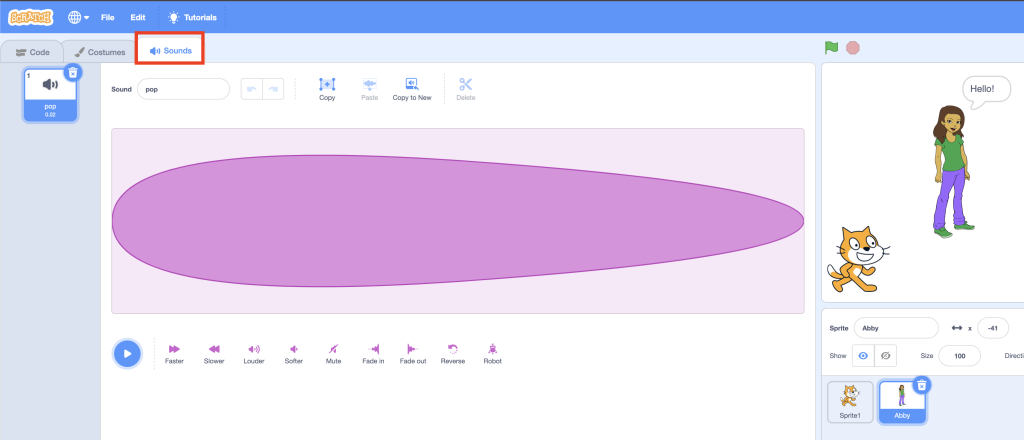
Theo thống kê từ trang Statista, đầu năm 2023, số lượng người dùng smartphone trên thế giới hiện nay là 6.92 tỷ người, nghĩa là có đến 86.34% dân số thế giới sở hữu smartphone. Thị trường phát triển ứng dụng smartphone ngày càng có nhu cầu lớn hơn, cũng chính vì thế mà lập trình viên ứng dụng di động – Mobile Developer trở thành 1 ngành nghề hot với nhu cầu tuyển dụng rất lớn. Bài viết hôm nay chúng ta cùng tìm hiểu về ngành này cũng như lộ trình để trở thành lập trình viên ứng dụng di động nhé.
Mobile Developer là gì?
Mobile Developer là những lập trình viên phát triển những ứng dụng dành cho các thiết bị di động, phổ biến hiện nay là các ứng dụng trên smartphone với 2 hệ điều hành chính là Android và iOS. Các hệ điều hành chạy trên thiết bị smartphone đều được trang bị các công cụ (SDK, IDE) và ngôn ngữ giúp các nhà phát triển tạo ra ứng dụng của mình, với Android sử dụng Java hay Kotlin; iOS sử dụng Objective-C hay Swift.
Ngoài ra có các thư viện hay framework và ngôn ngữ khác nhau giúp tạo ra ứng dụng đa nền tảng (có thể chạy trên nhiều hệ điều hành) như React Native viết bằng JavaScript, Flutter viết bằng Dart,… Nhiệm vụ của lập trình viên di động là nắm vững các kiến thức về lập trình, trang bị cho mình 1 hoặc nhiều trong số các ngôn ngữ, thư viện hay framework kể trên để có thể tạo ra những ứng dụng theo yêu cầu.
Mô tả về công việc cụ thể của 1 lập trình viên di động như sau:
Tham gia thiết kế xây dựng phần mềm dựa vào ý tưởng, nhu cầu của người dùng và những kinh nghiệm phát triển ứng dụng di động đã có
Viết code lập trình xây dựng giao diện và tính năng cho ứng dụng theo như khách hàng yêu cầu
Tham gia chạy, kiểm thử ứng dụng trên các thiết bị, phần mềm giả lập
Sửa chữa và nâng cấp các lỗi xuất hiện trong quá trình sử dụng ứng dụng
Publish (phát hành) ứng dụng lên các nền tảng chợ (market) như Google Play với Android hay AppStore với iOS
Nghiên cứu các công nghệ mới, cập nhật các bản phát hành của hệ điều hành, công cụ phát triển (SDK, IDE) tương ứng để áp dụng vào công việc, hỗ trợ cập nhật phần mềm khi có phiên bản hệ điều hành mới
Khác với lập trình Web hay Desktop, có 1 số đặc thù mà chỉ riêng ngành lập trình di động mới có và nó tác động khá lớn đến dự định trở thành 1 mobile developer của bạn:
Làm việc với nhiều thiết bị phần cứng khác nhau: hiện nay có vô số các thiết bị smartphone với đủ kích thước màn hình, cấu hình phần cứng khác nhau. Ứng dụng của bạn sẽ phải đối ứng với đủ các kiểu màn hình như tai thỏ, giọt nước, đục lỗ, … khiến cho ứng dụng của bạn có thể gặp nhiều vấn đề mà trên PC sẽ không bao giờ gặp phải.
Tương tác trực tiếp với các thiết bị cảm biến phần cứng: nếu như trên PC hay các ứng dụng Web, việc truy cập và làm việc với các thiết bị ngoại vi như camera, mic, loa mặc dù không quá thường xuyên nhưng có thể khiến bạn đau đầu; thì với smartphone hiện nay, có hàng chục các loại cảm biến khác nhau từ định vị, cảm biến con quay hồi chuyển, cảm biến gia tốc, vân tay, faceid, cảm biến tiệm cận, … với đủ các thứ quyền mà bạn cần xin phép mới có thể sử dụng.
Phát hành ứng dụng lên các chợ: ứng dụng của bạn nếu muốn đến tay người dùng thì không chỉ cần 1 địa chỉ website như ứng dụng Web, cũng không chỉ cần 1 bản cài đặt như ứng dụng trên Desktop; bạn cần phải phát hành chúng trên các chợ như Google Play, Appstore để người dùng tìm kiếm và có thể download về cài đặt. Việc tuân thủ tất cả các chính sách có thể khiến bạn phải đau đầu, chưa kể sự cập nhật thường xuyên về hệ điều hành cũng khiến ứng dụng của bạn cần update để đáp ứng.
Với việc đặc thù là tạo ra ứng dụng chạy trên nhiều nền tảng hệ điều hành di động khác nhau, vì thế có 2 định hướng khá rõ trong lộ trình trở thành 1 lập trình viên di động.
Hướng thứ nhất là tập trung làm mobile trên 1 nền tảng duy nhất (single platfom):
iOS: sử dụng ngôn ngữ Swift, Objective-C trên IDE Xcode sử dụng iOS SDK do Apple cung cấp để viết các ứng dụng dành riêng cho nền tảng iOS, chạy trên các thiết bị iPhone, iPad, Mac, …
Android: sử dụng ngôn ngữ Java, Kotlin trên IDE Android Studio sử dụng Android SDK do Google cung cấp để tạo ra các ứng dụng dành riêng cho nền tảng Android, chạy trên các thiết bị di động sử dụng hệ điều hành Android
Đối với hướng này, các lập trình viên sẽ tìm hiểu sâu vào từng ngôn ngữ, từng thư viện được cung cấp sẵn trong SDK, tương tác sâu và trực tiếp với các thiết bị phần cứng.
Đặc thù của ứng dụng bạn viết ra là sẽ chỉ chạy được trên nền tảng duy nhất, bạn không thể lấy source code ứng dụng Android để tạo ra ứng dụng tương ứng cho iOS. Nhưng cũng chính đó là ưu điểm của hướng phát triển này khi bạn có thể tối ưu hóa 1 cách tốt nhất cho ứng dụng của mình.
Hướng thứ 2 là việc phát triển các ứng dụng đa nền tảng (cross platform), được hiểu là có thể tạo ra ứng dụng chạy được trên nhiều nền tảng hệ điều hành khác nhau. 2 loại kỹ thuật phát triển ứng dụng đa nền tảng là Hybrid và Native:
Hybrid: các ứng dụng hybrid chủ yếu được viết trên nền tảng Web sử dụng HTML, CSS và JS. Bằng việc bao bọc ứng dụng bằng 1 trình duyệt để nó có thể chạy trên nền tảng di động, ứng dụng hybrid tạo ra 1 giao diện duy nhất cho nhiều nền tảng hệ điều hành khác nhau. Có thể kể đến 1 vài framework hay thư viện giúp xây dựng ứng dụng Hybrid như Cordova, Ionic, jQuery Mobile, HTML5, …
Native: khác với Hybrid khi chỉ tạo ra 1 ứng dụng duy nhất, các ứng dụng Native cho phép bạn viết 1 source code duy nhất và tạo ra các ứng dụng dành riêng cho từng hệ điều hành khác nhau bằng các công cụ biên dịch. Lựa chọn này giúp ứng dụng của bạn có thể tối ưu tốt hơn khi tương tác với phần cứng cụ thể của từng hệ điều hành cũng như tối ưu hóa hiệu năng. Có thể kể đến các framework như React Native, Flutter, Xamarin.
Ưu điểm của hướng thứ 2 chính là việc tiết kiệm thời gian, nguồn lực và kinh phí phát triển ứng dụng so với hướng thứ 1. Tuy vậy thì nhược điểm của nó là khả năng tạo ra các ứng dụng với trải nghiệm tốt nhất về giao diện cũng như hiệu năng dành cho người dùng.
Mobile Developer cần xác định trước lộ trình mình mong muốn trở thành ngay từ đầu để có thể lựa chọn học đúng, học đủ và học sâu những kiến thức theo lộ trình. Sau khi thành thạo 1 trong 2 hướng thì có thể chuyển qua học hướng còn lại để nâng cao khả năng lập trình của mình.
Kết bài
Như vậy qua bài viết này, mình đã cùng các bạn tìm hiểu về ngành lập trình ứng dụng di động – Mobile Developer cũng như lộ trình, các kiến thức cần thiết nếu bạn có dự định dấn thân vào ngành này. Đây là 1 ngành nghề hay và thú vị, cùng với nhu cầu lớn của thị trường sẽ là 1 lựa chọn tiềm năng dành cho bạn. Cảm ơn các bạn đã đọc và theo dõi, hẹn gặp lại trong các bài viết tiếp theo của mình.
Laravel tuy một PHP framework mạnh mẽ khi cung cấp rất nhiều tính năng hay ho cho developer. Nhưng thực tế, nhiều bạn developer mới chỉ sử dụng Laravel như một framework MVC đơn thuần mà không biết rằng ngoài cái đó ra, Laravel còn có nhiều tính năng cao cấp khác.
Vì vậy, trong bài viết này mình sẽ chỉ ra một số tính năng hữu ích khác của Laravel (bên cạnh một MVC framework thuần túy). Hy vọng các bạn sẽ có thêm kiến thức để giải quyết các vấn đề trong dự án tốt hơn.
I. Queue
Queue – Hàng đợi trong Laravel là giải pháp để xử lý các request tốn nhiều thời gian thực thi, trong khi bạn lại không muốn user phải đợi quá lâu mới có response.
Để hiểu rõ hơn, chúng ta sẽ cùng làm một tính năng theo 2 cách, cách 1 không sử dụng queue, cách 2 sử dụng queue để xem sự khác nhau như thế nào nhé:
Xét bài toán như sau:
Xây dựng tính năng đăng ký tài khoản, sau khi đăng ký thành công, sẽ gửi tới email của user một thông báo “Chào mừng bạn đến với website … “, đồng thời hiện một thông báo lên màn hình là “Bạn đã đăng ký thành công“.
Cách 1 yêu cầu user phải đợi cho đến khi email được gửi thành công thì mới thực hiện bước 4.
Cách 2 thì tạo ra một “job gửi email” và được đưa vào trong queue, job này sẽ chạy sau, nên user không cần phải đợi mà có thể chuyển sang bước 4 ngay.
Vì cách 2 không yêu cầu phải đợi, nên cách 2 user sẽ sớm nhận được thông báo “Bạn đã đăng ký thành công“, làm user có trải nghiệm tốt hơn.
Job đưa vào trong queue đúng là chạy sau, nhưng nó gần như chạy sau khi user nhận được thông báo “Bạn đã đăng ký thành công hơn“, nên user sẽ vẫn nhận được email ngay sau khi đăng ký.
Laravel là PHP framework, mà ứng dụng PHP sẽ chỉ hoạt động khi có request (tức có user truy cập). Nhưng trong thực tế đôi khi sẽ có những yêu cầu mà ứng dụng PHP phải tự nó chạy mà không cần request nào được gửi đến.
Như việc backup dữ liệu vào 12h đêm mỗi ngày chẳng hạn, không lẽ bạn cứ phải căn đúng 12h đêm để vào website, nhấn nút “backup” sao. Thật ra nếu muốn thì bạn cũng có thể làm như vậy, nhưng có cách khác tiện hơn nhiều, đó chính là Task scheduling.
Task scheduling là tính năng cho phép bạn lập lịch chạy một tác vụ nào đó.
Quay trở lại ví dụ backup database ở trên, mình sẽ tạo ra một task mà cứ đúng 12h đêm nó sẽ tự động được chạy, để rồi sáng hôm sau mình sẽ chỉ việc download file database đã được backup về máy, mà không cần phải thức đêm để nhấn nút “backup”.
Cách sử dụng Laravel task scheduling
Laravel task scheduling hoạt động dựa trên crontab, vì thể để sử dụng được tính năng này bạn cần phải cấu hình một cronjob như sau:
Crontab là chương trình lập lịch chạy trên Linux, mỗi một tác vụ được lập lịch chạy được gọi là một cronjob.
Cronjob trên có ý nghĩa là “Cứ mỗi phút thì thực hiện lệnh cd /path-to-your-project && php artisan schedule:run >> /dev/null 2>&1 một lần”. Bạn có thể tìm hiểu thêm về cú pháp của Crontab tại đây.
Sau khi cấu hình crontab, giờ bạn có thể cấu hình task scheduling trong file app/Console/Kernel.php.
// app/Console/Kernel.php// ...protectedfunctionschedule(Schedule $schedule){$schedule->call(function() {// Task làm gì sẽ được định nghĩa ở đây})// daily() nghĩa là task này sẽ được chạy mỗi ngày ngày.// ngoài daily() thì còn nhiều phương thức khác nữa// chi tiết tìm hiểu trên docs của Laravel bạn nhé->daily();}
Về cách khai báo task, cũng như lập lịch task (mỗi ngày, mỗi tuần, chạy lúc mấy giờ,…) thì tài liệu Laravel đã viết rất rõ, nên mình lười không muốn viết lại nữa, bạn có thể đọc thêm ở đây.
III. Compiling Assets
Là một PHP framework, nhưng Laravel cũng chú trọng cả frontend, điều này được thể hiện qua tính năng “Compiling assets” (Biên dịch các file assets như scss, js). Ở phiên bản hiện tại (Laravel 8), Laravel thực hiện compiling assets thông qua gói Laravel Mix.
Nếu bạn đã từng sử dụng các tool build frontend như webpack, gulp thì Laravel Mix cũng là cái gì đó tương tự như vậy.
Frontend của các dự án web ngày càng phức tạp, trong khi đó kiểu lập trình web truyền thống thì chưa tập trung nhiều vào tối ưu frontend. Ví dụ, để viết CSS cho website, chúng ta thường tạo một file style.css và nhúng nó vào phần head của trang web. Nhưng khi các trang web ngày càng trở nên phức tạp (ngày càng nhiều trang, ngày càng nhiều css) thì cách làm này dần phát sinh nhiều nhược điểm:
File style.css quá nặng.
Không tối ưu css: do toàn bộ css đều được viết trong một file, và không phải trang nào cũng sử dụng hết các class được khai báo trong đó, thậm chí có những đoạn css đã không còn dùng tới.
Khó quản lý các class: các class mới thì ngày càng được bổ sung, và có thể bị trùng lặp, hoặc xung đột với các class trước đó.
Đứng trước các nhược điểm trên, người ta đã tạo ra các công cụ giúp để tối code frontend, giúp việc code và quản lý các file css, js trở nên đơn giản hơn gấp bội phần. Webpack hiện đang là công cụ được sử dụng nhiều nhất, và Laravel Mix thì được xây dựng dựa trên Webpack.
Về cơ bản Laravel Mix sẽ giúp bạn viết css bằng các css preprocessor, đóng gói (bundle) các file js và minify chúng.
Laravel Mix đã được tích hợp mặc định trong source code Laravel, để sử dụng Laravel Mix, bạn chỉ cần chạy lệnh npm install để cài đặt.
Điểm danh trước 3 tính năng “Premium” trong Laravel mà chưa hẳn ai cũng biết, các tính năng còn lại mình sẽ tổng hợp và chia sẻ với các bạn qua Phần 2, Phần 3, … Phần N nhé.
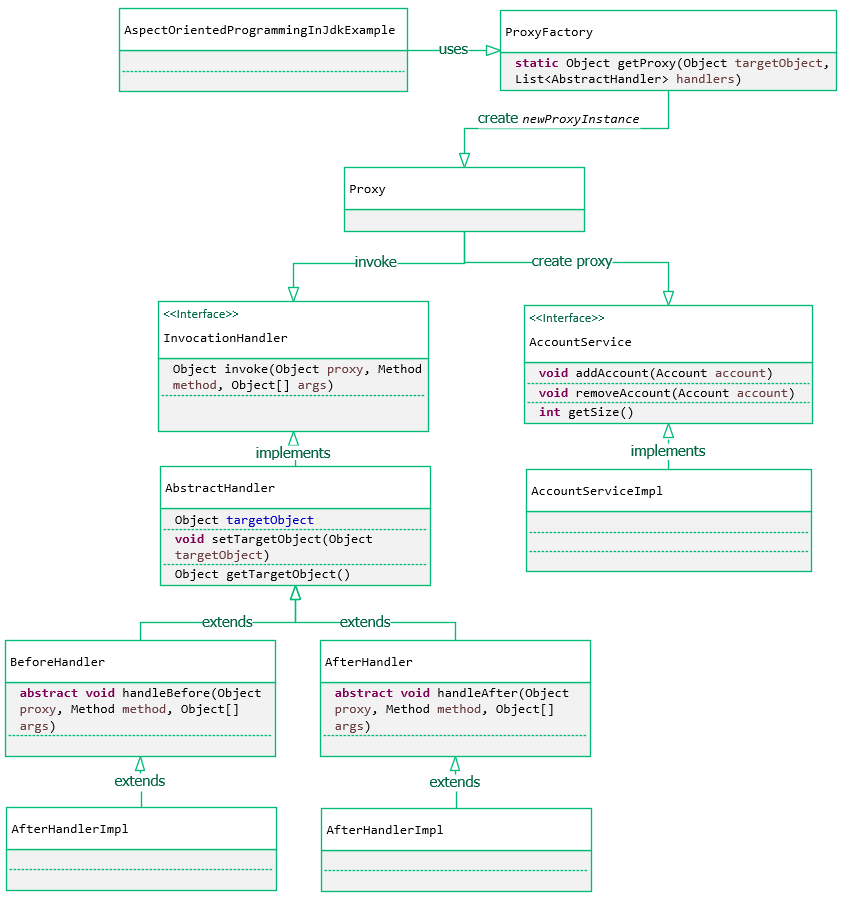
Khi cần điều khiển truy nhập tới một đối tượng được thực hiện từ quá trình khởi tạo nó cho tới khi thực sự cần sử dụng nó. Hoặc cần bảo vệ quyền truy xuất vào các phương thức của object thực. Trong trường hợp như vậy, ta nên dùng mẫu thiết kế Proxy.
Proxy Pattern là gì?
Provide a surrogate or placeholder for another object to control access to it.
Proxy Pattern là một trong những Pattern thuộc nhóm cấu trúc (Structural Pattern).
Proxy có nghĩa là “ủy quyền” hay “đại diện”. Mục đích xây dựng Proxy pattern cũng chính vì muốn tạo ra một đối tượng sẽ ủy quyền, thay thế cho một đối tượng khác.
Proxy Pattern là mẫu thiết kế mà ở đó tất cả các truy cập trực tiếp đến một đối tượng nào đó sẽ được chuyển hướng vào một đối tượng trung gian (Proxy Class). Mẫu Proxy (người đại diện) đại diện cho một đối tượng khác thực thi các phương thức, phương thức đó có thể được định nghĩa lại cho phù hợp với múc đích sử dụng.
Để đơn giản hơn bạn có thể nghĩ đến khái niệm HTTP proxy trong mạng máy tính, nó là một gateway giữa trình duyệt (client) và máy chủ (server). HTTP proxy giúp nâng cao trải nghiệm người dùng, tăng tốc với lưu đệm các dữ liệu, loại bỏ các trang quảng cáo, giới hạn các vùng thông tin được xem… Proxy Pattern cũng có chung một mục đích như với HTTP proxy.
Proxy Pattern còn được gọi là Surrogate (thay thế) hoặc Placeholder (trình giữ chỗ).
Virtual Proxy : Virtual Proxy tạo ra một đối tượng trung gian mỗi khi có yêu cầu tại thời điểm thực thi ứng dụng, nhờ đó làm tăng hiệu suất của ứng dụng.
Protection Proxy : Phạm vi truy cập của các client khác nhau sẽ khác nhau. Protection proxy sẽ kiểm tra các quyền truy cập của client khi có một dịch vụ được yêu cầu.
Remote Proxy : Client truy cập qua Remote Proxy để chiếu tới một đối tượng được bảo về nằm bên ngoài ứng dụng (trên cùng máy hoặc máy khác).
Monitor Proxy : Monitor Proxy sẽ thiết lập các bảo mật trên đối tượng cần bảo vệ, ngăn không cho client truy cập một số trường quan trọng của đối tượng. Có thể theo dõi, giám sát, ghi log việc truy cập, sử dụng đối tượng.
Firewall Proxy : bảo vệ đối tượng từ chối các yêu cầu xuất xứ từ các client không tín nhiệm.
Cache Proxy : Cung cấp không gian lưu trữ tạm thời cho các kết quả trả về từ đối tượng nào đó, kết quả này sẽ được tái sử dụng cho các client chia sẻ chung một yêu cầu gửi đến. Loại Proxy này hoạt động tương tự như Flyweight Pattern.
Smart Reference Proxy : Là nơi kiểm soát các hoạt động bổ sung mỗi khi đối tượng được tham chiếu.
Synchronization Proxy : Đảm bảo nhiều client có thể truy cập vào cùng một đối tượng mà không gây ra xung đột. Khi một client nào đó chiếm dụng khóa khá lâu khiến cho số lượng các client trong danh sách hàng đợi cứ tăng lên, và do đó hoạt động của hệ thống bị ngừng trệ, có thể dẫn đến hiện tượng “tắc nghẽn”.
Copy-On-Write Proxy : Loại này đảm bảo rằng sẽ không có client nào phải chờ vô thời hạn. Copy-On-Write Proxy là một thiết kế rất phức tạp.
Cung cấp mức truy cập gián tiếp vào một đối tượng.
Tham chiếu vào đối tượng đích và chuyển tiếp các yêu cầu đến đối tượng đó.
Cả Proxy và đối tượng đích đều kế thừa hoặc thực thi chung một lớp giao diện. Mã máy dịch cho lớp giao diện thường “nhẹ” hơn các lớp cụ thể và do đó có thể giảm được thời gian tải dữ liệu giữa server và client.
Các thành phần tham gia vào mẫu Proxy Pattern:
Subject : là một interface định nghĩa các phương thực để giao tiếp với client. Đối tượng này xác định giao diện chung cho RealSubject và Proxy để Proxy có thể được sử dụng bất cứ nơi nào mà RealSubject mong đợi.
Proxy : là một class sẽ thực hiện các bước kiểm tra và gọi tới đối tượng của class service thật để thực hiện các thao tác sau khi kiểm tra. Nó duy trì một tham chiếu đến RealSubject để Proxy có thể truy cập nó. Nó cũng thực hiện các giao diện tương tự như RealSubject để Proxy có thể được sử dụng thay cho RealSubject. Proxy cũng điều khiển truy cập vào RealSubject và có thể tạo hoặc xóa đối tượng này.
RealSubject : là một class service sẽ thực hiện các thao tác thực sự. Đây là đối tượng chính mà proxy đại diện.
Client : Đối tượng cần sử dụng RealSubject nhưng thông qua Proxy.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
Ví dụ Virtual Proxy
Trì hoãn việc tạo ra real subject bên trong proxy class. Chỉ đến khi cần, proxy class mới thật sự khởi tạo real class. Loại Proxy này làm việc theo cơ chế Lazy Loading.
Lazy Loading là một khái niệm mà ứng dụng trì hoãn việc tải các đối tượng cho đến thời điểm mà người dùng cần nó. Nói một cách đơn giản là tải theo yêu cầu của người dùng chứ không phải tải đối tượng không cần thiết. Lợi ích của việc này là giảm thiểu số lượng yêu cầu, giảm thiểu số lượng tài nguyên thừa cần tải cho tới khi người dùng cần đến chúng thực sự. Chúng ta đã thấy điều này qua cơ chế Lazy load của Hibernate.
