Được thành lập năm 2011, Kidsloop là ứng dụng học tập và giải trí dành cho trẻ em, cung cấp các giải pháp công nghệ toàn diện cho nhà trường, giáo viên và phụ huynh với kho nội dung học thuật tương tác được chọn lọc kỹ lưỡng cùng những ý tưởng phong phú, giúp khơi gợi cảm hứng học tập của trẻ.
Kidsloop – Nền tảng giáo dục hiện đại, giúp đem đến sự đổi mới trong cách thức tiếp cận tri thức cho trẻ
Kidsloop khởi nguồn là công ty hoạt động trong lĩnh vực giáo dục dành cho trẻ em. Trải qua gần 10 năm hình thành và phát triển, Kidsloop đã không ngừng vươn lên chiếm lĩnh thị trường, trở thành nền tảng đẳng cấp thế giới, thu hút sự quan tâm của các bậc cha mẹ trong việc giáo dục con cái trong những năm phát triển đầu đời.
Dưới sự nghiên cứu kỹ lưỡng từ các chuyên gia về những đặc điểm nổi bật tại từng giai đoạn lứa tuổi của trẻ, Kidsloop đem đến các sản phẩm ưu việt, giúp giúp phụ huynh và giáo viên định hướng con đường phát triển tốt nhất cho trẻ trên hành trình học tập của mình.
“Cùng con làm chủ tương lai” với Kidsloop qua các tính năng đặc sắc thu hút sự quan tâm từ phụ huynh
Xây dựng thành công nền tảng giáo dục hiện đại với các tính năng: Remote, In-class và Home study, Kidsloop mang đến cho trẻ cơ hội học tập ở mọi lúc, mọi nơi, tận dụng tối đa thời gian với lộ trình cụ thể, phù hợp.
Remote là tính năng mà trong đó, giáo viên và học sinh tương tác và trải nghiệm môi trường lớp học hoàn chỉnh thông qua các thiết bị máy tính, máy tính bảng hoặc điện thoại thông minh. Với nền tảng CLMS, Kidsloop đem đến phần mềm từ xa có khả năng tương tác tiên tiến và thư viện nội dung tích hợp, tạo sự trải nghiệm tốt nhất cho trẻ trong quá trình học tập.
Tính năng In-class cung cấp cho giáo viên công cụ áp dụng công nghệ giúp tăng trải nghiệm và hiệu quả sử dụng, đem đến các nội dung trực quan ngay tại lớp học. Thông qua màn hình tương tác, mỗi học sinh được trải nghiệm các hoạt động sáng tạo có kết thúc mở và các đánh giá sau mỗi bài học, giúp trẻ tư duy và ghi nhớ nội dung bài giảng dễ dàng.
Tính năng Home Study hướng đến môi trường học tập vui vẻ, lấy trẻ làm trung tâm và đồng thời cho phép giáo viên theo dõi tiến trình phát triển, giao bài tập về nhà cũng như đề ra các giải pháp học tập cho từng cá nhân, phù hợp với khả năng của từng trẻ thông qua thu thập dữ liệu sắc thái và phân tích cá nhân hóa. Qua đó, tương tác của người học trên nền tảng được chuyển đổi thành các đơn vị thông tin có ý nghĩa thông qua một thuật toán độc quyền, cho phép chúng tôi điều chỉnh trải nghiệm học tập của từng trẻ.
Chương trình giáo dục thú vị từ nội dung sinh động, phong phú – Điểm cộng lớn cho sự trải nghiệm của trẻ với nền tảng kiến thức mới
“Giáo dục sớm” – một thuật ngữ không còn xa lạ đối với các bậc phụ huynh thời hiện đại. Hiểu được tầm quan trọng của giáo dục từ giai đoạn 0 đến 6 tuổi, Kidsloop thành công trong việc khai thác những đặc điểm tâm lý, cũng như quá trình phát triển của trẻ trong từng giai đoạn tuổi và đưa ra lộ trình học tập phù hợp.
Chương trình giáo dục của Kidsloop nổi bật với 3 sản phẩm: Badanamu ESL, Bada Math, Bada Science. Các sản phẩm tạo nên tên tuổi của Kidsloop qua những cuộc phiêu lưu học tập vui vẻ và thú vị và quan trọng nhất là tăng mức độ tương tác. Từ hoạt ảnh 2D cổ điển đến chuỗi tương tác 3D sáng tạo, nội dung của Kidsloop mang đến niềm vui và sự ngạc nhiên khi học.
Đón đầu xu hướng giáo dục mới, Kidsloop tìm kiếm nhân tài cùng góp sức, định vị giá trị của bản thân trên thị trường
Để có được sự thành công như hôm nay, Kidsloop đã không ngừng cố gắng cải tiến chất lượng với đội ngũ sáng tạo đáng kinh ngạc đến từ khắp nơi trên thế giới, bao gồm Hàn Quốc, Trung Quốc, Anh, Mỹ, Indonesia, Việt Nam, Malaysia, v.v.
Không dừng lại ở đó, hướng đến mục tiêu trở thành “kẻ dẫn đầu” trên thị trường toàn cầu,
Kidsloop liên tục mở rộng cơ hội cho các nhân tài công nghệ Việt tỏa sáng tài năng.
Kidsloop ngỏ lời chiêu mộ “chiến binh” công nghệ, những người góp sức tạo nên Kidsloop hùng mạnh, giữ vững vị trí hàng đầu trong công cuộc phát triển “hệ thống giáo dục của tương lai”.
Và nếu bạn đã sẵn sàng đồng hành cùng Kidsloop tạo nên những sản phẩm tuyệt vời nhất?
Đừng chần chờ thêm nữa, nhanh tay apply ngay hôm nay và khám phá những điều thú vị đang chờ tại Kidsloop:
Mức lương cạnh tranh với nhiều khoản thưởng hấp dẫn;
Tham gia phát triển các dự án đầy thách thức cùng đội ngũ năng động, chuyên nghiệp trong một nền văn hóa mang tính quốc tế và sẵn sàng hợp tác cùng phát triển;
Nhiều cơ hội phát triển chuyên môn và sự nghiệp với vai trò quan trọng trong việc định hình giai đoạn phát triển tiếp theo của công ty.
>>> Khám phá ngay những vị trí hấp dẫn tại Kidsloop cho bạn bứt phá sự nghiệp:
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Hellu! Lại là tôi đây. Trong bài trước chúng ta đã học về 1 design biến hoá việc kế thừa thành việc bao hàm. Nghĩa là mặc dù kế thừa là hay nhưng trong trường hợp đó nó lại đâm ra dở. Tách biệt chức năng không phụ thuộc lớp A vào lớp B. Khi cần thì lớp B có thể chứa lớp A và sử dụng các chức năng của nó. Design đó tôi nêu tên cho các bạn đánh index trong đầu: Strategy =))
Hôm nay chúng ta có 1 trường hợp như sau. Có 1 anh chàng. Lúc học cấp 3 anh ta chỉ cần cô ấy là gái, nói chuyện vui là yêu được. Sau khi lên DH, anh ta sống trong cảnh xa nhà, mì tôm gặm suốt ngày. Anh ta bắt muốn yêu các cô gái có mông to đễ khoã lấp nỗi cô đơn. Rồi anh ta đi làm, anh ta kiếm được tiền nên anh ta nâng tiêu chí người yêu là phải có ngực to nữa. Ngực to không lo chết đói =))
Trong lập trình cũng gặp hoàn cảnh tương tự. Ban đầu khách hàng yêu cầu tính năng A, sau đó đòi thêm B, rồi C. Rồi một ngày đẹp trời nào đó, ông khách này lại muốn bỏ B đi. =)) Rất là mệt mỏi .. Vậy chúng ta phải tạo liên kết giữa các lớp một cách mềm dẻo, sao cho việc bảo trì là đơn giản nhất.
Vậy thì các bạn thiết kế 1 lớp cha làm sao cho bon con cái kế thừa có thể cùng chung vỏ mà tính tình mỗi thằng khác nhau, tránh trường hợp đổ vỏ con nhà hàng xóm =))
Vậy đầu tiên trong lớp Mylove, các bạn cần hàm virtual để các lớp con kế thừa như sau:
Ở đây các bạn cũng không cần virtual thuần ảo, không bắt buộc lớp con kế thừa lại hàm getDesscripttion này.
Sau đó tôi tạo thêm 1 lớp wrap lại các tính chất như mông, ngực… cho các lớp tính chất phát triển về sau:
OK, bây giờ các lớp tính chất chúng ta sẽ kế thừa từ lớp này. Ví dụ tôi làm lớp Mông trước: Trong lớp trên, hàm getDescription được kế thừa lại, mô tả lại là mông phải to. Chứ mông lép là anh này anh hổng có yêu :3
Rồi tương tự ta làm lớp Ngực:
Và bây giờ là demo. Trong hàm main ta triển khai như sau:
Kết quả chương trình như sau:
Rồi sau đó anh ta lại nâng tiêu chí mông lên. Anh ta new 1 tính chất mới về mông:
Kết quả:
Một thời gian anh ta lại muốn ngực to =))
Code thêm như sau:
Kết quả:
Ok, vậy rõ ràng các bạn thấy việc bảo trì nâng cấp code rất đơn giản, chỉ cần tạo thêm lớp mới là ok. Đây chỉ là phần design sơ khai và cũng dễ hiểu. Cái này có tên là DECORATOR =))
Bài viết được sự cho phép của tác giả Nguyễn Hữu Đồng
Hế nhô các bạn, để tiếp tục cho bài viết trước hôm nay mình xin giới thiệu với các cách giao tiếp giữa client/server với tốc độ bàn thờ, mà mình vừa mới tìm hiểu.
Trước hết gRPC theo google giới thiệu
gRPC is a modern open source high performance RPC framework that can run in any environment. It can efficiently connect services in and across data centers with pluggable support for load balancing, tracing, health checking and authentication. It is also applicable in last mile of distributed computing to connect devices, mobile applications and browsers to backend services.
gRPC là một RPC framework gíup bạn kết nối giữa các service trong hệ thống, nó hỗ trợ load balancing, tracing, health checking và authentication, hỗ trợ từ ứng dụng mobile, trình duyệt cho tới back-end service.
gRPC sử dụng ProtocolBuffer để transfer data thay vì JSON/XML truyền thống nên tốc độ được gia tăng đáng kế, ngoài ra nó cũng dùng RPC thay cho REST API, trong việc thiết kế API, sự khác biệt giữa REST API vs RPC là REST được thiết kế để tập trung vào Resource còn RPC thì tập trung vào action, hành động. Bạn có thể xem kĩ hơn ở đây.
Về cơ bản, khi làm việc với gRPC bạn định nghĩa các action, input message, output mesage trong service, sau đó protobuf compiler sẽ generate code ra file theo ngôn ngữ bạn sử dụng. Sau đó bạn sẽ triển khai các action của service như những gì đã bạn đã mô tả .
Trong bài viết này, mĩnh sẽ triển khai một User Service cho phép client thực hiện chức năng cơ bản là đăng kí và đăng nhập mình định nghĩa các message và service gồm những action như sau.
Như các bạn có thể thấy Service của mình sẽ có 2 action có thể được thực hiện là UserLogin và UserRegister, mình đã mô tả in,out message đầy đủ trong file “user.rpc.go”. Mình sẽ tiến hành biên dịch ra go file.
Để biên dịch ra go file mình dùng lệnh dưới, lênh này sẽ biên dịch tất cả các file proto trong thư mục protobuf và lưu lại trong thư mục rpc.
Mình nói qua chút về cấu trúc thư muc của project.
Protobuf là nơi mình lưu trữ tất cả các file .proto
rpc là nơi mà các file output mà đã được biên dịch
entity là nơi mình khai báo các action cho từng service, các action của một service sẽ nằm trong một file, ví dụ tất cả các action của user service sẽ nằm trong file user.go.
server tên là server nhưng nó sẽ có 2 vài trò, 1 là làm vai trò server nhận request từ nơi nào đó (A) sau đó sẽ làm vai trò là client, gọi 1 action từ gRPC server nhận kết quả sau đó trả về cho phía (A).
main.go đây là nơi mình khởi tạo gRPC server và đăng kí các service vào server.
Sau khi định nghĩa các action, in,out message cho từng action, mình sẽ tiến hành khai báo cụ thể các action sẽ thực hiện như thế nào, mình sẽ không đi sâu vào các action và sẽ demo đơn giản như thế này.
Như ảnh phía trênm mình định nghĩa hai chi tiết 2 action UserLogin, UserRegister sẽ được thực hiện như thế nào, hai action function này sẽ được khai báo trên struct user_service để implement interface mà ta đã định nghĩa ở trong phần khai báo trong file proto.
Trong file main.go phía trên, mình start một client cho gRPC, client này đống vai trò như là một server đối với người dùng.
Để tạo Client đối với gRPC server như hình dưới, Package RPC được compile từ proto đã có những method cho phép tạo đăng kí client cho service được miêu tả.
Client ( đối với gRPC server sẽ gọi là C1 )này sẽ lắng nghe request từ người dùng ( sẽ gọi là A) , sau đó tạo ra một message để gọi 1 action trên gRPC server, nhận response và lại trả về cho phía (A). Ví dụ khi user thực hiện đăng kí tài khoản thì C1 sẽ tạo một message từ data từ phía A dạng JSON đó ra Protobuf rồi call một action của User Service trên gRPC server sau đó nhận kết qủa và trả về cho phía A, như hình dưới.
Tiếp theo thử chạy Server và thực hiện 1 Request Register từ phía người dùng, để start bạn chạy lệnh
go run main.go
Dùng Postman để gửi request lên Server(C1).
Vậy là mình đã thực hiện được việc giao tiếp đơn giản giữa client/server (
server C1 vs gRPC server ) bằng gRPC framwork. Do mới tìm hiểu nên mình chỉ có thể viết đến đây thôi, trong tương lai, nếu có cơ hội làm việc mới gRPC thì mình sẽ học hỏi và chia sẻ với các bạn nhiều hơn, Cảm ơn các bạn đã đọc bài viết, Bye bye các bạn 😀
Bài viết được sự cho phép của tác giả Nguyễn Việt Hưng
Function là gì?
Function là một phần tất yếu của mọi phần mềm. Một chương trình (Python) không bắt buộc phải có function, nhưng nó là cách làm cơ bản, phổ biến nhất, tương tự như những ngôn ngữ lập trình khác. Về bản chất, function là một khái niệm / cơ chế để dùng lại code. Thay vì viết một đoạn code nhiều lần mà mỗi lần chỉ thay đổi chút chút, ta viết một function, nhận vào các tham số khác nhau.
Chuyện một function nhận đầu vào, xử lý và trả về đầu ra thì ai cũng biết. Phần đầu vào luôn phải được định nghĩa rõ ràng đầy đủ (trừ *args và **kwargs – thì có chúa mới biết function nhận những cái gì!), nhưng phần đầu ra thì không có quy tắc cụ thể nào. Vậy nên mới xảy ra chuyện, ai thích làm gì thì làm, và thường thì người ta sẽ làm khá tệ khi không có quy tắc nào.
Đây là một trường hợp phổ biến, hãy tưởng tượng 1 đoạn code làm nhiệm vụ CO_KHA_THI. Đầu vào dễ dàng định nghĩa những thứ ta cần cho vào, tên người dùng chẳng hạn:
defCO_KHA_THI(username):pass
Đầu ra là gì? chuyện này không dễ dàng thống nhất. Xét về mặt nhiệm vụ, function này chỉ có thể có 2 khả năng: thành công, hoặc thất bại. Bạn có thể tạo user, hoặc không tạo được, chấm hết. Trong nhóm chỉ có 2 kết quả trái nhau như vậy, rõ ràng boolean là ứng cử viên sáng giá, thành công: return True, thất bại return False. Nhưng nếu thất bại, bạn muốn biết lý do (user đã tồn tại, vượt quá giới hạn số lượng user, …) thì làm thế nào?
Vậy là giải pháp return string ra đời.
Return string?
Nếu thành công, return "Success", nếu thất bại vì username đã tồn tại, return "Failed user exists", nếu thất bại vì quá giới hạn, return "Failed limit exceeded", … tiếp tục như vậy với những lý do thất bại khác.
Function này làm tốt nhiệm vụ của nó, nhưng đầu ra giờ là một trời khả năng. Thay vì 2, giờ ta có N khả năng xảy ra. Thì sao?
Không sao cả, cho đến khi có ai đó gọi function này.
username="laptrinhvien"result=CO_KHA_THI(username)ifresult=="Success":print("Added user {}".format(username))elifresult=="Failed limit exceeded":...elifresult=="Failed user exists":......
Người gọi function CO_KHA_THI phải biết tất cả các khả năng mà function này trả về, và cách duy nhất để làm điều đó là ngồi đọc toàn bộ code của function CO_KHA_THI. Function này có thể vài dòng, nhưng cũng có thể là vài chục dòng, vài chục câu if else… nếu việc sử dụng 1 function yêu cầu bạn phải đọc code của function đó, thì đó là một function tồi.
Ta không cần biết math.sqrt tính căn 2 như thế nào, ta chỉ cần đưa đầu vào, và sẽ thu được kết quả ở dạng số float. Ta chỉ cần đưa đường dẫn vào requests.get và nhận kết quả của HTTP GET requests đó, không cần biết nó làm thế nào.
Xử lý lỗi
Khi lỗi xảy ra thì sao?
Mỗi ngôn ngữ lập trình có cách xử lý lỗi khác nhau – khái niệm này gói chung vào từ khóa “error handling”.
Chuyện gì xảy ra khi lấy căn bậc 2 của -2? Python sẽ “raise” (tung ra) một Exception object:
Ta dùng try/except để xử lý khi có exception xảy ra.
Golang sử dụng cơ chế khác: một function thường trả về lỗi, và kết quả. Nếu không có lỗi, giá trị lỗi là nil (tương đương None của Python). Việc gọi 1 function trong Golang thường trông như sau:
Mỗi cách làm sẽ có ưu nhược điểm khác nhau. Trong Python, ta có thể làm tương tự như Golang, với ví dụ function CO_KHA_THI, return 1 tuple chứa boolean chỉ định việc thành công hay thất bại, và string chứa thông điệp muốn gửi tới người dùng là một cách làm tốt hơn chỉ trả về string. Người dùng có thể không quan tâm đến lỗi gì, vậy khi đó chỉ cần xử lý dựa trên giá trị boolean. Nếu quan tâm đến lỗi, lúc đó lại phải dựa vào giá trị string. Mà dựa vào string lại khiến vấn đề quay lại từ đầu. Liệu nội dung lỗi là string chữ thường hay chữ hoa? liệu sau này nội dung string đó có bị thay đổi không, nếu có làm sao ta biết? (đọc lại function?!?!!!).
Tạo các exception và raise khi có lỗi là cách làm đơn giản hơn cả. Exception có kiểu, là các class có kế thừa, dễ dàng phân loại các lớp lỗi khác nhau mà không dựa vào string.
classMyException(Exception):passclassMyFirstException(MyException):passclassMySecondException(MyException):passdefdo_something(username):result=do_job()iferror1inresult:raiseMyFirstException(error1)eliferror2inresult:raiseMySecondException(error2)...else:raiseMyException("Unknown error: %s"%error_msg)try:do_something('pymi')exceptMyFirstExceptionase:print('Failed with error1',e)exceptMySecondExceptionase:print('Failed with error2',e)exceptMyExceptionase:print('Failed with error not 1 and 2',e)else:print('Success')
Dù dùng cách nào đi nữa, đừng chỉ trả về string – trừ khi function được tạo ra để xử lý string.
Bài viết được sự cho phép của BQT Kinh nghiệm lập trình
Performance testing là một loại test quan trọng để xác định ứng dụng web đang được kiểm tra có đáp ứng các yêu cầu tải cao hay không. Loại test này được dùng để phân tích hiệu năng máy chủ một cách tổng thể khi chịu tải nặng.
Ở bài viết trước, mình đã giới thiệu tới các bạn các thành phần cơ bản và cốt lõi của Jmeter cũng như cách sử dụng chúng. Các bạn có thể xem lại ở Đây.
Mình xin nhắc lại chuỗi bài viết của mình gồm 4 phần sau:
Phần 1: Giới thiệu và cài đặt Phần 2: Hướng dẫn xây dựng kịch bản test
Phần 3: Sử dụng Regular Expressions làm việc với Session IDs và Tokens
Phần 4: Mở rộng – Tạo lập Scripts tự động bằng HTTP(S) Test Script Recorder.
Trong bài viết này, chúng ta sẽ cùng nhau xây dựng 1 kịch bản test đầy đủ từ việc lên ý tưởng cho tới triển khai và đánh giá kết quả.
Các bước xây dựng kịch bản test
Bước 1: Phân tích yêu cầu
Bước 2: Tạo lập Scripts test
Bước 3: Thiết lập kịch bản test
Bước 4: Thưc thi kịch bản test
Bước 5: Đánh giá kết quả test
Bước 1: Phân tích yêu cầu
Đây là bước lên ý tưởng, kịch bản test sẽ thực hiện. Trước khi thực hiện test ta cần định nghĩa rõ ràng các thông tin sau:
Mục tiêu test là gì? Bạn cần xác định được kết quả mong muốn sau khi kiểm thử hiểu năng là gì. Kiểm tra giới hạn chịu tải của hệ thống (Stress testing) hay theo dõi diễn biến của hệ thống khi có nhiều người cùng truy cập (Load testing)
Số lượng user sẽ giả lập? Cho dù mục tiêu của bạn là gì, thì việc không thể thay đổi đó là ta sẽ mô phỏng 1 số lượng người dùng thao tác trên hệ thống. Vậy số lượng này là bao nhiêu, hoàn toàn tùy thuộc vào nhu cầu sử dụng hệ thống của bạn, hoặc cũng là yêu cầu từ phía đối tác. Có hệ thống đòi hỏi đáp ứng hàng chục ngàn lượt truy cập cùng lúc tuy nhiên 1 số hệ thống lại chỉ cần đáp ứng lượng truy cập ít hơn mà vẫn hoạt động ổn định.
Work follow sẽ test? Mỗi hệ thống sẽ có các chức năng khác nhau, nghiệp vụ khác nhau. Do đó bạn cần tự định nghĩa được kịch bản sử dụng của người dùng khi họ truy cập hệ thống của mình là gì. Từ đó sẽ tiến hành tạo lập script test theo flow đó.
Kết quả đầu ra yêu cầu?
VD: Kiểm tra hiệu năng của hệ thống với 1000 user với luồng thao tác sau: Đăng nhập sau đó Đăng xuất.
Mục tiêu: Tìm ra khoảng thời gian đáp ứng chạy tốt của hệ thống khi 1000 user cùng thao tác liên tục. Tức là hệ thống cần đảm bảo 1000 user truy cập trong X phút. Tỉ lệ request lỗi 0%. Tìm X?
Số lượng user: 1000. Lặp lại: 1 lần. Thời gian: X phút.
Work follow: Truy cập trang login -> Ấn nút Đăng nhập -> Truy cập trang chủ -> Ấn nút Đăng xuất.
Kết quả đầu ra yêu cầu: tỉ lệ lỗi 0%, thời gian phản hồi trung bình < 10 000 ms.
Bước 2: Tạo lập Scripts test
Dựa vào kế hoạch test bên trên, ta sẽ đi tạo lập các script tương ứng cho từng action. Để giả lập truy cập của người dùng trên hệ thống.
Trong ví dụ bên trên thì ta sẽ cần tạo 4 Http request như sau:
Truy cập trang login
Logic check login
Truy cập trang chủ
Logic logout
Chi tiết các bước như sau:
Tạo thread group: Quy định 1000 user truy cập trong 600s (10 phút). Ở đây giả định X cần tìm là 600s. Sau khi phân tích kết quả test. Ta sẽ đánh giá xem X như vậy đã đáp ứng được yêu cầu chưa?
Tạo Thread Group
Thêm Http request default, Http cookie manager.
Thêm request truy cập trang login:
Url truy cập trang login
Request check login: Thực hiện cấu hình parameter + file chứa thông tin tài khoản của user như giới thiệu ở Phần 1.
Cấu hình parameter và Url check Login.
Load file CSV config dữ liệu 1000 tài khoản.
Để biết logic check login truy cập vào url nào và paramater gửi lên như thế nào. Ta thực hiện Login vào hệ thống từ trình duyệt web. Sau đó sử dụng Developer tool (F12) để phân tích dữ liệu. Hoặc đơn giản hơn, hãy yêu cầu team phát triển hệ thống cung cấp giúp bạn logic của việc kiểm tra login này, để bạn tạo lập script chính xác hơn. Ở đây mình đang thực hiện 1 ví dụ minh họa để bạn hiểu được cách thức thực hiện. Chúng ta cùng sang bước tiếp theo.
Request vào trang chủ: /home
Request logout: /login/logout
Thêm listener để theo dõi kết quả
Như vậy là ta đã hoàn thiện xong script giả lập các thao tác của người dùng trên hệ thống. Việc tiếp theo chúng ta sẽ thay đổi tham số của Thread group và tiến hành test, theo dõi kết quả.
Bước 3: Thiết lập kịch bản test
Ở bước này, trước khi test ta cần đề ra các kịch bản test và kết quả đầu ra mong muốn của hệ thống.
VD:
– Kịch bản 1: 1000 user test liên tục trong 10 phút. Yêu cầu hệ thống phản hồi < 1000 ms. Tỉ lệ lỗi 0 %.
– Kịch bản 2: 2000 user test liên tục trong 10 phút. Yêu cầu hệ thống phản hồi < 3000 ms. Tỉ lệ lỗi < 1%.
Bước 4: Thưc thi kịch bản test
Để bắt đầu chạy test, ấn nút Start và theo dõi các report trên giao diện
Bước 5: Đánh giá kết quả test
Theo dõi kết quả test và đưa ra các điều chỉnh phù hợp cho Thread Group để tiến hành test các trường hợp khác cho tới khi tìm được đầu ra mong muốn. Để xem lại chi tiết ý nghĩa các Report. Xem lại Hướng dẫn sử dụng Jmeter test hiệu năng website – Phần 1.
Như vậy mình đã hướng dẫn các bạn các bước để thực hiện 1 kịch bản test một cách cơ bản nhất. Trong quá trình áp dụng thực tế, sẽ có các vấn đề cần lưu ý tùy thuộc vào công nghệ bạn tạo ra hệ thống của mình. Mình sẽ chia sẻ thêm phần này ở bài viết sau nhé.
Mọi người có ý kiến trao đổi gì thì comment bên dưới nhé!
Tư duy phản biện là một kỹ năng quan trọng trong ngành Nhân sự. Việc tuyển dung freelancer it hay bất cứ vị trí nào đều đòi hỏi các kỹ năng đặc biệt. Dưới đây là list 5 cuốn sách TopDev đã tổng hợp.
Cẩm nang tư duy phản biện: Khái niệm và công cụ
Cuốn sách này Là 1 trong 6 tài liệu quan trọng thuộc bộ sách tư duy. Với 46 trang sách, bạn đọc sẽ biết thêm nhiều điều tú vị về tư duy phản biện. Đối với các ứng viên freelancer IT, Junior, Senior, tuyển dụng Data Scientist… đều có thể áp dụng các quy tắc được hệ thiết lập và hệ thống hóa.
Tất nhiên, đây không phải là một tác phẩm dễ ngấm. Sách tư duy về kỹ năng đòi hỏi người tiếp thu phải chủ động, sáng tạo trong việc tìm tòi; sẵn sàng đặt ra các thắc mắc.
Điều này có ý nghĩa quan trọng đối với thông điệp chính của sách. Đó là dẫn dắt và mang lại giá trị thông qua sự liên kết và thực hiện hành vi thực tiễn.
Cẩm nang tư duy phản biện: Khái niệm và công cụ
Tư duy nhanh và chậm
Nếu là một ứng viên trẻ, thì đây là cuốn sách lý tưởng dành cho bạn. Hãy thử đọc nó để cảm nhận các giá trị mà nó mang lại. đơn xin nghỉ việc
Cuốn sách nói về tính hợp lý và phi lý của con người trong tư duy. 2 phần như hai khía cạnh đối lập. Song nó phụ ứng lẫn nhau để giúp cho khả năng tuy duy được linh động hơn.
