Bài viết được sự cho phép của tác giả Phạm Bình
Chào các bạn,
Có lẽ không cần dài dòng, nếu chưa biết gì về coding convention thì mình đã có hẳn một bài viết xịn sò là Chuẩn coding convention trong PHP với PSR, bạn có thể tham khảo nếu thấy cần thiết. Còn trong bài viết này, mình sẽ hướng dẫn bạn cách sử dụng công cụ PHP CodeSniffer để kiểm tra convention tự động khi lập trình PHP.
I. PHP CODESNIFFER LÀ GÌ?
Vài điểm Hightlight về PHP CodeSniffer như sau:
– PHP CodeSniffer gồm 2 công cụ chính là phpcs, và phpcbf. Trong đó phpcs là công cụ giúp bạn phát hiện lỗi coding convention, còn phpcbf là công cụ giúp bạn tự động tìm và sửa lỗi coding convention – đương nhiên là chỉ sửa được những gì mà nó có thể sửa.
– PHP CodeSniffer là một package PHP, có thể cài đặt bằng composer như nhiều package php bình thường khác, nó có thể cài đặt theo từng dự án, hoặc có thể cài global trên máy tính của developer.
– PHP CodeSniffer kiểm tra lỗi coding convention dựa trên các PSR, và nếu muốn bạn cũng có thể tự tắt/bật một số quy tắc của PSR để phù hợp với từng dự án, từng team phát triển.
– Bạn có thể dễ dàng tích hợp PHP CodeSniffer với các editor phổ biến như Sublime Text, VsCode,… trong bài viết này, mình cũng sẽ hướng dẫn các bạn các tích hợp với VsCode.
Tìm việc làm PHP đãi ngộ tốt trên TopDev
II. CÀI ĐẶT VÀ SỬ DỤNG PHP CODESNIFFER
2.1 Chuẩn bị
- PHP 5.4 hoặc phiên bản cao hơn: PHP CodeSniffer được viết bằng PHP, nên máy của bạn chắc chắn cần được cài PHP. Kiểm tra phiên bản PHP bằng cách gõ
php -vtrên CLI của bạn. - Composer: Có nhiều cách để cài đặt PHP CodeSniffer, nhưng bạn nên cài thông qua Composer cho đơn giản, cũng như dễ dàng cập nhật PHP CodeSniffer khi có phiên bản mới. Mà mình nghĩ chẳng có php developer nào lại không có sẵn composer trên máy đâu. Kiểm tra composer đã có hay chưa bằng cách gõ
composertrên CLI của bạn.
2.2 Cài đặt PHP CodeSniffer
Như mình đã trình bày, CodeSniffer có thể cài global hoặc cài theo từng dự án, trong bài viết này mình sẽ cài global luôn cho máu.
composer global require "squizlabs/php_codesniffer=*"Sau khi cài xong, bạn cần tìm được thư mục home của composer, tùy vào từng hệ điều hành mà đường dẫn tới thư mục home sẽ khác nhau. Để tìm thư mục home, bạn chạy lệnh sau:
composer config --list --global | grep "home"Kết quả sẽ dạng như sau:
[home] /Users/admin/.composerThì /Users/admin/.composer chính là thư mục home của composer.
Bước tiếp theo, cùng kiểm tra xem PHP CodeSniffer đã được cài đặt hay chưa, bằng cách chạy lệnh sau:
ls /Users/admin/.composer/vendor/binNếu cài đặt thành công, thì sẽ có kết quả như sau:
phpcbf phpcs2.3 Chạy thử PHP CodeSniffer
Đây là phần trọng tâm của bài viết, các bạn đọc cẩn thận và làm theo ví dụ nhé.
Tạo trước một file PHP và cố tình code sai convention, để thử xem thằng PHP CodeSniffer có nhận ra hay không.
cd ~ # di chuyển ra thư mục root
mkdir test_php_sniffer # tạo thư mục test_php_sniffer
cd test_php_sniffer # di chuyển vào thư mục vừa tạo
touch test.php # tạo file test.phpCopy nội dung sau bỏ vào file test.php
// File này cố tình code sai convention để thử độ tin cậy của PHP CodeSniffer
function sum ($a ,$b){
return $a+$b;
}
echo sum(1,2);
Chuẩn bị đã xong, giờ mình sẽ chạy lệnh sau để kiểm tra lỗi convention có trong file test.php trên.
cd test_php_sniffer # di chuyển vào thư mục chứa file test.php
/Users/admin/.composer/vendor/bin/phpcs test.php # chạy nàyChạy xong, trên terminal xuất hiện kết quả như sau:
FILE: /Users/admin/test_php_sniffer/test.php -------------------------------------------------------------------------- FOUND 5 ERRORS AFFECTING 3 LINES -------------------------------------------------------------------------- 2 | ERROR | [ ] You must use "/**" style comments for a file comment 4 | ERROR | [ ] You must use "/**" style comments for a function comment 4 | ERROR | [x] Expected 0 spaces before opening parenthesis; 1 found 4 | ERROR | [x] Opening brace should be on a new line 8 | ERROR | [x] No space found after comma in argument list -------------------------------------------------------------------------- PHPCBF CAN FIX THE 3 MARKED SNIFF VIOLATIONS AUTOMATICALLY -------------------------------------------------------------------------- Time: 51ms; Memory: 4MB
Kết quả trên có 2 chỗ cần chú ý:
- FOUND 5 ERRORS AFFECTING 3 LINES: Phát hiện được 5 lỗi trên 3 dòng.
- PHPCBF CAN FIX THE 3 MARKED SNIFF VIOLATIONS AUTOMATICALLY: Nếu sử dụng
phpcbfthì nó nó thể tự động fix được 3 lỗi.
Thử chạy nốt thằng phpcbf để xem nó tự động fix lỗi như thế nào nhé.
/Users/admin/.composer/vendor/bin/phpcbf test.phpSau khi chạy xong lệnh trên, file test.php sẽ tự động được sửa lại, thành như sau:
 Sau khi chạy phpcbf, nhưng vẫn còn tồn đọng một số lỗi convention
Sau khi chạy phpcbf, nhưng vẫn còn tồn đọng một số lỗi conventionĐúng là code được sửa lại thật, nhưng có vẻ vẫn chưa đúng lắm, vẫn có 2 lỗi chưa fix được:
- Dòng 4 vẫn bị sai convention ở dấu phẩy. Dấu phẩy phải nằm sát biến
$a, và cách biến$bmột dấuspacemới đúng. - Dòng 6 vẫn bị sai convention ở dấu
+. Phía trước và sau dấu+phải có một dấuspacemới đúng.
– Ơ thế hóa ra thằng CodeSniffer này không được việc lắm nhỉ, có lỗi thì fix được có lỗi thì không?
– Không phải đâu nhé, là do mình chưa chỉ rõ chuẩn PSR cho nó thôi. Phần sau đây mình sẽ trình bày luôn.
Bạn tạo tiếp file tên là phpcs.xml ngang hàng với file test.php trên, có nội dung như sau:
<?xmlversion="1.0"?><rulesetname="PHP Standards"><ruleref="PSR12"/></ruleset>
Sau đó chạy lại lệnh phpcbf để fix lỗi:
/Users/admin/.composer/vendor/bin/phpcbf test.phpSau đó cùng xem lại file test.php để xem nó được fix lỗi như thế nào.
 Tất cả lỗi convention đã được fix
Tất cả lỗi convention đã được fixBất ngờ chưa, các lỗi convention được fix hết luôn rồi kìa.
Fix được là do file phpcs.xml mình đã chỉ ra code được tuân theo chuẩn PSR12, nhờ đó mà thằng phpcbf sẽ biết đường mà fix theo chuẩn đó.
Qua ví dụ trên, mình đã chỉ các bạn đi qua một lượt các tính năng cơ bản của PHP CodeSniff, bạn có thể tìm hiểu chi tiết hơn ở wiki của PHP_CodeSniffer.
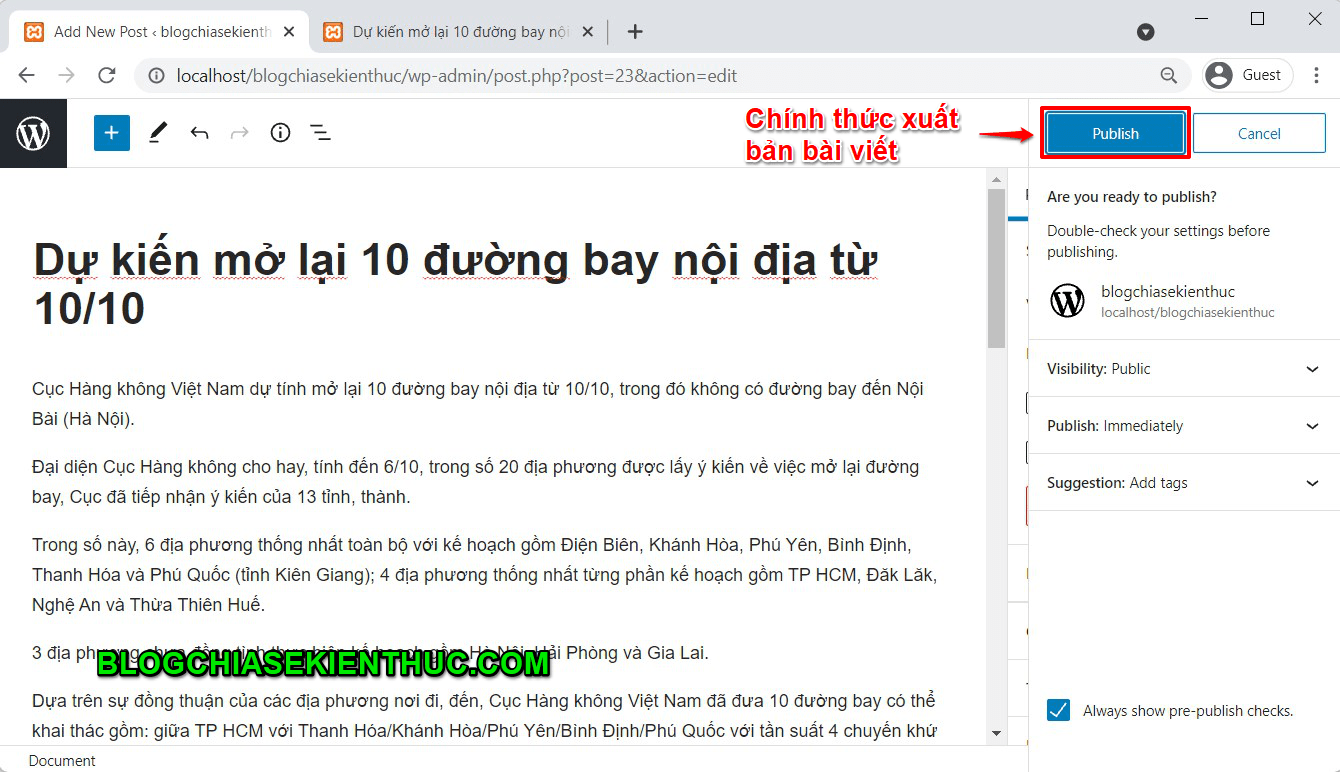
Click vào ảnh để xem.
III. LỜI KẾT
Bài viết này cũng khá dài rồi, nên mình tạm dừng ở đây, nhưng dự kiến sẽ còn 2 bài viết nữa xoay quanh thằng PHP CodeSniffer này. Một bài mình sẽ chia sẻ các rules trong file phpcs.xml, một bài mình sẽ chia sẻ cách tích hợp PHP_CodeSniffer với VsCode để vừa code vừa kiểm tra lỗi convention tiện lợi hơn. Hẹn gặp lại các bạn nhé.
Bài viết gốc được đăng tải tại phambinh.net
Có thể bạn quan tâm:
- Làm quen với phương pháp Atomic để structure source code, design
- Code PHP làm sao cho sạch (Phần 1)
- Chia sẻ kinh nghiệm khi chuẩn bị ra trường, xin việc và phỏng vấn (Phần 2)
Truy cập ngay việc làm IT đãi ngộ tốt trên TopDev


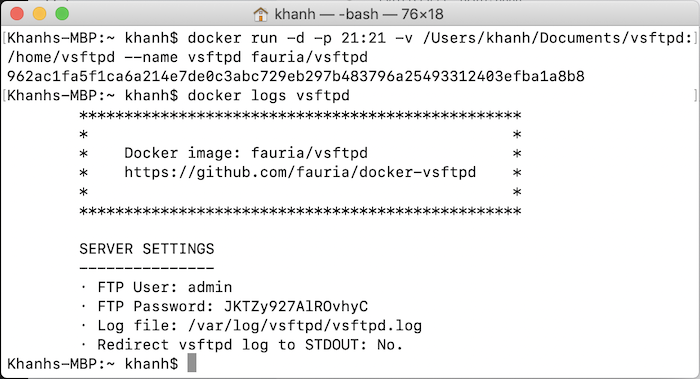




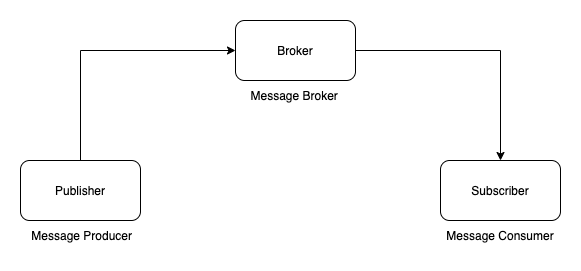















 Sau khi đã start Apache ZooKeeper rồi thì lúc này, các bạn có thể start Apache Kafka.
Sau khi đã start Apache ZooKeeper rồi thì lúc này, các bạn có thể start Apache Kafka. Đến đây thì chúng ta đã hoàn thành việc cài đặt Apache Kafka trên macOS rồi đó các bạn!
Đến đây thì chúng ta đã hoàn thành việc cài đặt Apache Kafka trên macOS rồi đó các bạn!





















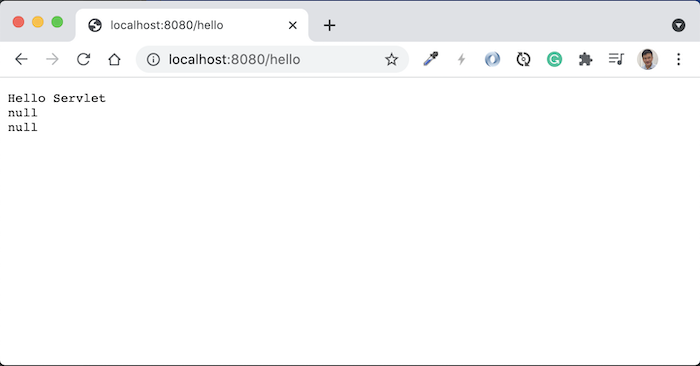
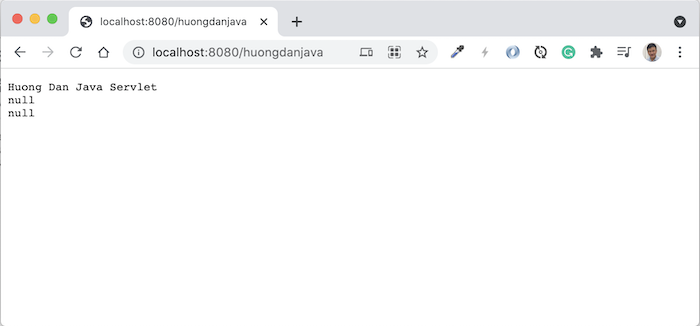
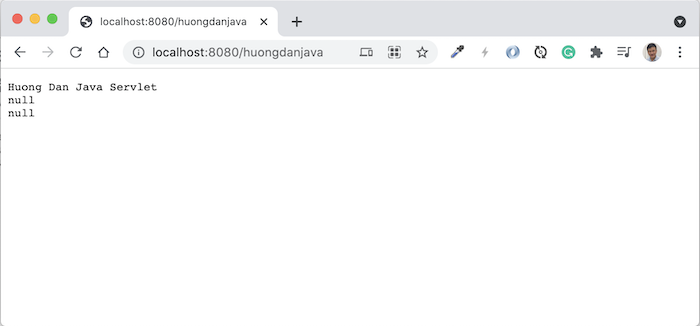
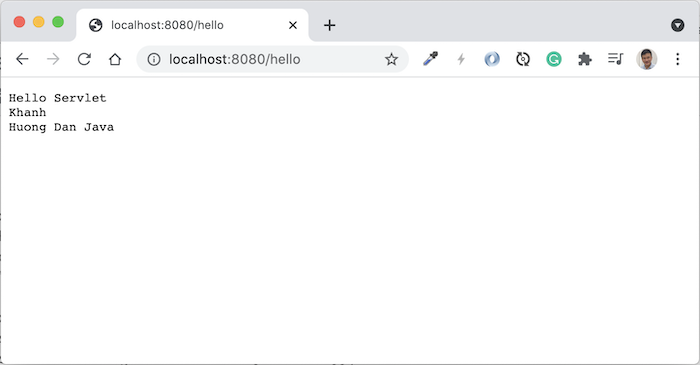 Request tới http://localhost:8080/huongdanjava, các bạn sẽ thấy kết quả như sau:
Request tới http://localhost:8080/huongdanjava, các bạn sẽ thấy kết quả như sau: