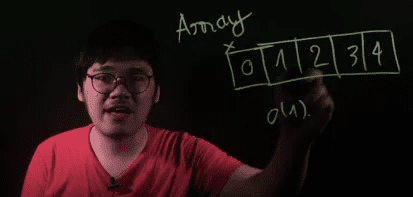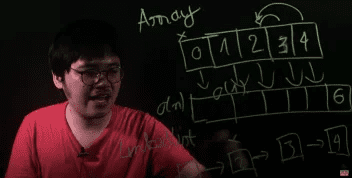Anh em khi ấn vào bài viết này hẳn đã không dưới một lần nghe qua về IOT (Internet of things), vạn vật kết nối internet, IoV (internet of vehicle) không là ngoại lệ, khác mỗi chữ V thôi à.
V ở đây không phải là Vinfast VF8 đang hot nha anh em, V ở đây là Vehicle. Internet of Vehicle (vạn phương tiện kết cmn nó nối). Vehicle bao gồm đủ thứ như xe, thuyền, tàu bay, ô tô, ..
Vậy IoV cụ thể là gì?. Xin mời anh em tới ngay phần định nghĩa.
1. IoV là gì?
The Internet of Vehicles is a network that interconnects pedestrians, cars, and parts of urban infrastructure. It uses various sensors, software, in-built hardware, and types of connection to enable reliable and continuous communication. As a part of a smart city, IoV strives to make transportation more autonomous, safe, fast, and efficient, reducing resource waste and detrimental impacts on the environment.
Internet of Vehicles là mạng lưới kết nối người đi bộ, người đi ô tô, và các bộ phận khác của cơ sở hạ tầng đô thị. Nó sử dụng nhiều cảm biến, phần mềm, phần cứng tích hợp và các loại kết nối khác nhau cho phép giao tiếp tin cậy và thông suốt giữa các phương tiện và hệ thống điều khiển. IoV là một phần của thành phố thông minh, IoV cố gắng làm cho giao thông trở nên tự chủ, an toàn, nhanh chóng và hiệu quả hơn, giảm thiểu tài nguyên sử dụng và tác động tiêu cực tới môi trường.
Đù cái định nghĩa nó dài, có 2 ý chính anh em có thể nhớ:
Là một phần của thành phố thông mình, IoV nhỏ hơn IoT (things lớn hơn nhiều so với vehicles)
Có thể giúp đỡ giao thông, tự chủ hơn, thông mình hơn, dễ dàng quản lý hơn
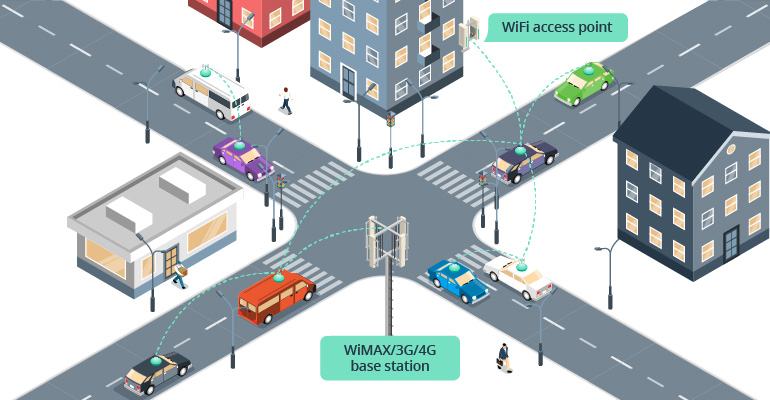
Kể cả IoT hay IoV, nếu muốn triển khai tất nhiên cần có cơ sở hạ tầng tốt, cộng với sự kết nối đồng bộ giữa hạ tầng, xe cộ và hệ thống quản lý.
Về cơ sở hạ tầng, đèn giao thông, làn đường, bãi đỗ xe và trạm giao thông công cộng cũng phải được kết nối, cung cấp giải pháp thông minh cho các phương tiện di chuyển trên đó.
Cụ thể hơn từng thành phần của từng layer trong kiến trúc 3 layer của IoV:
Perception (có thể dịch nôm na là lớp thu thập), bản thân từ perception thì thường được hiểu nhiều hơn với ý nghĩa là nhận thức, lớp này bao gồm nhiều các cảm biến và thiết bị được sử dụng để thu thập dữ liệu. Lớp này bao gồm các thiết bị như: các thiết bị phần cứng gắn bên trụ giao thông, trên làn đường, camera xe ô tô hoặc điện thoại thông minh.
Network (lớp kết nối), lớp này chịu trách nhiệm hiển thị các phương tiện được kết nối trong mạng IoV, truyền đi các kết nối, cung cấp thông tin về đường sá, tình trạng giao thông. Các mạng thường được sử dụng trên lớp kết nối bao gồm: Wifi, 4G/5G, WLAN, Bluetooth và WAVE
Application (lớp ứng dụng). Lớp này xử lý, lưu trữ và dùng những dữ liệu đã thu thập được. Từ dữ liệu và thông qua cách truyền tải của hai lớp trước, ta có thể sử dụng vào các mục đích khác nhau của IoV
3.1 Kiến trúc 3 layer
3 layer phân chia ở đây là mô hình lớn của IoV (vehicles và nhiều yếu tố liên quan khác phụ trợ như đèn, đường, camera giám sát giao thông). Đi vào bài toán cụ thể của IoV là cars (xe hơi). Ta cũng có 3 lớp tương tự.
The first layer includes sensor nodes inside the vehicle, which are used to collect local information and detect specific situations of importance such as the vehicle’s operating conditions and driving method.
Lớp đầu tiên bao gồm các con cảm biến bên trong thiết bị, sử dụng để lấy thông tin của xe và xác định tình hình hiện tại của phương tiện như điều kiện hoạt động và hiện đang lái xe theo phương thức nào
Lớp thứ hai
The communication layer is the second level, supporting different V2X communication activities. It ensures that current and emerging networks are linked seamlessly viaexisting communication standards
Lớp giao tiếp là lớp thứ hai, hỗ trợ các hoạt động giao tiếp V2X khác nhau. Đảm bảo rằng mạng lưới hiện tại được giao tiếp liền mạch với nhau thông qua các tiêu chuẩn giao tiếp hiện có
Lớp thứ ba
Layer three includes statistical hardware, storage capacity, processing unit, shaping IoV intelligence and provides big data-based processing capacity
Lớp thứ ba bao gồm phần cứng thống kê, dung lượng lưu trữ, các đơn vị xử lý, định hình. Trí tuệ nhân tạo của IoV và khả ănng xử lý dữ liệu lớn
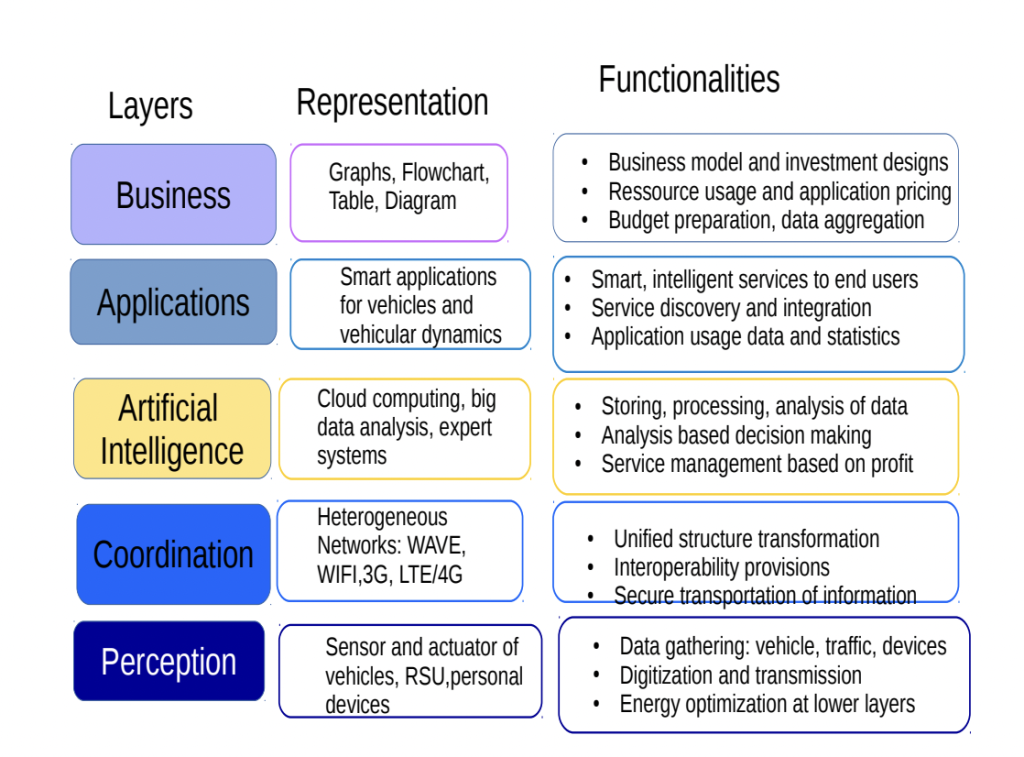
3.2 Kiến trúc 5 layer và 7 layer
Kiến trúc 5 lớp trong IoV
Đi sâu hơn vào IoV Architecture cho từng bài toán hoặc business cụ thể, người ta có thể vẽ ra mô hình 5 hoặc 7 lớp.
Bổ sung thêm lớp Coordination, lớp này chịu trách nhiệm chính về tương tác (interoperability), định tuyến (routing), message transportation security (bảo mật truyền vận). Ngoài ra các lớp khác như Business, Management là các lớp bổ sung thêm tuỳ thuộc vào từng dự án cụ thể.
Kiến trúc 7 lớp trong IoV
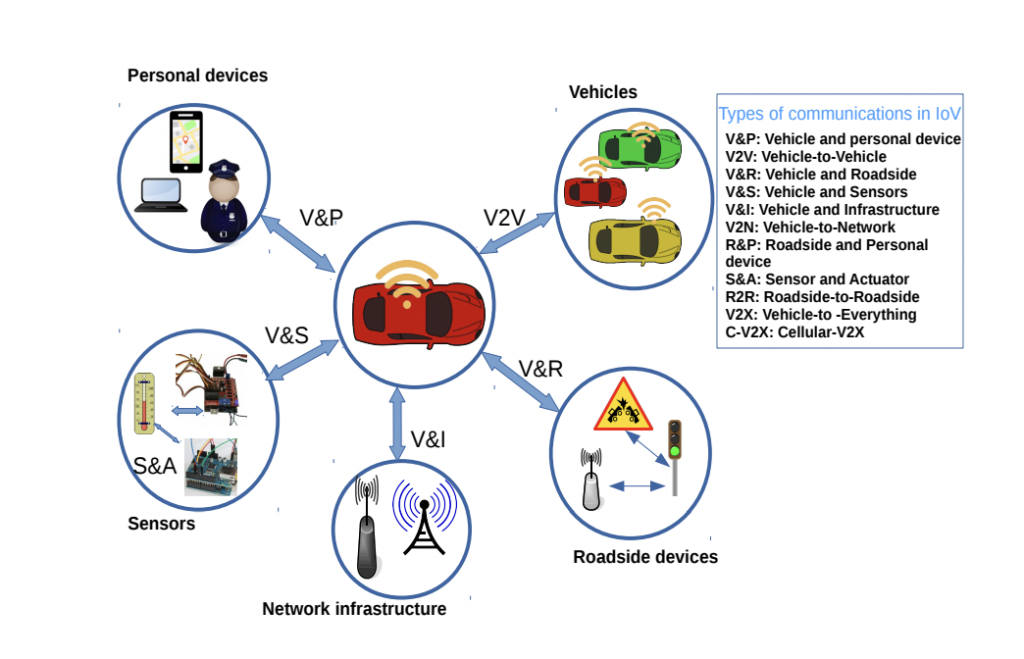
4. Giao tiếp trong IoV (IoV communication model)
Khi nói đến IoT hay IoV, điều tối quan trọng là các thực thể (entities) trong đó giao tiếp như thế nào. IoV communication model định nghĩa các phương thức giao tiếp. Tạo điều kiện trao đổi thông tin giữa ô tô với ô tô, giữa hạ tầng đường bộ, lịch trình, tình trạng giao thông với nhau.
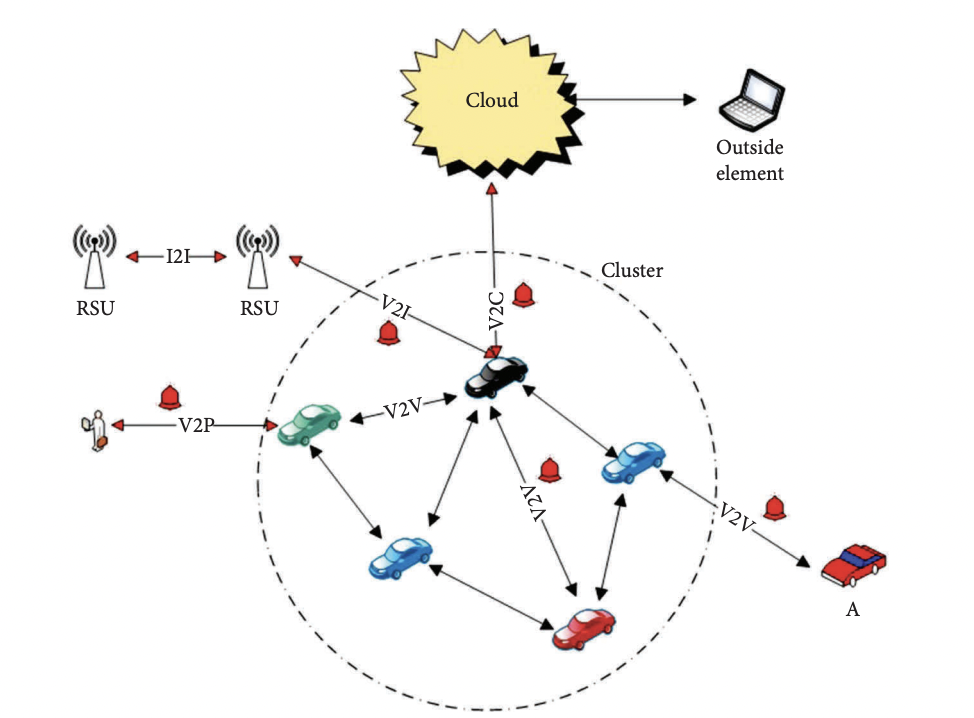
Một số phương thức giao tiếp chính trong IoV (bao gồm 5 kiểu kết nối chính)
Vehicle – to – Vehicle (phương tiện với phương tiện) – V2V
Vehicleto-Infrastructure (phương tiện với kiến trúc) – V2I
Vehicle-to-Pedestrian (phương tiện tới người đi bộ ) – V2P
Vehicle-to-Cloud (phương tiện với cloud) – V2C
InterVehicle (Inter-V, giao tiếp nội bộ trong xe)
Một số khái niệm khác về giao tiếp trong IoV
5. Ưu điểm của Internet of Vehicle (IoV)
Công nghệ luôn là yếu tố giúp con người nâng cao chất lượng sống, IoV cũng không phải là một ngoại lệ. IoV cũng là một thành phần quan trọng trong xây dựng thành phố thông minh. Đem lại những hiệu quả to lớn và rõ ràng cho giao thông vận tải.
Safety (an toàn), yếu tố đầu tiên. Trong mạng lưới, tất cả các xe đều cung cấp dữ liệu realtime về vị trí, tình trạng giao thông. Từ đó có thể đưa ra các phương án trợ giúp khi có sự cố. Việc hỗ trợ các phương tiện tự lái giúp loại bỏ khả năng tai nạn do anh em ngủ gật hay mệt mỏi.
Efficiency and speed (hiệu quả và tốc độ). Khi được kết nối và đồng bộ với các thành phần liên quan (như hệ thống giao thông, làn đường, các yếu tố tham gia giao thông khác, …). Từ những thông tin đã có IoV có thể giảm thiểu tắc đường, cung cấp lộ trình tốt hơn
Environment (môi trường). Với hệ thống hoàn chỉnh, người dân có thể chia sẻ phương tiện đi lại thông qua lộ trình đã có sẵn, từ đó giảm thiểu tác động tới môi trường thông qua phát thải của phương tiện giao thông. Phần lớn ô tô trong tương lai cũng chạy bằng điện, từ đó giảm thiểu tác động tới môi trường.
Business benefits (lợi ích kinh doanh). Dự liệu từ hệ thống cho phép các công ty cung cấp phương tiện bảo hành kịp thời, giảm trộm cắp xe, phân tích hành vi và tương tác của người dùng.
CSS là ngôn ngữ quen thuộc của bất kỳ web developer nào, bởi nó là một trong những ngôn ngữ “vỡ lòng” khi bạn bắt đầu học lập trình web. Bản thân CSS rất thú vị, bởi nó có nhiều màu sắc, nhiều thuộc tính hay ho. Tuy nhiên khi viết code CSS thì ngược lại – khá nhàm chán.
I. Vấn đề của CSS
Làm việc nhiều với CSS, mình nhận ra rằng có một số vấn đề như sau:
Tên class, id rất dễ bị trùng nhau, muốn phân biệt thì phải thêm tiền tố, hoặc sử kiểu tổ hợp các selector. Điều này làm code css dài ngoằng, khó nhìn, và bị lặp đi lặp lại.
Mặc dù hỗ trợ var() và env() giúp CSS có thể lưu giá trị và sử dụng biến, nhưng có vẻ cộng đồng developer không hoan nghênh cách làm này, do không phải trình duyệt nào cũng hỗ trợ, và tốc độ hiển thị css có thể sẽ chậm đi.
Trước khi đẩy lên production, CSS thường được minify
Từ những vấn đề trên, một khái niệm mới là CSS Preprocessor đã ra đời, giúp viết CSS nhanh hơn, gọn hơn và khoa học hơn.
CSS Preprocessor là những ngôn ngữ tiền xử lý CSS, có nhiệm vụ tương tự CSS, có cú pháp gần giống với CSS và có thể compile ra CSS.
Xét về ưu điểm, CSS Preprocessor giúp bạn viết CSS đơn giản hơn (đơn giản hơn thế nào thì còn tùy loại CSS Preprocessor, nhưng chắc chắn đơn giản hơn), tuy nhiên bạn sẽ phải tốn thêm một bước đó là compile (dịch) ra CSS. Mà để compile ra CSS, đồng nghĩa với việc bạn sẽ phải cài một số tool – điều mà những bạn mới bắt đầu không thích.
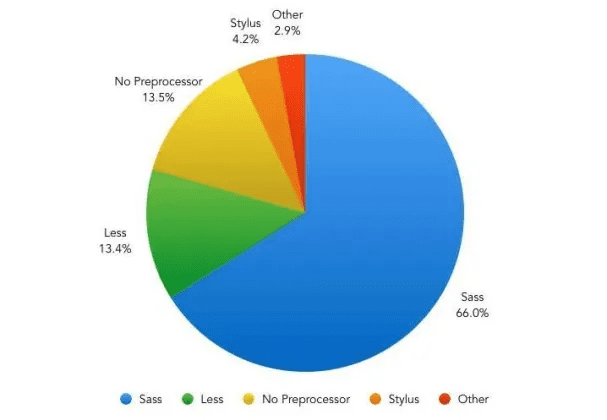
Hiện nay có khá nhiều ngôn ngữ CSS Preprocessor, với mỗi ngôn ngữ lại có ưu nhược điểm khác nhau. Tuy nhiên có SCSS là CSS Preprocessor language chiếm ưu thế hơn cả.
Độ phổ biến của các CSS Prepocessor languages
Như biểu đồ trên, bạn có thể thấy SASS chiếm tới 66%, ăn đứt tất cả các ngôn ngữ còn lại. Lý do SCSS chiếm được nhiều tình cảm của các developer đến vậy là do cú pháp của nó rất thân thiện, khá tương đồng với CSS.
Để chứng minh điều mình vừa nói, thì bạn có thể xem ví dụ so sánh về cú pháp của CSS và SCSS dưới đây:
Khá giống nhau phải không? Chỉ khác ở chỗ SCSS cho phép bạn viết các selector lồng nhau, còn CSS thì không. Cũng có thể nói SCSS là phiên bản mở rộng của CSS bởi trong cú pháp của SCSS, 100% cú pháp của CSS đều được hỗ trợ.
Giới thiệu qua một chú SCSS như vậy để các bạn thấy rằng nó rất dễ, còn chi tiết cú pháp, chi tiết cài đặt môi trường để viết SCSS như thế nào thì mình sẽ gửi tới bạn ở một bài viết khác.