Khi đọc nó, các freelancer IT sẽ biết thế nào là tư duy cảm tính – tư duy khách quan; tính tự động; năng lực điều tiết cảm xúc và giới hạn của những khuôn mẫu,… Đó đều là những cơ sở logic quan trọng giúp bạn phát triển lối tư duy này.
Tư duy nhanh và chậm
Lối mòn của tư duy cảm tính
Cuốn sách này thu hút độc giả bởi những lời cảnh báo đầy sắc nét. Khi tận hưởng những nội dung, bạn sẽ nhận ra các quyết định của mình liệu có cơ sở, có sự ảnh hưởng như thế nào đến sự phát triển bản thân trong tương lai.
Đồng thời, cuốn sách đã giải thích, phân tích các hành vi thực tế nhằm đi đến các kết luận về các giải pháp khoa học giúp hạn chế sự tác động tiêu cực của lối tư duy này. Đây được xem là một điều hết sức quan trọng.
Lối mòn của tư duy cảm tính
Critical Thinking: Tools for Taking Charge of Your Professional and Personal Life
Tạm dịch: Tư duy phản biện – Công cụ để đảm đương công việc và cuộc sống
Với cuốn sách này, các ứng viên freelancer it sẽ nắm được cách thức sử dụng hiệu quả và phát triển khả năng tư duy phản biện. Chính điều này sẽ giúp khám phá những cơ hội, giảm thiểu những quyết định sai nhằm đạt được những mục tiêu lớn của cuộc đời.
Cuốn sách khuyến khích bạn đặt ra các giả thuyết. Từ đó, quy chiếu đến hiện thực để đi đến các quyết định quan trọng. Đưa ra các quyết định đúng đắn sẽ khiến bạn trở nên tự tin hơn trong các thời khắc quan trọng của sự nghiệp.
Tư duy phản biện: Công cụ để đảm đương công việc và cuộc sống
Asking the right questions: A guide to critical thinking
Tạm dịch là Đặt câu hỏi đúng – Dẫn lối tư duy phản biện
Khi đọc quyển sách này, nhiều ứng viên freelancer it, senior sẽ hiểu được nguyên tắc đầu tiên của tư duy phản biện là biết đặt câu hỏi đúng. Một câu hỏi đúng phải thật sự được định hướng đúng trọng tâm của vấn đề.
Cuốn sách khai thác các khía cạnh khác nhau của lập luận (vấn đề, kết luận, lý do, bằng chứng, giả định, ngôn ngữ) và cách phát hiện các sai sót; trở ngại đối với lối tư duy này trong cả giao tiếp bằng văn bản và thị giác.
Làm sao phát hành thành công một sản phẩm ở vị trí Product Manager?
Tác giả: Dr. Nancy Li
Đây là câu hỏi chắc chắn sẽ xuất hiện trong bất cứ cuộc phỏng vấn nào liên quan đến Product Manager tuyển dụng. Những người phỏng vấn sẽ hỏi bạn rằng “Hãy cho biết lúc nào là thời điểm bạn quyết định chuyển từ các biểu mẫu dữ liệu sang thực thi xây dựng sản phẩm?” Bài viết dưới đây của tôi sẽ chia sẻ với bạn cách trả lời hợp lý nhất, dựa trên kinh nghiệm phỏng vấn hơn 100 ứng viên cũng như bài học tôi rút ra từ những thất bại của mình.
Ứng viên cho vị trí PM đối mặt với nhiều câu hỏi khá khó
Product Manager là gì? Lý do thật sự đằng sau câu hỏi này
Hiểu được ngọn nguồn vấn đề giúp bạn giải quyết câu hỏi tốt hơn. Mục đích của câu hỏi này có hai ý chính:
Bạn đã từng làm công việc Product Management trước đây chưa?
Tức là bạn đã có kinh nghiệm làm việc nào liên quan đến vị trí này trước đây chưa. Thông qua cách bạn trình bày sự hiểu biết của mình với khái niệm Product Manager là gì, công việc của Product Manager ra sao,… giám khảo có thể hiểu được phần nào khả năng của bạn.
Bạn đã sử dụng những phương pháp hiện đại để phát hành sản phẩm bao giờ chưa?
Bạn có biết về các loại biểu đồ hay quy trình làm việc nhanh chưa? Ở thời điểm hiện tại, khi phỏng vấn vị trí Product Manager, nhà tuyển dụng muốn tìm hiểu cách làm việc với công nghệ hiện đại mà bạn áp dụng trong việc quản lý sản phẩm của mình.
Do đó bạn cần đảm bảo mình phải trả lời đúng framework để ghi điểm!
Nghiên cứu thị trường đối với Product Manager là gì?
Cách nghiên cứu thị trường của Product Manager là gì? Lấy ví dụ, khi tôi tiến hành làm việc cho sản phẩm về mô hình thành phố thông minh, tôi sẽ bắt đầu bằng cách nghiên cứu thị trường để hiểu khách hàng muốn gì, đối thủ của mình trong thị trường này ai, có những giải pháp thay thế nào,… Thực chất mà nhà tuyển dụng muốn khai thác ở bạn, chính là bạn có thể tìm kiếm được những gì từ thị trường.
Bên cạnh đó, bạn phải đảm bảo là mình đã hỏi khách hàng về quan điểm của họ, hiểu rõ ràng và cặn kẽ yêu cầu của họ. Xác định được tiếng nói của khách hàng trong việc xây dựng phương án cho sản phẩm.
Một PM cần dành nhiều thời gian để nghiên cứu thị trường
Thứ hai là tiến trình MVP (Minimal Viable Product), khi nhắc đến MVP bạn cần phải chắc chắn rằng mình đã đưa ra ý tưởng chuyển đổi được thực hiện thông qua nghiên cứu thị trường. Tôi phát hiện rằng thành phố mình vẫn chưa có công nghệ đúng đắn để áp dụng cho việc giảm các vụ tai nạn xe hơi nên tôi đề xuất giải pháp A, B, C,… Và khi tôi làm việc với các kỹ sư trong công ty chúng tôi đã nảy ra ý tưởng về MVP, một phiên bản mới của MVP.
Bạn nên giải thích với khách hàng rằng phiên bản đầu tiên của MVP sẽ thu thập các data của thành phố với những chức năng a, b, c. Mô tả một cách thật sự đơn giản về MVP của bạn trong một câu. Sau đó giải thích cách bạn phát triển MVP này như thế nào. Khi nói về MMP, bạn nên nói với họ rằng bạn đã từng làm việc với một team dev, UI UX design và sẽ phản hồi lại thông tin cho khách hàng. Tất cả thông tin sẽ được lặp đi lặp lại như vậy.
Sản phẩm của Product Manager là gì sau khi chuẩn bị phát hành
Thứ 3, ứng viên cho vị trí Product Manager cần phải nói về sản phẩm sắp phát hành. Khi bước vào giai đoạn này, bạn cần phải đi vào chi tiết vấn đề liên quan đến việc bạn và team sẽ tung sản phẩm ra thị trường như thế nào, bạn sẽ làm việc với ai, chiến lược marketing mà bạn hướng đến là gì. Và tất cả tựu trung lại trong từ khóa, những gì người phỏng vấn đang tìm kiếm.
Kết luận
Điều duy nhất mà tôi muốn nhắc các bạn là đừng bao giờ tham lam kể quá nhiều các chi tiết trong mỗi gạch đầu dòng phía trên. Bạn chỉ nên mô tả mọi thứ trong khoảng 1, 2 câu với mỗi bước. Và cuối cùng bạn cần có khẳng định được kết quả rằng, trong vòng nửa năm làm việc tại công ty, bạn có thể cho phát hành một sản phẩm, đạt được doanh thu 100 triệu hay thu hút thêm 100 khách hàng sử dụng nó.
Kết thúc một cách mạnh mẽ bằng cách trình bày được những ảnh hưởng của bạn lên sản phẩm, đó là cách để bạn gây ấn tượng với nhà tuyển dụng. Trên đây chính là cách để bạn trả lời tốt nhất những câu hỏi liên quan đến vị trí PM, nhất là khi ứng tuyển vào các công ty đòi hỏi chuyên môn cao như KMS Technology tuyển dụng…
Bài viết được sự cho phép của tác giả Kien Dang Chung
Khi bạn đọc được bài viết này, tôi tin rằng bạn là một người may mắn, đơn giản là vì dưới đây tôi sẽ giới thiệu đến cho bạn một javascript framework có tên là Vue.js đang phát triển chóng mặt dù mới chỉ xuất hiện lần đầu vào năm 2014 với phiên bản Vue.js 1.0. Vue.js phát triển nóng hơn khi phát hành phiên bản Vue.js 2.0 vào tháng 10/2016. Với 51k đánh giá Vue.js trên Github, gấp đôi số lượng sao có được từ Angular, Vue.js thật sự đang có những bước phát triển vượt bậc. Tại sao Vue.js đạt được thành tựu lớn trong một thời gian ngắn như vậy, những nguyên nhân đó sẽ nói lên tại sao bạn may mắn khi biết đến Vue.
Vue.js là framework chịu học hỏi những gì tốt nhất từ các hệ thống khác, nó cũng giống như Laravel một PHP framework có độ phủ lớn nhất hiện nay, cả hai framework này đều sàng lọc những tính năng, cách thức thiết kế tốt nhất từ các framework đối thủ. Cũng chính vì vậy, Laravel cũng giới thiệu Vue.js như là một javascript framework nên dùng khi xây dựng hệ thống. Sự kết hợp các tính năng được học hỏi này tạo nên một framework không tưởng, “thật vi diệu” – tôi tin đấy là câu nói của bất kỳ ai khi tìm hiểu các tính năng của Vue.
Xây dựng dựa trên các Component là ý tưởng chính của Vue.js
Vue.js Component giúp module hóa trong việc lập trình HTML, Javascript, CSS, tạo ra các khối giao diện người dùng có thể tái sử dụng. Component vi diệu hơn các đối tượng ở chỗ nó có thể được sử dụng lại trong các template như là một phần tử HTML.
React chính là nguồn cảm hứng chính của Vue.js về ý tưởng component, đôi khi có thể bạn còn cảm thấy Vue.js lấy cảm hứng từ cả Polymer hay Web component. Tôi nghiêng về React hơn bởi Polymer được thiết kế để tạo ra các thành phần riêng mà có thể sử dụng trực tiếp trong HTML, trong khi đó React và Vue.js sử dụng component chỉ ở trong các template, sử dụng các render engine và bộ biên dịch template tạo ra các mã HTML với các thành phần đã biết. Thật sự mà nói cũng không thể biết được là ai lấy ý tưởng của ai nhưng chúng ta cảm nhận thấy có những tính năng rất hay từ các hệ thống được kế thừa vào những anh lính mới.
Chỉ thị – lệnh trong Vue.js
Vue.js Directive – tạm dịch là các chỉ thị hay các thành phần câu lệnh trong Vue.js giúp render engine hiểu được phải làm gì? Các chỉ thị này điều khiển luồng thực hiện và thao tác với DOM (Document Object Model) giúp xây dựng các mẫu, chỉ thị giống như thuộc tính trong các thành phần HTML.
<ul id="example-1"><li v-for="item in items">{{ item.message }}</li></ul>
v-for là một thuộc tính chỉ thị lặp qua các phần tử của items để hiển thị message của chúng trong các phần tử <li>. Angular cũng làm một điều tương tự như vậy:
<ul id="example-1"><li ng-repeat="item in items">{{ item.message }}</li></ul>
Với cách thức này “học hỏi” được từ Angular, các đoạn mã dễ dàng đọc và viết hơn khi sử dụng trộn lẫn giữa các mã Html và Javascript.
Kiến trúc Component trong các file riêng
Vue.js không phải là nguồn gốc của ý tưởng tạo ra các Component trên các file riêng biệt, Polymer và Web Component mới là những người đi đầu xây dựng kiến trúc này. Một ví dụ trên trang chủ của Polymer nói lên điều đó:
Vue.js không chỉ có vậy mà còn đi xa hơn các đàn anh của mình với việc hỗ trợ các ngôn ngữ tiền xử lý khác thay thế cho CSS (như Sass, Less, Stylus hay CSS Module), HTML(như Pub) và Javascript như TypeScript, CoffeeScrip. Tích hợp tất cả các ngôn ngữ và công nghệ vào một file giúp tạo ra một framework có những tính năng tuyệt vời.
Core Vue.js với tính năng tối thiểu
Vue.js chỉ tập trung vào việc render giao diện người dùng và các tương tác, nó cung cấp tối thiểu các tính năng cần thiết cho thiết kế và xây dựng kiến trúc. Về mục tiêu phát triển này, Vue.js cũng rất tương đồng với React, cả hai framework để các thư viện khác đảm nhận các công việc mở rộng như định tuyến, quản lý trạng thái tập trung… Chính bằng cách loại bỏ các tính năng không cần thiết ra khỏi thư viện lõi trong Vue.js, giúp cho framework này rất nhỏ gọn và mềm dẻo.
Lời kết
Chỉ một năm nữa, khi chúng ta quay lại bài viết này, Vue.js sẽ ở một đỉnh rất cao, tôi tin là như vậy, bởi cũng chính cách thức này mà Laravel hiện đang đứng đầu trong các PHP framework. Chúng ta cũng không lấy gì làm ngạc nhiên bởi những gì ưu việt nhất của các đối thủ, đã được Vue.js học tập, triển khai, không những thế còn phát triển xa hơn các đàn anh của mình.
Bài viết được sự cho phép của BQT Kinh nghiệm lập trình
Performance testing là một loại test quan trọng để xác định ứng dụng web đang được kiểm tra có đáp ứng các yêu cầu tải cao hay không. Loại test này được dùng để phân tích hiệu năng máy chủ một cách tổng thể khi chịu tải nặng.
Chuỗi bài viết này mình sẽ giới thiệu tới các bạn 1 công cụ test rất mạnh mẽ và phổ biến hiện nay: Apache Jmeter
Cụm bài viết của mình gồm các phần từ bắt đầu cho tới nâng cao: Phần 1: Giới thiệu và cài đặt
Phần 2: Hướng dẫn xây dựng kịch bản test
Phần 3: Sử dụng Regular Expressions làm việc với Session IDs và Tokens
Phần 4: Mở rộng – Tạo lập Scripts tự động bằng HTTP(S) Test Script Recorder.
Jmeter có thể làm gì?
Jmeter là công cụ giúp ta giả lập thao tác của người dùng trên web. Bằng việc giả lập các thao tác của một số lượng người dùng nhất định, Jmeter giúp ta đánh giá được các kết quả:
– Web có thể chịu được bao nhiêu lượt truy cập/thao tác liên tục cùng lúc?
– Để đáp ứng số lượng X người sử dụng, thì cần phân phối họ truy cập trong bao lâu? Như thế nào để Web vẫn hoạt động bình thường?
– Thời gian response dữ liệu của server với từng mức tải người dùng?
– Kết hợp với 1 số tool monitor server, ta có thể theo dõi thay đổi vật lý của server khi có tải lớn như: CPU, RAM, Network traffic… (Phần này mình sẽ có bài viết khác giới thiệu về các tool monitor – Link đang cập nhật)
Cài đặt và khởi chạy Jmeter
B1: Các bạn Download Apache Jmeter mới nhất tại Đây.
B2: Để chạy được Jmeter, bạn cần cài thêm JDK của Java nữa, download tại Đây
B3: Chạy JDK
B4: Chạy Jmeter: Sau khi download Jmeter, các bạn giải nén và chạy file .jar trong thư mục /bin
Hình 1: Khởi chạy Jmeter
Giới thiệu các thành phần trong Jmeter
Các bạn vui lòng đọc kĩ phần này, trước khi bắt tay vào test hiệu năng 1 cách nghiêm túc. Chúng ta cần hiểu và nắm được ý nghĩa của các thành phần trong Jmeter. Tất nhiên nếu đơn giản bạn chỉ muốn test lượt truy cập vào website của bạn mà không mô phỏng thao tác nào của họ trên đó thì có thể bỏ qua phần này.
Trong phần này chúng ta sẽ tìm hiểu các thành phần sau:
Tạo 1 thread group: TestPlan > Add > Threads (Users) > Thread group
Hình 2: Tạo thread group
Một Thread Group đại diện cho một nhóm người dùng, và nó chứa tất cả những yếu tố khác.Mỗi Thread Group sẽ mô phỏng những người dùng để thực hiện một trường hợp thử nghiệm cụ thể. Thread Group cho phép tester thực hiện những tùy chỉnh về:
Số lượng Thread: Mỗi Thread đại diện cho một người dùng ảo, JMeter cho phép thay đổi số lượng người dùng không hạn chế để thực hiện các thử nghiệm.
Ram-Up Period: Thời gian để bắt đầu tất cả những Thread.
Loop Count: Số lần lặp lại những yêu cầu của người dùng. Ngoài ra còn có những tùy chọn khác như việc chạy các Thread vào lịch biểu định sẵn, xác định hành động sẽ thực hiện khi xảy ra lỗi…
Hình 3: Các thành phần của Thread Group
VD: Number of Threads: 100, Ram-Up Period: 100, Loop Count: 1. Tức là Jmeter sẽ giả lập thao tác cho 100 user thực hiện trong 600s, tức là mỗi user sẽ tiến hành thực hiện cách nhau 1s (100s/100) và lặp lại 1 lần.
Chú ý: 100 user + Loop count: 1 khác gì 50 user + Loop count 2.
Về tổng số request thì bằng nhau, Jmeter sẽ thực hiện 100 lượt test.
Tuy nhiên có sự khác nhau về thứ tự thực hiện của các user như sau:
Controller: HTTP Request Defaults
Tạo HTTP Request Defaults: Add > Config Element > HTTP Request Defaults. HTTP Request Defaults: Định nghĩa trang web mà mình sẽ thực hiện xuyên suốt kịch bản test. 1 kịch bản test có thể có nhiều Http request khác nhau ở các URI (Path) khác nhau, nhưng đều xuất phát ở cùng 1 domain được định nghĩa ở HTTP Request Defaults.
Trong bảng HTTP Request Defaults, hãy nhập tên trang web cần được kiểm tra ( http://www.google.com ), port Number: 80 (Hầu hết các http request trả về dữ liệu qua cổng 80)
Http request: Định nghĩa 1 request mô phỏng cho 1 chức năng/thao tác của user trên hệ thống.
Để thêm mới Http request: Add -> Sampler -> HTTP Request.
Trong Bảng HTTP Request, trường Path cho biết yêu cầu URL nào bạn muốn gửi tới server. Nếu bạn để trống trường này, request sẽ được gửi tới URL: google.com (Đã được config trước đó ở http request default)
Ở đây ta còn có thể định nghĩa phương thức truy cập tới URL trên gồm: GET/POST/HEAD/PUT/DELETE/….
Phổ biến nhất hay dùng là GET/POST.
Để truyền thêm param cho request, ấn nút Add.
Configuration Element
HTTP Cookie Manager: Hầu hết các trang web đều sử dụng cookie để lưu dữ liệu. Do đó, cần thêm element này để có thể lưu dữ liệu của user sau khi thực hiện controller login.
CSV Data Set Config: Dùng để quy định file dữ liệu đầu vào cho kịch bản test với nhiều người dùng khác nhau cùng sử dụng 1 chức năng.
VD: Kịch bản test: 100 user login vào hệ thống sử dụng 100 tài khoản khác nhau. Danh sách username, password của 100 tài khoản đó sẽ được lưu trong file csv_account.txt. Jmeter sẽ đọc dữ liệu từ file này và lần lượt gửi dữ liệu vào mỗi request.
Mẫu file csv_account.txt
Giải thích CSV data
Filename: đường dẫn tới file dữ liệu Varible names: Tên các biến mình định nghĩa, theo thứ tự dữ liệu từ trái qua phải Delimiter: Kí tự dùng để phân cách giá trị các biến.
Theo như file csv_account.txt bên trên thì mình định nghĩa format dữ liệu sẽ là: username, password.
Để sử dụng các giá trị từ file dữ liệu đưa vào http request, cấu hình như sau:
Tại cột value, ta sử dụng các biến đã định nghĩa bên trên. Chú ý cú pháp sử dụng là: ${ten_bien}
Listener
Công cụ Listener mà JMeter cung cấp cho phép xem những kết quả thu được từ việc chạy thử nghiệm dưới các dạng khác nhau như: đồ thị, bảng biểu, cây.. Các listeners sẽ cung cấp một cách trực quan nhất những dữ liệu thu thập được từ việc thực thi các Test case. Tester cũng sẽ có thể tùy chỉnh những thông tin mà Listener trả về một cách dễ dàng bởi các tính năng trong giao diện cụ thể của từng Listener. Có rất nhiều dạng Listener được JMeter cung cấp, có thể kể đến một số Listener thường được sử dụng để cung cấp như:
Summary report: báo cáo tóm tắt kết quả thực hiện test.
View Results Tree: Báo cáo chi tiết kết quả thực hiện của từng request. Tại đây ta có thể xem lại dữ liệu request đó đã gửi đi, và dữ liệu nhận được từ phía server.
View Results in Table: Chi tiết kết quả thực hiện từng request ở dạng bảng. (Chi tiết của dạng summary report)
Graph Results: Biểu đồ thống kê thời gian phản hồi và các tham số sau mỗi request được gửi đi.
Summary Report
Label: Tên http request Sample: số lượng request đã thực hiện Avarage: Thời gian phản hồi trung bình. Đơn vị ms. Min: Thời gian phản hồi ngắn nhất; Max: Thời gian phản hồi lâu nhất Std. Dev: Độ lêch chuẩn thời gian phản hồi Error %: Tỉ lệ % số request bị lỗi (Không nhận được phản hồi từ server). Throughput: Số request server có thể xử lý/ second/minute/hour. Received KB/sec: Thông lượng KB nhận được/giây Sent KB/sec: Thông lượng KB gửi đi/giây Avg. Bytes: Dữ liệu phản hồi trung bình
View Results Tree
View Results In Table
Graph Results
Ở dưới cùng của hình ảnh, có các số liệu thống kê sau đây, được biểu thị bằng màu sắc:
• Đen: Tổng số mẫu hiện tại được gửi – 100.
• Màu xanh dương : Mức trung bình hiện tại của tất cả các mẫu được gửi – 428ms.
• Màu đỏ : Độ lệch chuẩn hiện tại – 325ms.
• Màu xanh lá cây : Tỷ lệ thông lượng biểu thị số lượng yêu cầu mỗi phút mà máy chủ xử lý. – 59 964 request/phút
1 vài chú ý: Throughput càng cao càng tốt. Chứng tỏ server xử lý được nhiều request/thời gian. Nó biểu hiện cho khả năng máy chủ xử lý tải nặng. Throughput càng cao thì hiệu suất máy chủ càng tốt Deviation: Tham số Deviation được hiện màu đỏ, nó chỉ ra sai lệch so với mức trung bình. Giá trị Deviation càng nhỏ thì càng tốt.
Timer
Timer là một phần rất quan trọng khi xây dựng một Test Plan, nó cho phép cài đặt khoảng thời gian giữa 2 yêu cầu kế tiếp nhau mà người dùng ảo gửi đến máy chủ. Điều này sẽ tạo ra một mô phỏng thực tế nhất so với hoạt động thực tế của người dùng trên website.
JMeter cung cấp nhiều Timer với các dạng khác nhau để thiết lập thời gian nghỉ giữa việc thực hiện 2 yêu cầu , như :
• Constant Timer: xác lập thời gian là một hằng số.
• Uniform Random Timer: xác lập thời gian nghỉ ở một khoảng xác định.
Để sử dụng Timer, ta tạo 1 Flow control action và đặt timer vào trong Follow đó.
Tạo Flow control action: Add -> Sampler -> Follow Control Action
Sau đó ta chọn thêm Timer cho Action này. Ở đây ta sử dụng Uniform Random Timer
Action này sẽ “Pause” lại trong khoảng từ 600 ms -> 1000 ms. Rồi mới chuyển qua request tiếp theo.
Vậy là mình đã giới thiệu các thành phần quan trọng của Jmeter trước khi bắt đầu xây dựng một kịch bản test cụ thể. Mọi người theo dõi Phần 2 nhé.
Trong hầu hết các dự án, vấn đề chất lượng là yêu cầu đầu tiên. Nếu bạn ở trong một dự án như vậy, và chưa có bất kỳ một hệ thống kiểm thử tự động chính thống nào được thiết lập, vậy bạn có thể là người đầu tiên triển khai nó. Nó sẽ giúp đỡ dự án của bạn trong việc xây dựng những sản phẩm chất lượng trong thời gian ngắn, và thúc đẩy việc thương mại hóa sản phẩm sớm hơn.
Trong phần ba của loạt bài này, chúng ta sẽ thảo luận về làm cách nào để áp dụng kiểm thử tự động trong dự án, hiểu rõ bước nào cần làm trước và các lý do.
Đi theo những bước này sẽ giúp chúng ta áp dụng kiểm thử tự động một cách liền mạch và cho phép ngăn chặn những cái bẫy mà có thể làm thất bại việc tự động hóa của chúng ta.
Những bước để áp dụng kiểm thử tự động vào dự án
Bước 1 – Thuyết phục ban lãnh đạo
Bất chấp chúng ta đã tìm hiểu và thiết lập kiểm thử tự động để áp dụng vào dự án như thế nào, bạn không thể làm gì được nếu ban lãnh đạo không bị thuyết phục về lợi ích mà kiểm thử tự động mang lại. Một sự thật hiển nhiên: kiểm thử tự động là tốn kém. Các công cụ mắc tiền (chi phí giấy phép cho HP QTP/UFT vào khoảng 8000$ cho một máy). Những chi phí cho kiến trúc sư kiểm thử tự động hay kỹ sư (theo một cách nhìn khác, cũng khá tốn kém). Sau cùng, lợi ích của kiểm thử tự động là không thể thấy ngay lặp tức. Chúng ta cần phải đợi 2-3 tháng trước khi mã kiểm thử được chuẩn bị, kiểm tra và có thể thực thi một cách chắc chắn để ứng dụng vào thực tế.
Vậy làm sao có thể thuyết phục được họ – ban lãnh đạo? Chúng ta cần nói về phân tích chi phí-lợi ích. Như chúng ta có thể hỏi về thời gian chúng ta đã bỏ ra để làm BAT (Build Acceptance Testing) cho ứng dụng? Và, chúng ta có thể nói, nếu làm thủ công mất một ngày, và với kiểm thử tự động, chúng ta có thể kiểm thử trong vòng 2 giờ đồng hồ. Chi phí là mua công cụ, đào tạo nhân sự và chờ đợi kết quả trong 2 tháng. Sau 2 tháng, chúng ta có thể thực thi kiểm thử BAT trong 2 giờ, và nó sẽ tiết kiệm 6 giờ kiểm thử thủ công bất kỳ khi nào ứng dụng có phiên bản mới. Nếu có 4 phiên bản trong một tháng, chúng ta sẽ tiết kiệm được 24 giờ, hay 3 ngày kiểm thử thủ công.
Nó không có nghĩa là kỹ sư kiểm thử thủ công không làm gì, họ sẽ dùng 6 giờ kiểm thử đó để tập trung vào các chức năng mới và quan trọng của ứng dụng, trong khi kiểm thử tự động sẽ làm những vấn đề qui hồi. Sự thiết lập này sẽ nâng cao chất lượng chung của sản phẩm lên nhiều lần.
Nếu quản lý không sẵn sàng trả giá cho chất lượng của sản phẩm, thì không ai có thể ép họ làm vậy. Họ sẽ học một cách tự động khi khách hàng than phiền về sản phẩm. Chất lượng ảnh hưởng lên mọi thứ. Nó ảnh hưởng đến bán hàng, ảnh hưởng mối quan hệ với khách hàng, ảnh hưởng nhận thức về chúng ta trong mắt khách hàng. Vậy nên, ban lãnh đạo thông minh luôn luôn đầu tư vào trong chất lượng của sản phẩm.