Nó giải quyết vấn đề rất lớn về hiệu suất, lý do là vì proxy class có chi phí khởi tạo rất ít, việc duy trì nó không mất nhiều tài nguyên hệ thống. Trong khi đó Real class thường rất tốn chi phí , vì thế với virtual proxies, chỉ khi nào cần thiết, real class mới được khởi tạo.
Ví dụ một website hiển thị ảnh, có thể có rất nhều ảnh trên một trang hay một ảnh được hiển thị nhiều lần. Trường hợp này chúng ta chỉ cần load ảnh khi nó cần hiển thị (khi ta scroll tới nơi đặt image) hoặc là nó chưa được load (không như các website truyền thống là load hình ngay khi load website, nó rất tốn tài nguyên và đôi khi không cần thiết do người dùng không scroll tới nơi đặt image, có thể load 1 ảnh nhiều lần).
Image.java
package com.gpcoder.patterns.structural.proxy.virtual;
public interface Image {
void showImage();
}
RealImage.java
package com.gpcoder.patterns.structural.proxy.virtual;
public class RealImage implements Image {
private String url;
public RealImage(String url) {
this.url = url;
System.out.println("Image loaded: " + this.url);
}
@Override
public void showImage() {
System.out.println("Image showed: " + this.url);
}
}
ProxyImage.java
package com.gpcoder.patterns.structural.proxy.virtual;
public class ProxyImage implements Image {
private Image realImage;
private String url;
public ProxyImage(String url) {
this.url = url;
System.out.println("Image unloaded: " + this.url);
}
@Override
public void showImage() {
if (realImage == null) {
realImage = new RealImage(this.url);
} else {
System.out.println("Image already existed: " + this.url);
}
realImage.showImage();
}
}
Client.java
package com.gpcoder.patterns.structural.proxy.virtual;
public class Client {
public static void main(String[] args) {
System.out.println("Init proxy image: ");
ProxyImage proxyImage = new ProxyImage("http://gpcoder.com/favicon.ico");
System.out.println("---");
System.out.println("Call real service 1st: ");
proxyImage.showImage();
System.out.println("---");
System.out.println("Call real service 2nd: ");
proxyImage.showImage();
}
}
Output của chương trình:
Init proxy image:
Image unloaded: http://gpcoder.com/favicon.ico
---
Call real service 1st:
Image loaded: http://gpcoder.com/favicon.ico
Image showed: http://gpcoder.com/favicon.ico
---
Call real service 2nd:
Image already existed: http://gpcoder.com/favicon.ico
Image showed: http://gpcoder.com/favicon.ico
Như bạn thấy image chỉ thật sử được load lên khi proxy class gọi hàm.
Ví dụ Protection proxy
Yêu cầu người gọi proxy class phải chứng thực trước khi proxy class truy xuất vào real class. Cái này rất hữu dụng khi bạn bạn viết library cho một bên khác sử dụng và yêu cầu họ xác thực trước khi gọi hàm.
package com.gpcoder.patterns.structural.proxy.protection;
public class UserServiceImpl implements UserService {
private String name;
public UserServiceImpl(String name) {
this.name = name;
}
@Override
public void load() {
System.out.println(name + " loaded");
}
@Override
public void insert() {
System.out.println(name + " inserted");
}
}
UserServiceProxy.java
package com.gpcoder.patterns.structural.proxy.protection;
public class UserServiceProxy implements UserService {
private String role;
private UserService userService;
public UserServiceProxy(String name, String role) {
this.role = role;
userService = new UserServiceImpl(name);
}
@Override
public void load() {
userService.load();
}
@Override
public void insert() {
if (isAdmin()) {
userService.insert();
} else {
throw new IllegalAccessError("Access denied");
}
}
private boolean isAdmin() {
return "admin".equalsIgnoreCase(this.role);
}
}
Client.java
package com.gpcoder.patterns.structural.proxy.protection;
public class Client {
public static void main(String[] args) {
UserService admin = new UserServiceProxy("gpcoder", "admin");
admin.load();
admin.insert();
UserService customer = new UserServiceProxy("customer", "guest");
customer.load();
customer.insert();
}
}
Output của chương trình:
gpcoder loaded
gpcoder inserted
customer loaded
Exception in thread "main"
java.lang.IllegalAccessError: Access denied
at com.gpcoder.patterns.structural.proxy.rotection.UserServiceProxy.insert(UserServiceProxy.java:23)
at com.gpcoder.patterns.structural.proxy.rotection.Client.main(Client.java:11)
Các bạn thấy khi Client muốn gọi hàm insert(), trong Proxy luôn xác thực quyền của user trước khi thực hiện nó.
Ví dụ Remote Proxy
Với Remote Proxy, proxy class và real class nằm ở 2 địa chỉ khác nhau. Thông qua network, proxy class sẽ encode và gửi request tới real class để khởi tạo, truy xuất, …
Chúng ta có thể thấy remote Proxy khi implements Java RMI hoặc thông dụng nhất là ở WebService. Bên phía client sẽ có 1 proxy class, client sẽ khởi tạo proxy class và gọi tới real class nằm ở 1 địa chỉ khác.
Ví dụ Smart Proxy
Proxy Class sẽ thay đổi hoặc thêm 1 số thao tác trước khi gọi tới real class. Một số trường hợp thường thấy là:
Ở lần đâu tiên khởi tạo real class, Proxy class sẽ lưu lại thông tin của real class vào cache và hữu dụng cho lần tái sử dụng sau. Ta có thể thấy việc xuất hiện ở lazy-load ở các connection xuống database.
Trước khi gọi real class, ta có thể lock real class lại và không cho các thread khác phải chờ cho tới khi thread hiện tại release real class.
Đếm số lượng reference tới real class.
Ở Virtual Proxy, mình cũng có lồng 1 ví dụ của Smart Proxy vào. Khi ta khởi tạo RealImage, mình đã lưu cache RealImage lại và lần sau gọi hàm ShowImage(), ta không phải khởi tạo lại RealImage.
Lợi ích của Proxy Pattern là gì?
Cãi thiện Performance thông qua lazy loading, chỉ tải các tài nguyên khi chúng được yêu cầu.
Nó cung cấp sự bảo vệ cho đối tượng thực từ thế giới bên ngoài.
Giảm chi phí khi có nhiều truy cập vào đối tượng có chi phí khởi tạo ban đầu lớn.
Dễ nâng cấp, bảo trì.
Sử dụng Proxy Pattern khi nào?
Khi muốn bảo vệ quyền truy xuất vào các phương thức của object thực.
Khi cần một số thao tác bổ sung trước khi thực hiện phương thức của object thực.
Khi tạo đối tượng ban đầu là theo yêu cầu hoặc hệ thống yêu cầu sự chậm trễ khi tải một số tài nguyên nhất định (lazy loading).
Khi có nhiều truy cập vào đối tượng có chi phí khởi tạo ban đầu lớn.
Khi đối tượng gốc tồn tại trong môi trường từ xa (remote).
Khi đối tượng gốc nằm trong một hệ thống cũ hoặc thư viện của bên thứ ba.
Khi muốn theo dõi trạng thái và vòng đời đối tượng.
So sánh Proxy Pattern với Decorator Pattern
Cấu trúc của Proxy Pattern và Decorator Pattern là tương tự nhau (bạn có thể coi ở class diagram). Hai Pattern này đều Wrap một đối tượng thực bên trong nó. Tuy nhiên, khác nhau thật sự giữa Proxy Pattern và Decorator Pattern nằm ở mục đích sử dụng. Với Decorator Pattern, người sử dụng sẽ nhắm tới mục tiêu là có thể thêm tính năng động vào một đối tượng có trước, trong khi đó Proxy Pattern cho phép ta tạo ra một đại diện cho một đối tượng khác.
Bài viết được sự cho phép của tác giả Trần Văn Dem
Hiện nay việc tìm kiếm các hướng dẫn về sử dụng hibernate, spring jpa là rất dễ. Tuy nhiên các hướng dẫn này thường chỉ giới thiệu cách sử dụng, quản lý Id của Entity thông qua strategy : AUTO,TABLE,SEQUENCE,IDENTITY. Nhưng rất ít hoặc rất khó tìm bài hướng dẫn nào nói cụ thể về các kiểu strategy này và cách sử dụng hiệu trong dự án. Bài viết này tôi sẽ giúp các bạn hiểu rõ hơn về các loại strategy này từ đó có thể tự tin lựa chọn trong project tránh các lỗi không đáng có.
1. sequence vs auto_increment
Trước khi tìm hiểu về các loại strategy thì chúng ta nên phân biệt các loại dữ liệu này. Trước tiên thì 2 loại này sẽ là cách cơ sở dữ liệu của bạn dùng để tạo id cho bảng lưu trữ dữ liệu.
auto increment
Cách sử dụng auto_increment
createtableuser
(
idint auto_increment
primary key,
namevarchar(255) null,
age intnull
);
insertintouser (age, name) values (104, 'mai4')
insertintouser (age, namevalues (103, 'mai3')
SELECT * FROMuser;
+----+------+------+
| id | name | age |
+----+------+------+
| 1 | mai4 | 104 |
| 2 | mai3 | 103 |
+----+------+------+
2 rows in set (0,00 sec)
Kiểu dữ liệu này chắc hầu hết mọi người đều đã biết và sử dụng thường xuyên kiểu này. Các loại database sau hỗ trợ: mysql, mariadb,…
Tạo 1 entity đơn giản như bên dưới lưu ý allocationSize phải đúng với giá trị INCREMENT BY khi tạo sequence. Loại strategy này sẽ hỗ trợ việc batch insert. Ví dụ bên dưới thực hiện với mariadb.
Ta thấy các id được service tạo ra nó có thứ tự liên tiếp khác với những id được chúng ta tạo với 2 câu lệnh insert đầu tiên. Hình ảnh bên dưới mô tả cơ chế GenerationType.SEQUENCE của hibernate.
Đầu tiên hibernate sẽ gọi vào database để lấy nextVal của sequece lưu lại nextVal này và tiếp tự generate id của entity từ nextVal – allocateSize-1 đến nextVal hoạt động tạo id này sẽ không cần truy cập vào database nên sẽ tối ưu về mặt tốc độ. Mặt khác vì kiểu sequence là kiểu đặc biệt nên 2 service cùng gọi để lấy nextVal tại 1 thời điểm thì kết quả trả về cho 2 service là khác nhau cho nên sẽ không có trường hợp bị trùng id giữa các service khác nhau sử dụng cùng một sequence để tạo id.
3. strategy = GenerationType.IDENTITY
Chúng ta sẽ sử dụng loại strategy này với mysql, strategy này ứng với dạng auto_increment. Chỉnh sửa một chút về file config, Entity, thư viện.
Vì trong hibernate khi batch insert chúng ta bắt buộc phải truyền theo Id, nhưng dạng này lại dựa vào cơ chế auto_increment của database nên lúc insert chúng ta chưa biết được id của nó là gì khiến cho dạng này hibernate sẽ không hỗ trợ batch insert mặc dù chúng ta vẫn cấu hình batch insert cho nó. Thực hiện gọi đến route và ta được kết quả.
Bằng các cách tạo id hiện nay, các service của chúng ta không cần phải trọc vào database vẫn có thể tạo ra các id khác nhau (Mình sẽ viết phương pháp này trong bài tiếp) . Ngay cả khi chúng ta thực hiện truyền id này vào trong entity sử dụng strategyGenerationType.IDENTITY hibernate cũng không thực hiện batch insert, thậm trí khi truyền Id chúng ta lại có một hiệu năng còn tệ hơn.
@PutMapping("/multi/user")
String insertMultiUser() {
List<User> savedUser = new ArrayList<>();
for (int i = 1; i < 6; i++) {
Useruser = newUser();
user.setId(1000 * i);
intindex = count.addAndGet(1);
user.setName("demtv" + index);
user.setAge(index);
savedUser.add(user);
}
repository.saveAll(savedUser);
return "done";
}
Thực hiện gọi route ta có kết quả
{"name":"Batch-Insert-Logger", "time":1, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["1000"]]}
Hibernate: insertintouser (age, name) values (?, ?)
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["insert into user (age, name) values (?, ?)"], "params":[["1","demtv1"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["2000"]]}
Hibernate: insertintouser (age, name) values (?, ?)
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["insert into user (age, name) values (?, ?)"], "params":[["2","demtv2"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["3000"]]}
Hibernate: insertintouser (age, name) values (?, ?)
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["insert into user (age, name) values (?, ?)"], "params":[["3","demtv3"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":1, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["4000"]]}
Hibernate: insertintouser (age, name) values (?, ?)
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["insert into user (age, name) values (?, ?)"], "params":[["4","demtv4"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["5000"]]}
Hibernate: insertintouser (age, name) values (?, ?)
{"name":"Batch-Insert-Logger", "time":1, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["insert into user (age, name) values (?, ?)"], "params":[["5","demtv5"]]}
Theo kết quả query của hibernate bên trên thì trước mỗi câu insert chúng ta đều phải có một câu select để kiểm tra id của chúng ta truyền vào đã tồn tại trong bảng hay chưa? Rồi mới đến bước insert vào database. Điều đó khiến hiệu năng giảm xuống. Tiếp theo check kết quả mysql chúng ta mới thấy sự bất ngờ.
Hibernate: select next_val as id_val fromserialforupdate
{"name":"Batch-Insert-Logger", "time":1, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select next_val as id_val from serial for update"], "params":[[]]}
Hibernate: updateserialset next_val= ? where next_val=?
{"name":"Batch-Insert-Logger", "time":1, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["update serial set next_val= ? where next_val=?"], "params":[["11","1"]]}
Hibernate: select next_val as id_val fromserialforupdate
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select next_val as id_val from serial for update"], "params":[[]]}
Hibernate: updateserialset next_val= ? where next_val=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["update serial set next_val= ? where next_val=?"], "params":[["21","11"]]}
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
{"name":"Batch-Insert-Logger", "time":2, "success":true, "type":"Prepared", "batch":true, "querySize":1, "batchSize":5, "query":["insert into user (age, name, id) values (?, ?, ?)"], "params":[["1","demtv1","1"],["2","demtv2","2"],["3","demtv3","3"],["4","demtv4","4"],["5","demtv5","5"]]}
Chúc mừng chúng ta cuối cùng đã thực hiện được batch insert với mysql. Nhưng sự thật có đáng để vui hay không? Theo như log bên trên mỗi lần thực hiện insert hibernate lại vào bảng serial lấy ra id tiếp theo Hibernate: select next_val as id_val from serial for update Cơ chế này sẽ làm giảm hiệu năng chương trình đi rất nhiều. Tiếp đến câu lệnh hibernate dùng để lấy id cũng gây lock table serial lại khiến hiệu năng lại giảm thêm. Cơ chế này không phải cơ chế SEQUENCE mà là cơ chế “TABLE” một trong các cơ chế mọi người nên tránh sử dụng. Chỉ sủ dụng khi loại database của mọi người không hỗ trọ cơ chế “auto_increment” và “sequence”. Với mysql hibernate chỉ sử dụng tốt nhất với strategy = GenerationType.IDENTITY
3.2 Không sử dụng strategy
Giả sử với phương pháp tạo Id, chúng ta không cần thiết phải dựa vào database để tạo id. Chúng ta dùng id tự tạo ra để insert vào database.
@PutMapping("/multi/user")
String insertMultiUser() {
List<User> savedUser = new ArrayList<>();
for (int i = 1; i < 6; i++) {
Useruser = newUser();
user.setId(1000 * (i + 1));
intindex = count.addAndGet(1);
user.setName("demtv" + index);
user.setAge(index);
savedUser.add(user);
}
repository.saveAll(savedUser);
return "done";
}
Chúng ta gọi đến route và check log
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["2000"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["3000"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["4000"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["5000"]]}
Hibernate: select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ fromuser user0_ where user0_.id=?
{"name":"Batch-Insert-Logger", "time":0, "success":true, "type":"Prepared", "batch":false, "querySize":1, "batchSize":0, "query":["select user0_.id as id1_0_0_, user0_.age as age2_0_0_, user0_.name as name3_0_0_ from user user0_ where user0_.id=?"], "params":[["6000"]]}
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
Hibernate: insertintouser (age, name, id) values (?, ?, ?)
{"name":"Batch-Insert-Logger", "time":2, "success":true, "type":"Prepared", "batch":true, "querySize":1, "batchSize":5, "query":["insert into user (age, name, id) values (?, ?, ?)"], "params":[["1","demtv1","2000"],["2","demtv2","3000"],["3","demtv3","4000"],["4","demtv4","5000"],["5","demtv5","6000"]]}
Cách này cũng giống như khi sử dụng strategy=IDENTITY cũng gây hiệu năng giảm sút vì cần các câu select trước các câu insert.
4. Bulk insert with mariadb
Các bạn có thể biết cách batch insert không phải là cách insert nhanh nhất khi thực hiện insert dữ liệu vào database. Nó chỉ tiết kiệm được IO truyền qua mạng bằng cách gửi nhiều lệnh insert lên database thực hiện một lần. Kiểu insert nhanh nhất vào database phải là bulk insert rất tiếp hibernate không hỗ trợ kiểu này. Nhưng với mariadb và mysql chúng ta có config rewriteBatchedStatements nếu set config này rewriteBatchedStatements=true thì jdbc sẽ viết lại các câu lệnh batch insert thành bulk insert.
Chú ý phần argument của câu lệnh insert nó đã được viết lại thành bulk insert điều này tăng hiệu năng của chương trình.
5. Kết luận
Sau khi thử nghiệm các loại strategy khác nhau chúng ta có kết luận sau:
Sử dụng SEQUENCE khi database hỗ trợ dạng này. Kể cả hỗ trợ SEQUENCE lẫn IDENTITY thì vẫn chọn dạng SEQUENCE vì hibernate hỗ trợ tốt nhất với dạng này.
Nếu database hỗ trợ IDENTITY thì chỉ nên dùng IDENTITY đùng sử dụng các loại khác
Không sử dụng loại TABLE trừ khi database của bạn không hỗ trợ “auto_increment” hoặc “sequence”
Không nên truyền id khi thực hiện insert trong hibernate nếu không hiệu năng chương trình của bạn sẽ có vấn đề
Sử dụng config “rewriteBatchedStatements” với mariadb, mysql để tăng hiệu năng của chương trình.
Trên môi trường local, chúng ta khởi động queue bằng cách chạy command:
php artisan queue:work
Nhưng trên môi trường production thì không ai rảnh mà lúc nào cũng bật một terminal để chạy command trên cả, mà sẽ có cách khác, và trong bài viết ngắn gọn này mình sẽ chỉ bạn điều đó.
I. Supervisor
1.1 Cấu hình supervisor để chạy queue
Supervisor là một chương trình giám sát tiến trình trên hệ điều hành Linux, mặt khác Laravel thường được deploy trên các server Linux, vì thế mình sẽ sử dụng Supervisor để giám sát việc chạy queue Laravel.
Hiểu nôm na, Supervisor sẽ giúp chúng ta chạy ngầm cái command php artisan queue:work ngay cả khi tắt terminal.
Để sử dụng supervisor làm “giám sát viên” cho queue, ta thực hiện các bước sau:
Bước 1: Cài đặt Supervisor trên Linux (ở đây mình sử dụng Ubuntu)
sudo apt-get install supervisor
Bước 2: Cấu hình supervisor
Mỗi một tiến trình do Supervisor giám sát sẽ được cấu hình ở một file dạng *.conf nằm trong thư mục /etc/supervisor/conf.d. Nên mình sẽ tạo ra một file có tên là laravel-workder.conf để cấu hình tiến trình chạy queue của Laravel.
sudo vim /etc/supervisor/conf.d/laravel-workder.conf
Nội dung của file laravel-workder.conf như sau:
[program:laravel-worker]
process_name=%(program_name)s_%(process_num)02d
command=php /path/to/your/project/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
# user thực hiện command 'php artisan queue:work'
# nhớ thay bằng user có quyền thực hiện command trên nhé
user=forge
numprocs=8
redirect_stderr=true
# Các vấn đề sẽ được log vào đây
stdout_logfile=/path/to/your/project/worker.log
Nhớ thay các đoạn bôi đỏ thành thông tin phù hợp với dự án của bạn, sau đó lưu file lại.
Khi sử dụng Supervisor để chạy queue Laravel, thường có một số vấn đề (lỗi) kèm hướng khắc phục như sau:
Queue không chạy
Có rất nhiều nguyên nhân dẫn đến queue không chạy, vì thế hãy đọc file log worker.log để biết thêm thông tin (cũng nên kết hợp đọc cả file storage/logs/laravel.log nữa).
Vẫn chạy “job cũ“
Code trong job được update, thế nhưng nó không chạy theo code mới, mà lại chạy theo code cũ. Gặp trường hợp này, hãy thử khởi động lại supervisor:
sudo service supervisor restart
II. Queue Driver
Queue đã tự động chạy với Supervisor, giờ chúng ta tìm hiểu kỹ hơn về các queue driver có trong Laravel.
Queue driver là các “loại queue” có trong Laravel, chúng đều có mục đích là giúp queue có thể hoạt động, nhưng mỗi loại queue lại có các tính chất (hiệu năng, cách cài đặt, cách chạy) khác nhau, và tùy từng dự án mà chúng ta sẽ sử dụng các loại queue khác nhau.
Từ Laravel 6.x, Queue driver được gọi là Queue connection, chỉ là đổi cách gọi tên, còn chúng vẫn là một.
2.1 Sync
Queue sync là queue mà … dùng như không dùng. Các job khi đưa vào queue sẽ được thực hiện ngay lập tức. Cũng có thể hiểu, khi cấu hình queue driver là sync tức là bạn đã tắt queue trong Laravel.
Queue sync chỉ nên sử dụng để dev trên local, không nên để trên production.
Cách cài đặt
Mở file .env, tìm dòng QUEUE_DRIVER=XXX, đổi thành QUEUE_DRIVER=sync.
Lưu ý: với Laravel 6.x trở nên thì QUEUE_DRIVER đổi thành QUEUE_CONNECTION.
2.2 Database
Với queue database, các job sẽ được lưu vào trong database để chạy dần dần. Vì lưu trữ job trong database, nên chúng ta sẽ cần tạo một vài table mới để lưu trữ, nhưng không sao, laravel đã tạo sẵn cho bạn command để cài đặt rồi.
Cách cài đặt
Chạy command sau để tạo bảng lưu trữ các job:
php artisan queue:tablephp artisan migrate
Cấu hình .env
QUEUE_DRIVER=database
Queue database cũng phù hợp để sử dụng trên production.
2.3 Redis
Redis là một dạng database lưu trữ trên RAM, đặc điểm của nó là tốc độ đọc – ghi rất nhanh, rất phù hợp để làm nơi lưu trữ các job của queue. Để sử dụng queue driver là redis, trước tiên bạn cần cấu hình thông tin kết nối tới redis ở config/database.php trước đã:
// config/database.php
// ...
'redis' => [
'client' => 'predis',
// Hãy đảm bảo các thông tin kết nối tới redis là chính xác
'default' => [
'host' => env('REDIS_HOST', '127.0.0.1'),
'password' => env('REDIS_PASSWORD', null),
'port' => env('REDIS_PORT', 6379),
'database' => 0,
],
],
Bạn có thể tìm hiểu thêm về cách cài đặt và cấu hình redis database theo tài liệu của Laravel.
Cách cài đặt
Về cơ bản, bạn chỉ cần cấu hình thông tin kết nối tớ redis ở file config/database.php là đủ, nhưng bạn cũng nên xem qua file config/queue.php
Công nghệ Blockchain mang một tiềm năng to lớn, được xem là “chìa khóa” cho chuyển đổi số và mở ra một xu hướng mới cho nhiều lĩnh vực trong tương lai. Vậy công nghệ blockchain là gì? Các đặc điểm nổi bật của blockchain? Và ứng dụng nó như thế nào?
Công nghệ Blockchain là gì?
Blockchain là công nghệ chuỗi khối, cho phép chia sẻ thông tin một cách minh bạch và an toàn dựa trên hệ thống mã hóa vô cùng phức tạp. Dữ liệu sẽ được lưu trữ trong các khối, liên kết với nhau trong một chuỗi và được mở rộng theo thời gian.
Mỗi khối sẽ chứa đựng các thông tin về dữ liệu giao dịch và liên kết với khối trước đó nên việc can thiệp thay đổi thông tin là điều không thể xảy ra.
Một điều khác biệt của blockchain so với các công nghệ khác là thông tin không nằm tập trung ở một máy chủ nào cả, cũng không ai kiểm soát được nó, mọi thông tin sẽ được sao lưu trên nhiều máy chủ khác nhau. Thiết kế của mạng lưới này giúp chống lại sự thay đổi của dữ liệu và quản lý dưới mạng lưới phi tập trung. Ngay cả khi một phần của hệ thống blockchain sụp đổ thì các nút khác vẫn sẽ tiếp tục lưu trữ và giữ cho mạng lưới hoạt động bình thường.
Các chuỗi blockchain không thể làm giả và phá hủy: Chỉ khi máy Internet trên toàn cầu biến mất blockchain mới bị phá hủy.
Bất biến: Dữ liệu không thể được sửa chữa nếu giao dịch đã xảy ra.
Bảo mật: Các thông tin và dữ liệu về các chuỗi blockchain được phân tán và an toàn tuyệt đối.
Minh bạch: AI sẽ theo dõi đườngđi của blockchain từ địa chỉ này qua địa chỉ khác và ghi lại toàn bộ lịch sử đó.
Hợp đồng thông minh: Đây là một dạng hợp đồng kỹ thuật số được nhúng vào đoạn code if-this-then-that (IFTTT) cho phép chúng tự động thực thi khi đáp ứng các điều kiện đã định sẵn mà không cần can thiệp bởi bên thứ ba.
Công nghệ blockchain và ứng dụng
Blockchain là một công nghệ mới và ngày càng chứng minh được khả năng ứng dụng tuyệt vời của nó vào thực tiễn. Dưới đây là một số ứng dụng điển hình của công nghệ blockchain trong nhiều lĩnh vực.
Truyền thông và viễn thông: Blockchain sẽ giúp các nhà cung cấp dịch vụ truyền thông tối ưu hóa quy trình, tăng cường khả năng bảo mật mạng cũng như quản lý danh tính trong mô hình kinh doanh của mình.
Sản xuất: Công nghệ blockchain mang đến các giải pháp giúp theo dõi quá trình sản xuất, quản lý hàng tồn kho, truy xuất nguồn gốc sản phẩm qua các khâu, theo dõi nguồn cung cấp nguyên liệu sản xuất, ghi nhận thông tin giao dịch,…
Y tế: Blockchain được sử dụng để quản lý tài sản và lưu trữ thông tin sức khỏe bệnh nhân, quản lý chuỗi cung ứng thuốc, thiết bị y tế (nguồn gốc, hạn sử dụng,…), tăng cường tính minh bạch và tự động hóa trong các giao dịch khám chữa bệnh,…
Giáo dục:Công nghệ blockchain giúp lưu trữ các thông tin về quá trình học, các kinh nghiệm thực tế, trình độ học vấn, kỷ luật,… tránh tình trạng ứng viên gian lận trong quá trình xin học bổng, thăng tiến. Blockchain còn giúp thực hiện các khoản nội quy đào tạo của nhà trường, xử lý các trường hợp vi phạm và cải thiện quy trình làm việc.
Tài chính & ngân hàng: Khả năng tạo hợp đồng thông minh của blockchain sẽ giải quyết được các rủi ro khi giao dịch, loại bỏ tình trạng tập trung quyền lực, cho phép giao dịch ngay cả khi không có trung gian xác minh. Người dùng sẽ tiết kiệm được chi phí, tăng tốc độ giao dịch và hạn chế rủi ro trong quá trình thanh toán.
Thương mại điện tử: Công nghệ blockchain sẽ giải quyết các vấn đề liên quan đến nguồn gốc sản phẩm, quá trình vận chuyển bằng các hợp đồng thông minh, tạo điều kiện cho các doanh nghiệp đa quốc gia dễ dàng ký kết.
Nông nghiệp:Blockchain được ứng dụng trong nông nghiệp giúp lưu trữ thông tin giao dịch, tăng tính minh bạch của thông tin trong quá trình vận chuyển sản phẩm từ cơ sở sản xuất đến cơ sở chế biến, nhà phân phối, cửa hàng hay siêu thị. Điều này giúp truy xuất nguồn gốc hiệu quả, nâng cao lòng tin cho người tiêu dùng.
Ngoài ra, công nghệ blockchain còn được ứng dụng ở nhiều lĩnh vực khác như vận tải và logistics, ngành bán lẻ, du lịch, bảo hiểm, năng lượng, xây dựng,…
Thành công lớn nhất của công nghệ blockchain là tạo ra “hợp đồng thông minh”, các giao dịch thỏa thuận trong hợp đồng sẽ được xác nhận mà không cần thông qua bên trung gian. Mọi giao dịch đều an toàn và minh bạch, khó có thể làm giả và nếu có chắc chắn sẽ để lại dấu vết.
Công nghệ blockchain đã mở ra một xu hướng mới cho các lĩnh vực như tài chính ngân hàng, bảo hiểm, kế toán kiểm toán, y tế, game,… Kéo theo cơn khát nhân sự blockchain nóng hơn bao giờ hết.
Trong thời đại công nghệ, nhu cầu bảo mật, kết nối và tiện lợi của khách hàng ngày càng cao, việc nắm bắt xu hướng công nghệ mới sẽ tạo lợi thế khác biệt để thương hiệu vươn lên trước đối thủ cạnh tranh. Hiện nay đã có rất nhiều công ty và tập đoàn lớn bắt tay vào xây dựng blockchain như Facebook, Apple, Alibaba, Ford,… tạo nên một làn sóng công nghệ mới cho tương lai.
Tóm lại, công nghệ blockchain ra đời đã và đang trở thành một điểm sáng trong nền khoa học 4.0 của thế kỷ 21. Đây là thời điểm thích hợp để các công ty/doanh nghiệp khai thác và tận dụng công nghệ mới này một các tối ưu và hiệu quả nhất. Hy vọng bài viết này đã giúp bạn hiểu rõ hơn về công nghệ blockchain, chúc bạn có những định hướng tốt trong trong tương lai.
Vạn sự khởi đầu nan, câu nói này chưa bao giờ sai, kể cả trong việc học lập trình cũng vậy. Bài viết này mình sẽ kể ra những cái “khó” mà mình gặp phải trong những ngày đầu tiên học lập trình, để xem giữa mình và bạn có đặc điểm chung nào không nhé.
I. Nản do phải học nhiều thứ
Trước khi học lập trình, mình có ước mơ là sẽ tạo ra một phần mềm gì đó thật ngầu, làm thay đổi thế giới, và trở nên giàu có nhờ phần mềm đó. Nhưng khi bắt đầu học, thì mới thấy cái ước mơ đầu quá xa vời. Vì để tạo ra một phần mềm vĩ đại như thế, mình cần phải học rất nhiều thứ (cho tới bây giờ cũng chưa học hết). Khi biết được điều này, thật sự mình cảm thấy nản và muốn bỏ cuộc. Nhưng nghĩ kỹ thì lại thấy làm gì có gì dễ dàng đâu, thôi thì giảm mục tiêu xuống vậy.
– Trước khi học lập trình: Mình sẽ tạo ra một con game làm “điên đảo” game thủ thế giới
– Khi học được 1 năm: Mình sẽ tạo ra một cổng thông tin về game lớn nhất Việt Nam
– Khi học được 2 năm: Mình sẽ tạo ra một blog và tự tay viết các tin về game
– Khi học được 3 năm: Mình sẽ dùng một nền tảng blog có sẵn để viết bài thay vì tự code
– Khi học xong: Code gì cũng được, miễn là code
– Khi đi làm: Ai đó fix giúp tôi cái bug này
Nếu bạn có rơi vào trường hợp này giống mình, thì cũng hãy thử giảm mục tiêu xuống xem sao. Giảm mục tiêu không phải là sợ mình không làm được việc lớn, mà là biết lượng sức mình. Hoàn thiện nhiều việc nhỏ giúp mình có kiến thức và kinh nghiệm để sau này làm việc lớn.
Khi học lập trình, mình gặp rất nhiều kiến thức được gắn mác “cơ bản”, nhưng khi học mình lại khó vô cùng (nhất là kiến thức về giải thuật), làm mình có suy nghĩ “có phải mình quá ngu để học lập trình hay không”, và lại bắt đầu chán nản lần 2.
Nhưng một người khác đã nói với mình “cơ bản không có nghĩa là dễ học dù phần lớn kiến thức cơ bản đều dễ học“. Nghĩ thì thấy đúng thật.
kiến thức cơ bản là những kiến thức mang tính cơ sở để học các kiến thức khác, và nó không có “nghĩa vụ” là phải dễ học. Nếu một kiến thức gắn mác “cơ bản”, nghĩa là mình phải học nó, chứ không có nghĩa là mình có thể học nó một cách dễ dàng. Quan điểm này đã giúp mình thay đổi suy nghĩ và tiếp tục học một cách nghiêm túc.
Mình đã bỏ thời gian học hành nghiêm túc, mình đã học hết các kiến thức cơ bản, mình đã có thể tạo ra một giao diện web hoặc một phần mềm giả lập máy tính bỏ túi, và mình cũng tự tin là nắm rõ một vài ngôn ngữ lập trình. Nhưng mình vẫn không thể tạo ra một phần mềm ưng ý. Phần mềm mình tạo ra rất khó sử dụng, thường xuyên gặp lỗi, bố cục lộn xộn, giao diện xấu xí, và mình còn chẳng muốn sử dụng nó chứ đừng nói là cho người khác sử dụng – nói chung là “Học được nhưng làm không được”.
Nhưng mà kệ, đâm lao thì phải theo lao thôi, học được đến đây rồi không lẽ bỏ cuộc.
Mình cũng cho rằng việc “học được nhưng làm không được” là do thiếu kinh nghiệm, nên mình cố gắng code nhiều hơn, cải tiến các dự án cũ cho bớt lỗi và dễ sử dụng hơn, cũng như tham khảo các dự án opensource được tạo ra bởi các developer có kinh nghiệm để học tập.
Mình chẳng nhớ là đã làm bao nhiêu dự án cá nhân (pet project) nữa, chắc phải đến cả trăm cái, qua mỗi dự án như vậy, mình lại rút ra được một chút kinh nghiệm. Lâu dần, tích tiểu thành đại, mình đã nâng cao khả năng code đáng kể.
IV. Một vài khó khăn khác
Một vài khó khăn khác nhỏ hơn, nhưng vẫn đáng nói:
Không quen “mặt bug”: Khi mới học lập trình, có những lỗi rất khó hiểu, mặc dù trình biên dịch hiển thị lỗi rất cụ thể, nhưng đọc vẫn không hiểu. Đành copy lên google xem có ai gặp phải hay chưa rồi xem cách khắc phục của họ. Lâu ngày, bug cũ lặp đi lặp lại thì thành ra “quen mặt”, nên cũng dễ fix hơn.
Không quen “mặt code”: Mỗi ngôn ngữ lập trình lại có cú pháp khác nhau, cái dài cái ngắn, cái có dấu chấm phẩy cái lại không có. Nên thời gian đầu đọc hơi khó hiểu, nên đành phải code nhiều, nhìn nhiều cho quen.
Chọn cách giải nào: Cùng một vấn đề, nhưng có thể có nhiều cách giải, và mình phải tốn khá nhiều thời gian và chất xám để tìm ra cách giải nào là tốt nhất.
V. Lời kết
Bài viết này không chỉ mang tính chất “kể khổ”, mà còn muốn nhắn nhủ tới các bạn newbie rằng “vạn sự khởi đầu nan”. Dù khó khăn của bạn có giống của mình hay không, thì thời gian đầu chắc chắn khó học, nhưng khó ở đây là khó chung chứ không riêng gì bạn, vì thế hãy cố gắng vượt qua nhé. Chúc các bạn thành công.
Trong thế giới công nghệ, thỉnh thoảng chúng ta thường bắt gặp cụm từ “LTS“. Ví dụ như Ubuntu 16.04 LTS, Ubuntu 18.04 LTS, Laravel 6 LTS,… Vậy LTS có nghĩa là gì?
LTS là viết tắt của Long Term Support có nghĩa là Hỗ trợ dài hạn.
Như định nghĩa trên:
các phiên bản có gắn mác LTS sẽ là phiên bản được hỗ trợ dài hạn. Tức là cho dù đã phát hành được một thời gian và kể cả đã có phiên bản khác mới hơn được phát hành thì phiên bản có gắn mác LTS sẽ vẫn được hỗ trợ bảo trì như bình thường.
Ví dụ một ứng dụng A phát hành phiên bản 4.0 LTS vào năm 2020, hỗ trợ bảo trì tới năm 2024. Thì trong khoảng thời gian từ năm 2020 tới năm 2024 có thể ứng dụng A đã phát hành thêm các phiên bản 5.0, 6.0 khác, nhưng phiên bản 4.0 vẫn sẽ được cập nhật các bản vá lỗi và vá lỗi bảo mật một như bình thường.
Việc sử dụng phiên bản LTS sẽ đem lại một số lợi thế sau:
Phiên bản LTS thường là các phiên bản hoạt động ổn định, có cộng đồng sử dụng đông đảo.
Không tốn thời gian, chi phí cho việc phải thường xuyên cập nhật phiên bản mới mà vẫn nhận được sự hỗ trợ từ chính tổ chức phát hành.
Trên là hai lý do cơ bản nhất khiến bạn nên sử dụng phiên bản có gắn mác LTS thay vì các phiên bản thông thường khác. Tuy nhiên bạn vẫn nên sử dụng các phiên bản thông thường (hoặc phiên bản mới nhất) nếu như 2 lợi thế kể trên không đặc biệt quan trọng với bạn.
Công ty mình đang làm hiện tại luôn ưu tiên sử dụng các phiên bản LTS thay vì các phiên bản khác (kể cả phiên bản mới nhất), vì sản phẩm của công ty luôn yêu cầu tính ổn định cao. Hơn nữa mọi người cũng muốn tập trung nguồn lực để phát triển các business của sản phẩm thay vì chỉ trực có phiên bản mới là update.
Còn với cá nhân mình, trong các dự án dạng “làm chơi cho vui” thì cứ phiên bản mới nhất là mình quất. Cốt lõi là muốn trải nghiệm các tính năng mới, bởi các phiên bản hỗ trợ dài hạn cũng thường đi với sự lỗi thời.
Để đảm bảo một hệ thống chạy tốt và ổn định, các việc thiết kế hệ thống như : chọn mô hình (micro, monolithic), loại database, cách truyền tải dữ liệu (message queue, http, socket,..), cách load balancing,… là việc rất quan trọng đánh dấu sự thành công của hệ thống. Song song với đó việc chúng ta thiết kế một service cũng là một mấu chốt quan trọng. Service bạn chịu trách nhiệm thiết kế có thể có các thao tác đọc ghi trên một dữ liệu tranh chấp. Khi 2 luồng của service của bạn cùng sửa một tài nguyên bị tranh chấp sẽ gây ra sự sai sót của hệ thống. Vậy khi thiết kế chúng ta cần có các kỹ thuật tránh điều này. Trong bài viết này tôi sẽ chia sẻ kinh nghiệm của mình khi thiết kế các service như vậy. Đây là phần một của bài viết sẽ nói về cách các bạn xử lý dữ liệu khi đến service chưa nói đến phân tải khi bạn có nhiều service cùng thực hiện một việc cũng như các service cùng một việc sẽ đồng bộ với nhau như thế nào.
2. Mô tả bài toán
Giả sử chúng ta cần thiết kế một service cho phép khách hàng thực hiện rút tiền. Chúng ta có một bảng đơn giản lưu lại thông tin của khách hàng như sau.
Yêu cầu của service là khi khách hàng rút tiền số dư sẽ được thay đổi và được lưu lại trong database. Trong đề bài này phần tài nguyên tranh chấp là số tiền của khách hàng. Chúng ta sẽ thiết kế theo mô hình đơn giản sau
3. Tránh tranh chấp bằng từ khóa synchronized hoặc lock trong java
Cách đơn giản để tránh tranh chấp các loại tài nguyên này là bạn chỉ cho phép một luồng được thực hiện với thao tác với tài nguyên tranh chấp. Trong java chúng ta có thể dùng synchronized hoặc lock.
public synchronized User doUpdate(int amount){
//...
user.setTotalMoney(user.getTotalMoney() - withDrawRequest.getAmount());
user = service.updateUser(user);
CacheManager.user.put(user.getId(), user);
response.setMsg("ok");
//...
}
private ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.WriteLock lock = readWriteLock.writeLock();
public User doUpdate(int amount){
lock.lock();
try{
//...
user.setTotalMoney(user.getTotalMoney() - withDrawRequest.getAmount());
user = service.updateUser(user);
CacheManager.user.put(user.getId(), user);
response.setMsg("ok");
//...
}finally {
lock.unlock();
}
}
3.1. Ưu điểm.
Dễ implement không cần database để xử lý tranh chấp
3.2. Nhược điểm.
Không thể phục vụ nhiều khách hàng cùng lúc được.
Khó triển khai trên nhiều node service với các cách phân tải hay dùng hiện nay ví dụ : roundrobin, ip, WeightedResponseTimeRule … Phải có bộ phân tải hợp lý sao cho mỗi một node service chỉ phục vụ một số lượng user nhất định.
Với thiết kế này trên database sẽ có 1 trường mang đánh dấu là version của dữ liệu khi 2 luồng cùng thực hiện update trên cùng một dữ liệu trên database thì chỉ có 1 luồng thực hiện update thành công. Kỹ thuật đó là optimistic locking chi tiết mọi người xem tại link. Với spring boot các bạn có thể tham khảo tại link. Hoặc tham khảo đoạn code dưới đây
import lombok.Data;
import javax.persistence.*;
@Entity@Table(name = "users")@DatapublicclassUser{
@Id@GeneratedValue(strategy = GenerationType.IDENTITY)privateint id;
private String name;
privateint age;
privateint totalMoney;
@Versionprivateint version;
}
// thao tác với databasetry {
user = service.updateUser(user);
CacheManager.user.put(user.getId(), user);
response.setMsg("ok");
} catch (IllegalStateException exception) {
exception.printStackTrace();
response.setMsg("version is not ok");
}
4.1. Ưu điểm
Phương pháp này có thể phục vụ nhiều khách hàng khác nhau cùng thực hiện thao tác rút tiền.
Nếu bạn có nhiều node service phương pháp này vẫn phục vụ tốt cho bạn không sợ sai lệch dữ liệu
Rất dễ dàng để implement với tất cả developer
4.2. Nhược điểm
Phương pháp phải dùng database để bảo vệ tài nguyên tranh chấp gây lên cao tải cho database. Khi database cao tải bạn tăng số lượng service cũng không làm hệ thống bạn chạy tốt hơn.
5. Xác định cụ thể User nào sẽ được luồng nào xử lý.
Ý tưởng của request rất đơn giản thay vì mỗi request đến chúng ta có một luồng không xác định xử lý và thao tác với database. Giờ chúng ta sẽ tạo trước một số lượng luồng xử lý với database nhất định. Sau đó mỗi request đến ta sẽ lần lượt chia vào từng luồng này để xử lý. Điều này dẫn đến chúng ta sẽ ít sảy ra trường hợp insert fail vào database hơn vì với cùng request của một user chúng ta đã chỉ có 1 luồng duy nhất thao tác với nó nên trong cùng một node service sẽ không gây ra tranh chấp tài nguyên.
5.1. Ưu điểm
Không cần dùng đến database để xử lý tài nguyên tranh chấp cho nên không gây cao tải nên database khiến hệ thống chạy nhanh hơn. Khi bị hệ thống cao tải có thể add thêm service để phục vụ.
Nếu database bị cao tải ta có thể sử dụng phương pháp acsync insert/update vào database không gây ảnh hưởng đến trải nghiệm khách hàng.
5.2. Nhược điểm
Khó implement với những developer mới code. Mọi người có thể tham khảo link github sau được implement bằng springboot. Nếu nó có ích cho tôi xin 1 sao nhé. :))
Khi có nhiều node service thì cách này sẽ không thực sự hiệu quả với các cách load balacing thông thường như : roundrobin, ip, WeightedResponseTimeRule,… Vì như thế chúng ta sẽ không biết được cùng một user có rơi vào 2 node khác nhau không. Chúng ta nên sử dụng thêm version trong database.
Khi triển khai nhiều node service chúng ta cần có phương pháp phân tải thích hợp cho mỗi user sẽ chỉ vào một node nhất định. Khi node đó bị chết thì request của user đó sẽ chỉ chuyển sang một node khác. Có cơ hội sẽ trình bài ở các phần sau.
6. Kết luận
Ở đây tôi đã trình bày xong các cách giúp mọi người có thể thực hiện để tránh tranh chấp tài nguyên khi lập trình vào các request phải thay đổi dữ liệu hy vọng sẽ giúp ích được cho mọi người.
Tất cả các phương pháp đều có thể kết hợp với cache để tăng tốc độ khi không cần thực hiện giao tiếp nhiều với database. Ở các phần sau tôi sẽ giới thiệu một cách phân tải khá thông minh để áp dụng với cách thứ 3 trong bài này và nếu mọi người thấy việc implement cách thứ 3 khá khó thì tôi cũng sẽ có bài hướng dẫn mọi người implement tùy xem Hà Nội cách ly bao ngày nữa :))
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Trong bài này mình sẽ làm ví dụ chuyển data từ MongoDB sang Elasticsearch bằng Transport.
1. Transporter là gì? Cài đặt transporter trên ubuntu
Transporter là một phần mềm mã nguồn mở để di chuyển / đồng bộ dữ liệu trên các kho dữ liệu khác nhau.
Các kho dữ liệu được đồng bộ ở đây có thể là database, files…
Dữ liệu được đọc từ kho dữ liệu nguồn (source) sau đó được chỉnh sửa, tách lọc… (transformer) rồi chuyển tới kho dữ liệu đích (sink) thông qua pipeline do bạn định nghĩa.
ChatGPT là gì mà khiến anh em bà con không chỉ trong mà còn cả ngoài ngành phải thử ít nhất một lần? Điều gì khiến Chat GPT trở nên hot như vậy?
Trong thế giới công nghệ hiện nay, trí tuệ nhân tạo (AI) đang dần trở thành một phần không thể thiếu của cuộc sống. Một trong những công nghệ AI đang thu hút sự chú ý là ChatGPT. Vậy Chat GPT là gì? Nó có thể làm gì và ứng dụng như thế nào? Hãy cùng tìm hiểu trong bài viết này
Chat GPT là gì? Ứng dụng tuyệt vời và cách chatGPT hoạt động
Chat GPT là gì?
Chat GPT hay chatGPT, viết tắt của Chat Generative Pre-trained Transformer là một mô hình AI được phát triển bởi OpenAI. Nó sử dụng các thuật toán deep learning để hiểu và tạo ra văn bản tự nhiên giống như con người. Chat GPT có khả năng trả lời câu hỏi, viết văn bản, dịch ngôn ngữ, và thậm chí tham gia vào các cuộc trò chuyện phức tạp.
ChatGPT là mô hình được đào tạo để có thể tương tác theo cách đàm thoại. Ở định dạng đối thoại, Chat GPT có thể trả lời các câu hỏi tiếp theo (có tính kế tiếp), thừa nhận lỗi nếu nó có lỗi. Từ chối các yêu cầu không phù hợp. Chat GPT là mô hình anh em với InstructGPT, được đào tạo để làm theo hướng dẫn ngay lập tức và cung cấp phản hồi chi tiết.
OpenAI, một công ty nghiên cứu và phát triển về AI có trụ sở ở San Francisco đã ra mắt ChatGPT vào ngày 30 tháng 11 năm 2022. Bản chất của chatGPT vẫn đang là một mô hình sử dụng trí tuệ nhân tạo. Hằng ngày vẫn đang học hỏi chứ không phải là đã hoàn thành.
ChatGPT là gì?
Chat GPT cho phép người dùng đặt câu hỏi hoặc kể lại một câu chuyện. Từ đó BOT sẽ trả lời bằng câu chuyện hoặc câu trả lời có liên quan. Giao diện được thiết kế cho gần giống nhất với cuộc trò chuyện giữa con người với con người.
Các phiên bản chatGPT hiện nay
Kể từ khi ra mắt, Chat GPT đã trải qua nhiều phiên bản nâng cấp để cải thiện hiệu suất và khả năng xử lý. Các phiên bản chính bao gồm:
GPT-1
Giới thiệu: GPT-1 là phiên bản đầu tiên của mô hình GPT được phát triển bởi OpenAI và ra mắt vào năm 2018. Đây là bước đầu tiên trong việc sử dụng kiến trúc Transformer để xử lý ngôn ngữ tự nhiên.
Cải tiến chính: GPT-1 sử dụng 117 triệu tham số, đánh dấu sự chuyển đổi từ các mô hình truyền thống sang kiến trúc Transformer, giúp cải thiện đáng kể hiệu suất xử lý ngôn ngữ.
