


Bài viết sẽ bàn về một framework C++ RP, ko yêu cầu bước code generation để glue code. Trước khi đi vào chi tiết, hãy tìm hiểu một số tính năng cơ bản của công cụ:
- Mã nguồn tại https://bitbucket.org/ruifig/czrpc
- Đoạn mã nguồn trên vẫn chưa hoàn chỉnh. Mục tiêu của nó chỉ là để thể hiện nền tảng xây dựng framework. Hơn nữa, để rút ngắn, đoạn code là hỗn hợp của code từ repo lúc viết và custom sample code, nên có thể sẽ xảy ra lỗi.
- Một số đoạn trong mã nguồn (không liên quan trực tiếp đến nội dung ta đang bàn đến) sẽ chỉ được xem xét nhanh mà không quá quan tâm đến hiệu năng. Bất cứ cải tiến nào sẽ được thêm vào repo mã nguồn sau.
- Modern C++ (C++11/14)
- Yêu cầu ít nhất Visual Studio 2015. Clang/GCC cũng tạm ổn.
- Type-safe
- Framework xác định những RPC call không hợp lệ trong lúc compile, như tên RPC không rõ, số thông số sai, hoặc kiểu thông số sai.
- API tương đối nhỏ, không dài dòng
- Nhiều cách xử lý RPC reply
- Bộ xử lý không đồng bộ (Asynchronous handler)
- Futures
- Client có thể xác định nếu một RPC gây exception bên phía server
- Cho phép sử dụng (gần như) bất kỳ kiểu RPC parameter nào
- Giả sử nguời dùng chạy đúng hàm để xử lý kiểu parameter đó
- RPC hai chiều (server có thể call RPC trên client)
- Thông thường, client code không thể tin tưởng được, nhưng vì framework nhằm sử dụng giữa các bên uy tín, nên đây không phải là vấn đề quá lớn
- Không xâm nhập
- Một object dùng cho RPC call không cần biết bất cứ thứ gì về RPC hoặc network cả.
- Từ đó có thể bọc các class bên thứ ba cho RPC call.
- Chi phí băng thông tối thiểu mỗi RPC call
- Không phụ thuộc bên ngoài
- Dù supplied transport (trong repo mã nguồn) dùng Asio/Boost Asio, nhưng bản thân framework không phụ thuộc vòa đó. Bạn có thể tự cắm transport của mình.
- Không có tính năng bảo mật
- Vì frame work được thiết kế sử dụng cho các bên tin tưởng lẫn nhau (như giữa server chẳng hạn).
- Ứng dụng có thể tự chọn transport riêng, nên sẽ có cơ hội encrypt bất cứ thứ gì nếu cần thiết.
Có thể bạn muốn xem:
Mặc dù mã nguồn vẫn chưa hoàn thiện, bài viết vẫn rất nặng về code. Code được tách thành nhiều phần nhỏ và một phần sau sẽ dựa theo phần trước. Để bạn hình dung được, sau đây là một mẫu code hoạt động hoàn chỉnh sử dụng repo mã nguồn tại thời điểm viết bài:
//////////////////////////////////////////////////////////////////////////
// Useless RPC-agnostic class that performs calculations.
//////////////////////////////////////////////////////////////////////////
class Calculator {
public:
double add(double a, double b) { return a + b; }
};
//////////////////////////////////////////////////////////////////////////
// Define the RPC table for the Calculator class
// This needs to be seen by both the server and client code
//////////////////////////////////////////////////////////////////////////
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
REGISTERRPC(add)
#include "crazygaze/rpc/RPCGenerate.h"
//////////////////////////////////////////////////////////////////////////
// A Server that only accepts 1 client, then shuts down
// when the client disconnects
//////////////////////////////////////////////////////////////////////////
void RunServer() {
asio::io_service io;
// Start thread to run Asio's the io_service
// we will be using for the server
std::thread th = std::thread([&io] {
asio::io_service::work w(io);
io.run();
});
// Instance we will be using to serve RPC calls.
// Note that it's an object that knows nothing about RPCs
Calculator calc;
// start listening for a client connection.
// We specify what Calculator instance clients will use,
auto acceptor = AsioTransportAcceptor<Calculator, void>::create(io, calc);
// Start listening on port 9000.
// For simplicity, we are only expecting 1 client
using ConType = Connection<Calculator, void>;
std::shared_ptr<ConType> con;
acceptor->start(9000, [&io, &con](std::shared_ptr<ConType> con_) {
con = con_;
// Since this is just a sample, close the server once the first client
// disconnects
reinterpret_cast<BaseAsioTransport*>(con->transport.get())
->setOnClosed([&io] { io.stop(); });
});
th.join();
}
//////////////////////////////////////////////////////////////////////////
// A client that connects to the server, calls 1 RPC
// then disconnects, causing everything to shut down
//////////////////////////////////////////////////////////////////////////
void RunClient() {
// Start a thread to run our Asio io_service
asio::io_service io;
std::thread th = std::thread([&io] {
asio::io_service::work w(io);
io.run();
});
// Connect to the server (localhost, port 9000)
auto con =
AsioTransport<void, Calculator>::create(io, "127.0.0.1", 9000).get();
// Call one RPC (the add method), specifying an asynchronous handler for
// when the result arrives
CZRPC_CALL(*con, add, 1, 2)
.async([&io](Result<double> res) {
printf("Result=%f\n", res.get()); // Prints 3.0
// Since this is a just a sample, stop the io_service after we get
// the result,
// so everything shuts down
io.stop();
});
th.join();
}
// For testing simplicity, run both the server and client on the same machine,
void RunServerAndClient() {
auto a = std::thread([] { RunServer(); });
auto b = std::thread([] { RunClient(); });
a.join();
b.join();
}
Đây đa phần là setup code, vì transport được nhắc đến sử dụng Asio. Bản thân RPC có thể đơn giản như:
// RPC call using asynchronous handler to handle the result
CZRPC_CALL(*con, add, 1, 2).async([](Result<double> res) {
printf("Result=%f\n", res.get()); // Prints 3.0
});
// RPC call using std::future to handle the result
Result<double> res = CZRPC_CALL(*con, add, 1, 2).ft().get();
printf("Result=%f\n", res.get()); // Prints 3.0
Tìm việc làm C++ nhanh chóng trên TopDev
Lý do tôi viết công cụ này
Tôi đang làm việc với một game có code named G4 cũng được vài năm rồi, trò chơi cung cấp cho player những chiếc máy tính mô phỏng nhỏ in-game mà thậm chí có thể code được. Điều này yêu cầu tôi phải cho nhiều server cùng chạy song song:
- Gameplay Server(s)
- VM Server(s) (mô phỏng máy tính ingame)
- Để vẫn có thể mô phỏng máy tính ngay cả khi người chơi hiện không online
- VM Disk Server(s)
- Xử lý lưu trữ của máy tính ingame, như đĩa mềm hoặc ổ cứng.
- Database server(s)
- Login server(s)
Tất cả những server này cần trao đổi dữ liệu, vì vậy ta cần một RPC framework linh hoạt.
