Trang web tuyển dụng ITrất cần trong tình huống mất cân bằng cung cầu nhân sự IT như hiện nay. Đây là nơi nhà tuyển dụng và ứng viên có cơ hội “gặp gỡ” nhanh chóng, từ đó đáp ứng được nhu cầu tuyển dụng một cách hiệu quả.
Nhu cầu nhân lực IT Việt Nam
Theo các số liệu thống kê từ năm 2018 được đưa ra, nhu cầu nhân lực cho ngành công nghệ thông tin tại Việt Nam vẫn đang tăng cao liên tục. Dựa trên Báo cáo về thị trường IT Việt Nam của TopDev, dự báo năm 2022 Việt Nam sẽ cần đến 530.000 nhân lực trong ngành công nghệ thông tin. Trong khi đó, số lượng lập trình viên hiện tại của Việt Nam mới chỉ đạt khoảng 430.000 người.
Việc chênh lệch này là một trong những nguyên nhân dẫn đến khó khăn trong quá trình tìm kiếm ứng viên phù hợp cho doanh nghiệp, bởi một ứng viên sẽ có nhiều sự lựa chọn hơn và thụ động hơn trong quá trình tìm kiếm việc làm.
Từ đó, để quá trình tuyển dụng IT đỡ vất vả hơn, bạn có thể tham khảo những trang web tuyển dụng IT uy tín. Với những hiểu biết về thị trường IT, chân dung lập trình viên Việt như thế nào, mong muốn của ứng viên là gì,… họ sẽ giúp bạn tiếp cận, tìm kiếm và tuyển dụng lập trình viên phù hợp.
Tại sao bạn nên chọn các trang web tuyển dụng lập trình viên uy tín?
Trang web tuyển dụng là trung gian kết nối nhà tuyển dụng và người tìm việc, tạo điều kiện thuận lợi cho con đường tuyển dụng / tìm việc diễn ra nhanh chóng và hiệu quả. Vậy, thuận lợi mà những trang web này mang lại là gì và tại sao bạn nên chọn những trang web tuyển dụng IT uy tín.
Đối với lập trình viên
Thay vì phải lặn lội tìm kiếm trên hội nhóm mạng xã hội, chắt lọc thông tin riêng lẻ từ website của từng công ty, ứng viên chỉ cần truy cập vào một trang web tuyển dụng IT uy tín với một kho data việc làm khổng lồ.
Tiếp theo, dựa theo nhu cầu và năng lực bản thân, ứng viên dễ dàng tìm kiếm công việc phù hợp bằng những filter phân loại theo chuyên môn, cấp bậc, địa điểm,…
Thêm vào đó, nhiều trang web còn cung cấp tính năng tạo CV IT dành riêng cho Developer giúp ứng viên dễ dàng thể hiện khả năng của bản thân cũng như nhà tuyển dụng đánh giá ứng viên chính xác hơn.
Ví dụ với công cụ tạo CV IT của TopDev được thiết kế với hình thức theo chuẩn cách sàng lọc CV của thế giới. Tạo CV IT online tại đây!
Đối với nhà tuyển dụng
Tin tuyển dụng của doanh nghiệp được tiếp cận dễ dàng, đúng ứng viên nhờ vào lượng người dùng truy cập lớn của trang web tuyển dụng. Bên cạnh đó, đội ngũ của trang web này sẽ thay bạn thực hiện nhiệm vụ tiếp cận và tìm kiếm ứng viên. Ngoài ra, khi mua gói tin đăng với những mức phí cụ thể, nhà tuyển dụng sẽ được “bảo hành” hoặc “push” bằng cách highlight tin đăng, gia hạn ngày đăng tin,…
Đánh giá trang web tuyển dụng dựa vào yếu tố gì?
Hiện nay rất nhiều trang web tuyển dụng ra đời và không phải tất cả đều uy tín. Do đó, NTD nên chọn lọc cẩn thận để tránh bị lừa đảo và lộ thông tin người dùng. Mời bạn theo dõi cách đánh giá trang web tuyển dụng IT hiệu quả, uy tín với những thông tin dưới đây.
Giao diện web có tốt hay không?
Điều này có nghĩa là trang web có dễ nhìn, dễ sử dụng cho cả nhà tuyển dụng và ứng viên hay không. Một trang web với giao diện rối mắt có thể khiến ứng viên ra đi không trở lại.
Một website tối ưu sẽ có giao diện rõ ràng, tập trung truyền tải thông tin chính đến người dùng. Chẳng hạn, tin tức tuyển dụng hoặc nội dung kiến thức IT sẽ chiếm phần lớn trang web thay vì hàng loạt quảng cáo gây xao nhãng.
Danh sách khách hàng đã từng sử dụng dịch vụ tại trang web
Một trong những cách đánh giá độ uy tín của nền tảng tuyển dụng đơn giản nhất là hãy xem khách hàng đã sử dụng dịch vụ tại trang web họ có những ai. Một platform tuyển dụng với hơn 3.000 khách hàng từ kỳ lân công nghệ, ngân hàng nhà nước đến cả startup đều tin dùng thì bạn hoàn toàn có thể tin tưởng và sử dụng dịch vụ tại đây.
Website có những blog cho người tuyển dụng và ứng viên hay không?
Một trang web tuyển dụng IT hiệu quả sẽ chú ý đến điểm này. Họ cần tạo ra những nội dung thu hút, kiến thức hữu ích để ứng viên gắn bó với trang web không chỉ trong mỗi giai đoạn tìm việc mà cả giai đoạn trước và sau đó.
Mặt khác, việc phát triển blog giúp website gia tăng độ nhận diện người dùng hơn. Cụ thể, thông qua tìm kiếm google, ứng viên có thể dễ dàng truy cập vào những nội dung mà site đó cung cấp. Sau nhiều lần nhận được giải đáp cho vấn đề của mình, sự tin tưởng trong nhận thức của người dùng sẽ gia tăng.
Giải pháp cho sự kết nối giữa nhà tuyển dụng và người tìm việc
Nhận thức được những khó khăn của nhà tuyển dụng và ứng viên đi kèm với đó là định hướng góp phần phát triển ngành IT Việt Nam. TopDev cung cấp giải pháp kết nối nhà tuyển dụng và người tìm việc với dịch vụ chính là tin đăng tuyển dụng khối ngành công nghệ, IT.
Với nhiều nỗ lực trong việc tạo nên giao diện website thân thiện, phát triển hàng loạt nội dung kiến thức chuyên môn về lập trình công nghệ và nỗ lực cải thiện chất lượng dịch vụ mỗi ngày, đến nay TopDev đã nhận được sự tin tưởng của nhiều doanh nghiệp lớn nhỏ về việc lựa chọn trang web tuyển dụng IT uy tín, hiệu quả.
Tham khảo giá, ưu đãi dịch vụ tin đăng của TopDev, tính năng / đặc điểm của TopDev so với các kênh tuyển dụng khác trên thị trường, tham khảo những khách hàng đã sử dụng dịch vụ đăng tin tuyển dụng tại TopDev, mời bạn xem tại đây!
Cám ơn bạn đã theo dõi bài viết này, chúc bạn sớm tìm được giải pháp tuyển dụng hiệu quả và nhanh chóng.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Khi làm việc với RESTful APIs, cho một đối tượng data, chúng ta thường phải expose nhiều request URLs khác nhau. Ví dụ, bạn đang làm việc với ứng dụng quản lý thông tin sinh viên, để provide thông tin sinh viên thông qua RESTful APIs, chúng ta có thể sẽ phải expose một số request URLs sau:
Danh sách toàn bộ sinh viên với đầy đủ các trường thông tin
Danh sách tên của tất cả sinh viên
Danh sách sinh viên của một lớp học nào đó
…
Cứ mỗi một nhu cầu lấy thông tin khác nhau của thông tin sinh viên này, chúng ta lại phải expose thêm mới một request URL. Thêm nữa, cho một request URL, ví dụ như request URL để lấy thông tin toàn bộ sinh viên với đầy đủ các trường thông tin, thì cũng không phải tất cả các trường thông tin của sinh viên đều được sử dụng, chúng ta có thể chỉ cần thông tin tên, tuổi của sinh viên để hiển thị, các thông tin khác như địa chỉ, lớp học thì không cần. Việc return các thông tin này là dư thừa và không cần thiết.
Làm thế nào để giải quyết những hạn chế của RESTful API ở trên? Các bạn có thể sử dụng GraphQL.
Giới thiệu GraphQL
GraphQL là ngôn ngữ dùng để thao tác và truy vấn dữ liệu cho API, cung cấp cho client 1 cách thức dễ dàng để request chính xác những gì họ cần, giúp việc phát triển API dễ dàng hơn.
Với GraphQL, chúng ta chỉ cần expose một API cho thông tin sinh viên, client có thể sử dụng API này để query đúng thông tin cần thiết. Cụ thể như thế nào? Trong bài viết này, mình sẽ giới thiệu với các bạn về GraphQL, cách nó làm việc để giải quyết những hạn chế của RESTful API như thế nào các bạn nhé!
So sánh RESTful API và GraphQL
Để thấy rõ sự khác nhau giữa RESTful API và GraphQL, mình sẽ tạo mới một Spring Boot project và implement cả RESTful API và GraphQL để thao tác với thông tin sinh viên mà mình đã đề cập ở trên:
Kết quả:
Ví dụ sử dụng RESTful API
Mình sẽ hiện thực RESTful API trước.
Mình sẽ định nghĩa các request URL trên sử dụng OpenAPI và sử dụng Maven plugin của OpenAPI để generate API contract. Nội dung tập tin student.yaml trong thư mục src/main/resources/api như sau:
openapi: 3.0.3
info:title: Student Information Management Systemversion: 1.0.0
servers:
- url: https://localhost:8081/api
paths:/students:get:operationId: getStudentssummary: Get all students information, can be filtered by clazz name
parameters:- name: clazzin: querydescription: Class of studentsrequired: falseschema:type: stringresponses:200:description: Get all students informationcontent:application/json:schema:type: arrayitems:$ref: '#/components/schemas/Student'example:- id: 1code: '001'name: Khanhage: 30address: 'Binh Dinh'clazz: A- id: 2code: '002'name: Quanage: 25address: 'Ho Chi Minh'clazz: B/students/names:get:operationId: getStudentNamessummary: Get student namesresponses:200:description: Get student informationcontent:application/json:schema:type: arrayitems:type: string
components:schemas:Student:type: objectproperties:id:type: integerformat: int64code:type: stringname:type: stringage:type: integerformat: int64address:type: stringclazz:type: string
Để thao tác với table Student trong database với cấu trúc như sau:
CREATETABLE student (
id bigintNOT NULL,
code varchar(10) NOT NULL,
name varchar(50) NOT NULL,
age bigintNOT NULL,
address varchar(100) DEFAULTNULL,
class varchar(20) NOT NULL,
PRIMARY KEY (id)
)
mình sẽ cấu hình thông tin database trong tập tin application.properties như sau:
Bây giờ, chúng ta sẽ hiện thực tất cả các nhu cầu ở trên chỉ với 1 request URL sử dụng GraphQL các bạn nhé!
Để làm việc với GraphQL, điều đầu tiên chúng ta cần làm là định nghĩa một tập tin schema. Nói nôm na thì tập tin schema này định nghĩa những thông tin mà GraphQL server có thể cung cấp cho client truy vấn data. Nó cũng giống như việc chúng ta định nghĩa API specs sử dụng tập tin .yaml trong OpenAPI vậy các bạn!
Với Spring Boot application thì các bạn có thể định nghĩa một tập tin schema.graphqls nằm trong thư mục src/main/resources/graphql. Cho ví dụ của bài viết này, mình sẽ định nghĩa tập tin schema này với nội dung như sau:
Trong tập tin schema của GraphQL, chúng ta sẽ định nghĩa nhiều loại type khác nhau. Ngoài các type định nghĩa cho các đối tượng data mà chúng ta sẽ provide cho client, trong ví dụ của mình là đối tượng Student, GraphQL còn có 3 type đặc biệt là Query, Mutation và Subscription. Type Query dùng để truy vấn data, type Mutation dùng để thêm, sửa, xoá data còn type Subscription thì tương tự như type Query nhưng kết quả trả về sẽ thay đổi theo thời gian (tương tự như Server Send Event đó các bạn). Trong ví dụ của mình, mình đã định nghĩa type Query với field là students cùng với tham số clazz để filter, kết quả trả về sẽ là một danh sách data với type là Student.
Chúng ta cần implement một Controller để định nghĩa cách mà Spring sẽ lấy data cho chúng ta như sau:
Spring sẽ tự động mapping Query type với annotation @QueryMapping và tên của method chính là tên của query. Ở đây, các bạn còn có thể truyền argument của query sử dụng annotation @Argument.
Để hỗ trợ cho việc testing, Spring cung cấp cho chúng ta một GUI tên là GraphiQL để làm việc với GraphQL, nhưng mặc định GUI này bị disable. Các bạn có thể enable nó bằng cách cấu hình property spring.graphql.graphiql.enabled trong tập tin application.properties như sau:
spring.graphql.graphiql.enabled=true
Bây giờ thì các bạn có thể chạy ứng dụng của chúng ta lên và kiểm tra kết quả rồi!
Khi đi đến địa chỉ http://localhost:8081/graphiql, các bạn sẽ thấy kết quả như sau:
Trong cửa sổ này, bên trái là nơi cho phép chúng ta viết câu truy vấn, còn bên phải là nơi sẽ hiển thị kết quả đó các bạn!
Chúng ta sẽ sử dụng GraphQL query để truy vấn dữ liệu. Một GraphQL query sẽ bắt đầu với “{” và chúng ta sẽ khai báo field mà chúng ta muốn truy vấn. Ví dụ để lấy thông tin tất cả sinh viên với GraphQL, mình sẽ viết query như sau:
{students{idcodenameageaddressclazz}}
Kết quả:
Để lấy danh sách sinh viên của lớp A, mình sẽ viết query như sau:
{students(clazz:"A"){idcodenameageaddressclazz}}
Kết quả:
Còn danh sách tên của tất cả sinh viên thì mình chỉ cần remove các sub-field khác, chỉ giữ lại sub-field name như sau:
{students(clazz:"A"){name}}
Kết quả:
Như các bạn thấy, chỉ với một query mapping của GraphQL cho đối tượng data Student, chúng ta có thể lấy hết thông tin mà chúng ta muốn và thông tin trả về cũng có thể được giới hạn tuỳ theo nhu cầu.
Bài viết được sự cho phép của tác giả Võ Xuân Phong
Nếu bạn vẫn còn đang ngồi trên giảng đường đại học, xin chúc mừng bạn những chia sẻ của mình dưới đây, có thể giúp bạn hiểu và có định hướng rõ ràng hơn mình thời còn là sinh viên. Nếu bạn đã đi làm rồi thì cũng nên tham khảo những chia sẻ này nó có thể giúp bạn ít nhiều.
Thời mình còn là sinh viên, mình rất sợ hai từ thất nghiệp nó ám ảnh mình khiến mình học tập rất chăm chỉ, chỉ mong rằng sự cố gắng của mình sẽ được đền đáp sau đó. Thời điểm đó mình chỉ có một hy vọng duy nhất là được nhận vào một công ty nào đó, để học hỏi và lấy kinh nghiệm, mình cũng không mường tượng được một công ty tốt nó trông như nào, được gì và mất gì khi xin việc vào một công ty. Đến khi vào làm việc tại công ty A, B, C thì mình vẫn chỉ biết cố gắng trau dồi, học hỏi mỗi ngày để có được càng nhiều kiến thức và kinh nghiệm càng tốt. Mình đã cày như một cái máy, thật sự đó. Nhưng chắc chắn đó là cái nhân mình đã gieo, sau gần 4 năm lăn lộn thì mình thấy trước mắt mình có nhiều cánh cửa rộng mở hơn, có nhiều sự lựa chọn hơn và mình có thể đúc kết được thế nào là một công ty tốt để mình có thể cống hiến lâu dài.
Dưới đây có những câu hỏi mà bạn nên tự đặt ra cho bạn, để bạn có thể tìm được con đường đi của mình nhé.
Quy trình và môi trường làm việc
Quy trình làm việc của công ty có hiện đại và phù hợp với xu hướng hay không?, hay nó đã cũ và lỗi thời. Quy trình làm việc rất quan trọng, nó giúp tất cả các thành viên của công ty làm việc một cách khoa học và chuyên nghiệp, nếu như quy trình của công ty không còn phù hợp với xu hướng thì bạn khó có thể được đánh giá cao khi xin vào một công ty khác có quy trình chuẩn hơn. Giả sử như công ty bạn đang sử dụng quy trình Waterfall thay vì Agile.
Bạn có thể học hỏi những công nghệ và những điều mới mẻ tại công ty hay không? Công nghệ thay đổi một cách chóng mặt nên bạn phải chắc rằng mình được cập nhật và học hỏi được những điều mới mẻ nhất.
Leader sẽ là người trực tiếp dẫn dắt, giúp bạn hoàn thiện bản thân và đưa bạn đến những nền tảng cao hơn và hãy tự hỏi bản thân mình những câu hỏi dưới đây nhé:
Leader của bạn có phải là người mà bạn ngưỡng mộ hay không? Bạn có thể học hỏi được gì từ người đó?
Leader của bạn có tiếp nhận ý kiến cá nhân của bạn hay không, họ có bảo thủ hay không?
Người leader này có chỉ số trí tuệ cảm xúc EQ cao hay không?
Họ có cân nhắc và tạo cơ hội để bạn phát triển và hoàn thiện kỹ năng của bạn hay không?
Leader của bạn có công nhận những đóng góp của bạn cho công ty hay không?.
Đồng nghiệp
Những người mà bạn tiếp xúc và giao tiếp hằng ngày, sẽ ảnh hưởng đến một phần nào đó trạng thái cảm xúc và hiệu quả công việc. Thế nên nếu như bạn có những người teammate tốt, luôn hỗ trợ, giúp đỡ và thúc đẩy nhau vì mục đích của team thì thật sự rất may mắn. Còn không thì ít nhất bạn phải có trí tuệ cảm xúc cao, để giải quyết những xung đột và mâu thuẫn không đáng có, chứ không thì mỗi ngày bạn đi làm như mỗi ngày bạn đi xuống địa ngục vậy.
Quá Trình Thăng Tiến
Bạn không ngừng học hỏi để tiến về phía trước và công ty cần có lộ trình rõ ràng để bạn có thể bước lên những nấc thang cao hơn trên con đường sự nghiệp. Không ai muốn làm mãi một vị trí sau nhiều năm cả.
Lương
Bạn hãy thường xuyên tham khảo và tìm hiểu về thị trường việc làm và nhiều công ty khác, với khả năng và vị trí hiện tại của bạn, thì mức lương của bạn có tương xứng với giá trị mà bạn mang lại cho công ty hay không? Công ty của bạn đang trả lương thấp hơn hay cao hơn những công ty khác cùng lĩnh vực.
Tiền lương sẽ giúp bạn trang trải cuộc sống và giúp cho tài chính cá nhân của bạn ngày càng ổn định hơn, thế nên nếu bạn có cảm giác không vui vẻ mấy khi nhận lương thì nên xem xét lại. Tiền lương nên tương xứng với công sức bạn bỏ ra thì lúc đó bạn nhận lương sẽ thấy vui vẻ hơn.
Bảo Hiểm Xã Hội
Khi mình mới ra trường đi làm, cũng như bao bạn khác mình không quan tâm đến vụ bảo hiểm xã hội này. Bảo hiểm xã hội rất quan trọng, nó sẽ là vị cứu tinh của mình khi mình bị mất khả năng lao động, hoặc về hưu thì mình còn có tiền mà dưỡng già. Khi phỏng vấn xin việc bạn nên hỏi HR về mức bảo hiểm xã hội mà công ty đóng cho bạn mỗi tháng nhé, phần lớn các công ty đều đóng bảo hiểm xã hội ở mức lương cơ bản tầm 4 đến 5 triệu khá bèo bọt, những công ty có chế độ và chính sách minh bạch thì sẽ đóng full lương bảo hiểm xã hội cho bạn nhé. Nếu mức lương của bạn bao nhiêu thì sẽ đóng bảo hiểm cho bạn bấy nhiêu tối đa là 29 triệu 800 ngàn theo pháp luật quy định. Bạn hãy suy nghĩ nếu bạn cống hiến cho công ty 10 đến 20 năm thì số tiền bảo hiểm xã hội bạn tích lũy được là bao nhiêu nhé.
Bảo Hiểm Sức Khỏe
Bảo hiểm sức khỏe sẽ chi trả cho bạn khi bạn ốm đau hay phải nằm viện, công ty nên có chế độ bảo hiểm sức khỏe cho bạn nếu không may bạn bị ốm. Mình và các bạn mình hay dùng bảo hiểm này để đi khám răng và trám răng, một năm được mấy triệu chăm sóc răng lận.
Một số lợi ích khác
Số ngày nghỉ lễ và nghỉ phép.
Người phụ thuộc: Tiền này là tiền hỗ trợ hằng tháng nếu như ba, mẹ mình quá tuổi lao động hoặc hỗ trợ cho con cái.
Một số ưu đãi khác cho người thân.
Đồ ăn thức uống
Team fund
Company trip
Còn nhiều ưu đãi khác nữa nếu công ty bạn có 😛
Xem review công ty
Cuối cùng nhưng không kém phần quan trọng, đó là bạn hãy lên google và tìm kiếm để xem review công ty. Bạn sẽ thu thập được nhiều ý kiến và đánh giá của những đồng nghiệp đã và đang làm tại công ty. Đó là cách nhanh nhất mà bạn có thể nắm được tình hình chung của công ty để đưa ra quyết định của riêng mình.
Tóm lại
Nếu bạn đã cố gắng và nỗ lực rất nhiều nhưng vẫn chưa có thành quả, thì bạn chưa chọn đúng môi trường để phát triển mà thôi. Nếu bạn phi thường mà trong môi trường tầm thường thì bạn cũng khó mà tiến xa được. Hãy cứ cố gắng và chờ đợi một cơ hội, một quý nhân, một môi trường giúp bạn trở thành phiên bản tốt nhất của chính mình.
Viettel Digital là đứa con sinh sau đẻ muộn nhưng đầy tâm huyết và khát vọng của Tập đoàn Viettel – Top 1 Nơi làm việc tốt nhất Châu Á năm 2021 do HR Asia đánh giá. VDS tự hào đi tiên phong trong lĩnh vực Fintech nhờ sở hữu cho mình báu vật là những nhân tài. Họ là những chiến binh công nghệ, không ngừng sáng tạo và phát triển bản thân để cùng chung sức xây dựng nên vị thế hùng mạnh cho cái tên Viettel Digital trên thị trường.
Nguyễn Đình Thắng – Kỹ sư phần mềm hệ thống
Đồng hành cùng VDS từ rất sớm, với tư duy sắc bén và tài năng vượt trội, anh Thắng đã đóng góp phát triển Tiền di động – một trong những dự án trọng điểm của VDS. Anh Thắng chia sẻ: “Tôi tham gia dự án Tiền di động khi chỉ là chàng sinh viên chuẩn bị tốt nghiệp, có thể nói là còn “non và xanh” so với những đồng nghiệp khác.”
Anh Thắng cho biết:
“Việc ứng dụng chuyển đối số không chỉ dừng lại ở công cụ, ngôn ngữ lập trình, cấu trúc hệ thống… mà còn ở tư duy của chính người phát triển sản phẩm, họ sẽ định hình từng “nguyên vật liệu” và “cách xây dựng” để tạo nên ngôi nhà cuối cùng cho khách hàng. Với một ngành luôn biến động như Fintech, cũng như với môi trường năng động như VDS, việc luôn linh hoạt và sáng tạo trong công việc là cực kì cần thiết. Đối với tôi, làm sản phẩm phải có máu “liều” và phải liều một cách có cơ sở.”
Nguyễn Thùy Linh – Kỹ sư giải pháp
Nguyễn Thuỳ Linh – cô kỹ sư Giải pháp của VDS là đại diện duy nhất của Việt Nam được Bộ TT&TT đề cử và Hội đồng chuyên gia của Diễn đàn Kinh tế thế giới lựa chọn tham gia chương trình học tập, nghiên cứu các dự án thuộc lĩnh vực Thanh toán Số và Thương mại Số tại trụ sở Trung tâm chuyển đổi công nghiệp 4.0, thuộc Diễn đàn Kinh tế thế giới (C4IR- WEF), San Francisco – Hoa Kỳ. Thùy Linh chia sẻ: “Dự án ấn tượng nhất khi gia nhập VDS là phát triển Tiền di động. Không chỉ đột phá về mặt công nghệ và sản phẩm, Tiền di động còn có ý nghĩa to lớn trong việc phát triển Tài chính toàn diện tới mọi người dân Việt Nam. Nhờ VDS và Tiền di động, tôi mới có cơ hội chạm tay đến WEF”.
“Tôi tin rằng với quyết tâm chuyển đối Số của Chính phủ hiện nay, Việt Nam và Viettel sẽ gần hơn với trình độ phát triển của quốc tế, vì vậy chỉ cần kiên trì học hỏi, không ngừng làm mới bản thân thì ngay tại Việt Nam chúng ta cũng có nhiều cơ hội hơn để tham gia vào các dự án và các công việc ở tầm quốc tế.”, Linh khẳng định.
Gia nhập VDS với vai trò là một kỹ sư phân tích dữ liệu từ hơn 1 năm trước, Hoàng Nam Anh là người đầu tiên của Tập đoàn thi đạt chứng chỉ Senior Big Data Analyst – DASCA – Chứng chỉ nhà nghề của Mỹ về Khoa học dữ liệu.
Sau thời gian tích lũy và nghiên cứu, Nam Anh đã có “đứa con đầu lòng” là Credit Score – Chấm điểm xếp hạng tín dụng. Đặc biệt, Nam Anh là người chủ trì xây dựng hệ thống Recommendation System, đáp ứng yêu cầu cá nhân hóa trải nghiệm người dùng trên Viettel Money bằng ứng dụng phân tích dữ liệu. Nhận thấy hệ thống Recommendation là công nghệ phổ biến trên thế giới hiện nay và được áp dụng cho Netflix; Amazon, Shopee… Nam Anh và cả team dự án đã nghiên cứu tất cả ứng dụng thành công, các nền tảng thuật toán và từ đó đề xuất ra một vài trường hợp có thể đưa vào xây dựng recommendation trên Viettel Money.
