Trong quá trình thiết kế hệ thống, có rất nhiều khái niệm cần hiểu rõ để tránh việc hiểu sai yêu cầu của khách hàng, một trong những khái niệm quan trọng là Quality Attributes.
Khái niệm này thường bị nhầm lẫn bởi một số bạn có điều kiện lắng nghe trực tiếp requirement từ khách hàng. Bài viết này mình xin chia sẻ thêm về Quality Attributes và một số ví dụ cụ thể.
Đối với System Design thì nỗi sợ lớn nhất là không adapt được với functional requirements. Nhưng không phải tất cả yếu tố giúp thiết kế hệ thống đều xoay quanh functional requirements.
System are frequently redesigned NOT because of the functional requirement
Qua trình thay đổi thiết kế của hệ thống đôi khi không chỉ bởi functional requirement (yêu cầu từ khách hàng, yêu cầu hệ thống)
Một số points có thể khiến hệ thống phải design đi, design lại nhiều lần bao gồm:
Không đủ nhanh
Không thể scale lên được
Làm chậm quá trình development
Khó khăn khi maintain hệ thống
Không đáp ứng được các tiêu chí về security
2. Quality Attributes Definition
Quality Attributes are non function requirement
Quality attributes không phải là yêu cầu về chức năng
Khái niệm này ngắn nhưng vô cùng chính xác. Trong quá trình làm việc, mình thấy một số bạn khi nhận được requirement từ khách hàng thường nhầm lẫn giữa functional requirement và Quality Attributes.
Cái này hoàn toàn dễ hiểu, bởi vì client (khách hàng), người mà mình trực tiếp làm việc đôi khi là non-technical. Tất cả những gì họ trình bày hoặc họ nói là về vấn đề hiện tại họ cần giải quyết.
Chính vì Qualiy attributes không phải là chức năng nên bản thân nó định nghĩa hai thứ sau:
The qualities of function requirements
The overrall properties of the systems
Đầu tiên là chất lượng của một function. Ví dụ:
When user click a search button after they typed in a particular search keywords, the user will be provided a list of products that closely match with search keywords within at most a 100 miliseconds
Khi người dùng click butotn search sau khi đã nhập keywords để tìm kiếm, user sẽ được cung cấp một list các sản phẩm gần khớp nhất trong khoảng thời gian 100 miliseconds.
Rõ ràng mà nói, nguyên câu có thể nhầm tưởng là requirement, nhưng thực chất không phải. Ta sẽ chia nhỏ thành hai phần.
Actions (hoặc có thể vẽ thành Sequence Diagram) thì khi user click search ta sẽ trả về một list product.
Nhưng phần còn lại, within a 100 miliseconds (cái này thì lại là QA). Thời gian khách hàng mong muốn là nhỏ hơn 100 miliseconds.
Một ví dụ khác:
The online store must be available to user a request at least 99.9% of time
Cửa hàng online phải có tính sẵn sàng cho các request từ user với mức phần trăm available khoảng 99,9%
Trong requirement này thì tính sẵn sàng là một yêu cầu, nhưng con số cụ thể 99,9% lại là Quality Attributes.
3. Quality Attributes Considerations
Nếu nắm vững và hiểu rõ về Quality Attributes và phân biệt rõ ràng được giữa Fucntional Requirements và Quality Attributes sẽ giúp quá trình thiết kế hệ thống trở nên dễ dàng hơn.
Đội development khi làm việc với PO hoặc SA cũng clear rõ ràng hơn cái nào là SRS và cái nào là QA.
3.1 Đo lường được, test được
Tuy nhiên, có 2 yếu tố chính cần quan tâm khi định nghĩa Quality Attributes.
Measureable
Testable
Thứ nhất là Measureable (đo lường), các định nghĩa về Quality Attributes cần phải đo lường được. Nếu anh muốn thời gian phản hồi nhanh (100 miliseconds).
Con số cụ thể đó thực hiện ở môi trường nào?
Server nằm ở đâu?
Yếu tố thứ hai là Testable, cái này là điểm đáng sợ nhất. Nếu không cụ thể và không test được, cả Developer và Production Owner đều sẽ không clear rõ ràng được với nhau. Dẫn tới hiểu sai về requirement và làm sai. Cái này rất tai hại.
Ví dụ:
When user click a buy button, the purchase confirmation must displayed quickly to the user
Khi người dùng ấn nút mua, cái thông tin xác nhận cần phải hiện lên rất nhanh cho user
Cái nguy hiểm chỉ nằm đúng ở một chữ (quickly). Nếu BrSe hoặc SA không clear được cụ thể cái Quality Attributes này, rất dễ là cả function requirement đều không thể xong do bất đồng về Definition Of Done của cả hai bên (client và developer)
3.2 Feasibility – Tính khả thi
Tính khả thi cũng là một yếu tố mà ở vị trí Tech Lead hoặc Solutions Architecture cần cân nhắc. Một số yêu cầu từ khách hàng (client) có thể xung đột với nhau hoặc không khả thi về mặt technical.
Ví dụ Quality Attributes của khách hàng là Login Time phải nhở hơn 1s, nhưng yêu cầu về Security phải an toàn. Với SSL, ta có thể mất nhiều hơn 1s để thực hiện đăng nhập. Các điểm này dường như xung đột với nhau và đòi hỏi người thiết kế hệ thống phải có cái nhìn đủ sâu. Kinh nghiệm cũng là một yếu tố quan trọng giúp xác định rõ các điểm QA.
Là một lập trình viên, bàn phím là một vật dụng bạn phải sờ vào hằng ngày, thậm chí số lần bạn sờ nó còn nhiều hơn số lần bạn sờ vào vợ hoặc bạn gái. Chính vì vậy, chúng ta phải đầu tư cho nó một cách xứng đáng, bằng 2 cách:
Mua một cái bàn phím cơ
Tự làm một cái
Và, với những ai tự gọi mình là kĩ sư (software engineer, backend engineer, frontend engineer, hay copy-pasta engineer, stackoverflow engineer,… nói chung là mọi thể loại engineer), chẳng có lý do gì để không tự làm một cái cho riêng mình, để tự mình quyết định bố cục (layout), màu sắc (keycaps), và tốc dộ gõ (key switches, scanning time).
Suy cho cùng, tự mình build một cái gì đó, và tự tay giải quyết những vấn đề hóc búa trong quá trình build, học hỏi và thu lại được kinh nghiệm cho bản thân, cũng có thể gọi là cái raison d’être của một engineer . Hay nói cách khác, như vậy mới gọi là dân chơi đúng nghĩa .
Hình ảnh sẽ xuất hiện trong bài sau, không phải bài này =)))
Đó cũng là lý do mà mình quyết định tự build một cái bàn phím 40% cho riêng mình. Tuy nhiên, làm việc gì cũng có thử nghiệm, thất bại, rút kinh nghiệm,… để hạn chế những vấn đề đó, chúng ta sẽ bắt đầu với một bản prototype đơn giản nhưng đủ phức tạp để thấy được các vấn đề trong thực tế.
1. Nguyên vật liệu
Đối với bản prototype này, chúng ta cần chuẩn bị:
4 x Cherry MX Brown Switches (chọn switch nào là sở thích cá nhân thôi, hè hè)
Đa phần các bàn phím tên tuổi thường chỉ khác nhau về bố cục (layout), và đây là phần bất biến, sau khi sản xuất, còn lại những thứ khác (case, plate, key mapping…) thì đều có thể được custom tùy ý.
Đối với bản prototype này, chúng ta sẽ thiết kế một layout vô cùng phức tạp, như thế này:
Quá phức tạp!
Sau khi đã thiết kế xong bố cục thì chúng ta có thể move sang bước tiếp theo đó là thiết kế và cắt tấm đệm (plate).
Trong thiết kế của bàn phím cơ, có 2 cách lắp ghép (mount) swtiches, là Plate Mount và PCB Mount.
PCB mount bên trái. Plate mount bên phải.
Nguồn: https://www.mouser.com/new/Cherry-Electrical/cherry-mx-keyswitch/
PCB Mount là cách lắp các switches trực tiếp trên board mạch. Ưu điểm của thiết kế này là bàn phím nhẹ hơn, cảm giác gõ sâu hơn, có thể cảm nhận rõ độ nẩy và lún của switch. Có khá ít bàn phím thiết kế theo dạng này, có thể kể đến Minvan, KBC Poker,… là các bàn phím như vậy.
Plate Mount là cách lắp các switches trên một tấm nền thường là bằng kim loại, plate thường có độ dày khoảng 1.5mm (rất quan trọng nếu bạn tự làm plate), trên thân của switch cũng có các khớp để “móc” vừa vào plate. Sau đó là đến PCB nằm bên dưới.
Ưu điểm của cách bố trí này là bàn phím sẽ rất cứng cáp, cảm giác gõ rất chắc chắn, nhưng độ gõ không sâu.
Hầu hết bàn phím cơ trên thị trường được thiết kế dùng plate mount.
Vì bản prototype này chúng ta tự hàn mạch bằng tay chứ chưa thiết kế PCB, nên chúng ta sẽ chọn cách plate mount. Và tùy vào độ khéo tay cũng như vật liệu mà bạn kiếm được, mình suggest dùng giấy bìa cứng =)) cắt một tấm hình vuông nhỏ nhắn xinh xinh kiểu này:
Mấy cái ô trống thì cắt hình vuông là được rồi, không cần phải phức tạp như trong hình kia đâu. Căn cứ vào kích thước của switch (ở đây là Cherry MX), mỗi ô trên plate sẽ có kích thước tầm 15mm - 15.6mm
Tiếp đến là bước nối mạch điện. Sau khi lắp xong swtich vào plate thì lật ngửa nó ra, các bạn sẽ thấy bố trí như hình bên dưới, với mỗi switch gồm 2 chân, các chân bên trái nằm cao hơn bên phải. Nối diode vào chân bên trái, và nối lại với nhau để tạo thành một hàng, đồng thời, nối các chân bên phải lại với nhau tạo thành các cột.
Sơ đồ mạch điện trên lý thuyết
Và thực tế
Cách mắc mạch điện như trên cũng là cách mắc phổ biến trong các loại bàn phím cơ, các switch tạo thành một mam trận nhiều hàng nhiều cột, cách mắc này có ưu điểm là tiết kiệm được số cổng kết nối trên board điều khiển, trong bản prototype này chúng ta không thể thấy rõ điều đó, nhưng giả sử với một bàn phím 60%, thường sẽ có 5 hàng và 15 cột, như vậy ta chỉ cần 20 cổng kết nối trên board điều khiển, nhưng vẫn có thể xử lý được từ 60 đến 65 phím.
Nếu các bạn thắc mắc tại sao phải lắp thêm diode vào các switch thì có thể tham khảo thêm về vấn đề Ghosting.
Sau khi hoàn tất công đoạn hàn mạch, thì chúng ta sẽ nối mạch này vào Teensy, chúng ta gọi các dây xanh là hàng (row), và dây đỏ là cột (column), mạch của chúng ta gồm có 2 hàng và 2 cột, tiến hành nối các hàng và cột này vào 4 cổng digital của Teensy, cổng nào là tùy ý các bạn chọn.
Trong hình trên, mình nối các cột vào các chân số 2 và 3. Các hàng vào các chân số 6 và 7.
4. Thiết kế Firmware
Khi mình bắt đầu phần này thì khá là nhiều người trên Reddit và Geekhack khuyên mình đừng nên tự viết firmware riêng mà hãy dùng các firmware có sẵn như TMK hoặc QMK. Tuy nhiên khi thử build hai loại firmware trên thì rất may là mình dùng Teensy 3.2, board này xài chip ARM 32-bit (Cortex-M4), chưa được support tốt lắm trên cả 2 firmware trên, nên build không chạy được . Thế nên mình quyết định là tự viết riêng cho mình một bản firmware riêng.
Để cho đơn giản, thì mình sẽ sử dụng Teensyduino để lập trình. Đây là một add-on của Arduino IDE, cho phép chúng ta lập trình trên Teensy bằng bộ thư viện của Arduino, và sử dụng cấu trúc chương trình của Arduino.
Một firmware cơ bản sẽ là một event loop thực hiện các công việc sau:
Scan: quét liên tục để tìm ra các phím được nhấn
Processing: xây dựng một buffer chứa keycode của các phím đang được nhấn xuống, dựa trên keymap mà chúng ta đã thiết lập.
Output: Gửi buffer này về máy tính thông qua cổng USB.
Trước khi bắt tay vào thực hiện code logic trên, chúng ta cần phải khai báo một vài thông số liên quan:
Ở trên, chúng ta include thư viện Keyboard.h (đi kèm theo SDK của Arduino), chỉ vì chúng ta muốn sử dụng hàm Keyboard.print() có trong thư viện này để gửi phím được nhấn về cho máy tính.
Tiếp theo, chúng ta khai báo 2 hằng ROWS và COLS quy định số hàng và số cột của bàn phím, mảng keys chính là keymap, là mảng quy ước các kí tự nào thuộc về phím nào trên bàn phím của chúng ta, ở đây khi nhấn các phím 1, 2, 3, 4 thì bàn phím sẽ gửi về máy tính các kí tự A, B, C, D.
Hai mảng rowPins và colPins lưu vị trí các chân cắm trên board điều khiển, theo như cách chúng ta đã nối dây ở phần trước.
Đến đây, nếu tinh ý thì các bạn sẽ nhận ra, là ở bài viết tiếp theo khi chúng ta xây dựng firmware cho một cái bàn phím thực sự, thì chỉ cần thay đổi các thông số ở trên là xong.
Bây giờ đến phần implement event loop cho firmware của chúng ta, đầy đủ 3 bước scan, process và output:
Hàm scan() của chúng ta sẽ có nhiệm vụ quét tất cả các hàng và các cột của mạch điện, kiểm tra xem phím nào được nhấn xuống và trả về một giá trị kiểu byte chứa thông tin các phím được nhấn.
C không có kiểu byte nên chúng ta dùng kiểu char để thay thế.
Để cho đơn giản, thì chúng ta chỉ support việc nhấn một phím một lần, ở bài sau chúng ta sẽ cải tiến firmware để xử lý việc nhấn tổ hợp phím, macro,…
Việc quét phím được thực hiện thông qua thuật toán sau:
1: Đưa tất cả các chân về trạng thái INPUT, mang giá trị HIGH 2: Lần lượt đưa từng hàng (row) về trạng thái OUTPUT, giá trị LOW 3: Trên mỗi hàng, lần lượt đọc trạng thái của từng cột (col) 4: Nếu phím K[r][c] tại hàng r cột c được nhấn, cột c sẽ mang giá trị LOW 5: Ghi nhận giá trị r và c. 6: Trả lại trạng thái ban đầu cho hàng hiện tại. 7: Trả về giá trị r và c
Nếu cảm thấy khó hiểu ở bước 3 và 4, bạn có thể đọc thêm cách hoạt động của các chân digital tại đây.
Vì mạch của chúng ta chỉ đơn giản gồm có 4 nút, mỗi hàng và mỗi cột chỉ có nhiều nhất là 2 phàn tử (index là 0 hoặc 1), vậy nên ta có thể “gói” hai giá trị hàng cột này vào cho một số kiểu byte, bằng phương pháp dịch bit.
Giả sử chúng ta đang ở hàng r = 0 và cột c = 1, chúng ta có thể chèn giá trị r vào bit thứ nhất, và c vào bit thứ 2:
charscan(){
char code = -1;
// Đưa tất cả các pin về trạng thái INPUT/HIGHfor (int i = 0; i < ROWS; i++) {
pinMode(rowPins[i], INPUT_PULLUP);
digitalWrite(rowPins[i], HIGH);
}
for (int i = 0; i < COLS; i++) {
pinMode(colPins[i], INPUT_PULLUP);
digitalWrite(colPins[i], HIGH);
}
// Đưa từng hàng về trạng thái OUTPUT/LOW và quétfor (int row = 0; row < ROWS; row++) {
pinMode(rowPins[row], OUTPUT);
digitalWrite(rowPins[row], LOW);
for (int col = 0; col < COLS; col++) {
if (!digitalRead(colPins[col])) {
// Lưu giá trị hàng và cột thành một số int
code = (row << 0) | (col << 1);
}
}
pinMode(rowPins[row], INPUT_PULLUP);
digitalWrite(rowPins[row], HIGH);
}
return code;
}
4.2. Vấn đề #2: Gửi tín hiệu về máy tính
Tiếp theo, chúng ta cần chuyển thông tin về hàng/cột nhận được thành kí tự đã được khai báo trong keymap.
Bước này khá là đơn giản, chỉ cần đọc giá trị trả về từ hàm scan() và trả về giá trị tương ứng từ mảng keys :
Hàm gửi tín hiệu output() sẽ sử dụng hàm Keyboard.print của bộ thư viện Keyboard.h và truyền thông tin sang máy tính:
voidoutput(char c){
Keyboard.print(c);
}
Đến bước này, bạn có thể compile và upload firmware vào Teensy để test thử.
Máy tính đã nhận diện được bàn phím mới, và gõ thì có ra được nội dung thật. Tuy nhiên sẽ có một vấn đề đó là hiện tượng nhấn một nút, máy tính sẽ in ra rất nhiều lần phím được nhấn. Đây gọi là hiện tượng key chatter.
Ở bài viết tiếp theo, chúng ta sẽ tìm hiểu sâu hơn về hiện tượng này, và implement kĩ thuật debounce để giải quyết nó.
Làm IT Cho Ngân Hàng Có Phải Là Hướng Đi Phù Hợp Cho Lập Trình Viên?
Là ngành nghề phù hợp với xu hướng phát triển thời đại nên không khó hiểu khi nhân lực cho ngành IT cũng đang tăng lên theo cấp số nhân. Rất nhiều lập trình viên khi tốt nghiệp vẫn đang băn khoăn không biết đâu mới là lựa chọn phù hợp cho công việc của mình. Tại sao không thử cân nhắc đến việc làm IT cho ngân hàng? Đây chắc chắn sẽ là công việc hấp dẫn nếu các lập trình viên biết nắm bắt và tận dụng cơ hội của mình.
Làm IT Cho Ngân Hàng Có Phải Là Hướng Đi Phù Hợp Cho Lập Trình Viên?
Tổng quan công việc làm IT cho ngân hàng
Làm IT cho ngân hàng là gì?
Có thể hiểu một cách khái quát nhất, khi làm IT cho ngân hàng, các lập trình viên sẽ chịu trách nhiệm hoạt động các phần mềm số cũng như kỹ thuật máy tính. Lập trình viên sẽ thu thập, xử lý, chuyển đổi, truyền tải và lưu trữ thông tin toàn bộ dữ liệu của ngân hàng. Trong thời đại chuyển đổi ngân hàng số như hiện nay, hầu như tất cả các ngân hàng đang đẩy mạnh hơn nữa việc số hóa và ứng dụng công nghệ thông tin trong dịch vụ khách hàng của ngân hàng mình.
Công việc mà lập trình viên ngân hàng đảm nhận gồm những gì?
