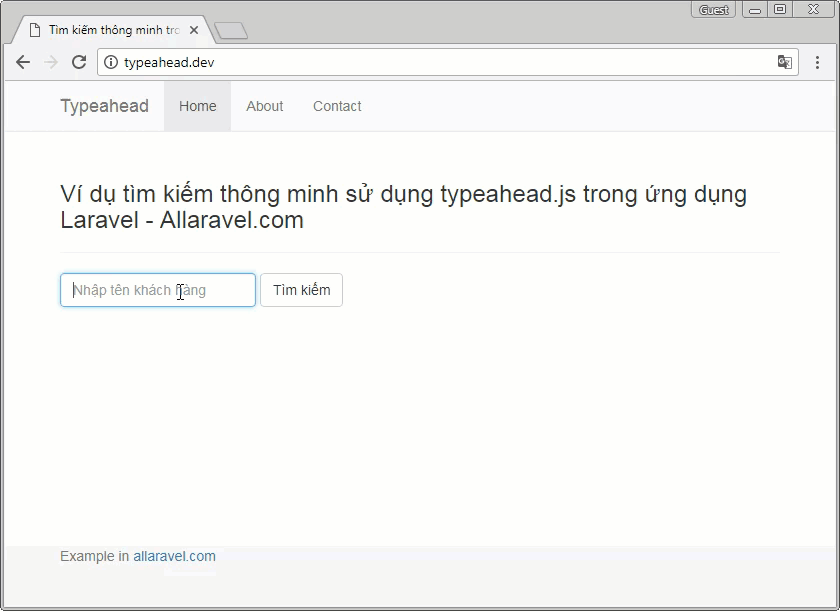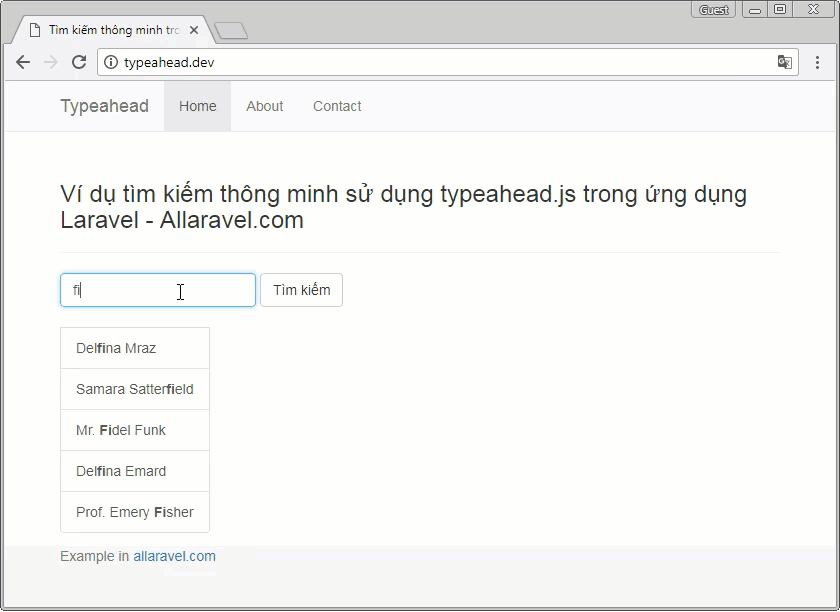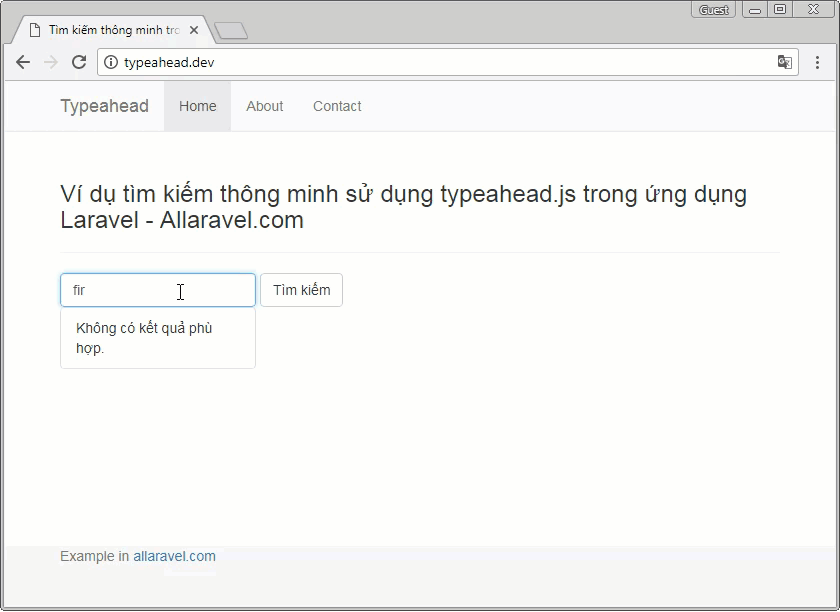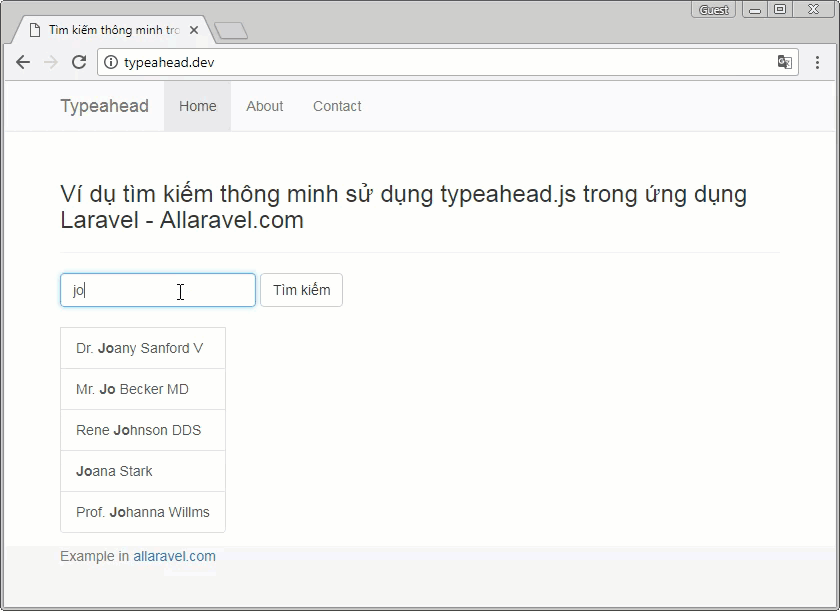
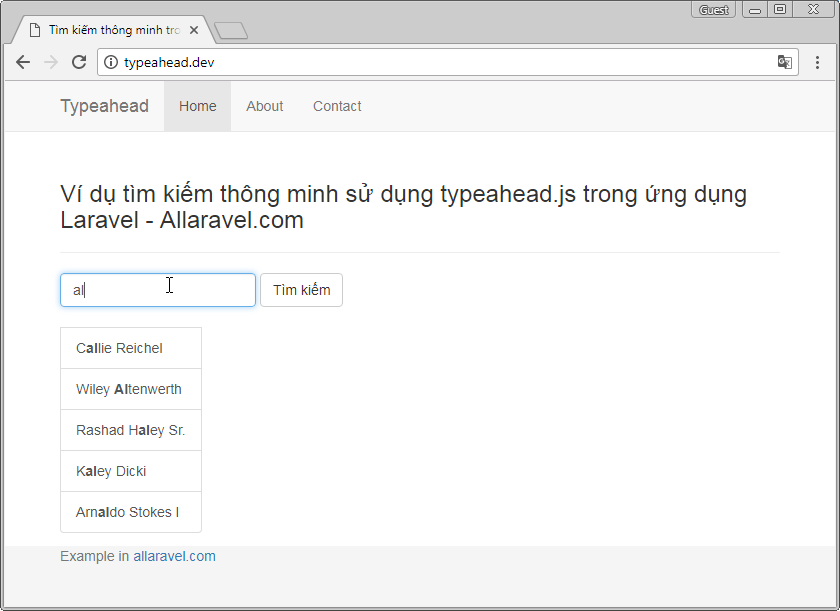
Mẫu CV IT tiếng Việt là công cụ để thể hiện bản thân một cách hiệu quả nhất đối với nhà tuyển dụng. 3s, 5s hay 10s để đủ tạo ấn tượng với nhà tuyển dụng IT. Điều đó còn phụ thuộc vào độ dài CV của bạn. Vậy đâu là độ dài nào là lý tưởng cho một CV đủ “chất”? Đừng lo lắng về mẫu CV IT tiếng việt của bạn! Vì bài viết sau đây sẽ giúp bạn giải đáp những thắc mắc đó.
Yếu tố nào quy định độ dài của một CV IT tiếng Việt?
CV có độ dài lý tưởng sẽ thể hiện mức độ phụ ứng giữa những trải nghiệm chuyên môn; các kinh nghiệm mà mỗi ứng viên đúc kết được trong sự nghiệp.
Đâu là độ dài lý tưởng cho một CV IT tiếng Việt?
CV dài 1 trang
Đối với CV cho sinh viên IT mới ra trường (CV IT student) thì CV một trang là sự lựa chọn hoàn hảo và an toàn nhất. Đơn giản vì họ chưa có nhiều kinh nghiệm. Họ còn “non” trong một môi trường IT khá cạnh trạnh. Đây cũng là thời điểm tốt để họ bắt đầu những trải nghiệm, tích lũy để nâng cấp cho CV của mình.
Xem thêm các vị tri tuyển dụng IT nổi bật tại Keizu Vietnam
Nếu xét trong một phạm vi lý tưởng, mẫu CV IT tiếng việtsẽ có độ dài tiêu chuẩn 2 trang CV. Một khảo sát thực tế cho thấy đó là sự yêu thích của 91% nhà tuyển dụng. Đặc biệt, nhiều công ty ở Anh đã từ chối CV ít hơn 2 trang của các ứng viên với lý do CV họ chưa nhiều ấn tượng. Nguyên nhân được cho là chưa biết cách chọn lọc, hiểu rõ về các kỹ năng thế mạnh của bản thân.
Hãy thật sự quan tâm đến mẫu CV IT tiếng việt của bạn. Vì nhiều trường hợp đòi hỏi bạn viết CV IT tiếng Anh (CV English IT); hay khi bạn apply các vị trí đa dạng như App Mobile Developer, Senior Developer thì CV IT Developer cũng cần được đảm độ về độ dài song song với việc kết hợp lựa chọn các kỹ năng phù hợp.
CV IT tiếng Việt 3 trang (hoặc nhiều hơn)
Nói một cách thực tế, không một nhà tuyển dụng thích các ứng viên có CV quá dài. Tuy nhiên, nên nhìn nhận sâu hơn vì phạm vi sử dụng CV 3 trang vẫn được biết đến.
Đồng thời, viết CV giúp bạn định hình và có những trải nghiệm tốt hơn. Trường hợp bạn ứng tuyển các vị trí khác như freelancer it hay Senior Developer đều sẽ đạt hiệu quả ứng tuyển cao hơn.
CV 3 trang sẽ phù hợp với các nhà quản lý, giám đốc cấp cao, các học giả, nhà khao học khi muốn truyền tải các nội dung; thông điệp đính kèm với các ấn phẩm tài liệu, nghiên cứu của mình.
Một số tips sau đây có thể giúp bạn cải thiện mẫu CV IT tiếng việt của mình trở nên ngắn gọn hơn.
Ưu tiên các kỹ năng – kinh nghiệm có liên quan đến vị trí ứng tuyển
Đây là mẹo nhưng cũng chính là một kỹ năng quan trọng khi viết CV. Thông minh trong việc chọn lọc thông tin về các kinh nghiệm. Ứng viên chỉ nên liệt kê các kỹ năng – trải nghiệm có liên quan đến vị trí ứng tuyển. Điều này giúp CV đạt chuẩn hơn, chuyên nghiệp hơn. Vì vừa đảm bảo tính khoa học, vừa truyền tải đúng các thông điệp.
Đảm bảo tính dể hiểu, dễ đọc cho CV
Đừng quá dài dòng, thê lê nhiều con chữ! Điều đó chỉ khiến CV trở nên không điểm nhấn. Bạn nên rút gọn câu từ, sử dụng những từ ngữ đơn giản. Hoặc tương tư như CV Template IT, sơ yếu lý lịch cho dân IT, cover letter cho dev thì mẫu CV IT tiếng việt của bạn nên lượt bỏ đi những phần không thật sự quan trọng, cần thiết.
Quan tâm đến yếu tố định dạng (Format)
Kích thước cỡ chữ, font chữ trong mẫu CV IT tiếng Việt cũng là một yếu tố quan trọng. Đừng để font chữ quả to hoặc quá nhỏ. Cần lưu ý đến khoảng cách lề trang sao cho nhất quán. Điều này có ý nghĩa quan trọng vì chi phối trực tiếp đến định dạng bố cục thông tin được trình bày trên mẫu CV IT tiếng việt.
Bỏ túi các thủ thuật tinh gọn CV tiếng Việt cho dân IT
– Điểm lại những yếu tố cốt lõi tạo nên giá trị chính của CV: mục tiêu nghề nghiệp, kỹ năng, trình độ và kinh nghiệm chuyên môn của bạn.
– Phải nhớ: Tính ngắn gọn, súc tích, mạch lạc – dễ hiểu trong mẫu CV IT tiếng việt rất quan trọng. Vì đó tạo nên sức hút cho nhà tuyển dụng từ những ánh nhìn đầu tiên.
– Đừng để CV xin việc dài quá 2 trang .
– Kiểm soát thông tin, không nén quá nhiều thông tin trong CV của bạn.
Lời kết
Để viết CV hiệu quả, bạn cần rất nhiều kỹ năng. Và thực tế cho thấy, việc của bạn có trở nên đắt giá hay không còn phụ thuộc vào rất nhiều yếu tố. TopDev hi vọng bài viết đã có những chia sẻ bổ ích giúp bạn hiểu thế nào là độ dài lý tưởng của một mẫu CV IT tiếng Việt. Từ đó, bạn có những bài học để định hướng hoàn thiện tốt hơn CV của riêng mình. Chúc các bạn thành công!
Bài viết được sự cho phép của tác giả Trần Khôi Nguyên Hoàng
Microsoft Word là một công cụ soạn thảo văn bản cực kỳ mạnh mà ai cũng biết. Nhưng thật lòng mà nói, mình không phải là fan của Microsoft Word. Tại sao?
Nguyên bộ Office không hoạt động trên Linux – Thực sự là có nhưng nó khá là sida thần chưởng.
Mình không biết xài Microsoft Word – Mình chỉ biết gõ chữ, format in đậm in nghiêng thôi.
Word không phù hợp với một Developer. Bạn có nhớ lần cuối bạn gõ văn bản trên Word là khi nào không?
Một Developer đơn giản chỉ cần một công cụ nào đó để gõ chữ và format đơn giản thôi. Một công cụ gõ chữ? Bạn nghĩ ngay đến Notepad hoặc Gedit? Đúng rồi, các bạn chỉ cần Notepad để gõ chữ thôi. Nhưng nếu bạn muốn format một chút thì sao? Markdown là sự lựa chọn hoàn hảo.
Markdown là gì?
Markdown là một ngôn ngữ đánh dấu với cú pháp văn bản thô,[5] được thiết kế để có thể dễ dàng chuyển thành HTML và nhiều định dạng khác[6] sử dụng một công cụ cùng tên. Nó thường được dùng để tạo các tập tin readme, viết tin nhắn trên các diễn đàn, và tạo văn bản có định dạng bằng một trình biên tập văn bản thô. (Wikipedia)
Một cách ngắn gọn, Markdown là một syntax dùng để viết cho file .md. Hơn nữa, Markdown còn dễ dàng convert qua html và đọc trên trình duyệt mà không cần cài Microsoft Office Word.
Tại sao nên sử dụng Markdown?
Dễ học
Cú pháp của Markdown dễ học nhất quả đất. Bạn phải bỏ tiền ra để đi học Microsoft Office nếu muốn giỏi. Còn với Markdown thì bạn chỉ cần 30 phút là có thể gõ ầm ầm được rồi.
Tập trung vào Viết
Để viết được một Document tốt thì cần phải tập trung vào một vấn đề duy nhất. Đó là viết. Bạn không phải bị phân tâm vì phải format cho văn bản. Dù bạn không có ý định format khi sử dụng Word hay không, thì bạn sẽ vẫn phải format. Markdown chỉ có thể format Document đơn giản thì nó sẽ giúp bạn tránh việc này.
Viết Document
Một trong những công việc quan trọng của một Developer là viết Document. Nếu viết Document bằng Word thì thật sự là thảm họa vì nó mất cực kỳ nhiều thời gian với việc format. Hơn nữa, việc chèn code sample vào Document cũng là cực hình khi dùng Word. Chính vì vậy Markdown sẽ là sự lựa chọn hoàn hảo cho việc viết Document. Nó giúp bạn chèn code inline hoặc block code một cách dễ dàng. Viết Document trên Github phải sử dụng Markdown phải có lý do của nó. Thậm chí không chỉ là Document, bạn hoàn toàn có thể viết sách bằng Markdown cũng được. Chẳng hạn như cuốn You Don’t Know JS.
Document của ExpressJS được viết bằng Markdown. Nhìn rất đẹp và rõ ràng.
Một số thứ hay ho khác
Nếu các bạn sinh viên lên thuyết trình, nhưng cần một slide cool ngầu hơn. Hãy thử Markdown và reveal.js
Khi viết Email mà cần format? Dùng thử Extension này. Các bạn sẽ nói rằng dùng bộ format của Google sẽ nhanh hơn. Tin mình đi, khi các bạn đã quen với Markdown thì nó sẽ nhanh hơn bạn nghĩ đấy.
Bài viết được sự cho phép của tác giả Trần Anh Tuấn
Xin chào các bạn đặc biệt là các bạn mới học ngành web này. Đây là một series về kiến thức HTML cơ bản toàn tập dành cho người mới mà mình quyết định viết và chia sẻ cách học, cách sử dụng áp dụng chúng vào thực tế như thế nào, cấu trúc ra sao… thông qua những năm kinh nghiệm mình đi làm và trau dồi. Hi vọng những kiến thức về HTML cơ bản toàn tập mà mình chia sẻ sẽ giúp các bạn hiểu hơn về HTML cơ bản cũng như sử dụng chúng một cách tốt nhất.
Mình thấy nhiều bạn mới học ở nhiều nguồn như w3schools hay MDN là những nguồn học nước ngoài tốt, tuy nhiên đôi khi các bạn đọc tiếng Anh không hiểu cũng như học xong không biết các thẻ trong HTML có những thẻ gì, áp dụng ra sao, lưu ý gì, thuộc tính gì… thì mình sẽ cố gắng chia sẻ hết cho các bạn trong series HTML cơ bản toàn tập này. OK bắt đầu thôi nào.
