Bất cứ khi nào đọc được một câu chuyện về thành công, tôi sẽ ngay lập tức tìm kiếm thông tin của tác giả, hy vọng rằng nó cũng tương tự như mình. Và chưa bao giờ có một ai có quá khứ giống cuộc đời của tôi.
Tuy nhiên, tôi hy vọng rằng câu chuyện của mình sẽ truyền cảm hứng cho người khác và đóng vai trò là một bài học có giá trị cho thành công của bạn.
Tôi tốt nghiệp từ một trường đại học tốt với bằng kỹ thuật hóa học và điểm trung bình tốt. Tuy nhiên, tôi không hề thực sự nghiêm túc theo đuổi lập trình cho đến năm ngoái.
Sau khi tốt nghiệp đại học, tôi đã được nhận vào làm dưới vai trò kỹ sư tại một nhà máy lọc dầu. Mãi đến 2017 thì tôi mới chuyển qua làm lập trình viên phần mềm.
Tại sao tôi muốn thay đổi sự nghiệp?
Tôi thích giải quyết vấn đề liên quan tới kỹ thuật, nhưng đồng thời bản thân cũng muốn làm về kinh doanh.
Vào ngày 27 tháng 5 năm 2017, tôi nhận ra phát triển phần mềm có vẻ như là một sự phù hợp hoàn hảo.
Nhu cầu thì trường luôn cao, mức lương hấp dẫn và đó là ngành công nghiệp hoàn hảo để bắt đầu startup mà không cần nhiều vốn ban đầu. Tất cả bạn cần là một chiếc laptop, và cơ hội của bạn là vô hạn.
Mục tiêu
Bạn cần có một mục tiêu rõ ràng. Đặc biệt là nếu bạn đang cố gắng vừa học vừa làm. Mục tiêu của bạn nên đơn giản như sau:
Có được một công việc liên quan đến lập trình trong vòng một năm với mức lương tương đương hoặc tốt vị trí bây giờ.
Kế hoạch
Một khi bạn có một mục đích, ta sẽ cần một kế hoạch để giúp đạt được điều đó.
Vào ngày 27 tháng 5 năm 2017, tôi quyết định dành khoản 40 giờ mỗi tuần cho công việc của mình, để có thời gian để code sau khi làm việc và vào cuối tuần.
Kế hoạch của tôi khi đấy sẽ như thế này:
Tham gia khóa học về CS để có được sự hiểu biết cơ bản vững chắc về các khái niệm CS cốt lõi
Theo học tại freeCodeCamp cho đến khi tôi có thể xây dựng các full stack web app
Refactor để làm sạch mã, thêm testing, tập trung vào các khái niệm tiên tiến
Đóng góp vào nguồn mở
Chuẩn bị cho các cuộc phỏng vấn việc làm
Để bắt đầu, kế hoạch của tôi rất đơn giản. Vào thời điểm đó, tôi nghĩ là mình sẽ theo Google’s Technical Guide, vì vậy tôi bắt đầu với khóa học Udacity CS101.
Tháng 0 – Udacity CS101, Harvard CS50
Bước tiến đầu tiên này làm tôi vô cùng phấn khích. Việc học code được bắt đầu ngay khi tôi trở nhà sau giờ làm việc và sẽ không dừng lại cho đến khi tôi đi ngủ. Tôi đã hoàn thành 75% đầu tiên của khóa học Udacity CS101 trong 10 ngày. 25% cuối cùng là về đệ quy, và nó có một chút khó khăn hơn cho tôi. Do đó mà tôi mất tổng cộng 20 ngày để hoàn thành Udacity CS101.
Trong cùng lúc đó, tôi đã bắt đầu đọc các bài viết trên subreddit và điều quan trọng đối với các lập trình viên tự học cần phải có các tài khoản online. Tôi quyết định tạo các tài khoản mới trên Twitter, Reddit, Stack Overflow, Medium và Quora với tên họ đầy đủ.
Ngoài ra, tôi đã quyết định ngừng sử dụng các mạng xã hội dễ gây mất tập trung như Instagram, Facebook, …. Tôi chỉ kiểm tra điện thoại của mình về các tin tức và bài đăng liên quan đến lập trình. Điều này rất quan trọng trong việc đảm bảo rằng bản thân có thể tiếp cận với con đường học và tài liệu tốt nhất.
Và đó là nguyên cơ đã đưa tôi đến với khóa học Harvard CS50. Sinh viên CS ở các trường khác đã tham gia khóa học này và nói rằng họ đã học được nhiều thứ trong CS50 hơn cả một hai năm ngồi tại đại học.
Tháng thứ 1 – Harvard CS50, Linux, freeCodeCamp
Tôi đã hoàn thành CS50 trong vòng nửa tháng. Đó là một khóa học tuyệt vời mà bạn không thể bỏ qua. David Malan là một giảng viên xuất sắc, và có rất nhiều tài liệu để giúp bạn vượt qua nó. Bắt đầu với C, rồi chuyển sang Python, và sau đó kết thúc với việc phát triển web.
Sau khi CS50, tôi quyết định thiết lập XPS 15 cho dual boot Windows và Ubuntu. Đó là một ngày cuối tuần bực bội. Tôi làm rối tung các phân vùng và gần như biến chiếc máy của mình thành một cục gạch.
Tôi dần tách rời khỏi Windows và cuối cùng chỉ sử dụng mỗi Ubuntu.
Với kế hoạch coding 100 ngày do bản thân đề ra, bạn sẽ nhận ra rằng bản thân đã thực sự tiến bộ sau khi coi lại dữ liệu từ khoảng thời gian trên.
Mặt khác, tôi cũng chủ động mở rộng mối quan hệ trong thế giới của lập trình viên. Điều mà một người luôn ngại giao tiếp và chưa hề có tham gia buổi meetup sẽ gặp rất nhiều khó. Tôi có lúc đã định bỏ về khi chỉ còn vài bước đến buổi hẹn.
Tuy vậy, tôi nhanh chóng nhận ra rằng không có lý do để lo lắng. Không ai biết nhau, cũng như chả ai có quyền phán xét, và mọi người đều háo hức học hỏi. Và kể từ đó, tôi đã tham dự hơn 50 cuộc gặp gỡ trong 9 tháng.
Hầu hết mọi người chỉ bắt đầu tham dự buổi họp mặt khi họ đang tìm kiếm việc làm, nhưng vào thời điểm đó gần như là quá muộn. Có rất nhiều lý do để bắt đầu sớm, bao gồm:
Phát triển mối quan hệ mất rất nhiều thời gian. Bắt đầu sớm có nghĩa là bạn sẽ có kết nối để bảo đảm việc tìm kiếm một công việc trở nên dễ dàng.
Nói về lập trình với người lạ là một cách tuyệt vời để chuẩn bị cho các cuộc phỏng vấn
Bạn có thể tìm hiểu các framework, công cụ và tài nguyên học tập mới từ những người đi trước bạn. Điều này có thể ảnh hưởng đến kế hoạch học tập trong tương lai.
Cuối cùng, tôi đã chọn phát triển web vì nó có vẻ như có nhu cầu cao và cũng có rất dễ học trực tuyến. Một số người khuyên rằng ở giai đoạn này tôi nên suy nghĩ về các ứng dụng web tôi muốn xây dựng. Họ đã đề xuất Dự án Odin hoặc freeCodeCamp.
Ban đầu tôi quyết định tham gia Odin.
Và sau đó hai ngày, ý tưởng đó ngay lập tức bị bỏ qua.
Đây là một trong những nhược điểm của việc đi theo con đường tự học. Một phút bạn nghĩ rằng bạn biết con đường bạn nên đi, nhưng rồi vào ngày hôm sau bạn tự hỏi: liệu đó có phải là lựa chọn đúng !
Tháng thứ 2 – YDKJS, freeCodeCamp Front End, React
Tôi bắt đầu đọc You Don’t Know JavaScript, bởi vì tất cả mọi người khuyên bạn nên xem nó trên CodeCamp. Tôi đã phải mất một khoảng thời gian vì nó khá khó, nhưng đó là một nguồn tài liệu hoàn hảo để học về lexical scope, closures, promises, và tất cả các phần khác của JavaScript mà bạn muốn học nhưng không bao giờ làm vì chúng có vẻ khó khăn.
Tôi đã hoàn thành phần front-end của freeCodeCamp. Tuy vậy, kiến thức hiện tại chỉ tạm đủ cho những hiểu biết cơ bản. Do đó mà tôi quyết định học sâu hơn về CSS.
Tôi đã nghe rất nhiều về nó và giờ đây thì đã sẵn sàng. Tuy nhiên, tôi đã hơi do dự khi các vấn đề giấy phép bản quyền vào thời điểm đó. Thật may là Facebook đã nhanh chóng loại bỏ vấn đề trên.
Tôi đã cố gắng đọc các tài liệu và làm theo hướng dẫn của Tic-Tac-Toe của Facebook, nhưng vẫn không hiểu hết về nó. Tôi đã được bảo rằng đó là vì bản thân không hiểu JavaScript đủ. Vì vậy, sau đó tôi đã quyết định đọc lại cuốn You Don’t Know JavaScript.
Bài viết sẽ bàn về một framework C++ RP, ko yêu cầu bước code generation để glue code. Trước khi đi vào chi tiết, hãy tìm hiểu một số tính năng cơ bản của công cụ:
Đoạn mã nguồn trên vẫn chưa hoàn chỉnh. Mục tiêu của nó chỉ là để thể hiện nền tảng xây dựng framework. Hơn nữa, để rút ngắn, đoạn code là hỗn hợp của code từ repo lúc viết và custom sample code, nên có thể sẽ xảy ra lỗi.
Một số đoạn trong mã nguồn (không liên quan trực tiếp đến nội dung ta đang bàn đến) sẽ chỉ được xem xét nhanh mà không quá quan tâm đến hiệu năng. Bất cứ cải tiến nào sẽ được thêm vào repo mã nguồn sau.
Modern C++ (C++11/14)
Yêu cầu ít nhất Visual Studio 2015. Clang/GCC cũng tạm ổn.
Type-safe
Framework xác định những RPC call không hợp lệ trong lúc compile, như tên RPC không rõ, số thông số sai, hoặc kiểu thông số sai.
API tương đối nhỏ, không dài dòng
Nhiều cách xử lý RPC reply
Bộ xử lý không đồng bộ (Asynchronous handler)
Futures
Client có thể xác định nếu một RPC gây exception bên phía server
Cho phép sử dụng (gần như) bất kỳ kiểu RPC parameter nào
Giả sử nguời dùng chạy đúng hàm để xử lý kiểu parameter đó
RPC hai chiều (server có thể call RPC trên client)
Thông thường, client code không thể tin tưởng được, nhưng vì framework nhằm sử dụng giữa các bên uy tín, nên đây không phải là vấn đề quá lớn
Không xâm nhập
Một object dùng cho RPC call không cần biết bất cứ thứ gì về RPC hoặc network cả.
Từ đó có thể bọc các class bên thứ ba cho RPC call.
Chi phí băng thông tối thiểu mỗi RPC call
Không phụ thuộc bên ngoài
Dù supplied transport (trong repo mã nguồn) dùng Asio/Boost Asio, nhưng bản thân framework không phụ thuộc vòa đó. Bạn có thể tự cắm transport của mình.
Không có tính năng bảo mật
Vì frame work được thiết kế sử dụng cho các bên tin tưởng lẫn nhau (như giữa server chẳng hạn).
Ứng dụng có thể tự chọn transport riêng, nên sẽ có cơ hội encrypt bất cứ thứ gì nếu cần thiết.
Mặc dù mã nguồn vẫn chưa hoàn thiện, bài viết vẫn rất nặng về code. Code được tách thành nhiều phần nhỏ và một phần sau sẽ dựa theo phần trước. Để bạn hình dung được, sau đây là một mẫu code hoạt động hoàn chỉnh sử dụng repo mã nguồn tại thời điểm viết bài:
//////////////////////////////////////////////////////////////////////////
// Useless RPC-agnostic class that performs calculations.
//////////////////////////////////////////////////////////////////////////
class Calculator {
public:
double add(double a, double b) { return a + b; }
};
//////////////////////////////////////////////////////////////////////////
// Define the RPC table for the Calculator class
// This needs to be seen by both the server and client code
//////////////////////////////////////////////////////////////////////////
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
REGISTERRPC(add)
#include "crazygaze/rpc/RPCGenerate.h"
//////////////////////////////////////////////////////////////////////////
// A Server that only accepts 1 client, then shuts down
// when the client disconnects
//////////////////////////////////////////////////////////////////////////
void RunServer() {
asio::io_service io;
// Start thread to run Asio's the io_service
// we will be using for the server
std::thread th = std::thread([&io] {
asio::io_service::work w(io);
io.run();
});
// Instance we will be using to serve RPC calls.
// Note that it's an object that knows nothing about RPCs
Calculator calc;
// start listening for a client connection.
// We specify what Calculator instance clients will use,
auto acceptor = AsioTransportAcceptor<Calculator, void>::create(io, calc);
// Start listening on port 9000.
// For simplicity, we are only expecting 1 client
using ConType = Connection<Calculator, void>;
std::shared_ptr<ConType> con;
acceptor->start(9000, [&io, &con](std::shared_ptr<ConType> con_) {
con = con_;
// Since this is just a sample, close the server once the first client
// disconnects
reinterpret_cast<BaseAsioTransport*>(con->transport.get())
->setOnClosed([&io] { io.stop(); });
});
th.join();
}
//////////////////////////////////////////////////////////////////////////
// A client that connects to the server, calls 1 RPC
// then disconnects, causing everything to shut down
//////////////////////////////////////////////////////////////////////////
void RunClient() {
// Start a thread to run our Asio io_service
asio::io_service io;
std::thread th = std::thread([&io] {
asio::io_service::work w(io);
io.run();
});
// Connect to the server (localhost, port 9000)
auto con =
AsioTransport<void, Calculator>::create(io, "127.0.0.1", 9000).get();
// Call one RPC (the add method), specifying an asynchronous handler for
// when the result arrives
CZRPC_CALL(*con, add, 1, 2)
.async([&io](Result<double> res) {
printf("Result=%f\n", res.get()); // Prints 3.0
// Since this is a just a sample, stop the io_service after we get
// the result,
// so everything shuts down
io.stop();
});
th.join();
}
// For testing simplicity, run both the server and client on the same machine,
void RunServerAndClient() {
auto a = std::thread([] { RunServer(); });
auto b = std::thread([] { RunClient(); });
a.join();
b.join();
}
Đây đa phần là setup code, vì transport được nhắc đến sử dụng Asio. Bản thân RPC có thể đơn giản như:
// RPC call using asynchronous handler to handle the result
CZRPC_CALL(*con, add, 1, 2).async([](Result<double> res) {
printf("Result=%f\n", res.get()); // Prints 3.0
});
// RPC call using std::future to handle the result
Result<double> res = CZRPC_CALL(*con, add, 1, 2).ft().get();
printf("Result=%f\n", res.get()); // Prints 3.0
Tôi đang làm việc với một game có code named G4 cũng được vài năm rồi, trò chơi cung cấp cho player những chiếc máy tính mô phỏng nhỏ in-game mà thậm chí có thể code được. Điều này yêu cầu tôi phải cho nhiều server cùng chạy song song:
Gameplay Server(s)
VM Server(s) (mô phỏng máy tính ingame)
Để vẫn có thể mô phỏng máy tính ngay cả khi người chơi hiện không online
VM Disk Server(s)
Xử lý lưu trữ của máy tính ingame, như đĩa mềm hoặc ổ cứng.
Database server(s)
Login server(s)
Tất cả những server này cần trao đổi dữ liệu, vì vậy ta cần một RPC framework linh hoạt.
Ban đầu, giải pháp tôi tìm đến là tag method của một class với attribute cụ thể, rồi từ parser gốc Clang (clReflect) tạo bất cứ serialization cần thiết nào, và glue code.
Dù cách này vẫn áp dụng được, nhưng nhiều năm qua tôi vẫn luôn canh cánh làm cách nào tôi có thể dùng tính năng C++11/14 mới để tạo một minimal type safe C++ RPC framework, một phương pháp không cần bước code generation cho glue code, mà vẫn giữa một API chấp nhận được.
Với serialization của non-fundamental type, code genaration vẫn còn hữu dụng, vậy nên tôi không cần phải xác định thủ công làm sao để serialize tất cả các field của một struct/class cho trước. (dù khâu xác định thủ công này cũng chả phiền phức cho lắm).
RPC Parameters
Xét một function, để có type safe RPC call, ta phải làm được:
Xác định lúc compile nếu function là một RPC function hợp lệ (đúng số thông ố, đúng kiểu parameter,…)
Kiểm tra liệu các parameter được supply khớp (hoặc convert được) sang thứ mà function signature chỉ ra.
Serialize tất cả parameter.
Deserialize tất cả parameter.
Call những function mong muốn
Parameter Traits
Vấn đề đầu tiên bạn đối mặt là việc xác định kiểu parameter nào được chấp nhập. Một số RPC framework chỉ chấp nhật một số kiểu giới hạn, như Thrift. Hãy xem thử vấn đề.
Xét các function signature sau:
void func1(int a, float b, char c);
void func2(const char* a, std::string b, const std::string& c);
void func3(Foo a, Bar* b);
Vậy làm cách nào ta bắt compile kiểm tra theo parameter? Những kiểu fundamental type khá dễ và chắc chắn phải được framework hỗ trợ. Một bản copy dumb memory là đủ cho trường hợp như thế này, trừ khi bạn muốn cắt giảm số bit cần thiết để hy sinh một ít hiệu năng lấy bandwidth. Vậy chòn với các kiểu phức tạp như std::string, std::vector, hoặc chính class của mình? Còn pointer, reference, const reference, rvalue thì sao?
Ta có thể lấy một số ý tưởng từ những thứ C++ Standard Library đang làm trong type_traits header. Ta cần truy vấn một kiểu cho trước dựa theo tính chất RPC của nó. Hãy thử biến ý tưởng trên thành một template class `ParamTraits<T>`, với layout như sau:
Member constants
valid
true if T is valid for RPC parameters, false otherwise
Member types
store_type
Type dùng để giữ copy tạm thời cần cho deserializing
Member functions
write
Ghi parameter đến một stream
read
Đọc parameter vào một store_type
get
Xét một store_type parameter, kết quả nó trả có thể được chuyển đến RPC function làm parameter
Trong ví dụ này,hãy thực thi `ParamTraits<T>` cho kiểu thuật toán, trong trường hợp ta có stream class với method `write` và `read`:
`ParamTraits<T>` còn được sử dụng để kiểm tra nếu return type hợp lệ, và vì một void function hợp lệ, ta cần phải chuyên hóa `ParamTraits` cho void nữa.
Một điều khá kỳ lạ là khi chuyên hóa cho `void` là còn chỉ định một `store_type` nữa. Chúng ta không thể sử dụng nó để lưu trữ bất cư thứ gì, nhưng sẽ làm một vìa đoạn template code về sau dễ dàng hơn.
Với những ví dụ `ParamTraits`, reference không phải là RPC parameter hợp lệ. Trong thực tế, bạn ít nhất sẽ muốn cho phép const reference, đặc biệt với fundamental type. Bạn có thể thêm một tweak để kích hoạt hỗ trợ cho `const T&` cho bất kỳ T hợp lệ nào khi ứng dụng của bạn cần đến.
// Make "const T&" valid for any valid T
#define CZRPC_ALLOW_CONST_LVALUE_REFS \
namespace cz { \
namespace rpc { \
template <typename T> \
struct ParamTraits<const T&> : ParamTraits<T> { \
static_assert(ParamTraits<T>::valid, \
"Invalid RPC parameter type. Specialize ParamTraits if " \
"required."); \
}; \
} \
}
Bạn cũng có thể thực hiện những tweak tương tự để kích hoạt hỗ trợ `T&` hoặc `T&&` nếu cần thiết, mặc dù nếu function thay đổi đến những parameter này, những thay đổi đó sẽ mất đi.
Hãy thử thêm hỗ trợ cho các kiểu phức tạp như `std::vector<T>`. Để hỗ trợ `std::vector<T>`, ta buộc phải hỗ trợ thêm cả `T`:
namespace cz {
namespace rpc {
template <typename T>
struct ParamTraits<std::vector<T>> {
using store_type = std::vector<T>;
static constexpr bool valid = ParamTraits<T>::valid;
static_assert(ParamTraits<T>::valid == true,
"T is not valid RPC parameter type.");
// std::vector serialization is done by writing the vector size, followed by
// each element
template <typename S>
static void write(S& s, const std::vector<T>& v) {
int len = static_cast<int>(v.size());
s.write(&len, sizeof(len));
for (auto&& i : v) ParamTraits<T>::write(s, i);
}
template <typename S>
static void read(S& s, std::vector<T>& v) {
int len;
s.read(&len, sizeof(len));
v.clear();
while (len--) {
T i;
ParamTraits<T>::read(s, i);
v.push_back(std::move(i));
}
}
static std::vector<T>&& get(std::vector<T>&& v) {
return std::move(v);
}
};
} // namespace rpc
} // namespace cz
// A simple test
void testVector() {
TEST(ParamTraits<std::vector<int>>::valid); // true
// true if support for const refs was enabled
TEST(ParamTraits<const std::vector<int>&>::valid);
}
Để tiện hơn, chúng ta có thể dùng toán tử `<<` và `>>` với class `stream` (không thế hiện ở đây). Với những toán tử này, hãy đơn thuần call các function `ParamTraits<T> read` và `ParamTraits<T> write` tương ứng.
Giờ đây ta đã có thể kiểm tra xem một type nhất định có được phép cho RPC parameter hay không, chúng ta có thể build trên đó kiểm tra xem một function có được dùng cho RPC hay không. Cách này được thực thi với variadic template.
Trước hết hãy tạo một template cho ta biết nếu nhóm parameter có hợp lệ hay không.
namespace cz {
namespace rpc {
//
// Validate if all parameter types in a parameter pack can be used for RPC
// calls
//
template <typename... T>
struct ParamPack {
static constexpr bool valid = true;
};
template <typename First>
struct ParamPack<First> {
static constexpr bool valid = ParamTraits<First>::valid;
};
template <typename First, typename... Rest>
struct ParamPack<First, Rest...> {
static constexpr bool valid =
ParamTraits<First>::valid && ParamPack<Rest...>::valid;
}
} // namespace rpc
} // namespace cz
// Usage example:
void testParamPack() {
TEST(ParamPack<>::valid); // true (No parameters is a valid too)
TEST((ParamPack<int, double>::valid)); // true
TEST((ParamPack<int, int*>::valid)); // false
}
Using ParamPack, we can now create a FunctionTraits template to query a function's properties.
namespace cz {
namespace rpc {
template <class F>
struct FunctionTraits {};
// For free function pointers
template <class R, class... Args>
struct FunctionTraits<R (*)(Args...)> : public FunctionTraits<R(Args...)> {};
// For method pointers
template <class R, class C, class... Args>
struct FunctionTraits<R (C::*)(Args...)> : public FunctionTraits<R(Args...)> {
using class_type = C;
};
// For const method pointers
template <class R, class C, class... Args>
struct FunctionTraits<R (C::*)(Args...) const>
: public FunctionTraits<R(Args...)> {
using class_type = C;
};
template <class R, class... Args>
struct FunctionTraits<R(Args...)> {
// Tells if both the return type and parameters are valid for RPC calls
static constexpr bool valid =
ParamTraits<R>::valid && ParamPack<Args...>::valid;
using return_type = R;
// Number of parameters
static constexpr std::size_t arity = sizeof...(Args);
// A tuple that can store all parameters
using param_tuple = std::tuple<typename ParamTraits<Args>::store_type...>;
// Allows us to get the type of each parameter, given an index
template <std::size_t N>
struct argument {
static_assert(N < arity, "error: invalid parameter index.");
using type = typename std::tuple_element<N, std::tuple<Args...>>::type;
};
};
} // namespace rpc
} // namespace cz
// A simple test...
struct FuncTraitsTest {
void func1() const {}
void func2(int) {}
int func3(const std::vector<int>&) { return 0; }
int* func4() { return 0; }
};
void testFunctionTraits() {
TEST(FunctionTraits<decltype(&FuncTraitsTest::func1)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func2)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func3)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func4)>::valid); // false
}
`FunctionTraits` cho ta một vài tính chất sẽ được sử dụng sau. Lưu ý với ví dụ rằng `FunctionTraits::param_tuple` build trên `ParamTraits<T>::store_type`. Việc này cần thiết, vì ở một thời điểm nào đó, chung ta cần cách ể deserialize tất cả parameter thành một tuple trước khi call function.
Serialization
Vì chúng ta giờ đây có code cần thiết để truy vấn parameter, return type và validating function, chúng ta có thể gộp code lại để serialize một function call. Hơn nữa, đây chính là type safe. Nó sẽ không complie nếu nhập sai số hoặc kiểu parameter, hoặc nếu bản thân function không hợp lệ cho RPC (không hỗ trợ các return/parameter type).
namespace cz {
namespace rpc {
namespace details {
template <typename F, int N>
struct Parameters {
template <typename S>
static void serialize(S&) {}
template <typename S, typename First, typename... Rest>
static void serialize(S& s, First&& first, Rest&&... rest) {
using Traits =
ParamTraits<typename FunctionTraits<F>::template argument<N>::type>;
Traits::write(s, std::forward<First>(first));
Parameters<F, N + 1>::serialize(s, std::forward<Rest>(rest)...);
}
};
} // namespace details
template <typename F, typename... Args>
void serializeMethod(Stream& s, Args&&... args) {
using Traits = FunctionTraits<F>;
static_assert(Traits::valid,
"Function signature not valid for RPC calls. Check if "
"parameter types are valid");
static_assert(Traits::arity == sizeof...(Args),
"Invalid number of parameters for RPC call.");
details::Parameters<F, 0>::serialize(s, std::forward<Args>(args)...);
}
} // namespace rpc
} // namespace cz
//
// A simple test
//
struct SerializeTest {
void func1(int, const std::vector<int>) {}
void func2(int*) {}
};
void testSerializeCall() {
Stream s;
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2, 3});
// These fail to compile because of the wrong number of parameters
// serializeMethod<decltype(&SerializeTest::func1)>(s);
// serializeMethod<decltype(&SerializeTest::func1)>(s, 1);
// Doesn't compile because of wrong type of parameters
// serializeMethod<decltype(&SerializeTest::func1)>(s, 1, 2);
// Doesn't compile because the function can't be used for RPCs.
// int a;
// serializeMethod<decltype(&SerializeTest::func2)>(s, &a);
}
Deserialization
Như đã đề cập ở trên, `FunctionTraits<F>::param_tuple` là type `std::tuple` ta dùng được để giữ tất cả parameter của function. Để có thể sử dụng tuple này để deserialize parameter, chúng ta phải chuyên hóa `ParamTraits` cho các tuple. Bên cạnh đó, ta còn có thể sử dụng `std::tuple` cho RPC parameter.
namespace cz {
namespace rpc {
namespace details {
template <typename T, bool Done, int N>
struct Tuple {
template <typename S>
static void deserialize(S& s, T& v) {
s >> std::get<N>(v);
Tuple<T, N == std::tuple_size<T>::value - 1, N + 1>::deserialize(s, v);
}
template <typename S>
static void serialize(S& s, const T& v) {
s << std::get<N>(v);
Tuple<T, N == std::tuple_size<T>::value - 1, N + 1>::serialize(s, v);
}
};
template <typename T, int N>
struct Tuple<T, true, N> {
template <typename S>
static void deserialize(S&, T&) {}
template <typename S>
static void serialize(S&, const T&) {}
};
} // namespace details
template <typename... T>
struct ParamTraits<std::tuple<T...>> {
using tuple_type = std::tuple<T...>; // for internal use
using store_type = tuple_type;
static constexpr bool valid = ParamPack<T...>::valid;
static_assert(
ParamPack<T...>::valid == true,
"One or more tuple elements is not a valid RPC parameter type.");
template <typename S>
static void write(S& s, const tuple_type& v) {
details::Tuple<tuple_type, std::tuple_size<tuple_type>::value == 0,
0>::serialize(s, v);
}
template <typename S>
static void read(S& s, tuple_type& v) {
details::Tuple<tuple_type, std::tuple_size<tuple_type>::value == 0,
0>::deserialize(s, v);
}
static tuple_type&& get(tuple_type&& v) {
return std::move(v);
}
};
} // namespace rpc
} // namespace cz
// A simple test
void testDeserialization() {
Stream s;
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2});
// deserialize the parameters into a tuple.
// the tuple is of type std::tuple<int,std::vector<int>>
FunctionTraits<decltype(&SerializeTest::func1)>::param_tuple params;
s >> params;
};
Từ tuple đến function parameters
Sau khi deserialize tất cả parameter thành tuple, chúng ta giờ đâu phải tìm cách tháo tuble để call matching function. Một lần nữa, ta có thể dùng variadic template.
Vậy, giờ đây ta đã biết cách xác thực một function, serialize, deserialize, và call function đó. Vậy là đã xong bước code “level thấp” rồi. Lớp tiếp theo chúng ta sắp sửa phủ lên code này sẽ là RPC API thực sự.
The RPC API
Header
Header có chứa những thông tin sau:
Field
size
Tổng dung lượng (byte) của RPC. Có dung lượng là một phần của header sẽ đơn giản hóa mạnh mẽ, vì chúng ta có thể kiểm tra nếu ta nhận tất cả dữ liệu trước khi thử xử lý RPC.
counter
Số call. Mỗi lúc ta gọi RPC, một counter sẽ tăng và được chỉ định đến RPC call đó.
rpcid
The function to call
isReply
Nếu true, đây là reply đến RPC. Nếu false, đây là RPC call.
success
Chỉ áp dụng cho reply (isReply==true). Nếu true, call thành công và data là reply. Nấu false, data là exception information
Counter và rpcid hình thành một key xác định RPC call instance, cần khi ghép một incoming RPC reply đế RPC call gây ra nó.
// Small utility struct to make it easier to work with the RPC headers
struct Header {
enum {
kSizeBits = 32,
kRPCIdBits = 8,
kCounterBits = 22,
};
explicit Header() {
static_assert(sizeof(*this) == sizeof(uint64_t),
“Invalid size. Check the bitfields”);
all_ = 0;
}
struct Bits {
uint32_t size : kSizeBits;
unsigned counter : kCounterBits;
unsigned rpcid : kRPCIdBits;
unsigned isReply : 1; // Is it a reply to a RPC call ?
unsigned success : 1; // Was the RPC call a success ?
};
Chúng ta đã serialize và deserialize một RPC, nhưng không phải là cách map một RPC đã serialize đến đúng function bên phía server. Để giải quyết vấn đề này, chúng ta cần chỉ định một ID đến mỗi function. Client sẽ biết nó muốn call function nào, và điền đúng ID vào header. Server kiểm tra header, và khi biết được ID, nó sẽ gửi đến đúng handler. Hãy tạo một số ID cơ bản để xác định bảng phân phối tương tự.
namespace cz {
namespace rpc {
//
// Helper code to dispatch a call.
namespace details {
// Handle RPCs with return values
template <typename R>
struct CallHelper {
template <typename OBJ, typename F, typename P>
static void impl(OBJ& obj, F f, P&& params, Stream& out) {
out << callMethod(obj, f, std::move(params));
}
};
// Handle void RPCs
template <>
struct CallHelper<void> {
template <typename OBJ, typename F, typename P>
static void impl(OBJ& obj, F f, P&& params, Stream& out) {
callMethod(obj, f, std::move(params));
}
};
}
struct BaseRPCInfo {
BaseRPCInfo() {}
virtual ~BaseRPCInfo(){};
std::string name;
};
class BaseTable {
public:
BaseTable() {}
virtual ~BaseTable() {}
bool isValid(uint32_t rpcid) const {
return rpcid < m_rpcs.size();
}
protected:
std::vector<std::unique_ptr<BaseRPCInfo>> m_rpcs;
};
template <typename T>
class TableImpl : public BaseTable {
public:
using Type = T;
struct RPCInfo : public BaseRPCInfo {
std::function<void(Type&, Stream& in, Stream& out)> dispatcher;
};
template <typename F>
void registerRPC(uint32_t rpcid, const char* name, F f) {
assert(rpcid == m_rpcs.size());
auto info = std::make_unique<RPCInfo>();
info->name = name;
info->dispatcher = [f](Type& obj, Stream& in, Stream& out) {
using Traits = FunctionTraits<F>;
typename Traits::param_tuple params;
in >> params;
using R = typename Traits::return_type;
details::CallHelper<R>::impl(obj, f, std::move(params), out);
};
m_rpcs.push_back(std::move(info));
}
};
template <typename T>
class Table : public TableImpl<T> {
static_assert(sizeof(T) == 0, "RPC Table not specified for the type.");
};
} // namespace rpc
} // namespace cz
The Table template cần phải được chuyên hóa cho class mà ta muốn dùng cho RPC call. Giả sử ta có một Calculator class muốn dùng cho RPC calls:
class Calculator {
public:
double add(double a, double b) {
m_ans = a + b;
return m_ans;
}
double sub(double a, double b) {
m_ans = a - b;
return m_ans;
}
double ans() {
return m_ans;
}
private:
double m_ans = 0;
};
Ta có thể chuyên hóa Table template cho Calculator, để cả client và server đều có thể tham gia:
Với một ID,function `get` sẽ trả dispatcher về đúng method `Calculator`. Rồi ta có thể chuyển `Calculator` instance, input và output streams sang dispatcher để xử lý mọi thứ còn lại.
Quá trình chuyên hóa khá dài dòng và không thể tránh khỏi sai sót, vì enum và `registerRPC` call phải khớp. Nhưng chúng ta có thể rút ngắn rõ rệt quá trình với một vài macro. Đầu tiên, hãy xem thử một ví dụ dài dòng để thấy cách dùng bảng này:
void testCalculatorTable() {
// Both the client and server need to have access to the necessary table
using CalcT = Table<Calculator>;
//
// Client sends RPC
Stream toServer;
RPCHeader hdr;
hdr.bits.rpcid = (int)CalcT::RPCId::add;
toServer << hdr;
serializeMethod<decltype(&Calculator::add)>(toServer, 1.0, 9.0);
//
// Server receives RPC, and sends back a reply
Calculator calc; // object used to receive the RPCs
toServer >> hdr;
auto&& info = CalcT::get(hdr.bits.rpcid);
Stream toClient; // Stream for the reply
// Call the desired Calculator function.
info->dispatcher(calc, toServer, toClient);
//
// Client receives a reply
double r;
toClient >> r;
printf("%2.0f\n", r); // Will print "10"
}
Một lần nữa, ví dụ này khá dài dòng, chỉ để thể hiện code flow. Chúng ta sẽ có ví dụ tối ưu hơn sau.
Vậy, chúng ta đơn giản quá trình chuyên hóa bảng như thế nào? Nếu ta đặt gist của chuyên hóa bảng trong một header không được guard, bạn chỉ cần một vài define theo sau là một include của header (không guard) đó để tạo tương tự.
`RPCGenerate.h` là một header không được guard, trông như sau:
#ifndef RPCTABLE_CLASS
#error "Macro RPCTABLE_CLASS needs to be defined"
#endif
#ifndef RPCTABLE_CONTENTS
#error "Macro RPCTABLE_CONTENTS needs to be defined"
#endif
#define RPCTABLE_TOOMANYRPCS_STRINGIFY(arg) #arg
#define RPCTABLE_TOOMANYRPCS(arg) RPCTABLE_TOOMANYRPCS_STRINGIFY(arg)
template<> class cz::rpc::Table<RPCTABLE_CLASS> : cz::rpc::TableImpl<RPCTABLE_CLASS>
{
public:
using Type = RPCTABLE_CLASS;
#define REGISTERRPC(rpc) rpc,
enum class RPCId {
RPCTABLE_CONTENTS
NUMRPCS
};
Table()
{
static_assert((unsigned)((int)RPCId::NUMRPCS-1)<(1<<Header::kRPCIdBits),
RPCTABLE_TOOMANYRPCS(Too many RPCs registered for class RPCTABLE_CLASS));
#undef REGISTERRPC
#define REGISTERRPC(func) registerRPC((uint32_t)RPCId::func, #func, &Type::func);
RPCTABLE_CONTENTS
}
static const RPCInfo* get(uint32_t rpcid)
{
static Table<RPCTABLE_CLASS> tbl;
assert(tbl.isValid(rpcid));
return static_cast<RPCInfo*>(tbl.m_rpcs[rpcid].get());
}
};
#undef REGISTERRPC
#undef RPCTABLE_START
#undef RPCTABLE_END
#undef RPCTABLE_CLASS
#undef RPCTABLE_CONTENTS
#undef RPCTABLE_TOOMANYRPCS_STRINGIFY
#undef RPCTABLE_TOOMANYRPCS
Thêm vào đó, việc chuyên hóa bảng thế này giúp ta hỗ trợ inheritance dễ dàng hơn. Hãy tưởng tượng chúng ta có một `ScientificCalculator` kế thừa từ Calculator:
class ScientificCalculator : public Calculator {
public:
double sqrt(double a) {
return std::sqrt(a);
}
};
Khi đã define riêng biệt các content của Calculator, chúng ta có thể tái sử dụng define này:
// Separately define the Calculator contents so it can be reused
#define RPCTABLE_CALCULATOR_CONTENTS \
REGISTERRPC(add) \
REGISTERRPC(sub) \
REGISTERRPC(ans)
// Calculator table
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
RPCTABLE_CALCULATOR_CONTENTS
#include "RPCGenerate.h"
// ScientificCalculator table
#define RPCTABLE_CLASS ScientificCalculator
#define RPCTABLE_CONTENTS \
RPCTABLE_CALCULATOR_CONTENTS \
REGISTERRPC(sqrt)
#include "RPCGenerate.h"
Transport
Chúng ta phải xác định dữ liệu được chuyển đổi như thế nào giữa client và server. Hãy đặt dữ liệu đó vào `Transport` interface class. Interface bị cố ý để rất đơn giản để ứng dụng xác định một custom transport. Tất cả chúng ta cần là method để gửi, nhận, và đóng.
namespace cz {
namespace rpc {
class Transport {
public:
virtual ~Transport() {}
// Send one single RPC
virtual void send(std::vector<char> data) = 0;
// Receive one single RPC
// dst : Will contain the data for one single RPC, or empty if no RPC
// available
// return: true if the transport is still alive, false if the transport
// closed
virtual bool receive(std::vector<char>& dst) = 0;
// Close connection to the peer
virtual void close() = 0;
};
} // namespace rpc
} // namespace cz
Result
Kết quả RPC phải trông như thế nào? Mỗi khi chúng ta tạo một RPC call, kết quả có thể đi theo 3 hình thức.