Thông thường hiện nay, công việc của các lập trình viên ngân hàng sẽ gồm 3 nhiệm vụ chính:
Giám sát các hoạt động của ngân hàng liên quan đến CNTT: Vì ngân hàng luôn đòi hỏi tính chính xác cao trong từng con số cũng như hạn chế thấp nhất các sự cố có thể xảy ra, ảnh hưởng đến người dùng, lập trình viên cần liên tục giám sát hoạt động của phòng IT, đảm bảo hoạt động diễn ra liên tục và hiệu quả.
Vận hành các phần mềm phục vụ xây dựng ngân hàng số: Do ảnh hưởng của việc chuyển đổi công nghệ thông tin, tất cả các ngân hàng hiện nay đều đầu tư rất mạnh cho việc xây dựng app, website để đáp ứng nhu cầu của người dùng. Các lập trình viên sẽ chịu trách nhiệm xây dựng và vận hành hệ thống được hoạt động tốt nhất.
Bên cạnh đó, các devs phải liên tục cập nhật thông tin, xử lý sự cố, fix bugs có thể xảy ra gây ảnh hưởng đến quá trình giao dịch của khách hàng. Ngoài ra, các devs cũng vận hành hệ thống phần mềm dành cho các bộ phận nhân viên hoạt động trong ngân hàng như POS, BO, HRM,…
Theo dõi, kiểm tra hạ tầng hệ thống CNTT: Ngân hàng là một trong những bộ máy hoạt động xuyên suốt, không ngừng nghỉ bất kể ngày đêm, vậy nên các devs cần giám sát hoạt động liên tục của máy chủ ứng dụng, hệ thống mạng LAN, hệ thống mạng Wifi – Internet, tổng đài nội bộ. Trong quá trình kiểm tra hệ thống cũng cần kịp thời phát hiện và tiến hành xử lý sự cố để không làm ảnh hưởng đến hoạt động của ngân hàng.
Lập trình viên của ngân hàng sẽ xử lý nhiều công việc khác nhau
Yêu cầu tuyển dụng với nhân viên IT ngân hàng như thế nào?
Với khối lượng công việc như thế, hiện nay yêu cầu tuyển dụng đặt ra với nhân sự ngành ngân hàng cũng liên tục được cập nhật và chú trọng nhiều hơn vào chất lượng. Về bằng cấp, thông thường ngân hàng sẽ tuyển dụng nhân sự tốt nghiệp với bằng khá trở lên và đã được đào tạo chuyên môn có liên quan đến công việc khi còn trên ghế nhà trường sẽ là một điểm cộng.
Về mặt kinh nghiệm chuyên môn, ứng viên nên có ít nhất 1 năm kinh nghiệm làm việc ở những vị trí tương tự hay ở ngân hàng. Công việc ở ngân hàng luôn có áp lực cực kỳ lớn với khối lượng công việc nhiều, liên tục nên những ứng viên có khả năng chịu áp lực tốt sẽ được đánh giá cao hơn. Ở vị trí là một lập trình viên, kiến thức và kỹ năng trong ngành IT chắc chắn là điều cần có nếu bạn muốn ứng tuyển vào ngân hàng.
Ngoài ra, cũng như mọi ngành nghề khác, các kỹ năng mềm như kỹ năng làm việc nhóm, kỹ năng giao tiếp, khả năng trình bày và xử lý vấn đề,… cũng thật sự rất quan trọng trong quá trình nhà tuyển dụng đánh giá và lựa chọn ứng viên. Đầu tư thêm cho các chứng chỉ ngoại ngữ và khả năng giao tiếp ngoại ngữ cũng là điểm cộng cực lớn cho các ứng viên IT ngân hàng.
Chất lượng nhân sự IT ngân hàng ngày càng cao hơn
Mức lương của nhân viên IT ngành ngân hàng hiện đang nằm ở mức nào?
Có nhiều yếu tố khác nhau ảnh hưởng đến mức lương của nhân viên IT ngành ngân hàng. Nhìn chung trên thị trường hiện nay lương đang dao động trong khoảng từ 7 – 15 triệu đồng/tháng với những nhân viên từ 1 – 5 năm kinh nghiệm. Đối với các nhân viên đã có nhiều năm kinh nghiệm và chuyên môn cao hoặc đã ở trình độ quản lý thì mức lương hoàn toàn có thể tốt hơn như thế. Trung bình có thể nằm trong khoảng trên 25 triệu đồng/tháng.
Thu nhập hấp dẫn, công việc năng động, môi trường làm việc chất lượng chính là những lý do giúp các việc làm ngành ngân hàng thu hút rất nhiều ứng viên. Để có được cho mình công việc yêu thích, sự chuẩn bị kỹ càng và đam mê chính là yếu tố tiên quyết của sự thành công. Tìm hiểu thêm nhiều việc làm IT cho ngân hàng với cơ hội công việc đầy hứa hẹn cùng TopDev nhé!
Nuxt Authentication là một module của Nuxtjs hỗ trợ Authentication. Mà bạn nào làm việc với Nuxt nhiều cũng biết rồi đấy.
Nuxtjs là framework base trên Vuejs, với Nuxt ta có thể tạo cả hai loại apps là SSR (Server Side Render) và SPA (Singple Page Application) nên Nuxt đã mạnh lại càng mạnh hơn.
Trong thực tế dự án hiện tại project mình có xài Nuxt + GraphQL, application có login/logout nên có tìm hiểu về Nuxt Authentication (auth). Mạn phép viết bài này chia sẻ anh em chút kiến thức về Nuxt Auth.
Cũng trong project mình xài JWT nên có thể có ví dụ về Nuxt auth + JWT.
Authentication / Authorization thì là nhu cầu cơ bản của một applications, các application xây dựng với Nuxt cũng không phải là một ngoại lệ.
Nuxt Authentication là một modules xây dựng dựa trên Nuxtjs.
Trong vài dòng ngắn ngủi ta có một cái nhìn sơ bộ về module này như sau:
The module authenticates users using a configurable authentication scheme or by using one of the directly supported providers. It provides an API for triggering authentication and accessing resulting user information. While it takes care of storing the information on the client-side, it does NOT implement session handling or provide session based authentication on the NuxtJS server
Module xác thực người dùng sử dụng xác thực bằng scheme hoặc bởi providers. Nó cung cấp một API cho phép trigger xác thực và truy cập thông tin user sau khi đã xác thực thành công. Trong khi đó nó cũng đảm nhiệm việc lưu trữ thông tin ở phía client. Nhưng nhấn mạnh là nó không làm gì với session handling (quản lý session) hoặc cung cấp session dựa trên việc xác thực trên NuxtJS Server
Rồi, với Nuxt Authentication thì sau khi xác thực thành công, module này sẽ hỗ trợ về lưu trữ token ở phía client. Nhưng đối với việc handle session (validate token này kia đã hết hạn hay chưa) thì vẫn phải thực hiện ở phía server.
Nguồn ảnh / Source: https://auth.nuxtjs.org/
2. Schemes và Providers
Về setup cho Nuxt Authentication thì anh em có thể tham khảo trên trang của Nuxt ha. Bài viết này mình muốn phần tích về các khái niệm Schemes và Providers kĩ hơn.
Đôi khi xài chứ mà không hiểu thì nguy hiểm lắm. LOL
Authen/ Autho là common solution, nhưng những logic đằng sau đó thì không như vậy. Do đó ta cần Schemes.
2.1 Scheme Authentication
Schemes define authentication logic. Strategy is a configured instance of Scheme. You can have multiple schemes and strategies in your project.
Schemes định nghĩa logic xác thực. Object Strategy là cấu hình instance của Scheme. Ta cũng có thể có nhiều schemes và các chiến lược khác nhau trong Project
Trời má, đọc vô hiểu chết liền. Nói không điêu chứ đôi cái logic nó huyền bí cho tới khi ta thấy code.
Để dễ hiểu hơn thì ta cần quay lại khái niệm của Authentication Scheme.
An authentication scheme is a definition of what is required for an authentication process. This includes the following:
The login module stack used to determine whether a user is granted access to an application
The user interfaces used to gather the information required to authenticate a user
Priority, enabling authentication schemas to be ordered
Cách giải thích khác về Authentication Scheme. Nguồn ảnh/ Source: simpleid.org
Theo như cái định nghĩa dễ hiểu hơn ở trên thì authentication scheme là định nghĩa những thứ cần có trong quá trình xác thực người dùng. Tại phương thức xác thực đôi khi khác nhau.
Rồi, từ chiến lược – Strategy dễ hiểu hơn. Ta có thể có nhiều cách để xác thực người dùng, nhiều chiến lược khác nhau.
import { LocalScheme } from '~auth/runtime'
export default class CustomScheme extends LocalScheme {
// Override `fetchUser` method of `local` scheme
async fetchUser (endpoint) {
// Token is required but not available
if (!this.check().valid) {
return
}
// User endpoint is disabled.
if (!this.options.endpoints.user) {
this.$auth.setUser({})
return
}
// Try to fetch user and then set
return this.$auth.requestWith(
this.name,
endpoint,
this.options.endpoints.user
).then((response) => {
const user = getProp(response.data, this.options.user.property)
// Transform the user object
const customUser = {
...user,
fullName: user.firstName + ' ' + user.lastName,
roles: ['user']
}
// Set the custom user
// The `customUser` object will be accessible through `this.$auth.user`
// Like `this.$auth.user.fullName` or `this.$auth.user.roles`
this.$auth.setUser(customUser)
return response
}).catch((error) => {
this.$auth.callOnError(error, { method: 'fetchUser' })
})
}
}
Với fetchUser, ta có thể thoải mái custom process trong Nuxt Authentication. Do process và flow có thể can thiệp nên Nuxt auth trở nên flexible hơn bao giờ hết. Một big plus point.
Providers là bên cung cấp (platform) mà từ đó user có thể xác thực tài khoản của mình. Nuxt Authentication cung cấp rất nhiều các providers khác nhau.
List providers được cung cấp bởi Nuxt. Nguồn ảnh / Source: https://auth.nuxtjs.org/
Providers có vẻ là dễ hiểu hơn, tuy nhiên với từng loại providers ta cần đọc kỹ tài liệu. Ngoài ra Nuxt Authentication cũng hỗ trợ Extending Auth Plugin.
Đơn giản là nếu ta có một plug in nào khác, ta có thể dễ dàng sử dụng thông tin sau khi đã xác thực.
Gần đây có một trick mà mình rất hay dùng, đó là sử dụng hai phép bitwise NOT~~ để chuyển nhanh một số kiểu float thành int, thay cho việc dùng hàm Math.floor:
Ngoài hiệu quả về mặt performance ra, trick này có thể được sử dụng trong các buổi phỏng vấn để… làm màu . Tuy nhiên, việc sử dụng phải đi kèm với việc hiểu và giải thích được cơ chế hoạt động của phép tính này.
Vậy vì lý do gì mà phép tính này có thể chuyển một số kiểu float thành int?
Về mặt bản chất, tất cả các kiểu số trong JavaScript đều chiếm 64-bit trong bộ nhớ theo chuẩn IEEE 754
Để tiết kiệm bộ nhớ và hiệu năng, với đa số các JavaScript engine (như là V8, SpiderMonkey,…), nếu một biến xx kiểu số có giá trị nguyên vừa đủ nhỏ (ví dụ −231≤x≤231−231≤x≤231), thì biến đó sẽ được thể hiện dưới dạng một số kiểu 32-bit intege. Chừng nào con số trên đủ lớn, hoặc hoặc không phải là số nguyên nữa thì nó sẽ được tự động chuyển về dạng 64-bit.
Theo đặc tả ECMAScript, khi thực hiện các phép toán bitwise, các toán hạng sẽ tự động bị chuyển về kiểu 32-bit integer.
Tức là khi ta thực hiện bất kỳ một phép toán bitwise nào trên một số, thì kết quả trả về luôn là kiểu 32-bit integer.
Và thường thì chúng ta sẽ sử dụng các phép bitwise vô nghĩa, để tránh làm thay đổi giá trị của số ban đầu, ví dụ:
Chúng ta có thể sử dụng trick này cho rất nhiều tình huống. Ví dụ như thuật toán kiểm tra một số có phải là lũy thừa của 4 hay không (Leetcode #342).
Nếu một số nguyên n∈Zn∈Z là lũy thừa bậc 4 của một số xx nào đó, thì xx cũng phải là một số nguyên (x∈Zx∈Z). Hay nói cách khác, giá trị logarithm cơ số 4 của nn cũng phải là một số nguyên (log4n∈Zlog4n∈Z).
Để tính logarithm cơ số bất kì, ta có thể sử dụng công thức chuyển đổi cơ số để đưa về cùng một dạng logarithm mà máy tính hỗ trợ sẵn, ví dụ log10log10:
logab=log10blog10alogab=log10blog10a
Thuật toán của chúng ta sẽ được implement như sau:
var isPowerOfFour = function(num) {
let lg4 = Math.log(num) / Math.log(4);
return lg4 === (~~lg4);
};
Trong những năm gần đây, làn sóng niêm yết cổ phiếu lần đầu (IPO) trở nên mạnh mẽ hơn bao giờ hết cho thấy dấu hiệu đáng mừng của những doanh nghiệp vừa và nhỏ đang mạnh dạn tìm kiếm cơ hội để chuyển mình. Và trong “cuộc đua” này, Hybrid Technologies chính thức được xướng tên trở thành doanh nghiệp đầu tiên do người Việt thành lập và điều hành thành công IPO trên sàn giao dịch chứng khoán Tokyo tại Nhật Bản với giá trị vốn hoá thị trường tương đương gần 1700 tỷ VNĐ.
CEO Trần Văn Minh đại diện Hybrid Technologies nhận chứng nhận IPO tại Sở Giao dịch Chứng khoán Tokyo. (Nguồn ảnh: Hybrid Technologies)
Ngày 23/12/2021 vừa qua, vào 13 giờ (theo giờ Nhật Bản), Hybrid Technologies đã chính thức chào bán cổ phiếu ra công chúng lần đầu tại Sở giao dịch Chứng khoán Tokyo – Tokyo Stock Exchange (Nhật Bản) với mã cổ phiếu 4260. Trong số 90 doanh nghiệp thực hiện IPO thành công tại thị trường Nhật trong năm 2021, Hybrid Technologies chính là doanh nghiệp Việt Nam hiếm hoi nằm trong danh sách này. CEO Trần Văn Minh của Hybrid Technologies cũng cùng lúc trở thành người Việt đầu tiên thực hiện niêm yết chứng khoán thành công tại Nhật Bản – thị trường chứng khoán sôi động nhưng cũng khắt khe nhất từ trước đến nay.
Nhân sự kiện này, Đại sứ Đặc mệnh toàn quyền Việt Nam tại Nhật Bản – ông Vũ Hồng Nam đã gửi lời chúc mừng tới CEO Trần Văn Minh và tập thể Hybrid Technologies. Đại sứ Vũ Hồng Nam nhấn mạnh: “Đây không chỉ là niềm vui riêng của Hybrid Technologies mà còn là niềm vui cho toàn thể các doanh nghiệp hoạt động trong lĩnh vực công nghệ tại Nhật Bản (V-Tech) nói riêng và Việt Nam nói chung. Việc Hybrid Technologies thành công IPO chính là nguồn khích lệ rất lớn cho VN-Tech tiếp tục phát triển không chỉ ở trong nước, đáp ứng kỳ vọng của chính phủ Việt Nam mà còn là động lực thúc đẩy, giúp doanh nghiệp Việt vươn tầm thế giới.”
Đại sứ Đặc mệnh toàn quyền Việt Nam tại Nhật Bản – ông Vũ Hồng Nam đã gửi lời chúc mừng tới CEO Trần Văn Minh và tập thể Hybrid Technologies (Nguồn ảnh: Hybrid Technologies)
Để có thể IPO vào cuối năm 2021, CEO Trần Văn Minh cùng đội ngũ nhân sự đã có hơn 5 năm nuôi khát vọng và nỗ lực không ngừng nghỉ cho mục tiêu này. Ngay từ những ngày đầu thành lập, CEO của Hybrid Technologies đã định hướng công ty hoạt động theo mô hình hybrid, mô hình uỷ thác và AI, đóng vai trò cung cấp các giải pháp toàn diện cho khách hàng. Từ chỗ chỉ vài nhân sự đến nay Hybrid Technologies đã có 500 nhân viên trong toàn hệ thống. Từ một vài khách hàng ban đầu sau 5 năm Hybrid Technologies đã có hàng trăm khách hàng, trong đó có những thương hiệu lớn mang tầm cỡ toàn cầu như: Yahoo, Docomo, Uniqlo, BMW…
CEO Trần Văn Minh chia sẻ rằng: “Việt Nam hoàn toàn có thể làm chủ cuộc chơi công nghệ với thị trường giàu tiềm năng như Nhật Bản bởi đội ngũ kỹ sư Công nghệ Thông tin của chúng ta mạnh về khoa học Tự nhiên, đặc biệt là Toán học – một trong những yếu tố cốt lõi để lập trình giỏi. Tôi cũng vô cùng tự hào khi trong đội ngũ nhân sự của Hybrid Technologies có rất nhiều chuyên gia hàng đầu về công nghệ từng làm việc tại các tập đoàn công nghệ lớn tại Mỹ và Nhật Bản”. Chính vì vậy mà CEO Trần Văn Minh đã luôn tự tin khi phát triển mô hình Hybrid của mình. Vị CEO này khẳng định: “Với mô hình Hybrid chất xám của đội ngũ kỹ sư CNTT được định giá cao hơn, vị thế của công ty trong mắt đối tác cũng giữ một vai trò quan trọng hơn vì chúng ta không chỉ nhận gia công phần mềm đơn thuần theo yêu cầu của khách hàng mà với mô hình Hybrid chúng ta đóng vai trò là chuyên gia tư vấn, định hướng cho khách hàng để đưa ra các giải pháp tối ưu nhất.”
Hybrid Technologies IPO thành công tại Nhật Bản không chỉ là câu chuyện tài chính. Nhìn từ góc độ khác, Hybrid Technologies và CEO Trần Văn Minh đã khai màn cho một xu thế bước ra thế giới và tìm kiếm cơ hội. Chúng ta có quyền tự hào về một thế hệ mới của cộng đồng các doanh nghiệp hoạt động trong lĩnh vực phát triển phần mềm Việt Nam. Họ không chỉ giỏi về chuyên môn mà còn đầy khát vọng nâng tầm vị thế Việt trên bản đồ công nghệ thế giới.
Hybrid Technologies Co., Ltd. là công ty công nghệ phần mềm liên doanh Nhật – Việt, chính thức thành lập vào tháng 4/2016 với tiền thân là Evolable Asia Solutions Co., Ltd., phát triển các dịch vụ và mô hình làm việc đa dạng trong lĩnh vực công nghệ phần mềm như mô hình hybrid, mô hình ủy thác hay lĩnh vực trí tuệ nhân tạo.
Đến nay, trải qua 5 năm phát triển không ngừng nghỉ và gặt hái được những thành tựu nhất định, Hybrid Technologies từ một Startup với 4 nhân sự, đến nay đã có 4 trụ sở văn phòng tại Việt Nam và Nhật Bản, với 500 nhân viên cùng hàng trăm các dự án, khách hàng trong nhiều lĩnh vực công nghệ khác nhau. Trong đó, Hybrid Technologies vinh hạnh nhận được sự tin tưởng hợp tác của nhiều thương hiệu lớn tầm cỡ thế giới như: Uniqlo, BMW, Doccomo, Yahoo… Đóng vai trò cung cấp các giải pháp toàn diện cho khách hàng và là đối tác đồng hành bền vững, Hybrid Technologies tự hào và tin tưởng sẽ tiếp tục phát triển song hành với sự thành công của khách hàng để cùng nhau vươn tới một tầm cao mới!
Two-Factor Authentication (2FA) hoạt động như thế nào?
Bài viết được sự cho phép của tác giả Kiên Nguyễn
Bắt đầu với sự thật không thể trần trụi hơn: Đối với những giao dịch quan trọng như Internet Banking, Trading, sẽ có ngày tiền bốc hơi nếu không sử dụng Two-Factor Authentication (2FA).
Chỉ với Username và Password là không đủ để bảo vệ tài khoản cá nhân. Hiện tại có vô vàn cách để hacker đánh cắp tài khoản. Trộm tiền ngay cả khi đang ngủ mà không nỏ bất cứ thông báo nào.
Vậy Two-Factor Authentication là gì? Bằng cách nào mà Two-Factor Authentication có thể bảo vệ được tài khoản cá nhân. Anh em sử dụng nhiều application, nhiều website chắc cũng hiểu sơ sơ cách nó hoạt động, tuy nhiên viết rõ ra thì vẫn hay hơn.
2FA (Two-Factor Authentication) được gọi là xác minh bảo mật 2 bước hoặc xác thực hai yếu tố, là một quy trình bảo mật trong đó người dùng cung cấp hai yếu tố xác thực khác nhau để xác minh.
2FA được triển khai để bảo vệ tốt thông tin xác thực của người dùng và các tài nguyên mà người dùng có thể truy cập. Xác thực hai yếu tố cung cấp mức độ bảo mật cao hơn so với các phương pháp xác thực phụ thuộc vào xác thực một yếu tố (SFA), trong đó người dùng chỉ cung cấp một yếu tố – thường là mật khẩu hoặc mật mã.
Các phương pháp xác thực hai yếu tố dựa vào việc người dùng cung cấp mật khẩu làm yếu tố đầu tiên và yếu tố thứ hai, thường là mã thông báo bảo mật (qua địa chỉ email hoặc số điện thoại) hoặc yếu tố sinh trắc học, chẳng hạn như dấu vân tay hoặc quét khuôn mặt.
Hình ảnh đơn giản mô tả cách xác thực 2 bước (Two-Factor Authentication) hoạt động
Việc bật xác thực hai yếu tố khác nhau tùy thuộc vào ứng dụng hoặc nhà cung cấp cụ thể. Tuy nhiên, quy trình xác thực hai yếu tố bao gồm cùng một quy trình chung, nhiều bước:
Người dùng sẽ được ứng dụng hoặc trang web nhắc đăng nhập.
Người dùng nhập thông tin được yêu cầu, thường là tên người dùng và mật khẩu. Sau đó, máy chủ của trang web tìm thấy sự trùng khớp và nhận dạng người dùng.
Đối với các quy trình không yêu cầu mật khẩu, trang web sẽ tạo một khóa bảo mật duy nhất cho người dùng. Công cụ xác thực sẽ xử lý khóa và máy chủ của trang web sẽ xác thực khóa đó.
Sau đó, trang web sẽ nhắc người dùng bắt đầu bước đăng nhập thứ hai. Mặc dù bước này có thể có nhiều hình thức, nhưng người dùng phải chứng minh rằng họ có thứ mà chỉ họ mới có, chẳng hạn như sinh trắc học, mã thông báo bảo mật, thẻ căn cước, điện thoại thông minh hoặc thiết bị di động khác.
Sau đó, người dùng có thể phải nhập mã một lần được tạo ở bước bốn.
Sau khi cung cấp cả hai yếu tố, người dùng sẽ được xác thực và cấp quyền truy cập vào ứng dụng hoặc trang web.
Nói bổ sung một lớp bảo mật thì đơn giản, nhưng ta phải clear với nhau là 2FA chỉ là một phương pháp tiếp cận vấn đề (approach). Tức là nhắc tới Two-Factor Authentication thì hiểu nó là một cách tiếp cận vấn đề (thêm một lớp cho bảo mật)
Còn về methods (phương thức, cách thức) triển khai thì có nhiều loại. 2FA chỉ là cái chung chung chứ không phải là một phương pháp cụ thể.
Apple giải thích như thế nào về 2FA? Cùng xem video:
Các phương thức 2FA phổ biến hiện nay
Hiện nay, có nhiều loại xác thực hai yếu tố (2FA) phổ biến được sử dụng để tăng cường bảo mật cho tài khoản trực tuyến. Dưới đây là một số loại 2FA phổ biến:
Mã OTP
OTP (One Time Password) đây là một trong những phương pháp 2FA phổ biến nhất. Sau khi nhập mật khẩu, người dùng sẽ nhận được một mã xác nhận qua tin nhắn SMS hoặc cuộc gọi đến trên điện thoại di động. Mã này chỉ có thời gian hiệu lực hữu hạn, sau thời gian đó thì sẽ không còn sử dụng được.
Ứng dụng xác thực
Các ứng dụng như Google Authenticator, Authy, và Microsoft Authenticator tạo ra mã xác thực thời gian dựa trên thuật toán HMAC (Time-based One-Time Password, TOTP). Sau khi nhập mật khẩu, người dùng cần mở ứng dụng xác thực để lấy mã và nhập vào trang đăng nhập.
Điểm khác giữa Authenticate Applications và Text message là phương thức này không cần mạng viễn thông, chỉ cần internet
Email
Một mã xác thực hoặc liên kết xác nhận được gửi đến địa chỉ email đã đăng ký của người dùng. Người dùng phải nhập mã này hoặc nhấp vào liên kết để hoàn tất quá trình đăng nhập.
YubiKey và các thiết bị phần cứng khác
Đây là các thiết bị phần cứng nhỏ được cắm vào cổng USB hoặc kết nối không dây (NFC, Bluetooth) để xác thực. Người dùng chỉ cần cắm thiết bị vào máy tính hoặc chạm thiết bị vào điện thoại để hoàn tất quá trình xác thực.
Sinh trắc học
Các phương pháp xác thực sinh trắc học bao gồm nhận dạng vân tay, nhận dạng khuôn mặt, và nhận dạng giọng nói. Các thiết bị di động và máy tính hiện đại thường tích hợp sẵn các cảm biến sinh trắc học để hỗ trợ phương pháp này.
Tuy nhiên nó cũng tồn tại rủi ro nhất định. Dữ liệu sinh trắc học tuy là duy nhất nhưng theo chúng ta tới suốt đời. Không giống như mật khẩu có thể thay đổi được.
Câu hỏi bảo mật
Một số dịch vụ sử dụng câu hỏi bảo mật làm lớp xác thực thứ hai. Người dùng cần trả lời đúng các câu hỏi đã thiết lập trước đó để hoàn tất quá trình đăng nhập.
Recovery codes
Recovery codes là mã mà bạn đã tạo đầu tiên khi thiết lập tài khoản. Phần thông tin đăng nhập chỉ có chính chủ tài khoản mới biết. Cái này bao gồm một số thông tin như câu hỏi bảo mật hoặc mã pin (tự nhớ hoặc lưu trữ local). Do đó hãy lưu giữ thật kỹ mã này bạn nhé!
Một ví dụ rõ ràng dễ thấy nhất của loại này là Google Backup Codes
Push Notification
Người dùng sẽ nhận được một thông báo đẩy (push notification) approve đăng nhập từ các app đã cài trước đó của chính chủ. Ví dụ cụ thể và thấy rõ nhất là Facebook. Khi đã đăng nhập trên phone thì sign in lần nữa trên web -> Gửi confirm về app chứ không cần text message hay một số phương thức OTP.
Sign in approve của Facebook
Mặc dù thông báo đẩy an toàn hơn các hình thức xác thực khác, nhưng vẫn có rủi ro bảo mật. Ví dụ, người dùng có thể vô tình chấp thuận yêu cầu xác thực gian lận vì họ đã quen với việc chạm vào chấp thuận khi nhận được thông báo đẩy.
Hạn chế của 2FA
Mất yếu tố xác thực
Không có sự đảm bảo rằng các yếu tố xác thực sẽ luôn sẵn sàng khi bạn cần. Trong nhiều trường hợp, người dùng có thể bị khóa tài khoản chỉ sau một lần mắc lỗi.
Ví dụ, nếu mất điện thoại hoặc điện thoại bị hư hỏng do nước, bạn sẽ không thể nhận mã SMS làm yếu tố xác thực thứ hai. Tương tự, việc dựa vào khóa USB cũng rủi ro vì chúng có thể bị mất hoặc hư hỏng. Nếu bạn tin tưởng vào các mã PIN, luôn có khả năng bạn sẽ quên chúng. Các yếu tố sinh trắc học như dấu vân tay hay quét mắt cũng có thể bị mất trong các tai nạn.
Các nạn nhân của bão Harvey và Irma đã gặp khó khăn trong việc truy cập tài khoản vì không có cách sạc điện thoại, dẫn đến việc không thể nhận mã xác thực. Khôi phục tài khoản là có thể, nhưng thường mất thời gian và phức tạp. Nếu bạn có nhiều tài khoản được bảo vệ bằng một yếu tố duy nhất và yếu tố đó bị mất, bạn sẽ phải khôi phục tất cả các tài khoản đó.
False security
2FA cung cấp một mức độ bảo mật, nhưng thường bị phóng đại. Nếu bạn bị khóa khỏi dịch vụ vì mất yếu tố xác thực, bạn ở trong tình huống tương tự như một hacker cố gắng truy cập vào tài khoản của bạn. Nếu bạn có thể đặt lại tài khoản mà không cần yếu tố xác thực, thì hacker cũng có thể làm điều đó. Các tùy chọn khôi phục thường mâu thuẫn với mục đích của 2FA, đó là lý do tại sao các công ty như Apple đã loại bỏ chúng.
Tuy nhiên, nếu không có tùy chọn khôi phục, tài khoản của bạn có thể bị mất vĩnh viễn. Có những dịch vụ như PayPal sử dụng 2FA nhưng không thực hiện đầy đủ. Công ty này cung cấp một yếu tố thứ hai gọi là “PayPal Security Key”, nhưng vào năm 2014, nó có thể bị hoàn toàn bỏ qua một cách dễ dàng. Điều này có nghĩa là bạn có thể tuân theo 2FA và vẫn bị xâm nhập tài khoản.
Bị lợi dụng để chống lại người dùng
Mặc dù 2FA nhằm mục đích ngăn chặn hacker truy cập vào tài khoản của bạn, điều ngược lại có thể xảy ra. Hacker có thể thiết lập hoặc cấu hình lại 2FA để ngăn bạn truy cập vào chính tài khoản của mình. 2FA có thể không đủ hiệu quả để bảo vệ tài khoản của bạn nhưng cũng có thể quá hiệu quả nếu bạn không cẩn thận. Khi các dịch vụ cải tiến với các biện pháp 2FA và làm cho việc khôi phục tài khoản trở nên khó khăn hơn, điều quan trọng là thiết lập xác thực trên các tài khoản cần thiết trước khi hacker làm điều đó.
Tổng kết
Xác thực hai yếu tố (2FA) là hệ thống bảo mật yêu cầu hai hình thức nhận dạng riêng biệt, khác nhau để có thể truy cập vào một nội dung nào đó.
Yếu tố đầu tiên là mật khẩu và yếu tố thứ hai thường bao gồm tin nhắn có mã được gửi đến điện thoại thông minh của bạn hoặc thông tin sinh trắc học sử dụng dấu vân tay, khuôn mặt hoặc võng mạc của bạn.
Mặc dù 2FA cải thiện được tính bảo mật nhưng vẫn chưa phải là giải pháp hoàn hảo.
Tiếp theo, cài đặt biến môi trường LC_CTYPE của máy thành vi_VN.UTF-8:
export LC_CTYPE=vi_VN.UTF-8
Từ bây giờ, bạn đã có thể gõ tiếng Việt trên Emacs (chỉ trong terminal mode emacs -nw thôi nhé**.
Update Ngày 20/5/2018
Tình hình là mình vừa update lên Emacs 27, nên quyết định ngồi config lại lần nữa, quyết tâm gõ cho bằng được tiếng Việt trên Emacs =))) thế mà lại gõ được thiệt luôn không biết từ bản 26, 27 có update gì không, nhưng khả năng là do các config mới và cài thêm gói ibus-el. Cách làm như sau:
Đầu tiên, update Emacs, hoặc cài bản mới, xóa bản cũ:
yaourt -R emacs
yaourt -S emacs-git
Tiếp theo, cài đặt các biến môi trường để Ibus hoạt động trên các môi trường như GTK, QT (Emacs mặc định xài GTK):
Kinh Nghiệm Phỏng Vấn Tester Thành Công Được Áp Dụng Nhiều Nhất
Tester là công việc liên quan đến kiểm thử các phần mềm. Sự phát triển của công nghệ thông tin đã giúp ngành tester có được chỗ đứng vững chắc của riêng mình. Nhiều người lựa chọn theo đuổi công việc tester nhờ mức lương hấp dẫn và công việc thú vị. Vậy làm thế nào để ứng tuyển thành công vị trí tester khi số lượng ứng viên vẫn đang ngày một nhiều lên? Tìm hiểu thêm kinh nghiệm phỏng vấn tester hay ho với bài viết này nhé.
Kinh Nghiệm Phỏng Vấn Tester Thành Công Được Áp Dụng Nhiều Nhất
Công việc tester là làm gì?
Tester được biết đến là công việc liên quan đến kiểm định và thử nghiệm chất lượng phần mềm. Các hoạt động của tester nhằm bảo đảm sản phẩm cuối cùng đến tay khách hàng sẽ hoạt động suôn sẻ và không gây ra bất cứ lỗi hay kết quả không mong đợi nào. Một tester khi kiểm định phần mềm cần tìm ra những lỗi, lỗ hổng và các yêu cầu không đúng với thực tế để có cách khắc phục kịp thời cùng đội ngũ devs.
Đa phần các tester hiện nay có thể làm việc với những công cụ hỗ trợ việc test tự động. Tuy nhiên, trong nhiều trường hợp, việc kiểm tra thủ công bằng mắt cũng có thể được thực hiện để đảm bảo không có lỗi nào bị bỏ qua khi kiểm tra bằng máy. Một tester giỏi không chỉ đảm bảo thực hiện việc kiểm tra quy trình chất lượng sản phẩm, kiến thức chuyên môn mà còn có khả năng chỉnh sửa những lỗi sai mà mình phát hiện.
Những kinh nghiệm phỏng vấn tester hay ho mà các kiểm định viên phần mềm không nên bỏ qua
Để trở thành một tester chắc chắn ứng viên cần phải thông qua phỏng vấn của công ty. Một số câu hỏi phỏng vấn tester chất lượng và thường gặp dưới đây sẽ giúp bạn có thêm thông tin hữu ích cho mình.
Câu hỏi này được nhà tuyển dụng đặt ra nhằm mục đích xác định chính xác và cụ thể hơn định hướng của bản thân cũng như sự nghiêm túc của bạn khi lựa chọn theo đuổi công việc này. Tùy theo mong muốn và định hướng mà mỗi ứng viên mà bạn có thể đưa ra câu trả lời phù hợp. Nhưng hãy nhớ nhà tuyển dụng là những người đã dày dặn kinh nghiệm và họ biết rõ đâu là sự thật, chính vì thế nên chia sẻ một cách thẳng thắn và thật lòng để có thể trò chuyện với người phỏng vấn một cách hiệu quả nhất.
2. Một test case tốt sẽ gồm những đặc điểm gì?
Một test case chuẩn và tốt sẽ thể hiện khá rõ kết quả mà một tester sẽ đạt được trong quá trình làm việc của mình. Một test case tốt thường bao gồm các yếu tố sau: tiêu đề (nêu rõ mục đích của việc thử nghiệm), mục đích (lý do của việc thực hiện test case), mô tả đặc điểm của vấn đề, đối tượng thử nghiệm (tính năng hay mô-đun được thử nghiệm), điều kiện tiên quyết cần được thỏa mãn trong quá trình thực hiện.
Một số câu hỏi dành cho các tester
Ứng viên có thể dựa vào các gợi ý trên cũng như cân nhắc quá trình làm việc thực tế của mình để đưa ra câu trả lời phù hợp nhất với câu hỏi của nhà tuyển dụng.
3. Bạn hiểu thế nào về test case, use case?
Để định nghĩa thì test case là một dạng tài liệu sẽ cung cấp cho tester từng bước trong quá trình thực hiện, những gợi ý chi tiết về cách để kiểm tra được một ứng dụng. Trong một test case sẽ bao gồm hướng giải quyết, các mô tả, nhận xét, hành động cũng như kết quả, kể cả thành công và thất bại.
Trong khi đó, use case có thể hiểu một cách đơn giản là một tài liệu có thể giúp tester hiểu được hành động của người dùng. Bên cạnh đó use case cũng bao gồm một số phản ứng của hệ thống, sản phẩm khi được tìm thấy trong một chức năng cụ thể nào đó.
4. Có những phương pháp thử nghiệm nào và các cấp độ của chúng?
Về cơ bản hiện nay có 3 phương pháp kiểm thử phần mềm được áp dụng nhiều nhất gồm:
Kiểm tra hộp đen: Cách kiểm tra này chủ yếu phát hiện các sai sót liên quan đến thông số kỹ thuật. Kiểm tra hộp đen không yêu cầu tester phải có kiến thức về các đường dẫn nội bộ, cấu trúc hoặc việc triển khai phần mềm đang được thử nghiệm.
Kiểm tra hộp trắng: Ngược lại với việc kiểm tra hộp đen, kiểm tra hộp trắng lại dựa các link nội bộ, cấu trúc code và triển khai phần mềm đang được thử nghiệm. Vậy nên kiểm tra hộp trắng cũng đòi hỏi kỹ năng lập trình chi tiết cao hơn.
Kiểm tra hộp xám: Với phương pháp kiểm tra này, tester sẽ không có nhiều kiến thức liên quan đến các hạn chế, các lỗi xảy ra bên trong chương trình.
Kiểm thử phần mềm nói chung, về cơ bản quy trình hoạt động sẽ diễn ra từ giai đoạn kiểm tra đơn vị đến khi các lỗi đã được sửa và chấp nhận. Trong đó gồm 4 bước chính:
Kiểm tra đơn vị
Thử nghiệm hội nhập
Thử nghiệm hệ thống
Kiểm tra chấp nhận
Để trở thành một tester, từ kỹ năng làm việc đến kiến thức chuyên môn đều là những yếu tố cần có. Hy vọng một số thông tin được cung cấp trên đây có thể giúp cho các tester tương lai có thêm thông tin và sự tự tin cho những vòng phỏng vấn tới của mình. Đón đọc thêm nhiều thông tin bổ ích khác với những bài viết hấp dẫn cùng topdev.vn/blog
Vào một ngày đẹp trời, một mail rì pọt từ user gửi đến, nội dung như này:
Tui đang dùng app ABC của mấy người. Ở màn hình order, tui copy một đoạn text từ Powerpoint ra và dán vào mục Order Message. Xong tui bấm nút tiếp tục, thì app ngừng hoạt động, màn hình chỉ hiện lên một nửa, đây là nội dung lời nhắn:
“Happy birthday, Dave! We got a gift for you! Hope you like it, Mom and Dad.”
Nhìn từ bên ngoài, lời nhắn kia trông không có gì khả nghi, nhưng nếu nhìn kĩ bằng cách bật chế độ hiển thị các kí tự ẩn (hidden characters) trên editor (với Emacs thì M-x whitespace-mode, với các editor khác thì các bạn tự Google đi), thì ta có thể thấy ngay một vài kí tự lạ xuất hiện:
"Happy birthday, Dave!^K^K We got a gift for you!^K^K Hope you like it,^K Mom and Dad."
Để chi tiết hơn, ta có thể dùng một công cụ xem các kí tự ẩn nào đó, ví dụ như công cụ này. Ta sẽ thấy kí tự lạ kia là 0x0b.
Té ra, 0x0b hay còn gọi là vertical tab \v, là một dạng kí tự ngắt dòng giống như \n, mã ASCII là 11, có thể được chèn vào bằng cách gõ Ctrl + K (đó là vì sao Emacs hiện ra ^K). Giống như kí tự tab \t (giúp nhảy nhanh về bên phải vài kí tự), \v có chức năng tương tự nhưng là nhảy xuống dòng, nhưng ở thời điểm hiện tại thì không còn ai dùng đến kí tự này nữa.
Nhưng khổ cái là nó vẫn còn tồn tại trong nhiều tài liệu, và nghiêm trọng hơn, nó không nằm trong chuẩn của JSON [1]. Chính vì thế nên đa số các JSON parser (như của V8 và Spidermonkey) đều không thể parse được nếu nội dung có chứa \v, và còn nhiều dạng kí tự ẩn (non-printable characters [2]) khác nữa. Và sẽ quăng lỗi khi phải parse nội dung chứa các kí tự lạ đó.
Ở ví dụ đầu bài, vì user input chứa kí tự không hợp lệ, JSON.parse() quăng lỗi khiến cho chương trình không thể chạy tiếp, và ngắt luôn quá trình render (nhân tiện, thằng nào nghĩ ra ba cái vụ client-side rendering vậy???). Mọi thứ diễn ra bên dưới, chỉ để lại cái màn hình render nửa vời cho anh bạn user xấu số.
Cho nên cẩn tắc vô áy náy, chúng ta nên replace hết các kí tự không mong muốn trước khi đưa một đoạn nội dung nào đó từ user vào xử lý, ví dụ:
// Viết regex phải có tâm:// - \v: thay thế kí tự \v thành \n// - \p{C}: match tất cả các kí tự non-printableconst filterUnwantedChars = str => str.replace(/\v/g, "\n")
.replace(/\p{C}/g, "");
Và một lưu ý khác, đó là đừng bao giờ sử dụng hàm JSON.parse() trực tiếp, vì nó sẽ throw error, mà nên wrap nó và handle lỗi có thể xảy ra một cách hợp lý để tránh làm “bể” UI chỉ vì user input như ví dụ đầu bài (nhớ dùm, chúng ta là JS dev, không phải Elixir hay Erlang dev, chúng ta không có cái triết lý gọi là “Let it crash”).
const safeParseJSON = str => {
let result = null;
try {
result = JSON.parse(str);
} catch (e) {
console.error("Failed to parse JSON", e);
}
return result;
};
Bằng cách này, chúng ta expect hàm safeParseJSON trả về một object khi parse thành công, và trả về kết quả null khi có lỗi xảy ra, đồng thời có thể kiểm tra log để biết chính xác là lỗi gì, mà không làm ngắt quá trình thực thi của code [3].
Bổ sung: Sau khi published bài viết này, thì thím @nhducit có bổ sung thêm một điểm, đó là đối với React, từ v16 có hỗ trợ method componentDidCatch(), hoạt động giống như catch {} để không làm crash quá trình execute code của component [4], bằng cách này chúng ta có thể handle lỗi một cách an toàn.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
MicroProfile là một tập hợp các APIs dựa trên Jarkata EE giúp chúng ta dễ dàng xây dựng các ứng dụng Java Enterprise theo mô hình kiến trúc microservices. Các APIs này bao gồm:
Trong đó:
Open Tracing dùng để theo dõi flow của một request tới các service.
Open API dùng để tạo API documentation, chúng ta cũng thường hay gọi nó là Swagger. Các bạn có thể xem thêm Swagger trong Spring Boot.
Rest Client dùng để gọi tới một RESTful Web Service, tương tự như RestTemplate hoặc WebClient trong Spring.
Config dùng để làm những việc liên quan đến cấu hình của ứng dụng.
Fault Tolerance dùng để handle các trường hợp ứng dụng đang bị lỗi.
Metrics dùng để định nghĩa các metrix của ứng dụng.
JWT Propagation dùng để làm việc với access token trong OAuth2 và OpenId Connect.
Health expose các thông tin runtime của các services.
CDI của Jakarta EE, hỗ trợ dependency injection trong ứng dụng.
JSON-P (JSON Processing) dùng để convert Java object POJO qua JSON.
JAX-RS hiện thực RESTful Web Service.
JSON-B (JSON Binding) dùng để convert JSON qua Java object.
Jakarta Annotation của Jakarta EE, định nghĩa một tập các annotation để làm việc với các ứng dụng Jakarta EE.
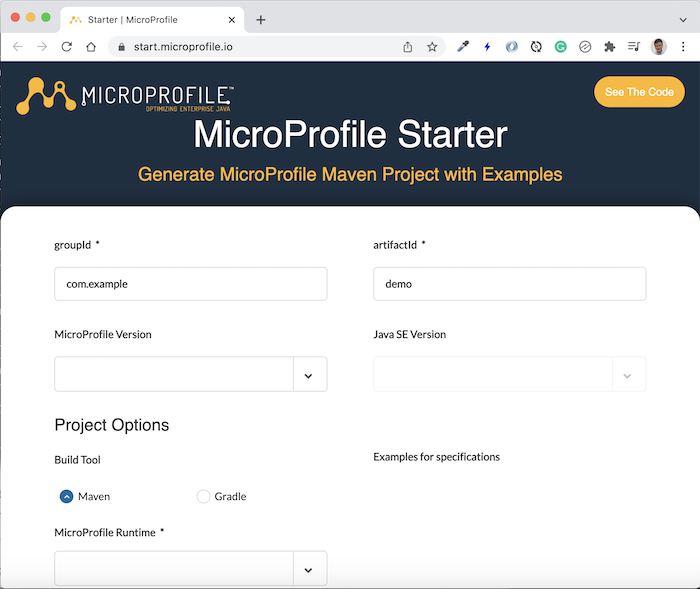
Chúng ta có thể sử dụng công cụ MicroProfile Starter để tạo mới project MicroProfile, tương tự như Spring framework, tại https://start.microprofile.io/:
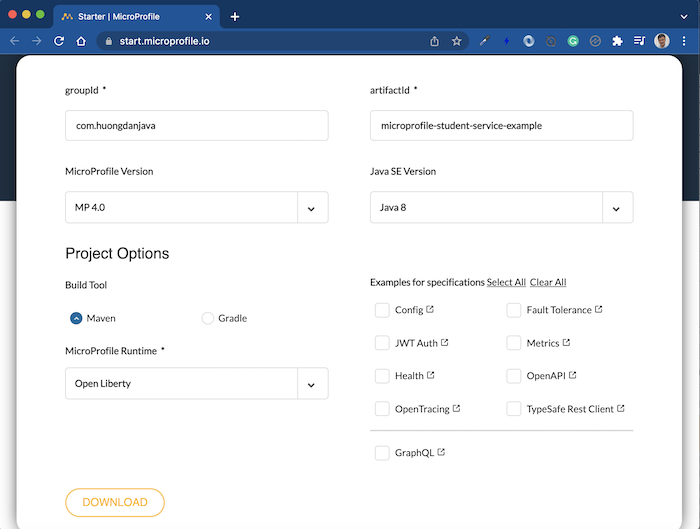
Để làm ví dụ cho bài viết này, mình sẽ tạo mới một service sử dụng MicroProfile như sau:
Các bạn không cần select các APIs nhé! Mặc định thì tất cả các APIs của MicroProfile sẽ được khai báo trong ứng dụng.
Nhấn DOWNLOAD để tải project về máy, sau đó thì import nó với Maven project vào IDE mà các bạn đang sử dụng nhé!
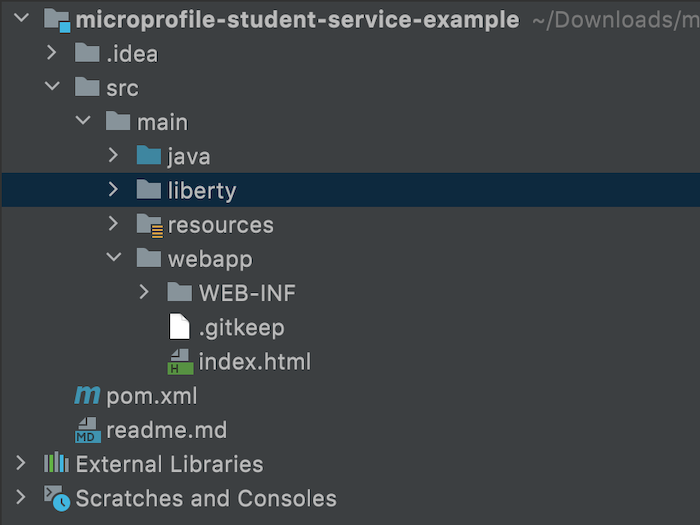
Kết quả của mình như sau:
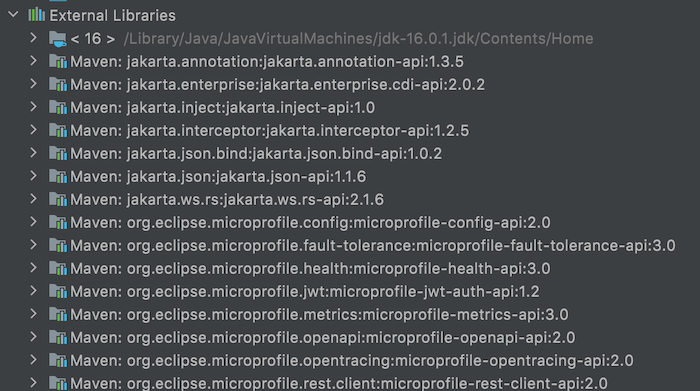
Kiểm tra External Libraries của Maven project này:
các bạn sẽ thấy ngoài các dependencies của MicroProfile, chúng ta còn thấy các dependencies của Jakarta EE. Chúng toàn là các APIs, không có implementation nên để chạy được ứng dụng MicroProfile, chúng ta phải sử dụng các server runtime có hỗ trợ cho MicroProfile như Open Liberty, Payara, WildFly,… các bạn nhé!
Mình đã chọn sử dụng Open Liberty với Liberty Maven plugin để chạy ví dụ cho bài viết này như sau:
Nội dung của tập tin server.xml được generated như sau:
<?xml version="1.0" encoding="UTF-8"?>
<server description="${project.name}">
<featureManager>
<feature>microProfile-4.0</feature>
</featureManager>
<httpEndpoint id="defaultHttpEndpoint"
httpPort="9080"
httpsPort="9443"/>
<webApplication location="${project.name}.war" contextRoot="${app.context.root}">
<classloader apiTypeVisibility="+third-party"/>
</webApplication>
<mpMetrics authentication="false"/>
<!-- This is the keystore that will be used by SSL and by JWT. -->
<keyStore id="defaultKeyStore" location="public.jks" type="JKS" password="atbash"/>
<!-- The MP JWT configuration that injects the caller's JWT into a ResourceScoped bean for inspection. -->
<mpJwt id="jwtUserConsumer" keyName="theKeyId" audiences="targetService" issuer="${jwt.issuer}"/>
</server>
Như các bạn thấy, feature microProfile-4.0 được khai báo để sử dụng trong thẻ <featureManager>. Ngoài ra còn có một số cấu hình khác. Các properties như project.name, jwt.issuer, app.context.root được khai báo trong thẻ <bootstrapProperties> của Liberty Maven plugin trong tập tin pom.xml các bạn nhé!
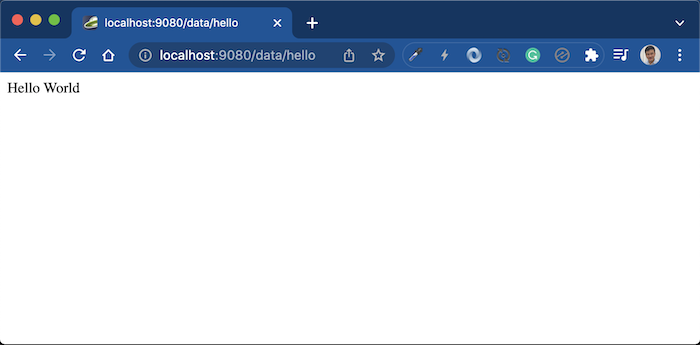
Chạy project với Liberty Maven plugin, các bạn có thể access tới endpoint mặc định của generated project là http://localhost:9080/data/hello, kết quả như sau:
Ngoài ra thì với feature microProfile-4.0 được khai báo để hỗ trợ thì chúng ta còn có thể access tới một số endpoint khác như:
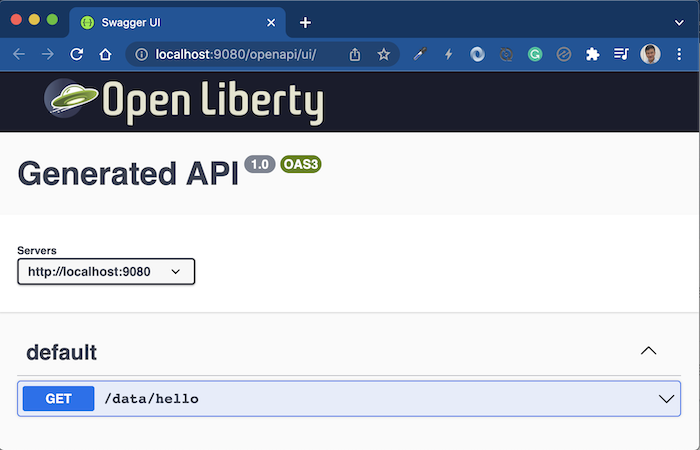
OpenAPI để xem API documentation http://localhost:9080/openapi/ui/:
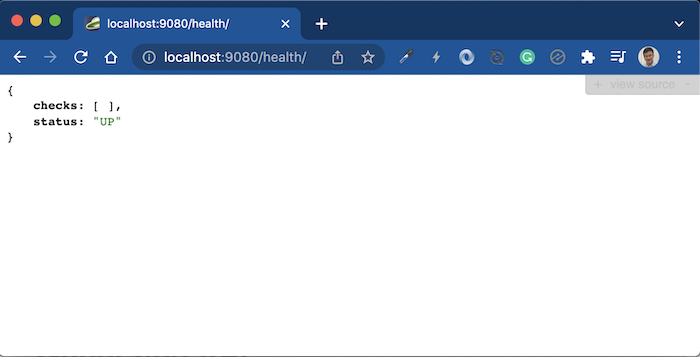
Health check service http://localhost:9080/health/:
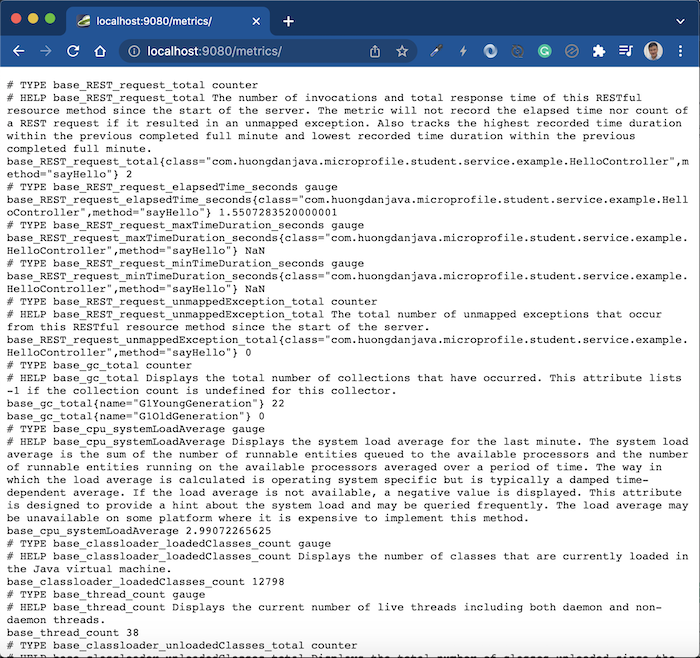
Metrics http://localhost:9080/metrics/:
Tuỳ theo nhu cầu thì các bạn hãy sử dụng MicroProfile cho phù hợp nhé!
Bài viết này chỉ đề cập đến V8 (là JavaScript engine đứng sau Google Chrome và NodeJS), sau khi đọc bài này, nên tìm đọc thêm về SpiderMonkey (Firefox), Chakra (Edge) và Carakan (Opera), các yếu tố về kĩ thuật trong các engine này có thể sẽ khác nhiều so với V8.
Lý do chọn viết về V8 thì rất là đơn giản, vì engine này có nguồn tài liệu cực kì phong phú và gần như là, hễ tìm với từ khóa JavaScript engine thì nó cứ ra V8 =))
Thực ra, nếu nhìn nhận một cách khách quan về V8 cũng như những kĩ thuật mà team này bỏ ra cho công việc optimization một ngôn ngữ như JavaScript, và đào sâu vào những kĩ thuật đó, thì đó là một kho tàng kiến thức đồ sộ mà chỉ có dại lắm mới dám bỏ qua không ngó ngàng tới.
Viết bài này, mình không có tham vọng gom hết đống kiến thức đồ sộ đó vào một bài viết nhỏ, nên tất nhiên sẽ còn nhiều điểm thiếu sót, hy vọng các bạn đọc xong sẽ nhiệt tình góp ý, cũng như thu về được một ít thông tin vụn vặt, để từ đó mà đem đào sâu hơn vào engine lý thú này.
■ Trong khi đọc, các bạn nên hạn chế đọc những dòng in nghiêng, đây là những đoạn bình luận nhố nhăng không đóng góp gì nhiều vào nội dung bài viết =))
1. Hidden Class
Mọi thứ trong JavaScript đều là object, và mọi thuộc tính của một object thì đều có thể được thêm vào hoặc bỏ đi (thay đổi layout), hoặc thay đổi kiểu dữ liệu (type) bất cứ lúc nào (on the fly). Điều này khiến cho việc optimize một ngôn ngữ “động” như JavaScript (dynamically typed language) trở nên rất khó khăn.
Ví dụ luôn, giả sử ta có đoạn code như thế này:
classCar{
door_open() {
// ...