Ở trong HTML thì việc tìm hiểu cấu trúc một thẻ có thể là quá dễ tuy nhiên các bạn mới học thì nên biết chúng trông như thế nào, và cách sử dụng ra sao để làm cho chuẩn hơn
<p>Content</p>
Ở trên thì là thẻ p với <p> là thẻ mở sau đó đến nội dung là chữ content rồi đến thẻ đóng là </p> các bạn thấy thẻ đóng nó giống thẻ mở nhưng có dấu / phía trước nhé. Ngoài ra sau này các bạn học thêm thì sẽ thấy có một số thẻ người ta gọi là thẻ tự đóng nó như thế này
<img src=""alt=""/>
Những thẻ có cấu trúc như trên gọi là thẻ tự đóng nghĩa là chúng ta không thể truyền nội dung vào giữa như thẻ đóng mở ở chỗ thẻ p mình nói ở trên, nếu các bạn code như dưới đây là sai nhé, vì thế khi dùng thẻ hãy học cách sử dụng một cách đúng đắn nhất để code chuẩn hơn nhé và tránh gặp lỗi nha.
<img src=""alt="">content</img>
# Các thuộc tính của thẻ trong HTML
Những thẻ trong HTML được tạo ra đều có những thuộc tính đi kèm ví dụ như class, id là chung nhất ngoài ra mỗi thẻ sẽ có thêm các thuộc tính riêng ví dụ như thẻ a thì sẽ có href, target, input thì type, require, placeholder… Thì các bạn cần nắm được những cái này để sử dụng một cách đúng đắn nhất để code cho tốt như này
<ahref="evondev.com"target="_blank">evondev</a><input type="text"placeholder="Please type your name..."/>
Còn nếu thẻ đó không có mà các bạn đưa nó vào thì nhìn code của các bạn nó tệ lắm như này
Các bạn nhìn vậy có thể sẽ nói sao mà code vậy được chứ mình thấy nhiều bạn mới hay code như này lắm nên mình chia sẻ ở đây nếu các bạn đang đọc blog của mình thì sẽ biết mà né để cho code của các bạn tốt hơn nhá.
Thuộc tính thì rất nhiều và thẻ cũng thế, mình sẽ cố gắng liệt kê kèm giải thích cho các bạn dễ hiểu nhất trong những phần mình sẽ viết tiếp dưới đây
# Sự khác nhau giữa thẻ block và thẻ inline
Khi các bạn học tới các thẻ thì hay bị cái là dùng thẻ này thẻ kia mà không biết chúng khác nhau như thế nào từ đó dẫn tới việc code HTML không được tốt hoặc sai mục đích…Thì mình sẽ giải thích cho các bạn biết là thẻ inline và thẻ block khác nhau như thế nào và làm sao để biết thẻ nào là thẻ block và thẻ nào là thẻ inline.
Để nhận biết nhanh nhất đó chính là vào trang web htmlreference.io ở trang này nó sẽ tổng hợp toàn bộ các thẻ trong HTML và có mục đánh dấu thẻ nào là inline thẻ nào là block, thẻ nào là thẻ đóng mở, thẻ nào là thẻ tự đóng luôn để các bạn biết cách sử dụng cho tốt nhất luôn nhé.
Quay lại vấn đề chính thì thẻ inline và thẻ block có những điểm gì mà các bạn cần lưu ý
Thẻ inline sẽ bị hạn chế về CSS như margin-top margin-bottom, padding-top, padding-bottom… khi sử dụng thẻ inline thì nên biết mà tuỳ trường hợp mà sử dụng, có thể dùng CSS để biến thẻ inline thành block hoặc inline block
Khi các thẻ inline nằm cùng nhau thì nó sẽ nằm trên một hàng như tên gọi của nó là inline
Thẻ inline sẽ có độ rộng bằng nội dung mà nó chứa
Thẻ block sẽ có độ rộng full 100% phần tử cha chứa nó
Thẻ block không bị hạn chế về CSS
Vì nó full 100% phần tử cha chứa nó cho nên khi dùng thẻ block cùng với nhau thì tụi nó sẽ rớt xuống hàng
Thẻ inline và thẻ block có thể sử dụng cùng với nhau, điển hình là thẻ a nằm trong thẻ p khi các bạn đọc bài viết mình có gắn link vào để các bạn nhấn
Khi sử dụng CSS biến thẻ thành inline-block thì nó là sự kết hợp giữa thẻ inline và thẻ block, tức là nó sẽ có độ rộng theo nội dung nó chứa mà thôi(đặc điểm của thẻ inline), và không bị hạn chế về CSS(đặc điểm của thẻ block), nằm gần nhau thì nằm trên 1 hàng(đặc điểm của thẻ inline)
# Tất tần tật các thẻ trong HTML hay dùng nhất
Ở những mục trên mình đã nói về cấu trúc cơ bản của một thẻ, các thuộc tính trong HTML, sự khác nhau giữa thẻ inline và thẻ block và cách sử dụng đúng đắn rồi. Ở mục này và các bài tiếp theo của series này mình sẽ tập trung nói về các thẻ, các thuộc tính kèm giải thích chi tiết hơn và cách sử dụng cho các bạn để các bạn thông não hơn về HTML nhé.
## Thẻ p
Thẻ p là thẻblock, thẻ p có các thuộc tính hay dùng là class, id. Thẻ p theo mình nghĩ nó là viết tắt của paragraph là thẻ đại diện cho những đoạn văn bản, ví dụ các bạn đang đọc bài viết của mình các bạn nhấn F12 sẽ thấy các đoạn văn bản đều nằm trong thẻ p, vì thế khi các bạn code các bạn có thể dùng thẻ p để chứa những đoạn văn bản nhé. Tuy nhiên đoạn chữ ngắn vài 3 chữ dùng thẻ p cũng được không sao cả, tuy nhiên chữ ngắn thì mình khuyến khích dùng thẻ inline hoặc các thẻ tiêu đề hơn
<pclass="text">Lorem ipsum dolor sit amet,consectetur adipiscing elit</p>
## Thẻ div
Là thẻ block, thẻ div cũng có các thuộc tính như class, id. Thẻ div là thẻ được sử dụng rộng rãi nhất hiện nay. Nó thường được dùng cho một khối nào đó lớn, bên trong khối đó có thể có nhiều khối nhỏ(cũng là thẻ div) hoặc các thẻ p, và nhiều thẻ khác. Các bạn sẽ dùng nó rất nhiều khi code HTML và nó cũng có thể chứa văn bản như thẻ p nhe, tuy nhiên khi dùng thẻ p thì về mặt ý nghĩa thì thẻ p sẽ rõ ràng hơn cho việc đại diện văn bản.
Là thẻ inline, thẻ này dùng cho các liên kết, tức là các bạn muốn cho người dùng nhấn vào ra một trang web nào đó hay chỉ đơn giản là scroll tới mục nào đó trong body với điều kiện mục đó phải có id và trong thuộc tính href của thẻ a phải bắt đầu bằng dấu # như sau
Trong thẻ a các bạn cần biết 3 thuộc tính quan trọng đó chính là href, target và rel, href sẽ truyền vào đường dẫn hoặc như mình nói ở trên dấu #, target thì có 2 giá trị thường được sử dụng nhất là _self và _blank, _self thì nó sẽ mở trong tab hiện tại luôn(dễ hiểu hơn nó sẽ thay thế tab hiện tại trên trình duyệt bằng link các bạn nhấn vào), còn _blank nó sẽ mở ra một tab mới trên trình duyệt.
Còn rel thì khi các bạn sử dụng với target có giá trị là _blank thì Google Chrome khuyến khích là thêm vào giá trị cho rel là noopener noreferrer để tăng tính bảo mật. Mặc định giá trị trong target là _self rồi nên các bạn có thể không cần ghi vào cũng được, ví dụ dưới đây
Khi làm việc với thẻ a các bạn cần lưu ý thêm nữa là thẻ a không nên bọc thẻ a vì như vậy nó sẽ sai về code lẫn ý nghĩa sử dụng vì khi nhấn vào liên kết nó đã chạy rồi sẽ không có tác dụng cho một thẻ a con bên trong nữa như này và bên ngoài trình duyệt cũng render ra sai như sau, nên các bạn cần cẩn thận nhé.
<ahref="evondev.com"><ahref="google.com">evondev.com</a></a>->nó sẽ render ra như này<ahref="evondev.com"></a><ahref="google.com">evondev.com</a>
Bên trong thẻ a có thể chứa nhiều thẻ khác luôn nhé như thẻ block khác, thẻ inline…Sau này các bạn code giao diện mà có cho người dùng nhấn vào một khối nào đó thì chắc chắn các bạn sẽ dùng thẻ a bao lại hết chúng.
## Thẻ img
Là thẻ inline và là thẻ tự đóng nên không truyền nội dung vào giữa như các thẻ đóng mở khác được. Thẻ này sử dụng rất nhiều trong trang web để hiển thị hình ảnh, thẻ img có 2 thuộc tính chính mà các bạn cần nắm đó là src và alt trong đó src truyền vào đường dẫn hình ảnh để hiển thị hình ảnh lên trang web, còn thẻ alt thì là liên quan tới SEO một chút, khi hình ảnh đường dẫn sai sẽ không hiển thị được thì nội dung trong thẻ alt sẽ hiển thị lên.
<img src="unsplash.com/nature.jpg"alt="nature/>
Ngoài ra trong thẻ img còn có thêm thuộc tính srcset để hiển thị hình ảnh ở nhiều kích thước màn hình khác nhau tuy nhiên thuộc tính này khá khó sử dụng cho newbie nên mình chưa giải thích ở phạm vi dành cho người mới.
## Các thẻ tiêu đề
Các thẻ tiêu đề là những thẻ h1,h2,h3,h4,h5,h6 là thẻ block và thường đại diện cho các tiêu đề từ to cho đến nhỏ và có cách sử dụng khác nhau nhé(h1 là to nhất tới h6 là nhỏ nhất). Thẻ h1 là thẻ thường được sử dụng cho một tiêu đề to nhất của trang web và lưu ý trong một trang web thì chỉ có tối đa một thẻ h1 mà thôi, vì nó ảnh hưởng tới SEO cho nên nếu các bạn sử dụng nhiều hơn một thẻ h1 thì không tốt đâu nhé.
Thẻ h2 được sử dụng cho một khối lớn, các bạn sẽ thấy khi làm giao diện landing page chẳng hạn, thì thẻ h2 này được dùng làm tiêu đề to cho một khối nào đó để người ta biết được khối đó là gì.
Thẻ h3 được dùng nhỏ hơn ở bên trong các khối lớn đó sẽ có các bài viết nhỏ, khối nhỏ thì dùng h3, và cứ thế khối nhỏ hơn cho đến h4, h5, rồi h6. Các bạn có thể thấy thực tế luôn là bài mà các bạn đang đọc nè tiêu đề to trên cùng là h1 đó, trong nội dung sẽ có các tiêu đề nhỏ hơn là h2, h3, h4, h5 hay h6…
<h1>Welcome toour website</h1><h2>Post list</h2><h3>Thisisasimple title forpost</h3>
Như tên gọi của nó thì nó được dùng cho cấu trúc có tiêu đề ví dụ như tiêu đề khối, tiêu đề bài viết, tiêu đề blog, các bạn xem hình minh hoạ là hiểu ngay ấy mà…. Bên trong nó có thể chứa thẻ a, hoặc các thẻ inline khác, hay thẻ block… Và các bạn lưu ý đừng code như dưới này nhé
<h2><h2>Heading</h2></h2><h2><h3>Title</h3></h2>
Hoặc các đoạn văn bản dài như ở thẻ p thì nên dùng thẻ p hoặc thẻ div chẳng hạn chứ đừng dùng những thẻ tiêu đề này cho một đoạn văn bản quá dài nha.
## Thẻ danh sách
Thẻ danh sách thì có 2 thẻ chính với cấu trúc hay dùng là ul li và ol li. Trong đó ul nghĩa là unorderedlist nghĩa danh sách không có thứ tự, tức là khi dùng nó sẽ hiển thị dưới dạng như này với các chấm tròn mặc định hoặc vuông dựa vào CSS sẽ nói sau này.
a
b
Còn ol là orderedlist nghĩa là danh sách có thứ tự tức được đánh số như mục lục vậy 1 2
a
b
Cấu trúc ul li được sử dụng rất nhiều khi làm menu như này
Lưu ý thêm thẻ li cũng không bọc trực tiếp thẻ li để tránh lỗi nhé nó như dưới đây
<ul><li><li>item</li></li></ul>
Tuy nhiên nó sẽ bọc lại được khi không phải trực tiếp li li mà là li ul li để làm menu đa cấp trong HTML hay được sử dụng như sau
<ul><li><ul><li>It isworking</li></ul></li></ul>
## Các thẻ semantic
Các thẻ semantic các bạn có thể sẽ thấy khi kiểm tra code blog mình hoặc các blog trang web khác… như thẻ header, thẻ footer, thẻ nav, thẻ aside, thẻ article, thẻ main, thẻ section thì các bạn có thể hiểu như này những thẻ này theo cách mình dùng thì nó sẽ làm cho cấu trúc code của chúng ta nó rõ ràng mạch lạc hơn thôi chứ các bạn dùng toàn thẻ div thay vì dùng các thẻ semantic này vẫn ổn, không sao cả.
Tuy nhiên như mình nói dùng những thẻ này thì nhìn cấu trúc code nó rõ ràng mạch lạc hơn là vì nhìn vào là biết nó làm gì, ví dụ các bạn dùng thẻ header thì sẽ biết à nó là header nằm ở phía trên trang web, thẻ nav là dùng cho điều hướng menu, thẻ footer nó nằm ở dưới cùng, thẻ article là bài viết, thẻ section là một khối, …. các bạn có thể check code blog của mình ở trang chủ là sẽ thấy những thẻ này, và nó là thẻ block dùng y chang thẻ div không khác gì, có thể thêm class hay id….
Cho nên là nếu các bạn dùng không quen mà dùng thẻ div không cũng không sao cả nhé.
Đây đều là những thẻ inline, ngược với thẻ p thì những thẻ này thường được sử dụng cho các đoạn chữ ngắn thôi, chữ ngắn là như thế nào ví dụ các bạn sẽ thấy một số thiết kế có đoạn chữ như ngày giờ, tên tác giả,… nó nằm bên trong một khối nào đó nhưng không phải tiêu đề chính nha vì tiêu đề thì nên dùng các thẻ h hơn, tuy nhiên những thẻ này có thể nằm bên trong thẻ h nha, hoặc bên trong các thẻ block khác như này
Thẻ strong và thẻ b giống nhau sẽ làm cho chữ in đậm, còn thẻ em và thẻ i giống nhau sẽ làm cho chữ in nghiêng nha.
# Tạm kết phần 1
Woww viết ra cũng dài cũng được khá nhiều kiến thức tuy cơ bản nhưng rất quan trọng cho các bạn mới học HTML. Ở phần tiếp theo mình sẽ nói đến tất tần tật các thẻ về Form nha. Chúc các bạn học tập tốt và một ngày tốt lành nhen.
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Định danh là gì?
Trong ngôn ngữ lập trình, định danh được sử dụng với mục đích nhận biết, phân biệt. Trong Java, một định danh có thể là tên một class, tên một phương thức, tên một biến.
*Lưu ý: tên project, tên file không phải là định danh trong Java.
Nguyên tắc đặt tên, định danh hợp lệ.
Trong quá trình viết code, nếu các định danh không hợp lệ nó sẽ xảy ra lỗi ngay ở lúc complie. Thường thì các IDE (Eclipse, Netbeans…) hiện nay đều hỗ trợ báo lỗi ngay khi bạn sử dụng định danh không hợp lệ.
Các nguyên tắc, qui định bắt buộc về đặt tên, định danh như sau:
Chỉ bao gồm các ký tự là chữ số hoặc chữ cái ([A-Z],[a-z],[0-9]), ký tự ‘$’ và ký tự ‘_’
Định danh không được bắt đầu bằng chữ số.
Định danh có phân biệt hoa thường. Ví dụ int age và int Age là hai định danh khác nhau.
Chiều dài của định danh không bị giới hạn nhuwnng chỉ nên dùng các định danh có chiều dài 4 – 15 ký tự.
Không được sử dụng các từ khóa trong Java để làm định danh (ví dụ: if, else, true, false…)
Bài viết được sự cho phép của tác giả Nguyễn Hữu Đồng
Hào hứng sau khi viết xong một app với go, việc tiếp theo cần làm là chạy ứng dụng đó trên server, hôm nay mình xin được chia sẻ hai các mà mình thường dùng khi chạy go app
Chaỵ ứng dụng với systemd service.
Chạy ứng dụng trong docker container.
Chạy ứng dụng với systemd service
Nói sơ qua một chút về systemd, systemd là một chương trình quản lí các ứng dụng trong linux, tất cả các ứng dụng được quản lí bởi systemd đều được chạy dưới dạng daemon( chữ d trong systemd đón ^_^ ) và được quản lí bằng file cấu hình ( được gọi là unix file ) có 12 loại unix file
service (các file quản lý hoạt động của 1 số chương trình)
socket (quản lý các kết nối)
device (quản lý thiết bị)
mount (gắn thiết bị)
automount (tự đống gắn thiết bị)
swap (vùng không gian bộ nhớ trên đĩa cứng)
target (quản lý tạo liên kết)
path (quản lý các đường dẫn)
timer (dùng cho cron-job để lập lịch)
snapshot (sao lưu)
slice (dùng cho quản lý tiến trình)
scope (quy định không gian hoạt động)
Service là loại phổ biến và được dùng nhiều, nhất trong phần này mình sẽ dùng service unix file để setup các thông số cho app cuả mình.
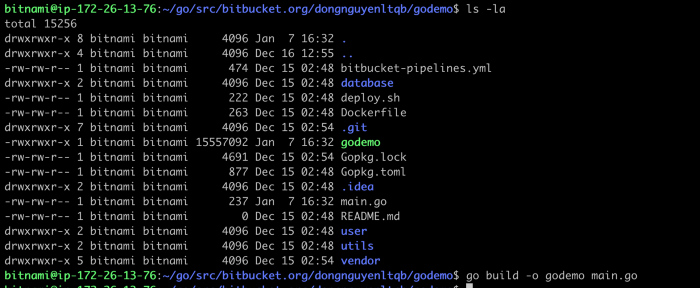
Nói sơ qua một chúng mình sẽ build app ra binary sau đó sẽ tiến hành đăng kí app với systemd service. Và khởi chạy nó, repository mình để ở đây.
Sau khi build app mình được file binary là “godemo”. Mình sẽ tạo file service cho app và đăng kí app với systemd service.
Mình tạo một file trong “/lib/systemd/system/” với nội dung như sau.
Nói sơ qua về nội dung của file.
Phần Unit mình khai báo Description của go app , ConditionPathExists là điều kiện là thư mục với path đó có tồn tại thì mới chạy app và sau cùng After có nghĩa là app của mình sẽ chạy sau khi network service sẵn sằng.
Phần Service, mình có khai báo WorkingDirectory và ExecStart là nơi mà Go App sẽ làm việc và file sẽ được chạy phải đúng là file “exec start” chỉ định. Khai báo “ Restart=on-failure” + “RestartSec=10” thì app sẽ tự khởi chạy là sau 10s nếu lần chạy trước fail.
Để tiến hành đăng kí app của mình với systemd service mình chạy lệnh
sudo systemctl enable godemo.service
Output như sau.
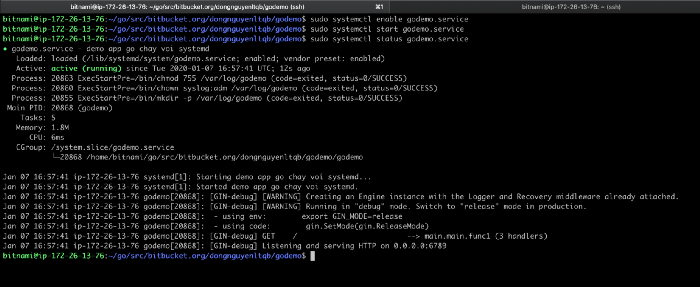
Như vậy là mình đã đăng kí thành công app với systemd service.
Để tiến hành chạy app mình chạy lệnh. Và mình không nhận được output gì cả, chỉ là lệnh đã thực thi thành công.
sudo systemctl start godemo
Để kiểm tra tình trang app mình dùng lệnh. Và mình nhận được kết quả sau.
Vậy là app của mình đã không thể chạy được, do không qua được kiểm ConditionPathExists,check kĩ lại đúng ra phải là “bitbucket.org’ thay cho ‘github.com’ mình tiến hành chỉnh sửa lại file và chạy lại. Do mình mới sửa file godemo.service nên mình phải tiến hành đăng kí mới file và sau đó lại start nó, sau đó sẽ kiểm tra tình trạng app.
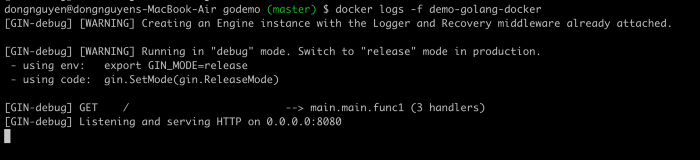
Và đây là Ouput mình nhận được. Mình thấy log của gin-web-server và điều đó chứng tỏ là app của mình đã chạy ngon lành.
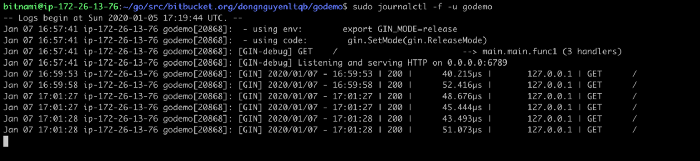
Và để tiến hành xem realtime log mình dùng công cụ “journalctl”
sudo journalctl -f -u godemo
Mình tiến hàng gửi vài request và xem log có đang hoạt động tốt không và đây là kết quả.
Vậy là app của mình đã chạy dưới với systemd service rồi. Với kiểu chạy này, mình thường hay triển khai như sau.
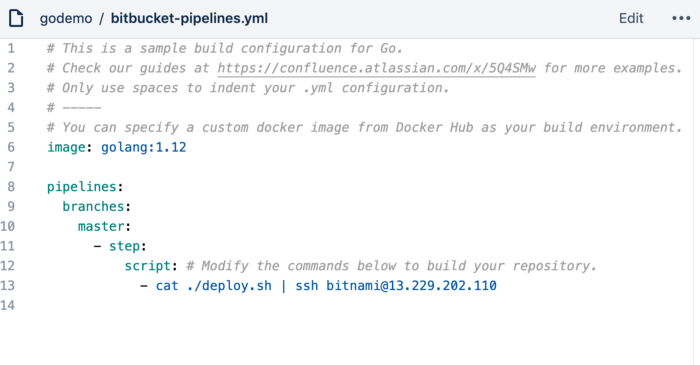
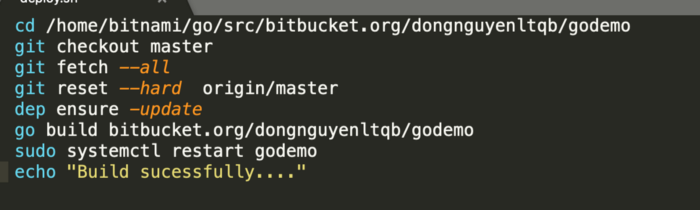
Nội dung của file deploy.sh
Mỗi khi mình push 1 commit lên nhánh master, bitbucket sẽ chạy pipelines và nội dung mình sẽ chạy là chạy các lệnh để pull và merge code từ nhánh master về, sau đó build app và start lại app với systemd service, để start app các bạn chỉ cần chạy lệnh.
sudo systemctl restart godemo
Vậy là xong cách một, à để tìm hiểu sâu hơn về systemd các bạn có thể tìm hiểu thêm tại đây. Tiếp theo là các 2 chạy go app trong docker container.
Chạy ứng dụng trong Docker Container
Trước hết,mình giới thiệu qua một chút về docker.
Nếu ngày xưa câu chuyện “code work on my machine” khiến bao developer phải học máu thì ngày nay nó có phức tạp hơn khi code không chỉ phải chạy được trên “my machine” phải còn phải “ run on every enviroment”.
Và Docker được tạo ra để giải quyết vấn đề đó, tránh confic giữa các app khi chạy, mỗi app sẽ được wrap trong 1 cái container và giao tiếp với bên ngoài thông qua network port. N app thì sẽ chạy trong N container và từ đó sẽ tránh được xung đột không lường trước ( nếu mà lường trước được hết thì đã không đẻ ra thằng Docker ^-^ ).
Trước hết để chạy ứng dụng của bạn trong docker container bạn phải build image và tạo một container trên image đó và tiếp theo là chaỵ container đó .
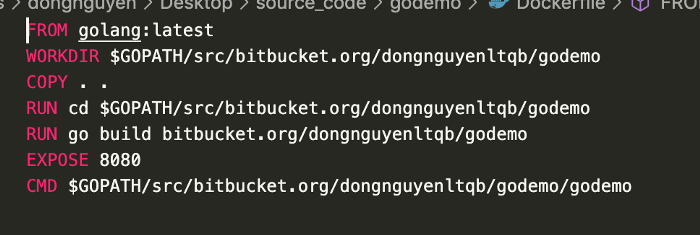
Docker build image dựa vào “Dockerfile” các bạn cùng xem qua nội dung file.
Ở đây
FROM : chỉ đỉnh image của mình khi được tạo nó sẽ dựa trên image có sẵn của golang bản (latest)
WORKDIR : đây là folder mà app của mình sẽ làm việc.
COPY . . : đây là lệnh COPY tất cả các file trong thư mục hiện tại vào trong WORKDIR của container.
RUN : hai lệnh RUN trên sẽ được chạy lần lượt trong khi create image. sơ qua thì mình sẽ chạy đến workdir và build file của mình.
EXPOSE : đây là lệnh mở port để giao tiếp với thế giới bên ngoài, vì nó là container khép kinh nên phải có một cái lỗ gì đó để thông với bên ngoài và trường hợp này là mình mở PORT 8080 trên container xD
CMD : đây là lệnh sẽ được thực thi khai mình thực hiện “start container” tức là chạy container. Phía trên thì khi chạy container mình sẽ khởi chaỵ app đã được build.
Thưc hành cùng mình nhé.
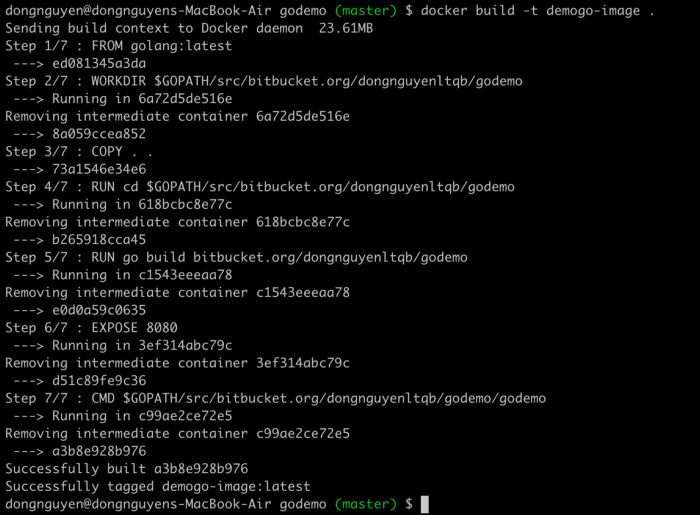
Để build image mình chạy đến folder của app và tiến hàng chạy lệnh và mình nhận được output
docker build -t godemo-image .
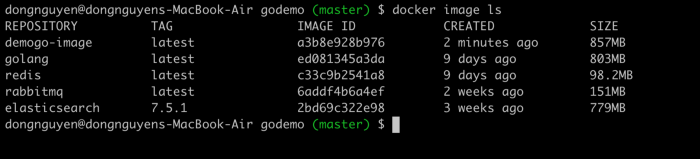
Vậy là mình đã build thành công image, mình tiến hành kiểm tra xem có bao nhiêu image đang tồn tại bằng lệnh.
docker image ls
docker image ls
Như hình trên thì image của mình đã nằm trong kho image.
Để tiến hành tạo một container và chạy container mình dùng lệnh dưới, lệnh dưới sẽ tiến hành chạy docker-container theo kiểu “daemon” hay “background”, map port 6666 thông với port 8080 của container, đặt tên cho container là “demo-golang-docker” và tạo container dựa trên image có tên là “godemo-image” mình đã tạo ở trên kia.
docker run -d -p 6666:8080 --name demo-golang-docker demogo-image
Mình chạy lênh và nhận được id đang chaỵ của container.
docker run container.
Và để kiểm tra status cũng như log realtime của app đang chạy trong container mình dùng lệnh.
docker logs -f demo-golang-docker
Và nhận được output như sau, chứng tỏ app mình đã chạy trong container ngon lành.
docker logs container
Và để check xem docker có map được port 6666 thông với 8080 không mình tiến hành gửi một GET REQUEST tới cổng 6666 và xem kết quả.
curl get
Vậy là app của mình đã giao tiếp được với thế giới bên ngoài. @_@
Trên đây mình đã giới thiệu với các bạn 2 cách mình hay dùng để triển khai Go Application trên server, nếu có sai sót chỗ nào xin được các bạn comment để mình sửa đổi, nếu các bạn có cách nào hay hơn xin hãy comment để mình cùng học hỏi và trở nên tốt hơn.
Đến đây mình xin dừng bút, và cảm ơn các bạn đã đọc bài viết. Hẹn gặp lại các bạn trong các bài viết sau.
Ngày xưa khi Firefox ra đời đánh dấu sự tàn lụi của IE6, với những tính năng siêu ngầu như: cho phép user cài thêm extensions, thay theme như thay áo. Ai cũng khoái.
Vài năm sau, dân chơi thứ thiệt bước vào cuộc đấu, cái tên ai cũng biết là ai đấy – Chrome. Khi vừa xuất hiện thực sự Chrome trở thành cơn địa chấn, số lượng người dùng lúc ban đầu nhiều không tưởng, và không ngừng tăng, bởi vì nó được chống lưng bởi Google, con ác chủ bài để Google có thể chiếm hết thị phần trình duyệt. Chắc chắn bạn cũng đang dùng Chrome để đọc blog này!
Web bây giờ khác xưa nhiều rồi, công nghệ tân thời tốn điện hơn xưa, à ko, tốn RAM và CPU hơn, web ko còn là những trang tin đơn giản, nó còn là những ứng dụng phức tạp chạy trên trình duyệt bằng những công nghệ, ngôn ngữ không ngừng thay đổi để thõa mãn thú tính của người sử dụng, chúng ta đấy.
Tui một developer chạy con Macbook Pro cấu hình cao nhất, mới nhất. Khi bắt đầu lập trình và bật Chrome DevTools lên, pin tụt nhanh như chó phóng qua hàng rào
Và nếu bạn cũng là developer như tui, chắc bạn cũng sẽ bật Task manager lên và kiểm tra, a đù, sao Chrome mày ăn RAM tao kinh dị vạy.
Rồi bạn nghe đâu với bản Firefox Quantum mới bọn dev của mozila đã ngồi fix hơn 7 triệu dòng code để Firefox cạnh tranh về tốc độ với Google! Quảng cáo ngầu ghê!
Năm 2017 Quantum chạy chính thức trên Android, Linux, iOS, Mac, Windows, nói chung chạy tuốt, phải hơn sau 10 năm từ ngày phiên bản đầu tiên, phiên bản đã giết chết IE mới có một cập nhập thực sự đáng đồng tiền bát cháo.
Bên cạnh giao diện cool mới, nó load web nhanh hơn gấp đôi so với phiên bản Firefox 6, sử dụng ít hơn 30% RAM so với Chrome.
Sau 10 năm lăn lộn trên chiến trường, Mozilla đã hiểu được rằng để cạnh tranh được với đối thủ bây giờ thì không chỉ cần một vài cải tiến nhỏ là được, mọi thứ phải thực sự AWSOME.
Có thể những tính năng được đưa vào Firefox Quantum bạn cũng có thể tìm thấy trên Chrome, nhưng điều gì khiến tui vẫn thích Firefox và luôn muốn mình sử dụng Firefox khi có thể?
Các công ty lớn điều sẽ muốn người sử dụng sản phẩm từ một nhà cung cấp khác quay lưng và sử dụng sản phẩm của mình, công ty sẽ cung cấp những tính năng chỉ-có-thể-tìm-thấy trên sản phẩm của họ để cầm chân người dùng trong ecosymtem của công ty.
Lấy ví dụ như Apple Keynote chỉ có thể sử dụng với Safari, iMessage chỉ có trên iOS, bạn phải say-good-bye khi chuyển qua Android, trang update của Microsoft chỉ có thể sự dụng trên IE, Edge, để chép nhạc vào iphone bạn phải cài iTune,… ngược lại Firefox có thể nói là kẻ phá đám đứng ngoài khu vườn thượng uyển đó, là đối thủ cạnh tranh để chống lại sự độc quyền và khiến việc các công ty lớn bắt chúng ta phụ thuộc ngày càng nhiều vào các công ty này trở nên khó hơn, khiến họ phải dè chừng và không ngừng cái tiến sản phẩm. Như câu nói nghe suốt “Có cạnh tranh thì mới có phát triển”, như khi Grab đã loại đi Uber rồi và khi chúng ta sẽ ra sau, Youtube của google một khi đã giết hết tất cả đối thủ trong mảng Video trực tuyến, chúng ta ăn quảng cáo còn hơn cả trên truyền hình, xem một clip 10 phút là đã có quảng cáo, vừa vào xem đã phải xem quảng cáo trước.
Bonus: từ hàng triệu yêu cầu từ user, Firefox đã có tính năng tắt hết cái Push-Notify, một trong những yêu cầu hết sực bực mình khi các trang web bây giờ đều đòi cấp phép cho nó quăng thông báo quảng cáo qua trình duyệt dù mình không đang truy cập nó.
Sử dụng slot để component dễ hiểu hơn và dễ tùy biến hơn
Bài viết hướng dẫn chi tiết khái niệm và cách dùng slot bạn đọc lại ở đây. Với việc sử dụng slot bạn sẽ có những component với khả năng xào đi nấu lại dễ hơn.
Khi mới nhận thiết kế từ bên design, popup modal vô cùng đơn giản, chỉ gồm title, description và dâm ba cái button bên dưới. Thoạt nhìn chúng ta chỉ cần 3 cái prop và một sự kiện bắn ra khi click button để thay đổi tùy theo tình huống sử dụng.
Nhưng sau một thời gian, bên design họ vẽ vời thêm một mớ mới, nhúng form, chèn hẳn một component khác vào trong đó, vâng vâng. Prop không đáp ứng nổi độ khùng của mấy bạn design. Và cách mà chúng ta refactor lại cái modal bằng slot
Một lập trình viên bắt đầu mò mẫm cách xài Vuex vì họ gặp 2 vấn đề sau
Cần truy cập vào dữ liệu từ một component khác, nó nằm xa ơi là xa so với component hiện tại.
Sau khi component bị xóa khỏi DOM, bạn vẫn muốn dữ liệu đó không bị xóa
Khi bắt đầu tạo Vuex Store, chúng ta bắt đầu học được khái niệm module và cách sử dụng trong ứng dụng.
Không một quy chuẩn nào để tổ chức module, đồng nghĩa là mỗi người mỗi ý, đa phần các lập trình viên sẽ tổ chức theo dạng tính năng
Auth
Blog
Inbox
Setting
Hợp lý mà, một cách tiếp cận khác cũng hợp lý luôn là tổ chức theo dữ liệu trả về từ API
User
Team
Message
Widget
Article
Vì là quan điểm nên không thể nói đúng sai, nhưng chúng ta phải thống nhất một cách tổ chức Vuex Store mà mọi người đều đồng ý là hợp lý. Người mới vào team cũng dễ follow hơn.
Sử dụng action để lấy và gửi dữ liệu
Hầu hết các network request được đưa vào Vuex action. Bạn có thắc mắc, tại sao lại thế? 🤨
Đơn giản là vì hầu hết các dữ liệu lấy về sẽ được đưa vào trong store. Mặc khác, xét trên khía cạnh đóng gói và tái sử dụng thì đây là cách mang lại sự dễ chịu khi sử dụng nhất.
Sử dụng mapState, mapGetters, mapMutations và mapActions
Không có lý do gì phải có nhiều giá trị computed hoặc phương thức chỉ vì bạn cần truy cập vào state/getter hoặc gọi actions/mutations bên trong component. Sử dụng các hàm được cung cấp sẵn của Vuex mapState, mapGetters, mapMutations và mapActions
Tạo một hàm this.$api để có thể gọi ở bất kỳ đâu khi cần tạo network request. Trong thư mục gốc, thêm một thư mục tên api chứa tất cả các phương thức liên quan
Trong bộ source chúng ta sẽ luôn cần những biến chưa config trên môi trường khác nhau
config
├── development.json
└── production.json
Nếu có thể truy cập những biến này thông qua this.$config có phải tiện lợi lắm không
importVuefrom"vue";import development from"@/config/development.json";import production from"@/config/production.json";if(process.env.NODE_ENV==="production"){Vue.prototype.$config=Object.freeze(production);}else{Vue.prototype.$config=Object.freeze(development);}
Tuân theo một nguyên tắc chung khi viết commit
Nếu bạn nào có contribute cho các dự án trên Github, sẽ thấy lợi ích của việc có một chuẩn chung khi viết diễn giải cho commit. Có thể lấy cách viết của Angular tham khảo
git commit -am "<type>(<scope>): <subject>"# Một vài ví dụgit commit -am "docs(changelog): update changelog to beta.5"git commit -am "fix(release): need to depend on latest rxjs and zone.js"
Khi lên production, fix luôn các package version đang xài
Không phải package nào cũng được đặt version theo quy tắc đã chuẩn hóa. Để tránh nửa đêm bị gọi dậy vì một trong các package đã cài bộ source bỗng dưng không tương thích, production không còn chạy như trên local.
Tội đồ là cái prefix ^ này. Xóa hết nó khi lên production
Sử dụng Virtual Scroller khi hiển thị nhiều dữ liệu
Khi cần hiển thị một số lượng lớn các hàng dữ liệu trên mộ trang, việc loop qua toàn bộ dữ liệu và render sẽ bị chậm. Dùng vue-virtual-scroller
npminstall vue-virtual-scroller
Nó sẽ chỉ render các dữ liệu có thể vừa vặn trong viewport, phần dữ liệu chưa hiển thị trên viewport sẽ được lazy render khi cuộn tới, tăng tốc độ đáng kể
Bộ source lớn thường đồng nghĩa sử dụng nhiều package lụm được trên mạng, nếu không để ý, việc cài đặt bừa bãi các package này dễ dẫn đến việc dung lượng tăng vọt
Để custom page transition trong flutter, các bạn sẽ thực hiện animation khi một route mới được thêm vào Stack Navigator. Ví dụ như thông qua push, pushNamed… Để làm được điều này, chúng ta sẽ sử dụng thuộc tính onGenerateRoute của MaterialApp.
Thuộc tính onGenerateRoute của MaterialApp là một function, function này sẽ được thực hiện khi chúng ta push một route vào Stack Navigator.
Thuộc tính onGenerateRoute nhận vào một tham số là RouteSettings, chúng ta sẽ cần thuộc tính name từ tham số này. Chúng ta cần trả về một PageRouteBuilder và sử dụng 3 thuộc tính của nó là pageBuilder, transitionDuration và transitionsBuilder.
Thuộc tính pageBuilder là thuộc tính xác định route nào sẽ được trả về (tức route mà bạn đang push vào stack navigator). Nhận vào một hàm có tham số lần lượt là Context, Animation, Animation, chúng ta chỉ cần quan tâm đến tham số Context, đơn giản bạn chỉ cần trả về route được push dựa vào thuộc tính name của tham số settings được truyền vào thuộc tính onGenerateRoute sử dụng Context.
Vậy để có thể nhận biết được route nào được push vào, các bạn phải sử dụng routes map (tương tự như thuộc tính routes trong MaterialApp). Thêm nữa, để có thể truy cập được routes từ trong các thuộc tính, chúng ta cần phải để biến routes map là biến toàn cục.
Thuộc tính tiếp theo là transitionsBuilder, thuộc tính này cho phép chúng ta custom transition cho page. Thuộc tính này nhận vào một hàm có tham số lần lược là Context, Animation, Animation và child. Ở lần này, chúng ta sẽ sử dụng hai tham số là animation thứ nhất và child.
Tham số animation thứ nhất là để chúng ta thực hiện animation khi navigate route. Do đó, chúng ta sẽ sử dụng các thuộc tính này trong thuộc tính animation value của các widget như SlideTransition, ScaleTransition… và thuộc tính child chính là tham số child truyền vào.
Các Transition Widget đều có thể lồng nhau, do đó, các bạn có lồng nhiều Transition Widget vào nhau để tạo ra các hiện ứng transition đẹp mắt của riêng bạn.
Thuộc tính cuối cùng là transitionDuration, mình có thể custom duration của animation khi navigate route. Thuộc tính này đơn giản nhận vào một Duration, các bạn có thể để thời gian bao lâu tùy thích, milliseconds, seconds…
Ví dụ như mình muốn có hiệu ứng vừa slide, vừa scale từ dưới lên và fade luôn, thì mình sẽ có đoạn code sau:
Nếu các bạn muốn ứng dụng của bạn có hiệu ứng transition như trên iOS, bạn có thể sử dụng Widget CupertinoPageRoute thay cho Widget PageRouteBuilder.
Không giống như Widget PageRouteBuilder, Widget CupertinoPageRoute không đòi hỏi bạn phải custom quá nhiều. Bạn chỉ cần trả về Widget CupertinoPageRoute, bên trong Widget này có thuộc tính builder nhận vào một funciton có tham số là Context, bạn chỉ cần trả về một route dựa trên route name.
Mình sẽ code như sau để có hiệu ứng transition như trên iOS:
Đối với Widget CupertinoPageRoute, các bạn không thể custom được gì nhiều, chỉ dùng là có transition effect như iOS thôi, tù y hệt như trên iOS luôn.
Tổng kết
Một lưu ý nhỏ là nếu các bạn sử dụng thuộc tính routes trong MaterialApp, hàm trong thuộc tính onGenerateRoute sẽ không được gọi do nó đã tìm được route trong thuộc tính routes rồi. Do đó, các bạn không nên truyền routes vào cho thuộc tính routes của MaterialApp nếu muốn custom transition hoạt động.
Qua bài này, mình đã hướng dẫn các bạn cách custom page transition flutter đơn giản bằng việc sử dụng các Widget Transition có sẵn. Nếu bạn thấy video và bài viết này hay, đừng quên chia sẻ cho bạn bè được biết. Cảm ơn các bạn đã theo dõi bài viết!
Thuật toán sắp xếp là lời giải của bài toán sắp xếp. Mục đích của việc sắp xếp chính là giúp ta có cái nhìn tổng quan hơn về những dữ liệu là cơ sở cho các giải thuật nâng cao với hiệu suất cao hơn.
Ví dụ như khi thực hiện tìm kiếm, thuật toán tìm kiếm nhị phân có độ phức tạp thời gian là O(log(n)) và ổn định, nhưng thuật toán này chỉ áp dụng được với dãy đã được sắp xếp. Vậy khi này, bạn có thể thực hiện sắp xếp trước sau đó áp dụng thuật toán tìm kiếm nhị phân.
Trong bài viết này, TopDev sẽ giới thiệu đến các bạn một số thuật toán sắp xếp trong C++ phổ biến nhất mà lập trình viên nào cũng nên biết. Hãy cùng bắt đầu thôi!
Thuật toán sắp xếp – hàm sort() trong C++ được định nghĩa là một hàm trong thư viện <algorithm> của C++ dùng để sắp xếp các phần tử trong một phạm vi (range) nhất định theo thứ tự tăng dần hoặc theo một tiêu chí cụ thể do người dùng định nghĩa.
Hàm sort C++ được cài đặt sẵn là hàm intro - sort, đây là sự kết hợp của 2 thuật toán sắp xếp rất hiệu quả là quick sort và heap sort. Hàm này mặc định sắp xếp các giá trị tăng dần, nếu muốn sắp xếp giảm dần cần thêm tham số greater().
#include<iostream>#include<algorithm>#include<vector>intmain(){
std::vector<int> vec = {5, 2, 9, 1, 5, 6};
// Sắp xếp tăng dần
std::sort(vec.begin(), vec.end());
// In kết quảfor (int i : vec) {
std::cout << i << " ";
}
return0;
}
Các thuật toán sắp xếp trong C++
Các hàm sort trong C++ phổ biến:
Sắp xếp nổi bọt (Bubble Sort)
Sắp xếp chọn (Selection Sort)
Sắp xếp chèn (Insertion Sort)
Sắp xếp nhanh (Quick Sort)
Sắp xếp trộn (Merge Sort)
Sắp xếp vun đống (Heap Sort)
Sắp xếp đếm (Counting Sort)
Hàm sắp xếp nổi bọt (Bubble Sort)
Sắp xếp nổi bọt hay bubblesort là thuật toán sắp xếp đầu tiên mà mình giới thiệu đến các bạn và cũng là thuật toán đơn giản nhất trong các thuật toán mà mình sẽ giới thiệu, ý tưởng của thuật toán này như sau:
Duyệt qua danh sách, làm cho các phần tử lớn nhất hoặc nhỏ nhất dịch chuyển về phía cuối danh sách, tiếp tục lại làm phần tử lớn nhất hoặc nhỏ nhất kế đó dịch chuyển về cuối hay chính là làm cho phần tử nhỏ nhất (hoặc lớn nhất) nổi lên, cứ như vậy cho đến hết danh sách Cụ thể các bước thực hiện của giải thuật này như sau:
Gán i = 0
Gán j = 0
Nếu A[j] > A[j + 1] thì đối chỗ A[j] và A[j + 1]
Nếu j < n – i – 1:
Đúng thì j = j + 1 và quay lại bước 3
Sai thì sang bước 5
Nếu i < n – 1:
Đúng thì i = i + 1 và quay lại bước 2
Sai thì dừng lại
Thật đơn giản đúng không nào, chúng ta hãy cùng cài đặt thuật toán này trong C++ nha.
voidBubbleSort(int A[],int n){for(int i =0; i < n -1; i++)for(int j =0; j < n - i -1; j++)if(A[j]> A[j +1])swap(A[j], A[j +1]);// đổi chỗ A[j] và A[j + 1]}
Sắp xếp nổi bọt là một thuật toán sắp xếp ổn định. Về độ phức tạp, do dùng hai vòng lặp lồng vào nhau nên độ phức tạp thời gian trung bình của thuật toán này là O(n2).
Các bạn có thể xem mình trình bày ý tưởng của giải thuật này trong bên dưới:
Hàm sắp xếp chọn (Selection Sort)
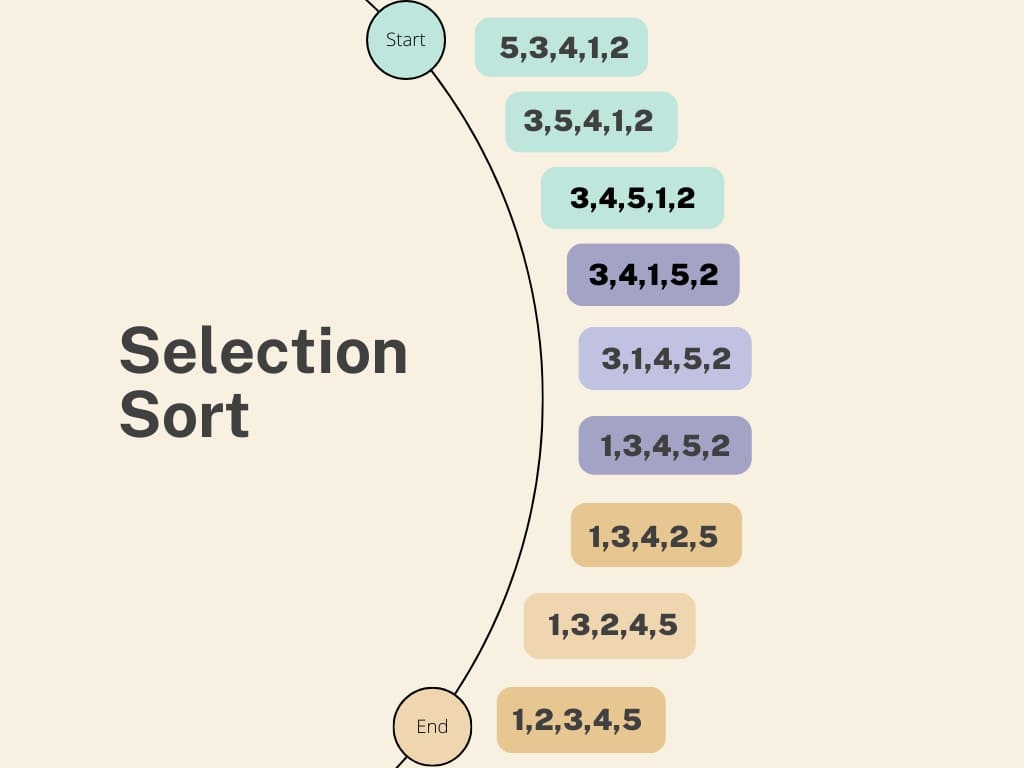
Sắp xếp chọn hay SelectionSort sẽ là thuật toán thứ hai mà mình giới thiệu đến các bạn, ý tưởng của thuật toán này như sau: duyệt từ đầu đến phần tử kề cuối danh sách, duyệt tìm phần tử nhỏ nhất từ vị trí kế phần tử đang duyệt đến hết, sau đó đổi vị trí của phần tử nhỏ nhất đó với phần tử đang duyệt và cứ tiếp tục như vậy.
Hàm sắp xếp chọn (Selection Sort)
Cho mảng A có n phần tử chưa được sắp xếp. Cụ thể các bước của giải thuật này áp dụng trên mảng A như sau:
Gán i = 0
Gán j = i + 1 và min = A[i]
Nếu j < n:
Nếu A[j] < A[min] thì min = j
j = j + 1
Quay lại bước 3
Đổi chỗ A[min] và A[i]
Nếu i < n – 1:
Đúng thì i = i + 1 và quay lại bước 2
Sai thì dừng lại
Ý tưởng và từng bước giải cụ thể đã có, bây giờ mình sẽ sử dụng thuật toán này trong C++:
voidSelectionSort(int A[],int n){int min;for(int i =0; i < n -1; i++){
min = i;// tạm thời xem A[i] là nhỏ nhất// Tìm phẩn tử nhỏ nhất trong đoạn từ A[i] đến A[n - 1]for(int j = i +1; j < n; j++)if(A[j]< A[min])// A[j] mà nhỏ hơn A[min] thì A[j] là nhỏ nhất
min = j;// lưu lại vị trí A[min] mới vừa tìm đượcif(min != i)// nếu như A[min] không phải là A[i] ban đầu thì đổi chỗswap(A[i], A[min]);}}
Đối với thuật toán sắp xếp chọn, do sử dụng 2 vòng lặp lồng vào nhau, độ phức tạp thời gian trung bình của thuật toán này là O(n2). Thuật toán sắp xếp chọn mình cài đặt là thuật toán sắp xếp không ổn định, nó còn có một phiên bản khác cải tiến là thuật toán sắp xếp chọn ổn định.
Giải thích ý tưởng thuật toán:
Hàm sắp xếp chèn (Insertion Sort)
Sắp xếp chèn hay insertion sort là thuật toán tiếp theo mà mình giới thiệu, ý tưởng của thuật toán này như sau: ta có mảng ban đầu gồm phần tử A[0] xem như đã sắp xếp, ta sẽ duyệt từ phần tử 1 đến n – 1, tìm cách chèn những phần tử đó vào vị trí thích hợp trong mảng ban đầu đã được sắp xếp.
Hàm sắp xếp chèn (Insertion Sort)
Giả sử cho mảng A có n phần tử chưa được sắp xếp. Các bước thực hiện của thuật toán áp dụng trên mảng A như sau:
Gán i = 1
Gán x = A[i] và pos = i – 1
Nếu pos >= 0 và A[pos] > x:
A[pos + 1] = A[pos]
pos = pos – 1
Quay lại bước 3
A[pos + 1] = x
Nếu i < n:
Đúng thì i = i + 1 và quay lại bước 2
Sai thì dừng lại
Bây giờ thì áp dụng nó vào trong C++ thôi!
voidInsertionSort(int A[],int n){int pos, x;for(int i =1; i < n; i++){
x = A[i];// lưu lại giá trị của x tránh bị ghi đè khi dịch chuyển các phần tử
pos = i -1;// tìm vị trí thích hợp để chèn xwhile(pos >=0&& A[pos]> x){// kết hợp với dịch chuyển phần tử sang phải để chừa chỗ cho x
A[pos +1]= A[pos];
pos--;}// chèn x vào vị trí đã tìm được
A[pos +1]= x;}}
Cũng tương tự như sắp xếp chọn, thuật toán sắp xếp chèn cũng có độ phức tạp thời gian trung bình là O(n2) do có hai vòng lặp lồng vào nhau.
Video giải thích ý tưởng thuật toán:
Sắp xếp trộn (Merge Sort)
Sắp xếp trộn (merge sort) là một thuật toán dựa trên kỹ thuật chia để trị, ý tưởng của thuật toán này như sau: chia đôi mảng thành hai mảng con, sắp xếp hai mảng con đó và trộn lại theo đúng thứ tự, mảng con được sắp xếp bằng cách tương tự.
Giả sử left là vị trí đầu và right là cuối mảng đang xét, cụ thể các bước của thuật toán như sau:
Nếu mảng còn có thể chia đôi được (tức left < right)
Tìm vị trí chính giữa mảng
Sắp xếp mảng thứ nhất (từ vị trí left đến mid)
Sắp xếp mảng thứ 2 (từ vị trí mid + 1 đến right)
Trộn hai mảng đã sắp xếp với nhau
Bây giờ mình sẽ cài đặt thuật toán cụ thể trong C++ như sau:
// Hàm trộn hai mảng con vào nhau theo đúng thứ tựvoidMerge(int A[],int left,int mid,int right){int n1 = mid - left +1;// Số phần tử của mảng thứ nhấtint n2 = right - mid;// Số phần tử của mảng thứ hai// Tạo hai mảng tạm để lưu hai mảng conint*LeftArr =newint[n1];int*RightArr =newint[n2];// Sao chép phần tử 2 mảng con vào mảng tạmfor(int i =0; i < n1; i++)
LeftArr[i]= A[left + i];for(int i =0; i < n2; i++)
RightArr[i]= A[mid +1+ i];// current là vị trí hiện tại trong mảng Aint i =0, j =0, current = left;// Trộn hai mảng vào nhau theo đúng thứ tựwhile(i < n1 && j < n2)if(LeftArr[i]<= RightArr[j])
A[current++]= LeftArr[i++];else
A[current++]= RightArr[j++];// Nếu mảng thứ nhất còn phần tử thì copy nó vào mảng Awhile(i < n1)
A[current++]= LeftArr[i++];// Nếu mảng thứ hai còn phần tử thì copy nó vào mảng Awhile(j < n2)
A[current++]= RightArr[j++];// Xóa hai mảng tạm đidelete[] LeftArr, RightArr;}// Hàm chia đôi mảng và gọi hàm trộnvoid_MergeSort(int A[],int left,int right){// Kiểm tra xem còn chia đôi mảng được khôngif(left < right){// Tìm phần tử chính giữa// left + (right - left) / 2 tương đương với (left + right) / 2// việc này giúp tránh bị tràn số với left, right quá lớnint mid = left +(right - left)/2;// Sắp xếp mảng thứ nhất_MergeSort(A, left, mid);// Sắp xếp mảng thứ hai_MergeSort(A, mid +1, right);// Trộn hai mảng đã sắp xếpMerge(A, left, mid, right);}}// Hàm sắp xếp chính, được gọi khi dùng merge sortvoidMergeSort(int A[],int n){_MergeSort(A,0, n -1);}
Về độ phức tạp, thuật toán Merge Sort có độ phức tạp thời gian trung bình là O(nlog(n)), về không gian, do sử dụng mảng phụ để lưu trữ, và 2 mảng phụ dài nhất là hai mảng phụ ở lần chia đầu tiên có tổng số phần tử bằng đúng số phần tử của mảng nên độ phức tạp sẽ là O(n). Sắp xếp trộn là thuật toán sắp xếp ổn định.
Video minh họa của GeeksforGeeks:
Hàm sắp xếp nhanh (Quick Sort)
Sắp xếp nhanh (quick sort) hay sắp xếp phân đoạn (Partition) là là thuật toán sắp xếp dựa trên kỹ thuật chia để trị, cụ thể ý tưởng là: chọn một điểm làm chốt (gọi là pivot), sắp xếp mọi phần tử bên trái chốt đều nhỏ hơn chốt và mọi phần tử bên phải đều lớn hơn chốt, sau khi xong ta được 2 dãy con bên trái và bên phải, áp dụng tương tự cách sắp xếp này cho 2 dãy con vừa tìm được cho đến khi dãy con chỉ còn 1 phần tử.
Cụ thể áp dụng thuật toán cho mảng như sau:
Chọn một phần tử làm chốt
Sắp xếp phần tử bên trái nhỏ hơn chốt
Sắp xếp phần tử bên phải nhỏ hơn chốt
Sắp xếp hai mảng con bên trái và bên phải pivot
Phần tử được chọn làm chốt rất quan trọng, nó quyết định thời gian thực thi của thuật toán. Phần tử được chọn làm chốt tối ưu nhất là phần tử trung vị, phần tử này làm cho số phần tử nhỏ hơn trong dãy bằng hoặc sấp xỉ số phần tử lớn hơn trong dãy. Tuy nhiên, việc tìm phần tử này rất tốn kém, phải có thuật toán tìm riêng, từ đó làm giảm hiệu suất của thuật toán tìm kiếm nhanh, do đó, để đơn giản, người ta thường sử dụng phần tử chính giữa làm chốt.
