Bài viết được sự cho phép của tác giả Ngo Thang
Đối với những hệ thống nhỏ chỉ cần 1 Database thì chắc chẳng mấy ai quan tâm đến việc tạo ra ID cho bản ghi. Vì dùng auto increment trong MySQL là có thể làm được rồi, chẳng cần phải làm gì thêm.
Thế nhưng với dữ liệu càng ngày càng to ra thì hệ thống chỉ có 1 database duy nhất có thể sẽ không thể đáp ứng được. Bởi vì traffic đang tập trung hết vào database đó.

Để giải quyết bài toán đó thì người ta đã tách database ra thành nhiều database khác nhau, và mỗi database đó sẽ chứa 1 phần dữ liệu. Ví dụ db01 chứa thông tin user từ 1 đến 1000, db02 chứa thông tin user từ 1001 đến 2000 chẳng hạn. Và khi query sẽ tìm xem user thuộc database nào và thực hiện truy vấn.
Tuyển dụng database vị trí lương cao, hấp dẫn
Và kĩ thuật này người ta gọi là sharding.
Thế nhưng có vấn đề xảy ra ở đây là làm thế nào sinh ra ID cho user mà không bị trùng lặp giữa các database đó? Dùng auto increment mặc định của database có giải quyết được không? Làm thế nào để từ 2 ID có thể phán đoán cái nào được sinh ra trước, cái nào được sinh ra sau?
Vậy cùng đọc bài này xem các kĩ sư Instagram đã giải quyết bài toán này thế nào nhé.
Mục tiêu bài viết:
- Hiểu thêm được 1 cơ chế sinh ID mới.
- Có thể áp dụng vào các bài toán sharding data trong database.
Bối cảnh
Instagram là 1 trong những mạng xã hội chia sẻ ảnh nổi tiếng nhất cái hành tinh này.
Theo thống kê năm 2016 thì cứ mỗi giây sẽ có 915 photos, 1k post được tạo ra. Quá khủng khiếp phải không nào.
Khi dữ liệu tăng lên kinh khủng như thế thì 1 database sẽ không thể lưu trữ hết được dữ liệu, cùng với tốc độ truy vấn sẽ trở nên ì ạch và tốn nhiều dung lượng bộ nhớ.
Để đảm bảo tất cả dữ liệu quan trọng luôn được lưu trữ trên memory, và sẵn sàng trả về kết quả nhanh nhất cho người dùng thì Instagram bắt đầu thực hiện Sharding dữ liệu.
Ảnh bên dưới là 1 ví dụ về sharding trong database. Database sẽ được tách ra thành nhiều database khác nhau, mỗi database sẽ chứa 1 phần dữ liệu. Như ví dụ bên dưới là tách bảng user ra thành nhiều database, mỗi database sẽ chứa 1 phần dữ liệu của bảng user.
Người ta gọi mỗi database tách biệt này là ”Shard“.
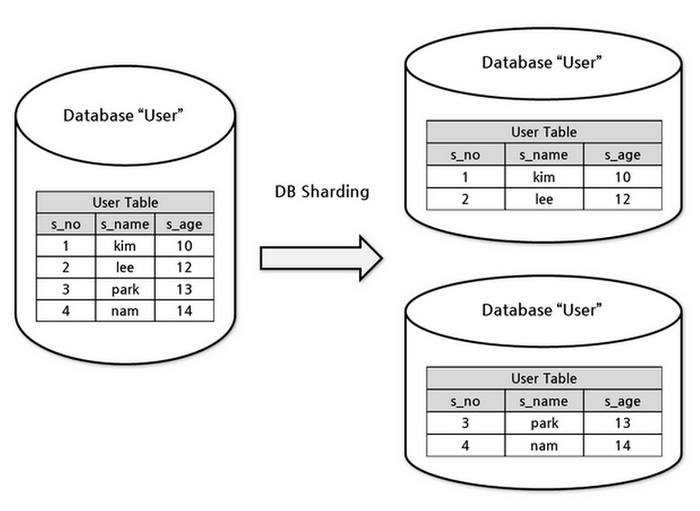
Tuy nhiên tại thời điểm này có 1 bài toán được đặt ra. Làm thế nào có thể sinh ra ID duy nhất trên từng shard mà không sợ bị trùng lặp (Ví dụ như mỗi photo được upload vào trong hệ thống)? Cùng đi đọc tiếp phần tiếp theo nhé.
Yêu cầu về mặt chức năng
Trước khi đi vào giải quyết bài toán bên trên, thì cùng xem hệ thống Instagram yêu cầu những gì về ID của từng shard nhé.
- ID được tạo ra phải được sắp xếp theo thời gian. Ví dụ như với 2 ID thì có thể phán đoán được ID nào tạo ra trước, ID nào tạo ra sau.
