Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Ahi hi :)) khọc khọc  Tôi viết bài thấy mấy anh em chê dễ quá nên thôi tôi giành 1 ít thời gian viết một vài thứ nâng cao cho các anh em đỡ kêu vậy. Bài này ta sẽ tìm hiểu 1 design pattern khá là khó xài, nhưng một khi đã làm chủ nó thì cuộc đời ơi đẹp lắm. Bạn ghi vào CV của bạn là tôi biết PureMVC này, nhận tôi đi nếu không công ty sẽ mất 1 nhân tài đó =)) Tôi đùa thôi. Đôi khi đi xin việc, bạn cũng cần hài hước mà chém gió cho nhà tuyển dụng họ sợ Thôi tôi không khoác lác nữa, dù chém gió hay như nào thì bạn cũng phải biết code nạ
Tôi viết bài thấy mấy anh em chê dễ quá nên thôi tôi giành 1 ít thời gian viết một vài thứ nâng cao cho các anh em đỡ kêu vậy. Bài này ta sẽ tìm hiểu 1 design pattern khá là khó xài, nhưng một khi đã làm chủ nó thì cuộc đời ơi đẹp lắm. Bạn ghi vào CV của bạn là tôi biết PureMVC này, nhận tôi đi nếu không công ty sẽ mất 1 nhân tài đó =)) Tôi đùa thôi. Đôi khi đi xin việc, bạn cũng cần hài hước mà chém gió cho nhà tuyển dụng họ sợ Thôi tôi không khoác lác nữa, dù chém gió hay như nào thì bạn cũng phải biết code nạ
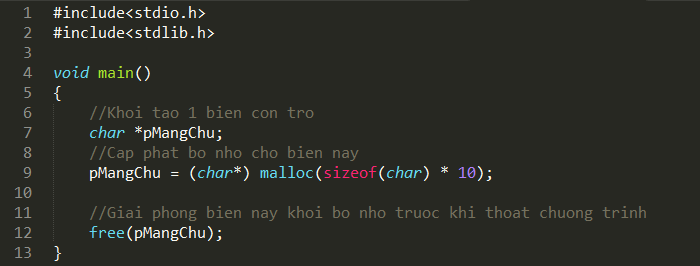
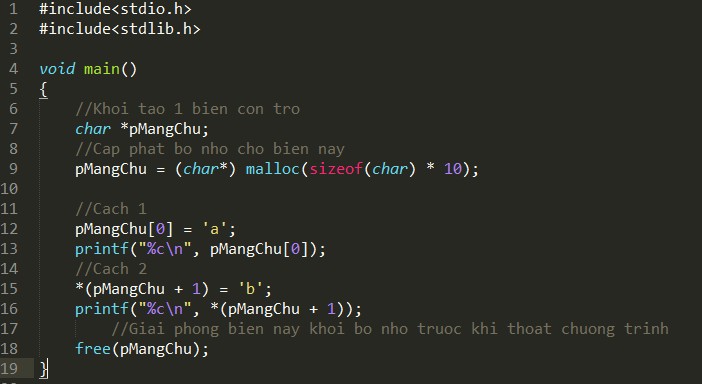
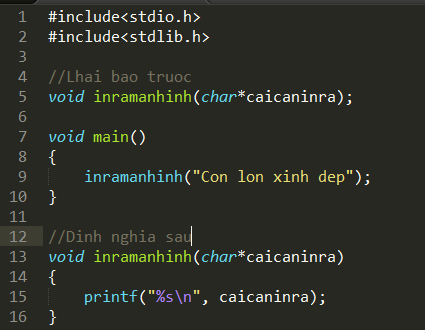
Đầu tiên tôi giới thiệu PureMVC là 1 design phát triển cũng na ná MVC, trong đó:
M = Model(Data)
V= View(Màn hình hiển thị)
C = Controller(Điều khiển).