Trong bài viết này, mình cũng sẽ sử dụng phần tử chính giữa làm chốt, thuật toán cài đặt trong C++ như sau:
voidPartition(int A[],int left,int right){// Kiểm tra xem nếu mảng có 1 phần tử thì không cần sắp xếpif(left >= right)return;int pivot = A[(left + right)/2];// Chọn phần tử chính giữa dãy làm chốt// i là vị trí đầu và j là cuối đoạnint i = left, j = right;while(i < j){while(A[i]< pivot)// Nếu phần tử bên trái nhỏ hơn pivot thì ok, bỏ qua
i++;while(A[j]> pivot)// Nếu phần tử bên phải nhỏ hơn pivot thì ok, bỏ qua
j--;// Sau khi kết thúc hai vòng while ở trên thì chắc chắn// vị trí A[i] phải lớn hơn pivot và A[j] phải nhỏ hơn pivot// nếu i < jif(i <= j){if(i < j)// nếu i != j (tức không trùng thì mới cần hoán đổi)swap(A[i], A[j]);// Thực hiện đổi chổ ta được A[i] < pivot và A[j] > pivot
i++;
j--;}}// Gọi đệ quy sắp xếp dãy bên trái pivotPartition(A, left, j);// Gọi đệ quy sắp xếp dãy bên phải pivotPartition(A, i, right);}// Hàm sắp xếp chínhvoidQuickSort(int A[],int n){Partition(A,0, n -1);}
Thuật toán sắp xếp nhanh không phải là thuật toán sắp xếp ổn định, tuy nhiên vẫn có thể cải tiến nó thành thuật toán sắp xếp ổn định. Độ phức tạp thời gian trung bình của thuật toán này là O(nlog(n)).
Hàm sắp xếp vun đống (Heap Sort)
Heap Sort là một thuật toán sắp xếp dựa trên cấu trúc dữ liệu heap, thường là heap nhị phân. Thuật toán này có độ phức tạp thời gian là O(n log n) và hoạt động tốt với các mảng lớn.
Cách thức hoạt động:
Tạo một max-heap từ mảng đầu vào.
Hoán đổi phần tử gốc của heap với phần tử cuối của mảng.
Giảm kích thước heap bằng cách bỏ qua phần tử cuối cùng đã được sắp xếp.
Điều chỉnh lại heap để duy trì tính chất max-heap.
Lặp lại các bước trên cho đến khi toàn bộ mảng được sắp xếp.
Cú pháp và ví dụ:
#include<iostream>#include<vector>voidheapify(std::vector<int>& arr, int n, int i){
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest])
largest = left;
if (right < n && arr[right] > arr[largest])
largest = right;
if (largest != i) {
std::swap(arr[i], arr[largest]);
heapify(arr, n, largest);
}
}
voidheapSort(std::vector<int>& arr){
int n = arr.size();
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
for (int i = n - 1; i > 0; i--) {
std::swap(arr[0], arr[i]);
heapify(arr, i, 0);
}
}
intmain(){
std::vector<int> arr = {12, 11, 13, 5, 6, 7};
heapSort(arr);
std::cout << "Sorted array is: \n";
for (int i = 0; i < arr.size(); i++)
std::cout << arr[i] << " ";
std::cout << std::endl;
return0;
}
Hàm sắp xếp đếm (Counting Sort)
Counting Sort là một thuật toán sắp xếp không so sánh, có độ phức tạp thời gian là O(n + k) với n là số phần tử và k là phạm vi giá trị của các phần tử. Thuật toán này hiệu quả khi k nhỏ hơn rất nhiều so với n.
Cách thức hoạt động:
Tạo một mảng đếm để lưu số lần xuất hiện của mỗi giá trị trong mảng đầu vào.
Thay đổi mảng đếm để lưu vị trí cuối cùng của mỗi giá trị trong mảng sắp xếp.
Xây dựng mảng kết quả bằng cách đặt các phần tử vào vị trí chính xác của chúng trong mảng đếm.
Cú pháp và ví dụ:
#include<iostream>#include<vector>voidcountingSort(std::vector<int>& arr){
int max = *max_element(arr.begin(), arr.end());
int min = *min_element(arr.begin(), arr.end());
int range = max - min + 1;
std::vector<int> count(range), output(arr.size());
for (int i = 0; i < arr.size(); i++)
count[arr[i] - min]++;
for (int i = 1; i < count.size(); i++)
count[i] += count[i - 1];
for (int i = arr.size() - 1; i >= 0; i--) {
output[count[arr[i] - min] - 1] = arr[i];
count[arr[i] - min]--;
}
for (int i = 0; i < arr.size(); i++)
arr[i] = output[i];
}
intmain(){
std::vector<int> arr = {4, 2, 2, 8, 3, 3, 1};
countingSort(arr);
std::cout << "Sorted array is: \n";
for (int i = 0; i < arr.size(); i++)
std::cout << arr[i] << " ";
std::cout << std::endl;
return0;
}
Lời kết
Vậy là qua bài viết này, mình đã giới thiệu đến các bạn các thuật toán tìm kiếm phổ biến nhất. Nếu bạn có thắc mắc hoặc góp ý nào, đừng quên để lại bình luận bên dưới bài viết. Đừng quên chia sẻ bài viết này cho bạn bè cùng biết nha. Cảm ơn các bạn đã theo dõi bài viết!
Như bạn có thể thấy, nó là một chức năng rất đơn giản.
Tuy nhiên, có một điều thực sự khó chịu về chức năng này.
Nó tự động in một dòng mới ‘\ n’ ở cuối dòng!
Hãy xem ví dụ này
print("Hello World!")
print("My name is Nguyenpv")
# output:# Hello World!
# My name is Nguyenpv
Như bạn có thể nhận thấy, hai chuỗi không được in lần lượt từng chuỗi trên cùng một dòng mà thay vào đó là các dòng riêng biệt.
Mặc dù đây có thể là những gì bạn thực sự muốn, nhưng không phải lúc nào cũng như vậy.
nếu bạn đến từ một ngôn ngữ khác, bạn có thể thoải mái hơn khi đề cập rõ ràng liệu một dòng mới có nên được in ra hay không.
Ví dụ: trong Java, bạn phải thể hiện rõ ràng mong muốn in một dòng mới bằng cách sử dụng chức năng println hoặc nhập ký tự dòng mới (\ n) bên trong chức năng in của bạn:
Python 3 cung cấp giải pháp đơn giản nhất, tất cả những gì bạn phải làm là cung cấp thêm một đối số cho hàm print.
# use the named argument "end" to explicitly specify the end of line string
print("Hello World!", end = '')
print("My name is Nguyenpv")
# output:
# Hello World!My name is Nguyenpv
Bạn có thể sử dụng đối số end để đề cập rõ ràng chuỗi cần được nối ở cuối dòng.
Bất cứ điều gì bạn cần làm là thêm đối số end sẽ là chuỗi kết thúc.
Vì vậy, nếu bạn cung cấp một chuỗi trống, thì sẽ không có ký tự dòng mới và không có khoảng trắng nào sẽ được thêm vào đầu vào của bạn.
Trong python 2, cách dễ nhất để tránh dòng mới kết thúc là sử dụng dấu phẩy ở cuối câu lệnh in của bạn
# no newlines but a space will be printed out
print "Hello World!",
print "My name is Nguyenpv"
# output
# Hello World! My name is Nguyenpv
Như bạn có thể thấy, mặc dù không có dòng mới, chúng tôi vẫn có một ký tự khoảng trắng giữa hai câu lệnh in.
Nếu bạn thực sự cần một không gian, thì đây là cách đơn giản nhất và đơn giản nhất để đi.
Nhưng nếu bạn muốn in mà không có dấu cách hoặc dòng mới thì sao?
Trong trường hợp này, bạn có thể sử dụng hàm sys.stdout.write từ module sys .
Hàm này sẽ chỉ in bất cứ thứ gì bạn nói rõ ràng để in.
Không có chuỗi kết thúc.
Không có phép thuật!
Hãy lấy một ví dụ
import sys
sys.stdout.write("Hello World!")
sys.stdout.write("My name is Nguyenpv")
# output
# Hello World!My name is Nguyenpv
Haiz, đoạn này thấy nhì nhằng, phức tạp hơn ngôn ngữ lập trình khác rồi đấy, ví dụ PHP, ở PHP thì chỉ cẩn dùng 1 hàm ví dụ “echo“, rồi muốn in như nào thì in : ))
Danh sách liên kết (DSLK) đơn (Singly linked list) là một cấu trúc dữ liệu cơ bản và có cực kì nhiều ứng dụng. Ý tưởng của DSLK đơn khá đơn giản. Tuy nhiên, để cài đặt cấu trúc DSLK đơn một cách ngắn gọn, hiệu quả thì không phải là điều hiển nhiên. Trong bài này, chúng ta sẽ thảo luận các cách cài đặt danh sách liên kết (trong C) sao cho hiệu quả và ngắn gọn.
Cài đặt DSLK trong C không thể tránh khỏi sử dụng con trỏ (pointer) và struct. Con trỏ là một kiểu dữ liệu cực kì mạnh của ngôn ngữ C. Nó cho phép người lập trình thao tác bộ nhớ rất hiệu quả. Những lập trình viên giỏi luôn là những lập trình viên biết thao tác con trỏ một cách thuần thục. Tuy nhiên, điểm yếu của con trỏ là khó học, khó nắm bắt và cũng khó debug các chương trình có con trỏ, nhất là đối với những người lần đầu tiếp xúc với khái niệm con trỏ.
Trong bài này, mình cũng không có gắng giải thích ý nghĩa, mặc dù có nhắc lại, con trỏ. Mình khuyến khích các bạn tự tìm hiểu, vì có rất nhiều nguồn, kể cả tiếng Anh và tiếng Việt. Phần cuối bài mình sẽ liên kết một số bài viết hay về con trỏ. Mục tiêu của bài này là minh họa tối đa khả năng kì diệu của con trỏ trong thao danh sách liên kết. Các bài khác trong blog mình thường minh họa bằng giả mã. Tuy nhiên, bài này mình sẽ trực tiếp sử dụng code C.
Con trỏ và struct
Một con trỏ (pointer) là một biến dùng để lưu trữ địa chỉ của một biến khác. Biến khác ở đây có thể là một biến thông thường như biến số nguyên, biến số thực, hoặc có thể là một mảng, một hàm, và có khi cũng chính là một con trỏ khác. Vì con trỏ là một biến nên nó cũng cần phải được lưu trữ ở đâu đó trong bộ nhớ; có nghĩa là bản thân biến con trỏ cũng có một địa chỉ trong bộ nhớ. Do đó, ta có thể dùng con trỏ đề lưu địa chỉ của một con trỏ khác. Tính chất này cũng chính là sự kì diệu của con trỏ mà mình sẽ minh họa trong bài này.
Cú pháp khai báo con trỏ trong C, nói một cách đơn giản (nhưng không hoàn toàn chính xác), gồm 3 phần: (i) kiểu của biến khác mà con trỏ lưu trữ địa chỉ, (2) dấu * và (3) tên của con trỏ. Con trỏ hàm thì khai báo hơi khác một chút, nhưng đây không phải vấn đề trọng tâm của bài viết. Ví dụ, khai báo một số con trỏ:
int *a; // pointer to an integer
float *b; // pointer to a float
char *c; // pointer to character
Khai báo thì như vậy, nhưng ý nghĩa của con trỏ thì không phải lúc nào cũng nhất quán. Ví dụ con trỏ int *a vừa có thể hiểu là con trỏ tới một biến số nguyên, vừa có thể hiểu là con trỏ tới phần tử đầu tiên của một mảng số nguyên.
Struct trong C cho phép chúng ta tập hợp một hoặc một vài kiểu dữ liêu khác nhau thành một kiểu dữ liệu mới. Các kiểu dữ liệu thành phần của một struct có thể là kiểu dữ liệu sẵn có như số nguyên, số thực, con trỏ, hoặc một kiểu struct đã định nghĩa trước đó. Tóm lại, struct cho phép chúng ta “gộp” một số kiểu dữ liệu đã có lại với nhau để tiện thao tác.
Trong DSLK, struct được sử dụng để khai báo một “mắt xích” của danh sách. Ví dụ ta muốn khai báo một mắt xích của một danh sách liên kết các biến kiểu int thì ta có thể khai báo như sau:
typedef struct llnode{
int x;
struct llnode *next;
} llnode;
Biến trong khai báo trên là dữ liệu của mỗi mắt xích và nó có kiểu int. Kiểu của còn có thể là con trỏ, hay một struct. Mỗi mắt xích thường được minh họa như trong Figure 1, trong đó, mũi tên ám chỉ con trỏ lưu địa chỉ của mắt xích tiếp theo (con trỏ next). Con trỏ này trong mắt xích cuối cùng của danh sách thường là Null. Figure 1: Biểu diễn một mắt xích của danh sách liên kết.
Để khởi tạo một mắt xích, ta sẽ dùng hàm malloc (viết tắt của memory allocation). Malloc là một hàm quản lí bộ nhớ của C. Bản thân hàm này cũng khá phức tạp. Bạn đọc xem thêm tại liên kết ở cuối bài.
llnode * create_new_node(int datum){
llnode * node = (llnode *)malloc(sizeof(llnode)); // allocate memory for a new linked list node
node->x = datum;
node->next = NULL;
return node;
}
Danh sách liên kết đơn
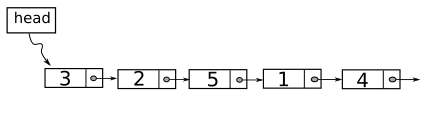
Danh sách liên kết đơn, về mặt trực quan, là cấu trúc dữ liệu tuyến tính giống như một cái xích dài liên kết các “mắt xích” với nhau. Mỗi mắt xích có dạng khai báo llnode ở trên. Figure 2 minh họa một danh sách liên kết với 5 phần tử.
Figure 2: Một danh sách liên kết với 5 phần tử.
Để theo dõi danh sách, ta sẽ dùng một con trỏ đặc biệt, gọi là con trỏ head. Con trỏ này lưu trữ địa chỉ của mắt xích đầu tiên của danh sách. Như đã nói ở trên, con trỏ của mắt xích cuối cùng của danh sách sẽ có giá trị Null. Ta có thể duyệt qua danh sách này bằng cách bắt đầu từ phần tử đầu tiên, đi theo con trỏ liên kết để đi tới nút tiếp theo. Đến khi ta gặp con trỏ Null thì ta đã duyệt xong danh sách. Đoạn code dưới đây là thủ tục walk_down để duyệt danh sách.
void walk_down(llnode *head){
while(head->next != NULL){
printf("%d," head->x);
head = head->next; // walk to the next node
}
}
Trong đoạn code trên, liệu ta có bị mất con trỏ head? Câu trả lời là không vì mỗi lần gọi một hàm walk_down như trên, một bản “copy” của con trỏ head sẽ được tạo ra, và hàm walk_down sẽ thay đổi bản copy này. Bản gốc vẫn không thay đổi. Nếu bạn thay đổi con trỏ head trong hàm main (hàm mà bạn tạo ra con trỏ này) hoặc con trỏ head là một biến toàn cục, thì con trỏ head sẽ bị thay đổi, hay bị mất. Điều gì sẽ xảy ra nếu như ta “làm mất” con trỏ head? Bạn sẽ mất dấu của danh sách và do đó, sẽ không thể thao tác được với danh sách nữa. Phần bộ nhớ của danh sách lúc này sẽ vẫn bị chiếm bởi danh sách, do đó, tạo ra rác (garbage) trong hệ thống. Phần rác này tồn tại cho đến khi chương trình kết thúc. Bài học rút ra: khi nào bạn không còn cần danh sách nữa thì sử dụng hàm free để giải phóng bộ nhớ, đừng bao giờ để mất dấu con trỏ head vì nó sẽ tạo ra rác.
Thêm phần tử mới vào danh sách liên kết
Khi thêm phần tử mới vào danh sách, nếu bài toán không có yêu cầu gì đặc biệt, thì bạn nên thêm vào đầu của danh sách. Nếu bạn thêm vào đuôi của danh sách (theo tư duy thông thường), thì ngoài phải trả thêm bộ nhớ để lưu trữ con trỏ đuôi của danh sách (nếu không lưu con trỏ này thì sẽ phải duyệt rất tốn thời gian), bạn phải xét trường hợp khi danh sách rỗng (con trỏ đuôi là Null), i.e, thêm if-then trong code. Điều này làm code vừa chậm vừa “tối sủa” (xem code ví dụ dưới đây).
llnode * head; // head is a global variable
llnode* insert_to_tail(llnode *tail, int datum){
llnode *node = create_new_node(datum); // create a new node
if( tail == NULL) { // the list is empty
tail = node;
head = tail;
} else{
tail->next = node;
tail= node;
}
return tail;
}
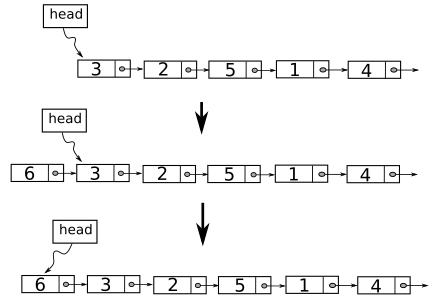
Tóm lại, luôn thêm vào đầu danh sách nếu có thể. Đoạn code sau minh họa thao tác chèn vào đầu. Rõ ràng đoạn code dưới đây đẹp hơn rất nhiều.
llnode * head; // head is a global variable
void insert_to_head(int datum){
llnode *node = create_new_node(datum); // create a new node
node->next = head; // dont need to care whether head is null or not
head = node;
}
Figure 3: Các bước chèn một mắt xích có giá trị 6 vào đầu DSLK trong Figure 2.
Xóa một phần tử khỏi danh sách liên kết
Giả sử bạn muốn xóa một mắt xích có trường dữ liệu có giá trị ra khỏi danh sách, bạn có thể làm như sau (xem minh họa trong Figure 4):
Duyệt danh sách (từ đầu) để tìm ra mắt xích có giá trị . Trong quá trình duyệt, bạn sẽ lưu trữ con trỏ prev, để trỏ tới mắt xích cha của mắt xích hiện tại. Mắt xích cha được hiểu là mắt xích có con trỏ trỏ vào nút hiện tại.
Cập nhật con trỏ prev để trỏ vào mắt xích con của mắt xích có dữ liệu .
Figure 4: Các bước xóa mắt xích có giá trị ra khỏi danh sách.
