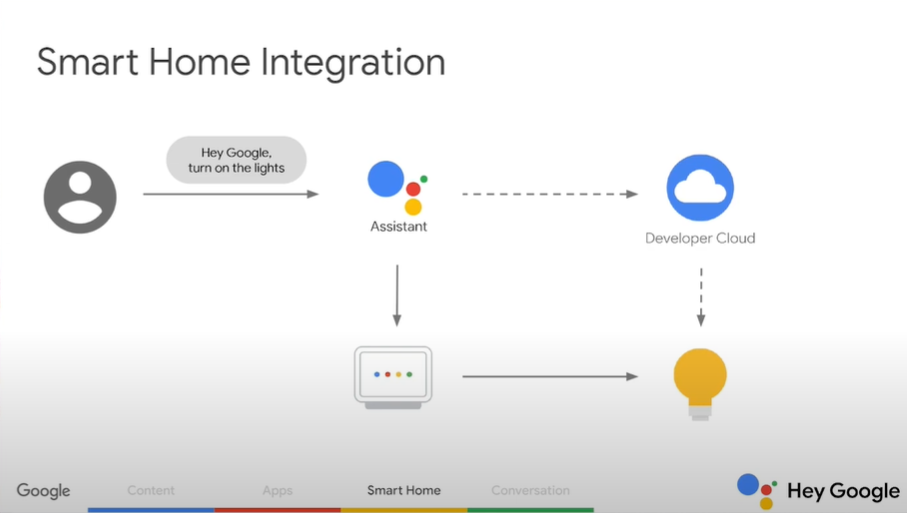
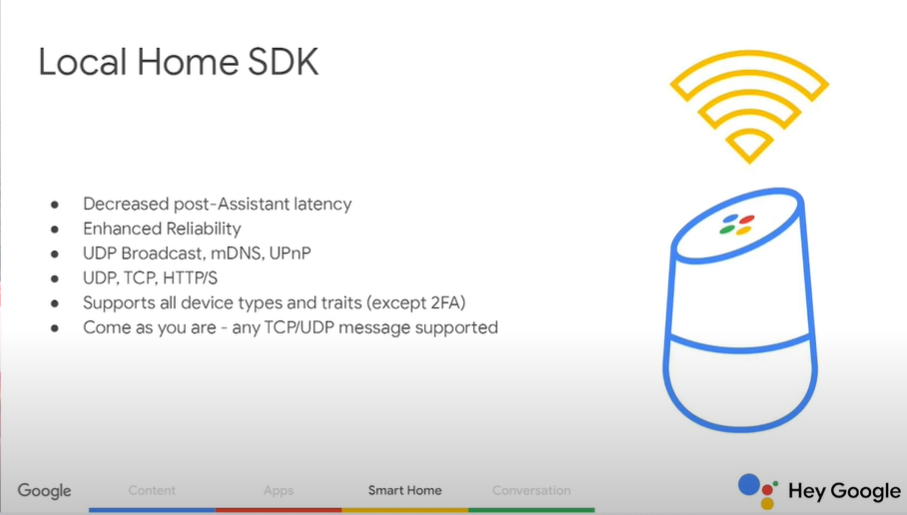
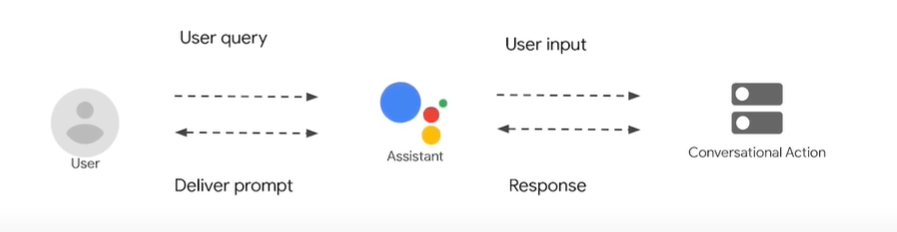
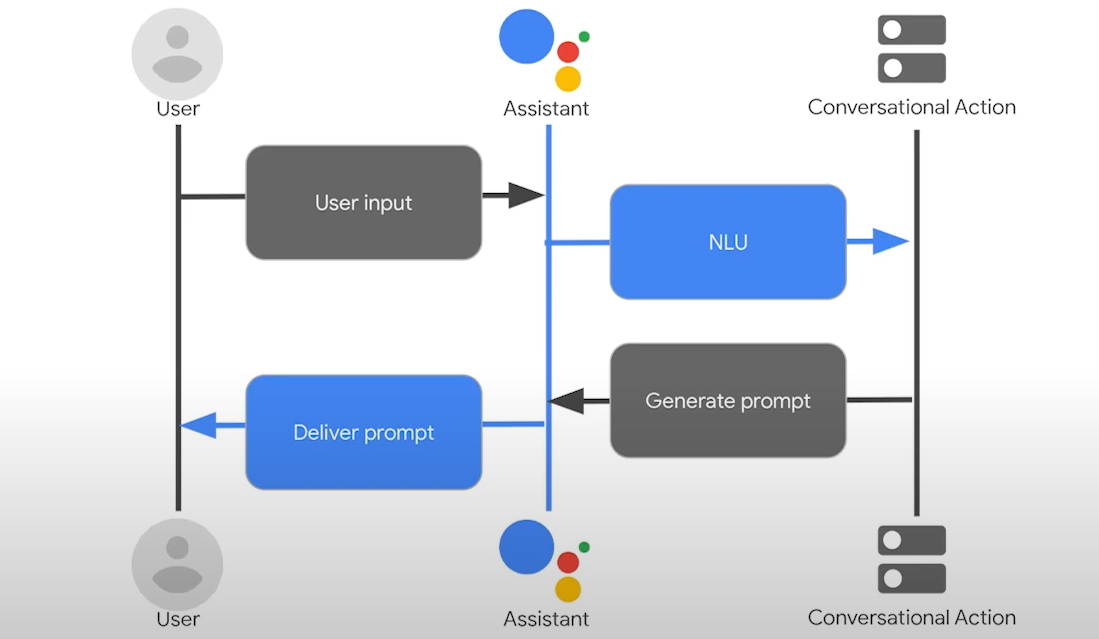
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
RxCocoa
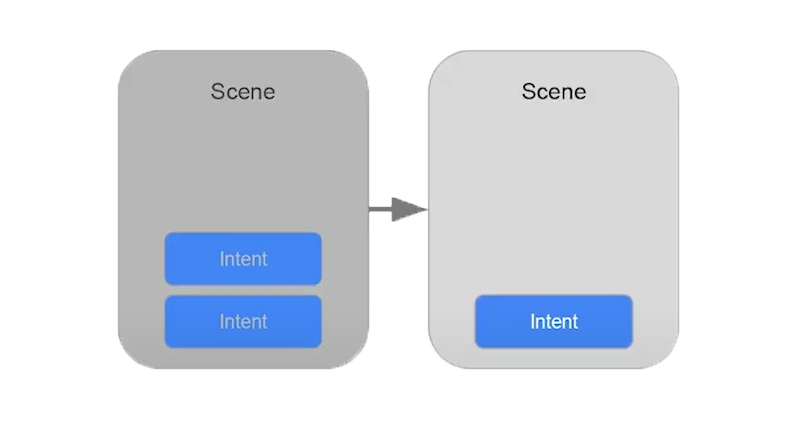
RxSwift triển khai các hàm tương tự của Cocoa. RxCocoa hỗ trợ tất cả các API của UIKit và Cocoa. Ngoài ra RxCocoa còn có các tính năng mở rộng, và bạn cũng có thể tự viết hàm mở rộng cho nó.
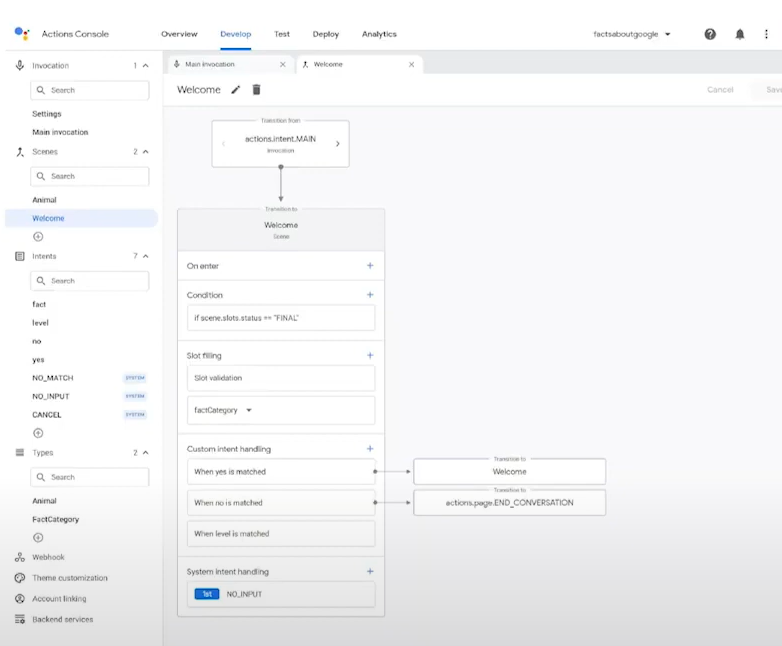
trong sự kiện onNext, mỗi khi có sự thay đổi trạng thái của nút mà hiển thị nó đang bật hay tắt, hoặc xử lý tùy ý theo logic app. RxCocoa cung cấp rx.isOn để bạn có thể đăng ký lắng nghe sự kiện đó.
Tương tự, RxCocoa cung cấp API cho nhiều control khác như UITextField, URLSesion, UIViewController…
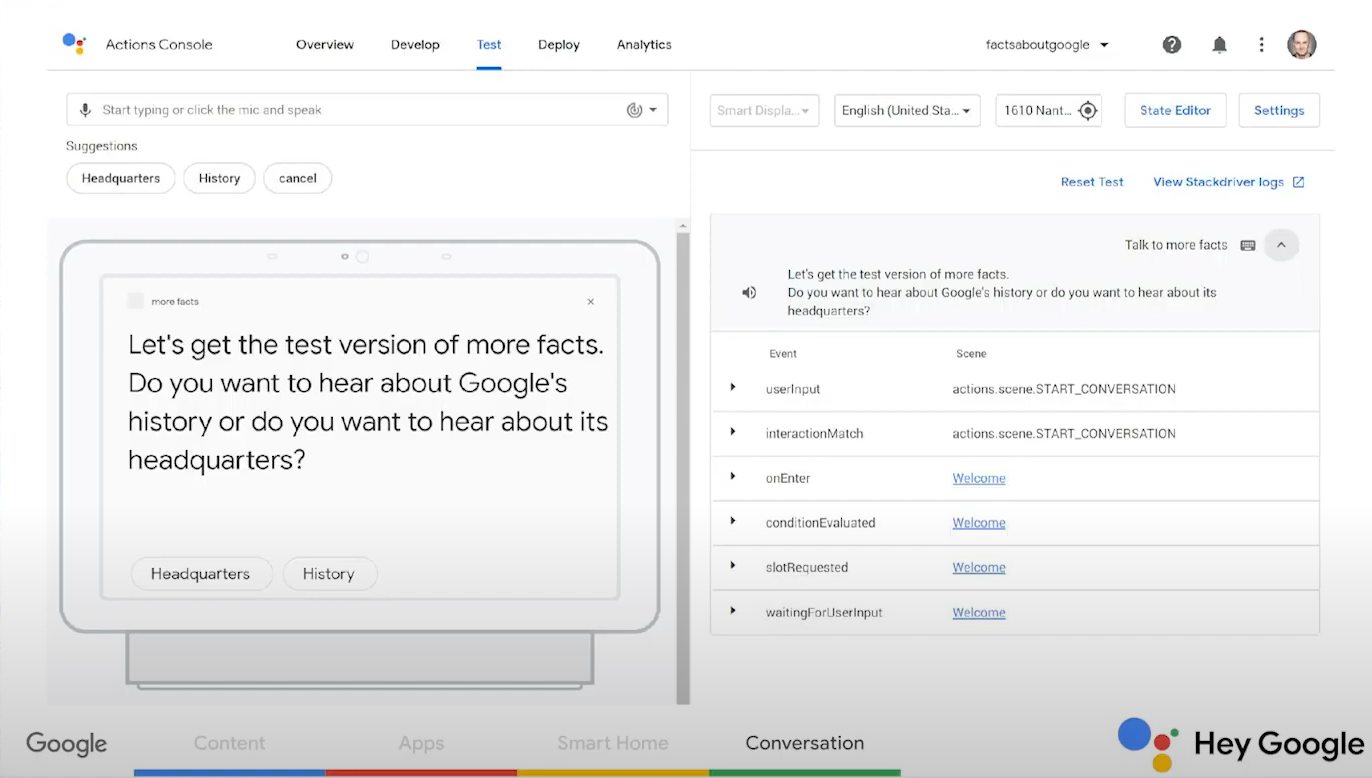
RxSwift được phát hành dưới giấy phép MIT, nói đơn giản là bạn có quyền làm gì tùy ý với source code, với điều kiện bạn phải thông báo quyền phải được bao gồm trong các ứng dụng bạn phân phối. Có rất nhiều thứ cần khám phá trong repository này, bao gồm thư viện RxSwift và RxCocoa, nhưng bạn vẫn có thể tìm thấy RxTest và RxBlocking trong đó, cho phép bạn viết unit test. Bên cạnh mã nguồn tuyệt vời, bạn sẽ thấy Rx.playground, trình diễn nhiều toán tử của nó, hay RxExample, chứa nhiều ví dụ trong thực tế. Có nhiều cách để cài đặt RxSwift:
Cài đặt bằng CocoaPods
B1: Đầu tiên các bạn tạo project của mình.
B2: init pod file bằng lệnh: pod init.
Trường hợp nếu máy bạn chưa cài CocoaPod thì gõ lệnh này trước:
sudo gem install cocoapods
B3: sửa Podfile thành:
# Podfile
use_frameworks!
target 'YOUR_TARGET_NAME' do
pod 'RxSwift', '6.0.0-rc.2'
pod 'RxCocoa', '6.0.0-rc.2'
end
# RxTest and RxBlocking make the most sense in the context of unit/integration tests
target 'YOUR_TESTING_TARGET' do
pod 'RxBlocking', '6.0.0-rc.2'
pod 'RxTest', '6.0.0-rc.2'
end
Vậy qua 5 bài đầu tiên, bạn đã có 1 cái nhìn cơ bản về RxSwift. Bạn đã tìm hiểu về sự phức tạp của lập trình bất đồng bộ, chia sẻ state, tạo ra side effects.
Bây giờ bạn đã biết RxSwift là giải pháp tuyệt vời để giải quyết các khó khăn đó. Chúng ta sẽ cùng nhau đi sâu vào từng phần của RxSwift trong bài tiếp theo. Cùng nghiên cứu về Observables.
Bài viết được sự cho phép của tác giả Nguyễn Việt Hưng
Python là một ngôn ngữ già, có thể bạn chưa biết, Python tuổi dê Python ra đời từ thời mới có HTTP, và nổi tiếng là hỗ trợ tận răng, nên không có gì lạ nếu Python có kèm sẵn thư viện standard để thực hiện HTTP request với tên urllib.
Vậy nhưng khi lên mạng tìm kiếm hay hỏi quanh đây: dùng gì để gọi HTTP trong Python?, câu trả lời phần lớn đều là cài: pip install requests.
Requests không phải có từ ngày Python xuất hiện, nhưng vào thời Python 2.6 2.7 (cỡ 2012-2013), requests đã rất phổ biến, ví dụ như câu trả lời trên StackOverFlow năm 2013.
Requests (có chữ s) xuất hiện với một API cực kỳ thân thiệt, với motto (khẩu hiệu): Python HTTP for Humans do urllib có sẵn trong Python2 quá rắc rối. API của requests nổi tiếng đến mức gần như ngôn ngữ lập trình nào cũng có một thư viện “nhái” requests của Python, nó quá đơn giản, tới mức … trước đây không thư viện nào từng làm vậy.
(API của thư viện là các function mà thư viện đó public cho người dùng sử dụng, ví dụ requests có: requests.get, requests.post.)
International Domains and URLs
Keep-Alive & Connection Pooling
Sessions with Cookie Persistence
Browser-style SSL Verification
Basic/Digest Authentication
Elegant Key/Value Cookies
Automatic Decompression
Unicode Response Bodies
Multipart File Uploads
Connection Timeouts
Thread-safety
Có thể dễ đoán rằng những tính năng được quảng cáo trên chính là những gì urllib Python thời đó chưa hỗ trợ (trong Python còn có cả thư viện tên urllib2… để thêm phần phức tạp). Nhưng với Python 3.5 trở đi, rất nhiều trong số trên đã được hỗ trợ trong urllib.
Changed in version 3.4.3: This class now performs all the necessary certificate and hostname checks by default. To revert to the previous, unverified, behavior ssl._create_unverified_context() can be passed to the context parameter.
Connection Pooling: bình thường khi viết code truy cập vào 1 website, ta có thể nghĩ đơn giản là requests.get rồi lấy kết quả là xong chuyện, hết phiên. Nếu muốn truy cập trang khác cùng website đó, ta lại requests.get để truy cập mới. Phía dưới requests.get thực hiện tạo 1 TCP connection, sau đó mới gửi HTTP request qua connection này. Việc tạo connection là công việc khá tốn kém (CPU, thời gian), đặc biệt với HTTPS, tạo SSL connection còn tốn hơn nhiều lần. Do vậy, để tăng hiệu năng, requests sẽ tự giữ lại connection và dùng lại để truy cập website nếu như các yêu cầu sau đó cùng website, khác page. Xem code tại adapters.py.
Việc này ảnh hưởng tới hiệu năng, nhưng không ảnh hưởng gì nếu bạn chỉ gọi 1 request tới mỗi website.
Đọc code requests
Lib requests thuộc loại nhỏ, tổng cộng 5000 dòng gồm rất nhiều comment. Nó tận dụng các thư viện ngoài khác thay vì tự làm tất cả: urllib3 để thực hiện connection pooling, thực hiện HTTP requests, dùng certifi để cung cấp các SSL certificate mới nhất như các trình duyệt.
Phần API đơn giản lừng danh nằm trong file api.py, trích bỏ comment:
from.importsessionsdefrequest(method,url,**kwargs):# By using the 'with' statement we are sure the session is closed, thus we# avoid leaving sockets open which can trigger a ResourceWarning in some# cases, and look like a memory leak in others.withsessions.Session()assession:returnsession.request(method=method,url=url,**kwargs)defget(url,params=None,**kwargs):kwargs.setdefault('allow_redirects',True)returnrequest('get',url,params=params,**kwargs)defoptions(url,**kwargs):kwargs.setdefault('allow_redirects',True)returnrequest('options',url,**kwargs)defhead(url,**kwargs):kwargs.setdefault('allow_redirects',False)returnrequest('head',url,**kwargs)defpost(url,data=None,json=None,**kwargs):returnrequest('post',url,data=data,json=json,**kwargs)defput(url,data=None,**kwargs):returnrequest('put',url,data=data,**kwargs)defpatch(url,data=None,**kwargs):returnrequest('patch',url,data=data,**kwargs)defdelete(url,**kwargs):returnrequest('delete',url,**kwargs)
urllib3
urllib3 là dependency quan trọng của requests, nó đảm nhận những công việc nặng nề:
urllib3 brings many critical features that are missing from the Python standard libraries:
Thread safety.
Connection pooling.
Client-side SSL/TLS verification.
File uploads with multipart encoding.
Helpers for retrying requests and dealing with HTTP redirects.
Support for gzip and deflate encoding.
Proxy support for HTTP and SOCKS.
urllib và urllib2 thời Python2.7 là những em gái dính lời nguyền mà ai cũng muốn tha thứ. Nhưng ở Python 3.6+, việc dùng urllib không còn quá phức tạp, hãy coi nó như 1 file, nhớ đóng file, hoặc dùng with.
Có thể dùng urllib khi script/chương trình chỉ truy cập mỗi website một lần, dùng trong các script ngắn, hay khi không tiện cài requests. Nhớ sử dụng requests Session khi truy cập 1 website nhiều lần để tăng hiệu năng.
Kết luận
Requests thành công vì sự đơn giản không thể hơn của nó, chứ không phải vì kỹ thuật cao siêu phức tạp.
A designer knows he has achieved perfection not when there is nothing left to add, but when there is nothing left to take away. The New Hacker’s Dictionary – Eric S. Raymond,
Nhớ mặc định là dùng requests, nhưng không bị sốc khi thấy người ta dùng urllib.
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Lập trình reactive không phải là một khái niệm mới, nó đã tồn tại trong thời gian khá dài. Tuy nhiên không phải lập trình viên nào cũng muốn học về nó. Nếu bạn đang đọc bài này, bạn ít nhiều quan tâm đến nó. Khi đến 1 trình độ nào đó, bạn sẽ thấy các vấn đề xoay quanh lập trình tuần tự liên quan đến tính bất đồng bộ của chương trình, từ phía web, ứng dụng, server. Do vậy nhu cầu xử lý tính bất đồng bộ của chương trình là cần thiết.
Lịch sử ra đời từ 1 nhóm của Microsoft, muốn xử lý các vấn đề này. Năm 2009 họ tạo ra 1 nền tảng cung cấp cho .Net, gọi là Rx. Sau này nó được open source, các bạn có thể xem thêm tại đây:
Biểu tượng cho dự án Rx có tên là Volta – 1 con lươn điện!
Chúng ta sẽ lần lượt tìm hiểu các khái niệm của “lươn điện”: observables, operators và schedulers. Nào chúng ta cùng tìm hiểu nào!
Observables
Một lớp Observable<T> cung cấp cho Rx khả năng tạo ra 1 chuỗi các sự kiện không đồng bộ, tại bất cứ thời gian nào, mà các lớp khác có thể đăng ký lắng nghe được. Nghĩa là có thể nhiều lớp cùng đăng ký lắng nghe(observers) các sự kiện xảy ra trong thời gian thực. Observable có thể hiểu đơn giản là 1 cái trạm phát sóng, và các quan sát viên(giống như cái radio) gọi là observers, có thể lắng nghe 1 trong 3 loại sự kiện:
Một next event: là sự kiện mới nhất, đây là cách observers nhận dữ liệu.
Một completed event: nghĩa là sự kiện thành công, nghĩa là trạm phát observable đã hoàn thành công việc của mình và không phát ra thêm tín hiệu nào nữa.
Một error event: nghĩa là phát ra 1 lỗi và sẽ không phát thêm sự kiện nào nữa.
Nhấn mạnh: Hãy lẩm bẩm trong miệng 2 khái niệm mới đến khi thuộc lòng và hiểu bản chất:
Observable – trạm phát tín hiệu
observers – các quan sát viên thu tín hiệu
Ví dụ, 1 chuỗi phát ra các giá trị nguyên theo thời gian thực được mô tả ở hình sau:
Ngoài số nguyên, bạn có thể phát ra bất cứ thứ gì bạn muốn. Và một trạm phát có thể có nhiều quan sát viên, do vậy bạn thích bao nhiêu observer cũng được, mà không cần phải kế thừa hay ủy quyền gì cả.
1 trạm phát và 3 quan sát viên
Để hiểu hơn, chúng ta xét tình huống cụ thể, khi ứng dụng ios đang tải xuống 1 file lớn trên mạng. Các sự kiện của chuỗi phát ra như sau:
File bắt đầu tải, bắt đầu quan sát dữ liệu đến
Sau đó, chúng ta liên tục nhận được các phần dữ liệu tải về
Nếu có lỗi kết nối mạng, quá trình tải xuống dừng do lỗi
Nếu không file tải thành công và quá trình kết thúc thành công
Follow code sẽ như sau:
API.download(file: "http://www...")
.subscribe(onNext: { data in
... nối các phần của file lại
},
onError: { error in
... hiển thị lỗi cho người dùng
},
onCompleted: {
... sử dụng file download xong
})
Trong đoạn code trên, API.Download sẽ trả về 1 Observable<Data>, phát ra chuỗi các data gửi về qua mạng. Bạn đăng ký nghe các sự kiện ở onNext, ở trên là nối các phần của file tải về và lưu tạm vào ổ đĩa. Bạn đăng ký lắng nghe lỗi ở onError, có thể hiển thị lỗi cho người dùng biết. Bạn đăng ký sự kiện tải file thành công ở onCompleted, có thể mở file, hay làm bất cứ thứ gì mà logic app của bạn muốn.
Infinite observable sequences
Hay còn gọi là chuỗi quan sát vô hạn. Không giống như ví dụ trên, chúng ta sẽ có những tính huống quan sát các sự kiện vô hạn. Ví dụ khi bạn muốn quan sát sự kiện thiết bị người dùng thay đổi khung hình ngang hay dọc.
Chuỗi này là không có kết thúc, bạn chỉ biết thời điểm bắt đầu khi bạn quan sát, và luôn xử lý nó cho đến khi ứng dụng kết thúc.
thiết bị xoay ngang hay xoay dọc
Trong RxSwift, code được mô tả như sau:
UIDevice.rx.orientation
.subscribe(onNext: { current in
switch current {
case .landscape:
... sắp xếp giao diện người dùng ngang
case .portrait:
... sắp xếp giao diện người dùng dọc
}
})
Lưu ý đoạn code trên là hư cấu(không chạy được), để mô tả việc rx phát ra chuỗi phát thiết bị đang ở chế độ ngang hay dọc. Tuy nhiên chúng ta sẽ dễ dàng biến điều hư cấu trên thành thật bằng cách tự viết được đoạn code cho nó trong các bài tiếp theo.
Operators
Khác với toán tử thông thường, các toán tử trong Rx cung cấp khả năng mở rộng để giải quyết các phương thức tính toán trừu tượng, giải quyết các vấn đề phức tạp của bất đồng bộ. Bởi vì chúng có khả năng tách biệt và đồng bộ, nên gọi là toán tử. Chúng có khả năng nhận đầu vào không đồng bộ, kết hợp với nhau tạo thành 1 bức tranh lớn hơn về logic app.
Ví dụ phép tính số học thông thường (5 + 6) * 10 – 2. Chúng ta vận dụng thứ tự ưu tiên trong ngoặc trước, nhân chia trước, cộng trừ sau để đưa ra kết quả cuối cùng. Tương tự trong Rx, các toán tử cũng được kết hợp như vậy, theo thứ tự ưu tiên xác định, cuối cùng đưa ra kết quả.
Ví dụ lại cách Rx lắng nghe sự kiện thiết bị thay đổi chiều:
UIDevice.rx.orientation
.filter { value in
return value != .landscape
}
.map { _ in
return "Portrait is the best!"
}
.subscribe(onNext: { string in
showAlert(text: string)
})
Mỗi khi thiết bị xoay ngang hay dọc thì rx sẽ phát ra sự kiện đó.
Đầu tiên chúng ta dùng toán tử filter để lọc những giá trị không phải là landscape. Tiếp theo chúng ta dùng toán tử map để trả về 1 đoạn string thông báo “Portrait is the best!”
Schedulers
Hiểu sơ sơ nó na ná giống bộ lập lịch của Apple, tuy nhiên chúng ta sẽ nghiên cứu chúng sau khi đã hoàn thành các kiến thức cơ bản về RxSwift.
Trong hình ảnh trên, phần network màu xanh biển sẽ chạy trên NSOperation based scheduler
Phần data binddings màu xanh lá cây chạy trên bộ lập lịch background GDC
Phần màu đỏ UI để cập nhật các sự kiện UI trên main thread
Trông có vẻ đơn giản đúng không? Nhưng tạm thời chúng ta sẽ quan tâm nó vào các bài sau cùng nhé.
Kiến trúc ứng dụng
Chúng ta có thể chọn lựa bất kỳ loại kiến trúc nào cho RxSwift, có thể MVC – kiến trúc base của apple. Hoặc bạn có thể dùng MVVM – để giải quyết các vấn đề của MVC. Nó là sự chọn lựa của bạn.
Điều đó có nghĩa là bạn cũng có thể dùng RxSwift với những tính năng mới của app, không bắt buộc phải dùng từ đầu.
Có 1 điều là, bằng kinh nghiệm thực tiễn thì MVVM và RxSwift là 1 sự kết hợp tuyệt vời. Sau này có thể bạn ngầm hiểu dùng RxSwift thì mặc định dùng MVVM để triển khai project của mình.
View Model sẽ cho phép bạn hiển thị các thuộc tính quan sát được, bạn có thể liên kết trực tiếp với UI nên dễ dàng cho việc viết mã.
Tuy nhiên tất cả các ví dụ sau này chúng ta sẽ dùng MVC cho việc học RxSwift đơn giản nhất.
Vậy là chúng ta đã hiểu một phần về RxSwift. Trong bài tiếp theo chúng ta sẽ nghiên cứu cách cài đặt môi trường RxSwift cho việc nghiên cứu bộ môn Rx tuy cũ nhưng lại hay ho này.
Tìm hiểu về NoSQLvà Amazon Web Services tất nhiên không thể bỏ qua khái niệm về Key Value Stores. Đây là nội dung quan trọng cần nắm vững.
Hiểu biết về cơ chế, cách thức lưu trữ và ưu nhược điểm giúp phát triển hệ thống thành công. Ngoài ra, nó cũng rất có ích cho những ai đang muốn thiết kế các hệ thống phân tán lớn.
Bắt đầu ngay thôi nào!
1. Key Value Stores là gì?
A key-value store, or key-value database is a simple database that uses an associative array (think of a map or dictionary) as the fundamental data model where each key is associated with one and only one value in a collection. This relationship is referred to as a key-value pair.
Key value stores, hoặc key value database là kiểu cơ sở dữ liệu sử dụng mảng kết hợp. Trong đó mỗi key sẽ tồn tại duy nhất một value trong collection. Mối quan hệ này được gọi là một cặp key-value
Đối với hệ cơ sở dữ liệu phân tán (Distributed System), các khối dữ liệu dữ liệu có thể lên tới vài triệu khối
Theo cách thông thường, mỗi table sẽ tồn tại nhiều column. Đơn cử như video, ta có video id, title, url, description, …
Đối với Key Value Stores, key ở đây là video id, tất cả các thành phần khác như title, url, description đều có thể gom thành 1 trong object Json.
Đại điện của kiểu lưu trữ này là Dynamo DB, một số use case phổ biến có thể đề cập tới là:
1.1 Use case
Session store: A session-oriented application such as a web application starts a session when a user logs in and is active until the user logs out or the session times out. During this period, the application stores all session-related data either in the main memory or in a database. Session data may include user profile information, messages, personalized data and themes, recommendations, targeted promotions, and discounts.
Lưu trữ session như web application có thể bắt đầu các session khi user đã đăng nhập. Tất cả sẽ biến mất khi user logout hoặc session hết hạn. Trong quá trình này, ứng dụng sẽ lưu trữ tất cả dữ liệu session vào bộ nhớ hoặc DB. Session có thể bao gồm thông tin cá nhân, tin nhắn, cấu hình dữ liệu và themes, …
Do chỉ với một key và value, kiểu lưu trữ này còn ứng dụng trong Shopping Cart
During the holiday shopping season, an e-commerce website may receive billions of orders in seconds. Key-value databases can handle the scaling of large amounts of data and extremely high volumes of state changes while servicing millions of simultaneous users through distributed processing and storage.
Trong mùa nghỉ lễ mua sắm, các trang thương mại điện tử có thể nhận tới hàng tỷ đơn hàng. Key-value databases có thể giải quyết vấn đề scaling cho lượng dữ liệu khổng lồ này. Phục vụ hàng triệu người dùng đồng thời thông qua quá trình xử lý và lưu trữ phân tán.
2. Hai kiểu Key Value Stores
Có hai kiểu Key Value Stores thường được sử dụng khi thiết kế hệ thống là Object Stores và In Memory DB. Ta sẽ tìm hiểu cả hai kiểu này trong bài viết. Đại diện cho Object Stores là Amazon S3 và In Memory DB là Amazon Redis.
2.1 Object Stores
Object storage, often referred to as object-based storage, is a data storage architecture for handling large amounts of unstructured data
Object storage, hay còn được gọi là object-based storage, là kiến trúc lưu trữ dữ liệu handle dữ liệu lớn (không có cấu trúc)
Về cách lưu trữ này, dữ liệu được chia thành các đơn vị rời rạc được gọi là object và được lưu giữ trong một kho lưu trữ duy nhất, thay vì được lưu giữ dưới dạng tệp trong thư mục hoặc dưới dạng khối trên server.
Object Storage chia dữ liệu lớn thành các unit nhỏ (có kích thước giới hạn). Mỗi Object bao gồm data, meta data (for index, management). Cuối cùng là ID, sử dụng để tìm kiếm trong hệ cơ sở dữ liệu phân tán (Distributed System)
Ngoài ra, Object Storage còn cho phép lưu trữ nhiều bản copy của dữ liệu, nếu một phiên bản bị mất có thể backup hoặc sử dụng phiên bản thay thế một cách nhanh chóng
Performs best for big content and high stream throughput – Cung cấp hiệu năng tuyệt vời cho dữ liệu lớn và luồng dữ liệu khổng lồ.
Data can be stored across multiple regions – Dữ liệu có thể được lưu trữ trên nhiều vùng.
Scales infinitely to petabytes and beyond – Quy mô lớn, mở rộng lên tới hàng petabytes.
In Memory DB giống như cái tên của nó. Thay về sử dụng SSD, Hard Disk để lưu trữ dữ liệu. IM DB muốn sử dụng Ram hoặc các phần Memory khác để lưu trữ dữ liệu.
Đại diện tiêu biểu của In Memory là Amazon Elasticache for Redis.
Use case phổ biến thường được áp dụng là Real-time bidding (đấu giá trực tuyến)
Real-time bidding refers to the buying and selling of online ad impressions. Usually the bid has to be made while the user is loading a webpage, in 100-120 milliseconds and sometimes as little as 50 milliseconds.
Real-time bidding đề cập lớn vấn đề mua bán trên các trang online. Thông thường các lệnh đặt được thực hiện khi người dùng đang loading webpage, chỉ trong 100-120 milliseconds, đôi khi là dưới 50 milliseconds.
Để đáp ứng độ trễ này, In Memory tỏ ra là giải pháp hoàn hảo. Tất nhiên, IMDB cũng là vị trí lưu trữ, cách thức lưu trữ thì vẫn giống như Object Store. Cả hai đều là Key Value Stores.
Với IMDB, actions writes, reads thực hiện vô cùng nhanh
Bài viết được sự cho phép của tác giả Trần Hữu Cương
JavaScript Engine là gì?
JavaScript Engine là một chương trình máy tính thực thi các đoạn code JavaScript (JS).
JavaScript đọc các đoạn mã JavaScript rồi chuyển nó sang mã máy để máy tính (hoặc phần mềm máy tính như trình duyệt web, server node.js…) có thể hiểu và chạy được.
Nếu bạn đã lập trình với Java hay C/C++ thì có thể hiểu JavaScript tương đương với JDK trong Java hay trình Compiler C/C++ trong lập trình C/C++.
Các bản JavaScript Engine phổ biến
Có nhiều bản JavaScript Engine được phát triển bởi các các vendor (nhà cung cấp) khác nhau. Một số JavaScript Engine phổ biến như:
SpiderMonkey – Phiên bản Javascript engine đầu tiên, được dùng trên trình duyệt web đầu tiên trên thế giới – Netscape Navigator, hiện tại đang được sử dụng trên Firefox, viết bằng C và C++.
Chakra– Là một Javascript engine cũng khá lâu đời, ban đầu được sử dụng trên Internet Explorer và biên dịch JScript, nay được dùng cho Microsoft Edge, viết bằng C++.
Rhino– Một Engine viết hoàn toàn bằng Java, cũng có lịch sử phát triển lâu đời từ Netscape Navigator, hiện tại được phát triển bởi Mozilla Foundation.
Google V8– Được phát triển bới Google (Chromium Project).
Ngoài các JS Engine trên, còn rất nhiều JavaScript Engine khác như Carakan, JavaScriptCore, Tamarin, Nashorn…
JavaScript dùng ở đâu?
Đầu tiên, các JavaScript Engine chủ yếu được phát triển và cài đặt cho các trình duyệt web (web browser). Ví dụ Chrome V8 dùng cho Google Chrome, SpiderMonkey dùng cho trình duyệt FireFox… Tức là chỉ dùng cho client.
Sau này, các JavaScript Engine được áp dụng để lập trình server với Node.jsruntime system.
Một số phần mềm cũng áp dụng JavaScript Engine để lập trình phần mềm bằng JavaScript như MongoDB…
Bài viết được sự cho phép của tác giả Nguyễn Việt Hưng
Code Python phải chuẩn PEP8
Ngay khi bạn mới làm quen với Python được vài tuần, mới biết tí for loop hay function, PEP8 từ đâu đó sẽ hiện ra. PEP8 là hướng dẫn viết code chuẩn Python, chứ không phải chuẩn C, Java, hay không có chuẩn nào cả. Nếu tự hoc code một mình, có khi giờ này bạn đã làm ra vài chục script, chạy ầm ầm mà vẫn chưa 1 lần nghe PEP8. Tiêu chuẩn code là thứ chỉ hiện ra rõ ràng, khi ta làm việc với người khác, chỉ sau vài function, sự mâu thuẫn về style sẽ hiện ra ngay, và khi ông Chí Phèo không đồng ý với style của Bá Kiến, thì cả 2 phải lên phường và thống nhất dùng chuẩn chung mà làng Vũ Đại đặt ra – hay ở đây ta gọi là PEP8.
PEP8 có thể xem chi tiết tại PEP0008 hay https://pep8.org/, tiêu chuẩn PEP8 được chấp nhận trên toàn trái đất, thậm chí CIA, Google cũng chỉ sửa đi chút xíu, bởi nó là chuẩn hay, chuẩn tốt.
Chuyện đau đầu về xì tai (style)
Style vốn là một thứ dễ gây ra tranh cãi. Tôi thích kiểu Việt Nam dịu dàng, anh thích kiểu Pháp say đắm, ông kia thích kiểu Mỹ mạnh mẽ và hùng hục. Vậy ai là người sai? Cuộc tranh cãi về style viết code đã kéo dài suốt từ ngày lập trình xuất hiện, tới giờ vẫn chưa kết thúc. Bởi đã là style, thì khó nói chuyện đúng sai.
Thế rồi mọi cuộc chơi vui, cũng phải đến hồi kết. Một ngôn ngữ lập trình đơn giản xuất hiện với tên hai chữ Go (sau để tránh nhầm lẫn thì gọi là Golang), và để tăng thêm sự đơn giản, nó đi kèm sẵn một chương trình với tên gofmt (đọc là gâu phằm) – chương trình này sẽ format tất cả code trong thư mục về một chuẩn mà nó đã quy định. Ban đầu, người ta vẫn còn tranh cãi về việc bị ép style, nhưng rồi sau một hồi, lợi ích của mỗi cái tôi đã sụp đổ trước lợi ích tập thể mà gofmt mang lại: mọi đoạn code đều trông giống nhau, khiến style không còn gì để tranh cãi, lập trình viên nhìn code của thằng kia cũng giống như của mình, dễ đọc – dễ hiểu hơn, expert hay newbie đều chung 1 style cả.
gofmt không phải là chương trình đầu tiên làm vậy, trước đây, trong cộng đồng Python đã xuất hiện 1 chương trình tên autopep8 hay Google cũng có YAPF. Nhưng Go là ngôn ngữ đầu tiên mang code formatter vào chính thống, chính thức chấm dứt cuộc chiến vô bổ về style kéo dài vài thập kỷ. Để rồi từ đó, các ngôn ngữ lập trình khác đua nhau học theo như Rust, Elixir và Python thì có black.
Không có giải pháp nào để giải quyết 1 vấn đề tốt hơn là làm cho nó biến mất.
black là gì
Black là một câu lệnh cài bằng pip: pip install black, yêu cầu Python3.6 trở lên mới chạy. black xuất hiện như một project của một lập trình viên nào đó trên in tơ nét, sau vài năm trở nên cực kỳ phổ biến, và giờ đã chính thức được nằm dưới mái nhà PSF (Python Software Foundation) cùng với requests.
Code của black chỉ vọn vẹn 4000 dòng, sử dụng các tính năng mới nhất của Python như f-string, type annotation, asyncio… (vì thế nên yêu cầu Python3.6+ để chạy, mặc dù vẫn có thể format code 2.7)
Dùng black để format code Python
Ví dụ có 1 file foo.py
def sum_two(a,b):
c= a + b
return c
Nếu thành thạo PEP8, thấy ngay có 4 chỗ phải sửa ở đây: a,b thiếu dấu space sau ,, c thiếu dấu space theo sau, sau a thừa 1 space, thừa 1 dòng trống trước return. Vậy chỉ 3 dòng code, người review phải gõ ra 4 “vấn đề” về style, và người code ra 3 dòng này, khi đọc review cũng chẳng vui vẻ gì, kể cả người ta nói đúng.
Chạy:
$ black foo.py
reformatted foo.py
All done! ✨ 🍰 ✨
1 file reformatted.
$ cat foo.py
def sum_two(a, b):
c= a + b
return c
Đẹp, chuẩn, ngon! Không còn gì mong đợi thêm. black có nhiều option để chỉnh style cho phù hợp với tiêu chuẩn của bạn, hay dùng nhất là để set độ dài của 1 dòng, vốn là 79 ký tự theo chuẩn PEP8, thì black mặc định là 88:
-l, --line-length INTEGER How many characters per line to allow.
[default: 88]
Bạn có thể gọi black -l79 . để theo PEP8.
Hành động của chúng ta
Đã đến lúc để quên đi việc format code bằng tay, nhớ vài chục tiêu chuẩn của PEP8, format code hãy để cho đen (black) không vâu lo – việc này để đen không vâu lo. Thêm dòng này vào Makefile của bạn:
fmt:black-l79.
hay cài đặt text editor/IDE tự động chạy black sau mỗi lần save code.
Thêm dòng sau vào CI để bắt quả tang thằng nào không dùng black:
black --check .
Black sẽ thông báo các file chưa chuẩn format:
$ black --check .
would reformat /home/hvn/me/people/content/mypy_simple.py
would reformat /home/hvn/me/people/publishconf.py
would reformat /home/hvn/me/people/pelicanconf.py
would reformat /home/hvn/me/people/fabfile.py
Oh no! 💥 💔 💥
4 files would be reformatted, 1 file would be left unchanged.
Kết luận
Hãy dùng black! Và đừng quên share bài viết này, để cộng đồng code Python không còn mất thời gian ít bổ.
Đánh giá chất lượng có thể được thực hiện dưới hình thức phỏng vấn hoặc các thử nghiệm khả năng sử dụng được quan sát trực tiếp khác. Nó mang tính chất khám phá và với mục tiêu hiểu sâu hơn về trải nghiệm của người dùng. Nhằm mục đích thu thập thông tin về động cơ và trải nghiệm cuộc sống hàng ngày của người dùng hoặc nhóm để xem những chi tiết này có thể ảnh hưởng như thế nào đến việc sử dụng sản phẩm hoặc công cụ của họ.
Đánh giá chất lượng trải nghiệm người dùng giúp cải thiện chất lượng app
Tổng hợp và phân tích kết quả
Khi sử dụng các phương pháp đánh giá chất lượng, điều quan trọng là nhà nghiên cứu phải nhận ra rằng chúng có thể có ảnh hưởng đến kết quả nghiên cứu. Vì trải nghiệm của con người đang được nghiên cứu thay vì dữ liệu cứng (số lần nhấp chuột, xu hướng vị trí đăng nhập,…), rất khó để duy trì sự khách quan một cách tuyệt đối trong quá trình thử nghiệm hoặc khi đánh giá kết quả.
Kết quả cũng không nhất thiết phải được sử dụng lại. Điều này là do các yếu tố ảnh hưởng đến trải nghiệm của người dùng rất đa dạng và có thể thay đổi hàng ngày.
Những yếu tố này có thể khiến người dùng bị căng thẳng vào ngày này hơn ngày khác do những sự kiện mới trong cuộc sống của họ hoặc có nhiều trách nhiệm hơn vào ngày hôm đó, người dùng có trải nghiệm cuộc sống hoàn toàn khác nhau. Thậm chí, cả các yếu tố như thời tiết xấu cũng ảnh hưởng đến tâm trạng của người dùng và bất cứ điều gì khác ảnh hưởng đến cuộc sống cá nhân hoặc tình cảm của một người.
Phỏng vấn trực tiếp: nhà nghiên cứu đặt câu hỏi cụ thể cho người dùng và cố gắng so sánh câu trả lời với những người dùng khác.
Phỏng vấn gián tiếp: nhà nghiên cứu cố gắng thảo luận chung nhiều hơn với (các) người dùng.
Phỏng vấn mang tính cộng đồng: nhà nghiên cứu quan sát (các) người dùng trong môi trường của chính họ để hiểu cách họ tiếp cận các khía cạnh nhất định, hoàn thành các nhiệm vụ nhất định.
Thực hiện khảo sát
Đây là một cách nhanh chóng để thu thập thông tin từ một số lượng lớn người dùng. Nhưng hạn chế rõ ràng của nó chính là thiếu sự tương tác giữa nhà nghiên cứu và người dùng.
Kiểm tra khả năng sử dụng
Kiểm tra có kiểm duyệt: người dùng được đưa vào phòng thí nghiệm và được giao các nhiệm vụ hoặc bài kiểm tra cụ thể để thực hiện.
Kiểm tra không kiểm duyệt: người dùng hoàn thành kiểm tra theo thời gian của họ thường từ xa.
Kiểm tra đột xuất: là một hình thức thử nghiệm thông thường hơn trong đó người dùng ngẫu nhiên tại một địa điểm xã hội hoặc cộng đồng được yêu cầu sử dụng ứng dụng / sản phẩm và cung cấp phản hồi không chính thức.
Bài viết được sự cho phép của tác giả Kien Dang Chung
Trước khi bắt đầu với câu hỏi Tại sao Matplotlib là một thư viện phổ biến trong Python? chúng ta đến với vài câu nói đúc kết của người xưa mà còn nguyên giá trị đến nay.
A picture is worth a thousand words – Một bức tranh hơn ngàn lời nói
Ngạn ngữ Anh
Như chúng ta đã biết Python được sử dụng nhiều nhất trong lĩnh vực phân tích dữ liệu, mà trong khoa học dữ liệu, việc trực quan hóa thông qua các đồ thị, biểu đồ giúp cho chúng ta hiểu được các mối quan hệ trong dữ liệu dễ dàng hơn rất nhiều. Matplotlib là một thư viện sử dụng để vẽ các đồ thị trong Python, chính vì vậy nó là thư viện cực phổ biến của Python. Bạn thử tưởng tượng một file dữ liệu khoảng 20MB, khi vẽ ra đồ thị từ dữ liệu này bạn sướng như phát điên vì có thể hiểu được ngay 20MB đó nói lên cái gì? Ngày nay, khi Big data đang trở thành thực tế, hàng ngày có quá nhiều dữ liệu, việc trực quan hóa dữ liệu càng trở nên cấp thiết và càng thúc đẩy những thư viện như Matplotlib phát triển hơn.
Mục đích của bài hướng dẫn này giúp bạn hiểu được cách vẽ các đồ thị, biểu đồ với thư viện matplotlib và từ đó bạn có thể sử dụng thành thạo nó cho trực quan hóa dữ liệu.
Matplotlib là một thư viện vẽ đồ thị trong Python, cho phép bạn tạo ra các biểu đồ và hình ảnh chất lượng cao. PyLab là một mô-đun trong Matplotlib, cung cấp một giao diện giống như Matlab để làm việc với các biểu đồ một cách dễ dàng.
John D. Hunter, một nhà thần kinh học bắt đầu phát triển matplotlib năm 2003 để mô phỏng các tập lệnh MATLAB, ông qua đời năm 2012 ở tuổi 44. Matplotlib giờ được phát triển và duy trì bởi cộng đồng các nhà phát triển khác.
Trong MATLAB, chúng ta không cần import gì mà có thể sử dụng các hàm có sẵn ngay lập tức khác với Python phải thực hiện import các thư viện cần thiết. Matplotlib có nguồn gốc từ MATLAB do đó module Pylab trong thư viện Matplotlib được xây dựng để có được cách thức sử dụng hàm như MATLAB. Nó đưa một số hàm và lớp từ Numpy và Matplotlib vào namespace giúp cho người dùng MATLAB có thể chuyển đổi sang Python sử dụng dễ dàng.
Khi bạn thực hiện lệnh import sau vào Python:
from pylab import *
Bạn có thể sử dụng ược ngay các hàm như plot(), array() như trong MATLAB. Vấn đề là với câu lệnh import này không ổn, nó bị chồng chéo các module sử dụng trong chương trình Python. Pylab do lịch sử để lại và nó không được khuyến cáo sử dụng, nó sử dụng các tên vô tội vạ với các chức năng ẩn giấu bên trong và rất khó để kiểm tra lỗi, do đó nên sử dụng Matplotlib.
Trong Pylab có rất nhiều các import tiền ẩn khả năng xung đột được che đậy kín. Matplotlib đã từ bỏ module này và khuyến cáo không nên sử dụng Pylab, mang mọi thứ trở nên rõ ràng hơn là để ngầm định. Không có pylab, chúng ta thường sử dụng một câu lệnh thay thế một cách chính tắc:
import matplotlib.pyplot as plt
Phân cấp đối tượng trong Matplotlib
Nếu bạn đã đọc tài liệu của Matplotlib, dòng code dưới đây là một phân cấp với các đối tượng Python lồng vào nhau. Phân cấp ở đây nghĩa là kiểu cấu trúc cây các đối tượng Matplotlib trả về từ plot(). Đối tượng Figure là nơi chứa đồ họa Matplotlib, nó có thể chứa các đối tượng Axes. Dưới Axes là hệ thống phân cấp các đối tượng nhỏ hơn như các đường thẳng, các textbox… Hầu hết các phần tử của đồ thị đều có thể tương tác như đối tượng trong Python.
Trong đoạn code trên chúng ta tạo ra hai biến với plt.subplots(), biến đầu tiên là fig chứa Figure, biến thứ hai _ chứa những thứ khác. Đây là cấu trúc Tuple trong Python do plt.subplots() cũng trả về kiểu Tuple. Do cấu trúc phân cấp hình cây, chúng ta muốn truy xuất đến phần tử đánh dấu chẳng hạn:
Biến fig là instance của lớp Figure chứa bên trong nhiều các đối tượng Axes. Mỗi Axes có một yaxis và xaxis và chúng lại chứa một tập các major_sticks và chúng ta lấy cái đầu tiên.
Một ví dụ sau đến từ Matplotlib cho chúng ta hiểu hơn về phân cấp đối tượng trong Matplotlib.
Hình ảnh trên được sinh ra từ đoạn code sau đây, bạn có thể tham khảo tại Matplotlib.
Vẽ đồ thị với plot()
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot([1,2,3,4,10])
plt.show()
Khi sử dụng module pylot trong thư viện matplotlib chúng ta sẽ import vào với tên ngắn gọn là plt. %matplotlib inline là câu lệnh của Jupyter Notebook để vẽ được các đồ thị bên trong cell của Jupyter Notebook.
Để vẽ một dạng đồ thị, chúng ta cần xem đối tượng plt có những phương thức nào, bạn có thể sử dụng:
dir(plt)
Câu lệnh plt.plot() sẽ vẽ một đồ thị bằng cách nối các điểm bằng đường thẳng (matplotlib.lines.Line2D). Trong ví dụ này, chúng ta đưa vào một List các số và Matplotlib sẽ vẽ ra đồ thị bằng cách nối các điểm. Bởi vì plt.plot() trả về một đối tượng, do vậy khi muốn hiển thị đồ thị, chúng ta cần gọi plt.show().
Phương thức plot() có 3 tham số:
plot(x, y, format)
Tham số x là danh sách các tọa độ trục x
Tham số y là danh sách các tọa độ trục y
format định dạng đồ thị
Trong ví dụ đầu, khi chúng ta đưa vào một List thì mặc định đó là danh sách tọa độ trục y và định dạng mặc định là vẽ đường thẳng giữa các điểm. Ví dụ trên tương đương với:
plt.plot([1,2,3,4,10])
Kết quả được đường sau khi sử dụng plt.show():
Chú ý, trong bài viết này tôi sẽ sử dụng Jupyter Notebook để demo các ví dụ. Nếu bạn chưa biết cài đặt, sử dụng Jupyter Notebook có thể tham khảo:
Quay lại với phần định dạng đồ thị trong tham số thứ 3 của phương thức plot(). Định dạng này ở dạng viết tắt, nó là tổ hợp của ba thành phần {color}{marker}{line}. Ví dụ “go-” sẽ cho định dạng điểm có màu xanh và nối hai điểm là đường thẳng. Chúng ta thử thực hiện nó xem sao:
Chúng ta có một số định dạng khác như sau:
‘r*–‘ các điểm hình ngôi sao màu đỏ, đường nối các điểm dạng –.
‘bD-.’ các điểm hình kim cương màu xanh dương, đường nối các điểm dạng -.
‘g^-‘ các điểm hình tam giác hướng lên màu xanh lá, đường nối các điểm dạng -.
Nếu bạn không muốn các điểm nối với nhau, có thể bỏ định dạng đường thẳng đi, ví dụ ‘go-‘ sẽ thành ‘go’
Vẽ nhiều tập điểm phân tán trên cùng đồ thị
Bạn có thể vẽ nhiều tập điểm phân tán trên cùng một đồ thị bằng cách gọi phương thức plot() nhiều lần. Ví dụ dưới đây sẽ vẽ hai đường đồ thị dựa trên hai tập điểm khác nhau với định dạng khác nhau:
import matplotlib.pyplot as plt
# Vẽ đồ thị
plt.plot([0, 1, 2, 3, 4], [1, 2, 3, 4, 10], 'go-', label='Python')
plt.plot([0, 1, 2, 3, 4], [10, 4, 3, 2, 1], 'ro-', label='C#')
plt.plot([2.5, 2.5, 2.5, 1.5, 0.5], [1, 3, 5, 7, 10], 'bo-', label='Java')
# Đặt tiêu đề và nhãn cho các trục
plt.title('Vẽ đồ thị trong Python với Matplotlib')
plt.xlabel('X')
plt.ylabel('Y')
# Hiển thị chú thích
plt.legend(loc='best')
# Hiển thị đồ thị
Trong ví dụ này có thêm một số điểm cần chú ý:
Thêm nhãn cho từng tập điểm với tham số thứ 4 trong plot().
Hiển thị ghi chú các thành phần trong đồ thị với phương thức legend().
Hiển thị nhãn các trục tọa độ x, y với xlabel() và ylabel().
Phần đầu bài viết chúng ta đã biết về phân cấp đối tượng trong Matplotlib, mỗi plt.plot() trả về một đối tượng Figure (là hình ảnh bên ngoài), trong Figure này có rất nhiều các đối tượng Axes là một đồ thị con bên trong. Trong phần này chúng ta sẽ vẽ hai đồ thị cạnh nhau nằm trong cùng một Figure (Hình ảnh).
import matplotlib.pyplot as plt
# Tạo các subplot
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(10, 4), sharey=True, dpi=120)
# Vẽ đồ thị cho từng subplot
ax1.plot([0, 1, 2, 3, 4], [1, 2, 3, 4, 10], 'go-')
ax2.plot([0, 1, 2, 3, 4], [10, 4, 3, 2, 1], 'ro-')
ax3.plot([2.5, 2.5, 2.5, 1.5, 0.5], [1, 3, 5, 7, 10], 'bo-')
# Đặt tiêu đề cho từng đồ thị
ax1.set_title('Python')
ax2.set_title('C#')
ax3.set_title('Java')
# Đặt nhãn cho trục X
ax1.set_xlabel('X')
ax2.set_xlabel('X')
ax3.set_xlabel('X')
# Đặt nhãn cho trục Y
ax1.set_ylabel('Y')
ax2.set_ylabel('Y')
ax3.set_ylabel('Y')
# Đặt giới hạn cho trục X
ax1.set_xlim(0, 6)
ax2.set_xlim(0, 6)
ax3.set_xlim(0, 6)
# Đặt giới hạn cho trục Y
ax1.set_ylim(0, 12)
ax2.set_ylim(0, 12)
ax3.set_ylim(0, 12)
# Căn chỉnh bố cục
plt.tight_layout()
# Hiển thị đồ thị
plt.show()
Vẽ tập hợp điểm phân tán với scatter()
Sự khác biệt giữa plot() và scatter():
plot() không có khả năng thay đổi màu và kích thước điểm trong tập hợp điểm ban đầu nhưng scatter() lại có thể.
plot() có thể vẽ các đường nối hai điểm liên tiếp, scatter() thì không.
Ví dụ dưới đây vẽ ra các điểm trên đồ thị với dữ liệu về chiều cao và cân nặng, mỗi điểm có màu ngẫu nhiên và có kích thước cũng ngẫu nhiên.
import matplotlib.pyplot as plt
import numpy as np
# Dữ liệu về chiều cao và cân nặng
height = np.array([167, 170, 149, 165, 155, 180, 166, 146, 159, 185, 145, 168, 172, 181, 169])
weight = np.array([86, 74, 66, 78, 68, 79, 90, 73, 70, 88, 66, 84, 67, 84, 77])
# Màu sắc và kích thước cho các điểm dữ liệu
colors = np.random.rand(15)
area = (30 * np.random.rand(15)) ** 2# Đặt giới hạn cho trục x và y
plt.xlim(140, 200)
plt.ylim(60, 100)
# Tạo biểu đồ phân tán
plt.scatter(height, weight, s=area, c=colors)
# Đặt tiêu đề và nhãn trục
plt.title("Chiều cao và cân nặng")
plt.xlabel("Chiều cao - cm")
plt.ylabel("Cân nặng - kg")
# Hiển thị biểu đồ
plt.show()
Trong ví dụ này mình sử dụng 1 project maven trên github có url: https://github.com/stackjava/spring-boot-hello. Đây là 1 ví dụ về spring, đã được cấu hình chạy trên port 8081. Các bạn có thể fork/clone về account github của các bạn để dùng.
Hướng dẫn build java project, maven project trên Jenkins
Đầu tiên, ta tạo 1 plan build bằng cách click vào New Item
Chọn Maven Project và nhập tên cho plan build
Ở đây mình dùng source code từ github nên mình sẽ chọn Git (khi build, jenkins sẽ clone source từ github về)
Để Jenkins clone được source code, ta cần cấu hình account git cho nó.
Nhập username/password của tài khoản github mà bạn sử dụng để clone source code. (nếu bạn dùng bitbucket, gitlab… thì cũng nhập username/password tương ứng)
Nhập repository URL của project git.
Phần Credentials chọn account git mà bạn vừa thêm.
Click Save.
Sau khi Save, ở màn hình chính chúng ta sẽ thấy plan build vừa tạo.
Click vào icon build để build project.
Ở menu bên trái sẽ có trạng thái build của project. Click vào đó để xem.
Click vào Console Ouput để xem log realtime của quá trình build.
Bạn sẽ thấy Jenkins tạo workspace, clone source code từ github về workspace, thực hiện build maven project (download các thư viện) thành file jar.
Trong ví dụ tiếp theo chúng ta sẽ thực hiện deploy project, tức là quá trình chạy file jar sẽ được chạy tự động. Có thể là chạy giống như 1 service, up lên server tomcat…
Chat là hệ thống lớn, bao gồm nhiều thành phần và nhiều vấn đề cần giải quyết. Đại thể có thể nói tới: gửi file, các tệp định dạng khác nhau, group chat, thả reaction, …
Chính vì vậy, tóm gọn trong nội dung bài viết, ta chỉ xem xét qua thiết kế hệ thống Chat ở mức basic nhất có thể, qua đó hiểu thêm về Load Balancers và Scalable Web Application.
Bắt đầu ngay thôi!
1. Yêu cầu hệ thống
Messaging Service khi thiết kế yêu cầu phải có những tính năng tối thiểu như sau:
Send and receive text messages between two devices – Gửi và nhận tin nhắn giữa hai thiết bị
One-on-one conversations with different users – Giao tiếp 1 vs 1 với các user khác nhau trong hệ thống
User can see the time of each message – User có thể thấy được thời gian khi gửi từng tin nhắn
Do bài viết có giới hạn nên mình chỉ đề cập tới thiết kế một hệ thống Chat đơn giản:
Messages are one-on-one only, i.e, no group messages – Tin nhắn gửi 1-1, không có chat theo nhóm
Our server will not store the messages after they’re delivered – Server sẽ không lưu tin nhắn sau khi đã gửi
Our messages will be text-only – Nội dung tin nhắn tạm thời chỉ là text.
2. User case Messaging Service
Về user case cơ bản của hệ thống được thiết kế gồm có:
Send a message to a person – Gửi tin nhắn tới ai đó
If you receive a message and you are online, immediately deliver it. – Nếu nhận được tin nhắn và đang online, tin nhắn tới ngay lập tức.
If you receive a message and you are offline, wait till you come online – Nếu nhận được tin nhắn và đang offline, chờ tới khi online trở lại.
Get a notification and receive a message – Thông báo khi nhận được tin nhắn mới
Về phía user, nội dung lưu trữ cũng không cần quá nhiều.
Java
User:
- id
- username
- password
- list<unread_messages>
Java
Message Properties:
- message text
- timestamp
- sender's Id
Rồi, cơ bản về User, System Requirement đơn giản chỉ cần có vậy. Bắt đầu đi sâu hơn vào phần thiết kế tính năng quan trọng nhất – Gửi tin nhắn.
3. Xử lí gửi và nhận tin nhắn
Không lòng vòng lèo vèo, về cơ bản, có hai cách để xử lí gửi tin nhắn là Push và Pull. Ta sẽ tìm hiểu chi tiết từng loại, ưu nhược điểm khi sử dụng trong Messaging Service System.
Đầu tiên là PULL
This is a less sophisticated way to “send” notifications. The device can periodically ask the server if there are any new messages. Say every 2 minutes, the device sends a REST API request to check if there are new messages, and the server responds with yes or no.
PULL là cách đơn giản để gửi notifications. Thiết bị sẽ gửi request tới server định kì trong một khoảng thời gian nhất định về tin nhắn mới. Cứ mỗi 2 phút, sẽ gửi REST API kiểm tra xem có tin nhắn mới hay không, server sẽ phản hồi với có hoặc không.
Cách này rõ ràng tồn tại hai nhược điểm lớn:
Độ trễ cao, nếu thời gian định kì lớn thì tin nhắn bị delay quá lâu, không thể chấp nhận tới tận 2 phút.
Tuy nhiên, nếu thời gian quá ngắn, request server phải nhận là cực kì lớn. Số lượng người dùng tới vài triệu -> toang.
Một phương thức khác cũng sử dụng PULL là Long Polling. Khi gửi request, server sẽ hold cho tới khi có tin nhắn mới và trả về response.
Thứ hai là PUSH
Thay vì chỉ giao tiếp một chiều với client ở phía chủ động gửi request. Tại sao không giữ connection liên tục giữa client và server sau khi đã mở
Once the client initiates the connection though, it can be kept alive and there can be bi-directional communication.
Tuy nhiên, một khi client khởi tạo kết nối, nó có thể được giữ nguyên và có thể giao tiếp hai chiều. Đó là cơ sở để đẩy dữ liệu đến các device.
3.1 Websocket
Websocket là lựa chọn tốt, đáng để cân nhắc
These are a good choice. WebSockets give you a single bi-directional connection over TCP. Once the connection is established, the client and server can freely exchange information.
Websocket cung cấp kết nối hai chiều (bi-driectional) duy nhất thông 1qua TCP. Một khi kết nối đã được khởi tạo, client và server có thể thoải mái để trao đổi thông tin
3.2 Push Notifications
Với push notification thì hện tại đã có nhiều sự lựa chọn tới từ Google hoặc Apple, mặc dù đôi khi chúng thường chậm hơn Websocket. Tuy nhiên các vấn đề vặt vãnh xung quanh đó thì lại hỗ trợ tốt hơn
Apple thì có Apple Push Notification Service (APNS), hỗ trợ tốt cho các thiết bị iOS. Google thì hỗ trợ với Firebase Cloud Messaging (FCM).
Với tam giác ba điểm kết nối, Notification cho device iOS hay Android trở nên đơn giản hơn bao giờ hết. Mỗi khi server nhận được tin nhắn mới, nó sẽ gửi request Push Notification tới APNS hoặc GCM. Tuy nhiên, giới hạn cho notification với APNS là nội dung maximum có thể gửi tối đa dừng ở mức 2KB
3.3 Còn với XMPP?
XMPP cũng là một loại protocol phổ biến để messaging communications. XMPP is a protocol (giống như HTTP). Cũng có thể kết hợp XMPP với Websockets và Long Polling
4. Bắt tay vào thiết kế
Thiết kế đơng giản cho Messaging Service như sau. Lưu ý phần Caching và CDN có thể xử lí sau
Đầu tiên, phía App Server sẽ là stateless, không quan tâm tới trạng thái của client. Cũng không lưu trữ gì ở đây (not store anything). App Server sẽ chỉ nhận request và lưu vào distributed In-Memory Cache và NoSQL
Khi App Server nhận được request từ notification rằng có message mới, App Servers sẽ đọc từ cache, nếu cache không có thì thực hiện query
Phần Load Balancer và Distributed Database tất nhiên là phần không thể thiếu cho các hệ thống muốn large scale
Trên đây là thiết kế tổng quan cho hệ thống, sẽ có phần 2 phân tích kĩ càng hơn về các feature, trả lời các câu hỏi về kĩ thuật cũng như các vấn đề có thể phải giải quyết trong thực tế.
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Để đi sâu vào Rx, trước tiên chúng ta phải hiểu những khái niệm cơ bản nhất của nó. Sau đây Rx sẽ giải quyết các vấn đề về bất đồng bộ thông qua các khái niệm, thuật ngữ như sau:
Cụ thể ở đây là trạng thái có thể thay đổi và chia sẻ. Trạng thái khó để mô tả, do vậy chúng ta sẽ hiểu nó thông qua các ví dụ. Khi bạn mở máy tính của mình lên, ban đầu chạy ổn định. Nhưng bạn để chế độ ngủ và tiếp tục mở nó lên, thì sau 1 thời gian nó không còn nhanh nữa, bị crash đột ngột… do trạng thái máy tính đã bị thay đổi. Dữ liệu trong bộ nhớ, tình trạng pin, các thao tác của người dùng vào máy,… là tổng hợp tất cả các trạng thái của máy tính. Quản lý các trạng thái đó, chia sẻ các trạng thái không đồng bộ và xử lý chúng là điều mà các bạn sẽ học ở loạt bài hướng dẫn Rx này.
Lập trình tuần tự
Là mô hình lập trình mà bạn sử dụng mã để thay đổi trạng thái chương trình của mình. Ví dụ bạn đang chơi với 1 con chó, bạn yêu cầu nó nằm, chạy hay sủa.. theo yêu cầu của bạn.
Mã tuần tự là mã mà bạn có thể đơn giản hiểu được, và CPU máy tính cũng làm theo 1 chuỗi tuần tự đơn giản, và vấn đề phức tạp khi làm các ứng dụng không đồng bộ phức tạp sẽ khó xử lý. Cùng xem ví dụ sau:
Chúng ta có thể nôm na dịch hiểu đoạn lệnh trên làm những việc sau: tạo giao diện, kết nối các control trên giao diện với controller, tạo data source, và cuối cùng là lắng nghe các sự kiện thay đổi của nó. Chắc chúng ta hằng ngày vẫn làm những việc như này đúng không? Và có thể bạn đã gặp tình huống ai đó thay đổi thứ tự sắp xếp quá trình trên, ví dụ chúng ta lắng nghe sự kiện trước khi kết nối controls, thì crash sẽ xảy ra!
Các trạng thái của ứng dụng – Side effects
Khi người dùng thay đổi các input vào ứng dụng, thì các trạng thái khác nhau của ứng dụng sẽ sinh ra. Và tùy thuộc vào đầu vào mà sẽ sinh những side effects khác nhau. Ví dụ khi login, người dùng bấm sai thì báo alert, khi đăng nhập mà không có mạng, khi nhập thiếu ô,… Rất nhiều các effect khác nhau có thể xảy ra. Rx sẽ giải quyết toàn bộ những side effects đó, thông qua các khái niệm sau.
Declarative code
Trong lập trình tuần tự, bạn thay đổi trạng thái theo ý muốn. Trong lập trình sự kiện, bạn không tạo ra bất cứ side effects nào. Vì bạn đang sống trong 1 thế giới không hoàn hảo, cho nên sẽ có sự giao thoa giữa 2 hướng lập trình trên. RxSwift chính là sự giao thoa đó.
Declarative code – khái niệm cho phép bạn xử lý các side effects của app giống như lập trình tuần tự. Nghĩa là xử lý các sự kiện bất đồng bộ của app như là các sự kiện tuần tự có thể hiểu được.
Reactive systems
Reactive systems – dịch sát nghĩa hơi khó, bạn hiểu nôm na nó là hệ thống phản ứng sự kiện app cũng được! Nó được định nghĩa thông qua các khái niệm trừu tượng sau:
Responsive: luôn luôn cập nhất UI của người dùng, thể hiện trạng thái mới nhất. Nghĩa là trên màn hình của app đang có gì thì nó luôn lấy được trạng thái mới nhất đó.
Resilient: Mỗi hành vi được xác định riêng biệt và linh hoạt, có cơ chế sửa lỗi. Ví dụ hành vi nhập text vào 1 ô được xử lý riêng so với hành vi bấm nút.
Elastic: Mã xử lý các công việc như điền data vào table, thu thập dữ liệu, chia sẻ tài nguyên..
Message driven: Điều hướng sự kiện app nhằm tái sử dụng, tách lớp của các sự kiện trên app.
Bây giờ hẳn đọc đến đây thì bạn vẫn còn mơ hồ lắm chưa hiểu những khái niệm trên là gì. Tuy nhiên đừng hoảng sợ, bạn đầu ai cũng vậy thôi. Thật khó để giải thích nó khi mà không thực hành đúng không nào. Vậy chúng ta hãy đọc tiếp trong bài 4 nhé.
Bài viết được sự cho phép của tác giả Kien Dang Chung
Video trong bài viết
Trong các bài toán machine learning hoặc các bài toán tối ưu, chúng ta thường phải làm việc với những điểm cực trị (thường là điểm cực tiểu) của một hàm số. Hẳn bạn còn nhớ trong Phần 1 của khóa học này về dự đoán doanh thu phim với Linear Regression, chúng ta đã phải cố gắng tìm giá trị nhỏ nhất của hàm chi phí (cost function) mà đôi khi còn gọi là hàm mất mát (loss function). Vậy Thuật toán Gradient Descent là gì?, Gradien Descent có liên hệ gì với việc tìm kiếm cực trị bài toán tối ưu?, chúng ta sẽ cùng tìm hiểu trong bài học này nhé.
Trong kiến thức toán phổ thông chúng ta đã biết, muốn tìm cực trị một hàm số y=f(x)y=f(x) chúng ta sẽ giải phương trình đạo hàm của hàm sốf(x)f(x) bằng 0.
f′(x)=0f′(x)=0
Tuy nhiên phương trình trên không phải lúc nào cũng giải được dễ dàng, có những trường hợp việc giải phương trình trên là bất khả thi. Vậy khi gặp những tình huống này, chúng ta phải làm gì? May thay, thuật toán Gradient Descent cho chúng ta cách thức tìm các điểm cực tiểu cục bộ này một cách xấp xỉ sau một số vòng lặp. Trong thực tế, các giá trị dữ liệu không có đúng 100% mà đôi khi chúng ta chỉ cần những con số gần đúng. Khi một người hỏi tôi, xác suất cho lần đầu tư chứng khoán lần này là 72%, tôi có nên đầu tư không? Thật sự mà nói 72% đã là một con số khá ấn tượng, mọi thứ ngoài đời không bao giờ có 1+1=21+1=2, nên những cách tính toán xấp xỉ, gần đúng là một giải pháp tuyệt vời.
Trước khi đi vào chi tiết thuật toán Gradient Descent, chúng ta hãy cùng trải nghiệm với một tình huống sau đây. Bạn đang ở trên một ngọn núi đầy sương mù, tầm nhìn bị hạn chế, làm cách nào để có thể xuống được thung lũng một cách nhanh nhất (Ở đây thung lũng chính là những điểm cực tiểu trong bài toán tối ưu). Cách đơn giản là nhìn xung quanh chỗ nào cảm nhận dốc nhất thì bạn bước xuống và từng bước một, cho đến khi bạn không cảm nhận được xung quanh có độ dốc thì đấy chính là thung lũng, nơi bằng phẳng và là điểm cực tiểu của đồ thị.
Tuyệt vời phải không, thuật toán Gradient Descent mô tả chính xác những gì bạn đang trải nghiệm ở tình huống trên. Trong bài viết về Đạo hàm hàm số, độ dốc (slope) của hàm số tại điểm x0x0 chính là đạo hàm của hàm số tại điểm x0x0. Bước đi xuống từ điểm x0x0 sang điểm x1x1 sẽ bằng Δ0Δ0. Ta có:
x1=x0+Δ0x1=x0+Δ0
Chúng ta sẽ tìm hiểu xem thành phần của Δ0Δ0 là gì? Để hướng đi xuống chúng ta có
Δ0=−ηf′(x0)Δ0=−ηf′(x0)
Dấu âm trong độ dốc nghĩa là chúng ta đang đi xuống và với hệ số ηη. Vậy ta có thể viết lại
Nhưng đến khi nào thì kết thúc không bước tiếp? Như trong tình huống, khi nào cảm thấy xung quanh không còn dốc, nghĩa là khi đó xn≈xn−1xn≈xn−1 hay xn−xn−1xn−xn−1 đạt đến một giá trị khá nhỏ mà chúng ta chấp nhận được.
2. Viết code Gradient Descent trong Python
Ví dụ chúng ta có một hàm số y=x2−6sinxy=x2−6sinx, đây là một hàm số mà phương trình y′=0y′=0 không tìm được nghiệm bằng cách giải phương trình, do vậy chúng ta cần dùng đến Gradient Descent để tìm cực tiểu.
Ở đây có 4 biến x_0 chứa giá trị trước đó, x_1 là giá trị trong bước tiếp theo, step_multiplier là hệ số kết hợp với độ dốc, ở phần cuối bài chúng ta sẽ biết đến nó với tên gọi tốc độ học (learning rate). Biến precision quyết định khi nào dừng thuật toán, nó là độ chính xác trong phép tính xấp xỉ mà chúng ta mong muốn, ở đây độ chính xác đến 1/100k.
Tiếp theo, chúng ta sẽ cài đặt thuật toán Gradient Descent kết hợp với định nghĩa các phần vẽ hoạt họa:
Thuật toán dừng lại khi độ chính xác đạt như mong muốn hay xn−xn−1<percisionxn−xn−1<percision. Nếu chưa đạt được độ chính xác tính toán bước tiếp theo x1=x0−ηf′(x0)x1=x0−ηf′(x0) với
Những đoạn có độ dốc lớn thuật toán sẽ vượt qua nhanh chóng, những đoạn độ dốc nhỏ, sẽ rất lâu để vượt qua, ví dụ ở dải x[-4,-2] tại đây phải mất hơn 10 vòng lặp để vượt qua.
Khi độ dốc lớn thì bước di chuyển cũng lớn do Δ=xn−xn−1=−ηf′(xn−1)Δ=xn−xn−1=−ηf′(xn−1).
Nhìn vào công thức trên, ta có thể kết luận số bước lặp để đi đến kết quả sẽ phụ thuộc các yếu tố:
Giá trị khởi tạo của thuật toán
Độ chính xác percision
Hệ số step_multiplier hay là tốc độ học (learning rate)
3. Điều chỉnh các thông số trong Gradient Descent
Trong kết quả phần trước chúng ta đã nhận xét một số các yếu tố có liên quan đến kết quả của Gradient Descent, chúng ta sẽ cùng tìm hiểu từng yếu tố liên quan này. Công thức cần nhớ là:
Δ=xn−xn−1=−ηf′(xn−1)Δ=xn−xn−1=−ηf′(xn−1)
3.1 Giá trị khởi tạo
Giá trị khởi tạo là điểm x0x0, nếu điểm này càng gần với điểm cực tiểu thì số bước lặp ít đi. Do bước nhảy phụ thuộc vào độ dốc do đó nếu điểm x0x0 nằm ở phía có độ dốc lớn thì số bước lặp cũng ít đi. Thật vậy, chúng ta điều chỉnh các thông số trong phần 2 như sau:
x_1 =10
Tức là điểm khởi tạo sẽ ở x0=10x0=10 và xuất kết quả ra được hình sau:
Bạn có thể thấy với điểm khởi tạo ở -10, thuật toán hội tụ (đạt đến điểm cực tiểu mong muốn) sau 33 bước lặp, trong khi với điểm khởi tạo là 10 thì chỉ cần 15 bước lặp thuật toán đã hội tụ. Do vậy, việc lựa chọn điểm khởi tạo cho Gradient Descent cũng rất quan trọng để đạt được kết quả nhanh.
3.2 Độ chính xác mong muốn
Trong ví dụ chính, chúng ta sử dụng độ chính xác là 1/100k, vậy nếu thử tăng độ chính xác thêm 1 chữ số 0 nữa tức là chính xác đến 1/1 triệu xem thuật toán hội tụ sau bao nhiêu bước.
Chúng ta thấy cần đến 35 bước lặp mới đạt đến độ chính xác 1/1 triệu trong khi chỉ cần 33 bước lặp với độ chính xác 1/100k. Trong thực tế, tùy vào lĩnh vực và bài toán cụ thể mà cần có độ chính xác cao hay thấp. Ví dụ với một bài toán kinh tế, khi đưa ra xác xuất lựa chọn phương án là 70% (1/trăm) và 72.3473% (1/triệu) là như nhau, vậy nên chúng ta chọn độ chính xác percision = 0.01 thì thuật toán sẽ hội tụ nhanh hơn mà vẫn đạt được kết quả mong muốn.
3.3 Tốc độ học – Learning rate
Tốc độ hội tụ của Gradient Descent phụ thuộc vào nhiều vào learning rate ηη. Để kiểm tra chúng ta thử tăng tốc độ học ηη từ 0.1 lên 0.2. Kết quả như hình sau:
Chỉ sau 18 bước lặp thuật toán đã hội tụ so với 33 bước khi learning rate tăng từ 0.1 lên 0.2. Câu hỏi đặt ra, vậy có thể tăng tốc độ học lên thật cao không. Trong ví dụ tiếp theo chúng ta sẽ đẩy learning rate lên 0.5 xem thế nào.
Thuật toán nhanh chóng kéo đến điểm cực tiểu nhưng không thể hội tụ, nó chạy qua chạy lại hai bên điểm cực tiểu nhưng không thể tiến đến điểm cực tiêu mặc dù chạy qua hơn 50 bước.
Như vậy có thể thấy việc chọn tốc độ học là rất quan trọng trong Gradient Descent, nếu learning rate bé thì tốc độ hội tụ lâu nhưng nếu chọn lớn quá thì thuật toán không thể hội tụ. Do vậy, trong thực tế để chọn được learning rate phù hợp chúng ta cần thực hiện các tốc độ khác nhau và sau vài lần thực hành, chúng ta sẽ có được con số phù hợp.
Bài viết được sự cho phép của tác giả Nguyễn Việt Hưng
I. Markdown
Markdown được nói trong bài này là cú pháp để phục vụ việc chuyển text thành HTML. Tức là khi viết bằng cú pháp markdown, đưa qua 1 chương trình xử lý, nó sẽ cho ra kết quả là HTML.
Kết quả: (lưu ý, xem source html của kết quả để biết chính xác, việc trình bày có thể bị ảnh hưởng bới template của blog)
H1
H2
H3
H4
H5
H6
Định dạng chữ:
Chữ nghiêng: *nghiêng* hoặc _nghiêng_. (*: asterik, _: underscore)
Chữ đậm: **đậm** hoặc __đậm__.
Nghiêng đậm: **_nghiêng đậm_** hoặc *__nghiêng đậm__*
Gạch ngang chữ: <s>gạch ngang</s>
Kết quả:
Chữ nghiêng: nghiêng hoặc nghiêng. (*: asterik, _: underscore)
Chữ đậm: đậm hoặc đậm.
Nghiêng đậm: nghiêng đậm hoặc nghiêng đậm
Gạch ngang chữ: gạch ngang
Link
[I'm an inline-style link](http://fml.vn)
[I'm an inline-style link with title](http://fml.vn "FML Academy")
[I'm a reference-style link][Arbitrary case-insensitive reference text]
[I'm a relative reference to a repository file](../blob/master/LICENSE)
[You can use numbers for reference-style link definitions][1]
Or leave it empty and use the [link text itself].
[arbitrary case-insensitive reference text]: http://fml.vn
[1]: http://fml.vn
[link text itself]:http://fml.vn
Kết quả:
I’m an inline-style link
I’m an inline-style link with title
I’m a reference-style link
I’m a relative reference to a repository file
You can use numbers for reference-style link definitions
Or leave it empty and use the link text itself.
Image
Here's our logo (hover to see the title text):
Inline-style:

Reference-style:
![alt text][logo]
[logo]: https://github.com/adam-p/markdown-here/raw/master/src/common/images/icon48.png "Logo Title Text 2"
Pelican là một công cụ để tự động tạo file html, được viết bằng python. Hỗ trợ cú pháp reStructure (file đuôi .rst) và markdown (file đuôi .md)
1. Tạo virtualenv, kích hoạt và cài pelican, markdown vào virtualenv:
╭─htl@htl-homeserver ~/pelican
╰─$ virtualenv -p $(which python3) venv
Running virtualenv with interpreter /usr/local/bin/python3
Using base prefix '/usr/local'
New python executable in venv/bin/python3
Also creating executable in venv/bin/python
Installing setuptools, pip, wheel...done.
╭─htl@htl-homeserver ~/pelican
╰─$ source ./venv/bin/activate
(venv)╭─htl@htl-homeserver ~/pelican
╰─$ pip install pelican markdown
Collecting pelican
Using cached pelican-3.6.3-py2.py3-none-any.whl
Collecting markdown
Collecting docutils (from pelican)
Using cached docutils-0.12-py3-none-any.whl
Collecting six>=1.4 (from pelican)
Using cached six-1.10.0-py2.py3-none-any.whl
Collecting unidecode (from pelican)
Collecting jinja2>=2.7 (from pelican)
Using cached Jinja2-2.8-py2.py3-none-any.whl
Collecting feedgenerator>=1.6 (from pelican)
Collecting pytz>=0a (from pelican)
Using cached pytz-2016.4-py2.py3-none-any.whl
Collecting pygments (from pelican)
Using cached Pygments-2.1.3-py2.py3-none-any.whl
Collecting blinker (from pelican)
Collecting python-dateutil (from pelican)
Using cached python_dateutil-2.5.3-py2.py3-none-any.whl
Collecting MarkupSafe (from jinja2>=2.7->pelican)
Installing collected packages: docutils, six, unidecode, MarkupSafe, jinja2, pytz, feedgenerator, pygments, blinker, python-dateutil, pelican, markdown
Successfully installed MarkupSafe-0.23 blinker-1.4 docutils-0.12 feedgenerator-1.8 jinja2-2.8 markdown-2.6.6 pelican-3.6.3 pygments-2.1.3 python-dateutil-2.5.3 pytz-2016.4 six-1.10.0 unidecode-0.4.19
2. Tạo thư mục chứa blog và chạy pelican-quickstart để thiết lập các thông số ban đầu:
(venv)╭─htl@htl-homeserver ~/pelican
╰─$ mkdir blog
mkdir: created directory 'blog'
(venv)╭─htl@htl-homeserver ~/pelican
╰─$ cd blog
(venv)╭─htl@htl-homeserver ~/pelican/blog
╰─$ pelican-quickstart
Welcome to pelican-quickstart v3.6.3.
This script will help you create a new Pelican-based website.
Please answer the following questions so this script can generate the files
needed by Pelican.
> Where do you want to create your new web site? [.]
> What will be the title of this web site? Test blog
> Who will be the author of this web site? htl
> What will be the default language of this web site? [en] vn
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
> Do you want to enable article pagination? (Y/n) y
> How many articles per page do you want? [10]
> What is your time zone? [Europe/Paris] Asia/Ho_Chi_Minh
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) y
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) y
> Do you want to upload your website using FTP? (y/N) n
> Do you want to upload your website using SSH? (y/N) n
> Do you want to upload your website using Dropbox? (y/N) n
> Do you want to upload your website using S3? (y/N) n
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
> Do you want to upload your website using GitHub Pages? (y/N) y
> Is this your personal page (username.github.io)? (y/N) n
Done. Your new project is available at /home/htl/pelican/blog
3. Viết blog trong thư mục content:
Đơn giản là chỉ cần tạo 1 file .md tại thư mục /blog/content, nội dung file được định dạng theo cú pháp markdown.
Các thông tin (metadata) cần thiết cho 1 bài viết được ghi ngay trên đầu file. Metadata tối thiểu bắt buộc phải có là Title, ngoài ra với cấu hình mặc định thì nên thêm Date:
Title: Tiêu đề bài viết
Date: 2016-06-28
Nội dung viết ở đây, định dạng **markdown**
Nếu metadata Date không được cung cấp trong nội dung bài viết thì pelican sẽ lấy thời gian tạo ra file, với điều kiện trong file pelicanconf.py phải có dòng (mà mặc định là chưa có):
DEFAULT_DATE='fs'
4. Tạo file html:
Điều kiện là khi khởi tạo bằng lệnh pelican-quickstart phải bật công cụ tự động tạo html ở câu hỏi này:
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) y
Khi đó sẽ có file Makefile tại thư mục gốc của blog. Tạo blog bằng cách chạy lệnh make html:
(venv)╭─htl@htl-homeserver ~/pelican/blog
╰─$ make html
pelican /home/htl/pelican/blog/content -o /home/htl/pelican/blog/output -s /home/htl/pelican/blog/pelicanconf.py
Done: Processed 1 article, 0 drafts, 0 pages and 0 hidden pages in 0.22 seconds.
Vậy là đã tạo được 1 file html trong thư mục output (ngang hàng với content).
Thử xem blog mình vừa viết trông như thế nào, dùng lệnh make serve:
(venv)╭─htl@htl-homeserver ~/pelican/blog
╰─$ make serve
cd /home/htl/pelican/blog/output && python -m pelican.server
1. Tạo 1 github repo có tên là username.github.io với username là tên tài khoản github của bạn.
2. Clone repo về local:
(venv)╭─htl@htl-homeserver ~/pelican
╰─$ git clone git@github.com:fmltestblog/fmltestblog.github.io.git
Cloning into 'fmltestblog.github.io'...
warning: You appear to have cloned an empty repository.
3. Copy tất cả folder output vào thư mục của github repo:
Có rất nhiều ý kiến cho rằng JavaScript không phải là ngôn ngữ lập trình hướng đối tượng vì nó không có từ khóa class để tạo bản thiết kế đối tượng như các ngôn ngữ lập trình OOP khác (Java, Python, C#…). Tuy nhiên, trong JavaScript ta có thể làm điều tương tự với function
Về thừa kế (inheritance) trong JavaScript, tất cả các đối tượng đều thừa kế từ prototype. (protype là thuộc tính đặc biệt mà tất cả các đối tượng đều có. Nó tương tương như trong Java, tất cả các class đều thừa kế class Object. Phần prototype này mình sẽ viết một bài riêng để mọi người hiểu rõ hơn)
Tóm lại, JavaScript là một ngôn ngữ lập trình hàm nhưng đồng thời nó cũng là một ngôn ngữ lập trình hướng đối tượng vì nó có đầy đủ các tính chất của ngôn ngữ lập trình hướng đối tượng.
Một số ngôn ngữ wrapper lại JavaScript như TypeScript hay CoffeeScript cung cấp các từ khóa như class , extends sẽ giúp ta thấy rõ hơn tính chất hướng đối tượng của JavaScript. (Các ngôn ngữ này sau khi build chính là JavaScript).
Bài viết được sự cho phép của tác giả To Thi Van Anh
Nhắc lại cái vấn đề ở bài ngoại truyện đã đề cập đến đó là khi bạn thực hiện download một file là các định dạng như MS Excel, MS Word, Zip File, PDF, CSV, Text file… với Selenium Webdriver từ một ứng dụng web nào đó. Sau khi nhấn nút Download để tải file xuống, thì một popup window sẽ hiển thị ra, nó sẽ hỏi bạn là bạn muốn Mở file này, hay là bạn muốn Lưu nó lại xuống máy. Cửa sổ này không phải là HTML popup thông thường để chúng ta có thể inspect và lấy locator như các popup khác đâu nha, vì nó là window popup mà.
Như chúng ta đều biết, thì Selenium webdriver được sử dụng với các ứng dụng web mà thôi, tức là các ứng dụng chạy qua trình duyệt đó, và với kiểu popup trên ta sẽ không thể sử dụng trực tiếp Selenium webdriver rồi. Vậy thì bằng cách nào có thể xử lý được đây? Các bạn theo dõi tiếp bài viết này của mình nhé!
Có một cái ý nho nhỏ mà mình sẽ nói qua ở đoạn này đó là với trình duyệt Firefox và trình duyệt IE, bình thường nếu làm việc với IE thì nó sẽ luôn luôn hỏi là bạn muốn Mở file, hoặc Lưu, hoặc là Lưu ở một nơi khác (click vào rồi chọn đến thư mục bạn muốn lưu file ở đó). Còn với Firefox và Chrome thì bạn có thể vào phần Settings, để tùy chọn mặc định lưu file ở một nơi nào đó mà không cần hỏi gì hết, hoặc là chọn lựa chọn là mỗi khi download sẽ phải hỏi bạn xem bạn muốn lưu ở đâu rồi mới thực hiện lưu – lựa chọn này chính là hiển thị popup mà mình đã nói phía trên đó.
Và ở bài này mình sẽ nói đến trường hợp download file với Firefox thôi nhé, Chrome chắc cũng tương tự thôi, vì mình cũng chưa thử, nên không khẳng định chỗ này đâu ha. :D. Và trước khi bắt đầu chúng ta sẽ nói về một khái niệm hơi lạ nhưng lại hơi liên quan đó là MIME một chút nhé! :v
MIME là gì?
MIME viết tắt của Multi-purpose Internet Mail Extensions, nó là một chuẩn Internet về định dạng cho thư điện tử, hầu như mọi thư điện tử Internet được truyền qua giao thức SMTP theo định dạng MIME. Ví dụ như Web server và các trình duyệt đều có một danh sách các loại MIME, vì thế mà các browser và server có thể trao đổi các loại file khác nhau theo cùng phương thức. Một loại MIME có hai phần là type và subtype, ngăn cách nhau bởi 1 dấu /, ví dụ cho dễ hình dung nhé:
TextFile (.txt): text/plain
PDFFile (.pdf): application/pdf
CSVFile (.csv): text/csv
MS Excel File(.xlsx): application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
MS word File(.docx): application/vnd.openxmlformats-officedocument.wordprocessingml.document
Và liên quan trực tiếp đến mục đích lớn nhất của chúng ta là download được file, thì trước tiên phải truyền các MIME type nào vào một cái gọi là Firefox profile.
Firefox Profile Preferences
Để thực hiện download một file với Selenium Webdriver thì chúng ta sẽ cần phải thực hiện một vài setting cho trình duyệt thông qua Firefox profile preferences, không phải đi cài đặt bằng tay đâu nhá, mà là đưa nó vào trong code ấy :v. Dưới đây là một vài preference cần lưu ý:
setPreference(“browser.download.folderList”, 2);
0 – Default. Truyền vào là 0 nếu bạn muốn lưu file trên màn hình desktop.
1 – Với giá trị 1 thì lưu file mặc định vào thư mục Downloads
2 – Lựa chọn này khi bạn muốn lưu file vào một thư mục cụ thể nào đó trong máy tính của bạn.
Mặc định thì là một chuỗi trống – không có nội dung đó. Đoạn này bạn có thể truyền vào danh sách các loại MIME được lưu luôn xuống máy mà không cần hỏi bạn có muốn lưu file này hay không.
Tương tự như trên, giá trị mặc định của cái này cũng là một chuỗi trống, ở đây bạn sẽ truyền vào danh sách các loại MIME được mở luôn mà cũng không cần hỏi bạn nữa.
setPreference(“browser.download.dir”,path);
Giá trị của thằng này cũng là chuỗi trống, ở đây bạn có thể truyền vào đường dẫn mà bạn muốn lưu file ở một thư mục cụ thể nào đó trên máy bạn.
Về cơ bản thì những cái trên kia đã đủ đáp ứng nhu cầu cho việc download file của chúng ra rồi, tuy nhiên mình sẽ đưa thêm một vài preferences khác nữa để các bạn tham khảo nhé, và có thể bổ sung vào trong những trường hợp cần thiết khác mà không phải là download nữa!
Giá trị mặc định là True. Với True thì nó sẽ cảnh báo khi người dùng muốn mở một tập tin có khả năng thực thi, như kiểu các file exe, html, js gì đó đó. Nếu để False thì nó sẽ không hiển thị cảnh báo nữa mà sẽ luôn cho phép run.
Preference này có giá trị mặc định là False. Với giá trị True – Nó sẽ cho phép cửa sổ trình quản lý download được hiển thị khi quá trình download bắt đầu, ngược lại với False thì cửa sổ sẽ không được hiển thị, quá trình download diễn ra ngầm thôi.
Theo mình tìm hiểu thì có khá nhiều các preference khác nhau hỗ trợ các tác vụ khác nhau nữa, nhưng mà liên quan đến việc download file thì chủ yếu sẽ sử dụng những cái trên này, còn cả những cái khác nữa đấy :v nhưng nói đến đây đủ dùng rồi, nếu thiếu thì sau này bổ sung sau cũng được. hehe.
Bài viết mình có tham khảo từ nhiều nguồn thông qua tìm kiếm Google, trên stack overflow cũng nhiều người hỏi lắm, mình không tìm theo từ khóa tiếng việt, nên không rõ đã có ai nói chưa. Hehe. Hi vọng bài viết hữu ích cho tất cả các bạn, mình cũng rất mong nhận được các bình luận góp ý từ các bạn để hoàn thiện hơn mặt kiến thức cũng như trình bày.
Máy tính ảo là một trong những công cụ rất quan trọng đối với nhiều nhóm đối tượng sử dụng khác nhau, đặc biệt là những bạn đang theo học và làm việc trong các ngành như: mạng máy tính, máy chủ, lập trình web, phát triển phần mềm..
Mà để học những ngành trên thì Ubuntu nói riêng hay các hệ điều hành Linux nói chung là một trong những lựa chọn rất tốt, nếu không muốn nói là rất tuyệt vời.
Giống với hệ điều hành Windows 10, Linux cũng có một mớ các ứng dụng hỗ trợ cho việc tạo máy tính ảo, nhưng chỉ một vài trong số đó là miễn phí và đáng để sử dụng. Tiêu biểu là 2 cái tên VMWare Workstation - Player và Oracle VM VirtualBox.
Về công dụng thì 2 phần mềm này là như nhau, tùy vào nhu cầu và đặc thù công việc của bạn mà lựa chọn thôi.
Trên blog đã có bài hướng dẫn chi tiết về cách cài đặt VMWare Workstation trên Ubuntu rồi, nay mình hướng dẫn nốt cách cài phần mềm VM VirtualBox trên Ubuntu để các bạn có thêm sự lựa chọn, ok – giờ thì tiến hành thôi 🙂
I. Hướng dẫn cài đặt VirtualBox trên Ubuntu
Cách #1: Cài VirtualBox trên Ubuntu bằng Software Installer
Tương tự như trên Windows 10, có vài phần mềm trên Linux cho phép bạn có thể cài đặt chỉ với vài cú click chuột mà không cần động đến dòng lệnh nào, và may mắn là VirtualBox của chúng ta nằm trong số đó.
+ Bước 1: Trước hết, bạn cần truy cập vào trang Wiki của VirtualBox để tải về bộ cài của phần mềm này, phiên bản mới nhất tính tới thời điểm mình viết bài này là 6.1.18.
+ Bước 2: Bạn sẽ thấy giao diện của trang Wiki tương tự như hình bên dưới, có thể thấy VirtualBox hỗ trợ hầu hết các hệ điều hành phổ biến của máy tính.
Vì chúng ta đang muốn cài trên Ubuntu => nên bạn hãy click vào dòng Linux distributions để tiếp tục.
+ Bước 3: Sau đó bạn sẽ thấy danh sách các bản phân phối Linux có thể sử dụng được VirtualBox, phiên bản mới nhất của Ubuntu là Ubuntu 20.04 cũng đã được hỗ trợ luôn rồi.
Giờ hãy chọn hệ điều hành phù hợp với máy tính của bạn, ở bài viết này chúng ta sẽ chọn dòng Ubuntu 19.10 / 20.4 nhé.
Ngay lập tức một file cài đặt có đuôi .deb với dung lượng tầm 90MB sẽ được tải xuống máy tính. Tải xong bạn hãy click vào file này để bắt đầu quá trình cài đặt VirtualBox sử dụng Software Installer của Ubuntu.
+ Bước 4: Một cửa sổ virtualbox-6.1 hiện lên cung cấp cho một vài thông tin về ứng dụng VirtualBox mà bạn sắp sửa cài đặt, tất nhiên là chúng ta chẳng đọc bao giờ.
Giờ hãy bấm vào nút Install màu xanh như trong hình để cài đặt VirtualBox vào Ubuntu. Cách này na ná giống việc bạn Search và cài đặt một ứng dụng từ cửa hàng ứng dụng của macOS và Linux, rất dễ và ai cũng có thể làm được.
+ Bước 5: Tiếp theo, bạn cần nhập mật khẩu tài khoản Admin của mình để xác nhận việc cài đặt ứng dụng này, bao giờ cũng vậy.
Việc hỏi mật khẩu root nhằm giúp bảo vệ hệ điều hành khỏi những phần mềm độc hại, những phần mềm muốn có quyền can thiệp sâu vào hệ điều hành và nó gần giống với User Account Control của Windows, chỉ khác là không thể tắt được như UAC mà thôi.
Quá trình cài đặt sẽ diễn ra trong khoảng 30S sau đó và nếu không có lỗi gì xảy ra thì bạn đã cài thành công ứng dụng VirtualBox trên Ubuntu và nút Install lúc đầu sẽ chuyển thành nút Remove màu đỏ.
Giờ hãy bấm phím Windows trên bàn phím => gõ từ khóa Virtualbox vào ô tìm kiếm và bạn sẽ thấy duy nhất một kết quả là Oracle VM VirtualBox như hình bên dưới => Click vào đó để chạy ứng dụng VirtualBox.
+ Bước 6: Giao diện của VirtualBox trên Ubuntu và macOS sẽ hơi khác với giao diện của VirtualBox trên Windows 10 một chút, nhưng về cơ bản thì cách sử dụng thì không có gì khác biệt, nhưng mình vẫn sẽ có bài hướng dẫn chi tiết cách sử dụng sau.
Okay, vậy là việc cài đặt VirtualBox trên Ubuntu đã xong !
Cách #2: Cài đặt VirtualBox trên Ubuntu bằng Terminal
Terminal là một trong những công cụ cực kỳ mạnh mẽ trên các hệ điều hành nhân Linux và tạo sự khác biệt giữa Windows và macOS.
Bạn hoàn toàn có thể cài đặt bất cứ phần mềm nào chỉ với một vài dòng lệnh trong Terminal, mình sẽ lấy luôn ví dụ là ứng dụng Oracle VM VirtualBox này nhé !
Khi muốn cài bất cứ phần mềm nào trên Ubuntu nói riêng và Linux nói chung, việc cần làm đầu tiên phải là cập nhật hệ thống.
+ Bước 1: Bạn hãy bấm tổ hợp phím Ctrl + Alt + T trên bàn phím để mở cửa sổ Terminal lên => rồi cập nhật hệ thống Ubuntu bằng dòng lệnh sau:
Ngoài ra, lệnh này còn tự động loại bỏ những gói phần mềm bổ sung của các ứng dụng đã bị gỡ ra trước đó, giúp tối ưu và tăng tốc hệ thống.
Sau khi hệ thống đã được cập nhật xong, chúng ta cần phải cài đặt gói Linux Ubuntu Headers, nó chứa các tập tin Header và các tập lệnh để xây dựng module cho nhân Linux, và đây cũng cũng là một thành phần cần thiết để có thể sử dụng được Virtual Box trên Ubuntu.
+ Bước 2: Nhập vào cửa sổ Terminal dòng lệnh dưới đây => rồi bấm Enter để cài gói Linux Ubuntu Headers, thời gian cài đặt cũng khá lâu nên bạn cần kiên nhẫn chờ đợi nha:
sudo apt-get -y install gcc make linux-headers-$(uname -r) dkms
+ Bước 3: Các ứng dụng muốn cài được bằng dòng lệnh thì phải có kho lưu trữ gọi là các Repository trên Internet, đa số các ứng dụng phổ biến đều đã nằm trong kho lưu trữ mặc định của Linux hoặc kho lưu trữ của chúng đã được thêm vào Linux rồi, chỉ cần gõ lệnh nữa là xong.
Danh sách các kho lưu trữ của ứng dụng được lưu vào một tập tin có tên sources.list nằm trong thư mục etc/apt/ trên ổ đĩa hệ thống.
Đối với những ứng dụng còn lại, muốn cài được bằng dòng lệnh thì bạn phải thêm kho lưu trữ theo cách thủ công giống như cách mình làm với ứng dụng Virtual Box dưới đây.
Trước hết hãy tải về các khóa của Virtual Box về máy để có được quyền truy cập vào kho lưu trữ của ứng dụng này.
+ Bước 5: Giờ hãy cập nhật lại hệ thống một lần nữa để Ubuntu lấy dữ liệu các gói cài đặt từ kho lưu trữ của Virtual Box mà bạn vừa đã thêm vào ở trên, lệnh sau:
sudo apt-get update
Cuối cùng nhập vào Terminal lệnh bên dưới =>rồi bấm phím Enter và chờ cho Virtual Box được cài đặt vào Ubuntu.
sudo apt-get install virtualbox-6.1 -y
Lưu ý về phiên bản của VirtualBox khi cài đặt, ở đây phiên bản mới nhất của VirtualBox đang là 6.1.18 nên mình nhập virtualbox-6.1, bạn cần lưu ý để chọn đúng phiên bản muốn cài đặt.
Và đây là thành quả, nói chung là 2 cách cài này đều cài như nhau, bạn thích dùng cách nào thì tùy 😀
II. Làm thế nào để gỡ cài đặt VirtualBox trên Ubuntu?
Khi Virtual Box không đáp ứng được yêu cầu công việc của bạn, hoặc đơn giản là bạn thích dùng VMWare Workstation hơn thì việc gỡ cài đặt ứng dụng này cũng không có gì phức tạp.
+ Đối với những người cài bằng cách dùng Software Installer, bạn hãy chạy lại file .deb đã dùng lúc cài đặt lên, nếu lỡ xóa rồi thì vào trang download của VirtualBox để tải lại.
Cửa sổ Software Installer quen thuộc lại hiện lên nhưng thay vì nút Install như lúc đầu, bạn sẽ thấy một nút Remove màu đỏ => Bấm vào đó rồi nhập mật khẩu root để gỡ VirtualBox.
+ Còn với những người cài bằng Terminal, việc gỡ cài đặt thậm chí còn đơn giản hơn nữa. Chỉ việc mở Terminal lên => rồi gõ dòng lệnh sudo apt-get remove virtualbox* --purge -y và bấm phím Enter là xong rồi.
Khác với Windows, bạn có thể cài nhiều phiên bản của cùng một ứng dụng mà không gặp bất cứ lỗi gì.
Vậy nên nếu có lỡ cài nhầm và nhiều phiên bản khác của Virtual Box, hãy sử dụng lệnh tương tự dưới đây để gỡ từng phiên bản còn lệnh bên trên sẽ gỡ toàn bộ phiên bản đã cài :
sudo apt-get remove virtualbox virtualbox-5.0
sudo apt-get remove virtualbox virtualbox-5.2
sudo apt-get remove virtualbox virtualbox-6.1
………….
III. Lời kết
Vâng, như vậy là mình đã hướng dẫn xong cho các bạn 2 cách cài đặt ứng dụng VirtualBox trên Ubuntu rồi nhé. Hi vọng là qua bài viết này bạn sẽ có thêm những lựa chọn để tạo và sử dụng máy tính ảo trên Ubuntu, phục vụ cho công việc của bạn được tốt hơn.
Ở trong bài tiếp theo thì mình sẽ nói về cách tạo máy ảo bằng VirtualBox trên Ubuntu vì nó sẽ hơi khác Windows một tí, mời bạn cùng theo dõi nha. Nếu thấy thủ thuật này hay và có ích đừng quên chia sẻ để ủng hộ Blog. Chúc các bạn thành công !
Như bài 1 đã có giới thiệu, định dạng data trong API thường dùng 2 loại chính là JSON (JavaScript Object Notation) và XML (Extensible Markup Language). Hôm nay, mình sẽ nói kỹ hơn về từng loại định dạng.
Ngày nay, JSON được sử dụng nhiều trong Restful API. Nó được xây dựng từ Javascript, ngôn ngữ mà được dùng nhiều, tương thích với cả front-end và back-end của cả web app và web service. JSON là 1 định dạng đơn giản với 2 thành phần: keys và values.
– Key thể hiện thuộc tính của Object
– Value thể hiện giá trị của từng Key
Ví dụ:
Trong ví dụ trên, keys nằm bên trái, values nằm bên phải.
Có nhiều trường hợp, 1 Key sẽ có Value là 1 dãy key + value. Ví dụ như hình:
Trong hình trên Key có tên là Data có Value là 2 cặp Key + value.
XML
Trong JSON dùng { } và [ ] để dánh dấu dữ liệu. XML thì tương tự như HMTL, dùng thẻ để đánh dấu và được gọi là nodes.
Lấy luôn ví dụ ở trên nhưng viết bằng xml, nó sẽ như thế này:
Định dạng dữ liệu được sử dụng như thế nào trong HTTP.
Quay lại bài 2, phần header có chức năng lưu những thông tin mà người dùng không biết, trong đó có 1 thành phần xác định format của data: Content-Type
Khi client gửi Content-Type trong header của request, nó đang nói với server rằng dữ liệu trong phần body của request là được định dạng theo kiểu đó. Khi client muốn gửi JSON nó sẽ đặt Content-Type là “application/json”. Khi bắt đầu nhận request, server sẽ check cái Content-Type đầu tiên và như thế nó biết cách đọc dữ liệu trong body. Ngược lại, khi server gửi lại client 1 response, nó cũng gửi lại Content-Type để cho client biết cách đọc body của response.
Đôi khi client chỉ đọc được 1 loại định dạng, ví dụ là JSON mà server lại trả về XML thì client sẽ bị lỗi. Do đó, 1 thành phần khác ở trong header là Accept sẽ giúp client xử lý vấn đề trên bằng cách nói luôn với server loại nó có thể đọc được. Ví dụ : Accept : “application/json” . Chốt lại: dựa vào 2 thành phần Content-Type và Accept, client và server có thể hiểu và làm việc một cách chính xác. Ở những bài sử dụng công cụ, mình sẽ chụp ảnh và minh họa rõ ràng Content-Type và Accept trong Header. Chọn ảnh tiêu biểu
Trong môi trường Developement mà thao tác với dữ liệu thực là chết người. Nên khi có 1 ứng dụng cần sử dụng API để xử lý hàng nghìn dữ liệu thì việc thực hiện test rất cần thiết và nếu tạo bằng tay data để test thì không ai rãnh vì thế tạo dữ liệu ảo là rất cần thiết.
Vậy việc đầu tiên sau khi có Database test thì chúng ta sẽ “Dummy Data” hay tạo dữ liệu ảo và tên gọi của việc này là Database seeding.
name;// Tạo dữ liệu ảo Địa chỉ
echo $faker->address;// Tạo dữ liệu ảo Đoạn văn
echo $faker->text;// Nếu muốn tạo nhiều dữ liệu mẫu cùng lúc thì để trong vòng For nhé
for ($i=0; $i < 10; $i++) {
echo $faker->name, "\n";
}
Trợ lý giọng nói (voice assistant) và tìm kiếm bằng giọng nói (voice search) đang dần trở thành một xu hướng mới. Trong số những trợ lý ảo phổ biến nhất hiện nay thì Google Assistant là cái tên bạn không nên bỏ qua. Hiện tại, Google Assistant đang hỗ trợ hơn 19 ngôn ngữ, trên hơn 80 quốc gia và có mặt trên nhiều loại thiết bị khác nhau như các thiết bị Smart Display, các dòng điện thoại Android, Iphone, Google Home, loa thông minh,…
Bạn có thể tận dụng Google Assistant để tiếp cận lượng người dùng lớn của trợ lý ảo này bằng cách tạo ra các action thông qua nền tảng Actions on Google. Bài viết sẽ hướng dẫn chi tiết về nền tảng này thông qua topic “Multiple ways to build for Google Assistant” của Ms. Jessica Dene Earley-Cha – Developer Advocate @Google tại sự kiện Vietnam Web Summit 2020 LIVE – biên tập bởi TopDev.
Bài viết sẽ phù hợp nếu bạn:
Là một Web Content Owner, hãy tìm hiểu về Content Actions: các loại công thức, những nội dung hướng dẫn, podcast, tin tức,…
Là một Android App Developer, hãy tìm hiểu về App Actions.
Là một người thích tìm hiểu về công nghệ giao tiếp bằng giọng nói, hãy tìm hiểu về Conversational Actions với Interactive Canvas.
Là một Hardware Developer, hãy tìm hiểu về Smart Home SDK.
Google Assistant hỗ trợ người dùng, khiến đời sống và công việc trở nên hiệu quả hơn
Content Action – Khiến nội dung của bạn xuất hiện trên Google Assistant
Nếu bạn đã có một website, một podcast hay một danh sách công thức thì bạn có thể đưa những nội dung trên của bạn vào trong Google Assistant.
Tương tự như việc tối ưu website cho Google Search, bạn cần cấu trúc website nhằm giúp Google Search có thể hiểu được dữ liệu đó và có thể mang chúng đến và phục vụ cho user thì với Google Assistant điều này cũng diễn ra tương tự.
Tất cả những việc bạn cần làm là thêm vào scheme.org và cấu trúc các trang làm sao để Google Assistant có thể nhận biết, hiểu và mang những nội dung của bạn đến người dùng.
Các loại nội dung trên Google Assistant
Thường những nội dung trong Google Assistant được phân loại thành: news; podcast; recipes; FAQs; how-to.
Việc bạn cần làm là hãy thêm vào Structured Data Markup (Đánh dấu dữ liệu có cấu trúc) để content của bạn có thể được tìm thấy bởi nhiều công cụ tìm kiếm hơn, trong đó có cả Google Assistant.
Đây là một ví dụ về một quyển sách nói. Họ chỉ sử dụng RSS, đồng thời có thể thêm vào cấu trúc dữ liệu ấy, từ đó mà có thể được tối ưu hoạt động trên cả Search và Assistant.
App Action – Kích hoạt chức năng giọng nói cho các ứng dụng Android
App Action là một hành động giúp bạn gửi một ứng dụng Android đến người dùng thông qua câu thoại lệnh “Hey Google, open *your app*”.
Thách thức “Tái tương tác ứng dụng”
Thông thường doanh nghiệp sẽ phải tốn rất nhiều chi phí để có thể khiến người dùng cài đặt app cũng như khiến họ tương tác, sử dụng ứng dụng một cách thường xuyên. Một trong số những lý do tại sao khiến chi phí này lại trở nên đáng kể là bởi trên thiết bị người dùng thường có hàng tá icon khiến ứng dụng của bạn bị lu mờ (mình biết điều này vì trên điện thoại mình cũng thế :P)
Bởi thế, việc mà chúng ta cần làm chính là tìm cách xem rằng làm thế nào để vượt qua những rào cản trên, giúp người dùng không cần phải nhớ xem app của bạn trông như thế nào và họ có thể dễ dàng tìm thấy nó.
Với App Action, công nghệ này cho phép Android Developer sử dụng Google Assistant như một công cụ để mang ứng dụng của bạn nhanh chóng đến người dùng thông qua giọng nói.
Để hiểu rõ hơn, chúng ta cùng xem một ví dụ được gọi là SmoresSmores.
Hoàn tất ‘chiếc bánh’ S’more theo cách cũ
Bước 1: Tìm ứng dụng SmoreSmores bên trong mớ icon hỗn độn trên thiết bị.
Bước 2: Chọn loại bánh quy.
Bước 3: Chọn loại marshmallow.
Bước 4: Chọn loại chocolate.
Bước 5: Xác định độ nóng giòn.
Bước 6: Xác định số lượng.
Bước 7: Xem lại order.
Bước 8: Hoàn tất order.
Bạn có thể hình dung một số bước có thể diễn ra để hoàn tất một chiếc bánh S’more trên ứng dụng theo cách thông thường:
Đầu tiên, người dùng sẽ phải tìm kiếm icon của ứng dụng trong số mớ icon hỗn độn trong thiết bị của họ. Sau đó, họ sẽ phải lựa chọn từng option cho mình như: loại bánh quy nào , loại marshmallow nào, có thêm chocolate hay không, độ chính và số lượng bánh,…
Người dùng sẽ phải trải qua nhiều bước mới có thể hoàn tất order của mình. Điều này sẽ mất khá nhiều thời gian. Tuy nhiên, có một phương pháp khác để hoàn tất order và tiết kiệm công sức hơn cho người dùng, đó là triển khai thực hiện App Action. Người dùng sẽ có thể nói chuyện và thực hiện order một cách tự nhiên nhất thông qua chính cách nói chuyện của họ.
Hoàn tất S’more bằng giọng nói với App Actions
Với giải pháp này, người dùng chỉ cần thực hiện 2 bước đơn giản.
Bước 1: Thao tác bằng giọng
Bước 2: Xác nhận order
Theo cách này, tất cả thông tin sẽ được đưa vào ứng dụng và ứng dụng mở lên trang xác nhận thông tin mà người dùng đã cung cấp. Điều này sẽ khiến cho người dùng dễ dàng thao tác hơn.
Với App Actions, tất cả thông tin sẽ được đưa vào ứng dụng và ứng dụng sẽ mở lên đến ngay trang xác nhận thông tin mà người dùng đã cung cấp bằng chính giọng nói của họ (loại bánh, marshmallow, chocolate, độ nóng và số lượng,…)
Một ví dụ khác, hãy tham khảo trường hợp của Nike
Bạn có thể nói chuyện với ứng dụng của Nike, yêu cầu mở ứng dụng Nike Run Club.
Ngoài ra bạn còn có thể thực hiện những thao tác khác như chuyển tiền hay đặt hàng thông qua ứng dụng.
Tất cả những tác vụ như trên có thể được thực hiện là bởi Google Assistant sử dụng một thứ được gọi là built-in intents.
Built-in intents
Hãy để Google biết rằng bạn có những tính năng nào, chẳng hạn như tính năng đặt đồ ăn hay bắt đầu một buổi tập luyện, từ đó giúp Google có thể biết được đâu là nơi mà nó cần kết nối đến.
Hãy cho Google biết đâu là những tính năng mà người dùng có thể sử dụng; các loại parameter mà bạn cung cấp, đâu là các fulfillment URL, đâu là trang đích khi tôi tổng hợp tất cả các parameter đó lại.
Bạn có thể sử dụng bao nhiêu built-in intent và thêm vào bao nhiêu mà bạn muốn.
Các intent google assistant đang hỗ trợ
Và đây là một file XML để ví dụ cho việc sử dụng built-in intent cho hành động gọi món.
Một file XML để ví dụ cho việc sử dụng built-in intent cho hành động gọi món
Bạn có thể thấy trên ví dụ sử dụng:
intentName=“actions.intent.ORDER_MENU_ITEM”
Đây là một built-in intent mà Google đã cung cấp và bạn có thể sử dụng nó và người dùng sẽ có thể gọi món từ menu.
Android Slices
Slices là các UI template có thể hiển thị các nội dung tương tác động từ ứng dụng của bạn bên trong Google Assistant.
Hẳn rằng nhiều lần bạn muốn cung cấp cho người dùng một thông báo nhanh hay một xác nhận đơn hàng nào đó. Bạn có thể sử dụng Android Slice để cung cấp những thông tin ấy một cách đơn giản và thân thiện đến người dùng và giúp họ cập nhật thông tin một cách nhanh chóng.
Một lưu ý nhỏ: khi bắt đầu với các built-in intent và item này, Google Assistant đã kiểm soát và quản lý tất cả NLU (Natural Language Understanding) nên bạn không cần phải lo về cách mà người dùng nói chuyện khi bạn sử dụng built-in intent trong Android Slices.
Smart home – Control hardware with just your voice
Smart Home Device Integration
Khi nhắc về Smart Home, tất cả những gì chúng ta cần nói đến đều chỉ là về tích hợp với phần cứng (integrating with hardware).
Nếu bạn quan tâm đến việc tự động hóa ngôi nhà của mình, bạn có thể hiện thực hóa điều ấy thông qua giải pháp Smart Home Integration của Google.
Giải pháp này sẽ cung cấp cho bạn một Home Graph, giúp ngôi nhà nắm được trạng thái và khả năng thực hiện của tất cả các thiết bị kết nối bên trong ngôi nhà. Người dùng có thể đưa ra yêu cầu như “làm mờ đèn một chút” và ngôi nhà sẽ biết rằng chúng cần làm gì.
NLU
Phần hay nhất nội dung này chính là Natural Language Understanding. Giống với Android và built-in intents, Google Assistant sẽ kiểm soát tất cả vấn đề này cho bạn. Nếu ai đó nói “làm ấm phòng” hay “bật/tắt đèn” hay nói về một nhiệt độ cụ thể như “tôi muốn 24 độ”, nó sẽ chuyển dữ liệu đó như một parameter và thực hiện yêu cầu đó.
Types & traits
Type thực chất là những thiết bị, phần cứng (hardware). Bạn có thể nghĩ đến những thứ như cửa sổ, đèn, lò sưởi, rèm che,…
Trait là thuộc tính hay đặc điểm, chức năng của type. Bạn có thể hình dung về những yêu cầu đơn giản như bật/tắt đèn, nhưng cũng có một số loại đèn có thể điều chỉnh độ sáng.
Google có đề cập rất nhiều về nội dung này trong tài liệu, bạn có thể kiểm tra chúng tại đây.
Smart Home Integration
Để có thể tích hợp thiết bị của bạn với Google Assistant, nhà phát triển cần cung cấp cloud service của chính họ cho người dùng để đăng ký và quản lý thiết bị, điện thoại thông minh và Action Platform. Sau đó, hãy tích hợp với cloud service thông qua một chuỗi các webhook để truy cập và kiểm soát các thiết bị đó.
Một thứ mà chúng tôi tự hào khi bắt đầu nó từ năm ngoái chính là local SDK. Local home SDK của Google được thực hiện thông qua wifi. Các thiết bị trên local network có thể được phát hiện và kiểm soát với local protocols, giúp giảm chi phí giao dịch đám mây.
Conversation
Cuối cùng, nếu bạn muốn xây dựng một trải nghiệm phong phú cho người dùng, bạn nên xây dựng các conversation action.
Tương tự như cách smart home được cấu trúc và những thứ tương tự, người dùng sẽ gửi một request và Google Assistant tiến hành xử lý.
Tuy nhiên, không giống như với Android hay với Smart Home – chúng đã có các built-in intents hay types of traits, nơi mọi thứ đã được định nghĩa và Google đã xử lý phần natural language processing, tại đây, Google Assistant sẽ xử lý phần text-to-speech và cho bạn text của người dùng. Sau đó, tùy vào action mà bạn muốn thực hiện mà hệ thống sẽ xác định đâu là thứ cần gửi lại, nhưng việc xác định đâu là thứ mà cần hệ thống gửi lại bạn vẫn là người quyết định. Hãy gửi một response tới Google Assistant và Google Assistant sẽ chuyển nó đến cho người dùng.
Natural Language Understanding (NLU)
Giả sử, nếu người dùng chỉ nói “yes” thì việc phân tích cú pháp sẽ tiến hành khá nhanh phải không?
Tuy nhiên, nếu người dùng nói “yes” theo nhiều cách (biến/variation) khác nhau như: “Perfect”, “Let’s do it”, “Go ahead”, “Sure”, “Yep”, “oke”,… thì bây giờ phải làm sao?
Lúc này, bạn sẽ cần một công cụ để quản lý tất cả các biến và đó chính là NLU.
Để giúp xử lý thông tin của người dùng, bạn hãy xác định các intent khác nhau mà người dùng có thể sẽ thể hiện một “yes” intent hay “no” intent, hay khi người dùng muốn chơi một trò chơi nào đó.
Khi bạn đã xác định những thứ trên thì hãy đưa ra những hướng dẫn (training phrases) cho các intent ấy, từ đó Google Assistant có thể hiểu được và biết được rằng khi người dùng nói về các intent đó, như “yes” chẳng hạn, Google sẽ đóng gói tất các các biến của “yes” và tiếp tục xây dựng thêm dựa trên đó.
Nhưng ai sẽ làm việc đó?
Cuộc đối thoại hai chiều với action của bạn được thực hiện theo cách sau.
Input của người dùng sẽ được gửi đến, và sau đó, Google Assistant sẽ tiến hành xử lý nó bằng NLU và gửi thông tin đó đến Action.
Tiếp đến, action sử dụng chúng để tạo ra một prompt và gửi prompt ấy đến Google Assistant. Cuối cùng, Google Assistant sẽ chuyển nó đến người dùng.
Nhưng làm sao để bạn biết được khi nào người dùng nói “yes”? Họ sẽ nói “yes” ở vị trí nào trong câu thoại? Có phải họ đang nói “yes, I want to play the game” hay “yes, I want to drink the magic potion in the game”. Bạn không thể xây dựng các intent kiểu như “fly around”. Bạn cần phải tổ chức nó theo một cách nào đó.
Quản lý mô hình hội thoại (conversational model) cho action chính là chìa khóa để tạo ra các prompt phù hợp ấy và bạn có thể sử dụng Actions Builder để thực hiện điều này.
Actions Builder
Actions Builder là một web-based IDE được tích hợp hoàn toàn vào Action Console.
Hiện tại bạn chỉ có duy nhất một window để xây dựng các action. Bạn có thể thiết kế các luồng hội thoại một cách trực quan và đồng thời hỗ trợ và cải tiến NLU khi nó tiến hành xử lý các input của người dùng. Đồng thời, nó cũng bao gồm một inline editor vì thế bạn cũng có thể xây dựng các phản hồi động bằng cách sử dụng webhook.
Với Actions Builder, nó sẽ xử lý input của người dùng và cũng làm như thế với intent matching hoặc slot filling khi nó đến các types. Bạn cũng có thể lấy các phần dữ liệu ra khi nó đến users responses.
Tương tự, chúng ta có khái niệm scenes để quản lý logic. Nếu nó thực sự bắt đầu và người dùng nói “yes”, intent sẽ khớp với “Yes” intent, nhưng bởi vì nó đang ở start scene, hệ thống biết “oh, họ đang nói yes để bắt đầu trò chơi chứ không phải nói yes để sử dụng item hồi máu”. Từ đấy, nó có thể chuyển tiếp bạn tới scene kế tiếp để bắt đầu trò chơi, và bạn cũng có thể xây dựng các prompt động hoặc tĩnh bằng cách sử dụng công cụ này.
Scenes
Scene là một khái niệm mới khi “Action Developer” sử dụng công cụ cũ của Google.
Scenes là những khối logic (logical chunks) của Mô hình thoại hội của bạn và chúng cũng là thứ sẽ thực thi các action của bạn. Chúng sẽ xử lý những phần nặng nhọc, xử lý các logic cần thiết để định hướng cuộc trò chuyện. Đây là một cách thức để modularize action của bạn.
Bạn có thể nhận được một welcome scene, và ở scene này, bạn sẽ được hỏi rằng liệu bạn có muốn làm cái này, làm cái kia hay không. Chúng có mối liên hệ chặt chẽ với nhau.
Nếu một người dùng nói gì đó, hệ thống có thể sẽ chuyển tiếp họ đến scene tiếp theo. Điều thú vị là scene của bạn có thể hỏi và thu thập dữ liệu thông qua các slot. Nếu socket của bạn được fill, một scene có thể chuyển tiếp đến scene tiếp theo. Tương tự, bạn có thể liên tưởng đến việc order, bạn có thể lấp đầy hoặc chúng ta có thể có tất cả thông tin như mua một chiếc đầm dạ hội, chúng ta sẽ biết được họ muốn mua size nào, sau đó chuyển tiếp bạn đến nơi có thể mua hàng hoặc nơi cung cấp thêm thông tin.
Vòng đời thực thi của scene
Các scene rất linh hoạt, chúng cho phép bạn thực hiện những thứ rất tuyệt và tất cả các scene chạy bên trong vòng lặp, mọi thứ điều tuyệt vời, thế nên, vòng đời thực thi (executor lifecycle) là một thứ gì đó mà chúng ta nên thử phân tích cú pháp và đào sâu thêm vào nội dung này. Hãy xem video ngắn bên dưới.
Action SDK
Bổ sung thêm cho Actions Builder là Actions SDK. Action SDK sẽ cho bạn một file-based representation của action và khả năng sử dụng các local IDE của chính bạn. Phần hay nhất là nó hoạt động song song với Actions Builder. Nó bao gồm tất cả các tài nguyên cấu hình của action của bạn, gồm có khả năng hỗ trợ và quốc tế hóa.
Bạn có thể build bằng cách sử dụng Actions Builder, sau đó kéo dự án xuống local, thay đổi và đẩy những thay đổi mới ấy lên Action Builder và cuối cùng là cho phép team làm việc với công cụ yêu thích của họ.
Google cũng đã cải thiện phần giả lập – thứ cung cấp cho bạn các execution log cùng với các dữ liệu về request và response để giúp bạn dễ dàng debug các action của mình. Chúng được tổ chức theo scene, theo sự tương tác giữa người dùng và Google Assistant.
Sau đó, bạn có thể click lên nó và bạn có thể nhìn thấy dữ liệu của scene.
Bạn có thể thấy những parameter nào đang được chuyển qua khi các webhook đang bị gọi.
Google cũng đã thêm state editor để khiến nó dễ dàng để update và debug content của bạn.
Thông qua việc tạo ra các thay đổi trong scene, trong phần scene editor, bạn không nhất thiết phải trải qua tất cả flow, bạn có thể kết nối tới các thứ dễ dàng hơn hoặc khiến nó như kiểu người dùng đã hoàn thành việc xyz và theo cách đó, bạn có thể đi trực tiếp đến nơi mà bạn muốn test bên trong luồng hội thoại.
Gia tăng trải nghiệm cho người dùng
Action Builder và Action SDK cung cấp các thành phần hội thoại (conversational components) của action nhưng bạn cũng có thể thêm vào những thành tố (element) khác để gia tăng trải nghiệm cho người dùng.
Bạn có thể sử dụng Interactive Canvas để build những trải nghiệm game thú vị, cung cấp những hình ảnh trực quan sinh động cho cuộc trò chuyện của bạn.
Một điều rất tuyệt chính là Interactive Canvas chỉ sử dụng như web app, vì thế HTML, CSS và JavaScript là tất cả những gì bạn cần để có thể tạo ra một web app ấy. Interactive Canvas sẽ kết nối trang web với cuộc hội thoại của người dùng và sẵn sàng để thực hiện trải nghiệm giọng nói khi bắt đầu action này.
Bạn có thể tìm hiểu chi tiết về công nghệ Interactive Canvas tại bài viết này.
Continuous Match Mode
Một điều khác là bạn có thể gia tăng thêm trải nghiệm người dùng với chế độ khớp liên tục (Continuous Match Mode). Thứ công nghệ này cho phép người dùng có thể nói nhiều từ hoặc cụm từ khác nhau nhất quán.
Một ví dụ điển hình là khi bạn muốn có một bản đồ quốc gia với tất cả các vùng, hoặc bản đồ thế giới có tất cả các quốc gia bên trong bản đồ đó, việc bạn cần làm là hiển thị chúng thông qua interactive canvas. Nhờ đó, bạn có thể trực quan hóa chúng và cho phép người dùng nói tên các quốc gia và thậm chí nói một cách nhanh chóng. Người dùng sẽ chỉ cần gọi tên từng quốc gia liên tục và chúng – hình ảnh các quốc gia sẽ được hiển thị liên tục thông qua công nghệ Continuous Match Mode.
