Trước khi bắt đầu, anh em cần hiểu AWS Appsync có sử dụng GraphQL. Nếu anh em nào chưa biết GraphQL là gì, khác biệt gì so với REST API thì anh em có thể tham khảo qua bài viết này.

Lưu ý về mặt concept thì GraphQL khác hoàn toàn so với REST API thông thường nha anh em.
Sau khi đã nắm sơ bộ và hiểu thêm về GraphQL, anh em có thể thoải mái xúc ông AppSync này. Túm cái váy lại thì không có gì khó đâu. Nên cứ từ từ là dứt hết thôi anh em
Bắt đầu ngay thôi nào!
1. AWS Appsync là gì?
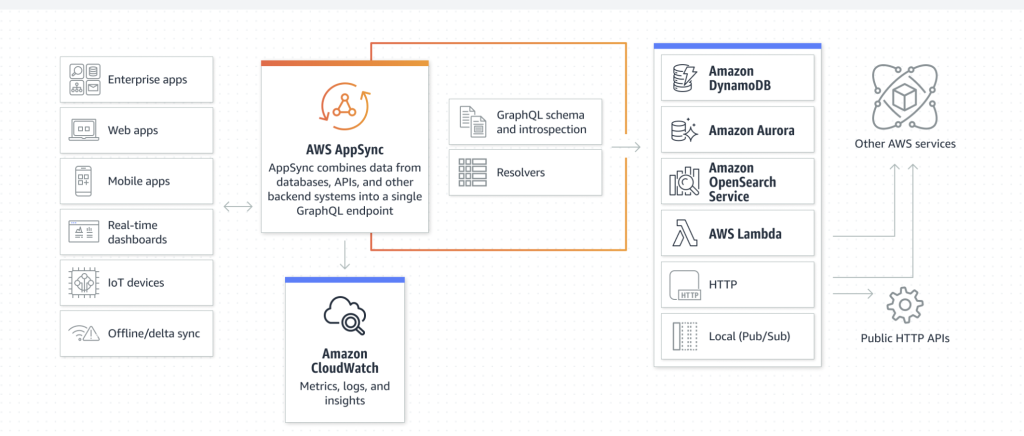
AWS Appsync sử dụng Graph Query Language như là một endpoint duy nhất thay thế cho REST API. Anh em frontend thay vì gửi request tới một số endpoint khác nhau để lấy dữ liệu, giờ đây có thể gọi tới một endpoint duy nhất.
Cần gì lấy đó, cần gì sửa đó, chính là điểm mạnh của GraphQL.
Mô hình này giảm độ phức tạp của các web application và nâng cao trải nghiệm cho enduser lúc họ truy cập trang web. Giảm thời gian tải trang web.
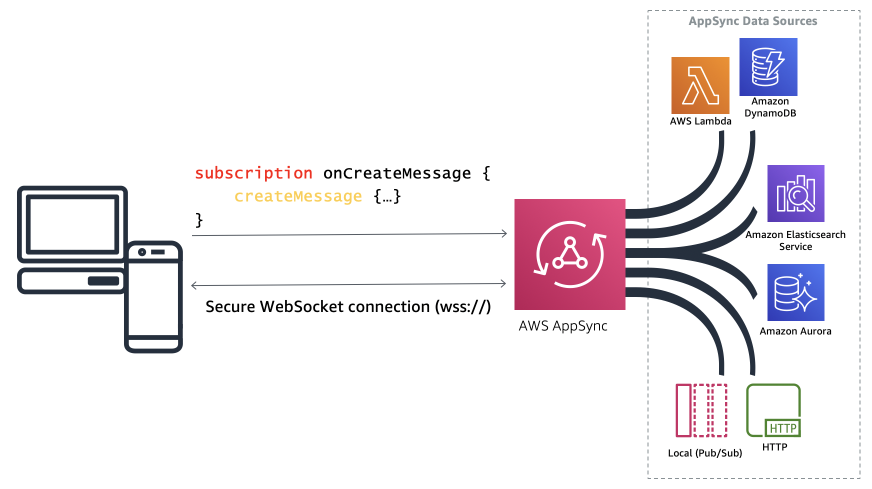
AWS AppSync is a fully managed GraphQL API layer developed by Amazon Web Services. AppSync allows developers to build GraphQL APIs without much of the usual work; it handles the parsing and resolution of requests as well as connecting to other AWS services like AWS Lambda, NoSQL and SQL data stores, and HTTP APIs to gather backend data for the API. AWS AppSync là lớp quản lý GraphQL API được phát triển bởi Amazon Web Services. AppSync cho phép lập trình viên xây dựng GraphQL API mà không cần phải bỏ quá nhiều công sức, nó cũng giúp xử lý cú pháp, giải quyết các yêu cầu các AWS services như AWS Lambda, NoSQL và SQL data stores.
2. AppSync hoạt động như thế nào?
Về cơ bản AWS Appsync là một GraphQL proxy. Ở proxy này, nó nhận và xử lý tất cả GraphQL request. Proxy này sẽ xử lý tất cả các request được hỗ trợ bởi GraphQL.
Ví dụ như queries (để truy vấn dữ liệu), mutations (để thay đổi dữ liệu thông qua API) và subscriptions (dữ liệu realtime để streaming data thông qua API).
Appsync cũng cho phép developers định nghĩa và sử dụng schema của GraphQL API, thêm các function resolver cho từng request đã được định nghĩa.
Vì nằm trong hệ sinh thái AWS nên phía sau GraphQL của Appsync có thể là:
-
- Amazon DynamoDB tables
-
- RDS databases
-
- Amazon Elasticsearch domains
-
- AWS Lambda functions
Các RDBMS này đóng vai trò như datasources, giúp GraphQL có thể trả về các truy vấn với dữ liệu chính xác.
3. AppSync integrate với các AWS services khác như thế nào?
Do được phát triển bởi Amazon nên AppSync có thể dễ dàng tương tác với các services khác trong hệ sinh thái AWS. Một số ví dụ cụ thể có thể kể tới như:
-
- AWS Lambda functions: GraphQL resolver có thể mapping với Lambda function.
-
- DynamoDB tables: Lấy hoặc truy vẫn dữ liệu từ DynamoDB table sử dụng cho GraphQL API.
-
- Amazon Elastic search domains: use an Elasticsearch domain có thể được xem như data source cho GraphQL queries.
-
- AWS RDS: Kết nối tới SQL và NoSQL database instances available với RDS, và sử dụng databases and tables from that service như là data sources.
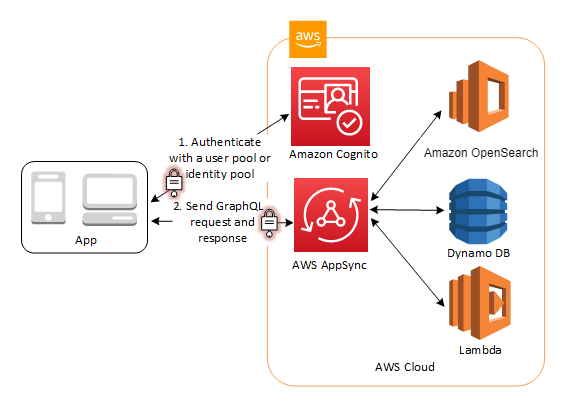
AppSync cũng hỗ trợ một số cách để authentication:
-
- AWS Cognito User Pools: dùng được authentication và authorization mechanism choGraphQL API trong AppSync.
-
- AWS IAM: quản lý API access bằng cách tạo IAM users.
-
- OpenID Connect: authenticate API users sử dụng OpenID identity service.
Xem thêm nhiều việc làm Java lương cao trên TopDev
4. Điểm mạnh của AppSync
Ngoài việc AppSync được hỗ trợ và phát triển với AWS, sử dụng AppSync còn có 3 ưu điểm chính sau đây. Còn có ý nào anh em cứ thoải mái bổ sung giúp nha.
Đầu tiên là kiểm soát GraphQL, với AWS tất nhiên thời gian tiết kiệm hơn nhiều
-
- Fully managed GraphQL API layer: AppSync tự động tạo ra GraphQL resolver và kết nối với data source. Việc này giúp anh em tiết kiệm kha khá thời gian khi thiết lập mới API GraphQL
Thứ hai là điểm mạnh tới từ chính GraphQL
-
- Real-time subscriptions and offline functionality built in: Sử dụng AppSync cho phép sử dụng subscriptions GraphQL. Loại này thì keep connection alive, rất thích hợp cho anh em build những app sử dụng dữ liệu realtime thường xuyên. Kết hợp giữa AppSync và Amplify còn giúp anh em lưu trữ dữ liệu local, đồng bộ sau khi dữ liệu đã được chuyển lên.
Thứ ba là kết hợp với các AWS Services khác
-
- Integrations with core AWS services: Do AppSync có tích hợp với AWS lambda, RDS và DynamoDB nên anh em sẽ không cần làm gì nhiều nếu muốn connect tới data source. Dành thời gian tập trung vào logic business, tránh mất thời gian vào một số thứ setup loằng ngoằng.
5. AppSync một số điểm hạn chế
Tuy tốt nhưng AppSync cũng tồn tại một số nhược điểm, theo như mặc định thì mỗi tài khoản AWS có giới hạn 25API GraphQL với App Sync. Số lượng truy vấn bị giới hạn ở mức 1000 truy vấn/s cho mỗi API.
Để tăng những con số này, anh em có thể gửi ticket yêu cầu lên AWS. Nhưng một số cái không thể tăng, anh em lưu ý check lại những điểm này xem có phù hợp với ứng dụng của mình hay không?
-
- The maximum number of API keys per GraphQL API is fixed at 50. (Maximum API key cho mỗi GraphQL là 50)
-
- The maximum schema document size is 1MB (maximum schema size là 1MB, nếu anh em có schema quá to nên cân nhắc)
-
- The maximum GraphQL query execution timeout is 30 seconds (query thực hiện maximum là 30s, không thể config, nếu backend xử lý loằng ngoằng hơn 30s thì anh em cẩn thận chỗ này)
3 mục này là 3 mục hạn chế của AppSync anh em cần lưu ý, kiểm tra kĩ và check lai một lần nữa với business application mình định làm trước khi quyết định sử dụng GraphQL với AppSync
6. Ai và lúc nào nên sử dụng AppSync
Do App Sync tập trung vào sử dụng GraphQL, nên các ứng dụng trước đó đã tiếp cận hoặc sử dụng với GraphQL sẽ có khả năng tích hợp nhanh và dễ dàng hơn.
Với GraphQL thì anh em biết rồi, nếu team FE quyết định chọn, vậy công việc sẽ nhẹ gánh phần nào cho team BE. Tuy nhiên cần cân nhắc trình độ và khả năng thay đổi từ REST sang GraphQL của team.
Một yếu tố nữa cần quan tâm là mô hình business, nếu business của anh em nhỏ, cứ quẩy với REST. Nhưng nếu anh em muốn xây một application có khả năng chịu tải tốt, sử dụng dữ liệu realtime thường xuyên. Mạnh dạn quẩy xúc với GraphQL và AppSync
Ngoài ra nếu các thành phần khác như BE, Gateway, Security, Authen, Autho của anh em đã go với AWS, tất nhiên AppSync là một lựa chọn tốt. Tuy nhiên nếu datasource nằm ở Azure mà GraphQL lại AppSync thì hơi cực. Cái này anh em cũng có thể lưu tâm
7. Giá cả của AWS App Sync
Nếu anh em dùng miễn phí, AWS cho phép có 250.000 queries GraphQL hoặc mutations. Kèm theo đó là 250.000 data updates.
Về thời gian kết nối thì anh em có 600,000 phút kết nối trong 12 tháng sau khi tài khoản AWS được tạo. Ngoài bậc miễn phí thì anh em trả tiền theo bảng dưới đây.
| Yếu tốt | Giá |
|---|---|
| Queries and data modification requests | $4.00 / 1 million |
| Data transfer for API responses | $0.09 / GB (decreases with higher data volume) |
| Real-time updates | $2.00 / 1 million |
| Connection-minutes | $0.08 / 1 million |
Giá cả cũng là một yếu tố quan trọng anh em cần lưu tâm ha.
8. Tham khảo thêm về AppSync
Cảm ơn anh em đã đọc bài – Thank you for your time – Happy coding!
Tác giả: Kiên Nguyễn
Bài viết liên quan

Test REST Web Service đơn giản hơn với REST Assured
Type Query trong GraphQL với Spring Boot

REST Web service: Tạo ứng dụng Java RESTful Client với Jersey Client 2.x
Ứng tuyển ngay việc làm IT lương cao trên TopDev!







































 Công việc của SRE là đảm bảo hệ thống hoạt động ổn định. Chưa có uptime thì thôi làm gì có downtime bao giờ?
Công việc của SRE là đảm bảo hệ thống hoạt động ổn định. Chưa có uptime thì thôi làm gì có downtime bao giờ?















 (1) (1)")