vị trí Product Manager ấn tượng nhất với câu hỏi đầu tiên cực kỳ phổ biến “Giới thiệu qua về bản thân bạn”. Câu hỏi nghe có vẻ khá đơn giản đúng không? Nhưng những thông tin bạn chia sẻ được xác định là cơ sở để nhà tuyển dụng có hứng thú muốn làm việc với bạn hay không đấy!
Product Manager là gì?
Product Manager là gì đến nay vẫn là câu hỏi khó có câu trả lời cụ thể và định nghĩa chính xác nhất cho nó. Có thể hiểu một cách khái quát nhất đây là người chịu trách nhiệm quyết định đâu là thứ cần có cho sản phẩm và giám sát, điều hành toàn bộ quy trình làm việc của sản phẩm. Cũng như cần phải làm thế nào để sản phẩm tốt nhất, phù hợp nhất với người dùng.
Product Manager là một công việc đa nhiệm
Bên cạnh tìm hiểu các vấn đề liên quan đến khái niệm Product Manager là gì, chuyên môn của Product Manager, việc làm thế nào để ứng tuyển thành công cho vị trí này cũng được nhiều người quan tâm. Bài viết này sẽ mang đến cho bạn một số thông tin cần thiết.
Gây ấn tượng với nhà tuyển dụng Product Manager qua câu hỏi “Giới thiệu về bản thân” bằng cách nào?
Lý do đầu tiên liên quan đến việc tại sao Product Manager tuyển dụng khá chú trọng vào câu hỏi này là vì họ không thể nhớ hết tất cả các thông tin mà bạn đã cung cấp trong CV hay resume của mình. Số lượng ứng viên cho vị trí Product Manager ngày càng đông, do đó họ cần bạn cung cấp một cách ngắn gọn nhất những gì mà bạn đang “sở hữu”, những kỹ năng mà bạn có. Nói một dễ hiểu là “Tại sao bạn nghĩ mình đủ tiêu chuẩn để apply cho vị trí này?”
Hai yếu tố quan trọng nhất để có câu trả lời thuyết phục là hãy trả lời một cách ngắn gọn và ấn tượng. Đây là mẹo mà bạn có thể áp dụng cho xin nhiều việc khác nhau, kể cả là khi apply vào các công ty tuyển dụng tester chưa có kinh nghiệm chẳng hạn.
Trong CV bạn đã cung cấp các thông tin chi tiết cho nhà tuyển dụng với những kinh nghiệm làm việc mà mình có. Chính vì thế lúc phỏng vấn, họ muốn bạn chia sẻ thật sự ngắn gọn và cô đọng các thông tin đó. Hơn nữa khi phỏng vấn trực tiếp, bất cứ lúc nào họ cũng có thể yêu cầu bạn dừng lại để hỏi chi tiết về một vấn đề mà họ hứng thú hoặc quan tâm. Vậy nên bạn hãy cố gắng để trả lời ngắn gọn nhất và chuẩn bị tinh thần cho việc sẽ bị đào sâu thêm vấn đề với các câu hỏi khác nhau.
3 bước nên thực hiện để apply thành công vị trí Product Manager
1. Giới thiệu tên và kinh nghiệm làm việc
Chẳng hạn như, tôi sẽ giới thiệu về bản thân mình là “I’m Dr. Nancy Li”. Sau đó hãy chia sẻ với nhà tuyển dụng bạn đã có bao nhiêu năm kinh nghiệm làm việc ở vị trí này. Một số kiến thức liên quan đến Product Manager là gì cũng là cách hay để tạo ấn tượng. Tôi sẽ giới thiệu mình đã có 8 năm kinh nghiệm triển khai và phát hành các sản phẩm công nghệ.
Nếu bạn chưa có nhiều năm kinh nghiệm làm việc, bạn có thể giới thiệu rằng mình đã có 2 lần thực tập với vị trí Product Owner hoặc đã có 4 năm kinh nghiệm thiết kế sản phẩm chẳng hạn. Điều quan trọng nhất là hãy kể về những năm kinh nghiệm liên quan đến vị trí mà bạn đang ứng tuyển. Những ví dụ được tôi đưa ra đều liên quan đến công việc Product Manager để bạn có thể tham khảo thêm.
2. Kể về trải nghiệm làm việc đáng nhớ của bạn
Đây cũng là phần quan trọng nhất để bạn tạo ấn tượng khi vị trí Product Manager tuyển dụng. Hãy kể về những kinh nghiệm bạn đã có được ở những công việc trước, sao cho nó có thể làm nổi bật khả năng của bạn so với những ứng viên khác. Chẳng hạn nếu ứng tuyển vào vị trí Product Manager, tôi sẽ giới thiệu mình là người nhận được bằng Tiến sĩ về kỹ thuật trẻ nhất. Đây là cách khá ấn tượng để bạn trở nên đặc biệt hơn.
Đặc biệt là với công việc Product Manager, bạn cần chia sẻ về các sản phẩm mà bạn đã làm việc trước đây. Tôi đã từng phát hành một sản phẩm liên quan đến thành phố thông minh, sản phẩm nhận giải nhất vào năm 2017 được trao tặng bởi thị trưởng thành phố và nhanh chóng được triển khai trên 10 thành phố khác nhau. Đây là cách tôi trình bày về kinh nghiệm làm việc của mình.
Hãy thể hiện những tác động mà sản phẩm của bạn có thể tạo ra thay vì chỉ kể về các yêu cầu để design sản phẩm đó. Hoặc nếu bạn là người đã dày dặn kinh nghiệm, hãy cho nhà tuyển dụng thấy được cả career path với lộ trình thăng tiến của bạn thì càng tốt. Chẳng hạn như, nhờ sự thành công của sản phẩm mà tôi triển khai, tôi trở thành leader của team các Senior Managers để xây dựng danh mục sản phẩm cho một platform,… Những minh chứng này sẽ thể hiện được khả năng lãnh đạo và dẫn dắt của bạn trong công việc tiếp theo.
Kinh nghiệm làm việc là một yếu tố quan trọng
Nếu không có kinh nghiệm lãnh đạo, bạn hãy cố gắng tóm tắt về những kinh nghiệm làm việc Product Manager liên quan đến các sản phẩm khác nhau mà bạn đã có. Bạn đã đạt được những giải thưởng gì với sản phẩm đó, sản phẩm bạn tạo ra có hàng triệu người dùng,… bất cứ thành tích nào khiến bạn trở nên nổi bật hơn!
Có một thực tế bạn nên biết là, những gì bạn viết trong CV mà nhà tuyển dụng đọc được sẽ không được nhớ lâu nhưng những gì bạn chia sẻ trực tiếp sẽ đặc biệt gây ấn tượng với người phỏng vấn. Sự hứng thú sẽ khiến họ đặt thêm nhiều câu hỏi khác nhau để khai thác các tiềm năng trong bạn. Và đó chính là điều mà các ứng viên cho vị trí Product Manager cần.
3. Chia sẻ những gì mà bạn mong đợi ở công việc này
Bạn có thể chia sẻ với nhà tuyển dụng rằng mình đang tìm kiếm vị trí Product Leadership hay vị trí Product Manager trong ngành công nghiệp cung ứng với AI hay bất kỳ công nghệ tiên tiến nào có thể tạo ra tác động và giúp người tiêu dùng giải quyết được khó khăn. Hãy nhấn mạnh về những gì bạn đang tìm kiếm cũng như lĩnh vực mà bạn muốn làm việc để tạo ấn tượng.
Tip phỏng vấn là một cách hay để bạn có thể tìm được các công việc tốt ở những môi trường chuyên nghiệp. Như với công ty KMS Technology tuyển dụng, đây được xem là nơi tạo cơ hội làm việc ấn tượng và hỗ trợ nhân viên hết mình trong quá trình làm việc của họ. Bên cạnh đó, KMS tuyển dụng intern khá thường xuyên tạo cơ hội tuyệt vời cho các sinh viên sớm có cơ hội thử sức làm việc trong quy mô doanh nghiệp.
Kết luận
Những vấn đề mà tôi chia sẻ hôm nay đều là những trải nghiệm thực tế của tôi trong nhiều năm làm việc. Tin rằng nếu áp dụng tốt sẽ giúp bạn rộng mở hơn với cánh cửa đến với công việc Product Manager.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Đồng
Như các bạn đã biết, mongodb là một cơ sở dữ liệu không có quan hệ rất nổi tiếng (NoSQL). Thay vì việc sử dung các bảng có các thuộc tính cố định, mongodb lưu trữ dữ liệu dưới dạng document, dạng key-value, mongodb cũng hỗ trợ scale ngang khi prod lớn lên. Trong bài này mình sẽ hướng dẫn các bạn setup cluster theo phong cách mi ăn liền.
Trước khi bắt đầu các bạn hãy nhìn qua hình dưới đây là cách mà mongo cluster hoạt động
Nhìn vào hình trên cluster gồm 3 phần chính.
shard: Mỗi shard chứa đựng một tập nhỏ các data đã sharded, từ phiên bản 3.6 trở lên, shards phải được cấu hình chạy replicaset nếu muốn trở thành một phần của cluster.
mongos: Đây thực ra là một query router, cung cấp một giao diện tương tác giữa ứng dụng và các sharded cluster.
config servers: Config server chứa đựng metadata và cấu hình cho cluster, từ phiên bản 3.4 trở lên config server phải deploy dưới dạng replicaset.
Chuẩn bị
Dểcài đặc chúng ta cần phải chuẩn bị đủ ba phần của cluster,bao gồm 2 config sever, 1 query router server, và 1 shard. Đối với shard mình sẽ dùng 2 server chạy replicaset, mặc dù có thể dùng docker để gộp lại nhưng làm vậy sẽ mất tính tổng quan và rườm ra.
Trước khi bắt đầu chúng ta phải chuẩn bị mongo-keyfile. Mongo keyfile thứ giúp các server xác định là chúng nó là gà cùng một mẹ. Mình sẽ chỉ authenticate bằng mongo-keyfile để cho nó đơn giản, nếu các bạn muốn authen bằng cả username và password thì trên 2 con server config, và 2 con server để tạo 1 shard các bạn dùng mongo shell để tạo username và password cho nó. Trên cả 4 con server đó bạn chạy các lệnh sau
mongo
# lệnh trên dùng mongo shell để kết nối tới server, vì lúc đầu chưa # có username hay password gì cả nên bạn sẽ vào đượcuse admin
# lệnh trên dùng database admin,để lưu trữ những user mà ta sẽ tạo
# phía saudb.createUser({user: "mongo-admin", pwd: "123", roles:[{role: "root", db: "admin"}]})
# lệnh trên tạo ra một user có username là "mongo-admin" và password # là "123" trên và có vai trò là root của database có tên là admin
Để tạo ra key file các bạn dùng lệnh.
openssl rand -base64 756 > mongo-keyfile
Sau Khi tạo ra keyfile, hãy copy chúng lên trên cả 5 con server, đặt trong /opt/mongo và phân quyền cho file đó, chỉ phân quyền cho file đó.
# sudo mkdir /opt/mongo
# tạo folder nếu chưa có# sudo mv ~/mongo-keyfile /opt/mongo
# nếu bạn dùng SSH để copy thì nhớ copy vào /opt/mongo # lệnh bên dưới chmod 400 set quyền chỉ đọc cho người sở hữu còn lại # thì không có quyền hạn gì cả
sudo chmod 400 /opt/mongo/mongo-keyfile# lệnh dưới gán quyền sở hữu cho mongodb, kết hợp với lệnh trên thì chỉ có mongodb mới có quyền đọc( ngoại lệ đối với root, root là full quyền)
sudo chown mongodb:mongodb /opt/mongo/mongo-keyfile
Để cho đơn giản mình giả sử bạn có 5 con server có ip và port mở như bên dưới. Chúng nó đều có thể kết nối tới nhau.
# 2 config server mình sẽ gán nó là conf1:27017 và conf2:27017
- 100.100.100.101:27017
- 100.100.100.102:27017
# 1 con router server mình sẽ gán nó à router:27017
- 200.200.200.200:27017
# 2 con server để tạo ra một con shard chạy replicaset mình sẽ gán luôn là shard1
- 300.300.300.301:27017
- 300.300.300.302:27017
Rồi bắt đầu, chúng ta sẽ bắt đầu setup config server chạy replicatSet trước.
BƯỚC 1 : CÀI ĐẶT CONFIG SERVER
Chui vào cả hai con config server. Sửa nội dung file /etc/mongod.conf lại sao cho đúng, cho nó bindIp đúng với ip của nó và thêm field xác thực nhau bằng mongo-keyfile ,replication replSetName và trong file đó. Ngoài ra thêm sharding clusterRole cho cả hai server, nội dung file có thêm vài trường như bên dưới. Đảm bảo là các bạn đã thực hiện trên hai server conf1 và conf2.
