Đối với nghề lập trình nói chung và công việc Frontend nói riêng, theo mình, cái khoảnh khắc tự mình đọc hiểu hoặc viết ra được một đoạn Regex (biểu thức chính quy – reqular expression) có thể coi là một trong những khoảnh khắc đáng nhớ nhất (well…).
Thực ra cũng như nhiều người khác, mình được tiếp xúc với Regex từ khá sớm – từ những ngày đầu tiên bắt đầu nghề mần web, với PHP. Xuất hiện thường xuyên nhất chắc là khi phải viết các route handler, rồi thì kiểm tra độ chính xác của email,… Và trong một thời gian rất dài, mình cũng chỉ đi copy paste. Nhưng rồi mình quyết định phải học để hiểu được thứ cú pháp ngoài hành tinh này. Và cũng trong một thời gian dài mình vỗ ngực tự khen là đã học được Regex, xong rồi muối mặt khi nhận ra bất cứ ai nghiêm túc theo nghề lập trình đều biết Regex hết :)) và nhất là cái bọn xài vim.
Khoan hãy bàn đến tính hiệu quả của Regex, bài viết này mình muốn nói đến một thực trạng của rất đông đảo các lập trình viên, tech blogger, mentor, giảng-bài-viên ở các trung tâm,…
Đó là việc chia sẻ và copy về sử dụng các đoạn Regex một cách mù quáng.
Không quá khó để có thể tìm thấy trên Google các kết quả như: n đoạn biểu thức chính quy cần biết cho tất cả mọi thể loại lập trình viên. Mình không hiểu viết ra những bài này thì đem lại lợi ích gì cho người đọc?
Đồng ý là vì Regex có cú pháp không hề đẹp mắt, dẫn đến khó đọc và khó hiểu (nhưng không hề khó học), đa số chúng ta có xu hướng thích copy những đoạn được viết sẵn về để sử dụng. Và đa số sẽ bỏ ra hơn 10 giờ đồng hồ chỉ để tìm được một đoạn Regex nào đó được post sẵn trên mạng mà chạy gần đúng nhất đối với một cái requirement ất ơ nào đó của dự án mà chúng ta đang làm. Đó là chưa kể nếu dự án có ra những yêu cầu trên trời rơi xuống thì biết Google ở đâu cho ra đây?
Và việc này hoàn toàn không đáng nếu bạn có thể bỏ ra 30 phút để học cú pháp của Regex và tự sửa nó cho đúng chính xác với cái requirement ất ơ kia.
Nói chung là còn rất nhiều những ví dụ và những trường hợp mà chúng ta buộc phải học cách sử dụng Regex một cách linh động, và việc học để hiểu được cú pháp của nó là giải pháp duy nhất. Nếu bạn vẫn còn đang đi tìm một đoạn Regex ăn sẵn nào đó trên mạng, thì thôi hãy dừng lại và bắt đầu học Regex ngay và luôn đi.
Và đôi lời cho bạn nào vẫn có ý định viết về Regex: Thay vì copy dán các đoạn Regex vào bài viết của bạn một cách vô trách nhiệm, hãy bớt chút thời gian tìm hiểu cú pháp của nó và giải thích cặn kẽ từng phần của mỗi biểu thức. Việc bạn muốn chia sẻ kiến thức thì rất đáng hoan nghênh, nhưng xin đừng chia sẻ sự lười biếng và ngu dốt.
IT Helpdesk Cần Học Gì Để Làm Tốt Chuyên Môn Của Mình?
IT Helpdesk là một trong những vị trí quan trọng liên quan đến các công việc của ngành công nghệ thông tin. Vị trí này phụ trách hỗ trợ và kết nối thông tin giữa người dùng với bên cung cấp dịch vụ công nghệ, nhằm đảm bảo mọi hoạt động được diễn ra thông suốt. Vậy IT Helpdesk cần học gì để trở thành một nhân viên có chuyên môn tốt và đảm bảo hoàn thành các công việc của mình?
IT Helpdesk Cần Học Gì Để Làm Tốt Chuyên Môn Của Mình?
1. Tổng quan về vị trí IT Helpdesk
IT Helpdesk là nhân viên làm việc tại bộ phận hỗ trợ các dịch vụ chăm sóc khách hàng ngành công nghệ thông tin. Các IT Helpdesk chính là người có vai trò kết nối người dùng dịch vụ với bên cung ứng dịch vụ để đảm bảo các hoạt động sử dụng được thông suốt.
Công việc chính của IT Helpdesk là tiếp nhận các thông tin về khó khăn hoặc các yêu cầu hỗ trợ của người dùng và tư vấn thông tin, hướng dẫn cách khắc phục cho họ. Các vấn đề người sử dụng thường gặp phải như việc cài đặt, sử dụng máy tính, app, hỗ trợ xử lý các sự cố liên quan đến phần mềm, phần cứng,… IT Helpdesk sẽ tiếp nhận thông tin và hỗ trợ trong khả năng của mình, vấn đề khó hơn sẽ được chuyển đến bộ phận kỹ thuật chuyên môn để xử lý.
Bên cạnh đó, còn có các công việc nội bộ dành cho IT Helpdesk liên quan đến việc giải quyết các vấn đề kỹ thuật trong công ty. Vị trí này chủ yếu hoạt động ở các công ty chuyên về công nghệ thông tin nhằm giúp xử lý các tình huống như đường truyền internet, phần cứng máy tính,…
Vị trí IT Helpdesk yêu cầu người làm việc cần được trang bị những kiến thức chuyên môn đầy đủ cũng như phải rèn luyện cho bản thân những kỹ năng mềm thích hợp.
2.1. Yêu cầu về chuyên môn
Vì đây là công việc sẽ hỗ trợ khá nhiều các vấn đề liên quan đến CNTT nên việc người làm việc ở vị trí cần có những kiến thức từ cơ bản đến chuyên sâu về công nghệ máy tính, phần cứng, phần mềm,… là cần thiết.
Am hiểu quy trình làm việc gồm tiếp nhận, hỗ trợ xử lý sự cố và cung ứng dịch vụ IT cho người dùng.
Nắm vững các thông tin liên quan đến việc vận hành hệ thống của công ty. Đây là một trong những yếu tố quan trọng để các nhân viên IT Helpdesk có thể hỗ trợ, tư vấn cũng như giải đáp thắc mắc cho người dùng một cách nhanh nhất, phù hợp nhất.
Cũng như các vị trí khác trong ngành CNTT, IT Helpdesk cũng nên có khả năng đọc hiểu tiếng Anh để dễ dàng hơn cho bản thân trong quá trình đọc và xử lý tài liệu nước ngoài.
Đây đều là những thông tin cần thiết cho việc tiếp nhận và đón nhận nhanh nhất các thông tin công nghệ mới nhất.
2.2. Các yêu cầu về kỹ năng mềm
Kỹ năng giao tiếp: Đây có thể xem là kỹ năng cực kỳ quan trọng ở công việc này vì IT Helpdesk sẽ phải giao tiếp một cách thường xuyên và liên tục với nhiều khách hàng để tiếp nhận phản ánh của họ. Biết cách nói chuyện rõ ràng và giải thích dễ hiểu sẽ giúp công việc của bạn trở nên trôi chảy hơn rất nhiều.
Khả năng tiếp nhận và xử lý sự cố: Do vị trí công việc, các IT Helpdesk bắt buộc phải có khả năng phát hiện ra vấn đề cũng như nhanh chóng đưa ra hướng giải quyết theo mô tả của khách hàng. Có những người dùng lớn tuổi hay quá nhỏ tuổi và họ không thể diễn tả chính xác vấn đề mà họ đang gặp phải thì IT Helpdesk cần thể hiện rõ hơn nữa vai trò của mình trong vấn đề này.
Khả năng giao tiếp ngoại ngữ: Như đã đề cập ở bên trên, kỹ năng đọc hiểu cũng như giao tiếp bằng ngoại ngữ khá quan trọng với các IT Helpdesk. Do đó, ngay từ bây giờ, nếu đang nuôi dưỡng mong muốn trở thành một IT Helpdesk, bạn hãy chú trọng dành thời gian cho việc cải thiện kỹ năng ngoại ngữ của mình.
Kỹ năng làm việc nhóm: Vì công việc của IT Helpdesk cần có sự phối hợp giữa nhiều phòng ban liên quan nên không có kỹ năng teamwork sẽ rất khó để bạn làm việc được với nhiều người. Khả năng lắng nghe và hợp tác trong quá trình làm việc sẽ giúp công việc diễn ra suôn sẻ hơn. Và hãy dám chịu trách nhiệm cho những lỗi sai của mình nếu có vấn đề xảy ra.
Kỹ năng chăm sóc khách hàng: Giữ thái độ tích cực, thể hiện sự thông cảm và quan tâm đến khách hàng chắc chắn sẽ giúp bạn dễ dàng hơn trong việc xử lý vấn đề. Nhất là trong trường hợp tư vấn cho những khách hàng còn nhỏ tuổi hay những người lớn tuổi không hiểu nhiều về công nghệ, sự giúp đỡ của bạn là rất cần thiết với họ.
Để trở thành một IT Helpdesk, việc trau dồi và học hỏi thêm nhiều kỹ năng liên quan để làm tốt công việc hơn là rất cần thiết. Hy vọng các thông tin được cung cấp trong bài đã phần nào giúp người đọc có thêm định hướng về việc nên học gì, lựa chọn hướng đi nghề nghiệp nào là phù hợp với mình. Đón đọc thêm nhiều bài viết hấp dẫn trong lĩnh vực IT và nhân sự tại TopDev nhé!
Chuyện là cái ông owner của Kieblog nhận được yêu cầu build UI Library cho một dự án lớn. Build thì được nhưng gặp phải một số điểm khó nhắn.
Khó nhằn thì cũng xử xong, nhưng muốn viết ra đây cho anh em nào tương lai muốn build UI Library có vài điểm để lưu ý.
Tránh đi vào vết xe hơi sâu chứ méo đổ nha =)))
Rồi bắt đầu, bài viết này viết theo ý kiến cá nhân nên có cái nào chưa đủ nhờ anh em comment thêm nha.
1. Có depend trên UI Library nào khác không?
Hiện tại có rất nhiều UI Library, với Vuejs ta có Vuetify, Bootstrap Vue và Element UI. Nói chung là rất rất nhiều UI Library khác, nhưng trước khi build UI Lib ta cần ra quyết định.
Câu hỏi như cái title, có cần dựa vào một UI Library nào khác không?. Dựa vào thì có cái lợi là thời gian implement sẽ bớt đi, còn bỏ qua tất cả để tự viết mới thì cần rất nhiều thời gian.
Đơn cử như vấn đề về CSS, nếu ta chọn Buefy thì đã có sẵn nền là Bulma Css. Còn nếu không thì phải tự build bộ variable scss và sass cho riêng mình.
Có hai yếu tố chính để anh em cân nhắc:
Thứ nhất là quỹ thời gian có hay không?
Thứ hai là độ custom của UI Library có yêu cầu nhiều không?
Ở nội dung bài viết và theo quan điểm cá nhân thì tôi không đánh giá cái nào ngon cái nào dở. Tất cả phụ thuộc vào requirement của anh em lúc build UI Library.
Đã depend thì hơi khó custom, nên tuỳ vào tính chất UI Library anh em muốn build mà cân nhắc nha
2. Tổ chức source code như thế nào?
Bản thân build UI Library không hề khó. Tại sao vậy?, vì ta có nhiều nguồn để tham khảo. Hầu hết đều có source sẵn trên github cho anh em tham khảo. Tuy nhiên anh em cần tìm đúng cái cần cho UI Library của riêng mình.
Ông Buefy thì viết kiểu Vue components
Ông Vuetify thì Typescript thuần + mixins
Ông Bootstrap Vue thì viết js thuần
Tất nhiên là đều render ra component với props, directives và một số thứ khác nữa, nhưng khi tiến hành quyết định build UI Library anh em nên tham khảo ý kiến của từng thành viên trong team.
Một số bạn có thể thoải mái với Typescript, nhưng một số thì lại thích Javascript thuần. Tuỳ vào tình hình cụ thể trong team mà ta phải ra quyết định cho phù hợp.
3. Visualization sao cho tốt?
Cái UI Library build ra bản thân dành cho developer xài. Không chỉ mỗi người implement component đó xài mà các developer khác. Chính vì vậy vấn đề Trực Quan quá trở nên cực kì quan trọng.
Cái này tuỳ theo nhu cầu, thời gian và cách mà team dev muốn làm. Anh em có thể có vài lựa chọn.
Có mấy cái có thể suggest anh em:
Thứ nhất là dùng StoryBook (cách này ít tốn effort và dễ làm) vì Storybook hỗ trợ visualization.
Thứ hai là tự viết và deploy docs như cách mà các UI Library khác đang làm (cách này tốn effort)
Tất nhiên là cái nào cũng có điểm mạnh riêng của nó. Nếu nhanh thì khó custom và nếu dễ custom thì lại tốn effort.
Tự viết docs theo kiểu Vuetify
Hoặc sử dụng Storybook
4. Tổ chức component như thế nào?
Đây cũng là một vấn đề cần lưu ý. Nếu khách hàng hoặc project đã quyết chí build UI Library riêng, chứng tỏ style component và component business có gì đó khác biệt so với các UI Library đang có trên thị trường.
Các component phổ biến như Dropdown, Input, Radio, Checkbox anh em có thể gom vào 1 phần.
Những component đặc biệt phụ thuộc vào business và đặc thù dự án thì gom vào một chỗ. Các component phổ biến mình có thể tham khảo props và cách viết.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Trait trong RAML được sử dụng để định nghĩa những thành phần giống nhau trong các request URI khác nhau để có thể sử dụng lại được. Nó giống như common class, method trong Java đó các bạn!
Trong 2 request này, request parameter “name” được định nghĩa giống nhau. Do đó, chúng ta có thể sử dụng Trait để định nghĩa cho request parameter này và sử dụng lại trong 2 request. Khi thay đổi định nghĩa cho request parameter “name”, chúng ta không cần phải sửa nhiều chỗ nữa.
Chúng ta định nghĩa Trait cho request parameter “name” với tên gọi là “hasNameParam” như sau:
LÀM THẾ NÀO ĐỂ HỢP TÁC TRONG CÔNG VIỆC VỚI NGƯỜI BẠN KHÔNG THÍCH?
Bài viết được sự cho phép của tác giả Ánh Nguyệt
1. Tự chiêm nghiệm lại nguyên nhân
Việc bạn không thích người đó, và cách bạn đã phản ứng với các tình huống gây căng thẳng giữa hai người.
Bạn phải hiểu rằng: Bạn sẽ không hòa đồng với tất cả mọi người. Hãy nhìn nhận một cách trung thực điều gì đang gây ra căng thẳng và vai trò của bạn trong việc tạo ra nó. Có thể phản ứng của bạn với tình huống là cốt lõi của vấn đề (và bạn không thể kiểm soát bất cứ điều gì khác ngoài phản ứng của mình).
2. Tìm nhiều cách để hiểu quan điểm của người đó
Hãy dành thời gian để suy nghĩ về quan điểm của người kia, đặc biệt nếu người đó là yếu tố cần thiết cho sự thành công của bạn
– Tại sao người này lại phản ứng theo cách đó?
– Điều gì là động lực của họ?
– Người đó đang nhìn mình như thế nào?
– Điều gì họ muốn & cần ở mình?
3. Đứng ở vị trí là người giải quyết vấn đề hơn là người đánh giá hay người cạnh tranh
Để làm việc cùng nhau tốt hơn, điều quan trọng là phải chuyển từ quan điểm cạnh tranh sang quan điểm hợp tác . Một chiến thuật là “đưa ra” vấn đề cho người khác. Thay vì cố gắng làm việc thông qua hoặc xung quanh người khác, hãy thu hút họ trực tiếp.
Có thể mời người đó ăn trưa hoặc cafe rồi mở lòng với họ: mình không cảm thấy chúng ta đang làm việc với nhau tốt như chúng ta có thể. Bạn nghĩ sao về điều này? Bạn có ý tưởng gì để chúng ta có thể làm việc tốt hơn không?
4. Hỏi nhiều hơn
Trong những tình huống căng thẳng, nhiều người trong chúng ta cố gắng “nói” theo cách của mình điều này thường làm cho tình hình trở nên tồi tệ hơn. Thay vào đó, hãy thử đặt câu hỏi mở nhằm tạo ra cuộc trò chuyện.
Sử dụng những câu hỏi với mục đích xây dựng và thật lòng kiên nhẫn lắng nghe câu trả lời
5. Nâng cao nhận thức về bản thân
Trong những mối quan hệ với những loại tính cách khác nhau
Thật dễ dàng làm cho xung đột trở thành “phản ứng hóa học kém”Với một người khác nhưng mọi người đều có phong cách khác nhau và thường xuyên nhận thức được những khác biệt đó có thể giúp ích
Ví dụ bạn là người mới vào, người đó đã làm việc ở tổ chức lâu hơn bạn:Mình cảm thấy đã bắt đầu hiểu về tổ chức, tuy nhiên mình cần thêm sự trợ giúp của bạn: Điều gì mình nên làm nhiều hơn hoặc ít đi? Mình đã bỏ qua điều gì hay mình nên kết nối với ai? Bạn đã từng ước ai đó nói cho bạn điều gì khi bạn bắt đầu công việc ở đây?
Tiếp tục với sê ri Algorithm in Frontend, kì này nói về một loại cấu trúc dữ liệu được dùng thường xuyên trên frontend, đó là Kiểu dữ liệu dạng cây (tree).
Nhắc đến cây thì hẳn chúng ta nghĩ ngay đến DOM và các thao tác trên đó, ví dụ như tìm kiếm một element trên DOM, thêm/xóa element,… tuy nhiên các thao tác này chúng ta thường sử dụng DOM API có sẵn của trình duyệt và bài này cũng không có ý định nói đến phần đó
Thực ra đây là một câu hỏi phỏng vấn cho vị trí Frontend Engineer tại công ty G cũng khá là có tiếng tăm (vì họ bắt mình ký NDA không được tiết lộ nội dung buôi phỏng vấn, nhưng mà để viết bài này thì phải lộ đề rồi, nên thôi mình không tiết lộ tên công ty đó vậy hình như đây là lần thứ 2 mình nhắc đến NDA rồi, mấy cái công ty cứ thích dùng cái này để bịt miệng người ta quài).
Câu hỏi này gây ấn tượng mạnh với mình vì lúc đó là lần đầu tiên mình gặp một câu hỏi phỏng vấn núp bóng dưới dạng một ứng dụng thực tiễn rõ ràng như thế này.
Mặc dù đề bài yêu cầu xây dựng một component in ra một menu đa cấp, nhưng bản chất bài toán vẫn là xây dựng thuật toán chuyển cục JSON kia về dạng cây.
Nói thì dễ, đến lúc vào phỏng vấn thì mặt mình tái mét, dành hết 40 phút để implement cái cơ chế tạo và mount một custom component theo kiểu Angular Directive, trong khi không đả động gì đến cái đề bài, kết quả là fail dập mặt
Nhìn vào dữ liệu input (tạm gọi là II) ta có thể thấy đây là một mảng “phẳng” (flat array), và mỗi phần tử của mảng này có thể có hoặc không có mối liên hệ nào với nhau. Nếu một phần tử IjIj là “con” của IiIi thì tên Ij.nameIj.name sẽ có mặt trong mảng Ii.itemsIi.items.
Nhiệm vụ của chúng ta sẽ biến mảng phẳng này thành một cây dữ liệu, dựa trên mối quan hệ vừa đề cập.
3. Cấu trúc dữ liệu
OK, vậy thì đầu tiên ta phải nghĩ về cấu trúc dữ liệu của một Node trên cây, sẽ có dạng như sau:
pseudo code
struct Node {
name: String,
items: Array<Node>
}
Với cấu trúc trên, một Node cha sẽ có các Node con nằm trong trường items, và với một Node lá, không có Node con nào, thì trường items chỉ là một mảng rỗng.
Như vậy, nếu ThinkpadThinkpad là một Node lá, và cũng là con của LaptopLaptop thì cây của chúng ta sẽ có dạng:
Ý tưởng của thuật toán sẽ gồm 2 công đoạn, giống như chơi xếp hình vậy:
Màn dạo đầu: để thống nhất về kiểu dữ liệu, ta đưa mảng input II thành một mảng có mỗi phần tử là một cây riêng biệt, có gốc (root) chính là phần tử IiIi đang xét, và các node lá là các phần tử của Ii.itemsIi.items.
Xếp hình: gọi là lắp ráp thì đúng hơn, ở bước này ta sẽ ráp nối các cây lại với nhau theo kiểu, cây nào con cây nào thì cắm vào cây đó. Kết thúc việc lắp ráp thì chúng ta sẽ có một cây hoàn chỉnh như đề bài yêu cầu.
Thuật toán đầy đủ được mô tả như sau:
Bước 1: Duyệt qua tất cả các phần tử của mảng II
Bước 2: Với mỗi phần tử IiIi (còn gọi là một cây IiIi), duyệt qua tất cả các phần tử của mảng Ii.itemsIi.items (các cây con của IiIi).
Bước 3: Gọi nodenode là phần tử Ii.itemsjIi.itemsj đang xét. Tìm trong mảng II một phần tử ItIt sao cho It.name==nodeIt.name==node.
Bước 3a: Nếu tìm thấy một phần tử ItIt thỏa điều kiện trên thì thay thế nodenode thành ItIt. Đánh dấu ItIt thành một cây cần xóa.
Bước 3b: Nếu không thì biến nodenode thành một lá của cây IiIi
Bước 4: Xóa tất cả các cây IiIi đã được đánh dấu trong mảng II. Mảng thu được chính là mảng kết quả.
Khác với các ngôn ngữ lập trình khác, vì JavaScript là dynamic typing, ta có thể dễ dàng thay đổi giữa nhiều kiểu dữ liệu cho một biến, chính vì thế, rất có khả năng bạn sẽ bị confuse khi đọc đến bước 3 và 3a
Ở bước 3, một giá trị node=Ii.itemsjnode=Ii.itemsj sẽ mang kiểu string, đến bước 3a ta lại gán nodenode thành một giá trị ItIt (là một cây).
Nếu ngôn ngữ mà các bạn sử dụng không phải JavaScript mà là một ngôn ngữ strong typing nào đó ví dụ như Go hay Rust hay C/C++, thì thuật toán ở trên cần phải được sửa lại.
Còn bây giờ thì implement thôi:
const buildTree = (nodes) => {
for (let i = 0; i < nodes.length; i++) {
for (let j = 0; j < nodes[i].items.length; j++) {
let node = nodes[i].items[j];
let found = nodes.find(n => n.name == node);
if (found) {
nodes[i].items[j] = Object.assign({}, found);
found.removed = true;
} else {
nodes[i].items[j] = {
name: node,
items: []
};
}
}
}
return nodes.reduce((arr, item) => {
if (!item.removed) {
arr.push(item);
}
return arr;
}, []);
}
Chúng ta chạy thử và in kết quả dưới dạng một chuỗi JSON để thấy rõ cấu trúc dạng cây:
let list = require('./menu.json');
let result = buildTree(list);
console.log(JSON.stringify(result, null, ' '));
Nội dung JSON của kết quả thu được
5. Phức tạp quá, làm vậy chi cho cực?
Đọc đến đây hẳn có bạn sẽ đặt ra câu hỏi: Tại sao ngay từ ban đầu lại dùng kiểu dữ liệu dạng như thế này trên frontend? Chẳng phải đây là việc của backend hay sao? Trên thực tế có ai làm vậy không?
Câu trả lời nằm ở tính tiện lợi khi cần mở rộng menu dạng cây như thế này, ví dụ, với mảng II đã cho ở trên, khi chúng ta cần mở rộng, ví dụ thêm vào một loại laptop khác bên cạnh dòng Thinkpad, hoặc thêm vào một hãng xe ô tô mới, ta có thể thêm trực tiếp một hoặc nhiều item mới vào mảng II, ví dụ:
Nếu lưu dữ liệu trực tiếp dạng cây thì việc cả việc lưu trữ lẫn việc thêm/bớt này quả thực là một vấn đề không đơn giản. Hay nói cách khác thì giải pháp đó không scalable.
6. Bài viết này có giúp tôi được tăng lương không?
Lưu ý: Bản quyền câu nói trên thuộc về blog Quần Cam, để đưa câu nói này vào bài viết, mình đã phải trả một khoản “tiền” khá lớn, mong các bạn đừng bắt chước.
Chân thành mà nói thì việc tăng lương hay không phụ thuộc vào… sếp của bạn
Tuy nhiên, là một frontend developer, bạn cũng là một phần rất quan trọng trong team, nếu phải lựa chọn giữa một giải pháp tiện lợi cho cá nhân mình nhưng sẽ tạo ra gánh nặng cho phần còn lại của team, và một giải pháp tạo ra vài thách thức nhỏ cho bản thân nhưng đem lại hiệu quả cho toàn bộ hệ thống, thì có lẽ hy sinh một chút thời gian và sự thoải mái của bản thân sẽ tốt hơn so với việc ngồi câu nệ xem việc này là của ai và ai phải làm gì.
Rất cảm ơn các bạn đã đọc đến tận dòng này, hy vọng các bạn thích sê ri này, đừng ngại để lại comment nếu các bạn có bất kỳ góp ý hay gợi ý gì. Hẹn gặp lại các bạn trong các bài viết sắp tới.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Khi định nghĩa API specs với RAML, việc chúng ta định nghĩa tất cả các thông tin chỉ trong một tập tin RAML sẽ gây khó khăn trong việc maintain và sẽ có những phần, những data types được sử dụng đi, sử dụng lại trong nhiều request URI khác nhau, nếu định nghĩa như vậy thì không phải là best practice. Việc chia nhỏ định nghĩa những phần được sử dụng đi sử dụng lại này thành những fragments trong những tập tin RAML khác, sẽ giúp chúng ta quản lý cách định nghĩa API specs tốt hơn, tránh lặp đi lại những thứ không cần thiết. Trong bài viết này, mình sẽ hướng dẫn các bạn cách định nghĩa API specs với các fragments trong RAML các bạn nhé!
Như các bạn thấy là, tất cả các thông tin về Student object, các example đều được khai báo trong cùng một tập tin RAML. Giả sử sau này ứng dụng của mình được mở rộng để thêm các request URI thêm xoá sửa lớp học, lấy thông tin student của một lớp học:
thì như các bạn thấy: nội dung của tập tin RAML này sẽ phình ra nhiều hơn gây khó khăn trong việc chỉnh sửa, các example không được reusable, … Sử dụng các fragments sẽ giúp chúng ta giải quyết những bất cập này.
Để sử dụng các fragments, điều các bạn cần phải làm đó là chia nhỏ tập tin RAML của chúng ta (mình sẽ gọi tập tin RAML này là tập tin root RAML các bạn nhé!) bằng cách định nghĩa fragment cho các data types, các thông tin chung giữa các request URI sử dụng các tập tin RAML khác và khai báo để sử dụng những tập tin RAML này trong tập tin root RAML sử dụng từ khoá “!include”.
Trong ví dụ của mình ở trên thì việc đầu tiên chúng ta có thể làm là định nghĩa fragment cho các data type object trong các tập tin RAML khác.
Mình sẽ tạo mới 2 tập tin student.raml và class.raml nằm trong thư mục data-types/objects:
để định nghĩa data type cho các object Student, Class.
Để định nghĩa fragment cho các data type, chúng ta cần khai báo dòng “#%RAML 1.0 DataType” ở đầu của mỗi tập tin .raml. Ví dụ nội dung của tập tin student.raml sẽ như sau:
Tổng Hợp Những Câu Hỏi Phỏng Vấn Front End Thường Xuyên Xuất Hiện Trong Các Buổi Phỏng Vấn
Front-end và Back-end là một trong những vị trí quan trọng trong các dự án công nghệ thông tin, triển khai phần mềm. Để vượt qua vòng phỏng vấn, ứng viên nên có sự chuẩn bị kỹ càng ngay từ việc trang bị kiến thức, kỹ năng trả lời cũng như tham khảo một số mẫu câu phỏng vấn thường xuyên xuất hiện để làm quen trước. Bài viết dưới đây sẽ tổng hợp một số câu hỏi phỏng vấn Front End Developer mang tính chuyên môn được hỏi nhiều nhất.
Tổng Hợp Những Câu Hỏi Phỏng Vấn Front End Thường Xuyên Xuất Hiện Trong Các Buổi Phỏng Vấn
API Gateway, một thanh niên điều đào chính hiệu trong làng Micro Services và Architecture. Tui không hề nói điêu, đúng nghĩa điều đào. Không tin anh em cứ đọc bài thử là sẽ biết.
Như kiểu tú ông, nhưng có lợi cũng đi kèm hại và một số điểm ta cần consideration nha.
1. API Gateway Movitation
Nói tới Movitation thì nói với ví dụ là dễ để mà hiểu nhất. Đây, giả sử ta có requirement build Video Streaming System + Sharing System.
Những tính năng chính mà ta cần implement bao gồm:
Upload Videos
Watch Videos
Comment on Videos
Từ những tính năng chính nay, tiến hành bẻ nhỏ ta sẽ có:
Một đống các feature nho nhỏ ta cần quan tâm
Một list các features cần implement, nhưng do ta đã biết về Micro Services và build Scalable System nên ta sẽ tách các nhóm feature này thành các services. Một điểm yếu nữa với kiến trúc ở hình trên, ta sẽ gặp rất nhiều khó khăn khi maintain.
Làm về lâu về dài rất dễ dẫn tới out of control source code.
Anh em nào muốn tìm hiểu về Scalable có thể đọc chuỗi bài này nha:
Chính vì vậy, ta sẽ split thành các service nhỏ như sau:
Với nhóm tính năng trên, ta split thành 4 nhóm services chính là Frontend Service, Users Service, Video Service và Comments Services.
Vấn đề là mỗi services này cần phải implement Authentication, Authorization và xử lí các Business Logic riêng. Việc xử lí riêng rẽ ở từng Service không những gây tốn kém về effort mà còn gây ra vấn đề về Performance.
Đây rồi, lúc này API Gateway solutions ra đời (anh em đọc tiếp phần 2)
Thay vì để user gọi từng service riêng rẽ, API Gateway sẽ đứng ra “điều đào” là API Management Services, đứng giữa End User và các Services
Thanh niên “Điều đào” API Gateway
Tính search hình “Điều đào” gửi cho anh em có khí thế đọc bài mà nó ra hình quả điều. Clm. Thôi tới định nghĩa API Gateway
The API Gateway follows a software architecture pattern called API Composition
API Gateway được sinh ra dựa trên một pattern của kiến trúc phần mềm là Composition
Ở pattern này, ta sẽ gom toàn bộ các API ở phía services thành 1 API Services, end user chỉ cần giao tiếp với một API services duy nhất.
Gom lại hết có lợi nha, chính vì có lợi nên mới để nó thành một pattern. Chi tiết anh em mình tiếp tục tới mục số 3
3. Benefit và Quality Attributes
3.1 Seamless internal modification/refactoring
Cái này nếu nói đúng thì là điểm mạnh của micro services. Tuy nhiên nhờ có anh API Gateway đừng mũi chịu sào nên ta có thể sửa đổi (modification) hoặc sửa code (refactoring) một cách dễ dàng hơn.
Ví dụ, nếu hệ thống Video Streaming của ta chia thành 2 services cho 2 loại Mobile và Desktop. Ta có thể dễ dàng tạo ra 2 services để handle từng loại devices.
Tách riêng thành 2 services handle cho Mobile và Desktop
Một ví dụ khác cũng khá hợp lí là xử lí chất lượng cho từng loại device (high quality và low quality)
Tách thành 2 services cho High Resolution và Low Resolution
3.2 Consolidating all security, authorization, authentication
Cái này thì là benefits nhìn thấy rõ của API Gateway. Gom toàn bộ phần Authorization, Authentication về một mối. Thay vì không có API Gateway, từng services phải handle Autho, Authen riêng nó. Các vấn đề về Security cũng handle riêng.
Giờ tất cả trong một mối, handle ở API Gateway. Nếu không có vấn đề gì thì request sẽ được chuyển tiếp tới các Services con.
Cũng với Authorization, ta có thể phân quyền cho từng user, mỗi loại user sẽ được access tới một số lượng nhất định các services.
Ta cũng có thể implement rate-limiting nhằm phòng chống các cuộc tấn công DDos. Lợi nhiều vô kể.
3.3 Request routing
Request routing cũng là một điểm cộng lớn của API Gateway. Như đã nói ở trên, thay vì từng services phải thực hiện Authen Autho thì giờ chỉ API Gateway làm việc đó. Giảm tải, tăng performance.
Thứ hai nữa là mỗi user bây giờ chỉ cần gửi một request duy nhất tới API Gateway, nhân về một response duy nhất. Còn việc gọi những services con nào thì để API Gateway lo
Như ví dụ ở trên đây, trường hợp user muốn xem một video thì sẽ cần request tới 3 Services. Nếu không có Gateway thì gọi 3 lần nha.
Đầu tiên là Frontend Services để thấy layout trang xem video
Video service để thấy video cần xem
Comments Service để load ra toàn bộ comment của video đó
3.4 Static content và response cache
Trường hợp ta có sử dụng cache để cache lại content ở API Gateway, ta có thể trả về nội dung nhanh chóng hơn cho người dùng.
Điều này cũng làm tăng performance thấy rõ cho application
3.5 Protocols Translation
Với API Gateway, giờ đây sự khác biệt giữa các Service cũng có thể đem thành một thể thống nhất.
Gateway luôn trả về JSON format cho người dùng, nhưng các services có thể được define ở các kiểu khác nhau. Frontend Service có thể là gRPC và PROTO BUFFER.
Comments Service có thể là HTTP 1.0 REST API và XML. Nhưng với API Gateway thì tất cả được gom về một mối, end user hoặc phía Frontend client chỉ cần làm việc với REST API và JSON
4. Consideration
Tuy là API Gateway tiện lợi như vậy, trung gian đầu mối của tất cả các server trong hệ thống. Nhưng nó cũng tồn tại những điểm yếu chết người.
Chính vì là trung gian nên có một số thứ ta cần cẩn trọng khi áp dựng API Gateway.
4.1 Bussiness Logic
Đầu tiên là cách implement
API Gateway should not contain any business logic
API Gateway không nên bao gồm bất cứ logic nào về business
Do mục đích chính của Gateway sinh ra chỉ bao gồm 2 thứ sau:
Thứ nhất là API Composition
Thứ hai là Routing request tới các services khác
Nếu chính trong bản thân Gateway có business logic, nó sẽ làm mất đi tính năng điều phối. Nếu lạm dụng đưa logic hoặc business vào đây, ta sẽ trượt xa khỏi micro services architecture. Gom toàn bộ lại vào API Gateway, biến nó thành một bộ code khổng lồ.
Thứ hai:
API Gateway may become a Single Point of Failure
API Gateway có thể trở thành điểm chết duy nhất
Chính vì API Gateway là thanh niên điều đào cho các Service, nên nếu thằng cha này mà ngủm thì cả đường dây chết. Mà nguyên nhân nó ngủm thì đôi khi tới từ những lí do ngớ ngẩn nhất.
Cũng không trách được, vì nếu có tác động của Human thì make a mistake là chuyện bình thường. Nhưng anh em nhớ là nếu nó ngủm thì tất cả đều ngủm.
Cách đây mấy hôm mình có share cái screenshot trên Facebook, khoe linh tinh vụ mình đang viết lại cái CHIP-8 emulator bằng Rust.
Mãi cho đến hôm nay thì vẫn viết chưa xong, chán quá nên ngồi viết mấy dòng linh tinh về quá trình này.
Phàm làm bất cứ chuyện gì, đều là cả một quá trình viết Emulator hay code bất cứ thứ gì cũng vậy. Và trong quá trình đó thì người viết luôn phải trải qua vô số những quyết định về mặt kĩ thuật, ví dụ như nên dùng if..else hay pattern matching, viết test hay ko test , chia module hay viết 100 ngàn dòng trong 1 file,…
Một trong những quyết định đau đầu nhất của mình đó là chọn cấu trúc dữ liệu để biểu diễn ma trận hiển thị (display matrix) – tức là cái màn hình cho emulator.
Như đã đề cập ở bài Tự viết Emulator, màn hình của CHIP-8 là một ma trận 64×3264×32. Nên cách biểu diễn thường gặp nhất đó là một mảng số nguyên (integer) hai chiều.
Tuy nhiên, việc dùng số nguyên rất là tốn kém, trong Rust, kiểu số nguyên nhỏ nhất là i8, chiếm 1 byte (8 bits), và trong JavaScript thì còn tệ hơn nữa khi một giá trị kiểu Number mặc định chiếm bà nó 8 bytes (64 bits). Nhân lên, để khai báo một mảng hai chiều cho ma trận hiển thị của CHIP-8 ta cần 64×32×8=16,38464×32×8=16,384 bits trong bộ nhớ nếu dùng Rust (tương đương với 2 KB), và 131,072 bits tương đương với hơn 16 KB nếu xài JavaScript.
Con số có vẻ không lớn nếu chạy trên máy tính, nhưng nếu bạn đang implement cho các nền tảng èo ọp hơn như là Arduino thì đây là cả một vấn đề cực kì lớn. Đơn cử, dòng Arduino phổ biến nhất là UNO R3, sử dụng vi xử lý ATmega328P và bộ nhớ SRAM (static random access memory) của nó chỉ có đúng 2 KB.
Quèo, trên thực tế thì bạn vẫn không thể chạy trực tiếp CHIP-8 emulator trên Arduino được vì tính riêng dung lượng bộ chớ chính của nó cũng đã ngốn mất 4096 bytes rồi trong trường hợp này chúng ta cần dùng thêm một con chip khác để làm external RAM, tuy nhiên, vấn đề này nằm ngoài phạm vi bài viết, có thể mình sẽ nói tới trong một bài khác.
Dễ nhận thấy, đối với CHIP-8, màn hình hiển thị chỉ gồm 2 màu trắng đen, mỗi pixel chỉ có 2 trạng thái đó là on hoặc off, tương đương với chỉ có 2 giá trị 0 hoặc 1, vậy thì việc dùng số nguyên để biểu diễn là không cần thiết.
Kiểu dữ liệu nào chỉ có 2 trạng thái nhỉ? bool! Tuy nhiên ngay cả kiểu bool trong Rust cũng chiếm tới 1 byte (8 bits). Còn trong JavaScript thì mình chịu, không có tài liệu nào nói cụ thể, các đoạn code tính size của 1 type thì ghi nó tận 4 bytes . Mình không tin có bằng chứng thì mới tin.
Bản thân một bit có thể chứa được 2 giá trị (0 và 1), như vậy là đã thỏa mãn cho yêu cầu của một ma trận hiển thị.
Vậy thì có cách nào chỉ dùng đúng 64×32=204864×32=2048 bits trong bộ nhớ không? Có!
Rust có hỗ trợ kiểu u64 (64-bit unsigned integer), là một kiểu số nguyên không đấu, khi khai báo một biến kiểu này tất nhiên nó sẽ chiếm 64 bits trong bộ nhớ.
Và nếu chúng ta khai báo một mảng gồm 32 số nguyên 64 bit[u64; 32] thì sao? Chúng ta sẽ có 2048 bits! Đủ để chứa toàn bộ ma trận hiển thị.
Đến đây thì vấn đề sẽ là: Làm sao để đọc/ghi vào một bit bất kì của một số u64.
Lưu ý: về thứ tự cao thấp của các bit, ở đây chúng ta theo quy ước các số đều là big endian, các bit được sắp xếp theo thứ tự từ bit cao đến bit thấp. Ví dụ trong hình sau là một số u16 gồm có 2 bytes:
Từ trái qua phải, bit đầu tiên gọi là bit cao nhất (highest bit), bit cuối cùng gọi là bit thấp nhất (lowest bit).
Vì thế, khi nói một bit thứ i, chúng ta có thể hiểu là bit thứ i tính từ bit thấp nhất (bên phải) qua .
2. Đọc một bit
Để đọc một bit thứ i của một số n, ta dịch phải số n một khoảng bằng i - 1 bits, và thực hiện phép AND kết quả thu được với 1:
(n >> (i - 1)) & 1(n >> (i - 1)) & 1
Ví dụ: Để đọc bit thứ 6 của số 0xA1, ta sử dụng công thức trên qua từng bước như sau:
Số 0xA1 biểu diễn dưới dạng nhị phân là 1010 0001. Để lấy được bit thứ 6, ta cần dịch phải 5 bit:
1010 0001 >> 5=0000 01011010 0001 >> 5=0000 0101
Tiếp theo, ta thực hiện phép AND kết quả trên với số 1, thực chất có biểu diễn nhị phân là 0000 0001:
Để xóa một bit thứ i (đưa bit đó về giá trị ban đầu, là 0) của một số n, ta làm như sau:
n & !(1 << (i - 1))n & !(1 << (i - 1))
Ví dụ: Để chuyển giá trị 0xA9 thu được ở ví dụ trên về lại thành 0xA1, ta phải xóa bit thứ 4 cua số đó. Tương tự như ở ví dụ trước, đầu tiên ta sẽ dịch trái số 1 một khoảng 3 bit, lần này ta lấy giá trị nghịch đảo NOT của nó.
Cá nhân mình thì ko biết nữa, nhưng thấy khá là hại não tuy nhiên hiệu quả đem lại thì rất lớn, chúng ta đã tiết kiệm được một lượng lớn bộ nhớ, từ 2KB xuống còn 2048 bits.
Bây giờ thì có thể implement thành hàm hay class để dùng lại cho tiện. Ví dụ, đây là hai hàm mình viết để sử dụng trong emulator:
// Lưu ý, code này không có chính xác :vimpl Screen {
...
pubfnset_pixel(&mutself, x: usize, y: usize, on: bool) {
if on {
self.display[y] |= 1 << x;
} else {
self.display[y] &= (!(1 << x));
}
}
pubfnget_pixel(&self, x: usize, y: usize) -> u64 {
(self.display[y] >> x) & 1
}
...
}
Ngoài việc dùng cho emulator (màn hình trắng đen) ra, thì cách thể hiện ma trận dùng bit array này còn có thể được dùng cho nhiều trường hợp khác như bảng đèn điện tử (tín hiệu bật/tắt), lưu các đỉnh của một đồ thị, lưu bàn cờ hoặc các thể loại map đơn giản nếu bạn làm game, hoặc có thể cải tiến để sử dụng từng byte thay vì từng bit để lưu trữ được nhiều thông tin hơn.
Hy vọng qua bài viết này, mình đã ít nhiều chia sẽ được cho các bạn chút gì đó, mặc dù cho đến thời điểm này mình vẫn chưa biết là mình đã chia sẽ được gì
Cảm ơn các bạn đã kiên nhẫn đọc đến tận những dòng này. Nếu các bạn cảm thấy bài viết này thú vị, đừng ngại để lại comment, và nhớ subscribe vào mailing list của mình để nhận thông báo về các bài viết mới, hoặc like trang Facebook để đọc những dòng status ất ơ ngẫu nhiên của mình vào một ngày đẹp trời nào đó. Chào thân ái và quyết thắng.
Công Việc & Mức Lương Chuyên Viên Phân Tích Nghiệp Vụ
Một trong những ngành nghề liên quan đến lĩnh vực công nghệ thông tin được nhiều người quan tâm có thể kể đến là Chuyên viên Phân tích nghiệp vụ. Công việc phù hợp với thời đại, cơ hội phát triển sự nghiệp tốt cùng với mức lương hấp dẫn chính là những yếu tố giúp công việc này thu hút được nhiều nhân tài. Vậy cụ thể công việc của chuyên viên phân tích nghiệp vụ là làm gì? Lương chuyên viên phân tích nghiệp vụ đang nằm trong khoảng nào?
Mức lương của chuyên viên phân tích nghiệp vụ
1. Chuyên viên phân tích nghiệp vụ là làm gì?
Chuyên viên phân tích nghiệp vụ – Business Analyst được xem như một chiếc cầu nối, một kênh liên lạc giữa các doanh nghiệp và đơn vị phát triển phần mềm. Công việc của các BA sẽ không quá thiên về mảng kinh doanh hay công nghệ mà sẽ phối hợp các công việc để vận hành trơn tru quá trình làm việc giữa công ty outsource phần mềm với các doanh nghiệp cần dịch vụ.
Nhiệm vụ chính trong công việc hằng ngày của họ là thu thập các dữ liệu công việc, yêu cầu từ khách hàng, phân tích quy trình kinh doanh của công ty khách hàng để từ đó đưa ra các phương án làm việc khả thi với yêu cầu cũng như tình hình tài chính của doanh nghiệp.
Sau khi đã nắm được các vấn đề cần giải quyết trong dự án và đã có sản phẩm hoàn thành, các BA sẽ là người liên hệ với khách hàng để giới thiệu dự án. Chuyên viên phân tích nghiệp vụ cần thuyết phục khách hàng về tính khả thi và tối ưu của sản phẩm, sản phẩm mới này sẽ giúp ích gì cho công việc kinh doanh của công ty cũng như cải thiện vấn đề doanh thu như thế nào.
Trong vai trò và công việc hàng ngày của mình, để cho ra đời được các sản phẩm đáp ứng đúng yêu cầu như trên, các chuyên viên BA còn cần làm việc và giao tiếp thường xuyên với các lập trình viên, chuyên viên quản lý phần mềm để hệ thống hóa các thông tin mà khách hàng yêu cầu cũng như cung cấp thông tin cần thiết cho lập trình viên phát triển sản phẩm. BA sẽ giúp các thành viên trong dự án gắn kết với nhau và cho ra đời những sản phẩm, những dự án tốt nhất, phù hợp nhất với khách hàng.
2. Lương chuyên viên Phân tích nghiệp vụ như thế nào?
Khi công nghệ thông tin phát triển mạnh cũng là lúc các ngành nghề liên quan đến BA không ngừng tăng lên, kéo theo nhu cầu nhân lực theo đuổi ngành cũng ngày càng lớn. Trong khoảng thời gian từ năm 2012 đến nay, có thể nói nghề BA chưa bao giờ ngừng “hot” trong thị trường việc làm lĩnh vực công nghệ thông tin.
Mức lương của BA
Đặc biệt tại Việt Nam, nhờ chính sách mở cửa và nhiều ưu đãi cho các doanh nghiệp nước ngoài nên ngày càng có nhiều công ty nước ngoài được thành lập tại nước ta. Công ty nước ngoài luôn đòi hỏi rất cao trong các vấn đề chuyên môn cũng như các yêu cầu đặt ra trong việc hợp tác phát triển phần mềm. Hợp tác phát triển phần mềm ngày càng tăng mở ra nhiều cơ hội việc làm cho doanh nghiệp công nghệ Việt nhưng cũng đồng thời đặt ra các yêu cầu về việc đáp ứng tốt chuyên môn và kỹ năng để cho ra đời những sản phẩm mà khách hàng mong muốn.
Theo các thống kê được công bố trên trang Bloomberg, nghề BA là nghề có thu nhập đứng top 3 trong số 31 nghề có thu nhập cao nhất trên hợp đồng được tìm kiếm cho đến thời điểm này. Mức lương của chuyên viên phân tích nghiệp vụ hiện nay cũng được xếp hạng khá cao so với thị trường. Tùy theo mỗi dự án khác nhau cũng như tính chất công việc, mức thưởng trên mỗi dự án và chuyên môn của mỗi BA mà mức lương sẽ có sự chênh lệch nhất định.
Lương của chuyên viên phân tích nghiệp vụ mới vào nghề dưới 2 năm kinh nghiệm thường dao động trong mức từ 10 – 15 triệu đồng. Trong khi đó, mức lương của các Senior Business Analyst cao nhất có thể đạt đến khoảng 40 triệu đồng.
3. Chuyên viên phân tích nghiệp vụ cần rèn luyện những kỹ năng nào?
Công việc của một chuyên viên phân tích nghiệp vụ sẽ phụ trách nhiều nhiệm vụ khác nhau và vì là người trung gian, đóng vai trò kết nối giữa nhóm lập trình dự án và công ty khách hàng nên kỹ năng mềm là một trong những yếu tố bắt buộc phải có của các BA. Khả năng thấu hiểu khách hàng, kỹ năng trình bày và giải quyết vấn đề cũng như tư duy logic là một trong những yêu cầu mà bất cứ BA nào cũng nên có.
Các BA cần làm tốt việc tiếp thu vấn đề mà khách hàng đưa ra, tóm tắt chúng và truyền đạt lại cho các lập trình viên trong nhóm dự án. Một sản phẩm hoàn thiện nhanh và đáp ứng đúng chất lượng dự án khi chuyên viên phân tích nghiệp vụ có thể làm tốt vai trò cầu nối của mình cũng như giải quyết các mâu thuẫn nếu có. Có những vấn đề khách hàng không thể cung cấp cho phía công ty phần mềm nhưng BA vẫn phải tìm hiểu vấn đề và đưa ra được những thông tin mà khách hàng cần.
Bên cạnh đó, khả năng giao tiếp ngoại ngữ cũng là yếu tố cần thiết với một BA giỏi. Các khách hàng làm việc cho những dự án phần mềm hiện nay có khá nhiều khách nước ngoài. Chính vì thế việc có thể giao tiếp cũng như nắm bắt văn hóa giao tiếp của nước bạn cũng là một trong những cách hay để các BA có thể dễ dàng hơn trong việc nắm bắt thông tin của đối phương.
Để có được một công việc với mức thu nhập tốt, những yêu cầu về công việc cũng như kỹ năng chuyên môn được đặt ra là rất lớn. Hiểu sớm vấn đề sẽ dễ dàng hơn với bạn trong việc trở thành một BA tương lai cũng như có được một mức lương chuyên viên phân tích nghiệp vụ đủ tốt như mong muốn của mình.
Bài viết được sự cho phép của BBT Tạp chí lập trình
Ngày mai tôi trông có vẻ ngu dốt hơn nhưng lại cảm thấy tốt hơn về điều đó. Giữ im lặng và cố đoán xem xem điều gì đang diễn ra không phải là cách làm tốt. —Jake Scruggs in “My Apprenticeship at Object Mentor”
Bối cảnh
Đối với những người trả tiền để thuê một lập trình viên như bạn, họ cần bạn cho họ biết là bạn đang làm được gì.
Vấn đề
Người quản lý và các thành viên trong nhóm cần có niềm tin là bạn làm được việc, nhưng bạn lại chưa quen thuộc với những công nghệ đang sử dụng. Điều này không chỉ xảy ra với các nhà tư vấn, nó xảy ra với tất cả mọi người. Có thể bạn đã được lựa chọn vào nhóm bởi vì bạn có hiểu biết sâu sắc về lĩnh vực kinh doanh hoặc một số khía cạnh khác trong các công việc liên quan đến kỹ thuật mà nhóm đang sử dụng.Hoặc có thể đơn giản là vì bạn là người duy nhất còn rảnh để làm việc này.
Giải pháp
Hãy thể hiện cho mọi người thấy rằng việc học tập cũng là một phần của quá trình phát triển phần mềm. Hãy chứng tỏ cho họ thấy bạn đang tiến bộ.
Theo nghiên cứu của nhà tâm lý học Carol Dweck, nhu cầu thể hiện bản thân ăn sâu vào hầu hết tất cả mọi người trong phần lớn các nền xã hội công nghiệp hóa. Xã hội này ngày càng phụ thuộc vào khả năng lập trình của bạn, vì phần mềm ngày càng gắn liền với cuộc sống hàng ngày của chúng ta. Tuy nhiên, vì bạn còn thiếu kinh nghiệm nên có nhiều thứ bạn chưa biết. Bạn đang kẹt trong một tình huống khó khăn. Những người xung quanh bạn – quản lý, khách hàng và đồng nghiệp của bạn, chưa kể chính bạn -cũng đang phải chịu áp lực rất lớn để có thể cung cấp phần mềm. Bạn có thể thấy sự kỳ vọng trong con mắt của mọi người khi họ hỏi xem bạn sẽ hoành thành tính năng X trong bao lâu. Có thể bạn sẽ nhận lấy nhiều áp lực trong việc trấn an họ và đảm bảo với họ rằng bạn biết chính xác những gì họ muốn, bạn biết lúc nào và làm cách nào để hoàn thành nó.
Các thợ gia công phần mềm xây dựng danh tiếng của họ thông qua các mối quan hệ tốt với khách hàng và đồng nghiệp. Chấp nhận những áp lực, không nói ra và chỉ nói với mọi người những gì họ muốn nghe không phải là một cách tốt để xây dựng mối quan hệ tốt. Hãy nói cho mọi người biết sự thật. Hãy cho họ biết rằng bạn đang bắt đầu hiểu những gì họ muốn và bạn đang học cách để có thể bàn giao nó cho họ. Nếu bạn trấn an họ, hãy trấn an họ bằng khả năng học hỏi của bạn chứ đừng giả vờ biết điều mình không biết. Bằng cách này, bạn sẽ xây dựng được danh tiếng dựa trên khả năng học tập của mình chứ không phải từ những gì bạn đã biết.
Cách rõ ràng nhất để thể hiện bạn chưa thật sự hiểu vấn đề là đặt câu hỏi. Điều này nói thì dễ hơn là làm, đặc biệt khi người bạn hỏi lại cho rằng bạn đã biết câu trả lời. Hãy cố gắng! Bạn hoàn toàn có thể giữ thể diện cho mình bằng cách đi đường vòng để có được những kiến thức cần thiết, nhưng hãy nhớ rằng con đường trở thành thợ lành nghề sẽ được rút ngắn nếu bạn đi theo đường thẳng. Theo thời gian cùng với sự luyện tập, bạn sẽ thấy viêc đặt câu hỏi trực tiếp cho những người có kiến thức uyên thâm nhất trong nhóm trở nên dễ dàng hơn. Song song với việc mạnh dạn bày tỏ sự thiếu hiểu biết của mình thì bạn cũng đang thể hiện với nhóm về khả năng học tập của bạn. Và đôi khi họ cũng sẽ hiểu rõ hơn về kiến thức của mình trong khi trả lời câu hỏi của bạn.
Lập trường “không biết”
Với tư cách là một nhà trị liệu gia đình, tôi đã được đào tạo để bỏ ý niệm rằng tôi có kiến thức chuyên môn về cuộc sống của người khác, qua đó tôi có thể tiếp cận với mọi người nhờ lập trường “không biết”. Đây là một việc khó có thể dễ chấp nhận cho dù bạn là một nhà trị liệu mới vào nghề hoặc một lập trình mới. Thường thì bản năng sẽ thôi thúc bạn giấu đi sự thiếu hiểu biết củacủa mình và giả vờ là có kiến thức chuyên môn về nó, nhưng điều này chỉ cản trở sự phát triển và hạn chế công việc bạn đang cố gắng đạt được mà thôi. Áp dụng bài học này đã giúp tôi rất nhiều trong các ngành nghề khác nhau. Tôi thực sự đã phát triển nhờ áp dụng sử dụng lập trường “không biết”hàng ngày; nó cho tôi thấy rằng tôi đã ở đúng nơi. Và tôi đã phát triển.
—David H. Hoover
Hãy làm quen với cách học này. Đây chính là học nghề. Có những người cảm thấy không thoải mái với việc này. Thay vì trở thành thợ gia công, những người này trở thành chuyên gia – những người đạt được kiến thức chuyên sâu trên một nền tảng hoặc trong một lĩnh vực và gắn bó với nó. Nhờ tập trung sâu, họ khả năng cao hơn người khác trong một lĩnh vực cụ thể. Các chuyên gia trong ngành là điều cần thiết và không thể tránh khỏi, nhưng đó không phải là mục tiêu của học nghề.
Các lĩnh vực chuyên môn thì phụ thuộc vào từng sản phẩm trên con đường mà chúng ta đang đi, nhưng nó không phải là đích đến của chúng ta. Trong hành trình của mình, thợ gia công sẽ làm việc với vô số công nghệ và lĩnh vực khác nhau. Nếu vì yêu cầu công việc hoặc sở thích riêng mà họ đào sâu và phát triển một hoặc một vài kỹ thuật trên thì càng tốt. Điều này là hoàn toàn bình thường, giống như việc luyện tập cho một cuộc chạy marathon thì sẽ giúp phát triển các cơ bắp chân. Cô ấy không luyện tập để có đôi chân khỏe, cô ấy luyện tập để chạy. Cũng giống như một nhà phát triển phần mềm tâm huyết đã đạt được kiến thức sâu về Python sau khi làm việc trong một dự án Python trong hai năm, các cơ bắp chân của vận động viên chạy marathon phát triển chỉ là phương tiện chứ không phải là mục tiêu cuối cùng.
Vài chuyên gia sẽ làm mọi việc có thể để duy trì gắn bó với duy nhất một lĩnh vực, thu hẹp phạm vi học tập, thực hành và các dự án. Trái lại, thợ thủ công, cần có lòng can đảm và khiêm tốn để gạt sự hiểu biết mình sang một bên và khoác lên mình chiếc đai trắng (White Belt) khi họ học một kỹ thuật hoặc miền mới.
Một trong những đặc điểm quan trọng nhất mà một thợ gia công có thể sở hữu là khả năng học hỏi, xác định một lĩnh vực mà mình còn kém và làm việc để cải thiện điều đó. Giống như những khoảng trống trong vườn, sự thiếu hiểu biết có thể được giảm đi bằng cách gieo trồng hạt giống hạt giống tri thức. Hãy tưới cho hạt giống bằng cách thử nghiệm, thực hành và đọc sách. Bạn có thể chọn cách giấu những chỗ trống, xấu hổ bởi kích thước của chúng, che đây chúng để không làm mất thể diện của bạn. Hoặc bạn có thể chọn cách phơi bày chúng, trung thực với bản thân và những người đang tin tưởng bạn, và yêu cầu được trợ giúp.
Khi kết thúc khóa học nghề, bạn sẽ có kiến thức sâu về một vài chủ đề về công nghệ. Với những chủ đề này bạn có thể tạo ra một số ít ứng dụng phần mềm mạnh mẽ trên một số nền tảng và lĩnh vực. Người thợ bậc thầy có khả năng dệt một tấm thảm từ vô số chủ đề. Không có gì đáng nghi ngờ khi họ có một vài đề tài và tổ hợp yêu thích nhưng số lượng các chủ đề sẽ lớn, cho phép họ thích ứng với một loạt các môi trường công nghệ. Đây là nơi The Long Road sẽ đưa bạn đến. Bằng cách bày tỏ và đối mặt với sự thiếu hiểu biết củamình, bạn sẽ nắm được các chủ đề còn thiếu nhanh hơn nhiều so với bạn cách giả vờ biết nó để trông có vẻ có đủ khả năng.
Hành động
Viết ra một danh sách năm thứ mà bạn thực sự không hiểu trong công việc của bạn. Đặt danh sách đó nơi người khác có thể nhìn thấy nó. Sau đó, tạo thói quen làm mới danh sách này mỗi khi công việc của bạn thay đổi.
Algorithm Visualization là kĩ thuật hình tượng hóa quá trình hoạt động của một thuật toán, chúng ta thường thực hiện nó bằng nhiều cách khác nhau như: viết, vẽ, lập bảng giá trị,…
Tuần vừa rồi mình có làm một project nho nhỏ để giải trí, vừa để thực hành xem cách mà người ta thực hiện việc visualization nó như thế nào. Mình sử dụng phương pháp được giới thiệu bởi Chris Wellons qua bài viết Inspecting C’s qsort Through Animation.
Ý tưởng cơ bản sẽ là: In trạng thái của input ra sau mỗi bước của thuật toán.
In bằng cách nào thì còn tùy thuộc vào kết quả mà bạn muốn thể hiện, ví dụ ở đây mình muốn tạo ra một ảnh GIF động, nên mỗi một bước của thuật toán, mình sẽ in ra input dưới dạng một frame của tấm ảnh GIF ấy.
Thuật toán sử dụng để minh họa là Bubble Sort và được implement thông qua 2 hàm swap() và bubble_sort(), trong này sẽ thấy mỗi bước chúng ta gọi hàm draw_frame().
Chỉ có một đoạn cuối hàm main() thì mình chạy một vòng for để add thêm vài frame, mục đích là để kéo dài thời gian cho dễ nhìn kết quả cuối cùng.
Cuối cùng, mình dùng lệnh convert của ImageMagick để chuyển đổi các frame định dạng PPM sang GIF.
Vì tính mình mau chán nên làm tới đây thì chán luôn rồi đành open source để mọi người tham khảo, ai có hứng thú thì có thể nghiên cứu tiếp kĩ thuật này, đây là một hướng khá là hay ho 😀
Viết nhiều về Design Pattern nhưng có vẻ đang thiếu bên Structural Pattern nên nay mạnh dạn viết cho anh em về Adapter Pattern.
Theo như truyền thống ở Kieblog thì pattern luôn chú trọng vào cái mục đích, nhớ rõ hiểu sâu chứ không đi thẳng vào code. Đi thằng vào code thì muôn hình vạn trạng, bạn thì làm Golang, bạn thì PHP, bạn thì Python nếu nhớ được concept là cách học chuẩn nhất.
Lại như truyền thống. F@!k, ông truyền thống gì mà lắm vậy?. Anh em tin tôi, truyền thống đôi khi là tốt. Bắt đầu chú ý vào chứ Adapter, cái tên không tự nhiên mà có.
Search thử adapter trên mạng ta sẽ có kết quả như này.
Nguồn ảnh / Source: google.com
Quan sát thì thấy mỗi cái adapter có 2 đầu, 1 đầu vào là cái ổ cắm 2 chấu và đầu ra có thể cũng là 2 chấu hoặc 1 chấu (ví dụ như cái cấp nguồn hoặc là sạc đầu tiên).
Rồi, tới thẳng định nghĩa
Adapter is a structural design pattern that allows objects with incompatible interfaces to collaborate.
Adapter là pattern cấu trúc, cho phép các object khác nhau về interfaces có thể work chung với nhau được.
Đấy, như là 2 cái đầu của hình adapter, Adapter Pattenr đơn giản là để hai thằng objects có interface khác nhau có thể work được với nhau.
Thêm quả hình nữa thì hợp lý luôn, Adapter Pattenr giúp cái xe ô tô (4 bánh không phải loại chạy xe lửa), thông qua dăm ba cái khúc gỗ trục xoay quỷ ma gì đó thì có thể chạy trên đường ray. Hợp lí.
2. Vấn đề
Quay lại với ví dụ trong nghề ha. Anh em tưởng tượng ta đang build một stock market monitoring app. Kiểu bao gồm các chart, dữ liệu chứng khoán và các diagrams xịn xò.
Ok, sau đó app anh em mình cần bổ sung analytics library (thống kê các kiểu cho manager). Nhưng vấn đề sẽ phát sinh, thằng quỷ Statistic Library chỉ work với JSON input. Nghĩa là đầu vào của nó chỉ nhận JSON, còn cái ouput của system hiện tại lại là XML.
Đấy, các ông lại không tin tôi. Pattern giờ trở nên rõ ràng dễ hiểu, còn giải pháp cho vấn đề ở trên thì.
You can create an adapter. This is a special object that converts the interface of one object so that another object can under- stand it.
Bạn có thể tạo adapter. Cái object đặc biệt này convert interface từ một object sang một object khác và nó có thể hiểu được.
Ví dụ là vậy nhưng Adapter Pattern không đơn thuần chỉ là convert data đâu nha anh em. Một số điểm dưới đây cho anh em hiểu rõ hơn Pattern này work như thế nào?
The adapter gets an interface, compatible with one of the existing objects (Adapter sẽ lấy ra được interface tương thích với một trong các đối tượng đang có sẵn.
Using this interface, the existing object can safely call the adapter’s methods. (Sử dụng cái interface này, object hiện tại có thể gọi được cái adapter methods)
Upon receiving a call, the adapter passes the request to the second object, but in a format and order that the second object expects. (Dự vào cái kết quả nhận được, nó gửi cho object số 2, tất nhiên format thằng 2 hiểu được)
Về cơ bản thì giải pháp cho vấn đề ta nêu ra ở mục số 2 sẽ như hình trên.
4. Cấu trúc (Structure)
Implement Adapter Pattern sẽ theo nguyên lý composition (đóng gói lại). Adapter sẽ implement interface của một object và đóng gói lại xài cho cái object khác.
Client Interface thì định nghĩa những protocols hoặc interface nào ta cần theo nếu muốn work với class Client
Services thì bao gồm một số class, methods cần thiết
Adapter là thằng quan trong nhất, work với cả Client Interface và Service. Adapter sẽ được call từ client thông qua Adapter Interface, chuyển đổi nó làm sao cho thằng Service nó hiểu được.
Còn một điểm nữa liên quan tới Adapter.
Nếu sử dụng đa kế thừa (multiple inheritance) thì thằng adapter sẽ kế thừa interface từ cả hai objects ở cùng một lúc. Tuy nhiên anh em chú ý là nó chỉ khả thi ở những ngôn ngữ cho phép đa kế thừa như C++ thôi nha.
Single Responsibility Principle. You can separate the interface or data conversion code from the primary business logic of the program.
Thứ nhất là chữ nguyên lý Single Responsibility: Ta có thể chia các interfaces hoặc code từ luồng business chính ra thành các logic nhỏ, sau đó kết nối lại với nhau bằng Adapter Pattern.
Open/Closed Principle. You can introduce new types of adapters into the program without breaking the existing client code, as long as they work with the adapters through the client interface.
Chữ O trong SOLID, với Adapter Pattern ta có thể kết nối các phần code với nhau mà không cần thêm/xoá sửa gì code cũ. Open cho Extension mà đóng cho Modification. Quá hợp lý!
Về nhược điểm thì đôi khi ta cần cân nhắc kĩ độ phức tạp hoặc tính khả thi khi áp dụng Adapter Pattern. Và nếu project đi theo một thể thống nhất thì vẫn hợp lý hơn.
Dịp cuối tuần vừa rồi thì mình cũng bắt đầu học Elm và làm thử 1 project nho nhỏ, mục đích là clone lại Trello chơi.
Trong quá trình làm thì cũng nhận thấy có nhiều thứ cần phải note lại.
Elm là một ngôn ngữ lập trình hàm (functional programming language) khá thú vị, chịu ảnh hưởng khá nhiều từ Haskell, và được biên dịch trực tiếp ra JavaScript.
Ngoài việc giống Haskell ra thì điểm nổi bật nhất của Elm chính là kiến trúc của nó (Elm Architecture) , giúp cho việc phát triển web apps với các ngôn ngữ functional programming trở nên dễ dàng hơn. Redux của hội React cũng chịu ảnh hưởng lớn từ kiến trúc này.
Với Elm Architecture, chúng ta không cần phải (và không thể) tương tác trực tiếp với một DOM element nào cả, thay vào đó, chúng ta tương tác với dữ liệu (data) biểu diễn element đó. Mọi thao tác mà người dùng thực hiện trên web app của bạn, đều là việc tương tác (cập nhật) với các dữ liệu này.
Nếu bạn đã biết khái niệm data binding trong các framework khác như React hay Angular, thì đây chính là nó đó.
Ví dụ trong project của mình, các task hiển thị trên màn hình được biểu diễn bằng một List trong Model, như sau:
Để hiển thị các task ra màn hình, việc chúng ta cần làm chỉ là hiển thị từng item có trong List đó, thông qua sự hỗ trợ của Html helper:
src/Views.elm
taskItemView : Int -> Task -> HtmlMsgtaskItemView index task =
li [ class"task-item" ] [ text task.name ]
Khi user muốn thêm một task mới, việc chúng ta làm là tương tác với Model để add thêm một task:
src/Models.elm
addNewTask : Model -> ( Model, Cmd Msg )
addNewTask model =
let
newModel = { model | tasks = model.tasks ++ [ newTask ] }
in
( newModel, Cmd.none )
Elm sẽ tự thực hiện phần việc bên dưới, bao gồm: kiểm tra sự thay đổi của Model, update lại DOM (như là thêm, xóa, update các element,…) tương ứng.
3. “Tương tác” với DOM element
Như đã nói ở phần vừa rồi, chúng ta không thể tương tác với bất kì một DOM element nào, vậy khi cần… tương tác thì phải làm sao?
Ví dụ chúng ta có một textbox và muốn lấy nội dung của nó (thuộc tính value).
Việc đầu tiên chúng ta cần làm chính là định nghĩa phần dữ liệu để biểu diễn nó, mà ở đây chúng ta tạo một trường mới trong Model:
src/Models.elm
typealiasModel = {
...
taskInput: String,
...
}
Tiếp theo, chúng ta sẽ thực hiện “binding” phần data này với textbox:
src/Models.elm
typeMsg = ... | TextInput String
src/Main.elm
view : Model -> Html Msg
view model =
...
input [ type_ "text",
placeholder "What's on your mind right now?",
onInput TextInput,
value model.taskInput
] []
...
Khi người dùng gõ vào textbox, sự kiện onInput được trigger, chúng ta sẽ phát đi một Message tạm gọi là TextInput kèm theo một tham số kiểu String để update giá trị của Model.textInput.
src/Main.elm
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
case msg of
...
TextInput content ->
( { model | taskInput = content }, Cmd.none )
Như vậy, tại bất kì thời điểm nào, chúng ta cũng có thể lấy được nội dung của textbox thông qua giá trị Model.textInput, hoặc thay đổi nó thành một giá trị khác.
4. Side effects
Một đặc điểm của functional programming đó là việc hạn chế side effect, mỗi một hàm được viết ra đều chỉ thực hiện một việc duy nhất (pure function). Nghe qua thấy khà là mâu thuẫn đối với việc làm web, vì side effects là một phần tất yếu của các web apps (HTTP calls, Web socket,…).
Elm có một loại effect gọi là managed effects. Và cũng tương tự như khi làm việc với DOM, đối với managed effects, chúng ta khai báo data để biểu diễn thao tác mà chúng ta muốn thực hiện, Elm sẽ lo phần còn lại.
Có 2 kiểu managed effects chúng ta có thể dùng trong Commands và Subscriptions.
Commands là các thao tác mà chúng ta muốn thực hiện (ví dụ: HTTP call, “bắn” một message khác,…)
Subscriptions là thao tác listen một message hay một event nào đó, ví dụ nhận tín hiệu từ web socket,…
Trong project mà mình giới thiệu, khi muốn gọi một hàm setStorage để lưu dữ liệu vào localStorage sau khi add một task mới, ta có thể gọi nó dưới dạng một command, ở đây là setStorage:
src/Models.elm
addNewTask : Model -> ( Model, Cmd Msg )
addNewTask model =
( newModel, setStorage newModel )
5. Kết nối với JavaScript thông qua Ports
Để tương tác được với JavaScript (ví dụ sử dụng thư viện, sử dụng các hàm JS đã được viết trước đó,…), chúng ta có thể kết nối thông qua Ports.
Việc khai báo một port từ phía Elm khá đơn giản, ví dụ đây là đoạn code khai báo hàm setStorage, hàm này trả về một Command, và sẽ được gọi từ phía JavaScript.
src/Models.elm
port setStorage : Model -> Cmd msg
Từ khóa port đóng vai trò tương tự như extern trong C.
Ở phía JavaScript, ta viết:
main.js
app.ports.setStorage.subscribe(function(model) {
// Do something
});
Như vậy, khi command setStorage được gọi từ phía Elm, phía JavaScript sẽ nhận được message này kèm với dữ liệu đi kèm (là Model) và thực hiện việc xử lý trong hàm callback của lệnh subscribe.
6. Pattern Matching
Pattern Matching là một phương pháp khá là hữu ích, xuất hiện trong nhiều ngôn ngữ lập trình, trong đó có cả Rust và Elm.
Việc sử dụng pattern matching trong Elm phụ thuộc nhiều vào cú pháp case .. of, ví dụ sau đây là một hàm kiểm tra một List có rỗng hay không:
isEmpty : List a -> BoolisEmpty xs =
case xs of
[] ->
True
_ ->
False
Nếu a là một List rỗng [] thì trả về True, ngược lại nếu nó match với một giá trị bất kì thì trả về False.
Hoặc ta có thể sử dụng pattern matching để viết hàm tính số Fibonacci:
fibo : Int -> Intfibo n =
case n of0 -> 11 -> 1
_ -> fibo (n-1) + fibo (n-2)
Đối với dân Haskell thì sẽ thấy cách viết này hơi khó chịu một tí, vì đã quen với cách viết của bên đó là:
fibo : Int -> Int
fibo 0 = 1
fibo 1 = 1
fibo n = fibo (n-1) + fibo (n-2)
Tuy như vầy có “đẹp” hơn, nhưng anh bạn tác giả của Elm lại không thích, nên anh ấy quyết định không đưa chức năng này vào .
Ngoài ra thì pattern matching còn làm được rất nhiều việc khác, rất là hữu dụng trong quá trình viết code Elm, các bạn có thể tham khảo ở gist Elm Destructuring cheatsheet.
Nhìn chung, Elm là một ngôn ngữ đáng để học, nhất là nếu bạn đã có sẵn background về lập trình (thường là imperative programming) và đang muốn dòm ngó sang functional programming thì Elm thực sự là điểm khởi đầu khá tốt.
Hôm nay nói về một ứng dụng của Hashmap trong việc optimize một số thuật toán thường gặp trên Frontend.
Giả sử có một mảng languages lưu danh sách các ngôn ngữ lập trình:
const languages = ["c++", "java", "javascript", "ruby", "rust", "golang"];
Và một hàm getLanguages nhận vào một mảng input, trả ra mảng gồm các phần tử vừa có trong input vừa có trong languages (nói theo kiểu tập hợp thì là phép giao hai tập input∩languagesinput∩languages):
Về mục đích của hàm trên, thì hãy tưởng tượng bạn đang làm một trang web về tuyển dụng, cho phép user (là ứng viên) nhập vào các ngôn ngữ mình sử dụng, có người sẽ nhập Ruby, có người nhập ruBy, ruby,… hàm trên sẽ filter các input sai lệch đó và trả về input đúng với database nhất.
Hàm getLanguages sẽ có độ phức tạp trong trường hợp xấu nhất là O(n∗k)O(n∗k), hoặc nếu tập input có kích thước bằng tập languages luôn thì độ phức tạp sẽ là O(n2)O(n2).
Sở dĩ tốn kém như vậy là vì chúng ta dùng array, và với array, để tìm ra tập giao nhau, hay nói cách khác, để tìm một phần tử languages[i] bất kì có cùng giá trị tương ứng với một phần tử input[j], ta không có cách nào khác là phải duyệt qua toàn bộ cả 2 mảng.
Vậy đây có thể là mấu chốt để chúng ta optimize thuật toán trên. Liệu có cách nào để từ giá trị của một phần tử input[j], ta có thể truy xuất ngay đến phần tử tương ứng nếu có của languages không? (truy xuất với độ phức tạp O(1)O(1)).
Một kiểu dữ liệu phù hợp với tính chất truy xuất trên đó là Hashmap, vậy nếu dùng hashmap để thực hiện bước lookup, ta có thể loại bỏ được một vòng lặp lồng bên trong.
Bằng cách lợi dụng tính chất truy xuất nhanh và ít tốn kém của Hashmap, ta đã có thể loại bỏ việc phải chạy 2 vòng lặp lồng nhau, và optimize thuật toán ban đầu từ O(n∗k)O(n∗k) về O(n+k)O(n+k), hay trong trường hợp k=nk=n thì ta có thể nói là độ phức tạp giảm từ O(n2)O(n2) về O(n)O(n).
Atomic design – Ưu nhược điểm từ kinh nghiệm thực tế
Bài viết được sự cho phép của tác giả Kiên Nguyễn
Bài viết này mình chia sẻ kinh nghiệm thực tế của mình khi apply Atomic Design vào project. Project nếu theo đánh giá của cá nhân mình thì cũng khá lớn (tầm 150 atom components).
Atomic Design không còn quá xa lạ với anh em.
Những loại phổ biến như Dropdown, Button, Pagination thì không nói làm gì. Do dự án đặc biết nên cần thêm các component khác (theo requirement của khách hàng)
Kinh nghiệm này là kinh nghiệm xương móng (lộn, xương máu) muốn share cho anh em. Những anh em nào đã/ đang và sẽ sử dụng Atomic vào project có thể đọc qua, cân đo đong đếm sao cho hợp lý, tránh lặp lại một số sai lầm như mình đã bị.
Sai, sai vừa vừa thôi nha mấy sếp. LOL
1. Ưu điểm của Atomic Design
1.1 Write one time, use many time
Đây là ưu điểm rõ ràng nhất của Atomic. Viết component chỉ một lần thôi, viết cho chỉn chu thì cứ thế mà sử dụng.
Viết mà như … thì thôi xong, nhưng thôi cái đó là nhược điểm. Tui không lạc đề. Một khi đã viết atomic chuẩn, hoặc là build UI Library thì anh em cứ mặc nhiên mà sử dụng, dùng rất dễ và nhanh. Build ban đầu thì lâu nhưng đã có rồi thì atomic chấp các loại implement component khác.
Đã có atom build hoàn chỉnh ngon lành thì implement page nhanh như chó chạy ngoài đồng.
1.2 Tuỳ biến
Rõ ràng là nguyên cái UI Libary các ông viết từng component một. Nên khả năng tuỳ biến sẽ rất cao, cần gì sửa đó. Một số công ty hay tập đoàn lớn họ build thành UI Library, vừa dễ thay đổi, vừa đáp ứng các requirement đặc biệt của công ty.
Ưu điểm lênh láng mênh mông nhưng Atomic Design cũng không thiếu nhược điểm. Dưới đây là một số kinh nghiệm xương máu của tôi khi sử dụng atomic design vào dự án thực tế.
Viết ra để giúp anh em đỡ phải mắc sai lầm khi apply.
2.1 Time is big problem
Atomic Design là đi build từng thứ nhỏ nhặt. Cần button, ta phải đi viết component button, cần pagination ta phải đi viết component pagination.
Tất nhiên trường hợp đi build các atoms là do dự án không sử dụng bất cứ library nào khác.
Cái gì cũng lợi kèm hại, nếu tự viết thì tuỳ biến và customize rất chi là dễ, nếu sử dụng thì nhanh nhưng hơi khó customize nếu dự án có những yêu cầu về requirement khác biệt.
Những dự án đặc biệt sẽ phát sinh những component đặc biệt. Nguồn ảnh/ Source: syncfusion.com
Trường hợp build component với Atomic Design ngay từ ban đầu. Thời gian sẽ là một vấn đề cần phải xem xét. Rõ ràng là viết từng component.
Với các component phức tạp, thời gian build component Atom thậm chí còn lâu hơn. Phía trên mình có dẫn nguồn từ Syncfusion, trang này chuyên bán các component phức tạp đã được viết sẵn.
Bán được chứng tỏ viết component đặc biệt không hề đơn giản, thời gian và chi phí bỏ ra để viết là không hề nhỏ. Một số dự án gấp hoặc chi phí nằm ngoài khả năng thì người sử dụng sẽ chọn mua component cho nhanh.
2.2 Đòi hỏi kĩ năng
Trong thực tế apply Atomic Design vào project, bản thân mình thấy Atomic khó đối với những component Atom. Khi viết atom, nếu người viết không đủ kinh nghiệm, props sẽ bị thiếu, cách tổ chứng props cũng sẽ bị lằng nhằng phiền hà
Người viết atomic tốt tất nhiên sẽ lường gần hết (nhấn mạnh là gần hết , chứ méo thể nào mà hết được) các trường hợp sử dụng của component đó.
Ví dụ cụ thể ta có thể xem component Pagination (Paging) phía dưới.
Còn nhiều nhiều các props khác, tuy nhiên nếu kinh nghiệm sử dụng thực tế thiếu, người viết Atomic component sẽ phải sửa đổi rất nhiều lần về sau (khi component purpose thay đổi).
Nếu không có kinh nghiệm hoặc không tham khảo các trường hợp sử dụng thực tế của paging component, rất nhiều ta sẽ thiếu props. Component viết ra cũng không quá hữu dùng vì phải viết thêm quá nhiều.
Props là điều quan trọng của atom components, ngoài ta còn cả cách sử dụng và tổ chức props sao cho hiệu quả, sao cho khoa học.
Chính vì vậy, trước khi apply atomic design cho project. Hãy cẩn thận xem xét kĩ năng của các member, những component quan trọng như atom nên được giao cho những thành viên có nhiều kinh nghiệm.
Đó là kinh nghiệm xương máu của mình.
2.3 Chi phí cao và khó sửa đổi
Mới đầu nói khó sửa đổi chắc một số anh em đã sử dụng atomic bảo điên. Ông viết từng component như thế, có depend trên cái UI nào đâu. Có gì đâu mà khó sửa?
Sự thật khi đã vào project rồi mới thấy khó. Chứ tui thì không ngáo tới mức viết tầm bậy tầm bạ.
Chuyện là bọn tui viết cái component Button bị thiếu cái options link. Tức là props link khi click button thì open link mới. Cái này cơ bản, nhưng tui review thiếu, lỗi tui. LOL
Sửa thì dễ, không có gì khó. Nhưng cái khó là atomic, mà atomic thì các ông biết rồi đấy. Viết một lần, sử dụng khắp nơi.
Lên production rồi thì phải test lại tất cả. Chả ông nào dám chắc là cái props thêm vào có ảnh hưởng gì hay không. Bắt QC,QA team test lại thì quá tốt thời gian. Nhưng cuối cùng cũng phải làm.
Thêm một cái nữa là đôi khi các ông dev không phân biệt được đâu là atom, đâu là molecules. Sửa tên 1 component thôi nhưng phải đi sửa source cả mấy chục chỗ, nhức cả đầu. Sợ là còn sửa sót.
Đây là cách làm khá hay khi anh em sử dụng atoms. Component ở cấp độ nào cứ comment vào cho nó dễ nhìn.
Một số anh em bảo phía dưới sẽ có import, cần thì kéo xuống xem. Nhưng một số project nuxt nó có auto import, một hai tháng sau quay lại nhìn component đảm bảo rối cmn não.
Quick and Dirty Stack, Queue and Deque in JavaScript
Bài viết được sự cho phép của tác giả Huy Trần
Trong quá trình phỏng vấn, dùng JavaScript, nếu đề bài không yêu cầu bắt buộc phải implement Stack hoặc Queue thì chúng ta có thể tiết kiệm thời gian bằng cách sử dụng Array.
Sở dĩ tiêu đề nói Quick and Dirty là vì cách làm này có thể không bảo đảm đúng hoàn toàn về time complexity, nhưng bù lại nó đúng về mặt concept và behavior của các kiểu dữ liệu, giúp tiết kiệm thời gian khi làm bài phỏng vấn (nhưng đồng thời bạn cũng phải nói rõ vấn đề này với người phỏng vấn, nếu không thì ăn hành ngay).
Việc khai báo Array trong JavaScript khá đơn giản:
// Khai báo mảng rỗnglet array = [];
// Hoặc khai báo mảng n phần tử, fill nó bằng các giá trị 0let array = Array.from(Array(n)).map(x =>0);
Trong JavaScript thì Array cũng được hỗ trợ một số thao tác, mà ta sẽ dùng nó để mô phỏng lại các kiểu dữ liệu đã đề cập, đó là:
push: thêm một phần tử vào cuối array
pop: lấy ra phần tử cuối cùng của array
unshift: thêm một phần tử vào đầu array
shift: lấy ra phần tử đầu tiên của array
Từ đây, ta có thể mô phỏng lại behavior của các kiểu dữ liệu thường gặp.
Hai thao tác chính trên stack đó là push và pop, hai hàm này có sẵn trong Array của JavaScript:
let stack = [];
stack.push(5);
stack.pop();
Một thao tác cũng thường gặp trong các implementation của stack đó là peek, giúp xem trước giá trị nằm trên cùng của stack mà không cần lấy nó ra, ta có thể thực hiện việc này bằng cách truy cập trực tiếp dùng index:
let last = stack[stack.length - 1];
2. Mô phỏng Queue
Hai thao tác thường gặp của queue là enqueue (thêm một phần tử vào queue), và dequeue (lấy một phần tử ra khỏi queue), ta có thể thực hiện việc này bằng hai cách:
let queue = [];
// Enqueue
queue.unshift(5);
// Dequeue
queue.pop();
Hoặc:
let queue = [];
// Enqueue
queue.push(5);
// Dequeue
queue.shift();
Và bạn có thể thấy hai cách trên cũng thể hiện hai hướng hoạt động của một queue (từ trái qua phải, và từ phải qua trái), và nếu gộp chung cả hai cách thì nó cũng chính là một deque (double-ended queue).
Thao tác peek cũng tương tự như với stack, đặc biệt nếu là deque, thì ta sẽ có peek_first (để xem phần tử đầu), và peek_last (để xem phần tử cuối):
let first = queue[0];
let last = queue[queue.length - 1];
3. Độ phức tạp
Như đã nói ở đầu bài, mình không chắc về độ phức tạp của các thao tác trên nếu dùng Array, nhưng chắc chắn nó sẽ không đúng với độ phức tạp của các thao tác của stack và queue.
Ví dụ như hàm shift, trên queue nó chỉ là O(1), tuy nhiên với JavaScript thì có lẽ nó sẽ chậm hơn rất nhiều.
Để hiểu rõ thêm cách mà JavaScript implement các hàm trên, bạn có thể xem qua đặc tả ECMAScript:
Bây giờ mình sẽ thử một bài đơn giản, là implement thuật toán BFS (breadth-first search) và DFS (depth-first search) để duyệt một cây nhị phân, bằng cách sử dụng Array để mô phỏng stack và queue cho từng trường hợp.
Chúng ta sử dụng queue để implement thuật toán BFS, sau khi duyệt trả về một mảng các giá trị đã duyệt:
const BFS = (root) => {
let queue = [root];
let result = [];
while (queue.length) {
let node = queue.shift();
if (node.left) queue.push(node.left);
if (node.right) queue.push(node.right);
result.push(node.val);
}
return result;
};
Để implement DFS thì ta dùng stack:
const DFS = (root) => {
let stack = [root];
let arr = [];
while (stack.length) {
let node = stack.pop();
if (node.left) stack.push(node.left);
if (node.right) stack.push(node.right);
arr.push(node.val);
}
return arr;
};
Thực tập luôn là một cơ hội tuyệt vời để các sinh viên có thể làm quen và học hỏi cách làm việc trong một môi trường chuyên nghiệp và thực tế hơn. Các sinh viên công nghệ thông tin có thể tham khảo thêm thông tin các công ty tuyển dụng thực tập sinh CNTT dưới đây để mở rộng cơ hội làm việc với tư cách là một thực tập sinh cho các ứng viên.
1. Công ty TNHH Keizu Việt Nam
Được thành lập từ năm 2013 và cho đến nay, công ty vẫn luôn nằm trong top các công ty hàng đầu trong lĩnh vực Tư vấn CRM Salesforce – phần mềm quản lý quan hệ khách hàng hàng đầu thế giới, nghiên cứu công nghệ, tư vấn CRM và chuyển đổi CNTT tại Việt Nam và Châu Á Thái Bình Dương.
ASIM TELECOM là nhà phát triển mạng di động Local. Là nhà mạng di động thứ 8 của Việt Nam với sự kết hợp giữa các dịch vụ viễn thông dựa trên hạ tầng của MobiFone và hệ sinh thái dịch vụ số trên Siêu ứng dụng myLocal.vn.
3. Bkav Corporation
Bkav là Tập đoàn công nghệ hoạt động trong các lĩnh vực an ninh mạng, phần mềm, chính phủ điện tử, nhà sản xuất smartphone, thiết bị điện tử thông minh, Smart City và AI camera. Bkav tự hào là 1 trong 10 thương hiệu Nổi tiếng nhất Việt Nam hiện nay.
SPLUS-SOFTWARE cung cấp cho khách hàng các sản phẩm sáng tạo, hấp dẫn, đồng thời đảm bảo nhanh chóng đưa sản phẩm ra thị trường. Được đánh giá là một trong những công ty đang phát triển mạnh trong lĩnh vực outsource ngành CNTT.
5. Creative Force
Creative Force là công ty cung cấp các phần mềm quản lý Photo Studio hàng đầu trong ngành quảng cáo hiện nay. Đến nay Creative Force đã hợp tác với nhiều thương hiệu lớn trên thế giới như Aldo, OTTO, Debenhams, SCOTCH & SODA,… Công ty có trụ sở tại Đan Mạch và hiện đang đặt văn phòng tại nhiều quốc gia như New York, San Francisco, Đức và Việt Nam.
Liên tục cập nhật
Các vị trí công việc và thông tin các công ty tuyển dụng thực tập sinh CNTT sẽ liên tục được cập nhật. Đón đọc các bài viết và thông tin CNTT khác tại TopDev để được tiếp cận những thông tin hay nhất một cách sớm nhất nhé!
Làm việc với Apollo Client Fetching chắc chắn anh em sẽ gặp 4 từ khoá chính là Queries, Mutation, Subscriptions và Fragment.
Bài viết này mình tham khảo từ trang document của Apollo Client GraphQL, giải thích lại một cách dễ hiểu hơn về các kiểu Fetching. Do tham khảo từ document nên một số nội dung khác ngoài định nghĩa và ví dụ tôi sẽ không đem vào.
Queries thì chắc chắn là quá familiar với anh em rồi. Query là để collect data, Apollo Client Queries cũng sinh ra với mục đích tương tự như vậy (Fetch data với useQuery hook).
Tuy nhiên Query này thì khác với Query bên SQL, nên nếu anh em nào beginner với GraphQL chắc ghé đọc qua tí rồi hãy quay lại.
Phía trên là câu query với GraphQl, query name là GET_DOGS. Primary API mà ta sử dụng là useQuery, argument cho nó là query string. Data trả về từ query sẽ bao gồm 3 thứ.
loading
error
data
Một cái hay của Apollo Client Queries là nó hỗ trợ Caching query result.
Whenever Apollo Client fetches query results from your server, it automatically caches those results locally. This makes subsequent executions of the same query extremely fast.
Khi Apollo Client fetch data từ server, nó sẽ tự động cache lại kết quả ở phía local. Điều này tăng performance do ở những lần query tiếp theo, kết quả sẽ trả về rất nhanh.
Nguồn ảnh: apollographql.com
Cache thì dễ, nhưng lúc update data mới thì sao?. Phải clear hoặc update cache nếu không data trả về sẽ bị sai.
1.1 Các loại Queries Cache
Với câu hỏi này thì Apollo hỗ trợ 2 chiến lược để update lại data:
Thứ nhất là Polling
Thứ hai là Refetching
Polling thì đúng như cái tên của nó, về cơ bản thì thằng này gần với realtime. Gần thôi nha anh em, vì nó sẽ fetch data theo định kì chứ không phải fetch liên tục.
Polling provides near-real-time synchronization with your server by executing your query periodically at a specified interval.
Polling cung cấp giải pháp gần với realtime data. Cách làm là query theo định kì tới server (theo khoảng thời gian thiết lập cố định)
Ông cố nội Refetching thì khác, ông này cũng update query result, nhưng chỉ lúc nào user có action nào đó. Ví dụ như khi chuyển page sẽ update lại total items chưa xem chẳng hạn.
Refetching enables you to refresh query results in response to a particular user action, as opposed to using a fixed interval.
Refetch chung cho phép “Làm tươi mới” kết quả lấy được từ query dựa trên actions của user. Cái này thì là fixed interval
Thôi viết đến đây, chi tiết cụ thể anh em có thể lên Docs của Apollo đọc ha, ta đi tiếp với Mutation.
Khác với Queries như ở mục một, nhắc tới query là anh em biết ngay collect data từ backend. Định nghĩa về mutation trong Apollo Client đơn giản hơn nhiều.
2.1 Định nghĩa
Mutations đẻ ra để trả lời cho câu hỏi:
How to modify back-end data?
Làm thế nào để chỉnh sửa data backend?
Câu trả lời thì không thể dễ dàng hơn, mutations. Mutations đẻ ra để thực hiện các methods như REST API ta thường thực hiện (POST, PUT, UPDATE, PATCH, …)
Tiện lợi không khác gì Queries, nhưng có một điều anh em cần nhớ kĩ:
Unlike useQuery, useMutationdoesn’t execute its operation automatically on render. Instead, you call this mutate function.
Không giống như useQuery, useMutation không thực thi một cách tự động khi component khi render. Thay vào đó, ta cần phải gọi mutate function
Cái này thì dễ hiểu, tại vì các actions change tới DB thường mapping tới các actions của user trên FE. Tuy nhiên, với các actions initial khi render, ta cũng thoải mái gọi các function mutation để thực thi.
2.2 Một số thứ khác
Còn data, loading thì tương tự như useQuery, cái này anh em có thể tham khảo ở mục Result bên Apollo Client
function AddTodo() {
let input;
const [addTodo, { data, loading, error }] = useMutation(ADD_TODO);
if (loading) return 'Submitting...';
if (error) return `Submission error! ${error.message}`;
return (
);
}
Ví dụ trên đây thì onSubmit (line 12) sẽ gọi tới mutation function. Apollo Client lúc này sẽ gọi tới Apollo Server để thực thi.
Ngoài queries và mutations, GraphQL cũng support thêm một kiểu tương tác với Apollo Server khác là Subscriptions.
3.1 Định nghĩa
Vậy Subscriptions là gì?
Về mặt bản chất thì Subscriptions cũng giống như Queries, nhưng có một điểm khác biệt chí mạng là chữ “real time”.
Unlike queries, subscriptions are long-lasting operations that can change their result over time. They can maintain an active connection to your GraphQL server (most commonly via WebSocket), enabling the server to push updates to the subscription’s result.
Không giống như queries, subscriptions là một hoạt động lâu dài có thể thay đổi kết quả của chúng trong thời gian thực. Nó cho phép ta duy trì kết nối tới GraphQL Server (thông thường thông qua WebSocket), cho phép máy chủ gửi data mới nhất về kết quả của subscriptions.
Lý thuyết lèo nhèo là thế, về cơ bản ta cứ nhớ Apollo client Subscriptions là real time data. Dựa trên cơ chế của web socket, server có thể liên tục trả về data mới cho client thông qua một connection alive. Tiện lợi mà không cần mò mẫm tới Web Socket.
Subscriptions are useful for notifying your client in real time about changes to back-end data, such as the creation of a new object or updates to an important field.
Subscription rất có lợi khi ta muốn thông báo cho user sự thay đổi data real time. Giống như khởi tạo một object mới hoặc update một field nào đó quan trọng.
3.2 Khi nào nên xài?
Khi nào ta nên sử dụng Subscriptions?
Small, incremental changes to large objects. Repeatedly polling for a large object is expensive, especially when most of the object’s fields rarely change. Instead, you can fetch the object’s initial state with a query, and your server can proactively push updates to individual fields as they occur.
Các đối tượng nhỏ, tăng dần đôi với các đối tượng bự hơn. Lặp đi lặp lại polling cho một object bự thì khá là tốn kém. Đặc biệt là field trong một object rất ít khi thay đổi. Thay vào đó, ta có thể fetch trạng thái ban đầu của một object thông qua query, sau đó server sẽ trả về các update tới các field đo khi có thay đổi.
Má, viết vậy có khi dễ hiểu hơn.
Sau đây là ví dụ cụ thể. Về phía server:
type Subscription {
commentAdded(postID: ID!): Comment
}
Subscriptions là đăng kí, ở phía server khi viết function này đồng nghĩa với việc ta đăng kí bất kì khi nào người dùng có comment mới add vào thì ta sẽ thực hiện một actions gì đó.
Ở phía client thì ta chỉ cần define subscription ta muốn Apollo Client thực thi:
Fragments thì hơi confuse, nhưng anh em cứ bám vào title trên document nha.
Share fields between operations
Chia sẻ fields giữa các thao tác
A GraphQL fragment is a piece of logic that can be shared between multiple queries and mutations.
GraphQL Fragment là một phần logic cho phép chia sẻ giữa các câu queries và mutations.
fragment NameParts on Person {
firstName
lastName
}
Mỗi thằng Fragment sẽ bao gồm một tập hợp con của các trường thuộc kiểu liên kết của nó. Ví dụ ở trên thì thằng Person sẽ khai báo firstName, và thằng lastName thì thuộc về thằng NameParts.
Lúc này thằng NameParts sẽ trở thành Fragments, ta có thể thêm Fragment vào bất kì cái queries và mutations nào có liên quan tới Person.
Ngon, vậy lúc nào thì ta cần xài tới Fragments. Cái này quan trọng, kinh nghiệm thực tế là nhiều bạn trong teams mình sử dụng Fragments theo kiểu dùng dao mổ trâu đi thịt chim sẻ.
Sharing fields between multiple queries, mutations or subscriptions.
Breaking your queries up to allow you to co-locate field access with the places they are used.
Đầu tiên là chia sẻ fields giữa các queries, mutations. Thứ hai là bẻ nhỏ queries ra, cho phép xác định chính xác field đó sẽ được sử dụng ở đâu.
Viết mệt vãi nhưng anh em yên tâm. GraphQL sẽ là một topics lớn và có bài ra thường xuyên nha.











