Những năm trở lại đây, Internet vạn vật (IoT) đã có bước phải triển vượt bậc nhờ sự kết hợp với các xu hướng công nghệ mới như nền tảng trí tuệ nhân tạo AI. Chuyển đổi số diễn ra ở khắp mọi nơi, trong từng ngõ ngách của cuộc sống xung quanh hàng ngày. Để đồng bộ việc tích hợp giữa IoT và dữ liệu, một xu hướng công nghệ mới đã ra đời gọi là Digital Twins (Cặp song sinh kỹ thuật số). Bài viết hôm nay chúng ta cùng tìm hiểu về xu hướng công nghệ mới này nhé.
Digital Twins là gì?
Digital Twins là một công nghệ thực hiện việc nhân bản kỹ thuật số của tất cả mô hình ngay thời điểm hiện tại, hay nói cách khác là nó cung cấp một bản sao chính xác của thế giới vật lý cùng với cập nhật theo thời gian thực tương ứng.
Khái niệm này được giới thiệu và phát hành lần đầu tiên bởi NASA từ năm 2012, với những tiêu chí đặt ra cho Digital Twins trên một hệ thống mô phỏng chiếc máy bay. Trong đó tiêu chí quan trọng là có thể mô phỏng tích hợp đa vật lí, đa tỷ lệ, xác suất của một phương tiện hoặc hệ thống được chế tạo thông qua sử dụng các mô hình vật lý tốt nhất hiện có, cập nhật cảm biến, lịch sử đội bay,… để phản ánh tuổi thọ của chiếc máy bay song sinh tương ứng của nó.
Trong quá trình nghiên cứu và phát triển, Digital Twins cho thấy sự hiệu quả và hứa hẹn trong nhiều lĩnh vực ứng dụng sản suất hay kinh doanh; công nghệ này như là một chiếc cầu nối giữa thế giới thực và không gian số. Với sự phát triển của IoT, số lượng các thiết bị trong thực tế kết nối với Internet ngày càng nhiều; các nhà phát triển tham vọng có thể xây dựng được gần như hoàn chỉnh một bản sao số hóa tái hiện lại được không gian, thời gian và vật chất trong cuộc sống; từ đó đưa ra các mô phỏng, dự đoán có tính chính xác cao hơn.
Để xây dựng, tạo ra một đại diện ảo sinh đôi, chính xác của một sản phẩm, một hệ thống bao gồm cả các hành vi theo thời gian thực; các yếu tố mà một hệ Digital Twins phải có bao gồm:
Cảm biến: thu thập dữ liệu và cung cấp cho đại diện ảo trong suốt quá trình hoạt động vật lý trong thế giới thực.
Dữ liệu: dữ liệu từ các cảm biến, từ bản vẽ thiết kế, từ hiểu biết về hệ thống hay những thông tin từ môi trường giúp hệ thống ảo vận hành chuẩn xác như thật hơn.
Bộ truyền động: mỗi hành động trong thế giới thực đều phải được phản ánh chính xác đến bản sao song sinh của nó và ngược lại, để những tác động lên bản sao số có thể thay đổi được lên chính bản thể vật lý của nó, chúng ta cần xây dựng những bộ truyền động chịu sự can thiệp của con người.
Theo nghiên cứu của Gartner, hãng nghiên cứu thị trường hàng đầu, tháng 8 năm 2022, công nghệ Digital Twins nằm trong top 10 xu hướng công nghệ chiến lược 10 nămsắp tới. Công nghệ này hiện vẫn đang trong giai đoạn khởi đầu, các công ty công nghệ sử dụng IoT hiện nay cũng đang tìm cách triển khai Digital Twins.
Việc làm AI lương thưởng hấp dẫn, mới nhất dành cho bạn!
Lợi ích mà Digital Twins mang lại
Với khả năng tạo ra bản sao số tương ứng với sản phẩm vật lý, lợi ích đầu tiên dễ thấy nhất của công nghệ sao chép sinh đôi số này là việc có thể giúp doanh nghiệp đánh giá sản phẩm một cách chi tiết và chính xác trước khi đưa ra thị trường. Hệ thống xây dựng lên sản phẩm số với lượng dữ liệu cung cấp lớn, đầy đủ các mặt của thiết bị vật lý, từ đó mang lại khả năng phân tích dữ liệu một cách toàn diện.
Digital Twins cũng mang lại khả năng giám sát, theo dõi và điều khiển từ xa cho người dùng; đồng thời giảm tối đa chi phí dành cho rủi ro của việc sản xuất. Nhờ khả năng số hóa mang lại cho chúng ta những kịch bản khó xảy ra để kiểm thử, lưu lại các bản ghi để làm cơ sở cho những hoạt động phục hồi và lưu trữ kiến thức.
Ứng dụng trong thực tế
Dù vẫn trong giai đoạn đầu của quá trình phát triển, Digital Twins cũng đã có những ứng dụng thực tế rõ rệt kết hợp với sự phát triển của AI, Machine Learning và IoT trong cuộc cách mạng công nghiệp 4.0.
Mô hình smartcity Virtual Singapore 3D
Đây là một bản sao kỹ thuật số có thể tương tác được của thành phố Singapore, được hiển thị dưới dạng hình ảnh 3D. Smartcity này cho phép chính phủ quan sát hoạt động của toàn bộ cơ sở hạ tầng thành phố theo thời gian thực; theo dõi mọi thứ, phân tích từ tình hình an ninh, mật độ dân cư hay tình trạng không khí.
Ứng dụng vận hành hệ thống khám phá vũ trụ của NASA
Nasa hiện nay ứng dụng Digital Twins để vận hành, bảo trì và sửa chữa hệ thống khi khám phá vũ trụ. Các nhà khoa học của NASA cần phải làm việc với các máy móc trong không gian vũ trụ, nơi mà nó gần như không thể hiển diện thực tế và vì thế bản sao số này vô cùng hữu ích
Tập đoàn Chevron sử dụng trong các mỏ dầu
Tập đoàn Chevron đang sử dụng công nghệ này để dự đoán các vấn đề bảo trì trong các mỏ dầu và nhà máy lọc dầu của mình. Công ty đặt mục tiêu có các cảm biến được kết nối với hầu hết các thiết bị giá trị cao vào năm 2024 và hy vọng rằng việc ngăn chặn sự cố trên các thiết bị quan trọng nhất của họ sẽ giúp tiết kiệm hàng triệu đô la mỗi năm.
Kết bài
Có một cuộc cách mạng về AI nói chung và Digital Twins nói riêng đang âm thầm diễn ra. Công nghệ ngày càng mang lại cho chúng ta nhiều sự tiện lợi trong cuộc sống. Dù còn nhiều thách thức nhưng công nghệ Digital Twins sẽ có nhiều bước đột phá trong thời gian tới. Hy vọng bài viết đã mang lại cho các bạn những kiến thức hữu ích về xu hướng công nghệ mới này, hẹn gặp lại các bạn trong bài viết tiếp theo của mình.
Lâu rồi chưa viết tutorial cho anh em. Tự thấy có lỗi với những anh em newbie với Reactjs. Bài viết này hướng dẫn cụ thể, bao gồm cả giải thích cho anh em từng bước xây dựng web app với Reactjs.
Trước khi bắt đầu với Reactjs, anh em nào chưa có kiến thức với HTML, DOM và JS chắc phải quay lại học sơ mấy môn này đã ha.
Okie bắt đầu thôi nào anh em ơi!
1. React virtual DOM
Chắc hẳn một số anh em sẽ nghe tới DOM, Virtual DOM trong quá trình xây dựng web app với Reactjs. Vậy DOM và Virtual DOM là gì?.
DOM là Document Object Model, là cây HTML của chúng ta, là nội dung được hiển thị lên chính trên trang web. Trong quá trình xây dựng web app với Reactjs, ta thường thao tác với cây DOM, giúp thêm hoặc xoá các object vào cây DOM.
Ví dụ như đoạn code dưới đây, cây DOM sẽ thay đổi khi người dùng nhập số vào textfield.
Ở đoạn code này, có 2 object trên dom sẽ thay đổi. Đầu tiên là input, khi anh em gõ vào input, giá trị của input trên DOM sẽ thay đổi. Thứ hai là Time, do có hàm Interval sẽ lặp đi lặp lại mỗi giây nên giá trị thời gian cũng sẽ liên tục cập nhật trên DOM
Với Reactjs CreateElement, anh em có thể tự xây dựng được web app. Một công cụ khá hay là babeljs.io. Với công cụ này, các element trên html có thể auto convert ra JSX. Tức là dùng reactjs, anh em có thể thử dùng babeljs tại đây.
Phía bên phải là nội dung html thuần anh em paste vào. Phía bên trái là code đã được convert để ReactJS có thể hiểu được.
Sửa lại một chút đoạn code ở phía trên. Tương tự như việc tạo từng element trên DOM, đoạn code phía dưới khai báo element1 bao gồm đầy đủ các object html.
Reactjs hỗ trợ khởi tạo project mới bằng cú pháp create-react-app. Với create-react-app, reactjs sẽ tạo ra project mặc định và một số module cần thiết (babel, Webpack). Những công cụ này là cần thiết để xây dựng web app với reactjs.
Trước khi thực hiện câu lệnh này, anh em cần cài đặt nodejs và npm.
Anh em thực hiện chạy 2 lệnh npm-v và node-v để kiểm tra cài đặt nodejs và npm đã thành công hay chưa. Lưu ý phiên bản tối thiểu của node phải là 14.0.0 và npm là 5.6 nha anh em
Rồi, giờ thì vào terminal, chọn thư mục Desktop hoặc Downloads (tuỳ anh em). Chạy câu lệnh
npx create-react-app react-todo-app
Câu lệnh này sẽ tạo ra project react-todo-app bao gồm tất cả các file cần thiết để bắt đầu với Reactjs. Thư mục sẽ có cấu trúc như sau
Đầu tiên là node_modules, thư mục này chứa các file có liên quan tới dự án xây dựng webapp bằng reactjs. Bao gồm thư viện, các file cần thiết từ bên thứ 3.
Index.html chứa nội dung mà ứng dụng web app sẽ xuất hiện.
Thư mục src chứa các file anh em sẽ phải làm việc cùng. File index.js là file chính, đóng vai trò là điểm đầu vào của toàn ứng dụng.
Package.json chứa các script và thông tin các module cần sử dụng trong dự án. File gitignore chứa những thành phần sẽ bị bỏ qua khi anh em commit source lên git.
5. Thêm source
Anh em mở file index.js, thêm vào đoạn code sau. Từng bước từng bước rồi sẽ xây dựng được web app với Reactjs thôi anh em. Đừng lo.
import React from 'react';
import ReactDOM from 'react-dom/client';
const rootElement = document.getElementById('root');
const root = ReactDOM.createRoot(rootElement);
root.render(<h1>Hello from React application</h1>);
Trong đoạn source này, anh em thấy React và ReactDOM đã được import. Root element là root của cây DOM, có id là root. Sau khi có root element, ta gọi phương thức createRoot từ ReactDOM để tạo ra cây DOOM doot có 1 object với id là root.
Sau đó render ra duy nhất một thẻ h1 có nội dung là Hello from React application.
Mở file package.json lên anh em sẽ thấy một số script như sau:
Với anh đã có kinh nghiệm thiết kế, phát triển các hệ thống có áp dụng các nguyên lý thiết kế microservices không còn là điều xa lạ.
Tuy nhiên với các anh em mới bắt đầu, việc áp dụng tốt các nguyên lý thiết kế microservices sẽ giúp anh em phát triển tốt hệ thống. Hệ thống cũng có thể scale up, scale down tốt về sau.
Bản thân các nguyên lý đã được đúc rút ra từ rất rất nhiều các lập trình viên có kinh nghiệm khi họ sử dụng microservices. Chính vì thế, anh em nên bỏ chút ít thời gian đọc và ghi nhớ các nguyên lý thiết kế này.
Các cụ dạy rồi, học từ cái ông đã làm sai, đã gặp vấn đề luôn là cách học tốt mà.
1. Single Responsibility Principle
Với anh em developer đã có kinh nghiệm thì nguyên lý này cũng không phải mới mẻ gì. Single Responsibility Principle là chữ S nằm trong SOLID. Mà SOLID thì quá nổi tiếng trong giới phần mềm.
Nội dung của nguyên lý này nói rằng mỗi microservices mà anh em thiết kế hoặc implement chỉ nên handle một công việc (handle only one thing). Microservices chỉ nên giao tiếp với microservices để hoàn thành task của nó. Nhưng về mặt lý thuyết, bản thân nó vẫn chỉ handle một việc duy nhất. Chính vì chỉ xử lý một việc duy nhất, nó đáp ứng được S trong SOLID.
Ví dụ: Anh em đang thiết kế hệ thống ecommerce. Thương mại điện tử yêu cầu người dùng đăng nhập, cho phép người dùng thanh toán đơn hàng. Trường hợp này ta cần hai microservices, một để xác thực người dùng (Authentication Service), microservice thứ hai dùng để thanh toán (Payment Service). Không nên viết một Service duy nhất mà ở đó xử lý cả việc Authentication và Payment.
2. Decentralized Data Management (Dữ liệu phi tập trung)
Trái ngược với dữ liệu tập trung (Centralized). Nguyên lý này trong thiết kế microservices khuyên ta nên thiết kế sao cho dữ liệu không tập trung ở một nơi (Decentralized).
Mỗi microservices nên quản lý dữ liệu của riêng nó. Việc mỗi microservices tự quản lý được data mà nó cần đảm bảo sự độc lập, khả năng mở rộng và độ tin cậy.
Anh em có thể đặt câu hỏi tại sao lại nói về độ tin cậy? Độ tin cậy ở đây được hiểu là khi một microservices khác down (hoặc gặp bất cứ vấn đề gì), các microservices được tin cậy vẫn có thể hoạt động bình thường (do bản thân không có liên kết gì với các microservices khác).
Như hình trên đây thì 3 microservices User, Messages, Friends. Bản thân mỗi microservices có một database riêng, MessageDB có thể dùng MongoDB, trong khi Users với Friends dùng các RDBMS khác?
Tới đây một số anh em có thể thắc mắc. Ủa rồi keep cho data độc lập ai chả muốn, nhưng nếu cần data ở microservices khác thì sao? Chẳng lẽ cứ giữ khăng khăng như thế? Đây đây, cái số 3 đây sẽ giải quyết vấn đề này.
Nguyên lý thứ 3 trong nguyên lý thiết kế microservices là API-Driven. Bắt đầu với định nghĩa API-Driven ha.
API-driven development is the practice of designing and building APIs first, then creating the rest of an application around them.
Phát triển API-driven là thực hành thiết kế và xây dựng API trước, sau đó với xây dựng phần còn lại của ứng dụng xung quanh các API đã làm
Nguyên lý này vô cùng hữu ích khi thiết kế, xây dựng và làm việc với mô hình microservices. Theo nguyên lý này, microservices nên thiết kế xung quanh API. Mỗi microservices cung cấp rõ ràng một bộ API để giao tiếp với các microservices khác.
4. Stateless
Để hiểu được nguyên lý này, anh em cần phân biệt được sự khác nhau giữa Stateful và Stateless.
Trong các điểm khác biệt, có một điểm anh em cần lưu ý. Stateless sẽ không quan tâm tới state hiện tại của request. Nếu một microservices xử lý giỏ hàng của khách hàng trong hệ thống ecommerce, services đó sẽ không quan tâm trạng thái hiện tại của request là gì. Bản thân nó sẽ luôn xử lý request bằng cách lấy toàn bộ giữ liệu giỏ hàng và tiến hành bước tiếp theo.
Chính sự không quan tâm tới state hiện tại giúp bản thân microservices độc lập, có thể scale up và có độ ổn định cao.
Nhưng trong quá trình phát triển microservices. Giữ cho stateless không phải là dễ nha anh em.
5. Loose Coupling
Loose Coupling trong nguyên lý thiết kế microservices cũng giống như Loose Coupling trong hướng đối tượng (Object Oriented Design). Nguyên lý này nhắm tới việc loại bỏ một vài class, package và module.
Loose Coupling cũng mang ý nghĩa lỏng lẻo. Nguyên lý này nói rằng các microservices nên được liên kết lỏng lẻo với nhau, không nên liên kết chặt chẽ với nhau. Việc không có mối liên kết chặt chẽ giữa các microservice đảm bảo khả năng scale cho các microservices.
Như hình bên trái, các microservices có mối liên hệ chặt chẽ với nhau. Việc này dẫn tới các microservices bị phụ thuộc vào nhau, khó trở nên độc lập. Ngược lại, Loosely Coupled cho phép các microservices chỉ có một vài liên kết giữa các microservices.
6. Auto scaling
Nguyên lý cuối được đều cập liên quan tới nguyên lý thiết kế microservices là Auto-scaling (tự động mở rộng).
Thực chất một hệ thống khi lựa chọn áp dụng microservices, bản thân hệ thống đó đã cân nhắc hoặc ít nhất là có nhu cầu về scale (mở rộng). Bản thân mỗi microservices phải có thể tự mở rộng khi có nhiều hơn các request. Giảm bớt các instance đi trong trường hợp chỉ có số ít các request.
Ví dụ: nếu số lượng user truy cập tới microservices tăng, bản thân microservices phải tự mở rộng được. Khi user giảm truy cập, các instance trước đó phải được xoá bớt đi.
Hiện nay, Kubernetes có thể đáp ứng yêu cầu này. Nên lúc thiết kế anh em nhớ cân nhắc yếu tố Scaling để tận dụng tối đa Cloud, các công cụ như Kubernetes
Cụ thể như thế nào sẽ viết rõ cho anh em trong bài viết khác ha. Bài viết này chỉ nói về các principles (nguyên lý thôi)
7. Tham khảo thêm về thiết kế microservices
Một số cuốn sách cũng như tài liệu hay về nguyên lý thiết kế microservices anh em có thể tham khảo
Anh em lập trình viên, Product Owner, BA, QC nếu đã tham gia một số dự án apply mô hình phát triển phần mềm Agile chắc không còn lạ gì về khái niệm Agile cũng như những thuật ngữ liên quan tới nó.
Bài viết này ngoài việc giải thích lại về Agile, còn cung cấp cái nhìn thực tế trong quá trình làm việc với mô hình này.
Mong sẽ giúp đỡ được nhiều hơn các anh em mới bắt đầu hoặc đang tìm hiểu mô hình Agile.
Thôi thì biết hay chưa biết ta đều nhắc lại cái định nghĩa cho nó máu. Làm nhiều chứ đôi khi hỏi định nghĩa lại nói không ra. Coi lại cho chắc.
1. Agile là gì?
Theo như định nghĩa tới từ ông Atlassian thì Agile được nghĩa như sau:
“Agile is an iterative approach to project management and software development that helps teams deliver value to their customers faster and with fewer headaches. Instead of betting everything on a “big bang” launch, an agile team delivers work in small, but consumable, increments. Requirements, plans, and results are evaluated continuously so teams have a natural mechanism for responding to change quickly.”
Agile là cách tiếp cận lặp đi lặp lại để quản lý dự án và phát triển phần mềm giúp các teams (teams này là team bao gồm đầy đủ thành phần nha) đem tới cho khách hàng giá trị nhanh hơn, ít bị đau đầu hơn. Thay vì đặt được vào “big bang” kiểu như demo fail, thì agile giúp cho các nhóm thực hiện các công việc nhỏ, có thể xử lý được. Các yêu cầu, kế hoạch và kết quả được đánh giá một cách liên tục giúp các nhóm thích ứng nhanh hơn với các yêu cầu thay đổi liên tục
Tạm cho cái định nghĩa từ ông Atlassian (công ty sản xuất phần mềm ở Úc, chuyên cung cấp phần mềm cho phát triển phần mềm, quản lý dự án,… Cũng coi như là một bên uy tín khi nói về Agile.
Túm cái váy lại, có mấy ý chính anh em cần chú ý về Agile:
Agile là các tiếp cận và lặp đi lặp lại (cứ hết 2 tuần, 1 tuần tuỳ theo quy định lại cứ quay lại từ đầu). Từ đầu là từ đầu cách thức làm việc, chứ không phải từ đầu của kết quả, xoá code đi viết lại thì toang.
Agile giúp cả team và khách hàng (customer) bớt đau đầu. Ok, thay vì làm 3 tháng rồi demo cái bùm fail, không đúng ý khách hàng. Sai requirement.
Agile chia nhỏ khối lượng công việc giúp phù hợp với team, giúp team có thể hoàn thành trong thời gian ngắn
Nếu không thay đổi nhanh, có thể toang từ PO cho tới dev vì không đúng ý khách hàng.
Cái nữa do khối lượng công việc nhỏ và nghiệm thu đánh giá trong từng giai đoạn ngắn, nên có gì thay đổi cái là anh em quay xe ngay. Xe nhỏ dễ quay đầu hay bẻ lái
2. Thuật ngữ Agile
Sau khi đã hiểu rõ agile là gì, kế tiếp là các thuật ngữ liên quan tới Agile. Thuật ngữ Agile ở đây được hiểu là các từ khoá thường được sử dụng trong mô hình này.
Không phải chém gió nhưng theo số liệu thống kê thì hiện nay có tới 86% lập trình viên làm việc với mô hình Agile. Mô hình này có nhiều điểm ưu việt, apply từ công ty á tới âu. Trong nhiều loại hình dự án.
Tuy nhiên, nếu mới bắt đầu, anh em đôi khi còn lạ lẫm với một vài thuật ngữ. Thôi thì ta đi từ từ từng bước, từng bước.
Số liệu từ Stackoverflow. 85.4, má chém gió với anh em rồi. Làm tròn tí chắc ok mờ.
3. Thuật ngữ Agile thường dùng
3.1 A-E: Acceptance Criteria to Epic
Định nghĩa về AC, AC ở đây dịch là tiêu chí chấp nhận nha anh em.
“Acceptance criteria are a set of conditions that software must meet in order to be accepted by a customer or stakeholder.”Tiêu chí chấp nhận (AC) là tập các điều kiện mà phần mềm phải đáp ứng để được khách hàng hoặc các bên liên quan chấp nhận.
Rồi, anh em được đưa cho cái task A, ấn vào nút B sẽ đi tới vào màn hình C. Vậy AC sẽ là
“ấn vào B sẽ đi được tới C”
“nút B xuất hiện ở màn hình A”
“nút A ấn được”
Nếu có logic gì thêm anh em có thể viết vào, tuy nhiên lưu ý rằng “accepted by a customer or stakeholder). Viết cho ông nào có quyền chấp nhận thì chú ý viết cho các ông đó hiểu nha. Cái AC viết ra cho ai thì phải xem người đó sẽ hiểu ở mức độ nào. Đừng đem logic code hay thứ gì đó quá sâu về kĩ thuật vào trong AC.
AC gần như là bắt buộc phải có, để cả PO, cả BA cà QC và Dev đều biết cái đó như thế nào sẽ gọi là xong.
Không chời tới cuối ngày cuối tháng hết giờ thì đốt bỏ AC nha.
3.2 Backlog Refinement
Okie cứ định nghĩa trước mà quất nha. Backlog Refinement là thuật ngữ Agile khá quan trọng.
“It’s a Scrum meeting where the Scrum team organizes the backlog to make sure it’s ready for the next sprint or iteration. In other words, it’s like spring cleaning… but for Scrum teams!”
Đầu tiên thì nó là một buổi meeting. Thành phần tham dự bao gồm cả Scrum team. Ở buổi meeting đó cả nhóm sắp xếp lại công việc tồn đọng. Hiểu và chuẩn bị để đảm bảo rằng nó hoạt động cho lần chạy tiếp theo (Sprint tiếp theo). Nói cách khác nó giống như dọn Sprint nhưng cho Scrum teams.
Anh em chú ý một khúc quan trọng ‘make sure it’s ready for the next sprint or iteration’. Đảm bảo sẵn sàng cho Sprint tiếp theo. Các yếu tố cần cân nhắc bao gồm:
Team development đã hiểu đúng requirement và cần làm gì chưa?
Team BA, PO đã hiểu đúng những gì khách hàng expect trong Sprint này?
Effort của team, velocity của team có đủ hay chưa?
Có ai nghỉ không?. Nếu thiếu effort thì cần bao nhiêu là đủ?
Thường những meeting như Backlog Refinement rất dài. Dài nhưng mà bổ ích, thà là hiểu với nhau tất cả để bắt đầu còn hơn tới cuối cùng miss understand.
Đem lên, đem lên Sprint chứ không kéo xuống Backlog nha các đại ca.
3.3 Daily Scrum
Daily Scrum là thuật ngữ Agile phổ biến nhất. Theo như định nghĩa:
“It’s a daily meeting usually hosted by the Scrum master. Every morning, the Scrum team gets together for 15 minutes to discuss their day ahead.”
Daily Scrum là buổi gặp mặt hằng ngày, trưởng tổ chức là ông Scrum master. Vào mỗi buổi sáng, scrum teams gặp mắt trong 15 phút, xem nay sẽ làm gì, qua đã làm được gì.
Chính vì Agile chia nhỏ công việc nên việc thực hiện meeting hàng ngày là yếu tố cần thiết. Để nắm được xem có gì khó khăn, đã làm gì. Anh em mới bắt đầu với Agile không nên quá stress vì tinh thần của Agile không quá stress. Vì tinh thần Agile sẽ nói tiếp ở mục sau.
What they plan to do today (hôm nay anh em dự định sẽ làm gì)
What they did yesterday (hôm qua anh em đã làm gì)
Issues they have encountered (những vấn đề nào anh em đang gặp phải)
Về cơ bản daily mọi người chỉ chia sẻ với nhau từng đó. Nếu có khó khăn gì thì raise lên để biết. Anh em cứ mạnh dạn nói vì Sprint rất ngắn. Nếu có khó khăn hoặc bất cứ vấn đề gì trong quá trình làm thì phải raise lên.
Đâu có ai bảo là phải đứng đâu trời. Ngồi nằm gì cũng được vậy.
3.4 Epics
Epics là thuật ngữ Agile thường biết tới nhiều hơn ở vị trí BA và PO. Nhưng anh em lập trình viên, QA, QC nếu muốn biết bức tranh lớn. Tức là nhóm chức năng lớn cũng có thể tìm hiểu về Epics.
“An epic is a big idea or feature that can be broken down into smaller user stories. Much like how large ‘epics’ like Lord of the Rings are split into 3 books.
Epic là ý tưởng lớn hoặc tính năng lớn có thể bẻ nhỏ ra thành các user stories. Giống như chúa tể những chiếc nhẫn chia thành 3 phần.”
Ví dụ rõ hơn: Nếu Epics là improve UI (cải thiện UI) thì nó là nhóm tính năng lớn, nhiều việc cần làm. Chia nhỏ thành 3 users stories là “Thêm giỏ hàng”, “Cải thiện tốc độ load”, “Thay font chữ”, …
Thông thường nhìn vào Epics, hoặc danh sách các Epics sẽ biết định hướng tương lai của phần mềm. Đôi khi làm Agile Sprint quá ngắn, cái nhìn xa trông rộng để liệu cơm gắp mắm nó mất đi. Lúc đó ta có Epics.
3.5 Scrum of Scrums
Scrum of scrums là thuật ngữ Agile sử dụng khi có nhiều scrum team hoạt động. Nhiều team nhưng chung product. Về khái niệm thì cũng đơn giản thôi.
It’s a special Scrum meeting for large Scrum teams.
Là scrum meeting đặc biệt cho team scrum lớn.
Thông thường khi team scrum đã lớn hơn 12 người, thường được chia nhỏ thành các scrum team nhỏ hơn (từ 5 tới 10 người). Mỗi nhóm sẽ bốc một ông ra làm đại sứ, họp hành với các scrum team khác.
Cũng có daily nhưng không phải trong team. Các ông đại sứ gặp nhau để report tiến độ, nêu ra các vấn đề. Việc họp này đảm bảo product lớn chạy êm, chạy xuôi.
Nói cho oai thì như đi họp hội đồng bảo an. Mỗi ông một ghế.
4. Tổng kết
Bài viết này mình đã nêu ra 5 thuật ngữ Agile phổ biến. Tuy nhiên còn nhiều nữa các thuật ngữ khác, nếu có thời gian sẽ viết tất cả cho anh em. Agile là mô hình tốt, hiểu thêm về nó giúp anh em làm việc năng suất cao hơn, không quá stress và tự tin lựa chọn mô hình này khi phát triển phần mềm.
Chắc phải ra series 2 cho anh em, cứ ăn dần 5 từ khoá một cho nó dễ nhai. Không quá ngộp.
Trong những năm gần đây, với sự phát triển của AI, xử lý dữ liệu big data,… thì Python luôn là một trong những cái tên mà các nhà tuyển dụng săn đón nhiều nhất ở các ứng viên với mức đãi ngộ cao. Để chuẩn bị cho một buổi phỏng vấn tốt nhất, hôm nay mình cùng các bạn đi qua top 10 câu hỏi phỏng vấn Python Developer thường gặp nhất nhé.
Câu hỏi lý thuyết
Câu 1: Bạn có thể nói gì về Python?
Python là một ngôn ngữ lập trình bậc cao được thiết kế với cấu trúc cho phép người sử dụng viết mã lệnh với số lần gõ phím tối thiểu, nó được đánh giá là dễ học, cấu trúc rõ ràng, phù hợp và thuận tiện cho người bắt đầu học lập trình. Python ra mắt lần đầu năm 1991, ban đầu chỉ chạy trên nền Unix , sau đó mở rộng sang mọi hệ điều hành từ DOS, Windows, MacOS, Linux,… Đến nay thì Python vẫn luôn được xếp hạng là ngôn ngữ lập trình phổ biến nhất.
Python dựa trên trình thông dịch, là một ngôn ngữ kịch bản hướng đối tượng và tương tác. Nhờ tính đa năng của nó nên Python được sử dụng trong rất nhiều lĩnh vực đa nền tảng như Web, Machine Learning, Big Data, các mô hình khoa học,…
Câu 2: Những ưu điểm của Python và vì sao nó được ưa chuộng trong lĩnh vực AI, BigData
Ngoài ưu điểm về cấu trúc rõ ràng, cú pháp gọn, đẹp, dễ đọc thì Python còn mang nhiều tính năng ấn tượng cho người dùng:
Mã nguồn mở: Python hoàn toàn free, mã nguồn mở và thân thiện với người dùng. Cũng nhờ đó là Python có một cộng đồng support lớn mạnh, sẵn sàng hỗ trợ các lỗi nhỏ nhất.
Đa nền tảng: Python chạy được hầu như trên các nền tảng phổ biến nhất, từ Windows, MacOS, Linux và trên cả các nền tảng OS từ Unix sinh ra. Nhờ đó Python tạo được ra các ứng dụng từ nhỏ đến lớn một cách đa dạng.
Kho thư viện module khổng lồ: với hơn 300 thư viện module cùng nhiều tính năng khác nhau giúp các lập trình viên tiết kiệm thời gian làm việc một cách tối đa. Nhiều module trên Python như xử lý ảnh, xử lý số liệu, tính toán, … trở thành tiêu chuẩn vì sự đầy đủ của nó.
Năng suất cao: Python tích hợp hết các quy trình, framework unit test đầy đủ để cải thiện hiệu năng và chất lượng của ứng dụng.
Với những ưu điểm trên, Python là ngôn ngữ lập trình phù hợp với các xử lý dữ liệu lớn, phức tạp; đồng thời có nhiều lợi thế với các module tích hợp có sẵn cho việc tính toán, xử lý số liệu; phù hợp với các yêu cầu của ngành AI, Big Data.
Python hỗ trợ các kiểu dữ liệu cơ bản bao gồm số (integer và float), boolean và string.
Với dữ liệu số, ngoài việc hỗ trợ integer và float; Python cũng hỗ trợ biểu diễn các số ở hệ nhị phân (cơ số 2), bát phân (cơ số 8) và thập lục phân (cơ số 16). Để biểu diễn được chúng, ta thêm các tiền tố xác định như 0b, 0x, 0o tương ứng.
Ngoài ra Python còn tích hợp sẵn module complex cho việc xử lý số phức, viết dưới dạng x +yj (x là phần thực, y là phần ảo; module decimal cho việc xử lý số thập phân với độ chính xác cao (float chỉ hỗ trợ độ chính xác tối đa 15 chữ số phần thập phân)
Với kểu boolean thì Python quy định True có giá trị là 1 và False có giá trị là 0. Vì thế trong Python thì 1 == True và 0 == False.
Python không có kiểu dữ liệu ký tự (character) như một số ngôn ngữ khác; lúc này để biểu diễn 1 ký tự thì chúng ta sử dụng một chuỗi (string) có độ dài là 1.
Câu 4: Kiểu dữ liệu mutable/immutable trong Python
Mutable là những kiểu dữ liệu mà giá trị của dữ liệu có thể thay đổi được, bao gồm: List, Set, Dictionary. Ngược lại với kiểu dữ liệu immutable thì giá trị của dữ liệu không thể thay đổi được gồm: Chuỗi, Tuple, Số.
Ví dụ như List và Tuple là 2 loại dữ liệu tương đồng nhau, có thể xem Tuple là một List không thể chỉnh sửa được). Thông thường Tuple sẽ được sử dụng để lưu trữ những thông tin mà bạn không muốn thay đổi trong quá trình thực thi, chẳng hạn như các thông tin thiết lập (giới tính, quốc gia, dân tộc, …). Sử dụng Tuple giúp tiết kiệm bộ nhớ sử dụng hơn so với List. List cần được lưu trong 2 khối bộ nhớ: 1 có kích thước cố định để lưu biến, và 1 có kích thước biến đổi để lưu trữ dữ liệu.
Để khai báo List chúng ta sử dụng ngoặc vuông: [1,2,3]; còn tuple sẽ sử dụng ngoặc đơn (1,2,3)
Câu 5: Phân biệt shallow copy và Deep copy trong Python
Khi chúng ta sao chép 1 đối tượng bằng toán tử gán (=), Python sẽ chỉ xử lý việc trỏ biến mới đấy vào cùng 1 đối tượng đã có trên bộ nhớ; đây chính là shallow copy (sao chép tương đối). Điều này dẫn đến việc khi bạn thay đổi giá trị của một biến thì cũng sẽ ảnh hưởng đến biến kia do cùng trỏ vào một đối tượng. Lưu ý shallow copy không thực hiện trên các dữ liệu cơ bản (primitive type).
Deep copy hay sao chép tuyệt đối là một tính năng cho phép bạn tạo ra 1 đối tượng mới hoàn toàn, nghĩa là trong bộ nhớ sẽ tạo thêm 1 vùng nhớ lưu trữ đối tượng giống với bản ghi gốc. Deep copy hữu ích khi sử dụng sao chép danh sách (list) hay các kiểu dữ liệu dạng tập hợp các objects.
Câu 6: Làm thế nào để xử lý đa luồng trong Python
Python cung cấp thread modue và threading module để bạn tạo và thực thi một thread, handle xử lý các tác vụ đa luồng. Mỗi thread trong Python đều có vòng đời gồm 3 giai đoạn: bắt đầu, chạy và kết thúc. Thread có thể bị ngắt (interupt) trong quá trình chạy, hoặc có thể tạm thời bị dừng (sleeping) trong khi các thread khác đang chạy (trạng thái yielding).
Để start một thread chúng ta dùng phương thức thread.start_new_thread bằng việc import module thread. Chúng ta cũng có thể sử dụng module threading với nhiều hỗ trợ mạnh mẽ và cao cấp hơn được Python thêm vào từ version 2.4. Ngoài các phương thức có trong module thread, threading còn cung cấp một số method khác như activeCount, currentThread, hay các phuowg thức triển khai đa luồng như run, start, join, …
Câu 7: Phân biệt break, continue, pass khi xử lý vòng lặp trong Python
Giống như hầu hết các ngôn ngữ lập trình, Python cung cấp 2 từ khóa break và continue cho việc kết thúc vòng lặp hiện tại (loop) mà không cần kiểm tra biểu thức điều kiện. Trong đó, break sẽ kết thúc vòng lặp chứa nó ngay lập tức, không thực hiện tiếp các lệnh tiếp theo sau break. Trường hợp break đặt trong nhiều vòng lặp lồng nhau thì nó sẽ thực hiện việc kết thúc vòng gặp gần nhất.
Continue thì sẽ bỏ qua phần còn lại của đoạn mã bên trong vòng lặp trong lần lặp hiện tại, nghĩa là sau continue thì vòng lặp vẫn sẽ tiếp tục chạy lần lặp tiếp theo.
Pass là một câu lệnh khá đặc biệt và ít gặp trong các ngôn ngữ lập trình khác. Pass có nhiệm vụ giữ chỗ cho vòng lặp để đoạn code sẽ được thêm vào sau trong tương lai. Thực tế thì pass không có tác dụng gì khác ngoài việc “không làm gì cả” trong vòng gặp, chỉ để tránh lỗi cú pháp nếu bạn khai báo 1 vòng lặp rỗng (không thực hiện câu lệnh gì) trong Python.
Câu 8: Cách sử dụng hàm any và all trong Python
any() và all() là 2 function sử dụng để check điều kiện trong 1 mảng kết quả, any sẽ trả về true khi tồn tại 1 giá trị true trong mảng truyền vào; ngược lại thì all chỉ trả về true khi tất cả các giá trị trong mảng truyền vào trả về true.
any() và all() được ứng dụng nhiều trong việc xử lý check điều kiện của các dữ liệu dạng List, Tuple hay Array nhằm kiểm tra điều kiện thỏa mãn của 1 thuộc tính trong tập dữ liệu; any tương đương với điều kiện OR và all tương đương với điều kiện AND
Câu 9: Kể tên một số thư viện, framework phổ biến cho Python
Flask: framework xây dựng ứng dụng Web, được thiết kế nhẹ và mang tính module, nó được phân loại là 1 microframework vì không yêu cầu các công cụ hoặc thư viện cụ thể nào.
Django: framework hỗ trợ phát triển Web, được đánh giá là 1 trong những framework Python tốt nhất và được sử dụng để phát triển nhanh chóng các API.
NumPy: thư viện cung cấp rất nhiều tính năng hữu ích cho các phần xử lý ma trận, mảng đa chiều; cung cấp khả năng vector hóa các vận hành về toán giúp cải thiện hiệu suất và tốc độ thực thi.
Scipy: thư viện phần mềm dành cho đại số tuyến tính, thống kê.
Matplotlib: 1 thư viện của Python với khả năng visualizations mạnh mẽ trong việc xây dựng biểu đồ, diagram, charts,…
Câu 10: Compiling và Linking có vai trò gì trong Python
Như đã nói, Python là 1 ngôn ngữ thông dịch; nhưng không chỉ thế, cơ chế của Python cho phép nó có thể compiling biên dịch các phần mở rộng mới trong source code của bạn mà không gây ra lỗi. Điều này giúp Python có khả năng mở rộng code cao, không bị ảnh hưởng đến các phần xử lý khác.
Sau quá trình biên dịch thư viện mở rộng, linking liên kết sẽ móc nối phần mở rộng đấy với những phần source code còn lại trong chương trình của bạn.
Câu hỏi thực hành
1. Câu hỏi về list
Khởi động bằng một câu tương đối nhẹ nhàng với hai dòng code. Hầu hết các developer mới làm quen với Python cũng đều thấy thở vào nhẹ nhõm với câu hỏi này.
Tuy nhiên, trả lời đúng hay không thì còn chưa chắc
listA = ['1', '2', '3', '4', '5', '6']
print list[10:]
A – Index Error
B – []
C – 6
List chỉ có 5 phần tử, xong chưa?. Kết quả là:
Cần phải chú ý dấu hai chấm (:). Cái bẫy nằm ở đây, nếu gõ listA[10], kết quả chắc chắn là IndexError (do array chỉ có 6 phần tử). Tuy nhiên trường hợp này lại đang cố gắng slice List, nên kết quả không bao giờ là Index Error.
C – [[1], [1], [1]] và [[1, 2], [ 1, 2 ], [ 1, 2 ]]
Đáp án: C
Tại sao lại C. Cái bẫy là bẫy từ đầu ở chỗ [ [ ] ] * 3, cú pháp này tạo ra 3 phần tử trong list. Nhưng 3 phần tử này không độc lập để edit dữ liệu theo từng index.
[[]] * 3 chính xác tạo ra 3 item trong một list nhưng là references to the same list. Tức là cả ba đều tham chiếu tới cùng một giá trị.
list[0].append(1) đầu tiên nạp ba thằng giá trị 1 cho kết quả [[1], [1], [1]] . Bồi thêm phát nữa list[1].append(2) cho ra kết quả [[1, 2], [ 1, 2 ], [ 1, 2 ]]
Cái này thì như cái trick (thủ thuật thôi). Bạn nào cứ siêng đọc một loạt câu hỏi phỏng vấn Python thì nhớ, tiếp tục thôi nào
3. Python có multi-threading không? Có cách nào viết code Python chạy parallel không?
A – Chắc là có, cũng như Java – Parallel Stream các kiểu đồ (bạn nào chưa biết có thể đọc thêm về Parallel Stream tại Kieblog)
B – Làm gì có – chưa đọc câu nào phỏng vấn Python mà bảo có multi-threadting hết
C – Có multi-threading nhưng không triển khai parallel được
Đáp án là B. Không có.
Python có một cái gọi là Global Interpreter Lock (GIL). GIL đảm bảo rằng chỉ có duy nhất một thread được thực thi tại một thời điểm nhất định.
Ngoài ra, Python cũng có một cái gọi là Python’s threading package.
4. *args, **kwargs là gì? Sự khác biệt?
Không có ABC. Câu này thuộc dạng câu hỏi phỏng vấn Python dễ nhất rồi đấy!
*args được sử dụng khi ta KHÔNG BIẾT CHÍNH XÁC bao nhiêu đối số (arguments) được pass qua cho function. Hoặc khi ta muốn pass arguments là một list, một loại data đặc biệt.
**kwargs sử dụng khi BIẾT CHÍNH XÁC bao nhiêu arguments được truyền qua cho function.
Cũng có thể sử dụng *bob và**billy nhưng cũng khá ít người dùng.
Trường hợp list1 và list3, nó chỉ truyền duy nhất một arguments. Đối với các câu hỏi phỏng vấn Python, cần nhớ rằng arguments trong def được tính toán khi function được define (định nghĩa ra). Chứ không phải lúc được gọi extendList()
Chính vì define một lần, nên ở lần gọi list1 và list3, nó lấy giá trị list cũ append giá trị mới vào -> Đáp án A, không lăn tăn.
Kết bài
Như vậy chúng ta đã đi qua top 15 câu hỏi phỏng vấn Python Developer thường gặp nhất, hy vọng bài viết này giúp bạn trang bị kiến thức tốt và tự tin hoàn thành buổi phỏng vấn Python sắp tới. Hẹn gặp lại các bạn trong các bài viết tiếp theo của mình.
Có là dot NET hay dot NET core thì anh em cũng cần nắm vững một số kiến thức cơ bản để tham gia phỏng vấn .NET Developer. Thời thế đổi thay nhưng những kiến thức cơ bản luôn cần thiết và cần nhớ bền, nhớ vững trong đầu.
Nói là lựa chọn vậy chứ hiện nay hầu hết các vị trí tuyển dot NET đều yêu cầu kinh nghiệm ở cả dot NET và dot NET CORE. không khó để tìm ra các JD (job description) kiểu như này.
Technical requirements:
.NET (C#, Visual Basic.NET) – 5 years+
.NET Core
API’s
SQL Server – 3 years+
Microservices / Messaging
Event-Driven / Distributed System
Bài viết này giới thiệu tới anh em top 5 câu hỏi phỏng vấn .NET developer. Giúp anh em tham khảo, tổng hợp lại kiến thức và hiểu biết của mình. Chuẩn bị tốt cho buổi phỏng vấn chưa bao giờ là thừa đúng không anh em?
Ok, bắt đầu ngay thôi nào!
1. .NET framework hoạt động như thế nào?
Câu hỏi đâu tiên, đập ngay vào là .NET hoạt động như nào. Tưởng dễ mà không dễ tẹo nào. Cụ thể thì .NET framework hoạt động như thế nào?.
Như bao ngôn ngữ khác, anh em viết code .NET với C# hoặc VB bằng ngôn ngữ tự nhiên, thông qua Native compiler rồi đem tới CIL (common intermediate language), intermediate là trung gian. Tức qua bước trung gian này từ ngôn ngữ tự nhiên sẽ chuyển qua ngôn ngữ code.
Sau khi qua bước này, CLR sẽ làm việc để compile toàn bộ nội dung từ CIL thành mã máy, lúc này machine có thể hiểu được và thực thi.
Về mặt bản chất việc compile từ mã code qua mã máy giống với các ngôn ngữ khác, đều dùng Just In Time(JIT) compiler để biên dịch qua mã máy. Tuy nhiên anh em lưu ý .NET compiler code qua file có định dạng dll hoặc exe.
Anh em chú ý hoạt động như thế nào thường là câu hỏi được hỏi khi phỏng vấn .NET developer nha.
Câu hỏi thứ hai phỏng vấn .NET hỏi về life cycle. Câu này đánh mạnh vào kinh nghiệm làm việc thực tế. Nếu anh em đã có thời gian debug từng event trong life cycle tất nhiên sẽ nhớ được.
Page_PreInit
Page_Init
Page_InitComplete
Page_PreLoad
Page_Load
Page_LoadComplete
Page_PreRender
Render
Về thứ tự thì anh em nhớ là init luôn đầu tiên, khi nào init xong thì mới tới load, load hết xong xuôi tất cả đâu vào đấy rồi mới tới render.
Xin thưa boxing không phải là uýnh lộn trong .NET. Trả lời lèo nghèo coi chừng toang.
Boxing is the process of converting a value type into a reference type directly.
Boxing là quá trình chuyển đổi giá trị từ kiểu giá trị sang kiểu tham chiếu
Trong khi đó unboxing
Unboxing is the process where reference type is converted back into a value type.
Unboxing là quá trình chuyển đổi kiểu tham chiếu ngược trở lại thành kiểu giá trị
int a = 10; // a value type
object o = a; // boxing
int b = (int)o; // unboxing
Trong ví dụ này biến á từ kiểu giá trị int được chuyển thành object, có thể tham chiếu là o. Sau đó được chuyển ngược lại thành kiểu giá trị và gán vào biến b.
Vẫn là một câu hỏi đơn giản phỏng vấn .NET developer. Vậy sao không nhào qua tí về OOP, để xem .NET khác gì so với các ngôn ngữ khác khi so sánh giữa Abstract và Interface?
4. Sự khác biệt giữa Abstract và Interface trong .NET
Câu hỏi Abtract, Interface nó như cái gì đó default và cơ bản khi phỏng vấn bất cứ ngôn ngữ lập trình hướng đối tượng nào.
Cụ thể anh em có thể tham khảo bảng so sánh dưới đây:
Abstract class
Interface
Sử dụng để khai báo properties, events, methods và fields
Trong interface không thể khai báo các field.
Nhiều loại hình access biến như public, private, protected được hỗ trợ bởi Abstract
Với interface thì chỉ public được hỗ trợ
Với Abstract thì bản thân nó chấp nhận kiểu static
Interface không hỗ trợ kiểu static
Abstract không hỗ trợ đa kế thừa
Interface hỗ trợ đa kế thừa
Về kế thừa và đa kế thừa thì dễ hiểu vì interface là can-do, tất nhiên một objects (đối tượng) có thể làm can do nhiều thứ khác nhau. Còn abstract là is-a, tức là cái gì đó. Việc cho phép đa kế thừa với interface và không cho kế thừa với abstract .NET giống với các ngôn ngữ lập trình bậc cao khác.
Nói chung là đi phỏng vấn .NET developer hay Java hay Python mà ở vị trí Backend thì thường anh em sẽ được hỏi câu hỏi này. Nếu có thể đưa ra ví dụ cụ thể giải thích Abstract và Interface nữa thì càng tuyệt.
5. Sự khác nhau giữa từ khoá ref và out
Khác với một số ngôn ngữ lập trình phổ biến như Java chỉ hỗ trợ pass by value .NET hỗ trợ cả pass by reference và pass by value. Nhưng sự khó hiểu giữa ref và out thì khác hẳn so với hai cái pass ở trên kia. Cả hai đều là pass by reference, nhưng vẫn tồn tại một số điểm khác biệt.
Quay lại với câu hỏi.
ref keyword is used to pass an already initialized variable to a method as a reference type, facilitating bi-directional data passing.
Từ khoá ref sử dụng để giá trị của biến vào function thông qua hình thức (pass by reference). Tiếng việt gọi là tham chiếu. Dữ liệu 2 chiều. Tại sao hai chiều hồi sau sẽ rõ.
out keyword is used to pass a variable as an empty container that can store multiple values to a method as a reference type. out keyword allows uni-directional data passing, as the container passed using out keyword doesn’t need to be initialized beforehand.
Trong khi đó từ khoa out sử dụng để chuyển giá tị của biến vào trong vùng chứa dưới loại tham chiếu. Với từ khoá out, biến được chuyển vào mà không cần khởi tạo vùng chứa.
Chu choa, nghe hơi căng. Thôi ví dụ gấp.
5.1 Ví dụ về ref và out
using System;
class GFG {
// Main method
static public void Main()
{
// Khai báo biến
string str3 = "Kien";
// Gọi hàm với từ khoá ref
initializeString(ref str3);
Console.WriteLine("Chào {0}", str3);
}
// Dùng từ khoá ref khai báo kiểu reference
public static void initializeString(ref string str1)
{
if (str1 == "Kien") {
Console.WriteLine("Chào Kien dep trai");
}
// Vì biến là reference nên khi khai báo lại cái nó mất ngay
// Tưởng đẹp nhưng không ngờ khi khai báo lại phát nữa thì anh Kiên lại xấu như quỷ
str1 = "Anh Kien xau nhu quy";
}
}
Kết quả khi chạy chương trình anh em sẽ nhận được 2 dòng chữ:
Chao Kien dep trai
Độp phát ngay sau đó là “anh Kien xấu như quỷ”
using System;
class GFG {
// Main method
static public void Main()
{
// Khai báo biến
string str3 = "Kien";
// Gọi hàm với từ khoá ref
initializeString(out str3);
Console.WriteLine("Chào {0}", str3);
}
// Dùng từ khoá ref khai báo kiểu reference
public static void initializeString(out string str1)
{
str1 = "Kien dep trai";
// Check parameter value
if (str1 == "Kien dep trai") {
Console.WriteLine("ok dep trai that");
}
}
}
Giá trị out put của đoạn code này là;
ok dep trai that
Chao Kien dep trai
Một ví dụ khác của out
// C# program to illustrate the
// concept of out parameter
using System;
class GFG {
// Main method
static public void Main()
{
// Declaring variable
// without assigning value
int G;
// Pass variable G to the method
// using out keyword
Sum(out G);
// Display the value G
Console.WriteLine("The sum of" +
" the value is: {0}", G);
}
// Method in which out parameter is passed
// and this method returns the value of
// the passed parameter
public static void Sum(out int G)
{
G = 80;
G += G;
}
}
Output của chương trình này
The sum of the value is: 160
In ra cả hai dòng chữ như này cho ta thấy cả out và ref đều là kiểu tham trị. Tức là vào và ra function thì giá trị của biến đều thay đổi. Vậy điểm khác nhau của out và ref là gì?.
Parameter truyền vào function thông qua hình thức ref cần được khởi tạo trước
Parameter truyền vào function thông qua hình thức out không cần được khởi tạo trước
Không cần khởi tạo giá trị trước khi trả về cho function gọi
Cần khởi tạo để trả về vì lúc đưa vào đã không có gì còn trả ra không có gì thì toang
Hữu dụng khi giá trị vào hàm ra hàm phát là thay đổi mãi mãi luôn, không cần quay lại giá trị cũ như pass by value
Không cần khởi tạo nên nhận vào một nhưng trả về 3,4,5. Hữu dụng khi hàm trả về nhiều giá trị
Câu này đem đi phỏng vấn .NET developer mà trả lời trôi chảy thì cũng khá là khoai đó chơ.
6. Tham khảo thêm câu hỏi phỏng vấn .NET developer
Trên đây là 5 câu hỏi phỏng vấn .NET developer. Mong rằng với các câu hỏi này, anh em có thời gian tổng hợp lại kiến thức. Chuẩn bị tốt nhất cho buổi phỏng vấn .NET developer.
Đôi khi chúng ta cần phải ghi lại trạng thái bên trong của một đối tượng. Điều này là bắt buộc khi thực hiện tại các điểm kiểm tra và cung cấp cơ chế hoàn tác cho phép người dùng có thể khôi phục từ các lỗi. Chúng ta phải lưu thông tin trạng thái ở đâu đó để có thể khôi phục các đối tượng về trạng thái trước đó của chúng. Nhưng các đối tượng thường đóng gói một phần hoặc tất cả trạng thái của chúng, khiến nó không thể truy cập được vào các đối tượng khác và không thể lưu ở bên ngoài. Public các trạng thái này sẽ vi phạm nguyên tắc đóng gói, có thể làm giảm độ tin cậy và khả năng mở rộng của ứng dụng. Trong những trường hợp như vậy chúng ta có thể nghĩ đến Memento Pattern, nó sẽ giúp chúng ta giải quyết vấn đề này.
Memento Pattern là gì?
“Without violating encapsulation, capture and externalize an object’s internal state so that the object can be returned to this state later.”
Memento là một trong những Pattern thuộc nhóm hành vi (Behavior Pattern). Memento là mẫu thiết kế có thể lưu lại trạng thái của một đối tượng để khôi phục lại sau này mà không vi phạm nguyên tắc đóng gói.
Dữ liệu trạng thái đã lưu trong đối tượng memento không thể truy cập bên ngoài đối tượng được lưu và khôi phục. Điều này bảo vệ tính toàn vẹn của dữ liệu trạng thái đã lưu.
Hoàn tác (Undo) hoặc ctrl + z là một trong những thao tác được sử dụng nhiều nhất trong trình soạn thảo văn bản (editor). Mẫu thiết kế Memento được sử dụng để thực hiện thao tác Undo. Điều này được thực hiện bằng cách lưu trạng thái hiện tại của đối tượng mỗi khi nó thay đổi trạng thái, từ đó chúng ta có thể khôi phục nó trong mọi trường hợp có lỗi.
Originator : đại diện cho đối tượng mà chúng ta muốn lưu. Nó sử dụng memento để lưu và khôi phục trạng thái bên trong của nó.
Caretaker : Nó không bao giờ thực hiện các thao tác trên nội dung của memento và thậm chí nó không kiểm tra nội dung. Nó giữ đối tượng memento và chịu trách nhiệm bảo vệ an toàn cho các đối tượng. Để khôi phục trạng thái trước đó, nó trả về đối tượng memento cho Originator.
Memento : đại diện cho một đối tượng để lưu trữ trạng thái của Originator. Nó bảo vệ chống lại sự truy cập của các đối tượng khác ngoài Originator.
Lớp Memento cung cấp 2 interfaces: 1 interface cho Caretaker và 1 cho Originator. Interface Caretaker không được cho phép bất kỳ hoạt động hoặc bất kỳ quyền truy cập vào trạng thái nội bộ được lưu trữ bởi memento và do đó đảm bảo nguyên tắc đóng gói. Interface Originator cho phép nó truy cập bất kỳ biến trạng thái nào cần thiết để có thể khôi phục trạng thái trước đó.
Lớp Memento thường là một lớp bên trong của Originator. Vì vậy, originator có quyền truy cập vào các trường của memento, nhưng các lớp bên ngoài không có quyền truy cập vào các trường này.
Ví dụ Memento Pattern quản lý trạng thái của một đối tượng
Ví dụ đơn giản bên dưới cho phép chúng ta lưu trữ trạng thái của một đối tượng và có thể phục hồi lại trạng thái của nó tại một thời điểm đã được lưu trữ.
package com.gpcoder.patterns.behavioral.memento.state;
import java.util.ArrayList;
import java.util.List;
class Originator {
private String state;
public void set(String state) {
System.out.println("Originator: Setting state to " + state);
this.state = state;
}
public Memento saveToMemento() {
System.out.println("Originator: Saving to Memento.");
return new Memento(this.state);
}
public void restoreFromMemento(Memento memento) {
this.state = memento.getSavedState();
System.out.println("Originator: State after restoring from Memento: " + state);
}
public static class Memento {
private final String state;
public Memento(String stateToSave) {
state = stateToSave;
}
public String getSavedState() {
return state;
}
}
}
class MementoExample {
public static void main(String[] args) {
List<Originator.Memento> savedStates = new ArrayList<>(); // caretaker
Originator originator = new Originator();
originator.set("State #1");
originator.set("State #2");
savedStates.add(originator.saveToMemento());
originator.set("State #3");
savedStates.add(originator.saveToMemento());
originator.set("State #4");
originator.restoreFromMemento(savedStates.get(1)); // This point need roll back
}
}
Output của chương trình:
Originator: Setting state to State #1
Originator: Setting state to State #2
Originator: Saving to Memento.
Originator: Setting state to State #3
Originator: Saving to Memento.
Originator: Setting state to State #4
Originator: State after restoring from Memento: State #3
Ví dụ Memento Pattern với ứng dụng quản lý tọa độ các điểm ảnh
Trong ví dụ bên dưới chúng ta sẽ tách biệt các thành phần của Memento Pattern ra từng class riêng lẻ để tiện quản lý. Chương trình cho phép chúng ta có thể khôi phục lại dữ liệu tại một thời điểm đã lưu trữ trước đó.
Originator.java
package com.gpcoder.patterns.behavioral.memento.point;
public class Originator {
private double x;
private double y;
public Originator(double x, double y) {
this.x = x;
this.y = y;
}
public double getX() {
return x;
}
public double getY() {
return y;
}
public void setX(double x) {
this.x = x;
}
public void setY(double y) {
this.y = y;
}
public Memento save() {
return new Memento(this.x, this.y);
}
public void undo(Memento mem) {
this.x = mem.getX();
this.y = mem.getY();
}
@Override
public String toString() {
return "X: " + x + ", Y: " + y;
}
}
Memento.java
package com.gpcoder.patterns.behavioral.memento.point;
public class Memento {
private double x;
private double y;
public Memento(double x, double y) {
this.x = x;
this.y = y;
}
public double getX() {
return x;
}
public double getY() {
return y;
}
}
CareTaker.java
package com.gpcoder.patterns.behavioral.memento.point;
import java.util.HashMap;
import java.util.Map;
public class CareTaker {
private final Map<String, Memento> savepointStorage = new HashMap<>();
public void saveMemento(Memento memento, String savedPointName) {
System.out.println("Saving state..." + savedPointName);
savepointStorage.put(savedPointName, memento);
}
public Memento getMemento(String savedPointName) {
System.out.println("Undo at ..." + savedPointName);
return savepointStorage.get(savedPointName);
}
public void clearSavepoints() {
System.out.println("Clearing all save points...");
savepointStorage.clear();
}
}
State initial: X: 510.0, Y: 10.0
Saving state...SAVE #1
State changed: X: 510.0, Y: 23.181818181818183
Undo at ...SAVE #1
State after undo: X: 510.0, Y: 10.0
Saving state...SAVE #2
State changed: X: 1.32651E8, Y: 10.0
Saving state...SAVE #3
State saved #3: X: 1.32651E8, Y: 1.3265097E8
Saving state...SAVE #4
State saved #4: X: 1.32651E8, Y: 6029590.909090909
Undo at ...SAVE #2
Retrieving at saved #2: X: 1.32651E8, Y: 10.0
Lợi ích của Memento Pattern là gì?
Lợi ích:
Bảo bảo nguyên tắc đóng gói: sử dụng trực tiếp trạng thái của đối tượng có thể làm lộ thông tin chi tiết bên trong đối tượng và vi phạm nguyên tắc đóng gói.
Đơn giản code của Originator bằng cách để Memento lưu giữ trạng thái của Originator và Caretaker quản lý lịch sử thay đổi của Originator.
Một số vấn đề cần xem xét khi sử dụng Memento Pattern:
Khi có một số lượng lớn Memento được tạo ra có thể gặp vấn đề về bộ nhớ, performance của ứng dụng.
Khó đảm bảo trạng thái bên trong của Memento không bị thay đổi.
Sử dụng Memento Pattern khi nào?
Các ứng dụng cần chức năng cần Undo/ Redo: lưu trạng thái của một đối tượng bên ngoài và có thể restore/ rollback sau này.
Thích hợp với các ứng dụng cần quản lý transaction.
Anh em khi tìm hiểu Database Developer chắc chắn là có biết về database (hệ cơ sở dữ liệu). Nhìn sơ cái tên có thể đoán ra Database Developer là lập trình viên liên quan tới cơ sở dữ liệu. Nhưng có phải ông lập trình viên này ăn rồi ngồi viết query lấy data này, xoá dữ liệu kia?
Ăn uống thoải mái xong bật Caplocks viết SQL thui hở chời?
Tất cả những câu hỏi, thắc mắc của anh em về Database Developer sẽ được làm rõ qua bài viết này. Ok, bắt đầu thôi nào!.
1. Database Developer cụ thể là làm gì?
Tất nhiên rồi, không có định nghĩa không hình dung được Database Developer là làm gì đâu?
“Database Developers commonly work to a process known as the Software Development Life Cycle (SDLC), which contains six stages: analysis, design, development and testing, implementation, documentation, and evaluation. They work in the IT department of tech–driven organisations in a broad range of industries.”
Database Developer thường làm việc cho một quy trình thường gọi là Quy trình phát triển phần mềm (SDLC), bao gồm sau quá trình chính là phân tích, thiết kế, phát triển và kiểm thử, hiện thực, tài liệu và đánh giá. Họ làm việc trong IT department của nhiều nghành công nghiệp. Họ cũng có thể làm việc tự do cho một loạt khách hàng khác nếu muốn.
À rồi, vậy Database developers vẫn tham gia vào quá trình phát triển phần mềm như những anh em khác trong đội Frontend, Backend hay Product Owner. Nhưng focus vào hệ cơ sở dữ liệu.
Không phải chỉ ăn rồi ngồi rõ query. Một số nhiệm vụ chính của DB Developer bao gồm:
Thiết kế hệ cơ sở dữ liệu (Designing database systems – cái này không dễ đâu nha).
Tạo và cập nhật tài liệu liên quan tới hệ cơ sở dữ liệu (Creating and updating database documentation).
Thu thập yêu cầu của dự án bằng cách liên hệ với các bên có liên quan (Gathering project requirements by liaising with stakeholders).
Anh em nhớ chỉ là một số nhiệm vụ chính thôi nha. Trong thực tế Database Developer có thể tham gia vào quá trình kiểm thử phần mềm. Bản thân có thể kết hợp mượt mà với QC (quality control) vì bản thân ông Database Developer hiểu rất rõ về dữ liệu hệ thống.
Ngoài ra phần tài liệu về hệ cơ sở dữ liệu cũng quan trọng không kém. Dùng loại nào, có function, có function hay store procedure nào không? Database trigger như nào?,… Tất cả đều được ghi vào tài liệu rõ ràng và cụ thể.
Rõ ràng là dữ liệu là thứ sống còn với bất cứ ứng dụng hay hệ thống nào. Dữ liệu là thứ quý giá, được bảo vệ kỹ càng. Mà đã là người làm việc với thứ quý giá thì auto trở nên quan trọng đúng không anh em?.
Là người trực tiếp làm việc với Database (hệ cơ sở dữ liệu), tham gia vào quá trình thiết kế hệ cơ sở dữu liệu. Database developers có vai trò vô cùng quan trọng trong dự án.
Thiết kế hệ cơ sở dữ liệu mà không đúng hoặc không adapt được với requirement thì xem như ứng dụng không thể hoàn thành.
Nếu thiết kế hệ cơ sở dữ liệu bị sai mà vẫn đem vào vận hành thì còn thảm hoạ hơn, khi dữ liệu đã là production mà nó còn sai thì anh em chỉ có đường ngồi nhìn.
Anh em Backend developer cần có data test hoặc có câu queries này chạy chậm, hay query chưa đúng business (lấy ra đúng thứ cần lấy) thì biết hỏi ai. Có Database developer thì còn nói gì nữa.
Rồi chị QC cần có dữ liệu để mock test nhưng mà nhìn vào danh sách một đống bảng biểu thư từ thì chị ấy tiền đình ra (do một phần ở nhà có con nhỏ, phóng đại lên tý cho điêu thôi). Mà tạo mock data thì nhờ ai. Lại nhờ Database developer chứ ai?
Một số ví dụ trên cho ta biết Database developer là một vị trí quan trọng trong quá trình phát triển phần mềm. Vậy giờ muốn trở thành Database developer thì cần có những kỹ năng nào?
Tất nhiên là mỗi vị trí đều đòi hỏi những kỹ năng riêng. Database Developer cũng vậy. Đã liên quan tới hệ cơ sở dữ liệu thì sẽ yêu cầu những kỹ năng làm việc với DB.
Cụ thể liệt kê đưới đây:
Hiểu biết về SQL, T-SQL và PL/SQL, DB2 – Proficient knowledge of SQL, T-SQL and PL / SQL, DB2
Kinh nghiệm với Oracle database – Experience with Oracle databases
Hiểu biết về hệ cơ sở dữ liệu NoSQL – Knowledge of non-relational databases like NoSQL
Chuẩn bị data – Knowing how to prepare data
Ước lượng tiền – Ability to perform cost calculations
Integratioin hệ thống và kiểm thử chất lượng – system integration and quality testing
Hiểu biết về hệ điều hành như Windows hoặc Linux – Knowledge of operating systems like Windows and Linux
Hiểu biết về ngôn ngữ lập trình như C++ hay Java – Knowledge of programming languages like C ++, Java, C#, etc.
Hiểu biết về HTML – Experience with page description languages like HTML
Hiểu biết về nhiều loại hình cơ sở dữ liệu luôn là một điểm cộng. Mà hiểu là hiểu sâu nha
3.1 Nice to have – có thêm càng tốt
Ủa gì có code Java, C++ luôn hở? Tất nhiên rồi anh em ơi, vẫn cần có tư duy lập trình và tốt nhất là nên biết một ngôn ngữ lập trình nào đó. Kỹ sư hệ thống hay kiến trúc phần nhiều họ cũng từ developers đi lên. Nên cũng biết về code, như bài viết về Data Analyist cũng có phân tích với anh em về điểm này rồi.
Phía trên chỉ viết về Oracle với database. Nhưng anh em nếu có kinh nghiệm với các hệ cơ sở dữ liệu khác như Postgres, MySQL, MariaDB càng tốt.
Một số kỹ năng khác nếu có thì là điểm cộng lớn như:
Chuẩn bị dữ liệu test – Kiểu mock data phục vụ cho IT (Integrations test), RT (Regression test)
Migration data từ hệ cơ sở dữ liệu này qua hệ cơ sở dữ liệu khác (từ Oracle qua Postgres, …). Trước nhớ có đợt Oracle đắt qua các công ty thường chuyển qua hệ cơ sở dữ liệu Postgres.
4. Con đường cho Database Developers
Nói về hiểu biết thì mức độ hiểu biết về hệ cơ sở dữ liệu của Database developer nhất thiết phải sâu và rộng hơn so với Backend developer. Kinh nghiệm về thiết kế DB cũng phải dày dặn hơn. Những kinh nghiệm này có được do đã trải qua nhiều lần sai trước đó về mặt dữ liệu.
Về hướng đi thi Database develops có thể chuyển qua Data Analytics, Computer Science hoặc Solution Architect nếu muốn. Tất nhiên các hướng đi về Computer Science đòi hỏi nỗ lực lớn để học thêm (không những về kinh nghiệm làm việc mà còn các kiến thức khác về toán học).
Nếu lựa chọn theo hướng Solutions Architect thì cần kinh nghiệm code và hiểu biết rộng hơn về ngôn ngữ lập trình và hệ thống. SA đòi hỏi cái nhìn và góc nhìn bao quát rộng, không chỉ gói gọn ở hệ cơ sở dữ liệu.
Trong top những ngôn ngữ lập trình phổ biến thì Java luôn luôn có một vị trí vững chắc; cũng vì thế mà nhu cầu tuyển dụng Java Developer luôn cao cho bất cứ lĩnh vực nào. Để chuẩn bị cho một buổi phỏng vấn vị trí lập trình viên Java, bài viết hôm nay mình cùng các bạn liệt kê ra top 10 câu hỏi phỏng vấn Java Developer thường gặp nhất cùng cách trả lời cụ thể nhé.
Câu 1: Bạn có thể nói gì về Java?
Java là một ngôn ngữ lập trình bậc cao, hướng đối tượng, dựa trên class (lớp); được phát triển bởi Sun Microsystems từ những năm 1995, hiện nay thuộc sở hữu của Oracle. Đặc điểm nổi bật nhất của Java là khả năng cho phép các nhà phát triển ứng dụng viết code một lần và có thể chạy ở mọi nơi. Để làm được điều này thì các ứng dụng Java sẽ được biên dịch thành bytecode, sau đó chạy trên nền máy ảo JVM đã được cài sẵn trên nền tảng hệ điều hành.
Cú pháp của Java tương tự như C và C++; phiên bản mới nhất hiện nay là Java 19 phát hành tháng 9/2022. Java được sử dụng trong đa dạng các lĩnh vực:
Desktop Application
Web Application
Enterprise Application (phổ biến như các nghiệp vụ ngân hàng)
Những tính năng nổi trội của ngôn ngữ lập trình Java:
Hướng đối tượng: tất cả trong Java đều là Object nên có thể dễ dàng mở rộng
Nền tảng độc lập: Java biên dịch source code thành bytecode chạy trên nền tảng máy ảo JVM và không phụ thuộc vào nền tảng hệ điều hành
Đa luồng: Java hỗ trợ đa luồng, tức là chương trình viết ra có thể thực hiện nhiều tác vụ cùng lúc
Dễ học, dễ hiểu: Java có cú pháp dựa trên C/C++, đồng thời loại bỏ các tính năng phức tạp và hiếm sử dụng; có tính năng tự động hủy cấp phát bộ nhớ,… giúp người học dễ đọc, dễ hiểu code.
Bảo mật cao: việc chạy bên trong một máy ảo JVM giúp các chương trình Java khó bị can thiệp tác động, ngoài ra Java có sẵn các lớp giúp chương trình của bạn bảo mật tốt hơn: Classloader, Bytecode Verifier, Security Manager
Tính phân tán: Java tạo điều kiện cho người dùng tạo những ứng dụng phân tán bằng RMI và EJB, nó giúp chúng ta có thể truy cập đến các tệp bằng cách gọi phương thức từ bất kỳ máy nào trên Internet
JVM: Java Virtual Machine là máy ảo để thực thi các Java bytecode. Để chạy chương trình Java thì bắt buộc bạn phải cài đặt JVM trên máy của bạn (mỗi hệ điều hành sẽ có phiên bản khác nhau); sau đó source code Java được biên dịch thành bytecode và chuyển vào chạy trên nền JVM
JRE: Java Runtime Environment là môi trường thực thi Java, nó chính là trình triển khai JVM cùng với các plugins, thư viện cần thiết để thực thi chương trình
JDK: Java Development Kit là bộ công cụ phát triển ứng dụng Java. Nó chứa JRE, trình biên dịch bytecode cùng các công cụ hỗ trợ khác về debug, doc. Để lập trình Java chúng ta cần cài đặt JDK
Nói tóm lại:
JDK = JRE + Development Tool
JRE = JVM + Library Classes
Câu 4: Lập trình hướng đối tượng là gì?
Lập trình hướng đối tượng (OOP – Object Oriented Programming) là một phương pháp lập trình dựa trên khái niệm về lớp và đối tượng. Đối tượng ở đây là thể hiện của 1 lớp, bao gồm các thuộc tính và phương thức. OOP bao gồm 4 tính chất:
Tính đóng gói: che giấu thông tin quan trọng của 1 lớp
Tính đa hình: 1 hành động có thể thực hiện theo nhiều cách khác nhau
Tính trừu tượng: ẩn các triển khai chi tiết và chỉ hiển thị tính năng với người dùng
Tính kế thừa: khả năng tái sử dụng thuộc tính và phương thức của lớp
Java là một ngôn ngữ lập trình hướng đối tượng, mọi thứ trong Java đều là một đối tượng; vì thế trong hầu hết các bài giảng, khóa học về OOP thì luôn dùng Java làm ngôn ngữ thực hành.
Trong Java, có 4 từ khóa xác định phạm vi truy cập (access specifiers) gồm:
Public (công khai): cho phép truy cập vào bất kỳ lớp nào hoặc thông qua bất kỳ phương thức nào thông qua tên của chúng
Private (riêng tư): chỉ cho phép truy cập trong chính lớp mà chúng chỉ định.
Protected (bảo vệ): cho phép truy cập từ trong lớp, từ một lớp con hoặc từ lớp chung gói
Default (mặc định): phạm vi tiêu chuẩn, chỉ cho phep truy cập từ cùng một gói
Câu 6: Có những kiểu dữ liệu nào trong Java. Autoboxing và Unboxing là gì?
Trong Java có 8 kiểu dữ liệu cơ bản (Primitive Type):
byte
short
int
long
float
double
boolean
char
Trong Java, tất cả đều là Object; vì thế trong quá trình biên dịch, Java sẽ tự động chuyển đổi giữa kiểu dữ liệu cơ bản (Primitive Type) về đối tượng tương ứng với lớp (Wrapper class) của kiểu dữ liệu đó. Chẳng hạn int chuyển sang lớp Integer, kiểu double chuyển sang Double, … Quá trình này gọi là Autoboxing. Và ngược lại để chuyển từ Integer về int, gọi là Unboxing.
Câu 7: Thread trong Java là gì?
Trong Java, quá trình thực thi một chương trình gọi là Process; một Process có thể có nhiều thực thi đơn bên trong gọi là Thread (luồng).
Một Thread có thể có những trạng thái sau:
New: khi tạo 1 lớp instance của lớp Thread và chưa gọi phương thức start
Runnable: trạng thái Thread sẵn sàng thực thi
Running: đang xử lý code trong Thread
Non-Runable (Blocked): trạng thái khi Thread vẫn còn tồn tại nhưng không thể chạy do không đủ điều kiện. Nó bao gồm việc bị blocked trên I/O và blocked trên Synchronization.
Terminated: Thread kết thúc
Câu 8: Deadlock là gì? Làm sao để tránh nó.
Deadlock là một trạng thái xảy ra khi có 2 process A và B cùng thực hiện, trong đó A cần chờ B thực hiện xong để chạy tiếp và đồng thời B cũng chờ A thực hiện xong mới có thể chạy tiếp. Kết quả là cả 2 process A và B đều không thể chạy được, chờ nhau vô thời hạn.
Để tránh deadlock, có 1 số cách xử lý như sau:
Tránh Nested Locks: không cấp khóa cho nhiều thread
Tránh cấp khóa không cần thiết
Sử dụng Thread.join set timeout cho Thread
Câu 9: Các interface cơ bản của Collections
Java Collections framework sử dụng để thao tác dữ liệu dạng tập hợp các objects. Có gồm các interface sau:
Collection: lớp cơ bản nhất chứa các phương thức làm việc với tập hợp objects như duyệt qua các phần tử
Set: mỗi phần tử trong tập hợp chỉ xuất hiện một lần duy nhất
List: danh sách tuyến tính sắp xếp theo một thứ tự nhất định
Queue: hàng đợi, kiểu dữ liệu FIFO (first-in first-out) vào trước ra trước
Map: đồ thị, ánh xạ lưu trữ dạng key-value
Lưu ý là Set, Lis, Queue đều kế thừa Collection; riêng Map thì là một interface độc lập với chỉ những phương thức riêng nó.
Câu 10: Garbage Collectors là gì?
Bộ thu gom rác Garbage Collectors là một quá trình thụ động thực thi nhiệm vụ quản lý bộ nhớ trong Java. Trong quá trình chạy chương trình Java, các đối tượng được tạo ra ở vùng nhớ heap (một phần bộ nhớ dành cho chương trình), sau đó nếu đối tượng không được sử dụng đến nữa thì garbage collectors sẽ truy tìm và xóa bỏ để thu hồi dung lượng bộ nhớ.
Nếu một object được set reference null thì đối tượng đó sẽ được đánh dấu là sẵn sàng cho viện thu gom rác trong chu kỳ hoạt động tiếp theo của Garbage Collectors. Để khởi động việc dọn rác, chúng ta có thể sử dụng các methods System.gc hoặc Runtime.gc
Kết bài
Trên đây là 10 câu hỏi thường gặp nhất trong một cuộc phỏng vấn vị trí Java Developer, hy vọng bài viết này mang lại cho bạn sự chuẩn bị tốt nhất, sẵn sàng đáp ứng yêu cầu của công ty tuyển dụng. Cảm ơn các bạn đã đọc bài, hẹn gặp lại trong các bài viết tiếp theo của mình.
Bài viết được sự cho phép của tác giả Trần Hữu Cương
Ở bài này chúng ta sẽ thảo luận về sự khác nhau giữa vài method của Session interface: save, persist, update, merge, saveOrUpdate.
(Các framework ORM khác có thể không dùng interface session mà dùng interface entityManager nên sẽ có sự khác nhau giữa tên của các method)
1. Session là 1 cài đặt của Persitence Context
Session interface có một và method thực hiện lưu dữ liệu vào database như persist, save, update, merge, saveOrUpdate. Để hiểu sự khác nhau giữa những method này trước hết ta cần phải hiểu mục đích của Session interface và các trạng thái/quan hệ của 1 thể hiện entity với Session
Chúng ta cũng nên hiểu một chút về lịch sử phát triển của Hibernate, điều gì dẫn tới sự trùng lặp một số API method.
1.1. Quản lý các thể hiện entity
Ngoài mối quan hệ giữa các object, một vấn đề khác được Hibernate dự định giải quyết là vấn đề quản lý các entity trong thời gian chạy (runtime). Khái nhiệm “persistence context” là giải pháp của Hibernate cho vấn đề này. Persistence context có thể hiểu như là 1 container hoặc mức cache đầu tiên cho tất cả các object mà ta đã tải hoặc save vào database trong 1 session.
Session là 1 lý luận transaction, nó bao là ranh giới để định nghĩa logic nghiệp vụ của ứng dụng của bạn. Khi bạn làm việc với database thông qua một persistence context và tất cả các thể hiện entity đều được gán với context, bạn nên có 1 thể hiện phân biệt của entity cho mỗi bản ghi database mà bạn giao tiếp trong suốt suốt session.
Trong 1 Session persistence context, các entity có 4 trạng thái:
transient: đối tượng chưa bao giờ bị quản lí bởi session và nó không tương ứng với bản ghi nào trong database; thông thường đây là 1 đối tượng mới được tạo để save vào database
persistent: đối tượng bị quản lý bởi session và là unique (trong 1 session không thể tồn tại 2 object có cùng id), sau khi flush bởi session sẽ tồn tại 1 bản ghi tương ứng đối tượng này trong database.
detached: đối tượng này đã từng bị quản lý bởi session nhưng hiện tại thì không. (bị evict(), clear(), close())
removed:cũng giống như detached nhưng bản ghi tương ứng với đối tượng này trước đó đã bị xóa khỏi database. (bị remove())
Hibernate là cài đặt ORM Java thành công nhất. Không ngạc nhiên khi mà các đặc tả cho Java persistence API (JPA) bị ảnh hưởng nhiều bởi Hibernate API. Cũng không ngạc nhiên khi Hibernate là ORM Framework phổ biến nhất.
Để thực hiện các cài đặt theo chuẩn của JPA, nhiều Hibernate API phải sửa lại. Một vài method được thêm vào Session interface để khớp với EntityManager interface. Những method này phục vụ các mục đích giống với method gốc.
2. Sự khác nhau giữa các hành động thực thi
Các method persist, save, update, merge, saveOrUpdate không lập tức đưa ra kết quả tương ứng SQL UPDATE hoặc INSERT. Thực tế thì việc cập nhật dữ liệu vào database xảy ra khi transaction được commit hoặc flushing session.
2.1. Persist
Method persist được dùng để thêm 1 thể hiện entity mới vào persistence context (ví dụ chuyển trạng thái của entity từ transient sang persistent
Chúng ta thường gọi method này khi chúng ta muốn thêm 1 bản ghi vào database:
Person person = newPerson();person.setName("John");session.persist(person);
Điều gì xảy ra sau khi method persist được gọi? Đối tượng person bị đổi trạng thái từ transient sang persistent. Đối tượng vào trong persistence context nhưng vẫn chưa được lưu vào database. Thông thường lệnh INSERT sẽ chỉ xuất hiện khi commit transaction hoặc flushing/close session.
Lưu ý rằng persist method trả về kiểu void.
Ý nghĩa của method persist:
Thay đổi trạng thái 1 đối tượng từ transient sang persistent (và thực hiện cascades tới tất cả các relations của nó nếu cascade = PERSIST hoặc cascade = ALL)
Nếu đối tượng đã là persistent thì nó không làm gì cả (nhưng vẫn thực hiện cascades tới tất cả các relations của nó nếu cascade = PERSIST hoặc cascade = ALL)
Nếu đối tượng là detached nó sẽ xảy ra exception khi gọi method hoặc khi commit hoặc khi flushing session.
Person person = newPerson();person.setName("John");session.persist(person);session.evict(person);session.persist(person); // PersistenceException!
2.2. Save
Method save là một method gốc trong đặc tả của JPA
Mục đích cơ bản của method save giống với persist, tuy nhiên nó có sự khác nhau trong cài đặt chi tiết. Tài liệu cho method này nhấn mạnh rằng nó persists 1 thể hiện (hiểu nôm na là nó sẽ tạo ra 1 định danh mới cho thể hiện)
Person person = newPerson();person.setName("John");Long id = (Long) session.save(person);
Nó khác với method persist khi bạn cố gắng save 1 thể hiện detached:
Person person = newPerson();person.setName("John");Long id1 = (Long) session.save(person);session.evict(person);Long id2 = (Long) session.save(person);
Giá trị của id2 sẽ khác với id1. Khi gọi method save 1 thể hiện detached nó sẽ tạo ra 1 thể hiện persistent và chỉ định cho một định danh/id mới. Kết quả là tạo ra 2 bản ghi vào database khi commit hoặc flushing.
2.3. Merge
Mục đích chính của method merge là update một thể hiện entity có trạng thái persistent vào 1 một thể hiện entity có trạng thái detached.
Trong ví dụ dưới đây, chúng ta eviect(detach) 1 entity đã saved, thay đổi name và merge.
Person person = newPerson(); person.setName("John"); session.save(person);
session.evict(person);person.setName("MarPerson mergedPerson = (Person) session.merge(person);
Lưu ý rằng method merge trả về 1 đối tượng, đó là đối tượng đã được merge không phải đối tượng truyền vào.
2.4. Update
Cũng giống như method persist và save, method update là method gốc trong đặc tả JPA
Nó giống với method merge và đã có từ khá lâu trước khi method merge được thêm vào, 1 số ý nghĩa khác của method update là:
Trả về kiểu void, thay đổi trạng thái của object truyền vào từ detached sang persistent
Person person = newPerson();person.setName("John");session.save(person);session.evict(person);person.setName("Mary");session.update(person);
Xảy ra exception nếu bạn truyền vào 1 đối tượng transient.
Person person = newPerson();person.setName("John");session.update(person); // PersistenceException!
2.5. saveOrUpdate
Method saveOrUpdate chỉ xuất hiện trong Hibernate API và không có
Điểm khác chính của method saveOrUpdate là nó không xảy ra exception khi truyền vào 1 đối tượng transient. Thay vì đó, nó sẽ tạo ra 1 thể hiện persistent
Person person = newPerson();person.setName("John");session.saveOrUpdate(person);
3. Kết luận
Chúng ta đã thảo luận mục đích của sự khác nhau trong các method của Hibernate Session. Các trạng thái của object trong persistence context, sự chuyển đổi giữa các trạng thái và tại sao lại có các method có chức năng giống nhau. Phân biệt save, persist, update, merge, saveOrUpdate trong hibernate.
Bài viết được sự cho phép của tác giả Trần Văn Dem
ThreadLocal là một công cụ rất mạnh mẽ của Java Concurrent. Nó cung cấp API để lưu data trên từng Thread, các Thread tự quản lý data của mình. Khi cần dùng thì không cần phải khởi tạo lại dữ liệu mà có thể lấy ra dùng trực tiếp mà không cần khởi tạo lại đối tượng từ đó giúp tiết kiệm thời gian.
Chúng ta thường hay sử dụng các loại API sau :
public T get() : dùng để lấy dữ liệu lưu trong Thread.
public void set(T value) : dùng để lưu dữ liệu vào Thread.
Tuy nhiên sau khi đọc code của Java tôi nhận thấy ThreadLocal không tối ưu cho 2 loại API này. Cụ thể tôi đã search trên mạng và thấy một bài khá hay về FastThreadLocal của netty.
Các bạn tham khảo tại link sau. Dưới đây tôi xin giải thích đơn giản như sau.
Đầu tiên hãy phân tích hàm set của Java.
publicvoidset(T value){
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t){
return t.threadLocals;
}
/**
* Set the value associated with key.
*
* @param key the thread local object
* @param value the value to be set
*/privatevoidset(ThreadLocal<?> key, Object value){
// We don't use a fast path as with get() because it is at// least as common to use set() to create new entries as// it is to replace existing ones, in which case, a fast// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
/**
* Increment i modulo len.
*/privatestaticintnextIndex(int i, int len){
return ((i + 1 < len) ? i + 1 : 0);
}
Như thường lệ thì Java sẽ sử dụng Array để lưu giá trị của một Map. Khác với HashMap sử dụng LinkedList hoặc BTree để lưu giá trị của Key khi bị trùng HashCode để đảm bảo được khi lấy dữ liệu ra sẽ được O(1). Tại ThreadLocal với implement bên trên ta thấy như sau:
Khi 2 key không trùng mã HashCode thì các key được lưu tại vị trí int i = key.threadLocalHashCode & (len-1); điều này đảm bảo được việc set,get đạt độ phức tạp O(1)
Khi 2 key trùng mã HashCode thì sẽ tìm vị trí liền kề tiếp theo trong table mà tại đó giá trị bằng null, sau đó gán value vào vị trí đó. Điều này dẫn đến khi ta dùng phương thức get,set không còn đạt được độ phức tạp O(1) nữa. Điều này sẽ dẫn đến key tiếp theo của bạn đã bị 1 key khác không trùng mã hashcode dữ vị trí đó.
/**
* Returns the value in the current thread's copy of this
* thread-local variable. If the variable has no value for the
* current thread, it is first initialized to the value returned
* by an invocation of the {@link #initialValue} method.
*
* @return the current thread's value of this thread-local
*/public T get(){
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
/**
* Get the entry associated with key. This method
* itself handles only the fast path: a direct hit of existing
* key. It otherwise relays to getEntryAfterMiss. This is
* designed to maximize performance for direct hits, in part
* by making this method readily inlinable.
*
* @param key the thread local object
* @return the entry associated with key, or null if no such
*/private Entry getEntry(ThreadLocal<?> key){
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
elsereturn getEntryAfterMiss(key, i, e);
}
/**
* Version of getEntry method for use when key is not found in
* its direct hash slot.
*
* @param key the thread local object
* @param i the table index for key's hash code
* @param e the entry at table[i]
* @return the entry associated with key, or null if no such
*/private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e){
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
returnnull;
}
ThreadLocal sẽ tìm rất nhanh nếu không bị trùng HashCode nhưng vấn đề sẽ tăng lên khi chúng ta bị trùng mã HashCode, khi đó ThreadLocal sẽ phải duyệt qua 1 lượt các phần tử lưu trong table để tìm ra key,value chính xác điều này sẽ mất rất nhiều thời gian. Vì vấn đề này netty đã xây dựng 1 class FastThreadLocal riêng nhằm tối ưu phương pháp get,set bạn có thể tìm tại blog.
Custom FastThreadLocal
Để dùng FastThreadLocal của netty ta phải import thư viện netty vào project điều đó có thể gây lãng phí vì vậy tại đây tôi sẽ dựa trên ý tưởng của netty xây dụng ra một FastThreadLocal hy vọng sẽ giúp ích cho project của các bạn.
Đê xây một FastThreadLocal chúng ta cần phải xây dụng 2 thứ sau :
DThread một Thread kế thừa Thread của Java nhưng sẽ chứa thêm DThreadLocalMap để lưu giá trị của Thread thay vì ThreadLocal.ThreadLocalMap của Java
FastThreadLocal<T> để quản lý API get,set.
publicclassFastThreadLocal<T> {
privatestatic final AtomicInteger MARK = new AtomicInteger(0);
private final int index = MARK.getAndIncrement();
private ThreadLocal<T> local;
private Supplier<T> supplier;
publicFastThreadLocal() {
}
public T get(){
Thread t = Thread.currentThread();
if (t instanceof DThread){
DThread.DThreadLocalMap map =((DThread)t).getdThreadLocalMap();
T value = (T) map.getData(this.index);
if (value == null && supplier !=null){
value = supplier.get();
}
returnvalue;
}else {
if (local == null) local = new ThreadLocal<>();
return local.get();
}
}
publicvoidset(T value){
Thread t = Thread.currentThread();
if (t instanceof DThread){
DThread.DThreadLocalMap map =((DThread)t).getdThreadLocalMap();
map.setData(this.index , value);
}else {
if (local == null) local = new ThreadLocal<>();
local.set(value);
}
}
publicstatic <T> FastThreadLocal<T> withInit(Supplier<T> supplier){
FastThreadLocal<T> instance = new FastThreadLocal<>();
instance.local = ThreadLocal.withInitial(supplier);
instance.supplier = supplier;
return instance;
}
}
publicclassDThreadextendsThread {
private final DThreadLocalMap dThreadLocalMap;
publicDThread(Runnable runnable, String s) {
super(runnable, s);
this.dThreadLocalMap = new DThreadLocalMap();
}
publicDThread(Runnable runnable) {
super(runnable);
this.dThreadLocalMap = new DThreadLocalMap();
}
publicDThread() {
this.dThreadLocalMap = new DThreadLocalMap();
}
public DThreadLocalMap getdThreadLocalMap() {
return dThreadLocalMap;
}
publicstaticclassDThreadLocalMap {
privatestatic final int INIT_SIZE = 8;
private Object[] data;
publicDThreadLocalMap() {
this.data = new Object[INIT_SIZE];
}
public Object getData(int index) {
if (index > data.length) returnnull;
return data[index];
}
privatevoidexpand(){
Object[] oldArray = data;
// copy fom nettyint newCapacity = oldArray.length;
newCapacity |= newCapacity >>> 1;
newCapacity |= newCapacity >>> 2;
newCapacity |= newCapacity >>> 4;
newCapacity |= newCapacity >>> 8;
newCapacity |= newCapacity >>> 16;
newCapacity ++;
data = Arrays.copyOf(oldArray, newCapacity);
}
publicvoidsetData(int index, Object value) {
if (index > data.length){
expand();
}
Object[] temp = data;
temp[index] = value;
}
}
}
Các bạn có thể tham khảo cách code này hoặc cải tiến lên để phù hợp với bài toán của mình. Chắc chắn cách implement này sẽ có độ phức tạp O(1).
Câu lệnh điều kiện là một phần kiến thức của câu lệnh điều khiển luồng (control flow). Cũng bởi vì kiến thức về câu lệnh điều khiển luồng này hơi nhiều và quan trọng, nên mình tách chúng ra làm hai nhóm. Nhóm thứ nhất bao gồm các câu lệnh điều kiện (hay còn gọi là các câu lệnh rẽ nhánh) mà bạn sẽ làm quen hôm nay. Nhóm còn lại là câu lệnh lặp bạn sẽ được làm quen ở bài sau.
Đầu tiên chúng ta nói về khái niệm chung của hai nhóm, khái niệm câu lệnh điều khiển luồng là gì nhé.
Khái Niệm Câu Lệnh Điều Khiển Luồng
Để dễ hiểu khái niệm này nhất, thì bạn hãy nhớ lại việc code của mình ở các bài học trước xem nào (mặc dù chúng ta chưa code nhiều lắm). Các bạn có thể thấy khi bạn code, và các dòng code đó được IDE thực thi, chúng sẽ được trình biên dịch này đọc và thực hiện một cách tuyến tính từ trên xuống đúng không nào, từ dòng số 1 đến dòng cuối cùng.
Nhưng thực tế không phải lúc nào chúng ta cũng xây dựng một ứng dụng với logic đơn giản như vậy. Các project thực tế đều cần các giải thuật phức tạp hơn, chẳng hạn như cần truy xuất vào cơ sở dữ liệu và in ra console từng thông tin của sinh viên. Thì khi đó việc thực hiện tuyến tính từng dòng code sẽ vô cùng phức tạp, bạn phải viết hàng ngàn dòng code cho việc đọc tuần tự hàng ngàn sinh viên trong cơ sở dữ liệu. Chưa hết nếu với mỗi sinh viên được đọc lên có một số điều kiện nào đó, như chỉ in ra số sinh viên có giới tính nữ, thì việc code và thực thi tuyến tính thật sự là một cơn ác mộng.
Chính vì vậy mà các câu lệnh điều khiển luồng được các ngôn ngữ cho ra đời, nhằm tạo ra một luồng thực thi mới, đó có thể là một luồng lặp, hay luồng rẽ nhánh, sao cho chúng có thể hướng trình biên dịch thực thi một đoạn code nào đó nhiều lần, hoặc bỏ qua không thực thi đoạn code nào đó,… Như đã nói thì bài hôm nay bạn làm quen với nhóm đầu tiên trong câu lệnh điều khiển luồng, đó là nhóm các câu lệnh điều kiện giúp rẽ nhánh luồng.
Trước khi vào làm quen đến các câu lệnh, mình xin bắt đầu nói rõ về hai ký hiệu “thần thánh” mà từ bài đầu tiên bạn đã gặp, hai ký hiệu này giúp ích rất nhiều cho bài học hôm nay và cả việc code của các bạn sau này, đó là ký hiệu { và }. Cặp ngoặc nhọn này giúp tạo thành một khối lệnh (hay còn gọi là block).
Như bạn vừa biết thì khối lệnh trong Java được biểu thị bằng cặp dấu ngoặc nhọn ({ và }).
Ngược lại quá khứ quay về các bài trước, bạn sẽ thấy cặp ngoặc này đã xuất hiện trong khai báo class (bạn sẽ học đến class ở các bài viết về OOP sau). Trong trường hợp này cặp ngoặc đã tạo ra một khối lệnh đóng vai trò bao lấy code và cho biết tất cả các code bên trong đó đều là các code của class. Khi đó, chúng (các code trong cặp ngoặc đó) phải tuân theo các nguyên tắc của class (bạn sẽ biết các nguyên tắc này sau). Mọi dòng code nằm ngoài cặp ngoặc nhọn này sẽ không thuộc quyền quản lý của class đó. Cặp ngoặc nhọn mà mình nói đến xuất hiện như hình sau.
Minh họa cặp ngoặc nhọn bao lấy code của class
Hay cặp ngoặc nhọn xuất hiện ở khai báo phương thức (bạn cũng sẽ học đến phương thức ở bài sau), giúp tạo ra một khối lệnh đóng vai trò bao lấy code cho biết tất cả các code bên trong đó đều là code của phương thức đó. Cũng như trên, mọi dòng code nằm ngoài cặp ngoặc nhọn của phương thức này sẽ nằm ngoài xử lý logic của phương thức đó. Cặp ngoặc nhọn phương thức xuất hiện như sau.
Minh họa cặp ngoặc nhọn bao lấy code của phương thức
Ngoài các cặp ngoặc nhọn của class và của phương thức ra thì bạn cũng có thể tạo bất cứ khối lệnh nào trong các dòng code của bạn, chỉ cần bao các câu lệnh đó vào một cặp ngoặc nhọn. Việc tạo ra các khối lệnh như thế này có thể giúp cho các dòng code được tổ chức rõ ràng hơn.
Minh họa cặp ngoặc nhọn bao lấy code của một khối lệnh
Và hiển nhiên khối lệnh còn được áp dụng cho các câu lệnh điều kiện mà chúng ta sẽ làm quen dưới đây nữa. Chính vì vậy mà chúng ta cần làm quen với khối lệnh trước khi đi vào bài học chính thức là vậy.
Nhưng dù cho có sử dụng khối lệnh với mục đích nào đi nữa, thì bạn cũng phải nhớ một điều, là nếu có khai báo dấu { để bắt đầu một khối lệnh, thì phải có dấu } ở đâu đó để đóng khối lệnh lại. Nếu một chương trình mà có tổng số lượng dấu { không bằng với tổng số lượng dấu } sẽ có lỗi xảy ra đấy nhé.
Chúng ta làm quen với một kiến thức nữa. Vì khi các bạn đã quen với khối lệnh, thì bạn cũng nên biết phạm vi của biến. Vì phạm vi của biến sẽ bị ảnh hưởng rất lớn dựa trên các khối lệnh này.
Chúng ta xác định phạm vi của biến như thế nào? Thực ra mình cũng có đọc nhiều tài liệu về vấn đề này, có nhiều cách để xác định phạm vi, nhưng cách xác định trực quan nhất có lẽ là phân biệt phạm vi của biến dựa trên ảnh hưởng local hay global của nó.
Phạm vi local, là phạm vi mà biến đó chỉ ảnh hưởng cục bộ trong một khối lệnh, không thể dùng đến biến đó ở bên ngoài khối lệnh.
Phạm vi global, là phạm vi mà biến đó được khai báo ở khối lệnh bên ngoài, khi đó nó có ảnh hưởng đến các khối lệnh bên trong, tức các khối lệnh bên trong có thể dùng được biến global này.
Trong ví dụ dưới đây, bạn có thể thấy là biến name được mình khai báo trong một khối lệnh, nên nó là biến local của khối lệnh đó, bạn không thể dùng lại biến này ở khối lệnh khác (bạn có thể thấy hệ thống báo lỗi như hình dưới). Bạn chỉ có thể dùng được biến tên name này nếu khai báo lại biến ở khối lệnh khác, nhưng lưu ý khi đó hai biến name ở hai khối lệnh khác nhau sẽ chẳng liên quan gì với nhau cả.
Ví dụ biến name là biến local bên trong một khối lệnh
Cũng ví dụ này nhưng mình khai báo biến name ở bên ngoài khối lệnh, khi đó biến name này được xem như biến global của hai khối lệnh con, và vì vậy nó được gọi đến thoải mái mà không bị lỗi.
Ví dụ biến name là biến global của 2 khối lệnh con
Được nước lấn tới, mình tiếp tục ví dụ với biến name được để bên ngoài phương thức main() luôn, khi này nó sẽ được xem là biến global của tất cả các phương thức có trong class này (không riêng gì phương thức main() đâu nhé, và bạn cũng đừng để ý đến khai báo static của biến, khai báo dạng này sẽ được nói đến ở bài này khi bạn học sang OOP).
Ví dụ biến name là biến global các phương thức bên trong class
Hai ví dụ sau cùng trên đây đều cho ra console cùng một kết quả. Bạn cứ code và thực thi thử chương trình để kiểm chứng nhé.
Câu Lệnh if
Đến đây thì chúng ta đã xong kiến thức râu ria rồi, giờ hãy bắt đầu đi vào câu lệnh điều kiện đầu tiên, câu lệnh if. Chỉ với cái tên if thôi nhưng thực chất có tới bốn biến thể của câu lệnh dạng này mà bạn phải nắm, đó là: if, if else, if else if, và ?:. Chúng ta bắt đầu làm quen với từng loại như sau.
if
Cú pháp cho câu lệnh if như sau.
if (biểu_thức_điều_kiện) {
các_câu_lệnh;
}
Trong đó:
biểu_thức_điều_kiện là một biểu thức mà sẽ trả về kết quả là một giá trị boolean.
các_câu_lệnh sẽ được thực thi chỉ khi mà biểu_thức_điều_kiện trả về giá trị true mà thôi. Bạn thấy rằng khối lệnh đã được áp dụng để bao lấy các_câu_lệnh.
Ví dụ cho câu lệnh if.
Scanner scanner = newScanner(System.in);System.out.println("Please enter your age: ");int age = scanner.nextInt();if(age <18){ System.out.printf("You can not access");}
Mình giải thích một chút ví dụ trên, các bạn thấy biểu_thức_điều_kiện lúc này là age <18. Nghĩa là nếu biến age mà user nhập từ bàn phím nhỏ hơn 18, thì biểu thức này sẽ trả về true, khi đó trong khối lệnh của câu lệnh if này (dòng in ra console câu thông báo chưa đủ tuổi) sẽ được thực thi. Còn nếu user nhập vào một age lớn hơn 18, sẽ không có chuyện gì xảy ra, ứng dụng kết thúc. Ví dụ này đã bắt đầu dùng đến kiến thức về nhập/xuất trên console rồi đấy nhé.
Một lưu ý nhỏ thôi, là với trường hợp trong khối lệnh của if nếu chỉ có một dòng code như ví dụ trên, nhiều khi người ta bỏ luôn cả dấu { và }, khi đó câu lệnh if trên sẽ như sau.
if(age <18)
System.out.printf("You can not access");
Hay thậm chí viết như sau.
if(age <18) System.out.printf("You can not access");
if else
Cú pháp cho câu lệnh if else như sau.
if (biểu_thức_điều_kiện) {
các_câu_lệnh_1;
} else {
các_câu_lệnh_2;
}
Trong đó:
biểu_thức_điều_kiện cũng sẽ trả về kết quả là một giá trị boolean.
các_câu_lệnh_1 được thực thi trong trường hợp biểu_thức_điều_kiện là true.
các_câu_lệnh_2 sẽ được thực thi trong trường hợp biểu_thức_điều_kiện là false.
Ví dụ cho câu lệnh if else.
if(age <18){ System.out.printf("You can not access");}else{ System.out.printf("Welcome to our system!");}
Bạn thấy ví dụ này làm rõ hơn trường hợp user nhập một age lớn hơn 18, khi đó biểu_thức_điều_kiện sẽ trả về kết quả false, và vì vậy các_câu_lệnh_2 sẽ được thực thi, trong ví dụ này là dòng in ra console “Welcome to our system!”.
Cũng bởi khối lệnh của if và else chỉ có một dòng nên bạn có quyền viết thế này.
if(age <18) System.out.printf("You can not access");else System.out.printf("Welcome to our system!");
Hay thế này, nhưng lưu ý code dài quá sẽ khó đọc lắm đấy, mình không khuyến khích viết như vậy.
if(age <18) System.out.printf("You can not access"); else System.out.printf("Welcome to our system!");
if else if
Cú pháp cho câu lệnh if else if như sau.
if (biểu_thức_điều_kiện_1) {
các_câu_lệnh_1;
} else if (biểu_thức_điều_kiện_2) {
các_câu_lệnh_2;
} else if (...) {
...
} else if (biểu_thức_điều_kiện_n) { các_câu_lệnh_n;
} else {
các_câu_lệnh_n+1;
}
Đây là dạng mở rộng hơn của câu lệnh if else. Khi đó:
các_câu_lệnh_1 được thực thi trong trường hợp biểu_thức_điều_kiện_1 trả về true.
các_câu_lệnh_2 được thực thi trong trường hợp biểu_thức_điều_kiện_1 trả về false và biểu_thức_điều_kiện_2 trả về true.
các_câu_lệnh_n được thực thi trong trường hợp các biểu_thức_điều_kiện trước nó đều trả về false và biểu_thức_điều_kiện_n trả về true.
Nếu không có bất kỳ biểu_thức_điều_kiện nào trả về true cả thì các_câu_lệnh_n+1 sẽ được thực thi.
Ví dụ cho câu lệnh if else if.
Scanner scanner = newScanner(System.in);System.out.println("Please enter a number of week (1 is Monday): ");int day = scanner.nextInt();if(day == 1){ System.out.printf("Monday");}elseif(day == 2){ System.out.printf("Tuesday");}elseif(day == 3){ System.out.printf("Wednesday");}elseif(day == 4){ System.out.printf("Thursday");}elseif(day == 5){ System.out.printf("Friday");}elseif(day == 6){ System.out.printf("Saturday");}elseif(day == 7){ System.out.printf("Sunday");}else{ System.out.printf("Invalid number!");}
?:
Câu lệnh này thực chất không mới, nó như là câu lệnh if else nhưng được biểu diễn ngắn gọn hơn.
Mình thấy nhiều tài liệu gom kiến thức về việc sử dụng ?: này vào bài viết về các Toán tử. Khi đó nó được gọi là toán tử tam nguyên (ternary operator). Vì công dụng của nó được dùng cho mục đích tính toán nhanh giá trị hơn là một câu lệnh giúp điều khiển luồng. Nhưng với mình nó không khác gì if else cả, mình xem nó là một cách viết ngắn gọn hơn của if else nên gộp chung vào mục này. Còn sở dĩ gọi là toán tử tam nguyên là bởi hai ký tự mà bạn nhìn thấy (? và :) giúp tách các thành phần của câu lệnh ra làm ba phần (hay ba toán hạng), các bạn xem cú pháp của nó như sau.
kết_quả có thể có hoặc không, biến kết_quả này sẽ lưu lại giá trị là kết quả của câu lệnh, nó phải là kiểu dữ liệu của câu_lệnh_nếu_true và câu_lệnh_nếu_false, lý do tại sao thì mời bạn đọc tiếp đoạn sau.
biểu_thức_điều_kiện tương tự như ở các câu lệnh if phía trên.
câu_lệnh_nếu_true sẽ thực thi khi biểu_thức_điều_kiện trả về true, vế này sẽ trả về một kết quả về cho kết_quả, có thể là kiểu String, hoặc boolean, hoặc int,…
Ngược lại câu_lệnh_nếu_false sẽ thực thi khi biểu_thức_điều_kiện trả về false, và vế này cũng sẽ trả kết quả về cho kết_quả.
Ví dụ cho câu lệnh ?: (ví dụ này được viết lại từ ví dụ if else ở trên).
Scanner scanner = newScanner(System.in);System.out.println("Please enter your age: ");int age = scanner.nextInt();String access = (age <18) ? "You can not access" : "Welcome to our system!";System.out.printf(access);
Bạn cũng thấy rằng câu lệnh này chỉ thích hợp thay thế cho if else mà thôi, và thực sự nó giúp chúng ta rút ngắn số dòng code lại, nhưng lại làm cho thuật toán khó đọc hơn đúng không nào. Tùy bạn cân nhắc sử dụng if else hay ?: nhé.
Một chút lưu ý là với code trên, bạn không cần dùng biến kết_quảaccess mà in trực tiếp ra console từ câu lệnh này luôn cũng được, mình điều chỉnh một tí như sau.
Scanner scanner = newScanner(System.in);System.out.println("Please enter your age: ");int age = scanner.nextInt();System.out.printf((age <18) ? "You can not access" : "Welcome to our system!");
Câu Lệnh switch case
Câu lệnh này có thể dùng để thay thế if else if nói trên nếu như các biểu_thức_điều_kiện đều dùng một đối tượng giống nhau để so sánh (ví dụ ở if else if trên đây chúng ta dùng biến day để so sánh đi so sánh lại với các giá trị khác nhau). Khi này bạn nên dùng switch case để giúp cho if else if trông tường minh hơn.
Cú pháp cho câu lệnh switch case như sau:
switch (đối_tượng_so_sánh) {
case giá_trị_1:
các_câu_lệnh_1;
break;
case giá_trị_2:
các_câu_lệnh_2;
break; case ...:
...;
break; case giá_trị_n:
các_câu_lệnh_n;
break;
default:
các_câu_lệnh_n+1;
break;
}
Thay vì so sánh đối tượng ở từng biểu_thức_điều_kiện như ở if else if, bạn chỉ cần truyền nó vào đối_tượng_so_sánh, rồi chỉ định từng giá_trị_x của nó để thực thi kết quả của nó ở các_câu_lệnh_x tương ứng.
Bạn nhớ ở mỗi case đều có kết thúc là câu lệnh đặc biệt break (câu lệnh break này sẽ được nói ở bài sau). Hiện tại, bạn chỉ nên biết là câu lệnh break này giúp bạn dừng việc thực thi ở một khối lệnh của các_câu_lệnh_x nào đó, nếu không có break, hệ thống sẽ đi tiếp qua case tiếp theo để xử lý và như vậy sẽ cho kết quả sai.
Thành phần cuối cùng trong câu lệnh này là từ khóa default, thành phần này giống như else cuối cùng của một if else if, nó biểu thị rằng nếu như các so sánh case không thỏa các giá_trị của đối_tượng_so_sánh, thì các_câu_lệnh_n+1 trong default sẽ được gọi.
Ví dụ cho câu lệnh switch case (ví dụ này được viết lại từ ví dụ if else if ở trên).
Scanner scanner = new Scanner(System.in);
System.out.println("Please enter a number of week (1 is Monday): ");
int day = scanner.nextInt();
switch (day) {
case 1:
System.out.printf("Monday");
break;
case 2:
System.out.printf("Tuesday");
break;
case 3:
System.out.printf("Wednesday");
break;
case 4:
System.out.printf("Thursday");
break;
case 5:
System.out.printf("Friday");
break;
case 6:
System.out.printf("Saturday");
break;
case 7:
System.out.printf("Sunday");
break;
default:
System.out.printf("Invalid number!");
break;
}
Bạn có thấy giống if else if không nào.
Kết Luận
Chúng ta vừa đi qua các câu lệnh điều kiện – Một phần trong câu lệnh điều khiển luồng. Qua đó bạn cũng đã hiểu khối lệnh và phạm vi của biến trong chương trình Java rồi, bạn hãy theo dõi các bài học kế tiếp để nắm rõ hơn ngôn ngữ Java này nhé.
CV và Resume là những “tấm vé thông hành” giúp bạn có được công việc mơ ước. Tuy nhiên, nhiều người không biết Resume là gì và vẫn lầm tưởng CV và Resume là một, nhưng thật ra chúng hoàn toàn khác nhau đấy. Vậy bạn nên lựa chọn CV hay Resume để nộp cho nhà tuyển dụng, cái nào sẽ phù hợp với bạn và thu hút nhà tuyển dụng nhất? Cùng TopDev theo dõi bài viết dưới đây để tìm ra câu trả lời nhé!
Resume là gì?
Resume là gì?
Resume là một bản tài liệu tóm tắt về kinh nghiệm làm việc, kỹ năng và thành tựu của ứng viên. Resume thường ngắn hơn, thường chỉ có 1-2 trang và tập trung vào các thông tin quan trọng nhất về kinh nghiệm làm việc, kỹ năng và thành tựu của ứng viên liên quan đến vị trí ứng tuyển. Resume thường được sử dụng trong các ngành nghề liên quan đến kinh doanh, quản lý, tiếp thị và truyền thông.
Resume có nguồn gốc từ tiếng Pháp và được viết chính xác là Résumé có nghĩa trong tiếng Anh là “summary”.
Vậy còn CV?
CV (Curriculum Vitae) thường là một bản tài liệu chi tiết và toàn diện về trình độ học vấn, kinh nghiệm làm việc và kỹ năng của ứng viên. CV thường có độ dài từ 2-3 trang và chứa đầy đủ thông tin về quá trình học tập, kinh nghiệm làm việc, thành tựu, kỹ năng và nghiên cứu khoa học của ứng viên. CV thường được sử dụng trong các ngành nghề yêu cầu nhiều kinh nghiệm và trình độ học vấn cao.
Sau khi hiểu khái niệm CV và Resume là gì, ta thấy rằng cả CV và Resume đều là các hồ sơ đăng ký ứng tuyển cho công việc, nhưng chúng có một số điểm khác biệt về nội dung và mục đích sử dụng
Nội dung
CV thường là một bản tài liệu chi tiết và toàn diện hơn về trình độ học vấn, kinh nghiệm làm việc và kỹ năng của ứng viên. Trong khi đó, Resume tập trung vào các thông tin quan trọng nhất về kinh nghiệm làm việc, kỹ năng và thành tựu của ứng viên liên quan đến vị trí ứng tuyển.
Chiều dài
CV là một tài liệu chi tiết tổng hợp mọi sự kiện quan trọng xảy ra trong cuộc đời của mỗi người. Do đó, độ dài của CV không xác định. Nếu bạn học lên càng cao, trải qua nhiều công việc và có nhiều thành tựu thì CV của bạn sẽ càng dài. CV của một sinh viên mới tốt nghiệp thông thường có thể dài từ 2 đến 3 trang, trong khi đó CV của một nhà nghiên cứu lâu năm có thể dài lên đến 10 trang hoặc hơn.
Trái ngược với CV, Resume là một bản tóm tắt ngắn gọn học vấn và kỹ năng của bạn. Vì vậy, độ dài của nó càng ngắn càng tốt, lý tưởng là từ 1 đến 2 trang là đủ. Trong Resume, bạn không nên liệt kê tất cả những gì đã trải qua mà chỉ nên lọc ra những thành tích hoặc thành tựu có liên quan và nổi bật nhất của mình.
Mục đích sử dụng
CV thường được sử dụng trong các ngành nghề yêu cầu nhiều kinh nghiệm và trình độ học vấn cao, như giáo dục, nghiên cứu và y tế, hoặc dùng để nộp hồ sơ cho các học bổng du học.
Trong khi đó, Resume thường được dùng để xin việc, sử dụng trong các ngành nghề liên quan đến kinh doanh, quản lý, tiếp thị và truyền thông. Vì vậy, bạn nên điều chỉnh Resume, chỉ cho các kỹ năng liên quan đến vị trí ứng tuyển vào Resume để làm bật lên bạn là người phù hợp với vị trí này.
Bố cục
CV thường có bố cục đơn giản và rõ ràng, tập trung vào việc trình bày các thông tin liên quan đến kinh nghiệm làm việc và kỹ năng của ứng viên. Mỗi mục trong CV được sắp xếp theo thứ tự thời gian ngược dần, từ kinh nghiệm mới nhất đến cũ hơn. Trong khi đó, Resume thường có bố cục theo độc đáo hơn, sắp xếp tùy ý dựa vào mục đích và yêu cầu của thông tin tuyển dụng được đưa ra.
Độ phổ biến
Mặc dù CV và Resume có nhiều điểm khác biệt và mục đích sử dụng không giống nhau nhưng nhiều nơi trên thế giới vẫn xảy ra nhầm lẫn. Hiện nay, nhiều khu vực ở châu Á, châu Âu, châu Phi và Trung Đông thường lựa chọn CV trong quá trình tuyển dụng, trong khi ở Mỹ và Canada lại được ưa chuộng Resume hơn.
Bên cạnh đó, một số quốc gia như Vương Quốc Anh, New Zealand và Ireland chấp nhận cả Resume và CV khi nộp đơn xin việc. Còn ở Việt Nam, nhà tuyển dụng và ứng viên không quá rạch ròi trong việc phân biệt CV hay Resume, nên thường bạn sẽ rất ít bị bắt lỗi vấn đề này.
Bạn nên lựa chọn CV hay Resume để phỏng vấn việc làm?
Sự khác biệt giữa CV và resume mở ra nhiều lựa chọn cho bạn trong quá trình tìm việc. Nếu bạn là ứng viên mới ra trường hoặc chưa có nhiều kinh nghiệm, resume có thể là lựa chọn tốt để bắt đầu sự nghiệp. Đơn giản vì nó ngắn gọn và yêu cầu bạn tập trung vào những thông tin cần thiết nhất, tránh lan man tới những chi tiết không liên quan mà nhà tuyển dụng không cần biết.
Tuy nhiên, khi bạn tích lũy được nhiều kinh nghiệm làm việc và đạt được nhiều thành tựu, cập nhật resume thành một bản CV chi tiết và chuyên nghiệp sẽ là một điều rất hữu ích. Điều này đặc biệt quan trọng khi bạn muốn ứng tuyển cho các vị trí cấp cao, nơi nhà tuyển dụng cần những kỹ năng chuyên môn cao và kinh nghiệm xử lý công việc phức tạp.
Tóm lại, việc lựa chọn giữa Resume và CV phụ thuộc vào nhiều yếu tố, nhưng hiểu rõ sự khác biệt giữa chúng sẽ giúp bạn tạo ra bản hồ sơ phù hợp với mục tiêu tìm việc của mình. Truy cập ngay TopDev để tìm việc làm lương cao và tạo ngay cho mình một CV hấp dẫn, thu hút nhà tuyển dụng bạn nhé!
Chà chà… Mình biết khi các bạn đọc đến bài học này, chắc hẳn các bạn đều rất muốn được nhìn thấy diện mạo của ứng dụng khi thực thi (khởi chạy trên thiết bị) sẽ trông như thế nào đúng không.
Chưa cần biết nhiều về kiến thức Android, tại đây, khi đã đọc qua và thực hiện các thao tác cài đặt theo các bài học trước, hôm nay bạn đã có thể chạy ứng dụng được rồi, thậm chí bạn có thể mang ứng dụng này để cài đặt lên các thiết bị khác để lòe bạn bè nữa đấy. Vậy làm thế nào? Trước hết chúng ta điểm qua các cách thiết lập máy ảo và máy thật ở các bước sau. Như vậy cho dù bạn đã có hay chưa có trong tay một thiết bị Android (điện thoại hoặc máy tính bảng đều được), thì với bài học này, bạn đã có thể tự tạo ra cho mình một môi trường để chạy thử ứng dụng của mình được rồi đó.
Máy Ảo
Máy ảo (Emulator) là một phần mềm giả lập, nó được tạo ra với cấu hình và hoạt động giống như máy thật nhất có thể. Câu hỏi là nếu bạn đã có trong tay một máy thật Android lúc này rồi thì sao? Câu trả lời là: không gì tốt bằng. Nhưng không phải vì vậy mà bạn lại không tạo cho riêng mình một máy ảo.
Vì sao? Có hai lý do chính. Lý do thứ nhất, là không phải lúc nào bạn cũng dùng máy thật để chạy đi chạy lại ứng dụng mà bạn đang làm dở dang chưa ổn định, điều này có thể làm hư cái máy thật của bạn. Lý do thứ hai, là số lượng máy thật của bạn sẽ chỉ có một hoặc rất ít, thì việc bạn có thêm một hay nhiều máy ảo giả lập các cấu hình phần cứng khác mà các máy thật của bạn chưa có, giúp bạn kiểm tra kỹ hơn sự tương thích của ứng dụng trên nhiều phần cứng và màn hình khác nhau trước khi “xuất xưởng”.
Bạn có thể sử dụng một trong hai loại máy ảo sau (hoặc sử dụng cả hai đều được), mỗi loại sẽ có ưu điểm và khuyết điểm riêng mà chúng ta sẽ nói rõ theo từng phần bên dưới. Lưu ý là chúng ta còn nhiều tùy chọn máy ảo khác chứ không riêng hai loại này, nhưng các máy ảo được giới thiệu với các bạn sau đây đang là hai máy ảo hot nhất đối với dân lập trình Android ở thời điểm hiện tại.
AVD là một máy ảo Android được hỗ trợ chính thức từ Google. Vì là bản “chính chủ” nên máy ảo này sẽ có tính ổn định cao.
Chẳng hạn như nó sẽ tiêu tốn bộ nhớ của máy tính ít hơn các máy ảo khác, nó còn hỗ trợ giả lập tất cả các loại thiết bị, từ điện thoại, máy tính bảng, thiết bị đeo được, và kể cả Android TV nữa đấy. Nhược điểm của máy ảo này là khá ít, khi mà mới đây mình đã thấy AVD có hỗ trợ ứng dụng Google Play, giúp bạn có thể install các ứng dụng có trên store về để mà vọc thoải mái.
Đầu tiên, đảm bảo bạn đã mở Android Studio lên rồi. Từ màn hình chính của Android Studio, có hai cách để khởi động AVD, bạn có thể đi từ menu Tools > Android > AVD Manager, hoặc tìm kiếm icon trên thanh công cụ (toolbar).
Cửa sổ Quản LýAVD – Android Virtual Device Manager sẽ xuất hiện như sau.
Với cửa sổ như trên đây, hoặc bạn đang mở một cửa sổ trông khác chút, thì bạn cứ tìm kiếm nút Create Virtual Device…. Nhấn vào nút này sẽ mở ra một cửa sổ cho bạn chọn các thiết bị giả lập.
Mình sẽ điểm sơ qua các thành phần của cử sổ này, để giúp bạn có một chọn lựa máy ảo hợp lý (nếu bạn lỡ tạo lầm một máy ảo không ưng ý cũng không sao, bạn cứ tạo và chạy lên thử, nếu không thích hoàn toàn có thể gỡ bỏ và tạo lại máy ảo khác một cách nhanh chóng).
– Khung bên trái (Category): khung này cho phép bạn chọn loại máy ảo như điện thoại (Phone), máy tính bảng (Tablet), thiết bị đeo được (Wear OS), hay là TV. Với ứng dụng TourNote, chúng ta sẽ trải nghiệm ứng dụng trên điện thoại trước, do đó bạn hãy chọn Phone như hình trên.
– Khung lớn ở giữa: chính là các thiết bị giả lập tương ứng với từng loại thiết bị bên trái, có vài thiết bị được tạo ra dựa vào thiết bị thật đang được kinh doanh phổ biến trên thị trường, như các dòng Pixel, Nexus hay Galaxy (hiển thị ở cột Name). Cột Play Store cho biết máy ảo này có hỗ trợ ứng dụng Google Play hay không, nếu có, một icon sẽ xuất hiện, mình khuyến khích các bạn nên chọn các loại máy ảo có xuất hiện icon này. Cột Size cho biết kích cỡ màn hình mà máy ảo giả lập, kích cỡ này tính theo đơn vị inch như ngoài thực tế. Cột Resolution là độ phân giải của màn hình, độ phân giải này được tính theo đơn vị pixel, chính là điểm ảnh theo các chiều ngang & dọc. Density cho biết mật độ điểm ảnh của màn hình, căn cứ vào kích cỡ màn hình (size) và độ phân giải (resolution) mà ta có tỷ lệ (resolution) tương ứng như mdpi, hdpi, xhdpi, xxhdpi, 420dpi…, thông số này bạn sẽ được làm quen ở các bài học sau, chẳng hạn như bài học về dimen này.
– Khung bên phải: như một tóm tắt trực quan cho chọn lựa của bạn ở các khung khác.
Như hình trên, chúng ta sẽ chọn con máy ảo là điện thoại Nexus 5X, có sẵn Google Play, màn hình 5.2″, độ phân giải 1080×1920, có density là 420dpi. Sau khi bạn đã chọn máy ảo, bạn hãy nhấn Next và xem màn hình kế tiếp.
Đến bước như hình trên đây chính là bước mà bạn sẽ cài hệ điều hành Android vào cho con Nexus 5X ảo mà bạn đã chọn. Lưu ý là bạn phải đảm bảo tab Recommended đang được chọn, đây chính là tab mà hệ thống sẽ gợi ý gói hệ điều hành Android tốt nhất cho bạn. Có khá nhiều loại hệ điều hành, nhưng để dễ dàng kiểm thử xem ứng dụng của bạn trông như thế nào trên các giao diện hệ điều hành mới thì bạn nên chọn loại mới nhất, cho đến thời điểm hiện tại, hệ điều đáng để chạy chính là Pie (API Level 28).
À nếu bạn chưa cài đặt gói máy ảo nào, thì nó sẽ xuất hiện nút download bên cạnh tên hệ điều hành như hình trên, và nút Next bị mờ đi, khi đó phải nhấn download để down gói máy ảo mà bạn cần về trước. Sau khi nhấn download thì cửa sổ download và install sẽ xuất hiện như hình sau.
Sau khi download xong, bạn sẽ thấy chọn lựa của chúng ta không còn nút download kế bên nữa, và chúng ta hoàn toàn có thể nhấn nút Next để qua bước cuối cùng.
Bước tiếp theo như hình dưới, sẽ là bước cho bạn vài tùy chỉnh cuối cùng trước khi hoàn thành. Bạn có thể đổi tên máy ảo (ở mục AVD Name), tỷ lệ scale, hiển thị màn hình theo chế độ mặc định là đứng/ngang, dung lượng Ram và bộ nhớ dành cho máy ảo này, camera cho máy ảo,… như hình dưới đây. Nhưng tốt nhất bạn nên để mặc định và nhấn Finish.
Sau khi kết thúc quá trình cài đặt bạn sẽ nhìn thấy cửa sổ như hình dưới. Máy ảo mà bạn vừa tạo sẽ hiển thị trong danh sách máy ảo của cửa sổ này, bạn có thể tạo thêm nhiều máy ảo khác, hay nhấn chuột phải vào bất kỳ máy nào và chọn xóa nó đi, hoặc click đúp vào để khởi chạy máy ảo lên.
Trường hợp nhấn đúp vào một máy ảo. Máy ảo sẽ khởi động như thế này.
Sau khi khởi động xong màn hình máy ảo sẽ trông như hình dưới đây. Bạn nên mở ứng dụng Google Play (Play Store) có sẵn trong máy ảo lên và đăng nhập vào tài khoản Gmail của bạn.
Lưu ý là trong suốt quá trình mở máy ảo để kiểm thử, bạn đừng nên tắt máy đi nhé, tưởng tượng như đây là máy thật và không ai cứ tắt mở nguồn liên tục cả, bạn chỉ việc chạy và chạy và chạy ứng dụng lên máy đã mở sẵn mà thôi.
Thực Thi Ứng Dụng Lên AVD
Đảm bảo Android Studio đang mở. Đảm bảo máy ảo AVD vẫn đang mở. Nếu bạn đang ở màn hình Welcome của Android Studio như hình dưới thì chọn vào project TourNote ở danh sách bên trái để vào màn hình chính của Android Studio. Nếu không thấy danh sách ứng dụng nào bên trái thì bạn có thể chọn Open an existing Android Studio project và tìm đến đường dẫn chứa project TourNote mà bạn đã tạo ở bài trước.
Khi màn hình chính của Android Studio được mở, bạn nhấn vào nút Run trên thanh công cụ (toolbar).
Một cửa sổ xuất hiện với tên máy ảo mà bạn đang chạy như hình dưới đây.
Giờ thì nhấn OK và đợi một phút. Xin chúc mừng, bạn đã thành công với việc khởi chạy ứng dụng đầu tiên của mình lên thiết bị (ảo)!!!
Máy Ảo Genymotion
Genymotion là một máy ảo đa năng, trước đây mình rất thích dùng Genymotion, nhưng giờ đây máy ảo AVD đã giúp mình “thỏa mãn” hơn rồi. Tuy nhiên nếu bạn muốn thử nghiệm một ứng dụng từ một nhà cung cấp khác không phải Google, thì hãy vào trang chủ của Genymotion https://www.genymotion.com/ để đăng ký thành viên và down file cài đặt về nhé.
Một vài điểm cộng cho Genymotion, đó là máy ảo này chạy khá ổn định, nó có thể giúp giả lập được cả việc chụp hình với camera trước/sau, giả lập hiệu quả định vị GPS (AVD cũng có nhưng khó sử dụng hơn). Genymotion cũng cho bạn cài Google Play. Nói chung, Genymotion so với AVD thì như là “kẻ tám lạng người nửa cân” vậy.
Khuyết điểm của Genymotion cũng không nhiều, có thể kể đến như là, do đây là bên cung cấp dịch vụ thứ ba (third party), nên nó không hoàn toàn miễn phí, bạn chỉ được phép sử dụng miễn phí khi mà bạn chỉ muốn học chơi, nhưng nếu bạn đang làm việc cho công ty hay tổ chức nhỏ nào đó, thì bạn nên dùng bản có phí. Ngoài ra vì cũng vì là bên dịch vụ thứ ba, nên bạn phải tốn thời gian download và cài đặt ban đầu hơn là với AVD.
Có một điều với mục này là, mình chỉ nói đến đây cho máy ảo Genymotion thôi. Trước đây mình viết rất nhiều ở mục này, nhưng giờ mình xóa đi hết rồi. Thứ nhất, mình cũng muốn khuyến khích các bạn dùng AVD nhiều hơn, vì đây là công cụ “chính chủ” và hoàn toàn miễn phí từ Google. Thứ hai, do áp lực phải ra nhiều bài viết mới trên blog của mình sao cho hợp thời với các kỹ thuật lập trình mới, nên mình sẽ không có đủ thời gian để điều chỉnh bài viết theo sát sự thay đổi của Genymotion. Các bạn có thể tự tìm hiểu thêm trên mạng để sử dụng tốt Genymotion nhé.
Máy Thật
Với máy thật thì dễ dàng hơn nhiều, bạn sẽ không tốn công chọn lựa và cài đặt, việc duy nhất lúc này là bạn cần mở chế độ Developer options mà thôi.
Mặc định nếu thiết bị của bạn đang có hệ điều hành Android 4.2 trở lên, thì khi vào Settings của máy, bạn sẽ không thấy Developer options ở đâu. Đơn giản vì hệ thống đã giấu tùy chọn này, chỉ những nhà phát triển (developer) mới biết cách cho nó hiện ra. Để hiện ta tùy chọn này bạn làm như sau, mở ứng dụng Settings, tìm đến mục About phone, một số máy bạn phải vào tiếp mục Software info, bạn sẽ thấy mục Build number. Xem hình sau.
Lúc này bạn hãy nhấn nhanh nhiều lần lên Build number, cho đến khi bạn thấy thông báo dạng toast (một thông báo nhỏ ở phía dưới màn hình) với nội dung Developer mode has been turned on thì đã thành công, khi này quay lại màn hình Settings bạn đã thấy mục Developer options như hình dưới đây.
Sau đó bạn hãy vào Developer options, và check chọn USB debugging như hình này.
Từ giờ trở đi khi bạn cắm thiết bị thật Android vào máy tính thông qua dây cáp và nhấn nút Run trên thanh công cụ (giống như ở các bước khởi chạy với máy ảo ở trên) thì khi đó cửa sổ xuất hiện tiếp theo sẽ có tên thiết bị của bạn trong đó, như hình sau.
Đến đây bạn hoàn toàn có thể nhấn OK để xem kết quả trên máy thật.
Tuy nhiên nếu bạn gặp trục trặc như hai tình huống dưới đây thì bạn phải làm tiếp vài bước nhỏ nữa, còn các bạn nào đã chạy ứng dụng được lên máy thật rồi thì không cần đọc hai ý dưới này nhé.
1. Tôi không thấy tên thiết bị xuất hiện ở cửa sổ như hìnhtrên. Có thể bạn đang xài Windows và máy bạn không có sẵn driver cho thiết bị rồi, bạn đọc bài này để install driver nhé https://developer.android.com/studio/run/oem-usb.html.
2. Tên thiết bị của tôi có xuất hiện ở cửa sổ như hình trên, nhưng nút OK bị mờ không nhấn được. Điều này xảy ra với thiết bị Android lần đầu tiên kết nối với máy tính của bạn, bạn hãy nhìn lại màn hình thiết bị Android xem nếu có xuất hiện hộp thoại sau thì hãy check chọn vào Always allow from this computerrồi nhấn OK như hình dưới nhé, khi đó cửa sổ trên máy tính sẽ trông giống như trên thôi.
Bạn vừa trải qua một bài học dài về cách thiết lập máy ảo và khởi chạy ứng dụng trên máy ảo và máy thật. Từ giờ bạn đã có thể thoải mái chạy thử ứng dụng để xem kết quả như thế nào rồi nhé. Các bạn có thể chọn cho mình một máy ảo hoặc máy thật để kiểm thử, nhưng các bài học từ đây về sau mình sẽ dùng AVD để chạy ứng dụng và dùng để chụp màn hình ứng dụng cho các bạn cùng xem.
Trong OOP, một class có thể có rất nhiều instance nhưng ngược lại Singleton là một dạng class mà chỉ hỗ trợ tối đa một instance duy nhất và một đối tượng khi đã được khởi tạo sẽ tồn tại suốt vòng đời chương trình. Trong một số trường hợp, chúng ta cần khởi tạo và sử dụng một tập hợp các đối tượng. Khi với số lượng lớn các đối tượng giống nhau, thì việc khởi tạo nhiều lần sẽ gây lãng phí không cần thiết. Chúng ta cũng có thể sử dụng Prototype Pattern để cãi thiện performance bằng cách cloning object. Tuy nhiên, không phải lúc nào object cũng có thể được clone đầy đủ. Trong những trường hợp như vậy, chúng ta có thể dùng Object pool pattern.
Object Pool Pattern là gì?
Object Pool Pattern là một trong những Creational pattern. Nó không nằm trong danh sách các Pattern được giới thiệu bởi GoF. Object Pool Pattern cung cấp một kỹ thuật để tái sử dụng objects thay vì khởi tạo không kiểm soát.
Ý tưởng của Object Pooling là: chúng ta dùng Object Pool Pattern quản lý một tập hợp các objects mà sẽ được tái sử dụng trong chương trình. Khi client cần sử dụng object, thay vì tạo ra một đối tượng mới thì client chỉ cần đơn giản yêu cầu Object pool lấy một đối tượng đã có sẵn trong object pool. Sau khi object được sử dụng nó sẽ không hủy mà sẽ được trả về pool cho client khác sử dụng. Nếu tất cả các object trong pool được sử dụng thì client phải chờ cho tới khi object được trả về pool.
Object pool thông thường hoạt động theo kiểu: tự tạo đối tượng mới nếu chưa có sẵn hoặc khởi tạo trước 1 object pool chứa một số đối tượng hạn chế trong đó.
Một Object Pool Pattern bao gồm các thành phần cơ bản sau:
Client : một class yêu cầu khởi tạo đối tượng PooledObject để sử dụng.
PooledObject : một class mà tốn nhiều thời gian và chi phí để khởi tạo. Một class cần giới hạn số lượng đối tượng được khởi tạo trong ứng dụng.
ObjectPool : đây là lớp quan trọng nhất trong Object Pool Pattern. Lớp này lưu giữ danh sách các PooledObject đã được khởi tạo, đang được sử dụng. Nó cung cấp các phương thức cho việc lấy đối tượng từ Pool và trả đối tượng sau khi sử dụng về Pool.
Một hãng taxi A chỉ hữu hạn N chiếc taxi, hãng taxi chịu trách nhiệm quản lý trạng thái các xe (đang rảnh hay đang chở khách), phân phối các xe đang rảnh đi đón khách, chăm sóc, kéo dài thời gian chờ đợi của khách hàng cho trong trường hợp tất cả các xe đều đang bận (để chờ một trong số các xe đó rảnh thì điều đi đón khách luôn), hủy khi việc chờ đợi của khách hàng là quá lâu.
Ta mô phỏng và thiết kế thành các lớp sau:
Taxi: đại diện cho một chiếc taxi, là một class định nghĩa các thuộc tính và phương thức của một taxi.
TaxiPool: Đại diện cho công ty taxi, có:
Phương thức getTaxi() : để lấy về một thể hiện Taxi đang ở trạng thái rảnh, có thể throw ra một exception nếu chờ lâu mà không lấy được thể hiện.
Phương thức release() : để trả thể hiện Taxi về Pool sau khi đã phục vụ xong.
Thuộc tính available : lưu trữ danh sách Taxi rãnh, đang chờ phục vụ.
Thuộc tính inUse : lưu trữ danh sách Taxi đang bận phục vụ.
ClientThread: đại diện cho khách hàng sử dụng dịch vụ Taxi, mô phỏng việc gọi, chở và trả khách.
Trong đoạn code bên dưới, tôi sẽ cài đặt mô phỏng với TaxiPool quản lý được 4 taxi, cùng lúc có 8 cuộc gọi của khách hàng đến công ty để gọi xe, thời gian mỗi taxi đến địa điểm chở khách là 200ms, mỗi taxi chở khách trong khoảng thời gian từ 1000ms đến 1500ms (ngẫu nhiên), mỗi khách hàng chịu chờ tối đa 1200ms trước khi hủy.
Taxi:
package com.gpcoder.patterns.creational.objecpool.taxi;
public class Taxi {
private String name;
public Taxi(String name) {
super();
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Taxi [name=" + name + "]";
}
}
TaxiPool:
package com.gpcoder.patterns.creational.objecpool.taxi;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Lazy pool
*
* @author gpcoder
*/
public class TaxiPool {
private static final long EXPIRED_TIME_IN_MILISECOND = 1200; // 1.2s
private static final int NUMBER_OF_TAXI = 4;
private final List<Taxi> available = Collections.synchronizedList(new ArrayList<>());
private final List<Taxi> inUse = Collections.synchronizedList(new ArrayList<>());
private final AtomicInteger count = new AtomicInteger(0);
private final AtomicBoolean waiting = new AtomicBoolean(false);
public synchronized Taxi getTaxi() {
if (!available.isEmpty()) {
Taxi taxi = available.remove(0);
inUse.add(taxi);
return taxi;
}
if (count.get() == NUMBER_OF_TAXI) {
this.waitingUntilTaxiAvailable();
return this.getTaxi();
}
Taxi taxi = this.createTaxi();
inUse.add(taxi);
return taxi;
}
public synchronized void release(Taxi taxi) {
inUse.remove(taxi);
available.add(taxi);
System.out.println(taxi.getName() + " is free");
}
private Taxi createTaxi() {
waiting(200); // The time to create a taxi
Taxi taxi = new Taxi("Taxi " + count.incrementAndGet());
System.out.println(taxi.getName() + " is created");
return taxi;
}
private void waitingUntilTaxiAvailable() {
if (waiting.get()) {
waiting.set(false);
throw new TaxiNotFoundException("No taxi available");
}
waiting.set(true);
waiting(EXPIRED_TIME_IN_MILISECOND);
}
private void waiting(long numberOfSecond) {
try {
TimeUnit.MILLISECONDS.sleep(numberOfSecond);
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
}
ClientThread:
package com.gpcoder.patterns.creational.objecpool.taxi;
import java.util.Random;
import java.util.concurrent.TimeUnit;
public class ClientThread implements Runnable {
private TaxiPool taxiPool;
public ClientThread(TaxiPool taxiPool) {
this.taxiPool = taxiPool;
}
@Override
public void run() {
takeATaxi();
}
private void takeATaxi() {
try {
System.out.println("New client: " + Thread.currentThread().getName());
Taxi taxi = taxiPool.getTaxi();
TimeUnit.MILLISECONDS.sleep(randInt(1000, 1500));
taxiPool.release(taxi);
System.out.println("Served the client: " + Thread.currentThread().getName());
} catch (InterruptedException | TaxiNotFoundException e) {
System.out.println(">>>Rejected the client: " + Thread.currentThread().getName());
}
}
public static int randInt(int min, int max) {
return new Random().nextInt((max - min) + 1) + min;
}
}
TaxiNotFoundException:
package com.gpcoder.patterns.creational.objecpool.taxi;
public class TaxiNotFoundException extends RuntimeException {
private static final long serialVersionUID = -6670953536653728443L;
public TaxiNotFoundException(String message) {
System.out.println(message);
}
}
TaxiApp:
package com.gpcoder.patterns.creational.objecpool.taxi;
public class TaxiApp {
public static final int NUM_OF_CLIENT = 8;
public static void main(String[] args) {
TaxiPool taxiPool = new TaxiPool();
for (int i = 1; i <= NUM_OF_CLIENT; i++) {
Runnable client = new ClientThread(taxiPool);
Thread thread = new Thread(client);
thread.start();
}
}
}
Kết quả thực thi chương trình trên:
New client: Thread-0
New client: Thread-1
New client: Thread-2
New client: Thread-3
New client: Thread-4
New client: Thread-5
New client: Thread-6
New client: Thread-7
Taxi 1 is created
Taxi 2 is created
Taxi 3 is created
Taxi 4 is created
Taxi 1 is free
Served the client: Thread-1
Taxi 2 is free
Served the client: Thread-7
No taxi available
>>>Rejected the client: Thread-0
Taxi 3 is free
Served the client: Thread-6
Taxi 4 is free
Served the client: Thread-5
Taxi 2 is free
Served the client: Thread-4
Taxi 1 is free
Served the client: Thread-3
Taxi 3 is free
Served the client: Thread-2
Nhận xét:
Ưu điểm của việc cài đặt Pool là việc tận dụng được các tài nguyên đã được cấp phát. Với ví dụ về taxi ở trên với 4 taxi, trong nhiều trường hợp vẫn có thể đáp ứng được nhiều hơn 4 yêu cầu cùng một lúc. Nó làm tăng hiệu năng hệ thống ở điểm không cần phải khởi tạo quá nhiều thể hiện (trong nhiều trường hợp việc khởi tạo này mấy nhiều thời gian), tận dụng được các tài nguyên đã được khởi tạo (tiết kiệm bộ nhớ, không mất thời gian hủy đối tượng).
Việc cài đặt Pool có thể linh động hơn nữa bằng cách đặt ra 2 giá trị N và M. Trong đó: N là số lượng thể hiện tối thiểu (trong những lúc rảnh rỗi), M là số thể hiện tối đa (lúc cần huy động nhiều thể hiện nhất mà phần cứng đáp ứng được). Sau khi qua trạng thái cần nhiều thể hiện, Pool có thể giải phóng bớt một số thể hiện không cần thiết.
Khi làm việc với cơ sở dữ liệu hay cho những hệ thống tương đối lớn ở các công ty, thì vấn đề performance rất quan trọng. Nếu mỗi request đến chúng ta phải mở và đóng kết nối thủ công thì rất khó quản lý, điều quan trọng hơn nữa đó là cứ mỗi lần open và close connection mất khoảng từ 2-3s thì chắc chắn rằng hiệu năng hoạt động của ứng dụng web không tốt. Để giải quyết được vấn đề này, chúng ta sẽ dùng kỹ thuật connection pool để quản lý và chia sẻ số kết nối. Connection Pool cũng là một trong các ứng dụng của Object Pool Pattern.
Connection pooling là gì?
Connection pool (vùng kết nối) : là kỹ thuật cho phép tạo và duy trì 1 tập các kết nối dùng chung nhằm tăng hiệu suất cho các ứng dụng bằng cách sử dụng lại các kết nối khi có yêu cầu thay vì việc tạo kết nối mới.
Cách làm việc của Connection pooling?
Connection Pool Manager (CPM) là trình quản lý vùng kết nối, một khi ứng dụng được chạy thì Connection pool tạo ra một vùng kết nối, trong vùng kết nối đó có các kết nối do chúng ta tạo ra sẵn. Và như vậy, một khi có một request đến thì CPM kiểm tra xem có kết nối nào đang rỗi không? Nếu có nó sẽ dùng kết nối đó còn không thì nó sẽ đợi cho đến khi có kết nối nào đó rỗi hoặc kết nối khác bị timeout. Kết nối sau khi sử dụng sẽ không đóng lại ngay mà sẽ được trả về CPM để dùng lại khi được yêu cầu trong tương lai.
Ví dụ
Một connection pool có tối đa 10 connection trong pool. Bây giờ user kết nối tới database (DB), hệ thống sẽ kiểm tra trong connection pool có kết nối nào đang rảnh không?
Trường hợp chưa có kết nối nào trong connection pool hoặc tất cả các kết nối đều bận (đang được sử dụng bởi user khác) và số lượng connection trong connection < 10 thì sẽ tạo một connection mới tới DB để kết nối tới DB đồng thời kết nối đó sẽ được đưa vào connection pool.
Trường hợp tất cả các kết nối đang bận và số lượng connection trong connection pool = 10 thì người dùng phải đợi cho các user dùng xong để được dùng.
Sau khi một kết nối được tạo và sử dụng xong nó sẽ không đóng lại mà sẽ duy trì trong connection pool để dùng lại cho lần sau và chỉ thực sự bị đóng khi hết thời gian timeout (lâu quá không dùng đến nữa).
Thread Pool cũng là một trong các ứng dụng của Object Pool Pattern.
Tạo ra một Thread mới là một hoạt động tốn kém bởi vì nó đòi hỏi hệ điều hành cung cấp tài nguyên để có thể thực thi task (tác vụ). ThreadPool được dùng để giới hạn số lượng Thread được chạy bên trong ứng dụng của chúng ta trong cùng một thời điểm.
Thay vì tạo các luồng mới khi các task (nhiệm vụ) mới đến, một ThreadPool sẽ giữ một số luồng nhàn rỗi (no task) đã sẵn sàng để thực hiện tác vụ nếu cần. Sau khi một thread hoàn thành việc thực thi một tác vụ, nó sẽ không chết. Thay vào đó nó vẫn không hoạt động trong ThreadPool và chờ đợi được lựa chọn để thực hiện nhiệm vụ mới.
Xác định số lượng tối đa các đối tượng được khởi tạo trong Pool?
Tùy vào ứng dụng, chúng ta cần xác định con số này sao cho hợp lý để đảm bảo không khởi tạo quá dư thừa đối tượng gây lãng phí tài nguyên, hay quá ít làm cho các ứng dụng client phải chờ lâu hay bị lỗi.
Thời gian timeout?
Để quản lý thời gian timeout bạn cần xác định:
Khi một đối tượng không được sử dụng trong một thời gian xác định có cần thiết hủy bỏ để giải phóng tài nguyên hay không? Chẳng hạn: nếu giới hạn số lượng tối thiểu là 4, số lượng tối đa là 100. Điều này có nghĩa là có ít nhất 4 đối tượng sẵn dùng trong Object Pool, tối đa là 100 đối tượng được tạo ra và được quản lý trong pool. Đối tượng không được sử dụng sau khoảng thời gian timeout, thì sẽ được hủy bỏ cho tới khi còn lại 4 đối tượng.
Khi một client giữ một object quá lâu mà không trả về object pool thì có cần thiết set timeout để trả về cho đối tượng khác sử dụng không? Chẳng hạn: một client1 cần sử dụng object trong khoảng thời gian 10 phút, một client2 cần sử dụng trong 20 giây. Khi client1 yêu cầu sử dụng trước, nếu không set timeout thì client2 phải chờ 10 phút mới được sử dụng trong 20 giây.
Khi một client chờ quá lâu thì sẽ xử lý như thế nào? Chờ đến khi có tài nguyên sử dụng hay sẽ throw ngoại lệ.
Làm gì khi Pool không chứa đối tượng nào?
Chúng ta có thể sử dụng một trong ba chiến lược để xử lý một yêu cầu từ client khi trong object pool không chứa đối tượng nào (rỗng):
Tạo mới: khởi tạo thêm một đối tượng mới và trả về cho client nếu nó chưa vượt quá số lượng đối tượng được phép khởi tạo.
Chờ: Trong một môi trường đa luồng, một object pool có thể block các yêu cầu từ client cho đến khi một luồng khác trả về một đối tượng có thể sử dụng vào object pool.
Trả lỗi: không cung cấp một đối tượng và ngay lập tức trả lại lỗi cho client. Hoặc chờ một khoảng thời gian (timeout) và trả lại lỗi cho client.
Đảm bảo trạng thái của object không bị thay đổi khi trả về Object Pool?
Khi triển khai mô hình Object pool, chúng ta phải cẩn thận để đảm bảo rằng trạng thái của các đối tượng quay trở lại object pool phải được đặt ở trạng thái hợp lý cho việc sử dụng tiếp theo của đối tượng. Nếu không kiểm soát được điều này, đối tượng sẽ thường ở trong một số trạng thái mà chương trình client không mong đợi và có thể làm cho chương trình client lỗi (failed), không nhất quán, rò rỉ thông tin.
Lợi ích của Object Pool Pattern là gì?
Tăng hiệu suất của ứng dụng.
Hiệu quả trong một vài tình huống mà tốc độ khởi tạo một object là cao.
Quản lý các kết nối và cung cấp một cách để tái sử dụng và chia sẻ chúng.
Có thể giới hạn số lượng tối đa các đối tượng có thể được tạo ra.
Sử dụng Object Pool Pattern khi nào?
Objects pool được sử dụng khi:
Khi cần tạo và hủy một số lượng lớn các đối tượng trong thời gian ngắn, liên tục.
Khi cần sử dụng các object tương tự thay vì khởi tạo một object mới không có kiểm soát.
Các đối tượng tốn nhiều chi phí để tạo ra.
Khi có một số client cần cùng một tài nguyên tại các thời điểm khác nhau.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Trong các bài trước, chúng ta đã tìm hiệu về thư viện Gson để chuyển đổi từ đối tượng Java sang JSON và từ JSON sang đối tượng Java. Trong bài này, tôi sẽ hướng dẫn bạn sử dụng thư viện Jackson, một thư viện mã nguồn mở miễn phí rất mạnh mẽ được sử dụng trong nhiều ứng dụng Java.
Giới thiệu
Jackson là một thư viện Java chứa rất nhiều chức năng để đọc và xây dựng JSON. Nó có khả năng ràng buộc dữ liệu rất mạnh mẽ và cung cấp một framework để tùy chỉnh quá trình chuyển đối tượng Java sang chuỗi JSON và chuỗi JSON sang đối tượng Java.
Tạo JSON từ đối Java
Có 3 cách để tạo JSON từ Java:
Từ một đối tượng Java
Từ cây JsonNode
Từ Json Stream
Phân tích chuỗi JSON
Có 3 cách thường dùng để phân tích chuỗi JSON sang Java:
Streaming : sử dụng JsonParser để phân tích cú pháp json. Nó cung cấp các phần tử json như là các token. Sử dụng JsonGenerator để tạo ra json từ chuỗi, số nguyên, boolean, …
Tree Traversing : json có thể được đọc thành một JsonNode. Node sau đó có thể đi qua để có được thuộc tính cần thiết. Một cây cũng có thể được tạo ra và sau đó được viết như chuỗi json.
Data Binding (liên kết dữ liệu) : sử dụng Annotation để đánh dấu các thuộc tính trên đối tượng (POJO) liên kết với các phần tử của chuỗi JSON.
Web Developer là những lập trình viên tạo ra các ứng dụng Web có thể chạy được trên các trình duyệt website. Để xây dựng được một ứng dụng Web thì cần có nhiều phần khác nhau, đòi hỏi sự tham gia của nhiều lập trình viên với các kỹ năng khác nhau, cũng vì thế mà khái niệm Web Developer khá là rộng và dùng cho nhiều ngôn ngữ lập trình khác nhau. Bài viết hôm nay mình sẽ cùng các bạn tìm hiểu về ngành này cũng như lộ trình học để trở thành một Web Developer nhé.
Web Developer là gì?
Lập trình viên Web là những người sử dụng ngôn ngữ lập trình để xây dựng, phát triển, vận hành và bảo trì các website, ứng dụng trên nền tảng web và chạy với các trình duyệt web. Có nhiều ngôn ngữ cùng thư viện đa dạng mà các Web Developer có thể sử dụng: từ Java, JavaScript đến C, Python, Ruby, …
Một website cơ bản thông thường được chia thành 2 phần chính bao gồm phần hiển thị với khách hàng (gọi là clientside) và phần xử lý dữ liệu, tiếp nhận yêu cầu trả về kết quả (gọi là server side). Cũng vì thế mà khi nhắc đến Web Developer thì thường sẽ chia ra làm 3 công việc chính, bao gồm:
Frontend Developer: thiết kế, xây dựng giao diện người dùng ở phía client
Backend Developer: xây dựng ứng dụng chạy trên server tiếp nhận xử lý yêu cầu gửi đến từ client, thực hiện đọc ghi dữ liệu cập nhật vào cơ sở dữ liệu (database) và trả về kết quả
Full Stack Developer: đây là những lập trình viên có thể làm được cả 2 công việc Frontend và Backend trong cùng 1 dự án phát triển Web. Có thể sử dụng một vài ngôn ngữ lập trình cùng lúc để viết code xuyên suốt cả 2 bên trong dự án.
Như đã nói ở trên, Web Developer được chia thành nhiều vị trí khác nhau trong một dự án phát triển, vì thế với mỗi vai trò sẽ cần những kỹ năng cụ thể khác nhau. Tất nhiên cũng có những kỹ năng mà bất cứ lập trình viên Web nào cũng nên được trang bị, cụ thể:
Kiến thức cơ bản về web: những khái niệm liên quan đến Internet về hosting, domain, dns, http, … hay cách trình duyệt (browsers) hoạt động là những kiến thức cơ bản nhất của hệ thống Web mà bất cứ lập trình viên làm Web nào cũng cần nắm vững. Chúng ta cũng hiểu rõ phương thức giao tiếp giữa client và server trong hệ thống sẽ làm, thông thường là thông qua cách gọi API, gửi request và nhận response cùng với các phương thức giao tiếp hỗ trợ.
Ngôn ngữ lập trình, quản lý source code: Lập trình viên thì đương nhiên là sẽ viết code, tùy vào phần dự án bạn tham gia mà sẽ cần trang bị kiến thức lập trình tương ứng. HTML, CSS, JS với Frontend, Java, C#, Ruby, PHP … với Backend. Cùng với đó, kỹ năng quản lý source code bằng các tool như Git, SVN là điều bắt buộc để có thể tham gia vào bất cứ dự án nào.
Sử dụng các tool làm việc với API và Database: dữ liệu trong ứng dụng Web sẽ được lưu vào cơ sở dữ liệu, vì thế bạn cần biết cách thao tác với Database thông qua các câu query SQL hoặc với các hệ thống noSQL. Cùng với đó là để kiểm tra cách giao tiếp giữa Frontend và Backend thì bạn cần biết cách sử dụng tool như Postman để có thể gọi thử API.
Kiến thức về nghiệp vụ: mỗi ứng dụng web được tạo ra đều có mục đích sử dụng hay giải quyết một vấn đề cụ thể cho khách hàng. Chẳng hạn một bệnh viện cần tạo ra hệ thống đặt khám cho người bệnh, một cửa hàng cần website bán đồ trực tuyến, … Để lập trình bạn cần hiểu về nghiệp vụ, về business logic của hệ thống, từ đó mới viết ra được những dòng code phù hợp, tạo ra được hệ thống hữu ích.
Kỹ năng làm việc nhóm: đây là điều rất quan trọng với mọi lập trình viên, càng quan trọng hơn khi gần như Web Developer sẽ làm việc nhóm trong một dự án. Việc giao tiếp, đọc hiểu, cùng giải quyết vấn đề để đảm bảo lợi ích của dự án là điều quan trọng và cũng không hề dễ dàng để học.
Dựa trên những kỹ năng cần có của một Web Developer, để trở thành lập trình viên Web, bạn hãy trang bị các kiến thức cơ bản chung về ngành ở bước đầu tiên bao gồm kiến thức về ngành, về Internet, về lập trình, quản lý code hay sử dụng các tool làm việc như Postman, DevTool trên Chrome, IDE Visual Studio Code, MySQL tools, …
Bước tiếp theo, hãy chọn cho mình một trong 2 hướng để bắt đầu, làm Frontend hoặc Backend. Kể cả với những bạn có mong muốn trở thành một Fullstack Developer thì việc chọn 1 hướng trước tiên cũng là điều quan trọng. Khi xác định được hướng đi, bạn sẽ học những ngôn ngữ lập trình, thư viện hay framework tương ứng. Ví dụ Frontend chúng ta bắt buộc phải biết HTML, CSS, JS ở mức thành thạo; sau đó có thể tìm hiểu chuyên sâu hơn về một trong các thư viện như React, Angular, VueJS, … để có thể làm việc. Ngược lại Backend thì sẽ bắt buộc phải nắm được về ngôn ngữ lập trình như Java, PHP, Ruby, JavaScript, … cùng với hiểu biết về database, các hệ quản trị cơ sở dữ liệu như MySQL, Oracle, MongoDB,…
Có một ngôn ngữ giúp chúng ta sớm trở thành Fullstack Developer hơn chính là JavaScript (JS), nó có thể làm được cả Frontend và Backend (sử dụng NodeJS); vì thế bạn có thể cân nhắc hướng đi này. Mặc dù vậy mình vẫn có lời khuyên là hay chuyên vào một mảng trước khi có mong muốn làm tốt cả hai thứ và trở thành một Fullstack Web Developer.
Một vài gạch đầu dòng những kỹ năng, kiến thức cần học thêm cho từng hướng mà bạn có thể tham khảo nhé:
Với Frontend:
Framework: React, Angular, Vue.js, Svelte
Package Manager: npm, yarn, pnpm
Formatters: ESLint, Prettier
Module Bundlers: Webpack, Vite
CSS framework: Material, Tailwind
Mobile, Desktop application
GraphQL
SSR, SSG
Với Backend:
Relational Databases: PostgreSQL, MySQL, Oracle
NoSQL Databases: MongoDB, Firebase
Kiến thức chuyên sâu về databases: Transactions, Normalization, ACID
Kiến thức về OS (hệ điều hành): quản lý memory, input/output
APIs: REST, JSON APIs, SOAP, GraphQL
Security: MD5, bcrypt, scrypt
Sau những kiến thức chuyên sâu hơn về cả Frontend và Backend thì bạn có thể trở thành Fullstack Web Developer; lúc đấy công việc của chúng ta sẽ bao gồm việc thiết kế và xây dựng lên những kiến trúc hệ thống Web đáp ứng nhu cầu của khách hàng.
Kết bài
Với tốc độ phát triển của Internet, nhu cầu số hóa hiện nay thì gần như tất cả các thông tin đều được đưa lên Internet và thông qua các ứng dụng website để tương tác với người dùng. Vì vậy Web Developer đang là một ngành nghề rất hot trong thời gian vừa qua cũng như thời gian sắp tới. Nếu có dự định trở thành lập trình viên Web, hãy bắt đầu ngay từ những kiến thức mình đã đưa ra trong bài nhé. Cảm ơn các bạn đã đọc bài, hẹn gặp lại trong những bài viết tiếp theo của mình
Trong thời đại công nghệ “bùng nổ” như hiện nay, ngành công nghiệp phần mềm đang trở thành một trong những ngành có tốc độ phát triển nhanh nhất. Trong lĩnh vực này, Software Developer đóng vai trò rất quan trọng trong việc tạo ra các sản phẩm phần mềm với những chức năng mới phục vụ nhu cầu người dùng. Vậy Software Developer là gì? Những cơ hội và thách thức của công việc này như thế nào? Hãy cùng TopDev đi tìm câu trả lời dưới bài viết này nhé!
Software Developer là gì? (Kỹ sư phần mềm)
Software Developer là hay còn gọi là kỹ sư phần mềm, họ là những người chịu trách nhiệm thiết kế, xây dựng và duy trì các ứng dụng phần mềm. Những ứng dụng họ tạo ra có thể là ứng dụng di động, phần mềm máy tính, hoặc bất kỳ sản phẩm phần mềm nào khác để giải quyết một vấn đề nào đó của người dùng.
Một Software Developer không chỉ đơn thuần là viết code để xây dựng phần mềm mà còn nhiều công việc liên quan khác. Cụ thể:
Phân tích yêu cầu khách hàng: Software Developer sẽ gặp gỡ khách hàng hoặc các bên liên quan để trao đổi, phân tích nhu cầu của họ. Từ đó hình dung được phần mềm cần tạo ra sẽ như thế nào, cần những tính năng gì để đáp ứng đúng những gì khách hàng muốn.
Thiết kế phần mềm: Sau khi đã thu thập đủ thông tin, các Software Developer sẽ tổng hợp lại và đưa ra ý tưởng thiết kế phần mềm, đảm bảo nó đáp ứng các yêu cầu và chức năng cần thiết.
Viết code: Sử dụng các ngôn ngữ lập trình như Java, C++, Python, hoặc các ngôn ngữ khác để viết mã phần mềm.
Giải quyết vấn đề: Phát hiện và giải quyết các vấn đề trong quá trình phát triển phần mềm.
Triển khai và duy trì: Software Developer sẽ hỗ trợ khách hàng trong việc chạy phần mềm, tiếp nhận các yêu cầu chỉnh sửa để cải tiến phần mềm. Họ cũng sẽ theo dõi và cập nhật phần mềm thường xuyên để đảm bảo mang lại trải nghiệm tốt nhất cho người dùng.
Tùy vào loại công ty, các yêu cầu công việc của một Software Developer có thể khác nhau, nhưng đa phần đều liên quan đến việc phát triển, xây dựng và bảo trì phần mềm.
Hiện nay, nhu cầu nhân lực trong lĩnh vực Software Developer tại Việt Nam đang ở mức cao. Tuy nhiên, số lượng ứng viên đáp ứng được nhu cầu của doanh nghiệp lại quá ít. Vậy để trở thành một ứng viên mà các doanh nghiệp đang tìm kiếm bạn cần có những kỹ năng gì?
Kiến thức chuyên môn:Cần phải hiểu sâu về các ngôn ngữ lập trình như Java, C++, Python, Ruby,… kiến trúc phần mềm, quy trình phát triển phần mềm, các công nghệ phần mềm và những chuẩn mực của ngành.
Kiến thức về các framework: Hiểu biết về các framework phổ biến như AngularJS, ReactJS, NodeJS, Spring.
Tư duy logic và sáng tạo:Có khả năng giải quyết các vấn đề phức tạp bằng cách tư duy và sáng tạo để tạo ra các sản phẩm phần mềm chất lượng.
Kỹ năng lập trình: Có khả năng viết mã lệnh, hiểu và sử dụng các thư viện, framework và các công cụ phát triển phần mềm.
Kỹ năng phân tích: Có khả năng phân tích yêu cầu của khách hàng và thiết kế kiến trúc phần mềm phù hợp.
Kỹ năng làm việc nhóm:Có khả năng tương tác và làm việc hiệu quả với các thành viên trong team.
Kỹ năng tự học:Có khả năng nghiên cứu và học hỏi các công nghệ mới để cập nhật kiến thức và kỹ năng phát triển phần mềm.
Với sự phát triển mạnh mẽ của công nghệ thông tin, các doanh nghiệp đang ngày càng tìm kiếm những nhân tài có khả năng phát triển và thiết kế các sản phẩm phần mềm chất lượng cao. Điều này giúp Software Developer trở thành một ngành rất tiềm năng.
Theo các thống kê, nhu cầu tuyển dụng Software Developer tại Việt Nam đang tăng trưởng mạnh mẽ và dự kiến sẽ tiếp tục gia tăng trong tương lai. Nhiều doanh nghiệp công nghệ lớn như FPT, Tiki, VNG, VCCorp,… luôn có nhu cầu tuyển dụng lập trình viên để phát triển sản phẩm và mở rộng quy mô kinh doanh.
Bên cạnh đó, Software Developer cũng có cơ hội làm việc tại các công ty phần mềm, doanh nghiệp khởi nghiệp (startup) hoặc làm việc tự do với các dự án phát triển phần mềm riêng. Ngoài ra, Software Developer cũng có thể trở thành giảng viên, nhà nghiên cứu hoặc chuyên gia tư vấn về phát triển phần mềm.
Với sự phát triển của công nghệ thông tin, cơ hội nghề nghiệp cho Software Developer sẽ còn ngày một mở rộng, đặc biệt là với những người có khả năng thích nghi nhanh với các công nghệ mới và có khả năng giải quyết các vấn đề phức tạp.
Mức lương “đáng ngưỡng mộ” của Software Developer
Mức lương của Software Developer thường khá cao, điều này phần lớn là do tính chất công việc của Software Developer đòi hỏi kiến thức chuyên môn cao và kỹ năng đặc thù trong lĩnh vực lập trình.
Theo thống kê của các trang tuyển dụng hay các báo cáo về mức lương của ngành công nghệ thông tin tại Việt Nam, mức lương trung bình của Software Developer dao động từ 15 triệu đến 25 triệu đồng mỗi tháng. Tuy nhiên, mức lương cụ thể sẽ phụ thuộc vào nhiều yếu tố như kinh nghiệm làm việc, trình độ chuyên môn, kỹ năng và năng lực của từng cá nhân.
Bên cạnh đó, những người có kỹ năng và năng lực tốt hơn còn có thể nhận được mức lương cao hơn, thậm chí là mức lương gấp đôi hoặc gấp ba so với mức lương trung bình. Ngoài ra, cơ hội thăng tiến và phát triển sự nghiệp của Software Developer cũng rất cao, giúp họ có thể tăng thu nhập và đạt được thành công trong lĩnh vực công nghệ thông tin.
Nghề Software Developer đang trở thành một trong những lĩnh vực hot nhất hiện nay. Nếu bạn muốn trở thành một Software Developer giỏi, hãy bắt tay vào học tập và rèn luyện các kỹ năng cần thiết. Để có thêm thông tin về cơ hội nghề nghiệp của một Software Developer, bạn có thể truy cập TopDev để tìm kiếm các công việc phù hợp với năng lực và kinh nghiệm của mình. Chúc bạn tìm được công việc ưng ý!
Bài hôm nay chúng ta sẽ nói về 2 vấn đề “nhỏ”, đó là ép kiểu và comment source code. Bạn cũng nên biết nhỏ ở đây là nhỏ về tổng số chữ viết, chứ thực ra hai vấn đề hôm nay đều rất quan trọng cho các bài học kế tiếp đấy nhé. Với kiến thức về ép kiểu, chúng là kiến thức nền để bạn hiểu rõ cách sử dụng các kiểu dữ liệu khác nhau trong các ứng dụng của bạn. Còn comment source code sẽ trở thành phong cách viết code sao cho có đầy đủ chú thích dễ hiểu cho chính bạn và những người khác đọc source code của bạn sau này.
Nào để hiểu nó là gì, mời bạn đến với bài học.
Khái Niệm Ép Kiểu
Trước khi đi sâu vào tìm hiểu về ép kiểu, mình cũng xin nhắc lại một chút, là chúng ta đã từng làm quen với việc khai báo một biến (hoặc hằng), khi đó bạn cần chỉ định một kiểu dữ liệu cho biến hoặc hằng đó trước khi sử dụng. Việc khai báo một kiểu dữ liệu ban đầu như vậy mang tính tĩnh. Có nghĩa là nếu bạn định nghĩa biến đó là kiểu int, nó sẽ mãi là kiểu int, nếu bạn định nghĩa nó là kiểu float, nó sẽ mãi là kiểu float. Có bao giờ bạn thắc mắc nếu đem hai biến có kiểu dữ liệu khác nhau này vào tính toán với nhau, liệu nó sẽ tạo ra một biến kiểu gì? Và liệu chúng ta có thể thay đổi kiểu dữ liệu của một biến, hay một giá trị đã được khai báo hay không?
Câu hỏi trên cũng chính là nội dung của bài ép kiểu hôm nay. Cụ thể có thể mô tả ép kiểu như sau, ép kiểu là hình thức chuyển đổi kiểu dữ liệu của một biến sang một biến mới có kiểu dữ liệu khác. Vậy việc ép kiểu này không làm thay đổi kiểu dữ liệu của biến cũ, nó chỉ giúp bạn tạo ra một biến mới với kiểu dữ liệu mới, và mang dữ liệu từ biến cũ sang biến mới này. Khái niệm là vậy, còn mục đích là gì các bạn hãy đọc tiếp bài học hôm nay nhé.
Nên nhớ là vì các bạn chỉ mới làm quen với kiểu dữ liệu nguyên thủy, nên ép kiểu hôm nay cũng chỉ nói đến ép kiểu dữ liệu nguyên thủy mà thôi.
Nếu phân loại ép kiểu dựa vào khả năng lưu trữ của biến, thì chúng ta có hai loại ép kiểu sau.
Nới rộng (widening) khả năng lưu trữ. Việc ép kiểu này sẽ làm chuyển đổi dữ liệu từ kiểu dữ liệu có kích thước nhỏ hơn sang kiểu dữ liệu có kích thước lớn hơn. Điều này không làm mất đi giá trị của dữ liệu sau khi thực hiện việc ép kiểu. Ví dụ ban đầu bạn có một biến kiểu int, có giá trị là 6, bạn ép dữ liệu từ kiểu int sang float, rồi gán vào biến mới float, thì biến mới float sẽ mang giá trị 6.0f. Việc ép kiểu theo dạng này thông thường người ta cứ để cho hệ thống thực hiện một cách ngầm định.
Thu hẹp (narrowing) khả năng lưu trữ. Việc ép kiểu này sẽ làm chuyển đổi dữ liệu từ kiểu dữ liệu có kích thước lớn hơn sang kiểu dữ liệu có kích thước nhỏ hơn. Điều này có thể làm mất đi giá trị của dữ liệu. Ví dụ bạn ban đầu bạn có một biến kiểu float, có giá trị là 6.5, bạn ép dữ liệu từ kiểu float sang int, rồi gán vào biến mới int, thì biến mới int sẽ mang giá trị 6. Việc ép kiểu này không thể để cho hệ thống thực hiện một cách ngầm định được, lúc này hệ thống sẽ báo lỗi, bạn phải thực hiện ép kiểu tường minh cho nó.
Kiểu phân loại thứ hai được chia làm hai dạng, đó là ngầm định và tường minh như mình có nhắc đến trên đây. Việc chia thành hai dạng này mang tính đặt tên để gọi đến, với lại để cho bạn nắm được cách gọi phòng khi bạn đọc tài liệu đâu đó có dùng đến các từ này, bản chất của nó vẫn tương ứng với phân biệt theo khả năng lưu trữ trên kia.
Ép kiểu ngầm định. Việc ép kiểu này có thể diễn ra một cách tự động bởi hệ thống, khi hệ thống phát hiện thấy cần phải thực hiện việc ép kiểu, nó sẽ tự thực hiện. Như mình có nhắc đến ở ngay trên đây, ép kiểu ngầm định chính là nới rộng khả năng lưu trữ, kiểu nới rộng này sẽ không làm mất đi giá trị của dữ liệu. Khi bắt đầu thực hiện ép kiểu, hệ thống sẽ kiểm tra các nguyên tắc sau, nếu thỏa sẽ ép.
byte có thể ép kiểu sang short, int, long, float, double.
short có thể ép kiểu sang int, long, float, double.
int có thể ép kiểu sang long, float, double.
long có thể ép kiểu sang float, double.
float có thể ép kiểu sang double.
Ép kiểu tường minh. Khi không thỏa điều kiện để có thể tự động ép kiểu, thì hệ thống sẽ báo lỗi. Việc còn lại là bạn phải chỉ định ép kiểu một cách tường minh. Vì cách ép kiểu này có thể làm mất đi giá trị của dữ liệu, cho nên rất cần bạn đưa ra quyết định, chứ hệ thống không dám tự quyết. Bạn sẽ chỉ định như sau khi muốn thực hiện việc ép kiểu tường minh này.
(kiểu_dữ_liệu_cần_ép) tên_biến;
Bài Thực Hành Số 1
Bài thực hành này sẽ giúp bạn làm quen với dạng ép kiểu ngầm định. Với cách ép kiểu này bạn chú ý là chúng ta không cần làm gì cả, cứ code đi rồi hệ thống sẽ tự thực hiện việc ép kiểu thôi. Bạn hãy nhìn code sau.
publicclass MyFirstClass { publicstaticvoidmain(String[] args){ byte b = 50; short s = b; int i = s; long l = i; float f = l; double d = f; System.out.println("This is a byte: " + b); System.out.println("This is a short: " + s); System.out.println("This is a int: " + i); System.out.println("This is a long: " + l); System.out.println("This is a float: " + f); System.out.println("This is a double: " + d); System.out.println("What type is it? " + (i + f)); }
}
Bạn thấy với b ban đầu được khai báo là kiểu byte với giá trị 50. Sau phép gán cho biến s (giá trị là short) thì giá trị 50 trong biểu thức này được chuyển tự động thành kiểu giữ liệu short cao hơn và gán vào biến s. Tương tự cho các phép gán vào i, l, f, d.
Dòng cuối cùng in ra “What type is it?” cho thấy một dạng ép kiểu ngầm định khác của hệ thống. Khi này bạn không khái báo trước một kiểu dữ liệu nào cả mà dùng hai biến có các kiểu int và float vào biểu thức. Bạn thấy hệ thống sẽ tự ép kiểu dữ liệu nhỏ hơn về kiểu lớn hơn, cụ thể lúc này là ép int về float và thực hiện phép cộng với hai số float. Kết quả chúng ta có một kiểu float in ra màn hình.
Bạn hãy so sánh kết quả in ra như hình sau.
Kết quả sau khi ép kiểu ngầm định
Nhưng nếu bạn thử trắc nghiệm bằng cách kêu hệ thống ép một kiểu dữ liệu lớn hơn về kiểu nhỏ hơn xem. Hệ thống sẽ báo lỗi ngay. Và vì vậy bạn cần phải can thiệp mục kế tiếp dưới đây.
int i = 50;
short s = i;
Bài Thực Hành Số 2
Quay lại ví dụ báo lỗi trên đây, hệ thống đã từ chối tự động ép kiểu ngầm định, vậy nếu vẫn có nhu cầu muốn ép kiểu thì bạn hãy ép kiểu tường minh cho nó, lúc này bạn cần dùng đến cấu trúc ép kiểu tường minh mà mình có đưa ra ở trên kia, như vầy.
publicclass MyFirstClass { publicstaticvoidmain(String[] args){ int i = 50; short s = (short) i; System.out.println("This is a short: " + s); }}
Bạn hãy nhìn vào dòng
short s = (short) i;
, dòng này sẽ ép kiểu giá trị của i về short và gán cho biến s. Việc bạn chỉ định ép kiểu với (short) nhìn vào là biết ý đồ ngay, vì vậy mới có cái tên là tường minh.
Bạn hãy xem một ví dụ nữa thực tế hơn, có một số trường hợp bạn muốn bỏ dấu thập phân của một kiểu số thực, cách nhanh nhất để làm điều này là ép kiểu số thực này về một kiểu số nguyên. Cách ép kiểu này thực chất là làm mất giá trị của biến một cách… cố tình.
publicclass MyFirstClass { publicstaticvoidmain(String[] args){ double d = 7.5; int i = (int) d;
System.out.println("This is a int: " + i); System.out.println("This is a double: " + d); }}
Kết quả của việc ép kiểu này được in ra như sau, bạn chú ý dòng in ra kiểu int nhé, mất tiêu phần thập phân rồi.
Kết quả sau khi ép kiểu tường minh
Comment Source Code
Vì kiến thức về ép kiểu ngắn quá, nên mình nói luôn về comment source code ở bài này. Hai kiến thức này không ăn nhập gì với nhau hết, nhưng nó sẽ giúp bổ trợ tốt cho bạn trong quá trình code đấy.
Sở dĩ mình dùng từ comment chứ không dịch sang tiếng Việt là vì để tránh hiểu lầm thôi, vì đa số các bạn đều biết comment nghĩa là “bình luận”, nhưng thực ra mục đích của comment trong việc code lại chính là “ghi chú” hay “chú thích”. Nó giúp bạn giải nghĩa cho một số dòng code, bạn có thể comment thoải mái ở bất kỳ đâu trong source code, trình biên dịch sẽ bỏ qua các comment này khi build, do đó sẽ không có lỗi xảy ra với chúng.
Cách Thức Comment
Bạn có 3 cách comment như sau.
// text
. Khi trình biên dịch gặp ký hiệu //, nó sẽ bỏ qua tất cả các ký tự từ // đến ký tự cuối cùng của dòng đó. Như vậy với mỗi // sẽ giúp bạn comment được 1 dòng.
/* text */
. Khi trình biên dịch gặp ký hiệu /*, nó sẽ bỏ qua tất cả các ký tự từ /* đến hết */. Cách comment này có thể giúp bạn comment được nhiều dòng cùng lúc.
/** document */
. Tương tự như trên nhưng bạn chú ý có hai dấu * khi bắt đầu. Cách comment này giúp trích xuất ra các tài liệu hướng dẫn. Người ta gọi là document. Cách comment này mình đã nói rõ hơn ở bài viết này.
Bài Thực Hành Số 3
Với bài thực hành này bạn hãy tiến hành gõ comment tổng hợp “3 trong 1” sau đây, mình đã gộp cả ba cách comment được nói ở trên vào một chương trình. Thực ra thì bạn không cần phải comment quá nhiều như ví dụ, bạn nên comment khi cần thiết phải giải nghĩa cho một dòng code lạ nào đó, hoặc ghi chú tác giả dòng code đó là bạn, hoặc ngày sửa chữa dòng code này,…
publicclass MyFirstClass { /** * Kiểu comment cho document, sẽ được nói đến sau * * @param args */ publicstaticvoidmain(String[] args){ // Comment một dòng // Muốn dòng thứ 2 thì như thế này double d = 7.5; int i = (int) d; // Cast the double into int /* * Các câu lệnh bên dưới sẽ in ra console, * và có thể comment nhiều dòng như sau * một dòng nữa, chỉ cần enter mà thôi */ System.out.println("This is a int: " + i); System.out.println("This is a double: " + d); }}
Kết Luận
Bạn vừa xem qua các cách thức ép kiểu trong Java, và các cách thức comment source code. Bài học này tuy nhẹ nhưng rất quan trọng nhé, bạn sẽ sử dụng việc ép kiểu và thực hiện việc comment thường xuyên trong các project của mình.
Được thành lập vào năm 2016, Katalon là một công ty sản phẩm toàn cầu cung cấp nền tảng quản lý chất lượng toàn diện (Quality Management Platform), phục vụ hơn 30,000 đội ngũ phát triển phần mềm ở hơn 175 quốc gia và được Gartner Peer Insights trao giải Best Test Automation (Công cụ kiểm thử tự động tốt nhất) năm 2022. Với 2 trụ sở chính đặt tại Mỹ và Việt Nam, Katalon đang từng bước mở rộng nguồn nhân lực ra quy mô toàn cầu, đáp ứng nhu cầu ngày một tăng của thị trường.
Thành công đến từ đội ngũ nhân lực tài năng và đa văn hoá
Katalon được vận hành bởi đội ngũ lãnh đạo, kỹ sư, chuyên viên kinh doanh và marketing làm việc chính tại văn phòng Việt Nam, Mỹ và một số quốc gia khác như Ấn Độ, Pháp, Canada, Australia, Myanmar. Khởi nguồn từ vườn ươm công nghệ với 6 thành viên, công ty đã phát triển “thần tốc”, xây dựng đội ngũ nhân sự hơn 300 người và tiếp tục lên kế hoạch tuyển dụng thêm nguồn nhân lực tài năng trên toàn cầu.
Với phương châm con người là cốt lõi của thành công, Katalon hướng tới xây dựng đội ngũ tinh nhuệ, có kiến thức chuyên sâu để phát triển sản phẩm tạo được uy tín trên thế giới, đồng thời thích ứng với những yêu cầu cao từ khách hàng doanh nghiệp quốc tế.
Văn hoá doanh nghiệp hướng tới sự gắn kết
Vào năm 2022, sau vòng khảo sát minh bạch với sự giám sát tiêu chuẩn quốc tế được thực hiện bởi tổ chức Great Place To Work (GPTW), Katalon chính thức được công nhận là “Nơi làm việc tuyệt vời” ở cả hai văn phòng Việt Nam và Mỹ. Đây là danh hiệu uy tín dành cho những công ty chú trọng văn hóa doanh nghiệp và độ tin cậy của nhân viên.
Tại Katalon, ngoài giờ làm việc, những hoạt động gắn kết nội bộ như câu lạc bộ thể thao, giải trí, các chương trình đào tạo và phát triển bản thân… thường xuyên được đẩy mạnh nhằm tạo điều kiện cho mọi nhân viên tận hưởng và phát huy tối đa khả năng trong một môi trường lành mạnh, năng động và cởi mở.
Môi trường hiện đại thúc đẩy mô hình làm việc linh hoạt
Văn phòng Katalon lấy cảm hứng chủ đạo từ yếu tố công nghệ, mang đến phong cách hiện đại và ứng dụng không gian mở để tăng cường kết nối, hợp tác giữa các nhân viên. Các không gian làm việc, phòng họp và sinh hoạt chung cũng được chú trọng để làm nổi bật sự hiện đại, minh bạch và linh hoạt, đáp ứng được nhu cầu tăng trưởng nhân sự, mở rộng kinh doanh trong thời gian sắp tới.
Từ nền tảng con người vững chắc, Katalon và hành trình ươm mầm tài năng trí tuệ Việt sẽ tiếp tục là điểm sáng trên bản đồ công nghệ thế giới. Công ty sẽ tiếp tục tổ chức nhiều chương trình, hoạt động tuyển dụng nhằm thu hút nguồn nhân lực chất lượng cao. Katalon luôn sẵn sàng đón chào các thành viên mới để cùng phát triển và vươn xa đến những mục tiêu xa hơn trong tương lai. Tìm hiểu về những vị trí Katalon đang tuyển dụng ngay tại: katalon.com/careers.



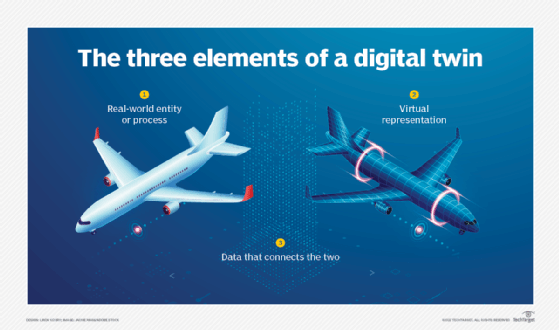






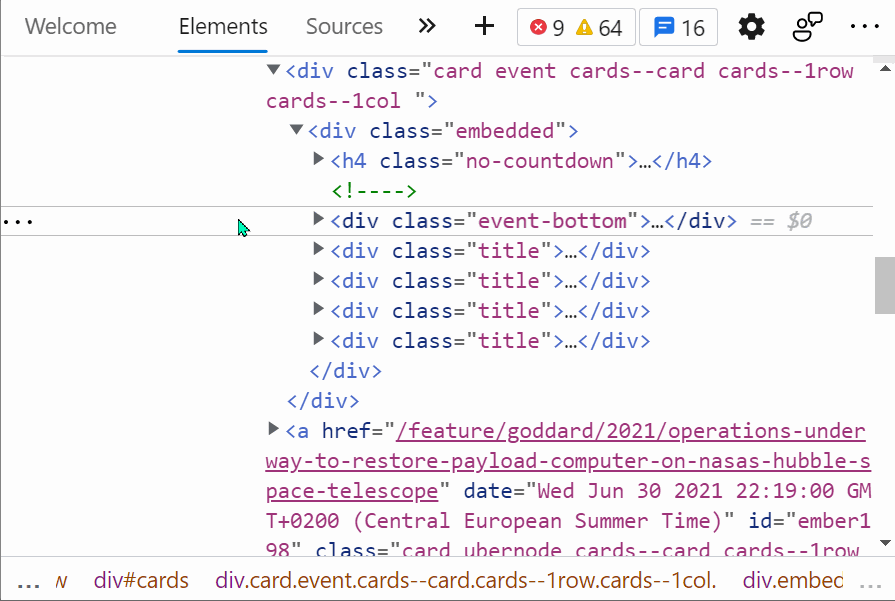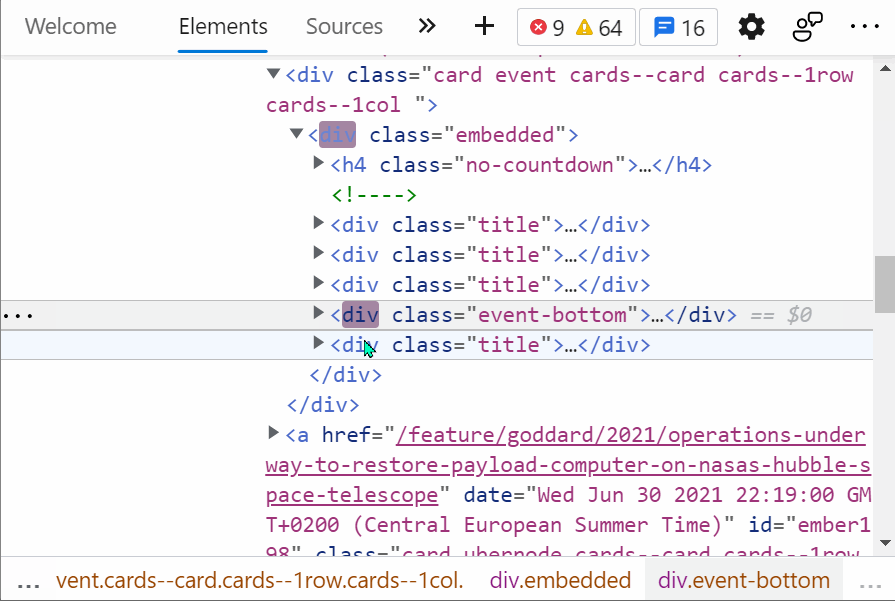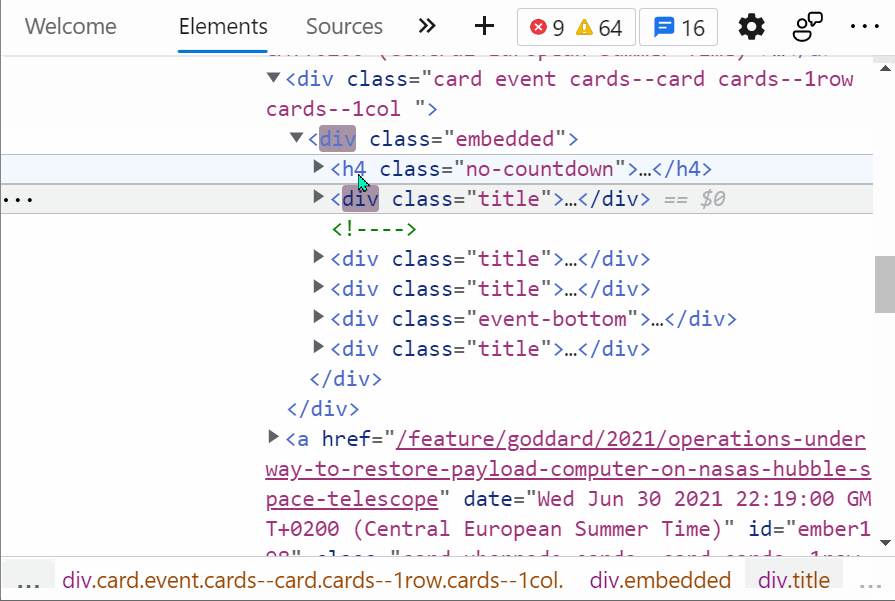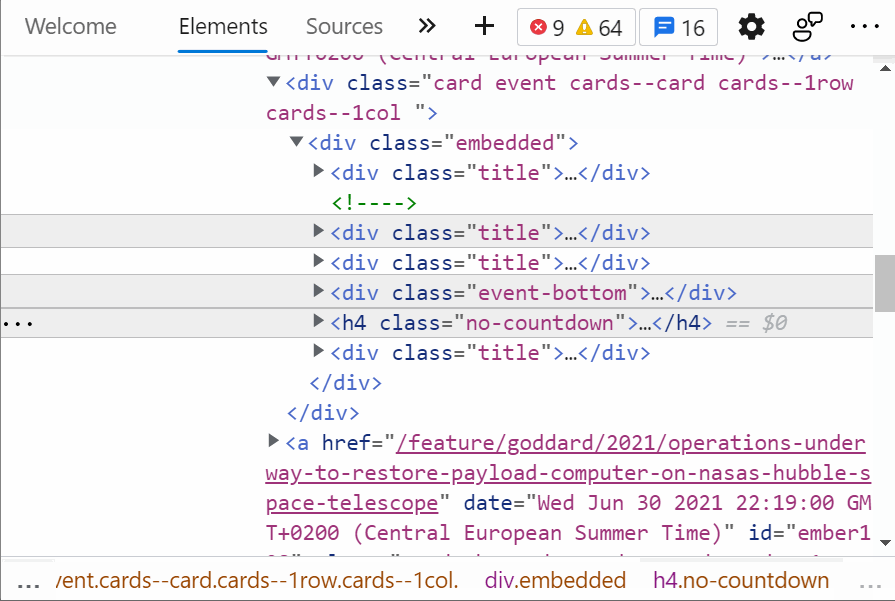
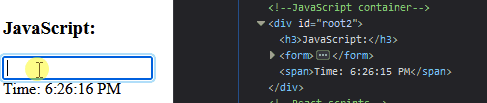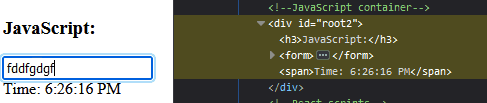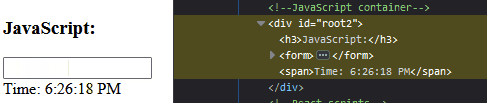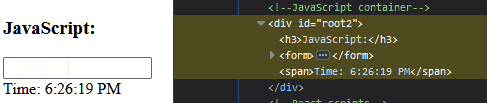

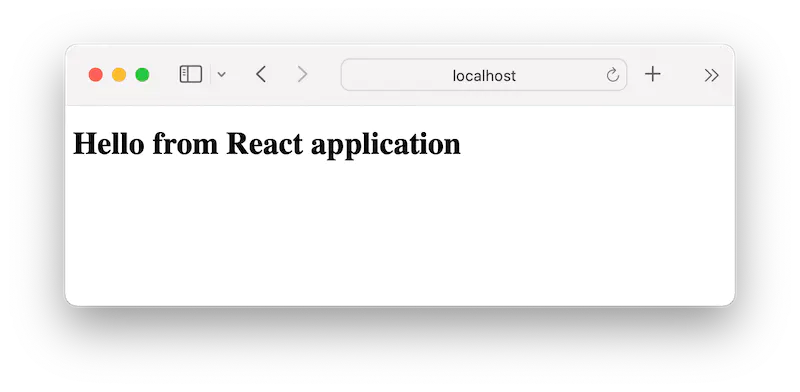


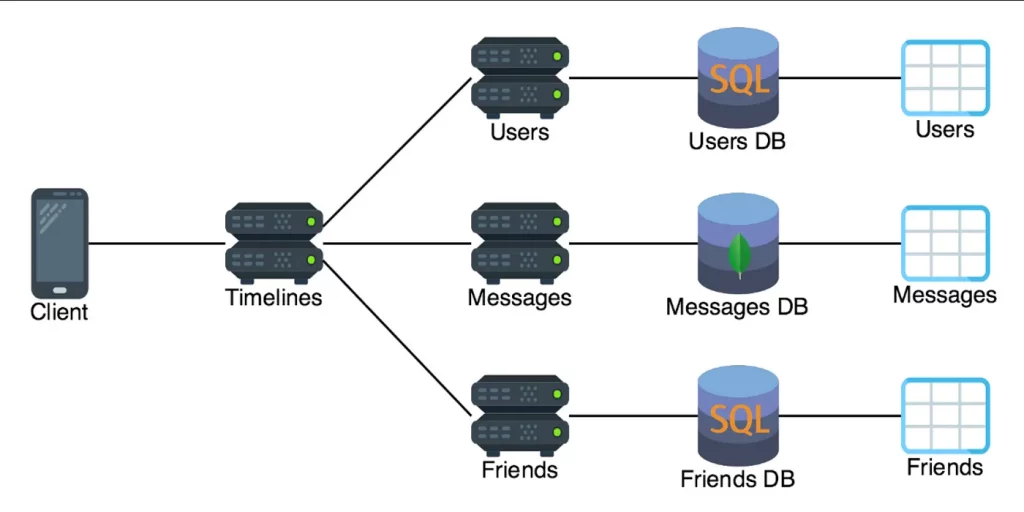

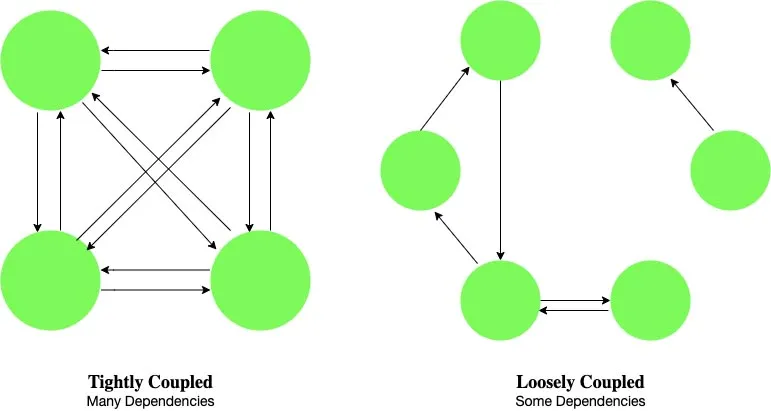

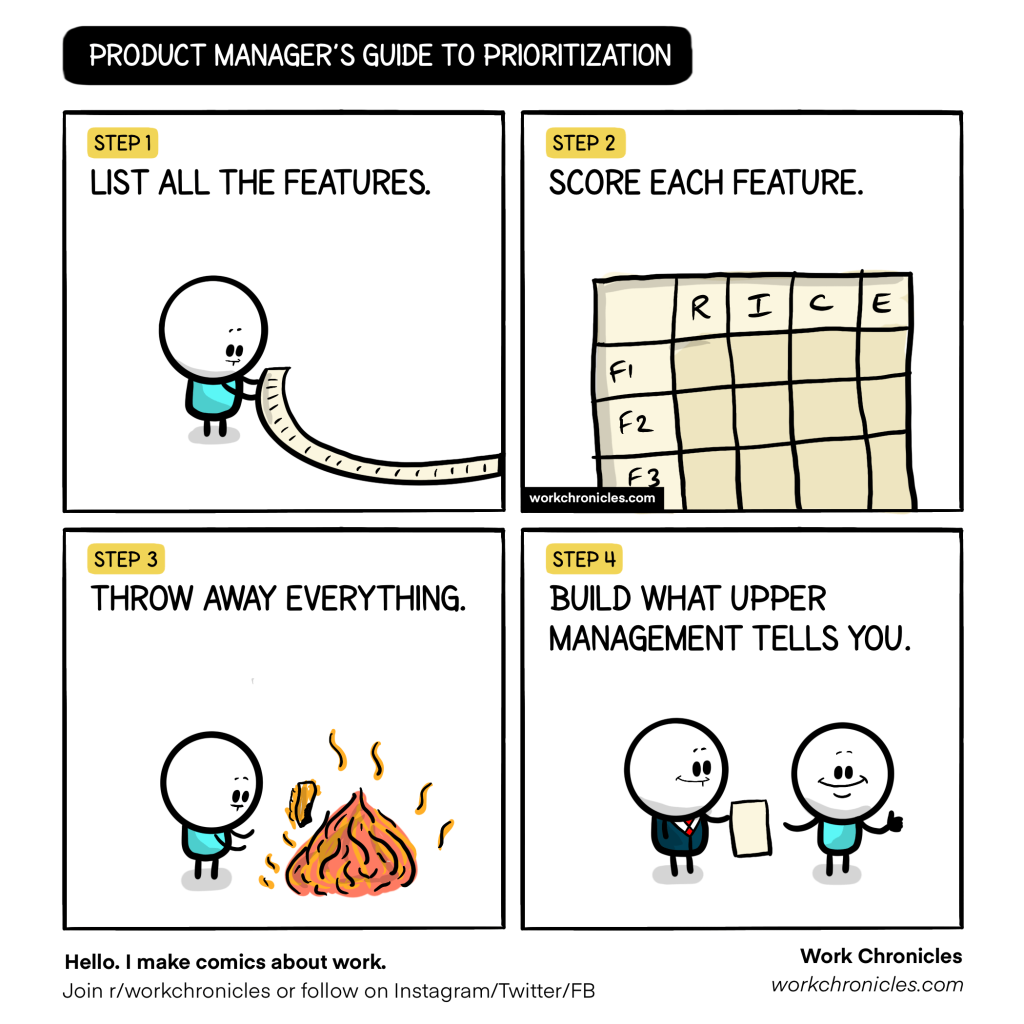
 Nếu không thay đổi nhanh, có thể toang từ PO cho tới dev vì không đúng ý khách hàng.
Nếu không thay đổi nhanh, có thể toang từ PO cho tới dev vì không đúng ý khách hàng.








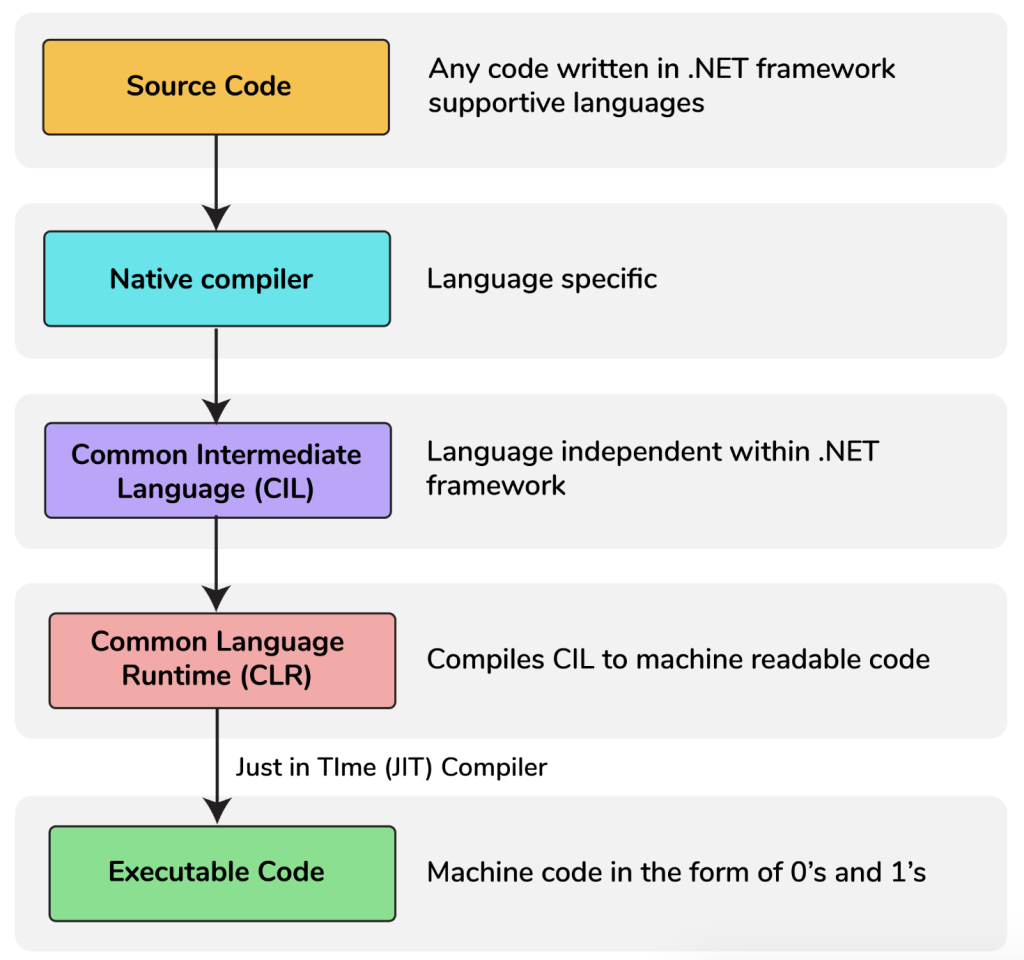
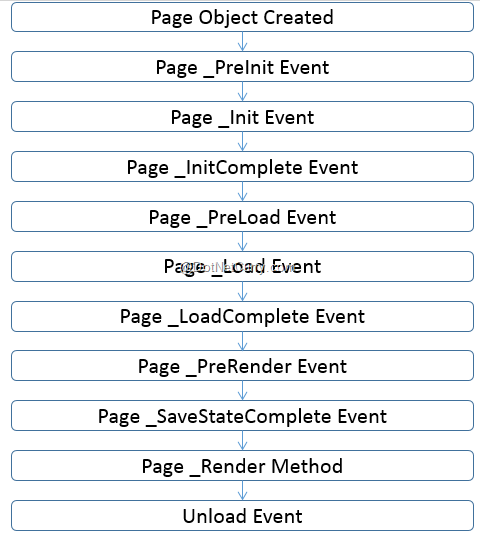
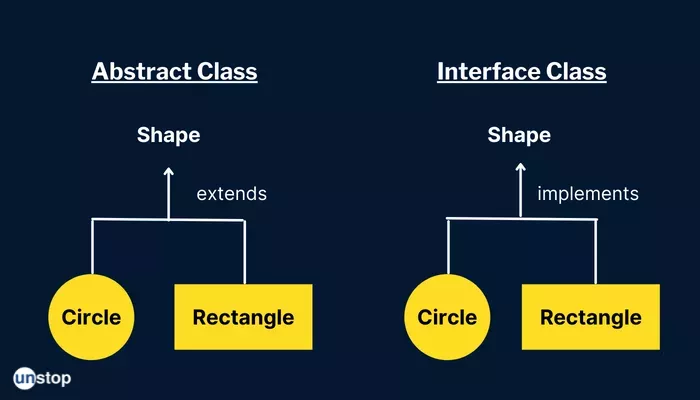









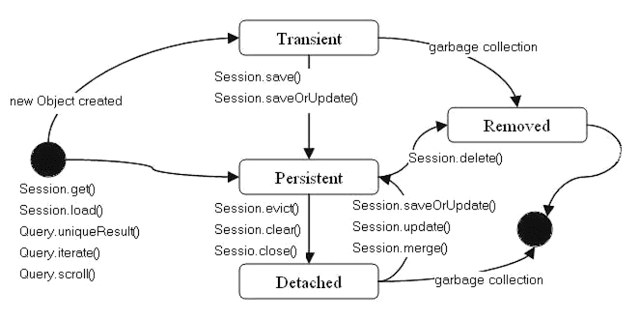


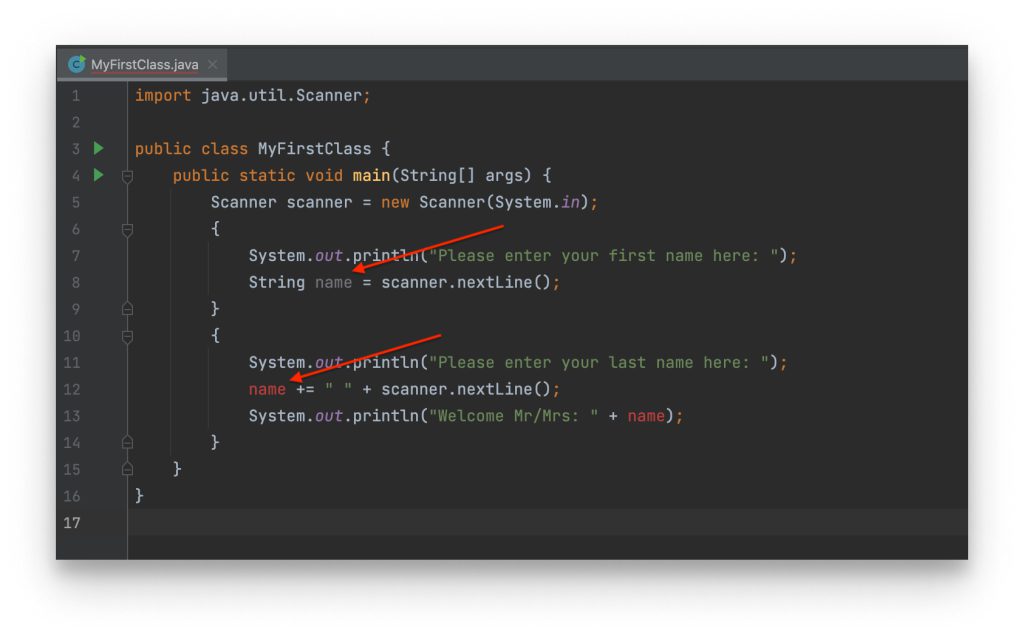
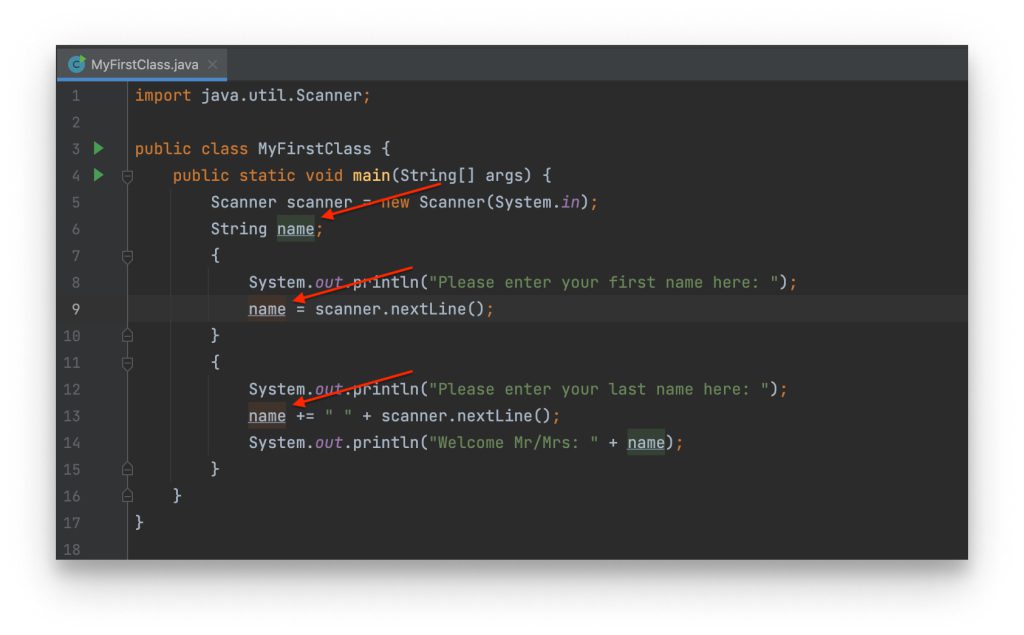
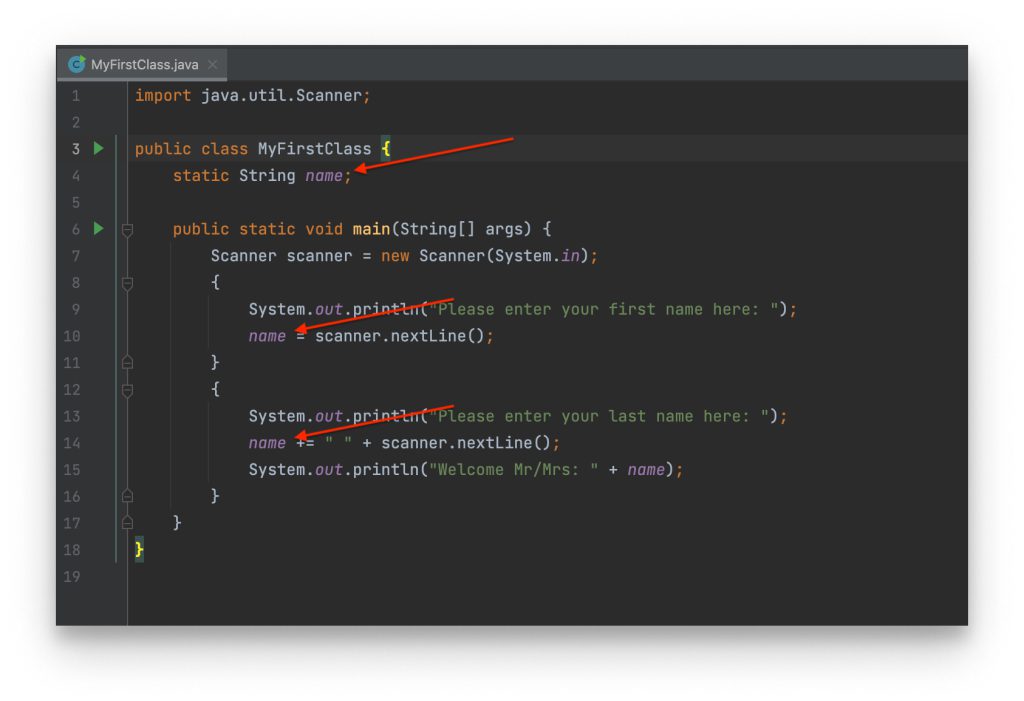




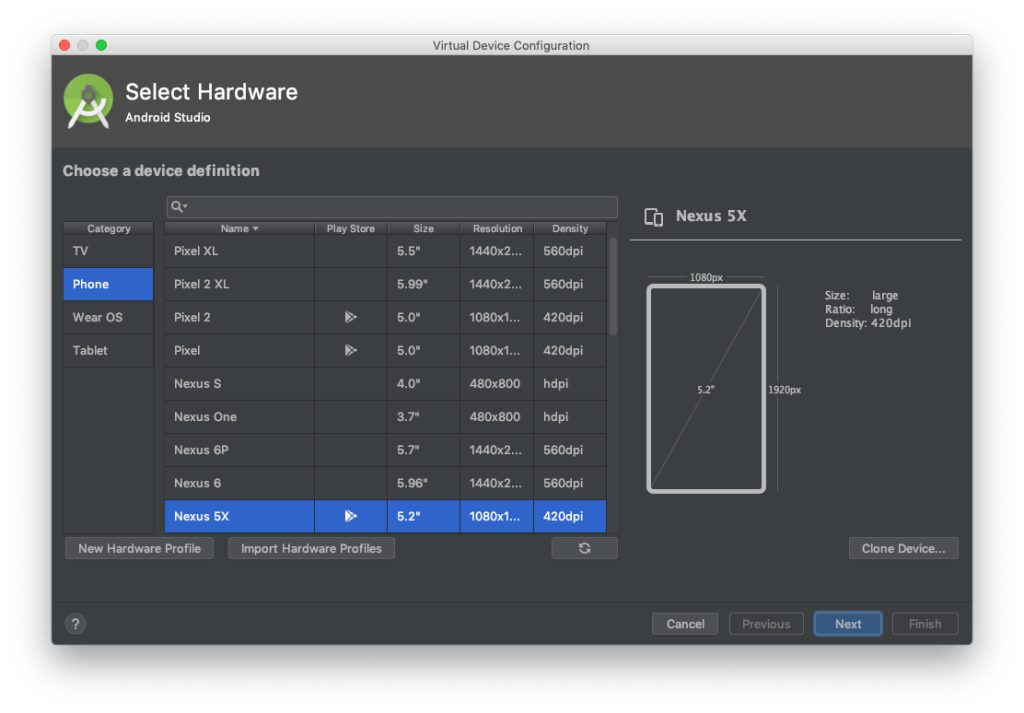








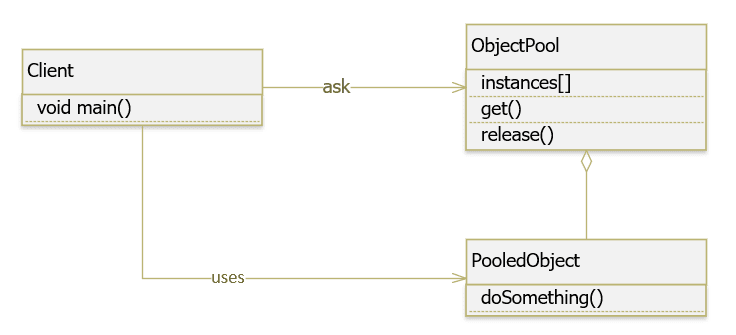
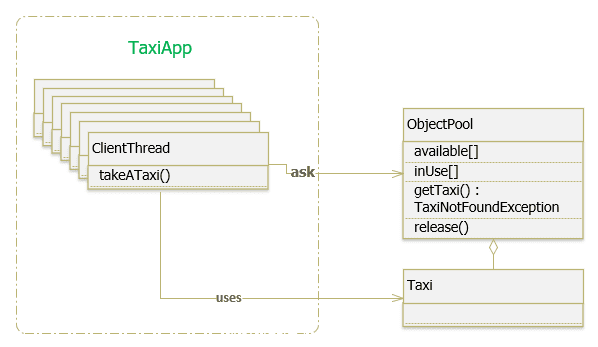
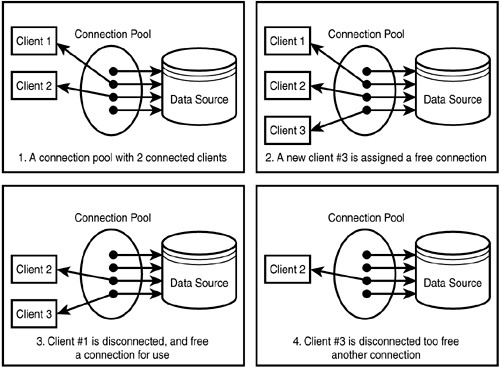














Ép Kiểu & Comment Source Code trong Java
Bài viết được sự cho phép của tác giả Nhựt Danh
Bài hôm nay chúng ta sẽ nói về 2 vấn đề “nhỏ”, đó là ép kiểu và comment source code. Bạn cũng nên biết nhỏ ở đây là nhỏ về tổng số chữ viết, chứ thực ra hai vấn đề hôm nay đều rất quan trọng cho các bài học kế tiếp đấy nhé. Với kiến thức về ép kiểu, chúng là kiến thức nền để bạn hiểu rõ cách sử dụng các kiểu dữ liệu khác nhau trong các ứng dụng của bạn. Còn comment source code sẽ trở thành phong cách viết code sao cho có đầy đủ chú thích dễ hiểu cho chính bạn và những người khác đọc source code của bạn sau này.
Nào để hiểu nó là gì, mời bạn đến với bài học.
Khái Niệm Ép Kiểu
Trước khi đi sâu vào tìm hiểu về ép kiểu, mình cũng xin nhắc lại một chút, là chúng ta đã từng làm quen với việc khai báo một biến (hoặc hằng), khi đó bạn cần chỉ định một kiểu dữ liệu cho biến hoặc hằng đó trước khi sử dụng. Việc khai báo một kiểu dữ liệu ban đầu như vậy mang tính tĩnh. Có nghĩa là nếu bạn định nghĩa biến đó là kiểu int, nó sẽ mãi là kiểu int, nếu bạn định nghĩa nó là kiểu float, nó sẽ mãi là kiểu float. Có bao giờ bạn thắc mắc nếu đem hai biến có kiểu dữ liệu khác nhau này vào tính toán với nhau, liệu nó sẽ tạo ra một biến kiểu gì? Và liệu chúng ta có thể thay đổi kiểu dữ liệu của một biến, hay một giá trị đã được khai báo hay không?
Câu hỏi trên cũng chính là nội dung của bài ép kiểu hôm nay. Cụ thể có thể mô tả ép kiểu như sau, ép kiểu là hình thức chuyển đổi kiểu dữ liệu của một biến sang một biến mới có kiểu dữ liệu khác. Vậy việc ép kiểu này không làm thay đổi kiểu dữ liệu của biến cũ, nó chỉ giúp bạn tạo ra một biến mới với kiểu dữ liệu mới, và mang dữ liệu từ biến cũ sang biến mới này. Khái niệm là vậy, còn mục đích là gì các bạn hãy đọc tiếp bài học hôm nay nhé.
Nên nhớ là vì các bạn chỉ mới làm quen với kiểu dữ liệu nguyên thủy, nên ép kiểu hôm nay cũng chỉ nói đến ép kiểu dữ liệu nguyên thủy mà thôi.
Phân Loại Ép Kiểu
Nếu phân loại ép kiểu dựa vào khả năng lưu trữ của biến, thì chúng ta có hai loại ép kiểu sau.
Tham khảo việc làm Java hấp dẫn trên TopDev
Kiểu phân loại thứ hai được chia làm hai dạng, đó là ngầm định và tường minh như mình có nhắc đến trên đây. Việc chia thành hai dạng này mang tính đặt tên để gọi đến, với lại để cho bạn nắm được cách gọi phòng khi bạn đọc tài liệu đâu đó có dùng đến các từ này, bản chất của nó vẫn tương ứng với phân biệt theo khả năng lưu trữ trên kia.
Bài Thực Hành Số 1
Bài thực hành này sẽ giúp bạn làm quen với dạng ép kiểu ngầm định. Với cách ép kiểu này bạn chú ý là chúng ta không cần làm gì cả, cứ code đi rồi hệ thống sẽ tự thực hiện việc ép kiểu thôi. Bạn hãy nhìn code sau.
Bạn thấy với b ban đầu được khai báo là kiểu byte với giá trị 50. Sau phép gán cho biến s (giá trị là short) thì giá trị 50 trong biểu thức này được chuyển tự động thành kiểu giữ liệu short cao hơn và gán vào biến s. Tương tự cho các phép gán vào i, l, f, d.
Dòng cuối cùng in ra “What type is it?” cho thấy một dạng ép kiểu ngầm định khác của hệ thống. Khi này bạn không khái báo trước một kiểu dữ liệu nào cả mà dùng hai biến có các kiểu int và float vào biểu thức. Bạn thấy hệ thống sẽ tự ép kiểu dữ liệu nhỏ hơn về kiểu lớn hơn, cụ thể lúc này là ép int về float và thực hiện phép cộng với hai số float. Kết quả chúng ta có một kiểu float in ra màn hình.
Bạn hãy so sánh kết quả in ra như hình sau.
Nhưng nếu bạn thử trắc nghiệm bằng cách kêu hệ thống ép một kiểu dữ liệu lớn hơn về kiểu nhỏ hơn xem. Hệ thống sẽ báo lỗi ngay. Và vì vậy bạn cần phải can thiệp mục kế tiếp dưới đây.
Bài Thực Hành Số 2
Quay lại ví dụ báo lỗi trên đây, hệ thống đã từ chối tự động ép kiểu ngầm định, vậy nếu vẫn có nhu cầu muốn ép kiểu thì bạn hãy ép kiểu tường minh cho nó, lúc này bạn cần dùng đến cấu trúc ép kiểu tường minh mà mình có đưa ra ở trên kia, như vầy.
Bạn hãy nhìn vào dòng
short s = (short) i;, dòng này sẽ ép kiểu giá trị của i về short và gán cho biến s. Việc bạn chỉ định ép kiểu với (short) nhìn vào là biết ý đồ ngay, vì vậy mới có cái tên là tường minh.
Bạn hãy xem một ví dụ nữa thực tế hơn, có một số trường hợp bạn muốn bỏ dấu thập phân của một kiểu số thực, cách nhanh nhất để làm điều này là ép kiểu số thực này về một kiểu số nguyên. Cách ép kiểu này thực chất là làm mất giá trị của biến một cách… cố tình.
Kết quả của việc ép kiểu này được in ra như sau, bạn chú ý dòng in ra kiểu int nhé, mất tiêu phần thập phân rồi.
Comment Source Code
Vì kiến thức về ép kiểu ngắn quá, nên mình nói luôn về comment source code ở bài này. Hai kiến thức này không ăn nhập gì với nhau hết, nhưng nó sẽ giúp bổ trợ tốt cho bạn trong quá trình code đấy.
Sở dĩ mình dùng từ comment chứ không dịch sang tiếng Việt là vì để tránh hiểu lầm thôi, vì đa số các bạn đều biết comment nghĩa là “bình luận”, nhưng thực ra mục đích của comment trong việc code lại chính là “ghi chú” hay “chú thích”. Nó giúp bạn giải nghĩa cho một số dòng code, bạn có thể comment thoải mái ở bất kỳ đâu trong source code, trình biên dịch sẽ bỏ qua các comment này khi build, do đó sẽ không có lỗi xảy ra với chúng.
Cách Thức Comment
Bạn có 3 cách comment như sau.
. Khi trình biên dịch gặp ký hiệu //, nó sẽ bỏ qua tất cả các ký tự từ // đến ký tự cuối cùng của dòng đó. Như vậy với mỗi // sẽ giúp bạn comment được 1 dòng.
. Khi trình biên dịch gặp ký hiệu /*, nó sẽ bỏ qua tất cả các ký tự từ /* đến hết */. Cách comment này có thể giúp bạn comment được nhiều dòng cùng lúc.
. Tương tự như trên nhưng bạn chú ý có hai dấu * khi bắt đầu. Cách comment này giúp trích xuất ra các tài liệu hướng dẫn. Người ta gọi là document. Cách comment này mình đã nói rõ hơn ở bài viết này.
Bài Thực Hành Số 3
Với bài thực hành này bạn hãy tiến hành gõ comment tổng hợp “3 trong 1” sau đây, mình đã gộp cả ba cách comment được nói ở trên vào một chương trình. Thực ra thì bạn không cần phải comment quá nhiều như ví dụ, bạn nên comment khi cần thiết phải giải nghĩa cho một dòng code lạ nào đó, hoặc ghi chú tác giả dòng code đó là bạn, hoặc ngày sửa chữa dòng code này,…
Kết Luận
Bạn vừa xem qua các cách thức ép kiểu trong Java, và các cách thức comment source code. Bài học này tuy nhẹ nhưng rất quan trọng nhé, bạn sẽ sử dụng việc ép kiểu và thực hiện việc comment thường xuyên trong các project của mình.
Bài viết gốc được đăng tải tại yellowcodebooks.com
Xem thêm:
Tìm việc làm IT mọi cấp độ tại TopDev