Ban đầu, giải pháp tôi tìm đến là tag method của một class với attribute cụ thể, rồi từ parser gốc Clang (clReflect) tạo bất cứ serialization cần thiết nào, và glue code.
Dù cách này vẫn áp dụng được, nhưng nhiều năm qua tôi vẫn luôn canh cánh làm cách nào tôi có thể dùng tính năng C++11/14 mới để tạo một minimal type safe C++ RPC framework, một phương pháp không cần bước code generation cho glue code, mà vẫn giữa một API chấp nhận được.
Với serialization của non-fundamental type, code genaration vẫn còn hữu dụng, vậy nên tôi không cần phải xác định thủ công làm sao để serialize tất cả các field của một struct/class cho trước. (dù khâu xác định thủ công này cũng chả phiền phức cho lắm).
RPC Parameters
Xét một function, để có type safe RPC call, ta phải làm được:
- Xác định lúc compile nếu function là một RPC function hợp lệ (đúng số thông ố, đúng kiểu parameter,…)
- Kiểm tra liệu các parameter được supply khớp (hoặc convert được) sang thứ mà function signature chỉ ra.
- Serialize tất cả parameter.
- Deserialize tất cả parameter.
- Call những function mong muốn
Parameter Traits
Vấn đề đầu tiên bạn đối mặt là việc xác định kiểu parameter nào được chấp nhập. Một số RPC framework chỉ chấp nhật một số kiểu giới hạn, như Thrift. Hãy xem thử vấn đề.
Xét các function signature sau:
void func1(int a, float b, char c); void func2(const char* a, std::string b, const std::string& c); void func3(Foo a, Bar* b);
Vậy làm cách nào ta bắt compile kiểm tra theo parameter? Những kiểu fundamental type khá dễ và chắc chắn phải được framework hỗ trợ. Một bản copy dumb memory là đủ cho trường hợp như thế này, trừ khi bạn muốn cắt giảm số bit cần thiết để hy sinh một ít hiệu năng lấy bandwidth. Vậy chòn với các kiểu phức tạp như std::string, std::vector, hoặc chính class của mình? Còn pointer, reference, const reference, rvalue thì sao?
Ta có thể lấy một số ý tưởng từ những thứ C++ Standard Library đang làm trong type_traits header. Ta cần truy vấn một kiểu cho trước dựa theo tính chất RPC của nó. Hãy thử biến ý tưởng trên thành một template class `ParamTraits<T>`, với layout như sau:
| Member constants | |
| valid | true if T is valid for RPC parameters, false otherwise |
| Member types | |
| store_type | Type dùng để giữ copy tạm thời cần cho deserializing |
| Member functions | |
| write | Ghi parameter đến một stream |
| read | Đọc parameter vào một store_type |
| get | Xét một store_type parameter, kết quả nó trả có thể được chuyển đến RPC function làm parameter |
Trong ví dụ này,hãy thực thi `ParamTraits<T>` cho kiểu thuật toán, trong trường hợp ta có stream class với method `write` và `read`:
namespace cz {
namespace rpc {
// By default, all types for which ParamTraits is not specialized are invalid
template <typename T, typename ENABLED = void>
struct ParamTraits {
using store_type = int;
static constexpr bool valid = false;
};
// Specialization for arithmetic types
template <typename T>
struct ParamTraits<
T, typename std::enable_if<std::is_arithmetic<T>::value>::type> {
using store_type = typename std::decay<T>::type;
static constexpr bool valid = true;
template <typename S>
static void write(S& s, typename std::decay<T>::type v) {
s.write(&v, sizeof(v));
}
template <typename S>
static void read(S& s, store_type& v) {
s.read(&v, sizeof(v));
}
static store_type get(store_type v) {
return v;
}
};
} // namespace rpc
} // namespace cz
Và một ví dụ đơn giản:
#define TEST(exp) printf("%s = %s\n", #exp, exp ? "true" : "false");
void testArithmetic() {
TEST(ParamTraits<int>::valid); // true
TEST(ParamTraits<const int>::valid); // true
TEST(ParamTraits<int&>::valid); // false
TEST(ParamTraits<const int&>::valid); // false
}
`ParamTraits<T>` còn được sử dụng để kiểm tra nếu return type hợp lệ, và vì một void function hợp lệ, ta cần phải chuyên hóa `ParamTraits` cho void nữa.
namespace cz {
namespace rpc {
// void type is valid
template <>
struct ParamTraits<void> {
static constexpr bool valid = true;
using store_type = void;
};
} // namespace rpc
} // namespace cz
Một điều khá kỳ lạ là khi chuyên hóa cho `void` là còn chỉ định một `store_type` nữa. Chúng ta không thể sử dụng nó để lưu trữ bất cư thứ gì, nhưng sẽ làm một vìa đoạn template code về sau dễ dàng hơn.
Với những ví dụ `ParamTraits`, reference không phải là RPC parameter hợp lệ. Trong thực tế, bạn ít nhất sẽ muốn cho phép const reference, đặc biệt với fundamental type. Bạn có thể thêm một tweak để kích hoạt hỗ trợ cho `const T&` cho bất kỳ T hợp lệ nào khi ứng dụng của bạn cần đến.
// Make "const T&" valid for any valid T
#define CZRPC_ALLOW_CONST_LVALUE_REFS \
namespace cz { \
namespace rpc { \
template <typename T> \
struct ParamTraits<const T&> : ParamTraits<T> { \
static_assert(ParamTraits<T>::valid, \
"Invalid RPC parameter type. Specialize ParamTraits if " \
"required."); \
}; \
} \
}
Bạn cũng có thể thực hiện những tweak tương tự để kích hoạt hỗ trợ `T&` hoặc `T&&` nếu cần thiết, mặc dù nếu function thay đổi đến những parameter này, những thay đổi đó sẽ mất đi.
Hãy thử thêm hỗ trợ cho các kiểu phức tạp như `std::vector<T>`. Để hỗ trợ `std::vector<T>`, ta buộc phải hỗ trợ thêm cả `T`:
namespace cz {
namespace rpc {
template <typename T>
struct ParamTraits<std::vector<T>> {
using store_type = std::vector<T>;
static constexpr bool valid = ParamTraits<T>::valid;
static_assert(ParamTraits<T>::valid == true,
"T is not valid RPC parameter type.");
// std::vector serialization is done by writing the vector size, followed by
// each element
template <typename S>
static void write(S& s, const std::vector<T>& v) {
int len = static_cast<int>(v.size());
s.write(&len, sizeof(len));
for (auto&& i : v) ParamTraits<T>::write(s, i);
}
template <typename S>
static void read(S& s, std::vector<T>& v) {
int len;
s.read(&len, sizeof(len));
v.clear();
while (len--) {
T i;
ParamTraits<T>::read(s, i);
v.push_back(std::move(i));
}
}
static std::vector<T>&& get(std::vector<T>&& v) {
return std::move(v);
}
};
} // namespace rpc
} // namespace cz
// A simple test
void testVector() {
TEST(ParamTraits<std::vector<int>>::valid); // true
// true if support for const refs was enabled
TEST(ParamTraits<const std::vector<int>&>::valid);
}
Để tiện hơn, chúng ta có thể dùng toán tử `<<` và `>>` với class `stream` (không thế hiện ở đây). Với những toán tử này, hãy đơn thuần call các function `ParamTraits<T> read` và `ParamTraits<T> write` tương ứng.