Năm bước cần nhớ để thuyết phục quản lý
Nói về lợi ích của kiểm thử tự động một cách chi tiết
Nói rõ kiểm thử tự động là tốn kém và nó tốn chi phí ban đầu, nhưng chi phí sẽ giảm dần khi mã kiểm thử được chuẩn bị và sẵn sàng thực thi
Nói về thời gian 3 tháng chờ đợi trước khi mong muốn bất kỷ kết quả nào từ kiểm thử tự động
Nói rõ kiểm thử tự động không thay thế kiểm thử thủ công, nhưng có thể hỗ trợ kỹ sư kiểm thử thủ công bằng cách kiểm thử nhiều hơn trong cùng một thời gian
Kiểm thử tự động không có nghĩa là kiểm thử với thời gian ít hơn; nó có nghĩa kiểm thử nhiều hơn với cùng thời gian (nếu kỹ sư kiểm thử thủ công thường dùng 8 giờ để kiểm thử BAT, họ sẽ có thể vừa làm BAT cộng với kiểm thử chức năng mới, đồng thời những thứ khác trong cùng 8 giờ với sự trợ giúp của kiểm thử tự động)
Hãy nhớ, thuyết phục quản lý là bước đầu tiên và quan trọng nhất để áp dụng kiểm thử tự động vào dự án/công ty. Nếu họ không bị thuyết phục, hãy quên kiểm thử tự động đi (hoặc tìm một dự án/công ty khác :-))
Bước 2 – Tìm những chuyên gia về kiểm thử tự động
Có hai dạng chuyên gia về kiểm thử tự động
Kiến trúc sư kiểm thử tự động
Kỹ sư kiểm thử tự động
Kiến trúc sư kiểm thử tự động là rất hiếm. Họ khó tìm, cực kỳ mắc và cũng cực kỳ cần thiết cho sự thành công của dự án kiểm thử tự động. Những người này thường chịu trách nhiệm xây dựng mô hình kiểm thử tự động. (Chúng ta sẽ thảo luận về mô hình kiểm thử tự động một cách chi tiết ở một bài khác).
Kiến trúc sư kiểm thử tự động có kinh nghiệm với các loại công cụ khác nhau và họ biết điểm mạnh cũng như điểm yếu của từng công cụ. Họ sẽ giúp ban quản lý tìm công cụ thích hợp cho kiểm thử tự động với các phân tích ứng dụng và công nghệ dùng trong ứng dụng một cách cẩn thận. Họ cũng sẽ giúp xây dựng mô hình, thiết kế các quy ước đặt tên và tạo ra các qui định cho việc viết mã. Họ cũng hỗ trợ trong việc lựa chọn kịch bản kiểm thử nào nên được tự động hóa trước.
Nếu bạn có thể tìm nhân sự chính xác cho vị trí kiến trúc sư kiểm thử tự động, một nữa công việc của bạn đã hoàn thành.
Kỹ sư kiểm thử tự động, mặt khác, là những người sẽ chuyển hóa kịch bản kiểm thử thủ công thành mã kiểm thử tự động. Họ sẽ làm việc dưới quyền kiến trúc sư kiểm thử tự động và sẽ chịu trách nhiệm tạo và thực thi mã kiểm thử.
Vài công ty tuyển dụng kỹ sư kiểm thử tự động từ bên ngoài, và vài công ty làm tuyển dụng nội bộ với việc đào tạo từ những kỹ sư thủ công đang có sẵn. Dù với trường hợp nào, nhân sự cũng phải có khả năng lập trình, đặc biệt là lập trình hướng đối tượng. Một kết hợp của một kiến trúc sư kiểm thử tự động và các kỹ sư kiểm thử tự động là tuyệt vời cho hầu hết các dự án/sản phẩm.
Bước 3 – Dùng công cụ chính xác cho tự động hóa
Vần đề này xứng đáng có một bài viết riêng, (và sẽ có). Nó là một bước khó khăn trong toàn quá trình bắt đầu kiểm thử tự động. Có rất nhiều công cụ tự động trên thị trường, nhưng chúng ta phải lựa chọn những công cụ tốt nhất cho ứng dụng/dự án của chúng ta.
Nói ngắn gọn, ở đây chỉ liệt kê ra những điểm cần xem xét khi lựa chọn công cụ. Phần giải thích chi tiết sẽ được nói trong một bài riêng.
Những điểm quan trọng cần xem cét khi lựa chọn công cụ chính xác:
Công cụ phải hợp với ngân sách. Những công cụ kiểm thử tự động thật sự rất tốn kém. Vậy nên công ty nên có một ngân sách để mua công cụ.
Công cụ phải hỗ trợ cho công nghệ đang dùng trong ứng dụng/dự án của chúng ta. Nếu ứng dụng sử dụng Flash hay Silverlight, công cụ phải hỗ trợ nó. Nếu ứng dụng là thực thi trên di động, công cụ phải có khả năng thực thi kiểm thử di động. Chúng ta có thể mua một công cụ mà hỗ trợ toàn bộ công nghệ dùng trong ứng dụng, hoặc chúng ta có thể mua nhiều công cụ khác nhau cho từng công nghệ. Ví dụ, chúng ta dùng Selenium cho ứng dụng Web, Robotium cho ứng dụng Android và MS Coded UI cho ứng dụng Windows. Bất kể quyết định là như thế nào, nó phải nằm trong ngân sách của công ty.
Chúng ta phải có nhân sự với kỹ năng cần thiết, những người sẽ sử dụng công cụ hay học dùng công cụ trong thời gian ngắn. Ví dụ, chúng ta đã thuê một kiến trúc sư kiểm thử với kinh nghiệm làm QTP nhưng lại mua giấy phép sử dụng MS Coded UI. Công cụ chỉ như một chiếc xe tốt, và chúng ta cần phải có một tài xế tốt để lại những chiếc xe đó.
Công cụ phải một cơ chế báo cáo tốt để hiển thị kết quả cho các bên liên quan sau mỗi lần thực thi.
Có có những nhân tố khác ảnh hưởng đến việc lựa chọn công cụ, và chúng ta sẽ thảo luận chi tiết ở một bài khác.
Bước 4 – Phân tích ứng dụng khác nhau để xác định những gì phù hợp nhất cho tự động hóa
Nếu công ty đang làm với 5 ứng dụng, không cần thiết toàn bộ sẽ được tự động hóa. Chúng ta cần xem xét những nhân tố khác nhau để lựa chọn ứng dụng nên tự động hóa kiểm thử.
Ứng dụng nên tự động hóa kiểm thử cần có những yếu tố:
Ứng dụng không nên ở giai đoạn đầu của chu trình phát triển (Ứng dụng nên có toàn bộ hay vài chức năng mà đã ổn định và đã kiểm thử bởi kỹ sư kiểm thử thủ công)
Giao diện của ứng dụng cần ổn định (Giao diện không được thay đổi một cách thường xuyên)
Kịch bản kiểm thử thủ công đã được viết ra
Mục tiêu chính của kiểm thử tự động là đảm bảo nếu ứng dụng không có lỗi ở một phiên bản, nó sẽ không có lỗi ỡ phiên bản kế tiếp. Kỹ sư kiểm thử thủ công không nên tốn thời gian của họ để tìm lỗi qui hồi, những vấn đề đó nên được phát hiện bởi kiểm thử tự động.
Vậy nên, để tìm lỗi qui hồi, chúng ta cần một ứng dụng mà đã ổn định và đã có kịch bản kiểm thử cho nó. Nhóm kiểm thử tự động sẽ chuyển hóa những kịch bản kiểm thử thành mã và sẽ thực thi những mã này trên những phiên bản để đảm bảo lỗi qui hồi không xuất hiện.
Bài viết được sự cho phép của tác giả Phạm Văn Nguyên
Web sever có ở khắp mọi nơi.
Cho dù bạn là loại kỹ sư phần mềm nào, tại một số thời điểm trong sự nghiệp, bạn sẽ phải tương tác với các máy chủ web. Có thể bạn đang xây dựng một máy chủ API cho dịch vụ phụ trợ. Hoặc có thể bạn chỉ đang cấu hình một máy chủ web cho trang web của bạn.
Trong bài viết này, tôi sẽ đề cập đến cách tạo máy chủ web http cơ bản nhất trong Python.
Nhưng vì tôi muốn chắc chắn rằng bạn hiểu những gì chúng tôi đang xây dựng, tôi sẽ đưa ra một cái nhìn tổng quan trước tiên về máy chủ web là gì và cách chúng hoạt động.
Nếu bạn đã biết máy chủ web hoạt động như thế nào, thì bạn có thể bỏ qua trực tiếp đến phần này.
Máy chủ web HTTP không có gì ngoài một quy trình đang chạy trên máy của bạn và thực hiện chính xác hai điều:
1- Listen các yêu cầu http đến trên một địa chỉ TCP socket cụ thể (địa chỉ IP và số cổng mà tôi sẽ nói về sau)
2- Xử lý yêu cầu này và gửi phản hồi lại cho người dùng.
Cụ thể thì hãy xem ví dụ sau:
Hãy tưởng tượng bạn kéo trình duyệt Chrome của mình lên và nhập www.yahoo.com vào thanh địa chỉ.
Tất nhiên, bạn sẽ nhận được trang chủ Yahoo được hiển thị trên cửa sổ trình duyệt của bạn.
Nhưng những gì thực sự chỉ xảy ra?
Trên thực tế rất nhiều điều đã xảy ra và tôi có thể dành cả một bài viết để giải thích sự kỳ diệu đằng sau việc này xảy ra như thế nào.
Ở cấp độ cao, khi bạn nhập www.yahoo.com trên trình duyệt của mình, trình duyệt của bạn sẽ tạo một thông báo mạng được gọi là yêu cầu HTTP .
Yêu cầu này sẽ đi đến tất cả các máy tính Yahoo có máy chủ web đang chạy trên đó. Máy chủ web này sẽ chặn yêu cầu của bạn và xử lý nó bằng cách phản hồi lại bằng html của trang chủ Yahoo.
Cuối cùng, trình duyệt của bạn hiển thị html này trên màn hình và đó là những gì bạn thấy trên màn hình.
Mọi tương tác với trang chủ Yahoo sau đó (ví dụ: khi bạn nhấp vào liên kết) sẽ bắt đầu một yêu cầu mới và phản hồi chính xác như yêu cầu đầu tiên.
Để nhắc lại, máy nhận được yêu cầu http có một quy trình phần mềm được gọi là máy chủ web chạy trên nó. Máy chủ web này chịu trách nhiệm chặn các yêu cầu này và xử lý chúng một cách thích hợp .
Được rồi, bây giờ bạn đã biết máy chủ web là gì và chức năng của nó chính xác là gì, bạn có thể tự hỏi làm thế nào để yêu cầu đến được máy yahoo đó ngay từ đầu?
Câu hỏi hay!
Trong thực tế đây là một trong những câu hỏi yêu thích của tôi mà tôi hỏi các ứng viên tiềm năng trong một cuộc phỏng vấn lập trình viên .
Hãy để tôi giải thích làm thế nào, nhưng một lần nữa.
Để tạo một máy chủ web trong Python 3 , bạn sẽ cần import 2 module: http.server và socketserver
Lưu ý rằng trong Python 2 , có một module có tên SimpleHTTPServer . Module này đã được hợp nhất vào http.server trong Python 3
Chúng ta hãy xem mã để tạo một máy chủ http
importhttp.serverimport socketserverPORT =8080Handler=http.server.SimpleHTTPRequestHandlerwith socketserver.TCPServer(("", PORT), Handler) as httpd:print("serving at port", PORT)httpd.serve_forever()
Bây giờ hãy phân tích từng dòng mã này.
Đầu tiên, như tôi đã đề cập trước đó, máy chủ web là một quá trình lắng nghe các yêu cầu đến trên địa chỉ TCP cụ thể.
Và như bạn biết bây giờ, một địa chỉ TCP được xác định bởi một địa chỉ IP và số cổng .
Thứ hai, một máy chủ web cũng cần được cho biết cách xử lý các yêu cầu đến.
Những yêu cầu đến được xử lý bởi các xử lý đặc biệt. Bạn có thể nghĩ về một máy chủ web như một người điều phối, một yêu cầu đến, máy chủ http kiểm tra yêu cầu và gửi nó đến một trình xử lý được chỉ định.
Tất nhiên những người xử lý này có thể làm bất cứ điều gì bạn muốn.
Nhưng bạn nghĩ xử lý cơ bản nhất là gì?
Vâng, đó sẽ là một trình xử lý chỉ phục vụ một tệp tĩnh.
Nói cách khác, khi tôi truy cập yahoo.com , máy chủ web ở đầu kia sẽ gửi lại một tệp html tĩnh.
Đây thực tế là những gì chúng tôi đang cố gắng làm chính xác.
Và đó, bạn của tôi, là http.server.SimpleHTTPRequestHandler là gì: một trình xử lý yêu cầu HTTP đơn giản phục vụ các tệp từ thư mục hiện tại và bất kỳ thư mục con nào của nó.
Bây giờ hãy nói về lớp socketserver.TCPServer .
Một phiên bản của TCPServer mô tả một máy chủ sử dụng giao thức TCP để gửi và nhận tin nhắn (http là giao thức lớp ứng dụng trên đầu TCP).
Để khởi tạo Máy chủ TCP, chúng tôi cần hai điều:
1- Địa chỉ TCP (địa chỉ IP và số cổng)
2- Handler
socketserver.TCPServer(("", PORT), Handler)
Như bạn có thể thấy, địa chỉ TCP được truyền dưới dạng một tuple của (địa chỉ ip, port)
IP bằng rỗng có nghĩa là máy chủ sẽ lắng nghe trên bất kỳ giao diện mạng nào (tất cả các địa chỉ IP có sẵn).
Và vì PORT lưu trữ giá trị 8080, nên máy chủ sẽ lắng nghe các yêu cầu đến trên cổng đó.
Đối với handler, chúng ta đang vượt qua trình xử lý đơn giản mà chúng ta đã nói trước đó.
Handler =http.server.SimpleHTTPRequestHandler
Vâng, làm thế nào về serve_forever ?
Serve_forever là một phương thức trên phiên bản TCPServer khởi động máy chủ và bắt đầu lắng nghe và trả lời các yêu cầu đến.
Thật tuyệt, hãy lưu tệp này dưới dạng server.py trong cùng thư mục với index.html vì theo mặc định, SimpleHTTPRequestHandler sẽ tìm một tệp có tên index.html trong thư mục hiện tại.
Trong thư mục đó, khởi động máy chủ web:
$ python server.py
Bằng cách đó, giờ đây bạn có một máy chủ HTTP đang lắng nghe trên bất kỳ giao diện nào tại cổng 8080 đang chờ các yêu cầu http đến.
Bây giờ là thời gian cho những thứ thú vị!
Mở trình duyệt của bạn và nhập localhost: 8080 vào thanh địa chỉ.
Tuyệt vời! Hình như mọi thứ đều hoạt động tốt.
Nhưng localhost là gì?
localhost là tên máy chủ có nghĩa là máy tính này . Nó được sử dụng để truy cập các dịch vụ mạng đang chạy trên máy chủ thông qua giao diện mạng loopback.
Và vì máy chủ web đang nghe trên bất kỳ giao diện nào , nó cũng đang nghe trên giao diện loopback.
Trong thực tế, bạn hoàn toàn có thể thay thế localhost bằng 127.0.0.1 trong trình duyệt của mình và bạn vẫn sẽ nhận được kết quả tương tự.
Cách viết mẫu tin tuyển dụng – Bạn cảm thấy bế tắc khi viết một mẫu tin tuyển dụng có JD – Job Descriptions? Đừng lo lắng vì bài viết này là dành cho bạn. Dù bạn là freelancer it hay các vị trí IT khác nhau, việc nắm bắt yêu cầu tuyen dung it rất quan trọng. Cùng TopDev tìm hiểu nhé!
Nhưng đầu tiên để viết được JD thì cần biết những thứ liên quan đến JD.
Vấn đề của JD trong mẫu tin tuyển dụng?
Đôi khi nói việc viết một JD hay còn dễ hơn là lúc bắt tay vào làm. Hãy bình tĩnh, bây giờ bạn sẽ không phải như vậy nữa đâu! Cùng Let’s go tìm hiểu các vấn đề của JD để các freelancer it sẽ dễ dàng nắm bắt thông tin.
Hãy quan tâm hai vấn đề trọng tâm sau đây:
Cải thiện giao tiếp nội bộ
Bạn phải đảm bảo JD được truyền tải một cách rõ ràng. Điều này giúp freelancer IT, hay các ứng viên IT khác dễ dàng hình dung và nắm bắt tốt các yêu cầu công việc.
Nếu như không có JD, hay JD không rõ ràng thì HR professionals hay các phòng ban khác sẽ không hiểu vị trí bạn đang tuyển dụng như thế nào. Dẫn đến việc khó hỗ trợ bạn một cách tốt nhất để thực hiện quy trình tuyển dụng it.
Vì vậy, điều quan trọng là cần thảo luận để đưa ra các góc nhìn, quan điểm để cùng xây dựng một JD hoàn thiện nhất.
Cải thiện giao tiếp bên ngoài
Vị trí công việc được mô tả rõ ràng và chính xác là rất quan trọng.
Phác thảo một mô tả công việc hấp dẫn là bước đầu tiên trong việc tìm kiếm và tuyển dụng ứng viên chất lượng. Một bản mô tả công việc hấp dẫn có thể giúp bạn thu hút ứng viên chất lượng cao.
Vậy làm sao để viết JD “chất ngầu”
Dưới đây là một vài tips nhỏ cũng như các kiến thức cần thiết, công cụ và resources, sẽ giúp bạn trong việc viết một JD thiệt xịn xò.
Xác định sự khác nhau giữa mô tả công việc và đăng tải công việc
Những thú vị xoay quanh JD
Ai làm chuyên viên tuyển dụng đều cần nhận biết được sự khác biệt giữa mô tả công việc và đăng tải công việc.
Vị trí công việc là một tài liệu nội bộ giải thích chi tiết về vai trò, trách nhiệm của vị trí freelancer IT. Còn đăng tải công việc là chiêu thức để chiêu mộ ứng viên freelancer it. Đây là tài liệu được public rộng rãi ra bên ngoài.
Sử dụng cấu trúc JD chung
Tất cả người làm về tuyển dụng nên viết JD theo một khuôn mẫu chung. Khuôn mẫu này giúp bạn có những điều cơ bản nhất của JD. Tuy nhiên bạn có thể tỏa sức sáng tạo trên JD của chính.
Khuôn mẫu chung bao gồm những thành phần cơ bản sau:
Vị trí công việc
Vị trí công việc phải được viết rõ ràng và dễ hiểu. Đồng thời, sử dụng tên hay vị trí công việc được nhiều người biết đến; phù hợp với các tiêu chuẩn ngành.
Ví dụ như trong ngành IT, mình suggest một vài vị trí công việc như freelancer it, senior developer, junior developer, …. Với mỗi ngành đều có tiêu chuẩn tên công việc riêng. Bạn khó có thể nào đề title công việc là lập trình viên cấp cao thay vì để senior developer. Vậy đó, nghe nó chẳng hợp lý chút nào cả (mà lại kém sang nữa).
Tóm tắt vai trò công việc
List ra những đầu công việc cần phụ trách; giải thích tại sao vị trí công việc này quan trọng trong công ty bạn. Đừng quên ghi thêm vào đó mục tiêu, định hướng của công ty. Điều này giúp tránh trường hợp phát sinh ngoài ý muốn. Ví dụ như Nói một cách dễ hiểu hơn là tuyển sai người.
Trách nhiệm và vai trò công việc
Đừng quên list ra các đầu mục về trách nhiệm ứng viên cần có; các vai trò của công việc đó trong công ty như thế nào. Mỗi vị trí trong công ty đều mắt xích với nhau cả. Bạn cần lưu tâm về việc giải thích rõ cụ thể các vai trò của từng vị trí. Nếu không, bạn sẽ khó khăn khi chọn lọc ra CV IT phù hợp.
Yêu cầu chuyên môn và những kỹ năng liên quan
Hãy list ra các yêu cầu về trình độ học vấn; chứng chỉ chuyên môn cần có và những kỹ năng mềm khác liên quan đến vị trí công việc đang tuyển. Chính những tiêu chí này sẽ giúp bạn chọn lựa đánh giá được các ứng viên thật sự phù hợp nhất.
Checklist các kỹ năng cần thiết
Viết JD “có hàng có lối”
Khuyến khích sử dụng cv template it để chuyên nghiệp hóa cách viết JD. Chỉ cần vào lựa chọn loại nào phù hợp với công ty hoặc với gu thẩm mĩ của bạn là ổn nhất. Sau đó điều chỉnh một chút để phù hợp với JD mà bạn mong muốn. Điều này giúp tiết kiệm thời gian trong việc tuyển dụng các ứng viên freelancer it, senior developer, tuyển dụng Data Scientist,…
Sử dụng công cụ bổ trợ chuyên nghiệp
Các công cụ tuyển dụng chuyên ngành được sử dụng nhiều hơn để đáp ứng nhu cầu viết viết và promote JD tuyển dụng.
Bạn sẽ dễ dàng truy cập các mẫu mô tả công việc miễn phí; xây dựng các trang web tuyển dụng đẹp đẽ (mà không cần coding gì cả). Đồng thời, nó cũng giúp tối ưu hóa việc xuất bản bài đăng trên các trang tuyển dụng khác nhau chỉ với một click chuột.
Bạn cũng có thể thiết lập các chương trình tuyển dụng riêng của công ty mình. Tạo các chiến dịch email hấp dẫn để JD match với mục tiêu ứng viên trên social media. Tất nhiên, những cách thức trên đều có ý nghĩa lớn trong việc thiết lập JD. Và việc tuyển dụng ứng viên freelancer it, senior developer hay bất kỳ một ví trí it nào đó sẽ không còn là vấn đề lớn nữa.
Đối với lĩnh vực eCommerce, việc cạnh tranh thị phần liên tục mở ra thách thức về đổi mới công nghệ cho mỗi doanh nghiệp. Không dừng lại ở những tính năng độc đáo, mới lạ, mỗi thương hiệu cũng cần chú trọng việc cá nhân hóa sản phẩm và nâng cao trải nghiệm người dùng trên website. PWAs (Progressive Web Apps) mang đến lợi thế của một website hoạt động tương tự native apps, thích hợp hiển thị đa kênh, tối ưu hóa khả năng tiếp cận người dùng dễ dàng trên di động, từ nhiều nguồn đa dạng và phù hợp với bối cảnh headless commerce lên ngôi trong ngành bán lẻ.
Đối với lập trình viên, việc chủ động tìm hiểu xu hướng công nghệ mới như PWA luôn là điều đúng đắn. Tiếp nối thành công từ workshop đầu tiên, Workshop số 2 của Sutunam, với sự đồng hành của TopDev, các chuyên gia công nghệ sẽ giải đáp sâu hơn về kỹ thuật và cách thức triển khai PWAs. Đặc biệt các bạn lập trình đang làm trong lĩnh vực eCommerce sẽ tìm được cho mình một số chú ý về UI/UX khi phát triển PWA cho website thương mại điện tử.
Các chuyên đề và Chuyên gia nào sẽ đồng hành cùng bạn vào workshop ngày 10/12/2020:
1. Introduction to PWA architecture ► Diễn giả: Việt Thái – Lập trình viên Senior về Javascript, Sutunam Vietnam
2. Share capabilities – How thing’s going with PWA? ► Diễn giả: Thanh Tùng – Lập trình viên Senior về Javascript, Sutunam Vietnam
3. Performant components through customization ► Diễn giả: Maya, thành viên Core team Storefront-UI, Israel
Tham gia workshop, bạn sẽ “bỏ túi” những kiến thức thú vị
– Tổng quan về cấu trúc của PWAs. Các hướng tiếp cận và tính năng cần thiết để thiết kế và xây dựng một ứng dụng PWA.
– Góc nhìn cụ thể hơn (kèm demo) để hiểu về cách thức hoạt động về cách chia sẻ dữ liệu trong PWAs.
– Vài nét về giải pháp PWA của headless frontend dành cho các nền tảng e-commerce tối ưu nhất thời điểm hiện tại. Ta cũng sẽ tìm hiểu một số chú ý trong khi tùy biến thiết kế cho các tình huống đặc thù trong e-commerce.
– Hiểu rõ cách tạo ra một UI library cho phép tùy chỉnh các component một cách tự do nhất có thể, trong khi vẫn có thể bảo đảm tối ưu hiệu suất và khả năng mở rộng?
Đối tượng: các lập trình viên, PM và những người làm trong lĩnh vực lập trình, thương mại điện tử. Vì số lượng chỗ ngồi có hạn, bạn vui lòng đăng ký sớm để giữ những slots cuối cùng nhé!
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Chạy file jar giống như một service trên Ubuntu (Linux).
Trong bài này chúng ta sẽ thực hiện chạy 1 ứng dụng java (file .jar) trên ubuntu giống như 1 service (chạy ngầm). Tức là chúng ta có thể start, stop nó giống như 1 service hay có thể thể lựa chọn khởi động cùng hệ thống, xem log …
Giả sử mình có 1 file jar là spring-boot-hello.jar nằm trong folder /home/cuongth/workspace . Bây giờ mình sẽ thực hiện chạy file jar này giống như 1 service.
Bước 1: Tạo một service
Ở đây mình sẽ tạo 1 service với tên là spring-boot-hello. Do đó mình cần tạo file spring-boot-hello.service trong folder /etc/systemd/system với nội dung sau:
spring-boot-hello.service
[Unit]Description=Demo Spring Boot Hello[Service]User=cuongth# The configuration file application.properties should be here:#change this to your workspaceWorkingDirectory=/home/cuongth/workspace#path to executable.#executable is a bash script which calls jar fileExecStart=/bin/bash /home/cuongth/workspace/spring-boot-hello.shSuccessExitStatus=143TimeoutStopSec=10Restart=on-failureRestartSec=5[Install]WantedBy=multi-user.target
Trong đó:
Description: mô tả service
User: user dùng để chạy service
ExecStart: lệnh chạy script (ở đây mình chạy file bash ở vị trí: /home/cuongth/workspace/spring-boot-hello)
Để tạo file trên các bạn có thể dùng lệnh vi, rồi copy nội dung trên vào là được. (hoặc dùng text editor như nano, gedit…)
sudo vi /etc/systemd/system/spring-boot-hello.service
Ở đây mình dùng lệnh java để chạy file spring-boot-hello.jar, hiện trên máy mình đang cài java ở folder /opt/java/jdk1.8.0_241. Các bạn sửa lại thành folder chứa java trên máy của các bạn là ok.
Trong file spring-boot-hello.jar của mình là 1 web app đã nhúng sẵn tomcat và chạy trên port 8081, sau khi start service thì truy cập đường dẫn http://localhost:8081 sẽ có kết quả như sau:
Bước 4: Xem log
Để xem log của service ta dùng lệnh sau:
sudo journalctl --unit=my-webapp . See real-time logs by using the -f option.
If you want to trim them, use -n <# of lines> to view the specified number of lines of the log:
sudo journalctl -f -n 1000 -u spring-boot-hello
Trong đó:
-f: xem log realtime (log thay đổi gì sẽ hiện ra luôn)
-n: hiển thị số dòng log từ thời điểm hiện tại về trước đó
-u: tên service
Kết quả:
Để stop lại service ta dùng lệnh:
sudo systemctl stop spring-boot-hello
Để không cho service khởi động cùng hệ thống ta dùng lệnh:
Hiện nay, “Microservices” là một trong những thuật ngữ hay từ khóa phổ biến nhất (buzz-words) trong lĩnh vực kiến trúc phần mềm. Bạn có thể tìm thấy khá nhiều tài liệu giới thiệu và nói về những nguyên tắt cũng như lợi ích của microservices, tuy nhiên khá ít tài liệu hướng dẫn cách áp dụng microservices trong những hoàn cảnh thực tế.