Trong bước này, chúng ta sẽ cài đặt MongoDB query router, nó sẽ thu lượm thông tin metadata từ config servers, cache nó và sự dụng để gửi các request đọc ghi đến đúng shards. Cài đặt query router thực chất là chạy một tiến trình mongos ta có thể đăng kí nó như là một systemd service. Nhưng trước hết phải tạo file config cho mongos , file config cho mongos đặt ở /etc/mongos.conf
# chỉ định nơi để ghi log.
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongos.log
# cài đặt mạng bind trên ip
net:
port: 27017
bindIp: 200.200.200.200# sử dụng mongo-keyfile để authenticate trong cluster
security:
keyFile: /opt/mongo/mongo-keyfile# setup config server cho nó
sharding:
configDB: configReplSet/100.100.100.101:27017,100.100.100.101:27017
Sau đó ta sẽ đăng kí mongos với systemd. Tạo một file lib/systemd/system/mongos.service với nội dung như bên dưới.
[Unit]
Description=Mongo Cluster Router
After=network.target
[Service]
User=mongodb
Group=mongodb
ExecStart=/usr/bin/mongos --config /etc/mongos.conf
# file size
LimitFSIZE=infinity
# cpu time
LimitCPU=infinity
# virtual memory size
LimitAS=infinity
# open files
LimitNOFILE=64000
# processes/threads
LimitNPROC=64000
# total threads (user+kernel)
TasksMax=infinity
TasksAccounting=false
[Install]
WantedBy=multi-user.target
Để mongos chạy thì phải tắt phải mongod tránh trường hợp confic data, sau khi tắt thì sẽ enable các mongos service đó và start nó. Tiếp theo là check status của mongos.
Trước khi thêm shard vào server thì các bãn hãy setup 2 con server còn lại để chúng nó chạy replicaSet với nhau. Setup giống hoàn toàn so với config server chỉ khác là trong file config. Thay vì vai trò của nó là config server thì vai trò của nó là “shardsvr” còn tên replicaSet thì để nguyên cũng được, không thì các bạn đổi tùy thích. Còn IP thì các bạn bind cho đúng
300.300.300.301
300.300.300.302
sharding:
clusterRole: shardsvr
Sau khi setup xong 2 con server chạy replicaSet thì mình sẽ tiến hành đưa nó vào shard.
Từ một trong hai server vừa mới setup đó (hoặc ở đâu cũng được) , bạn hãy kết nối đến query router.
Sau khi kết nối thành công các bạn chạy lệnh sau để add shard chúng ta vừa mới tạo ra để đưa nó vào cluster. Giả sử lúc nãy các bạn setup shard chạy replicaSet với name là rs999.
Tại thời điểm này, các bạn đã setup thành công cluster. Để test liệu nó có hoạt động hay không các bạn hãy kết nối từ máy của bạn tới query router server.
Nếu kết nối được chúng ta sẽ thử kích hoạt tính năng sharding ở tầng database.
Các bạn hãy thử tạo vài document, để thực hiện các thao tác find, update, delete xem cluster của chúng ta hoạt động ổn không nhé. Còn về phần mình, đã khuya rồi mình xin đừng viết tại đây, sáng mai còn phải đi về chợ dọn hàng ra bán nữa :v
Trong tương lai, mình sẽ tìm hiểu các kĩ thuật sharding và hi vọng sẽ có nhưng điều thú vị để viết về và chia sẻ, các ơn các bạn đã đọc bài.
Dãy Fibonacci là một dãy vô hạn các số tự nhiên, bắt đầu dãy là hai phần tử 1, các phần tử sau đó là tổng của hai phần tử trước đó. Công thức truy hồi của số dãy Fibonacci là:
Nếu n = 1 hoặc n = 2
F(n) := 1
Nếu n > 2
F(n) := F(n – 1) + F(n – 2)
Trong lập trình, bài toán tĩnh dãy Fibonacci thường được dùng để làm quen với đệ quy hoặc quy hoạch động cơ bản. Trước khi bắt đầu cài đặt thuật toán, hãy chắc chắn rằng bạn đã biết cơ bản về python, còn bây giờ thì bắt đầu thôi.
Lưu ý: trong bài viết mình có đề cập đến thời gian thực thi, thời gian này chỉ để tham khảo, thời gian thực thi sẽ luôn sai khác do cấu hình mỗi máy là khác nhau.
Theo như khái niệm về dãy Fibonacci, chúng ta sẽ có 2 trường hợp cơ sở (base case) là n = 1 và n = 2, lúc đó F(n) := 1, đây chính là điều kiện dừng cho hàm đệ quy của chúng ta.
Ngược lại đối với n > 2, lúc này F(n) := F(n – 1) + F(n – 2), F(n – 1) và F(n – 2) chính là phần gọi lại chính hàm F(n) với n lúc này là n – 1 và n – 2, hay chính là phương thức đệ quy. Vậy chúng ta sẽ có đoạn code sau:
defF(n):if n ==1or n ==2:# base casereturn1return F(n -1)+ F(n -2)# recursion
Giờ hãy cùng xem hàm tính số Fibonacci của chúng ta hoạt động như thế nào nha!
Bạn có nhận thấy là thời gian thực thi khi của F(35) mất 3.9s nhưng của F(40) lại đến 42.9s mặc dù n chỉ cách nhau có 5 đơn vị. Hãy nhìn vào đồ thị sau:
Đồ thị đệ quy của hàm F(5)
Bạn có thể dễ dàng nhận thấy là các hàm với n giống nhau được lặp lại nhiều lần, F(3) 2 lần, F(2) 3 lần và F(1) 2 lần. Đây chỉ mới là tính F(5) thôi, nếu bạn tĩnh các số lớn hơn thì hãy tưởng tượng có bao nhiều hàm với tham số trùng nhau được lặp lại. Đây chính là nhược điểm của thuật toán trên, vậy chúng ta xử lý vấn đề đó như thế nào?
Để xử lý vấn đề trên, cách tốt nhất là xử dụng quy hoạch động (dynamic programming). Như đã giải thích ở trên, các hàm tính số Fibonacci với tham số n trùng nhau bị gọi lặp lại nhiều lần, vậy nên chúng ta sẽ lưu chúng lại và sử dụng cho lần khác (memoize).
Thuật toán được đưa ra là chúng ta sẽ dùng một mảng lưu lại các giá trị của hàm F(n), nếu như phần tử n có tồn tại giá trị trong mảng thì ta sử dụng luôn mà không cần tính toán lại giá trị. Ngược lại thì tính F(n – 1) + F(n – 2) và lưu nó vào mảng, sau đó trả về giá trị vừa tính.
Chúng ta sẽ không gọi trực tiếp hàm tính số Fibonacci với chiến lược quy hoạch động mà thông qua một hàm khác, hàm này có chức năng tạo mảng gồm n + 1 phần tử, sau đó gọi hàm tính số Fibonacci thực sự với tham số là n và mảng vừa tạo.
Với ý tưởng trên, chúng ta sẽ có thuật toán như sau:
defF_memo(n, memo):if n ==1or n ==2:# base casereturn1ifnot memo[n]==None:# kiểm tra có tồn tại giá trị của F(n) trong mảng khôngreturn memo[n]
result = F_memo(n -1, memo)+ F_memo(n -2, memo)# gọi đệ quy và lưu vào biến result
memo[n]= result # thêm F(n) vào mảngreturn result
defF(n):
memo =[None]*(n +1)# tạo mảng n + 1 phần tử có giá trị Nonereturn F_memo(n, memo)
Giờ hãy cùng thử xem thời gian thực thi có được cải thiện hay không, hãy cùng bắt đầu với F(40) ban nãy.
print(F(40))# 102334155, mất 0.1s
Với F(40), ban đầu thực thi đến 42.9s nhưng sau khi dùng quy hoạch động thì chỉ còn 0.1s, thực sự rất hiệu quả. Giờ hãy cùng test với những bộ test lớn hơn xem như thế nào.
Bạn thấy là thậm chí chúng ta đã có thể tính đến F(995), kết quả là một con số cực kỳ lớn nhưng cũng chỉ mất 0.1s để thực thi. Tuy nhiên, vấn đề xảy ra khi bạn tính với n > 1000, bạn sẽ nhận được một thông báo lỗi là “RecursionError: maximum recursion depth exceeded in comparison”. Lỗi RecursionError xảy ra khi bạn thực hiện đệ quy quá sâu.
Để tính F(995), bạn phải gọi đệ quy tính F(994), F(993), … F(2), F(1), sau đó mới truy hồi ngược lên, nghĩa là phải gọi đến 1000 lần hàm F(n), sau đó truy hồi lên thì ta mới có được kết quả. Điều này làm giảm đáng kể hiệu suất của chương trình. Vậy làm sao để tối ưu thuật toán này hơn nữa?
Bottom-Up approach hay tiếp cận từ dưới lên sẽ giải quyết được vấn đề đệ quy sâu. Từ khái niệm “các phần tử sau đó là tổng của hai phần tử trước đó”, cùng với công thức truy hồi, ta sẽ lập được thuật toán theo cách Bottom-Up. Theo như đồ thị của hàm đệ quy, thay vì tính từ đỉnh của đồ thị là F(5) đi xuống, ta sẽ tính từ các phần tử cuối đồ thị tính dần lên trên, tức là tính F(1), F(2) … F(n).
Ta sẽ sử dụng một mảng để lưu trữ giá trị F(n), với base case là n = 1 và n = 2, ta sẽ gán phần tử thứ nhất và hai của mảng bằng 1. Tiếp theo, chúng ta cho một biến chạy từ 3 đến n, phần tử thứ i của mảng sẽ bằng hai phần tử trước đó cộng lại, tức là phần tử i – 1 và i – 2. Kết quả cuối cùng, phần tử thứ n chính là kết quả F(n) cần tìm, chúng ta sẽ có thuật toán sau:
defF_bottom_up(n, memo):if n ==1or n ==2:return1
memo[1]=1
memo[2]=1for i inrange(3, n +1):
memo[i]= memo[i -1]+ memo[i -2]return memo[n]defF(n):
memo =[None]*(n +1)return F_bottom_up(n, memo)
Giờ hãy cùng thử xem, với n = 1000, thuật toán của chúng ta có thực thi được không và hiệu suất như thế nào nhé. Do kết quả quá dài nên mình sẽ không tiện ghi kết quả ra, mình sẽ chỉ ghi thời gian thực thi.
So với lúc đầu, tính F(40) mà đã mất 42.9s, giờ đây chúng ta đã có thể tính lên đến F(200000) mà chỉ mất có 15.8s. Vậy là thuật toán mình cài đặt thực sự có hiệu suất rất cao.
Tổng kết
Vậy là trong bài viết này, mình đã giới thiệu đến các bạn về dãy Fibonacci, thuật toán tính số Fibonacci sử dụng ngôn ngữ Python, tối ưu thuật toán. Nếu bạn có thuật toán hay, đừng ngại chia sẻ nó bằng cách comment bên dưới bài viết. Đừng quên chia sẻ bài viết với bạn bè nha. Cảm ơn các bạn đã theo dõi bài viết!
