Trong kỷ nguyên số hiện tại, các công ty, các chính phủ và bản thân các lập trình viên đều chạy đua với nhau để vượt trội hơn về mặt công nghệ, một trong các công nghệ nổi bật lên là Low Code.
Bài viết này hân hạnh giới thiệu với anh em khái niệm về Low-Code. Nếu anh em có đọc ở đâu, hoặc nhìn thấy Low-Code ở đâu thì cũng đừng vội lướt qua. Biết đâu cách giải thích của tui hay hơn thì sao.
Nội dung truyền đạt trong bài viết này chắc là sẽ phù hợp với cả những nhân vật cấp cao như giám đốc đơn vị, quản lý dự án, CTO,…
Không để anh em phải đợi lâu, nhảy luôn vô định nghĩa. Phải chăng Low-Code là ngồi xuống thấp thấp mà code?
1. Low Code là gì?
Đầu tiên low ở đây không phải là ngồi xuống thấp thấp mà code nha anh em. Low ở đây được hiểu là ít code lại.
Low Code là một phương pháp phát triển phần mềm yêu cầu ít hoặc không cần viết code để xây dựng các ứng dụng và quy trình. Thay vì anh em phải sử dụng ngôn ngữ lập trình phức tạp. Theo mô hình Low-Code, anh em có thể sử dụng các giao diện trực quan với các logic ở mức bình thường để phát triển ứng dụng.
Tuyệt vời hơn nữa anh em có thể kéo thả (giao diện trực quan) để xây dựng ứng dụng. Giúp tiết kiệm thời gian, công sức và tiền bạc.
Lại là chỉ nghe thôi cũng thấy hấp dẫn, nhưng có thật sự là Low-Code giúp anh em không phải code nữa mà chỉ cần các thao tác trực quan là đã có ứng dụng? Hay tất cả chỉ là cú lừa?
Công bằng mà nói thì Low Code là cho người sử dụng nền tảng (platform). Còn bản thân lập trình viên vẫn phải là người tạo ra các component, các model có thể trên platform. Nên nếu nói Low-Code là không code hoặc ít code thì thực chất đó là dành cho người sử dụng. Không phải các lập trình viên tạo nên các platform Low-Code. Anh em nhớ nha!.
Sự phát triển của Low-Code các năm gần đây được xem như một hiện tượng, khi mà số hoá và chuyển đổi số đi sâu vào từng ngõ ngách trong cuộc sống:
Theo như báo cáo mới nhất của Gartner, Inc’s thì thị trường toàn cầu cho các công ty phát triển Low Code sẽ đạt khoảng 26.9 tỷ đô vào năm 2023 (tăng 19.6% so với năm 2022).
Trong tương lai thị trường sẽ đạt khoảng 65 tỷ Biden vào năm 2027 và 187 tỷ Biden vào năm 2030.
Thực tế mà nói thị trường Low-Code đã tăng 30% từ năm 2020 cho tới năm 2023 và tạo ra 5,8 tỷ Biden năm 2022.
Thị trường rộng mở ha anh em, tương lai sáng ngời và chói lọi.
Rõ ràng là Low Code sẽ đem lại kết quả nhanh chóng và nhìn thấy được cho các chủ doanh nghiệp. Quá trình phát triển cũng trở nên cực kì nhanh chóng.
Đầu tiên tất nhiên phải nói tới tính nhanh chóng.
3.1 Increased agility (Tăng độ nhanh nhạy)
Với Low-Code, các component, model, thậm chí tới các flow phức tạp đều đã được dựng lên từ trước. Việc này giúp việc triển khai trở nên cực kì nhanh chóng. Anh em không cần phải có kiến thức sâu rộng về lập trình để tạo ra sản phẩm.
Việc này cực kì hữu ích khi mô hình kinh doanh thay đổi nhanh chóng (vô cùng phổ biến ở thời điểm này). Các doanh nghiệp có lợi thế khi họ có thể nhanh chóng thay đổi theo.
3.2 Reduced costs (Giảm giá thành)
Tất nhiên là việc sử dụng Low Code platform sẽ tạo ưu thế cạnh tranh về giá thành. Anh em cũng biết là chi phí phát triển phần mềm từ trước tới nay chưa bao giờ là rẻ.
Với các platform đã phát triển Low-Code thì ngược lại. Công sức chỉ bỏ ra một lần ban đầu và tái sử dụng nhiều lần sau đó. Việc này giúp doanh nghiệp giảm được chi phí ở mức tối đa.
3.3 Faster time to market (Xuất hiện nhanh chóng)
Ở cái thời đại mà ý tưởng chỉ vừa với ra đầu môi thì đã có ngay ứng dụng trên store thì Low-Code giúp doanh nghiệp triển khai ý tưởng nhanh chóng. Thời gian phát triển giảm xuống đồng nghĩa với việc business xuất hiện trên thị trường nhanh hơn. Tạo ưu thế cạnh tranh so với đối thủ.
4. Tính năng của Low Code
Sau khi đã hiểu rõ về lợi thế, ưu điểm của Low-Code thì giờ là lúc lướt qua một số tính năng nổi bật của nó. Đầu tiên không thể không nhắc tới Visual Modeling Tools.
4.1 Visual Modeling Tools
Visual Modeling Tools ở đây được hiểu là trực quan hoá các mô hình. Các mô hình phổ biến sẽ được xây dựng sẵn. Các mô hình này sẽ được xây dựng cực kì trực quan, giúp người sử dụng dễ nắm bắt.
Ngoài ra, người sử dụng Visual Modeling Tools cũng không cần hiểu biết nhiều về công nghệ. Dễ dàng hơn cho các doanh nghiệp.
4.2 Out-of-the-Box Functionality
OOTB, viết tắt của (out-of-the-box) là tính năng được phát triển bởi các công ty phát triển hàng đầu cho Low-Code. Bản thân nó giúp người sử dụng có thể bỏ qua các khởi tạo ban đầu khi bắt đầu sử dụng Low Code.
Ví dụ anh em làm application cần có DB, OOTB sẽ xử các phần đó cho anh em.
4.3 Drag-and-Drop Interface
Kế tiếp là feature về Drag và Drop, anh em suy luận một chút thì hiểu ngay tính năng này quan trọng thế nào với Low-Code. Các model, component có sẵn tất nhiên chỉ cần kéo thả vào là hoạt động. Độc lập là ok rồi, giờ chỉ cần kéo thả đặt vào đúng chỗ nữa là được thôi.
4.4 Security (bảo mật)
Cái này là tính năng sống còn của Low-Code, anh em lập trình code xong review tới review lui mà còn có bug về bảo mật. Chưa kể ứng dụng đôi khi còn bị tấn công liên tục bởi các hacker thì security là yếu tố quan trọng cần quan tâm.
4.5 Scalability (mở rộng)
Cuối cùng là tính năng mở rộng. Này là điểm thường được đem ra so sánh giữa Low-Code và cái code cắm đầu. Ở mặt này, hiện tại Low-Code đang có phần kém hoặc chưa thể bằng với cách phát triển phần mềm truyền thống do tính chất phức tạp về mặt kiến trúc (architecture). Tuy nhiên tương lai thì khó nói nha. Vượt lên lúc nào không hay
Bài viết được sự cho phép của tác giả Lê Nhật Thanh
Trong thế giới kiếm hiệp Kim Dung, Trương Tam Phong là nhân vật có võ công cao nhất (theo Kim Dung). Bởi vì ông sở hữu bộ võ công Thái Cực Quyền và Thái Cực Kiếm. Tinh hoa võ công khác hẵn hoàn toàn với thế giới võ công đương đại. Lấy nhu khắc cương.
Các bạn tiếp cận với OOP rất sớm, ngay lúc mới bắt đầu học lập trình.
Có rất nhiều người cho rằng OOP là mô hình để thiết kế phần mềm tốt nhất. Và mình xin nhắc lại, OOP là mô hình lấy đối tượng (object) làm gốc.
Mình ví OOP như là thế giới võ công đương đại trong Kim Dung. Vậy Thái Cực Quyền trong thế giới lập trình là gì?
Bạn đã bao giờ nghe về functional programming chưa? Lập trình theo phong cách lấy hàm (function) là trung tâm.
Bây giờ, hãy cùng đi vào thế giới hoàn toàn khác với những gì chúng ta thường biết với OOP.
#1 Thái cực bắt nguồn từ đâu
Ngày xửa ngày xưa, có hai cao thủ võ lâm. Alan Turing và Alonzo Church.
Alan Turing tinh thông môn võ Turing Machine. Còn Alonzo Church thì nổi danh với Lambda Calculus.
Cả hai đều là võ lâm cao thủ thời bấy giờ. Đã trãi qua nhiều trận đấu long trời lở đất. Nhưng đều không phân biệt thắng thua.
Sau đó, cả hai mới thống nhất với nhau một bản hiệp ước Church – Turing.
Khẩu quyết của Turing Machine chính là việc nắm giữ các trạng thái của tiến trình và state machine.
Còn linh hồn của Lambda Calculus tập trung cho việc xây dựng các tính chất của các hàm toán học.
Sau này, chính Turing Machine đã đặt nền móng cho sự ra đời của lập trình hướng đối tượng (OOP). Còn Lambda Calculus là nguồn gốc ra đời của Functional Programming (FP).
Lưu ý rằng, hai trường phái này chỉ là hai trong số nhiều trường phái trong võ lâm lúc bấy giờ. Nhưng đây là hai trường phái lớn nhất!
Lịch sử trôi qua, có vẻ OOP chiếm ưu thế hơn rất nhiều so với FP. Bạn thử nhìn xung quanh để kiểm chứng. Các buổi phỏng vấn, ngay trong trường đại học. Bạn tiếp xúc với OOP rất nhiều.
Nhưng ở một thế giới khác, FP vẫn luôn âm thầm phát triển từng ngày một. Hãy nhìn những Lisp, F#, Haskell, Clojure, Erlang, … là những ngôn ngữ đại diện cho trường phái FP.
Trong 1 thập kỉ trở lại đây. FP đang trở lại! Người ta bắt đầu phàn nàn về OOP.
Trên thực tế! FP hay OOP là hai trường phái tu luyện khác nhau. Phần nào cũng có cái lợi thế hay bất lợi riêng. Chúng ta không nên so sánh bên nào ngon hơn!
Trong phần này, chúng ta sẽ đi vào những thứ cơ bản nhất của FP. Bước đầu dấn thân vào thái cực!
Mình có một lưu ý: FP là một con đường dài. Nếu muốn giác ngộ, bạn phải kiên trì! Và trong bài viết này, mình không thể đi hết các khẩu quyết (concept) của FP. Vì đơn giản là không đủ!
Functional Programming là phương pháp lập trình lấy function làm đơn vị thao tác cơ bản.
Về lý tưởng, FP chỉ có function với function. Không có lệnh gán, không có vòng lặp, không có trạng thái toàn cục. Trong FP, chúng ta sẽ kết hợp các function lại với nhau và nhảy múa với chúng!
Phải nói rằng FP đang dần dần trở lại thế giới lập trình ở hiện đại. Bằng chứng là các bản cập nhật của các ngôn ngữ, framework mới. Đang dần hướng về FP (như Javascript, Python, Golang, …).Bạn hãy nhìn vào ReacJS, một framework với 70% FP và 30% OOP (có thể nói rằng như thế).
Các lập trình viên hiện đại thường kết hợp sự linh hoạt của OOP và FP lại với nhau. Mục đích cuối cùng là để có được một chương trình đúng, nhanh, gọn, đẹp.
Và để có thể bước vào thế giới Functional Programming. Bạn phải học một số khẩu quyết quan trọng sau!
Khẩu quyết thứ nhất của functional programing là: Những gì đã được khai báo trước đó thì không được thay đổi nữa!
Nghĩa là những thứ đã được khai báo trước đó. Sẽ không bao giờ được thay đổi trong quá trình chạy chương trình!Bạn có thấy điều này lạ không? Khác hẵn với những gì ta đã học trong OOP. Những tư duy lập trình cũ. Nhưng nó chính là khẩu quyết đầu tiên của FP – tính bất biến.
Chúng ta cùng lấy một ví dụ về tính bất biến và không bất biến:
/* Đoạn code dưới đây không phải là bất biến vì giá trị biến bị thay đổi */
var immutabilityVar = "lenhatthanh.com";
immutabilityVar = "coderdocs.info";
/* Còn đoạn code dưới đây thoả mãn tính bất biến của FP */
var immutabilityVar = "lenhatthanh.com";
var immutabilityVar2 = "coderdocs.info";
Bất biến là khẩu quyết tối quan trọng trong FP. Nếu viết code theo phong cách FP, bạn cần hạn chế tối đa việc thay đổi giá trị biến hay object. Tốt nhất là không nên thay đổi, mọi thứ trong FP nên là const.
Khi ES6 release, đã cho ra 2 cách khai báo mới là const và let. Người ta khuyên rằng nên dùng const và dùng let chỉ khi nào cần thiết.
Bạn có nhớ tới vòng lặp for, while không? Những vòng lặp này hay dùng một biến index duyệt vòng lặp. Và vì tính bất biến, nên FP đã loại bỏ vòng lặp!
Vậy thì bạn sẽ hỏi là, chúng ta sẽ dùng gì để thay thế cho vòng lặp?
Đệ quy (recursive), cao hơn chúng ta dùng một số function khác. Tùy vào độ support của ngôn ngữ! Quay lại, đệ quy sẽ thay thế cho vòng lặp. Có nhiều bạn có lẽ không quen với tư duy của đệ quy. Nhưng nếu bạn đã bước vào FP, thì hãy luyện đệ quy.
/**
* Bài toán ở đây là tính giai thừa của n (n!)
* Chúng ta sẽ giải quyết bài toán theo vòng lặp và đệ quy
**/
// Chúng ta viết theo vòng lặp cực kì đơn giản
result = 1;
for (i = 1; i <= n; i++) {
result *= i;
}
// Còn nếu chúng ta viết với đệ quy thì sao?
function factorialOfNumber (n) {
if (n === 1) {
return n;
}
return n * factorialOfNumber(n - 1);
}
Vậy lợi ích của tính bất biến là gì?
Bạn cũng biết chúng ta hay gặp bug khi thay đổi giá trị của biến mà chúng ta không kiểm soát được. Hoặc các trạng thái bị thay đổi một cách bất ngờ. Vì bất biến, nên việc thay đổi là không xảy ra. Nên rủi ro gặp bug (do các biến gây ra) là nhỏ hơn và chương trình dễ debug hơn. Chúng ta dễ dàng kiểm soát được giá trị các biến. Và tránh được những thay đổi không mong muốn trong chương trình.
Purity
Purity là sự thật khiết, trinh trắng!
Khẩu quyết thứ 2 trong FP là.
Tất cả các function đều phải là Pure function. Nghĩa là những function này không được thay đổi bất cứ thứ gì bên ngoài nó. Không được thay đổi tham số đầu vào. Không có hiệu ứng phụ (side effect).
Chúng ta cùng lấy một ví dụ về function có hiệu ứng phụ.
function handleX (n) {
const returnVal = n * n + n * 2 + 1;
makeAjaxCall(returnVal);
return returnVal;
}
Rõ ràng trong function handleX còn gọi thêm Ajax, và không biết sẽ xử lý gì trong đó. Nên đây được gọi là hiệu ứng phụ. Và function này không phải là Pure function.
Javascript hay những ngôn ngữ như khác thường có rất nhiều hiệu ứng phụ side effect. Rõ ràng là chương trình chúng ta viết không thể nào thiếu những hiệu ứng phụ quan trong như Ajax, giao tiếp database,… FP sẽ làm một nhiệm vụ là cô lập và tách biết các hiệu ứng phụ ra. Nhằm mục đích giúp cho code của chúng ta rõ ràng. Và đặc biệt là dễ kiểm soát. Vì hiệu ứng phụ sẽ làm thay đổi giá trị biến hay cái gì đó bất cứ lúc nào.
Trên đây là hai tính chất, khẩu quyết đầu tiên trong Functional Programming. Đây là những tính chất cơ bản nhất. Và chắc chắn bắt buộc đối với những ai muốn dấn thân vào con đường này.
Higher-Order Function
Higher-order function (HOF) là một function có ít nhất một trong hai đặc điểm sau:
Tham số đầu vào là một hoặc nhiều function
Return một function
Nảy giờ chúng ta đã lấy ví dụ về Javascript nhiều rồi. Bây giờ là ví dụ PHP về Higher-order function.
<?php
/* Hàm twice có tham số đầu vào là một function và return một function */
$twice = function($add, $number) {
return $add($add($number));
};
$add = function($number) {
return $number + 1;
};
echo($twice($add, 5));
Function twice vừa có tham số đầu vào là một function vừa return một function. Cho nên hàm này thừa sức để làm một Higher-order function.
Khẩu quyết thứ ba này rất đơn giản và dễ hiểu. Nhưng có một câu hỏi được đặt ra. Tại sao phải dùng Higher-order function?
FP như giới thiệu ban đầu! Là một kiểu lập trình theo phong cách nhảy múa cùng với function. Higher-order function giúp cho chúng ta dễ dàng làm được việc này. Mọi flow, ngóc ngách, mọi dòng chảy code, chúng ta dễ dàng control chúng với HOF.
Giới thiệu về Functional Programming tới đây thôi. Vì như mình đã nói từ đầu bài. FP là một con đường dài.
FP còn rất nhiều khẩu quyết phía sau như: Function Composition, Currying function, Object Composition, không có new/this, class citizens,…
Flow control sử dụng việc gọi hàm hay sử dụng đệ quy
Flow control sử dụng vòng lặp hay câu lệnh if
Thứ tự thực hiện các câu lệnh không quan trọng
Thứ tự thực hiện các câu lệnh cực kì quan trọng
Hổ trợ cả “Abstraction over Data” và “Abstraction over Behavior”.
Chỉ hổ trợ “Abstraction over Data”.
#Kết
Bài viết này, mình chỉ trình bày sơ bộ về functional programming. Và so sánh đôi chút nó với lập trình hướng đối tượng.
Đương nhiên chỉ với giới hạn một bài viết. Không thể cover hết tinh hoa của functional programming. Mình để những tinh hoa đó cho chúng ta cùng nhau research.
Functional programming đòi hỏi người luyện phải chuyên tâm, kiên trì. Không phải ngày một ngày hai mà có thể luyện thành.
Chúc các bạn thành công trên con đường tu luyện với Functional Programming!
Graphic Design là một trong những ngành đang được săn đón và có nhu cầu tuyển dụng cao. Nếu bạn muốn trở thành một Graphic Designer, việc chuẩn bị kỹ càng cho buổi phỏng vấn là rất quan trọng. Trong bài viết này, TopDev sẽ giúp bạn tìm hiểu các câu hỏi phỏng vấn Graphic Designer thường gặp cùng cách trả lời thông minh và hiệu quả nhất. Hãy cùng đọc và trau dồi kỹ năng để thành công trong buổi phỏng vấn sắp tới!
Tại sao bạn muốn làm việc ở đây?
Trước khi tham gia phỏng vấn Graphic Designer, hãy đảm bảo rằng bạn đã tìm hiểu kỹ về công ty đó. Dù bạn đã tham gia nhiều buổi phỏng vấn ở nhiều công ty khác nhau nhưng nhà tuyển dụng không muốn bạn đề cập đến điều đó. Thay vào đó, họ muốn biết điều gì về thương hiệu hoặc sản phẩm của họ, văn hóa công ty hay những yếu tố khác làm cho bạn muốn làm việc với họ.
Nếu bạn có thể đề cập đến các thiết kế cụ thể trong câu trả lời này, đó là điều tuyệt vời, vì nó cho thấy bạn đã đầu tư thời gian để tìm hiểu về công ty của họ.
Bạn nghĩ xu hướng thiết kế tiếp theo sẽ là gì?
Đây là câu hỏi quan trọng giúp nhà tuyển dụng đánh giá mức độ đam mê và quan tâm của bạn đối với ngành thiết kế đồ họa. Các Graphic Designer hàng đầu thường rất nhạy bén với các xu hướng thiết kế mới và luôn đón nhận những thay đổi trong tương lai.
Để trả lời câu hỏi này thật tốt, bạn cần phải cập nhật những xu hướng thiết kế mới nhất, đọc nhiều sách và tạp chí chuyên ngành, và đặc biệt là luôn quan sát và tìm hiểu. Dù cho bạn mới bắt đầu nhưng đừng lo lắng, hãy chuẩn bị tâm lý và trả lời câu hỏi này một cách tự tin và sáng tạo nhất.
Nếu cần phải thay đổi thiết kế thương hiệu của chúng tôi, bạn sẽ thực hiện những thay đổi nào?
Những câu hỏi như thế này giúp nhà tuyển dụng đánh giá khả năng sáng tạo và đổi mới của bạn, cũng như cách bạn đánh giá các thiết kế hiện có của công ty. Để trả lời tốt, bạn cần chuẩn bị trước bằng cách tìm hiểu về đối tượng khách hàng, sứ mệnh, giá trị và định hướng của công ty. Đặc biệt, bạn nên hỏi người phỏng vấn về các mục tiêu kinh doanh của công ty liên quan đến việc xây dựng thương hiệu để đưa ra câu trả lời phù hợp nhất. Hãy tự tin thể hiện khả năng của mình và cho thấy bạn là một Graphic Designer sáng tạo và có tầm nhìn.
Bạn sẽ xử lý phản hồi tiêu cực của khách hàng về thiết kế của mình như thế nào?
Nhà tuyển dụng muốn biết cách bạn xử lý và giải quyết tình huống này. Trong câu trả lời, hãy cho thấy sự kiên nhẫn và tôn trọng của bạn đối với quan điểm của khách hàng. Bạn cũng có thể đề cập đến kinh nghiệm của mình trong việc giải quyết các tình huống khó khăn và cách bạn sẽ tận dụng phản hồi để cải thiện kỹ năng của mình trong tương lai.
Ví dụ: Những phản hồi không tốt của khách hàng về sản phẩm khiến tôi phiền lòng, vì tôi luôn muốn mang lại những sản phẩm tốt nhất để thể hiện sự uy tín của công ty và làm hài lòng khách hàng. Trong những tình huống này, tôi sẽ sử dụng phản hồi của khách hàng làm động lực để cải tiến các dự án tiếp theo phù hợp hơn với những yêu cầu của họ.
Những phần mềm thiết kế nào bạn dùng cho công việc Graphic Designer?
Các Graphic Designer cần sử dụng thành thạo các phần mềm thiết kế để phục vụ cho công việc của mình. Câu hỏi trên để nhà tuyển dụng đánh giá các kỹ năng sử dụng công cụ của bạn có đáp ứng được công việc không.
Bạn có thể trả lời như sau: Tùy thuộc vào nhu cầu thiết kế của từng dự án, tôi sẽ sử dụng các phần mềm khác nhau. Tuy nhiên, những phần mềm thiết kế mà tôi thường sử dụng bao gồm Adobe Photoshop, Illustrator và InDesign. Với Photoshop, tôi có thể chỉnh sửa và xử lý hình ảnh; với Illustrator, tôi có thể tạo ra các vector graphics và sử dụng những đối tượng để thiết kế banner, poster; và với InDesign, tôi có thể thiết kế các tài liệu đa trang như sách, tạp chí hoặc brochure. Ngoài ra, tôi cũng có kinh nghiệm trong việc sử dụng các phần mềm thiết kế khác như Sketch và Figma để thiết kế giao diện người dùng cho ứng dụng và trang web.
Bạn có bao giờ phải làm việc với một dự án thử thách chưa và làm thế nào để bạn vượt qua được nó?
Câu hỏi này giúp để nhà tuyển dụng biết được khả năng làm việc của bạn và tư duy giải quyết vấn đề khi gặp các dự án khó nhằn. Bạn có thể tham khảo cách trả lời sau:
Đầu tiên, tôi sẽ đánh giá kỹ năng của mình để xác định những điểm yếu và mạnh của mình trong việc xử lý dự án này.
Tiếp theo, tôi sẽ tìm hiểu kỹ thông tin về dự án, yêu cầu của khách hàng, đối tượng khách hàng và thị trường liên quan đến dự án.
Sau đó, tôi sẽ tạo ra một kế hoạch làm việc chi tiết với các bước cụ thể và đặt ra các mục tiêu cho từng giai đoạn của dự án.
Tôi sẽ cố gắng thực hiện các bước trong kế hoạch một cách chính xác và hiệu quả, cùng với đó là việc trao đổi với khách hàng và các thành viên trong nhóm để đảm bảo rằng dự án đang diễn ra tốt nhất có thể.
Nếu tôi gặp phải bất kỳ thử thách nào trong quá trình làm việc, tôi sẽ tìm kiếm giải pháp phù hợp, bằng cách thảo luận với đồng nghiệp, tìm kiếm ý kiến từ khách hàng hoặc các chuyên gia trong lĩnh vực của tôi.
Cuối cùng, tôi sẽ đánh giá lại dự án sau khi hoàn thành để xem những điểm mạnh và yếu của mình, từ đó học hỏi và cải thiện kỹ năng của mình trong các dự án tiếp theo.
Bạn thường làm gì để giúp kỹ năng thiết kế của mình được cải thiện?
Những câu hỏi như thế này giúp nhà tuyển dụng đánh giá khả năng phát triển của bạn trong công việc. Để trả lời tốt, bạn cần đưa ra những cách để nâng cao kỹ năng thiết kế của mình. Hãy lưu ý rằng chỉ khi bạn đã thực sự thực hiện những cách này thì mới nên trình bày trước nhà tuyển dụng.
Dưới đây là một số cách để bạn nâng cao kỹ năng thiết kế của mình và trở thành một Graphic Designer tài năng hơn:
Tham gia các khóa học trực tuyến hoặc khóa học ngắn hạn để học các kỹ thuật và công nghệ mới nhất
Đọc các sách và tài liệu liên quan đến thiết kế, cũng như đọc các bài báo, tạp chí và blog chuyên ngành để cập nhật kiến thức và xu hướng thiết kế mới.
Cố gắng tìm kiếm các cơ hội thực hành thiết kế, bao gồm làm các dự án cá nhân hoặc tham gia các dự án tình nguyện để có thêm kinh nghiệm.
Thường xuyên đăng tải các thiết kế của mình lên các trang web và cộng đồng thiết kế để nhận được phản hồi và đánh giá từ những người có kinh nghiệm.
Luôn sẵn sàng tiếp thu phản hồi và ghi nhận các lỗi để cải thiện kỹ năng thiết kế của mình.
Một số câu hỏi Graphic Design khác
Bạn có thể nêu điểm mạnh, điểm yếu của bạn trong công việc không?
Bạn sẽ làm gì khi có mâu thuẫn với team Marketing về thiết kế của mình?
Bạn sẽ làm gì khi gặp deadline quá gấp?
Các thành phần của thiết kế đồ họa là gì?
Các nguyên tắc thiết kế đồ họa cốt lõi là gì?
Lý thuyết màu sắc là gì và tại sao nó lại quan trọng trong thiết kế đồ họa?
Tỷ lệ vàng trong bố cục thiết kế đồ họa là gì và tại sao nó lại quan trọng?
Làm thế nào để bạn đo lường sự thành công của các thiết kế của bạn?
Hy vọng những câu hỏi phỏng vấn Graphic Designer này sẽ giúp bạn chuẩn bị tốt hơn cho buổi phỏng vấn sắp tới. Đừng ngại nhờ đồng nghiệp hoặc bạn bè giúp bạn thực hiện các buổi phỏng vấn mô phỏng để cải thiện kỹ năng phỏng vấn của mình. Tự tin bước vào buổi phỏng vấn chính thức và chúc bạn may mắn!
Lại là chuỗi bài câu hỏi phỏng vấn và lần này là bộ câu hỏi phỏng vấn Software Developer. Ở chuỗi bài viết này, xin phép anh em được tách ra thành 4 phần.
Nguyên nhân là vì Software Developer là vị trí đòi hỏi cực nhiều kiến thức, không chỉ đơn giản 1 phần mà đã nêu ra được hết toàn bộ kiến thức cần có. Ngoài kiến thức về mặt kỹ thuật, vị trí Software Developer còn đòi hỏi một lượng kiến thức khổng lồ về quy trình phát triển phần mềm, kinh nghiệm làm việc thực tế. Vân vân và mây mây.
Ở bài viết phần 1 này xin mạn phép viết trước cho anh em về mặt kỹ thuật. Tuy số lượng câu hỏi không nhiều, nhưng với các câu hỏi được nêu, mong rằng anh em sẽ hệ thống lại được kiến thức. Từ câu hỏi được nêu xem lại các phần kiến thức liên quan để chuẩn bị thật tốt cho buổi phỏng vấn.
Không có thời gian mà thở chứ chả nói tới đùa. Software Engineer (Software Developer) đòi hỏi một lượng kiến thức cực khủng
1. Làm sao bind methods hoặc event trong JSX callbacks?
Okie, câu hỏi phỏng vấn Software Developer chắc chắn liên quan tới coding. Phần mềm về cơ bản được dựng lên bởi code. Nếu không code được chắc chắn không gọi là Software Developer.
Câu trả lời là có 3 cách để binding bao gồm:
Binding in Constructor: Ở constructor khi khởi tạo class là đã bind luôn method cần thiết
Ở mục này, mong muốn anh em mạnh ngôn ngữ lập trình nào thì xem lại kỹ ngôn ngữ lập trình đó. Coi thật sâu, ví dụ Java thì xem lại JVM, String pool, kiến trúc của Java. Lật lại cuốn sách nổi tiếng về Java như kiểu Effective Java 3rd Edition để đọc lại.
Nếu anh em là Frontend, work với Reactjs, Vuejs. Làm ơn coi kĩ lại DOM, kiến trúc Reactjs, Vuejs. Rồi life cycle, các vấn đề optimization code, vân vân và mây mây.
Nói chung phỏng vấn Software Developer đầu tiên là xem lại code. Củng cố kỹ năng code của mình nha anh em.
Câu hỏi số hai phỏng vấn Software Developer là câu hỏi liên quan tới hệ cơ sở dữ liệu. Dưới đây tui nêu ra một số khác biệt giữa SQL và NoSQL. Có thể chưa nêu được hết nhưng lúc phỏng vấn anh em cứ nêu ý nổi bật là được ha:
SQL
NoSQL
Là cấu trúc dữ liệu có thể truy vấn và có cấu trúc (Structural Query Language)
Kiểu dữ liệu không có cấu trúc (Non Structual Query Language)
Thích hợp với dữ liệu có cấu trúc và các schema rõ ràng được định nghĩa từ trước
Thích hợp cho dữ liệu không có cấu trúc
Dữ liệu lưu dạng dòng và cột (row, column)
Dữ liệu lưu kiểu collection hoặc documents
Theo nguyên lý ACID (Atomicity, Consistency, Isolation, Durability)
Không theo nguyên lý ACID
Hỗ trợ JOIN và các câu queries phức tạp
Không hỗ trợ join
Nếu cần cứ nêu kinh nghiệm thực tế là tốt nhất. NoSQL là DB nào, SQL là DB nào. So sánh các kiểu
Đôi khi sao phũ phàng tới lạ
2.1 Cần xem thêm
Câu hỏi này chỉ là câu hỏi ngẫu nhiên liên quan tới hệ cơ sở dữ liệu thôi nha anh em. Anh em làm với cái nào nhiều thì cần xem lại hết. Benefit, advantages (điểm mạnh), điểm yếu các kiểu của RDBMS đó. Suggest một số keywords cho anh em xem lại, nhưng mà có thể không đủ nha.
2.2 Topics cho anh em
Database Optimization
SQL optimization
Sự khác biệt giữa các loại DB (Postgres, MySQL, Oracle)
Advantages, disadvantages của DB
Các khái niệm về CAP theorem (nói chung là có liên quan tới DB)
…
3. Giải thích blackbox testing và whitebox testing
Câu hỏi số 3 phỏng vấn Software Developer là câu hỏi liên quan tới testing. Thực tế mà nói kỹ năng testing và kỹ năng cần có của Software Developer. Nếu không code được thì ít nhất là vị trí này nắm chắc kiến thức cơ bản của các loại testing.
Blackbox Testing
Whitebox Testing
Test làm cấu trúc bên trong chương trình không được show ra. Chỉ có input và output, không cần biết code làm gì
Người tester có kiến thức và hiểu biết về những gì xảy ra trong chương trình
Implement code không cần thiết cho blackbox
Implement code quan trọng với Whitebox
Thường thực hiện bởi Tester
Thường được thực hiện bởi Software Developer
Là bài kiểm tra dạng functional (chức năng)
Là bài test hoặc kiểm tra dạng kiến trúc (structural testing)
Thường ít toàn diện hơn so với Whitebox test
Tương đối toàn diện hơn so với Blackbox testing
3.1 Cần xem thêm
Câu trả lời phía trên về blackbox hay whitebox có thể chưa đủ và chưa chi tiết. Tuy nhiên mục đích của câu hỏi này là nhấn mạnh với anh em vị trí Software Developer là một vị trí cần biết về testing chứ không phải chỉ đơn giản là code và code
Cross site scripting (XSS) is a common attack vector that injects malicious code into a vulnerable web application. XSS differs from other web attack vectors (e.g., SQL injections), in that it does not directly target the application itself. Instead, the users of the web application are the ones at risk.
Cross site scription là kiểu tấn công phổ biến nhằm đưa mã độc vào trong ứng dụng web dễ bị tấn công. XSS khác với các loại tấn công cơ bản khác như SQL Injection là nó không nhắm trực tiếp vào ứng dụng. Thay vào đó nó nhắm tới người dùng của web application.
XSS đầu tiên nhắm tới các website có lỗ hổng, tiến hành viết các đoạn mã độc có thể thực thê trên web site đó. Sau khi đã có sẽ chèn vào website, thực thi mỗi lần có ai đó truy cập trang web (được cấp session cookies). Mỗi lần khi truy cập website, mã độc đều được thực thi để tấn công đánh cắp thông tin. Sở dĩ câu này là câu số 4 phỏng vấn Software Developer vì ở cái thời đại này, bảo mật là vấn đề được ưu tiên hàng đầu.
Một lập trình viên nếu không biết gì về bảo mật rất dễ dính tới các vấn đề về bảo mật lúc development.
4.1 Cần xem thêm
Chỉ là một câu hỏi đơn giản về một trong các loại hình tấn công. Anh em nên bỏ time thêm để xem lại các kiểu tấn công. Mà đã biết tấn công như nào thì cần có phương án phòng tránh. Có gợi ý cho anh em một số từ khoá, anh em có thể xem nhiều hơn nha
React Native là một framework phát triển ứng dụng di động mã nguồn mở do Facebook tạo ra và ra mắt từ năm 2015, đến nay nó trở thành một lựa chọn phổ biến cho các nhà phát hành ứng dụng mobile khi muốn xây dựng và phát triển ứng dụng của mình. Trong bài viết hôm nay, chúng ta cùng tìm hiểu về React Native Developer là gì cũng như cần học gì để trở thành lập trình viên trong ngành này nhé.
React Native là gì?
React Native là một framework viết bằng JavaScript giúp chúng ta tạo ra được những ứng dụng di động chạy trên các nền tảng hệ điều hành Android hay iOS.
React Native là một cross platform (đa nền tảng) phát triển ứng dụng bằng cách viết một lần code và có thể build được ra nhiều ứng dụng trên các hệ điều hành khác nhau. Lợi ích lớn nhất của những cross platform như React Native là việc tiết kiệm thời gian cũng như chi phí phát triển, đồng thời khả năng tái sử dụng mã nguồn (source code) cao. Các ứng dụng nổi tiếng được phát triển từ React Native có thể kể đến như Facebook, Skype, Instagram, Airbnb,…
React Native Developer là gì?
React Native Developer hay lập trình viên React Native là những người sử dụng framework này tham gia vào quá trình thiết kế, xây dựng và phát triển các ứng dụng dành cho thiết bị di động. Công việc cụ thể của những lập trình viên này bao gồm:
Tham gia lên ý tưởng, thiết kế, xây dựng và phát triển các ứng dụng di động, chủ yếu là trên nền tảng Android và iOS
Đảm bảo việc hoạt động của ứng dụng một cách ổn định, hiệu quả bằng việc thường xuyên nâng cấp, chỉnh sửa ứng dụng nếu có lỗi hoặc khi cần thiết thay đổi
Phối hợp với các team khác cùng dự án như team Backend cho việc call API lấy dữ liệu và cập nhật dữ liệu
Hỗ trợ việc phát hành ứng dụng lên các nền tảng chợ ứng dụng như Google Play hay AppStore
Thực hiện việc chuyển đổi các ứng dụng chạy trên nền tảng Web (hybrid app) hoặc các nền tảng khác hiện có sang React Native
Tối ưu các native APIs mà các hệ điều hành Android, iOS cung cấp và cập nhật để áp dụng vào ứng dụng viết bằng React Native
Nghiên cứu, tìm hiểu các công nghệ mới liên quan đến lập trình mobile nói chung và React Native nói riêng
Kỹ năng cần có để trở thành React Native Developer
React Native là một framework viết bằng JavaScript, vì vậy để học được React Native, bạn cần trang bị kiến thức về ngôn ngữ lập trình này. Bản thân JavaScript là một ngôn ngữ phổ biến và thông dụng, nhất là với việc làm Web, vì vậy React Native cũng được xem là một lựa chọn học thêm khi các lập trình viên Web muốn phát triển, xây dựng các ứng dụng dành cho mobile.
Một điều quan trọng nữa cùng cần trang bị để sẵn sàng học React Native là kiến thức về lập trình mobile, các đặc thù của ứng dụng chạy trên thiết bị di động. Hãy nắm được các kiến thức cơ bản cũng như thuật ngữ sử dụng trong ngành này:
Hệ điều hành: các thiết bị di động smartphone hiện nay chủ yếu chạy hệ điều hành Android của Google hoặc iOS của Apple.
Thiết bị phần cứng: thông thường bạn sẽ cần một thiết bị di động thật (iphone cho iOS và các điện thoại chạy Android của các hãng như Samsung, Xiaomi,…). Có một đặc thù dành cho các thiết bị iOS là bắt buộc phải chạy trên nền tảng Mac OS, chính vì thế mà lựa chọn sử dụng các thiết bị đến từ Apple như Macbook, Macmini,… sẽ giúp bạn có thể build và chạy thử ứng dụng của mình trên cả 2 nền tảng cùng một lúc.
SDK và IDE: Google trang bị Android SDK và IDE mặc định là Android Studio; với iOS thì chúng ta được cung cấp Xcode IDE cùng bộ iOS SDK dành cho việc phát triển. Mặc dù vậy cũng sẽ có những lựa chọn khác như việc tích hợp các extensions trên IDE Visual Studio Code.
Market: Như đã nhắc ở phần trước, việc phát hành ứng dụng luôn phải thông qua các chợ ứng dụng của Google và Apple là Google Play và AppStore; vì thế bạn cũng cần tìm hiểu kĩ các chính sách và các bước để publish app lên store.
Sau khi chuẩn bị được các kiến thức cơ bản, hãy bắt đầu với React Native bằng việc setup môi trường phát triển, tạo dự án và chạy thử ứng dụng. React Native cung cấp cho chúng ta các thẻ View khá tương đồng với HTML tags, cách styling cũng giống như viết CSS; vì thế nếu có kiến thức nền tảng về HTML, CSS và JS thì việc bắt đầu viết code với React Native hoàn toàn không gặp quá nhiều vấn đề.
Concept cơ bản đằng sau React cũng như React Native là việc chia nhỏ ứng dụng của chúng ta thành các Component (thành phần) nhằm giúp tăng khả năng tái sử dụng cũng như mở rộng ứng dụng. Vì thế bạn hãy bắt đầu từ việc tạo ra những Component nhỏ cùng với những props (thuộc tính) và state (trạng thái) của chúng. Nắm được vòng đời của một component từ giai đoạn mouting đến updating và unmount sẽ giúp bạn tự tin trong việc quản lý các thành phần trong ứng dụng của mình.
Đến bước này chúng ta sẽ vào các bài toán tổng quan hơn với việc quản lý trạng thái của component và ứng dụng kết hợp với các thư viện sẵn có như Redux, MobX,… Cùng với đó là sử dụng các UIComponent từ các bộ thư viện hoặc tự mình xây dựng nên. Việc tham gia vào các dự án sẽ giúp các bạn củng cố kiến thức tốt hơn trong quá trình trở thành một React Native Developer.
Mức lương của một React Native Developer cũng giống như những vị trí khác, cao hay thấp phụ thuộc vào level và kinh nghiệm. Dưới đây là một cái nhìn tổng quan về mức lương trung bình cho React Native Developer:
Có kinh nghiệp lập trình Native App hoặc Hyprid App
Thành thạo React Native
Nắm vững các khái niệm lập trình OOP, mô hình MVC
Có kiến thức về Multithreading, Data structures, Algorithm và Design pattern
Hiểu biết về API REST
Có khả năng thiết kế và tối ưu cơ sở dữ liệu cho ứng dụng có lượng truy cập lớn
Có tinh thần học hỏi và nâng cao trình độ bản thân
Khả năng làm việc trong môi trường nhóm
Kỹ năng tư duy logic và thuật toán tốt, phân tích và giải quyết vấn đề
MÔ TẢ CÔNG VIỆC
Tham gia thiết kế, xây dựng và triển khai ứng dụng mobile với React Native
Xây dựng giao diện người dùng mượt mà, hoàn hảo về độ phân giải trên cả hai nền tảng di động
Tối ưu native APIs để tích hợp chắc chẽ với các nên tảng
Liên tục tối ưu và nâng cấp mã nguồn để đảm bảo hiệu quả, ổn định và an toàn
Chuyển các ứng dụng web React hiện có sang React Native
Hoàn thành các dự án đúng tiến độ, chủ động học hỏi, nghiên cứu, tìm kiếm các công nghệ mới
Hỗ trợ, phối hợp với các bộ phận khác.
React Native hiện nay vẫn đang là một lựa chọn tiềm năng nếu bạn muốn có một công việc lập trình với mức đãi ngộ cao nhờ nhu cầu tuyển dụng lớn của nó. Để thành thạo bất kỳ ngôn ngữ, thư viện hay framework nào, chúng ta đều cần có sự đầu tư học hỏi chuyên sâu vào nó. Hy vọng bài viết này đã mang lại chút kiến thức hữu ích dành cho những React Native Developer tương lai. Hẹn gặp lại các bạn vào những bài viết tiếp theo của mình.
Django nhanh như chóng chóng, dựng web với Django thì lẹ khỏi phải bàn, nhưng điều gì giúp cho Django trở nên mạnh và nhanh tới vậy? Đó là một trong vô vàn câu hỏi phỏng vấn Django.
Bài viết này tổng hợp chút kiến thức về Django Web Framework. Lướt qua đầy đủ từ kiến trúc, cache, các vấn đề bảo mật. Mong rằng nó sẽ có ích cho anh em trong các buổi phỏng vấn.
Ok, bắt đầu thôi anh em, từng câu từng câu một là chiến. Chiến xong tổng hợp kiến thức là tham gia interview thôi. Nhớ coi thêm các phần khác chứ không là bỏ sót nha.
Lạy chúa sao khác xa nhau vậy nè. Interview, lại là interview
1. Giải thích Django Architecture
Câu hỏi đầu tiên phỏng vấn Django là câu hỏi về kiến trúc. Tất nhiên là đã làm về Django anh em sẽ hiểu kiến trúc chính của Django
Như anh em đã biết, Django tuân theo kiến trúc MVT (Model, View và Template). Dành cho anh em nào chưa biết có thể tham khảo lại bài viết giới thiệu Django tại đây nha. Nhưng 3 thành phần đó trong kiến trúc của Django đã hoạt động như thế nào?
Khúc này cần nêu ra kiến trúc bắt đầu từ Client (mà client là template). Bản thân nó nằm ở phía Client side.
Còn Model và View (cả model và view đều nằm ở phía server side nha). Anh em thường nhầm là view nằm ở phía client, nhưng không phải, view vẫn nằm ở phía server.
Để rõ hơn, anh em ta cùng bàn luận qua ví dụ thực tế này. Anh em tạo một website, mở ra phát là giao diện đăng nhập. Trước khi bàn tới template thì khi anh em access qua URL trên browser, một request sẽ gửi tới ngay server. Sau khi server phản hồi lại, anh em có form để điền thông tin. Điền thông tin xong, bấm đăng nhập. Lúc này data lại gửi tới view, view đi tới model để xác thực người dùng, ok thì đăng nhập.
Sau khi đã nắm rõ kiến trúc của Django và các mà các thành phần trong MVT giao tiếp với nhau. Câu hỏi phỏng vấn Django thứ hai muốn anh em trả lời được về điểm mạnh của frameworks này.
Tại sao lại là Django mà không phải những web development framework khác? Có thể nêu bật ra một số ưu điểm của Django như sau:
Đầu tiên về mặt tài liệu (document), Django cung cấp tài liệu cụ thể, chi tiết và dễ hiểu.
Phát triển nhanh chóng (được phát triển bởi các lập trình viên có kinh nghiệm, áp dụng KISS và DRY – Don’t repeat yourself).
Ngoài nhanh, Django còn tối ưu cho SEO, rất thích hợp với các website thương mại điện tử.
Bảo mật tốt và khả năng mở rộng cao.
Hỗ trợ kết nối với CDN và có hỗ trợ CMS (content management system).
Tất nhiên đây chỉ là những ý chính. Còn thực tế sau khi đã có kinh nghiệm làm việc với Django anh em có thể nói rõ ra các ví dụ cụ thể. Cũng có thể đem ra với các framework khác cũng dùng để phát triển web như PHP Laravel,…
Câu hỏi số 3 phỏng vấn Django nhắm tới các lập trình viên đã có nhiều năm kinh nghiệm và hiểu rõ về Django.
Đầu tiên thì session trong Django được sử dụng để theo dõi trạng thái giữa web server và một trình duyệt cụ thể nào đó. Cái này nếu muốn hiểu rõ hơn anh em cần đọc thêm về stateful và stateless tại đây.
Mỗi khi session được cấp, nó sẽ gắn với một ID và ID này được đặt trong cookies. Anh em lưu ý là chỉ chứa ID của session đó chứ không phải dữ liệu của session. Chính vì thế nên tính bảo mật của session trong Django rất cao.
Ngoài ra Django còn hỗ trợ anonymous session (session ẩn danh). Session này dành cho các user không đăng nhập.
4. Django caching là gì?
Gọi là Django caching vậy thôi chứ caching là khái niệm cơ bản. Câu hỏi phỏng vấn Django này chủ yếu muốn anh em nêu rõ ra các lại cache. Lúc nào thì nên sử dụng loại cache nào.
Cũng cứ lướt qua tí là cache là việc lưu trữ lại kết quả đã có trước đó. Lúc nào cần cứ qua cache mà lấy, không cần phải thực hiện query hay tính toán lại.
Còn về các loại cache, anh em cần nêu ra được các lại cache trong Django.
Memcached
Cái này thì cache trên bộ nhớ (nhanh và dễ sử dụng). Cache thẳng trên mem của server ha. Không cache được nhiều
Filesystem caching
Django lưu trữ cache trong file, chia thành các file nhỏ khác nhau và nối tiếp nhau. Các file riêng biệt.
Local-memory caching
Cái này thì mặc định trên Django, lưu ở mem trên browser.
Database caching
Cuối cùng là database cache, cái này đúng như cái tên, lưu ở phía DB. Anh em nếu có DB và đánh index tốt thì database caching sẽ phát huy hiệu quả
5. Django có thực sự bảo mật?
Ở cái thời đại mà bảo mật được xem như vấn đề cốt lỗi của ứng dụng thì Django cũng không phải là ngoại lệ. Câu hỏi phỏng vấn Django này cần anh em có kiến thức về bảo mật.
Ngoài việc hiểu rõ từng vấn đề bảo mật, anh em cần nêu được Django đã support hoặc hỗ trợ giải quyết các vấn đề bảo mật nào. Cụ thể ở đây có thể nêu ra một số ưu điểm khi sử dụng Django.
Có 7 thứ giúp Django framework trở nên tốt hơn trong vấn đề bảo mật. Từ những phương thức tấn công được biết nhiều như XSS, SQL Injection. Django còn hỗ trợ bảo mật phiên (session security), CSRF,…
Bài viết được sự cho phép của tác giả Lê Nhật Thanh
Anh ơi, qua cài win cho em với! Anh ới, máy tính em bị màn hình xanh đỏ tím vàng rồi!
Máy tính em bị virus rồi, anh qua cứu em với, huhu! Hình như anh học ngành IT mà phải không?
Trong cuộc sống thường nhật của mình, mình rất rất hay bị nhờ những chuyện như vậy. Chỉ vì một thứ, mình là dân IT (Bạn chắc chắn cũng như thế, đúng chưa?)
Mấy ai hiểu nổi khổ của dân trong ngành IT. Trong khi mình là một thằng lập trình viên. Làm gì mà biết sửa máy tính, ống nước này nọ!
Thông qua câu chuyện trên, mình muốn nhắn nhủ một điều rất quan trọng. Dành cho những bạn ĐANG PHÂN VÂN. Không biết đi đâu về đâu trong thế giới IT. Chính là,… thế giới IT cực kì rộng, và bạn đang ở đâu? Nào là web, nhúng, mobile, data, AI, blockchain, IT helpdesk, Security, System admin, tester,…
Đây chắc chắn là một nỗi lo lắng, phân vân của hầu hết sinh viên ngành IT. Vì trong trường, bạn được dạy rất nhiều, bao quát hầu hết các ngành học. Nếu bạn là một người biết đầu tư cho tương lại. Bạn có thể đã tìm ra được hướng đi cho mình ngay trong trường. Nhưng bạn là số ít trong đó.
Đa số các bạn sinh viên chưa biết được mình sẽ làm gì khi ra trường. Thậm chí chưa biết ở ngoài các công ty họ làm gì. Đó là sự thật!
À, trước khi đi vào các ngành chính, mình muốn giới thiệu bạn một tip nhỏ. Với mỗi chuyên ngành (cụ thể là công việc), bạn hãy dùng trang TopDev. Dùng trang này để làm gì? Tra cứu! Mình sẽ đưa cho các bạn một số từ khóa. Bạn lên đây tra cứu thông tin. Để biết các công ty ngoài kia TUYỂN GÌ, CẦN GÌ. Và biết được lượng công việc nhiều hay ít. Từ đó đưa ra những định hướng cho bản thân mình.
Lập trình Web
Lập trình web chưa bao giờ hết hot từ xưa đến nay trong ngành IT. Ngày nay, nhu cầu về web là cực kì cao. Các công ty, doanh nghiệp mọc lên như nấm. Họ chắc chắn cần một website phục vụ cho mình. Nào là marketing, quảng bá thương hiệu, sản phẩm… Kể cả các cá nhân (mình đây) cũng sở hữu riêng một website.
Cho nên lập trình web LUÔN LÀ NGÀNH HOT! Công việc ở đây cực kì nhiều. Lương ở đây cũng rất cao, nhưng tùy vào bạn. Thật tế bạn giỏi thì đi đâu cũng lương cao thôi (câu này ai cũng nói, mà đúng thật).
Trở thành web developer
Lập trình web được chia ra làm 2 nhánh chính: Back-end và Front-end. Trước tiên, nếu bạn chưa hiểu một website hoạt động như thế nào. Thì hãy tìm hiểu thêm trên google (vì nó rất dễ hiểu).
Back-end là phần xử lý logic ở phía server. Các bạn có thể hay thấy các job kiểu như PHP, .NET, Java, NodeJS,… Hãy dùng những từ khoá này để search trên các trang tìm việc. Bạn sẽ thấy rất rõ ràng về Job Description (mô tả những thứ bạn sẽ làm ở công ty) và Job Requirement (những yêu cầu để bạn có thể đậu phỏng vấn).
Font-end là phần xử lý phía client, giao diện người dùng. Ngày nay việc làm front-end cũng cực kì đa dạng. Nào là React, Angular, VueJs, ….
Ngoài ra, nếu bạn có khả năng đảm nhận cả Front-end và Back-end. Vị trí của bạn lúc này là full-stack developer.
Lưu ý một lần nữa! Bạn hãy dùng những từ khoá mình đề cập đến trong bài để search trên các công cụ tìm kiếm việc làm.
Để bạn có thể bước vào ngành phát triển web. Bạn cần xác định mình muốn làm Font-End hay Back-End hay full-stack. Rồi tiếp đến là chọn cho mình một ngôn ngữ chính để luyện. Nhiều khi bạn đã định hướng là vào Back-End. Nhưng nhiều bạn còn phân vân chưa biết đi theo ngôn ngữ nào đâu. Người thì chọn .NET, người thì PHP, NodeJS, JAVA,…
Phải nói là có quá nhiều thứ trong lập trình web. Hãy cố gắng để có một background IT tốt nhất có thể nhé.
Cũng giống như web, bạn nhìn thấy và sử dụng các ứng dụng mobile hằng ngày. Mọi ứng dụng trên điện thoại (android, IOS,…) đều là sản phẩm của lập trình mobile trong ngành IT. Bạn có thích tạo ra những mobile app như vậy? Nếu thích thì đến với lập trình mobile.
Về phương diện tiếp cận cũng khá giống bên web. Ban đầu khi tiếp cận cũng tương đối dễ, nhưng về sau để trở nên thành thạo thì cũng rất phức tạp.
Trở thành mobile developer
Lập trình mobile thì được chia thành 2 hướng chính: Single Platform và Cross Platform.
Single Platform kiểu như bạn code chỉ cho mỗi Android hoặc IOS. Code cho thằng này thì không chạy cho thằng kia được. Bởi vậy mới sinh ra Cross Platform. Code một lần, chạy được trên nhiều nền tảng.
Vì sao lại như thế thì bạn có thể thử bước vào thế giới mobile.
Lưu ý: Khi bạn tò mò một job nào đó. Search nó trên google hoặc web tìm việc. Bạn sẽ biết job đó như thế nào. Cần học NGÔN NGỮ, CÔNG CỤ gì.
Lập trình nhúng
Embedded hay còn gọi là lập trình nhúng, là một ngành IT đang rất hot ở thời điểm hiện tại (2019) và sẽ trở nên rất hot trong tương lai với IoT (Internet of Things).
TV thông minh, nhà thông minh, xe hơi thông minh, thành phố thông minh, vv. Tất cả những thứ này đều là sản phẩm của lập trình nhúng.
Mình nói đơn giản về nhúng, bạn sẽ phải viết code, sau đó “nạp code” và một phần cứng nào đó để phần cứng này có thể hoạt động được theo một yêu cầu nhất định. Ví dụ, bạn chắc chắn một lần đi thang máy, người ta đã viết một chương trình và nạp vào hệ thống điều khiển của thang máy, hệ thống này sẽ điều khiển mọi thứ mà bạn đã nhìn thấy khi thang máy hoạt động đấy. Hay một ví dụ khác là hệ thống quẹt thẻ khi bạn gửi xe, đó cũng là một ứng dụng của lập trình nhúng.
Bạn cứ hiểu đơn giản, nhúng là sự kết hợp giữa 2 thứ phần cứng và phần mềm.
Bây giờ bạn có thể tưởng tượng ra lập trình nhúng là như thế nào rồi, bạn có thấy thích hay tự tin khi bước vào thế giới này?
Lập trình nhúng khác với web hay mobile ở chổ. Bạn phải giao tiếp với phần cứng trực tiếp và một điểm quan trọng nữa. Ban đầu tiếp cận với lập trình nhúng tương đối phức tạp, hay mình muốn nói luôn là khó. Điều này trái ngược với web hay mobile. Và khi bạn đã có những bước đầu thành công với lập trình nhúng, con đường phía sau sẽ dễ dàng hơn một chút cho bạn.
Trở thành embedded developer
Có rất nhiều nhận định nói rằng, ban đầu học lập trình web phải học rất nhiều thứ, rất nhiều ngôn ngữ, rất nhiều công nghệ, và bản thân ngành lập trình web thay đổi quá nhanh về công nghệ, nói chung là học web rất phức tạp và gian nan. Mình hoàn hoàn công nhận với điều này, nhưng theo quan điểm của mình, nhúng mới là ngành khó học và khó theo nhất, cũng như là ngành khô khan nhất trong 3 ngành. Và kiến thức phải học trong nhúng của rất rất nhiều không thua kém bên web và thậm chí nó còn khó và khô khan hơn nhiều. Để mình giải thích thêm về nhận định này.
Mình quen khá nhiều người làm về nhúng (vì mình xuất thân từ dân lập trình nhúng) và thông thường họ làm việc chủ yếu với testing C/C++, khi họ đã quen với công việc thì họ hay cho rằng mình đã giỏi về lập trình nhúng, tự tin đánh giá điểm rất cao khi được hỏi về nhúng. Nhưng thực tế, họ hoàn toàn chưa biết về thế giới lập trình nhúng, họ thậm chí chưa từng tiếp xúc với một con chip hay thậm chí chưa từng nghe về các khái niệm như SPI, I2C, Bootloader,….
Khi đọc đến đây, sẽ có nhiều bạn phản đối và cho rằng, embedded software có nhiều người họ không cần biết nhiều về phần cứng và vẫn làm việc được. Đúng là có rất nhiều embedded software biết rất ít về phần cứng ngoài kia. Nhưng chỉ với như thế bạn khó có thể phát triển và tồn tại trong thế giới nhúng được, trừ khi bạn làm công việc đó trong hết sự nghiệp lập trình viên của bạn. Và bạn thật sự là một lập trình viên với công việc của một công nhân, thay vì một lập trình viên với công việc và đầu óc của một kĩ sư.
Một người lập trình viên nhúng đúng nghĩa, thật sự họ rất tuyệt, họ am hiểu sâu về phần cứng, làm thế nào để tối ưu hóa, thậm chí họ tự thiết kế ra phần cứng đó sao cho tối ưu. Họ rất giỏi về điện tử nữa là đằng khác, và có những developer nhúng nhưng cực kì giỏi về web hay mobile. Họ tự thiết kế một hệ thống full-stack từ hardware đến software, application… Những người như thế mới được gọi là một lập trình viên embedded đúng nghĩa.
Một số job bạn có thể nghĩ tới: Embedded tester (C/C++), AUTOSAR, IOT, Thiết kế chip, Embedded developer, Embedded hardware, Embedded software.
Tester
Song song với lập trình viên (developer), đó chính là tester. Một số nơi gọi là QA, hay QC hay đơn giản là tester. Nói một cách đơn giản về công việc của một tester. Họ là người tìm bug trong sản phẩm.
Một cách hiểu đơn giản, trong quá trình phát triển sản phẩm. Sẽ chia ra thành hai phần chính. Phát triển (develop) và kiểm thử (test). Để cho sản phẩm khi đã tung ra thị trường (release) hạn chế lỗi nhất có thể.
Kể cả web, mobile, hay nhúng, chúng ta đều có tester trong mỗi khâu phát triển. Tùy thuộc vào sản phẩm chúng ta dùng mô hình phát triển nào. Agile/Scrum hay V-Model.
Các sản phẩm web, mobile với thời gian release ngắn thường dùng mô hình Agile/Scrum. Còn đối với nhúng, đặt biệt là AUTOSAR, họ dùng V-Model.
Test là một phần không thể thiếu trong quá trình phát triển. Cho nên một sản phẩm không thể thiếu tester. Ngày nay Automation Test phát triển rất mạnh. Nên các bạn đi theo hướng tester có thể học thêm. Để làm tăng giá trị cho bản thân mình.
Một số ngành khác
Như mình đã đề cập ở phía đầu bài. Chúng ta còn rất nhiều ngành khác nữa cũng là IT.
IT helpdesk hay IT support hay một số nơi gọi là IT thôi. Công việc của họ là xử lý các vấn đề trục trặc liên quan tới IT. Nói chung khi bạn có vấn đề gì liên quan tới máy móc, mạng,… thì hãy liên hệ với họ. Đôi khi học kiêm luôn vị trí của một System Admin hay một DevOops.
Security, là những người đảm bảo an toàn cho toàn bộ nhân viên, máy móc. Hay nói cách khác là toàn bộ công ty bạn khỏi các cuộc tấn công mạng. Một số team security thì chịu trách nhiệm thực hiện các cuộc tấn công đến chính sản phẩm của công ty mình nhằm tìm ra lỗ hỏng bảo mật (penetration testing).
Và còn nhiều nghề nghiệp liên quan tới IT nữa. Nhưng bài viết này đủ dài rồi. Bạn có thể tìm hiểu trên internet. Mình có thể đề xuất thêm như: hệ thống thông tin, database, thương mại điện tử. Hay thậm chí là Blockchain, trí tuệ nhân tạo (AI), phân tích dữ liệu (data analysis), data science,…
#2 Cái thứ mà bạn mong chờ – Roadmap
Trong phần trên, mình đơn giản chi là giới thiệu qua về các ngành nghề chính. Nhưng nó thực sự chưa chi tiết. Có lẽ các bạn đang cần một roadmap cho từng ngành cụ thể.
Roadmap sẽ chỉ cho các bạn TỪNG BƯỚC TỪNG BƯỚC một khi bạn chọn một ngành. Bạn sẽ nhìn thấy được bạn cần học gì, làm gì để chinh phục ngành đó. Hoặc đơn giản là sống tốt trong ngành đó.
#Kết
Thật sự là còn khá nhiều công việc liên quan tới ngành IT mình chưa kể hết ở đây. Chỉ cần bạn bước vào con đường IT. Bạn sẽ nhận ra nó rất rộng.
Và sau khi đi làm một vài năm, bạn sẽ có định hướng riêng cho mình. Người thì muốn làm một manager. Người thì thích làm một senior dev thuần. Có người thì muốn làm một technical lead hoặc software architecture.
Bạn đi đâu, về đâu, không ai có thể chỉ đường cho bạn được. Đường đi nằm ở trong con người bạn. Bài viết của mình nhằm mục đích. Cho bạn thấy những con đường có thể đi. Bạn đi đâu, tới đâu, là do sự lựa chọn của bạn. Nếu bạn đi đúng, sự nghiệp của bạn thành công rực rỡ. Nếu bạn đi sai… không biết chuyện tồi tệ gì sẽ xảy ra.
Nhưng cũng đừng sợ sai mà không dám bước. Phàm trên đời này ai cũng có những bước đi sai lầm. Quan trọng là bạn biết quay đầu và làm lại.
Chúc các bạn có một sự lựa chọn đúng nhất cho sự nghiệp của mình trong ngành IT khắc nghiệt này!
Bài viết được sự cho phép của tác giả Lê Nhật Thanh
Có bao giờ bạn thắc mắc, một website hoạt động như thế nào không? Trong bài này, chúng ta sẽ cùng tìm hiểu về kiến trúc website. Từ những web nhỏ cho tới những web lớn và khổng lồ.
Hay nói một cách khác. Những kĩ sư, lập trình viên đã làm như thế nào để làm ra được một website.
Một website đơn giản (như web của mình) hay đến một kiến trúc website phức tạp (như google, facebook, amazone,…) sẽ có kiến trúc như thế nào? Đây cũng là một câu hỏi phỏng vấn cho các lập trình viên, kĩ sư.
#1 Cấu trúc của một website
Để biết và hiểu được kiến trúc phức tạp của các website lớn. Chúng ta nên bắt đầu từ cái nhỏ nhất! Tìm hiểu một website đơn giản. À, website của mình cũng thuộc dạng là một website đơn giản. Vì nó là đơn thuần là một blog site. Chỉ xử lý về text và hình ảnh chứ không xử lý nhiều về nghiệp vụ.
Kiến trúc
Một website đơn giản hay phức tạp đều sẽ có hai thành phần chính: Client và Server. Nhưng những website đơn giản thì đương nhiên phần client và server của nó cũng đơn giản.
Mình sẽ cố gắng dùng những ngôn từ BÌNH DÂN nhất để giải thích cặn kẽ cho các bạn.
Client là những thứ bạn nhìn thấy trên browser (trình duyệt web).
Còn server là những gì xử lý ở phía sau mà người dùng bình thường không thấy được. Server sẽ được đặt ở một nơi nào đó và gửi dữ liệu về phía client cho người dùng thấy.
Và một lưu ý nữa, server là một phần cứng nhé. Nó y chang cái máy tính của bạn vậy (thật ra nó khác chút). Nó có CPU, RAM, ổ cứng và những “phụ kiện” khác!
Cấu hình một server sẽ như thế này
Sau đây mình sẽ trình bày cụ thể hơn một chút về cách thức client và server hoạt động. Đương nhiên cũng ở mức cơ bản.
Khi bạn gõ Facebook.com thì chuyện gì xảy ra?
Bạn mở trình duyệt (Chrome chẳng hạn), gõ Facebook.com. Và bạn đơn thuần là… lướt Facebook. Chứ… ít khi bạn nghĩ về chuyện gì đã xảy ra để trang Facebook hiển thị ra cho bạn xem.
Nhưng ở trong bài viết này. Bạn sẽ phải tìm hiểu về điều đó.
Facebook.com được gọi là domain hay tên miền. Và phía sau domain này là một hệ thống server (khổng lồ). Khi bạn truy cập tới facebook.com. Nghĩa là bạn yêu cầu server của Facebook gửi cho bạn trang login để bạn đăng nhập. Và yêu cầu này được trình duyệt gửi tới Facebook server thông qua các gói tin.
Chúng ta gọi đây là một HTTP request giữa trình duyệt và Facebook server. Sau đó, server nhận được yêu cầu của bạn. Nó tiến hành đọc và phân tích gói tin HTTP này. Và server sẽ trả lại cho trình duyệt trang login cũng thông qua HTTP response. Nói tóm lại là phía client và phía server giao tiếp với nhau thông qua giao thức HTTP.
Thôi, nhìn hình dưới cái là hiểu liền!
HTTP request và HTTP response
Trên đây là cách hoạt động tổng quan của một website. Ở mức độ mà ai ai cũng có thể hiểu. Ở trong phần sau, chúng ta sẽ đi sâu hơn về kiến trúc của một kiến trúc website lớn. Bởi vì một website lớn, phục vụ cho hàng triệu người dùng thì kiến trúc sẽ rất phức tạp.
Như bạn cũng đã được học trong phần trên. Một hệ thống website sẽ có hai thành phần chính là client và server. Bạn cũng biết là ở dưới server sẽ lưu dữ liệu của website (để render ra cho phía client đó). Cho nên phần server chúng ta có thể tách ra làm 2 phần chính: webserver và database server.
Web server và database server
Web server sẽ chịu trách nhiệm tiếp nhận những yêu cầu từ browser. Và nó sẽ lấy những dữ liệu cần thiết dưới database server để trả về cho browser. Vì nơi lưu trữ dữ liệu của website sẽ là database server. Kiểu như bạn (browser) cần gì thì mình (web server) sẽ xuống database lấy cho bạn. Hiểu đơn giản vậy đó.
Và trước tiên mình muốn nói đến các website nhỏ, phục vụ ít người dùng trước.
Một website đơn giản, phục vụ ít người dùng, chỉ xử lý những tác vụ đơn giản. Thì họ không cần phải có một server KHỦNG. Vì điều đó là không cần thiết, vì sẽ tốn chi phí xây dựng server mạnh (vì nó là phần cứng mà).
Phần server của một website như thế thường có cấu hình bình thường (phục vụ đủ nhu cầu). Nhiều khi cả database server và web server cùng một nơi. Họ không tách hai phần này ra.
Cho nên những website có server như thế chỉ phục vụ cho một lượng người dùng nhất định.
Mình lấy ví dụ trong chính website của mình luôn. Giả sử cấu hình của một kiến trúc website chỉ đủ phục vụ cho khoảng 10.000 người dùng trong một lúc. Vậy nếu trong một lúc, website của mình có khoảng 1 triệu hay 10 triệu người dùng thì sao?
Câu trả là là TẠCH! Vì server không chịu nổi một lượng request lớn như vậy.
Vậy thì mình sẽ làm cách gì để có thể đáp ứng được lượng truy cập lớn như vậy?
TĂNG CẤU HÌNH SERVER LÊN chứ còn gì! Ví dụ gắn thêm RAM, gắn thêm core CPU, thay ổ cứng mạnh hơn chẳng hạn. Những giải pháp này sẽ giúp cho hệ thống website của bạn tăng đáng kể khả năng chịu tải.
Nhưng có một điều quan trọng. Phần cứng luôn có giới hạn của nó, chắc chắn là như thế. Cho nên bạn chỉ có thể tăng tốc độ xử lý ở server lên tới một giới hạn nào đó thôi. Không thể tăng mãi được!
Vậy thì mới có một câu hỏi được đặt ra. Những hệ thống như Facebook, Goolge, Youtube, Tiki,… đã làm cách nào để xử lý hàng triệu, hay hàng tỉ user. Vì đơn thuần với những hệ thống vậy. Một server có cấu hình cực mạnh cũng không thể chịu nổi lượng request khổng lồ như thế được. Vậy họ đã làm như thế nào với hệ thống của họ?
Một hệ thống lớn trên thực tế?
Đây cũng là một dạng câu hỏi / yêu cầu tuyển dụng đối với một senior developer. Câu hỏi kiểu như: “Xử lý hàng triệu người dùng một lúc không phải là vấn đề của bạn”.
Có thể bài này sẽ dài vì mình muốn trình bày rõ ràng nhất có thể về kiến trúc thực tế của một hệ thống.
Kiến trúc website trên thực tế
À, nhìn vào hình trên bạn hiểu không? Những senior developer có thể sẽ hiểu được toàn bộ bức hình trên. Nhưng mình muốn trình bày cho mọi developer đều hiểu về nó.
Ở phần đầu bài viết. Khi bạn gõ vào trình duyệt facebook.com, trình duyệt sẽ gửi yêu cầu của bạn tới server của Facebook. Bạn nhớ đoạn này chứ?
Vậy làm sao trình duyệt (browser) biết đường để tìm đến server của Facebook chỉ với tên miền facebook.com bạn đã cung cấp? DNS server sẽ giúp trình duyệt… biết Facebook server nằm ở đâu.
DNS Server
Một server sẽ có một địa chỉ IP để định danh nó trên internet. Giống như địa chỉ nhà của bạn vậy.
Và Domain Name System (DNS) là một hệ thống phân giải tên miền. Giúp trình duyệt tìm ra được địa chỉ IP của một server thông qua tên miền.
Ở ví dụ trên, DNS sẽ giúp trình duyệt phân tích tên miền facebook.com. Và sau khi phân tích xong, DNS sẽ trả về cho trình duyệt IP của Facebook Server.
Tới đây thì trình duyệt đã biết sẽ gửi gói tin HTTP đến đâu rồi.
Chúng ta nhắc lại một chút về vấn đề lượng user request tăng lên đột ngột. Giải pháp ở đây là chúng ta sẽ phải mở rộng server (kiểu như nâng cấp).
Và cách nâng cấp ở trên, mình có đề cập đến chính là mở rộng thêm phần cứng cho một server. Và thuật ngữ của cách mở rộng này là vertical scaling (hay mở rộng theo chiều dọc). Cái này rõ ràng là có hạn chế vì phần cứng chỉ đạt đến một giới hạn nào đó thôi.
Và có một cách thứ hai để mở rộng server chính là horizontal scaling (hay mở rộng theo chiều ngang). Nghĩa là chúng ta mở rộng thêm nhiều server nữa song song với server hiện tại. Bây giờ server chúng ta không chỉ có một, mà có nhiều server chạy một lúc.
Rõ ràng là khi ta mở rộng server như vậy. Chúng ta có thể đẩy sức mạnh của server lên mức chúng ta mong muốn một cách dễ dàng (trên thực tế không dễ không ngen =]]] ). Vì đơn giản chúng ta chỉ việc lắp thêm những server khác song song thôi. “Một cây làm chẳng lên non, ba cây chụm lại nên hòn núi cao” mà.
Và việc mở rộng này nhằm mục đích chia sẻ tải giữa các server. Thậm chí khi có một server bị sự cố thì các server khác vẫn còn hoạt động.
Và lúc này vấn đề số lượng user tăng đã được giải quyết. Khi có cả triệu triệu request tới server, thì lượng request sẻ chia đều cho các server. Giúp server có thể đáp ứng được nhu cầu của người dùng. Nhìn hình bên dưới để hiểu nhé!
Một hệ thống load balancer trên thực tế
Và để phía server có thể làm được công việc chia sẻ tải này. Chúng ta có một công nghệ gọi là load balancer (cân bằng tải).
Khi client gửi request tới server, load balancer sẽ nhận request, rồi bắt đầu gửi request tới server nào thích hợp nhất.
Nói về lý thuyết thì rất là đơn giản. Những khi triển khai thực tế một hế thống server với load balancer là một điều CỰC KÌ KHÓ và phức tạp.
À ngoài ra chúng ta có thể lắp load balancer dự phòng nữa. Công nghệ này cực kì hay.
Load balancer dự phòng
Web Server
Đây là phần server mà mình nói nảy giờ đó. Phần này là nơi xử lý logic (hay business logic). Các bạn backend-developer sẽ làm việc ở đây. Ở web server này, chúng ta hay dùng các ngôn ngữ như PHP, Nodejs, Java, .NET,… để xây dựng. Mình không nói nhiều về phần này nữa.
Database Servers
Phần này mình cũng đã từng nói rất cơ bản. Ở đây mình muốn mổ xẻ xâu hơn một xíu. Với một hệ thống lớn, phần database rất phức tạp.
Giả sử Facebook chỉ có một máy chủ để làm database server với hệ thống load balancer như trên. Rõ ràng hệ thống này cũng sẽ tạch. Như hình bên dưới!
Load balancer với một database server duy nhất
Rõ ràng khi bạn nhìn vào bức hình trên, nó quá đẹp. Nhưng ở đây, database sẽ chịu không nổi số lượng request của các web server. Rõ ràng đó cũng là một vấn đề tương tự với web server.
Chúng ta bắt buộc phải mở rộng database server! Nhưng mở rộng nó như thế nào? Không lẽ cứ tăng phần cứng cho nó lên cực hạn. Đây cũng không phải là cách giải quyết hay.
Ở đây chúng ta có một cách để mở rộng database. Dùng kiến trúc master/slave.
Master slave architecture
Master là database chính với mục đích là để ghi. Database master này sẽ có vài con slave (đệ tử) để nó đồng bộ dữ liệu qua. Và khi với lượng request lớn, chúng ta có thể đọc ở từng con server như vậy. Để đáng kể tải ở master. Đây là một cách cực kì hay.
Nhưng nó chỉ thích hợp với các hệ thống đọc database nhiều, ghi thì ít hơn. Bởi vì khi chúng ta ghi nhiều vào database thì master server cũng sẽ tạch vì chịu không nổi. Ví dụ như Facebook, lượng request ghi vào database cực kì nhiều (like, comment, chat, …). Cho nên chúng ta sẽ sinh ra thêm một cách mở rộng database khác – Sharding Database.
Ví dụ Facebook đi! Facebook sẽ có nhiều database nằm ở các nước khác khác nhau. Ở Việt Nam cũng có. Và giả sử các user Việt Nam muốn truy cập và database, thì phía server sẽ điều hướng làm sao đó để lương request này tới database nằm ở Việt Nam. Chúng ta hiểu đơn giản vậy thôi. Hiện nay có rất nhiều công nghệ hổ trợ chúng ta xây dựng Sharding Database như vậy! Bạn tìm hiểu thêm trên Google nhé!
Trên thực tế thì việc mở rộng database rất là khó, đòi hỏi các kĩ sư rất giỏi. Còn lý thuyết thì đơn giản như vậy thôi =]]].
Caching
Caching là một phần gì đó không thể thiếu đối với hầu hết các website hiện tại. Nếu bạn muốn tăng tốc website thì bạn không thể không nghĩ tới caching.
Nghĩ đơn giản như vậy. Mỗi khi trình duyệt request đến server, là mỗi lần server lại xuống database để lấy dữ liệu. Như vậy sẽ làm chậm trãi nghiệm duyệt web của bạn (vì query database thường sẽ chậm). Lúc đó chúng ta cần đến kĩ thuật caching. Hay hiểu đơn giản là nó lưu tạm dữ liệu ở một nơi nào đó (thường là RAM hay ổ cứng).
Kĩ thuật caching
Khi chúng ta request tới server, server không cần phải mất công xuống database nữa mà vào thẳng cache server để lấy dữ liệu ra. Dữ liệu ở cache sẽ được đọc nhanh gấp nhiều lần. Nên tăng tốc một cách khủng khiếp.
Hiện tại có 2 hệ thống lưu trữ phổ biến là Redis và Memcache. Website của mình dùng Memcache ha!
Job Queues và Servers
Hầu hết ứng dụng web đều cần làm một số công việc bất đồng bộ ở phía back-end mà không kết hợp trực tiếp vào dữ liệu trả về cho người dùng. Ví dụ, Google cần crawl và index toàn bộ internet để trả về kết quả tìm kiếm cho chúng ta. Nó không được làm mỗi lần bạn tìm kiếm. Thay vào đó, nó crawl các trang web một cách bất đồng bộ, và cập nhật index theo thời gian (schedule).
Mặc dù có nhiều kiến trúc khác nhau cho các công việc bất đồng bộ, nhưng phố biến nhất là kiến trúc job queue. Nó chứa 2 thành phần: một hàng đợi job cần được chạy, và một hoặc nhiều job server (hay còn lại là worker) để chạy job trong hàng đợi.