Giờ đây ta đã có thể kiểm tra xem một type nhất định có được phép cho RPC parameter hay không, chúng ta có thể build trên đó kiểm tra xem một function có được dùng cho RPC hay không. Cách này được thực thi với variadic template.
Trước hết hãy tạo một template cho ta biết nếu nhóm parameter có hợp lệ hay không.
namespace cz {
namespace rpc {
//
// Validate if all parameter types in a parameter pack can be used for RPC
// calls
//
template <typename... T>
struct ParamPack {
static constexpr bool valid = true;
};
template <typename First>
struct ParamPack<First> {
static constexpr bool valid = ParamTraits<First>::valid;
};
template <typename First, typename... Rest>
struct ParamPack<First, Rest...> {
static constexpr bool valid =
ParamTraits<First>::valid && ParamPack<Rest...>::valid;
}
} // namespace rpc
} // namespace cz
// Usage example:
void testParamPack() {
TEST(ParamPack<>::valid); // true (No parameters is a valid too)
TEST((ParamPack<int, double>::valid)); // true
TEST((ParamPack<int, int*>::valid)); // false
}
Using ParamPack, we can now create a FunctionTraits template to query a function's properties.
namespace cz {
namespace rpc {
template <class F>
struct FunctionTraits {};
// For free function pointers
template <class R, class... Args>
struct FunctionTraits<R (*)(Args...)> : public FunctionTraits<R(Args...)> {};
// For method pointers
template <class R, class C, class... Args>
struct FunctionTraits<R (C::*)(Args...)> : public FunctionTraits<R(Args...)> {
using class_type = C;
};
// For const method pointers
template <class R, class C, class... Args>
struct FunctionTraits<R (C::*)(Args...) const>
: public FunctionTraits<R(Args...)> {
using class_type = C;
};
template <class R, class... Args>
struct FunctionTraits<R(Args...)> {
// Tells if both the return type and parameters are valid for RPC calls
static constexpr bool valid =
ParamTraits<R>::valid && ParamPack<Args...>::valid;
using return_type = R;
// Number of parameters
static constexpr std::size_t arity = sizeof...(Args);
// A tuple that can store all parameters
using param_tuple = std::tuple<typename ParamTraits<Args>::store_type...>;
// Allows us to get the type of each parameter, given an index
template <std::size_t N>
struct argument {
static_assert(N < arity, "error: invalid parameter index.");
using type = typename std::tuple_element<N, std::tuple<Args...>>::type;
};
};
} // namespace rpc
} // namespace cz
// A simple test...
struct FuncTraitsTest {
void func1() const {}
void func2(int) {}
int func3(const std::vector<int>&) { return 0; }
int* func4() { return 0; }
};
void testFunctionTraits() {
TEST(FunctionTraits<decltype(&FuncTraitsTest::func1)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func2)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func3)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func4)>::valid); // false
}
`FunctionTraits` cho ta một vài tính chất sẽ được sử dụng sau. Lưu ý với ví dụ rằng `FunctionTraits::param_tuple` build trên `ParamTraits<T>::store_type`. Việc này cần thiết, vì ở một thời điểm nào đó, chung ta cần cách ể deserialize tất cả parameter thành một tuple trước khi call function.
Serialization
Vì chúng ta giờ đây có code cần thiết để truy vấn parameter, return type và validating function, chúng ta có thể gộp code lại để serialize một function call. Hơn nữa, đây chính là type safe. Nó sẽ không complie nếu nhập sai số hoặc kiểu parameter, hoặc nếu bản thân function không hợp lệ cho RPC (không hỗ trợ các return/parameter type).
namespace cz {
namespace rpc {
namespace details {
template <typename F, int N>
struct Parameters {
template <typename S>
static void serialize(S&) {}
template <typename S, typename First, typename... Rest>
static void serialize(S& s, First&& first, Rest&&... rest) {
using Traits =
ParamTraits<typename FunctionTraits<F>::template argument<N>::type>;
Traits::write(s, std::forward<First>(first));
Parameters<F, N + 1>::serialize(s, std::forward<Rest>(rest)...);
}
};
} // namespace details
template <typename F, typename... Args>
void serializeMethod(Stream& s, Args&&... args) {
using Traits = FunctionTraits<F>;
static_assert(Traits::valid,
"Function signature not valid for RPC calls. Check if "
"parameter types are valid");
static_assert(Traits::arity == sizeof...(Args),
"Invalid number of parameters for RPC call.");
details::Parameters<F, 0>::serialize(s, std::forward<Args>(args)...);
}
} // namespace rpc
} // namespace cz
//
// A simple test
//
struct SerializeTest {
void func1(int, const std::vector<int>) {}
void func2(int*) {}
};
void testSerializeCall() {
Stream s;
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2, 3});
// These fail to compile because of the wrong number of parameters
// serializeMethod<decltype(&SerializeTest::func1)>(s);
// serializeMethod<decltype(&SerializeTest::func1)>(s, 1);
// Doesn't compile because of wrong type of parameters
// serializeMethod<decltype(&SerializeTest::func1)>(s, 1, 2);
// Doesn't compile because the function can't be used for RPCs.
// int a;
// serializeMethod<decltype(&SerializeTest::func2)>(s, &a);
}
Deserialization
Như đã đề cập ở trên, `FunctionTraits<F>::param_tuple` là type `std::tuple` ta dùng được để giữ tất cả parameter của function. Để có thể sử dụng tuple này để deserialize parameter, chúng ta phải chuyên hóa `ParamTraits` cho các tuple. Bên cạnh đó, ta còn có thể sử dụng `std::tuple` cho RPC parameter.
namespace cz {
namespace rpc {
namespace details {
template <typename T, bool Done, int N>
struct Tuple {
template <typename S>
static void deserialize(S& s, T& v) {
s >> std::get<N>(v);
Tuple<T, N == std::tuple_size<T>::value - 1, N + 1>::deserialize(s, v);
}
template <typename S>
static void serialize(S& s, const T& v) {
s << std::get<N>(v);
Tuple<T, N == std::tuple_size<T>::value - 1, N + 1>::serialize(s, v);
}
};
template <typename T, int N>
struct Tuple<T, true, N> {
template <typename S>
static void deserialize(S&, T&) {}
template <typename S>
static void serialize(S&, const T&) {}
};
} // namespace details
template <typename... T>
struct ParamTraits<std::tuple<T...>> {
using tuple_type = std::tuple<T...>; // for internal use
using store_type = tuple_type;
static constexpr bool valid = ParamPack<T...>::valid;
static_assert(
ParamPack<T...>::valid == true,
"One or more tuple elements is not a valid RPC parameter type.");
template <typename S>
static void write(S& s, const tuple_type& v) {
details::Tuple<tuple_type, std::tuple_size<tuple_type>::value == 0,
0>::serialize(s, v);
}
template <typename S>
static void read(S& s, tuple_type& v) {
details::Tuple<tuple_type, std::tuple_size<tuple_type>::value == 0,
0>::deserialize(s, v);
}
static tuple_type&& get(tuple_type&& v) {
return std::move(v);
}
};
} // namespace rpc
} // namespace cz
// A simple test
void testDeserialization() {
Stream s;
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2});
// deserialize the parameters into a tuple.