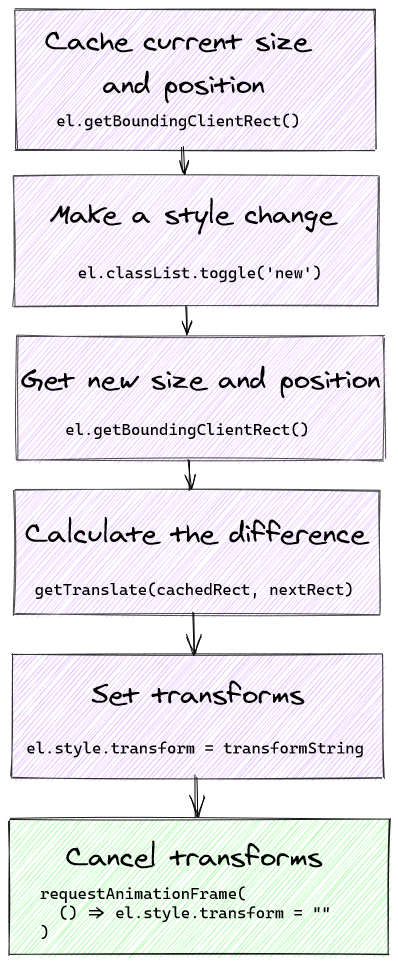
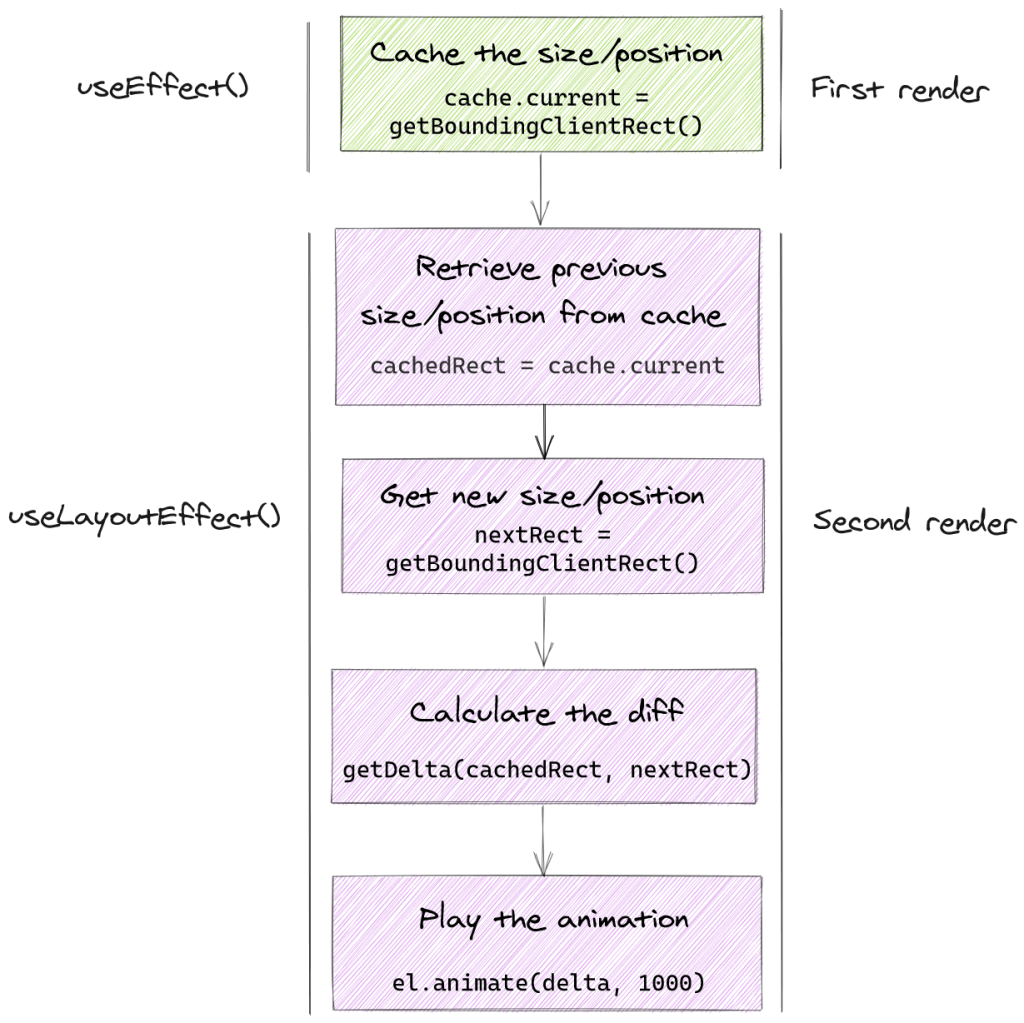
Để đạt mục đích transform trước khi trình duyệt thực hiện paint, chúng ta sẽ sử dụng useLayoutEffect, những gì diễn ra ở đây sẽ xảy ra sau khi DOM cập nhập, trước khi paint
Với lần render đầu tiên, chúng ta cần cache lại vị trí cuối cùng của animation
useEffect(()=>{// ...const rects =useRef(newMap()).current;const squares =document.querySelectorAll('.square');for(const square of squares){
rects.set(square.id, square.getBoundingClientRect());}},[])useLayoutEffect(()=>{const squares =document.querySelectorAll('.square');for(const square of squares){const cachedRect = rects.get(square.id);if(cachedRect){const nextRect = square.getBoundingClientRect();// invertconst translateX = cachedRect.x- nextRect.x;// cache position và size
rects.set(square.id, nextRect);// play animation
square.animate([{ transform:`translateX(${translateX}px)`},{ transform:`translateX(0px)`}],1000)}}}, ids);
Tóm tắt những gì đã thực hiện bằng hình minh họa sau
Một vài lưu ý
Đảm bảo các tính toán không vượt quá 100ms, điều này nhằm đảm bảo user không cảm nhận có một độ trễ trên giao diện, có thể kiểm tra bằng DevTools
Để tránh re-render không cần thiết, chúng ta ko được dùng useState, thay vào đó chúng ta phải dùng useRef một object cố định chúng ta có thể thay đổi giá trị mà không gây ra re-render
Không thực hiện đọc vị trí -> chạy animate ngay và luôn trên element đó, luôn thực hiện theo dạng đọc hàng loạt, sau đó animate một loạt
Đạo đức có lẽ là một trong những bài học sớm nhất của mỗi người. Không biết các bạn thế nào chứ từ bé mình đã được dạy “sống phải có có đạo đức”, thậm chí mình còn được dạy điều đó trước khi mình thực sự hiểu được “đạo đức là gì”.
Đạo đức là một từ Hán Việt, được dùng từ xa xưa để chỉ một thành tố trong tính cách và giá trị của mỗi con người. Đạo có nghĩa là con đường, Đức có nghĩa là tính tốt hoặc những công trạng tạo nên. Khi mình nói một người có đạo đức ý là nói người đó có nếp sống chuẩn mực với xã hội, có nét đẹp trong đời sống và cả tâm hồn.
Đạo đức nghề nghiệp là gì?
Đạo đức nói chung thì là chuẩn mực của xã hội. Còn đạo đức nghề nghiệp là những chuẩn mực trong nghề nghiệp mà mình nói đến, ở mỗi ngành nghề lại có chuẩn mực khác nhau.
Ví dụ ở đạo đức trong nghề giáo dục là:
Không gian lận trong thành tích học tập, thi đua
Luôn giúp đỡ học sinh, sinh viên của mình
Đối xử công bằng với tất cả học sinh, sinh viên của mình
Đạo đức trong nghề y:
Lấy việc cứu chữa người bệnh là trên hết
Kê thuốc đúng liều lượng và an toàn
Chữa bệnh vì đúng lương tâm, không chữa vì đồng tiền
Bản thân mình là một developer thôi nên chỉ có thể kể ra được một số chuẩn mực tiêu biểu của nghề y và nghề giáo. Còn thực tế thì bộ chuẩn mực này còn nhiều hơn nhiều nhé.
Đạo đức trong nghề lập trình
Đây chính là phần quan trọng mà mình muốn nhấn mạnh trong bài viết này – Đạo đức nghề lập trình.
Như bạn thấy rồi đó, công nghệ đang dần làm thay đổi cuộc sống của chúng ta bằng cách có mặt trong tất cả các lĩnh vực trong xã hội. Từ kinh tế, chính trị, giáo dục, y tế cho tới vận tải, du lịch, giải trí,… nói chung là không chừa bất kỳ một ngành nghề nào mà không có sự góp mặt của công nghệ cả. Điều này khiến cho các anh em lập trình viên như chúng ta cảm thấy thật vinh dự và tự hào. Nhưng càng vinh dự, tự hào bao nhiêu thì trách nhiệm cũng lớn bấy nhiêu.
Câu nói của bác Ben khiến mình vô cùng ấn tượng
“Quyền lực càng cao, trách nhiệm càng nhiều”
Bác Ben, Spider-Man
Thật vậy, xin kể một câu chuyện do mình bịa ra để chứng minh điều này.
Một developer phát triển phần mềm giao dịch ngân hàng nhưng chẳng may quên một dấu chấm phẩy, gây Exception và làm sai sót trong các phiên giao dịch. Trong khi công ty X sử dụng dịch vụ của ngân hàng này để trả lương cho anh A, vì tính năng giao dịch bị lỗi nên ngân hàng mặc dù đã ghi nhận công ty X đã trả lương nhưng tài khoản của anh A vẫn không nhận được tiền. Vậy là anh A bị mất lương tháng này, không có tiền trả tiền nhà trọ, không có tiền đưa bạn gái đi chơi, tệ hơn, anh A còn bị bạn gái bỏ vì bị nghi ngờ mang tiền đi “nuôi em gái” khác. Anh A chán nản, sinh ra nghĩ quẩn và làm liều…
Vậy là chỉ từ câu chuyện của một dấu chấm phẩy đã đưa số phận của anh A sang một trang mới.
Mặc dù câu chuyện trên là hư cấu, nhưng không hẳn là không có những chuyện như vậy xảy ra. Trong thực tế, đã từng xảy ra những tình huống mà developer chúng ta vô tình “giết người”. Vâng, giết người đấy bạn không nghe lầm đâu.
Xin tiếp tục được lấy dẫn chứng như sau
Sự kiện cỗ máy Therac-25 gây ra 6 tai nại thảm khốc trong những năm từ 1985 đến 1987 chính là câu chuyện nổi tiếng nhất về việc những dòng code giết người. Therac-25 là một cỗ máy xạ trị cho bệnh nhân ung thư được sản xuất vào năm 1982. Do sai lầm trong việc code và kiểm thử, máy chiếu phóng xạ quá liều, làm chết 4 người, bị thương 2 người.
Năm 1994 ở Scotland, lỗi phần mềm dẫn đến một vụ tai nạn máy bay, giết chết 29 người.
Tháng 6 năm 2010, con worm máy tính Stuxnet được các chuyên viên Semactec tìm thấy. Con worm “vô hại” này được biết là có khả năng thâm nhập và phá hoại các lò phản ứng hạt nhân. Stuxnex lây lan khá rộng ở Iran, nhưng chưa rõ có lò phản ứng nào bị nổ hay thiệt hại vì nó chưa.
Cơ quan quản lý thực phẩm và dược phẩm Hoa Kỳ (FDA) đã xác nhận sự liên quan giữa các vấn đề phần mềm của máy bơm thuốc tiêm truyền với hơn 700 ca tử vong và 20 000 ca bị thương nặng từ năm 2005 đến 2009.
Mặc dù để xảy ra những sự việc đáng tiếc như vậy trách nhiệm không hoàn toàn thuộc về các developer, nhưng cũng không thể nói rằng chúng ta vô tội. Giá như chúng ta cẩn thận hơn một chút, giá như chúng ta chịu khó test thêm 1 case nữa, giá như chúng ta tập trung hơn một chút nữa thì đã có thể cứu sống hàng chục sinh mạng, tiết kiệm hàng nghìn đô la, vun vén hạnh phúc lứa đôi cho hàng tỷ người trên thế giới. Nói thì nghe to tát vậy thôi chứ tực tế thì nó đúng là như vậy đấy các developer ạ.
Lập trình cần phải có đạo đức như thế nào?
Sau một hồi các dẫn chứng thực tế lẫn bịa đặt, chắc bạn cũng nắm được phần nào về trách nhiệm và tầm ảnh hưởng của một developer tới xã hội rồi chứ. Vậy làm sao để developer chúng ta trở thành những người có đức đạo đức nghề nghiệp, luôn luôn code có đạo đức. IEEE-CS và ACM có một bài viết về code đức như thế này Software Engineering Code of Ethics and Professional Practice.
Nội dung bài viết này này gồm 8 nguyên tắc về public interest, client & employer, sản phẩm, sự phán xét, quản lý, nghề nghiệp, đồng nghiệp và bản thân.
Mình sẽ tóm tắt lại mốt số ý quan trọng như sau
Chỉ approve sản phẩm khi tin rằng nó an toàn: Tuyệt đối không cung cấp các sản phẩm không an toàn, làm giảm chất lượng cuộc sống, hay khi biết chắc chắn rằng nó sẽ ảnh hưởng xấu tới người khác.
Sẵn sàng đóng góp kĩ năng của mình cho các mục đích tốt: Theo cách hiểu của mình thì là giúp đỡ các bạn newbie, đóng góp cho các phần mềm mã nguồn mở, nâng cao cảnh giác của mọi người về bảo mật, vv.
Thành thật về kinh nghiệm và kĩ năng: Không khai man CV, không chém gió về khả năng của mình, không nhận những gì mà mình không làm. Theo tui nghĩ thì nếu không tuân theo nguyên tắc này, ảnh hưởng tiêu cực cho bạn nhiều hơn là cho cộng đồng.
Giữ bí mật thông tin có được trong quá trình làm việc: Giữ bí mật các thông tin của công ty, thông tin của team, thông tin vận hành sản phẩm, thông tin khách hàng,…
Không chấp nhận các job ngoài luồng mà ảnh hưởng đến công việc chính: Nếu có nhận các job ngoài công ty thì hãy tranh thủ thời gian buổi tối và cuối tuần để làm việc, đừng làm nó trong lúc làm việc ở công ty.
Cố gắng tối đa để đưa ra sản phẩm chất lượng cao, với một acceptable cost và schedule: Không phóng đại deadline, không vẽ thêm việc để làm, không charge tiền khách hàng quá mức.
Trả lương công bằng: Ngược lại là một nhà quản lý, phải đảm bảo việc trả lương công bằng cho developer.
Luôn không ngừng nâng cao bản thân: Dev phải cầu thị, luôn học hỏi để nâng cao trình độ kĩ thuật và kinh nghiệm của bản thân.
Kết luận
Ngành nghề nào cũng vậy, cũng cần phải có đạo đức, đặc biệt là các ngành nghề ảnh hưởng nhiều tới xã hội như công nghệ thông tin, giáo dục, y tế, thực phẩm thì lại càng phải đề cao tinh thần đạo đức nghề nghiệp. Bởi nếu để ra sai sót dù nhỏ thì hậu quả chúng khó mà đoán trước được. Các cụ dạy cấm có sai “sai một ly, đi một dặm”.
Freelancer IT hiện tại là một trong những xu hướng ngành nghề được quan tâm. Nhiều thắc mắc được đặt ra xoay quanh Freelancer ngành lập trình. Vậy Freelancer IT là gì? Cùng TopDev tìm hiểu về những điều thú vị xoay quanh Freelancer IT qua bài viết sau!
Freelancer IT là gì?
Freelancer IT là gì?
Hiểu một cách đơn giản, Freelancer IT (người làm lập trình tự do) là những người được tự do trải nghiệm công việc của mình và không chịu một giới hạn nào về thời gian, môi trường. Họ được trả tiền để đảm bảo các nhiệm vụ về ngành lập trình IT. Các nhiệm vụ được họ thực hiện trong một thời gian nhất định theo hợp đồng freelancer. Và mỗi một Freelancer lập trình cần có trách nhiệm hoàn thiện công việc, cam kết tiến độ và chất lượng, hiệu quả công việc.
Xem ngay những tin đăng tuyển freelancer IT trên TopDev
Điều gì thú vị đối với một lập trình viên Freelancer IT?
Tất nhiên là có. Bản chất của công việc freelancer là không gò bó về mặt thời gian, phạm vi. Và tùy thuộc vào từng quy mô doanh nghiệp, mỗi freelance sẽ có những giới hạn riêng trong phong cách tổ chức nghề nghiệp của mình.
Một Freelancer IT có những điều gì thú vị?
Đối với những freelancer IT, bạn hoàn toàn có thể lựa chọn loại hình ngôn ngữ lập trình dựa trên các hệ giá trị riêng như sở thích, lĩnh vực chuyên sâu trong ngành IT: tuyển dụng Data Scientist, Business Analyst, Mobile App Developer,… Hoặc tương ứng với nhiều ngôn ngữ lập trình khác nhau như Java, PHP, HTML, CSS,…
Do vậy, bạn sẽ chủ động hơn trong mọi thứ. Freelancer lập trình sẽ có cơ hội tự tìm tòi, sáng tạo và thách thức bản thân nhiều hơn.
Những thay đổi đến mức “biến động” về thu nhập
Thực tế cho thấy, nếu là một Freelancer IT thì sự lựa chọn của bạn thật sự mạo hiểm.Vì đặc thù nổi trội của những người làm việc tự do chính là sự không ổn định. Có thể nói đây là nước đi khá nhiều thách thức trên hành trình phát triển sự nghiệp của họ.
Chúng ta không thể phủ nhận nhiều người có thể kiếm được vài ngàn đô hoặc thậm chí là những con số khủng hơn với công việc freelancer IT. Thế nhưng, chắc chắn những áp lực vẫn hiện hữu. Chỉ là, việc áp lực ấy không quá nhiều như dân lập trình IT toàn thời gian.
Quyết định lựa chọn và theo đuổi ngành lập trình là tùy vào định hướng phát triển của mỗi người. Lương là yếu tố chi phối và ảnh hưởng khá nhiều đến quyết định lựa chọn. Song, vẫn có nhiều người là freelancer lập trình nhưng họ vẫn đảm bảo được tính cân bằng.
Tính linh động và nhiều cơ hội phát triển
Không lên công ty, doanh nghiệp, bạn có nhiều thời gian hơn để làm nhiều thứ. Rèn luyện chuyên môn từ các khóa học, trải nghiệm freelancer lập trình tại nhiều môi trường khác nhau; có nhiều thời gian dành cho gia đình,..
Hiện nay, số dự án mà mỗi freelancer IT nhận được có thể ngang hoặc nhiều hơn cả các nhân viên lập trình fultime nhận được. Điều này cũng giúp freelancer IT có nhiều sự lựa chọn hơn trong việc tìm kiếm công việc/dự án phù hợp với chuyên môn; trình độ hiện tại cũng như bề dày trải nghiệm tương ứng.
Liệu Freelancer IT sẽ thoát khỏi các áp lực ngành lập trình?
Freelancer IT cũng chịu sức ép từ thị trường cạnh tranh so với các đối thủ. Đối thủ của freelancer IT chính là những đơn vị nhỏ, các freelancer IT khác. Đó đôi khi đều là những đơn vị với các ekip được đầu tư lớn về thương mại, truyền thông. Họ được kết nối bài bản và quy mô. Vì thế, nếu là tay ngang, một Freelancer lập trình sẽ phải gặp nhiều khó khăn, đặc biệt là ở giai đoạn đầu.
Nếu thật sự yêu thích, hãy dành sự kiên nhẫn và luôn nỗ lực cố gắng. Freelancer IT không thật sự khó thích nghi và phát triển. Rào cản duy nhất chính là những khó khăn cạnh tranh của một newbie freelancer lập trình trong giai đoạn đầu “khởi nghiệp”.
Một tips quan trọng giúp Freelancer IT có thể tiến xa hơn là hãy trau dồi và hiểu biết thật chuyên sâu một ngôn ngữ lập trình nào đó. Đó là một lợi thế lớn giúp gia tăng cơ hội. Đồng thời, thúc đẩy các cơ hội phát triển nghề nghiệp của mỗi Freelancer lập trình.
Những xu hướng phát triển định hình thị trường Freelancer IT
Hiện nay, có một số kỹ năng công nghệ thông tin phổ biến của các freelancer IT. Chúng có sức ảnh hưởng lớn và dần tạo ra xu thế phát triển toàn diện. Đây cũng được xem là cơ sở quan trọng để các freelance ngành lập trình theo dõi và cập nhật các tình hình.
Ngành công nghiệp an toàn thông tin (The industry of information security)
Đây là xu hướng ngành đã mở rộng đáng kể trong thời gian gần đây. Có rất nhiều lĩnh vực chuyên môn, bao gồm khoa học pháp y kỹ thuật số, kiểm toán hệ thống thông tin và lập kế hoạch kinh doanh liên tục. Tùy theo trình độ và trải nghiệm riêng biệt, các freelancer có thể tự tạo cơ hội cho mình khi tiếp xúc với xu hướng phân ngành lĩnh vực này.
Thông tin mạng máy tính (Computer Networking Information)
Mạng tạo nên một thành phần quan trọng trong hoạt động của nhiều cơ sở. Các yếu tố của mạng lưới mạng có xu hướng được kết nối mật thiết với IT. Mạng máy tính thường được coi là một tiểu kỷ luật của các lĩnh vực như: khoa học máy tính, công nghệ thông tin, viễn thông hoặc kỹ thuật máy tính. Đây thật sự là một xu hướng khá tiềm năng và hấp dẫn đối với nhà lập trình viên tự do.
Dịch vụ Linux (Linux Services)
Bắt đầu như một hệ thống máy tính cá nhân, Linux kể từ đó đã được chấp nhận bởi một số lượng đáng kể các tập đoàn lớn. Chẳng hạn như IBM và Sun Microsystems.
Hiện tại, về cơ bản nó hoạt động như một hệ điều hành máy chủ. Với một vài tổ chức lớn áp dụng các phiên bản doanh nghiệp cho máy tính để bàn. Một freelancer Linux IT có thể cung cấp các dịch vụ phần mềm mã nguồn mở hiệu quả. Cụ thể là tại các cơ sở và qua các mạng bảo mật từ xa. Đây là xu hướng có tính chuyên biệt cao đòi hỏi sự am hiểu chuyên sâu của các freelancer.
Quản lý dự án (Project Management)
Noi về xu hướng này thì không còn quá xa lạ. Quản lý dự án chịu trách nhiệm quản lý nguồn lực của các dự án lớn. Các freelancer IT sẽ chịu trách nhiệm đảm nhận quản lý quy trình dự án từ đơn giản đến phức tạp. Họ có trách nhiệm đảm bảo một dự án được hoàn thành trong một tập hợp các hạn chế nhất định. Tất nhiên, tính hiệu quả của dự án sẽ được cam kết. Thế nhưng cần phải hiểu tính tương đối và dự án thành công hay không phụ thuộc rất nhiều yếu tố.
Đâu là kỹ năng quan trọng của một Freelancer lập trình
Hầu hết mọi người thường nghĩ kỹ năng chuyên môn về ngành lập trình rất quan trọng. Tuy nhiên, kỹ năng giao tiếp mới thật sự quan trọng đối với một freelancer lập trỉnh. Tại sao lại như vậy?
Tầm quan trọng của thế mạnh giao tiếp
Đơn giản vì freelancer IT làm việc trực tiếp khách hàng. Bạn cần có nghệ thuật giao tiếp để tiếp cận trao đổi, thương lượng, đàm phán, bàn bạc, thậm chí là phân tích để hiểu được nhu cầu khách hàng. Đó là một kỹ năng thật sự cần thiết.
Nếu các kỹ năng sử dụng ngôn ngữ lập trình, viết và xử lý code,… đều hoàn hảo nhưng việc vận hành dự án của bạn sẽ không hiệu quả. Điều này thật tệ!
Để giảm thiểu các mâu thuẫn, bạn nên hỏi rõ về các yêu cầu của khách hàng. Đồng thời, bạn có thể note lại các thông tin trong buổi trao đổi. Điều này có ý nghĩa lớn trong việc minh chứng nếu có trường hợp cần thảo luận chi tiết trước những phát sinh.
Ngoại ngữ vẫn là yếu tố gia tăng cơ hội
Là một freelancer lập trình, rèn luyện trình ngoại ngữ ở mức đủ tốt trở lên là điều quan trọng. Đặc biệt là đối với những Freelancer IT muốn tiến xa. Vì nếu xác định theo nghề lâu dài, bạn chắc chắn sẽ làm việc với các khách hàng nước ngoài. Bạn sẽ được tiếp cận với mô hình làm việc chuẩn quốc tế. Đây là lúc bạn thật sự nhận ra tiềm năng phát triển và những cơ hội lớn mà một freelancer lập trình có thể đạt được. Vì vậy, hãy trau đồi vốn ngoại ngữ thật tốt.
Tiếng Anh, tiếng Trung, tiếng Hàn, tiếng Nhật,… đều là những ngoại ngữ đang thịnh hành hiện tại. Hãy chuẩn bị có bản thân những kỹ năng cần thiết trước khi xác định theo đuổi hành trình trở thành một người làm lập trình tự do chuyên nghiệp.
Không phải ai cũng làm Freelancer IT được?
Thực tế có rất ít người thành công với nghề freelancer. Không phải ai cũng đáp ứng được những đòi hỏi của nghề này.
Ngay cả những freelancer IT dày dạn kinh nghiệm, nhiều khi cũng cảm thấy mệt mỏi sau quãng thời gian “lăn lộn” với nghề. Hơn nữa, hiện ngày càng có nhiều người trở thành freelancer và điều này tạo ra môi trường cạnh tranh khốc liệt. Chính vì vậy, nhiều người phải nghĩ đến việc tìm kiếm một công việc ổn định tại doanh nghiệp hay tổ chức nào đó.
Trước tiên hãy là một Freelancer lập trình bán thời gian
Tức là có một công việc cố định bên cạnh công việc làm Freelancer; từng bước thiết lập được một nền tảng ổn định về khách hàng và dự án trước khi bạn có thể làm Freelancer toàn thời gian.
Điều đó không dễ dàng một chút nào.
Bạn sẽ phải chấp nhận làm thêm ngoài giờ rất nhiều. Ít nhất là gấp đôi những người bình thường khác khác. Vì đơn giản, bạn phải làm 2 công việc cùng lúc. Nhưng đó là điều cần thiết. Bởi lẽ, không đơn thuần chỉ là xây dựng các mối quan hệ, mà còn là cơ hội để thử thách đam mê. Đây củng được xem là cơ hội để bạn đánh giá lại năng lực bản thân mình.
Có lẽ bạn sẽ gặp phải một số điều khó chịu trong quá trình làm freelancer. Và không phải ai cũng có thể trở thành một freelancer được. Nếu bạn không vượt qua được thử thách này, nó cũng là cách để nhận ra khả năng của mình trước khi bạn từ bỏ một công việc có thu nhập ổn định và theo đuổi một công việc “tay làm hàm nhai, tay quai miệng trễ”.
Nhiều bạn muốn trở thành freelancer IT nhưng chưa biết bắt đầu từ đâu. Đó cũng là một trong những lý do khiến nhiều freelancer lập trình nghiệp dư bỏ cuộc vào giai đoạn đầu. Vì thế, để không chóng chán vì những áp lực phát sinh, các bạn cần có những lộ trình cơ bản để bắt đầu hành trình làm feelancer IT.
Xác định và phát huy thế mạnh
Phải thật sự hiểu rõ bản thân mong muốn điều gì trước mọi quyết định. Hãy dành thời gian tự nhìn nhận, đánh giá về chuyên môn bản thân. Điều này có ý nghĩa đặc biệt đối với một freelancer IT.
Nó giúp xác định phạm vi thuận lợi phát triển trước mọi sức ép cạnh tranh. Thế mạnh cũng chính là thước đo kết nối giúp bạn tìm ra các ranh giới về giới hạn. Từ đó, freelancer lập trình dễ dàng lựa chọn các dự án phù hợp với năng lực của mình.
Hồ sơ xin việc “xịn”
Tiếp theo, bạn hãy chuẩn bị một bộ hồ sơ xin việc bao gồm CV IT Developer, Cover Letter cho dev và một số tài liệu liên quan. Tất nhiên bạn có thể tham khảo các CV Template IT để hoàn thiện CV IT của mình.
CV sẽ thể hiện mọi hệ giá trị phản ánh bản thân một freelancer IT về các khía cạnh: kỹ năng, phẩm chất, kinh nghiệm,… một cách trọn vẹn.
Đặc biệt hơn, đừng quên đình kèm thêm hình ảnh cá nhân. Một bức ảnh cá nhân là điều cần thiết giúp cho hồ sơ sinh việc của bạn thêm chuyên nghiệp. Vì thế, chuẩn bị ngay cho mình những bức hình đẹp nhất giúp quá trình tiếp cận trở nên hiệu quả hơn.
Bắt đầu hành trình tìm việc freelancer IT
Các kênh Social Channel
Mạng xã hội được xem là nguồn tìm kiếm khá hữu ích dành cho các feeelancer. Bạn hoàn toàn có thể dễ dàng khai thác các công việc phù hợp trên nền tảng các group tìm việc có liên quan đến freelancer trên Facebook, Linkedin,…
Những webiste thông tin dành cho việc freelancer IT
Có rất nhiều trang web dành riêng cho cộng đồng các freelancer tìm việc. Bạn có nhiều sự lựa chọn để tham khảo. Tuy nhiên, các bạn freelancer IT nên cần nhắc việc chọn lọc.
Tìm ra các trang web tìm việc uy tín, chất lượng với số lượng thành viên tiềm năng. Đó là cách để bạn giảm thiểu các tình trạng rủi ro.
TopDev đã thống kê một số trang web tin cậy với độ phổ biến người dùng ờ mức độ ổn định như:
Các webiste nước ngoài: Upwork.com, Freelancer.com, Guru.com,…
Các trang web Việt Nam: Vlance.vn, Freelancerviet.vn,…
Sai lầm khi bắt đầu làm việc Freelancer IT
Mọi trải nghiệm đều cần có giai đoạn đầu để mọi cá nhân tự nhìn nhận ưu – khuyết. Từ đó có nền tảng thiết lập lộ trình phát triển tốt hơn. Cung như nhiều vị trí khác nhau từ Junior Developer, Senior Developer,… việc nắm bắt tốt những sai lầm trong quá trình đầu luôn có ý nghĩa quan trọng.
Nhận quá nhiều dự án cùng một lúc
Đây được xem một sai lầm khá phổ biến mà mọi Freelancer lập trình đều mắc phải. Thực tế, bạn là người hiểu rõ chính khả năng và giới hạn của bản thân mình. Tuy nhiên, dường như ai cũng muốn “take care” quá nhiều thứ và nghĩ rằng mình sẽ làm tốt. Thế nhưng, việc chịu trách nhiệm quản lý và thực hiện nhiều jobs/tasks là điều không tốt. Tất nhiên, biểu hiện cụ thể nhất chính là sự quá tải. Từ đó, bạn bị phân tâm, khó tập trung vào một sản phẩm/quy trình thực hiện. Điều đó chi phối đến hiệu quả và hiệu suất thực hiện công việc.
Về lâu dài, chất lượng của các nhiệm vụ sẽ không còn được đảm bảo như cam kết về tiêu chuẩn được thỏa thuận ngay từ ban đầu. Lúc này, bạn sẽ bị stress khi vừa mất đi uy tín của một người làm freelancer IT, vừa cảm thấy tệ cho bản thân khi chưa hoàn thành trọn vẹn những công việc thuộc chính chuyên môn nghề nghiệp của mình.
Hãy dành thời gian đầu để phân bố các nhiệm vụ phù hợp. Phải thật sự đảm bảo rằng mọi thứ thuộc ranh giới khả năng của bạn. Khi thuần thục và tự tin hơn trong cách tiếp cận, bạn có thể nhận nhiều job hơn.
Bài viết được sự cho phép của tác giả To Thi Van Anh
Trong Selenium – Wait là một yếu tố đóng vai trò rất quan trọng khi thực thi các test case. Vì thế hôm nay trong bài viết này mình sẽ nói về một vài kiểu wait được nhắc đến khá nhiều trong Selenium webdriver, để mọi người cùng hiểu và áp dụng nhé!
Đã bao giờ bạn sử dụng Selenium IDE để record một vài thao tác nào đó, bạn đã chắc chắn là các key như bạn đã get như id/name chuẩn như Lê Duẩn rồi, sau đấy còn xem đi xem lại là không thể sai ở chỗ nào được mà khi run script vẫn báo fail? Điên đầu là lúc mà lâu lắm thì tự dưng với vẫn script đấy nó lại chạy pass được một lần! Nếu bạn đã từng làm với IDE thì đảm bảo là bạn đã từng gặp vấn đề này rồi!
Hoặc khi sử dụng Selenium Webdriver, bạn cũng đã rà soát kỹ lắm rồi, chắc nhẩm mình không thể nhầm lẫn ở đâu được ấy thế mà console vẫn ra dòng exception này “ElementNotVisibleException“, quái lạ, rõ ràng cái id/name/xpath của nó là như thế rồi mà, sao lại không tìm thấy được nhỉ?
Sau nhiều lần gặp phải, cũng đi tìm khắp nơi mới phát hiện nguyên nhân là do script của mình cứ đi tìm phần tử web ấy, trong khi trang web nó chưa tải được xong, lúc này thì tất nhiên là nó không thể tìm được phần tử web kia rồi. Vấn đề ở đây có thể do mạng kém, hay dữ liệu cần load lên quá lớn, trong một khoảng thời gian ngắn không thể load kịp với tốc độ của script test được.
Ngoài ra nó còn vì một số nguyên nhân chính khác liên quan đến việc xử lý các phần tử web, Ajax và Javascript ở phía ứng dụng web, nên việc load các phần tử không thể diễn ra cùng một lúc được.
Để giải quyết vấn đề này, lời khuyên dành cho bạn là hãy sử dụng Waits!
Selenium waits bao gồm một số loại như:
Implicit wait
Explicit wait
Fluent wait
Implicit wait
Sử dụng implicit wait khi run test script, nó sẽ yêu cầu web driver tạm dừng một khoảng thời gian nhất định mà mình đã thiết lập ban đầu, trước khi bật ra một exception có nội dung giống như này: “No Such Element Exception”.
Ví dụ đơn giản như sau, khi run 1 test script, trình duyệt được bật lên, đường dẫn ứng dụng được mở ra, theo tiến trình script sẽ tự động dừng lại 5 giây – do trước đó ta đã set implicit wait = 5 giây, rồi sau đó mới thực hiện tiếp thao tác tiếp theo là click vào login. Thay vì trước đây nếu không sử dụng wait, sau khi mở link, script sẽ run luôn bước tiếp theo là click vào nút login, và ở đoạn này có thể xảy ra trường hợp là code chạy nhanh quá, nút login chưa kịp hiển thị thì sẽ không tìm thấy element này để click, vì vậy sẽ có exception được trả về thôi.
Giá trị mặc định của khoảng thời gian này là 0. Ta có thể set các giá trị này tùy ý.
Như ví dụ trên, thì ta set thời gian chờ trước khi bật ra expeption là 10 giây, chỗ TimeUnit, bạn có thể thay đổi thành SECONDS, MINUTES, MILISECOND, MICROSECONDS, NANOSECONDS, DAYS, HOURS,… tùy theo yêu cầu của bạn.
Explicit Wait
Khác với implicit wait, khi sử dụng explicit wait nó sẽ đi kèm với một điều kiện nào đó, tức là thay vì chờ đợi một khoảng thời gian được thiết lập sẵn thì ở đây chúng sẽ chờ một điều kiện cụ thể nào đó hay kiểm tra khi việc wait đã vượt qua khoảng thời gian maximum nào đó, trước khi output ra một exception có nội dung kiểu như là “ElementNotVisibleException”.
Ví dụ như là wait cho đến khi phần tử A có thể click được, hay phần tử B được enable, hoặc visible. Trong khi bình thường, nếu không sử dụng explicit wait, thì mặc dù phần tử A chưa click được, nhưng script của mình vẫn chạy, chưa click được nhưng cố click thì tất nhiên là ra exception thôi. Dễ hình dung đúng không nào!
Đây được đánh giá là một kiểu wait rất là thông minh, nhưng nó chỉ có thể sử dụng được cho một số các element cụ thể nào đó thôi kiểu như trong trường hợp clickable, visible, invisible, display… . Và nó khá phù hợp trong những case mà có element động được load bằng Ajax.
Để sử dụng explicit wait thì có nhiều cách khác nhau, nhưng mình thì thích cách viết luôn cái này thành một method, và để nó vào một common nào đó, khi nào cần thì chỉ cần gọi ra và dùng thôi:
public void waitForElement(int seconds, String waitConditionLocator){
WebDriverWait wait = new WebDriverWait(driver, seconds);
wait.until(ExpectedConditions.visibilityOfElementLocated
(By.xpath(waitConditionLocator)));
}
Bạn cũng có thể sử dụng trực tiếp như ví dụ dưới đây:
WebDriver driver = new FirefoxDriver();
driver.get("http://somedomain/url_that_delays_loading");
WebElement myDynamicElement = (new WebDriverWait(driver, 10))
.until(ExpectedConditions.presenceOfElementLocated
(By.id("myDynamicElement")));
Thêm ví dụ với điều kiện là element có thể click được hay display và enable như sau:
WebDriverWait wait = new WebDriverWait(driver, 10);
WebElement element = wait.until(ExpectedConditions.elementToBeClickable
(By.id("idOfElementToBeClicked")));
Ngoài ra các bạn có thể tham khảo thêm một số ví dụ khác về sử dụng wait theo link mình để phía cuối bài viết nhé!
Fluent wait
Sử dụng Fluent wait trong những trường hợp kiểu như, đôi khi là ta gặp những phần tử mà cần từ một đến hai giây để load, nhưng khi khác có khi lại cần nhiều thời gian hơn đến tận mấy chục giây chẳng hạn. Fluent wait sẽ tìm kiếm đi tìm kiếm lại cho đến khi tìm được phần tử đó hoặc đến khi time out thì thôi.
Ví dụ khi dùng Fluent wait, nó sẽ chờ phần tử A một khoảng thời gian cho đến khi nó xuất hiện, trong mỗi khoảng thời gian nào đó nó lại thực hiện kiểm tra xem phần tử này đã xuất hiện chưa, nếu chưa thì qua khoảng thời gian đó nó lại check lại, nếu đã tìm được thì nó sẽ đi bước tiếp theo. Hoặc đến khi vượt quá khoảng thời gian time out đã set thì lúc này mới bật ra exception.
// Sẽ chờ 30 giây để mỗi element hiển thị trên page
// và sẽ thực hiện lặp lại mỗi 5 giây nếu chưa tìm thấy phần tử đó
Wait<WebDriver> wait = new FluentWait<WebDriver>(driver)
.withTimeout(30, SECONDS)
.pollingEvery(5, SECONDS)
.ignoring(NoSuchElementException.class);
WebElement foo = wait.until(new Function<WebDriver, WebElement>()
{
public WebElement apply(WebDriver driver) {
return driver.findElement(By.id("foo"));
}
});
Trên đây là một vài cơ bản về các wait hay gặp và một số ví dụ chung chung một chút. Chi tiết hơn mình sẽ tìm hiểu thêm và hẹn các bạn trong bài viết khác nhé! hehe
Công nghệ thông tin hiện đang là một trong những ngành học “hot” nhất trong những năm trở lại đây.
Nguyên nhân thì có lẽ các bạn cũng đã biết hết rồi. Một phần là do công cuộc chuyển đổi số của toàn xã hội, hai nữa là mức lương cho ngành IT thường cao hơn các ngành khác do đặc thù của ngành học này.
Nhưng cái gì cũng có cái giá của nó các bạn ạ! Các bạn cứ tưởng tượng xem, nếu ai cũng “có thể” học và làm được IT thì mọi chuyện sẽ như thế nào? Mình chắc chắn là chuyện đó sẽ không bao giờ xảy ra. Tại vì sao?
Học IT lương cao đấy, “hot” đấy, NHƯNG các bạn học đi rồi biết. Nó không dễ ăn như các bạn nghĩ đâu. Không phải cứ học ra là có việc đâu.
Nó khó ra phết đấy, mình từng gặp nhiều bạn đã bỏ học vì lý do học IT khó quá. Chính vì vậy, trong bài viết này mình sẽ chia sẻ với các bạn 5 điều mà bạn nên làm khi bạn cảm thấy học IT quá khó. Tham khảo xem nó có giúp được gì cho bạn không nhé !
#1. Dừng lại! và xem lại bạn có thực sự phù hợp với ngành IT?
Chúng ta đều biết rằng, công tác hướng nghiệp cho học sinh ở Việt Nam không là được tốt cho lắm.
Có nghĩa là phần đa các bạn học sinh sau khi tốt nghiệp phổ thông đều chọn học đại học phù hợp với điểm số mà mình thi đại học chứ chưa chắc phù hợp với năng lực cũng như năng khiếu của bản thân.
Từ đó dẫn đến một hệ lụy là sau khi vào học, các bạn cảm thấy không hợp, khó rồi đâm ra chán học rồi bỏ học…
Mình từng gặp nhiều bạn như thế, những bạn tìm được hướng đi mới thì mình không nói. Mà ở đây mình đang muốn nói đến những bạn cảm thấy bế tắc và không phù hợp với ngành.
Khi đó các bạn nên làm gì?
Vâng. Theo quan điểm của cá nhân mình thì mình nghĩ là các bạn nên dừng lại, tự đặt ra câu hỏi xem bản thân mình có phù hợp với ngành học mà mình đã lựa chọn không. Vậy một câu hỏi khác được đặt ra là, hỏi như thế nào?
Dễ thôi! Bạn cảm thấy như thế nào khi đi học? hay là khi tìm hiểu về các kiến thức mà bạn đang học bạn thấy ra sao (chán, không hứng thú, cảm thấy khô khan chẳng có ích gì, hay là hào hứng, cảm giác muốn chinh phục…).
Nếu như bạn rơi vào tình trạng chán, không có hứng thú… thì bạn đã biết được kết quả rồi đấy. Nhưng mình khuyên bạn nên làm thêm một bước. Đó là hỏi bạn bè, thầy cô của bạn (đặc biệt là những người đã đi làm, có kinh nghiệm) tư vấn thêm cho bạn.
Sau khi nhận được những lời tư vấn rồi mà bạn vẫn cảm thấy chán thì mình nghĩ là bạn nên tìm một hướng đi khác. Xem bạn đam mê về cái gì nhất, bạn thích làm về cái gì, những lúc rảnh rỗi thì bạn hay làm gì?..
Đừng trói buộc bản thân trong định kiến là phải học để lấy tấm bằng, học cho xong rồi làm gì thì làm. Như vậy chỉ càng khiến cho bạn thêm chán và lãng phí thời gian mà thôi ! Thật đấy.
#2. Đây là tình trạng chung và bạn phải đối mặt
Nếu bạn đã trải qua được bước đầu tiên và xác định rằng bạn vẫn phù hợp với ngành IT khi bạn cảm thấy nó khó thì bạn phải hiểu đây là tình trạng chung, nhiều người ngoài kia cũng như bạn vậy, và bạn không đơn độc đâu.
Điều duy nhất bạn phải làm đó là đối mặt, trở nên lì lợm hơn. Mình nghĩ đây sẽ là thử thách lớn nhất trong giai đoạn này. Vì sao mình lại nói như vậy?
Vì khi cảm thấy khó, người ta thường có xu hướng buông bỏ, từ bỏ. Đây là tâm lý chung của con người mà, nhưng ai vượt qua được thử thách thì mình chắc chắn là họ sẽ phù hợp với ngành IT này.
Vì vậy lời khuyên của mình đó là nếu bạn đã xác định học IT thì bạn phải kiên trì, chịu khó, chịu khổ vì, tự mày mò nghiên cứu, vì đặc thù của ngành học này là tìm tòi, khám phá và tự học là chính.
Đôi khi bạn sẽ cảm thấy bế tắc trong việc giải quyết một số vấn đề nào đó, lúc này bạn hãy tìm cách để giải tỏa căng thẳng bằng một việc gì đó, rồi quay trở lại “chiến đấu” tiếp.
Làm việc gì để cảm thấy thư giãn thì tùy thuộc vào mỗi người nên mình không có câu trả lời cụ thể được. Bình thường bạn làm gì khiến bạn cảm thấy vui và hanh phúc nhất thì những lúc khó khăn, buồn chán bạn hãy làm những việc đó nhé.
Ví dụ như mình, khi cảm thấy căng thẳng, áp lực thì mình hay đi bộ, chạy bộ hoặc là đi bơi.. Đây là những cách giúp mình đỡ stress hơn và giúp mình tỉnh táo hơn khi quay trở lại với công việc.
Hoặc là bạn cũng có thể tìm kiếm giải pháp trên mạng hoặc từ một ai đó. Cứ kiên trì rồi bạn sẽ dần yêu thích ngành IT này hơn thôi.
#3. Xác định lĩnh vực là thế mạnh của bạn
IT là một khái niệm rất rộng, khi học ngành IT bạn sẽ có rất nhiều lựa chọn để theo đuổi.
Nói chung thì chuyên ngành IT nào cũng yêu cầu bạn phải có tư duy, đặc biệt là tư duy logic, tư duy giải quyết vấn đề để có thể giải quyết các vấn đề kỹ thuật.
Bạn không cần quá giỏi toán hay là quá thông minh đâu! Mình lấy ví dụ bạn xác định đi theo hướng Kỹ sư phần mềm (Software Engineer), cụ thể ở đây là lập trình ứng dụng di động (Mobile App) thì bạn sẽ nghiên cứu sâu về mảng này.
Tìm hiểu xem một ứng dụng di động hoạt động như thế nào, để tạo ra được một ứng dụng như thế thì cần những kiến thức cũng như công cụ gì. Cứ dần dần học hỏi bạn sẽ mở mang ra thôi !
#4. Cần cù bù thông minh
Mình đoán là nhiều bạn đã từng nghe người ta nói học IT phải thông minh thì mới học được, chăm chỉ thôi là không đủ đâu. Đúng! Nhưng mình không hoàn toàn đồng ý với quan điểm này. Vì sao?
Thường những bạn thông minh thì họ tiếp cận vấn đề rất nhanh, họ tư duy rất nhạy bén. Mình cũng quen rất nhiều bạn như thế, thực sự rất “đáng sợ” vì nhiều thứ mình chưa kịp hình dung vấn đề thì họ đã có giải pháp rồi.
Nhưng bạn cũng đừng lo, không phải ai cũng thông minh như vậy đâu! Mình cũng chẳng phải là một người quá thông minh nhưng mình vẫn hằng ngày chịu khó học hỏi, cần cù bù thông minh, nhưng cũng cần lưu ý là các bạn phải cần cù đúng cách nha.
Thế nào là cần cù đúng cách? Tất nhiên không phải kiểu mọt sách đâu nha các bạn. Mình không biết các ngành học khác như thế nào nhưng học IT chủ yếu là các bạn phải tự học.
Các bạn nên đi sâu vào lĩnh vực sở trường, sau đó học rộng ra vì một sản phẩm công nghệ thông tin thường là cả một hệ thống, mà hệ thống thì lại bao hàm rất nhiều thứ.
Hãy cứ chăm chỉ tìm tòi khám phá nha các bạn, học IT chẳng cần thông minh quá đâu. Một câu nói rất hay mà mình muốn gửi tặng đến các bạn “Kiên trì còn quan trọng hơn cả sự tài năng” đấy !
#5. Nếu có điều kiện, hãy vừa học vừa làm để tích lũy kinh nghiệm
“Học đi đôi với hành” – trong ngành IT câu này phải nói chuẩn không cần chỉnh luôn. Có một hướng đi là theo hướng nghiên cứu, hướng này thường giành cho các bạn học cao lên, còn đa phần mình thấy nhiều bạn theo hướng là đi làm sau khi ra trường.
Mà đã đi làm thì phải có kinh nghiệm thực tế. Chắc các bạn cũng từng nghe việc nhà tuyển dụng yêu cầu sinh viên mới ra trường nhưng phải có kinh nghiệm rồi đúng chứ.
Nhiều bạn lại kêu ầm lên là em mới ra trường lấy đâu ra kinh nghiệm. Xin lỗi nha! Ông hỏi mấy đứa bạn ông xem, năm 3, năm 4 chúng nó đã làm đông làm tây, còn ông thì ngồi nhà cày game bảo sao chưa có kinh nghiệm. Do mình cả thôi. OK !
Nói vậy không có nghĩa là cứ năm 3, năm 4 các bạn phải đi làm. Ở đây mình đang muốn nhấn mạnh rằng bạn làm thế nào thì làm, hãy tìm cách trang bị cho mình những kiến thức thực tế để sau khi ra trường không bị ngộp và đó cũng là một điểm cộng khi bạn định ứng tuyển vào bất kỳ công ty nào.
Bài viết cũng khá dài rồi, nói tóm lại là nếu bạn đã xác định theo học IT thì bạn phải kiên trì, lì lợm vào. Sẽ có lúc bế tắc đấy, nhưng vượt qua được thì bạn sẽ thấy học IT thực sự rất thú vị. Hẹn gặp các bạn trong các bài viết tiếp theo nha !
Automation Test nghe có vẻ cao siêu, đặc biệt là với các bạn Tester mới. Chỉ cần chú ý đến 4 điều dưới đây, Automation Test sẽ dễ không tưởng.
1. Chú ý về cách dùng Locators
Element Locators là một yếu tố quan trọng để quyết định sự ổn định một một automation test script. Nhiều bạn mới học thường không quan tâm nhiều đến việc lấy locator hiệu quả mà chỉ lấy để nó chạy được ngay lúc đó. Tuy nhiên việc một XPath chạy được ngay lúc đó không có nghĩa là một thời gian sau nó sẽ chạy tốt. Nhất là khi có một sự thay đổi nhỏ trên ứng dụng và tác động đến cấu trúc của XPath. Việc đầu tư thời gian để tìm hiểu về locator, về các kiểu locating đang hỗ trợ, XPath tương đối – tuyệt đối & XPath tối ưu sẽ giúp ích rất nhiều và cũng giảm thời gian để sửa lại sau này. Việc tìm và sửa XPath nói riêng hay locator nói chung là một việc làm mệt mỏi và tốn thời gian.
Hai XPath này là cùng một element, nhưng cách thứ nhất sẽ hay hơn.
//*[@class=’nav-logo’]
//*[@id=”main-nav”]/div[1]/a/svg
2. Chú ý về việc chuẩn bị Test Data
Việc chuẩn bị test data (hay còn gọi là bước Pre-Conditions) cũng là một việc quan trọng. Phần lớn script lỗi là do locator, phần còn lại là về test data. Nhiều bạn thường sử dụng data có sẵn để test và không tự chuẩn bị data. Ví dụ như khi kiểm tra chức năng tìm kiếm thì lấy ngẫu nhiên một tên sản phẩm để search. Tuy nhiên cách này chỉ là cách tạm thời và mang nhiều rủi ro, vì có thể sau một thời gian tên sản phẩm đó bị đổi, bị xoá bới một người khác, và khi đó script sẽ không tìm ra sản phẩm và trả về kết quả là Fail.
Việc tự tạo một data để test sẽ giúp chúng ta kiểm soát được điều kiện và đảm bảo luôn có đúng dữ liệu cần thiết, ví dụ như kịch bản phía trên, thay vì chọn ngẫu nhiên một tên sản phầm thì việc tạo mới sản phẩm trước để có data cần thiết, hoặc có thể tham khảo thêm một số cách để chuẩn bị data như bên dưới tương tự phần #3.
3. Chú ý về khôi phục Test Data
Việc khôi phục test data (Post-Conditions) cũng quan trọng như bước chuẩn bị, ví dụ như sau khi thực hiện test case thay đổi mật khẩu của một tài khoản thành công, chúng ta phải có bước để khôi phục lại giá trị cũ để những test khác có dùng đến tài khoản (hoặc data đó nói chung) không bị ảnh hưởng, tương tự như việc đổi quyền hạn, trạng thái của những data cần test.
Một số ý tưởng để restore lại data sau khi chạy automation test script
3.1. Dùng luôn UI để restore sau khi chạy test xong (Ví dụ sau khi tạo tài khoản và verify thành công thì xoá tài khoản đó trên web UI luôn). Cách này không cần can thiệp vào DB tuy nhiên sẽ tốn thời gian và làm script trở nên dài hơn.
3.2. Có API thì nên gọi API, nếu có thể nhờ dev viết thêm cho những API để sử dụng thì càng tốt. Cách này nhanh & an toàn tuy nhiên cần phải có sẵn những API cần thiết.
3.3. Xoá thông qua query SQL. Ví dụ tạo user a1122 thì query user đó ra để xoá, tuy nhiên đòi hỏi phải có quyền connect trực tiếp vào data và mang nhiều rủi ro.
3.4. Snapshot cả DB trước khi chạy test, test xong hết thì restore cả DB lại. Cách này sẽ đảm bảo DB sạch như ban đầu.
3.5. Không cần restore trên môi trường test nếu không lo lắng về việc data rác. Cái này không phải giải pháp hay.
3.6. Tạo sẵn 1 list các câu query cần thiết trước, chạy nó (hoặc nhờ DB admin chạy) sau khi run test. Áp dụng trong trường hợp không có quyền thực hiện trên DB mà phải nhờ DB admin chạy giúp các câu lệnh.
4. Chú ý về việc phụ thuộc giữa các test cases (Dependency)
Các test không nên phụ thuộc nhau, hay nói cách khác nó nên độc lập (Independence Tests).
Ví dụ mình có 3 test cases, thì 3 testcase này nên độc lập nhau, nếu chỉ lấy ra một trong ba thì vẫn có khả năng chạy được, tránh việc các test phụ thuộc gì đó với nhau và khi chạy riêng thì bị lỗi là không đúng. Nếu có ràng buộc thì cần chuẩn bị nó như một pre-condition tương tự bước #2.
Việc phụ thuộc nhau còn dẫn đến tình huống nếu một test gặp lỗi sẽ ảnh hưởng đến những test khác phía sau.
Lời kết
Trên đây là 4 điều cần lưu ý trong giai đoạn bắt đầu với automation test, có thể nó sẽ tốn thêm một chút thời gian để tìm hiểu nhưng nó rất đáng và giúp ích nhiều đặc biệt là khi bạn sẽ tham gia vào một dự án thật tế trong công ty. Nếu cần thêm thông tin hay thắc mắc bạn có thể comment bên dưới nhé!
Làm sao inherit từ một object khác? Câu trả lời là dùng Prototype
Nếu pet là một prototype của cat, khi đó cat sẽ có luôn property legs
Khi khởi tạo object bằng cách viết object literal, chúng ta có thêm một property đặc biệt __proto__ để set prototype cho object đó.
Với ví dụ trên, chúng ta sẽ làm như sau
const pet ={ legs:4}const cat ={ sound:'Meow!', __proto__: pet }
cat.legs;// => 4
Property sound, chỉ tồn tại trong cat, người ta gọi tên nó là Own Property (property này là của anh, do anh tạo ra, anh không thừa hưởng từ bất kỳ ai).
Bạn có thể sẽ thắc mắc, tại sao lại sinh ra inheritance trong JS lằng nhằng thế ?
Vì bản chất JS ngày xưa không hỗ trợ class.
const pet ={ legs:4};const cat ={ sound:'Meow!', __proto__: pet };const dog ={ sound:'Bark!', __proto__: pet };const pig ={ sound:'Grunt!', __proto__: pet };
Sử dụng __proto__ không còn được chấp nhận, thay vào đó hay dùng Object.create()
const pet ={ legs:4};const cat =Object.create(pet);
cat.sound='Meow!';
Bên dưới, code trên sẽ được viết lại (bằng babel) gần giống thế này
const pet ={
legs:4};functionCreatePet(sound){return{ sound, __proto__: pet };}CreatePet.prototype= pet;const cat =CreatePet('Moew!');
cat.legs;// => 4
cat instanceofCreatePet;// => true
Bạn có thể sẽ thấy hơi bối rối, nếu bạn có nền tảng từ những ngôn ngữ có hỗ trợ class ngay trong trứng như Java hay PHP, không sao cả, ai cũng cần thời gian để tiếp thu những kiến thức mới.
Khi dùng React, hầu hết chúng không bận tâm đến việc tối ưu code vì bản thân nó đã khá nhanh. Trong bài viết hôm nay, chúng ta sẽ cùng xem qua cách sử dụng useMemo trong React để tối ưu tốc độ chương trình, hiểu và biết cách sử dụng useMemo sẽ giúp ích cho bạn trong sự nghiệp developer của mình đấy!
useMemo là gì?
useMemo là một hook trong React được sử dụng để ghi nhớ kết quả của một phép tính tốn kém (expensive calculation) và chỉ thực hiện lại phép tính đó khi các dependencies thay đổi. Hook này giúp tối ưu hóa hiệu suất bằng cách tránh việc thực hiện lại các phép tính không cần thiết mỗi khi component re-render.
computeExpensiveValue: Hàm tính toán mà bạn muốn ghi nhớ kết quả.
[a, b]: Danh sách các dependencies. Kết quả được ghi nhớ sẽ chỉ được tính lại khi một trong các dependencies này thay đổi.
Ví dụ
Ví dụ sử dụng useMemo
Trong ví dụ này, giá trị expensiveValue sẽ chỉ được tính toán lại khi giá trị của a hoặc b thay đổi. Điều này giúp tối ưu hóa hiệu suất của component bằng cách tránh các tính toán lại không cần thiết.
Khi nào sử dụng useMemo
Khi có những tính toán để lấy giá trị khá mất công, chúng ta lưu kết quả tính lại cho tiết kiệm thời gian tính toán.
Đừng dùng nhầm với React.memo và useCallback, chúng nó được dùng vào những mục đích rất khác nhau.
Bài viết được sự cho phép của tác giả Edward Thien Hoang
Cloud computing thì ai cũng đã quá quen thuộc, người người lên Cloud, nhà nhà lên Cloud. Gần đây lại xuất hiện trào lưu Cloud-native. Cloud native đã xuất hiện ở nước ngoài khá lâu rồi nhưng chỉ cập bến ở Việt Nam chúng ta vài năm gần đây thôi. Vậy Cloud-native là gì? Khác gì với Cloud computing vậy? Cloud-native là 1 buzzword, cũng giống như Cloud Computing, Blockchain. Buzzword mang một nghĩa chung chung mà không thể nào hiểu theo nghĩa đen được. Điện toán đám mây là gì? Có phải là máy tính để lên các đám mây cho mát thì gọi là điện toán đám mây. Trong bài này mình sẽ không cắt nghĩa Cloud Computing hay nói tắt là Cloud nữa, vì giờ ai cũng biết nó rồi. Quay lại với Cloud-native.
Cloud-native gồm 2 phần: “cloud” và “native”. Cloud trong Cloud Computing. Còn native? Google dịch sẽ ra: tự nhiên, bản xứ, bẩm sinh. Yeah, để dễ hình dung, hãy nghĩ về native speaker, là 1 người sinh ra và lớn lên đã sử dụng 1 ngôn ngữ làm ngôn ngữ mẹ đẻ. Và Cloud-native cũng vậy, nghĩa là từ khi sinh ra cho đến khi sản phẩm đưa vào vận hành thì phải chạy trên Cloud. Tuy nhiên, một ứng dụng Cloud-native thì chắc chắn chạy trên Cloud rồi, nhưng một ứng dụng chạy trên Cloud thì chưa chắc đã đạt tới cảnh giới Cloud-native. Như người Việt nói tiếng Anh tài đến cách mấy cũng chỉ đạt trình độ của người bản xứ được.
Tuy nhiên, cũng cần lưu ý thêm về các định nghĩa phổ biến về Cloud-native, đó là một ứng dụng Cloud-native sẽ không đề cập đến việc ứng dụng đó được triển khai ở đâu – WHERE (cụ thể ở đây chắc chắn là trên Cloud rồi), mà đề cập đến việc làm thế nào – HOW để ứng dụng có tính “bẩm sinh”, “native”.
“Cloud-native” is an approach to building and running applications that exploits the advantages of the cloud computing delivery model. “Cloud-native” is about howapplications are created and deployed, not where.
CONTAINER-NATIVE
OK, để có thể hiểu hơn về Cloud-native thì mình khuyên các bạn nên đọc qua bài viết về “Container-native” của tác giả Minh Monmen đăng trên Kipalog, mình xin trích dẫn 1 xíu ở đây.
…1 bác bên techcrunch có đưa ra 1 định nghĩa khá sát về khái niệm container-native:
Software that treats the container as the first-class unit of infrastructure (as opposed to, for example, treating the physical machine or the virtual machine as the first-class unit)
Software that does not just “happen to work” in, on or around containers, but rather is purposefully designed for containers
Đại khái định nghĩa này nói rằng bạn 1 là phải coi container là thứ sẽ triển khai ứng dụng của bạn, không phải 1 con VM hay máy chủ vật lý. Thứ 2 là việc bạn định hướng container-native phải được làm từ đầu khi khởi tạo ứng dụng, chứ không phải là cứ code rồi… Bụp một cái mang nó vào container là chạy được…
Sau khi đọc xong, có thể là cái hiểu của bạn sẽ được tăng lên để hiểu được từ “native”.
VẬY TẠI SAO PHẢI CẦN CLOUD-NATIVE?
What thì mình đã cắt nghĩa ở trên. Còn Why, mình sẽ đưa ra 1 số ý kiến. Như mọi người đã biết và hiểu được một trong những đặc tính quan trọng bậc nhất của Cloud Computing đó là tính đàn hồi (elasticity), giúp cho ứng dụng chạy trên Cloud sẽ có thể co dãn, scaling up and down hay in and out một cách dễ dàng, phù hợp với nhu cầu, workload hiện tại của system. Tuy nhiên càng hiện đại thì càng hại điện. Có bao nhiêu hệ thống hoặc ứng dụng có thể tận dụng tối đa lợi ích mà Cloud Computing mang lại? Trong quá trình phát triển sản phẩm, bạn có đặt ưu tiên về scalability của ứng dụng lên trên cùng? Hay việc vận hành, bảo trì, CI/CD? Với việc microservices đang ngày càng thịnh hành, thì việc quản lý một đống service cũng không phải là điều dễ dàng. Và yeah, Cloud-native chính là keyword, tập hợp rất nhiều practices, guideline, là cứu cánh cho chúng ta. Cùng điểm qua 1 số ý chính bằng tiếng Anh (vì lười dịch quá :D)
10 Key Attributes of Cloud-Native Applications
Packaged as lightweight containers
Developed with best-of-breed languages and frameworks
Designed as loosely coupled microservices
Centered around APIs for interaction and collaboration
Architected with a clean separation of stateless and stateful services
Isolated from server and operating system dependencies
Deployed on self-service, elastic, cloud infrastructure
Phìu, có thể túm qua 1 số ý chính là: hệ thống nên buid dạng microservices, chạy trong container (Docker) và có sự hỗ trợ của các Container management platform như Kubernetes. Cần, agility và automation với DevOps và mọi thứ trên Cloud. Và quan trọng nhất là mọi thứ phải được consider ngay từ khâu thiết kế, chứ không phải đợi đến lúc triển khai thì too late và có thể là impossible
VẬY LÀM SAO ĐỂ ĐẠT TỚI CẢNH GIỚI NATIVE?
Cái khó nhất khi tìm hiểu 1 vấn đề nào đó nằm ở WHAT and WHY, chứ HOW thì đó là nghề của anh em developer rồi. Google phát là ra ngay, nên mình để phần này cho anh em tự khám phá.
Hôm nay tình cờ đọc được 1 quyển sách về MySQL thấy khá hay nên muốn chia sẻ lại với mọi người những cái mình đã học được.
Về MySQL thì chắc ai cũng đã từng dùng hay đang dùng nó cho một số dự án từ vài người dùng đến hàng triệu người dùng. Từ các website về blog cho đến các trang thương mại điện tử, các server dành cho game…
Với hệ thống nhỏ nhỏ thì chắc chẳng cần quan tâm gì nhiều đến cách hoạt động của nó làm gì cho mệt. Nhưng mà khi hệ thống dã lớn lên, phải xử lí hàng nghìn, hàng triệu queries/s thì việc hiểu rõ được cơ chế hoạt động cũng nó là điều vô cùng quan trọng.
Việc master được tất tần tật về MySQL thì vô cùng khó, nhưng mà hiểu được cái gì đó sâu sâu 1 chút thì cũng giúp chúng ta hơn hẳn được nhiều người rồi.
Nên hôm nay mình sẽ giới thiệu đến mọi người 1 số vấn đề mà mọi người đang chưa hiểu hoặc hiểu nhầm về MySQL nhé.
Mục tiêu bài viết:
・Hiểu được chức năng bên trong MySQL
・Biết cách thiết kế dữ liệu cho tối ưu nhất
Đối tượng hướng đến:
・Người đã từng làm việc với MySQL
・Người muốn tối ưu hiệu năng MySQL
1. Đơn vị I/O
Khi dùng MySQL thì đa số là thao tác trên các record(bản ghi) của MySQL. Nên đa số chúng ta đều nghĩ là dữ liệu được xử lí theo đơn vị record. Nhưng thực tế MySQL lại thao tác dữ liệu theo từng đơn vị page (trang) có kích thước được định nghĩa trước.
Để dễ hiểu thì chúng ta cùng xem ảnh bên dưới:
Nhìn vào ảnh bên trên thì mình nghĩ mọi người có thể hiểu được. Thì đơn vị I/0 nhỏ nhất trong MySQL không phải là record mà là page nhé.
Với MySQL thì kích thước của page default là 16KB. (Ở đây mọi người nên chú ý 1 điểm là nếu muốn change size của page thì chúng ta phải xoá instance đi và tạo lại thì mới change được, còn chỉ start stop mysql thì không thể change được nhé)
Chính vì lí do đó mà thằng RDS của AWS không có option change được size của page.
Vậy đến đây đa số cũng biết được đơn vị cấu tạo nhỏ nhất của I/O trong MySQL là gì rồi đúng không ak?
Vậy biết được cái này để làm gì? Thì đi đến phần tiếp theo nhá.
2. Ảnh hưởng to lớn của AUTO_INCREMENT
Việc setting primary key (khoá chính) với AUTO_INCREMENT thì chắc ai cũng biết rồi. Nhưng mà việc setting này có ảnh hưởng to lớn đến hiệu năng như thế nào thì chúng ta cùng đi xem 2 ví dụ dưới đây nhé.
Để dễ hiểu, mình sẽ lấy 1 ví dụ trong game nhé. Đó là muốn tạo ra 1 bảng lưu giữ thông tin nhân vật(character) của người dùng.
Ví dụ 1:
CREATE TABLE user_characters {
user_id INT NOT NULL DEFAULT 0,
user_character_id INT NOT NULL DEFAULT 0,
character_id INT NOT NULL DEFAULT 0,
PRIMARY_KEY (user_id, user_character_id),
}
Ví dụ 2:
CREATE TABLE user_characters {id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL DEFAULT 0,
user_character_id INT NOT NULL DEFAULT 0,
character_id INT NOT NULL DEFAULT 0,
}
Khi chúng ta muốn lấy thông tin nhân vật mà người dùng có ID =4 1234 đang giữ thì sẽ thực hiện câu SQL như sau:
SELECT * FROM user_characters WHERE user_id = 41234
Vậy hiệu năng khi thực hiện câu SQL này trên 2 ví dụ trên khác nhau thế nào?
Cụ thể như ảnh bên dưới:
Với ví dụ 1, thì userid được gắn là khoá chính. Nên dữ liệu sẽ được sắp xếp theo thứ tự của userid. Do đó mà thông tin lấy được từ user_characters khả năng cao sẽ được nằm trong 1 page. Mà nếu dữ liệu được nằm trong 1 page thì chắc chắn I/O sẽ được giảm mạnh, và hiệu suất query sẽ tốt hơn.
Nhưng với ví dụ 2 thì hoàn toàn khác. Lúc này khoá chính của chúng ta là id. Nên việc dữ liệu tất cả nhân vật mà user_id = 41234 đang nắm giữ khả năng cao sẽ nằm rải rác trên nhiều page khác nhau. Kết quả là I/O sẽ tăng và hiệu năng query sẽ giảm đi rất là nhiều.
Chính vì vậy, với nhiều dữ liệu sử dụng đồng thời như ví dụ trên thì chúng ta cố gắng sắp xếp nó cùng vào 1 page nhé.
Kết luận
Hôm nay thế thôi nhỉ. Để hôm khác mình sẽ bổ sung thêm(Tại ngại vẽ hình). Hi vọng qua bài này sẽ giúp ích mọi người trong quá trình thiết kế cơ sở dữ liệu sao cho hiệu năng tốt nhất.
Mỗi ngành khác nhau đều có những thuật ngữ mà chỉ những người trong ngành mới hiểu, bạn là người vừa mới đi làm thì sẽ khá lạ lẫm với những thuật ngữ chuyên ngành của lập trình nên tôi viết bài này để chia sẻ này để bạn có thể hiểu được những anh chị trong công ty đang nói về chủ đề gì.
Source code dịch ra tiếng việt đó là mã nguồn, khi nói về source code thì ta hiểu là đang nói về những tất cả những cái mà mình lập trình ở trong một dự án nhé.
2. Commit code
Trong mỗi dự án của chúng ta thì đều sử dụng SVN hoặc GIT. SVN/GIT công cụ để quản lý source code, là nơi để chứa source code, tất cả lập trình viên mà làm chung một dự án sẽ sử dụng chung một nguồn này. Tại sao người ta dùng nó thì tôi sẽ có một bài viết chi tiết hơn nói về những tính năng hay ho của nó. Phần này đang nói về thuật ngữ commit code. Commit code có nghĩa là mình sẽ đẩy hết những cái gì mình vừa code được lên nơi chứa source code của SVN/GIT.
3. Testcase
Thường thì sau khi kết thúc giai đoạn code thì sẽ đến một giai đoạn nữa đó là test(kiểm thử) sản phẩm của mình xem có làm đúng theo yêu cầu của khách hàng chưa, có bug gì hay không. Testcase là các trường hợp kiểm tra cho những đoạn mã (code) của mình đảm bảo rằng nó đã chạy đúng với yêu cầu, không phát sinh vấn đề gì.
4. Bug, Fix Bug
Bug là những cái sau khi test theo testcase nhưng không đúng với yêu cầu khách hàng hoặc bug do lỗi coding (exeption..) . Sau khi phát sinh bug thì người lập trình phải đi sửa lỗi, làm sao cho nó đúng với yêu cầu của khách hàng. Lúc này người ta gọi là Fix bug.
5. Schedule
Mỗi khi vào dự án thì các leader sẽ chuẩn bị schedule, đây là lịch trình làm dự án, ví dụ màn hình A sẽ code vào ngày 16/03/2020 – 18/03/2020. Schedule sẽ lên danh sách tất cả các màn hình và thời gian làm của mỗi màn hình đó, việc của bạn là phải tuân thủ đúng thời gian trong schedule
6. Evidence
Evidence dịch ra tiếng việt là bằng chứng. Khi thực hiện công việc test, thì nhiều khi phải chụp lại bằng chứng cho khách hàng biết là mình đã test qua trường hợp này rồi.
7. Kick off
Kick off là bắt đầu một dự án mới.
8. UT
Về test thì có rất nhiều kiểu test khác nhau, UT là viết tắt của unit test.





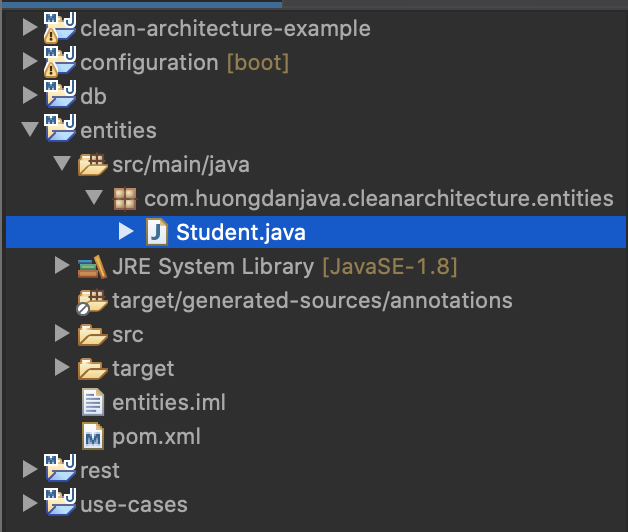
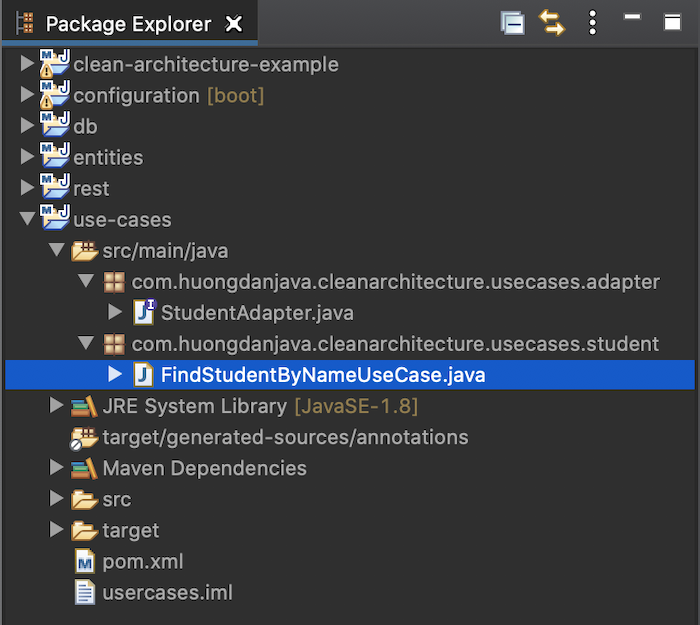
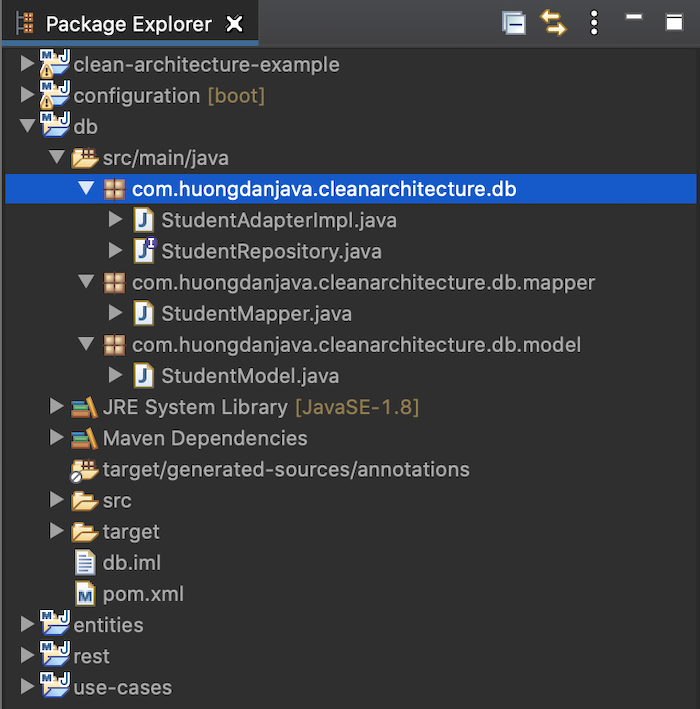
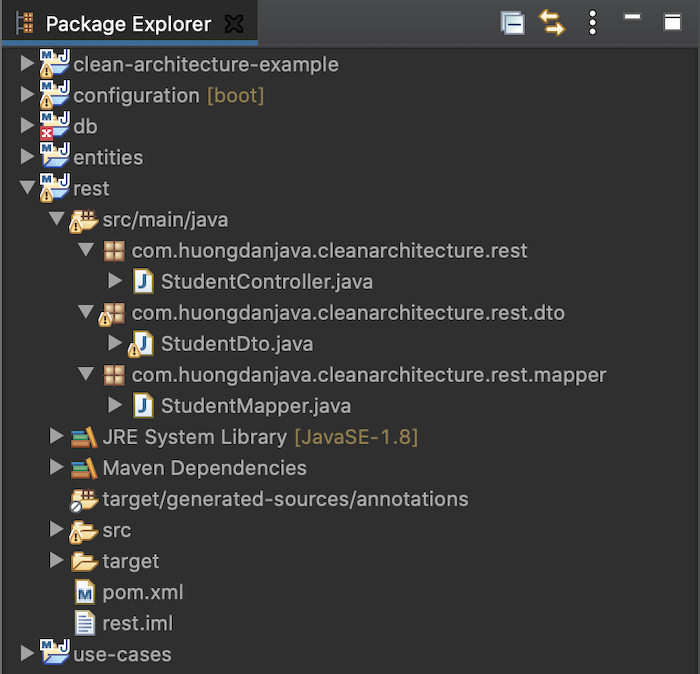
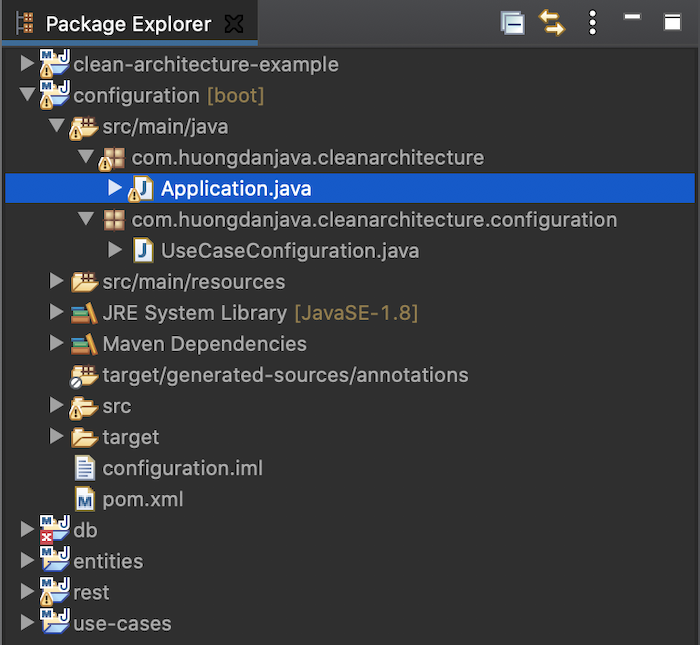
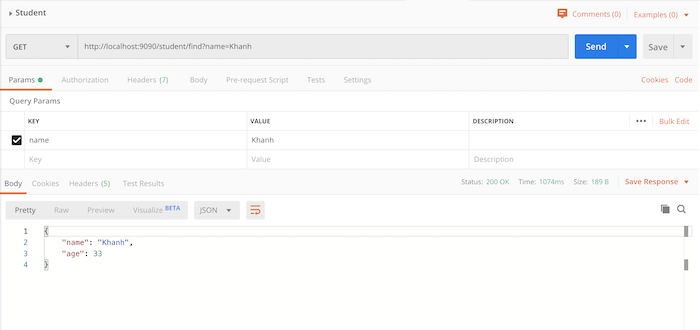




![Dãy Fibonacci [Bài tập Python]](https://topdev.vn/blog/wp-content/uploads/2020/11/python.png)