Continuous Match Mode Developer
Ở góc độ của một lập trình viên, tất cả việc bạn cần làm là cung cấp cấu hình bao gồm danh sách các cụm từ chính xác mà người dùng có thể sử dụng / nói.
Trở lại ví dụ về bản đồ thế giới với khả năng hiển thị tất cả các quốc gia ở trên, bạn sẽ cần liệt kê ra tất cả các quốc gia và cung cấp thông tin đó đến action. Lúc này, interactive canvas web app có thể tiến hành xử lý chúng một cách nhanh chóng cho người dùng.
Bài viết được trích dẫn từ phần trình bày của Jessica Dene Earley-Cha tại sự kiện Vietnam Web Summit 2020 LIVE do TopDev tổ chức
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Qua 5 bài trước, chúng ta đã hiểu các khái niệm cơ bản về RxSwift. Và bây giờ, chúng ta sẽ bắt đầu làm quen với Observables, khái niệm quan trọng của RxSwift. Dịch sát nghĩa là có thể quan sát được. Ở Rx, nó là 1 lớp cho phép bạn quan sát bất cứ thứ gì mà có sự thay đổi về trạng thái, như trạng thái bấm nút, ô text,..
Sau gõ mở terminal, cd vào thư mục source code và gõ:
pod install
để cài đặt RxSwift cho project.
Vậy 1 observable là gì?
observable là trái tim của RxSwift. Chúng ta sẽ giành thời gian để nghiên cứu, thử nghiệm với nó.
Bạn sẽ nghe các khái niệm observable, observable sequence hay sequence trong Rx. Thậm chí bạn sẽ nghe các khái niệm stream từ các developer khác bằng các khái niệm ở môi trường phát triển khác tương tự. Tuy nhiên ở Rx nó không phải là stream, mà mọi thứ đều là sequence.
Nghĩa là trong Rx mọi thứ đều là luồng quan sát – dịch sát nghĩa là đối tượng quan sát sự kiện có thứ tự.
stream: sự kiện phát liên tục
sequence: sự kiện phát không đồng bộ, tùy ý
Sự kiện luồng phát 3 sự kiện 1, 2, 3 trong thời gian thực
Mũi tên từ trái sang phải mô tả thời gian, vòng tròn đánh số thể hiện sự kiện phát ra. Đầu tiên sự kiện 1 phát ra, tiếp theo lần lượt sự kiện 2, và cuối cùng là 3. Vậy lúc nào thì phát ra sự kiện? Nó có thể bất kỳ lúc nào ở trong vòng đời của 1 observable.
Vòng đời của 1 obserbvable
Sự kiện bấm vào nút
Những thứ có thể quan sát được và phát ra các sự kiện như nút bấm, được thể hiện bằng sơ đồ trên. Nút được phát ra 3 lần bấm, và kết thúc.
Tuy nhiên đôi khi sự kết thúc có thể trước 3 lần, do trục trặc lỗi.
Sự kiến phát ra có lỗi thể hiện màu đỏ
Khi 1 sự kiện lỗi phát ra, nó kết thúc luôn vòng đời của observable.
Một observable có thể quan sát và phát ra các sự kiện tiếp theo cho đến khi tạo ra một sự kiện lỗi và kết thúc
Hoặc phát ra 1 sự kiện hoàn thành và kết thúc
Một khi observable kết thúc, nó sẽ không thể phát ra thêm sự kiện nào nữa
Ví dụ trực tiếp từ mã nguồn RxSwift:
/// Represents a sequence event.
///
/// Sequence grammar:
/// **next\* (error | completed)**
public enum Event<Element> {
/// Next element is produced.
case next(Element)
/// Sequence terminated with an error.
case error(Swift.Error)
/// Sequence completed successfully.
case completed
}
Như ta thấy ở đây:
Sự kiện Next chứa instance của Element
Sự kiện error chứa lỗi Swift.Error
Sự kiện completed đơn giản là dừng và không có bất kỳ dữ liệu nào
Tạo observables
Quay lại với project các bạn vừa tạo ở đầu bài, chúng ta thêm đoạn code sau vào file playground:
example(of: "just, of, from") {
// 1
let one = 1
let two = 2
let three = 3
// 2
let observable: Observable<Int> = Observable<Int>.just(one)
}
Ở đoạn code trên:
Tạo 3 biến one, two, three
Tạo 1 observable và phát ra sự kiện one – tức là phát ra số nguyên one
just là hàm phát ra 1 sự kiện, nó là phương thức của observable. Tuy nhiên trong Rx, nó được gọi là toán tử.
Thêm tiếp mã sau vào cuối chương trình:
let observable2 = Observable.of(one, two, three)
Lần này, chúng ta không chỉ định rõ ràng kiểu cho observable, tuy nhiên chúng ta hiểu đây là 1 observable kiểu int, và đây không phải là mảng. Bấm Option + click chuột để xem:
observable tự chuyển về kiểu int
Nếu bạn muốn tạo 1 observable kiểu mảng, chúng ta dùng toán tử of như sau:
let observable3 = Observable.of([one, two, three])
Còn khi dùng toán tử from, chúng ta tạo 1 observable như sau:
let observable4 = Observable.from([one, two, three])
Toán tử from nhận các giá trị từ mảng, và tạo 1 observable riêng rẽ, nó có kiểu int, chứ không phải kiểu mảng [int].
from tạo ra 1 observable kiểu int, từ 1 mảng kiểu int
Subscribing tới 1 observable
Là một nhà phát triển IOS, chắc các bạn đã quen thuộc với NotificationCenter, nó phát ra 1 notification tới observers. Dưới đây là ví dụ về xử lý sự kiện UIKeyboardDidChangeFrame, được xử lý ở hàm closure:
let observer = NotificationCenter.default.addObserver(
forName: .UIKeyboardDidChangeFrame,
object: nil,
queue: nil
) { notification in
// Handle receiving notification
}
Việc đăng ký – subscribing tới 1 observable cũng tương tự. Thay vì dùng hàm addObserver(), thì ta dùng hàm subscribe().
Tuy nhiên việc đăng ký các observable hợp lý hơn. Như đã trình bày, các observable phát ra các sự kiện next, completed và error. Để hiểu hơn, chúng ta thêm ví dụ sau vào cuối chương trình:
example(of: "subscribe") {
let one = 1
let two = 2
let three = 3
let observable = Observable.of(one, two, three)
observable.subscribe { event in
print(event)
}
}
Kết quả:
--- Example of: subscribe ---
next(1)
next(2)
next(3)
completed
Observable phát ra các sự kiện 1, 2, 3 và completed để kết thúc.
Thường chúng ta sẽ quan tâm giá trị phát ra từ các sự kiện đó hơn là chính nó. Chúng ta sửa ví dụ trên sau:
observable.subscribe { event in
if let element = event.element {
print(element)
}
}
Kết quả:
--- Example of: subscribe ---
1
2
3
Sự kiện phát ra chứa giá trị, và là 1 giá trị optional. Vì vấy chúng ta check trước giá trị đó để tránh nil. Các sự kiện không chứa phần tử(ở đây là completed) sẽ không được in ra. Như ta đã biết, các sự kiện onNext đều có phần tử.
Thay thế đoạn code trên như sau:
observable.subscribe(onNext: { element in
print(element)
})
Vậy là bạn đã biết cách tạo các observable có phần tử. Vậy muốn tạo 1 observable rỗng(empty) thì làm thế nào? Xem ví dụ sau:
example(of: "empty") {
let observable = Observable<Void>.empty()
observable
.subscribe(
// 1
onNext: { element in
print(element)
},
// 2
onCompleted: {
print("Completed")
} )
}
Một observable phải được định nghĩa 1 kiểu có thể quan sát được. Trong trường hợp này nó là kiểu void.
Giống như sự kiện onNext bạn xem ở ví dụ trước
sự kiện onCompleted không trả ra phần tử nào mà chỉ đơn giản là phát sự kiện hoàn thành.
--- Example of: empty ---
Completed
Nhưng mục đích của việc sử dụng 1 observable empty là gì? Nó thật sự hữu ích khi bạn muốn trả về 1 sự kiện kết thúc ngay lập tức và không trả về giá trị.
Trái với toán tử empty, toán tử never không emit ra sự kiện nào và không bao giờ kết thúc. Cùng xem ví dụ sau:
example(of: "never") {
let observable = Observable<Any>.never()
observable
.subscribe(
onNext: { element in
print(element)
},
onCompleted: {
print("Completed")
}
) }
Nó không in ra bất cứ thứ gì kể cả Completed, vậy làm sao để biết là nó hoạt động? Hãy giữ vững tinh thần học hỏi cho đến phần Challenges sau này nhé.
Cho đến bây giờ, bạn đang làm việc với các observable có thể quan sát được. Nhưng bạn cũng có thể tạo ra observable từ 1 loạt các giá trị. Cùng xem ví dụ sinh dãy Phibonaci sau:
example(of: "range") {
// 1
let observable = Observable<Int>.range(start: 1, count: 10)
observable
.subscribe(onNext: { i in
// 2
let n = Double(i)
let fibonacci = Int(((pow(1.61803, n) - pow(0.61803, n)) /
2.23606).rounded())
print(fibonacci)
})
}
Tạo 1 observable từ các số có phạm vi từ 1 đến 10
Tính toán và in ra số fibonacci thứ n cho mỗi phần tử được emit ra.
hàm pow(x, y) trả về x^y.
Trên thực tế, có 1 nơi tốt hơn ngoài xử lý onNext, để đặt mã biến đổi emit sự kiện. Chúng ta sẽ tìm hiểu vấn đề này sau ở bài Transforming Operators.
Ngoài trừ ví dụ về never(), cho đến thời điểm này bạn đang làm việc với các observables có thể quan sát tự động phát ra sự kiện completed để kết thúc. Điều này giúp bạn tập trung vào cơ chế đăng ký observables, tuy nhiên lại gạt đi 1 khía cạnh quan trọng trong việc đăng ký đã xử lý như nào. Khi cấp phát thì nghĩa là cần phải giải phóng cho nó. Đã đến lúc chúng ta nghiên cứu việc giải phóng 1 observable như nào trong bài tiếp theo.








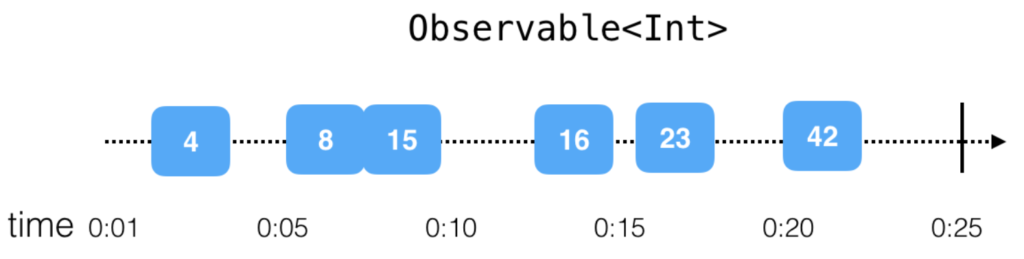
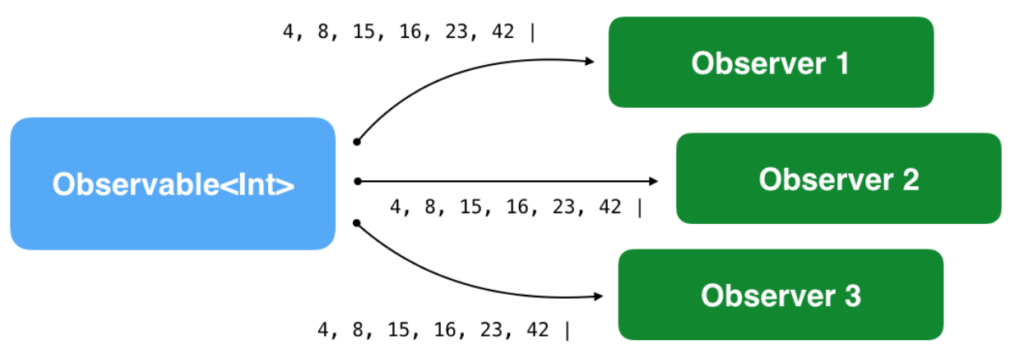
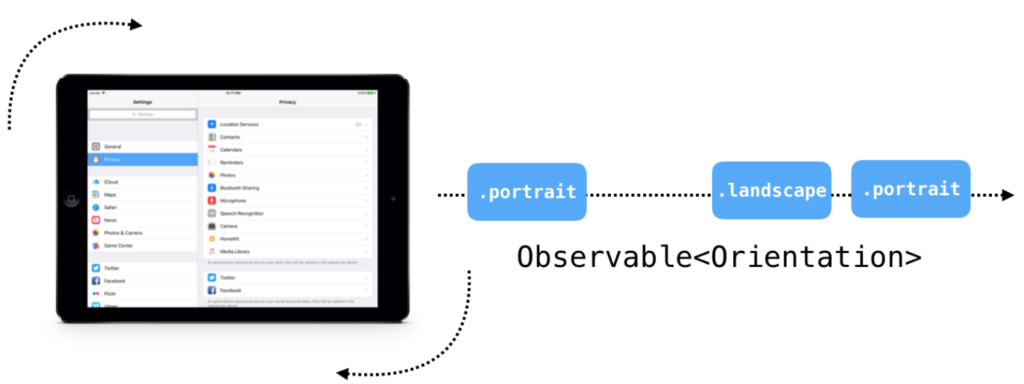
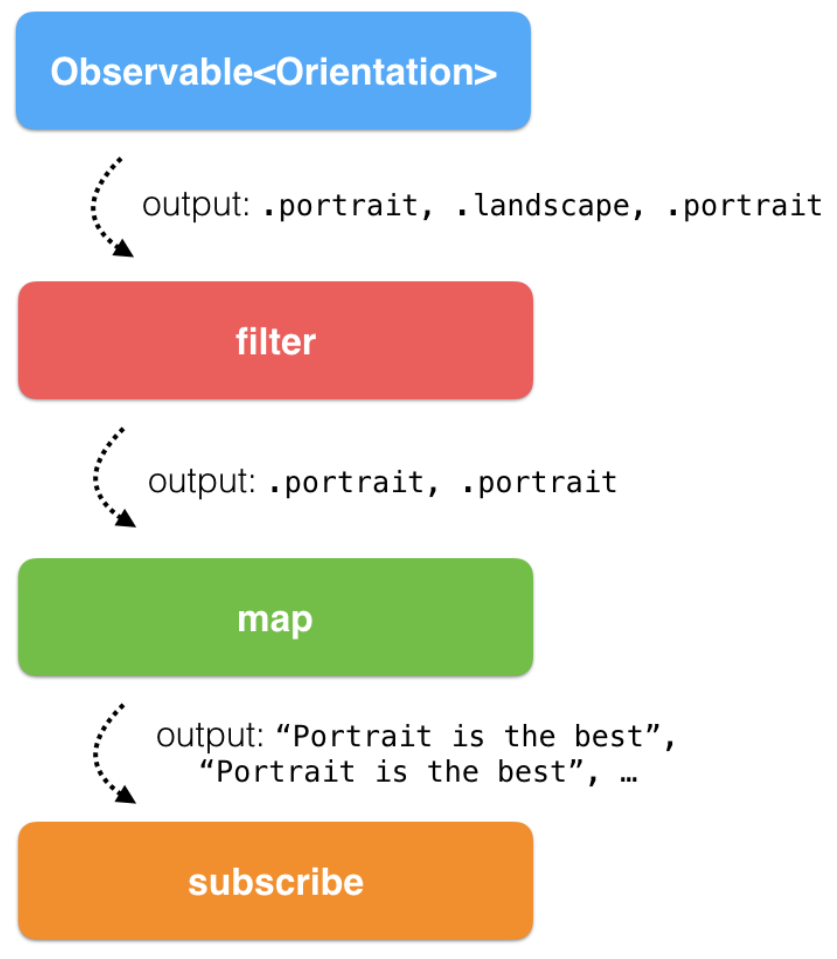
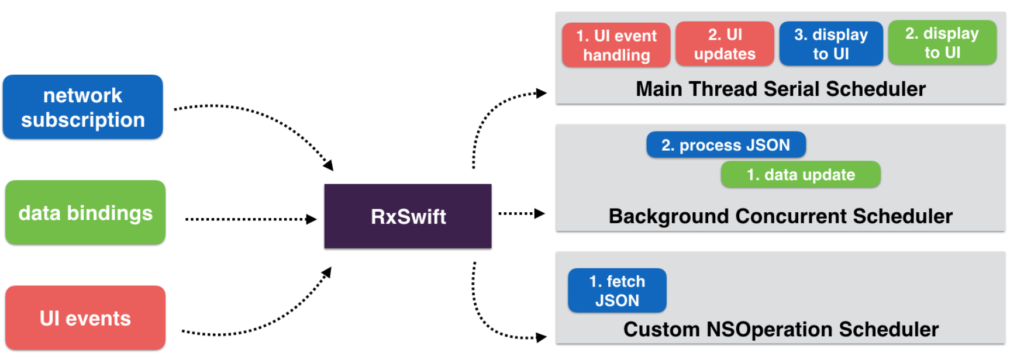
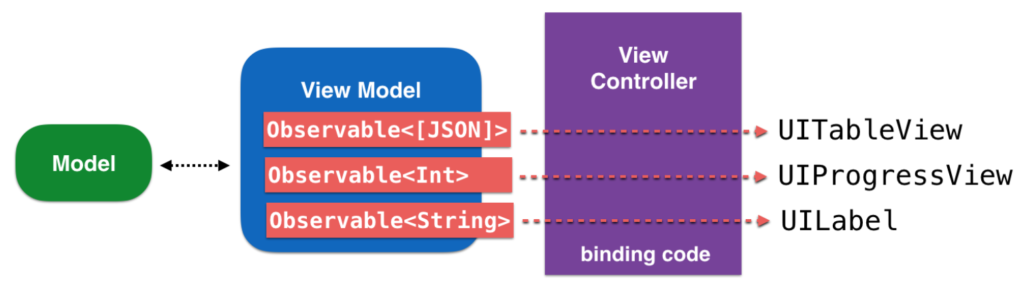

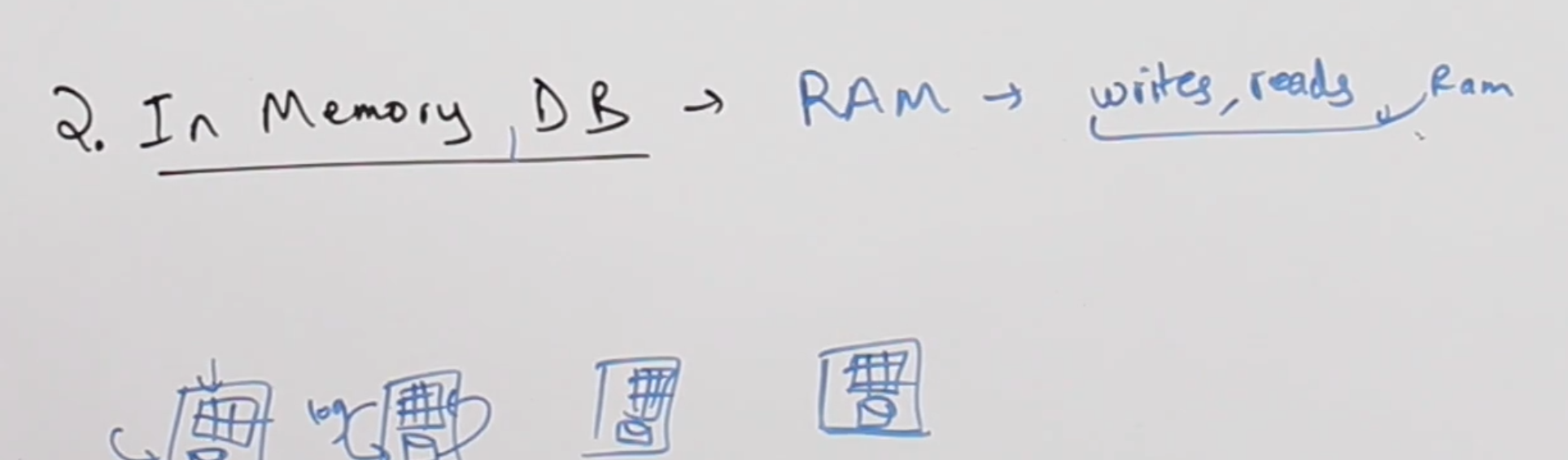






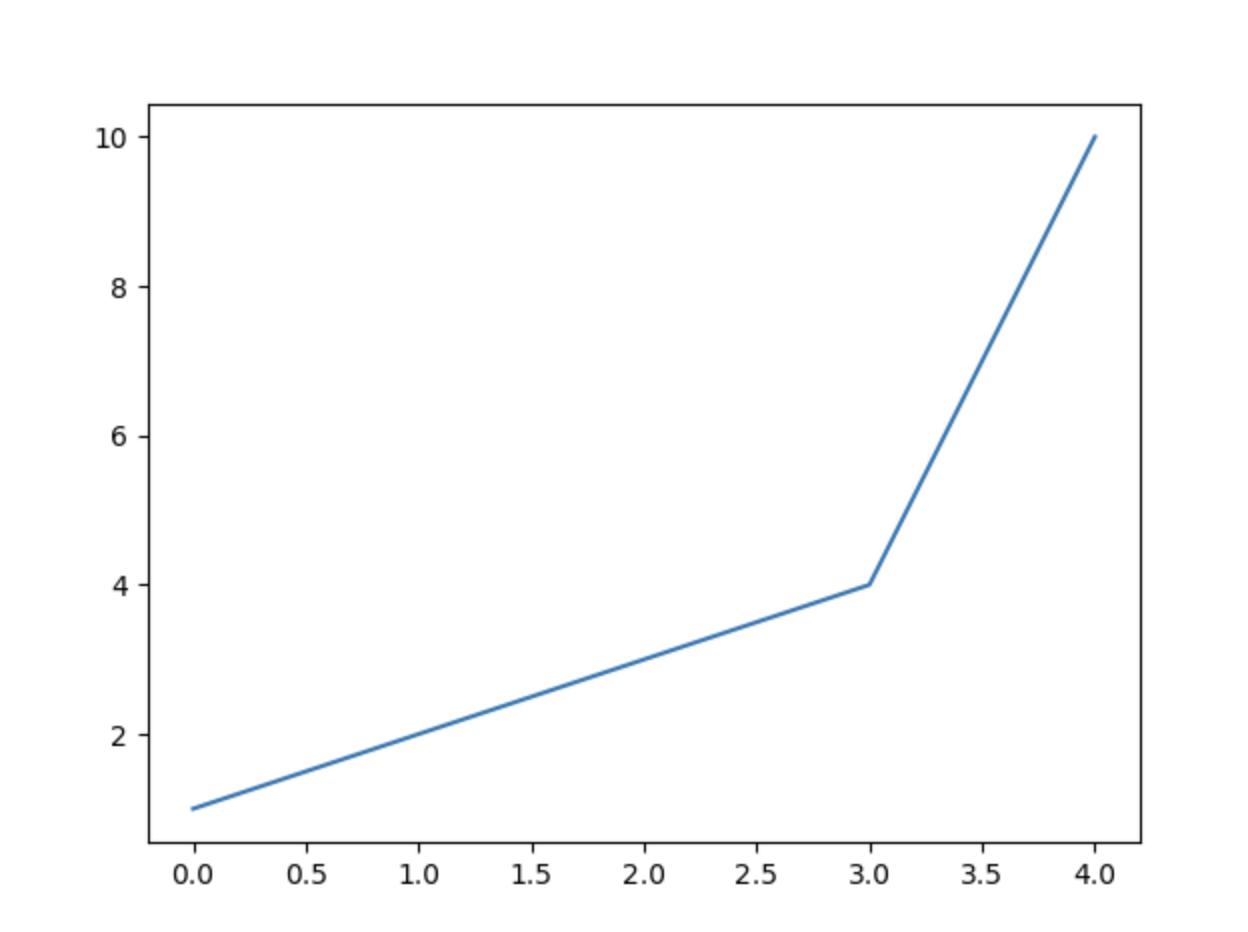
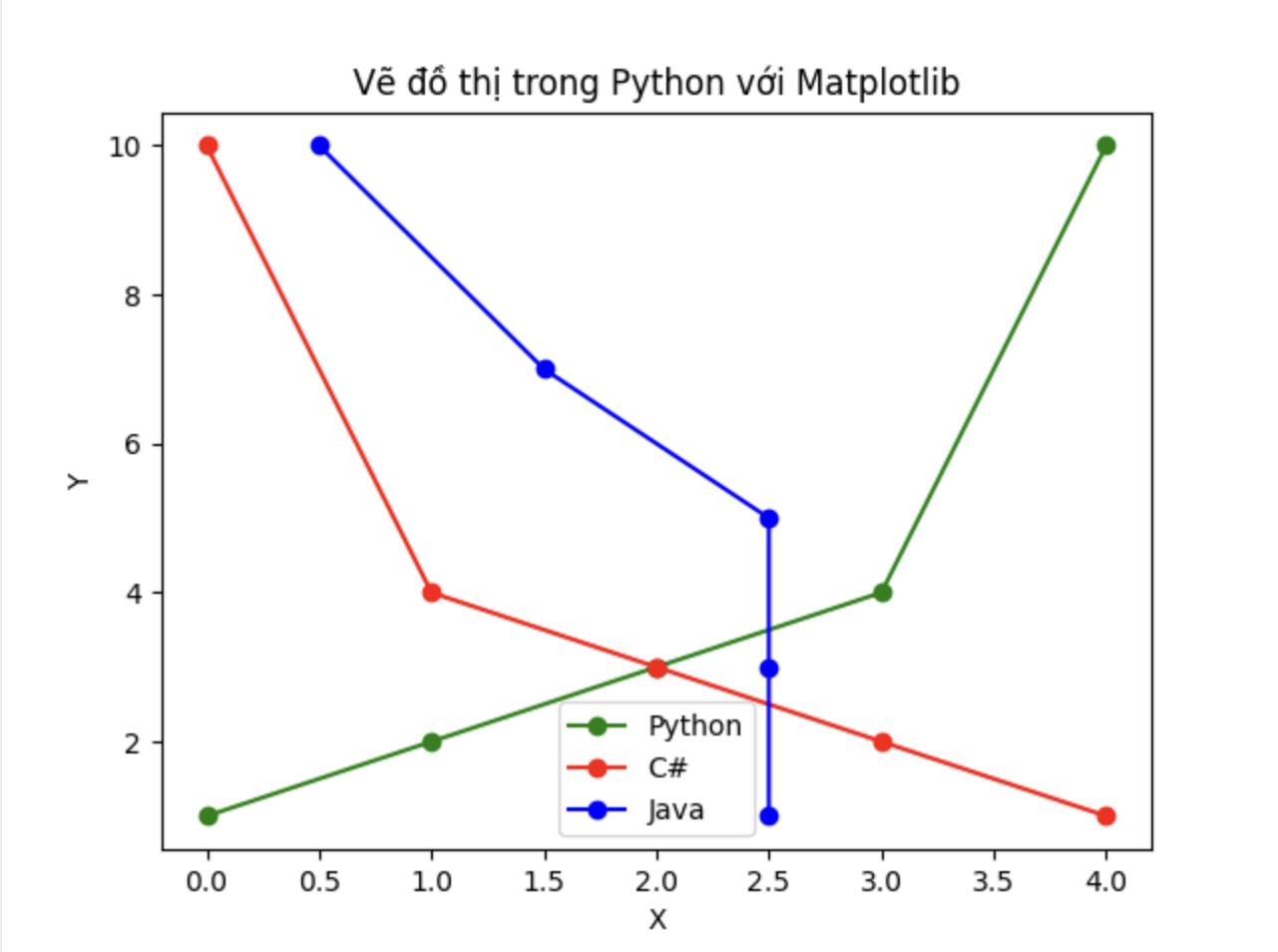
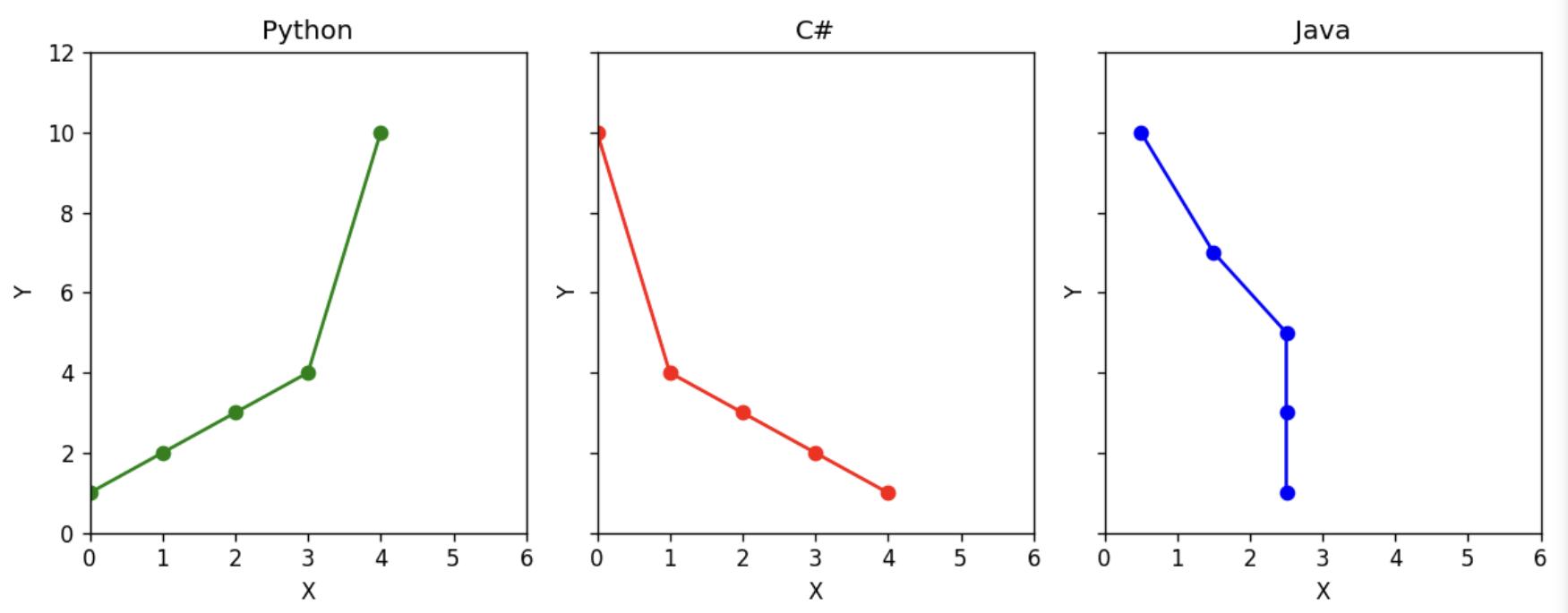
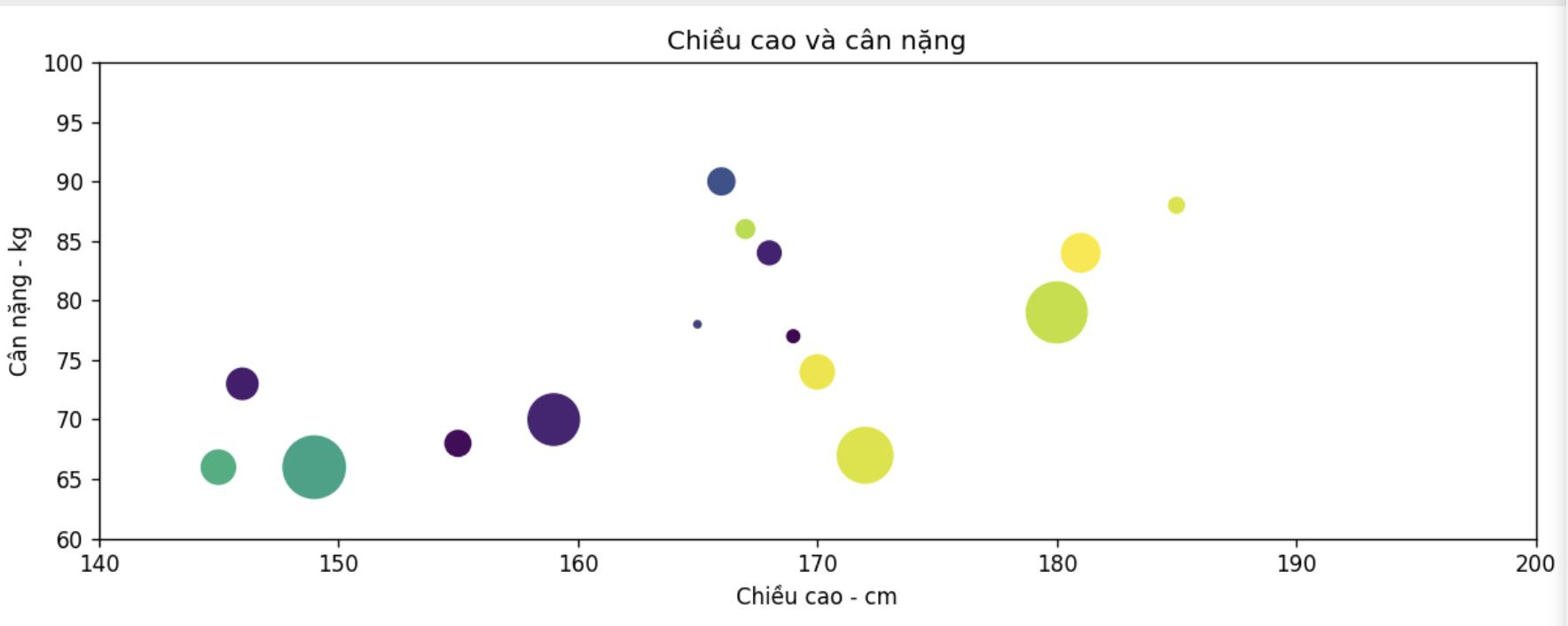

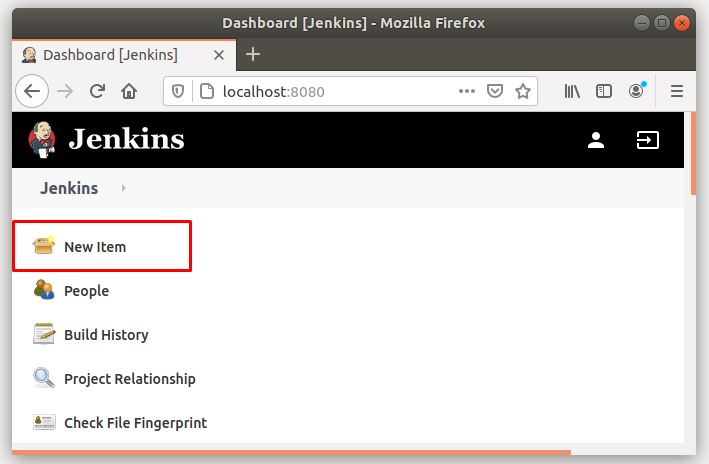
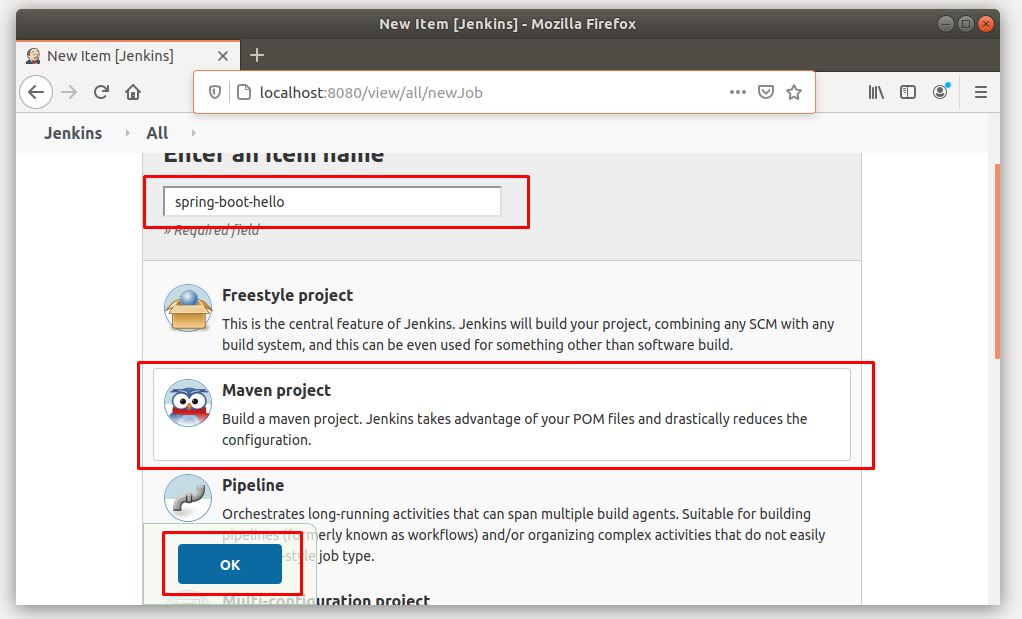
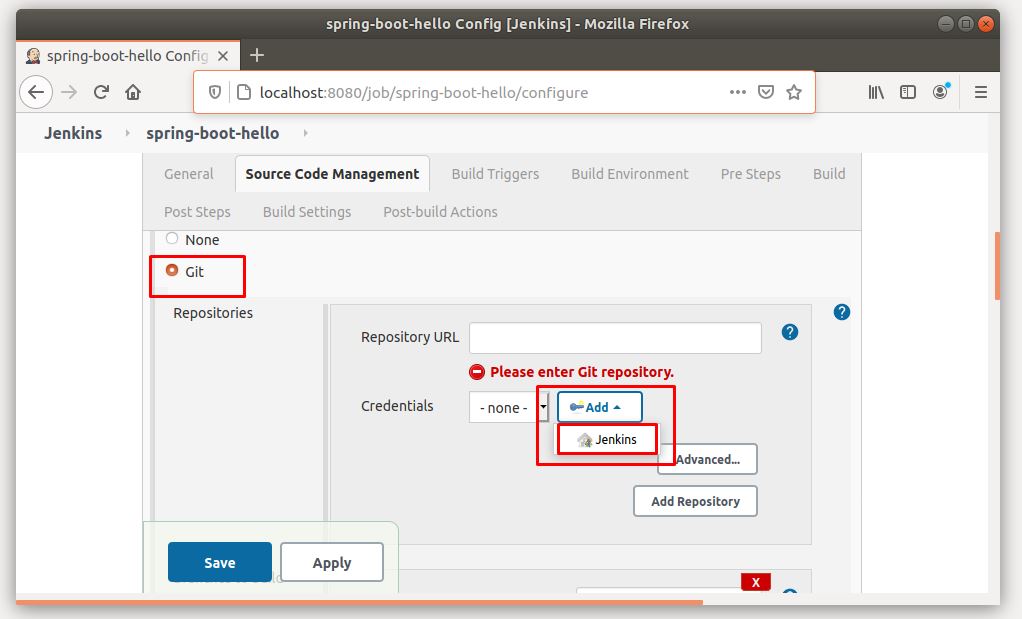
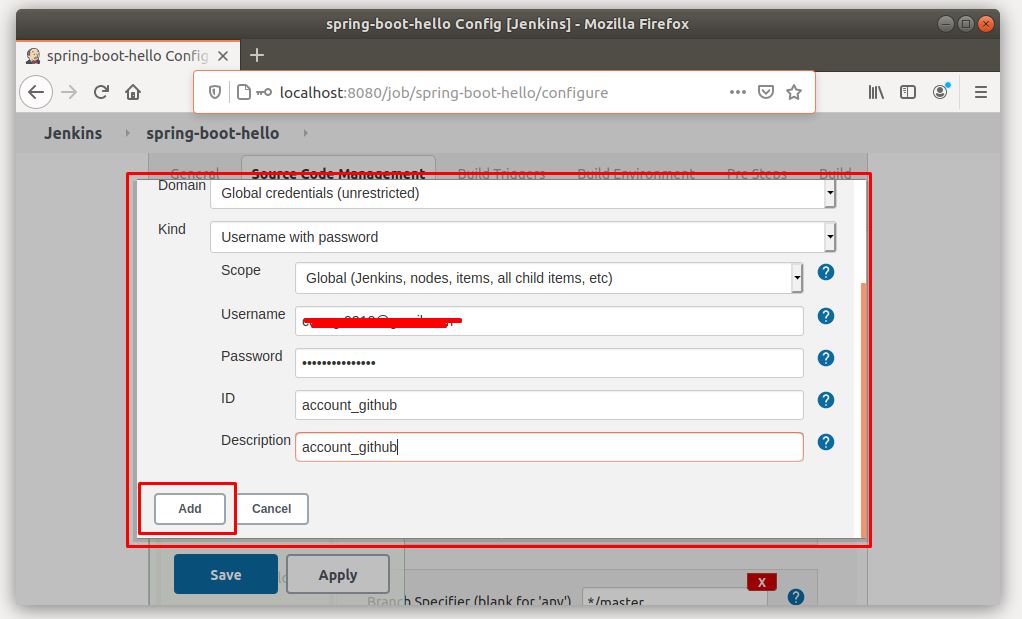
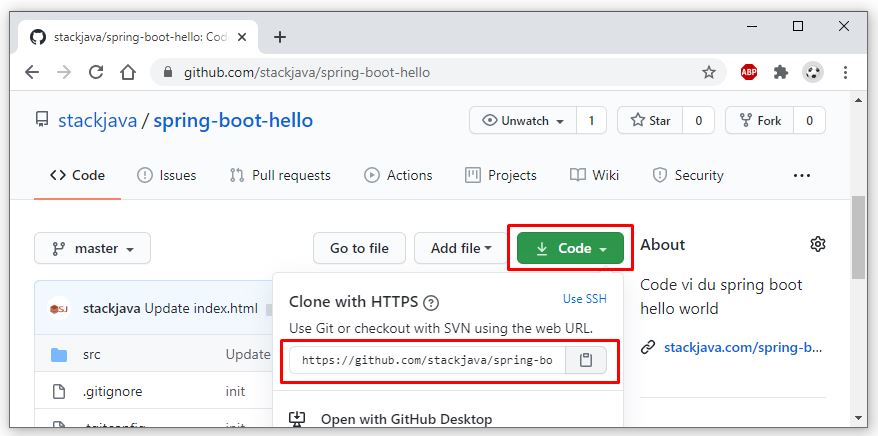
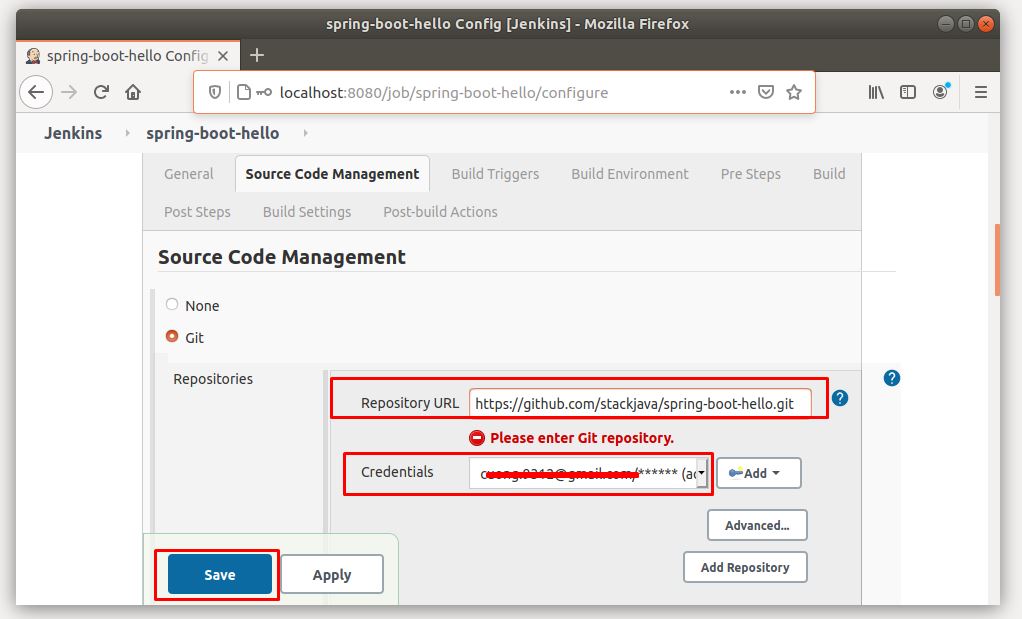
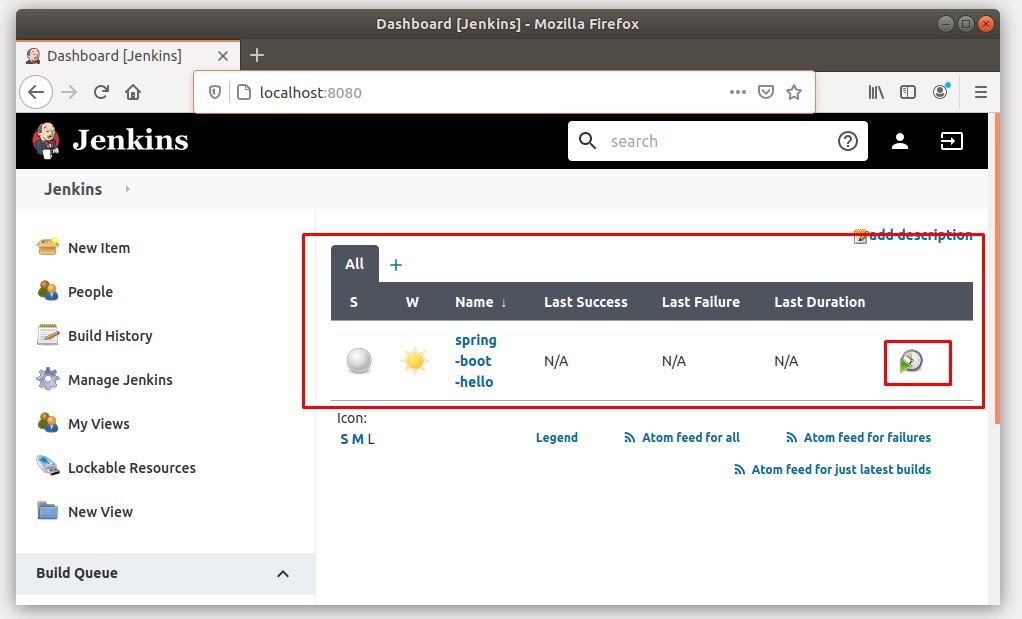
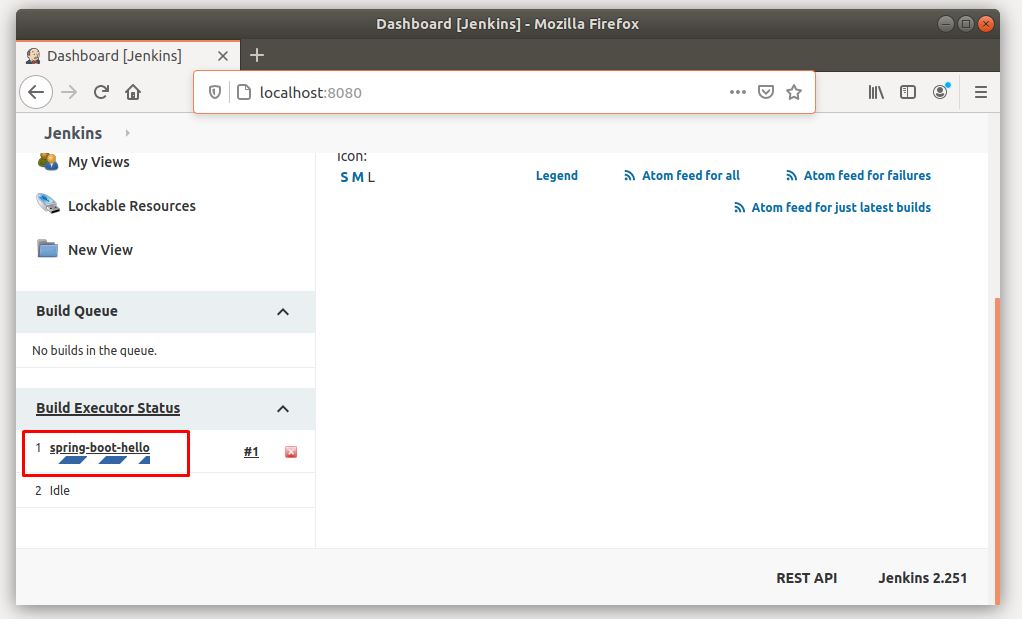
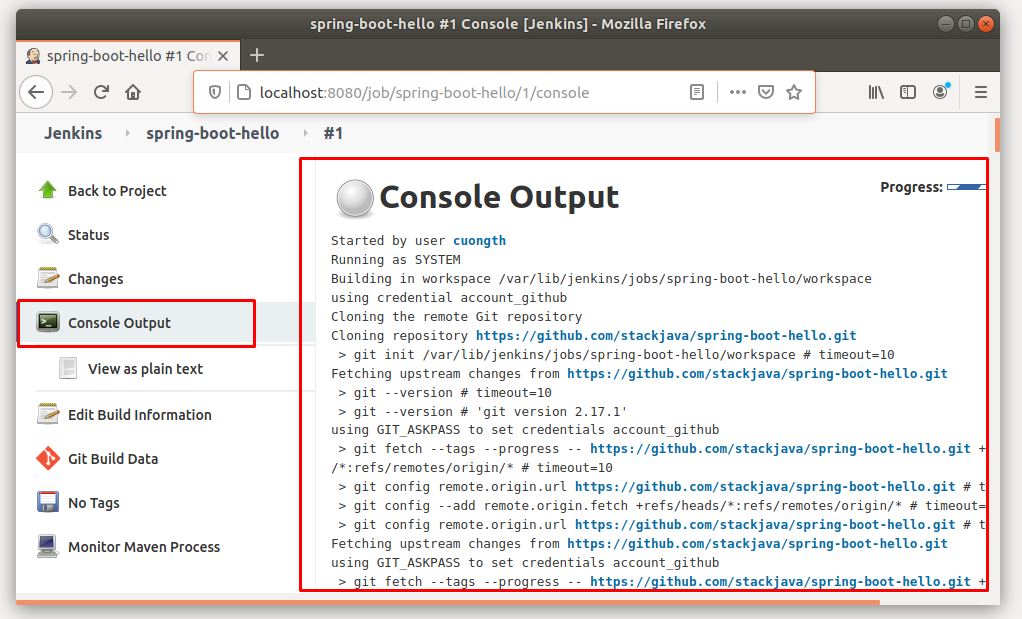
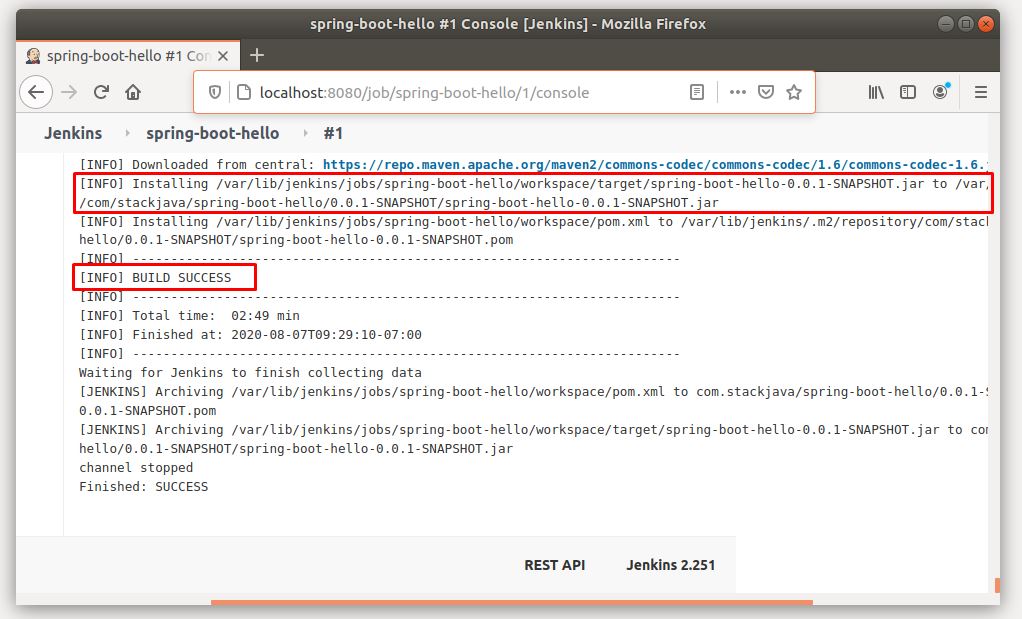
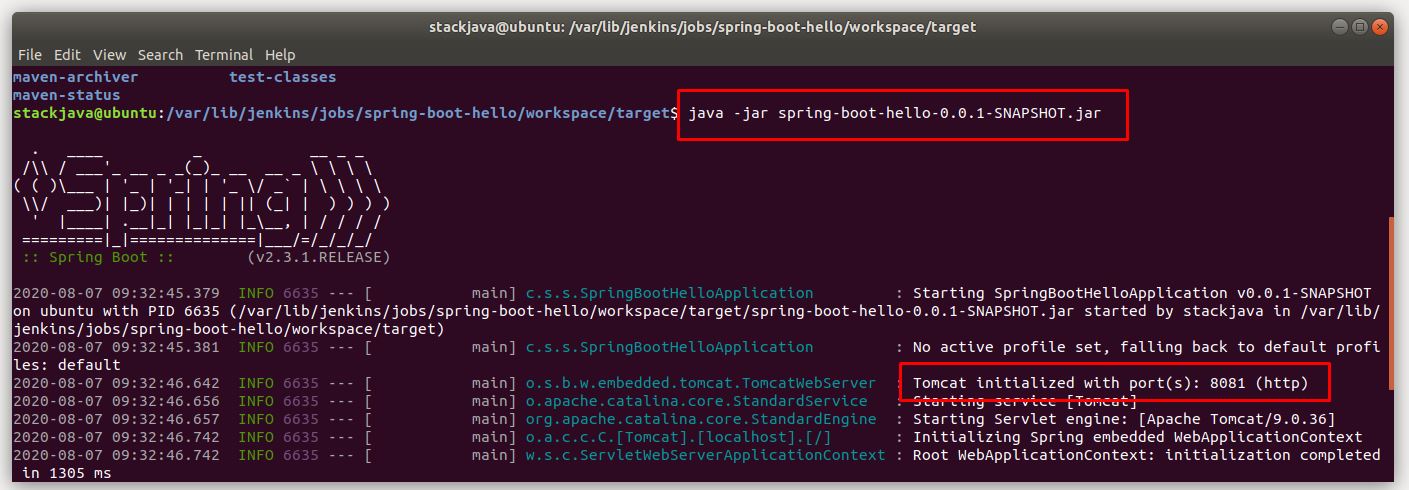
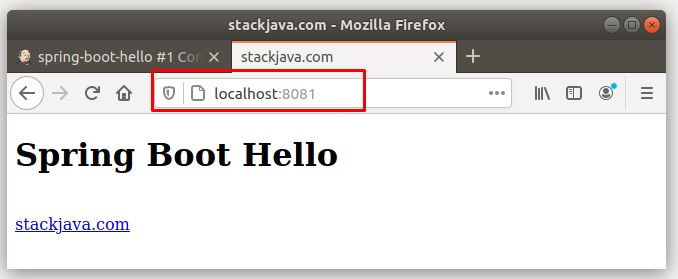

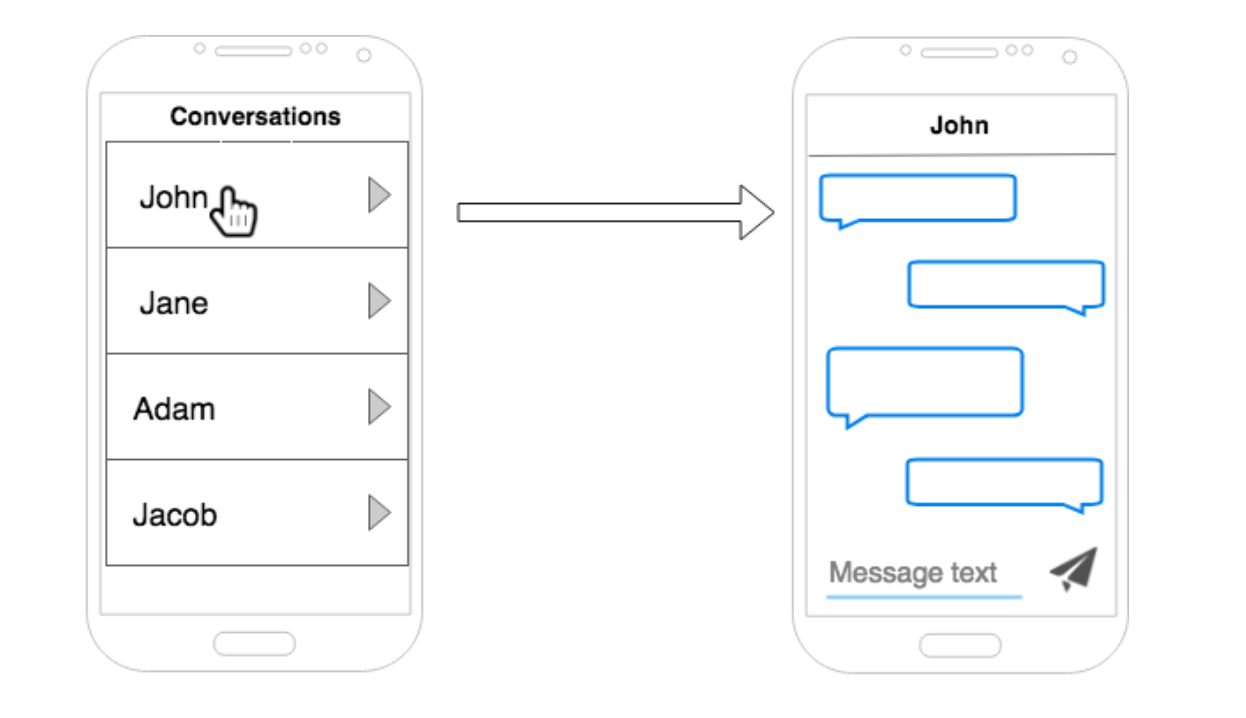
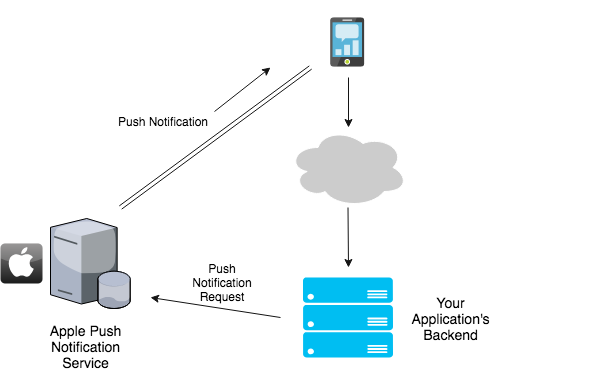
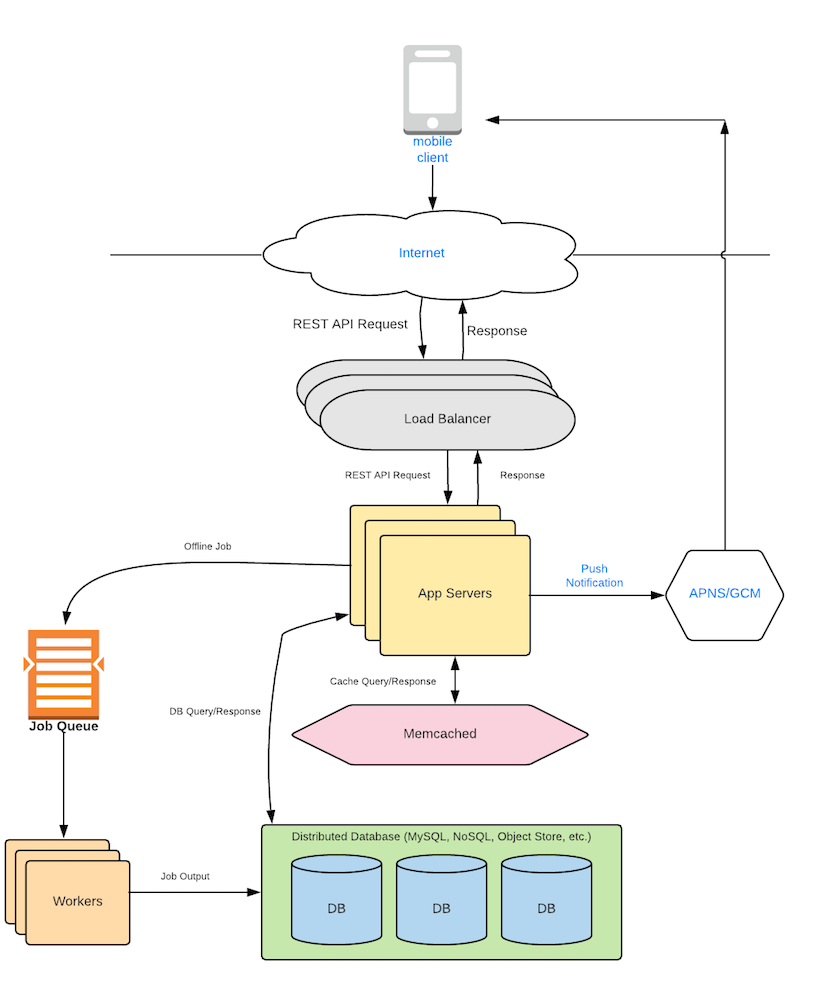













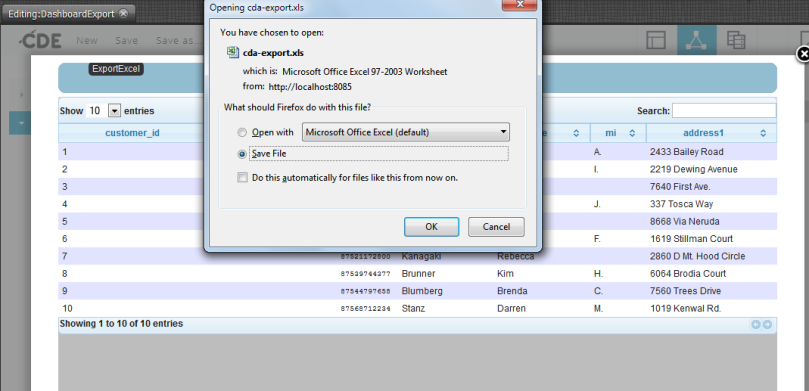
 Vậy thì bằng cách nào có thể xử lý được đây? Các bạn theo dõi tiếp bài viết này của mình nhé!
Vậy thì bằng cách nào có thể xử lý được đây? Các bạn theo dõi tiếp bài viết này của mình nhé! 

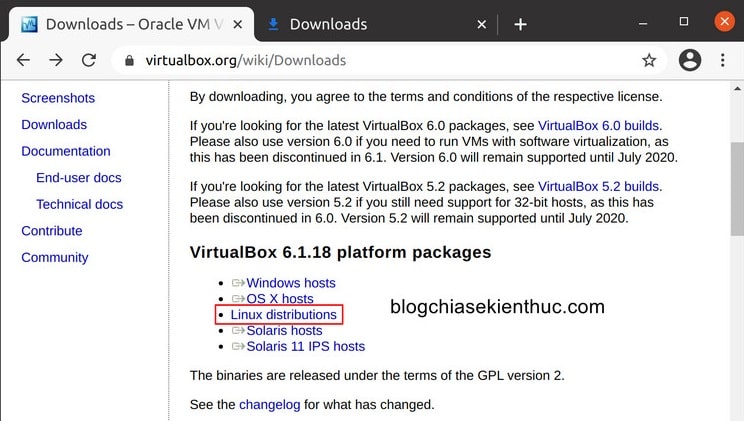
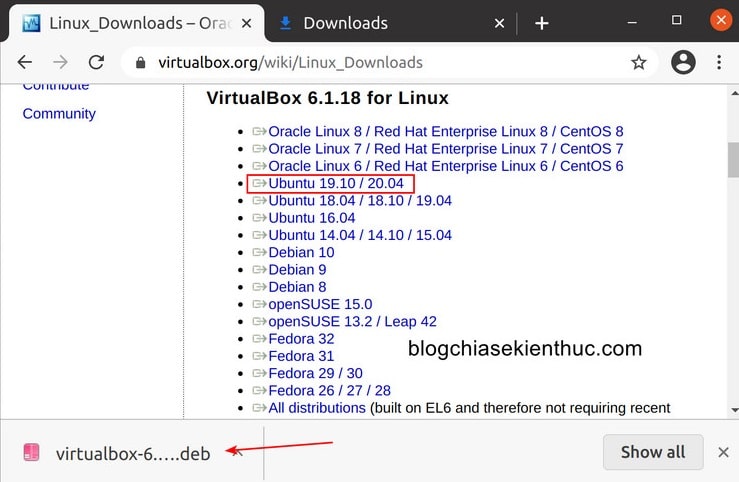
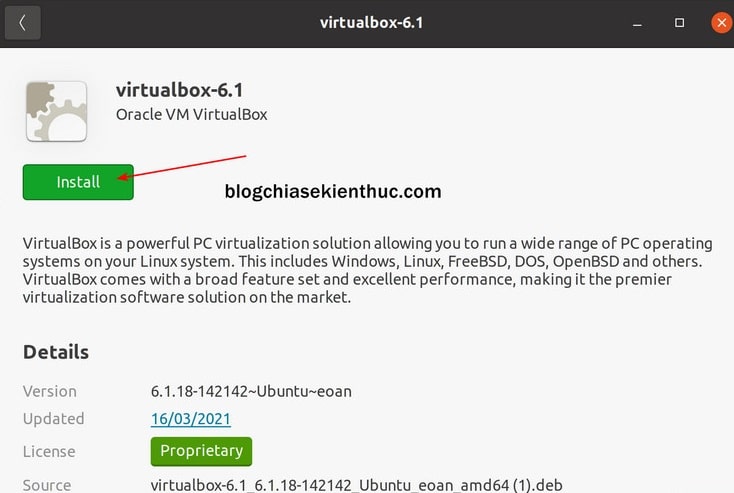
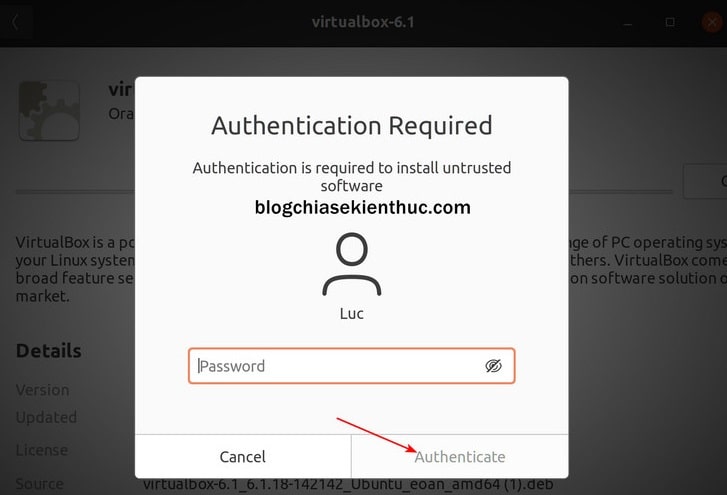

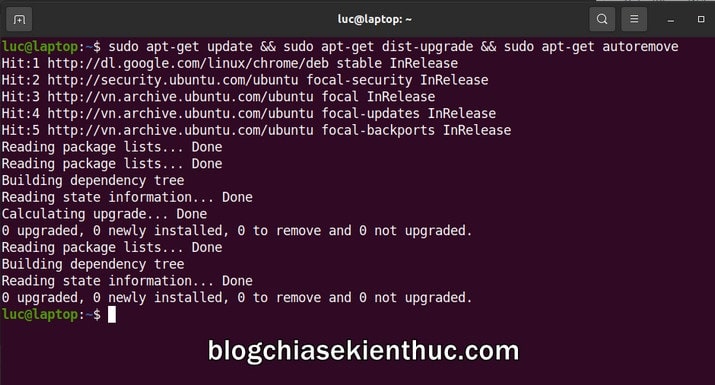
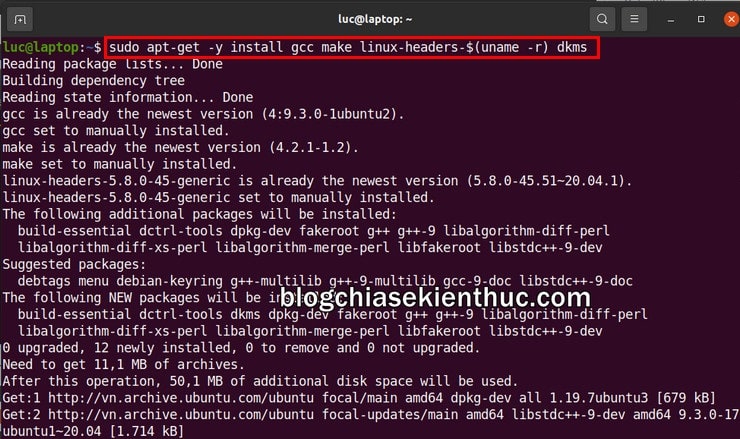
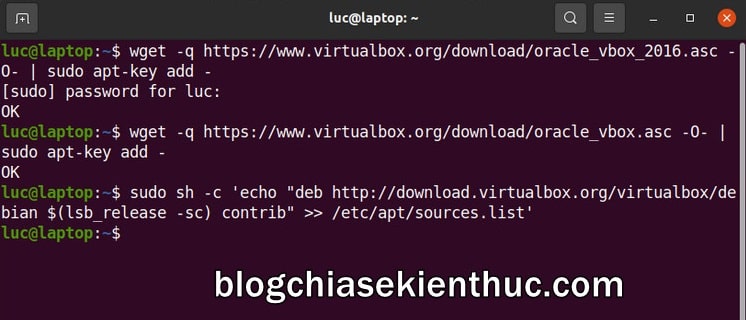
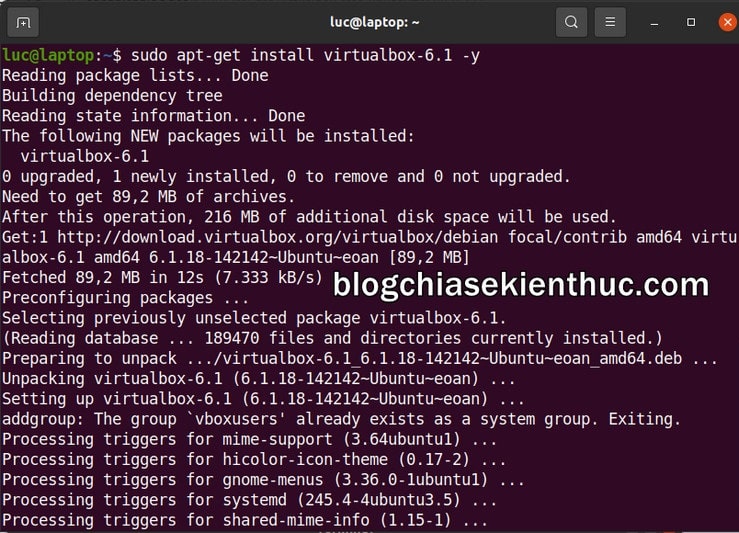


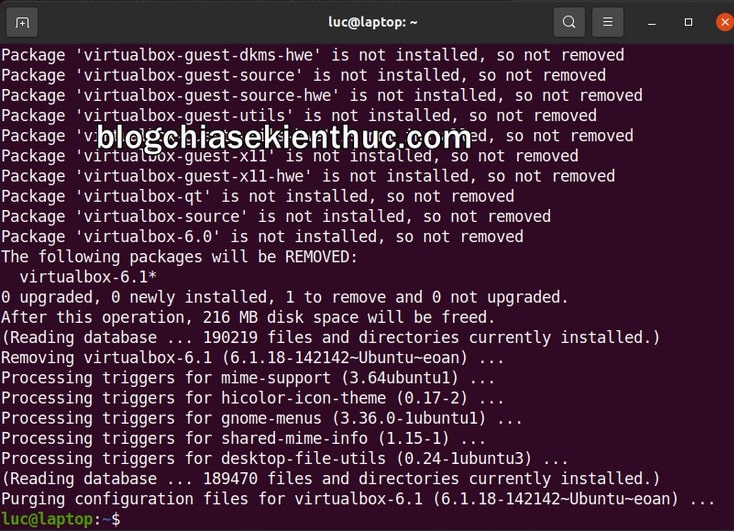




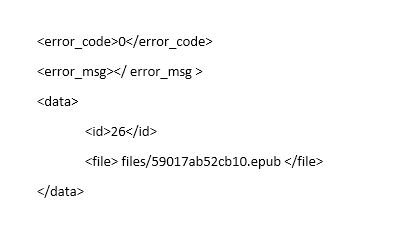


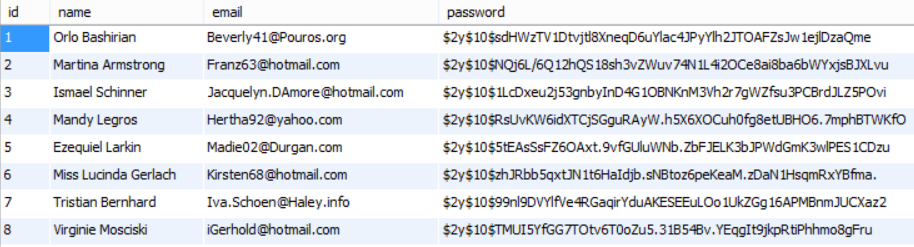


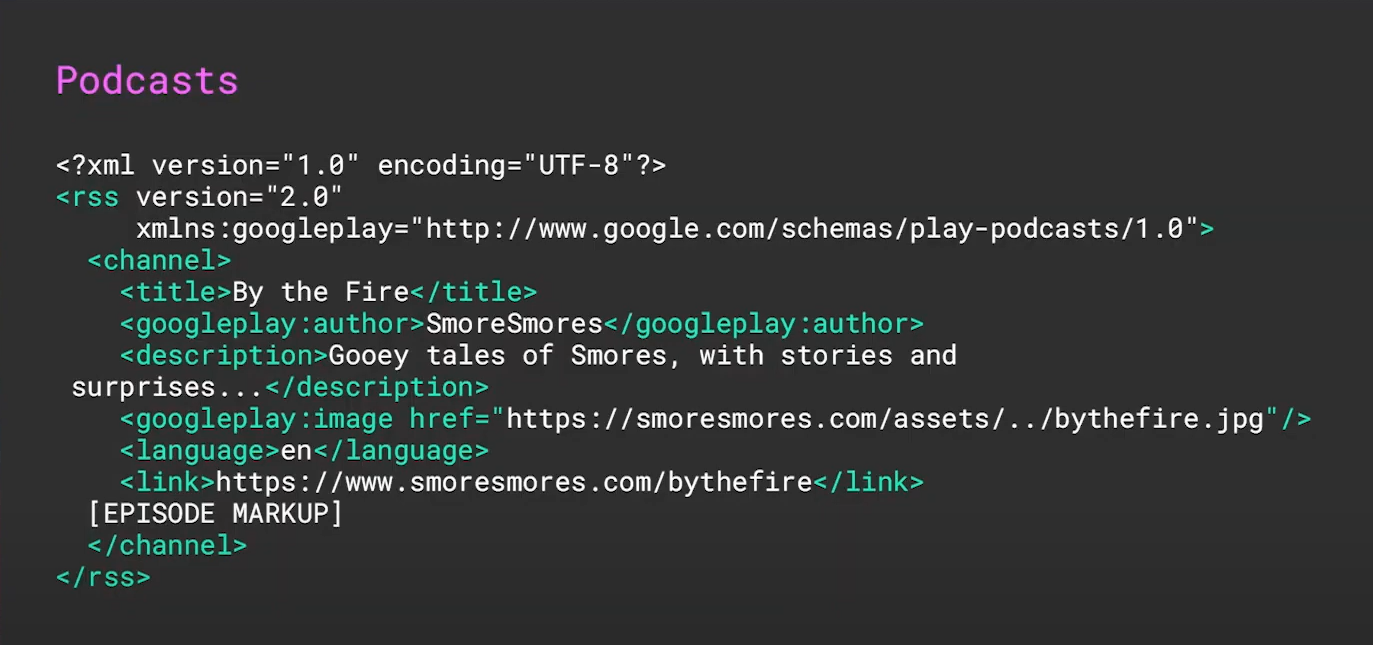



 Smart Home Device Integration
Smart Home Device Integration