// the tuple is of type std::tuple<int,std::vector<int>>
FunctionTraits<decltype(&SerializeTest::func1)>::param_tuple params;
s >> params;
};
Từ tuple đến function parameters
Sau khi deserialize tất cả parameter thành tuple, chúng ta giờ đâu phải tìm cách tháo tuble để call matching function. Một lần nữa, ta có thể dùng variadic template.
namespace cz {
namespace rpc {
namespace detail {
template <typename F, typename Tuple, bool Done, int Total, int... N>
struct callmethod_impl {
static decltype(auto) call(typename FunctionTraits<F>::class_type& obj, F f,
Tuple&& t) {
return callmethod_impl<F, Tuple, Total == 1 + sizeof...(N), Total, N...,
sizeof...(N)>::call(obj, f,
std::forward<Tuple>(t));
}
};
template <typename F, typename Tuple, int Total, int... N>
struct callmethod_impl<F, Tuple, true, Total, N...> {
static decltype(auto) call(typename FunctionTraits<F>::class_type& obj, F f,
Tuple&& t) {
using Traits = FunctionTraits<F>;
return (obj.*f)(
ParamTraits<typename Traits::template argument<N>::type>::get(
std::get<N>(std::forward<Tuple>(t)))...);
}
};
} // namespace details
template <typename F, typename Tuple>
decltype(auto) callMethod(typename FunctionTraits<F>::class_type& obj, F f,
Tuple&& t) {
static_assert(FunctionTraits<F>::valid, "Function not usable as RPC");
typedef typename std::decay<Tuple>::type ttype;
return detail::callmethod_impl<
F, Tuple, 0 == std::tuple_size<ttype>::value,
std::tuple_size<ttype>::value>::call(obj, f, std::forward<Tuple>(t));
}
} // namespace rpc
} // namespace cz
// A simple test
void testCall() {
Stream s;
// serialize
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2});
// deserialize
FunctionTraits<decltype(&SerializeTest::func1)>::param_tuple params;
s >> params;
// Call func1 on an object, unpacking the tuple into parameters
SerializeTest obj;
callMethod(obj, &SerializeTest::func1, std::move(params));
};
Vậy, giờ đây ta đã biết cách xác thực một function, serialize, deserialize, và call function đó. Vậy là đã xong bước code “level thấp” rồi. Lớp tiếp theo chúng ta sắp sửa phủ lên code này sẽ là RPC API thực sự.
The RPC API
Header
Header có chứa những thông tin sau:

| Field | |
| size | Tổng dung lượng (byte) của RPC. Có dung lượng là một phần của header sẽ đơn giản hóa mạnh mẽ, vì chúng ta có thể kiểm tra nếu ta nhận tất cả dữ liệu trước khi thử xử lý RPC. |
| counter | Số call. Mỗi lúc ta gọi RPC, một counter sẽ tăng và được chỉ định đến RPC call đó. |
| rpcid | The function to call |
| isReply | Nếu true, đây là reply đến RPC. Nếu false, đây là RPC call. |
| success | Chỉ áp dụng cho reply (isReply==true). Nếu true, call thành công và data là reply. Nấu false, data là exception information |
Counter và rpcid hình thành một key xác định RPC call instance, cần khi ghép một incoming RPC reply đế RPC call gây ra nó.
// Small utility struct to make it easier to work with the RPC headers
struct Header {
enum {
kSizeBits = 32,
kRPCIdBits = 8,
kCounterBits = 22,
};
explicit Header() {
static_assert(sizeof(*this) == sizeof(uint64_t),
“Invalid size. Check the bitfields”);
all_ = 0;
}
struct Bits {
uint32_t size : kSizeBits;
unsigned counter : kCounterBits;
unsigned rpcid : kRPCIdBits;
unsigned isReply : 1; // Is it a reply to a RPC call ?
unsigned success : 1; // Was the RPC call a success ?
};
uint32_t key() const {
return (bits.counter << kRPCIdBits) | bits.rpcid;
}
union {
Bits bits;
uint64_t all_;
};
};
inline Stream& operator<<(Stream& s, const Header& v) {
s << v.all_;
return s;
}
inline Stream& operator>>(Stream& s, Header& v) {
s >> v.all_;
return s;
}
} // namespace rpc
} // namespace cz
Table
Chúng ta đã serialize và deserialize một RPC, nhưng không phải là cách map một RPC đã serialize đến đúng function bên phía server. Để giải quyết vấn đề này, chúng ta cần chỉ định một ID đến mỗi function. Client sẽ biết nó muốn call function nào, và điền đúng ID vào header. Server kiểm tra header, và khi biết được ID, nó sẽ gửi đến đúng handler. Hãy tạo một số ID cơ bản để xác định bảng phân phối tương tự.
namespace cz {
namespace rpc {
//
// Helper code to dispatch a call.
namespace details {
// Handle RPCs with return values
template <typename R>
struct CallHelper {
template <typename OBJ, typename F, typename P>
static void impl(OBJ& obj, F f, P&& params, Stream& out) {
out << callMethod(obj, f, std::move(params));
}
};
// Handle void RPCs
template <>
struct CallHelper<void> {
template <typename OBJ, typename F, typename P>
static void impl(OBJ& obj, F f, P&& params, Stream& out) {
callMethod(obj, f, std::move(params));
}
};
}
struct BaseRPCInfo {
BaseRPCInfo() {}
virtual ~BaseRPCInfo(){};
std::string name;
};
class BaseTable {
public:
BaseTable() {}
virtual ~BaseTable() {}
bool isValid(uint32_t rpcid) const {
return rpcid < m_rpcs.size();
}
protected:
std::vector<std::unique_ptr<BaseRPCInfo>> m_rpcs;
};
template <typename T>
class TableImpl : public BaseTable {
public:
using Type = T;
struct RPCInfo : public BaseRPCInfo {
std::function<void(Type&, Stream& in, Stream& out)> dispatcher;
};
template <typename F>
void registerRPC(uint32_t rpcid, const char* name, F f) {
assert(rpcid == m_rpcs.size());
auto info = std::make_unique<RPCInfo>();
info->name = name;
info->dispatcher = [f](Type& obj, Stream& in, Stream& out) {
using Traits = FunctionTraits<F>;
typename Traits::param_tuple params;
in >> params;
using R = typename Traits::return_type;
details::CallHelper<R>::impl(obj, f, std::move(params), out);
};
m_rpcs.push_back(std::move(info));
}
};
template <typename T>
class Table : public TableImpl<T> {
static_assert(sizeof(T) == 0, "RPC Table not specified for the type.");
};
} // namespace rpc
} // namespace cz
The Table template cần phải được chuyên hóa cho class mà ta muốn dùng cho RPC call. Giả sử ta có một Calculator class muốn dùng cho RPC calls:
class Calculator {
public:
double add(double a, double b) {
m_ans = a + b;
return m_ans;
}
double sub(double a, double b) {
m_ans = a - b;
return m_ans;
}
double ans() {
return m_ans;
}
private:
double m_ans = 0;
};
Ta có thể chuyên hóa Table template cho Calculator, để cả client và server đều có thể tham gia:
// Table specialization for Calculator
template <>
class cz::rpc::Table<Calculator> : cz::rpc::TableImpl<Calculator> {
public:
enum class RPCId { add, sub, ans };
Table() {
registerRPC((int)RPCId::add, "add", &Calculator::add);
registerRPC((int)RPCId::sub, "sub", &Calculator::sub);
registerRPC((int)RPCId::ans, "ans", &Calculator::ans);
}
static const RPCInfo* get(uint32_t rpcid) {
static Table<Calculator> tbl;
assert(tbl.isValid(rpcid));
return static_cast<RPCInfo*>(tbl.m_rpcs[rpcid].get());
}
};
Với một ID,function `get` sẽ trả dispatcher về đúng method `Calculator`. Rồi ta có thể chuyển `Calculator` instance, input và output streams sang dispatcher để xử lý mọi thứ còn lại.
Quá trình chuyên hóa khá dài dòng và không thể tránh khỏi sai sót, vì enum và `registerRPC` call phải khớp. Nhưng chúng ta có thể rút ngắn rõ rệt quá trình với một vài macro. Đầu tiên, hãy xem thử một ví dụ dài dòng để thấy cách dùng bảng này:
void testCalculatorTable() {
// Both the client and server need to have access to the necessary table
using CalcT = Table<Calculator>;
//
// Client sends RPC
Stream toServer;
RPCHeader hdr;
hdr.bits.rpcid = (int)CalcT::RPCId::add;
toServer << hdr;
serializeMethod<decltype(&Calculator::add)>(toServer, 1.0, 9.0);
//
// Server receives RPC, and sends back a reply
Calculator calc; // object used to receive the RPCs
toServer >> hdr;
auto&& info = CalcT::get(hdr.bits.rpcid);
Stream toClient; // Stream for the reply
// Call the desired Calculator function.
info->dispatcher(calc, toServer, toClient);
//
// Client receives a reply
double r;
toClient >> r;
printf("%2.0f\n", r); // Will print "10"
}
Một lần nữa, ví dụ này khá dài dòng, chỉ để thể hiện code flow. Chúng ta sẽ có ví dụ tối ưu hơn sau.
Vậy, chúng ta đơn giản quá trình chuyên hóa bảng như thế nào? Nếu ta đặt gist của chuyên hóa bảng trong một header không được guard, bạn chỉ cần một vài define theo sau là một include của header (không guard) đó để tạo tương tự.
Ví dụ:
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
REGISTERRPC(add) \
REGISTERRPC(sub) \
REGISTERRPC(ans)
#include "RPCGenerate.h"
Quá đơn giản, đúng không?
`RPCGenerate.h` là một header không được guard, trông như sau:
#ifndef RPCTABLE_CLASS
#error "Macro RPCTABLE_CLASS needs to be defined"
#endif
#ifndef RPCTABLE_CONTENTS
#error "Macro RPCTABLE_CONTENTS needs to be defined"
#endif
#define RPCTABLE_TOOMANYRPCS_STRINGIFY(arg) #arg
#define RPCTABLE_TOOMANYRPCS(arg) RPCTABLE_TOOMANYRPCS_STRINGIFY(arg)
template<> class cz::rpc::Table<RPCTABLE_CLASS> : cz::rpc::TableImpl<RPCTABLE_CLASS>
{
public:
using Type = RPCTABLE_CLASS;
#define REGISTERRPC(rpc) rpc,
enum class RPCId {
RPCTABLE_CONTENTS
NUMRPCS
};
Table()
{
static_assert((unsigned)((int)RPCId::NUMRPCS-1)<(1<<Header::kRPCIdBits),
RPCTABLE_TOOMANYRPCS(Too many RPCs registered for class RPCTABLE_CLASS));
#undef REGISTERRPC
#define REGISTERRPC(func) registerRPC((uint32_t)RPCId::func, #func, &Type::func);
RPCTABLE_CONTENTS
}
static const RPCInfo* get(uint32_t rpcid)
{
static Table<RPCTABLE_CLASS> tbl;
assert(tbl.isValid(rpcid));
return static_cast<RPCInfo*>(tbl.m_rpcs[rpcid].get());
}
};
#undef REGISTERRPC
#undef RPCTABLE_START
#undef RPCTABLE_END
#undef RPCTABLE_CLASS
#undef RPCTABLE_CONTENTS
#undef RPCTABLE_TOOMANYRPCS_STRINGIFY
#undef RPCTABLE_TOOMANYRPCS
Thêm vào đó, việc chuyên hóa bảng thế này giúp ta hỗ trợ inheritance dễ dàng hơn. Hãy tưởng tượng chúng ta có một `ScientificCalculator` kế thừa từ Calculator:
class ScientificCalculator : public Calculator {
public:
double sqrt(double a) {
return std::sqrt(a);
}
};
Khi đã define riêng biệt các content của Calculator, chúng ta có thể tái sử dụng define này:
// Separately define the Calculator contents so it can be reused
#define RPCTABLE_CALCULATOR_CONTENTS \
REGISTERRPC(add) \
REGISTERRPC(sub) \
REGISTERRPC(ans)
// Calculator table
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
RPCTABLE_CALCULATOR_CONTENTS
#include "RPCGenerate.h"
// ScientificCalculator table
#define RPCTABLE_CLASS ScientificCalculator
#define RPCTABLE_CONTENTS \
RPCTABLE_CALCULATOR_CONTENTS \
REGISTERRPC(sqrt)
#include "RPCGenerate.h"
Transport
Chúng ta phải xác định dữ liệu được chuyển đổi như thế nào giữa client và server. Hãy đặt dữ liệu đó vào `Transport` interface class. Interface bị cố ý để rất đơn giản để ứng dụng xác định một custom transport. Tất cả chúng ta cần là method để gửi, nhận, và đóng.
namespace cz {
namespace rpc {
class Transport {
public:
virtual ~Transport() {}
// Send one single RPC
virtual void send(std::vector<char> data) = 0;
// Receive one single RPC
// dst : Will contain the data for one single RPC, or empty if no RPC
// available
// return: true if the transport is still alive, false if the transport
// closed
virtual bool receive(std::vector<char>& dst) = 0;
// Close connection to the peer
virtual void close() = 0;
};
} // namespace rpc
} // namespace cz
Result
Kết quả RPC phải trông như thế nào? Mỗi khi chúng ta tạo một RPC call, kết quả có thể đi theo 3 hình thức.
| Form | Meaning |
| Valid | Nhận reply từ server với giá trị kết quả của RPC call |
| Aborted | Connection failed hoặc bị đóng, và chúng ta không nhận được giá trị kết quả |
| Exception | Nhận reply từ server với exception string (RPC call gây exception bên server side) |
namespace cz {
namespace rpc {
class Exception : public std::exception {
public:
Exception(const std::string& msg) : std::exception(msg.c_str()) {}
};
template <typename T>
class Result {
public:
using Type = T;
Result() : m_state(State::Aborted) {}
explicit Result(Type&& val) : m_state(State::Valid), m_val(std::move(val)) {}
Result(Result&& other) {
moveFrom(std::move(other));
}
Result(const Result& other) {
copyFrom(other);
}
~Result() {
destroy();
}
Result& operator=(Result&& other) {
if (this == &other)
return *this;
destroy();
moveFrom(std::move(other));
return *this;
}
// Construction from an exception needs to be separate. so
// RPCReply<std::string> works.
// Otherwise we would have no way to tell if constructing from a value, or
// from an exception
static Result fromException(std::string ex) {
Result r;
r.m_state = State::Exception;
new (&r.m_ex) std::string(std::move(ex));
return r;
}
template <typename S>
static Result fromStream(S& s) {
Type v;
s >> v;
return Result(std::move(v));
};
bool isValid() const {
return m_state == State::Valid;
}
bool isException() const {
return m_state == State::Exception;
};
bool isAborted() const {
return m_state == State::Aborted;
}
T& get() {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
return m_val;
}
const T& get() const {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
return m_val;
}
const std::string& getException() {
assert(isException());
return m_ex;
};
private:
void destroy() {
if (m_state == State::Valid)
m_val.~Type();
else if (m_state == State::Exception) {
using String = std::string;
m_ex.~String();
}
m_state = State::Aborted;
}
void moveFrom(Result&& other) {
m_state = other.m_state;
if (m_state == State::Valid)
new (&m_val) Type(std::move(other.m_val));
else if (m_state == State::Exception)
new (&m_ex) std::string(std::move(other.m_ex));
}
void copyFrom(const Result& other) {
m_state = other.m_state;
if (m_state == State::Valid)
new (&m_val) Type(other.m_val);
else if (m_state == State::Exception)
new (&m_ex) std::string(other.m_ex);
}
enum class State { Valid, Aborted, Exception };
State m_state;
union {
Type m_val;
std::string m_ex;
};
};
// void specialization
template <>
class Result<void> {
public:
Result() : m_state(State::Aborted) {}
Result(Result&& other) {
moveFrom(std::move(other));
}
Result(const Result& other) {
copyFrom(other);
}
~Result() {
destroy();
}
Result& operator=(Result&& other) {
if (this == &other)
return *this;
destroy();
moveFrom(std::move(other));
return *this;
}
static Result fromException(std::string ex) {
Result r;
r.m_state = State::Exception;
new (&r.m_ex) std::string(std::move(ex));
return r;
}
template <typename S>
static Result fromStream(S& s) {
Result r;
r.m_state = State::Valid;
return r;
}
bool isValid() const {
return m_state == State::Valid;
}
bool isException() const {
return m_state == State::Exception;
};
bool isAborted() const {
return m_state == State::Aborted;
}
const std::string& getException() {
assert(isException());
return m_ex;
};
void get() const {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
}
private:
void destroy() {
if (m_state == State::Exception) {
using String = std::string;
m_ex.~String();
}
m_state = State::Aborted;
}
void moveFrom(Result&& other) {
m_state = other.m_state;
if (m_state == State::Exception)
new (&m_ex) std::string(std::move(other.m_ex));
}
void copyFrom(const Result& other) {
m_state = other.m_state;
if (m_state == State::Exception)
new (&m_ex) std::string(other.m_ex);
}
enum class State { Valid, Aborted, Exception };
State m_state;
union {
bool m_dummy;
std::string m_ex;
};
};
} // namespace rpc
} // namespace cz
Chuyên hóa `Result<void>` rất cần thiết, vì trong trường hợp đó không có kết quả, nhưng caller vẫn muốn biết neus RPC call có được xử lý đúng cách hay không. Mới đầu, tôi từng xem xét sử dụng `Expected<T>` cho RPC reply. Nhưng `Expected<T>` về cơ bản có hai trạng thái (Value hoặc Exception), mà chúng ta lại cần tới 3 (Value, Exception, và Aborted). Ta hay cho rằng Aborted có thể được xem là exceptiom, nhưng từ góc nhìn của client, điều này không phải lúc nào cũng đúng. Trong một số trường hợp bạn sẽ muốn biết một RPC fail vì đóng kết nối, mà không phải vì server phản hồi exception.
Video: Sendo.vn xây dựng kiến trúc hệ thống mở rộng để đáp ứng tăng trưởng 10x mỗi năm như thế nào?
OutProcessor
Chúng ta cần phải theo dõi những RPC call đang diễn ra để user code nhận kết quả khi chúng đến. Ta có thể handle một kết quả theo hai cách. Thông qua handle không đồng bộ (tương tự Asio), hoặc với một future.
Ta cần hai class cho việc này: một outgoing processor và một wrapper cho một RPC call duy nhất. Một class khác (Connection) để buộc các outgoing processor và incoming processor với nhau. Class này sẽ được giới thiệu sau.
namespace cz {
namespace rpc {
class BaseOutProcessor {
public:
virtual ~BaseOutProcessor() {}
protected:
template <typename R>
friend class Call;
template <typename L, typename R>
friend struct Connection;
template <typename F, typename H>
void commit(Transport& transport, uint32_t rpcid, Stream& data,
H&& handler) {
std::unique_lock<std::mutex> lk(m_mtx);
Header hdr;
hdr.bits.size = data.writeSize();
hdr.bits.counter = ++m_replyIdCounter;
hdr.bits.rpcid = rpcid;
*reinterpret_cast<Header*>(data.ptr(0)) = hdr;
m_replies[hdr.key()] = [handler = std::move(handler)](Stream * in,
Header hdr) {
using R = typename ParamTraits<
typename FunctionTraits<F>::return_type>::store_type;
if (in) {
if (hdr.bits.success) {
handler(Result<R>::fromStream((*in)));
} else {
std::string str;
(*in) >> str;
handler(Result<R>::fromException(std::move(str)));
}
} else {
// if the stream is nullptr, it means the result is being aborted
handler(Result<R>());
}
};
lk.unlock();
transport.send(data.extract());
}
void processReply(Stream& in, Header hdr) {
std::function<void(Stream*, Header)> h;
{
std::unique_lock<std::mutex> lk(m_mtx);
auto it = m_replies.find(hdr.key());
assert(it != m_replies.end());
h = std::move(it->second);
m_replies.erase(it);
}
h(&in, hdr);
}
void abortReplies() {
decltype(m_replies) replies;
{
std::unique_lock<std::mutex> lk(m_mtx);
replies = std::move(m_replies);
}
for (auto&& r : replies) {
r.second(nullptr, Header());
}
};
std::mutex m_mtx;
uint32_t m_replyIdCounter = 0;
std::unordered_map<uint32_t, std::function<void(Stream*, Header)>>
m_replies;
};
template <typename T>
class OutProcessor : public BaseOutProcessor {
public:
using Type = T;
template <typename F, typename... Args>
auto call(Transport& transport, uint32_t rpcid, Args&&... args) {
using Traits = FunctionTraits<F>;
static_assert(
std::is_member_function_pointer<F>::value &&
std::is_base_of<typename Traits::class_type, Type>::value,
"Not a member function of the wrapped class");
Call<F> c(*this, transport, rpcid);
c.serializeParams(std::forward<Args>(args)...);
return std::move(c);
}
protected:
};
// Specialization for when there is no outgoing RPC calls
// If we have no outgoing RPC calls, receiving a reply is therefore an error.
template <>
class OutProcessor<void> {
public:
OutProcessor() {}
void processReply(Stream&, Header) {
assert(0 && "Incoming replies not allowed for OutProcessor<void>");
}
void abortReplies() {}
};
} // namespace rpc
} // namespace cz
Nên nhớ `OutProcessor<T>` không cần một reference/pointer đến object của T. Nó chỉ cần biết type mà ta gửi RPC đến, để biết được phải dùng `Table<T>`.
Đây là ví dụ sử dụng OutProcessor:
//
// "trp" is a transport that sends data to a "Calculator" server
void testOutProcessor(Transport& trp) {
// A processor that calls RPCs on a "Calculator" server
OutProcessor<Calculator> outPrc;
// Handle with an asynchronous handler
outPrc.call<decltype(&Calculator::add)>(
trp, (int)Table<Calculator>::RPCId::add, 1.0, 2.0)
.async([](Result<double> res) {
printf("%2.0f\n", res.get()); // prints '3'
});
// Handle with a future
Result<double> res = outPrc.call<decltype(&Calculator::add)>(
trp, (int)Table<Calculator>::RPCId::add, 1.0, 3.0)
.ft().get();
printf("%2.0f\n", res.get()); // prints '4'
}
Một lần nữa, hơi quá dài dòng, vì tôi chưa giới thiệu tất cả code để áp dụng tối ưu. Nhưng chí ít, ta đã thấy được interface `OutProcessor<T>` và `Call` làm việc như thế nào. Thực thi `std::future` build đơn giản trên thực thi không đồng bộ.
InProcessor
Giờ đây ta có thể gửi một RPC và đợi kết quả, hãy xem thử ta cần gì ở bên kia. Phải làm gì khi server nhận được một RPC call.
Hãy tạo class `InProcessor<T>`. Trái với `OutProcessor<T>`, `InProcessor<T>` cần phải giữ một reference tới một object thuộc kiểu T. Điều này sảy ra khi nhận được RPC, nó có thể gọi requested method lên object đó, và gửi kết quả trở lại client.
namespace cz {
namespace rpc {
class BaseInProcessor {
public:
virtual ~BaseInProcessor() {}
};
template <typename T>
class InProcessor : public BaseInProcessor {
public:
using Type = T;
InProcessor(Type* obj, bool doVoidReplies = true)
: m_obj(*obj), m_voidReplies(doVoidReplies) {}
void processCall(Transport& transport, Stream& in, Header hdr) {
Stream out;
// Reuse the header as the header for the reply, so we keep the counter
// and rpcid
hdr.bits.size = 0;
hdr.bits.isReply = true;
hdr.bits.success = true;
auto&& info = Table<Type>::get(hdr.bits.rpcid);
#if CZRPC_CATCH_EXCEPTIONS
try {
#endif
out << hdr; // Reserve space for the header
info->dispatcher(m_obj, in, out);
#if CZRPC_CATCH_EXCEPTIONS
} catch (std::exception& e) {
out.clear();
out << hdr; // Reserve space for the header
hdr.bits.success = false;
out << e.what();
}
#endif
if (m_voidReplies || (out.writeSize() > sizeof(hdr))) {
hdr.bits.size = out.writeSize();
*reinterpret_cast<Header*>(out.ptr(0)) = hdr;
transport.send(out.extract());
}
}
protected:
Type& m_obj;
bool m_voidReplies = false;
};
template <>
class InProcessor<void> {
public:
InProcessor(void*) {}
void processCall(Transport&, Stream&, Header) {
assert(0 && "Incoming RPC not allowed for void local type");
}
};
} // namespace rpc
} // namespace cz
Define `CZRPC_CATCH_EXCEPTIONS` cho phép chúng ta tweak nếu ta muốn exception phía server được chuyển sang phía client.
Nếu việc sử dụng `InProcessor<T>` (và `Table<T>`) cho phép call RPC lên object (không biết gì về RPC hoặc netwrk). Ví dụ như, hay xem xét giả dụ sau:
oid calculatorServer() {
// The object we want to use for RPC calls
Calculator calc;
// The server processor. It will call the appropriate methods on 'calc' when
// an RPC is received
InProcessor<Calculator> serverProcessor(&calc);
while (true) {
// calls to serverProcessor::processCall whenever there is data
}
}
Object `Calculator` được dùng cho RPC không biết gì về RPC. `InProcessor<Calculator>` sẽ đảm nhiệm mọi nhiệm vụ liên quan. Từ đó ta không thể sử dụng các class bên thức ba cho PRC. Trong một số trường hợp, chung ta muốn class dùng cho RPC biết biết về RPC và/hoặc network. Ví dụ như, nếu bạn đang tạo một chat system, bạn sẽ khiến client gửi message (RPC call) đến server. Server cần biết client được kết nối đến thứ gì, để có thể truyền phát message.
Connection
Ta giờ đây đã có thể gửi nhận RPC. dù API có hơi dài một chút. Những template class `OutProcessor<T>` và `InProcessor<T>` sẽ xử lý những sự kiện sảy ra với data tại cả hai đầu kết nối. Vậy, hiện ta cần chính điều này. Một `Connection` để buộc mọi thức cần để gửi nhận dữ liệu, và đơn giản là API, về một chỗ.
namespace cz {
namespace rpc {
struct BaseConnection {
virtual ~BaseConnection() {}
//! Process any incoming RPCs or replies
// Return true if the connection is still alive, false otherwise
virtual bool process() = 0;
};
template <typename LOCAL, typename REMOTE>
struct Connection : public BaseConnection {
using Local = LOCAL;
using Remote = REMOTE;
using ThisType = Connection<Local, Remote>;
Connection(Local* localObj, std::shared_ptr<Transport> transport)
: localPrc(localObj), transport(std::move(transport)) {}
template <typename F, typename... Args>
auto call(Transport& transport, uint32_t rpcid, Args&&... args) {
return remotePrc.template call<F>(transport, rpcid,
std::forward<Args>(args)...);
}
static ThisType* getCurrent() {
auto it = Callstack<ThisType>::begin();
return (*it) == nullptr ? nullptr : (*it)->getKey();
}
virtual bool process() override {
// Place a callstack marker, so other code can detect we are serving an
// RPC
typename Callstack<ThisType>::Context ctx(this);
std::vector<char> data;
while (true) {
if (!transport->receive(data)) {
// Transport is closed
remotePrc.abortReplies();
return false;
}
if (data.size() == 0)
return true; // No more pending data to process
Header hdr;
Stream in(std::move(data));
in >> hdr;
if (hdr.bits.isReply) {
remotePrc.processReply(in, hdr);
} else {
localPrc.processCall(*transport, in, hdr);
}
}
}
InProcessor<Local> localPrc;
OutProcessor<Remote> remotePrc;
std::shared_ptr<Transport> transport;
};
} // namespace rpc
} // namespace cz
Từ đây ta có output processor, the input processor, và the transport. Để user code có thể xác định liệu mó có đang phục vụ RPC không. nó sử dụng một class Callstack. Class cho phép tạo RPC/network aware code nếu cần thiết, giống server class.