GPT-2
Giới thiệu: Ra mắt vào năm 2019, GPT-2 là phiên bản cải tiến của GPT-1 với khả năng xử lý ngôn ngữ mạnh mẽ hơn.
Cải tiến chính: GPT-2 có 1,5 tỷ tham số, lớn hơn nhiều so với GPT-1, cho phép mô hình tạo ra văn bản tự nhiên hơn và phản hồi phức tạp hơn. GPT-2 có khả năng hoàn thành các nhiệm vụ như viết tiếp câu, trả lời câu hỏi, và thậm chí tạo ra đoạn văn từ một số gợi ý ban đầu.
GPT-3
Giới thiệu: GPT-3 được ra mắt vào năm 2020 và là phiên bản phổ biến nhất hiện nay của OpenAI.
Cải tiến chính: GPT-3 sử dụng tới 175 tỷ tham số, một bước nhảy vọt lớn so với GPT-2. Điều này giúp GPT-3 có khả năng hiểu và tạo ra văn bản với mức độ phức tạp và chính xác cao hơn nhiều. Nó có thể thực hiện nhiều tác vụ phức tạp như dịch ngôn ngữ, viết bài, sáng tác nhạc, và tham gia vào các cuộc trò chuyện dài và chi tiết.
GPT-4
Giới thiệu:GPT-4 là phiên bản mới nhất, ra mắt vào năm 2023.
Cải tiến chính: GPT-4 tiếp tục nâng cao khả năng xử lý ngôn ngữ và tích hợp nhiều cải tiến về hiệu suất và độ chính xác. Mặc dù OpenAI không tiết lộ chính xác số lượng tham số của GPT-4, nhưng nó được cho là lớn hơn và hiệu quả hơn GPT-3. GPT-4 có khả năng hiểu ngữ cảnh tốt hơn, giảm thiểu lỗi và cung cấp các phản hồi mượt mà và tự nhiên hơn.
Tìm hiểu thêm về các phiên bản GPT-4 phát hành mới nhất: GPT-4o và GPT-4o mini
GPT-5
Chat GPT-5 dự kiến được ra mắt vào cuối năm 2025 hoặc đầu năm 2026 (theo Giám đốc công nghệ (CTO) của OpenAI – Mira Murati cho biết). Bà Mira tiết lộ rằng GPT-5 sẽ là thế hệ có thể đạt được trí thông minh của một tiến sĩ trong một số lĩnh vực nghiên cứu cụ thể. Để so sánh, GPT-3 tương đương với mức độ thông minh của một đứa trẻ, trong khi GPT-4 giống với mức độ thông minh của học sinh trung học.
Chat GPT hoạt động ra sao?
Chat GPT hoạt động ra sao?
Chat GPT hoạt động dựa trên mô hình học máy tiên tiến gọi là Transformer, được huấn luyện trên lượng lớn dữ liệu văn bản để hiểu và tạo ra văn bản tự nhiên. Dưới đây là mô tả chi tiết về cách thức hoạt động của Chat GPT:
Kiến trúc Transformer
Kiến trúc Transformer là nền tảng của Chat GPT, được giới thiệu trong bài báo “Attention is All You Need” bởi Vaswani et al. vào năm 2017. Transformer sử dụng cơ chế Attention, cho phép mô hình tập trung vào các phần quan trọng của văn bản đầu vào trong quá trình xử lý.
Quá trình huấn luyện
Chat GPT được huấn luyện thông qua hai giai đoạn chính: tiền huấn luyện (pre-training) và tinh chỉnh (fine-tuning).
Tiền huấn luyện (Pre-training)
Trong giai đoạn này, mô hình được huấn luyện trên một lượng lớn dữ liệu văn bản từ internet. Mục tiêu là giúp mô hình học cách dự đoán từ tiếp theo trong một câu. Cụ thể, GPT sử dụng phương pháp học máy không giám sát để huấn luyện trên các cặp câu liên tiếp, qua đó học được các cấu trúc ngữ pháp, ngữ nghĩa và thông tin ngữ cảnh từ dữ liệu đầu vào.
Tinh chỉnh (Fine-tuning)
Sau khi hoàn thành giai đoạn tiền huấn luyện, mô hình được tinh chỉnh trên một tập dữ liệu nhỏ hơn, có giám sát, để cải thiện độ chính xác và khả năng đáp ứng cho các tác vụ cụ thể. Giai đoạn này sử dụng các dữ liệu đã được gán nhãn, bao gồm các câu hỏi và câu trả lời hoặc các đoạn văn bản có chủ đề nhất định. Điều này giúp mô hình hiểu rõ hơn về các yêu cầu cụ thể và cải thiện khả năng phản hồi chính xác.
Cơ chế Attention
Cơ chế Attention là một phần quan trọng của Transformer, cho phép mô hình tập trung vào các từ quan trọng trong câu để hiểu ngữ cảnh và mối quan hệ giữa các từ. Attention giúp mô hình xác định và tập trung vào các từ có liên quan trực tiếp đến từ đang được dự đoán, qua đó cải thiện độ chính xác của phản hồi.
Tạo văn bản
Khi nhận được đầu vào từ người dùng, Chat GPT sử dụng các kiến thức đã học trong quá trình huấn luyện để tạo ra văn bản đầu ra. Quá trình này bao gồm các bước sau:
Tiếp nhận đầu vào: Chat GPT nhận một câu hỏi hoặc yêu cầu từ người dùng.
Phân tích ngữ cảnh: Mô hình sử dụng các kiến thức đã học để phân tích ngữ cảnh và hiểu yêu cầu của người dùng.
Tạo văn bản: Sử dụng cơ chế Attention và các tham số đã được huấn luyện, Chat GPT dự đoán từ tiếp theo và tạo ra câu trả lời phù hợp.
Phản hồi: Mô hình gửi câu trả lời trở lại cho người dùng.
ChatGPT cũng có thể được sử dụng để tạo trải nghiệm kể chuyện tương tác, cho phép người dùng khám phá và học hỏi từ thế giới ảo.
Với Chat GPT, anh em có thể sử dụng vào các mục đích dưới đây:
Tạo phản hồi trong chatbot hoặc trợ lý ảo để cung cấp tương tác tự nhiên và hấp dẫn hơn với người dùng (kiểu con bot này nói chuyện như thật zậy chời).
Lên ý tưởng nội dung về từ khóa hoặc chủ đề (thời đại viết bài bằng AI tới đây rồi đấy thôi)
Tạo thông tin liên lạc được cá nhân hóa, chẳng hạn như phản hồi email hoặc đề xuất sản phẩm (hỏi phát biết ngay bố mày là ai)?
Ngoài ra, một số nghề có thể biến mất nếu Chat GPT hoạt động xuất sắc.
Tạo nội dung tiếp thị như bài đăng trên blog hoặc cập nhật trên mạng xã hội (nghề content writer có thể ra đi).
Dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác (học nhiều học lâu có khi google dịch cũng ra đi luôn).
Tóm tắt tài liệu dài bằng cách cung cấp toàn văn và yêu cầu ChatGPT tạo bản tóm tắt ngắn hơn (rồi nhà báo ngày viết trăm bài lun)
Sử dụng câu trả lời do chatbot tạo ra để tạo công cụ chăm sóc khách hàng tự động (rồi mẹ chăm sóc khách hàng hoạt động năm 365 ngày lun)
Hạn chế của ChatGPT
Mặc dù Chat GPT có nhiều ưu điểm và ứng dụng hữu ích, nó cũng gặp phải một số hạn chế đáng kể. Dưới đây là các hạn chế chính của Chat GPT:
1. Thiếu hiểu biết ngữ cảnh sâu
Chat GPT, dù có khả năng xử lý và tạo ra văn bản tự nhiên, đôi khi vẫn gặp khó khăn trong việc hiểu ngữ cảnh phức tạp hoặc đa nghĩa. Nó có thể đưa ra các phản hồi không chính xác hoặc không phù hợp nếu ngữ cảnh không được xác định rõ ràng từ đầu.
2. Phụ thuộc vào dữ liệu huấn luyện
Chất lượng và độ chính xác của Chat GPT phụ thuộc rất nhiều vào dữ liệu huấn luyện. Nếu dữ liệu đầu vào có sai sót hoặc thiên lệch, kết quả đầu ra của mô hình cũng sẽ bị ảnh hưởng. Điều này có thể dẫn đến việc mô hình tạo ra thông tin không chính xác hoặc phản ánh các thiên lệch có trong dữ liệu.
3. Rủi ro bảo mật
Chat GPT có thể bị lợi dụng để tạo ra thông tin sai lệch, spam, hoặc thực hiện các hành vi lừa đảo. Khả năng tạo ra văn bản giống như con người khiến nó trở thành công cụ tiềm năng cho các hoạt động không lành mạnh nếu không được kiểm soát chặt chẽ.
4. Thiếu tính sáng tạo thực sự
Mặc dù Chat GPT có thể tạo ra văn bản mới từ dữ liệu đã học, nó vẫn dựa vào các mẫu và thông tin đã có trong dữ liệu huấn luyện. Điều này nghĩa là mô hình có thể thiếu tính sáng tạo thực sự và khó có thể đưa ra các ý tưởng hoàn toàn mới mẻ hoặc khác biệt.
5. Hiệu suất không ổn định
Hiệu suất của Chat GPT có thể không nhất quán trong các tình huống khác nhau. Đôi khi, mô hình có thể cung cấp các phản hồi xuất sắc, nhưng trong những trường hợp khác, nó lại có thể tạo ra các câu trả lời thiếu logic hoặc không liên quan.
6. Giới hạn về kiến thức cập nhật
Chat GPT không thể truy cập trực tiếp vào các sự kiện hoặc thông tin mới nhất sau khi quá trình huấn luyện kết thúc. Điều này có nghĩa là nó có thể không biết về các sự kiện hiện tại hoặc những thay đổi gần đây trong các lĩnh vực khác nhau.
7. Khả năng xử lý đa ngôn ngữ hạn chế
Mặc dù Chat GPT có thể xử lý nhiều ngôn ngữ, khả năng hiểu và tạo văn bản có thể không đồng đều giữa các ngôn ngữ khác nhau. Ngôn ngữ nào có ít dữ liệu huấn luyện hơn sẽ dẫn đến hiệu suất thấp hơn trong việc tạo ra các phản hồi chất lượng.
9. Thiếu khả năng tương tác đa phương thức
Hiện tại, Chat GPT chủ yếu xử lý văn bản. Nó không thể dễ dàng tương tác hoặc hiểu các dạng dữ liệu khác như hình ảnh, âm thanh, hoặc video, hạn chế khả năng ứng dụng trong các tình huống yêu cầu tương tác đa phương thức.
10. Phản hồi quá mức (Overfitting)
Trong một số trường hợp, Chat GPT có thể phản hồi quá mức, tạo ra văn bản dài hơn hoặc phức tạp hơn mức cần thiết. Điều này có thể dẫn đến sự mất mạch lạc và gây khó khăn cho người dùng trong việc hiểu rõ ý nghĩa của phản hồi.
Chat GPT là một công cụ mạnh mẽ nhưng cũng có những hạn chế cần được cân nhắc khi sử dụng. Việc nhận thức và hiểu rõ những hạn chế này sẽ giúp người dùng áp dụng Chat GPT một cách hiệu quả và tránh các rủi ro tiềm ẩn.
Chat GPT có khả dụng ở Việt Nam không?
Ứng dụng chat GPT đã có mặt ở Việt Nam
Ngày đầu ra mắt, chatGPT chỉ truy cập và đăng kí tài khoản sử dụng ở một số quốc gia, và Việt Nam không nằm trong danh sách đó, nếu muốn sử dụng chúng ta phải mua tài khoản được đăng kí ở quốc gia khác.
Tuy nhiên vào ngày 02/11/2023, chat GPT đã chính thức có mặt ở Việt Nam, bạn có thể đăng ký và sử dụng miễn phí ChatGPT tại Việt Nam trên nền tảng website chat.openai.com, ứng dụng ChatGPT trên Android, iOS.
Chat GPT vs Google – nên dùng cái nào?
Chat GPT và Google là hai công cụ mạnh mẽ được sử dụng rộng rãi trên toàn thế giới. Tuy nhiên, mỗi công cụ có những ưu điểm và hạn chế riêng biệt, phục vụ cho các mục đích khác nhau. Dưới đây là sự so sánh chi tiết giữa Chat GPT và Google để giúp bạn quyết định nên sử dụng công cụ nào trong từng tình huống cụ thể.
Chat GPT
Google
Mục đích sử dụng
Tạo văn bản tự nhiên: Chat GPT được thiết kế để tạo ra văn bản tự nhiên giống như con người. Nó có thể tham gia vào các cuộc trò chuyện, trả lời câu hỏi, viết bài, sáng tác và dịch ngôn ngữ.
Hỗ trợ khách hàng: Chat GPT có thể được tích hợp vào các hệ thống hỗ trợ khách hàng để trả lời câu hỏi và giải quyết các vấn đề của người dùng.
Giáo dục và học tập: Chat GPT có thể cung cấp thông tin học thuật, giải đáp thắc mắc và giúp học sinh, sinh viên trong việc học tập.
Tìm kiếm thông tin: Google là công cụ tìm kiếm thông tin mạnh mẽ nhất thế giới, giúp người dùng tìm kiếm thông tin trên internet một cách nhanh chóng và hiệu quả.
Dịch vụ trực tuyến: Google cung cấp nhiều dịch vụ trực tuyến khác nhau như Gmail, Google Docs, Google Drive, Google Maps và YouTube.
Quảng cáo và kinh doanh: Google Ads và Google Analytics là công cụ quan trọng giúp doanh nghiệp quảng cáo sản phẩm và phân tích dữ liệu khách hàng.
Cách thức hoạt động
Xử lý ngôn ngữ tự nhiên (NLP): Sử dụng mô hình học máy và kiến trúc Transformer để hiểu và tạo ra văn bản tự nhiên dựa trên ngữ cảnh của câu hỏi hoặc yêu cầu.
Tương tác theo ngữ cảnh: Có khả năng duy trì ngữ cảnh trong cuộc trò chuyện, giúp phản hồi một cách mạch lạc và logic.
Thu thập và lập chỉ mục dữ liệu: Sử dụng các thuật toán tìm kiếm để thu thập, lập chỉ mục và xếp hạng hàng tỷ trang web trên internet.
Cung cấp kết quả tìm kiếm: Trả về danh sách các liên kết web liên quan đến từ khóa mà người dùng tìm kiếm, thường kèm theo các đoạn trích dẫn và thông tin bổ sung.
Ưu điểm
Tương tác tự nhiên: Có khả năng tạo ra văn bản tự nhiên và tham gia vào các cuộc trò chuyện phức tạp.
Linh hoạt: Ứng dụng trong nhiều lĩnh vực khác nhau từ hỗ trợ khách hàng đến sáng tác nghệ thuật.
Không yêu cầu từ khóa chính xác: Có thể hiểu và phản hồi dựa trên ngữ cảnh mà không cần từ khóa chính xác.
Tìm kiếm thông tin nhanh chóng: Có thể tìm kiếm thông tin từ hàng tỷ trang web chỉ trong vài giây.
Kiến thức cập nhật: Kết quả tìm kiếm thường xuyên được cập nhật, đảm bảo người dùng nhận được thông tin mới nhất.
Nhiều dịch vụ hỗ trợ: Cung cấp nhiều dịch vụ trực tuyến hữu ích cho cả cá nhân và doanh nghiệp.
Hạn chế
Thiếu kiến thức cập nhật: Kiến thức bị giới hạn trong phạm vi dữ liệu huấn luyện và không thể cập nhật theo thời gian thực.
Chi phí sử dụng cao: Việc sử dụng mô hình lớn như GPT-3 hoặc GPT-4 có thể tốn kém, đặc biệt khi sử dụng API
Phụ thuộc vào từ khóa: Cần sử dụng từ khóa chính xác để nhận được kết quả tìm kiếm phù hợp.
Không tương tác theo ngữ cảnh: Không thể duy trì ngữ cảnh cuộc trò chuyện và cung cấp phản hồi như con người.
Cập nhật và chỉnh sửa từ bài viết của tác giả: Kiên Nguyễn
Kết nối hệ cơ sở dữ liệu với hệ thống backend là điều bắt buộc phải làm trước khi viết API hoặc thực hiện một số thao tác liên quan tới hệ cơ sở dữ liệu, bài viết này mình sẽ đi từng bước giúp anh em kết nối PHP với SQL Server ở local.
1. Cài đặt SQL Server
Kết nối php với SQL server sẽ đi qua 2 bước, anh em cứ từ từ nha. Không có gì nóng vội, ta cứ cài đặt đã. Đầu tiên, anh em truy cập trang web của microsoft về SQL Server tại link này. Kéo xuống bên dưới chỗ phía cho developer.
Sau khi đã tải về file exe để cài đặt, anh em double click lên. Mở ra trình cài đặt của SQL server
Phần serverName nếu anh em sử dụng local thì nó là localhost. Phần connectionOptions là các thông tin liên quan tới DB, Uid (tài khoản) và mật khẩu. Anh em chú ý là lưu ở array.
Sau khi đã mở kết nối tới database, anh em có thể thực hiện các câu truy vấn.
Có phải để tạo ra một sản phẩm phần mềm thì chỉ cần các bạn developer thôi là đủ không? Câu trả lời là vừa có … vừa không. Vì một team bao gồm những ai thì phụ thuộc rất nhiều vào quy mô, cũng như tốc tốc độ phát triển của dự án đó.
Để các bạn hiểu rõ về các vai trò trong một team phát triển sản phẩm, thì mình sẽ mô tả quá trình thay đổi của một team dự án, từ lúc nó bé xíu, cho tới lúc đã có tương đối đủ thành viên, như vậy bạn sẽ dễ hiểu hơn về vai trò của từng thành viên trong team.
Lưu ý:
Không phải tất cả các dự án phần mềm đều có sự phát triển giống như trong bài viết này. Mình chỉ lấy ví dụ để các bạn dễ hình dung ra vai trò của từng bộ phận trong team hơn thôi nhé.
Vai trò của Developer
Developer là dân kỹ thuật chính hiệu, kỹ năng mạnh nhất của họ chính là viết code để tạo ra phần mềm.
Thời điểm này, dự án chỉ bao gồm 3 developer. Họ có chung ý tưởng, và quyết định hợp tác với nhau để cùng biến ý tưởng đó thành một sản phẩm thực tế. Họ phác thảo ý tưởng ra giấy, rồi phân chia công việc. Họ cũng bầu ra một leader (gọi là developer leader) để chịu trách nhiệm điều phối, và đảm bảo chất lượng sản phẩm.
Giai đoạn này, công việc chủ yếu là code, đôi khi phát sinh một số công việc khác nhưng không nhiều, cũng không quá khó, họ vẫn có thể tự chia nhau hoàn thành.
Sau một thời gian phát triển, họ đã có phiên bản đầu tiên, sẵn sàng ra mắt khách hàng, và hy vọng là sẽ có nhiều khách hàng sử dụng.
Sau khi ra mắt sản phẩm, cũng có một vài bug, nhưng nó không nghiêm trọng lắm, các developer vẫn làm việc bình thường, và sản phẩm cũng đã “nhen nhúm” có khách hàng sử dụng. Tuy nhiên, ý tưởng ban đầu của họ đã được khai thác hết, tất cả các tính năng cần thiết đều đã xuất hiện trên sản phẩm, họ bắt đầu cạn ý tưởng và không biết phải làm gì tiếp theo.
Các developer cũng bắt đầu ý thức được rằng, việc đưa ra một ý tưởng thì không khó, nhưng đưa ra một ý tưởng thiết thực thì lại rất khó. Trong khi họ là các developer, nên việc tìm ra một ý tưởng như vậy không phải là điều dễ dàng.
Họ bắt đầu đi tìm kiếm một product owner – người sẽ chịu trách nhiệm tìm ra các ý tưởng, sao cho các ý tưởng đó là hay, là thiết thực, vừa đem lại giá trị cho khách hàng, lại vừa đem lại lợi ích cho sản phẩm (gọi chung là tối ưu hóa sản phẩm).
Có Product Owner, các ý tưởng hay liên tục được đưa ra, nhờ đó mà sản phẩm phát triển nhanh hơn rất nhiều so với trước kia – cả về mặt tính năng lẫn số lượng khách hàng sử dụng.
Ban đầu, PO và các developer phối hợp với nhau rất tốt, công việc rất trôi chảy, suôn sẻ. Nhưng càng về sau, thì càng xuất hiện nhiều vấn đề, chủ yếu xoay quanh:
Sản phẩm đã trở nên khá phức tạp, và không một ai trong team có thể nhớ rõ chính xác nó hoạt động như thế nào. Nên các ý tưởng của PO khi đưa ra tuy rất phù hợp về mặt hướng đi, nhưng lại xung đột nhiều với các tính năng đã có.
Các ý tưởng mà PO đưa ra ngày càng phức tạp, và các developers sẽ không thể “nghe một lần rồi hiểu ngay”, nên họ thường xuyên code “lệch” so với ý tưởng của PO.
Các developer trễ deadline, do việc việc triển khai ý tưởng mới phải gánh thêm việc giải quyết xung đột với tính năng cũ, trong khi đó, không ai biết chính việc sửa tính năng cũ tốn bao nhiêu thời gian, có thể rất nhiều, hoặc rất ít.
Vì vậy, cả team quyết định sẽ phân tích kỹ lưỡng, đồng thời mô tả sử thay đổi của sản phẩm ra văn bản, coi nó là tài liệu mô tả yêu cầu trước khi code. Tuy nhiên, không biết nên để công việc này cho ai vì:
Vai trò của PO là người đi tìm các ý tưởng, và chứng minh là đó là ý tưởng thiết thực mà sản phẩm nên có. Đây là công việc cực kỳ quan trọng, PO không nên tốn thời gian vào việc mô tả chi tiết yêu cầu.
Nếu PO không làm công việc trên, thì developer lại càng không. Vì trò của developer chủ yếu là về mặt công nghệ – đây cũng là một công việc rất quan trọng, không nên để developer tốn thời gian vào việc viết mô tả chi tiết yêu cầu. Mặt khác, chính các developer sẽ là người chuyển yêu cầu thành code, nếu để họ để họ viết yêu cầu, thì không khác gì bảo họ viết hai lần, một lần bằng ngôn ngữ tự nhiên, và một lần viết bằng code.
Vì thế, team quyết định tìm thêm một bạn làm về business analyst (BA) – Chuyên viên phân tích nghiệp vụ.
BA sẽ đảm nhiệm phân tích ý tưởng ban đầu của PO thành các yêu cầu cụ thể trên sản phẩm (như sản phẩm cần thêm, sửa, xóa tính năng gì), đồng thời văn bản hóa các yêu cầu đó thành tài liệu SRS (*), trực tiếp giải thích cho các developer hiểu. Nếu yêu cầu tính năng quá khó để miêu tả bằng văn bản, thì BA sẽ vẽ các bản mockup (*), prototype (*) để dễ hình dung hơn.
Kể từ khi có BA, công việc lại trở nên ổn định, deadline đã chính xác hơn trước, PO cũng tự tin đưa khi đưa ý tưởng mới mà không lo các developer than “Ui nó ảnh hưởng nhiều lắm, code phức tạp lắm“. Số lượng tính năng mới, và khách hàng vẫn liên tục tăng lên.
Về mặt team phát triển, cơ bản là không có vấn đề gì, nhưng vấn đề lúc này lại đến từ khía khách hàng. Ngoại trừ việc sản phẩm có một vài lỗi nhỏ, thì còn một vấn đề lớn nữa đó là “các tính năng quá khó để sử dụng”. Khách hàng đã tiếp cận với sản phẩm, nhưng rồi lại lặng lẽ đi ra vì … không biết dùng như thế nào.
Cả team từng cho rằng BA sẽ cần phân tích thêm cả việc sản phẩm nên thể hiện như thế nào với khách hàng, nhưng không, BA đang rất bận rộn với việc phân tích yêu cầu của PO. Mặt khác, BA sẽ tập trung trả lời cho câu hỏi “sản phẩm sẽ cần thay đổi những gì về mặt tính năng?“, chứ ít khi trả lời câu hỏi “sản phẩm phải làm thế nào để đẹp hơn và dễ dùng hơn“.
Vì thế, để sản phẩm thu hút hơn, và đem lại trải nghiệm tốt hơn với khách hàng, team đã tìm thêm một bạn UI/UX designer. Bạn này sẽ đảm nhiệm việc thiết kế giao diện (màu sắc, bố cục), và các luồng sử dụng trên sản phẩm, sao cho thân thiết, đẹp mắt, dễ tiếp cận và dễ dàng sử dụng với khách hàng, ngay cả khi họ là người mới.