Job queue chứa một danh sách job cần được chạy bất đồng bộ. Hàng đợi đơn giản nhất là FIFO (first in first out) mặc dù hầu hết ứng dụng sẽ cần một vài hàng đợi có ưu tiên (theo priority). Mỗi khi ứng dụng cần chạy job thì nó chỉ cần thêm job đó vào hàng đợi.
Một vài xử lý tường sử dụng kĩ thuật này: encode video và ảnh, xử lý file CSV, thống kê người dùng, gửi mật khẩu reset email,…
Job server xử lý job. Chúng thăm dò job queue để xác định có job cần làm hay không, và nếu có thì chúng sẽ đẩy job vào hàng đợi và thực thi nó.
Full-text Search Service
Hiểu đơn giản của dịch vụ này. Hệ thống website sẽ cho bạn một khung search. Và khi bạn search một vấn đề nào đó ví dụ “programming”, thì server sẽ trả cho bạn những kết quả trong database có liên quan tới programming ha.
Nhưng cứ mỗi lần server chúng ta đều phải query xuống database thì hơi “cực”. Nên các công nghệ full-text search ra đời để giúp trải nghiệm search nhanh hơn rất nhiều.
Nền tảng full-text search phổ biến nhất hiện nay là Eltasticsearch, bên cạnh một số lựa chọn khác như Sphinx hoặc Apache Solr.
Services
Khi hệ thống của chúng ta lớn dần lớn dần. Có một số services sẽ được chia nhỏ ra để chạy như một ứng dụng riêng, Web app và các Service khác có thể tương tác đến chúng. Ví dụ: Content service dùng để lưu trữ lượng dữ liệu lớn về video, ảnh, file audio. Payment service cung cấp giao diện để trả phí qua thẻ tín dụng, …
Data
Ngày nay, các công ty tồn tại hay phá sản dựa trên việc họ khai thác dữ liệu như thế nào. Khi các app đạt đến trạng thái hoạt động ổn định, nó sử dụng quy trình xử lý dữ liệu để chắc chắn rằng dữ liệu được thu thập, lưu trữ, phân tích. Một quy trình xử lý dữ liệu điện hình có ba giai đoạn:
App gửi dữ liệu, thông qua tương tác user, đến data firehose để lưu trữ và xử lý dữ liệu. Thường thì dữ liệu gốc được biến đổi hoặc tăng thêm và chuyển đến cho firehose khác. AWS Kinesis và Kafka là hai công nghệ thường sử dụng cho mục đích này.
Dữ liệu gốc sau khi được biến đổi sẽ được lưu trữ trong cloud storage. AWS Kinesis cung cấp thiết lập được gọi là firehose để lưu trữ dữ liệu gốc vào cloud storage (S3).
Dữ liệu đã biến đổi được đưa vào trong kho dữ liệu để phân tích. Sử dụng AWS Redshift sẽ giải quyết được việc này.
Cloud Storage
Cloud storage là cách đơn giản để lưu trữ, truy cập và chia sẻ dữ liệu trên Internet thông qua các nền tảng cloud như: AWS. Bạn có thể dùng nó để lưu trữ và truy cập đến mọi thứ bạn đã lưu trữ trên hệ thống thông tin cục bộ. Và có thể tương tác đến chúng qua Restful API.
Amazon S3 hiện nay là cloud storage phổ biến nhất để lưu trữ video, ảnh, audio, file css, js, …
CND
CDN viết tắt bởi Content Delivery Network là mạng lưới gồm nhiều máy chủ lưu trữ đặt tại nhiều vị trí địa lý khác nhau, cùng làm việc chung để phân phối nội dung, truyền tải hình ảnh, CSS, Javascript, Video clip, Real-time media streaming, File download đến user.
Cơ chế hoạt động của CDN giúp cho user truy cập nhanh vào dữ liệu máy chủ web gần họ nhất thay vì phải truy cập vào dữ liệu máy chủ web tại trung tâm dữ liệu.
Các hệ thống lớn như Facebook, Google đều sử dụng CDN để tăng trải nghiệm của user.
#Kết
Trên đây là mình đã trình bày dường như tổng quan về kiến trúc website của một hệ thống lớn. Và các vấn đề phát sinh trong quá trình xây dựng hệ thống để đáp ứng với lượng user không lồ. Rõ ràng lý thuyết là vậy, nhưng để thực hiện được những điều này phải có một đội ngũ cực giỏi.
Mình không hi vọng bạn hiểu hết các vấn đề trên. Đến cả bản thân mình cũng chưa hoàn toàn hiểu hết. Vì đơn giản mình chưa trải nghiệm qua tất cả các giai đoạn / công nghệ trên.
Nhưng mình muốn một phần nào giúp bạn có một cái nhìn tổng qua. Cũng như cung cấp các keyword cần thiết để bạn có thể tìm hiểu thêm trên internet.
Internationalization và Localization trong Java sẽ đề cập đến Internationalization và Localization.
Internationalization cũng có thể được viết tắt là i18n vì có 18 ký tự ở giữa I và N. Internationalization(quốc tế hoá) là một kỹ thuật cho phép chúng ta tạo ra các ứng dụng mà có thể thích ứng với nhiều ngôn ngữ và nhiều khu vực khác nhau.
Localization cũng có thể được viết tắt là l10n vì 10 ký tự ở giữa L và N. Localization (nội địa hoá) là kỹ thuật giúp tạo ra một ứng dụng có thể thích ứng với một ngôn ngữ và vùng miền cụ thể.
Như vậy, một ứng dụng hỗ trợ đa ngôn ngữ thì gọi là Internationalization (quốc tế hoá) và khi người dùng chọn một ngôn ngữ cụ thể để hiển thị thì gọi là Localization (nội địa hoá)
Internationalization và localization trong Java – Các thành phần trong ứng dụng cần được quốc tế hóa
Internationalization và localization trong Java – Quốc tế hoá các thông điệp (Messages)
Chúng ta sẽ sử dụng lớp ResourceBundle để xử lý quốc tế hoá cho các message. Các message trong ứng dụng sẽ được khai báo trong tập tin properties thay vì viết trong code (hardcoded).
Tên của tập tin properties đặt theo qui tắc filename_languagecode_countrycode với filename là tên tập tin, languagecode là mã ngôn ngữ, countrycode là mã quốc gia. Bên dưới là bảng mô tả language code và country code theo từng quốc gia.
Ví dụ tạo chương trình hiển thị chuỗi “Hello World” và “Xin chào thế giới!” tuỳ thuộc vào lựa chọn của người dùng là tiếng Anh hay tiếng Việt. Các bước thực hiện như sau:
Bước 1: Tạo 2 tập tin properties tương ứng 2 ngôn ngữ muốn hiển thị
Tạo tập tin MessageBundle_en_US bằng cách chuột phải vào project hoặc package -> chọn New -> chọn Properties File -> nhập tên tập tin tại File Name -> chọn Finish
Nhập nội dung cho tập tin MessageBundle_en_US
#key = value
greeting = Hello World!
Tạo tập tin MessageBundle_vi_VN và nhập nội dung sau
greeting = Xin chào thế giới!
Lưu ý key trong các tập tin phải giống nhau, các tập tin này chỉ khác nhau về value. Mỗi value tương ứng cho một ngôn ngữ.
Hình bên dưới cho biết hai tập tin properties được lưu trong packge tên internationalization.message
Bước 2: Tạo lớp I18NMessages và cài đặt xử lý
package internationalization.message;
import java.util.Locale;
import java.util.ResourceBundle;
import java.util.Scanner;
/**
*
* @author giasutinhoc.vn
*/
public class I18NMessages {
public static void main(String[] args) {
int lang;
Scanner s = new Scanner(System.in);
ResourceBundle bundle;
do {
System.out.println("1. English");
System.out.println("2. Vietnamese");
System.out.println("3. Exit program");
System.out.print("Please choose your language: ");
lang = s.nextInt();
switch (lang) {
case 1:
//internationalization.message is package name
//MessageBundle is properties file name
bundle = ResourceBundle.getBundle("internationalization.message.MessageBundle", Locale.US);
System.out.println("Message in " + Locale.US
+ ": " + bundle.getString("greeting"));
break;
case 2:
//changing the default locale to Vietnamese
Locale.setDefault(new Locale("vi", "VN"));
bundle = ResourceBundle.getBundle("internationalization.message.MessageBundle");
System.out.println("Message in " + Locale.getDefault()
+ ": " + bundle.getString("greeting"));
break;
}
} while (lang != 3);
}
}
Khi chạy chương trình trên, chúng ta sẽ nhận được kết quả sau
Internationalization và localization trong Java – Quốc tế hoá ngày (Date)
Chúng ta có thể quốc tế hoá ngày bằng cách sử dụng phương thức getDateInstance() của lớp DateFormat. Phương thức này nhận vào 2 tham số là style với các kiểu như DEFAULT, SHORT, LONG và locale.
Ví dụ sau đây sẽ hiển thị ngày hiện tại theo những vùng miền khác nhau như JP và VN
package internationalization;
import java.text.DateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.Scanner;
/**
*
* @author giasutinhoc.vn
*/
public class I18NDate {
private static void printDate(Locale locale) {
DateFormat formatter = DateFormat.getDateInstance(DateFormat.LONG,
locale);
Date currentDate = new Date();
String date = formatter.format(currentDate);
System.out.println(locale + " : " + date);
}
public static void main(String[] args) {
int region;
Scanner s = new Scanner(System.in);
do {
System.out.println("1. Japan");
System.out.println("2. Vietnam");
System.out.println("3. Exit program");
System.out.print("Please choose your region: ");
region = s.nextInt();
switch (region) {
case 1:
printDate(Locale.JAPAN);
break;
case 2:
printDate(new Locale("vi", "VN"));
break;
}
} while (region != 3);
}
}
Khi chạy chương trình
Internationalization và localization trong Java – Quốc tế hoá thời gian (Time)
Trong ví dụ này, chương trình sẽ hiển thị thời gian hiện tại dựa theo vùng miền được chỉ định.
package internationalization;
import java.text.DateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.Scanner;
/**
*
* @author giasutinhoc.vn
*/
public class I18NTime {
static void printTime(Locale locale) {
DateFormat formatter = DateFormat.getTimeInstance(DateFormat.LONG, locale);
Date currentDate = new Date();
String time = formatter.format(currentDate);
System.out.println(time + " in locale: " + locale);
}
public static void main(String[] args) {
int region;
Scanner s = new Scanner(System.in);
do {
System.out.println("1. England");
System.out.println("2. Vietnam");
System.out.println("3. Exit program");
System.out.print("Please choose your region: ");
region = s.nextInt();
switch (region) {
case 1:
printTime(Locale.ENGLISH);
break;
case 2:
printTime(new Locale("vi", "VN"));
break;
}
} while (region != 3);
}
}
package internationalization;
import java.text.DateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.Scanner;
/**
*
* @author giasutinhoc.vn
*/
public class I18NTime {
static void printTime(Locale locale) {
DateFormat formatter = DateFormat.getTimeInstance(DateFormat.LONG, locale);
Date currentDate = new Date();
String time = formatter.format(currentDate);
System.out.println(time + " in locale: " + locale);
}
public static void main(String[] args) {
int region;
Scanner s = new Scanner(System.in);
do {
System.out.println("1. England");
System.out.println("2. Vietnam");
System.out.println("3. Exit program");
System.out.print("Please choose your region: ");
region = s.nextInt();
switch (region) {
case 1:
printTime(Locale.ENGLISH);
break;
case 2:
printTime(new Locale("vi", "VN"));
break;
}
} while (region != 3);
}
}
Internationalization và localization trong Java – Quốc tế hoá số (Number)
Cài đặt ví dụ
package internationalization;
import static internationalization.I18NTime.printTime;
import java.text.NumberFormat;
import java.util.Locale;
import java.util.Scanner;
/**
*
* @author giasutinhoc.vn
*/
public class I18NNumber {
private static void printNumber(Locale locale) {
double n = 10000.12345;
NumberFormat formatter = NumberFormat.getNumberInstance(locale);
String number = formatter.format(n);
System.out.println(number + " for the locale " + locale);
}
public static void main(String[] args) {
int region;
Scanner s = new Scanner(System.in);
do {
System.out.println("1. England");
System.out.println("2. Vietnam");
System.out.println("3. Exit program");
System.out.print("Please choose your region: ");
region = s.nextInt();
switch (region) {
case 1:
printNumber(Locale.ENGLISH);
break;
case 2:
printNumber(new Locale("vi", "VN"));
break;
}
} while (region != 3);
}
}
Kết quả khi chạy chương trình
Internationalization và localization trong Java – Quốc tế hoá tiền tệ (Currency)
package internationalization;
import java.text.NumberFormat;
import java.util.Locale;
import java.util.Scanner;
/**
*
* @author giasutinhoc.vn
*/
public class I18NCurrency {
private static void printCurrency(Locale locale) {
float n = 10500.3245F;
NumberFormat formatter = NumberFormat.getCurrencyInstance(locale);
String currency = formatter.format(n);
System.out.println(currency + " for the locale " + locale);
}
public static void main(String[] args) {
int region;
Scanner s = new Scanner(System.in);
do {
System.out.println("1. Japan");
System.out.println("2. Vietnam");
System.out.println("3. Exit program");
System.out.print("Please choose your region: ");
region = s.nextInt();
switch (region) {
case 1:
printCurrency(Locale.JAPAN);
break;
case 2:
printCurrency(new Locale("vi", "VN"));
break;
}
} while (region != 3);
}
}
Kết quả khi chạy chương trình
Tổng kết Internationalization và localization trong Java
Chưa kịp viết Django là gì thì độp ngay phát chị Google đã cho biết “Django: The web framework for perfectionists with deadlines”. Theo như cái tiêu đề giật tít hót hòn họt này thì Dỉ ản gô là web framework dành cho những người cầu toàn với deadlines.
À thế chưa gì là đã khoe, nhìn ngay ra cái ưu điểm đầu tiên của Django là development nhanh chóng, anh em nào chạy deadline sấp mặt có thể xem như một vị cứu tinh.
Rồi buồn cười cái nữa là search Django meme lại ra ông thần Leonardo DiCaprio vì có dính chút gì đó với tên ổng. Ôi cái framework này đích thị là thứ anh em mình cần tìm hiểu rồi.
Đùa tí cho vui để anh em có tinh thần khí thế tìm hiểu. Bắt đầu với Django ngay thôi nào!
1. Django là gì?
Luôn luôn là khái niệm, ngắn gọn mà súc tích. Cô đọng mà không cô đơn
Django is a high-level Python web framework that encourages rapid development and clean, pragmatic design. Built by experienced developers, it takes care of much of the hassle of web development, so you can focus on writing your app without needing to reinvent the wheel. It’s free and open source.
Django là web framework base trên ngôn ngữ lập trình bậc cao Python, khuyến khích sự phát triển nhanh chóng, gọn gàng và thiết kế thực dụng. Được phát triển bởi những lập trình viên có kinh nghiệm, nó xử lý nhiều rắc rối trong quá trình phát triển web, vì vậy bạn có thể tập trung viết app của mình mà không cần tập trung vào phát triển bánh xe. Nó miễn phí và mã nguồn mở.
Rồi, có hai ý quan trọng, thứ nhất là Django là web framework và nó chú trọng vào việc phát triển nhanh web. Cái thứ hai là nó lo hết những thứ phụ trợ xung quanh, anh em chỉ cần tập trung vào viết code. Bánh xe hình tròn phát minh có từ hàng ngàn năm rồi, anh em không cần lo nghĩ nữa.
Má dùng từ đúng kiểu châm biếm. Nhưng thôi đang bận tìm hiểu bỏ qua, chứ gặp ông mà viết bài này chắc tẩn cho trận.
Nhìn thôi là đã thấy xanh, không biết là xanh hy vọng hay là xanh cỏ
Rồi, đọc thôi là đã thấy nhanh rồi, nhưng cụ thể là nhanh như nào?
Anh em nếu đã có kinh nghiệm hoặc có chút ít tìm hiểu về web framework chắc sẽ có ít thông tin về MVC, MVM,… Với Django, web framework này triển khai dựa trên mô hình MVT design pattern.
Anh em nào nếu chưa biết về mô hình này có thể tham khảo ở đây nha.
Với mô hình này
M được hiểu là Model, là dữ liệu bạn muốn trình bày, thường là dữ liệu từ hệ cơ sở dữ liệu.
V ở đây được hiểu là View, là nơi xử lý các request và trả về các template kèm với nội dung (dựa trên yêu cầu của enduser).
Cuối cùng là T, được hiểu là Template. Template là tập các file html chứa bố cục trang web ta muốn xây dựng. Không chỉ đơn thuần data, tất nhiên chưa cả logic về quy cách hiển thị dữ liệu.
Cần phải nói lại để anh em clear là nhanh ở đây nhanh trong quá trình development web nha. Chứ không phải nhanh cái khác đâu ha.
Đầu tiên phải nói tới Django luôn tuân thủ 2 nguyên tắc DRY và KISS. Dành cho anh em nào chưa biết thì DRY là (Don’t repeat yourself, nghĩa là cái gì đã có đã làm rồi thì đừng cố gắng làm lại cho mất nhiều thời gian).
KISS thì không phải hôn mà là Keep it short and simple), giữ cho nó ngắn gọn và đơn giản. Càng ngắn gọn và đơn giản càng tốt.
Chính vì focus vào phát triển và dựng sẵn những thứ đã có. Bản thân Django đã hỗ trợ rất nhiều những thứ anh em cần làm trong quá trình phát triển web. Tất cả đã có, chỉ cần sử dụng.
Ngoài ra nếu những thứ này chưa có thì anh em có thể tìm kiếm hơn 4000 packages khác đã có, tuỳ cơ sử dụng. Từ testing, debugging tới profilling.
Ngoài ra nếu muốn deploy hoặc tích hợp deploy ở đâu đó, Django cũng sẽ hỗ trợ anh em hết sức nhiệt tình. Kiểu một nút lên là lên.
4. Django có an toàn và bảo mật không?
Hỏi này là hợp lý. Cái gì nhanh cũng sợ là ẩu, đi nhanh còn sợ ẩu nữa huống hồ là Django.
Bản thân Django đã hỗ trợ phòng tránh các lỗ hổng bảo mật thường gặp trong quá trình phát triển web. Một số anh em có thể kể tới như sau:
Cross site scripting (XSS) protection (Tấn công này cho phép đem các file từ phía client vào thực thi trên browser của người khác)
Cross site request forgery (CSRF) protection (lấy thông tin hoặc chứng chỉ xác thực từ người khác mà người đó không biết hoặc không đồng ý)
SQL injection protection (cái này quá phổ biến ha, anh em có thể tìm hiểu qua tại đây)
Clickjacking protection
SSL/HTTPS
Host header validation
Referrer policy
Còn nhiều nhiều nhiều thứ khác nữa anh em có thể ghé trang chủ để biết Django đã hỗ trợ và liên tục cập nhật để tránh các lỗ hổng trên web như thế nào nha.
Cố gắng nhanh nhưng mà không ẩu. Vừa nhanh vừa an toàn và đảm bảo security
À bản thân Django cũng có những bản LTS (Long-term support), các bản này support người dùng dài dài. Tăng uy tín liền.
Release roadmap kèm với thời gian support. Thời gian kéo dài nếu là LTS
5. Django có khả năng mở rộng không?
Đúng thiệt lắm chuyện. Vừa nhanh, vừa an toàn vừa bảo mật mà còn đòi hỏi phải có khả năng mở rộng tốt. Thiệt là đòi hỏi hết sức.
Tuy nhiên Django lại chiều anh em được vụ Scale này. Do phát triển web, biết đâu chừng business của anh em vụt lên trông thấy. Chính lúc đó ta cần khả năng scale nhanh chóng
Django hiện tại hỗ trợ cả Horizontal Scaling và Vertical Scaling (scaling cả theo chiều ngang là chiều dọc). Cũng hỗ trợ cả database pooling trong trường hợp có nhiều kết nối tới hệ cơ sở dữ liệu.
Về scale thì nếu theo nhiều ngang (Horizontal), Django hỗ trợ Cache Backends (Memcache or Redis). Lưu dữ liệu ở các máy chủ khác nhau. Anh em cứ yên tâm khi lựa chọn Django để phát triển web mà yêu cầu scale nha.
Theo như thông tin từ bài viết này thì Django còn có thể giải quyết tới 45 nghìn request trong mỗi giây.
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Monstache là gì?
Monstache là một công cụ, phần mềm thực hiện đồng bộ dữ liệu từ MongoDB sang Elasticsearch.
Monstache khá giống với Transporter tuy nhiên nó thực hiện đồng bộ dữ liệu một cách realtime, tức là khi có bất kỳ thay đổi dữ liệu nào trên MongoDB (thêm/sửa/xóa) nó sẽ tự động cập nhật tới Elasticsearch.
Việc sử dụng Monstache được áp dụng khi bạn muốn kết hợp MongoDB với Elasticsearch. Ví dụ bạn dùng MongoDB để lưu dữ liệu nhưng khi thực hiện query thì query trên Elasticsearch vì Elasticsearch hỗ trợ search tốt hơn MongDB ở nhiều trường hợp khác nhau.
Cài đặt Monstache
Yêu cầu đã cài đặt MongoDB và Elasticsearch. Vì Monstache được viết bằng ngôn ngữ lập trình Golang nên cần phải cài Golang nữa nhé.
Ở ví dụ này mình sẽ cài đặt trên Ubuntu 16.04 (Các bạn có thể cài trên windows cũng được nhé)
Lưu ý: phải bật chức năng oplog trên MongoDB lên, vì oplog sẽ chứa tất cả thông tin về các thay đổi của MongoDB và monstache sẽ dựa trên sự thay đổi đó để đồng bộ dữ liệu sang Elasticsearch, để bật chức năng oplog ta có 2 cách như sau:
Download file trên và giải nén về, bạn sẽ thấy nó có cả 3 mục cho windows, linux và macOS
Mình sử dụng trên ubuntu nên sẽ vào folder linux-adm64, các bạn sẽ thấy file monstache (monstache là file binary nha) và file conf.properties dùng để cấu hình thông tin MongoDB và Elasticsearch, nếu chưa có file này thì bạn tự tạo mới nhé.
Thêm đường dẫn của thư mục chứa file monstache vào biến PATH
# connection settings# connect to MongoDB using the following URLmongo-url = "mongodb://someuser:password@localhost:40001"# connect to the Elasticsearch REST API at the following node URLselasticsearch-urls = ["https://es1:9200", "https://es2:9200"]# frequently required settings# if you don't want to listen for changes to all collections in MongoDB but only a few# e.g. only listen for inserts, updates, deletes, and drops from mydb.mycollection# this setting does not initiate a copy, it is a filter on the change listener onlynamespace-regex = '^mydb\.mycollection$'# additionally, if you need to seed an index from a collection and not just listen for changes from the oplog# you can copy entire collections from MongoDB to Elasticsearchdirect-read-namespaces = ["mydb.mycollection", "db.collection", "test.test"]# additional settings# compress requests to Elasticsearchgzip = true# generate indexing statisticsstats = true# index statistics into Elasticsearchindex-stats = true# use the following PEM file for connections to MongoDBmongo-pem-file = "/path/to/mongoCert.pem"# disable PEM validationmongo-validate-pem-file = false# use the following user name for Elasticsearch basic authelasticsearch-user = "someuser"# use the following password for Elasticsearch basic authelasticsearch-password = "somepassword"# use 4 go routines concurrently pushing documents to Elasticsearchelasticsearch-max-conns = 4# use the following PEM file to connections to Elasticsearchelasticsearch-pem-file = "/path/to/elasticCert.pem"# validate connections to Elasticsearchelastic-validate-pem-file = true# propogate dropped collections in MongoDB as index deletes in Elasticsearchdropped-collections = true# propogate dropped databases in MongoDB as index deletes in Elasticsearchdropped-databases = true# do not start processing at the beginning of the MongoDB oplog# if you set the replay to true you may see version conflict messages# in the log if you had synced previously. This just means that you are replaying old docs which are already# in Elasticsearch with a newer version. Elasticsearch is preventing the old docs from overwriting new ones.replay = false# resume processing from a timestamp saved in a previous runresume = true# do not validate that progress timestamps have been savedresume-write-unsafe = false# override the name under which resume state is savedresume-name = "default"# exclude documents whose namespace matches the following patternnamespace-exclude-regex = '^mydb\.ignorecollection$'# turn on indexing of GridFS file contentindex-files = true# turn on search result highlighting of GridFS contentfile-highlighting = true# index GridFS files inserted into the following collectionsfile-namespaces = ["users.fs.files"]# print detailed information including request tracesverbose = true# enable clustering modecluster-name = 'apollo'# do not exit after full-sync, rather continue tailing the oplogexit-after-direct-reads = false
Trong đó:
mongo-url là url tới database MongoDB
elasticsearch-urls là url tới các server elasticsearch mà bạn muốn đồng bộ với MongoDB
direct-read-namespaces là các database, collection của MongoDB sẽ được đồng bộ hóa
Ngoài ra ở dưới còn các thông tin khác như username/password của Elasticsearch…
Demo
Ở đây mình sử dụng luôn MongoDB và Elasticsearch trên local với url lần lượt là:
Kết quả trên Elasticsearch sẽ có thêm bản ghi mà bạn vừa thêm ở MongoDB, tương tự bạn có thể thêm bản ghi mới, xóa hoặc chỉnh sửa bản ghi trên MongoDB nó cũng sẽ đều cập nhật luôn sang Elasticsearch.
Bài viết được sự cho phép của tác giả Lê Nhật Thanh
Bài viết này mình đề cập tới nguyên lý Dependency Inversion hay đảo ngược sự phụ thuộc khi dịch ra tiếng Việt.
Anh em tìm đọc được bài viết này, chứng tỏ anh em đang có nhu cầu tìm hiểu về các nguyên lý SOLID đúng không? Thôi thì chúng ta vào bài luôn và mình giới thiệu về SOLID một chút.
À bài viết này hơi dài một chút, hơi nhiều code một chút. Because dài và nhiều code thì mình mới có thể truyền tải hết được các kiến thức về nguyên lý Dependency Inversion cho anh em được. Chúc mừng anh em trước nếu anh em đọc và lĩnh hội được kiến thức trong bài viết này.
Sơ lược các nguyên lý Solid
SOLID Principles được giới thiệu lần đầu năm 2000 bởi Robert C. Martin (Uncle Bob), và có 5 nguyên lý sau:
Single Responsibility (S)
Open / close principle (O)
Liskov substitution principle (L)
Interface Segregation (I)
Dependency Inversion (D)
Bài viết này mình sẽ trình bày chi tiết nhất về nguyên lý cuối cùng – Dependency Inversion Principle (DIP). Sẽ có anh em thắc mắc là không biết gì mấy nguyên lý đầu thì thì quất luôn nguyên lý cuối sẽ hiểu không? Anh em đừng lo, sẽ hiểu bình thường, mình lo tất =]].
Giải thích nguyên lý Dependency Inversion Principle
Nguyên văn của DIP như sau:
High-level modules should not depend on low-level modules. Both should depend on abstractions.
Abstractions should not depend on details. Details should depend on abstractions.
Dịch ra tiếng Việt:
Module cấp cao (high-level module) không nên phụ thuộc vào module cấp thấp (low-level module). Mà cả 2 nên phụ thuộc vào abstractions.
Abstraction không nên phụ thuộc vào chi tiết (implementation). Mà chi tiết (implementation) nên phụ thuộc vào abstraction.
Đọc thôi là thấy khó hiểu ** rồi phải không anh em =]]? Đừng lo! Mình sẽ giải thích cho anh em hiểu. Chứ ban đầu khi đọc về nguyên lý này, mình cũng như anh em, thua và muốn chửi thề!
Xem ví dụ bên dưới – Ví dụ về thiết kế một chương trình nghe nhạc siêu siêu đơn giản. Đây là một cách viết code rất phổ biến. Có thể anh em sẽ thấy quen, hoặc chính anh em đã từng viết như thế cũng nên.
classMusicPlayer{private$file;publicfunction__construct(){$this->file=newMP3File();// Vi phạm DIP}publicfunctionplay(){return$this->file->play();}}classMP3File{publicfunctionplay(){return"Play MP3 file!";}}
Hoặc một cách viết khác như bên dưới: Inject dependency thông qua constructor của class. Cách viết này cho phép chúng ta viết Unit test dễ hơn nhưng vẫn vi phạm DIP.
Lưu ý: Có một số từ ngữ như dependency, unit test, inject, high/low-level module, … Anh em nếu mới tiếp xúc lần đầu thì sẽ không hiểu. Anh em đừng lo lắng, mình sẽ cho anh em “tiếp xúc” nhiều lần hơn trong xuyên suốt bài viết để anh em hiểu.
publicfunction__construct(MP3File$file)// Vi phạm DIP{$this->file=$file;}
Code như thế này thì …
Giải thích một chút về thiết kế chương trình ở trên, chúng ta bắt đầu phát triển một phần mềm nhỏ để có thể chơi nhạc. Chúng ta có class MusicPlayer đang sử dụng class MP3File (Hay còn gọi là phụ thuộc – dependency).
Như vậy, với đoạn code trên chúng ta có thể giải thích một số khái niệm dưới đây:
High (low)-level module: Class A nào đó sử dụng class B thì class A chính là high-level module. Và class B chính là low-level module. Như vậy ở ví dụ trên thì MusicPlayer là high-level module, còn MP3File chính là low-level module.
Dependency: MP3File chính là 1 dependency (hay còn gọi là sự phụ thuộc) của high-level module MusicPlayer
Hard dependency: Bạn có thể nhìn dòng code này $this->file = new MP3File(); ở trên. Và đây được gọi là một hard dependency. Lưu ý thêm, khi trong code bạn có hard dependency thì bạn sẽ khó viết Unit test.
Đọc tới đây ổn đúng không anh em? Chúng ta cùng đi tiếp nào.
Class MusicPlayer bị phụ thuộc vào class MP3File (dependency). Khi chúng ta thay đổi class MP3File thì class MusicPlayer cũng bị thay đổi theo. Điều này vi phạm Open / close principle (anh em có thể search google 1p29s để đọc sơ sơ và nắm được nguyên lý này một xíu xíu nhá). Và giả sử trong tương lai hệ thống của chúng ta có rất nhiều class như MusicPlayer (đang phụ thuộc vào MP3File). Mỗi khi chúng ta thay đổi class MP3File, thì phải thay đổi tất cả những nơi sử dụng class này. Dẫn đến khó bảo trì và dễ gây ra bug trong quá trình chỉnh sửa, phát triển hay bảo trì.
Mình lấy luôn một ví dụ cụ thể về sự thay đổi được đề cập ở trên cho anh em dễ nắm. Đọc đoạn code dưới sau đó đọc phần comment trong code để nắm nhá.
classMusicPlayer{private$file;publicfunction__construct(){// Thì phải đổi code ở đây để đối ứng // cho việc thay đổi classname bên dưới$this->file=newMP3MusicFile();}publicfunctionplay(){return$this->file->play();}}classMP3MusicFile// Thay đổi classname ở đây.{publicfunctionplay(){return"Play MP3 file!";}}
Hiện tại thiết kế trên chỉ chạy cho file MP3, và khi hệ thống của anh em chỉ support cho duy nhất file MP3 thì đây là một thiết kế ổn. Nhưng trên thực tế, chẳng có cái máy chơi nhạc quái nào lại chỉ support cho duy nhất file MP3 cả, còn nhiều file khác như WAV, AAC, M4A, e.g. nữa chứ. Đây là vấn đề khó mở rộng cho hệ thống. Code theo phong cách này mà mở rộng cho nhiều file khác là anh em… há mỏ ngay =]].
Chính vì vậy thiết kế trên chính là Bad design. Một thiết kế như sh**.
Khó viết Unit Test
Sơ lược một chút nhé!
Ở thiết kế trên khi chúng ta sử dụng new MP3MusicFile(), đây là một hard dependency nên sẽ cực kì khó viết unit test. Làm sao biết là khó viết, thì chúng ta sẽ đi sơ lượt qua Unit test một chút. Mình sẽ giải thích cho cả những anh em chưa từng viết unit test vẫn có thể hiểu được. Nên sẽ hơi dài, anh em nào rành unit test rồi (và hiểu tại sao khó viết unit test) thì có thể bỏ qua phần này.
Tại sao chúng ta lại đề cập tới Unit test trong bài này? trên thực tế, khi anh em và đội ngũ làm ra một sản phẩm phần mềm, thì chúng ta thường gọi nó là production code (hay code sản phẩm). Bên cạnh production code, trong một số project “được đầu tư kĩ lưỡng hơn“ thì sẽ có thêm testing code (thông thường là unit test, và đôi khi có cả automation test nhưng trong bài viết này chúng ta chỉ đề cập tới unit test). Mục đích của unit test nói nôm na là kiểm tra tính đúng đắn theo từng đơn vị nhỏ như function, method, class, modules. Khi sản phẩm có unit test, chắc chắn rằng anh em sẽ hạn chế được bug một cách tối đa trong quá trình phát triển sản phẩm cũng như mở rộng, bảo trì, refactor.
Và một điều chắc chắn khi anh em viết code theo nguyên lý Dependency Inversion thì việc viết Unit test sẽ vô cùng đơn giản!
Ví dụ nè
Ví dụ chúng ta có một method downloadMusicFile và với những kiến thức đã đọc tới bây giờ thì trong method này có một hard dependency là MusicFileRepository.
// Đây là production codepublicfunctiondownloadMusicFileById(int$fileId){$musicFileRepository=newMusicFileRepository();$musicFileRepository->download($fileId);}
Chúng ta sẽ thử viết Unit test như bên dưới.
Về ý tưởng để test hàm downloadMusicFileById thì đơn giản làm sao khi hàm này được gọi. Chúng ta phải kiểm tra xem method download có được gọi đúng với $fileId không là đủ rồi. Chúng ta không cần quan tâm method download có chạy đúng hay không. Vì muốn biết nó chạy đúng hay không thì chúng ta sẽ viết unit test riêng cho hàm download.
Và rõ ràng unit test (viết bằng PHPUnit) sẽ không thể chạy được (failed case) bởi vì chúng ta không thể mock hard dependency MusicFileRepository.
À, mock là một kĩ thuật được xài trong unit test rất nhiều. Anh em có 1p29s để search google và quay lại bài viết vì mình không thể giải thích quá nhiều sẽ dẫn tới một bài viết quá dài.
// Đây là unit test cho production code ở trên// Tạo một mock object cho MusicFileRepository class// chỉ mock cho method downloadMusicFileById()$stub=$this->getMockBuilder(MusicFileRepository::class)->setMethods(['downloadMusicFileById'])->getMock();// Expect method download được call 1 lần$stub->expects($this->once())->method('downloadMusicFileById');
Nếu dùng kĩ thuật inject dependency vào constructor hoặc method thì có thể dễ dàng mock MusicFileRepository với kĩ thuật như trên.
Bên dưới là 2 cách để có thể viết unit test đơn giản hơn: Constructor injection và method injection.
Túm cái váy lại, nếu trong code xuất hiện Hard Dependency thì việc viết Unit test sẽ trở nên khó khăn hơn. Chúng ta đề cập tới chữ khó ở đây để nói lên rằng, trong một số trường hợp vẫn có thể viết Unit test được. Đó chính là kĩ thuật Black Box. Nói đơn giản là chúng ta không cần quan tâm tới cấu trúc bên trong function/method viết gì. Mà chỉ cần quan tâm tới input, output thì khi đó có thể áp dụng kĩ thuật Black Box được.
Anh em có thể để lại comment nếu muốn một bài viết chuyên sâu về Unit Test. Hoặc có thể tìm kiếm thêm thông tin trên Internet về các kĩ thuật Unit test
Dependency Inversion Principle Design
Vậy câu hỏi đặt ra là làm thế nào để chương trình của chúng ta vừa dễ phát triển, vừa dễ dàng bảo trì và mở rộng. Bây giờ hãy xem chương trình ở trên được thiết kế lại như sau:
classMusicPlayer{private$file;// Chổ này bây giờ là phụ thuộc vào interfacepublicfunction__construct(PlayerFile$file){$this->file=$file;}publicfunctionplay(){return$this->file->play();}}// Xuất hiện interface ở đâyinterfacePlayerFile{publicfunctionplay();}classMP3FileimplementsPlayerFile{publicfunctionplay(){return"Play MP3 file!";}}classFLACFileimplementsPlayerFile{publicfunctionplay(){return"Play FLAC file!";}}
Chúng ta đã tạo ra một interface PlayerFile để phá vỡ sự phụ thuộc. Bây giờ thiết kế mới sẽ là
Hay nói cách khác, chúng ta đã tuân thủ nguyên tắc thứ nhất của DIP: High-level modules should not depend on low-level modules. Both should depend on abstractions.
Và 2 class MP3File và FLACFile đang phụ thuộc vào interface PlayerFile tuân thủ nguyên tắc thứ 2 của DIP: Abstractions should not depend on details. Details should depend on abstractions.
Bây giờ với thiết kế mới, MusicPlayer hoàn toàn chỉ phụ thuộc vào interface. Nên dù có thay đổi MP3, FLAC, hay thêm, mở rộng bất cứ loại file nhạc mới nào thì class MusicPlayer vẫn sẽ không bị thay đổi. Hay nói cách khác là đã tuân thủ nguyên lý Open / close principle. Điều này sẽ làm cho các developer khác tiếp cận tốt hơn, code clean hơn, dễ bảo trì và mở rộng hơn. Xong!
Đọc tới đây nếu anh em còn chưa hiểu thì có thể đọc lại vài lần nữa. Còn nếu vẫn không hiểu thì anh em để lại comment cho mình bên dưới. Mình sẽ giải đáp thắc mắc cho anh em. Chúc mừng và cám ơn anh em đã đọc tới
Lời chia sẻ “thật lòng”
Chúng ta là lập trình viên cũng có thể được xem là những kiến trúc sư trong thế giới lập trình. Việc thiết kế ra những chương trình/phần mềm ổn định, dễ bảo trì và mở rộng là điều cực kì quan trọng đối với một lập trình viên. Không phải ai mới bước vào thế giới lập trình cũng có thể ngày một ngày hai trở nên giỏi giang. Nhưng có một điều chắc chắn rằng, nếu anh em rèn luyện càng nhiều, thì khả năng sẽ càng tăng. Sẽ ngày càng giỏi hơn và dần trở thành một lập trình viên thực thụ.
Lập trình game với java dành cho người mới bắt đầu sẽ trình bày những kiến thức cũng như những xử lý đặc thù khi lập trình game như xử lý va chạm, xử lý chuyển động, xử lý âm thanh, xử lý vòng lặp game,…
Các bạn lưu ý, để học tốt bài này người học phải có kiến thức về lập trình với ngôn ngữ Java. Trong bài học này, người học sẽ dùng ngôn ngữ Java để thiết kế giao diện game, cài đặt xử lý game. Chúng ta hãy bắt đầu bài học bằng một game nhỏ (mini game) với tựa là Mini Tennis.
Game này có luật chơi rất đơn giản. Quả bóng di chuyển từ trên xuống dưới. Nếu đụng biên dưới, trò chơi kết thúc. Người chơi sẽ sử dụng 2 phím mũi tên để di chuyển thanh ngang qua trái/phải sao cho quả bóng không được đụng biên dưới.
Để vẽ một cái gì đó, trước tiên chúng ta cần một bề mặt để vẽ. Đó chính là JPanel. Khi vẽ một đối tượng nào đó, chúng ta phải xác định được toạ độ (x, y) và kích thước của đối tượng đó.
Phần code dùng để vẽ các hình oval và hình chữ nhật
public class Game extends JPanel { public void paint(Graphics g) { g.setColor(Color.RED);
// Hình oval có tô màu tại vị trí 0,0
g.fillOval(0, 0, 30, 30);
// Hình oval không tô màu tại vị trí 0, 50 g.drawOval(0, 50, 30, 30);
// Hình chữ nhật có tô màu tại vị trí 50, 0 g.fillRect(50, 0, 30, 30);
// Hình chữ nhật không tô màu tại vị trí 50, 50 g.drawRect(50, 50, 30, 30);
// Hình oval không tô mau tại vị trí 0, 100
g.drawOval(0, 100, 30, 30); } }
Lập trình game với java – Chuyển động và vòng lặp game (game loop)
Mỗi lần vẽ một đối tượng nào đó, chúng ta phải biết vị trí (x,y) và để di chuyển đối tượng, chúng ta sẽ thay đổi vị trí này theo quy tắc:
Thay đổi giá trị của x sẽ làm cho đối tượng chuyển động theo chiều ngang
Thay đổi giá trị của y sẽ làm cho đối tượng chuyển động theo chiều dọc
private void moveBall() {
// Tăng toạ độ x lên 1
x = x + 1;
// Tăng toạ độ y lên 1
y = y + 1;
}
Phần code dùng để xử lý vòng lặp game (game loop)
while (true) {
// Xử lý chuyển động cho quả bóng
moveBall();
// Vẽ lại quả bóng ở vị trí mới
repaint();
// Delay
Thread.sleep(20);}
Lập trình game với java – Nhân vật trong game (Sprite)
Giống như các lĩnh vực nghệ thuật khác, trò chơi có một dàn các nhân vật và mỗi nhân vật có một vai trò cụ thể. Mỗi nhân vật có các đặc điểm như vị trí (x,y), tốc độ và hướng di chuyển.
Tốc độ và hướng di chuyển của nhân vật được hiểu như sau
Gọi xa, ya đại diện cho tốc độ quả bóng đang di chuyển.
Nếu xa = 1 thì quả bóng di chuyển về bên phải và xa = -1 thì bóng di chuyển về bên trái.
Nếu ya = 1 thì bóng di chuyển xuống và ya = -1 thì bóng di chuyển lên trên.
Mỗi lần di chuyển, tọa độ được cập nhật tăng/giảm một hoặc nhiều hơn một đơn vị tùy thuộc vào hướng di chuyển.
Phần code dùng để xử lý thay đổi hướng di chuyển và tốc độ
private void moveBall() { if (x + xa < 0) xa = 1; if (x + xa > getWidth() - 30) xa = -1; if (y + ya < 0) ya = 1; if (y + ya > getHeight() - 30) ya = -1; //Cập nhật tọa độ x = x + xa; y = y + ya; }
Lập trình game với java – Xử lý sự kiện trong game
Xử lý sự kiện chính là xử lý sự tương tác giữa người chơi với game. Sự tương tác đó có thể là chạm, nghiêng màn hình (game cho mobile); hoặc khi người chơi click chuột, nhấn một phím trên bàn phím (game cho pc),…
Đối với Mini Tennis, khi người chơi nhấn phím mũi tên left thì cây vợt sẽ chuyển động sang trái, khi người chơi nhấn phím mũi tên right thì cây vợt sẽ chuyển động sang phải. Đây chính là sự kiện bàn phím.
Bên dưới là đoạn code mẫu
KeyListener kl = new KeyListener() {
// Xử lý khi một phím được nhả
public void keyReleased(KeyEvent arg0) { // Viết xử lý của bạn tại đây }
// Xử lý khi một phím được nhấn
public void keyPressed(KeyEvent arg0) { // Viết xử lý của bạn tại đây }};addKeyListener(kl);setFocusable(true);
Lập trình game với java – Xử lý va chạm trong game (collision)
Một trong nhiều phương pháp được xử dụng đó là kiểm tra biên (bound). Đầu tiên người lập trình phải xác định đâu là va chạm trong game. Đối với game Mini Tennis, người lập trình phải xử lý va chạm giữa quả bóng và cây vợt.
Sau khi xác định được va chạm, người lập trình sẽ tạo biên cho những đối tượng này. Tuỳ theo hình dáng của đối tượng mà chúng ta lựa chọn biên cho phù hợp. Hãy xem hình bên dưới.
Phần code mẫu
Tạo biên cho quả bóng
public Rectangle getBallBound() {
return new Rectangle(x, y, DIAMETER, DIAMETER);
}
Tạo biên cho cây vợt
public Rectangle getBattledoreBound() {
return new Rectangle(x, y, WIDTH, HEIGHT);
}
Kiểm tra va chạm xử dụng phương thức intersects(). Nếu biên của quả bóng và cây vợt giao nhau thì đông nghĩa quả bóng chạm cây vợt. Phương thức này sẽ trả về true. Phương thức này trả về false cho trường hợp ngược lại.
Go hay Golang là ngôn ngữ lập trình do Google thiết kế và phát triển từ năm 2009, ra đời với mục đích khai thác tối đa nền tảng đa lõi của bộ vi xử lý và hoạt động đa nhiệm tốt hơn. Với sức mạnh của Golang, hiện nay có khá nhiều dự án đang lựa chọn ngôn ngữ lập trình này để phát triển, và vì thế nhu cầu tuyển dụng Golang ngày càng lớn hơn. Trong bài viết này chúng ta cùng nhau tìm hiểu top 10 câu hỏi phỏng vấn Golang Developer để cùng có sự chuẩn bị tốt nhất trước cơ hội việc làm này nhé.
Câu 1: Bạn có thể nói gì về ngôn ngữ lập trình Golang
Go hay Golang là một ngôn ngữ lập trình mã nguồn mở giúp xây dựng phần mềm một cách dễ dàng, tin cậy và hiệu quả do các kỹ sư hàng đầu của Google phát triển. Golang được khởi nguồn từ năm 2007 và được chính thức công bố dưới dạng mã nguồn mở năm 2009. Phiên bản ổn định 1.0 được Google giới thiệu vào tháng 3/2012. Năm 2018, Google có thông báo về Golang 2 với sự chung tay phát triển của cộng đồng, mặc dù vậy đến hiện nay thì Golang 2 vẫn chưa có kế hoạch về ngày ra mắt.
Sứ mệnh của Golang là giúp tăng năng suất phần mềm, đặc biệt là ở lĩnh vực multicore processing (xử lý đa nhân), network (mạng) và những dự án có source code rất lớn.
Câu 2: Nêu những đặc tính của Golang
Golang là một ngôn ngữ kiểu tĩnh (static typed) tức là mọi thứ trong nó đều phải được khai báo kiểu. Ban đầu ngôn ngữ này sử dụng trình biên dịch thông qua ngôn ngữ C, từ phiên bản 1.5 thì tác giả đã tự viết luôn một trình compiler dành riêng cho ngôn ngữ. Ưu điểm của trình compiler này là thời gian build rất nhanh so với các trình biên dịch của các ngôn ngữ kiểu tĩnh khác.
Golang hỗ trợ kiến trúc 64 bits, nó cũng có một trình thu dọn rác tự động (Garbage Collector), ngoài ra nó còn hỗ trợ cả Web Assembly. Golang hỗ trợ lập trình đồng thời (concurrent) với từ khóa go đặt ngay trước nơi gọi hàm, kỹ thuật này gọi là Goroutine.
Với những đặc tính trên, Go là một ngôn ngữ phù hợp với việc phát triển các dự án về system như Network, Proxy, Distributed Computing, Cloud Native,…
Kiểu dữ liệu dẫn xuất (derived types) xây dựng từ những kiểu dữ liệu cơ bản và tích hợp sẵn trong Golang bao gồm Pointer (con trỏ), Array (mảng), Structure, Union, Function (hàm), Slice, Interface, Map và Channel.
Golang không phải là một ngôn ngữ lập trình hướng đối tượng nên nó không hỗ trợ các lớp (class), mặc dù vậy chúng ta có thể sử dụng struct trong Golang nhằm thay thế cho class. Để có được hành vi tương tự như các lớp (class) trong các ngôn ngữ lập trình khác, Golang hỗ trợ các methods (phương thức) – nó là một hàm(function) được khai báo cho riêng một kiểu dữ liệu đặc biệt được gọi là receiver. Cú pháp để tạo một Method như sau: “func (t Type) methodName(parameter list)”.
Điểm khác cơ bản của methods so với function là việc khai báo receiver, từ đó cho phép khai báo trùng tên và chỉ cần khác kiểu dữ liệu nhận (receiver).
Câu 5: Interface trong Golang là gì?
Interface trong OOP giúp chúng ta xác định các hành vi sẽ có của một đối tượng (chưa cần khai báo nội dung bên trong). Interface trong Golang cũng là tập hợp những khai báo phương thức mà cho phép chúng ta có thể định nghĩa hoạt động cho nó được. Khi một kiểu dữ liệu định nghĩa tất cả các phương thức trong một interface thì nó được gọi là implement của interface đó. Hay nói cách khác thì trong Golang, Interface được implement một cách ngầm định (implicitly) mà không cần khai báo tường minh bằng từ khóa nào.
Một tính năng thú vị khác của interface là dùng để khai báo kiểu dữ liệu any (đại diện cho bất kỳ kiểu dữ liệu nào). Cú pháp interface{} gọi là Empty Interface giúp bạn không cần xác định rõ kiểu dữ liệu của biến, rất hay được sử dụng khi làm value cho kiểu dữ liệu map trong Golang.
Câu 6: Phân biệt Array, Slice và Map trong Golang
Array hay mảng là một tập hợp các phần tử có cùng kiểu dữ liệu nằm liên tiếp nhau, hay nói cách khác thì Array là một tập hợp có thứ tự, vì thế chúng ta có thể truy cập Array bằng chỉ số (index) của phần tử đó trong mảng.
Slice về bản chất là các tham chiếu đến mảng hiện có, nó mô tả một phần hoặc toàn bộ Array, vì thế nó có kích thước động (thay đổi được). Thông thường Slice sẽ được tạo từ 1 Array bằng cách lấy từ vị trí phần tử bắt đầu và kết thúc trên Array đó.
Map cũng là một kiểu dữ liệu tập hợp, tuy nhiên các phần tử trong nó không có thứ tự, tức là chúng ta không thể truy xuất đến phần tử trong Map bằng chỉ số như Slice hay Array. Map sẽ chứa các phần tử dạng key-value, từ đó việc truy xuất sẽ thực hiện qua các key.
Câu 7: Giải thích về Concurrency trong Golang
Concurrency là tính năng xử lý song song nhiều tác vụ cùng một lúc, giúp tận dụng năng lực xử lý của CPU. Trong Golang, một luồng được quản lý bởi Go runtime gọi là Goroutine, cú pháp khai báo của Goroutine đơn giản chỉ cần thêm từ khóa “go” vào trước mỗi hàm cần gọi.
Các Goroutine có khả năng chạy song song cùng lúc, ngoài ra chúng có thể trao đổi dữ liệu với nhau trong qua Channel (kênh). Việc sử dụng Channel cho phép đồng bộ hóa dữ liệu giữa các Goroutine; khi một Goroutine truyền dữ liệu vào Channel thì nó sẽ dừng lại để đợi một Goroutine khác lấy dữ liệu ra thì mới tiếp tục thực hiện tiếp.
Câu 8: Phương pháp xử lý lỗi trong Golang
Xử lý lỗi (error handling) trong Golang không giống với xử lý try/catch như các ngôn ngữ khác; lỗi trong Go sẽ được trả về như 1 giá trị của hàm nếu có điều gì không mong đợi (errors hoặc exceptions) xảy ra.
Kiểu error trong Go có một phương thức Error() trả về thông báo lỗi dưới dạng string. Go cũng cung cấp cho chúng ta một package error tích hợp sẵn và public với hàm gọi New. Để đưa ra những Exception thì Go cung cấp cho chúng ta cơ chế Panic. Khi một hàm gặp Panic, nó lập tức dừng xử lý, chấm dứt chương trình và giải phóng stack gọi; thông báo lỗi sẽ được trả về khi chương trình kết thúc.
Câu 9: Kể tên một số thư viện, framework phổ biến của Golang
Beego: web framework với các module chứa các tính năng phổ biến cho ứng dụng web, nó cũng bao gồm 1 ORM (object relationship map) để truy cập dữ liệu và thư viện cho các operation với những đối tượng HTTP
Iris: cũng là một web framework, ưu điểm của Iris là khả năng xây dựng các ứng dụng web và API hiệu suất cao
Viper: thư viện giúp viết và đọc các nội dung liên quan tới thông số cấu hình trong Golang, hỗ trợ các định dạng như TOML, JSON, YAML,…
Cobra: một thư viện giúp bạn xây dựng một CLI (command line interface: giao diện dòng lệnh) trong Golang
Colly: công cụ thu thập dữ liệu tùy chỉnh từ các trang web của Golang
Câu 10: Kể tên những dự án nổi tiếng viết bằng Go
Docker: nền tảng cung cấp cách dựng, kiểm thử và triển khai ứng dụng nhanh chóng thông qua các container
Kubernetes: một hệ thống mã nguồn mở giúp việc triển khai, nhân rộng dễ dàng và tự động thông qua việc sử dụng các container Docker
NATS: một Message System, là thành phần quan trọng trong các hệ thống pub/sub, event-driven
Consul: một service dành cho việc thiết lập mạng (network) trong microservices một cách dễ dàng
Kết bài
Như vậy chúng ta đã đi qua được top 10 câu hỏi phỏng vấn thường gặp nhất cho vị trí Golang Developer. Hy vọng bài viết này mang lại thêm sự tự tin cho bạn để chinh phục được nhà tuyển dụng. Hẹn gặp lại các bạn trong bài viết tiếp theo của mình.
Bài viết được sự cho phép của tác giả Trần Hữu Cương
1. Immutable là gì? Sự khác nhau giữa Immutable với mutable.
Immutable hiểu nôm na là không thể thay đổi còn mutable là có thể thay đổi. hai khái niệm Immutable và mutable thường được dùng class, object (Immutable đôi khi còn dùng với Collection nhưng mình sẽ không để cập ở bài này).
Ví dụ: Trong Java String là Immutable còn StringBuffer và StringBuilder là mutable.
1 Class/Đối tượng được coi là immutable nếu các thuộc tính của nó không bao giờ bị thay đổi và chỉ có thể thiết lập lúc khởi tạo.
// Khởi tạo str1 = "first"String str1 = newString("first");// Khởi tạo str2 tham chiếu tới str1String str2 = str1;// String là immutable, bất kì thao tác nào trên String đều tạo ra 1 đối tượng mới// str1.concat("-second") sẽ trả về 1 đối tượng String mới có giá trị là "first-second"str1 = str1.concat("-second");System.out.println("str1: "+str1);System.out.println("str2: "+str2);
Kết quả
str1: first-secondstr2: first
Ví dụ Mutable với StringBuffer
// Khởi tạo str1 = "first"StringBuffer str1 = newStringBuffer("first");// Khởi tạo str2 tham chiếu tới str1StringBuffer str2 = str1;// StringBuffer là mutable, do đó khi append thì giá trị của nó sẽ thay đổi trên chính vùng nhớ ban dầustr1.append("-second");System.out.println("str1: "+str1);System.out.println("str2: "+str2);
Giống như ví dụ với String bên trên, ta thấy được sử dụng immutable sẽ tránh được sự thay đổi lẫn nhau khi đa tham chiếu (str1 và str2 cùng tham chiếu tới 1 vùng nhớ nhưng khi str1 thay đổi thì str2 sẽ không thay đổi)
Thread Safe: Khi sử dụng immutable object ta sẽ không cần phải lo tới việc nhiều thread cùng làm thay đổi giá trị của 1 object
Sử dụng các immutable object làm tham số của method sẽ không sợ nó bị thay đổi sau khi method kết thúc
Sử dụng immutable object để làm key trong HashMap hoặc đẩy vào HashTable mà không gặp vấn đề gì khi lấy ra.
3. Cách tạo 1 Class Immutable
Phải là final class (không thể thừa kế bởi class khác)
Các field phải là private final
Không có các method làm thay đổi trạng thái của các field (Ví dụ: chỉ có hàm get, không có các hàm set)
Nếu có field nào là Object thì field đó cũng phải là 1 immutable Object hoặc khi khởi tạo/lấy ra field đó ta phải clone ra 1 bản khác.
Linux là một hệ điều hành không xa lạ gì với các lập trình viên, nhất là các vị trí thường xuyên thao tác với hệ thống (System). Thành thạo Linux là một yêu cầu mà nhiều nhà tuyển dụng bắt buộc khi phỏng vấn lập trình viên, vì thế để chuẩn bị tốt cho buổi phỏng vấn của mình, chúng ta cùng nhau tìm hiểu top 10 câu hỏi thường gặp liên quan đến hệ điều hành Linux này nhé.
Câu 1: Hệ điều hành mã nguồn mở là gì?
Mã nguồn mở (open-source) là thuật ngữ chung đề cập đến các phần mềm và ứng dụng chạy trên thiết bị máy tính mà cho phép người dùng có thể sử dụng, xem và tùy chọn sửa đổi các mã nguồn (source code). Hệ điều hành mã nguồn mở (Open-Source Operating System) là những hệ điều hành cho phép cá nhân hay tổ chức được phép can thiệp vào sâu bên trong để tùy biến và sử dụng với các mục đích khác nhau mà không thu phí.
Một số hệ điều hành mã nguồn mở hiện nay như Linux (cha đẻ của những Ubuntu, Fedora, Android,…) Open Solaris, Free BSD. Ngược lại với hệ điều hành mã nguồn mở là hệ điều hành đóng như iOS, macOS của Apple hay Windows của Microsoft.
Câu 2: Linux là gì?
Linux là một họ các hệ điều hành tự do mã nguồn mở dựa trên Linux kernel (hạt nhân Linux). Linux được phát hành lần đầu vào năm 1991, bản phát hành bao gồm nhân Linux (kernel), các thư viện và phần mềm hệ thống hỗ trợ.
Từ bản phát hành của Linux, nhiều hệ điều hành dựa trên Linux ra đời và trở nên phổ biến như Ubuntu, Debian hay Fedora. Android – hệ điều hành phổ biến chạy trên các smartphone hiện nay cũng là một hệ điều hành dựa trên nền tảng Linux. Ngoài ra Linux cũng chạy được trên các hệ thống nhúng, từ đó mà các thiết bị điện tử khác như Tivi, máy quay, các thiết bị điện trong smarphone,… cũng đang được chạy phần mềm hoạt động trên nền tảng Linux.
Ngoài việc là một hệ điều hành mã nguồn mở, hoàn toàn miễn phí thì Linux còn nhiều ưu điểm đáng để sử dụng:
Tính tùy biến cao: bạn có thể dễ dàng thay đổi, tùy biến Linux theo nhu cầu và mục đích sử dụng của mình hay thậm chí tạo ra một hệ điều hành mới của riêng bạn bằng cách sử dụng Linux.
Tính tương thích cao: Linux có thể chạy trên hầu hết các thiết bị phần cứng đến từ Intel, IBM,… Các trình điều khiển thiết bị (driver) cũng được cộng đồng hỗ trợ phát triển để có thể sử dụng tốt trên nền tảng Linux.
Hiệu suất cao: Hệ điều hành Linux được tối giản giúp nó nhẹ, ít các ứng dụng đi kèm, nhờ vậy mang lại hiệu năng sử dụng cao. Việc cài đặt Linux cũng đòi hỏi cấu hình phần cứng thấp, nhờ vậy các máy tính cũ, cấu hình yếu vẫn có thể chạy tốt khi dùng hệ điều hành này.
Tính bảo mật cao: Linux mã nguồn mở nên bất cứ ai cũng có thể đào sâu vào hệ điều hành để đảm bảo rằng nó không có lỗi hay các back door. Nhờ cộng đồng hỗ trợ mà Linux có ít lỗ hổng hơn so với các hệ điều hành đóng khác.
Kernel: phần nhân – là phần cốt lõi của hệ điều hành, chịu trách nhiệm cho tất cả các hoạt động từ quản lý thiết bị, bộ nhớ, quy trình và xử lý các lệnh gọi hệ thống.
Thư viện hệ thống: System Libraries là các chương trình giúp truy cập các tính năng của Kernel
Công cụ hệ thống: System Tools là tập hợp các công cụ tiện ích, thường là các lệnh đơn giản giúp người dùng truy cập file, thao tác với thư mục, với dữ liệu,…
Công cụ phát triển: Development Tools là những công cụ và thư viện bổ sung giúp các lập trình viên tạo ra các ứng dụng hoạt động trên Linux.
Câu 5: Linux Shell là gì?
Linux Shell là một chương trình cung cấp giao diện dành cho người dùng để sử dụng các dịch vụ hệ điều hành. Shell nhận các lệnh mà người dùng nhập vào, đọc và thực hiện chuyển đổi chúng thành thứ mà Kernel (nhân Linux) có thể hiểu được.
Để làm được điều này thì Shell được trang bị một trình thông dịch để thực thi các lệnh mà người dùng nhập vào. Shell được chia thành 2 loại:
Command Line Shell: người dùng sử dụng Terminal để thực hiện việc nhập lệnh để shell thực thi, kết quả cũng trả về trực tiếp trên Terminal. Các lệnh được quy định sẵn trong Shell và người dùng bắt buộc phải nhớ chúng
Graphical Shells: Linux cung cấp một số Shell thao tác trên GUI (graphical user interface) như đóng mở cửa sổ, hiển thị thông số dưới dạng biểu đồ,…
Câu 6: Root là gì? Có các loại chủ sở hữu nào trong Linux?
Root là tên người sử dụng (tài khoản) mặc định có quyền truy cập vào tất cả các lệnh và file trên Linux. Quyền Root dùng để chỉ quyền hạn mà tài khoản root có trên hệ thống, đây là đặc quyền lớn nhất trên hệ thống, có quyền tuyệt đối thao tác với dữ liệu, file, thư mục; ngoài ra còn có quyền cấp và thu hồi quyền truy cập đối với các tài khoản user khác trên hệ thống.
Trong Linux, có 3 loại chủ sở hữu (ownership) được gắn lên mỗi file và thư mục bao gồm:
User: Khi người dùng tạo ra file hay folder thì sẽ trở thành chủ sở hữu của file, folder đó
Group: một group bao gồm nhiều User có cùng quyền truy cập vào một file hay thư mục. Group sử dụng khi bạn muốn chia sẻ dữ liệu cho một nhóm những người dùng chung và cùng muốn set giá trị quyền truy cập, thao tác, chỉnh sửa lên dữ liệu
Other: dùng để chỉ bất kỳ người dùng nào không thuộc 2 đối tượng trên.
Linux quy định 3 chủ sở hữu trên để phân quyền và kiểm soát hành vi của người dùng.
Câu 7: Permissions trong Linux. Làm sao để thay đổi quyền của file hay thư mục trong Linux?
Permissions hay quyền giúp kiểm soát hành vi của người dùng trong Linux. Mỗi file hay thư mục trong Linux đều có 3 quyền: đọc, ghi và thực thi. Cụ thể là:
Quyền đọc: ký hiệu là r – Read cho phép mở file, đọc file; xem danh sách thư mục và file chứa trong 1 thư mục
Quyền ghi: ký hiệu là w – Write cho phép sửa nội dung file; thêm, xóa hay đổi tên các file trong thư mục
Quyền thực thi: ký hiệu là x – Execute cho phép chạy file
Trường hợp không có quyền nào thì Linux sẽ hiển thị ký hiệu –
Để xem được quyền của file hay thư mục, chúng ta sử dụng lệnh: “ls – l”
Để thay đổi quyền truy cập vào 1 file hay folder chúng ta sử dụng lệnh: “chmod <permissions-number> <filename>”. Trong đó permissions-number sẽ có 3 chữ số với ý nghĩa lần lượt từ trái sang phải là quyền của user, quyền của group và quyền của others.
Câu 8: Trình soạn thảo Vi trong Linux
Trình soạn thảo Vi là một trong những cách phổ biến nhất để người dùng thao tác chỉnh sửa nội dung file trong Linux, nó được ưu chuộng bởi việc nhẹ, chiếm ít tài nguyên và mặc định có sẵn trong các hệ điều hành Linux. Phiên bản nâng cấp của Vi là Vim – Vi Improved. Một số lệnh cơ bản khi thao tác với Vi
Chế độ soạn thảo: Vi cung cấp 2 chế độ, chạy command để người dùng thao tác các lệnh tìm kiếm, thay thế, xóa,… và chế độ nhập văn bản (insert mode) thao tác trực tiếp với nội dung file. Để chuyển đổi giữa 2 chế độ chúng ta sử dụng phím i, a, o hoặc Insert để nhập văn bản và Esc để về chế độ command
vi <filename> cho việc mở file nếu đã tồn tại, hoặc tạo mới nếu file chưa tồn tại và mở nó lên
:q cho việc thoát chế độ văn bản, nếu muốn thoát mà không lưu chúng ta thêm !
:w cho việc lưu file. Để lưu và thoát chúng ta kết hợp :wq
yy cho việc sao chép dòng hiện tại, p cho việc dán bản sao vào vị trí con trỏ, dd thực hiện việc xóa dòng
Câu 9: stdin, stdout, stderr là gì?
Stdin, stdout và stderr là ba luồng dữ liệu được tạo khi bạn khởi chạy một lệnh trong Linux, trong đó:
stdin là dòng đầu vào tiêu chuẩn
stdout là dòng đầu ra tiêu chuẩn
stderr là dòng báo lỗi tiêu chuẩn
Nói cách khác chúng ta có 1 luồng đầu vào và 2 luồng đầu ra. Mặc định khi chạy chương trình thì kết quả sẽ được hiện ra ở 2 nơi stdout và stderr; để có thể dễ dàng kiểm tra cũng như xử lý các tiến trình tiếp theo thì chúng ta thường sử dụng kỹ thuật trong bash Linux để gửi 2 kết quả đầu ra trên về cùng 1 nơi nào đó, ví dụ như lưu vào 1 file. Kỹ thuật này gọi là sự chuyển hướng câu lệnh.
Câu 10: Những phiên bản phổ biến nhất của hệ điều hành Linux
Red Hat Enterprise Linux: được sử dụng chủ yếu bởi các tổ chức có yêu cầu tính bảo mật cao như cơ quan, tổ chức nhà nước
CentOS: hệ điều hành cho các server và hoàn toàn miễn phí, đây cũng là 1 bản phân phối miễn phí của Red Hat, vì thế nó được đánh giá cao nhờ mức độ bảo mật
Fedora: cũng là một phiên bản được tài trợ bởi Red Hat, nó được dùng để kiểm tra các tính năng mới trước khi được thương mại hóa của Red Hat Enterprise Linux
Debian Linux: bản phân phối miễn phí của Linux, chúng ta có thể dùng để tham khảo source code hay tùy biến để thương mại hóa hoàn toàn hợp pháp
Ubuntu: được xem là Windows của Linux, dễ sử dụng, tương đối đầy đủ các phần mềm và công cụ với hiệu năng ổn đáp ứng nhu cầu của người dùng.
Kết bài
Trên đây là top 10 câu hỏi liên quan đến hệ điều hành Linux mà bạn có thể bắt gặp trong buổi phỏng vấn của mình. Nếu đi sâu vào hệ điều hành Linux, sẽ có rất nhiều kiến thức chuyên sâu mà bạn cần chuẩn bị thêm, liên quan đến phần nhân và cách hệ điều hành hoạt động. Hy vọng bài viết này hữu ích dành cho các bạn có cái nhìn tổng quan về Linux và chuẩn bị thật tốt cho buổi phỏng vấn sắp tới. Hẹn gặp lại các bạn trong các bài viết tiếp theo của mình.
Các hàm xây dựng (constructor) trong Java được sử dụng để tạo đối tượng và có thể lấy các tham số cần thiết để tạo đối tượng. Vấn đề khi một đối tượng có thể được tạo ra với nhiều tham số (param), một số có thể là bắt buộc và một số khác có thể là tùy chọn tuỳ theo từng yêu cầu của người dùng, tuỳ vào hoàn cảnh của ứng dụng. Chúng ta, có thể tạo ra nhiều constructor theo từng nhu cầu hoặc gán giá trị null cho các param không cần thiết. Tuy nhiên, code rất khó đọc, khó bảo trì, người sử dụng có thể gán nhầm giá trị nếu một loạt các tham số có cùng kiểu. Chúng ta cũng có thể sử dụng một giải pháp khác là sử dụng setter() để thay thế cho constructor. Tuy nhiên, nếu muốn đối tượng này là immutable thì không thể.
Do vậy, người ta mong muốn giao công việc này cho một đối tượng chịu trách nhiêm khởi tạo và chia việc khởi tạo đối tượng riêng lẽ, từng bước, để có thể tiến hành khởi tạo riêng biệt ở các hoàn cảnh khác nhau. Và giải pháp được đưa ra là sử dụng Builder Pattern như một người xây dựng.
Builder Pattern là gì?
Builder is a creational design pattern that separate the construction of a complex object from its representation so that the same construction process can create different representations.
Builder pattern là một trong những Creational pattern. Builder pattern là mẫu thiết kế đối tượng được tạo ra để xây dựng một đối tượng phức tạp bằng cách sử dụng các đối tượng đơn giản và sử dụng tiếp cận từng bước, việc xây dựng các đối tượng đôc lập với các đối tượng khác.
Builder Pattern được xây dựng để khắc phục một số nhược điểm của Factory Pattern và Abstract Factory Pattern khi mà Object có nhiều thuộc tính.
Có ba vấn đề chính với Factory Pattern và Abstract Factory Pattern khi Object có nhiều thuộc tính:
Quá nhiều tham số phải truyền vào từ phía client tới Factory Class.
Một số tham số có thể là tùy chọn nhưng trong Factory Pattern, chúng ta phải gửi tất cả tham số, với tham số tùy chọn nếu không nhập gì thì sẽ truyền là null.
Nếu một Object có quá nhiều thuộc tính thì việc tạo sẽ phức tạp.
Chúng ta có thể xử lý những vấn đề này với một số lượng lớn các tham số bằng việc cung cấp một hàm khởi tạo với những tham số bắt buộc và các method getter/ setter để cài đặt các tham số tùy chọn. Vấn đề với hướng tiếp cận này là trạng thái của Object sẽ không nhất quán cho tới khi tất cả các thuộc tính được cài đặt một cách rõ ràng. Nếu cần xây dựng một đối tượng Immutable thì cách này cũng không thể thực hiện được.
Product : đại diện cho đối tượng cần tạo, đối tượng này phức tạp, có nhiều thuộc tính.
Builder : là abstract class hoặc interface khai báo phương thức tạo đối tượng.
ConcreteBuilder : kế thừa Builder và cài đặt chi tiết cách tạo ra đối tượng. Nó sẽ xác định và nắm giữ các thể hiện mà nó tạo ra, đồng thời nó cũng cung cấp phương thức để trả các các thể hiện mà nó đã tạo ra trước đó.
Director/ Client: là nơi sẽ gọi tới Builder để tạo ra đối tượng.
Trường hợp đơn giản, chúng ta có thể gộp Builder và ConcreteBuilder thành static nested class bên trong Product.
Ví dụ sử dụng Builder
Ví dụ: sử dụng Builder cho việc gọi món tại một cửa hàng thức ăn nhanh.
package com.gpcoder.patterns.creational.builder.food.director;
import com.gpcoder.patterns.creational.builder.food.concretebuilder.FastFoodOrderBuilder;
import com.gpcoder.patterns.creational.builder.food.product.order.Order;
import com.gpcoder.patterns.creational.builder.food.product.type.BreadType;
import com.gpcoder.patterns.creational.builder.food.product.type.OrderType;
import com.gpcoder.patterns.creational.builder.food.product.type.SauceType;
public class Client {
public static void main(String[] args) {
Order order = new FastFoodOrderBuilder()
.orderType(OrderType.ON_SITE).orderBread(BreadType.OMELETTE)
.orderSauce(SauceType.SOY_SAUCE).build();
System.out.println(order);
}
}
Output của chương trình trên:
Order [orderType=ON_SITE, breadType=OMELETTE, sauceType=SOY_SAUCE, vegetableType=null]
Ví dụ sử dụng Builder để tạo đối tượng Immutable
Một vài điểm quan trọng về implement class Product:
Constructor là private, điều này có nghĩa là class này không thể gọi khởi tạo trực tiếp từ bên ngoài.
Tất cả các thuộc tính đều là private final, vì vậy nó chỉ được gán giá trị trong constructor và nó chỉ có thể được cung cấp các phương thức getter().
Việc khởi tạo đối tượng chỉ có thể thông qua Builder.
Một vài điểm quan trọng về implement class Builder:
Tạo một static nested class (đây được gọi là builder class) và copy tất cả các tham số từ class bên ngoài vào. Chúng ta nên đặt tên class này theo định dạng: [tên class] + Builder. Ví dụ class là BankAccount thì builder class sẽ là BankAccountBuilder.
Class Builder có một hàm khởi tạo public với tất cả các thuộc tính bắt buộc.
Class Builder có các method setter() cho các tham số tùy chọn.
Cung cấp method build() trong Class Builder để trả về đối tượng mà client cần.
Ví dụ: Một tài khoản ngân hàng bao gồm các thông tin: Tên chủ tài khoản, số tài khoản, địa chỉ email, nhận thông báo, sử dụng mobile banking. Một tài khoản được tạo phải có tên chủ tài khoản và số tài khoản. Các thông tin khác tùy theo nhu cầu của khách hàng có thể đăng ký sử dụng.
Lưu ý: class BankAccount có hàm khởi tạo là private, nên chỉ có một cách duy nhất để lấy một đối tượng BankAccount là thông qua class BankAccountBuilder.
Lợi ích của Builder Pattern là gì?
Hỗ trợ, loại bớt việc phải viết nhiều constructor.
Code dễ đọc, dễ bảo trì hơn khi số lượng thuộc tính (propery) bắt buộc để tạo một object từ 4 hoặc 5 propery.
Giảm bớt số lượng constructor, không cần truyền giá trị null cho các tham số không sử dụng.
Ít bị lỗi do việc gán sai tham số khi mà có nhiều tham số trong constructor: bởi vì người dùng đã biết được chính xác giá trị gì khi gọi phương thức tương ứng.
Đối tượng được xây dựng an toàn hơn: bởi vì nó đã được tạo hoàn chỉnh trước khi sử dụng.
Cung cấp cho bạn kiểm soát tốt hơn quá trình xây dựng: chúng ta có thể thêm xử lý kiểm tra ràng buộc trước khi đối tượng được trả về người dùng.
Builder Pattern có nhược điểm là duplicate code khá nhiều: do cần phải copy tất cả các thuộc tính từ class Product sang class Builder.
Tăng độ phức tạp của code (tổng thể) do số lượng class tăng lên.
Sử dụng Builder Pattern khi nào?
Tạo một đối tượng phức tạp: có nhiều thuộc tính (nhiều hơn 4) và một số bắt buộc (requried), một số không bắt buộc (optional).
Khi có quá nhiều hàm constructor, bạn nên nghĩ đến Builder.
Muốn tách rời quá trình xây dựng một đối tượng phức tạp từ các phần tạo nên đối tượng.
Muốn kiểm soát quá trình xây dựng.
Khi người dùng (client) mong đợi nhiều cách khác nhau cho đối tượng được xây dựng.
So sánh Builder Pattern với Factory/ Abstract Factory Pattern
Factory Pattern cũng có thể được sử dụng để xây dựng một đối tượng phức tạp, vậy sự khác biệt của nó với mô hình Builder Pattern là gì?
Sự khác biệt lớn duy nhất giữa Builder Pattern và Factory Pattern cung cấp cho bạn nhiều quyền kiểm soát hơn đối với quá trình tạo đối tượng.
Factory/ Abstract Factory Pattern là câu trả lời cho “WHAT” và Builder Pattern là câu trả lời cho “HOW“.
Trong Builder Pattern, đối tượng được xây dựng từng bước (step by step). Builder Pattern có nhiều bước nhỏ, mỗi bước sẽ có các đơn vị logic nhỏ kèm theo trong đó. Cũng sẽ có một chuỗi (sequence) liên quan. Nó sẽ bắt đầu từ bước 1 và sẽ đi lên tối đa bước n và bước cuối cùng là trả về đối tượng. Nhưng trong Factory Pattern, bạn sẽ không thấy được đối tượng phức tạp được tạo như thế nào, nó không có từng bước xây dựng đối tượng.
Thông qua bài Sqlite trong android chúng tôi muốn giới thiệu SQLite là một cơ sở dữ liệu mã nguồn mở được sử dụng để lưu trữ dữ liệu dạng văn bản (text) trên thiết bị di động.
SQLite hỗ trợ tất cả các tính năng của cơ sở dữ liệu quan hệ. Để truy cập cơ sở dữ liệu SQLite, bạn không cần phải thiết lập bất kỳ một loại kết nối đến SQLite như JDBC, ODBC,…
SQLite là hệ quản trị cơ sở dữ liệu cho nền tảng mobile như Android, IOS, Windows Phone. SQLite được sử dụng để quản lý thông tin bao gồm các chức năng như lưu trữ và truy xuất thông tin.
SQLite trong Android – Các bước thực hiện
Bước 1: Tạo một lớp kế thừa lớp SQLiteOpenHelper dùng để thao tác với cơ sở dữ liệu. Trong đó ClassName là tên lớp.
public class ClassName extends SQLiteOpenHelper {
//Tạo phương thức khởi tạo
//Override phương thức onCreate
public void onCreate(SQLiteDatabase db) {
String sql = "câu lệnh tạo bảng";
db.execSQL(sql);
}
/*Các phương thức:
thêm dữ liệu, cập nhật dữ liệu,
xóa dữ liệu và truy vấn dữ liệu*/
}
Xây dựng phương thức thêm dữ liệu
public void methodName([parameter]) {
SQLiteDatabase db = this.getWritableDatabase();
ContentValues cv = new ContentValues();
cv.put(columnName1, value);
cv.put(columnName2, value);
...
db.insert(tableName, null, cv);
}
Xây dựng ứng dụng ToDoList (Danh sách công việc cần thực hiện)
Tên cơ sở dữ liệu là todolistdb
Tên bảng dữ liệu todolisttbl, có cấu trúc như sau
FieldName
Type
Description
id
Integer
Khóa chính (Primary Key), kiểu số nguyên tự tăng (AutoIncrement)
job
Text
Nội dung công việc cần nhớ
date
Text
Thời gian công việc cần phải thực hiện
Thiết kế giao diện cho ứng
Khi chọn nút lệnh “Thêm”, chuyển sang màn hình cho phép nhập nội dung và thời gian thực hiện công việc (Hình 2). Khi người dùng chọn nút lệnh “Lưu và trở về”, thực hiện lưu nội dung công việc vào cơ sở dữ liệu, quay về màn hình 1 và hiển thị tất cả nội dung công việc đã tạo.
Trường hợp muốn xóa 1 công việc dự định trong danh sách hay tất cả công việc trong danh sách, người dùng chọn và giữ trên mục công việc để hiện lên context menu và chọn chức năng cần thiết. Lưu ý, bổ sung thêm chức năng cho phép người dùng cập nhật lại nội dung và thời gian thực hiện trong context menu.
Lại là chuỗi bài series phỏng vấn, SQL có rồi, các hệ cơ sở dữ liệu (RDBMS) khác có rồi, giờ tới lượt MySQL. DB phổ biến hàng đầu thế giới liệu phỏng vấn có gì khác biệt?
Tất cả sẽ tới trong 3 phần của chuỗi bài viết phỏng vấn MySQL.
Bắt đầu thôi nào anh em. Meme cuối cùng cũng chỉ là meme chứ không ý gì là dìm hàng MongoDB. Coi chứ nhiều khi đâu phải MySQL là ngon nhất, nhưng thôi cứ cập nhật kiến thức phỏng vấn đã.
1. VARCHAR và CHAR khác nhau thế nào? Lúc nào thì sử dụng cái nào?
Câu hỏi phỏng vấn MySQL này là câu hỏi cơ bản ha anh em. Đánh giá ở mức độ Junior, nắm chắc kiến thức về các kiểu dữ liệu.
Đầu tiên thì CHAR và VARCHAR chắc chắn là kiểu dữ liệu dạng chuỗi ha. Độ dài các kí tự là cần được quy định.
CHAR lưu trữ các kí tự có độ dài cố định, trong khi VARCHAR lưu trữ các ký tự có độ dài không cố định (có thể thay đổi được)
Với kiểu CHAR, khi đã khai báo độ dài cố định, nếu chuỗi input vào có độ dài nhỏ hơn, các kí tự phía sau sẽ được tự động thêm vào bằng khoảng trắng.
Về hiệu suất thì CHAR tốt hơn VARCHAR một chút.
Chính vì độ dài CHAR cấp là cố định từ trước nên bộ nhớ cấp phát cũng có giới hạn, VARCHAR thì ngược lại, bộ nhớ của VARCHAR chưa giới hạn trước mà có thể thay đổi.
2. MySQL có bao nhiêu stored objects (đối tượng lưu trữ)?
Làm việc nhiều với MySQL tất nhiên anh em ít nhất đã từng một lần nghe hoặc dùng tới VIEW, STORED PROCEDURE, STORED FUNCTION.
Câu hỏi phỏng vấn MySQL này được phân loại ở mức độ Middle. Có 5 đối tượng dùng để lưu trữ trong MySQL nha anh em, bao gồm VIEW, STORED PROCEDURE, STORED FUNCTION, TRIGGER, EVENT.
Liệt kê từng loại:
VIEW – View được xem như một bảng ảo dưa trên kết quả truy vấn dữ liệu. Gom 3 field này ở bảng A, 2 field kia ở query B gom gom xếp xếp lại đem đặt vào VIEW.
STORED PROCEDURE – Là stored objects, được gọi tới về lệnh call. Có cái đặc biệt là procedure không trả về giá trị. Chỉ thực hiện làm một việc gì đó nha
STORED FUNCTION – Function thì ngược với PROCEDURE, nó có thể trả về một giá trị duy nhất. Có thể được gọi từ một câu lệnh khác.
TRIGGER – Trigger là một chương trình được liên kết với bảng. Cái này có thể gọi trước hoặc gọi sau các thao tác anh em thực hiện với table (insert, update, delete)
EVENT – Cái này anh em thường ít dùng, Event dùng để chạy một chương trình hoặc một tập các lệnh theo lịch trình đã lên từ trước đó.
Chú ý là bài viết này chỉ đang đề cập tới MySQL nha anh em. SQL Server và MariaDB thì procedure có thể khác đấy.
3. Khác biệt giữa Heap Table và Temporary Table?
Anh em xài nhiều MySQL và thực hiện nhiều truy vấn hoặc có kinh nghiệm tối ưu performance có thể tự tin trả lời câu hỏi phỏng vấn MySQL này. Cũng không khó để trả lời câu này nếu nhìn vào từ khoá (Heap và Temporary).
Temporary tất nhiên là tạm, nên một số điểm khác biệt cốt lõi có thể nêu ra như sau:
Heap thì tồn tại trên memory, nếu anh em restart DB hay gì đó thì mất ha. Temporary thì ngược lại, do tính chất tạm bợ nên temporary chỉ tồn tại theo sessions. Session mất nghĩa là ta cũng mất.
Cũng phân biệt đối xử như vậy thì heap có thể chia sẻ giữa một vài client khi query tới DB, trong khi temporary table không chia sẻ giữa các clients.
Có cái hơn là để tạo được bảng tạm (temporary) anh em cần được cấp quyền, còn Heap thì không, cứ tạo thoải mái.
Thông tin thêm là MySQL heap table sẽ dử dụng hash index và rất nhanh nha anh em.
Câu hỏi phỏng vấn MySQL này chỉ nêu ví dụ là sự khác biệt với MongoDB. Tuy nhiên anh em nếu có hiểu biết thêm về các hệ cơ sở dữ liệu khác thì càng tốt ha.
Về khác biệt thì có nhiều nhưng anh em có thể liệt kê một số khác biệt chính như sau:
MongoDB
MySQL
Là hệ cơ sở dữ liệu mã nguồn mở lưu trữ dạng JSON
Là hệ cơ sở dữ liệu mã nguồn mở nhưng lưu trữ theo kiểu dữ liệu dạng quan hệ (relation)
Mỗi dòng dữ liệu khác nhau được lưu trữ theo kiểu document (tài liệu)
Mỗi dòng dữ liệu được lưu trữ dưới dạng các hàng trong bảng
Tài liệu một nhóm các Documents sẽ được lưu trữ trong Collection.
Một nhóm các records sẽ được lưu trữ trong một bảng
Anh em cũng có thể nói thêm về kiến trúc, sự khác biệt về hiệu năng, lúc nào nên sử dụng MongoDB, lúc nào nên sử dụng MySQL.
5. Kiểu timestamp và đôi điều đặc biệt trong MySQL
Câu này bảo là trick thì cũng đúng, nhưng nếu anh em biết thêm thì cũng hay. Đầu tiên cho 1 statement tạo bảng. Bảng này có 2 cột kiểu TIMESTAMP là start và end
CREATE TABLE phongvan (cau1 VARCHAR(32), cau2 VARCHAR(32), batdau TIMESTAMP, kethuc TIMESTAMP);
INSERT INTO game VALUES ("laptrinh", "cautrucvagiaithuat", now(), now());
Sau khi chạy xong câu này dữ liệu trong bảng như sau:
Câu hỏi là khi thực hiện câu SQL dưới đây, những dữ liệu nào sẽ thay đổi?
UPDATE phongvan SET cau1 = "cautrucvagiaithuat" WHERE cau1 = "laptrinh";
Hầu hết anh em đều cho rằng chỉ có cột cau1 là cập nhật. Nhưng kết quả lại là cả cột batdau cũng cập nhật theo, mặc dù ta không thực hiện chạy update. Nguyên nhân là do batdau và ketthuc thuộc kiểu TIMESTAMP. Trong MySQL kiểu timestamp sẽ tự động cập nhật khi thực hiện câu UPDATE. Nhưng chỉ duy nhất cột đầu tiên thực hiện cập nhật đó. Trớ trêu cuộc tình ghê.
Câu này trong bộ câu hỏi phỏng vấn MySQL thì liệt vào dạng trick ha. Nếu anh em có biết trả lời được thì tốt, nếu không cũng không thể đánh giá gì vì nó thuộc dạng trick người thì biết, người không.
Bữa trước mình có đi ăn búp phê với người yêu, trong thực đơn có món “bề bề hấp”. Mình quê ở Quảng Ninh, vốn gần biển nên món này chẳng có gì lạ lẫm cả, nhưng người yêu quê lại ở Thái Nguyên, ít được ăn đồ biển nên khá thích món này. Biết thế nên mình lấy mấy con rồi mang vào bàn ăn. Cái giống bề bề này tuy ngon, nhưng bóc lại cực kỳ khó và mất thời gian, do vỏ với thịt của nó gắn khá chặt với nhau. Nói không đùa, chứ bóc vỏ bề bề là cả một nghệ thuật đấy.
Con bề bề trong như thế này
Oh vậy việc ăn bề bề thì có gì liên quan tới làm phần mềm ở đây?
Trước khi trả lời câu hỏi trên, thì dưới đây là cách bóc bề bề vừa nhanh, vừa dễ mà mình đã đúc kết ra được sau gần 20 năm sống ở Quảng Ninh:
Bước 1: Cắt bỏ phần đầu.
Bước 2: Cắt bỏ phần đuôi.
Bước 3: Cắt bỏ hai bên sườn, khi cắt thì cắt sâu một chút.
Bước 4: Lột vỏ trên lưng và dưới bụng.
Thực hiện 4 bước trên, bạn sẽ có một miếng bề bề ngon lành, công đoạn tiếp theo chỉ là cho vào miệng và thưởng thức thôi.
Nhưng khoan đã, hình như có điều gì không ổn trong 4 bước trên … Đúng rồi, có vẻ như mình đã “cắt bỏ” quá nhiều thì phải, bạn có thấy thế không? Hết cắt đầu, cắt đuôi rồi lại cắt hai bên sườn. Vậy sau cùng thì chỉ còn có một mẩu ở giữa thôi à?
Đúng vậy, nếu thực hiện 4 bước trên, bạn sẽ chỉ còn phần thịt ở giữa, nhưng đó là phần nhiều thịt nhất và cũng là phần có thịt ngon nhất. Nói thẳng ra, có một sự đánh đổi ở đây, để bóc bề bề nhanh và dễ, mình đã phải hi sinh phần thịt ở đầu, đuôi và hai bên sườn. Nhưng đây là một cuộc đánh đổi hợp lý và có lợi cho mình:
Nếu bỏ đi các phần có ít thịt (đầu đuôi và hai bên sườn), mình chỉ mất 30 giây để bóc, đổi lại mình vẫn giữ được phần thịt ở phần thân ngon lành.
Nếu mình chọn cách bóc cẩn thận, tỷ mỉ để lấy được thịt cả ở phần đầu và đuôi, mình sẽ mất tới 2 phút (gấp 4 lần cách trên) hoặc thậm chí hơn, nhưng số lượng thịt lấy được không đáng so với thời gian mình bỏ ra.
Nguyên lý 80/20 được áp dụng trong cả lĩnh vực phát triển phần mềm, nó giúp các nhà phát triển đưa sản phẩm của họ đến với khách hàng sớm hơn, cũng như tối ưu được các tính năng cần thiết khi tới tay người dùng. Cụ thể quy tắc này được áp dụng như thế nào, mình sẽ trình bày trong phần dưới đây.
3.1 80% tính năng của sản phẩm có thể được hoàn thiện với 20% thời gian
Viết đầy đủ luận điểm trên phải là: 80% tính năng của sản phẩm có thể được hoàn thiện với 20% thời gian, nhưng để hoàn thiện nốt 20% tính năng còn lại, bạn cần bỏ ra 80% thời gian.
Lấy ví dụ với dự án website thương mại điện tử cho gần gũi, thì để tạo ra nơi cho phép “người bán có thể bán hàng và người mua có thể mua hàng” thì thời gian code khá nhanh. Bạn chỉ cần code sao để sản phẩm hiển thị được lên website, khách hàng vào đặt hàng, và thông tin đơn hàng được gửi tới người bán là chấm hết. Code sẽ chỉ mất thời gian khi chúng ta làm thêm các tính năng phụ, giúp việc mua, bán, quản lý sản phẩm diễn ra dễ dàng hơn, hoặc để tối ưu trải nghiệm người dùng như:
Website có giao diện responsive.
Tính năng chat giữa người mua và người bán.
Có thông báo thời gian thực tới người bán khi có đơn hàng.
Mặc dù có thể thấy rằng các tính năng trên đều rất điển hình với một dự án thương mại điển tử hiện nay, nhưng suy cho cùng chúng đều là các tính năng phụ. Bởi cho dù có hay không, thì quy trình mua và bán trên hệ thống vẫn có thể diễn ra bình thường. Nếu không nhất thiết phải làm, bạn có thể bỏ qua cho nhẹ đầu, hoặc làm trong các phiên bản tiếp theo.
Việc lược bỏ các tính năng không cần thiết, hoặc chưa cần thiết trong giai đoạn hiện tại giúp bạn tiết kiệm được rất nhiều thứ, đặc biệt là thời gian.
Kể thêm một trường hợp mà chính mình từng trải qua. Hồi đó mới đi làm, mình nhận task làm tính năng quản lý user trên thống, yêu cầu task như sau:
Hiển thị danh sách user có phân trang với 20 user mỗi trang.
Có bộ lọc user.
Có tính năng ban/unban user.
Thật sự task này chẳng có gì khó, nếu chọn phương án làm đơn giản chắc mình chỉ mất 2 giờ, thế nhưng mình đã mất tới … 8 giờ vì cách làm quá “cồng kềnh”:
Danh sách user mình load từ một enpoint, sau đó dùng vuejs để xử lý thay vì dùng dữ liệu trực tiếp từ controller, kết hợp nhanh với một vài vòng lặp để tạo danh sách.
Bộ lọc user thông minh, tất cả bộ lọc chỉ có một ô tìm kiếm, khi nhập email, nó sẽ tự tìm kiếm user theo email, khi nhập số điện thoại, nó sẽ tự tìm kiếm user theo số điện thoại. Trong khi đó mình có thể làm cách đơn giản và tiết kiệm thời gian hơn là tạo 2 ô tìm kiếm, 1 ô tìm theo email và 1 ô tìm theo số điện thoại, khi muốn tìm theo tiêu chí nào thì điền vào ô tương tứng.
Trước khi ban/unban user mình hiển thị alert bằng thư viện sweetalert nhìn “ngầu lòi” thay vì dùng hàm alert() mặc định của javascript. Mình cũng mạnh dạn code thêm tính năng ban/unban nhiều user cùng lúc trong khi task không yêu cầu tính năng này.
Cuối cùng mình nhận ra rằng bản thân đã tốn quá nhiều thời gian cho một task đơn giản, mà nguyên nhân gây mất thời gian chính là quá tập trung vào các tiểu tiết trong khi giá trị nó đem lại là không cao. Giống như việc cố gắng bóc vỏ ở phần đầu và đuôi của con bề bề chỉ để lấy một chút thịt.
3.2 80% user chỉ sử dụng 20% tính năng sản phẩm.
Có bao nhiêu người mua một chiếc Iphone X và sử dụng hết các tính năng của nó, hay mọi người chỉ dùng mấy tính năng cơ bản như chụp hình, nghe – gọi, nhắn tin, lướt facebook, xem youtube, call facetime? Hay chính bạn đấy, bạn cài bao nhiêu app trên smartphone của mình, và trong số đó có bao nhiêu app được bạn sử dụng thường xuyên.
Đây là một sự thật khá “phũ phàng” với những người làm phần mềm như chúng ta. Vì có nhiều tính năng mà bạn tâm huyết, tốn nhiều ngày để code, rồi lại nhiều đêm đóng vai dũng sĩ diệt bug, vất vả lắm mới kịp deadline nhưng kết quả lại … chẳng có ai sử dụng. Thật đáng buồn phải không?
Lại tiếp tục kể một câu chuyện, ngày trước mình có làm một sản phẩm quản lý học viên cho một trung tâm Tiếng Anh. Các tính năng chia làm 2 giai đoạn, giai đoạn 1 làm các tính năng cơ bản như quản lý lớp học, quản lý học sinh trong lớp, sắp xếp thời khóa biểu,… Giai đoạn 2 làm các tính năng như xin nghỉ học, điểm danh học viên, thu chi,… Giai đoạn 1 làm trong 2 tháng thì xong, giai đoạn 2 làm trong 1 tháng tiếp theo. Nhưng kết quả là các tính năng ở giai đoạn 2 chẳng mấy ai sử dụng cả. Xin nghỉ thì học viên toàn nhắn tin trực tiếp cho giáo viên chứ chẳng thèm lên hệ thống tạo đơn; Học viên mỗi lớp quá ít để diểm danh, giáo viên chỉ cần nhìn là nhận biết được ai đi học, ai nghỉ học; Có tính năng thu chi thì lúc dùng, lúc không dùng, nói chung cũng không cần thiết. Vậy rõ ràng, chỉ với các tính năng ở giai đoạn 1 là sản phẩm đã có thể đáp ứng được các nhu cầu của người dùng mà không cần tới các tính năng ở giai đoạn 2.
80% user chỉ sử dụng 20% tính năng sản phẩm – luận điểm này giúp chúng ta hạn chế việc “vẽ hươu vẽ vượn” các tính năng trên phần mềm. Vì chỉ có 20% tính năng được sử dụng bởi phần lớn khách hàng. Thế nên bạn đừng có “tự đẻ” thêm các tính năng nếu không có căn cứ rõ ràng nhé.
4. Lời kết
Làm phần mềm cũng giống như cách bóc bề bề, nhiều khi bạn phải loại bỏ các tính năng ít giá trị để đối lấy thời gian phát triển nhanh. Và điều này được áp dụng rất nhiều trong các startup công nghệ hiện nay.
Hồi mới vào làm ở công ty, mình thấy mấy tool nội bộ của công ty cùi vãi, cứ thắc sao không áp dụng công nghệ A B C tiên tiến này, sao không làm hiệu ứng loading đẹp chút này, không tối ưu trải nghiệm này,… Cứ nghĩ mấy ông dev trước không biết gì nên mới làm thế, nhưng hóa ra là họ “không thèm làm” vì nó không cần thiết. Và đó cũng là dịp mình được nghe giải thích về nguyên lý 80/20 này, thật sự mình cảm thấy rất tâm đắc. Hôm nay được dịp chia sẻ lại với các bạn, hy vọng giúp các bạn có cái nhìn khách quan về công việc phát triển sản phẩm.
Xin chào, hẹn gặp lại trong các bài viết tiếp theo.




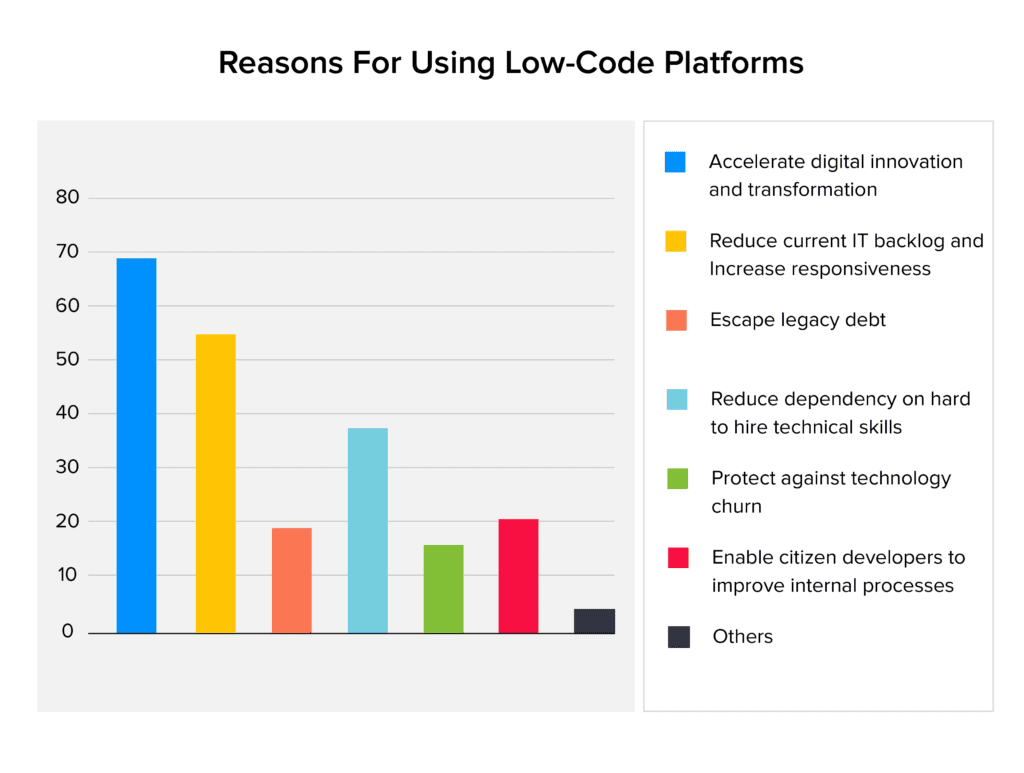










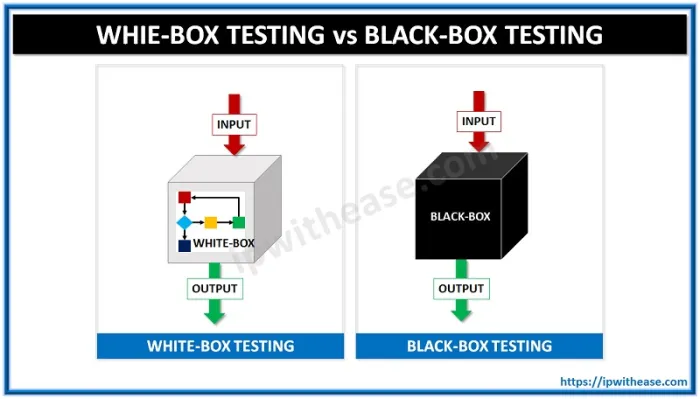
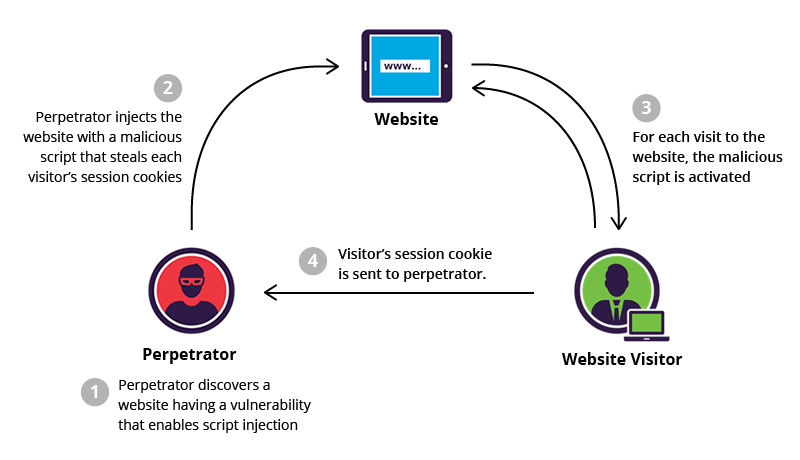






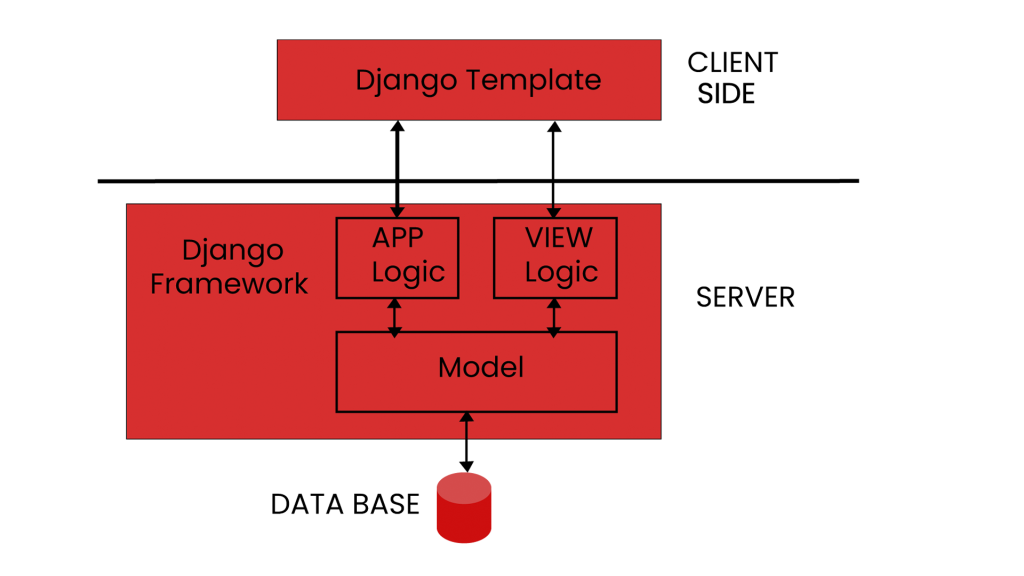
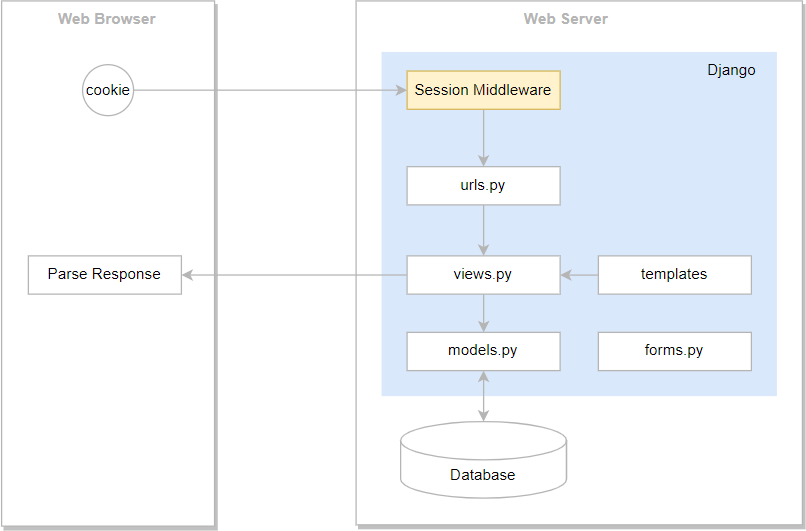
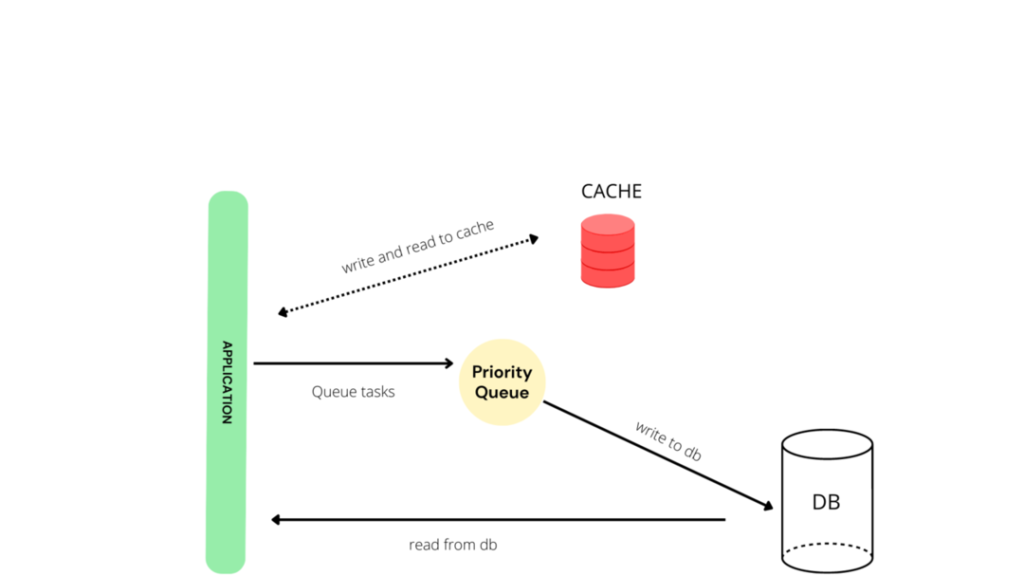
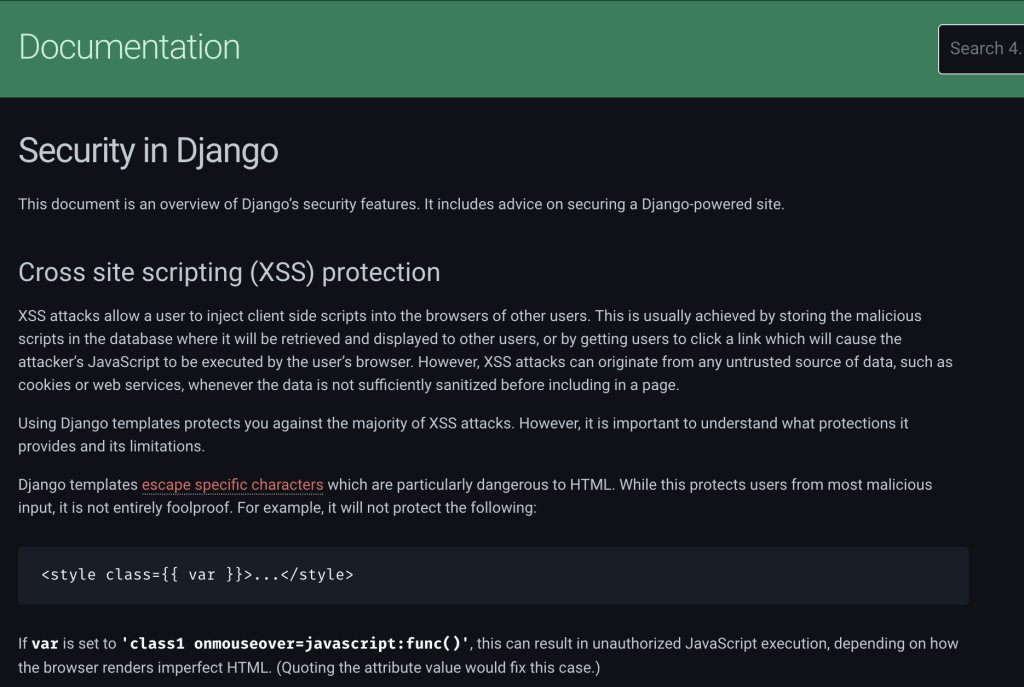

 Trở thành web developer
Trở thành web developer Trở thành mobile developer
Trở thành mobile developer Trở thành embedded developer
Trở thành embedded developer

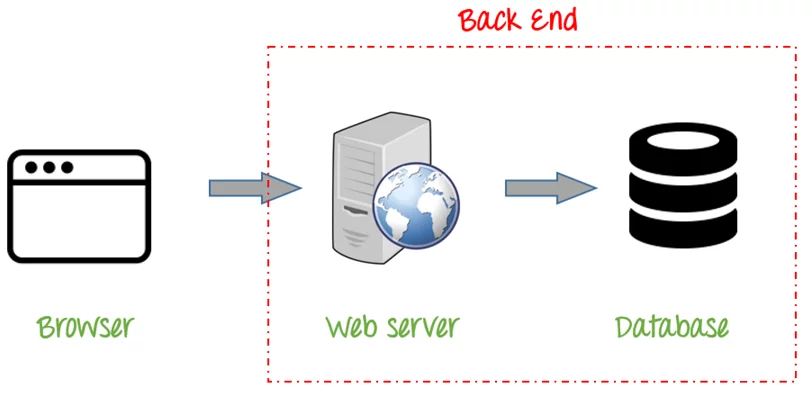
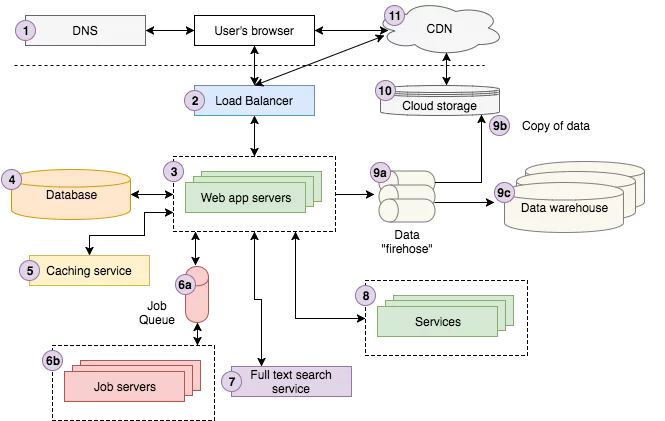
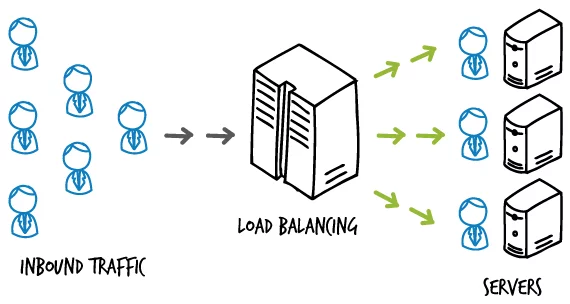
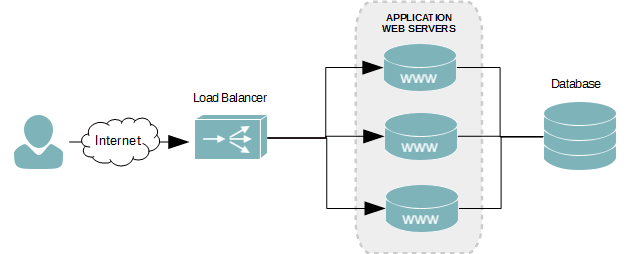
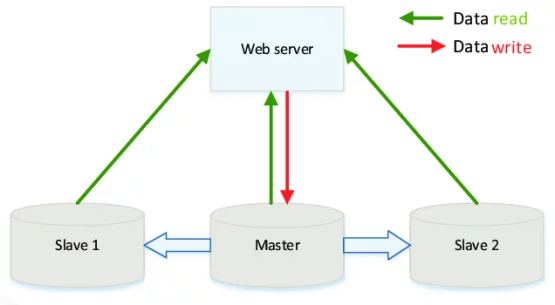
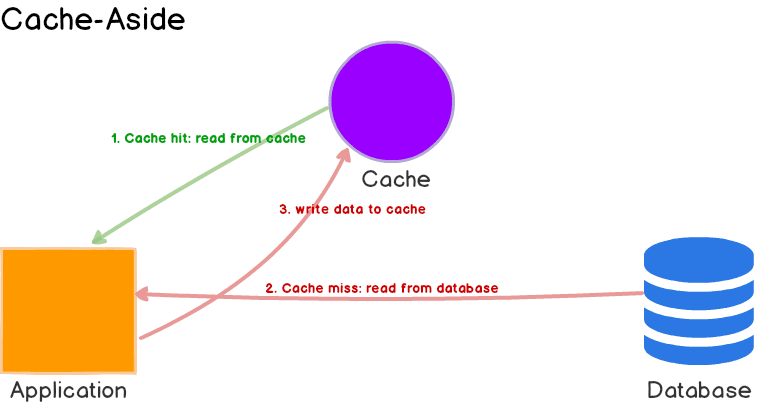



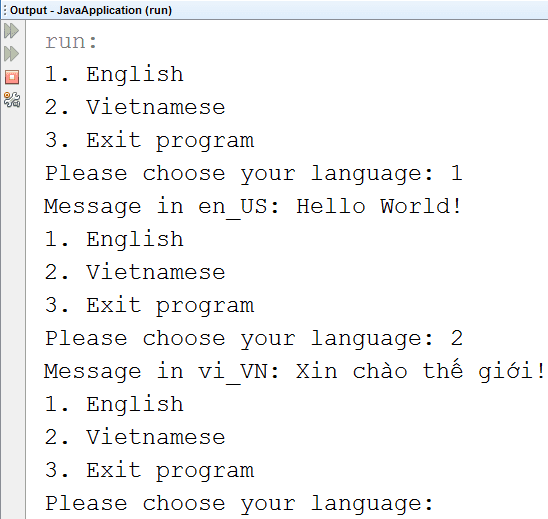
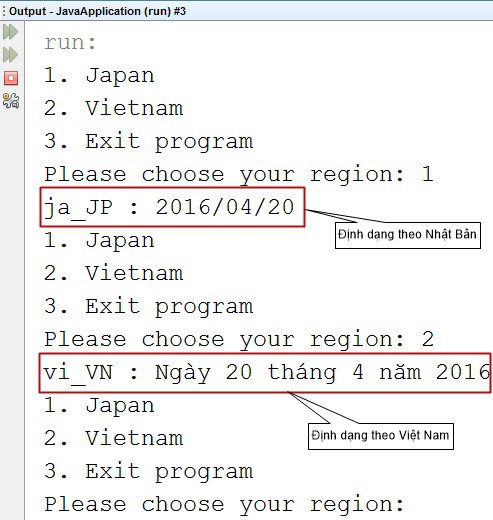
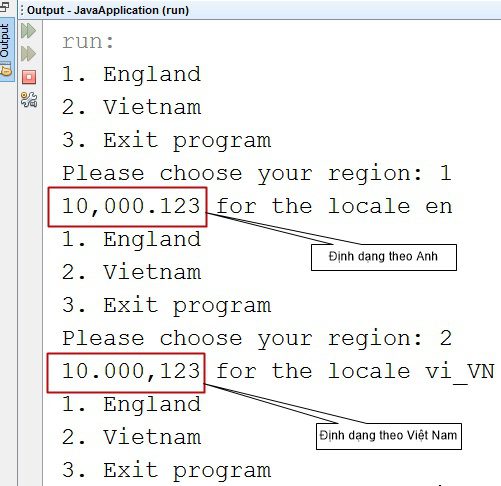
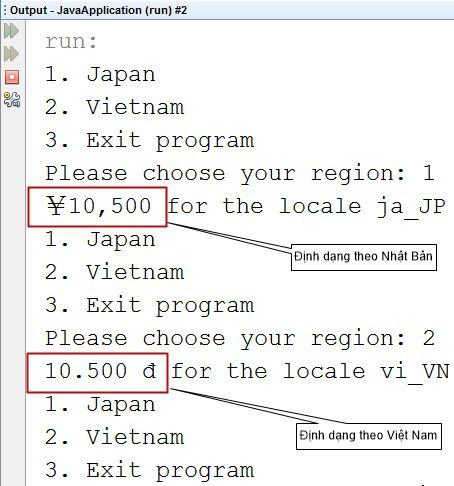

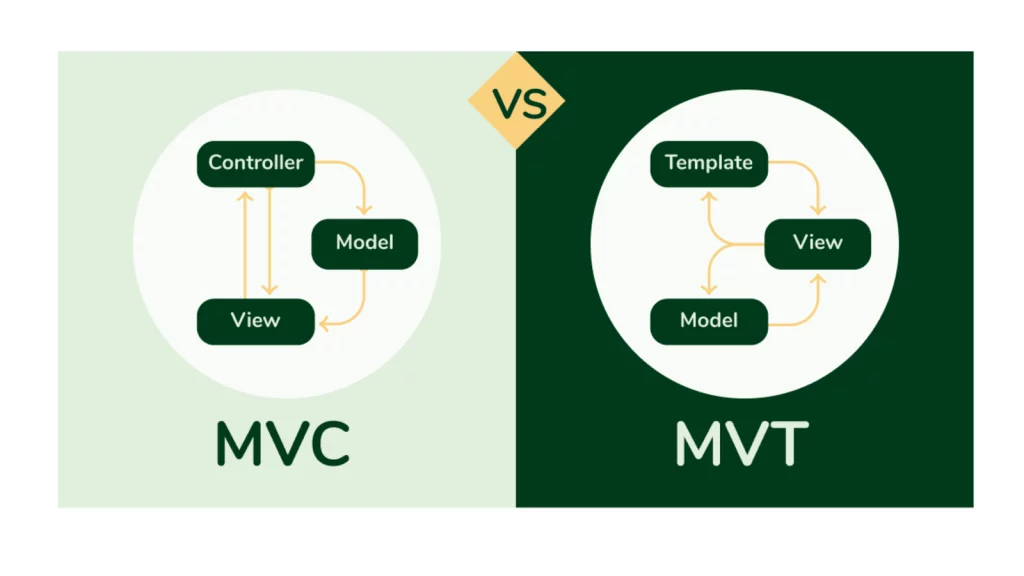
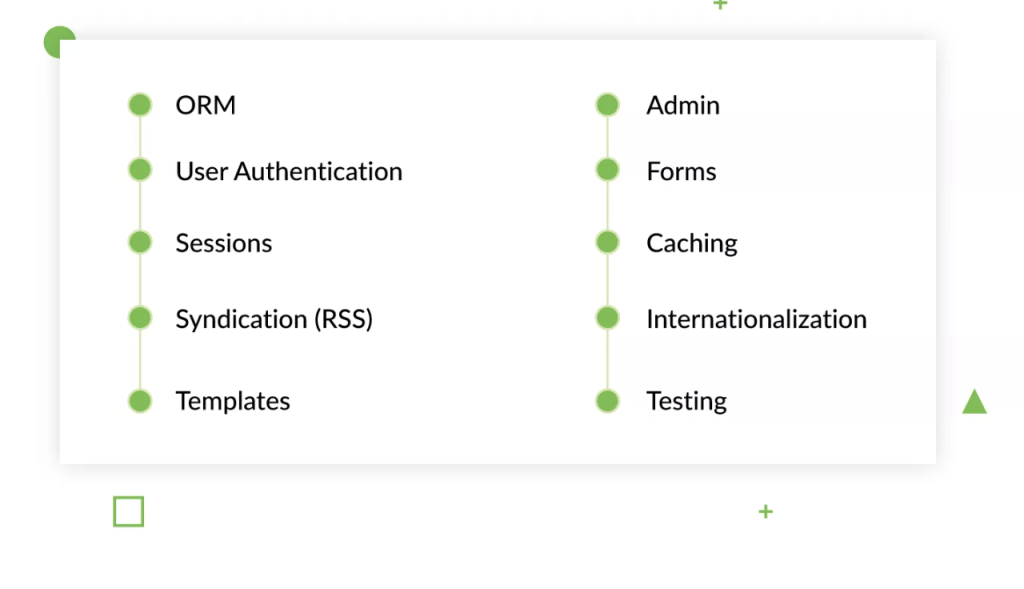

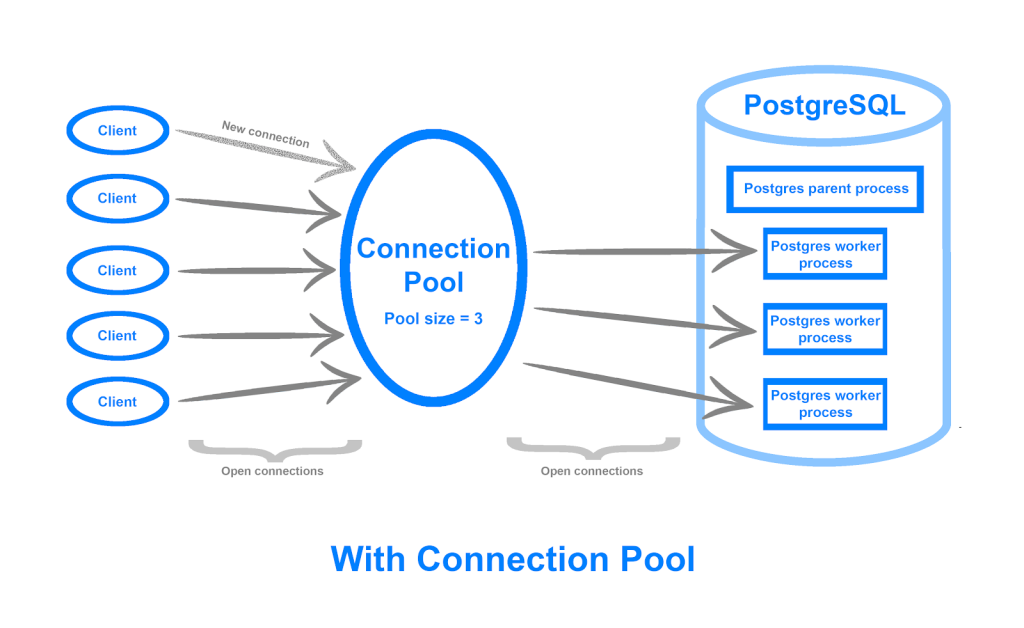











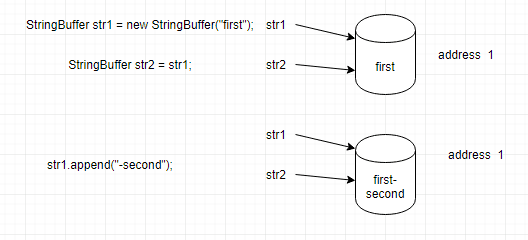




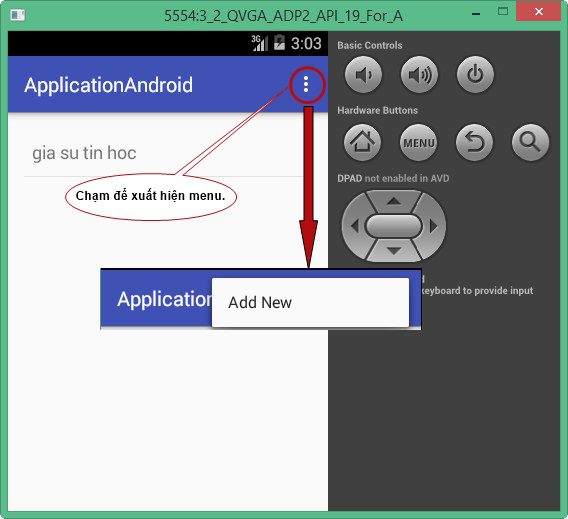
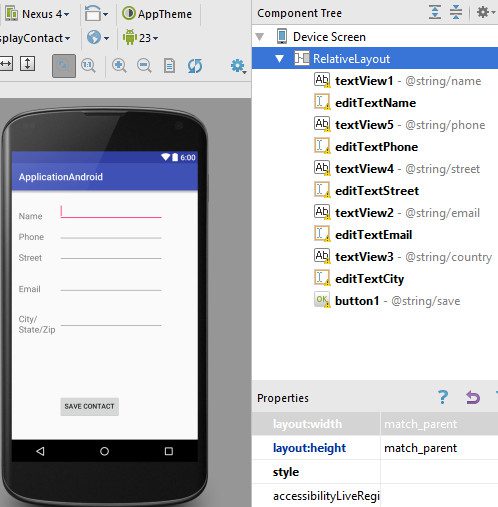
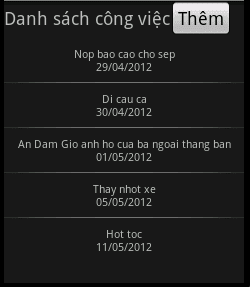
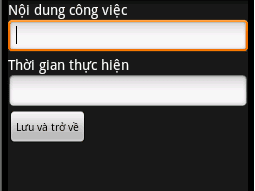




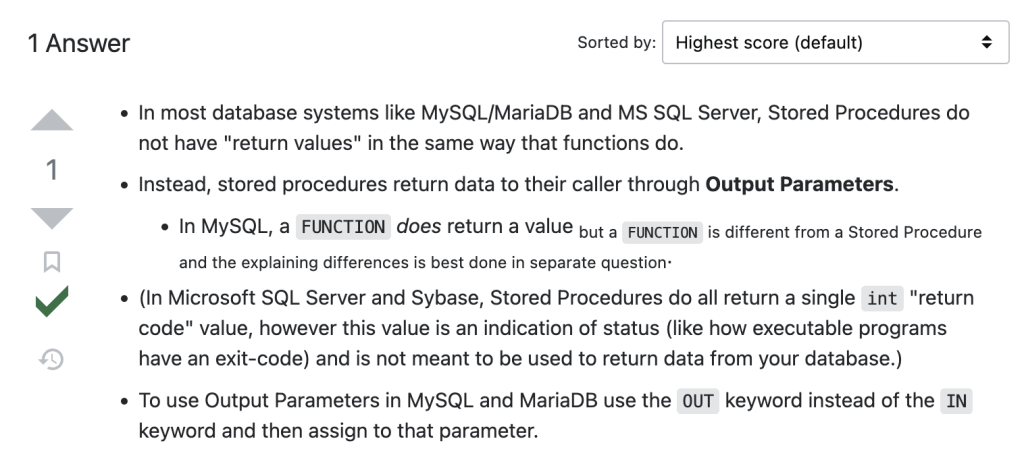 Chú ý là bài viết này chỉ đang đề cập tới MySQL nha anh em. SQL Server và MariaDB thì procedure có thể khác đấy.
Chú ý là bài viết này chỉ đang đề cập tới MySQL nha anh em. SQL Server và MariaDB thì procedure có thể khác đấy.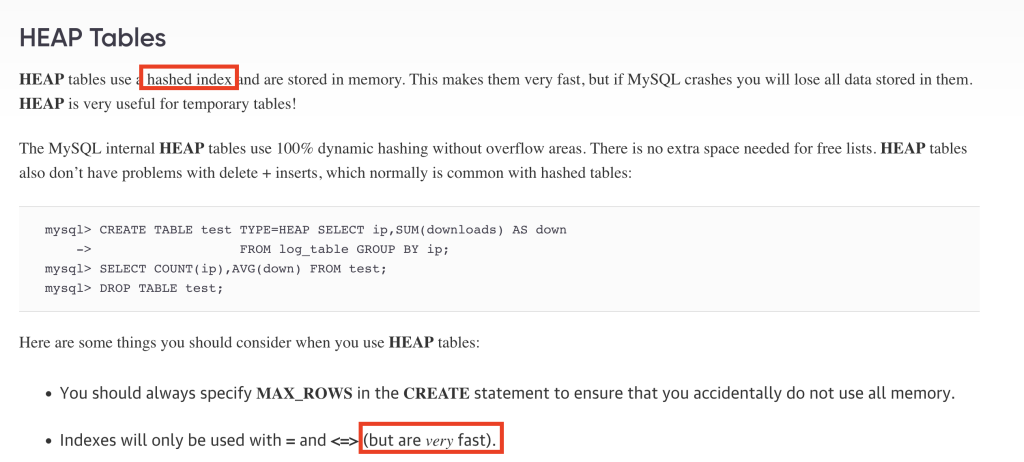


 … Đúng rồi, có vẻ như mình đã “cắt bỏ” quá nhiều thì phải, bạn có thấy thế không? Hết cắt đầu, cắt đuôi rồi lại cắt hai bên sườn. Vậy sau cùng thì chỉ còn có một mẩu ở giữa thôi à?
… Đúng rồi, có vẻ như mình đã “cắt bỏ” quá nhiều thì phải, bạn có thấy thế không? Hết cắt đầu, cắt đuôi rồi lại cắt hai bên sườn. Vậy sau cùng thì chỉ còn có một mẩu ở giữa thôi à?