Vậy, ta đơn giản hóa API bằng cách nào? Vì `Connection<T>` có mọi thứ ta cần, một macro dưới dạng paramether của connection object, một function name và parameter, xử lý mọi thứ, bao gồm cả type check để nó không compile nếu là call không hợp lệ.
#define CZRPC_CALL(con, func, ...) \
(con).call<decltype(&std::decay<decltype(con)>::type::Remote::func)>( \
*(con).transport, \
(uint32_t)cz::rpc::Table< \
std::decay<decltype(con)>::type::Remote>::RPCId::func, \
##__VA_ARGS__)
Khi dùng marcro này, cú pháp RPC call sẽ trở nên cực kỳ đơn giản. Hãy xe, thử client code ví dụ dưới đây:
// Some class to use for RPC calls
class MagicSauce {
public:
int func1(int a, int b) {
return a + b;
}
int func2(int a, int b) {
return a + b;
}
};
// Define RPC table for MagicSauce
#define RPCTABLE_CLASS MagicSauce
#define RPCTABLE_CONTENTS REGISTERRPC(func1)
#include "RPCGenerate.h"
// 'trp' is a fully functional transport
void test_Connection(std::shared_ptr<Transport> trp) {
Connection<void, MagicSauce> con(nullptr, trp);
// Doesn't compile : Invalid number of parameters
// CZRPC_CALL(con, func1, 1);
// Doesn't compile : Wrong type of parameters
// CZRPC_CALL(con, func1, 1, "hello");
// Doesn't compile: func3 is not a MagicSauce method
// CZRPC_CALL(con, func3, 1, 2);
// Doesn't compile: func2 is a method of MagicSauce, but not registered as
// RPC
// CZRPC_CALL(con, func2, 1, 2);
// Compiles fine, since everything is valid
CZRPC_CALL(con, func1, 1, 2).async([](Result<int> res) {
printf("%d\n", res.get()); // print '3'
});
}
Bạn có để ý là `void` và `nullptr` được sử dụng khi tạo kết nối với `Connection<void`, `MagicSauce> con(nullptr, trp);`? Thao tác này sẽ điều tiết bidirectional RPC (server cũng có thể call RPC lên một client). Trong trường hợp này, chúng ta không trong đợi vào client side RPC, vậy nên client side `Connection` object không có một local object để call RPC.
Một ví dụ đơn giản (nhưng không hoạt động) của bidirectional RPC:
class ChatClient;
class ChatServer {
public:
// Called by clients to post new messages
void msg(const char* msg);
void addNewClient(std::shared_ptr<Transport> trp);
private:
// Connection specifies both a LOCAL, and REMOTE object types
std::vector<std::unique_ptr<Connection<ChatServer, ChatClient>>> m_clients;
};
#define RPCTABLE_CLASS ChatServer
#define RPCTABLE_CONTENTS REGISTERRPC(msg)
#include "RPCGenerate.h"
class ChatClient {
public:
void onMsg(const char* msg);
};
#define RPCTABLE_CLASS ChatClient
#define RPCTABLE_CONTENTS REGISTERRPC(onMsg)
#include "RPCGenerate.h"
void ChatServer::msg(const char* msg) {
// Simply broadcast the message to all clients
for (auto&& c : m_clients) {
CZRPC_CALL(*c, onMsg, msg);
}
}
void ChatServer::addNewClient(std::shared_ptr<Transport> trp) {
auto con = std::make_unique<Connection<ChatServer, ChatClient>>(this, trp);
m_clients.push_back(std::move(con));
}
void ChatClient::onMsg(const char* msg) {
printf("%s\n", msg);
}
void test_ChatServer() {
ChatServer server;
while (true) {
// Wait for connections, and call ChatServer::addClient
}
}
// 'trp' is some fully functional transport connected to the ChatServer
void test_ChatClient(std::shared_ptr<Transport> trp) {
ChatClient client;
// In this case, we have a client side object to answer RPCs
Connection<ChatClient, ChatServer> con(&client, trp);
while (true) {
// call the 'msg' RPC whenever the user types something, like this:
CZRPC_CALL(con, msg, "some message");
// The server will call our client 'onMsg' when other clients send a
// message
}
}
Các parameter của `Connection` template trên server và client được đảo ngược. Khi nhận được dữ liệu, object `Connection` sẽ forward xử lý đến `InProcessor` nếu là một incoming RPC call, hoặc đến `OutProcessor` nếu đó là reply đến outgoing RPC call trước đó. Data flow của bidirectional RPC trông như thế này: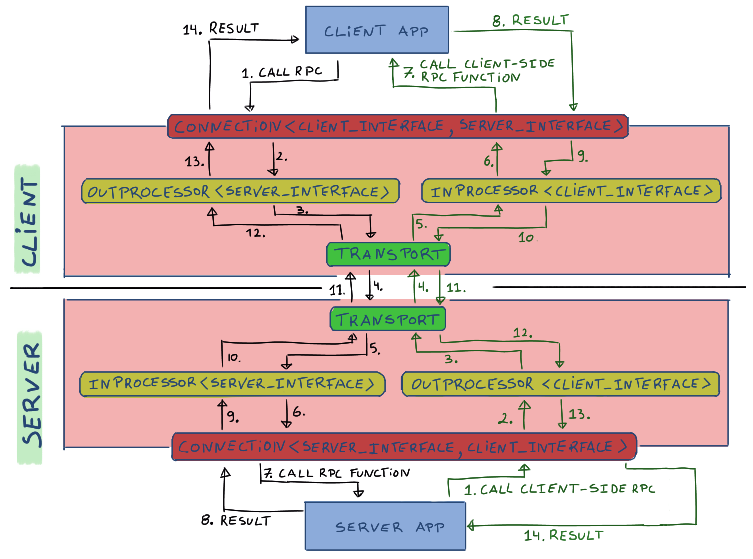
Improvements
Có một số phần được cố ý không đưa vào framework, để từ đó ứng dụng có thể quyết định thế nào là tốt nhất. Ví dụ:
- Transport initialization
- Giao diện transport rất đơn giản, nên nó không quá chú trọng vào hướng khởi tạo cụ thể hoặc xác định incoming data. Việc cung cấp một transport hiệu quả đến class `Connecttion` hoàn toàn phụ thuộc vào ứng dụng. Đây cũng là lý do tại sao tôi tránh hiển thị transport initialization, vì tôi phải trình bày một transport implementation hoạt động hoàn chỉnh.
- Tại thời điểm viết bài, repo mã nguồn có một transport implementation dùng Boost Asio (hoặc Asio biệt lập)
- Xác định disconnection
- Như với initialization, có những đoạn code để xử lý và xác định shutdown.Ứng dụng sẽ có nhiệm vụ quyết định thao tác như thế nào với bất cứ custom implementation nó cung cấp.
- Và nhiều hơn nữa
TopDev via gamasutra
Xem ngay những tin đăng tuyển dụng IT mới nhất trên TopDev



























")











")




")