Sau khi có UI/UX designer, sản phẩm như được lột xác. Bố cục rõ ràng, màu sắc hài hòa, cùng với một tính năng, trước kia khách hàng phải tốn 10 click, thì giờ chỉ tốn 3 click. Tóm lại trải nghiệm được tăng lên đáng kể.
Vai trò của Tester
Số lượng khách hàng sử dụng bây giờ đã rất nhiều, và các bug ngày trước được coi là nhỏ, thì bây giờ sẽ được coi là lớn, các bug ngày trước được coi là lớn, thì bây giờ không được phép xuất hiện trên sản phẩm.
Mặc dù các developer không cố tình tạo ra bug, họ cũng đã kiểm tra lại kỹ càng các tính năng trước khi đưa cho khách hàng sử dụng. Nhưng suy cho cùng, họ vẫn là con người, không thể tránh được thiếu sót, và các bug “không thể chấp nhận được” vẫn đôi lúc xuất hiện.
Vì vậy, team quyết định tìm thêm một bạn tester – người sẽ đảm bảo chất lượng sản phẩm trước khi nó tới tay khách hàng.
Từ khi có tester, các đợt cập nhật phiên bản mới đều được kiểm tra kỹ càng rồi mới đưa đến tay khách hàng, các bug “không thể chấp nhận được” đã không còn xuất hiện nữa.
Vai trò của team Manager
Điểm lại một chút, lúc này team đã có khá nhiều vai trò: developer, PO, UI/UX designer, tester. Và các bộ phận này này đang gặp một số vấn đề như sau:
Không biết cách phối hợp với nhau thế nào cho hiệu quả.
Lúc thì bộ phận này bận SML, còn bộ phận kia thì rảnh và ngược lại.
Đôi khi có các công việc “không tên”, thì không ai muốn nhận nó về mình, ai có lý do từ chối hợp lý.
Hiện tại thì team vẫn đang có một leader (chính là bạn developer được bầu ra ở level 1). Nhưng suy cho cùng đó là kiêm nhiệm vị trí, và bạn đó vẫn đang làm việc ở vị trí developer nhiều hơn.
Để team hoạt động hiệu quả hơn, team quyết định để bạn developer leader kia lên làm team manager – bạn này chịu trách nhiệm điều phối công việc trong team, cân bằng khối lượng công việc giữa các bộ phận, tìm ra quy trình phù hợp và áp dụng vào team.
Trong thực tế, nếu team không bầu được ai, thì có thể tuyển người mới. Tuy nhiên vị trí này ít khi được tuyển mới mà thường được cất nhắc từ người trong team hiện tại – nhất là với các team nhỏ.
Kể từ khi có team manager, công việc lại trôi chảy hơn nhiều, mọi người đi làm cảm thấy vui vẻ, không còn lo quá nhiều hoặc quá ít việc. Các bộ phận cũng phối hợp hiệu quả hơn do có quy trình làm việc rõ ràng.
Tạm kết câu chuyện của team tới đây, vì nếu mình viết tiếp thì sẽ rất dài, thậm chí không có hồi kết. Cũng như mình chia sẻ ở đầu bài viết, quy mô của dự án sẽ quyết định các vai trò trong team, tuy nhiên, đều tuân theo một quy luật là “nghẽn ở đâu, thì giãn nở ở đó”. Khi dự án phát triển tới mức độ được coi là lớn, thì bất kỳ một công việc nhỏ nào trước kia đều có thể trở nên cực kỳ phức tạp, và cần một bộ phận chuyên trách để xử lý – đó là lúc team cần bổ sung thêm một vai trò mới.
Ngoài các vai trò đã được nếu phía trên, thì dưới đây mình bổ sung thêm một số vai trò điển hình khác:
Vai trò của DevOps Developer: Chịu trách nhiệm về hạ tầng sản phẩm (server, mạng,…), giúp sản phẩm chạy ổn định với khách hàng.
Vai trò của Security: Đảm bảo hệ thống an toàn, không bị xâm nhập trái phép.
Vai trò của Software Architecture: Thiết kế kiến trúc của phần mềm, để sản phẩm có tính mở rộng cao, dễ dàng thay đổi, và ít để lại nợ công nghệ
SRS: Viết tắt của Software Requirement Specification, được dịch ra tiếng việt là Tài liệu đặc tả yêu cầu. SRS là tài liệu được sử dụng để mô tả chi tiết các yêu cầu chức năng và phi chức năng của hệ thống.
Prototype, mockup: Ám chỉ các bản vẽ mô tả về sản phẩm.
Backend Developer chưa bao giờ hết hot là vị trí được tuyển dụng nhiều và trả lương cao chót vót, phỏng vấn Backend Developer cũng không hề dễ. Nói thì không phải troll chứ Frontend Developer luôn tạo ra những thứ hoa mỹ bóng bẩy. Ngược lại, Backend Developer luôn gồng gánh phần nặng nhất, chịu trách nhiệm cho hệ thống hoạt động ổn định.
Mà làm source code đẹp hay không ai biết, chỉ toàn meme chế backend là một đống hỗ độn, che dấu đằng sau cái vẻ đẹp lồng lộn của Frontend.
Quả không điêu khi Backend Developer đòi hỏi một lượng kiến thức khổng lồ khi tham gia phỏng vấn. Mà có phải là code không đẹp đâu. Tí nữa rồi anh em sẽ rõ thông qua 1,2 câu hỏi về clean architecture. Code đẹp, structure đẹp cho bọn meme nó bớt chế.
Kiến thức cần có ở Backend Developer trải dài từ hệ cơ sở dữ liệu qua tới kinh nghiệm làm việc với API. Ở mức độ cao hơn, Backend Developer có kinh nghiệm còn cần có giải pháp cho những vấn đề hóc búa xảy ra trong quá trình làm việc.
Những kinh nghiệm này là kinh nghiệm thực tế, tức là trong quá trình làm việc xảy ra những vấn đề hóc búa ở phía Backend, tìm tòi xử lý các vấn đề. Tích luỹ thành kinh nghiệm.
Bắt đầu danh sách câu hỏi phỏng vấn Backend Developer bằng một câu hỏi lý thuyết. Bắt đầu bằng câu hỏi này bởi vì đi thẳng vào từng ngôn ngữ lập trình thì sẽ có series phỏng vấn Java, Python sau cho anh em thoải mái focus vào từng ngôn ngữ.
Quay lại với câu hỏi đầu tiên, CAP Theorem là định lý ban đầu được tạo ra cho hệ thống phân tán (distributed computer system) bởi Eric Brewer. C,A,P là viết tắt của 3 yếu tố cần có. Kiến thức này khá là quan trọng với Backend Developer, người thường xuyên làm việc với hệ thống phân tán.
Bắt đầu với C – Consistency (tính nhất quán). Tính nhất quán ở đây mang ý nghĩ client luôn thấy cùng một data. Bất kể client đang được liên kết tới node nào. Để được vậy, phải thực hiện đồng bộ dữ liệu cho tất cả. Lặp lại cho tất cả các nốt.
Thứ hai là A – Availability – tính sẵn sàng. Tính sẵn sàng được hiểu rằng bất cứ khi nào client gửi request. Họ đều sẽ nhận được response. Thậm chí một hoặc vài node bị down.
Thứ ba là P (Partition tolerance). Phía bên hệ thống phân tán, lúc thiết kế phải đảm bảo sao cho khi một số node die, cả hệ thống vẫn hoạt động bình thường.
Về câu hỏi này anh em có thể tham khảo qua bài viết này. Đây là câu hỏi lý thuyết cơ bản cho anh em học vừa mới ra trường hoặc đã nhiều năm kinh nghiệm đều cần phải nắm vững. CAP theorem tuy đơn giản nhưng là tiêu chuẩn cho tất cả các hệ thống lớn ở Amazon, Google. Anh em chú ý.
2. Tại sao bạn lại chọn kiến trúc micro services?
Câu hỏi thứ hai khi phỏng vấn Backend Developer là kiến trúc phổ biến đối với các hệ thống Microservices. Nhưng tại sao và lúc nào ta nên lựa chọn microservices?
Trả lời cho câu hỏi này, trước tiên là kiến trúc micro services có rất nhiều ưu điểm. Một số câu trả lời cho anh em có thể tham khảo
Microservices can adapt easily to other frameworks or technologies. – Microservices có thể dễ dàng thích ứng với các framework hoặc công nghệ khác.
Failure of a single process does not affect the entire system. – Việc một microservices bị fail có thể không ảnh hưởng tới toàn bộ hệ thống.
Provides support to big enterprises as well as small teams. – Microservices phù hợp cho cả doanh nghiệp lớn và các đội nhóm nhỏ hơn.
Can be deployed independently and in relatively less time – Có thể triển khai độc lập trong một thời gian ngắn hơn các kiến trúc thông thường.
Lý thuyết là vậy nhưng trong quá trình phỏng vấn, anh em có thể nêu thêm các ví dụ để làm rõ ý của mình. Ví dụ như deploy độc lập dùng docker hay kubenetes?. Trường hợp một microservices down tại sao lại không ảnh hưởng tới các services khác?.
3. SQL Injection là gì?
Câu hỏi này tập trung chủ yếu vào Web Security. Làm backend mà không biết hoặc không chú trọng tới security thì nguy hiểm lắm. Khái niệm và những lỗ hổng đã được phát hiện trước đây nếu anh em biết thêm thì quá tuyệt.
Chính vì vậy, câu hỏi thứ 3 trong bộ câu hỏi phỏng vấn backend developer là câu hỏi liên quan tới một lỗ hổng đã phát hiện từ lâu SQL Injection.
Trả lời cho câu hỏi này anh em cần biết bản chất của Injection (chèn vào, tiêm chích vào). Bản chất phương thức tấn công này nhắm vào việc chèn các đoạn mã SQL không được phép. Thực hiện các câu SQL độc hại thông qua lỗ hổng. Biết tất nhiên cần có cách phòng tránh.
Prepared statements with parameterized queries – Các truy vấn cần được chuẩn hoá.
Input validation – blacklist validation and whitelist validation – Thực hiện validation chặt chẽ đầu vào
Principle of least privilege – Application accounts shouldn’t assign DBA or admin type access onto the database server. – Đặt quyền tối thiểu, tài khoản ứng dụng tất nhiên không thể có quyền truy cập vào dữ liệu nhạy cảm.
4. Điểm yếu của REST web services là gì?
Câu hỏi thứ 4 trong bộ câu hỏi phỏng vấn backend developer là câu hỏi liên quan tới API design. Để trả lời được câu hỏi này. Anh em cần có kinh nghiệm ở REST. Không những chỉ REST mà còn ở các kiến trúc API khác.
Khi đã có kinh nghiệm kha khá hoặc có cơ hội khác tiếp xúc với GraphQL chẳng hạn. Anh em sẽ có cái nhìn rõ hơn về điểm yếu của REST web services.
Để trả lời cho câu hỏi này, anh em có thể liệt kê ra một số nhược điểm của REST bao gồm:
Trường hợp không có API contract giữa client và server. Nên REST cần có tài liệu đi kèm để giải thích cụ thể những gì được viết hoặc thực hiện ở API.
REST web services hoạt động dựa trên HTTP nên không thể có các request bất đồng bộ (asynchronous)
Với kiến trúc REST, session can’t be maintained (không được duy trì lâu).
5. Giải thích API Gateway Pattern
Với backend developer ở trình độ cao, bộ câu hỏi phỏng vấn không thể không có các câu hỏi liên quan tới Software Architecture. Gateway là một trong các câu hỏi đó, trong bộ các câu hỏi phỏng vấn backend developer.
Để trả lời câu hỏi này, anh em có thể tham khảo:
An API Gateway is a server that is the single entry point into the system. It is similar to the Facade pattern from object‑oriented design. The API Gateway encapsulates the internal system architecture and provides an API that is tailored to each client. It might have other responsibilities such as authentication, monitoring, load balancing, caching, request shaping and management, and static response handling. API gateway là server và nó là điểm vào duy nhất của hệ thống. Nó tương tự như Facade Pattern trong lập trình hướng đối tượng. API Gateway đóng gói kiến trúc nội bộ và cung cấp API phù hợp cho từng client. Ngoài ra API Gateway có thể có các chức năng khác như xác thực, giám sát, cân bằng tải, cache đóng gói và quản lý các response.
Kieblog có bài viết cụ thể và giải thích rõ ràng hơn về API gateway ở đây. Anh em có thể đọc để hiểu sâu hơn
6. B-tree index trong hệ cơ sở dữ liệu hoạt động như thế nào?
Câu hỏi thứ 6 trong bộ câu hỏi phỏng vấn backend developer liên quan tới hệ cơ sở dữ liệu (database). Tất nhiên rồi, đã làm backend mà không biết hoặc không một lần đụng tới index thì quả thật là hết sức vô lý.
Đối với anh em có nhiều thời gian làm việc với database, với cơ sở dữ liệu lớn hoặc ít nhất là các task liên quan tới tối ưu SQL sẽ biết tới index. Tuy nhiên biết là một chuyện, nhưng nó hoạt động ra sao lại đòi hỏi thời gian để tìm tòi.
Trả lời cho câu hỏi này anh em cần biết về cây nhị phân (binary tree). B-tree tốt hơn cây nhị phân ở chỗ dữ liệu được lưu trữ trên đĩa. Việc truy cập để lấy dữ liệu trên đĩa thực sự chậm hơn so với bộ nhớ (memory). B-tree được hình dung như việc lấy hoặc tìm kiếm thông tin một cuốn sách ở trong thư viện.
Bản thân cuốn sách đó đã được đánh dấu hoặc sắp xếp các câu hỏi bắt đầu bằng A,B,C và D,E,F. Nếu cần D, ta sẽ bỏ qua một khoảng tương đối dài của A,B,C. Việc này giúp tối ưu hiệu quả tìm kiếm. B-tree cần tới logB N
7. Sự khác biệt giữa Acceptance Test và Functional Test?
Sẽ thật sự là thiếu sót to lớn nếu bỏ qua Software Testing khi phỏng vấn Backend Developer. Testing từ lâu đã là một kỹ năng cần có của mọi lập trình viên. Bất kể Front hay là Back, tất cả đều yêu cầu có kiến thức về Software Testing. Testing là công đoạn không thể thiếu giúp tạo ra một sản phẩm phần mềm tốt.
Trả lời cho câu hỏi này:
Functional testing: This is a verification activity; did we build a correctly working product? Does the software meet the business requirements? A functional test verifies that the product actually works as you (the developer) think it does. Test tính năng; Đây là hoạt động xác minh. Thông thường với các câu hỏi, chúng tôi đã xây dựng một sản phẩm chính xác chưa?. Phần mềm có đáp ứng được yêu cầu nghiệp vụ không? Sản phẩm đã đáp ứng được yêu cầu thực tế hay chỉ như người lập trình viên nghĩ?
Tiếp đến là kiểm thử chấp nhận (khác với kiểm tra tính năng)
Acceptance testing: This is a validation activity; did we build the right thing? Is this what the customer really needs? Acceptance tests verify the product actually solves the problem it was made to solve. This can best be done by the user (customer), for instance performing his/her tasks that the software assists with. Test xác nhận. Thường bắt đầu với các câu hỏi, thứ chúng ta xây dựng ra đã đúng chưa?. Đây có phải thật sự là những gì khách hàng cần tới?. Acceptance testing xác định rằng sản phẩm thực sử giải quyết được vấn đề. Việc này tốt nhất nên được thực hiện bởi khách hàng (các tác vụ của họ được phần mềm hỗ trợ)
8. Tham khảo thêm câu hỏi khác phỏng vấn backend developer
Qua bài viết này, anh em backend phần nào cũng hiểu ra rằng phỏng vấn backend developer không hề đơn giản. Trải qua nhiều các topics, các nội dung cần nắm, các kiến thức cần tìm hiểu thêm.
Mong rằng một số câu hỏi liên quan tới API Design, Software Architecture và Software Testing phần nào giúp đỡ anh em trong các đợt phỏng vấn.
Lập trình Scratch từ lâu đã là ngôn ngữ lập trình phổ biến cho học sinh, sinh viên và các em nhỏ. Với Scratch, việc lập trình từ ban đầu được gán cho cái mác khó nhằn, khó hiểu, đơn điệu và tẻ nhạt bỗng trở thành ngôn ngữ lập trình được các em nhỏ không cần cha mẹ nói cũng vào học.
Quả không sai, cách thức tiếp cận là tất cả. Vậy điều gì làm nên sức hút của Scratch. Ví dụ tạo project với scratch như thế nào? Tất cả sẽ có trong bài viết này.
1. Lập tình Scratch là gì?
Bắt đầu với định nghĩa về lập trình Scratch, bài viết này dành cho học sinh sinh viên nên định nghĩa cũng được giải thích rõ ràng dễ hiểu hơn.
Scratch is a visual programming language that allows students to create their own interactive stories, games and animations Scratch là ngôn ngữ lập trình trực quan cho phép học sinh tạo ra các câu chuyện của họ, trò chơi và các hoạt hình tương tác của bản thân mình.
Lập trình scratch vô cùng thú vịNghe thôi đã thấy hấp dẫn rồi. Với lập trình Scratch, học sinh được học cách thiết kế, suy nghĩ sáng tạo, lập luận có hệ thống và cùng nhau làm việc để tạo ra dự án riêng. Scratch được tạo ra bởi nhóm Lifelong Kindergarten tại phòng thí nghiệm của MIT.
Các bạn có thể tải miễn phí Scratch tại https://scratch.mit.edu/.
Để bắt đầu với lập trình scratch, truy cập trang chủ và ấn vào start creating. Các bạn cũng có thể signup (tạo tài khoản để lưu trữ các project của cá nhân mình).
Truy cập trang chủ và ấn vào Start Creating
Scratch sẽ chuyển hướng ta tới trang bắt đầu để lập trình với Scratch.
Giao diện sau khi đã khởi tạo project tại ScratchTrước khi bắt đầu, các bạn nên xem qua video hướng dẫn một số thao tác cơ bản và thành phần của scratch.
Video hướng dẫn cụ thể và rõ ràngLập trình scratch chú trọng tới các đối tượng và lập trình animations cho các đối tượng. Đối tượng ban đầu và mặc định là chú mèo scratch. Để thêm các đối tượng khác. Ấn vào góc bên dưới bên phải màn hình.
Góc dưới bên phải cho phép thêm nhiều hơn các đối tượng.
Sau khi đã có các đối tượng, bước tiếp theo là các thao tác, âm thanh được tuỳ chọn để lập trình. Việc lựa chọn đúng các thao tác giúp đối tượng trở nên sinh động hơn.
Scratch hiện tại hỗ trợ code (trực quan không code), costumes (tuỳ chỉnh cao hơn) và Sounds (phần âm thanh cho các đối tượng)
2.1 Các đối tượng trong Scratch
Về mặt code, hiện tại scratch hỗ trợ danh sách sau:
Motion (di chuyển 10 bước, xoay ngang dọc, di chuyển tới vị trí có toạ độ x và y)
Looks (xin chào, thay đổi kích thước, ẩn (hide), hiện (show), …
Sounds (âm thanh bắt đầu tới lúc kết thúc, thay đổi volume tăng hoặc giảm, …)
Events (khi ấn vào thì sao?, khi nhận được tin nhắn, …)
Control (kiểm soát, các câu lệnh cơ bản của lập trình, nếu a thì b, nếu như thế này thì thế kia, …)
Sensing (các sự kiện của chuột, các sự kiện chờ cho câu hỏi, câu trả lời, …)
Operators (các phép cộng trừ, so sánh, tính toán độ dài, …)
Variables (các biến tuỳ chỉnh, thiết lập dữ liệu, thay đổi các biến, …)
Các đối tượng được hỗ trợ trong khối Variables
3. Tuỳ biến, tuỳ chỉnh cao hơn với lập trình Scratch
Sau khi đã hiểu rõ và thực hành một số thành phần code được hỗ trợ bởi Scratch. Nếu các animations và lập trình cần tới tuỳ chỉnh các đối tượng. Việc tuỳ chỉnh đối tượng cho phép làm ra các đoạn code sinh động hơn, phù hợp hơn với yêu cầu.
Mục consumes dành cho các đối tượng tuỳ chỉnh. Cho phép chỉnh sửa màu sắc, hình dạng, kích thước các đối tượng.
Thay đổi màu sắc quần của đối tượng sang màu tím.
Một thành phần khác giúp cho các video animations được lập trình trở nên tuyệt vời hơn là âm thanh. Âm thanh cũng có thể tuỳ chỉnh ở mục Sounds.
Nếu hình ảnh trong bộ sưu tập có sẵn của Scratch không phù hợp hoặc chưa đáp ứng được nhu cầu của bạn. Các bạn có thể tự tải lên các hình ảnh riêng của mình bằng nút nhấn phía bên dưới phải màn hình.
Tải lên các hình ảnh cá nhân hoặc tự xây dựng là hoàn toàn khả thi với scratch
4. Các tuỳ chỉnh khác
Scratch giúp tăng tư duy toán tức IQ, kỹ năng giải quyết tình cảm tức EQ, ngôn ngữ, sáng tạo và hợp tác với bạn bè và máy tính. Scratch luôn luôn miễn phí và được thông dịch qua hơn 70 ngôn ngữ. Các bạn có thể lựa chọn ngôn ngữ tiếng việt giúp dễ dàng hơn khi bắt đầu với Scratch
Nút nhấn quả địa cầu là khu vực để lựa chọn ngôn ngữCó sẵn ngôn ngữ tiếng việt giúp dễ dàng hơn khi lập trình với Scratch
Khả năng lập trình máy tính là một phần quan trọng trong học vấn của xã hội ngày nay. Khi mọi người học cách lập trình bằng Scratch, bản thân họ sẽ học được những chiến thuật quan trọng để giải quyết vấn đề, thiết kế các chương trình và truyền đạt những ý tưởng.
Chính vì vậy, không chỉ riêng tập lớp trẻ em, học sinh là nên tiếp thu với lập trình scratch. Người già, các đối tượng khác trong xã hội nếu có điều kiện cũng có thể thử sức, sáng tạo với lập trình scratch
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
AOP là gì?
Trong khi xây dựng các chương trình ứng dụng, có rất nhiều những vấn đề liên quan đến phần mềm mà chúng ta cần quan tâm. Chẳng hạn, chúng ta xây dựng một hệ thống đăng ký tạo tài khoản cho một ngân hàng. Ngoài công việc chính cho phép người dùng có thể tạo tài khoản (core concern), hệ thống còn phải đảm bảo các vấn đề khác (cross-cutting concern) như chứng thực người dùng, kiểm tra ràng buộc, quản lý transaction, xử lý ngoại lệ, ghi log, debug, đo hiệu năng của ứng dụng,…
Như bạn thấy, logic của chương trình của chúng ta phải làm rất nhiều việc như ghi log, mở/ đóng transaction, xử lý ngoại lệ, … Khi có nhiều phương thức tương tự vậy trong ứng dụng, code chúng ta bị liên kết chặt vào nhau, duplicate code, phân mảnh nhiều nơi, khó khăn khi sửa đổi thay thêm logic mới, … Để giải quyết vấn đề này, chúng ta có thể sử dụng kỹ thuật AOP.
AOP là từ viết tắt của Aspect Oriented Programming, dịch ra tiếng Việt là “phương pháp lập trình hướng khía cạnh”. AOP là một kỹ thuật lập trình cho phép phân tách chương trình thành cách module riêng rẽ, không phụ thuộc nhau. Khi hoạt động, chương trình sẽ kết hợp các module lại để thực hiện các chức năng nhưng khi sửa đổi chức năng thì chỉ cần sửa đổi trên một module cụ thể.
AOP còn được gọi là Aspect Oriented Software Development (AOSD) là một nguyên tắc thiết kế, giúp tách rời các yêu cầu hay các vấn đề được quan tâm (separation of concerns) trong chương trình thành các thành phần độc lập và từ đó tăng tính uyển chuyển cho chương trình. Trong Separation of concerns, người ta cho rằng những vấn đề tương tự nhau nên được giải quyết trong một unit of code. Khi lập trình thủ tục (functional programming), một unit of code là một function/ method, còn trong lập trình hướng đối tượng (OOP) thì unit of code là một class.
Trong AOP, chương trình của chúng ta được chia thành 2 loại concern:
Core concern/ Primary concern: là requirement, logic xử lý chính của chương trình.
