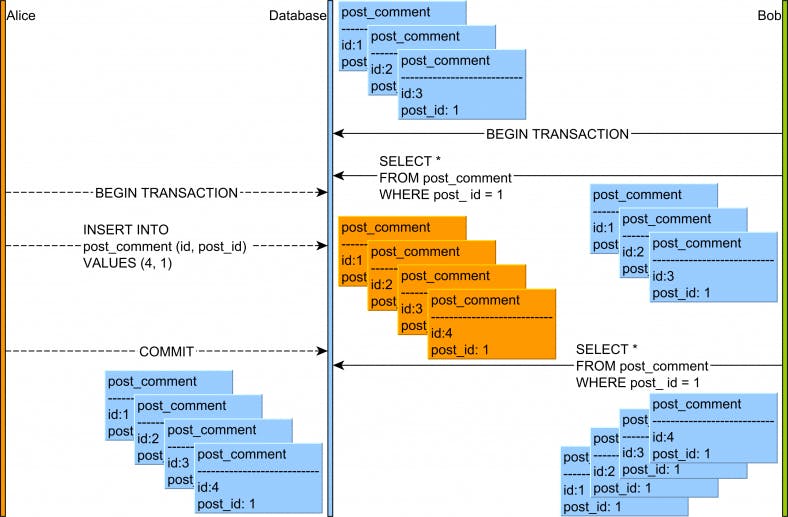
Giả sử hôm thứ 2 vừa rồi sếp giao cho task viết chương trình in ra dòng chữ “Hello World!”, sau một ngày cân nhắc lựa chọn các ngôn ngữ lập trình, công nghệ, mình quyết định chọn Swift để viết, vì ngôn ngữ này có tên trùng với tên ca sĩ mình yêu thích Taylor Swift.
Sau 2 ngày làm việc, cuối cùng mình cũng hoàn thành chương trình của mình, chương trình có nội dung như sau:
print(“Hello World!”)
Thật ra một Junior Dev thì sẽ viết như vậy, mà viết như vậy thì bài viết của mình có gì hấp dẫn nữa. Với cương vị của một Senior Developer, mình sẽ phải ứng dụng các kiến thức lập trình hướng đối tượng, phân tích thiết kế hệ thống để viết ra chương trình Hello World hoàn hảo.
Xem xét các đối tượng trong chương trình.
Đối tượng thứ nhất là đối tượng chứa logic business của ứng dụng, mình đặt tên là HelloWorldApplication cho khoẻ. Đây là lớp chứa quyết định chính của chương trình, là in ra dòng chữ Hello World!
Yêu cầu của nhiệm vụ lần này là in ra màn hình console dòng chữ “Hello World!”, nên mình cần thiết kế một lớp in ra dòng chữ này, nghe thật đơn giản đúng không? Nhưng không, hãy suy nghĩ về tính mở rộng của chương trình, giả sử một ngày nào đó trong tương lai, người ta không muốn in ra console nữa, mà muốn in lên một cửa sổ, in ra một tờ giấy, in ra một máy tính khác qua mạng thì sao, thế là mình nghĩ ra lớp đối tượng trừu tượng thứ nhất, Printer. Printer là một protocol cho phép in ra một chuỗi, mình chỉ quan tâm vậy thôi. Đó là cách mình khái quát hoá một đối tượng trong chương trình.
protocol Printer { func print(message: String)}
Dependency và Dependency Injection
Lớp HelloWorldApplication của mình là lớp high level chứa logic của chương trình, sẽ cần 1 printer để in ra thông điệp. Do đó mình cần truyền đối tượng printer này vào trong lớp HelloWorldApplication, gọi là inject dependency.
Mình inject quả constructor như sau:
class HelloWorldApplication { private let printer: Printer init(printer: Printer) { self.printer = printer }}
Bây giờ mình có thể xài đối tượng printer ở trong lớp HelloWorldApplication mà không cần quan tâm nó được cài đặt ra sao.
Viết kiểm thử đơn vị (unit test)
Trước khi đi implement lớp HelloWorldApplication, mình sẽ viết test case để kiểm tra xem chương trình có chạy đúng, không, theo phương thức Kiểm Thử trước tiên.
Để đơn giản mình viết 1 lớp MockPrinter như sau
class MockPrinter: Printer { var printedMessage: String? func print(message: String) { printedMessage = message }}
Và chương trình của mình cũng chỉ cần có 1 test case
final class HelloWorldApplicationTest: XCTestCase { func testRunShouldPrintHelloWorldMessage() throws { let printer = MockPrinter() let application = HelloWorldApplication(printer: printer) application .run() XCTAssertEqual("Hello World!", printer.printedMessage) }}
Vì hàm print của mình đặt trùng tên của hàm print của Swift nên mình hack 1 xíu như trên. (hảo hack)
Viết chương trình chính và test
Bây giờ mình có thể hoàn thiện chương trình:
let application = HelloWorldApplication(printer: ConsolePrinter())application .run()
HORRAY!! Chương trình đã in ra dòng Hello World! đúng như yêu cầu, và còn sử dụng nhiều kỹ thuật hiện đại, dễ mở rộng và khá đơn giản dễ hiểu.
Bây giờ muốn in cái dòng Hello World lên 1 UILabel chẳng hạn, ta chỉ cần extend UILabel để cài đặt cái protocol là xong, và cần thay ConsolePrinter thành đối tượng UILabel là được.
Đó là Senior sẽ viết vậy, nhưng nếu là super Senior Dev thì sẽ thêm 1 bước.
Refactor – Xoá những chi tiết dư thừa trong chương trình
Đây là bước khá quan trọng, bây giờ chúng ta sẽ xoá những chi tiết dư thừa trong chương trình, để cuối cùng đạt được kết quả thành 1 chương trình ngắn gọn như sau:
print(“Hello World!”)
Thật tuyệt vời!
Các bạn đang ở trình nào rồi? Mà dù là Fresher, Junior, Senior hay super Senior thì TopDev đều có nhiều jobs hot cho các bạn phát triển sự nghiệp. Tham khảo tại đây nè!
SQL là dễ với Senior, nhưng với những bạn bắt đầu tìm hiểu SQL thì thực tế lại không hề đơn giản như vậy, nắm bắt được nhu cầu, tâm tư tình cảm như vậy, TopDev giới thiệu tới anh em bài viết giải thích tường tận về Case When trong SQL.
Mong là qua bài viết này, anh em bắt đầu với SQL dễ dàng hơn, từ Case When sẽ tới các mục khác khó hơn trong SQL.
Anh em chú ý đón đọc chuỗi bài viết về SQL trên TopDev, ngày trở thành SQL Master không còn xa. Bắt đầu ngay thôi nào!.
1. Luôn luôn bắt đầu với ví dụ và định nghĩa
Rồi, giả sử ha, anh em được cô giao cho chức vụ quyền uy nhất lớp, lớp trưởng (à đâu, lớp phó phụ trách văn nghệ). Đợt này cần tập múa (múa quạt đi cho máu), mà tập ở Quận 6 nên cô cần biết danh sách các bạn ở HCM.
Cô già mắt kém, chữ ngắn khó đọc nên HCM thì khó cho cô, cô yêu cầu nhìn thấy bạn nào ở TP Hồ Chí Minh để cô lựa.
Trong hệ cơ sở dữ liệu cô đang có sẵn danh sách các bạn cùng lớp (teammate), khổ cái là cái tool mà cô sử dụng để input lúc viết lại do một ông thần khác có tính cách không lèo nhèo.
Ví dụ bạn Sơn Tùng ở TP Hồ Chí Minh thì ổng chỉ lưu là HCM, còn bạn Erik tuy là chạy về nhà khóc với anh nhưng nhà ở Đồng Nai, chạy bộ không nổi. Ở Đồng Nai thì lưu xuống lại là DN2, do trùng với Đà Nẵng, chua lè.
Cơ bản thì từ mã tỉnh thành viết tắt lưu xuống ta có thể lấy được địa chỉ đầy đủ như này
1.1 Tìm hướng giải quyết
Rồi, yêu cầu của cô là lấy danh sách các bạn cùng lớp thân thương yêu quý lên. Nhưng chỗ địa chỉ thì không được viết tắt. Tức là nếu bạn đó ở HCM thì show ra chỗ SQL result là Hồ Chí Minh, còn nếu bạn ở ĐN thì SQL result là Đồng Nai.
Tiền đề là không có bảng “Địa chỉ” để mà left join, inner join gì luôn nha anh em. Đang đưa đường dẫn lối cho Case When trong SQL nên không chơi kiểu thế. Haha.
Rồi mường tượng trong đầu là có một danh sách các bạn, giờ nếu mà gặp cái cột TinhThanh (hiện đang viết tắt). Mường tượng trong đầu ta có 4 bước.
Thơm lun, thấy có “Nếu bạn nào” là thấy giống If Else rồi. Đúng, là giống, nhưng đang học syntax Case When trong SQL nên cứ từ từ.
Để giải bài tập cô giao bằng SQL, ta có thể sử dụng câu SQL sau.
SELECT TinhThanh,
CASE
WHEN
TinhThanh = "HCM"
THEN
"Ho Chi Minh"
WHEN
TinhThanh = "DN"
THEN "Da Nang"
ELSE TinhThanh
END AS "Cap Nhat Thanh Pho"
FROM BanBe
1.2 Giải thích chi tiết
Với câu SQL trên, nhìn rối rắm khó hiểu cho người bắt đầu nên cứ bẻ nhỏ từng chữ từng chữ. Không có gì phải vội. SELECT là rồi ha, dễ hiểu.
CASE: indicates a condition loop has been started and that the conditions will follow.
CASE là trường hợp, nó xác định rằng một điều kiện kiểm tra sắp bắt đầu và tiếp theo sau nó sẽ là điều kiện kiểm tra
WHEN: indicates the start of a condition that should be checked by the query.
WHEN là trong khi, nó xác định rằng một điều kiện cần được kiểm tra bởi câu truy vấn
THEN: executed when the condition is true, determines the output for the true condition.
THEN là thì, nó thực thi nếu điều kiện ở WHEN là đúng.
ELSE: catches all of the entries that were not true for any of the WHEN conditions.
Else là khác, nó sẽ xử lý trong trường hợp không có điều kiện WHEN nào thỏa mãn (false)
END: Indicates the end of the CASE loop.
END là kết thúc, kết thúc CASE
Từ khóa thì chỉ có 5 cái vậy, mà vẫn khó hiểu nên mình quay lại ví dụ SQL ở phần 1 ha. Diễn giải theo cách dễ hiểu hơn (kiểu ngôn ngữ tự nhiên).
LẤY TinhThanh,
TRƯỜNG HỢP
KHI
TinhThanh = "HCM"
THÌ
"Ho Chi Minh"
KHI
TinhThanh = "DN"
THÌ "Da Nang"
KHÁC THÌ TinhThanh
KẾT THÚC AS "Cap Nhat Thanh Pho"
LẤY TỪ BanBe
Cách này thì Case When trong SQL tự nhiên trở nên dễ hiểu hơn rất nhiều. Dễ hơn vạn lần cho những bạn mới tiếp cận với SQL.
Kết thúc phần một, hiểu để sử dụng được case when trong sql. Tiếp đến là nó hoạt động như thế nào?, thú vị hơn nha.
2. Ví dụ cụ thể với Database postgres
Sau khi đã tìm hiểu qua mục 1, anh em chắc hẳn sẽ tự tin vỗ ngữ là: Ối dồi ôi, dăm ba cái Case When này, dễ hiểu ấy mà, tương tự như If Else.
Uầy, thì đúng là xài dễ, nhưng cụ thể cho dễ mường tượng thì vẫn tốt hơn. Mình ví dụ dưới đây với hệ cơ sở dữ liệu postgres.
Yêu cầu là với news_type (loại tin tức), hiện tại trong các bảng đang lưu là id (là số), nếu không có bảng master quy định các thông tin này thì để lấy ra được nội dung dễ đọc, ta cần sử dụng case when trong sql.
Nếu news_type=4 loại hình này là Chung Cư (ví dụ thôi nha), nếu khác 4 là loại hình đất nền, column mình lấy ra là loainhadat.
Dưới đây là trường hợp case, anh em thấy trong 5 row lấy ra chỉ có dòng cuối cùng là thỏa điều kiện
Kết quả là chỉ có row số 5 là Chung Cu, 4 row phía trên là Dat nen.
4 case phía trước do news_type không bằng 4 nên sẽ lọt vào case ELSE -> dẫn tới kết quả là 4 row phía trên ‘Dat nen’.
Ví dụ cụ thể sinh động như cá bơi trong chậu rồi nha, giờ tới một số lưu ý khi sử dụng SQL.
3. Một số lưu ý khi sử dụng Case When trong SQL
3.1 Kiểu dữ liệu
Cái này anh em khi mới bắt đầu sử dụng Case When trong SQL thường gặp lỗi này. Việc so sánh sai kiểu dữ liệu dẫn với Case when không work như cách mà anh em mong muốn.
Nếu so sánh sai kiểu dữ liệu, ở một số hệ cơ sở dữ liệu còn trả về “Invalid Input Syntax”.
Ví dụ trường hợp phía dưới đây cột Name có kiểu dữ liệu là VARCHAR (ký tự).
SELECT Track.Name, Track.GenreId,
CASE WHEN (Track.Name = 40) THEN 'Rock'
END AS Genre FROM Track
ORDER BY Track.Name ASC LIMIT 10;
Anh em chú ý khúc CASE WHEN (Track.Name = 40), 40 ở đây đang là số. Trường hợp execute sẽ dẫn tới lỗi.
ERROR: operator does not exist: character varying = integer
Nên trước khi viết case when so sánh cột nào anh em nên mở bảng đó ra xem kiểu dữ liệu trước khi thực hiện chạy SQL nha.
3.2 Nhiều case when trong SQL
Trường hợp có nhiều Case When, ta lưu ý rằng:
After THEN is executed, CASE will return to the top of the loop and begin checking the next entry.
If the condition is false, the next WHEN statement will be evaluated.
Sau khi mà CASE WHEN đã true – đúng, CASE sẽ trở lại đầu vòng lặp và check tiếp row sau, bất kể phía dưới còn bao nhiêu SQL. Cái này anh em lưu ý.
Thứ hai là nếu WHEN đã sai – fasle, CASE lúc này sẽ di chuyển tới CASE tiếp theo, chỗ này có thể ảnh hưởng tới performance nếu có quá nhiều CASE WHEN cần kiểm tra.
3.3 Không có else
Một số anh em viết case when trong sql hay miss trường hợp else.
If no ELSE statement is present and all WHEN conditions are false, the returned value will be NULL. Nếu trường hợp không có ELSE và tất cả các điều kiện WHEN đều false (tức là không match) cái nào
4. Tổng kết để khỏi quên ha
CASE WHEN được sử dụng để xác định các câu lệnh điều kiện trong SQL CASE khai báo sự bắt đầu của các điều kiện
WHEN khai báo điều kiện
THEN khai báo thứ trả về khi điều kiện WHEN là true
ELSE bắt tất cả các trường hợp không pass ở WHEN
END kết thúc cho CASE
Ta có thể có nhiều WHEN trong một CASE nha
AS sử dụng để định nghĩa name của cột trả về, nếu không có thì default là “case”
Kết bài bằng một trò đùa zui zẻ nha anh em. Đừng viết SQL kiểu này không có ông nào sau đi maintain ổng kiếm tới tận nhà lun á.
5. Tham khảo
SQL CASE Statement – W3School: https://www.w3schools.com/sql/sql_case.asp
How CASE WHEN Works – The Data School: https://dataschool.com/how-to-teach-people-sql/how-case-when-works/
CASE statement in SQL: https://www.sqlshack.com/case-statement-in-sql/
Cảm ơn vì đã đọc bài – Thank for you time – Happy coding!
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
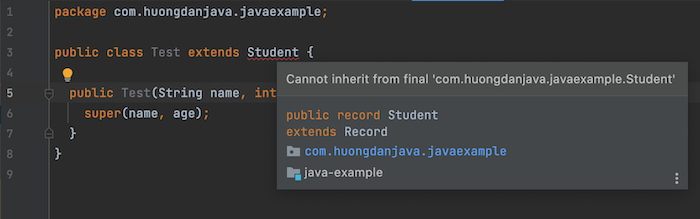
Các bạn có cảm thấy lười biếng mỗi khi phải khai báo các phương thức Getter, Setter cho các class Java không? Các bạn có thấy nhàm chán khi làm việc với những đoạn code theo khuôn mẫu trong Java không? Nếu tất cả các câu trả lời là có thì hãy xem xét sử dụng Project Lombok. Nó sẽ giúp các bạn loại bỏ những công việc nhàm chán này.
Project Lombok là gì?
Project Lombok là một công cụ giúp chúng ta generate code một cách tự động nhưng không phải giống như các IDE làm cho chúng ta. Các IDE generate các phương thức Getter, Setter và một số phương thức khác trong các tập tin .java. Project Lombok cũng generate các phương thức đó nhưng là trong các tập tin .class file.
Trang chủ: https://projectlombok.org/
Tất cả công việc chúng ta cần làm chỉ là sử dụng một số annotation của Project Lombok như @Getter, @Setter, @Builder, … việc còn lại Project Lombok sẽ làm cho chúng ta. Tất nhiên, những thứ các bạn không muốn làm tự động thì bạn cũng có thể chỉ định để Project Lombok không generate chúng.
Để các IDE có thể hiểu được code do Project Lombok generate, các bạn cần cài đặt Project Lombok plugin cho chúng. Xem hướng dẫn cài đặt Project Lombok cho IntelliJ IDE ở đây.
Getter, Setter và Constructors với Project Lombok
Trong bài viết này, mình sẽ giới thiệu với các bạn cách sử dụng Project Lombok để generate các phương thức Setter, Getter và constructor trong một đối tượng Java một cách tự động.
Đầu tiên, mình sẽ tạo một Maven project để làm ví dụ:
Các bạn hãy nhớ là chúng ta cần phải install Project Lombok plugin vào trong IDE của chúng ta để IDE có thể hiểu và không bị lỗi compile.
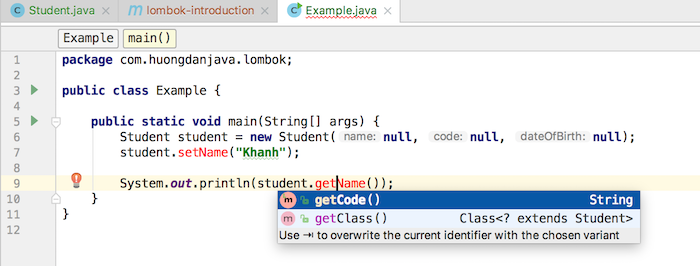
Bây giờ, ví dụ mình có class Student với một số thông tin như sau: name, code, dateOfBirth. Nếu không sử dụng Project Lombok thì mình phải khai báo các thông tin này như sau:
package com.huongdanjava.lombok;
import java.util.Date;
public class Student {
private String name;
private String code;
private Date dateOfBirth;
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public Date getDateOfBirth() {
return dateOfBirth;
}
public void setDateOfBirth(Date dateOfBirth) {
this.dateOfBirth = dateOfBirth;
}
}
Với Project Lombok, mình có thể remove các phương thức Getter, Setter trong Student class và để cho Project Lombok tự generate chúng bằng cách sử dụng annotation @Getter và @Setter:
và thêm một default constructor, một constructor với tất cả các thông tin của class Student bằng cách sử dụng các annotation @NoArgsConstructor và @AllArgsConstructor như sau:
Chúng ta còn có thể khai báo Getter, Setter cho chỉ một số thuộc tính của đối tượng Java sử dụng @Getter, @Setter annotation. Ví dụ như, bây giờ mình chỉ khai báo Getter, Setter cho thuộc tính code của Student class, mình sẽ khai báo như sau:
Bây giờ, các bạn chỉ có thể sử dụng Getter, Setter cho thuộc tính code của đối tượng Student mà thôi:
Thông qua những nội dung trên chắc hẳn bạn đã hình dung được Project Lombok là gì và bước đầu ứng dụng được những hiệu quả mà nó mang lại. Chúc bạn làm việc hiệu quả.
Thời điểm kỳ thi THPTQG kết thúc cũng là lúc các cuộc tranh luận về việc chọn ngành học để có công việc tốt trong tương lai trở nên sôi nổi hơn bao giờ hết. Chuyện học ngành Công nghệ thông tin để có mức lương ngàn đô sau khi ra trường vẫn tiếp tục là đề tài được nhiều người quan tâm. Vậy cơ hội việc làm cho sinh viên CNTT mới ra trường đang phát triển như thế nào? Khả năng phát triển với ngành này ra sao? Cùng TopDev tìm hiểu thêm ở bài viết này nhé!
Nhiều cơ hội việc làm hấp dẫn cho sinh viên ngành IT
Bối cảnh ngành CNTT tại Việt Nam hiện nay
Dựa trên kết quả Báo cáo thị trường IT Việt Nam 2021 do TopDev thực hiện, dù chịu ảnh hưởng của các đợt Covid-19 liên tục trong hơn một năm trở lại đây, Việt Nam hiện vẫn đứng thứ hai trên thế giới về sản xuất điện thoại di động và linh kiện, đứng thứ mười thế giới về sản xuất linh kiện điện tử. Đây cũng là hai yếu tố giúp Công nghệ thông tin – Truyền thông (ICT) trở thành ngành xuất siêu lớn nhất trong nền kinh tế Việt Nam.
Theo thống kê trong báo cáo, đến năm 2021 Việt Nam cần đến 450.000 nhân lực Công nghệ thông tin. Tuy nhiên, tổng số lập trình viên hiện tại ở Việt Nam (tính đến Q1/ 2021) là 430.000, đồng nghĩa với việc sẽ có khoảng 20.000 vị trí lập trình viên sẽ không được lấp đầy trong tương lai gần. Đáng chú ý hơn, với số lượng hơn 55.000 sinh viên IT tốt nghiệp mỗi năm ở Việt Nam hiện nay, chỉ có khoảng 16.500 sinh viên (30%) đáp ứng được những yêu cầu về kỹ năng và chuyên môn của doanh nghiệp.
Nguyên nhân chủ yếu là do sự chênh lệch giữa trình độ Lập trình viên và yêu cầu của doanh nghiệp. Rõ ràng, cơ hội việc làm cho sinh viên CNTT mới ra trường là rất lớn, tuy nhiên ứng viên cần đảm bảo các yêu cầu chuyên môn và kỹ năng để đáp ứng các tiêu chuẩn từ doanh nghiệp.
Cơ hội việc làm cho sinh viên ngành lập trình ở level Fresher là rất lớn, các bạn sinh viên IT mới ra trường hoàn toàn có thể thử sức ở bất kỳ lĩnh vực và công nghệ nào bản thân tự tin và muốn học hỏi thêm. Bạn có thể tham khảo một số việc làm IT Fresher ứng với thế mạnh công nghệ của bạn:
Có rất nhiều các vị trí khác nhau mà ứng viên có thể tham khảo. Tuy nhiên, tùy theo đặc thù từng công việc và yêu cầu cụ thể của mỗi công ty, bạn có thể sẽ gặp phải khó khăn về vấn đề kinh nghiệm làm việc. Do đó, hãy linh hoạt theo nhu cầu cá nhân và yêu cầu năng lực để tìm cho mình một công việc phù hợp. Chỉ cần có sự kiên trì và sẵn sàng học hỏi, dù làm việc ở bất cứ chuyên môn nào bạn cũng hoàn toàn có thể làm tốt.
Cùng TopDev tìm hiểu một số thông tin vị trí IT Fresher phổ biến:
Back-end Developer: Lập trình viên chuyên duy trì logic cốt lõi về chức năng và hiệu suất của một phần mềm hoặc hệ thống CNTT bao gồm các thành tố chính như máy chủ, ứng dụng & cơ sở dữ liệu. Back-end Developer cần thông thạo một trong ngôn ngữ lập trình nhất định như PHP, Java, Python, .Net… Tham khảo việc làm Fresher Back-end tại đây.
Front-end Developer: Lập trình viên chuyên về tính thẩm mỹ của bố cục website/ ứng dụng và lập trình ra các giao diện trực quan mà người dùng cuối/ khách hàng tương tác/ sử dụng. Front-end Developer cần đảm bảo các kỹ năng & kiến thức về giao diện người dùng (UI – User Interface), CSS, JavaScript, HTML… Tham khảo việc làm Fresher Front-end tại đây.
Tester: Vị trí chịu trách nhiệm thử nghiệm, kiểm định một sản phẩm mới, một tính năng mới hoặc tính khả dụng, chất lượng của một dự án… để tìm bugs, errors… hoặc bất kỳ vấn đề nào mà người sử dụng cuối cùng, khách hàng có thể gặp phải và báo cáo cho nhóm phát triển dự án để tiến hành sửa lỗi hoặc cải thiện sản phẩm. Tham khảo việc làm Fresher Tester tại đây.
Ngành IT vẫn luôn được xem là ngành có mức lương cao ngất ngưởng, liệu câu chuyện bên trong có thật sự như những gì ta nghe thấy? Theo thống kê từ Báo cáo thị trường IT Việt Nam năm 2021 của TopDev, ước tính thị trường lao động CNTT năm 2021 sẽ có 117.180 việc làm CNTT, tăng 36,5% so với năm 2020. Không chỉ nhu cầu tuyển dụng gia tăng mà mức lương cho các vị trí liên quan đến công nghệ và thông tin vẫn không ngừng cải thiện theo thời gian.
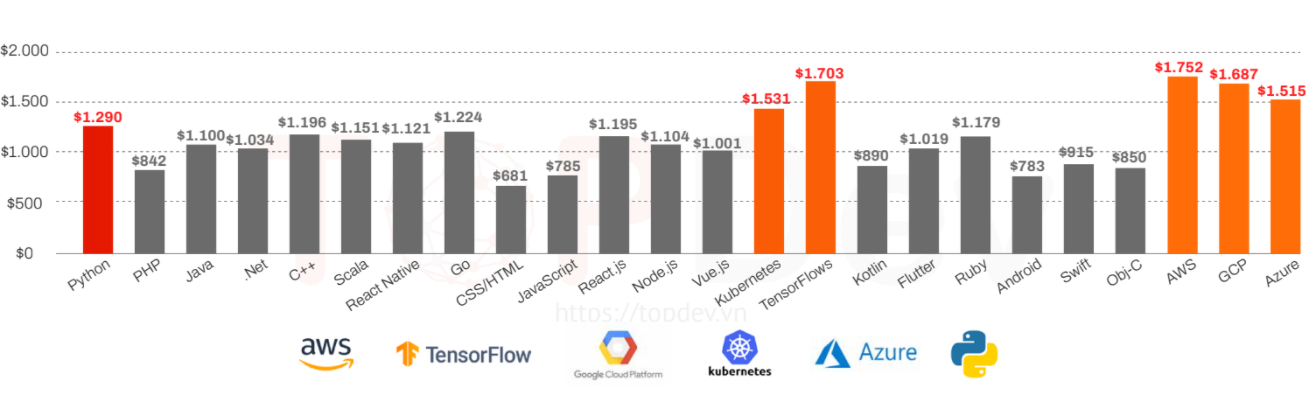
Theo đó, danh sách hai nhóm chuyên môn được trả lương cao nhất hiện nay gồm:
High tech liên quan đến các xu hướng như AI/ML (Kubernetes, TensorFlows, Python)
Điện toán đám mây (AWS, GCP, Azure)
Sở dĩ mức lương của các nhóm ngành cao hơn hẳn so với các ngành nghề khác là do ảnh hưởng từ quá trình chuyển đổi số trên toàn cầu. Top 3 ngành có mức thu nhập cao nhất thị trường IT hiện nay là Security, High Tech và Fintech. Trong đó, lĩnh vực Hightech – công nghệ cao như AI, IoT, điện toán đám mây,… được coi là xu hướng bắt buộc trong năm 2021 và thời gian tới.
Dựa trên số liệu thu thập được, mức lương lập trình viên cao nhất (với các đối tượng có khoảng 3 năm kinh nghiệm) dựa theo công nghệ hiện đang thuộc về AWS với mức 1.752$/tháng, TensorFlows nằm trong khoảng 1.703$/tháng.
Mức lương khi làm việc với các công nghệ cơ bản về phát triển web, hệ thống và thiết bị di động hiện vẫn đang giữ ở mức khá cao, như công nghệ lập trình bằng ngôn ngữ Python khoảng 1.290$/tháng, C++ ở mức 1.196$/tháng.
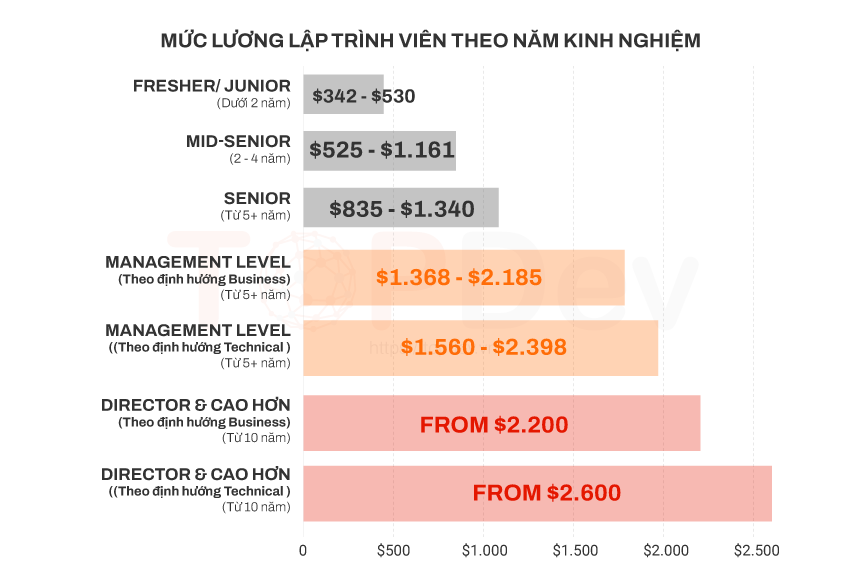
Theo ước tính của Báo cáo thị trường IT Việt Nam 2021, trong khoảng 5 năm đầu tiên sau khi ra trường, mức lương của lập trình viên sẽ dao động trong mức 342$/tháng (fresher) đến dưới 1.161$/tháng với vị trí Senior. Từ sau 5 năm, mức lương sẽ phụ thuộc vào vị trí và chức vụ mà bạn đảm nhận ở công ty.
Cơ hội và việc làm cho sinh viên CNTT mới ra trường chưa bao giờ là khan hiếm trên thị trường. Vậy nên để có thể thuận lợi tìm cho mình một công việc như ý, ngay từ bây giờ, bạn hãy cố gắng tìm hướng đi chuyên môn cho mình và trau dồi hơn nữa các kỹ năng để làm tốt hơn trong tương lai. Tìm đọc thêm nhiều bài viết hữu ích khác về lĩnh vực CNTT cùng TopDev nhé!
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Trong phần 1, chúng ta đã tìm hiểu về cách dùng interfaces và về interface rỗng. Phần này, chúng ra sẽ nghiên cứu tiếp:
Con trỏ và interfaces
Một điểm tinh tế khác của interface là định nghĩa interface không quy định liệu người triển khai có nên triển khai interface bằng cách sử dụng kiểu con trỏ hay kiểu giá trị hay không. Khi bạn được cung cấp một giá trị interface, không có gì đảm bảo rằng nó là kiểu thông thường hay là kiểu con trỏ. Trong ví dụ bài trước, chúng ta đã định nghĩa các function của interface trên các kiểu thông thường. Bây giờ chúng ta sẽ thay đổi 1 chút để triển khai thành kiểu con trỏ:
func (c *Cat) Speak() string {
return "Meow!"
}
Nếu bạn thay đổi chương trình như https://go.dev/play/p/TvR758rfre, và bạn cố tình chạy nó bạn sẽ nhận được lỗi sau:
cannot use Cat{} (type Cat) as type Animal in slice literal:
Cat does not implement Animal (Speak method has pointer receiver)
Thành thật mà nói, thông báo lỗi này hơi khó hiểu lúc đầu. Ý người ta nói không phải là interface Animal yêu cầu bạn xác định phương thức của mình như một kiểu con trỏ, nhưng bạn cố gắng chuyển đổi cấu trúc Cat thành giá trị interface Animal thì chỉ *Cat đáp ứng interface đó. Bạn có thể fix bug bằng cách chuyển *Cat thay vì dùng Cat, bằng cách sử dụng new(Cat) thay vì Cat{}(hay nói cách khác dùng &Cat{}), trông nó như sau:
Chương trình bây giờ sẽ như sau: https://go.dev/play/p/x5VwyExxBM
Hãy thay đổi theo hướng ngược lại: hãy thay thế kiểu con trỏ *Dog thay vì kiểu giá trị Dog, nhưng chúng ta sẽ không viết lại phương thức Speak cho Dog:
Chương trình sẽ như sau: https://go.dev/play/p/UZ618qbPkj
Chương trình hoạt động bình thường và chúng ta nhận ra 1 sự khác biệt nhỏ: Chúng ta không phải thay đổi phương thức Speak. Điều này hoạt động vì kiểu con trỏ có thể truy cập vào method của kiểu giá trị được kết hợp của nó, còn điều ngược lại thì không được phép. Có nghĩa là kiểu con trỏ *Dog có thể truy cập phương thức của kiểu giá trị Dog, và như chúng ta thấy trước đó, kiểu Cat không thể truy cập vào phương thức Speak của *Cat.
Điều đó nghe có vẻ khó hiểu, nhưng sẽ có ý nghĩa khi bạn nhớ những điều sau: mọi thứ trong Go đều được truyền theo giá trị. Mỗi khi bạn gọi một hàm, dữ liệu bạn đang truyền vào nó sẽ được sao chép. Trong trường hợp một phương thức định nghĩa thuộc kiểu giá trị, giá trị được sao chép khi gọi phương thức. Điều này rõ ràng hơn một chút khi bạn xem đoạn code sau:
func (t T)MyMethod(s string) {
// ...
}
là một hàm kiểu func (T, string); các giá trị được truyền vào hàm dạng giá trị dù bạn thay đổi tên biến bất kỳ. Bất kỳ thay đổi hàm Speak nào giống như func (d Dog) Speak() { … } sẽ không hiển thị khi người dùng gọi vì nó tạo thành 1 phương thức khác mất rồi. Vì mọi thứ đều được truyền bởi giá trị, nên rõ ràng tại sao một phương thức của con trỏ *Cat không thể sử dụng được bởi một giá trị Cat. Bất cứ giá trị Cat nào cũng có thể được trỏ bằng nhiều con trỏ *Cat vào. (Cat là giá trị nằm trên vùng nhớ, nên tất nhiên nhiều con trỏ sẽ trỏ vào được). Nếu ta cố tình sử dụng method của *Cat bằng 1 giá trị Cat, thì không tồn tại con trỏ để truy cập vào method đó. Ngược lại nếu chúng ta sử dụng 1 method trên Cat bằng 1 con trỏ *Cat, thì chúng ta luôn biết chính xác giá trị Cat luôn có method này, bởi vì con trỏ *Cat luôn trỏ chính xác vào giá trị Cat. Điều đó giải thích tại sao với con trỏ *Cat là d và method Speak thì ta luôn gọi được d.Speak(), không giống như cách gọi của C++ là d->Speak() mà ta thường thấy.
Thế giới thực: Lấy giá trị timestamp từ twitter API
Các API Twitter trả về thời gian như sau:
“Thu May 31 00:00:01 +0000 2012″
Giá trị này có thể hiện thị bất cứ đâu theo chuẩn JSON, ví dụ:
"created_at": "Thu May 31 00:00:01 +0000 2012"
Chúng ta có chương trình để lấy giá trị của nó như sau:
package main
import (
"encoding/json"
"fmt"
"reflect"
)
// start with a string representation of our JSON data
var input = `
{
"created_at": "Thu May 31 00:00:01 +0000 2012"
}
`
func main() {
// our target will be of type map[string]interface{}, which is a
// pretty generic type that will give us a hashtable whose keys
// are strings, and whose values are of type interface{}
var val map[string]interface{}
if err := json.Unmarshal([]byte(input), &val); err != nil {
panic(err)
}
fmt.Println(val)
for k, v := range val {
fmt.Println(k, reflect.TypeOf(v))
}
}
Chạy chương trình tại https://go.dev/play/p/VJAyqO3hTF
Chạy chương trình và chúng ta thu được kết quả:
map[created_at:Thu May 31 00:00:01 +0000 2012]
created_at string
Chúng ta có thể thấy đã lấy được key của timestamp và giá trị của nó. Tuy nhiên kết quả ở sau thì không thực sự hữu dụng lắm. Bây giờ hãy thử dùng time.Time để chuyển đổi nó:
var val map[string]time.Time
if err := json.Unmarshal([]byte(input), &val); err != nil {
panic(err)
}
Khi chạy chúng ta được lỗi sau:
parsing time ""Thu May 31 00:00:01 +0000 2012"" as ""2006-01-02T15:04:05Z07:00"": cannot parse "Thu May 31 00:00:01 +0000 2012"" as "2006"
thông báo lỗi hơi khó hiểu đó xuất phát từ cách Go xử lý việc convert bằng time.Time values sang string. Tóm lại, ý nghĩa của việc biểu diễn chuỗi mà chúng tôi đưa ra không khớp với định dạng thời gian tiêu chuẩn (vì API của Twitter ban đầu được viết bằng Ruby và định dạng mặc định cho Ruby không giống với định dạng mặc định cho Go). Chúng tôi sẽ cần xác định loại của riêng mình để loại bỏ giá trị này một cách chính xác. Gói encoding/json sẽ xem liệu các giá trị được truyền đến json.Unmarshal có đáp ứng giao diện json.Unmarshaler hay không, trông giống như sau:
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
Bạn có thể xem thêm tài liệu ở đây: https://pkg.go.dev/encoding/json#Unmarshaler
Do vậy những gì chúng ta cần là time.Time với phương thức UnmarshalJSON([]byte) error:
Bằng cách triển khai phương pháp này, chúng ta đáp ứng interface json.Unmarshaler, khiến json.Unmarshal gọi thông báo lỗi khi nhìn thấy giá trị Timestamp. Đối với trường hợp này chúng ta cần gọi method thông qua con trỏ, bởi vì chúng ta muốn nhìn thấy những thay đổi của giá trị nhận. Để cài đặt thủ công con trỏ chúng ta dùng toán tử *. Bên trong phương thức UnmarshalJSON, t đại diện cho 1 con trỏ kiểu Timestamp. Hãy nhớ rằng mọi thứ được truyền bằng giá trị. Do vậy con trỏ t trong hàm trên không phải là con trỏ đúng ngữ cảnh của nó, mà nó chỉ là 1 bản sao. Nếu bạn định trực tiếp gán t cho một giá trị khác, bạn sẽ chỉ định lại một con trỏ hàm cục bộ; người gọi sẽ không nhìn thấy thay đổi. Tuy nhiên, con trỏ bên trong của phương thức gọi trỏ đến cùng một dữ liệu với con trỏ trong phạm vi gọi của nó; bằng cách tham chiếu đến con trỏ, chúng ta hiển thị thay đổi của mình cho nơi gọi.
Chúng ta có thể dùng phương thức time.Parse, cụ thể là func(layout, value string) (Time, error). Với 2 tham số truyền vào: 1 là format của timestamp truyền vào, 2 là giá trị value cần chuyển đổi. Hàm có thể trả về kiểu time. Time hoặc là lỗi nếu không convert được. Cụ thể hàm viết như sau:
map[created_at:{0 63474019201 0x58dd00}]
created_at main.Timestamp
2012-05-31 00:00:01 +0000 UTC
Vậy chúng ta đã chuyển đổi string thành giá trị time.Time mong muốn.
Thế giới thực: Cách lấy 1 object từ http request
Chúng ta hãy kết thúc bằng cách xem cách chúng ta có thể thiết kế interface để giải quyết một vấn đề lập trình web phổ biến: chúng ta muốn phân tích cú pháp phần body của một request HTTP thành một số dữ liệu object. Lúc đầu, đây không phải là một interface rõ ràng để xác định. Chúng ta có thể cố gắng nói rằng ta sẽ nhận được resource từ một request HTTP như sau:
GetEntity(*http.Request) (interface{}, error)
Bởi vì interface{} có thể nhận bất cứ kiểu dữ liệu cơ bản nào, nên chúng ta có thể parse body và trả về kiểu mà ta mong muốn. Điều này hóa ra là một chiến lược khá tệ, lý do là chúng ta thêm quá nhiều logic vào hàm GetEntity, nó cần modify cho mọi kiểu mới để trả về kiểu interface{}. Thực tế các hàm trả về interface{} có xu hướng khá khó chịu, và như một quy tắc chung, bạn chỉ có thể nhớ rằng thông thường tốt hơn nếu lấy giá trị interface{} làm tham số hơn là trả về giá trị interface{} .
Chúng ta cũng có thể bị cám dỗ để viết một số chức năng kiểu cụ thể như thế này:
GetUser(*http.Request) (User, error)
Điều này cũng trở nên không linh hoạt, bởi vì bây giờ chúng ta có các chức năng khác nhau cho mọi kiểu, nhưng không có cách nào tốt để tổng quát chúng. Thay vào đó, những gì chúng ta thực sự muốn làm là một cái gì đó giống như thế này:
type Entity interface {
UnmarshalHTTP(*http.Request) error
}
func GetEntity(r *http.Request, v Entity) error {
return v.UnmarshalHTTP(r)
}
Trong đó hàm GetEntity nhận một giá trị interface được đảm bảo có phương thức UnmarshalHTTP. Để sử dụng điều này, chúng ta sẽ xác định trên đối tượng User của mình một số phương thức cho phép User mô tả cách nó sẽ tự thoát ra khỏi một request HTTP:
func (u *User) UnmarshalHTTP(r *http.Request) error {
// ...
}
Trong ứng dụng của mình, bạn sẽ khai báo một var thuộc kiểu User, rồi chuyển một con trỏ đến hàm này vào GetEntity:
var u User
if err := GetEntity(req, &u); err != nil {
// ...
}
Điều đó rất giống với cách bạn giải nén dữ liệu JSON. Điều này là nhất quán và an toàn vì câu lệnh var u User sẽ tự động tạo 1 struct User với giá trị rỗng. Go không giống như một số ngôn ngữ khác trong việc khai báo và khởi tạo diễn ra riêng biệt, và rằng bằng cách khai báo một giá trị mà không khởi tạo nó, bạn có thể tạo ra một sai lầm, trong đó bạn có thể truy cập vào một phần dữ liệu rác; khi khai báo giá trị, trong thời gian thực Go sẽ tạo không gian bộ nhớ thích hợp để giữ giá trị đó. Ngay cả khi phương thức UnmarshalHTTP thất bại, thì các trường giá trị rỗng sẽ thay thế giá trị rác.
Điều đó sẽ có vẻ lạ đối với bạn nếu bạn là một lập trình viên Python, vì về cơ bản, nó hoàn toàn khác với những gì chúng ta thường làm trong Python.
Kết thúc
Tôi hy vọng, sau khi đọc bài này, bạn cảm thấy thoải mái hơn khi sử dụng các interface trong Go. Hãy nhớ những điều sau:
Tạo sự trừu tượng bằng cách xem xét chức năng phổ biến giữa các kiểu dữ liệu, thay vì các trường phổ biến giữa các kiểu dữ liệu.
Kiểu interface{} không phải là bất kỳ kiểu dữ liệu nào; nó chính xác là 1 kiểu.
Interface được xác định bởi 2 từ, về cơ bản nó là {kiểu, giá trị}.
Tốt nhất là truyền 1 giá trị interface{} hơn là trả về 1 giá trị interface{}.
Kiểu con trỏ có thể gọi tới các phương thức tới giá trị của kiểu đó, nhưng điều ngược lại thì không thể.
Mọi thứ được truyền vào đều là giá trị, ngay cả đối số nhận vào là 1 phương thức.
Một interface không hoàn toàn là con trỏ, hoặc không phải là con trỏ. Nó chỉ là interface.
nếu bạn cần ghi đè hoàn toàn một giá trị bên trong một interface, hãy sử dụng toán tử * để tham chiếu thủ công một con trỏ.
Ok, tôi nghĩ rằng điều đó tổng hợp mọi thứ về interface mà cá nhân tôi thấy khó hiểu. Chúc bạn viết mã vui vẻ
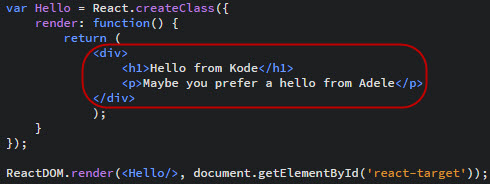
React là gì mà hiện nay đâu đâu các Công ty cũng tuyển vị trí lập trình viên React, bao gồm cả ReactJs và React Native. Lộ trình học thế nào để trở thành 1 lập trình viên React và có thể apply các vị trí với mức đãi ngộ cao hiện nay? Bài viết này sẽ cung cấp cho các bạn có được phần nào câu trả lời cho những câu hỏi trên.
React là gì?
React còn được gọi là ReactJS hoặc React.js, là 1 thư viện JavaScript mã nguồn mở được phát triển bởi đội ngũ kỹ sư đến từ Facebook; nó được giới thiệu vào năm 2011, tuy nhiên đến năm 2013 mới được giới thiệu cho cộng đồng lập trình viên.
Nguyên lý xây dựng của React dựa trên components (component-based approach), có thể tái sử dụng và phù hợp với ứng dụng 1 trang (Single Page Application – SPA). React giúp lập trình viên xây dựng giao diện người dùng dựa trên JSX (môt cú pháp mở rộng của JavaScript), tạo ra các DOM ảo (virtual DOM) để tối ưu việc render 1 trang web.
ReactJs sau khi ra đời đã cho thấy sự phù hợp của nó trong việc phát triển các ứng dụng Web với nhiều chức năng được tích hợp. Nó đã tạo thành 1 xu thế, 1 hình mẫu phát triển website với nhiều chức năng, khả năng tương tác đa dạng với người dùng. Hiện tại sau hơn 10 năm phát triển thì React vẫn đang chiếm vị trí số 1 trong các thư viện Front-end hiện tại.
Để phát triển ứng dụng trên nền tảng di động, đội ngũ React đã cho ra đời framework React Native vào năm 2015; một cross-platform SDK giúp các lập trình viên có thể viết code Javascript, sử dụng thư viện React và phát triển ứng dụng dành cho Android hay iOS. Các nguyên tắc hoạt động của React Native gần như giống hệt với React ngoại trừ việc React Native không thao tác với DOM thông qua DOM ảo. Nó sử dụng một trung gian cầu nối (React Native Bridge) để giao tiếp với các phần tử native của các thiết bị đầu cuối.
Sự phổ biến của ReactJS và React Native hiện nay khiến cho nhu cầu tuyển dụng ngành IT về mảng này rất lớn. Các bạn lập trình viên mới ra trường có thể dễ dàng tìm được công việc tốt ở các công ty (bao gồm cả môi trường outsourcing và product) nếu có trang bị kiến thức về mảng lập trình React.
React hoạt động như thế nào?
Component-Based Architecture
React sử dụng kiến trúc dựa trên component, trong đó giao diện người dùng được chia thành các thành phần nhỏ, độc lập và có thể tái sử dụng. Mỗi component trong React là một lớp hoặc một hàm JavaScript, chứa logic và giao diện riêng biệt. Các component có thể lồng vào nhau để tạo ra cấu trúc UI phức tạp.
Trong React, thay vì thường xuyên sử dụng JavaScript để thiết kế bố cục trang web thì sẽ dùng JSX. JSX được đánh giá là sử dụng đơn giản hơn JavaScript và cho phép trích dẫn HTML cũng như việc sử dụng các cú pháp thẻ HTML để render các subcomponent. JSX tối ưu hóa code khi biên soạn, vì vậy nó chạy nhanh hơn so với code JavaScript tương đương.
Redux
Một thành phần cực kỳ quan trọng, không một react developer nào mà không biết. Vì vậy hãy tìm hiểu ngay Redux là gì?
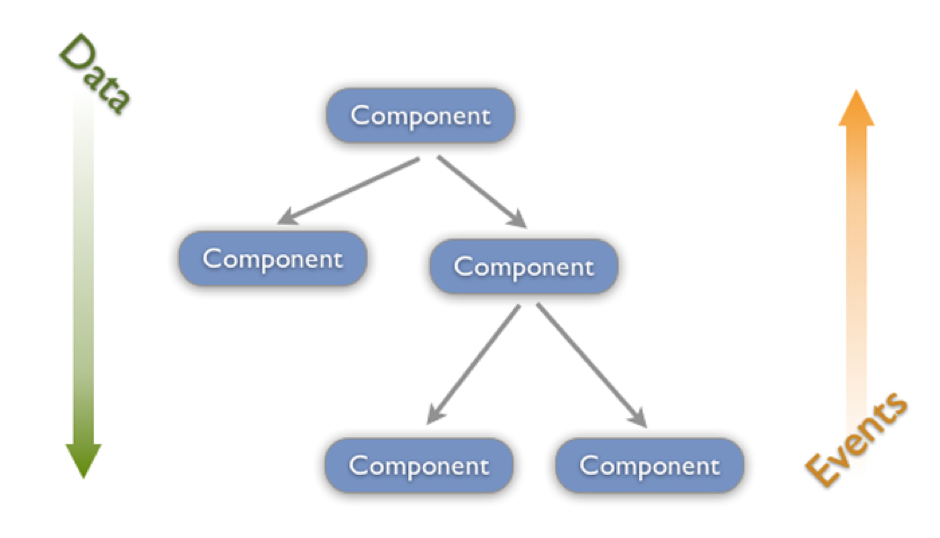
Single-way data flow (Luồng dữ liệu một chiều)
ReactJS không có những module chuyên dụng để xử lý data, vì vậy ReactJS chia nhỏ view thành các component nhỏ có mỗi quan hệ chặt chẽ với nhau. Tại sao chúng ta phải quan tâm tới cấu trúc và mối quan hệ giữa các component trong ReactJS? Câu trả lời chính là luồng truyền dữ liệu trong ReactJS: Luồng dữ liệu một chiều từ cha xuống con. Việc ReactJS sử dụng one-way data flow có thể gây ra một chút khó khăn cho những người muốn tìm hiểu và ứng dụng vào trong các dự án. Tuy nhiên, cơ chế này sẽ phát huy được ưu điểm của mình khi cấu trúc cũng như chức năng của view trở nên phức tạp thì ReactJS sẽ phát huy được vai trò của mình.
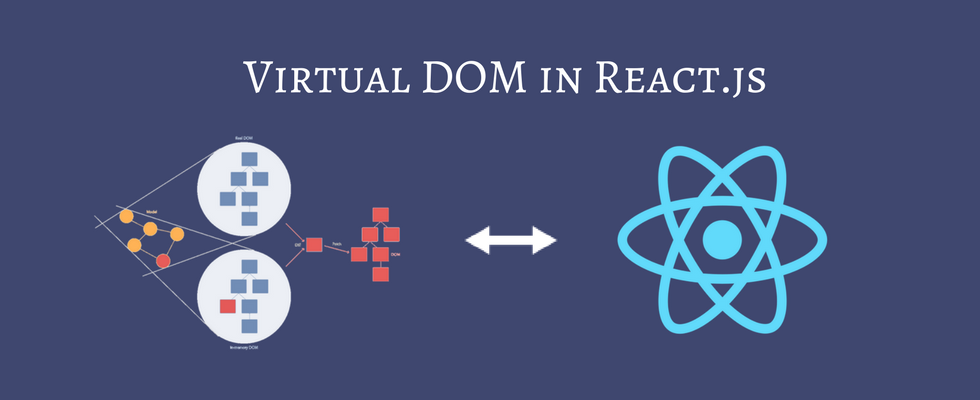
Virtual DOM
Những Framework sử dụng Virtual-DOM như ReactJS khi Virtual-DOM thay đổi, chúng ta không cần thao tác trực tiếp với DOM trên View mà vẫn phản ánh được sự thay đổi đó. Do Virtual-DOM vừa đóng vai trò là Model, vừa đóng vai trò là View nên mọi sự thay đổi trên Model đã kéo theo sự thay đổi trên View và ngược lại. Có nghĩa là mặc dù chúng ta không tác động trực tiếp vào các phần tử DOM ở View nhưng vẫn thực hiện được cơ chế Data-binding. Điều này làm cho tốc độ ứng dụng tăng lên đáng kể – môt lợi thế không thể tuyệt vời hơn khi sử dụng Virtula-DOM.
State và Props
State: State là một đối tượng quản lý dữ liệu động trong component. Khi state thay đổi, React sẽ tự động cập nhật giao diện để phản ánh các thay đổi này. State thường được sử dụng trong các component stateful, nghĩa là các component có trạng thái thay đổi theo thời gian.
Props: Props (viết tắt của properties) là các giá trị được truyền từ component cha xuống component con. Props giúp truyền dữ liệu và các hàm giữa các component và không thể thay đổi trong component con (component stateless).
Các component trong React có các phương thức vòng đời (lifecycle methods) cho phép lập trình viên can thiệp vào các giai đoạn khác nhau của vòng đời component. Một số phương thức vòng đời phổ biến:
componentDidMount: Được gọi sau khi component được render lần đầu tiên. Thường dùng để thực hiện các tác vụ như gọi API.
componentDidUpdate: Được gọi sau khi component được cập nhật (state hoặc props thay đổi).
componentWillUnmount: Được gọi ngay trước khi component bị gỡ bỏ khỏi DOM. Thường dùng để dọn dẹp các tài nguyên như bộ đếm thời gian hoặc kết nối mạng.
Handling Events
React xử lý các sự kiện bằng cách sử dụng cú pháp camelCase và truyền hàm sự kiện trực tiếp trong JSX. Điều này tương tự như cách làm việc với các sự kiện trong DOM, nhưng với React, bạn không cần phải sử dụng addEventListener.
Những ưu điểm tuyệt vời mà ReactJS mang lại cho lập trình viên
ReactJS, một thư viện JavaScript mã nguồn mở do Facebook phát triển, đã trở thành công cụ phát triển ứng dụng web phổ biến nhờ vào những ưu điểm nổi bật mà nó mang lại cho lập trình viên. Dưới đây là một số ưu điểm tuyệt vời của ReactJS:
Dễ học và sử dụng
ReactJS có cú pháp đơn giản và dễ hiểu, đặc biệt là đối với những người đã quen thuộc với JavaScript. JSX, một phần mở rộng của JavaScript, cho phép lập trình viên viết mã HTML trong JavaScript, làm cho quá trình phát triển trở nên trực quan và dễ dàng hơn. Điều này giúp các lập trình viên mới dễ dàng tiếp cận và bắt đầu sử dụng React nhanh chóng.
Hỗ trợ Reusable Component trong Java
ReactJS cho phép xây dựng các thành phần UI nhỏ gọn và độc lập, gọi là component. Các component này có thể được tái sử dụng nhiều lần trong cùng một ứng dụng hoặc trong các dự án khác nhau, giúp tiết kiệm thời gian và công sức phát triển, đồng thời đảm bảo tính nhất quán của giao diện người dùng. Đặc biệt, React có thể tích hợp tốt với các ứng dụng Java, cho phép sử dụng các component React trong các dự án Java hiện có.
Viết component dễ dàng hơn
Cấu trúc component-based của ReactJS giúp việc viết và quản lý các thành phần UI trở nên dễ dàng và hiệu quả hơn. Lập trình viên có thể tách biệt các phần của giao diện người dùng thành các component nhỏ hơn, dễ dàng kiểm thử và bảo trì. Việc viết các component này trở nên đơn giản nhờ JSX, cho phép kết hợp JavaScript và HTML một cách tự nhiên và dễ hiểu.
Hiệu suất tốt hơn với Virtual DOM
ReactJS sử dụng Virtual DOM để tối ưu hóa hiệu suất ứng dụng. Thay vì cập nhật toàn bộ DOM thật mỗi khi có thay đổi, React sẽ cập nhật Virtual DOM trước, sau đó so sánh với DOM thật để chỉ thay đổi những phần cần thiết. Điều này giúp giảm thiểu số lượng thao tác trên DOM thật, từ đó cải thiện tốc độ và hiệu suất của ứng dụng.
Thân thiện với SEO
Một trong những thách thức lớn đối với các ứng dụng JavaScript truyền thống là khả năng thân thiện với SEO. ReactJS giải quyết vấn đề này bằng cách cho phép render trên server (Server-Side Rendering – SSR), giúp các công cụ tìm kiếm dễ dàng lập chỉ mục các trang web. Điều này làm tăng khả năng hiển thị và xếp hạng của trang web trên các công cụ tìm kiếm, từ đó thu hút lượng truy cập lớn hơn.
Dễ dàng bảo trì và mở rộng
Cấu trúc dựa trên component của ReactJS giúp mã nguồn dễ dàng quản lý, bảo trì và mở rộng. Mỗi component có thể được phát triển, kiểm thử và bảo trì độc lập, giúp việc sửa lỗi và thêm tính năng mới trở nên đơn giản hơn. Điều này cũng giúp các nhóm phát triển có thể làm việc song song trên các phần khác nhau của ứng dụng mà không gây ra xung đột.
Hỗ trợ đa nền tảng cả web và mobile
Với React Native, một framework dựa trên React, lập trình viên có thể phát triển các ứng dụng di động cho cả iOS và Android sử dụng cùng một codebase. Điều này giúp tiết kiệm thời gian và nguồn lực, đồng thời đảm bảo tính nhất quán của ứng dụng trên các nền tảng khác nhau.
Phát triển ứng dụng một cách nhanh chóng
Nhờ vào việc tái sử dụng component và các công cụ hỗ trợ mạnh mẽ, lập trình viên có thể phát triển và triển khai các ứng dụng nhanh chóng hơn so với nhiều công nghệ khác. Điều này đặc biệt quan trọng trong môi trường phát triển phần mềm hiện đại, nơi tốc độ ra mắt sản phẩm đóng vai trò then chốt.
Những ưu điểm trên đã giúp ReactJS trở thành một công cụ phát triển mạnh mẽ và phổ biến, được ưa chuộng bởi các lập trình viên và doanh nghiệp trên toàn thế giới. Từ các dự án cá nhân đến các ứng dụng doanh nghiệp lớn, ReactJS mang lại sự linh hoạt, hiệu quả và hiệu suất cao, giúp lập trình viên tạo ra các sản phẩm chất lượng.
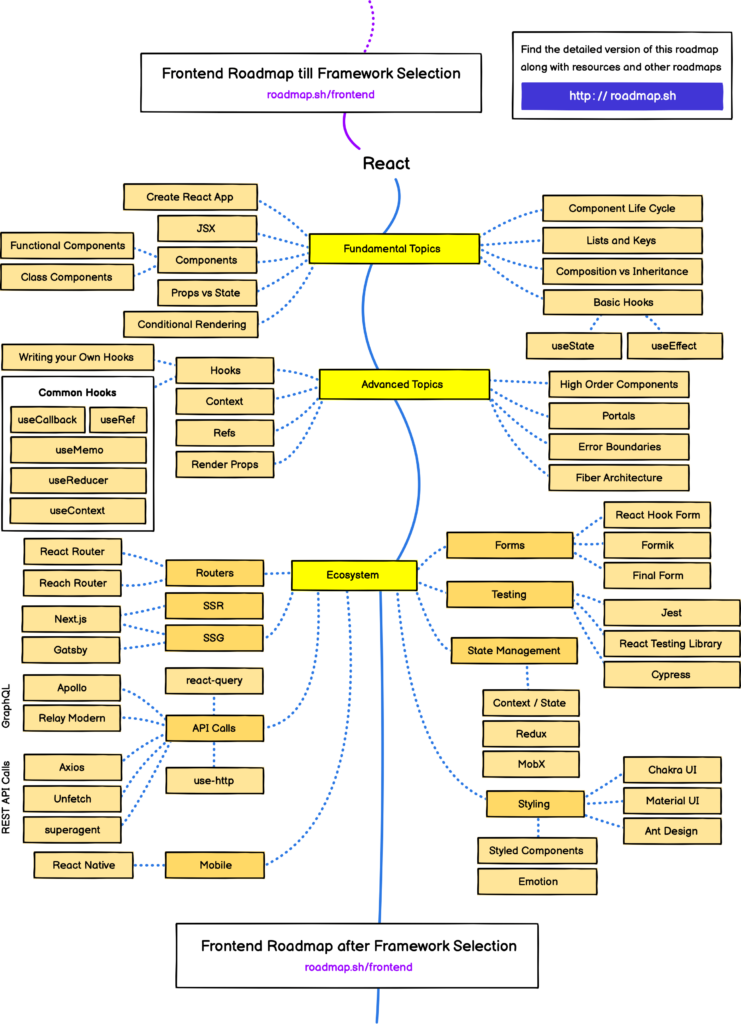
Lộ trình học ReactJs
Trước tiên các bạn cần xác định rằng React là 1 thư viện dành cho Frontend, chính vì thế để có thể học được React, chúng ta cần trang bị các kiến thức liên quan đến Frontend và những công cụ chắc chắn sẽ sử dụng:
HTML, CSS và JavaScript
NodeJS, NPM, ES6
IDE: Visual Studio Code
Sau khi nắm được cơ bản những kiến thức trên, chúng ta có thể bước ngay vào tìm hiểu React và những kiến thức liên quan. Mình sẽ tạm chia thành 3 mức level: Cơ bản, Nâng cao và Chuyên sâu.
Ở level này chúng ta cần tìm hiểu các khái niệm cơ bản nhất liên quan đến React. Các bạn có thể lên trang chủ của React sẽ có đầy đủ tài liệu về phần này:
JSX (JavaScript XML): 1 cú pháp mở rộng của JavaScript được React sử dụng
Components: thành phần, với React thì tất cả được tạo nên từ components. Phân biệt được Functional Components và Class Components
Props và State: thuộc tính và trạng thái của 1 component trong React
Component Life Cycle: vòng đời của 1 component trong React
React Hook: 1 khái niệm được React đưa vào từ phiên bản 16.8 giúp cải thiện việc tái sử dụng chức năng trong React
Level nâng cao
Sau khi nắm vững được các khái niệm ở Level cơ bản trên, chúng ta có thể tiến hành tạo ra các ứng dụng, project của riêng cá nhân mình. Trong quá trình đó, các bài toán thực tế sẽ được giải quyết bằng những kiến thức ở phần nâng cao này:
High Order Components: một kỹ thuật nâng cao trong React giúp tái sử dụng lại các components.
State Managements: Việc quản lý các biến trạng thái là 1 bài toán cơ bản và quan trọng nhất trong 1 ứng dụng React. Có khá nhiều thư viện giải quyết bài toán này: useContext Hook, Redux, MobX
Custom Hook: tự mình tạo ra các hook để giúp tái sử dụng logic trong code React
Refs và DOM: Ref cho phép chúng ta truy cập đến DOM node, giúp chúng ta tham chiếu đến 1 node để sử dụng các thuộc tính và action của chúng.
Level chuyên sâu
Đến bước này, các bạn đã tự tin với những kiến thức bạn đã trang bị rồi. Cùng gây dựng sản phẩm của mình bằng các thư viện chuyên sâu hơn. Chọn 1 bộ styling UI, chọn 1 thư viện quản lý state, chọn 1 framework cụ thể để tuân theo kiến trúc của nó hay tìm cách tích hợp các công cụ kiểm thử, tài liệu hóa, unit test, … để hoàn thiện dự án của mình. Một số gợi ý của bạn như sau:
Framework ReactJS: NextJS, Gatsby, Appollo
Thư viện xử lý API giao tiếp với backend: Axios, Fetch
UI Library: Chakra UI, Material UI, Ant Design
Tạo form submit dữ liệu: React Hook Form, Formik
Testing, Validation: Jest, Cypress
Documentation: Storybook
Hy vọng bài viết này đã mang đến cho các bạn những kiến thức cơ bản nhất giúp trả lời được câu hỏi React là gì và xác định rõ được lộ trình học và trở thành 1 lập trình viên React. Nếu có dự định muốn trở thành 1 lập trình viên React trong tương lai, đừng ngại ngần và hãy bắt đầu ngay từ hôm nay.
Tương lai của ReactJS
Facebook và toàn bộ đội phát triển ReactJS vẫn luôn cố gắng chứng tỏ trong việc cam kết nâng cao tính hiệu quả của ReactJS. Đây là vấn đề tiên quyết để vượt qua sự phát triển nhanh chóng của các framework khác như Vue.js. Một số cập nhật của React được mong đợi trong tương lai có thể kể đến như:
Sẽ có những loại render mới như việc add thêm những đoạn cú pháp độc đáo vào JSX mà không cần đến keys.
Cải thiện trong việc xử lý các lỗi phát sinh. Trước đây, các lỗi Javascript bên trong các Components sẽ làm hỏng state của component và cũng gây ra các lỗi trong quá trình render trong các component cha khác. Các lỗi này được thông báo rất khó hiểu gây ra khó khăn trong việc khắc phục. Một vấn đề khác là trong các phiên bản trước đây thì React không cung cấp cách thức để có thể bắt và xử lý lỗi và phục hồi khi xảy ra lỗi một cách rõ ràng trong Components.
Trên đây chính là những kiến thức cơ bản nhất về ReactJS, nếu như bạn đã có một base khá ổn về ReactJS, vậy bạn có bao giờ nghĩ rằng mình sẽ thay đổi và tối ưu tốc độ của nó cũng như lấn sân sang React Native để trở thành một React Developer???
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Để kiến thức của bài học sẽ không trôi đi mất sau khi đọc xong, bạn hãy mở Visual Code hay bất cứ IDE nào có thể code được Golang ra và thực hành.
Giới thiệu về interfaces
Interfaces là gì? Một interface có 2 điểm: Nó là 1 tập hợp các phương thức (methods), nhưng cũng là 1 kiểu. Trước tiên chúng ta hãy tập hợp vào điểm thứ nhất là tập hợp các methods.
Thông thường, chúng ta sẽ giới thiệu về interfaces thông qua các ví dụ cụ thể, dễ hiểu. Hãy xem xét 1 ví dụ thực tế là giả sử chúng ta cần định nghĩa kiểu dữ liệu Động vật (Animal). Kiểu Animal có 1 interface đó là động vật có thể giao tiếp được bằng tiếng. Gà kêu ò ó o, chó sủa gâu gâu, mèo kêu meo meo.. chẳng hạn như vậy.
Đây là khái niệm cốt lõi trong Golang, thay vì thiết kế các loại giao diện trừu tượng mà data có thể chứa, thì chúng ta thiết kế những hành động mà các kiểu của data có thể thực thi.
Hãy bắt đầu bằng interface của lớp Animal như sau:
type Animal interface {
Speak() string
}
Trông rất đơn giản: động vật có thể “nói” bằng ngôn ngữ của chúng. Phương thức Speak không nhận đối số và trả về 1 kiểu string để viết ra âm thanh mà con vật có thể phát ra(meo meo, gâu gâu…). Bất kỳ kiểu nào định nghĩa phương thức này đều thỏa mãn interface Animal. Không có từ khóa implements trong Go. Việc 1 kiểu có thỏa mãn hay không được xác định tự động. Hãy tạo 1 vài kiểu thỏa mãn giao diện này như sau:
Bây giờ chúng ta có 4 con vật: 1 con chó, 1 mèo, 1 thằng Llama và 1 thằng lập trình viên java(xin lỗi đây chỉ là ví dụ cho vui thôi nha). Trong hàm main chúng ta có thể tạo 1 slices chứa 4 động vật này như sau:
Bạn có thể chạy và xem kết quả tại đây: http://play.golang.org/p/yGTd4MtgD5
Tuyệt vời, bây giờ bạn đã biết cách sử dụng các giao diện và tôi không cần phải nói về chúng nữa, phải không? Không, không hẳn. Hãy xem xét một số điều không quá rõ ràng đối với những con chuột chũi mới chớm :v
Kiểu interface{}
Kiểu interface{} là 1 kiểu interface rỗng, là nguồn gốc của mọi sự nhầm lẫn. Rõ ràng nó không có method nào cả. Vì không có từ khóa nào để triển khai, và do vậy tất cả các kiểu trong Golang đều thỏa mãn nó 1 cách tự động. Điều đó có nghĩa là nếu bạn viết 1 hàm nhận interface{} làm đối số, bạn có thể truyền vào bất kỳ kiểu nào. Cho 1 ví dụ:
func DoSomething(v interface{}) {
// ...
}
Nó sẽ chấp nhận bất kỳ tham số nào.
Ở đây nó tạo ra 1 sự khó hiểu: vậy v ở trong hàm DoSomething là kiểu dữ liệu gì? Những người mới bắt đầu được dẫn dắt để tin rằng v là bất kỳ kiểu nào, nhưng điều đó là sai. v không thuộc kiểu nào, nó thuộc kiểu interface rỗng. Chờ đã, gì cơ? Khi chuyển một giá trị vào hàm DoSomething, thời gian thực Go sẽ thực hiện chuyển đổi kiểu (nếu cần) và chuyển đổi giá trị đó thành giá trị interface{}. Tất cả giá trị đó là chính xác trong thời gian thực, và nó là 1 kiểu tĩnh(static) của interface{}. Điều này sẽ khiến bạn tự hỏi: được rồi, vậy nếu một sự chuyển đổi đang diễn ra, thì điều gì đang thực sự được chuyển vào một hàm nhận giá trị {} interface (hoặc, thứ thực sự được lưu trữ trong [] Animal slice)? Giá trị của 1 interface được tạo thành bởi 2 điều: Một là con trỏ trỏ tới method table định nghĩa tên biến cho loại kiểu; và một là sử dụng để trỏ đến dữ liệu thực tế đang được giữ bởi giá trị biến đó. Nếu bạn muốn tìm hiểu thêm về cách triển khai các giao diện, tôi nghĩ rằng mô tả của Russ Cox về các giao diện là rất, rất hữu ích.
Trong ví dụ trên của chúng ta, khi chúng ta xây dựng một phần giá trị Animal, chúng ta không cần phải nói điều gì đó khó hiểu như Animal (Dog {}) để đặt một giá trị của kiểu Dog vào slices Animals, bởi vì chuyển đổi đã được xử lý tự động. trong slice Animals, mỗi phần tử thuộc kiểu Animal, nhưng chúng có giá trị khác nhau từ các kiểu khác nhau.
Vậy… tại sao điều này lại quan trọng? Chà, việc hiểu cách các interface được biểu diễn trong bộ nhớ làm cho một số điều có thể gây nhầm lẫn trở nên rất rõ ràng. Cho ví dụ, với câu hỏi “Tôi có thể convert kiểu []T thành kiểu []interface{} không?” rất dễ trả lời khi bạn hiểu cách các giao diện được biểu diễn trong bộ nhớ.
Dưới đây là một số mã gây hiểu lầm phổ biến về interface:
package main
import (
"fmt"
)
func PrintAll(vals []interface{}) {
for _, val := range vals {
fmt.Println(val)
}
}
func main() {
names := []string{"stanley", "david", "oscar"}
PrintAll(names)
}
Chạy code tại đây: http://play.golang.org/p/4DuBoi2hJU
Khi chạy bạn sẽ nhận được lỗi sau:
cannot use names (type []string) as type []interface {} in argument to PrintAll
Nếu chúng ta thực sự muốn làm cho nó hoạt động, chúng ta sẽ phải chuyển đổi []string thành []interface{}:
package main
import (
"fmt"
)
func PrintAll(vals []interface{}) {
for _, val := range vals {
fmt.Println(val)
}
}
func main() {
names := []string{"stanley", "david", "oscar"}
vals := make([]interface{}, len(names))
for i, v := range names {
vals[i] = v
}
PrintAll(vals)
}
Chạy code ở đây: http://play.golang.org/p/Dhg1YS6BJS
Điều này khá xấu, nhưng nó chạy ổn. Không phải mọi thứ đều hoàn hảo. (trong thực tế, điều này không xuất hiện thường xuyên, bởi vì []interface{}hóa ra ít hữu ích hơn như bạn mong đợi ban đầu.
Bạn muốn tìm hiểu SQL Server là gì? Vì sao SQL Server lại giúp Developer làm việc dễ dàng hơn? Những phiên bản của SQL Server có cải tiến như thế nào và phù hợp với mục đích gì? Theo dõi bài viết bên dưới nhé.
SQL Server là gì?
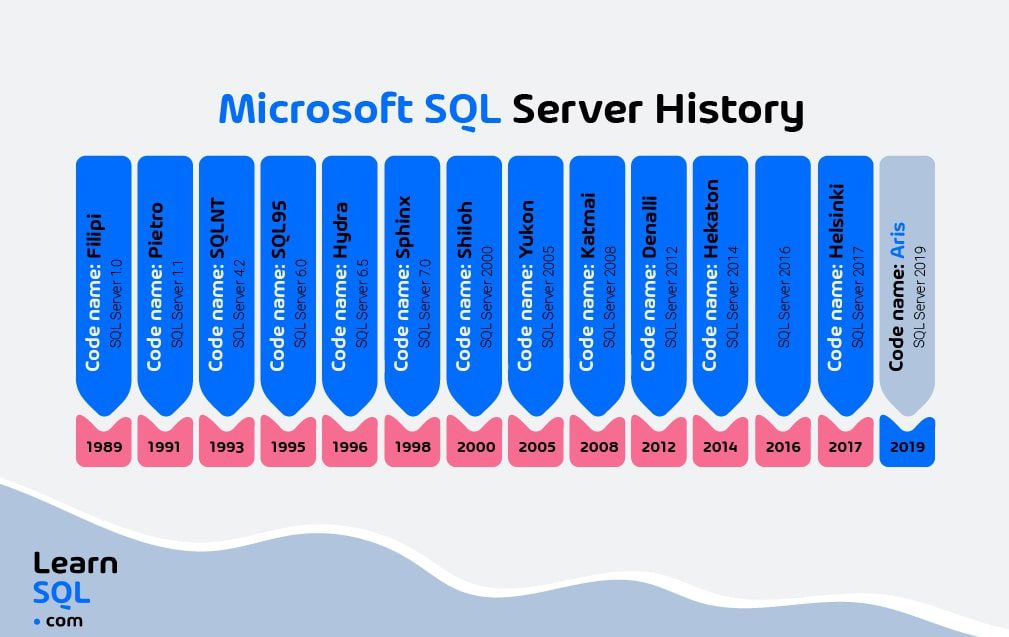
SQL Server là gì? SQL Server hay Microsoft SQL Server là một hệ thống quản trị cơ sở dữ liệu quan hệ (Relational Database Management System – RDBMS) được phát triển bởi Microsoft vào năm 1988. Nó được sử dụng để tạo, duy trì, quản lý và triển khai hệ thống RDBMS.
Được thiết kế để quản lý và lưu trữ dữ liệu, SQL Server cho phép người dùng truy vấn, thao tác và quản lý dữ liệu một cách hiệu quả và an toàn. SQL Server là một trong những hệ quản trị cơ sở dữ liệu phổ biến nhất trên thế giới và được sử dụng rộng rãi trong các doanh nghiệp.
Phần mềm SQL Server được sử dụng khá rộng rãi vì nó được tối ưu để có thể chạy trên môi trường cơ sở dữ liệu rất lớn lên đến Tera – Byte cùng lúc phục vụ cho hàng ngàn user. Bên cạnh đó, ứng dụng này cung cấp đa dạng kiểu lập trình SQL từ ANSI SQL (SQL truyền thống) đến SQL và cả T-SQL (Transaction-SQL) được sử dụng cho cơ sở dữ liệu quan hệ nâng cao.
T-SQL là một ngôn ngữ mở rộng của SQL với các tính năng bổ sung như biến, điều kiện, vòng lặp và xử lý ngoại lệ, giúp người dùng viết các đoạn mã SQL mạnh mẽ và linh hoạt hơn.
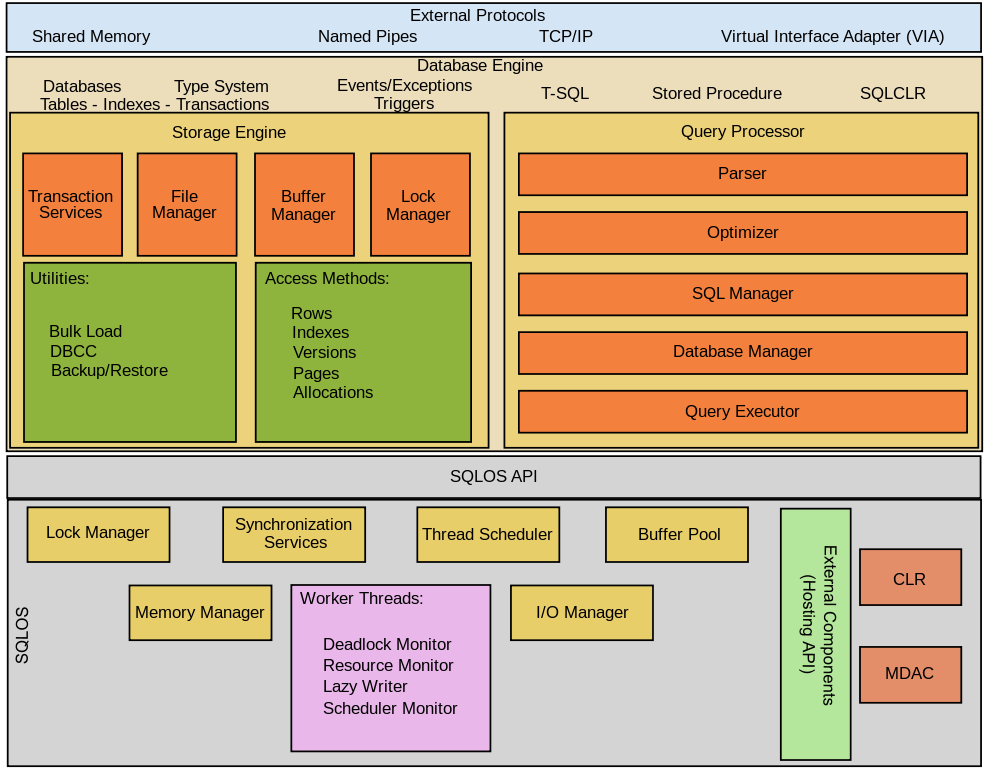
SQL Server là một hệ quản trị cơ sở dữ liệu phức tạp với nhiều thành phần cấu thành giúp nó hoạt động hiệu quả và đáng tin cậy. Trong đó, SQL Server gồm ba thành phần quan là Database Engine, External Protocols và SQLOS.