Code:
// Warning: this piece of code is BUGGY
void buggy_remove(int datum){
llnode *prev = NULL;
llnode *iterator = head;
while(iterator->x != datum){
prev = iterator;
head = iterator->next;
}
prev->next = iterator->next;
free(iterator); // officially remove the node having value datum
}
Đoạn code trên chỉ minh họa ý tưởng, và nó là đoạn code có bug, nghĩa là nó chỉ thành công trong một số trường hợp. Điều gì sẽ xảy ra nếu ta chạy đoạn code trên trong trường hợp mắt xích đầu tiên có giá trị datum? Khi đó đoạn code trong vòng while sẽ không thực hiện, và kết quả là prev vẫn là Null sau vòng lặp while. Đến đây bạn có thể gặp lỗi Segmentation fault. Bạn có thể sửa đổi code trên như sau:
// Warning: this piece of code is possibly buggy
void good_but_not_clean_remove( int datum){
llnode *prev = NULL;
llnode *iterator = head;
while(iterator->x != datum){
prev = iterator;
iterator = iterator->next;
}
if( prev == NULL){ // datum is the head
head = head->next;
} else {
prev->next = iterator->next;
}
free(iterator); // officially remove the node having value datum
}
Đoạn code này ok, có thể không có lỗi, nhưng trông không được “sạch sẽ” và chậm vì có if-then. Cách tốt hơn, không có if-then, đó là thao tác trên địa chỉ của con trỏ. Phương pháp này minh họa cách sử dụng con trỏ rất thông minh. Hiểu đoạn code này có thể khó nhưng một khi đã hiểu thì bạn sẽ thấy cái hay của nó.
void remove( int datum){
llnode **iterator = &(head); // take the address of the head pointer
while(*(iterator)->x != datum){
iterator = &((*iterator)->next);
}
*iterator = (*iterator)->next;
}
Nhắc lại, toán tử & là toán tử lấy địa chỉ của một biến, còn toán tử * là toán tử lấy giá trị của biến có địa chỉ lưu trong con trỏ. Nhìn vào đoạn code trên, sự khác biệt so với đoạn code good_but_not_clean_remove là chúng ta thao tác trên địa chỉ của con trỏ, thay vì thao tác trên con trỏ. Đoạn code trên được sửa đổi từ bài viết ở đây.
Đôi khi trong một số trường hợp, ta muốn xóa một nút khỏi danh sách khi mà ta biết trước địa chỉ của nút đó. Cụ thể, ta muốn đoạn code tương tự như sau:
Nếu chỉ đơn giản gán current_node = Null thì đoạn code trên sẽ không thực hiện đúng như mong muốn (bạn đọc nên thử và giải thích tại sao). Có hai cách để làm. Cách làm không mấy sạch sẽ là copy dữ liệu từ nút mắt xích sau đó vào nút hiện tại và ta xóa nút sau đó.
void remove_by_copy_data(llnode * current_node){
llnode *next_node = current_node->next;
current_node->x = next_node->x; // copy data from next to current
current_node->next = next_node->next;
free(next_node); // delete next_node
}
Tuy nhiên, cách này không áp dụng được nếu current_node là mắt xích cuối cùng của DSLK (bạn đọc có thể thử để kiểm tra). Cách tốt hơn, lấy ý tưởng hàm remove ở trên sử dụng địa chỉ của con trỏ, ta sẽ truyên vào hàm địa chỉ của current_node.
Cách này áp dụng được ngay cả khi current_node là mắt xích cuối cùng của DSLK.
Một số biến thể của DSLK đơn
Danh sách liên kết đôi
Biến thể đầu tiên là DSLK đôi (doubly linked list), trong đó, mỗi mắt xích có 2 con trỏ. Con trỏ đầu tiên trỏ vào mắt xích trước nó trong DSLK và con trỏ thứ hai trỏ vào mắt xích sau đó trong DSLK.
DSLK đôi so với DSLK đơn cần nhiều bộ nhớ hơn để lưu trữ thêm một con trỏ. Các thao tác xóa và thêm mới cũng lâu hơn vì ta còn phải cập nhật cả con trỏ prev mỗi khi ta cần xóa hoặc thêm vào DSLK. Về điểm mạnh, DSLK đôi mềm dẻo hơn vì từ một nút, ta có thể đi đến nút trước nó mà không phải duyệt từ đầu DSLK. Tính mềm dẻo này được Knuth [2] khai thác triệt để trong thiết kế cấu trúc Dancing Links, một cấu trúc dữ liệu hỗ trợ các thuật toán quay lui cho bài toán liệt kê tổ hợp.
Ngoài ra, ta có thể không cần con trỏ head để xác định nút đầu tiên của danh sách như DSLK đơn (tại sao?). Nếu con trỏ head bị mất, ta vẫn có thể tìm được phần tử đầu tiên của DSLK nếu ta được phép truy nhập đến một phần tử bất kì của DSLK. DSLK đôi cũng chính là cấu trúc đằng sau LinkedList của Java.
Danh sách liên kết vòng
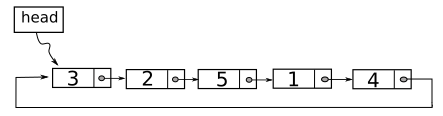
Danh sách liên kết vòng (circularly linked list) là một biến thể khác của DSLK đơn, trong đó con trỏ next của mắt xích cuối cùng của danh sách trỏ vào mắt xích đầu tiên của danh sách để tạo thành một vòng tròn (xem Figure 6). Với cấu trúc này, khái niệm đầu và cuối không thực sự có ý nghĩa. Do đó, ta thường chỉ lưu một con trỏ đặc biệt để trỏ vào một nút nào đó trong danh sách.
Figure 6: Một DSLK vòng với 5 mắt xích.
Danh sách liên kết vòng thường được dùng trong các ứng dụng trong đó các thành phần tham gia được thực thi theo lượt. Ví dụ trong các game đánh bài khi mỗi người chơi được phép đi một lượt theo vòng. Một bài tập hay ứng dụng danh sách liên kết vòng là bài toán Josephus.
Liên kết về con trỏ trong C
Chú ý: Phần này sẽ liên tục được cập nhật. Bạn nào có tài liệu hay về con trỏ cũng như quản lí bộ nhớ thì comment xuống dưới để mình liên kết tới bạn đọc.
[1] T.H Cormen, C.E. Leiserson, R. Rivest, C. Stein. Introduction to Algorithms (2nd ed.), Chapter 10 . MIT Press and McGraw-Hill (2001). ISBN 0-262-03293-7.
[2] D.E. Knuth, Donald E. Dancing links. arXiv preprint cs/0011047 (2000).
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Nếu bạn biết về ARC là gì và tại sao lại rò rỉ bộ nhớ trong ứng dụng IOS thì bạn có thể chuyển sang phần 2. Vì đây là 1 bài viết rất dài, đề cập đến các nội dung sau:
Thế nào là rò rỉ bộ nhớ trong IOS(Memory Leaks)
Tại sao lại Memory Leaks
Cách mà ARC không thể giải phóng bộ nhớ
Memory Leaks trong hàm Closure
Giải pháp khả thi
Những tình huống đặc biệt(Singleton và static Classes Memory leaks)
Khác nhau giữa weak và unowned
Xác định leaks sử dụng Memory Graph Debugger
Một số quy tắc Thumbs
Swift sử dụng Automatic Reference Counting(ARC) để theo dõi và quản lý bộ nhớ ứng dụng. Trong đa số trường hợp, điều này nghĩa là sự quản lý chỉ làm việc trong Swift framework 1 cách tự động, và bạn không cần phải hiểu về quản lý bộ nhớ như nào. ARC tự động giải phóng bộ nhớ bởi việc khi 1 instances của class sẽ giải phóng khi không cần thiết nữa.
Phần 1: Memory leaks trong IOS
Một memory leak xảy ra khi bộ nhớ giữ chiếm giữ và không thể giải phóng bằng ARC bởi vì nó không phân biệt được thực sự có được sử dụng hay không. Và vấn đề phổ biến nhất là chúng ta tạo ra memory leaks khi tạo ra 1 vòng retained cycles – nắm giữ lẫn nhau xảy ra! Chúng ta sẽ trình bày kỹ hơn ở dưới.
Mỗi khi bạn tạo ra 1 đối tượng(object) từ class, ARC sẽ lưu thông tin về vùng bộ nhớ mà đối tượng này sử dụng. Khi 1 object cần được giải phóng, thì làm thế nào ARC biết được điều đó. Để hiểu về vấn đề này chúng ta sẽ tìm hiểu cách ARC làm việc.
Mọi biến khởi tạo sẽ mặc định là kiểu strong. (strong là kiểu ràng buộc mạnh, weak yếu). Khi bạn tạo ra instance của nó với kiểu strong, thì ARC sẽ tăng biến đếm lên 1. Hiểu nôm na là ARC tạo ra 1 biến count = 0, khi obj tạo ra thì tăng lên 1, khi giải phóng thì trừ đi 1. Bao giờ biến count này = 0 nghĩa là nó không cần nữa, và ARC sẽ tự động giải phóng biến này ra. Cùng xem ví dụ sau:
var referenceOne: Person? = Person()
chúng ta tạo ra 1 referenceOne của lớp Person. ARC sẽ tự động cấp phát bộ nhớ cho nó kiểu strong và tăng count của biến này thành 1.
Khi khởi tạo object
var reference2 = referenceOne
Sau khi thực hiện câu lệnh trên, chúng ta tạo 1 liên kết mạnh tới object Person bằng việc gán địa chỉ sang reference2. Như bạn thấy ở hình sau, biến count = 2 do 2 thằng cùng nắm giữ địa chỉ này.
cả 2 cùng gán tới object đã khởi tạo
referenceOne = nil
Chúng ta loại bỏ tham chiếu strong tới biến referenceOne bằng cách gán nil cho nó. Như hình sau biến count lại quay về là 1.
reference2 = nil
Tương tự, chúng ta bỏ tham chiếu strong tới biến reference2 và hiện tại biến count = 0.
Như vậy object đã tạo không còn ai tham chiếu, ARC sẽ xóa ra khỏi bộ nhớ. Đấy là cách mà ARC làm việc.
Thế tại sao bộ nhớ lại rò rỉ?
Như chúng ta hiểu ARC sẽ tự động xóa biến khỏi bộ nhớ khi count = 0, nhưng vì lý do nào đó mà count không bao giờ = 0 được, nên không giải phóng được bộ nhớ. Hãy đọc tiếp nhé!
Khi nào ARC cố gắng kiểm tra count của 1 biến RC(reference count)
Khi bạn làm việc với cocoa hay cocoa touch thì đơn giản là nó kiểm tra khi một hàm thoát khỏi vòng lặp trên thread. Luật kiểm tra như sau:
Nếu không ai tham chiếu tới 1 object thì ARC giải phóng
Nếu 1 object không có tham chiếu mạnh tới nó.
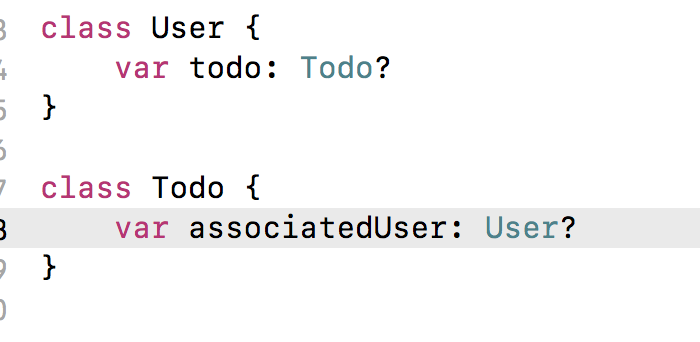
Sau đây là ví dụ cụ thể:
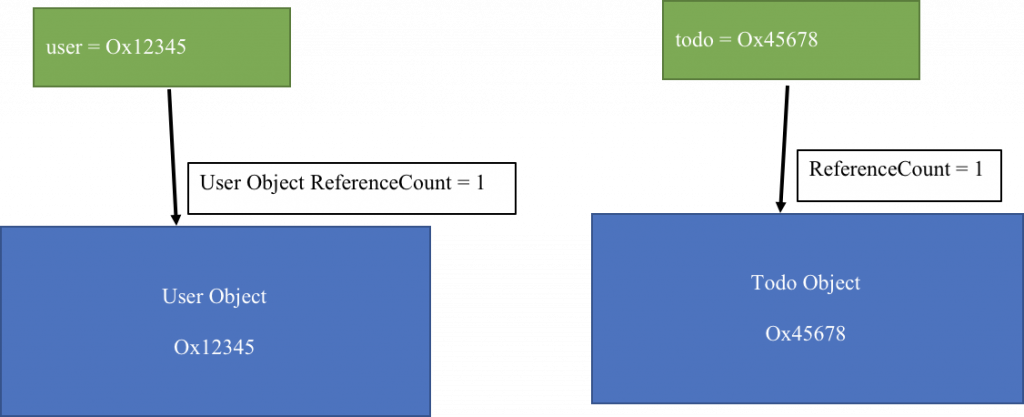
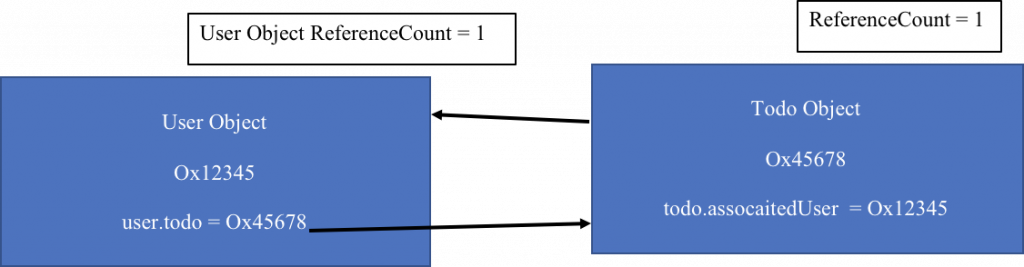
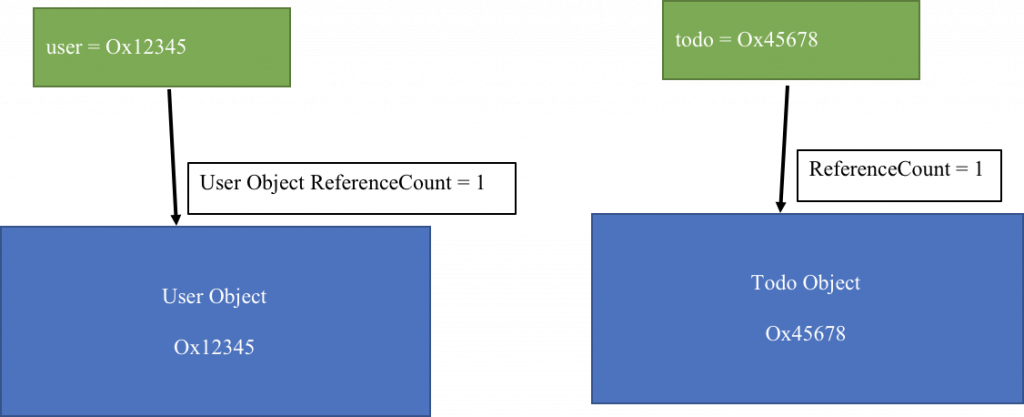
var user: User? = User() //1 tham chiếu tới user
var todo: Todo? = Todo() //1 tham chiếu tới todo
Như hình dưới, ARC tạo ra 1 tham chiếu strong tới user và todo.
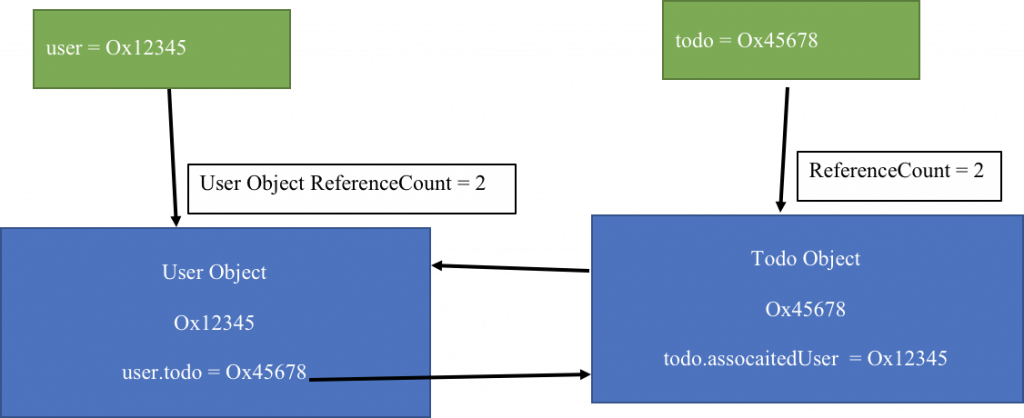
user?.todo = todo //2 tham chiếu mạnh tới todo
todo?.associatedUser = user// 2 tham chiếu mạnh tới user
2 câu lệnh trên hoạt động như sau:
Tăng RC của todo lên 2, todo có 2 chủ sở hữu, 1 lần tạo ra và 1 lần gán.
Tăng RC của user lên 2, tương tự như trên.
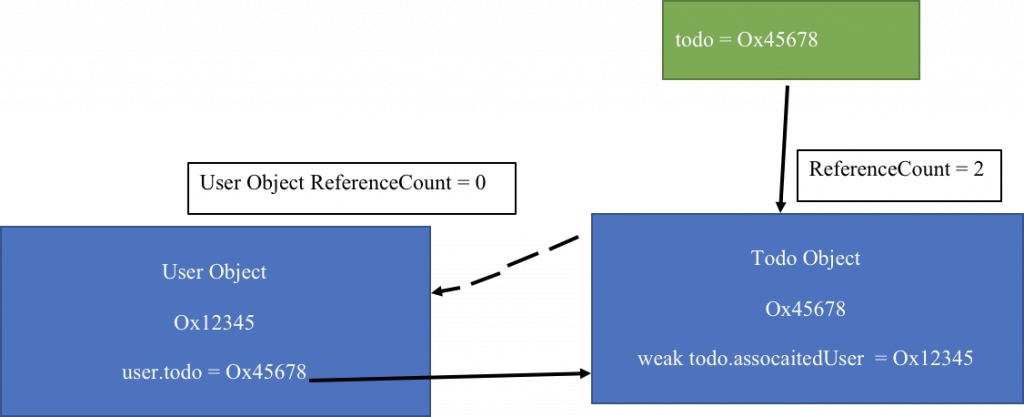
user = nil //giảm RC của user còn 1
todo = nil //giảm RC của todo còn 1
Lý tưởng nhất là khi đặt user về nil thì đáng ra RC phải là 0. Tuy nhiên lúc này trong mỗi object lại tham chiếu mạnh tới nhau nên không thể giải phóng được. Và do vậy chúng ta tạo ra strong reference cycle – vòng tròn tham chiếu mạnh lẫn nhau không thể giải phóng được.
Giải pháp
Có 2 giải pháp, dùng tham chiếu yếu weak hoặc tham chiếu unowned.
Sửa lại code như sau:
var user: User? = User() //RC = 1 tới user
var todo: Todo? = Todo() //RC = 1 tới todo
Câu lệnh trên sẽ tăng RC cho mỗi biến lên 1.
user?.todo = todo //RC = 2 tới todo
todo?.associatedUser = user //RC = 1 tới user
RC = 2 tham chiếu mạnh tới todo, còn user có RC = 1 do associatedUser là tham chiếu yếu.
user = nil
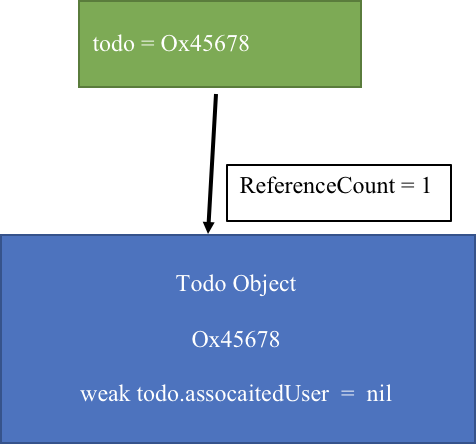
Câu lệnh làm RC của user về 0.
ARC kiểm tra và xóa user ra khỏi bộ nhớ. Vậy todo còn 1 tham chiếu mạnh tới nó.
todo = nil
Lúc này todo có RC = 0 và bị xóa khỏi bộ nhớ.
Quy tắc: Khi 2 đối tượng tham chiếu lẫn nhau thì biến tham chiếu trở về weak hoặc unowned.
Memory Leaks trong Closure
Memory Leak in Closure = self refers to → object refers to → self
Closure là một hàm được tạo ra từ bên trong một hàm khác (hàm cha), nó có thể sử dụng các biến toàn cục, biến cục bộ của hàm cha và biến cục bộ của chính nó. Và khi sử dụng thì nó capture(chụp lấy) các biến hay hằng và ném vào trong scope của nó.
Thế nào là capturing?
Cách hoạt động:
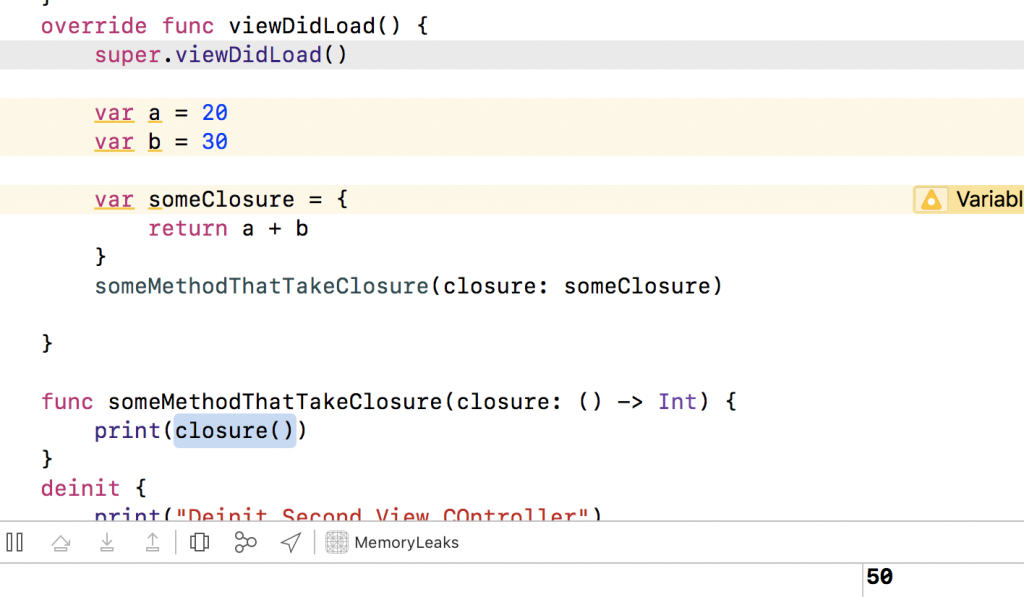
Chúng ta tạo 2 biến a,b với 2 giá trị khác nhau 20 và 30.
Chúng ta tạo hà someClosure và captures a, b bởi tham chiếu mạnh.
Khi phương thức someMethodThatTakeClosure gọi closure và nó sẽ trả về 2 giá trị tổng của a, b captures từ hàm viewDidLoad. Giá trị là 50
Bài viết được sự cho phép của tác giả Nguyễn Chí Thức
Trong bài Python này bạn sẽ học về biến toàn cục (global), biến cục bộ (local), biến nonlocal trong Python và trường hợp sử dụng các biến này.
Biến toàn cục trong Python
Trong ngôn ngữ lập trình Python, một biến được khai báo bên ngoài hàm hoặc trong phạm vi toàn cục được gọi là biến toàn cục hay biến global. Biến toàn cục có thể được truy cập từ bên trong hoặc bên ngoài hàm.
Hãy xem ví dụ về cách tạo biến toàn cục trong Python.
x = "Biến toàn cục"#khai báo biến x#Gọi x từ trong hàm vidu()defvidu():
print("x trong hàm vidu() :", x)
vidu()
#Gọi x ngoài hàm vidu()
print("x ngoài hàm vidu():", x)
Trong ví dụ trên, ta khai báo biến x là biến toàn cục, và định nghĩa hàm vidu() để in biến x. Cuối cùng ta gọi hàm vidu() để in giá trị của biến x. Chạy code trên ta sẽ được kết quả là:
x trong hàm vidu(): Biến toàn cục
x ngoài hàm vidu(): Biến toàn cục
Chuyện gì sẽ xảy ra nếu bạn thay đổi giá trị của x trong hàm?
x = 2defvidu():
x=x*2
print(x)
vidu()
Nếu chạy code này bạn sẽ nhận được thông báo lỗi:
UnboundLocalError: local variable 'x' referenced before assignment
Lỗi này xuất hiện là do Python xử lý x như một biến cục bộ và x không được định nghĩa trong vidu().
Để thay đổi biến toàn cục trong một hàm bạn sẽ phải sử dụng từ khóa global. Chúng tôi sẽ nói kỹ hơn trong bài về từ khóa global.
Ở đây, chúng ta sẽ học cách dùng biến cục bộ và toàn cục trong cùng một code.
x = 2defvidu():global x
y = "Biến cục bộ"
x = x * 2
print(x)
print(y)
#Viết bởi uCode.vn
vidu()
Chạy code trên ta sẽ có đầu ra:
4
Biến cục bộ
Trong code trên, chúng ta khai báo x là biến toàn cục và y là biến cục bộ trong vidu() và dùng toán tử * để thay đổi biến toàn cục và in cả giá trị của x và y. Sau khi gọi hàm vidu() giá trị của x sẽ thành 4 vì được nhân đôi.
Ví dụ sử dụng biến toàn cục và cục bộ trùng tên:
x = 5defvidu():
x = 10
print("Biến x cục bộ:", x)
vidu()
print("Biến x toàn cục:", x)
Sau khi chạy code trên ta có đầu ra:
Biến x cục bộ: 10
Biến x toàn cục: 5
Trong code trên, chúng ta sử dụng cùng tên x cho cả biến cục bộ và biến toàn cục. Khi in cùng biến x chúng ta nhận được hai kết quả khác nhau vì biến được khai báo ở cả hai phạm vi, cục bộ (bên trong hàm vidu()) và toàn cục (bên ngoài hàm vidu()).
Khi chúng ta in biến trong hàm vidu() nó sẽ xuất ra Biến x cục bộ: 10, đây được gọi là phạm vi cục bộ của biến. Tương tự khi ta in biến bên ngoài hàm vidu() sẽ cho ra Biến x toàn cục: 5, đây là phạm vi toàn cục của biến.
Từ nonlocal này mình không biết dịch sang tiếng Việt sao cho chuẩn. Trong Python, biến nonlocal được sử dụng trong hàm lồng nhau nơi mà phạm vi cục bộ không được định nghĩa. Nói dễ hiểu thì biến nonlocal không phải biến local, không phải biến global, bạn khai báo một biến là nonlocal khi muốn sử dụng nó ở phạm vi rộng hơn local, nhưng chưa đến mức global.
Để khai báo biến nonlocal ta cần dùng đến từ khóa nonlocal.
Ví dụ:
defham_ngoai():
x = "Biến cục bộ"defham_trong():nonlocal x
x = "Biến nonlocal"
print("Bên trong:", x)
ham_trong()
print("Bên ngoài:", x)
hamngoai()
Chạy code trên bạn sẽ có đầu ra:
Bên trong: Biến nonlocal
Bên ngoài: Biến nonlocal
Trong code trên có một hàm lồng là ham_trong(), ta dùng từ khóa nonlocal để tạo biến nonlocal. Hàm ham_trong() được định nghĩa trong phạm vi của ham_ngoai().
Lưu ý: Nếu chúng ta thay đổi giá trị của biến nonlocal, sự thay đổi sẽ xuất hiện trong biến cục bộ.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Đồng
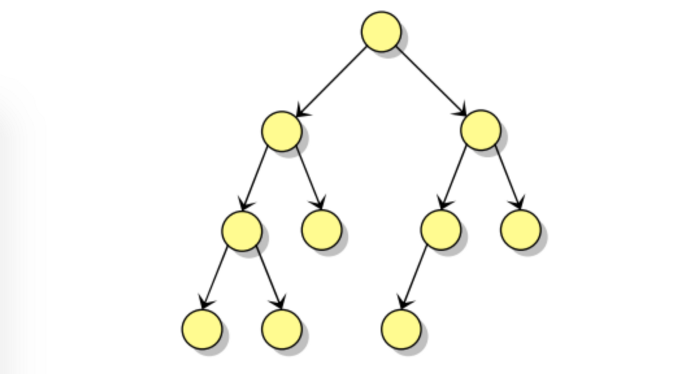
Trước khi nói tới heap, hãy nhớ lại kiến thức cây nhị phân
Cây nhị phân là một cây, mỗi nút trên cây có tối đa hai nhánh con, nút thứ i sẽ có 2 con là 2i và 2i+1.
Cây nhị phân
Heap là một câu trúc cây nhị phân đầy đủ, mỗi nút trên cây đều chứa một nhãn có độ ưu tiên cao hơn các con của nó, nút gốc (root) là nút có độ ưu tiên cao nhất. Ví dụ heap min là cây là mọi con của nút i đều có giá trị >= heap[i], heap max thì mọi nút con đều nhỏ hơn nút cha.
Heap nhị phân được ứng dụng rộng rãi dùng để cài đặt một hàng đợi ưu tiên, hay là trong thuật toán Distra tìm đường đi ngắn nhất, và trong bài này ta sẽ sử dụng Binary Heap để sắp xếp mảng.
Các thao tác thường dùng trên Heap là
Tìm nút có độ ưu tiên cao nhất
Thêm một nút vào heap
Xóa bỏ nút gốc, nút có độ ưu tiên cao nhất.
Xây dựng heap từ tập có n phần tử
Để tìm nút có độ ưu tiên cao nhất, ta chỉ cần lấy nút gốc.
Để thêm một nút vào heap
Nếu heap rỗng thì ta chỉ cần thay gốc bằng nút đó
Nếu heap không rỗng
Chọn vị trí để thêm nút.
Giả sử heap có độ cao là h, và mọi nút ở độ cao h-1 có một nút nào đó chưa đủ 2 con (tổng số nút ở độ cao đó < 2^h) — thì gắn nút vào phía bên phải của nút ngoài cùng
Nếu ở độ cao h đã đầy đủ nút thì thêm nút vào độ cao h+1
Tiến hành vun đống nút dưới lên, nếu nút cha có độ ưu tiên thấp hơn nút con thì tiến hành đổi chỗ nút con và nút cha, sau đó lại xét tiếp nút cha đó cho tới khi nào thỏa mãn nút cha có độ ưu tiên hơn nút chon hoặc nút đang xét là nút cha thì thôi.
Để xóa nút gốc
Nếu cây đó chỉ có 1 nút thì chỉ xóa nút đó
Nếu cây có nhiều hơn 1 nút là tiến hành lấy nút dưới dùng bên phải thế vào nút gốc sau đó tiến hành quá trình down heap.
Quá trình down heap, so sánh độ ưu tiên với cả hai nút con(nếu có) , nếu độ ưu tiên thấp hơn 1 trong 2 nút con hoặc thấp hơn cả hai nút con thì tiến hành chọn nút có độ ưu tiên cao nhất trong 2 nút con và đổi vị trị với nó, cho tới khi nào nút đang xét là nút lá ( không có nút con)
Độ phức tạp.
Thao tác lấy nút gốc O(1)
Thao tác thêm nút mới vào cây O(log N)
Thao tác xóa nút gốc : Tổng O(log N)
Thao tác xóa nút gốc O(1)
Thao tác down heap O(log N)
Áp dụng tính chất của Heap để sắp xếp
Trong phần này mình sẽ triển khai thuật toán sắp xếp nhanh bằng cách sử dụng tính chất, nút gốc là nút có độ ưu tiên cao nhất, mình sẽ xây dựng một heap từ mảng a có n phần tử sau đó, lấy lần lượt các phần tử trong heap ra thì mình có có các giá trị lấy ra có độ ưu tiên giảm dần.
Ngôn ngữ thực hiện. : Go
Cấu trúc Heap : struct Heap có field Leng, là độ dài của Heap và field Value là giá trị của các phần tử trong heap.
type Heap struct {
Leng int
Value []int
}
Thao tác khởi tạo Heap : Mình sẽ xây dựng heap Min thiết lập Leng = 0, heap rỗng
Thao tác thêm một phần tử vào Heap : Thêm vào và sau đó vun đống từ dưới lên qua function UpHeap.
func (h *Heap) Insert(x int) *Heap {
h.Leng++
h.Value[h.Leng] = x
h.UpHeap(h.Leng)
return h
}
Thao tác UpHeap
func (h *Heap) UpHeap(i int) *Heap {
if (i == 1) || (h.Value[int(math.Floor(float64(i)/2))] <= h.Value[i]) {
return h
}
t := h.Value[i]
h.Value[i] = h.Value[int(math.Floor(float64(i)/2))]
h.Value[int(math.Floor(float64(i)/2))] = t
h.UpHeap(int(math.Floor(float64(i) / 2)))
return h
}
Thao tác xóa nút gốc : Sau khi loại bỏ nút gốc, ta lấy phần tử ngoài cùng ở độ cao cao nhất thế vào nút gốc sau đó thực hiện quá trình DownHeap từ nút gốc
func (h *Heap) RemoveRoot() *Heap {
h.Value[1] = h.Value[h.Leng]
h.Leng--
if h.Leng > 1 {
h.DownHeap(1)
}
return h
}
Thao tác DownHeap
func (h *Heap) DownHeap(i int) *Heap {
m := i * 2
if m > h.Leng {
return h
}
if h.Value[m] > h.Value[m+1] {
m++
}
if h.Value[m] < h.Value[i] {
t := h.Value[m]
h.Value[m] = h.Value[i]
h.Value[i] = t
h.DownHeap(m)
return h
}
return h
}
Hàm Main : Tạo mảng a sau đó đẩy mỗi phần tử của a vào Heap, sau đó lấy trong heap ra dần dần ta có kết quả theo độ ưu tiên giảm giần
func main() {
a := []int{8, 6, 4, 5, 7, 9, 2, 3, 2, 2, 6, 3, 6, 3, 6, 123, 6541, 3, 6, 3, 461, 35, 2}
for _, v := range a {
h.Insert(v)
}
for i := 1; i <= len(a); i++ {
fmt.Print(h.Value[1],)
h.RemoveRoot()
}
}
package main
import (
"fmt"
"math"
)
type Heap struct {
Leng int
Value []int
}
var h Heap
const nMax = 10000
const maxValue = 100000000
func init() {
h.Leng = 0
h.Value = make([]int, nMax+1, nMax+1)
}
func (h *Heap) Insert(x int) *Heap {
h.Leng++
h.Value[h.Leng] = x
h.UpHeap(h.Leng)
return h
}
func (h *Heap) UpHeap(i int) *Heap {
if (i == 1) || (h.Value[int(math.Floor(float64(i)/2))] <= h.Value[i]) {
return h
}
t := h.Value[i]
h.Value[i] = h.Value[int(math.Floor(float64(i)/2))]
h.Value[int(math.Floor(float64(i)/2))] = t
h.UpHeap(int(math.Floor(float64(i) / 2)))
return h
}
func (h *Heap) DownHeap(i int) *Heap {
m := i * 2
if m > h.Leng {
return h
}
if h.Value[m] > h.Value[m+1] {
m++
}
if h.Value[m] < h.Value[i] {
t := h.Value[m]
h.Value[m] = h.Value[i]
h.Value[i] = t
h.DownHeap(m)
return h
}
return h
}
func (h *Heap) RemoveRoot() *Heap {
h.Value[1] = h.Value[h.Leng]
h.Leng--
if h.Leng > 1 {
h.DownHeap(1)
}
return h
}
func main() {
a := []int{8, 6, 4, 5, 7, 9, 2, 3, 2, 2, 6, 3, 6, 3, 6, 123, 6541, 3, 6, 3, 461, 35, 2}
for _, v := range a {
h.Insert(v)
}
for i := 1; i <= len(a); i++ {
fmt.Print(h.Value[1], " ")
h.RemoveRoot()
}
}
Thuật toán Heap Sort ứng dụng tính chất khá đơn giản của Heap nhưng nếu là mình khi sort thì mình khi sort mình sẽ sử dụng QuickSort để hạn chế việc mất đi một mớ mem cho cái heap.
Mình sẽ thực hiện tiếp Quick Sort trong phần sau của bài, cảm ơn các bạn đã đọc 😀
Bài viết được sự cho phép của BBT Kinh nghiệm lập trình
Chào các bạn, hôm nay mình xin chia sẻ 1 mẹo nhỏ trong PHP: Destroy session_id của user khác từ server.
Tại sao cần làm việc này?
Bài toán đặt ra: Tại một thời điểm, chỉ cho phép người dùng có duy nhất 1 phiên đăng nhập trên hệ thống.
Mô tả chi tiết: Thực tế hiện tay rất nhiều hệ thống web ứng dụng bán license theo số lượng tài khoản sử dụng. Do vậy, nếu không có biện pháp ngăn chặn việc người dùng sử dụng chung tài khoản để làm việc trên hệ thống thì việc thất thoát doanh thu là khó tránh khỏi. Chính vì thế, hệ thống cần có phương án để ngăn chặn việc này, tại một thời điểm, chỉ cho phép người dùng có 1 phiên đăng nhập trên 1 thiết bị và thao tác trên hệ thống.
Cách thực hiện trên với PHP?
Mình sẽ nói tóm tắt các bước thực hiện, logic này có thể áp dụng tương tự với ngôn ngữ khác. Mục đích là sử dụng tài khoản hiện tại, để destroy session id khác trên server.
Bước 1:Commit session ID nếu nó đã tồn tại
Bước 2: Store current session id
Bước 3: Destroy session specified
Bước 4: Restore current session id
Ứng tuyển ngay các vị trí PHP tuyển dụng mới nhất trên TopDev
Code demo!
<?php
$session_id_to_destroy = ‘nill2if998vhplq9f3pj08vjb1’; // 1. commit session if it’s started. if (session_id()) { session_commit();
}
// 2. store current session id session_start(); $current_session_id = session_id(); session_commit();
// 4. restore current session id. If don’t restore it, your current session will refer to the session you just destroyed! session_id($current_session_id); session_start(); session_commit();
?>
Xong, một mẹo khá nhỏ nhưng đôi khi lại rất cần thiết cho hệ thống của bạn. Chúc các bạn áp dụng thành công!
Bài viết được sự cho phép của tác giả Phạm Văn Nguyên
Trong Python hoặc bất kỳ ngôn ngữ lập trình nào khác, đôi khi bạn muốn thêm thời gian trễ trong chương trình của mình trước khi bạn tiếp tục đến phần tiếp theo của mã.
Nếu đây là những gì bạn muốn làm, thì bạn nên sử dụng chức năng sleep từ module time .
Đầu tiên, tôi sẽ bắt đầu bằng cách thảo luận về cách sử dụng chức năng sleep của Python . Sau đó tôi sẽ nói nhiều hơn về một số câu hỏi thường gặp và cách thức thực hiện của function(hàm) sleep.