Cross-cutting concern: là những logic xử lý phụ cần được thực hiện của chương trình khi core concern được gọi như security, logging, tracing, monitoring, …
Một số thuật ngữ khác trong AOP:
Joinpoint: là một điểm trong chương trình, là những nơi có thể được chèn những cross-cutting concern. Chẳng hạn chúng ta cần ghi log lại sau khi chạy method nào đó thì điểm ngay sau method đó được thực thi gọi là một Jointpoint. Một Jointpoint có thể là một phương thức được gọi, một ngoại lệ được throw ra, hay một field được thay đổi.
Pointcut: có nhiều cách để xác định Joinpoint, những cách như thế được gọi là Pointcut. Nó là các biểu thức được sử dụng để kiểm tra nó có khớp với các Jointpoint để xác định xem Advice có cần được thực hiện hay không.
Advice: những xử lý phụ (crosscutting concern) được thêm vào xử lý chính (core concern), code để thực hiện các xử lý đó được gọi Advice. Advice được chia thành các loại sau:
Before: được thực hiện trước join point.
After: được thực hiện sau join point.
Around: được thực hiện trước và sau join point.
After returning : được thực hiện sau join point hoàn thành một cách bình thường.
After throwing : được thực hiện sau khi join point được kết thúc bằng một Exception.
Aspect: tương tự như một Java class. Một Aspect đóng gói toàn bộ cross-cutting concern và có thể chứa các JointPoint, PointCut, Advice.
Target Object : là những đối tượng mà advice được áp dụng.
Một vài cross-cutting concern thường thấy trong ứng dụng:
Logging
Monitor
Access control
Error handling
Transaction management
Session management
Input/output validation
Weaving là gì?
Về cơ bản Weaving (đan/ dệt) là quá trình liên kết các thành phần aspect và non-aspect của một chương trình để tạo ra đầu ra mong muốn.
Có một vài cách khác nhau giữa các hệ thống AOP về cách tạo ra Weaving. Có thể chia làm các loại Weaving: Compile-time weaving (static weaving), Load-Time Weaving và Run-time weaving (dynamic weaving).
Compile-time weaving :
Pre-Compile Weaving : sử dụng bộ tiền xử lý (pre-processor) để combine code của aspect và code non-aspect lại với nhau trước khi code được biên dịch thành byte code Java (.class).
Post-Compile Weaving / Binary weaving : cách này dùng để inject code của aspect vào những tập tin .class của Java đã được compile.
Load-Time Weaving : cách này dùng để inject code của aspect khi class cần sử dụng aspect được load vào JVM, nghĩa là trong khi ứng dụng đang chạy.
Run-time weaving: thực hiện weaving và unweaving code của aspect và non-aspect tại run-time.
Static weaving
Static weaving là quá trình combine code của aspect và code non-aspect lại với nhau trước khi code được biên dịch thành Java byte code (.class) bằng cách sử dụng bộ tiền xử lý (pre-processor). Do đó, code gốc chỉ được thay đổi một lần tại thời gian biên dịch (compile). Hiệu suất của code được combine này tương đương với code được viết theo truyền thống.
Hạn chế của phương pháp Static weaving là khó khăn trong việc xác định code của aspect sau này hoặc thực hiện thay đổi đối với code của aspect. Mỗi khi code của aspect bị thay đổi, tất cả tất cả code sử dụng aspect phải được biên dịch lại.
Dynamic weaving
Dynamic weaving khắc phục một số hạn chế gặp phải khi weaving được thực hiện tại thời gian biên dịch (Compile-time weaving/ Static weaving). Có thể tránh được yêu cầu biên dịch lại (recompilation), triển khai lại (redeployment) và khởi động lại (restart) bằng cách thực hiện quy trình weaving trong thời gian chạy (run-time weaving).
Có một chút khác biệt giữa load-time và run-time weaving.
Load-time weaving chỉ đơn giản là trì hoãn quá trình weaving cho đến khi các lớp được nạp bởi class loader. Cách tiếp cận này yêu cầu sử dụng một weaving class loader hoặc thay thế class loader bằng một loader khác. Hạn chế là load-time tăng lên và thiếu quyền truy cập vào các aspect trong khi chạy.
Run-time weaving là quá trình weaving và unweaving tại run-time. Cách tiếp cận này yêu cầu các cơ chế mới để can thiệp vào việc tính toán chạy.
Các AOP Framework khác nhau có cách thực hiện dynamic weaving khác nhau. Trong khi AspectWerkz sử dụng sửa đổi byte code thông qua chức năng cấp JVM và kiến trúc “hotswap” để thực hiện weaving các lớp tại run-time, thì Spring AOP Framework dựa trên các proxy thay vì các class loader hoặc dựa vào các đối số JVM.
Dynamic weaving cho phép tăng tốc các giai đoạn thiết kế và kiểm thử trong phát triển phần mềm, vì các aspect mới có thể được thêm vào hoặc các aspect hiện tại có thể được thay đổi mà không cần biên dịch lại và triển khai lại các ứng dụng. Tuy nhiên, một nhược điểm lớn là hiệu suất giảm, vì weaving xảy ra tại run-time.
Cài đặt AOP trong Java như thế nào?
Một vài ý tưởng để implement AOP trong chương trình của chúng ta:
Class-weaving : như đã đề cập ở phần trên.
Proxy-based : bạn có thể tưởng tượng nó như là một ví dụ sử dụng >Decorator Pattern. Sử dụng công cụ mã hóa byte code của một số thư viện như JDK proxy, CGLib proxy, chúng ta có thể chặn các lệnh gọi hàm và thêm code của riêng mình để được thực thi trước.
JDK proxy : đây là cách đơn giản nhất, nhưng chỉ có thể xử lý với các phương thức public được gọi, không thể xử lý các cuộc gọi nội bộ (các cuộc gọi bắt nguồn từ chính lớp đó).
CGLib proxy : yêu cầu chỉnh sửa byte code bị giới hạn và có thể xử lý các lời gọi phương thức private, nhưng vẫn không thể xử lý truy cập thuộc tính trực tiếp.
Sử dụng các thư viện sau: Google Guice, AspectJ, Spring AOP.
Ví dụ tự xây dựng một AOP framework
Trong ví dụ bên dưới chúng ta sẽ tự viết code để tạo AOP Framework sử dụng JDK Proxy mà không cần sử dụng bất cứ một thư viện thứ ba nào (third-party libraries).
Để xử dụng JDK Proxy chúng ta thực hiện các bước sau:
Tạo Invocation Handler: class này phải implemenet java.lang.reflect.InvocationHandler. InvocationHandler là interface được thực hiện bởi trình xử lý lời gọi (invocation handler) của một proxy instance. Khi một phương thức được gọi trên một proxy instance, lời gọi phương thức được mã hóa và gửi đến phương thức gọi của invocation handler của nó.
Tạo Proxy Instance : sử dụng phương thức Proxy.newProxyInstance() được cung cấp bởi factory method java.lang.reflect.Proxy.
Ví dụ: chúng ta cần thêm một vài xử lý trước và sau khi các phương thức trong class AccountService được gọi.
Account.java
package com.gpcoder.aop.account;
import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
public class Account {
private String owner;
private String currency;
private int balance;
}
AccountService.java
package com.gpcoder.aop.account;
public interface AccountService {
void addAccount(Account account);
void removeAccount(Account account);
int getSize();
}
AccountServiceImpl.java
package com.gpcoder.aop.account;
import java.util.ArrayList;
import java.util.List;
public class AccountServiceImpl implements AccountService {
private List<Account> accounts = new ArrayList<>();
@Override
public void addAccount(Account account) {
System.out.println("addAccount: " + account);
accounts.add(account);
}
@Override
public void removeAccount(Account account) {
System.out.println("removeAccount: " + account);
accounts.remove(account);
}
@Override
public int getSize() {
System.out.println("getSize: " + accounts.size());
return accounts.size();
}
}
AbstractHandler.java
package com.gpcoder.aop.handler;
import java.lang.reflect.InvocationHandler;
public abstract class AbstractHandler implements InvocationHandler {
private Object targetObject;
public void setTargetObject(Object targetObject) {
this.targetObject = targetObject;
}
public Object getTargetObject() {
return targetObject;
}
}
BeforeHandler.java
package com.gpcoder.aop.handler;
import java.lang.reflect.Method;
/**
* The class BeforeHandler provides a template for the before execution
*/
public abstract class BeforeHandler extends AbstractHandler {
/**
* Handles before execution of actual method.
*/
public abstract void handleBefore(Object proxy, Method method, Object[] args);
/*
* (non-Javadoc)
*
* @see java.lang.reflect.InvocationHandler#invoke(java.lang.Object,
* java.lang.reflect.Method, java.lang.Object[])
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
handleBefore(proxy, method, args);
return method.invoke(getTargetObject(), args);
}
}
BeforeHandlerImpl.java
package com.gpcoder.aop.handler.impl;
import java.lang.reflect.Method;
import com.gpcoder.aop.handler.BeforeHandler;
/**
* This class provides implementation before actual execution of method.
*/
public class BeforeHandlerImpl extends BeforeHandler {
@Override
public void handleBefore(Object proxy, Method method, Object[] args) {
// Provide your own cross cutting concern
System.out.println("Handling before actual method execution");
}
}
AfterHandler.java
package com.gpcoder.aop.handler;
import java.lang.reflect.Method;
public abstract class AfterHandler extends AbstractHandler {
/**
* Handles after the execution of method.
*/
public abstract void handleAfter(Object proxy, Method method, Object[] args);
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(getTargetObject(), args);
handleAfter(proxy, method, args);
return result;
}
}
AfterHandlerImpl.java
package com.gpcoder.aop.handler.impl;
import java.lang.reflect.Method;
import com.gpcoder.aop.handler.AfterHandler;
/**
* This class provides an implementation of business logic which will be
* executed after the actual method execution.
*/
public class AfterHandlerImpl extends AfterHandler {
@Override
public void handleAfter(Object proxy, Method method, Object[] args) {
// Provide your own cross cutting concern
System.out.println("Handling after actual method execution");
System.out.println("---");
}
}
ProxyFactory.java
package com.gpcoder.aop.handler;
import java.lang.reflect.Proxy;
import java.util.List;
/**
* A factory for creating Proxy objects.
*/
public class ProxyFactory {
private ProxyFactory() {
throw new UnsupportedOperationException();
}
public static Object getProxy(Object targetObject, List<AbstractHandler> handlers) {
if (handlers != null && !handlers.isEmpty()) {
Object proxyObject = targetObject;
for (AbstractHandler handler : handlers) {
handler.setTargetObject(proxyObject);
proxyObject = Proxy.newProxyInstance(targetObject.getClass().getClassLoader(),
targetObject.getClass().getInterfaces(), handler);
}
return proxyObject;
}
return targetObject;
}
}
AspectOrientedProgrammingInJdkExample.java
package com.gpcoder.aop;
import java.util.ArrayList;
import java.util.List;
import com.gpcoder.aop.account.Account;
import com.gpcoder.aop.account.AccountService;
import com.gpcoder.aop.account.AccountServiceImpl;
import com.gpcoder.aop.handler.AbstractHandler;
import com.gpcoder.aop.handler.ProxyFactory;
import com.gpcoder.aop.handler.impl.AfterHandlerImpl;
import com.gpcoder.aop.handler.impl.BeforeHandlerImpl;
/**
* This class to verify an AOP example using JDK proxy.
*/
public class AspectOrientedProgrammingInJdkExample {
public static void main(String[] args) {
List<AbstractHandler> handlers = new ArrayList<>();
handlers.add(new BeforeHandlerImpl());
handlers.add(new AfterHandlerImpl());
AccountService proxy = (AccountService) ProxyFactory.getProxy(new AccountServiceImpl(), handlers);
Account account = new Account("gpcoder", "USD", 100);
proxy.addAccount(account);
proxy.getSize();
proxy.removeAccount(account);
proxy.getSize();
}
}
Output của chương trình:
Handling before actual method execution
addAccount: Account(owner=gpcoder, currency=USD, balance=100)
Handling after actual method execution
---
Handling before actual method execution
getSize: 1
Handling after actual method execution
---
Handling before actual method execution
removeAccount: Account(owner=gpcoder, currency=USD, balance=100)
Handling after actual method execution
---
Handling before actual method execution
getSize: 0
Handling after actual method execution
---
Lợi ích của AOP là gì?
Tăng hiệu quả của Object-orented programming (OOP).
AOP không phải dùng để thay thế OOP mà để bổ sung cho OOP, nơi mà OOP còn thiếu sót trong việc tạo những ứng dụng thuộc loại phức tạp.
Tăng cường tối đa khả năng tái sử dụng của mã nguồn.
Anh em lập trình viên JavaScript chắc không xa lạ gì với Promise hay async/await trong việc xử lý các tác vụ bất đồng độ trong ứng dụng của mình; tuy vậy trong thực tế dự án có nhiều bài toán cần không chỉ 1 Promise và cần handle (xử lý) kết quả trả về trong từng Promise con, lúc này thứ chúng ta cần là Promise.all và 1 vài thứ tốt hơn thế. Bài viết này mình sẽ chia sẻ cùng các bạn cách sử dụng Promise.all trong những bài toán cụ thể ở dự án mình từng trải qua.
Nhắc lại cú pháp Promise
Trước hết cùng nhắc lại cú pháp Promise cũng như async/await cho các bạn đỡ quên nhé (lưu ý là async/await được thêm vào từ ES8 nhé).
letpromise = newPromise(function(resolve, reject) {setTimeout(() =>resolve("done!"), 1000);
});// resolve runs the first function in .thenpromise.then(result=>alert(result), // shows "done!" after 1 seconderror=>alert(error) // doesn't run);
2 ví dụ trên là cách sử dụng Promise hay async/await để thực hiện việc chờ 1 xử lý bất đồng bộ thực hiện xong, nhận kết quả trả về để thực hiện 1 hành động nào đó – cũng khá dễ hiểu đúng không. Vậy nếu bài toán của chúng ta là cần chờ 2 hành động bất đồng bộ (ví dụ như cần call 2 API lên server) thực hiện xong để lấy kết quả thì sẽ cần làm gì? JS cung cấp cho chúng ta Promise.all.
Promise1, Promise2 và Promise3 là những promise, bản thân Promise.all cũng là 1 promise. Vậy nó khác gì với việc chạy riêng lẻ 3 promise từ 1-3 một cách độc lập. Đầu tiên thì trong Promise.all, cả 3 Promise1-3 sẽ được thực hiện đồng thời, không cái nào cần chờ cái nào, vì thế giảm được thời gian chờ đợi và đương nhiên là tăng performance. Tiếp theo chúng ta cần lưu ý, nếu 1 trong 3 Promise1-3 đẩy ra lỗi (reject) thì Promise sẽ ngay lập tức dừng lại và nhảy vào catch chứ không thực hiện tiếp các promise khác. Trong trường hợp các task con thực hiện thành công thì Promise.all cũng sẽ trả về resolve với kết quả là 1 mảng chứa tất cả các resolve của task con.
Đến đây chúng ta vẫn thấy quen thuộc đúng không, thực tế Promise.all được sử dụng thường xuyên trong các bài toán thực tế dự án. Mặc dù vậy sẽ có 1 số vấn đề khi sử dụng Promise.all như sau:
Làm sao để tạo 1 mảng Promise sử dụng map
Nếu muốn tất cả các Promise con thực hiện xong mà không bị dừng bị 1 trong các Promise khác thì làm sao?
Nếu muốn chỉ 1 trong các Promise con thực hiện xong (resolve) là hủy các Promise còn lại thì làm sao?
Nếu muốn chỉ 1 trong các Promise con trả về (bất kể resolve hay reject) là hủy các Promise còn lại thì làm sao?
Chúng ta cùng đi giải quyết các câu hỏi trên nhé.
Promise.all với map()
Một bài toán cũng hay gặp với Promise.all là việc sử dụng nó kết với với map nhằm tạo ra 1 group các xử lý bất đồng bộ theo mảng đầu vào. Chẳng hạn như bạn cần gửi email cho n users có sẵn trong 1 mảng dữ liệu; lúc này chúng ta có thể sử dụng hàm map() để tạo ra mảng promise con làm tham số đầu vào cho Promise.all. Ví dụ như dưới đây:
Promise.allSettled([Promise.reject("This failed."),Promise.reject("This failed too."),Promise.resolve("Ok I did it."),Promise.reject("Oopps, error is coming."),]).then((res) => {console.log(`Here's the result: `, res);});
Kết quả trả về:
[ { status:"rejected", reason:"This failed." }, { status:"rejected", reason:"This failed too." }, { status:"fulfilled", value:"Ok I did it." }, { status:"rejected", reason:"Oopps, error is coming." },];
JavaScript cung cấp cho chúng ta Promise.allSettled để giải quyết vấn đề đầu tiên của Promise.all. Promise.allSettled trả về 1 Promise mới mà ở đó nó sẽ chờ tất cả các task con thực hiện xong, không kể có hoàn thành (resolve) hay bị reject. Kết quả trả về là 1 mảng theo thứ tự các Promise con truyền vào, mỗi object chứa status (trạng thái) của promise cùng giá trị trả về value hay reason (lí do) khi bị reject. Tất nhiên Promise.allSettled sẽ cần nhiều thời gian xử lý hơn so với Promise.all, tuy nhiên nó đảm bảo tất cả Promise được thực hiện.
Giả sử chúng ta có 2 bài toán như sau, các bạn hãy xem và lựa chọn các dùng nào của Promise nhé.
Bài toán 1: có 3 API get thông tin thời tiết và trả về kết quả như nhau, do vậy chỉ cần gọi 1 trong 3 API, cái nào có kết quả là được; không cần gọi tất cả 3 cái. Chúng ta sẽ làm thế nào?
Bài toán 2: chức năng upload cần upload file lên 3 server khác nhau và phải đảm bảo việc upload thực hiện thành công trên cả 3 server, nếu 1 trong 3 task fail thì dừng luôn 2 task còn lại.
Để giải quyết 2 bài toán trên, JavaScript cung cấp thêm cho chúng ta 2 function nữa là Promise.race và Promise.any. Promise.race và Promise.any có điểm chung là đều sẽ hoàn thành (resolve) khi 1 trong các promise con được thực hiện xong. Như ví dụ bài toán 1, nếu có 1 API get thông tin thời tiết hoàn thành xong thì nếu dùng Promise.race hoặc Promise.any, 2 API get thông tin thời tiết còn lại sẽ không cần thực hiện nữa.
Điểm khác nhau giữa race và any là ở trường hợp reject: any sẽ chỉ reject khi tất cả các promise con reject (hay không có promise nào trả về resolve); còn race sẽ reject khi chỉ cần 1 promise con reject. Điều này giúp Promise.race giải quyết bài toán thứ 2 ở trên. Khi có 1 trong 3 task upload file lên server thất bại thì sẽ dừng luôn 2 task còn lại.
Chúng ta có thể tổng kết họ hàng nhà Promise.all như sau:
Kết bài
Như vậy chúng ta đã đi qua hết được các phương thức xử lý bất đồng bộ Promise.all cùng cách sử dụng chúng trong từng bài toán cụ thể. Trong thực tế dự án sẽ có nhiều trường hợp các bạn sẽ vận dụng kết hợp các function khác nhau, có thể là Promise.all trong Promise.all chẳng hạn. Vì thế hãy nắm vững cách case sử dụng từng function trên nhé. Hy vọng bài viết của mình hữu ích dành cho các bạn.
Với 1 hệ thống bất kỳ, việc xây dựng kiến trúc luôn là bước đầu tiên và quan trọng nhất quyết định tính khả thi của cả hệ thống. Đầu ra của bước thiết kế hệ thống sẽ giải quyết nhu cầu đề ra của người dùng, đồng thời là bước quan trọng để bắt đầu việc xây dựng các ứng dụng cũng như cách giao tiếp giữa các phần trong hệ thống. Bài viết hôm nay mình sẽ cùng các bạn tìm hiểu Kiến trúc hệ thống là gì và tại sao nó lại có vai trò quyết định sự thành công của 1 dự án nhé.
Kiến trúc hệ thống là gì?
1 hệ thống bất kỳ nào đó sẽ luôn có 1 kiến trúc vật lý của riêng mình, từ những website đến các ứng dụng trên thiết bị di động, hầu hết chúng đều cần phải giao tiếp với server để thực hiện các thao tác lấy dữ liệu, cập nhật chỉnh sửa thông tin dữ liệu.
Để dễ hình dung trong bài viết này mình sẽ nhắc đến 1 hệ thống web và ứng dụng mobile sử dụng mô hình client-server như hình dưới đây.
Kiến trúc hệ thống, hiểu đơn giản đó là cách tổ chức của 1 hệ thống, bao gồm tất cả các thành phần, cách chúng tương tác với nhau, môi trường mà chúng hoạt động và các nguyên tắc được sử dụng để thiết kế ra phần mềm trong hệ thống. Như ở hệ thống trên, chúng ta có thể dễ thấy 2 phần chính là CLIENT và SERVER, trong đó:
CLIENT: các trình duyệt web, các ứng dụng trên desktop hay smartphone truy cập để lấy và update dữ liệu bằng cách tương tác với SERVER (thông qua API)
SERVER: máy chủ, hiểu đơn giản đó là 1 máy tính với CPU, RAM, ổ cứng và các phần mềm phục vụ cho việc phát triển web.
Kiến trúc hệ thống như 1 bản thiết kế cho 1 ngôi nhà, nó cung cấp 1 sự trừu tượng để quản lý độ phức tạp của hệ thống và thiết lập 1 cơ chế giao tiếp giữa các thành phần. Vai trò của kiến trúc hệ thống có thể được list ra như sau:
Xác định 1 giải pháp có cấu trúc để đáp ứng tất cả các yêu cầu kỹ thuật và vận hành
Tối ưu hóa về mặt hiệu suất và bảo mật
Tác động đến chất lượng, hiệu suất và sự thành công chung của sản phẩm cuối cùng
Quyết định đến cách xây dựng và phát triển phần mềm bao gồm việc lựa chọn ngôn ngữ, thư viện, framework sử dụng hay kể cả giao diện người dùng.
Kiến trúc này tạo ra 1 đơn vị phần mềm không thể chia tách, các thành phần khác nhau của ứng dụng được kết hợp thành 1 chương trình duy nhất trên 1 nền tảng duy nhất. Các thành phần trong kiến trúc nguyên khối thường bao gồm: cơ sở dữ liệu (database), giao diện phía người dùng (client) và ứng dụng phía máy chủ (server)
Một kiến trúc nguyên khối (Monolith) sẽ thích hợp thực hiện cho các công ty nhỏ, các thành phần được kết nối với nhau và phụ thuộc nhau giúp phần mềm được khép kín. Ưu điểm của nó là tiết kiệm được thời gian phát triển và triển khai 1 cách đơn giản; hiệu suất ứng dụng cũng cao hơn do các thành phần giao tiếp với nhau 1 cách trực tiếp, đồng thời bộ nhớ được chia sẻ. Tuy vậy, nhược điểm của kiến trúc này là càng theo thời gian, khi lượng code, chức năng càng lớn thì hệ thống càng trở lên cồng kềnh và kém linh hoạt; chưa kể nếu 1 thành phần nhỏ trong cả hệ thống bị lỗi sẽ kéo theo việc toàn bộ hệ thống không thể hoạt động được.
Kiến trúc Microservice
Như hình ở trên, kiến trúc microservice thường được đưa ra so sánh với Monolith cho việc giải quyết các vấn đề mà kiến trúc nguyên khối gặp phải. Microservice là 1 loại kiến trúc hệ thống hướng dịch vụ, tập trung vào việc xây dựng 1 loạt các thành phần có khả năng tự quản lý tạo nên ứng dụng. Cách tiếp cận microservice đã trở thành 1 xu hướng trong những năm gần đây khi ngày càng có nhiều công ty áp dụng, sử dụng nhiều công nghệ DevOps. Các công ty lớn như Netflix, Amazon, Twitter, Paypal là những công ty đã phát triển chuyển đổi từ cách tiếp cận Monolith sang Microservice.
Ưu điểm lớn nhất của microservice chính là việc có thể dễ dàng triển khai, thử nghiệm các ứng dụng nhỏ 1 cách độc lập mà không làm ảnh hưởng đến hệ thống hiện có. Các service khác nhau cũng không bị tình trạng phải chờ đợi nhau hoàn thành mới có thể triển khai và chạy được, nhờ đó rủi ro khi triển khai cũng được giảm xuống trên đơn vị 1 service con. Với microservice, hệ thống của chúng ta có khả năng mở rộng theo chiều ngang, tức là dễ dàng nâng cấp, bổ sung phần cứng cho từng service với chi phí vừa phải, không cần đầu tư vào 1 máy có cấu hình cao như kiến trúc monolith để chạy hệ thống.
Tuy vậy thì hệ thống nào cũng có nhược điểm, với microservice đó là sự phức tạp khi chia ứng dụng thành các service nhỏ độc lập khiến cần nhiều công việc quản lý hơn cho từng service đó. Ngoài ra tính bảo mật cũng là 1 vấn đề khi giờ đây các API sẽ phải public ra bên ngoài để các service khác có thể gọi tới, điều đó khiến nguy cơ bị tấn công cũng cao hơn.
Kiến trúc hướng dịch vụ (SOA)
SOA – Service-Oriented Architecture là kiểu kiến trúc phần mềm dùng để chỉ ứng dụng bao gồm các tác nhân phần mềm rời rạc và lỏng lẻo thực hiện 1 chức năng cần thiết.
Ứng dụng trong SOA có thể được thiết kế và xây dựng theo kiểu module hóa , tích hợp dễ dàng và có thể sử dụng lại.
SOA có thể xem như 1 là kiến trúc nằm giữa Monolith và Microservice, khi nó được tạo thành từ các thành phần độc lập nhưng gần như không giao tiếp (hoặc rất ít) với các thành phần khác kiểu trong microservice. Cách chia module của SOA cũng sẽ khác với cách tiếp cận dạng service trong microservice.
Kết bài
Như vậy chúng ta đã cùng đi qua khái niệm cơ bản về kiến trúc hệ thống cũng như 1 số kiến trúc hệ thống thường được áp dụng hiện nay. Đây là 1 phần khó trong lĩnh vực kỹ thuật lập trình nói riêng và kỹ sư công nghệ nói chung, vì thế nếu bạn yêu thích phần này, hãy tìm hiểu sâu thêm về các kiến trúc hệ thống mà các công ty đang áp dụng nhé. Hy vọng bài viết hữu ích dành cho bạn và hẹn gặp lại trong các bài viết tiếp theo của mình.
Công nghệ ngày càng phát triển với nhịp độ nhanh và cải tiến không ngừng. Cập nhật và đón đầu các xu hướng công nghệ mới là cơ hội cho các developer lên kế hoạch, nắm bắt thời cơ, để vươn lên mạnh mẽ trên con đường sự nghiệp. Hãy cùng TopDev điểm qua 5 công nghệ chính sẽ dẫn dắt “làn sóng” công nghệ trong năm 2024 này nhé!
Blockchain & Web3
Các hệ sinh thái phi tập trung Blockchain & Web3 sẽ phát triển mạnh mẽ hơn trong năm 2024 bởi những trải nghiệm an toàn, minh bạch mà chúng mang lại.
Blockchain sẽ giúp người dùng tin tưởng vào những thứ được lưu trữ trên mạng lưới và ngăn chặn việc thay đổi hay giả mạo thông tin. Cùng với đó, Web3 sẽ cho phép người dùng trao đổi thông tin và giao dịch dựa trên công nghệ blockchain, ngoài ra nó còn giúp ngăn chặn sự phụ thuộc của người dùng vào các cá nhân hay tổ chức trung gian.
Tuy vẫn còn nhiều tranh cãi xung quanh khả năng ứng dụng và tính minh bạch của blockchain & web3, nhưng không thể phủ nhận những giải pháp mà chúng có thể mang lại cho người dùng. Dự đoán năm 2024 sẽ là một năm phát triển mạnh mẽ hơn nữa của công nghệ này.
Các công nghệ như blockchain, metaverse sẽ không phát triển hết mức do khả năng kết nối hạn chế. Các công nghệ này cần phải truyền tải một lượng thông tin khổng lồ cùng một lúc, vậy nên sự phát triển của 5G là vô cùng cần thiết. Cùng với đó, IoT (Internet of Thing) sẽ kết nối tất cả mọi thứ lại với nhau dễ dàng nhờ vào mạng lưới cảm biến, thiết bị và cơ sở hạ tầng thông minh.
Cùng với sự phát triển của IoT, một khái niệm mới cũng được cho ra đời có tên là IoV (Internet of vehicle). IoV là mạng lưới kết nối người đi bộ, người đi ô tô, và các bộ phận khác của cơ sở hạ tầng đô thị, nó là một phần của thành phố thông minh. IoV cố gắng làm cho giao thông trở nên tự chủ, an toàn, nhanh chóng và hiệu quả hơn, giảm thiểu tài nguyên sử dụng và tác động tiêu cực tới môi trường.
Trí tuệ nhân tạo AI sẽ tiếp tục bùng nổ trong năm 2024 nhờ khả năng thích ứng nhanh chóng với nhu cầu phát triển không ngừng trong bối cảnh kinh doanh hiện nay. Doanh nghiệp có thể tận dụng AI để tạo ra các sản phẩm, dịch vụ thông minh hơn, cải tiến quy trình sản xuất và làm được nhiều điều hơn nữa.
Song song với đó, Machine Learning (ML) hay máy học là một nhánh của trí tuệ nhân tạo. Hoạt động bằng khả năng cải thiện chính bản thân chúng dựa trên dữ liệu mẫu (training data) hoặc dựa vào kinh nghiệm (những gì đã được học). Machine Learning được áp dụng trong mọi lĩnh vực và vượt trội hơn hẳn con người.
Công nghệ Thực tế ảo (VR) và Thực tế ảo tăng cường (AR) sẽ mở đường cho các mô hình kinh doanh mới nhờ khả năng độc đáo “thực tế không giới hạn”. Bắt đầu từ lĩnh vực game sau đó đến việc ứng dụng trong các mô hình giáo dục, chăm sóc sức khỏe và tiến xa hơn là tạo môi trường tương tác mở rộng với thực tế hỗn hợp.
Đây chắc chắn sẽ là những công nghệ cốt lõi định hình thế giới trong tương lai.
>>> Xem thêm bài viết về Thực tế ảo (VR) và Thực tế ảo tăng cường (AR) tại đây.
Điện toán đám mây (Cloud Computing)
Trong tương lai, điện toán đám mây sẽ là “đầu tàu” tiên phong trong lĩnh vực công nghệ bên cạnh các công nghệ như metaverse, AI, 5G & IoT. Với dịch vụ điện toán đám mây, người dùng có thể truy cập thông tin từ bất cứ đâu và bất cứ khi nào mà chỉ thông qua một trung tâm kỹ thuật số.
Điện toán đám mây sẽ giúp ích rất nhiều cho doanh nghiệp trong việc phát triển trí tuệ nhân tạo (AI) và máy học (ML). Vấn đề không gian lưu trữ cho các thuật toán phức tạp sẽ được giải quyết triệt để với công nghệ này.
Đây là top 5 xu hướng sẽ dẫn dắt “làn sóng” công nghệ trong năm 2024 mà TopDev đã tổng hợp được. Hy vọng anh em Dev sẽ nắm bắt thật tốt để khai thác và chuẩn bị cho các chiến lược tốt hơn trong năm sau.
Những năm trở lại đây, cứ nhắc đến công nghệ là người ta lại nhắc đến 4.0, nhắc đến IoT, smartthing, … Với lĩnh vực lập trình, cộng đồng Dev hiện nay cũng có nhiều lĩnh vực để học và phát triển hơn liên quan trực tiếp đến phần cứng và 1 trong những vị trí đang hot hiện nay là kỹ sư lập trình nhúng – Embedded Developer. Vậy thì công việc của kỹ sư lập trình nhúng là gì và tại sao nó lại hot trong hiện tại là thời gian sắp tới, bài viết này mình sẽ cùng các bạn đi tìm hiểu sâu hơn về ngành này nhé.
Hệ thống nhúng (Embedded System) là gì?
Trước tiên chúng ta cùng tìm hiểu về khái niệm hệ thống nhúng (Embedded System).
Embedded System là tập hợp bao gồm phần cứng và 1 phần mềm viết riêng để điều khiển, tương tác với phần cứng đó được gọi là phần mềm nhúng (Embedded Software). Đặc điểm của hệ thống nhúng là chúng có thể tự điều hành (hoạt động) với 1 mục đích cụ thể và được thiết kế để có thể tích hợp vào hệ thống lớn hơn tùy theo mục đích sử dụng.
Hiện nay các hệ thống nhúng đang có vai trò quan trọng và hữu ích trong nhiều ngành công nghiệp cũng như đời sống của chúng ta, có thể kể vài ví dụ như sau:
Ngành công nghiệp chế tạo máy: hầu hết các dây chuyền lắp ráp, sản xuất máy móc hiện đại ngày nay đều là những hệ thống nhúng với quy mô từ nhỏ đến lớn. Chúng có khả năng tự vận hành, thiết kế chuyên biệt để sử dụng tùy theo mục đích.
Ngành công nghiệp ô tô: Hộp số tự động, hệ thống phanh, cảm biến lùi, … đều là những hệ thống nhúng mà các hãng sản xuất xe trang bị và cũng được quảng cáo là những tính năng mới của họ.
Smarthome, Smartcity: cái này có lẽ là gần gũi nhất với anh em lập trình khi có rất nhiều dự án liên quan với mục đích tạo ra các ứng dụng điều khiển thiết bị điện, điện tử trong gia đình. Đấy cũng chính là những hệ thống nhúng, 1 phần quan trọng trong lĩnh vực IoT nói chung ngày nay.
Xưa nay anh em lập trình viên vẫn hay than vãn rằng: em chỉ là lập trình viên, em không biết sửa máy tính, máy in hay máy giặt. Tuy vậy thì câu nói này không hẳn đúng với anh em làm lập trình nhúng nhé. Mặc dù trong lĩnh vực lập trình nhúng vẫn thường chia ra mảng chuyên lập trình và mảng chuyên thiết kế phần cứng, dù vậy thì với việc phải làm trực tiếp trên thiết bị phần cứng đặc thù thì các Embedded Developer hầu như sẽ đều phải trang bị kiến thức về phần cứng. Cụ thể thì trong 1 hệ thống nhúng, chúng ta cần nắm được các thành phần cơ bản như sau:
ROM: Chứa chương trình, các dữ liệu được fix hoặc các constant data.
RAM: Chứa chương trình thực thi và các biến tạm
MCU: bộ xử lý tính toán trung tâm
Ngoài ra là các thiết bị ngoại vi khác để giao tiếp hay điều khiển phần cứng.
Thêm 1 khái niệm mà chúng ta cần nắm đó là firmware.
firmware là 1 chương trình hướng dẫn được ghi vào bộ nhớ của 1 thiết bị điện tử đơn với mục đích cụ thể và thực hiện các chức năng cấp thấp, ví dụ như chuyển đổi tín hiệu cảm biến. Firmware được viết bằng ngôn ngữ cấp thấp và sau đó được dịch sang mã máy để phần cứng của thiết bị có thể đọc và thực thi nó.
Như vậy, công việc của 1 kỹ sư lập trình nhúng bao gồm:
Viết và lập trình firmware
Phân tích để lựa chọn những giải pháp hợp lý nhất cho toàn hệ thống nhúng: điều này cực kỳ quan trọng liên quan đến việc tối ưu chi phí phần cứng mà vẫn đáp ứng được nhu cầu hệ thống.
Viết code, test, document, tài liệu liên quan cho sản phẩm của mình
Phối hợp với các team phát triển phần mềm khác để xây dựng các ứng dụng điều khiển cho thiết bị di động, trên các hệ điều hành, driver, …
Như đề cập ở phần trên thì việc viết code vẫn là 1 phần quan trọng với kỹ sư lập trình nhúng, vì thế cũng giống như nghề lập trình viên nói chung, bạn cần trang bị khả năng lập trình, khả năng đọc hiểu tài liệu đa phần bằng tiếng Anh (vì hầu hết các thiết bị phần cứng sẽ được nhập về lắp ráp). Ngoài ra, 1 số kiến thức đặc thù mà bạn cần trang bị thêm trong mảng này như sau:
Lập trình C: C là ngôn ngữ quan trọng nhất trong lập trình nhúng, bạn cần nắm vững và thậm chí cần chuyên sâu về C.
Kiến thức về điện tử: các kiến thức về logic, vi điều khiển, vi xử lý, …
Kiến thức về hệ điều hành: kiến trúc máy tính, hệ điều hành Linux (phần lớn sẽ sử dụng hệ điều hành này), hệ điều hành thời gian thực (Realtime OS)
Memory (bộ nhớ): RAM, DRAM, SRAM, NOR, NAND, …
Cấu trúc dữ liệu và giải thuật: cái này thì thật ra lập trình nào cũng cần
Các loại giao tiếp: USB, SATA, PCIE, UART,…
Về kiến thức chuyên ngành, hãy bổ sung các mục dưới đây:
Lập trình driver thiết bị sử dụng ngôn ngữ C
Ngôn ngữ script: Perl, Python, Shell Script trên Linux
Thiết kế mạch PCB: Allegro hay Antinum
Thiết kế sơ đồ – Schematic Design
Build Environments: Makefile, Cmake
Ngoài ra cần học cách tương tác với phần cứng như sử dụng các công cụ đo, test board, hay thậm chí là hàn mạch sửa mạch nếu cần
Một số tool mà bạn có thể tham khảo trước: Cross ToolChains (Linux), Keil Embedded Tool (Windows), Putty (Windows)
Như đã nhắc ở trên, có 2 hướng đi lâu dài dành cho lập trình viên nhúng.
1 là trở thành 1 lập trình viên chuyên viết phần mềm cho hệ thống nhúng (Embedded software). Công việc của bạn sẽ tập trung vào việc viết code, test, viết tài liệu cho sản phẩm mà bạn tạo ra bao gồm các driver, firmware, hệ điều hành hay các ứng dụng khác chạy trên hệ thống nhúng hoặc chạy trên các nền tảng web, mobile, PC điều khiển thiết bị.
Hướng thứ 2 thì nếu có sở thích về phần cứng nhiều hơn, hãy lựa chọn trở thành 1 người chuyên thiết kế bo mạch (board) hay còn gọi là thiết kế PCB. Hướng này đòi hỏi bạn cần trang bị kiến thức sâu về phần cứng cũng như điện tử.
Cả 2 hướng đều có tương lai phát triển rất lớn vì hiện nay nhu cầu về mảng lập trình nhúng là rất cao, ngoài ra không dễ để học và hiểu sâu được, vì thế cần có sự tìm tòi, tìm hiểu và nắm vững chuyên môn mới có thể tiến xa được trong nghề này.
Kết bài
Như vậy mình đã cùng các bạn tìm hiểu về những khái niệm cơ bản nhất trong nghề lập trình viên nhúng – Embedded Developer. Qua bài viết này hy vọng các bạn có cái nhìn tổng quát hơn về lĩnh vực lập trình này cũng như định hướng rõ ràng hơn nếu các bạn có sở thích về mảng nhúng nói riêng và IoT nói chung. Cảm ơn các bạn đã đọc bài, hẹn gặp lại các bạn trong các bài viết tiếp theo của mình.




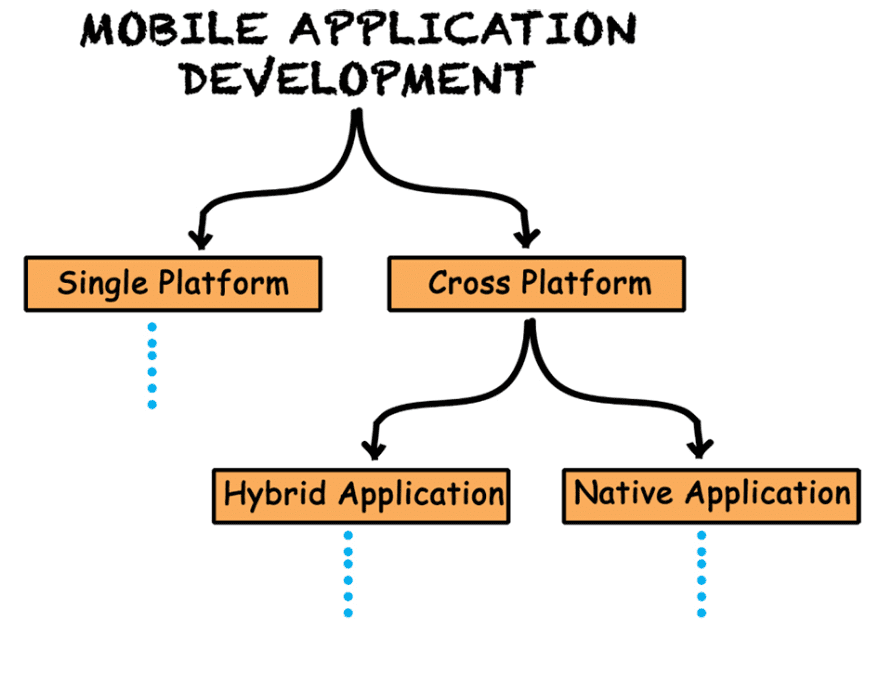



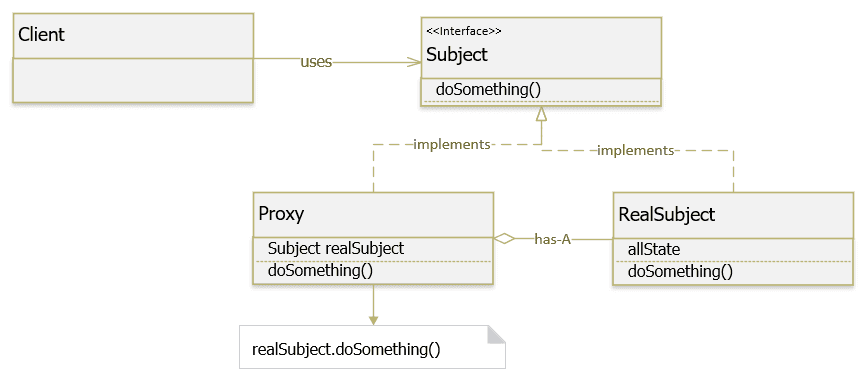
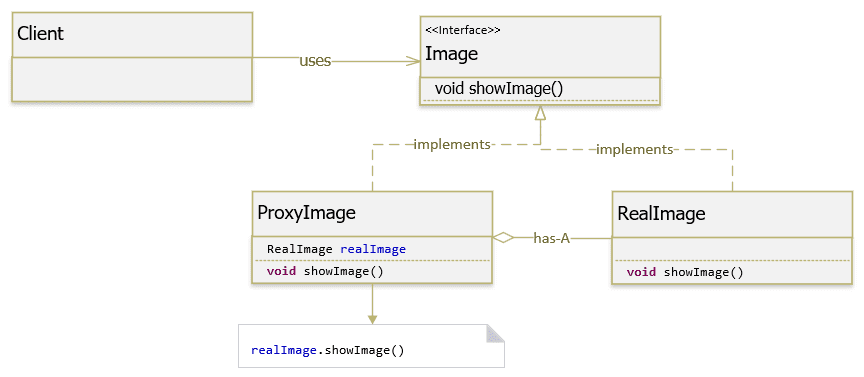
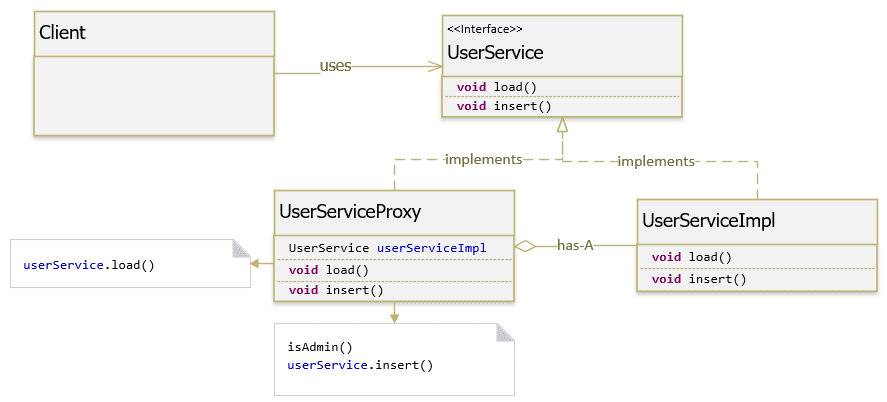



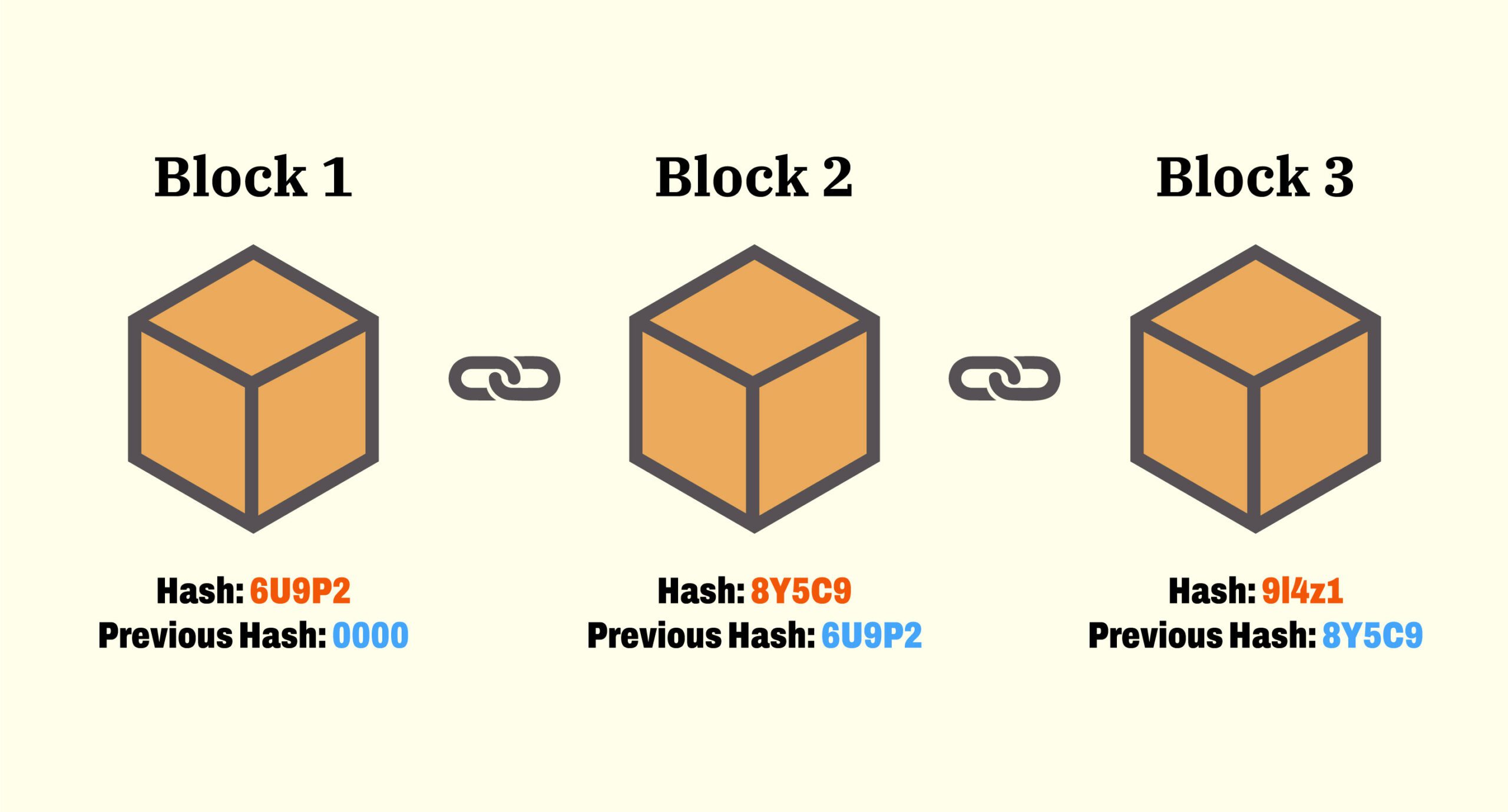
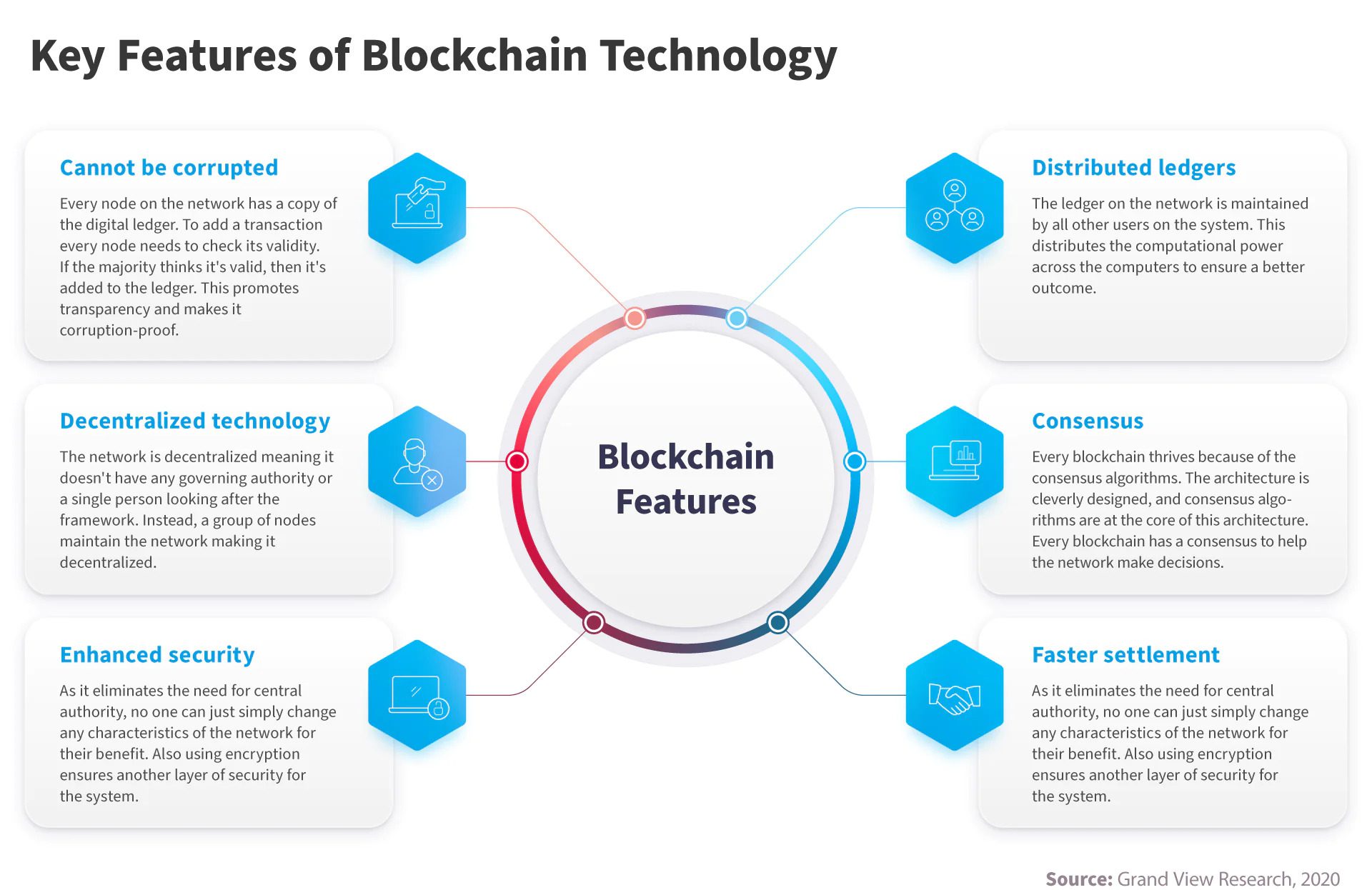



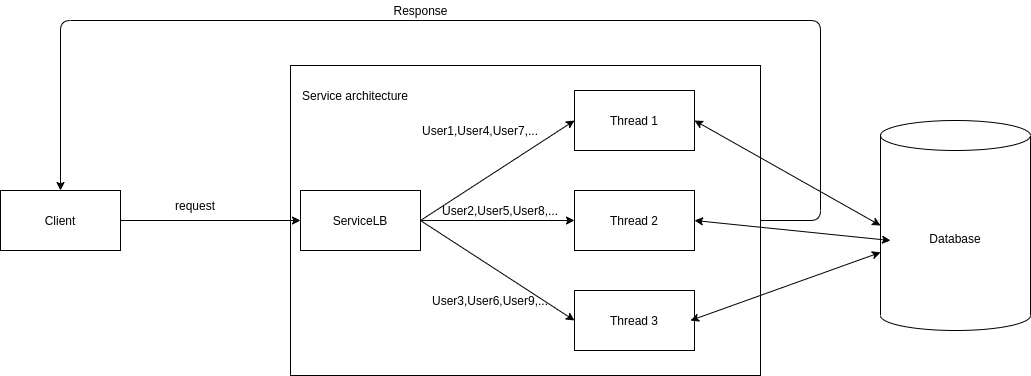

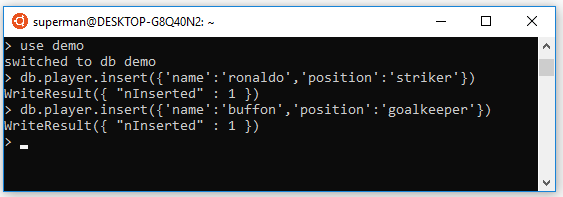
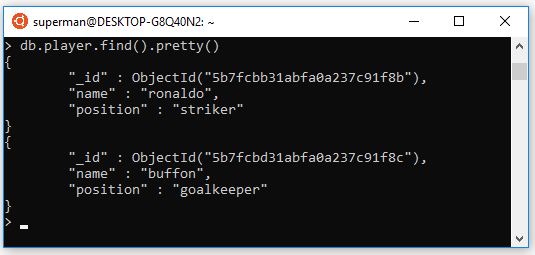
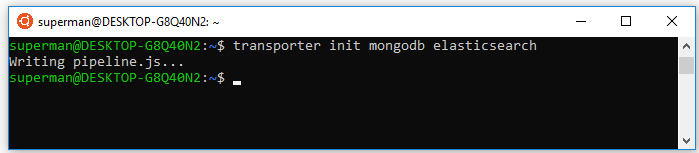
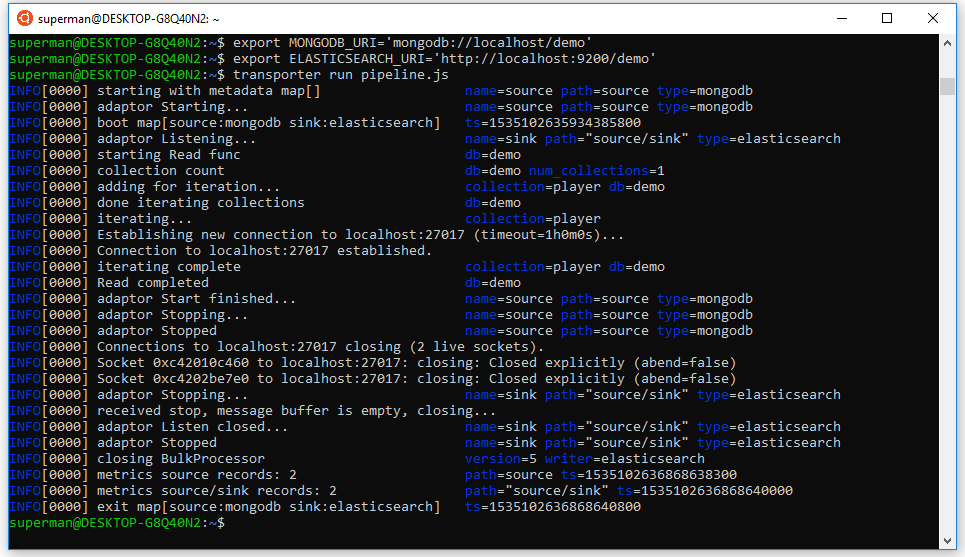
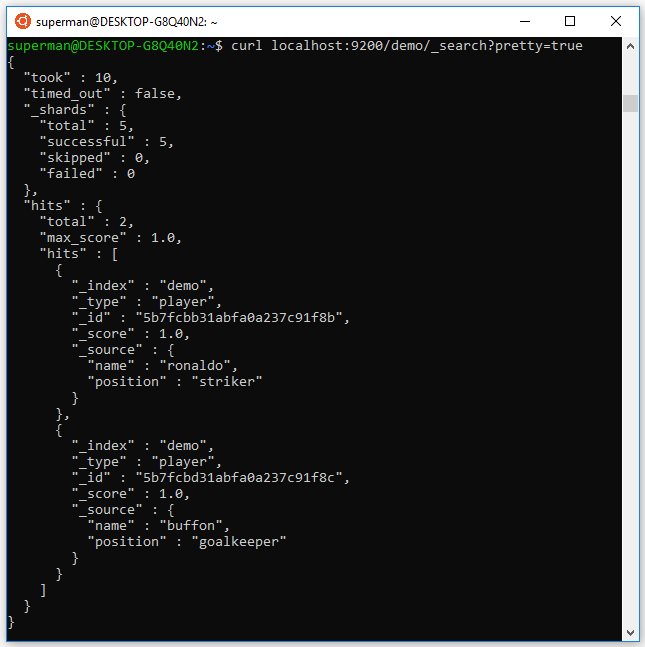






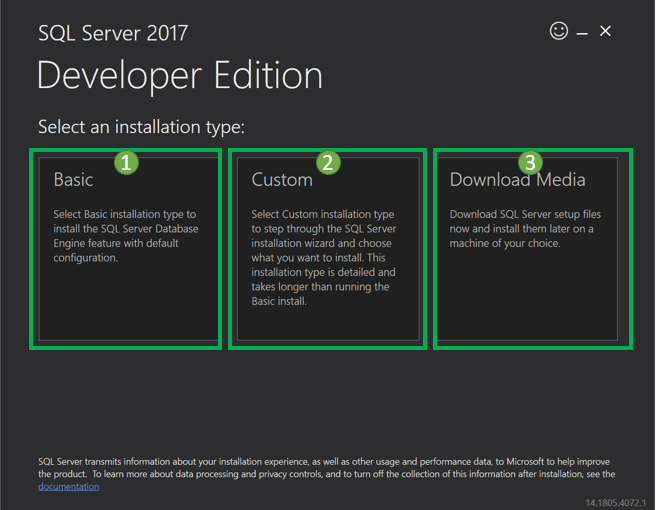
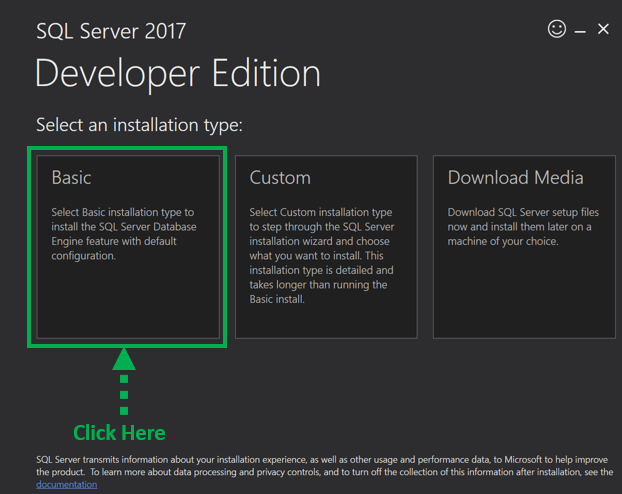
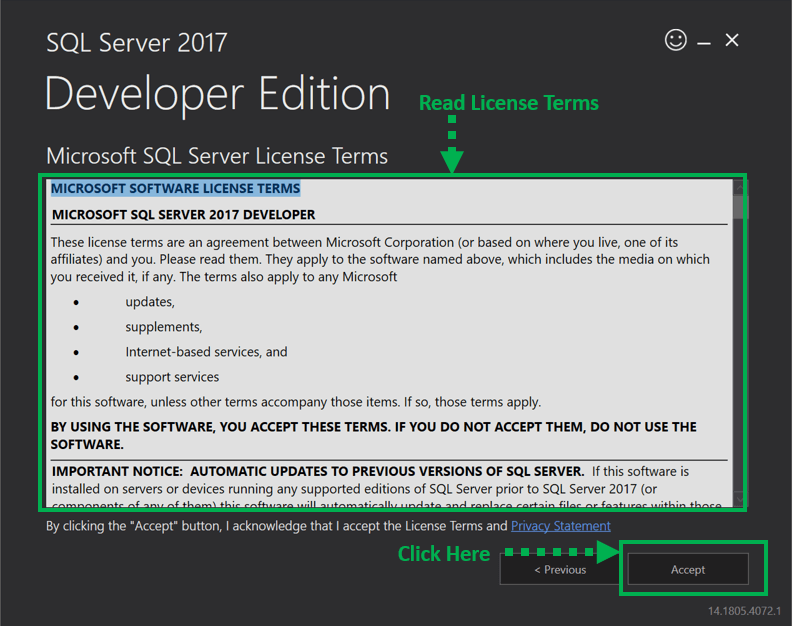
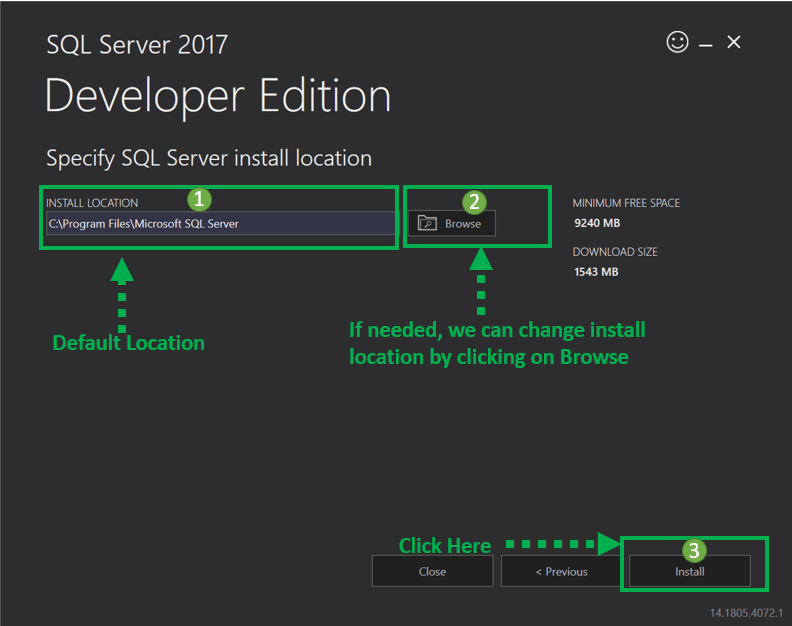
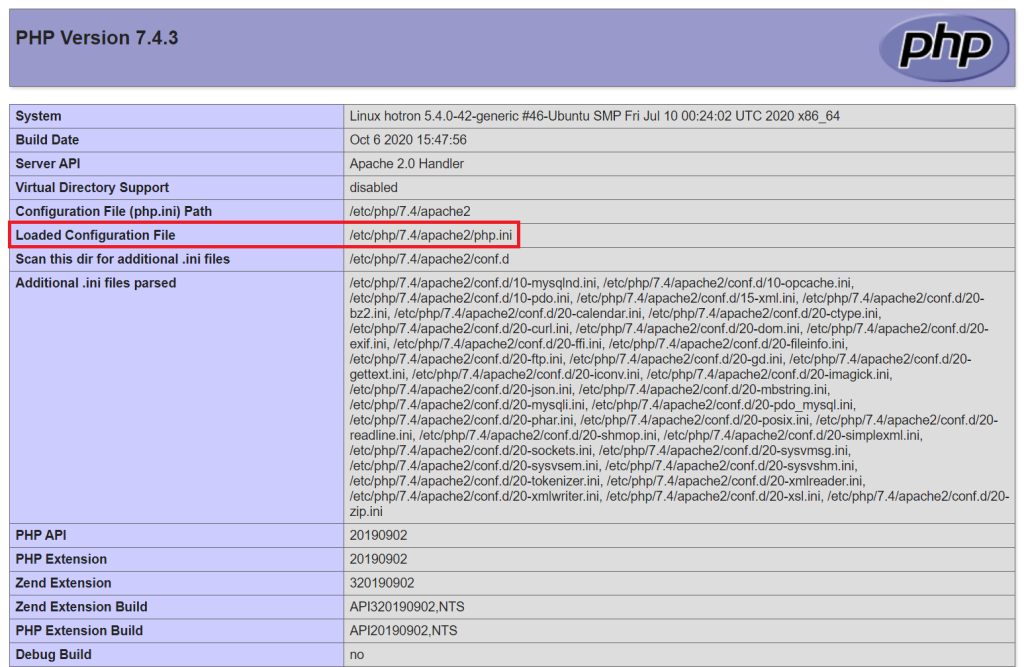
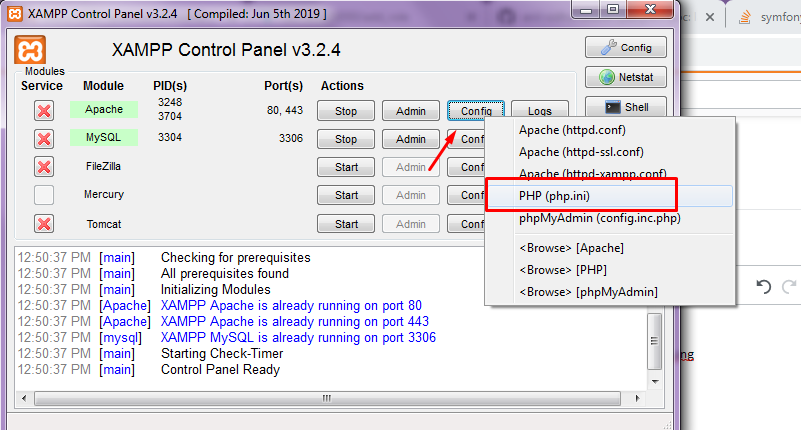


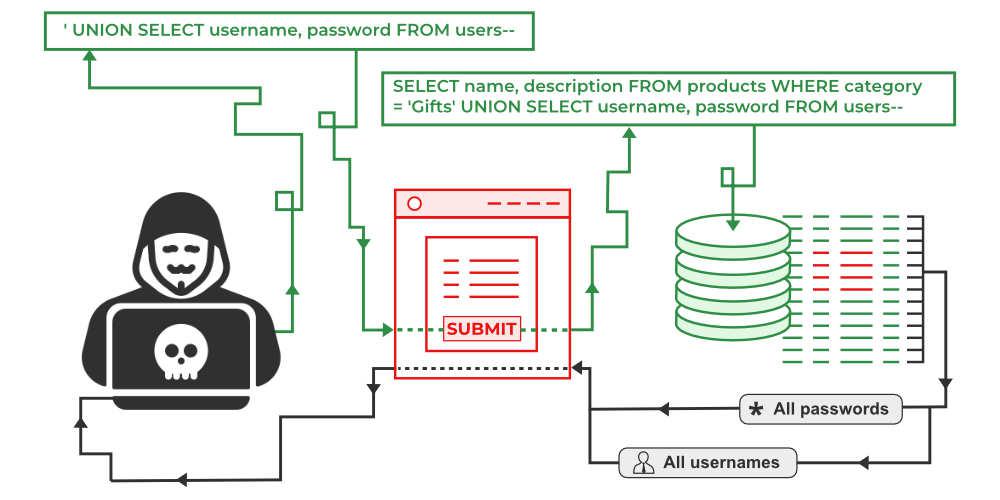
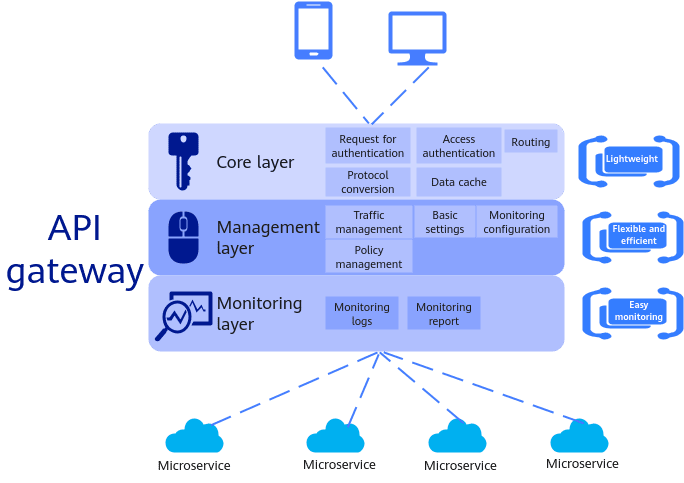

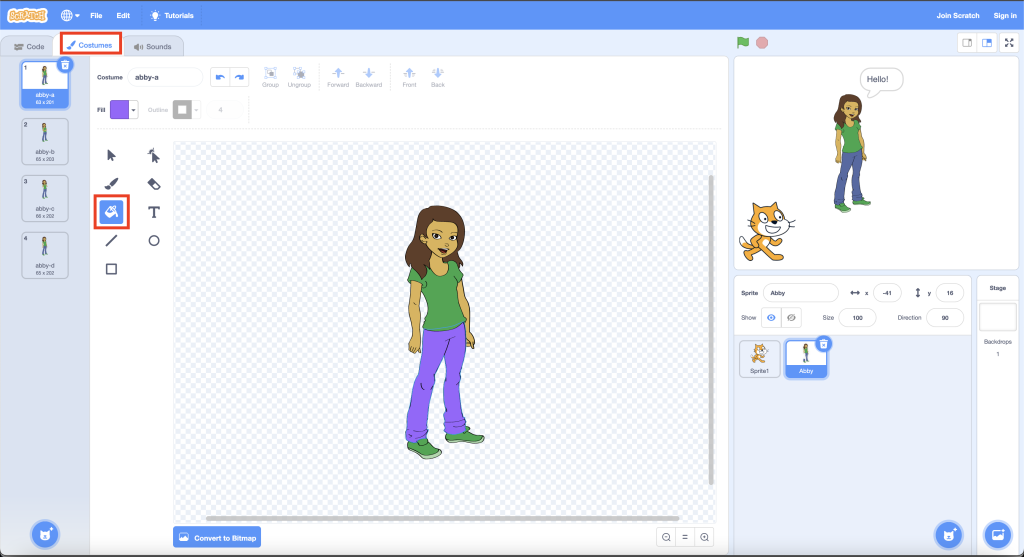 Mục consumes dành cho các đối tượng tuỳ chỉnh. Cho phép chỉnh sửa màu sắc, hình dạng, kích thước các đối tượng.
Mục consumes dành cho các đối tượng tuỳ chỉnh. Cho phép chỉnh sửa màu sắc, hình dạng, kích thước các đối tượng.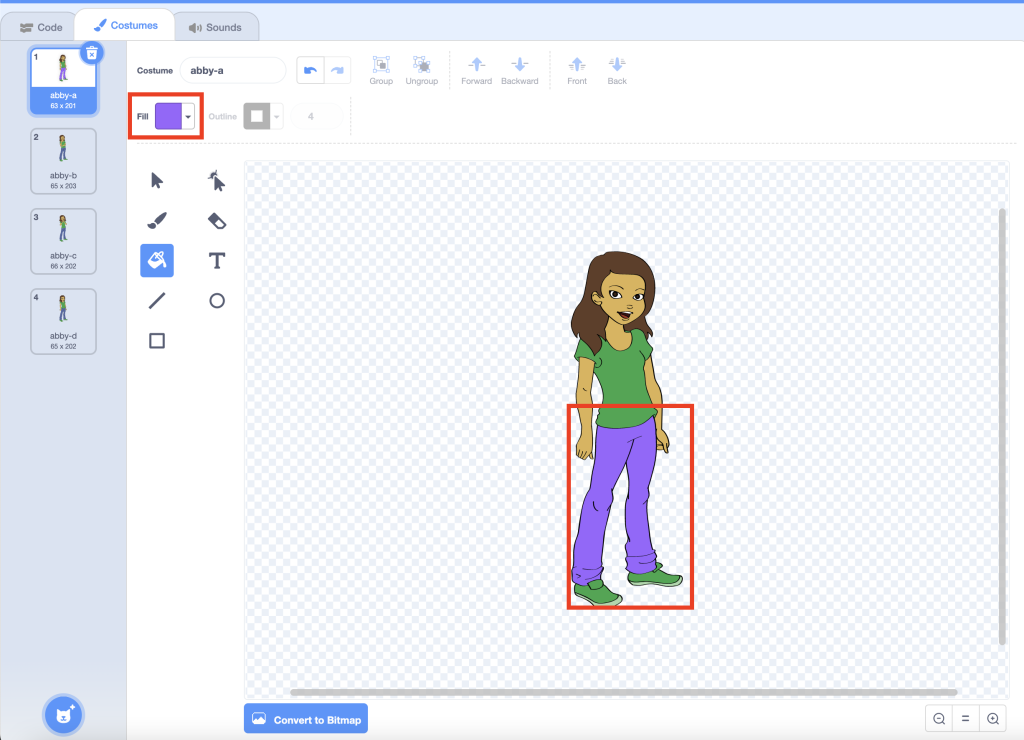 Thay đổi màu sắc quần của đối tượng sang màu tím.
Thay đổi màu sắc quần của đối tượng sang màu tím.