IV. Kết luận
Học cách sử dụng CSS Preprocessor không khó nhưng lại đem lại hiệu quả to lớn, rất đáng để bạn đầu tư thời gian tìm hiểu.
Hy vọng với bài viết ngắn gọn trên, mình sẽ giúp bạn hình dung được ra CSS Prepocessor là gì.
MySQL là một hệ thống quản trị cơ sở dữ liệu mã nguồn mở (RDBMS) hoạt động theo mô hình client-server ; phổ biến nhất thế giới và được các lập trình viên, nhà phát triển hệ thống, ứng dụng rất ưa chuộng. MySQL gần như trở thành một kiến thức bắt buộc phải có với 1 lập trình viên muốn trở thành Backend Developer, nó cũng được sử dụng để giảng dạy trong hầu hết các khóa học liên quan đến việc thao tác với cơ sở dữ liệu (Databases). Hôm nay mình sẽ cùng các bạn tìm hiểu về hệ thống này và lộ trình học MySQL cho công việc của 1 lập trình viên nhé.
Các khái niệm hệ thống cơ sở dữ liệu
Database: là tập hợp dữ liệu theo cùng 1 cấu trúc, nơi chứa và sắp đặt dữ liệu
RDBMS: hệ thống quản lý cơ sở dữ liệu quan hệ, cho phép bạn triển khai 1 Database với các bảng dữ liệu, cột(column), chỉ mục(index); thông dịch 1 truy vấn SQL và tổ hợp thông tin từ các bảng khác nhau.
SQL: ngôn ngữ truy vấn có cấu trúc, phục vụ việc lưu trữ và xử lý thông tin trong cơ sở dữ liệu quan hệ.
Như vậy MySQL là 1 RDBMS giúp chúng ta triển khai được 1 database, và sử dụng các câu lệnh SQL để thực hiện việc đọc, ghi, truy vấn cơ sở dữ liệu.
MySQL là mã nguồn mở được thiết kế bởi 1 công ty phần mềm Thụy Điển có tên là MySQL AB từ những năm 1995; hiện tại thì nó đang được sở hữu bởi Oracle do các thương vụ mua lại vào năm 2008 và 2010. MySQL làm việc được trên nhiều hệ điều hành và với hầu hết các ngôn ngữ lập trình hiện nay từ PHP, Java, C, JS, Python … chính vì thế nó rất phổ biến và được sử dụng cho nhiều công ty, tập đoàn từ lớn đến nhỏ.
MySQL là 1 công cụ giúp bạn tạo ra cơ sở dữ liệu và thao tác với nó, tất nhiên trong 1 hệ thống thì không thể chỉ tồn tại MySQL, nó cần những thành phần khác để kết nối và sử dụng. Vì thế trước khi bắt đầu học MySQL, bạn hãy chắc chắn rằng mình đã trang bị 1 số kiến thức về frontend cũng như backend để giao tiếp với MySQL. Tiếp theo chúng ta sẽ cùng đi cùng bước trong lộ trình học MySQL:
Cài đặt, thiết lập môi trường và thao tác với Database
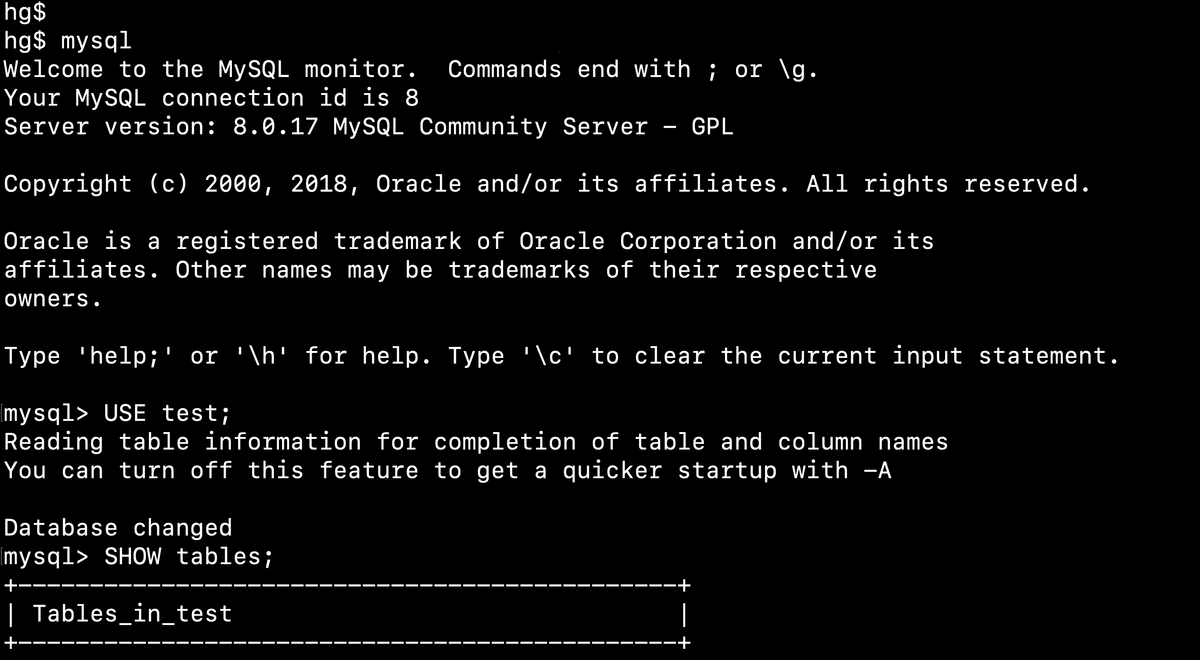
Bạn có thể dễ dàng tải MySQL từ trang chủ và cài đặt khá dễ dàng trên nhiều nền tảng Window, MacOS hay Linux. MySQL có cung cấp cho các bạn 1 số tool, ứng dụng để thao tác với database 1 cách trực quan, tuy nhiên khi ban đầu học MySQL, 1 lời khuyên cho bạn là hãy sử dụng command lines để học và nhớ các lệnh cần thiết.
Hãy thử và ghi nhớ các thao tác lệnh cơ bản với database thông qua MySQL như dưới đây:
Tạo database: CREATE DATABASE Ten_co_so_du_lieu;
Xóa database: DROP DATABASE ten_co_so_du_lieu;
Tạo bảng: CREATE TABLE ten_bang (ten_cot kieu_du_lieu_cucot);
Xóa bảng: DROP TABLE ten_bang;
Chèn dữ liệu vào bảng: INSERT INTO ten_bang ( truong1, truong2,…truongN ) VALUES ( giatri1, giatri2,…giatriN );
Lấy dữ liệu: SELECT truong1, truong2,…truongN FROM ten_bang
MySQL cung cấp các hàm mysql_connect để mở kết nối tới cơ sở dữ liệu dành cho từng ngôn ngữ lập trình khác nhau. Trong đó các tham số dùng chung bạn cần lưu ý:
Server: hostname đang chạy database server, mặc định sẽ dùng port 3306
User/Passwd: thông tin tài khoản đăng nhập
Client_flags: 1 số config mặc định của MySQL như MYSQL_CLIENT_SSL, MYSQL_CLIENT_COMPRESS, MYSQL_CLIENT_IGNORE_SPACE, MYSQL_CLIENT_INTERACTIVE
Sau khi kết nối thành công, bạn có thể tương tác với cơ sở dữ liệu trong MySQL, thực hiện các câu lệnh truy vấn từ ứng dụng của bạn. Để đóng kết nối đến MySQL, chúng ta sử dụng function mysql_close.
Đến bước này chúng ta đã sẵn sàng với MySQL, có thể tạo ra ứng dụng thực tế để chạy và học nó. Bước tiếp theo hãy đi vào kiến thức cơ bản về ngôn ngữ SQL cũng như MySQL.
MySQL cơ bản
Kiểu dữ liệu
Kiểu dữ liệu trong MySQL: có 3 loại cơ bản là kiểu số, kiểu datetime và kiểu chuỗi
Hãy cố gắng nắm rõ các loại dữ liệu này, với bài toán thực tế khi mà database của bạn có hàng triệu bản ghi thì việc 1 field chuyển được từ INT xuống thành TINYINT giúp size database của bạn giảm xuống được rất nhiều.
Các câu lệnh truy vấn
SQL viết tắt của Structured Query Language – ngôn ngữ truy vấn có cấu trúc, nó là 1 ngôn ngữ, là tập hợp các lệnh để tương tác với cơ sở dữ liệu. SQL là ngôn ngữ chuẩn được sử dụng hầu hết cho hệ cơ sở dữ liệu quan hệ, vì thế muốn học MySQL thì bạn bắt buộc phải học SQL.
Các lệnh SQL tiêu chuẩn để tương tác với cơ sở dữ liệu quan hệ là CREATE, SELECT, INSERT, UPDATE, DELETE và DROP, về bản chất chúng được chưa thành 3 nhóm:
Định nghĩa dữ liệu: CREATE, ALTER, DROP
Thao tác dữ liệu: SELECT, INSERT, UPDATE, DELETE
Điều khiển dữ liệu: GRANT, REVOKE
Trong 1 câu query SQL (truy vấn đơn) thì không chỉ sử dụng dữ liệu trong 1 bảng, vì thế bạn cũng cần tìm hiểu sử dụng JOIN 1 cách hiệu quả. Ngoài ra các từ khóa khác phục vụ cho từng bài toán cụ thể thì SQL cũng cung cấp cho chúng ta như WHERE, LIKE, ORDER BY, GROUP BY, …
Transaction trong MySQL
Transaction là 1 đơn vị công việc được thực hiện bởi 1 database; hiểu đơn giản thì đó là thì bạn sẽ gộp nhiều truy vấn SQL vào thành một nhóm và thực thi tất cả chúng cùng nhau. Nếu trong 1 transaction có hoạt động riêng nào đó thất bại thì toàn bộ transaction đó sẽ thất bại.
Transaction quan trọng tương tự như Promise trong ngôn ngữ lập trình, nó bắt đầu với lệnh BEGIN WORK và kết thúc với hoặc 1 lệnh COMMIT (khi thành công) hoặc lệnh ROLLBACK (khi thất bại). Transaction đảm bảo rằng database của bạn được thay đổi 1 cách chính xác và không bị ảnh hưởng từ các yếu tố khác chen vào giữa.
Đến đây các bạn có thể tự tin với các kiến thức về MySQL của mình để làm việc trong các dự án thực tế và phục vụ cho công việc. Bước tiếp theo hãy cố gắng tìm hiểu những kiến thức nâng cao hơn về MySQL.
MySQL nâng cao
MySQL nâng cao là những kỹ thuật, khái niệm được MySQL định nghĩa ra để chúng ta sử dụng nhằm giải quyết các bài toán khó, đặc thù, hay thao tác với dữ liệu lớn. Có thể kể ra ở đây 1 số kỹ thuật mà các bạn nên tham khảo:
View: tác dụng như 1 bảng ảo với các fields và records tự định nghĩa giúp tăng tốc độ truy vấn dữ liệu từ database
Stored Procedure: các hàm xử lý điều kiện (IF ELSE, SWITCH CASE) hay xử lý chuỗi (replace, concat, count), … giống hệt như ngôn ngữ lập trình viết ngay trong câu truy vấn của MySQL. Nó giúp tăng hiệu suất của ứng dụng, giảm thời gian giao tiếp với database nếu bạn biết sử dụng đúng cách.
Index: là dữ liệu có cấu trúc B-Tree giúp cải thiện tốc độ tìm kiếm trên 1 bảng và giảm chi phí thực hiện truy vấn. Thực tế thì kỹ thuật này áp dụng ngay từ lúc bạn học MySQL cơ bản, tuy nhiên để đào sâu và tận dụng nó thì có rất nhiều thứ cần tìm hiểu.
Full Text Search: kỹ thuật tìm kiếm các tài liệu không phù hợp với tiêu chí tìm kiếm. Nó được sử dụng phổ biến nhất khi tìm kiếm file hay các tài liệu kích thước lớn, được sử dụng rất nhiều bởi các công cụ tìm kiếm như Google, Bing
Trigger: trình kích hoạt được sử dụng để thực hiện 1 hành động nào đó khi có tác động theo thiết lập từ trước. Kỹ thuật này cũng tương tự như trong ngôn ngữ lập trình, giúp các bạn thêm các hoạt động ngầm tác động trực tiếp lên database khi có điều kiện nhất định xảy ra.
Còn rất nhiều các kỹ thuật, kiến thức khác trong MySQL mà các bạn có thể tìm hiểu và học thêm. Khi đã khá thành thạo và quen thuộc với MySQL nói riêng cũng như 1 hệ quản trị cơ sở dữ liệu nào đó, nếu xác định trở thành 1 Database Developer, bạn có thể cân nhắc 2 hướng:
Đi thiên về kỹ thuật: trở thành Data Architect – thiết kế ra các cơ sở dữ liệu cho doanh nghiệp; nhất là trong thời kỳ hiện nay với AI và BigData thì vị trí này đang trở nên rất cần thiết.
Theo thiên hướng quản lý: trở thành PM, BA – việc nắm được kiến thức SQL giúp bạn có thể hỗ trợ được rất nhiều cho cả team Dev và team Tester trong dự án làm việc.
Kết bài
Qua bài viết này chúng ta đã cùng nhau tìm hiểu về lộ trình học MySQL, cũng có rất nhiều kiến thức để học và tìm hiểu tương tự như 1 ngôn ngữ lập trình nào. Nếu muốn trở thành 1 MySQL Developer, hãy bắt đầu học và làm thử từng bước như trên nhé. Cảm ơn các bạn đã đọc và hẹn gặp lại trong các bài viết sau của mình.
Nếu đã có bài làm một website trong năm 2016 nó như thế nào, thì giờ ta sẽ nói xem viết css trong năm 2024 sẽ ra mần sao
Anh technical leader: em biết sao không, anh đã không viết code từ năm 2016 tới giờ, công việc của anh giờ chỉ toàn làm chính trị trong công ty thôi. Giờ em thấy cái dự án này công ty mình mới lấy về, họ muốn thêm phần giao diện cho nó khác đi, sửa responsive lại chút
Ngon ăn đấy anh, nhận đi.
Cái này họ làm React, nhưng mà lúc đó không biết đứa nào viết chỉ có một file css duy nhất với hơn 3000 dòng code, nhìn gớm quá, nhiều cái cứ xài tới xài lui mà không chịu kế thừa, cấu trúc thì khỏi nói rồi, gớm luôn, em thấy giờ mình làm sao cho tốt?
Đúng rồi anh, ai mà làm như thế.
Trước mắt, chúng ta coi hết lại đống này, xóa bớt mấy cái không cần thiết, sắp xếp lại, comment mọi thứ cho nó rõ ràng
Làm trên một file CSS đó luôn hả anh?
Ừ thì mình làm thêm bộ màu mới, thêm mấy tương tác cho nó cool hơn, sửa lỗi media queries, chắc là đủ rồi
Được mà, mà giờ không ai viết CSS thuần nữa đâu anh.
Giờ mình có những lựa chọn khác nào vậy em?
Giờ mình có nhiều framework, với những bộ màu đã định nghĩa sẵn, làm sẵn luôn responsive và hiệu ứng nhè nhẹ.
Kiểu bootstrap đúng không?
Xài cũng được, nhưng em không khuyến khích anh xài cái đó.
Sao vậy ta, hồi anh còn code, nó nổi lắm mà
Bớt nổi rồi anh. Giờ còn nhiều em hót không kém như Foundation, Bulma, Materialize, Semantic UI, Tailwind
Chọn đại một cái được không em
Mỗi thằng có ưu nhược khác nhau anh à, mà xài những cái này, các website bây giờ cứ na ná nhau, kiểu template, nói thật nhìn nó khắm lắm.
Vậy hổng lẽ tự viết sao em?
Bậy nè, anh không nên tự viết từ đầu chi, mà anh phải đi override lại chúng thôi, cũng khá khá nhiều thứ cần override.
Ít nhất nó cũng giúp chúng ta đơn giản hóa việc layout và responsive đúng chứ?
Nếu mà không yêu cầu cao, anh dùng những thư viện nhẹ hiều như Skeleton hay Pure CSS đi.
Pure CSS, anh tưởng anh đã đang viết pure css
Bậy nè, nó là tên thư viện, mà anh ít nhất biết dùng Flexbox chứ?
Nó là gì đó, anh dùng float không à, ủa mà tại sao ít nhất?
Kiểu layout bây giờ dùng flexbox không anh, còn cao cấp hơn thì dùng luôn css grid
Nó có gì hay ho vậy?
Nếu mà flexbox là kiểu layout một chiều, thì css grid là kiểu layout 2 chiều
Kiểu 2 chiều, như X, Y đúng không
Nó cho phép anh đưa nội dung về dạng row và column, rất nhiều tính năng xịn sò để làm các layout bay bổng
Ngon, vậy xài được đó
Chịu khó học nghe anh, lúc đầu hơi chua ăn đó.
Còn lựa chọn nào khác cho css không em?
Giờ anh có css variable nè, mixins, nesting, import, tính toán, hàm helper để code anh có tổ chức hơn.
Anh có nghe nhầm không, function và variable?
Không nhầm ạ
Mấy cái syntax lạ lồng như thế, có nguy hiểm không
Anh có mấy cái CSS preprocessor lo rồi mà
Như SASS/SCSS?
Đúng. Mà nó khác nhau đó nghe anh, SCSS > SASS, giờ cũng ít ai viết SASS lắm
LESS xài được ko em, anh quen viết LESS
Xưa rồi anh ơi, ai mà viết less nữa, nó chết bà rồi.
Nhiều thứ quá nhỉ
Đó em chưa kể đến mấy cái preprocessor mới ra là Stylus, CSS Crush, Myth đó.
Khó quá, bỏ qua, chọn đại một cái đi
Anh định dùng animation không, có quan tâm tới việc support nhiều trình duyệt không?
Có chứ em
Vậy anh phải coi thêm post-processor nữa, như PostCSS vậy
Nó là gì nữa á
Pre là xử lý đường vào, post là xử lý đường ra đó anh, nó đơn giản là thêm mấy cái syntax phù hợp cho các trình duyệt khác nhau
Vậy còn kinh nghiệm của em, thì chúng ta nên tổ chức sao cho tốt?
Xem thêm BEM á anh, một chuẩn mực đặt tên class sao cho dễ đọc để nuốt
Em có tự chế không đó?
Nào có anh ơi, em còn biết đến OOCSS và SUITCSS nữa mà không dám nói sợ anh nói em nói xạo
Kiểu này là anh phải sấp mặt mấy tháng để cập nhập kiến thức rồi em
Mà anh biết CSS-in-JS chưa?
Nó là cái nồi gì nữa em?
Nó cho anh viết CSS trong file JS
Em đùa vui quá
Xạo làm chó, bây giờ React nó hổng viết CSS như bình thường nữa anh, nó chơi kiểu CSS in JS, hay là styled component. Còn không anh dùng inline style sheet,, CSS module,…
Inline CSS, cái đó là Bad practice mà em
Giờ người ta không nghĩ vậy nữa đâu anh, nó là chuyện bình thường mà. Còn chưa nói đến JSS nữa đó anh
Thôi em à, anh thấy chúng ta đi xa quá rồi, từ CSS mà em chuyển nó thành JSS
Nhưng đó là những gì đang hót nhất mà anh, anh thấy không hót hả.
Anh nghĩ mình nên để yên cái project này và không thêm thắt gì nữa đi em, nó như vậy là đẹp rồi
Ở phần 1, bọn mình đã ôn lại một số khái niệm như Big-O Notation, Time và Space Complexity rồi. Bạn nào chưa đọc thì đọc lại mới hiểu được trong phần 2 này nha.
Trong phần này, tụi mình sẽ ôn lại những cấu trúc dữ liệu rất cơ bản như Array, LinkedList, Stack and Queue nha!
Mình sẽ giải thích sơ về độ phức tạp, ứng dụng của chúng, cũng như những bài toán các bạn hay gặp với các cấu trúc dữ liệu này nhé.