Hàm sleep
Giống như tôi đã đề cập, Sleep là một hàm tích hợp Python trong mô-đun time .
Vì vậy, để sử hàm sleep , bạn sẽ cần import module time trước.
Hàm sleep có một đối số là khoảng thời gian tính bằng giây mà bạn dừng.
Sử dụng hàn sleep trong Python 2 và Python 3 hoàn toàn giống nhau, vì vậy bạn sẽ không cần phải lo lắng về phiên bản Python nào mà mã của bạn đang chạy.
Nó thực sự rất đơn giản và dễ hiểu. Chúng ta hãy đi qua một số ví dụ.
Nhưng dù bằng cách nào, bạn có thể nghĩ về Cuộc gọi hệ thống như một API hoặc giao diện mà HĐH cung cấp cho các chương trình không gian người dùng để tương tác với HĐH.
Vậy HĐH sẽ làm gì khi nhận được System call sleep?
Về cơ bản, hệ điều hành sẽ làm là nó sẽ tạm dừng quá trình (chương trình của bạn) được lên lịch trên CPU trong khoảng thời gian mà bạn đã chỉ định.
Lưu ý rằng điều này hoàn toàn khác với việc thêm độ trễ bằng cách sử dụng vòng lặp giả không làm gì cả (đó là điều bạn KHÔNG BAO GIỜ nên làm).
Trong trường hợp giả cho vòng lặp, quy trình của bạn thực sự vẫn đang chạy trên CPU.
Nhưng trong trường hợp Sleep () , quy trình của bạn sẽ không hoạt động trong một thời gian cho đến khi HĐH bắt đầu lập lịch lại trên CPU.
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Constructor Declarations
Trong Java, các đối tượng được khởi tạo thông qua hàm khởi tạo (constructor). Mỗi lần bạn tạo mới một đối tượng sẽ có ít nhất một hàm khởi tạo được thực thi.
Mỗi class đều có một hàm khởi tạo, nếu bạn không khai báo thì complier sẽ tự động khai báo một hàm khởi tạo không tham số cho bạn.
Có rất nhiều nguyên tắc khác nhau liên quan đến hàm khởi tạo (sẽ tìm hiểu ở bài sau). Ở bài này chúng ta sẽ chỉ tập trung vào các nguyên tắc khai báo cơ bản.
Hàm khởi tạo cũng được coi như một hàm với kiểu dữ liệu trả về của hàm khởi tạo chính là một thể hiện của class chứa nó. Hàm khởi tạo có thể đi kèm với các access modifier
voidPerson(){} // đây là một method, không khải constructorstaticPerson(){} // không thể đi kèm với từ khóa staticfinalPerson(){} // không thể đi kèm với từ khóa finalabstractPerson(){} // không thể đi kèm với từ khóa abstract
Một class có thể có nhiều hàm khởi tạo (tương tự như một class có thể có nhiều hàm cùng tên – tính đa hình) nhưng tham số đầu vào của các hàm khởi tạo phải khác nhau.
Khi bạn gọi lệnh new thì đầu tiên nó sẽ chạy vào hàm khởi tạo của đối tượng rồi sau đấy mới chạy các khối static, method…
Bài viết được sự cho phép của tác giả Kien Dang Chung
Trong những website lớn, các phần tìm kiếm hay nhập liệu rất cần những tính năng thông minh như gợi ý dựa trên các từ nhập vào, nó giúp cho nâng cao trải nghiệm người dùng, giúp tìm kiếm và nhập liệu trở lên đơn giản hơn. Google là một minh chứng không cần phải bàn cãi cho vấn đề này. Những năm đầu của thế kỉ 21, Google xuất hiện với chỉ duy nhất một ô tìm kiếm và tính năng gợi ý ngay lập tức khi từ khóa được đánh vào, nó đã giúp người dùng định hướng được ngay khi chỉ gõ vào 1-2 từ trong từ khóa.
Ở thời điểm đó, gợi ý khi tìm kiếm là một tính năng phức tạp và xa xỉ, nhưng khi công nghệ phần mềm phát triển, đặc biệt với phần mềm mã nguồn mở, những tính năng như vậy thật đơn giản để thực hiện. Bài viết này sẽ hướng dẫn bạn thực hiện các tìm kiếm thông minh hay gợi ý nhập liệu sử dụng thư viện Typeahead là một gói phần mềm mã nguồn mở của Twitter trong các ứng dụng Laravel.
Trong bài viết này chúng ta sẽ thực hiện một ví dụ tìm kiếm thông minh thông tin khách hàng bằng cách tạo ra dữ liệu mẫu khoảng 10,000 khách hàng. Như bạn thấy khi tìm kiếm hệ thống sẽ gợi ý các bản ghi trong database rất nhanh giúp người dùng có thể lựa chọn luôn chính xác người dùng. Typeahead sử dụng kết hợp Bloodhound cho tốc độ rất nhanh mặc dù dữ liệu là 10k bản ghi.
1. Giới thiệu về Typeahead
Typeahead.js là một thư viện Javascript rất linh hoạt, nó có thể làm nền tảng tốt để xây dựng các tính năng tìm kiếm gợi ý thông minh. Typeahead bao gồm hai thành phần: Typeahead: Phần chuyên xử lý giao diện người dùng
Hiển thị gợi ý đến người dùng ngay khi họ nhập liệu
Hiển thị các gợi ý ngay trên ô nhập liệu
Hỗ trợ các tùy chỉnh giao diện linh hoạt
Highlight các từ khóa trùng khớp trong phần gợi ý
Kích hoạt các sự kiện tùy chỉnh cho phép mở rộng các xử lý
Bloodhound: Bộ máy gợi ý nâng cao
Cho phép các dữ liệu được hardcode
Lấy dữ liệu từ trước để giảm độ trễ khi gợi ý
Sử dụng Local Storage giảm số lượng các request đến máy chủ.
Sử dụng rate limit và bộ đệm cho các request đến máy chủ làm giảm nhẹ tải dữ liệu
Bộ máy gợi ý Bloodhound sẽ được sử dụng để tính toán kết quả với các truy vấn cho trước và Typeahead sẽ sử dụng để render ra mã HTML. Cả hai thành phần này là độc lập, trong bài viết này chúng ta sẽ sử dụng cả hai để xây dựng công cụ tìm kiếm gợi ý thông minh.
1.1 Cài đặt Typeahead
Trước khi đi vào sử dụng Typeahead chúng ta cần cài đặt gói thư viện này, có ba cách thức để cài đặt.
Sử dụng npm
npm i typeahead
Tải gói thư viện dạng file zip
Vào đường dẫn Github của Typeahead chọn Clone or download và click vào Download zip. Giải nén ra chúng ta sẽ thấy trong thư mục dist có những file như sau:
bloodhound.js (chỉ có thành phần Bloodhound).
typeahead.bundle.js (Bao gồm cả Typeahead và Bloodhound).
typeahead.jquery.js (chỉ có thành phần Typeahead).
Các file có thêm min.js là các file được tối ưu hóa dung lượng.
Chú ý: Typeahead yêu cầu jquery phiên bản từ 1.9 trở lên. Trong bài viết này chúng ta sẽ sử dụng cách thứ ba cho nhanh, với dự án lớn nên sử dụng cách 1 để tối ưu hóa các tài nguyên với Laravel Mix.
1.2 Khởi tạo Typeahead
Typeahead có nhiều cách khởi tạo và sau đây là cách khởi tạo hay dùng nhất jQuery#typeahead(options, [*datasets]). Tính năng typeahead được áp dụng cho các input dạng text input[type=”text”] có hai tham số cho khởi tạo: options là các tùy chọn cấu hình, một số giá trị cần quan tâm như sau:
highlight: thêm thẻ <strong> vào các từ trùng khớp trong phần gợi ý. Mặc định là false.
hint: hiển thị cả từ gợi ý trong ô nhập liệu, mặc định true.
minLength: Số ký tự tối thiểu cần nhập khi tính năng gợi ý được bắt đầu, mặc định là 1.
classNames: Cho phép sử dụng tên class khác với mặc định.
dataset: một typeahead có thể có nhiều dataset, ví dụ khi bạn tìm kiếm trong một trang bán hàng có thể trả về gợi ý cho cả sản phẩm và các tin tức liên quan đến sản phẩm. Các dataset có một số các tùy chọn cấu hình như sau:
name: tên của dataset.
source: nguồn dữ liệu dùng cho gợi ý, có thể là một instance của Bloodhound, như ở phần đầu chúng ta có nói Typeahead chỉ xử lý giao diện người dùng và Bloodhound với là bộ máy thực hiện các gợi ý.
limit: Số gợi ý tối đa sẽ được hiển thị, mặc định là 5.
Bloodhound là bộ máy gợi ý cho Typeahead.js, sử dụng thành phần này mang lại nhiều tính năng nâng cao hơn vì nó có thể lấy dữ liệu từ một nguồn remote và sử dụng bộ đệm để tăng tốc.
Chúng ta sẽ thiết lập đường dẫn /find?q= trong phần Laravel, datumTokenizer cần một mảng JSON. Như vậy, chúng ta đã có dữ liệu và có thể sử dụng nó cho thiết lập source của typeahead như sau:
source: engine.ttAdapter()
1.4 Tạo mẫu cho các gợi ý
Typeahead cho phép sử dụng các template để thay đổi kiểu mẫu cho các gợi ý, bạn cũng có thể sử dụng bootstrap để style:
templates:{
empty:['<div class="list-group search-results-dropdown"><div class="list-group-item">Không có kết quả phù hợp.</div></div>'],
header:['<div class="list-group search-results-dropdown">'],
suggestion:function(data){return'<a href="'+ data.id +'" class="list-group-item">'+ data.name +'</a>'}}
Tham khảo công cụ Laragon cài đặt nhanh môi trường Laravel, chúng ta tạo ra một môi trường test có tên là typeahead và Laragon tự động tạo ra tên miền ảo typeahead.dev. Laragon cũng tự động tạo ra database tên typeahead cho chúng ta. Việc đầu tiên là thiết lập file .env:
Có nhiều các bảng khác được tạo ra do các bảng này được sử dụng cho xác thực người dùng (xem Laravel Authentication xác thực người dùng thật đơn giản). Tiếp theo chúng ta sẽ sử dụng Laravel Seeding để tạo ra 10000 dữ liệu customer mẫu trong database.
D:\Laragon\www\typeahead
λ php artisan make:seeder CustomersTableSeeder
Seeder created successfully.
Tạo file CustomerFactory.php trong thư mục database\factories:
Chúng ta đã tạo ra bảng customer với 10 nghìn dữ liệu khách hàng mẫu được đưa vào, tiếp theo chúng ta cần tạo ra một đường dẫn để thực hiện tìm kiếm khách hàng và trả về dữ liệu dạng JSON cho truy vấn Bloodhound, thêm route sau đây vào file routes\api.php:
Route::get('find','SearchController@find');
Tạo thêm một route trong routes\web.php để hiển thị thông tin chi tiết của khách hàng, ở đây chỉ thực hiện in ra màn hình thông tin mà không có tạo view, coi như bài tập thêm cho các bạn :).
Vào đường dẫn http://typeahead.dev/customer?q=jo chúng ta sẽ có kết quả là dữ liệu dạng JSON:
2.5 View
Tiếp đến chúng ta thay đổi welcome view nằm trong thư mục resources\views:
<!DOCTYPE html><html lang="vi"><head><meta charset="utf-8"><meta http-equiv="X-UA-Compatible"content="IE=edge"><meta name="viewport"content="width=device-width, initial-scale=1"><meta name="description"content="Tìm kiếm thông minh sử dụng Typeahead trong ứng dụng Laravel"><meta name="author"content="FirebirD ['www.allaravel.com']"><title>Tìm kiếm thông minh trong Laravel sử dụng Typeahead - Allaravel.com</title><link rel="stylesheet"href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css"><!-- HTML5 shim and Respond.js for IE8 support of HTML5 elements and media queries --><!--[if lt IE 9]>
<script src="https://oss.maxcdn.com/html5shiv/3.7.3/html5shiv.min.js"></script>
<script src="https://oss.maxcdn.com/respond/1.4.2/respond.min.js"></script>
<![endif]--><style type="text/css">html{position:relative;min-height:100%;}body{margin-bottom:60px;}.footer{position:absolute;bottom:0;width:100%;height:60px;background-color:#f5f5f5;}body>.container{padding:60px 15px 0;}.container.text-muted{margin: 20px 0;}.footer>.container{padding-right:15px;padding-left:15px;}code{font-size:80%;}</style></head><body><!-- Fixed navbar --><nav class="navbar navbar-default navbar-fixed-top"><div class="container"><div class="navbar-header"><button type="button"class="navbar-toggle collapsed"data-toggle="collapse"data-target="#navbar"aria-expanded="false"aria-controls="navbar"><span class="sr-only">Toggle navigation</span><span class="icon-bar"></span><span class="icon-bar"></span><span class="icon-bar"></span></button><a class="navbar-brand"href="https://allaravel.com">Typeahead</a></div><div id="navbar"class="collapse navbar-collapse"><ul class="nav navbar-nav"><li class="active"><a href="#">Home</a></li><li><a href="#about">About</a></li><li><a href="#contact">Contact</a></li></ul></div><!--/.nav-collapse --></div></nav><!-- Begin page content --><div class="container"><div class="page-header"><h3>Ví dụ tìm kiếm thông minh sử dụng typeahead.js trong ứng dụng Laravel - Allaravel.com</h3></div><div class="row"><div class="col-md-12"><form class="form-inline typeahead"><div class="form-group"><input type="name"class="form-control search-input"id="name"autocomplete="off"placeholder="Nhập tên khách hàng"></div><button type="submit"class="btn btn-default">Tìm kiếm</button></form></div></div></div><footer class="footer"><div class="container"><p class="text-muted">Example in <a href="https://allaravel.com">allaravel.com</a></p></div></footer><script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.3/jquery.min.js"></script><script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/js/bootstrap.min.js"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/typeahead.js/0.11.1/typeahead.bundle.min.js"></script><script>jQuery(document).ready(function($){var engine =newBloodhound({
remote:{
url:'api/customer?q=%QUERY%',
wildcard:'%QUERY%'},
datumTokenizer: Bloodhound.tokenizers.whitespace('q'),
queryTokenizer: Bloodhound.tokenizers.whitespace
});$(".search-input").typeahead({
hint:true,
highlight:true,
minLength:1},{
source: engine.ttAdapter(),
name:'usersList',
templates:{
empty:['<div class="list-group search-results-dropdown"><div class="list-group-item">Không có kết quả phù hợp.</div></div>'],
header:['<div class="list-group search-results-dropdown">'],
suggestion:function(data){return'<a href="customer/'+ data.id +'" class="list-group-item">'+ data.name +'</a>'}}});});</script></body></html>
Kết quả khi vào http://typeahead.dev và thực hiện tìm kiếm khách hàng chúng ta được như sau:
3. Lời kết
Với việc sử dụng Typeahead trong ứng dụng Laravel, trải nghiệm người dùng được nâng cao hơn. Typeahead không chỉ sử dụng trong các phần tìm kiếm mà chúng ta có thể sử dụng trong các form nhập liệu giúp gợi ý thông tin nhập liệu. Hi vọng bài viết sẽ giúp ích cho các bạn trong các dự án riêng sử dụng Laravel, có bất kỳ thắc mắc hoặc góp ý các bạn comment cuối bài nhé.
Hãy bắt đầu bằng cách so sánh cả hai. Đây là một ví dụ về “switch” cổ điển:
switch($statusCode){case200:case300:$message=null;break;case400:$message='not found';break;case500:$message='server error';break;default:$message='unknown status code';break;}
Đoạn code ở dưới đây sẽ tương đương với ở trên khi dùng biểu thức “match“:
$message= match ($statusCode){200,300=>null,400=>'not found',500=>'server error',default=>'unknown status code',};
Trước hết, biểu thức khớp ngắn hơn đáng kể:
nó không yêu cầu break statement
nó có thể kết hợp các trường hợp giống nhau thành một bằng dấu phẩy
nó trả về một giá trị, vì vậy bạn chỉ phải gán giá trị một lần
Nhưng thậm chí còn nhiều hơn thế!
Không ép kiểu
match sẽ kiểm tra loại nghiêm ngặt thay vì kiểm tra lỏng lẻo. Giống như sử dụng === thay vì ==. Mọi người có thể sẽ không đồng ý liệu đó có phải là điều tốt hay không, nhưng đó là một chủ đề riêng chúng ta sẽ bàn sau.
$statusCode='200';$message= match ($statusCode){200=>null,default=>'unknown status code',};// Kết quả trả về// $message = 'unknown status code'
Giá trị không xác định gây ra lỗi
Nếu bạn quên kiểm tra giá trị và khi không có nhánh default được chỉ định, PHP sẽ đưa ra ngoại lệ UnhandledMatchError. Tuy kiểm tra chặt chẽ, nhưng nó sẽ ngăn chặn các lỗi nhỏ nhặt không được chú ý.
$statusCode=400;$message= match ($statusCode){200=>'perfect',};// UnhandledMatchError sẽ throw
Hiện tại chỉ có các biểu thức một dòng
Bạn chỉ có thể viết một biểu thức trên một dùng. Các khối biểu thức có thể sẽ được thêm vào tại một thời điểm nào đó, nhưng vẫn chưa rõ chính xác khi nào .
Ứng tuyển ngay các vị trí PHP tuyển dụng mới nhất trên TopDev
Kết hợp điều kiện
match có thể kết hợp nhiều điều kiện lại với nhau và viết trên 1 dòng ngăn cách bởi dấu phẩy
$message= match ($statusCode){200,300,301,302=>'combined expressions',};
Throwing exceptions
Trong PHP 8 có thay đổi về cách dùng throw trước đây throw chỉ bắt đầu từ câu lệnh thì giờ có thể bắt đầu từ biểu thức, nghĩa là bạn có thể throw exception ở giá trị 500 mà k phải cần đưa vào trong hàm
$message= match ($statusCode){200=>null,500=>thrownewServerError(),default=>'unknown status code',};
Pattern matching
Ok, có một điều nữa: Pattern matching. Đây là một kỹ thuật được sử dụng trong các ngôn ngữ lập trình khác, để cho phép kết hợp phức tạp hơn các giá trị đơn giản. Hãy nghĩ về nó như regex, nhưng đối với các biến thay vì văn bản.
Pattern matching không được hỗ trợ ngay bây giờ, vì đây là một tính năng khá phức tạp, nhưng Ilija Tovilo (tác giả RFC) đã đề cập đến nó như là một tính năng có thể có trong tương lai.
Vậy thì, switch hay là match?
match với phiên bản chặt chẽ và hiện đại hơn so với người anh switch
Trong một số trường hợp switch sẽ cung cấp linh hoạt hơn so với match, đặc biệt là với các khối code có nhiều dòng. Tuy nhiên, sự nghiêm ngặt của toán tử match là hấp dẫn và pattern matching sẽ là một yếu tố thay đổi cuộc chơi cho PHP.
Tôi thừa nhận tôi chưa bao giờ viết một switch statement trong những năm qua vì nhiều điều kỳ quặc của nó. Vì vậy, trong khi nó chưa hoàn hảo, nhưng có những trường hợp sử dụng được thì match sẽ là một sự lựa chọn tốt đối với tôi.