}
}
classGirl{
// girls has no door
}
const open_the_door = (object) => {
object.door_open();
};
Trong ví dụ trên, hàm open_the_door() nhận vào một object và gọi hàm door_open() của object đó, tuy nhiên, vì không có cách nào quy định một cách cụ thể kiểu dữ liệu nhận vào của hàm open_the_door(), compiler sẽ không thể nào biết trước được liệu object truyền vào có tồn tại hàm door_open() hay không. Mà nếu không biết thì phải kiểm tra, bằng cách tra cứu (lookup – duyệt hết toàn bộ hàm/thuộc tính có trong object đó và tìm). Rõ ràng, là không hề tối ưu, và nguyên nhân thì lại do chính thiết kế của JavaScript.
■ “not a design weakness, but a weakness by design”
Team V8 giới thiệu một khái niệm gọi là hidden class, gán vào cho mỗi object để giúp cho việc tracking kiểu và các thuộc tính của chúng một cách thuận tiện hơn. Và mỗi lần object thay đổi, thì hidden class của nó cũng sẽ thay đổi tương ứng.
Với cách viết như trên, ta có tổng cộng 3 lần thay đổi cấu trúc của object product. Đầu tiên, là ở câu lệnh let product = {}, lúc này V8 sẽ tạo ra hidden class C0 để biểu diễn cấu trúc của product (là một object rỗng). Tiếp theo, khi gặp câu lệnh gán product.title, thì cấu trúc thay đổi, V8 thay thế hidden class C0 thành C1 (có thêm thuộc tính .title), và cuối cùng là thành C2 ở câu lệnh gán product.pages, quá trình thay đổi diễn ra như hình bên dưới:
Việc xảy ra đến 3 lần thay đổi cấu trúc, dẫn đến 3 lần V8 phải tạo ra hidden class mới là không hề tối ưu. Ta nên khởi tạo tất cả các thuộc tính của một object ngay trong khi khởi tạo chính object đó, bằng cách viết rút gọn:
Với cách viết này, V8 chỉ tạo ra một hidden class duy nhất cho object product, vì không có sự thay đổi cấu trúc nào xảy ra sau câu lệnh khởi tạo:
Các object có cùng kiểu hoặc cấu trúc (hoặc thuộc cùng một class) thì sẽ có chung một hidden class, V8 sẽ không tạo mới mà sử dụng lại các hidden class đã có nếu trùng khớp.
Ví dụ với câu lệnh sau, hidden class của product thay đổi từ C2 về lại C1 chứ không tạo mới:
delete product.pages;
Tuy nhiên, nếu trong trường hợp trên, thuộc tính bị xóa là .title thì sẽ lại có một hidden class C3 được tạo ra.
Bằng cách sử dụng hidden class, V8 luôn biết trước được cấu trúc của một class/object, từ đó có thể tối ưu việc truy xuất đến các thuộc tính của chúng bằng nhiều cách, một trong các kĩ thuật tối ưu mà V8 áp dụng đó là inline caching.
Có thể hiểu nôm na, inline caching là việc tạo ra “đường tắt” (lưu luôn vị trí chính xác của từng vùng nhớ cho từng thuộc tính vào trong code) giúp cho việc truy xuất đến thuộc tính đó diễn ra nhanh hơn, thay vì cách dùng “đường chính” (thực hiện lookup vị trí của thuộc tính đang cần truy xuất trong bộ nhớ).
■ Cái chữ “đường tắt” kia đúng ra phải gọi là “fast path”, bản thân cái từ đó nó cũng mang nhiều ý nghĩa và đọc vào nghe thấm thía hơn. Thế nào là fast path? có fast hẳn phải có slow, vậy slow path khác fast path như nào? Bạn phải tự đặt ra đc câu hỏi như vậy. Tiếc là viết tiếng Việt không dùng được những cái vô lời hữu ý như vậy được, chán bỏ bà.
Ví dụ khi truy xuất một thuộc tính của một object:
let x = product.title;
Giả sử V8 sẽ sinh ra machine pseudo code để xử lý câu lệnh trên như thế này:
■ Okay, khi thực thi, V8 sẽ sinh ra machine code và chạy trực tiếp đống code đó, trên đây không phải là machine code, mà chỉ là pseudo code mà mình chế ra nhằm giúp dễ theo dõi bài viết hơn mà thôi. Suy cho cùng, đâu có ai muốn đọc machine code trong một bài viết về JavaScript đâu đúng không?
Ở đây ta thấy có việc tra cứu một thuộc tính xảy ra (hàm lookup_property, giả sử hàm này trả về kết quả là vị trí của vùng nhớ chứa thuộc tính title, là 0xDAEDBEEF).
Nếu thuộc tính product.title được sử dụng thường xuyên trong chương trình, thì việc tra cứu liên tục như vậy rất tốn kém, để tối ưu, V8 sẽ cache output của hàm này lại sau lần gọi đầu tiên, để rồi nó sẽ thay đổi đống machine pseudo code đã sinh ra thành:
create $x
assign $x = 0xDAEDBEEF
Trong bài viết tiếp theo, chúng ta sẽ tìm hiểu thêm về cơ chế sinh code và tối ưu động này của V8. Còn bây giờ, hy vọng các bạn đã hiểu được tầm quan trọng của hidden class cũng như những lợi ích mà nó đem lại trong việc cải thiện performance của JavaScript.
Nói đến công việc dọn rác (thu dọn và xóa sổ những object/giá trị không còn được dùng tới, trả lại bộ nhớ để dùng cho việc khác), đây là một phần khá quan trọng mà ít người quan tâm trong JavaScript. Ngày nay, khi mà JavaScript được dùng càng nhiều cho cả phía server lẫn các single page application, vòng đời của một JS app ngày một dài ra, vai trò của GC ngày một lớn.
■ Trước đây nhiều người vẫn hay nói đùa là JavaScript thì cần gì GC, chạy trên browser, khi nào hết mem thằng user nó F5 một phát thì tất cả bay biến hết mẹ nó rồi còn đâu
GC của V8 là một Generational Garbage Collector. Trong quá trình thực thi, các giá trị (biến, object,…) được tạo ra nằm trong bộ nhớ heap. V8 chia heap ra làm nhiều khu vực, trong đó ta chỉ đề cập đến hai khu vực chính là new-space (chứa các đối tượng nhỏ, có vòng đời ngắn) và old-space (chứa các thành phần sống dai hơn, bự hơn).
Hai khu vực này cũng là hai đối tượng cho hai loại thuật toán GC khác nhau, đó là scavenge và mark-sweep / mark-compact.
Khi chúng ta khai báo một giá trị mới, giá trị này sẽ được cấp phát nằm rải rác trong khu vực new-space, khu vực này có một kích thước nhất định, thường là rất nhỏ (khoảng 1MB đến 8MB, tùy vào cách hoạt động của ứng dụng). Việc khai báo như thế này tạo ra nhiều khoảng trống không thể sử dụng được trong bộ nhớ.
■ Vì sao lại có những khoảng trống đó thì là kiến thức cơ bản, và bắt buộc các bạn phải biết, không biết thì Google, mình không thích nói nhiều.
Khi new-space đã đầy, thì scavenge sẽ được kích hoạt để dọn dẹp các vùng nhớ “chết”, giải phóng mặt bằng, có thể sẽ gom góp các vùng nhớ rời rạc lại gần nhau cho hợp lý, vì new-space rất nhỏ, nên scavenge được kích hoạt rất thường xuyên. Trong quá trình giải tán đô thị của scavenge, nếu các vùng nhớ nào còn trụ lại được sau 2 chu kỳ, thì được điều đi vùng kinh tế mới promote lên khu vực old-space, nơi mà có sức chứa lên đến hàng trăm megabytes, và là nơi mà thuật toán mark-sweep hoặc mark-compact hoạt động, với chu kỳ dài hơn, ít thường xuyên hơn.
Tất cả những thuật toán GC trên đều hoạt động thông qua hai bước chính là:
Bước đánh dấu: thuật toán sẽ duyệt qua tất cả các giá trị có trong khu vực bộ nhớ mà nó quản lý, bước duyệt này đơn giản chỉ là depth-first search, tìm gặp và đánh dấu.
Bước xử lý: sau quá trình duyệt, tất cả những giá trị chưa được đánh dấu, sẽ bị coi là đã “chết”, và sẽ bị xóa bỏ, trả lại bộ nhớ trống (sweep), hoặc gom góp lại để lấy lại các khoảng trống trong bộ nhớ không sử dụng được (compact).
Điểm khác nhau giữa scavenge và mark-sweep/mark-compact nằm ở cách mà chúng được implement, các bạn có thể xem thêm chi tiết về hai thuật toán trên trong bài A tour of V8: Garbage Collection mà mình sẽ dẫn link bên dưới.
Về nguyên lý đánh dấu (marking) của các thuật toán trên, chúng ta sẽ làm quen với khái niệm reachability.
Tất cả mọi đối tượng được khai báo trong global scope, hoặc các DOM elements thì được gọi là root. Và đứng từ các roots, tất cả mọi giá trị local có quan hệ trực tiếp hoặc gián tiếp với các roots này sẽ được coi là còn “sống” (reachable). Những đối tượng nào không có mối liên hệ trực tiếp hoặc gián tiếp vói bất kì roots nào, thì coi như là đã “chết” (unreachable).
Ví dụ với đoạn code sau:
let a = { name: "huy" };
functionhello() {
let b = a;
// you're here
}
Trạng thái của heap và sơ đồ biểu diễn reachability của từng giá trị, ngay tại vị trí // you're here được thể hiện như sau:
Ở đây ta có a và hello là hai giá trị thuộc global scope, vì thế chúng được gọi là các root. Biến a tham chiếu đến một object nằm trong heap, và biến b bên trong hàm hello cũng tham chiếu tới chính object này.
Khi hàm hello() được thực thi xong, và chúng ta đi ra khỏi scope của hàm đó, thì mọi tham chiếu đến các giá trị bên trong hàm đó đều sẽ bị hủy đi, lúc này b trở thành unreachable, và sẽ trở thành đối tượng để bị GC nó thịt (mặc dù bị thịt lúc nào thì không ai biết trước được).
Lưu ý, đối với các root, chúng ta không thể sử dụng lệnh delete để xóa sổ chúng, ví dụ:
delete a; // trả về falsedelete hello; // trả về false
Nhưng chúng ta có thể gán chúng bằng null để cho các giá trị mà chúng tham chiếu tới bị GC hốt (nhưng chính biến đó thì lại vẫn còn tồn tại, ở đây, cả a lẫn hello đều vẫn bảo toàn tính mạng), ví dụ, sau lệnh dưới đây, sơ đồ của chúng ta sẽ là:
a = null;
Vậy thì đến bao giờ a và hello mới bị giải phóng khỏi bộ nhớ? Câu trả lời là: chừng nào ứng dụng của chúng ta còn chạy, thì chúng vẫn sẽ còn tồn tại trong bộ nhớ. Dân gian gọi là memory leak. Chính vì thế, nên hạn chế việc tạo và sử dụng các biến global, nếu không thực sự cần thiết.
Nói tiếp về vấn đề khi sử dụng delete và null, ở trên chúng ta đã biết delete không thể xóa sổ các root, tuy nhiên nó vẫn hoạt động tốt thuộc tính của các object:
delete a.name;
Khi chạy lệnh trên, ta có thể chủ động làm cho giá trị a.name trở thành mục tiêu của GC, nhưng cách này có một hiệu ứng tiêu cực, đó là nó làm thay đổi hidden class của a, mà như chúng ta đã biết ở phần trước, việc này gây ảnh hưởng tới performance. Tương tự, nếu chúng ta gán a.name là null, nó cũng sẽ trở thành mục tiêu của GC.
a.name=null;
Nhưng lại một lần nữa, việc gán một biến thành null chỉ có thể làm cho giá trị mà biến đó tham chiếu tới trở thành mục tiêu bị xóa sổ, nhưng không thể xóa sổ chính biến đó. Trong trường hợp này thì biến a.null vẫn còn tồn tại.
Cách tốt nhất để hủy một giá trị là đưa nó vào một scope nào đó, ví dụ như sử dụng JS Modules hoặc IIFE (immediately invoked function expression):
(function() {
let a = { name: "huy" };
})();
a; // ReferenceError: a is not defined
Tiếp, khi truyền một hàm vào setInterval hoặc setTimeout, một tham chiếu đến hàm đó sẽ được tạo ra, khiến cho hàm này không thể bị GC hốt, dù cho chúng ta đã ra khỏi scope chứa nó, và sẽ vẫn tồn tại cho đến chừng nào nó được kích hoạt.
Đối với trường hợp của setTimeout, chúng ta có thể yên tâm, vì sau một khoảng thời gian, nó sẽ được chạy, và cuối cùng sẽ bị GC hốt, tuy nhiên đối với setInterval, chuyện lại không hề đơn giản:
functiondo_something() {
setInterval(functionrun() {
// do something
}, 1000);
}
// you're here
Hàm run vẫn còn tồn tại và vẫn còn được thực thi sau mỗi 1 giây, kể cả khi hàm do_something đã kết thúc vòng đời của nó. Chính vì thế, phải luôn luôn lưu lại tham chiếu của mỗi câu lệnh setInterval, và chạy clearInterval khi không còn cần đến:
functiondo_something() {
let runner = setInterval(functionrun() {
// do something
}, 1000);
// do more thing
clearInterval(runner);
}
Một vài lưu ý khác, GC của V8 là stop-the-world, có nghĩa là, khi GC chạy thì toàn bộ chương trình sẽ bị dừng lại, thời gian dừng có khi lên đến vài trăm mili giây, là một con số khá lớn.
Team V8 áp dụng một vài kĩ thuật khác gọi là concurrent marking, giúp cho ứng dụng JavaScript vẫn có thể được thực thi (tất nhiên là concurrent) trong khi GC hoạt động. Tuy không hoàn toàn giúp cho ứng dụng tránh bị đứng, nhưng cũng cải thiện được performance rõ rệt, các bạn có thể đọc thêm qua bài Concurrent marking in V8 (link bên dưới).
Trên đây là một vài ghi chép về Garbage Collection trong V8, hy vọng qua bài viết này, các bạn đã hiểu thêm phần nào về những gì xảy ra bên dưới một ứng dụng JavaScript, và về cách mà JavaScript hoạt động, từ đó có cái nhìn sâu sắc hơn, và cẩn trọng hơn trong quá trình làm việc với thứ ngôn ngữ quái đản đó.
Hôm nào có thời gian mình sẽ làm một bài đi sâu hơn về cơ chế thực thi code của V8 (Crankshaft, TurboFan,…). Cảm ơn các bạn đã đọc đến tận những dòng này
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Open Liberty cũng là một Java Server runtime giúp chúng ta chạy các ứng dụng Java web application. Sử dụng Liberty Maven plugin sẽ giúp chúng ta nhanh chóng deploy ứng dụng lên Open Liberty một cách dễ dàng trong quá trình development. Trong bài viết này, mình sẽ hướng dẫn các bạn cách sử dụng Liberty Maven plugin này các bạn nhé!
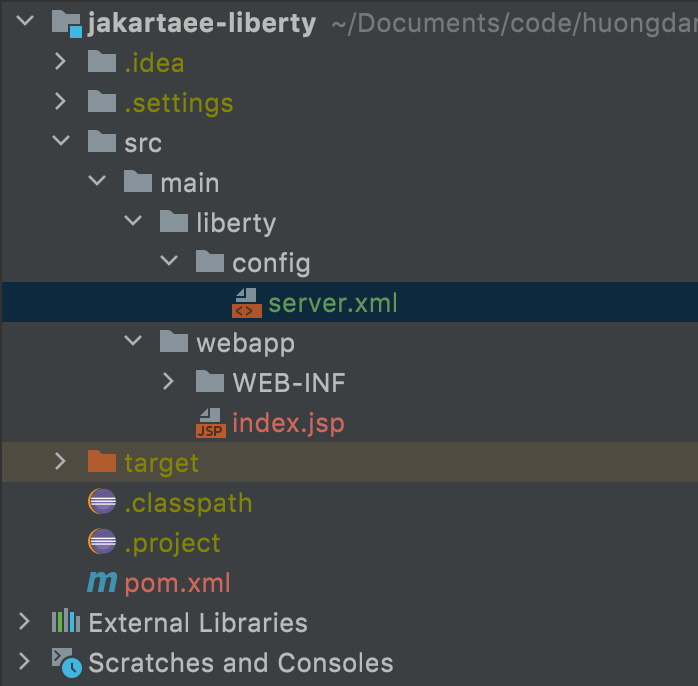
Để plugin này hoạt động, chúng ta cần định nghĩa thông tin về Open Liberty server trong một tập tin tên là server.xml nằm trong thư mục /src/main/liberty/config:
Liberty Maven plugin sẽ tự động replace giá trị của các properties với key bắt đầu với liberty.var, được khai báo trong tập tin pom.xml với các properties được khai báo trong tập tin server.xml.
Với Liberty Maven plugin, chúng ta cần định nghĩa feature mà chúng ta muốn chạy trong tập tin server.xml này. Như các bạn thấy, ở đây mình đang cần chạy Jakarta EE 9.1 nên mình đã khai báo feature này trong thẻ <featureManager>. Các bạn có thể xem toàn bộ feature của Open Liberty tại đây.
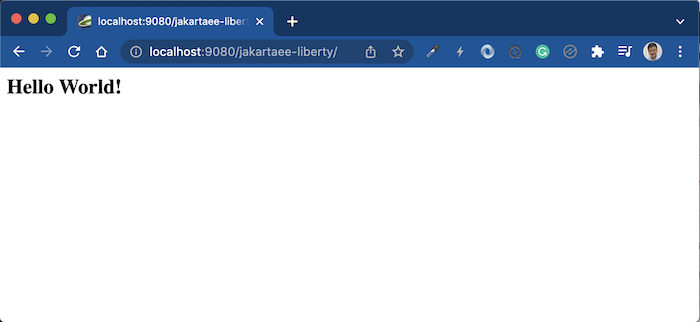
Lúc này, nếu chạy ứng dụng bằng Maven với “mvn clean liberty:run” và đi đến địa chỉ http://localhost:9080/, các bạn sẽ thấy kết quả như sau:
Với khai báo trong tập tin server.xml thì ứng dụng của chúng ta sẽ chạy ở địa chỉ http://localhost:9080/jakartaee-liberty/ các bạn nhé!
Kết quả như sau:
Liberty Maven plugin hỗ trợ chúng ta live coding, có nghĩa là Open Liberty sẽ tự động load những thay đổi của chúng ta trong code trong quá trình development. Các bạn có thể chạy câu lệnh Maven “mvn clean liberty:dev” để làm được điều này, giúp cho quá trình development của chúng ta nhanh hơn, rất tiện đó các bạn!
Trong phần trước, chúng ta phải chạy các câu lệnh Java với Selenium Server để khởi tạo Hub và Node. Và chúng ta có hai màn hình Console để điều kiển Hub và Node. Điều này đôi khi gây ra một số bất lợi cho chúng ta khi theo dõi quá trình chạy của kịch bản kiểm thử tự động.
Phần này, mình xin giới thiệu với các bạn một công cụ mà cho phép chúng ta khởi tạo Hub và Node trên UI – VisGrid.
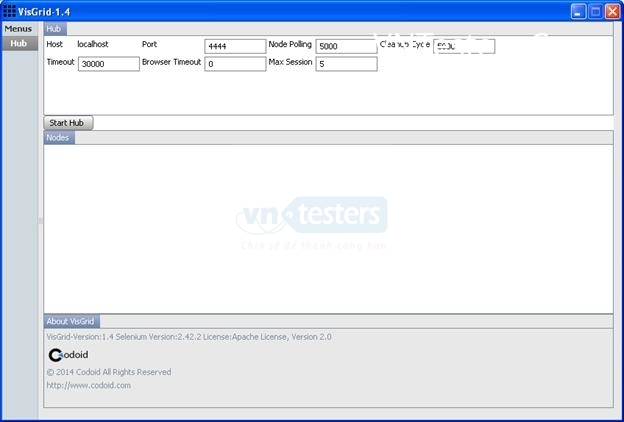
Sau khi download VisGrid về, chúng ta chạy chương trình VisGrid-*.jar và một UI sẽ hiện thị như sau:
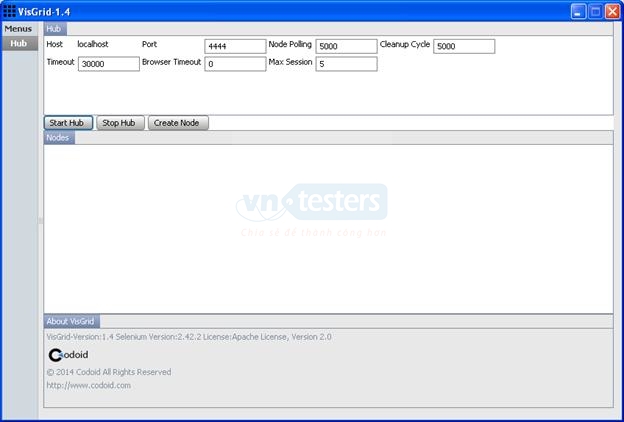
Kế tiếp, chúng ta thiết lập các thông số cho Hub tại tab Hub và nhấn vào nút Start Hub. Sau khi khởi động Hub, hai nút Stop Hub và Create Node sẽ được hiển thị
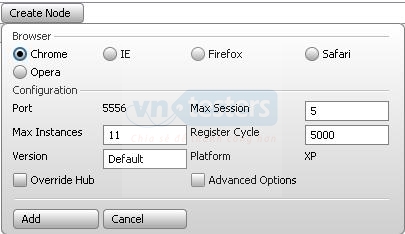
Để khởi tạo các Node, chúng ta nhấn vào nút Create Node. Khi nhấn vào Create Node, một panel sẽ được hiển thị để chúng ta thiết lập cấu hình cho Node. Nhấn nút Add để khởi tạo một Node.
Như vậy là chúng ta đã có thể sử dụng Hub và Node cho việc thực thi kịch bản kiểm thử Selenium qua Selenium-Grid.
Chuyển từ vim sang emacs, sự lựa chọn hàng đầu là spacemacs. Lý do? vì spacemacs có evil-mode, giúp sử dụng keybinding giống vim trên emacs, có khả năng tự động cài đặt những package cần thiết (ví dụ khi mở file *.rs mà chưa cài rust-mode), tự động gỡ bỏ các package không sử dụng, giao diện được config sẵn, và kèm theo hơn 200 packages các kiểu được cài sẵn… nói chung đây là một bản emacs không có gì ngoài magic
Tuy nhiên, magic quá mức vừa là điểm mạnh, vừa là vấn đề hết sức nghiêm trọng của spacemacs. Ngoài việc nó làm cho quá trình khởi động chậm đi rất nhiều (mình đã từng rất bất ngờ khi biết emacs của nhiều người chỉ tốn có 2 giây để khởi động), việc sử dụng khái niệm layer làm giấu đi nhiều thứ mà đáng lẽ ra chính người dùng phải kiểm soát được, và tạo thêm nhiều sự phức tạp không đáng có, ví dụ như không ít lần spacemacs bị crash hoặc tệ hơn là một chức năng nào đó bỗng nhiên dở chứng không hoạt động được nữa, sau khi cài một hoặc một vài packages mới, và dù gỡ nó ra cũng không giúp ích gì được.
Trên kênh support chính của team spacemacs, là github, thì đa phần mọi issue đều được reply một cách chung chung là:
“Bạn đã thử chạy emacs với lệnh –debug-init chưa?”
“Bạn post cấu hình file .spacemacs lên xem nào?”
Những câu trả lời như thế này không hề có ích, đơn giản là vì output của --debug-init không thực sự hữu dụng vì spacemacs còn load thêm quá nhiều thứ linh tinh khiến cho việc debug gặp khá là nhiều khó khăn.
Thêm một vấn đề khi sử dụng spacemacs và evil-mode đó là cảm giác sợ bỏ lỡ mất những gì thuộc về emacs truyền thống, tuy nhiên vấn đề này về sau không phải là mối bận tâm của mình nữa.
Nhìn chung, spacemacs là một giải pháp khá thích hợp cho những ai muốn chuyển từ vim sang, nhưng chỉ thích hợp dùng một thời gian. Để có thể tìm hiểu sâu hơn về emacs, thì kiểu gì cũng nên tự tìm cách xây dựng cho mình một file config riêng. Nhiều người cực đoan thậm chí còn nói như này (hơi tục một tí nhé ):
“Xài spacemacs cũng giống như mặc quần sịp của thằng khác vậy”
Thế nên sau một thời gian thì mình cũng bắt đầu thử nghiệm một vài phiên bản emacs customized khác, như doom-emacs (sau đó thì bợ luôn cái theme doom-one của ông này), centaur-emacs (không thích lắm),… nhưng nhìn chung thì vẫn đi tới quyết định tự cấu hình một file init.el riêng.
Kết quả là giờ mình có một bản emacs mà tự mình có thể kiểm soát mọi thứ bên trong nó, tốc độ startup chỉ 2.8s (kiểm tra bằng M-x emacs-init-time), và quan trọng là cực kì nhanh, mượt. Kèm theo đó là việc viết code Emacs Lisp cũng rất là sướng
Cách cấu hình như nào thì mình sẽ không ghi lại ra bài này, vì đã từng post ở bên blog tiếng Anh rồi, và nó cực kì dễ, ai cũng có thể làm theo
Các bạn cũng có thể tham khảo thêm cấu hình init.el mà mình đang sử dụng, sử dụng use-package để cài đặt và quản lý config, kèm theo các package cơ bản như là evil-mode cho vim keybinding, doom-one theme, helm cho vụ search và fuzzy match, projectile để quản lý project, neotree để hiện cây thư muc, which-key để hiện danh sách các keybinding khi bắt đầu gõ phím tắt, general để customize phím tắt, flycheck để kiểm tra code khi đang gõ, company cho vụ autocomplete,…
Nginx là gì, setup một server serve static file với Nginx.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Đồng
Chắc hẳn nếu bạn đang là lập trình viên, bạn cũng đã có đôi lần nghe qua Nginx. Nginx là một web server rất nổi tiếng, nó có thể được dùng để serve static file, làm load balancer cho hệt thống đằng sau nó, hay thậm chí là mail server hay video streaming server, với việc sử dụng thêm “rtmp module”
Do sự giới hạn về trình đô nên hôm nay mình sẽ chỉ nói về cách mà Nginx hoạt động xử lí request đang tới như thế nào và sau đó mình sẽ hướng dẫn các bạn setup một server để serve static file.
Đầu tiên Nginx hoạt động như thế nào và nó ra đời để giải quyết vấn đề gì.
Trước khi nginx ra đời thì có Apache Server cũng đã làm rất tốt nhiệm vụ của một web server. Nhưng sau này khi mà internet đến với nhiều người hơn, một lượng lớn kết nối đổ dập tới server khiến cho Apache không xử lí được.
Apache handle mỗi request bằng cách tạo ra 1 thread để xử lí nó, khiến server tiêu tốn rất nhiều RAM và bị sập khi số lượng Request đồng thời lớn do bộ nhớ không đám ứng được.
Còn đối với Nginx, nginx không xử lí request theo hướng thread, nó xử lí request bất đồng bộ theo hướng sự kiện, sử dụng ít tài nguyên.
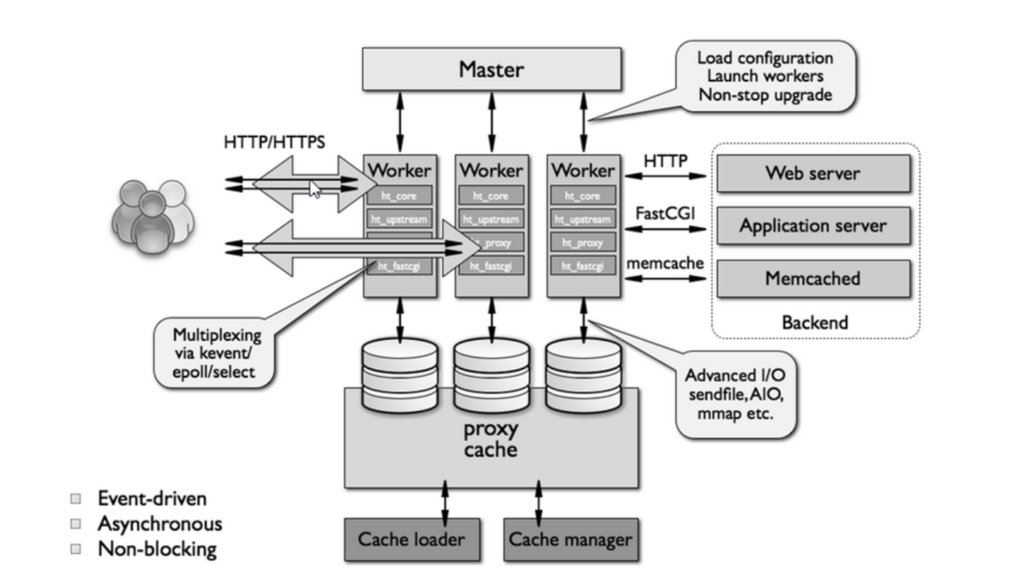
Thành phần chính của Nginx là Master Process và N Worker Process.
Master Process là cái được khởi chạy đầu tiền, đọc file cấu hình, khởi tạo và chạy N Worker processs, hứng request phân chia cho Worker và đồng thời cũng nhận kết quả từ Worker Process để trả lại cho client.
Tiếp theo, hãy cùng tạo 1 server serve static file.
Trước hết cài đặt Nginx, với linux các bạn chỉ cần chạy lệnh sau
sudo apt install nginx
Mặc định thì File config nằm ở “/etc/nginx/nginx.conf”
Theo mặc định khi bạn chạy một server và cần nginx là front-end cho server đó thì bạn phải khai báo server và các thuộc tính cần thiết trong thư mục “site-enabled”, giả sử mình có một server có tên là “dongnguyen.dev” đang chạy thì mình phải tạo một file config trong thư mục “sites-enabled” có tên tuỳ thích nhưng hơn hết đễ dễ nhìn mình sẽ đặt tên file config của mình là “dongnguyen.dev.conf”
Theo mặc định Nginx khi khởi chạy sẽ gom tất cả nội dung trong thư mục “sites-enabled” để phân tích là xử lí. Có thể nhận thế điều này khi trong file “nginx.conf” trên có xuất hiện dòng này
Mình cấu hình nội dung file như sau.
Trong Block “server” chúng ta đang cho nói với Nginx rằng hãy lắng nghe trên cổng 443 và sử dụng giao thức HTTP/2 và sử dụng chứng chỉ SSL cho server có tên là “dongnguyen.dev”
Để thêm SSL config cho server chúng ta include ssl config trong thư mục snippet của Nginx. Để tạo SSL cho server chúng ta có thể sử dụng một dịch vụ miễn phí của “https://letsencrypt.org/”
Đầu tiên chạy lệnh sau, lệnh này sẽ install certbot cli cho chúng ta.
sudo apt-get update
sudo apt-get install software-properties-common
sudo add-apt-repository universe
sudo add-apt-repository ppa:certbot/certbot
sudo apt-get update
Chạy tiếp
sudo apt-get install certbot python-certbot-nginx
Giờ mình sẽ dùng certbot để generate private key và fullchain, nếu tạo thành công bạn sẽ nhìn thấy 2 file quan trọng tên là “fullchain.pem” và “privkey.pem”
Các bạn thêm 2 file sau vào thư mục Snippet của Nginx, nhớ thay đổi tên server cho phù hợp với bạn.
Qua trở lại với file config cho con server của chúng ta trong “sites-enabled”
ở đây chúng ta có hai location để nói với nginx sau khi “listen” trên cổng 443 nếu nhận được request nào match với các location trên thì xử lí theo những gì quy ước trong đó
Lưu ý không giống như Golang Router Handler function nào được khai báo trước thì sẽ được check trước, với nghinx thì người lại các location được khia báo sau sẽ có độ ưu tiên cao hơn.
Như trong hình khi client truy cập vào “dongnguyen.dev/static/xxx/yyy/zzz” thì sẽ match,l nó sẽ thực hiện tiếp việc “try_files “ và check em liệu trong “/var/www/dongnguyen.dev” có file mà client đang lấy hay không nếu không sẽ trả về status 404.
Trước khi khởi động server hãy chắc chắn bạn chỉnh sửa đúng file config
Chạy lệnh “sudo nginx -t” nếu các file config của bạn OK thì nó sẽ báo như hình dưới.
Khởi chạy server bằng cách chạy lệnh “sudo systemctl start nginx”.
Tạo một vài static file trong thư mục “/var/root/www/dongnguyen.dev/static/” xem chúng ta có lấy được gì ko.
Mình đã copy một đống anh vào trong server của mình, mình tạo thư mục “/var/root/www/dongnguyen.dev/static/image” để chứa ảnh. và bây giờ nếu muốn lấy ảnh nào đó thì mình chỉ cần map theo đúng đường dẫn của ảnh là được. Ví dụ để lấy file “cold.png” thì mình chỉ cần truy cập
Vậy là ta đã dùng nginx để static file và nếu mình truy cập vào “https://dongnguyen.dev” thì nó sẽ proxy_pass qua con server đang chạy trên cổng 8080 của mình.
Đến đây là hết rồi :)) Nginx có thể làm được rất nhiều thứ hay nếu bạn muốn học Nginx hay vào ngay trang chủ của nó. Riêng mình do giới hạn về trình độ nên mình chỉ có thể chia sẻ đến đây.
Những dấu hiệu bạn đang không làm tốt công việc kiểm thử
Bài viết được sự cho phép của vntesters.com
Trong cuộc sống chúng ta không quá xa lạ với những dấu hiệu. Khi ra đường chúng ta sẽ dễ dàng bắt gặp những dấu hiệu về đường một chiều, bảng báo cấm đậu xe. Khi khám bác sĩ, bác sĩ cũng hay hỏi về những dấu hiệu như hắc hơi, sổ mũi, ho v.v. Việc nhận biết những dấu hiệu đó giúp ích chúng ta rất nhiều trong cuộc sống.
Tương tự trong kiểm thử cũng có những dấu hiệu của riêng nó. Khi bạn nhận được nhiều lời phàn nàn từ khách hàng, khi số lượng bug bạn để “lọt” đến tay khách hàng ngày càng nhiều, khi tất cả các trường hợp kiểm thử có kết quả “Passed”, khi bạn không biết tài liệu kiểm thử lưu ở đâu, một lỗi được trao đổi liên tục qua lại giữa bạn và developer, khi bạn chẳng học được gì mới trong dự án v.v Tất cả những dấu hiệu đó cho thấy có thể bạn đang không làm tốt công việc của một kỹ sư kiểm thử. Việc nhận ra những dấu hiệu đó càng sớm càng tốt sẽ giúp bạn điều chỉnh, chỉnh sửa ngay lập tức hay ngăn ngừa vấn đề diễn biến xấu thêm.
Cách đây vài tuần, mình có đặt một câu hỏi tương tự về những dấu hiệu giúp nhận biết bạn không làm tốt công việc kiểm thử trên LinkedIn và nhận được gần 100 lượt bình luận và chia sẻ của cộng đồng kỹ sư kiểm thử trên thế giới. Mặc dù có nhiều dấu hiệu còn nhiều tranh cãi nhưng cũng có một số dấu hiệu nhận được sự đồng thuận cao của giới kỹ sư kiểm thử và mình cũng muốn chia sẻ với cộng đồng kỹ sư kiểm thử Việt Nam về những dấu hiệu này
*Lưu ý: Những dấu hiệu bên dưới là tập hợp của những ý kiến của các cá nhân và những dấu hiệu họ quan sát được và trong một ngữ cảnh cụ thể. Có thể đúng và có thể sai. Việc bạn đang có những dấu hiệu trên không đồng nghĩa bạn là một “tester dở” hay bạn đang gặp rắc rối mà đó chỉ đơn thuần là “dấu hiệu”, “biểu hiện” hay “triệu chứng”. Việc giải mã những dấu hiệu trên và tìm ra nguyên nhân thực sự của vấn đề đòi hỏi phân tích chi tiết hơn.
Những dấu hiệu liên quan đến Lỗi:
Tỉ lệ lỗi đến tay người dùng tăng cao (Defect Leakage Rate)
Lỗi được tìm thấy trễ trong các giai đoạn sau của chu kỳ kiểm thử
Lỗi tìm thấy nhiều trong User Acceptance Test (Kiểm thử chấp nhận)
Lỗi được đóng và mở nhiều lần, lặp đi lặp lại
Lỗi không hợp lệ chiếm hơn 15% tổng số lỗi của dự án
Khách hàng tìm được lỗi crash hệ thống
Rất ít lỗi được tìm thấy và log lên hệ thống
Chỉ tập trung tìm lỗi mà không tập trung ngăn ngừa lỗi
Không tập trung phân tích hệ thống để tìm lỗi nghiêm trọng
Lỗi được tìm thấy trong các trường hợp kiểm thử đã được kiểm thử và đánh dấu là “Passed”
Bên thứ 3 tìm được lỗi trong bộ trường hợp kiểm thử “Happy path”
Lỗi đáng ra phải được phát hiện bởi Tester nhưng lại được phát hiện bởi Developer hay được đánh dấu trong Release Note
Khi bạn quá tự tin để đưa sản phẩm ra thị trường và bỏ qua “luật Murphy”
Có 7000 trường hợp kiểm thử cho một chức năng đơn giản của hệ thống
Tự động hóa tất cả các trường hợp kiểm thử và chỉ sử dụng một công cụ duy nhất
Không nắm được Developer đã kiểm thử những gì rồi
Viết nhiều trường hợp kiểm thử dư thừa và quá tập trung và một tính năng
Dành nhiều thời gian để debug lỗi của automation hơn là kiểm thử sản phẩm
Tập trung quá nhiều và các tài liệu kiểm thử (kế hoạch kiểm thử, trường hợp kiểm thử, v.v) hơn là mục đích chính của kiểm thử
Không tập trung vào quá trình kiểm thử như thực thi kiểm thử sai môi trường yêu cầu, cắt bỏ các bước, hiểu sai yêu cầu/hướng dẫn kiểm thử, tài liệu kiểm thử
Đã 12h trưa và không ai trong đội kiểm thử biết hôm nay sẽ kiểm thử cái gì, chỉ kiểm thử ngẫu nhiên vài chỗ
Khi có ai thắc mắc về một tính năng của ứng dụng thì bạn luôn trả lời “tính năng này xưa giờ nó vậy..”
Không hiểu được yêu cầu business đối với sản phẩm đang kiểm thử
Kỹ sư kiểm thử đọc qua tài liệu đặc tả yêu cầu và tuyên bố “Hiểu hết, không hỏi gì thêm”
Những dấu hiệu liên quan đến Quản lí kiểm thử:
Hoãn đưa sản phẩm ra thị trường chỉ để tìm câu trả lời cho câu hỏi “Làm sao con bug này có thể sót được”
Điều chỉnh công việc kiểm thử chỉ để cho khớp với ước tính ban đầu
Không biết nơi lưu trữ các tài liệu, trường hợp hay kết quả kiểm thử khi người phụ trách vắng mặt
Tài liệu kiểm thử chỉ có một version duy nhất
Tài liệu, các trường hợp kiểm thử không được cập nhật các tính năng mới của sản phẩm kiểm thử
Khi việc kiểm thử vượt quá ngân quỹ, thời gian và chất lượng kém
Khi bạn phải làm việc nhiều thời gian hơn bình thường
Khi ai đó đánh thức bạn khi bạn đang ngủ (đặc biệt là trong giờ làm :-))
Sếp tự động thêm tính năng vào sprint và không thông báo cho đội kiểm thử
Khi bạn không rõ milestone kế tiếp của dự án là khi nào
Bạn không trả lời được câu hỏi “Bạn test tới đâu rồi”
Bạn không có sẵn các kế hoạch hay chiến lược kiểm thử cho việc kiểm thử phần nào, kiểm thử nhiều ít, cách tiếp cận, rủi ro v.v
Những dấu hiệu liên quan đến Giao tiếp:
Đội kỹ sư kiểm thử tách biệt với các đội khác
Kỹ sư kiểm thử ngồi trước máy tính nhiều giờ, tai đeo headphone
Kỹ sư kiểm thử không nói chuyện với Dev và ngược lại
Kỹ sư kiểm thử không nói chuyện với Chủ sản phẩm và ngược lại
Kỹ sư kiểm thử không nói chuyện với Khách hàng và ngược lại
Không ai tìm bạn để hỏi hay xin ý kiến
Kênh giao tiếp chủ yếu thông qua e-mail và bảng báo bug
Khi mọi người quyết định mà không thông qua kỹ sư kiểm thử
Khi bạn cảm thấy dường như bạn đứng ngoài lề trong các cuộc thảo luận về công nghệ, công cụ, qui trình
Quản lí dự án dường như “tránh né” bạn. Không cung cấp đủ nguồn lực cho công việc kiểm thử và xếp kiểm thử của bạn vào độ ưu tiên thấp
Kỹ sư kiểm thử ít khi đặt câu hỏi cho bạn đồng nghiệp, Dev, quản lí dự án, chủ sản phẩm, khách hàng v.v
Khi bạn không rõ phần nào đã kiểm thử rồi, phần nào chưa
Không tham gia hoặc nhận được báo cáo hàng ngày từ Dev, BA, Scrum Master, quản lí dự án
Bạn có những phát kiến, tìm hiểu thú vị…và bạn không chia sẻ cho team
Bạn không nói cho mọi người biết sai lầm/lỗi của bạn để giúp mọi người nhận biết và phòng tránh nó
Bạn không thường xuyên hỏi “Tại sao…”
Bạn và Developer thường xuyên phải hỏi qua hỏi lại một con bug vì mọi người không hiểu bạn đang mô tả vấn đề gì
Bạn yêu cầu về thiết bị và nguồn lực chỉ 1 ngày trước khi bạn tiến hành kiểm thử
Bạn phớt lờ lỗi
Bạn không chỉ ra được phần thiếu sót trong đặc tả yêu cầu. Không hiểu và sử dụng công cụ phù hợp cho từng giai đoạn của dự án
Khi bạn quan sát thấy một kỹ sư kiểm thử ngồi “yên lặng” và không có ý kiến suốt buổi họp
Những dấu hiệu liên quan đến Liên tục cải tiến:
Không thường xuyên thử học những kỹ năng mới để làm công việc tốt hơn
Nhận việc một cách cam chịu cũng như phớt lờ học hỏi những điều mới mẻ hay triển khai những ý tưởng mới
Không thường xuyên tự đánh giá bản thân để cải hoàn thiện mình
Không học thêm điều gì mới hay thấy thử thách trong cả tuần làm việc
Những dấu hiệu khác (nhưng không kém phần quan trọng):
Nhận được nhiều phàn nàn từ khách hàng
Luôn mặc định áp dụng một qui trình (đã từng chạy tốt trong quá khứ) cho những dự án khác nhau
Bị sa thải
Bạn thức dậy và thấy mệt mỏi
Bạn có cùng cách tiếp cận cho các dự án kiểm thử
Bạn cho rằng từ khách hàng, Developer đến Quản lí là những tên ngốc
Bạn/những lỗi bạn tìm thấy không nhận được sự tôn trọng cần thiết từ các phòng ban khác.
Bên trên là những dấu hiệu mình tổng hợp từ diễn đàn LinkedIn và dĩ nhiên không phải là một danh sách của tất cả các dấu hiệu. Nếu bạn phát hiện thêm những dấu hiệu khác, bạn có thể chia sẻ bằng cách comment bên dưới bài viết. Ngoài ra bài viết chỉ tập trung liệt kê các dấu hiệu chứ không đi sâu vào phân tích cũng như đưa ra giải pháp. Nếu mọi người có hứng thú thì có thể tìm đọc quyển “Common System and Software Testing Pitfalls” của Donald G. Firesmith để có cái nhìn chi tiết và sâu hơn những vấn đề nêu trên.
Các Phần Mềm Dành Cho Dân IT Mà Mọi Lập Trình Viên Nên Biết
Lập trình chưa bao giờ là dễ dàng nhưng tại sao chúng ta không làm cho nó dễ dàng hơn? Bằng cách sử dụng các ứng dụng hỗ trợ việc lập trình trở nên thuận tiện và nhanh chóng hơn bao giờ hết. Việc sử dụng các ứng dụng để thực hiện công việc một cách hiệu quả nhanh chóng hơn đã không còn là một việc xa lạ. Một ứng dụng tốt sẽ hỗ trợ rất nhiều trong quá trình làm việc, tăng tốc độ làm việc và nâng cao hiệu quả hơn. Vậy đâu là phần mềm thích hợp dành cho lập trình viên? TopDev sẽ giới thiệu đến bạn các phần mềm dành cho dân IT mà mọi lập trình viên nên biết.
Các phần mềm dành cho dân IT mà mọi lập trình viên nên biết
1. Notepad++
Notepad++ (Notepad Plus) là một công cụ để soạn thảo ngôn ngữ lập trình dành cho hệ điều hành Microsoft Windows. Notepad++ không chỉ gây ấn tượng bởi sự gọn nhẹ mà còn hỗ trợ nhiều ngôn ngữ lập trình khác nhau gồm: ASP, PHP, Java, C#…
Notepad++
Đây là một phần mềm được biết đến bởi nhiều lập trình viên từ những người mới vào nghề đến những lập trình viên có kinh nghiệm lâu năm. Mặc dù đơn giản, gọn nhẹ nhưng Notepad++ không chỉ dừng lại ở những tính năng cơ bản mà còn cực kỳ hữu ích khi cho phép người dùng cài đặt thêm các plugin hỗ trợ, mang lại hiệu quả tốt hơn khi lập trình nên nó đã dần trở thành một công cụ lập trình phổ biến và được yêu thích bởi các Coder.
Bên cạnh những ưu điểm về tính năng, dung lượng nhỏ gọn, việc được cung cấp miễn phí cũng là một ưu điểm để người dùng biết đến nhiều hơn. Với Notepad++ người dùng chỉ cần tải về và sử dụng thôi nhé, không tốn một chi phí nào chỉ tốn tiền mạng thôi.
2. Adobe Dreamweaver
Adobe Dreamweaver là một công cụ lập trình đơn giản dùng để thiết kế web. Đây là một trong những công cụ giảng dạy được yêu thích tại các trường học do sự đơn giản dễ sử dụng, đồng thời cung cấp nhiều mẫu giao diện trang web để người dùng có thể sử dụng hoặc tham khảo.
Để tiện cho người dùng Adobe Dreamweaver hỗ trợ nhiều ngôn ngữ lập trình khác nhau như: PHP, HTML, CSS, JavaScript, ASP… Bạn có thể sử dụng chính phần mềm này để đưa trang web của bạn launching mà không cần công cụ nào khác.
3. Microsoft Visual Studio code
Đến từ Microsoft thì Visual Studio Code chưa bao giờ làm các anh em IT phải thất vọng. Visual Studio Code được xem là có mọi tính năng mà bất kỳ lập trình viên nào cũng mong đợi ở một phần mềm soạn thảo code. Bên cạnh đó là các tính năng khác vô cùng hữu ích.
Là một phần mềm dành cho dân IT, Visual Studio Code, nhẹ nhưng mạnh mẽ, sẽ không khiến chúng ta phải đợi lâu trong việc khởi động. Đồng thời ứng dụng cũng cung cấp mã nguồn mở và đa nền tảng và nhiều tính năng thú vị khác.
Với thiết kế giao diện đơn giản, đẹp và dễ sử dụng Visual Studio Code sẽ được chào đón bởi cộng đồng IT.
Trên hết, Visual Studio Code là phần mềm miễn phí, vẫn thường xuyên được hãng cập nhật để tốt hơn. Ứng dụng đã nhận được sự công nhận và tin từ hàng triệu lập trình viên trên toàn thế giới.
4. ReQtest
ReQtest là một ứng dụng được phát triển dựa trên đám mây, bao gồm một bộ mô-đun: quản lý yêu cầu, quản lý kiểm thử, theo dõi và báo cáo lỗi. ReQtest được thiết kế với mục đích thực hiện các nhiệm như kiểm tra, theo dõi lỗi và quản lý những yêu cầu được đưa ra. Về cơ bản ứng dụng này là một nền tảng dùng để quản lý dự án, được sử dụng trong việc phát triển và triển khai phần mềm.
OutSystems là một nền tảng cung cấp các công cụ cho các công ty để phát triển, triển khai và quản lý các ứng dụng doanh nghiệp đa kênh. OutSystems có đủ những thứ mà các nhà phát triển ứng dụng cần có để dễ dàng tạo, thực hiện và quản lý các ứng dụng doanh nghiệp một cách nhanh chóng và dễ dàng hơn. Nền tảng OutSystems rất tốt trong việc giảm chi phí phát triển ứng dụng, với các công cụ tùy chỉnh được tạo ra với một phần chi phí phù hợp.
6. Eclipse
Eclipse
Eclipse là một ứng dụng cung cấp môi trường phát triển tích hợp dùng cho lập trình trên máy tính. Nó chứa một không gian làm việc cơ sở và một hệ thống plug-in mở rộng để tùy chỉnh môi trường.
Eclipse hỗ trợ các công cụ thao tác các kiểu nội dung bất kỳ nhờ vậy lập trình viên hoàn toàn có thể tự mình phát triển các phần mềm dựa trên các ngôn ngữ lập trình phổ biến Java, Python… Bên cạnh đó, Eclipse cũng hỗ trợ tốt cho người dùng trên nhiều hệ điều hành khác nhau. Nhờ vậy mà Eclipse được nhiều người biết tới và đánh giá cao trong lĩnh vực lập trình.
Bằng phần mềm Eclipse, Google đã phát triển thành công một bộ công cụ phát triển ứng dụng cho di động.
Tương tự như những phần mềm lập trình khác Brackets có đầy đủ các tính năng cơ bản cho lập trình viên. Nhưng khác với các công cụ khác mặc dù là công cụ lập trình nhưng Brackets lại hướng đến nhóm đối tượng là những người chuyên thiết kế website.
Phần mềm hỗ trợ sử dụng các ngôn ngữ thiết kế như HTML, CSS hay Javascript.
Trên đây là các phần mềm dành cho dân IT mà một lập trình viên nên biết. Hy vọng sau khi tham khảo những phần mềm trên thì bạn sẽ tìm được cho mình công cụ phù hợp để tạo ra những sản phẩm tuyệt vời cho mình và người dùng.
Intern: Nguyễn Thị Huyền Trang
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Trong bài trước, mình đã giới thiệu với các bạn về Selenium IDE, một công cụ mặc định của Selenium cho phép chúng ta có thể record/playback các kịch bản kiểm thử, đồng thời chuyển các kịch bản kiểm thử này thành các mã nguồn với các ngôn ngữ khác nhau như C#, Java, Python, Ruby…
Trong phần này, mình sẽ giới thiệu với các bạn một công cụ khác tương đương với IDE – Wisard – có thể record với Internet Explorer hoặc Chrome bên cạnh Firefox, với một cách Record khác – không có Playback. Tuy nhiên, công cụ này chỉ có thể kết xuất ra mã nguồn với Java với JUnit Framework mà thôi.
Để Wisard có thể tương tác được với trình duyệt, chúng ta cần phải để tập tin thực thi Wisard cùng thư mục với Selenium Server. Các bạn có thể xem lại cách thiết lập và kiểm tra Selenium Server ở các bài trước.
Bước kế tiếp là khởi động chương trình Wisard
Như hình trên, chúng ta có bốn chức năng chính trong Wisard: Elements, Generated Code, Settings, About.
Elements: Trong tab này, Wisard sẽ liệt kê toàn bộ các đối tượng UI hiện có trong trang web hiện hành.
Generated Code: Trong tab này, Wisard cho chúng ta mã nguồn Java với những hành động mà chúng ta tương tác trên browser.
Settings: Tab này dùng để thiết lập các thuộc tính cho chương trình Wisard.
About: Tab này đơn thuần chỉ là thông tin cơ bản của Wisard mà thôi.
Record với Wisard
Nhấn vào nút Inspect, Wisard sẽ bắt đầu bắt các đối tượng UI đang có trên trang hiện tại. Nhấn chuột phải vào từng đối tượng UI, một danh sách các hành động mà đối tượng UI có thể đáp ứng được.
Sau khi trang web mới được cập nhật, nhấn nút Refresh sẽ cho chúng ta một danh sách đối tượng UI mới trên trang mới.
Chúng ta tiếp tục tương tác với trang mới và cập nhận danh sách đối tượng UI với các trang tiếp theo.
Sao chép mã nguồn
Chuyển sang tab Generated Code, mã nguồn Java đã sẵn sàng cho chúng ta sao chép và sử dụng. Các bạn chú ý là mã nguồn này là ở JUnit Framework.
Thiết lập hệ thống
Trong tab Settings, Wisard cho phép thiết lập trang mặc định ban đầu hay lựa chọn trình duyện để record.
Nhìn chung mà nói thì đây không hẳn là một công cụ hay để tạo lập một kịch bản kiểm thử tự động với Selenium. Bản thân công cụ này không hỗ trợ việc playback sau khi record là một thiếu sót khá rõ ràng. Bên cạnh đó, việc chỉ hỗ trợ ngôn ngữ Java làm mất đi tính đại chúng của Selenium. Dù cách tiếp cận để bắt và tương tác với đối tượng UI khá đặc biệt, nhưng số lượng cách tương tác với đối tượng UI lại quá ít ỏi.
Điểm sáng làm cho Wisard trở nên đặc biệt hơn IDE chính là khả năng record với Internet Explorer hoặc Chrome.
Có một cái sai mà người ta thường hay mắc phải khi làm việc với async/await, đó là khi kết hợp nó với các hàm Array.map/Array.reduce, họ hiểu sai tác dụng của async/await, dẫn tới việc kết quả trả về không như ý.
Giả sử ta có hàm parseUrl(<url>) nhận vào một chuỗi (là địa chỉ của một RSS feed), và trả về danh sách các item có trong RSS feed đó, mà ở đây chúng ta biểu diễn bằng một mảng [article], kết quả trả về thông qua Promise, nội dung hàm này như nào thì không ảnh hưởng nhiều tới bài viết, nên chả cần ghi ra làm gì:
// parseUrl :: string -> Promise [article]
Khi sử dụng await, ta có thể lấy kết quả của Promise đó như thế này, có thể minh họa bằng sơ đồ:
Tiếp theo, là hàm getArticles([urls]) nhận vào một mảng nhiều RSS feed URL, và trả về nhiều mảng chứa danh sách các item tương ứng với từng feed, theo như hiểu biết về cách làm việc với Promise thông qua hàm await như trên, mà await chỉ sử dụng được bên trong các hàm async, vậy thì thêm async vào, ta có thể dễ dàng implement như sau:
Chúng ta tưởng rằng, sử dụng lệnh await sẽ giúp trả về kết quả được resolved của một Promise, mà cụ thể ở đây bên trong hàm source.map(), chúng ta có thể nhận được một mảng chứa kết quả của các promise parseUrl. Nhưng trong trường hợp này, kết quả trả về lại là các Promises, vậy chúng ta đã làm sai ở chỗ nào?
Hàm async luôn trả về một Promise, viết type singature theo kiểu mấy ngôn ngữ functional là:
// async increase :: number -> Promise number
Còn từ khóa await thì có tác dụng dừng việc thực thi code lại và chờ lấy trực tiếp giá trị trả về trong một Promise:
// await Promise number -> numberlet two = await increase(1);
// two = 2
Nếu không dùng await thì ta phải dùng .then(), là cách truyền thống để nhận giá trị trả về của một Promise, giá trị trả về chỉ có thể sử dụng được trong scope (phạm vi) của .then(), và không biết sử dụng nó trực tiếp ở scope hiện tại như thế nào luôn.
let two = increase(1).then(n => {
// n = 2
...
})
// two = Promise
Quay trở lại ví dụ đầu bài, hãy cùng xem lại hàm getArticles trả về kết quả như thế nào. Chúng ta sẽ đi từ trong ra ngoài.
Ngay tại đây chúng ta thấy, hàm callback của sources.map() trả về một Promise chứ không phải là một mảng các article như dự tính ban đầu.
■ Mặc dù chúng ta sử dụng await để lấy kết quả trả về từ parseUrl() (vốn là một Promise), tuy nhiên vì nằm trong một hàm async, kết quả này rốt cuộc cũng bị wrap lại vào bên trong một Promise.
Điều này dẫn đến việc, kết quả của câu lệnh map là một mảng các Promises, thay vì là mảng của các mảng [article] như ta nghĩ.
Và kết quả là hàm getArticles() trả về một mảng các Promises, và mỗi một Promise trong mảng này lại chứa các [article] của chúng ta:
Vậy nên, cách để giải quyết vấn đề trên là, sử dụng Promise.all() để lấy toàn bộ kết quả trả về từ các Promise có trong sources.map(), sau đó mới đưa ra cho hàm getArticles():
asyncfunctiongetArticles(sources) {
let promises = sources.map(async (url) => {
returnawait parseUrl(url);
});
returnawaitPromise.all(promises);
}
let url = await getArticles([
"https://thefullsnack.com/rss.xml",
"https://news.ycombinator.com/rss"
])
// Output:
[ [ { title: 'Giấy với bút',
link: 'https://thefullsnack.com/posts/paper-and-pen.html' },
{ title: 'Vài ghi chép về V8 và Garbage Collection',
link: 'https://thefullsnack.com/posts/javascript-v8-notes.html' },
...
],
[ { title: 'Elon Musk Accused by SEC of Misleading Investors in August Tweet',
link: 'https://news.ycombinator.com/item?id=18088099' },
{ title: 'People can die from giving up the fight',
link: 'https://news.ycombinator.com/item?id=18083509' },
...
] ]
Bài học rút ra ở đây là gì? Đó là, luôn luôn đọc kĩ tài liệu trước khi cắm đầu sử dụng, và quan trọng nhất là không được đoán mò , async/await, cũng giống như mọi khái niệm khác trong JavaScript, luôn cực kì rắc rối và khó hiểu cho tới chừng nào chúng ta… hiểu nó.
Mình biết điều này vì chính mình cũng đã lười đọc tài liệu, dẫn đến làm sai, nên mới có bài viết này





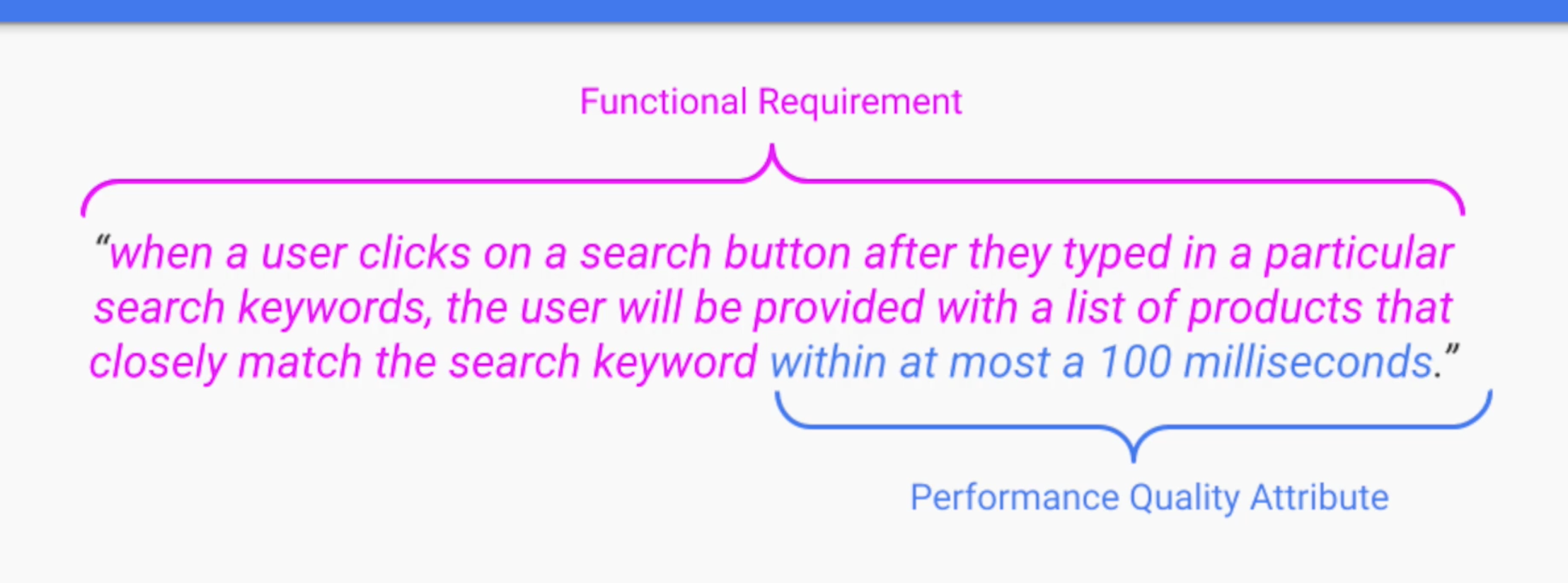

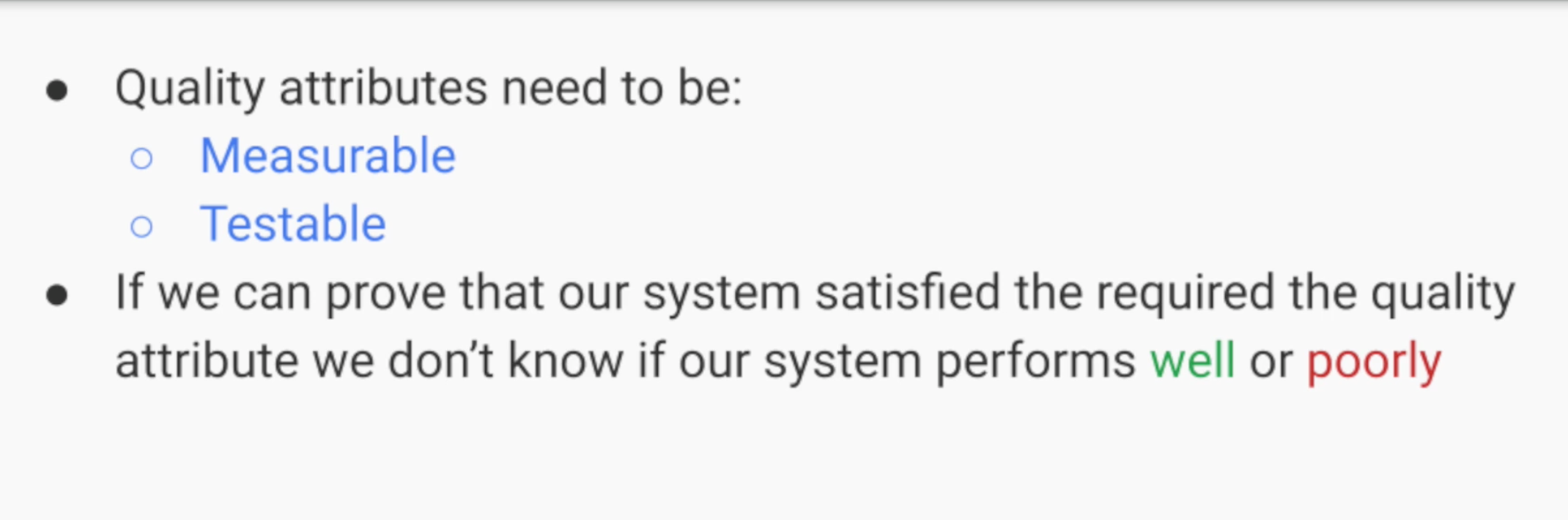

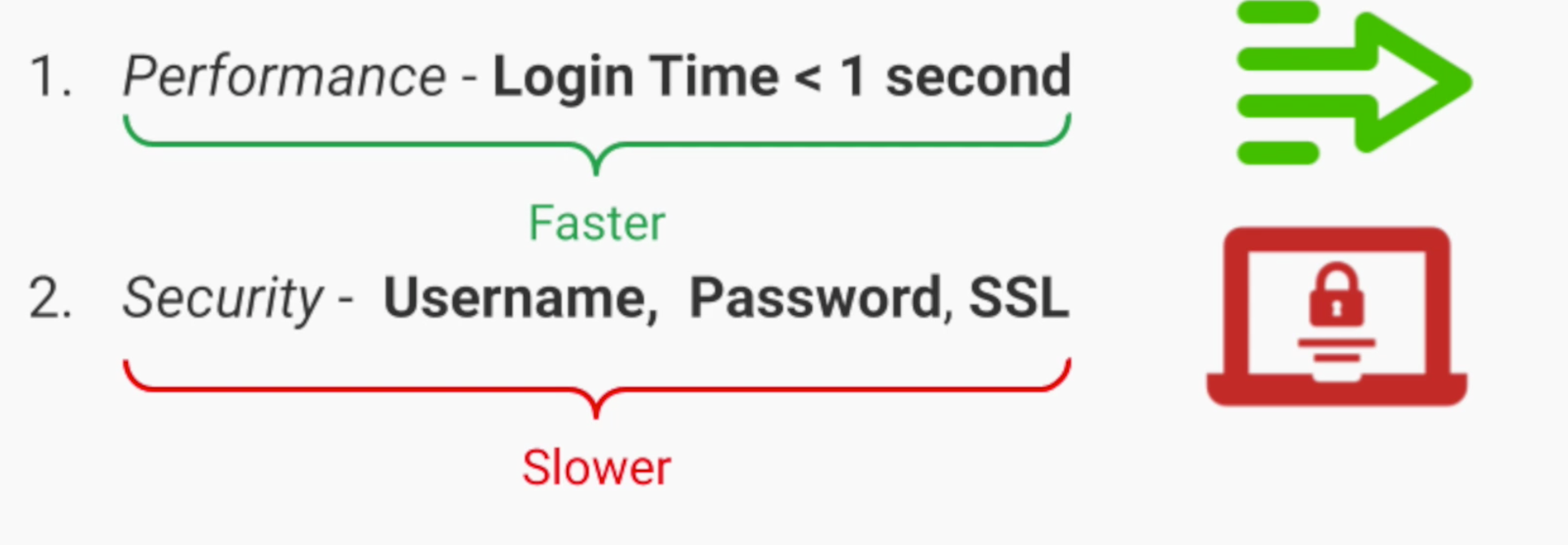


 Hình ảnh sẽ xuất hiện trong bài sau, không phải bài này =)))
Hình ảnh sẽ xuất hiện trong bài sau, không phải bài này =)))














 Nguồn ảnh / Source: https://auth.nuxtjs.org/
Nguồn ảnh / Source: https://auth.nuxtjs.org/ Cách giải thích khác về Authentication Scheme. Nguồn ảnh/ Source: simpleid.org
Cách giải thích khác về Authentication Scheme. Nguồn ảnh/ Source: simpleid.org List providers được cung cấp bởi Nuxt. Nguồn ảnh / Source: https://auth.nuxtjs.org/
List providers được cung cấp bởi Nuxt. Nguồn ảnh / Source: https://auth.nuxtjs.org/





 Hình ảnh đơn giản mô tả cách xác thực 2 bước (Two-Factor Authentication) hoạt động
Hình ảnh đơn giản mô tả cách xác thực 2 bước (Two-Factor Authentication) hoạt động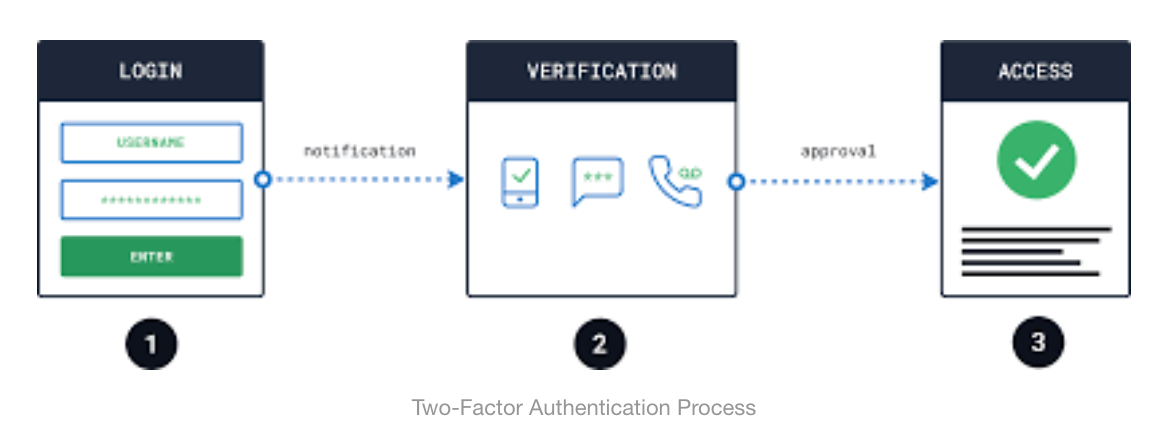
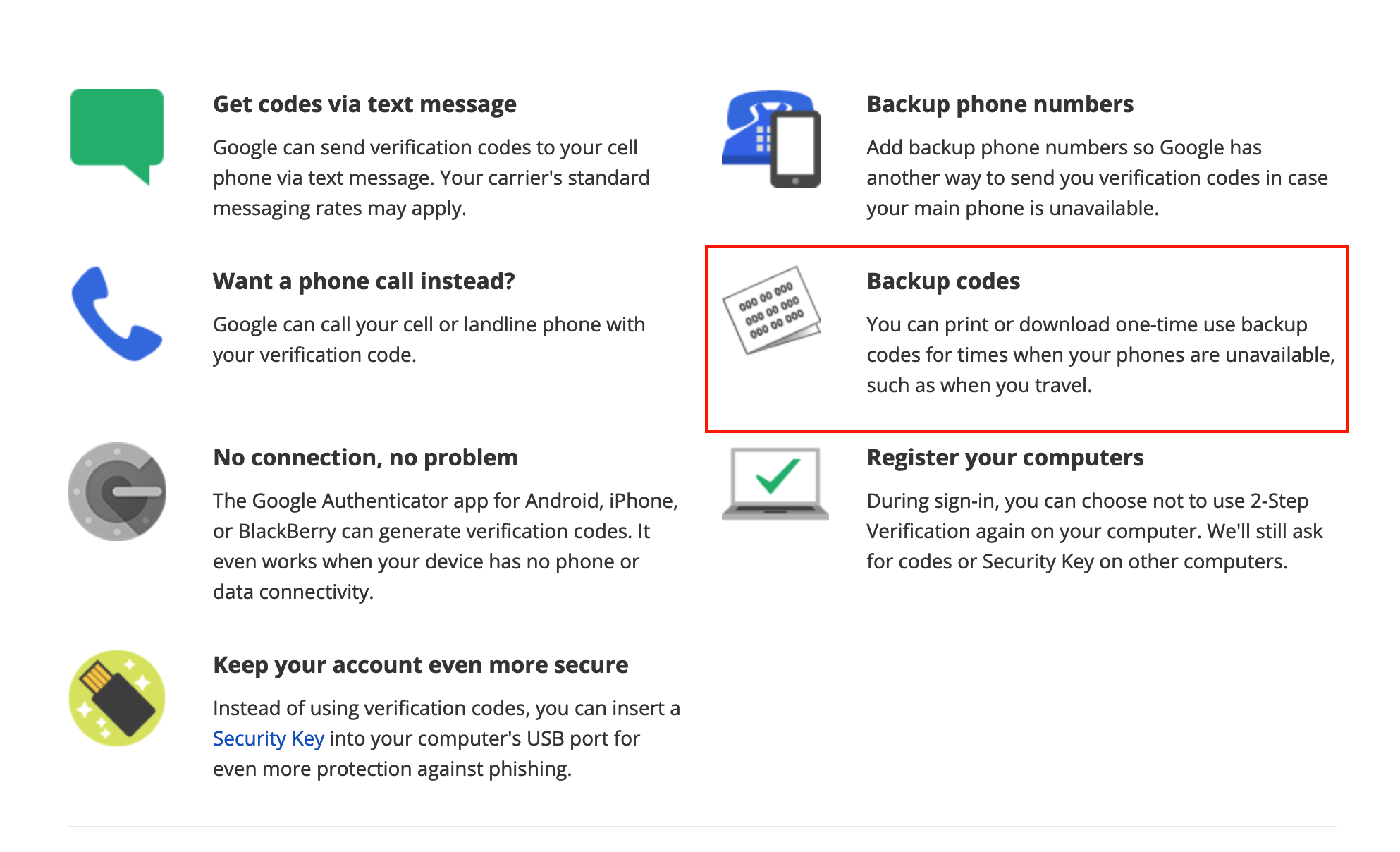
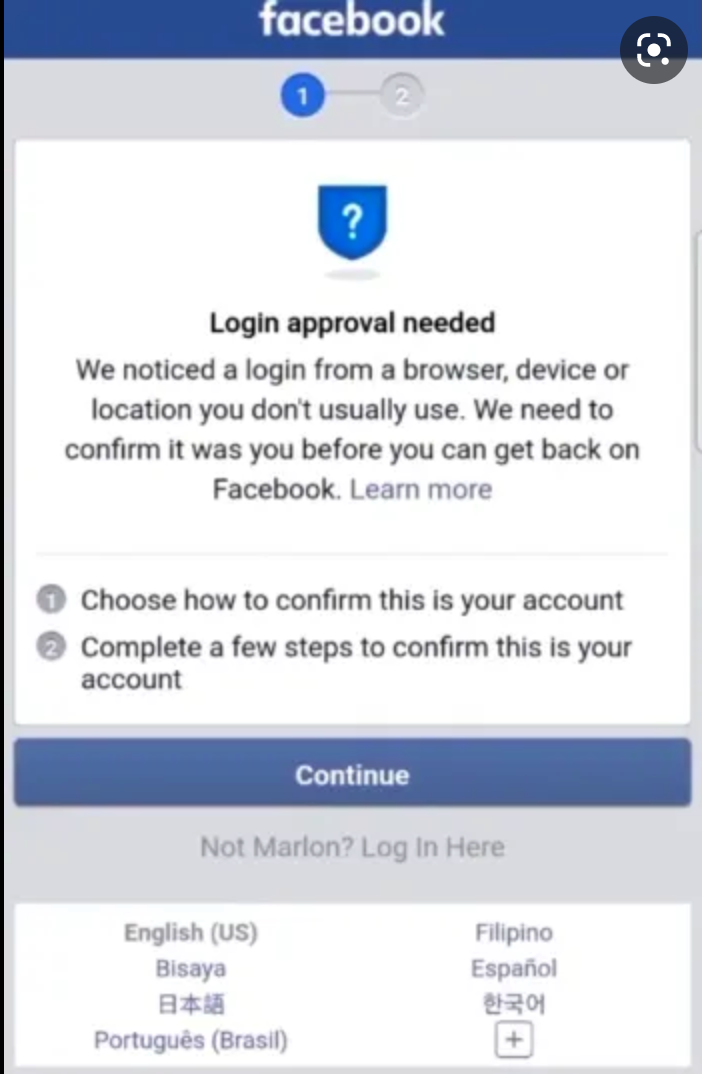 Sign in approve của Facebook
Sign in approve của Facebook






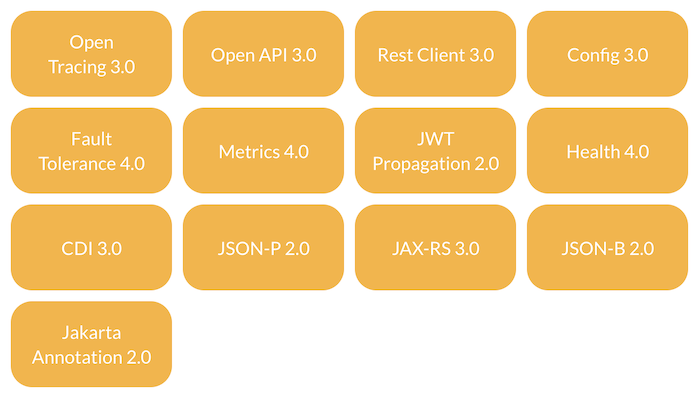 Trong đó:
Trong đó: