


Nhân viên được xem là nguồn nhân lực – “khối tài sản” quan trọng nhất của các tổ chức. Những sự kết nối tạo ra giá trị cho các doanh nghiệp bắt nguồn từ hiệu quả quản lý nguồn nhân lực. Từ đó, một vấn đề được đặt ra là liệu giữ chân nhân viên có thật sự quan trọng hay không? Và tại sao cần phải thực hiện điều đó? Cùng TopDev tìm hiểu thông qua bài viết sau.
Yếu tố con người chi phối, quyết định khả năng vận hành doanh nghiệp

Có quá nhiều chiến lược nhằm đánh giá khả năng vận hành doanh nghiệp. Đồng thời cũng có rất nhiều yếu tố chi phối đến sự thành công của tổ chức. Chúng ta có thể kể đến như:
- Xây dựng chiến lược Marketing hiệu quả;
- Phát triển thương hiệu thông qua các sản phẩm được cải tiến về chất lượng;
- Các dịch vụ hỗ trợ tuyệt vời;
Nếu là một freelancer it đang muốn tìm kiếm công việc, bạn có thể bị thu hút bởi những yếu tố trên trong quy trình tổ chức nhân sự.
Tuy nhiên, dường như mọi người đã quên đi một nhân tố quan trọng – nhân tố con người.
Xem thêm: Phân tích con người – Chiến lược quan trọng trong ngành Nhân sự
Con người nhân sự là nhân tố rất quan trọng. Họ sẽ là người trực tiếp trải nghiệm và đưa ra những đánh giá khách quan nhất. Chính con người nhân sự cũng là các cá nhân lên kế hoạch phát triển chiến lược cho doanh nghiệp một cách hiệu quả nhất. Do chủ động tìm hiểu về thị trường, họ luôn nắm bắt nhanh chóng mọi thứ. Đó là lý do họ luôn thấu hiểu sự thay đổi về nhu cầu thị trường. Từ đó, dễ dàng hơn trong việc thiết lập một quy trình hoàn hảo. Đồng thời, đảm bảo mọi thứ được vận hành một cách tối ưu.
Mặc dù việc tự động hóa, sử dụng các hệ thống điều khiển giúp giảm thiểu sự can thiệp của con người, rất hữu ích trong nhiều trường hợp, nhưng nó cũng không thể thay thế các tương tác của con người.
Tính cạnh tranh luôn tồn tại, giữ chân nhân viên là điều tất yếu phải thực hiện
Sự cạnh tranh nhân viên diễn ra ở mọi quy mô doanh nghiệp. Nếu bạn vuột mất những cơ hội giữ chân nhân viên, họ có thể rơi vào những bến đỗ mới từ các công ty đối thủ. Các freelancer it dù không phải là official nhưng trong công tác tuyển freelancer it, công ty vẫn phải có chiến lược thiếp lập và xây dưng độ uy tín thông qua việc đồng hành và giữ chân. Giữ chân nhân viên rất không dễ dàng như bạn tưởng. Nó giống như bạn đang cố bảo vệ những bí mật thương mại của doanh nghiệp. Chúng là tài sản và cần được bảo vệ.

Tuy nhiên, các nhà quản lý nhân sự cũng phải thật tỉnh táo trong các quyết định. Chỉ những nhân viên có tiềm năng phát triển mới có cơ hội được tạo điều kiện đồng hành. Nếu có nguồn nhân lực chất lượng, tố chất phù hợp thì đó là một lợi thế to lớn cho doanh nghiệp.
Tính cạnh tranh luôn tồn tại và nó dường như càng khốc liệt hơn khi thời đại ngày một phát triển hơn, con người cũng chuyên nghiệp hơn. Đặc biệt, trong thời đại số, tính cạnh tranh trên thị trường lao động rất mạnh mẽ. Nếu các nhà quản lý không thể giải quyết được bài toán về việc giữ chân nhân viên, đó sẽ là một sự thụt lùi đáng kể.
Câu chuyện nắm bắt được thị trường và tính cạnh tranh là điều cần quan tâm. Song, các nhà quản lý nhân sự cũng cần có những giải pháp thực tế. Điều này giúp tạo ra lợi thế khai mở tiềm năng thu hút nhân sự, góp phần xây dựng một lực lượng nhân viên vững mạnh.
Nhân viên cũng có “giá”
Liệu có thể tính được giá trị cụ thể của một nhân viên dưới góc độ tài chính hay không? Đáp án là có và tất nhiên có.
Hãy thử đặt ra câu hỏi và giải đáp nó bằng những hình dung.
Mất đi một sự đồng hành, doanh nghiệp sẽ mất đi những gì?

