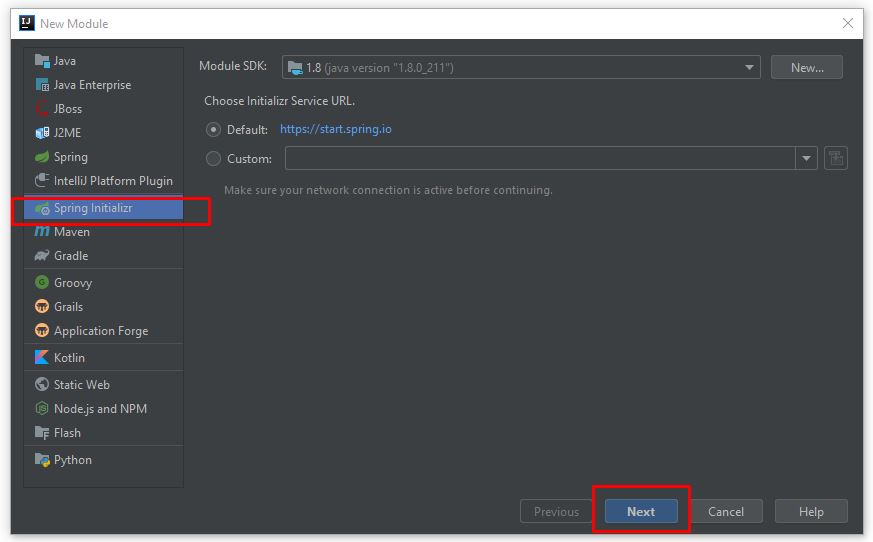
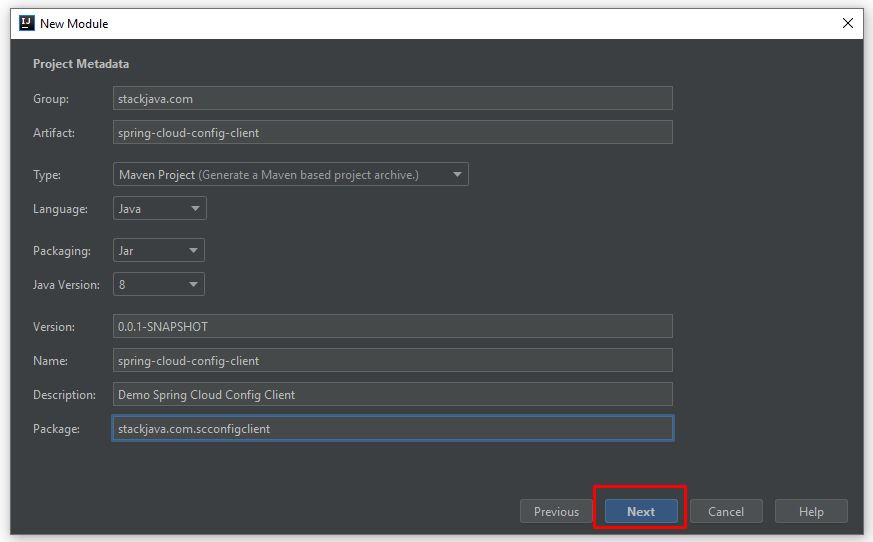
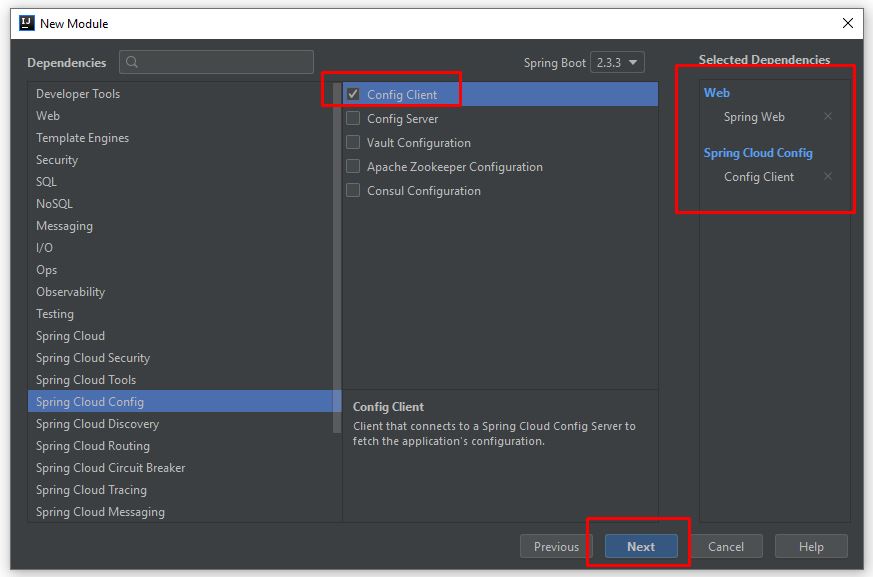
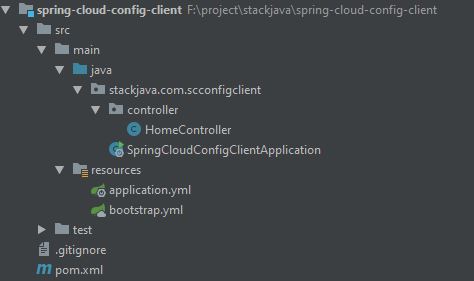
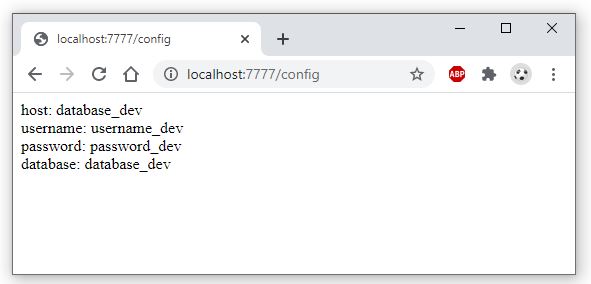
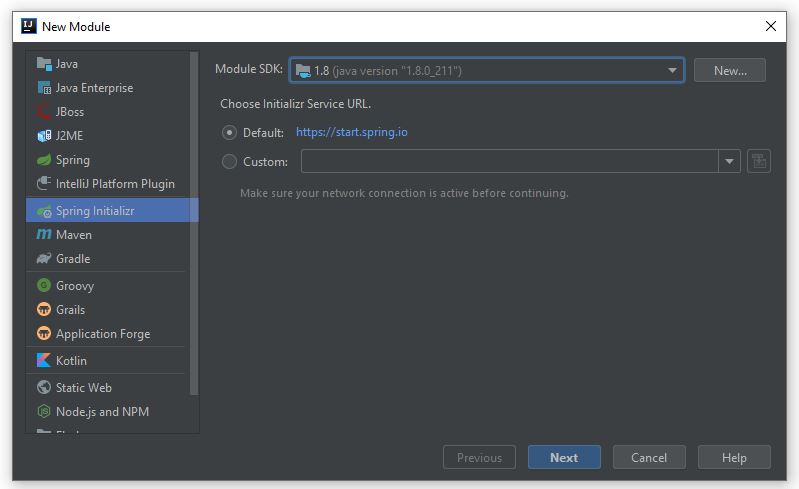
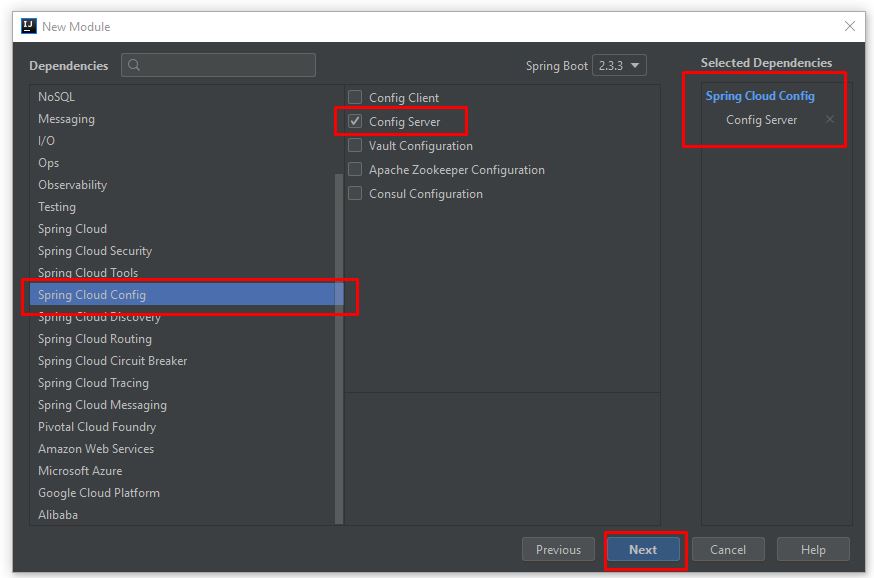
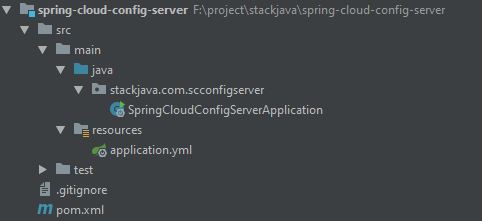
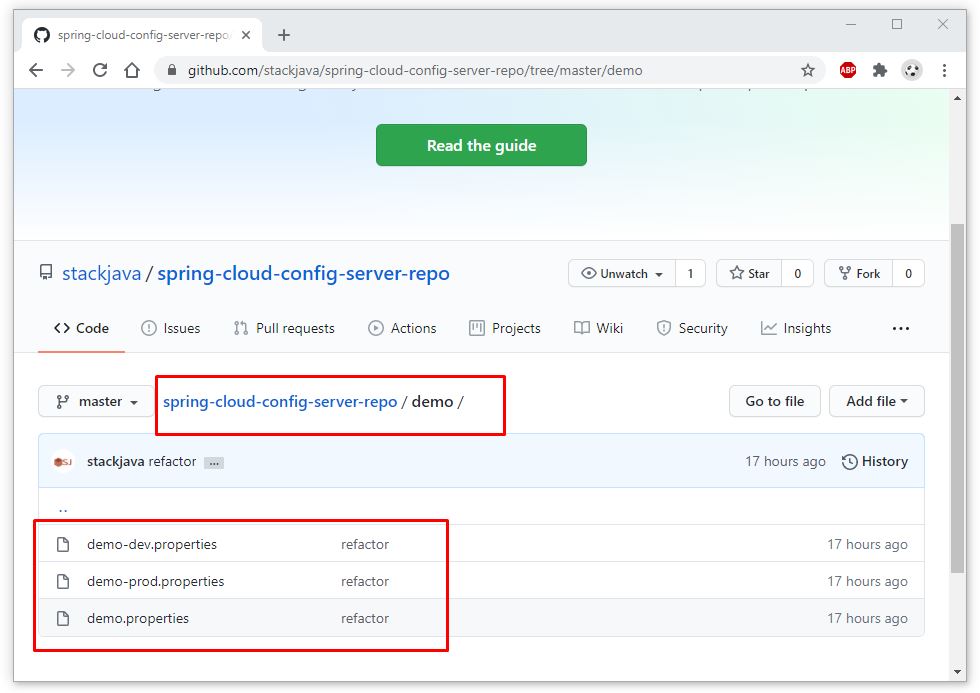
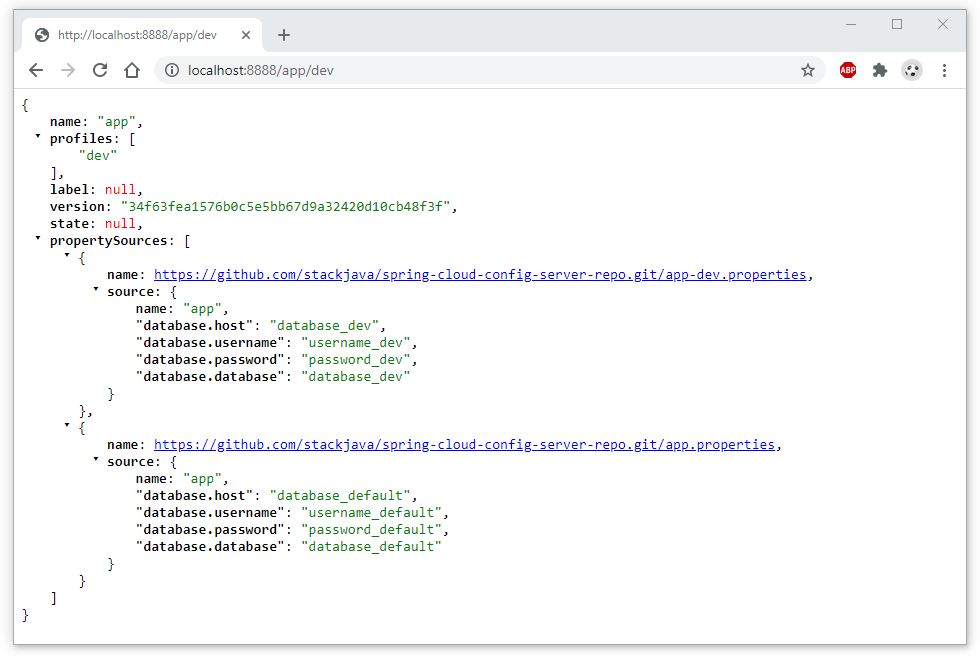
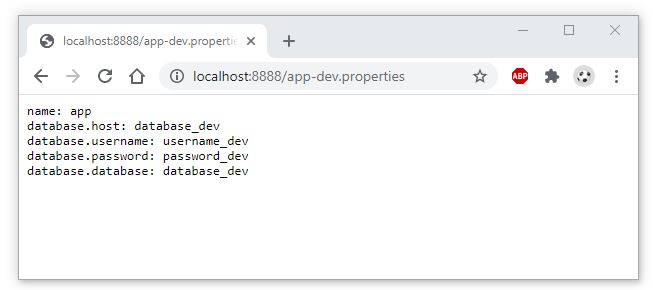
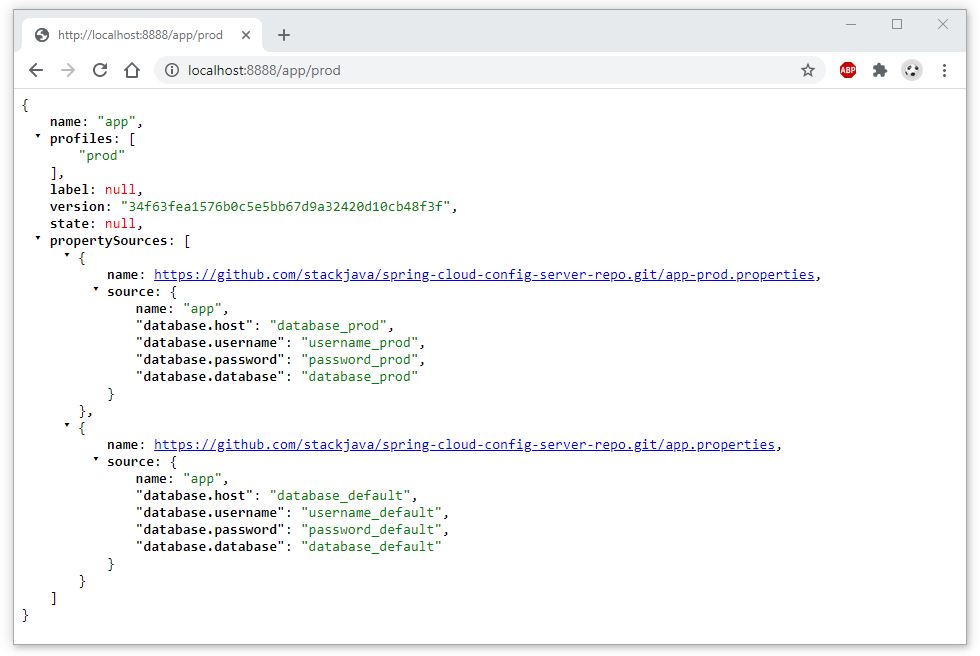
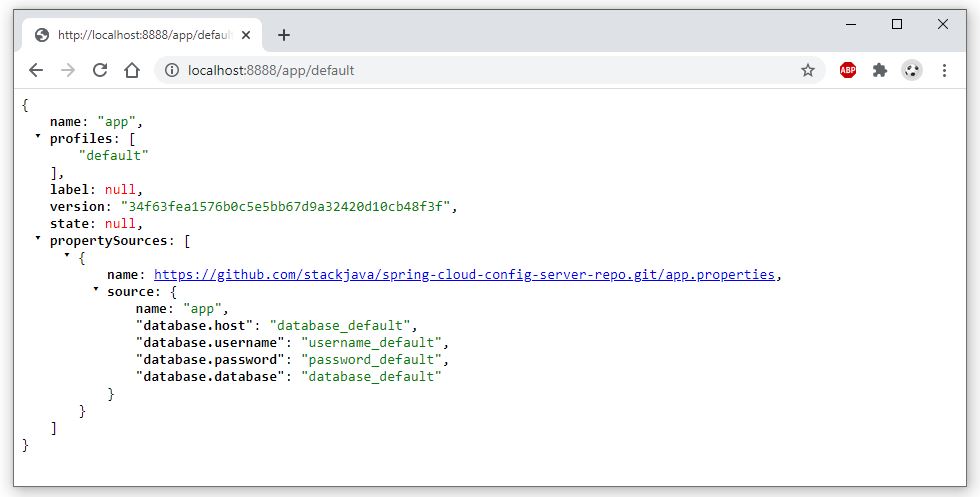
Nếu bạn đã có lựa chọn ngay từ khi tốt nghiệp THPT, và theo học đúng chuyên nghành Quản trị Nhân sự thì đây hoàn toàn là một lợi thế để bắt đầu với công việc này
Chào mừng các bạn đang đến với series các bài học trong Khóa học Nhân sự cơ bản cho người mới (newbie) hoàn toàn miễn phí. Tôi là Thành HR sẽ đồng hành cùng bạn trong khoá học này. Và chủ đề mà chúng ta cùng nhau tìm hiểu ngày hôm nay là Những ai có thể làm Nghề Nhân sự?
Trong bài học Nghề Nhân sự là gì, mình đã cùng nhau tìm hiểu và có cái nhìn tổng quan về Nghề Nhân sự rồi. Vậy để trở thành một chuyên viên Nhân sự khó hay dễ? Học nghành gì để làm được công việc này? Học trái nghành thì sao? Nếu bạn đang là người ngoại đạo và muốn tìm hiểu về nó thì đây là bài học dành cho bạn.
Theo quan sát từ thực tế của mình đến thời điểm này, thì có những lý do hoặc có thể gọi là duyên để bạn đến với công việc Nhân sự. Mình gọi là duyên vì thực sự có những bạn đã, đang làm nghề này nhưng có bằng cấp chuyên nghành khác. Mình cùng nhau bắt đầu bài học Những ai có thể làm Nghề Nhân sự để tìm hiểu xem ai có thể trở thành chuyên viên nhân sự bạn nhé!
Nếu bạn đã có lựa chọn ngay từ khi tốt nghiệp THPT và theo học đúng chuyên nghành Quản trị Nhân sự thì đây hoàn toàn là một lợi thế để bắt đầu với công việc này. Bạn sẽ có kiến thức nền tảng tốt hơn về nghề, các kỹ năng bài bản, cũng như ít nhiều được tiếp xúc với Nghề nhân sự trong thời gian học tại trường và thời gian thực tập tại doanh nghiệp.
Vậy nên con đường trở thành chuyên viên Nhân sự của bạn sẽ dễ dàng hơn. Và mình muốn nhấn mạnh, nó là lợi thế chứ không phải là yếu tố duy nhất quyết định bạn sẽ thành công khi học đúng chuyên ngành nhé!
Tuy nhiên, thực tế thì có những bạn ra trường lại không theo đuổi nghề này. Mà thay vào đó, họ chọn làm nhân viên kinh doanh, marketing hoặc làm các công việc trái nghành khác để phát huy hết các điểm mạnh của riêng họ.
Theo cá nhân mình, tính cách bạn có một chút xíu hướng nội, tức là nhóm S trong mô hình nhận diện tích cách DISC sẽ phù hợp với nghề nhân sự này hơn. Điều này không đồng nghĩa là các nhóm tính cách khác thì không được làm nghề này bạn nhé!
Bạn là Kế toán trong một công ty nhỏ
Thường ở các công ty quy mô nhỏ, bộ phận kế toán hay kiêm luôn việc tính lương, làm bảo hiểm xã hội cho nhân viên công ty. Thậm chí cả việc tuyển dụng nhân viên khi có người nghỉ cần thay thế. Tức là công ty không có bộ phận tuyển dụng và C&B. Nên bạn có cơ hội tìm tòi và tìm hiểu Nghề Nhân sự để phục vụ công việc.
Đến một lúc nào đó, khi công ty mở rộng quy mô và thành lập thêm Phòng Nhân sự thì bạn được điều chuyển hoặc chủ động xin chuyển qua phòng ban mới. Có thể trong quá trình phụ trách các công việc liên quan, bạn lại cảm thấy thích thú hơn với nghề này và quyết định chuyển hướng. Nó tuyệt vời đó chứ!
Bạn bắt đầu từ một thực tập sinh
Rất nhiều bạn học chuyên ngành quản trị kinh doanh hoặc các nghành nghề khác, rồi quyết định chọn Nhân sự làm nghề nghiệp sẽ theo đuổi. Chúc mừng bạn đã biết mình thích gì và sẽ phải làm gì. Việc này giúp bạn biết bản thân có thể bắt đầu Nghề Nhân sự như thế nào là phù hợp
Thường các bạn sẽ bắt đầu bằng việc xin thực tập ở các vị trí của Phòng Nhân sự từ 6 tháng đến 1 năm để có cơ hội học hỏi và theo đuổi nó. Mình đánh giá rất cao điều này, vì bạn đã có hành động đúng để thực hiện ước mơ và đam mê của mình.
Và thực tế trong quá trình làm nghề của mình, có ghi nhận một số ít bạn thực tập và học nghề tại Phòng Nhân sự khoảng 1 đến 2 tháng, nhưng sau đó thấy không hợp. Và chuyển qua làm nhân viên kinh doanh hoặc tự khởi nghiệp. Điều đó hoàn toàn bình thường và không có gì đáng tiếc bạn nhé! Quan trọng là bạn đã nhận ra đam mê của mình và không hối tiếc về sau, kiểu như cứ tự trách bản thân là biết ngày đó mình theo nghề nhân sự thì hay rồi…
Bạn bắt đầu bằng một khóa học ngắn hạn
Ra trường với tấm bằng đại học, rất nhiều bạn loay hoay mãi để tìm cho mình điểm bắt đầu. Sau đó đi học tất cả các khóa học nghiệp vụ có thể: nào là Kế toán, Nhân sự, Marketing,…Một số ít tìm được niềm đam mê và dấn thân với nghề Nhân sự.
Hành trình bắt đầu nào cũng khó khăn cả, nhưng trong các trường hợp trên mà mình đưa ra là tất cả họ đều quyết tâm thực hiện, vượt qua khó khăn thử thách để thực hiện đam mê của mình. Chứ không chỉ là ước mơ viễn vông.
Và đó là các ví dụ có thật trong thực tế làm nghề mình thấy, cá nhân mình cũng xuất phát từ một tấm bằng trái ngành. Qua đây, mình muốn truyền tải đến các bạn thông điệp là chỉ cần bạn chọn, xác định nghề Nhân sự phù hợp với bạn để theo đuổi lâu dài, thì chắc chắn sẽ có cách, nếu bạn bắt đầu vạch ra kế hoạch để thực hiện nó, thay vì chỉ ước mơ.
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Bạn có thể sử dụng OrgMode để quản lý công việc (todo list), hay làm công cụ soạn thảo nội dung có trình bày một cách hệ thống,… tùy theo nhu cầu cá nhân.
Trên Vim, chúng ta cũng có thể sử dụng OrgMode bằng cách cài plugin vim-orgmode.
Sau khi cài đặt xong thì Vim sẽ tự động chuyển sang orgmode khi mở một file *.org bất kì.
Giả sử chúng ta có file ~/today.org, mở file này với vim bạn sẽ thấy kí hiệu org ở phần filetype, cho biết đây là file mở dạng orgmode, nếu không thấy thì chúng ta có thể set filetype tự động bằng lệnh:
:set ft=org
Heading
Heading là các đầu mục để bạn có thể dễ dàng phân loại, tổ chức nội dung của mình (tương tự các thẻ h1, h2,… trong HTML)
Chèn heading
Để chèn một đầu mục (heading), bạn dùng các dấu sao * theo thứ tự của nó, ví dụ:
Khi đứng tại một heading, bạn có thể gõ } hoặc { để nhảy nhanh tới các heading tiếp theo/trước đó.
Nâng cấp, giáng cấp heading
Bạn cũng có thể chuyển một heading level 1 thành level 2 (giáng cấp – demote) hoặc một heading level 3 thành level 2 (nâng cấp – promote) bằng cách gõ >> hoặc <<.
Đóng/mở heading
Đứng tại một heading, bạn có thể nhấn phím TAB hoặc SHIFT-TAB để đóng (collapse) hoặc mở (expand) heading đó và tất cả các heading con bên trong nó theo thứ tự xoay vòng:
,-> FOLDED -> CHILDREN -> SUBTREE --. '-----------------------------------'
Task
Trong mỗi heading, bạn có thể gõ vào bất kì nội dung gì bạn muốn. Trong trường hợp sử dụng orgmode để làm todo list, thì nội dung bạn gõ nhiều nhất đó chính là các task.
Chèn task
Để chèn một task ta có thể chèn theo cú pháp sau:
- [ ] <nội dung task>
Đây là một task dạng check box để chúng ta có thể tick vào hoặc bỏ tick nó bất cứ lúc nào.
Để chèn nhanh, có thể xài phím tắt đã config ở trên kia là <Leader>nc (n-c có nghĩa là new check).
Tick và bỏ tick
Để tick vào một task, bạn điền dấu X vào phần trống giữa dấu ngoặc vuông [ ]:
- [X] <nội dung task>
Hoặc tick tự động bằng phím <Leader><Tab>.
Lặp lại thao tác này sẽ bỏ tick.
Làm việc với agenda
Agenda là một chức năng cực kì hay giúp tổng hợp nội dung trên file org hiện tại thành một bảng tóm tắt, cho chúng ta cái nhìn tổng quan về các task ở trạng thái TODO, hoặc tóm tắt theo ngày, theo tuần.
Trạng thái TODO/DONE
Bạn có thể thêm trạng thái TODO hoặc DONE vào đầu mỗi heading để dễ dàng theo dõi và để khởi tạo agenda, ví dụ:
* Today** TODO Project A ...** DONE Project B
Nội dung như trên có nghĩa là mục Project A đang ở trạng thái TODO và mục Project B ở trạng thái DONE.
Các nội dung có trạng thái DONE sẽ không được hiện ra khi xem agenda.
Chèn ngày tháng
Để chèn ngày tháng tại vị trí hiện tại của con trỏ, chúng ta dùng lệnh <Leader>nd (n-d là new date).
Dòng lệnh hiện ra cho phép bạn chọn ngày hiện tại bằng cách nhấn <Enter>, hoặc tăng giảm số ngày bằng cách gõ vào, ví dụ: +1d (tăng 1 ngày), +4w (tăng 4 tuần), -5m (giảm 5 tháng),…
Xem agenda các task TODO
Để xem danh sách các mục có trạng thái TODO, ta gõ <Leader>td (t-d tức là todo).
Khi ở màn hình danh sách To Do, bạn có thể dùng phím <Tab> để nhảy đến nội dung tương ứng trên file.
Xem agenda trong tuần
Để xem danh sách các task cần làm trong tuần, chúng ta dùng lệnh <Leader>wa (w-a là weekly agenda).
Trên đây là một vài thao tác cơ bản để bạn có thể bắt đầu sử dụng vim-orgmode một cách hiệu quả. Trong quá trình sử dụng, bạn có thể tìm hiểu thêm thông qua hướng dẫn sử dụng của vim-orgmodetrên Github để làm việc hiệu quả hơn nhé.
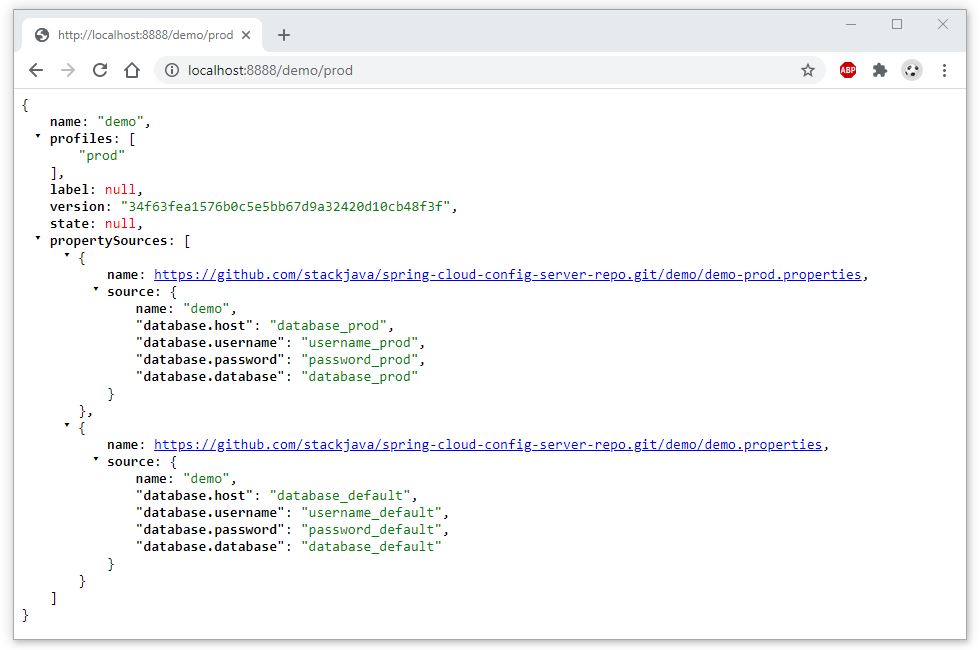
Cơ bản về định nghĩa RESTful Web Service API specs sử dụng OpenAPI Specification
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Mình đã hướng dẫn các bạn cách định nghĩa RESTful Web Service API specs sử dụng RAML. Có một cách khác để làm điều này là sử dụng OpenAPI Specification. Cụ thể như thế nào? Trong bài viết này, chúng ta sẽ cùng nhau tìm hiểu làm thế nào để định nghĩa RESTful Web Service API specs sử dụng OpenAPI Specification các bạn nhé!
Chúng ta sẽ sử dụng tập tin YAML hoặc JSON để định nghĩa API specs với OpenAPI Specification. Dưới đây là nội dung tập tin YAML định nghĩa API specs trong bài viết Giới thiệu về RAML sử dụng OpenAPI Specification:
openapi: 3.0.3
info:
title: Student Information Management System
version: "1.0"
servers:
- url: https://localhost:8081/api
paths:
/students:
get:
operationId: getStudents
summary: Get all students
responses:
200:
description: Get all students successfully
content:
application/json:
example: [{ "ID": 1, "code": "001", "name": "Khanh" }, { "ID": 2, "code": "002", "name": "Quan" }]
/students/{ID}:
get:
operationId: getStudentById
summary: Get a student by ID
parameters:
- name: ID
in: path
description: "ID of the Student"
required: true
schema:
type: string
responses:
200:
description: Get student information successfully
content:
application/json:
example: { "ID": 1, "code": "001", "name": "Khanh" }
delete:
operationId: deleteStudentById
summary: Delete a student by ID
parameters:
- name: ID
in: path
description: "ID of the Student"
required: true
schema:
type: string
responses:
200:
description: Delete student information successfully
content:
application/json:
example: { "message": "Student deleted!"}
Như các bạn thấy, tương tự như định nghĩa API specs với RAML, ở đầu tập tin YAML này, chúng ta sẽ định nghĩa một số thông tin overview về API specs của mình. Chúng ta sử dụng field openapi để định nghĩa OpenAPI Specification version chúng ta sẽ sử dụng để định nghĩa API specs, thông tin về API specs bao gồm mục đích của nó (field info.title), version của API specs này (info.version). Base URL sẽ được định nghĩa sử dụng field servers.url.
Các request URL sẽ được định nghĩa với section paths.
Chúng ta không định nghĩa các request URL với giá trị bắt đầu giống nhau theo kiểu extends như bên RAML được. Chúng ta chỉ có thể gom các request có HTTP method khác nhau nhưng cùng một request URL. Trong ví dụ trên thì request URL “/students/{ID}” được định nghĩa với GET và DELETE method, chúng ta có thể gom 2 request URL này lại với nhau.
Chúng ta có thể sử dụng field operationId để identify cho mỗi request URL. Giá trị của field này là duy nhất trong 1 API specs cho mỗi request URL.
Tương tự như RAML, chúng ta cũng có thể định nghĩa response cho mỗi response status code, mỗi response có thể có kiểu dữ liệu khác nhau. Trong ví dụ của mình thì đó là application/json.
Để định nghĩa parameter cho các request URL, chúng ta sẽ sử dụng section parameters trong mỗi request. Các parameter có thể là path parameter, query parameter hay nằm trong header, cookie. Chúng ta sử dụng field in của mỗi parameter để khai báo điều này.
OpenAPI cũng hỗ trợ nhiều kiểu dữ liệu khác nhau như RAML. Các bạn có thể tham khảo thêm ở đây các bạn nhé!
Việc định nghĩa API specs trước khi bắt tay vào implement API sẽ giúp chúng ta thống nhất được API contract, các bên liên quan chỉ cần follow theo API contract này để sử dụng, giảm thiểu rất nhiều rủi ro có thể xảy ra. Hãy suy nghĩ tới nó trước khi bắt đầu implement các API RESTful Web Service các bạn nhé!
Giới thiệu Web service – SOAP, WSDL và ASP.NET Web Service cơ bản
Bài viết được sự cho phép của tác giả Lê Chí Dũng
Hôm nay ôn lại bài web service vừa học trên lớp sẳn tìm kiếm thông tin về web service và mình vừa thu thập được một số thông tin hay về web service và share cho ace xem. Trước tiên là phần cơ bản về SOAP, WSDL, ASP.NET Web Service (trích từ YinYangit.wordpress.com)
Web Service là gì?
– Dịch vụ Web (Web Service) là một chuẩn để tích hợp các ứng dụng trên nền web (Web-based applications). Các ứng dụng có thể sử dụng các thành phần khác nhau để tạo thành một dịch vụ.Về bản chất, Web service dựa trên XML và HTTP, trong đó XML làm nhiệm vụ mã hóa và giải mã dữ liệu và dùng SOAP để truyền tải. Web Service không phụ thuộc vào platform nào, do đó bạn có thể dùng Web Service để truyền tải dữ liệu giữa các ứng dụng hay giữa các platform.
Ví dụ như máy chủ chạy một trang web thương mại điện tử kết nối với cổng thanh toán điện tử qua một API ( Application Programming Interface – tạo bởi công nghệ .NET) thì web services chính là nền máy chủ (IIS – Internet Information Services), và các thành phần thanh toán, các thành phần .NET được coi là các thành phầm bên ngoài (component). Các thành phần này được gọi bởi phương thức SOAP (Khác phương thức POST, GET) nên không bị gặp phải firewall khi truy xuất các thành phần bên ngoài máy chủ. Và toàn bộ các thành phần đó gọi là một Web Services.
Một ví dụ về Web Service sẵn có là dịch vụ được cung cấp bởi PayPal cho phép những người có tài khoản có thể thanh toán trên các trang web thương mại như AMAZONE bằng cách thông qua SOAP nó sẽ lấy ID của người dùng nhập vào lúc thanh toán, sau đó ID đó sẽ được đưa đến Web Service của PayPal xử lý, sau khi xử lý xong thì nó sẽ trả kết quả cho trang thanh toán của AMAZONE là tài khoảng đó có thanh toán được hay là không. Và tất nhiên là các trang web thương mại và PayPal phải có mối liên kết với nhau thì mới có thể sử dụng Web Service của PayPal.
SOAP – Một tiêu chuẩn của W3C, là giao thức sử dụng XML để định nghĩa dữ liệu dạng thuần văn bản (plain text) thông qua HTTP. SOAP là cách mà Web Service sử dụng để truyền tải dữ liệu. Vì dựa trên XML nên SOAP là một giao thức không phụ thuộc platform cũng như bất kì ngôn ngữ lập trình nào.
Một thông điệp SOAP được chia thành hai phần là header và body. Phần header chỉ ra địa chỉ Web Service, host, Content-Type, Content-Length tương tự như một thông điệp HTTP.
Khi tạo một dự án Web Service, mặc định Web Visual Develop sẽ tạo cho bạn phương thức HelloWorld() sau:
public string HelloWorld()
{
return "Hello World";
}
Một HTTP Request sẽ có dạng sau:
POST /MathService.asmx/HelloWorld HTTP/1.1Host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: length
Trong phần <soap12:Body> của đoạn SOAP request trên, thẻ <HelloWorld xmlns=”http://tempuri.org/” /> được dùng để các phần tử con tương ứng với các dữ liệu mà phương thức HelloWorld yêu cầu để làm tham số. Bởi vì phương thức HelloWorld không yêu cầu bất kì tham số nào, nên thẻ này cũng không có bất kì phần tử con nào.
Xem ngay tin việc làm .NET tại các doanh nghiệp hàng đầu trên TopDev
Tạo một ASP.NET Web Service đơn giản
Trong .Net, bạn tạo ra một Web Service ra bằng cách tạo một subclass của lớp System.Web.Services.WebService, sau đó định nghĩa các phương thức có thể được triệu gọi từ client. Các phương thức này phải được đánh dấu với attribute [WebMethod].
Khi tạo một dự án mới, nếu bạn đặt phiên bản .Net sử dụng là 4, template Web Service sẽ không tồn tại do Microsoft nghĩ rằng template đó quá đơn giản. Vì vậy muốn tạo một project Web Service, bạn phải chuyển phiên bản .Net sang 3.5 . Ở đây tôi vẫn sử dụng phiên bản .Net 4 và tạo một project ASP.NET Empty Web Application với tên là Y2FirstWebService.
Tiếp đó bạn thêm item Web Service (phím tắt Ctrl + Shift + A để mở cửa sổ Add New Item) với tên là HelloService.asmx.
File code-behind HelloService.asmx.cs khi được tạo ra đã chứa sẵn phương thức HelloWorld().
Bạn có thể nhấn F5 chạy thử, trình duyệt sẽ mở ra và hiển thị đường link với nội dung HelloWorld. Đây chính là tên của phương thức của lớp HelloService trên. Nhấn vào link này, bạn được đưa đến một trang dùng để test phương thức HelloWorld.
Note: Bạn có thể xem nội dung WSDL được tạo ra để mô tả cho Web Service này bằng cách bằng cách nhấn vào link Service Description với địa chỉ có dạng (chạy trên localhost, port của bạn có thể khác): http://localhost:1107/MathService.asmx?WSDL.
Bên dưới bạn có thể thấy thông điệp SOAP request và response sẽ được sử dụng để giao tiếp giữa client với Web Service.
Nhấn nút Invoke, trình duyệt sẽ mở ra một trang mới với nội dung theo định dạng XML, kết quả thực sự trả về của phương thức là nội dung nằm trong thẻ <string>:
Bây giờ ta thêm một phương thức mới với tên Hello, đồng thời tạo thêm class Person để làm kiểu trả về cho phương thức Hello() này.
HelloService.asmx.cs (v2):
Chạy lại Web Service và kiểm tra phương thức Hello(), giao diện trang web sẽ thay đổi cho phép bạn nhập tham số vào:
Nhập tên vào textbox và nhấn Invoke, trình duyệt sẽ mở ra trang kết quả:
Như bạn thấy dữ liệu trả về của phương thức Hello là một đối tượng kiểu Person có hai property Name và Age. Đối tượng này sẽ được mã hóa thành XML thành nội dung mà bạn thấy ở trên với tên các thẻ khớp với tên class, property mà ta khai báo.
Vậy là bạn đã tạo được một Web Service, và như bạn có thể thấy, công việc thật đơn giản. Tuy nhiên bạn vẫn chưa biết cách áp dụng Web Service vào một vấn đề cụ thể, cũng như chưa biết cách sử dụng Web Service như thế nào. Nếu bạn quan tâm đến đề tài này, vui lòng đón xem các phần sau. Tôi sẽ trình bày chi tiết hơn về Web Service cũng như cách tạo các ứng dụng client để truy xuất Web Service.
Cũng giống như trong lập trình Python, chúng ta có PyUnit để viết các đoạn mã thực thi việc kiểm thử đơn vị (unit test); trong lập trình .Net, chúng ta có NUnit và MSTest, 2 công nghệ để tự động hóa việc kiểm thử đơn vị. MSTest là một testing framework được phát triển bởi đội ngũ Visual Studio của MicroSort, và được cài đặt chung với phiên bản Ultimate của Visual Studio. Tất nhiên, phiên bản này là phiên bản thương mại, và chúng ta phải mua bản quyền để sử dụng. Ngược lại, NUnit là một testing framework mã nguồn mở được phát triển bởi một nhóm lập trình viên (Charlie Poole, Rob Prouse and Simone Busoli), tương tác trực tiếp với Visual Studio, đồng thời có thể chạy độc lập mà không phụ thuộc vào Visual Studio.
Download chương trình cài đặt NUnit tại đây và cài đặt NUnit theo hướng dẫn như cài một ứng dụng bình thường, các bạn có thể xem clip dưới đây.
Các từ khóa cơ bản sử dụng trong khi viết kiểm thử tự động với NUnit
Thuộc tính trong NUnit để xác định lớp kiểm thử (test class), phương thức kiểm thử (test method), điều khiện đầu vào (pre-condition) và kết thúc (post-condition).
TestFixture: Được sử dụng ở đầu mỗi lớp, xác định lớp đó là một lớp kiểm thử.
Test: Được sử dụng ở đầu mỗi phương thức bên trong một lớp TestFixture, xác định đó là một phương thức kiểm thử.
SetUp: Được sử dụng ở đầu một phương thức bên trong một lớp TestFixture, xác định đó là một phương thức điều kiện đầu vào cho từng phương thức Test. Có thể có hoặc không trong một lớp TestFixture, và chỉ nên được khai báo một lần duy nhất trong một lớp TestFixture.
Teardown: Được sử dụng ở đầu một phương thức bên trong một lớp TestFixture, xác định đó là một phương thức điều kiện kết thúc cho từng phương thức Test. Có thể có hoặc không trong một lớp TestFixture, và chỉ nên được khai báo một lần duy nhất trong một lớp TestFixture.
SetUpFixture: Được sử dụng ở đầu một lớp, xác định một lớp kiểm thử cơ bản. Trong lớp này sẽ có điều kiện bắt đầu và điều kiện kết thúc cho toàn bộ các lớp TestFixture trong một không gian tên (namespace). Có thể có hoặc không trong một không gian tên, nhưng chỉ được khai báo một lần duy nhất.
TestFixtureSetUp: Được sử dụng ở đầu một phương thức bên trong một lớp TestFixture, xác định đó là một phương thức điều kiện bắt đầu cho từng lớp TestFixture. Có thể có hoặc không trong một lớp TestFixture, và chỉ được khai báo một lần duy nhất.
TestFixtureTearDown: Được sử dụng ở đầu một phương thức bên trong một lớp TestFixture, xác định đó là một phương thức điều kiện kết thúc cho từng lớp TestFixture. Có thể có hoặc không trong một lớp TestFixture, và chỉ được khai báo một lần duy nhất.
Trong bài tới, mình sẽ giải thích thêm về các từ khóa khác trong NUnit.
[adToAppearHere]
Thực thi các phương thức kiểm thử
Sau khi viết các đoạn mã kiểm thử, chúng ta không thể chạy trực tiếp các đoạn mã này trên Visual Studio mà phải chuyển nó thành ngôn ngữ máy, và thực thi trên ứng dụng NUnit hoặc Visual Studio (từ VS2013 trở lên).
Các bạn có thể download mã nguồn Visual Studio của đoạn mã trên ở đây (hướng dẫn download tu Tusfile).
Cách Tạo CV Xin Việc Trên Điện Thoại Bằng TopDevCV
Nếu đã từng mất rất nhiều thời gian để tham khảo và tạo được một chiếc CV hoàn chỉnh trên máy tính, chắc chắn bạn sẽ cảm thấy khá bất tiện. Hiện nay, app TopDev đã hỗ trợ tính năng tạo CV ngay trên chính chiếc điện thoại của bạn. Vừa nhanh gọn vừa cập nhật đầy đủ thông tin, lại cho ra một chiếc CV hoàn chỉnh nhất.
Một trong những đặc điểm nổi bật của CV được tạo trên app TopDev là thiết kế của CV được thiết kế theo chuẩn dành cho các devs với một cấu trúc thống nhất. Các nhà tuyển dụng sẽ dễ dàng hơn trong việc thu thập thông tin bạn cung cấp trong CV và có được đánh giá phù hợp.
Hơn nữa, các mẫu CV của TopDev đã được sàng lọc và lựa chọn kỹ càng từ CV của các lập trình viên nổi tiếng trên khắp thế giới, đảm bảo giúp bạn cung cấp đúng những gì cần thiết và quan trọng cho vị trí công việc của mình. Với app TopDev, CV của bạn sẽ được đồng bộ với tất cả các thiết bị chỉ trong một tài khoản, nhờ thế bạn sẽ dễ dàng theo dõi hồ sơ của mình ở bất cứ đâu, bất cứ thiết bị nào.
Vậy cách tạo CV xin việc trên điện thoại bằng app TopDev được thực hiện như thế nào?
Hướng dẫn chi tiết cách tạo CV xin việc trên điện thoại bằng app TopDev:
Bước 1: Mở ứng dụng TopDev trên điện thoại > TopDevCV
Bước 2: Chọn Upload/Create new CV > Create new CV
Bước 3: Điền tên CV và chọn ngôn ngữ bạn muốn dùng trong quá trình tạo CV > chọn Start Making CV
Bước 4: Bạn nên đọc qua hướng dẫn được đính kèm trong app để biết cách tạo nội dung CV chất lượng nhất.
Người dùng cần điền các trường thông tin bắt buộc cần có trong CV gồm:
Profile information
Summary introduction
Working experience
Technical skill
Education
Các trường thông tin bắt buộc sẽ xuất hiện với thứ tự cố định trong CV của bạn và không thể sắp xếp lại.
Ngoài ra, còn có mục thông tin bổ sung – Additional Information, người dùng có thể lựa chọn điền các thông tin này hoặc không. Những thông tin nào bạn muốn thể hiện trong CV thì có thể điền và ngược lại. Bạn cũng có thể thay đổi thứ tự các trường thông tin này tùy theo nhu cầu của mình.
Bước 5: Sau khi hoàn thành việc điền thông tin và Save > chọn Preview để xem lại toàn bộ thông tin mình đã điền.
Bước 6: Chọn định dạng hiển thị CV mong muốn. TopDevCV hiện tại cung cấp 5 templates khác nhau để người dùng lựa chọn.
Sau khi chọn template ưng ý > chọn Chosen > Download/View PDF.
Hoàn thành.
Sau khi đã hoàn thành việc tạo CV, toàn bộ lịch sử chỉnh sửa sẽ được lưu và sử dụng cho lần sau. Nếu bạn muốn bổ sung thông tin hoặc thay đổi những thông tin khác trên CV, chỉ việc quay lại và chọn Edit để thay đổi.
Đơn giản, nhanh chóng và cung cấp đầy đủ thông tin, là những tiêu chí mà TopDevCV hướng đến. Hãy thử trải nghiệm sản phẩm mới này và có cho mình chiếc ưng ý nhất với vai trò là một lập trình viên nhé!
Các bài giới thiệu về Rust thì nhiều quá rồi nhưng chưa thấy bài nào nói về việc sử dụng Rust hết, nên hôm nay mình sẽ bắt đầu viết một vài bài áp dụng Rust để implement một số thuật toán cơ bản, mở đầu sẽ là: Thuật toán duyệt cây nhị phân với Rust.
Sao? Không thích thuật toán à? Từ từ, đừng bỏ đi vội, mặc dù đề bài có vẻ khô khan nhưng qua bài viết này các bạn sẽ học được kha khá kiến thức quan trọng trong Rust:
Làm việc với struct
Sử dụng kiểu Option<>
Sử dụng kiểu Box<>
Khai báo biến trong Heap và Stack
Sử dụng các attribute để tùy biến Rust compiler
Sử dụng pattern matching
Làm việc với macro
Khai báo method dùng impl
Thao tác cơ bản với String
Và quan trọng nhất là cách sử dụng các thông báo lỗi của Rust compiler để tìm manh mối giải quyết vấn đề một cách hiệu quả.
Nói sơ qua một chút kiến thức cơ bản, cây nhị phân (binary tree) là một loại cấu trúc dữ liệu dạng cây (tree), mỗi một node có từ một đến hai node con.
Các tên gọi quy ước trong một node của cây nhị phân:
Root: là node hiện tại đang xét.
Left: là node con bên trái của node đang xét.
Right: là node con bên phải của node đang xét.
Duyệt cây nhị phân (binary tree traversal) là một trong các thuật toán cơ bản khi làm việc với kiểu dữ liệu này. Có 2 cách để duyệt một cây nhị phân đó là duyệt sâu (depth first traversal) và duyệt rộng (breadth first traversal).
Đối với cách duyệt sâu, chúng ta có 3 phương pháp khác nhau, phân loại dựa theo thứ tự thăm (visit) các node con của cây:
In-order: Duyệt theo thứ tự Left -> Root -> Right. Ví dụ cây ở hình trên, thứ tự duyệt sẽ là: 2, 7, 5, 6, 11, 1, 8, 4, 9.
Pre-order: Duyệt theo thứ tự Root -> Left -> Right. Ví dụ ở cây trên, thứ tự duyệt là: 1, 7, 2, 6, 5, 11, 8, 9, 4.
Post-order: Duyệt theo thứ tự Left -> Right -> Root. Ví dụ ở cây trên, thứ tự duyệt là: 2, 5, 11, 6, 7, 4, 9, 8, 1.
Duyệt rộng thì chúng ta sẽ đi từng level của cây, và duyệt hết tất cả các node ở từng level. Ví dụ cây trên thứ tự duyệt sẽ là: 1, 7, 8, 2, 6, 9, 5, 11, 4.
Implementation
Chúng ta sẽ implement kiểu dữ liệu binary tree trong Rust, sau đó sẽ implement thuật toán duyệt cây cho kiểu dữ liệu này.
Trong quá trình implement, mình sẽ chỉ ra một số lỗi mà người mới học Rust thường gặp phải, và Rust compiler sẽ giúp chúng ta nhận ra và giải quyết các lỗi đó rất hiệu quả.
Còn bây giờ thì chúng ta bắt đầu thôi.
Khởi tạo dự án
Vì đây là một chương trình nhỏ, chúng ta không nhất thiết phải sử dụng cargo để tạo project mới, mà có thể tạo trực tiếp file *.rs và biên dịch nó bằng rustc.
Ở đây mình sẽ đặt tên source file của chúng ta là binary_tree.rs nằm trong thư mục ~/code/playground/.
$ mkdir -p ~/code/playground$ cd ~/code/playground$ touch binary_tree.rs
Chúng ta có thể chạy thử một chương trình nhỏ, ví dụ gõ vào file binary_tree.rs nội dung sau:
Bạn có thể viết 2 lệnh này vào một makefile và chạy bằng lệnh make. Hoặc nếu xài vim, bạn có thể sử dụng plugin vim-quickrun (do mình viết, shameless PR :v) để chạy nhanh bằng tổ hợp phím <Leader>e.
Xong rồi, giờ zô code thiệt nè.
Khai báo cấu trúc dữ liệu của một node
Thông thường khi implement kiểu tree, chúng ta sẽ bắt đầu implement từ một node của tree đó.
Theo như định nghĩa ở trên, một node mà chúng ta implement sẽ có các trường (fields) sau:
Value: Giá trị của node này, ở đây chúng ta dùng kiểu i32 (số nguyên)
Left: Reference tới node bên trái, giá trị này có thể rỗng (optional)
Right: Reference tới node bên phải, giá trị này cũng có thể rỗng (optional)
Vậy chúng ta sẽ khai báo một struct mới, gồm có 3 fields như trên:
Ở đây i32 là kiểu dữ liệu số nguyên, tương tự như int ở mấy ngôn ngữ khác vậy. Option tức là kiểu optional, nghĩa là nó có thể có giá trị tham chiếu tới đâu đó, hoặc có thể không có. Compile thử xem nào:
$ rustc binary_tree.rs -o binary_treeerror[E0072]: recursive type `Node` has infinite size --> walkthrough_binary_tree.rs:1:1 |1 | struct Node { | ^ recursive type has infinite size | = help: insert indirection (e.g., a `Box`, `Rc`, or `&`) at some point to make `Node` representableerror: aborting due to previous error
É, lỗi rồi. Lỗi ngay từ shot đầu tiên luôn :)) để xem lỗi gì nào.
Vấn đề recursive type trong Rust
Nội dung thông báo lỗi nó ghi là: recursive type Node has infinite size, tức là: Node là kiểu dữ liệu đệ quy (vì chúng ta tham chiếu tới Node bên trong chính nó), nên Rust không xác định được kích thước của nó — quá bự, vô hạn. Tại sao vậy? OK, dừng lại để nói về vấn đề này một chút nhé.
Cũng giống như C/C++, kích thước của một struct sẽ được xác định bằng tổng số kích thước các field bên trong nó. Lấy ví dụ đơn giản, nếu ta có một struct như sau:
struct Point { x: i32, y: u8}
Thì kích thước của Point sẽ bằng kích thước của x (kiểu i32, có 4 bytes) cộng với kích thước của biến y (kiểu u8 có 1 byte), là 5 bytes cả thảy.
Quay trở lại với Node struct của chúng ta, kiểu i32 có 4 bytes, kiểu Option có 1 byte, kích thước của Node sẽ được tính bằng công thức:
Compile lại thì sẽ thấy lỗi đó đã hết, ngon lành! Có một cái warning xuất hiện, nhưng bây giờ chúng ta chưa cần nói tới nó, để nói tiếp về vụ Box cái đã.
Tại sao dùng Box<> lại giải quyết được vấn đề recursive struct? Đầu tiên cần hiểu Box<> là gì.
Trong Rust, mặc định mọi giá trị đều được khai báo trong stack[3], chúng ta sử dụng Box<T> khi cần khai báo một biến kiểu T trong heap. Một box thực chất là một smart pointer trỏ tới một giá trị đã được tạo ra trong heap.
Trong trường hợp này, chúng ta đặt Node vào trong Box<> để khai báo dạng Box<Node>, thì thực chất chúng ta đang khai báo một pointer trỏ tới một vùng nhớ kiểu Node trong heap, vậy nên bên trong Node struct của chúng ta lúc này, kích thước của left và right thực chất là kích thước của pointer Box<Node>, và pointer này có kiểu Option.
Trên StackOverflow cũng có một câu hỏi được trả lời khá kĩ về vấn đề Box trong recursive struct, các bạn có thể tham khảo tại đây.
Dead code warning khi compile
Okay, bây giờ quay về lại với cái warning mà rustc đưa ra lúc nãy nhé. Nội dung warning như sau:
warning: struct is never used: `Node`, #[warn(dead_code)] on by default --> walkthrough_binary_tree.rs:1:1 |1 | struct Node { | ^
rustc nói cho chúng ta biết là cái Node struct mà chúng ta tạo ra chưa bao giờ được sử dụng cả. Và thông báo này được đưa ra vì attribute #[warn(dead_code)] được bật sẵn khi biên dịch.
Điều này rất có ích để viết code đẹp, code chuẩn, có thể hạn chế được lượng mỡ thừa không cần thiết… à nhầm, code thừa.
Tuy nhiên vì chúng ta đang học, cho nên có thể tạm tắt thông báo này đi bằng cách thêm attribute #[allow(dead_code)] ở trước phần khai báo struct để báo cho compiler biết rằng dead_code là người quen biết, và việc cho anh ấy đi qua khỏi khâu kiểm duyệt là đúng quy trình, không cần phải lo gì cả:
Vậy là chúng ta đã khai báo thành công thành phần cơ bản nhất của một binary tree, giờ chúng ta thử dùng kiểu Node này để tạo ra một binary tree xem sao nhé.
Lấy ví dụ với cây sau:
Chúng ta sẽ đi từng bước, tạo từng node một. Đầu tiên là root node của cây trên, khai báo một biến tree, kiểu Node, có 2 nhánh left và right đều là None.
#[allow(unused_variables)]fn main() { let tree = Node { value: 1, left: None, right: None };}
Đây là trạng thái cây của chúng ta lúc này:
Chúng ta cũng chèn thêm vào attribute #[allow(unused_variables)] để rust compiler không warning vì chúng ta chưa cần sử dụng biến tree này.
Giá trị của một biến Option và Box
Vậy là chúng ta đã tạo được một node đầu tiên của cây, có giá trị là 1 và 2 node con chưa có gì cả. Giờ mình sẽ giải thích tại sao lại xuất hiện giá trị None, và phải làm gì nếu muốn gán left hoặc right thành một node khác.
Một biến kiểu Option có thể mang giá trị Some(T) (trả về giá trị của T) hoặc mang giá trị None (không trả về gì cả).
Vậy để gán một giá trị không None vào cho một biến Option, chúng ta dùng lệnh Some(...), ví dụ:
let optional: Option<T> = Some(T);
Tiếp, đối với kiểu Box<T>, chúng ta có method Box::new(...) để khởi tạo giá trị cho nó, ví dụ:
let value: Box<i32> = Box::new(5);
Kết hợp 2 cú pháp trên lại, đối với kiểu Option<Box<Node>> của các node left và right, chúng ta sẽ có cách khai báo như sau:
...left: Some(Box::new(Node { ... })),...
Giờ thử chèn tiếp 2 node số 7 và 8 vào cây trên nào:
Hẳn là bạn cũng cảm thấy khó chịu với câu lệnh dài dòng Some(Box::new(Node { ... })) cứ lặp đi lặp lại liên tục ở trong code.
Rust cho phép chúng ta tạo ra các macro để rút gọn các thao tác dài dòng, lặp đi lặp lại. Bạn có thể coi macro tương tự như #define của C/C++ nhưng lợi hại hơn rất nhiều. [4]
Thực ra ngay từ đầu chúng ta đã dùng macro rồi, đó chính là lệnh println!, lệnh này cũng là một macro, bạn có thể tham khảo source của Rust để xem nó được khai báo thế nào.
Sẽ rất dài dòng nếu nói chi tiết về macro ở đây, nên bạn có thể tham khảo thêm tài liệu của Rust nhé.
Chúng ta sẽ tạo ra một macro để rút gọn thao tác tạo optional Node ở trên:
Giờ chúng ta đã có một cây nhị phân hoàn chỉnh đúng với yêu cầu ban đầu.
Duyệt cây
Giờ chúng ta sẽ implement thuật toán duyệt cây, vì bài viết cũng khá dài rồi nên mình sẽ chỉ trình bày một loại của thuật toán duyệt DFS, cụ thể là In-order.
Nhắc lại lý thuyết: chúng ta sẽ duyệt theo thứ tự Left -> Root -> Right.
Ý tưởng để implement thuật toán này là tạo ra một hàm trả về một chuỗi, chuỗi này lưu lại quá trình duyệt từ Node hiện tại đến các node con bên trong nó theo thứ tự của In-order.
Tạo methods với impl
Như vậy là chúng ta cần tạo ra một method cho kiểu dữ liệu Node, trong Rust chúng ta có thể sử dụng từ khóa impl để định nghĩa ra các method cho một kiểu. [5]
impl Node { fn traversal(&self) -> String { let mut output = String::new(); // Implement here return output; }}
Bằng cách sử dụng impl, chúng ta đã khai báo một hàm traversal() cho kiểu Node, hàm này không nhận tham số nào cả, đối vối tham số &self trong lệnh khai báo, chúng ta có thể xem nó như là từ khóa this trong các ngôn ngữ như JavaScript để xác định context của hàm hiện tại. Bạn có thể đọc thêm tài liệu về vấn đề này ở phần cuối.
Sử dụng matching để kiểm tra Node rỗng
Giải pháp của chúng ta khá là đơn giản, duyệt từng node và trả về giá trị của node đó nếu có, cộng dồn lại và trả về 1 string để in ra.
Vậy thì việc tiếp theo phải làm đó là kiểm tra xem các node con có tồn tại hay không. Nhớ lại ở trên có đề cập, một biến kiểu Option luôn trả về một trong 2 giá trị Some(...) hoặc None, vậy để kiểm tra ta có thể dùng match, cú pháp của match cũng na ná giống như switch ở các ngôn ngữ khác nên chắc không cần giải thích nhiều [6]:
Chắc không cần giải thích các bạn cũng sẽ hiểu là việc tiếp theo chúng ta có thể sử dụng được biến node ở trong scope của trường hợp Some(...) để tương tác với node hiện tại rồi đúng không nào? Còn trường hợp None, mặc dù không làm gì cả nhưng chúng ta vẫn phải handle nó, nếu không sẽ gặp lỗi khi compile như thế này:
error[E0004]: non-exhaustive patterns: `None` not covered --> binary_tree.rs:21:15 |21 | match self.left { | ^^^^^^^^^ pattern `None` not coverederror: aborting due to previous error
Thông báo lỗi nói rằng: Trường hợp None chưa được cover. Đây cũng là một ví dụ cho thấy sự khắt khe của Rust để đảm bảo không lọt bất kì trường hợp khả nghi nào có khả năng trở thành bug trong lúc runtime cả.
Đối với giá trị của một node, là kiểu i32, chúng ta có thể chuyển về kiểu String bằng lệnh .to_string(), và để thực hiện việc cộng chuỗi, ta cần đưa nó về kiểu &str, vậy cần thêm vào lệnh .as_str(), như vậy ta có đoạn code implement đầy đủ của hàm traversal() như sau:
Vậy là chúng ta đã implement thành công một thuật toán đơn giản trong Rust. Và học được khá là nhiều thứ trong quá trình implement.
Các bạn có thể thử thay đổi chương trình trên để implement tiếp các kiểu Pre-order, Post-order hoặc suy nghĩ để implement thuật toán duyệt BFS xem nhé.
Vì bài viết có mục đích dẫn các bạn đi từng bước để ứng dụng Rust vào giải quyết các vấn đề thường gặp, nên thuật toán đưa ra trong bài không phải là giải pháp tối ưu cho bài toán duyệt cây nhị phân, ở phần tiếp theo chúng ta sẽ bàn về các kĩ thuật tối ưu thuật toán này.
Và đừng quên đọc thêm các link tham khảo mình tổng hợp lại ở bên dưới. Hy vọng qua bài viết khá dài này, các bạn cũng làm quen được các điểm đặc biệt trong Rust so với các ngôn ngữ khác, và có thể tiếp tục tìm hiểu thêm về ngôn ngữ thú vị này.
5 BƯỚC CƠ BẢN HÌNH THÀNH NÊN MỘT CHƯƠNG TRÌNH ĐÀO TẠO HIỆU QUẢ TRONG DOANH NGHIỆP
Bài viết được sự cho phép của tác giả Ánh Nguyệt
Chào buổi sáng thứ bẩy đẹp trời tại Thái Bình
Mình đang ngồi trong một lớp học về kỹ năng tuyển dụng cho các bạn phòng nhân sự của một nhà máy may, đứng lớp là hai tiền bối đầy mình kinh nghiệm và ngập tràn nhiệt huyết. Chắc chắn lớp học ngày hôm nay sẽ rất vui và hiệu quả.
Đang ngồi giữa những âm thanh thảo luận nhóm sôi nổi, mình nghe 1 cuộc điện thoại từ một hậu bối hỏi về quy trình xây dựng chương trình đào tạo đội ngũ kế cận của doanh nghiệp
Để có được một chương trình đào tạo phù hợp, dù là ở bất cứ vị trí nào, bạn cũng nên làm các bước sau:
Bước 1: Xác định tiêu chuẩn/Yêu cầu về KSAO của vị trí (Knowledge, Skills, Attitude, Others) nói nôm na là tìm thước đo
Nếu chuẩn chỉnh thì bạn lấy từ frame khung năng lực của công ty, trong khung năng lực đó sẽ có khung năng lực của từng vị trí. Đó chính là tiêu chuẩn
Còn nếu công ty chưa làm từ điển năng lực, chưa có khung năng lực thì cách làm rất đơn giản là bạn đi hỏi chính những người đã ở vị trí đó, những người là sếp/là nhân viên của vị trí đó để hỏi xem để làm được vị trí đó thì cần những KSAO cụ thể nào
Sau khi hỏi xong, bạn sẽ ra một list các danh sách KSAO của vị trí theo quan điểm và kinh nghiệm của những người liên quan, bạn chuẩn hóa lại, và có thể hỏi tham vấn/so sánh với các vị trí tương tự ở các công ty cùng ngành hoặc các vị trí cùng level trên thị trường => bạn ra được 1 bản KSAO tạm gọi là ok cho vị trí đó (có thể gửi confirm lại với những người bạn đã phỏng vấn)
Cùng đưa ra tất cả các vị trí để xác định các KSAO chung của đội ngũ quản lý, những KSAO đặc thù của từng vị trí sẽ được liệt kê riêng
Bước 2: Tìm khoảng trống của người kế cận so với vị trí, bao gồm KSAO chung và KSAO đặc thù
Cách thức tiến hành: Phỏng vấn 360 dựa trên các KSAO – có thể dùng bảng trên google form
Sau khi có kết quả, bạn sẽ thấy các khoảng trống về KSAO của ứng viên cho vị trí so với tiêu chuẩn
Đó chính là căn cứ lên kế hoạch/chương trình đào tạo
Bước 3: Lên kế hoạch/Chương trình đào tạo
Bước này rất thú vị
Cách làm nhanh là lấy KSAO chung, tìm khoảng trống chung của các ứng viên tiềm năng và lên chương trình đào tạo chung.
Còn nếu làm HR đến level cao nhất hiện nay là quan tâm đến từng cá nhân thì mình sẽ ra được kế hoạch riêng cho từng cá nhân có sự thống nhất với cá nhân đó và sếp của cá nhân đó (hiện tại gọi là IDP – Individual Development Plan).
Trong chương trình đào tạo này cũng có nhiều thứ rất thú vị
Có những môn sẽ học chung vì theo KSAO chung, và có những môn phải học riêng theo KSAO đặc thù
Cách thức học có thể là đào tạo inhouse, bên ngoài, tự học, on-job-training …
Người dạy học cũng không kém phần quan trọng, giảng viên nội bộ, giảng viên bên ngoài, học qua các dự án cần phối hợp …
Và cần có lộ trình học tập trong thời gian nhất định
Khi bạn thảo luận và thống nhất được IDP với từng cá nhân, bạn sẽ rất rõ mục tiêu của cá nhân đó, và sẽ hiểu rõ hơn những lý do của từng cá nhân khi họ học. Với các cá nhân, họ cũng hiểu rõ hơn bản thân mình, và chủ động hơn trong quá trình học tập.
Bước 4: Triển khai đào tạo
Trong chương trình đào tạo tại doanh nghiệp, để hiệu quả tốt, theo kinh nghiệm triển khai mình thấy, nên có các bài kiểm tra, check, các kế hoạch hành động, các bá cáo review, các báo cáo kết quả … rất quan trọng. Vì thói quen học tập của người Việt là cứ có kiểm tra mới học hành nghiêm túc.
Và nên có một cuộc thi đua trong quá trình học tập, nên có những bảo vệ tốt nghiệp, nên có những khen thưởng kịp thời …
Những thứ nhỏ xinh làm cho lớp học hấp dẫn hơn thì việc để tâm vào các triển khai và hiểu sở thích cũng như khơi gợi được học viên dám thể hiện bản thân và chủ động khai thác thông tin từ giảng viên, chủ động đưa ra vấn đề của bản thân để cả lớp cùng giải đáp rất quan trọng – hãy là những người triển khai đào tạo có tâm
Bước 5: follow up và đánh giá hiệu quả đào tạo
Có thể định kỳ 6 tháng hoặc 1 năm sau chương trình đào tạo bạn lại thực hiện khảo sát 360 để xem khoảng trống khi trước có được rút ngắn không
Bạn cũng có thể tham khảo các thành tích, so sánh chức danh, …
Các đối tượng khác cũng theo trình tự như vậy, để hiệu quả đào tạo phát huy hết tác dụng thì việc kiểm tra thường xuyên và followup rất quan trọng
Những công cụ chi tiết để thực hiện các bạn có thể tự tìm hiểu thêm, hoặc chúng ta cùng giao lưu để chia sẻ ^^
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Như ở bài trước mình có nói, trong Selenium IDE cũng có một số các mở rộng (extensions) để hỗ trợ người dùng. Bài này, mình sẽ giới thiệu với các bạn một extensions khá mạnh mẽ trong việc điều hướng luồng thực thi của mã kiểm thử trên Selenium IDE – Selenium IDE Flow Control.
Để cài đặt phần extensions, chúng ta truy cập vào trang chủ của Selenium và download về trình duyện Firefox. Quá trình cài đặt này cũng giống như khi chúng ta cài đặt những add-on khác cho Firefox. Các bạn có thể xem clip dưới đây:
Các câu lệnh trong Selenium IDE Flow Control
Sau khi cài đặt Selenium IDE Flow Control, trong command dropdown list cua Selenium IDE, chúng ta sẽ có 7 câu lệnh mới:
label | mylabel – Tạo ra một nhãn
goto | mylabel – Di chuyển đến một nhãn
gotoLabel | mylabel – Tương tự như câu lệnh “goto”
gotoIf | expression – Đi đến một nhãn nếu thỏa điều kiện
while | expression – Lặp một đoạn mã với điều kiện
endWhile – Kết thúc một vòng lặp
push | value | arrayName – Điền một giá trị vào bên trong một mảng
Sử dụng các câu lệnh Flow Control
Mình ví dụ một kịch bản kiểm thử như sau:
Truy cập trang web Google
Tìm kiếm với từ khóa Selenium
Nhấp vào đường dẫn đến trang chủ của Selenium
Nếu tiêu đề của trình duyệt hiện tại không phải là Downloads thì nhấn nút Download Selenium
Tập tin cho kịch bản kiểm thử này, các bạn có thề download ở đây.
Nhược điểm của giải pháp trên rất rõ ràng, đó là thời gian tính toán. Đối với mỗi lần tính toán, hàm fibo phải thực hiện tính toán lại từ đầu (từ n = 0) đến n. Trong quá trình đó một giá trị fibo(n) sẽ bị tính đi tính lại liên tục, một sự lãng phí không hề nhỏ.
Thời gian chạy của thuật toán trên cho kết quả fibo(50):
// fibo(50);➜ time node fibo.js193.97s user 0.56s system 99% cpu 3:15.24 total
Và như ta đã nhận thấy, thì phần lớn thời gian tiêu tốn vào việc tính đi tính lại các giá trị trùng lặp, vậy để cải thiện, ta cần tìm một cách nào đó để lưu lại giá trị của từng phép tính fibo(n), và tránh việc tính lại từ đầu mỗi khi chạy. Cách này gọi là caching.
Vì đối với mỗi số n bất kì, ta luôn luôn chỉ có duy nhất một giá trị sau khi tính toán với hàm fibo(n). Vậy nên ta có thể tạo ra một mảng tên là cache để lưu lại các giá trị fibo(n) đã tính toán, ở lần chạy tiếp theo, chỉ việc lấy nó ra và sử dụng, không cần phải tính lại.
Kết quả thời gian chạy fibo(50) được cải thiện đáng kể:
// fibo(50);➜ time node fibo.js0.05s user 0.02s system 98% cpu 0.072 total
Memoize
Ví dụ trên cho chúng ta thấy được tầm quan trọng của việc cache trong việc cải thiện tốc độ xử lý của một ứng dụng.
Tuy nhiên, cứ phải tạo một biến toàn cục cache một cách thủ công như vậy không phải là một giải pháp hay, chưa kể đến việc cần cache nhiều thứ trong một ứng dụng, chúng ta cần một phương pháp tổng quát hơn, và hiệu quả hơn. Đó là memoize.
Memoize khác với các kĩ thuật cache thông thường ở chỗ: Nó được dùng để cache giá trị trả về của một hàm, và cache được tạo ra dựa trên tham số của hàm đó.
Sau đây là một cách implement đơn giản cho hàm memoize:
const memoize = (func) => { let cache = {}; let that = this; return (...args) => { let key = JSON.stringify(args); if(cache[key]) { return cache[key]; } else { let val = func.apply(that, args); cache[key] = val; return val; } }};
Hàm memozie nhận vào tham số là một hàm, tạo cache dựa trên các tham số truyền vào của hàm đó. Khi được gọi thì nó sẽ trả về giá trị được cache nếu có, nếu chưa có giá trị cache thì chạy chính hàm được truyền vào và lưu lại giá trị trả về.
Cực kì đơn giản đúng không? Giờ chúng ta thử implement lại hàm fibo ở đầu bài dùng memoize:
Phần logic vẫn được giữ nguyên so với cách implement đầu tiên, nhưng vẫn sử dụng được cache, đó là ưu điểm của việc dùng memoize.
Chạy thử hàm memfibo vừa tạo với tham số n = 100 luôn coi sao:
// memfibo(100);➜ time node fibo.js0.06s user 0.02s system 97% cpu 0.077 total
Quá xịn 😀
Các implement khác của memoize
Trong thực tế, có thể bạn sẽ không đủ tự tin để sử dụng hàm memoize do chính mình implement, hoặc team/sếp không tin tưỏng bạn, ok, không sao, mặc dù bị tổn thưong nhưng không nên vì thế mà nản.
Chúng ta có thể sử dụng một vài implement khác như:
Nguyên nhân của lỗi trên là vì: hàm reduce trả về một mảng mới mỗi lần bạn chạy filter evenNumbers, khiến cho Angular “hiểu lầm” kết quả trả về đã đưọc thay đổi và nó phải chạy một digest cycle mới để kiểm tra, và việc chạy này xảy ra liên tục.
Khi gặp những trưòng hợp như vậy, bản chỉ cần đặt hàm filter vào bên trong memoize để cache lại giá trị trả về là xong:
Có một trưòng hợp mà dù có sử dụng memoize thì cũng vô dụng, đó là khi dữ liệu trả về của một hàm nó thay đổi không phụ thuộc vào tham số truyền vào của hàm đó. Ví dụ dữ liệu tracking dạng time series, hay giá chứng khoán, hay danh sách status trên tưòng nhà đứa bạn thích trên Facebook chẳn hạn.
Và thêm nữa, vì memoize cũng là caching, tức là dữ liệu tính toán xong được lưu lại và nằm đó luôn, không mất đi đâu cả, cho nên bạn phải nghĩ tới vấn đề khi app chạy trong một khoản thời gian dài, thì dung lưọng bộ nhớ cũng vì thế mà tăng lên. Cho nên cần phải giải phóng bộ nhớ cache của hàm memoize sau một khoản thời gian nhất định, nếu không sẽ dẫn tới tràn bộ nhớ hoặc memleak.
Vì sử dụng memoize tức là bạn đang đánh đổi memory để lấy tốc độ, chứ không có cái gì là free cả, nên nếu biết chừng mực và dùng đúng lúc đúng chỗ thì sẽ đem lại hiệu quả cao, còn ngược lại, lạm dụng quá mức thì hậu quả sẽ khó lường. Cho nên gì gì thì cũng phải hiểu để xài nhau cho tốt hơn, nhé 😀
Một khái niệm nữa mà những bạn đang tìm hiểu Công việc C&B không thể bỏ qua đó là xây dựng, tính và chi trả lương theo 3P.
Chào mừng các bạn đang đến với series các bài học trong Khoá học C&B cơ bản cho người mới (newbie) hoàn toàn miễn phí. Tôi là Thành HR sẽ đồng hành cùng bạn trong khoá học này. Và chủ đề mà chúng ta cùng nhau tìm hiểu ngày hôm nay là Tìm hiểu hệ thống lương 3P.
Chúng ta đã cùng nhau tìm hiểu về Cách xây dựng thang bảng lương, rồi cũng đã tìm hiểu qua hệ thống lương thưởng trong công ty quy mô nhỏ. Và có một khái niệm nữa mà những bạn đang tìm hiểu Công việc C&B không thể bỏ qua đó là xây dựng, tính và chi trả lương theo 3P.
Bất kỳ doanh nghiệp nào, khi phát triển đến một giai đoạn nào đó thì Ban Lãnh Đạo luôn muốn cải thiện năng suất người lao động, nâng cao hiệu quả làm việc để từ đó gia tăng lợi nhuận cho công ty. Và việc xây dựng được một phương pháp trả lương phù hợp cũng giúp góp phần vào điều này.
Trả lương theo 3P là một mô hình trả lương hiệu quả của Mercer được khá nhiều doanh nghiệp tại Việt Nam áp dụng trong thời gian qua nhờ tính ưu việt của nó. Tuy nhiên, lương 3P có khá nhiều phiên bản và cách áp dụng khác nhau để phù hợp với các mô hình đa dạng của các Doanh nghiệp nhỏ.
3P (3P Compensation) là hình thức trả lương được xây dựng để trả lương theo vị trí, năng lực và hiệu quả công việc của nhân viên nhằm tạo sự công bằng, khuyến khích và tạo động lực giúp mỗi nhân viên phát huy tối đa khả năng của mình trong công việc, đóng góp cho sự phát triển của công ty.
3P là từ viết tắt của 3 từ: Position, Person, Performance. Đây là 3 hạng mục cấu thành nên thu nhập của một Người lao động được nhận. Có thể hiểu nôm na là:
Thu nhập = P1 + P2 + P3.
– P1 (Position) – Pay or position: Trả lương theo vị trí công việc. Doanh nghiệp trả lương hàng tháng cho chức danh đó, bất kể người đảm nhận là ai và có năng lực thế nào. Thông thường các Công ty sẽ căn cứ trên thang bảng lương để trả P1 này.
– P2 (Person) – Pay for Person: Trả lương theo năng lực. Dùng kết quả đánh giá năng lực nhân sự để định ra số tiền tương xứng với năng lực đó. Với các doanh nghiệp đang hoạt động thì phần P2 này có thể được thể hiện trong Quy chế lương thưởng.
– P3 (Performance) – Pay for Performance: Trả lương theo kết quả đạt được. Phần lương này nhân viên có thể được nhận hàng tháng hoặc hàng quý tùy chính sách công ty.
Tính lương chuẩn xác với công cụ tính lương gross to net của TopDev ngay!
Cách xây dựng Hệ thống lương 3P
Trong phần này, chúng ta sẽ cùng tìm hiểu các bước chuẩn để có thể xây dựng một hệ thống lương 3P. Còn thực tế triển khai thì một số công ty chấp nhận thay đổi một chút cho phù hợp với thực tế doanh nghiệp của mình.
Vì không phải Công ty nào cũng đủ điều kiện để thực hiện và áp dụng theo mô hình chuẩn. Chằng hạn như Xây dựng được khung năng lực chuẩn, áp dụng công nghệ để đánh giá hoàn thành công việc…Và mô hình chuẩn ấy chưa chắc đã hoàn toàn phù hợp ngay với văn hóa doanh nghiệp hiện tại.
Nên ở đây, mình sẽ cùng nhau tìm hiểu cách thực hiện cho một doanh nghiệp quy mô nhỏ. Vẫn giữ lại phần lõi, nhưng vẫn đảm bảo phát huy được các điểm mạnh của hệ thống lương 3P này:
Bước 1: Xây dựng P1 (Position) – Pay or position
Phần P1 – Trả lương theo vị trí công việc: Bạn có thể hình dung nó chính là phần lương mà bạn đã xây dựng trong thang bảng lương. Cho nên, nếu Công ty bạn đã xây dựng được thang bảng lương chuẩn thì có thể lấy để áp vào P1. Mình cùng tham khảo lại các bước chuẩn để xây dựng P1 như sau:
– Bắt đầu từ chiến lược kinh doanh của Công ty thể hiện qua Sứ mệnh / Tầm nhìn / Giá trị cốt lõi. Và dựa vào đó để xây dựng cơ cấu tổ chức trên cơ sở chuỗi giá trị của doanh nghiệp.
– Chuẩn hóa hệ thống chức danh, giá trị công việc (Job Evaluation) và mô tả công việc (Job Description) trên cơ sở phân bổ các phòng ban chức năng của doanh nghiệp. Từ đó xác định được cấp bậc lương và dải lương của các vị trí chức danh đảm bảo hài hòa với quỹ lương của Doanh nghiệp và cạnh tranh với thị trường.
Bước 2: Xây dựng P2 (Person) – Pay for Person
Để hiểu rõ phần P2 – Trả lương theo năng lực thì đầu tiên mình cùng nhau tìm hiểu khái niệm năng lực là gì? Các công cụ nào có thể đo lường và dùng để đánh giá năng lực nhân viên?
Năng lực (Competency): được hiểu là kiến thức, kỹ năng, khả năng và hành vi mà người lao động cần phải có để đáp ứng yêu cầu công việc, và là yếu tố giúp một cá nhân làm việc hiệu quả hơn so với những người khác. Tùy vào mỗi doanh nghiệp sẽ xây dựng hệ thống đánh giá năng lực với các tiêu chí phù hợp.
Xây dựng khung năng lực chuẩn: Để làm được việc này thì đầu tiên công ty cần xây dựng được từ điển năng lực, sau đó mới xây dựng khung năng lực cho các vị trí. Cần lưu ý phần năng lực mong đợi và thực tế mà các nhân viên đang có. Khung năng lực này cũng là cơ sở để tuyển dụng nhân sự mới đúng yêu cầu.
Bạn có thể tham khảo Mô hình ASK để xây dựng và đánh giá năng lực nhân viên theo chuẩn quốc tế. ASK là viết tắt của Attitude (Phẩm chất / Thái độ) – Skill (Kỹ năng) – Knowledge (Kiến thức), mỗi một nhóm là những yêu cầu mà doanh nghiệp đặt ra cho cá nhân để hoàn thành xuất sắc vị trí công việc cụ thể.
Những năng lực này được chấm theo 5 mức độ:
Mức độ 5 – Mức độ xuất sắc
Mức độ 4 – Mức độ tốt
Mức độ 3 – Mức độ khá
Mức độ 2 – Mức độ cơ bản
Mức độ 1 – Mức độ kém
Từ những căn cứ trên, Công ty sẽ tiến hành đánh giá năng lực cá nhân theo khung năng lực của từng vị trí, từ đó xác dựng level lương P2 này. Nếu công ty có số lượng nhân sự ít có thể thực hiện việc đánh giá bằng excel, nhưng nếu số lượng nhiều thì phải nghĩ đến việc sử dụng phần mềm.
Bước 3: Xây dựng P3 (Performance) – Pay for Performance
Về phần P3 – Trả lương theo kết quả đạt được này có thể hiểu nôm na như một phần thưởng thêm cho Người lao động khi họ hoàn thành tốt công việc, mang lại giá trị cộng thêm cho doanh nghiệp. Vậy thì rõ ràng, P3 là phần tạo động lực và thúc đẩy nhân viên nâng cao hiệu suất lao động, được đo đếm bằng con số rõ ràng.
Cần xác định rõ ràng ngay từ đầu phần lương P3 này sẽ chi trả hàng tháng hay hàng quý. Nếu trả hàng tháng thì P3 có thể nằm trong khoảng từ bao nhiêu đến bao nhiêu, thậm chí là bằng 0, cần cân nhắc khi cho P3 là một số âm như một số công ty đang áp dụng. Còn nếu trả theo quý thì cũng cần quy định rõ ràng và trả đúng thời hạn.
Để xây dựng được P3 thì phải bắt đầu từ Mục tiêu chiến lược của Công ty, rồi đến mục tiêu phòng ban, mục tiêu cá nhân. Mục tiêu cá nhân này được cụ thể hóa bằng tiêu chí KPI, đánh giá hàng tháng hay hàng quý thì tùy công ty quy định.
Lưu ý khi xây dựng KPI cho cá nhân cần đảm bảo yếu tố đơn giản dễ hiểu, từ 3 – 5 tiêu chí chứ đừng quá nhiều, có thể đo lường kết quả bằng các con số thì mới giúp tạo động lực cho nhân viên cố gắng hoành thành vượt chỉ tiêu. Nếu không nó chỉ mang tính hình thức và Người lao động xem phần lương P3 là phần không thể đạt được và không quan tâm thì mất ý nghĩa của lương 3P.
Một số công ty lấy mức P1 + P2 cũng sẽ là mức đóng các khoản Bảo hiểm bắt buộc cho người lao động (BHXH, BHYT, BHTN…). Vì P3 là phần biến thiên hàng tháng hoặc hàng quý mới được nhận nhân nên có thể không nằm trong khoản bắt buộc đóng. Một số khác thì chỉ đóng cho Người lao động trên mức P1, còn phần P2 họ sẽ chia thành các khoản phụ cấp không nằm trong danh mục đóng.
Một số công ty đang hoạt động khi chuyển đổi sang trả lương theo 3P cần đảm bảo việc xếp lại level lương của nhân viên ở P1 + P2 không nên thấp hơn thu nhập họ đang nhận. Nên lưu ý phần năng lực kỳ vọng và năng lực thực tế khi đánh giá của nhân viên hiện tại. Có thể xử lý bằng cách bổ sung các khóa đào tạo để nâng cao năng lực cho phù hợp.
Nên xem phần lương P3 là phần mà nếu Người lao động đạt hoặc vượt chỉ tiêu mong đợi thì sẽ được nhận. Chứ đừng cắt xén ra từ thu nhập đang có của họ để hình thành phần P3 này, vì như vậy nó chẳng khác gì lấy mỡ nó rán nó. Họ sẽ xem là công ty đang không công bằng và không minh bạch.
Phần lương P3 cần quy định rõ ràng thời gian chi trả, một số công ty trả theo quý thường không trả đúng hạn dẫn đến sự bất mãn và mất động lực làm việc của nhân viên dẫn đến nghỉ việc hàng loạt. Nếu có suy nghĩ này thì công ty không nên áp dụng hệ thống lương 3P làm gì cả.
Và đặc biệt, để áp dụng hệ thống lương 3P chuẩn thì công ty nên đầu tư và hướng đến việc số hóa dữ liệu, áp dụng phần mềm trong việc phân phối chỉ tiêu, tổng hợp kết quả đánh giá tự động và có cảnh báo đánh giá theo thời gian thực sẽ phát huy được tối đa hiệu quả của hệ thống lương 3P này.
Trên đây mình đã cùng nhau tìm hiểu hệ thống lương 3P ở bước hiểu và nắm được phần cơ bản nhất của nó. Nếu bạn có bất kỳ thắc mắc nào vui lòng để lại comment bên dưới, mình sẽ trả lời cho các bạn trong thời gian sớm nhất. Trân trọng.
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Thói quen viết code an toàn trong khi xây dụng ứng dụng PHP
Bài viết được sự cho phép của tác giả Lê Chí Dũng
Bất cứ khi nào bạn xây dựng một hệ thống xong xui và hệ thống đang chạy ngon lành đều bị phá hoại vào ngày đẹp trời nào đó.!? Vì lý do bla, bla,… gì đó họ sẵn sàng dùng mọi cách phá hoại dự án kỳ công của bạn chính vì thế xây dựng code an toàn từ lúc xuất xưởng là cần thiết, hãy áp dụng thói quen này để đảm bảo rằng các ứng dụng của bạn là an toàn mức cao nhất có thể nhé.
Kiểm tra hợp lệ đầu vào (validate ngoài form)
Bảo vệ post form (validate trong file xử lý)
Bảo vệ hệ thống file (ghi logs khi phát sinh tải file mà mình giới hạn)
Bảo vệ cơ sở dữ liệu (Chống lại sự tấn công SQL INJECTION)
Bảo vệ dữ liệu phiên làm việc (đảm bảo hệ thống luôn chạy tốt)
Bảo vệ chống lại các sơ hở của ứng dụng lệnh xuyên các trang (Cross-Site Scripting – XSS)
Bảo vệ chống lại các giả mạo yêu cầu xuyên các trang (Cross-Site Request Forgeries – CSRF)
Đây là quy tắc cơ bản trong lập trình và nó cũng có 4 bước cơ bản, bạn làm theo thì chắc chắn sẽ K.O.
Lập ra danh sách hợp lệ(while list) vs bất hợp lệ (black list)
Luôn luôn kiểm tra hợp lệ trong black list.
Kiểm tra kiểu dữ liệu đúng. ví dụ như là các số, chuỗi,…
Trong quá trình xử lý danh sách bất hợp lệ cần dùng hàm thoát để giảm tải quá trình xử lý.
Tuy nhiên hiện nay các jquery validate ngày càng thông dụng nên bạn có thể tham khảo cách viết trong các jquery đó. Còn dùng framework JS thì nó cũng đảm bảo nhiều thứ hơn.
Bảo vệ post form (validate trong file xử lý)
– Attacker có thể dễ dàng fake 1 post form của bạn ở đâu đó rồi gửi vào file PHP xử lý của bạn vì mục đích nào đó. Do các ứng dụng web là phi trạng thái (stateless), nên không có cách nào để chắc chắn tuyệt đối là dữ liệu đã được gửi lên từ nơi mà bạn muốn nó đến từ đó. Mọi thứ từ các địa chỉ IP cho đến tên máy chủ, cuối cùng rồi đều có thể bị fake.
Ví dụ:
<html><head><title>Collecting your data</title></head><body><form action="http://path.example.com/processStuff.php"
method="post"><input type="text" name="answer"
value="There is no way this is a valid response to a yes/no answer..."/><input type="submit" value="Save" name="submit"/></form></body></html>
– Tuy nhiên một kỹ thuật mà bạn có thể sử dụng là thẻ bài sử dụng một lần (single-use token), nó không làm cho việc fake post form của bạn bất khả thinhưng nó trở thành một điều rắc rối kinh khủng cho người fake.!? Vì token thay đổi mỗi khi mẫu được đưa xuống client, attacker cần phải lấy một form đang gửi, lấy token, và đặt nó vào phiên bản post fake đó. Kỹ thuật này rất hại não vì khó có khả năng một ai đó lập ra một fake post form lâu dài để gửi các yêu cầu không mong muốn đến ứng dụng của bạn.
Ví dụ một thí dụ về một thẻ bài biểu mẫu dùng một lần.
Bảo vệ hệ thống file (ghi logs khi phát sinh tải file mà mình giới hạn)
– Vấn đề đặt ra là có những file quan trọng mà bạn không muốn bất kỳ ai cũng có quyền lấy xuống mà giới hạn lấy xuống. Chính vì vậy tốt nhất là thiết kế ứng dụng sử dụng một cơ sở dữ liệu và các tên file được tạo ra và giấu kín. Tuy nhiên, không phải lúc nào cũng có thể làm thế.
Ví dụ về một thủ tục kiểm tra hợp lệ tên tệp tin. Nó sử dụng các biểu thức chính quy để đảm bảo rằng chỉ các ký tự hợp lệ là được sử dụng trong tên tệp tin và đặc biệt kiểm tra các ký tự chấm chấm: ...
function isValidFileName($file) {
/* don't allow .. and allow any "word" character /*/
return preg_match('/^(((?:.)(?!.))|w)+$/', $file);
}
Bảo vệ cơ sở dữ liệu (Chống lại sự tấn công SQL INJECTION)
– Vấn đề đặt ra là attacker có thể vượt qua rào validate trong front end hoặc fake post form thành công và truyền dc những giá trị không mong muốn vào file PHP để xử lý nếu ta không chặn dc những giá trị này thì 0.O sẽ có những câu lệnh SQL ko chính quy thâm nhập vào những câu SQL chính quy của bạn phá hỏng database của bạn tồi tệ hơn là tạo ra những người dùng siêu quyền hạn để đánh cắp thông tin, bla bla….
Ví dụ về form lỏng lẻo có thể bị attack
<html><head><title>SQL Injection Example</title></head><body><form id="myFrom" action="<?php echo $_SERVER['PHP_SELF']; ?>" method="post">
Account <input name="account" type="text"/>
Number <input name="number" type="text"/>
Name <input name="name" type="text"/>
Address <input name="address" type="text"/></form><?php if ($_POST['submit']=='Save') {
/* do the form processing */$link = mysql_connect('hostname', 'user', 'password') or die ('Could not connect' . mysql_error());
mysql_select_db('test', $link); $col =$_POST['col']; $select ="SELECT " . $col . " FROM account_data WHERE account_number = " . $_POST['account_number'] . ";" ;
echo '<p>' . $select . '</p>'; $result = mysql_query($select) or die('<p>' . mysql_error() . '</p>');
echo '<table>';
while ($row = mysql_fetch_assoc($result)) {
echo '<tr>';
echo '<td>' . $row[$col] . '</td>';
echo '</tr>';
}
echo '</table>';
mysql_close($link);
} ?></body></html>
– Chúng ta có thể khắc phục dc việc này bằng nhiều cách đơn giản như
dùng hàm mysql_real_escape_string(). Hàm này làm sạch đầu vào của bạn, sao cho nó không còn bao gồm các ký tự không hợp lệ.
Kiểm tra xem định dạng chuỗi: email, username, password… đều có một định dạng nhất định, do đó có thể viết các biểu thức chính qui (Regular Expression) cho mỗi định dạng này.
– Vấn đề đặt ra là chúng ta 1 hệ thống có nhiều server khác nhau để duy trì 1 hệ thống site vậy làm sao để đảm bảo được các session trong giao dịch dùng để xử lý, có thể hoạt động trên các server khác trong cùng hệ thống.!?
Để làm được điều này chúng ta cần xử lý sao cho tất cả các máy chủ đều sử dụng chung một hệ thống quản lý session .
Hoặc đơn giản là sử dụng chung một session storage .
Mặc định trong php sẽ sử dụng file session handle các file chứa session sẽ nằm trong /tmp của mỗi server .
Điều này có thể gợi ý cho chúng ta việc share chung 1 vùng lưu trữ (ví dụ dùng NFS để share chung /tmp giữa các máy chủ).
Tuy nhiên cách này lại ảnh hưởng đến tốc độ truy xuất (vì phải qua mạng – sau đó là đến việc máy host session sẽ quá tải diskio).
Một hướng khác là sử dụng một db mysql chung để lưu session , thực tế thì cách này tạm được .
Để làm như vậy chúng ta cần override lại các hàm xử lý session của php
Sử dụng hàm session_set_save_handler để trỏ các call back function cần thiết , như vậy chúng ta cần viết lại 6 hàm open, close , read ,write ,destroy , gc .
tạm thời chúng ta viết tạm các hàm như sau :
<?php
function open($save_path, $session_name)
{
echo "open";
}
function close()
{
echo "close";
}
function read($id)
{
echo "read";
}
function write($id, $sess_data)
{
echo "write";
}
function destroy($id)
{
echo "destroy";
}
function gc($maxlifetime)
{
echo "gc";
}
session_set_save_handler("open", "close", "read", "write", "destroy", "gc");// test thử phát
session_start();
?>
Chạy thử . kết quả : openread writeclose …
Như vậy chúng ta thấy thứ tự của một quá trình đọc session .
Việc tiếp theo là implement mấy hàm trên vào mysql , memcached , file , hay bất kỳ một storage nào có thể dùng chung được là xong .
với file (cái này chỉ là làm lại những gì php đã làm )
<?php
$sess_save_path=".";
function open($save_path, $session_name)
{
global $sess_save_path;$sess_save_path =$save_path;
return(true);
}
function close()
{
return(true);
}
function read($id)
{
global $sess_save_path;$sess_file ="$sess_save_path/sess_$id";
return (string) @file_get_contents($sess_file);
}
function write($id, $sess_data)
{
global $sess_save_path;$sess_file ="$sess_save_path/sess_$id";
if ($fp = @fopen($sess_file, "w")) {
$return = fwrite($fp, $sess_data);
fclose($fp);
return $return;
} else {
return(false);
}
}
function destroy($id)
{
global $sess_save_path;$sess_file ="$sess_save_path/sess_$id";
return(@unlink($sess_file));
}
function gc($maxlifetime)
{
global $sess_save_path;
foreach (glob("$sess_save_path/sess_*") as $filename) {
if (filemtime($filename) +$maxlifetime < time()) {
@unlink($filename);
}
}
return true;
}
session_set_save_handler("open", "close", "read", "write", "destroy", "gc");//test
session_start();
?>
Hay với mysql đại khái thế này :
function read($id)
{
$sql ="select * from `tb_session` where `session_id`=$id";
mysql_query($sql);//....
}
function write($id, $sess_data)
{
$sql ="INSERT INTO `tb_session` (`session_id`, `updated_on`) VALUES ('{$this->session_id}', NOW())";
mysql_query($sql);
}
function destroy($id)
{
$sql ="Delete from `tb_session` where `session_id`=$id";
mysql_query($sql);
}
Hay với memcached :
function read($id)
{
return memcached::get("sessions/{$id}");
}
function write($id, $data)
{
return memcached::set("sessions/{$id}", $data, 3600);
}
function destroy($id)
{
return memcached::delete("sessions/{$id}");
}
Dùng memcache hay mysql cũng khá nhanh , mysql thì chạy bàng memory storage engine , bật query cache tướng đối lớn cho nhanh , có thể replication ra nhiều server để đẩy performed lên cao nữa nếu tải lớn .
Bảo vệ chống lại các sơ hở của ứng dụng lệnh xuyên các trang (Cross-Site Scripting – XSS)
– Vấn đề đặt ra là người dùng sẽ nhập nội dung và hệ thống của bạn sẽ hiển thị nội dung đó lên. Nếu nội dung người dùng nhập là script có chứa mã độc phát tán virus,… thì sao.!?
<html><head><title>Results demonstrating XSS</title></head><body><?php
echo("<p>You typed this:</p>");
echo("<p>");
echo($_POST['myText']);//Mã script độc lấy từ database sẽ hiển thị ở đây
echo("</p>");
?></body></html>
– Để tự bảo vệ bạn chống lại các tấn công XSS, hãy lọc đầu vào của bạn thông qua hàm htmlentities() bất cứ khi nào giá trị của một biến được in đến đầu ra. Hãy nhớ làm theo thói quen đầu tiên về kiểm tra hợp lệ dữ liệu đầu vào bằng các giá trị trong danh sách trắng trong ứng dụng web của bạn đối với tên, địa chỉ email, số điện thoại, và thông tin về hoá đơn thanh toán.
<html><head><title>Results demonstrating XSS</title></head><body><?php
echo("<p>You typed this:</p>");
echo("<p>");
echo(htmlentities($_POST['myText']));//htmlentities(): đã chặn việc thực thi đoạn script độc mà chỉ hiển thị chúng lên như thml
echo("</p>"); ?> </body></html>
Bảo vệ chống lại các giả mạo yêu cầu xuyên các trang (Cross-Site Request Forgeries – CSRF)
– Một vấn đề là chúng ta phải thật cẩn trọng với người dùng đã là member chính thức vì lúc đó họ đã có dc quyền hạng trong site và họ có thể upload, post,… thoải mái nếu họ lợi dụng quyền này để tấn công bằng cách upload file image nhưng đó thực sự không phải là file image thì sao.!?
Các cuộc tấn công CSRF thường được thực hiện dưới dạng các thẻ <img> vì trình duyệt gọi URL một cách không ý thức để lấy hình ảnh. Tuy nhiên, nguồn hình ảnh dễ dàng có thể chỉ là URL của một trang web trên cùng một site, thực hiện các việc xử lý nào đó dựa trên các tham số chuyển cho nó. Khi thẻ <img> này được đặt trong một cuộc tấn công XSS — cũng là các tấn công phổ biến nhất được ghi chép lại — người sử dụng dễ dàng có thể làm một việc gì đó với quyền ưu tiên được cấp mà không biết mình đã làm — như vậy, có thể giả mạo.
– Lúc đó ngoài việc áp dụng các cách bảo vệ bên trên trước XSS thì chúng ta cần xác minh các form gửi lên chặc hợn. Ngoài ra, sử dụng biến hiển $_POST thay vì $_REQUEST và kiểm tra kỹ lưỡng các file được up lên nếu là hình ảnh ngoài kiểm tra file_upload,… thì cần kiểm tra size ảnh để chắc chắn đó là một hình ảnh thông qua hàm getimagesize() trong php.
Ở phần trước, mình đã giới thiệu với các bạn một phần mở rộng của Selenium IDE cho phép chúng ta điều hướng luồng thực thi của mã Selenium IDE – Selenium IDE Flow Control. Phần này, mình sẽ giới thiệu với các bạn một công cụ khác của Selenium IDE hỗ trợ chúng ta chạy kiểm thử theo hướng Data-Driven – SelBlocks.
Các bạn có thể download phần SelBlocks ở đây. Vì cách cài đặt cũng giống như Selenium IDE Flow Control hay những add-on khác của Selenium, nên mình sẽ không nói chi tiết, các bạn có thể xem lại cách cài đặt của Selenium IDE Flow Control trong clip dưới đây
SelBlocks, bên cạnh việc hỗ trợ chúng ta thực thi kiểm thử theo hướng data-driven, nó có cung cấp một số câu lệnh đặc biệt như:
if/elseIf/else
try/catch/finally/throw
for/foreach/while
continue/break
call/function/return
loadXmlVars/loadJsonVars
forXml/forJson
exitTest
Nhưng trong bài này, mình chỉ tập trung vào phần Data-Driven thôi
Sử dụng SelBlocks
Ví dụ như chúng ta có một kịch bản như sau
Truy cập trang web Google
Tìm kiếm với từ khóa Selenium/SeleniumHq
Nhấp vào đường dẫn đến trang chủ của Selenium
Kiểm tra trang chủ của Selenium được hiển thị thành công.
SelBlocks sử dụng 1 tập tin XML để chứa các thông tin dữ liệu cho việc thực thi kiểm thử theo hướng data-driven. Vậy nên, trước hết chúng ta cần một file xml, chứa các thông tin mà chúng ta muốn sử dụng để lặp lại phần mã kiểm thử. Chúng ta sẽ có một tập tin xml cho hai trang từ khóa cần tìm: Selenium và SeleniumHq
Sau đó, chúng ta tiến hành record các bước kiểm thử từ khóa đầu tiên. Và, thêm các câu lệnh dành cho việc data-driven. Các bước được mô tả ở video dưới đây.
[adToAppearHere]
Hẳn là các bạn xài Linux (dù là distro nào) thì cũng đều gặp phải một vấn đề giống nhau, đó là gõ tiếng Việt.
Đã từng gõ tiếng Việt trên Windows với Unikey hay Vietkey ngày xưa thì hẳn ai cũng cảm thấy khá là khó chịu với cái dấu gạch đít quái đản khi chuyển qua xài macOS hoặc Linux. Đối với các bạn chưa biết, thì dấu này gọi là preedit và là một phương pháp “chính thống” theo lời tác giả Trung Ngo (thành viên team phát triển BogoEngine) trong bài viết Ước mơ bộ gõ kiểu Unikey.
Đại ý của bài viết trên thì: tựu chung, các bộ gõ tiếng Việt hiện nay có 2 cách để xử lý tiếng Việt khi gõ, đó là Backspace và Preedit.
Preedit: là cách gõ xuất hiện dấu gạch đít, đây thực chất là một vùng buffer lưu tạm các kí tự đang gõ, thay thế nó, ví dụ aa đưọc thay thành â, khi ngưòi dùng nhấn space để kết thúc từ đang gõ thì nó sẽ commit từ đó về cho UI của ứng dụng. Các bộ gõ tiếng Việt sử dụng kĩ thuật này thì có: ibus-unikey, bộ gõ tiếng Việt mặc định của macOS,…
Backspace giả: là cách gõ không xuất hiện dấu gạch đít, cơ chế hoạt động của giải pháp này là khi gõ các kí tự tiếng việt như aa, bộ gõ sẽ tự động gửi 2 dấu backspace vào ứng dụng, và gửi tiếp một kí tự â thay thế. Các bộ gõ sử dụng kĩ thuật này có ibus-bogo, fcitx-bogo, GoTiengViet trên macOS,…
2. Kĩ thuật Backspace
Lại nói về Backspace giả, trong bài viết của mình, tác giả Trung Ngo có nói:
Gần như tất cả các bộ gõ trên Windows (tôi không dám chắc nhưng không thể kiểm chứng được vì phần lớn là phần mềm nguồn đóng) giải quyết vấn đề này bằng cách sử dụng dấu backspace giả.
Mình nghĩ là đúng, ít ra là với một vài bộ gõ như GoTiengViet trên Windows (không biết phiên bản trên macOS và Linux anh Trần Kỳ Nam có cải tiến hay sử dụng kĩ thuật khác không, mình không kiểm chứng đưọc), vì từng có một thời gian lúc mình còn tham gia diễn đàn Câu lạc bộ VB, mọi ngưòi cũng thảo luận về vấn đề phát triển bộ gõ, kĩ thuật hồi đó mọi ngưòi áp dụng là:
- Hook keyboard để bắt lại các kí tự đang gõ- Đưa kí tự vừa đưọc hook vào buffer và kiểm tra theo luật gõ (Telex, VNI,...)- Gửi backspace để xóa các kí tự đã gõ, ví dụ `aa`- Đưa kí tự cần thay thế, ví dụ `â`, vào clipboard và gửi phím `Shift + Insert` hoặc `Ctrl + V` để "dán" kí tự này vào ứng dụng đang chạy.- Hoặc gửi trực tiếp kí tự cần thay thế vào thông qua API của Windows
Và thêm một lý do nữa đó là lần cuối cùng mình check thì không nhớ trên Windows có API nào để hỗ trợ các kĩ thuật khác ngoài chuyện send key.
Hiện giờ nội dung các bài thảo luận đó vẫn còn, các bạn có thể tìm đọc để hiểu thêm:
Phải nói là trên X Window System mới đúng. Các bộ gõ khác nhau có nhiều cách xử lý khác nhau, đoạn này mình chỉ nói đến các bộ gõ dùng kiến trúc X Input Method (XIM) như ibus, SCIM,…
Nếu để ý, các bạn sẽ thấy các bộ gõ như ibus-bogo hay scim-unikey thưòng hay tự gọi mình là một frontend cho một cái engine gì đó để dùng với ibus hoặc scim:
IBus frontend for the BoGo engine.
scim-unikey là một bộ xử lý nhập liệu tiếng Việt cho scim, sử dụng engine xử lý tiếng Việt của unikey
Đọc phần này sẽ giúp các bạn hiểu thêm về cái vụ “engine gì đó” đó.
Hình sau mô tả toàn cảnh việc xử lý nhập liệu trong một hệ thống X Window System:
Hình vẽ lại từ tài liệu [Xlib Programming Manual – Chapter 11: Internationalized Text Input](http://menehune.opt.wfu.edu/Kokua/Irix_6.5.21_doc_cd/usr/share/Insight/library/SGI_bookshelves/SGI_Developer/books/XLib_PG/sgi_html/ch11.html)
Khi user nhấn một phím trên bàn phím, keycode của phím này sẽ đưọc gửi về cho X Server.
X Server gửi một sự kiện nhấn phím (KeyPress Event) tới cho các X client đang đăng ký chờ event (application sẽ làm nhiệm vụ báo cho client biết nó có nên đăng kí nhận event hay ko)
Event loop trên X client sẽ đọc KeyPress Event đó bằng một lệnh gọi tới hàm XNextEvent()
Thông tin của Event này sẽ được gửi sang Input Method (ibus, scim,…) và tại đây, tùy theo mỗi bộ gõ khác nhau, mà sẽ thực hiện việc kiểm tra các tổ hợp phím đưọc nhấn, rồi thay thế kí tự cho phù hợp với tập luật của bộ gõ, các nhà phát triển thưòng viết riêng phần xử lý này thành một engine để có thể sử dụng lại với nhiều loại bộ gõ khác nhau.
Trong quá trình xử lý (compose), Input Method cũng sẽ báo lại cho application biết để nó update phần preedit cho phù hợp.
Sau khi xử lý xong, Input Method sẽ gửi lại nội dung đã đưọc xử lý (một từ tiếng Việt hoàn chỉnh – composed text) về cho X client để in ra màn hình (bưóc này là bước commit). Commit xong thì application cũng thôi không in cái preedit ra nữa.
Engine xử lý việc bỏ dấu (thay thế kí tự phù hợp với tập luật của bộ gõ) có rất nhiều loại khác nhau, đây là tài liệu mô tả logic cho engine mà ibus-bogo sử dụng.
Việc trao đổi giữa X client và Input Method được thực hiện thông qua một phương thức gọi là XIM Protocol.
Và như các bạn thấy thì mô hình này phụ thuộc lớn vào preedit, chính vì vậy mới nói preedit là phưong pháp chuẩn cho việc soạn thảo với các ngôn ngữ ngoài tiếng Anh.
4. Thử nghiệm các bộ gõ trên Linux
Vì phần lớn thời gian làm việc của mình là trên terminal, nên chuyện chấp nhận thưong đau mà dùng Preedit khi gõ lệnh hay xài trong VIM thì mình chịu, không làm đưọc, nên dù không hoàn thiện, mình vẫn chấp nhận được các bộ gõ dùng phưong pháp dùng Backspace, vậy nên bài viết này mình chỉ nhắm tới việc tìm ra bộ gõ xài Backspace hoạt động hiệu quả nhất trên Linux.
4.1. xvnkb
Bộ gõ đầu tiên mình tìm hiểu thử là xvnkb, vì khá ấn tưọng với cái dòng release notes trên trang chủ:
WoW! After 6 years, we have a new official release! L0LzZzzZZzz… Some bugs with Firefox and other apps have been fixed in this release. Still having fun! Hahaha!
LOL.
Quá trình download và cài đặt diễn ra rất trơn tru, không có lỗi gì xảy ra.
Nhưng sau khi cài đặt xong và restart lại máy tính thì xvnkb làm crash luôn X server và máy tính không thể khởi động vào môi trưòng đồ họa đưọc nữa, đáng lý ra thì tới đây mình phải tìm hiểu thêm lý do crash là gì nhưng vì vừa tốn công cài đặt lại máy xong, khá là lưòi, không thấy chạy nữa thì cứ remove thẳng tay thôi :)) thành thật xin lỗi tác giả.
Thế là ứng viên đầu tiên đã bị loại.
4.2. ibus-bogo
Thật sự là sau khi đọc bài viết của tác giả Trung Ngo và xem homepage của project trên Github xong thì không muốn xài ibus-bogo tí nào, nhưng vì đã hết option rồi nên thôi cài vào xài luôn. Quá trình cài đặt thì khá là đơn giản:
$ sudo pacman -S ibus$ yaourt -S ibus-bogo
Để ibus tự động khởi động thì chúng ta có thể thêm dòng sau vào ~/.xinitrc:
ibus-daemon -drx
Kết quả gõ thử nghiệm cho thấy ibus-bogo hoạt động rất tốt trên terminal, trên các trình duyệt như surf, firefox,… không hiện thanh preedit phiền toái.
Tuy nhiên với chế độ gõ TELEX, một vài từ có các nguyên âm ươ như trước, bước, nước, ta bắt buộc phải gõ uwow hoặc uow nếu không muốn bị sót mất chữ ơ, ví dụ nưóc, trưóc. Các bộ gõ như GoTiengViet hay Unikey trên Mac và Windows không bị trường hợp này.
Một nhược điểm khác của ibus-bogo là không hỗ trợ các trình duyệt Chromium, Google Chrome, lý do thì tác giả Trung Ngo đã giải thích trong Issue #216 – ibus-bogo.
Lý do lớn nhất khiến nhiều người ngại dùng ibus-bogo có lẽ là vì project này đã không còn được maintain nữa. Ở thời điểm viết bài này, có 63 open issues trên trang Github của project. Thành viên của team phát triển là Trung Ngo đã ngừng maintain dự án vì bất đồng quan điểm với tác giả Ha-Duong Nguyen và fork ra một project khác tên là ibus-ringo (project này add thêm vài chức năng khác trong đó có preedit, nên mình ko xài :D)
4.3. fcitx-bogo
Một phiên bản khác cũng dùng BogoEngine đó là fcitx-bogo, xây dựng cho fcitx. Cách cài đặt thì cũng đơn giản:
$ pacman -S fcitx$ yaourt -S fcitx-bogo
Khởi động với lệnh sau trong ~/.xinitrc:
fcitx -d
Kết quả thử nghiệm cho thấy bộ gõ này hoạt động tạm gọi là tốt trên mọi phần mềm, trong đó đặc biệt là có thể gõ đưọc tiếng Việt trên Chromium và Google Chrome luôn.
Tuy nhiên khi sử dụng trên terminal thì khá là lag, thời gian từ lúc gõ phím cho tới lúc hiện ra kí tự tiếng Việt rất chậm, không như ibus-bogo, và thêm một điểm trừ nữa là rất không ổn định, hay bung lụa kiểu:
^B chính là phím backspace đó ( ̄▽ ̄)
Và khi gõ trên Firefox thì vẫn gặp hiện tượng không gõ đầy đủ dduwocj tiêngs Viêjt =.= (đó, bị như vậy đó).
5. Kết luận
Hy vọng bài viết này giúp các bạn có thêm cái nhìn sâu hơn về các loại bộ gõ tiếng Việt hiện có và những thử thách về mặt kĩ thuật mà chúng ta đang phải đối mặt để có thể phát triển đưọc một bộ gõ tiếng Việt hoàn chỉnh cho môi trưòng Linux.
Bài viết chỉ dựa trên quan điểm chủ quan của tác giả khi tìm hiểu về các bộ gõ không dùng preedit, nên còn nhiều thiếu sót và có nhiều nội dung liên quan đến phưong pháp chuẩn (preedit) và các kĩ thuật khác như surrounding text,… đã bị bỏ qua.
Hy vọng các bạn quan tâm có thể nhiệt tình góp ý, bổ sung và giúp mình hoàn thiện bài viết. Xin cảm ơn 😀
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Code ví dụ Spring Cloud Config Client
Trong ví dụ này chúng ta sẽ thực hiện load cấu hình để sử dụng cho project từ 1 server khác (Spring Cloud Config)
Việc load cấu hình từ 1 server khác thường áp dụng cho các project có nhiều instance trên nhiều server, mỗi lần đổi cấu hình ta chỉ cần đổi cấu hình trên server config là được chứ không cần phải sửa cho từng server một.
Đây là một project spring cloud nên các thông tin cấu hình về server config, name ta sẽ đặt trong file bootstrap.yml
Trong ví dụ này mình sẽ load cấu hình từ server có địa chỉ http://localhost:8888, cấu hình được load sẽ có tên là app với profiles là dev. (Đây là server mình đã dựng trong bài trước)
Annotation @RefreshScope là 1 annotation của spring cloud. Các Bean được đánh dấu với annotation này sẽ được làm mới tại thời gian chạy (runtime). Mỗi khi gọi tới thì nó sẽ tạo 1 bean mới.
Start project:
. _________ /\\ / ___'_____(_)______ \ \ \ \(()\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | )))) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.3.3.RELEASE)2020-08-2014:20:12.155 INFO 12476 --- [ main] c.c.c.ConfigServicePropertySourceLocator : Fetching config from server at : http://localhost:88882020-08-2014:20:12.984 INFO 12476 --- [ main] c.c.c.ConfigServicePropertySourceLocator : Located environment: name=app, profiles=[dev], label=null, version=31254e088069d8f5c2651156237f2973613a9781, state=null2020-08-2014:20:12.985 INFO 12476 --- [ main] b.c.PropertySourceBootstrapConfiguration : Located property source: [BootstrapPropertySource {name='bootstrapProperties-configClient'}, BootstrapPropertySource {name='bootstrapProperties-C:/Users/stackjava/Desktop/spring-cloud-config-server-repo/app-dev.properties'}, BootstrapPropertySource {name='bootstrapProperties-C:/Users/stackjava/Desktop/spring-cloud-config-server-repo/app.properties'}]...2020-08-2014:20:14.616 INFO 12476 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 7777(http) with context path ''2020-08-2014:20:15.227 INFO 12476 --- [ main] s.c.s.SpringCloudConfigClientApplication : Started SpringCloudConfigClientApplication in 5.492seconds(JVM running for6.63)2020-08-2014:20:19.989 INFO 12476 --- [nio-7777-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'2020-08-2014:20:19.989 INFO 12476 --- [nio-7777-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'2020-08-2014:20:19.992 INFO 12476 --- [nio-7777-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 3 ms
Mở trình duyệt web và truy cập vào địa chỉ: http://localhost:7777/config
Mặc dù các biến database.host, database.name... không có trong file cấu hình là application.yml nhưng nó vẫn có giá trị là do chúng đã được load từ server config.
Trong bài tiếp theo chúng ta sẽ tìm hiểu việc authen khi giao tiếp giữa spring cloud config server với spring cloud config client. Refresh lại cấu hình cho client khi cấu hình trên server, repository được thay đổi.
Download code ví dụ trên tại đây hoặc tại: https://github.com/stackjava/spring-cloud-config-client
REST Web service: Tạo ứng dụng Java RESTful Client với Jersey Client 2.x
Bài viết được sự cho phép của tác giả Giang Phan
Trong bài trước chúng ta đã cùng tìm hiểu cách xây dựng ứng dụng Java Restful web service với Jersey 1.x. Trong bài này, chúng ta sẽ cùng tìm hiểu cách tạo ra ứng dụng Java Restful web service với Jersey 2.x và ứng dụng Java RESTful Client sử dụng Jersey Client API để gọi tới RESTful web service.
Lưu ý: đối với project chỉ bao gồm Client (không bao gồm Server), chúng ta chỉ cần 2 thư viện jersey-client và jersey-media-json-jackson.
Sau khi đã cập nhật file pom.xml, chúng ta cần update lại mavent project: Nhấn chuột phải lên project -> Maven -> Update Project… -> OK.
Tạo file jersey config: file này bao gồm config package chứa api và logging.
JerseyServletContainerConfig.java
package com.gpcoder.config;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.glassfish.jersey.logging.LoggingFeature;
//Deployment of a JAX-RS application using @ApplicationPath with Servlet 3.0
//Descriptor-less deployment
import org.glassfish.jersey.server.ResourceConfig;
public class JerseyServletContainerConfig extends ResourceConfig {
public JerseyServletContainerConfig() {
// if there are more than two packages then separate them with semicolon
packages("com.gpcoder.api");
register(new LoggingFeature(Logger.getLogger(LoggingFeature.DEFAULT_LOGGER_NAME), Level.INFO,
LoggingFeature.Verbosity.PAYLOAD_ANY, 10000));
}
}
Tạo file WebContent/WEB-INF/web.xml với nội dung như sau:
<?xmlversion="1.0"encoding="UTF-8"?><web-appxmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns="http://xmlns.jcp.org/xml/ns/javaee"xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"version="4.0"><display-name>RESTful CRUD Example by gpcoder</display-name><servlet><servlet-name>jersey2-serlvet</servlet-name><servlet-class>org.glassfish.jersey.servlet.ServletContainer</servlet-class><init-param><param-name>javax.ws.rs.Application</param-name><param-value>com.gpcoder.config.JerseyServletContainerConfig</param-value></init-param><init-param><param-name>jersey.config.server.provider.classnames</param-name><param-value>org.glassfish.jersey.jackson.JacksonFeature</param-value></init-param><load-on-startup>1</load-on-startup></servlet><servlet-mapping><servlet-name>jersey2-serlvet</servlet-name><url-pattern>/rest/*</url-pattern></servlet-mapping></web-app>
2. Jersey chuyển đổi XML và JSON sang Model Class như thế nào?
Theo mặc định Jersey API sử dụng JAXB là XML-Binding mặc định để chuyển đổi các đối tượng Java thành XML và ngược lại. Chúng ta cần gắn các Annotation của JAXB lên các class model để chú thích cách chuyển đổi cho JAXB. Chi tiết về JAXB Annotation và cách sử dụng các bạn xem lại bài viết: Hướng dẫn chuyển đổi Java Object sang XML và XML sang Java Object sử dụng Java JAXB.
Jersey sử dụng MOXy là JSON-Binding mặc định để Jersey chuyển đổi các đối tượng JSON thành Java và ngược lại. Chúng ta không gần gắn các Annotation lên các class model.
3. Tạo Java REST Web service với Jersey2
Tạo data model:
User.java
package com.gpcoder.model;
import javax.xml.bind.annotation.XmlRootElement;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
@XmlRootElement(name = "user")
public class User {
private Integer id;
private String username;
}
Tạo Restful CRUD:
UserService.java
package com.gpcoder.api;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import javax.ws.rs.Consumes;
import javax.ws.rs.DELETE;
import javax.ws.rs.GET;
import javax.ws.rs.POST;
import javax.ws.rs.PUT;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
import com.gpcoder.model.User;
// URI:
// http(s)://:(port)/// // http://localhost:8080/RestfulWebServiceExample/rest/users
@Path("/users")
public class UserCrudService {
private static final Map<Integer, User> USERS = new HashMap<>();
static {
// Create dummy data
for (int i = 1; i <= 10; i++) { USERS.put(i, new User(i, "dummy " + i)); } } private int generateUniqueId() { return USERS.keySet().stream().max((x1, x2) -> x1 - x2).orElse(0) + 1;
}
@GET
@Path("/{id}")
@Produces({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
public User get(@PathParam("id") int id) {
return USERS.getOrDefault(id, new User());
}
@GET
@Produces({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
public List getAll() {
return new ArrayList<>(USERS.values());
}
@POST
@Consumes({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
@Produces({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
public int insert(User user) {
Integer id = generateUniqueId();
user.setId(id);
USERS.put(id, user);
return id;
}
@PUT
@Consumes({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
@Produces({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
public boolean update(User user) {
return USERS.put(user.getId(), user) != null;
}
@DELETE
@Path("/{id}")
@Produces({ MediaType.APPLICATION_JSON, MediaType.APPLICATION_XML })
public boolean delete(@PathParam("id") int id) {
return USERS.remove(id) != null;
}
}
Ứng dụng Client ở trên gửi và nhận dữ liệu kiểu json. Để gửi dữ liệu và nhận kiểu dữ liệu xml, các bạn đơn giản thay thế MediaType.APPLICATION_JSON sang MediaType.APPLICATION_XML.
Cách Viết Thư Cảm Ơn Phỏng Vấn Chinh Phục Nhà Tuyển Dụng Từ 3 Giây Đầu Tiên!
Việc gửi thư cảm ơn nhà tuyển dụng sau buổi phỏng vấn là một văn hóa phổ biến ở các quốc gia. Tuy nhiên, ở Việt Nam, nhiều ứng viên vẫn chưa thật sự chú trọng đến vấn đề này. Một bức thư cảm ơn sau buổi phỏng vấn sẽ giúp bạn gây ấn tượng tốt hơn trong mắt nhà tuyển dụng. Vậy làm thế nào để viết thư cảm ơn phỏng vấn đạt chuẩn? Tìm hiểu thêm với bài viết này nhé!
Tại sao nên gửi thư cảm ơn phỏng vấn?
Thực tế thì những ứng viên có sự chủ động ngay từ vòng phỏng vấn vẫn luôn gây được ấn tượng tốt với nhà tuyển dụng hơn so với các ứng viên khác. Vậy nên thay vì ngồi chờ đợi thư báo kết quả phỏng vấn từ nhà tuyển dụng, bạn hãy chủ động soạn một bức thư cảm ơn với nội dung ngắn gọn trong vòng 24 giờ sau khi phỏng vấn xong. Một cách hay để vừa cảm ơn, vừa cho thấy sự nhiệt tình và mong muốn của bạn với công việc này.
Nội dung bức thư như đã đề cập, sẽ cảm ơn nhà tuyển dụng vì đã dành thời gian để phỏng vấn bạn cũng như cảm ơn vì đã cho ứng viên cơ hội để trao đổi thêm về suy nghĩ và định hướng công việc giữa hai bên. Ngắn gọn, đơn giản nhưng đủ tôn trọng nhà tuyển dụng, đó chính là cách viết thư cảm ơn phỏng vấn hay nhất.
Khi đã làm việc với email, việc viết mail với một tiêu đề chuyên nghiệp thật sự rất quan trọng. Tiêu đề của mail cần được đặt một cách rõ ràng, mạch lạc và đề cập đến nội dung chính của vấn đề bạn muốn nhắc đến trong thư. Khi viết rõ ràng như thế sẽ khiến người nhận thư xem thư của bạn ngay thay vì bỏ qua hay thêm vào danh sách xem sau do nội dung không rõ ràng.
2. Mở đầu thư
Sau tiêu đề thư sẽ bắt đầu với nội dung chính của bức thư. Trong phần mở đầu, người viết thư nên gửi lời chào cũng như nêu rõ họ tên và vị trí mình ứng tuyển, ngày phỏng vấn. Đó là cách để nhắc nhớ nhà tuyển dụng về bạn giữa rất nhiều các ứng viên đã phỏng vấn. Các thông tin cơ bản như trên là đủ để nhà tuyển dụng biết được bạn là ai.
Bức thư cần đảm bảo các tiêu chuẩn về mặt hình thức
3. Nội dung chính của thư cảm ơn phỏng vấn
Có một ưu điểm khác của thư cảm ơn phỏng vấn mà có thể bạn chưa biết đó là giúp bạn khắc phục những khuyết điểm của mình trong buổi phỏng vấn. Trong lúc phỏng vấn, có thể vì những lý do cá nhân hay quá căng thẳng mà có thể bạn không đủ tự tin thể hiện hết năng lực của mình. Thư cảm ơn giúp ứng viên giải quyết được vấn đề này.
Nếu gặp phải trường hợp này, hãy trình bày thêm về những điều bạn ấn tượng hay cảm thấy thú vị trong buổi phỏng vấn. Có thể đề cập thêm một số điểm để cho thấy bạn là ứng viên phù hợp với công ty và cho thấy mong muốn thật sự muốn tham gia vào hoạt động công ty của bạn.
Hoặc ngược lại, ngay cả khi bạn cảm thấy mình không phù hợp với văn hóa công ty sau buổi phỏng vấn thì việc viết thư cảm ơn vẫn cần thiết. Bạn có thể nêu rõ trong email những lý do bản thân không hợp với công việc. Việc này không chỉ giúp tiết kiệm thời gian của hai bên mà nhà tuyển dụng cũng đánh giá rất cao sự trung thực của ứng viên.
4. Lời cảm ơn cuối thư
Để kết thúc email, ứng viên hãy gửi lời cảm ơn chân thành đến nhà tuyển dụng vì đã dành thời gian phỏng vấn cũng như xem qua thư. Và đừng quên thể hiện mong muốn được đồng hành với công ty trong thời gian tới cũng như bạn đang chờ đợi kết quả phỏng vấn.
Một số lưu ý khi viết thư cảm ơn phỏng vấn
Bên cạnh một nội dung hợp lí thì có một số lỗi thường gặp khi viết mail mà ứng viên nên chú ý để tránh mắc sai lầm.
Độ dài của thư: độ dài một email cảm ơn hợp lý nằm trong khoảng nửa trang A4 trở lại. Bạn không nên kể lể quá dài dòng nhưng cũng không nên viết quá ngắn vì sẽ không cho thấy được sự chân thành của người viết.
Lỗi chính tả: đây là một lỗi nhỏ nhưng rất dễ khiến người đọc mất cảm tình. Vậy nên sau khi viết thư xong bạn hãy đọc lại một lần nữa toàn bộ nội dung để đảm bảo không có lỗi chính tả trong thư.
Thời gian gửi thư: khoảng thời gian hợp lý nhất để gửi thư cảm ơn là trong vòng 24 giờ sau khi kết thúc buổi phỏng vấn. Nếu bạn phỏng vấn vào thứ 6, hãy gửi thư cảm ơn vào thứ 2 tuần sau thay vì gửi vào cuối tuần là thời gian không làm việc.
Một quy trình phỏng vấn thành công luôn ẩn chứa nhiều khó khăn, thậm chí là thử thách. Để đảm bảo có được công việc mình mong ước, hãy dành thời gian nhiều hơn cho vị trí đó. Sự chân thành và tận tâm với công việc sẽ giúp bạn có được công việc mình mong muốn. Đón đọc thêm nhiều bài viết hấp dẫn khác trong lĩnh vực nhân sư và IT tại topdev.vn/blog
Trong ví dụ này chạy server trên port 8888 và lưu cấu hình ở github với uri như trên.
Mặc định thì các file cấu hình lưu ở root folder, tuy nhiên nếu muốn load các file cấu hình ở folder con ta có thể dùng thêm search-paths
Trường hợp git repository của bạn là private thì bạn có thể dùng thêm thuộc tính username, password
Nếu bạn không muốn dùng github mà dùng một folder trên local để chứa các file cấu hình thì bạn thay uri bằng địa chỉ folder đó là được. (lưu ý, folder đó cũng phải là 1 repository, và chỉ những data đã được commit mới được sử dụng)
Đây là git repository của mình:
Gồm các file chứa cấu hình cho ứng dụng spring có name là app với các profiles khác nhau:
Tương tự mình có một sub folder để chứa cấu hình cho ứng dụng spring có name là demo với các profiles tương ứng:
Start ứng dụng spring boot này:
. _________ /\\ / ___'_____(_)______ \ \ \ \(()\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | )))) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.3.3.RELEASE)2020-08-2009:54:57.120 INFO 7956 --- [ main] c.c.c.ConfigServicePropertySourceLocator : Fetching config from server at : http://localhost:88882020-08-2009:54:58.878 INFO 7956 --- [ main] c.c.c.ConfigServicePropertySourceLocator : Located environment: name=app, profiles=[dev], label=null, version=34f63fea1576b0c5e5bb67d9a32420d10cb48f3f, state=null2020-08-2009:54:58.879 INFO 7956 --- [ main] b.c.PropertySourceBootstrapConfiguration : Located property source: [BootstrapPropertySource {name='bootstrapProperties-configClient'}, BootstrapPropertySource {name='bootstrapProperties-https://github.com/stackjava/spring-cloud-config-server-repo.git/app-dev.properties'}, BootstrapPropertySource {name='bootstrapProperties-https://github.com/stackjava/spring-cloud-config-server-repo.git/app.properties'}]2020-08-2009:54:58.884 INFO 7956 --- [ main] s.c.s.SpringCloudConfigClientApplication : The following profiles are active: dev2020-08-2009:54:59.256 INFO 7956 --- [ main] o.s.cloud.context.scope.GenericScope : BeanFactory id=ab77c954-7bc9-3c62-b748-55ed0878c2e02020-08-2009:54:59.407 INFO 7956 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 7777(http)2020-08-2009:54:59.413 INFO 7956 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]2020-08-2009:54:59.413 INFO 7956 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.37]2020-08-2009:54:59.415 INFO 7956 --- [ main] o.a.catalina.core.AprLifecycleListener : An older version [1.2.21] of the Apache Tomcat Native library is installed, while Tomcat recommends a minimum version of [1.2.23]2020-08-2009:54:59.415 INFO 7956 --- [ main] o.a.catalina.core.AprLifecycleListener : Loaded Apache Tomcat Native library [1.2.21] using APR version [1.6.5].2020-08-2009:54:59.415 INFO 7956 --- [ main] o.a.catalina.core.AprLifecycleListener : APR capabilities: IPv6 [true], sendfile [true], accept filters [false], random [true].2020-08-2009:54:59.415 INFO 7956 --- [ main] o.a.catalina.core.AprLifecycleListener : APR/OpenSSL configuration: useAprConnector [false], useOpenSSL [true]2020-08-2009:54:59.418 INFO 7956 --- [ main] o.a.catalina.core.AprLifecycleListener : OpenSSL successfully initialized [OpenSSL 1.1.1a20 Nov 2018]2020-08-2009:54:59.499 INFO 7956 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext2020-08-2009:54:59.499 INFO 7956 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 603 ms2020-08-2009:54:59.643 INFO 7956 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'2020-08-2009:55:00.429 INFO 7956 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 7777(http) with context path ''2020-08-2009:55:01.028 INFO 7956 --- [ main] s.c.s.SpringCloudConfigClientApplication : Started SpringCloudConfigClientApplication in 6.098seconds(JVM running for7.174)2020-08-2009:55:37.804 INFO 7956 --- [nio-7777-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'2020-08-2009:55:37.804 INFO 7956 --- [nio-7777-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'2020-08-2009:55:37.809 INFO 7956 --- [nio-7777-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 5 ms
Bạn có thể xem thông tin các file cấu hình theo path như sau:
Cũng lâu rồi mình chưa viết bài mới, dạo này toàn draft mấy bài kĩ thuật dài dòng lê thê thành ra viết nửa chừng toàn tụt hết cảm xúc, thôi thì hôm nay tranh thủ ngồi viết tí random vậy.
Bài này nói về những chuyện thường gặp khi làm nghề gõ code thuê. Trong đây có một vài từ ngữ không hợp với thuần phong mỹ tục, cân nhắc kĩ trước khi đọc.
Gõ code thuê tức là code bạn viết ra không thuộc về bạn, mà thuộc về công ty, khách hàng, chủ dự án, người trả tiền cho bạn để bạn code.
Gõ code thuê xuất hiện ở mọi nơi, mọi lúc và đối với mọi người. Nói như vậy để các bạn không có cãi, vì dù bạn là nhân viên của một công ty outsourcing, offshore hay công ty làm product, thì chừng nào người ta vẫn trả tiền cho bạn để bạn code, thì đó là bạn đi code thuê.
Và đây là khúc mà vấn đề xuất hiện. Suy nghĩ của số đông những người đi code thuê là: Vì đi code thuê, nên không việc gì chúng ta phải dồn hết tâm huyết, trách nhiệm vào cho nó hết.
Viết code kiểu hack đại cho xong, tạm bợ, overwrite lại code của người khác,…: Code kiểu này thường là fix được bug rất nhanh, qua mặt được QA và không màn tới ngày mai, vì kiểu gì ngày mai nó cũng sẽ phòi ra bug, hoặc fix xong bug của mình rồi đó, nhưng tự nhiên hôm sau sẽ có thằng nào đó trong team ngồi chửi thề, đơn giản vì cái chỗ fix này làm hỏng phần khác của nó. Kệmẹnóđi, việc của nó mà, đ’ phải việc của mình là được rồi. Ví dụ: xài !important =)))
Hard code: Code kiểu này cũng rất nhanh, giải quyết vấn đề một cách cực kì chính xác, khỏe quá mà, nhưng nếu ngày mai business logic có thay đổi thì việc update là gần như không thể. Kiểu code 1 giây cho thằng khác maintain mất 1 tháng.
Không review code: Đây là việc mà hầu như team nào cũng có trong quy trình làm việc của mình, nhưng số người làm tốt việc này là rất ít, nếu bạn thường review code một cách nghiêm túc thì xin chúc mừng bạn, và cũng chúc bạn may mắn luôn khi review code của đồng nghiệp, bảo trọng! Nếu bạn có một thằng khó tính chuyên bắt lỗi mình ở khâu review trong team, xin chúc mừng bạn, đó là người bạn tốt, đừng gây sự với người ta. Nếu bạn thường xuyên review code theo kiểu scroll 1 phát từ đầu trang tới cuối trang rồi bấm nút Approve, merge code, thì xin phép được chửi vào mặt bạn 1 phát, hai cái tính xấu nêu ở trên đều dễ dàng lọt qua được vòng review vì những thằng cẩu thả như bạn. Mình thề là 10 năm đi review code bạn sẽ chẳng học thêm được cái gì từ đồng nghiệp, đừng nói đến chuyện truyền thụ lại được gì cho đàn em.
Đổ thừa, không fix những thứ không phải của mình: Việc bạn thường làm khi bị giao một con bug đó là bật git blame để truy xem thằng nào viết cái đoạn code bị lỗi đó, và nếu không phải là bạn thì bạn nhất quyết không fix, cố cãi cho bằng được để cái thằng sinh ra bug dù đang bận cắm đầu ra cũng phải quay lại fix con bug đó. Tưởng tượng bạn đánh DotA và bạn đi top, thằng kia đi bot, và dưới bot đang bị 1vs4, bạn từ chối xuống cứu bot chỉ vì top lane đang không có hero địch nào, farm xả láng và def bot là nhiệm vụ của thằng kia, hay lắm $!& #^ #@&…
Chỉ làm đúng requirement, không hơn không kém: Bạn vào một dự án outsource, anh PM dặn trước với bạn là chỉ làm những gì trong scope, không chiều lòng khách hàng mà làm những thứ ngoài phạm vi những gì mà họ đã thỏa thuận với công ty. Và bạn được giao làm một user story về thanh toán online, trong đó bạn PO có ghi là: user nhập thông tin thẻ tín dụng vào form -> frontend gửi thông tin đó về cho backend để tiến hành thanh toán, không có đề cập tới chuyện có mã hóa hay không, nên bạn không làm dù bạn thừa biết là phải mã hóa thì mới đảm bảo về mặt security, và cũng vì nó ngoài scope, bạn cũng không việc gì phải raise vấn đề này lên trong team hoặc với PO để họ sửa sai, đơn giản vì việc đó nằm ngoài scope, hay lắm $!& #^ #@&…
… còn nhiều lắm …
Và khi tất cả những việc trên xảy ra, thì khách hàng sẽ phàn nàn, thậm chí là mắng chửi, rồi sẽ bắt bạn và cả team đi làm OT vào cuối tuần, rồi các bạn sẽ vừa làm vừa chửi: “Đ!& #^ bọn tây, bóc lột vcl”, hoặc chửi bạn PM không biết cách quản lý dự án để cả team phải đi nhận tiền OT như thế này =)))
OK, giờ nhìn lại vấn đề theo một hướng khác:
Tèo là nhân viên của một tiệm bán bánh mì nổi tiếng trong thành phố, vì vậy Tèo cũng là thằng làm bánh thuê, vì đi làm thuê nên Tèo không việc gì phải dồn hết tâm huyết vào mỗi ổ bánh mì mà mình làm ra, Tèo có thể cầm điện thoại vào nhà vệ sinh để ngồi làm chuyện đại sự trong 30 phút sau đó không cần rửa tay và đi ra quầy bánh bốc từng mảng patê trét vào ổ bánh mì thịt chả mà bạn đang chờ mua trên đường đi làm mỗi sáng. Bạn nhận lấy ổ bánh mì được gói trong tờ giấy báo Tèo mua lại từ mấy bà bán ve chai, và nhai ngấu nghiến một cách đầy biết ơn, mì hơi dở, nhưng được cái nó rẻ, kệ. Đến trưa thì bạn bị đau bụng (hiển nhiên rồi =))) bạn bực mình chạy tới tiệm và chửi, đơn giản vì bạn bỏ tiền ra mua bánh mì. Tèo bị chửi thì bực tức suốt từ trưa đến tối. Sau vài tháng thì tiệm bánh mì phải đóng cửa vì quá dở và không đảm bảo vệ sinh, Tèo cũng vì thế mà thất nghiệp vì dính phốt “đi ra” từ cái tiệm mất vệ sinh nhất thành phố, không ai dám nhận Tèo vào làm nữa. ¯\_(ツ)_/¯
Trích một đoạn trong cuốn The Pragmatic Programmer:
When you do accept the responsibility for an outcome, you should expect to be held accountable for it. When you make a mistake (as we all do) or an error in judgment, admit it honestly and try to offer options.
Don’t blame someone or something else, or make up an execuse. Don’t blame all the problems on a vendor, a programming language, management, or your coworkers. Any and all of these may play a role, but it is up to you to provide solutions, not execuses.
Kêt bài: vì là random nên chả có kết bài gì đâu :)) các bạn đọc cho vui thôi nha.
Bài viết được sự cho phép của tác giả Võ Xuân Phong
Webp là gì?
Webp là một định dạng hình ảnh hiện đại, nó cung cấp cơ chế nén lossless (nén không mất mát) và lossy (nén mất mát), hiểu nôm na cơ chế nén lossless giúp file được nén giữ nguyên chất lượng ban đầu, còn cơ chế nén lossy làm cho hình ảnh có độ phân giải và chất lượng bị thay đổi.
Những hình ảnh được nén theo cơ chế nén lossless dung lượng giảm đi 26% khi nén từ định dạng PNG và giảm từ 25% đến 34% khi nén từ định dạng JPEG mà vẫn giữ nguyên chất lượng hình ảnh.
Cơ chế nén lossless và lossy đều hỗ trợ transparency (hình ảnh trong suốt). Hình ảnh có thể giảm dung lượng đi 3 lần so với dung lượng hình ảnh ban đầu khi nén ở cơ chế lossy ở định dạng PNG.
Ưu điểm của Webp
Tăng tốc độ tải trang: Do webp làm giảm dung lượng của file ảnh vì thế tốc độ tải trang khi sử dụng định dạng webp sẽ nhanh hơn các định dạng như PNG và JPEG.
Tiết kiệm băng thông hơn: Cũng do dung lượng file ảnh nhỏ mà chi phí băng thông sẽ giảm đi đáng kể.
Tốt cho SEO: Trang web tăng tốc độ tải đồng nghĩa trải nghiệm người dùng trên trang sẽ tốt và google sẽ đánh giá cao trang web của anh em.
Hiển thị hình ảnh đủ chất lượng: Như đã trình bày với anh em ở trên thì cơ chế nén lossless sẽ giúp cho hình ảnh giảm đi dung lượng nhưng chất lượng hình vẫn không thay đổi là bao.
Hỗ trợ nhiều loại hình ảnh khác nhau như ảnh động và ảnh trong suốt.
Nhược điểm của Webp
Định dạng webp còn khá mới nên chưa được hỗ trợ rộng rãi ở một số phần mềm xem ảnh và các trình duyệt.
Trong thư mục bin này anh em sẽ thấy libwebp có rất nhiều công cụ như cwebp, dwebp, gif2webp v..v. Trong bài viết này mình chỉ quan tâm đến công cụ cwebp thôi, những công cụ khác anh em có thể tự tìm hiểu thêm.
⦿ anim_diff → công cụ cho chỉ ra sự khác biệt giữa các hình ảnh động.
⦿ anim_dump → công cụ dành cho việc xuất ra sự khác biệt giữa các hình ảnh động.
⦿ cwebp → công cụ để mã hóa webp.
⦿ dwebp → công cụ dành cho giải mã webp.
⦿ gif2webp → công cụ cho chuyển đổi ảnh GIF sang webp.
⦿ img2webp → công cụ cho chuyển đổi chuỗi hình ảnh thành tệp web động.
⦿ vwebp → đây là một trình xem tệp tin webp.
⦿ webpinfo → công cụ xem thông tin về một tập tin webp.
⦿ webpmux → công cụ tạo ra những hình ảnh webp động từ những hình ảnh tĩnh.
Với cách cài đặt thủ công như thế này thì anh em cần phải cài đặt thêm biến môi trường nữa.
Anh em nhớ đổi đường dẫn tới libwebp cho đúng nha, bây giờ thì mình đã sử dụng được công cụ cwebp rồi hãy thử xem nào.
Cách sử dụng Webp để chuyển đổi định dạng ảnh
Sau khi đã cài đặt được webp, anh em hãy thử dùng lệnh cwebp để chuyển đổi hình ảnh nào đó sang định dạng webp ví dụ:
cwebp -q 80 old_image.png -o new_image.webp
Trong đó -q 80 tương ứng với chất lượng hình ảnh là 80%, anh em có thể chỉnh lại thông số tùy theo nhu cầu về chất lượng hình ảnh sau khi hình ảnh mới được tạo ra.
#!/bin/sh
MONITORDIR="/home/vxphong/test-webp"
inotifywait -m -r -e move -e create --format '%w%f'"${MONITORDIR}"| while read NEWFILE;do
echo "File has ${NEWFILE} been created"if[!-f "${NEWFILE%.*}.webp"]; then
sleep 10
cwebp -q 80"${NEWFILE}"-o "${NEWFILE%.*}.webp"
fi
done
File này mục đích để giám sát những hình ảnh trong thử mục /home/vxphong/test-webp được tạo ra hoặc được di chuyển vào thì nó sẽ tự động tạo ra 1 file webp.
Trong file này anh em nhớ thay đổi đường dẫn MONITORDIR đến đúng đường dẫn anh em lưu các file hình ảnh nha.
Ở đây mình tạo ra thư mục test-webp và sẽ lưu hình ảnh ở thư mục này
mkdir /home/vxphong/test-webp
Thiết lập quyền excute cho file.
chmod 755 monitor-file-creation.sh
Tới bước này anh em nhớ cài thêm inotify-tools nữa nhé tool này dùng để giám sát sự thay đổi các file trong thư mục nào đó.
sudo apt update
sudo apt install inotify-tools
Sau khi đã cài đặt xong thì tạo 1 service để chắc chắn cái script chuyển đổi file webp của anh em luôn hoạt động.
nano /etc/systemd/system/webp.service
Anh em tạo một service webp ở đường dẫn /etc/systemd/system/webp.service với nội dung sau:
Ở file service này anh em nhớ thay đổi đường dẫn của ExecStart thành đường dẫn mà anh em đã lưu file monitor-file-creation.sh nha.
Khởi chạy service
systemctl start webp
Khởi chạy khi khởi động service
systemctl enable webp
Kiểm tra status của webp service
systemctl status webp
Kiểm tra kết quả:
Mình sẽ copy một hình ảnh jpg từ ngoài Desktop vào hoặc anh em có thể sử dụng ứng dụng web của anh em để upload hình ảnh lên thư mục này và chờ xem kết quả.
Sau khi thực hiện việc copy hình ảnh vào thư mục này thì anh em đã thấy nó đã tạo ra 1 hình ảnh có đuôi .webp rồi đấy. Bước tiếp theo là hiển thị hình ảnh trên UI dựa vào đường dẫn tới hình.
Ở trên mình đã trình bày ưu và nhược điểm khi sử dụng webp, webp giúp tăng tốc độ tải của trang web, tiết kiệm được băng thông do dung lượng webp có kích thước khá nhỏ. Bên cạnh đó thì anh em cũng cần phải lưu trữ cả định dạng gốc để trường hợp trình duyệt không hỗ trợ định dạng webp thì sẽ phải tải hình ảnh với định dạng gốc, điều này thì mình thấy khá rườm rà.













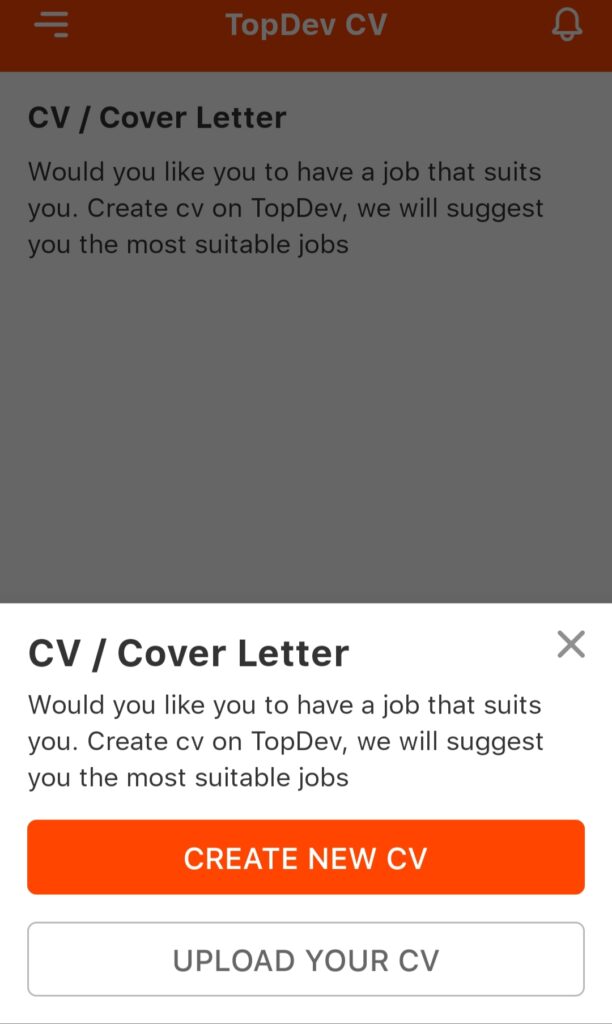
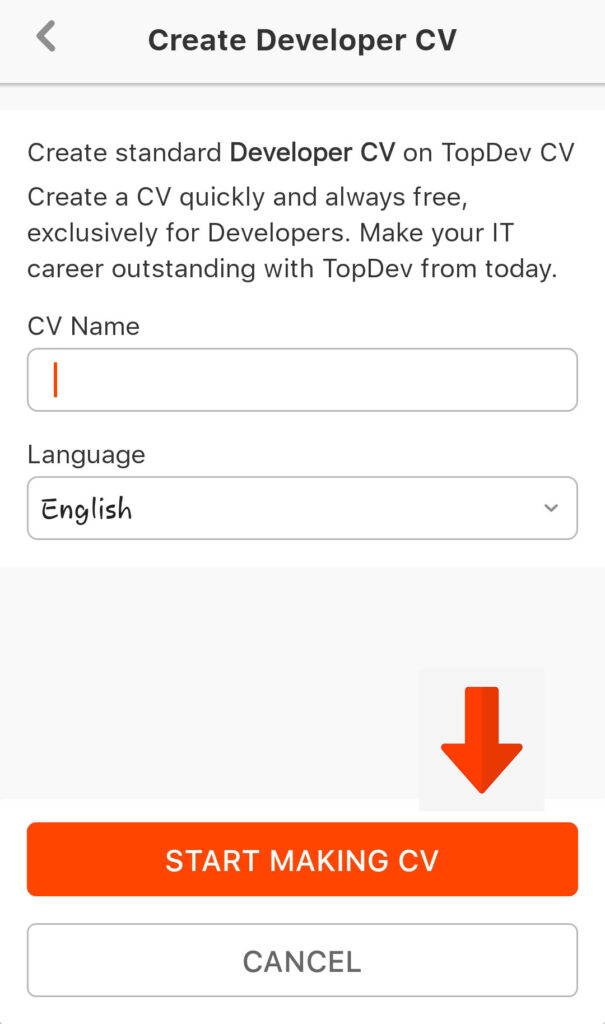
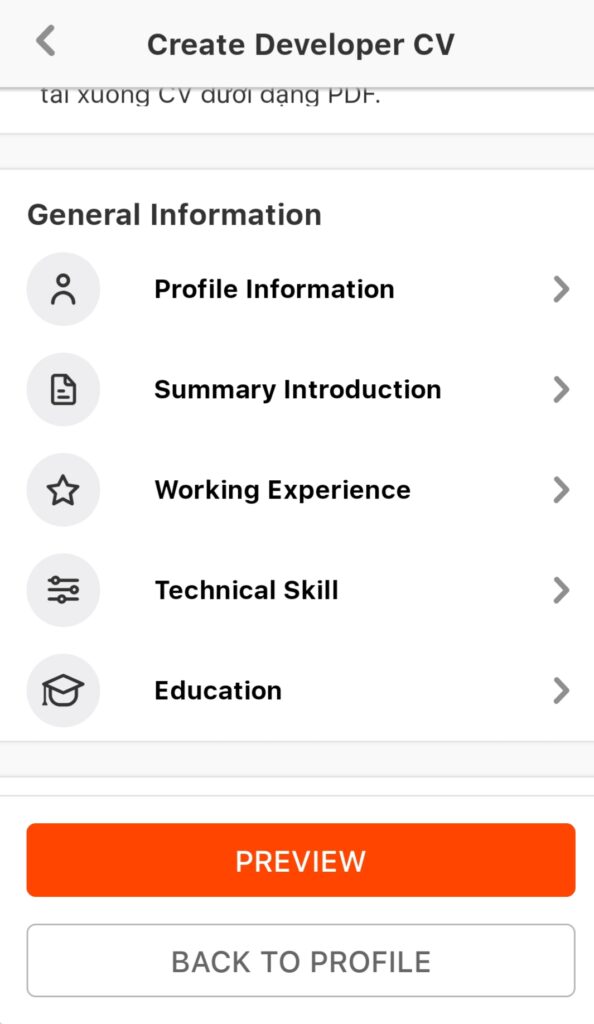
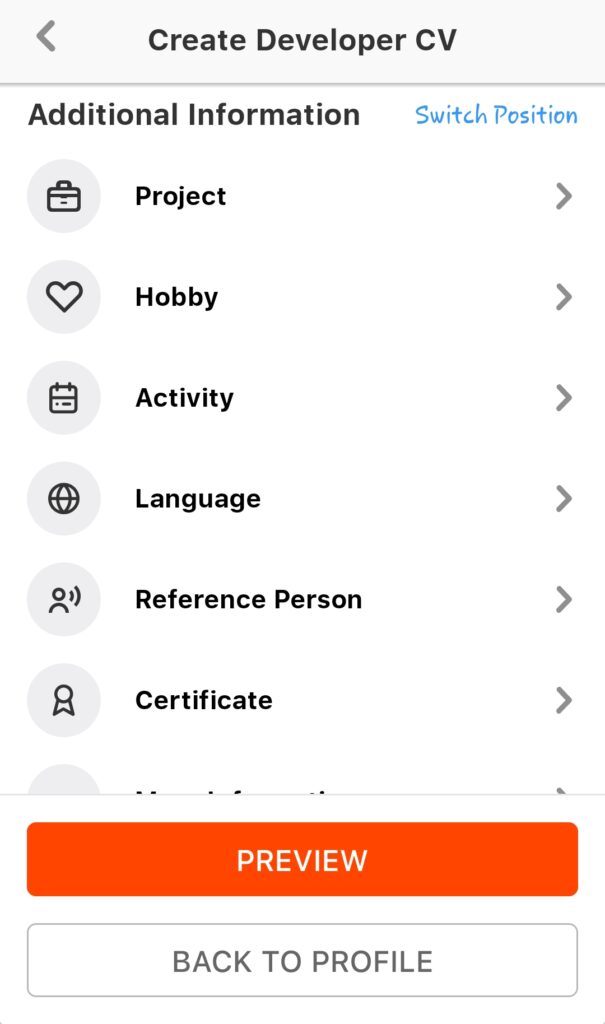
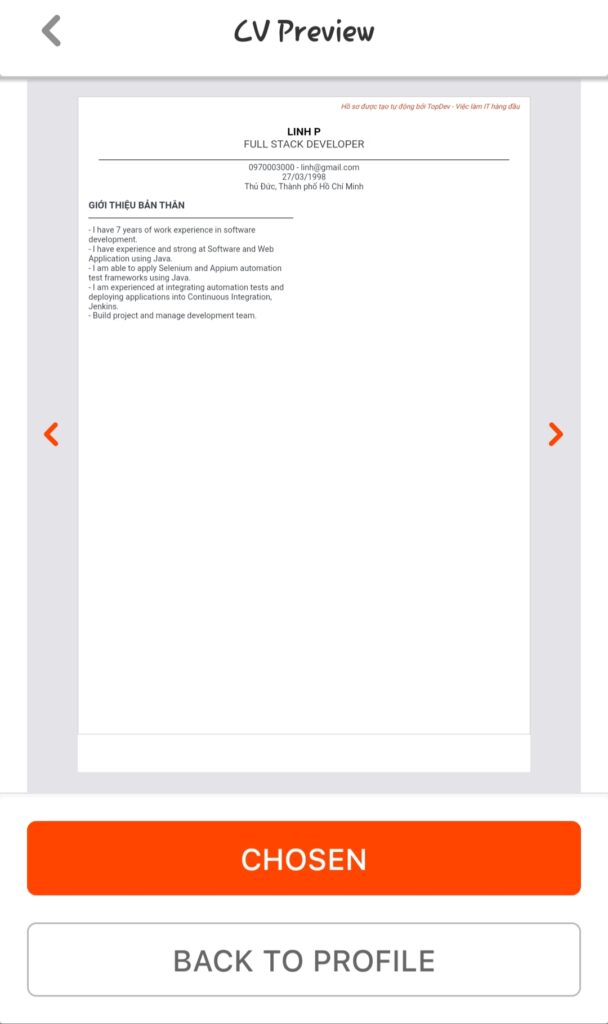
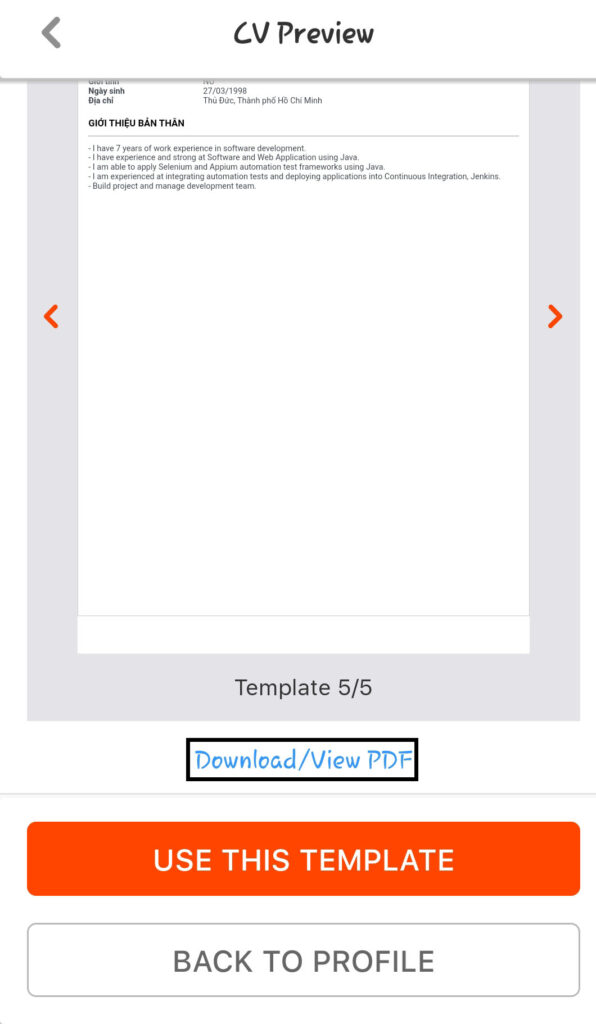

















 )
)