Form
Meaning
Valid
Nhận reply từ server với giá trị kết quả của RPC call
Aborted
Connection failed hoặc bị đóng, và chúng ta không nhận được giá trị kết quả
Exception
Nhận reply từ server với exception string (RPC call gây exception bên server side)
namespace cz {
namespace rpc {
class Exception : public std::exception {
public:
Exception(const std::string& msg) : std::exception(msg.c_str()) {}
};
template <typename T>
class Result {
public:
using Type = T;
Result() : m_state(State::Aborted) {}
explicit Result(Type&& val) : m_state(State::Valid), m_val(std::move(val)) {}
Result(Result&& other) {
moveFrom(std::move(other));
}
Result(const Result& other) {
copyFrom(other);
}
~Result() {
destroy();
}
Result& operator=(Result&& other) {
if (this == &other)
return *this;
destroy();
moveFrom(std::move(other));
return *this;
}
// Construction from an exception needs to be separate. so
// RPCReply<std::string> works.
// Otherwise we would have no way to tell if constructing from a value, or
// from an exception
static Result fromException(std::string ex) {
Result r;
r.m_state = State::Exception;
new (&r.m_ex) std::string(std::move(ex));
return r;
}
template <typename S>
static Result fromStream(S& s) {
Type v;
s >> v;
return Result(std::move(v));
};
bool isValid() const {
return m_state == State::Valid;
}
bool isException() const {
return m_state == State::Exception;
};
bool isAborted() const {
return m_state == State::Aborted;
}
T& get() {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
return m_val;
}
const T& get() const {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
return m_val;
}
const std::string& getException() {
assert(isException());
return m_ex;
};
private:
void destroy() {
if (m_state == State::Valid)
m_val.~Type();
else if (m_state == State::Exception) {
using String = std::string;
m_ex.~String();
}
m_state = State::Aborted;
}
void moveFrom(Result&& other) {
m_state = other.m_state;
if (m_state == State::Valid)
new (&m_val) Type(std::move(other.m_val));
else if (m_state == State::Exception)
new (&m_ex) std::string(std::move(other.m_ex));
}
void copyFrom(const Result& other) {
m_state = other.m_state;
if (m_state == State::Valid)
new (&m_val) Type(other.m_val);
else if (m_state == State::Exception)
new (&m_ex) std::string(other.m_ex);
}
enum class State { Valid, Aborted, Exception };
State m_state;
union {
Type m_val;
std::string m_ex;
};
};
// void specialization
template <>
class Result<void> {
public:
Result() : m_state(State::Aborted) {}
Result(Result&& other) {
moveFrom(std::move(other));
}
Result(const Result& other) {
copyFrom(other);
}
~Result() {
destroy();
}
Result& operator=(Result&& other) {
if (this == &other)
return *this;
destroy();
moveFrom(std::move(other));
return *this;
}
static Result fromException(std::string ex) {
Result r;
r.m_state = State::Exception;
new (&r.m_ex) std::string(std::move(ex));
return r;
}
template <typename S>
static Result fromStream(S& s) {
Result r;
r.m_state = State::Valid;
return r;
}
bool isValid() const {
return m_state == State::Valid;
}
bool isException() const {
return m_state == State::Exception;
};
bool isAborted() const {
return m_state == State::Aborted;
}
const std::string& getException() {
assert(isException());
return m_ex;
};
void get() const {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
}
private:
void destroy() {
if (m_state == State::Exception) {
using String = std::string;
m_ex.~String();
}
m_state = State::Aborted;
}
void moveFrom(Result&& other) {
m_state = other.m_state;
if (m_state == State::Exception)
new (&m_ex) std::string(std::move(other.m_ex));
}
void copyFrom(const Result& other) {
m_state = other.m_state;
if (m_state == State::Exception)
new (&m_ex) std::string(other.m_ex);
}
enum class State { Valid, Aborted, Exception };
State m_state;
union {
bool m_dummy;
std::string m_ex;
};
};
} // namespace rpc
} // namespace cz
Chuyên hóa `Result<void>` rất cần thiết, vì trong trường hợp đó không có kết quả, nhưng caller vẫn muốn biết neus RPC call có được xử lý đúng cách hay không. Mới đầu, tôi từng xem xét sử dụng `Expected<T>` cho RPC reply. Nhưng `Expected<T>` về cơ bản có hai trạng thái (Value hoặc Exception), mà chúng ta lại cần tới 3 (Value, Exception, và Aborted). Ta hay cho rằng Aborted có thể được xem là exceptiom, nhưng từ góc nhìn của client, điều này không phải lúc nào cũng đúng. Trong một số trường hợp bạn sẽ muốn biết một RPC fail vì đóng kết nối, mà không phải vì server phản hồi exception.
Video: Sendo.vn xây dựng kiến trúc hệ thống mở rộng để đáp ứng tăng trưởng 10x mỗi năm như thế nào?
OutProcessor
Chúng ta cần phải theo dõi những RPC call đang diễn ra để user code nhận kết quả khi chúng đến. Ta có thể handle một kết quả theo hai cách. Thông qua handle không đồng bộ (tương tự Asio), hoặc với một future.
Ta cần hai class cho việc này: một outgoing processor và một wrapper cho một RPC call duy nhất. Một class khác (Connection) để buộc các outgoing processor và incoming processor với nhau. Class này sẽ được giới thiệu sau.
namespace cz {
namespace rpc {
class BaseOutProcessor {
public:
virtual ~BaseOutProcessor() {}
protected:
template <typename R>
friend class Call;
template <typename L, typename R>
friend struct Connection;
template <typename F, typename H>
void commit(Transport& transport, uint32_t rpcid, Stream& data,
H&& handler) {
std::unique_lock<std::mutex> lk(m_mtx);
Header hdr;
hdr.bits.size = data.writeSize();
hdr.bits.counter = ++m_replyIdCounter;
hdr.bits.rpcid = rpcid;
*reinterpret_cast<Header*>(data.ptr(0)) = hdr;
m_replies[hdr.key()] = [handler = std::move(handler)](Stream * in,
Header hdr) {
using R = typename ParamTraits<
typename FunctionTraits<F>::return_type>::store_type;
if (in) {
if (hdr.bits.success) {
handler(Result<R>::fromStream((*in)));
} else {
std::string str;
(*in) >> str;
handler(Result<R>::fromException(std::move(str)));
}
} else {
// if the stream is nullptr, it means the result is being aborted
handler(Result<R>());
}
};
lk.unlock();
transport.send(data.extract());
}
void processReply(Stream& in, Header hdr) {
std::function<void(Stream*, Header)> h;
{
std::unique_lock<std::mutex> lk(m_mtx);
auto it = m_replies.find(hdr.key());
assert(it != m_replies.end());
h = std::move(it->second);
m_replies.erase(it);
}
h(&in, hdr);
}
void abortReplies() {
decltype(m_replies) replies;
{
std::unique_lock<std::mutex> lk(m_mtx);
replies = std::move(m_replies);
}
for (auto&& r : replies) {
r.second(nullptr, Header());
}
};
std::mutex m_mtx;
uint32_t m_replyIdCounter = 0;
std::unordered_map<uint32_t, std::function<void(Stream*, Header)>>
m_replies;
};
template <typename T>
class OutProcessor : public BaseOutProcessor {
public:
using Type = T;
template <typename F, typename... Args>
auto call(Transport& transport, uint32_t rpcid, Args&&... args) {
using Traits = FunctionTraits<F>;
static_assert(
std::is_member_function_pointer<F>::value &&
std::is_base_of<typename Traits::class_type, Type>::value,
"Not a member function of the wrapped class");
Call<F> c(*this, transport, rpcid);
c.serializeParams(std::forward<Args>(args)...);
return std::move(c);
}
protected:
};
// Specialization for when there is no outgoing RPC calls
// If we have no outgoing RPC calls, receiving a reply is therefore an error.
template <>
class OutProcessor<void> {
public:
OutProcessor() {}
void processReply(Stream&, Header) {
assert(0 && "Incoming replies not allowed for OutProcessor<void>");
}
void abortReplies() {}
};
} // namespace rpc
} // namespace cz
Nên nhớ `OutProcessor<T>` không cần một reference/pointer đến object của T. Nó chỉ cần biết type mà ta gửi RPC đến, để biết được phải dùng `Table<T>`.
Đây là ví dụ sử dụng OutProcessor:
//
// "trp" is a transport that sends data to a "Calculator" server
void testOutProcessor(Transport& trp) {
// A processor that calls RPCs on a "Calculator" server
OutProcessor<Calculator> outPrc;
// Handle with an asynchronous handler
outPrc.call<decltype(&Calculator::add)>(
trp, (int)Table<Calculator>::RPCId::add, 1.0, 2.0)
.async([](Result<double> res) {
printf("%2.0f\n", res.get()); // prints '3'
});
// Handle with a future
Result<double> res = outPrc.call<decltype(&Calculator::add)>(
trp, (int)Table<Calculator>::RPCId::add, 1.0, 3.0)
.ft().get();
printf("%2.0f\n", res.get()); // prints '4'
}
Một lần nữa, hơi quá dài dòng, vì tôi chưa giới thiệu tất cả code để áp dụng tối ưu. Nhưng chí ít, ta đã thấy được interface `OutProcessor<T>` và `Call` làm việc như thế nào. Thực thi `std::future` build đơn giản trên thực thi không đồng bộ.
InProcessor
Giờ đây ta có thể gửi một RPC và đợi kết quả, hãy xem thử ta cần gì ở bên kia. Phải làm gì khi server nhận được một RPC call.
Hãy tạo class `InProcessor<T>`. Trái với `OutProcessor<T>`, `InProcessor<T>` cần phải giữ một reference tới một object thuộc kiểu T. Điều này sảy ra khi nhận được RPC, nó có thể gọi requested method lên object đó, và gửi kết quả trở lại client.
namespace cz {
namespace rpc {
class BaseInProcessor {
public:
virtual ~BaseInProcessor() {}
};
template <typename T>
class InProcessor : public BaseInProcessor {
public:
using Type = T;
InProcessor(Type* obj, bool doVoidReplies = true)
: m_obj(*obj), m_voidReplies(doVoidReplies) {}
void processCall(Transport& transport, Stream& in, Header hdr) {
Stream out;
// Reuse the header as the header for the reply, so we keep the counter
// and rpcid
hdr.bits.size = 0;
hdr.bits.isReply = true;
hdr.bits.success = true;
auto&& info = Table<Type>::get(hdr.bits.rpcid);
#if CZRPC_CATCH_EXCEPTIONS
try {
#endif
out << hdr; // Reserve space for the header
info->dispatcher(m_obj, in, out);
#if CZRPC_CATCH_EXCEPTIONS
} catch (std::exception& e) {
out.clear();
out << hdr; // Reserve space for the header
hdr.bits.success = false;
out << e.what();
}
#endif
if (m_voidReplies || (out.writeSize() > sizeof(hdr))) {
hdr.bits.size = out.writeSize();
*reinterpret_cast<Header*>(out.ptr(0)) = hdr;
transport.send(out.extract());
}
}
protected:
Type& m_obj;
bool m_voidReplies = false;
};
template <>
class InProcessor<void> {
public:
InProcessor(void*) {}
void processCall(Transport&, Stream&, Header) {
assert(0 && "Incoming RPC not allowed for void local type");
}
};
} // namespace rpc
} // namespace cz
Define `CZRPC_CATCH_EXCEPTIONS` cho phép chúng ta tweak nếu ta muốn exception phía server được chuyển sang phía client.
Nếu việc sử dụng `InProcessor<T>` (và `Table<T>`) cho phép call RPC lên object (không biết gì về RPC hoặc netwrk). Ví dụ như, hay xem xét giả dụ sau:
oid calculatorServer() {
// The object we want to use for RPC calls
Calculator calc;
// The server processor. It will call the appropriate methods on 'calc' when
// an RPC is received
InProcessor<Calculator> serverProcessor(&calc);
while (true) {
// calls to serverProcessor::processCall whenever there is data
}
}
Object `Calculator` được dùng cho RPC không biết gì về RPC. `InProcessor<Calculator>` sẽ đảm nhiệm mọi nhiệm vụ liên quan. Từ đó ta không thể sử dụng các class bên thức ba cho PRC. Trong một số trường hợp, chung ta muốn class dùng cho RPC biết biết về RPC và/hoặc network. Ví dụ như, nếu bạn đang tạo một chat system, bạn sẽ khiến client gửi message (RPC call) đến server. Server cần biết client được kết nối đến thứ gì, để có thể truyền phát message.
Connection
Ta giờ đây đã có thể gửi nhận RPC. dù API có hơi dài một chút. Những template class `OutProcessor<T>` và `InProcessor<T>` sẽ xử lý những sự kiện sảy ra với data tại cả hai đầu kết nối. Vậy, hiện ta cần chính điều này. Một `Connection` để buộc mọi thức cần để gửi nhận dữ liệu, và đơn giản là API, về một chỗ.
namespace cz {
namespace rpc {
struct BaseConnection {
virtual ~BaseConnection() {}
//! Process any incoming RPCs or replies
// Return true if the connection is still alive, false otherwise
virtual bool process() = 0;
};
template <typename LOCAL, typename REMOTE>
struct Connection : public BaseConnection {
using Local = LOCAL;
using Remote = REMOTE;
using ThisType = Connection<Local, Remote>;
Connection(Local* localObj, std::shared_ptr<Transport> transport)
: localPrc(localObj), transport(std::move(transport)) {}
template <typename F, typename... Args>
auto call(Transport& transport, uint32_t rpcid, Args&&... args) {
return remotePrc.template call<F>(transport, rpcid,
std::forward<Args>(args)...);
}
static ThisType* getCurrent() {
auto it = Callstack<ThisType>::begin();
return (*it) == nullptr ? nullptr : (*it)->getKey();
}
virtual bool process() override {
// Place a callstack marker, so other code can detect we are serving an
// RPC
typename Callstack<ThisType>::Context ctx(this);
std::vector<char> data;
while (true) {
if (!transport->receive(data)) {
// Transport is closed
remotePrc.abortReplies();
return false;
}
if (data.size() == 0)
return true; // No more pending data to process
Header hdr;
Stream in(std::move(data));
in >> hdr;
if (hdr.bits.isReply) {
remotePrc.processReply(in, hdr);
} else {
localPrc.processCall(*transport, in, hdr);
}
}
}
InProcessor<Local> localPrc;
OutProcessor<Remote> remotePrc;
std::shared_ptr<Transport> transport;
};
} // namespace rpc
} // namespace cz
Từ đây ta có output processor, the input processor, và the transport. Để user code có thể xác định liệu mó có đang phục vụ RPC không. nó sử dụng một class Callstack. Class cho phép tạo RPC/network aware code nếu cần thiết, giống server class.
Vậy, ta đơn giản hóa API bằng cách nào? Vì `Connection<T>` có mọi thứ ta cần, một macro dưới dạng paramether của connection object, một function name và parameter, xử lý mọi thứ, bao gồm cả type check để nó không compile nếu là call không hợp lệ.
Khi dùng marcro này, cú pháp RPC call sẽ trở nên cực kỳ đơn giản. Hãy xe, thử client code ví dụ dưới đây:
// Some class to use for RPC calls
class MagicSauce {
public:
int func1(int a, int b) {
return a + b;
}
int func2(int a, int b) {
return a + b;
}
};
// Define RPC table for MagicSauce
#define RPCTABLE_CLASS MagicSauce
#define RPCTABLE_CONTENTS REGISTERRPC(func1)
#include "RPCGenerate.h"
// 'trp' is a fully functional transport
void test_Connection(std::shared_ptr<Transport> trp) {
Connection<void, MagicSauce> con(nullptr, trp);
// Doesn't compile : Invalid number of parameters
// CZRPC_CALL(con, func1, 1);
// Doesn't compile : Wrong type of parameters
// CZRPC_CALL(con, func1, 1, "hello");
// Doesn't compile: func3 is not a MagicSauce method
// CZRPC_CALL(con, func3, 1, 2);
// Doesn't compile: func2 is a method of MagicSauce, but not registered as
// RPC
// CZRPC_CALL(con, func2, 1, 2);
// Compiles fine, since everything is valid
CZRPC_CALL(con, func1, 1, 2).async([](Result<int> res) {
printf("%d\n", res.get()); // print '3'
});
}
Bạn có để ý là `void` và `nullptr` được sử dụng khi tạo kết nối với `Connection<void`, `MagicSauce> con(nullptr, trp);`? Thao tác này sẽ điều tiết bidirectional RPC (server cũng có thể call RPC lên một client). Trong trường hợp này, chúng ta không trong đợi vào client side RPC, vậy nên client side `Connection` object không có một local object để call RPC.
Một ví dụ đơn giản (nhưng không hoạt động) của bidirectional RPC:
class ChatClient;
class ChatServer {
public:
// Called by clients to post new messages
void msg(const char* msg);
void addNewClient(std::shared_ptr<Transport> trp);
private:
// Connection specifies both a LOCAL, and REMOTE object types
std::vector<std::unique_ptr<Connection<ChatServer, ChatClient>>> m_clients;
};
#define RPCTABLE_CLASS ChatServer
#define RPCTABLE_CONTENTS REGISTERRPC(msg)
#include "RPCGenerate.h"
class ChatClient {
public:
void onMsg(const char* msg);
};
#define RPCTABLE_CLASS ChatClient
#define RPCTABLE_CONTENTS REGISTERRPC(onMsg)
#include "RPCGenerate.h"
void ChatServer::msg(const char* msg) {
// Simply broadcast the message to all clients
for (auto&& c : m_clients) {
CZRPC_CALL(*c, onMsg, msg);
}
}
void ChatServer::addNewClient(std::shared_ptr<Transport> trp) {
auto con = std::make_unique<Connection<ChatServer, ChatClient>>(this, trp);
m_clients.push_back(std::move(con));
}
void ChatClient::onMsg(const char* msg) {
printf("%s\n", msg);
}
void test_ChatServer() {
ChatServer server;
while (true) {
// Wait for connections, and call ChatServer::addClient
}
}
// 'trp' is some fully functional transport connected to the ChatServer
void test_ChatClient(std::shared_ptr<Transport> trp) {
ChatClient client;
// In this case, we have a client side object to answer RPCs
Connection<ChatClient, ChatServer> con(&client, trp);
while (true) {
// call the 'msg' RPC whenever the user types something, like this:
CZRPC_CALL(con, msg, "some message");
// The server will call our client 'onMsg' when other clients send a
// message
}
}
Các parameter của `Connection` template trên server và client được đảo ngược. Khi nhận được dữ liệu, object `Connection` sẽ forward xử lý đến `InProcessor` nếu là một incoming RPC call, hoặc đến `OutProcessor` nếu đó là reply đến outgoing RPC call trước đó. Data flow của bidirectional RPC trông như thế này:
Improvements
Có một số phần được cố ý không đưa vào framework, để từ đó ứng dụng có thể quyết định thế nào là tốt nhất. Ví dụ:
Transport initialization
Giao diện transport rất đơn giản, nên nó không quá chú trọng vào hướng khởi tạo cụ thể hoặc xác định incoming data. Việc cung cấp một transport hiệu quả đến class `Connecttion` hoàn toàn phụ thuộc vào ứng dụng. Đây cũng là lý do tại sao tôi tránh hiển thị transport initialization, vì tôi phải trình bày một transport implementation hoạt động hoàn chỉnh.
