Bài viết được sự cho phép của tác giả Phạm Văn Nguyên
Bạn vừa tìm hiểu về lists và tuples và bạn đang tự hỏi làm thế nào chúng khác nhau?
Đây là một câu hỏi phổ biến đáng ngạc nhiên.
Cả 2 cũng khá giống nhau.
Cả lists và tuples là các kiểu dữ liệu chuỗi có thể lưu trữ một bộ sưu tập các item(mục).
Mỗi item được lưu trữ trong một list hoặc một tuple có thể thuộc bất kỳ loại dữ liệu nào.
Và bạn cũng có thể truy cập bất kỳ item nào theo chỉ mục của nó.
Vì vậy, câu hỏi là, họ có khác nhau không?
Và nếu không, tại sao chúng ta có hai loại dữ liệu hoạt động khá giống nhau?
Chúng ta không thể sống với lists hoặc tuples?
Vâng, chúng ta hãy cố gắng tìm câu trả lời.
Sự khác biệt chính giữa list và Tuple
Sự khác biệt chính giữa list và tuples là thực tế là list có thể thay đổi (mutability) trong khi bộ dữ liệu là bất biến (immutability) .
Điều đó có nghĩa gì, bạn nói gì?
Một kiểu dữ liệu có thể thay đổi có nghĩa là một đối tượng python thuộc loại này có thể được sửa đổi.
Một đối tượng bất biến không thể.
Chúng ta hãy xem điều này có nghĩa là gì.
Hãy tạo một list và gán nó cho một biến.
>>> a = ["apples", "bananas", "oranges"]
Bây giờ hãy xem điều gì xảy ra khi chúng ta cố gắng sửa đổi item(mục) đầu tiên của danh sách.
Chúng ta hãy thay đổi apples thành một berries .
>>> a[0] = "berries" >>> a ['berries', 'bananas', 'oranges']
Hoàn hảo! mục đầu tiên của a đã thay đổi.
Bây giờ, điều gì sẽ xảy ra nếu chúng ta muốn thử điều tương tự với một tuple thay vì một list? Hãy xem nào.
>>> a = ("apples", "bananas", "oranges")
>>> a[0] = "berries"
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment
Lý do chúng tôi gặp lỗi này là vì các đối tượng tuple, không giống như list, là bất biến, điều đó có nghĩa là bạn không thể sửa đổi một đối tượng tuple sau khi nó được tạo.
Nhưng chờ đã, hãy xem ví dụ sau:
>>> a = ("apples", "bananas", "oranges")
>>> a = ("berries", "bananas", "oranges")
>>> a
('berries', 'bananas', 'oranges')
Ô điều gì đã xảy ra vậy?
Hãy xem, chúng ta có thực sự sửa đổi item đầu tiên trong tuple a với code ở trên không?
Câu trả lời là Không , hoàn toàn không.
Để hiểu tại sao, trước tiên bạn phải hiểu sự khác biệt giữa một biến và một đối tượng python.
Sự khác biệt giữa một biến và một đối tượng
Bạn có thể nhầm lẫn các biến với các đối tượng. Đây là một quan niệm sai lầm rất phổ biến ở những người mới bắt đầu.
Hãy nhớ rằng một biến không là gì ngoài tham chiếu đến đối tượng python thực tế trong bộ nhớ.
Bản thân biến không phải là đối tượng.
Ví dụ: chúng ta hãy cố gắng hình dung những gì xảy ra khi bạn gán một list (danh sách) cho một biến a .
>>> a = ["apples", "bananas", "oranges"]
Khi bạn làm điều này, một đối tượng python kiểu list kiểu được tạo trong bộ nhớ và biến a tham chiếu đến đối tượng này bằng cách giữ vị trí của nó trong bộ nhớ .
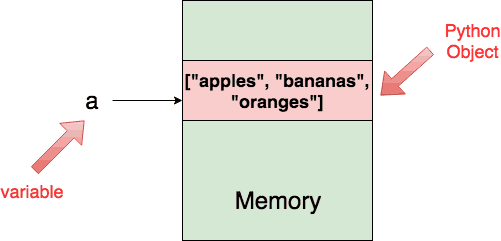
Trong thực tế, bạn thực sự có thể lấy lại vị trí của đối tượng list trong bộ nhớ bằng cách kiểm tra a bằng cách sử dụng function id () .
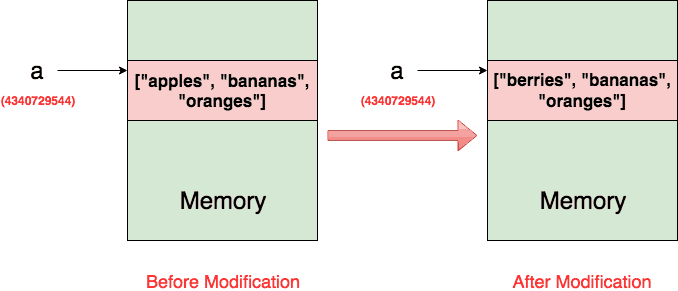
>>> a = ["apples", "bananas", "oranges"] >>> id(a) 26953168
Bây giờ nếu bạn sửa đổi chỉ item đầu tiên của danh sách và kiểm tra lại id () , bạn sẽ nhận được cùng một giá trị chính xác vì a vẫn đang tham chiếu đến cùng một đối tượng.
>>> a[0] = "berries" >>> id(a) 4340729544
Hình dưới đây cho thấy chính xác những gì đã xảy ra sau khi sửa đổi.
Bây giờ, hãy xem điều gì xảy ra nếu chúng ta thực hiện điều tương tự trên các tuples.
>>> a = ("apples", "bananas", "oranges")
>>> id(a)
4340765824
>>> a = ("berries", "bananas", "oranges")
>>> id(a)
4340765464
Như bạn có thể thấy, hai địa chỉ là khác nhau.
Điều này có nghĩa là sau lần gán thứ hai, a đang đề cập đến một đối tượng hoàn toàn mới.
Con số này cho thấy chính xác những gì đã xảy ra.
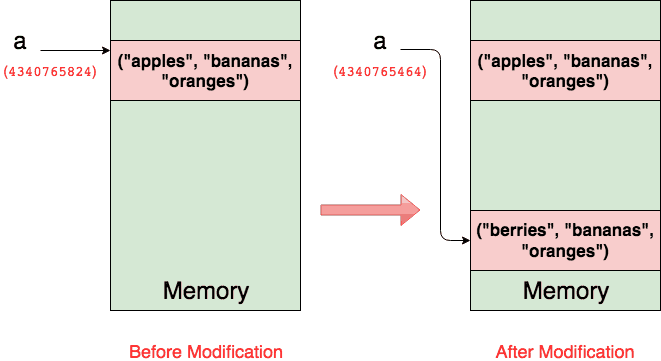
Hơn nữa, nếu không có biến nào khác trong chương trình của bạn đề cập đến bộ dữ liệu cũ hơn thì trình thu gom rác của python sẽ xóa hoàn toàn bộ dữ liệu cũ khỏi bộ nhớ.
Vì vậy, bạn có nó, khái niệm về khả năng biến đổi này là sự khác biệt chính giữa list và tuples.
Mutability (khả năng biến đổi) không chỉ là một khái niệm python, nó là một khái niệm ngôn ngữ lập trình mà bạn sẽ gặp trong các ngôn ngữ lập trình khác nhau .
Nhưng bây giờ có lẽ toàn bộ cuộc thảo luận này gợi lên một câu hỏi khác trong đầu bạn.
Tại sao chúng ta có các đối tượng có thể thay đổi và bất biến?
Tại sao chúng ta cần các đối tượng có thể thay đổi và bất biến?
Thật ra, cả hai đều phục vụ các mục đích khác nhau.
Chúng ta hãy thảo luận về một số khía cạnh phân biệt giữa các đối tượng có thể thay đổi và bất biến
1. Hiệu suất bổ sung

Khả năng tương tác sẽ hiệu quả hơn khi bạn biết bạn sẽ thường xuyên sửa đổi một đối tượng.
Ví dụ: giả sử bạn có một số đối tượng có thể lặp lại (iterable object) (giả sử x) và bạn muốn nối từng phần tử của x vào danh sách.
Tất nhiên bạn chỉ có thể thực hiện L = list (x) kiểu như thế này:
L = [] for item in x: L.append(item)
Điều này hoạt động ổn. Bạn tiếp tục sửa đổi đối tượng danh sách tại chỗ cho đến khi tất cả các yếu tố của x tồn tại trong danh sách L .
Nhưng bạn thậm chí có thể tưởng tượng điều gì sẽ xảy ra nếu chúng ta đã sử dụng một tuple thay thế?
T = () for item in x: T = T + (item,)
Bạn có thể hình dung những gì đang xảy ra trong bộ nhớ?
Vì các bộ dữ liệu là bất biến, về cơ bản, bạn đang sao chép nội dung của bộ dữ liệu Tsang một đối tượng bộ dữ liệu mới tại Mỗi lần lặp.
Nếu vòng lặp for lớn, đây là một vấn đề hiệu năng rất lớn.
Trên thực tế, chúng ta hãy sử dụng python để đo hiệu suất của việc thêm vào list so với việc thêm vào một tuple khi x = range (10000).
Bài viết này hướng dẫn bạn cách sử dụng module time để đo thời gian thực hiện của nhiều dòng python .
$ python3 -m timeit \ -s "L = []" \ -s "x = range(10000)" \ "for item in x:" " L.append(item)" 1000 loops, best of 3: 1.08 msec per loop
Khá tốt, mất khoảng 1,08 mili giây .
Sẽ thế nào nếu chúng ta làm điều tương tự với tuples?
$ python3 -m timeit \ -s "T = ()" -s "x = range(10000)" \ "for item in x:" " T = T + (item,)" 10 loops, best of 3: 1.63 sec per loop
Một con lớn hơn rất nhiều 1,63 giây ! ( gấp khoảng 1500 lần)
Đây là một sự khác biệt lớn về hiệu suất giữa các list và tuples.
Nếu bạn muốn kiểm tra sự kiên nhẫn của mình, hãy thử x = range(1000000).
Bây giờ khi ai đó nói với bạn việc append nhiều lần vào một đối tượng string(chuỗi) không hiệu quả, bạn sẽ hiểu chính xác lý do tại sao (các đối tượng chuỗi cũng không thay đổi trong python).
Hiệu suất bổ sung: Thắng: đối tượng có khả năng thay đổi
Xem thêm việc làm python hấp dẫn trên TopDev
2. Dễ dàng gỡ lỗi

Mutility (khả năng biến đổi) là tuyệt vời và tất cả nhưng một điều có thể thực sự gây phiền nhiễu với các đối tượng có thể thay đổi là gỡ lỗi.
Ý tôi là gì?
Chúng ta hãy xem ví dụ rất đơn giản này.
>>> a = [1, 3, 5, 7] >>> b = a >>> b[0] = -10 >>> a [-10, 3, 5, 7]
Lưu ý rằng khi chúng ta gán b = a , chúng ta sẽ không sao chép đối tượng list từ b sang a .
Chúng tôi thực sự nói với python rằng hai biến a và b nên tham chiếu cùng một đối tượng danh sách.
Bởi vì a vị trí có hiệu quả giữ vị trí của đối tượng Python trong bộ nhớ, khi bạn nói b = a bạn sao chép vị trí địa chỉ đó (không phải đối tượng thực tế) vào b .
Điều này dẫn đến việc có hai tham chiếu (a và b) cho cùng một đối tượng list.
Nói cách khác, khi chúng ta thực hiện b [0] = -10 , nó có tác dụng tương tự như a[0] = -10 .
Tất nhiên bạn có thể nhìn vào code và nghĩ đúng rằng nó rất dễ gỡ lỗi.
Chà, bạn đúng với những đoạn code nhỏ như thế này, nhưng hãy tưởng tượng nếu bạn có một dự án lớn với nhiều tham chiếu đến cùng một đối tượng có thể thay đổi.
Sẽ rất khó khăn để theo dõi tất cả các thay đổi đối với đối tượng này bởi vì bất kỳ sửa đổi nào trong số các tham chiếu đó sẽ sửa đổi đối tượng.
Đây không phải là trường hợp với các đối tượng bất biến ngay cả khi bạn có nhiều tài liệu tham khảo đến chúng.
Một khi một đối tượng bất biến được tạo ra, nội dung của nó sẽ không bao giờ thay đổi.
Dễ dàng gỡ lỗi: Thắng: đối tượng bất biến!
3. Hiệu quả bộ nhớ

Một lợi ích khác của tính bất biến là nó cho phép thực hiện ngôn ngữ để có hiệu quả bộ nhớ cao hơn.
Hãy để tôi giải thích những gì tôi có ý nghĩa bởi điều đó.
Trong CPython (cách triển khai Python phổ biến nhất) nếu bạn tạo các đối tượng bất biến có cùng giá trị, python (trong một số điều kiện nhất định) có thể bó các đối tượng khác nhau này thành một.
Ví dụ, hãy xem code này:
>>> a = "Nguyenpv" >>> b = "Nguyenpv" >>> id(a) 58752160 >>> id(b) 58752160
Hãy nhớ rằng String(Chuỗi) (cũng như Integer, Float và Bools) đều là ví dụ về các đối tượng bất biến.
Như bạn có thể thấy, mặc dù trong chương trình python của chúng tôi, chúng tôi đã tạo rõ ràng hai đối tượng chuỗi khác nhau, python đã bó chúng lại thành một.
Làm thế nào chúng ta biết điều đó?
À bởi vì danh tính của a giống hệt như danh tính của b .
Python đã có thể làm điều đó bởi vì tính bất biến của chuỗi giúp cho việc thực hiện gói này an toàn.
Điều này không chỉ giúp chúng ta tiết kiệm bộ nhớ (bằng cách không lưu trữ chuỗi nhiều lần trong bộ nhớ) mà còn mỗi khi bạn muốn tạo một đối tượng mới có cùng giá trị, python sẽ chỉ tạo một tham chiếu đến đối tượng đã tồn tại trong bộ nhớ chắc chắn hiệu quả hơn.
Khái niệm này được gọi là String Interning , và đây là một bài viết tuyệt vời nếu bạn muốn tìm hiểu sâu hơn .
Không chỉ strings. Điều này cũng áp dụng cho integer (số nguyên) (trong điều kiện nhất định).
>>> a = 1 >>> b = 1 >>> id(a) 1788568672 >>> id(b) 1788568672
Điều đó thật tuyệt phải không?
Thế còn tuples thì sao?
CPython cho đến khi python 3.6 đưa ra quyết định thiết kế không tự động bundle (bó) hai bộ dữ liệu tương đương thành một.
>>> a = (1, 2) >>> b = (1, 2) >>> id(a) 58751816 >>> id(b) 58751536
Như bạn có thể thấy, a có bản sắc khác với b .
Quyết định thiết kế này có ý nghĩa bởi vì thực hiện thực tập cho các tuples đòi hỏi phải đảm bảo rằng tất cả các item (mục, phần tử) của tuples là bất biến.
Hiệu quả bộ nhớ: Thắng: bất biến
Phần kết luận
Để hiểu sự khác biệt giữa lists và tuples trong python, trước tiên bạn phải hiểu khái niệm về tính biến đổi (mutability) / immutability (bất biến).
Lists là các đối tượng có thể thay đổi, có nghĩa là bạn có thể sửa đổi một đối tượng list sau khi nó được tạo.
Mặt khác, các tuple là các đối tượng bất biến, có nghĩa là bạn không thể sửa đổi một đối tượng tuple sau khi nó được tạo.
Cả Mutility(có thể thay đổi) và Immutability (bất biến) đều có những ưu điểm và nhược điểm riêng.
Bài viết gốc được đăng tải tại nguyenpv.com
Có thể bạn quan tâm:
- Vừa đủ để đi (go)
- 71 trích đoạn code Python cho các vấn đề hàng ngày của bạn
- Lộ trình trở thành Backend Developer
Tuyển dụng lập trình viên lương cao trên TopDev