 Tự viết docs theo kiểu Vuetify
Tự viết docs theo kiểu Vuetify Hoặc sử dụng Storybook
Hoặc sử dụng Storybook Các component chung thường gom vào một chỗ
Các component chung thường gom vào một chỗ
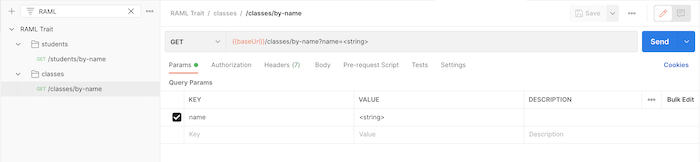




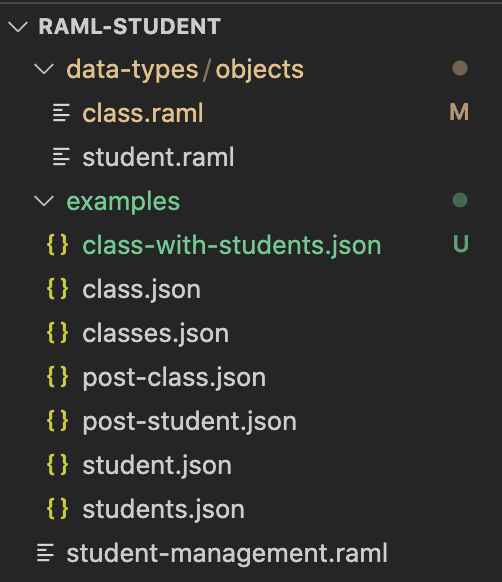




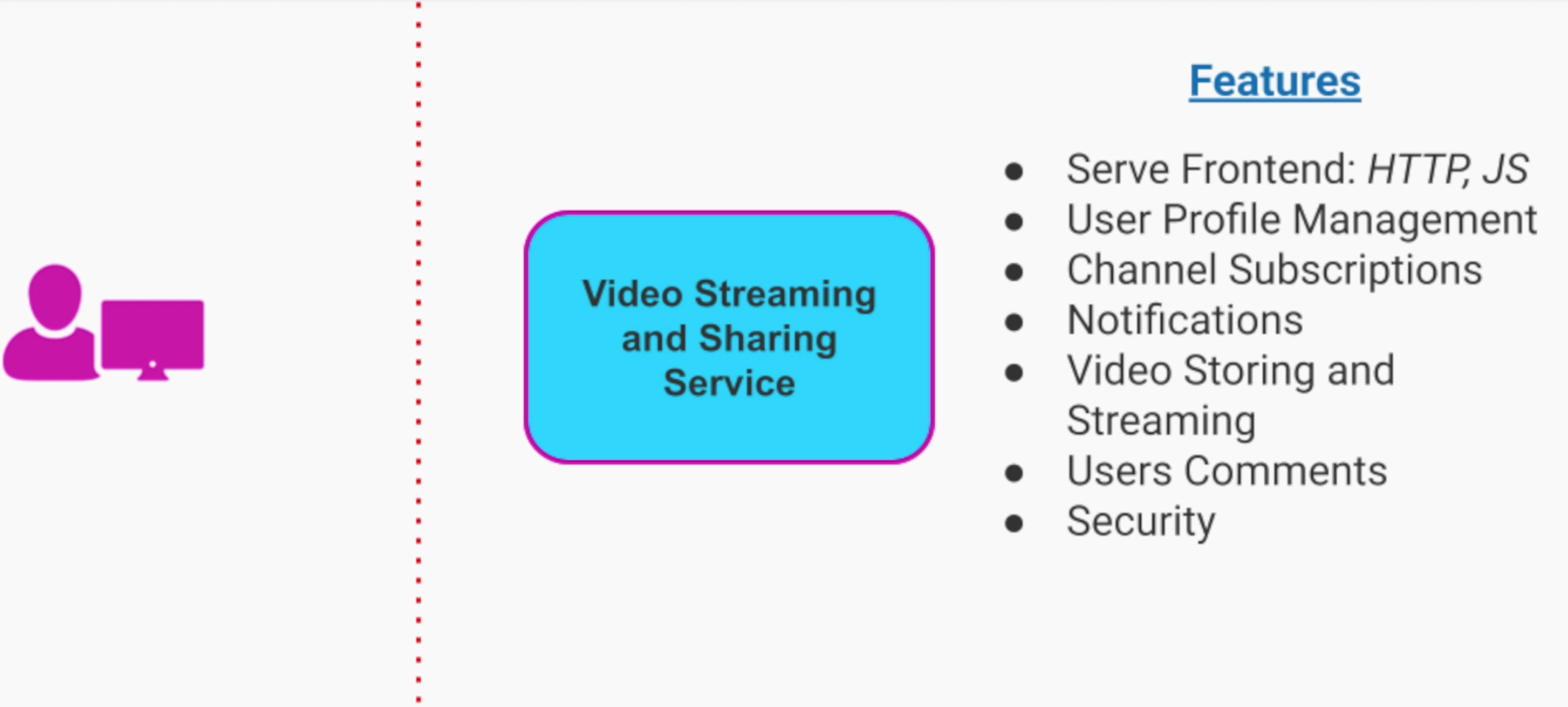 Một đống các feature nho nhỏ ta cần quan tâm
Một đống các feature nho nhỏ ta cần quan tâm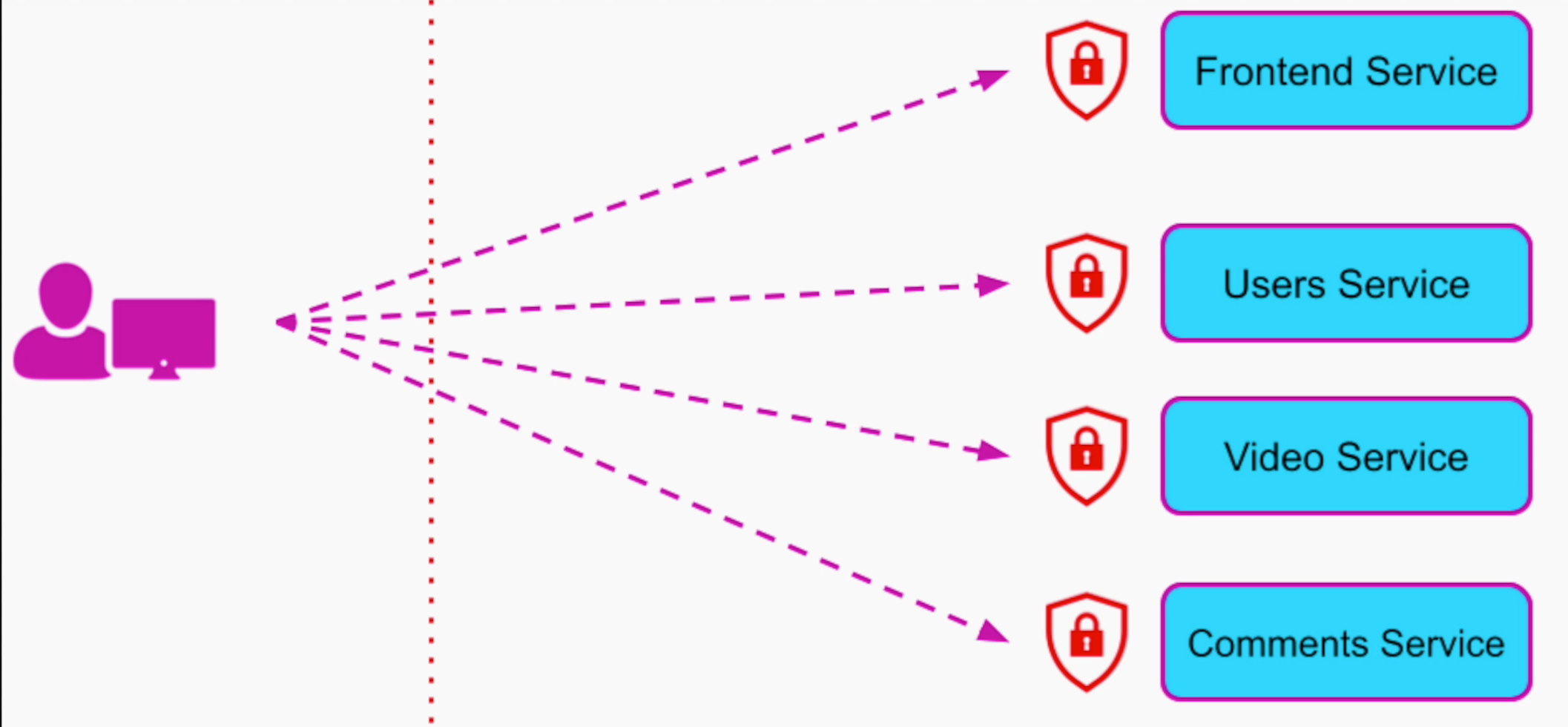
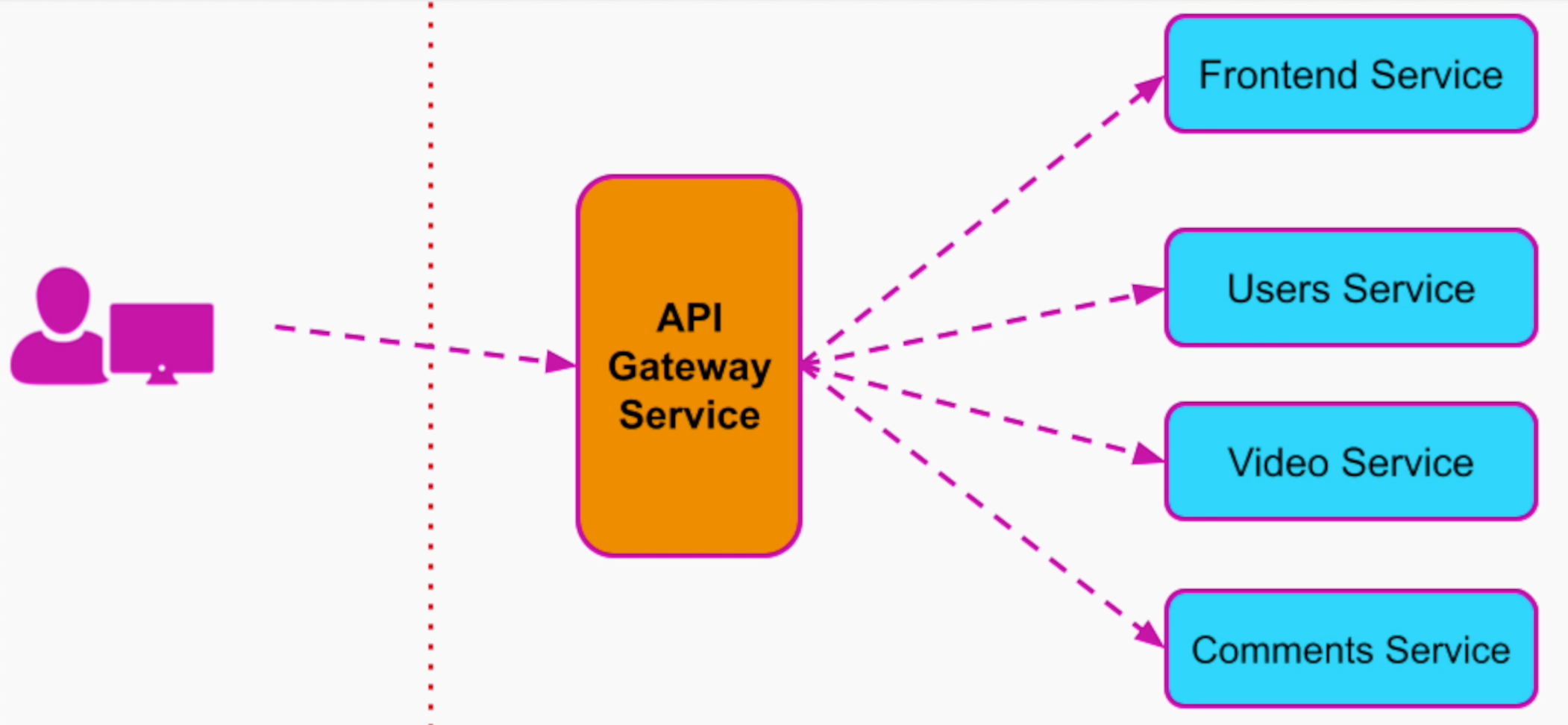 Thanh niên “Điều đào” API Gateway
Thanh niên “Điều đào” API Gateway
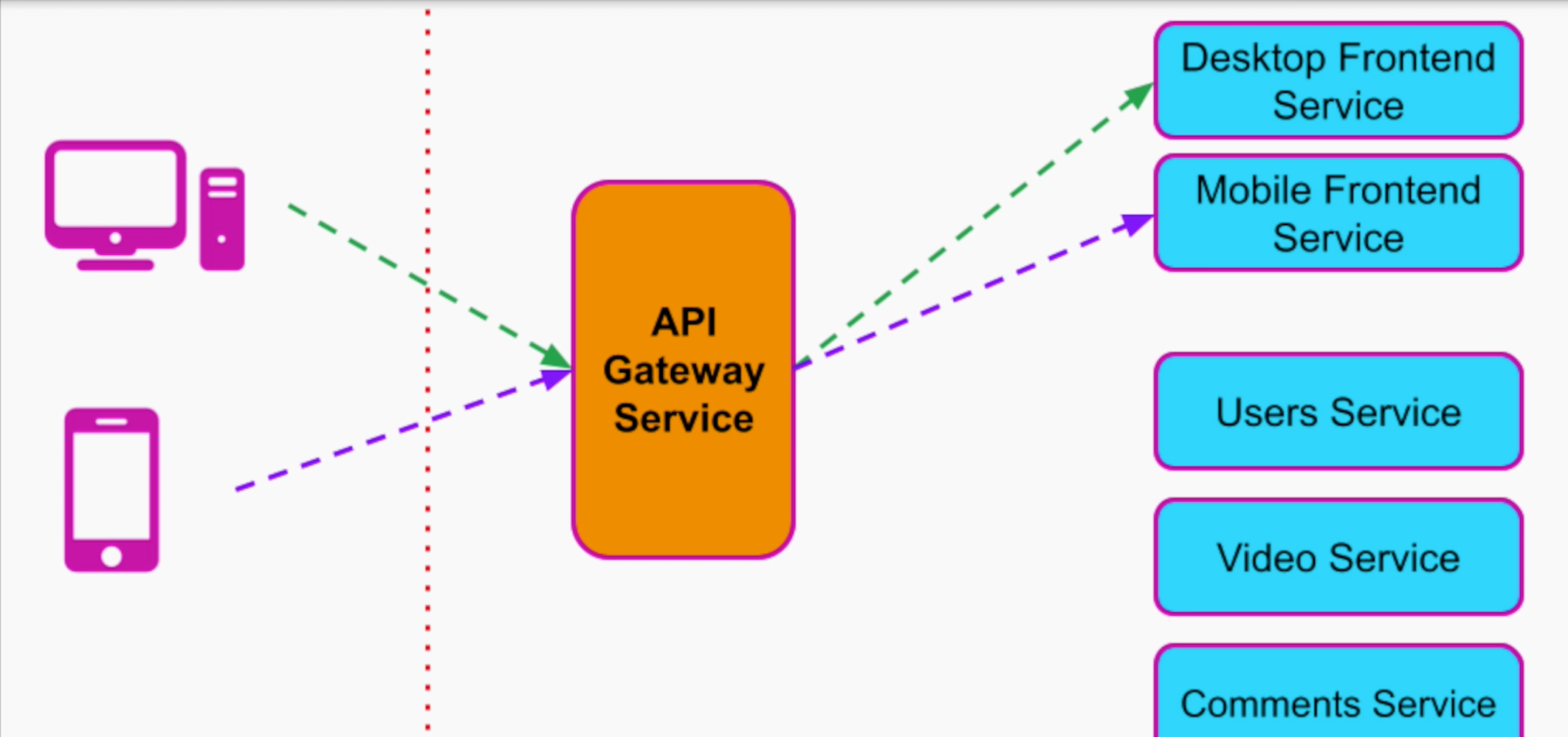 Tách riêng thành 2 services handle cho Mobile và Desktop
Tách riêng thành 2 services handle cho Mobile và Desktop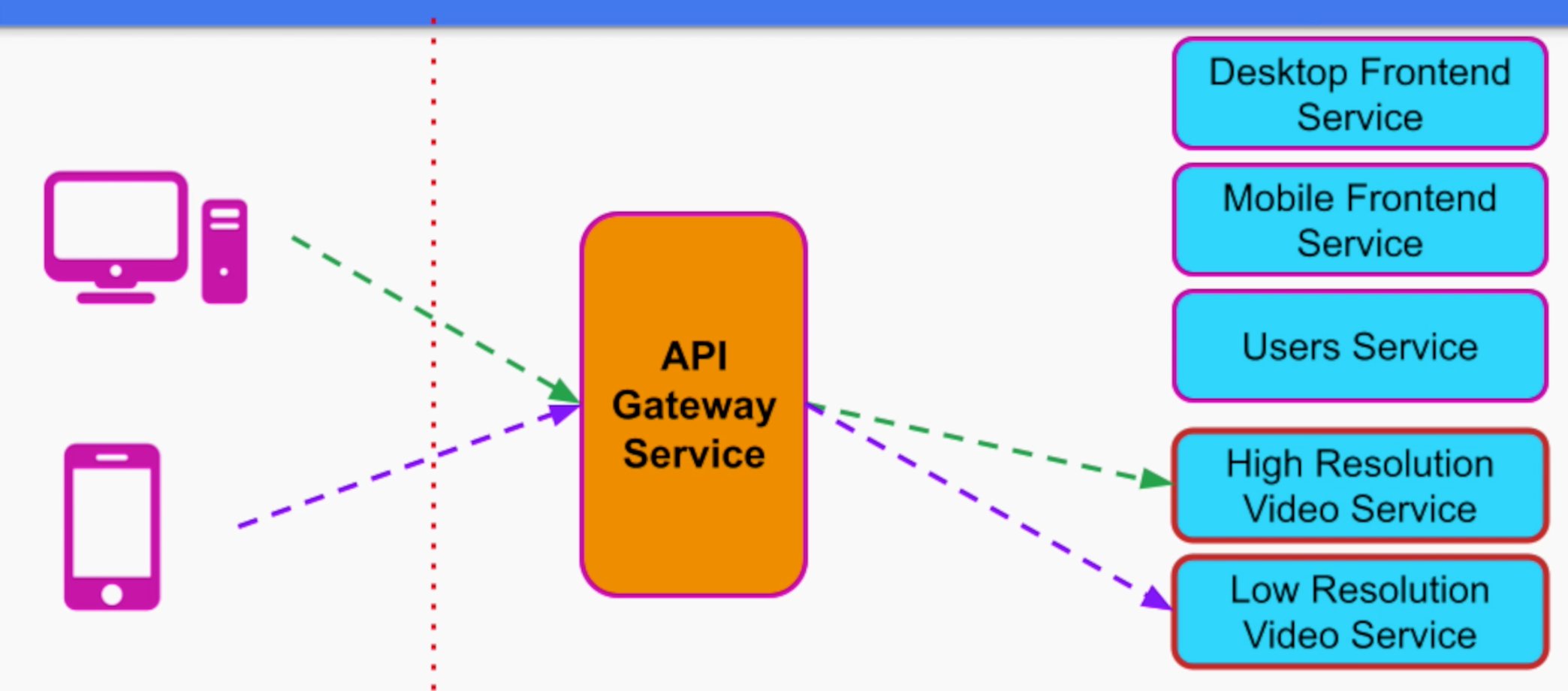 Tách thành 2 services cho High Resolution và Low Resolution
Tách thành 2 services cho High Resolution và Low Resolution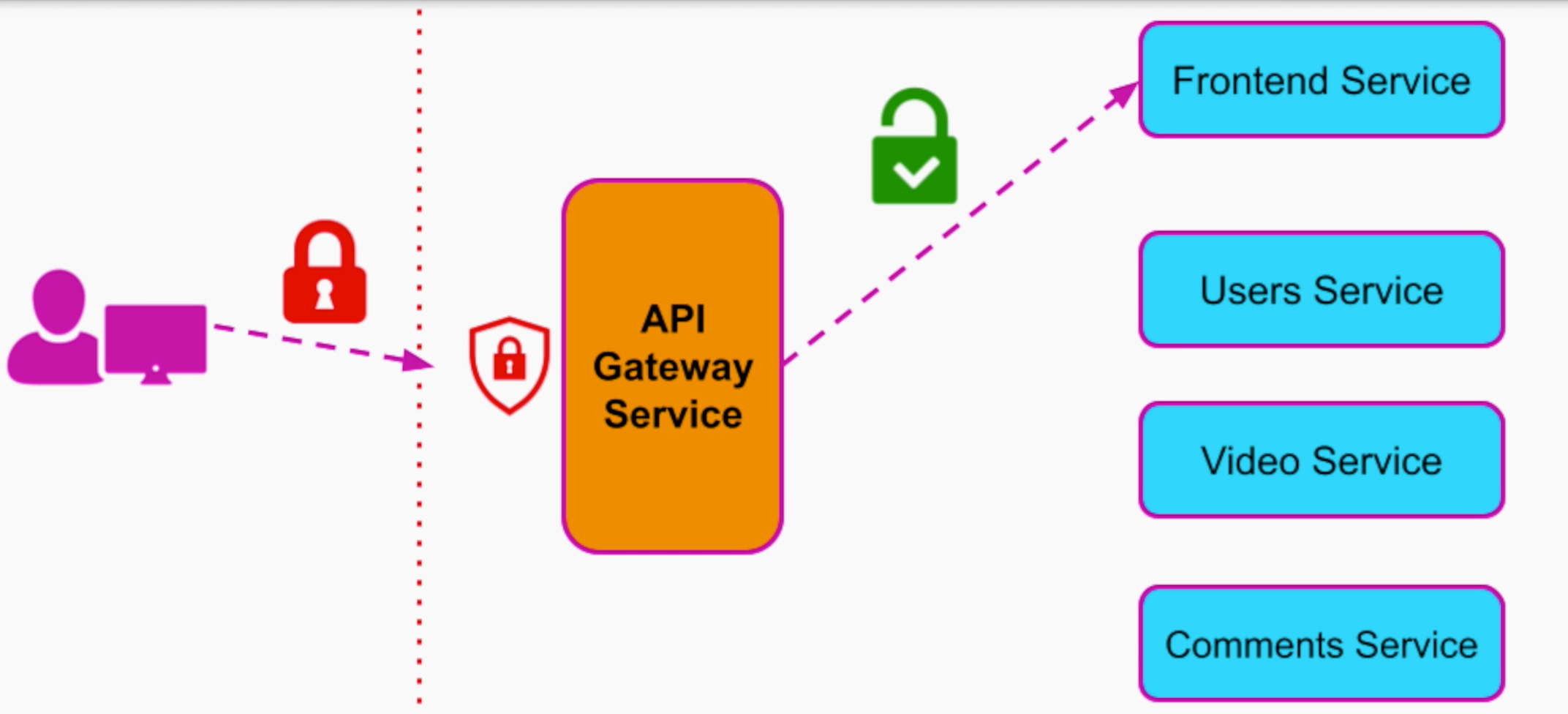
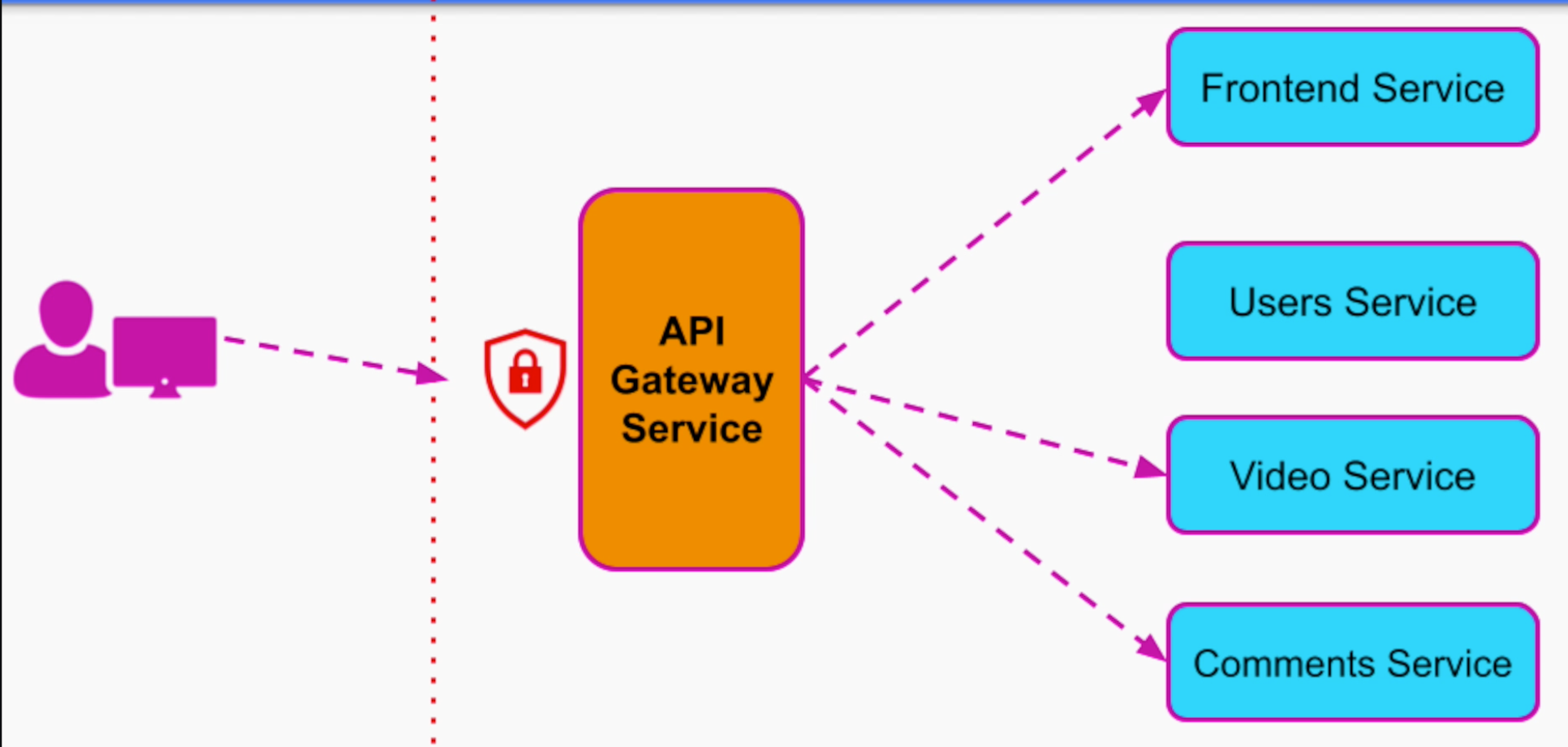
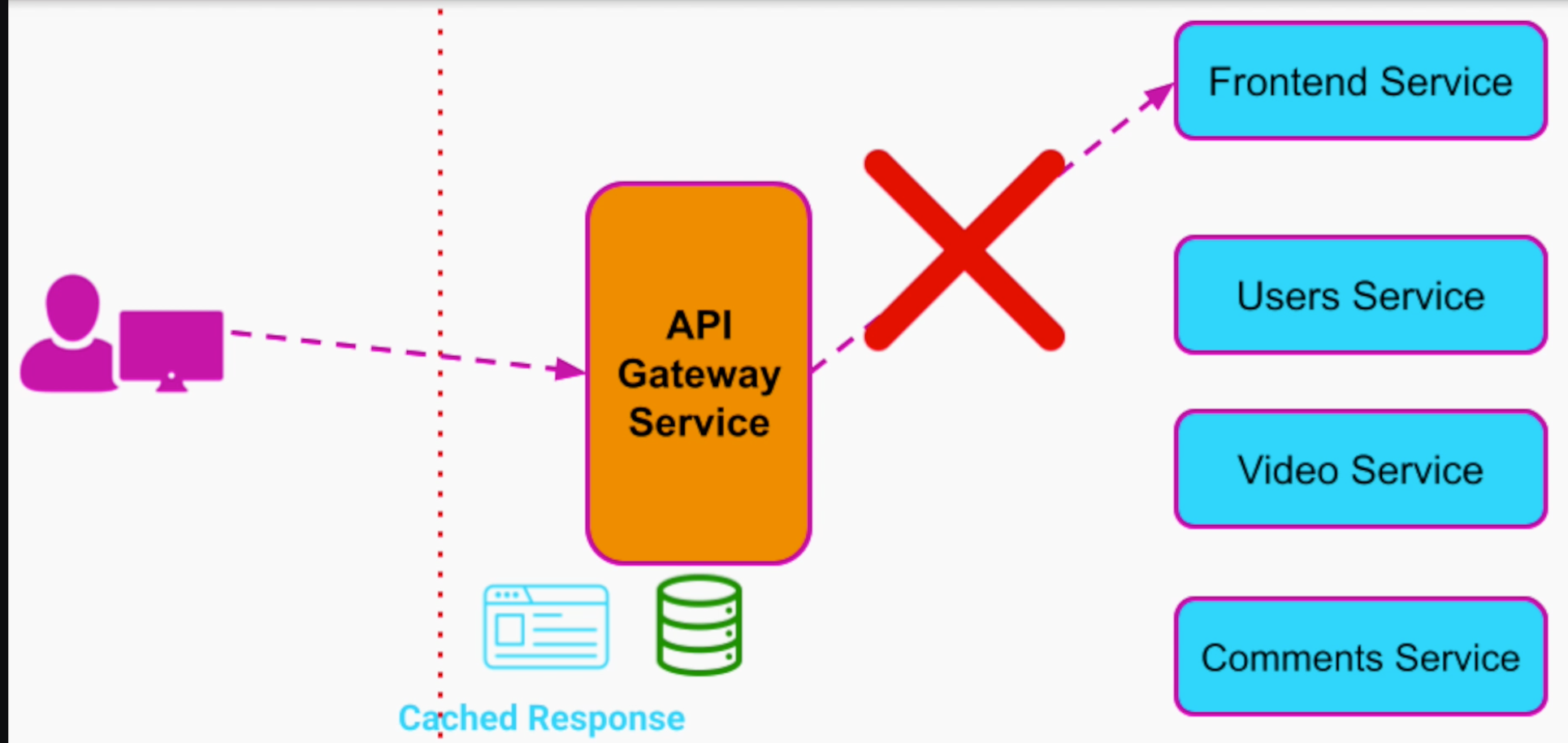
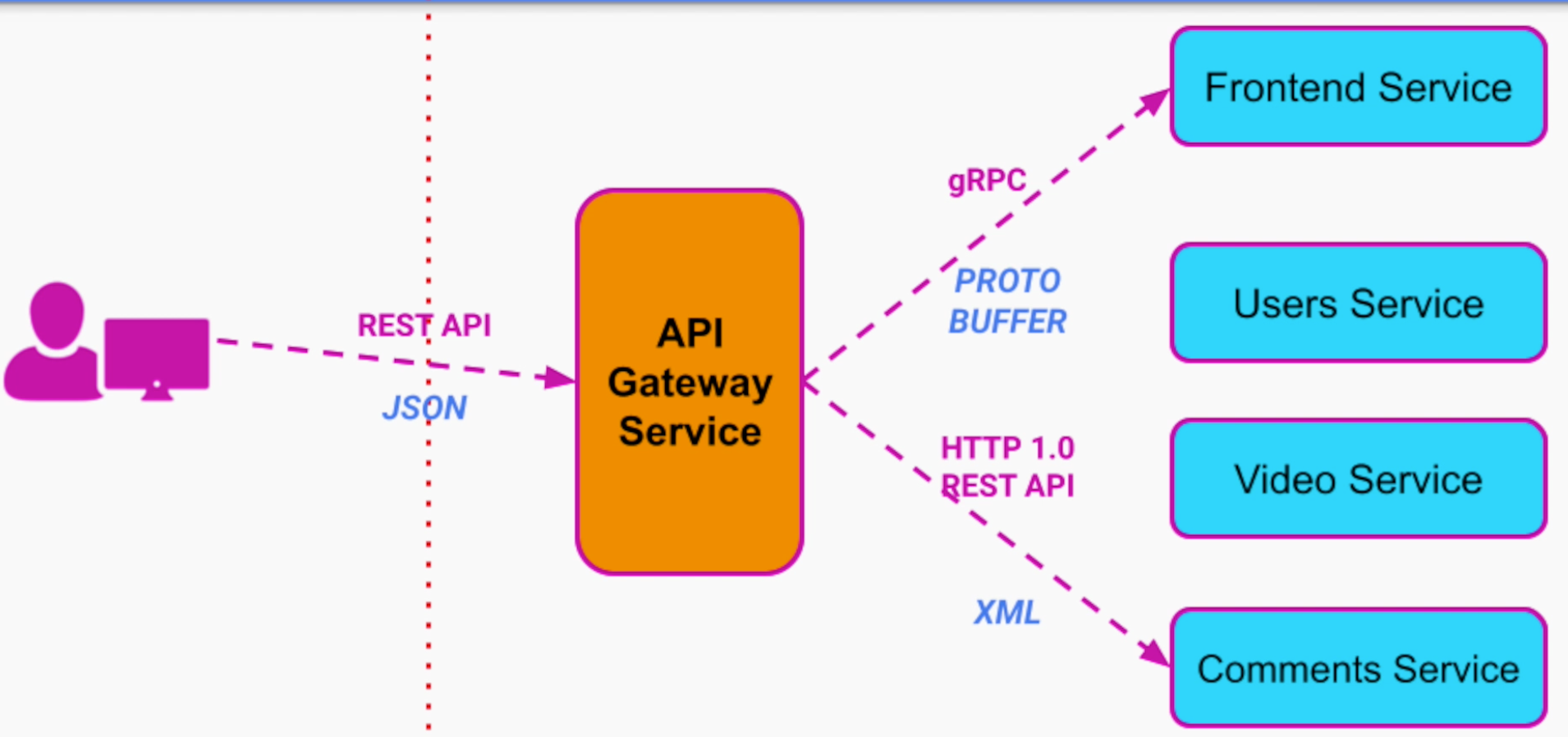


 Mãi cho đến hôm nay thì vẫn viết chưa xong, chán quá nên ngồi viết mấy dòng linh tinh về quá trình này.
Mãi cho đến hôm nay thì vẫn viết chưa xong, chán quá nên ngồi viết mấy dòng linh tinh về quá trình này.










 Nguồn ảnh / Source: google.com
Nguồn ảnh / Source: google.com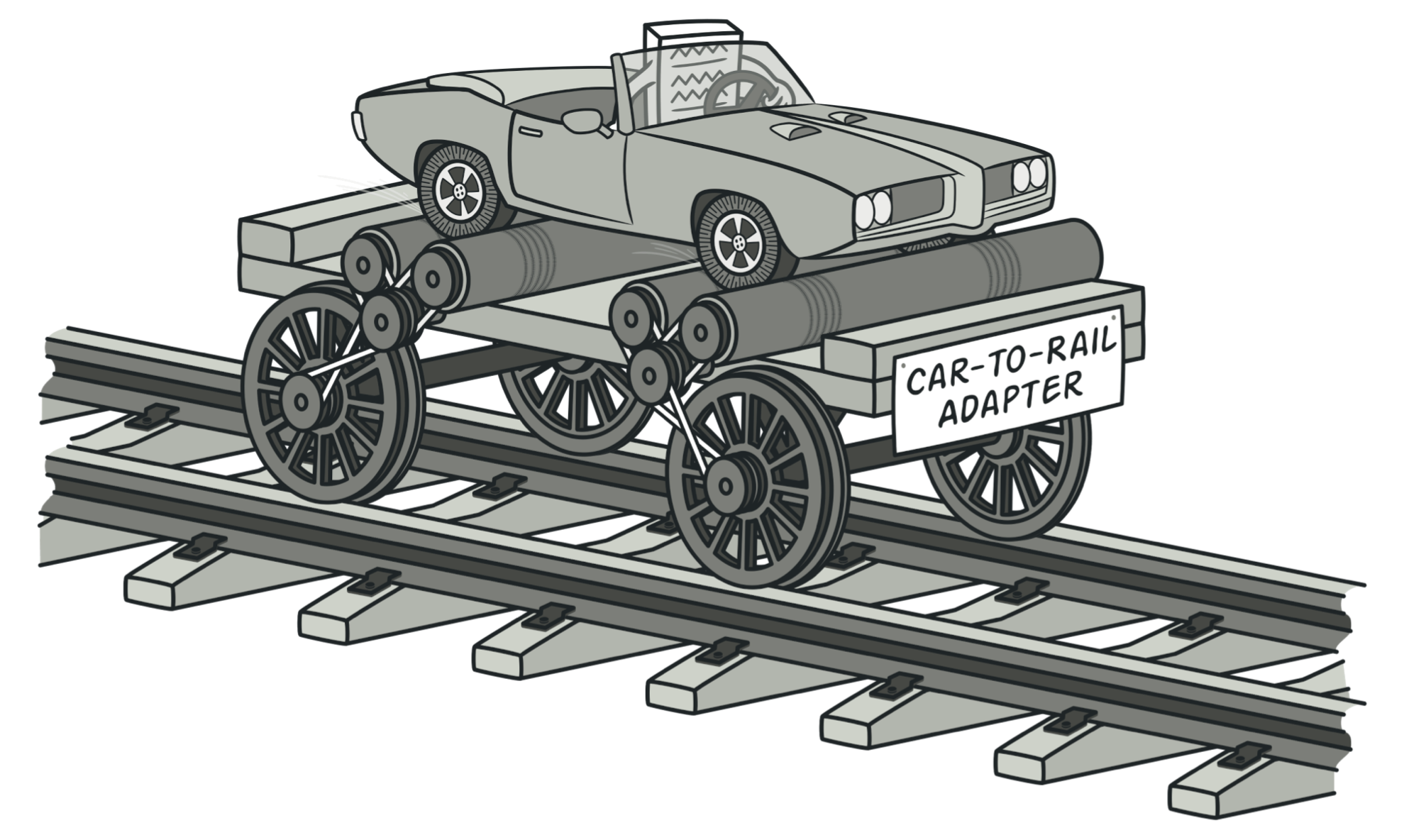 Adapter Pattern: Nguồn ảnh/Source:
Adapter Pattern: Nguồn ảnh/Source: 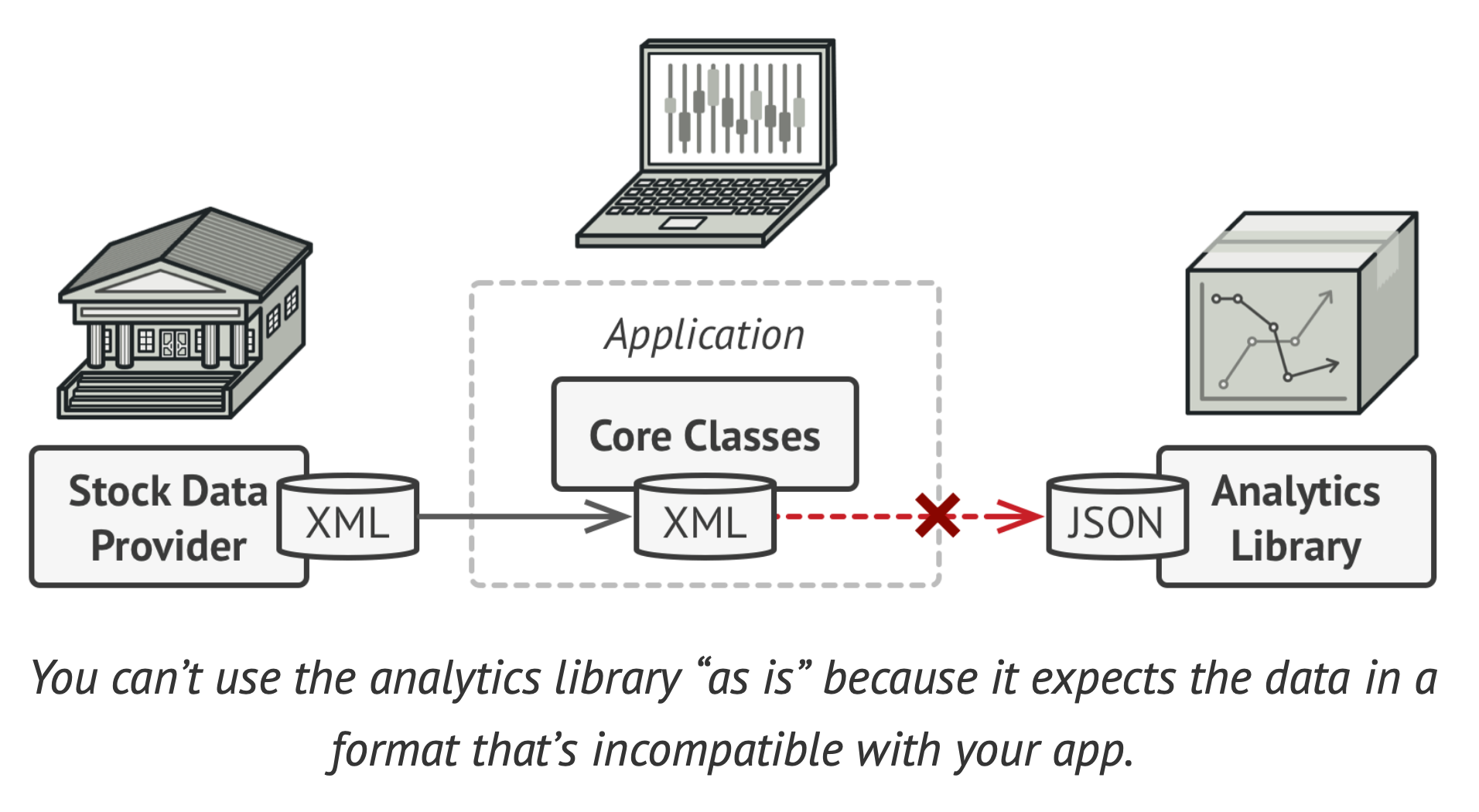 Adapter Pattern: Nguồn ảnh/Source:
Adapter Pattern: Nguồn ảnh/Source: 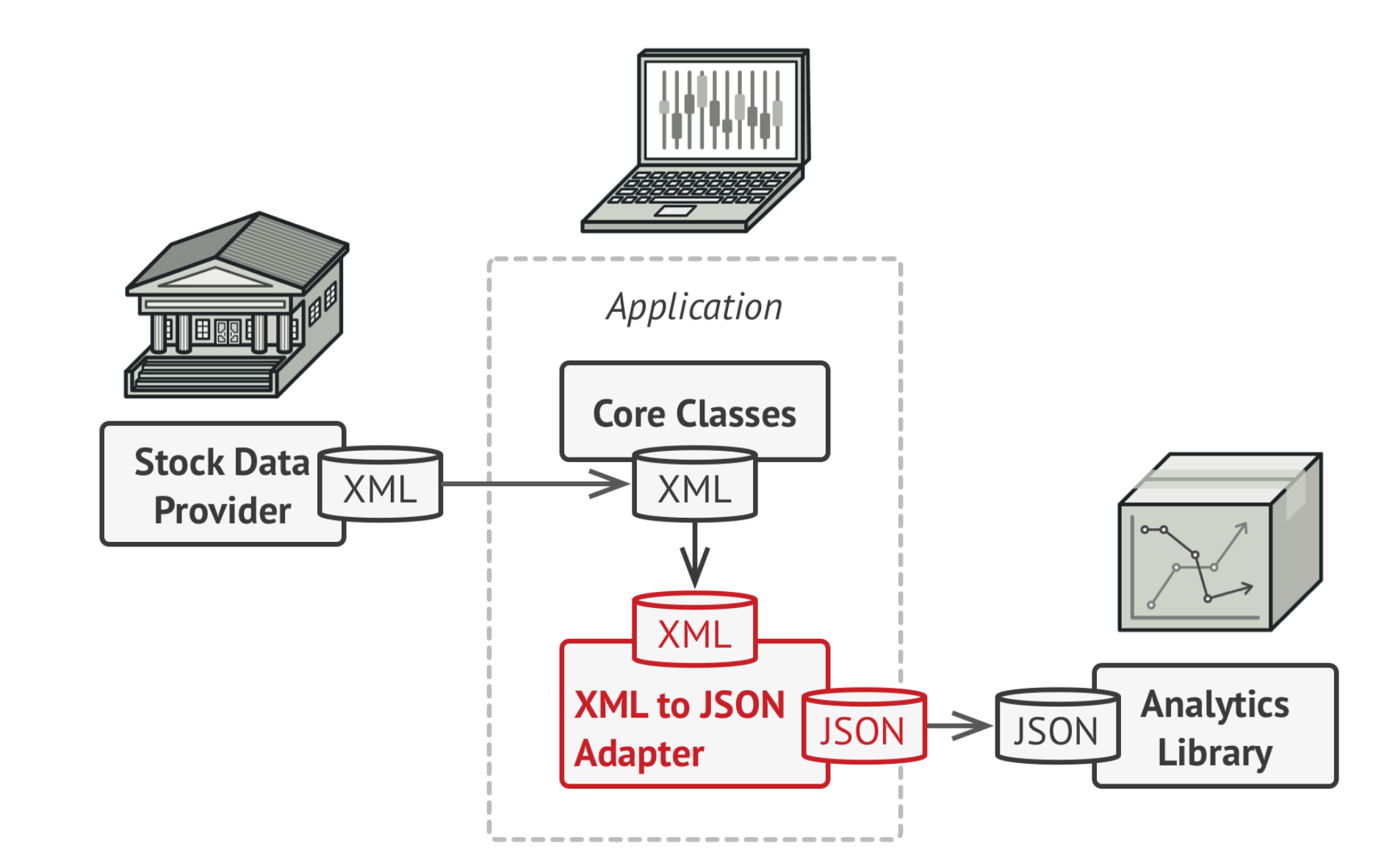 Adapter Pattern: Nguồn ảnh/Source:
Adapter Pattern: Nguồn ảnh/Source: 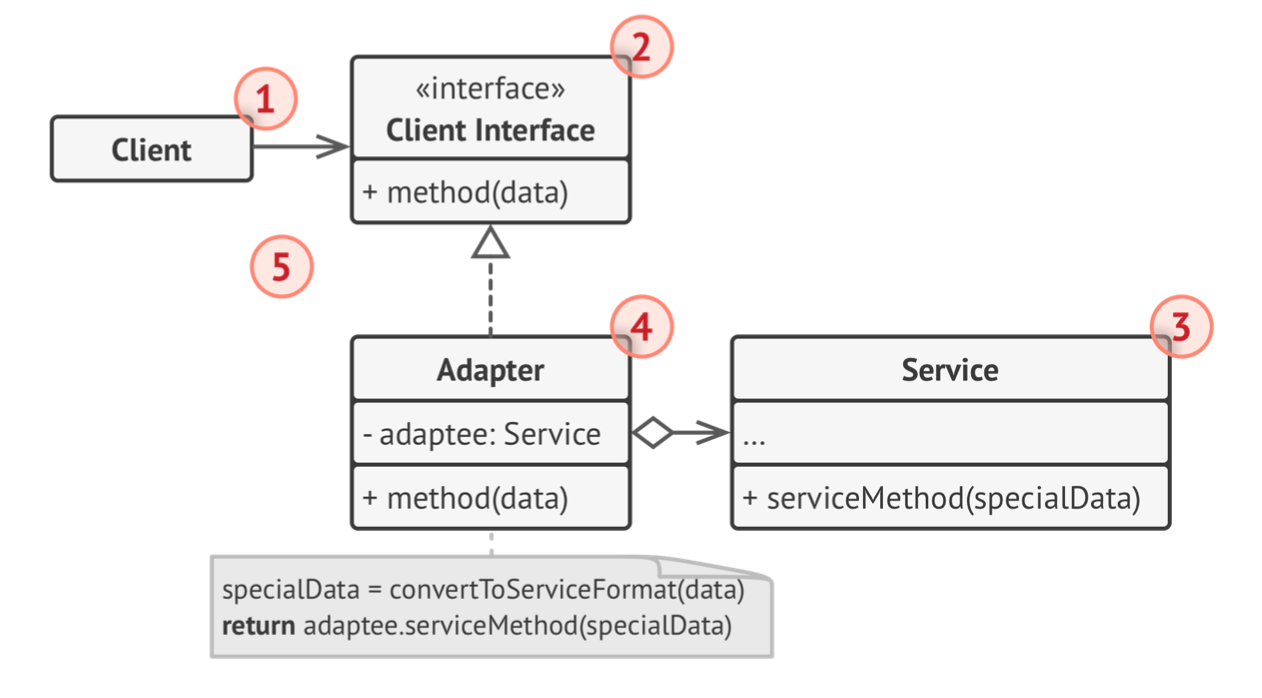 Adapter Pattern: Nguồn ảnh/Source:
Adapter Pattern: Nguồn ảnh/Source: 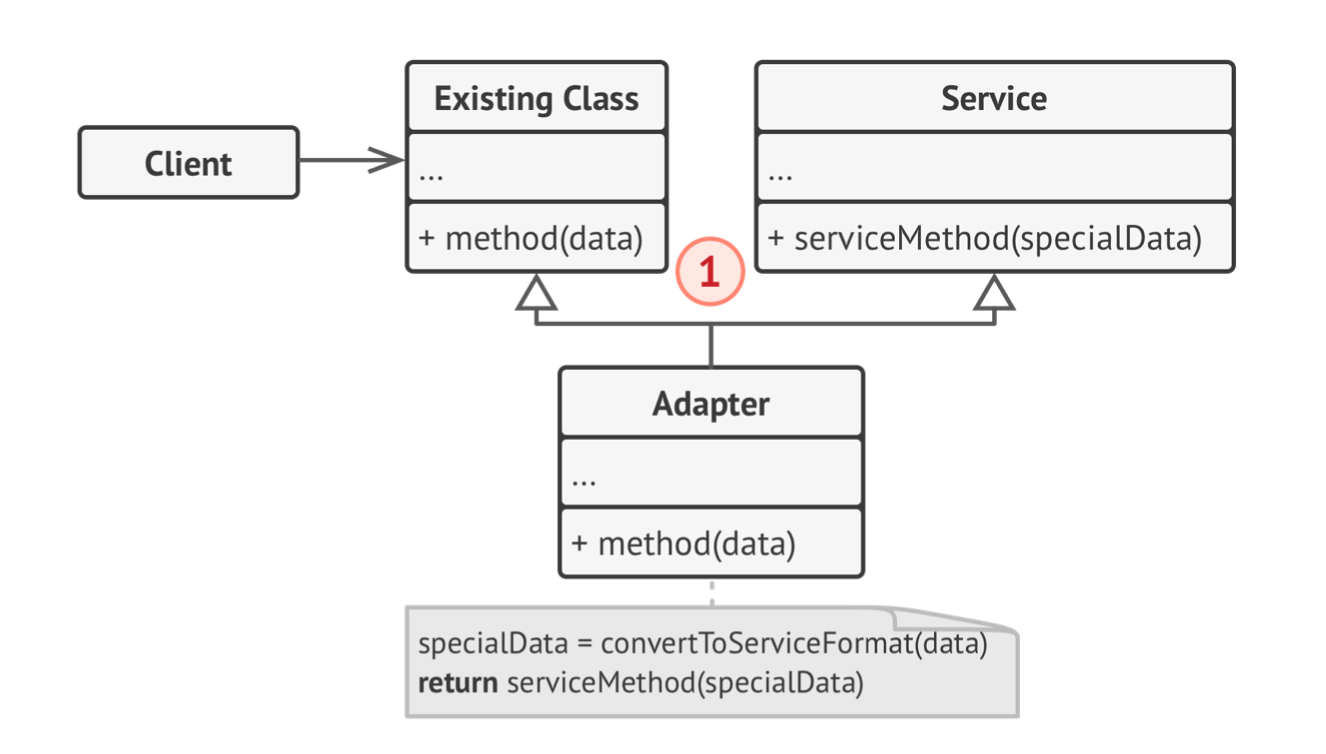 Adapter Pattern: Nguồn ảnh/Source:
Adapter Pattern: Nguồn ảnh/Source: 




 Atomic Design không còn quá xa lạ với anh em.
Atomic Design không còn quá xa lạ với anh em. Sai, sai vừa vừa thôi nha mấy sếp. LOL
Sai, sai vừa vừa thôi nha mấy sếp. LOL Đã có atom build hoàn chỉnh ngon lành thì implement page nhanh như chó chạy ngoài đồng.
Đã có atom build hoàn chỉnh ngon lành thì implement page nhanh như chó chạy ngoài đồng. Nguồn ảnh/ Source:
Nguồn ảnh/ Source:  Những dự án đặc biệt sẽ phát sinh những component đặc biệt. Nguồn ảnh/ Source:
Những dự án đặc biệt sẽ phát sinh những component đặc biệt. Nguồn ảnh/ Source: 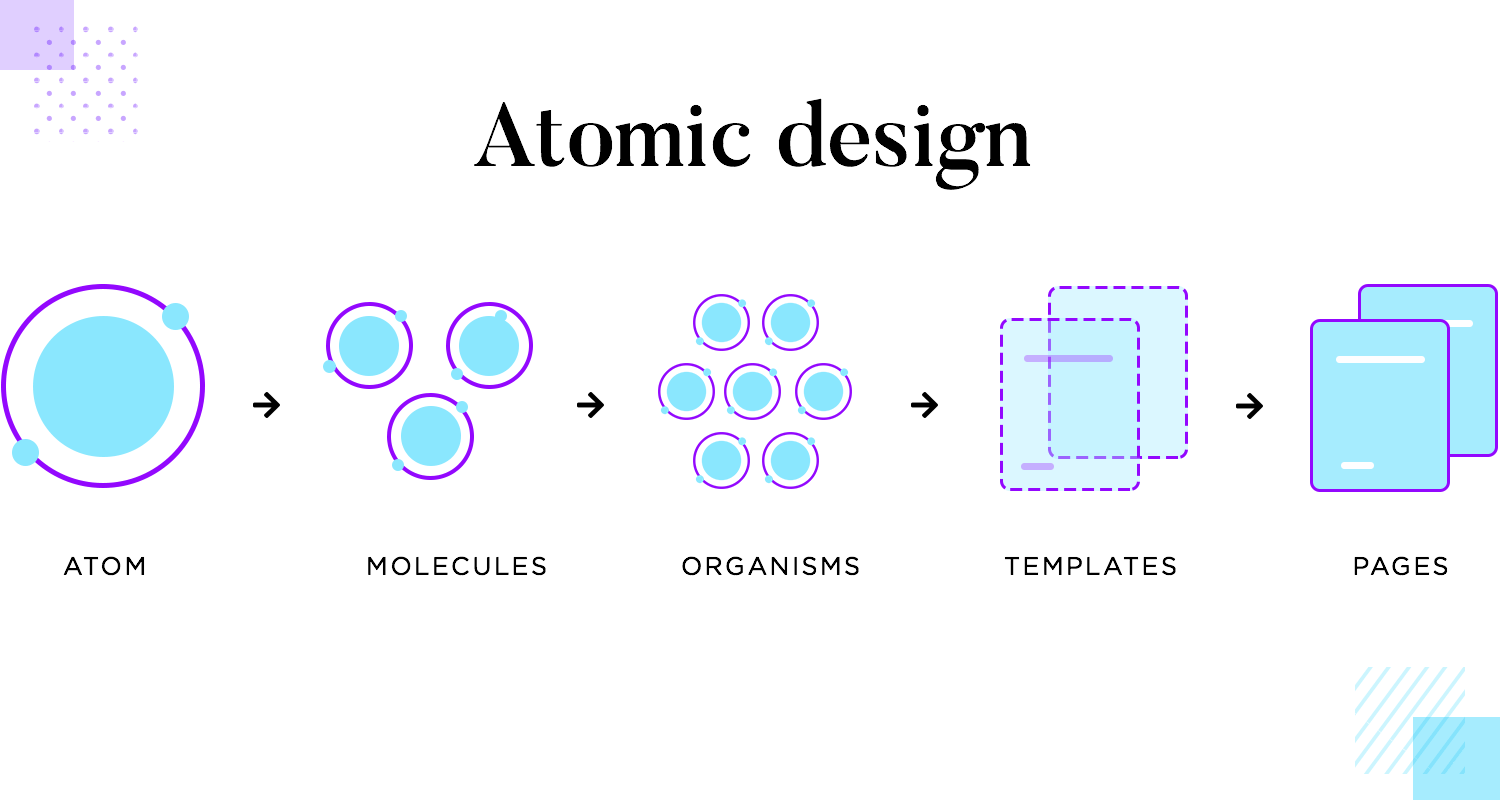 Nguồn ảnh/ Source:
Nguồn ảnh/ Source: 


 Nguồn ảnh: apollographql.com
Nguồn ảnh: apollographql.com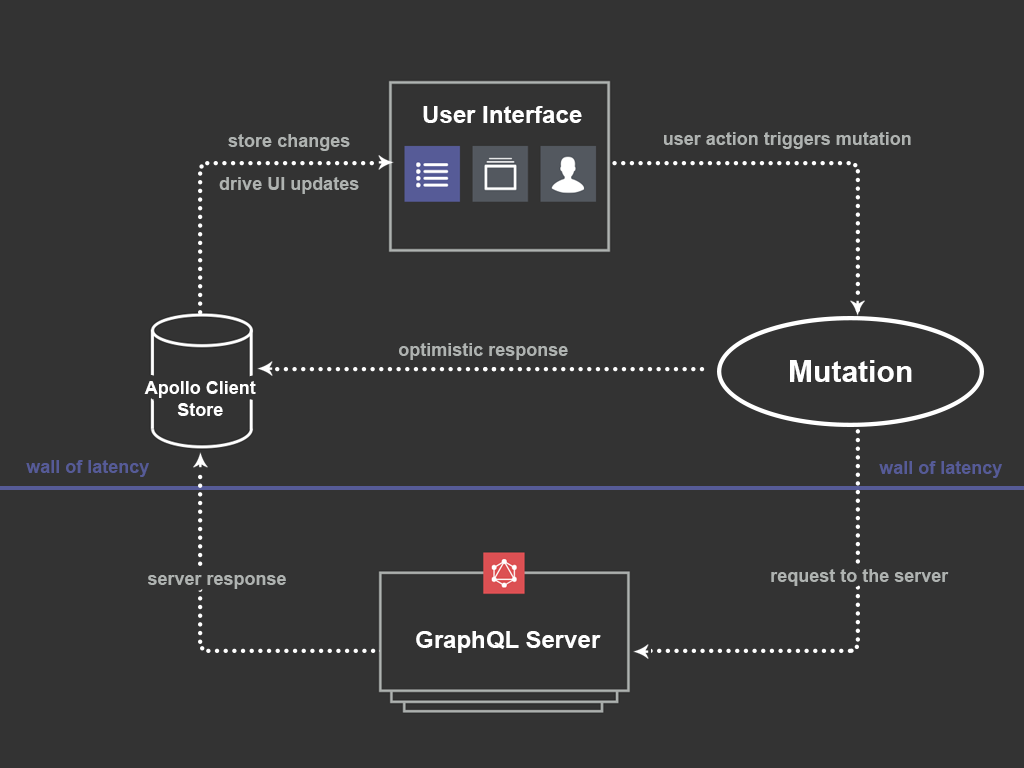 Nguồn ảnh: apollographql.com
Nguồn ảnh: apollographql.com