Bài viết được sự cho phép của tác giả Khiêm Lê
Con trỏ (pointer) là một khái niệm quan trọng và khó nhất trong C++, nó thường được dùng để đánh giá mức độ thành thạo C++ của bạn. Việc sử dụng thành thạo con trỏ đi cùng với việc thành thạo các thao tác cấp phát động, quản lý bộ nhớ một cách chặt chẽ trong C++.
Kiến trúc máy tính
Để hiểu được bài này, chúng ta cần biết được kiến thức cơ bản về bộ nhớ máy tính, cụ thể là RAM. Chúng ta sẽ không tìm hiểu quá sâu mà chỉ ở mức cơ bản, đủ để có thể hiểu được con trỏ hoạt động như thế nào.
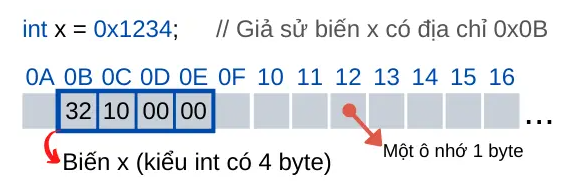
RAM (Random Access Memory) là bộ nhớ được dùng để lưu trữ dữ liệu tạm thời để xử lý và dữ liệu sẽ mất đi khi ngưng cấp điện cho RAM. RAM chứa rất nhiều ô nhớ và mỗi ô nhớ có kích thước là 1 byte (1 byte = 8 bit). Các ô nhớ có địa chỉ duy nhất và được đánh số từ 0 trở đi.
Khi trình biên dịch thực hiện biên dịch code, nó sẽ dành riêng một vùng nhớ cho biến được khai báo, liên kết địa chỉ ô nhớ đầu tiên của vùng nhớ đó với tên biến và mỗi khi gọi đến biến đó, nó sẽ tự truy xuất đến vùng nhớ đã được liên kết với tên biến đó. Vùng nhớ của một biến là tập các ô nhớ liền kề nhau. Các biến khác nhau không nhất thiết các vùng nhớ của nó phải liền kề nhau.
Tùy vào kích thước của kiểu dữ liệu mà trình biên dịch sẽ cấp phát số ô nhớ liền kề khác nhau tương ứng. Ví dụ như kiểu char có kích thước 1 byte thì sẽ cấp cho biến kiểu char 1 ô nhớ, kiểu int có 4 byte thì sẽ cấp cho 4 ô nhớ liền kề nhau và địa chỉ của biến đó là địa chỉ của ô nhớ đầu tiên của vùng nhớ đó. Ví dụ như hình trên thì ta có biến x kiểu int được cấp phát 4 ô nhớ và địa chỉ của biến x chính là địa chỉ của ô nhớ đầu tiên của vùng 4 ô nhớ đó chính là 0x0B.
Cấp phát bộ nhớ trong C++
Cấp phát bộ nhớ tĩnh (Static memory allocation)
Biến tĩnh hay biến được cấp phát tĩnh là biến được khai báo bằng cú pháp khai báo biến, có tên và được cấp phát một vùng nhớ cố định trước khi sử dụng. Vùng nhớ cố định ở đây nghĩa là vùng nhớ đó luôn tồn tại khi chương trình thực thi, không thể được xóa đi (tức trả lại cho hệ điều hành) hoặc là thay đổi kích thước (đối với mảng), sau khi kết thúc chương trình sẽ tự động trả vùng nhớ đó lại cho hệ điều hành.
Chính việc cấp phát vùng nhớ cố định cho biến tĩnh gây chiếm dụng bộ nhớ nếu ta không có nhu cầu sử dụng biến đó nữa, hoặc ta không thể thay đổi kích thước nếu dữ liệu vượt quá kích thước lưu trữ của biến (đối với mảng). Đây chính là lúc chúng ta sử dụng biến động.