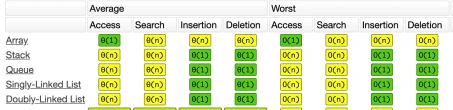
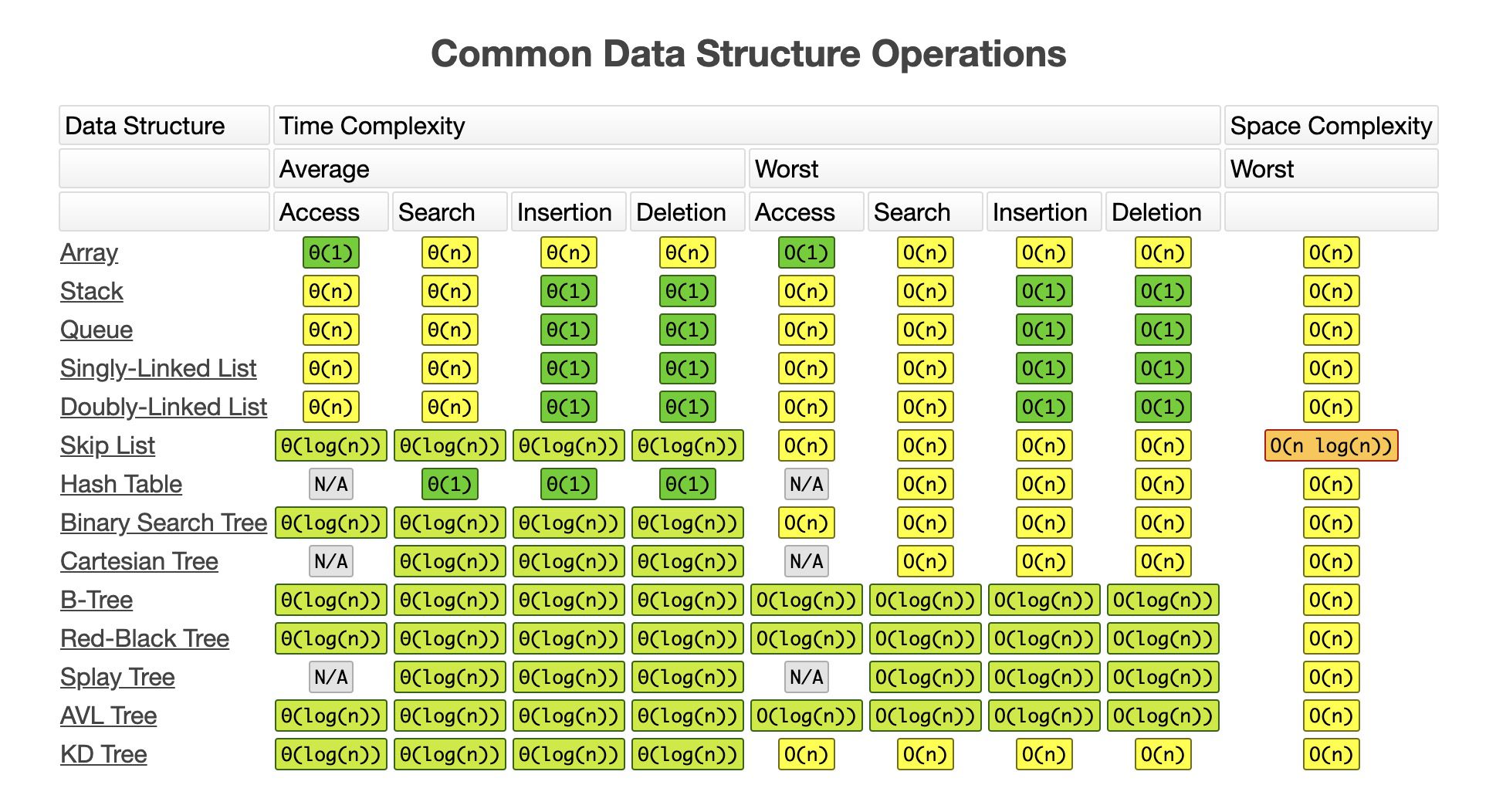
Các bạn tham khảo độ phức tạp của các operation của các CTDL này trong ảnh dưới. Lâu lâu đang đọc mà quên cứ kéo lên xem lại nhé!
Array (Mảng) – Người bạn thân thuộc của lập trình viên
Độ phức tạp
Về bản chất, 1 array là 1 vùng nhớ, gồm nhiều phần tử nằm liền kề nhau.
Dựa vào index i và địa chỉ của phần tử đầu tiên, ta có thể dễ dàng tính ra địa chỉ của phần thử thứ i. Do vậy, ta có thể truy xuất dữ liệu tại vị trí thứ (i) trong array với độ phức tạp (time complexity) là O(1).
Khi array còn chỗ trống, ta cũng có thể dễ dàng thêm phần tử vào array. Thế nhưng, khi array đã đầy, ta không thể thêm phần tử mới. Muốn thêm, ta phải tìm 1 vùng nhớ lớn có thể chứa toàn bộ phần tử, copy toàn array cũ, cộng thêm phần tử mới qua vùng nhớ đó.
Do vậy, thao tác thêm khi array đã đầy sẽ có time complexity và space complexity là O(n). Khi muốn xoá cũng vậy, ta phải bỏ phần tử đó, dồn các phần tử phía sau lên 1 vị trí nên cũng tốn O(n) luôn.
Array là một cấu trúc dữ liệu cực kì quen thuộc, học từ trước cả môn cấu trúc dữ liệu. Array được dùng hàng ngày trong công việc, khi ta muốn lưu trữ 1 danh sách nhiều phần tử. Các thuật toán cơ bản như tìm kiếm, sắp xếp đều sử dụng trên array cả.
Note nhẹ: Trong C#, class List cũng sử dụng Array để lưu trữ. Khi array bị đầy, nó sẽ tạo 1 array khác có dung tích gấp đôi array hiện tại, để hạn chế số lần cần tạo array mới.
Một số bài toán hay gặp:
Các bài toán liên quan đến sắp xếp và tìm kiếm: implement binary search, implement quick sort/merge sort,….
Tìm tổng toàn bộ các phần tử trong array (các phần tử chẵn, lẻ v…v)
Đếm số lần xuất hiện của các phần tử, tìm phần tử xuất hiện nhiều nhất
Như đã nói ở phần trên, nhược điểm của array là thêm phần tử mới khá lâu. Do vậy, người ta sáng tạo ra Linked List.
Mỗi phần tử trong Linked List sẽ có 1 con trỏ, trỏ tới phần tử phía sau nó, khi muốn thêm phần tử ta chỉ việc cho phần tử cuối (tail) trỏ tới phần tử mới là được, khi muốn xoá cũng vậy. Do vậy độ phức tạp chỉ là O(1).
Bù lại, việc truy cập sẽ tốn thời gian hơn. Do ta không biết phần tử thử (n) nằm ở đâu, ta phải duyệt qua n phần tử để tìm phần tử đó, time complexity là O(n).
Ứng dụng
LinkedList được dùng khi lưu trữ một danh sách có số lượng phần tử không cố định (dynamic), cần thêm và xoá phần tử. Nếu biết trước số lượng phần tử là cố định, không cần xoá thì cứ dùng array sẽ nhanh hơn.
Linked List có 2 biến thể là Single-linked list và Double-linked list. Với Double-linked list thì 1 phần tử sẽ lưu 2 con trỏ, trỏ về phía trước và phía sau. Tuy tốn bộ nhớ hơn nhưng truy cập tiện hơn.
Cặp bài trùng Stack (Ngăn xếp) và Queue (Hàng đợi)
Độ phức tạp
Stack cho phép ta thêm 1 phần tử lên đầu stack (push), lấy phần tử trên đầu stack ra (pop). Các phần tử nào vào sau sẽ được ra trước, nên gọi là Last In First Out (LIFO)
Queue thì ngược lại, cho phép ta thêm 1 phần tử vào queue (enqueue), lấy 1 phần tử ra khỏi queue (dequeue). Các phần tử nào vào trước sẽ được ra trước, nên gọi là First In First Out (FIFO)
Hai cấu trúc dữ liệu này cho phép ta thêm/xoá các phần tử dựa theo thứ tự đưa vào, mà không cần phải lưu trữ thời gian. Độ phức tạp của việc đưa vào/lấy ra đều là O(1).
Ứng dụng
Stack được dùng để implement chức năng Undo/Redo, chức năng Go Back/ Go Next các bạn thấy trên trình duyệt
Queue được dùng để implement message queue, cho phép các thành phần trong 1 hệ thống trao đổi thông tin
Implement queue/stack bằng array hoặc linked listz
Dùng 2 stack để implement 1 queue (và ngược lại)
Duyệt các phần tử trong 1 tree (cây) bằng cách dùng stack hoặc queue
Kiểm tra xem 1 chuỗi có đóng mở ngoặc ({[]}) hợp lý hay không – dùng stack
Tạm kết
Các bạn thấy đấy, 4 cấu trúc dữ liệu trong bài này đều có độ phức tạp O(n) khi tìm kiếm. Để tìm 1 phần tử, ta sẽ phải duyệt qua toàn bộ các phần tử chứa trong mảng/linked-list/stack/queue.
Ở phần sau, mình sẽ giới thiệu về 1 CTDL bá đạo có thể tìm kiếm với độ phức tạp O(1) mang tên HashTable; cùng 1 số những CTDL hay ho nhưng ít gặp như Tree hay Graph nhé!
Bài viết được sự cho phép của BBT Tạp chí lập trình
Học một ngôn ngữ lập trình có thể giúp bạn mở ra cơ hội nghề nghiệp mới hoặc có một mức lương cao hơn hiện tại. Nhưng học lập trình có khó không?
Nhiều người mới bắt đầu học lập trình lo lắng rằng việc học một ngôn ngữ lập trình là quá khó. Tuy nhiên, hầu hết họ đều có thể thành thạo việc viết code theo thời gian với tần suất hàng ngày và có cường độ.
Nhiều yếu tố định hình mức độ chăm chỉ của người học đối với việc viết mã. Một số ngôn ngữ lập trình ưu tiên các lệnh đơn giản, trong khi những ngôn ngữ khác sử dụng cú pháp dày đặc. Và một số ngôn ngữ đi kèm với nhiều tài nguyên học tập hơn những ngôn ngữ khác. Một chút nghiên cứu trước khi chọn ngôn ngữ lập trình đầu tiên có thể giúp bạn đỡ gặp khó khăn và bỡ ngỡ khi học một ngôn ngữ lập trình.
Học lập trình có khó không? Điều gì làm cho một số ngôn ngữ lập trình trở nên khó? Và những ngôn ngữ lập trình dành cho người mới bắt đầu tốt nhất là gì? Bài viết sẽ hướng dẫn mọi thứ bạn cần biết trước khi học viết mã.
Học lập trình có khó không?
Học lập trình có khó không? Đối với nhiều người học, việc bắt đầu viết mã thật dễ dàng nhưng khó để thành thạo một ngôn ngữ lập trình. Đó là bởi vì nhiều người học đã va phải một bức tường nào đó trong quá trình học của họ.
Việc bắt đầu học lập trình trở nên dễ dàng hơn bao giờ hết đối với người mới bắt đầu. Trên thực tế, nhiều trường học, khoá học đã dạy lập trình cho học sinh từ nhỏ. Có được kiến thức cơ bản về lập trình sớm giúp bạn dễ dàng sử dụng ngôn ngữ lập trình sau này.
Các ngôn ngữ đơn giản như HTML và CSS lại cực kỳ phù hợp cho người mới bắt đầu, chúng giúp củng cố các kỹ năng viết mã cơ bản. Là bước đệm chuẩn bị cho người học các ngôn ngữ lập trình nâng cao hơn.
Người mới bắt đầu cũng được hưởng lợi từ các nguồn học tập đa dạng. Hiện nay có rất nhiều tài liệu, video, khoá học bao gồm miễn phí và trả phí trên mạng Internet và các chương trình học Offline thuộc nhóm ngành Công nghệ thông tin ở các trường Đại học và các chương trình Coding Bootcamps ở những trung tâm dạy lập trình.
Với rất nhiều lựa chọn, người học có thể tìm thấy một phong cách học tập phù hợp với mình.
Tại sao viết mã lại khó như vậy? Chà, nhiều người học phải vật lộn với việc chuyển đổi từ hướng dẫn sang những đoạn mã.
Học một ngôn ngữ lập trình cũng giống như học một ngoại ngữ.
Khi mới bắt đầu, nhìn một dòng mã dài có thể cảm thấy choáng ngợp, giống như nhặt một cuốn sách viết bằng ngôn ngữ khác. Nhưng bắt đầu từ những mục tiêu nhỏ và thực tế sẽ giúp người mới bắt đầu học ngôn ngữ lập trình.
Học lập trình có khó không? Tất nhiên là có nhiều yếu tố ảnh hưởng. Mọi ngôn ngữ lập trình đều có thể đặt ra những thách thức cho người học và một số lập trình viên nhận thấy một số ngôn ngữ nhất định trực quan hơn.
Tuy nhiên, một số yếu tố nhất định khiến việc học một ngôn ngữ lập trình trở nên dễ dàng hơn hoặc khó hơn. Một ngôn ngữ khó hiểu với ít tài liệu giải thích và cú pháp phức tạp có thể trở thành thách thức ngay cả với những lập trình viên có kinh nghiệm.
Nguồn tài liệu
Các ngôn ngữ lập trình phổ biến hơn thường đi kèm với các tài nguyên học tập phong phú.
Người mới bắt đầu và lập trình viên có kinh nghiệm có thể đăng câu hỏi trên diễn đàn, chia sẻ chiến lược và hỗ trợ lẫn nhau. Các ngôn ngữ phổ biến cũng đi kèm với hướng dẫn trực tuyến miễn phí, video trên YouTube và các lớp dành riêng cho việc học viết mã.
Mặt khác, tài nguyên cho một số ngôn ngữ lập trình rất ít. Các ngôn ngữ lập trình rất cũ hoặc rất mới thường cung cấp ít hỗ trợ hơn. Các ngôn ngữ cực kỳ chuyên biệt cũng có xu hướng thiếu tài nguyên.
Cấp cao và cấp thấp
Ngôn ngữ lập trình được chia thành hai loại: cấp cao hoặc cấp thấp. Ngôn ngữ cấp thấp hoạt động gần với phần cứng máy tính và mã máy hơn. Điều đó có thể khiến các lập trình viên khó diễn giải hơn.
Ngược lại, ngôn ngữ cấp cao ưu tiên ngôn ngữ rõ ràng hơn cho người dùng so với máy tính.
Cái nào khó hơn? Một số lập trình viên thấy lập trình bằng ngôn ngữ cấp thấp nhanh hơn. Nhưng nhiều người mới bắt đầu thấy ngôn ngữ cấp thấp khó thành thạo hơn.
Một ngôn ngữ cấp cao, như Python, sử dụng các lệnh bằng tiếng Anh giúp mọi người viết hoặc diễn giải mã dễ dàng hơn. Các ngôn ngữ C thường được phân loại là cấp thấp.
Cú pháp
Các lập trình viên sử dụng cú pháp để cho máy tính biết cách diễn giải mã. Và các ngôn ngữ lập trình khác nhau sử dụng cú pháp khác nhau.
Một số ưu tiên cú pháp đơn giản sử dụng các lệnh có thể dự đoán được. Số khác yêu cầu cú pháp phức tạp hơn nhiều.
Cú pháp quan trọng rất nhiều. Máy tính không thể chạy các chương trình có cú pháp sai — hoặc thậm chí là lỗi đánh máy trong một lệnh. Trong quá trình sửa lỗi, lập trình viên phải xác định và sửa lỗi cú pháp.
Vậy học lập trình có khó không? Có thể, nhưng bắt đầu với ngôn ngữ lập trình phù hợp sẽ giúp quá trình này dễ dàng hơn.
Thay vì nhảy vào một ngôn ngữ lập trình khó, hãy bắt đầu với một trong những ngôn ngữ lập trình đơn giản nhất, dễ dàng nhất giúp quá trình này trở nên suôn sẻ hơn cho người mới bắt đầu.
HTML
Mọi trang web đều sử dụng HTML, làm cho nó trở thành ngôn ngữ linh hoạt cho các nhà phát triển web, nhà thiết kế web và người viết blog. Và người học có thể tiếp thu kiến thức cơ bản về HTML chỉ trong vài ngày.
Không phải là ngôn ngữ lập trình chính thức, HTML hoạt động như một ngôn ngữ đánh dấu. Các lập trình viên sử dụng HTML để định hình văn bản trên các trang web, thường kết hợp với CSS.
JavaScript
JavaScript vận hành internet và nó cũng được xếp hạng là ngôn ngữ lập trình phổ biến nhất trong cuộc khảo sát nhà phát triển StackFlow năm 2022. Các nhà phát triển web dựa vào JavaScript để tạo các trang web tương tác, hấp dẫn.
Nhờ có nhiều ứng dụng, những người mới bắt đầu thường bắt đầu học lập trình với JavaScript. Ngôn ngữ này làm cho việc gỡ lỗi trở nên dễ dàng, vì các lập trình viên có thể sử dụng bất kỳ trình duyệt nào để kiểm tra các đoạn mã.
Là một ngôn ngữ linh hoạt nổi tiếng thân thiện với người mới bắt đầu, Python cũng được xếp hạng trong số các ngôn ngữ lập trình được sử dụng nhiều nhất. Các lập trình viên chuyển sang Python để phân tích dữ liệu, phát triển back-end và phát triển ứng dụng.
Cú pháp đơn giản của nó giúp Python dễ học hơn, đặc biệt đối với các lập trình viên hiện tại. Người học cũng được hưởng lợi từ nhiều khóa học Python miễn phí và trả phí.
Ngôn ngữ lập trình “khó học”
Một số ngôn ngữ lập trình nổi tiếng với độ khó học, cùng liệt kê vài ví dụ sau đây:
C++
Mọi thứ từ trò chơi điện tử đến ô tô tự lái đều dựa trên C++. Nhưng nó cũng nằm trong số những ngôn ngữ lập trình khó học nhất.
C++ là một ngôn ngữ mạnh mẽ, phức tạp, có thể mất nhiều năm để thành thạo. Các lập trình viên cần viết nhiều mã hơn để hoàn thành các tác vụ mà các ngôn ngữ khác tự động hóa. Tuy nhiên, nhờ các ứng dụng của nó, sự phổ biến của C++ vẫn tiếp tục tăng lên.
COW
COW, một ngôn ngữ chỉ có 12 lệnh, được xếp vào loại ngôn ngữ bí truyền. Còn được gọi là esolang, những ngôn ngữ lập trình này cố tình không thực tế. Các lập trình viên phát triển những ngôn ngữ này để thử thách bản thân hoặc như một trò đùa.
Hiểu về esolang đòi hỏi một nền tảng vững chắc về lập trình, vì vậy một số lập trình viên coi chúng là nghệ thuật hoặc sử dụng chúng để thể hiện kỹ năng của họ.
LISP
Được phát triển vào những năm 1950 như một trong những ngôn ngữ lập trình đầu tiên, LISP vẫn đang được sử dụng. Ngày nay, các lập trình viên dựa vào LISP để nghiên cứu trí tuệ nhân tạo.
Cú pháp của ngôn ngữ này trông khác với nhiều ngôn ngữ gần đây hơn, điều này có thể khiến bạn khó tiếp thu hơn. LISP có nhiều phương ngữ, bao gồm Scheme, Clojure và Racket.
Lập trình còn đáng học trong năm tới?
Nhiều công việc lập trình được trả lương cao yêu cầu kỹ năng viết mã, bao gồm công việc về an ninh mạng, phát triển phần mềm và phát triển web. Thêm lập trình vào CV của bạn cũng mở ra cơ hội nghề nghiệp mới trong các lĩnh vực ngoài công nghệ.
Lập trình có khó để tự học?
Bạn sẽ dễ cảm thấy thất vọng hoặc thắc mắc tại sao lập trình lại khó đến vậy nếu bạn đang tự học viết code. Một số người học thấy các bài học viết code nếu tự học sẽ rất khó và họ có xu hướng tham gia các khoá học Coding Bootcamp Offline lần Online.
Bài viết được sự cho phép của tác giả Trần Hữu Cương
1. Đối tượng là gì (Object là gì?)
Khoan nói tới lập trình, chúng ta hãy nói tới đối tượng trong đời sống thực tế hàng ngày. Đối tượng là một thực thể vật lý, có thể là một con vật, một đồ vật… Ví dụ như ngôi nhà, cái xe, người…
Mỗi đối tượng sẽ có đặc trưng riêng của nó:
Trạng thái của đối tượng: ví dụ cái xe màu gì, bao nhiêu phân khối, giá tiền…
Hành vi: các hành động của đối tượng. Ví dụ cái xe có thể chạy, phát tiếng còi, phát ánh đèn…
Định danh / nhận diện: là một tính chất giúp các đối tượng phân biệt được với nhau. Các đối tượng có thể nhìn giống nhau không phải là một. Ví dụ hai người sinh đôi nhìn giống hệt nhau nhưng là hai người (đối tượng) riêng biệt.
Trong lập trình hướng đối tượng, các đối tượng trong Java cũng có ba đặc trưng trên:
Trạng thái: thể hiện ở giá trị của các biến class (các field của đối tượng)
Hành vi: các method/phương thức của class
Định danh: Mỗi khi bạn tạo một đối tượng mới thì chúng sẽ được lưu trong bộ nhớ với địa chỉ, kích thước khác nhau. JVM phân biệt được các đối tượng theo các địa chỉ nhớ đó. Nếu bạn thấy có 2 đối tượng A và B có cùng 1 bộ nhớ thì bản chất nó là 1 đối tượng với các tên gọi khác nhau mà thôi (Nếu A thay đổi thì B cũng thay đổi y hệt, ngược lại B thay đổi thì A cũng sẽ thay đổi y hệt).
Chương trình Java được tạo nên từ trạng thái, hành vi và sự tương tác giữa các đối tượng.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
2. Class trong Java là gì?
Trong Java nói riêng và trong lập trình hướng đối tượng nói chung thì class được hiểu là một nhóm các đối tượng có các đặc điểm chung.
Ví dụ ta tạo class Xe thì có thể hiểu đây là một nhóm các đối tượng có thể dùng làm phương tiện di chuyển…
Class là một mẫu thiết kế, khi thực thi mẫu thiết kế đó ta có được đối tượng.
Ví dụ class XeMay gồm các thuộc tính (màu sắc, phân khối, tốc độ…) thì ta có thể hiểu đây là thiết kế của một chiếc XeMay, và khi tạo một chiếc xe máy (object) từ bản thiết kế đó ta sẽ có nhiều lựa chọn khác nhau: màu sắc (màu vàng, màu đen), phân khối (phân khối 100cc, 150cc), tốc độ (100km/h, 80km/h)…
Việc tạo ra các đối tượng phải tuân theo bản thiết kế (class) đã định nghĩa trước đó,
Ví dụ class XeMay không được thiết kế với cánh quạt thì đối tượng được tạo sẽ không thể nào có cánh quạt.
Các bản thiết kế có thể được mở rộng từ các bản thiết kế khác (kế thừa):
Ví dụ đầu tiên người ta tạo thiết kế nhà gồm các chi tiết (cửa sổ, cửa ra vào, mái nhà, tường, chân móng). Sau đấy người ta tạo ra bản thiết kế biệt thự dựa theo bản thiết kế nhà nhưng thêm các chi tiết khác như bể bơi, hàng rào… Các bản thiết kế con có thể sử dụng lại toàn bộ các chi tiết của bản thiết kế cha hoặc chỉ sử dụng lại một phần (tương đương với access modifier của các biến)
3. Các thành phần của class trong Java
Trong Java, để tạo một class ta sử dụng từ khóa class, mỗi class có thể có các thành phần sau:
Các thuộc tính (các fields/ biến instance): chứa trạng thái của các đối tượng (object) được tạo ra
Các method – phương thức: mô tả các hành vi của đối tượng được tạo ra
Hàm khởi tạo (hành động thực thi bản thiết kế để tạo ra đối tượng): bản chất cũng là một method, được dùng để tạo ra đối tượng. Hàm khởi tạo chứa các tham số để thiết lập giá trị mặc định cho các thuộc tính gọi là hàm khởi tạo có tham số (mặc định nếu không khai báo hàm khởi tạo thì ta hiểu nó có hàm khởi tạo không tham số).
Các block code: các đoạn code được thực thi ngay khi đối tượng được khởi tạo.
publicclass Person { // block code (khối code)
{ System.out.println("run block code"); } // instance variable - field String name; // method (phương thức) publicvoidhello(){ System.out.println(name); } // hàm khởi tạo không có tham số publicPerson(){ } // hàm khởi tạo có tham số publicPerson(String name){ this.name = name; } // nested class class NestedClass{}}
4. Tạo đối tượng trong Java
Cách khởi tạo đối tượng đơn giản nhất là dùng từ khóa new
Ví dụ, với class Person như ở trên, ta có thể tạo đối tượng bằng lệnh new Person();
Ngoài dùng từ khóa new thì ta còn một số phương pháp khác để tạo đối tượng như áp dụng reflection, deserialization, clone. Tuy nhiên mấy cách sau sẽ hơi khó hiểu với những người bắt đầu nên mình sẽ giới thiệu ở một bài riêng.
Chắc các bạn đều biết Bootstrap là một trong những framework để xây dựng giao diện website phổ biến nhất hiện nay. Cũng vì Bootstrap phổ biến, nên cách chúng ta sử dụng nó trong các dự án cũng vô cùng đa dạng, đa dạng tới mức nhiều khi ta không biết nên sử dụng sao cho đúng, cho hay. Nên trong bài viết này, mình xin phép được chia sẻ một vài best practice (tạm dịch là các mẹo hay, các lưu ý) khi sử dụng Bootstrap trong dự án mà mình tự đúc kết được trong quá trình làm việc với nó.
Let’s go…
1. Nên tích hợp Bootstrap thông qua NPM
Khi vào trang chủ của Bootstap, bạn sẽ bị “mời gọi” bởi một nút Download như trong hình dưới.
Trang chủ getbootstrap.com
Vì sự mời gọi này, mà nhiều bạn tích hợp Bootstrap vào dự án bằng cách download về, và đưa Bootstrap trực tiếp vào source code của dự án. Thực chất thì đây cũng là một cách, nhưng bạn đã bao giờ tích hợp bằng cách sử dụng npm chưa? Nó nhanh chóng, và tiện lợi hơn nhiều.
Để tích hợp Bootstrap vào dự án bằng npm, bạn chỉ cần chạy lệnh đơn giản như sau:
npm install bootstrap
npm là một trình quản lý gói của nodejs. Cể cài nodejs và npm, bạn tham khảo tại trang chủ nodejs.org nhé.
Nếu Bootstrap có cập nhật, thì việc nâng cấp cũng dễ dàng.
Dễ dàng tùy biến lại Bootstrap, nếu các styles (màu sắc, kích thước chữ) không đúng ý bạn. Lợi ích này là cực kỳ quan trọng, là tiền đề cho các best practice khác dưới đây.
Mình thấy nhiều dự án tùy biến lại styles của Bootstrap bằng cách tạo 01 file style.css, sau đó cho file này load sau style của Bootstrap. Và nếu muốn tùy biến gì, thì viết trong file style.css này.
Nhưng không, đó không phải là cách hay, nhất là khi bạn đã tích hợp Bootstrap vào dự án thông qua npm. Thực chất, Bootstrap được viết thằng scss (một dạng CSS Preprocessor), còn css mà bạn nhúng vào web là kết quả của việc build scss. Vì thế, nếu muốn tùy biến style đúng cách, bạn cần tùy biến ở phần scss.
Tận dụng được lợi thế của CSS Preprocessor, cụ thể trong trường hợp này là scss.
Css build ra sẽ được minify, và nằm gọn gàng trong 1 file css duy nhất.
Dễ dàng tùy biến lại các style của Bootstrap nếu nó không đúng ý bạn.
Một vài trường hợp điển hình khi tùy biến lại style của Bootstrap có thể kể đến như:
2.1 Tùy biến lại số lượng component được sử dụng
Mặc định, Bootstrap cung cấp một số lượng tương đối các component, ví dụ như: Alert, Button, Modal, Card, List,… Tuy nhiên, không phải lúc nào chúng ta cũng sử dụng hết các component này trong dự án. Vì thế, chúng ta chỉ nên import các component mà được sử dụng trong dự án, để file css khi build ra được tối ưu nhất.
2.2 Tùy biến style bằng cách điều chỉnh scss variables
Giả sử bạn muốn tùy biến lại style của Bootstrap, ví dụ muốn đổi màu primary của Bootstrap từ màu blue thành green chẳng hạn. Có 02 cách giúp bạn thực hiện điều này:
Cách 1: Ghi đè tất cả các thuộc tính liên quan tới màu từ blue thành green (overrde border color, background color, color,..) của các class mà Bootstrap dựng sẵn (btn-primary, text-primary, border-primary, …)
Cách 1 này dễ, chẳng cần nói thì bạn cũng biết. Nhưng làm sao bạn xác định được hết nhỉ, vì class trong Bootstrap có rất nhiều. Với lại, bạn sẽ sớm nhận ra đây không phải là cách hay ngay khi đọc cách 2 dưới đây.
Cách 2: Tìm biến $primary trong file _variables.scss và đổi thành màu green.
Bootstrap cung cấp sẵn cơ chế cho mình tùy biến style (màu sắc, box-shadow, font,…) ở trong file _variables.scss, bạn chỉ cần override lại thông tin cho đúng ý là được.
Bạn có thể tham khảo nội dung của file _variables.scss của Bootstrap tại đây.
Đương nhiên, với cách 2 bạn không nên ghi đè trực tiếp trong file _variables.scss của Bootstrap, mà nên tạo một file mới (VD _custom-variables.scss), sau đó cho file này load sau file _variables.scss.
2.3 Thêm color bằng cách thêm vào $theme-colors
Mặc định, Bootstrap cung cấp sẵn các màu là: primary, secondary, success, danger, warning, info, light, dark.
Các màu trên cũng sẽ đi kèm với các component, như với button, thì ta có btn-primary, btn-secondary,… với text, ta cũng có text-primary, text-seconday,…
Giả sử một ngày đẹp trời, mình cần thêm 01 color nữa là negative, và mình cũng muốn các component khác có chung color này (btn-negative, text-negative,…) thì mình sẽ làm thế nào?
Cách đơn giản, và hay nhất là khai báo thêm color cho Bootstrap như sau:
// _custom-variables.scss
// Tạo các màu muốn bổ sung
$custom-colors: (
"negative": red
// Nếu muốn thêm các màu khác, thì cũng viết nốt vào đây
);
// Merge vào biến $theme-colors của Bootstrap
$theme-colors: map-merge($theme-colors, $custom-colors);
3. Đừng cố sử dụng Grid System để chia layout cho những thành phần nhỏ
Bootstrap cung cấp Grid system để giúp chúng ta chia layout web dễ dàng hơn. Nhưng layout web mà chúng ta hiểu nên là các component có kích thước lớn và độc lập trên website, VD như header, footer, các cột trên website, chứ không phải là các thành phần nhỏ, tiểu tiết.
Mặt khác, nếu bạn để ý, thì các class .col-*-* của Bootstrap sẽ có padding là 15px, vậy giữa content của 02 cột đặt cạnh nhau sẽ cách khau một khoảng là 30px, và khoảng cách này là cố định, nếu tùy biến sẽ rất dễ bị vỡ layout. 30px là khoảng cách hợp lý giữ 02 thành phần lớn trên website, chứ với các thành phần tiểu tiết, 30px là một khoảng cách lớn.
Trong trường hợp bạn cần chia layout cho các thành phần nhỏ, hãy thử tham khảo Flex utility của Bootstrap.
Để hiểu rõ hơn ý ở phần này, mình sẽ minh họa bằng một ví dụ. Giả sử mình cần style cho component (phần được khoanh đỏ) trong design sau:
Nếu sử dụng grid system, bạn có thể sẽ code như sau:
<div class="messages>
<div class="row message-item"><!-- Mỗi class row, đại diện cho một dòng trong list trên -->
<div class="col-md-2 message-item-icon"><!-- Khu vực cho phần icon, rộng 2 -->
<!-- Icon ở đây -->
</div>
<div class="col-md-10 message-item-content"><!-- Khu vực cho phần nội dung, rộng 10 -->
<!-- Content ở đây -->
</div>
</div>
<!-- more ... -->
</div>
Tuy nhiên, như mình đã phân tích, thì việc sử dụng Grid system trong component trên là chưa hợp lý, vì:
Mình cho rằng trên là một component nhỏ, không phải một component lớn trên website, lại không có nhu cầu responsive, nên không cần sử dụng grid system.
Khoảng cách giữa phần icon, đến phần nội dung chỉ khoảng 15px, nếu sử dụng grid system, thì khoảng cách này cần được tùy biến lại, gây mất công.
Độ rộng của phần icon chưa chắc đã là 2, phần rộng của phần nội dung chưa chắc đã là 10. Nếu sử dụng tỷ lệ 2 – 10 ở chỗ này chỉ mang tính tương đối.
Cho nên, nếu sử dụng thì hãy dùng Flex utility sẽ đơn giản, dễ dàng hơn:
<div class="messages">
<div class="d-flex message-item">
<div class="message-item-icon mr-3">
<!-- Icon ở đây -->
</div>
<div class="message-item-content">
<!-- Content ở đây -->
</div>
</div>
<!-- more ... -->
</div>
4. Hãy sử dụng Utility Class thay vì Inline Style
Bootstrap có cung cấp một loạt các utility class (tạm dịch là các class tiện ích). Các class này sẽ hướng tới việc tùy biến một thuộc tính nào đó như border, color, background-color,… mà khi kết hợp lại với nhau, sẽ tạo nên một kết quả vô cùng linh hoạt.
Nếu bạn nào từng làm việc với tailwindcss, thì các class tại đây cũng được thiết kế với mục đích tương tự.
Để hiểu hơn thế nào là utility class, và thế nào là inline style, mình sẽ thể hiện bằng ví dụ trong đoạn code sau đây:
<!-- Bad -->
<div style="border-color: red"></div>
<!-- Good -->
<div class="border-danger"></div>
<!-- Bad -->
<div style="display: flex"></div>
<!-- Good -->
<div class="d-flex"></div>
<!-- Bad -->
<div style="padding: 10px"></div>
<!-- Good -->
<div class="p-3"></div>
Trong các ví dụ trên, bad là sử dụng inline style, good là sử dụng utility class
Chi tiết về utility class, bạn có thể xem tại đây.
Việc sử dụng utility class, thay vì inline style sẽ có các lợi ích sau:
Dễ nhìn hơn, inline style thì các thuộc tính ngăn cách nhau bằng dấu chấm phẩy, nếu sử dụng class thì ngăn cách nhau bằng dấu cách.
Utility class viết ngắn gọn hơn.
Code dạng inline style thì được coi là hard code (code cứng, không có tính linh hoạt), sử dụng utility class thì được coi là dynamic code (code linh hoạt, có thể thay đổi dễ dàng).
5. Hãy thường xuyên để ý tới Document
Suy cho cùng, Bootstrap là một framework css, mà css đối với web developer thì thuộc vào dạng kiến thức cơ bản, mà cơ bản nên đôi khi anh em sẽ tự code để giải quyết vấn đề mà không biết rằng Bootstrap đã có class để hỗ trợ đến tận răng. Cho nên, với những phần document mà các bạn chưa bao giờ đọc, thì hãy bỏ thời gian ra đọc, và cũng nên lui tới thường xuyên để xem có gì cập nhật hay không.
Với mình, sau khi bỏ thời gian để xem tất cả các ngõ ngách có trên document của Bootstrap, mình đã học thêm được vài kiến thức rất bổ ích.
Tạm kết
Trước mắt mình chia sẻ với các bạn 5 best practice đầu tiên khi sử dụng Bootstrap css, các best practice khác mình sẽ chia sẻ ở các phần tiếp theo.
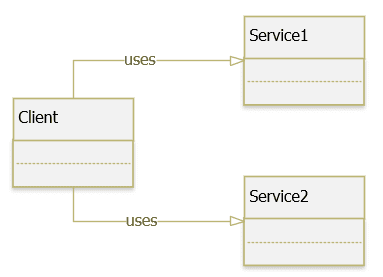
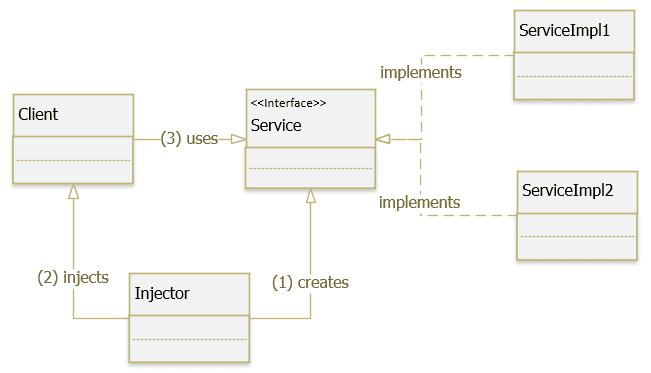
Trong các ứng dụng, chúng ta thường gặp trường hợp một class Client phụ thuộc vào một service hoặc một component là những lớp cụ thể (concrete class) trong lúc chạy ứng dụng.
Sự phụ thuộc của class Client vào các service này sẽ có một số vấn đề cần phải giải quyết:
Nếu thay thế hoặc cập nhật các service phụ thuộc, chúng ta cần thay đổi mã nguồn của class Client.
Các concrete class của một phụ thuộc có thể thay đổi tại thời điểm run-time hay không?
Các class cần phải viết những đoạn code cho việc quản lý, khởi tạo các phụ thuộc.
Khó khăn khi viết Unit Test do các lớp được kết hợp chặt chẽ.
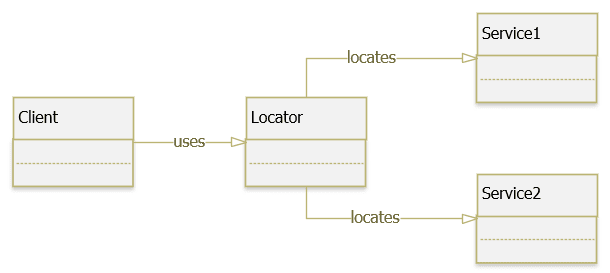
Giải pháp cho vấn đề này chính là áp dụng Service Locator pattern, nó tạo ra một class chứa các tham chiếu đến các service và nó đóng gói các xử lý nghiệp vụ để xác định các service.
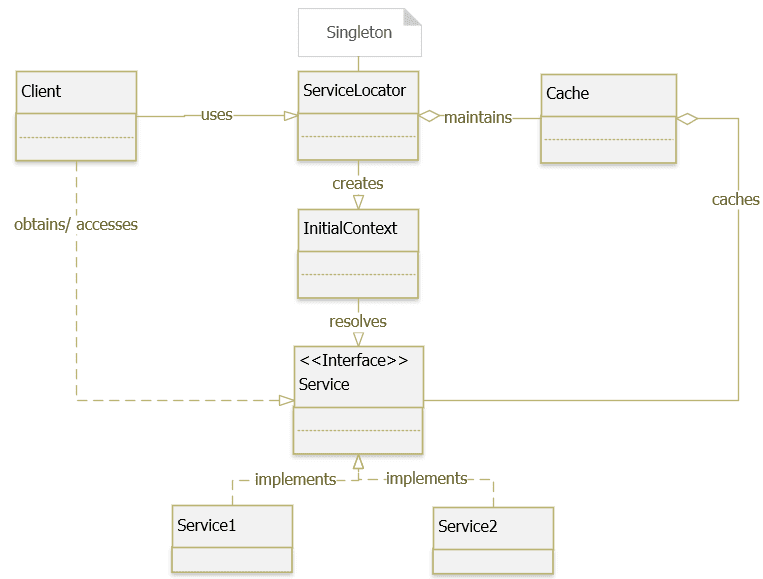
The service locator pattern is a design pattern used in software development to encapsulate the processes involved in obtaining a service with a strong abstraction layer. This pattern uses a central registry known as the “service locator” which on request returns the information necessary to perform a certain task.
The ServiceLocator is responsible for returning instances of services when they are requested for by the service consumers or the service clients.
Service Locator là một design pattern thông dụng cho phép tách rời (decouple) một class với các dependency (hay được gọi là service) của nó. Service Locator có thể coi là một đối tượng trung gian trong việc liên kết class và các dependency.
Service Locator pattern mô tả cách để đăng ký và lấy các dependency để sử dụng. Thông thường Service Locator được kết hợp với Factory Pattern hoặc Dependency Injection Pattern để có thể tạo ra các instance của service.
package com.gpcoder.patterns.creational.servicelocator;
public class EmailService implements MessagingService {
public String getMessageBody() {
return "This is message body of Email message";
}
public String getServiceName() {
return "EmailService";
}
}
SMSService.java
package com.gpcoder.patterns.creational.servicelocator;
public class SMSService implements MessagingService {
public String getMessageBody() {
return "This is message body of SMS message";
}
public String getServiceName() {
return "SMSService";
}
}
InitialContext.java
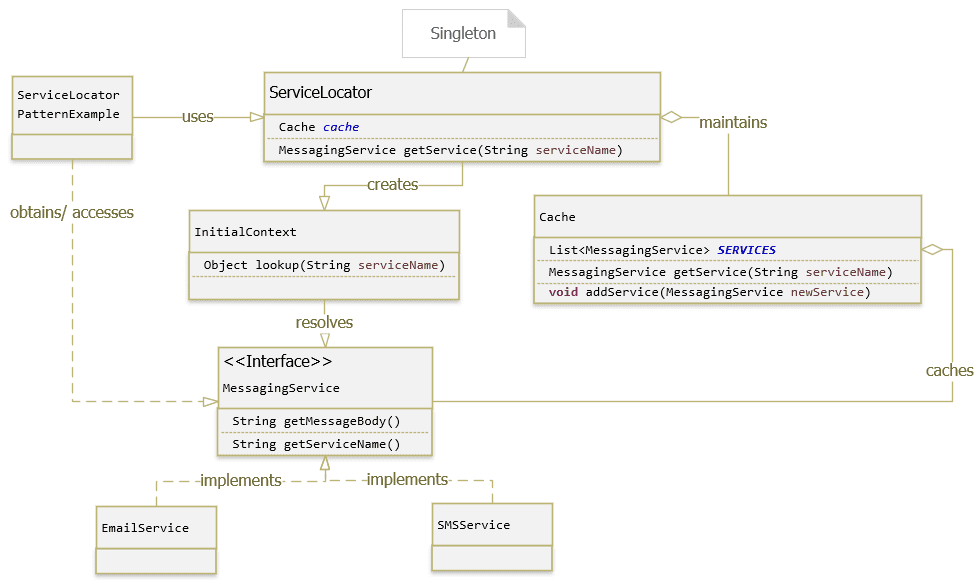
package com.gpcoder.patterns.creational.servicelocator.example1;
public class InitialContext {
public MessagingService lookup(String serviceName) {
if (serviceName.equalsIgnoreCase("EmailService")) {
return new EmailService();
} else if (serviceName.equalsIgnoreCase("SMSService")) {
return new SMSService();
}
return null;
}
}
Cache.java
package com.gpcoder.patterns.creational.servicelocator.example1;
import java.util.ArrayList;
import java.util.List;
public class Cache {
private static final List<MessagingService> SERVICES = new ArrayList<>();
public MessagingService getService(String serviceName) {
for (MessagingService messagingService : SERVICES) {
if (messagingService.getClass().getSimpleName().equals(serviceName)) {
return messagingService;
}
}
return null;
}
public void addService(MessagingService newService) {
SERVICES.add(newService);
}
}
ServiceLocator.java
package com.gpcoder.patterns.creational.servicelocator.example1;
public final class ServiceLocator {
private static Cache cache = new Cache();
private ServiceLocator() {
throw new IllegalAccessError("Can't construct this class directly");
}
public static MessagingService getService(String serviceName) {
MessagingService service = cache.getService(serviceName);
if (service != null) {
System.out.println("Get service from cache: " + serviceName);
return service;
}
System.out.println("Create a new service and add to cache: " + serviceName);
InitialContext context = new InitialContext();
service = context.lookup(serviceName);
cache.addService(service);
return service;
}
}
ServiceLocatorPatternExample.java
package com.gpcoder.patterns.creational.servicelocator.example1;
public class ServiceLocatorPatternExample {
public static void main(String[] args) {
MessagingService service = ServiceLocator.getService("EmailService");
System.out.println(service.getMessageBody());
MessagingService smsService = ServiceLocator.getService("SMSService");
System.out.println(smsService.getMessageBody());
MessagingService emailService = ServiceLocator.getService("EmailService");
System.out.println(emailService.getMessageBody());
}
}
MessagingService.java
Create a new service and add to cache: EmailService
This is message body of Email message
Create a new service and add to cache: SMSService
This is message body of SMS message
Get service from cache: EmailService
This is message body of Email message
Ví dụ cải tiến Service Locator Pattern với Reflection
Trong ví dụ trên, lớp InitialContext chịu trách nhiệm khởi tạo các class dựa trên đối số serviceName. Cách làm này chưa được tốt, mỗi khi có service mới chúng ta phải sửa đổi code của class này để khởi tạo Service tương ứng. Chúng ta có thể sử dụng sửa đổi class này lại bằng cách nhận đối số là một serviceName có đầy đủ cả package của nó, sau đó sử dụng Reflection để khởi tạo instance cho Service. Ví dụ: com.gpcoder.patterns.creational.servicelocator.EmailService
Code của InitialContext được viết lại như sau:
package com.gpcoder.patterns.creational.servicelocator.example2_reflection;
import com.gpcoder.patterns.creational.servicelocator.MessagingService;
public class InitialContext {
public MessagingService lookup(String serviceName) {
try {
Class<MessagingService> clazz = (Class<MessagingService>) Class.forName(serviceName);
Object newInstance = clazz.newInstance();
return cast(newInstance, clazz);
} catch (ClassNotFoundException | InstantiationException | IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
public static <T> T cast(Object obj, Class<T> clazz) {
if (clazz.isAssignableFrom(obj.getClass())) {
return clazz.cast(obj);
}
throw new ClassCastException("Failed to cast instance.");
}
}
Class Cache của chúng ta cũng cần sửa lại đôi chút:
package com.gpcoder.patterns.creational.servicelocator.example2_reflection;
import java.util.ArrayList;
import java.util.List;
import com.gpcoder.patterns.creational.servicelocator.MessagingService;
public class Cache {
private static final List<MessagingService> SERVICES = new ArrayList<>();
public MessagingService getService(String serviceName) {
for (MessagingService messagingService : SERVICES) {
if (messagingService.getClass().getCanonicalName().equals(serviceName)) {
return messagingService;
}
}
return null;
}
public void addService(MessagingService newService) {
SERVICES.add(newService);
}
}
Source code đầy đủ của ví dụ này, các bạn có thể tham khảo thêm trên Github.
Lợi ích của Service Locator Pattern là gì?
Ưu điểm:
Nó tạo và giữ một thể hiện của các class Service trong một ServiceLocator duy nhất.
Tách rời một class với các dependency của nó, nhờ đó có thể dễ dàng thay thế các dependency tại thời điểm run-time mà không cần phải re-compile hay thậm chí là restart ứng dụng.
Các dependency sẽ được sử dụng dưới dạng interface, đảm bảo không sử dụng các class cụ thể (concrete) của dependency.
Dễ dàng test các class do không phụ thuộc vào các dependency.
Ứng dụng có thể được chia ra các phần ít bị ràng buộc (loose coupling) với nhau. Các đoạn code để tạo, quản lý dependency được tách riêng ra khỏi các class.
Nhược điểm:
Khó khăn khi debug và phát hiện lỗi do Client không biết được phần còn lại của hệ thống, Service nào sẽ được thực thi, mọi thứ được đăng ký với Service Locator.
Service Locator phải là duy nhất, nên có thể gặp hiện tượng thắt cổ chai.
Service Locator che dấu các lớp được đăng ký với Client, do đó có thể gặp lỗi run-time thay vì compile-time khi Service không tồn tại.
Service Locator làm cho code khó bảo trì hơn so với việc sử dụng DI (Dependency Injection). Các concrete class vẫn có phụ thuộc vào ServiceLocator, ServiceLocator chịu trách nhiệm tạo ra các phụ thuộc của nó. Với DI chỉ được gọi 1 lần để tiêm phụ thuộc vào một số lớp chính. Các lớp mà lớp chính này phụ thuộc vào sẽ đệ quy các phụ thuộc của chúng, cho đến khi có một đối tượng hoàn chỉnh. DI dễ viết Unit Test hơn.
Sử dụng Service Locator Pattern khi nào?
Khi cần tách rời một class với các dependency của nó.
Khi cần quản lý tập trung việc khởi tạo các Service.
Lời kết:
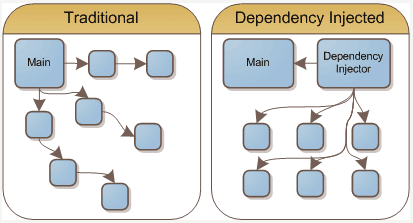
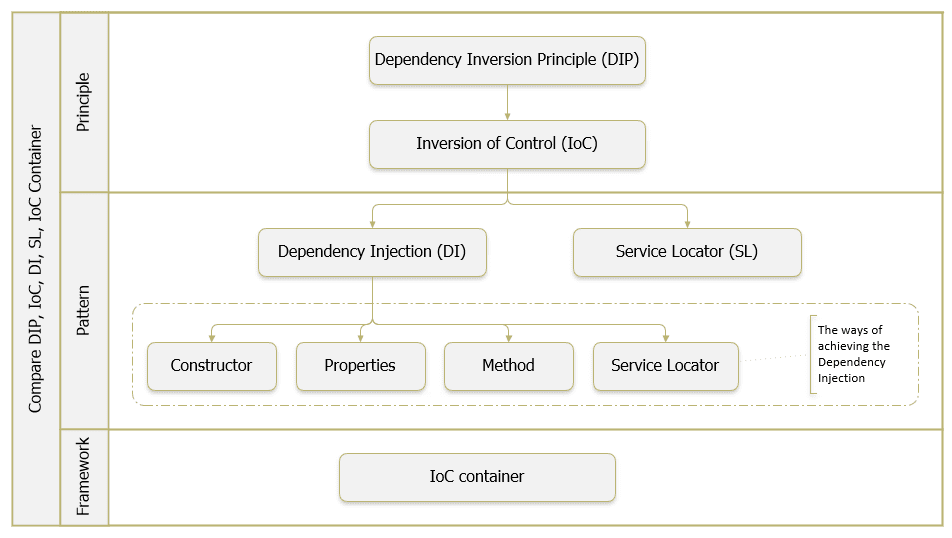
Service Locator Pattern là một mẫu đơn giản để giúp chúng ta giảm sự phụ thuộc giữa các service trong ứng dụng với việc áp dụng nguyên lý Inversion of Control. Tuy nhiên, trong trường hợp sử dụng các lớp trong nhiều ứng dụng, Dependency Injection là sự lựa chọn tốt hơn.
Service Locator cũng là một thuật ngữ hay được nhắc đến cùng với nguyên lý Dependency Inversion trong SOLID, IoC Container, DI container. Service Locator chính là một cách thực hiện của IoC Container. Trong các bài viết tiếp theo chúng ta sẽ cùng tìm hiểu về các khái niệm liên quan này.
Bài viết được sự cho phép của tác giả Phạm Minh Khoa
Ở bài viết trước chúng ta đã biết được Redux middleware là gì, và vấn đề gặp phải với lỗi: “Error: Actions must be plain objects. Use custom middleware for async actions” khi chúng ta cần xử lý các action bất đồng bộ như lấy dữ liệu từ API.
Trước hết phải thống nhất với nhau vị trí bạn nên xử lý các hành động bất đồng bộ (Asynchronous actions) trong Redux. Nếu như bên React chúng ta có thể gọi chúng trong useEffect (hoặc componentDidMount với class component) thì với Redux chúng ta nên đặt trong action creator. Tại sao? Cùng nhìn lại Redux Cycle nhé:
Rõ ràng không thể viết các xử lý bất đồng bộ vào trong action được vì nó là 1 plain object; cũng không nên viết vào Reducers vì reducers theo như kiến trúc redux thì chỉ là những functions nhận giá trị đầu vào là state hiện tại và 1 action để trả về 1 state mới: (state, action) => newState.
Để giải quyết lỗi “Error: Actions must be plain objects. Use custom middleware for async actions” chúng ta có Redux-thunk, một middleware dành riêng cho việc xử lý các action bất đồng bộ trong redux.
Để sử dụng được thunk, bạn cần phải nạp middleware này vào redux store của bạn trước.
import { createStore, applyMiddleware, compose } from "redux"
import rootReducer from "../reducers/index";
import { forbiddenWordsMiddleware } from "../middleware";
import thunk from "redux-thunk";
const storeEnhancers = window.__REDUX_DEVTOOLS_EXTENSION_COMPOSE__ || compose;
const store = createStore(
rootReducer,
storeEnhancers(applyMiddleware(forbiddenWordsMiddleware, thunk))
);
export default store;
Lúc đó hàm getData sẽ thực hiện việc fetch dữ liệu các từ khóa bị cấm từ API, sau khi nhận được response trả về thì sẽ thực hiện dispatch action DATA_LOADED:
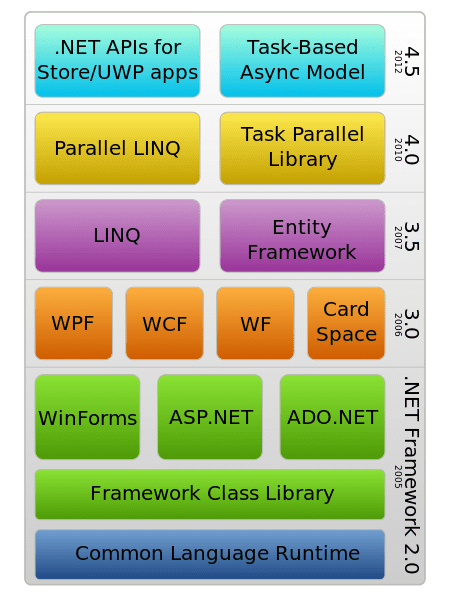
.NET (hay Dot NET) là 1 nền tảng lập trình và cũng là 1 nền tảng thực thi ứng dụng chủ yếu trên hệ điều hành Window được phát triển bởi Microsoft từ năm 2002. Nó không phải là ngôn ngữ lập trình, mà là nền tảng cho phép các ngôn ngữ lập trình khác nhau như C#, Visual Basic sử dụng để tạo nên các website, ứng dụng trên Internet. Với đặc điểm nổi bật về tính bảo mật và nhất quán trong lập trình cùng với sự hỗ trợ tuyệt vời đến từ Microsoft, .NET framework đã và đang được sử dụng ở rất nhiều các công ty, tập đoàn lớn; và cũng vì thế .NET Developer luôn luôn là vị trí mà nhiều lập trình viên định hướng trở thành. Bài viết hôm nay mình cùng các bạn đi tìm hiểu về framework này và những kiến thức cần để trở thành một .NET Developer nhé.
.NET là gì?
.NET framework là 1 framework tập hợp các API (Giao diện lập trình ứng dụng) và 1 thư viện code được chia sẻ giúp các lập trình viên khi viết ứng dụng có thể gọi ra và sử dụng mà không cần phải viết lại từ đầu. Thư viện code được chia sẻ đó có tên là Framework Class Library (FCL).
.NET framework không chỉ là 1 framework đơn thuần, mà nó còn cung cấp 1 môi trường để chạy các ứng dụng, nó có tên là Common Language Runtime (CLR). 1 ví dụ dễ gặp khi bạn sử dụng hệ điều hành Windows là khi cài đặt và sử dụng 1 số phần mềm thì nó yêu cầu cài đặt thêm .NET framework mới có thể thực thi được.
Việc tạo ra 1 môi trường thực thi ứng dụng CLR của .NET cũng khá tương tự như Java với máy ảo JVM; nó giúp các nhà phát triển viết code 1 lần trên các ngôn ngữ được hỗ trợ và có thể chạy trên nhiều phần cứng khác nhau, miễn nó hỗ trợ .NET. Tuy vậy, với tính chất độc quyền và mã nguồn đóng đến từ Microsoft thì hầu như nó chỉ được sử dụng dành cho các ứng dụng Window.
.NET với sức mạnh của đội ngũ phát triển từ Microsoft, nó chứa rất nhiều ưu điểm dành cho framework này:
Thư viện lập trình lớn: Rất nhiều lập trình viên lựa chọn .NET nhờ sự hỗ trợ quá đầy đủ của nó, .NET có khả năng hỗ trợ tối đa cho việc tạo lập, xây dựng các ứng dụng Web; Truy cập, kết nối các cơ sở dữ liệu, cấu trúc dữ liệu, lập trình giao diện, …
Năng suất làm việc cao: Nhờ thư viện đầy đủ mà .NET cung cấp sẵn, nếu bạn học được cách sử dụng các thành phần cũng như tùy biến đoạn code có sẵn thì sẽ tiết kiệm được rất nhiều thời gian lập trình.
Biến đổi linh hoạt: .NET được thiết kế với cấu trúc ghép nối lỏng vì thế nó có khả năng biến đổi rất linh hoạt và mang lại nhiều lợi thế về hiệu suất.
Đa ngôn ngữ: .NET hỗ trợ đa ngôn ngữ lập trình giúp lập trình viên có thể tạo ra ứng dụng bằng nhiều riêng ngôn ngữ của mình
Bảo mật cao: .NET được trang bị mô hình bảo mật evidence-based với phần kiến trúc bảo mật được thiết kế theo dạng từ dưới lên giúp bảo vệ được dữ liệu và các ứng dụng của bạn tốt hơn.
Tận dụng các dịch vụ sẵn có trong hệ điều hành: .NET và Windows đều cùng hệ sinh thái của Microsoft và dĩ nhiên .NET có khả năng sử dụng, kết nối đến các dịch vụ sẵn có trong Windows.
.NET Developer là những lập trình viên tìm hiểu, xây dựng và phát triển các ứng dụng web dựa trên nền tảng .NET framework. Windows hiện nay vẫn đang là nền tảng của nhiều ứng dụng lớn hiện nay, hơn nữa Microsoft còn đang phát triển .NET Core cho việc mở rộng khả năng chạy được trên nhiều nền tảng khác ngoài Window; vì thế nhu cầu việc làm .NET lại càng lớn hơn.
Có 1 thực tế hiện nay là các công ty nhỏ hay các dự án cần phát triển nhanh thường không lựa chọn .NET làm ngôn ngữ, framework phát triển do yêu cầu về chi phí. .NET không phải mã nguồn mở, và để triển khai ứng dụng thì cũng cần server được cài đặt hệ điều hành Windows (Windows Server) với licenses không hề rẻ. Vì thế hiện nay thường chỉ các dự án lớn, các công ty, tập đoàn lớn mới lựa chọn .NET cho việc phát triển các ứng dụng của mình. Điều đó cũng sẽ là 1 thách thức cho các bạn lập trình viên muốn theo con đường trở thành 1 lập trình viên .NET, sẽ cần học 1 cách bài bản, thực sự nắm vững được các thư viện, các khái niệm trong .NET framework để có thể apply vào các công ty sử dụng nó.
Xem ngay tin tuyển dụng .NET tại các doanh nghiệp hàng đầu trên TopDev
Kiến thức cần trang bị
Những kiến thức và kỹ năng quan trọng, cần thiết mà bất cứ một lập trình viên .NET nào cũng cần trang bị, bao gồm:
Ngôn ngữ lập trình: .NET cho phép bạn viết code bằng 1 số ngôn ngữ khác nhau như C#, F# hay VB.NET; tuy vậy phần đông chúng ta sẽ lựa chọn C# cho việc lập trình. Hãy trang bị kiến thức cơ bản về cú pháp của C#, mô hình MVC, thư viện chuẩn C
Trang bị kiến thức về HTML, CSS, JS là cần thiết cho bất cứ lập trình viên phát triển ứng dụng Web nào, và .NET Developer cũng không phải ngoại lệ. Các thư viện nâng cao khác như bootstrap hay jquery cũng là cần thiết
Làm việc với Database: hãy bổ sung kiến thức giúp tăng khả năng thi hành cho cơ sở dữ liệu SQL
Một vài kỹ năng cần thiết trong .NET: .NET Basics, C#, .NET MVC, WCF, Visual Studio, SQL Server
Những kiến thức hỗ trợ liên quan: Web API, LINQ, Entity Framework
Kết bài
Hiện nay, .NET Developer luôn nhận được những đãi ngộ tốt, những vị trí công việc tốt ở các công ty, tập đoàn lớn hơn so với nhiều lập trình viên các ngôn ngữ khác. .NET không khó để học, nhưng khó để thành thạo và tìm hiểu được hết những gì mà Microsoft cung cấp cho nền tảng này. Hy vọng qua bài viết này các bạn cũng đã có cái nhìn chi tiết hơn về công việc của 1 lập trình viên .NET và con đường để trở thành một .NET Developer trong tương lai. Cảm ơn các bạn đã đọc bài và hẹn gặp lại các bạn trong các bài viết tiếp theo của mình.
Thay vì ngồi học mấy công nghệ cao siêu, kì này tụi mình ngồi học lại cơ bản, ôn lại kiến thức về thuật toán, về các cấu trúc dữ liệu thôi nhỉ?
Kiến thức về thuật toán không được dùng hằng ngày trong việc code, nhưng nó giúp bạn viết code tối ưu hơn, xử lý nhanh hơn. Ngoài ra, rất nhiều công ty bây giờ khoái phỏng vấn bằng thuật toán.
Số lượng thuật toán, cấu trúc dữ liệu có rất rất nhiều, kể vài quyển sách chưa hết. Tuy vậy, tụi mình chỉ cần tập trung vào 8 cấu trúc dữ liệu cơ bản này là được!
96,69% các bài phỏng vấn, leetcode, thuật toán … đều dựa trên 8 cấu trúc dữ liệu này, và 1 số biến thể của nó. Nắm vững 8 cấu trúc dữ liệu này, biết cách sử dụng nó là các bạn đã có kiến thức kha khá rồi nhé!
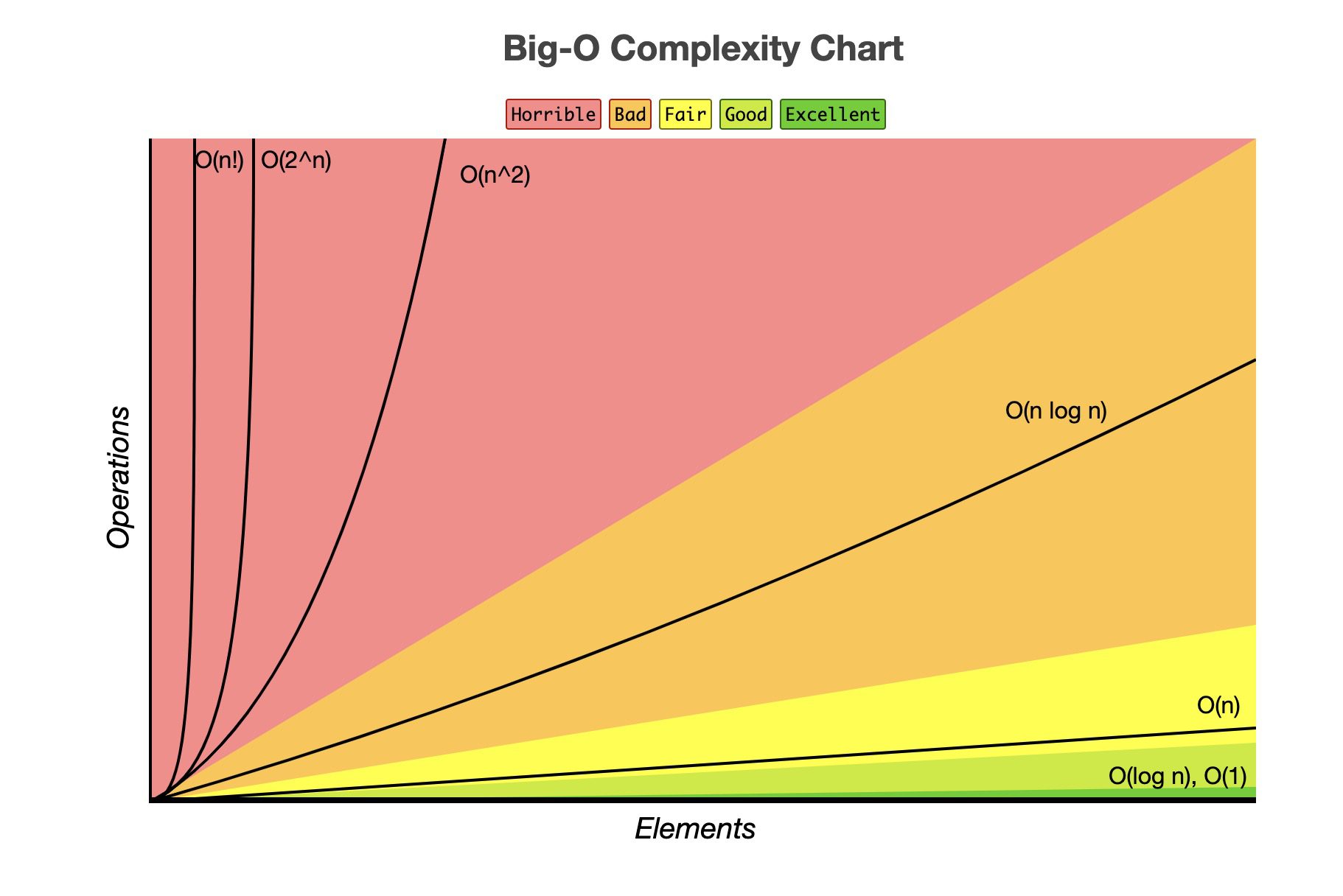
Độ phức tạp của thuật toán (biểu diễn bằng Big-O Notation), là một biểu thức mô tả hành vi thuật toán (ví dụ, về mặt thời gian tính toán hoặc lượng bộ nhớ cần dùng) khi kích thước dữ liệu thay đổi.
Nói đơn giản, Big O mô tả mối liên hệ giữa số lượng phần tử đầu vào và số lượng operation – thời gian chạy, hoặc số lượng bộ nhớ mà thuật toán cần sử dụng.
Nhìn vào hình dưới các bạn sẽ hiểu ngay.
Với các thuật toán có độ phức tạp là O(n), khi dữ liệu đầu vào có 10 phần tử, chương trình phải chạy 10 operation. Khi số dữ liệu đầu vào tăng gấp đôi, số lượng câu lệnh phải tăng gấp đôi
Nếu độ phức tạp là O(n²), khi số lượng dữ liệu đầu vào tăng gấp đôi, số lượng câu lệnh phải tăng gấp 2² tức là gấp 4 lần
Nói túm lại, thuật toán có độ phức tạp càng lớn, khi số lượng dữ liệu càng nhiều hơn lên thì nó sẽ chạy càng chậm.
Cho 1 mảng gồm N số không trùng nhau. Hãy tìm 2 số trong mảng có tổng bằng X
Các bạn có thể giải theo 2 cách:
Cách 1: Dùng 2 vòng lặp, lặp qua toàn bộ các phần tử của mảng để lấy các cặp.
Cách này không tốn thêm bộ nhớ, nhưng time complexity là O(n²), vì ta phải chạy 2 vòng lặp lồng nhau, mỗi vòng lặp gồm n phần tử.
Cách 2: Duyệt từng phần tử, lưu các phần tử đã duyệt vào 1 set. Mỗi khi gặp 1 phần tử có giá trị A, ta tính ra B = X – A, rồi kiểm tra xem trong set có B hay không?
Cách này chỉ phải loop 1 lần, nên time complexity là O(n).
Tuy vậy, ta phải cần thêm bộ nhớ để lưu các phần tử này vào 1 set, nên space complexity sẽ là O(n) luôn.
Nói túm lại, cách 2 sẽ chạy nhanh hơn cách 1, nhưng cần tốn nhiều bộ nhớ hơn. Các bạn có thể xem giải thích và code mẫu ở clip dưới nhé.
Tại sao lại để ra nhiều thuật toán/cấu trúc dữ liệu quá vậy??
Có bao giờ bạn thắc mắc “Tại sao lại đẻ ra lắm cấu trúc dữ liệu, lắm thuật toán vậy” chưa?
Đọc tới phần này, chắc bạn đã đoán ra rồi đấy! Mỗi thuật toán sẽ có time/space complexity khác nhau, giải quyết vấn đề khác nhau. Với 1 vấn đề nào đó, dùng thuật toán A, cấu trúc dữ liệu A thì sẽ nhanh hơn, đỡ tốn tài nguyên hơn so với dùng thuật toán B, cấu trúc dữ liệu B.
Khi đi phỏng vấn thuật toán cũng vậy. Với 1 bài toán đưa ra, các bạn thường sẽ nghĩ ra cách brute-force, chạy chậm nhất nhưng giải quyết được vấn đề. Sau đó, các bạn sẽ tìm cách optimize, dùng thuật toán/cấu trúc dữ liệu phù hợp để giảm time/space complexity, cho kết quả tối ưu nhất.
Do vậy, việc nắm vững các cấu trúc dữ liệu cơ bản, độ phức tạp của các operation của chúng là rất quan trọng. Chúng sẽ giúp bạn tìm ra cách giải tối ưu của 1 bài toán, khi làm việc cũng như đi phỏng vấn. (Nói đâu xa, kĩ thuật cache ta dùng hàng ngày, là dựa trên CTDL HashTable, tốn thêm bộ nhớ để giảm thời gian tính toán dữ liệu đấy).
Độ phức tạp của các operation (thêm, xoá, tìm kiếm) của các cấu trúc dữ liệu hay dùng
Tạm kết
Đấy, do bài đã khá dài rồi, nên ở phần này, tụi mình chỉ ôn lại sơ về Big-O Notation, Time/Space Complexity của 1 thuật toán, cấu trúc dữ liệu thôi!
Ở 2 phần sau, mình sẽ giới thiệu kĩ hơn về 8 cấu trúc dữ liệu cơ bản, chúng được sử dụng trong trường hợp nào, một số bài toán phổ biến… để mọi người cùng luyện tập nhé.
Note: Môn thuật toán trong trường Đại Học sẽ dạy kĩ hơn 1 số biểu thức khác như Big-Omega, Big Theta, Small O,… Tuy nhiên, đi làm vài năm mình … chưa từng dùng tới chúng bao giờ nên mình bỏ qua luôn.
Trải qua hành trình 25 năm phát triển, Công ty Cổ phần Viễn thông FPT (FPT Telecom) vẫn luôn khẳng định vị thế dẫn đầu của mình khi là một trong những nhà cung cấp dịch vụ Viễn thông và Internet hàng đầu khu vực, song hành cùng với tinh thần thấu hiểu, thân thiện và tận tâm, cung cấp cho Khách hàng sản phẩm hiện đại với dịch vụ chuyên nghiệp nhất.
Tự hào là Môi trường làm việc tốt nhất
Trải qua những vòng đánh giá gắt gao với các tiêu chí như Danh tiếng công ty, Chất lượng công việc, Lãnh đạo và quản lý, Chế độ đãi ngộ, Cơ hội phát triển, Văn hóa và Môi trường…, Tập đoàn FPT nói chung hay FPT Telecom nói riêng luôn ghi danh vào Top Những nơi làm việc tốt nhất trong nhiều năm qua.
Ông Chu Quang Huy, Giám đốc Nhân sự FPT đại diện nhận vinh danh #1 Nơi làm việc tốt nhất trong ngành CNTT, Phần mềm & Ứng dụng, Thương mại điện tử
Hệ thống giá trị cốt lõi với 6 chữ vàng “Tôn – Đổi – Đồng – Chí – Gương – Sáng” (Tôn trọng, Đổi mới, Đồng đội, Chí công, Gương mẫu, Sáng suốt) luôn là kim chỉ nam cho người nhà F học tập, làm việc và phát triển. FPT chấp nhận cả mặt mạnh, mặt yếu, cả điểm tốt và chưa hoàn thiện của nhân viên nên đây chính là cơ hội để bất kì ai cũng có điều kiện được thể hiện mình, dám đương đầu với thách thức để phát triển bản thân.
Tại FPT, con người là tài sản quý giá nhất, mỗi cán bộ nhân viên (CBNV) là một đối tác sự nghiệp quan trọng. Công ty luôn đưa ra những chủ trương, hành động và hệ thống chính sách phù hợp nhằm thu hút, phát triển, giữ chân nhân tài.
Bên cạnh đó, các giá trị văn hóa doanh nghiệp tốt đẹp luôn được truyền tải qua các hoạt động đoàn thể thường xuyên như Ngày vì Cộng đồng, Hướng về Cội nguồn, Ngày Thể thao FPT, Hội làng FPT…
Ngoài ra, FPT còn chú trọng phát triển cơ sở vật chất, xây dựng môi trường làm việc hiện đại, thân thiện môi trường. Trong đó có những khu văn phòng được xây dựng theo mô hình campus như F-Ville, F-Town, FPT Đà Nẵng… nhằm tạo ra một môi trường làm việc sáng tạo giúp CBNV có thể phát huy tốt nhất khả năng của mình trong công việc.
Liên tiếp góp mặt trong Top Nhà tuyển dụng được yêu thích nhất
Là sự kiện khảo sát phi lợi nhuận thường niên do CareerBuilder Việt Nam thực hiện, FPT Telecom luôn đạt thành tích cao với danh hiệu Nhà tuyển dụng được yêu thích nhất (#18 năm 2019, #8 năm 2020 và #6 năm 2021). Việc nắm giữ vị trí cao đã ghi nhận những nỗ lực của FPT Telecom trong việc phát triển văn hóa doanh nghiệp, không ngừng nỗ lực hoàn thiện và nâng cao chính sách nguồn nhân lực của mình.
Trong suốt mùa dịch bệnh Covid-19, trong khi các doanh nghiệp lớn nhỏ cắt giảm nhân sự, FPT Telecom vẫn đảm bảo không có nhân viên nào bị sa thải và tạo điều kiện giúp nhân viên làm việc tại nhà trong suốt mùa dịch.
Bên cạnh những hoạt động nội bộ dành cho CBNV, FPT Telecom luôn sẵn sàng hợp tác cùng các trường đại học trong quá trình đào tạo nguồn nhân lực chất lượng cao, hỗ trợ sinh viên xây dựng nền tảng kỹ năng, kiến thức, tìm kiếm cơ hội việc làm và điều kiện tiếp cận công nghệ hiện đại phục vụ cho quá trình học tập. Có thể kể đến những chương trình đặc biệt như chuỗi Talkshow FPT Career Booming, FPT Tour – Tham quan doanh nghiệp, Ngày hội việc làm,…
Với những chính sách tuyển dụng phù hợp, FPT Telecom luôn chào đón ứng viên như một khách hàng và mang đến những trải nghiệm ứng tuyển tuyệt vời, sẵn sàng tạo cơ hội học tập và làm việc cho những bạn trẻ nhiệt huyết, đam mê và năng động.
Xem thêm về FPT Telecom tại fpt.vn và tìm kiếm các thông tin việc làm tại fptjobs.com
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Thay vì tạo thread bằng việc Extend Thread hoặc implement Runable và tự quản lý số lượng thread. Thì ta có một hướng tiếp cận khác đó là sử dụng Callable và Future. (Cho phép hủy các thread, kiểm tra thread đã hoàn thành chưa, quản lý số thread chạy cùng lúc …).
Callable, Future, Executors là gì?
Callablelà một interface trong java, nó định nghĩa một công việc và trả về một kết quả trong tương lai và có thể throw Exception.
Future là kết quả trả về của Callable, nó thể hiện kết quả của một phép tính không đồng bộ, cho phép kiểm tra trạng thái của phép tính (đã thực hiện xong chưa, kết quả trả về là gì…).
Executors là một class tiện ích trong Java, dùng để tạo thread pool, đối tượng Callable cho các xử lý bất đồng bộ.
Mỗi đối tượng Calculator có thể hiểu là một thread, khi nó được submit vào ExecutorService thì nó sẽ được thực thi.
Executors.newFixedThreadPool(10); tức là tạo ra một thread pool chứa tối đa 10 thread chạy cùng lúc.
executor.shutdown();: Thực hiện tắt executor khi không còn task (đối tượng Callable) nào ở bên trong (các task đã hoàn thành). Nếu bạn không có lệnh này thì chương trình của bạn sẽ chạy mãi vì nó luôn có một thread kiểm tra task trong executor để thực thi.
Khi bạn gọi f1.get() thì nó sẽ block thread chính lại để khi nào đối tượng c1 thực hiện xong và trả về kết quả.
Trường hợp đối tượng c1 mất quá nhiều thời gian để tính tổng 2 số thì cả chương trình sẽ bị delay rất lâu. Giải pháp cho trường hợp này là sử dụng method get() với thời gian timeout:
Ví dụ nếu sau 1 giây mà chưa có kết quả thì không chờ nữa: f1.get(1, TimeUnit.SECONDS)
Một số hạn chế của Future
Future không thông báo khi nó hoàn thành: (không biết được khi nào hoàn thành): ví dụ mình muốn sau khi f1 hoàn thành thì làm gì đó nhưng Future không hỗ trợ bắt được sự kiện hoặc xử lý callback khi f1 hoàn thành
Không thể thực hiện xử lý chờ hoặc xử lý theo thứ tự các future: ví dụ mình muốn f1 và f2 hoàn thành xong thì mới thực hiện f3 hoặc thực hiện theo thứ tự f1, f2, f3 nhưng Future không có cách nào xử lý được việc này.
Nếu muốn xử lý các vấn đề trên ta lại phải dùng while hoặc tạo 1 thread riêng và sử dụng method f1.isDone() để check khi nào future hoàn thành…
Từ Java 8 ta có thêm CompleteFuture để khắc phục những hạn chế bên trên. (Mình sẽ làm ví dụ CompleteFuture trong bài sau).
Drupal là một hệ quản trị nội dung (CMS) mã nguồn mở viết bằng PHP; trong hầu hết các bảng xếp hạng về top những CMS platform (nền tảng phát triển) phổ biến thì Drupal thường xuyên có mặt trong top 5. Điều đó cho thấy sự phổ biến và nhu cầu sử dụng rất lớn của CMS PHP này. Ở Việt Nam, nhu cầu tuyển dụng PHP luôn luôn đứng top đầu, và sẽ có nhiều nhà tuyển dụng ưu tiên cho những lập trình viên biết, thành thạo các thư viện, framework như Drupal. Bài viết hôm nay mình sẽ cùng các bạn đi tìm hiểu về CMS platform này và các kiến thức cần có để trở thành 1 Drupal Developer nhé.
Drupal là gì?
Như đã nói ở trên, Drupal là một hệ quản trị nội dung mã nguồn mở giúp phát triển website từ các blog cá nhân cho tới các trang web của chính phủ, doanh nghiệp, hay các trang thương mại điện tử.
Hiểu đơn giản thì với Drupal, bạn có thể tạo ra website bạn cần và có sẵn những ứng dụng giúp thay đổi, chỉnh sửa nội dung website của bạn. Drupal được viết bởi Dries Buytaert – một lập trình viên người Bỉ, và được giới thiệu lần đầu tiên vào năm 2000; hiện tại nó vẫn được tác giả update phiên bản 1 cách đều đặn, mới nhất thì phiên bản Drupal 10 đang được lên kế hoạch ra mắt vào tháng 12 này.
Drupal được viết bằng PHP và hoàn toàn miễn phí, vì thế nó được nhiều lập trình viên ưa chuộng. Tính đến tháng 3 năm 2021, cộng đồng Drupal bao gồm hơn 1,39 triệu thành viên, đóng góp hơn 46 nghìn module miễn phí để mở rộng, gần 3 nghìn theme miễn phí để thay đổi giao diện. Drupal có thể chạy trên bất kỳ nền tảng máy tính nào có máy chủ hỗ trợ PHP và cơ sở dữ liệu để lưu trữ nội dung, cấu hình.
Đa ngôn ngữ: Drupal hỗ trợ 100 ngôn ngữ cho phép bạn cài đặt, tạo và sử dụng website ở mọi nơi trên thế giới.
Hỗ trợ quản lý nhiều site: Drupal có công cụ giúp bạn quản lý nhiều site trong chiến dịch, thương hiệu hay tổ chức, vùng địa lý mà bạn quản lý. Điều đó giúp bạn không phải đăng nhập qua lại nhiều tài khoản khác nhau, tối ưu hóa việc quản lý nội dung
Khả năng tương thích cao: Drupal không chỉ hỗ trợ thiết kế trên trình duyệt web mà khả năng tương thích với các định dạng thiết bị khác, đặc biệt là trên di động rất tốt.
Tính tin cậy cao: Hệ thống Drupal có độ bảo mật cao, nhiều tính năng cảnh báo lỗ hổng bảo mật và tự vá lỗi. Ngoài ra nó cũng đã được kiểm chứng bởi rất nhiều nhà phát triển web trên khắp thế giới
Tính tùy biến cao: người dùng hoàn toàn có thể tự định nghĩa ra các cấu trúc dữ liệu của riêng mình trên hệ thống Drupal, điều này giúp giải quyết nhiều bài toán theo nghiệp vụ cụ thể.
Khi nhắc đến lập trình viên Drupal thì thường sẽ có 3 lĩnh vực chuyên môn chính:
Drupal Site Builder: là những người xây dựng những trang web Drupal bằng cách cài đặt, thiết lập trên giao diện Admin (trang quản lý) mà có thể không cần viết thêm code tùy chỉnh nào.
Drupal Themer: đây là những Frontend Developer giúp thiết kế và tạo ra các theme dành cho Drupal.
Drupal Module Developer: là những người viết code PHP để tạo ra các module dành cho Drupal, có thể tích hợp vào chạy như những tiện ích bổ sung trên nền web chính. Thông thường thì Backend Developer có những kỹ năng phù hợp để đảm nhiệm công việc này.
Như vậy lập trình viên Drupal không chỉ là những người trực tiếp viết code PHP nhằm tùy biến hay thêm mới các chức năng cho hệ sinh thái Drupal, mà đôi khi việc thành thạo làm việc với trang quản trị CMS Drupal cũng giúp chúng ta trở thành 1 Drupal Developer.
Để trở thành lập trình viên Drupal, đầu tiên bạn hãy xác định chuyên môn, vị trí của mình trong hệ thống CMS Drupal.
Nếu muốn trở thành những người xây dựng, quản trị trang web Drupal, hãy cố gắng tìm hiểu tất cả những gì mà CMS Drupal cung cấp cho bạn từ việc cài đặt, cấu hình đến việc vận hành, bảo trì. Kĩ năng và kiến thức liên quan đến server, hosting, database là cần thiết cho vị trí này.
Hãy hình dung những công việc cơ bản sau đây bạn sẽ đảm nhiệm
Cài đặt Drupal lên hosting của bạn
Chuẩn bị cấu hình Database để kết nối với Web của bạn
Tìm hiểu sử dụng các module trong phần quản trị (Admin) của Drupal CMS
Content: quản trị nội dung và tài nguyên
Structure: cấu hình layout, module hiển thị
Appearance: cài đặt themes
Configuration: cấu hình website
People: quản trị người dùng
Reports: các báo cáo, nhật ký liên quan
Helps: các hướng dẫn sử dụng
Nếu bạn yêu thích việc tạo ra các themes dành cho website Drupal của mình, yếu tố đầu tiên là bạn cần có kiến thức liên quan của 1 Frontend Developer; đó là HTML, CSS, JS. Để tạo ra và sử dụng theme trên hệ sinh thái của mình, Drupal quy định 1 số file cơ bản giúp bạn thiết lập theme:
template.php: khai báo các hàm dùng trong theme
theme-settings.php: khai báo tùy chỉnh , config của theme
html.tpl.php: hiển thị những thông tin cơ bản của website
node.tpl.php: hiển thị thông tin của các node trong drupal
themes_name.info: khai báo các file css, js tùy chỉnh
page.tpl.php: cấu trúc giao diện chính trong Drupal
Nếu bạn tự tin và yêu thích công việc viết code bằng PHP, hãy tạo ra các module Drupal với những kiến thức về ngôn ngữ lập trình PHP cùng hiểu biết về cấu trúc, source code Drupal của bạn. Trước tiên hãy đọc và tìm hiểu về cấu trúc cũng như các thành phần sẵn có trong Drupal được mô tả chi tiết trên trang chủ của nó, các bạn có thể tham khảo ở link dưới đây:
Hãy nắm vững các khái niệm sau trong Drupal để có thể viết được 1 module hoàn chỉnh:
Node: các kiểu nội dung trong Drupal như blog, post, page, recipe, …
Block: các khối trên trang
Hook: xử lý các event tương tác với nhân Drupal
Views: phẩn hiển thị, chế độ xem dành cho các users
Công việc tiếp theo của bạn là kết hợp các thành phần lại với nhau để tạo ra các module tùy theo mục đích bạn tạo ra.
Kết bài
Drupal Developer không chỉ là những người viết code, đấy là những người tham gia vào hệ sinh thái của Drupal và cùng tạo ra những website theo yêu cầu, và xây dựng nên hệ sinh thái phong phú cho nền tảng CMS Drupal. Hy vọng qua bài viết này các bạn đã nắm được phần nào những điểm mấu chốt về nền tảng CMS này cũng như có cái nhìn rõ hơn về cách để trở thành 1 lập trình viên Drupal. Cảm ơn các bạn đã đọc, hẹn gặp lại các bạn trong các bài viết sau của mình.
Bài viết được sự cho phép của tác giả Võ Quang Huy
Đây là những đoạn code bạn sẽ dùng thường xuyên trong quá trìnhlập trình theme wordpress. Bạn chỉ cần hiểu tác dụng của nó như thế nào sau đó copy và dán nó để chạy thôi. Mình đã viết sẵn cho bạn rồi, không cần phài suy nghĩ chi nhiều nhé he he.
1.Code lấy bài viết mặt định
<!-- Get post mặt định -->
<?php if (have_posts()) : ?>
<?php while (have_posts()) : the_post(); ?>
<?php endwhile; else : ?>
<p>Không có</p>
<?php endif; ?>
<!-- Get post mặt định -->
Đoạn code đặt trong index sẽ lấy list bài viết mới nhất, Đặt trong category sẽ lấy danh sách bài viết của category đó, đặt trong single sẽ lấy nội dung của bài đó!.
2.Code lấy 10 bài viết mới nhất theo category
<!-- Get post News Query -->
<?php $getposts = new WP_query(); $getposts->query('post_status=publish&showposts=10&post_type=post&cat=1'); ?>
<?php global $wp_query; $wp_query->in_the_loop = true; ?>
<?php while ($getposts->have_posts()) : $getposts->the_post(); ?>
<?php endwhile; wp_reset_postdata(); ?>
<!-- Get post News Query -->
Đây là code lấy nội dung bài viết được chỉ định số từ nhất định. Cách dùng <?php echo teaser(30); ?>, Với được code trên mình sẽ lấy 30 từ đầu tiên trong bài viết!
14.Code lấy tất cả hình ảnh trong nội dung bài viết.
function get_link_img_post(){
global $post;
preg_match_all('/src="(.*)"/Us',get_the_content(),$matches);
$link_img_post = $matches[1];
return $link_img_post;
}
Chèn code này trong file functions.php, để hiển thị chúng ta dùng forech nó ra nhé!
24. Code lấy ảnh đầu tiên trong bài viết làm ảnh đại diện
function catch_that_image() {
global $post, $posts;
$first_img = '';
ob_start();
ob_end_clean();
$output = preg_match_all('/<img.+src=[\'"]([^\'"]+)[\'"].*>/i', $post->post_content, $matches);
$first_img = $matches [1] [0];
if(empty($first_img)){ //Defines a default image
$first_img = "/images/default.jpg"; //Duong dan anh mac dinh khi khong tim duoc anh dai dien
}
return $first_img;
}
Cách sử dùng: Chèn đoạn code nào vào khu vực muốn hiển thị hình đại diện.
This is the most significant addition to our platform, previously called LeapXpert’s Federated Messaging Orchestration Platform (or FMOP™ for short), since its release in 2019.
Why now?
Because as business communication continues shifting to a new model, it requires new solution types.
Because enterprises are facing new constraints and want to reach new goals but are lacking the right solutions for these new problems.
This new platform aims at serving enterprises, both in regulated and non-regulated industries, and enables their employees to better communicate responsibly with their clients, partners, and colleagues.
So what’s new?
iMessage
As the new hybrid work model is here to stay, business communication is now all about convenience, speed, security, productivity, and engagement for both external and internal communications, to cover the different needs of clients, employees, and enterprises.
Clients want to communicate on their preferred messaging apps such as WhatsApp, WeChat, Signal, Telegram, etc. They often favor text messaging over other channels, including e-mail. Consumers have embraced native messaging channels such as iMessage, whose use is growing fast, especially in the US. In 2021, more than 70% of US consumers aged 18-24 owned an iPhone (from 47% in 2018) and many are heavy iMessage users.
That’s why we’re excited to announce the general availability of iMessage support. It’s the only robust and scalable iMessage support on the market.
A single employee identity
Employees want to choose the best communication channel that matches convenience, productivity, and enterprise policies while keeping personal and professional communications separate. Some want a unified messaging and voice solution – as voice is still a part of any business interaction. Some prefer to use native messaging channels when communicating externally and even internally. Wither others want to do more with their selected enterprise collaboration and productivity platform, such as Microsoft Teams.
This is why the new LeapXpert Communications Platform now provides:
A single employee identity across communication channels – The LeapXpert Communications Platform is based on a single employee identity or phone number across all supported communication channels. This phone number can be an individual business or personal number, or a pooled business number provided by mobile carriers or cloud telephony providers.
The new solution eases and improves client satisfaction and engagement while removing the complex management of phone numbers in siloed solutions and addressing the lack of available phone numbers globally.
Voice support
LeapXpert’s platform now supports incoming and outgoing voice calls (IP and PSTN calls) in addition to messaging and SMS, through the single employee phone number. Employees can use their existing enterprise apps like Leap Work mobile and desktop apps or integrated third-party applications like Teams Phone while keeping their business and personal conversations separate.
Governed and Native modes
If at first we required that our platform be accessed through enterprise applications, we listened to the market and understood that some prefer the native messenger experience, so we developed the only solution that supports both models.
The platform now adapts to different employee behaviors and preferences – application-based or native communication channel, BYOD or corporate device, single enterprise application for internal and external communication, or dedicated applications.
Leap Work for Microsoft Teams
Enterprises are looking for converged, secure, compliant, and open communication solutions breaking with the current siloed solution approach that is expensive and difficult to maintain.
Convergence includes internal and external communications in one platform like Teams or Slack, text and voice communications triggering for example IP or PSTN voice calls from text messages, and fixed and mobile communications integrating native mobile voice channels into collaboration and productivity applications like Microsoft Teams Phone Mobile solution.
Information protection, security, and data governance are becoming a top priority for many enterprises. They notice that more files are exchanged through messaging channels, and therefore risks of viruses and cyber attacks increase. They also must monitor business information access and sharing to protect themselves against possible internal misconduct affecting their business and brand.
Communications recordkeeping and regulatory compliance are driving lots of investments among financial institutions as regulators are cracking down on US banks with more than $1.8 billion in fines. A similar crackdown in Europe or other regions is likely underway.
Finally, an open platform is a must-have in a complex disaggregated technical environment where cloud, mobility, enterprise systems, communication supervision, and industry-specific solutions must work together.
This is why The LeapXpert Communications Platform now supports:
Leap Work for Microsoft Teams – The LeapXpert Communications Platform integrates with Microsoft Teams with Leap Work for Teams, our mobile and desktop app, available on the Teams store. It’s now possible to chat with external parties on their messaging app of choice from within Microsoft Teams. The native integration allows users to use the same Teams chat interface for internal and external communication increasing user productivity and improving client engagement. The platform ensures external conversations remain compliant and secure following enterprise governance guidelines.
All platform enterprise controls such as antivirus, antimalware, information barriers, and ethical walls are part of The LeapXpert Communications Platform and apply to the new features.
Growing ecosystem of partners
Thanks to its open interfaces, the new platform has increased its number of out-of-the-box integrations and technological partners in the last few months including Microsoft (Azure services and Teams), Blackberry and Mobileiron (Mobile Device Management), and OpenFin (Operating System for Finance). As system integration is painful for many enterprises, we want our platform to work seamlessly with leading market solutions and technologies.
What’s next?
Our new product, which supports all previous functionalities, has been renamed The LeapXpert Communications Platform. This name reflects the value LeapXpert brings to enterprises embracing the modern work environment:
A new way of conducting business communications that is responsible, secure, and compliant across the latest communications channels like consumer messaging apps, as well as traditional channels, such as voice calls.
Please contact us for a demo or join us in a series of upcoming events where we will be unveiling the solution in the US, Europe, and Asia.
Vietnam/Cairo, tháng 12/2022 – Tập đoàn Công Nghệ NFQ với trụ sở chính tại Đức và hơn 300 nhân sự lập trình viên chất lượng cao tại Việt Nam, chuyên cung cấp và xây dựng giải pháp phần mềm cho các khách hàng lớn trên khắp Châu Âu và Châu Á, đã và đang mở rộng thị trường quốc tế sang khu vực Châu Phi sau khi mua lại phần lớn cổ phần của Dlivr.io có trụ sở ở thủ đô Cairo – Ai Cập
Việc mở rộng tại thị trường Châu Phi và sáp nhập với Dlivr.io LLC lần này nâng tổng số nhân viên tại Tập đoàn NFQ lên đến hơn 900 nhân viên tại mười văn phòng trải khắp ba Châu lục trên toàn cầu.
Thông qua việc tăng cường hệ thống vận hành từ Châu Á và Châu Âu sang thị trường vẫn luôn được đánh giá cao về tiềm năng phát triển CNTT như Châu Phi, đánh dấu một bước tiến quan trọng trong lộ trình nâng cao năng lực cạnh tranh, cung ứng nguồn nhân lực CNTT chuyên môn cao trên quy mô toàn cầu của Tập đoàn NFQ.
Dẫn lời người đồng sáng lập Tập đoàn NFQ, ông Lars Jankowfsky:
“Châu Phi hiện đang đóng một vai trò quan trọng trong sự phát triển của hệ sinh thái CNTT trên toàn thế giới. Việc mở rộng trung tâm phát triển phần mềm này giúp cho NFQ có thể tiếp cận với nguồn nhân lực dồi dào của lục địa này cũng như mang đến những cơ hội tuyệt vời hơn cho các đối tác của NFQ có thể tiếp cận với nguồn nhân lực chất lượng cao trên toàn thế giới. Bên cạnh đó là cơ hội cho các nhân viên của NFQ có thể trao đổi, học tập, làm việc và phát triển, nâng cao các kỹ năng chuyên môn với những đồng nghiệp trên toàn cầu.”
Ông cho biết thêm:
“Qua kinh nghiệm mở rộng thành công trung tâm phát triển phần mềm khu vực Châu Á của NFQ tại TP.HCM năm 2015 từ 5 nhân sự lên hơn 300 nhân sự trong năm 2022 trải khắp Việt Nam và Thái Lan. Chúng tôi thấy nhiều điểm tương đồng khi chọn Cairo làm văn phòng đầu tiên của NFQ tại Châu Phi bởi trình độ học vấn, kỹ năng chuyên môn, Tiếng Anh và năng lực làm việc của các kỹ sư CNTT nơi đây được xem là một trong những nơi tốt nhất trên thế giới.”
Tại Cairo, nhà sáng lập và điều hành Dlivr.io – Senan Sharhan đang dẫn dắt một đội ngũ với gần 30 lập trình viên chuyên môn cao chuyên về thiết kế và lập trình những dự án công nghệ số tiên phong. Tại đây, công ty đã và đang phát triển những dự án đột phá, các phần mềm mang tính linh hoạt cao cho các công ty/tập đoàn thương mại điện tử tại Châu Âu và Ả Rập. Việc sáp nhập thêm các kỹ sư CNTT tay nghề kỹ thuật cao từ Dlivr.io lần này đã giúp Tập đoàn NFQ củng cố thêm tiềm lực của đội ngũ tại Châu Âu và Châu Á, đồng thời mở rộng nguồn khách hàng dồi dào vào các thị trường tiềm năng trong tương lai.
Sự kiện này khẳng định NFQ đang ngày càng vươn rộng ra toàn cầu.
Thông tin bổ sung
Thông tin thêm về NFQ
NFQ là công ty CNTT đa quốc gia với đội ngũ nhân viên lên đến 900 trải dài khắp thế giới. Tập đoàn NFQ chuyên cung cấp chiến lược công nghệ số và thực hiện các dự án cho các doanh nghiệp đang tìm kiếm cơ hội mở rộng kinh doanh và nâng cao khả năng cạnh tranh bằng việc đầu tư vào xây dựng phần mềm và các nền tảng công nghệ, số hóa doanh nghiệp, đưa trí tuệ công nghệ và khoa học số vào kinh doanh. NFQ cung cấp giải pháp về phát triển phần mềm, thiết kế giao diện người dùng (UI/UX), Tối ưu hóa tỉ lệ chuyển đổi (CRO) và tham vấn phát triển dịch vụ cho các doanh nghiệp làm ở các lĩnh vực khác nhau trên toàn thế giới như du lịch, bán lẻ đa kênh, vận tải, hậu cần, liên doanh… NFQ đã tạo tiếng vang trong việc phát triển và xây dựng các nhóm kỹ sư phần mềm CNTT có năng lực vượt bậc đang phụ trách chính trong dự án KAYAK và thúc đẩy công nghệ cho nền tảng đặt phòng hàng đầu như HomeToGo. NFQ cũng đã xây dựng thành công nền tảng tìm kiếm chuyến bay Swoodoo ở Đức và DACH, một trong những nền tảng được cho là dẫn đầu về kỹ thuật và giải pháp trong lĩnh vực này thời điểm bấy giờ.
Tại Việt Nam, NFQ đã xây dựng được một mạng lưới trung tâm phát triển phần mềm rộng khắp với hơn 300 nhân sự tại 4 văn phòng trên các thành phố lớn Hồ Chí Minh, Đà Nẵng, Cần Thơ, Hà Nội. NFQ Asia được chứng nhận là một trong những công ty công nghệ có môi trường làm việc tốt nhất tại Việt Nam trong suốt 4 năm vừa qua theo bình chọn từ ITviec.
Mục tiêu của NFQ là trở thành tập đoàn công nghệ uy tín, nổi tiếng hàng đầu, không chỉ ở chất lượng dịch vụ, sản phẩm mà còn ở môi trường làm việc.
Bài viết được sự cho phép của tác giả Phạm Minh Khoa
Để hiểu rõ hơn khái niệm Redux middleware, chúng ta cùng thử xử lý 1 bài toán như sau:
Bạn cần phải ngăn chặn người dùng (users) không được sử dụng các từ khóa bị cấm (ví dụ như vl, vkl, cmnr, …) trong bài viết của họ. Để đơn giản thì mình sẽ xử lý lúc người dùng submit bài viết (trong ví dụ sẽ chỉ check trong tiêu đề bài viết thôi nhé)
handleSubmit(event) {
event.preventDefault();
const { title } = this.state;
this.props.addArticle({ title });
this.setState({ title: "" });
}
Việc kiểm tra tất nhiên sẽ được đặt trước dòng this.props.addArticle và nó sẽ kiểu như này:
Việc làm như này tất nhiên cũng chẳng sao, tuy nhiên trong đoạn code trên chứa phần xử lý logic (business logic) và nó nằm trong UI Component; thế là không đạt được mục đích của Redux là chuyển logic ra khỏi React Component rồi. Redux middleware sinh ra để giải quyết bài toán trên cho mọi người. Hiểu 1 cách đơn giản thì Redux middleware cho phép chúng ta can thiệp vào giữa thời điểm dispatch 1 action và thời điểm action đến được reducer. Bạn có thể nhìn flow dưới đây để dễ hình dung.
Redux middleware là 1 function trả về 1 function, nhận next như 1 tham số. Bên trong function sẽ trả về 1 function khác nhận action như 1 tham số và cuối cùng là trả về next(action). Nó sẽ giống như thế này:
function forbiddenWordsMiddleware() {
return function(next){
return function(action){
// do your stuff
return next(action);
}
}
}
Ở đây bạn sẽ luôn luôn phải gọi next(action) ở trong middleware của bạn, nếu không thì Redux sẽ dừng lại, không có 1 action nào được đưa tới reducer. Trong middleware bạn cũng có thể truy cập vào state và sử dụng dispatch như sau:
function forbiddenWordsMiddleware({ getState, dispatch }) {
return function(next){
return function(action){
// do your stuff
return next(action);
}
}
}
Middleware trong Redux đóng vai trò rất quan trọng vì chúng sẽ chứa phần lớn logic ứng dụng của bạn với những lợi ích khi sử dụng:
Giúp tách biệt hầu hết logic ra khỏi giao diện (UI library)
Có khả năng tái sử dụng
Có thể test được 1 cách độc lập
Quay lại bài toán ban đầu, để sử dụng được middleware thì chúng ta phải apply nó vào trong store
import { createStore, applyMiddleware } from "redux";
import rootReducer from "../reducers/index";
import { forbiddenWordsMiddleware } from "../middleware";
const store = createStore(
rootReducer,
applyMiddleware(forbiddenWordsMiddleware)
);
export default store;
Khi submit action thêm mới bài viết (ADD_ARTICLE), middleware sẽ thực hiện việc check xem có từ khóa bị cấm hay không. Nếu không thì action thêm mới bài viết (ADD_ARTICLE) sẽ được thực hiện bình thường thông qua next(action). Nếu gặp từ khóa bị cấm, chúng ta sẽ dispatch 1 action khác mang tên là “FOUND_BAD_WORD” để gửi đến cho reducer. Code cụ thể sẽ được viết như dưới:
import { ADD_ARTICLE } from "../constants/action-types";
const forbiddenWords = ["spam", "money"];
export function forbiddenWordsMiddleware({ dispatch }) {
return function(next) {
return function(action) {
// do your stuff
if (action.type === ADD_ARTICLE) {
const foundWord = forbiddenWords.filter(word =>
action.payload.title.includes(word)
);
if (foundWord.length) {
return dispatch({ type: "FOUND_BAD_WORD" });
}
}
return next(action);
};
};
}
Ở ví dụ trong bài hôm nay, các xử lý của chúng ta đều là xử lý đồng bộ. Bài toán sẽ trở nên phức tạp hơn nếu như việc check từ khóa bị cấm cần thiết phải thông qua việc call API từ phía backend. Lúc đó cần xử lý bất đồng bộ. Tuy nhiên việc dispatch 1 action là đồng bộ; không thể thực hiện call 1 Promise trong này được. Nếu vẫn cố chày cối viết vào thì sẽ ra sao, thử xem nhé.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Với lập trình hướng đối tượng, chúng ta thường xuyên làm việc với rất nhiều class trong một chương trình, các class được liên kết với nhau theo một mối quan hệ nào đó. Dependency là một loại quan hệ giữa 2 class mà trong đó một class hoạt động độc lập và class còn lại phụ thuộc bởi class kia. Sự phụ thuộc chặt chẽ này gây rất nhiều khó khăn khi hệ thống cần thay đổi, nâng cấp. Để giải quyết vấn đề này chúng ta có thể sử dụng Dependency Injection (DI), một dạng design pattern được thiết kế nhằm ngăn chặn sự phụ thuộc nêu trên.
DI – Dependency Injection
Dependency Inversion Principle (DIP), Inversion of Control (IoC), Dependency Injection (DI) là gì
Trước khi bắt đầu với Dependency Injection, các bạn hãy dành chút thời gian xem lại nguyên lý SOLID trong OOP. Nguyên lý cuối cùng, tương ứng với chữ D trong SOLID chính là DIP – Dependency Inversion Principle (nguyên lý đảo ngược sự phụ thuộc). Nội dung của nguyên lý này như sau :
Các module cấp cao không nên phụ thuộc vào các module cấp thấp. Cả 2 nên phụ thuộc vào abstraction.
Interface (abstraction) không nên phụ thuộc vào chi tiết, mà ngược lại, chi tiết nên phụ thuộc vào abstraction. Các class giao tiếp với nhau thông qua interface, không phải thông qua implementation.
Chúng ta thường hay lẫn lộn giữa các khái niệm Dependency Inversion Principle (DIP), Inversion of Control (IoC), Dependency Injection (DI). Ba khái niệm này tương tự nhau, tất cả đều hướng đến một mục đích duy nhất là tạo ra ứng dụng ít kết dính (loosely coupling), dễ mở rộng (flexibility) cũng như giúp lập trình viên tập trung chủ yếu vào công việc business flow.
Dependency Inversion Principle (DIP): là một nguyên lý để thiết kế và viết code.
Inversion of Control (IoC): là một design pattern được tạo ra để code có thể tuân thủ nguyên lý Dependency Inversion. Có nhiều cách hiện thực Pattern này như ServiceLocator, Event, Delegate, … và Dependency Injection là một trong các cách đó.
Dependency Injection (DI): là một Design Pattern, một cách để hiện thực Inversion of Control Pattern. DI chính là khả năng liên kết giữa các thành phần lại với nhau, các module phụ thuộc (dependency) sẽ được inject vào module cấp cao.
Đơn giản chúng ta chỉ cần ghi nhớ:
DI is about wiring, IoC is about direction, and DIP is about shape.
IoC là hướng đi, DIP là định hình cụ thể của hướng đi, còn DI là một hiện thực cụ thể.
Dependency Injection (DI) là một design pattern, một kỹ thuật cho phép xóa bỏ sự phụ thuộc giữa các module, làm cho ứng dụng dễ dàng hơn trong việc thay đổi module, bảo trì code và testing.
DI cung cấp cho một đối tượng các thể hiện phụ thuộc (dependencies) của nó từ bên ngoài truyền vào mà không phải khởi tạo trực tiếp từ trong class sử dụng.
Nhiệm vụ của dependency injection:
Tạo các đối tượng.
Quản lý sự phụ thuộc (dependencies) giữa các đối tượng.
Cung cấp (inject) các phụ thuộc được yêu cầu cho đối tượng (được truyền từ bên ngoài đối tượng).
Nguyên tắc hoạt động của DI:
Các module không giao tiếp trực tiếp với nhau, mà thông qua interface. Module cấp thấp sẽ implement interface, module cấp cao sẽ gọi module cấp thấp thông qua interface.
Việc khởi tạo các module cấp thấp sẽ do DI Container/ IoC Container thực hiện.
Việc Module nào gắn với interface nào sẽ được config trong file properties, trong file XML hoặc thông qua Annotation. Annotation là một cách thường được sử dụng trong các Framework, chẳng hạn như @Inject với CDI, @Autowired với Spring hay @ManagedProperty với JSF.
Các thành phần tham gia Dependency Injection Pattern:
Client : là một class cần sử dụng Service.
Service : là một class/ interface cung cấp service/ dependency cho Client.
ServiceImpl: cài đặt các phương thực cụ thể của Service.
Injector: là một lớp chịu trách nhiệm khởi tạo các service và inject các thể hiện này cho Client.
Các dạng Dependency Injection
Constructor Injection: Các dependency sẽ được container truyền vào (inject vào) 1 class thông qua constructor của class đó. Đây là cách thông dụng nhất.
Setter Injection: Các dependency sẽ được truyền vào 1 class thông qua các hàm Setter.
Fields/ properties: Các dependency sẽ được truyền vào 1 class một cách trực tiếp vào các field.
Interface Injection: Class cần inject sẽ implement 1 interface. Interface này chứa 1 hàm tên Inject. Container sẽ injection dependency vào 1 class thông qua việc gọi hàm Inject của interface đó. Đây là cách rườm rà và cũng ít được sử dụng.
Service Locator: nó hoạt động như một mapper, cho phép thay đổi code tại thời điểm run-time mà không cần biên dịch lại ứng dụng hoặc phải khởi động lại.
Ví dụ chúng ta có một class cho phép User có thể gửi message.
EmailService.java
package com.gpcoder.patterns.creational.dependencyinjection.message.simple;
public class EmailService {
public void sendEmail(String message) {
System.out.println("Message: " + message);
}
}
UserController.java
package com.gpcoder.patterns.creational.dependencyinjection.message.simple;
public class UserController {
private EmailService emailService = new EmailService();
public void send() {
emailService.sendEmail("Hello Dependency injection pattern");
}
}
Chương trình trên rất đơn giản, chỉ gồm có 2 class. Tuy nhiên, nó có một vài giới hạn như sau:
Lớp UserController phụ thuộc trực tiếp vào class EmailService. Mỗi khi có thay đổi trong lớp EmailService, chẳng hạn thêm tham số cho constructor của class này lên sẽ ảnh hưởng trực tiếp đến class UserController.
Một User khác không muốn sử dụng cách gửi message thông qua email, chẳng hạn qua sms, facebook, …
Khó khăn khi viết Unit Test cho UserController do phụ thuộc trực tiếp vào EmailService.
Bây giờ chúng ta sẽ áp dụng Dependency Injection để giải quyết các giới hạn trên.
MessageService.java
package com.gpcoder.patterns.creational.dependencyinjection.message.di;
public interface MessageService {
void sendMessage(String message);
}
EmailService.java
package com.gpcoder.patterns.creational.dependencyinjection.message.di;
public class EmailService implements MessageService {
@Override
public void sendMessage(String message) {
System.out.println("Email message: " + message);
}
}
MessageService.java
package com.gpcoder.patterns.creational.dependencyinjection.message.di;
public class SmsService implements MessageService {
@Override
public void sendMessage(String message) {
System.out.println("Sms message: " + message);
}
}
UserController.java
package com.gpcoder.patterns.creational.dependencyinjection.message.di;
public class UserController {
private MessageService messageService;
public UserController(MessageService messageService) {
this.messageService = messageService;
}
public void send() {
messageService.sendMessage("Hello Dependency injection pattern");
}
}
DependencyInjectionPatternExample.java
package com.gpcoder.patterns.creational.dependencyinjection.message.di;
public class DependencyInjectionPatternExample {
public static void main(String[] args) {
MessageService messageService = new EmailService();
UserController userController = new UserController(messageService);
userController.send();
}
}
Như bạn thấy, thay vì sử dụng trực tiếp lớp EmailService chúng ta sử dụng interface. Lớp UserController không trực tiếp khởi tạo message service mà nó được truyền từ bên ngoài vào. Chính vì vậy mà các lớp không còn phụ thuộc vào nhau, chúng ta có thể dễ dàng sử đổi hay thêm bất kỳ service nào khác mà không ảnh hưởng đến UserController. Đây chính là dạng Constructor Injection của Dependency Injection Pattern.
Tuy nhiên, chương trình trên vẫn còn một hạn chế là chúng ta phải khởi tạo một thể hiện cụ thể cho MessageService ở rất nhiều nơi, chương trình cũng rất khó khăn khi cần thay thế một service cho toàn bộ hệ thống. Để giải quyết vấn đề này, chúng ta có thể áp dụng Inversion of Control Container (IoC container), một nơi để quản lý các thành phần phụ thuộc này và cung cấp thể hiện cụ thể khi cần sử dụng.
Ưu điểm và khuyết điểm của Dependency Injection
Ưu điểm:
Reduced dependencies: giảm sự kết dính giữa các module.
Reusable: code dễ bảo trì, dễ tái sử dụng, thay thế module. Giảm boiler-plate code do việc tạo các biến phụ thuộc đã được injector thực hiện.
Testable: rất dễ test và viết Unit Test.
Readable: dễ dàng thấy quan hệ giữa các module vì các dependecy đều được inject vào constructor.
Khuyết điểm:
Khái niệm DI khá khó hiểu đối với người mới tìm hiểu.
Sử dụng interface nên đôi khi sẽ khó debug, do không biết chính xác module nào được gọi.
Các object được khởi tạo toàn bộ ngay từ đầu, có thể làm giảm performance.
Có thể gặp lỗi ở run-time thay vì compile-time.
Sử dụng Dependency Injection khi nào?
Một số trường hợp sử dụng DI:
Khi cần inject các giá trị từ một cấu hình cho một hoặc nhiều module khác nhau.
Khi cần inject một dependency cho nhiều module khác nhau.
Khi cần một vài service được cung cấp bởi container.
Khi cần tách biệt các dependency giữa các môi trường phát triển khác nhau. Chẳng hạn, với môi trường dev chỉ cần log việc gửi mail, trong môi trường product cần gởi mail thông qua một API thật sự.
Inversion of Control (IoC) dịch là đảo ngược điều khiển. Ý của nó là làm thay đổi luồng điều khiển của ứng dụng, giúp tăng tính mở rộng của một hệ thống.
IoC được chia thành 2 loại:
Dependency Lookup : sẽ tìm kiếm đối tượng phụ thuộc trong khung chứa IoC và sau đó chúng ta có thể dùng code để đưa đối tượng phụ thuộc vào trong đối tượng bị phụ thuộc. Dependency Lookup được chia thành hai loại khác nhau đó là:
Dependency Pull: các đối tượng phụ thuộc sẽ được lấy ra từ một nơi mà các đối tượng phụ thuộc đã được đăng ký chứ không phải lấy trực tiếp từ khung chứa.
Contextualized Dependency Lookup (CDL): việc lấy đối tượng phụ thuộc xảy ra trực tiếp với khung chứa luôn chứ không thông qua nơi mà đối tượng phụ thuộc đã đăng ký.
Dependency Injection : sẽ đưa luôn đối tượng phụ thuộc vào đối tượng bị phụ thuộc.
Hollywood principle cũng thường được gọi là một IoC hay DI:
Inversion of Control Container (IoC container) là gì?
Khi áp dụng kỹ thuật Dependency Injection, thì một vấn đề khác nảy sinh là làm thế nào chúng ta biết được một lớp sẽ phụ thuộc vào những lớp nào để khởi tạo nó. Để giải quyết điều này, người ta nghĩ ra Dependency Injection Container hay còn gọi là Inversion of Control Container (IoC container).
IoC Container được xây dựng dựa trên ý tưởng của IoC, nó có nhiệm vụ quản lý các thành phần khác nhau, cung cấp tài nguyên cho các thành phần khi chúng đòi hỏi tài nguyên dựa vào thông tin từ các file cấu hình. Nhờ đó việc quản ý sẽ dễ dàng hơn, tập trung hơn và đơn giản, hiệu quả hơn rất nhiều so với việc phải phân tán tài nguyên cho từng thành phần tự xử lý.
Về bản chất thì IoC Conainter như một tấm bản đồ, nó cho ta biết một lớp phụ thuộc vào những lớp nào khác bằng kỹ thuật Reflection, hoặc từ danh sách đã được đăng ký trước.
Sức mạnh của IoC Container được thể hiện thông qua việc nó được áp dụng trong các Framework. Một đặc điểm quan trọng của Framework là các phương thức được định nghĩa bởi người dùng thông thường được gọi từ trong bản thân Framework chứ không phải từ code ứng dụng của người dùng. Framework đóng vai trò của chương trình chính trong việc điều phối và sắp xếp hoạt động ứng dụng. Sự đảo ngược điều khiển này tạo ra cho Framework sức mạnh thông qua việc mở rộng. Chính IoC mang đến sự khác biệt giữa một Framework và một thư viện.
Thư viện là tập hợp các tính năng mà chúng ta có thể sử dụng, nó được tổ chức thành các class. Sau mỗi lần gọi một phương thức, thư viện sẽ làm một số việc và sau đó trả quyền điều khiển về cho người dùng.
Framework là một biểu hiện của thiết kế trừu tượng với nhiều hành vi được xây dựng sẵn bên trong, để sử dụng nó chúng ta cần chèn các hành vi của mình vào các nơi khác nhau trong Framework bằng các class hoặc plugin. Code của Framework sẽ gọi đến code của chúng ta tại những điểm cần thiết.
Tự xây dựng 1 framework đảo ngược điều khiển (IoC)
Chúng ta tiếp tục với ví dụ trên bằng cách áp dụng IoC để quản lý việc khởi tạo đối tượng.
Để xây dựng một framework đảo ngược điều khiển, ta dùng kỹ thuật Reflection để khởi tạo đối tượng động. Trước tiên ta cần đọc file cấu hình để lấy ra thông tin về tên lớp hiện thực cần được dùng.
Tạo file một Injector để đọc thông tin cấu hình và khởi tạo đối tượng cho ứng dụng.
Injector.java
package com.gpcoder.patterns.creational.dependencyinjection.ioc;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
import javax.management.InstanceNotFoundException;
public class Injector {
private static final String IOC_CONFIGURATION_FILE_NAME = "ioc.properties";
private Injector() {
throw new UnsupportedOperationException();
}
public static Object getInstance(String key) throws InstanceNotFoundException {
try (InputStream input = new FileInputStream(IOC_CONFIGURATION_FILE_NAME)) {
// load a properties file
Properties prop = new Properties();
prop.load(input);
// get the property value
String className = prop.getProperty(key);
return Class.forName(className).newInstance();
} catch (IOException | InstantiationException | IllegalAccessException | ClassNotFoundException e) {
e.printStackTrace();
throw new InstanceNotFoundException(
"Can't create instance of " + key + " base on the configuration of " + IOC_CONFIGURATION_FILE_NAME);
}
}
}
Chương trình của chúng ta được viết lại như sau:
package com.gpcoder.patterns.creational.dependencyinjection.ioc;
import javax.management.InstanceNotFoundException;
import com.gpcoder.patterns.creational.dependencyinjection.di.MessageService;
import com.gpcoder.patterns.creational.dependencyinjection.di.UserController;
public class DependencyInjectionPatternExample {
public static void main(String[] args) throws InstanceNotFoundException {
MessageService messageService = (MessageService) Injector.getInstance("messageService");
UserController userController = new UserController(messageService);
userController.send();
}
}
Như bạn thấy, bây giờ chương trình của chúng ta chỉ còn một nơi để khởi tạo và inject đối tượng, khi muốn thay đổi message service chỉ cần thay đổi trong file properties.
So sánh Dependency Injection Pattern với các Pattern khác
So sánh Dependency Injection Pattern với Singleton Pattern
Dependency Injection (DI) có nhiều ưu điểm hơn Singleton, ở một số ý sau:
Dễ dàng thay thế:Singleton thì lúc nào cũng chỉ có thể truy xuất 1 Object duy nhất, không thay thể bằng cái khác được. Với DI có thể thay thế bằng object khác tại thời điểm run-time.
Linh hoạt:Singleton thì luôn chỉ có một Object. Với DI có thể dùng riêng từng thể hiện cho mỗi Object hoặc một thể hiện dùng chung cho nhiều Object.
Kế thừa:Singleton thì không thể thừa kế. Với DI thì không giới hạn.
Một nhược điểm của DI so với Singleton là chi phí khởi tạo lớn hơn, do sử dụng Reflection để truy xuất các property trong object.
Với các hệ thống lớn, phức tạp, có khả năng thay đổi, mở rộng thì nên dùng DI. Với những trường hợp object muốn truy xuất được sử dụng ở khắp mọi nơi trong dự án, ở khắp các tầng trong hệ thống có thể sử dụng Singleton.
So sánh Dependency Injection Pattern với Factory Pattern
Cả hai Dependency Injection (DI) và Factory đều nhằm mục đích cung cấp một cách tiện lợi cho việc tạo một thể hiện của một class. Hai Pattern này đều dựa trên quy tắc “lập trình cho interface chứ không phải để implement interface đó”.
Một vài khác biệt chủ yếu giữa DI và Factory Pattern là:
DI giúp chúng ta tạo ra ứng dụng ít kết dính, với Factory Pattern mỗi class có một dependency với Factory method.
Sử dụng Factory Pattern khó khăn khi viết Unit test do phụ thuộc vào các dependency. Ngược lại với DI thì dễ dàng viết Unit do không phụ thuộc vào dependency.
Hạn chế của DI so với Factory Pattenr là cần phải cấu hình và cần một container để inject các dependency.
So sánh Dependency Injection Pattern với Service Locator Pattern
Cả hai Dependency Injection (DI) và Service Locator (SL) đều tuân theo DIP principle. Nó giúp chúng ta tạo ra ứng dụng ít kết dính, dễ hiểu, dễ viết test, dễ mở rộng, bảo trì.
Sự khác biệt giữa DI và SL:
Sự khác biệt chủ yếu giữa DI và SL là cách cài đặt (implement) để cung cấp một thể hiện cho các lớp của ứng dụng. DI sử dụng một builder object để khởi tạo các đối tượng và cung cấp (inject) các phụ thuộc được yêu cầu cho đối tượng từ lớp bên ngoài. SL sử dụng một locator object để giải quyết (resolve) sự phụ thuộc trong một lớp.
Khi sử dụng SL, các đối tượng được yêu cầu một cách rõ ràng để nhận một thể hiện của đối tượng và mỗi class có một dependency với SL. Trong khi sử dụng DI không có yêu cầu rõ ràng, dependency injector chỉ được gọi một lần dựa vào config tại thời điểm startup để inject các dependency vào main class.
SL có thể ẩn các dependency với class client, nhưng client cần phải thấy được Locator. Với DI, client không thấy được class Injector.
SL cần cung cấp ít nhất một tham số để nhận về thể hiện của một đối tượng do đó gây khó khăn khi viết unit test hơn. Với DI, chúng ta có thể pass một mock object để test.
Hạn chế của DI so với SL là cần phải cấu hình và cần một container để inject các dependency.
SL dễ code, dễ hiểu hơn so với DI. Tuy nhiên, nó thích hợp với các dụng nhỏ. DI thích hợp với các ứng dụng lớn, có nhiều class phụ thuộc.
Lời kết
Dependency Injection và IoC container là những khái niệm rất quan trọng, hầu hết các ứng dụng, framework hiện tại đều sử dụng nó. Chúng ta cần tìm hiểu để biết rõ DI và IoC được ứng dụng trong trường hợp nào. Nếu áp dụng hợp lý code của chúng ta sẽ ít kết dính hơn (loose coupling), dễ bảo trì, dễ test hơn, tổ chức ứng dụng hợp lý và gọn gàng hơn.
Hy vọng bài viết này đã giúp bạn hiểu hơn về Dependency Injection (DI) cũng như những ưu điểm