- Chi phí về tuyển dụng quảng cáo, freelancer it, phỏng vấn và sàng lọc một ứng viên mới.
- Tiếp đến chính là chi phí để thiết lập lộ trình đào tạo một người mới: đào tạo và quản lý.
- Năng suất có sự tác động khi một nhân viên mới sẽ mất từ 1-2 năm để đạt được hiệu suất làm việc như nhân tài cũ.
- Các chi phí xử lý cho các rủi ro nhỏ có thể xảy ra trở nên nhiều hơn. Do đang thích nghi, họ khó nắm bắt kịp các vấn đề trọng tâm trong công việc.
- Tạo ra sự tác động đến môi trường làm việc: Một ai đó rời đi, nhiều suy nghĩ sẽ được đặt ra. Điều này tạo ra sự nghi ngờ, tâm lý hoang mang xung quanh môi trường làm việc.
Chi phí để thay thế một nhân viên là bao nhiêu?
Theo một nghiên cứu của CAP, chi phí trung bình để thay thế một nhân viên được diễn đạt như sau:
– 16% tiền lương hàng năm cho các công việc lương thấp (dưới 30.000 đô la/năm).
Ví dụ: chi phí để thay thế một nhân viên bán lẻ 10$/ giờ sẽ là 3,328$.
– 20% tiền lương hàng năm cho các vị trí tầm trung (30.000 đến 50.000 đô/năm).
Ví dụ: chi phí để thay thế người quản lý $40.000 sẽ là $8.000.
– 213% tiền lương hàng năm cho các vị trí điều hành có trình độ học vấn cao.
Ví dụ: chi phí để thay thế một CEO 100 nghìn đô la là 213.000 đô la.
Lời kết
Mọi nhân viên đều có một vị trí, một cái “giá” riêng. Và việc bạn đánh mất đi một hay nhiều nhân viên tài năng là một sự thiệt thòi lớn. Giữ chân nhân viên là một việc hết sức quan trọng và cần được đầu tư đúng mức. Một doanh nghiệp có phát triển lâu dài được hay không là dựa vào một đội ngũ nhân viên chất lượng. Vì thế, hãy lập các kế hoạch giữ chân nhân viên của bạn nhé. Tất nhiên, kế hoạch đó chỉ dành cho những nhân viên thật sự xứng đáng với các giá trị mà họ đang sở hữu.


Có thể bạn quan tâm:
- Để thăng tiến, cần phải có chiến lược?
- Recruitment Challenge: “Em có xứng đáng với mức lương ấy không?”
- Đồng hành và gắn bó với một công ty, bao lâu là đủ?
Xem thêm Top Việc làm Developer trên TopDev








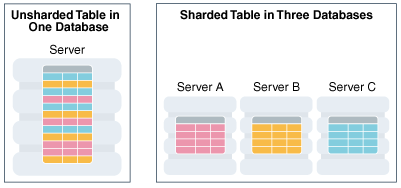
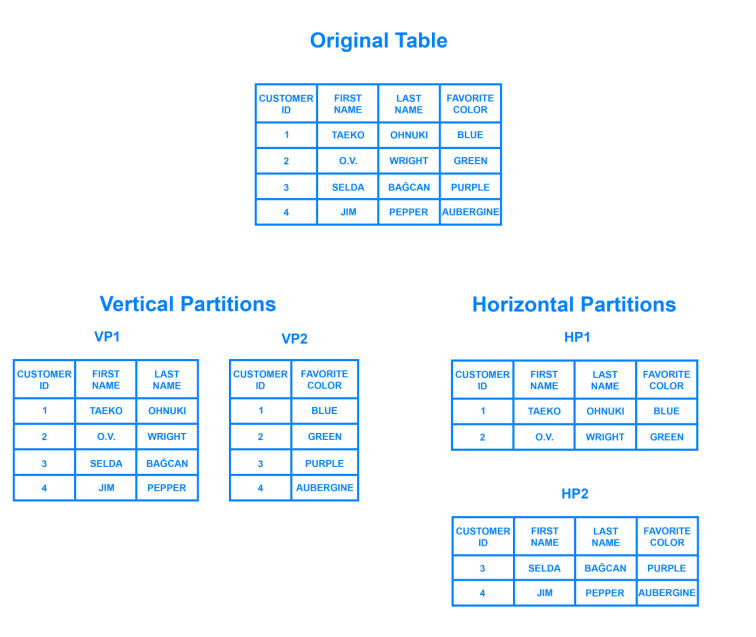

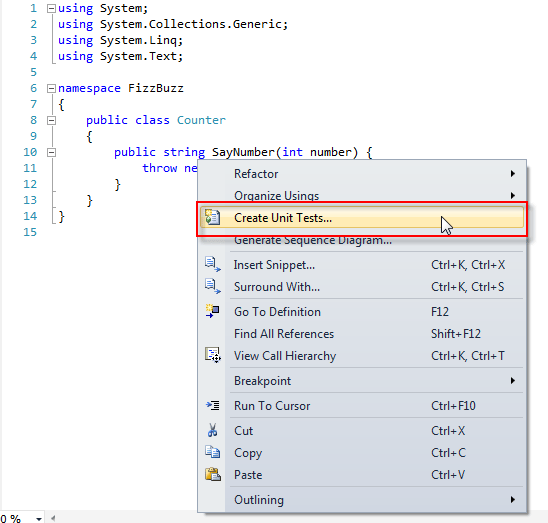
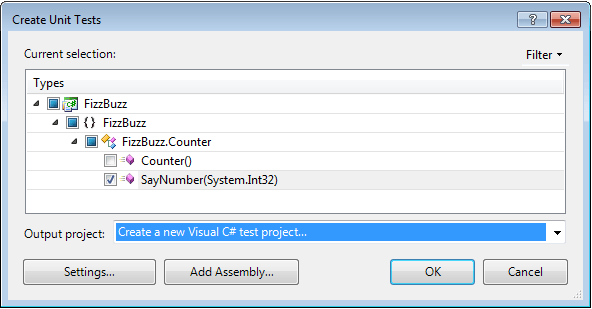
 Aha, tôi việt hóa hàm này cho bạn biết nha. Nhắc lại chương trình cũ của chúng ta như sau:
Aha, tôi việt hóa hàm này cho bạn biết nha. Nhắc lại chương trình cũ của chúng ta như sau: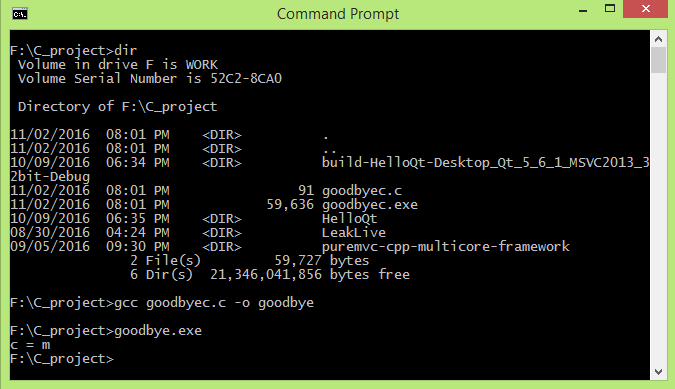

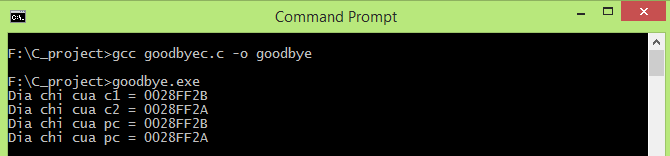
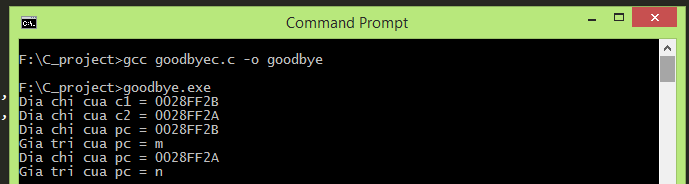





























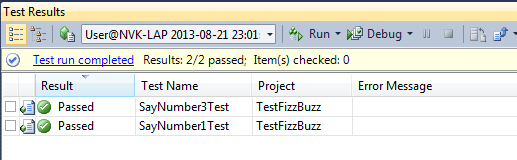

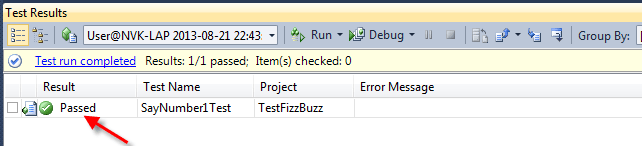
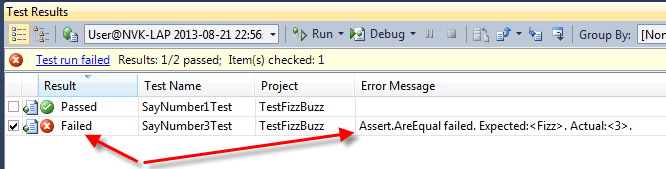
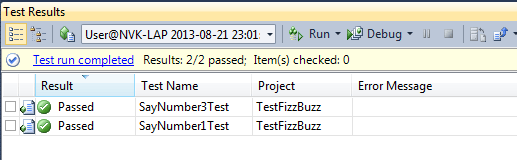

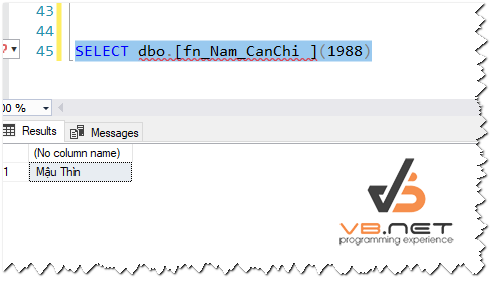

 Sau đó ta khởi động lại MySQL. Gõ lệnh:
Sau đó ta khởi động lại MySQL. Gõ lệnh:


