Bài viết đến từ anh Vũ Tuấn Nghĩa – Quản lý cao cấp hoạch định dữ liệu Data Engineering team @Techcombank
DynamoDB là một dịch vụ cơ sở dữ liệu NoSQL cung cấp hiệu năng nhanh và nhất quán – có khả năng mở rộng và linh hoạt trong cách sử dụng. Khác với cơ sở dữ liệu quan hệ (RDMS), DynamoDB không sử dụng joins và các cấu trúc quan hệ khác để lưu trữ và truy vấn dữ liệu. Thay vào đó, bạn sẽ thiết kế table của mình theo Single design table – 1 table duy nhất phục vụ toàn bộ application hay service, việc này giúp hiệu suất đọc và ghi nhanh hơn ở scale lớn và giảm chi phí cloud.
Trong bài viết này, chúng mình sẽ khám phá các lợi ích và thách thức của việc sử dụng Single design table trong DynamoDB, cũng như cách Datalake ở Techcombank sử dụng để đáp ứng và tối ưu như cầu sử dụng.


Single table design
Trong tài liệu trang chủ AWS có đề cập:
You should maintain as few tables as possible in a DynamoDB application. Having fewer tables keeps things more scalable, requires less permissions management, and reduces overhead for your DynamoDB application. It can also help keep backup costs lower overall.
Thật vậy, nhưng làm thế nào để hạn chế số lượng bảng hay thậm chí một bảng duy nhất cho toàn bộ application/service tuy nhiên vẫn đảm bảo được thiết kế đó phục vụ được tất cả nhu cầu?
Multi-table vs Single-table
Hãy nhìn vào ví dụ như sau:
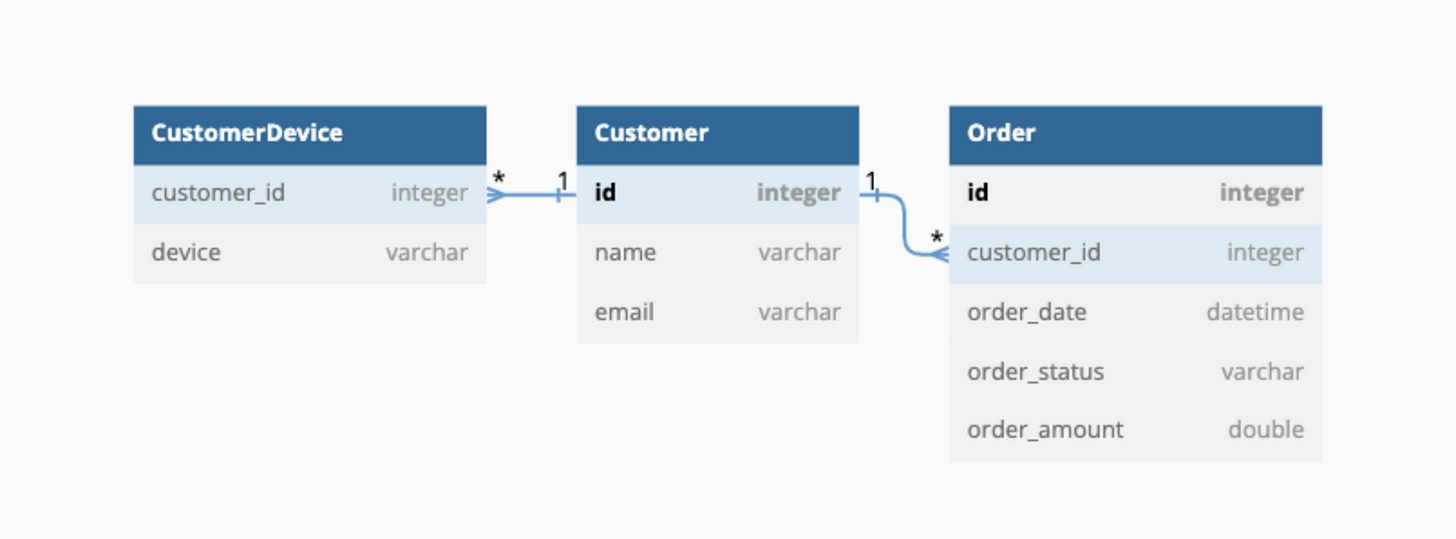
Đây là cách làm thông thường khi thiết kế data ở các hệ thống RDMS, sử dụng các chuẩn Database Normalization(1NF, 2NF, 3NF,…).
Mindset khi thiết kế data dạng Multi-table là tư duy lưu trữ data đầu tiên, tối ưu trong việc lưu trữ và đáp ứng tất cả query patterns ở một hiệu năng (performance) trung bình.
Giờ hãy tiếp cận theo một hướng khác:
Know your query patterns first
Luôn tiếp cận bài toán với xu hướng dành nhiều thời gian để thu thập cách User sử dụng hệ thống của mình là như thế nào, các query patterns là gì.
…you shouldn’t start designing your schema for DynamoDB until you know the questions it will need to answer. Understanding the business problems and the application use cases up front is essential.
Giả dụ với bài toán bên trên, chúng ta có 2 query patterns là:
- Query thông tin Customer bằng email
- Query thông tin Order bằng Customer’s email
Khi đã có thông tin như trên, chúng ta đi vào kỹ thuật đầu tiên khi thiết kế Single-table:
Index overloading
Với Query pattern đầu tiên
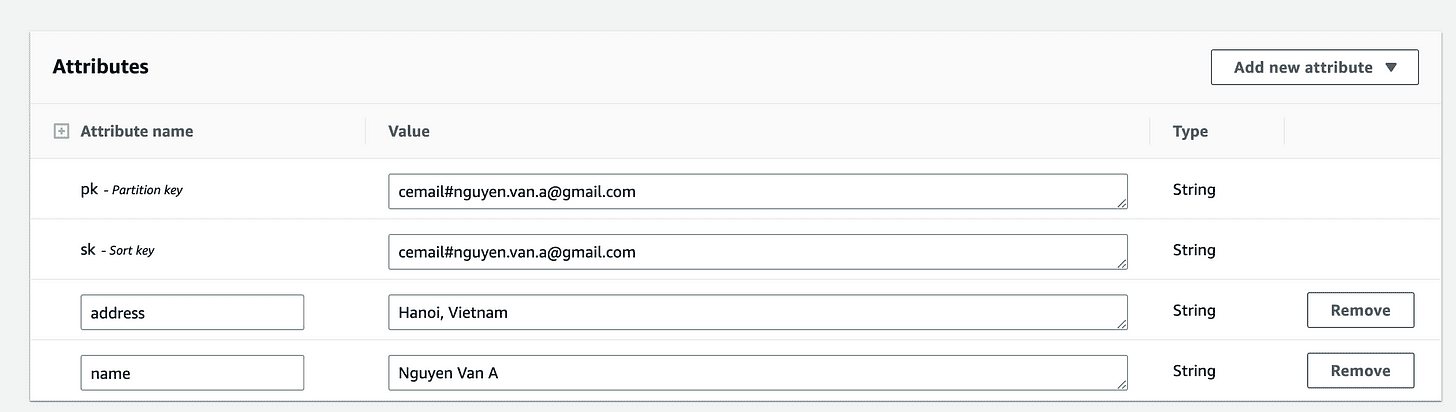
- Composite primary key:
a. pk – Partition key: email
b. sk – Sort key: email
2. Attributes:
a. name
b. address
Cùng với table đó, để serving query pattern thứ 2
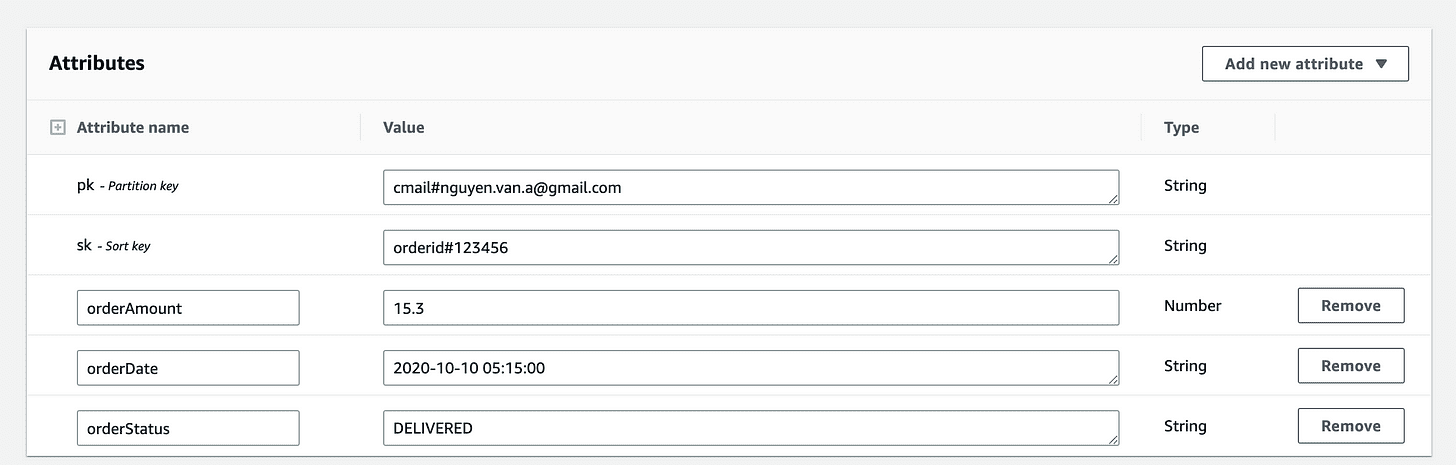
- Composite primary key:
a. pk – Partition key: email
b. sk – Sort key: orderID
2. Attributes:
a. order date
b. order status
c. order amount
Mỗi record sẽ có composite PK khác nhau để phục vụ cho từng query patterns. Nhờ indexes (partition key, sort key) giờ đây được sử dụng đa dạng, nhiều loại data giúp cho số lượng cần indexing giảm xuống, từ đó:
- Tăng write performance: do ít index cần update lúc thực hiện write operation.
- Giảm chi phí cloud: do ít index cần maintaining cho Database.
Comfort with De-normalized and Pre-join
Với đặc thù thiết kế của single-table, bạn phải làm quen với chuyện de-normalized trong lúc thiết kế schema, cũng như thực hiện pre-join data vào Attributes của 1 record nhiều nhất có thể – hạn chế round trip khi truy xuất data.
Single-table design at Datalake Techcombank
Agile vs Know your query pattern first
Hầu hết các dự án IT hiện nay đều theo đuổi mô hình Agile – chấp nhận sự thay đổi, vậy làm thế nào để thiết kế Single-table có thể thành hiện thực khi nó yêu cầu “Know your query pattern first”. Câu trả lời là nhờ có index overloading cộng với đặc thù flexible attributes của DynamoDB(NoSQL) chúng ta hoàn toàn có thể mở rộng thêm các query patterns. Có một số những tips trong quá trình sử dụng bọn mình có đúc kết được như sau:
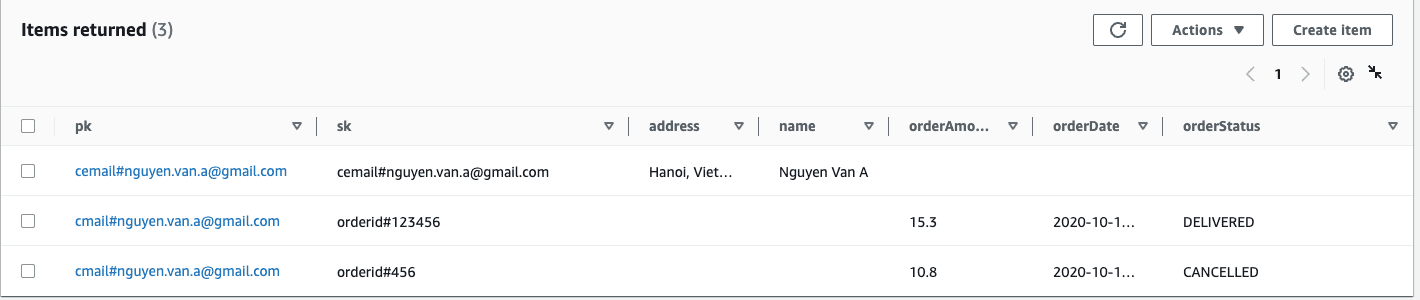
- Prefix in PK and SK: như ví dụ bên trên với PK của customer email sẽ có prefix là “cemail#”, với SK của orderID sẽ có prefix là “orderid#”, việc này giúp việc về sau mở rộng indexes một cách dễ dàng và tránh bị trùng lặp do mình đã quy hoạch từ ban đầu.
- Update data trong Single-table sẽ phức tạp hơn, do data bị duplicate (attributes) ở các item với nhiều bộ Primary key khác nhau, do đó khi có 1 field data được update, bạn cần update tất cả các item ở các bộ Primary key chứa field đó.
Schema migration
Đây là một trong những bài toán phức tạp nhất trong quá trình vận hành DynamoDB (NoSQL) cùng với single-table design, việc schema upgrade thường xuyên xảy ra (thêm cột, thay đổi column type, thay đổi primary key,..) khiến như cầu schema migration một cách dễ dàng càng cần thiết:
- Schema migration cho attributes: do mang yếu tố flexible Attributes, mỗi Record là 1 object với schema độc lập, để có thể thêm cột ở tất cả các object, đòi hỏi phải scan tất cả các object để update. Nhược điểm là full scan để update sẽ tốn nhiều thời gian, và trong lúc đó table của mình sẽ ở trạng thái inconsistent, có những records đã được update, có records không.
- Schema migration cho việc thay đổi primary key: về bản chất việc thay đổi Partition key hay sort key thì DynamoDB sẽ tạo 1 record mới và xoá record cũ đi. Trong trường hợp này hãy cân nhắc sử dụng overloading-index nếu có thể, trong trường hợp bắt buộc phải chuyển sang Primary key mới làm tương tự như với schema migration.
Kết luận
Việc chọn sử dụng multi-table hay single-table phụ thuộc vào nhiều yếu tố, team đang muốn tối ưu điều gì, và hơn hết không có một giải pháp hoàn hảo nào giải quyết được tất cả các bài toán.
Ở Datalake của Techcombank, chúng tôi muốn tối ưu:
- Thời gian của Engineers tập trung giải quyết các bài toán business, mà ít phải lo lắng đến việc vận hành servers.
- Khả năng mở rộng, chi phí tối ưu sử dụng.
- Mang đến trải nghiệm linh hoạt cho engineers.
Từ đó chúng tôi chọn DynamoDB cũng với Single-table design (một trong những storage stack của Datalake) để đáp ứng cũng như giải quyết các yêu cầu phát triển.

Có thể bạn quan tâm:
- Data is all about orchestration (Tầm quan trọng của việc điều phối khi làm việc với dữ liệu)
- Data Lake – Nền tảng lý trí cho mọi quyết định tài chính
[topdev-job ids=”2030222,2030051,2030077″]
[topdev-related-blogs ids=”53960,53425″]