Database Engine
Database Engine là thành phần chính của MS SQL Server, chịu trách nhiệm quản lý và xử lý dữ liệu. Nó bao gồm các thành phần con quan trọng sau:
Storage Engine
File Storage: Quản lý các tệp dữ liệu và tệp nhật ký giao dịch. Dữ liệu được lưu trữ trong các tệp dữ liệu (.mdf và .ndf), trong khi các giao dịch được ghi lại trong tệp nhật ký giao dịch (.ldf).
Buffer Manager: Quản lý bộ nhớ đệm (buffer pool), lưu trữ các trang dữ liệu được truy cập gần đây để tăng tốc độ truy vấn.
Transaction Log: Ghi lại mọi thay đổi dữ liệu để đảm bảo tính toàn vẹn và khả năng phục hồi của cơ sở dữ liệu.
Query Processor
Parser: Phân tích cú pháp các câu lệnh SQL và chuyển chúng thành các cây cú pháp (syntax tree) để xử lý tiếp theo.
Optimizer: Tối ưu hóa các kế hoạch thực hiện truy vấn để đảm bảo hiệu suất cao nhất. Nó chọn lựa các kế hoạch truy vấn tối ưu dựa trên thống kê và chi phí ước tính.
Executor: Thực hiện các kế hoạch truy vấn đã được tối ưu hóa, xử lý các câu lệnh SQL và trả về kết quả.
Relational Engine
Metadata Manager: Quản lý thông tin về cấu trúc cơ sở dữ liệu như bảng, chỉ mục, ràng buộc và các đối tượng khác.
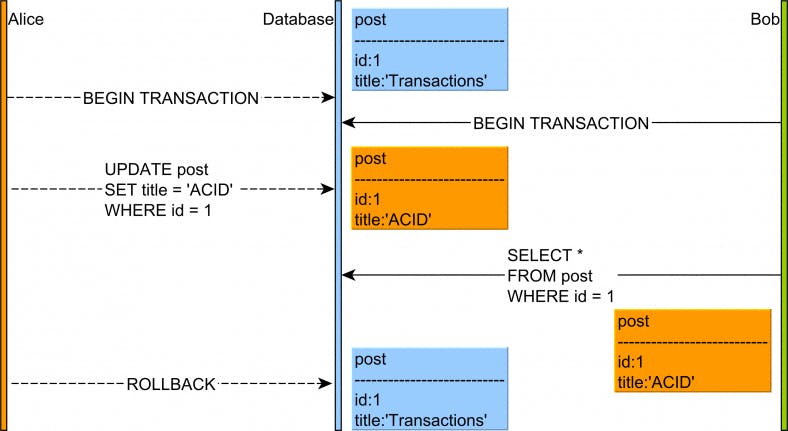
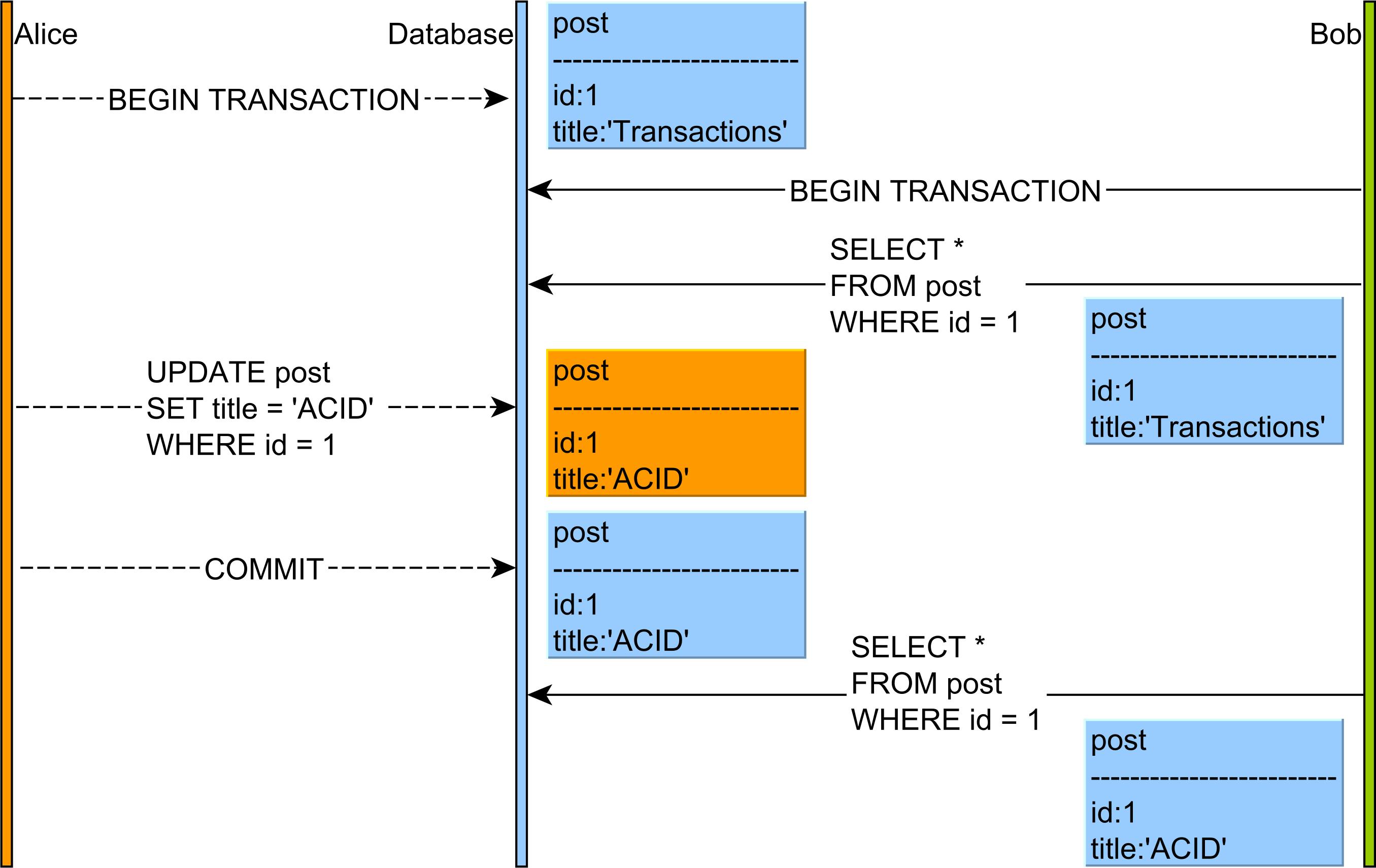
Transaction Manager: Quản lý các giao dịch, đảm bảo tính nhất quán, cách ly và độ bền của các giao dịch thông qua các nguyên tắc ACID.
Concurrency Control: Điều khiển đồng thời, sử dụng các kỹ thuật như khóa (locking) và phiên bản (versioning) để quản lý các truy cập đồng thời đến dữ liệu.
SQLOS (SQL Server Operating System)
SQLOS là lớp trừu tượng phần cứng và hệ điều hành của SQL Server, cung cấp các dịch vụ cơ bản cho Database Engine. SQLOS chịu trách nhiệm quản lý tài nguyên hệ thống như bộ nhớ, CPU và I/O. Dưới đây là các thành phần chính của SQLOS:
Memory Management
Memory Allocation: Quản lý phân bổ và giải phóng bộ nhớ cho các hoạt động của SQL Server.
Buffer Pool: Điều khiển bộ nhớ đệm, lưu trữ các trang dữ liệu được truy cập gần đây để giảm thiểu truy cập đĩa.
Scheduler
Task Management: Quản lý các tác vụ và luồng, đảm bảo rằng các tác vụ được thực hiện hiệu quả và không có tác vụ nào bị bỏ lỡ.
Worker Threads: Quản lý các luồng công việc (worker threads), thực hiện các yêu cầu truy vấn và các hoạt động khác của SQL Server.
I/O Management
I/O Requests: Quản lý các yêu cầu I/O, bao gồm đọc và ghi dữ liệu từ đĩa.
Async I/O: Hỗ trợ I/O không đồng bộ để cải thiện hiệu suất bằng cách cho phép các yêu cầu I/O được xử lý đồng thời.
Synchronization
Lock Manager: Quản lý các khóa để điều khiển truy cập đồng thời đến dữ liệu, đảm bảo tính nhất quán và tránh xung đột.
Latches and Spinlocks: Sử dụng các cơ chế khóa nhẹ hơn như latches và spinlocks để bảo vệ các cấu trúc dữ liệu nội bộ của SQL Server.
External Protocol
External Protocol bao gồm các giao thức và công nghệ cho phép SQL Server tương tác với các hệ thống và ứng dụng bên ngoài. Các giao thức chính bao gồm:
TDS (Tabular Data Stream): Giao thức chính được sử dụng để trao đổi dữ liệu giữa SQL Server và các ứng dụng khách như SQL Server Management Studio (SSMS), ứng dụng web và các ứng dụng tùy chỉnh. TDS xử lý việc truyền dữ liệu truy vấn, kết quả và các thông báo giữa máy chủ và khách.
ODBC (Open Database Connectivity) và OLE DB: Các giao thức tiêu chuẩn cho phép các ứng dụng kết nối và tương tác với SQL Server. ODBC và OLE DB cung cấp các API để thực hiện các truy vấn, cập nhật và thao tác dữ liệu khác.
JDBC (Java Database Connectivity): Giao thức tiêu chuẩn cho phép các ứng dụng Java kết nối và tương tác với SQL Server. JDBC cung cấp các API để thực hiện các truy vấn và thao tác dữ liệu từ các ứng dụng Java.
HTTP/HTTPS: SQL Server hỗ trợ các giao thức HTTP/HTTPS để cung cấp các dịch vụ web, chẳng hạn như SQL Server Reporting Services (SSRS) và SQL Server Integration Services (SSIS). Điều này cho phép SQL Server cung cấp các dịch vụ dữ liệu qua web và tích hợp với các ứng dụng web.
SQL Server dùng để làm gì?
SQL Server là một hệ quản trị cơ sở dữ liệu mạnh mẽ và linh hoạt do Microsoft phát triển, được sử dụng rộng rãi trong nhiều lĩnh vực khác nhau. Các chức năng chính của SQL Server bao gồm tạo và duy trì cơ sở dữ liệu, phân tích dữ liệu và tạo báo cáo. Dưới đây là các ứng dụng cụ thể của SQL Server:
Tạo và duy trì cơ sở dữ liệu
SQL Server được sử dụng để tạo và duy trì các cơ sở dữ liệu quan hệ, cung cấp nền tảng vững chắc cho việc lưu trữ và quản lý dữ liệu. Các chức năng chính bao gồm:
Quản lý dữ liệu: SQL Server cho phép người dùng tạo, sửa đổi và xóa các bảng dữ liệu, chỉ mục, và các mối quan hệ giữa các bảng. Hệ thống quản lý dữ liệu của SQL Server hỗ trợ các thao tác CRUD (Create, Read, Update, Delete), giúp quản lý dữ liệu một cách hiệu quả.
Bảo mật dữ liệu: SQL Server cung cấp các tính năng bảo mật mạnh mẽ như mã hóa dữ liệu, kiểm soát truy cập dựa trên vai trò và xác thực người dùng. Các biện pháp bảo mật này đảm bảo rằng dữ liệu được bảo vệ khỏi các mối đe dọa và truy cập trái phép.
Quản lý giao dịch: SQL Server hỗ trợ các tính năng quản lý giao dịch như Atomicity, Consistency, Isolation và Durability (ACID), đảm bảo rằng các thay đổi trong cơ sở dữ liệu được thực hiện một cách nhất quán và an toàn. Điều này rất quan trọng đối với các ứng dụng yêu cầu độ tin cậy cao như tài chính, ngân hàng và thương mại điện tử.
Sao lưu và phục hồi: SQL Server cung cấp các tính năng sao lưu và phục hồi dữ liệu, cho phép người dùng tạo các bản sao lưu toàn bộ, gia tăng và khác biệt. Các tính năng này giúp bảo vệ dữ liệu khỏi mất mát do lỗi phần cứng, phần mềm hoặc lỗi con người và đảm bảo rằng dữ liệu có thể được phục hồi nhanh chóng trong trường hợp xảy ra sự cố.
Phân tích dữ liệu và tạo báo cáo
SQL Server không chỉ là công cụ quản lý dữ liệu mà còn cung cấp các tính năng phân tích dữ liệu mạnh mẽ và tạo báo cáo chi tiết, giúp các tổ chức ra quyết định dựa trên dữ liệu một cách hiệu quả. Các chức năng chính bao gồm:
Phân tích dữ liệu: SQL Server tích hợp sẵn các công cụ phân tích dữ liệu như SQL Server Analysis Services (SSAS), cho phép người dùng xây dựng các mô hình dữ liệu phức tạp và thực hiện các phân tích sâu. Các công cụ này hỗ trợ việc tạo ra các báo cáo phân tích, biểu đồ và bảng điều khiển (dashboards) giúp người dùng hiểu rõ hơn về dữ liệu và xu hướng.
Tạo báo cáo: SQL Server Reporting Services (SSRS) là một công cụ mạnh mẽ cho phép người dùng tạo, quản lý và triển khai các báo cáo. SSRS hỗ trợ nhiều định dạng báo cáo khác nhau như PDF, Excel và HTML, giúp người dùng dễ dàng chia sẻ và trình bày thông tin. Các báo cáo có thể được tùy chỉnh để đáp ứng nhu cầu cụ thể của doanh nghiệp, từ báo cáo tài chính đến báo cáo hiệu suất kinh doanh.
Khai thác dữ liệu: SQL Server hỗ trợ các tính năng khai thác dữ liệu (data mining) giúp phát hiện các mẫu và xu hướng ẩn trong dữ liệu lớn. Các công cụ khai thác dữ liệu này giúp doanh nghiệp đưa ra các dự đoán và quyết định dựa trên dữ liệu, cải thiện hiệu suất và tăng cường khả năng cạnh tranh.
Tích hợp dữ liệu: SQL Server Integration Services (SSIS) là một công cụ mạnh mẽ cho phép người dùng tích hợp dữ liệu từ nhiều nguồn khác nhau vào một cơ sở dữ liệu duy nhất. SSIS hỗ trợ các hoạt động ETL (Extract, Transform, Load), giúp làm sạch, chuyển đổi và tải dữ liệu từ các hệ thống khác nhau vào SQL Server. Điều này giúp đảm bảo rằng dữ liệu luôn được cập nhật và nhất quán.
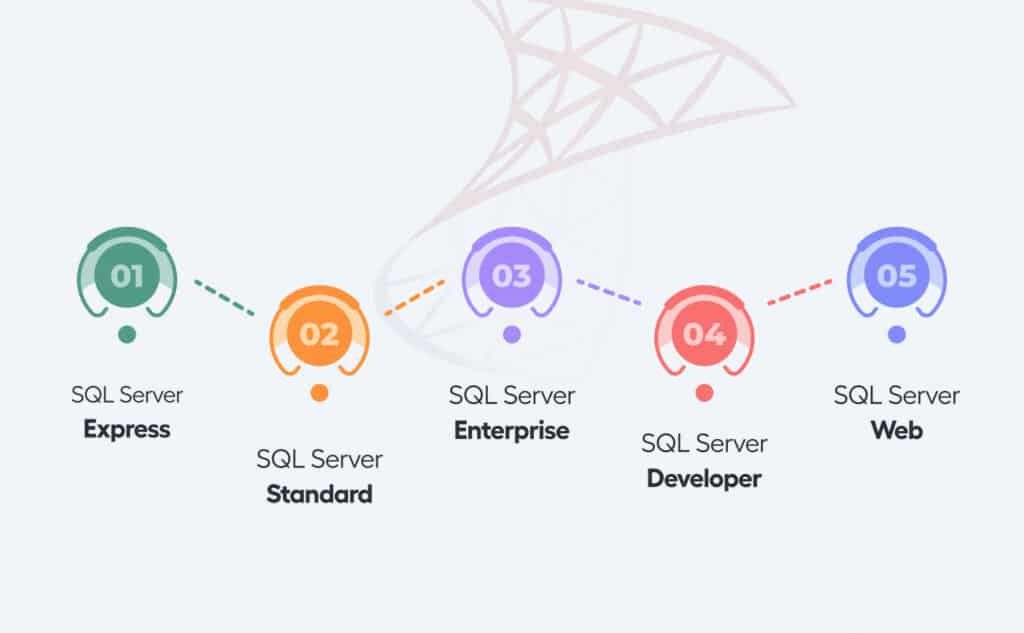
Các ấn bản SQL Server
SQL Server có bốn phiên bản chính với những dịch vụ khác nhau:
Developer: sử dụng cho việc phát triển và thử nghiệm cơ sở dữ liệu.
Expression: dành cho lượng cơ sở dữ liệu nhỏ, dung lượng lưu trữ trên đĩa không quá 10GB.
Enterprise: sử dụng cho những ứng dụng lớn hơn và quan trọng hơn, phiên bản này bao gồm tất cả các tính năng của SQL Server.
Standard: ở ấn bản này chứa một phần tính năng của ấn bản Enterprise và giới hạn về cấu hình số lượng lõi bộ xử lý và bộ nhớ trên máy chủ.
SQL Server giúp bạn làm việc dễ dàng hơn như thế nào?
Xét qua những ưu điểm cũng như thuận lợi của SQL Server và ta có thể hiểu nó giúp cho công việc của Developer dễ dàng hơn như thế nào.
Giao diện SQL Server rất dễ dàng để các Backend Developer tập trung nhiều vào việc chăm sóc dữ liệu hơn là việc nó hoạt động như thế nào.
Tích hợp với giao diện người dùng: SQL Server được tích hợp với ứng dụng giao diện người dùng, thường là các ứng dụng web để cung cấp cơ chế thay đổi dữ liệu động.
Vì là sản phẩm của Microsoft nên việc tích hợp framework .Net sẽ dễ dàng hơn do chúng có cùng một tổ chức.
So với các phương tiện lưu trữ dữ liệu khác như Excel, văn bản,… cơ sở dữ liệu luôn được ưa chuộng hơn chủ yếu do khả năng lưu trữ lớn, tính bảo mật cao và sức mạnh xử lý dữ liệu.
SQL Server 2012 cung cấp thêm những tính năng mới như chỉ mục cột lưu trữ, có thể được sử dụng để lưu trữ dữ liệu theo định dạng cột cho các ứng dụng. Mặt khác, phiên bản này có tính khả dụng cao và được trang bị công nghệ khắc phục sau thảm họa.
SQL Server 2014
SQL Server 2014 đã thêm OLTP trong bộ nhớ, từ đó cho phép người dùng chạy các ứng dụng xử lý giao dịch trực tuyến. Một tính năng mới khác trong SQL 2014 đó là phần mở rộng vùng đệm bằng cách tích hợp bộ nhớ đệm và ổ đĩa – đây là cách thiết kế để tăng thông lượng I/O thông qua việc giảm dữ liệu từ các đĩa cứng thông thường.
SQL Server 2016
Trong bối cảnh chiến lược công nghệ “mobile first, cloud first”, SQL Server 2016 được phát triển như một phần trong chiến lược này với những tính năng mới như: điều chỉnh hiệu suất, phân tích hoạt động thời gian thực, trực quan hóa dữ liệu và báo cáo trên thiết bị di động và sự hỗ trợ của hybrid cloud. SQL Server 2016 còn tăng cường hỗ trợ cho việc phân tích dữ liệu lớn và các ứng dụng phân tích nâng cao.
SQL Server 2017
SQL Server 2017 hỗ trợ chạy trên Linux, điều này làm SQL Server chuyển từ nền tảng cơ sở dữ liệu sang một hệ điều hành mã nguồn mở thường thấy trong các doanh nghiệp. Thêm vào đó, ở phiên bản này còn hỗ trợ ngôn ngữ lập trình Python, một ngôn ngữ mã nguồn mở được sử dụng rộng rãi trong các ứng dụng phân tích.
SQL Server 2019
Ở bản 2019, SQL Server cho phép người dùng kết hợp các vùng chứa SQL Server, HDFS và Spark với nhau bằng cách sử dụng tính năng Big Data Cluster mới. Thêm vào đó, một tính năng mới khác là khả năng phục hồi dữ liệu được tăng tốc nhanh hơn.
SQL Server 2022
Phiên bản cập nhật mới nhất phát hành vào 16 tháng 11 năm 2022. Ở phiên bản này có tích hợp Azure Synapse Link, giúp đồng bộ hóa dữ liệu giữa SQL Server và Azure Synapse Analytics.Ngoài ra, cải tiến tính năng Query Store, Intelligent Query Processing (IQP), và nhiều tính năng tối ưu hiệu suất khác.
Cách tải và cài đặt SQL Server
Dưới đây là hướng dẫn chi tiết về cách tải và cài đặt SQL Server, kèm theo hình ảnh minh họa để bạn dễ dàng thực hiện. Các bước dưới đây sử dụng phiên bản SQL Server 2022 Express, một phiên bản miễn phí phù hợp cho học tập và phát triển.
Bước 1: Tải SQL Server
Truy cập trang tải SQL Server: Truy cập trang web chính thức của Microsoft để tải SQL Server Express: SQL Server Express
Chọn phiên bản SQL Server Express: Tại trang tải xuống, bạn sẽ thấy các tùy chọn tải về. Chọn phiên bản SQL Server 2019 Express và nhấn nút Download now.
Bước 2: Cài đặt SQL Server
Khởi chạy file cài đặt: Sau khi tải về, chạy file cài đặt SQL2022-SSEI-Expr.exe.
Chọn kiểu cài đặt: Trong cửa sổ cài đặt, chọn Basic để thực hiện cài đặt cơ bản.
Chấp nhận điều khoản: Đọc và chấp nhận các điều khoản sử dụng của Microsoft. Nhấn Accept để tiếp tục.
Chọn thư mục cài đặt: Chọn thư mục để cài đặt SQL Server hoặc giữ mặc định. Nhấn Install để bắt đầu quá trình cài đặt.
Chờ quá trình cài đặt hoàn tất: Quá trình cài đặt có thể mất vài phút. Đợi cho đến khi cài đặt hoàn tất.
Hoàn thành cài đặt: Khi cài đặt hoàn tất, bạn sẽ thấy màn hình xác nhận. Nhấn Close để hoàn thành quá trình cài đặt SQL Server.
Bước 3: Cài đặt SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) là công cụ quản lý và phát triển SQL Server. Dưới đây là các bước để cài đặt SSMS:
Truy cập trang tải SSMS: Truy cập trang web chính thức của Microsoft để tải SQL Server Management Studio: Download SSMS
Tải SSMS: Nhấn vào liên kết tải xuống để tải file cài đặt SSMS.
Khởi chạy file cài đặt: Sau khi tải về, chạy file cài đặt SSMS-Setup-ENU.exe.
Chọn thư mục cài đặt: Chọn thư mục để cài đặt SSMS hoặc giữ mặc định. Nhấn Install để bắt đầu quá trình cài đặt.
Chờ quá trình cài đặt hoàn tất: Quá trình cài đặt có thể mất vài phút. Đợi cho đến khi cài đặt hoàn tất.
Hoàn thành cài đặt: Khi cài đặt hoàn tất, bạn sẽ thấy màn hình xác nhận. Nhấn Close để hoàn thành quá trình cài đặt SSMS.
Bước 4: Kết nối với SQL Server bằng SSMS
Khởi chạy SSMS: Mở SQL Server Management Studio từ menu Start hoặc tìm kiếm SSMS.
Kết nối với SQL Server: Trong cửa sổ Connect to Server, nhập thông tin kết nối:
Server type: Chọn Database Engine.
Server name: Nhập tên máy chủ của bạn (ví dụ: localhost cho cài đặt cục bộ).
Authentication: Chọn Windows Authentication hoặc SQL Server Authentication tùy thuộc vào cài đặt của bạn.
Nhấn Connect để kết nối.
Tóm lại, nói một cách ngắn gọn và dễ hiểu thì SQL Server là công cụ được sử dụng để thực hiện cơ chế của một hệ quản trị cơ sở dữ liệu quan hệ. Nó cho phép các Developer làm việc với dữ liệu để cung cấp trải nghiệm tốt cho người dùng. Trong các tổ chức, nó là phương tiện xử lý dữ liệu được ưa dùng vì khả năng xử lý lượng lớn dữ liệu.
Có thể nói SQL Server mang đến những cơ hội phát triển tốt và dự kiến nó sẽ tiếp tục phát triển theo sự gia tăng cấp số nhân của thương mại điện tử và phương tiện truyền thông xã hội.
Đến đây thì chắc hẳn bạn đã hiểu SQL Server là gì cũng như những điểm mạnh mà nó mang lại. Nếu bạn quan tâm đến việc phát triển sự nghiệp về Backend Development thì công nghệ máy chủ SQL Server đáng để bạn tìm hiểu sâu hơn.
Bài viết được sự cho phép của tác giả Edward Thien Hoang
Phần trước mình đã điểm qua 1 số mặt sách dành cho các bạn developer mới vào nghề nhằm khuyến khích niềm đam mê và kỹ năng code sạch từ sớm. Phần này mình sẽ điểm qua các cuốn sách mà các bạn senior và tech lead nên đọc để nâng cao kỹ năng thiết kế và quản lý các team ở quy mô nhỏ.
REFACTORING: IMPROVING THE DESIGN OF EXISTING CODE
Các bạn senior, technical lead nên đọc, để có thể review code của các bạn junior và đưa ra lời khuyên. Làm sao để biến những đoạn code không theo pattern để sử dụng các pattern thích hợp. Khi đó bạn sẽ thấy chất lượng và cấu trúc mã nguồn sẽ trở nên dễ đoán và dễ bảo trì hơn.
Code đẹp ngay từ đầu là một chuyện tốt, tuy nhiên đa số các bạn sẽ được tham gia vào dự án đã và đang chạy. Codebase có thể lên tới hàng chục năm tuổi với hằng hà technical debt. Working Effectively with Legacy Code cung cấp nhiều hướng dẫn để các bạn có thể cải thiện chất lượng của mã nguồn “legacy”.
Working Effectively with Legacy Code: Feathers, Michael
97 THINGS EVERY PROGRAMMER SHOULD KNOW
Tập hợp các lời khuyên hữu ích cho tất cả các bạn lập trình viên.
97 Things Every Programmer Should Know: Collective Wisdom
TALKING WITH TECH LEADS: FROM NOVICES TO PRACTITIONERS
Một cuốn sách không thể không đọc để có thể trở thành 1 tech lead thực thụ. Ngoài công việc coding, các bạn tech lead sẽ bắt đầu được giao nhiệm vụ quản lý một nhóm nhỏ hoặc đưa ra các giải pháp thiết kế, đề xuất về mặt kỹ thuật nhiều hơn.
Talking with Tech Leads: From Novices to Practitioners
DOMAIN-DRIVEN DESIGN: TACKLING COMPLEXITY IN THE HEART OF SOFTWARE
Một cuốn sách để giúp hình thành các suy nghĩ về cách thiết kế các hệ thống phức tạp. Có rất nhiều phương pháp thiết kế “driven” ví dụ như Event Driven, Domain Driven, Data Driven, nhưng mình thích cách tiếp cận từ Domain (nghiệp vụ), phân tách nghiệp vụ thành các sub-module, sub-system sẽ giúp bạn có một cái nhìn tổng thể nhất về các thành phần trong hệ thống mà mình đang xây dựng
Domain-Driven Design: Tackling Complexity in the Heart of Software
SYSTEM DESIGN INTERVIEW – AN INSIDER’S GUIDE
Một bước tạo đà nữa để giúp các bạn làm quen với các thuật ngữ và kỹ thuật thường dùng trong thiết kế hệ thống, đặc biệt là các hệ thống large-scale, distributed với rất nhiều ví dụ từ các hệ thống thực tế (được đơn giản hóa)
System Design Interview – An insider’s guide, Second Edition
Bonus 3: https://github.com/donnemartin/system-design-primer Tác giả của page này cũng đã đưa ra được 1 mô hình kiến trúc điển hình cho các hệ thống mà chúng ta sẽ build.
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Tóm tắt về Go và C ++
Go là một ngôn ngữ có mục đích chung đơn giản, gọn nhẹ và đa năng. C ++ là một ngôn ngữ đa năng, nhanh nhưng phức tạp. Cả Go và C ++ là ngôn ngữ biên dịch và có cộng đồng người dùng mạnh mẽ. C++ được sử dụng trong nhiều loại ứng dụng, trong khi Go được sử dụng nhiều nhất cho các phần mềm backend web.
C++ được sử dụng rộng rãi. Là một ngôn ngữ lập trình hệ thống, nó đóng vai trò là xương sống cho số lượng lớn các chương trình, tác vụ tính toán và các ngôn ngữ lập trình khác. Nó nằm dưới rất nhiều nền tảng và được sử dụng để phát triển mọi thứ từ trò chơi điện tử đến các chương trình điều khiển tàu thăm dò không gian. Nó đã được sử dụng trong một thời gian dài và nó đã trải qua nhiều giai đoạn.
Go (hay Golang) gần như hoàn toàn mới trong lĩnh vực lập trình. Được tạo ra bởi Google, nó được nhắm mục tiêu thay thế C++ làm ngôn ngữ lập trình hệ thống có mục đích chung, và nó được xây dựng đặc biệt để đảm nhận vị trí đó. Vì vậy, cái nào tốt hơn: Kẻ mới yếu hơn hay nhà vô địch gạo cội?
Lập trình Golang
Như các ngôn ngữ lập trình mới ra đời, Golang khá mới. Go được tạo ra bởi Rob Pike, Robert Griesemer và Ken Thompson dành riêng cho Google. Nó là một ngôn ngữ lập trình dạng statically-typed – được biên dịch và có mục đích đa năng, giống như C++. Trình biên dịch cho ngôn ngữ ban đầu được viết bằng C nhưng bây giờ đã có trình biên dịch riêng.
Go cũng như nhiều IDE và thư viện của nó, được phân phối theo giấy phép nguồn mở hấp dẫn. Go được tạo ra cho các bộ vi xử lý đa lõi hiện đại. Nó hỗ trợ lập trình đồng thời; nghĩa là nó có thể chạy nhiều tiến trình cùng lúc bằng các luồng khác nhau thay vì chỉ chạy một tác vụ tại một thời điểm. Nó cũng có tính năng thu thập rác thực hiện quản lý bộ nhớ để ngăn chặn rò rỉ bộ nhớ (memory leak).
Lập trình C++
C++ là một trong những ngôn ngữ lập trình được sử dụng rộng rãi nhất trên thế giới. Đó là ngôn ngữ lập trình hướng đối tượng, bậc trung, được biên dịch, được xây dựng chú trọng đến hiệu suất và hiệu quả. C++ được xây dựng cho mọi thứ. C++ nhanh nhưng khó sử dụng (và nó là anh em họ với C) , tạo thành xương sống của phần lớn thế giới máy tính.
C++ được tạo ra cách đây khá lâu, vào năm 1979, khi một nhà khoa học máy tính người Đan Mạch tên là Bjarne Stroustrup muốn tạo một phần mở rộng cho C để cho phép nó sử dụng các lớp(class). Bây giờ C++ được sử dụng ở khắp mọi nơi. Nó thậm chí còn được sử dụng để viết trình biên dịch và thông dịch cho các ngôn ngữ khác.
So sánh giữa Go và C++
Bây giờ chúng ta đã biết một chút về nguồn gốc của từng ngôn ngữ, hãy cùng nhau đặt chúng vào và xem chúng đứng vững như thế nào trong các danh mục sau:
Go vs C++: Tốc độ và khả năng tương thích
C++ đã được gọi là ngôn ngữ DIY, vì vậy mặc dù nó có thể không đi kèm nhiều tính năng, nhưng bạn có thể xây dựng bất kỳ tính năng nào bạn muốn nếu bạn biết ngôn ngữ này đủ tốt. Cũng cần lưu ý rằng, C++ được coi là ngôn ngữ cấp trung, vì vậy nó không đơn giản và trực quan như ngôn ngữ cấp cao, nhưng nó không thô như ngôn ngữ assembly.
Tuy nhiên, điều đó có nghĩa là viết mã bằng ngôn ngữ cấp cao hơn sẽ đơn giản hơn. Thứ gì đó có thể mất một vài dòng trong một ngôn ngữ như Python có thể mất hàng tá dòng trong C++.
Golang nhỏ gọn hơn. Nó được xây dựng dựa trên sự đơn giản và khả năng mở rộng. Nó loại bỏ các dấu ngoặc và ngoặc đơn không cần thiết, nhằm hạn chế ít lỗi hơn.
Nó cũng là ngôn ngữ biên dịch giống như C++, nghĩa là người lập trình phải khai báo mọi kiểu biến trước khi biên dịch. Tuy nhiên, Go dễ học và viết mã hơn C++ vì nó đơn giản và nhỏ gọn hơn. Nó cũng có một số tính năng tích hợp không cần phải viết cho mọi dự án (như thu gom rác) và những tính năng đó hoạt động tốt.
Một xem xét khác là thời gian biên dịch. C++ có thời gian biên dịch nổi tiếng là chậm. Mặc dù thời gian biên dịch phụ thuộc vào những gì bạn thực sự đang viết mã, nhưng Go nhanh hơn đáng kể so với C++.
Vì mã của bạn cần được biên dịch trước khi chạy và biên dịch lại sau mỗi lần thay đổi code do bạn thực hiện, nên thời gian biên dịch rất quan trọng đối với tốc độ lập trình. Ví dụ khi bạn cần chạy mã lặp đi lặp lại để tìm dấu chấm phẩy bị thiếu trong mã C++ của mình, thời gian biên dịch đó sẽ nhiều lên nhanh chóng.
Cũng cần đề cập đến cấu trúc dữ liệu. C++ thể hiện cấu trúc hướng đối tượng nổi tiếng và quen thuộc, trong khi Go là ngôn ngữ lập trình thủ tục và đồng thời. Không giống như C++, Go không có các lớp (class) với các hàm tạo và hàm hủy.
Go rất nhanh so với các ngôn ngữ lập trình bậc cao khác. Tính năng biên dịch, static types và bộ thu gom rác hiệu quả giúp việc này diễn ra cực kỳ nhanh chóng. Go cũng rất tốt trong việc quản lý bộ nhớ; nó có con trỏ thay thế tham chiếu. Golang có thể tự hào về tốc độ nhanh hơn gần bốn lần so với những ngôn ngữ kiểu động(dynamic type) – các ngôn ngữ thông dịch.
Điều đó nói rằng, Go kém C++ về hiệu năng (và ngôn ngữ C) khi nói đến tốc độ. Tất cả thời gian dành cho viết mã và biên dịch đều được đền đáp ở đây. Vì C++ là một ngôn ngữ khó viết mã, cấp trung, nên nó gần với mã máy hơn: và khi được biên dịch, nó sẽ phù hợp với mã máy và chạy nhanh hơn.
Nó cũng thiếu những tính năng giúp viết mã dễ dàng hơn nhưng đến lúc chạy, C++ nhẹ, gọn và nhanh hơn.
Go được trang bị tất cả các công cụ giúp cuộc sống của bạn dễ dàng hơn trong quá trình viết mã, vì vậy nó chạy chậm hơn. Một trong những phần lớn nhất là công cụ thu gom rác chậm, mặc dù nó tuyệt vời.
Go vs C++: Bảo mật
Một số lỗ hổng bảo mật tồi tệ nhất trong các chương trình ngôn ngữ C liên quan đến việc lợi dụng lỗi tràn bộ đệm. Đây là khi một bộ đệm được tải quá nhiều thông tin và thông tin đó sẽ được ghi vào bộ nhớ liền kề. Điều này có thể tạo ra một sự cố, hoặc như nhiều người đã phát hiện ra, một lỗ hổng để truy cập leo thang đặc quyền.
Go có những hạn chế được tích hợp để giúp ngăn chặn vấn đề này. Ví dụ, Go không cho phép pointer arithmetic – bạn không thể truy cập các mảng bằng cách sử dụng các giá trị con trỏ (bạn phải truy cập các phần tử này thông qua index). Điều này buộc lập trình viên phải sử dụng các phương pháp bao gồm kiểm tra giới hạn, điều này ngăn chặn sự tràn số.
Tuy nhiên, cần lưu ý rằng lỗi tràn bộ đệm không phải là một lỗ hổng cố hữu trong tất cả các chương trình C++. Phương pháp bắt buộc trong Go cũng có thể thực hiện được trong C++, điểm khác biệt duy nhất là C++ cho phép lập trình viên lười biếng tạo ra những lỗ hổng này.
C++ vs Go: Tính ứng dụng
Ứng dụng không giới hạn là một trong những lý do chính khiến C++ vẫn chống lại Go. C++ là một cuốn sách mở. Một lập trình viên và sau đó là một chương trình có thể truy cập vào mọi phần của chính mã nguồn và máy chạy nó.
Nó không có bất kỳ tính năng tích hợp nào để bật hoặc tắt, nó là một phương tiện gọn gàng để tạo các chương trình và hệ thống. Đó là lý do tại sao thậm chí có thể tạo một hệ điều hành bằng C++; bạn có quyền truy cập vào mọi thứ.
Trong khi đó, Go là một hệ thống kín hơn. Việc tiếp cận hoạt động bên trong của Go khó hơn nhiều. Ví dụ: lấy bộ thu gom rác của Go hoạt động rất tốt. Nếu một lập trình viên muốn sửa đổi cách thức hoạt động của bộ thu gom rác đó hoặc liệu bộ thu gom rác đó có ở đó hay không, họ sẽ vô cùng khó khăn khi làm như vậy.
Mặc dù Go là một ngôn ngữ xuất sắc, nhưng nó không được thiết kế để hoạt động ở mức “thấp” như C++ có thể. Do đó, Go không được sử dụng rộng rãi như C++ và hiện tại nơi phổ biến nhất hay dùng Go là backend cho web.
Go vs C++: Cộng đồng
C++ đã xuất hiện được một thời gian khá lâu. Nó có một cộng đồng lớn đằng sau nó và do đó sẽ có câu trả lời cho gần như bất kỳ câu hỏi nào bạn có thể có đối với C++. Nếu bạn cần tích hợp, có thể ai đó đã tạo ra nó, hoặc nhiều khả năng hơn, bất cứ thứ gì bạn đang tích hợp đều đã có các tính năng để tích hợp với mã bạn đang viết.
Tuy nhiên, cũng phải nói thêm. C++ đã cũ; rất nhiều thư viện, mô-đun và hướng dẫn của nó đã lỗi thời. Tùy thuộc vào việc tìm ra một giải pháp không chỉ áp dụng được mà còn phải hiện đại.
Go mới hơn, với trường hợp sử dụng ít hơn và ít người hiểu ngôn ngữ hơn. Cho đến gần đây, tài liệu rất khan hiếm nên nhiều lập trình viên không hề quan tâm đến ngôn ngữ này.
Tuy nhiên, trong khi thư viện của nó nhỏ hơn C++, Go là một ngôn ngữ mới hơn. C++ không có tất cả các bộ công cụ, câ trả lời và phương án tích hợp dành cho nhà phát triển cũ từ năm 1998 vẫn còn lẩn quẩn trên web. Mọi thứ bạn có thể tìm thấy cho Go sẽ mới và gần như cập nhật nhất. Tất cả các mã hiện có cho Go đều hoạt động và được viết để phù hợp với các tiêu chuẩn hiện đại để phát triển.
Cộng đồng Go cũng sống động hơn. Vì đây là một ngôn ngữ mới nên cộng đồng xung quanh vẫn hào hứng khám phá những gì nó có thể làm và tất cả nội dung hiện có mà C++ đã có là những gì hiện do các lập trình viên và nhà phát triển của Go tạo ra. Thật thú vị khi trở thành một phần của ngôn ngữ mới, nơi vẫn còn những góc cần khám phá và các tính năng cần được phát triển.
Nếu việc phát triển một trong hai ngôn ngữ nghe có vẻ thú vị với bạn, đừng ngần ngại chọn ngôn ngữ này hơn ngôn ngữ kia. Mặc dù Go có thể không sớm thay thế C++ nhưng nó vẫn được sử dụng thường xuyên và có nhu cầu cao.
Kết luận
Bạn đã nắm được sự khác nhau, mạnh yếu của 2 loại ngôn ngữ trên chưa? Nếu bạn thực sự thích 1 ngôn ngữ mạnh, nhanh và có thể code mà hạn chế được bug thông qua sự hiểu biết của bạn thân, hãy chọn C++.
Nếu bạn thích 1 ngôn ngữ hiện đại, tuy không nhanh và mạnh như C++ nhưng cũng đang rất mới mẻ, nhiều cơ hội nghề nghiệp thì đừng ngần ngại chọn Golang.
ITCloudsea đang cung cấp 5 dịch vụ công nghệ thông tin tại 4 quốc gia với 32 đối tác. Mục tiêu của chúng tôi là sẽ cung cấp 30 dịch vụ CNTT tại 6 quốc gia với 100 đại lý trong tương lai. Vì vậy, với tư cách là đối tác bán hàng tiềm năng của chúng tôi, bạn có thể mở rộng lĩnh vực kinh doanh, mở rộng thị trường và luôn sẵn có một network vững chắc.
Chúng tôi đang tuyển đại lý toàn quốc với cơ chế và giá cả cực kỳ ưu đãi:
– Lợi nhuận hấp dẫn lên tới 40%.
– Không chi phí ban đầu
– Miễn phí toàn bộ chi phí đào tạo và khởi tạo hệ thống.
– Cung cấp số tay hướng dẫn sử dụng.
– Đội ngũ tư vấn chuyên nghiệp, hỗ trợ miễn phí qua hotline và groupchat.
– Hỗ trợ đa ngôn ngữ: trong trường hợp phần mềm không có phiên bản ngôn ngữ của bạn, bạn có thể hợp tác hỗ trợ dịch sang ngôn ngữ đó trong vòng 1 năm. Đồng thời, bạn sẽ được cung cấp độc quyền dịch vụ trong thời gian khi đang thực hiện dịch thuật.
– Đa dạng loại hình dịch vụ công nghệ thông tin.
– Hỗ trợ thanh toán trả sau, không yêu cầu đặt cọc.
Hiện nay, chuyển đổi số đang là mục tiêu quốc gia trong giai đoạn 2020-2030. Do đó, nhu cầu sử dụng các giải pháp công nghệ trong doanh nghiệp đang dần được tăng mạnh. Nếu bạn đang là:
– Doanh nghiệp cần sản phẩm để mở rộng kinh doanh
– Cá nhân đơn lẻ đang tìm kiếm một cơ hội để Kiếm tiền và sở hữu doanh nghiệp của chính bạn
Hãy liên hệ ngay với chúng tôi qua số hotline: 028.3520.2367 hoặc để lại thông tin tại: https://bit.ly/3NIooCM
Tập đoàn Daoukiwoom Group và thương hiệu ITCloudSea
ITCloudSea là một thương hiệu của công ty Daoukiwoom Innovation, là đơn vị 100% đầu tư từ tập đoàn Daoukiwoom Hàn Quốc. Lĩnh vực hoạt động của chúng tôi gồm có: dịch vụ IT, Tài chính – đầu tư, và R&D – Outsourcing. Hiện, Daoukiwoom Group sở hữu 33 công ty thành viên với 3900 nhân viên.
ITCloudSea tự hào là đơn vị cung cấp các giải pháp quản trị cho doanh nghiệp ở Châu Á. Trong đó Top E-office và Salesmemo là 2 giải pháp đang được mọi người quan tâm.
Top E-ofice là phần mềm văn phòng điện tử, được sử dụng bởi 62% doanh nghiệp Hàn Quốc. Đây là một giải pháp hỗ trợ, giúp doanh nghiệp chuyển đổi số, hướng đến một môi trường làm việc hiện đại và chuyên nghiệp. Nền tảng giúp doanh nghiệp: điều hành từ xa, quản lý công việc dự án, quản lý tài liệu, tăng tương tác nội bộ, tiết kiệm thời gian và chi phí, nâng cao năng lực nhân viên. Nền tảng đang có 200.000+ user tin dùng, đã có mặt ở 6 quốc gia và hỗ trợ 7 loại ngôn ngữ.
Salesmemo là phần mềm quản lý bán hàng với 3 nhóm phân cấp rõ ràng: Giám đốc kinh doanh, trưởng nhóm kinh doanh và nhân viên kinh doanh. Giải pháp này hỗ trợ người bán hàng quản lý việc kinh doanh trở nên đơn giản, hiệu quả và chính xác hơn nhằm tiết kiệm thời gian, chi phí, kiếm soát được khối lượng công việc cho nhân viên và tránh được sai sót trong quá trình bán hàng.
Hiện nay, với mong muốn mang sản phẩm gần hơn tới người tiêu dùng, chúng tôi đang mở chương trình tuyển dụng đại lý với các phần mềm đang cung cấp.
Các bước để bạn trở thành đối tác bán hàng
Tại ITCloudSea, chúng tôi sẵn lòng chào đón các đối tác có cùng mục tiêu kinh doanh. Bởi vậy, quy trình thẩm định đối tác bán hàng là điều cần thiết.
Cụ thể:
Bước 1: Đăng ký trở thành đại lý tại đây
Bước 2: Thẩm định đại lý.
Bước 3: Thiết lập ID/PW.
Bước 4: Lựa chọn phần mềm.
Bước 5. Ký kết hợp đồng.
Sau khi ký kết hợp đồng, bạn đã chính thức trở thành một trong những đại lý tiềm năng của ITCloudSea. Mỗi khách hàng của bạn đều sẽ nhận được sự hỗ trợ nhiệt tình từ đội ngũ CS của chúng tôi. Vì vậy, hãy đăng ký ngay, để cùng hành động và kỳ vọng vào tương lai của thị trường CNTT Châu Á.
Mình đã giới thiệu với các bạn về Project Lombok, về lợi ích của nó trong việc giảm thiểu việc viết code cho những phương thức Getter, hay constructor, … khi khai báo một class. Với immutable class Student ở trên, chúng ta có thể viết lại với Project Lombok như sau:
Từ Java 14 trở đi, chúng ta có thể làm điều này nhanh hơn rất nhiều, đơn giản hơn rất nhiều, không cần sử dụng Project Lombok nữa, bằng cách sử dụng từ khoá record khi khai báo class. Giờ thì chúng ta chỉ cần 1 dòng code để implement immutable class Student ở trên, như sau:
Java compiler sẽ generate các private, final fields, public constructor với đầy đủ các fields (constructor này còn được gọi là canonical constructor), các phương thức Getter cho những field này, phương thức equals(), phương thức hashCode() và phương thức toString() khi chúng ta sử dụng record để khai báo một class. Đối tượng của những class này sẽ là các đối tượng immutable các bạn nhé!
Giờ thì các bạn có thể khởi tạo và lấy thông tin của một đối tượng Student như sau:
Chúng ta không thể extend class Student này:
bởi vì class Student này là final class.
Các bạn có thể khai báo thêm các constructor khác cho class Student này theo nhu cầu của mình, ví dụ như default constructor hay constructor có 1 tham số, như sau:
Mở văn phòng đại diện tại Việt Nam từ 2019, EPAM đã tăng trưởng gấp 5 lần trong 3 năm và đứng thứ hai trong top 10 công ty có nơi làm việc tốt nhất năm 2022, theo Great Place to Work.
Những năm qua, Việt Nam đã phát triển nhanh chóng để trở thành IT hub trong khu vực, thu hút nhiều nhà cung cấp dịch vụ phát triển phần mềm trên khắp thế giới. Trong môi trường cạnh tranh cao này, những công ty đặt quyền lợi của nhân viên lên hàng đầu thu hút dụng được nhiều nhân tài và xây dựng thành công mối quan hệ lâu dài với nhân viên.
Có thể nhắc tới EPAM Việt Nam- công ty chuyên cung cấp dịch vụ chuyển đổi số và phát triển sản phẩm – như một ví dụ.
Nhân viên EPAM tại Việt Nam được mô tả bằng 3 từ: “Nhiệt huyết”, “cởi mở” và “luôn trong trạng thái sẵn sàng”. Đặc trưng của văn hóa doanh nghiệp là tính cộng đồng và tinh thần đoàn kết – điều đã được minh chứng trong thời gian chịu nhiều hạn chế, thách thức bởi đại dịch Covid-19. Ngay cả khi công ty đưa ra phương thức làm việc kết hợp (hybrid working), nhiều nhân viên vẫn sắp xếp đến văn phòng vài ngày nhất định trong tuần để gặp gỡ đồng nghiệp.
EPAM Việt Nam đặt tham vọng tạo ra hơn 3000 việc làm trong 5 năm tiếp theo và trở thành trung tâm phát triển phần mềm lớn nhất nước. Hiện nay, các nhóm kỹ sư Java, Manual/Automated QA, Frontend/Backend Javascript, Cloud và Devops, phân tích kinh doanh (Business Analyst) cũng như quản lý dự án (Project Manager) đang cùng làm việc tại nhiều dự án cho khách hàng trong và ngoài nước trên các lĩnh vực dịch vụ tài chính, bán lẻ, sản xuất và tự động hóa,…
EPAM cũng đã bắt đầu lên kế hoạch bằng cách hợp tác với các trường đại học, các cộng đồng công nghệ, tăng cường độ nhận diện thương hiệu cũng như xây dựng đội ngũ quản lý và kỹ sư cấp cao. Dù văn phòng chính đặt tại thành phố Hồ Chí Minh, EPAM vẫn không ngừng tuyển dụng nhiều vị trí việc làm từ xa và xây dựng đội ngũ nhân viên trên khắp cả nước. Trong năm nay, công ty dự kiến nâng cao sự hiện diện tại Việt Nam với văn phòng thứ hai ở Hà Nội.
EPAM Vietnam được thành lập vào năm 2019 với sự sáp nhập của một công ty khởi nghiệp và đã đạt mục tiêu tăng trưởng từ 40 lên 200 người vào năm 2022. Sự tăng trưởng mạnh mẽ khiến quy trình hoạt động bắt buộc phải diễn ra nhanh chóng hơn. Như khi được làm việc với các khách hàng quốc tế, họ thường yêu cầu đội ngũ quản trị phải thiết lập các quy trình phát triển vững chắc, triển khai các phương pháp tự động hóa và học hỏi việc đối phó với sự tăng trưởng của các dự án. Để đạt được điều này, đội ngũ nhân viên EPAM Việt Nam được khuyến khích đảm nhận những nhiệm vụ đầy thử thách và học hỏi từ cả những thất bại. Tất cả những điều này đều không thực hiện nếu không có sự hỗ trợ của hơn 61,000 đồng nghiệp từ hơn 45 quốc gia. Tại EPAM, mọi cá nhân đều hành động như công dân quốc tế và suy nghĩ xa hơn, vượt ra ngoài khuôn khổ địa phương.
EPAM Việt Nam là sự kết hợp của tính linh hoạt, khả năng ra quyết định nhanh chóng của một công ty khởi nghiệp với sự ổn định cùng các quy trình hoàn chỉnh. EPAM Việt Nam luôn xem mỗi một thử thách là một cơ hội, họ còn phát triển các cộng đồng mà ở đó, nhân viên có thể trau dồi kiến thức và rèn luyện kỹ năng một cách vui vẻ và hào hứng. Trong đó có thể kể đến “Cộng đồng nhà lãnh đạo tài năng – Emerging Leaders Community” được hình thành nhằm xây dựng môi trường cạnh tranh lành mạnh cho nhân viên, thử thách khả năng lãnh đạo với những ý tưởng sáng tạo đổi mới và thực hiện chúng. Đồng thời, nếu quan tâm đến các vấn đề kỹ thuật đều có thể tham gia Cộng đồng kỹ sư Việt Nam –Vietnam Engineering Community nơi thúc đẩy việc chia sẻ kiến thức thông qua các sự kiện chia sẻ chuyên sâu nội bộ và bên ngoài.
EPAM Việt Nam không chỉ cung cấp nhiều cơ hội đào tạo và phát triển, định hướng nghề nghiệp rõ ràng cùng mức lương thưởng cao mà còn hơn thế nữa. NNhằm tạo môi trường làm việc lành mạnh, bên cạnh công việc hàng ngày, công ty đã tổ chức nhiều chương trình trải nghiệm thú vị cho nhân viên. Nhân viên có thể tham gia các chương trình hội thảo, thể thao hoặc sự kiện trách nhiệm xã hội doanh nghiệp – CSR như trồng cây, dọn rác bãi biển hay từ thiện. Một trong những sáng kiến lớn nhất của công ty là tham gia nâng cao trình độ chuyên môn trên thị trường lao động thông qua chương trình “Học viện đào tạo kỹ sư tài năng – Emerging Engineers Academy”. Từ 2021, EPAMers đã tuyển dụng nhiều sinh viên mới ra trường cho các chương trình đào tạo này.
Bên cạnh tinh thần tập thể, EPAM vẫn luôn tôn trọng thành tựu của từng cá nhân và đã có nhiều sáng kiến để khiến nhân viên cảm thấy được ghi nhận và trân trọng. Ví dụ, chương trình công nhận hàng quý khuyến khích nhân viên nhận biết những thành tích của đồng nghiệp bằng cách trao đổi các “huy hiệu anh hùng” (heroes badges). Trong đợt chịu ảnh hưởng nặng nề của COVID, EPAM đã gửi tặng tới từng nhân viên các gói chăm sóc sức khỏe và tinh thần đồng thời bổ sung thêm thuốc vào phạm vi bảo hiểm của công ty. Hơn thês nữa, ttrong thời gian xảy ra xung đột giữa Nga và U-crai-na, công ty đã dành nhiều sự quan tâm tới các cá nhân tham gia Chương trình chuyển vùng– Relocation Program tới Việt Nam.
Tham khảo ngaytrang việc làm của họ để tìm hiểu các cơ hội việc làm hấp dẫn.
Bài viết được sự cho phép của tác giả Trần Văn Dem
Transaction
Transaction là một khái niệm rất quen thuộc với các lập trình viên backend. Nhưng trong thực tế làm việc không ít các lập trình viên backend chỉ biết transaction dùng để thực hiện một chuỗi câu lệnh insert,update,… với sql. Database thực sự thay đổi khi tất cả các lệnh trên đều thực hiện thành công ngược lại thì sẽ không có bất cứ thay đổi nào trên database. Các loại SQL còn cung cấp cho chúng ta các loại Isolation để tùy chỉnh Transaction theo ý muốn của mình.
Khi thực hiện 1 Transaction các cơ sở dữ liệu quan hệ (SQL) cung cấp cho chúng ta rất 4 loại Isolation khác nhau với nhiều mục đích sử dụng khác nhau. Loại Isolation càng cao thì sẽ có mức độ toàn vẹn dữ liệu càng cao nhưng ngược lại sẽ có hiệu năng thấp hơn với các loại khác.
TRANSACTION_READ_UNCOMMITTED mức độ 1
TRANSACTION_READ_COMMITTED mức độ 2
TRANSACTION_REPEATABLE_READ mức độ 3
TRANSACTION_SERIALIZABLE mức độ 4
Trong bài này tôi sẽ trình bày về các loại Isolation cũng như các Anomaly về dữ liệu khi thực hiện đồng thời Transaction.
Phân biệt các loại Anomaly
Dirty Reads
Dirty Read là việc ransaction (T1) đọc được dữ liệu đang được thay đổi từ một transaction (T2) khác mặc dù transaction chưa được commit nghĩa là T2 đó có thể bị rollback và dữ liệu được đọc từ và dùng ở T1 đã bị sai.
Ví dụ :
Transaction T1 begins.
UPDATE post SET title = 'ACID'WHEREid = '1'Transaction T2 begins.
SELECT * FROM post whereid = '1'
T2 sẽ nhìn thấy title = ‘ACID’ cái được update từ T1 mặc dù T1 chưa commit.
Nonrepeatable Reads
Nonrepeatable Reads xảy ra khi trong cùng một transaction (T2) query trả lại các quả khác nhau.
Nonrepeatable Reads xảy ra khi một transaction(T1) đã sửa đổi dữ liệu cái mà được đọc từ transaction (T2)
Ví dụ :
Transaction T2 begins.
SELECT * FROM post
WHEREid = '1'Transaction T1 begins.
UPDATE post SET title = 'ACID'WHEREid = '1'
Transaction T1 thay đổi giá trị cảu title thành ACID cái mà đang được transaction T2 đọc ra nếu transaction T2 tiếp tục đọc lại giá trị này thì sẽ được kết quả khác với kết quả lần đầu tiên đọc ra.
##Phantom Reads Phantom Reads xảy ra khi một transaction (T1) đọc ra một tập kết quả dữ liệu sau thỏa mãn điều kiện where của mình sau đó một transaction (T2) thực hiện thêm dữ liệu vào table. Transaction T1 chưa commit và thực hiện lại query 1 lần nữa thì được tập kết quả khác với tập đầu tiên đọc ra (nhiều bản ghi hơn).
Ví dụ
Transaction T1 beginselect * from post_comment where post_id =1;
Transaction T2 begininsertinto post_comment (id,post_id) Values(4,1)
Nếu Transaction T1 thực hiện lại câu query select * from post_comment where post_id =1; sẽ thu được số lượng kết quả lớn hơn so với ban đầu.
Cách sử dụng isolation
Bên trên là các Anomaly có thể xảy ra trong trường hợp có 2 hay nhiều transaction chạy song song. Để tránh xảy ra các loại Anomaly này thì người dùng cần phải chọn các loại Isolation cho phù hợp.
Tại ví dụ trên ta tạo 2 transaction chạy đồng thời. Transaction T1 chạy trước và sửa đổi giá trị amount, Sau đó chúng ta chạy Transaction T2. Nếu để mode trên sẽ thu được TRANSACTION_READ_UNCOMMITTED kết quả sau.
Transaction1 get amount = 13004200
Transaction2 get amount = 13004100
Mặc dù T1 đã rollback nhưng T2 vẫn đọc ra kết quả được T1 thay đổi. Điều này chứng tỏ TRANSACTION_READ_UNCOMMITTED không thể chống được Dirty Read.
TRANSACTION_READ_COMMITTED
Vẫn xét ví dụ trên nhưng ta sẽ thay đổi IsolateLevel của Transaction T2 thành conn.setTransactionIsolation(Connection.TRANSACTION_READ_UNCOMMITTED);
Kết quả ta thu được là :
Transaction1 get amount = 13004200
Transaction2 get amount = 13004200
Theo kết quả ta thấy được TRANSACTION_READ_COMMITTED chống được Dirty Read.
Ta sửa đổi class trên 1 chút thành dạng sau đây.
package tutorial.transaction;
import java.sql.*;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
importstatic tutorial.transaction.Test.*;
importstatic tutorial.transaction.Test.PASS;
publicclassIsolationLevelTest{
publicstaticvoidmain(String[] args){
CountDownLatch countDownLatch = new CountDownLatch(1);
ExecutorService service = Executors.newFixedThreadPool(2);
service.submit(() -> {
try {
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
conn.setAutoCommit(false);
conn.setTransactionIsolation(Connection.TRANSACTION_READ_UNCOMMITTED);
try {
int number = 100;
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery("select * from dev.`users` where id = 1");
resultSet.next();
int amount1 = resultSet.getInt("amount");
System.out.println("Transaction1 get ammount = " + amount1 );
String update1 = "UPDATE `dev`.`users` SET `amount` = " + (amount1 - number) + " WHERE (`id` = '1');";
statement.executeUpdate(update1);
countDownLatch.countDown();
conn.commit();
} catch (Exception e) {
conn.rollback();
System.out.println("1 rollback");
e.printStackTrace();
}
conn.close();
} catch (Exception throwables) {
throwables.printStackTrace();
}
});
service.submit(() -> {
try {
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
conn.setAutoCommit(false);
try {
Statement statement = conn.createStatement();
countDownLatch.await();
ResultSet resultSet = statement.executeQuery("select * from dev.`users` where id =1");
resultSet.next();
int amount2 = resultSet.getInt("amount");
System.out.println("Transaction2 get amount = " + amount2);
Thread.sleep(1000);
resultSet = statement.executeQuery("select * from dev.`users` where id =1");
resultSet.next();
amount2 = resultSet.getInt("amount");
System.out.println("Transaction2 re read get amount = " + amount2);
conn.commit();
} catch (Exception e) {
conn.rollback();
System.out.println("2 rollback");
e.printStackTrace();
}
conn.close();
} catch (Exception throwables) {
throwables.printStackTrace();
}
});
service.shutdown();
}
}
Tại đây ta thay đổi Transaction T2 đọc lại dữ liệu thêm 1 lần nữa. Nhưng lần này Transaction T1 đã commit thay đổi kết quả của mình. Kết quả sẽ là
Transaction1 get ammount = 13003900
Transaction2 get amount = 13003900
Transaction2 re readget amount = 13003800
Điều này thấy được TRANSACTION_READ_COMMITTED không chống lại được Nonrepeatable Reads
TRANSACTION_REPEATABLE_READ
Tiếp tục với ví dụ trên ta thay đổi IsolateLevel của Transaction T2 thành conn.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);
Kết quả sẽ thay đổi thành.
Transaction1 get ammount = 13003800
Transaction2 get amount = 13003800
Transaction2 re readget amount = 13003800
Đây là mode IsolateLevel mặc định của Jdbc với Mysql nhưng sẽ đưa lại hiệu năng kém hơn 2 mẫu còn lại.
Hiện tại bảng dùng để test đang dùng innodb của Mysql. Chúng ta cùng test xem liệu rằng TRANSACTION_REPEATABLE_READ có chống được lại Phantom Reads được hay không. Cùng xét ví dụ sau
Như vậy ta kết luận được TRANSACTION_REPEATABLE_READ của mysql sẽ chống lại Phantom Reads với innodb.
Chuyển sang dạng MyISAM và test lại code ta được kết quả sau:
first read = 2
second read = 3
Vậy với dạng MyISAM thì mysql sẽ không chống lại được Phantom Reads.
TRANSACTION_SERIALIZABLE
Cũng tương tự như TRANSACTION_READ_COMMITTED thì TRANSACTION_SERIALIZABLE cũng chống lại Phantom Reads với innodb.
Đến đây câu hỏi sẽ là vậy Mysql tạo ra thêm dạng Isolation này để làm gì? Hiệu năng của TRANSACTION_SERIALIZABLE mang lại là tệ nhất trong các loại Isolation.
Ta xét ví dụ chuyển tiền trong ngân hàng :
A -> B (100). A chuyển cho B 100
A -> C (50). B chuyển cho C 50
Ta sẽ xét đoạn code sau của Java
package tutorial.transaction;
import java.sql.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
importstatic tutorial.transaction.Test.*;
importstatic tutorial.transaction.Test.PASS;
publicclassIsolationLevelTest{
publicstaticvoidmain(String[] args){
ExecutorService service = Executors.newFixedThreadPool(2);
service.submit(() -> {
try {
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
conn.setAutoCommit(false);
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
try {
int number = 100;
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery("select * from dev.`users` where id = 1");
resultSet.next();
int amount1 = resultSet.getInt("amount");
String update1 = "UPDATE `dev`.`users` SET `amount` = " + (amount1 - number) + " WHERE (`id` = '1');";
statement.executeUpdate(update1);
resultSet = statement.executeQuery("select * from dev.`users` where id = 2");
resultSet.next();
int amount2 = resultSet.getInt("amount");
String update2 = "UPDATE `dev`.`users` SET `amount` = " + (amount2 + number) + " WHERE (`id` = '2');";
statement.executeUpdate(update2);
conn.commit();
} catch (Exception e) {
conn.rollback();
System.out.println("1 rollback");
e.printStackTrace();
}
conn.close();
} catch (Exception throwables) {
throwables.printStackTrace();
}
});
service.submit(() -> {
try {
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
conn.setAutoCommit(false);
try {
int number = 50;
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery("select * from dev.`users` where id = 1");
resultSet.next();
int amount1 = resultSet.getInt("amount");
String update1 = "UPDATE `dev`.`users` SET `amount` = " + (amount1 - number) + " WHERE (`id` = '1');";
statement.executeUpdate(update1);
resultSet = statement.executeQuery("select * from dev.`users` where id = 3");
resultSet.next();
int amount2 = resultSet.getInt("amount");
String update2 = "UPDATE `dev`.`users` SET `amount` = " + (amount2 + number) + " WHERE (`id` = '3');";
statement.executeUpdate(update2);
conn.commit();
} catch (Exception e) {
conn.rollback();
System.out.println("2 rollback");
e.printStackTrace();
}
conn.close();
} catch (Exception throwables) {
throwables.printStackTrace();
}
});
service.shutdown();
}
}
Khi bạn chạy chương trình không có lỗi gì xảy ra. Bạn sẽ thông báo là đã chuyển đủ tiền từ A sang các tài khoản khác. Nhưng khi check db thì thấy kết quả đang bị sai. Nó chỉ đang ghi nhận cho 1 transaction. Thay vì Tài khoản của A bị giảm đi 150 thì tài khoản của A sẽ chỉ giảm 50 hoặc 100. Điều này dẫn đến lỗi sai nghiêm trọng.
Để giải quyết bài toán cần sự tuần tự trong transaction này chúng ta cần sử dụng mode TRANSACTION_SERIALIZABLE sau khi thay đổi conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE); chúng ta chạy lại code sẽ được kết quả sau:
2 rollback
com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:123)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.StatementImpl.executeUpdateInternal(StatementImpl.java:1340)
at com.mysql.cj.jdbc.StatementImpl.executeLargeUpdate(StatementImpl.java:2089)
at com.mysql.cj.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1251)
at tutorial.transaction.IsolationLevelTest.lambda$main$1(IsolationLevelTest.java:75)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Đến đây thì 1 trong 2 transaction sẽ bị rollback và bắn ra exception. Điều này sẽ giúp bạn chống được lỗi trên.
Kết luận
Đến đây thì mọi người chắc cũng biết cách chọn loại transaction cho riêng mình rồi mình xin có 1 số ý kiến như sau:
Thông thường khi đọc kết quả từ 1 câu select chúng ta sẽ lưu lại nó trên RAM và rất ít khi thực hiện lại câu select tương tự vào SQL nên để đảm bảo performance thì hãy trọn mode TRANSACTION_READ_COMMITTED
Nếu hệ thống bạn cần phải thực hiện transaction tuần tự hóa thì hãy trọn TRANSACTION_SERIALIZABLE mặc dù hiệu năng nó rất tệ nhưng nó mang lại kết quả tốt.
Sử dụng TRANSACTION_SERIALIZABLE sẽ mang lại cho bạn 1 hệ thống Strong consistency nhưng hệ thống của bạn sẽ thật sự có hiệu năng rất tệ nếu có nhiều người sử dụng. Tất nhiên để chuyển tiền thì các bạn có thể sử dụng câu query khác mà không cần sử dụng đến TRANSACTION_SERIALIZABLE vẫn đảm bảo được yêu cầu nghiệp vụ của các bạn ở đây mình chỉ viết query để ví dụ cho loại TRANSACTION_SERIALIZABLE này.
Một kỹ thuật nữa là sử dụng eventual consistency một kỹ thuật tăng được hiệu năng nhưng cũng khá khó implement. Nếu có dịp mình sẽ xây 1 hệ thống chuyển tiền bằng kỹ thuật eventual consistency trên. Mình nghĩ kỹ thuật này đang được dùng tại nhiều hệ thống chuyển tiền để tăng trải nghiệm khách hàng.
Bài viết được sự cho phép của tác giả Edward Thien Hoang
Quay lại khoảng thời gian cách đây 8-10 năm, lúc đó thế giới công nghệ không có nhiều lựa chọn, loanh quanh thì cũng .NET và Java, PHP, … Không như bây giờ với hàng hàng sa số các công nghệ mới, framework, library mới ra đời khiến cho đa số các developer phải đổ xô để bắt kịp xu hướng.
Việc trau dồi kỹ năng của thế hệ developer trước đó cũng khác biệt. Họ có rất ít lưỡi dao trong tay nhưng lưỡi nào cũng sắc bén vô cùng, họ chăm chút từng dòng code, apply design principle, design pattern một cách kỹ lưỡng. Nhìn các developer hiện nay, theo những gì mình quan sát được từ các bạn developer trẻ ngày nay, họ quá ít quan tâm đến chất lượng code mà chỉ quan tâm đến việc đến số lượng công nghệ được apply, họ lại đi theo một xu hướng khác, đó là sắm cho mình những con dao của quân đội Thụy Sĩ, tuy số lượng thì nhiều nhưng thiếu đi độ bén.
Con dao của quân đội Thụy Sĩ
Bạn thích 1 con dao thật bén, hay thích một bó dao?
Nếu bạn muốn theo đuổi nghề lập trình thì hãy xác định việc học là việc cả đời. Và quan trọng hơn cả là tự học.
Dưới đây là danh sách các cuốn sách hay mà mình khuyên các bạn developer nên đọc qua một lần, thứ tự sách được liệt kê sẽ được nâng dần cấp độ theo quá trình phát triển của bản thân.
Hãy bắt đầu với những cuốn sách cho các bạn mới vào nghề.
1. CLEAN CODE
Clean Code của tác giả Bob Martin là cuốn sách kinh điển mà tất cả các developer của mình cần đọc ĐẦU TIÊN để rèn luyện tay nghề, code cần phải sạch và đúng ngay từ thuở ban đầu, developer cần quan tâm đến từng dòng code mình viết ra thì mới tạo ra được niềm vui từ sự hoàn hảo. Nếu trong các năm đầu các bạn không thể viết ra các đoạn code “sạch sẽ” thì khả năng cao điều đó sẽ rất khó chỉnh về sau.
Clean Code: A Handbook of Agile Software Craftsmanship
Các ví dụ trong sách được viết bằng Java, nhưng không khó để các bạn có thể tìm các phiên bản tương tự đâu đó trên Github.
Có 1 điều dễ nhận thấy là ngày càng ít người quan tâm đến design pattern hay nói chính xác hơn là Object Oriented Design Pattern. Nếu bạn làm việc với các ngôn ngữ Object Oriented mà không biết Design Pattern thì hãy trang bị ngay. Hãy đọc cuốn Head First Design Patterns, bắt đầu với Strategy Pattern, bạn sẽ hiểu khi có design pattern, life is easier.
Tips: ngoài design pattern, các bạn cũng nên tìm đọc về các Design Principle ví dụ như SOLID, KISS, YANGI, …
Head First Design Patterns: A Brain-Friendly Guide
Còn với các ngôn ngữ khác? Trước khi bắt đầu học một framework, ngôn ngữ nào mới, mình thường tìm kiếm các design pattern của nó.
Ví dụ https://reactpatterns.com/ tập hợp rất nhiều coding pattern, practice giúp mình xử lý các vấn đề lúc coding một cách chuẩn chỉnh hơn.
3. REFACTORING TO PATTERNS
Lại một cuốn sách hay nữa, Refactoring to Patterns sẽ giúp mình “chỉnh lại tay nghề” bằng cách chuyển những đoạn code không theo pattern vào nề nếp
Những đoạn code xấu thường bốc mùi. Hãy nhận biết mùi của code xấu và tìm cách làm cho nó thơm tho hơn
Các bạn có thể đọc phiên bản online ở đây: https://refactoring.guru/refactoring/smells
Hoặc mua các tài liệu premium để tìm hiểu sâu hơn: https://refactoring.guru/store
5. LẬP TRÌNH VÀ CUỘC SỐNG
“Để lập trình hiệu quả, viết code thôi là chưa đủ. Con người mới là nhân tố quan trọng”. Đây là lời trích từ trang bìa của cuốn sách. Mài dũa ngón tay của bạn, và cũng phải mài dũa cả tâm trí của mình.
Cuốn sách này được anh Hồ Sỹ Hùng tuyển tập và dịch từ trang https://blog.codinghorror.com/
Lập Trình Và Cuộc Sống
Hãy đọc để xem các lập trình viên khác họ nghĩ gì, và tìm kiếm lời khuyên cho chính mình.
Một số cuốn sách hay của tác giả Việt Nam:
Code dạo ký sự
Agile Y
6. CODE COMPLETE VÀ PRAGMATIC PROGRAMMER
Sách sẽ không dạy bạn lập trình, nhưng sẽ truyền đạt cảm hứng và dạy bạn một số kỹ năng mềm trong nghề lập trình. Tương tự như cuốn Lập trình và cuộc sống ở trên
Code Complete: A Practical Handbook of Software Construction
Pragmatic Bookshelf: By Developers, For Developers
Trên đây là những cuốn sách Developer nên đọc và nó giành cho cả những bạn mới bước vào nghề. Ở phần 2 sẽ là những sách dành cho các bạn senior và tech lead.
Bạn đang muốn phát triển trên con đường Backend Developer nhưng chưa thật sự hiểu rõ Backend là gì? Bài viết dưới đây sẽ cung cấp thật chi tiết thông tin về Backend, giúp bạn nắm được bức chân dung của ngành lập trình viên Backend.
Backend là gì?
Backend (còn được viết là Back-end hay Back end) là phần mà người dùng không thể nhìn thấy của một ứng dụng hoặc trang web nhưng đóng vai trò quan trọng trong việc đảm bảo hoạt động của ứng dụng diễn ra mượt mà.
Nói một cách đơn giản, backend là phía “máy chủ” của ứng dụng, chịu trách nhiệm xử lý dữ liệu, quản lý cơ sở dữ liệu, và đảm bảo mọi thứ hoạt động đúng cách để người dùng có thể tương tác với giao diện người dùng (frontend) một cách dễ dàng.
Một hình ảnh minh họa dễ hiểu, nếu frontend là phần nổi thì backend là phần chìm của tảng băng.
Backend là gì?
Các thành phần chính của backend bao gồm máy chủ, cơ sở dữ liệu, và các ứng dụng mà máy chủ sử dụng để giao tiếp với cơ sở dữ liệu và các dịch vụ khác.
Backend Developer là gì?
Backend Developer là người tạo ra những dòng code giúp trình duyệt giao tiếp với cơ sở dữ liệu để lưu trữ, đọc, cập nhật hoặc xóa thông tin từ cơ sở dữ liệu. Trách nhiệm chính của Backend Developer là xây dựng, duy trì và cải thiện phần mã nguồn hoạt động trong nền, đảm bảo rằng dữ liệu được xử lý một cách hiệu quả và chính xác.
Backend quản lý các chức năng chính của ứng dụng. Khi người dùng tương tác với frontend, một yêu cầu HTTP được gửi đến backend.
Dưới đây là cách backend hoạt động:
Nhận Yêu Cầu: Backend nhận yêu cầu từ người dùng thông qua HTTP.
Xác Thực và Xử Lý: Kiểm tra thông tin đăng nhập và quyền truy cập. Sau đó, truy vấn cơ sở dữ liệu để lấy hoặc cập nhật dữ liệu.
Giao Tiếp Với Các Dịch Vụ: Tương tác với các vi dịch vụ và API bên thứ ba nếu cần.
Xử Lý Logic: Thực hiện các phép toán và quy trình theo yêu cầu của ứng dụng.
Tạo Phản Hồi: Tạo phản hồi dựa trên kết quả xử lý và gửi lại cho giao diện người dùng.
Quản Lý Tải: Sử dụng kỹ thuật như phân bổ tải và bộ nhớ đệm để xử lý nhiều yêu cầu đồng thời và tối ưu hóa hiệu suất.
Ví Dụ Đăng Nhập: Khi người dùng đăng nhập, backend xác thực thông tin, truy xuất dữ liệu người dùng, và gửi phản hồi về trạng thái đăng nhập thành công hoặc lỗi.
Backend đảm bảo các yêu cầu từ người dùng được xử lý hiệu quả và chính xác, giúp ứng dụng hoạt động trơn tru.
Lập trình viên Backend đảm nhận nhiều nhiệm vụ quan trọng để đảm bảo hoạt động trơn tru của các ứng dụng và hệ thống phần mềm từ phía máy chủ. Dưới đây là những nhiệm vụ chính của lập trình viên Backend:
1. Thiết kế và Xây dựng Cơ sở Dữ liệu
Lập trình viên Backend chịu trách nhiệm thiết kế và triển khai cấu trúc cơ sở dữ liệu của ứng dụng. Công việc này bao gồm việc tạo ra các bảng dữ liệu, xác định các mối quan hệ giữa các bảng, và viết các truy vấn SQL để thực hiện các thao tác như thêm, sửa, xóa và truy vấn dữ liệu. Một thiết kế cơ sở dữ liệu tốt không chỉ giúp tổ chức dữ liệu một cách hiệu quả mà còn đảm bảo rằng ứng dụng có thể mở rộng và duy trì được lâu dài.
2. Phát Triển và Quản Lý API
Lập trình viên Backend phát triển các API (Application Programming Interface) để cho phép giao tiếp giữa frontend và backend, cũng như với các dịch vụ và hệ thống khác. Các API này đóng vai trò quan trọng trong việc truyền dữ liệu giữa các thành phần của ứng dụng. Lập trình viên cần phải đảm bảo rằng các API được thiết kế hiệu quả, an toàn, và dễ sử dụng, đồng thời xử lý các yêu cầu và phản hồi một cách chính xác.
3. Xử Lý và Tối Ưu Hiệu Suất Hệ Thống
Đảm bảo rằng hệ thống hoạt động mượt mà và hiệu quả là một phần quan trọng trong công việc của lập trình viên Backend. Họ cần phải tối ưu hóa hiệu suất của hệ thống bằng cách cải thiện tốc độ xử lý dữ liệu, giảm thiểu thời gian phản hồi của ứng dụng, và giải quyết các vấn đề liên quan đến hiệu suất. Việc theo dõi và phân tích hiệu suất của hệ thống thông qua các công cụ phân tích giúp lập trình viên phát hiện và khắc phục các vấn đề tiềm ẩn.
4. Tích Hợp Các Dịch Vụ và Ứng Dụng Bên Ngoài
Lập trình viên Backend thường phải tích hợp các dịch vụ và ứng dụng bên ngoài vào hệ thống của mình. Ví dụ, họ có thể tích hợp các dịch vụ thanh toán trực tuyến, hệ thống gửi email, hoặc các API của bên thứ ba để mở rộng chức năng của ứng dụng. Việc tích hợp phải được thực hiện một cách an toàn và hiệu quả, đảm bảo rằng các dịch vụ bên ngoài hoạt động hòa hợp với hệ thống hiện tại.
5. Quản Lý và Đảm Bảo An Ninh Dữ Liệu
Bảo mật dữ liệu là một yếu tố cực kỳ quan trọng trong phát triển phần mềm. Lập trình viên Backend phải đảm bảo rằng dữ liệu của người dùng được bảo vệ an toàn khỏi các mối đe dọa như tấn công SQL Injection, tấn công Cross-Site Scripting (XSS), và các lỗ hổng bảo mật khác. Điều này bao gồm việc áp dụng các biện pháp bảo mật như mã hóa dữ liệu, xác thực người dùng, và giám sát các hoạt động nghi ngờ.
6. Kiểm Tra và Sửa Lỗi
Lập trình viên Backend thực hiện kiểm tra và sửa lỗi mã nguồn để đảm bảo rằng hệ thống hoạt động đúng như mong đợi. Họ cần phải phát hiện và khắc phục các lỗi và sự cố trong mã nguồn, đồng thời thực hiện các bài kiểm tra đơn vị, kiểm tra tích hợp, và kiểm tra hệ thống để đảm bảo rằng tất cả các thành phần của ứng dụng hoạt động hài hòa với nhau.
7. Bảo Trì và Cập Nhật Hệ Thống
Sau khi hệ thống được triển khai, lập trình viên Backend tiếp tục thực hiện các nhiệm vụ bảo trì và cập nhật để duy trì hiệu suất và độ ổn định của ứng dụng. Điều này bao gồm việc cập nhật mã nguồn để sửa lỗi, cải thiện chức năng, và tích hợp các công nghệ mới. Họ cũng cần phải theo dõi các vấn đề liên quan đến hiệu suất và bảo mật và thực hiện các biện pháp khắc phục kịp thời.
Các công cụ chính mà lập trình viên Backend cần biết bao gồm các ngôn ngữ lập trình phía máy chủ và các framework hỗ trợ phát triển
Công cụ cần biết để trở thành Backend Developer
Ngôn Ngữ Lập Trình Phía Máy Chủ
Để máy chủ, ứng dụng và cơ sở dữ liệu có thể giao tiếp với nhau, Backend Devs sẽ sử dụng ngôn ngữ phía máy chủ (server-side languages) như PHP, Ruby, Python, Java, và .Net để xây dựng ứng dụng.
Python: Python là một ngôn ngữ lập trình mạnh mẽ và dễ học, nổi tiếng với tính linh hoạt và hiệu quả trong phát triển ứng dụng backend. Python hỗ trợ nhiều thư viện và công cụ giúp lập trình viên phát triển các ứng dụng web, xử lý dữ liệu, và triển khai các mô hình machine learning.
Java: Java là một ngôn ngữ lập trình phổ biến trong các ứng dụng doanh nghiệp nhờ vào tính ổn định và khả năng mở rộng. Java thường được sử dụng trong các hệ thống lớn, ứng dụng web, và dịch vụ web với sự hỗ trợ từ các thư viện và công cụ phong phú.
PHP: PHP là ngôn ngữ lập trình phía máy chủ được thiết kế đặc biệt cho phát triển web. Nó thường được sử dụng để xây dựng các trang web động và các hệ thống quản lý nội dung (CMS). PHP có thể hoạt động tốt với các cơ sở dữ liệu như MySQL và PostgreSQL.
Ruby: Ruby, cùng với framework Ruby on Rails, nổi tiếng với khả năng phát triển nhanh chóng các ứng dụng web. Ruby cung cấp một cú pháp sạch sẽ và dễ đọc, giúp lập trình viên dễ dàng viết mã và duy trì ứng dụng.
Node.js: Node.js là một môi trường chạy JavaScript trên phía máy chủ, giúp lập trình viên sử dụng JavaScript để phát triển cả frontend và backend. Nó cho phép xây dựng các ứng dụng web nhanh chóng với hiệu suất cao nhờ vào mô hình sự kiện không đồng bộ.
Những công cụ như MySQL, Oracle, and SQL Server được sử dụng để tìm kiếm, lưu trữ, hoặc thay đổi dữ liệu và phân phát chúng trở lại với người dùng trong frontend code.
Framework phổ biến cho Backend
Trong những bài tuyển dụng Backend Developer cũng thường yêu cầu bạn có kinh nghiệm về frameworks. Framework là các bộ công cụ và thư viện cung cấp cấu trúc và các công cụ hỗ trợ lập trình viên trong việc phát triển ứng dụng backend. Chúng giúp tăng tốc quá trình phát triển bằng cách cung cấp các giải pháp đã được kiểm nghiệm cho các vấn đề phổ biến. Dưới đây là một số framework phổ biến cho lập trình viên Backend:
Django: Django là một framework web cao cấp cho Python, nổi bật với tính năng bảo mật và khả năng mở rộng. Nó cung cấp các công cụ tích hợp sẵn cho quản lý cơ sở dữ liệu, xử lý các yêu cầu HTTP, và phát triển các giao diện quản lý.
Spring: Spring là một framework mạnh mẽ cho Java, được thiết kế để xây dựng các ứng dụng doanh nghiệp quy mô lớn. Spring hỗ trợ các tính năng như quản lý giao dịch, bảo mật, và tích hợp các dịch vụ web.
Laravel: Laravel là một framework PHP nổi tiếng với cú pháp thân thiện và các công cụ hỗ trợ phát triển mạnh mẽ. Nó cung cấp các tính năng như ORM (Eloquent), hệ thống xác thực, và hỗ trợ tạo API.
Ruby on Rails: Ruby on Rails, hoặc Rails, là một framework web cho Ruby, nổi bật với sự phát triển nhanh chóng và tính tiện lợi. Rails theo triết lý “Convention over Configuration,” giúp lập trình viên phát triển ứng dụng với ít cấu hình hơn và tốc độ cao.
Express.js: Express.js là một framework tối giản cho Node.js, được sử dụng để xây dựng các ứng dụng web và API. Express.js cung cấp một nền tảng linh hoạt và mạnh mẽ cho việc xử lý các yêu cầu HTTP và quản lý các tuyến đường.
Ngoài ta lập trình viên backend còn phải biết sử dụng các hần mềm kiểm soát như SVN, CVS hoặc Git; và hệ thống triển khai Linux.
Mặt khác, nếu bạn định hướng xa hơn với mong muốn trở thành một Full Stack Developer thì kiến thức về web service và API cũng rất quan trọng. Ví dụ như REST và SOAP.
Cuối cùng, bạn có thể cân nhắc luyện thêm thuật toán (Algorithms) và Data structures để tăng tính cạnh tranh trên thị trường tuyển dụng.
Trông có vẻ vị trí này cần quá nhiều kiến thức và kỹ năng nhỉ? Bạn đừng hoảng, những thứ mình liệt kê phía trên bạn chỉ cần chọn 1 thứ trong mỗi mục và sử dụng thành thạo nó.
Backend Developer cần những kỹ năng gì?
Kiến thức về lập trình
Ngôn Ngữ Lập Trình: Backend Developers cần nắm vững ít nhất một ngôn ngữ lập trình backend như Java, Python, Ruby, PHP, C#, hoặc JavaScript (Node.js).
Frameworks: Sử dụng các framework giúp tăng tốc phát triển và đảm bảo mã nguồn dễ bảo trì. Ví dụ: Spring Boot (Java), Django (Python), Ruby on Rails (Ruby), Laravel (PHP), Express.js (Node.js).
Hệ Quản Trị Cơ Sở Dữ Liệu: Hiểu biết sâu về các hệ quản trị cơ sở dữ liệu quan hệ như MySQL, PostgreSQL, và Microsoft SQL Server. Kỹ năng viết các câu lệnh SQL để truy xuất, cập nhật, và quản lý dữ liệu là rất quan trọng.
RESTful APIs: Kỹ năng thiết kế và phát triển các API RESTful để các ứng dụng có thể giao tiếp với nhau qua HTTP.
SOAP: Đối với các ứng dụng yêu cầu tính năng SOAP, hiểu biết về cách tạo và tiêu thụ các web services SOAP cũng là một lợi thế.
Kiến trúc Microservices: Hiểu biết về thiết kế và triển khai kiến trúc microservices, giúp xây dựng các ứng dụng phân tán và dễ mở rộng. Ngoài ra, các dịch vụ serverless như AWS Lambda có thể giúp giảm bớt công việc quản lý server và tối ưu hóa chi phí.
Containerization: Kỹ năng sử dụng Docker và Kubernetes để triển khai và quản lý các ứng dụng trong môi trường container, giúp đảm bảo tính nhất quán và dễ dàng mở rộng.
CI/CD: Hiểu biết về tích hợp liên tục (CI) và triển khai liên tục (CD) với các công cụ như Jenkins, GitLab CI/CD, hoặc CircleCI để tự động hóa quá trình xây dựng và triển khai ứng dụng.
Các kỹ năng mềm
Phân Tích và Giải Quyết Vấn Đề: Khả năng phân tích các vấn đề phức tạp trong hệ thống và tìm ra giải pháp hiệu quả. Điều này bao gồm khả năng xác định nguyên nhân gốc rễ của sự cố và đưa ra các phương án sửa chữa.
Tư duy phản biện: Kỹ năng phân tích vấn đề và đưa ra các quyết định dựa trên dữ liệu và thông tin cụ thể. Tư duy phản biện giúp lập trình viên backend đánh giá các tùy chọn khác nhau và chọn giải pháp tối ưu.
Kỹ năng giao tiếp Khả năng giao tiếp hiệu quả với các thành viên trong nhóm phát triển, cũng như với các bên liên quan như quản lý dự án, thiết kế và khách hàng. Kỹ năng này giúp truyền đạt ý tưởng, yêu cầu và giải pháp một cách rõ ràng và dễ hiểu.
Làm việc nhóm Khả năng làm việc tốt trong môi trường nhóm và hợp tác với các bộ phận khác, chẳng hạn như frontend developers và QA testers, để đạt được mục tiêu chung của dự án.
Quản Lý Dự Án: Kỹ năng quản lý thời gian và tổ chức công việc để hoàn thành các nhiệm vụ đúng hạn, đồng thời giữ cho dự án trên đúng lộ trình và đáp ứng các yêu cầu về chất lượng.
Những kỹ năng này giúp một Backend Developer thực hiện hiệu quả các nhiệm vụ từ thiết kế hệ thống, phát triển và duy trì các ứng dụng, đến giải quyết các vấn đề kỹ thuật phức tạp và làm việc hiệu quả trong môi trường nhóm.
Mức lương và cơ hội việc làm cho vị trí Backend Developer
Mức lương của một Backend Developer có thể dao động tùy thuộc vào vị trí địa lý, kinh nghiệm làm việc, và kỹ năng chuyên môn. Tại Việt Nam, mức lương trung bình của một Backend Developer dao động từ 15 triệu đến 40 triệu đồng mỗi tháng, tùy thuộc vào cấp bậc và kinh nghiệm.
Trên thế giới, mức lương của một Backend Developer cao hơn nhiều. Theo báo cáo của Glassdoor, mức lương trung bình của một Backend Developer tại Mỹ là khoảng 85.000 USD mỗi năm. Tại các quốc gia châu Âu, mức lương có thể dao động từ 50.000 đến 70.000 EUR mỗi năm, tùy thuộc vào quốc gia và thành phố. Các vị trí cao cấp hoặc chuyên gia trong lĩnh vực này có thể đạt mức lương lên tới 120.000 USD mỗi năm hoặc hơn.
Cơ hội việc làm cho Backend Developer vẫn rất rộng mở. Với sự gia tăng nhanh chóng của công nghệ và nhu cầu ngày càng cao về các giải pháp phần mềm hiệu quả, các doanh nghiệp và tổ chức đều cần những lập trình viên backend tài năng để phát triển và duy trì các hệ thống của họ. Ngành này dự kiến sẽ tiếp tục phát triển và tạo ra nhiều cơ hội việc làm trong tương lai, đặc biệt là trong các lĩnh vực như công nghệ tài chính, y tế, và thương mại điện tử.
Trước làn sóng các tập đoàn toàn cầu không chỉ trong lĩnh vực công nghệ mà còn nhiều lĩnh vực khác ngày càng mở rộng chi nhánh tại Việt Nam, giờ đây làm việc tại công ty Global đang dần trở thành mục tiêu, mơ ước của nhiều kỹ sư. Vậy công ty Global có gì khác biệt? Thông qua góc nhìn từ LINE Technology Việt Nam, bài viết sẽ mang tới bức tranh tổng quát nhất về trải nghiệm tại một Global Corp.
Là trung tâm phát triển của LINE Corporation, LINE Technology Vietnam được thành lập với sứ mệnh hợp tác chặt chẽ cùng đội ngũ kỹ sư lành nghề toàn cầu, xây dựng và tối ưu hóa các ứng dụng và dịch vụ đa dạng dựa trên nền tảng cốt lõi của tập đoàn. Với thế mạnh gây dựng thành công thương hiệu cùng hệ sinh thái công nghệ lâu năm tại nhiều quốc gia trước đó như Nhật Bản, Hàn Quốc, Thái Lan, Đài Loan, Malaysia,…. LINE Technology Việt Nam luôn nỗ lực giữ gìn và phát huy mạnh mẽ vai trò của mình cũng như thu hút nhân tài đa quốc gia.
Với sứ mệnh “Closing the distance” và tầm nhìn “Life on LINE”, sản phẩm công nghệ của LINE mang con người, thông tin và dịch vụ đến gần nhau hơn. Khởi nguồn từ một ứng dụng gọi và nhắn tin, giờ đây LINE đã xây dựng thành công dựng hệ sinh thái lớn mạnh với hàng trăm triệu người dùng trên toàn thế giới. Ngoài ra, LINE đang tận dụng Fintech và AI để làm mờ ranh giới giữa trực tuyến và ngoại tuyến, tạo ra trải nghiệm mới và mang tính cá nhân hóa cao cho người dùng.
Một sản phẩm hoàn hảo chỉ có thể được tạo ra trong môi trường tốt nhất, đảm bảo về cả thể chất lẫn tinh thần cho những kỹ sư tạo ra nó. Vì thế, LINE Technology Vietnam luôn tạo cơ hội cho thành viên được làm việc trong môi trường chuyên nghiệp, minh bạch thông tin và được thể hiện cá tính, quan điểm riêng. LINE luôn đảm bảo 100% văn hoá tôn trọng sự khác biệt giữa nhân viên và cấp trên trong công ty. Hằng năm, công ty tổ chức chương trình giao lưu cho nhân viên giữa các nước nhằm thúc đẩy trao đổi văn hoá, học hỏi lẫn nhau.
Về quy trình công việc, LINE Technology Vietnam xây dựng các hệ thống nội bộ chuẩn chỉnh, cam kết bảo mật thông tin và phát triển bền vững. Điều này giúp cho việc giao tiếp giữa các phòng ban, chi nhánh toàn cầu hiệu quả hơn, tiết kiệm thời gian và nâng cao năng suất. Việc áp dụng quy trình Agile trong phát triển phần mềm theo xu thế cũng được triển khai nhằm đảm bảo release sản phẩm đúng hạn và hiệu quả hơn.
LINE Technology Vietnam vừa đón diện mạo mới cho văn phòng kể từ năm 2021 Thuộc tầng 20 và 21 của toà nhà Capital Place, văn phòng mới nằm giữa trung tâm quận Ba Đình. Tầng 20 là không gian tiếp đón khách và diễn ra mọi sự kiện lớn nhỏ hay sinh hoạt giao lưu của nhân viên trong công ty. Trang thiết bị đa dạng từ bàn bi lắc, bi-a, bóng bàn, PS5 đến thư viện sách, quầy mini bar,… giúp thành viên lấy lại năng lượng và kết nối sau những giờ căng thẳng. Tầng 21 là khu làm việc, được trang bị ghế công thái học, bàn nâng hạ thông minh, màn hình chống cận. Ngoài ra, nhân viên mới gia nhập đều có quyền lựa chọn loại hình, cấu hình máy mà bản thân quen thuộc nhất.
Nhằm đảm bảo đời sống nhân viên, đồng thời giữ chân và thu hút nhân tài, LINE Technology Vietnam luôn trăn trở để mang đến chế độ đãi ngộ tốt nhất, mọi hoạt động đều hướng đến con người. Ngay cả trong quá trình thử việc, thành viên vẫn được tham gia gói khám sức khoẻ cao cấp, các khoá đào tạo kĩ năng cứng và kĩ năng mềm, nhận các chi phí hỗ trợ như di chuyển, tiền điện nếu phải làm việc tại nhà. LINE khuyến khích mọi nhân viên giao tiếp và kết nối với nhau nhiều hơn. Chính vì vậy mỗi người sẽ được nhận trợ cấp “Communication fee” để gặp gỡ, liên hoan hằng tháng.
Với xu hướng toàn cầu hoá hiện nay, làm việc tại Global Corp đối với người Việt không còn là trở ngại về thủ tục hay khoảng cách địa lý, mà chỉ cần tìm thấy điểm phù hợp về văn hoá, phong cách, hay trau dồi kĩ năng chuyên nghiệp.
Còn chần chừ gì mà không thử thách bản thân trong môi trường quốc tế. Nếu bạn có cùng quan điểm và phong cách giống LINE Technology Vietnam, hãy truy cập https://vietnamdevcenter.linecorp.com/en/careers/?region=HN để tìm hiểu thêm về các cơ hội nghề nghiệp nhé!
Bài viết được sự cho phép của tác giả Phạm Minh Khoa
Singleton là gì?Singleton là 1 trong 5 design pattern của nhóm khởi tạo (Creational Design Pattern). Vậy cấu trúc của Singleton ra sao và cách triển khai như thế nào, cùng mình tìm hiểu nội dung dưới đây.
Định nghĩa
Singleton is a creational design pattern that lets you ensure that a class has only one instance, while providing a global access point to this instance.
Dịch: Singleton là 1 mẫu design pattern thuộc nhóm khởi tạo cho phép bạn đảm bảo rằng 1 lớp sẽ chỉ có duy nhất 1 instance và nó cung cấp 1 method cho instance này ở bất cứ đâu trong chương trình.
Singleton giải quyết bài toán nào?
Singleton Pattern giải quyết 2 vấn đề dưới đây cùng 1 lúc:
Đảm bảo rằng 1 lớp (class) sẽ chỉ có 1 instance duy nhất: Sẽ có 1 số trường hợp mà bạn cần kiểm soát việc truy cập đến các tài nguyên dùng chung ví dụ như database hay 1 file nào đó; lúc này bạn cần kiểm soát được số lượng instance mà 1 class đó có.
Cách nó hoạt động sẽ như sau: Thử tưởng tượng rằng bạn đã tạo 1 object rồi, tuy nhiên sau đó bạn lại quyết định tạo thêm 1 object mới. Lúc này thay vì việc nhận được 1 object mới thì bạn sẽ nhận về object mà bạn tạo ra lúc trước.
Lưu ý rằng hành vi này không thể thực hiện với 1 phương thức khởi tạo thông thường (như sử dụng new), vì nó sẽ luôn trả về 1 object mới.
Ở đây khách hàng có thể không nhận ra rằng họ đang làm việc với cùng 1 đối tượng
Cung cấp 1 điểm truy cập global đến instance đó: Biến global (toàn cục) thường được sử dụng để lưu trữ 1 số đối tượng thiết yếu. Mặc dù nó rất là tiện dụng, nhưng chúng cũng rất không an toàn vì bất cứ đoạn code nào trong chương trình cũng có thể ghi đè nội dung của những biến đó khiến cho ứng dụng của chúng ta bị crash. Singleton cũng giống như biến toàn cục, nó cho phép bạn truy cập đến 1 số object ở bất kỳ đâu trong chương trình, tuy nhiên nó cũng bảo vệ instance đó tránh khỏi việc bị ghi đè bởi code khác.
Có 1 cách nhìn khác cho vấn đề này: bạn không muốn phần code giải quyết vấn đề #1 ở trên bị phân tán khắp nơi trong chương trình, source code của mình. Sẽ tốt hơn khi chúng được viết hết trong 1 class đặc biệt là nếu các phần code khác đã phụ thuộc vào nó.
Cách triển khai Singleton
Tất cả các triển khai (implementations) của Singleton đều sẽ gồm 2 bước chung sau:
Đặt phương thức khởi tạo mặc định (default constructor) là private để ngăn việc các đối tượng khác sử dụng toán tử new cho lớp Singleton
Tạo 1 phương thức khởi tạo static hoạt động như 1 khởi tạo (constructor), trong đó phương thức này sẽ gọi private constructor để tạo ra 1 object và lưu nó vào trường static (static field). Tất cả các lệnh gọi sau đến phương thức này đều trả về đối tượng được lưu trong cached.
Nếu code của bạn truy cập đến lớp Singleton, nó có thể gọi đến phương thức static của Singleton, và sẽ luôn luôn được trả về chung 1 object.
Ví dụ thực tế
Singleton có nhiều ví dụ thực tế:
1 đất nước có thể chỉ có 1 chính phủ chính thức. Bất kể ai, cá nhân nào làm việc cho chính phủ thì danh xưng “Chính phủ” vẫn là 1 khái niệm chỉ định chung dùng để chỉ nhóm những người phụ trách. Chính phủ ở đây được xem như 1 ví dụ về Singleton.
Khi bạn muốn tăng giảm âm lượng của 1 chiếc điện thoại. Bất kể có gọi từ phần mềm thứ 3, hay thao tác trực tiếp trên phần cứng; thì việc tăng giảm âm lượng cũng đều được thực hiện thông qua 1 phần điều khiển hệ thống. Ta cũng xem lớp điều khiển âm lượng này là 1 singleton
Máy in cũng có thể xem là 1 singleton khi nó nhận yêu cầu và xử lý từ mọi người trong hệ thống.
Cấu trúc, cách triển khai Singleton
Lớp Singleton khai báo phương thức static getInstance trả về cùng 1 instance của nó.
Phương thức khởi tạo Singleton nên được ẩn khỏi code client, cách duy nhất để lấy đối tượng Singleton là gọi phương thức getInstance.
Triển khai Singleton Pattern code với TypeScript
/**
* The Singleton class defines the `getInstance` method that lets clients access
* the unique singleton instance.
*/
class Singleton {
private static instance: Singleton;
/**
* The Singleton's constructor should always be private to prevent direct
* construction calls with the `new` operator.
*/
private constructor() { }
/**
* The static method that controls the access to the singleton instance.
*
* This implementation let you subclass the Singleton class while keeping
* just one instance of each subclass around.
*/
public static getInstance(): Singleton {
if (!Singleton.instance) {
Singleton.instance = new Singleton();
}
return Singleton.instance;
}
/**
* Finally, any singleton should define some business logic, which can be
* executed on its instance.
*/
public someBusinessLogic() {
// ...
}
}
/**
* The client code.
*/
function clientCode() {
const s1 = Singleton.getInstance();
const s2 = Singleton.getInstance();
if (s1 === s2) {
console.log('Singleton works, both variables contain the same instance.');
} else {
console.log('Singleton failed, variables contain different instances.');
}
}
clientCode();
Nội dung trên đã phần nào giải đáp được thắc mắc Singleton là gì cũng như những ứng dụng thực tế của Singleton. Nếu bạn muốn góp ý đừng ngần ngại phản hồi với TopDev nhé. Chúc bạn code mau lên trình.
Game Developer là gì? Có phải Game Developer là lập trình viên game? Phải xây dựng lộ trình trở thành Game Developer như thế nào là tốt? Bài viết dưới đây sẽ lần lượt giải đáp những thắc mắc này.
1. Game Developer là gì?
Khi được hỏi Game Developer là gì? nhiều bạn hiểu lầm rằng Game Developer là lập trình viên game. Thực tế, Game Developer là khái niệm chỉ chung cho tất cả những người tham gia vào việc thiết kế một trò chơi. Ví dụ: lập trình viên, nhà thiết kế đồ họa 2D/3D, người quản lý dự án,… Trong phạm vi bài này, mình sẽ nói về Game Developer dưới vai trò là một lập trình viên.
Game Developer được xem là nhà phát triển phần mềm chuyên tạo ra game trên nhiều nền tảng máy tính hoặc điện thoại thông minh. Họ đóng vai trò là người chuyển đổi ý tưởng của những nhà thiết kế Game (Game Designer) thành trò chơi thực tế bằng công việc chính là coding.
Bên cạnh đó, nhà phát triển game còn làm những việc như lập trình phần mềm (software-programming), tạo hiệu ứng âm thanh (sound effects), thiết lập kỹ thuật (engineering), kết xuất (rendering), kiểm tra (test) và một số quy trình khác để duy trì sự vận hành của trò chơi.
Một nhà phát triển game có thể tập trung vào một khía cạnh cụ thể như lập trình trí tuệ nhân tạo hoặc cảnh quan ảo của trò chơi. Với nghề Game Developer bạn cũng có thể làm việc với tư cách là một freelancer.
Xét theo phương diện Game Developer là một lập trình game thì kỹ năng đầu tiên cần có là kỹ năng lập trình. Khả năng coding giỏi sẽ giúp nhà phát triển game hệ thống tất cả khái niệm, bản phác thảo và cốt truyện thành hàng nghìn dòng mã hóa để hiện thực hóa trò chơi và tung ra thị trường.
2.2. Khả năng tự học, cập nhật kiến thức
Phần mềm game là một trong những ngành nghề liên tục thay đổi. Cùng với đó, xu hướng chơi game thay đổi dẫn đến sự thay đổi của những trò chơi điện tử. Để theo kịp thị trường, Game Developer cần có khả năng tự học hỏi, liên tục cập nhật kiến thức về game.
2.3. Khả năng ngoại ngữ
Nếu bạn muốn làm việc trong một công ty nước ngoài thì khả năng giao tiếp tiếng anh là một kỹ năng không thế thiếu. Bạn không nhất thiết phải nói chuyện như người bản xứ nhưng ít ra bạn phải biết cách sử dụng nó để mọi người hiểu mình đang nói gì.
Nếu nói bạn không có ý định làm việc trong công ty nước ngoài nên bạn không cần ngoại ngữ. Thực tế, ít nhất bạn cũng phải đọc được tiếng anh để tìm hiểu tài liệu chứ.
2.4. Kỹ năng làm việc nhóm
Một kỹ năng quen thuộc nhưng mình không thể không nhắc đến. Để xây dựng một game thành công và nhanh chóng đòi hỏi có sự phối hợp ăn ý giữa những vị trí với nhau. Kỹ năng làm việc nhóm thể hiện bạn là một người biết lắng nghe và thuyết phục đồng đội về những vấn đề xảy ra trong quá trình phát triển game.
2.5. Thích chơi game
Đây không hẳn là một kỹ năng nhưng khi bạn thích và đam mê game thì bạn mới có thể phát triển lâu dài trên con đường Game Developer đầy thử thách.
Theo đánh giá của nhiều “người trong nghề”, hoạt động làm Game ở Việt Nam chủ yếu tập trung vào mobile, ít người quan tâm đến PC. Mặt khác, Game trên PC yêu cầu kinh phí cao và khó tiếp cận người dùng nên hầu hết các nhà đầu từ đều ngại bỏ vốn. Có thể nói lập trình game ở Việt Nam chưa thật sự tốt và phát triển vượt bậc như những ngành lập trình khác.
Tuy nhiên, trong những năm tới sự ưa chuộng điện thoại, máy tính, máy tính bảng cũng như nhu cầu giải trí sẽ gia tăng khiến nghề lập trình game sẽ phát triển hơn. Do đó, nếu muốn đón đầu xu hướng trên con đường Game Developer bạn nên tìm hiểu kỹ và thật kiên trì để phát triển cùng với thị trường này.
4. Lộ trình trở thành Game Developer
4.1. Bắt đầu từ đâu?
Học Đại học
Nếu bạn chưa biết bắt đầu như thế nào hãy khởi điểm bằng những môn học cơ bản ở Trường Đại học. Mặc dù không phải lúc nào cũng cần bằng cấp nhưng bằng cấp có thể giúp bạn xây dựng những kỹ năng và kỹ thuật cơ bản để trở thành Game Developer.
Nhiều công ty phát triển game luôn tìm kiếm những ứng viên có bằng cử nhân về những ngành liên quan đến lập trình Game. Vậy Game Developer học ngành gì? Dưới đây là một vài ngành chủ yếu bạn có thể tham khảo:
Khoa học máy tính
Công nghệ thông tin
Kỹ thuật phần mềm
Câu hỏi đặt ra là “Không học đại học thì có làm lập trình game được không?”. Chắc chắn câu trả lời là có. Bạn hoàn toàn có thể tự học hoặc đăng ký những khóa học như bạn muốn. Tuy nhiên, sẽ khó khăn hơn rất nhiều nếu bạn không có đủ kiến thức nền tảng ở trường đại học.
Tập làm game và học Code
Hai yêu cầu bạn thường gặp trên bảng mô tả công việc đó là kinh nghiệm với công cụ phát triển game và khả năng lập trình (thường là C++ hoặc C#).
Unity: là một công cụ trò chơi đa nền tảng cho phép bạn phát triển các trò chơi 2D và 3D. Unity phổ biến đối với indie games (trò chơi độc lập) và mobile games. Đặc biệt công cụ này miễn phí cho nhân viên vì vậy bạn có thể bắt đầu tạo trò chơi và tích lũy kinh nghiệm trước khi đi làm.
Unreal Engine: một phần mềm dùng để phát triển trò chơi điện tử trên nhiều nền tảng từ PC đến các hệ máy console như PS4, Xbox One và Nintendo Switch. Unreal hỗ trợ hai ngôn ngữ lập trình là C++ và Python.
C#: ngôn ngữ lập trình thường được sử dụng để phát triển trò chơi và các ứng dụng di động, đặc biệt là với công cụ Unity.
C++: một ngôn ngữ lập trình đa năng thường được sử dụng để phát triển không chỉ trò chơi mà còn cả hệ điều hành và ứng dụng.
4.2. Mẹo giúp bạn cạnh tranh hơn trong thị trường tuyển dụng Game Developer
Bắt đầu với những game nhỏ: để phát triển kỹ năng bước đầu bạn có thể thử tạo một hành vi trong game hoặc cơ chế chuyển động của bàn phím trong C#.
Tạo portfolio xịn: bạn đã xây dựng những dự án nào, học ngôn ngữ lập trình nào, C++ hay C#, hãy suy nghĩ và thêm nó vào mục kinh nghiệm của bạn.
Bắt đầu với tư cách là một QA tester: QA là người kiểm tra trò chơi một cách có hệ thống để tìm bất kỳ sai sót hoặc lỗi nào. Đây cũng là một khởi đầu tốt để bạn tích lũy kinh nghiệm.
Tham gia những sự kiện về Game: đây là những nơi bạn có thể gặp gỡ những Game Developer thực thụ và cả những công ty phát triển game. Tham dự sự kiện là cơ hội tốt để bạn làm quen, xây dựng mối quan hoặc đơn giản là tìm việc.
Đến đây bài đã khá dài rồi. Mong rằng những thông tin trên có ích trên con đường trở thành Game Developer của bạn hoặc chí ít bạn có thể hiểu Game Developer là gì. Chúc bạn thành công.
Tin tuyển dụng IT mới nhất trên TopDev, tìm việc ngay!
Bài viết được sự cho phép của tác giả Nguyễn Hồng Quân
Trong quá trình phát triển ứng dụng cho hệ thống nhúng, do sự hạn chế của thiết bị, đôi khi có những việc lắt nhắt làm tốn mớ thời gian. Sau đây mình liệt kê một số mẹo để đi tắt, giúp tiết kiệm thời gian cho công việc. Các hướng dẫn này chỉ dành cho hệ điều hành Linux (như Ubuntu).
1. Chia sẻ Internet từ laptop cho máy tính nhúng
Đây là tình huống mà bạn đang phát triển ứng dụng cho máy tính mini (NUC, Raspberry Pi, Beagle Bone…) và chủ yếu dùng mạng dây (chưa setup wifi hoặc máy đó không có card wifi). Đôi lúc bạn cần phải xách nó đi đâu đó (để trình diễn demo, để cài đặt lại chẳng hạn) mà chỗ đó không có router để cấp mạng, bạn có thể chia sẻ Internet từ laptop (laptop đang kết nối Internet qua wifi) cho nó. Để cho ngắn gọn, mình sẽ gọi máy tính nhúng là RPi trong bài này.
Nguyên lý của việc này là biến laptop của bạn thành một thiết bị router mạng đơn sơ, tạo một mạng con với RPi, do laptop của bạn quản lý.
Với Ubuntu 20.04+ thì việc này rất đơn giản. Sau khi dùng dây LAN nối giữa RPi với laptop, bạn chỉ việc mở phần mềm tên là “Settings”, tìm đến mục “Network”, bấm vào nút “chỉnh sửa” (có hình bánh răng) cho mạng dây (Wired):
Ở màn hình kế tiếp, chọn tab “IPv4” rồi chọn “Shared to other computers”.
Sau khi lưu lại cấu hình này, bấm vào tab “Details”, bạn sẽ thấy địa chỉ IP của laptop trong mạng con mới tạo này. Thông thường là 10.42.0.1. Tuy nhiên, đó chỉ là địa chỉ của laptop, còn địa chỉ của RPi là gì, làm sao truy cập đến nó? Có các cách sau đây:
a) Dùng mDNS
Cách này áp dụng khi cả laptop và RPi của bạn đều đã cài đặt phần mềm avahi-daemon và bạn nhớ tên hostname của RPi. Khi đó địa chỉ của RPi sẽ có dạng [hostname].local, ví dụ raspberrypi.local. Thử ping vào địa chỉ đó, bạn sẽ thấy RPi trả lời:
$ ping raspberrypi.local
PING raspberrypi.local (10.42.0.95)56(84) bytes of data.
64 bytes from 10.42.0.95 (10.42.0.95): icmp_seq=1ttl=64time=1.05 ms
64 bytes from 10.42.0.95 (10.42.0.95): icmp_seq=2ttl=64time=0.844 ms
64 bytes from 10.42.0.95 (10.42.0.95): icmp_seq=3ttl=64time=1.21 ms
Với mDNS thì thật ra bạn không cần dùng đến địa IP nữa, có thể dùng địa chỉ “*.local” này để truy cập bằng bất cứ phương thức nào, như SSH, FTP, HTTP:
b) Dùng nmap để quét
Nếu lỡ quên cài avahi-daemon cho RPi thì ta dùng nmap để quét trong mạng con:
$ sudo nmap -sn 10.42.0.0/24
[sudo] password for quan:
Starting Nmap 7.80 ( https://nmap.org ) at 2020-08-06 12:15 +07
Nmap scan report for10.42.0.95
Host is up (0.0011s latency).
MAC Address: B8:27:EB:D1:AB:91 (Raspberry Pi Foundation)
Nmap scan report for Fossa (10.42.0.1)
Host is up.
Nmap done: 256 IP addresses (2 hosts up) scanned in 3.89 seconds
Địa chỉ của mạng con được xác định bằng cách thay số cuối của địa chỉ laptop bằng số 0 rồi gắn thêm /24 vào, ví dụ 10.42.0.1 -> 10.42.0.0/24.
nmap không được cài sẵn trong Ubuntu, bạn phải cài bằng cách:
sudo apt install nmap
c) Xem trong danh sách địa chỉ IP đã cấp
Tìm trong thư mục /var/lib/NetworkManager/ (cần quyền sudo), coi có file nào có tên dạng dnsmasq-[ifname].leases, ví dụ, vì card mạng của tôi có tên enp2s0 nên sẽ có file dnsmasq-enp2s0.leases. Mở nội dung file đó sẽ thấy địa chỉ nào được cấp cho RPi:
Giải thích thêm, NetworkManager là chương trình quản lý mạng phổ biến trên hệ điều hành Linux dành cho desktop (và smartphone) (còn có các chương trình khác dành cho bối cảnh sử dụng khác). Khi dùng nó để tạo mạng con, nó sẽ gọi thêm một chương trình tên là dnsmasq lên để đảm nhiệm chức năng DHCP server và DNS server cho mạng con đó.
Với một số phiên bản Ubuntu cũ hơn (khoảng 18.10 đến 19.10), bạn sẽ không thấy lựa chọn “Shared to other computers”. Đó chỉ là thiếu sót của giao diện “Settings”, bạn vẫn có thể cấu hình chia sẻ mạng trong một ứng dụng khác, tên là “Advanced Network Configuration”. Ứng dụng này có thể tìm thấy trong màn hình Dash (ấn phím Super/Windows để mở). Với Ubuntu 19.04 và 19.10 thì ứng dụng này bị giấu khỏi Dash, bạn phải mở bằng dòng lệnh:
nm-connection-editor
Sau khi mở “Advanced Network Configuration”, bạn có thể chọn để sửa một cấu hình mạng dây đang có, tương tự với chương trình “Settings” phía trên.
Mẹo nhỏ:
Để đưa “Advanced Network Configuration” trở lại màn hình Dash thì sửa file /usr/share/applications/nm-connection-editor.desktop và xóa dòng “NotShowIn=GNOME;” đi.
[Desktop Entry]Name=Advanced Network ConfigurationComment=Manage and change your network connection settingsIcon=preferences-system-networkExec=nm-connection-editorTerminal=falseStartupNotify=trueType=ApplicationX-GNOME-Bugzilla-Bugzilla=GNOMEX-GNOME-Bugzilla-Product=NetworkManagerX-GNOME-Bugzilla-Component=nm-connection-editorCategories=GNOME;GTK;Settings;X-GNOME-NetworkSettings;X-GNOME-Utilities;NotShowIn=GNOME; # <~~ Xóa dòng này, hoặc comment lại.X-Ubuntu-Gettext-Domain=nm-applet
Tình huống này có liên quan đến bài Áp dụng quy trình hiện đại khi làm phần mềm cho hệ thống nhúng. Đó là khi mình cần cho phần mềm server giao tiếp với một thiết bị kết nối qua cổng serial (bên Windows gọi là cổng COM). Như đã kể, trong khi phát triển ứng dụng IoT thì mình luôn viết phần mềm mô phỏng để thay mặt thiết bị, khi thiết bị chưa được chế tạo xong, chưa được viết code nhúng. Cả phần mềm server lẫn phần mềm mô phỏng cùng chạy trên PC mà lại cần giao tiếp qua cổng serial thì phải làm sao? Đó là lúc cần phải tạo một cổng serial ảo để phần mềm server nắm một đầu, phần mềm mô phỏng nắm một đầu. Phần mềm này ghi dữ liệu vào đầu này thì tại đầu kia, phần mềm kia sẽ đọc được.
Để tạo cổng serial ảo thì mình dùng socat. Cách tạo như sau:
Mở một tab của Terminal, gõ lệnh:
socat -d -d PTY,link=writer PTY,link=reader
Khi đó, socat sẽ tạo ra hai file, writer và reader. Hai tên này thích đặt sao cũng được, không nhất thiết phải là writer và reader.
Trong lúc vẫn giữ socat chạy, mở một tab khác của Terminal lên, chạy phần mềm mô phỏng, truyền tên của một trong hai file kia vào, giống với cách bạn truyền tên cổng serial thật vào, ví dụ:
./device-emulator writer
Và ở một Terminal khác thì bạn cấu hình cho phần mềm server truy cập vào file còn lại, thay cho cổng serial thật.
Lưu ý là tên file đặt là gì không quan trọng, nên tại đầu “reader” bạn vẫn có thể ghi, để đầu “writer” đọc được.
Bạn cũng có thể bỏ tham số “link” khỏi socat, ví dụ:
socat -d -d PTY PTY
Nhìn vào thông báo của socat để lấy tên file tương ứng với cổng serial ảo, ví dụ:
2017/10/06 17:09:49 socat[6828] N PTY is /dev/pts/5
2017/10/06 17:09:49 socat[6828] N PTY is /dev/pts/6
2017/10/06 17:09:49 socat[6828] N starting data transfer loop with FDs [5,5] and [7,7]
Tuy nhiên, đây là cách rất không được khuyến khích, vì mỗi lần tắt socat mở lại, socat sẽ phải tạo file mới với con số mới (để tránh đụng với các file pseudo-terminal sinh ra mỗi khi bạn mở một tab Terminal mới), ứng dụng của bạn sẽ phải cấu hình lại, nếu không sẽ vô tình ghi vào file pts của một Terminal nào đó.
Sau đây là minh họa:
Với cổng serial ảo tạo bởi socat, bạn có thể truy cập, theo dõi bằng hầu hết các phần mềm giao tiếp serial, ngoại trừ các phần mềm viết bằng Qt như CuteCom. Cụ thể, nếu cần phần mềm có giao diện đồ họa thì nên dùng GtkTerm:
Nếu thấy thoải mái với dòng lệnh thì bạn nên dùng thư viện PySerial của Python, khởi chạy công cụ dòng lệnh của nó bằng cách:
$ python3 -m serial.tools.miniterm /tên/port
PySerial cũng là thư viện đảm nhiệm tính năng truy cập serial trong các bộ công cụ lập trình nhúng sau:
IDF của Espressif (tương tác với ESP32/8266)
PlatformIO (tương tác với tất cả các loại board mà PlatformIO hỗ trợ).
(và tất nhiên, cùng với các thư viện Python khác, đã đóng góp phần rất lớn trong các sản phẩm của AgriConnect).
Trên đây mình đã kể xong hai mẹo. Không biết có tầm thường không, nhưng với mình thì nó đã tiết kiệm rất nhiều thời gian làm việc, và từ đó cũng thấy Linux có nhiều đồ chơi hay thật.





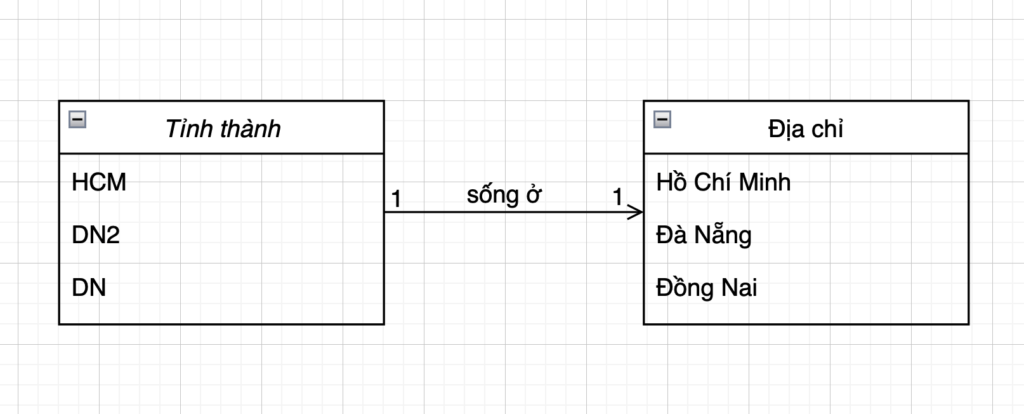 Cơ bản thì từ mã tỉnh thành viết tắt lưu xuống ta có thể lấy được địa chỉ đầy đủ như này
Cơ bản thì từ mã tỉnh thành viết tắt lưu xuống ta có thể lấy được địa chỉ đầy đủ như này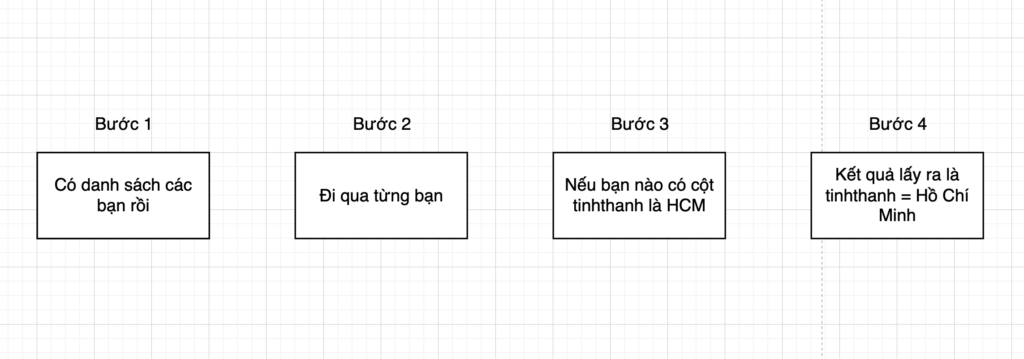
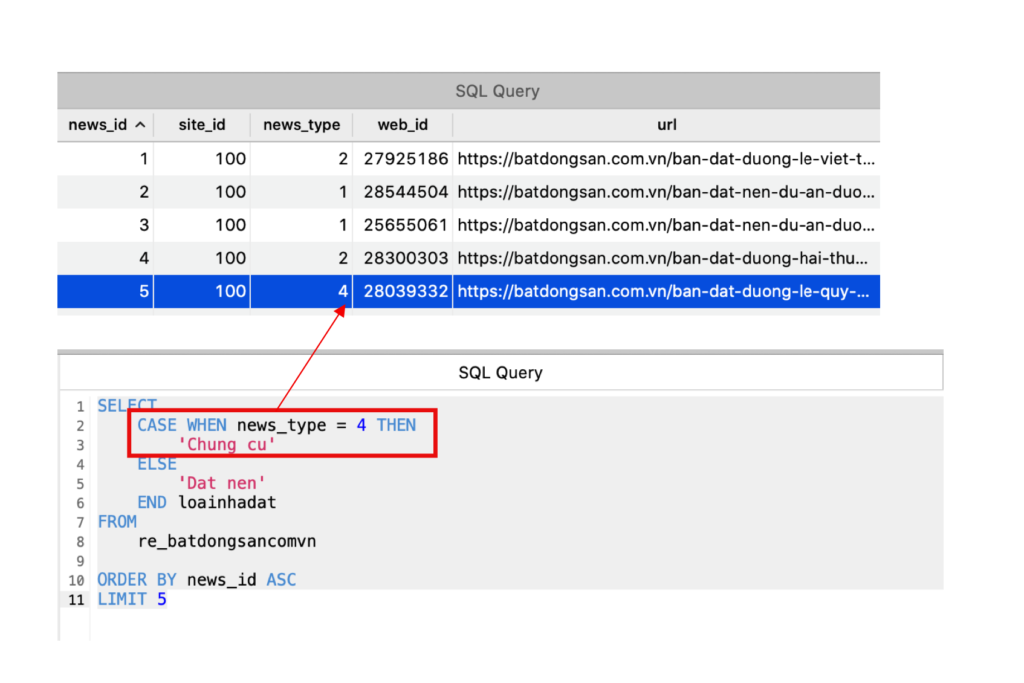

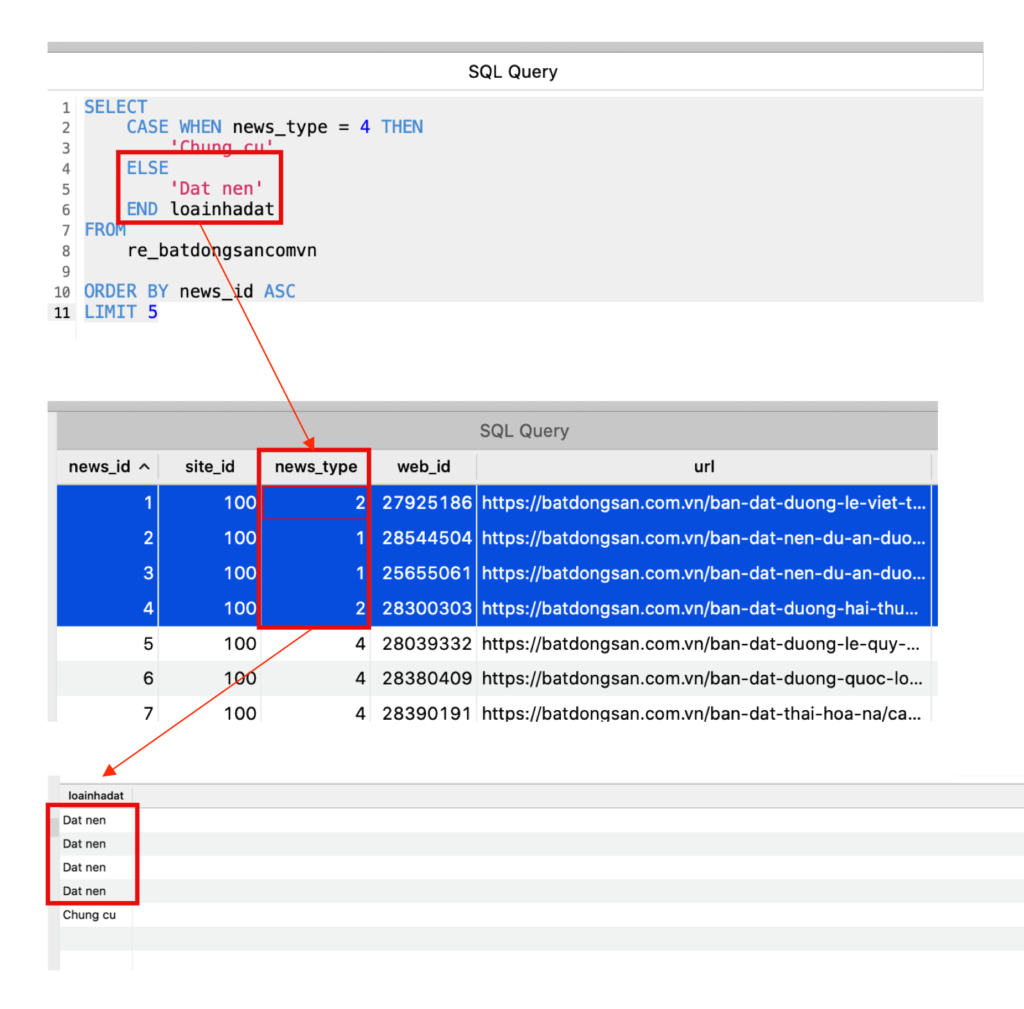

 Chúng ta còn có thể khai báo Getter, Setter cho chỉ một số thuộc tính của đối tượng Java sử dụng @Getter, @Setter annotation. Ví dụ như, bây giờ mình chỉ khai báo Getter, Setter cho thuộc tính code của Student class, mình sẽ khai báo như sau:
Chúng ta còn có thể khai báo Getter, Setter cho chỉ một số thuộc tính của đối tượng Java sử dụng @Getter, @Setter annotation. Ví dụ như, bây giờ mình chỉ khai báo Getter, Setter cho thuộc tính code của Student class, mình sẽ khai báo như sau: