Bài viết được sự cho phép của tác giả Giang Phan
Semaphore là gì?
Semaphore là một cơ chế giúp quản lý các nguồn chia sẻ và đảm bảo access không bị tắc nghẽn.
Có hai loại semaphore: binary semaphore và counting semaphore.
- Binary semaphore (Mutex): được dùng làm lock vì nó chỉ có 2 giá trị là 0 và 1. Hai giá trị này đại diện cho trạng thái lock hay unlock.
- Counting semaphore: thực hiện đếm resource để cho biết mức độ sẵn sàng của resource.
Xem thêm tuyển dụng Java lương hấp dẫn trên TopDev
Cơ chế hoạt động
Một Semaphore lưu trữ một danh sách các permit (hay ticket), mỗi khi gọi acquire() sẽ lấy 1 ticket từ Semaphore, mỗi khi gọi release() sẽ trả ticket về Semaphore. Nếu ticket không có sẵn, acquire() sẽ bị lock cho đến khi có ticket. Để kiểm tra số lượng ticket còn lại, sử dụng phương thức availablePermits().
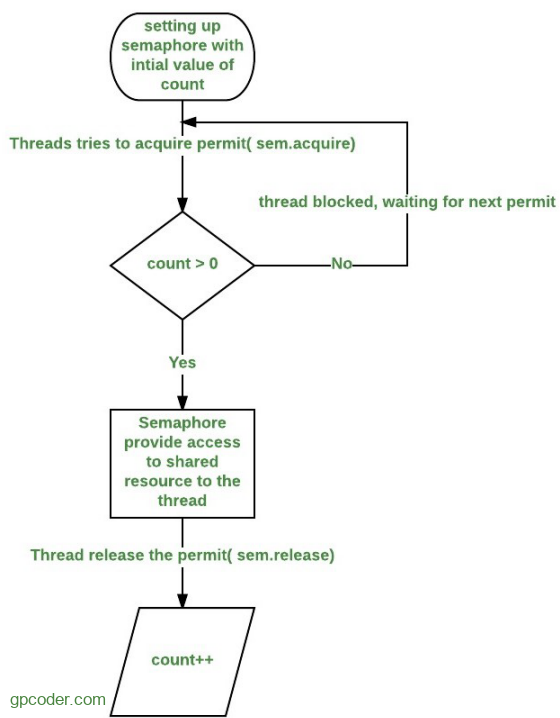
Ví dụ chúng ta gọi các phương thức tuần tự như sau:
// Tạo một Semaphore có 5 ticket Semaphore semaphore = new Semaphore(5); // Yêu cầu lấy 1 ticket để sử dụng semaphore.acquire(); // 5-1 // Đếm về số lượng ticket có sẵn int numberOfAvailableTickets = semaphore.availablePermits(); // 4 // Trả 1 ticket về Semaphore semaphore.release(); // 4+1 // Đếm về số lượng ticket có sẵn semaphore.availablePermits(); // 5
Ví dụ sử dụng Semaphore
Giả sử một ngân hàng có 4 cây ATM, mỗi cây chỉ có thể phục vụ được một khách hàng tại một thời điểm. Chương trình bên dưới cho thấy Semaphore có thể đảm bảo chỉ tối đa 4 người có thể truy cập tại một thời điểm.
WorkerThread.java
package com.gpcoder.semaphore;
import java.util.concurrent.Semaphore;
public class WorkerThread extends Thread {
private final Semaphore semaphore;
private String name;
public WorkerThread(Semaphore semaphore, String name) {
this.semaphore = semaphore;
this.name = name;
}
public void run() {
try {
System.out.println(name + ": acquiring lock...");
System.out.println(name + ": available Semaphore permits now: " + semaphore.availablePermits());
semaphore.acquire();
System.out.println(name + ": got the permit!");
try {
System.out.println(name + ": is performing operation, available Semaphore permits : "
+ semaphore.availablePermits());
Thread.sleep(100); // simulate time to work
} finally {
// calling release() after a successful acquire()
System.out.println(name + ": releasing lock...");
semaphore.release();
System.out.println(name + ": available Semaphore permits now: " + semaphore.availablePermits());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
SemaphoreExample.java
package com.gpcoder.semaphore;
import java.util.concurrent.Semaphore;
public class SemaphoreExample {
private static Semaphore semaphore = new Semaphore(4);
public static void main(String[] args) {
System.out.println("Total available Semaphore permits: " + semaphore.availablePermits());
for (int i = 1; i <= 6; i++) {
WorkerThread atmWorker = new WorkerThread(semaphore, "AMT " + i);
atmWorker.start();
}
}
}
Chạy chương trình trên, ta có kết quả sau:
Total available Semaphore permits: 4 AMT 1: acquiring lock... AMT 1: available Semaphore permits now: 4 AMT 1: got the permit! AMT 1: is performing operation, available Semaphore permits : 3 AMT 2: acquiring lock... AMT 2: available Semaphore permits now: 3 AMT 2: got the permit! AMT 2: is performing operation, available Semaphore permits : 2 AMT 3: acquiring lock... AMT 3: available Semaphore permits now: 2 AMT 3: got the permit! AMT 3: is performing operation, available Semaphore permits : 1 AMT 6: acquiring lock... AMT 4: acquiring lock... AMT 4: available Semaphore permits now: 1 AMT 4: got the permit! AMT 4: is performing operation, available Semaphore permits : 0 AMT 5: acquiring lock... AMT 5: available Semaphore permits now: 0 AMT 6: available Semaphore permits now: 1 AMT 3: releasing lock... AMT 4: releasing lock... AMT 1: releasing lock... AMT 4: available Semaphore permits now: 2 AMT 2: releasing lock... AMT 2: available Semaphore permits now: 2 AMT 6: got the permit! AMT 6: is performing operation, available Semaphore permits : 2 AMT 5: got the permit! AMT 5: is performing operation, available Semaphore permits : 2 AMT 1: available Semaphore permits now: 3 AMT 3: available Semaphore permits now: 2 AMT 6: releasing lock... AMT 6: available Semaphore permits now: 3 AMT 5: releasing lock... AMT 5: available Semaphore permits now: 4
Ví dụ sử dụng Mutex
Mutex là một Semaphore với bộ đếm là 1. Tình huống có thể sử dụng là lock tài khoản khi rút tiền. Tại một thời điểm chỉ 1 thao tác rút tiền được chấp nhận.
Chúng ta sẽ sử dụng lại worker ở trên. Giả sử có 6 user cùng login vào một tài khoản ở các cây ATM khác nhau để thực hiện rút tiền, nếu chúng ta không sử dụng cơ chế synchronized thì cả 6 người đều có thể rút tiền cùng lúc và có thể rút nhiều hơn số tiền hiện có trong tài khoản.
Đoạn code bên dưới sử dụng Mutex giúp chúng ta kiểm soát được vấn đề này một cách dễ dàng.
package com.gpcoder.semaphore;
import java.util.concurrent.Semaphore;
public class MutexExample {
private static Semaphore semaphore = new Semaphore(1);
public static void main(String[] args) {
System.out.println("Total available Semaphore permits: " + semaphore.availablePermits());
for (int i = 1; i <= 6; i++) {
WorkerThread atmWorker = new WorkerThread(semaphore, "AMT " + i);
atmWorker.start();
}
}
}
Chạy chương trình trên, chúng ta có kết quả sau:
Total available Semaphore permits: 1 AMT 1: acquiring lock... AMT 2: acquiring lock... AMT 1: available Semaphore permits now: 1 AMT 2: available Semaphore permits now: 1 AMT 1: got the permit! AMT 1: is performing operation, available Semaphore permits : 0 AMT 3: acquiring lock... AMT 3: available Semaphore permits now: 0 AMT 4: acquiring lock... AMT 4: available Semaphore permits now: 0 AMT 5: acquiring lock... AMT 6: acquiring lock... AMT 6: available Semaphore permits now: 0 AMT 5: available Semaphore permits now: 0 AMT 1: releasing lock... AMT 1: available Semaphore permits now: 1 AMT 2: got the permit! AMT 2: is performing operation, available Semaphore permits : 0 AMT 2: releasing lock... AMT 2: available Semaphore permits now: 0 AMT 3: got the permit! AMT 3: is performing operation, available Semaphore permits : 0 AMT 3: releasing lock... AMT 3: available Semaphore permits now: 1 AMT 4: got the permit! AMT 4: is performing operation, available Semaphore permits : 0 AMT 4: releasing lock... AMT 6: got the permit! AMT 6: is performing operation, available Semaphore permits : 0 AMT 4: available Semaphore permits now: 0 AMT 6: releasing lock... AMT 5: got the permit! AMT 5: is performing operation, available Semaphore permits : 0 AMT 6: available Semaphore permits now: 0 AMT 5: releasing lock... AMT 5: available Semaphore permits now: 1
Bài viết đến đây là hết. Hy vọng sau bài viết này các bạn hiểu rõ hơn về Semaphore, cũng như biết cách sử dụng nó trong một số tình huống thích hợp.
Tài liệu tham khảo:

















 Sau khi đã start Apache ZooKeeper rồi thì lúc này, các bạn có thể start Apache Kafka.
Sau khi đã start Apache ZooKeeper rồi thì lúc này, các bạn có thể start Apache Kafka.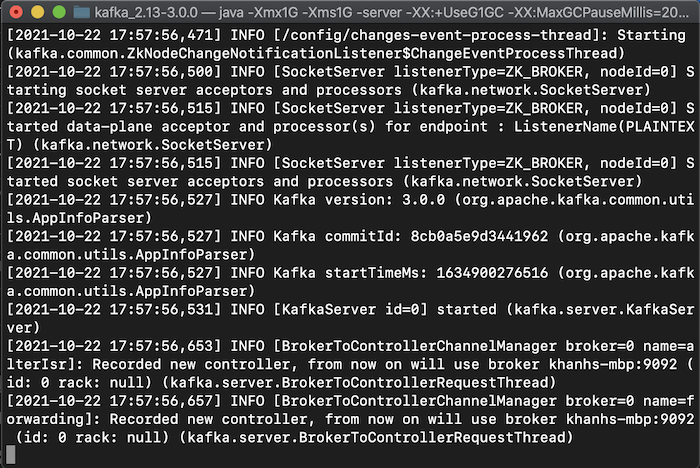 Đến đây thì chúng ta đã hoàn thành việc cài đặt Apache Kafka trên macOS rồi đó các bạn!
Đến đây thì chúng ta đã hoàn thành việc cài đặt Apache Kafka trên macOS rồi đó các bạn!





















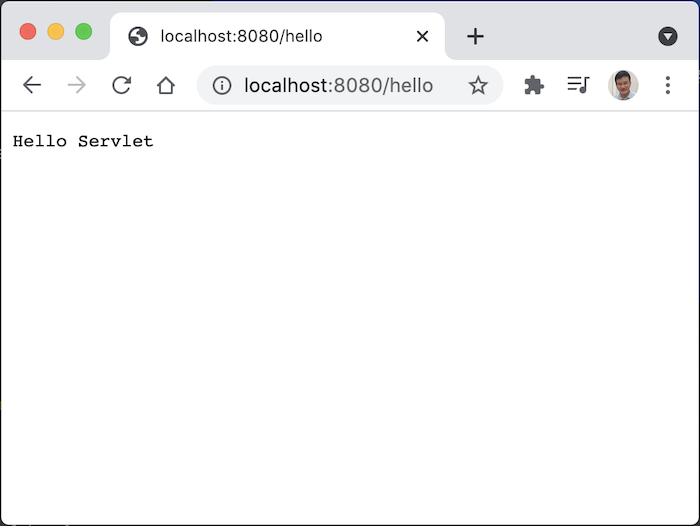
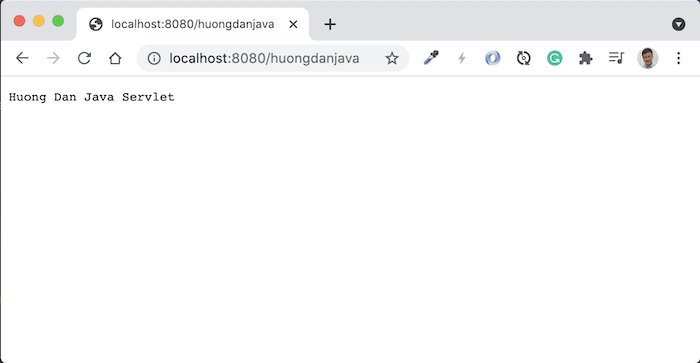
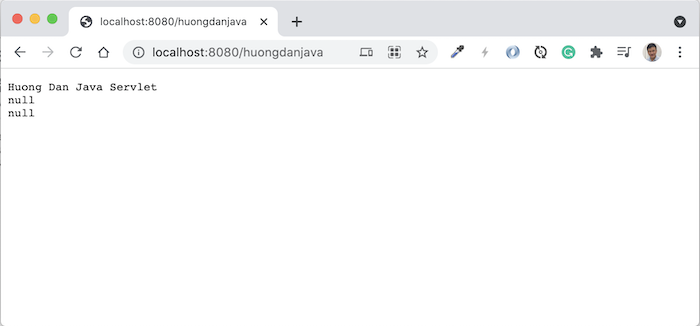
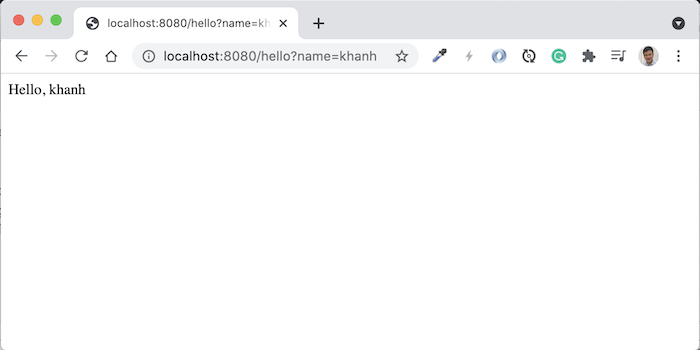
 Request tới http://localhost:8080/huongdanjava, các bạn sẽ thấy kết quả như sau:
Request tới http://localhost:8080/huongdanjava, các bạn sẽ thấy kết quả như sau: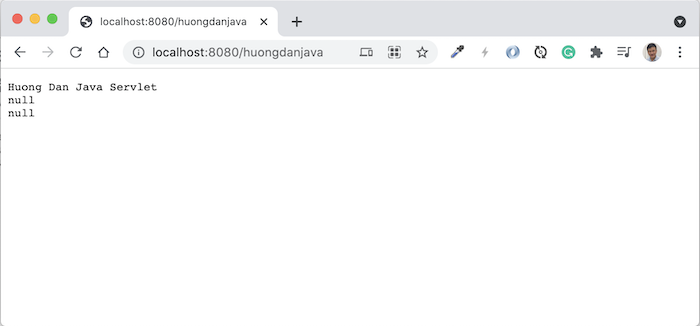





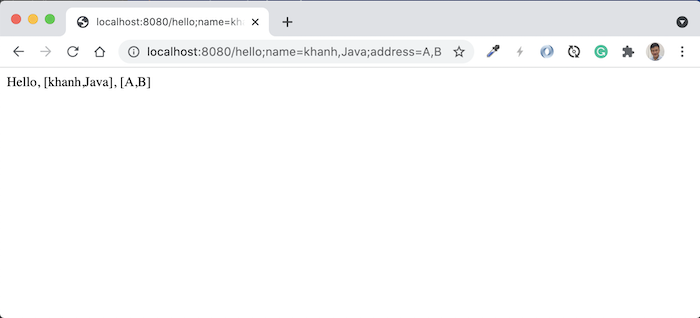
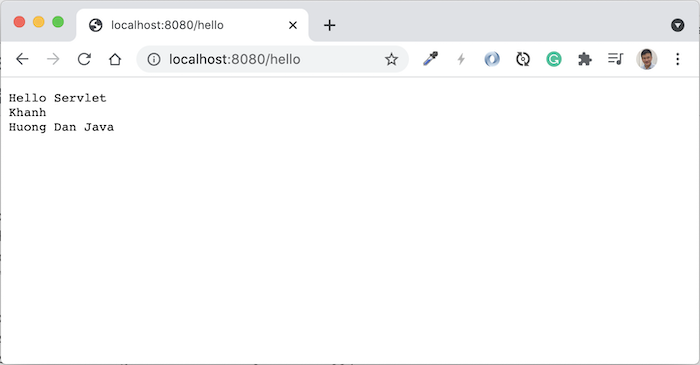
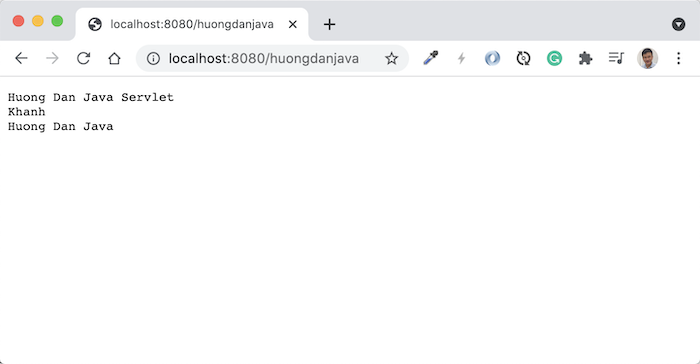
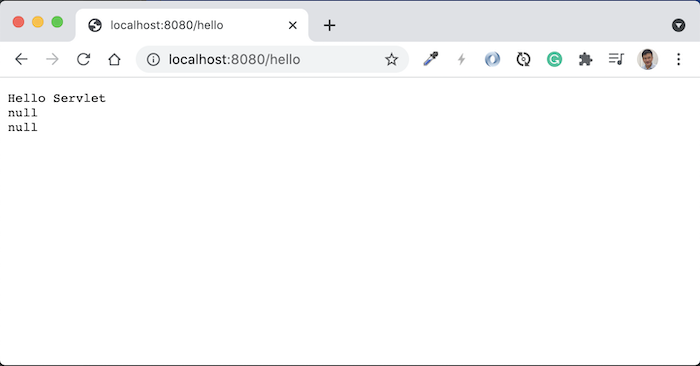
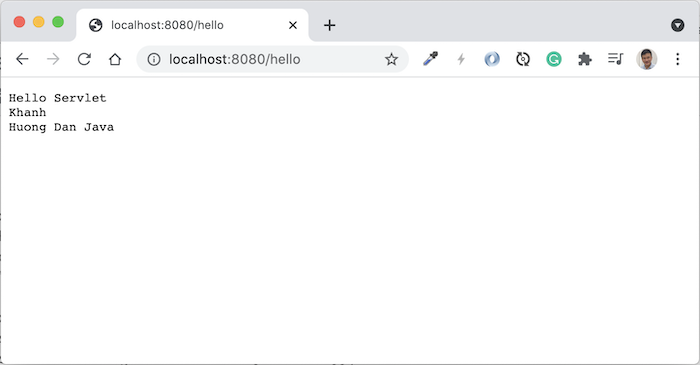
 Để định nghĩa request parameter cho các request URL, chúng ta sẽ sử dụng annotation @QueryParam.
Để định nghĩa request parameter cho các request URL, chúng ta sẽ sử dụng annotation @QueryParam.