Bài viết đến từ anh Vũ Tuấn Nghĩa – Quản lý cao cấp hoạch định dữ liệu Data Engineering team @Techcombank
Data orchestration là một khối xây dựng cốt lõi của các hệ thống ETL dữ liệu, và là một công cụ đã có từ lâu đời và được áp dụng trong nhiều hệ thống khác nhau. Khi xây dựng Data Lake tại Techcombank, chúng mình có cơ hội thiết kế nhiều component/system từ đầu, từ hệ thống Data sourcing đến Datalake, đến hệ thống data ETL pipeline trên các zones của Data Lake. Để đáp ứng các nhu cầu và thách thức thực tế, ta cần có một hệ thống Data orchestration để giải quyết các bài toán:
Cơ chế trigger các downstream job một cách linh hoạt mà không gây khó khăn trong quá trình vận hành
Rút ngắn thời gian phát triển, xây dựng và kiểm thử
Hạn chế sự phụ thuộc lẫn nhau gây ra chain failure
Hôm nay chúng ta sẽ tìm hiểu về Data orchestration và cách giải quyết bài toán ở Techcombank.
Data Orchestration là gì?
Data orchestration là nền tảng platform có nhiệm vụ quản lý và tự động hoá flow của data xuyên suốt giữa các hệ thống, application và các hệ thống lưu trữ.
Có thể hiểu đơn giản như như hình dưới như sau:
Khi có 1 lệnh trigger
Job 1 được execute
Khi Job 1 done, Job 2 và Job 3 được execute
Khi Job 2 và Job 3 cùng done, Job 4 được execute
Nhu cầu cần một Data Orchestration xuất hiện khi có dependency giữa các hệ thống. Khi có một job phụ thuộc vào job khác, thì sẽ cần 1 hệ thống ở giữa để không chỉ trigger mà còn đảm bảo với từng Job riêng biệt, chỉ được bắt đầu sau khi tất cả các phần phụ thuộc đã hoàn tất (ví dụ: Job 4).
Sự phát triển của Data Orchestration patterns
First Gen – Flight schedule
Phiên bản đầu tiên cũng như cổ điển nhất của Orchestration, được dùng khá phổ biến ở nhiều IT system (ví dụ: hệ thống giờ bay của máy bay).
Job được trigger dựa theo fixed time hoặc interval time và không phụ thuộc vào các job upstream có hoàn tất hay không. Để phòng trừ trường hợp các Job chạy tốn thời gian hơn kế hoạch, thường sẽ thêm các buffer giữa các job.
Điểm hạn chế của design này là cũng chính là task delay – buffer time
Lúc này Job 2 sẽ nhận stale input data khiến data output của Job 2 cũng sai, dẫn đến cả pipeline đang xử lý data bị sai lệch.
Current Gen – Train schedule
Phiên bản orchestration được sử dụng rộng rãi trong các software hiện đại ngày nay, nổi bật có Airflow, Dagster, Prefect, và dbt. Core concept sử dụng Directed Acyclic Graph (DAG) để định nghĩa sự phụ thuộc giữa các job và stateful application để quản lý trigger và start job.
Điểm hạn chế của design này là
Mono-DAG
Việc sử dụng DAG để liên kết phụ thuộc giữa các job với nhau, dẫn đến trong quá trình phát triển
a. việc liên tục thêm những job vào dẫn đến “mạng nhện” DAG, khiến chi phí maintain bao gồm: compile, test càng ngày càng tăng cao khiến development cycle chậm dần theo thời gian.
b.
c. việc xác định owner of DAG cũng là vấn đề nhức đầu, nhất là khi có issue, việc ảnh hưởng đến nhiều job (nhiều team) khiến chi phí phối hợp rất tốn nhiều thời gian.
2. DAG of DAG Một hướng giải quyết khác là thay vì sử dụng một mono-DAG, chúng ta sẽ tạo DAG of DAG. Tuy nhiên ta lại gặp phải vấn đề lớn là do giờ đây tầng phụ thuộc là DAG, sẽ giảm sự linh hoạt trong định nghĩa sự phụ thuộc của các job, nhất là trong trường hợp các data flow quan trọng, với SLA thấp.
Bài toán ở Techcombank
Hệ thống Datalake của Techcombank được chia làm 2 part:
ETL Sourcing dữ liệu từ tất cả các hệ thống Data sources, tập kết data ở Raw zone, do đặc thù đơn giản về mặt nghiệp vụ, không có transformation, không dependency → Data orchestration sử dụng Airflow – out of the box solution.
Với các ETL giữa các zone trên On-cloud Datalake, các ETL về mặt nghiệp vụ yêu cầu các dependency phức tạp, việc sử dụng các stateful Orchestration(current Gen) như Airflow hay AWS StepFunction gặp phải nhiều khó khăn trong quá tình development or operation (mono-DAG và DAG of DAG) → dẫn đến không đáp ứng được nhu cầu sử dụng của các team development.
Từ đó team mình có phát triển framework Orchestration để giải quyết bài toán gặp phải.
Event-driven Orchestration
Thay vì build 1 hệ thống centralized stateful orchestration thì team mình tiếp cận theo một mindset khác:
Condition-based over state
Events within queue over hardly dependency
Configuration as code over code-first approach
Condition-based over state
Việc sử dụng Conditions để xác định xem khi nào job được trigger thay vì đơn giản dùng state của upstream job khiến việc config trigger rất linh hoạt trong quá trình sử dụng. Sau đây là một số ví dụ trong quá trình sử dụng:
Condition để trigger job khi cả 2 job_1, job_2 succeeded
Những functions như “last_run_succeeded“, “all_jobs_succeeded” đều là những custom function, do đó khi có nhu cầu trigger theo một logic nào đó, các bạn engineer hoàn toàn có thể contribute vào core Orchestration framework.
Events within queue over hardly dependency
Thay vì dùng DAG để định nghĩa dependency giữa các Job một cách chặt chẽ, chúng ta sẽ dùng queue system(ở đây bọn mình dùng AWS SQS) để decoupling giữa producer và consumer từ đó giải quyết:
Không còn Mono-DAG – mỗi Job được định nghĩa độc lập ở small unit DAG, mỗi khi job hoàn thành, sẽ bắn ra event với naming đã được định nghĩa trong config {"finish_events": [ { "name": "job_1_completed" } ] }
Tăng tốc độ build và testing time – do mỗi DAG được định nghĩa độc lập và ở small unit nhất do đó tăng thời gian development và testing
Configuration as code over code-first approach
Hệ thống Datalake theo đuổi mindset “Configuration as Code“
để tách biệt Operation khỏi development từ đó tăng tốc khả năng release của các system, hầu hết các system của Datalake ở Techcombank đều có 2 repo:
Repository chứa core code logic
Repository chứa configuration
Sau đây là ví dụ một ví dụ 1 config:
Kết luận
Dù đã đáp ứng được hầu hết các nhu cầu sử dụng đồng thời khá hiệu quả trong quá trình development và operation, nhưng Data orchestration framework ở Techcombank vẫn còn nhiều điểm đang phát triển thêm:
Resource manager
Retry mechanism: back-off retry and dead letter queue
Thuộc dự án “Inside GemTechnology” do Techcombank x TopDev triển khai, chuỗi nội dung thuần Tech “độc quyền” được chia sẻ bởi đội ngũ Tech Leader đến từ Silicon Valley tại Techcombank sẽ được cập nhật liên tục tại chuyên mục Tech Blog Techcombank x TopDev. Cùng theo dõi & gặp gỡ các chuyên gia bạn nhé!
Anh Nguyễn Quang Huy từng có kinh nghiệm nhiều năm về Khoa học dữ liệu cũng như phát triển và quản lý Hệ thống Dữ liệu lớn (Big Data) khi công tác tại các tập đoàn đa quốc gia tại tại Sing và Mỹ. Được truyền cảm hứng từ những bài toán lớn trên hành trình số hóa mà Techcombank đang giải quyết cho thị trường ngân hàng, Anh Nguyễn Quang Huy đã quyết định quay trở về Việt Nam để đồng hành với đội ngũ Techcombank trong giai đoạn chuyển đổi số mạnh mẽ nhất từ trước đến nay.
Ở thời điểm hiện tại, anh đang giữ vị trí Director, Data Engineer tại Techcombank. Công việc chính của anh là phụ trách xây dựng các hoạt động, dự án liên quan đến Data Lake (Hồ dữ liệu) tại Techcombank. Hãy cùng nghe câu chuyện về Data Lake sẽ giải quyết những bài toán lớn nào cho hàng triệu khách hàng của Techcombank.
Theo anh đâu là tầm quan trọ [...]
Bài viết đến từ anh Vũ Tuấn Nghĩa - Quản lý cao cấp hoạch định dữ liệu Data Engineering team @Techcombank
DynamoDB là một dịch vụ cơ sở dữ liệu NoSQL cung cấp hiệu năng nhanh và nhất quán - có khả năng mở rộng và linh hoạt trong cách sử dụng. Khác với cơ sở dữ liệu quan hệ (RDMS), DynamoDB không sử dụng joins và các cấu trúc quan hệ khác để lưu trữ và truy vấn dữ liệu. Thay vào đó, bạn sẽ thiết kế table của mình theo Single design table - 1 table duy nhất phục vụ toàn bộ application hay service, việc này giúp hiệu suất đọc và ghi nhanh hơn ở scale lớn và giảm chi phí cloud.
Trong bài viết này, chúng mình sẽ khám phá các lợi ích và thách thức của việc sử dụng Single design table trong DynamoDB, cũng như cách Datalake ở Techcombank sử dụng để đáp ứng và tối ưu như cầu sử dụng.
Single table design
Trong tài liệu trang chủ AWS có đề cập:
You should maintain as few tables as [...]
Khoa học dữ liệu là một trong những chiếc chìa khóa giúp nhiều doanh nghiệp cũng như các tổ chức tài chính lớn như ngân hàng đột phá trong kỷ nguyên 4.0. Càng ngày việc thu thập và hiểu dữ liệu dần trở thành một kim chỉ nam giúp các doanh nghiệp tạo ra tính đột phá trong tương lai.
Anh Nguyễn Hoàng Huy hiện đang là Giám đốc khoa học dữ liệu, và đã được trao bằng tiến sĩ ngành Khoa học máy tính của Đại học tổng hợp Greifswald. Năm 2012, anh được giải thưởng bài báo xuất sắc nhất của Hội khoa học dữ liệu CHLB Đức. Sau đó anh trở về Việt Nam tham gia nhiều công ty được đầu tư bài bản vào dữ liệu lớn.
Ứng dụng Data Science: dữ liệu là nguồn nhiên liệu cho trí tuệ nhân tạo
Theo anh, dữ liệu quan trọng như thế nào với tương lai của Digital Banking?
“Thực ra dữ liệu quan trọng trong mọi lĩnh vực nói chung, khi chúng ta phải ra quyết định chứ không chỉ với Digital Banking “
Để đơn giản chúng ta hình dung thế này: trong sinh tồn, một con khỉ tinh mắt thấy được vài nải chuối đang treo trên cây nhưng cũng thấy một con sư tử đang gần đó. Khi đó con khỉ phải tính toán các xác suất chết đói nếu không ăn chuối so với xác suất bị sư tử vồ dựa trên rất nhiều dữ liệu ví dụ như: mình cách nải chuối bao xa? cách con sư tử bao xa? bản thân có thể chạy nhanh đến đâu? sư tử có thể chạy nhanh như nào? con sư tử thức hay ngủ, có vẻ đói hay no? nải chuối đó có bao nhiêu quả, quả lớn hay nhỏ, xanh hay chín? rồi thông tin về điều kiện bên trong cơ thể, bản thân đang đói không? có cần liều lĩnh ăn những quả chuối không?. Trong tất cả các lĩnh vực, đặc biệt trong các giao dịch kinh tế, tài chính, bên sở hữu nhiều kiến thức, thông tin, dữ liệu thực tế đều có nhiều lợi thế hơn so với bên còn lại.
Như chúng ta biết, hoạt động ngân hàng diễn ra mọi lúc mọi nơi trong cuộc sống hàng ngày của khách hàng, ví dụ như giao dịch mua bán, chuyển tiền, thanh toán dịch vụ v.v, những hoạt động này được thực hiện theo thời gian thực trong nhiều bối cảnh khác nhau, thông qua nhiều dịch vụ công nghệ khác nhau. Vì vậy nếu chúng ta có những dữ liệu giàu bối cảnh đó, AI có thể hỗ trợ chúng ta để gỡ bỏ những rào cản trong gắn kết, tiếp cận khách hàng, gợi ý sản phẩm phù hợp với bối cảnh cá nhân, chuyển các quy trình thẩm định cũng như phân phối sản phẩm lên môi trường số, theo thời gian thực, khi đó việc đi đầu và mở rộng thị trường không nằm ngoài tầm tay.
“Phiên bản ngân hàng số (digital banking) 4.0, mục tiêu mà tất cả các ngân hàng ở những nước tiên tiến hiện đang hướng đến, Việt Nam cũng không nằm ngoài câu chuyện này”
Phiên bản ngân hàng tương lai chủ yếu vận hành đa kênh số, không có yêu cầu về việc phân phối sản phẩm/dịch vụ qua kênh vật lý, hướng đến trải nghiệm khách hàng trong từng bối cảnh, cá nhân hóa trải nghiệm, loại bỏ ma sát ra khỏi trải nghiệm khách hàng. Ngân hàng này sẽ vận hành dựa trên nhiên liệu là dữ liệu, nhưng không chỉ loại dữ liệu giao dịch, hay dữ liệu tham chiếu tín dụng mà các ngân hàng đang sở hữu hiện nay mà phải xoay quanh các dữ liệu cung cấp theo bối cảnh. Từ đó, ngân hàng có thể cung cấp sản phẩm/dịch vụ dựa trên bối cảnh “Ở đâu, khi nào, vì sao và như thế nào?”, theo thời gian thực.
Cụ thể, dữ liệu và AI sẽ là phần cốt lõi trong sự dịch chuyển mô hình hoạt động tư vấn tài chính của ngân hàng. Lời tư vấn có khả năng biến thành trải nghiệm theo thời gian thực được thực hiện bằng AI thông qua hiểu rõ về hành vi, khẩu vị rủi ro của khách hàng, cũng như tìm ra được công cụ, sản phẩm tốt nhất giải quyết vấn đề của khách hàng. Công nghệ giọng nói sẽ dần dần giúp khách hàng tin tưởng vào trợ lý AI của mình trong việc đưa ra những gợi ý về giải pháp tài chính hàng ngày cho họ, thay vì họ phải tự đi tìm kiếm giải pháp. Ví dụ trợ lý AI có thể đưa ra tư vấn như: Bạn đang thanh toán qua thẻ tín dụng quá nhiều rồi đấy, tôi có những phương án khác giúp bạn có tiền mua sắm tiết kiệm được 1,2 triệu đồng mỗi tháng bằng cách tự động liên kết với ví Apple Pay của bạn, bạn muốn xem không?. Thậm chí ngân hàng Emirates NBD đề xuất sản phẩm tiết kiệm với lãi suất dựa trên số bước chân mà khách hàng đi hoặc chạy bộ mỗi ngày, để khích lệ họ tiếp tục lối sống lành mạnh hơn cả về thể chất lẫn tài chính. Bạn thậm chí không cần phải làm hồ sơ mở tài khoản tiết kiệm thì mới bắt đầu tiết kiệm được mà chỉ cần xin quyền truy cập vào ứng dụng của ngân hàng số như Moven.
Với nhiều ứng dụng ngân hàng số đột phá, tất yếu trong tương lai, nếu không có chiến lược dữ liệu áp dụng xuyên suốt toàn bộ tổ chức, bạn sẽ chỉ có 1 ốc đảo dữ liệu riêng rẽ và không biết khách hàng của mình là ai, nhu cầu, hoàn cảnh của họ để đưa ra những dịch vụ tốt nhất. Như chúng ta đã thấy gần đây, hiện tượng tư vấn up-sale, cross-sale các sản phẩm bảo hiểm, đầu tư một cách cứng nhắc, chạy theo KPI, gây một số điều tiếng tại các ngân hàng thương mại trong nước gần đây là do chúng ta thiếu dữ liệu bối cảnh, hành vi theo thời gian thực của khách hàng để đề xuất đúng sản phẩm theo kịp thời gian, nhu cầu của khách hàng dẫn đến giảm sự gắn kết, lòng trung thành của khách hàng.
Như trên chúng ta đã thấy xu hướng ngân hàng số, nhúng toàn diện, ngân hàng mở là tất yếu. Trong cuộc dịch chuyển về ngân hàng số trở nên hoàn thiện, thì những ngân hàng hàng đầu không phải là những ngân hàng sở hữu mạng lưới phân phối lớn, mà là những ngân hàng có năng lực dữ liệu quy mô lớn, mang lại những lợi thế cung cấp bối cảnh cho hoạt động ngân hàng hàng ngày.
Vì vậy, các ngân hàng phải có nền tảng công nghệ mở, xây dựng mối quan hệ hợp tác với đối tác bên ngoài lĩnh vực ngân hàng, đi đôi với khả năng tiếp cận, sở hữu và tận dụng dữ liệu có được. Từ đó mang đến sự khác biệt thực sự trong việc gợi ý sản phẩm/dịch vụ ngân hàng theo thời gian thực dựa trên dự đoán hành vi khách hàng. Ví dụ ngân hàng Emirates NBD hợp tác với mạng xã hội Twitter xây dựng ngân hàng xã hội, cải thiện trải nghiệm dịch vụ ngân hàng dựa trên phân tích nhu cầu khách hàng kịp thời từ dữ liệu mạng xã hội.
Ngày nay nếu muốn thu hút khách hàng sử dụng dịch vụ ngân hàng của mình, bạn phải tiếp cận họ xung quanh một giao dịch hoặc sự tương tác nào đó, khi họ cần tín dụng để hoàn tất một cuộc mua bán nào đó chẳng hạn. Ngoài ra, một khi người tiêu dùng đã sử dụng dịch vụ ngân hàng nhúng trong một nền tảng khác, các ngân hàng sẽ không còn biết khách hàng đang làm gì, cần gì, do ngân hàng hoàn toàn không có dữ liệu của khách hàng trên nền tảng đó. Ngân hàng sẽ hoàn toàn mất dấu, bối cảnh khách hàng, do đó ngân hàng cần chiến lược hợp tác tích hợp các sản phẩm, dữ liệu của các công ty Fintech, hoặc các công ty công nghệ nền tảng.
Những thử thách của người làm dữ liệu “thực địa”
Có rất nhiều thách thức ở “thực địa” đối với các nhà khoa học dữ liệu. Đầu tiên là vấn đề chất lượng dữ liệu cho xây dựng các mô hình học máy, dự báo, sản phẩm trí tuệ nhân tạo. Đối với các tổ chức có lịch sử phát triển lâu dài, các quy trình nghiệp vụ phải tuân thủ các quy trình chặt chẽ, phức tạp, đặc biệt như các ngân hàng, dữ liệu thường silos. Dữ liệu quá khứ có thể đến từ nhiều nguồn, hệ thống cũ, bộ phận khác nhau không liên thông với nhau, mô hình dữ liệu không nhất quán, meta data thiếu hoặc không được định nghĩa đầy đủ. Điều này dẫn đến sự mất kết nối giữa nguồn dữ liệu với cách sử dụng dữ liệu sao cho đúng, mất manh mối với bối cảnh kinh doanh. Thậm chí mã chương trình, tài liệu của các luồng xử lý dữ liệu không đầy đủ, không được cập nhật. Những điều này gây ra rất nhiều những khó khăn cho việc tiền xử lý, khảo sát dữ liệu từ quá khứ, lên ý tưởng, xây dựng các đầu vào cho các mô hình dự báo. Tất nhiên còn nhiều khó khăn khác như phải xử lý, xây dựng các mô hình dự báo trên dữ liệu lớn, luôn cập nhật. Tuy nhiên với nền tảng công nghệ của mình, Techcombank đã giảm thiểu một cách tối đa những khó khăn này cho các nhà khoa học dữ liệu.
Thử thách lớn thứ hai là phải rút ngắn thời gian phát triển một vòng đời của một mô hình dự báo, đặc biệt rút ngắn thời gian xây dựng mô hình từ khi xác định được các yêu cầu, mục tiêu của bộ phận kinh doanh. Để làm được điều này, chúng ta phải có một nền tảng tính toán xử lý, lưu trữ các thuộc tính, đặc điểm (biến đầu vào của các mô hình dự báo) cơ bản, đầy đủ, toàn diện của khách hàng, cũng như các kỹ thuật xây dựng mô hình dự báo tương đối phổ quát cho đa dạng các sản phẩm, yêu cầu nhanh của các bên kinh doanh. Tất nhiên không thể có mô hình, hệ thống thuộc tính luôn tốt nhất, thậm chí phù hợp cho mọi bài toán, yêu cầu kinh doanh. Hơn nữa những kỹ thuật xây mô hình này còn phải đảm bảo tính khái quát hoá, giữ được hiệu năng trong sự thay đổi của dữ liệu thực tế, trong điều kiện chất lượng dữ liệu không cao, dữ liệu không được xử lý đồng bộ. Suy cho cùng, hiệu năng thực sự của mô hình dự báo chỉ được đánh giá trong tương lai. Nhưng có lẽ thách thức hơn cả, có những bài toán, yêu cầu khoa học dữ liệu thực tế của bên kinh doanh hóc búa ngay cả trong điều kiện lý tưởng, lý thuyết và rất khó đưa ra giải pháp thích hợp trong điều kiện thực tế.
Xuất phát nhu cầu am hiểu khách hàng, cung cấp sản phẩm/dịch vụ, cải thiện trải nghiệm khách hàng trong bối cảnh, vòng đời khách hàng, Techcombank tiên phong phát triển một nền tảng dữ liệu khách hàng tổng thể trên Cloud. Và để giảm thiểu khó khăn như trao đổi ở trên, cũng như đảm bảo sự tuân thủ, bảo mật khi khai thác dữ liệu, một bộ khung về quản trị dữ liệu với Collibra đã được tiên phong triển khai đồng bộ ở ngân hàng. Khi đó chất lượng, độ tin cậy, xác thực của dữ liệu được quản lý, tạo thuận lợi cho triển khai các dự án về khoa học dữ liệu. Đặc biệt một nền tảng về học máy trên Cloud với SageMaker đang được ngân hàng đầu tư và triển khai. Rồi sự chuẩn bị nền tảng dữ liệu mở, dữ liệu bối cảnh từ các đối tác, hệ sinh thái mới được bổ xung. Tất cả những điều này giúp ươm mầm những dự án khoa học dữ liệu lớn hơn, tạo nhiều ảnh hưởng tích cực đến ngân hàng, khách hàng.
Techcombank là một trong những ngân hàng đầu tiên trong nước đầu tư mạnh mẽ các tài năng dữ liệu nói chung hay khoa học dữ liệu nói riêng. Có lẽ Techcombank là một trong những ngân hàng có khối dữ liệu riêng đầu tiên với đông đảo hơn 200 nhân sự, chuyên gia tài năng nhiều kinh nghiệm. Khối có cấu trúc với năm phòng:
Sản phẩm dữ liệu
Hoạch định dữ liệu
Phân tích và am hiểu dữ liệu kinh doanh
Phân tích nâng cao và sáng tạo (AAI)
Quản trị dữ liệu như những ngân hàng tiên tiến trên thế giới.
Phòng phân tích nâng cao và sáng tạo với trách nhiệm xây dựng các công cụ, năng lực, mô hình phân tích nâng cao, dự báo, học máy, có nhiều chuyên gia quốc tế, như từ Google DeepMind đến làm việc. Quan trọng hơn cả Techcombank đang phát triển văn hoá dữ liệu từ tất cả các khối, phòng ngoài dữ liệu, từ đó có thể thúc đẩy nhiều hơn nữa những dự án khoa học dữ liệu sáng tạo, có sức ảnh hưởng lớn.
Theo anh, đâu là những kỹ năng và kiến thức cần có dành cho những bạn muốn trở thành một Data Scientist trong tương lai?
Techcombank có nhiều bạn Intern, sinh viên mới ra trường đang theo đuổi trở thành nhà khoa học dữ liệu. Cũng như mọi ngành nghề khác chúng ta đều cần tư duy giải quyết vấn đề sáng tạo, tư duy thiết kế, phản biện. Đầu tiên nhà khoa học dữ liệu luôn phải thiết kế, chuyển đổi các yêu cầu, mục tiêu của các bài toán kinh doanh thành các bài toán học máy, trí tuệ nhân tạo. Cụ thể chúng ta cần một số kiến thức, kỹ năng như:
Kiến thức về Khoa học dữ liệu, Học máy, Tính toán, Thống kê
Kiến thức, kỹ năng về lập trình, tính toán phân tán cho dữ liệu lớn
Kiến thức, kỹ năng về cấu trúc, kiến trúc dữ liệu, tiền xử lý, trực quan hoá dữ liệu
Kỹ năng nghiên cứu, thích khám phá, thử nghiệm, tập trung, tỉ mỉ
Kỹ năng giao tiếp, trình bày, do trong vòng đời phát triển mô hình học máy chúng ta luôn phải kết hợp, đánh giá hiệu quả mô hình, nhận phản hồi với/từ các đơn vị kinh doanh
Kiến thức đại cương về các nguyên lý cơ bản trong kinh tế, tài chính, các sản phẩm trong ngân hàng
Cảm ơn anh về những chia sẻ rất bổ ích giúp đem lại nhiều góc nhìn tích cực cho những ai đang muốn tham gia vào lĩnh vực Khoa học dữ liệu tại ngân hàng, hy vọng team AAI của Techcombank sẽ gặt hái được nhiều thành công trong tương lai.
Một ngày làm việc của một Data Scientist ở Techcombank
Cũng như những công việc trong ngành IT nói chung, chúng tôi cũng có buổi daily standup hàng sáng trao đổi về những công việc đang tập trung, những khó khăn đang gặp phải, rồi các buổi sprint retro, review hàng tuần.
Tuy nhiên có lẽ công việc yêu thích nhất mỗi ngày của một nhà khoa học dữ liệu là được đắm chìm vào trong các thử nghiệm, đánh giá các ý tưởng trên dữ liệu, phát hiện ra những mẫu hình, xu hướng, bản chất bên trong dữ liệu.
Rồi những buổi seminar chia sẻ kiến thức, giờ đào tạo thú vị hàng tuần, những buổi brainstorming để chuyển đổi yêu cầu kinh doanh thành bài toán học máy, tìm các hướng tiếp cận, thuật toán phù hợp, hiệu quả, đề xuất những ý tưởng biểu diễn, trực quan hoá những mẫu hình, bản chất tìm được, hay hơn là lựa chọn các giải pháp toàn diện, viễn kiến, thách thức lớn cần giải quyết trong tương lai.
Thuộc dự án “Inside GemTechnology“ do TopDev hợp tác cùng Techcombank triển khai, chuỗi nội dung thuần “Tech” độc quyền được chia sẻ bởi đội ngũ chuyên gia Công nghệ & Dữ liệu tại Techcombank sẽ được cập nhật liên tục tại chuyên mục Tech Blog | Techcombank Careers x TopDev. Cùng theo dõi & gặp gỡ các chuyên gia bạn nhé!
Là một thành viên mới tại Techcombank, anh Bùi Nguyễn Tuấn Minh hiện đang là Giám đốc DevSecOps, đây cũng là công việc đầu tiên của anh sau những năm tháng làm việc tại Singapore. Anh cũng là một trong những người góp phần mang lại những góc nhìn mới trong các phương pháp phát triển phần mềm của Techcombank.
Được biết, Techcombank là một trong những đơn vị tiên phong ứng dụng phương pháp DevSecOps trong việc phát triển sản phẩm. Đây cũng được xem là một trong những định hướng giúp các ngân hàng số hóa và phát triển mạnh mẽ trong tương lai. Sau đây là những chia sẻ của anh Bùi Nguyễn Tuấn Minh về công việc DevSecOps tại Techcombank.
Anh có thể chia sẻ một chút về môi trường làm việc tại Techcombank?
Khi chuyển công tác từ Singapore về Việt Nam, mình nhận thấy môi trường và cách thức làm việc [...]
Bài viết đến từ Ngô Doãn Thông - DevSecOps Engineer
DevSecOps team @Techcombank
Giới thiệu
Trong 20 năm qua, DevOps đã cùng với Agile, thay thế cho mô hình phát triển Waterfall. Microservices được coi là công nghệ tiên tiến nhất để triển khai kiến trúc dịch vụ. Thời gian phát triển sản phẩm đã được giảm đi, triển khai tự động được thực hiện hàng tuần hoặc hàng ngày và cloud thì cung cấp khả năng tính toán, cơ sở hạ tầng, lưu trữ và mạng rất mạnh mẽ.
Triết lý DevOps thường được tóm tắt bằng khẩu hiệu "move fast and break things", điều này có nghĩa là triển khai mọi thứ nhanh hơn, mạnh dạn hơn và sẵn sàng, phá bỏ các cấu trúc silo, rào cản, chấp nhận rủi ro và khắc phục nhanh từ những rủi ro đó.
Tuy nhiên, có một yếu tố quan trọng chưa được đề cập tới. Các tổ chức áp dụng DevOps vẫn cần đáp ứng tiêu chuẩn an [...]
Bài viết được sự cho phép của tác giả Tống Xuân Hoài
Vấn đề
Closure là một kiến thức quan trọng trong lập trình, nhờ có nó mà bạn có thể triển khai những chức năng một cách dễ dàng hơn.
Closure cũng khá phổ biến trong giới lập trình Javascript, có những người chưa từng nghe đến closure nhưng có thể đã vô tình dùng hoặc cũng có những người nghe rồi nhưng lại chưa thực sự hiểu về closure bởi nó khá là trừu tượng. Vậy thì hãy tiếp tục đọc bài viết để khám phá thêm nhé.
Lexical scope
Trước tiên tôi xin giới thiệu một chút về Lexical scope (tức phạm vi biến Lexical): trong một nhóm các hàm lồng nhau, các hàm bên trong có quyền truy cập vào các biến và các tài nguyên khác trong phạm vi hàm cha của chúng. Lexical scope đôi khi còn được gọi là Static scope.
Ví dụ:
Tương tự, closure cũng theo nguyên tắc Lexical scope, nó có thể truy cập đến các biến của hàm khác ngoài các biến của nó và các biến toàn cục nhưng một điều quan trọng: các hàm closure vẫn có khả năng lưu giữ trạng thái của các biến bên trong nó, hay nói cách khác mỗi khi bạn trả về (return) một hàm hoặc gán một hàm cho một biến thì nó sẽ mang theo giá trị của tất cả các biến mà nó phụ thuộc.
Ví dụ:
Trong ví dụ trên hàm add nhận một tham số x sau đó trả về một hàm nhận vào tham số y rồi trả về tổng của x, y.
Đầu tiên khi gọi hàm add(5) xong thì ta nghĩ các biến x, y trong add sẽ không còn tồn tại nữa. Tuy nhiên sau khi gọi tiếp addFive(10) thì chúng ta vẫn nhận được kết quả là 15, điều này có nghĩa là trạng thái của hàm add vẫn được lưu lại ngay cả khi hàm đã được thực thi xong, nếu không lưu lại thì addFive(10) sẽ không biết giá trị của biến x ở lần gọi trước là 5.
Từ đó ta hiểu khi add trả về một hàm addTo thì addTo được gói lại trong một ngữ cảnh có cả x, y tại thời điểm đó.
Lý thuyết closure là vậy, thế thì closure có những tác dụng gì?
Thứ nhất quay lại với một ví dụ kinh điển như sau:
for(var i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 0);
}
Chúng ta mong muốn kết quả sẽ là 0 1 2 3 4 nhưng rất tiếc kết quả của nó lại là 5 5 5 5 5. Bởi vì setTimeout chỉ được thực thi sau khi vòng lặp kết thúc việc lặp, khi đó giá trị tham chiếu của biến i trong các hàm console.log đã bằng 5.
Để giải quyết vấn đề này, tôi có thể thay var bằng let hoặc sử dụng closure bao bọc setTimeout để tạo ra một ngữ cảnh riêng cho hàm ngay lúc đó:
for(var i = 0; i < 5; i++) {
(function(j) {
setTimeout(() => {
console.log(j);
}, 0);
})(i);
}
Ngoài ra closure còn được ứng dụng trong việc tạo ra phạm vi cho các thuộc tính trong object.
getName và setName được thêm vào để nổ lực ngăn chặn việc truy cập trực tiếp vào name, thế nhưng vì Class trong Javascript không hỗ trợ Access modifier nên nó vẫn bị dễ dàng chỉnh sửa như thường.
Hàm Person trả về hai hàm closure mà chúng có thể truy cập được vào _name.
Các bạn thấy đấy, không thể truy cập vào biến _name trực tiếp được. Mọi thao tác với _name phải thông qua hai hàm set và get kia.
Còn một ứng dụng của closure đó là curry function, nhờ có closure mà việc tạo ra một hàm curry trở nên dễ dàng hơn bao giờ hết, còn tính ứng dụng thì lại còn rất cao nữa.
Tổng kết
Closure không phải là khái niệm chỉ dành riêng cho javascript mà rất nhiều ngôn ngữ cũng hỗ trợ. Closure là một hàm theo nguyên tắc Lexical scope và có khả năng lưu giữ trạng thái của các biến liên quan bên trong nó. Closure có nhiều ứng dụng quan trọng có thể kể đến như tạo Access modifier, curry function… Closure cũng là một kiến thức quan trọng trong phỏng vấn để đánh giá mức độ hiểu biết của bạn về ngôn ngữ Javascript nữa đấy.
Sự phát triển bùng nổ của ngành công nghiệp Game khiến cho các tựa game hiện nay có hình ảnh, đồ họa, màu sắc không khác gì những bộ phim chiếu rạp. Để tạo ra được những tựa game lôi cuốn chất lượng cao như thế thì vai trò của Game Artist là không thể thiếu, thậm chí là quyết định đến 50% sự thành công của tựa game. Các công ty phát triển game hay phát hành game hiện nay cũng đều đang có nhu cầu tuyển dụng Họa sĩ vẽ Game chuyên nghiệp với mức đãi ngộ cao. Bài viết hôm nay chúng ta cùng nhau điểm qua những câu hỏi phỏng vấn cho vị trí Game Artist thường gặp nhé.
Game Artist là gì? Vai trò của một Game Artist
Game Artist hay Họa sĩ Game là những người tạo ra nhân vật, quần áo, xe cộ, phong cảnh, màu sắc, họa tiết,… cho game. Game Artist đóng vai trò quan trọng tạo ra những bản phác thảo sơ bộ về nhân vật trên đồ họa 2D hay 3D, kết hợp với xây dựng bối cảnh để tạo ra một thế giới trong game cũng như xây dựng cho game những câu chuyện riêng, game play thú vị.
Trong một đội ngũ phát triển game thì Game Artist thông thường chiếm số lượng phân nửa, nhất là trong những giai đoạn đầu khi lên tạo hình nhân vật và game play.
Game Artist được chia nhỏ vai trò chi tiết cụ thể như 3D Modeller, 2D Texture Artist, Environment Artist, Lighting hay Effect Artist,…
Game Artist và Game Design khác nhau thế nào?
Đây là 2 khái niệm hay bị nhầm lẫn với những người không ở trong ngành phát triển Game. Nếu như Game Artist là họa sĩ vẽ ra tất cả những gì liên quan đến hình ảnh trong game thì Game Design là những biên kịch xây dựng câu chuyện, tình tiết trong một tựa game.
Sự đầu tư chỉn chu của các tựa game hiện nay giúp cho chúng ta có những game với cốt truyện được xây dựng chứa nhiều tình tiết cuốn hút, độ khó trong game cũng tăng dần qua từng màn chơi, hệ thống tính điểm, làm việc vụ logic và cuốn hút;… tất cả những thứ đó đều được Game Design xây dựng và team phát triển sẽ triển khai xây dựng lên.
Game Artist và Game Design có vai trò và công việc khác nhau, cũng là 2 bộ phận quan trọng bậc nhất trong một team phát triển game quyết định đến yếu tố thành công hay thất bại của một dự án game.
Những yếu tố cần cân nhắc khi sắp xếp bố cục trong game
Bố cục trong game (Composition) là một khía cạnh quan trọng của game art vì nó ảnh hưởng đến mọi thứ trong game cũng như thao tác của người dùng. Một số yếu tố cân nhắc đến việc sắp xếp bố cục trong game như sau:
Giao diện tổng thể của trò chơi bao gồm phong cách nghệ thuật, bảng màu, không khí chung của trò chơi.
Cơ chế gameplay: ví dụ như game chiến đấu (combat) thì bố cục trong game tập trung tạo cảm giác căng thẳng và phấn khích.
Cốt truyện và bối cảnh của trò chơi.
Kinh nghiệm của người chơi, kinh nghiệm từ các tựa game khác tương tự cùng thể loại.
Perspective hay Phối cảnh là kỹ thuật giúp truyền tải thực tế 3 chiều của không gian, vật thể lên bề mặt hai chiều của màn hình. Nhờ có Perspective mà hình ảnh hiện thị lên người chơi mới tạo được cảm giác có chiều sâu, xác định vật thể đứng trước, đứng sau.
Các quy luật phối cảnh đều được xây dựng trên các quy tắc hình học chặt chẽ, có 3 loại Perspective thường được sử dụng:
Phối cảnh 1 điểm tụ: tất cả các đường thẳng theo chiều sâu sẽ được kết nối với 1 điểm tụ là điểm trung tâm của tầm nhìn.
Phối cảnh 2 điểm tụ: có 2 điểm tụ nằm trên đường tầm mắt ở 2 bên của màn hình game tạo thành hệ thống phối cảnh 2 điểm tụ.
Phối cảnh 3 điểm tụ: là loại phối cảnh ít được sử dụng trong game, chủ yếu sử dụng trong hội họa, ví dụ như trường hợp bạn đứng dưới chân 1 tòa nhà cao tầng nhìn lên.
VFX là gì? VFX được sử dụng thế nào trong Game
VFX là viết tắt của từ Visual Effect hay còn được gọi là hiệu ứng hình ảnh, nó được sử dụng để mang lại diện mạo chuyên nghiệp và trải nghiệm chơi game hấp dẫn giúp người chơi đắm chìm và kết nối với thế giới và trò chơi đó đang truyền tải.
Có 2 loại VFX chính thường được áp dụng trong game:
Gameplay Effects: hiệu ứng sử dụng trong lối chơi game, ví dụ như khi nhân vật bị tác động sát thương làm thay đổi thuộc tính điểm máu; hay lúc nhân vật được tăng sức mạnh chỉ số trong 1 thời gian ngắn (thường gọi là buffs sức mạnh)
Environmental Effects: hiệu ứng trong môi trường game, ví dụ như thời tiết (mưa, sương mù, tuyết,…) địa hình, thời gian tạo ra sự thay đổi về ánh sáng, hiệu ứng gió, cây cối,…
VFX trong game được chạy trong thời gian thực, nghĩa là sẽ thay đổi tùy theo nhân vật, thời gian, cách tác động của người chơi. Vì thế bài toán tối ưu một cách hiệu quả các effects cũng được cân nhắc quan tâm.
Animation là gì? Nguyên tắc để tạo ra animation
Animation là một phương pháp tạo ra những chuyển động của hình ảnh dựa vào các hình ảnh tĩnh và mang nội dung của câu chuyện hay một sự kiện với thông điệp nào đó cho người xem giúp tạo ra sự chân thực, sống động cho người xem.
Animation được tạo ra nhờ vào hiện tượng lưu ảnh ở mắt người kết hợp với sự thay đổi nội dung của các khung ảnh liên tiếp nhau trong đó có thể là thay đổi về kích thước, màu sắc, bối cảnh,… làm cho chúng ta thấy được sự chuyển động. Có 2 nguyên tắc chính tạo ra animation:
Frame by frame: tạo animation dựa trên sự thay đổi của các chuyển động theo giai đoạn trong từng khung; trong đó mỗi khung là một giai đoạn của chuyển động.
Tweened animation: tạo animation dựa vào sự hỗ trợ của công cụ flash. Các animator chỉ việc tạo ra khung ảnh đầu và hình ảnh kết thúc trong khung ảnh cuối, còn các giai đoạn chuyển động trung gian sẽ được công cụ flash tạo ra.
Hãy kể tên những công cụ thiết kế đồ họa 2D, 3D bạn thường sử dụng
Tùy thuộc vào mục đích của sản phẩm đầu ra mà chúng ta lựa chọn phần mềm, công cụ thiết kế khác nhau, dưới đây là một số công cụ phổ biến:
2D Artist: Photoshop, Adobe Flash Professional
3D Artist: 3ds Max, Zbrush, Maya
Animatior: 3ds Max, Maya
Effect/Partical Artist: After Effects
Kết bài
Trên đây là danh sách những câu hỏi dành cho vị trí Game Artist mà bạn sẽ có thể gặp trong buổi phỏng vấn của mình. Hy vọng bài viết này hữu ích dành cho những bạn đang chuẩn bị tìm một công việc họa sĩ game mới, hẹn gặp lại các bạn trong các bài viết tiếp theo của mình.
Không biết mọi người sử dụng Code Editor nào để viết ứng dụng React? Bản thân mình thì trung thành với Visual Code (mọi người hay viết tắt là vscode). Đây là trình code editor nhỏ gọn, nhưng lại nhiều tính năng, được hậu thuẫn bởi ông trùm Microsoft.
Điều mình thấy tâm đắc nhất ở vscode đó chính là kho extension hấp dẫn, cũng toàn miễn phí cả. Nếu bạn đang sử dụng VS Code thì mình khuyên nên thử các extension dưới đây, tăng hiệu suất công việc lên đáng kể đấy.
Trước khi mình giới thiệu các extension, mình sẽ nói qua cách cài đặt extension trong VS Code đã nhé.
Cài đặt extension trong VS Code
Visual code tích hợp extension market luôn trong ứng dụng, nên việc cài đặt extension rất đơn giản. Bạn chỉ vào biểu tượng extension, gõ tên extension muốn cài đặt -> chọn extension -> nhấn nút install.
Thông thường thì sau khi cài xong là bạn có thể sử dụng được luôn. Tuy nhiên, cũng có một vài ngoại lệ, bạn cần khởi động lại VS Code thì extension mới có hiệu lực.
Đây là tiện ích mà có lẽ hầu như ai cũng nên cài đặt. Nó giúp cho mã nguồn của bạn chất lượng hơn, hạn chế những lỗi tiềm tàng. Về cơ bản thì extension này đơn giản là tích hợp thư viện ESLint vào VS Code. Nếu bạn chưa biết ESLint là gì, mời bạn đọc tài liệu này.
Extension này sử dụng thư viện ESLint được cài đặt trong thư mục workspace mà bạn đang mở. Nếu mà thư mục này không có thì nó sẽ tìm thư viện ESLint trong máy tính.
Nếu bạn chưa cài đặt ESLint thì đơn giản gõ lệnh sau để cài:
npm install eslint --save-dev
Open native terminal
Việc phải duyệt qua lại giữa các thư mục (sử dụng lệnh “cd <tên thư mục>”) trong terminal thật là mệt mỏi. Tiện ích nhỏ này giúp bạn mở terminal và con trỏ đang ở thư mục gốc dự án luôn.
Bạn có thể mở terminal ở bất kỳ đâu, chỉ đơn giản là chuột phải và chọn ” Open in native terminal (current folder)” hoặc “Open in native terminal (root folder)“.
Việc phải thêm các propTypes thủ công rất thời gian. Tiện ích này sẽ tự động tạo propTypes. Bạn chỉ việc chọn component và nhấn tổ hợp phím ” ctrl + shift + alt + p”. Tiện ích này khá giống với ReactPropTypes trong Jetbrains’s Platform.
Reactjs code snippets
Mỗi khi bạn tạo một file mới, thông thường bạn sẽ phải tự thêm các component skeleton, component có thể là một class, function, hooks, redux… Tiện ích này sẽ giúp bạn tạo tất cả các đoạn mã đó chỉ với một nhấp chuột.
Reactjs code snippet có sẵn các đoạn mã cho React dựa trên babel-sublime-snippets package. Reactjs code snippets có khoảng 50 đoạn mã khác nhau, hỗ trợ 4 ngôn ngữ (file extensions):
Bất kể dự án nào, viết bởi ngôn ngữ gì thì đều nên viết code thật clean, tuân thủ các nguyên tắc viết code. Với dự án React cũng vậy. Nếu một ngày, bạn nghĩ mình cần phải refactoring lại mã nguồn dự án thì đây chính tiện ích dành cho bạn.
Một vài tính năng hữu ích của tiện ích này:
Hỗ trợ Extract JSX element thành một file hoặc function
Hỗ trợ cả TypeScript và TSX
Làm việc tốt với cả Class, function và arrow functions.
Xử lý key attribute và function bindings
Làm việc tốt với các Hooks API mới.
Như vậy là mình đã giới thiệu xong 5 vscode extensions hữu ích. Bạn có sử dụng các vscode extensions trên không? Ngoài ra, còn extension nào hay ho nữa không? Hãy để lại bình luận ở bên dưới nhé.
Sau rất nhiều sai lầm khi theo đuổi con đường lập trình viên, mình đã tự đúc kết được 10 quy tắc học lập trình. Mà mình nghĩ bất cứ ai mới bắt đầu cũng nên theo.
Nó có thể giúp cho các bạn tự tin hơn khi bắt đầu hành trình trở thành một developer chân chính. Tất nhiên là không nên lặp lại những sai lầm mà mình đã gặp trước đó.
Mình đã bắt đầu học lập trình như thế nào?
Mình vẫn nhớ năm 2014, là ngày mình đăng ký một khóa học lập trình Android tại một trung tâm gần học viện An Ninh. Giờ nghĩ lại mới thấy đó thật sự là quyết định vô cùng đúng đắn.
Sau đó là 3 năm đi làm, mình đã có nhiều cơ hội để trải nghiệm với nhiều dự án thực tế hơn.
Điểm xuất phát của mình là một con số “0” tròn trĩnh. Mình học code không có ai hướng dẫn, cũng không có bất kì ai nói với mình rằng: Hãy làm như thế này này, thế kia mới là đúng…
Dĩ nhiên, sai lầm trong quá trình làm việc là không thể tránh khỏi. Đặc biệt, trong khoảng thời gian đầu, mình gần như mất rất nhiều thời gian. Thậm chí mất luôn cả phương hướng khi “tự bơi” trong thế giới lập trình.
Một năm rưỡi sau đó, mình may mắn được cộng tác với các đàn anh rất giỏi và dày dạn kinh nghiệm trong lĩnh vực phát triển Android. Ở thời điểm đó, mình được anh hướng dẫn tận tình. Anh chỉ cho mình những quy tắc học lập trình mà mình vẫn còn nhớ như in đến tận bây giờ.
Lưu ý: Mình sẽ chủ yếu tập trung vào công việc phát triển Android và một số khái niệm lập trình và phát triển phần mềm. Nên một số bạn “ngoài ngành” sẽ hơi khó tiếp cận. Tuy nhiên, mình sẽ giải thích các khái niệm ở cuối bài viết nếu cần.
#1. Đừng cố gắng làm lại những gì mà thế giới đã làm tốt
Thuở mới vào nghề, mình không thích sử dụng thư viện mã nguồn mở (open-source code). Nếu cảm thấy cần thiết, mình sẽ tự tay tạo những mã code cho riêng mình. Và đó thật sự là một sai lầm.
Khi bạn gặp phải bất cứ vấn đề gì trong trình phát triển ứng dụng. Nếu nó đã có giải pháp khắc phục thì đừng ngần ngại tận dụng nó.
Hãy Google Search trước khi làm, không tội gì phải tự nghĩ giải pháp mới. Chắc chắn bạn sẽ tiết kiệm được rất nhiều thời gian trong quá trình làm việc đấy.
Hãy tập trung nhiều hơn vào việc giải quyết business của ứng dụng. Thay vì code lại những thứ đã có rồi. Giả sử ứng dụng của bạn cần kết nối mạng, bạn không cần phải code lại nguyên thư viện Retrofit đâu.
Như mình đã nói ở trên, với mỗi vấn đề thì thường luôn có sẵn một giải pháp mà người đi trước đã làm. Mình cũng khuyên bạn nên tận dụng nó nhưng phải khôn ngoan.
Bạn có thể tìm vô số thư viện hỗ trợ bạn giải quyết công việc một cách nhanh chóng. Nhưng trước khi lựa chọn bất kì một thư viện nào, bạn hãy kiểm tra số lượng rating mà người dùng trước đó đánh giá. Cũng như thời gian gần nhất mà tác giả cập nhật thư viện.
Ngoài ra, bạn cũng nên tham khảo danh sách issues của thư viện để có thể đánh giá độ tin cậy và khả năng hỗ trợ lâu dài của thư viện.
Nếu bạn ”max rảnh” thì có thể nhảy hẳn vào mã nguồn để tận mắt kiểm tra xem nó có thực sự tốt không? Cấu trúc mã nguồn có rõ ràng và có khả năng bảo trì cao không? Source code có được viết cẩn thận, có comment rõ ràng hay không?
Chỉ có như vậy bạn mới thực sự kiểm soát được chất lượng của thư viện mà bạn đang tham khảo.
Nếu bỏ qua bước này, bạn sẽ có nguy cơ tích trữ “một đống rác” cho dự án của mình, làm chậm tiến độ của dự án. Đấy là còn chưa nói đến hàng tá bugs mà thư viện khuyến mãi cho bạn!
#3. Ngồi xuống, nhâm nhi tách cà phê và đọc code nhiều hơn
Nếu bạn để ý, Khi đi làm thì thời gian chúng ta dành cho đọc code của người khác là vô cùng nhiều. Chủ yếu là bạn sẽ phải phân tích code của dự án, review code cho member… hơn là thời gian tự viết code.
Nếu bạn đang trong hoàn cảnh ngồi tự suy nghĩ và tự code tất cả thì hãy nhanh chóng thay đổi suy nghĩ đi thôi.
Bất kể đoạn code nào bạn viết ngày hôm nay, thực chất chỉ là những gì bạn đã đọc hoặc từng học được ở đâu đó mà thôi.
Tức là bạn không phải nhà phát minh gì đâu, chỉ là bạn “bắt chước” ở đâu đó và biến nó thành của mình một cách sáng tạo.
Thực tế đã chứng minh là bạn chỉ có thể phát triển và cải thiện khả năng code của mình bằng cách đọc và học hỏi từ người khác.
Android là một nền tảng mã nguồn mở. Bạn có thể đào sâu mã nguồn để tìm hiểu xem các chuyên gia lập trình ra framework như thế nào. (Xem thêm Flutter hay react native Framework)
Như mình đã nói ở phần trước, hiện đã có hàng nghìn thư viện open-source trên Github. Bạn chỉ cần chọn lọc và nghiên cứu xem họ đã phát triển chúng như thế nào. Rồi sau đó học hỏi và tự nâng cao trình độ của mình.
Một lập trình viên thành công luôn biết cách học hỏi một cách hữu ích.
Bonus: Đây là hai danh sách thư viện open-source code dành cho Android mà bạn sẽ cần đến khi bắt đầu triển khai dự án của mình:
Nếu bạn so sánh việc coding với viết văn, thì các tiêu chuẩn của coding cũng giống như chữ viết tay của bạn vậy.
Cũng giống như việc bạn đọc rất nhiều code của người khác (có thể là đồng nghiệp, chuyên gia hoặc sếp của bạn) trong khi họ cũng có thể đang đọc code của bạn viết ra.
Chắc hẳn bạn không hề muốn nhìn thấy cảnh họ phải thốt lên: “Trời ơi, nó đang viết cái quái gì đây?” đúng không?
Sẽ không khó hiểu nếu bạn bị đồng nghiệp của mình “xa lánh” khi chẳng may họ vô tình đọc được code do chính bạn tạo ra.
Hãy viết code thật ngắn gọn, rõ ràng và dễ đọc (Bạn biết từ khóa này chứ: DRY? Nghĩa là: Don’t repeat yourself. Nếu chưa biết thì hãy search google nhé).
Đỉnh cao của lập trình viên chính là: “Hãy viết code như viết một câu chuyện!”. Mình khuyên bạn nên đọc bài viết về clean code này của mình: Cách để viết Clean Code Android
Proguard là công cụ tuyệt vời không chỉ làm giảm kích thước code. Nó còn đảm bảo code của bạn an toàn trước các tay “đạo chích” có ý định “chôm chỉa” code của bạn.
Nếu bạn đang có ý định đưa ứng dụng của mình lên Google Play, mình có lời khuyên chân thành rằng bạn nên sử dụng Proguard “liền, ngay và lập tức”.
Mình từng bắt gặp một số ứng dụng được phát hành trên Google Play nhưng lại không sử dụng Proguard. Và kết quả là các hacker chỉ mất vỏn vẹn 5 phút để “chôm chỉa”. Chỉ đơn giản bằng cách biên dịch ngược lại mã nguồn từ file apk.
Pro Tip: Nhưng nếu bạn muốn bảo vệ mã nguồn ở mức cao nhất, thì Proguard chỉ như “tấm giấy bìa mỏng manh”, DexGuard mới là “vệ sĩ đích thực” bảo vệ mã nguồn của bạn.
#6. Không quên tận dụng các “cấu trúc” (Architecture)
Có khi nào bạn thầm tự cảm ơn khi đã may mắn lựa chọn một “cấu trúc” (Architecture) hợp lý từ ngày đầu của dự án chưa?
Một Architecture hợp lý sẽ đảm bảo dự án của bạn dễ dàng duy trì cũng như mở rộng. Từ đó việc đọc mã nguồn cũng trở nên đơn giản hơn rất nhiều.
Ở thế giới lập trình web, MVC là một trong những architecture phổ biến nhất. Trong khi đó, với lập trình Android mọi người lại sử dụng MVP (Model-View-Presenter), MVVM, Clean Architecture… nhiều hơn.
Với MVP, bạn có thể phân chia source code thành 3 tầng riêng biệt. Mục đích là tách phần View của Android ra khỏi phần xử lý logic. Như vậy, tầng Model-Presenter sẽ chỉ có thuần code Java mà không có code UI Android.
#7. “Giao diện người dùng” (User Interface) là cực kì quan trọng
Bất kì ứng dụng nào, nếu ngay từ lần sử dụng đầu tiên đã phải nhờ đến một bài hướng dẫn cách sử dụng dài lê thê. Thì đó chính là “điềm báo” cho một ứng dụng thất bại.
Nếu bạn làm việc trong một công ty lớn thì có thể bạn sẽ không cần quan tâm đến vấn đề này. Vì công ty đã có hẳn team UI/UX riêng để lo.
Nhưng nếu bạn là một nhà phát triển app độc lập, làm việc một mình thì UI/UX là vấn đề bạn phải luôn ghi nhớ trong đầu.
Người xưa có câu: “Tốt gỗ hơn tốt nước sơn”. Nhưng ở thế giới mà nhiều khi “nước sơn” tốt vẫn thu hút được rất nhiều người hơn là “gỗ tốt”.
Đặc biệt trong ngành phần mềm, sự cạnh tranh vô cùng khắc nghiệt cộng với người dùng ngày càng lười biếng thì UI là cái đập vào mắt họ đầu tiên trước khi họ kịp trải nghiệm tính năng bên trong.
Theo số liệu thống kê từ VnTalking, một ứng dụng với thiết kế UI cực tệ và khó sử dụng thì khả năng thất bại của nó sẽ tăng gấp 4 lần.
Chính vì vậy, hãy đầu tư cho “nước sơn” thật tốt vào nhé!
Bonus: Nếu bạn không có khả năng thiết kế hoặc không thể tự học được thì có thể nghĩ đến chuyện đi thuê. Có rất nhiều website cung cấp dịch vụ thiết kế với giá cả rất hợp lý, mình gợi ý một nơi đó là: Fiverr.com (Chỉ 5$ cho một dự án thành công)
#8. Phân tích số liệu – “bạn đồng hành” lý tưởng
Nếu bạn muốn tạo ra một ứng dụng thật sự tốt, bạn cần phải dựa vào các công cụ phân tích (Analytics tool) để biết được hiệu năng (Performance) và tần suất sử dụng các chức năng trên ứng dụng đó.
Dù bạn có là nhà phát triển Android thiên tài đi chăng nữa, bạn cũng không thể nào viết một ứng dụng hoàn hảo 100%.
Tất cả đều chỉ mới dừng lại ở mức “trên lý thuyết” mà thôi. Thực tế, có nhiều trường hợp ứng dụng hoạt động không đúng, khác xa so với lúc test. Thậm chí là crash và không thể chạy được.
Lúc này, công cụ Crash Reporting sẽ là trợ lý đắc lực. Nó giúp bạn biết cần phải làm gì, sửa lỗi như thế nào dù sự cố crash ấy chỉ xảy ra có một lần.
Ngoài ra, xét về khía cạnh marketing, các công cụ Analytics sẽ giúp những tính năng mà bạn xây dựng trở nên thực tế hơn.
Sẽ thật hoang đường nếu nghĩ rằng nhà phát triển ứng dụng android chỉ cần ngồi nhìn lên trời và biết được ngoài kia người dùng đang cần gì và muốn gì.
Tất cả đều phải có số liệu. Chỉ có số liệu mới giúp suy nghĩ hoặc suy luận của bạn chính xác và có độ tin cậy hơn.
#9. Hãy là một Ninja Marketing
Nếu bạn là một nhà phát triển app độc lập, hãy tự mình thoát ra khỏi suy nghĩ: “Mình chỉ là một nhà phát triển”.
Viết Code chỉ là một phần rất nhỏ trong số những việc bạn cần phải làm để hoàn thành một app và đưa nó đến tay người dùng.
Đây chính là bài học xương máu mà bản thân mình đã tự đúc kết được từ không ít thất bại.
Ban đầu, mình từng nghĩ hãy cứ làm một ứng dụng thật chất lượng, UI/UX thật ngon… Thì nhiều người sẽ tải và mình sẽ nhanh chóng nổi tiếng.
Nhưng thật trớ trêu, những ứng dụng mình đầu tư rất nhiều công sức thì lại chẳng có ai dùng. Còn những ứng dụng mình viết “chơi chơi” thì lại được đánh giá khá cao.
Sau rất nhiều đêm suy nghĩ, mình nhận ra ứng dụng của mình thật sự chất lượng. Nhưng lại không đáp ứng được nhu cầu thị trường.
Bản thân mình cũng chưa biết cách tiếp cận với khách hàng. Lại càng không biết họ thật sự muốn gì, cần gì ở một ứng dụng.
Nếu bạn thực sự nghiêm túc với việc kiếm tiền từ công việc viết ứng dụng thì bạn phải đầu tư công sức và thời gian vào việc tiếp thị ứng dụng, nghiên cứu đối thủ cạnh tranh để tự nhận biết điểm mạnh và yếu của mình từ đó đưa ra chiến lược marketing app ngắn và dài hạn.
“Biết người biết ta, trăm trận trăm thắng”, thành ngữ đó chẳng sai chút nào cả!
#10. Luôn luôn tối ưu ứng dụng
Cuối cùng trong 10 quy tắc học lập trình, đó là luôn luôn tối ưu ứng dụng. Khi bạn mới học lập trình, bạn sẽ có ít kinh nghiệm nên việc tối ưu sẽ khó khăn hơn. Nhưng khi bạn đã thời gian đúc kết kinh nghiệm thì cần phải để ý chuyện này.
Việc tối ưu code, tối ưu hiệu năng… là điều mà rất nhiều bạn thường quên làm.
Có một sự khác biệt lớn giữa viết code chạy được và “code tối ưu”. Viết code chạy được thì nhanh nhưng viết code để tối ưu được Memory, CPU, sử dụng ít Device Storage… Thì lại là cả một vấn đề lớn.
Một ứng dụng không được tối ưu có thể chạy tốt ở điều kiện bình thường. Nhưng thực tế sử dụng lại “muôn hình vạn trạng”. Không có gì để bạn đảm bảo rằng ứng dụng của mình sẽ chạy tốt trong mọi trường hợp.
Vì vậy, hãy luôn kiểm tra Memory bị chiếm dụng bởi ứng dụng, đề phòng các lỗi Memory Leaks. Hãy nhớ rằng: “Một vết thủng nhỏ cũng đủ để nhấn chìm cả một con tàu lớn”.
Pro Tip: Hãy dùng thư viện Leak Canary để tự động nhận diện các “Memory Leaks”. Thư viện này có thể được tích hợp dễ dàng vào code. Bạn chỉ cần khởi tạo và sau đó cứ để như thế, nó tự chạy. Khi phát hiện leaks, nó sẽ hiện thông báo và log lên màn hình.
Tạm kết
Mình đã chia sẻ quy tắc học lập trình được đúc kết trong quá trình làm việc.
Hi vọng rằng, những quy tắc này sẽ giúp cho bạn có thêm thông tin và nhanh chóng gặt hái thành công.
Hãy chia sẻ bài viết nếu thấy hay hoặc comment bên dưới để góp ý cho bài viết nhé!
Bài viết đến từ Ngô Doãn Thông – DevSecOps Engineer
DevSecOps team @Techcombank
Giới thiệu
Trong 20 năm qua, DevOps đã cùng với Agile, thay thế cho mô hình phát triển Waterfall. Microservices được coi là công nghệ tiên tiến nhất để triển khai kiến trúc dịch vụ. Thời gian phát triển sản phẩm đã được giảm đi, triển khai tự động được thực hiện hàng tuần hoặc hàng ngày và cloud thì cung cấp khả năng tính toán, cơ sở hạ tầng, lưu trữ và mạng rất mạnh mẽ.
Triết lý DevOps thường được tóm tắt bằng khẩu hiệu “move fast and break things”, điều này có nghĩa là triển khai mọi thứ nhanh hơn, mạnh dạn hơn và sẵn sàng, phá bỏ các cấu trúc silo, rào cản, chấp nhận rủi ro và khắc phục nhanh từ những rủi ro đó.
Tuy nhiên, có một yếu tố quan trọng chưa được đề cập tới. Các tổ chức áp dụng DevOps vẫn cần đáp ứng tiêu chuẩn an ninh thông tin và tuân thủ quy định. Sự linh hoạt, đa dạng và tính mở của chuỗi cung ứng phần mềm (software supply chain), đặc biệt là các phần mềm mã nguồn mở, buộc chúng ta phải đánh giá đến yếu tố security này.
Đó là giá trị cốt lõi của DevSecOps: Tưởng tượng ra các giải pháp an ninh mới để bảo vệ phần mềm cũng như quy trình phát triển phần mềm.
Tuy nhiên, đó là một con đường không hề dễ dàng. Cần có một sự hợp tác giữa các nhóm phát triển sản phẩm, đội an ninh thông tin và vận hành để làm cho “security” trở thành quá trình thông suốt. Software supply chain và các CI/CD pipeline là những thành phần vô cùng quan trọng cần được bảo vệ khi áp dụng DevSecOps.
Security: Bảo vệ thông tin cũng như tốc độ phát triển sản phẩm
Có một sự thật là việc áp dụng các tiêu chuẩn an ninh thông tin vào có thể là rào cản làm chậm quá trình phát triển phần mềm. Khi mà time-to-market là quan trọng, thì việc áp dụng tiêu chuẩn an ninh thông tin vào có thể trở thành “bottleneck”. Một số rào cản, vấn đề có thể đưa ra như sau:
Thiếu chuyên môn về security hoặc khả năng viết code an toàn trong suốt vòng đời phát triển sản phẩm. Developer thường được chấp nhận để triển khai nhanh hơn và khắc phục sau.
Security ownership: Ai chịu trách nhiệm về mặt security này? Nhà cung cấp dịch vụ cloud? Hay maintainer của các sản phẩm mã nguồn mở? Ta có thể thường mặc nhiên cho rằng các nhà cung cấp dịch vụ, phần mềm khác đã đảm bảo security cho ta khi ta sử dụng. Tuy nhiên đó là một giả định sai lầm.
Chuyên gia an ninh và kỹ sư phần mềm hoạt động độc lập với nhau, vì vậy an ninh bị đe dọa bởi sự thiếu giao tiếp, thiếu sự phối hợp từ đầu.
Những vấn đề này có thể gây ra những rủi ro tiềm ẩn về mặt security. Nhưng bản thân chúng cũng có thể giúp các tổ chức xây dựng một thái độ thận trọng hơn trước những rủi ro.
Khi mà hệ thống được mở rộng và trở nên phức tạp hơn, các tổ chức sẽ có xu hướng đánh giá nghiêm túc hơn về những rủi ro. Nỗi lo lắng về việc thiếu các tiêu chuẩn an ninh thông tin có thể ảnh hưởng lớn đến toàn bộ sản phẩm, quy trình phát triển tự động hóa, sẽ khiến các tổ chức chủ động tiếp cận đến với các giải pháp quản lý và ngăn ngừa rủi ro hơn.
Security: Sự bổ sung cho DevOps
Nắm bắt được những điểm yếu trong quá trình phát triển phần mềm
Hiện nay, các team DevOps hiện đại hiểu được tầm quan trọng của software supply chain trong chu trình phát triển sản phẩm. Supply chain là thuật ngữ rộng lớn bao gồm rất nhiều thứ khác nhau (công cụ mã nguồn mở hoặc đóng, dependency, platform…) để mô tả cách thức xây dựng phần mềm hiện đại. Software supply chain là một “con đường”, là một cấu trúc phân lớp bao gồm các phần cứng, Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), Software-as-a-Service (SaaS), và các công cụ khác, được kết hợp cùng với nhau để hỗ trợ cho phần mềm cũng như quá trình phát triển phần mềm đó.
Hiếm khi ta thấy được một công ty làm phần mềm mà có 100% phần mềm, công cụ được sử dụng là do họ tự phát triển. Hầu hết các công ty phần mềm hiện đại đều sử dụng hàng trăm, nếu không phải là hàng ngàn các building block, các thư viện và công cụ mã nguồn mở, các hệ thống triển khai, cơ sở hạ tầng đám mây và dịch vụ SaaS. Mỗi block này lần lượt là sản phẩm cuối cùng từ một supply chain riêng của nó, mà khi sử dụng, ta không kiểm soát được cũng như không có khả năng nhìn thấy được supply chain trước đó của nó.
CI/CD pipeline
CI/CD pipeline là xương sống, là trụ cột của DevOps. Nó dùng để kết nối developer tới các môi trường triển khai, dùng để tối ưu hóa 4 luồng sau đây:
Continuous integration: Tích hợp liên tục. Tự động hóa việc xây dựng các bản build ứng dụng từ source code và các library, dependency của chúng.
Continuous testing: Kiểm thử liên tục. Tự động hóa việc kiểm thử ứng dụng sau mỗi commit.
Continuous monitoring: Giám sát liên tục. Tự động hóa việc thu thập các dữ liệu về log, metric của ứng dụng cũng như hạ tầng trên từng môi trường triển khai.
Continuous delivery/deployment: Triển khai liên tục. “One-click” để triển khai toàn bộ ứng dụng lên bất cứ môi trường nào.
4 luồng này, được tích hợp trong các CI/CD pipeline, để nhắm tới mục tiêu tối thượng cuối cùng của DevOps, đó là: Continuous improvement – Cải tiến liên tục.
Lợi thế mà những CI/CD pipeline này đem lại là rất lớn. Chúng giúp cho từng thay đổi nhỏ cũng có thể được triển khai (cũng như phục hồi, rollback) một cách nhanh chóng và chính xác.
Tuy nhiên, bản thân chúng cũng tồn tại những mối rủi ro. Mỗi stage trong một CI/CD pipeline là một “interface” có thể bị tấn công, khai thác. Điều đáng lo ngại hơn là mỗi stage có thể đại diện cho mục tiêu có giá trị cao đối với các kẻ tấn công: Không chỉ vì nó có thể lưu giữ các secret, credential, mà còn vì đây là nơi mà một kẻ tấn công có thể thay đổi mã nguồn, thay đổi cấu hình nào đó một cách lặng lẽ ngay giữa luồng build và deploy mà không ai có thể can thiệp được bởi luồng này đang vận hành tự động.
Kết quả là, supply chain cũng như CI/CD pipeline đang trở nên ngày càng dễ bị tấn công do tính mở và phức tạp của chúng. Chúng để lại rất nhiều vùng xám chưa rõ ràng trong các security framework truyền thống.
Từ DevOps tới DevSecOps
DevSecOps là gì?
DevSecOps là kết hợp của việc tích hợp giữa những công cụ, tiêu chuẩn của Security và triết lý “Continuous improvement” của DevOps thành một phương pháp, quy trình phát triển, triển khai phần mềm nhất quán, tự động, hiệu quả và đảm bảo an toàn bảo mật.
DevSecOps sẽ giúp nhận diện các vấn đề an ninh sớm trong quá trình phát triển thay vì sau khi sản phẩm được release như trước kia.
DevSecOps có thể giảm chi phí liên quan đến việc khắc phục những lỗ hổng an ninh bằng cách tích hợp các công cụ security vào mỗi giai đoạn của quá trình phát triển, có thể ngay từ giai đoạn đưa ra yêu cầu, thiết kế trở đi.
Nguyên tắc bảo mật phải là một phần không thể thiếu trong văn hóa của bất kỳ công ty nào. An ninh thông tin phải là một phần của quá trình phát triển phần mềm. Nói ngắn gọn, DevSecOps sẽ giúp đưa những nguyên tắc, trách nhiệm đó đến với từng developer, đến từng bước trong quá trình phát triển phần mềm.
Giá trị cốt lõi của DevSecOps
Tăng tần suất triển khai ứng dụng an toàn
Khi security bao trùm lên toàn bộ CI/CD pipeline, chất tốc độ sẽ sản phẩm được cải thiện. Ta phải thực tế và chấp nhận rằng giai đoạn đầu của việc tích hợp có thể sẽ rất khó khăn. Khi việc phối hợp giữa các nhóm phát triển và security trở nên mượt mà hơn, những vấn đề này sẽ dần biến mất và chỉ còn lại kết quả tích cực.
Giảm thời gian khắc phục các lỗ hổng nguy hiểm
DevSecOps sẽ cải thiện đáng kể thời gian khắc phục trung bình nhờ việc rà quét sớm và tự động, có luồng feedback tốt hơn và mô hình chia sẻ trách nhiệm. Khi trách nhiệm về security được chia sẻ trên toàn bộ CI/CD pipeline cũng như trong quy trình phát triển phần mềm, thay vì tách biệt hoàn toàn về một nhóm security, các vấn đề an ninh được phát hiện sớm và nhanh hơn. Điều này cũng trực tiếp liên quan đến hiệu quả chi phí, vì nó sẽ tốn nhiều tiền hơn để khắc phục lỗi được tìm thấy trong quá trình vận hành hơn là sửa lỗi được xác định trong giai đoạn thiết kế phát triển.
Cải thiện tư duy về an ninh thông tin
Nói chung, việc phát triển phần mềm hiện nay tương đối là phức tạp. Đưa security vào như một “tính năng” từ đầu sẽ giúp tiết kiệm rất nhiều thời gian cho các nhóm security bằng cách loại bỏ các vấn đề vô hại hoặc false positive nhờ vào các quy trình tự động kiểm soát ở mỗi bước. Nó sẽ tạo ra một nền văn hóa mới, tư duy mới, nơi các phương pháp an ninh tốt nhất được chia sẻ và đem đến lợi ích cho tất cả – bắt đầu ngay từ bước thiết kế, phát triển cho tới quá trình triển khai, vận hành phần mềm ứng dụng.
Best practices
DevSecOps nhấn mạnh rằng security là trách nhiệm của tất cả thành viên trong một tổ chức, và mọi người đều phải tuân thủ và thực hiện đảm bảo an toàn bảo mật thông tin.
Chìa khoá để áp dụng thành công mô hình DevSecOps nằm ở ba yếu tố: Con người, quy trình và công nghệ.
Yếu tố con người
Không quan trọng bao nhiêu công nghệ được áp dụng, yếu điểm lớn nhất về mặt an ninh thông tin luôn là con người. Đây cũng là điểm khởi đầu cho bất cứ quá trình áp dụng DevSecOps nào.
Một trong những điều quan trọng nhất nhưng cũng là khía cạnh khó nhất của DevSecOps là thay đổi cách làm việc truyền thống của security team. Đa số cách tiếp cận rủi ro là loại bỏ khi nó đã xảy ra, thay vì chủ động phòng bị trước.
Security team cần chuyển từ việc hoạt động độc lập sang việc tham gia cùng trong luồng phát triển phần mềm. Điều này vừa giúp tăng nhận thức về an ninh thông tin tới tất cả thành viên trong đội dự án, vừa giúp nhận biết sớm các rủi ro tiềm tàng trong phần mềm, trong hệ thống.
Tại Techcombank, DevSecOps team sẽ nhắm tới việc phá bỏ rào cản này giữa security team và project team, đồng thời cung cấp những chính sách và công cụ hỗ trợ cho việc này. Việc tạo ảnh hưởng đến yếu tố con người này sẽ đặt nền móng vững chắc cho việc thay đổi hai yếu tố “Quy trình” và “Công nghệ” tiếp theo của DevSecOps.
Yếu tố quy trình
Các quy trình thông thường được quy phạm tới từng team và thường ít khi có sự chia sẻ giữa các team với nhau. Điều này có thể gây ra ảnh hưởng tới năng suất trong cả một tổ chức. DevSecOps hướng tới việc thiết lập các quy trình tiêu chuẩn chung, các tài liệu đảm bảo security cho tổ chức để tạo sự phối hợp giữa các team như là một khối thống nhất. Việc xây dựng ra một quy trình, tiêu chuẩn tự động hoá đảm bảo an toàn thông tin là trách nhiệm của team DevSecOps tại Techcombank.
Version control
Khi mọi thứ được tự động hoá, thứ quan trọng nhất cần được track đó là các thay đổi (changes). Mỗi hành động tạo ra changes phải được quản lý bởi version, cũng giống như version control khi code vậy. Việc versioning này sẽ giúp ta ghi lại được lịch sử thực hiện cũng như dễ dàng khi khôi phục lại. Để đáp ứng yếu tố này, DevSecOps team ở Techcombank đã xây dựng một hệ thống Gitlab private nhằm lưu trữ tất cả các mã nguồn được viết ra bởi developer.
Tích hợp
Security cần phải được đưa vào quá trình phát triển sản phẩm sớm nhất có thể, ngay từ bước thiết kế. Phương pháp này được gọi là “shift left” hay “shift security to the left”.
Techcombank áp dụng những công cụ rà soát an ninh thông tin tự động ngay từ giai đoạn đầu của việc phát triển ứng dụng. Điều này vừa giúp những vấn đề về an ninh được phát hiện và ngăn chặn sớm, đồng thời cũng giúp các developer có nhận thức tốt hơn về việc viết code an toàn.
Compliance
Tuân thủ compliance là điều bắt buộc. Nếu nền móng về yếu tố con người đã được thực hiện tốt trước đó, thì việc tuyên truyền về việc tuân thủ compliance sẽ trở nên rất đơn giản và hiệu quả. Bên cạnh đó, compliance có thể không chỉ là các văn bản quy phạm. Ta hoàn toàn có thể xây dựng các metadata biểu diễn cho các compliance requirement và đưa vào các security policy để thực hiện tự động hoá.
Xử lý sự cố
Phản ứng với các sự cố liên quan tới an ninh thông tin không nên là tạm bợ nhất thời. Thay vào đó, việc xây dựng workflow, action plan, runbook, playbook luôn cần được chuẩn bị sẵn sàng từ trước. Điều này sẽ đảm bảo việc phản ứng với các sự cố trở nên có tính chắc chắn, có khả năng đo đếm và nhanh chóng hơn. Theo quy trình và tiêu chuẩn DevSecOps tại Techcombank, các kịch bản khôi phục sự cố cần được thực hiện dưới dạng code và tự động thông qua CI/CD pipeline. Điều này sẽ giúp việc ứng phó sự cố hệ thống trên môi trường live được thực hiện nhanh chóng hơn và số lượng sự cố trong quá trình triển khai cũng sẽ giảm đi.
Yếu tố công nghệ
Công nghệ là thứ cho phép mọi người thực hiện được các quy trình DevSecOps. Đây cũng là yếu tố cuối cùng quyết định việc áp dụng DevSecOps của một tổ chức có đủ trưởng thành, có thành công hay không.
Tự động hóa việc quản lý cấu hình
Tổ chức quản lý và tự động hóa việc quản lý cấu hình dưới dạng code sẽ giúp việc audit, việc đảm bảo baseline, compliance trở nên dễ dàng hơn rất nhiều. Các template dưới dạng code được đưa ra giúp việc rà soát các thay đổi được kiểm soát qua version control, rollback, phục hồi cũng trở nên rất nhanh chóng.
Tại Techcombank, Puppet được sử dụng như là một công cụ kiểm soát cấu hình. Các cấu hình đạt tiêu chuẩn baseline sẽ được định nghĩa trước và quản trị thông qua Puppet. Mọi hành vi cố ý thay đổi ngoài baseline sẽ luôn được phục hồi lại nhanh chóng.
Host hardening
Trước khi bảo mật đến tầng ứng dụng, tầng OS cần phải được an toàn trước. Có vô số những sự cố an ninh bắt nguồn từ việc host, đặc biệt là các host bị expose ra internet, bị khai thác. Do đó, một hardening checklist là rất cần thiết trong việc xây dựng template cũng như trust model cho việc cấu hình host. Kết hợp với tự động hóa việc quản lý cấu hình, host sẽ luôn được đảm bảo ở trạng thái an toàn cao nhất.
Audit và scan tại tầng ứng dụng
Việc thực hiện audit và scan liên tục là một phương diện thiết yếu của DevSecOps, giúp cho tổ chức hiểu được rõ ràng về các mối nguy. Các giải pháp hiện tại ở Techcombank gồm có:
Quét mã nguồn: Việc quét mã nguồn có thể được thực hiện bằng cách áp dụng các SAST tool (Static Application Security Testing). SAST tool phân tích mã nguồn của dự án để xác định ra các lỗi liên quan đến bảo mật trong code cũng như vấn đề của các dependency và library mà ứng dụng sử dụng. Các công cụ được DevSecOps team đưa vào tiêu chuẩn gồm có SonarQube và Synopsys Coverity.
Tích hợp vào IDE: Mọi developer đều cần sử dụng IDE trong việc code. Sử dụng một số plugin trong IDE sẽ giúp ngăn chặn một phần lỗi trong code ngay từ máy cá nhân của developer trước khi cả commit code lên repository. Hiện tại, việc ngăn chặn này đang được thực hiện bằng pre-commit và sắp tới là SonarLint
Binary scanning: Các package của ứng dụng sau khi được build ra cần phải được rà quét lại dưới dạng binary bằng Synopsys BlackDuck. Việc một lần nữa rà quét lại bản build này giúp đảm bảo chắc chắn rằng phần mềm kể cả đã đóng gói cũng đảm bảo an toàn thông tin.
Audit trước và sau triển khai: Thêm một bước audit trước và sau triển khai sẽ đảm bảo ứng dụng an toàn tại day-0 và cả day-1 khi triển khai.
Quản lý secret
Secret và credential là các dữ liệu nhạy cảm hoặc thậm chí là tối mật được sử dụng cho ứng dụng. Trong quá trình thực hiện CI/CD, việc sử dụng đến các secret hay credential là một việc thường xuyên xảy ra. Do vậy, sử dụng các công cụ mã hoá và lưu trữ các dạng dữ liệu này là tối quan trọng, đặc biệt trong CI/CD pipeline. Các công cụ, nền tảng hỗ trợ cho việc này đang được áp dụng tại Techcombank có thể kể đến như HashiCorp Vault, AWS Secrets Manager, GPG, Ansible Vault…
Tổng kết
DevSecOps chuyển dịch security từ phản ứng sang chủ động tham gia vào quy trình phát triển phần mềm. Những ưu điểm mà DevSecOps mang lại cho tổ chức là rất nhiều, bao gồm giảm thiểu chi phí, tăng tốc độ triển khai, tăng tốc độ phục hồi, kiểm soát và truy tìm các mối nguy. DevSecOps cũng phá bỏ đi rào cản giữa DevOps và Security, giúp tất cả cùng hoạt động hướng tới những mục tiêu chung của tổ chức.
Thuộc dự án “Inside GemTechnology“ do TopDev hợp tác cùng Techcombank triển khai, chuỗi nội dung thuần “Tech” độc quyền được chia sẻ bởi đội ngũ chuyên gia Công nghệ & Dữ liệu tại Techcombank sẽ được cập nhật liên tục tại chuyên mục Tech Blog | Techcombank Careers x TopDev. Cùng theo dõi & gặp gỡ các chuyên gia bạn nhé!
Là một thành viên mới tại Techcombank, anh Bùi Nguyễn Tuấn Minh hiện đang là Giám đốc DevSecOps, đây cũng là công việc đầu tiên của anh sau những năm tháng làm việc tại Singapore. Anh cũng là một trong những người góp phần mang lại những góc nhìn mới trong các phương pháp phát triển phần mềm của Techcombank.
Được biết, Techcombank là một trong những đơn vị tiên phong ứng dụng phương pháp DevSecOps trong việc phát triển sản phẩm. Đây cũng được xem là một trong những định hướng giúp các ngân hàng số hóa và phát triển mạnh mẽ trong tương lai. Sau đây là những chia sẻ của anh Bùi Nguyễn Tuấn Minh về công việc DevSecOps tại Techcombank.
Anh có thể chia sẻ một chút về môi trường làm việc tại Techcombank?
Khi chuyển công tác từ Singapore về Việt Nam, mình nhận thấy môi trường và cách thức làm việc [...]
Bài viết đến từ anh Bùi Nguyễn Huy Hoàng - Quản lý DevSecOps DevSecOp team @Techcombank
I. Tại sao lại sử dụng Infrastructure as Code?
Những công việc như ảo hóa, điện toán đám mây (Cloud), container, tự động hóa (CI/CD) giúp đơn giản hóa công việc vận hành hành công nghệ thông tin (IT Operations). Việc triển khai, cấu hình, cập nhật và vận hành dịch vụ sẽ tiêu tốn ít thời gian và công sức hơn. Vấn đề sẽ được phát hiện và giải quyết nhanh chóng, các hệ thống luôn được cấu hình và cập nhật một cách đồng nhất. Những kỹ sư IT sẽ tiết kiệm được thời gian trong công việc vận hành hàng ngày, để có thể nhanh chóng thay đổi, học hỏi và cải tiến bản thân đáp ứng nhu cầu thay đổi liên tục của thế giới công nghệ.
Tuy nhiên, ngay cả với những công cụ và nền tảng mới nhất, các [...]
Game designer có phải là người thiết kế chính cho game? Vậy những kỹ năng nào cần có cho vị trí này, dưới đây là ví dụ 5 câu hỏi phỏng vấn Game Designer.
Tin tui đi bà con ơi, tui là game designer nè, thiết kế gì cũng chuẩn, game nào game nấy làm ra chỉ có chơi ghiền tới chết hông à!.
Đùa chút cho vui nhưng mong rằng qua bài viết này, anh em sẽ có các bước chuẩn bị thật tốt cho buổi phỏng vấn.
Bắt đầu ngay thôi nào!
1. Những kĩ năng nào là quan trọng nhất của Game Designer
Câu hỏi thứ nhất phỏng vấn Game Designer, tập trung vào những kĩ năng mà ứng viên cho rằng nó là quan trọng đối với vị trí mà mình đang ứng tuyển.
Việc xác định rõ những kĩ năng cần có hoặc quan trọng đối với bản thân giúp nhà tuyển dụng hiểu được ứng viên đang ở trình độ nào. Những kỹ năng mà ứng viên xem là quan trọng có phù hợp với công việc hiện tại hay không?
Ở vị trí Game designer, tất nhiên kỹ năng quan trọng nhất là thiết kế. Tuy nhiên một số kỹ năng khác ứng viên có thể nếu ra (tất nhiên tuỳ vào kinh nghiệm của từng ứng viên).
Kỹ năng giao tiếp
Kỹ năng giải quyết vấn đề
Kỹ năng trình bày giải pháp
Kỹ năng thương lượng với khách hàng
Trên đây chỉ là một số kĩ năng gợi ý, ứng viên có thể thoải mái nêu ra những kỹ năng mà mình cho là quan trọng. Hơn nữa các kỹ năng được cho là quan trọng ứng viên sẽ trau dồi kĩ năng đó như thế nào?
2. Game ưa thích nào của bạn bạn nghĩ có thể làm nó tốt lên?
Câu hỏi phỏng vấn Game Designer này đánh giá góc nhìn của Game Designer. Bản thân đã là Game Designer, bạn sẽ có nhiều cơ hội tiếp xúc với đủ thể loại game.
Nhưng game nào bạn nghĩ nó sẽ có thể làm tốt hơn. Ở góc nhìn của designer bạn có thể trình bày về mặt UI/UX của game. Ví dụ như:
Về behavior thì nhân vận này có thể thêm animation này để tăng độ phấn khích của người chơi
Về bố trí thì có thể sửa đổi vị trí đồ vật này để phù hợp với vật lý hơn
Về độ khó có thể tăng lên giúp game kịch tính hơn
Tuy là câu hỏi dành cho vị trí Game Designer, bạn cũng có thể nêu ra một số lỗi hoặc cải thiện có thể có liên quan tới game nhưng không thuộc trách nhiệm designer như backend, một số lỗi khác có trong game.
Về top 5 game designer nổi tiếng anh em có thể tham khảo tại đây.
3. Trong quá trình thiết kế game, bạn có gặp phải những hạn chế nào từ tuổi tác không?
Câu hỏi thứ 3 phỏng vấn Game Designer liên quan trực tiếp tới kinh nghiệm. Nếu quá trình làm việc đủ lâu và trải qua nhiều dự án, anh em sẽ trải qua những dự án game liên quan tới:
Tuổi tác
Giới tính
Quốc gia
Tôn giáo
Với những chủ đề có tính chất đặc thù như trên, quá trình phát triển game sẽ đòi hỏi Game Designer phải biết chính xác đối tượng game mình phát triển.
Biết mình làm game cho ai là hiểu biết quan trọng khi anh em bước vào design game cho mình
Trường hợp game phát triển cho trẻ em dưới 18 tuổi, game designer sẽ không được phép đem các hình ảnh hoặc video có nội dung bạo lực vào trong game. ESport thường không liên quan tới chính trị và tôn giáo, chính vì vậy tuyệt đối tránh các nội dung này khi thiết kế game.
4. Những thử thách nào khó nhằn nhất bạn gặp phải khi thiết kế game
Câu hỏi thứ 4 phỏng vấn Game Designer tập trung vào kinh nghiệm làm việc. Nếu đã trải qua từ 2 năm kinh nghiệm, chắc chắn bạn sẽ gặp phải một số khó khăn khi thiết kế game.
Câu hỏi này tạo điều kiện cho ứng viên trình bày về những khó khăn mà mình đã gặp phải, cách thức giải quyết vấn đề đó nếu có.
Trường hợp một game nào đó có các yêu cầu về hành động của nhân vật đặc biệt, không giống với những hành động thông thường? Bạn xử lý như thế nào. Một ví dụ khác là những game có nhiều đối tượng, tương tác với nhiều nhân vật (ví dụ như trong một trận chiến, hoặc game giết zombie, thông thường đòi hỏi sự xuất hiện của rất nhiều zombie).
Game có hiệu ứng phức tạp hoặc yêu cầu cao về xử lý hành động thường là những game khó khăn cho Game designer
Với những câu hỏi này, nhà tuyển dụng mong muốn ứng viên có thể nhận ra những khó khăn gặp phải trong quá trình làm việc. Nếu có những khó khăn đó, phương án xử lý như thế nào. Anh em lưu ý phương án xử lý không nhất thiết phải do mình đề xuất. Nên không nhất thiết phải trình bày các vấn đề khó khăn mà giải pháp phải do chính mình đưa ra.
5. Làm thế nào để luôn phát triển kĩ năng ở vị trí Game Designer
Câu hỏi thứ 5 phỏng vấn Game Designer mong muốn ứng viên có thể trình bày về khả năng tự học và cập nhật kiến thức.
Giống như các mảng khác liên quan tới phần mềm. Xu hướng và các công nghệ sử dụng cho Game Designer luôn luôn cập nhật và thay đổi cực kì nhanh chóng. Với đà phát triển như vũ bão của Trí tuệ nhân tạo và học máy, hình ảnh và các hiệu ứng liên quan tới nhân vật có thể được tạo ra một cách dễ dàng.
Để không bị bỏ lại phía sau. Theo các lối mòn về game, ứng viên cần nêu các phương án học hỏi và cập nhật kiến thức. Ví dụ như các xu hướng làm game mới, xu hướng thiết kế thịnh hành cho dòng game hành động.
Việc học hỏi và cập nhật thường xuyên giúp ứng viên ghi điểm lớn trong mắt nhà tuyển dụng. Việc học hỏi không ngừng cũng giúp ứng viên nâng cao trình độ. Hướng tới phát triển và làm việc hiệu quả hơn
Như bài viết trước, chúng ta đã hiểu cơ bản về vue jvs, biết cách cài đặt và tạo một ứng dụng bằng vuejs. Phần tiếp theo, mình muốn các bạn hiểu sâu hơn về cấu trúc dự án được tạo bằng Vuejs CLI sẽ như thế nào? Mô hình của vuejs là MVVM thì cấu trúc các folder trong dự án sẽ ra sao.
Để theo dõi bài viết này được suôn sẻ, bạn nhớ chuẩn bị sẵn những thứ bên dưới nhé:
Ngoài ra, ở bài viết trước, mình đã tạo sẵn bộ khung dự án, các bạn chỉ cần clone từ github về là xong. Ở bài này, mình sẽ hướng dẫn các bạn tự tạo dự án bằng câu lệnh Vuejs CLI.
Chúng ta bắt đầu nhé!
Vue CLI là gì?
Vue-CLI là một gói NPM được cài đặt trên toàn thế giới nhằm cung cấp vue trong terminal . Bằng cách sử dụng Vue Create, Vue serve nó sẽ hỗ trợ bạn xây dựng dự án dễ dàng và nhanh gọn.
#Cài đặt Vuejs CLI
Vues CLI, viết tắt của từ Command Line Interface, tức là công cụ cho phép bạn khởi tạo dự án một cách tự động. Để cài đặt Vuejs CLI, bạn sử dụng câu lệnh cài đặt bằng npm:
npm install -g vue-cli
Sau khi cài đặt thành công, mình sẽ chạy thử công cụ này để tạo một dự án có mới và sử dụng bộ template Webpack. Webpack là một module Official của Vue jvs, để generate các file static (html, css) tự động từ các module và dependencies của dự án.
Ok, tạo hiểu như vậy đã nhé. Giờ bạn vào một folder bất kỳ trên máy tính, rồi gõ lệnh sau:
vue init webpack AccountOwnerClient
Trong lúc tạo dự án, trình tạo sẽ hỏi bạn một số câu hỏi về thông tin dự án. Bạn cứ trả lời “thành thật” là được
Mình sẽ giải thích một số câu hỏi:
Project name: Bạn gõ account-owner-client là tên dự án thôi.
Author: Tác giả dự án là gì, bạn gõ theo đúng format sau: Name Surname <email@domain.tld>
Tiếp theo, nó sẽ hỏi về Runtime + Compiler hay chỉ Runtime thôi. Bạn chọn Runtime + Compiler nhé. Bởi vì chúng ta có thể sẽ phải tạo vuejs component nên sẽ cần cả compiler nữa.
Bạn có muốn sử dụng vue-router không? Tất nhiên là có rồi. Module này giúp bạn điều hướng các trang (page) trong ứng dụng.
Giải thích thì nó dài dòng vậy thôi, chứ thực ra thì ngắn không à.
Cuối cùng là chờ đợi npm hoàn thành nốt phần còn lại. Sau đó bạn mở dự án bằng bất kỳ trình code editor nào bạn có.
Với mình thì mình recommend các bạn sử dụng visual code. Sự kết hợp hoàn hảo giữa Visual code + Vue.js Extension Pack sẽ giúp bạn làm việc với vue jvs sướng mê li.
Sau khi bạn mở thư mục dự án vừa tạo, bạn sẽ thấy cấu trúc thư mục như sau:
Cấu trúc thư mục dự án tạo bởi vuejs cli
Mình sẽ giải thích ý nghĩa của từng thư mục:
src: đây là thư mục chưa mã nguồn dự án. Trong thư mục này lại phân chia tiếp.
assets: Module assets nơi mà bạn sẽ làm việc với Webpack
components: Tất cả UI components sẽ nằm ở đây.
router: đây là nơi bạn sẽ viết routes và kết nối chúng với UI components.
vue: Đây là entry point component. Là nơi sẽ khởi tạo tất cả các component khác. Hiểu nôm na là tệp chính của dự án.
js: Entry point file để mount App.vue.
assets: pure assets ( assets của riêng dự án), không liên quan tới webpack.
html: Bạn có nhớ là ứng dụng SPA (Single Page Application) thì có 1 trang duy nhất. Sau đó, nội dung của trang bị thay đổi mà không phải tải lại trang. Và đây chính là trang duy nhất đó.
Chúng ta sẽ xem qua nội dung của index.html
<!DOCTYPE html><html><head> <metacharset="utf-8"> <metaname="viewport"content="width=device-width,initial-scale=1.0"> <title>account-owner-client</title></head><body> <divid="app"></div> <!-- built files will be auto injected --></body></html>
Có một thẻ quan trọng trong tệp html này đó chính là thẻ div có id: app. Thẻ div này sẽ được replaced bởi app.vue sau này.
Sau đó, các nội dung khác sẽ được injected bên dưới thẻ div này.
Phần tiếp theo, chúng ta sẽ ngó qua tệp main.js. Đây là sẽ file mà chúng ta sẽ phải làm việc nhiều với nó.
import Vue from 'vue';import App from './App';import router from './router';Vue.config.productionTip=false;new Vue({ el:'#app', router, components:{ App }, template:'<App/>'});
Ở đoạn code ví dụ này, chúng ta sử dụng các component như vue, app, router.
Một template: Là phần hiển thị của một component. Hiểu nôm na là UI của component
Một script: là nơi thực hiện logic cho component
Và một style: định dạng trang, mục đích để trang trí “sắc đẹp” cho component.
#Tạm kết
Như vậy là bạn đã biết cách tạo mới dự án bằng cách sử dụng Vuejs CLI. Đây mới chỉ là những bước khởi đầu để khám phá thế giới tuyệt vời của Vuejs mà thôi.
Qua bài viết này, bạn đã biết:
Cách tạo mới một dự án Vuejs
Hiểu sơ lược SPA là gì? Và cách vuejs hỗ trợ SPA
Cấu trúc và ý nghĩa các folder trong một dự án Vuejs
Phần tiếp theo của loạt bài viết về vuejs, mình sẽ hướng dẫn cách cài đặt thư viện third party, cách sử dụng router và điều hướng các màn hình trong ứng dụng vuejs.
Các bạn đón đọc nhé.
Bài viết được sự cho phép của tác giả Tống Xuân Hoài
Vấn đề
Khóa bản ghi trong khi đọc hoặc cập nhật dữ liệu là một việc xảy ra với tần suất tương đối phổ biến. Ví dụ kinh điển cho trường hợp này là bài toán chuyển tiền giữa A và B: Trong khi A đang chuyển cho B một số tiền là x, khi đó chúng ta cần kiểm tra số dư của A, nếu còn đủ tiền thì trừ đi x đồng trong tài khoản rồi cộng thêm x đồng vào tài khoản của B. Đảm bảo rằng tất cả quá trình cộng trừ đó phải thành công thì giao dịch mới hoàn tất, vì nếu một lỗi xảy ra trong khi trừ tiền của A mà chưa cộng vào B hoặc ngược lại thì sẽ gây ra một vấn đề nghiêm trọng về tính chính xác của chương trình.
Ví dụ thứ tự để thực hiện các câu truy vấn trong trường hợp này với PostgreSQL sẽ giống như là:
BEGIN TRANSACTION;
SELECT balance FROM accounts WHEREuser='A';
// if a > x then...
UPDATE accounts SET balance = balance - x WHEREuser='A';
UPDATE accounts SET balance = balance + x WHEREuser='B';
COMMIT;
Hầu hết chúng ta biết được cách giải quyết bài toán này bằng transaction. Tức là khởi tạo một transaction và đảm bảo cả hai quá trình trừ tiền và cộng tiền thành công thì mới công nhận quá trình chuyển tiền thành công và lưu vào cơ sở dữ liệu. Nếu chẳng may 1 trong 2 bị lỗi thì giao dịch thất bại mà chẳng ai bị trừ tiền hay cộng tiền một cách vô lý nữa.
Nhưng trong trường hợp A có thể thực hiện nhiều lệnh chuyển tiền và “gần như cùng một lúc” thì có một vấn đề khác xảy ra. Đó là ở câu lệnh SELECT đầu tiên với mục đích kiểm tra số dư, vì khả năng cao một số lệnh SELECT ra được balance của A trước khi mà đến bước kiểm tra số dư, khi đó chúng đều thỏa mãn a > x và điều gì sẽ xảy ra nếu như tất cả chúng đều thực thi tiếp UPDATE sau đó?
Để giải quyết vấn đề này có nhiều cách. Một trong số đó là khóa bản ghi đang SELECT lại bằng truy vấn SELECT FOR UPDATE, nếu truy vấn sau gặp SELECT trên user A, nó sẽ phải xếp vào hàng đợi cho đến khi truy vấn đầu tiên hoàn thành. Kỹ thuật này gọi là Record Locking, ngoài ra chúng ta còn có thêm một cách khác nữa là Optimistic Locking. Bài viết ngày hôm nay, tôi sẽ nói về hai phương pháp khóa dữ liệu này để xem chúng hoạt động như thế nào, có ưu nhược điểm gì cũng như sử dụng trong trường hợp nào.
Record Locking là một kỹ thuật quản lý đồng thời trong cơ sở dữ liệu, trong đó các bản ghi (record) được khóa để đảm bảo tính nhất quán và ngăn chặn các transaction truy cập vào cùng một bản ghi cùng lúc.
Khi một transaction muốn cập nhật hoặc đọc dữ liệu từ một bản ghi, nó sẽ yêu cầu cơ sở dữ liệu khóa bản ghi đó để ngăn chặn các transaction khác truy cập vào. Sau khi transaction thực hiện xong, nó sẽ mở khóa để các transaction khác có thể tiếp tục truy cập.
Ví dụ như trong PostgreSQL, SELECT FOR UPDATE là một cách để khóa những bản ghi mà nó đang truy vấn đến. Bằng cách thay thế:
SELECT balance FROM accounts WHEREuser='A';
Thành:
SELECT balance FROM accounts WHEREuser='A'FORUPDATE;
Ngay lập tức transaction đầu tiên sẽ khóa bản ghi tại user = ‘A’ lại và các transaction sau không thể tiếp tục đọc mà phải đợi một lệnh COMMIT hoặc ROLLBACK được thực hiện thành công thì mới có thể tiếp tục.
Kỹ thuật Record Locking đảm bảo tính nhất quán dữ liệu, tuy nhiên nó có thể dẫn đến tình trạng deadlock. Do đó, việc sử dụng Record Locking cần được cân nhắc kỹ lưỡng để đảm bảo hiệu suất và tính nhất quán dữ liệu cho hệ thống cơ sở dữ liệu. Để hiểu rõ hơn về các loại khóa và deadlock, tôi khuyên bạn nên đọc thêm bài viết Tìm hiểu về các loại Khoá (Explicit Locking) trong PostgreSQL.
Optimistic Locking là một phương pháp mà trong đó các transaction sẽ không khóa bất kỳ bản ghi nào mà cho phép nó thực hiện như bình thường. Giống với tên gọi lạc quan, tư tưởng của Optimistic Locking là giả định rằng các transaction đang truy cập vào cùng một bản ghi sẽ không cập nhật dữ liệu cùng lúc, và chỉ một trong số các transaction đó sẽ hoàn thành việc cập nhật dữ liệu.
Khi một transaction muốn cập nhật dữ liệu, nó sẽ không khóa bản ghi để ngăn chặn các transaction khác truy cập vào. Thay vào đó, nó sẽ kiểm tra trạng thái của bản ghi trước khi cập nhật. Nếu trạng thái của bản ghi không bị thay đổi bởi các transaction khác, nó sẽ thực hiện cập nhật bản ghi đó. Ngược lại, nếu phát hiện trạng thái của bản ghi đã bị thay đổi, nó sẽ phải hủy bỏ việc cập nhật.
Để triển khai Optimistic Locking, chúng ta cần thêm một trường để đánh dấu cập nhật, nó có thể là version, updated_at… hay bất kỳ trường dữ liệu nào để mỗi khi cập nhật bản ghi thành công thì cũng sẽ cập nhật cả nó.
Ví dụ trong bảng accounts có thêm trường updated_at là thời gian bản ghi được cập nhật thành công. Chúng ta không cần SELECT FOR UPDATE nữa mà thay vào đó sẽ SELECT ra thêm updated_at.
SELECT balance, updated_at FROM accounts WHEREuser='A';
Sau đó thực hiện cập nhật “có điều kiện” của updated_at:
Với updated_at là kết quả của truy vấn SELECT trong transaction.
Để giải thích nguyên lý rất đơn giản, vì UPDATE sẽ khóa bản ghi lại trong khi cập nhật dữ liệu cho nên cùng một lúc chỉ có một transaction được phép cập nhật. Các transaction sau đó khi cố gắng cập nhật dữ liệu ở updated_at cũ thì sẽ hoàn toàn không thấy bản ghi nào trùng khớp. Lúc đó chúng ta có thể xử lý tiếp trường hợp này như là một giao dịch thất bại.
Optimistic Locking đơn giản và hiệu quả trong các tình huống mà các transaction cập nhật dữ liệu không xảy ra quá thường xuyên. Tuy nhiên, nó không đảm bảo tính nhất quán dữ liệu hoặc nguy cơ gây ra lỗi nhiều hơn do nó thường được xử lý ở tầng ứng dụng bằng mã lập trình.
Áp dụng trong trường hợp nào?
Vẫn là câu cửa miệng, trước tiên phải nói việc lựa chọn sử dụng Record Locking hay Optimistic Locking phụ thuộc vào từng bài toán cụ thể, vì mỗi phương pháp đều có ưu nhược điểm và ngữ cảnh riêng. Tuy nhiên, bạn có thể dựa vào một số gợi ý dưới đây để tăng khả năng quyết định cho mình.
Sử dụng Record Locking trong trường hợp:
Tính nhất quán dữ liệu là ưu tiên hàng đầu.
Các transaction cập nhật dữ liệu thường xuyên hoặc có nhiều transaction cập nhật cùng một bản ghi cùng lúc.
Sử dụng Optimistic Locking trong trường hợp:
Tính nhất quán dữ liệu không phải là yêu cầu cần thiết và ứng dụng cần tăng hiệu suất và tốc độ thực thi các transaction.
Các transaction không cập nhật dữ liệu thường xuyên hoặc không có nhiều transaction cập nhật cùng một bản ghi cùng lúc.
Ngoài ra, trong một số trường hợp, có thể kết hợp cả hai kỹ thuật để đạt được một giải pháp tối ưu. Ví dụ: sử dụng Optimistic Locking cho các transaction đọc dữ liệu, và sử dụng Record Locking cho các transaction cập nhật dữ liệu. Điều này giúp tối ưu hóa hiệu suất và tính nhất quán dữ liệu cho hệ thống cơ sở dữ liệu.
Tổng kết
Trong hệ thống cơ sở dữ liệu, có hai phương pháp khóa dữ liệu phổ biến là Optimistic Locking và Record Locking. Trong khi Optimistic Locking giả định rằng các transaction đang truy cập vào cùng một bản ghi sẽ không cập nhật dữ liệu cùng lúc, thì Record Locking lại “nhanh trí” khóa các bản ghi lại để đảm bảo transaction đầu tiên mới có quyền truy cập và ngăn chặn các transaction khác truy cập vào. Mỗi phương pháp đều có những ưu nhược điểm riêng nên cần được áp dụng sao cho phù hợp trong từng bài toán cụ thể.
Hành trình số hóa ngân hàng đang tạo nên những chuyển biến tích cực cho thị trường Việt Nam, tác động trực tiếp đến hành vi người tiêu dùng và mở ra những cơ hội nghề nghiệp mới cho nhân sự Công nghệ và Dữ liệu. Ngày 9/5/2023 vừa qua, các kênh truyền thông của TopDev – Nền tảng tuyển dụng IT và đơn vị tuyển dụng của Techcombank – Techcombank Career đã chính thức công bố cái “bắt tay” hợp tác nhằm lan tỏa giá trị đến cộng đồng công nghệ qua dự án với chủ đề InsideGEM Technology.
Câu chuyện phía sau và mong muốn lan tỏa giá trị đến cộng đồng Công nghệ & Dữ liệu
Dự án Techcombank Careers X TopDev – InsideGEM Technology được lấy cảm hứng từ “Gemology” – Khám phá những giá trị đặc biệt làm nên những viên ngọc. Techcombank Careers và TopDev mong muốn thông qua việc chia sẻ những kiến thức, kinh nghiệm thực tiễn trên hành trình số hóa ngân hàng sẽ góp phần vào việc nâng cao năng lực của nhân sự Công nghệ và Dữ liệu tại Việt Nam. Đồng thời, thông quan dự án này, Techcombank Careers cũng hy vọng giới thiệu đến cộng đồng Công nghệ và Dữ liệu những góc nhìn mới cũng như tiềm năng phát triển cùng ngành ngân hàng, một trong những bệ phóng mạnh mẽ cho sự nghiệp của bạn trong tương lai.
Tự hào là Techcombank – Ngân hàng dẫn dắt hành trình số hóa, TopDev – Một trong những chuyên trang tuyển dụng IT hàng đầu tại Việt Nam, chúng tôi hy vọng thông qua sự kết hợp này có thể tạo nên những giá trị hữu ích dành cho cộng đồng Công nghệ và Dữ liệu, đặc biệt giúp nhân sự Việt Nam có thể bắt kịp xu hướng của các tổ chức công nghệ thế giới. Song song việc áp dụng công nghệ mới nhất, hiện tại sẽ là thời điểm thuận lợi để phát triển và hoàn thiện những kỹ năng, vị trí đặc biệt (như Scrum Master, Engineering Manager, Agile Coach,…) để nâng tầm nhân lực Việt Nam.
Ngày 9/5/2023 vừa qua, các kênh truyền thông của TopDev – Nền tảng tuyển dụng IT và đơn vị tuyển dụng của Techcombank – Techcombank Career đã chính thức bắt tay hợp tác. Dự án lần này hứa hẹn sẽ mang đến những giá trị thiết thực cho cộng đồng Công nghệ & Dữ liệu và góc nhìn đa chiều về hành trình số hóa ngân hàng.
Khám phá những bài toán kỹ thuật, kinh nghiệm thực tiễn được Techcombank áp dụng, lần đầu đầu được chia sẻ từ chính các Chuyên gia hàng đầu trong và ngoài nước.
Lắng nghe những câu chuyện thực chiến và cập nhật xu hướng công nghệ mới nhất trên thế giới.
Hơn 100 vị trí tuyển dụng về Công nghệ & Dữ liệu tại Techcombank, ngân hàng dẫn đầu hành trình số hóa tại Việt Nam.
Chuyên Trang Dự Án Techcombank Careers x TopDev – InsideGEM Technology
Thực hiện mong muốn lan tỏa nhiều hơn các giá trị như trên đến với cộng đồng Công nghệ & Dữ liệu tại Việt Nam, Techcombank Career và TopDev mang đến chuyên trang dự án với loạt nội dung hấp dẫn:
Bí quyết mấu chốt cho Chuyển đổi số thành công, Tầm quan trọng của việc thấu hiểu cảm xúc người dùng, cách thức ứng dụng DevSecOps hiệu quả,… Cùng nhiều nội dung hấp dẫn khác đang chờ bạn tại loạt bài TechBlog trên chuyên trang Techcombank.
100+ vị trí Công nghệ & Dữ liệu đang tuyển với loạt OFFER hấp dẫn từ Techcombank: 100% lương tháng thử việc, lương thưởng hấp dẫn, gia nhập đội ngũ Ngân hàng dẫn đầu hành trình số hóa đang chờ bạn nắm bắt.
Cơ hội khám phá môi trường làm việc, văn hóa doanh nghiệp, các hoạt động phát triển kỹ năng, trau dồi kinh nghiệm, những câu chuyện nghề, … Tất cả được gói gọn lại trong Chuyên trang dự án Techcombank Careers x TopDev.
Techcombank và loạt câu chuyện chủ đề hấp dẫn sẽ đưa bạn đến với chuyến hành trình xây dựng những thay đổi cho cuộc sống tương lai nhờ quá trình Số hóa Ngân Hàng!
Cùng khám phá những nội dung hữu ích tại Chuyên trang Techcombank: https://topdev.vn/group/techcombank
Đừng bỏ lỡ và nhanh chóng truy cập đường dẫn bên dưới để KHÁM PHÁ NGAY.
Thuộc dự án “InsideGEM Technology“ do TopDev hợp tác cùng Techcombank triển khai, chuỗi nội dung thuần “Tech” độc quyền được chia sẻ bởi đội ngũ chuyên gia Công nghệ & Dữ liệu tại Techcombank sẽ được cập nhật liên tục tại chuyên mục Tech Blog | Techcombank Careers x TopDev. Cùng theo dõi & gặp gỡ các chuyên gia bạn nhé!
Với những bạn lập trình Java thì có lẽ biết rất rõ nguyên lý SOLID. Với Java thì SOLID gần như là quy tắc bất di bất dịch mà mọi lập trình viên phải nắm vững. Mình cũng đã có một bài viết về clean code với nguyên lý SOLID. Các bạn có thể đọc lại nhé.
Tuy nhiên, với Node.js hay Javascript nói chúng thì lại rất dễ dãi. Bạn viết code kiểu gì cũng được, bạ đâu viết đấy cũng được và tùy thuộc style code của mỗi người. Chính vì điều này mà Node.js/Javascript cực dễ học.
Nhưng vì viết code thoải mái, không có quy tắc sẽ dẫn đến dự án khó maintain, code sẽ rất rối, khó debug… Chính vì vậy, nếu có thể áp dụng được nguyên tắc SOLID cho dự án Node.js thì thật tuyệt.
Bài viết này mình sẽ chia sẻ cách thực hiện nguyên lý SOLIDtrong Node.Js với sự hỗ trợ của TypeScript.
1. SOLID là gì? Nguyên lý SOLID trong Node.js
Trước khi chúng ta bắt tay vào code thì phải hiểu SOLID là gì đã. Cần phải nắm vững lý thuyết trước khi thực hành là quan điểm của mình.
Về cơ bản thì các nguyên lý thiết kế phần mềm hay kiến trúc phần mềm sinh ra là để ứng dụng dễ maintain, dễ mở rộng về sau. Muốn đạt được điều đó thì người ta thực hiện nguyên tắc “Chia để trị“.
Tức là người ta chia ứng dụng thành các khía cạnh khác nhau, càng độc lập với nhau càng tốt.
Mình lấy ví dụ: Ứng dụng “quản lý siêu thị” chẳng hạn. Logic của nghiệp vụ quản lý siêu thị: quản lý thu nhân như nào, quản lý hàng nhập kho ra sao… được coi là một khía cạnh. Giao diện của ứng dụng là một khía cạnh.
Việc lập trình giao diện và logic ứng dụng nên độc lập với nhau. Để sau này khi đổi giao diện không cần phải đổi cả business logic của ứng dụng.
Về định nghĩa cụ thể từng nguyên tắc của SOLID đã được mình trình bày ở bài viết trước. Bài này mình chỉ tập trung vào cách thực hiện nguyên lý SOLID trong Node.js như thế nào mà thôi.
Chờ chút: Trong Node.js thì việc xây dựng kiến trúc tốt sẽ giúp bạn hạn chế rất nhiều những lỗi kinh điển. Trong đó có lỗi Callback Hell. Mời bạn đọc thêm về cách xử lý khi mã nguồn dự án bị Callback Hell tại đây >> Callback hell là gì? Cách xử lý triệt để Callback hell.
#Single responsibility principle
Được hiểu như sau:
Một class chịu trách một việc mà thôi
Ví dụ sau mình tạo một class Person bằng TypeScript. Trong đó mình định nghĩa các thuộc tính của một người như Tên, đệm, thông tin liên hệ( email), và các hành động chào hỏi – greet(), xác thực email – validateEmail().
class Person { public name : string; public surname : string; public email : string; constructor(name : string, surname : string, email : string){ this.surname= surname; this.name= name; if(this.validateEmail(email)){ this.email= email; } else{ thrownew Error("Invalid email!"); } } validateEmail(email : string){ var re =/^([\w-]+(?:\.[\w-]+)*)@((?:[\w-]+\.)*\w[\w-]{0,66})\.([a-z]{2,6}(?:\.[a-z]{2})?)$/i; return re.test(email); } greet(){ alert("Hi!"); }}
Nhìn qua class trên bạn thấy ngay rằng có chi tiết thừa. Đó chính là hàm validateEmail(), vì hành động này không phải là hành vi của một người. Không nên đặt hàm này trong class Person.
Chúng ta có cải tiến đoạn code như sau:
class Email { public email : string; constructor(email : string){ if(this.validateEmail(email)){ this.email= email; } else{ thrownew Error("Invalid email!"); } } validateEmail(email : string){ var re =/^([\w-]+(?:\.[\w-]+)*)@((?:[\w-]+\.)*\w[\w-]{0,66})\.([a-z]{2,6}(?:\.[a-z]{2})?)$/i; return re.test(email); }}class Person { public name : string; public surname : string; public email : Email; constructor(name : string, surname : string, email : Email){ this.email= email; this.name= name; this.surname= surname; } greet(){ alert("Hi!"); }}
#Open/close principle
Có thể hiểu nguyên tắc này như sau:
Chỉ nên mở rộng một class bằng cách kế thừa. Tuyệt đối không mở rộng
class bằng cách sửa đổi nó.
Điểm mấu chốt của nguyên tắc này là: Chỉ được THÊM mà không được SỬA.
Đoạn code dưới đây là một ví dụ cho vi phạm nguyên tắc này:
class Rectangle { public width: number; public height: number;}class Circle { public radius: number;}function getArea(shapes:(Rectangle|Circle)[]){ return shapes.reduce( (previous, current)=>{ if(current instanceof Rectangle){ return current.width* current.height; }elseif(current instanceof Circle){ return current.radius* current.radius* Math.PI; }else{ thrownew Error("Unknown shape!") } }, 0 );}
Đoạn code cho phép chúng ta tính diện tích của hình chữ nhật và hình tròn. Nếu giờ mình muốn mở rộng chương trình, muốn hỗ trợ thêm hình tam giác nữa. Vậy phải làm sao?
Mình sẽ phải SỬA code của hàm getArea(). Mà làm như vậy là vi phạm nguyên tắc rồi.
Để cải thiện, chúng ta sửa lại thành như sau:
interface Shape { area(): number;}class Rectangle implements Shape { public width: number; public height: number; public area(){ returnthis.width*this.height; }}class Circle implements Shape { public radius: number; public area(){ returnthis.radius*this.radius* Math.PI; }}function getArea(shapes: Shape[]){ return shapes.reduce( (previous, current)=> previous + current.area(), 0 );}
Với code mới này, để hỗ trợ thêm một hình dạng mới, bạn chỉ cần tạo THÊM một class và implement interface Shape là được, không cần phải sửa code đã có.
#Liskov substitution principle
Trong một chương trình, các object của class con có thể thay thế class cha
mà không làm thay đổi tính đúng đắn của chương trình
Với nguyên tắc này khuyến khích chúng ta sử dụng tính đa hình trong lập trình hướng đối tượng.
Chúng ta đã sử dụng interface Shape để đảm bảo chương trình có thể mở rộng mà không cần phải sửa code đã có.
Nguyên tắc thay thế Liskov cho chúng ta biết rằng chúng ta có thể chuyển bất cứ kiểu con nào của Shape( Ví dụ: Rectangle, Cyrcle…) sang hàm getArea() mà không làm thay đổi tính chính xác của chương trình.
Trong các ngôn ngữ kiểu như TypeScript/Java, thì trình biên dịch sẽ kiểm tra đã implement chính xác interface đó chưa( Nếu implement mà không override đủ method là bị lỗi biên dịch ngay). Nên bạn không phải làm thủ công để đảm bảo chương trình tuân thủ nguyên tắc Liskov.
# Interface segregation principle
Nên tách Interface thành nhiều interface nhỏ với những mục đích riêng biệt
Vẫn lấy đoạn code tính diện tích hình chữ nhật và hình tròn. Bây giờ có một vấn đề là: Nếu bạn sử dụng đoạn code cho nhiều mục đích khác nhau thì sao?
Nếu mình muốn tính diện tích xong rồi thì mã hóa thành JSON và trả về cho client. Nếu mình code như sau thì sẽ vi phạm nguyên tắc thứ 4 này.
interface Shape { area(): number; serialize(): string;}class Rectangle implements Shape { public width: number; public height: number; public area(){ returnthis.width*this.height; } public serialize(){ return JSON.stringify(this); }}class Circle implements Shape { public radius: number; public area(){ returnthis.radius*this.radius* Math.PI; } public serialize(){ return JSON.stringify(this); }}
Vi phạm bởi vì: Có lúc mình dùng không cần phải mã hóa thành JSON để trả cho client, có lúc mình lại cần JSON. Đoạn code đã mix cả hai mục đích ấy vào cùng một interface.
class Rectangle implements RectangleInterface, Shape { public width: number; public height: number; public area(){ returnthis.width*this.height; }}class Circle implements CircleInterface, Shape { public radius: number; public area(){ returnthis.radius*this.radius* Math.PI; }}function getArea(shapes: Shape[]){ return shapes.reduce( (previous, current)=> previous + current.area(), 0 );}
Và khi cần mã hóa thành JSON.
class RectangleDTO implements RectangleInterface, Serializable { public width: number; public height: number; public serialize(){ return JSON.stringify(this); }}class CircleDTO implements CircleInterface, Serializable { public radius: number; public serialize(){ return JSON.stringify(this); }}
Các bạn thấy code “ngon” hơn chưa?
#Dependency inversion principle
Đây là nguyên tắc quan trọng nhất trong nguyên lý SOLID. Nhưng vì nó là chữ D trong cụm từ SOLID nên luôn được giải thích sau cùng.
Nếu chúng ta xem lại các ví dụ ở các nguyên tắc trên, chúng ta thấy rằng interface là một yếu tố cơ bản nhất của mọi nguyên tắc. Và nguyên tắc dependency inversion chính là tổng hợp của 4 nguyên tắc trước.
Việc thực hiện nguyên lý SOLID trong các ngôn ngữ lập trình không hỗ trợ Interface như Javascript ES5, thậm chí ES6 thật là khiêm cưỡng. Nhưng với hỗ trợ của TypeScript thì lại thật tuyệt.
Mình định trình bày tiếp phần kiến trúc Onion (kiến trúc củ hành) kết hợp với nguyên lý SOLID trong Node.js để có được một mã nguồn clean “vô đối”. Nhưng do bài dài quá nên thôi, các bạn đợi bài viết sau nhé!
Business Analyst (BA) hay Chuyên viên phân tích nghiệp vụ là người có vai trò cầu nối giúp kết nối khách hàng với doanh nghiệp, team phát triển để tạo ra những sản phẩm đáp ứng được đúng nhu cầu, mong muốn của khách hàng. Với vai trò quan trọng này thì trong bất cứ tổ chức nào, vị trí BA luôn được đảm bảo với mức đãi ngộ hấp dẫn, cùng với đó các công ty cũng đòi hỏi yêu cầu cao với các ứng viên ứng tuyển vị trí này. Bài viết hôm nay chúng ta cùng nhau tìm hiểu về những câu hỏi phỏng vấn Business Analyst thường gặp nhé.
Vai trò và trách nhiệm cơ bản của một BA
Vai trò cũng như công việc chính trong việc xác định và quản lý yêu cầu nghiệp vụ của một BA gồm:
Rút trích yêu cầu
Dự đoán và xác định yêu cầu
Giới hạn và đảm bảo tính tập trung của yêu cầu
Tổ chức yêu cầu của giải pháp
Chuyển đổi yêu cầu
Bảo đảm tính đúng đắn của yêu cầu nghiệp vụ
Đơn giản hóa yêu cầu sản phẩm
Kiểm tra và xác thực yêu cầu sản phẩm
Quản lý yêu cầu nghiệp vụ
Vận hành, theo dõi và đề xuất cải tiến
Phân biệt yêu cầu chức năng và yêu cầu phi chức năng
Yêu cầu chức năng (Functional Requirements) là sự mô tả của chức năng hoặc dịch vụ của phần mềm hay hệ thống, phổ biến như xác thực, phân quyền, các chức năng hành chính, giao diện, báo cáo,… Yêu cầu phi chức năng (Non-Functional) chỉ ra những quy định về tính chất và ràng buộc cho phần mềm hay hệ thống. Một vài yêu cầu phi chức năng phổ biến như về hiệu suất hệ thống (thời gian phản hồi, khả năng chịu tải,…), độ tin cậy, độ bảo mật,….
Trong thực tế, yêu cầu phi chức năng sẽ được đánh giá có phần quan trọng hơn, nhất là trong những hệ thống lớn, nếu không thỏa mãn được những yêu cầu liên quan đến đặc tính chất lượng này thì phần mềm hoặc hệ thống sẽ không thể đưa vào sử dụng.
Sự giống và khác nhau giữa User Story (US) và Use Case (UC)
User Story (US) là một mô tả yêu cầu từ người dùng với ngôn ngữ dễ đọc hiểu gần gũi với người dùng và thường được viết trên Card, giấy note hay các công cụ tài liệu như Words, Excels,… Use Case (UC) là những mô tả cách tương tác giữa người dùng và phần mềm về tất cả những trường hợp mà người sử dụng phần mềm sẽ gặp phải.
Cả US và UC đều sử dụng ngôn ngữ tự nhiên mà người dùng có thể dễ dàng hiểu, mục đích để xác định người dùng hệ thống và mô tả mục tiêu của họ. Điểm khác nhau giữa 2 khái niệm này là trong khi một UC cụ thể hơn và xem xét trực tiếp cách thức hoạt động của hệ thống thì US là một kỹ thuật phát triển Agile tập trung vào kết quả của các hoạt động và lợi ích của quá trình được mô tả.
Acceptance Criteria (AC) là gì? Mục đích viết AC là gì?
Acceptance Criteria là những điều kiện mà phần mềm cần để đáp ứng nhu cầu của người dùng, thông thường AC sẽ được viết, mô tả trong mỗi User Story (một mô tả nhu cầu/ yêu cầu của người dùng). AC được viết ra với mục đích:
Xác định rõ ràng với các thành viên trong team cần thực hiện những phần nào trước, hay trong Sprint này sẽ cần làm những gì?
Đảm bảo tất cả mọi người trong team có chung một cái hiểu đúng về vấn đề.
Là điều kiện mà Tester dựa vào đó để có thể kiểm thử, kiểm tra User Story.
So sánh Sketch, Wireframe, Mockup và Prototype
Sketch, Wireframe, Mockup và Prototype là các bước trong quá trình thiết kế giao diện giúp BA lấy yêu cầu, phác thảo nên ý tưởng, xây dựng bản demo để xác nhận với người dùng và chuyển giao cho bên team phát triển.
Sketch – phác thảo: bản vẽ tự do, độ xác thực thấp với mục đích chủ yếu là lấy ý tưởng giúp mọi người dễ hình dung trong quá trình trao đổi.
Wireframe: bản vẽ xây dựng bộ khung cơ bản của website hay ứng dụng. Trên Wireframe thể hiện được các chức năng chính, các chế độ xem và mối quan hệ giữa các tính năng. Điểm phân biệt Wireframe với các bước tiếp theo là thông thường Wireframe sẽ không bao gồm các yếu tố về màu sắc, đồ họa hay kiểu dáng.
Mockup: sau khi có Wireframe hoàn chỉnh thì sẽ đến bước vẽ mockup. Nếu trong team phát triển có designer chuyên UI/UX thì thông thường bước này được thực hiện bởi bộ phận này. Màu sắc, kiểu dáng, đồ họa, icon, logo,… được thêm vào giúp khách hàng và team DEV dễ dàng hình dung ra sản phẩm một cách chân thực.
Prototype: Nếu như Mockup chỉ là những hình ảnh, thành phần tĩnh thì Prototype được xem là bước gần sát nhất với sản phẩm khi mà người dùng có thể tương tác động với Prototype. Prototype giúp người dùng trải nghiệm UX sản phẩm một cách chân thực nhất.
Nêu một số công cụ (Tools) mà BA thường sử dụng trong công việc
Jira và Confluence: quản lý công việc, tài liệu dự án
Trello: quản lý công việc
Rational RequisitePro: hỗ trợ thu thập yêu cầu
Balsamiq: thiết kế wireframe
Pencil: Tạo prototype, mockups
Microsoft Visio: quản lý dự án
Google Docs: quản lý, chia sẻ tài liệu
Định hướng phát triển chuyên môn của một BA
Ở câu hỏi này, nhà tuyển dụng có thể muốn hỏi về định hướng của bản thân bạn, dưới đây là 3 chuyên môn chính mà một BA có thể định hướng để phát triển chuyên sâu:
Management Analyst (chuyên gia tư vấn quản lý): là người đề xuất các cách cải thiện hiệu quả của công ty hoặc tổ chức; tư vấn cho các nhà quản lý giúp vận hành công ty một cách tốt hơn.
Systems Analyst (chuyên viên phân tích hệ thống): là người phân tích và thiết kế kỹ thuật để giải quyết vấn đề kinh doanh sử dụng technical; sau đó là bước đào tạo và chuyển giao cho người khác sử dụng hệ thống.
Data Analyst (chuyên viên dữ liệu): là người thu thập thông tin và kết quả, sau đó trình bày dưới dạng biểu đồ, bảng biểu, báo cáo,… để xác định xu hướng và mô hình dự đoán những gì có thể xảy ra.
Kết bài
Trên đây là danh sách những câu hỏi phỏng vấn dành cho vị trí Business Analyst – BA mà nhà tuyển dụng sẽ thường xuyên sử dụng. Để trở thành chuyên viên phân tích nghiệp vụ, bạn cần có những kiến thức chuyên môn về cả IT cũng như business, chính vì thế đây cũng là vị trí mà nhiều người lựa chọn cho con đường phát triển của mình. Hy vọng bài viết này hữu ích dành cho bạn, hẹn gặp lại các bạn trong các bài viết tiếp theo của mình.
Bài viết được sự cho phép của tác giả Tống Xuân Hoài
Vấn đề
Lưu ý: Phạm vi bài viết này nói trong khuôn khổ Oauth2 được mô tả tại rfc6749.
Xin chào mọi người, chuyện là mấy ngày hôm nay tôi có đọc một vài tranh luận của mọi người trên mạng về vấn đề sử dụng access token (AT) và refresh token (RT) sao cho hợp lý. Có người thì bảo chỉ cần triển khai AT thôi là đủ, có người thì bảo cần thêm cả RT nữa mới bảo mật. Ngoài ra cũng có những câu hỏi vậy nếu có cả AT và RT thì tôi nên lưu ở đâu trong trình duyệt để đảm bảo độ an toàn tuyệt đối?
Vậy ngày hôm nay, tôi cùng các bạn hãy mổ xẻ lần lượt từng vấn đề để xem thực hư nó là như thế nào nhé!
Access Token và Refresh Token là gì?
Đầu tiên cho những ai chưa biết, AT là một đoạn string (thường là jwt) được dùng để đại diện cho người dùng thao tác vào hệ thống. Ví dụ như khi bạn đăng nhập vào hệ thống sẽ trả về cho bạn một AT, bạn lưu lại mã AT đó cho mỗi lần gọi API sau đó.
Nếu như các trang web được xây dựng theo phong cách server render thì ngoài cách triển khai AT và RT chúng ta còn có thể định phiên người dùng bằng session – cookie. Nhưng xu thế ngày nay đang hướng đến những trang web client render như React, Angular, Vue… thì việc triển khai AT và RT rất là phổ biến.
Còn RT là đoạn mã được dùng để yêu cầu cấp một mã AT mới. Chúng ta hãy làm rõ vấn đề tại sao lại cần phải dùng RT?
Đầu tiên hãy làm rõ việc ủy quyền là gì? Thông thường việc xây dựng một website thì tính năng đăng ký/đăng nhập khá phổ biến. Đăng nhập thì bạn sẽ phải nhập một tài khoản + mật khẩu để xác nhận danh tính. Hệ thống xác nhận thông tin bạn nhập là chính xác thì sẽ trả về cho bạn một đoạn mã AT để đại diện cho bạn với một số quyền hạn nhất định trong hệ thống đó.
Hay trong Oauth, vấn đề ủy quyền thì nằm ở chỗ khi bạn bấm vào nút đăng ký/đăng nhập bằng tài khoản Google, Facebook… Hệ thống sẽ chuyển bạn qua một màn hình mà ở đó bạn sẽ phải đồng ý với việc cho phép cho hệ thống kia lấy một số thông tin như email, tên, ngày tháng năm sinh… của bạn. Khi đó thì Google hay Facebook cũng trả về một mã AT mà dựa vào đó, hệ thống kia có thể lấy được những thông tin của bạn phục vụ cho mục đính xác nhận danh tính.
Tóm lại, ủy quyền là việc xác nhận danh tính để lấy được một đoạn mã AT mà dựa vào mã AT đó có thể thay mặt người dùng để sử dụng được hệ thống.
Do đó, đôi khi việc có mã AT gần như là có luôn tài khoản của bạn trong một hệ thống nào đó. Việc bị lộ mã AT là rất nguy hiểm bởi vì kẻ tấn công có thể mạo danh bạn thao tác với hệ thống mà bạn hoàn toàn không hay biết. Chính vì lý do đó mã AT cần được lưu trữ một cách nghiêm ngặt nhất có thể, hoặc nếu không thì hãy giảm thời gian hiệu lực của mã AT lại, ví dụ như mã AT chỉ có hiệu lực trong thời gian 5 phút, hết 5 phút sẽ yêu cầu người dùng đăng nhập lại!? Nếu bạn chọn cách đó thì quả là một trải nghiệm tội tệ cho người dùng :D.
Một điều cần lưu ý là mã AT thường là mã JWT (json web token). Nó là một tiêu chuẩn để truyền thông tin an toàn giữa các bên với dữ liệu là một đối tượng JSON. Thông tin này có tính tin cậy cao bởi vì nó đã được kí bằng mã bí mật bằng các sử dụng các thuật toán như HMAC, RSA hoặc ECDSA.
Một đối tượng JWT gồm có 3 phần là header, payload và signature. Trong đó header giữ các thông tin cơ bản về chuỗi JWT như thuật toán dùng để kí, hạn sử dụng… Payload là dữ liệu cần truyền tải là đối tượng JSON đã được base64 encode. Cuối cùng là signature là phần mã hóa của cả hai header và payload kết hợp với mã bí mật cùng thuật toán mã hóa đã được chỉ định ở header.
Vì những thông tin cần thiết để truyền tải được nằm trong payload thế nên dựa vào payload hệ thống có thể xác định được danh tính của người dùng thông qua nó.
Ví dụ payload của tôi có nội dung như sau:
{"id":1,"username":"hoaitx"}
Thì khi lên hệ thống sẽ đọc được id của tôi và xác định được tôi là ai.
Có một lưu ý cực kì quan trọng đó là thông tin trong payload chỉ được mã hóa bằng base64, điều đó có nghĩa từ mã JWT tôi có thể trích xuất được những thông tin có trong payload vì thế bạn cần thận trọng trong việc đưa thông tin vào payload trước khi kí chúng. Chắc chắn rằng những thông tin nhạy cảm như password, hay các thông tin cá nhân không cần thiết thì không nên đưa vào.
Khi mã JWT được gửi lên máy chủ có thể dễ dàng xác định được phần chữ kí trong đó có hợp lệ không. Bởi bất kì một thông tin nào trong payload được sửa đổi để gửi lên sẽ kéo theo chữ kí sẽ bị thay đổi theo. Chưa kể đến kẻ tấn công sẽ không bao giờ biết được mã bí mật dùng để kí lại nội dung bị thay đổi đó.
Có nên dùng Refresh Token không?
Tôi sẽ không khuyến khích mọi người nên triển khai RT hay như thế nào. Vì tôi biết có nhiều hệ thống không cần triển khai đến RT mà vẫn hoạt động tốt. Thay vào đó tôi sẽ đưa ra một vài điểm cần chú ý khi sử dụng AT và RT.
Có một vài lý do để AT chỉ nên tồn tại trong thời gian ngắn như:
Access Token là một đoạn mã ủy quyền đã được kí bởi máy chủ ủy quyền, máy chủ tài nguyên chỉ cần nhận access token và xác nhận thế nên thời gian càng ngắn thì nguy cơ access token khi bị lộ càng ít rủi ro.
Nếu thời gian hợp lệ của AT quá dài, khi bị lộ AT thì rủi ro cao hơn vì t kẻ gian có nhiều thời gian hơn để khai thác, đồng thời có thể bạn ko biết rằng AT đã bị lộ.
Hãy tưởng tượng nếu bạn cho phép người dùng tạo quá nhiều mã AT, lúc đó nếu muốn vô hiệu hóa những mã AT còn lại thì bạn phải đánh dấu nó trong cơ sở dữ liệu. Hay nói cách khác là bạn cần phải lưu lại những mã AT đã được tạo ra.
Có một vài lý do để RT được sử dụng như:
Rút ngắn thời gian tồn tại của AT, khi AT bị hết hạn thì sử dụng RT để lấy mã AT mới.
Bạn cần phân biệt được máy chủ ủy quyền và máy chủ tài nguyên. Máy chủ ủy quyền có nhiệm vụ cung cấp mã RT và kí mã AT để đại diện cho người dùng. Máy chủ tài nguyên nhận mã đã kí từ máy chủ ủy quyền để có quyền như người dùng đang thao tác với dữ liệu của họ trên hệ thống như thông tin tài khoản, dữ liệu… Máy chủ ủy quyền và máy chủ tài nguyên có thể là một. RT thường được lưu trữ ở máy chủ ủy quyền phục vụ cho mục đích cấp mã AT mới. Còn mã AT được dùng ở máy chủ tài nguyên, dùng để định danh một người dùng.
Bạn không cần phải lưu lại nhiều AT, nếu muốn chấm dứt phiên chỉ đơn giản là vô hiệu hóa mã RT trên máy chủ ủy quyền.
Sau khi hiểu được những lý do trên thì việc sinh ra RT giúp giải quyết được một vài hạn chế khi chỉ sử dụng mỗi AT. Nhưng như vậy nếu mã AT hoặc RT bị lộ thì rủi ro sẽ rất cao sao? Và các lưu trữ chúng như thế nào thì mình xin viết tiếp ở phần sau.
Bài viết được sự cho phép bởi tác giả Nguyễn Trung Thành
Bài viết này là những chia sẻ từ đáy lòng của một kỹ sư/giảng viên với nhiều năm kinh nghiệm trong nghề lập trình. Khi bạn bắt đầu nhập môn lập trình, thì bài viết này sẽ định hướng cho bạn biết con đường tích lũy kinh nghiệm lập trình nhiều chông gai nhưng cũng rất thú vị phía trước.
Bài viết chia là 2 phần chính:
Phần 1: Những kinh nghiệm bản thân tác giả đã trải qua. Từ lúc học lập trình cho người chưa biết gì, đến khi trở thành lập trình viên chuyên nghiệp.
Phần 2: Tác giả sẽ tổng kết lại 9 level, hay nói theo ngôn ngữ kiếm hiệp thì là 9 cảnh giới từ thấp đến cao mà một lập trình viên có thể đạt được.
Chúng ta cùng nhau khám phá nhé!
Phần 1: Nhập môn lập trình
Thường thì người giỏi thật sự thì có lẽ họ ít chia sẻ kinh nghiệm tối cao. Người ta gọi là bí kíp gia truyền. Mà chỉ người được chỉ định mới có thể truyền thụ. Mà khi chia sẻ thì họ lại thường chia sẻ những kinh nghiệm phổ biến.
Bản thân mình cũng vậy, nhưng trong bài viết này mình chia sẻ những quan niệm hơi khác người một chút.
#1. Nền tảng ngành CNTT của Việt Nam
Để học tốt ngành CNTT, bạn phải có đủ 5 yếu cốt cốt lõi sau:
Tư duy
Kỹ năng IT
Kiến thức chuyên môn (lập trình, Toán học, Vật lý…).
Đam mê
Ngoại ngữ
5 yếu tố trên gộp lại thành 1 thứ gọi là “cốt cách”, “tư chất”.
Điều này giải thích một chuyện mà bạn thường hay thấy: có vài bạn học lập trình suốt 2 năm liền mà trình độ không bằng được vài bạn học lập trình trong… vài tháng.
Đơn giản là sự khác nhau ở “tư chất” và sự cần cù kiên trì mỗi người.
Để giải thích 5 yếu tố trên vừa dễ mà vừa khó. Dễ là vì bạn nào đọc cũng hiểu cả. Khó là vì để cho bạn hiểu đúng được ý nghĩa sâu xa thì không phải đơn giản.
Bạn có thể hiểu đơn giản như sau:
Giả sử 4 yếu tố đầu tiên bạn rất giỏi, nhưng bạn không giỏi yếu tố cuối cùng (tiếng Anh). Vì vậy mà bạn không thể leo lên mức cảnh giới thượng thừa mà mãi mãi bị giới hạn ở 1 mức nào đó.
Bạn chỉ đạt cảnh giới cao khi nội lực đầy đủ. Lấy hình trên minh họa chẳng hạn, với “minimum” là ngôn ngữ tiếng Anh.
Lưu ý: 5 yếu tố trên đây chỉ là “tư chất”, muốn phát huy được “tư chất” để đạt được thành công thì bạn phải rèn luyện, kiên trì và cần có nhiều yếu tố khác (thậm chí là cả may mắn). Nếu rèn luyện tốt tư chất thì bạn có thể học giỏi bất cứ lĩnh vực nào trong ngành CNTT chứ không phải riêng về lập trình. Đó là kinh nghiệm đầu tiên mình muốn chia sẻ với bạn muốn nhập môn lập trình.
#2. Coder là gì? Coder khác với Software Engineer chỗ nào?
Coder hiểu đơn giản là những người viết các đoạn mã để xây dựng các phần mềm. Đây là cách gọi dân dã kiểu tá điền. Tức là Coder là người viết code, và chỉ biết mỗi code thôi.
Với ý nghĩa ban đầu là coder là người chỉ thực hiện viết code. Nhưng với yêu cầu nhân lực ngày nay, thì coder gần giống với ý nghĩa Software Engineer.
Tức là người Coder không chỉ biết viết code theo chỉ thị, mà họ cần phải biết về thiết kế hệ thống, biết viết test case, biết làm việc nhóm, trao đổi với khách hàng… rất nhiều kĩ năng kèm theo.
#3. Copy code đúng cách
Thường thì đa số các bài viết chia sẻ kinh nghiệm lập trình họ đều nói rằng không được phép copy code của người khác, copy code là ngu, là gà, copy code là vô đạo đức, v.v.
Dĩ nhiên mình đồng ý hoàn toàn, vì “copy code” đối với đa số người là “lấy code của người khác mang về làm bài làm của mình”.
Còn với mình, thì quan niệm “copy code” đúng với ý nghĩa thuần túy của nó: “copy một đoạn code từ tài liệu, sau đó dán vào bài của mình, chạy thử”.
Vậy thì điều đó có gì khác nhau ? Rất khác. Khi mình tìm kiếm tài liệu, chạy thử code, để tiếp thu nhanh nhất thì mình phải copy code thấy được kết quả ngay, dễ dàng hình dung ra vấn đề.
Điều này rõ ràng tốt hơn việc “gõ code từ từ (không copy) để hiểu từng câu lệnh, gõ quá trời quá đất, chạy thử, ôi mẹ ơi 69 lỗi, thiếu thư viện tè le. Biết vậy khỏi gõ code chi cho mệt người tốn sức”.
Khi mình “copy code” thuần túy, mình sẽ thấy ngay kết quả, điều đó tạo động lực và cảm hứng. Từ đó bắt đầu chạy debug từ từ, dần dần hình dung ra vấn đề và hiểu được, sử dụng được. Đó là 1 trong những bí kíp tối thượng của mình khi học lập trình.
#4. Biết nhìn xa trông rộng
Nghe có vẻ khá là hoa mỹ nhưng thực tế là vậy.
Khi làm một đồ án (bài tập siêu lớn), các bạn của mình thường hay nhào vào code ngay, code được chức năng nào hay chức năng đó để kiếm điểm. Còn mình thì không.
Mình dành đến gần 50% thời gian làm đồ án cho sự chuẩn bị, chuẩn bị về mọi thứ. Mình học những công nghệ liên quan đồ án, tìm hiểu kĩ các hàm, code thử vài tính năng nho nhỏ để hiểu. Sau đó mình bắt đầu lên ý tưởng, thiết kế hệ thống class (lập trình hướng đối tượng).
Mình phải thiết kế làm sao mà phải mở rộng được tối đa các chức năng. Ví dụ đồ án yêu cầu chức năng vẽ hình cơ bản, nhưng mình thiết kế làm sao mà có thể dễ dàng mở rộng ra thành “vẽ hình phức tạp, vẽ hình mà chèn thêm được chữ”.
#5. Code đúng là một chuyện – Code để có thể tái sử dụng lại là chuyện khác
Giai đoạn nhập môn lập trình rất mệt, phải liên tục điều chỉnh cho hoàn thiện, nhưng bù lại khi cái lõi đã xong, thì giờ đến lúc mình sướng, bạn mình khổ. Bạn mình khổ vì nhào vào code liền, giờ code như 1 đống rác đọc chả hiểu gì (xin lỗi, dùng từ hơi xúc phạm).
Vì code miễn sao ra đúng chức năng là ok nên “làm được trước đã rồi tính tiếp”. Vì vậy bạn mình thường sẽ bị bế tắc về sau. Còn mình thì giai đoạn sau rất thoải mái, mở rộng tính năng tối đa, giựt điểm về ngon lành.
Mấu chốt quan trọng ở đây là phải biết nhìn xa trông rộng. Nền tảng đó là cấu trúc dữ liệu và giải thuật, phương pháp lập trình hướng đối tượng, tư duy hướng đối tượng. Dùng các mẫu thiết kế Hướng đối tượng làm cho code của mình hay hơn, chuyên nghiệp hơn.
Phần 2: 9 cảnh giới từ thấp đến cao trong giới lập trình
Nhằm đơn giản hóa vấn đề, mọi code minh họa trong bài sử dụng ngôn ngữ C/C++.
Cảnh giới 1: Nhập môn lập trình (beginner)
Mới bước vào ngành CNTT và lập trình thì ai ai cũng phải “nhập môn”, làm quen. Vì vậy mà nhiều khi code rất là trẻ trâu. Code đọc khó hiểu, tệ hơn là thụt dòng loạn xạ không có quy tắc.
Cảnh giới 2: Biết sử dụng hàm, thư viện chuẩn có sẵn
Có một điều trớ trêu thay là dù bạn học các ngành về khoa học kĩ thuật hay là về khoa học xã hội, thì vẫn len lỏi đâu đây một yếu tố gọi là “học thuộc lòng”.
Tất nhiên, với các ngành khoa học xã hội thì điều đó dễ dàng nhận ra, môn Văn chẳng hạn, học bài phát điên luôn. Còn với khoa học kĩ thuật thì sao ? Liệu có học bài không ?
Với quan điểm của mình, một trong những bước đệm để bạn giỏi lên là phải học thuộc càng nhiều hàm, càng nhiều thư viện càng tốt, giống như học từ vựng tiếng Anh ấy.
Điều này đôi khi nghe có vẻ phi lý, vì sao ta lại học thuộc lòng ?
Đơn giản vì ta đang muốn giải quyết nhanh một vấn đề, sao ta lại tốn công sức viết thủ công các hàm trong khi thư viện đã có sẵn, gọi 1 phát là xong ?
Ta sẽ tiết kiệm được thời gian, công sức để tập trung vào vấn đề chính nhiều hơn. Nhiều khi mình lo viết hàm phụ mà hàm phụ bị lỗi, gây rối, mất tập trung, xuống tinh thần.
Ghi chú: Chỉ khi bạn vững thuật toán cơ bản thì mới xài hàm để tiết kiệm thời gian.
Lấy ví dụ minh họa: Kiểm tra xem một số nguyên dương có phải số đối xứng hay không?
Ví dụ như số 121 là số đối xứng, số 123 thì không phải, số 9009 là số đối xứng, v.v
Làm bình thường chưa biết gì cả
Khi biết sử dụng hàm, bài toán giải quyết “ngọt” hơn
Cảnh giới 3: Tinh thông hàm, thư viện, nguyên lý
“Tinh thông” hoàn toàn khác với chuyện “biết biết một chút”.
Khi bạn hiểu rõ được cú pháp các hàm xử lý, bạn sẽ dễ dàng ứng dụng nó để xử lý bài toán tốt nhất. Lấy lại ví dụ “xác định số đối xứng”.
Khi bạn chưa hiểu rõ hàm strcmp, strrev, strcpy thì bạn chỉ hiểu đơn giản là nó giúp mình làm cái này, cái kia. Nhưng khi bạn hiểu rõ được cú pháp của hàm đó, nguyên lý xử lý của hàm đó, thì bạn có thể áp dụng để làm cho code mượt mà hay hơn như hình ở trên.
Cảnh giới 4: Cấu trúc dữ liệu và thuật toán
Đây là một lợi thế của những bạn từng học “đội tuyển Tin học” đi thi Học sinh giỏi cấp tỉnh, thành phố/quốc gia/Olympic.
Bạn sẽ ứng dụng những cấu trúc dữ liệu & thuật toán để giải quyết một vấn đề ở mức độ tối ưu (tối ưu về tốc độ là chính). Nó cũng sẽ tích lũy một phần kiến thức vào kinh nghiệm lập trình.
Có những thứ ở cuộc sống rất là trừu tượng, khi mang nó vào biểu diễn trong lập trình thì phải nói là 1 thảm họa khủng khiếp. Vì bình thường ta chỉ khai báo các biến, sử dụng các hàm có sẵn để xài, vậy thôi.
Ví dụ: hệ thống bản đồ. Làm sao mà các lập trình viên có thể mô phỏng lại bản đồ trên máy tính, và có thể giúp ta tìm đường đi ngắn nhất giữa 2 địa điểm nào đó?
Google Maps là 1 ví dụ rất điển hình. Nếu ta chỉ khai báo biến, sử dụng các hàm có sẵn như nhập số, tách chuỗi, ghép chuỗi, v.v thì liệu có thể làm được điều này?
Cấu trúc dữ liệu giúp ta giải quyết vấn đề triệt để
Nhờ những cấu trúc, dữ liệu cơ bản như số nguyên, số thực, mảng, v.v người ta kết nối chúng, tập hợp lại (trong struct, class) rồi áp dụng một quy tắc hoạt động đặc biệt.
Vậy là có thể hình thành nên 1 cấu trúc dữ liệu. Từ đó giúp ta giải quyết vấn đề cực kì hay và ngọt, mà lại hiệu quả nữa.
Đi kèm với cấu trúc dữ liệu, đó là thuật toán. Cấu trúc dữ liệu quyết định thuật toán. Thuật toán giúp bạn tư duy tốt hơn. Bạn cần phải luyện tập nhiều với thuật toán.
Cấu trúc dữ liệu thường hay gặp: Stack
Vì vậy nên, để đạt đến một cảnh giới cao hơn, nhìn mọi vật, mọi sự việc khác người bình thường, thì nhất định bạn phải tinh thông cấu trúc dữ liệu và thuật toán
Cảnh giới 5: Phương pháp lập trình Hướng đối tượng
Cảnh giới được nâng lên tối thượng hay không cũng là nhờ phương pháp lập trình Hướng đối tượng.
Tư duy cũ: lập trình hướng thủ tục/hàm (hàm là trung tâm của việc lập trình)
Minh họa tư duy lập trình với hàm: hàm TinhTong
Tư duy Hướng đối tượng: đối tượng là trung tâm của việc lập trình, hàm chỉ là phụ
Minh họa tư duy Hướng đối tượng
Khi có tư duy lập trình hướng đối tượng, bạn sẽ nhìn mọi vật, sự việc lên 1 tầm cao mới. Khác xa với con mắt của người bình thường.
Phương pháp lập trình Hướng đối tượng (PP LT HĐT) giúp bạn tiết kiệm thời gian, công sức. Bạn có thể tái sử dụng code, mở rộng phần mềm một cách nhanh chóng. Nếu áp dụng tốt phương pháp lập trình này và cấu trúc dữ liệu/thuật toán thì bạn có thể nói là rất vững cơ bản rồi đó.
Cảnh giới 6: Engine, framework, thư viện, đa nền tảng
Khi học, bạn học từ dưới đáy lên cao thì mới có thể đạt được cảnh giới. Khi bạn học ở trên rồi bạn đào sâu xuống dưới thì thường rất khó và gần như không thể.
5 cảnh giới trước là bạn đang ở đáy, và đến cảnh giới này là bạn bắt đầu học lên mức “ứng dụng thực tế”.
Bạn sử dụng các engine, framework, thư viện có sẵn để làm nên 1 chương trình hoàn thiện, có giao diện đàng hoàng, tung ra ngoài thị trường. Bạn có thể va chạm nhiều với MVC, MVP, XML, database, Windows Form, WPF, Kotlin cho Android, v.v
Tưởng tượng như 5 cảnh giới trước là bạn luyện nội công vững vàng. Thì ở cảnh giới này bạn học ngoại công để thể hiện ra ngoài.
Khi có nội công vững, ngoại công tốt thì thiên hạ nhìn vào biết bạn là cao thủ, thiên hạ khiếp sợ.
Chương trình vẽ MyPaint – niềm tự hào của mình giúp mình đạt điểm cao.
Dù giỏi bất kì Framework nào thì hiểu bản chất mới là quan trọng
Còn với những bạn chưa có nội công tốt mà đã lo vội thể hiện thì thật là thảm họa, vì vậy việc trau dồi để có kinh nghiệm lập trình thật tốt là cần thiết.
Ví dụ như có những bạn lo làm game Flappy Bird, bạn dễ dàng làm được game này nhưng chỉ là phần đồ họa bên ngoài.
Chỉ khi bạn học Vật lý, hiểu được công thức rơi tự do (của con chim) thì bạn mới mô phỏng được chính xác chim đang bay. Đó là nội công đó bạn. Hay hơn nữa là bạn lập trình trí tuệ nhân tạo cho con chim tự bay, né các ống cống, đây mới gọi là giỏi.
Tưởng tượng: một người chưa có nội lực, nhưng mà được học chút võ công bên ngoài (ngoại công), khi múa võ sẽ làm cho nhiều kẻ sĩ sợ hãi, nhưng mà khi gặp cao thủ chưởng 1 phát là bẹp dí luôn. Còn nếu một người có nội lực mà chưa có ngoại công, lỡ bị cao thủ chưởng thì có thể “ráng chịu đựng đi gặp thầy thuốc chữa trị”.
Có nội lực mà còn thêm ngoại công pro thì thôi khỏi nói rồi.
Học chuyên sâu cũng là một cách
Một số bạn học sâu thì lại có quan niệm khác. Các bạn học sâu thì đào xuống phía dưới chớ không lên trên. Bạn sử dụng các thư viện xử lý thread, xử lý va chạm Vật lý chẳng hạn. Đó cũng là một điều tốt.
Xa hơn nữa là bạn tính toán chuyện đa nền tảng. Làm sao bạn viết code 1 lần mà biên dịch được trên nhiều nền tảng Windows, Android, iOS, Linux,… (với ngôn ngữ C/C++ chẳng hạn) ???
Cơ bản nhất là sử dụng macro. Sau đây mình sẽ minh họa khi bạn đạt cảnh giới macro. Mình sẽ lấy lại ví dụ về việc “nhập vào một số nguyên dương, kiểm tra xem đó là số đối xứng hay không”.
Sử dụng macro trong tiền xử lý (preprocessor) và tùy biến code
Nâng cấp thêm 1 chút
Ở cảnh giới này thì đồng thời bạn đã biết sử dụng các thư viện bên ngoài, biết cách link thư viện với project, biết tạo DLL, LIB và sử dụng chúng.
Thường bạn sẽ chìm đắm rất lâu trong cảnh giới này vì ham mê thể hiện và học quá nhiều thứ, và tất nhiên nó sẽ giúp ích cho việc tích lũy kinh nghiệm lập trình =))
Cảnh giới 7. Phong cách lập trình
Lên đến cảnh giới này, bạn bắt đầu chăm chú cho code mình được đẹp hơn, ưu việt hơn, dễ đọc hơn.
Thử tưởng tượng: bạn viết 1 đống code cả ngàn dòng rất là cao siêu. Nhưng sau 1 năm bạn đọc lại code mình bạn còn hiểu không ?
Khoảng trắng giữa các thành phần là quan trọng. Bạn cần tách ra rõ ra phần nào ra phần đó.
Ví dụ bạn khai báo biến, sau đó nhập dữ liệu, sau đó xử lý, và xuất ra kết quả. Vậy thì: nên có thêm khoảng trắng giữa 4 thành phần trên.
Code là một nghệ thuật – Coder là một nghệ sĩ
Cách 1:if(x == 0) In_ra_dòng_chữ("Hello");Cách 2:if(0 == x) In_ra_dòng_chữ("Hello");
Câu hỏi: liệu có sự khác biệt nào giữa 2 đoạn code trên không ?
Xét về mặt vật lý thì câu trả lời là KHÔNG, đều giống như nhau hoàn toàn. Xét về mặt tư duy: có 1 sự khác biệt rất lớn về đẳng cấp. Vì sao vậy ?
Giả sử ta quên đi 1 dấu ‘=’ trong biểu thức ở lệnh if.
Với cách 1 ta có thể nhầm lẫn if (x = 0) (thiếu đi 1 dấu ‘=’). Và code vẫn hợp lệ với C/C++, vì đó là việc “gán x = 0” nằm bên trong lệnh if, nhưng nó mang 1 ý nghĩa khác hoàn toàn và dẫn đến code sai.
Với cách 2 thì if (0 = x) là câu lệnh vô lý, làm sao mà hằng số gán giá trị được ? IDE sẽ gạch đỏ và báo lỗi ngay cho ta biết ===> “Code tự định nghĩa, tự né tránh lỗi vô lý”.
Một vấn đề nữa đó là vấn đề đặt tên cho class/truct, tên hàm, tên biến, v.v (mặc định ta bàn tới tên biến cho dễ hiểu).
Bạn sẽ phải mất nhiều thời gian để đặt tên biến sao cho hay và đúng quy tắc, dễ nhớ. Chỉ có những cao thủ họ mới hiểu được chuyện này.
Khi bạn học code cơ bản thì bạn chỉ quan tâm “tạo ra biến để xài” chứ ít quan tâm “tên biến như thế nào”.
Đơn giản thôi, code vài dòng thì nhìn biến a, biến c, biến x biến y dễ dàng hiểu được. Còn code 10000 dòng thì nhìn vào x, y, z xem có hiểu nó là gì không ? Đó chính là kinh nghiệm học lập trình dễ dàng hơn đó ^_^
Cảnh giới 8. Hacking/cracking
Cảnh giới này dành cho những bạn nào thích học sâu về hệ thống bên dưới, có thể sâu đến mức nghiên cứu về hợp ngữ (asm).
Bạn sẽ học với Windows API, shell (Windows). Với Linux bạn có thể tìm hiểu về system calls, kernel, shell, v.v Mình không xài Linux nhiều nên chỉ chém vậy thôi.
Minh họa công cụ “SuperPointer” giúp bạn hack game đơn giản
2 hình trên là minh họa việc sử dụng Windows API để hack 1 game nho nhỏ. Bạn sẽ được demo thử công cụ “SuperPointer” của mình khi học khóa học “Kỹ thuật lập trình & PP lập trình Hướng đối tượng cơ bản” của mình (PR xíu, hihi).
Ở cảnh giới này, bạn sẽ đi rất sâu về bên dưới, hiểu rõ đươc cơ chế hoạt động của hệ điều hành, ví dụ bạn tiêm DLL, ghi đè dữ liệu lên không gian bộ nhớ của tiến trình để hack, viết ra [virus] keylog, trojan, backdoor.
Hoặc bạn có thể nghiên cứu về cơ chế hook, message để từ đó mô phỏng lại quá trình test phần mềm tự động (test automation) v.v..
Cảnh giới 9. Vô chiêu thắng hữu chiêu
Đến cảnh giới này thì có thể nói bạn đã bước chân đến mức master rồi.
Ở cảnh giới này thì mình đoán là nhìn code cũng chạy được code trong đầu, khỏi cần chạy trên IDE luôn haha. Bạn có thể tự viết thư viện riêng cho mình mà thậm chí còn hay hơn những thư viện bên ngoài.
Nói vậy thôi, chớ mình nghĩ rằng khi đạt đến mức độ này thì thường bạn sẽ đi nghiên cứu khoa học và công nghệ, về Big Data, Data Mining, Machine Learning, hay là Virtual Reality, v.v
Và dĩ nhiên còn nhiều cảnh giới cao hơn, tầm mắt của mình chỉ đạt tới mức này thôi.
Ghi chú: Trong nhà trường, bạn học theo hướng dẫn thầy cô thì cùng lắm bạn chỉ học được một chút ở mỗi cảnh giới chứ bạn chưa thật sự tinh thông. Chỉ có sự tự học mới đưa bạn được tới đỉnh cao thôi
Một điều quan trọng nữa là:
– Nếu bạn chỉ biết ở mỗi cảnh giới một chút chút. Thì tương đương bạn vẫn là con số 0. Biết 10 ngôn ngữ lập trình nhưng ở mỗi ngôn ngữ chỉ viết được chương trình Hello World).
– Nếu bạn tinh thông đầy đủ mỗi cảnh giới, thì bạn vẫn có thể đạt đỉnh cao (chỉ biết 1, 2 ngôn ngữ lập trình nhưng tạo ra được sản phẩm hay).
===> Nếu đã xác định mình đã đam mê, hãy học tới nơi tới chốn, học cho kĩ cho sâu, phóng 1 mũi tên tựa như lao đến được đích cuối cùng.
Vậy là mình đã chia sẻ kinh nghiệm từ khi nhập môn lập trình mà mình đã trải nghiệm lúc học lập trình cho người chưa biết gì. Hy vọng sẽ giúp ích được cho các bạn!
Tôi nghĩ chắc các bạn developer ai cũng đã nghe qua từ Race condition rồi. Trong bài này tôi sẽ đề cập đên 2 vấn đề chính: Race Condition là gì!? và Làm sao phòng tránh nó?
Race condition rất khó để debug đặc biệt là khi mà chính tôi cũng không biết nó có phải Race Condition hay không!
Race Condition là gì?
Khi 2 hoặc nhiều user vì 1 lý do nào đó cùng lúc read và update cùng 1 record ở cùng 1 thời điểm, nó sẽ dẫn đến 1 vài problem không mong muốn. Tôi lấy ví dụ 1 customer click vào button Pay ở trang checkout của website e-commerce. Một điều hoàn toàn có thể xảy ra là customer có thể charge cùng 1 order 2 lần vì 2 request charge có thể đến gần như cùng 1 lúc. Những trường hợp giống như vậy gọi là Race Condition.
Các cách phòng tránh Race Condition
Locking
Khi hệ thống của tôi cho phép multiple users access và edit cùng 1 record, tôi cần phải tìm cách tránh trường hợp khi 1 user overrides changes của 1 user khác mà thậm chí không check xem đó có phải record mình muốn update không.
Tôi lấy ví dụ, tôi có 1 cái web e-commerce, trong đó nhiều admin đều có quyền manage kho sản phẩm. Race Condition xảy ra khi nhiều Admin cùng update thông tin cùng 1 sản phẩm:
Admin 1 thêm sản phẩm mới tên “Bench Fitness Equipment for Home”
Admin 2 vào thấy có sản phẩm mới tạo có tên chưa đầy đủ và không đáp ứng về mặt thương mại. Nên quyết định đổi tên lại thành “RELIFE REBUILD YOUR LIFE Sit Up Bench Adjustable Workout Foldable Bench Fitness Equipment for Home Gym Ab Exercises New Version”
Cùng lúc đó, Admin 1 thấy rằng tên mình đặt chưa hay cho lắm nên vào đổi lại thành “Adjustable Workout Foldable Bench Fitness Equipment for Home Gym”
Admin 1 save tên sản phẩm sau khi Admin update vài milliseconds, đồng thời vô tình override tên sản phẩm đầy đủ nhất mà Admin 2 mới đổi.
Locking là 1 trong nhiều cách để ngăn chặn kich bản như vậy có thể xảy ra.
Để triển khai optimistic locking in Rails, tôi add lock_version column vào table mà tôi muốn lock. Rails sẽ tự động check cột này trước khi update record. Cứ mỗi lần record được update thì cột lock_version sẽ tự tăng lên, và cơ chế locking sẽ chắc chắn rằng nếu có record được update 2 lần thì record được save sau cùng sẽ raise StaleObjectError.
product1 =Product.find(1)
product2 =Product.find(1)
product1.name ="RELIFE REBUILD YOUR LIFE Sit Up Bench Adjustable Workout Foldable Bench Fitness Equipment for Home Gym Ab Exercises New Version"
product1.save
product2.name ="Adjustable Workout Foldable Bench Fitness Equipment for Home Gym"
product2.save # Raises an ActiveRecord::StaleObjectError
Pessimistic locking
Pessimistic locking sẽ lock cái record đó cho đến khi tất cả transaction trên record đó kết thúc. Một khi record được lock, user khác sẽ không thể nào thay đổi record đó cho đến khi lock được release. Pessimistic locking sử dụng cho row-locking bằng SELECT…FOR UPDATE và 1 vài loại lock khác nữa.
Để sử dụng Pessimistic locking trong Rails, thay vì sử dụng ActiveRecord::Base#find thì tôi đổi thành ActiveRecord::QueryMethods#lock:
product =Product.lock.find(1)#lock the record
product.name ="RELIFE REBUILD YOUR LIFE Sit Up Bench Adjustable Workout Foldable Bench Fitness Equipment for Home Gym Ab Exercises New Version"
product.save!#release the lock
Mặt khác tôi cũng có hể sử dụng ActiveRecord::Base#lock! để lock record bàng IDs của nó:
product =Product.find(1)
order =Order.find(order_id)ActiveRecord::Base.transaction do
product.lock!
product.name ="RELIFE REBUILD YOUR LIFE Sit Up Bench Adjustable Workout Foldable Bench Fitness Equipment for Home Gym Ab Exercises New Version"
product.save!
order.paid!end
Hoặc tôi có thể start transaction và lock record cùng lúc bằng with_lock:
product =Product.find(1)
product.with_lock do#lock the record
product.name ="RELIFE REBUILD YOUR LIFE Sit Up Bench Adjustable Workout Foldable Bench Fitness Equipment for Home Gym Ab Exercises New Version"
product.save!end
Rails’ ActiveRecord validation không phải database-level validation, nó là application-level validation, và nó hoạt đông tuyệt vời nếu không có Race Condition.
Bây giờ lấy ví dụ thực tế trong cuộc sống. Tôi có feature sign-up, tôi yêu cầu user chỉ được sử dụng 1 số điện thoại để đăng ký và không được trùng nhau, vì thế tôi viết logic validate như sau:
Giờ giả sử user click sign-up button 2 hay nhiều lần cách nhau chỉ vài millisecond, sẽ dẫn đến kịch bản như sau:
Request 1 – Kiểm tra xem người dùng có tồn tại với số điện thoại đó hay không và tiếp tục, vì không tìm thấy người dùng nào.
Request 2 – Kiểm tra xem người dùng có tồn tại với số điện thoại đó hay không và tiếp tục, vì không tìm thấy người dùng nào.
Request 1 – Tạo user mới và insert vào database.
Request 2 – Tạo user mới và insert vào database.
Request 2 vượt qua unique validate vì tại thời điểm kiểm tra xem có người dùng tồn tại hay không, Request 1 vẫn chưa lưu số điện thoại vào database. Do đó, cả hai Request cuối cùng đều có thể insert new user vào database.
Để phòng tránh trường hợp Race Condition như vậy tôi só thể thêm unique index constraint, sẽ thực hiện validate ở database-level:
classAddUniqueIndexToUsers<ActiveRecord::Migrationdefchange# Have the database raise an exception anytime any process tries to# submit a record that has a code duplicated for any particular account
add_index :users,:phone_number, unique:trueendend
Lời kết
Race condition, nếu không ngăn chặn sẽ ảnh hưởng tới sự toàn vẹn dữ liệu và đôi khi sẽ dẫn đến các vấn đề về security. Hy vọng các bạn có thêm chút kiến thức cơ bản trong công cuộc đi code của mình và tránh được những đêm dài chỉ để ngồi debug.
Bài viết hôm nay chúng ta sẽ cùng tìm hiểu và làm rõ ra thế nào là truyền tham số kiểu Tham chiếu, hay Tham trị, vào phương thức trong Java. Có thực sự như lời đồn rằng Java chỉ hỗ trợ việc truyền tham số kiểu Tham trị hay không?
Thực ra cũng bởi có nhiều bạn liên hệ mong muốn mình làm rõ vấn đề này của Java, nên nhân đây mình viết ra luôn. Vâng, mình cũng nhận thấy rằng kiến thức này khá là quan trọng, nó không những nói rõ hơn về việc truyền tham số kiểu Tham chiếu và Tham trị là gì, mà nó còn giúp chúng ta mở rộng hơn trong việc nhìn nhận một biến được tổ chức và quản lý trong Java như thế nào. Và mình cũng muốn nói thêm một ý rằng, cái chủ đề về Tham chiếu/Tham trị này là một chủ đề thắc mắc của không riêng bạn đâu, nó như trở thành một cuộc tranh luận sôi nổi trên các diễn đàn, một lát sau vào bài viết bạn sẽ thấy tại sao nó lại gây nên sự tranh luận này, nếu bạn chưa tin lắm, hãy thử Google với từ khóa “Is Java pass-by-reference or pass-by-value” sẽ thấy.
Bắt Đầu Từ Việc Khai Báo Biến
Vâng đúng rồi, bạn nhớ đúng, biến đã được nói đến ở Bài 4. Ở đây chúng ta sẽ không nói lại biến là gì và khai báo ra sao. Mà sẽ phân tích sâu hơn về việc quản lý biến trong Java, lát nữa vấn đề về Tham chiếu và Tham trị sẽ được sáng tỏ hơn nhờ việc phân tích này.
Giả xử chúng ta khai báo một biến x như sau trong Java.
int x = 10;
Khi dòng code trên được thực thi, dĩ nhiên Giá trị10 sẽ được chứa trong bộ nhớ. Tuy nhiên, có một giá trị khác cũng được hệ thống tạo ra, đó chính là Địa chỉ chỉ đến nơi chứa giá trị 10 này. Bạn cứ tưởng tượng bạn đi nhà sách, bạn cần phải để túi sách bên ngoài trước khi vào nhà sách đó, bạn sẽ đi đến các tủ chứa dành cho khách, cất túi xách vào một ngăn tủ, đóng cửa tủ lại. Bạn thấy rằng cửa tủ có ghi một con số, và khi bạn khóa cửa lại, trên chìa khóa cũng có một số tương ứng. Vậy thì túi xách của bạn tương tự như giá trị 10 mà bộ nhớ (hay cái tủ) dùng để chứa, còn con số trên chìa khóa tủ chính là địa chỉ của cái tủ, tương tự địa chỉ dẫn đến giá trị 10 của bộ nhớ. Địa chỉ trên chìa khóa giúp bạn không bị nhầm lẫn giữa tủ đồ của bạn và của người khác, và địa chỉ của hệ thống cũng giúp biến x tìm đến nơi chứa giá trị của nó trong bộ nhớ.
Việc khai báo và kịch bản lưu trữ trên đây được mình mô tả bằng sơ đồ trực quan, dễ hiểu như sau.
Sơ đồ diễn tả việc khai báo giá trị cho biến
Sơ đồ cho thấy khi dòng code khai báo trên được thực thi, giá trị 10 chứa trong bộ nhớ màu cam, và địa chỉ đến giá trị này (khung màu xanh dương) được tạo ra và lưu trữ như thế nào.
Bây giờ mới bắt đầu nội dung chính của bài hôm nay. Trước hết chúng ta hãy nhìn vào code sau.
public static void main(String[] args) {
int x = 10;
System.out.println("Before call process: " + x);
process(x);
System.out.println("After call process: " + x);
}
public static void process(int x) {
x = 7;
}
Ở phương thức main(), chúng ta cũng bắt đầu với việc khai báo x = 10. Sau đó chúng ta truyền biến x này dưới dạng tham số vào cho phương thức process(). Thế nhưng vào bên trong process(), tham số lúc này cũng có tên là x (hay thực ra đặt cái tên khác cũng được, mình cố tình đặt chung để dễ thấy sự liên quan với nhau hơn), và chúng ta còn gán lại giá trị mới cho x nữa, là 7. Vậy sau khi process() kết thúc, câu lệnh in x ra console “After call process: “ sẽ in ra số 10 hay số 7 vậy các bạn?
Là số… 10. Hi vọng các bạn đều thuộc team nói đúng.
Before call process: 10
After call process: 10
Trên đây là ví dụ rõ ràng nhất cho khái niệm truyền kiểu Tham trị vào phương thức. Vậy truyền theo kiểu Tham trị là gì. Đó là việc truyền tham số trong trường hợp trên đây, nó chỉ là sự sao chép giá trị khi tham số được truyền vào trong một phương thức. x trước khi truyền vào trong phương thức process() mang giá trị 10. Còn x bên trong process() không phải x ở ngoài, nó chỉ là một biến khác được sao chép ra, cũng mang tên x, cũng mang giá trị 10, nhưng không còn là x ở ngoài nữa. Do đó dù bên trong process() chúng ta có thay đổi x như thế nào thì cũng không ảnh hưởng với x bên ngoài.
Có thể vẽ lại sơ đồ trực quan như sau.
Sơ đồ diễn tả việc truyền tham số kiểu tham trị
Sơ đồ cho thấy x ở trên cùng là x trước khi đưa vào trong process() mang giá trị 10, khi đưa vào trong process(), x này sẽ là một x khác hoàn toàn, khác nơi chứa giá trị 10 và hiển nhiên sẽ khác luôn địa chỉ (địa chỉ của chúng khác nhau được minh họa bằng hai màu khác nhau). Việc thay đổi từ giá trị 10 sang 7 bên trong process() chỉ làm thay đổi x bên trong đó mà thôi, hoàn toàn không ảnh hưởng gì với x bên ngoài cả.
Trước khi đi vào giải nghĩa, mình xin nhắc lại rằng, Java chỉ hỗ trợ chuyền tham số kiểu Tham trị mà thôi.
Nói là không hỗ trợ vì chẳng có một cách nào để kêu Java giúp chúng ta truyền kiểu Tham chiếu cả. Tuy nhiên một số ngôn ngữ khác lại “công khai” hỗ trợ điều này, như mình biết đó là C++. Mình cũng còn nhớ một ít C++ nên sẽ minh họa việc truyền theo Tham chiếu như thế nào theo code như sau (bạn nào biết code C++ mà nhận thấy mình viết sai thì giúp mình sửa nhé, lâu quá không dùng đến mình cũng quên nhiều).
#include <iostream>
int main() {
int x = 10;
cout << "Before call process: " << x << endl;
process(someValue);
cout << "After call process: " << x << endl;
return 0;
}
void process(int& x) {
x = 7;
}
Bạn thấy code C++ cũng dễ hiểu đúng không nào. Cũng có phương thức main(), cũng in ra console trước và sau khi gọi phương thức process(). Nhưng khi khai báo tham số truyền vào cho process(), C++ cho phép khai báo kiểu int& hoặc int. Với khai báo tham số là kiểu int thì kết quả sẽ truyền tham số kiểu Tham trị như code Java trên kia, còn khai báo int& thì tham số sẽ truyền theo kiểu Tham chiếu. Và bạn biết không, với code C++ này thì sau khi thực thi, kết quả in ra ở dòng cuối cùng sẽ cho thấy x bị thay đổi sang giá trị 7.
Before call process: 10
After call process: 7
Vậy bạn đã phần nào phân biệt giữa truyền tham số kiểu Tham trị và Tham chiếu chưa. Truyền tham số theo kiểu Tham chiếu như ví dụ ngay trên đây, đó là việc truyền tham số dựa trên việc truyền địa chỉ của biến (không sao chép giá trị như code Java trên kia). x trước khi truyền vào trong phương thức process() mang giá trị 10, khi truyền vào trong process() chính là x bên ngoài, do đó khi chúng ta thay đổi giá trị x bên trong process(), x bên ngoài cũng thay đổi theo.
Chúng ta mô hình hóa một chút nào.
Sơ đồ diễn tả việc truyền tham số kiểu tham chiếu
Sơ đồ cho thấy x ở trên cùng mang giá trị 10, khi đưa vào trong process(), địa chỉ của x sẽ truyền vào, và như vậy chúng cùng chỉ đến chung một bộ nhớ. Do đó, việc thay đổi x từ giá trị 10 sang 7 bên trong process() cũng làm cho x bên ngoài thay đổi từ 10 sang 7 theo.
Chốt lại là bạn đã phân biệt giữa truyền tham số dạng Tham trị và truyền tham số dạng Tham chiếu chưa nào. Ơ nhưng bài viết chưa kết thúc? Phần tranh cãi trên mạng chính là phần sau này đây, mời bạn xem tiếp.
Vậy Nếu Tham Số Là Một Đối Tượng Thì Sao
Vâng, trên đây là các ví dụ liên quan đến truyền tham số là một giá trị nguyên thủy vào trong phương thức. Bạn thấy rõ rằng Java là một ngôn ngữ chỉ cho phép truyền tham số kiểu Tham trị. Tức là giá trị bên trong phương thức truyền vào chỉ là một bản sao của giá trị bên ngoài, việc thay đổi giá trị này bên trong phương thức Java không gây ảnh hưởng hay thay đổi giá trị của biến bên ngoài phương thức.
OK. Vậy mời bạn xem ví dụ sau. Trước hết chúng ta cần khai báo một lớp cái đã, mình giả sử có lớp MyCat, lớp bạn mèo này có một thuộc tính name để dễ phân biệt.
public class MyCat {
private String name;
public MyCat(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Trường Hợp 1
Ở trường hợp thử nghiệm này, chúng ta xem hai anh chàng main() và process() khi này sử dụng MyCat như thế nào.
Bạn có đoán được hai dòng in ra màn hình sẽ in tên của chú mèo nhà ta như thế nào không. Có phải cùng là “Kitty” không. Bạn có lý khi nghĩ là cùng in ra “Kitty”, vì như đã nói, Java chỉ hỗ trợ truyền tham số kiểu Tham trị, myCat bên trong process() không phải myCat bên ngoài. Vâng, mời bạn xem kết quả.
Before call process: Kitty
After call process: Doraemon
Ơ sao kỳ vậy. myCat đã thay đổi name bên trong process() được ư. Vậy sao gọi là Tham trị? Vâng, thắc mắc trên các diễn đàn hỏi đáp là đây. Khái niệm Tham trị của Java bị lung lay ư? Thực chất thì đến giờ phút này, mình vẫn khẳng định rằng Java vẫn chỉ hỗ trợ kiểu tham số là Tham trị thôi nhé.
Trường Hợp 2
Chúng ta cùng sửa lại code trên một chút để thử nghiệm một trường hợp khác xem sao.
public static void main(String[] args) {
MyCat myCat = new MyCat("Kitty");
System.out.println("Before call process: " + myCat.getName());
process(myCat);
System.out.println("After call process: " + myCat.getName());
}
public static void process(MyCat myCat) {
myCat = new MyCat("Doraemon");
}
Kết quả in ra console ngay đây.
Before call process: Kitty
After call process: Kitty
Uhm trường hợp này hơi rõ ràng rồi đấy. Với code ở trường hợp 2 trên đây đủ thấy rằng, myCat bên ngoài được khởi tạo với cái tên “Kitty”, sau khi truyền vào process(), dù cho có được khởi tạo lại với cái tên “Doraemon” nhưng thực chất chúng không phải là một, nên myCat bên trong không làm ảnh hưởng đến myCat bên ngoài. Vậy trường hợp này có thể khẳng định, đây đúng là truyền tham số kiểu Tham trị.
Dù vậy thì trường hợp 1 là gì, tại sao truyền tham số kiểu Tham trị mà có thể làm thay đổi giá trị của đối tượng truyền vào được.
Giải Thích Các Trường Hợp
Trước khi đi vào giải thích từng trường hợp. Chúng ta hãy quay lại việc khai báo biến kiểu đối tượng. Hãy nhìn lại dòng khai báo sau.
MyCat myCat = newMyCat(“Kitty”);
Nếu dùng sơ đồ trên để miêu tả. Thì chúng ta sẽ có một nơi trong bộ nhớ lưu trữ Giá trị của biến myCat đúng không nào. Và một Địa chỉ chỉ đến Giá trị này của biến. Ồ nhưng trong MyCat có chứa thuộc tính name, vậy lại phải có một Địa chỉ chỉ đến Giá trị của name nữa. Lòng vòng như vậy cho chúng ta thấy thực ra việc cấp phát và lưu trữ một đối tượng nó sẽ hơi khác với biến nguyên thủy một chút. Bạn xem.
Sơ đồ diễn tả việc khai báo đối tượng myCat
Ô màu xanh dương chính là Địa chỉ của biến myCat, chỉ đến Giá trị của nó là ô màu đỏ. Ô màu đỏ sẽ lại chứa các Địa chỉ chỉ đến các thuộc tính của MyCat, trong trường hợp này chỉ có mỗi thuộc tính name.
Như vậy với trường hợp 1 trên đây. myCat được truyền vào trong process(), thực chất đúng là truyền kiểu Tham trị. Có nghĩa là giá trị của biến myCat được sao chép qua. Nhưng trớ trêu thay, giá trị của một đối tượng lúc bây giờ chính là địa chỉ đến các thành phần của đối tượng đó. Do đó việc sao chép địa chỉ lúc này cũng như sao chép chìa khóa mà thôi, nó vẫn dùng để mở cùng một tủ. Bạn xem minh họa cho trường hợp 1 như sau.
Sơ đồ diễn tả việc truyền tham số kiểu tham trị cho đối tượng myCat
Cũng giống như sơ đồ truyền biến nguyên thủy trên kia. Giá trị của myCat khi này lại là cục màu đỏ, mà như chúng ta đã biết, việc sao chép cục màu đỏ cũng chính là sao chép lại địa chỉ tham chiếu đến thuộc tính name. Tuy myCat bên ngoài và bên trong khác nhau về địa chỉ, nhưng lại cùng giá trị chính là địa chỉ đến name. Chính vì vậy mà việc thay đổi name đối với myCat trong trường hợp 1 lại làm thay đổi cả name của myCat trước khi truyền vào process(). Nhưng như bạn thấy, Java khi này vẫn tuân thủ là truyền tham số kiểu Tham trị đấy nhé.
Trường hợp 2. Khi myCat truyền vào trong process(), việc sao chép giá trị (chính là địa chỉa của name) vào trong phương thức vẫn diễn ra. Nhưng vào đây, myCat được khởi tạo lại thành một đối tượng mới thông qua toán tử new, thế là giá trị mới cũng thay đổi theo (màu đỏ thay bằng màu tím), nên việc đặt tên cho myCat bên trong process() như thế nào trong trường hợp 2 này cũng không ảnh hưởng đến bên ngoài nhé.
Sơ đồ diễn tả việc truyền tham số kiểu tham trị cho đối tượng myCat
Kết Luận
Trên đây là tất cả thông tin liên quan đến việc phân biệt cho khái niệm truyền tham số kiểu Tham chiếu hay Tham trị, và khẳng định rằng Java chỉ hỗ trợ việc truyền tham chiếu kiểu Tham trị mà thôi, mặc dù với việc truyền dữ liệu kiểu đối tượng có phần gây tranh cãi với nhiều người. Qua bài viết này bạn đã hiểu rõ về Java hơn rồi đúng không.
Làm việc với Javascript nhiều rồi nhưng bạn đã bao giờ gặp trường hợp mà khi cần clone một object chưa? Có bao giờ bạn chỉnh sửa một object thì cả hai object đều bị thay đổi? Ví dụ một bài toán cụ thể là bạn tạo một object lưu cấu hình mặc định. Sau này, tùy từng chức năng mà cần sao chép cấu hình mặc định và chỉnh sửa nó. Lúc sau quay lại, object cấu hình mặc định cũng bị chỉnh sửa theo. Kì lạ!?
Đặt vấn đề khi copy một object trong Javascript
Để bạn dễ hình dung, mình ví dụ bằng đoạn code khi bạn thực hiện copy một object:
const defaultConfig ={ debug:true, name:"Cấu hình mặc định", connectType:"Wifi",}const customConfig = defaultConfig;customConfig["debug"]=false;customConfig["name"]="Cấu hình cho KH";console.log(defaultConfig);
Kết quả:
Như vậy, mặc dù bạn không hề chỉnh sửa defaultConfig nhưng nó cũng bị biến đổi theo sau khi cập nhật customConfig.
Nguyên nhân của vấn đề trên nó liên quan tới kiểu dữ liệu tham chiếu và tham trị. Với Object nó là kiểu dữ liệu tham chiếu. Thức là các biến chỉ lưu trữ địa chỉ vùng nhớ của object mà thôi. Nên khi gán biến đó cho một biến khác thì bản chất là tạo ra hai biến cùng trỏ tới một vùng nhớ.
Do đó, deep clone một object là phương pháp tạo một vùng nhớ mới độc lập với vùng nhớ ban đầu.
Giải pháp này thoạt nhìn thì hơi buồn cười nhưng nó thực sự có võ đấy.
4. Tự viết hàm clone object
Nếu trường hợp bạn muốn tự làm chủ công nghệ deep clone Object, chúng ta có thể tự viết hàm create object. Bằng cách đệ quy để duyệt qua từng thuộc tính của object gốc và tạo ra object mới.
function cloneObject(obj){ var clone ={}; for(var i in obj){ if(obj[i]!=null&&typeof(obj[i])=="object") clone[i]= cloneObject(obj[i]); else clone[i]= obj[i]; } return clone;}// Cách sử dụngconst defaultConfig ={ debug:true, name:"Cấu hình mặc định", connectType:"Wifi", data:{ position:1 }}const customConfig = cloneObject(defaultConfig)customConfig["debug"]=false;customConfig["data"]["position"]=2;console.log(defaultConfig);// {debug: true, name: "Cấu hình mặc định", connectType: "Wifi", data: {position: 1}}
Tạm kết
Trên đây là một số cách để bạn có thể deep Clone Objects trong Javascript. Mình hi vọng sẽ có ích cho dự án của bạn.
Những năm gần đây, nghề lập trình viên đã trở thành một trong những nghề rất được săn đón. Với sự phát triển không ngừng của ngành công nghiệp này, lập trình viên trở thành một sự lựa chọn hấp dẫn cho nhiều người. Tuy nhiên, như bất kỳ nghề nào khác, lập trình viên cũng có những ưu điểm và nhược điểm riêng. Trong bài viết này, chúng ta sẽ cùng đi tìm câu trả lời cho câu hỏi nghề lập trình viên có những ưu nhược điểm gì?
Lập trình viên là người sử dụng các ngôn ngữ lập trình để tạo ra các chương trình, ứng dụng, phần mềm cho các thiết bị điện tử như máy tính, điện thoại, máy tính bảng, v.v. Lập trình viên có thể làm việc cho các công ty công nghệ, doanh nghiệp, tổ chức hoặc làm freelancer.
Lập trình viên có thể chia thành nhiều loại khác nhau tùy theo ngôn ngữ lập trình, mục đích và phạm vi của chương trình mà họ tạo ra. Ví dụ:
Lập trình viên web: là người thiết kế và xây dựng các trang web, bao gồm cả giao diện và chức năng của web.
Lập trình viên ứng dụng: là người phát triển các ứng dụng cho các hệ điều hành khác nhau, như Windows, Android, iOS, v.v.
Lập trình viên phần mềm: là người tạo ra các phần mềm cho các mục đích khác nhau, như giáo dục, giải trí, kinh doanh, v.v.
Lập trình viên game: là người thiết kế và phát triển các trò chơi điện tử cho các nền tảng khác nhau, như PC, console, mobile, v.v.
Nhu cầu về kỹ thuật viên và lập trình viên đang tăng lên, đặc biệt là trong bối cảnh của cuộc Cách mạng Công nghiệp 4.0. Do đó, nguồn cung cầu lao động của lập trình viên đang tăng lên, làm tăng giá trị của nghề nghiệp này.
Thêm nữa, lập trình viên có thể kiếm được một số tiền khá lớn nhờ vào kinh nghiệm và kỹ năng của mình. Nếu bạn có kỹ năng về các ngôn ngữ lập trình phổ biến như Java, Python, C++, hoặc Ruby on Rails, bạn có thể tìm được một số công việc lương cao. Bên cạnh đó, các lập trình viên có thể cải thiện thu nhập của mình bằng cách chuyển sang các lĩnh vực như quản lý dự án, giám sát, hoặc đào tạo lập trình viên mới.
Cơ hội nghề nghiệp rộng mở
Hiện nay, các công ty CNTT đang phát triển rất nhanh chóng và đa dạng với nhiều lĩnh vực, từ phát triển ứng dụng di động, trò chơi, trí tuệ nhân tạo, đến an ninh mạng, khoa học dữ liệu và điện toán đám mây. Điều này tạo ra cơ hội cho lập trình viên để phát triển và chuyển đổi sang các lĩnh vực khác nhau nếu họ muốn thay đổi công việc hoặc mở rộng kiến thức của mình.
Bên cạnh đó, lập trình viên có thể làm việc trong các lĩnh vực khác nhau như y tế, giáo dục, tài chính, thương mại điện tử và các ngành công nghiệp khác. Điều này mở ra nhiều cơ hội nghề nghiệp cho các lập trình viên và giúp họ khai thác tiềm năng của mình trong các lĩnh vực khác nhau.
Lập trình viên thường làm việc trong ngành công nghệ thông tin, nơi mà các công ty thường có nhu cầu cao về sự sáng tạo và sự sẵn sàng đáp ứng với các thay đổi nhanh chóng trong thị trường. Vì vậy, môi trường làm việc của lập trình viên thường được thiết kế để tạo ra một sự linh hoạt và đa dạng trong các dự án và nhiệm vụ.
Một điểm đáng chú ý là các công ty công nghệ thường cho phép lập trình viên làm việc từ xa hoặc có thời gian làm việc linh hoạt. Điều này đặc biệt hữu ích đối với những lập trình viên có nhu cầu về thời gian và không muốn bị giới hạn bởi giờ làm việc cố định.
Công việc mang tính toàn cầu
Với sự phát triển của công nghệ thông tin, các công ty phần mềm và công nghệ thông tin đã trở nên phổ biến trên toàn thế giới. Những công ty này thường tìm kiếm các lập trình viên có kỹ năng và khả năng làm việc tốt trong môi trường toàn cầu.
Điều này có nghĩa là lập trình viên có thể làm việc cho các công ty và tổ chức trên toàn thế giới. Điều này mang lại cho lập trình viên nhiều cơ hội hơn để tìm kiếm các dự án và việc làm mới, tăng cơ hội cho sự phát triển nghề nghiệp và thu nhập.
Nhược điểm
Công nghệ thay đổi liên tục – Đòi hỏi sự nhạy bén
Các công nghệ mới được phát triển và giới thiệu liên tục, điều này đòi hỏi lập trình viên phải cập nhật và học tập những công nghệ mới để giữ được sự cạnh tranh và đáp ứng yêu cầu của thị trường.
Với tốc độ phát triển nhanh chóng của công nghệ, việc học tập và cập nhật liên tục là một yêu cầu bắt buộc đối với lập trình viên. Tuy nhiên, nếu không đủ tư duy linh hoạt và không đủ nỗ lực học tập, lập trình viên có thể rơi vào tình trạng lạc hậu và khó tìm được việc làm trong thị trường lao động.
Lương cao đi đôi với áp lực
Lập trình viên thường phải đối mặt với các dự án có thời hạn ngắn, yêu cầu chính xác và tính chất phức tạp. Việc hoàn thành các dự án trong thời gian ngắn và đáp ứng yêu cầu của khách hàng có thể tạo ra áp lực rất lớn cho lập trình viên.
Thêm vào đó, lập trình viên thường phải làm việc với các bug, lỗi phát sinh trong quá trình phát triển sản phẩm. Việc tìm kiếm và sửa lỗi có thể mất rất nhiều thời gian và công sức, đồng thời làm tăng áp lực và đòi hỏi kỹ năng giải quyết vấn đề của lập trình viên.
Trong doanh nghiệp hoạt động nhiều dự án, lập trình viên có thể đối mặt với áp lực để đáp ứng các yêu cầu của nhiều dự án cùng lúc. Việc phải quản lý và phân chia thời gian giữa các dự án có thể làm giảm hiệu quả công việc, cũng như ảnh hưởng đến sự cân bằng giữa công việc và cuộc sống cá nhân.
Tiềm ẩn rủi ro về sức khỏe
Lập trình viên thường phải làm việc nhiều giờ liên tục trên máy tính, đồng thời thường phải ngồi ở vị trí cố định trong nhiều giờ mỗi ngày. Điều này có thể dẫn đến các vấn đề về sức khỏe như đau lưng, đau cổ, đau vai và bệnh lý về mắt như căng thẳng mắt, mỏi mắt, và khô mắt.
Thêm vào đó, việc làm việc nhiều giờ liên tục và áp lực công việc cũng có thể dẫn đến căng thẳng và stress, gây ra các vấn đề về sức khỏe tâm lý như lo âu, trầm cảm và rối loạn giấc ngủ.
Bạn có bao giờ tự hỏi nghề lập trình viên có phải là một nghề hot trong thời đại công nghệ số không? Câu trả lời là có. Theo báo cáo của World Economic Forum, nghề lập trình viên là một trong những nghề có tốc độ tăng trưởng cao nhất trong thập kỷ này. Nhu cầu thị trường đối với những người có kỹ năng lập trình đang ngày càng tăng, không chỉ ở các lĩnh vực liên quan đến công nghệ thông tin, mà còn ở nhiều ngành nghề khác nhau.
Theo báo cáo của Topdev 2022, tổng số vị trí tuyển dụng thuộc ngành lập trình năm 2022 là 175.370 và sẽ tăng lên 229.345 trong năm 2023 (tăng 30,8%). Ngành lập trình có nhiều lĩnh vực khác nhau, như phát triển phần mềm, phát triển web, phát triển ứng dụng di động, phát triển trò chơi,… Mỗi lĩnh vực đều có những yêu cầu và kỹ năng riêng biệt, nhưng chung quy lại đều cần có khả năng sử dụng các ngôn ngữ lập trình, thiết kế giải pháp và triển khai các tính năng cho sản phẩm.
Tóm lại, nhu cầu thị trường đối với nghề lập trình viên đang tăng cao và có xu hướng tiếp tục tăng trong tương lai, đặc biệt là trong các lĩnh vực công nghệ mới và phát triển phần mềm.
Kết luận
Nghề lập trình viên không chỉ mang lại thu nhập cao và cơ hội nghề nghiệp linh hoạt, mà còn được đánh giá là một trong những nghề có nhu cầu tuyển dụng cao trên thị trường hiện nay. Tuy nhiên, như mọi nghề nghiệp khác, nghề lập trình viên cũng có những nhược điểm cần được cân nhắc trước khi lựa chọn. Hy vọng rằng qua bài viết này đã giúp bạn tìm được câu trả lời cho câu hỏi nghề lập trình viên có những ưu nhược điểm gì? Cùng đón chờ những bài viết mới trên TopDev bạn nhé!
Cookies – thành phần vừa nghe đến thì chợt có cảm giác quen thuộc nào đó vừa lướt qua, đảm bảo là ai cũng đã từng ít nhất nghe qua một lần. Thế nên, hôm nay mình sẽ nói về ‘chiếc bánh’ này, và một vài xử lý nó trong các kịch bản automation với Selenium thông qua một số method như add, get và delete cookies.
Cookies là gì?
Cookies là các tập tin được lưu trữ trên máy tính của bạn, nó bao gồm các thông tin của các trang web mà bạn truy cập. Cookies đươc sử dụng để duy trì thông tin trạng thái khi bạn truy cập vào các trang khác nhau trên một website, giúp bạn ghi nhớ các thông tin như đăng ký, đăng nhập, hoặc những thông tin mà bạn đã cung cấp khi truy cập trang web đó.
Cookies lưu trữ thông tin theo các cặp giá trị ‘key-value’. Những thông tin này sẽ được gửi tới trang web, các page tương ứng của trang web đó vào lần tiếp theo bạn truy cập.
Trong quá trình thực hiện automation, bạn có thể cân nhắc xử lý cookies nếu bạn có một số vấn đề như dưới đây nhé:
1. Trong kịch bản kiểm thử của chúng ta có các yêu cầu đặc biệt nào đó liên quan đến cookies mà cần phải automate, và yêu cầu cần phải validate các giá trị đầu vào của các file cookie.
2. Vì cookie lưu các thông tin đăng nhập của người dùng khi ta đăng nhập vào một website nào đó, do vậy ta có thể tạo và load các file cookies trong quá trình automation. Từ đó có thể bỏ qua một số kịch bản, hoặc một số bước đã được xử lý bởi cookies, giúp ta giảm thiểu thời gian trong việc execute các test case.
Ví dụ đơn giản như này cho dễ hình dung, như chức năng đăng nhập của Google, ta chỉ cần đăng nhập 1 lần, sau đó khi vào các ứng dụng khác của google thì vì cookie đã lưu thông tin của ta rồi, nên ta không cần phải thực hiện đăng nhập tiếp thể có thể truy cập các ứng dụng khác ấy nữa.
Thực ra những lý do trên cũng mang tính chủ quan đối với hai trường hợp điển hình có thể gặp thôi, bạn cũng có thể gặp trong một số trường hợp kiểm thử nào đó khác, những vấn đề mà bạn xác định cần phải xử lý các file cookies thì bạn cứ thế dùng thôi.
Một số method thường dùng với Cookies:
1. Get Cookies
Có hai cách giúp bạn thực hiện get Cookies như sau:
getCookieNamed(String cookieName) – Lấy ra một Cookies cụ thể theo name của cookies.
getCookies() – Lấy ra tất cả Cookies trong domain hiện tại.
//To fetch a Cookie by name
System.out.println(driver.manage().getCookieNamed(cookieName).getValue());
//To return all the cookies of the current domain
Set<Cookie> cookiesForCurrentURL = driver.manage().getCookies();
for (Cookie cookie : cookiesForCurrentURL) {
System.out.println(" Cookie Name - " + cookie.getName()
+ " Cookie Value - " + cookie.getValue()));
}
addCookie(Cookie cookie) – Được sử dụng để add một Cookies cụ thể nào đó vào trong các cookies.
Cookie cookie = new Cookie("cookieName", "cookieValue");
driver.manage().addCookie(cookie);
3. Delete cookies
Với trường hợp xóa cookies, ta có ba cách như dưới đây:
deleteCookieNamed(String cookieName) – Xóa một cookie cụ thể nào đó dựa theo name của cookie.
deleteCookie(Cookie cookie) – Xóa một cookie ra khỏi cookie jar của trình duyệt, method này sẽ bỏ qua domain của cookie đó.
deleteAllCookies() – Method này dùng để xóa tất cả cookies trong domain hiện tại.
//Delete a particular Cookie by name
driver.manage().deleteCookieNamed(cookieName);
//Delete a particular Cookie
driver.manage().deleteCookie(cookie);
//Delete all the Cookies
driver.manage().deleteAllCookies();
Đối với từng yêu cầu trong các trường hợp kịch bản kiểm thử cụ thể bạn có thể sử dụng các method tương ứng. Ngoài ra, các bạn có thể tham khảo các link dưới đây để tìm hiểu chi tiết và cụ thể hơn các ví dụ trong đó nhé, bao gồm cả code tham khảo đó.
Bài viết này nội dung hơn ngắn chút, nhưng mà cũng vi vọng là nó sẽ giúp ích trong việc nắm vững được khung kiến thức cơ bản liên quan đến cookie này. Vì thực tế thì mình mới dùng đến các trường hợp delele cookie thôi ah.
À dưới đây là code super basic của mình để run thử, các bạn có thể tham khảo thêm cũng được ạ:
import java.io.IOException;
import java.util.Set;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
public class Cookies {
public static void main(String[] args) throws IOException {
System.setProperty("webdriver.gecko.driver", "E:\\Program\\Firefox\\geckodriver.exe");
FirefoxOptions options = new FirefoxOptions();
options.setBinary("C:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
FirefoxDriver driver = new FirefoxDriver(options);
driver.get("http://flipkart.com/");
// we should pass name and value for cookie as parameters
// In this example we are passing, name=mycookie and value=123456789123
Cookie name = new Cookie("mycookie", "123456789123");
//Add cookie
driver.manage().addCookie(name);
// After adding the cookie we will check that by displaying all the cookies.
Set<Cookie> cookiesList = driver.manage().getCookies();
for (Cookie getcookies : cookiesList) {
System.out.println(getcookies);
}
/*
//To delete cookie with cookieName = "__utmb"
driver.manage().deleteCookieNamed("__utmb");
//To delete all cookies
driver.manage().deleteAllCookies();
*/
}
}


 (1)")

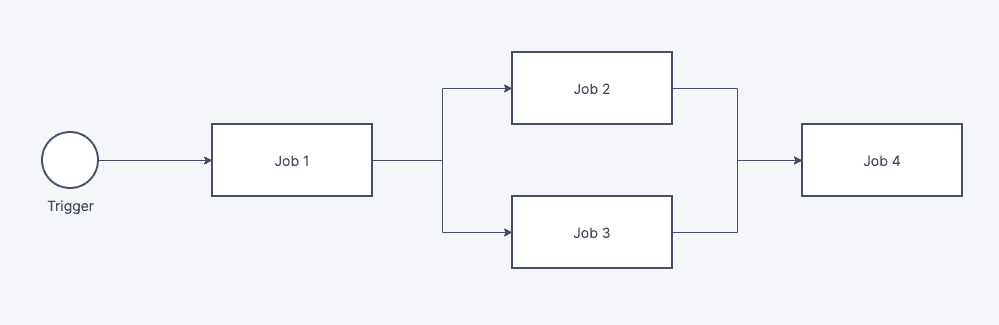

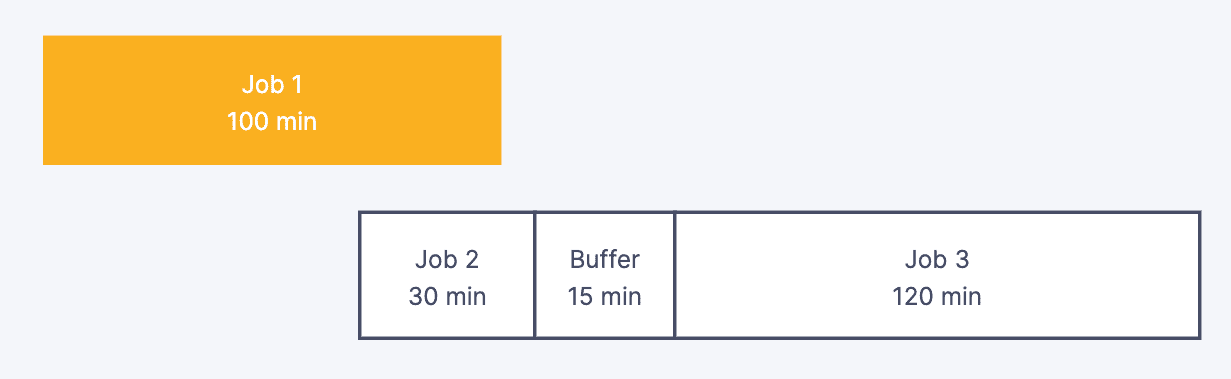


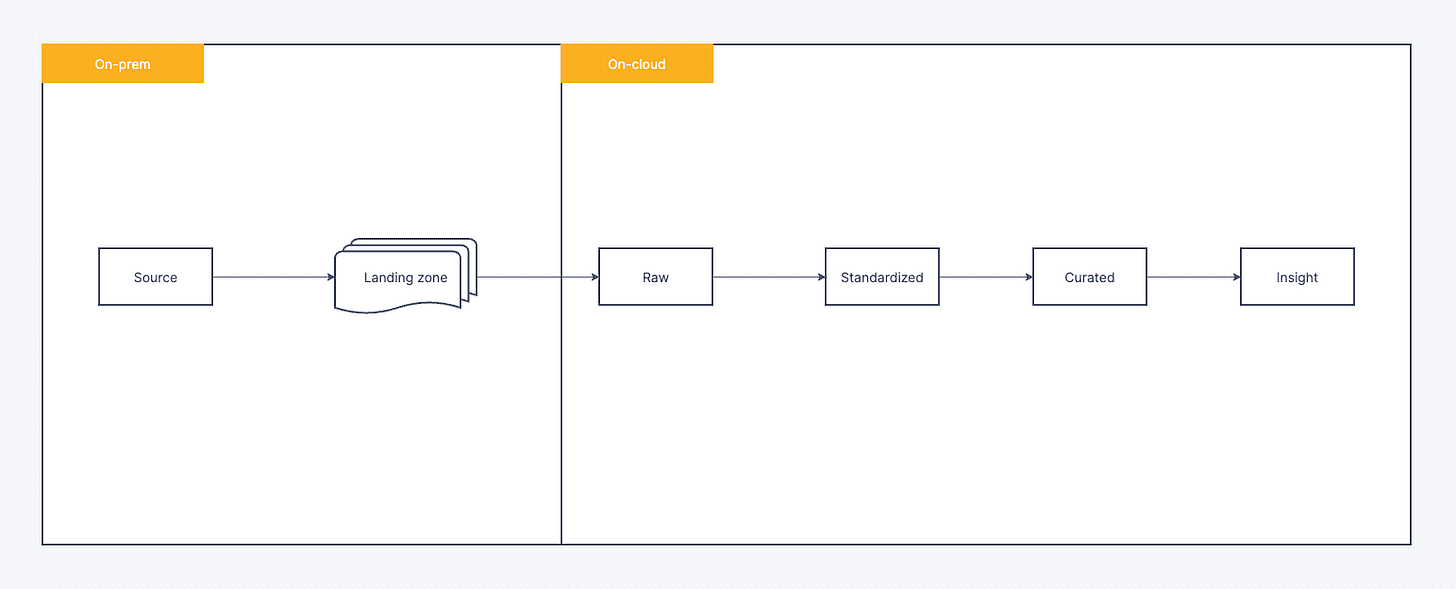
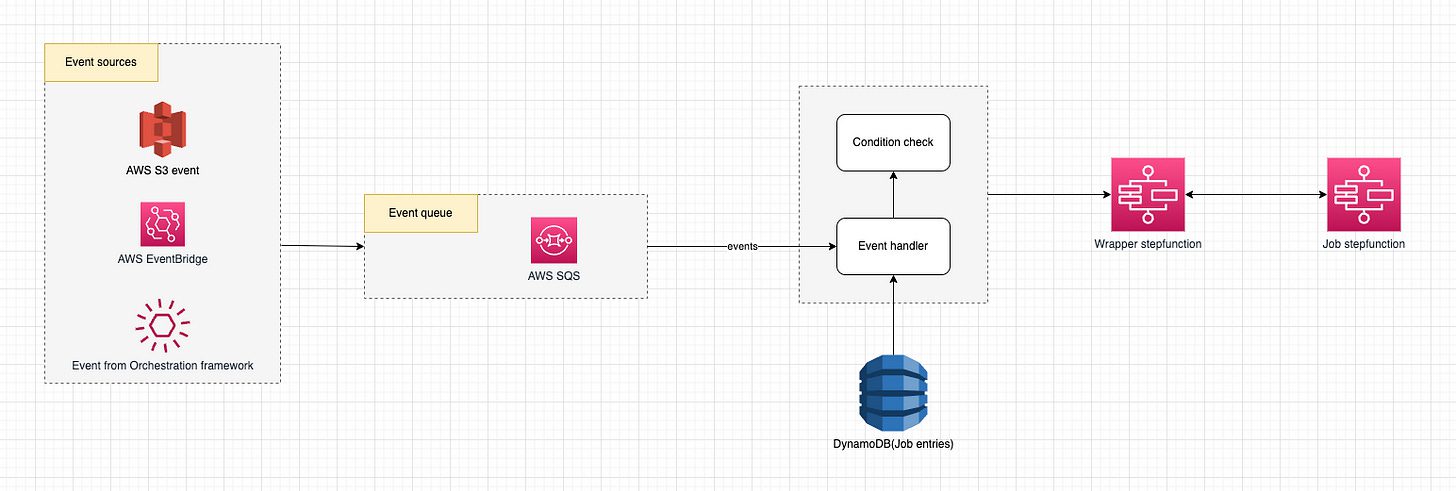
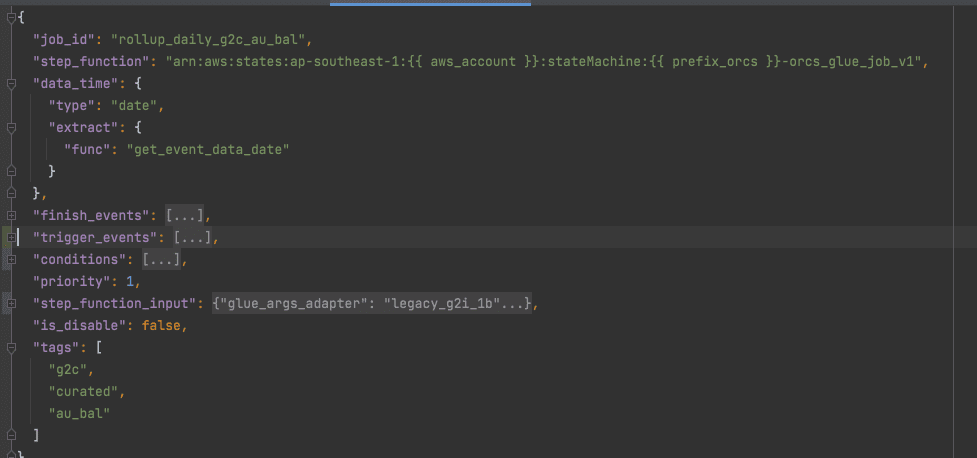



















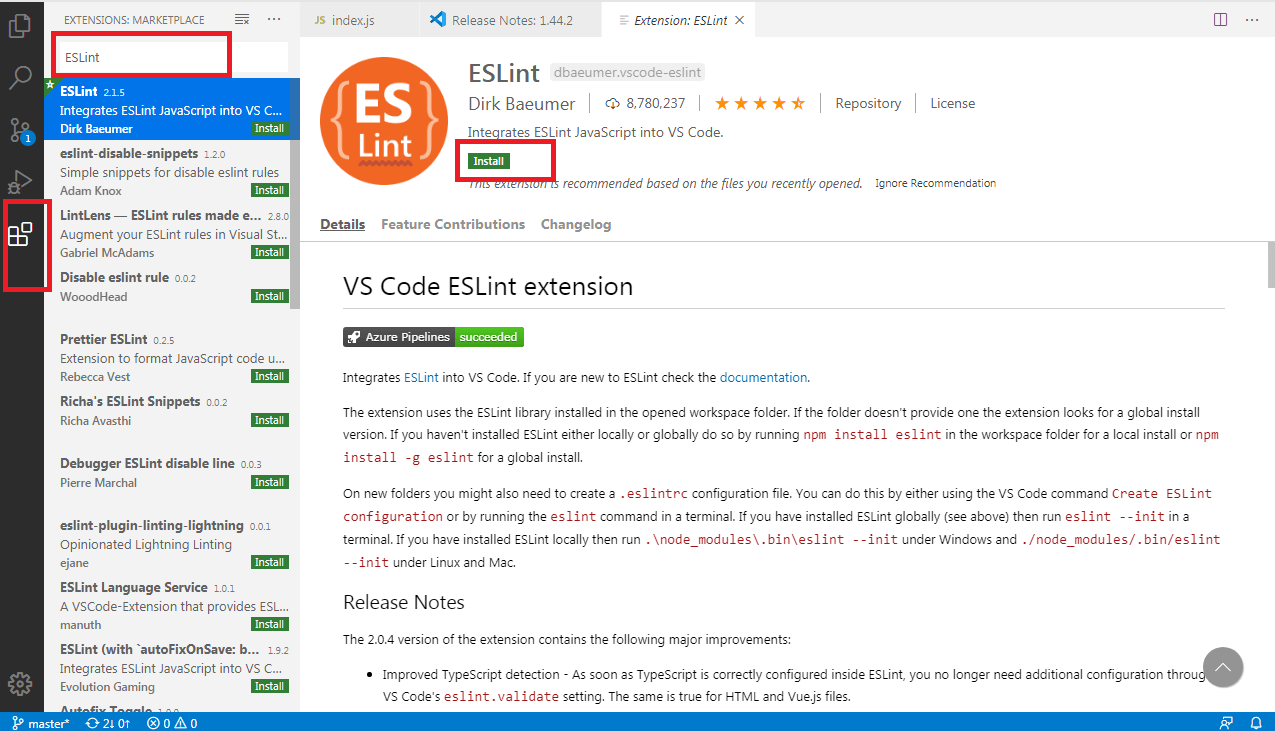




")

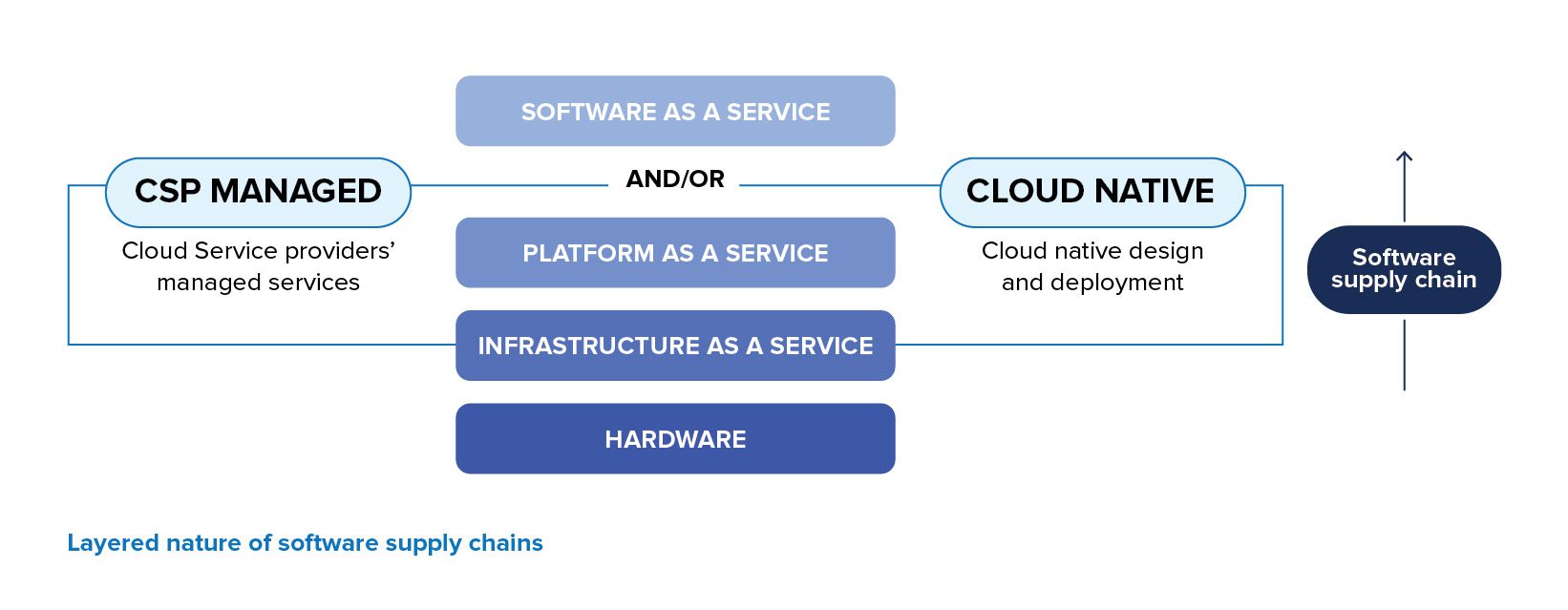
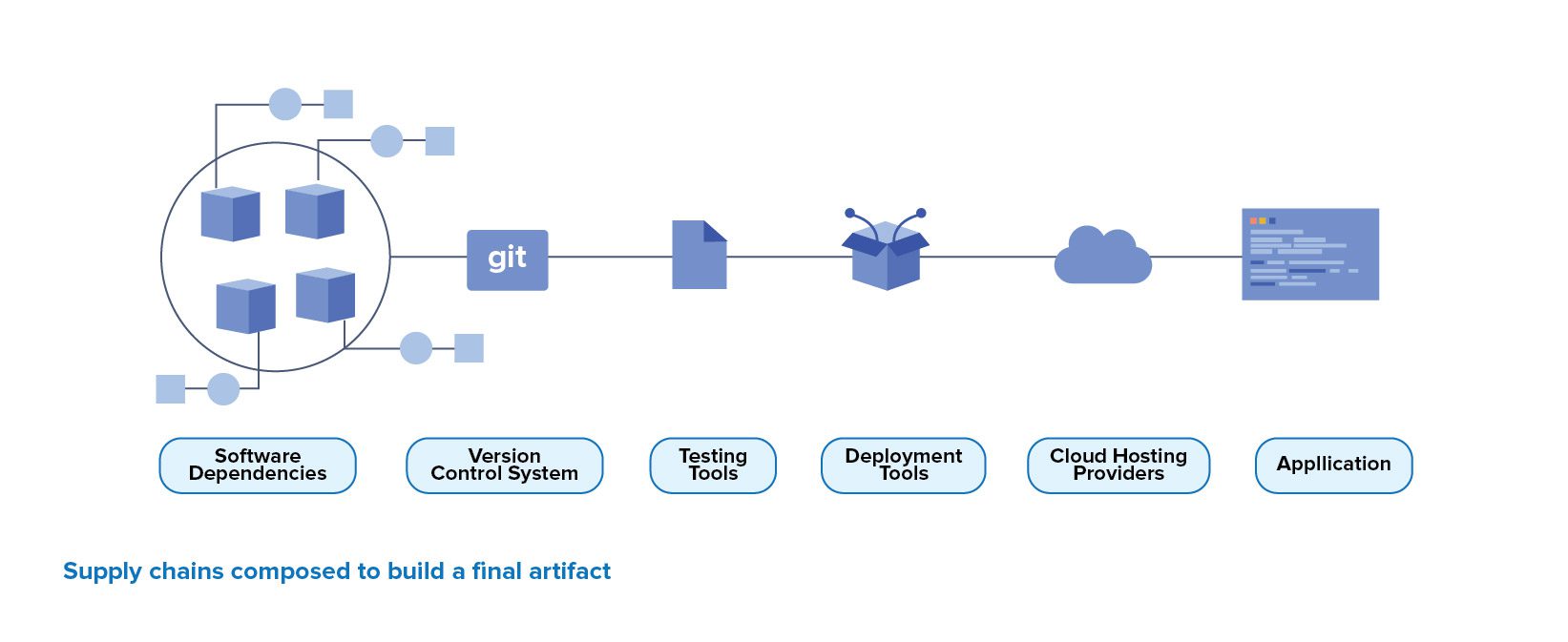
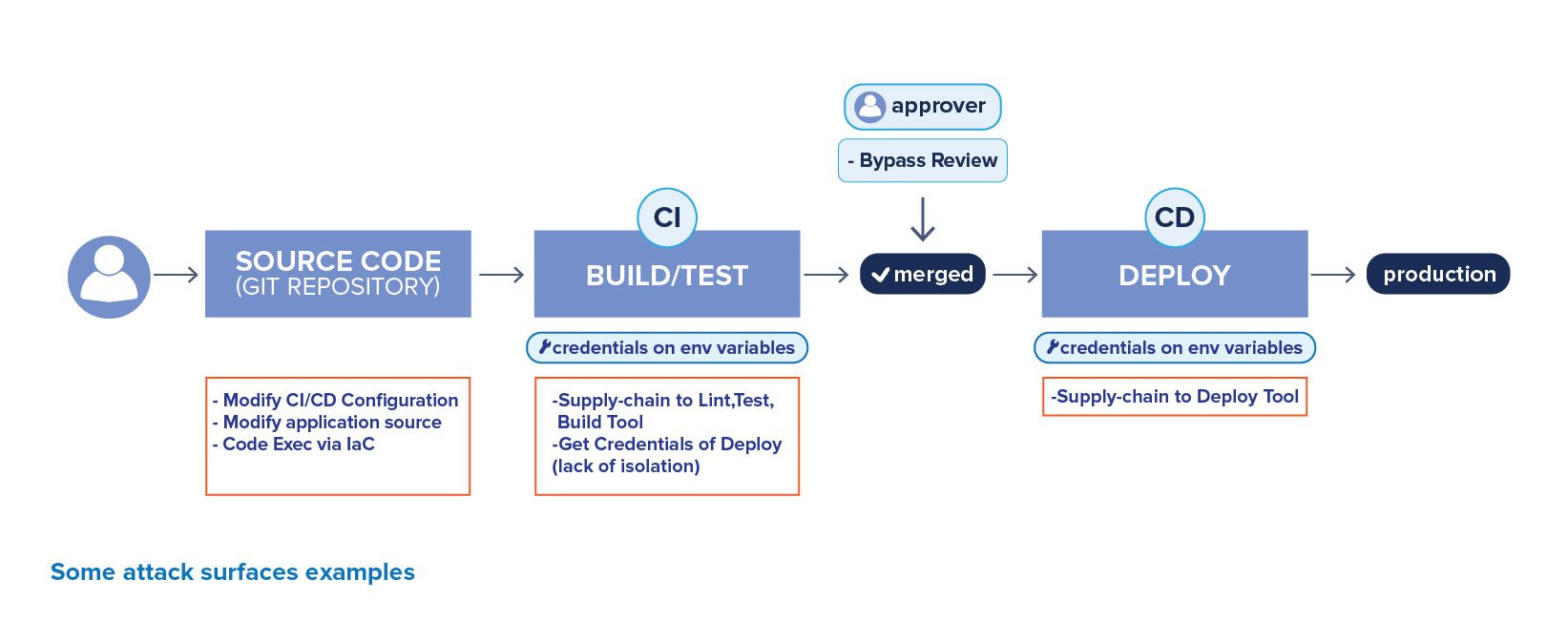




 Biết mình làm game cho ai là hiểu biết quan trọng khi anh em bước vào design game cho mình
Biết mình làm game cho ai là hiểu biết quan trọng khi anh em bước vào design game cho mình Game có hiệu ứng phức tạp hoặc yêu cầu cao về xử lý hành động thường là những game khó khăn cho Game designer
Game có hiệu ứng phức tạp hoặc yêu cầu cao về xử lý hành động thường là những game khó khăn cho Game designer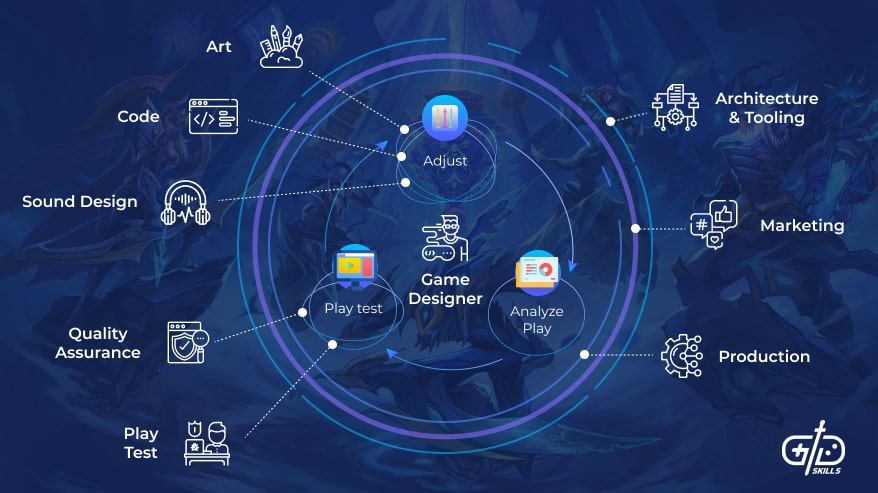

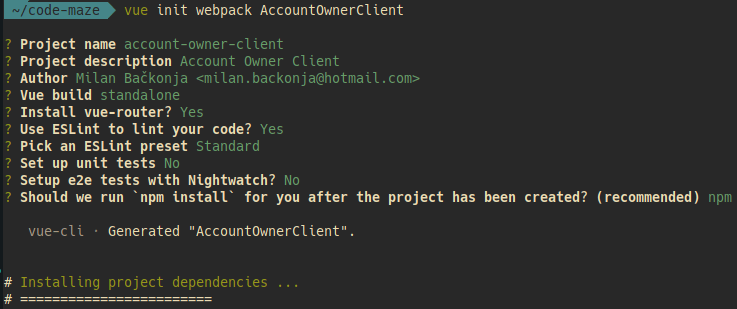
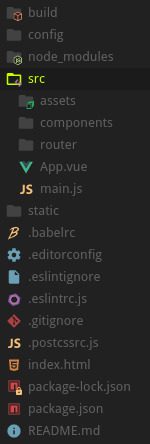





 Nguyên lý SOLID trong Nodejs
Nguyên lý SOLID trong Nodejs

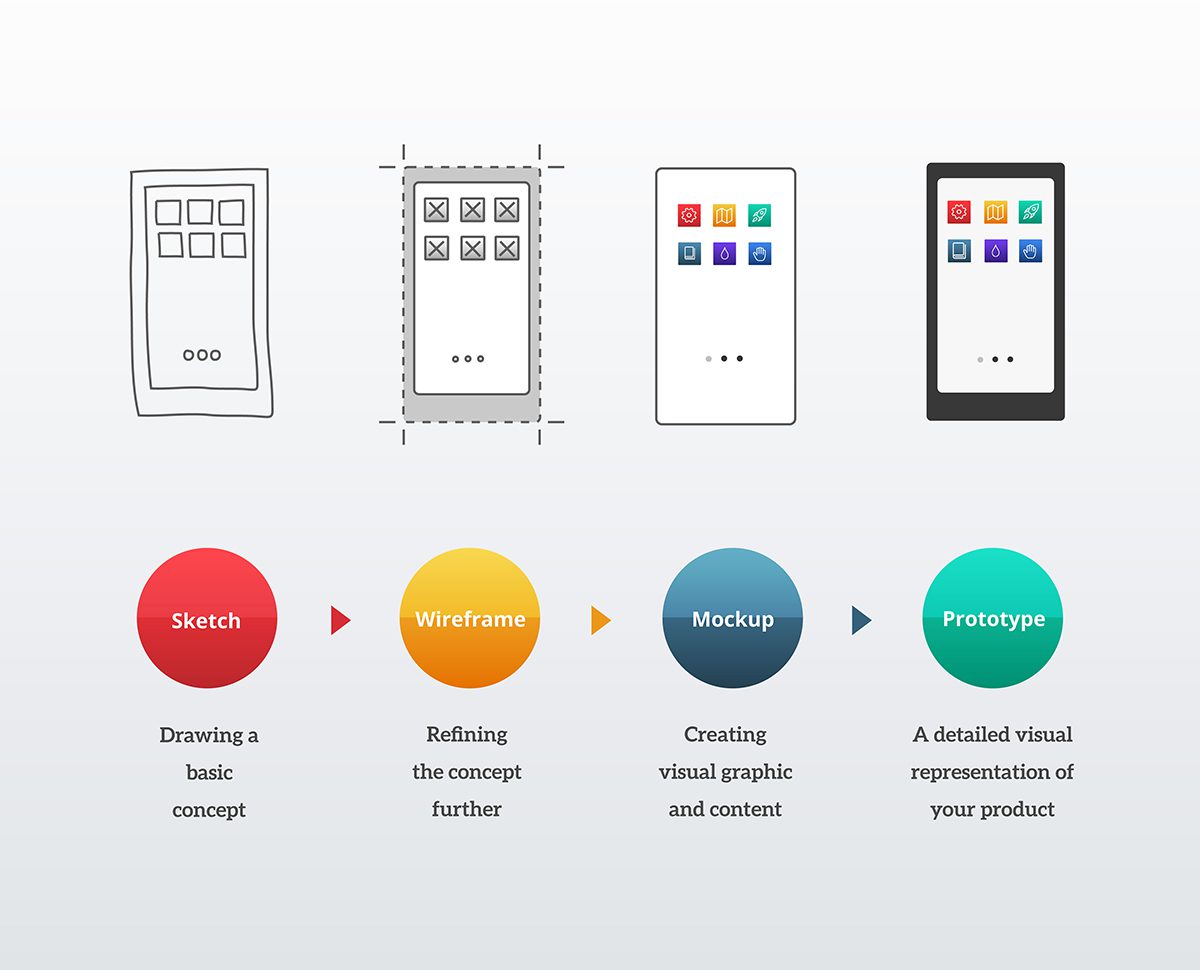






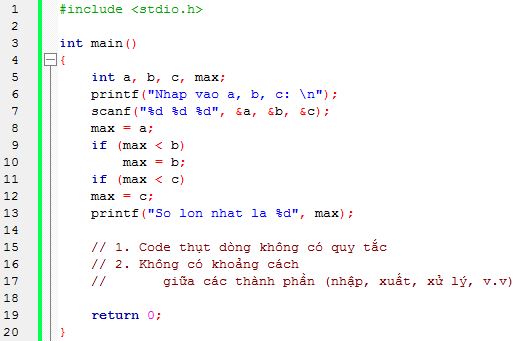
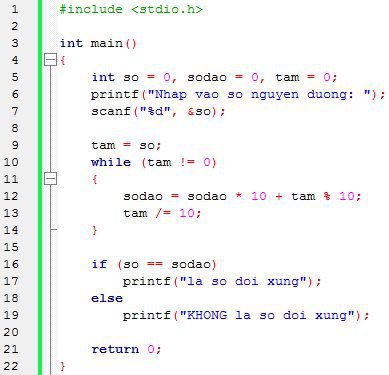
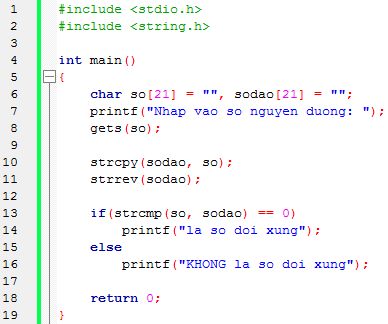
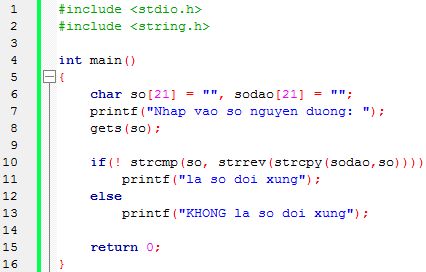

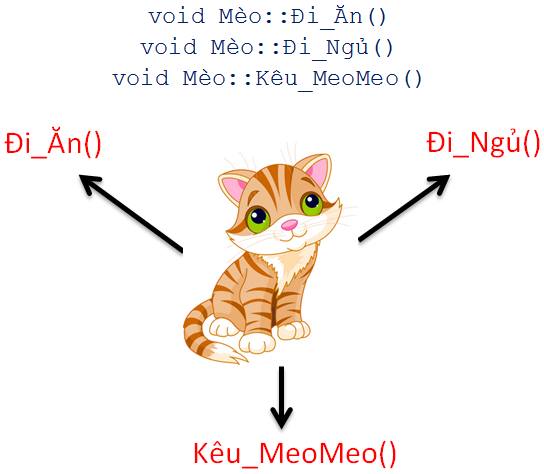
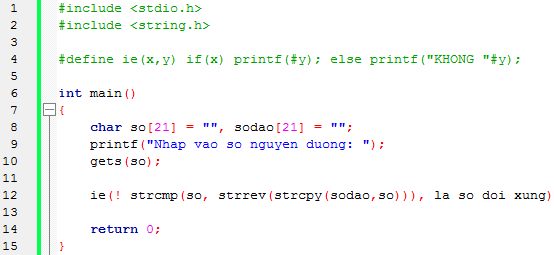
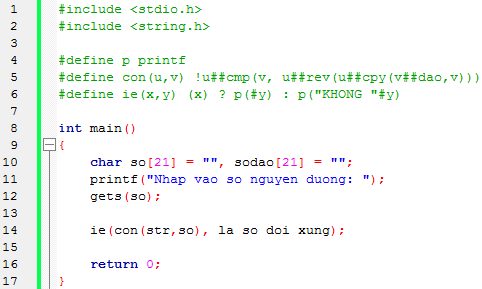
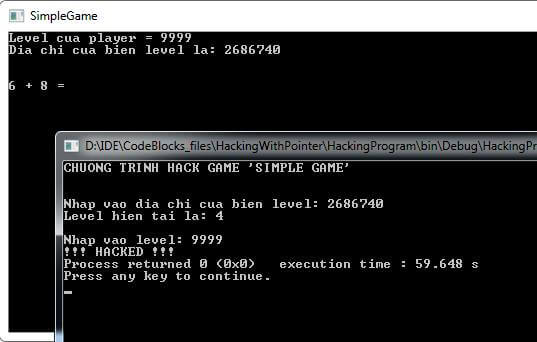


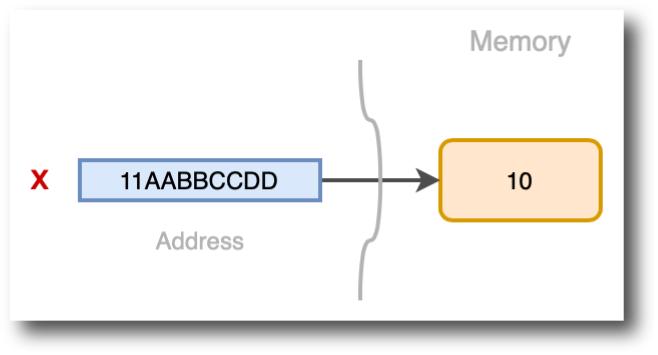 Sơ đồ diễn tả việc khai báo giá trị cho biến
Sơ đồ diễn tả việc khai báo giá trị cho biến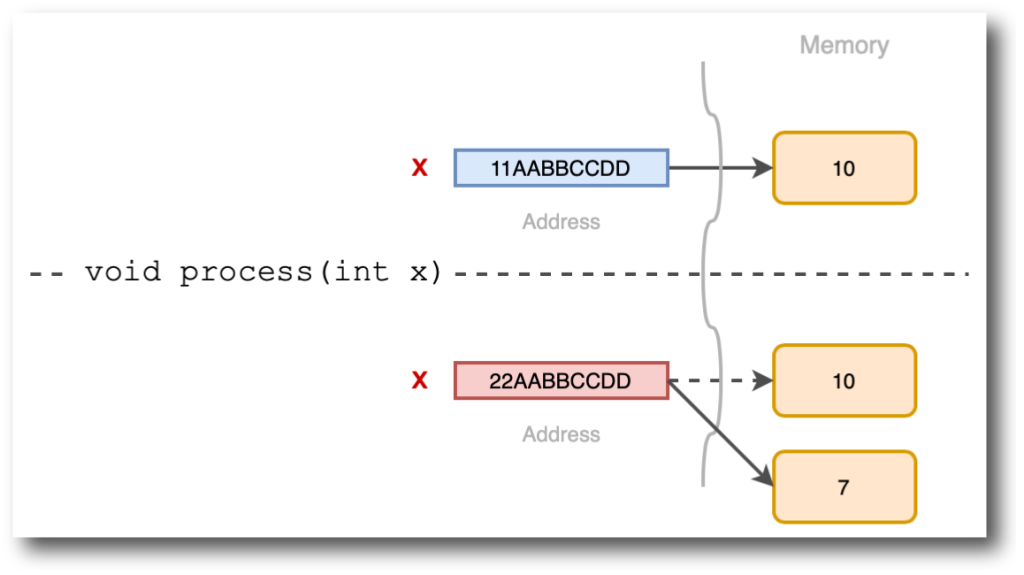 Sơ đồ diễn tả việc truyền tham số kiểu tham trị
Sơ đồ diễn tả việc truyền tham số kiểu tham trị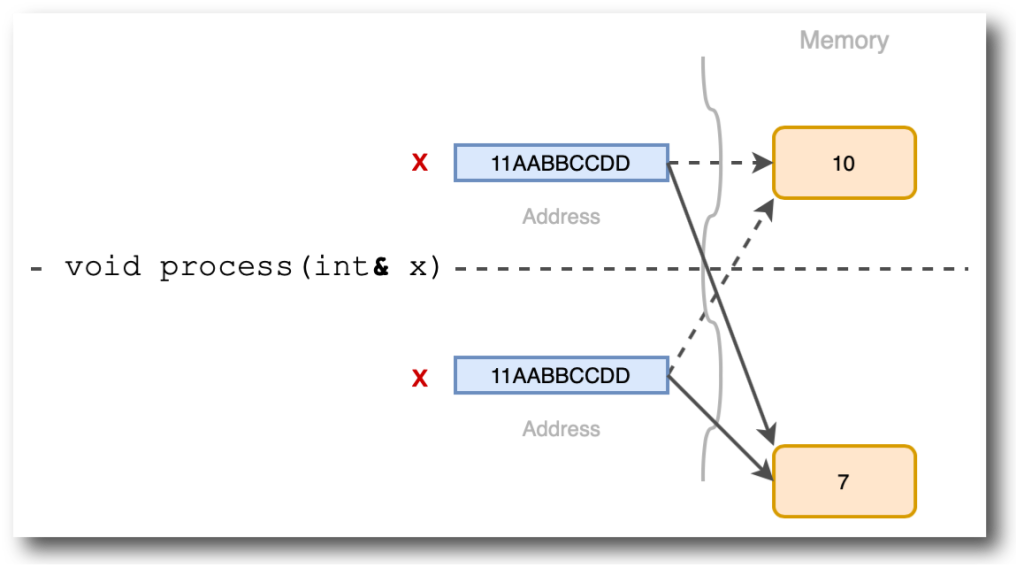 Sơ đồ diễn tả việc truyền tham số kiểu tham chiếu
Sơ đồ diễn tả việc truyền tham số kiểu tham chiếu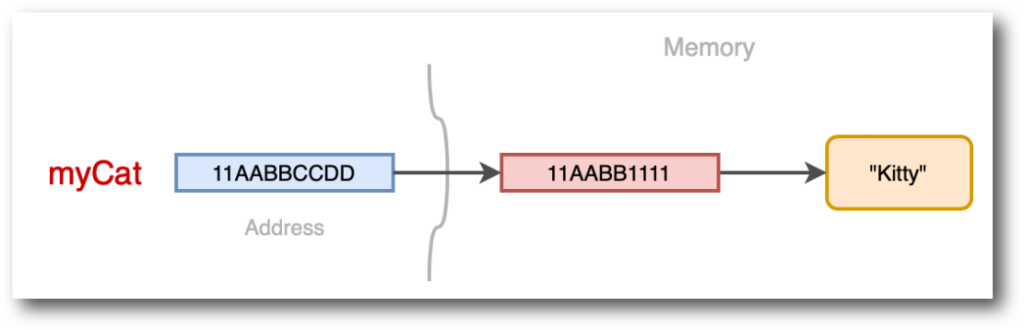 Sơ đồ diễn tả việc khai báo đối tượng myCat
Sơ đồ diễn tả việc khai báo đối tượng myCat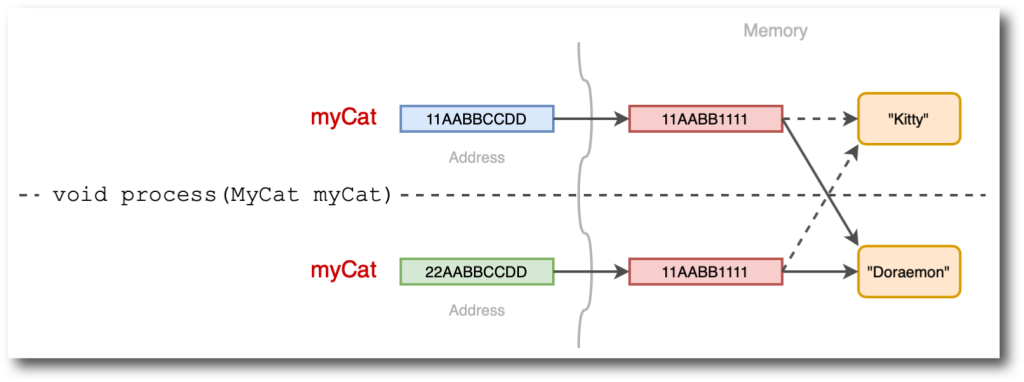 Sơ đồ diễn tả việc truyền tham số kiểu tham trị cho đối tượng myCat
Sơ đồ diễn tả việc truyền tham số kiểu tham trị cho đối tượng myCat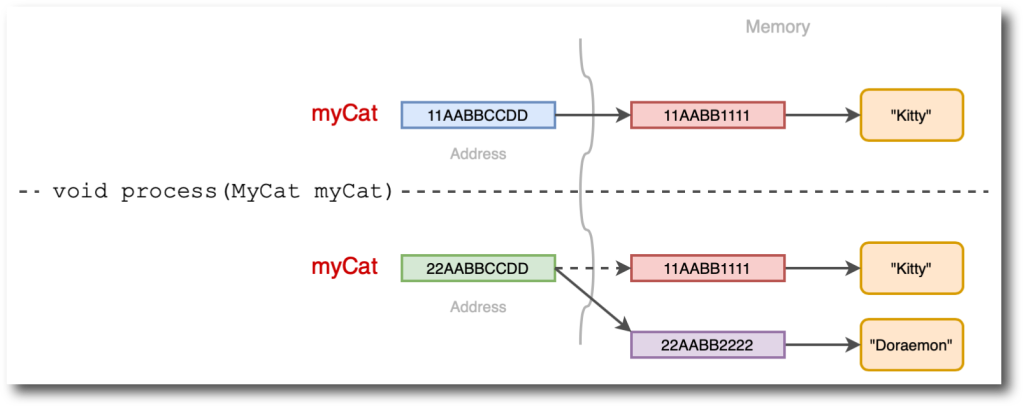 Sơ đồ diễn tả việc truyền tham số kiểu tham trị cho đối tượng myCat
Sơ đồ diễn tả việc truyền tham số kiểu tham trị cho đối tượng myCat