Tại thời điểm viết bài, repo mã nguồn có một transport implementation dùng Boost Asio (hoặc Asio biệt lập)
Xác định disconnection
Như với initialization, có những đoạn code để xử lý và xác định shutdown.Ứng dụng sẽ có nhiệm vụ quyết định thao tác như thế nào với bất cứ custom implementation nó cung cấp.
Flutter là mobile UI framework của Google để tạo ra các giao diện native chất lượng cao trên iOS và Android trong khoảng thời gian ngắn. Flutter hoạt động với source code có sẵn, được sử dụng bởi các nhà phát triển và các tổ chức trên khắp thế giới, đồng thời nó open-source và miễn phí.
Clip giới thiệu về Flutter:
Sự vượt trội của Flutter
Flutter là một công cụ mới được cung cấp bởi Google cho phép các nhà phát triển xây dựng các ứng dụng đa nền tảng có thể được thực hiện trong các hệ thống khác nhau chẳng hạn như Android hay iOS chỉ với một codebase chung.
Công cụ này được được xây dựng trong C và C ++ và cung cấp một cơ chế rendering 2D, một funtional-reactive framework là React-inspired, và một tập hợp các Material Design widget. Nó hiện đang được distribute bản alpha: version 0.0.20, tuy vậy giai đoạn đầu của nó đã được cho phép để tạo ra interfacing phức tạp, thực hiện kết nối mạng và thậm chí quản lý tập tin.
Cách tiếp cận Flutter’s là khác nhau từ các solution khác, ví dụ Cordova chạy trên một WebView là HTML, CSS và Javascript. Không giống như những công cụ này, nó chỉ sử dụng Dart như một ngôn ngữ lập trình duy nhất. Dart là khá dễ dàng để tìm hiểu và nếu bạn có kiến thức Java, 75% của công việc được gần như hoàn tất và làm quen với Dart sẽ chỉ mất một vài ngày.
Phát triển ứng dụng nhanh chóng: Tính năng hot reload của Flutter giúp bạn nhanh chóng và dễ dàng thử nghiệm, xây dựng giao diện người dùng, thêm tính năng và sửa lỗi nhanh hơn. Trải nghiệm tải lại lần thứ hai, mà không làm mất trạng thái, trên emulator, simulator và device cho iOS và Android.
UI đẹp và biểu cảm: Thỏa mãn người dùng của bạn với các widget built-in đẹp mắt của Flutter theo Material Design và Cupertino (iOS-flavor), các API chuyển động phong phú, scroll tự nhiên mượt mà và tự nhận thức được nền tảng.
Framework hiện đại và reactive: Dễ dàng tạo giao diện người dùng của bạn với framework hiện đại, reactive của Flutter và tập hợp các platform, layout và widget phong phú. Giải quyết các thách thức giao diện người dùng khó khăn của bạn với các API mạnh mẽ và linh hoạt cho 2D, animation, gesture, hiệu ứng và hơn thế nữa.
Truy cập các tính năng và SDK native: Làm cho ứng dụng của bạn trở nên sống động với API của platform, SDK của bên thứ ba và native code. Flutter cho phép bạn sử dụng lại mã Java, Swift và ObjC hiện tại của mình và truy cập các tính năng và SDK native trên iOS và Android.
Phát triển ứng dụng thống nhất: Flutter có các công cụ và thư viện để giúp bạn dễ dàng đưa ý tưởng của mình vào cuộc sống trên iOS và Android. Nếu bạn chưa có kinh nghiệm phát triển trên thiết bị di động, thì Flutter là một cách dễ dàng và nhanh chóng để xây dựng các ứng dụng di động tuyệt đẹp. Nếu bạn là một nhà phát triển iOS hoặc Android có kinh nghiệm, bạn có thể sử dụng Flutter cho các View của bạn và tận dụng nhiều code Java / Kotlin / ObjC / Swift hiện có của bạn.
Tôi đã nghe không ít developer nói rằng họ ghét CSS. Với kinh nghiệm của mình, đây là kết quả cho việc không dành thời gian để học CSS.
CSS không phải là “ngôn ngữ” đẹp nhất, nhưng nó đã thành công trong việc làm front-end cho các website trong hơn 20 năm nay. Tuy nhiên, khi bạn viết nhiều CSS, bạn sẽ nhận ra được thấy một nhược điểm lớn. Quá khó để developer có thể maintain CSS.
Các CSS tệ sẽ nhanh chóng trở thành một cơn ác mộng đối với các lập trình viên. Dưới đây là một số quy ước tên sẽ giúp bạn giảm vô số giờ để debug.
Các team có cách tiếp cận khác nhau để viết CSS selector. Một số nhóm sử dụng dấu phân cách, trong khi một số khác lại thích sử dụng một cách đặt tên có cấu trúc hơn gọi là BEM.
Nhìn chung, có 3 vấn đề mà qui tắc này giải quyết:
Để biết 1 selector làm cái gì, chỉ cần nhìn vào tên của nó
Để có một ý tưởng về nơi mà một selector được sử dụng, chỉ cần nhìn vào nó
Để biết mối quan hệ giữa các các class name, chỉ cần nhìn vào chúng
Bạn đã bao giờ nhìn thấy class name được viết như sau:
.nav--secondary {
...
}
.nav__header {
...
}
Đó là quy tắc BEM.
Video: Tối ưu Front-end để web của bạn load dưới 5 giây
Giải thích BEM
BEM cố gắng phân chia giao diện người dùng tổng thể thành các component nhỏ có thể tái sử dụng.
Hãy quan sát hình ảnh dưới đây:
Hình này biểu diễn một component, chẳng hạn như một khối thiết kế.
Bạn có thể dễ đoán được B trong BEM là viết tắt của ‘Block’.
Trong thực tế, ‘block’ này đại diện cho điều hướng trang, tiêu đề, chân trang hoặc bất kỳ khối thiết kế khác.
Theo thực tiễn được giải thích ở trên, một class name lý tưởng cho component này sẽ là stick-man.
Component nên theo kiểu sau:
.stick-man {
}
Chúng ta đã sử dụng các chuỗi giới hạn ở đây. Thật tuyệt vời!
E là viết tắt của “Elements”
E trong ‘BEM’ là viết tắt của Elements.
Khối thiết kế hiếm khi bị cô lập.
Ví dụ, stick-man phải có đầu, hai cánh tay và chân.
head, feet và arms là tất cả các element bên trong component. Chúng có thể được xem như các component con, nghĩa là con của component bố mẹ nó.
Sử dụng quy tắc BEM, các element của class name được lấy ra bằng cách thêm hai dấu gạch dưới, tiếp theo là tên phần tử.
Hãy lưu ý việc sử dụng các dấu gạch nối đôi trong ví dụ trên. Điều này biểu thị một modifier.
Đây là điều cơ bản về cách quy tắc BEM hiệu quả như thế nào.
Cá nhân tôi có xu hướng chỉ sử dụng các class name dùng phân cách gạch ngang cho các dự án đơn giản và BEM cho các giao diện người dùng có liên quan.
Tại sao sử dụng các quy ước đặt tên?
Đặt tên là một việc cực kì khó. Chúng tôi đang cố gắng làm mọi việc dễ dàng hơn và tiết kiệm thời gian cho chúng tôi trong tương lai với code có thể duy trì nhiều hơn.
Đặt tên đúng cách trong CSS sẽ làm cho code của bạn dễ đọc và dễ dàng hơn.
Đặt đúng tên trong CSS sẽ giúp bạn dễ đọc và duy trì code hơn.
Nếu bạn chọn sử dụng quy tắc BEM, nó sẽ trở nên dễ dàng hơn để xem mối quan hệ giữa các component của bạn/khối chỉ bằng cách nhìn vào đánh dấu.
Đặt tên CSS với JavaScript Hooks
VD ta được chuyển giao code HTML trông như sau:
<div class="siteNavigation">
</div>
ta đã đọc bài này và nhận ra rằng đây không phải là cách tốt nhất để đặt tên cho những thứ trong CSS. Vì vậy, ta tiếp tục code và tái cấu trúc các codebase trước:
<div class="site-navigation">
</div>
Một nơi nào đó trong JavaScript code, có sử dụng class mà ta chưa rename, siteNavigation:
//the Javasript code
const nav = document.querySelector('.siteNavigation')
Vì vậy, với sự thay đổi class name, biến nav biến thành null.
Để ngăn chặn các trường hợp này, developer đã đưa ra các chiến lược khác nhau.
1.Sử dụng js- class names
Một cách để giảm thiểu các lỗi như vậy là sử dụng class name js-* để biểu thị mối quan hệ với DOM element đang được đề cập.
const nav = document.querySelector("[rel='js-site-navigation']")
Tôi có nghi ngờ về kỹ thuật này, nhưng bạn có thể bỏ qua nó trong một số codebases. Yêu cầu ở đây là “có một mối quan hệ với Javascript, vì vậy tôi sử dụng thuộc tính rel để biểu thị điều đó”.
Web là một nơi lớn với rất nhiều “phương pháp” khác nhau để giải quyết cùng một vấn đề.
3. Không sử dụng data attribute
Một số developer sử dụng các data attributes như JavaScript Hooks. Điều này là không đúng. Theo định nghĩa, data attributes được sử dụng để lưu trữ dữ liệu tùy chỉnh.
Tip: Thêm các CSS comments
Điều này không liên quan gì đến các quy ước đặt tên, nhưng cũng sẽ giúp bạn tiết kiệm được nhiều thời gian.
Trong khi rất nhiều nhà phát triển web cố gắng không viết các bình luận JavaScript hoặc viết đại loại, tôi nghĩ bạn nên viết comment cho CSS.
Vì CSS không phải là “ngôn ngữ” thân thiện nhất, nếu có comment chi tiết rõ ràng thì bạn sẽ tiết kiệm thời gian khi bạn hoặc ai đó sau này xem lại code của mình.
TopDev chọn lọc và giới thiệu các tài liệu lập trình Android miễn phí từ cơ bản đến nâng cao cùng những công cụ dành cho các bạn muốn tìm hiểu và bắt đầu lập trình Android, cũng như muốn nâng cao “tay nghề” và dấn thân vào con đường lập trình Android chuyên nghiệp.
Đây là tài liệu Android dành cho những người mới sử dụng JAVA và lập trình Android. Tác giả cung cấp hơn 40 ứng dụng nhỏ trong suốt cuốn sách để đi cùng với lời giải thích đơn giản và rõ ràng về các chủ đề. Từ Android Studio đến JAVA đến vòng đời sản phẩm, cuốn sách này bao gồm tất cả các khái niệm cơ bản bạn cần nắm để bắt đầu xây dựng ứng dụng Android đầu tiên của mình.
Tuyển tập seri Head First đã mang đến cuốn sách tuyệt vời cho các lập trình viên. Head First Android Development thể hiện cách tiếp cận độc đáo, hướng dẫn bằng hình ảnh để việc học lập trình Android trở nên thú vị và hấp dẫn. Ngay cả đối với người mới bắt đầu làm quen Android, cuốn sách này sẽ giúp bạn nắm bắt cách xây dựng ứng dụng Android đầu tiên của mình một cách nhanh chóng.
Quyển sách dành cho các bạn muốn bắt tay vào xây dựng app trên nền tảng Android. Cập nhật các chương mới về phát triển giao diện người dùng và luồng nâng cao, thanh toán trong ứng dụng,…cùng với các kỹ thuật mới truy cập phần cứng NFC đến sử dụng Google Cloud Messaging. Bạn sẽ học các kỹ thuật thực hành tốt nhất để giải quyết hiệu quả các vấn đề phổ biến và để tránh những cạm bẫy trong toàn bộ vòng đời phát triển
Nếu bạn là người đã có kinh nghiệm lập trình JAVA, đây là một cuốn sách tuyệt vời cho việc học lập trình Android. Dựa trên khóa học Android Bootcamp trong một tuần được tài trợ bởi Big Nerd Ranch, cuốn sách này cung cấp những giải thích một cách toàn diện, thực tiễn và súc tích về các khái niệm, API trong lập trình Android.
Đây là một lựa chọn tuyệt vời khác cho lập trình viên Android đang tìm kiếm những thứ “nặng đô” hơn. Cuốn sách nhằm mục đích thúc đẩy các ranh giới lập trình Android với nhiều mẹo, thủ thuật và các kỹ thuật mà đa số chưa biết hoặc chưa được tận dụng. Đây sẽ giúp bạn trở thành lập trình viên Android cao cấp hơn.
Đối với lập trình viên Android dày dạn kinh nghiệm đang tìm kiếm các chủ đề nâng cao và chuyên sâu hơn, đây là một lựa chọn tuyệt vời. Cuốn sách cung cấp các kỹ thuật lập trình Android cao cấp để giúp các lập trình viên xây dựng các ứng dụng ở mức chuyên nghiệp hơn. Ngoài ra, Advanced Android Application Development cung cấp cho nhà phát triển một bộ hướng dẫn toàn diện chắc chắn sẽ có ích.
Quyển sách cung cấp các kiến thức quản lý hầu hết các chức năng cơ bản của Raspberry Pi từ điện thoại Android của bạn. Sử dụng các dự án được tạo trong cuốn sách này để phát triển các dự án thú vị hơn nữa trong tương lai. Trải nghiệm học tập dựa trên dự án để giúp bạn khám phá những cách tuyệt vời để kết hợp sức mạnh của Android và Raspberry Pi.
Trong Android Recipes, bạn sẽ tìm thấy các ví dụ mã trực tiếp. Nó cung cấp lời khuyên thực tế sẽ giúp bạn hoàn thành công việc một cách nhanh chóng và tốt đẹp. Điều này có thể giúp bạn tiết kiệm rất nhiều công việc so với việc tạo một dự án từ đầu!
Tập hợp một số công cụ tốt nhất để nâng cao hiệu suất phát triển và xây dựng các ứng dụng Android. Những công cụ này đã giúp các nhà lập trình tiết kiệm rất nhiều thời gian quý giá từ cuộc sống hàng ngày và cũng như tạo các ứng dụng tốt hơn và chất lượng được nâng lên đáng kể.
Là sự tiếp nối của phần 1, ở phần 2 tác giả đề cập những công cụ tiếp theo nhằm hỗ trợ đắc lực trong nâng cao hiệu suất phát triển và xây dựng các ứng dụng Android
Một CV tốt, đồng nghĩa với cơ hội bạn được nhà tuyển dụng để mắt đến càng cao. Để nâng cao khả năng trúng tuyển thì một bản CV chuyên dụng của từng ngành là điều không thể thiếu, nhất là đối với ngành đòi hỏi chuyên môn cao như công nghệ thông tin. Để viết CV xin việc IT thì có rất nhiều cách, và một CV IT gây ấn tượng thông thường có các đề mục cơ bản sau:
Thông tin cá nhân: Liệt kê đơn giản họ tên, năm sinh, địa chỉ, email, số ĐT kèm ảnh đại diện nên rõ mặt, nghiêm túc, chất lượng rõ nét, không nên là ảnh selfie. Email cũng cần nghiêm túc và tốt nhất là bằng tên thật của bạn để thể hiện sự chuyên nghiệp.
Mục tiêu nghề nghiệp: Nêu rõ định hướng của bạn trong con đường nghề nghiệp của mình. Hãy tóm tắt trong vòng 2-3 câu mục tiêu ngắn hạn/dài hạn của bạn đối với công việc đang ứng tuyển. Với mục này nhà tuyển dụng có thể đánh giá được phần nào năng lực cũng như tầm nhìn, và quyết định xem có nên đọc tiếp CV của bạn hay không.
Kỹ năng: Liệt kê những gì bạn biết và/hoặc có kinh nghiệm và nêu chính xác mức độ hiểu biết của bạn trong từng mục. Phần này cũng quan trọng không kém trong CV ngành công nghệ thông tin.
Kinh nghiệm làm việc: Tóm tắt, liệt kê những dự án, công ty mà bạn đã từng làm việc, kèm chức vụ và sắp xếp theo trình tự thời gian từ mới nhất đến cũ nhất. Đây có thể nói là phần quan trọng nhất của một CV IT.
Thành tựu: Liệt kê thành tựu cá nhân trong các dự án đó. Thành tựu ở đây có thể là những gì bạn tự hào rằng mình đã làm được cho dự án, những điều bạn nhận ra và cải thiện được cho bản thân nhờ dự án.
Thông tin khác: Bằng cấp, giải thưởng, dự án riêng (nếu có)
Tìm việc chỉ phụ thuộc vào may mắn là một quan niệm sai lầm. Sự chuẩn bị cẩn thận và đánh giá đúng khả năng của bản thân quyết định rất lớn đến việc thành công ứng tuyển của bạn. Để bạn không phải lo lắng quá nhiều về câu hỏi làm sao để có 1 CV IT chuẩn? TopDev đã tạo sẵn cho bạn những mẫu CV IT cực đẹp mà đơn giản kèm theo thông tin đầy đủ theo tiêu chuẩn. Bạn chỉ cần đơn giản là vào công cụ tạo CV online đáng tin cậy của TopDev.
Tổng hợp các mẫu CV IT đẹp – chuẩn dành cho các bạn lập trình viên Backend, Frontend, Fullstack, iOS, Android, PHP, .NET, Java… từ level Fresher cho đến Senior, Leader.
Giới thiệu
Viết CV luôn là một vấn đề nan giải cho bất kỳ ai. Tuy nhiên bạn chỉ cần dành ra 5 phút để tham khảo các mẫu CV IT chuẩn được TopDev thiết kế dành riêng cho lập trình viên, dựa trên hơn 1.000 mẫu CV Developer nổi bật trên thế giới, ứng tuyển thành công các vị trí tại các tập đoàn công nghệ lớn Microsoft, Google, Amazon…
Bạn sẽ biết cách làm thế nào để có một CV đúng, chuẩn và phù hợp với từng vị trí công việc cụ thể đối với ngành công nghệ thông tin, chọn lọc các thông tin tiêu chuẩn và cấu trúc thống nhất giúp Nhà tuyển dụng dễ dàng đánh giá kinh nghiệm và Tech stack của bạn.
Ngoài ra, việc có CV tốt cũng giúp cho bạn có được nhiều cơ hội tốt hơn trong tương lai, hãy nhớ rằng, trong CV phải luôn có đủ những thông tin sau đây.
Thông tin cá nhân: Liệt kê đơn giản họ tên, năm sinh, địa chỉ, email, số điện thoại kèm ảnh đại diện nên rõ mặt, nghiêm túc, chất lượng rõ nét, không nên là ảnh selfie. Email cũng cần nghiêm túc và tốt nhất là bằng tên thật của bạn để thể hiện sự chuyên nghiệp.