- ID sẽ bao gồm 64 bits. (Vì sao lại cần 64 bits? Vì nó tương thích với các hệ thống như Redis …)
- Thuật toán sinh ra ID phải đơn giản, dễ hiểu và đặc biệt không được làm thay đổi architecture server của Instagram.
1 số giải pháp generate ID
Hiện tại có rất nhiều giải pháp cho việc sinh ra ID unique. Cụ thể như:
Sử dụng auto increment trong database
Về chức năng này thì ai cũng biết rồi. Lúc tạo bảng chỉ cần khai báo auto increment là xong.
Ưu điểm:
- Cách dùng đơn giản.
Nhược điểm:
- Chỉ tập trung vào 1 database và không thể phân chia sang database khác được.
- Không thể đảm bảo rằng việc sinh ID ở nhiều database là không bị trùng nhau.
Sử dụng UUID
Đây cũng là 1 cách khá hay để giải quyết bài toán. UUID là 1 chuẩn chung nhằm sinh ra chuỗi random không trùng nhau (xác suất gần như bằng 0). Ví dụ như: b875d561-20fd-498d-8452-5d5ffa879856.
Thế nhưng cùng xem nó có ưu điểm nhược điểm gì nhé.
Ưu điểm:
- Cho dù chạy trên nhiều máy tính cùng thời điểm đi chăng nữa thì xác suất các string đó trùng nhau dường như gần bằng 0.
Nhược điểm:
- Nó bao gồm 128 bits nên hơi to, không phù hợp với yêu cầu của hệ thống (là 64 bits)
- Với 2 ID thì không thể phân biệt ID nào tạo trước, ID nào tạo sau.
Snowflake
Đây chính là 1 công cụ sinh ra ID random được phát triển bởi Twitter. Cái này sử dụng Apache Zookepper để phối hợp với các node để tạo ID 64 bit duy nhất.
Ưu điểm:
- Snowflake ID có 64 bit
- Có thể sử dụng time trong component đầu tiên của ID nên có thể sắp xếp được
Nhược điểm:
- Phải đưa ZooKeeper, Snowflake vào trong kiến trúc của Instagram.
Giải pháp của Instagram
Những giải pháp trên đều không đáp ứng được yêu cầu của Instagram nên họ quyết định tự xây dựng cho mình 1 giải pháp riêng.
Họ sẽ dùng thuật toán đơn giản để sinh ra 1 chuỗi ID random duy nhất từ 1 số input đầu vào. Và từ chuỗi ID đó có thể decode ngược lại để lấy ra được input.
ID ở đây chính là ID của photo, ID của posts chẳng hạn.
Database họ sử dụng là PostgreSQL.
Cụ thể như sau.
ID có độ dài 64 bits, sẽ bao gồm những bộ phận sau:
- 41 bits để lưu thời gian (đơn vị milliseconds). Khoảng thời gian này sẽ được tính từ ngày 2011/01/01 00:00.
- 13 bits để lưu shard ID. (tối đa có thể tạo ra được 2^13 = 8192 shard)
- 10 bits để lưu auto-incrementing sequence, sau đó module 1024. (Vì sao lại là 1024 vì tối đa có 10 bit thôi, mà 2^10 = 1024). Điều đó có nghĩa là có thể tạo ra 1024 IDs trên 1 shard, trên millisecond.
Câu hỏi đặt ra là nếu tạo upload quá 1024 bức ảnh trong 1ms có được không?
Câu trả lời là không nhé. Vì lúc đó thằng thứ 1025 sinh ra ID sẽ bị trùng với thằng thứ 1. Với cả ID là khoá chính nên khi insert vào sẽ bị lỗi. Nên lúc đó chỉ cần try cach đoạn đó là ok.
Công thức sinh ID như sau:
ID = (time << 23) | (shardID << 10) | (seqId <<0)
Trong đó:
・time = now - instagram_epoch_time (2011/01/01 00:00)
・shardId = userId % 2000
・seqId = (currentSeqID + 1) % 1024Từ công thức trên ta có thể thấy ID được tạo ra bằng cách:
**ID = (Dịch trái time sang trái 23 bit) bitwise OR (dịch trái shardID 10 bit) bitwise OR (dịch trái seqID 0 bit) **
Để mình tổng hợp lại kiến thức về bitwise cho mọi người hiểu nhé:
- Dịch trái, dịch phải nó cũng giống như chúng ta kéo cảnh cửa sang trái, sang phải thôi. Nếu dịch trái n bit tức là sẽ điền n số 0 vào sau số đó. Ví dụ như dịch trái số 7 (dạng nhị phân là 110) sang trái 5 bit, khi đó nó sẽ thành: 11000000
- bitwise OR tức là thực hiện OR từng bit 1 của 2 số từ phải sang trái. Nếu 2 bit đều là 1 thì sẽ cho kết quả là 1, ngược lại sẽ cho kết quả là 0. Ví dụ như 7 (dạng nhị phân là 110) OR 8 (dạng nhị phân là 111) khi đó kết quả là: 110 OR 111 = 110.
Ví dụ:
Giả sử như người dùng có user_id là 5001, post bức ảnh lên instagram vào thời điểm 2019/05/19 00:00. Tại thời điểm đó sequence hiện tại của table đang là 9000.
Cách tính:
Do thời gian được tính từ ngày 2011/01/01 00:00 nên từ thời điểm đó đến ngày 2019/05/19 00:00 có time = 264384000000 ms.
=> ID = 264384000000 << 23 (dịch sang trái 23 bit)
Do user_id = 5001, và instagram chỉ có 2000 shard. Nên shardId = 5001 % 2000 = 1001
=> ID |= 1001 << 10
sequence hiện tại của table đang là 9000, khi đó nextsequenceid là 9001. vậy seqId = 9001 % 1024 = 809
=> ID |= (809) << 0
Sau khi tính chúng ta ra kết quả ID = 2217813737473025832.
Vậy làm thế nào mà từ số 2217813737473025832 chúng ta có thể decode ngược lại ra time là 264384000000, shardId là 1001, seqId là 809?
Đây có lẽ là phần mình thấy hay nhất. Chúng ta cùng xem tiếp nhé:
Time = (2217813737473025832 >> 23) & 0x1FFFFFFFFFF = 264384000000
Shard ID = (2217813737473025832 >> 10) & 0x1FFF = 1001
seqID = (2217813737473025832 >> 0) & 0x3FF = 809Từ công thức trên ta có thể thấy được:
- Time sẽ được tính bằng cách dịch sang phải ID 23 bit, sau đó thực hiện AND với 1 số 41 bit toàn số 1. Cái số 41 bit toàn số 1 này chuyển sang dạng hex sẽ là 0x1FFFFFFFFFF.
- ShardID và seqId cũng được decode tương tự.
Đây là 1 example về encode và decode mình đã chuẩn bị được. Dành cho ai muốn test:
<?php
$uuid = 0;
$userId = 5001;
$currentSequenceId = 9000;
$time = 264384000000;
// ENCODE
$shardId = $userId % 2000;
$seqId = ($currentSequenceId + 1) % 1024;
$uuid = $time << 23;
$uuid = $uuid | ($shardId << 10);
$uuid = $uuid | ($seqId);
echo $uuid . PHP_EOL;
// DECODE
$time = ($uuid >> 23) & 0x1FFFFFFFFFF;
$shardId = ($uuid >> 10) & 0x1FFF;
$seqId = ($uuid >> 0) & 0x3FF;
echo $time . PHP_EOL;
echo $shardId . PHP_EOL;
echo $seqId . PHP_EOL;Sau khi lấy được shardId là chúng ta có thể dễ dàng truy cập vào từng shard để lấy ra record dựa vào ID (photoid, postid …) được rồi. Mà chẳng phải tốn công đi join, select làm gì cho mệt cả.
Hơn nữa nó thao tác giữa các bit nên cứ gọi là nhanh đừng hỏi.
Và đây là ví dụ về PL/PGSQL trong PostgreSQL:
CREATE OR REPLACE FUNCTION insta5.next_id(OUT result bigint) AS $
DECLARE
our_epoch bigint := 1293843600000;
seq_id bigint;
now_millis bigint;
shard_id int := 5;
BEGIN
SELECT nextval('insta5.table_id_seq') %% 1024 INTO seq_id;
SELECT FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000) INTO now_millis;
result := (now_millis - our_epoch) << 23;
result := result | (shard_id <<10);
result := result | (seq_id);
END;
$ LANGUAGE PLPGSQL;Khi tạo bảng sẽ làm như sau:
CREATE TABLE insta5.our_table (
"id" bigint NOT NULL DEFAULT insta5.next_id(),
...rest of table schema...
)Kết luận
Từ 1 con số mà có thể dễ dàng decode nó ra để lấy các thông tin bên trong nó. Đoạn này mình thấy thật vi diệu.
Đúng là mấy anh kĩ sư có kinh nghiệm về design mấy bo mạch, chip các thứ áp dụng vào thấy nó khác bọt thật.
Hi vọng qua bài này sẽ giúp các bạn có 1 kiến thức mới về việc sinh ra ID random, và decode ngược lại.
Xem thêm những nội dung liên quan:
- Top 5 công cụ mã nguồn mở dành cho MySQL administrator
- Tại sao không bao giờ nên sử dụng utf8 trong mysql
- Vì sao SQL tốt hơn NoSQL?
- Sử dụng Trigger trong SQL
Xem thêm việc làm IT Đà Nẵng, Hà Nội, HCM mới nhất tại TopDev
Bài viết gốc được đăng tải tại Nghệ thuật Coding


 – Cách sử dụng chi tiết")










 là gì? Đặc điểm và phân loại Database")