Nhưng thằng PureMVC nó có các kết nối lỏng lẻo hơn MVC nhiều. Việc tạo ra các kết nối lỏng lẻo như vậy sẽ giúp cho việc phát triển ứng dụng dễ dàng chỉnh sửa, đại tu các thứ. PureMVC hỗ trợ cho actionscript, C++, java, python, ruby.. Nhiều lắm. Anh em lên đây mà đọc nhé:
Ở C++, chúng ta có thể tải code từ đây và build tẹt ga cho window hay các nền tảng khác như linux, Macintosh.. Trích file howtobuild từ source code:
Supporting compilers:
=====================
+ Microsoft Visual C++ 6.0 7.0 8.0 9.0 10.0
+ Minimalist GNU for Windows G++ 3.4.5, 4.x.x (MinGW32)
+ GCC for Linux, MacOS: 3.4.5, 4.x.x
+ Embarcadero C++ Builder 6.21 (Borland C++ Builder in old-name)
+ Digital Mars C++ 8.42nSupporting operation systems:
=============================
+ Microsoft Windows XP SP3, Micorosoft Windows 7
+ Linux (Fedora 7, CentOS 5.2 64 bit & 32 bit)
+ Macintosh (Tiger X 10.4, Leopard 10.5)Terminology:
============
bcc: Borland C++ Compiler / Embarcadero C++ Compiler
vc: Visual C++ Compiler
dmc: Digital Marcs C++ Compiler
ic: Intel C++ Compiler
mgw: Minimalist GNU for Windows (MinGW32)
gcc: GNU C++ Compiler
Vậy, anh em làm ứng dụng cho nhiều nền tảng (cross platform) cứ yên tâm là sẽ support tận răng nha :))
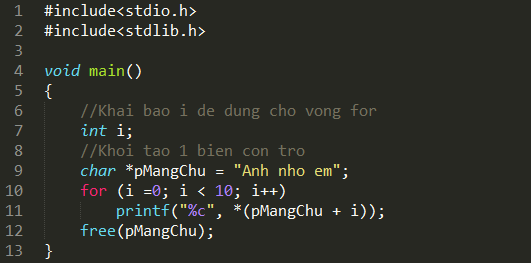
Rồi, bây giờ tìm hiểu tiếp các thành phần của framework này.
Tôi tạm lấy cái hình từ file tài liệu của các ổng code, trông nó bay bướm như này:
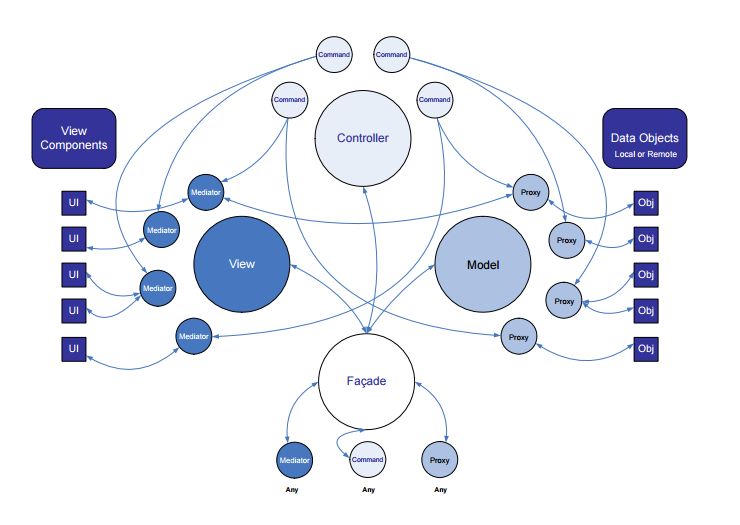
Anh em sẽ chiến từng thằng một
- Proxy: là thành phần của Model. Ổng này là thành phần chuyên xử lý transactions data. Ông request lấy data, ổng lưu, ổng xóa… Ổng này việc đơn giản là thế.Ví dụ ổng request lên server lấy thông tin của 1 user. Sau đó ông ấy lắng nghe data trả về, rồi ông ấy save data này lại vào lớp VO = Các lớp public chứa data của chúng ta. Vậy bạn nhớ cho tôi là Proxy và các VO mà bạn định nghĩa sẽ nằm cùng thư mục là Model.
- Mediator: là thành phần xử lý cho View. View là gì? Là khung nhìn, gồm giao diện chứa nút bấm, ô nhập… Các thứ mà người dùng có thể click, chạm, sờ, đập đá.. :)) Ổng vẽ các view lên. Ổng nhận các action này, rồi ông gửi action này cho các thằng khác thông qua sendnotification. Hiểu đơn giản là bắn tin nhắn cho ông nào thích thì cứ nhận mà xử lý. Mọi xử lý thuộc hàm handleNotification(INotification* notification). Ông lắng nghe các notification của những thằng khác, ông xử lý. Ở lớp này anh em nhớ có hàm: onRegister: hàm này để đăng ký lắng nghe các action.
- Command: là thành phần của Controller. Nghe cái tên là anh em nó chuyên xử lý. Ông này có hàm execute(INotification* notification) để thực thi các notification nó bắt được. Và nó cũng có thể gửi request cho các thành phần khác xử lý. Đơn giản nó có nhận có gửi xử lý notification.
Các bước mô tả như sau:
- Ứng dụng sẽ bắt đầu khởi động với 1 facade. Facade khá trừa tượng, nó là 1 đối tượng quản lý ứng dụng của chúng ta, nó như cái xương sống vậy. Chương trình sẽ bắt đầu từ đây. Ví dụ ta hay đặt tên: ApplicationFacade
- Facade sẽ gọi tới hàm startupCommand. Lớp này để khởi động ứng dụng. Khi ta viết với C++, ta sẽ gọi đối tượng facade->statup() và hàm starup sẽ gửi notification cho startupCommand.
- StartupCommand sẽ tiến hành đăng ký các proxy và các mediator cần sử dụng trong chương trình thông qua hàm registerProxy(yourproxy) và hàm registerMediator(yourMediator). Đồng thởi ở lớp này thì ông ấy sẽ remove cái command startup luôn. Ví dụ: removeCommand(ApplicationFacade::STARTUP). Sau khi đăng ký xong thì các thành phần này sẽ im lặng và lắng nghe các notificaiton để xử lý. Ông có thể bắn 1 cái notificaiton bật 1 cái view lên, chẳng hạn yêu cầu mở 1 cái view menu chương trình. Mọi thứ của startupCommand đều xử lý ở hàm StartupCommand::execute(INotification* notification). Các message được định nghĩa ở lớp ApplicationFacade.
- Application Mediator sẽ đăng ký các tiến trình của mediator
- Các process Mediator này sẽ đăng ký View và gửi message để load data.
- Facade sẽ nhận các notification này để pass data vào command.
- Data command sẽ lọc các notification này và gọi proxy load data.
- Proxy sẽ gửi các thông báo cho View thực hiện load data, Mediator sẽ xử lý việc này.
- Proxy sẽ gửi các notificaiton cho Mediator xử lý.
- …
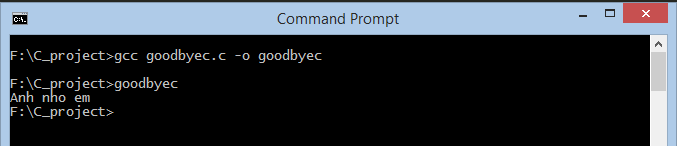
Cơ bản là như thế. Trong các bài sau tôi sẽ demo bằng visual Studio C++ cho các bạn dễ hình dung. Anh em cứ đọc thêm tài liệu nếu chưa hiểu lắm. Và bắt đầu cài đặt để code thì sẽ hiểu ngay
Happy
Bài viết gốc được đăng tải tại quynhlaptrinhc.wordpress.com
Có thể bạn quan tâm:
- 7 lí do để loại bỏ Functional Components của React
- 3 tools giúp bạn tăng hiệu năng của React App một cách bất ngờ
- Bí quyết sử dụng “Immutability” để code gọn và sạch hơn
Xem thêm Việc làm Developer hấp dẫn trên TopDev