Mục tiêu nghề nghiệp: Nêu rõ định hướng của bạn trong con đường nghề nghiệp của mình. Hãy tóm tắt trong vòng 2-3 câu mục tiêu ngắn hạn/dài hạn của bạn đối với công việc đang ứng tuyển.
Với mục này nhà tuyển dụng có thể đánh giá được phần nào năng lực cũng như tầm nhìn, và quyết định xem có nên đọc tiếp CV của bạn hay không.
Kỹ năng: Liệt kê những gì bạn biết và/hoặc có kinh nghiệm và nêu chính xác mức độ hiểu biết của bạn trong từng mục. Phần này cũng quan trọng không kém trong CV ngành công nghệ thông tin.
Kinh nghiệm làm việc: Tóm tắt, liệt kê những dự án, công ty mà bạn đã từng làm việc, kèm chức vụ và sắp xếp theo trình tự thời gian từ mới nhất đến cũ nhất. Đây có thể nói là phần quan trọng nhất của một CV IT. Lưu ý hãy trình bày kinh nghiệm làm việc theo thứ tự thời gian ưu tiên những vị trí gần đây nhất và những kinh nghiệm liên quan đến vị trí mà bạn đang ứng tuyển.
Thành tựu/ Dự án: Liệt kê vai trò của cá nhân trong các thành tựu/dự án đó. Thành tựu ở đây có thể là những gì bạn tự hào rằng mình đã làm được cho dự án, những điều bạn nhận ra và cải thiện được cho bản thân nhờ dự án.
Thông tin khác: Bằng cấp, giải thưởng, dự án riêng (nếu có)
CV của bạn chỉ có 5 giây để gây ấn tượng với nhà tuyển dụng!
“Rất nhiều CV của ứng viên ngành công nghệ thông tin đều viết quá dài và trình bày không được mạch lạc. Họ luôn cố gắng chia sẻ nhiều thông tin để có một hồ sơ thật ấn tượng. Tuy nhiên, trong một đợt tuyển dụng có rất nhiều CV được gửi về, nhà tuyển dụng chỉ có thời gian rất ngắn lướt qua và lựa chọn hồ sơ phù hợp để cân nhắc tiếp theo. Vì vậy để được nhận lời mời phỏng vấn, những gợi ý và mẫu CV IT dưới đây có thể giúp bạn nhanh chóng lọt vào mắt của nhà tuyển dụng” chia sẻ từ Mr. Xuân Sơn, Product Manager của Tuổi Trẻ Online.
1. ĐỘ DÀI
CV IT của bạn chỉ nên gói gọn trong 1 trang giấy khổ A4, nếu quá trình công tác của bạn lâu năm có thể kéo dài lên thành 2 trang để thể hiện rõ chi tiếp hơn.
2. CẤU TRÚC
Để thuận tiện cho nhà tuyển dụng, hãy đặt phần thông tin liên lạc ở phần đầu của hồ sơ, kế đến là tóm tắt về chuyên môn, những kỹ năng và kinh nghiệm của bạn, cuối cùng là phần học vấn và bằng cấp. Hiện nay, bạn có thể tham khảo một số mẫu CV IT Tiếng anh và tiếng Việt phổ biến để tiết kiệm thời gian hơn cho việc thiết kế của bạn.
3. NỘI DUNG VÀ TỪ NGỮ
Phần tóm tắt chuyên môn hãy mô tả ngắn gọn về định hướng công việc và vị trí mong muốn sắp tới. Trong mục kỹ năng, chỉ liệt kê từ 4 đến 6 kỹ năng quan trọng nhất mang đến thành công trong công việc của bạn. Khi mô tả về kinh nghiệm làm việc, hãy sử dụng những động từ diễn tả thành công như “đạt được”, “gia tăng”… kèm theo một vài số liệu ấn tượng, điều này giúp bạn nổi bật hơn so với các CV khác.
Hãy định dạng đơn giản và thông dụng nhất, để nhà tuyển dụng dễ dàng thấy được những điểm bạn muốn nhấn mạnh. Tránh dùng nhiều màu sắc, chữ in đậm hoặc viết hoa quá nhiều, chỉ gây khó chịu khi nhìn vào CV của bạn. Những thông tin quan trọng bạn nên đặt ở nữa trên hồ sơ và ở những khu vực nổi bật để gây chú ý nhà tuyển dụng khi họ lia mắt.
5. KIỂM TRA NHIỀU LẦN
Điều này giúp bạn tránh những sai sót lỗi chính tả, và đảm bảo bạn cung cấp đầy đủ thông tin để giới thiệu bản thân và thuyết phục nhà tuyển dụng hẹn bạn một buổi phỏng vấn. Đừng nghĩ tìm việc chỉ phụ thuộc vào may mắn. Sự chuẩn bị cẩn thận và đánh giá đúng khả năng của bản thân quyết định rất lớn đến việc thành công ứng tuyển của bạn. Bạn nên nhớ, nhà tuyển dụng chỉ có 5 giây để quyết định có xem tiếp hay không!
Đừng quên tham khảo nhiều mẫu CV đẹp dành cho lập trình viên, viết xong CV thì mạnh dạn apply vào những công việc IT với mức lương cực hấp dẫn ở TopDev nhé.
Sự kiện với quy mô toàn quốc, quy tụ cộng đồng thương mại điện tử trong và ngoài nước.
Với sự góp mặt đến từ các đại diện: VECOM, NIELSEN, AMAZON, TIKI, SHOPEE và FACEBOOK, GOOGLE.
Chỉ diễn ra 1 lần duy nhất trong năm, đây là cơ hội lớn cho các doanh nghiệp tiến lên bước mở rộng quy mô với chủ đề “Scaling Up Your Bussiness – Vươn ra toàn cầu”.
Bạn sẽ được nghe và cũng tham gia trao đổi với các chuyên gia hỗ trợ mở rộng quy mô kinh doanh, giúp bạn tiếp cận khách hàng cả nước, hoặc khách hàng toàn cầu.
200 người đăng ký sớm nhất sẽ được ƯU ĐÃI mức vé EARLY BIRD – Giá thấp nhất
* Thời gian: Ngày 28 Tháng 03 năm 2019, 8.30AM – 5PM * Địa điểm: Trung tâm Hội nghị Capella Parkview, Số 3 Đặng Văn Sâm, Phường 9, Phú Nhuận, Tp. Hồ Chí Minh
Lưu ý: Số lượng chỗ ngồi có hạn, BTC chỉ ưu tiên giữ chỗ cho những ai đăng ký và hoàn tất thanh toán sớm nhất!
Trong lập trình web, chúng ta có sự tương tác giữa client với server. Phần mềm gồm 2 thành phần chính: phần mềm và data. Như vậy, một phần mềm được thiết kế theo tương tác client – server thì phần nhiều tập lệnh sẽ nằm phía server. Client có nhiệm vụ gửi dữ liệu lên để xử lý sau đó nhận kết quả trả về. Vậy stateful vs stateless là gì?
Để hiểu khái niệm stateful vs stateless là gì chúng ta cần phải biết rằng, Stateless là thiết kế không lưu dữ liệu của client trên server. Có nghĩa là sau khi client gửi dữ liệu lên server, server thực thi xong, trả kết quả thì “quan hệ” giữa client và server bị “cắt đứt” – server không lưu bất cứ dữ liệu gì của client. Như vậy, khái niệm “trạng thái” ở đây được hiểu là dữ liệu.
Stateful là một thiết kế ngược lại, chúng ta cần server lưu dữ liệu của client, điều đó đồng nghĩa với việc ràng buộc giữa client và server vẫn được giữ sau mỗi request (yêu cầu) của client. Data được lưu lại phía server có thể làm input parameters cho lần kế tiếp.
Tổng kết và ví dụ
HTTP là một Application Protocol dạng stateless, tương tác client-server theo HTTP thì phần server sẽ không lưu lại dữ liệu của client. HTTP ban đầu chỉ được dùng đơn thuần cho website, client gửi request, server nhận request xử lý rồi trả về lại cho client hiển thị. Sau đó thì kết thúc 1 quy trình. Sau này người ta mới bắt đầu nâng cấp cho phép website giống như một ứng dụng stateful bao gồm html, database (mysql, mongodb…), transaction…
Có 4 cách lưu data của client khi xây dựng Web Application bao gồm: URL Rewriter, Form, Cookie, HTTP Session.
Sau 9 tháng làm việc tại Dexter với tư cách là một lập trình viên, tôi đã học được rất nhiều điều. Cũng vì vậy, tôi đã quyết định viết một bài đăng blog chia sẽ về những trải nghiệm, cũng như một bài đăng một bài kĩ thuật về Self Positioning React Component mà tôi đã thực hiện trong vài tháng làm việc tại đây. Nhận được công việc mới chỉ là bước khởi đầu, làm thật tốt công việc được giao lại là một câu chuyện hoàn toàn khác, là một lập trình viên tôi hoàn toàn hiểu điều đó.
Những suy nghĩ của tôi về vai trò của mình đã thay đổi đáng kể kể từ khi tôi bắt đầu. Tôi đã nghĩ rằng trở thành một nhà phát triển phần mềm thì phải “xử lý” đám code càng nhanh càng tốt. Tuy nhiên, điều đó có vẻ không đúng thực tế lắm, như chuyện bạn viết code nhanh nhưng không chất lượng, buộc phải thay đổi liên tục sẽ không phải là cách giúp cho doanh nghiệp của bản có thể bị trì trệ hơn. May mắn thay, tôi đã gặp một người sếp có suy nghĩ tương tự, anh ấy cũng là dân phần mềm như tôi.
Mục tiêu của bạn sẽ là: Viết code chất lượng tốt và giao tiếp tốt với đồng nghiệp. Bạn không phải được trả tiền chỉ để code, bạn được trả tiền để suy nghĩ và tìm ra vấn đề. Sản phẩm đi kèm là tư duy tinh tể và chỉ dẫn máy làm theo dưới dạng code. Tôi muốn giải quyết vấn đề trong một dòng code dễ đọc hơn 10 dòng code khó hiểu. Tôi muốn giải quyết vấn đề trong 5 dòng code có thể đọc được so với một dòng code phức tạp, nested code kèm theo nhiều loại toán tử phức tạp. Tôi nghĩ bạn sẽ hiểu ý tôi muốn nói gì.
Muốn biết phải hỏi muốn giỏi phải học.
Những ngày đầu, tôi đã được sếp gửi cho một đường link để tham khảo, sau khi đọc tôi thật sự lo lắng về khả năng của mình. Tôi vẫn luôn rất ý thức trước khi đặt bất kỳ câu hỏi nào.
Tôi có hẳn riêng mình một check list trước khi nhờ người khác hỗ trợ điều gì:
Đây có phải là một câu hỏi mà tôi đã hỏi trước đó, và nếu có, tôi đã ghi lại câu trả lời ở đâu?
Đây có phải là điều tôi có thể Google không?
Điều này đã được ghi chép lại ở đâu đó trong nội bộ?
Chuyện gì đang xảy ra ở đây? Nguyên nhân sâu xa của lỗi hoặc các phản ứng bất ngờ mà tôi đang gặp phải là gì?
Tôi có thực sự hiểu câu hỏi tôi đang cố gắng để trả lời? Bạn có thể dành thời gian để đọc lại vấn đề một lần nữa thay vì đưa ra câu trả lời nửa vời hoặc câu trả lời hấp tấp.
Sau khi làm theo các bước này, tôi sẽ thử giải quyết vấn đề một mình, tìm một giải pháp đã được từng được document lại, hoặc hỏi một câu hỏi với ngữ cảnh tốt hơn và chi tiết hơn để giúp người khác dễ dàng trả lời hơn. Thậm chí, tốt hơn nữa, nếu tôi có thể đặt một câu hỏi hay và được trả lời qua đoạn chat, đồng đội của tôi không cần phải bỏ mọi thứ để giúp tôi.
Nếu tôi đã đi hết 90% con đường để giải quyết vấn đề thì thật ra chỉ cần 10% sự trợ giúp nữa thôi, một nhà phát triển cấp cao sẽ rất vui khi giúp bạn vì biết rằng bạn đã cố gắng hết mức có thể. Tìm kiếm người khác để giải quyết vấn đề của bạn không phải là một cách tuyệt vời để xây dựng lòng tin trong nhóm của bạn.
Những người thông minh thích những câu hỏi hay – vì vậy đừng ngại khi hỏi họ.
Video: Trọn bộ các chủ đề nâng cao của DevOps
Tránh những sai lầm cũ và hỏi những câu hỏi mà ai cũng đã biết câu trả lời.
Điều này nói dễ hơn là thực hiện, bạn có thể ứng dụng nó vào bất cứ ngành nào, không chỉ lập trình. Rất nhiều khái niệm và thông tin mới sẽ khiến mắc phải những sai lầm không đáng có, và là không thể tránh khỏi. Để hạn chế việc này, hãy nghiên cứu nhiều hơn, Google có đầy đủ thông tin. Xem kĩ các tài liệu, chúng là bạn của bạn. Hãy hỏi nếu như sau khi tìm hiểu bạn vẫn không có trả lời. Sau đó hãy viết chúng ra thành tài liệu, và đặt cho mình những mục tiêu để cải thiện nó.
Hãy đảm bảo rằng lần tiếp theo bạn gặp vấn đề tương tự, bạn biết phải làm gì. Tất cả chúng ta đều mắc sai lầm, nhưng việc tự ý thức và nỗ lực thay đổi là cách để mọi người trở nên tốt hơn.
Luôn xem lại những gì mình đã làm
Không ai thích đi qua PR và bảo bạn gỡ bỏ console.logs, debuggers hoặc bảo bạn sửa lỗi linting. Tôi sẽ không xuất bản bài đăng này mà không đọc qua một vài lần và nhờ một người bạn xem qua nó trước.
Nhìn kĩ vào code của bạn và tự hỏi những câu hỏi sau:
Tôi đã viết một đoạn logic phức tạp. Có chức năng tương tự nào trong ứng dụng có thể giải quyết vấn đề này theo cách dễ đọc hơn, linh hoạt hơn hay chung chung không?
Nếu không, tôi có nhớ lý do tại sao tôi đã viết code này trong một tuần hay không? Nếu câu trả lời là không, tôi muốn đổi code hoặc bình luận nó. Người duyệt PR nên có một số lí do giải thích tại sao tôi lại đưa ra quyết định đó.
Hãy chắc chắn rằng code của bạn đang đi qua linting và được kiểm tra trước khi đưa nó cho bất kì ai khác.
Tôi có đang lặp lại hay không? Tôi có thể làm gọn logic bị lặp bằng một hàm hay không ?
Nếu đây là code của người khác mà tôi đang xem, tôi sẽ đưa ra những bình luận nào? Tôi muốn thay đổi gì để nó rõ ràng hơn?
Hãy thử nhìn vào code của bạn vào ngày hôm sau, bạn sẽ nhìn thấy rất nhiều sự khác biệt. Liệu có gì không ổn trong logic của các đoạn code? Liệu các component của bạn có xử lý logic đúng hay không?
Ngoài ra, việc tự đánh giá code tốt tiết kiệm thời gian và tiền bạc cho công ty. Đó là cách tốt nhất để bạn tìm ra bug của bạn và tự khắc phục chúng thay vì phải nhờ người khác tìm ra chúng sau hai ngày.
Điều cuối cùng nói về việc xem lại code của bạn. Test tất cả vào MỌI THỨ bạn đã làm. Tôi muốn code của tôi gửi cho bất cứ ai cũng phải tốt đến mức không thể chỉnh sửa. Nếu họ bấm vào một trang mới và thấy được một lỗi lớn hoặc màn hình trắng, điều đó chứng minh tôi đã không thực sự xem xét lại công việc của mình. Grep cho code bạn đã chỉnh sửa và đảm bảo rằng bạn không làm hỏng bất cứ thứ gì bằng việc bổ sung thêm vào component.
Nghe có vẻ ngớ ngẩn, nhưng những sản phẩm có quá nhiều dòng code lớn phức tạp và bạn có thể không nhận ra cho đến khi bạn đã làm hỏng một cái gì đó.
Tôi chắc rằng, bạn sẽ không muốn xem bản draft đầu tiên của bài blog này 🙂
Cảnh sát Victoria là cơ quan thực thi pháp luật chính của Victoria, Úc. Với hơn 16.000 xe bị mất cắp ở Victoria trong năm qua – tổn thất khoảng 170 triệu đô – cơ quan này đang thử nghiệm nhiều giải pháp kỹ thuật nhằm giải quyết nạn trộm xe. Họ gọi open source project – hệ thống này là BlueNet.
Để giúp ngăn chặn việc bán xe ăn cắp, đã có một dịch vụ dựa trên web tên VicRoads để kiểm tra tình trạng đăng ký xe. Bộ cũng đã đầu tư vào một máy quét tấm giấy cố định – một camera cố định quét qua lưu lượng để tự động xác định các xe bị đánh cắp.
Đừng hỏi tôi tại sao, nhưng một buổi chiều tôi đã có mong muốn mẫu thử nghiệm một chiếc máy quét nhãn đĩa xe gắn máy sẽ tự động thông báo cho bạn nếu một chiếc xe đã bị đánh cắp hoặc đã không đăng ký. Hiểu rằng những thành phần cá nhân này tồn tại, tôi tự hỏi làm thế nào để kết hợp chúng với nhau khó khăn đến thế nào.
Cảnh sát Victoria vừa mới tung ra bản thử nghiệm về một phần mềm tương tự, và chi phí phát hành ước tính đã ở đâu đó trong khoảng 86.000.000 đô. Một người bình luận đã chỉ ra rằng với 86 triệu đô để trang bị cho 220 chiếc xe thì sẽ tính ra trung bình 390,909 đô mỗi chiếc.
Chắc chắn chúng ta có thể làm tốt hơn một chút.
Các tiêu chí làm nên thành công
Trước khi bắt đầu, tôi lên kế hoạch về yêu cầu chính cho thiết kế sản phẩm:
#1: Việc xử lý hình ảnh phải được thực hiện local
Streaming video trực tiếp đến nơi xử lí trung tâm dường như là cách tiếp cận hiệu quả nhất để giải quyết vấn đề này. Bên cạnh tuyệt vời cho lưu lượng truy cập dữ liệu, bạn cũng giới thiệu độ trễ mạng vào một quá trình có thể đã được khá chậm.
Mặc dù một thuật toán về centralized machine learning chỉ có thể có được sự chính xác hơn theo thời gian, chúng ta muốn tìm hiểu nếu một local thực hiện trên thiết bị sẽ là “đủ tốt”.
#2: Phải làm việc với hình ảnh có chất lượng thấp
Bởi vì tôi không có Raspberry Pi hoặc webcam USB nên tôi sẽ sử dụng footage của dashcam – nó có sẵn và là nguồn lý tưởng cho dữ liệu mẫu. Giống như added bonus, dashcam video đại diện cho chất lượng chung của footage mà bạn mong muốn từ các camera gắn trên xe.
#3: Cần được xây dựng dựa trên công nghệ mã nguồn mở
Dựa trên một phần mềm độc quyền có nghĩa là bạn sẽ get stung mỗi khi bạn yêu cầu thay đổi hoặc tăng cường – và tiếp tục stinging cho mỗi yêu cầu được thực hiện sau đó. Sử dụng công nghệ mã nguồn mở là không cần suy nghĩ.
Relying upon a proprietary software means you’ll get stung every time you request a change or enhancement — and the stinging will continue for every request made thereafter. Using open source technology is a no-brainer.
Kết luận
Ở level cao, giải pháp của tôi lấy một hình ảnh từ dashcam video, đưa nó qua qua một hệ thống nhận dạng tấm giấy phép mã nguồn mở được cài đặt cục bộ trên thiết bị, truy vấn dịch vụ kiểm tra đăng ký, và sau đó trả về kết quả.
Dữ liệu được trả lại cho thiết bị được cài đặt trong xe thực thi pháp luật bao gồm xe và mô hình (mà nó chỉ sử dụng để xác minh các xe đã bị đánh cắp), tình trạng đăng ký và bất kỳ thông báo nào của chiếc xe được báo cáo bị đánh cắp.
Nghe có vẻ đơn giản, đó là bởi vì nó thực sự là. Ví dụ, xử lý hình ảnh tất cả có thể được xử lý bởi thư viện openalpr.
Tất cả được dùng để nhận diện các ký tự trên license plate:
openalpr.IdentifyLicense(imagePath, function (error, output) {
// handle result
});
Đây là những điều của tôi chứng minh khái niệm như sau:
// Open form and submit enquire for `rego`
function getInfo(rego) {
horseman
.userAgent('Mozilla/5.0 (Windows NT 6.1; WOW64; rv:27.0) Gecko/20100101 Firefox/27.0')
.open(url)
.type('#registration-number-ctrl input[type=text]', rego)
.click('.btn-holder input')
.waitForSelector('.ctrl-holder.ctrl-readonly')
.html()
.then(function(body) {
console.log(processInfo(body, rego));
return horseman.close();
});
}
// Scrape the results for key info
function processInfo(html, rego) {
var $ = cheerio.load(html);
var vehicle = $('label.label').filter(function() {
return $(this).text().trim() === 'Vehicle:';
}).next().text().trim();
var stolen = $('label.label').filter(function() {
return $(this).text().trim() === 'Stolen status:';
}).next().text().trim();
var registration = $('label.label').filter(function() {
return $(this).text().trim() === 'Registration status & expiry date:';
}).next().text().trim();
return {
rego,
vehicle,
stolen,
registration
};
}
Kết quả
Sự công nhận về giấy phép mã nguồn mở được không được công nhận. Ngoài ra, các thuật toán nhận dạng hình ảnh có thể không được tối ưu hóa cho tấm giấy phép của Úc.
Giải pháp đã có thể nhận diện tấm giấy phép trong một lĩnh vực rộng.
Các chú thích được thêm vào có hiệu lực. Biển số được nhận dạng mặc dù reflection và lens distortion.
Mặc dù, giải pháp này đôi khi gặp vấn đề với các chữ cái trên biển số.
Sai lầm trên biển số, nhầm M thành H
Nhưng … các giải pháp cuối cùng sẽ có được sự chính xác.
Một vài khung hình sau đó, M được xác định chính xác và ở mức độ tin cậy cao hơn
Như bạn thấy trong hai hình ảnh trên, việc xử lý hình ảnh một vài khung hình sau đó đã nhảy lên từ mức độ tự tin là 87% đối với tóc trên 91%.
Với tính chính xác có thể được cải thiện bằng cách tăng tỷ lệ mẫu và sau đó sắp xếp theo thứ hạng độ tin cậy cao nhất. Ngoài ra, một ngưỡng có thể được đặt chỉ chấp nhận sự tự tin lớn hơn 90% trước khi tiếp tục xác nhận số đăng ký.
Đây là các bản sửa lỗi code đầu tiên và không loại trừ việc đào tạo phần mềm nhận dạng license plate với bộ dữ liệu cục bộ.
Còn về 86,000,000 đô
Để công bằng, tôi hoàn toàn không biết có bao nhiêu con số 86 triệu đô – và tôi cũng không thể nói về tính chính xác của công cụ mã nguồn mở của tôi mà không cần đào tạo so với hệ thống BlueNet.
Tôi hy vọng phần của ngân sách đó bao gồm việc thay thế một số cơ sở dữ liệu và các ứng dụng phần mềm để hỗ trợ truy vấn các cấp phép có tần số cao, độ trễ thấp trên mỗi xe.
Mặt khác, chi phí khoảng 391k đô mỗi xe dường như khá tốn kém – đặc biệt nếu BlueNet không chính xác và không có các dự án công nghệ thông tin quy mô lớn để ngừng hoạt động hoặc nâng cấp các hệ thống bị phụ thuộc.
Các ứng dụng tương lai
Mặc dù rất dễ bị cuốn vào bản chất Orwellian của một mạng lưới những người tán thành tấm giấy phép luôn có nhiều ứng dụng tích cực của công nghệ này. Hãy tưởng tượng một hệ thống thụ động quét người cùng đi xe và tự động cảnh báo các nhà chức trách và thành viên gia đình đến vị trí hiện tại của họ.
Xe của Teslas đã được làm đầy bằng camera và cảm biến với khả năng nhận được các bản cập nhật OTA – hãy tưởng tượng biến những chiếc xe này thành một đội quân tốt. Các tài xế của Ubers và Lyft cũng có thể được trang bị các thiết bị này để tăng đáng kể phạm vi bảo hiểm.
Sử dụng công nghệ mã nguồn mở và các component hiện có, có vẻ như có thể cung cấp một giải pháp cung cấp một tỷ lệ lợi nhuận cao hơn nhiều – cho một khoản đầu tư ít hơn 86 triệu đô.
Ngày nay, chúng ta đã quen thuộc với các khái niệm như Trí tuệ nhân tạo (artificial intelligence). Điển hình như các gợi ý, đề xuất sách và phim trên Amazon và Netflix hay danh sách phát nhạc trên Spotify, Youtube, … Nhưng năm 2019 sẽ mang lại cho chúng ta những gì có thể xem là “siêu cá nhân hóa” (hyper-personalization) cho người tiêu dùng thông qua một loạt các ứng dụng về sức khỏe, tài chính, mua sắm và mọi thứ liên quan. Điều này là một bước tiến mới của các ứng dụng AI khi khả năng dự đoán chính xác ngày càng tăng cao, ít tốn chi phí hơn cho dù dữ liệu cá nhân người dùng thì ngày càng dày đặc. Dưới đây là một số lĩnh vực mà chúng ta có thể mong đợi “siêu cá nhân hóa” dựa trên AI vào năm nay.
1. Thể dục thể chất (Physical Fitness)
Sức khỏe là một trong những lĩnh vực hot của các ứng dụng AI. Các ứng dụng thể dục và thiết bị đeo như Fitbit và Apple Watch và thậm chí một số tai nghe VR có thể tự động thu thập dữ liệu của người dùng – chẳng hạn như bạn đã đi bao nhiêu bước hay leo bao nhiêu nấc thang – và tổng hợp với tất cả các dữ liệu của toàn bộ người dùng để tạo ra hồ sơ thể hình riêng biệt dành cho từng người và lên các kế hoạch theo đó, giống như bộ điều chỉnh nhiệt thông minh Nest sử dụng dữ liệu từ khắp các gia đình để tối ưu hóa các kế hoạch sử dụng năng lượng. Những gợi ý như “Giảm lượng thức ăn của bạn 210 calo / ngày để tăng tuổi thọ thêm 1,5 năm” sẽ không còn xa.
Bên cạnh đó, vấn đề thường xuyên ở hầu hết các ứng dụng tập thể dục – sức khỏe – thể hình là việc người dùng mệt mỏi khi nhập các loại thực phẩm họ đã ăn – hoặc gian lận và chọn không nhập chúng. Điều đó dẫn đến nếu không có dữ liệu chính xác thì các phân tích là vô nghĩa. Tuy nhiên, AI đã có giải pháp khắc phục: Khi AI trở nên tiên tiến hơn, bạn chỉ cần chụp ảnh những gì bạn ăn hoặc ứng dụng sẽ theo dõi lượng thức ăn thông qua camera của smartphone và tự động hóa quy trình thu thập dữ liệu. Một số ứng dụng như Lose It đã sử dụng công nghệ này.
2. Sức khỏe tâm thần (Mental Heath)
*Là một trạng thái không chỉ không có rối loạn hay dị tật tâm thần mà còn là một trạng thái tâm thần hoàn toàn thoải mái, cần phải có chất lượng nuôi sống tốt, có được sự cân bằng và hòa hợp giữa cá nhân, người xung quanh và môi trường xã hội.
Bạn có muốn biết thời gian nào trong ngày là lúc tâm trạng bạn suy sụp nhất? Hay cách mà mọi người tác động đến bạn sẽ có phản ứng với mức năng lượng như thế nào? Sẽ sớm có một ứng dụng cho điều đó. Các ứng dụng có thể tự thực hiện cảm biến, sử dụng cảm biến sinh học để theo dõi nhịp tim / nhịp thở, phản ứng ngoài da và các chỉ số khác để đánh giá phản ứng của chúng ta đối với mọi thứ từ buổi sáng đi làm đến bữa tối với luật pháp. Sau đó, chúng ta có thể sử dụng các báo cáo toàn diện được tạo ra cho lối sống thoải mái hơn, ít căng thẳng hơn, hoặc ít nhất là nhận thức được con người và các tình huống có nhiều khả năng làm cho lòng bàn tay đổ mồ hôi.
Công nghệ nhận dạng khuôn mặt dựa trên AI cũng có ứng dụng rộng rãi trong sức khỏe tâm thần. Affectiva, một doanh nghiệp xuất phát từ MIT, cung cấp các sản phẩm ứng dụng “kích hoạt cảm xúc” bằng cách đọc và phân tích biểu cảm khuôn mặt với độ chính xác tốt hơn con người. Vì vậy, các ứng dụng sẽ đánh giá mức độ căng thẳng hoặc các triệu chứng lo âu / trầm cảm của bạn và đưa ra gợi ý phù hợp: “Thực hiện hai phút thở sâu” hoặc “Hẹn gặp bác sĩ trị liệu”. Công ty cũng đã phát triển một sản phẩm trong xe hơi để đánh giá trạng thái cảm xúc trong khi lái xe từ biểu cảm khuôn mặt và giọng nói, cải thiện an toàn khi trên đường.
Có rất nhiều câu hỏi đặt ra trong lĩnh vực này: Làm thế nào để chúng ta biết những khoản đầu tư nào phù hợp nhất với sự tăng trưởng, rủi ro và nhu cầu thanh khoản của từng cá nhân? Và khi nào nên đầu tư vào chúng? Và đầu tư bao nhiêu? Và khi nào bán?
Câu trả lời ngắn gọn: “Chúng tôi không rõ. Nhưng AI thì có thể”
Các ứng dụng AI sẽ ngày càng cải thiện khả năng dự đoán rủi ro của chúng ta và các tính năng của hồ sơ đầu tư khác bằng cách “đọc giữa các dòng” theo nghĩa đen. Các nhà nghiên cứu đã phát triển một thuật toán deep learning có thể phân tích lời nói hoặc văn bản để đánh giá mức độ tin cậy của người nói / người viết về bất kỳ điều gì về hiệu quả của sản phẩm nào đó và xác định tính chính xác của các dự báo thu nhập được.
Một ứng dụng tài chính cá nhân kết hợp công nghệ như vậy có thể yêu cầu bạn viết phản hồi cho một số tình huống chấp nhận rủi ro khác nhau, sau đó đánh giá mức độ tự tin của bạn về mỗi kế hoạch để tạo ra một kế hoạch đầu tư được cá nhân hóa cao trong ngắn hạn hoặc dài hạn. Trên thực tế, công ty Narrative Science ở giai đoạn đầu đang sử dụng xử lý ngôn ngữ tự nhiên để phát triển các ứng dụng loại này và có khả năng giúp người dùng hiểu được mức độ chịu đựng của họ đối với các lớp đầu tư như cổ phiếu hòa vốn.
4. Mua sắm (Shopping)
Là người mua sắm, chúng ta muốn được cá nhân hóa trong các lựa chọn của mình, từ phụ kiện, quần áo cho đến ô tô; nhưng bên cạnh đó tôi cũng muốn mua những thứ mà những người giống tôi mua hoặc những thứ tôi muốn giống như vậy. Các ứng dụng AI tập trung vào bán lẻ có thể giúp xác định sở thích sản phẩm của chúng ta bằng cách không chỉ nhìn vào các hành vi mua hàng trong quá khứ, mà cả những người giống chúng ta, để đưa ra các đề xuất dựa trên hình thức đám đông hậu trường (behind-the-scenes crowdsourcing). Và điều này đã xảy ra khi Amazon đã tổng hợp dữ liệu cá nhân để phát triển các đề xuất sản phẩm và các dự đoán khác trong một thời gian trước đó. Nhưng cụ thể nó sẽ xuất hiện vào năm 2019 – trên các ngành và loại sản phẩm – và mức độ cá nhân hóa để mong đợi sẽ tăng lên.
Nhận dạng khuôn mặt nâng cao đồng nghĩa với việc trải nghiệm tại cửa hàng được cá nhân hóa hơn nhiều. Ví dụ, các nhà bán lẻ sẽ có thể nhận ra các khách hàng của chương trình khách hàng thân thiết đã bước vào và đẩy các giao dịch, các đề xuất được cá nhân hóa cho họ thông qua điện thoại của họ, cùng với việc cung cấp dịch vụ ở mức cao hơn (như tư vấn mua sắm). Nhận dạng khuôn mặt cũng sẽ cho phép doanh nghiệp phân tích phong cách mua sắm của khách hàng hoặc phân khúc hoặc đường dẫn trong cửa hàng chặt chẽ hơn.
Nhìn chung, siêu cá nhân hóa dựa trên AI mang lại lợi ích tiềm năng rất lớn nhưng nó cũng kèm theo một lời cảnh báo: Các doanh nghiệp càng sở hữu nhiều dữ liệu cá nhân của chúng ta, nguy cơ lạm dụng và mất cắp dữ liệu càng tiềm ẩn. Tuy nhiên, các vấn đề bảo mật đang được đẩy mạnh cùng với AI để nhằm đảm bảo độ an toàn và sự trải nghiệm để giúp cuộc sống chúng ta ngày một tốt hơn. Hiện nay TopDev đang có sự kiện “AI và NLP – Ứng dụng thực tiễn và cách bắt đầu” được mở rộng hơn từ chuỗi sự kiện “AI – Ứng dụng thực tiễn và cách bắt đầu” với nhiều cái nhìn đa chiều về AI và NLP trong thực tế xung quanh chúng ta.
THÔNG TIN CHI TIẾT
Thời gian & địa điểm: 17:30 – 21:00 ngày 19/03/2019
Năm 2018 có thể coi là một dấu mốc lớn trong lĩnh vực trí tuệ nhân tạo (AI), dù có cả những nốt thăng và trầm.
Các tin đáng chú ý về AI trong năm 2018
Xe tự động: Bất kể những diễn biến không mấy lạc quan, rõ ràng năm 2018 là một năm quan trọng trong việc thúc đẩy ngành công nghiệp sản xuất xe tự vận hành đi lên. Hàng loạt cuộc thử nghiệm được tiến hành của Uber, Waymo (của Google), Lyft cùng nhiều công ty khác được diễn ra và đã có những thành quả đầu tiên sau giai đoạn kiện tụng về quyền sở hữu trí tuệ giữa các ông lớn. Có thể nói xe tự lái đã chính thức có mặt dù vẫn còn nhiều vấn đề phải giải quyết trước khi các phương tiện có khả năng tự chủ hoàn toàn.
Trợ lý ảo, ứng dụng tại các doanh nghiệp: Các thiết bị tích hợp trợ lý “ảo” và được điều hành thông qua giọng nói đã được đầu tư về hình ảnh, tính năng một cách đáng kể và có một vị trí lớn trong xu hướng AI trong năm 2018. Các trợ lý ảo có thể gọi điện, trò chuyện với người thật hoàn hảo tới mức không thể hình dung là họ đang nói chuyện với máy. Chatbot trở nên phổ biến tại lĩnh vực dịch vụ chăm sóc khách hàng, trong khi những công nghệ tự quản lý thông tin tích hợp AI đã dần hoàn thiện hơn. Nhiều công ty cũng đang nỗ lực đưa ra những bước tiến mới trong quá trình xử lý ngôn ngữ tự nhiên, giúp doanh nghiệp có thể tìm hiểu rõ hơn các luồng dữ liệu phi cấu trúc của họ. Hoạt động marketing có sử dụng hỗ trợ từ AI cũng là một trong những xu hướng nổi bật trong năm 2018, với khái niệm siêu cá nhân hóa được chú ý hơn khi các công ty nhận ra lợi ích của AI trong hoạt động này.
Chương trình AI cấp quốc gia: Rất nhiều nước trên thế giới đều đẩy mạnh và xem việc phát triển AI là một trong những nhiệm vụ hàng đầu. Điển hình như lộ trình ba bước của Trung Quốc với nguồn quỹ đầu tư 5 tỷ USD cùng một công viên công nghệ trị giá 2,1 tỷ USD để tạo điều kiện phát triển công nghệ, Mỹ và Pháp với kế hoạch đầu tư lần lượt là 2 tỷ USD và 1,5 tỷ Euro cho các sáng kiến liên quan đến AI, …
Riêng ở Việt Nam, “Kế hoạch phát triển trí tuệ nhân tạo ở Việt Nam đến năm 2025” đã được ban hành và sẽ tập trung phát triển các công nghệ nền tảng về xử lý và nhận dạng âm thanh, tiếng nói, hình ảnh, thị giác máy, tích hợp dữ liệu, bản đồ số, quản lý dây chuyền sản xuất. Nhiều trường đại học cũng đã bổ sung và cập nhật các kiến thức liên quan đến AI vào chương trình đào tạo cũng như một số trường đào tạo miễn phí ngành Robot và Trí tuệ nhân tạo cho sinh viên.
Bên cạnh đó, các mảng khác của trí tuệ nhân tạo cũng thu được những kết quả rất tích cực: nhận diện khuôn mặt ngày càng phát triển giúp tăng cường khả năng bảo mật và quản lý, quá trình tự động hóa robot (RPA) và học máy ngày càng được đẩy mạnh, các nguồn vốn được rót vào cũng như bộ luật AI được ban hành giúp cho AI ngày càng lan rộng và phát triển mạnh mẽ hơn.
AI một trong những công nghệ đang xâm nhập vào thực tiễn, góp phần định hướng tương lai đang tạo ra nhiều cơ hội cho các doanh nghiệp trong thời kỳ chuyển đổi số. Nhưng để đi đến những điều lớn lao, AI là gì và đang được ứng dụng xung quanh chúng ta như thế nào? bạn nên nắm rõ. Một trong những tech-meetup đáng chú ý vào tháng 03/2019 là “AI và NLP – Ứng dụng thực tiễn và cách bắt đầu”
Độc giả TopDev Blog có thể tham gia sự kiện theo thông tin bên dưới:
Thời gian & địa điểm: 17:30 – 21:00 ngày 19/03/2019
Với sự lớn mạnh hơn 90 công ty trong và ngoài nước, Persol vẫn đang tiếp tục phát triển thêm nguồn lực để mở rộng quy mô. Với Persol, con người chính là nền tảng, mỗi cá nhân cần được đầu tư cho sự phát triển. Đó cũng là lý do tại sao môi trường việc làm tại Persol lại có thể thu hút được nhiều nhân tài.
Persol: “Work and Smile”!
Thương hiệu Persol có từ tháng 7 năm 2016, đến nay tập đoàn Persol đã lớn mạnh với hơn 90 công ty trong và ngoài nước, tham gia vào nhiều lĩnh vực: cung cấp các giải pháp về System, Outsourcing, Product, Global team system và Tư vấn công nghệ. Là một đối tác phát triển cá nhân, Tập đoàn Persol hoạt động để rút ra tiềm năng cá nhân và tối đa hóa các cơ hội sống. Persol mong muốn giúp tạo ra một xã hội trong đó tất cả những người làm việc có thể trải nghiệm niềm vui của Tagline nhóm của Persol: “Work and Smile”.
Song song với việc phát triển quy mô, Persol luôn luôn chú trọng đến phát triển nhân lực và thu hút nguồn lao động chất lượng. Bởi vì, Persol bắt nguồn từ “Person- con người” với tâm niệm: sự phát triển của mỗi cá nhân chính là cốt lõi sự phát triển của công ty.
5 yếu tố tạo nên giá trị của Persol Process & Technology Vietnam:
➤ Your job – your joy: niềm vui đến từ chính công việc bạn đang làm
➤ Work & smile: hăng say lao động và thư giãn khi cần
➤ When you like your work everyday is a holiday: được làm điều mình thích mỗi ngày, đó là sự tận hưởng.
➤ Hiring the right person: tuyển đúng người, dùng đúng lúc.
Persol không ngừng chiêu mộ nhân tài với nhiều đãi ngộ xứng đáng cả vật chất lẫn tinh thần. Đặc biệt hiện tại, Persol đang mở ra cơ hội cho những tài năng muốn thử sức ở vai trò lãnh đạo – vị trí Technical Project Manager (PHP, Java, C#) với mức lương lên đến 3,000 USD.
Persol Việt Nam tìm bạn đồng hành, vạch lối đi mới cho nền công nghệ Việt Nam
Persol luôn mong mỏi kết nối được với những nhà quản lý tài năng, cùng theo đuổi đam mê, cùng gặt hái cái kết ngọt cho những người trẻ đầy ý chí. Technical Project Manager (PHP, Java, C#) chính là tấm vé mà Persol muốn gửi đến các kỹ sư công nghệ tại Việt Nam với những quyền lợi đặc biệt:
Mức lương hậu hĩnh lên tới $3,000;
Được review hiệu quả công việc nâng mức thu nhập 2 lần/ năm;
Nghỉ phép thả ga tận 24 ngày lương vẫn về đều đặn;
Luôn có cà phê, trà và bia miễn phí giải tỏa “cơn say” công việc;
Có đãi ngộ riêng dành cho nhân viên có trẻ nhỏ;
Được chi thoải mái trong những ngày đặc biệt của nhân viên và gia đình;Vi vu du ngoạn với company trip, team building hàng tháng;
Được làm việc với đối tác người Nhật, rèn luyện kỹ năng chuyên môn trong môi trường toàn cầu;
Nhận sự hỗ trợ nhiệt tình từ đồng nghiệp, kề vai sát cánh chinh chiến các dự án lớn nhỏ.
Thành thạo tiếng Nhật để hiểu rõ những yêu cầu từ phía khách hàng;
Quản lý thay đổi phạm vi dự án, tiến độ dự án;
Quản lý lịch trình để đảm bảo công việc được xác định, phân công và hoàn thành đúng hạn;
Phân tích, làm rõ và chuyển giao yêu cầu cho các thành viên;
Tham gia vào việc design documents, test cases.
Yêu cầu:
Bằng N2 tiếng Nhật;
Kỹ năng viết và giao tiếp Tiếng Anh tốt;
Ít nhất 4 năm kinh nghiệm trong lĩnh vực phát triển phần mềm;
Có kiến thức vững chắc về JAVA hoặc PHP hoặc C;
Ưu tiên ứng viên đã làm việc tại Nhật Bản hoặc có kinh nghiệm làm việc với các đối tác Nhật Bản.
Để có thể cùng nhau đi trên chặng đường dài phía trước, Pesol rất mong tìm được người phù hợp để tiếp tục đồng hành chinh phục những giấc mơ lớn. Với vị trí Technical Project Manager (PHP, Java, C#) tại Persol, con số $3,000 không chỉ là mức thu nhập xứng đáng mà còn là niềm tự hào cho sự nỗ lực và ý chí của chính bạn!
Xác thực (authentication, trả lời câu hỏi bạn là ai) và phân quyền (authorization, trả lời câu hỏi bạn có thể làm được gì) microservices luôn là thành phần không thể thiếu của mọi hệ thống, nhưng mức độ áp dụng thì lại tùy thuộc vào từng giai đoạn.
Nếu bạn làm mọi thứ chặt chẽ ngay từ đầu, nó có thể làm tăng độ phức tạp và làm chậm sự phát triển của công ty. Nhưng nếu bạn làm nó quá muộn, thì có thể bạn sẽ hứng chịu nguy cơ bị tấn công và rủi ro từ đó. Với 1 công ty e-commerce như Tiki, rủi ro đó rất hiện hữu với các hệ thống liên quan tới thanh toán, tiền ảo (Tiki Xu), mã khuyến mại (coupon), phiếu quà tặng (giftcard) và nhiều hệ thống nhạy cảm khác…
Bắt đầu từ Monolithic
Tiki xuất phát là 1 hệ thống monolithic, thông thường ở hệ thống như vậy sẽ có 1 module chung quản lý việc xác thực và phân quyền, mỗi user sau khi đăng nhập sẽ được cấp cho 1 Session ID duy nhất để định danh.
Phía client có thể lưu Session ID lại dưới dạng cookie và gửi kèm nó trong mọi request. Hệ thống sau đó sẽ dùng Session ID được gửi đi để xác định danh tính của user truy cập, để người dùng không cần phải nhập lại thông tin đăng nhập lần sau
Khi Session ID được gửi lên, server sẽ xác định được danh tính của người dùng gắn với Session ID đó, đồng thời sẽ kiểm tra quyền của user xem có được truy cập tác vụ đó hay không.
Giải pháp session và cookie vẫn có thể sử dụng, tuy nhiên ngày nay chúng ta có nhiều yêu cầu hơn, chẳng hạn như các ứng dụng Hybrid hoặc SPA (Single Page Application) có thể cần truy cập tới nhiều hệ thống backend khác nhau, vì vậy session và cookie lấy từ 1 server có thể không sử dụng được ở server khác.
Bài toán khó Microservices
Trong kiến trúc microservices, hệ thống được chia nhỏ thành nhiều hệ thống con, đảm nhận các nghiệp vụ và chức năng khác nhau. Mỗi hệ thống con đó cũng cần được xác thực và phân quyền, nếu xử lý theo cách của kiến trúc Monolithic ở trên chúng ta sẽ gặp các vấn đề sau:
Mỗi service có nhu cầu cần phải tự thực hiện việc xác thực và phân quyền ở service của mình. Mặc dù chúng ta có thể sử dụng các thư viện giống nhau ở mỗi service để làm việc đó tuy nhiên chi phí để bảo trì thư viện chung đó với nhiều nền tảng ngôn ngữ khác nhau là quá lớn.
Mỗi service nên tập trung vào xây dựng các nghiệp vụ của mình, việc xây dựng thêm logic về phân quyền làm giảm tốc độ phát triển và tăng độ phức tạp của các service.
Các service thông thường sẽ cung cấp các interface dưới dạng RESTful API, sử dụng protocol HTTP. Các HTTP request sẽ được đi qua nhiều thành phần của hệ thống. Cách truyền thống sử dụng session ở server (stateful) sẽ gây khó khăn cho việc mở rộng hệ thống theo chiều ngang.
Service sẽ được truy cập từ nhiều ứng dụng và đối tượng sử dụng khác nhau, có thể là người dùng, 1 thiết bị phần cứng, 3rd-party, crontab hay 1 service khác. Việc xác định định danh (identity) và phân quyền (authorization) ở nhiều ngữ cảnh (context) khác nhau như vậy là vô cùng phức tạp
Dưới đây là một số giải pháp, kỹ thuật và hướng tiếp cận mà Tiki đã áp dụng cho bài toán này.
Định danh
Sử dụng JWT
JWT (Json Web Token) là 1 loại token sử dụng chuẩn mở dùng để trao đổi thông tin kèm theo các HTTP request. Thông tin này được xác thực và đánh dấu 1 cách tin cậy dựa vào chữ ký. JWT có rất nhiều ưu điểm so với session.
Stateless, thông tin không được lưu trữ trên server.
Dễ dạng phát triển, mở rộng.
Performance tốt hơn do server đọc thông tin ngay trong request (nếu session thì cần đọc ở storage hoặc database)
Mã hóa RSA cho JWT
Phần chữ ký sẽ được mã hóa lại bằng HMAC hoặc RSA.
HMAC: đối tượng khởi tạo JWT (token issuer) và đầu nhận JWT (token verifier) sử dụng chung 1 mã bí mật để mã hóa và kiểm tra.
RSA: sử dụng 1 cặp key, đối tượng khởi tạo JWT sử dụng Private Key để mã hóa, đầu nhận JWT sử dụng Public Key để kiểm tra.
Như vậy với HMAC, cả 2 phía đều phải chia sẻ mã bí mật cho nhau, và đầu nhận JWT hoàn toàn có thể khởi tạo 1 mã JWT khác hợp lệ dựa trên mã bí mật đó. Còn với RSA, đầu nhận sử dụng Public Key để kiểm tra nhưng không thể khởi tạo được 1 JWT mới dựa trên key đó. Vì vậy mã hóa sử dụng RSA giúp cho việc bảo mật chữ ký tốt hơn khi cần chia sẻ JWT với nhiều đối tượng khác nhau.
Sử dụng Opaque Token khi muốn để kiểm soát phiên làm việc tốt hơn
Opaque Token (còn được gọi là stateful token) là dạng token không chứa thông tin trong nó, thông thường là 1 chuỗi ngẫu nhiên và yêu cầu 1 service trung gian để kiểm tra và lấy thông tin. Ví dụ:
Transparent Token (còn được gọi là stateless token) thông thường chính là dạng JWT, token này bản thân chứa thông tin và không cần 1 service trung gian để kiểm tra. Hãy cùng so sánh 2 loại token này
Như vậy ta có thể thấy Transparent Token mang lại tốc độ tốt hơn, đơn giản dễ sử dụng với cả 2 phía, không phù thuộc vào 1 server trung tâm để kiểm tra. Còn Opaque Token kiểm soát tốt hơn các phiên làm việc của đối tượng, chẳng hạn khi bạn muốn thoát tất cả các thiết bị đang đăng nhập.
OAuth 2
Các token sẽ được khởi tạo thông qua OAuth 2, là phương thức chức thực phổ biến nhất hiện nay, mà qua đó một service, hay một ứng dụng bên thứ 3 có thể đại điện (delegation) cho người dùng truy cập vào 1 tài nguyên của người dùng nằm trên 1 dịch vụ nào đó.
OAuth 2 là chuẩn mở, có đầy đủ tài liệu, thư viện ở tất cả các ngôn ngữ khác nhau giúp cho việc tích hợp, phát triển dựa trên nó trở nên dễ dàng và nhanh chóng.
Kiến trúc cho xác thực và phân quyền
Sau khi đã có định danh và giao thức dùng để giao tiếp, câu hỏi tiếp theo là cần trả lời câu hỏi đối tượng với định danh đó có quyền thực hiện 1 hành động, truy cập 1 tài nguyên nào đó hay không. Ở Tiki, bên cạnh các service được xây dựng mới, vẫn còn tồn tại các hệ thống cũ (legacy) chạy song song, thế nên hiện nay Tiki có 2 cách thức tổ chức phân quyền như dưới đây.
Xác thực, phân quyền tại lớp rìa
Theo mô hình tất cả mọi request sẽ được xác thực khi đi qua API Gateway hoặc BFF (Backend For Frontend). BFF chính là lớp service ở rìa (Edge Service) được thiết kế riêng cho từng ứng dụng (ví dụ IOS, Android, Management UI). Chúng ta sẽ đặt xác thực và phân quyền ở lớp rìa này
API Gateway sẽ bắt buộc tất cả request sẽ cần gửi kèm token để định danh
Nếu token này là JWT (đối với OpenID Connect), Gateway có thể kiểm tra tính hợp lệ của token thông qua chữ ký (signature), thông tin (claim) hoặc đối tượng khởi tạo (issuer)
Nết token này là Opaque Token, Gateway có thể phân tích (introspect) token, đổi (exchange) lấy JWT và truyền tiếp vào trong cho các services.
API Gateway hoặc BFF kiểm tra các policy xem có hợp lệ hay không thông qua Authorization Server trung tâm.
Các microservices không thực hiện lớp xác thực và phân quyền nào, có thể tự do truy cập bên trong vùng nội bộ (internal network).
Mô hình này có điểm tương đồng với kiến trúc Monolithic khi đặt xác thực phân quyền tại 1 số service nhất định, việc xây dựng và bảo trì sẽ tốn chi phí nhỏ hơn, tuy nhiên sẽ để lộ 1 khoảng trống bảo mật rất lớn ở lớp trong do các service có thể tự do truy cập lẫn nhau.
Chúng ta có thể đặt 1 số rule ở góc độ network đối với các service bên trong này tuy nhiên các rule này sẽ tương đối đơn giản và không thể đáp ứng được các nghiệp vụ truy cập dữ liệu lẫn nhau giữa các team/service (mở rộng ra là các công ty nội bộ) độc lập nhau
Xác thực, phân quyền tại các service
Ở mô hình này, mỗi service (trừ 1 số ngoại lệ) khi được thiết kế và xây dựng các giao tiếp APIs (API Interface) mở rộng được và có thể phục vụ cho thế giới bên ngoài. Một service hôm nay được xây dựng cho các nghiệp vụ bên trong nội bộ công ty, nhưng ngày mai có thể sẵn sàng để mở ra cho các đối tác, các lập trình vên ngoài.
Điều này sẽ giúp cho các service/team chủ động được hoàn toàn về các tài nguyên hiện có, tài nguyên đó được cấp cho những đối tượng nào, được truy cập từng phần hay toàn phần…
Để làm được việc này, vai trò rất lớn sẽ nằm ở service IAM (Identity Access Management), IAM nắm giữ các định danh của toàn bộ các đối tượng (user, service, command…) cùng với các bộ luật phân quyền chi tiết cho từng loại tài nguyên.
Việc mỗi service phải tự thực hiện việc xác thực, phân quyền sẽ làm tăng chi phí khi xây dựng các service, bên ngoài các nghiệp vụ chính thì cần thêm lớp middleware để giao tiếp với IAM.
Tuy nhiên các service sẽ có được sự tự chủ hoàn toàn, chủ động về việc cung cấp tài nguyên cho các đối tượng, và tăng tốc phát triển hơn vì nhiều trường hợp client có thể truy cập thẳng tới các service mà không cần phát triển thêm lớp BFF ở giữa.
Access Control
Xây dựng hệ thống luật (rule) hiệu quả không bao giờ là dễ dàng, khi yêu cầu về nghiệp vụ tăng cao kéo theo yêu cầu về phân quyền càng phức tạp. Hãy lấy 1 ví dụ cụ thể để làm rõ, mỗi ứng dùng thông thường sẽ gán quyền cho 1 thành viên cụ thể (ví dụ John được quyền tạo sản phẩm). Mở rộng ra trong 1 hệ thống microservices, đối tượng ở đây có thể là người dùng, service, crontab…
Có 1 vài cách tiếp cận cho việc phân quyền như trên, hãy thử đi qua các cách khác nhau để có nhiều góc nhìn khác nhau.
Access Control List (ACL)
Trong ví dụ trên các bạn có thể thấy 1 ma trận của đối tượng và quyền, nó gần tương đương với cách quản lý file trên Linux (chmod) và phù hợp với những ứng dụng có ít đối tượng. Khi hệ thống lớn lên mô hình này sẽ không thể quản lý nổi bởi ma trận được tạo ra quá lớn và phức tạp. Do vậy và mô hình này không còn phổ biến hiện tại.
Role-Based Access Control (RBAC)
RBAC liên kết đối tượng tới các vai trò (role), và từ vai trò tới các quyền. Chẳng hạn vai trò Administratorcó thể thừa hưởng mọi quyền mà vai trò Manager có, điều này giúp làm giảm độ phức tạp của ma trận quyền, thay vì gán toàn bộ quyền cho Administrator thì chỉ cần cho Administrator thừa hưởng các quyền của Manager.
RBAC rất phổ biến và bạn có thể thấy ở mọi nơi, so với ACL thì RBAC giúp giảm thiểu độ phức tạp khi số lượng đối tượng + quyền tăng cao. Tuy nhiên RBAC chưa thỏa mãn được 1 số trường hợp, ví dụ khi cấp quyền 1 sản phẩm chỉ được sửa bởi người tạo, người dùng nằm trong 1 phòng ban xác định hoặc quyền phân biệt với các người dùng từ nhiều hệ thống (tenant) khác nhau.
Policy-Based Access Control (PBAC)
PBAC được xây dựng dựa trên Attribute Based Access Control (ABAC), qua đó định nghĩa các quyền để diễn đạt một yêu cầu được cho phép hay từ chối. ABAC sử dụng các thuộc tính (attribute) để mô tả cho đối tượng cần được kiểm tra, mỗi thuộc tính là 1 cặp key-value ví dụ Department = Marketing. Nhờ đó ABAC có thể giúp phân quyền mịn hơn, phù hợp với nhiều ngữ cảnh (context) và nghiệp vụ (business rules) khác nhau.
PABC được định nghĩa thông qua các policy được viết dưới dạng 1 ngôn ngữ chung XACML (eXtensible Access Control Markup Language). Một policy định nghĩa 4 đối tượng subject, effect, action và resource. Ví dụ john (subject) được allowed(effect) để mà delete(action) product với ID john-leman(resource). Nhìn qua thì nó gần giống với cách định nghĩa 1 ACL.
Các policy có thể bổ sung các điều kiện để thu hẹp phạm vi của quyền, ví dụ như chỉ áp dụng cho 1 dải IP nhất định, hoặc chỉ cho phép người tạo sản phẩm được sửa sản phẩm đó.
Việc liên tục mở rộng nghiệp vụ và hệ thống đòi hỏi các service phải tự xác thực, qua đó không phân biệt service đó là bên trong (internal) hay bên ngoài (external), giúp các team dễ dàng mở rộng tích hợp với nhau. Việc này đòi hỏi mô hình xác thực chung phải hoạt động ổn định, tối ưu và đáp ứng được hiệu năng cao.
Tham khảo thêm các vị trí tuyển dụng ngành cntt hấp dẫn tại đây
Không lúc này thì lúc khác, mỗi người chúng ta sẽ nhận được vài cái mail từ chối xin việc thôi. Bạn biết đấy, những mail như vậy thường bắt đầu với câu “Cảm ơn bạn đã quan tâm” và kết thúc với những giấc mơ tan vỡ, dập tắt mọi hy vọng đẹp đẽ vốn có. Xin lỗi, có vẻ tôi hơi cực đoan một chút. Tuy nhiên, việc nhận được mail từ chối là một trải nghiệm không dễ dàng gì.
Tin tôi đi, tôi hiểu rõ lắm! Vì sao ư? Vì tôi đã nhận được hơn 80 email từ chối công việc trong năm qua khi đăng ký làm thực tập sinh. Những con số sau sẽ cho bạn rõ tình trạng của tôi trước khi chúng ta vào vấn đề chính nhé!
Số công ty nộp đơn
234
Hồi âm
93
Từ chối
90
Offer
3
Điều đáng chú ý là, ít nhất là cho chương trình thực tập sinh, việc không nhận được phản hồi thường rất ít gặp. Trên thực tế, hơn 60% công ty mà tôi ứng tuyển đều không thấy phản ứng gì. Theo tôi, điều này đáng lo ngại hơn nhiều so với việc nhận được câu trả lời “không” rõ ràng. Ít nhất trong trường hợp đó, chúng ta sẽ tiếp tục tìm kiếm công ty khác thay vì tiếp tục hy vọng trong vô vọng.
Nhưng thử tưởng tượng xem, sau khi nghe từ “không” đến tận 80 lần, theo tự nhiên, bạn sẽ sinh ra một cảm giác “đối kháng”. Chính sự đối kháng ấy cùng với một chút tò mò là điều khiến tôi nảy ra dự án này. Tóm lại, tôi muốn điều tra xem nguyên nhân gì khiến nhà tuyển dụng gửi những mail từ chối tự động như vậy và chúng khác nhau như thế nào giữa các công ty. Nếu bạn muốn xem thêm về dự án của tôi, vui lòng truy cập vào GitHub repo.
Về phần còn lại của bài viết này, tôi sẽ chia sẻ cách tôi phân tích các email từ chối ra sao.
Bước 1: Thu thập dữ liệu
Trước tiên, hãy lấy dữ liệu! Khi truy vấn hộp thư đến Gmail của tôi, tôi đã tìm thấy hơn 1.000 email chứa các từ khóa “thực tập” và “ứng dụng”. Điều này khiến mọi việc trở nên khó khăn một chút từ góc nhìn tự động hóa.
Tôi đã ngồi phân loại các mail từ chối của mỗi công ty. Thậm chí tôi còn tạo một nhãn trong Gmail có tên “Job Rejection”. Xong xuôi, đã đến lúc tận dụng sức mạnh của Python. Tôi đã đăng nhập bằng imaplib và xóa bỏ các phần nổi của email. Để phân tích nội dung, tôi đã mã hóa văn bản bằng nltk và xóa bất kỳ dấu câu và stop words nào có trong mail.
Bạn có bao giờ thắc mắc rằng tại sao các mail từ chối đều sử dụng một ngôn ngữ chung không? Tôi thường gặp rất nhiều cụm từ giống nhau, dường như được sử dụng từ công ty này đến công ty khác. Một số công ty có cách dùng từ ngữ rất linh hoạt và sáng tạo, nhưng rất hiếm khi gặp những trường hợp như vậy.
Hãy xem các từ và cụm từ phổ biến nhất được sử dụng cho những email này.
Như bạn có thể thấy ở trên, các nhà tuyển dụng lựa chọn từ “application” và “your” nhiều hơn hẳn những từ khác. Không cần phải bỏ ra nhiều công sức, bạn đã có thể lọc ra các mail có chủ đề như vậy:
Thank you for your interest.
Update on your [Insert role] application.
Những từ này thường là điềm báo cho những tin xấu đấy!
Video: Nhận dạng âm thanh: phân biệt giọng nam, nữ và vùng miền (Bắc Trung Nam)
Bước 3: Khung thời gian
Hãy tiến hành thêm một bước nữa là tổng hợp thời gian các email từ chối được gửi đi. Điều này khiến tôi nhớ đến một lời khuyên lâu đời: đừng nên sa thải nhân viên vào thứ Sáu, vì chúng ta không biết cuối tuần họ sẽ làm gì. Mặc dù chuyện này không quan trọng bằng chuyện sa thải nhân viên, nhưng vẫn rất thú vị khi thử nghĩ xem nhà tuyển dụng chọn thời gian nào để gửi “hung tin” đến ứng viên.
Sau đây là phân tích của tôi dựa trên các ngày trong tuần:
Có vẻ “Hump Day” (thứ Tư theo tư duy của người Mỹ) ngày thứ tư đen tối. Thứ năm ở vị trí nhì bảng, các ngày còn lại có số lượng khá nhất quán. Cuối tuần là khoảng thời gian nghỉ ngơi, tuy nhiên vẫn có một số nhà tuyển dụng gửi mail vào thứ Bảy?! Xấu hổ…
Đối với giờ trong ngày, độ phân bố nhìn khá đều theo như dự đoán của chúng ta. Có vẻ như số lần từ chối dao động vào lúc 9 giờ sáng đến giữa trưa. Thông thường đây là giờ bắt đầu làm việc của các công ty theo múi giờ EST và PST. Chỉ có một lần từ chối duy nhất là sau 5 giờ chiều. Và công ty đó không ai khác ngoài P&G.
Đến đây, phần phân tích dữ liệu của thôi đã hoàn tất.
Tổng kết
Dư án phân tích email từ chối nhận việc đối với tôi khá thú vị. Hơn thế nữa, nó cho tôi kinh nghiệm thực tiễn trong quá trình tìm viêc sau này cũng như cách ứng xử khi nhận được email từ chối. Không nhiều người có đủ coi trọng kỹ năng đối diện với thất bại đâu.
“Tôi đã thất bại nhiều và nhiều lần trong cuộc sống của tôi … và đó là lý do tại sao tôi thành công” – Michael Jordan
Sau hơn 80 email từ chối, rõ ràng, bạn sẽ quen với khái niệm thất bại. Tôi thấy mình ngày càng ít do dự khi nộp đơn vào các vị trí tại các công ty uy tín. Điều này cho phép tôi có được cơ hội mà ban đầu tôi không nghĩ nó nằm trong tầm tay của mình.
Nếu bạn đang đọc bài này, hãy tận dụng những cơ hội đó, tiếp cận nhà tuyển dụng thêm một chút, và hãy tự tin đối diện với thất bại. Rồi lại đứng lên. Lại cố gắng. Chỉ qua quá trình dài cố gắng, chúng ta mới có được thành công. Và khi bạn đã chạm đến đỉnh vinh quang, đừng quên nhìn lại những thất bại đã qua và tự nói với lòng mình rằng:
Với vị thế hiện tại, ADVN đang dần chiếm ưu thế trong mối quan hệ hợp tác với các thương hiệu công nghệ hàng đầu. Nhằm mục đích tiến xa hơn trong lĩnh vực phát triển các dự án outsource, ADVN vẫn đang không ngừng chiêu mộ các tài năng IT với mức lương vô cùng hấp dẫn.
Sự tín nhiệm bởi các doanh nghiệp hàng đầu về công nghệ dành cho ADVN!
Từ năm 2016, ADVN trở thành nhà phân phối chính thức các thiết bị tin học mang thương hiệu tầm cỡ thế giới tại Việt Nam. ADVN đang ngày càng khẳng định vị thế của mình bởi sự tín nhiệm từ các thương hiệu công nghệ hàng đầu như MSI, Sony, Hitachi, InFocus, Prolink… Đây được xem là bước đà phát triển cho ADVN trong mối quan hệ hợp tác với các doanh nghiệp công nghệ ở thị trường quốc tế.
Hiện nay, ADVN đang tập trung sang các dự án outsource, thương mại điện tử và quảng cáo. Với mong muốn mang đến những sản phẩm, dịch vụ chất lượng kết hợp công nghệ tiên tiến nhất, ADVN đang ra sức săn đón các tài năng IT để cùng đồng hành phát triển.
Đội ngũ IT tại ADVN hiện đang tìm kiếm một mảnh ghép mới với vai trò là một Ruby on Rails Developer, là người thích phát triển phần mềm web, thương mại điện tử với việc tích hợp vào các ứng dụng mobile. Tại đây, ứng viên sẽ được phát triển năng lực của mình, phối hợp làm việc cùng với các lập trình viên khác, Project Manager và đội ngũ Infrastructure.
ADVN và con số offer đến $1,500 dành cho Ruby on Rails Developer
Nếu bạn muốn hợp tác cùng đội ngũ ADVN để nâng tầm giá trị kinh nghiệm và chuyên môn của mình, hãy gửi CV ứng tuyển ngay hôm nay. ADVN sẵn sàng tạo cho bạn một điều kiện không gian làm việc tốt nhất, đi kèm với mức lương thưởng và đãi ngộ xứng đáng:
Mức lương hấp dẫn $800 – $1,500;
Review lương hàng năm, nâng cao chất lượng sống;
Được đảm bảo mọi quyền lợi các chế độ (ngày phép năm, gói bảo hiểm) đầy đủ theo luật Việt Nam;
Cơ hội công tác tại Singapore tích lũy kinh nghiệm từ bạn bè quốc tế, nâng trình giao tiếp tiếng Anh;
Được thử sức mình với các dự án đầy tính thử thách, cải thiện và trau dồi kỹ năng làm việc theo nhóm;
Cơ hội phát triển mạnh mẽ với sự hướng dẫn tận tình, giúp đỡ trong suốt quá trình làm việc.
– Phát triển trang CMS website, e-commerce và ứng dụng mobile;
– Phân tích các yêu cầu của khách hàng để phát triển các yêu cầu phần mềm kỹ thuật và tính năng (outsourcing);
– Phối hợp chặt chẽ với Project Manager để đưa ra ý tưởng và giải pháp phát triển các tính năng mới;
– Đảm bảo tiến độ công việc được giao;
– Tham gia vào các dự án sản phẩm của ADVN.
Yêu cầu:
– Bằng cấp / Văn bằng Khoa học Máy tính, Công nghệ thông tin hoặc các ngành liên quan;
– Có ít nhất 2 năm kinh nghiệm vị trí Ruby on Rails Developer;
– Có kiến thức về web Front-end như HTML, CSS, JavaScript & jQuery, API RESTful;
– Có kiến thức về Angular JS, React JS, máy chủ Linux / CentOS là một điểm cộng;
– Kinh nghiệm với hệ thống cơ sở dữ liệu MySQL;
– Khả năng giám sát và cố vấn cho các junior engineers;
– Khả năng đọc và nói tiếng Anh;
– Khả năng tư duy logic;
– Tinh thần làm việc nhóm tốt.
Nhiều tin tuyển dụng IT lương cao trên TopDev, đăng ký ngay!
Công nghệ đang thay đổi với mức độ chóng mặt mỗi ngày. Những ngôn ngữ mới liên tục được ra đời như Ruby, Hadoop hay những công nghệ mới nhất cloud đang ngày càng phổ biến hơn. Tuy nhiên, những ngôn ngữ và kỹ năng cơ bản vẫn đóng vai trò như những bộ khung sườn vững chắc giúp mọi thứ vận hành suôn sẻ. Sau đây là 5 loại công nghệ vẫn đóng vai trò lớn cho đến tận thời điểm này.
COBOL
“Rất nhiều người dùng cuối hiện vẫn đang tương tác với các hệ thống được xây dựng bằng COBOL.” – Ed Airey, Product Marketing Director cho COBOL solution tại MicroFocus cho biết.
Các dịch vụ như Ngân hàng, bảo hiểm, tàu lửa hay hàng không là những dịch vụ mà khách hàng tương tác với COBOL nhiều nhất, vì ngôn ngữ này vượt trội ở khả năng tính toán và quản lý lưu lượng thông tin dữ liệu lớn.
“COBOL vượt trội hơn các ngôn ngữ khác ở khoảng xử lý các khối lượng dữ liệu rất lớn, tính năng này được gọi là batch processing,” Airey cho biết. Các hệ thống ngân hàng, công ty tín dụng, và các công ty IRS đều sử dụng hệ thống được lập trình bởi COBOL để xử lý một lượng lớn các giao dịch trong cùng một thời điểm. COBOL còn được sử dụng ở các hệ thống kiểm tra lý lịch di trú và nhập cảnh. Quá trình này còn giúp khoanh vùng các đối tượng cần được theo dõi.
“Hầu hết các hệ thống máy tính quy mô lớn đã được phát triển trong những năm 1960. Với kết cấu đồ sộ, chúng vẫn được phát triển tiếp tục đến tận bây giờ. Sự ổn định của nó cho phép mainframes (hay big iron) có thể chạy ổn định mà không bị gián đoạn trong suốt nhiều thập kỷ. Những ngành như Ngân Hàng, bán lẻ, dịch vụ tài chính, logistics, và sản xuất phụ thuộc khá nhiều vào công nghệ mainframe.” – Craig O’Malley, CEO của mainframe solutions Compuware cho biết.
“Công nghệ Mainframe chắc chắn vẫn sẽ đóng vai trò chủ chốt cho rất nhiều hệ thống back-end. Đây là giải pháp công nghệ tốt nhất, nhanh nhất và kinh tế nhất so với những gì mà nó làm được. Nó không chỉ được dùng cho batch processing, hay tăng tốc độ xử lý dữ liệu, mà nó chính là một giải pháp tối ưu để xử lý lưu lượng data cực lớn.”
Ngôn ngữ C
C được phát triển bởi Dennis Ritchie ở Bell Labs vào khoảng những năm 1969 và 1973. C được ví như một trong những ngôn ngữ lập trình được sử dụng nhiều nhất. Trên thực tế, rất nhiều ngôn ngữ “hậu bối” như C++, Python, Perl, Java và PHP đã mượn rất nhiều tính năng cơ bản từ C.
Ngôn ngữ này được dùng rất rộng rãi ở các hệ thống lập trình kể cả hệ điều hành hoặc các hệ thống nhúng, chưa kể đến các hệ thông siêu máy tính lớn cũng đang dựa vào ngôn ngữ này. Và đương nhiên C còn là nền tảng của khá nhiều hệ điều hành trong đó bao gồm cả Unix.
Video IoT and AI Thinking Linking Things Age of VUI
Fortran
Là ngôn ngữ được biết đến với tên gọi Formula Translation, là một ngôn ngữ được dùng cho các hệ thống máy tính lớn (mainframe) của IBM từ những năm 1950s. Nó được ví như “tiếng mẹ đẻ của khoa học máy tính”. FORTRAN được phát triển bởi Big Blue để đẩy nhanh tốc độ xử lý thông tin khoa học kỹ thuật trên các siêu máy tính.
Hiện nay, nó được dùng nhiều ở những lĩnh vực như dự báo thời tiết, động lực học, vật lý máy tính và những lĩnh vực đòi hỏi tốc độ xử lý cao.
Java
Về mặt kỹ thuật mà nói, Java không phải là một công nghệ siêu việt, nhưng nó sẽ chính thức ăn mừng sinh nhật thứ 20 của mình vào năm nay. Java được phát triển bởi James Gosling tại Sun Microsystem vào năm 1995. Nó được thiết kế với một mục đính giúp cho các nhà phát triển có thể “viết code ở một nơi, và chạy được ở nhiều nơi” (write once, run anywhere), mà không phải dịch lại thông qua một nền tảng nào khác.
Dù là một ngôn ngữ “trẻ tuổi” nhưng Java vẫn hiện đang nằm thuộc top những ngôn ngữ được cộng đồng sử dụng nhiều nhất, được đánh giá bởi cộng đồng Tiobe Software’s Programming Community Index. Với khoảng 9 triệu nhà phát triển, Java nằm vào top những ngôn ngữ được nhiều người dùng nhất, đa phần được dùng để xây dựng ứng dụng client-server Web.


")









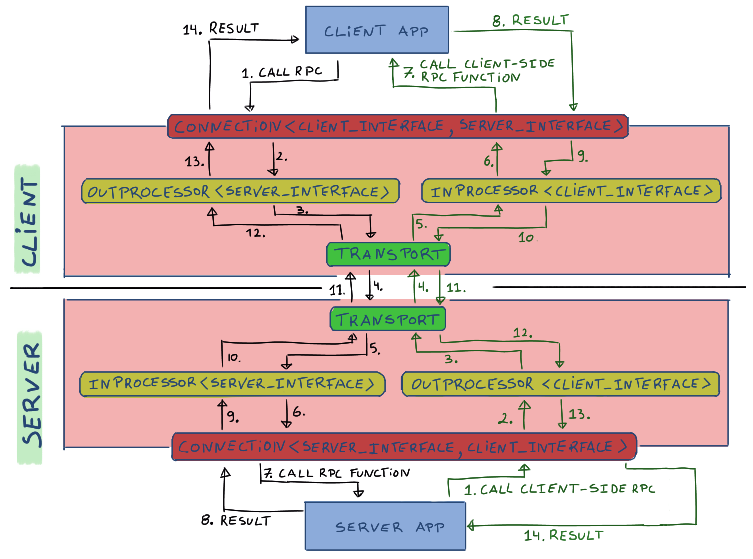


























")











")




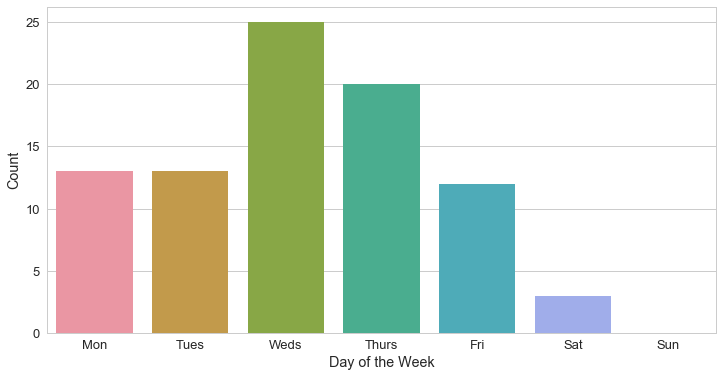
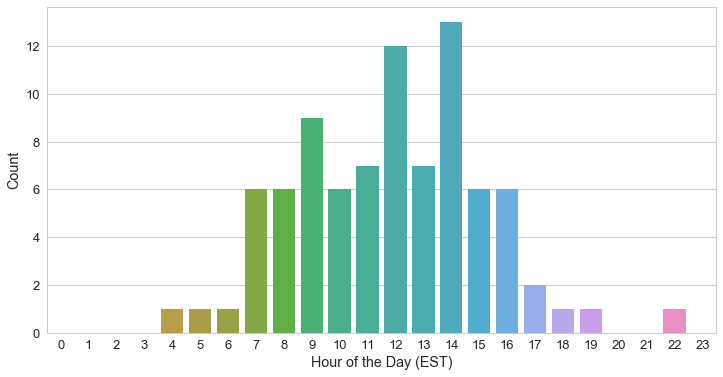
")






