Bài viết được sự cho phép của tác giả Phạm Bình
Chào các bạn,
Bạn biết đấy mình đang tìm hiểu về big data trong thời gian này. Tuy cũng chưa được nhiều, nhưng bằng bấy nhiêu đã khiến mình nhận ra rằng trước giờ mình đã hiểu sai về big data. Nguyên nhân chủ yếu khiến mình nhìn nhận sai là do mình đang tìm hiểu nó dưới cái nhìn của một software engineer thay vì là một data engineer.

Trên blog phambinh.net, các bạn đọc giả chủ yếu cũng là software engineer hoặc có định hướng trở thành software engineer, để tránh các bạn bị hiểu sai về big data như mình, nên mình viết bài viết này để chia sẻ với các bạn những lầm tưởng của mình về big data trước kia.
1. COI DATABASE NẶNG LÀ BIG DATA
Mình thường chỉ làm việc với những database (mysql) có table tầm 1tr records đổ lại. Tổng dung lượng database cũng chỉ xấp xỉ 1GB. Đương nhiên đây đều là các database trên môi trường dev, còn database trên môi trường production thì nặng hơn, có điều mình … lại chưa được làm việc với database của production bao giờ.
Vì vậy mà khi tiếp tục với những database nặng cỡ tầm 50GB – nó thật sự khiến mình cảm thấy bối rối vì chưa làm việc với những database nặng như vậy bao giờ. Mình nghĩ với lượng dữ liệu thế này chắc không thể áp dụng những cách truyền thống được để giải quyết được, mà cần phải áp dụng các công nghệ của big data vào để xử lý.
Chú thích thêm: Trước đó mình chưa từng tìm hiểu thế nào là big data mà chỉ tự nghĩ rằng big là lớn, data là dữ liệu, vậy big data là dữ liệu lớn, mà cỡ 50GB thì là là lớn rồi. Cho nên auto hiểu luôn database 50GB là big data.
Cho tới khi mình tìm hiểu được big data là gì, thì mình mới thay đổi quan điểm này. Nhắc lại chút thì big data sẽ phải đáp ứng được 3V là: Volume – Variety – Velocity (Dung lượng – Độ đa dạng – Tốc độ). Trong khi đó 50GB vẫn có thể lưu ngon trên một máy tính – chưa đáp ứng được tiêu chí về Volume, database thì thường là có cấu trúc hoặc bán cấu trúc – chưa đáp ứng được tiêu chí về Variety.
Vì vậy bạn nào mà có quan điểm này giống mình thì thay đổi đi nha, 50GB vẫn còn nhỏ lắm, chỉ cần biết tối ưu chút thì với cách xử lý truyền thống vẫn xử lý phà phà.
2. COI BIG DATA LÀ SKILL CỦA SOFTWARE ENGINEER
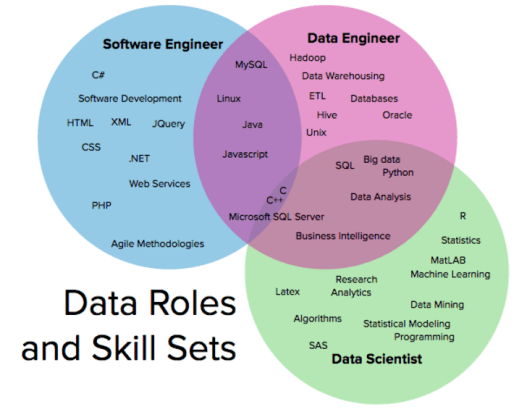
Bạn có nhìn thấy big data ở đâu không? Nó nằm ở giữa data engineer và data scientist chứ không hề liên quan tới software engineer. Điều này có nghĩa là bạn có thể yên tâm phát triển trên con đường trở thành software engineer mà không cần phải bận tâm tới big data nếu như bạn không thích nó.
Đương nhiên là bức ảnh trên cũng có phần quá đát (date) rồi, nhưng mình cũng có tham khảo qua nhiều tin tuyển dụng về software engineer thì không thấy có yêu cầu nào cần skill liên quan tới big data cả. Nếu như có tin tuyển dụng nào cần tới big data hay các công cụ xoay quanh big data như hadoop thì đều là tin tuyển data engineer.
Software engineer vs Data engineer
Software engineer là người tạo ra phần mềm, mỗi phần mềm sẽ đóng góp dữ liệu trong quá trình nó hoạt động vào một cái ao chung tạm gọi là Big data. Data engineer sẽ sử dụng dữ liệu trong cái ao này để thực hiện một yêu cầu nào đó dạng như: xuất báo cáo, vẽ biểu đồ, trích xuất dữ liệu để train cho model AI, trích xuất dữ liệu để làm database cho một ứng dụng khác,…
Data engineer sẽ sở hữu một ngách skill của software engineer và có không ít trong số họ đi lên từ software engineer.
3. NGHĨ RẰNG NGƯỜI DÙNG THÔNG THƯỜNG SẼ QUAN TÂM TỚI OUTPUT CỦA BIG DATA
Như mình đề cập ở trên, output của việc xử lý big data thường là một báo cáo, một tập tiêu chí và chỉ số, hay một tập dữ liệu nào đó, và dữ liệu khá vô nghĩa với người sử dụng thông thường.
Người dùng thông thường ở đây ám chỉ những người dùng mà cả hệ thống đang hướng tới và khai thác, như khách hàng mua hàng trên tiki, người dùng facebook, người dùng youtube,…
Ví dụ, một khách hàng mua hàng trên tiki sẽ chẳng quan tâm tới biểu đồ doanh thu của công ty trong 1 năm qua, họ chỉ quan tâm tới sản phẩm họ mua có tốt không và nhận hàng trong bao lâu. Một người đi xem phim hành động, họ chẳng quan tâm tới việc thể loại đó được bao nhiêu người khác quan tâm, họ chỉ quan tâm tới việc làm sao để mua vé mà không phải đứng đợi…
Output của big data thường là input của một ứng dụng khác, hoặc được sử dụng để ra quyết định thực hiện một chiến lược kinh doanh nào đó. Khác với output của các phần mềm do software engineer tạo ra, nó hướng trực tiếp tới người sử dụng thông thường.
4. “HIỆU NĂNG” CỦA BIG DATA GIỐNG VỚI “HIỆU NĂNG” CỦA PHẦN MỀM
Khi mình tìm hiểu về các công cụ xử lý big data, thỉnh thoảng sẽ gặp câu kiểu như “công nghệ XXX cho phép xử lý big data với hiệu năng cao“.
Xuất phát từ một software engineer, mình cho rằng hiệu năng ở đây ám chỉ tốc độ thực hiện rất nhanh, nhưng không phải. Cụm từ “hiệu năng” trong big data sẽ được hiểu là có khả năng tính toán trên một tập dữ liệu rất lớn, với độ chính xác cao, còn thời gian thì có thể là một vài tiếng hoặc thậm chí cả ngày mới ra kết quả cũng không sao.
Khi xử lý big data, yếu tố chính xác và đầy đủ thông tin được đặt lên hàng đầu, thời gian thì có thể đợi được.
5. TỔNG KẾT
Kể ra mới thấy góc nhìn của software engineer khác rất nhiều so với góc nhìn của data engineer, nhưng cũng may là mình đã sớm nhận ra chứ không cứ lao đầu học data theo hướng học lập trình thì có ngày sẽ đi vào ngõ cụt mất.
Một bài viết ngắn ngọn chia sẻ tới các bạn, hy vọng sẽ giúp ích cho cộng đồng.
Hẹn gặp lại.
Bài viết gốc được đăng tải tại phambinh.net
Có thể bạn quan tâm:
- Rèn giũa mindset của một Data Scientist
- Liệu Software Engineer có phải là nghề dễ ăn?
- Biến Git và GitHub trở thành công cụ đắc lực cho Software Engineer
Xem thêm các việc làm Developer hấp dẫn tại TopDev







")


")
")