Ứng dụng phần mềm doanh nghiệp được thiết kế để đáp ứng nhiều yêu cầu kinh doanh của doanh nghiệp. Do đó, các phần mềm cung cấp hàng trăm các tính năng và tất cả những tính năng này đều được gói trong một ứng dụng monolithic. Ví dụ: ERPs, CRMs hay nhiều phần mềm khác chứa hàng trăm tính năng. Việc triển khai, sửa lỗi, mở rộng và nâng cấp những phần mềm khổng lồ này trở thành một cơn ác mộng.
Kiến trúc hướng dịch vụ (Service Oriented Architecture – SOA) được thiết kể để giải quyết một phần của vấn đề bằng cách giới thiệu khái niệm “service”. Một dịch vụ (service) là một nhóm tổng hợp các tính năng tương tự trong một ứng dụng. Do đó trong SOA, ứng dụng phần mềm được thiết kế như một tổ hợp của các dịch vụ. Tuy nhiên, với SOA, giới hạn hay phạm vi của một dịch vụ khá là rộng và được định nghĩa khá “thô” (coarse-grained). Việc này khiến các services cũng có thể trở nên quá to và phức tạp.
Hình 1: Monolithic architecture
Trong phần lớn trường hợp, dịch vụ trong SOA là độc lập nhưng chúng lại được triển khai chung. Tương tự như ứng dụng monolithic, những dịch vụ này to và phức tạp lên theo thời gian vì thường xuyên thêm các tính năng. Và thế là những ứng dụng này lại trở thành một mớ các dịch vụ monolithic, cũng không còn khác mấy so với kiến trúc nguyên khối thông thường.
Hình 1 thể hiện một ứng dụng gồm nhiều services. Những services này được triển khai cùng một lúc vào 1 ứng dụng lớn. Dù bên trong có gồm các services thì đây là một ứng dụng monolithic. Một số tính chất của kiến trúc nguyên khối (Monolithic Architecture):
Được thiết kế, phát triển và triển khai theo một khối duy nhất.
Ứng dụng monolithic phức tạp và to gây khó khăn cho việc bảo trì, nâng cấp và thêm tính năng mới.
Khó áp dụng phát triển kiểu Agile.
Phải triển khai lại toàn bộ hệ thống dù chỉ cập nhật hay nâng cấp một phần.
Mở rộng: phải mở rộng cả khối ứng dụng, gặp khó khăn nếu có các yêu cầu về tài nguyên khác nhau (ví dụ một service yêu cầu thêm CPU, service khác lại yêu cầu nhiều memory).
Độ tin cậy: một service không ổn định có thể sập cả hệ thống.
Khó đổi mới: ứng dụng monolithic phải sử dụng chung công nghệ nên khó thay đổi hay áp dụng công nghệ mới.
Những tính chất giới hạn trên của kiến trúc nguyên khối dẫn tới sự phát triển của kiến trúc dịch vụ nhỏ (Microservices Architecture).
Kiến trúc dịch vụ nhỏ (Microservices Architecture)
Mục tiêu nền tảng của kiến trúc microservices là xây dựng một ứng dụng mà ứng dụng này là tổng hợp của nhiều services nhỏ và độc lập có thể chạy riêng biệt, phát triển và triển khai độc lập.
Một số khái niệm về microservices nói về quá trình chia tách ứng dụng monolithic thành nhóm các services độc lập. Tuy nhiên, theo quan điểm của tôi, microservices không chỉ về chia tách các servcies sẵn có trong monolithic.
Ý tưởng quan trọng chính là nhìn vào các tính năng trong một ứng dụng monolithic, ta có thể nhận biết, xác định các yêu cầu và khả năng cần thiết để đáp ứng một nghiệp vụ. Sau đó từng năng lực nghiệp vụ này sẽ được xây dựng thành những service nhỏ, độc lập. Những services này có thể sử dụng các nền tảng công nghệ khác nhau và phục vụ một mục đích cụ thể và có giới hạn.
Theo đó, ví dụ về hệ thống trong hình 1 có thể được chia theo microservices như trong hình 2. Đây có thể là một ứng dụng phần mềm bán hàng, với kiến trúc microservices, mỗi chức năng kinh doanh hay trong doanh nghiệp được tách thành một microservices. Trong kiến trúc microservices, một service mới được tạo ra từ những services gốc trong kiến trúc monolithic.
Hình 2: Microservices Architecture
Tiếp theo, chúng ta sẽ nói về các nguyên tắc chính của kiến trúc microservices và quan trọng hơn chính là cách chúng được sử dụng trong thực tế.
Thiết kế Microservices: kích cỡ, phạm vi và tính năng
Bạn có thể xây dựng ứng dụng mới với microservices hoặc chuyển đổi ứng dụng sẵn có sang microservices. Với cách nào thì việc quyết định kích cỡ, phạm vi và tính năng của microservices rất quan trọng. Có thể đây chính là phần khó nhất bạn gặp phải khi phát triển hệ thống microservices trong thực tế.
Dưới đây chúng ta sẽ xem xét một số vấn đề thực tế và những hiểu sai về kích cỡ, phạm vi và chức năng của microservices.
Số dòng code/ kích cỡ của một đội lập trình là chỉ số không chính xác: có vài cuộc bàn luận về kích thước của một service dựa vào số lượng dòng code hay kích thước của đội phát triển service đó (ví dụ two-pizza team). Tuy nhiên, những cách đo đếm này không thực tiễn và không chính xác, vì ta có thể phát triển services với ít dòng code hoặc với một đội nhỏ nhưng hoàn toàn đảm bảo được các nguyên lý trong kiến trúc microservices.
“Micro” là một từ khóa dễ gây nhầm lẫn. Một số lập trình viên nghĩ rằng họ nên tạo ra services nhỏ hết mức. Điều này là một cách hiểu sai.
Trong SOA, services thường trở thành các cục monolithic với nhiều hàm, chức năng khác hỗ trợ. Vì vậy, chỉ phát triển services kiểu SOA rồi dán nhãn microservices hoàn toàn lạc hướng và không mang lại bất kì lợi ích nào của kiến trúc microservices.
Do đó, câu hỏi là chúng ta nên thiết kế services trong kiến trúc microservices như thế nào thì phù hợp và đúng mực?
Một Số Chỉ Dẫn Khi Thiết Kế Microservices
Single Responsibility Principle (SRP): một service với phạm vi và chức năng giới hạn, tập trung vào một nhiệm vụ giúp quá trình phát triển và triển khai dịch vụ trở nên nhanh chóng hơn.
Trong quá trình thiết kế, ta nên xác định và giới hạn các services theo chức năng nghiệp vụ thực tế (theo Domain-Driven-Design).
Đảm bảo microservices có thể phát triển và triển khai độc lập.
Mục tiêu của thiết kế là phạm vi của microservices phục vụ một nghiệp vụ chứ không chỉ đơn giản làm các dịch vụ nhỏ hơn. Kích thước hợp lý của một service là kích thước đủ để đáp ứng yêu cầu của một chức năng trong hệ thống.
Khác với services trong SOA, một microservice không nên có quá nhiều hàm hay chức năng hỗ trợ xung quanh và định dạng thông báo/ gửi tin (messaging) phải đơn giản.
Một cách tốt là có thể bắt đầu với services to có phạm vi rộng rồi chia nhỏ dần (dựa theo nghiệp vụ thực tế của hệ thống).
Trong ví dụ về hệ thống bán hàng, bạn có thể thấy ứng dụng monolithic được tách thành bốn microservices là “inventory”, “accounting”, “shipping” và “store”. Chúng giải quyết một yêu cầu giới hạn nhất định nhưng tập trung vào chức năng đó. Theo đó, mỗi service tách biệt hoàn toàn khỏi nhau và đảm bảo tính linh hoạt và độc lập.
Ồ, nếu tách các services ra độc lập, vậy làm sao liên lạc và trao đổi thông tin/dữ liệu giữa các services với nhau?
Liên lạc giữa Microservices
Trong ứng dụng monolithic, các chức năng khác nhau nằm trong các component khác nhau được kết nối bằng cách gọi hàm hay phương thức. Trong SOA, việc này được chuyển sang một chế độ tách rời hơn với kiểu nhắn tin qua các dịch vụ web (web service messaging), phần lớn dùng SOAP trên nền giao thức HTTP, JMS. Những webservices này khá phức tạp. Như đã nói ở trên, microservices yêu cầu là phải có một cơ chế truyền tin đơn giản và nhẹ.
Vậy đó là những cơ chế nào?
Gửi Tin Đồng Bộ – REST, Thrift
Với truyền tin đồng bộ (người gửi – client sẽ chờ một khoảng thời gian để nhận kết quả từ service), REST là sự lựa chọn hàng đầu vì nó cung cấp hệ thống truyền tin đơn giản qua giao thức HTTP dạng request – response. Do đó, nhiều microservices sử dụng HTTP với API. Mỗi chức năng sẽ xuất ra (expose) API.
Hình 3: Dùng REST API để hiển thị microservices
Ngoài REST, Thrift cũng được sử dụng để truyền tin đồng bộ.
Gửi Tin Bất Đồng Bộ – AMQP, STOMP, MQTT
Trong một số kịch bản, truyền tin bất đồng bộ là cần thiết (client không mong đợi response ngay lập tức, hoặc không cần response). Các giao thức truyền tin bất đồng bộ như AMQP, STOMP hay MQTT được sử dụng rộng rãi.
Như vậy là chúng ta có gửi tin nhắn đồng bộ hoặc bất đồng bộ. Nhưng nên định dạng cho tin nhắn thế nào đây?
Các Định Dạng Tin Nhắn – JSON, XML, Thrift, ProtoBuf, Avro
Quyết định định dạng tin nhắn phù hợp cho microservices cũng là một yếu tố quan trọng. Với phần lớn các ứng dụng microservices, họ sử dụng những kiểu tin nhắn dạng chữ như JSON và XML trên nền giao thức HTTP với API. Trong trường hợp cần truyền tin dạng nhị phân, microservices có thể dùng dạng Thrift, Proto hay Avro.
Service Contracts – Định Nghĩa Service Interfaces – Swagger, RAML
Khi bạn có một nghiệp vụ được xây dựng như một dịch vụ, bạn cần định nghĩa và thông báo hợp đồng dịch vụ (service contract thể hiện giao kèo của service).
Bởi vì chúng ta xây dựng microservices trên kiểu kiến trúc REST, ta có thể sử dụng cùng kiểu REST API để định nghĩa hợp đồng của microservices. Do đó, microservices sử dụng các ngôn ngữ định nghĩa REST API tiêu chuẩn như Swagger, RAML để định nghĩa hợp đồng dịch vụ.
Đối với trường hợp microservices không được triển khai dựa trên HTTP/REST (cụ thể là dùng Thrift), chúng ta có thể dùng mức độ giao thức ‘Interface Definition Languages’ (ví dụ: Thrift IDL)
Kết Nối Microservices (Giao Tiếp Giữa Các Services)
Trong kiến trúc microservices, ứng dụng phần mềm được cấu thành từ các dịch vụ độc lập. Để hoàn thành một tác vụ của người dùng trên phần mềm, kết nối và giao tiếp giữa các microservices là cần thiết vì tác vụ gồm nhiều tác động khác nhau lên các services. Vì vậy, giao tiếp giữa các microservices là một vấn đề cực kì quan trọng.
Khi áp dụng SOA, giao tiếp giữa các services được tiến hành bởi một Enterprise Service Bus (ESB) và phần lớn logic nằm trong tầng trung gian này (định tuyến cho tin nhắn, chuyển đổi và điều phối tin nhắn). Tuy nhiên, kiến trúc microservices thúc đẩy việc loại trừ một tầng giao tiếp trung gian tập trung/ ESB và chuyển phần ‘smart-ness’ hay business logic sang các services (nó được gọi là ‘Smart Endpoints’).
Bởi vì microservices sử dụng giao thức tiêu chuẩn như HTTP/REST, JSON, …, Cho nên các giao tiếp giữa các microservices được cố gắng thống nhất về giao thức và hạn chế tối đa việc tích hợp với một giao thức khác. Một lựa chọn khác cho giao tiếp giữa microservices là sử dụng một message bus nhẹ hay gateway với khả năng định tuyến tối thiểu hoạt động như những đường truyền đơn thuần không xử lý business logic gì hết (dump pipe). Dựa vào những phong cách này, có một số kiểu mẫu giao tiếp trong microservices như dưới đây.
Point-to-point – Kết Nối Trực Tiếp Giữa Các Services
Với kiểu kết nối trực tiếp điểm nối điểm, toàn bộ logic của việc định tuyến truyền tin nhắn nằm trong mỗi điểm cuối (endpoint) hay chính là các services. Và services nói chuyện trực tiếp với nhau. Mỗi service mở ra một REST APIs và bất kì service hay khách hàng bên ngoài nào cũng có thể gọi service qua REST API của nó.
Hình 4: Giao tiếp giữa các microservices dùng point-to-point
Rõ ràng là mô hình này đơn giản và hoạt động ổn với ứng dụng microservices tương đối nhỏ nhưng khi số lượng services tăng lên, việc giao tiếp trở nên cực phức tạp. Đây là lý do trong mô hình SOA truyền thống người ta sử dụng Enterprise Service Bus (ESB), chính là để loại bỏ kết nối trực tiếp phức tạp và rối rắm. Sau đây là một số nhược điểm của kiểu giao tiếp trực tiếp (point to point).
Những yêu cầu như xác thực người dùng, điều tiết, giám sát,…phải được thực hiện (implement) ở mọi microservices.
Việc trên dẫn đến các tính năng phổ biến bị trùng lặp, việc thực hiện mỗi microservices có thể trở nên phức tạp.
Không có cách quản lý, kiểm soát giao tiếp giữa các services (chẳng hạn như muốn theo dõi, truy tìm hay lọc các giao hành động giữa các services).
Thường việc kết nối trực tiếp trong microservices được coi là anti-pattern cho việc triển khai các ứng dụng microservice có quy mô lớn.
Vì vậy, với những trường hợp phức tạp hơn, thay vì kết nối trực tiếp hay dùng một ESB trung tâm, chúng ta có thể sử dụng 1 messaging bus trung tâm gọn nhẹ. Nó cung cấp một lớp trừu tượng hóa các microservices (an abstraction layer). Cách này được gọi là API Gateway.
API-Gateway
Ý tưởng chính của API Gateway là sử dụng một cổng truyền tin gọn nhẹ như một điểm vào chính cho tất cả khách hàng/ người dùng và triển khai những chức năng chung mà không liên quan đến nghiệp vụ đặc thù ở cấp Gateway này.
Nhìn chung, một API Gateway cho phép bạn sử dụng một API được quản lý qua HTTP/REST. Vì thế, chúng ta có thể cung cấp tất cả các chức năng nghiệp vụ được phát triển thành microservices qua API Gateway như một APIs tập trung được quản lý.
Hình 5: Tất cả các microservices được giao tiếp thông qua API Gateway
Trong ví dụ bán hàng của chúng ta, theo Hình 5 tất cả microservices đều được xuất ra thông qua API Gateway và đây là một chốt đầu vào duy nhất cho người dùng. Nếu một microservice muốn giao tiếp với một microservice khác thì cần đi qua API Gateway.
API Gateway cung cấp các lợi thế dưới đây:
Cung cấp một lớp trừu tượng hóa các microservices. Ví dụ thay vì cung cấp một API cho tất cả khách hàng, API gateway có thể xuất ra hay hiển thị API khác nhau cho mỗi khách hàng.
Định tuyến và chuyển đổi tin nhắn gọn nhẹ ở cấp gateway.
Một điểm tập trung cho các chức năng chung không mang tính nghiệp vụ kinh doanh như bảo mật, giám sát và điều tiết.
Với API Gateway, microservices trở nên càng gọn nhẹ vì các chức năng chung không mang tính nghiệp vụ đều chuyển sang Gateway.
API Gateway có thể là kiểu mẫu được sử dụng rộng rãi nhất trong triển khai microservices.
Message Broker – Người truyền tin trung gian
Microservices có thể được kết nối qua truyền tin bất đồng bộ như yêu cầu một chiều (requests) hay thông báo/ đăng kí nhận thông báo (publish/ subscribe) qua queues hay topics. Với publish/ subscribe, một service có thể tạo tin nhắn và gửi bất đồng bộ đến một hàng chờ (queue hay topic). Sau đó service khác có thể nhận tin này từ queue hay topic. Phong cách này tách biệt người gửi và người nhận, và người truyền tin trung gian sẽ lưu tin nhắn đến khi người nhận có thể xử lý. Người gửi hoàn toàn không biết gì về người nhận.
Hình 6: Tích hợp gửi tin nhắn bất đồng bộ dùng pub-sub
Giao tiếp giữa người gửi/ người nhận được tạo ra bởi message broker qua các tiêu chuẩn truyền tin bất đồng bộ như AMQP, MQTT,…
Quản Lý Cơ Sở Dữ Liệu Phân Tán
Trong cấu trúc monolithic, ứng dụng lưu dữ liệu vào một cơ sở dữ liệu (CSDL) tập trung duy nhất.
Hình 7: Ứng dụng Monolithic dùng cơ sở dữ liệu tập trung cho tất cả các tính năng của nó
Trong microservices, các chức năng được tách thành nhiều microservices và nếu sử dụng cùng một CSDL trung tâm thì microservices không còn độc lập. Thay đổi dữ liệu của một service có thể làm hỏng các services khác. Do đó, mỗi microservice phải có CSDL riêng.
Hình 8: Microservices có database riêng và chúng không thể truy cập trực tiếp đến database của microservices khác
Dưới đây là vài đặc điểm chính khi phát triển việc quản lý dữ liệu phân tán trong kiến trúc microservices.
Mỗi service có thể có một CSDL riêng biệt để lưu trữ thông tin cần thiết cho nghiệp vụ của service đó.
Một microservice chỉ có thể truy xuất vào CSDL riêng của nó mà không có quyền truy xuất vào CSDL của microservices khác.
Trong một số hoàn cảnh, để hoàn thành một tác vụ bạn cần phải cập nhật nhiều CSDL. Khi đó CSDL của microservices khác chỉ nên được cập nhật qua API của những dịch vụ này (không trực tiếp thay đổi CSDL).
Việc phân tách quản lý dữ liệu cho phép bạn hoàn toàn phân tách các microservices và có thể chọn các công nghệ quản lý dữ liệu khác nhau (SQL hay NoSQL,…nhiều CSDL khác nhau cho các microservices). Tuy nhiên, với các giao dịch phức tạp liên quan đến nhiều microservices, giao dịch phải được thực hiện qua API.
Quản Trị Phân Tán
Kiến trúc microservices ủng hộ quản trị phân tán.
Nhìn chung, quản trị nghĩa là thiết lập và thực thi phương thức mà con người và các giải pháp làm việc cùng nhau để đạt được mục tiêu. Trong ngữ cảnh SOA, quản trị SOA (SOA governance) hướng dẫn việc phát triển các services có thể tái sử dụng, thiết lập cách services được thiết kế, phát triển và cách chúng thay đổi theo thời gian. Nó thiết lập một giao kèo giữa người cung cấp services và người sử dụng services, thông báo cho người sử dụng những thứ họ có thể nhận được và người sử dụng những thứ họ phải cung cấp. Trong quản trị SOA, có hai kiểu quản trị phổ biến:
Quản trị khi thiết kế – định nghĩa và kiểm soát việc tạo services, thiết kế và thực thi các chính sách của services.
Quản trị khi triển khai/ chạy – khả năng đảm bảo các chính sách của services trong quá trình hoạt động.
Vậy trong microservices thì quản trị là gì?
Microservices được xây dựng động lập và phân tán với nền tảng công nghệ khác nhau. Do đó, việc thiết lập một tiêu chuẩn thiết kế và phát triển chung là không cần thiết. Chúng ta có thể kết luận về khả năng quản trị phân tán trong kiến trúc microservices như sau:
Không cần phải có một hệ quản trị tập trung khi thiết kế.
Microservices có thể tự quyết định thiết kế và phát triển của nó.
Kiến trúc ủng hộ và hỗ trợ việc chia sẻ các services chung hay có thể tái sử dụng.
Một số mặt của quản trị trong quá trình hoạt động như SLAs, điều phối, giám sát, bảo mật hay tìm kiếm dịch vụ (service discovery) có thể được phát triển ở cấp API Gateway.
Service Registry & Service Discorvery (Truy Tìm Dịch Vụ).
Trong microservices, số lượng services mà bạn cần xử lý khá lớn. Và địa điểm của chúng có thể thay đổi nhanh và thường xuyên vì tính chất của việc phát triển microservices là nhanh. Nên bạn cần phải xác định được vị trí của một service trong quá trình chạy. Giải pháp cho vấn đề này là Service Registry.
Service Registry
Service Registry giữ các thực thể microservices và địa chỉ của chúng. Thực thể microservices được đăng kí với service registery khi bắt đầu chạy và hủy đăng kí khi tắt. Người dùng có thể tìm các services đang tồn tại và địa chỉ của chúng qua service registry.
Service Discovery
Để tìm các microservices đang tồn tại và địa điểm của chúng, chúng ta cần một quy trình truy tìm dịch vụ. Có hai mô hình là Client-side Discovery và Server-side Discovery. Hãy cùng xem xét hai mô hình này.
Client-side Discovery – Với mô hình này, client hay API Gateway lấy thông tin địa điểm của một thực thể service bằng cách truy vấn Service Registry.
Hình 9: Client-side discovery
Client hay API Gateway phải thực hiện logic tìm kiếm service bằng cách gọi vào Service Registry.
Server-side Discovery – Với cách này, client hay API Gateway gửi yêu cầu lên một component (có thể là một Load Balancer). Component này sẽ gọi Service Registry và quyết định địa điểm của các microservices.
Hình 10: Server-side discovery
Một số giải pháp triển khai microservices như Kubernetes cung cấp mô hình server-side discovery.
Deployment – Triển Khai
Việc triển khai các dịch vụ có một trò trọng yếu và gồm các yêu cầu sau:
Khả năng triển khai/ gỡ xuống độc lập mà không ảnh hưởng đến dịch vụ khác.
Có thể mở rộng theo cấp microservices, chỉ mở rộng microservices cần thiết.
Phát triển và triển khai microservices nhanh chóng.
Một microservice ngắt kết nối hay sập thì không ảnh hưởng các dịch vụ khác.
Docker (một công cụ mã nguồn mở cho phép lập trình viên và quản trị viên hệ thống triển khai các ứng dụng thành các containers trên môi trường Linux) cung cấp một công cụ tuyệt vời để triển khai microservices đáp ứng đủ các yêu cầu trên. Các bước chính gồm:
Đóng gói mỗi microservice thành một ảnh Docker (docker image).
Triển khai mỗi thực thể của service là một Docker container.
Mở rộng dựa vào số lượng thực thể.
Phát triển, triển khai và khởi động microservices trở nên nhanh hơn với Docker (nhanh hơn nhiều các máy ảo thông thường – VM).
Kubernetes mở rộng khả năng của Docker bằng cách quản lý một cụm các Linux container như một hệ thống duy nhất, quản lý và chạy các Docker containers trên nhiều hosts, cung cấp service discovery và kiểm soát việc nhân rộng. Như bạn có thể thấy, những tính năng này cần thiết cho kiến trúc microservices. Vì vậy sử dụng Kurbernetes (trên nền Docker) để triển khai microservices đang trở thành một phương pháp cực kì hữu dụng, đặc biệt với ứng dụng lớn.
Hình 11: Xây dựng và triển khai microservices như các containers
Hình 11 thể hiện tổng quát việc triển khai các microservices. Mỗi thực thể của microservices được triển khai thành một container và có hai containers trên mỗi host. Bạn có thể thay đổi số lượng containers chạy trên một host theo ý mình.
Security – Bảo Mật
Bảo mật microservcies là một yêu cầu phổ biến trong thực tế. Trước khi nói đến bảo mật microservices, hãy nhìn lại cách chúng ta thường thực hiện bảo mật của ứng dụng monolithic.
Bảo mật của một ứng dụng monolithic thường là về xác định xem “Ai là người gọi đến”, “Người này có quyền hạn gì” và “Ứng dụng thông báo về những thông tin này thế nào”.
Một component phụ trách bảo mật chung thường nằm ở đầu chuỗi xử lý yêu cầu và component sẽ trả về thông tin cần thiết.
Vậy chúng ta có thể chuyển đổi trực tiếp mô hình này sang kiến trúc microservices không?
Có nhưng điều này yêu cầu phát triển bảo mật ở từng microservices và kết nối với một cơ sở trung tâm về người dùng để lấy thông tin cần thiết. Đây là một cách khá rối rắm. Thay vào đó, chúng ta có thể tận dụng các API bảo mật tiêu chuẩn như OAuth2 và OpenID Connect để tìm một giải pháp tốt hơn cho vấn đề bảo mật. Trước khi nói sâu hơn, chúng ta sẽ tóm tắt mục tiêu của mỗi tiêu chuẩn và cách sử dụng chúng.
OAuth2 – một phương thức chứng thực kiểu ủy quyền. Client xác thực với server cấp quyền (authorization server) và nhận một token gọi là “Access token”. Access token không chứa bất kì thông tin gì về client. Nó chỉ là một tấm vé tham chiếu đến thông tin người dùng mà server cấp quyền có thể truy xuất đến. Do đó, đây cũng được gọi là token kiểu tham chiếu “by-reference token” và an toàn để sử dụng trên mạng lưới mở và internet.
OpenIDConnect hoạt động tương tự OAuth nhưng ngoài Access Token, server cấp quyền còn phát một ID token chứa thông tin người dùng. Token này thường dạng JWT (JSON Web Token) và được kí bởi server cấp quyền. JWT token do đó được coi là token kiểu tham trị “by-value token” bởi vì nó chứa thông tin về người dùng và có thể trở nên không an toàn.
Bây giờ, hãy xem xét những tiêu chuẩn này có thể bảo mật microservices trong ví dụ bán hàng của chúng ta như thế nào.
Hình 12: Bảo mật microservices với OAuth2 và OpenID Connect
Như hình trên, các bước chính để thực hiện bảo mật microservices gồm:
Chuyển việc xác thực cho server dạng OAuth và OpenID Connect (Authorization server).
Sử dụng API Gateway để có một điểm đầu vào duy nhất cho yêu cầu từ clients.
Client kết nối với server cấp quyền và nhận Access token. Sau đó gửi token này đến API Gateway cùng với yêu cầu.
Dịch token tại Gateway – API Gateway lấy ra access token và gửi đến server cấp quyền để lấy JWT.
Gateway truyền JWT cùng với yêu cầu đến microservices.
JWT chứa thông tin người dùng cần thiết để lưu user sessions,….
Ở mỗi lớp microservice, bạn có thể có một component xử lý JWT, việc này khác đơn giản.
Transactions – Các giao dịch
Các transactions (giao dịch) trong microservices được hỗ trợ thế nào?
Trên thực tế, hỗ trợ các giao dịch phân tán trên nhiều microservices là một nhiệm vụ đặc biệt phức tạp. Kiến trúc microservice tự khuyến khích sự phối hợp không có giao dịch giữa các dịch vụ.
Ý tưởng là một dịch vụ nhất định hoàn toàn khép kín và dựa trên nguyên lý Single Responsibility Principle.
Việc cần phải có các giao dịch phân tán trên nhiều microservice thường là một triệu chứng của lỗ hổng thiết kế trong kiến trúc microservice và thường có thể được sắp xếp bằng cách tái cấu trúc phạm vi của microservice.
Tuy nhiên, nếu có một yêu cầu bắt buộc là phải có các giao dịch phân tán trên nhiều dịch vụ, thì các kịch bản như vậy có thể được thực hiện với ‘compensating operations’ (các hoạt động bù ) ở cấp độ mỗi dịch vụ.
Ý tưởng chính là, một microservice cụ thể dựa trên nguyên lý Single Responsibility Principle và nếu một microservice nào đó không thực hiện được nhiệm vụ đã giao, chúng ta có thể coi đó là một thất bại của toàn bộ microservice đó. Sau đó, tất cả các hoạt động khác
(các hoạt động ở cấp trên) phải được hoàn tác bằng cách gọi hoạt động bù tương ứng của các dịch vụ siêu nhỏ đó.
Design for Failures – Thiết Kế Cho Các Thất Bại
Kiến trúc microservices tăng khả năng xảy ra thất bại tại microservices. Một microservice có thể sập do một vấn đề mạng, nguồn tài nguyên bị thiếu hụt hoặc không sẵn sàng,… Một microservice không đáp ứng lại thì không nên dẫn đến toàn bộ ứng dụng microservices sập. Do đó, mỗi microservices nên có khả năng chịu lỗi và hồi phục khi có thể. Người dùng phải có trải nghiệm tốt, nhẹ nhàng và không nhận ra lỗi bên trong hệ thống.
Thêm nữa, vì các dịch vụ có thể gặp lỗi bất cứ lúc nào, việc phát hiện (giám sát thời gian thực) lỗi nhanh chóng và nếu có thể tự động phục hồi dịch vụ là cực kì quan trọng.
Có một vài kiểu mẫu xử lý lỗi trong microservices phổ biến.
Circuit Breaker
Khi có lời gọi từ bên ngoài đến một microservice, bạn có thể cấu hình một component giám sát lỗi với mỗi lời gọi. Component này đếm số yêu cầu thành công và thất bại, khi lỗi đạt một giới hạn nhất định thì component này sẽ dừng hoạt động của service (ngắt giao mạch).
Cách này hữu dụng để tránh tiêu tốn tài nguyên không cần thiết, yêu cầu bị chậm vì timeouts, cách này cũng giúp giám sát hệ thống.
Bulkhead
Vì một ứng dụng kiến trúc microservices bao gồm nhiều microservices, một service dừng hoạt động không nên ảnh hưởng đến phần còn lại. Kiểu mẫu bulkhead tách biệt các phần của ứng dụng để khi có lỗi tại một nơi nào đó thì không ảnh hưởng hệ thống.
Timeout
Kiểu mẫu timeout là một quy trình cho phép dừng một yêu cầu khi thời gian chờ đợi vượt quá hạn mức. Bạn có thể cấu hình khung thời gian tùy ý.
Vậy khi nào chúng ta sử dụng những kiểu mẫu này?
Trong phần lớn trường hợp, những kiểu mẫu này được áp dụng ở lớp Gateway. Khi microservices không đáp lại hay không sẵn sàng, ở cấp Gateway chúng ta có thể quyết định có nên gửi yêu cầu đến microservices sử dụng circuit breakers hay timeout. Hơn nữa, sử dụng bulkhead ở Gateway khá quan trọng vì đây là một điểm đầu vào cho tất cả yêu cầu từ clients, nên nếu lỗi một service cũng không ảnh hưởng đến việc gửi yêu cầu đến các services khác.
Thêm vào đó, Gateway có thể được sử dụng như một điểm trung tâm ta có thể lấy thông tin về trạng thái và theo dõi các microservices hoạt động.
Microservices, Tích Hợp Cho Doanh Nghiệp, Quản Lý API và hơn thế nữa
Chúng ta đã trao đổi các đặc tính của kiến trúc Microservices và cách bạn có thể thực hiện chúng. Tuy nhiên, bạn nên lưu ý rằng Microservices không phải toa thuốc chữa bách bệnh. Việc áp dụng mù quáng những khái niệm đang nổi sẽ không xử lý vấn đề thực tế của bạn. Nếu bạn đã đọc toàn bộ bài này thì bạn sẽ thấy Microservices có nhiều lợi ích và chúng ta nên tận dụng. Tuy nhiên, bạn cần hiểu rằng mong chờ microservices giải quyết tất cả các vấn đề là không thực tiễn.
Chốt bài
Qua bài này chúng ta có thể hiểu được Microservices là gì, microservices giúp bạn được những gì, cách để chia nhỏ các microservices, cách để tích hợp và tương tác giữa các microservices với nhau, cách để bảo mật khi triển khai ứng dụng với microservices, những công cụ hỗ trợ để giúp bạn triển khai ứng dụng microservices dễ hơn.
Mong rằng các bạn đã có một cái nhìn rõ hơn về Microservices.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Đối tượng String, được định nghĩa trong package java.lang, là một đối tượng cơ bản trong Java. Các bạn sẽ sử dụng nó thường xuyên và là một đối tượng không thể thiếu đối với tất cả chúng ta khi lập trình với Java. Trong bài viết này, mình sẽ trình bày với các bạn sâu hơn về đối tượng String này để các bạn hiểu rõ thêm về nó các bạn nhé!
Khởi tạo đối tượng String
Chúng ta có nhiều cách để khởi tạo một đối tượng String, đó là:
– Sử dụng toán tử new
Ví dụ:
String a = new String("Khanh");
– Sử dụng toán tử gán (“=”)
Ví dụ:
String b = "Khanh";
– Khai báo trong dấu nháy kép
Ví dụ:
System.out.println("Khanh");
Sự khác nhau giữa các cách khai báo trên, đó là:
Nếu các bạn khai báo đối tượng String sử dụng toán tử new thì Java sẽ tạo ra những đối tượng Java riêng biệt, lưu trữ ở những vị trí khác nhau trong bộ nhớ.
Do đó, khi các bạn so sánh những đối tượng này sử dụng toán tử quan hệ (“==”) thì kết quả sẽ là false. Hãy xem ví dụ sau nhé các bạn:
package com.huongdanjava.javaexample;
public class Example {
public static void main(String[] args) {
String a = new String("Khanh");
String b = new String("Khanh");
System.out.println(a == b);
}
}
Kết quả:
Nếu các bạn khởi tạo đối tượng String bằng cách sử dụng toán tử gán (“=”) thì khi so sánh những đối tượng này sử dụng toán tử quan hệ (“==”) thì kết quả sẽ là true.
Hãy xem xét ví dụ sau nhé các bạn:
package com.huongdanjava.javaexample;
public class Example {
public static void main(String[] args) {
String a = "Khanh";
String b = "Khanh";
System.out.println(a == b);
}
}
Kết quả:
Nguyên nhân là do đâu các bạn? Đó là bởi vì khi bạn khởi tạo biến String a với nội dung là “Khanh” sử dụng toán tử gán (“=”) thì Java sẽ tạo một chuỗi “Khanh” được lưu trữ ở một vị trí xác định trong bộ nhớ gọi là String pool. Khi các bạn tạo các biến String khác cũng cùng nội dung là “Khanh”, thì Java sẽ trả về chuỗi ký tự “Khanh” đã được tạo ra trước đó trong String pool. Và do đó, khi các bạn so sánh những đối tượng như thế này, kết quả sẽ luôn là true.
Đối với trường hợp thứ ba thì cũng giống như trường hợp thứ hai, khi so sánh những String được khai báo trong dấu ngoặc kép bằng toán tử quan hệ (“==”) kết quả sẽ luôn luôn true.
Hãy xem xét ví dụ sau nhé:
package com.huongdanjava.javaexample;
public class Example {
public static void main(String[] args) {
System.out.println("Khanh" == "Khanh");
}
}
Kết quả:
Khái niệm Immutable trong String
Làm việc với String, các bạn sẽ gặp khái niệm Immutable. Vậy Immutable là gì? Mình sẽ nói ngay: Immutable là khái niệm để chỉ những đối tượng mà nội dung hay trạng thái của nó không thể bị thay đổi bởi bất cứ đối tượng nào khác.
String là một đối tượng Immutable như thế!
Vậy làm thế nào String có thể là một đối tượng Immutable, mình xin trình bày như sau:
– String lưu trữ giá trị của nó trong một biến mảng với kiểu dữ liệu char. Biến mảng này được định nghĩa với access modifier là private.
– Biến mảng này được khai báo với từ khóa final. Như các bạn đã biết, nếu một biến được định nghĩa với từ khóa final thì nó chỉ được khởi tạo một lần duy nhất.
– Không một phương thức nào trong đối tượng String thao tác với biến mảng này.
Khi trình duyệt nhận một dữ liệu HTML, nó sẽ parse qua DOM node
2 – External Resource
Khi gặp các file CSS, JS nó sẽ chạy đi lấy dữ liệu đó, quá trình parse vẫn tiếp tục, nhưng sẽ chặn việc render trên trình duyệt (CSS được sếp vào loại resource block render)
JS hơi khác, mặc định nó sẽ chặn quá trình parse HTML (block parse). Tuy nhiên với việc truyền thêm attribute defer hoặc async, việc parse js sẽ chạy ngầm, và không chặn parse HTML
Với defer, file sẽ được execute sau khi parse document xong, nếu nhiều file được thêm thuộc tính defer, nó sẽ được execute theo thứ tự trong HTML
Với async, file sẽ execute ngay khi load, nghĩa là có thể trong lúc parse hoặc sau lúc parse, vì vậy thứ tự đặt file không quan trọng, không đảm bảo file execute theo đúng thứ tự.
Với các trình duyệt sau này, nó sẽ hỗ trợ thêm việc preload, lấy về những resource chưa thật sự cần ở thời điểm hiện tại, nhưng trong tương lai có thể cần đến, việc này cũng tùy thuộc vào từng trình duyệt mà cách xử lý có khác nhau
<link href="style.css"rel="preload"as="style"/>
3 – Parse CSS
Sau khi đã có được source file css “trong tay”, trình duyệt làm tiếp 2 thao tác, parse CSS và build CSSOM
4 – Execute JS
Các trình duyệt khác nhau, quá trình parse-compile-execute sẽ khác nhau, cũng cần nhớ thêm việc parse JS rất tốn kém tài nguyên của máy.
Ngay sau khi JS đã load xong và DOM đã parse xong, sự kiện document.DOMContentLoaded sẽ được emit
Sau khi các async JS, image load xong, sự kiện window.load sẽ được emit
window.addEventListener('load',(event)=>{});
5 – Merge DOM và CSSOM để tạo render tree
Hợp thể giữa DOM và CSSOM sẽ cho ra render tree, là toàn bộ những gì sẽ hiển thị trên trình duyệt
6 – Calculate layout và paint
Sau khi đã nhận được render tree, trình duyệt đã có đủ thông tin để tính toán những phần tử nào, đặt ở đâu, kích thước ra làm sao, qua trình đó gọi là calculate layout, kết thúc quá trình tính toán này, trình duyệt sẽ bắt đầu quá trình paint, là những gì user sẽ thấy trên trình duyệt, đây cũng là bước cuối cùng.
Tuyen dung IT thông qua Omni-channel đang dần chiếm lấy vị trí dẫn đầu – khắc phục điểm yếu của multi-channel bằng việc cung cấp sự nhất quán; tập trung vào trải nghiệm của ứng viên. Từ đó giúp việc tuyen dung it trở nên đơn giản và tiết kiệm thời gian hơn. Cùng TopDev tìm hiểu về những điều thú vị xoay quanh Omni-channel trong tuyen dung it.
Omni-channel trong tuyen dung it là gì?
Thuật ngữ Omni-channel có vẻ đã quá quen thuộc trong ngành bán lẻ.
Nó được hiểu là mô hình đặt khách hàng làm trọng tâm trong quá trình mua hàng bằng việc tối đa hóa bán hàng từ kênh offline đến online trên hệ thống quản lý duy nhất; hướng đến sự “nhất quán hóa” trải nghiệm cho họ.
Omni-channel là gì?
Chiến lược này cũng áp dụng cho tuyen dung it. Omni-channel trong tuyen dung it đặt trọng tâm trong quá trình thu hút nhân tài dựa trên:
Tối đa hóa tỉ lệ ứng tuyển (trên cơ sở vận dụng đa kênh; đảm bảo sự tương tác liền mạch). Mục tiêu quan trọng: tạo ra trải nghiệm tuyệt vời cho ứng viên.
Ví dụ của Omni-channel trong tuyen dung freelancer it:
Chạy quảng cáo trên Facebook dẫn về Website của doanh nghiệp. Cùng lúc đó, ứng viên truy cập vào website doanh nghiệp và nhận được lời mời “chat” trong chức năng chat tự động. Các tính năng đa dạng từ đa kênh này chính là Omni-channel.
Tại sao Omni-channel giúp tuyen dung it hiệu quả hơn?
Tiết kiệm thời gian tuyển dụng
Lấy ví dụ là bài toán lớp 5 cơ bản: người thứ nhất làm xong việc trong 4 giờ; người thứ 2 hoàn thành trong 5 giờ; và khi 2 người làm chung, thời gian chỉ rút ngắn còn 2,22 giờ mà thôi.
Omni-channel cũng thế. Nếu như bạn chỉ dùng một kênh duy nhất thì thời gian tuyển được nhân tài vô cùng lâu (có khi tính theo tháng). Tuy nhiên nếu phối hợp khéo léo tất cả các kênh mà ứng viên có mặt thì, bạn biết rồi đấy, CV IT Developer về sau vài ngày không phải là chuyện lạ!
Thông tin doanh nghiệp đáng tin hơn
Khi ứng viên IT thấy doanh nghiệp bạn xuất hiện trên tất cả (hoặc hầu hết) những kênh mà họ truy cập thường ngày, họ sẽ cảm nhận rằng doanh nghiệp bạn biết kết nối và đầu tư vào tìm kiếm nhân tài. Dù freelancer IT hay Developer IT thì những thông tin luôn được cập nhật và chính xác hơn.
Nắm trong tay insights của các ứng viên
Có thể nói mức độ đa dạng của kênh tuyển dụng tỉ lệ thuận với lượng thông tin thu thập về ứng viên
Bạn sẽ có cơ hội tiếp cận nhiều hơn về hành vi; tâm lý ứng viên từ lúc bắt đầu tiếp cận doanh nghiệp đến khi quyết định ứng tuyển vào.
Và dĩ nhiên, những hành vi này là khác nhau với từng kênh tuyển dụng. Việc thu thập đủ thông tin sẽ giúp bạn biết nên đẩy mạnh kênh nào tương ứng với nội dung gì. Từ đó chuẩn bị tốt cho kế hoạch tuyển dụng cạnh tranh hơn. đơn xin nghỉ việc
Làm thế nào để tối ưu hóa vai trò Omni-channel trong tuyển dụng IT?
Tận dụng các dữ liệu hiện có
Ông bà ta có câu “Biết người biết ta trăm trận trăm thắng”. Điều đó không hề sai trong việc sử dụng Omni-channel trong tuyen dung it.
“Biết người” ở đây là thấu hiểu ứng viên IT. Bạn cần nắm rõ chân dung ứng viên IT, các đặc điểm về nhân khẩu học, hành vi, tâm lí,.. một cách sâu sắc nhất.
Ứng viên hay hỏi về doanh nghiệp qua phương tiện nào?… và kết hợp với các đặc điểm chung của thế hệ Milennial và Gen Z – hai thế hệ chiếm tỉ trọng lớn trong lượng ứng viên IT hiện nay. Họ mong đợi ở doanh nghiệp những gì? Liệu các freelancer IT giữa 2 thế hệ có gì khác nhau? Mức độ gắn kết thế nào?…
Tuyen dung it đối với các thế hệ khác nhau là một thách thức lớn
“Biết ta” là hiểu về mình – ở đây là hiểu những cách thức mà mình áp dụng để chiêu mộ nhân tài.
Hiện tại mình sử dụng bao nhiêu kênh? Lượng ứng viên IT sử dụng các kênh này có đông đảo không? Số lượng ứng tuyển từ mỗi kênh là bao nhiêu? Liệu các kênh này đang cho thấy vị trí ngày một quan trọng hay dần ít quan trọng đi?…
Lựa chọn các kênh phù hợp
Sau khi tổng hợp các dữ liệu và rút ra insights quan trọng từ bước 1, bạn có thể tham khảo các kênh tuyển dụng sau:
– Hội chợ việc làm (Job fair)
– Mạng xã hội thông dụng: LinkedIn, Facebook, Snapchat, Instagram, Twitter, Pinterest, Viadeo,.. (theo WeareSocial và Hootsuite, năm 2019, top 5 mạng xã hội được người Việt Nam sử dụng nhiều nhất: Youtube, Facebook, Instagram, Twitter và LinkedIn)
– Các nền tảng khác: TikTok, Houseparty, Lasso, Caffeine,…
– Sự kiện, hội nghị về công nghệCác phần mềm như Google AdWords, Facebook Ads,..
– Blogging, diễn đàn về công nghệ nơi ứng viên IT có thể thảo luận về chủ đề nào đó
– Employee Referral
– Trực tiếp gọi ứng viên
Sai lầm cần lưu ý
Có một sai lầm rằng thấy kênh nào “trendy” thì dùng kênh đó mà quên rằng mình đăng tin để tuyển nhân tài, nghĩa rằng mọi thứ phải đặt mục tiêu là ứng viên, hướng về ứng viên. TopDev sẽ cho bạn một số gợi ý để bạn có thể tự trả lời cho câu hỏi “Liệu mình có nên sử dụng kênh này để tuyển IT không?”
Số người tham gia hiện tại là bao nhiêu?
Có phương tiện truyền thông hay những người nổi tiếng trong lĩnh vực từng nói về nói chưa?
Những nền tảng cũ hơn có tính năng nào na ná không?
Nếu mình sử dụng kênh này cho tuyển dụng, ứng viên có thấy dễ dàng truy cập/sử dụng/tham gia không?
Liệu các ứng viên IT có hứng thú với những kênh mình sắp sử dụng không?
Loại nội dung nào là phù hợp với kênh đó?
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Bài viết được sự cho phép của tác giả Nguyễn Hữu Đồng
function_score
Khi search trong elasticsearch, đôi khi chúng ta mong muốn sẽ chấm điểm dựa trên những điều kiện đã đặt ra để lấy ra một danh kết quả chính xác.
Ví dụ khi bạn search những người có tên có chứa cụm từ “ste” và mong muốn nếu first_name tên đó là “steph ” thì + thêm 3 điểm hoặc nếu first_name của tên đó là “stephen” thì + 5 điểm, …vv, lúc này bạn chắc hẳn sẽ dùng đến function-score để custom hàm chấm điểm.
Như hình trên mỗi function-score là một kiểu “query”, chỉ là nó hơi đặc biệt, trong function-score, field “query” quy định điều kiện để mỗi index được chấm điểm như đoạn code trên.
"query": { "match_all": {} }
Điều này có nghĩa là mọi index sẽ được chấm điểm dựa, hoặc nếu như đoạn code đưới thì nếu index đáp ứng điều kiện là first_name hoặc last_name là “do” thì index sẽ được chấm điểm. Function-Score sẽ kết hợp điểm của query và điểm của function.
score_mode : định nghĩa các kết quả điểm được tạo ra bằng query và điểm tạo ra trong function (function trong function-scrore) sẽ được kết hợp như thế nào, có 6 kiểu nhân, cộng , trung bình cộng, max và min, hoặc là lấy điểm của function đầu tiên có filter match với index.
boost_mode : định nghĩa cách tính điểm khi mà có các điểm mới được tạo ra bằng function score, có 6 kiểu, nhân, cộng, trung bình cộng, thay thế, min, max
boost : điểm để tăng dùng để tính điểm cho các kết quả truy vấn bằng query ( query trong function_score)
functions : tập hợp các function để tính thêm với các index đã được chọn và tính điểm bằng “query”
Function trong Functions của Function-score là nơi chấm điểm cho các kết quả đã được trả về từ query, mỗi index được chấm điểm nếu nó match vs filter của function.
Như đoạn code trên nếu mỗi index sau khi chọn mà thoả mã filter trên thì sẽ được weight = 5 điểm trả về từ function. 5 Điểm này sẽ kết hợp với điểm của các function khác qua giá trị của “score-mode” ví dụ cộng lại điểm của các function hay lấy trung bình cộng, hoặc lên min,max … để trả về kết quả của “functions”.
Ngoài cách dùng functions tính điểm ta còn có thể dùng “script-score” để chấm điểm.
Nhìn sơ qua thì script score sẽ chạy một đoạn code với Index, dùng những tham số đã được truyền qua từ bên ngoài để trả về điểm.
Code demo, sau đây mình sẽ viết một query để chấm điểm cho những kết quả trả về khi mình search những user mà first_name hoặc last_name có chứa chữ “shar”, trả về 1 điểm và nếu first_name hoặc last_name là “sharland” thì mình sẽ cộng thêm 5 điểm.
Ở trên câu query trên, mình chỉ ra rằng, đầu tiền cần tìm ra những index có first_name hoặc last_name có chứa cụm từ “shar” và nếu có thì trả về 1 điểm cho những index này, sau đó tiếp tục tính điểm tiếp với function có filter, nếu index thoả mãn filter thì sẽ trả về 5 điểm.
Do mình setup “boost_mode = replace “ nghĩa là điểm của function score sẽ thay thế điểm của query trên, “score_mode = sum “, nhưng do chỉ có một function nên tổng điểm của functions = điểm của function.
Như các bạn thấy đó, function rất hữu dụng khi bạn muốn custom score trả về theo mong muốn, để tìm hiểu về function-score bạn có thể ghé thăm tại đây.
Cá nhân mình cũng mới tìm hiểu và không tránh khỏi nhiều sai sót, trong tương lai nếu có cơ hội mình sẽ chia sẻ tiếp về những điều thú vị của elasticsearch. Mình xin dừng bút tại đây, cảm ơn các bạn đã đọc bài ^_^
Đây là bài cuối trong loạt các bài về kiểm thử tự động. Bài này sẽ tổng hợp lại một số cách làm tốt nhất và các chiến lược để làm kiểm thử tự động.
Mặc dù những bài trước đã có đề cập đến vài cách làm hay (và vài điều sẽ được nhắc lại ở đây), bài này chỉ liệt kê vài điều, nhưng quan trọng nhất, để làm kiểm thử tự động.
Những chiến lược này không chỉ là từ kinh nghiệm bản thân mà còn từ những chuyên gia kiểm thử như Micheal Bolton, James Back và Cem Kaner. Những cách làm việc này nên được áp dụng trong mọi dự án kiểm thử tự động.
Thuê một đội ngũ hay kỹ sư kiểm thử chuyên trách
Đây là một điều cơ bản. Đừng đòi hỏi kỹ sư kiểm thử thủ công trong dự án tham gia vào kiểm thử tự động. Nếu chúng ta muốn họ phải làm được kiểm thử tự động, hãy giải phóng họ khỏi các công việc kiểm thử thủ công. Kiểm thử tự động là một công việc toàn thời gian. Để đạt được điều đó, chúng ta cần những nhân sự chuyên trách.
Một công cụ kiểm thử tự động là quan trọng, nhưng nó không phải là giải pháp cho tất cả
Chúng ta đã nói về cách lựa chọn một công cụ kiểm thử. Nhưng lựa chọn được một công cụ đúng chỉ là bước khởi đầu. Vài người quản lý có hiểu lầm rằng, nếu có một công cụ đúng, mọi chuyện về kiểm thử tự động sẽ dễ dàng. Hãy cẩn thận, công cụ kiểm thử tự động không cho chúng ta mọi thứ. Chúng chỉ làm cho quá trình tự động hóa dễ dàng hơn. Và chúng ta cần những nhân sự có kỹ năng để hoàn thành quá trình đó.
Thông thường, những công cụ kiểm thử tự động cũng có lỗi của nó và chúng gặp vấn đề khi xác định những đối tượng UI phức tạp của ứng dụng. Nhân sự mà chúng ta có, nếu họ có kỹ năng, sẽ đưa ra những giải pháp để đẩy nhanh quá trình làm việc. Ngược lại, nếu nhân sự không tốt, chỉ với công cụ không thể đảm bảo cho một dự án kiểm thử tự động thành công.
Lựa chọn công cụ kiểm thử quen thuộc với nhân sự đang có
Nếu nhân sự của chúng ta quen thuộc với C# và ứng dụng cần kiểm thử cũng phát triển bằng C#, vậy thì không có lý do nào để chúng ta lựa chọn một công cụ kiểm thử không hỗ trợ viết mã bằng C#.
Học ngôn ngữ lập trình là một quá trình tốn kém thời gian. Bỏ qua được bước này bằng cách sử dụng một công cụ hợp lý sẽ tối thiểu hóa thời gian làm quen với công cụ.
Hiểu biết về ứng dụng cần kiểm thử
Lựa chọn công cụ kiểm thử tự động phụ thuộc vào độ nặng của công nghệ được dùng trong ứng dụng. Hiểu biết về ứng dụng từ trong ra ngoài trước khi bắt đầu việc kiểm thử tự động.
Nếu là một ứng dụng web, biết về những trình duyệt mà nó sẽ hỗ trợ. Biết về những công nghệ được sử dụng trong nó. Nếu là một ứng dụng Desktop, biết về ngôn ngữ để xây dựng nó. Những đối tượng của bên thứ ba được dùng trong ứng dụng. Những điều này sẽ giúp chúng ta lựa chọn công cụ chính xác và kiểm thử tự động trong tương lai sẽ dễ dàng hơn.
Kiểm thử tự động tốt nghĩa là các kịch bản kiểm thử thủ công tốt
Những kịch bản kiểm thử thủ công tốt sẽ tiết kiệm công sức tự động hóa những kịch bản dễ được làm tự động nhưng không đủ mạnh để tìm lỗi.
Kết quả của việc tự động hóa mà không dựa vào thiết kế kiểm thử tốt là có quá nhiều việc để làm nhưng giá trị mang đến lại chẳng bao nhiêu.
Luôn luôn nên viết kịch bản kiểm thử ở định dạng dành cho kiểm thử thủ công. Xác định tất cả các điều kiện quyết định và dữ liệu kiểm thử. Viết các bước rõ ràng và viết các kết quả mong muốn cho các bước. Mục tiêu của từng kịch bản nên rõ ràng và nó nên độc lập với những kịch bản kiểm thử khác. Kỹ sư kiểm thử tự động nên thực thi kịch bản kiểm thử một cách thủ công, ít nhất một lần, để quyết định các đối tượng nào cần xác định và luồng làm việc. Nên tham khảo thêm từ những kỹ sư kiểm thử thủ công.
Hoạt động này, đôi khi, giúp xác định lỗi ngay cả trước khi bắt đầu viết mã kiểm thử. Những chuyên gia cho rằng, đa số các lỗi được xác định trong giai đoạn phát triển mã kiểm thử hơn là giai đoạn thực thi các mã đó.
Xác định mọi cơ hội với tự động hóa
Nếu chúng ta được giao kịch bản kiểm thử để tự động hóa, đừng chỉ tự động hóa bản thân kịch bản đó. Thay vào đó, hãy tìm kiếm những cơ hội trong việc tự động hóa đó, mở rộng giới hạn của kịch bản kiểm thử đó.
Ví dụ, nếu kịch bản kiểm thử yêu cầu chúng ta đăng nhập vào một hệ thống. Chúng ta có thể mở rộng kịch bản này bằng cách sử dụng hướng-dữ-liệu. Liệt kê toàn bộ nhựng kịch bản khả thi của việc đăng nhập như mật khẩu không hợp lệ, mật khẩu rỗng, tên đăng nhập rỗng, tên đăng nhập không hợp lệ, v.v… liệt kê nhưng kịch bản khả thi này vào trong một tập tin Excel và xem tập tin đó như một nguồn dữ liệu cho kịch bản kiểm thử. Và giờ, với một kịch bản kiểm thử ban đầu, với tự động hóa, chúng ta có thể kiểm thử toàn bộ kịch bản khả thi với một lần thực thi.
Luôn luôn tìm kiếm những cơ hội có thể làm với tự động hóa, những việc khó làm với cách làm thủ công. Như kịch bản kiểm thử sức tải, kiểm thử hiệu suất, cùng một kịch bản trên nhiều môi trường khác nhau, cấu hình khác nhau, v.v… đó là những kịch bản khó có thể làm với kiểm thử thủ công.
Chúng ta không thể tự động hóa mọi thứ
Kiểm thử tự động chỉ thực thi những kịch bản nào mà yêu cầu phài thực thi thường xuyên. Chúng ta bắt đầu với bộ kịch bản Smoke trước. Sau đó, đến bộ kịch bản cho kiểm thử chấp nhận. Rồi đến những kịch bản phải sử dụng thường xuyên, và những kịch bản mà tốn nhiều thời gian. Nhưng phải đảm bảo rằng mỗi kịch bản mà chúng ta đã tự động hóa, nó phải tiết kiệm thời gian cho kỹ sư kiểm thử thủ công để tập trung vào những thứ quan trọng khác.
Tự động hóa ở đây không phải để thay thế kỹ sư kiểm thử thủ công. Nó không thể. Tự động hóa có mặt để làm những công việc lặp đi lặp lại thay cho kỹ sư kiểm thử thủ công để họ dành sự tập trung và sức lực cho việc tìm kiếm những kịch bản kiểm thử mới và lỗi mới.
Tự động hóa những kịch bản giá trị và tiết kiệm thời gian hay khó để làm với kiểm thử thủ công. Nếu chúng ta làm được điều đó, công việc của kiểm thử tự động đã hoàn thành.
Bỏ qua kiểm thử tự động GUI khi có những giải pháp thay thế
Kiểm thử tự động GUI luôn là phần khó khăn hơn những kiểu kiểm thử tự động khác. Vậy nên, nếu có những tình huống mà chúng ta có thể đạt được mục tiêu mà không cần đụng đến GUI, bằng cách dùng các phương pháp khác như câu lệnh, thì chiến lược chính xác là bỏ qua phần kiểm thử tự động trên GUI.
Ví dụ, chúng ta cần kiểm thử sự cài đặt của một ứng dụng. Mục tiêu là kiểm tra ứng dụng có được cài đặt hay không trên một môi trường cụ thể. Một cách tiếp cận là khởi động chương trình cài đặt và nhấn vào “Next” liên tục thông qua công cụ kiểm thử tự động. Cách này khá khó để áp dụng, tốn kém thời gian và nó là một vấn đề khi bảo trì khi mà UI thay đổi. Một cách tiếp cận khác là khởi động quá trình cài đặt bằng câu lệnh với một tham số “silent”. Ứng dụng sẽ được cài đặt mà không có một GUI nào. Mục tiêu của kiểm thử sẽ đạt được với thời gian ít hơn và đáng tin cậy hơn.
Tự động hóa
Dùng tự động hóa cho những mục đích hữu ích khác
là một thứ tuyệt với. Chúng ta có thể đạt được nhiều thứ từ nó mà có thể chúng ta chưa từng nghĩ đến. Tự động hóa không chỉ là viết mã cho một kịch bản kiểm thử thủ công. Hơn thế, chúng ta có thể dùng tự động hóa để làm nhanh những hoạt động khác trong dự án.
Ví dụ, chúng ta có thể dùng tự động hóa để tạo những dữ liệu chính và thiết lập cấu hình môi trường một cách tự động cho kỹ sư kiểm thử thủ công. Sau đó, họ có thể bắt đầu việc kiểm thử của họ sớm nhất có thể.
Tôi có thể đưa cho các bạn một ví dụ từ công ty của tôi. Chúng tôi muốn thay đổi công cụ quản lý kiểm thử. Chúng ta đã dùng “Test Director” (HP ALM) và muốn chuyển sang dùng TFS (Team Foundation Server). Chúng ta có khoảng 4000 kịch bản kiểm thử và báo cáo lỗi trong Test Director. Chuyển toàn bộ dự liệu này sang TFS có thể mất cả tháng nếu làm thủ công. Do đó, quản lý của tôi yêu cầu tôi thử vài cách tự động hóa.
Tôi tìm hiểu vài công cụ và thấy rằng, Test Director sử dụng SQL Server làm cơ sở dữ liệu. Với TFS, tôi tìm ra một công cụ cho phép đọc kịch bản kiểm thử và báo cáo lỗi từ tập tin Excel, nếu nó có một định dạng cụ thể, và có thể ghi vào TFS. Phần còn lại của câu chuyện thật đơn giản. Tôi viết một đoạn SQL để lấy toàn bộ kịch bản kiểm thử và báo cáo lỗi, và ghi nó ra một tập tin Excel với một định dạng xác định. Sau đó, tôi dùng công cụ để đọc những dữ liệu này và ghi vào TFS. Toàn bộ quá trình chỉ mất khoảng 3 giờ. Quản lý của tôi rất hài lòng. Tôi hy vọng bạn thấy được vấn đề tôi đang nói ở đây.
Kiểm thử tự động là phát triển phần mềm
Nếu chúng ta phát triển một ứng dụng chất lượng, nó cần những bài thực hành tốt. Nó cần xem xét mã nguồn để viết mã có chất lượng. Nó cần một khuôn khổ để đi theo. Nó cần bảo trì liên tục.
Kiểm thử tự động về cơ bản là việc phát triển phần mềm. Do đó, những bài thực hành tốt nhất mà chúng ta đi theo khi phát triển ứng dụng cũng nên được áp dụng khi làm kiểm thử tự động. Khuôn khổ kiểm thử tự động nên có. Xem xét mã nên được tiến hành. Lỗi của kiểm thử tự động nên được báo cáo trong kho lỗi. Mã nguồn của kiểm thử tự động nên được để trong một hệ quản lý mã nguồn, v.v… chúng ta càng xem việc kiểm thử tự động giống phát triển ứng dụng, kiểm thử tự động càng thành công.
Kết luận
Đây là kết thúc bài này cũng như toàn chuỗi bài về kiểm thử tự động. Tôi đã học được nhiều thứ khi viết chuỗi bài này và tôi hy vọng bạn cũng học được khi đọc chúng. Kiểm thử tự động là một sự nghiệp đầy hứng khởi và xứng đáng. Làm nó đúng không chỉ mang lại lợi ích cho chúng mà còn cả cho công ty/dự án.
Mỗi ngày làm việc với kiểm thử tự động và những kỹ thuật của nó, tôi tìm thấy nhiều thách thức mới và hấp dẫn cần giải quyết. Chuỗi bài này chỉ đánh dấu vài thứ trên con đường kiểm thử tự động. Tôi hy vọng tôi chuyển tải nó đến các bạn một cách chính xác và rõ ràng.








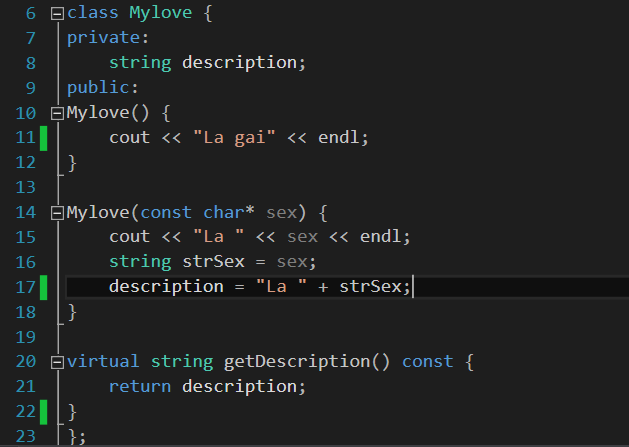

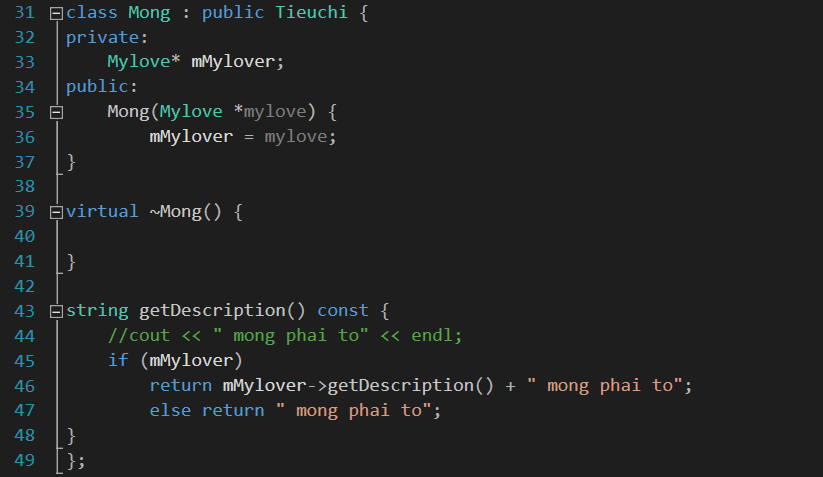 Trong lớp trên, hàm getDescription được kế thừa lại, mô tả lại là mông phải to. Chứ mông lép là anh này anh hổng có yêu :3
Trong lớp trên, hàm getDescription được kế thừa lại, mô tả lại là mông phải to. Chứ mông lép là anh này anh hổng có yêu :3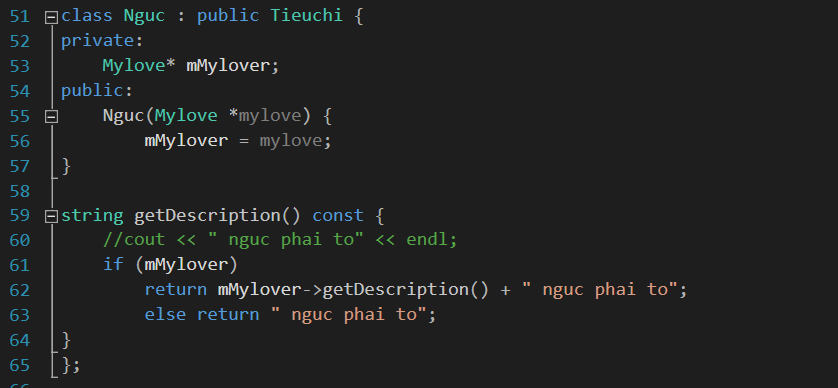
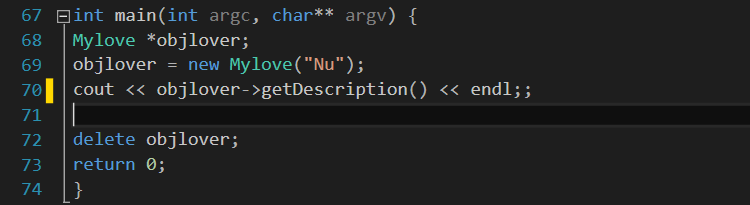

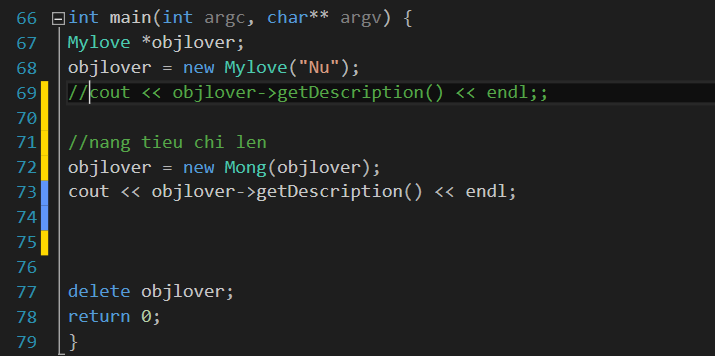
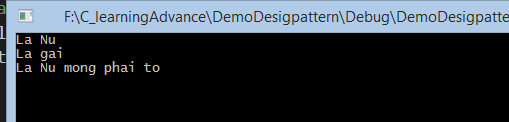
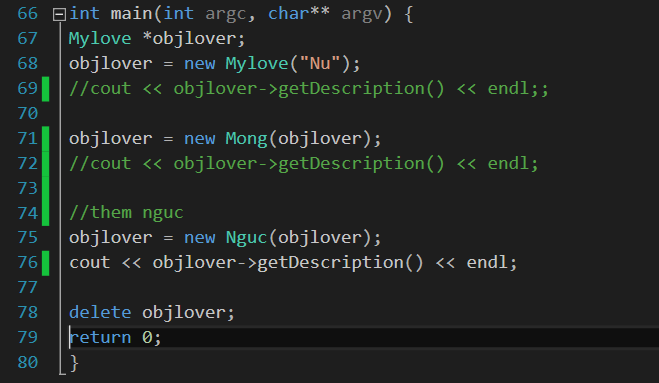
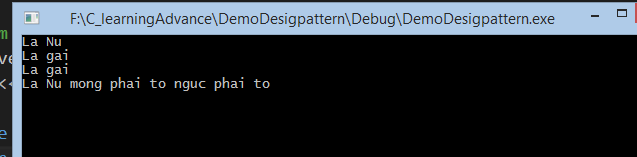


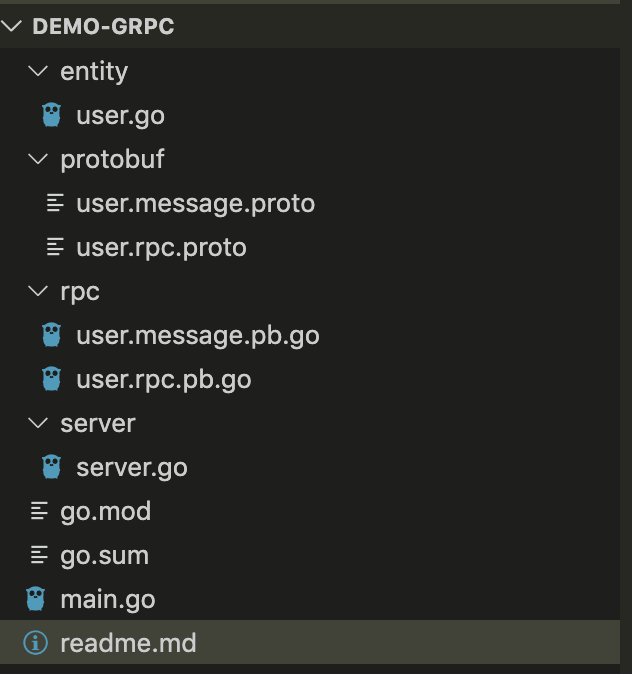
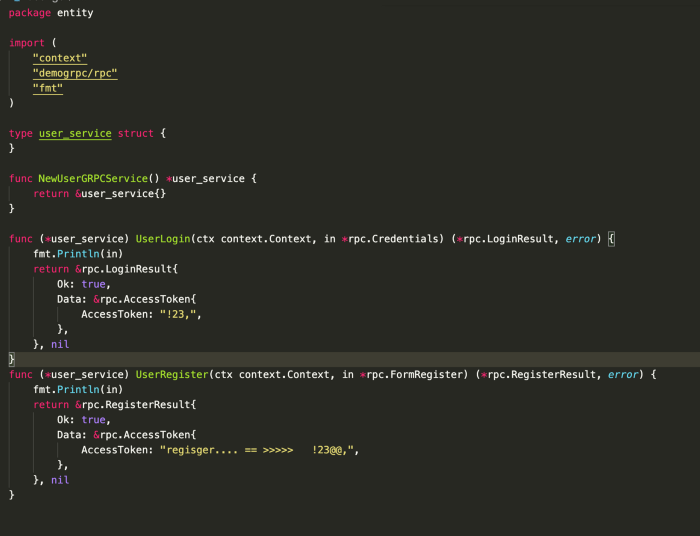
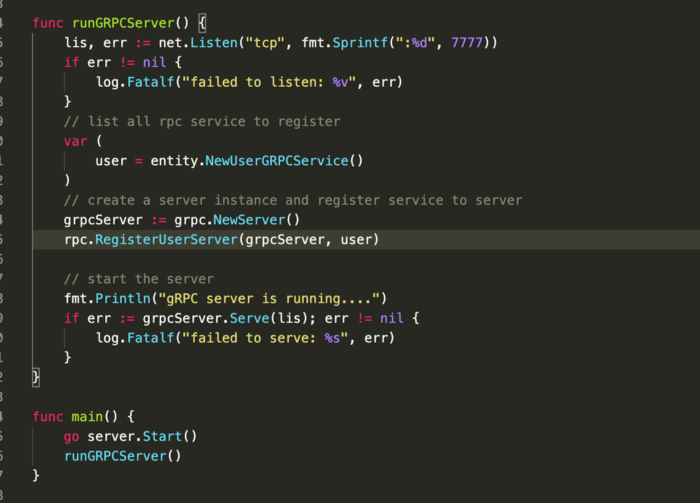
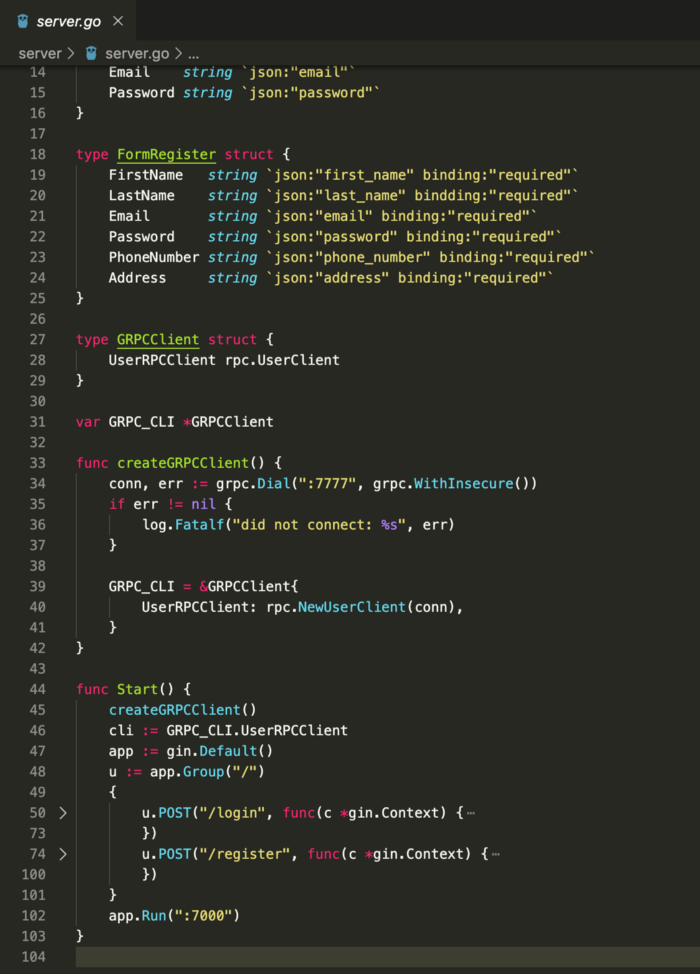
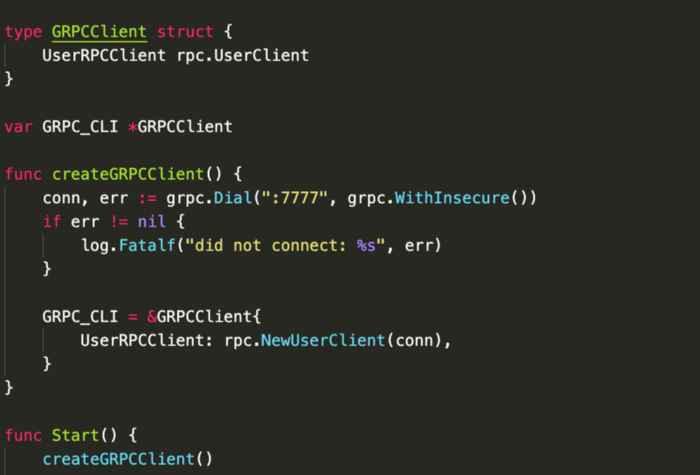
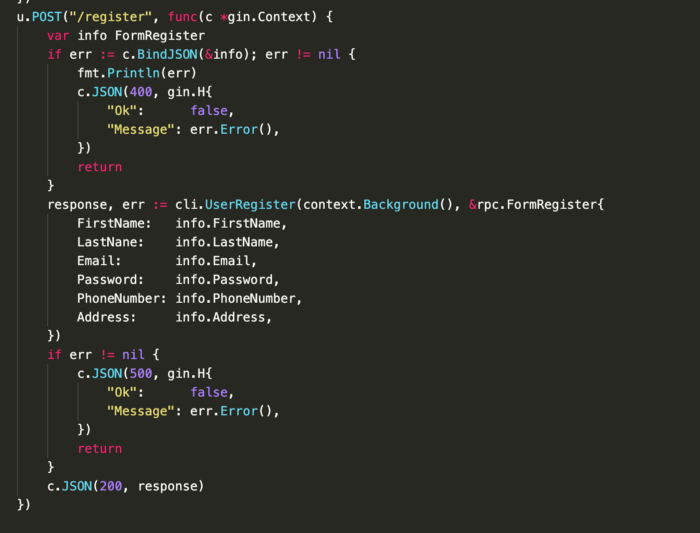
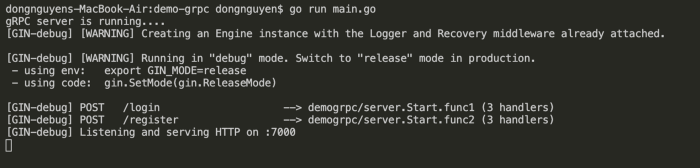
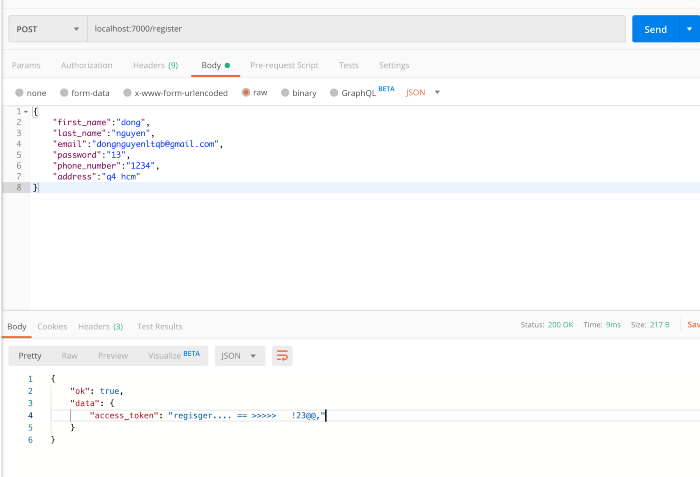


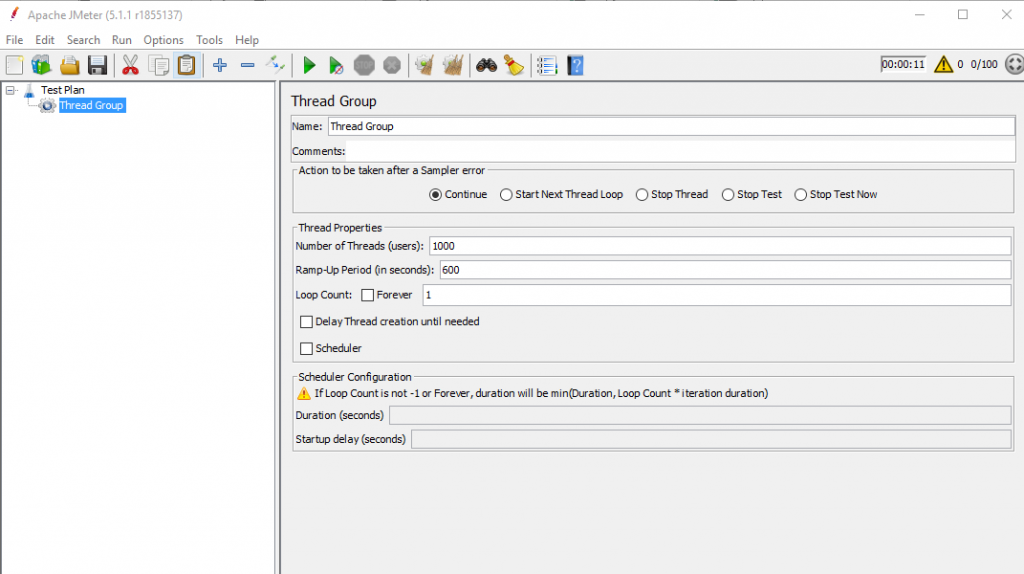
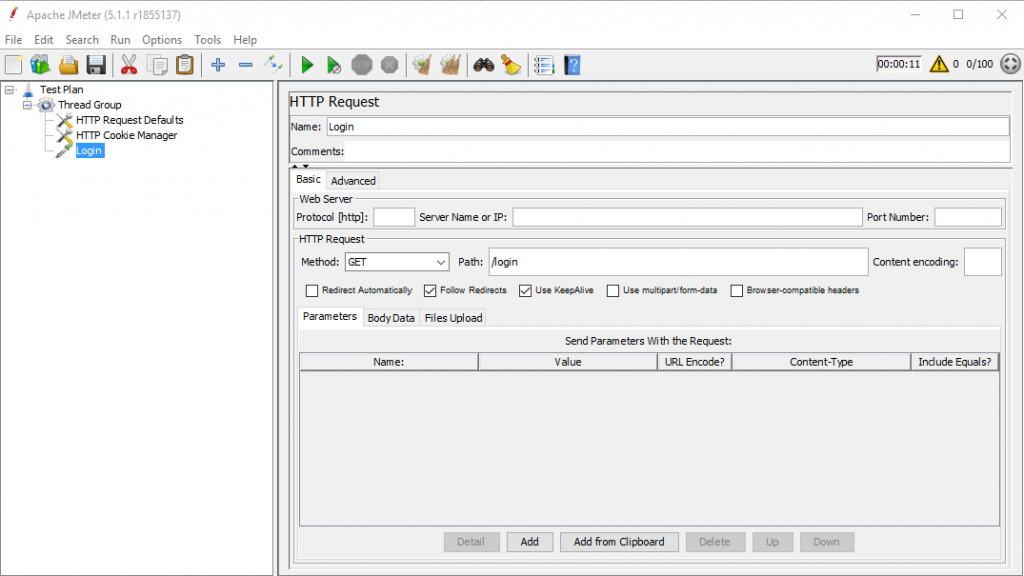
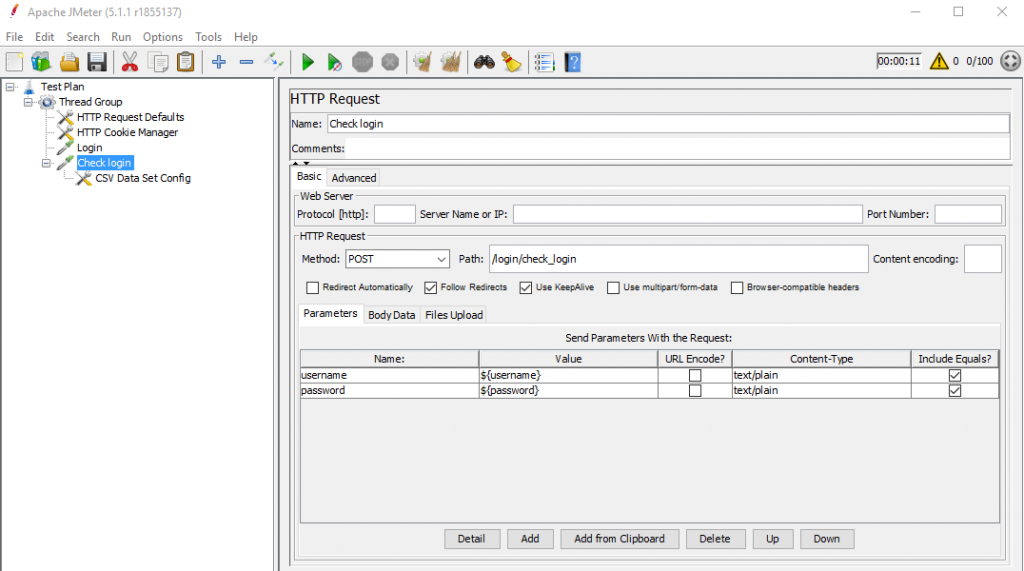
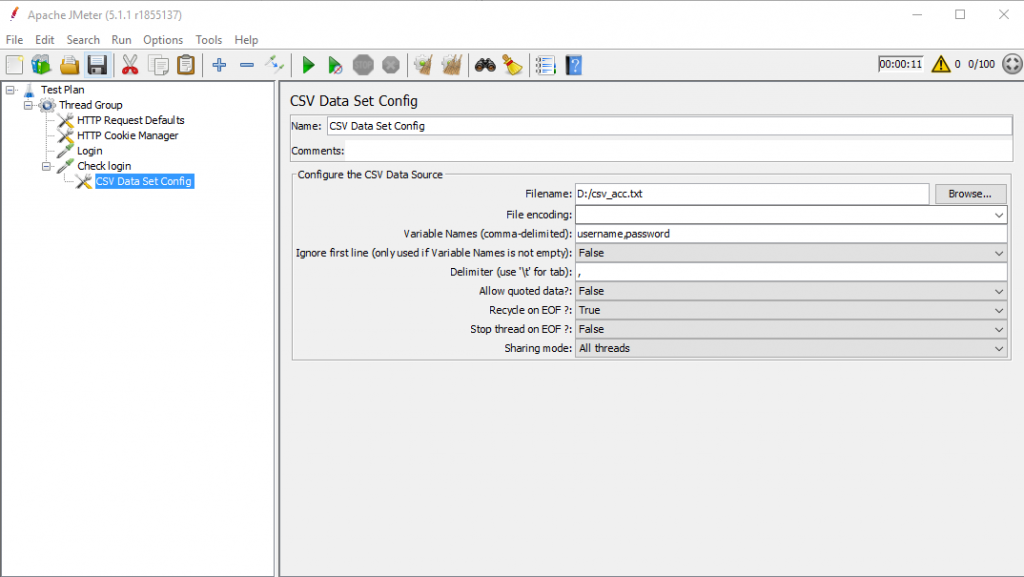
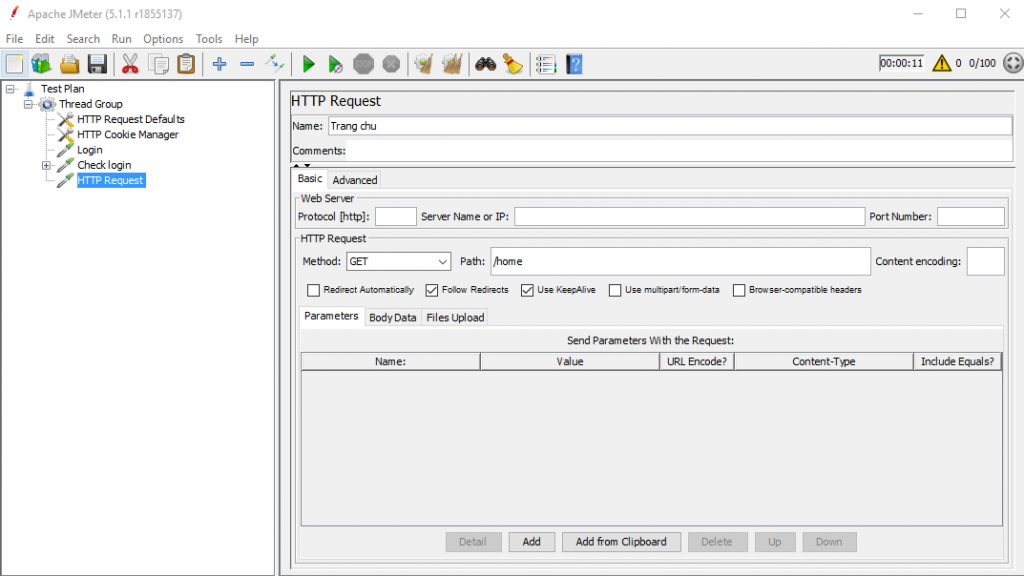
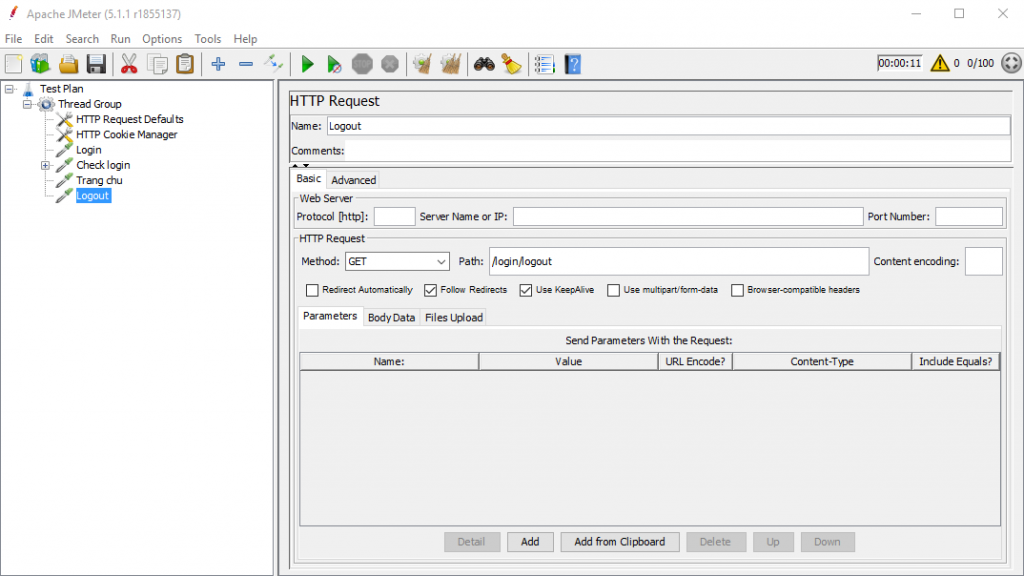
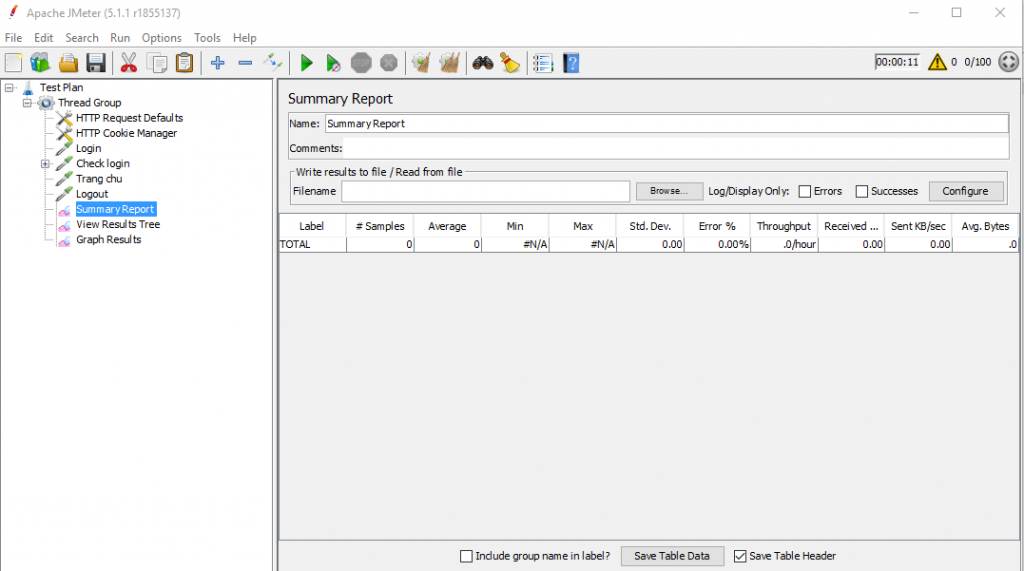
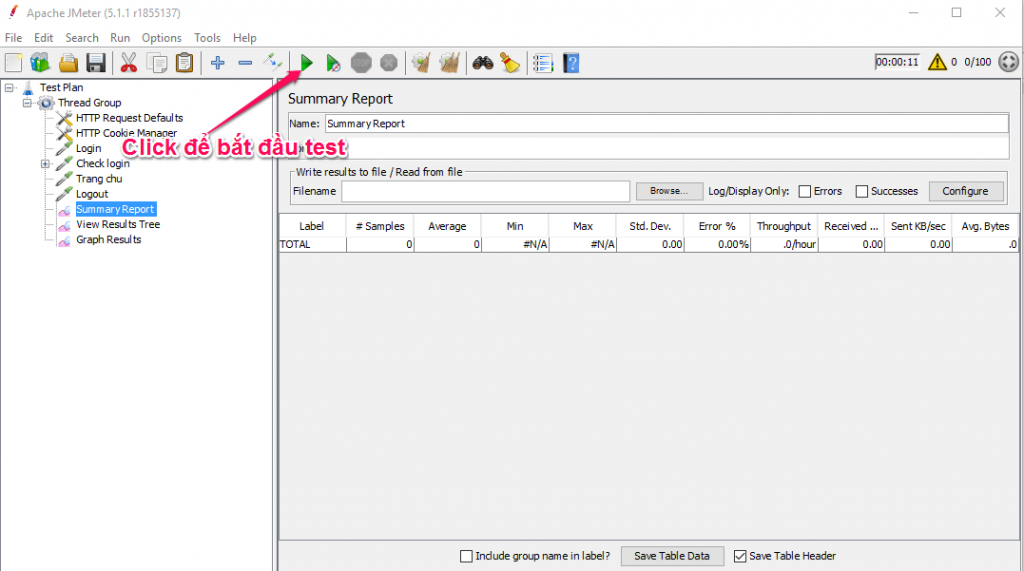










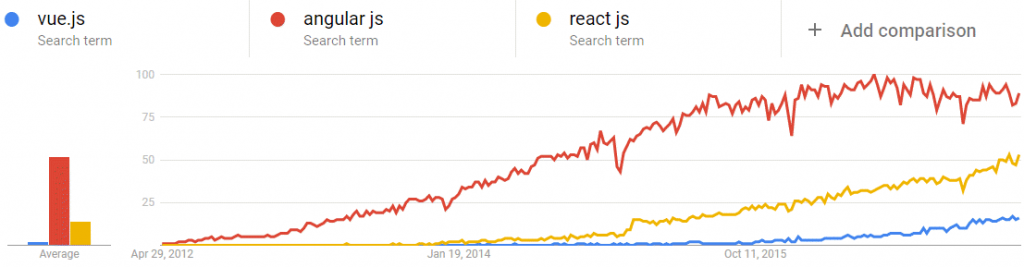

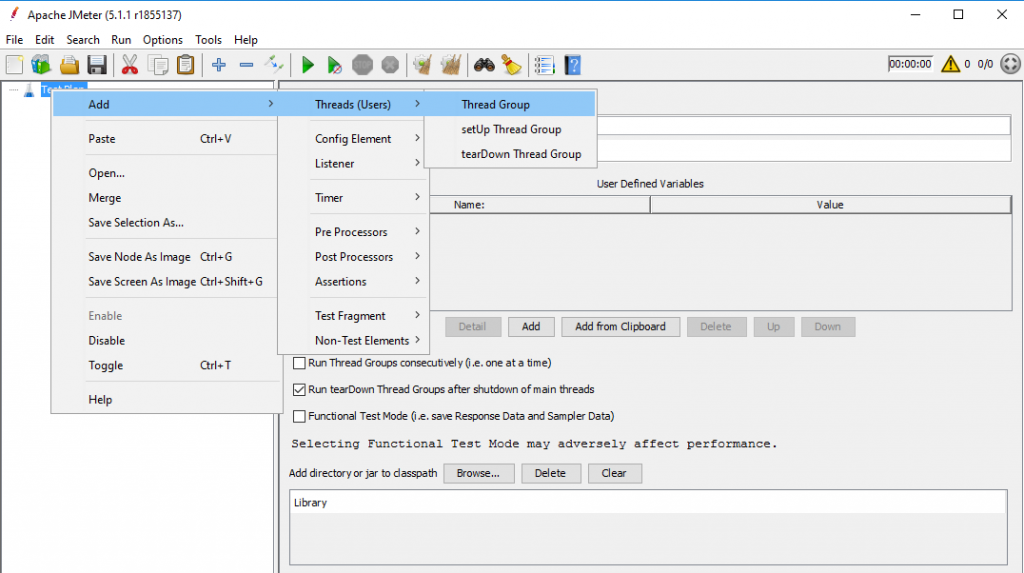
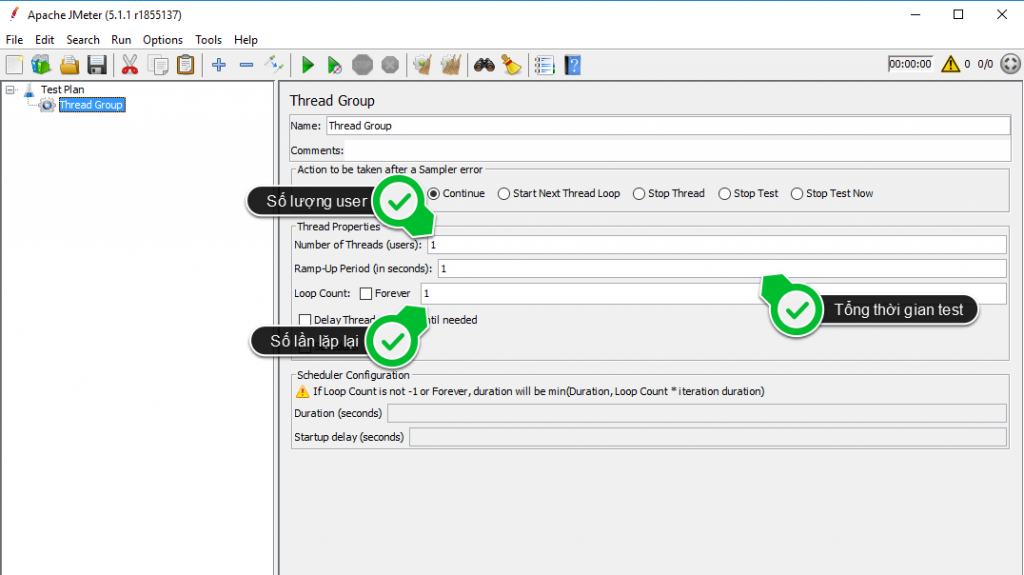
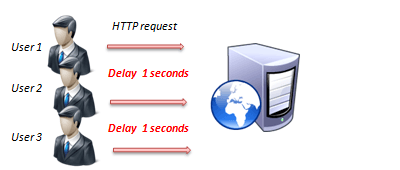
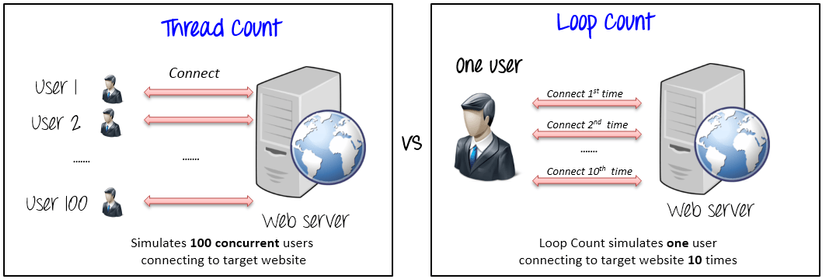
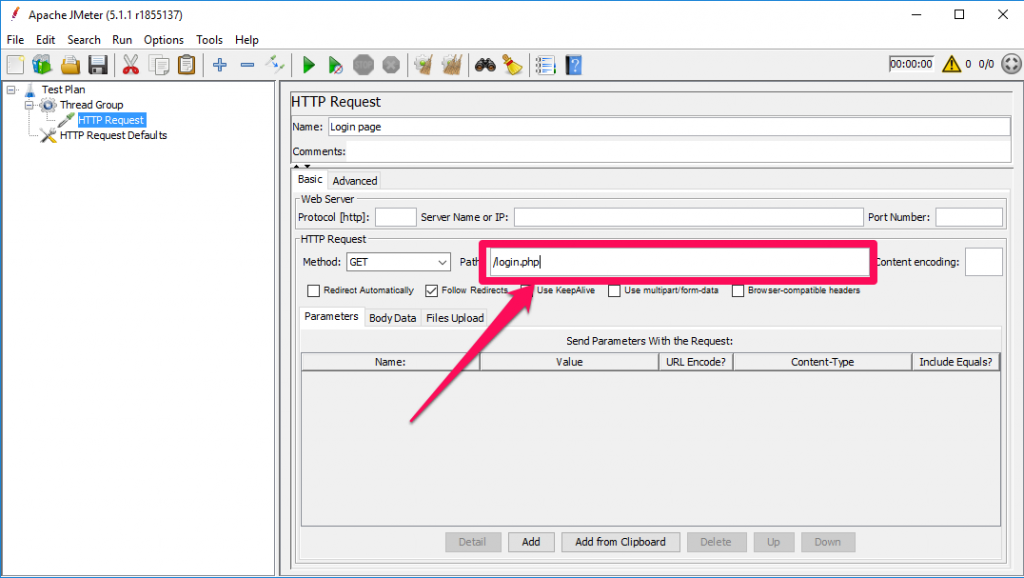
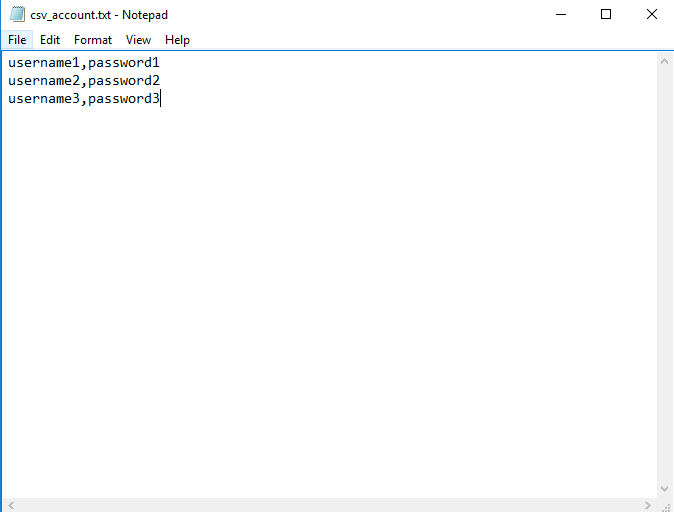
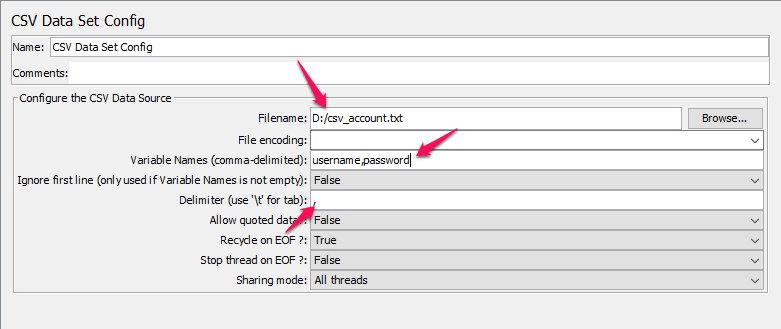
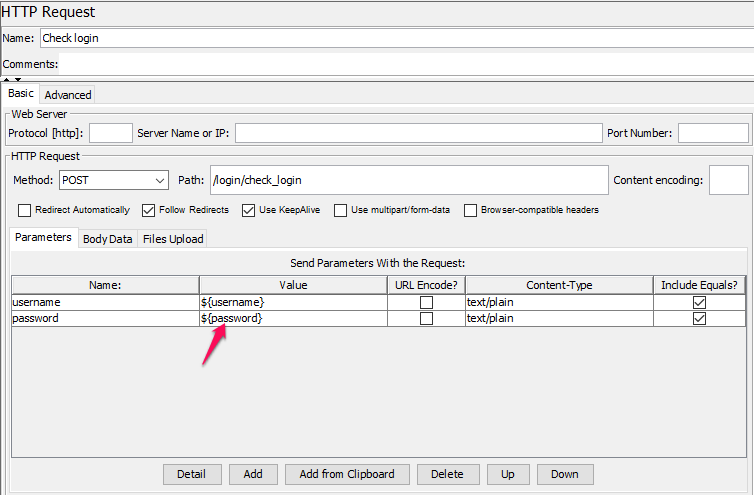
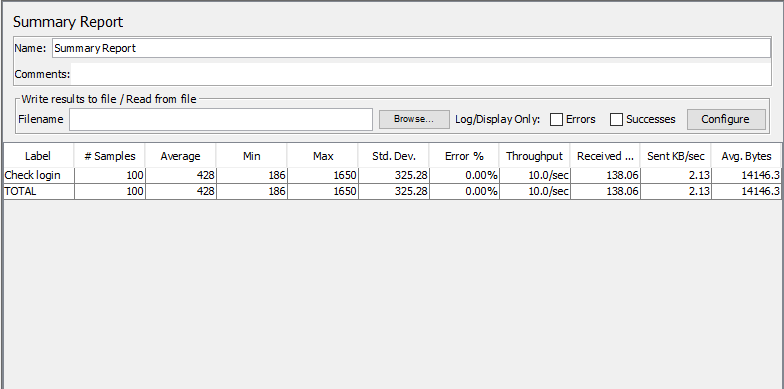
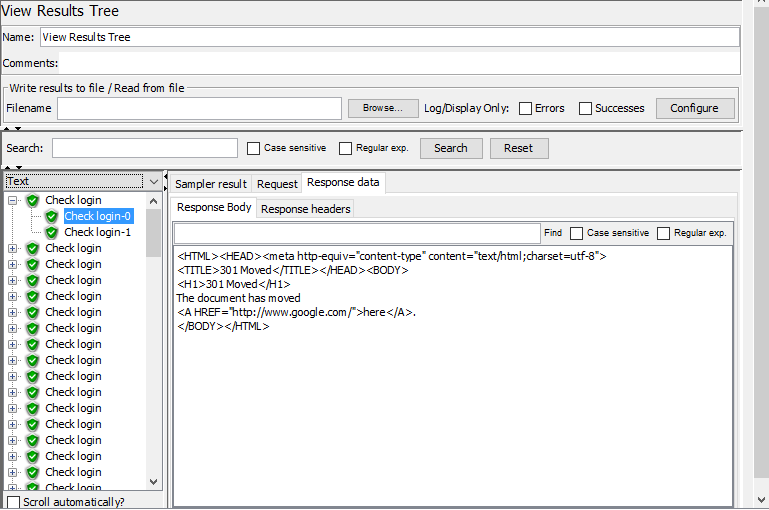
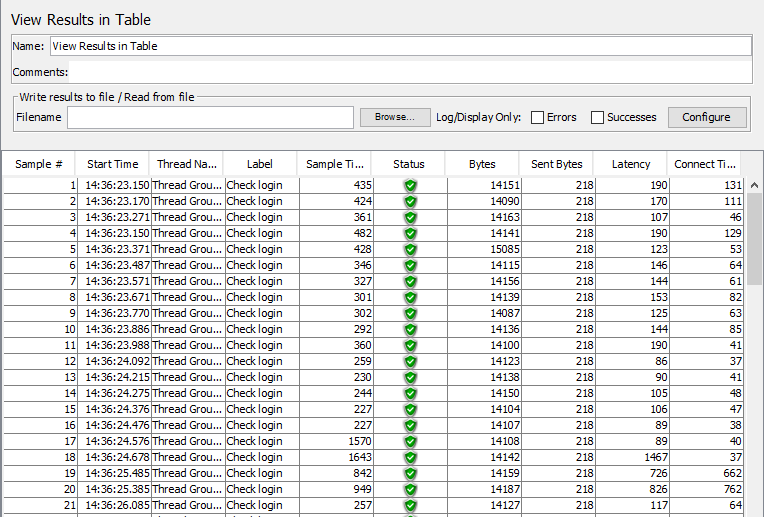
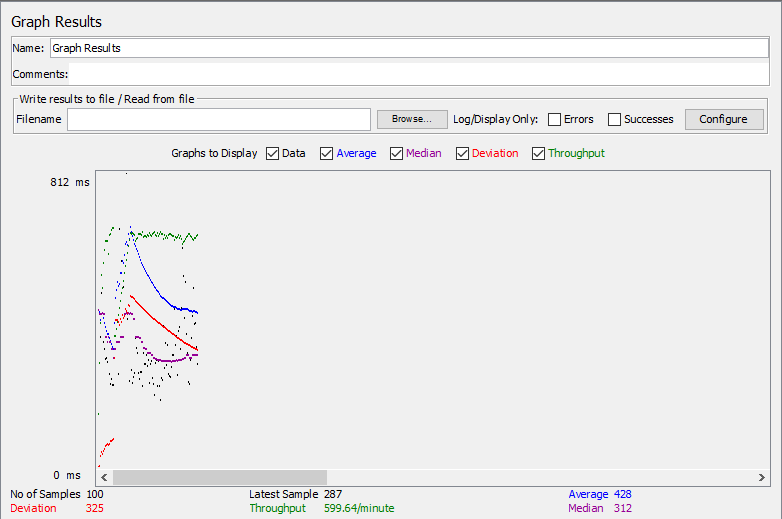
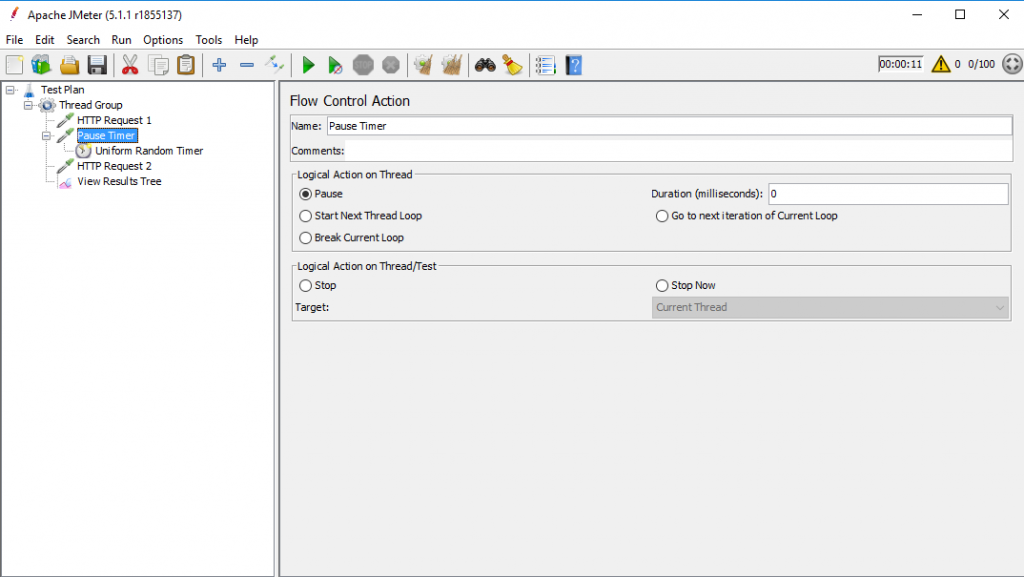
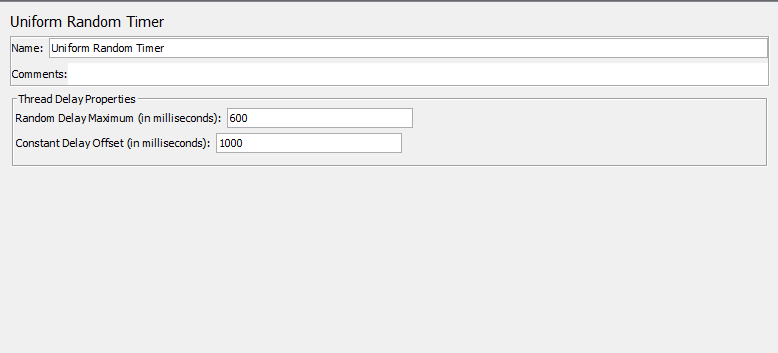


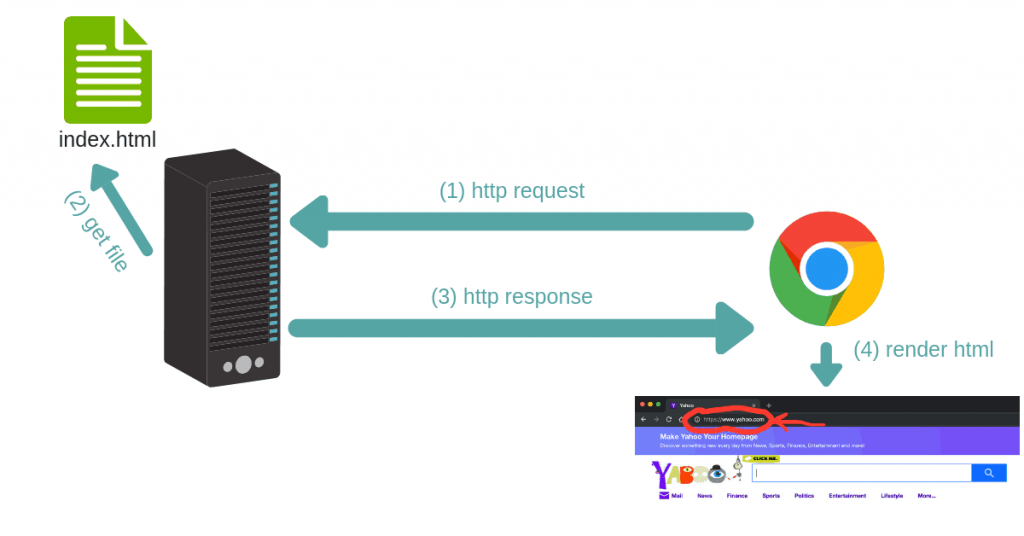
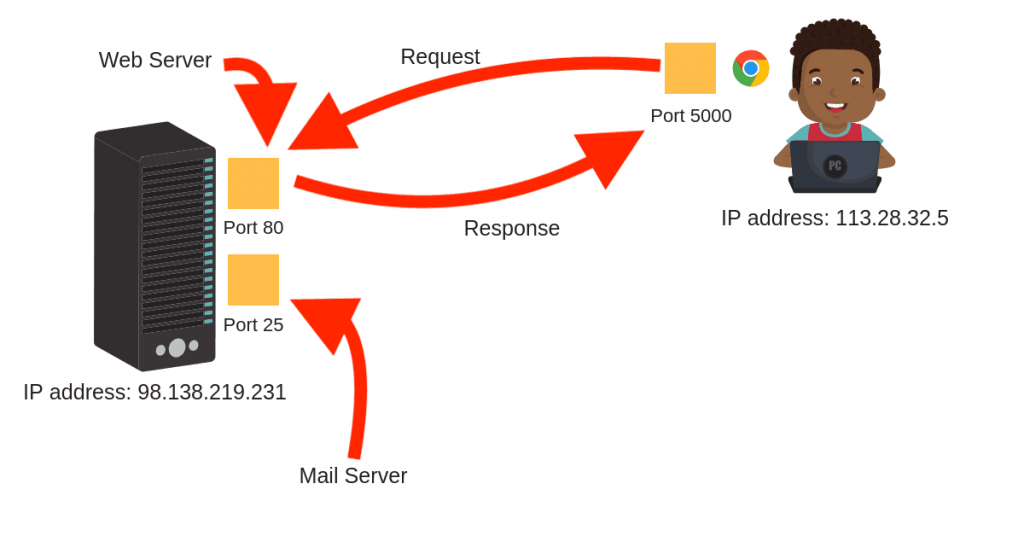
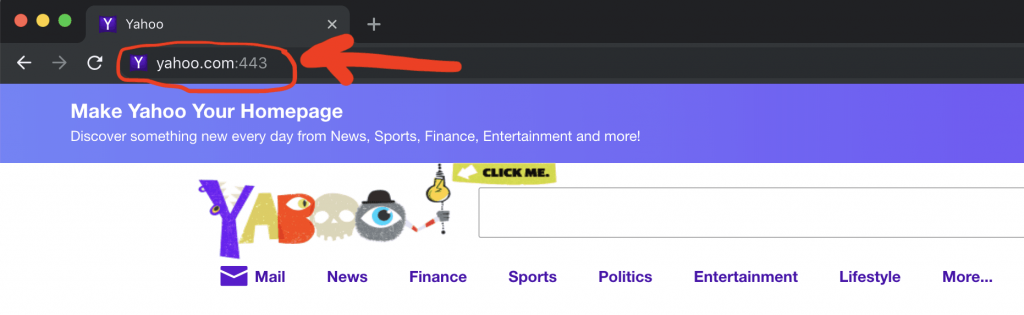
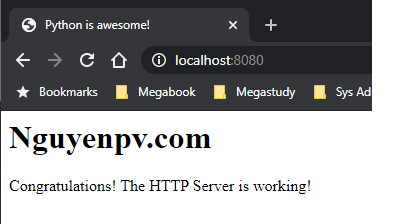

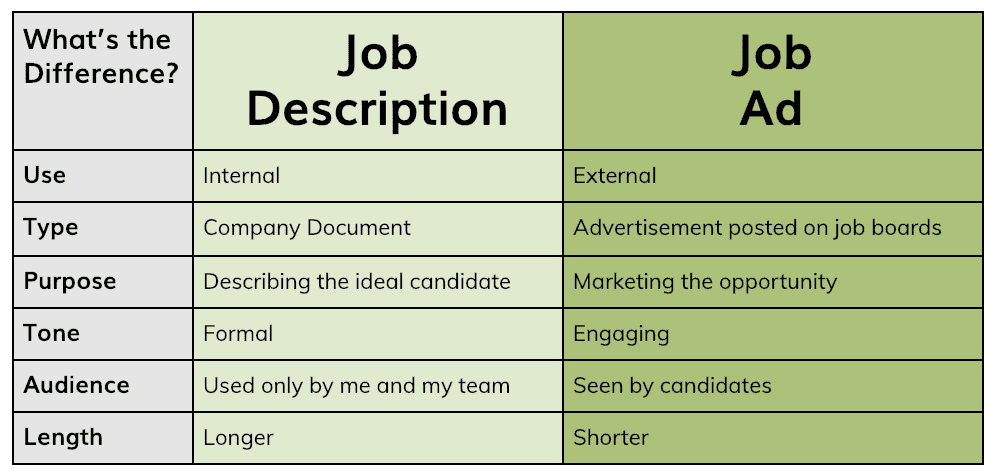







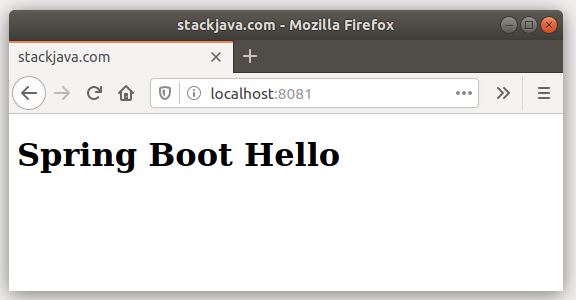
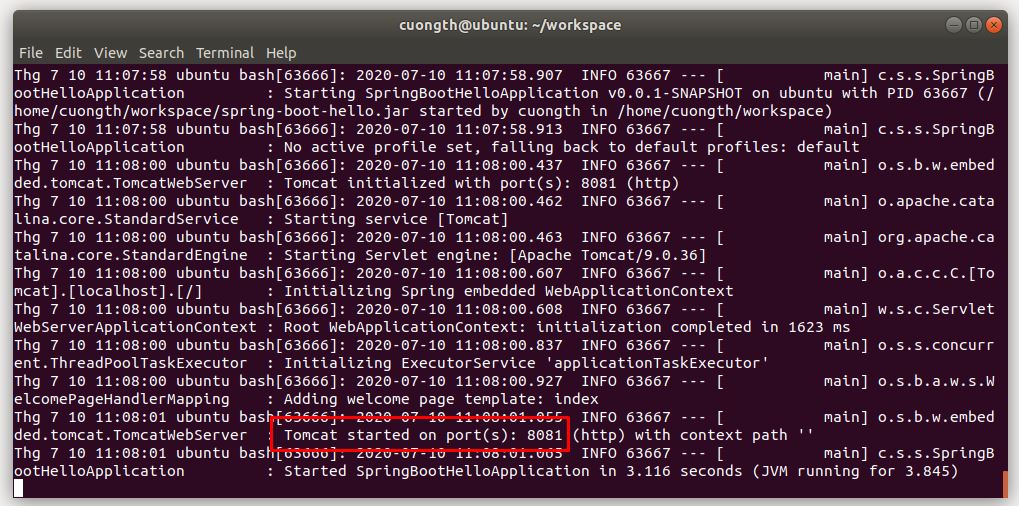

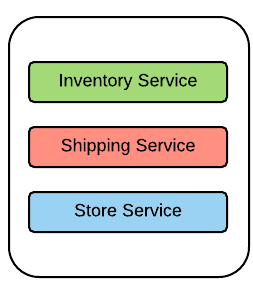
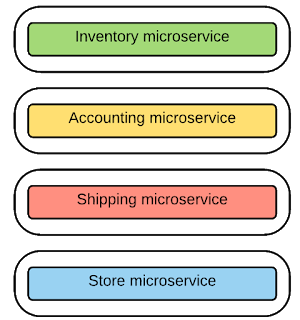
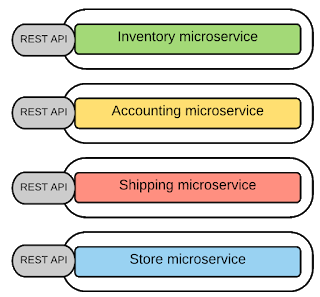
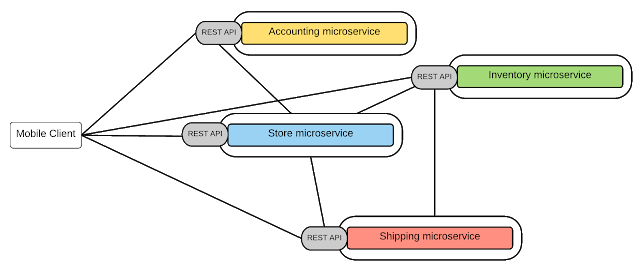
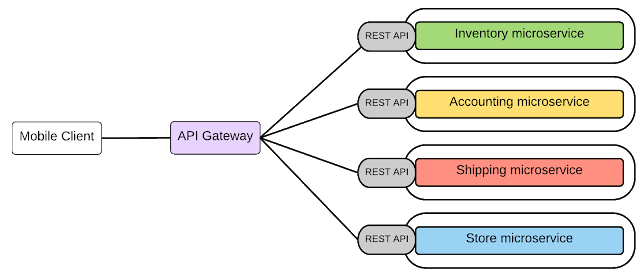
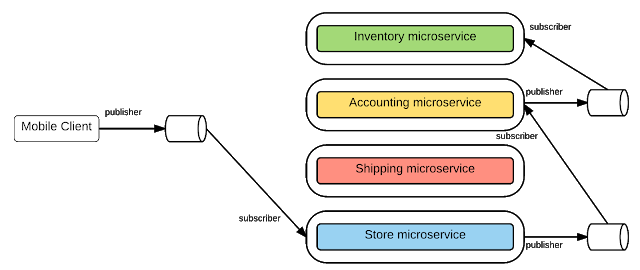
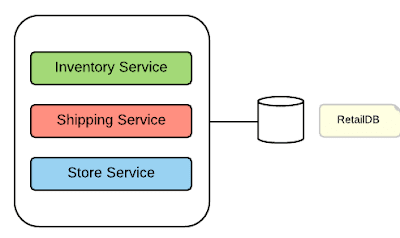
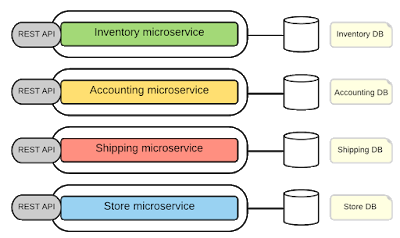
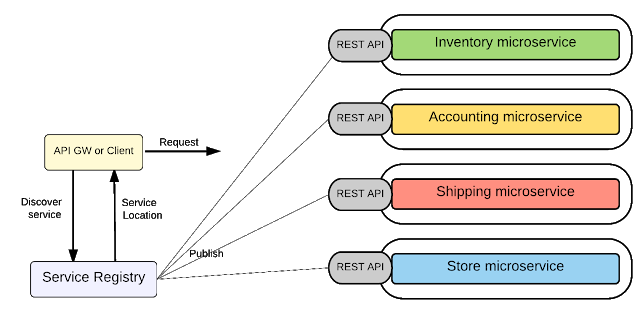
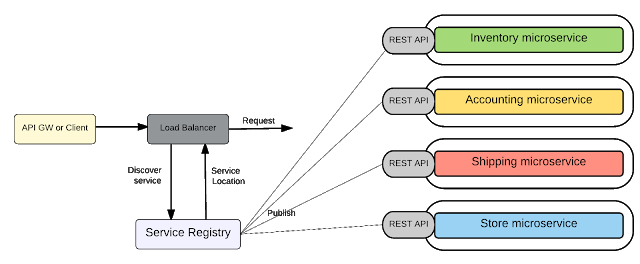
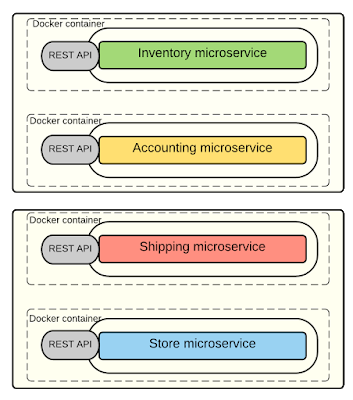
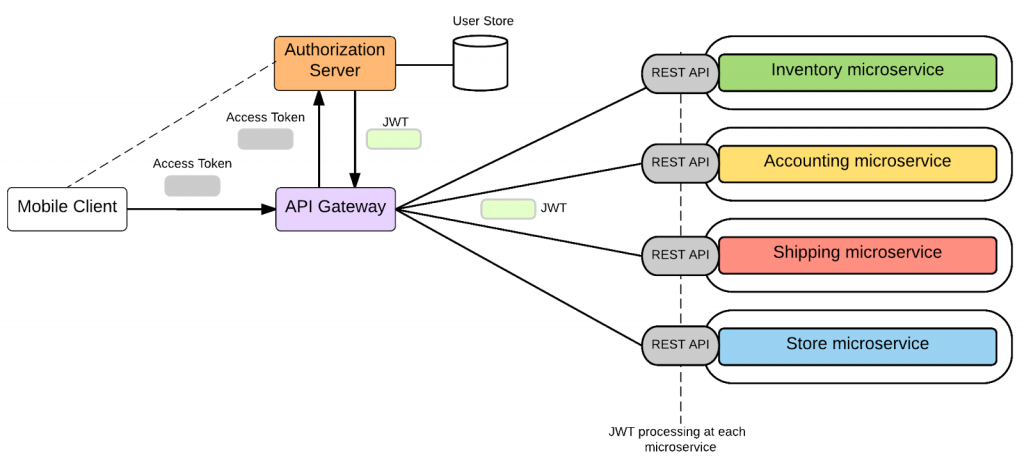

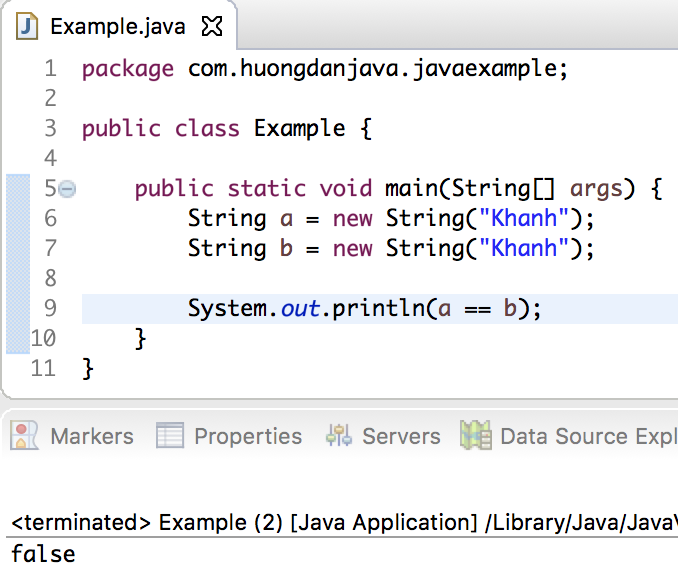
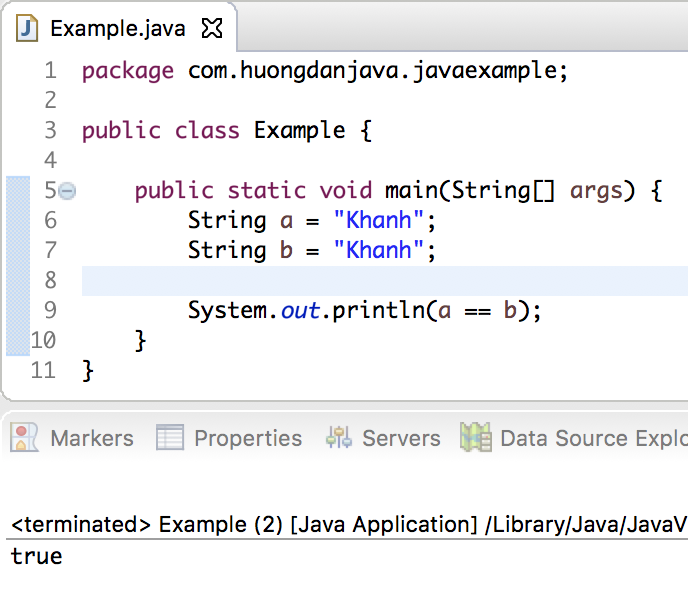
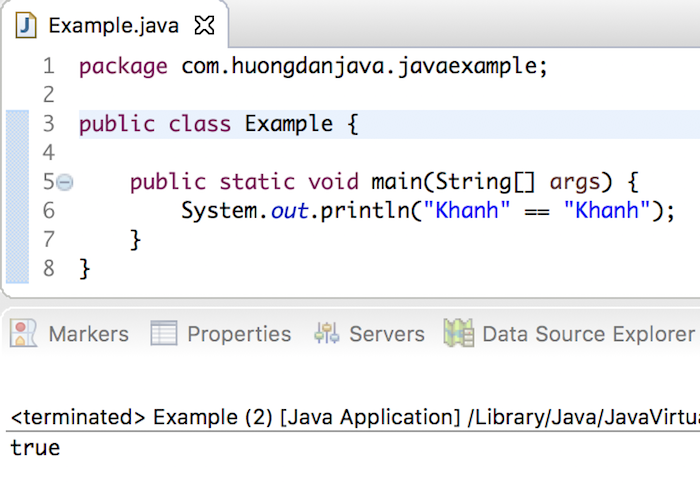

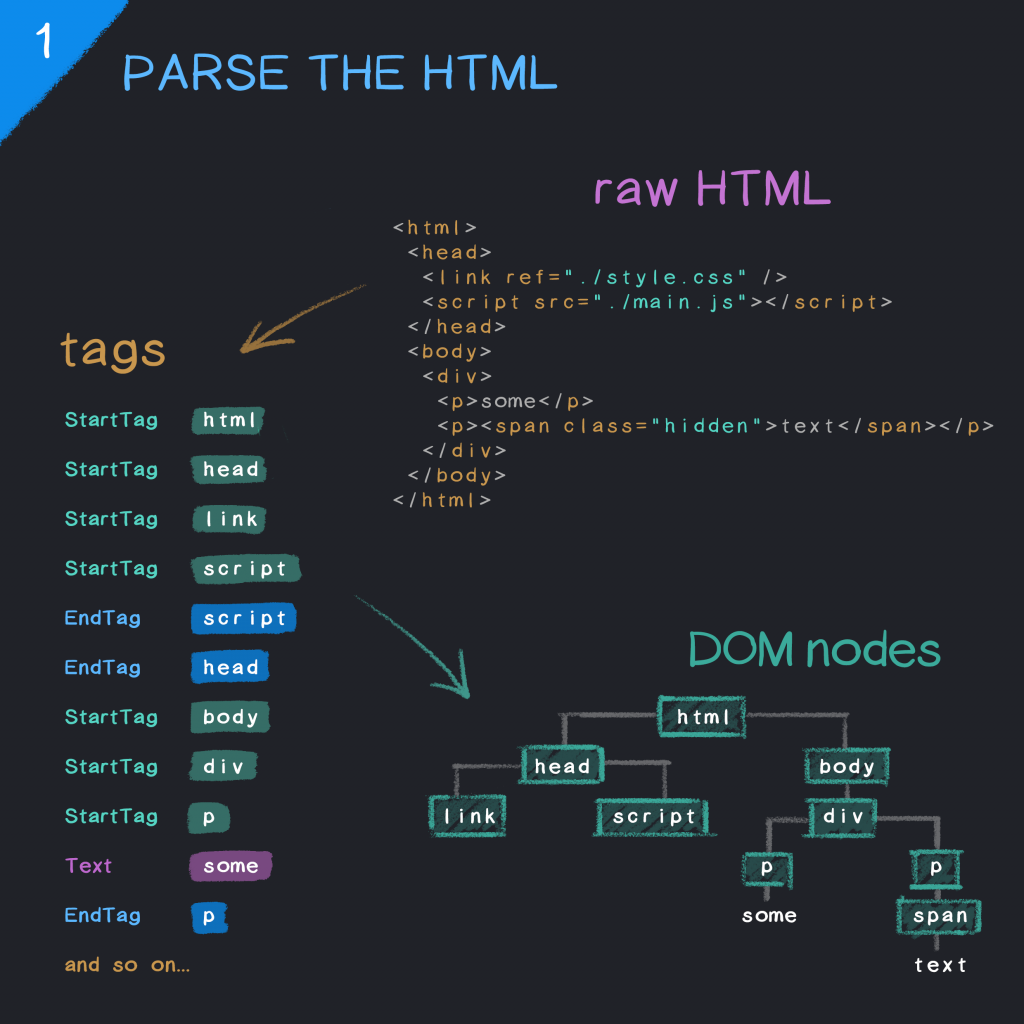
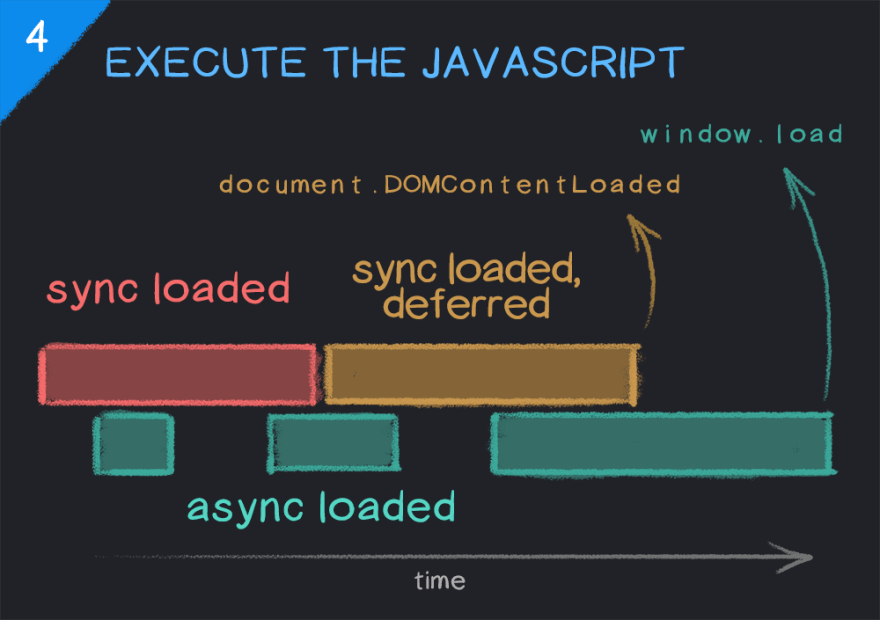
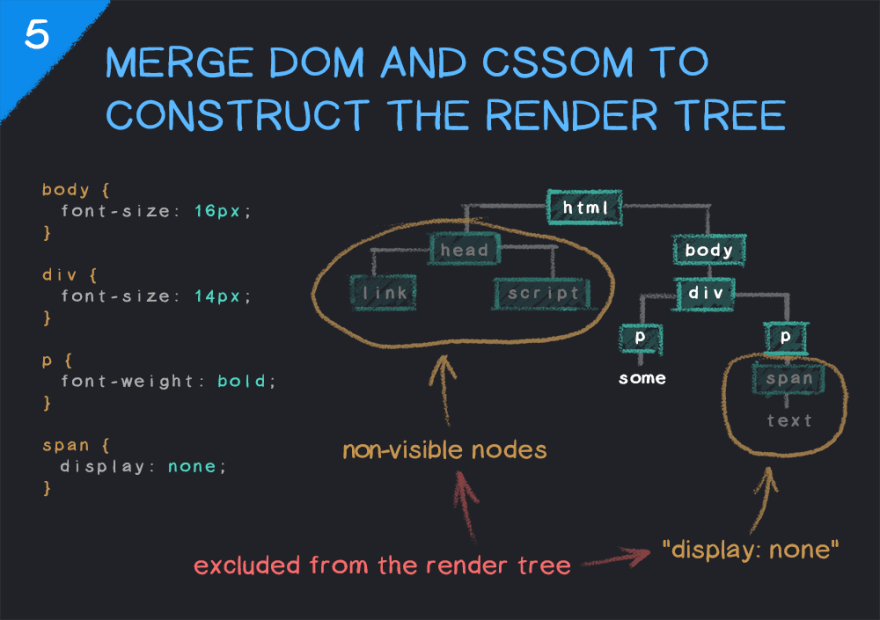









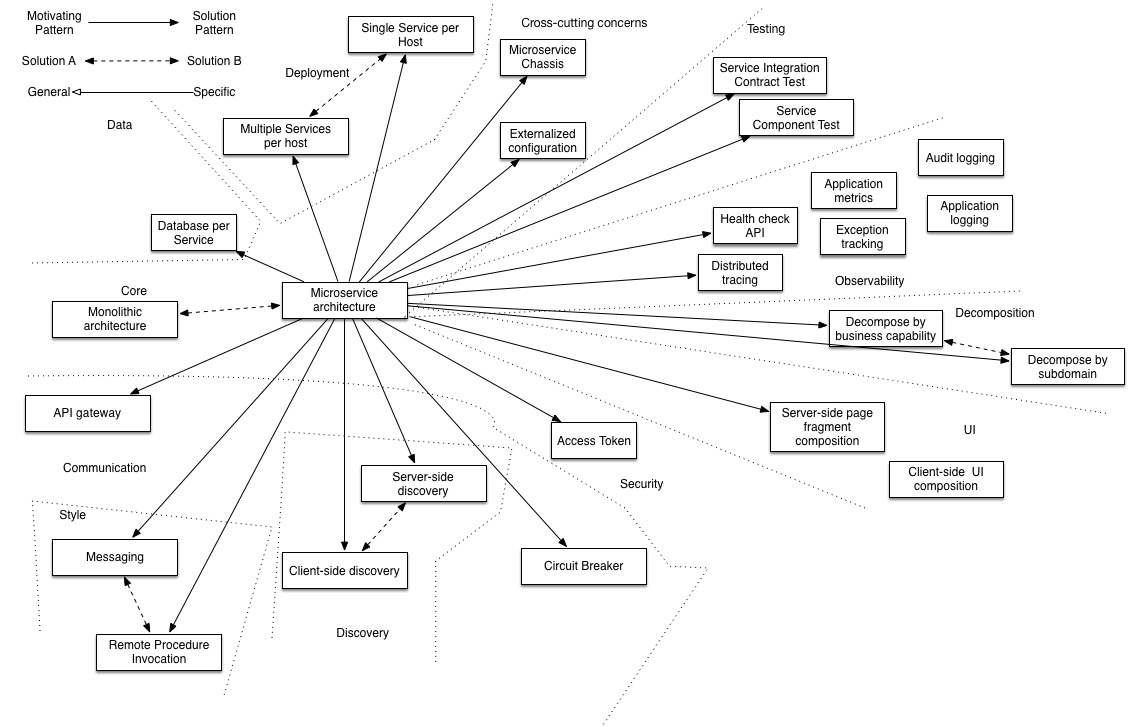{kind=link}