Cấp phát bộ nhớ động (Dynamic memory allocation)
Biến động hay biến được cấp phát động là biến thuộc một kiểu dữ liệu đã định nghĩa, không có tên, không được khai báo trong phần khai báo biến. Điều này có nghĩa là biến động là một biến được cấp phát một vùng nhớ trong bộ nhớ RAM, không được liên kết với tên biến do đó nó không có tên, nó chỉ là một vùng nhớ. Việc quản lý biến động được thực hiện qua con trỏ.
Cấp phát bộ nhớ tự động (Automatic memory allocation)
Cấp phát bộ nhớ tự động là quá trình cấp phát và giải phóng bộ nhớ diễn ra tự động cho các tham số hàm và biến cục bộ trong một chương trình. Khi chương trình đi vào một khối lệnh, vùng nhớ cho các biến cục bộ và tham số hàm sẽ được cấp phát. Khi khối lệnh kết thúc hoặc bị thoát, vùng nhớ này sẽ tự động được giải phóng. Điều này giúp giảm thiểu lỗi do quản lý bộ nhớ thủ công và tăng cường hiệu suất lập trình.
Con trỏ trong c++ là gì
Để hiểu nắm được kiến thức về cấp phát động, trước tiên, hãy điểm qua một số kiến thức về con trở (pointer).
Con trỏ (pointer) là một biến đặc biệt trong C++ được sử dụng để lưu trữ địa chỉ của một biến khác. Con trỏ không chỉ lưu trữ giá trị của biến mà còn có thể trỏ đến địa chỉ bộ nhớ nơi biến đó được lưu trữ. Con trỏ là một công cụ mạnh mẽ trong lập trình C++ vì chúng cung cấp một cách linh hoạt để truy cập và thao tác dữ liệu trong bộ nhớ.
Biến con trỏ
Biến con trỏ hay thường gọi là con trỏ là biến dùng để lưu trữ giá trị là địa chỉ ô nhớ. Nghĩa là bản thân con trỏ là một biến thông thường nhưng mà nó chứa địa chỉ của biến tĩnh hoặc biến động. Như đã trình bày ở trên, biến động không có tên do đó chỉ có thể được quản lý qua con trỏ, do đó, con trỏ thường được dùng để chứa địa chỉ của biến động, lúc này ta nói con trỏ này trỏ đến hoặc con trỏ này tham chiếu đến biến hoặc vùng nhớ đó. Do con trỏ chỉ chứa địa chỉ nên mọi con trỏ đều có kích thước như nhau.
Do con trỏ liên quan đến việc tham chiếu đến địa chỉ của biến, ta phải tìm hiểu các toán tử & và *. Toán tử & và * là toán tử một ngôi, toán tử & (address-of operator) được đặt trước tên biến và cho biết địa chỉ ô nhớ đầu tiên trong vùng nhớ của biến đó. Toán tử * (dereferencing operator hay indirection operator) được đặt trước một địa chỉ để lấy giá trị lưu trữ tại địa chỉ đó. Ví dụ:
int a = 2409;
cout << &a;
cout << *&a;
Để tạo một con trỏ, ta sử dụng cú pháp như sau:
<kiểu_dữ_liệu> *<tên_biến_con_trỏ>;
int *ptr_a;
Nhớ là kiểu con trỏ là kiểu gì thì ta chỉ được trỏ tới biến kiểu đó, ví dụ không thể đem một con trỏ int mà trỏ vào biến kiểu double được. Biến con trỏ không có kiểu riêng mà chỉ phụ thuộc vào đối tượng mà nó trỏ đến, do đó khi chưa xác định được kiểu dữ liệu của đối tượng trỏ đến, ta dùng kiểu void.
void *p;
int a = 2, *pt;
p = (void *) &a;
pt = (int *) p;
*pt += 3;
Dấu * khi khai báo con trỏ nên được đặt trước và sát vào tên biến:
int *ptr_1, *ptr_2;
int* ptr1, ptr2;
Lưu ý: để phân biệt con trỏ và biến thường, ta thường sử dụng prefix ptr để phân biệt con trỏ.
Một con trỏ lưu giá trị là địa chỉ, vậy nên để trỏ đến một biến, ta dùng toán tử & như sau:
int a = 2409;
int *ptr_a = &a;
cout << *ptr_a;
Do con trỏ trỏ tới biến là trỏ vào vùng nhớ mà biến đó được cấp nên khi ta thay đổi giá trị của vùng nhớ đó thì giá trị của biến cũng thay đổi theo. Quan sát ví dụ sau bạn sẽ thấy rõ hơn, biến a có giá trị là 2409, địa chỉ ô nhớ giả sử là 0x50, sau đó tạo con trỏ ptr_a trỏ tới biến a. Khi ta thực hiện thay đổi giá trị tại địa chỉ con trỏ đang giữ qua toán tử *, tức là đang thay đổi giá trị tại ô nhớ 0x50 do con trỏ đang trỏ tới a, mà 0x50 lại là địa chỉ của biến a, do đó giá trị của biến a cũng bị thay đổi theo.
int a = 2409;
int *ptr_a = &a;
*ptr_a = 2001;
cout << a;
Tóm lại về con trỏ, bạn cần nhớ được:
Một số bạn sẽ hơi thắc mắc dấu * trong lúc khai báo con trỏ và dấu * trước con trỏ. Dấu * trong lúc khai báo con trỏ chỉ là cú pháp để khai báo con trỏ mà thôi. Còn dấu * trước con trỏ là toán tử *, dùng để lấy giá trị lưu trữ tại địa chỉ mà con trỏ trỏ tới.
- *ptr_a và a đều là chỉ giá trị của a
- ptr_a và &a đều là địa chỉ của biến a
- Không thể thay đổi hay tự quyết định địa chỉ của biến (việc này do hệ điều hành thực hiện)
- Con trỏ chỉ có thể tham chiếu đến đối tượng có kiểu dữ liệu tương thích
- Không thể tham chiếu con trỏ đến một biểu thức hay hằng (vì biểu thức, hằng làm gì có địa chỉ)
Hằng con trỏ và đối tượng hằng
Như đã trình bảy ở trên, biến con trỏ cũng giống như một biến bình thường nhưng dùng để lưu trữ địa chỉ, con trỏ cũng có hằng con trỏ như hằng bình thường. Hằng con trỏ sẽ được khởi tạo giá trị một lần duy nhất và không được gán lại giá trị mới, hay nói cách khác là chỉ trỏ đến một đối tượng duy nhất mà thôi. Cú pháp khai báo tương tự con trỏ nhưng có từ khóa const phía trước tên biến:
int a = 2409;
int b = 2001;
int *const ptr_a = &a;
ptr_a = &b;
Đối tượng hằng tức là một con trỏ mà ta không thể sử dụng toán tử * để gán lại giá trị tại vùng nhớ mà nó trỏ tới. Đối tượng hằng vẫn có thể trỏ đến đối tượng khác được.
int a = 2409;
const int *ptr_a = &a;
*ptr_a = 2001;
Bạn không muốn thay đổi giá trị và cũng không muốn tham chiếu lại vào biến khác bạn có thể kết hợp cả hai như sau:
int a = 2409;
const int *const ptr_a = &a;
Con trỏ hàm
Ngoài những loại con trỏ trên, ta còn có một loại con trỏ đặc biệt nữa đó chính là con trỏ hàm (function pointer). Để khai báo một con trỏ hàm, ta sử dụng cú pháp sau:
<kiểu_dữ_liệu> (*<tên_con_trỏ>)([các_tham_số]);
int (*funcPtr_sum)(int a, int b);
int (*funcPtr_sum)(int, int);
Bạn có thể hiểu đơn giản rằng <kiểu_dữ_liệu> chính là kiểu dữ liệu mà hàm trả về, <tên_con_trỏ> là tên hàm, dấu ngoặc tròn “()” bên ngoài là bắt buộc để nói cho compiler biết đó là một con trỏ hàm và các tham số truyền vào giống như tham số truyền vào hàm vậy thôi và được đặt trong dấu ngoặc tròn.
Để trỏ tới một hàm, các bạn làm như sau:
int sum(int a, int b)
{
return a + b;
}
funcPtr_sum = sum;
funcPtr_sum = ∑
Các kiểu dữ liệu và tham số của con trỏ hàm phải tương đương với các tham số và kiểu dữ liệu trả về của hàm mà các bạn muốn trỏ tới. Như trong ví dụ trên kiểu trả về của hàm sum là int thì kiểu dữ liệu khai báo con trỏ cũng phải là int và kiểu dữ liệu tham số của con trỏ cũng giống với tham số hàm sum. Và để gọi hàm mà con trỏ đó trỏ tới, bạn chỉ cần thực hiện như cách sau:
funcPtr_sum(4, 5);
(*funcPtr_sum)(3, 4);
Có thể nhiều bạn sẽ hỏi tại sao phải sử dụng con trỏ hàm cho mất công vậy, mình có thể gọi trực tiếp hàm đó mà. Đúng thật là vậy nhưng khi sử dụng con trỏ hàm, bạn sẽ làm được một thứ mà không cách nào thực hiện được nếu không có con trỏ hàm đó chính là truyền tham số là hàm.
Để thực hiện truyền con trỏ hàm cho hàm, ta cũng thực hiện truyền như truyền một con trỏ thông thường. Hãy xem ví dụ sau để hiểu rõ hơn:
int sum(int a, int b)
{
return a + b;
}
void myFunc(int (*func_ptr)(int, int))
{
func_ptr(4, 5);
}
int (*funcPtr_sum)(int, int) = sum;
myFunc(funcPtr_sum);
Một số bạn quen với một số ngôn ngữ hiện đại thì sẽ quen cách truyền hàm cho hàm, tuy nhiên có thể bạn không hiểu được bản chất tại sao nó như vậy. Qua con trỏ hàm bạn có thể hiểu được cách thức mà một hàm có thể được truyền cho một hàm.
Có một só điều bạn cần lưu ý về con trỏ hàm như sau:
- Không như con trỏ thông thường, con trỏ hàm không phải là con trỏ trỏ vào vùng nhớ mà nó trỏ vào code. Có thể hiểu là nó trỏ vào điểm bắt đầu của một hàm hoặc là nó đang tham chiếu đến hàm đó và nó là nick name của hàm đó, do đó ta có thể gọi nó thay vì trực tiếp gọi hàm.
- Con trỏ hàm không cần cấp phát hay giải phóng vì nó không trỏ vào vùng nhớ.
- Bạn có thấy ở ví dụ trên mình có thể sử dụng toán tử & hoặc không, và cũng tương tự đối với việc sử dụng toán tử *. Đó là do tên hàm có thể được sử dụng để lấy địa chỉ (hay điểm bắt đầu) của hàm, do đó tên hàm giống như đã bao gồm toán tử & rồi.
- Giống như một con trỏ thông thường, ta cũng có thể có một mảng con trỏ hàm. Con trỏ hàm cũng có thể được sử dụng như để rẽ nhánh như sau:
- Giống như con trỏ thông thường, con trỏ hàm có thể được truyền cho hàm, giống như ví dụ bên trên. Loại con trỏ này rất thường đường sử dụng trong C++.
Con trỏ NULL
Con trỏ NULL (NULL pointer) hay con trỏ trỏ vào NULL là con trỏ không trỏ vào đâu cả, nó khác với con trỏ chưa được khởi tạo. Bởi vì khi được khai báo, con trỏ không được khởi tạo giá trị thì sẽ mang giá trị rác. Do đó, khi làm việc với con trỏ, khi chưa trỏ vào đâu cả thì ta nên khởi gán con trỏ đó bằng NULL (vì nếu không may, ta thực hiện truy xuất đến vùng nhớ rác không tồn tại sẽ gây ra kết quả không mong muốn).
int *ptr_a = 0;
int *ptr_b = NULL;
Ngoài ra, C++ 11 còn cung cấp một từ khóa mới là nullptr, cũng là dùng để chỉ con trỏ NULL.
int *ptr_a = nullptr;
Để kiểm tra xem một con trỏ có NULL hay không ta dùng câu lệnh if.
if (my_ptr)
cout << "NOT NULL";
else
cout << "NULL ptr";
Xem thêm các vị trí tuyển dụng lập trình C++ lương cao tại Topdev.
