Bài viết được sự cho phép của tác giả Giang Phan
Thiết lập kết nối cơ sở dữ liệu là một quá trình rất tốn tài nguyên và đòi hỏi nhiều chi phí. Hơn nữa, trong một môi trường đa luồng, việc mở và đóng nhiều kết nối thường xuyên và liên tục ảnh hưởng rất nhiều đến performance và tài nguyên của ứng dụng. Trong bài này, tôi sẽ giới thiệu với các bạn Connection Pool và cách sử dụng JDBC Connection Pool trong ứng dụng Java.
Connection Pooling
Connection Pooling là gì?
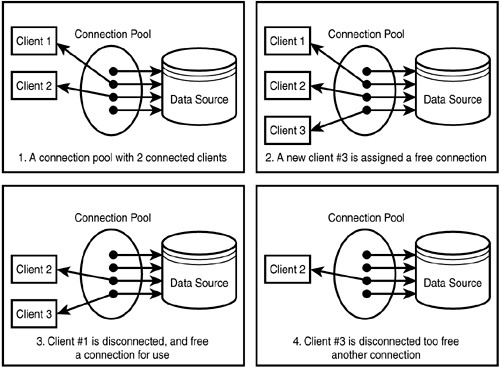
Connection pool (vùng kết nối) : là kỹ thuật cho phép tạo và duy trì 1 tập các kết nối dùng chung nhằm tăng hiệu suất cho các ứng dụng bằng cách sử dụng lại các kết nối khi có yêu cầu thay vì việc tạo kết nối mới.
Xem thêm nhiều việc làm Java lương cao trên TopDev
Cách làm việc của Connection pooling?
Connection Pool Manager (CPM) là trình quản lý vùng kết nối, một khi ứng dụng được chạy thì Connection pool tạo ra một vùng kết nối, trong vùng kết nối đó có các kết nối do chúng ta tạo ra sẵn. Và như vậy, một khi có một request đến thì CPM kiểm tra xem có kết nối nào đang rỗi không? Nếu có nó sẽ dùng kết nối đó còn không thì nó sẽ đợi cho đến khi có kết nối nào đó rỗi hoặc kết nối khác bị timeout. Kết nối sau khi sử dụng sẽ không đóng lại ngay mà sẽ được trả về CPM để dùng lại khi được yêu cầu trong tương lai.
Ví dụ:
Một connection pool có tối đa 10 connection trong pool. Bây giờ user kết nối tới database (DB), hệ thống sẽ kiểm tra trong connection pool có kết nối nào đang rảnh không?
- Trường hợp chưa có kết nối nào trong connection pool hoặc tất cả các kết nối đều bận (đang được sử dụng bởi user khác) và số lượng connection trong connection < 10 thì sẽ tạo một connection mới tới DB để kết nối tới DB đồng thời kết nối đó sẽ được đưa vào connection pool.
- Trường hợp tất cả các kết nối đang bận và số lượng connection trong connection pool = 10 thì người dùng phải đợi cho các user dùng xong để được dùng.
Sau khi một kết nối được tạo và sử dụng xong nó sẽ không đóng lại mà sẽ duy trì trong connection pool để dùng lại cho lần sau và chỉ thực sự bị đóng khi hết thời gian timeout (lâu quá không dùng đến nữa).
JDBC Connection Pooling

Cơ chế làm việc của JDBC Connection Pooling tuân thủ theo Connection Pooling. Sau khi ứng dụng được start, một Connection Pool object được tạo, các Connection object sau này được tạo sẽ được quản lý bởi pool này.
Có nhiều thư viện hỗ trợ JDBC Conection Pooling như: C3P0, Apache Commons DBCP, HikariCP, … Chúng ta sẽ lần lượt tìm hiểu các cài đặt và sử dụng chúng trong phần tiếp theo của bài viết này.
Cấu hình Maven Dependencies
Tạo maven project và thêm các maven dependencies trong file pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.gpcoder</groupId> <artifactId>JdbcExample</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>JdbcExample</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.17</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.10</version> </dependency> <dependency> <groupId>com.mchange</groupId> <artifactId>c3p0</artifactId> <version>0.9.5.4</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-dbcp2</artifactId> <version>2.7.0</version> </dependency> <dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> <version>3.4.0</version> </dependency> </dependencies> </project>
Lưu ý: các bạn chỉ cần sử dụng 1 trong các thư viện Conection Pooling trên, không cần phải thêm tất cả. Trong bài này mình hướng dẫn sử dụng tất cả thư viện đó nên cần thêm tất cả.
Sử dụng JDBC connection pool
Đầu tiên, cần tạo class constant chứa thông tin cấu hình kết nối database, số lượng connection tối thiểu, tối đa trong Pool.
DbConfiguration.java
package com.gpcoder.constants;
public class DbConfiguration {
public static final String HOST_NAME = "localhost";
public static final String DB_NAME = "jdbcdemo";
public static final String DB_PORT = "3306";
public static final String USER_NAME = "root";
public static final String PASSWORD = "";
public static final String DB_DRIVER = "com.mysql.cj.jdbc.Driver";
public static final int DB_MIN_CONNECTIONS = 2;
public static final int DB_MAX_CONNECTIONS = 4;
// jdbc:mysql://hostname:port/dbname
public static final String CONNECTION_URL = "jdbc:mysql://" + HOST_NAME + ":" + DB_PORT + "/" + DB_NAME;
private DbConfiguration() {
super();
}
}
c3p0
Khởi tạo Connection Pool sử dụng C3p0 và cung cấp phương thức để get Connection. Trong class này tôi sẽ thêm một số log để các bạn theo dõi cách Connection Pool hoạt động.
C3p0DataSource.java
package com.gpcoder.pool.thirdparties;
import java.beans.PropertyVetoException;
import java.sql.Connection;
import java.sql.SQLException;
import com.gpcoder.constants.DbConfiguration;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class C3p0DataSource {
private static ComboPooledDataSource cpds = new ComboPooledDataSource();
static {
try {
cpds.setDriverClass(DbConfiguration.DB_DRIVER);
cpds.setJdbcUrl(DbConfiguration.CONNECTION_URL);
cpds.setUser(DbConfiguration.USER_NAME);
cpds.setPassword(DbConfiguration.PASSWORD);
cpds.setMinPoolSize(DbConfiguration.DB_MIN_CONNECTIONS);
cpds.setInitialPoolSize(DbConfiguration.DB_MIN_CONNECTIONS);
cpds.setMaxPoolSize(DbConfiguration.DB_MAX_CONNECTIONS);
} catch (PropertyVetoException e) {
e.printStackTrace();
}
}
private C3p0DataSource() {
super();
}
public static Connection getConnection(String task) throws SQLException {
System.out.println("Getting connection for task " + task);
Connection conn = cpds.getConnection();
logPoolStatus(task);
return conn;
}
public synchronized static void logPoolStatus(String task) throws SQLException {
System.out.println("Received connection for task " + task);
System.out.println("+ Num of Connections: " + cpds.getNumConnections());
System.out.println("+ Num of Idle Connections: " + cpds.getNumIdleConnections());
System.out.println("+ Num of Busy Connections: " + cpds.getNumBusyConnections());
}
}
C3p0ConnectionPoolingExample.java
package com.gpcoder.pool;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.concurrent.CountDownLatch;
import com.gpcoder.pool.thirdparties.C3p0DataSource;
class C3p0WorkerThread extends Thread {
private String taskName;
private CountDownLatch latch;
public C3p0WorkerThread(CountDownLatch latch, String taskName) {
this.taskName = taskName;
this.latch = latch;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Starting. Task = " + taskName);
execute();
latch.countDown();
System.out.println(Thread.currentThread().getName() + " Finished.");
}
private void execute() {
try {
String sqlSelect = "SELECT COUNT(*) AS total FROM user";
try (Connection con = C3p0DataSource.getConnection(taskName);
Statement st = con.createStatement();
ResultSet rs = st.executeQuery(sqlSelect);) {
Thread.sleep(2000);
rs.next();
System.out.println("Task = " + taskName + ": Run SQL successfully " + rs.getInt("total"));
}
} catch (SQLException | InterruptedException e) {
e.printStackTrace();
}
}
}
public class C3p0ConnectionPoolingExample {
private static final int NUMBER_OF_USERS = 8;
public static void main(String[] args) throws SQLException, InterruptedException {
final CountDownLatch latch = new CountDownLatch(NUMBER_OF_USERS);
for (int i = 1; i <= NUMBER_OF_USERS; i++) {
Thread worker = new C3p0WorkerThread(latch, "" + i);
worker.start();
}
latch.await();
System.out.println("DONE All Tasks");
C3p0DataSource.logPoolStatus("Main");
}
}
Trong chương trình trên, tôi tạo 8 Thread khác nhau truy cập data cùng một thời điểm, Connection Pool của chúng ta ban đầu khởi tạo là 2 Connection, tối đa có 4 Connection và mỗi Thread sử dụng Connection trong 2 giây.
Chạy chương trình trên, chúng ta có kết quả sau:
Thread-0 Starting. Task = 1
Thread-1 Starting. Task = 2
Thread-3 Starting. Task = 4
Thread-2 Starting. Task = 3
Thread-4 Starting. Task = 5
Thread-5 Starting. Task = 6
Thread-6 Starting. Task = 7
Thread-7 Starting. Task = 8
Getting connection for task 1
Getting connection for task 8
Getting connection for task 7
Getting connection for task 6
Getting connection for task 5
Getting connection for task 3
Getting connection for task 4
Getting connection for task 2
Received connection for task 2
+ Num of Connections: 3
+ Num of Idle Connections: 1
+ Num of Busy Connections: 2
Received connection for task 8
+ Num of Connections: 3
+ Num of Idle Connections: 0
+ Num of Busy Connections: 3
Received connection for task 1
+ Num of Connections: 3
+ Num of Idle Connections: 0
+ Num of Busy Connections: 3
Received connection for task 4
+ Num of Connections: 4
+ Num of Idle Connections: 0
+ Num of Busy Connections: 4
Task = 8: Run SQL successfully 15
Task = 4: Run SQL successfully 15
Task = 2: Run SQL successfully 15
Thread-7 Finished.
Thread-1 Finished.
Thread-3 Finished.
Received connection for task 6
+ Num of Connections: 4
+ Num of Idle Connections: 1
+ Num of Busy Connections: 3
Received connection for task 7
+ Num of Connections: 4
+ Num of Idle Connections: 0
+ Num of Busy Connections: 4
Received connection for task 5
+ Num of Connections: 4
+ Num of Idle Connections: 0
+ Num of Busy Connections: 4
Task = 1: Run SQL successfully 15
Thread-0 Finished.
Received connection for task 3
+ Num of Connections: 4
+ Num of Idle Connections: 0
+ Num of Busy Connections: 4
Task = 6: Run SQL successfully 15
Thread-5 Finished.
Task = 7: Run SQL successfully 15
Thread-6 Finished.
Task = 3: Run SQL successfully 15
Task = 5: Run SQL successfully 15
Thread-2 Finished.
Thread-4 Finished.
DONE All Tasks
Received connection for task Main
+ Num of Connections: 4
+ Num of Idle Connections: 4
+ Num of Busy Connections: 0
Như bạn thấy, tại một thười điểm chỉ có thể tối đa 4 Connection được xử lý, khi một Connection rảnh (idle) sẽ có thể xử lý tiếp một yêu cầu Connection khác. Với cách làm này, chúng ta có thể quản lý được số lượng Connection có thể mở đồng thời để phục vụ trong ứng dụng.
Apache Commons DBCP
Tương tự như C3P0, chúng ta tạo class Connection Pool như sau:
package com.gpcoder.pool.thirdparties;
import java.sql.Connection;
import java.sql.SQLException;
import org.apache.commons.dbcp2.BasicDataSource;
import com.gpcoder.constants.DbConfiguration;
public class DBCPDataSource {
private static BasicDataSource ds = new BasicDataSource();
static {
ds.setDriverClassName(DbConfiguration.DB_DRIVER);
ds.setUrl(DbConfiguration.CONNECTION_URL);
ds.setUsername(DbConfiguration.USER_NAME);
ds.setPassword(DbConfiguration.PASSWORD);
ds.setMinIdle(DbConfiguration.DB_MIN_CONNECTIONS); // minimum number of idle connections in the pool
ds.setInitialSize(DbConfiguration.DB_MIN_CONNECTIONS);
ds.setMaxIdle(DbConfiguration.DB_MAX_CONNECTIONS); // maximum number of idle connections in the pool
ds.setMaxOpenPreparedStatements(100);
}
private DBCPDataSource() {
super();
}
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
}
DBCPConnectionPoolingExample.java
package com.gpcoder.pool;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.concurrent.CountDownLatch;
import com.gpcoder.pool.thirdparties.DBCPDataSource;
class DBCPWorkerThread extends Thread {
private CountDownLatch latch;
private String taskName;
public DBCPWorkerThread(CountDownLatch latch, String taskName) {
this.latch = latch;
this.taskName = taskName;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Starting. Task = " + taskName);
execute();
latch.countDown();
System.out.println(Thread.currentThread().getName() + " Finished.");
}
private void execute() {
try {
String sqlSelect = "SELECT COUNT(*) AS total FROM user";
try (Connection conn = DBCPDataSource.getConnection();
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery(sqlSelect);) {
Thread.sleep(2000);
rs.next();
System.out.println("Task = " + taskName + ": Run SQL successfully " + rs.getInt("total"));
}
} catch (SQLException | InterruptedException e) {
e.printStackTrace();
}
}
}
public class DBCPConnectionPoolingExample {
private static final int NUMBER_OF_USERS = 8;
public static void main(String[] args) throws SQLException, InterruptedException {
final CountDownLatch latch = new CountDownLatch(NUMBER_OF_USERS);
for (int i = 1; i <= NUMBER_OF_USERS; i++) {
Thread worker = new DBCPWorkerThread(latch, "" + i);
worker.start();
}
latch.await();
System.out.println("DONE All Tasks");
}
}
Hikari
package com.gpcoder.pool.thirdparties;
import java.sql.Connection;
import java.sql.SQLException;
import com.gpcoder.constants.DbConfiguration;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class HikariCPDataSource {
private static HikariConfig config = new HikariConfig();
private static HikariDataSource ds;
static {
config.setDriverClassName(DbConfiguration.DB_DRIVER);
config.setJdbcUrl(DbConfiguration.CONNECTION_URL);
config.setUsername(DbConfiguration.USER_NAME);
config.setPassword(DbConfiguration.PASSWORD);
config.setMinimumIdle(DbConfiguration.DB_MIN_CONNECTIONS);
config.setMaximumPoolSize(DbConfiguration.DB_MAX_CONNECTIONS);
// Some additional properties
config.addDataSourceProperty("cachePrepStmts", "true");
config.addDataSourceProperty("prepStmtCacheSize", "250");
config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");
ds = new HikariDataSource(config);
}
private HikariCPDataSource() {
super();
}
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
}
HikariConnectionPoolingExample.java
package com.gpcoder.pool;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.concurrent.CountDownLatch;
import com.gpcoder.pool.thirdparties.HikariCPDataSource;
class HikariWorkerThread extends Thread {
private CountDownLatch latch;
private String taskName;
public HikariWorkerThread(CountDownLatch latch, String taskName) {
this.latch = latch;
this.taskName = taskName;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Starting. Task = " + taskName);
execute();
latch.countDown();
System.out.println(Thread.currentThread().getName() + " Finished.");
}
private void execute() {
try {
String sqlSelect = "SELECT COUNT(*) AS total FROM user";
try (Connection conn = HikariCPDataSource.getConnection();
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery(sqlSelect);) {
Thread.sleep(2000);
rs.next();
System.out.println("Task = " + taskName + ": Run SQL successfully " + rs.getInt("total"));
}
} catch (SQLException | InterruptedException e) {
e.printStackTrace();
}
}
}
public class HikariConnectionPoolingExample {
private static final int NUMBER_OF_USERS = 8;
public static void main(String[] args) throws SQLException, InterruptedException {
final CountDownLatch latch = new CountDownLatch(NUMBER_OF_USERS);
for (int i = 1; i <= NUMBER_OF_USERS; i++) {
Thread worker = new HikariWorkerThread(latch, "" + i);
worker.start();
}
latch.await();
System.out.println("DONE All Tasks");
}
}
Tự tạo Connection Pool
Nếu không muốn sử dụng thư viện có sẵn, chúng ta có thể tự tạo một Connection Pool. Tương tự như sau:
GPConnectionPool.java
package com.gpcoder.pool.custom;
import java.sql.Connection;
public interface GPConnectionPool {
Connection getConnection();
boolean releaseConnection(Connection connection);
}
GPConnectionPoolImpl.java
package com.gpcoder.pool.custom;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.LinkedList;
import com.gpcoder.ConnectionUtils;
import com.gpcoder.constants.DbConfiguration;
public class GPConnectionPoolImpl implements GPConnectionPool {
private static final LinkedList availableConnections = new LinkedList<>();
private int maxConnection;
public GPConnectionPoolImpl(int maxConnection) {
this.maxConnection = maxConnection;
initializeConnectionPool();
}
private synchronized void initializeConnectionPool() {
try {
while (!checkIfConnectionPoolIsFull()) {
Connection newConnection = ConnectionUtils.openConnection();
availableConnections.add(newConnection);
}
notifyAll();
} catch (SQLException e) {
e.printStackTrace();
}
}
private boolean checkIfConnectionPoolIsFull() {
return availableConnections.size() >= maxConnection;
}
@Override
public synchronized Connection getConnection() {
while(availableConnections.size() == 0) {
// Wait for an existing connection to be freed up.
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// Retrieves and removes the first element of this list
return availableConnections.poll();
}
@Override
public synchronized boolean releaseConnection(Connection connection) {
try {
if (connection.isClosed()) {
initializeConnectionPool();
} else {
// Adds the specified element as the last element of this list
boolean isReleased = availableConnections.offer(connection);
// Wake up threads that are waiting for a connection
notifyAll();
return isReleased;
}
} catch (SQLException e) {
e.printStackTrace();
}
return false;
}
public synchronized String toString() {
StringBuilder sb = new StringBuilder()
.append("Max=" + DbConfiguration.DB_MAX_CONNECTIONS)
.append(" | Available=" + availableConnections.size())
.append(" | Busy=" + (DbConfiguration.DB_MAX_CONNECTIONS - availableConnections.size()))
;
return sb.toString();
}
}
GPDataSource.java
package com.gpcoder.pool.custom;
import java.sql.Connection;
import com.gpcoder.constants.DbConfiguration;
public class GPDataSource {
private static final GPConnectionPool gpPool = new GPConnectionPoolImpl(DbConfiguration.DB_MAX_CONNECTIONS);
private GPDataSource() {
super();
}
public static Connection getConnection() {
Connection connection = gpPool.getConnection();
System.out.println("GPPool status: " + gpPool);
return connection;
}
public static boolean releaseConnection(Connection connection) {
return gpPool.releaseConnection(connection);
}
}
GPConnectionPoolExample.java
package com.gpcoder.pool;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.concurrent.CountDownLatch;
import com.gpcoder.pool.custom.GPDataSource;
class GPWorkerThread extends Thread {
private String taskName;
private CountDownLatch latch;
public GPWorkerThread(CountDownLatch latch, String taskName) {
this.taskName = taskName;
this.latch = latch;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Starting. Task = " + taskName);
execute();
latch.countDown();
System.out.println(Thread.currentThread().getName() + " Finished.");
}
private void execute() {
try {
String sqlSelect = "SELECT COUNT(*) AS total FROM user";
Connection connection = GPDataSource.getConnection();
try (Statement st = connection.createStatement();
ResultSet rs = st.executeQuery(sqlSelect);) {
Thread.sleep(2000);
rs.next();
System.out.println("Task = " + taskName + ": Run SQL successfully " + rs.getInt("total"));
}
GPDataSource.releaseConnection(connection);
} catch (SQLException | InterruptedException e) {
e.printStackTrace();
}
}
}
public class GPConnectionPoolExample {
private static final int NUMBER_OF_USERS = 8;
public static void main(String[] args) throws SQLException, InterruptedException {
final CountDownLatch latch = new CountDownLatch(NUMBER_OF_USERS);
for (int i = 1; i <= NUMBER_OF_USERS; i++) {
Thread worker = new GPWorkerThread(latch, "" + i);
worker.start();
}
latch.await();
System.out.println("DONE All Tasks");
}
}
Output chương trình:
Thread-0 Starting. Task = 1
Thread-1 Starting. Task = 2
Thread-2 Starting. Task = 3
Thread-3 Starting. Task = 4
Thread-4 Starting. Task = 5
Thread-5 Starting. Task = 6
Thread-6 Starting. Task = 7
Thread-7 Starting. Task = 8
GPPool status: Max=4 | Available=2 | Busy=2
GPPool status: Max=4 | Available=1 | Busy=3
GPPool status: Max=4 | Available=0 | Busy=4
GPPool status: Max=4 | Available=2 | Busy=2
Task = 7: Run SQL successfully 15
Task = 1: Run SQL successfully 15
Task = 8: Run SQL successfully 15
GPPool status: Max=4 | Available=0 | Busy=4
GPPool status: Max=4 | Available=0 | Busy=4
Task = 6: Run SQL successfully 15
Thread-5 Finished.
Thread-7 Finished.
GPPool status: Max=4 | Available=1 | Busy=3
Thread-6 Finished.
Thread-0 Finished.
GPPool status: Max=4 | Available=0 | Busy=4
Task = 3: Run SQL successfully 15
Task = 5: Run SQL successfully 15
Thread-2 Finished.
Thread-4 Finished.
Task = 2: Run SQL successfully 15
Task = 4: Run SQL successfully 15
Thread-1 Finished.
Thread-3 Finished.
DONE All Tasks
Bài viết gốc được đăng tải tại gpcoder.com
Có thể bạn quan tâm:
Xem thêm việc làm IT hấp dẫn trên TopDev








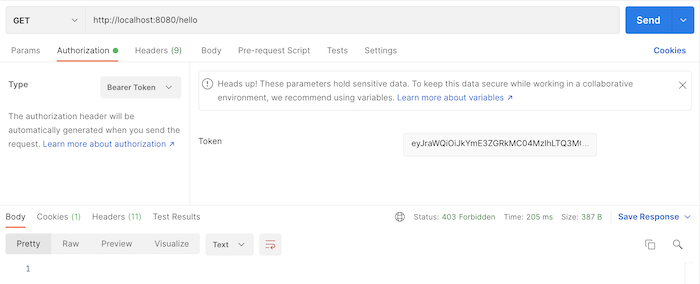
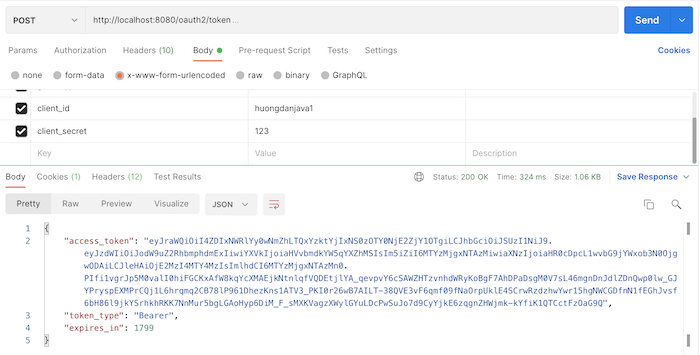
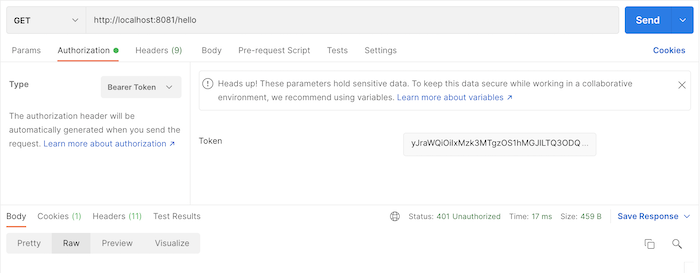
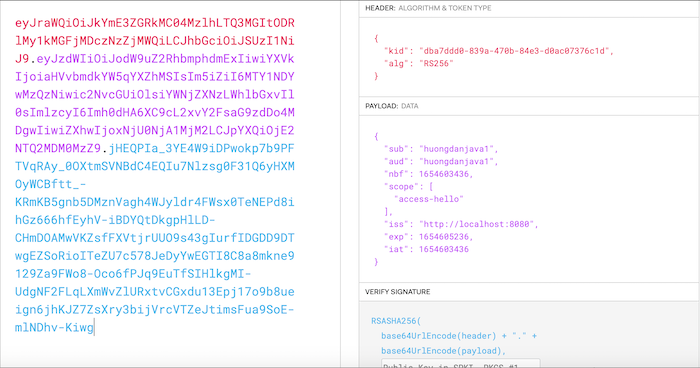
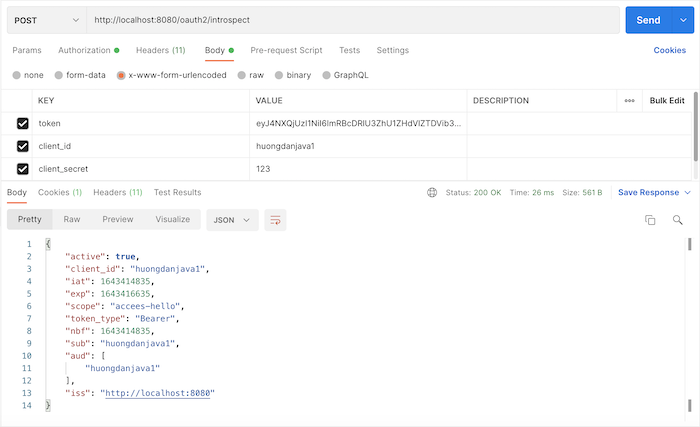 Bây giờ, nếu mình gọi tới request token revocation với 3 tham số trong phần body của request là token cần revoke, client_id và client_secret của access token này, các bạn sẽ thấy kết quả như sau:
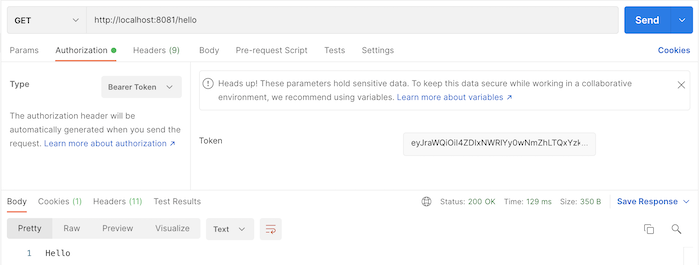
Bây giờ, nếu mình gọi tới request token revocation với 3 tham số trong phần body của request là token cần revoke, client_id và client_secret của access token này, các bạn sẽ thấy kết quả như sau: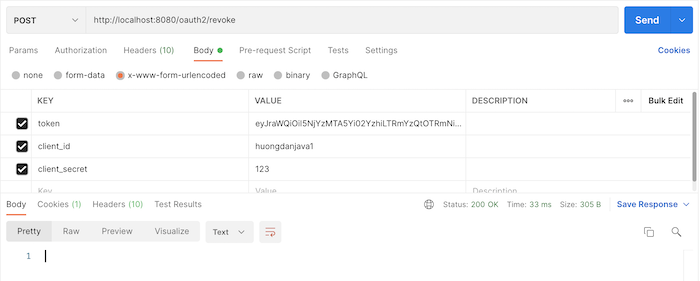 Vậy là chúng ta đã revoke thành công rồi đó các bạn.
Vậy là chúng ta đã revoke thành công rồi đó các bạn.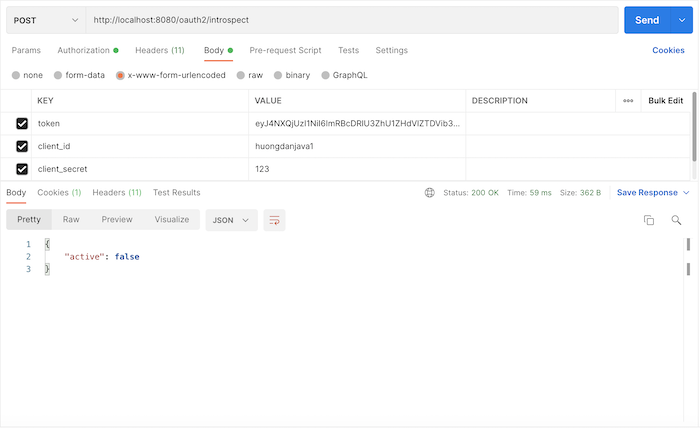






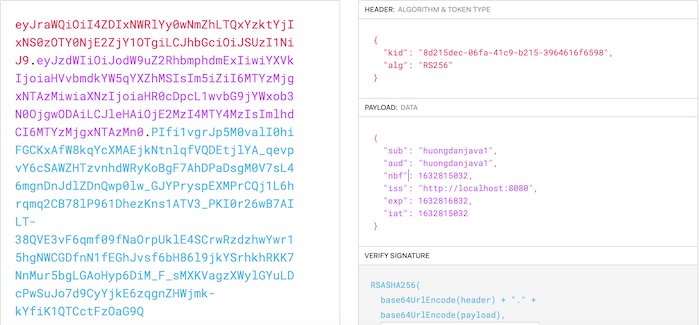






















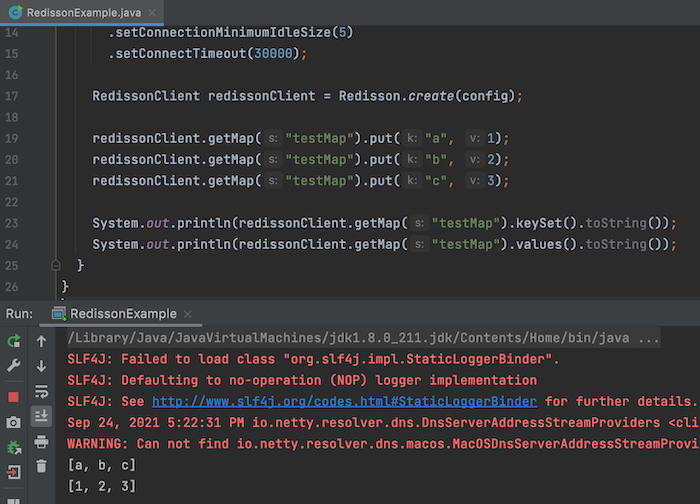
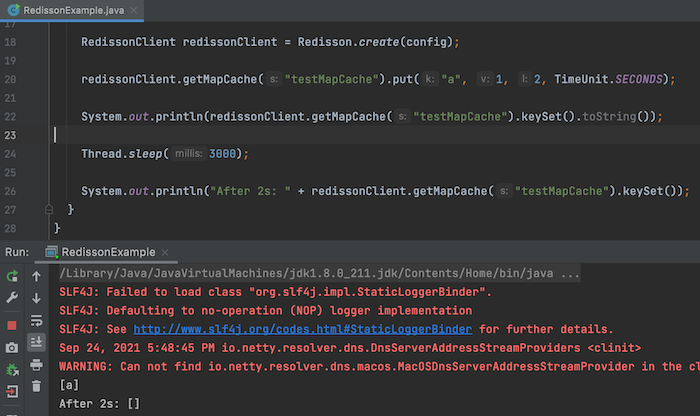
 Các bạn cũng có thể lưu thông tin một đối tượng Map và retrieve đối tượng Map này bằng key như sau:
Các bạn cũng có thể lưu thông tin một đối tượng Map và retrieve đối tượng Map này bằng key như sau: