Bài viết được sự cho phép của tác giả Huy Trần
Nhân dịp đầu năm, mình xin viết một bài bàn về chuyện đọc sách, dựa trên những kinh nghiệm cá nhân, dành tặng các bạn nào đã trót đặt ra mục tiêu đọc 10 hay 20 cuốn sách trong năm mới một lần nữa và chưa có cơ hội thực hiện. Và cả những bạn nào chưa có ý định đọc sách. Hy vọng các bạn sẽ hoàn thành mục tiêu mình đặt ra và đọc càng nhiều sách càng tốt trong năm nay 🙂
Mở bài
Như các bạn đã biết, ngay từ khi mới chập chững vào lớp 1 hay từ mẫu giáo cũng đã biết, đến khi lớn lên vào Đại học hay không vào đại học thì cũng biết luôn là đọc sách rất có lợi. Hằng ngày, mọi người vẫn kháo nhau rằng sách là kho tàng kiến thức của nhân loại, đọc sách là một phương pháp thể dục cho trí óc và là cách hiệu quả nhất để tiếp thu kho tàng kiến thức đó.
Và tất nhiên ai cũng muốn đọc sách để xem thử nó có nâng tầm hiểu biết của mình lên được không. Nhưng không phải ai cũng có thời gian để đọc, chắc hẳn chính bạn cũng đã từng rất quyết tâm mua về một tủ sách hoặc một vài ba cuốn sách, đặt ra mục tiêu trong vòng 3 tháng nghỉ hè sẽ lĩnh hội được hết cái đống này, rồi đúng y 3 năm sau cũng vẫn đặt mục tiêu tương tự cho những cuốn sách đó :v Vì một lý do đơn giản, thời gian đâu mà đọc.

Vậy một ngày có 24 tiếng, thời gian đi đâu hết nhỉ? Để xem nào, sáng 8h thức dậy, vội vã ăn sáng đánh răng, 9h phóng xe lên cty, đọc báo, “làm việc nước” trên skype, đến đâu tầm 12h thì rủ nhau ra ngoài ăn trưa, ăn trưa xong vào làm 1 giấc tới 1h30 hoặc có khi là đế chế, half-life, gần đây có cả dota, starcraft đến tận 2h chiều. Đến khi sếp bước xuống thì lật đật alt-tab ra ngoài bật IntelliJ hay Sublime lên ngồi gõ gõ. 6h chiều tắt máy đi về, tới nhà thì tầm 6h30, 7h đêm. Dân FA thì bật máy tính lên và chơi game hoặc lướt Kênh 14 tiếp, các bạn khá khẩm hơn tí thì dẫn gấu đi làm nghĩa vụ hằng ngày là chạy xe quanh thành phố, nộp sưu thuế cho mấy quán trà chanh, cà phê, loáng phát là đến 9, 10h đêm. Hôm nào cãi nhau với gấu thì đùng đùng bỏ về lấy điện thoại ra nhắn tin cãi nhau tiếp đến tận 1, 2h sáng, anh nào ko cãi nhau thì về mở máy ra chiến Freelancer hay 9gag đến tận rạng sáng ngày hôm sau…. Thế đấy, xong bà nó một ngày rồi. Thời gian đâu mà đọc sách nữa…
Dài dòng quá, thân bài
Thực ra đây là cái lịch trình sinh hoạt của mình đúng 1 năm về trước. Lúc đó thời gian thì tiêu biến thật là nhanh nhưng mà chung quy lại một ngày chả làm được cái gì nhiều, mặc dù lịch trình thì luôn sát nút như vậy. Và tất nhiên giấc mơ đọc sách để có ngày viết những bài review hoành tráng như các bậc vĩ nhân trên mạng, hay các bài xã hội học thâm nho như triết học đường phố luôn là cái giấc mơ xa vời, vì chưa bao giờ có cuốn sách nào được lật quá 10 trang đầu tiên…
Và đến lúc đó mình đặt ra câu hỏi, tại sao mình không làm được mỗi một việc đơn giản là đọc sách? Ngày xưa khi chưa có máy tính thì mình cũng đọc rất nhiều, và đọc ngấu nghiện, nào là Doraemon, Tepi, Subasa, Songoku, Kính vạn hoa, 1000 câu hỏi vì sao… tất nhiên truyện tranh cũng là sách, nhưng không phải là sách đọc vào để học, thêm vào cho vui thôi, nhưng mà hồi đó có thể đọc quên ăn quên ngủ, mặc dù các phương tiện giải trí khác nó có rất nhiều như là máy chơi game, phim hoạt hình,… toàn những thứ đầy sức cám dỗ.
Yếu tố thứ 1: Tìm ra thể loại sách ưa thích
Vậy là mình nghiệm ra một điều, lý do khiến lâu giờ mình không tài nào đọc được, một phần là do thể loại sách không phù hợp. Khi bắt đầu đọc một cuốn sách và thấy nó không có vẻ gì là lôi cuốn, đủ để giữ chân bạn, bạn sẽ mất dần kiên nhẫn và không thể đọc tiếp được nữa. Rõ ràng rồi.

Vậy là bắt đầu đi tìm những loại sách phù hợp với mình. Sau một thời gian lân la trên tiki.vn và các nhà sách, tìm và đọc thử (đọc lướt) các thể loại thì mình đã nhận ra mình không hề phù hợp với các thể loại truyện ngôn tình, sách dạy làm giàu và cả sách tin học, thể thao =))))) mình không chia sẽ các thể loại sách mình thích đọc ra đây vì cái này không phải ai cũng giống nhau, đưa ra sẽ làm ảnh hưởng đến tính khách quan của bài viết =))
Sau khi đã tìm ra thể loại sách ưa thích, mình bắt đầu đọc, nhưng vẫn không thể thoát khỏi chuyện bị phân tâm xao lãng. Đến lúc này mình quyết định tìm hiểu một cách bài bản về chuyện đọc sách. Và rút ra thêm một vài kinh nghiệm khác.
Yếu tố thứ 2: Đọc nhiều sách một lần
Một trong những cản trở lớn nhất trong quá trình đọc sách của mình chính là việc quá quyết tâm hoàn thành 1 quyển sách trước khi đọc sang cuốn sách khác. Và tất nhiên chưa bao giờ mình có đủ thời gian để đọc hết 1 cuốn sách nào cả. Thế nên mãi mãi mình cứ dậm chân tại chỗ.
Sau khi tham khảo nhiều trên các diễn đàn, mình thấy các bạn ấy có chia sẽ một kinh nghiệm đó là đọc nhiều cuốn sách một lần. Nghe qua có vẻ vô lý nhưng khi thử nghiệm thì đúng là nó hiệu quả.

Sỡ dĩ nó hiệu quả là vì, khi chúng ta ép bản thân quá tập trung đọc một loại sách, chúng ta dễ cảm thấy nhàm chán với nội dung cuốn sách đó. Khi đó, nếu chuyển sang đọc một cuốn sách khác với thể loại khác hẳn cuốn sách đang đọc, đầu óc chúng ta sẽ trở nên thoải mái hơn, tiếp thu câu chuyện mới hiệu quả hơn và khi quay trở lại cuốn sách cũ thì cũng cảm thấy tràn trề năng lượng chứ không bị gò bó, mệt mỏi. Giống như là một phương pháp refresh lại não bộ vậy.
Đó là chưa kể, đọc nhiều quyển sách một lần sẽ làm cho tiến độ đọc của bạn tăng lên thấy rõ, giống như trong lập trình, sử dụng nhiều thread để xử lý nhiều việc bao giờ cũng nhanh hơn là xử lý theo lối hàng đợi :v
Xem thêm tuyển dụng UI UX Designer hấp dẫn trên TopDev
Yếu tố thứ 3: Mua càng nhiều sách càng tốt
Yếu tố thứ 3 này là để phụ hoạ cho yếu tố thứ 2, một khi đã chấp nhận việc đọc nhiều cuốn sách một lần thì tại sao lại không mua một đống sách về chất đầy giường mà đọc?

Thực ra việc mua nhiều sách về để dành sẽ tạo ra một tác động tâm lý khá lớn, đó là, đã tốn tiền mua sách về rồi thì phải ráng đọc cho hết. Tác động thứ 2 đó là luôn có động lực phải cố gắng đọc để có thể hoàn thành tủ sách của mình. Bạn không thể có động lực bước đi tiếp trên một con đường tối mù, không biết phía trước có gì. Nhưng nếu thấy phía trước là cả một con đường đầy thức ăn ngon tuyệt vời thì ai lại không muốn bước tiếp, đúng không?
Sẽ có bạn nói là mua nhiều sách quá sẽ làm nản chí không muốn đọc nữa, điều này không đúng. Nếu bạn mua những cuốn sách hợp khẩu vị, thì sẽ không có thứ gì làm bạn nản chí được cả.
Yếu tố thứ 4: Đặt ra những mục tiêu ngắn hạn cho việc đọc
Hầu hết trong chúng ta khi bắt đầu đọc một cuốn sách, đều đặt ra một mục tiêu rất to lớn như là: Hoàn thành cuốn sách này trong vòng một tuần, hoặc đọc 20 cuốn sách trong vòng 12 tháng,… trong khi các bạn chưa hề biết được khả năng của bản thân đọc được bao nhiêu. Điều này dẫn đến mục tiêu kia trở nên quá xa vời và rất dễ gây nản chí.
Đặt mục tiêu một cách khôn ngoan khi đọc sách là một điều quan trọng, vậy, mục tiêu thế nào là khôn ngoan?
Các loại sách thông thường bây giờ có độ dài tầm 250 đến 300 từ trên một trang sách. Và tốc độ đọc trung bình của chúng ta là tầm 400-500 từ một phút. Như vậy Trong vòng một phút các bạn có thể đọc gần 2 trang sách (nếu tập trung cao độ), và một trang sách nếu đang ở trong một môi trường không phù hợp, bị phân tâm.
Dựa vào tốc độ đọc này, chúng ta có thể đặt ra các mục tiêu ngắn như là: Đọc 10 trang sách một ngày (tương đương với hơn 10 phút đọc sách một ngày). Mục tiêu này rất dễ để đạt được, vì vậy dần dần việc đọc sách đối với bạn sẽ không còn là cực hình nữa. Và tại sao không bỏ ra nỗi 10 phút để đọc sách trong khi chúng ta có đến 24 giờ?

Cũng giống như khi tập thể dục. Sau khi đã hoàn thành được mục tiêu đặt ra, chúng ta phải đặt ra các mục tiêu cao hơn. Ngày đầu tiên có thể là 10 phút, nhưng hôm sau có thể dành ra 15 phút, rồi 30 phút, rồi 1 tiếng một ngày cho việc đọc sách. Bước phát triển từ từ sẽ giúp cho não quen dần với việc trích xuất thời gian làm một việc gì đó mới mẻ (đọc sách), và lịch trình làm việc của bạn cũng sẽ dần dần thích nghi với việc này để có thể đọc nhiều hơn mỗi ngày.
Yếu tố thứ 5: Dẹp ngay việc đọc tin lung tung trên internet
Thời gian chúng ta bỏ ra để đọc các tin bài một cách ngẫu nhiên (random articles) trên internet rất nhiều, nhưng thường thì các bài viết này không đem lại bất cứ lợi ích gì về mặt lâu dài cả.
Ví dụ như đọc được một bài báo về Hari Won và Tiến Đạt hay Trấn Thành sẽ chẳng hề giúp bạn thu lượm được kiến thức gì ngoại trừ chuyện đời tư của các nghệ sĩ. Hay đọc một bài viết về cơ chế hạ cánh các tên lửa đẩy của hãng SpaceX cũng là một loại kiến thức quá xa vời và không hề thực tế đối với bạn. Cãi nhau trên internet để bảo vệ quan điểm của mình về việc Trung Quốc có nên từ bỏ việc đưa đồng Nhân Dân Tệ lên thay thế đồng tiền chung của khối Châu Âu không, hay Lỗ đen vũ trụ có phải là manh mối để du hành ngược thời gian không, cũng chẳng đem lại cái gì cho bạn cả…

Nếu các bạn để ý và làm một phép thống kê đơn giản, có lẽ bạn sẽ giật mình vì lượng thời gian tiêu tốn cho việc đọc lung tung đó. Thời gian các bạn lãng phí cho việc đó nếu dành vào việc đọc sách thì sẽ tốt hơn rất nhiều. Hãy đọc để có thêm kiến thức trước khi vác bàn phím lên tham gia vào các cuộc đấu khẩu trên thế giới ảo.
Yếu tố thứ 6: Đọc trên nhiều loại thiết bị
Nhìn qua một lượt, chúng ta có rất nhiều cách để đọc sách trong thời đại này: Sách giấy, máy tính, điện thoại, tablet, máy đọc sách,…
Một kinh nghiệm cho việc đọc là bạn nên thử thay đổi qua lại việc đọc cùng một quyển sách trên nhiều loại thiết bị khác nhau. Ví dụ, khi đi ra ngoài đường, đi dã ngoại, các bạn có thể đem bản sách giấy đi theo. Khi đi trên tàu điện hoặc xe bus, lấy máy đọc sách ra mà đọc, khi về đến nhà có thể đọc trên laptop hoặc trên iPad, khi… làm chuyện đại sự, có thể cầm điện thoại vào và đọc ngấu nghiến…
 Hầu hết các phần mềm đọc sách như iBook hay Amazon Cloud Reader có khả năng đồng bộ tiến trình đọc của bạn qua nhiều thiết bị giúp cho việc chuyển đổi giữa các thiết bị dễ dàng hơn, bạn có thể đọc liên tục mà không gặp trở ngại gì.
Hầu hết các phần mềm đọc sách như iBook hay Amazon Cloud Reader có khả năng đồng bộ tiến trình đọc của bạn qua nhiều thiết bị giúp cho việc chuyển đổi giữa các thiết bị dễ dàng hơn, bạn có thể đọc liên tục mà không gặp trở ngại gì.

Hiệu quả ở đây là gì? Việc thay đổi thiết bị khi đọc cũng giống như việc thay đổi môi trường làm việc vậy. Môi trường mới sẽ giúp cho chúng ta không cảm thấy nhàm chán và kích thích khả năng làm việc của chúng ta hiệu quả hơn. Đọc sách cũng cần thay đổi môi trường vậy.
Tuy nhiên, nếu có điều kiện mua các thiết bị máy đọc sách (giá tầm 1tr đến 3tr) thì nên chọn các loại máy chỉ có chức năng đọc sách, không có gì thêm như Kindle Basic, Paperwhite hay Kobo. Ưu điểm thứ nhất là các máy này khá nhẹ, cầm đọc thời gian dài không bị rớt vào mặt nếu lỡ buồn ngủ =)) Việc đọc trên iPad hay các máy Tablet khác đa dụng có thể bị các ứng dụng như Facebook, Twitter, Games,… làm phân tâm không tâp trung được.
Yếu tố thứ 7: Chọn cách đọc phù hợp tuỳ theo loại sách
Kinh nghiệm này đến từ bài viết Đọc sách nhanh trên Blog Khoa học máy tính. Mình vừa mới tìm ra bài viết này cách đây không lâu và chưa có cơ hội áp dụng nhiều, chỉ mới dùng kinh nghiệm này cho 2 cuốn sách gần đây nhất. Tuy vậy mình thấy cách này rất đáng để tham khảo.
 Tuỳ thuộc vào mục đích của loại sách mà chúng ta đang muốn đọc, không phải bất cứ quyển sách nào cũng đáng để đọc ngấu nghiến, có những quyển sách chúng ta chỉ nên lướt qua một lần hoặc là bỏ hẳn không nên đọc nữa, hoặc những cuốn sách chúng ta ít quan tâm hơn nhưng vẫn biết nó hữu dụng. Cách tốt nhất là phân loại nó thành các thể loại sách để đọc theo 2 mức độ (trong bài gốc có 3 mức độ nhưng mức độ 3 mình không nghĩ là nó thích hợp):
Tuỳ thuộc vào mục đích của loại sách mà chúng ta đang muốn đọc, không phải bất cứ quyển sách nào cũng đáng để đọc ngấu nghiến, có những quyển sách chúng ta chỉ nên lướt qua một lần hoặc là bỏ hẳn không nên đọc nữa, hoặc những cuốn sách chúng ta ít quan tâm hơn nhưng vẫn biết nó hữu dụng. Cách tốt nhất là phân loại nó thành các thể loại sách để đọc theo 2 mức độ (trong bài gốc có 3 mức độ nhưng mức độ 3 mình không nghĩ là nó thích hợp):
- Đọc kiểu Cưỡi ngựa xem hoa: Đọc lươn lướt để biết trên đời này có cái gì, và biết được thứ kiến thức gì nó nằm ở đâu để sau này có thể tiện tra cứu lại. Cách này có thể áp dụng khi đọc các bài viết kĩ thuật trên internet, nhất là các bài về lập trình, đảo mắt nhìn quanh một lượt, liếc qua vài dòng code rồi nếu thích thì đi vào đọc chi tiết nội dung bài.
- Đọc kiểu Hiểu: Phải đọc và lĩnh hội được cuốn sách ở mức độ có thể tự xây dựng lại nội dung, có thể khái quát cũng được, mà không cần nhìn vào sách nữa. Cần có sự thực hành đi đôi với quá trình đọc sách (chạy thử code, thử giải các câu đố có trong sách, lý giải một hành động nào đó của nhân vật chính trong sách, hoặc thực hành theo các kinh nghiệm làm giàu nếu bạn dám …), đòi hỏi cần phải đọc nghiêm túc hơn.
Kết bài
Trên đây là kinh nghiệm đọc của mình, lần mò ra được trong một năm qua, sau khi vận dụng và thay đổi thì mình cũng đã hoàn thành được kha khá một vài cuốn sách trong vô số cuốn sách mà mình muốn đọc. Hy vọng các bạn sẽ có thêm động lực để đọc sau bài viết này. Và nếu có ai còn những kinh nghiệm quý giá nào khác, xin mời các bạn chia sẽ ở phần comment cuối bài viết 😀
Chúc các bạn một năm mới thành công rực rỡ đọc nhiều, chơi nhiều và thành công cũng nhiều luôn 😀
Bài viết gốc được đăng tải tại snacky.blog
Có thể bạn quan tâm:
- Developers xây dựng thương hiệu blog của mình như thế nào?
- “Thiếu hiểu biết về Công nghệ ở thế kỷ 21 coi như là mù chữ” – Nhân Nguyễn, CEO tại KALAPA
- Làm thế nào để quản lý sự phụ thuộc của code thông qua việc giảm đi tính trừu tượng?
Xem thêm các việc làm ngành CNTT hấp dẫn trên TopDev













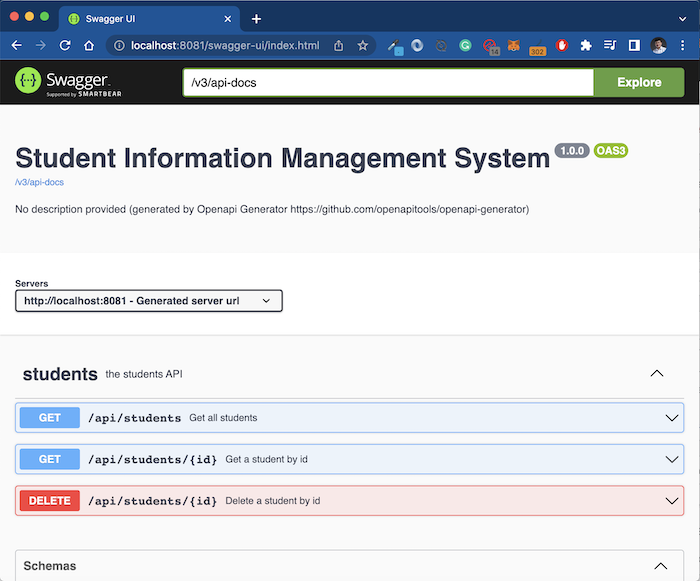 Đây chính là Swagger API documentation đó các bạn! Sử dụng nó, các bạn sẽ biết ứng dụng của chúng ta có bao nhiêu request URL được expose. Thông tin của mỗi request URL như thế nào, và chúng ta có thể sử dụng Swagger API documentation này để gọi đến các request URL thực tế luôn.
Đây chính là Swagger API documentation đó các bạn! Sử dụng nó, các bạn sẽ biết ứng dụng của chúng ta có bao nhiêu request URL được expose. Thông tin của mỗi request URL như thế nào, và chúng ta có thể sử dụng Swagger API documentation này để gọi đến các request URL thực tế luôn.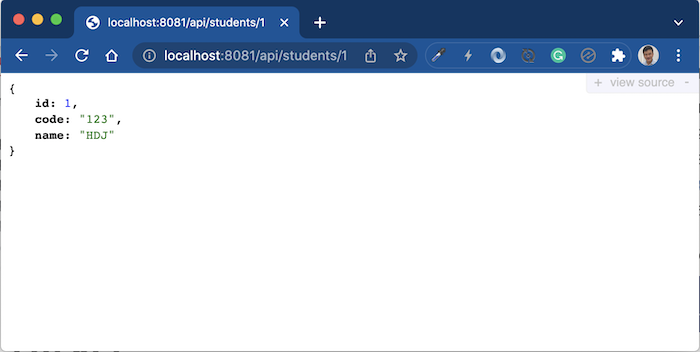



























 )
)