Con trỏ trỏ vào con trỏ
Con trỏ cũng giống như một biến thông thường nên nó sẽ có địa chỉ, do đó, một con trỏ có thể được một con trỏ khác trỏ tới. Ví dụ;
int *a = new int(2409);
int **ptr_a = &a;
Khi một con trỏ trỏ vào con trỏ, con trỏ đó sẽ giữ giá trị là địa chỉ của con trỏ mà nó trỏ tới, vậy nên nếu muốn lấy giá trị của biến của con trỏ mà nó đang trỏ tới ta phải dùng hai lần toán tử *, lần 1 là để lấy địa chỉ của con trỏ nó trỏ tới đang giữ, lần 2 là để lấy giá trị được lưu trữ tại địa chỉ mà biến của con trỏ mà nó trỏ tới đang giữ.
int *a = new int(2409);
int **ptr_a = &a;
cout << *ptr_a;
cout << **ptr_a;
Con trỏ trỏ vào con trỏ được ứng dụng để xây dựng mảng hai chiều như sau:
int** arr = new int* [10];
for (auto i = 0; i < 10; i++)
arr[i] = new int[10];
for (auto i = 0; i < 10; i++)
delete[] arr[i];
delete[] arr;
arr = nullptr;
Việc sử dụng con trỏ đối với mảng một chiều đã khá rắc rối rồi nên mình sẽ không đi sâu vào mảng nhiều chiều mà chỉ giới thiệu cho các bạn biết vậy thôi. Bạn nên sử dụng vector như trong bài giới thiệu ở trên.
Con trỏ và hàm
Con trỏ là một kiểu dữ liệu, do đó nó có thể được sử dụng trong lúc truyền tham số cho hàm hoặc kiểu dữ liệu trả về.
int* doSomething(int* n)
{
cout << *n;
cout << n;
return n;
}
Để truyền đối số vào tham số trong hàm, ta phải truyền cùng kiểu pointer hoặc là một địa chỉ như khi bạn tham chiếu con trỏ vậy.
int n = 5;
doSomething(&n);
int *pt = new int(5);
doSomething(pt);
Lưu ý do thao tác trên con trỏ là thao tác trên địa chỉ ô nhớ, vậy nên thay đổi giá trị tại địa chỉ ô nhớ cũng làm thay đổi luôn giá trị của biến nó tham chiếu tới tương tự như biến tham chiếu vậy.
>> Đọc tiếp: Chi tiết về Con trỏ và hàm trong C++
Con trỏ và đối tượng
Con trỏ không có kiểu dữ liệu cụ thể mà phụ thuộc vào đối tượng nó trỏ vào, do đó nó có thể là bất kỳ bao gồm kiểu dữ liệu do người dùng định nghĩa như struct hay class. Ví dụ:
struct MyStruct
{
int count;
};
MyStruct mStruct;
mStruct.count = 5;
MyStruct *ptr = &mStruct;
Thông thường để gọi một thuộc tính hay một phương thức của một đối tượng, ta sử dụng dấu chấm (.), nhưng đối với con trỏ khi đã trỏ đến đối tượng, ta sử dụng dấu mũi tên (->) như sau:
cout << mStruct.count;
cout << ptr->count;
Tương tự đối với class:
class MyClass
{
public:
int count;
MyClass(int n)
{
count = n;
}
void print() const
{
cout << count << endl;
}
};
MyClass mClass(5);
MyClass *ptr = &mClass;
cout << ptr->count;
ptr->print();
Ta cũng có thể thực hiện cấp phát động như sau:
MyStruct *ptr_struct = new MyStruct;
MyClass *ptr_class = new MyClass(5);
Chi tiết về cấp phát động
Ở phần đầu ta đã nắm khái quát về khái niệm cấp phát động, tiếp tục tìm hiểu chi tiết về Cấp phát bộ nhớ động.
Một số bạn sẽ hỏi tại sao lại dùng con trỏ chi cho mệt vậy, cứ biến tĩnh mà dùng, sao phải dùng rồi lại thêm toán tử &, * cho rối. Tất cả những ví dụ ở trên chỉ để cho bạn hiểu được con trỏ mà thôi, sức mạnh thực sự của con trỏ nằm ở chỗ nó được sử dụng để quản lý biến động.
Để cấp phát vùng nhớ cho một biến động ta làm như sau:
new <kiểu_dữ_liệu>;
new int;
new float;
Nếu như cấp phát vùng nhớ thành công, toán tử new sẽ trả về một con trỏ trỏ tới địa chỉ của vùng nhớ mới. Và như đã nói ở trên, biến động không có tên do đó nó được quản lý bằng con trỏ, vậy nên khi tạo biến động ta gán luôn địa chỉ của nó cho con trỏ như sau:
int *ptr = new int;
int *ptr1 = new int(2409);
Bây giờ bạn có thể thao tác trên biến động vừa cấp phát thông qua con trỏ như sau:
*ptr = 2001;
Cấp phát động là yêu cầu cấp phát một vùng nhớ, do đó sẽ có thể xảy ra trường hợp không đủ bộ nhớ để cấp phát, lúc này toán tử new sẽ trả về con trỏ NULL, bạn có thể kiểm tra như sau:
int* myPtr = new int;
if (myPtr != nullptr)
cout << "Memory allocated";
else
cout << "Bad allocate";
Sau khi đã sử dụng xong, dữ liệu trong vùng nhớ của biến động nên được xóa đi và trả lại cho hệ điều hành. Việc này rất quan trọng, việc không giải phóng sau khi sử dụng sẽ khiến cho vùng nhớ đó tồn tại nhưng hệ điều hành không được sử dụng do nó đã được cấp phát cho chương trình của chúng ta, dẫn đến việc rò rỉ bộ nhớ.
Hiện nay, hầu hết các hệ điều hành hiện đại quản lý việc cấp phát bộ nhớ một cách triệt để, mỗi khi chương trình kết thúc bộ nhớ đã được cấp phát sẽ được thu hồi lại, tuy nhiên dữ liệu trong vùng nhớ đó không được xóa, việc này cũng dẫn đến rò rỉ bộ nhớ. Do đó, bạn vẫn nên xóa và giải phóng biến động mỗi khi kết thúc chương trình hoặc sử dụng xong.
Việc xóa và giải phóng vùng nhớ của biến động được thực hiện qua toán tử delete. Cú pháp như sau:
delete <tên_biến_con_trỏ>;
delete ptr_a;
Sau khi xóa đi, vùng nhớ đó đã được xóa dữ liệu và trả lại cho hệ điều hành quản lý, tuy nhiên, con trỏ mà đang trỏ đến vùng nhớ đó vẫn đang chứa địa chỉ đó. Việc sử dụng con trỏ này sẽ gây ra hậu quả không mong muốn do biến động nó trỏ tới không còn tồn tại, do đó khi delete biến động, ta nên gán lại con trỏ NULL.
int *ptr = new int(1);
delete ptr;
ptr = nullptr;
Mảng động
Mảng động là một topic quan trọng trong C++, việc sử dụng mảng C++ thông thường, bạn sẽ không thể thay đổi kích thước của mảng (thêm khi cần và xóa khi không cần), mảng động sẽ giải quyết việc này. Để cấp phát một mảng động, ta sử dụng toán tử new và sau kiểu dữ liệu phải cung cấp số lượng phần tử [size]:
new <kiểu_dữ_liệu_của_mỗi_phần_tử>[size];
new int[100];
Hệ điều hành sẽ cấp phát cho biến động một dãy các vùng nhớ liền kề nhau, mỗi vùng nhớ có kích thước bằng với kích thước của phần tử của mảng đó. Tương tự với mảng thông thường bạn vẫn phải cung cấp kích thước mảng và kích thước đó phải là hằng. Và cũng tương tự như biến động thông thường, bạn vẫn quản lý thông qua con trỏ như sau:
int *myArr = new int[100];
Đối với mảng động, toán tử new sẽ trả về con trỏ trỏ vào ô nhớ đầu tiên của vùng nhớ được cấp phát cho mảng đó. Việc thao tác với mảng động thực hiện qua con trỏ cũng tương tự như đối với mảng thông thường như sau:
myArr[0] = 1;
myArr[1] = 2;
Hoặc thao tác theo cách “con trỏ style” như sau:
*(myArr + 0) = 1;
*(myArr + 1) = 2;
Việc thực hiện myArr + i tức là lấy địa chỉ của con trỏ myArr (tức địa chỉ phần tử đầu tiên) rồi cộng thêm i lần kích thước của mỗi vùng nhớ. Ví dụ như kiểu byte có kích thước là 4 byte, myArr đang trỏ vào phần tử đầu tiên giả sử địa chỉ 0x50, khi gọi đến myArr là phần tử đầu tiên nghĩa là không cộng thêm gì hết là chính nó do con trỏ trỏ vào phần tử đầu tiên của mảng tức là 0x50. Gọi myArr + 1 tức là địa chỉ của phần tử đầu tiên cộng với 1 lần kích thước của kiểu int là 4 byte, tức là phần tử 0x54, sau đó dùng toán tử * để lấy giá trị như ví dụ bên trên.
Và cũng để tránh rò rỉ bộ nhớ, không dùng đến nữa thì ta cũng phải xóa mảng động đi. Để xóa mảng động đi nó có hơi khác một chút là có dấu [] sau toán tử delete.
delete[] ptr;
Vậy thì việc thay đổi kích thước mảng thực hiện ra làm sao? Bạn sẽ không có phương thức hỗ trợ nào mà phải làm thủ công. Tức là bạn sẽ phải tạo một mảng mới với kích thước phần tử mới, sau đó copy phần tử sang mảng mới và xóa mảng cũ đi như sau:
int size = 3;
int* arr = new int[size] {1, 2, 3};
int newSize = 5;
int* newArr = new int[newSize];
for (auto i = 0; i < size; i++)
newArr[i] = arr[i];
delete[] arr;
arr = nullptr;
Về bản chất, mảng thông thường thật ra chính là một mảng động được một hằng con trỏ trỏ tới:
int *const arr = new int[10];
Do nó hơi phức tạp nên người ta thường sử dụng lớp vector cũng được dựa trên con trỏ và mảng động. Bạn có thể xem bài viết về vector trong C++.
Sử dụng con trỏ là một kĩ thuật rất quan trong, bạn sẽ cần sử dụng nó thật thành thạo để có thể học tốt các môn như Lập trình hướng đối tượng, Cấu trúc dữ liệu và giải thuật…
Lợi ích của cấp phát động
Linh Hoạt Trong Quản Lý Bộ Nhớ
Cấp phát động cho phép chương trình quản lý bộ nhớ một cách linh hoạt, đáp ứng nhu cầu thay đổi liên tục về dung lượng bộ nhớ trong suốt quá trình thực thi. Điều này đặc biệt hữu ích khi làm việc với các cấu trúc dữ liệu động như danh sách liên kết, cây, hoặc các mảng có kích thước thay đổi.
Tiết Kiệm Bộ Nhớ
Với cấp phát động, bộ nhớ chỉ được cấp phát khi cần thiết và có thể được giải phóng khi không còn sử dụng nữa. Điều này giúp tiết kiệm tài nguyên hệ thống và tránh lãng phí bộ nhớ.
Tối Ưu Hóa Hiệu Suất
Bằng cách cấp phát đúng lượng bộ nhớ cần thiết tại thời điểm sử dụng, chương trình có thể hoạt động hiệu quả hơn. Điều này giúp cải thiện hiệu suất chương trình, đặc biệt là trong các ứng dụng yêu cầu nhiều bộ nhớ hoặc có cấu trúc dữ liệu phức tạp.
Hỗ Trợ Các Cấu Trúc Dữ Liệu Động
Cấp phát động hỗ trợ việc tạo và quản lý các cấu trúc dữ liệu động như danh sách liên kết, ngăn xếp, hàng đợi, và các cấu trúc phức tạp khác một cách hiệu quả. Điều này giúp lập trình viên dễ dàng triển khai các thuật toán phức tạp mà không cần biết trước kích thước của dữ liệu.
Hạn chế của cấp phát động
Rò Rỉ Bộ Nhớ (Memory Leak)
Một trong những hạn chế lớn nhất của cấp phát động là nguy cơ rò rỉ bộ nhớ. Nếu bộ nhớ cấp phát động không được giải phóng đúng cách sau khi không còn sử dụng, nó sẽ dẫn đến rò rỉ bộ nhớ, làm tiêu tốn tài nguyên hệ thống và có thể gây ra lỗi chương trình hoặc làm chậm hệ thống.
Quản Lý Bộ Nhớ Phức Tạp
Quản lý bộ nhớ động đòi hỏi lập trình viên phải cẩn thận trong việc cấp phát và giải phóng bộ nhớ. Sai sót trong quản lý bộ nhớ có thể dẫn đến các lỗi nghiêm trọng như truy cập bộ nhớ không hợp lệ, lỗi phân đoạn (segmentation fault) hoặc các vấn đề về ổn định chương trình.
Hiệu Suất Giảm Do Quản Lý Bộ Nhớ
Việc cấp phát và giải phóng bộ nhớ động có thể tiêu tốn thời gian và tài nguyên hệ thống. Quá trình quản lý bộ nhớ động, đặc biệt là khi sử dụng các bộ thu gom rác (garbage collector), có thể gây ra độ trễ không mong muốn và ảnh hưởng đến hiệu suất tổng thể của chương trình.
Khó Khăn Trong Việc Gỡ Lỗi
Việc gỡ lỗi các vấn đề liên quan đến bộ nhớ động thường phức tạp hơn so với bộ nhớ tĩnh. Lập trình viên phải sử dụng các công cụ và kỹ thuật đặc biệt để phát hiện và khắc phục các vấn đề như rò rỉ bộ nhớ hoặc truy cập bộ nhớ không hợp lệ.
Vậy là trong bài viết này, mình đã giới thiệu cho các bạn về con trỏ và cấp phát động trong C++, bài viết này khá là dài nhưng có thể vẫn chưa đầy đủ vì con trỏ trong C++ là một kỹ thuật thật sự rất là hay mà nếu bạn giỏi C++, bạn phải nắm được hết tối thiểu những thứ mình đã giới thiệu trong bài viết. Cảm ơn các bạn đã dành thời gian theo dõi bài viết, nếu như bạn thấy hay, đừng quên chia sẻ với bạn bè. Cảm ơn các bạn rất nhiều!
Bài viết gốc được đăng tải tại khiemle.dev
Có thể bạn quan tâm: Danh sách liên kết đơn trong C++
Xem thêm vị trí tuyển it chất lượng hấp dẫn trên TopDev























 Viettelimex – Ra đời với mục tiêu cùng tập đoàn Viettel chinh phục kỷ nguyên số
Viettelimex – Ra đời với mục tiêu cùng tập đoàn Viettel chinh phục kỷ nguyên số