Là Tổng Công ty trẻ nhất của Tập đoàn Viettel, Viettel Digital sẽ tiếp tục mang trên vai sứ mệnh đặc biệt đi đến từng ngõ ngách, trao gửi Tài chính số tới tận tay mỗi người và luôn hướng tới những giá trị tốt đẹp cho cuộc sống. VDS tự hào là bến đỗ lý tưởng cho những người trẻ đam mê công nghệ, mang trong mình một bộ óc không thỏa hiệp với cái lỗi thời và luôn nung nấu trong bản thân ngọn lửa nhiệt huyết sẵn sàng rực cháy trên mọi mặt trận.
Khi nhắc đến lập trình di động Cross-Platform, chúng ta không thể không nhắc đến 2 nền tảng lớn nhất hiện nay là React Native và Flutter. Dù ra đời sau (tháng 5/2017 so với tháng 3/2015) nhưng Flutter đang vượt lên và trở thành Framework lập trình di động được yêu thích nhất hiện nay. Trong series bài viết này, mình sẽ cùng các bạn tìm hiểu về Flutter cơ bản, cách tiếp cận làm quen với Flutter và lộ trình học để trở thành 1 lập trình viên Flutter. Series gồm 3 bài viết:
Flutter cơ bản
Học lập trình Flutter
Lộ trình học Flutter
Hôm nay mình sẽ gửi đến các bạn bài viết đầu tiên trong series với nội dung: Flutter cơ bản – giới thiệu về Flutter và tại sao nó đang là framework di động được yêu thích nhất hiện nay. Cùng bắt đầu nhé!
Flutter là gì?
Flutter là 1 framework dành cho việc lập trình di động Cross-Platform, nó giúp các lập trình viên có thể tạo ra các ứng dụng chạy trên nhiều nền tảng như Web, Android, iOS (hiện tại và dự định tương lai Flutter còn có thể build được ứng dụng chạy trên cả Window, MacOS và Linux nữa).
Flutter được tạo ra bởi ông lớn Google và được cho ra mắt vào năm 2017, đến nay Flutter được cho phát hành phiên bản mới nhất 3.1.0 vào cuối tháng 5 vừa qua. Chính Google cũng sử dụng Flutter là phương thức chính để tạo ra các ứng dụng cho hệ điều hành Google Fuchsia – 1 hệ điều hành thời gian thực dựa trên năng lực vi hạt nhân
Flutter sử dụng ngôn ngữ lập trình Dart – một ngôn ngữ hướng đối tượng và tất nhiên cũng được phát triển bởi Google.
Flutter có đầy đủ các tính năng hot nhất hiện nay dành cho lập trình di động: hỗ trợ Hot Reload, Debug Devtool, nhiều IDE support: Android Studio, Visual Code. Các bạn cũng có thể hoàn toàn thử code và tạo ra ứng dụng Flutter mà không cần cài đặt bất cứ thứ gì bằng cách sử dụng Web Editor: https://dartpad.dev/flutter. Tuy nhiên trong series bài viết này mình sẽ hướng dẫn các bạn sử dụng IDE Android Studio, đơn giản vì nó cũng là 1 sản phẩm thuộc về Google khác.
Tại sao Flutter lại được yêu thích bởi các lập trình viên?
Theo thống kê từ Stack Overflow, Flutter đạt số điểm 68,8% về mức độ danh mục công nghệ được yêu thích (từ việc bắt đầu và tiếp tục sử dung nó), trong khi đó số điểm của React Native hiện tại chỉ là 57,9%.
Còn theo Google Trends, mức độ phổ biến của Flutter gần gấp đôi so với React Native.
Câu hỏi đặt ra ở đây là tại sao Flutter lại được yêu thích và quan tâm đến vậy? Để trả lời cho câu hỏi đó, chúng ta cùng đi vào điểm mạnh của Flutter dưới đây:
Đầu tiên phải nhắc đến đó là Flutter chính là con đẻ của Google, 1 ông lớn thực sự với gia tài hệ sinh thái đồ sộ liên quan đến lập trình di động. Đó là hệ điều hành Android, là IDE Android Studio, ngôn ngữ Kotlin, Dart, các thư viện mà gần như ai làm mobile cũng sẽ dùng như Firebase, Google Map, … Và quả thực thì Flutter được lợi rất nhiều từ việc Google cung cấp cho nó rất nhiều các package có sẵn, chỉ cần import vào để sử dụng.
Khác với cách tiếp cận của React Native, Flutter được team Google viết mới hoàn toàn bộ render UI. Điều đó có nghĩa là bạn sẽ có 1 bộ UI chung dành cho các nền tảng khác nhau (Flutter đặt tên cho chúng là các widgets), điều này tạo ra sự thống nhất trên các thiết bị giúp có được sự trải nghiệm tốt hơn cho người dùng.
Phát triển 1 ứng dụng bằng Flutter thực sự rất nhanh. Dart là 1 ngôn ngữ khá dễ hiểu, trong khi Flutter cũng đã cung cấp bộ Widgets và tài liệu thực sự chi tiết dành cho bạn.
Tối ưu về performance: mặc dù là 1 cross-platform, tuy nhiên Flutter lại mang lại được trải nghiệm về hiệu năng ứng dụng rất tốt. Để so sánh với React Native, chúng ta có thể đi sâu 1 chút vào kiến trúc và quy trình làm việc của 2 framework này.
React Native sử dụng JS Bridge để giao tiếp với các native module, đây chính là vị trí thường xuyên gây nghẽn cổ chai trong ứng dụng được viết bằng ngôn ngữ JS này. Flutter thì khác, kiến trúc ngôn ngữ Dart được tạo ra giúp chúng có thể giao tiếp thông qua chính các native interface, tất nhiên nó cũng là 1 dạng bridge, nhưng nó nhanh hơn rất nhiều vì “cầu rộng hơn và lại có nhiều cầu”, yên tâm gần như không bị nghẽn cổ chai được.
Tất nhiên, Framework hay ngôn ngữ nào cũng có nhược điểm của nó. Flutter dù được Google chống lưng rất nhiều, tốc độ phát triển hiện nay rất tốt tuy nhiên nó cũng không tránh được các vấn đề của nó:
Điều đầu tiên đương nhiên là về cộng đồng sử dụng và hỗ trợ. Ra mắt sau nên Flutter hiện nay cũng chưa phải là sự lựa chọn của các công ty hay tập đoàn lớn. Việc làm liên quan đến Flutter còn hạn chế, sẽ phải mất 1 thời gian nữa cùng với sự đầu tư của ông lớn Google thì điều này mới có thể cải thiện tốt lên được.
Flutter chưa đủ hoàn thiện để xử lý các dự án phức tạp. Đây là điểm mấu chốt mà các công ty chưa chọn Flutter làm nền tảng để phát triển 1 ứng dụng lớn của mình. Lý do cơ bản là việc Google sinh ra Flutter là dành cho sự tiện lợi, nhanh chóng, rút ngắn thời gian thử nghiệm và tạo ra 1 ứng dụng. Nếu bạn cần thử nghiệm 1 ứng dụng với chi phí và thời gian eo hẹp, hãy chọn Flutter vì nó rất nhanh; sau đó nếu thành công, hãy cân nhắc việc viết lại ứng dụng bằng native code. Những pattern như Flux, Redux nổi tiếng trên React Native chưa cho thấy sự tiện lợi trên Flutter để có thể giải quyết logic phức tạp; trong khi đó BloC – thứ được Google giới thiệu thì lại cho thấy sự khó hiểu, khó học của nó đối với các lập trình viên.
Kết bài
Trong bài viết đầu tiên của Series này, mình đã giới thiệu cho các bạn về Flutter cơ bản, những đặc trưng thế mạnh của Framework này so với các đối thủ khác hiện nay. Trong các bài viết tiếp theo mình sẽ đi sâu hơn vào cách tiếp cận và học để trở thành 1 lập trình viên Flutter. Cảm ơn sự theo dõi của các bạn.
Bắt đầu với một ngôn ngữ lập trình đòi hỏi cần có những kiến thức tổng quan về nó, trong thế giới của ngôn ngữ lập trình chia thành ngôn ngữ lập trình bậc cao (High level programming languages) và ngôn ngữ lập trình cấp thấp (Low level programming languages).
Vậy điều gì dẫn tới sự khác biệt này, liệu rằng thấp ở đây là trình độ thấp hay dễ hơn, còn cao thì khó và cần năng lực cao hơn để có thể nắm bắt?
Câu trả lời cho câu hỏi hóc búa này sẽ được giải đáp thông qua bài viết dưới đây.
Nhiều không kể xiết nhưng yếu tố nào xác định ngôn ngữ lập trình bậc cao, ngôn ngữ lập trình bậc thấp?
1. Hiểu ngôn ngữ lập trình bậc cao từ bậc thấp
Về Low level programming languages (LLP). Bắt đầu với định nghĩa khô khan từ wiki nha anh em.
A low-level programming language is a programming language that provides little or no abstraction from a computer’s instruction set architecture—commands or functions in the language map that are structurally similar to processor’s instructions
Ngôn ngữ lập trình cấp thấp là ngôn ngữ cung cấp ít hoặc không có sự trừu tượng (abstraction) từ kiến trúc máy tính. Nói chung điều này đề cập tới mã máy hoặc hợp ngữ
Tới đây với người mới bắt đầu tìm hiểu ngôn ngữ lập trình thì vẫn hơi trừu tượng và khó hiểu. Để hình dung đúng về Low level programming, ta cần thêm một đoạn thông tin khác.
Generally, this refers to either machine code or assembly language. Because of the low (hence the word) abstraction between the language and machine language, low-level languages are sometimes described as being “close to the hardware”. Programs written in low-level languages tend to be relatively non-portable, due to being optimized for a certain type of system architecture.
Về tổng quan, ngôn ngữ lập trình cấp thấp là ngôn ngữ lập trình cung cấp ít hoặc không có sự trừu tượng từ kiến trúc tập lệnh của máy tính — các lệnh hoặc chức năng trong bản đồ ngôn ngữ có cấu trúc tương tự như lệnh của bộ xử lý.
Rồi ngon, từ khóa là đây chứ đâu, anh em bám vào 2 cái “không có sự trừu tượng” và “có cấu trúc tương tự lệnh bộ xử lý”. Nắm được hai từ khóa này cũng là yếu tố then chốt giúp ta hiểu về Ngôn ngữ lập trình bậc cao.
1.1 Sự trừu tượng và cấu trúc
Không có sự trừu tượng nói tới việc ngôn ngữ này không gần với ngôn ngữ tự nhiên, còn cấu trúc tương tự lệnh bộ xử lý là đang muốn nói tới mã máy.
Một ví dụ cụ thể của cấu trúc tương tự lệnh bộ xử lý là mã máy (assembly code).
Ví dụ mã máy phía trên đây nhìn phát hiểu ngay là không gần ngôn ngữ tự nhiên. Bạn nào ở bắc thì là “cậu, tớ”, bạn nào ở miền trung là “mô, chi, tê, răng, rứa”, bạn nào ở miền nam thì “mèn đét ơi”. Đấy, những cái đấy là ngôn ngữ gần với tự nhiên.
Điểm này là điểm cốt lõi để phân biệt giữa LLP (ngôn ngữ lập trình bậc thấp) và HLP (ngôn ngữ lập trình bậc cao).
Dưới đây là ví dụ hàm khai báo 2 biến a và b, thực hiện in ra màn hình phép tính a + b. Điều cực kì đơn giản với bạn với C++ hay Java.
Một khi đã hiểu về ngôn ngữ lập trình bậc thấp, ta sẽ dễ dàng hiểu về ngôn ngữ lập trình bậc cao. Cũng vẫn phải bắt đầu với định nghĩa.
A high-level programming language is a programming language with strong abstraction from the details of the computer. In contrast to low-level programming languages, it may use natural language elements, be easier to use, or may automate
Ngôn ngữ lập trình bậc cao là ngôn ngữ lập trình có tính trừu tượng hóa mạnh mẽ từ các chi tiết của máy tính. Ngược lại với các ngôn ngữ lập trình cấp thấp, nó có thể sử dụng các yếu tố ngôn ngữ tự nhiên, dễ sử dụng hơn hoặc có thể tự động hóa
Cùng xem xét ví dụ dưới đây (ngôn ngữ lập trình Java). Đọc từ nào hiểu từ đó, dễ như ăn chè, sau anh em cuộn xuống xem đoạn code đơn giản hơn mà viết bằng assembly nha. Hết hồn hà.
import java.util.Scanner;
public class HelloWorld {
public static void main(String[] args) {
// Tạo scanner instance
// Nhập từ bàn phím
Scanner reader = new Scanner(System.in);
System.out.print("Nhập số: ");
// nextInt() đọc giá tị số từ bàn phím
int number = reader.nextInt();
// println() in ra ngoài màn hình
System.out.println("You entered: " + number);
}
}
Lấy một ví dụ khác về phép bình phương trong toán học. Với C++, ta đơn giản nhân 2 số với nhau để có giá trị bình phương.
int square(int num) {
return num * num;
}
Cũng với hàm xử lý này, nếu chuyển qua ngôn ngữ máy. Kiểu nhìn thấy là lạy chúa trên cao, cái gì thế này.
square(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov eax, DWORD PTR [rbp-4]
imul eax, eax
pop rbp
ret
Một số ngôn ngữ lập trình cấp cao phổ biến là C, C++, Python và Java.
3. Sự khác biệt
Sau khi đã hiểu rõ và nắm bắt được điểm cốt lõi để phân biệt ngôn ngữ lập trình cấp thấp và ngôn ngữ lập trình bậc cao. Anh em cùng đi sâu hơn tìm hiểu sự khác biệt của 2 ông thần này nha:
Ngôn ngữ lập trình cấp cao
Ngôn ngữ lập trình cấp thấp
It is programmer friendly language. Là ngôn ngữ thân thiện với ngôn ngữ tự nhiên.
It is a machine friendly language. Ngôn ngữ thân thiện với mã máy.
High level language is less memory efficient. Sử dụng bộ nhớ kém hiệu quả hơn
Low level language is high memory efficient. Sử dụng bộ nhớ hiểu quả
It is easy to understand. Dễ hiểu, rõ là vậy rồi
It is tough to understand. Khó hiểu, cũng rõ là vậy lun.
It is simple to debug. Dễ để debug tìm lỗi
It is complex to debug comparatively. Khó để debug và tìm kiếm lỗi
It is simple to maintain. Dễ dàng để bảo trì nâng cấp
It is complex to maintain comparatively. Khó để bảo trì nâng cấp
It is portable. Có thể chạy ở nhiều môi trường
It is non-portable. Thường set cứng và khó thay đổi
It can run on any platform. Có thể chạy trên bất cứ nền tảng nào
It is machine-dependent. Phụ thuộc vào máy
Từ sự so sánh trên đây, ngôn ngữ lập trình cấp thấp cũng không hẳn là “thấp” ở một số tiêu chí, nếu xét về sử dụng và quản lý memory, một số ngôn ngữ lập trình cấp cao vẫn chưa thể so kèo được với “ngôn ngữ lập trình cấp thấp”.
Vừa qua, các thí sinh đã hoàn thành kỳ thi Tốt nghiệp THPT 2022. Đề thi các môn năm nay được đánh giá có sự phân hóa cao hơn so với năm ngoái. Tuy nhiên, để có chiến lược chọn trường thông minh, các bạn học sinh cần dự đoán được số điểm của bản thân, đồng thời đánh giá khả năng đậu vào trường dựa vào điểm chuẩn năm ngoái.
Cho đến thời điểm hiện tại, ngành Công nghệ thông tin vẫn chiếm được sự quan tâm của nhiều bạn trẻ đam mê khối ngành Kỹ thuật với mức điểm đầu vào cao nhất trong nhóm ngành này. Điểm chuẩn ngành CNTT – IT của những trường thuộc top đầu được dự đoán không có biến động nhiều so với các năm trước.
SQL là một ngôn ngữ không còn xa lạ với mọi lập trình viên và đối với với lập trình viên backend việc làm chủ được SQL là một điều rất quan trọng. Trong quá trình làm việc của mình với SQL mình đã tham khảo rất nhiều nguồn để tối ưu câu truy vấn hiểu được hoạt động của SQL. Các bài nói về tối ưu với SQL trên mạng là rất nhiều nhưng mình chưa tìm thấy có một bài nào tổng hợp các kỹ thuật nên dùng để tối ưu SQL. Bài viết này mình sẽ chia sẻ những kỹ thuật mình đang sử dụng để tối ưu hệ thống của mình với SQL cụ thể hơn là MySQL vì nhiều kiến thức mình chưa thử ở các loại SQL khác.
Bài này sẽ dựa trên kinh nghiệm cá nhân nên mong được sự đóng góp của mọi người. Mình cập nhật bài viết này liên tục để update những kỹ thuật mới nhất mình sử dụng.
Index là gì?
Index là một khái niệm rất quan trọng trong SQL, mọi người nghe thấy nó và sử dụng nó hằng ngày nhưng không hẳn mọi người đều có thể hiểu được cách một Database xây dựng index. Do đó khi một câu query của mọi người bị chậm thì rất khó có thể tạo ra index tối ưu.
Trong lĩnh vực dữ liệu index giúp chỉ tới vị trí của một phần tử trong một cấu trúc dữ liệu như mảng hoặc danh sách. Nó giúp truy cập và quản lý dữ liệu một cách hiệu quả.
Theo mình tìm hiểu thì các SQL database thường sẽ tổ chức index dưới 2 dạng:
B-tree: Dựa theo kiến trúc của cây cân bằng. Hỗ trợ đa dạng query hơn.
Hash: Dựa theo cấu trúc dữ liệu Hash-Table. Dạng này sẽ hỗ trợ dạng = rất tốt nhưng lại không hỗ trợ dạng range query (>,<,>=,<=)
Và có thêm một dạng index nữa cho full text search là inverted index tại bài này mình xin phép không nói đến dạng này ạ.
Hash ít được dùng hiện nay và mình cũng chưa từng sử dụng nó trong project thực tế nên bài này mình chỉ nói đến dạng B-tree.
Các hình ảnh dưới đây mình lấy từ SQL Performance explained. Mọi người mua sách ủng hộ tác giả nhé. Quyển sách rất hay dạy chúng ta mọi thứ liên quan đến index.
Index data structure
Để hiểu được index chúng ta cần phải biết được cấu trúc dữ liệu của một index. Giả sử ta tạo một index trên column 2 dạng số. Database sẽ tạo ra một dạng cấu trúc dữ liệu B-tree dựa theo các dữ liệu có trong column 2 và các dữ liệu này sẽ được sắp xếp như hình bên dưới.
Leaf Nodes
Trong hình bên trên chúng ta sẽ chú ý đến các Leaf Nodes các Node này sẽ cung cấp cho chúng ta địa chỉ để đọc dữ liệu từ bảng được lưu trong cơ sở dữ liệu.
Tất nhiên sẽ có các Leaf Nodes không được các Branch Node trỏ tới nên các Leaf Node nãy sẽ được liên kết với nhau bằng danh sách liên kết đôi để đảm bảo được việc duyệt dữ liệu trong cây index.
Index Traversal
Tiếp đến chúng ta sẽ xem xét đến cách duyệt dữ liệu trên index để biết được tại sao nó lại nhanh hơn với việc scan table rất nhiều.
Giả sử chúng ta tìm dữ liệu bản ghi có giá trị là 57. Database sẽ bắt đầu duyệt từ gốc của cây index qua các Branch Node khác nhau cho đến khi đến đầu của Leaf Nodes. Tiếp tục duyệt theo qua các Leaf Node để tìm được giá trị 57.
Vì cây index đã được sắp xếp nên việc duyệt này sẽ rất nhanh và phụ thuộc vào độ sâu của cây và số lượng dữ liệu có trong 1 Node (vài KB và không đổi).
Với các thuật toán phát triển cây index thì cây index sẽ được gọi là đứa trẻ còi cọc so với độ phát triền của các Leaf Nodes vì vậy duyệt cây index cho chúng ta tốc độ nhanh hơn scan table.
Theo ví dụ bên trên thì một Branch Node sẽ chứa 4 giá trị vậy ta sẽ tính được độ sâu của cây theo công thức sau : Log4(số lượng phần tử của Branch Node).
Database sẽ tối ưu việc chọn số lượng phần tử sẽ tham gia cây index sao cho cây có độ sâu thấp nhất.
Ta có bảng dữ liệu sau để thấy rõ hơn độ lớn của cây sẽ phát triển chậm như thế nào nếu mỗi Branch Node có 4 phần tử.
Tạo index để tối ưu truy vấn
Chúng ta đã hiểu index là gì và tại sao khi sử dụng index lại cho chúng ta kết quả tốt hơn. Việc tiếp theo là áp dụng vào các trường hợp thực tế.
Có một lưu ý là trường bạn dùng để đánh index thì nên ít giá trị Null vì giá trị này gây khó cho database trong quá trình tạo cây index
Where Clause
query1
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
Với câu query này chúng ta chỉ cần tạo index theo trường employee_id để đạt được tốc độ tối ưu cho câu query.
query2
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123and subsidiary_id = 30
Giả sử employee_id không còn là unique nữa (trường hợp hợp nhất 2 công ty chẳng hạn) thì việc đánh index trên một trường employee_id sẽ không phải cách tối ưu nhất dành cho câu query trên.
Tại đây chúng ta cần đánh index trên 2 trường employee_id và subsidiary_id.
Việc đánh query trên >=2 trường khác nhau được gọi là concatenated index. Việc đánh index khiến database sắp xếp dữ liệu theo theo trường đứng đầu trước sau đó sẽ sắp xếp theo trường thứ 2.
Vậy nên việc chọn thứ tự các trường trong index dạng này là rất quan trọng ảnh hưởng trực tiếp đến hiệu năng của index.
Lời khuyên của mình cũng như sách mình đọc và nghiên cứu thì hãy chọn trường có selective nhất đứng đầu tiên. Vì các trường đó có tính chọn lọc cao (selective) thì khi tạo cây index sẽ có độ sâu thấp hơn. Điều này đúng cho các loại database có khái niệm concatenated index.
query3
SELECT first_name, last_name
FROM employees
WHERE employee_id between123and500and subsidiary_id = 30
Tương tự như câu query2 tại đây việc employee_id là unique thì chúng ta cần phải đánh index trên cả 2 trường.Và ưu tiên điều kiện bằng = trước như thế sẽ tối ưu được câu query
query4
SELECT first_name, last_name
FROM employees
WHERE employee_id between123and500
SELECT first_name, last_name
FROM employees
WHERE employee_id between123and500and subsidiary_id = 30
Chúng ta có 2 query thì chúng ta chỉ cần tạo 1 index cho 2 trường employee_id và subsidiary_id với employee_id đứng đầu. Mặc dù cách đánh index như query3 mới là tối ưu nhất nhưng cũng nên tạo ít index hơn.
Vì dữ liệu sẽ được sắp xếp theo employee_id nên chúng ta sẽ dùng được index này cho 2 câu query.
Đến đây mọi người tự suy luận tiếp về đánh index cho lớn hơn 2 trường nhé chỉ cần nhớ là index là cây sắp xếp và duyệt index giống duyệt cây là có thể suy luận ra thôi.
query5
SELECT first_name, last_name, date_of_birth
FROM employees
WHEREUPPER(last_name) = "DEMTV"
Việc sử dụng các function trong câu query thì phải đánh index cả function chứ không đánh trên trường được.
Tại đây chúng ta tạo index như sau CREATE INDEX emp_up_name ON employees (UPPER(last_name));
query6
SELECT first_name, last_name, date_of_birth
FROM employees
WHEREUPPER(last_name) < ?
AND date_of_birth < ?
Nếu câu query dạng này thì không thể đánh 1 index để thỏa mãn 2 range query được.
Vì vậy tại đây mình sẽ chọn đánh index trường nào có khả năng sau khi lọc bằng index xong ít phải lọc trong database nhất có thể. Hoặc có thể đánh 2 index cho cả 2 trường để database thực hiện merge dữ liệu và được gọi là Index Merge.
Câu hỏi nếu cùng câu query sử dụng 1 index có thể giúp bạn quét hết trường hợp và việc tạo 2 index để database gộp lại thì chọn cái nào? Tất nhiên là chọn 1 index.
Slow index
Index cho câu query thực hiện nhanh hơn điều này quá quen rồi nhưng bạn có thể tạo index cho query thực hiện chậm hơn hay không?
Câu trả lời là có nhé. Việc Tạo index không cẩn thận không hề giúp câu select của bạn nhanh hơn ngược lại khiến nó chậm hơn và hiển nhiên index sẽ khiến cho insert, update cũng chậm hơn dẫn đến thiệt cả 2 đường.
select *
fromuserswhere sex='M'andname='demtv'
Tại đây nếu bạn không nắm chắc về index có thể bạn sẽ tạo index trên trường sex.
Với câu query này và trong bảng users lớn và chỉ chứa 90% là sex='M' điều này sẽ khiến query này nếu dùng index sẽ chậm hơn với việc scan toàn bộ bảng.
Lý do khiến câu query trên chậm mặc dù đã sử dụng index là vì khi database sử dụng index trên thì nó sẽ nhận được các địa chỉ ngẫu nhiênkhông nằm cạnh nhau trong bảng. Tiếp đó nó sẽ phải lân lượt đi vào từng địa chỉ này để lọc ra dữ liệu.
Điều này sẽ là chậm hơn rất nhiều việc scan bảng từ đầu đến cuối vì việc scan sẽ chỉ là đọc các bản ghi liên tiếp nhau.
Tất nhiên thực tế sẽ không ai đánh index kiểu thế cả nhưng mọi người cần phải chú ý trường hợp sau khi lọc qua index rồi mà vẫn phải duyệt quá nhiều dữ liệu trong bảng. Tuân theo nguyên tắc chọn trường selective đánh index là một cách tránh được trường hợp này.
order by, group by
Việc đánh index cũng giúp ích rất nhiều đến các câu queryorder by hay group by vì làm trên tập sắp xếp lúc nào chẳng tiết kiệm hơn.
Một trong các phép quan trọng hay được sử dụng nữa là phép tính Join và nắm được một số nguyên tắc cơ bản để giúp join nhanh hơn là điều cần thiết.
Có 2 thuật toán chính được các database sử dụng khi thực hiện join 2 bảng dữ liệu đó là:
Hash Join (Mysql version 8 trở lên mới hỗ trợ thuật toán join này)
Nested Loop Join
Nested Loop Join
Đây là thuật toán phổ biến nhất và được áp dụng trong rất nhiều loại database khác nhau vậy nên ta sẽ tìm cách tối ưu phép tính join này trước. Nghe tên thì chắc các bạn cũng đoán ra được là nó sẽ thực hiện 2 vòng lặp để kiểm tra giữ liệu của 2 bảng.
Ta có query sau:
SELECT e0_.employee_id AS employee_id0
-- MORE COLUMNSFROM employees e0_
JOIN sales s1_
ON e0_.subsidiary_id = s1_.subsidiary_id
AND e0_.employee_id = s1_.employee_id
WHEREUPPER(e0_.last_name) LIKE'WIND%';
Và chúng ta tạo 2 index :
CREATEINDEX emp_up_name ON employees (UPPER(last_name));
CREATEINDEX sales_emp ON sales (subsidiary_id, employee_id);
Chúng ta sẽ có query plan sau :
Ở đây ta thấy Database đã sử dụng cả 2 index để thực hiện phép join sẽ nhanh hơn.
emp_up_name để access và filter trường last_name
sales_emp để thực hiện phép tìm kiếm tất cả những bản ghi tìm thấy sau khi UPPER(e0_.last_name) LIKE 'WIND%'; trong bảng sales
Như thế kết luận rằng đánh index trên trường dùng để join sẽ khiến cho câu join query sẽ nhanh hơn.
Vậy chúng ta đánh 3 index liệu rằng có giúp câu query nhanh hơn không?
CREATEINDEX emp_up_name ON employees (UPPER(last_name));
CREATEINDEX sales_emp ON sales (subsidiary_id, employee_id);
CREATEINDEX emp_up_emp ON sales (subsidiary_id, employee_id);
Câu trả lời là hoàn toàn không? Việc database sử dụng thuật toán Nested Loop Join thì chúng ta chỉ cần đánh index cho bảng nằm bên phải mà thôi.
Ví dụ Khi thực hiện join bảng A,B bằng trường c thì ta chỉ cần đánh index trên trường c của bảng B mà thôi. Nhưng thực tế databasekhông nhất thiết sẽ dữ lại thứ tự join cho bạn vì khi thay đổi thứ tứ join thì vẫn giữ được kết quả cuối nhưng sẽ ảnh hưởng rất nhiều đến performance của Database.
Có một quy tắc chung là Database sẽ luôn sắp xếp sao cho nó ít phải lookup bên bảng còn lại càng ít càng tốt. Theo query bên trên dù ta đảo ngược lại vị trí của bảng employees và bảng sales thì database vẫn sẽ đảo lại thứ tứ để đưa ra phương án join tốt nhất.
Lời Khuyên là nếu bạn không chắc chắn biết được bảng nào sẽ là bảng bên phải thì hãy nên sẽ dũng explain query. Và đừng join nhiều bảng quá không bộ optimize của Database sẽ hơi vất vả chọn thứ tự cho bạn đấy.
Nested Loop Join With ORM
Thực tế hiện nay chúng ta thường xuyên sử dụng ORM để thao tác với Database vậy nên chúng ta nên biết được ORM sẽ thực hiện phương pháp Nested Loop Join này như thế nào.
Nếu không cẩn thận thì khi sử dụng ORM rất có khả năng bạn sẽ gặp phải 1 vấn đề là N+1 select problem. Thay vì gửi 1 câu lệnh Join lên database để nhận lại kết quả thì ORM bạn đang dùng sẽ gửi N+1 câu query khác nhau để lấy dữ liệu về.
Ví dụ như câu query trên rất có thể loại ORM của bạn sẽ thực hiện các phép tính sau:
select employees0_.subsidiary_id as subsidiary1_0_
-- MORE COLUMNSfrom employees employees0_
whereupper(employees0_.last_name) like ?
select sales0_.subsidiary_id as subsidiary4_0_1_
-- MORE COLUMNSfrom sales sales0_
where sales0_.subsidiary_id=?
and sales0_.employee_id=?
select sales0_.subsidiary_id as subsidiary4_0_1_
-- MORE COLUMNSfrom sales sales0_
where sales0_.subsidiary_id=?
and sales0_.employee_id=?
Đầy tiên sẽ query lấy ra các bản ghi employee trước sau đó với từng bản ghi employee sẽ thực hiện 1 câu select nữa để lấy kết quả. Thực sự đây đúng là điều mà database thực sự sẽ làm khi bản gửi một câu join query đầy đủ với thuật toán Nested Loop Join nhưng nó sẽ tiết kiệm được rất nhiều thời gian giao tiếp giữa server và client.
Vậy nên các bạn nên tránh sảy ra trường hợp này nếu bạn thật sự muốn join 2 bảng. Hãy show sql của ORM bạn đang sử dụng ra để kiểm tra và search trên mạng cách khác phục nhé.
Hash Join
Đây là một thuật toán giúp ta tiết kiệm thời gian join hơn rất nhiều so với Nested Loop Join vì nó sẽ sử dụng cấu trúc dữ liệu Hash Table để lưu dữ liệu của 1 bảng lại. Nhưng không có gì là hoàn hảo cả vì sử dụng hash table nên nó sẽ rất tốn bộ nhớ.
Ta có query sau :
SELECT *
FROM sales s
JOIN employees e ON (s.subsidiary_id = e.subsidiary_id
AND s.employee_id = e.employee_id )
WHERE s.sale_date > trunc(sysdate) - INTERVAL'6'MONTH
Ta sẽ có query plan cho query này:
Database sẽ load hết dữ liệu 1 bảng vào hash-table trước như ở đây ta thấy nó sẽ load bảng employees vì nó có kích thước nhỏ hơn. Với dạng Join này chúng ta chỉ cần đánh index tại where vì khi thực hiện join nó đã sử dụng hash-table nên việc index cho trường cần join là không cần thiết.
Ta tạo index sau và sẽ có một query plan :
Vậy việc biết được database bạn đang sử dụng đang sử dụng join algorithms nào là điều rất cần thiết để biết được cách nâng cao hiệu năng của phép join.
Theo như tài liệu của Mysql thì phiên bản 8.0.18 mới hỗ trợ loại join này và nó cũng sẽ cung cấp cho bạn một số config như : join_buffer_size, open_files_limit. Bạn nên tham khảo tại Link Mysql-Doc. Tại đây sẽ mô tả cho bạn biết khi nào sẽ dùng hash join và cách tối ưu phép tính toán này.
Join Decomposition
Join Decomposition là kỹ thuật dùng để tách một câu join của bạn thành nhiều câu query khác nhau và sẽ thực hiện join trên Application của bạn để tối ưu hóa được các loại cache bạn đã lưu cũng như mở rộng database.
Cụ thể ta xét query sau :
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
Nếu sử dụng kỹ thuật Join Decomposition thì sẽ biến thành 3 câu query như sau:
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);
Bạn nhìn thấy sự lãng phí nhưng nếu bạn đã cache được bảng tag và bảng tag_post trong memory của Application thì nó chỉ cần thực hiện đúng query cuối mà thôi. Điều này tận dụng tối đa cache của bạn cũng như khiến Application nhanh hơn.
Một ưu điểm nữa là ba bảng tag, tag_post, post có thể lưu ở các server khác nhau điều đó khiến mở rộng database là dễ.
Trên thực thế phương pháp này được sử dụng rất nhiều trong các high-performance applications và chúng ta cũng hoàn toàn áp dụng được nó vì thực tế trừ màn hình dành cho admin các phép join đều khá đơn giản.
IN
Với Mysql version 5.7 thì bạn làm ơn đừng sử dụng câu query dạng này :
SELECT * FROM sakila.film
WHERE film_id IN(
SELECT film_id FROM sakila.film_actor WHERE actor_id = 1);
Vì nếu bạn mong muốn Mysql 5.7 se thực hiện sub query trong lệnh IN trước thì nó làm ngược lại đó. Hãy nhìn cách nó làm
Nó sẽ quét hết bảng film trước sau đó với thực hiện so sánh với sub query. Nếu dùng Mysql 5.7 thì bạn nên thay đổi nếu có query dạng này sang dạng join. Đến phiên bản Mysql 8 thì điều này đã được cải tiến nó sẽ thực hiện câu sub query trước.
Chopping Up a Query
Kỹ thuật này mình dùng nhiều trong quá trình xóa dữ liệu với các bảng không có partition theo range.
Nghĩa là thay vì xóa 1 năm dữ liệu thì mình sẽ viết code để xóa từng tuần 1 điều này khiến query của mình thực hiện nhanh hơn và khiến database phải lock dữ liệu ít hơn dẫn đến database không bị cao tải. Trước khi biết đến điều này mình đã phải chờ hàng tiếng đồng hồ để database thực hiện phép delete và nhiều khi mình phải Kill câu query ngu ngốc đó đi. Hy vọng các bạn không trải qua những thứ đau thương như mình.
Một ví dụ điển hình nữa là khi alter một bảng lớn trong sql. Các bạn chắc trải qua cảm giác câu lệnh alter của mình sẽ chạy mất hàng tiếng đồng hồ có khi là hơn thế nữa. Nguyên nhân của việc này là Mysql sẽ tạo ra một bảng mới và copy tất cả dữ liệu của bảng cũ sang bảng mới và trong suốt quá trình này bảng cũ sẽ bị locked. Nếu bảng cần alter có size quá lớn thì đây là vấn đề.
Áp dụng Chopping Up a Query ta sẽ làm như sau. Tạo một bảng mới sau đó copy từng chút một từ bảng mới sang bảng cũ (khoảng tầm 1000 row). Nhưng trong quá trình copy này sẽ có luồng thay đổi giá trị của bảng cũ như : delete,update,… Bạn cần tạo thêm các trigger để khi có update vào bảng cũ thì sẽ update vào bảng mới luôn hoặc update ra một bảng lưu thay đổi nữa cuối cùng sẽ thực hiện update giá trị của bảng thay đổi vào bảng mới.
Có một cách nữa để không phải dùng trigger mình để Link github cho các bạn tham khảo : github.com/github/gh-ost
Partition
Cùng với việc tạo index thì việc tạo partition cũng giúp câu query của bạn có tốc độ nhanh hơn.
Partition trong sql sẽ phân chia bảng của bạn ra thành nhiều bảng nhỏ hơn. Do đó khi câu query của bạn phù hợp với partition nào thì database chỉ cần đọc partition đó lên thôi điều này sẽ giúp câu query nhanh hơn nhiều.
Partition rất được chú trọng trong các distributed database nhất là với các loại noSql nó được nhắc đến rất nhiều. Vì khi chia partition một cách hợp lý thì partition sẽ có thể được lưu ở các server khác nhau khiến cho tăng được hiệu năng query vì câu query của bạn sẽ được tính toán trên nhiều máy thay vì 1 máy.
Trong Sql thì mình dùng chủ yếu dạng range partition chia dữ liệu của mình theo thời gian để thực hiện query nhanh hơn và khi cần thì xóa 1 partition sẽ nhanh hơn rất nhiều việc xóa bằng lệnh delete.
Có 2 dạng partition :
Hash
Range
Lưu ý khi chia partition
Một bảng trong Sql của bạn có nhiều partition thì thực tế nó sẽ là một bảng Logic chứa nhiều bảng Vật lý bên dưới. Nghĩa là khi bạn tạo index trên bảng có partition thì nó sẽ là index của nhiều bảng khác nhau.
Vậy nên khi query dữ liệu mà nằm trên nhiều partition thì mặc dù bạn đã index trên trường dùng để partition nhưng nó sẽ là query trên nhiều bảng khác nhau và dùng nhiều cây index khác nhau điều đó khiến câu query sẽ không tận dụng được tối đa index cũng như partition.
Vậy với partition dạng range thì đừng chia range quá nhỏ (mỗi ngày một partition) và số lượng partition có thể có cũng có giới hạn ví dụ Myslq sẽ có tối đa 8192 cho một bảng dữ liệu.
Type of column
Khi thiết kế database thì chỉ nên chọn kiểu dữ liệu vừa đủ cho cột bạn đang sử dụng. Kiểu dữ liệu càng nhỏ sẽ giúp CPU tính toán càng nhanh cũng như chiếm dung lượng nhỏ khi lưu.
Một sai lầm phổ biến mình thấy các bạn hay mắc đó là dùng string để lưu kiểu số. Và dùng các kiểu số quá lớn để lưu số nhỏ.
Bulk insert/update
Insert
Câu hỏi là bạn muốn insert 1 triệu dữ liệu vào database thì cách nào sẽ là cách tối ưu nhất. Nhiều bạn sẽ trả lời ngay là sử dụng batch insert của các framework của các bạn hay sử dụng. Điều đó đúng nhưng chúng ta nên biết câu lệnh sql sẽ là gì và các bạn khi sử dụng các orm framework cũng nên cẩn thận vì nó cũng có rất nhiều cú lừa.
Câu lệnh insert dữ liệu một cách nhanh nhất vào database là dạng :
Đây sẽ là gửi nhiều câu insert lên một lúc không phải dạng bulk insert. Để khắc phục điều này thì bạn nên sử dụng một config của jdbc là rewriteBatchedStatements=true. Trước khi gửi lên sql server thì jdbc sẽ thực hiện rewrite query của bạn thành dạng có thể insert nhanh nhất.
Update
Bây giờ mong muốn update1 triệu dữ liệu vào database thì cách nào sẽ là nhanh nhất. Cũng tương tự như insert các database cung cấp cho chúng ta query sau để thực hiện update nhanh nhất.
Khi học trong trường đại học và các bài tutorial dành cho người mới mình đã từng đọc cũng như các framework nổi tiếng đang thực hiện phân trang bằng query này.
SELECT film_id, description FROM sakila.film ORDERBY title LIMIT50, 5;
Điều này sẽ trở lên rất tốn chi phí nếu offset của bạn quá lớn giả sử LIMIT 10000, 20 thì database sẽ thực hiện tạo ra 10020 của câu query và sau đó vât đi 10000 kết quả.
Mình khuyên mọi người nên chuyển sang một dạng query khác như :
SELECT * FROM sakila.rental
WHERE rental_id < 16030ORDERBY rental_id DESCLIMIT20;
Dạng này thì bạn cần một trường unique. Mình sẽ để Link để mọi người tham khảo tốc độ query sẽ tốt hơn như thế nào khi chuyển sang dạng này.
Với dạng paging theo kiểu limit,order by mình thường xuyên sử dụng trong các job tạo báo cáo vì nó giúp mình lấy hết dữ liệu ra nhưng không gây out of memory cũng như nhanh hơn kiểu limit,offset rất nhiều vì dữ liệu cần lấy sẽ khiến cho offset là rất lớn.
Một điểm tối ưu nữa của phương pháp này là rất có thể order by sẽ tận dụng được index.
Query – Strategery
Khi thực hiện select Mysql cung cấp cho các bạn 3 loại query khác nhau:
normal
cursor
stream
Thật sự cách đây một năm thì mình không biết được là Mysql cung cấp cho chúng ta 3 loại query khác nhau cho đến khi mình gặp bài toán cần phải lấy một lượng lớn dữ liệu trong Mysql ra một cách nhanh nhất và không gây out of memory. Trước đó mình đã sử dụng dạng cải tiến của Paging như đã trình bày ở bên trên nhưng nó vẫn chưa phải là cách nhanh nhất.
Mình sẽ đính kèm Link về các dạng query này : https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-implementation-notes.html
Normal
Bạn cần lấy hết dữ liệu của bảng film để lưu xuống file. Bạn thực hiện câu query sau :
SELECT * FROM sakila.film;
Khi các bạn sử dụng ORM để lấy dữ liệu ra và nó sẽ load hết dữ liệu vào RAM của bạn và nếu bảng film to quá thì nó sẽ gây lên out of memory.
Tại đây bạn nghĩ mình nên sử dụng trực tiếp jdbc để lấy dữ liệu ra vì nó trả kết quả vào các Resultset và có các hàm next() để lấy dữ liệu và bạn hy vọng nó sẽ cache 1 phần dưới Application và khi nào hết sẽ thực hiện gọi lên mysql server để lấy kết quả về. Bạn vui vẻ thực hiện và kết quả vấn là out of memory.
Khi bạn không config gì đặc biệt thì jdbc sẽ sử dụng dạng query này cho bạn. Nó sẽ lấy hết dữ liệu từ sql server xuống lưu trong RAM và bạn sẽ lấy kết quả từ RAM ra.
Dạng này sẽ phù hợp với hầu như mọi yêu cầu của bạn trừ trường hợp bạn muốn lấy quá nhiều dữ liệu. Nếu muốn lấy quá nhiều dữ liệu mà không muốn out of mem thì hãy sữ dụng Paging kết với với dạng query này.
Cursor
Cũng đề bài như trên nhưng với một số config nhỏ như sau:
thì nó sẽ không fetch hết dữ liệu về Application cho bạn nữa và chỉ giới hạn 100 kết quả một lần nó sẽ không gây tăng memory cho hệ thống của bạn.
Nhưng khi sử dụng dạng query này nó có các nhược điểm sau :
Tăng tải lên sql server : Server sẽ phải thực hiện tính toán câu query sau đó tạo một vùng nhớ tạm thời để lưu kết quả của câu query sau khi lưu hết kết quả vào vùng nhớ tạm thời đó thì mới trả lại cho client cuối cùng sẽ xóa vùng nhớ đó đi. Điều này thật sự tốn kém đó.
Kết quả sẽ lâu hơn vì phải chờ server lưu kết quả xuống ổ đĩa xong thì mới có thể trả lại kết quả cho client
Mình nghĩ không nên dùng loại này.
Stream
Đây là dạng query nhanh nhất bạn có thể sử dụng để lấy dữ liệu từ mysql ra và không gây out of memory.
Cũng là đề bài của loại normal với các config sau jdbc và server sẽ thực hiện trả kết quả dưới dạng stream :
Với từng loại ORM khác nhau sẽ có cách cho các bạn config khác nhau nên ở đây mình chỉ config cho jdbc.
Với dạng này khi nào bạn thật sự cần dữ liệu thì nó mới fetch dữ liệu đó từ server về cho bạn.
Nếu câu query của bạn quá phức tạp và việc sử dụng paging với dạng normal khiến mất quá nhiều thời gian thì bạn mới suy nghĩ chuyển sang dạng stream này vì nó cũng có một số nhược điểm sau :
Khi nhận được kết quả thì connection chưa thể sử dụng để thực hiện query mới được nếu bạn trả connection vào pool thì sẽ sảy ra lỗi nếu hệ thống dùng connection đó query tiếp.
Phải tốn chi phí duy trì connection đến khi lấy hết dữ liệu và nếu không may nó bị mất kết nối thì sẽ có lỗi sảy ra.
Tổng kết
Bài này tổng hợp hết kiến thức của mình đã thực sự đã dùng trong các dữ án để nâng cao hiệu năng tổng thể khi làm việc với mysql. Mình có thể update thêm vào bài này nếu mình tìm được một điều gì đó hay hơn hoặc là mình nhớ ra điều gì đó.
Vì đây là bài viết tổng hợp nên có rất nhiều phần mình chỉ tóm gón lại cách sử dụng nhưng chưa nói cụ thể tại sao lại như thế nên các bạn nên search các tài liệu khác để nắm rõ hơn những phần đó hoặc ủng hộ mình để mình ra phần tiếp theo nhé. Hãy vote sao vì nó miễn phí.
Kiến thức mình có là do đồng nghiệp cung cấp khi làm các bài toán và từ 2 quyển sách rất tuyệt vời sau:
SQL Performance Explain. Cảm ơn thầy Trần Việt Trung đã giúp em có kiến thức đầu đời này.
High Performance Mysql. Cảm ơn anh Lâm đồng nghiệp đã cho em thêm 1 tài liệu hay.
Mình khuyên các bạn đọc bài này của mình là có chỗ nào không hiểu thì đừng vội tin những gì mình viết hãy thực hành luôn điều đó và khiến nó thành kiến thức của các bạn mình cũng đã bị nhiều bài tutorial trên mạng lừa nhiều rồi nên bạn đừng tin ai cả. Lập trình là môn thực hành
Bài này là rất dài hy vọng các bạn có thể đọc hết và vote một sao trên github để ủng hộ mình nếu có ích cho các bạn.
Từ trước tới giờ mình tùy biến VSCode rất nhiều và cũng có nhiều người hỏi về các đoạn code tùy biến đó, người này hỏi, người kia hỏi cho nên mình viết luôn bài này tổng hợp code những cái tùy biến đấy cho các bạn luôn.
Các bạn thấy là code rất là dài đúng không ? Mình nghiên cứu và làm ra đấy. Một lưu ý là đôi khi các bạn áp dụng vào nó không ra kết quả giống hình minh họa vì khác theme thì class nó sẽ khác, ở video ở trên có chỉ chi tiết rồi, các bạn tự tìm ra class tương ứng và áp dụng code styles mình chia sẻ là sẽ được thôi nhen.
Tùy biến active tab line gradient
Sử dụng đoạn code này thì khi active tab sẽ có một đường line ở trên cái tab khi mà nó active trong VSCode và nó sẽ chạy qua chạy lại với nhiều màu sắc cho các bạn
Nhiều bạn hỏi mình sao làm cho chỗ này nó có font chữ khác thì mình cũng chia sẻ cho các bạn luôn. Đầu tiên các bạn cần tải font Dank Mono và cài đặt cho máy tính của các bạn tại đây
Sau khi tải và cài đặt xong cho máy tính rồi thì áp dụng đoạn code này vào là được
Hãy lưu ý rằng hai class .mtk5 và .mtk26 là tương ứng cho theme mình đang xài (Evondev Dracula), nếu các bạn xài theme khác thì tự tìm class nhé vì mỗi theme thì class nó khác nhau. Tìm như thế nào thì coi video ở trên cùng. Mình đã chỉ tận răng rồi cho nên mấy vấn đề này mình không có hỗ trợ riêng đâu nhé.
Dành cho ai dùng theme Evondev Dracula
Thì đây là toàn bộ code tùy biến hiện tại của mình, nếu bạn thích thì có thể copy vào hết là y hệt mình, tuy nhiên nếu bạn đang dùng máy có độ phân giải cao thì nó sẽ đẹp hơn nhé, ví dụ như Macbook chẳng hạn
Trên đây là toàn bộ source code tùy biến hiện tại của mình. Hi vọng bài viết ngắn gọn súc tích này sẽ có ích cho các bạn. Giúp các bạn có cảm hứng khi coding hơn.
Trong lập trình di động, chúng ta thường được nghe đến các khái niệm như mobile native, web-based hay hybrid app. Đặc biệt hiện nay phần đông các lập trình viên mobile chọn làm về ứng dụng native. Vậy mobile native là gì? Mobile native có ưu điểm gì là được phần đông mobile dev lựa chọn. Bài viết này mình sẽ cùng các bạn phân tích để tìm hiểu rõ hơn vấn đề này nhé.
Mobile native là gì?
Mobile native là thuật ngữ dùng để chỉ những ứng dụng được viết bằng ngôn ngữ lập trình tương ứng cho từng nền tảng hệ điều hành mobile.
Như chúng ta biết hiện nay thì 2 nền tảng mobile chiếm thị phần lớn nhất là Android của Google và iOS của Apple. Số liệu năm 2022 cho thấy 2 nền tảng này chiếm đến hơn 99% thị phần trong thị trường mobile toàn cầu.
Nguồn: https://engineering.linecorp.com
2 ông lớn Google và Apple đều trang bị cho lập trình viên của họ những bộ công cụ, IDE, ngôn ngữ lập trình của riêng mình: với Android là bộ Android Studio, có thể viết bằng Java hay Kotlin; còn iOS được Apple trang bị IDE Xcode và viết bằng Objective-C hoặc Swift.
Nguồn: https://optech.vn
Điểm mấu chốt ở đây là mỗi ứng dụng mobile native khi được viết phải viết bằng 1 ngôn ngữ cố định và chỉ chạy được trên 1 nền tảng cố định; không thể mang code đó sang chạy lên 1 hệ điều hành khác được. Ví dụ bạn lựa chọn viết 1 ứng dụng native iOS bằng ngôn ngữ Swift; bạn chỉ có thể chạy nó trên các thiết bị sử dụng hệ điều hành iOS (như iPhone, iPad, …) của Apple, không có cách nào để build lại hay tái sử dụng code để chạy ứng dụng đó trên 1 thiết bị cài hệ điều hành Android.
Nghe có vẻ khá bất tiện khi so sánh với các nền tảng như web-based hay cross-platform hiện nay, khi chỉ viết 1 lần code và có thể build / chạy trên nhiều nền tảng khác nhau đúng không? Tuy nhiên không phải ngẫu nhiên mà các lập trình viên lại chọn mobile native, vậy ưu điểm của nó là gì?
Ưu điểm của Mobile native
Là con đẻ của các hệ điều hành
Google và Apple hàng năm đều phát triển các phiên bản mới của hệ điều hành Android và iOS, và đương nhiên các tool, IDE, SDK, các tính năng mới nhất của hệ điều hành sẽ được tích hợp trong đó. Các lập trình viên native sẽ được hỗ trợ đầy đủ nhất về tài liệu, các features mới thuộc riêng về hệ sinh thái của từng nền tảng.
Hiệu năng tối ưu
Đây là yếu tố quan trọng nhất khi một nhà phát hành lựa chọn nền tảng để phát triển ứng dụng của họ. Thực tế các ứng dụng viết ở dạng cross-platform vẫn phải sử dụng 1 cầu nối giao tiếp (ví dụ như react native phải sử dụng JS bridge) hoặc chạy trên 1 nền tảng ứng dụng có sẵn trong hệ điều hành (ví dụ như web-based app chạy trên các nền tảng browsers); điều đó khiến cho hiệu năng của các ứng dụng đó bị giảm sút đi khá nhiều so với các ứng dụng viết bằng native app.
Khả năng giao tiếp phần cứng
Ứng dụng mobile native có ưu điểm lớn trong tác vụ cần phải giao tiếp với phần ứng: ví dụ như Camera, GPS, các cảm biến của thiết bị như vân tay, con quay hồi chuyển, gia tốc, … hay khi cần phải truy cập vào các quyền sử dụng thiết bị như đọc ghi file, láy thông tin danh bạ, truy cập tin nhắn, thông tin cuộc gọi, … Khó khăn dành cho các ứng dụng cross-platform hay hybrid là việc phần cứng của 2 nền tảng nói trên khác nhau, cách truy cập, xin quyền và sử dụng cũng khác nhau; vì thế thực tế lúc này đoạn code các bạn xử lý cũng cần phải viết dạng if … else… cho mỗi nền tảng.
Nguồn:https://res.cloudinary.com
Khi nào nên sử dụng Mobile Native
Đối với 1 một nhà phát triển cần xây dựng ứng dụng của họ cho việc tiếp cận và thử nghiệm thị trường, lúc này yếu tố rút ngắn thời gian ra mắt sản phẩm là điều quan trọng nhất. Lúc đó việc lựa chọn phương án sử dụng cross-platform hay hybrid app là điều được ưu tiên hơn. Với mobile native, chúng ta sẽ có thể tạo ra được các ứng dụng 1 cách ổn định, tối ưu hóa về hiệu năng và trải nghiệm sử dụng; vì thế thường các nhà phát hành khi muốn đưa ra ứng dụng cung cấp cho khách hàng 1 trải nghiệm tốt sẽ lựa chọn phương án này. Các ứng dụng cần xử lý nhiều tác vụ nặng, hay giải quyết các bài toán phức tạp như thương mại điện tử, chỉnh sửa xử lý video, … sẽ thường được phát triển bằng ngôn ngữ native.
Kinh nghiệm khi bắt đầu học Mobile Native
Như đã đề cập ở trên, nếu bạn có định hướng theo đuổi trở thành 1 lập trình viên mobile native, trước hết hãy xác định nền tảng mà bạn sẽ làm: Android hay iOS. Tất nhiên bạn có thể học song song cả 2 cùng lúc tuy nhiên lời khuyên dành cho bạn là hãy làm tốt 1 thứ trước, sau đó việc học ngôn ngữ còn lại sẽ trở lên dễ dàng hơn.
Việc lựa chọn nền tảng cũng phụ thuộc hay quyết định thiết bị mà bạn sẽ trang bị để học tập: nếu chọn iOS, bắt buộc phải có macbook và các thiết bị chạy iOS như iPhone, iPad, ngược lại thì Android có thể chạy tốt trên các hệ điều hành Window, MacOS hay Linux nên bạn có nhiều sự lựa chọn hơn.
Về ngôn ngữ, theo xu hướng hiện tại thì với Android chúng ta nên sử dụng Kotlin, iOS thì sử dụng Swift để lập trình. Các bạn nên tự đọc tài liệu và hoàn thành các bài học được thiết kế sẵn cho từng ngôn ngữ:
Sau khi trang bị được đầy đủ kiến thức cơ bản về ngôn ngữ, cũng như thao tác với các IDE của từng nền tảng; hãy bắt đầu vào những project thực tế và tạo ra các ứng dụng mà bạn mong muốn. Lúc này bạn cũng dễ dàng apply vào các công ty, join vào các dự án về mobile native để nâng cao khả năng cũng như hiểu biết sâu hơn về ngành.
Hy vọng bài viết này đã mang đến cho các bạn cái nhìn tổng quát về việc phát triển ứng dụng di động trên nền tảng native. Mobile native là gì chắc chắn vẫn sẽ là từ khóa hot trong thời gian tới dành cho các bạn có định hướng trở thành lập trình viên di động. Cảm ơn các bạn đã theo dõi, hẹn gặp lại các bạn trong các bài viết tiếp theo cùng chủ đề lập trình di động này.
Có một người bạn mà mình từng ngồi nhiều cafe để bàn về những công nghệ mới để phục vụ cho dự án công ty. Một câu hỏi mà bạn hay đặt ra là dùng ngôn ngữ lập trình gì tiếp theo. Mình thì khá dày dạn về Python và đã từng xây dựng nền móng cho những dự án Python ở công ty bạn. Tuy nhiên, mình và bạn đều đồng ý là nên mở rộng phạm vi công nghệ để thích ứng với nhiều thể loại dự án khác nhau. Đi tham vấn nhiều nơi, được nghe khen ngợi về Go nên bạn rất muốn một lần được áp dụng Go trong cty của bạn. Còn mình thì, nếu đã chọn một ngôn ngữ biên dịch và phải bỏ thời gian cá nhân ra học thì mình thà chọn Rust hơn. Tất nhiên, ý thức được độ khó của Rust nên mình chả bao giờ muốn đem Rust vào công ty của bạn cả.
Trong khi lý do thường được nêu ra để chọn Go là cú pháp đơn giản, ít keyword, dễ học, thì với mình, độ khó của Rust là thứ đáng để đầu tư. Thà chịu khó ban đầu nhưng gặt hái kết quả tốt về sau.
Ngoài ra, điều khiến mình ưu ái Rust hơn Go là ở chỗ Rust không có garbage collector, không có runtime riêng, nên có thể dùng Rust để viết thư viện tầng dưới, phục vụ cho Python và các ngôn ngữ khác được, chưa kể, việc được thiết kế tốt và không có bộ runtime khiến Rust là ngôn ngữ duy nhất (ngoài C) khiến tác giả của Linux muốn thấy nó được ứng dụng vào nhân Linux. Lý do viết thư viện đã được mình hiện thực hóa, bằng một sản phẩm cá nhân là Defity, thư viện dành cho Python và dùng để nhận dạng loại file.
Hoàn cảnh ra đời
Câu chuyện ra đời của Defity cũng hơi lòng vòng. Mình chủ yếu làm việc bên backend nên hay đảm nhận việc thiết kế, viết API server cho các ứng dụng khác gọi vào, trong đó có chức năng upload. Và để thống nhất với các phần khác của API, mình cho dữ liệu upload ở dạng JSON luôn (trong ứng dụng HTTP thông thường thì việc upload dùng content type multipart), trong đó nội dung nhị phân của file sẽ được chuyển mã base64 để thành dạng text, đưa vào JSON.
Trong quá trình viết API thì mình phải test từng bước từng bước để xem phần mình vừa làm đã chạy đúng ý chưa. Quá trình test API này, thông thường người khác sẽ dùng công cụ như Postman, nhưng mình là dân Linux, làm việc nhiều trên Terminal nên mình ưa các công cụ dòng lệnh hơn.
Mình thường kết hợp jo và HTTPie để tạo request, gọi API HTTP trên Terminal, ví dụ:
$ jo -d. file.name=image.png file.content=%image.png | http example-api.vn/ekyc/
Chỉ thị % của jo là để yêu cầu jo đọc nội dung file và chuyển hóa thành base64. Lệnh jo phía trên sẽ tạo ra nội dung JSON dạng như:
Bên lề một xíu, API phía trên là mình viết cho một dự án nội bộ về eKYC, để đọc dữ liệu từ ảnh chụp CMND/CCCD, và nhận diện khuôn mặt, và phần server API mình dựa trên FastAPI (nhưng mình không làm lớp OCR, AI vì lớp đó đang dùng dịch vụ bên khác cung cấp).
Sau đó mình tham gia một dự án khác, cũng cần cung cấp chức năng upload qua API. Dự án này thì backend dựa trên Django và Django Rest Framework. Bên Django thì thư viện phong phú nên trước khi xắn tay vào làm thì mình thường kiểm tra coi đã có thư viện cho chức năng mình định làm chưa. Và thật thú vị là có luôn, đó là drf_base64. Tuy nhiên, khác với cách làm của mình trong dự án eKYC bên trên thì drf_base64 quy ước dữ liệu upload ở dạng Data URL, ví dụ data:image/gif;base64,R0lGODlhEAAQAMQAAORHHOVS... tức là ngoài chuỗi base64 còn phải kèm thêm thông tin “MIME type” của file ban đầu.
Để test API kiểu này thì mình cần công cụ dòng lệnh để sinh ra chuỗi Data URL như trên. Tìm các phần mềm có sẵn thì chỉ thấy datauri-cli, một phần mềm viết bằng NodeJS. Mình khá ngại các phần mềm viết bằng NodeJS vì nó hay tạo thư mục node_modules chiếm nhiều dung lượng đĩa, nên quyết định tự viết phần mềm mới. Nếu viết bằng Python, mình chỉ cần chục phút là xong, không kể thời gian viết tài liệu, unittest, sắp xếp chỉn chu để phát hành thành một dự án nguồn mở. Tuy nhiên, mình thấy đây là cơ hội để tranh thủ rèn luyện Rust nên quyết định viết bằng Rust. Thế là phần mềm Duri ra đời.
Có Duri thì kết hợp với jo và HTTPie như sau:
$ jo -d. file.name=image.png file.content=$(duri image.png)| http example-api.vn/ekyc/
Trong lúc viết Duri thì mình cần một thư viện Rust để nhận biết loại file và trả về tên MIME type, ví dụ image/png, image/jpeg, và mình tìm được tree_magic_mini. Thư viện dành cho mục đích này mình biết cũng nhiều, nhưng hầu hết là dựa trên libmagic. Bên phía server mình cũng cần thư viện loại này để kiểm tra file do người dùng upload lên, và từ chối nếu file không phù hợp. Ví dụ như ứng dụng eKYC bên trên, mình cần ảnh chụp CMND dưới dạng file hình ảnh hay PDF nhưng nếu người dùng upload file *.docx, *.exe lên thì phải từ chối và báo lỗi. Khi đọc mô tả của tree_magic_mini thì mình khá ấn tượng, và mình nghĩ đến việc ứng dụng nó bên phía server luôn. Để đưa được nó vào backend thì cần tạo thư viện Python phủ trên nó, và đây chính là cơ hội để mình tập viết một thư viện Python bằng ngôn ngữ Rust! Thành quả của lần mạnh dạn chơi lớn này là tạo ra Defity.
Để tạo ra lớp binding từ Rust sang Python thì mình dùng PyO3. Ở đây có sự chơi chữ. Tên “Rust” ban đầu là được lấy theo một loại nấm nhưng cộng đồng lại thích diễn giải nó theo nghĩa “rỉ sét”. Tương tự bên Python, tên nó được lấy theo một chương trình hài kịch, nhưng cộng đồng lại thích hiểu theo nghĩa là “trăn”. “Rỉ sét” nói theo khoa học là hiện tượng “oxy hóa”, nên PyO3 được đặt tên bắt chước công thức hóa học của một ô-xít.
Khi viết thư viện Python từ một ngôn ngữ biên dịch (C/C++, Rust) thì có 2 hướng làm:
Liên kết với mã nguồn C của trình thông dịch CPython (Python.h), gọi các hàm được định nghĩa trong đây, theo một quy ước để trình thông dịch nhận diện mình là một module.
Không liên kết với mã nguồn của CPython. Thay vào đó, cứ biên dịch ra file thư viện liên kết động (*.so, *.dll), theo giao diện nhị phân quy ước bởi ngôn ngữ C, rồi bên phía Python dùng ctypes để truy cập vào các hàm, kiểu dữ liệu C trong file này.
Khi dùng PyO3 là ta đang di theo hướng thứ nhất. Mặc dù code ta viết là Rust nhưng bên dưới, PyO3 sẽ phụ trách việc liên kết với mã nguồn C của CPython. Nhờ những tính năng hiện đại của Rust (ví dụ phần macro mạnh mẽ) nên khi viết thư viện Python bằng Rust, ta có code ngắn hơn nhiều so với khi viết bằng C/C++.
Đây là phần nhận dữ liệu từ Python, gọi với các hàm trong tree_magic_mini, và chuyển đổi đầu ra sao cho hợp với Python. Phần này cũng phụ trách tạo ra các hàm có tên và tham số sao cho đúng phong cách của Python. Ví dụ, tree_magic_mini đặt tên hàm from_u8 nghe rất tối nghĩa nếu dùng từ phía Python, vì trong Python không có kiểu dữ liệu nào tên là u8. Tại đây mình đặt ra hàm from_bytes để đúng với cách gọi của Python. Ngoài ra, tree_magic_mini còn có một hàm khác tên là from_filepath. Cách đặt tên này cho thấy nó chỉ nhận dữ liệu đầu vào là một đường dẫn file. Điều này thì không thỏa mãn ý đồ thiết kế của mình, nếu dùng bên phía Python. Bên phía Python mình muốn thiết kế hàm để nhận vào không chỉ đường dẫn file mà còn nhận vào một file object, như khi dùng với with open(), vì vậy mình đặt tên là from_file cho nó tổng quát hơn. Phần này cũng phụ trách tạo ra các thông báo lỗi theo đúng phong cách của Python. Ví dụ hàm from_filepath của tree_magic_mini có signature như sau:
Có nghĩa là trả về None nếu file không tìm thấy hoặc file không thể mở. Như thế khá mơ hồ. Mình muốn nó bắn ra lỗi chi tiết hơn, ví dụ đối với Python, nếu không tìm thấy file thì quăng ra exception FileNotFoundError, nếu không có quyền mở file thì quăng ra exception PermissionError.
Ở đây, nhờ việc implement các trường hợp lỗi, mình hiểu rõ hơn về cách hoạt động của toán tử ?, trait From để chuyển đổi kiểu Error này sang Error khác một cách tự động trong Rust.
Thông thường, phần Rust phía trên là đủ rồi. Nhưng mình có những ý đồ thêm mà không tiện hiện thực hóa trong phần Rust phía trên nên mình viết ở trong đây. Các hàm trong đây sẽ là hàm được phơi ra cho người viết ứng dụng, sau đó nó sẽ thực hiện một vài bước chuyển đổi, rồi gọi sang các hàm Rust phía trên. Ý đồ đâu tiên là mình muốn thêm type hint (chú thích) để giúp code dễ đoán cho người sử dụng thư viện. Ví dụ:
deffrom_file(file:Union[Path,str,IO])->str:
Hiện tại, type hint chưa được hỗ trợ đầy đủ trong C-API của Python, nên nếu đưa vào phần Rust phía trên cũng không ích lợi gì nhiều. Nhìn vào type hint, có thể thấy from_file nhận đầu vào thuộc 3 kiểu: Path, str, IO, trong đó Path, str ứng với đường dẫn file, IO ứng với file object. Như thế người dùng thư viện có thể dùng như sau:
Việc thấu hiểu đặc tính của từng ngôn ngữ để thiết kế được hàm sao cho tiện dùng, phát huy được ưu điểm của ngôn ngữ là một kỹ năng cần có nếu bạn muốn dấn thân vào con đường sáng tạo thư viện.
Phần này cũng phụ trách xử lý các kiểu dữ liệu điển hình trong Python, chuyển sang các kiểu đon giản hơn, rồi mới gọi hàm bên phía Rust. Ví dụ, hàm from_file ở đây là
deffrom_file(file:Union[Path,str,IO])->str:
nhưng phiên bản tương ứng bên code Rust (src/lib.rs) chỉ là
Có thể bạn sẽ thắc mắc, tại sao không để hàm phía Rust nhận file object luôn. Câu trả lời là, vì mình muốn hàm bên phía Rust không cần nắm giữ Global Interpreter Lock (GIL) của CPython, để giúp phía ứng dụng thoải mái chạy trong chế độ multi-threading. “File object” là kiểu dữ liệu của riêng Python nên hàm Rust muốn nhào nặn gì nó là phải nắm giữ GIL, khi đó nếu có thread nào đang có hành động cần đến GIL, nó sẽ phải tạm dừng, làm giảm ích lợi của multi-threading đi.
Phát hành
Defity được viết bằng ngôn ngữ biên dịch nên khi để sử dụng được nó, phải qua quá trình biên dịch thành file *.so. Thông thường các thư viện mã nguồn mở sẽ phát hành ở dạng mã nguồn. Khi người dùng cài thì chương trình quản lý gói (package manager) sẽ tự động làm bước biên dịch trên máy người dùng luôn. Điều náy sẽ tạo gánh nặng cho người dùng vì họ sẽ phải cài bộ công cụ biên dịch Rust trước. Thật may là Python có đề ra chuẩn để cho phép tác giả phân phối các gói thư viện build sẵn ở dạng binary, cụ thể là file wheel. Khi người dùng cài thư viện bằng pip, pip sẽ kiểm tra máy người dùng là nền tảng gì (hệ điều hành, vi xử lý gì) rồi tải file wheel tương ứng cho nền tảng đó để cài, không phải trải qua bước build. Vì mình cũng có kinh nghiệm về các board Linux nhúng (BeagleBone, Raspberry Pi) nên mình rất quan tâm tới việc build sẵn cho các nền tảng này. Điểm thiệt thòi cho các board nhúng này là vi xử lý yếu (ARM) mà trình biên dịch Rust thì lại chạy rất nặng (vì nó phải thực hiện việc kiểm tra chặt chẽ, chi tiết hơn các ngôn ngữ khác), nên bắt người dùng phải build thì tội cho họ quá. Thế là mình huy động các board Raspberry Pi mà mình có ra, để build cho các nền tảng như sau:
Python từ 3.6 đến 3.10.
Linux trên x86, 64 bit.
Linux trên ARMv7, 32 bit
Linux trên ARMv8, 64 bit.
Windows trên x86
MacOS trên x86
Trong đó bản cho Windows và MacOS build được là nhờ tận dụng GitHub Action, chứ mình cũng chẳng có máy Windows lẫn MacOS để mà tự build.
Các file wheel trên có thể tìm thấy trên PyPI: https://pypi.org/project/defity/#files
Danh sách kia thiếu ARMv6 (dùng trong Pi Zero và Pi đời đầu) vì con Raspberry Pi ARMv6 mà mình có hơi yếu, lại đang mắc làm nhiệm vụ khác, nên sức CPU còn lại build không nổi.
Để build cho các kiến trúc vi xử lý khác, thực ra không cần thiết bị thật mà có thể cross-build từ trên máy x86 luôn. Nhưng mình chọn build trên thiết bị thật cho… ngầu. Khi nào cần build cho các vi xử lý mà thiết bị thật yếu quá, ví dụ build cho MIPS (hay dùng trong các router wifi) thì mới còn lựa chọn duy nhất là cross-build, vì các router của mình quá yếu, thậm chí còn không có chỗ để cài trình biên dịch.
Việt Nam đã trải qua một năm đầy thách thức khi phải tăng tốc để khôi phục lại nền kinh tế hậu Covid. Bước sang năm 2023, nền kinh tế đứng trước những thời cơ, thuận lợi và khó khăn, thách thức đan xen, tuy nhiên thách thức vẫn rất lớn trong bối cảnh khó khăn chung của nền kinh tế thế giới.
Đứng trước điều đó, thị trường ngành công nghệ thông tin vẫn vươn lên mạnh mẽ. Dự đoán tốc độ tăng trưởng kinh tế internet bình quân hàng năm của Việt Nam đến năm 2025 lên đến 29%, đứng đầu Đông Nam Á (theo báo cáo thị trường IT Việt Nam 2022 của TopDev). Điều này đã tạo một động lực to lớn thúc đẩy nhu cầu nhân sự CNTT ở hiện tại và tương lai. Bên cạnh đó, nó còn tạo nên sức ép cho nhà tuyển dụng khi “cung không đủ cầu”, người tìm việc thì quá nhiều nhưng nhân lực có thể đáp ứng thì như “muối bỏ bể”.
Vậy nên, để thu hút được những nhân tài hàng đầu trong ngành công nghệ thông tin, nhà tuyển dụng không thể bỏ qua việc lên kế hoạch chi tiết ngay từ những bước đầu tiên. Điều quan trọng nhất chính là mẫu bài đăng tuyển dụng – đó là cách để gửi thông điệp tuyển dụng đến những ứng viên phù hợp. Một bài đăng không mấy thu hút hoặc không rõ ràng vô hình chung trở thành “chiếc phễu hỏng” lọc hết những ứng viên tiềm năng. Vậy, làm sao để có những mẫu bài đăng tuyển dụng IT hiệu quả? Bạn cần lưu ý những đặc thù gì khi tuyển dụng ngành IT? Mời bạn tham khảo bài viết dưới đây.
Vì sao nên chú trọng vào nội dung bài đăng tuyển dụng?
Dĩ nhiên, yếu tố đầu tiên đó chính là thu hút ứng viên. Bạn muốn tuyển vị trí nào, số lượng bao nhiêu, công việc cụ thể là gì, mức lương/quyền lợi ra sao, địa chỉ công ty ở đâu và môi trường văn hóa nội bộ như thế nào. Tất cả những thông tin này sẽ giúp tạo ấn tượng với ứng viên nếu bạn biết cách truyền tải chúng.
Bên cạnh đó, tuy là bước đơn giản nhưng bài đăng tuyển dụng là hình ảnh, thông điệp đầu tiên mà doanh nghiệp thể hiện trong tâm trí của ứng viên. Một bài đăng tuyển dụng với nội dung được đầu tư nhất định cho thấy sự uy tín, nghiêm túc và “khao khát” ứng viên của công ty.
Cách viết content tuyển dụng hay
Xác định đối tượng tuyển dụng
Xem xét ứng viên bạn hướng tới là ai, ở vị trí như thế nào sẽ giúp bạn chọn văn phong, giọng điệu và nội dung truyền tải phù hợp cho bài đăng tuyển dụng.
Chẳng hạn, bạn muốn tuyển một fresher thì mẫu bài đăng cần có sự trẻ trung, giọng điệu thân thiện, gần gũi và thể hiện được điều kiện môi trường làm việc có cơ hội phát triển – yếu tố quan trọng đối với những ứng viên fresher. Mặt khác, nếu bạn muốn tuyển vị trí senior bạn cần nhấn mạnh những điều mà họ sẽ cống hiến được cho công ty trong một bài đăng với văn phong chuyên nghiệp, nghiêm túc.
Thông qua nội dung công việc ứng viên có thể biết được bản thân có đủ kỹ năng và kinh nghiệm cho vị trí này hay không . Đây là điều mà ứng viên quan tâm nhất khi tìm hiểu về một bài đăng tuyển dụng, do đó việc mô tả rõ ràng công việc giúp bạn giữ chân ứng viên tiềm năng và cũng giúp tránh mất thời gian cho cả hai bên.
Minh bạch quyền lợi của ứng viên
Đứng sau mô tả công việc, quyền lợi là phần mà ứng viên quan tâm không kém. Sau khi đã phù hợp về công việc rồi thì liệu họ có được những quyền lợi gì khi ứng tuyển vào công ty. Từ đó, việc bạn công khai rõ quyền lợi là điều cần có. Hãy nhấn mạnh vào những đãi ngộ mà ứng viên không thể bỏ qua để gia tăng tính thu hút của bài tuyển dụng.
Chăm chút hình ảnh đi kèm
Hầu hết người xem tin đều có xu hướng xem những điều tóm gọn và hút mắt trước khi phải đọc một bài viết thật dài. Một hình ảnh màu sắc, một video sáng tạo với đầy đủ nội dung chính yếu sẽ giúp tăng khả năng “xem thêm” của người dùng.
Tiêu đề đủ thông tin cần thiết
Nếu chưa thể đưa ra một tiêu đề thật sáng tạo và ấn tượng bạn có thể tạo một tiêu đề với đủ 3 nội dung: tên công ty, địa chỉ làm việc và vị trí tuyển dụng. Chẳng hạn,[HCM, BÌNH THẠNH] BACKEND PHP DEVELOPER – TopDev Tuyển dụng. Với tiêu đề này ứng viên dễ dàng biết được nhu cầu của bạn và họ có match nhau không, bạn là ai và họ có thể di chuyển đến nơi làm việc thuận lợi hay không. Trước khi sáng tạo hãy thật rõ ràng.
Thử những phong cách content khác nhau
Theo nhiều khảo sát một văn phong hài hước với những từ ngữ lạ sẽ kích thích trí tò mò của ứng viên. Thêm vào đó, bên cạnh bài đăng tuyển dụng chính thống bạn có thể thử nhiều cách dẫn dắt khác nhau như storytelling, hình ảnh, video,… sẽ giúp đánh giá được hiệu quả tuyển dụng cho những lần sau. Tuy nhiên, bạn vẫn nên đảm bảo tính chuyên nghiệp trong bài đăng, hình ảnh được sử dụng thể hiện được văn hóa công ty.
Đặc thù tuyển dụng IT cần những yếu tố gì?
Tìm hiểu ngôn ngữ lập trình và vị trí công việc mà bạn đang tuyển dụng
Đầu tiên, việc hiểu rõ công việc giúp bạn trình bày phần mô tả công việc một cách chính xác và tiếp cận đúng đối tượng mục tiêu hơn. Đặc thù ngành IT có rất nhiều vị trí, mỗi vị trí lại sử dụng một công nghệ lập trình khác nhau, do đó việc tìm hiểu về vị trí công việc và ngôn ngữ lập trình (tech stack) là nên có.
Thêm vào đó, với những hiểu biết cơ bản về ngành IT, bạn hoàn toàn có thể trao đổi với ứng viên về công việc hiện tại của họ hay định hướng việc làm trong tương lai. Một ứng viên IT sẽ sẵn sàng tiếp cận và trao đổi thông tin việc làm với những người có kiến thức về ngôn ngữ IT như họ.
Đến đúng chỗ tìm đúng người
Do sự thiếu hụt nguồn cung nhân sự IT, nên hầu như lập trình viên đều là những ứng viên bị động. Để tiếp cận được ứng viên tiềm năng bạn có thể đến những nơi như:
Hội nhóm tuyển dụng IT trên mạng xã hội
Diễn đàn công nghệ
Sự kiện công nghệ như Vietnam Mobile Day, Vietnam Web Summit. Thông qua sự kiện, bên cạnh việc truyền thông công ty và những vị trí có sẵn, bạn có thể thu thập thông tin của nhiều ứng viên và tiếp cận hiệu quả bằng email tuyển dụng.
Nền tảng tuyển dụng chuyên môn ngành IT. Bạn có thể tham khảo TopDev – nền tảng tuyển dụng IT hàng đầu. TopDev sẽ chủ động tiếp cận ứng viên tiềm năng và mang CV về cho bạn.
Theo dõi Báo cáo thị trường IT của TopDev sẽ giúp bạn có góc nhìn mới nhất và tổng quan nhất về: chân dung Lập Trình Viên & thay đổi trong các năm, thị trường nhân lực IT – mức lương, nhu cầu và xu hướng, tình hình tuyển dụng IT,…
Mạng xã hội như Facebook mang tính chất mì ăn liền, thông tin được truyền tải phải dễ nắm bắt ngay. Do đó, đối với bài đăng tuyển dụng trên đây bạn có thể rút gọn nội dung bằng cách chỉ nêu những điểm quan trọng mà ứng viên không thể bỏ qua. Theo dõi những mẫu bài đăng tuyển dụng IT hiệu quả dưới đây:
[HN] Data Scientist nhanh tay gửi ngay CV để ứng tuyển và chớp ngay cơ hội rinh trọn các đãi ngộ từ nhà Viettel Digital cùng thu nhập khủng lên tới $3,500. Apply ngay nhé Dev! ✏️✏️
JD tại: https://topdev.vn/s/FRvLZujG
Dev cần:
Có ít nhất 02 năm kinh nghiệm làm việc trong lĩnh vực dữ liệu tài chính, ví điện tử, thương mại điện tử trên mobile
Có kinh nghiệm sử dụng các công cụ như Tableau hoặc PowerBI.
Offer xịn dành cho Dev:
Lương hấp dẫn lên đến $3,500.
Chính sách thưởng hấp dẫn: thưởng theo tháng, thưởng quý, thưởng năm, ngày lễ Tết, …
Hưởng BHXH, BHYT, BHTN theo quy định Nhà nước; được khám sức khỏe định kì hàng năm.
Nghỉ dưỡng 3 ngày nguyên lương trong năm, hỗ trợ nghỉ dưỡng lên đến 9 triệu/người.
Tham gia mệt nghỉ với các hoạt động thể thao văn hóa, team building, giải bóng đá, Viettel’s Got Talent, event quý, event năm, event ngày nghỉ lễ tết, event nhân dịp không có gì,…
Cơ hội tự ứng tuyển thử sức đi học tập và làm việc tại nước ngoài theo các khóa ngắn hạn, dài hạn.
======================================
Nhanh tay gửi CV về career@topdev.vnkèm tiêu đề [Viettel Digital – DS].
[Remote] Dev hãy săn ngay cơ hội việc làm về Front-End tại CycAI với vô vàn mức đãi ngộ hấp dẫn.
> Tiêu chí cần có:
Có từ 3 – 5 năm KN trở lên trong việc phát triển Front-End trên một trong số các nền tảng Node, React, CSS, Go hoặc Python.
> Mức đãi ngộ xịn sò:
Mức lương xịn sò lên đến $3,000.
Lương tháng 13.
Có cơ hội chuyển đến US làm việc nếu thể hiện tốt.
Ngày nghỉ không giới hạn.
Có thắc mắc cần được giải đáp, các Dev đừng ngần ngại comment hoặc inbox cho mình biết nhé!
Link JD & Apply nhanh: https://topdev.vn/s/DbUovTKz
Khác với mạng xã hội, ứng viên tìm việc trên những nền tảng tuyển dụng thường dành nhiều thời gian hơn để nghiên cứu công việc. Do đo, nội dung tuyển dụng ở những trang này nên thật cụ thể. Mời bạn xem qua một bài đăng cụ thể:
Bài đăng tuyển dụng IT trên nền tảng tuyển dụng TopDev
Trên đây là thông tin về cách viết nội dung cũng như một số mẫu bài đăng tuyển dụng IT hiệu quả. Nếu bạn vẫn đang loay hoay với việc tìm kiếm ứng viên trong lĩnh vực lập trình công nghệ, hãy sử dụng dịch vụ đăng tin tuyển dụng tại TopDev! Tin tuyển dụng của bạn sẽ dễ dàng tiếp cận với ứng viên hơn giúp gia tăng tỷ lệ “tìm đúng người”.
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Thông thường nếu bạn làm đúng các thao tác thì thời gian để hệ thống cập nhật trang web của bạn lên hosting mới là rất nhanh. Sau khi bạn đã di chuyển xong dữ liệu và trỏ lại DNS thì chỉ mất chừng vài giây đến vài phút là có thể sử dụng web trên hosting mới.
Mình đã từng viết bài viết hướng dẫn thay đổi hosting cho WordPress trước đây trên blog hocwp.net, bạn có thể tham khảo thêm qua về cách thực hiện. Trong bài viết này mình cũng sẽ tổng hợp lại thứ tự các bước di chuyển hosting cho WordPress.
Ngừng viết bài mới và sử dụng plugin thông báo đang bảo trì nếu cần thiết.
Sao lưu dữ liệu trên hosting cũ.
Tải dữ liệu đã được nén về máy tính.
Upload dữ liệu lên hosting mới sau đó giải nén hoặc ngược lại.
Thay đổi DNS trỏ tên miền về hosting mới.
Xóa cache để hệ thống nhận hosting mới.
Kiểm tra xem tên miền đã nhận IP của hosting mới hay chưa.
Hủy kích hoạt plugin thông báo đang bảo trì nếu có.
Các bước di chuyển dữ liệu về hosting mới có rất nhiều, nếu liệt kê ra cụ thể hơn thì có rất nhiều thao tác, bạn sẽ quy ra 3 bước chính: backup dữ liệu, upload dữ liệu lên hosting mới, trỏ lại DNS của tên miền sang hosting mới.
Để kỹ hơn thì trước khi tiến hành sao lưu dữ liệu, bạn viết bài thông báo và sử dụng plugin hiển thị thông báo website đang bảo trì. Thao tác sao lưu dữ liệu sẽ bao gồm sao lưu tập tin và cơ sở dữ liệu. Thao tác tải dữ liệu đã sao lưu về máy tính là bắt buộc, nếu bạn sao lưu full thì tải về file nén sau đó giải nén để lấy tập tin của web trong thư mục homedir/public_html, lấy cơ sở dữ liệu trong thư mục mysql.
Nếu bạn backup dữ liệu theo kiểu full thì bạn phải giải nén ra trước, sau đó upload tập tin và import cơ sở dữ liệu lên hosting mới. Thao tác thay đổi DNS cho tên miền có nghĩa là bạn đăng nhập vào chỗ quản lý tên miền, sửa các bản ghi mà có địa chỉ IP, bạn thay IP cũ thành IP của hosting mới.
Thao tác xóa cache ở đây là xóa cache trình duyệt, xóa cache trên bảng ghi DNS của máy tính bằng cách mở phần mềm Command Prompt lên, sau đó chạy lệnh ipconfig /flushdns. Bạn có thể kiểm tra tên miền có nhận IP của hosting mới hay chưa thì bạn sử dụng lệnh ping tên miền hoặc sử dụng tính năng kiểm tra DNS của whatsmydns.net. Nếu tên miền đã nhận IP của hosting mới thì bạn xóa cache trên blog nếu cần.
Hủy kích hoạt plugin thông báo website đang bảo trì và đăng bài viết thông báo việc di chuyển hosting đã hoàn tất.
Thời gian di chuyển hosting bao lâu là tùy vào dung lượng website nhiều hay ít, tùy vào vị trí của hosting đặt gần hay xa nơi bạn đang ở, tùy thuộc vào tốc độ mạng internet nhà bạn. Còn thời gian để hệ thống cập nhật IP của hosting mới sau khi bạn sửa DNS thì chỉ mất chừng vài giây đến vài phút. Nếu bạn chờ quá lâu mà hệ thống vẫn chưa cập nhật IP của hosting mới thì rất có thể bạn đã làm sai thao tác ở bước nào đó rồi.
Sau khi thay đổi DNS thì hệ thống thường thông báo sẽ tốn tối đa 24h đến 48h để tên miền cập nhật bảng ghi mới, tuy nhiên thời gian này là tối đa, còn bình thường hệ thống DNS cập nhật rất nhanh, cho dù bạn thay đổi nameserver hay hay đổi thông tin các bảng ghi. Chúc bạn thành công.
Giả sử hôm thứ 2 vừa rồi sếp giao cho task viết chương trình in ra dòng chữ “Hello World!”, sau một ngày cân nhắc lựa chọn các ngôn ngữ lập trình, công nghệ, mình quyết định chọn Swift để viết, vì ngôn ngữ này có tên trùng với tên ca sĩ mình yêu thích Taylor Swift.
Sau 2 ngày làm việc, cuối cùng mình cũng hoàn thành chương trình của mình, chương trình có nội dung như sau:
print(“Hello World!”)
Thật ra một Junior Dev thì sẽ viết như vậy, mà viết như vậy thì bài viết của mình có gì hấp dẫn nữa. Với cương vị của một Senior Developer, mình sẽ phải ứng dụng các kiến thức lập trình hướng đối tượng, phân tích thiết kế hệ thống để viết ra chương trình Hello World hoàn hảo.
Xem xét các đối tượng trong chương trình.
Đối tượng thứ nhất là đối tượng chứa logic business của ứng dụng, mình đặt tên là HelloWorldApplication cho khoẻ. Đây là lớp chứa quyết định chính của chương trình, là in ra dòng chữ Hello World!
Yêu cầu của nhiệm vụ lần này là in ra màn hình console dòng chữ “Hello World!”, nên mình cần thiết kế một lớp in ra dòng chữ này, nghe thật đơn giản đúng không? Nhưng không, hãy suy nghĩ về tính mở rộng của chương trình, giả sử một ngày nào đó trong tương lai, người ta không muốn in ra console nữa, mà muốn in lên một cửa sổ, in ra một tờ giấy, in ra một máy tính khác qua mạng thì sao, thế là mình nghĩ ra lớp đối tượng trừu tượng thứ nhất, Printer. Printer là một protocol cho phép in ra một chuỗi, mình chỉ quan tâm vậy thôi. Đó là cách mình khái quát hoá một đối tượng trong chương trình.
protocol Printer { func print(message: String)}
Dependency và Dependency Injection
Lớp HelloWorldApplication của mình là lớp high level chứa logic của chương trình, sẽ cần 1 printer để in ra thông điệp. Do đó mình cần truyền đối tượng printer này vào trong lớp HelloWorldApplication, gọi là inject dependency.
Mình inject quả constructor như sau:
class HelloWorldApplication { private let printer: Printer init(printer: Printer) { self.printer = printer }}
Bây giờ mình có thể xài đối tượng printer ở trong lớp HelloWorldApplication mà không cần quan tâm nó được cài đặt ra sao.
Viết kiểm thử đơn vị (unit test)
Trước khi đi implement lớp HelloWorldApplication, mình sẽ viết test case để kiểm tra xem chương trình có chạy đúng, không, theo phương thức Kiểm Thử trước tiên.
Để đơn giản mình viết 1 lớp MockPrinter như sau
class MockPrinter: Printer { var printedMessage: String? func print(message: String) { printedMessage = message }}
Và chương trình của mình cũng chỉ cần có 1 test case
final class HelloWorldApplicationTest: XCTestCase { func testRunShouldPrintHelloWorldMessage() throws { let printer = MockPrinter() let application = HelloWorldApplication(printer: printer) application .run() XCTAssertEqual("Hello World!", printer.printedMessage) }}
Vì hàm print của mình đặt trùng tên của hàm print của Swift nên mình hack 1 xíu như trên. (hảo hack)
Viết chương trình chính và test
Bây giờ mình có thể hoàn thiện chương trình:
let application = HelloWorldApplication(printer: ConsolePrinter())application .run()
HORRAY!! Chương trình đã in ra dòng Hello World! đúng như yêu cầu, và còn sử dụng nhiều kỹ thuật hiện đại, dễ mở rộng và khá đơn giản dễ hiểu.
Bây giờ muốn in cái dòng Hello World lên 1 UILabel chẳng hạn, ta chỉ cần extend UILabel để cài đặt cái protocol là xong, và cần thay ConsolePrinter thành đối tượng UILabel là được.
Đó là Senior sẽ viết vậy, nhưng nếu là super Senior Dev thì sẽ thêm 1 bước.
Refactor – Xoá những chi tiết dư thừa trong chương trình
Đây là bước khá quan trọng, bây giờ chúng ta sẽ xoá những chi tiết dư thừa trong chương trình, để cuối cùng đạt được kết quả thành 1 chương trình ngắn gọn như sau:
print(“Hello World!”)
Thật tuyệt vời!
Các bạn đang ở trình nào rồi? Mà dù là Fresher, Junior, Senior hay super Senior thì TopDev đều có nhiều jobs hot cho các bạn phát triển sự nghiệp. Tham khảo tại đây nè!
SQL là dễ với Senior, nhưng với những bạn bắt đầu tìm hiểu SQL thì thực tế lại không hề đơn giản như vậy, nắm bắt được nhu cầu, tâm tư tình cảm như vậy, TopDev giới thiệu tới anh em bài viết giải thích tường tận về Case When trong SQL.
Mong là qua bài viết này, anh em bắt đầu với SQL dễ dàng hơn, từ Case When sẽ tới các mục khác khó hơn trong SQL.
Anh em chú ý đón đọc chuỗi bài viết về SQL trên TopDev, ngày trở thành SQL Master không còn xa. Bắt đầu ngay thôi nào!.
1. Luôn luôn bắt đầu với ví dụ và định nghĩa
Rồi, giả sử ha, anh em được cô giao cho chức vụ quyền uy nhất lớp, lớp trưởng (à đâu, lớp phó phụ trách văn nghệ). Đợt này cần tập múa (múa quạt đi cho máu), mà tập ở Quận 6 nên cô cần biết danh sách các bạn ở HCM.
Cô già mắt kém, chữ ngắn khó đọc nên HCM thì khó cho cô, cô yêu cầu nhìn thấy bạn nào ở TP Hồ Chí Minh để cô lựa.
Trong hệ cơ sở dữ liệu cô đang có sẵn danh sách các bạn cùng lớp (teammate), khổ cái là cái tool mà cô sử dụng để input lúc viết lại do một ông thần khác có tính cách không lèo nhèo.
Ví dụ bạn Sơn Tùng ở TP Hồ Chí Minh thì ổng chỉ lưu là HCM, còn bạn Erik tuy là chạy về nhà khóc với anh nhưng nhà ở Đồng Nai, chạy bộ không nổi. Ở Đồng Nai thì lưu xuống lại là DN2, do trùng với Đà Nẵng, chua lè.
Cơ bản thì từ mã tỉnh thành viết tắt lưu xuống ta có thể lấy được địa chỉ đầy đủ như này
1.1 Tìm hướng giải quyết
Rồi, yêu cầu của cô là lấy danh sách các bạn cùng lớp thân thương yêu quý lên. Nhưng chỗ địa chỉ thì không được viết tắt. Tức là nếu bạn đó ở HCM thì show ra chỗ SQL result là Hồ Chí Minh, còn nếu bạn ở ĐN thì SQL result là Đồng Nai.
Tiền đề là không có bảng “Địa chỉ” để mà left join, inner join gì luôn nha anh em. Đang đưa đường dẫn lối cho Case When trong SQL nên không chơi kiểu thế. Haha.
Rồi mường tượng trong đầu là có một danh sách các bạn, giờ nếu mà gặp cái cột TinhThanh (hiện đang viết tắt). Mường tượng trong đầu ta có 4 bước.
Thơm lun, thấy có “Nếu bạn nào” là thấy giống If Else rồi. Đúng, là giống, nhưng đang học syntax Case When trong SQL nên cứ từ từ.
Để giải bài tập cô giao bằng SQL, ta có thể sử dụng câu SQL sau.
SELECT TinhThanh,
CASE
WHEN
TinhThanh = "HCM"
THEN
"Ho Chi Minh"
WHEN
TinhThanh = "DN"
THEN "Da Nang"
ELSE TinhThanh
END AS "Cap Nhat Thanh Pho"
FROM BanBe
1.2 Giải thích chi tiết
Với câu SQL trên, nhìn rối rắm khó hiểu cho người bắt đầu nên cứ bẻ nhỏ từng chữ từng chữ. Không có gì phải vội. SELECT là rồi ha, dễ hiểu.
CASE: indicates a condition loop has been started and that the conditions will follow.
CASE là trường hợp, nó xác định rằng một điều kiện kiểm tra sắp bắt đầu và tiếp theo sau nó sẽ là điều kiện kiểm tra
WHEN: indicates the start of a condition that should be checked by the query.
WHEN là trong khi, nó xác định rằng một điều kiện cần được kiểm tra bởi câu truy vấn
THEN: executed when the condition is true, determines the output for the true condition.
THEN là thì, nó thực thi nếu điều kiện ở WHEN là đúng.
ELSE: catches all of the entries that were not true for any of the WHEN conditions.
Else là khác, nó sẽ xử lý trong trường hợp không có điều kiện WHEN nào thỏa mãn (false)
END: Indicates the end of the CASE loop.
END là kết thúc, kết thúc CASE
Từ khóa thì chỉ có 5 cái vậy, mà vẫn khó hiểu nên mình quay lại ví dụ SQL ở phần 1 ha. Diễn giải theo cách dễ hiểu hơn (kiểu ngôn ngữ tự nhiên).
LẤY TinhThanh,
TRƯỜNG HỢP
KHI
TinhThanh = "HCM"
THÌ
"Ho Chi Minh"
KHI
TinhThanh = "DN"
THÌ "Da Nang"
KHÁC THÌ TinhThanh
KẾT THÚC AS "Cap Nhat Thanh Pho"
LẤY TỪ BanBe
Cách này thì Case When trong SQL tự nhiên trở nên dễ hiểu hơn rất nhiều. Dễ hơn vạn lần cho những bạn mới tiếp cận với SQL.
Kết thúc phần một, hiểu để sử dụng được case when trong sql. Tiếp đến là nó hoạt động như thế nào?, thú vị hơn nha.
2. Ví dụ cụ thể với Database postgres
Sau khi đã tìm hiểu qua mục 1, anh em chắc hẳn sẽ tự tin vỗ ngữ là: Ối dồi ôi, dăm ba cái Case When này, dễ hiểu ấy mà, tương tự như If Else.
Uầy, thì đúng là xài dễ, nhưng cụ thể cho dễ mường tượng thì vẫn tốt hơn. Mình ví dụ dưới đây với hệ cơ sở dữ liệu postgres.
Yêu cầu là với news_type (loại tin tức), hiện tại trong các bảng đang lưu là id (là số), nếu không có bảng master quy định các thông tin này thì để lấy ra được nội dung dễ đọc, ta cần sử dụng case when trong sql.
Nếu news_type=4 loại hình này là Chung Cư (ví dụ thôi nha), nếu khác 4 là loại hình đất nền, column mình lấy ra là loainhadat.
Dưới đây là trường hợp case, anh em thấy trong 5 row lấy ra chỉ có dòng cuối cùng là thỏa điều kiện
Kết quả là chỉ có row số 5 là Chung Cu, 4 row phía trên là Dat nen.
4 case phía trước do news_type không bằng 4 nên sẽ lọt vào case ELSE -> dẫn tới kết quả là 4 row phía trên ‘Dat nen’.
Ví dụ cụ thể sinh động như cá bơi trong chậu rồi nha, giờ tới một số lưu ý khi sử dụng SQL.
3. Một số lưu ý khi sử dụng Case When trong SQL
3.1 Kiểu dữ liệu
Cái này anh em khi mới bắt đầu sử dụng Case When trong SQL thường gặp lỗi này. Việc so sánh sai kiểu dữ liệu dẫn với Case when không work như cách mà anh em mong muốn.
Nếu so sánh sai kiểu dữ liệu, ở một số hệ cơ sở dữ liệu còn trả về “Invalid Input Syntax”.
Ví dụ trường hợp phía dưới đây cột Name có kiểu dữ liệu là VARCHAR (ký tự).
SELECT Track.Name, Track.GenreId,
CASE WHEN (Track.Name = 40) THEN 'Rock'
END AS Genre FROM Track
ORDER BY Track.Name ASC LIMIT 10;
Anh em chú ý khúc CASE WHEN (Track.Name = 40), 40 ở đây đang là số. Trường hợp execute sẽ dẫn tới lỗi.
ERROR: operator does not exist: character varying = integer
Nên trước khi viết case when so sánh cột nào anh em nên mở bảng đó ra xem kiểu dữ liệu trước khi thực hiện chạy SQL nha.
3.2 Nhiều case when trong SQL
Trường hợp có nhiều Case When, ta lưu ý rằng:
After THEN is executed, CASE will return to the top of the loop and begin checking the next entry.
If the condition is false, the next WHEN statement will be evaluated.
Sau khi mà CASE WHEN đã true – đúng, CASE sẽ trở lại đầu vòng lặp và check tiếp row sau, bất kể phía dưới còn bao nhiêu SQL. Cái này anh em lưu ý.
Thứ hai là nếu WHEN đã sai – fasle, CASE lúc này sẽ di chuyển tới CASE tiếp theo, chỗ này có thể ảnh hưởng tới performance nếu có quá nhiều CASE WHEN cần kiểm tra.
3.3 Không có else
Một số anh em viết case when trong sql hay miss trường hợp else.
If no ELSE statement is present and all WHEN conditions are false, the returned value will be NULL. Nếu trường hợp không có ELSE và tất cả các điều kiện WHEN đều false (tức là không match) cái nào
4. Tổng kết để khỏi quên ha
CASE WHEN được sử dụng để xác định các câu lệnh điều kiện trong SQL CASE khai báo sự bắt đầu của các điều kiện
WHEN khai báo điều kiện
THEN khai báo thứ trả về khi điều kiện WHEN là true
ELSE bắt tất cả các trường hợp không pass ở WHEN
END kết thúc cho CASE
Ta có thể có nhiều WHEN trong một CASE nha
AS sử dụng để định nghĩa name của cột trả về, nếu không có thì default là “case”
Kết bài bằng một trò đùa zui zẻ nha anh em. Đừng viết SQL kiểu này không có ông nào sau đi maintain ổng kiếm tới tận nhà lun á.
5. Tham khảo
SQL CASE Statement – W3School: https://www.w3schools.com/sql/sql_case.asp
How CASE WHEN Works – The Data School: https://dataschool.com/how-to-teach-people-sql/how-case-when-works/
CASE statement in SQL: https://www.sqlshack.com/case-statement-in-sql/
Cảm ơn vì đã đọc bài – Thank for you time – Happy coding!
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Các bạn có cảm thấy lười biếng mỗi khi phải khai báo các phương thức Getter, Setter cho các class Java không? Các bạn có thấy nhàm chán khi làm việc với những đoạn code theo khuôn mẫu trong Java không? Nếu tất cả các câu trả lời là có thì hãy xem xét sử dụng Project Lombok. Nó sẽ giúp các bạn loại bỏ những công việc nhàm chán này.
Project Lombok là gì?
Project Lombok là một công cụ giúp chúng ta generate code một cách tự động nhưng không phải giống như các IDE làm cho chúng ta. Các IDE generate các phương thức Getter, Setter và một số phương thức khác trong các tập tin .java. Project Lombok cũng generate các phương thức đó nhưng là trong các tập tin .class file.
Trang chủ: https://projectlombok.org/
Tất cả công việc chúng ta cần làm chỉ là sử dụng một số annotation của Project Lombok như @Getter, @Setter, @Builder, … việc còn lại Project Lombok sẽ làm cho chúng ta. Tất nhiên, những thứ các bạn không muốn làm tự động thì bạn cũng có thể chỉ định để Project Lombok không generate chúng.
Để các IDE có thể hiểu được code do Project Lombok generate, các bạn cần cài đặt Project Lombok plugin cho chúng. Xem hướng dẫn cài đặt Project Lombok cho IntelliJ IDE ở đây.
Getter, Setter và Constructors với Project Lombok
Trong bài viết này, mình sẽ giới thiệu với các bạn cách sử dụng Project Lombok để generate các phương thức Setter, Getter và constructor trong một đối tượng Java một cách tự động.
Đầu tiên, mình sẽ tạo một Maven project để làm ví dụ:
Các bạn hãy nhớ là chúng ta cần phải install Project Lombok plugin vào trong IDE của chúng ta để IDE có thể hiểu và không bị lỗi compile.
Bây giờ, ví dụ mình có class Student với một số thông tin như sau: name, code, dateOfBirth. Nếu không sử dụng Project Lombok thì mình phải khai báo các thông tin này như sau:
package com.huongdanjava.lombok;
import java.util.Date;
public class Student {
private String name;
private String code;
private Date dateOfBirth;
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public Date getDateOfBirth() {
return dateOfBirth;
}
public void setDateOfBirth(Date dateOfBirth) {
this.dateOfBirth = dateOfBirth;
}
}
Với Project Lombok, mình có thể remove các phương thức Getter, Setter trong Student class và để cho Project Lombok tự generate chúng bằng cách sử dụng annotation @Getter và @Setter:
và thêm một default constructor, một constructor với tất cả các thông tin của class Student bằng cách sử dụng các annotation @NoArgsConstructor và @AllArgsConstructor như sau:
Chúng ta còn có thể khai báo Getter, Setter cho chỉ một số thuộc tính của đối tượng Java sử dụng @Getter, @Setter annotation. Ví dụ như, bây giờ mình chỉ khai báo Getter, Setter cho thuộc tính code của Student class, mình sẽ khai báo như sau:
Bây giờ, các bạn chỉ có thể sử dụng Getter, Setter cho thuộc tính code của đối tượng Student mà thôi:
Thông qua những nội dung trên chắc hẳn bạn đã hình dung được Project Lombok là gì và bước đầu ứng dụng được những hiệu quả mà nó mang lại. Chúc bạn làm việc hiệu quả.
Thời điểm kỳ thi THPTQG kết thúc cũng là lúc các cuộc tranh luận về việc chọn ngành học để có công việc tốt trong tương lai trở nên sôi nổi hơn bao giờ hết. Chuyện học ngành Công nghệ thông tin để có mức lương ngàn đô sau khi ra trường vẫn tiếp tục là đề tài được nhiều người quan tâm. Vậy cơ hội việc làm cho sinh viên CNTT mới ra trường đang phát triển như thế nào? Khả năng phát triển với ngành này ra sao? Cùng TopDev tìm hiểu thêm ở bài viết này nhé!
Nhiều cơ hội việc làm hấp dẫn cho sinh viên ngành IT
Bối cảnh ngành CNTT tại Việt Nam hiện nay
Dựa trên kết quả Báo cáo thị trường IT Việt Nam 2021 do TopDev thực hiện, dù chịu ảnh hưởng của các đợt Covid-19 liên tục trong hơn một năm trở lại đây, Việt Nam hiện vẫn đứng thứ hai trên thế giới về sản xuất điện thoại di động và linh kiện, đứng thứ mười thế giới về sản xuất linh kiện điện tử. Đây cũng là hai yếu tố giúp Công nghệ thông tin – Truyền thông (ICT) trở thành ngành xuất siêu lớn nhất trong nền kinh tế Việt Nam.
Theo thống kê trong báo cáo, đến năm 2021 Việt Nam cần đến 450.000 nhân lực Công nghệ thông tin. Tuy nhiên, tổng số lập trình viên hiện tại ở Việt Nam (tính đến Q1/ 2021) là 430.000, đồng nghĩa với việc sẽ có khoảng 20.000 vị trí lập trình viên sẽ không được lấp đầy trong tương lai gần. Đáng chú ý hơn, với số lượng hơn 55.000 sinh viên IT tốt nghiệp mỗi năm ở Việt Nam hiện nay, chỉ có khoảng 16.500 sinh viên (30%) đáp ứng được những yêu cầu về kỹ năng và chuyên môn của doanh nghiệp.
Nguyên nhân chủ yếu là do sự chênh lệch giữa trình độ Lập trình viên và yêu cầu của doanh nghiệp. Rõ ràng, cơ hội việc làm cho sinh viên CNTT mới ra trường là rất lớn, tuy nhiên ứng viên cần đảm bảo các yêu cầu chuyên môn và kỹ năng để đáp ứng các tiêu chuẩn từ doanh nghiệp.
Cơ hội việc làm cho sinh viên ngành lập trình ở level Fresher là rất lớn, các bạn sinh viên IT mới ra trường hoàn toàn có thể thử sức ở bất kỳ lĩnh vực và công nghệ nào bản thân tự tin và muốn học hỏi thêm. Bạn có thể tham khảo một số việc làm IT Fresher ứng với thế mạnh công nghệ của bạn:
Có rất nhiều các vị trí khác nhau mà ứng viên có thể tham khảo. Tuy nhiên, tùy theo đặc thù từng công việc và yêu cầu cụ thể của mỗi công ty, bạn có thể sẽ gặp phải khó khăn về vấn đề kinh nghiệm làm việc. Do đó, hãy linh hoạt theo nhu cầu cá nhân và yêu cầu năng lực để tìm cho mình một công việc phù hợp. Chỉ cần có sự kiên trì và sẵn sàng học hỏi, dù làm việc ở bất cứ chuyên môn nào bạn cũng hoàn toàn có thể làm tốt.
Cùng TopDev tìm hiểu một số thông tin vị trí IT Fresher phổ biến:
Back-end Developer: Lập trình viên chuyên duy trì logic cốt lõi về chức năng và hiệu suất của một phần mềm hoặc hệ thống CNTT bao gồm các thành tố chính như máy chủ, ứng dụng & cơ sở dữ liệu. Back-end Developer cần thông thạo một trong ngôn ngữ lập trình nhất định như PHP, Java, Python, .Net… Tham khảo việc làm Fresher Back-end tại đây.
Front-end Developer: Lập trình viên chuyên về tính thẩm mỹ của bố cục website/ ứng dụng và lập trình ra các giao diện trực quan mà người dùng cuối/ khách hàng tương tác/ sử dụng. Front-end Developer cần đảm bảo các kỹ năng & kiến thức về giao diện người dùng (UI – User Interface), CSS, JavaScript, HTML… Tham khảo việc làm Fresher Front-end tại đây.
Tester: Vị trí chịu trách nhiệm thử nghiệm, kiểm định một sản phẩm mới, một tính năng mới hoặc tính khả dụng, chất lượng của một dự án… để tìm bugs, errors… hoặc bất kỳ vấn đề nào mà người sử dụng cuối cùng, khách hàng có thể gặp phải và báo cáo cho nhóm phát triển dự án để tiến hành sửa lỗi hoặc cải thiện sản phẩm. Tham khảo việc làm Fresher Tester tại đây.
Ngành IT vẫn luôn được xem là ngành có mức lương cao ngất ngưởng, liệu câu chuyện bên trong có thật sự như những gì ta nghe thấy? Theo thống kê từ Báo cáo thị trường IT Việt Nam năm 2021 của TopDev, ước tính thị trường lao động CNTT năm 2021 sẽ có 117.180 việc làm CNTT, tăng 36,5% so với năm 2020. Không chỉ nhu cầu tuyển dụng gia tăng mà mức lương cho các vị trí liên quan đến công nghệ và thông tin vẫn không ngừng cải thiện theo thời gian.
Theo đó, danh sách hai nhóm chuyên môn được trả lương cao nhất hiện nay gồm:
High tech liên quan đến các xu hướng như AI/ML (Kubernetes, TensorFlows, Python)
Điện toán đám mây (AWS, GCP, Azure)
Sở dĩ mức lương của các nhóm ngành cao hơn hẳn so với các ngành nghề khác là do ảnh hưởng từ quá trình chuyển đổi số trên toàn cầu. Top 3 ngành có mức thu nhập cao nhất thị trường IT hiện nay là Security, High Tech và Fintech. Trong đó, lĩnh vực Hightech – công nghệ cao như AI, IoT, điện toán đám mây,… được coi là xu hướng bắt buộc trong năm 2021 và thời gian tới.
Dựa trên số liệu thu thập được, mức lương lập trình viên cao nhất (với các đối tượng có khoảng 3 năm kinh nghiệm) dựa theo công nghệ hiện đang thuộc về AWS với mức 1.752$/tháng, TensorFlows nằm trong khoảng 1.703$/tháng.
Mức lương khi làm việc với các công nghệ cơ bản về phát triển web, hệ thống và thiết bị di động hiện vẫn đang giữ ở mức khá cao, như công nghệ lập trình bằng ngôn ngữ Python khoảng 1.290$/tháng, C++ ở mức 1.196$/tháng.
Theo ước tính của Báo cáo thị trường IT Việt Nam 2021, trong khoảng 5 năm đầu tiên sau khi ra trường, mức lương của lập trình viên sẽ dao động trong mức 342$/tháng (fresher) đến dưới 1.161$/tháng với vị trí Senior. Từ sau 5 năm, mức lương sẽ phụ thuộc vào vị trí và chức vụ mà bạn đảm nhận ở công ty.
Cơ hội và việc làm cho sinh viên CNTT mới ra trường chưa bao giờ là khan hiếm trên thị trường. Vậy nên để có thể thuận lợi tìm cho mình một công việc như ý, ngay từ bây giờ, bạn hãy cố gắng tìm hướng đi chuyên môn cho mình và trau dồi hơn nữa các kỹ năng để làm tốt hơn trong tương lai. Tìm đọc thêm nhiều bài viết hữu ích khác về lĩnh vực CNTT cùng TopDev nhé!
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Trong phần 1, chúng ta đã tìm hiểu về cách dùng interfaces và về interface rỗng. Phần này, chúng ra sẽ nghiên cứu tiếp:
Con trỏ và interfaces
Một điểm tinh tế khác của interface là định nghĩa interface không quy định liệu người triển khai có nên triển khai interface bằng cách sử dụng kiểu con trỏ hay kiểu giá trị hay không. Khi bạn được cung cấp một giá trị interface, không có gì đảm bảo rằng nó là kiểu thông thường hay là kiểu con trỏ. Trong ví dụ bài trước, chúng ta đã định nghĩa các function của interface trên các kiểu thông thường. Bây giờ chúng ta sẽ thay đổi 1 chút để triển khai thành kiểu con trỏ:
func (c *Cat) Speak() string {
return "Meow!"
}
Nếu bạn thay đổi chương trình như https://go.dev/play/p/TvR758rfre, và bạn cố tình chạy nó bạn sẽ nhận được lỗi sau:
cannot use Cat{} (type Cat) as type Animal in slice literal:
Cat does not implement Animal (Speak method has pointer receiver)
Thành thật mà nói, thông báo lỗi này hơi khó hiểu lúc đầu. Ý người ta nói không phải là interface Animal yêu cầu bạn xác định phương thức của mình như một kiểu con trỏ, nhưng bạn cố gắng chuyển đổi cấu trúc Cat thành giá trị interface Animal thì chỉ *Cat đáp ứng interface đó. Bạn có thể fix bug bằng cách chuyển *Cat thay vì dùng Cat, bằng cách sử dụng new(Cat) thay vì Cat{}(hay nói cách khác dùng &Cat{}), trông nó như sau:
Chương trình bây giờ sẽ như sau: https://go.dev/play/p/x5VwyExxBM
Hãy thay đổi theo hướng ngược lại: hãy thay thế kiểu con trỏ *Dog thay vì kiểu giá trị Dog, nhưng chúng ta sẽ không viết lại phương thức Speak cho Dog:
Chương trình sẽ như sau: https://go.dev/play/p/UZ618qbPkj
Chương trình hoạt động bình thường và chúng ta nhận ra 1 sự khác biệt nhỏ: Chúng ta không phải thay đổi phương thức Speak. Điều này hoạt động vì kiểu con trỏ có thể truy cập vào method của kiểu giá trị được kết hợp của nó, còn điều ngược lại thì không được phép. Có nghĩa là kiểu con trỏ *Dog có thể truy cập phương thức của kiểu giá trị Dog, và như chúng ta thấy trước đó, kiểu Cat không thể truy cập vào phương thức Speak của *Cat.
Điều đó nghe có vẻ khó hiểu, nhưng sẽ có ý nghĩa khi bạn nhớ những điều sau: mọi thứ trong Go đều được truyền theo giá trị. Mỗi khi bạn gọi một hàm, dữ liệu bạn đang truyền vào nó sẽ được sao chép. Trong trường hợp một phương thức định nghĩa thuộc kiểu giá trị, giá trị được sao chép khi gọi phương thức. Điều này rõ ràng hơn một chút khi bạn xem đoạn code sau:
func (t T)MyMethod(s string) {
// ...
}
là một hàm kiểu func (T, string); các giá trị được truyền vào hàm dạng giá trị dù bạn thay đổi tên biến bất kỳ. Bất kỳ thay đổi hàm Speak nào giống như func (d Dog) Speak() { … } sẽ không hiển thị khi người dùng gọi vì nó tạo thành 1 phương thức khác mất rồi. Vì mọi thứ đều được truyền bởi giá trị, nên rõ ràng tại sao một phương thức của con trỏ *Cat không thể sử dụng được bởi một giá trị Cat. Bất cứ giá trị Cat nào cũng có thể được trỏ bằng nhiều con trỏ *Cat vào. (Cat là giá trị nằm trên vùng nhớ, nên tất nhiên nhiều con trỏ sẽ trỏ vào được). Nếu ta cố tình sử dụng method của *Cat bằng 1 giá trị Cat, thì không tồn tại con trỏ để truy cập vào method đó. Ngược lại nếu chúng ta sử dụng 1 method trên Cat bằng 1 con trỏ *Cat, thì chúng ta luôn biết chính xác giá trị Cat luôn có method này, bởi vì con trỏ *Cat luôn trỏ chính xác vào giá trị Cat. Điều đó giải thích tại sao với con trỏ *Cat là d và method Speak thì ta luôn gọi được d.Speak(), không giống như cách gọi của C++ là d->Speak() mà ta thường thấy.
Thế giới thực: Lấy giá trị timestamp từ twitter API
Các API Twitter trả về thời gian như sau:
“Thu May 31 00:00:01 +0000 2012″
Giá trị này có thể hiện thị bất cứ đâu theo chuẩn JSON, ví dụ:
"created_at": "Thu May 31 00:00:01 +0000 2012"
Chúng ta có chương trình để lấy giá trị của nó như sau:
package main
import (
"encoding/json"
"fmt"
"reflect"
)
// start with a string representation of our JSON data
var input = `
{
"created_at": "Thu May 31 00:00:01 +0000 2012"
}
`
func main() {
// our target will be of type map[string]interface{}, which is a
// pretty generic type that will give us a hashtable whose keys
// are strings, and whose values are of type interface{}
var val map[string]interface{}
if err := json.Unmarshal([]byte(input), &val); err != nil {
panic(err)
}
fmt.Println(val)
for k, v := range val {
fmt.Println(k, reflect.TypeOf(v))
}
}
Chạy chương trình tại https://go.dev/play/p/VJAyqO3hTF
Chạy chương trình và chúng ta thu được kết quả:
map[created_at:Thu May 31 00:00:01 +0000 2012]
created_at string
Chúng ta có thể thấy đã lấy được key của timestamp và giá trị của nó. Tuy nhiên kết quả ở sau thì không thực sự hữu dụng lắm. Bây giờ hãy thử dùng time.Time để chuyển đổi nó:
var val map[string]time.Time
if err := json.Unmarshal([]byte(input), &val); err != nil {
panic(err)
}
Khi chạy chúng ta được lỗi sau:
parsing time ""Thu May 31 00:00:01 +0000 2012"" as ""2006-01-02T15:04:05Z07:00"": cannot parse "Thu May 31 00:00:01 +0000 2012"" as "2006"
thông báo lỗi hơi khó hiểu đó xuất phát từ cách Go xử lý việc convert bằng time.Time values sang string. Tóm lại, ý nghĩa của việc biểu diễn chuỗi mà chúng tôi đưa ra không khớp với định dạng thời gian tiêu chuẩn (vì API của Twitter ban đầu được viết bằng Ruby và định dạng mặc định cho Ruby không giống với định dạng mặc định cho Go). Chúng tôi sẽ cần xác định loại của riêng mình để loại bỏ giá trị này một cách chính xác. Gói encoding/json sẽ xem liệu các giá trị được truyền đến json.Unmarshal có đáp ứng giao diện json.Unmarshaler hay không, trông giống như sau:
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
Bạn có thể xem thêm tài liệu ở đây: https://pkg.go.dev/encoding/json#Unmarshaler
Do vậy những gì chúng ta cần là time.Time với phương thức UnmarshalJSON([]byte) error:
Bằng cách triển khai phương pháp này, chúng ta đáp ứng interface json.Unmarshaler, khiến json.Unmarshal gọi thông báo lỗi khi nhìn thấy giá trị Timestamp. Đối với trường hợp này chúng ta cần gọi method thông qua con trỏ, bởi vì chúng ta muốn nhìn thấy những thay đổi của giá trị nhận. Để cài đặt thủ công con trỏ chúng ta dùng toán tử *. Bên trong phương thức UnmarshalJSON, t đại diện cho 1 con trỏ kiểu Timestamp. Hãy nhớ rằng mọi thứ được truyền bằng giá trị. Do vậy con trỏ t trong hàm trên không phải là con trỏ đúng ngữ cảnh của nó, mà nó chỉ là 1 bản sao. Nếu bạn định trực tiếp gán t cho một giá trị khác, bạn sẽ chỉ định lại một con trỏ hàm cục bộ; người gọi sẽ không nhìn thấy thay đổi. Tuy nhiên, con trỏ bên trong của phương thức gọi trỏ đến cùng một dữ liệu với con trỏ trong phạm vi gọi của nó; bằng cách tham chiếu đến con trỏ, chúng ta hiển thị thay đổi của mình cho nơi gọi.
Chúng ta có thể dùng phương thức time.Parse, cụ thể là func(layout, value string) (Time, error). Với 2 tham số truyền vào: 1 là format của timestamp truyền vào, 2 là giá trị value cần chuyển đổi. Hàm có thể trả về kiểu time. Time hoặc là lỗi nếu không convert được. Cụ thể hàm viết như sau:
map[created_at:{0 63474019201 0x58dd00}]
created_at main.Timestamp
2012-05-31 00:00:01 +0000 UTC
Vậy chúng ta đã chuyển đổi string thành giá trị time.Time mong muốn.
Thế giới thực: Cách lấy 1 object từ http request
Chúng ta hãy kết thúc bằng cách xem cách chúng ta có thể thiết kế interface để giải quyết một vấn đề lập trình web phổ biến: chúng ta muốn phân tích cú pháp phần body của một request HTTP thành một số dữ liệu object. Lúc đầu, đây không phải là một interface rõ ràng để xác định. Chúng ta có thể cố gắng nói rằng ta sẽ nhận được resource từ một request HTTP như sau:
GetEntity(*http.Request) (interface{}, error)
Bởi vì interface{} có thể nhận bất cứ kiểu dữ liệu cơ bản nào, nên chúng ta có thể parse body và trả về kiểu mà ta mong muốn. Điều này hóa ra là một chiến lược khá tệ, lý do là chúng ta thêm quá nhiều logic vào hàm GetEntity, nó cần modify cho mọi kiểu mới để trả về kiểu interface{}. Thực tế các hàm trả về interface{} có xu hướng khá khó chịu, và như một quy tắc chung, bạn chỉ có thể nhớ rằng thông thường tốt hơn nếu lấy giá trị interface{} làm tham số hơn là trả về giá trị interface{} .
Chúng ta cũng có thể bị cám dỗ để viết một số chức năng kiểu cụ thể như thế này:
GetUser(*http.Request) (User, error)
Điều này cũng trở nên không linh hoạt, bởi vì bây giờ chúng ta có các chức năng khác nhau cho mọi kiểu, nhưng không có cách nào tốt để tổng quát chúng. Thay vào đó, những gì chúng ta thực sự muốn làm là một cái gì đó giống như thế này:
type Entity interface {
UnmarshalHTTP(*http.Request) error
}
func GetEntity(r *http.Request, v Entity) error {
return v.UnmarshalHTTP(r)
}
Trong đó hàm GetEntity nhận một giá trị interface được đảm bảo có phương thức UnmarshalHTTP. Để sử dụng điều này, chúng ta sẽ xác định trên đối tượng User của mình một số phương thức cho phép User mô tả cách nó sẽ tự thoát ra khỏi một request HTTP:
func (u *User) UnmarshalHTTP(r *http.Request) error {
// ...
}
Trong ứng dụng của mình, bạn sẽ khai báo một var thuộc kiểu User, rồi chuyển một con trỏ đến hàm này vào GetEntity:
var u User
if err := GetEntity(req, &u); err != nil {
// ...
}
Điều đó rất giống với cách bạn giải nén dữ liệu JSON. Điều này là nhất quán và an toàn vì câu lệnh var u User sẽ tự động tạo 1 struct User với giá trị rỗng. Go không giống như một số ngôn ngữ khác trong việc khai báo và khởi tạo diễn ra riêng biệt, và rằng bằng cách khai báo một giá trị mà không khởi tạo nó, bạn có thể tạo ra một sai lầm, trong đó bạn có thể truy cập vào một phần dữ liệu rác; khi khai báo giá trị, trong thời gian thực Go sẽ tạo không gian bộ nhớ thích hợp để giữ giá trị đó. Ngay cả khi phương thức UnmarshalHTTP thất bại, thì các trường giá trị rỗng sẽ thay thế giá trị rác.
Điều đó sẽ có vẻ lạ đối với bạn nếu bạn là một lập trình viên Python, vì về cơ bản, nó hoàn toàn khác với những gì chúng ta thường làm trong Python.
Kết thúc
Tôi hy vọng, sau khi đọc bài này, bạn cảm thấy thoải mái hơn khi sử dụng các interface trong Go. Hãy nhớ những điều sau:
Tạo sự trừu tượng bằng cách xem xét chức năng phổ biến giữa các kiểu dữ liệu, thay vì các trường phổ biến giữa các kiểu dữ liệu.
Kiểu interface{} không phải là bất kỳ kiểu dữ liệu nào; nó chính xác là 1 kiểu.
Interface được xác định bởi 2 từ, về cơ bản nó là {kiểu, giá trị}.
Tốt nhất là truyền 1 giá trị interface{} hơn là trả về 1 giá trị interface{}.
Kiểu con trỏ có thể gọi tới các phương thức tới giá trị của kiểu đó, nhưng điều ngược lại thì không thể.
Mọi thứ được truyền vào đều là giá trị, ngay cả đối số nhận vào là 1 phương thức.
Một interface không hoàn toàn là con trỏ, hoặc không phải là con trỏ. Nó chỉ là interface.
nếu bạn cần ghi đè hoàn toàn một giá trị bên trong một interface, hãy sử dụng toán tử * để tham chiếu thủ công một con trỏ.
Ok, tôi nghĩ rằng điều đó tổng hợp mọi thứ về interface mà cá nhân tôi thấy khó hiểu. Chúc bạn viết mã vui vẻ
React là gì mà hiện nay đâu đâu các Công ty cũng tuyển vị trí lập trình viên React, bao gồm cả ReactJs và React Native. Lộ trình học thế nào để trở thành 1 lập trình viên React và có thể apply các vị trí với mức đãi ngộ cao hiện nay? Bài viết này sẽ cung cấp cho các bạn có được phần nào câu trả lời cho những câu hỏi trên.
React là gì?
React còn được gọi là ReactJS hoặc React.js, là 1 thư viện JavaScript mã nguồn mở được phát triển bởi đội ngũ kỹ sư đến từ Facebook; nó được giới thiệu vào năm 2011, tuy nhiên đến năm 2013 mới được giới thiệu cho cộng đồng lập trình viên.
Nguyên lý xây dựng của React dựa trên components (component-based approach), có thể tái sử dụng và phù hợp với ứng dụng 1 trang (Single Page Application – SPA). React giúp lập trình viên xây dựng giao diện người dùng dựa trên JSX (môt cú pháp mở rộng của JavaScript), tạo ra các DOM ảo (virtual DOM) để tối ưu việc render 1 trang web.
ReactJs sau khi ra đời đã cho thấy sự phù hợp của nó trong việc phát triển các ứng dụng Web với nhiều chức năng được tích hợp. Nó đã tạo thành 1 xu thế, 1 hình mẫu phát triển website với nhiều chức năng, khả năng tương tác đa dạng với người dùng. Hiện tại sau hơn 10 năm phát triển thì React vẫn đang chiếm vị trí số 1 trong các thư viện Front-end hiện tại.
Để phát triển ứng dụng trên nền tảng di động, đội ngũ React đã cho ra đời framework React Native vào năm 2015; một cross-platform SDK giúp các lập trình viên có thể viết code Javascript, sử dụng thư viện React và phát triển ứng dụng dành cho Android hay iOS. Các nguyên tắc hoạt động của React Native gần như giống hệt với React ngoại trừ việc React Native không thao tác với DOM thông qua DOM ảo. Nó sử dụng một trung gian cầu nối (React Native Bridge) để giao tiếp với các phần tử native của các thiết bị đầu cuối.
Sự phổ biến của ReactJS và React Native hiện nay khiến cho nhu cầu tuyển dụng ngành IT về mảng này rất lớn. Các bạn lập trình viên mới ra trường có thể dễ dàng tìm được công việc tốt ở các công ty (bao gồm cả môi trường outsourcing và product) nếu có trang bị kiến thức về mảng lập trình React.
React hoạt động như thế nào?
Component-Based Architecture
React sử dụng kiến trúc dựa trên component, trong đó giao diện người dùng được chia thành các thành phần nhỏ, độc lập và có thể tái sử dụng. Mỗi component trong React là một lớp hoặc một hàm JavaScript, chứa logic và giao diện riêng biệt. Các component có thể lồng vào nhau để tạo ra cấu trúc UI phức tạp.
Trong React, thay vì thường xuyên sử dụng JavaScript để thiết kế bố cục trang web thì sẽ dùng JSX. JSX được đánh giá là sử dụng đơn giản hơn JavaScript và cho phép trích dẫn HTML cũng như việc sử dụng các cú pháp thẻ HTML để render các subcomponent. JSX tối ưu hóa code khi biên soạn, vì vậy nó chạy nhanh hơn so với code JavaScript tương đương.
Redux
Một thành phần cực kỳ quan trọng, không một react developer nào mà không biết. Vì vậy hãy tìm hiểu ngay Redux là gì?
Single-way data flow (Luồng dữ liệu một chiều)
ReactJS không có những module chuyên dụng để xử lý data, vì vậy ReactJS chia nhỏ view thành các component nhỏ có mỗi quan hệ chặt chẽ với nhau. Tại sao chúng ta phải quan tâm tới cấu trúc và mối quan hệ giữa các component trong ReactJS? Câu trả lời chính là luồng truyền dữ liệu trong ReactJS: Luồng dữ liệu một chiều từ cha xuống con. Việc ReactJS sử dụng one-way data flow có thể gây ra một chút khó khăn cho những người muốn tìm hiểu và ứng dụng vào trong các dự án. Tuy nhiên, cơ chế này sẽ phát huy được ưu điểm của mình khi cấu trúc cũng như chức năng của view trở nên phức tạp thì ReactJS sẽ phát huy được vai trò của mình.
Virtual DOM
Những Framework sử dụng Virtual-DOM như ReactJS khi Virtual-DOM thay đổi, chúng ta không cần thao tác trực tiếp với DOM trên View mà vẫn phản ánh được sự thay đổi đó. Do Virtual-DOM vừa đóng vai trò là Model, vừa đóng vai trò là View nên mọi sự thay đổi trên Model đã kéo theo sự thay đổi trên View và ngược lại. Có nghĩa là mặc dù chúng ta không tác động trực tiếp vào các phần tử DOM ở View nhưng vẫn thực hiện được cơ chế Data-binding. Điều này làm cho tốc độ ứng dụng tăng lên đáng kể – môt lợi thế không thể tuyệt vời hơn khi sử dụng Virtula-DOM.
State và Props
State: State là một đối tượng quản lý dữ liệu động trong component. Khi state thay đổi, React sẽ tự động cập nhật giao diện để phản ánh các thay đổi này. State thường được sử dụng trong các component stateful, nghĩa là các component có trạng thái thay đổi theo thời gian.
Props: Props (viết tắt của properties) là các giá trị được truyền từ component cha xuống component con. Props giúp truyền dữ liệu và các hàm giữa các component và không thể thay đổi trong component con (component stateless).
Các component trong React có các phương thức vòng đời (lifecycle methods) cho phép lập trình viên can thiệp vào các giai đoạn khác nhau của vòng đời component. Một số phương thức vòng đời phổ biến:
componentDidMount: Được gọi sau khi component được render lần đầu tiên. Thường dùng để thực hiện các tác vụ như gọi API.
componentDidUpdate: Được gọi sau khi component được cập nhật (state hoặc props thay đổi).
componentWillUnmount: Được gọi ngay trước khi component bị gỡ bỏ khỏi DOM. Thường dùng để dọn dẹp các tài nguyên như bộ đếm thời gian hoặc kết nối mạng.
Handling Events
React xử lý các sự kiện bằng cách sử dụng cú pháp camelCase và truyền hàm sự kiện trực tiếp trong JSX. Điều này tương tự như cách làm việc với các sự kiện trong DOM, nhưng với React, bạn không cần phải sử dụng addEventListener.
Những ưu điểm tuyệt vời mà ReactJS mang lại cho lập trình viên
ReactJS, một thư viện JavaScript mã nguồn mở do Facebook phát triển, đã trở thành công cụ phát triển ứng dụng web phổ biến nhờ vào những ưu điểm nổi bật mà nó mang lại cho lập trình viên. Dưới đây là một số ưu điểm tuyệt vời của ReactJS:
Dễ học và sử dụng
ReactJS có cú pháp đơn giản và dễ hiểu, đặc biệt là đối với những người đã quen thuộc với JavaScript. JSX, một phần mở rộng của JavaScript, cho phép lập trình viên viết mã HTML trong JavaScript, làm cho quá trình phát triển trở nên trực quan và dễ dàng hơn. Điều này giúp các lập trình viên mới dễ dàng tiếp cận và bắt đầu sử dụng React nhanh chóng.
Hỗ trợ Reusable Component trong Java
ReactJS cho phép xây dựng các thành phần UI nhỏ gọn và độc lập, gọi là component. Các component này có thể được tái sử dụng nhiều lần trong cùng một ứng dụng hoặc trong các dự án khác nhau, giúp tiết kiệm thời gian và công sức phát triển, đồng thời đảm bảo tính nhất quán của giao diện người dùng. Đặc biệt, React có thể tích hợp tốt với các ứng dụng Java, cho phép sử dụng các component React trong các dự án Java hiện có.
Viết component dễ dàng hơn
Cấu trúc component-based của ReactJS giúp việc viết và quản lý các thành phần UI trở nên dễ dàng và hiệu quả hơn. Lập trình viên có thể tách biệt các phần của giao diện người dùng thành các component nhỏ hơn, dễ dàng kiểm thử và bảo trì. Việc viết các component này trở nên đơn giản nhờ JSX, cho phép kết hợp JavaScript và HTML một cách tự nhiên và dễ hiểu.
Hiệu suất tốt hơn với Virtual DOM
ReactJS sử dụng Virtual DOM để tối ưu hóa hiệu suất ứng dụng. Thay vì cập nhật toàn bộ DOM thật mỗi khi có thay đổi, React sẽ cập nhật Virtual DOM trước, sau đó so sánh với DOM thật để chỉ thay đổi những phần cần thiết. Điều này giúp giảm thiểu số lượng thao tác trên DOM thật, từ đó cải thiện tốc độ và hiệu suất của ứng dụng.
Thân thiện với SEO
Một trong những thách thức lớn đối với các ứng dụng JavaScript truyền thống là khả năng thân thiện với SEO. ReactJS giải quyết vấn đề này bằng cách cho phép render trên server (Server-Side Rendering – SSR), giúp các công cụ tìm kiếm dễ dàng lập chỉ mục các trang web. Điều này làm tăng khả năng hiển thị và xếp hạng của trang web trên các công cụ tìm kiếm, từ đó thu hút lượng truy cập lớn hơn.
Dễ dàng bảo trì và mở rộng
Cấu trúc dựa trên component của ReactJS giúp mã nguồn dễ dàng quản lý, bảo trì và mở rộng. Mỗi component có thể được phát triển, kiểm thử và bảo trì độc lập, giúp việc sửa lỗi và thêm tính năng mới trở nên đơn giản hơn. Điều này cũng giúp các nhóm phát triển có thể làm việc song song trên các phần khác nhau của ứng dụng mà không gây ra xung đột.
Hỗ trợ đa nền tảng cả web và mobile
Với React Native, một framework dựa trên React, lập trình viên có thể phát triển các ứng dụng di động cho cả iOS và Android sử dụng cùng một codebase. Điều này giúp tiết kiệm thời gian và nguồn lực, đồng thời đảm bảo tính nhất quán của ứng dụng trên các nền tảng khác nhau.
Phát triển ứng dụng một cách nhanh chóng
Nhờ vào việc tái sử dụng component và các công cụ hỗ trợ mạnh mẽ, lập trình viên có thể phát triển và triển khai các ứng dụng nhanh chóng hơn so với nhiều công nghệ khác. Điều này đặc biệt quan trọng trong môi trường phát triển phần mềm hiện đại, nơi tốc độ ra mắt sản phẩm đóng vai trò then chốt.
Những ưu điểm trên đã giúp ReactJS trở thành một công cụ phát triển mạnh mẽ và phổ biến, được ưa chuộng bởi các lập trình viên và doanh nghiệp trên toàn thế giới. Từ các dự án cá nhân đến các ứng dụng doanh nghiệp lớn, ReactJS mang lại sự linh hoạt, hiệu quả và hiệu suất cao, giúp lập trình viên tạo ra các sản phẩm chất lượng.
Lộ trình học ReactJs
Trước tiên các bạn cần xác định rằng React là 1 thư viện dành cho Frontend, chính vì thế để có thể học được React, chúng ta cần trang bị các kiến thức liên quan đến Frontend và những công cụ chắc chắn sẽ sử dụng:
HTML, CSS và JavaScript
NodeJS, NPM, ES6
IDE: Visual Studio Code
Sau khi nắm được cơ bản những kiến thức trên, chúng ta có thể bước ngay vào tìm hiểu React và những kiến thức liên quan. Mình sẽ tạm chia thành 3 mức level: Cơ bản, Nâng cao và Chuyên sâu.
Ở level này chúng ta cần tìm hiểu các khái niệm cơ bản nhất liên quan đến React. Các bạn có thể lên trang chủ của React sẽ có đầy đủ tài liệu về phần này:
JSX (JavaScript XML): 1 cú pháp mở rộng của JavaScript được React sử dụng
Components: thành phần, với React thì tất cả được tạo nên từ components. Phân biệt được Functional Components và Class Components
Props và State: thuộc tính và trạng thái của 1 component trong React
Component Life Cycle: vòng đời của 1 component trong React
React Hook: 1 khái niệm được React đưa vào từ phiên bản 16.8 giúp cải thiện việc tái sử dụng chức năng trong React
Level nâng cao
Sau khi nắm vững được các khái niệm ở Level cơ bản trên, chúng ta có thể tiến hành tạo ra các ứng dụng, project của riêng cá nhân mình. Trong quá trình đó, các bài toán thực tế sẽ được giải quyết bằng những kiến thức ở phần nâng cao này:
High Order Components: một kỹ thuật nâng cao trong React giúp tái sử dụng lại các components.
State Managements: Việc quản lý các biến trạng thái là 1 bài toán cơ bản và quan trọng nhất trong 1 ứng dụng React. Có khá nhiều thư viện giải quyết bài toán này: useContext Hook, Redux, MobX
Custom Hook: tự mình tạo ra các hook để giúp tái sử dụng logic trong code React
Refs và DOM: Ref cho phép chúng ta truy cập đến DOM node, giúp chúng ta tham chiếu đến 1 node để sử dụng các thuộc tính và action của chúng.
Level chuyên sâu
Đến bước này, các bạn đã tự tin với những kiến thức bạn đã trang bị rồi. Cùng gây dựng sản phẩm của mình bằng các thư viện chuyên sâu hơn. Chọn 1 bộ styling UI, chọn 1 thư viện quản lý state, chọn 1 framework cụ thể để tuân theo kiến trúc của nó hay tìm cách tích hợp các công cụ kiểm thử, tài liệu hóa, unit test, … để hoàn thiện dự án của mình. Một số gợi ý của bạn như sau:
Framework ReactJS: NextJS, Gatsby, Appollo
Thư viện xử lý API giao tiếp với backend: Axios, Fetch
UI Library: Chakra UI, Material UI, Ant Design
Tạo form submit dữ liệu: React Hook Form, Formik
Testing, Validation: Jest, Cypress
Documentation: Storybook
Hy vọng bài viết này đã mang đến cho các bạn những kiến thức cơ bản nhất giúp trả lời được câu hỏi React là gì và xác định rõ được lộ trình học và trở thành 1 lập trình viên React. Nếu có dự định muốn trở thành 1 lập trình viên React trong tương lai, đừng ngại ngần và hãy bắt đầu ngay từ hôm nay.
Tương lai của ReactJS
Facebook và toàn bộ đội phát triển ReactJS vẫn luôn cố gắng chứng tỏ trong việc cam kết nâng cao tính hiệu quả của ReactJS. Đây là vấn đề tiên quyết để vượt qua sự phát triển nhanh chóng của các framework khác như Vue.js. Một số cập nhật của React được mong đợi trong tương lai có thể kể đến như:
Sẽ có những loại render mới như việc add thêm những đoạn cú pháp độc đáo vào JSX mà không cần đến keys.
Cải thiện trong việc xử lý các lỗi phát sinh. Trước đây, các lỗi Javascript bên trong các Components sẽ làm hỏng state của component và cũng gây ra các lỗi trong quá trình render trong các component cha khác. Các lỗi này được thông báo rất khó hiểu gây ra khó khăn trong việc khắc phục. Một vấn đề khác là trong các phiên bản trước đây thì React không cung cấp cách thức để có thể bắt và xử lý lỗi và phục hồi khi xảy ra lỗi một cách rõ ràng trong Components.
Trên đây chính là những kiến thức cơ bản nhất về ReactJS, nếu như bạn đã có một base khá ổn về ReactJS, vậy bạn có bao giờ nghĩ rằng mình sẽ thay đổi và tối ưu tốc độ của nó cũng như lấn sân sang React Native để trở thành một React Developer???
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Để kiến thức của bài học sẽ không trôi đi mất sau khi đọc xong, bạn hãy mở Visual Code hay bất cứ IDE nào có thể code được Golang ra và thực hành.
Giới thiệu về interfaces
Interfaces là gì? Một interface có 2 điểm: Nó là 1 tập hợp các phương thức (methods), nhưng cũng là 1 kiểu. Trước tiên chúng ta hãy tập hợp vào điểm thứ nhất là tập hợp các methods.
Thông thường, chúng ta sẽ giới thiệu về interfaces thông qua các ví dụ cụ thể, dễ hiểu. Hãy xem xét 1 ví dụ thực tế là giả sử chúng ta cần định nghĩa kiểu dữ liệu Động vật (Animal). Kiểu Animal có 1 interface đó là động vật có thể giao tiếp được bằng tiếng. Gà kêu ò ó o, chó sủa gâu gâu, mèo kêu meo meo.. chẳng hạn như vậy.
Đây là khái niệm cốt lõi trong Golang, thay vì thiết kế các loại giao diện trừu tượng mà data có thể chứa, thì chúng ta thiết kế những hành động mà các kiểu của data có thể thực thi.
Hãy bắt đầu bằng interface của lớp Animal như sau:
type Animal interface {
Speak() string
}
Trông rất đơn giản: động vật có thể “nói” bằng ngôn ngữ của chúng. Phương thức Speak không nhận đối số và trả về 1 kiểu string để viết ra âm thanh mà con vật có thể phát ra(meo meo, gâu gâu…). Bất kỳ kiểu nào định nghĩa phương thức này đều thỏa mãn interface Animal. Không có từ khóa implements trong Go. Việc 1 kiểu có thỏa mãn hay không được xác định tự động. Hãy tạo 1 vài kiểu thỏa mãn giao diện này như sau:
Bây giờ chúng ta có 4 con vật: 1 con chó, 1 mèo, 1 thằng Llama và 1 thằng lập trình viên java(xin lỗi đây chỉ là ví dụ cho vui thôi nha). Trong hàm main chúng ta có thể tạo 1 slices chứa 4 động vật này như sau:
Bạn có thể chạy và xem kết quả tại đây: http://play.golang.org/p/yGTd4MtgD5
Tuyệt vời, bây giờ bạn đã biết cách sử dụng các giao diện và tôi không cần phải nói về chúng nữa, phải không? Không, không hẳn. Hãy xem xét một số điều không quá rõ ràng đối với những con chuột chũi mới chớm :v
Kiểu interface{}
Kiểu interface{} là 1 kiểu interface rỗng, là nguồn gốc của mọi sự nhầm lẫn. Rõ ràng nó không có method nào cả. Vì không có từ khóa nào để triển khai, và do vậy tất cả các kiểu trong Golang đều thỏa mãn nó 1 cách tự động. Điều đó có nghĩa là nếu bạn viết 1 hàm nhận interface{} làm đối số, bạn có thể truyền vào bất kỳ kiểu nào. Cho 1 ví dụ:
func DoSomething(v interface{}) {
// ...
}
Nó sẽ chấp nhận bất kỳ tham số nào.
Ở đây nó tạo ra 1 sự khó hiểu: vậy v ở trong hàm DoSomething là kiểu dữ liệu gì? Những người mới bắt đầu được dẫn dắt để tin rằng v là bất kỳ kiểu nào, nhưng điều đó là sai. v không thuộc kiểu nào, nó thuộc kiểu interface rỗng. Chờ đã, gì cơ? Khi chuyển một giá trị vào hàm DoSomething, thời gian thực Go sẽ thực hiện chuyển đổi kiểu (nếu cần) và chuyển đổi giá trị đó thành giá trị interface{}. Tất cả giá trị đó là chính xác trong thời gian thực, và nó là 1 kiểu tĩnh(static) của interface{}. Điều này sẽ khiến bạn tự hỏi: được rồi, vậy nếu một sự chuyển đổi đang diễn ra, thì điều gì đang thực sự được chuyển vào một hàm nhận giá trị {} interface (hoặc, thứ thực sự được lưu trữ trong [] Animal slice)? Giá trị của 1 interface được tạo thành bởi 2 điều: Một là con trỏ trỏ tới method table định nghĩa tên biến cho loại kiểu; và một là sử dụng để trỏ đến dữ liệu thực tế đang được giữ bởi giá trị biến đó. Nếu bạn muốn tìm hiểu thêm về cách triển khai các giao diện, tôi nghĩ rằng mô tả của Russ Cox về các giao diện là rất, rất hữu ích.
Trong ví dụ trên của chúng ta, khi chúng ta xây dựng một phần giá trị Animal, chúng ta không cần phải nói điều gì đó khó hiểu như Animal (Dog {}) để đặt một giá trị của kiểu Dog vào slices Animals, bởi vì chuyển đổi đã được xử lý tự động. trong slice Animals, mỗi phần tử thuộc kiểu Animal, nhưng chúng có giá trị khác nhau từ các kiểu khác nhau.
Vậy… tại sao điều này lại quan trọng? Chà, việc hiểu cách các interface được biểu diễn trong bộ nhớ làm cho một số điều có thể gây nhầm lẫn trở nên rất rõ ràng. Cho ví dụ, với câu hỏi “Tôi có thể convert kiểu []T thành kiểu []interface{} không?” rất dễ trả lời khi bạn hiểu cách các giao diện được biểu diễn trong bộ nhớ.
Dưới đây là một số mã gây hiểu lầm phổ biến về interface:
package main
import (
"fmt"
)
func PrintAll(vals []interface{}) {
for _, val := range vals {
fmt.Println(val)
}
}
func main() {
names := []string{"stanley", "david", "oscar"}
PrintAll(names)
}
Chạy code tại đây: http://play.golang.org/p/4DuBoi2hJU
Khi chạy bạn sẽ nhận được lỗi sau:
cannot use names (type []string) as type []interface {} in argument to PrintAll
Nếu chúng ta thực sự muốn làm cho nó hoạt động, chúng ta sẽ phải chuyển đổi []string thành []interface{}:
package main
import (
"fmt"
)
func PrintAll(vals []interface{}) {
for _, val := range vals {
fmt.Println(val)
}
}
func main() {
names := []string{"stanley", "david", "oscar"}
vals := make([]interface{}, len(names))
for i, v := range names {
vals[i] = v
}
PrintAll(vals)
}
Chạy code ở đây: http://play.golang.org/p/Dhg1YS6BJS
Điều này khá xấu, nhưng nó chạy ổn. Không phải mọi thứ đều hoàn hảo. (trong thực tế, điều này không xuất hiện thường xuyên, bởi vì []interface{}hóa ra ít hữu ích hơn như bạn mong đợi ban đầu.





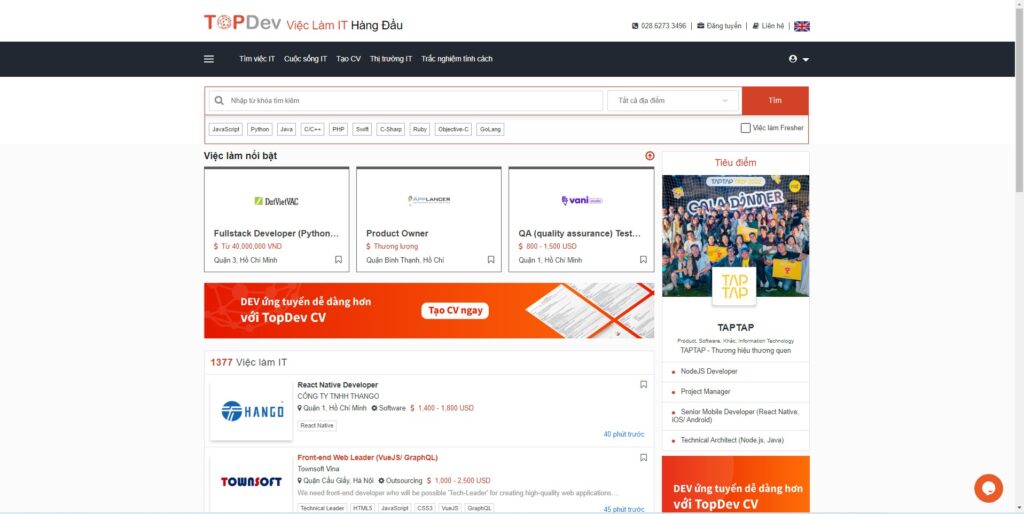




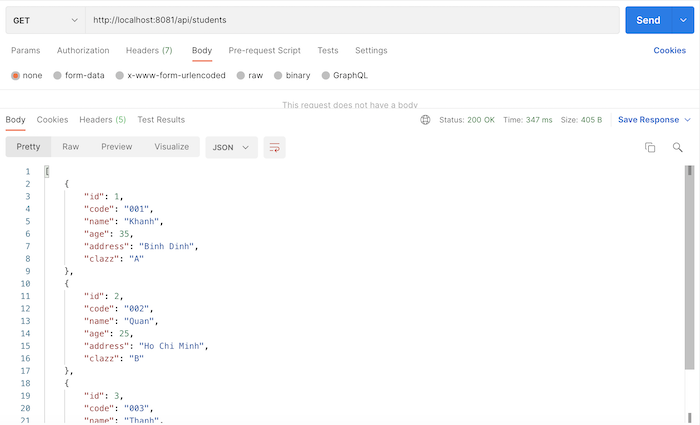
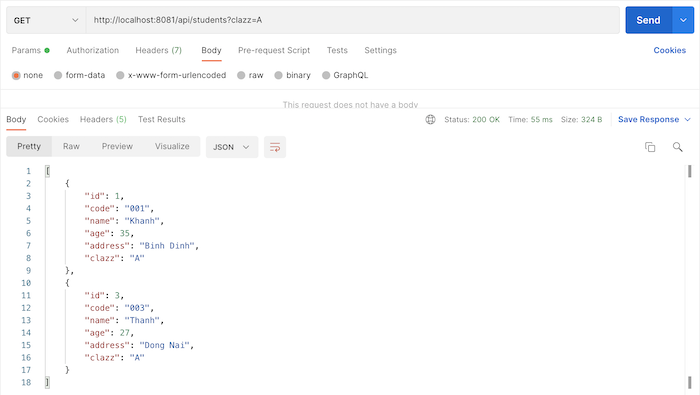
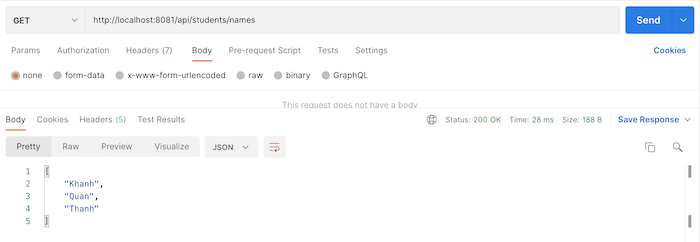
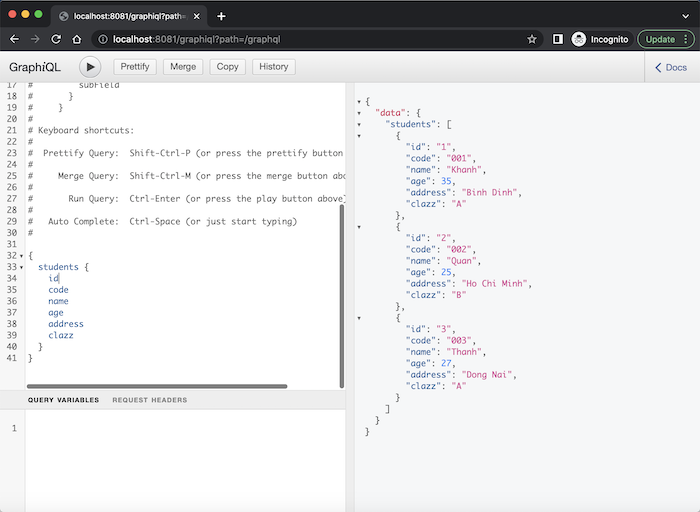
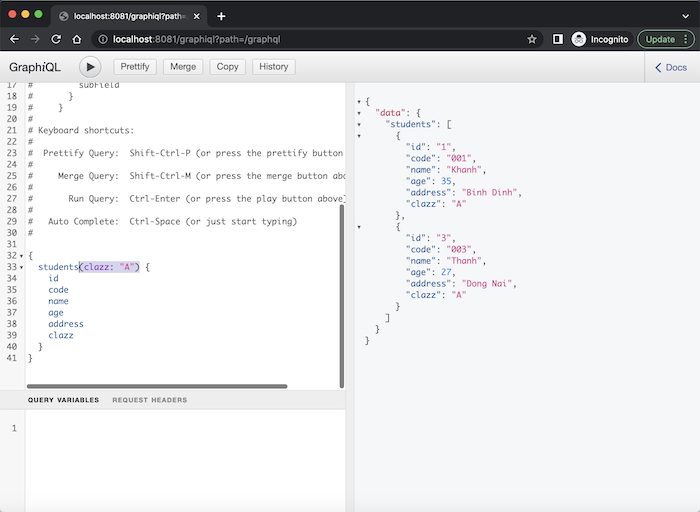
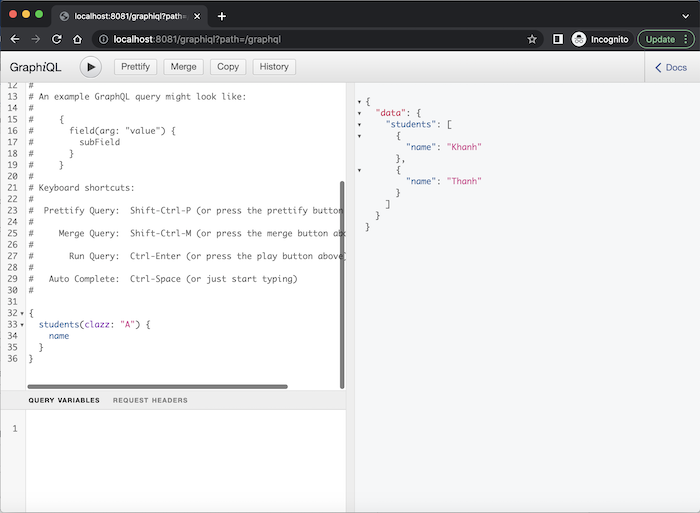 Như các bạn thấy, chỉ với một query mapping của GraphQL cho đối tượng data Student, chúng ta có thể lấy hết thông tin mà chúng ta muốn và thông tin trả về cũng có thể được giới hạn tuỳ theo nhu cầu.
Như các bạn thấy, chỉ với một query mapping của GraphQL cho đối tượng data Student, chúng ta có thể lấy hết thông tin mà chúng ta muốn và thông tin trả về cũng có thể được giới hạn tuỳ theo nhu cầu.






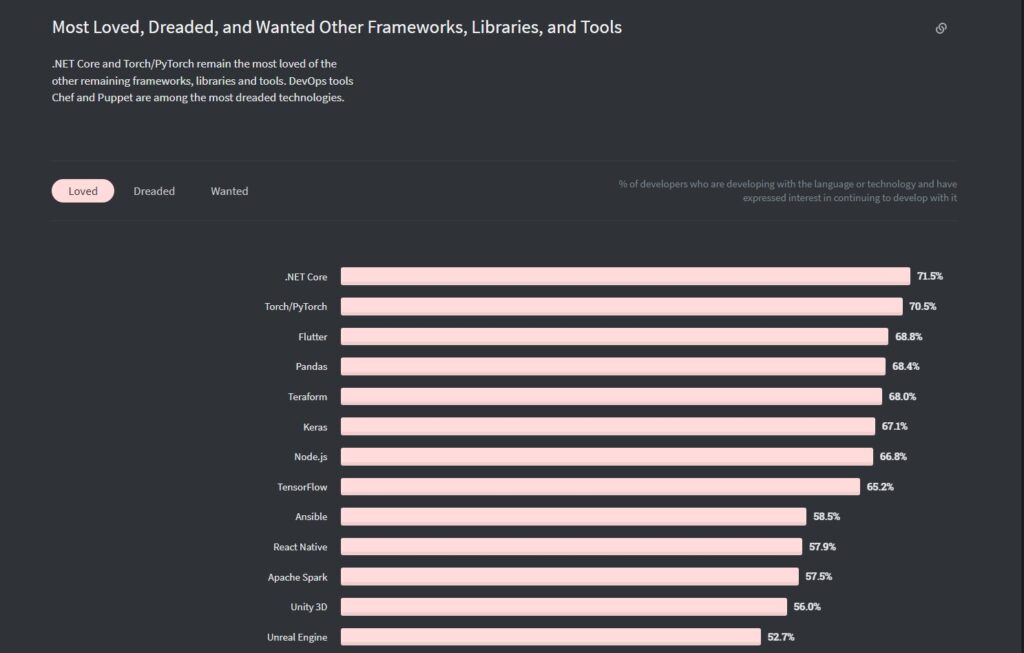
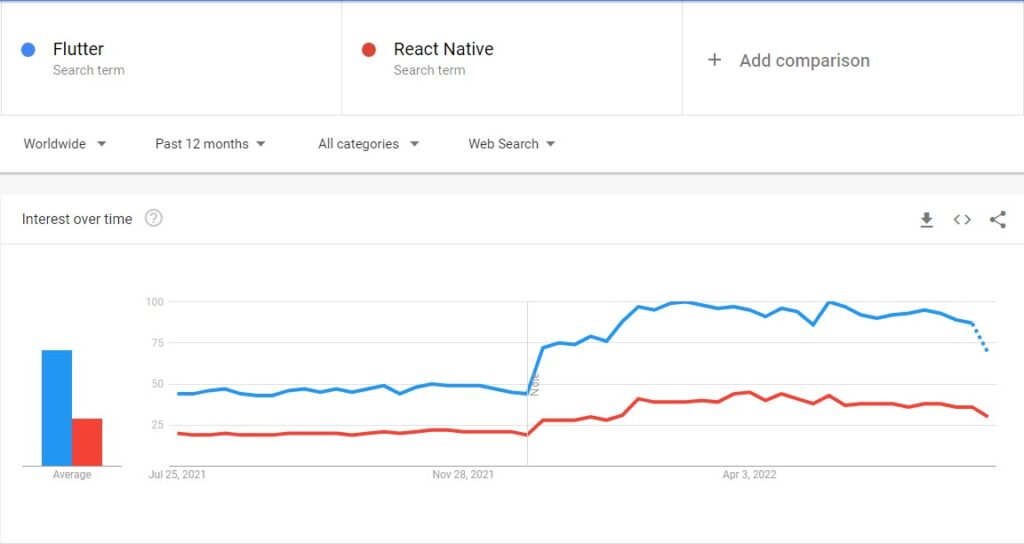
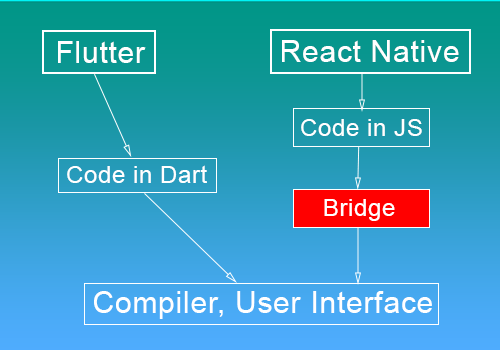






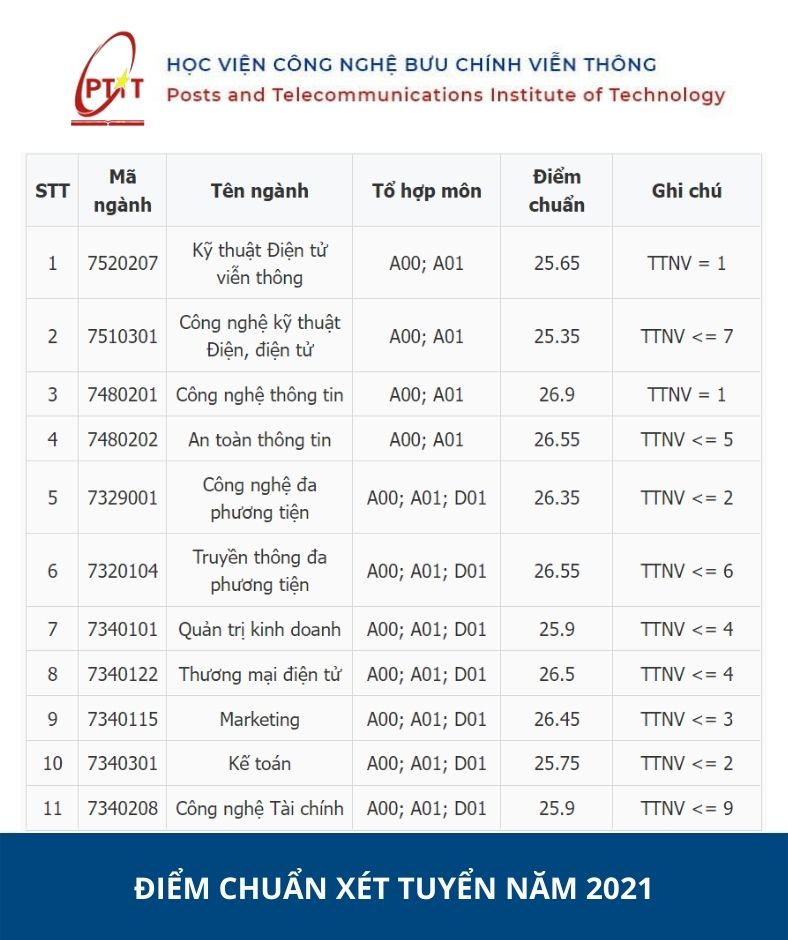
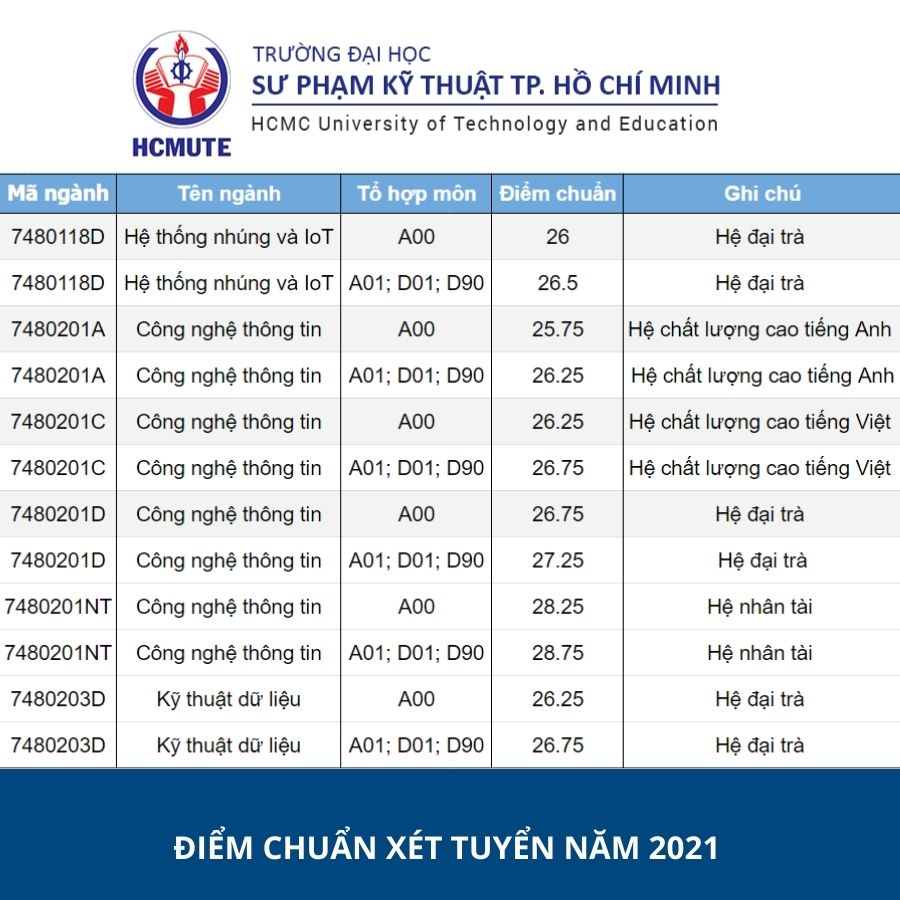
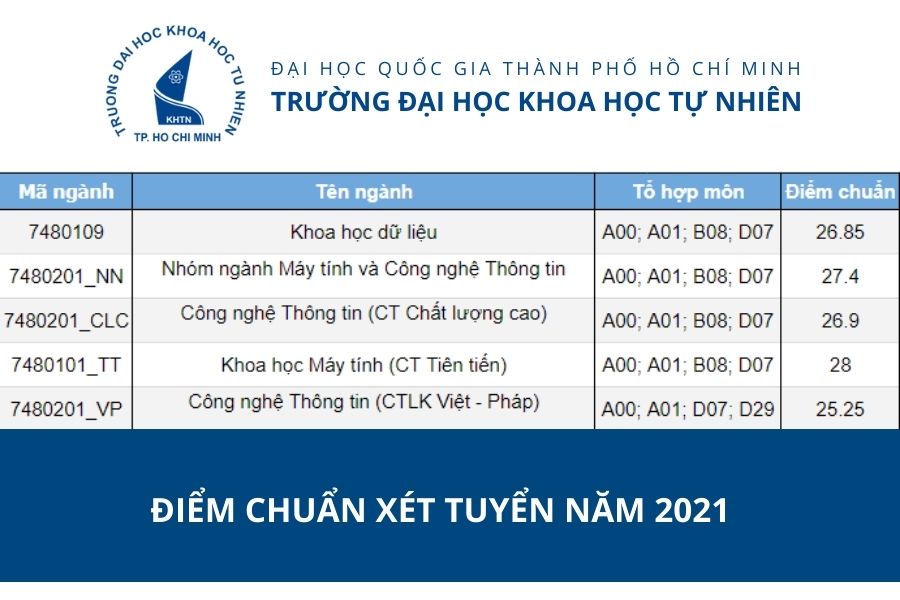
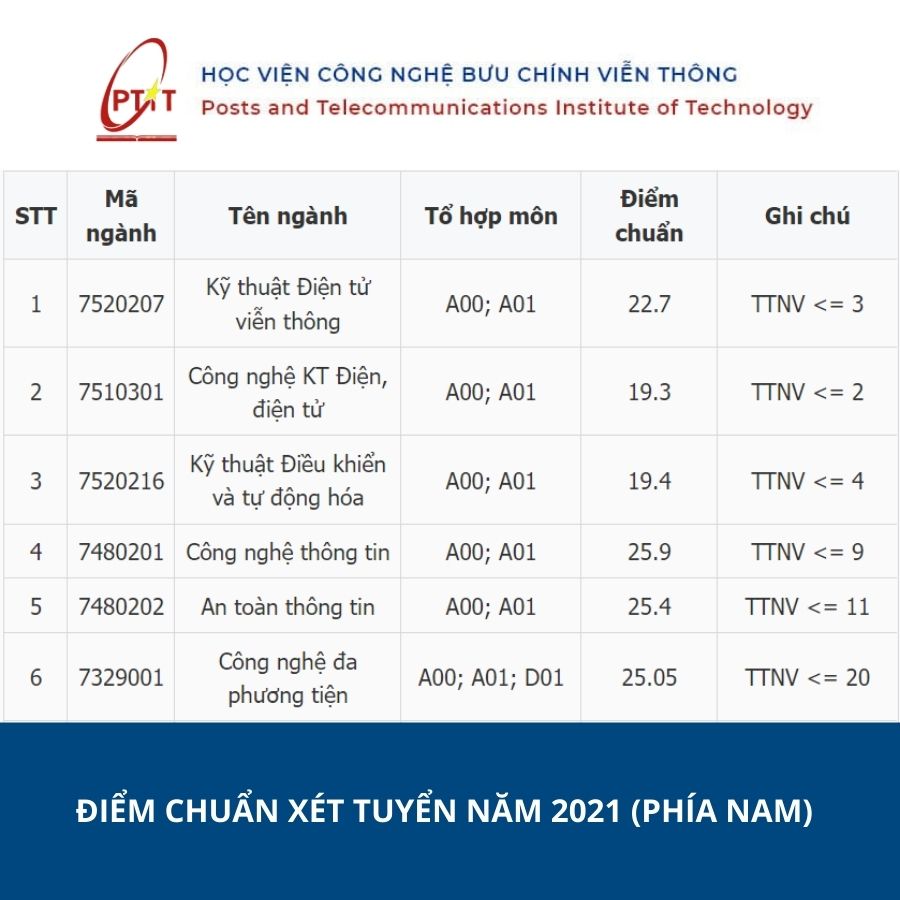
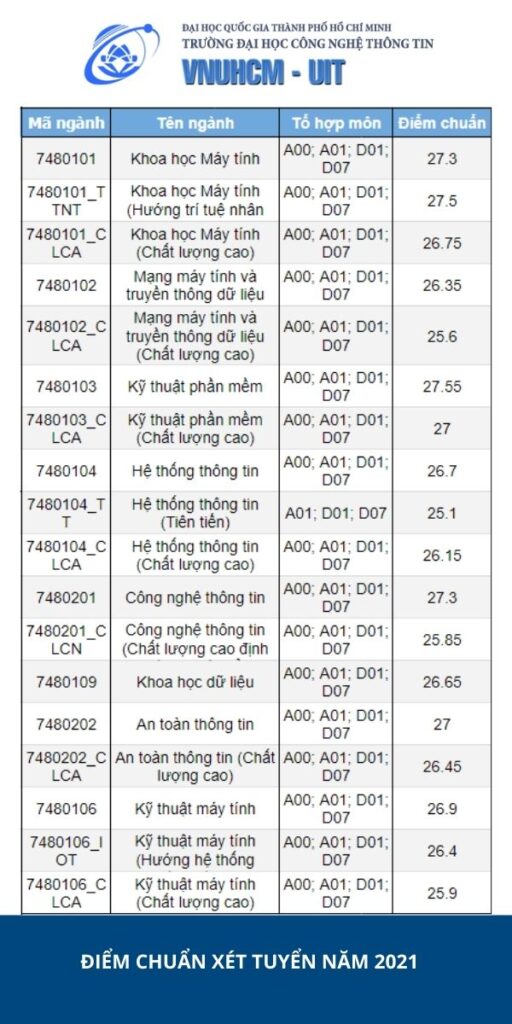

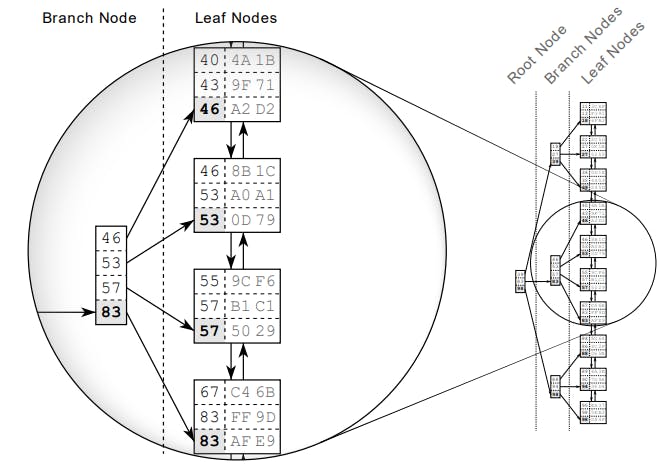
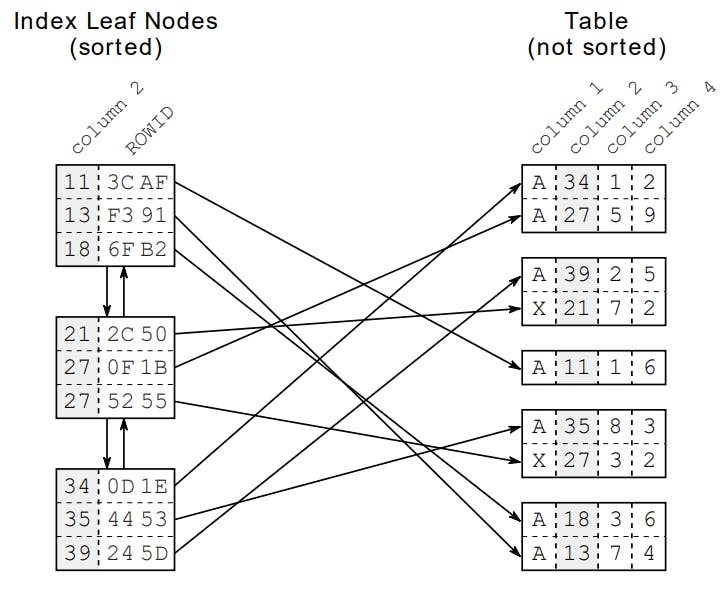
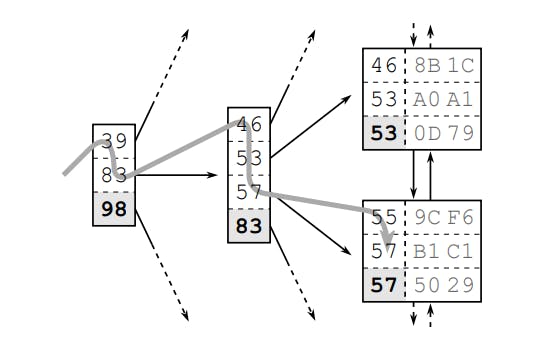
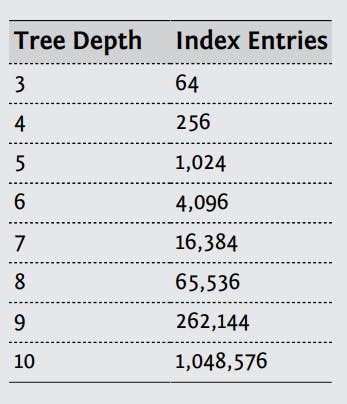
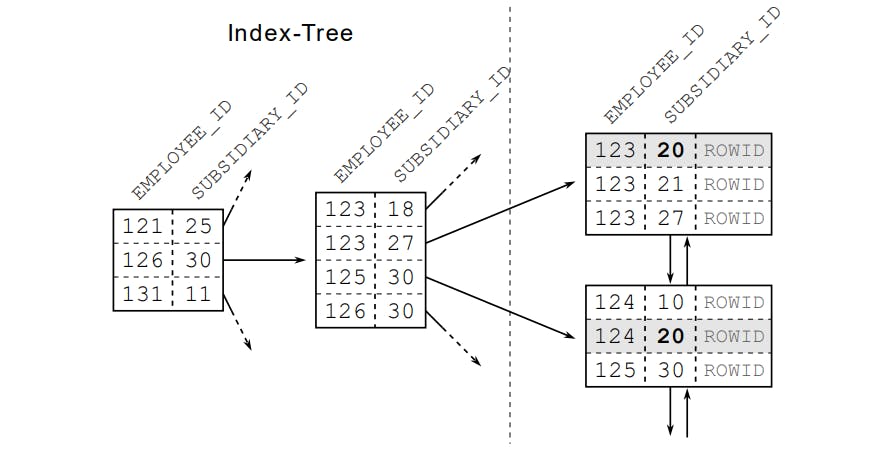

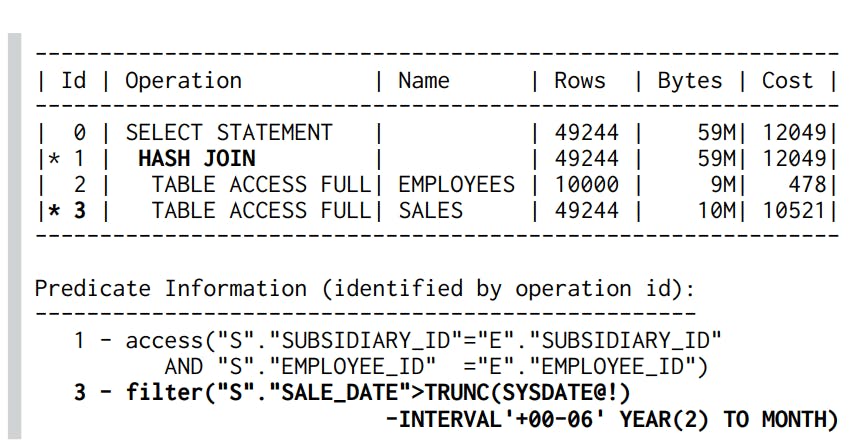
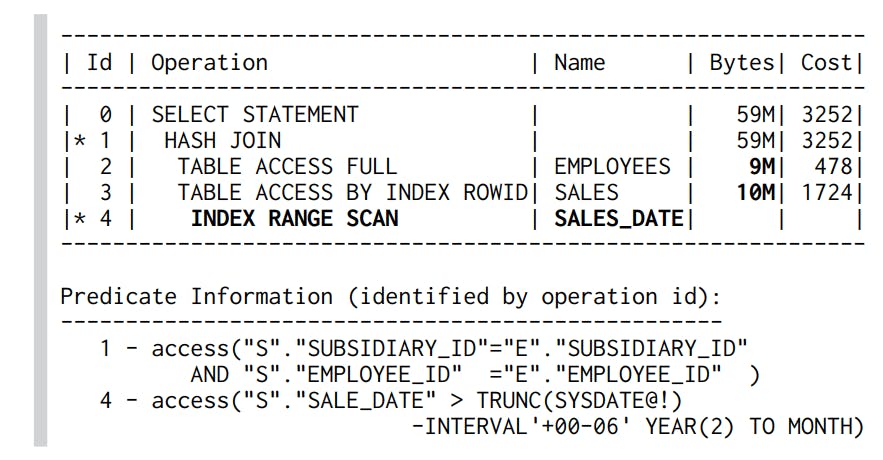

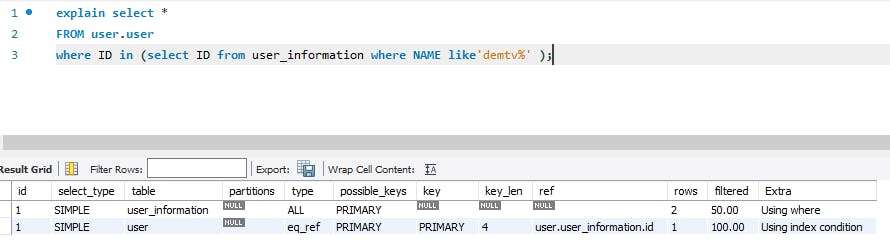

 Hình minh họa
Hình minh họa Hình minh họa
Hình minh họa
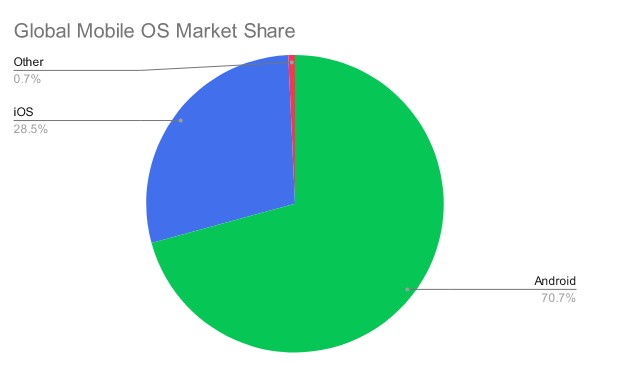












 Cơ bản thì từ mã tỉnh thành viết tắt lưu xuống ta có thể lấy được địa chỉ đầy đủ như này
Cơ bản thì từ mã tỉnh thành viết tắt lưu xuống ta có thể lấy được địa chỉ đầy đủ như này
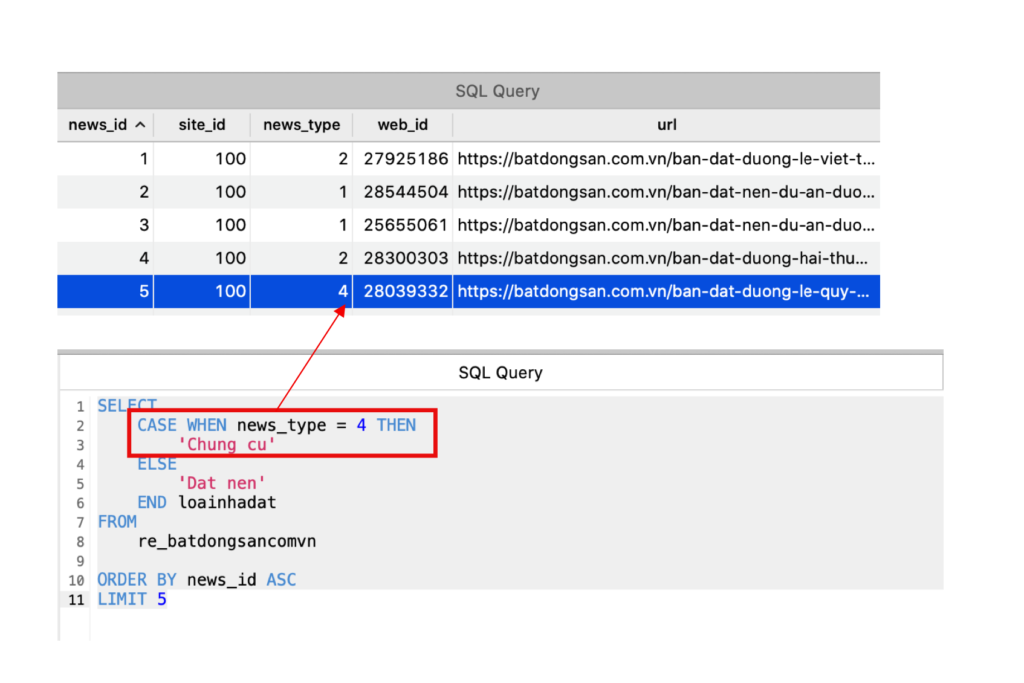

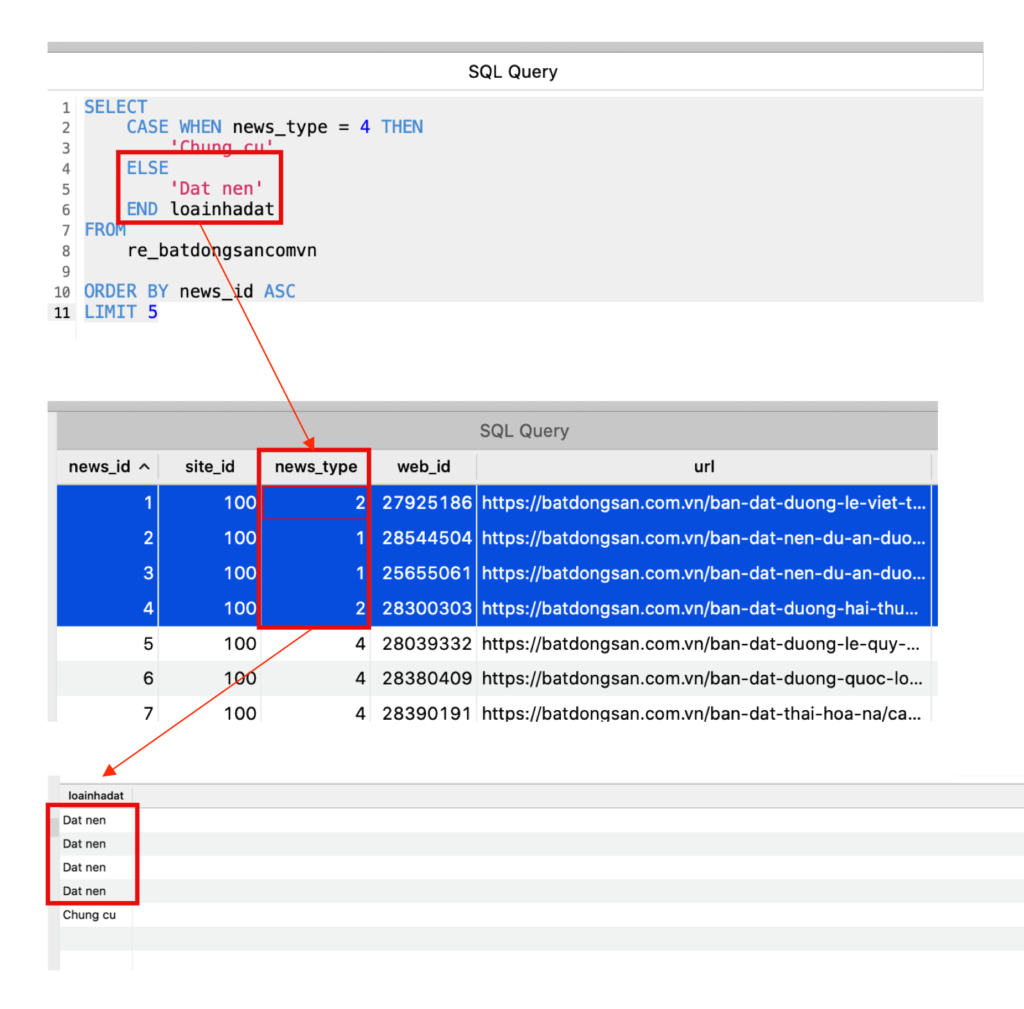

 Chúng ta còn có thể khai báo Getter, Setter cho chỉ một số thuộc tính của đối tượng Java sử dụng @Getter, @Setter annotation. Ví dụ như, bây giờ mình chỉ khai báo Getter, Setter cho thuộc tính code của Student class, mình sẽ khai báo như sau:
Chúng ta còn có thể khai báo Getter, Setter cho chỉ một số thuộc tính của đối tượng Java sử dụng @Getter, @Setter annotation. Ví dụ như, bây giờ mình chỉ khai báo Getter, Setter cho thuộc tính code của Student class, mình sẽ khai báo như sau: