Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Để giúp bạn chuẩn bị tốt nhất cho các cuộc phỏng vấn liên quan đến Docker, TopDev đã tổng hợp danh sách TOP 35 câu hỏi phỏng vấn Docker và cách trả lời hay nhất. Bỏ túi ngay để có một buổi phỏng vấn thật thành công bạn nhé.
21. Docker volume được lưu ở đâu trong docker?
Volume được tạo và quản lý bởi Docker và không thể truy cập bằng thực thể khác docker. Nó được lưu trữ trong hệ thống file host Docker ở /var/lib/docker/volumes/.
22. Lệnh docker info là gì?
Lệnh lấy thông tin chi tiết về Docker được cài đặt trên hệ thống host. Thông tin có thể giống như số lượng container hoặc image và chúng đang chạy ở trạng thái nào và các thông số kỹ thuật phần cứng như tổng bộ nhớ được cấp phát, tốc độ của bộ xử lý, phiên bản kernel,…
23. Ý nghĩa của các lệnh up, run và start của docker compose?
Sử dụng lệnh up để duy trì docker-compose (lý tưởng là mọi lúc), chúng ta có thể khởi động hoặc khởi động lại tất cả các mạng, dịch vụ và driver được liên kết với ứng dụng được chỉ định trong file docker-compos.yml. Bây giờ, nếu chúng ta đang chạy docker-compose ở chế độ “attached” thì tất cả log từ các container sẽ có thể truy cập được đối với chúng ta. Trong trường hợp docker-compose được chạy ở chế độ “detached”, thì khi các container được khởi động, nó sẽ thoát ra và không hiển thị log nào.
Sử dụng lệnh run, docker-compose có thể chạy các tác vụ một lần hoặc đột xuất dựa trên các yêu cầu nghiệp vụ. Ở đây, tên dịch vụ phải được cung cấp và docker chỉ bắt đầu dịch vụ cụ thể đó và cả các dịch vụ khác mà dịch vụ đích phụ thuộc (nếu có). Lệnh này hữu ích để kiểm tra container và cũng thực hiện các tác vụ như thêm hoặc xóa dữ liệu vào container,…
Sử dụng lệnh start, chỉ những container đó mới có thể được khởi động lại đã được tạo và sau đó dừng lại. Điều này không hữu ích cho việc tạo các container mới của riêng nó.
24. Các yêu cầu cơ bản để Docker chạy trên mọi hệ thống?
Docker có thể chạy trên cả nền tảng Linux và Windows.
Đối với nền tảng Windows, ít nhất docker cần có Windows 10 64bit với bộ nhớ RAM 2GB. Đối với các phiên bản thấp hơn, có thể cài đặt docker bằng cách sử dụng toolbox trợ giúp. Docker có thể được tải xuống từ trang web https://docs.docker.com/docker-for-windows/.
Đối với nền tảng Linux, Docker có thể chạy trên nhiều phiên bản Linux khác nhau như Ubuntu> = 12.04, Fedora> = 19, RHEL> = 6.5, CentOS> = 6, v.v.
25. Cách đăng nhập vào docker registry?
Sử dụng lệnh docker login để đăng nhập vào kho lưu trữ đám mây của riêng họ có thể được nhập và truy cập.
26. Các instructions phổ biến trong Dockerfile?
FROM: dùng cho thiết lập image cơ sở cho instruction sắp tới. File docker được xem là hợp lệ nếu nó bắt đầu bằng FROM.
LABEL: dùng cho tổ chức image dựa trên dự án, module hoặc license. Nó còn giúp tự động hoá như một cặp key-value cụ thể trong khi xác định label mà sau này có thể được truy cập và xử lý theo chương trình.
RUN: dùng cho thực thi instruction theo sau nó trên top image hiện tại trong lớp mới. Lưu ý: mỗi lần thực thi lệnh RUN, chúng ta thêm các lớp trên image và sử dụng lớp đó cho các bước tiếp theo.
CMD: dùng cho cung cấp giá trị mặc định của container thực thi. Trong trường hợp nhiều lệnh CMD, lệnh cuối cùng sẽ được xem xét.
27. Sự khác biệt giữa Daemon Logging và Container Logging?
Trong Docker, logging được hỗ trợ ở hai level là level Daemon và level Container.
Daemon: gồm 4 kiểu level
Debug có tất cả dữ liệu xuất hiện trong quá trình thực thi của tiến trình daemon.
Info quan tâm tất cả thông tin cùng với lỗi trong suốt quá trị thực thi tiến trình daemon.
Error gồm các lỗi xảy ra trong quá trình thực thi tiến trình daemon.
Fatal chức lỗi fatal trong quá trình thực thi tiến trình daemon.
Container:
Level container có thể thực hiện logging bằng lệnh: sudo docker run –it <container_name> /bin/bash.
Để kiểm tra log của level container ta có thể thực hiện: sudo docker logs <container_id>.
28. Cách thiết lập giao tiếp giữa docker host và linux host?
Điều này có thể được thực hiện bởi mạng bằng cách xác định “ipconfig” trên docker host. Lệnh này đảm bảo rằng một adapter ethernet được tạo miễn là docker có mặt trong host.
29. Cách xoá một container?
Ta có hai bước xoá container:
docker stop <container_id>
docker rm <container_id>
30. Sự khác biệt giữa CMD và ENTRYPOINT?
Lệnh CMD cung cấp các giá trị mặc định có thể thực thi cho một container đang thực thi. Trong trường hợp file thực thi phải được bỏ qua thì việc sử dụng lệnh ENTRYPOINT cùng với định dạng mảng JSON phải được kết hợp.
ENTRYPOINT chỉ định rằng lệnh bên trong nó sẽ luôn được chạy khi container khởi động. Lệnh này cung cấp một tùy chọn để cấu hình các tham số và các file thực thi. Nếu DockerFile không có lệnh này, thì nó sẽ vẫn được kế thừa từ image cơ sở được đề cập trong lệnh FROM.
ENTRYPOINT được sử dụng phổ biến nhất là /bin/sh hoặc /bin/bash cho hầu hết các image cơ sở.
Thực tế, tất cả Dockerfile nên có ít nhất một trong hai lệnh.
31. Có thể dùng JSON thay cho YAML khi phát triển docker-compose trong Docker không?
Có thể. Ta có thể chạy docker-compose trong json, như
docker-compose-f docker-compose.json up
32. Bạn có thể chạy bao nhiêu container trong docker và các yếu tố ảnh hưởng đến giới hạn này là gì?
Không có giới hạn xác định rõ ràng về số lượng container có thể chạy trong docker. Nhưng tất cả phụ thuộc vào những hạn chế – cụ thể hơn là những hạn chế về phần cứng. Kích thước của ứng dụng và tài nguyên CPU có sẵn là 2 yếu tố quan trọng ảnh hưởng đến giới hạn này. Trong trường hợp ứng dụng của bạn không quá lớn và bạn có tài nguyên CPU dồi dào, thì chúng ta có thể chạy một số lượng lớn các container.
33. Vòng đời của container trong Docker?
Các giai đoạn khác nhau của docker container từ khi bắt đầu tạo cho đến khi kết thúc được gọi là vòng đời của docker container.
Các giai đoạn quan trọng nhất là:
Created: Đây là trạng thái mà container vừa được tạo mới nhưng chưa bắt đầu.
Running: Trong trạng thái này, container sẽ chạy với tất cả các quy trình liên quan của nó.
Paused: Trạng thái này xảy ra khi container đang chạy bị tạm dừng.
Stopped: Trạng thái này xảy ra khi container đang chạy đã bị dừng.
Deleted: Trong trường hợp này, container ở trạng thái chết.
34. Làm thế nào để sử dụng docker cho nhiều môi trường ứng dụng?
Tính năng docker-compose của docker sẽ hỗ trợ bạn tại đây. Trong file docker-compose, chúng ta có thể xác định nhiều dịch vụ, mạng và container cùng với ánh xạ volume một cách rõ ràng và sau đó chúng ta chỉ cần gọi lệnh docker-compose up.
Khi có nhiều môi trường tham gia – đó có thể là máy chủ dev, staging, uat hoặc production, chúng ta muốn xác định các quy trình và phụ thuộc dành riêng cho server chủ để chạy ứng dụng. Trong trường hợp này, chúng ta có thể tiếp tục tạo file docker-compose theo môi trường cụ thể có tên là docker-compos. {environment}.yml và sau đó dựa trên môi trường, chúng ta có thể thiết lập và chạy ứng dụng.
35. Làm sao đảm bảo container1 chạy trước container2 trong khi dùng docker compose?
Docker-compose không đợi bất kỳ container nào “sẵn sàng” trước khi đến container kế tiếp. Để thực thi như vậy, ta có thể sử dụng:
Bạn có thể sử dụng depend_on đã được thêm vào phiên bản 2 của docker-compose khi được hiển thị trong file docker-compose.yml mẫu bên dưới:
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Để giúp bạn chuẩn bị tốt nhất cho các cuộc phỏng vấn liên quan đến Docker, TopDev đã tổng hợp danh sách TOP 35 câu hỏi phỏng vấn Docker và cách trả lời hay nhất. Bỏ túi ngay để có một buổi phỏng vấn thật thành công bạn nhé.
16. Sự khác biệt giữa ảo hoá (virtualization) và containerization?
virtualization
containerization
Nó giúp chạy nhiều hệ điều hành trên phần cứng của một server vật lý
Nó giúp triển khai nhiều ứng dụng trên cùng hệ điều hành trên một máy ảo hoặc server
Hypervisors cung cấp các máy ảo tổng thể cho hệ điều hành khách
Container đảm bảo cung cấp môi trường/không gian người dùng biệt lập để chạy các ứng dụng. Mọi thay đổi được thực hiện trong container không phản ánh trên server hoặc các container khác của cùng server
Các máy ảo này tạo thành một phần trừu tượng của lớp phần cứng hệ thống, điều này có nghĩa là mỗi máy ảo trên host hoạt động giống như một máy vật lý
Container tạo thành sự trừu tượng của lớp ứng dụng có nghĩa là mỗi container tạo thành một ứng dụng khác nhau
17. Sự khác biệt giữa lớp COPY và ADD trong Dockerfile?
Cả hai có chức năng giống nhau, nhưng COPY được ưa thích hơn vì mức độ minh bạch cao hơn ADD.
COPY cung cấp các hỗ trợ cơ bản cho sao chép file cục bộ trong khi ADD cung cấp tính năng bổ sung như URL từ xa và hỗ trợ xuất tar.
Có, chỉ có thể thực hiện được khi đang sử dụng một số chính sách do docker xác định trong khi sử dụng lệnh run của docker. Sau đây là các chính sách hiện có:
Off: container sẽ không được khởi động lại trong trường hợp nó bị dừng hoặc bị lỗi.
Un-failure: Ở đây, container chỉ khởi động lại khi nó gặp lỗi không liên quan đến người dùng.
Unless-stop: Sử dụng chính sách này, đảm bảo rằng container chỉ có thể khởi động lại khi người dùng thực hiện lệnh để dừng nó.
Always: Bất kể lỗi hay dừng, container luôn được khởi động lại trong loại chính sách này.
Các chính sách này có thể dùng như sau:
docker run -dit — restart [restart-policy-value][container_name]
Image: được xây dựng từ một loạt các lớp instruction. Một image tương ứng với container và được sử dụng để vận hành nhanh chóng do cơ chế lưu vào bộ nhớ đệm của mỗi bước.
Layer: Mỗi layer tương ứng với một instruction của image của Dockerfile. Nói đơn giản hơn layer còn là image nhưng nó là image của instruction.
Ví dụ:
FROM ubuntu:18.04COPY . /myappRUN make /myappCMD python /myapp/app.py
Quan trọng hơn, mỗi layer là một tập khác cảu layer trước đó.
Kết quả xây dựng file docker này là một image. Trong khi instruction hiện tại trong file thêm layer vào image.
20. Mục đích của tham số volume trong lệnh chạy docker là gì?
Cú pháp của lệnh chạy docker sử dụng volumn là: docker run -v host_path:docker_path <container_name>.
Tham số volume được dùng cho đồng bộ hoá một thư mục trong container với bất kỳ thư mục host nào. Ví dụ: docker run -v /data/app:usr/src/app myapp. Lệnh trên gắn thứ mục /data/app trong host vào thư mục usr/src/app. Ta có thể đồng bộ container với file dữ liệu từ host mà không cần khởi động lại.
Điều này đảm bảo rằng ngay cả khi container bị xóa, dữ liệu của container vẫn tồn tại trong vị trí host lưu trữ được ánh xạ theo volume, làm cho nó trở thành cách dễ dàng nhất để lưu trữ dữ liệu container.
Bài viết được sự cho phép của tác giả Tống Xuân Hoài
Vấn đề
Ngày xưa đi học không biết có ai thắc mắc tại sao lại phải học môn cấu trúc dữ liệu và giải thuật không? Môn học cho chúng ta biết một số cấu trúc dữ liệu phổ biến như là danh sách liên kết (linked list) đơn – đôi, mảng, queue, stack… Nhưng có vẻ như nó thật nhàm chán cho những ai đã biết và đang lập trình. Chưa kể hầu hết ngôn ngữ lập trình đều tự triển khai hoặc có thư viện hỗ trợ tất cả cấu trúc này, ấy vậy mà thầy cô vẫn yêu cầu chúng ta tự triển khai lại các cấu trúc này một cách thủ công.
Có lẽ mục đích thật sự đằng sau đó là muốn chúng ta hiểu về tầm quan trọng của cấu trúc dữ liệu. Thật vậy, rất nhiều ý tưởng, giải pháp được phát minh ra dựa trên chúng. Có thể kể đến là Message queue – một cấu trúc góp mặt trong thiết kế hệ thống phần mềm, nhằm tăng khả năng xử lý và giải quyết nhiều vấn đề phức tạp trong hệ thống phân tán.
Vài năm trở lại đây, khái niệm về hệ thống phân tán không còn quá xa lạ. Thay vì xử lý tất ở một nơi duy nhất thì chia nhỏ công việc ra để xử lý. Mỗi nơi xử lý một nhiệm vụ duy nhất, từ đó giúp cho hệ thống phân cấp rõ ràng hơn, năng xuất hơn và chịu lỗi tốt hơn.
Queue là hàng đợi, message queue là một hàng đợi tin nhắn. Một hàng đợi hoạt động theo kiểu vào trước ra trước (First In, First Out). Tưởng tượng như bạn có một cái ống nước đủ rộng để nhét những viên bi vào, thì cho có đổ tất cả các viên bi vào trong phễu ở một đầu, thì đầu kia vẫn chỉ lăn ra từng viên một theo thứ tự trước sau. Không thể nào có hai viên cùng lăn ra một lúc được, đó chính là một hàng đợi.
Trong hệ thống phần mềm, message queue là một cấu trúc quan trọng và được áp dụng rất nhiều bởi hệ thống phân tán. Vì thế, bài viết ngày hôm nay hãy cùng tôi đi qua một vài khái niệm cơ bản về cấu trúc này nhé.
Message queue là gì?
Message queue là một khái niệm trong lĩnh vực phân tán hệ thống và lập trình đa luồng. Nó là một cấu trúc dữ liệu dùng để lưu trữ các thông điệp (message) trong một hệ thống phân tán.
Message queue thường được sử dụng để giao tiếp giữa các thành phần của hệ thống thông tin, cho phép chúng truyền thông điệp (message) cho nhau một cách bất đồng bộ. Thay vì gửi trực tiếp thông điệp từ một thành phần đến thành phần khác, các thành phần này gửi thông điệp vào message queue và các thành phần khác có thể lấy thông điệp từ message queue để xử lý.
Tại sao lại không gửi thông điệp trực tiếp mà phải thông qua một message queue? Có nhiều lý do, trong đó nổi bất nhất là để quản lý được thông điệp. Hãy tưởng tượng nếu gửi trực tiếp thông điệp đến một điểm đích không khả dụng thì sẽ như thế nào? Thông điệp có thể bị mất và hệ thống cũng chẳng bao giờ xử lý được thông điệp nữa.
Về cơ bản, message queue là một hàng đợi tin nhắn. Ngoài ra, để đưa thông điệp được vào hàng đợi và xử lý thông điệp thì cần phải có sự tham gia của nhiều thành phần. Sự kết hợp giữa chúng tạo thành một hệ thống xử lý hàng đợi tin nhắn hoàn chỉnh.
Tùy thuộc vào dịch vụ cung cấp message queue mà chúng có nhiều thành phần khác nhau. Nhưng về cơ bản, phải có ít 3 thành phần tham gia vào quá trình xử lý là Producer, Message queue và Consumer.
Producer (nơi gửi thông điệp) gửi thông điệp vào message queue: Producer là thành phần hoặc ứng dụng tạo ra thông điệp và gửi nó vào message queue. Thông điệp có thể là bất cứ loại dữ liệu nào, ví dụ: tin nhắn, tác vụ xử lý, sự kiện, hay yêu cầu.
Message queue là nơi lưu trữ thông điệp: Message queue lưu trữ các thông điệp được gửi bởi Producer. Thông điệp có thể được lưu trữ bền vững trong bộ nhớ hoặc trên ổ đĩa tùy thuộc vào cấu hình của message queue.
Consumer (nơi nhận thông điệp) lấy thông điệp từ message queue: Consumer là thành phần hoặc ứng dụng muốn nhận và xử lý thông điệp. Consumer yêu cầu lấy thông điệp từ message queue, sau khi nhận được thông điệp, consumer tiến hành xử lý nó theo logic của ứng dụng.
Quá trình này lặp đi lặp lại mỗi khi Producer gửi thêm thông điệp vào Message queue và Consumer lấy và xử lý các thông điệp. Sự bất đồng bộ giữa Producer và Consumer cho phép hệ thống hoạt động hiệu quả và linh hoạt, đồng thời đảm bảo tính tin cậy và khả năng mở rộng.
Ứng dụng message queue như thế nào?
Message queue có rất nhiều ứng dụng trong các hệ thống phân tán và lập trình đa luồng có thể kể đến như:
Hệ thống xử lý dữ liệu theo thời gian thực: Trong các hệ thống xử lý dữ liệu theo thời gian thực, message queue được sử dụng để truyền tải dữ liệu từ các nguồn khác nhau đến các hệ thống xử lý. Các nguồn dữ liệu gửi thông điệp vào message queue và các hệ thống xử lý lấy thông điệp từ queue để xử lý dữ liệu một cách song song và bất đồng bộ.
Hệ thống đa luồng và bất đồng bộ: Message queue cho phép các thành phần trong hệ thống hoạt động độc lập và bất đồng bộ. Các thành phần có thể gửi thông điệp vào message queue và tiếp tục công việc của mình mà không cần chờ đợi phản hồi từ các thành phần khác. Điều này giúp tăng hiệu suất và khả năng mở rộng của hệ thống.
Hệ thống xử lý sự kiện: Trong các hệ thống xử lý sự kiện, message queue được sử dụng để gửi và nhận các sự kiện từ các nguồn khác nhau.
Giao tiếp giữa các dịch vụ: Trong kiến trúc dịch vụ phân tán, message queue được sử dụng để giao tiếp giữa các dịch vụ. Các dịch vụ gửi thông điệp vào message queue để yêu cầu hoặc truyền thông tin cho các dịch vụ khác.
Hàng đợi công việc: Message queue cũng được sử dụng trong các hệ thống hàng đợi công việc, nơi các công việc được gửi vào message queue, sau đó chúng được xử lý một cách lần lượt.
Hai cái tên nổi bật cung cấp cấu trúc message queue có thể kể đến RabbitMQ và Apache Kafka. Ngoài ra còn có một vài thư viện hỗ trợ triển khai message queue đơn giản dựa trên các dịch vụ khác như BullMQ, Kue, Agenda.
Một số ví dụ điển hình
Thật khó hình dung những ứng dụng của message queue nếu không có ví dụ cụ thể. Thực tế công việc hàng ngày của tôi ứng dụng cấu trúc này thường xuyên. Có thể kể đến một vài trường hợp phổ biến nhất như sau.
Trong một hệ thống thương mại điện tử, message queue có thể được sử dụng để xử lý đơn hàng. Khi khách hàng đặt hàng, thông tin đơn hàng được gửi vào message queue. Hệ thống xử lý đơn hàng lấy thông điệp từ queue và tiến hành xử lý đơn hàng, bao gồm kiểm tra hàng tồn kho, xác nhận thanh toán và gửi thông báo vận chuyển. Việc sử dụng message queue giúp tách biệt quá trình đặt hàng và xử lý đơn hàng, đồng thời đảm bảo tính tin cậy và khả năng mở rộng của hệ thống.
Trong một hệ thống gửi email hàng loạt, message queue có thể được sử dụng để xử lý và gửi email. Khi người dùng yêu cầu gửi email, thông điệp email được gửi vào message queue. Hệ thống xử lý email lấy thông điệp từ queue và thực hiện quá trình gửi email, bao gồm tạo nội dung, thêm tệp đính kèm và gửi đi. Việc sử dụng message queue giúp xử lý email một cách bất đồng bộ và đảm bảo tính tin cậy trong việc gửi email hàng loạt.
Trong một hệ thống xử lý sự kiện thời gian thực, message queue được sử dụng để truyền tải và xử lý sự kiện. Các sự kiện này liên quan nhiều đến việc tổng hợp, phân tích thông tin của một hệ thống thông tin.
Sử dụng message queue để trao đổi thông tin giữa các dịch vụ trong hệ thống phân tán nhằm tăng khả năng xử lý và chịu tải, đảm bảo không ảnh hưởng đến tốc độ xử lý thông tin luồng chính.
Đây chỉ là một số ví dụ điển hình về việc sử dụng message queue. Thực tế, message queue có thể được áp dụng trong nhiều lĩnh vực và tình huống khác nhau, tùy thuộc vào yêu cầu và mục đích sử dụng của hệ thống.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Docker đã trở thành một công cụ không thể thiếu trong việc triển khai và quản lý các ứng dụng container hóa. Với sự phổ biến ngày càng tăng của Docker, việc nắm vững kiến thức và kỹ năng về Docker không chỉ là một lợi thế mà còn là một yêu cầu quan trọng đối với các kỹ sư phần mềm, DevOps và những người làm việc trong lĩnh vực công nghệ thông tin.
Để giúp bạn chuẩn bị tốt nhất cho các cuộc phỏng vấn liên quan đến Docker, TopDev đã tổng hợp danh sách TOP 35 câu hỏi phỏng vấn Docker và cách trả lời hay nhất. Bỏ túi ngay để có một buổi phỏng vấn thật thành công bạn nhé.
Docker là một nền tảng mã nguồn mở rất phổ biến và mạnh mẽ được sử dụng để xây dựng, triển khai và chạy các ứng dụng. Docker cho phép bạn tách ứng dụng/phần mềm khỏi cơ sở hạ tầng bên dưới.
Container là một đơn vị tiêu chuẩn của phần mềm đi kèm với các phần phụ thuộc để các ứng dụng có thể được triển khai nhanh chóng và đáng tin cậy trên các nền tảng tính toán khác nhau.
Docker có thể được hình dung như một con tàu lớn (docker) chở những thùng sản phẩm (container) khổng lồ.
Docker container không yêu cầu cài đặt một hệ điều hành riêng biệt. Docker chỉ dựa vào hoặc sử dụng các tài nguyên của nhân và chức năng của nó để phân bổ chúng cho CPU và bộ nhớ, nó dựa vào chức năng của nhân và sử dụng cách ly tài nguyên cho CPU và bộ nhớ, đồng thời các namespace riêng biệt để tách biệt chế độ xem của ứng dụng đối với OS (hệ điều hành ).
Phát triển ứng dụng không chỉ đơn thuần là viết code! Chúng liên quan đến rất nhiều việc hậu trường như sử dụng nhiều framework và kiến trúc cho mọi giai đoạn trong vòng đời của nó, điều này làm cho quá trình trở nên phức tạp và đầy thử thách. Sử dụng bản chất của container hóa giúp các nhà phát triển đơn giản hóa và tăng tốc hiệu quả quy trình làm việc của ứng dụng, đồng thời cho phép họ tự do phát triển bằng cách sử dụng lựa chọn công nghệ và môi trường phát triển của riêng họ.
Tất cả những khía cạnh này tạo thành phần cốt lõi của DevOps, điều này càng trở nên quan trọng hơn đối với bất kỳ nhà phát triển nào cũng cần biết những điều này để cải thiện năng suất, thúc đẩy sự phát triển nhanh chóng cùng với việc ghi nhớ các yếu tố về khả năng mở rộng ứng dụng và quản lý tài nguyên hiệu quả hơn.
Hãy tưởng tượng container như một hộp rất nhẹ được cài đặt sẵn với tất cả các package, phần phụ thuộc, phần mềm theo yêu cầu của ứng dụng của bạn, chỉ cần triển khai production với những thay đổi cấu hình tối thiểu.
Rất nhiều tổ chức như PayPal, Spotify, Uber, v.v. sử dụng Docker để đơn giản hóa các hoạt động và đưa cơ sở hạ tầng và bảo mật đến gần hơn để tạo ra các ứng dụng an toàn hơn.
Mang tính di động, Container có thể được triển khai trên nhiều nền tảng như máy ảo, nền tảng Kubernetes, v.v. theo yêu cầu của quy mô hoặc nền tảng mong muốn.
Nói một cách đơn giản nhất, container bao gồm các ứng dụng và tất cả các phụ thuộc của chúng.
Chúng chia sẻ nhân và tài nguyên hệ thống với các container khác và chạy như các hệ thống biệt lập trong hệ điều hành chủ.
Mục đích chính của container là loại bỏ sự phụ thuộc vào cơ sở hạ tầng trong khi triển khai và chạy các ứng dụng. Điều này có nghĩa là bất kỳ ứng dụng được chứa trong container nào cũng có thể chạy trên bất kỳ nền tảng nào bất kể cơ sở hạ tầng đang được sử dụng bên dưới.
Về mặt kỹ thuật, chúng chỉ là các phiên bản runtime của docker image.
Chúng là các gói thực thi (được đóng gói với code ứng dụng và phần phụ thuộc, gói phần mềm, v.v.) nhằm mục đích tạo container. Docker image có thể được triển khai cho bất kỳ môi trường docker nào và các container có thể được xoay ở đó để chạy ứng dụng.
Hypervisor là một phần mềm giúp cho quá trình ảo hóa diễn ra vì nó đôi khi được gọi là Virtual Machine Monitor. Điều này phân chia tài nguyên của hệ thống máy chủ và phân bổ chúng cho từng môi trường khách được cài đặt.
Điều này có nghĩa là nhiều hệ điều hành có thể được cài đặt trên một hệ thống máy chủ duy nhất.
Hypervisor có 2 loại:
Native Hypervisor: Loại này còn được gọi là Bare-metal Hypervisor và chạy trực tiếp trên hệ thống máy chủ bên dưới, điều này cũng đảm bảo quyền truy cập trực tiếp vào phần cứng máy chủ, đó là lý do tại sao nó không yêu cầu hệ điều hành cơ bản.
Hosted Hypervisor: Loại này sử dụng hệ điều hành máy chủ cơ bản đã được cài đặt hệ điều hành hiện có.
Nó là một file YAML bao gồm tất cả các chi tiết liên quan đến các dịch vụ, mạng và khối lượng khác nhau cần thiết để thiết lập ứng dụng dựa trên Docker. Vì vậy, docker-compose được sử dụng để tạo nhiều container, lưu trữ chúng và thiết lập giao tiếp giữa chúng. Với mục đích giao tiếp giữa các container, các cổng được tiếp xúc bởi từng container.
Namespace về cơ bản là một tính năng của Linux đảm bảo phân vùng tài nguyên hệ điều hành theo cách loại trừ lẫn nhau. Điều này hình thành khái niệm cốt lõi đằng sau quá trình container hóa khi namespace giới thiệu một lớp cách ly giữa các container. Trong docker, namespace đảm bảo rằng các container có thể di động và chúng không ảnh hưởng đến máy chủ bên dưới. Ví dụ về các loại namespace hiện đang được Docker hỗ trợ – PID, Mount, User, Network, IPC.
7. Cách hiển thị trạng thái của tất cả docker container bằng dòng lệnh?
dockerps-a
8. Dữ liệu được lưu trữ trong container sẽ bị mất trong những trường hợp nào?
Dữ liệu của container vẫn ở trong đó cho đế khi bạn xóa container.
Theo thuật ngữ đơn giản, Docker image registry là một khu vực lưu trữ các docker image. Thay vì chuyển đổi các ứng dụng thành container mỗi lần, một nhà phát triển có thể sử dụng trực tiếp các iamge được lưu trữ trong registry. Docker image registry có thể là công khai hoặc riêng tư và DockerHub là tổ chức đăng ký công khai phổ biến và nổi tiếng nhất hiện có.
Docker Client: thành phần này sẽ thực hiện hành động “build” và “run” nhằm mục đích mở ra giao tiếp với docket host.
Docker Host: thành phần này gồm daemon chính của docker, các host container và image của chúng. Daemon thiết lập một kết nối đến docker registry.
Docker Registry: thành phần này lưu trữ docker image. Nó có thể là công khai hoặc riêng tư. Các registry công khai nổi tiếng là Docker Hub và Docker Cloud.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Trong quá trình phát triển phần mềm và quản lý dự án, việc bảo vệ thông tin bí mật như API key, mật khẩu, và các thông tin quan trọng khác là rất quan trọng. Một cách phổ biến để giải quyết vấn đề này là sử dụng file .env, một cách quản lý biến môi trường được nhiều lập trình viên sử dụng.
I. File .env là gì
Tệp .env là một tệp cấu hình chứa các biến môi trường cho một ứng dụng hoặc dự án phần mềm. Trong ngữ cảnh này, biến môi trường là các giá trị mà ứng dụng sử dụng để cấu hình chạy, chẳng hạn như API key, mật khẩu cơ sở dữ liệu, và các thông số cấu hình khác…
Tên .env là viết tắt của từ environment (môi trường), và tệp này thường được sử dụng để giữ các thông tin nhạy cảm mà bạn không muốn lưu trữ trực tiếp trong mã nguồn của bạn, đặc biệt là khi chia sẻ mã nguồn trên các hệ thống quản lý phiên bản như Git.
Mỗi dòng trong tệp .env thường chứa một biến môi trường và giá trị của nó, được đặt tên theo định dạng TEN_BIEN=GIATRI.
Các giá trị này sau đó có thể được đọc và sử dụng trong mã nguồn ứng dụng để cấu hình và thực hiện các tác vụ cụ thể. Thông thường, một thư viện như dotenv được sử dụng để tải các biến môi trường từ tệp .env vào quá trình chạy của ứng dụng.
II. Các đặc điểm của file .env
1. Quản lý biến môi trường một cách đơn giản
Một trong những ưu điểm lớn nhất của .env là khả năng đơn giản hóa quản lý biến môi trường. Thay vì trực tiếp nhúng thông tin bí mật vào mã nguồn, chúng ta có thể lưu trữ chúng trong tệp .env và gọi chúng trong mã nguồn khi cần thiết. Điều này giúp lập trình viên dễ dàng thay đổi cấu hình mà không cần sửa đổi mã nguồn.
2. Thông tin bí mật được an toàn
Thông tin bí mật như API key, mật khẩu và các thông tin nhạy cảm khác thường xuyên cần được bảo vệ khỏi sự truy cập trái phép. .env giúp ngăn chặn việc lộ thông tin này bằng cách giữ chúng trong một tệp không nằm trong lịch sử kiểm soát phiên bản (Git). Điều này đảm bảo rằng những thay đổi thông tin bí mật không được lưu trữ trong các commit của mã nguồn.
3. Quản lý phạm vi dự án hiệu quả
Mỗi dự án có thể có nhiều cấp độ biến môi trường tùy thuộc vào hệ điều hành, người dùng hay phiên làm việc. .env giúp quản lý phạm vi dự án một cách hiệu quả bằng cách giữ thông tin trong phạm vi chỉ của ứng dụng, tránh xung đột với các biến môi trường khác trên hệ thống.
4. Khả năng di chuyển và linh hoạt
Tệp .env có khả năng di chuyển, cho phép bạn đặt nó ở bất kỳ thư mục nào trong dự án. Điều này tăng cường an ninh bằng cách tránh hiển thị thông tin quan trọng khi có sự cố cấu hình máy chủ hoặc mã nguồn. Giống như việc lưu trữ SSH key tại một vị trí ổn định như ~/.ssh
5. Tích hợp dễ dàng trong quy trình phát triển
Sử dụng .env không chỉ giúp bảo vệ thông tin bí mật mà còn tạo ra một quy trình phát triển mạnh mẽ. Bạn có thể tích hợp .env vào công cụ CI/CD của mình để tự động hóa việc cung cấp các thông tin bí mật phù hợp với môi trường triển khai, tạo ra một quy trình triển khai an toàn và linh hoạt.
6. Tệp bị bỏ qua
Tệp .env có thể được bỏ qua khỏi hệ thống kiểm soát phiên bản, ngăn chặn thông tin bí mật bị commit vào lịch sử của mã nguồn (sử dụng git ignore). Bạn cũng có thể tạo một tệp .sample.env để hướng dẫn người sử dụng về cách thiết lập các biến môi trường mà không cần chia sẻ thông tin bí mật.
Sau khi toàn tất, bạn kiểm tra trong file .gitignore đã có .env hay chưa. Cuối cùng, khi push code hoàn tất, bạn có thể thêm các biến trong .env lên (ví dụ mình sử dụng Vercel như hình bên dưới).
IV. Kết luận
Sử dụng tệp .env không chỉ giúp bảo vệ thông tin bí mật của ứng dụng mà còn tăng cường tính di động và linh hoạt của mã nguồn. Điều này làm cho .env trở thành một công cụ quan trọng trong quá trình phát triển và bảo trì dự án. Hãy tích hợp .env vào quy trình phát triển của bạn để đảm bảo an toàn thông tin và sự thuận tiện trong quản lý biến môi trường.
Tháng 6 này, Monthly Reward trở lại với nhiều phần quà hấp dẫn. Khi sử dụng các tính năng như Tạo CV Online hoặc Chuẩn hóa CV trên TopDev, bạn sẽ có cơ hội nhận được các voucher Highlands thú vị. Đặc biệt, cuối chương trình sẽ có một bàn phím Keychron cực chất dành cho người may mắn nhất. Đừng bỏ lỡ, tham gia ngay để trải nghiệm và nhận quà!
Trong quá trình làm việc với Laravel Eloquent ORM, chắc hẳn các bạn từng thực hiện khá nhiều tác vụ lặp đi lặp lại – mà bạn không hề biết Laravel đã hỗ trợ sẵn. Thông qua vài mẹo và thủ thuật nhỏ trong bài viết này, mình hi vọng sẽ giúp các bạn giảm bớt sự phức tạp khi viết code cũng như bớt nhàm chán khi thực hiện các tác vụ lặp đi lặp lại theo cách thông thường.
Tăng hoặc giảm giá trị của một thuộc tính
Mình cá là có khá nhiều người đã từng viết những thứ đại loại như thế này:
Chà chà, đây là một nơi kỳ diệu mà Eloquent hỗ trợ chúng ta có thể ghi đè các hành vi mặc định khi thực hiện một số tác vụ nào đó.
Bên dưới là một ví dụ nhỏ về việc thêm một trường uuid vào bảng tại thời điểm tạo mới một User.
class User extendsModel{publicstaticfunctionboot(){parent::boot();static::creating(function($model){$model->uuid=(string)Uuid::generate();});}}
Cũng khá dễ hiểu đúng không các bạn ^^
Eloquent cũng cung cấp các phương thức obsever khác hỗ trợ cho quá trình thao tác với model như: updating, deleting… Bạn có thể tham khảo liên kết sau để biết thêm nhiều thông tin hơn https://laravel.com/docs/7.x/eloquent.
Thiết lập relationship với các điều kiện và thứ tự sắp xếp
Bên dưới là một ví dụ điển hình cho việc thiết lập relationship giữa 2 model User và Post:
class User extendsModel{publicfunctionposts(){return$this->hasMany(Post::class);}}
Nhưng nếu như bạn muốn thêm một số điều kiện ràng buộc ở đây, hoặc sắp xếp thứ tự hiển thị của các bài viết thì sao?
Bạn có thể cấu hình một số tham số của Eloquent dưới dạng thuộc tính của lớp. Dưới đây là một số thuộc tính phổ biến mà đa số lập trình viên đều biết:
class User extendsModel{/**
* Thiết lập tên bảng trong cơ sở dữ liệu của model này
* @var string
*/protected$table='users';/**
* Thiết lập các trường có thể được fill khi bạn dùng Mass Assignment
* @var array
*/protected$fillable=['first_name','last_name','uuid','status','gender',];/**
* Ngược lại với $fillable, đây là các trường không thể được fill khi bạn dùng Mass Assignment.
* Chú ý: Eloquent không cho phép bạn đồng thời định nghĩa cả $fillable và $guarded cho model của mình.
* @var array
*/protected$guarded=['id',];/**
* Định nghĩa các trường được tự động chuyển sang Carbon object - một class xử lí thời gian mà Laravel đang sử dụng
* @var array
*/protected$dates=['published_at',];/**
* Định nghĩa các trường sẽ được thêm vào trực tiếp trong dữ liệu trả về của model thông qua accessors
* @var array
*/protected$appends=['full_name',];/**
* Accessor trả về thông tin từ model khi người dùng gọi tới thuộc tính full_name
* @return string
*/publicfunctiongetFullNameAttribute(){return$this->first_name.' '.$this->last_name;}}
Nhưng thực ra thì Eloquent hỗ trợ nhiều hơn thế.
/**
* Định nghĩa khóa chính của bảng trong cơ sở dữ liệu
* @var string
*/protected$primaryKey='uuid';/**
* Đây là các trường lưu lại thông tin thời gian cập nhật dữ liệu của model.
* Bạn có thể cập nhật lại chúng cho phù hợp với cơ sở dữ liệu bạn đang có sẵn.
*/constCREATED_AT='created_at';constUPDATED_AT='updated_at';/**
* Chỉ định cho model biết có cần thiết lưu thông tin thời gian cập nhật model hay không.
* @var bool
*/public$timestamps=false;...
Ở đây mình chỉ nêu một số thuộc tính chúng ta hay sử dụng khi làm việc với model. Bạn có thể tham khảo liên kết sau để biết thêm nhiều thuộc tính khác mà Eloquent hỗ trợ hơn https://github.com/laravel/framework/…/Model.php.
Accessors và Mutators
Trong phần trên mình có nhắc tới Accessor. Vậy thì Accessor là gì?
Trong nhiều trường hợp, chúng ta cần truy cập vào một số thuộc tính của model khi mà chúng không thực sự tồn tại trong cơ sở dữ liệu. Ở ví dụ phía trên, chúng ta cần lấy thông tin full_name của User để hiển thị cho người dùng. Thay vì phải làm một cái gì đó tương tự như thế này:
{{$user->first_name.' '.$user->last_name}}
Thì chúng ta sẽ khai báo phương thức getFullNameAttribute() trong Model như ví dụ phía trên, sau đó ở phía người dùng, chúng ta chỉ cần gọi nó ra như sau:
{{$user->full_name}}
Để khai báo một accessor, bạn tạo ra một phương thức getFooBarAttribute() trong model của mình, với FooBar đặt theo chuẩn StudlyCase, còn thuộc tính bạn truy vấn ra sẽ dưới dạng snake_case ($user->foo_bar).
Giờ code nhìn sạch sẽ hơn rất nhiều rồi phải không nào ^^
Mutators thì ngược lại với Accessors, chúng được dùng trong quá trình cập nhật thay vì truy xuất dữ liệu như Accessors.
Đúng thế, bạn chỉ cần thay đổi tên của bất cứ trường nào trong model (foo_bar) và nối nó với tiền tố “where” dưới dạng StudlyCase (FooBar), Eloquent sẽ tự xử lí và khiến đoạn code chạy “chuẩn không cần chỉnh”.
Mặt khác, hãy chú ý tới một số phương thức đã được định nghĩa sẵn của Eloquent:
Thực ra thì có khá nhiều người ghét kiểu viết như thế này (trừ những hàm mặc định của Eloquent), nhưng Eloquent đã hỗ trợ và bạn muốn xài thì cứ xài thôi. Trên thực tế mình lại thích viết rõ ràng các tên trường ra thay vì gọi tên hàm, bởi mình thấy nó làm cho code khó tái sử dụng hơn.
Model có quan hệ belongsTo chứa giá trị mặc định
Hãy tưởng tượng bạn có các bài Post được đăng bởi một Author. Bạn cần xuất tên của Author ra ngoài view.
{{$post->author->name}}
Nhưng điều gì sẽ xảy ra nếu Author đã bị xóa, hoặc nó chưa được lưu xuống vì một lí do nào đó? Bạn sẽ gặp một lỗi Exception, đại loại là “try to get property of non-object“.
Thực ra bạn có thể tránh điều đó bằng cách sau:
{{$post->author->name??''}}
Nhưng bạn sẽ phải trả giá bằng cách kiểm tra giá trị như trên ở tất cả những nơi cần chúng. Khá phiền phức đúng không?
Có một cách hay hơn để làm điều này. Chúng ta sẽ thêm đoạn code như sau vào Eloquent model:
Đoạn code này sẽ trả về một lớp Author rỗng nếu không có Author nào đi kèm với bài Post. Hơn nữa chúng ta hoàn toàn có thể thiết lập các giá trị mặc định cho Author:
Một ngày đẹp trời, bạn muốn các Category được sắp xếp theo “name” bất cứ khi nào truy vấn dạng danh sách. Ủa không lẽ giờ ngồi tìm rồi sửa lại hết hay sao ta?
Có một cách để thực hiện điều này tốt hơn, ít “cơ bắp” hơn – chỉ định một Global Scope. Chúng ta cùng quay trở lại phương thức boot() đã đề cập trước đó:
Trong một số trường hợp, khi mà các phương thức xây dựng sẵn của Eloquent không đủ để chúng ta thực hiện truy vấn, chúng ta hoàn toàn có thể thêm vào các raw query.
Khi xử lí hàng ngàn kết quả từ Eloquent, sử dụng chunk sẽ giúp tiết kiệm tối đa bộ nhớ hệ thống. Thực ra phương thức này thuộc về xử lí Collection, chứ không hẳn là ở Model.
Câu lệnh này đã thực hiện việc cập nhật category_id cho toàn bộ các Product thỏa điều kiện, nhưng giá trị của $result ở đây là gì?
Câu trả lời chính là: số lượng các mục bị ảnh hưởng. Điều này có nghĩa là nếu bạn muốn kiểm tra xem có bao nhiêu mục đã được cập nhật, thì đây là chính xác những gì bạn cần, không cần gọi thêm thứ gì khác.
Truy vấn điều kiện nâng cao
Nếu bạn có một câu SQL đại loại như thế này:
...WHERE (gender ='Male'and age >=20)OR(gender ='Female'and age >=18)
Chuyển đoạn SQL này sang Eloquent như thế nào đây? Có lẽ nhiều người từng làm như thế này:
$query->whereRaw('(gender = ? and age >= ?) OR (gender = ? and age >= ?)',['Male',20,'Female',18]);
Viết như vầy thì “cơ bắp” quá các bạn, cũng khó bảo trì sau này nữa. Trừ trường hợp bất khả kháng, nếu không thì chúng ta nên cố gắng chuyển câu truy vấn sang Eloquent hết sức có thể.
Chúng ta có thể gom nhóm các điều kiện đi kèm với nhau trong dấu ngoặc bằng một hàm Closure như sau:
Trên đây là những kinh nghiệm và mẹo nhỏ mà mình tìm hiểu được khi làm việc với Laravel. Nếu bạn biết một vài mẹo nào đó và muốn chia sẻ, hãy để lại bình luận bên dưới nhé.
Cám ơn các bạn đã theo dõi. Hẹn gặp lại trong các bài viết tiếp theo.
Anh em lập trình viên chắc không xa lạ với khái niệm Clean Code trong lập trình, mặc dù vậy để viết được code một cách clean quả thực là một thách thức, nhất là đối với ngôn ngữ lập trình JavaScript. Bài viết hôm nay, mình cùng các bạn chia sẻ một số kinh nghiệm để thực hành viết Clean Code trong JS, và hãy thử xem các bạn đã áp dụng được bao nhiêu trong số những điều dưới đây nhé.
Clean Code là gì?
Clean Code – “Mã Sạch” là cách viết code đơn giản và dễ hiểu, dễ bảo trì, có khả năng mở rộng source code mà vẫn có thể đáp ứng được các yêu cầu về mặt tính năng, hiệu năng hay bảo mật. Khái niệm tuy đơn giản nhưng để một source code đáp ứng được tiêu chuẩn Clean Code lại là một vấn đề không dễ để giải quyết. Clean Code còn thể hiện kinh nghiệm, đồng thời ở một khía cạnh nào đó sẽ đánh giá trình độ của lập trình viên.
Mỗi ngôn ngữ lập trình đều có những tiêu chuẩn khi viết code, cùng các thủ thuật, lời khuyên từ kinh nghiệm của những lập trình viên đi trước giúp bạn áp dụng vào dự án của mình để có thể thực hành clean code. Mặc dù vậy, để áp dụng đúng và chuẩn thì luôn cần có những trải nghiệm thực tế cùng việc thực hành một cách tích cực.
Viết Clean Code trong JavaScript
JavaScript vốn dĩ là một ngôn ngữ lập trình động với các ràng buộc lỏng lẻo trong quy tắc viết code; vì thế lập trình viên JS thường dễ tạo ra những đoạn code rối, tiềm ẩn nguy cơ gặp lỗi hoặc chỉ đơn giản là rất khó để đọc, hiểu hay bảo trì về sau. Để khắc phục được điều này và giúp cải thiện chất lượng source code dự án thì việc áp dụng Clean Code cho JS là điều vô cùng cần thiết.
Chúng ta cùng nhau tìm hiểu một số kinh nghiệm để giúp viết Clean Code trong JavaScript dưới đây nhé.
1. Cách đặt tên biến
Nhiều bạn ngại đặt tên biến dài, thích đặt tên biến ngắn cho “tiện”; điều này vô tình khiến người khác hay chính bạn sau một thời gian đọc lại không hiểu mục đích biến đấy được tạo ra và sử dụng để làm gì. Lời khuyên cho bạn khi đặt tên biến là hãy sử dụng tên thể hiện ý định, mục đích sử dụng biến đó; không ngại việc đặt tên dài và tốt hơn nữa là có thể dễ gợi ý tìm kiếm sau này. Ví dụ:
Đừng cố gắng viết tắt tên biến, vì đoạn code của bạn sẽ có nhiều người khác trong team cần đọc. Hãy cố gắng viết code sao cho một người đọc code của bạn như đang đọc một đoạn văn có đầy ý nghĩa dễ hiểu mà không cần phải giải thích.
Robert Cecil Martin – tác giả của cuốn Clean Code đưa ra lời khuyên khi viết hàm rằng: Mỗi hàm (function) chỉ nên thực hiện một việc duy nhất. Bạn có thể tham khảo ví dụ dưới đây:
Việc đặt tên hàm cũng có những lưu ý tương tự như với đặt tên biến, không ngại đặt tên dài và cần có ý nghĩa gợi ý dễ tìm kiếm. Thông thường tên hàm sẽ là một động từ hoặc cụm động từ thể hiện chức năng mà hàm đó thực hiện.
// DON'T/** * Invite a new user with its email address * @param{String}user email address */functioninv (user) { /* implementation */ }// DOfunctioninviteUser (emailAddress) { /* implementation */ }
Trong trường hợp có nhiều tham số cần truyền vào trong hàm, bạn nên sử dụng cách truyền dạng Object, tốt hơn nữa là có thể model hóa Object đó lên để dễ dàng sử dụng và truyền vào trong lời gọi hàm.
Một số kinh nghiệm khác dành cho bạn khi viết hàm:
Viết các hàm thuần túy (pure functions) không phụ thuộc hay có ảnh hưởng đến các biến, thành phần bên ngoài; giảm tối đa side effects trong hàm, điều này giúp chúng ta dễ dàng sử dụng, kiểm thử mà không lo ảnh hưởng đến chương trình
Tổ chức thứ tự các hàm trong source code (trong một file script) theo level từ cao đến thấp; trong trường hợp trong xử lý của function A gọi đến function B thì function nên được đặt ở phía dưới. Điều này tạo ra một logic về thứ tự tự nhiên trong mã nguồn.
Tránh việc viết chung xử lý cập nhật/ sửa đổi dữ liệu và truy vấn dữ liệu trong cùng một hàm. Điều này sẽ phát sinh những kết quả không mong muốn trong lời gọi hàm sử dụng.
Trước khi bắt đầu một dự án, viết những dòng code đầu tiên; hãy tạo coding convention cho team của bạn cùng những quy tắc, nguyên tắc chung trong định dạng từ những điều nhỏ nhất như khoảng cách lề, dấu chấm phẩy, … Một gợi ý mà bạn có thể tham khảo là sử dụng Airbnb style dành cho JavaScript
Một ví dụ trong nguyên tắc chung đối với team khi viết code; bạn có thể sử dụng khi viết những đoạn xử lý bất động bộ sử dùng Promise.
2 cách viết trên đều có thể được chấp nhận, tuy nhiên cần có sự đồng bộ trong style viết code của cả dự án. Cách viết thứ 2 mang đến sự dễ nhìn, đồng thời có sự rõ ràng trong trình tự các bước xử lý đồng bộ hơn so với cách thứ nhất.
Để viết được những đoạn code “tốt” với hiệu suất chạy chương trình ở mức cao; trước tiên hãy bắt đầu với cách viết code đơn giản và rõ ràng. Bạn nên tập sử dụng các công cụ giám sát, đánh giá hiệu suất ứng dụng JavaScript Profiler để xác định, tìm ra những bottlenecks trong chương trình của mình.
Đừng cố gắng tối ưu, cải thiện hiệu suất ngay từ đầu; điều đó có thể khiến có công việc phát triển dự án của bạn trở nên nặng nề hơn. Hãy tối ưu hóa source code của bạn khi cần thiết và đánh giá tác động thực sự của nó lên dự án mà bạn đang triển khai. Ngoài ra, để cải thiện được hiệu suất, hãy cố gắng tạo ra các bản code mẫu (template) qua từng dự án và có kế hoạch tối ưu nó (upgrade version) một cách đồng bộ.
Kết bài
Clean Code thực sự là một kỹ năng quan trọng giúp bạn đi xa hơn trở thành một lập trình viên chuyên nghiệp. Mặc dù không dễ để áp dụng những điều trên xuyên suốt dự án của bạn, nhưng hãy bắt đầu thực hành và tạo thói quen ngay từ ban đầu; điều đó sẽ giúp cho những dòng code JavaScript của bạn trở nên sạch đẹp và hiệu quả hơn. Cảm ơn các bạn đã đọc bài và hẹn gặp lại trong các bài viết tiếp theo của mình.
Trở thành một software developer hiệu suất cao không phải là điều dễ dàng. Điều này đòi hỏi bạn phải có kỹ năng và kiến thức về lập trình, cũng như cách tiếp cận và giải quyết các vấn đề phức tạp. Tuy nhiên, nếu bạn có chút kiên nhẫn và sự nỗ lực, bạn hoàn toàn có thể trở thành một developer tài năng và thành công.
Cải thiện hiệu suất công việc và khả năng thăng tiến cho developers
Là những software developers, chúng ta luôn muốn liên tục cải thiện bản thân. Điều này có thể đạt được thông qua việc viết mã sạch hơn và hiệu quả hơn, sử dụng các design patterns mới, mở rộng phạm vi kiến thức và công việc, hoặc tìm hiểu sâu hơn vào một công nghệ cụ thể.
Chúng ta được khuyến khích viết report sau khi triển khai công việc cũng như cần đánh giá lại thứ gì đang đi đúng hướng và ngược lại.
Chúng ta cũng được khuyên thực hiện các cuộc họp retrospectives sau mỗi sprint để có thể cải thiện hơn trong lần sau.
Chúng ta cần yêu cầu nhận được phản hồi, thông qua việc review code hoặc là trong khuôn khổ cuộc họp 1:1 với leader.
Nói tóm lại, chúng ta cần nhận biết điểm mạnh và điểm yếu của bản thân để cải thiện chúng.
Sử dụng tools nếu nó giúp tăng hiệu quả công việc
Tốc độ không phải là tốc độ gõ phím nha các bạn 😀 mình đang nói đến tốc độ viết code, test, debug phần mềm để release sản phẩm đúng hạn.
Nguyên tắc đầu tiên bạn cần nhớ: sử dụng bất cứ thứ gì nếu bạn nhận thấy nó giúp bạn làm việc nhanh hơn, ngay cả khi nó không phổ biến hoặc trông giống bọn “tay mơ”.
Ví dụ, hầu hết các developer chỉ sử dụng Git CLI và do dự khi sử dụng Git UI vì sợ bị đánh dấu là “không chuyên nghiệp”. Mình có thể tự tin khẳng định rằng đối với nhiều trường hợp, sử dụng UI nhanh hơn nhiều so với sử dụng CLI.
Tại sao lại như vậy ư? Khi comment về các files hoặc dòng code cụ thể, giải quyết conflicts, xem các changes và cherry-pick, mình sẽ kết hợp cả UI và CLI.
Thiên đường có sẵn, xuống địa ngục làm gì vậy?
Có rất nhiều công cụ tuyệt vời của Git như GitKraken, Sourcetree… Sử dụng chúng xen kẽ nhau giúp cuộc sống của mình dễ dàng hơn và hiệu quả hơn nhiều.
Đừng chỉ là một lập trình viên, hãy là một người giải quyết vấn đề
Trong quá trình phát triển phần mềm, lập trình viên không chỉ cần phải biết cách viết code mà còn phải hiểu rõ vấn đề mà phần mềm cần giải quyết. Điều này đòi hỏi lập trình viên cần có khả năng tư duy phản biện, khả năng phân tích vấn đề và đưa ra các giải pháp tối ưu cho người dùng.
Nhiều lần chúng ta nhảy vào chi tiết kỹ thuật, mặc dù hầu hết thời gian, tất cả những gì chúng ta cần là một giải pháp đơn giản.
Chúng ta đôi khi làm những thứ không cần thiết. Một ví dụ cho điều đó là việc viết quá nhiều E2E tests. Các E2E tests tốn rất nhiều thời gian và công sức để viết và bảo trì, trong khi đối với hầu hết các trường hợp, việc viết unit/integration tests sẽ mang lại hiệu quả tương đương, mà chi phí bỏ ra thấp hơn nhiều.
Ngoài ra, để trở thành một người giải quyết vấn đề, lập trình viên cũng cần có khả năng giao tiếp và làm việc với các thành viên trong nhóm, bao gồm các nhà quản lý dự án, thiết kế đồ họa và những người sử dụng cuối.
Bằng cách trở thành một người giải quyết vấn đề, lập trình viên sẽ có thể đóng góp nhiều hơn vào quá trình phát triển phần mềm và đảm bảo rằng sản phẩm được phát triển sẽ giải quyết được các vấn đề thực tế mà người dùng đang gặp phải. Nó cũng giúp lập trình viên tăng khả năng tiếp cận với các cơ hội nghề nghiệp mới và tiến bộ trong sự nghiệp của mình.
Đừng code ngay, hay tìm hiểu vấn đề trước
Các lập trình viên thường bắt đầu viết code trước khi suy nghĩ.
Như mình đã nói trước đó, chúng ta hăng hái giải quyết vấn đề. Tuy nhiên, điều đó nên làm ngược lại!
Trước khi bắt đầu bất cứ điều gì, hãy dành 5 phút để vẽ vài sơ đồ về những gì bạn đang lên kế hoạch làm. Mình đảm bảo 5 phút đó sẽ mang lại cho giá trị gấp nhiều lần cho bạn.
Việc tìm hiểu vấn đề cũng giúp chúng ta đưa ra các giải pháp tối ưu cho vấn đề cụ thể đó. Ngoài ra, điều này cũng giúp developers có thể đưa ra các quyết định đúng đắn và hợp lý về các công nghệ và phương pháp phát triển phần mềm, giúp tăng khả năng thành công của dự án, tránh được những lỗi thường gặp và giảm thiểu rủi ro.
Nếu chúng ta viết code ngay mà không tìm hiểu kỹ về vấn đề cần giải quyết, có thể sẽ dẫn đến việc phát triển ứng dụng không đáp ứng được các yêu cầu cụ thể của khách hàng. Nếu không có kiến thức đầy đủ về các quy trình và hoạt động, chúng ta có thể thiếu một số tính năng quan trọng hoặc đưa ra những tính năng không cần thiết.
Nắm vững môi trường và công cụ bạn đang sử dụng để viết code
Khi bạn hiểu rõ hơn về môi trường và công cụ của mình, bạn có thể tận dụng tối đa các tính năng và công cụ để giải quyết các vấn đề phát sinh trong quá trình phát triển phần mềm, giúp tăng hiệu suất làm việc, giảm thời gian phát triển và đảm bảo chất lượng của sản phẩm. Tuy nhiên, hãy tránh những công cụ dư thừa.
Khi mình bắt đầu với một IDE hoặc ngôn ngữ mới, mình sẽ tìm hiểu:
Khả năng và điểm yếu của nó
Các phím tắt
Cách thức cài đặt thêm extensions
Cách tuỳ chỉnh cấu hình quen thuộc để tăng hiệu quả
Các extensions hỗ trợ ngôn ngữ
Cách cài đặt local environment…
Ứng dụng AI vào công việc
Hiện nay chúng ta đang trải qua một kỷ nguyên mới của trí tuệ nhân tạo khi mà chúng dần trở nên phổ biến hơn trong cuộc sống và công việc của chúng ta. Một trong những ví dụ là sự gia tăng của các công cụ được hỗ trợ bởi trí tuệ nhân tạo trong ngành phát triển phần mềm.
GitHub Co-Pilot là một công cụ được hỗ trợ bởi trí tuệ nhân tạo mới nhất và đã trở nên phổ biến trong cộng đồng các nhà phát triển. Nó sử dụng machine learning để đề xuất code và hoàn thành các code block cho các developer trong quá trình viết code. Công cụ này có thể giúp các nhà phát triển tiết kiệm thời gian và tăng năng suất bằng cách tự động hóa các tác vụ lặp lại và đề xuất cách viết code hiệu quả hơn.
Tuy nhiên, điều quan trọng cần lưu ý là các công cụ được hỗ trợ bởi trí tuệ nhân tạo không có ý định thay thế cho các developers con người. Chúng được thiết kế để hỗ trợ các chúng ta trong công việc, giúp quá trình phát triển trở nên hiệu quả và chính xác hơn. Ngoài ra, các công cụ được hỗ trợ bởi trí tuệ nhân tạo không phải lúc nào cũng hoàn hảo và có thể mắc lỗi hoặc đưa ra các đề xuất không chính xác. Do đó, các developer cần xem xét và xác minh các đề xuất được cung cấp bởi các công cụ này trước khi áp dụng vào code của mình.
Tóm lại, kỷ nguyên mới của trí tuệ nhân tạo mở ra các cơ hội hấp dẫn cho các developers tăng năng suất và hiệu quả làm việc. Tuy nhiên, việc sử dụng các công cụ này phải được thực hiện một cách có trách nhiệm và kết hợp với kiến thức chuyên môn của con người để đạt được kết quả tốt nhất.
Học tập liên tục
Học tập liên tục là một trong những yếu tố quan trọng giúp bạn phát triển sự nghiệp và thành công trong cuộc sống. Trong thế giới công nghệ ngày nay, sự thay đổi nhanh chóng và các công nghệ mới luôn xuất hiện, vì vậy học tập liên tục là cần thiết để đáp ứng nhu cầu thị trường và nâng cao năng lực chuyên môn của bản thân.
Để học tập liên tục, bạn có thể bắt đầu bằng cách đọc sách, tham gia các khóa học trực tuyến, các lớp học offline, tìm hiểu trên các diễn đàn và cộng đồng chuyên ngành. Đặc biệt, bạn cần cập nhật các xu hướng mới nhất trong lĩnh vực của mình và theo dõi các tạp chí, báo, tài liệu chuyên ngành.
Bạn cũng có thể học hỏi từ những người giỏi hơn, tìm kiếm các mentor hoặc đồng nghiệp để học tập từ họ. Ngoài ra, bạn có thể tham gia các dự án thực tế, đóng góp vào cộng đồng open source để rèn luyện kỹ năng và học hỏi kinh nghiệm thực tiễn.
Hãy luôn đặt mục tiêu học tập cụ thể và thực hiện các bước học tập theo kế hoạch. Hãy cố gắng rèn luyện kỹ năng mỗi ngày, đồng thời hãy kiên trì và chủ động trong việc học tập và áp dụng kiến thức vào thực tế. Học tập liên tục không chỉ giúp bạn phát triển nghề nghiệp mà còn giúp bạn trở thành một người tự tin và thành công trong cuộc sống.
Áp dụng các quy trình phát triển
Các quy trình phát triển là các bước chuẩn bị, thực thi và kiểm tra một sản phẩm phần mềm. Áp dụng các quy trình phát triển phần mềm là cách để đảm bảo rằng sản phẩm được phát triển theo đúng tiến độ, đảm bảo chất lượng và đáp ứng yêu cầu của khách hàng.
Có nhiều quy trình phát triển khác nhau như: Waterfall, Agile, Spiral, V-Model, Scrum, XP, Kanban, DevOps, và nhiều hơn nữa. Mỗi quy trình có ưu điểm và nhược điểm riêng và phù hợp với các dự án phần mềm khác nhau.
Việc áp dụng quy trình phát triển phần mềm sẽ giúp cho các nhà phát triển phần mềm nắm rõ tiến độ, tối ưu hóa tài nguyên, tăng tính minh bạch và giảm thiểu rủi ro trong quá trình phát triển. Ngoài ra, áp dụng quy trình phát triển phần mềm cũng giúp cho việc quản lý dự án trở nên dễ dàng hơn.
Tuy nhiên, việc áp dụng quy trình phát triển phần mềm cần phải được thực hiện một cách linh hoạt và tùy chỉnh cho từng dự án cụ thể. Các quy trình không nên bị nhốt vào một khung giờ chật chội, nhưng nên được điều chỉnh linh hoạt để đáp ứng nhu cầu cụ thể của dự án.
Cuối cùng, áp dụng các quy trình phát triển phần mềm không chỉ cần thiết cho các công ty phát triển phần mềm, mà còn cần thiết cho tất cả các nhà phát triển phần mềm đang làm việc trên các dự án của mình.
Lập kế hoạch và tập trung vào mục tiêu là hai yếu tố quan trọng giúp cho việc đạt được thành công trong bất kỳ lĩnh vực nào, đặc biệt là trong lĩnh vực phát triển phần mềm.
Để đạt được mục tiêu của mình, đầu tiên bạn cần phải lập kế hoạch. Lập kế hoạch giúp bạn xác định mục tiêu của mình và đưa ra kế hoạch cụ thể để đạt được mục tiêu đó. Kế hoạch cần được thiết lập một cách rõ ràng, bao gồm các bước cụ thể và thời gian để thực hiện các bước đó.
Sau khi lập kế hoạch, tập trung vào mục tiêu là một yếu tố quan trọng khác giúp bạn đạt được thành công. Tập trung vào mục tiêu có nghĩa là tập trung vào những hoạt động và quyết định giúp bạn đạt được mục tiêu của mình. Tránh phân tán tâm trí và chú ý vào những hoạt động không liên quan đến mục tiêu.
Các mục tiêu cần phải được xác định rõ ràng và có tính đo đếm được để đánh giá tiến độ và đạt được kết quả tốt nhất. Hãy luôn tập trung vào các hoạt động quan trọng nhất để giúp bạn đạt được mục tiêu một cách nhanh chóng và hiệu quả.
Cuối cùng, đừng quên rằng lập kế hoạch và tập trung vào mục tiêu là một quá trình liên tục. Hãy đánh giá tiến độ thường xuyên và điều chỉnh kế hoạch nếu cần thiết để đảm bảo rằng bạn đang trên đúng hướng để đạt được mục tiêu của mình.
Làm việc với những người khác
Hợp tác làm việc với những người khác là một kỹ năng quan trọng trong bất kỳ lĩnh vực nào. Để thành công trong công việc của mình, bạn cần phải biết làm việc với những người khác và xây dựng các mối quan hệ tốt với họ.
Để hợp tác hiệu quả, bạn cần phải thể hiện sự tôn trọng và sự quan tâm đến những người khác. Hãy lắng nghe ý kiến của họ và tìm cách để đưa ra giải pháp tốt nhất cho cả nhóm. Hãy chia sẻ thông tin và ý tưởng của mình một cách rõ ràng và dễ hiểu, và tạo một môi trường làm việc thoải mái và hỗ trợ cho những người khác.
Ngoài ra, bạn cần phải học cách đàm phán và giải quyết mâu thuẫn. Đừng sợ thể hiện quan điểm của mình, nhưng cũng cần lắng nghe và chấp nhận ý kiến của người khác. Tìm cách giải quyết các mâu thuẫn một cách hòa bình và công bằng để đạt được mục tiêu chung.
Cuối cùng, hãy luôn đặt mục tiêu của nhóm lên hàng đầu. Hãy làm việc chăm chỉ để đạt được mục tiêu chung và đảm bảo rằng tất cả các thành viên trong nhóm đều đóng góp một cách tích cực và có ý thức trách nhiệm cao. Hợp tác làm việc với những người khác có thể tạo ra những kết quả tốt nhất nếu bạn biết cách xây dựng và duy trì các mối quan hệ tốt với những người này.
JWT Tokens là một cách thức lưu trữ thông tin xác thực hiệu quả, nhưng làm cách nào để chúng ta có thể giúp chúng an toàn hơn? Có 2 cách thường dùng để lưu trữ JWT Tokens là LocalStorage và Cookies. Bây giờ chúng ta sẽ bắt đầu “mổ xẻ” các ưu – nhược điểm của mỗi loại nhé.
Tóm tắt đơn giản về Access Token và Refresh Token
Access Token thường là các JWT Tokens tồn tại trong một khoảng thời gian ngắn, được tạo ra từ phía server, và được server yêu cầu đính kèm trong mỗi Http Request để phía server xác thực người dùng.
Refresh Token thường là các chuỗi string đặc thù nào đó được lưu trong database của server, được sử dụng để tạo ra các Access Token mới mỗi khi chúng hết hạn.
Mỗi khi nhận được token rồi thì lưu chúng ở đâu?
Có 2 cách lưu trữ Access Token phổ biến, đó là localStorage và Cookies.
Khá nhiều cuộc tranh luận đã nổ ra nhằm xác định cái nào tốt hơn, tuy nhiên hầu hết mọi người đều cho rằng Cookies tốt hơn vì chúng an toàn hơn.
Local Storage
Ưu điểm: tiện lợi.
Đây là một tính năng hầu hết các trình duyệt đều hỗ trợ mà không phải cài gì thêm. Nếu bạn không có phần backend và phải dựa vào API của bên thứ 3 thì bạn không thể yêu cầu người ta đặt Cookies cụ thể cho website của mình.
Nó làm việc với các API bằng cách đặt Access Token vào Request Header như ví dụ sau đây:
Authorization:`Bearer ${accessToken}`
Nhược điểm: dễ bị tấn công XSS.
Cross-Site Scripting (XSS) là một trong những kĩ thuật tấn công phổ biến nhất hiện nay. Kỹ thuật XSS được thực hiện dựa trên việc chèn các đoạn script nguy hiểm vào trong source code ứng dụng web, nhằm thực thi các đoạn mã độc Javascript để chiếm phiên đăng nhập của người dùng.
Một cuộc tấn công XSS có thể xảy ra từ mã JavaScript của bên thứ ba có trong trang web của bạn, như React, Vue, jQuery, Google Analytics, v.v.
Ở thời điểm người người xài js, nhà nhà xài js như hiện tại, hầu như không thể không đưa bất kỳ thư viện bên thứ ba nào vào trang web của bạn.
Hacker có thể chạy 1 đoạn js kiểu: localStorage.get('token') trên site của mình để lấy đc token, sau đó gửi ajax tới server của hacker.
Có trời mới biết mấy cái thư viện bên thứ 3 như vầy có cái gì trong đó. Đến đây chắc bạn cũng biết mất token thì nguy hiểm như thế nào rồi chứ?
Vậy bạn có bao giờ tự hỏi, tại sao các trang dạy coding online lại thường sử dụng localStorage mặc dù biết nó không bảo mật?
Đơn giản là việc sử dụng localStorage sẽ tiện dụng và dễ dàng hơn cho họ khi demo.
Hầu hết khóa học ứng dụng các Javascript framework đều chỉ tập trung vào concept và cách triển khai chúng mà thôi, và khi ứng dụng thực tế sẽ có đôi điểm khác biệt.
Và nếu như cái gì cũng chỉ hết cho bạn rồi thì làm sao họ bán được các khóa học nâng cao hơn, phải không nào? =)))
Cookies
Ưu điểm: Không thể truy cập httpOnly và secure cookie qua JavaScript, do đó nó không dễ bị tấn công XSS như localStorage.
Nếu bạn đang sử dụng httpOnly và secure cookie, hacker không thể truy cập cookie của bạn bằng JavaScript. Điều này có nghĩa là, ngay cả khi hacker có thể chạy javascript trên trang web của bạn, chúng cũng không thể đọc các Access Token của bạn từ cookie.
Cookies tự động được gửi trong mọi yêu cầu HTTP đến máy chủ của bạn.
Nhược điểm: Tùy thuộc vào các use case cụ thể mà bạn có thể không lưu trữ được Access Token của mình vào trong cookie.
Cookie có giới hạn kích thước là 4KB. Do đó, nếu bạn đang sử dụng một JWT Access Token lớn, thì việc lưu trữ trong cookie không phải là một lựa chọn đúng đắn.
Có những trường hợp bạn không thể chia sẻ cookie với máy chủ API của mình hoặc API yêu cầu bạn đặt Access Token vào trong Authorization Header. Trong trường hợp này, bạn sẽ không thể sử dụng cookie để lưu trữ Access Token của mình.
localStorage dễ bị tấn công vì nó có thể dễ dàng truy cập bằng JavaScript và hacker có thể lấy Access Token của bạn và sử dụng nó sau này.
Tuy nhiên, mặc dù không thể truy cập cookie gắn cờ httpOnly bằng JavaScript, điều này không có nghĩa là bằng cách sử dụng cookie, bạn sẽ an toàn trước các cuộc tấn công XSS liên quan đến Access Token của mình.
Nếu kẻ tấn công có thể chạy JavaScript trong ứng dụng của bạn, thì chúng chỉ có thể gửi một HTTP Request đến server của bạn và điều đó sẽ tự động gửi kèm cookie của bạn. Nó chỉ kém thuận tiện hơn cho kẻ tấn công vì họ không thể đọc nội dung Access Token mặc dù họ hiếm khi phải làm vậy.
Việc hacker phải tấn công bằng cách sử dụng trình duyệt của nạn nhân (bằng cách gửi HTTP Request) đương nhiên sẽ tốt hơn là hacker có thể sử dụng máy của chính hacker để tấn công bạn bằng các phương thức khác.
Cookies và tấn công CSRF
CSRF (Cross-site Request Forgery) là một kiểu tấn công lợi dụng sự tin tưởng của người dùng. Chúng lừa nạn nhân gửi đi các HTTP Request không mong muốn đến website nào đó.
Khi gửi một HTTP Request (hợp pháp hoặc không hợp pháp), trình duyệt của nạn nhân sẽ gửi kèm theo các Cookies Header. Các cookies thường được dùng để lưu trữ một session nhằm định danh người dùng giúp họ không phải xác thực lại mỗi khi thực hiện Request.
Nếu phiên làm việc đã xác thực của nạn nhân được lưu trữ trong một Cookie vẫn còn hiệu lực, và website nạn nhân bảo mật kém và dễ bị tấn công CSRF, kẻ tấn công có thể sử dụng CSRF để chạy bất cứ Request nào với website nạn nhân mà website nạn nhân không biết được các Request này có hợp pháp hay không.
Một lỗ hổng CSRF sẽ ảnh hưởng đến các quyền của người dùng ví dụ như quản trị viên, kết quả là chúng truy cập được đầy đủ quyền hạn trên website nạn nhân.
Người dùng Trung Nghĩa truy cập 1 diễn đàn yêu thích của mình như thường lệ. Một người dùng khác, Duy PT – đăng tải một bài viết lên diễn đàn. Giả sử rằng Duy PT có ý đồ không tốt và hắn ta muốn xóa đi một dự án quan trọng nào đó mà Trung Nghĩa đang làm.
Duy PT sẽ tạo một bài viết trên diễn đàn, trong đó có chèn thêm một đoạn code như sau:
Thêm vào đó thẻ img sử dụng trong trường hợp này có kích thước 0x0 pixel và người dùng sẽ không thể thấy được.
Giả sử Trung Nghĩa đang truy cập vào tài khoản của mình ở www.nghiattran-sample.com và chưa thực hiện logout để kết thúc session. Bằng việc xem bài post bên diễn đàn mà Duy PT đăng lên, trình duyệt của Trung Nghĩa sẽ đọc thẻ img và cố gắng load ảnh từ www.nghiatran-sample.com, do đó sẽ gửi câu lệnh xóa đến địa chỉ này.
Ứng dụng web ở www.nghiatran-sample.com sẽ chứng thực Trung Nghĩa dựa trên cookie và sẽ xóa project với ID là 1. Nó sẽ trả về trang kết quả mà không phải là ảnh, do đó trình duyệt sẽ không hiển thị ảnh.
Kết luận
Mặc dù Cookies vẫn tồn tại nhiều khuyết điểm, nhưng bạn nên ưu tiên sử dụng Cookies bất cứ khi nào có thể.
Cả localStorage và cookie đều dễ bị tấn công XSS nhưng kẻ tấn công sẽ khó thực hiện cuộc tấn công hơn khi bạn đang sử dụng Cookie với cờ httpOnly.
Cookie dễ bị tấn công CSRF nhưng nó có thể được giảm thiểu bằng cách sử dụng cờ sameSite, secure và Anti CSRF Token. Nếu bạn sử dụng một số framework như Laravel thì nó đã có sẵn cơ chế xác thực CSRF.
Bạn đã biết CV bao gồm những phần nào, cần phải viết gì trong đó rồi đúng không? Tuy nhiên mỗi người lại có một background khác nhau, mỗi người lại ứng tuyển cho một công việc khác nhau nên cách sắp xếp các đề mục trong CV cũng phải khác nhau. Việc bạn sắp xếp các đề mục đúng chuẩn sẽ giúp nhà tuyển dụng đọc CV của bạn hiệu quả hơn và giúp bạn có nhiều cơ hội hơn được gọi đi phỏng vấn đấy.
1. Cách sắp xếp của số đông
Mục tiêu nghề nghiệp (có thể viết hoặc không)
Kinh nghiệm làm việc
Hoạt động ngoại khoá
Học vấn
Kĩ năng và thành tích
Đây là cách mà mình thấy những người mới bắt đầu thường việc. Nếu bạn có nhiều kinh nghiệm khác nhau ở những lĩnh vực khác nhau, thì bạn nên có một phần nhỏ như Tóm tắt nghề nghiệp hoặc Mục tiêu nghề nghiệpở đầu CV tóm tắt sơ bộ về quá trình làm việc của bạn.
Cách sắp xếp này phù hợp cho tất cả các bạn, vì cách sắp xếp này bao gồm những phần cơ bản nhất mà nhà tuyển dụng muốn nhìn thấy ở trong một bản CV. Việc bạn sắp xếp như này cũng giúp nhà tuyển dụng dễ hơn trong việc Scan và Skim CV của bạn đấy.
2. Với những bạn mới tốt nghiệp
Học vấn
Kĩ năng làm việc
Kinh nghiệm làm việc
Hoạt động ngoại khoá
Thành tích (optional)
Các bạn mới tốt nghiệm thì thường chưa có nhiều kinh nghiệm làm việc lắm, vì vậy cần phải sắp xếp theo kiểu khác để nổi bật những cái bạn đang có lên. Ví dụ là Kĩ năng và Học vấn thì nên ở trên đầu, và nếu kinh nghiệm chưa có nhiều thì cần viết thật kĩ về phần Hoạt động ngoại khoá nhé.
Với những bạn đang có ý định làm trái ngành trái nghề và chưa có nhiều kinh nghiệm lắm ở lĩnh vực đó, điều quan trọng là bạn cần phải đưa những thông tin có liên quan nhất xuất hiện ở đầu CV.
Ví dụ bạn có thể viết một đoạn ngắn về Mục tiêu nghề nghiệp để nhà tuyển dụng biết tại sao bạn học một ngành mà lại muốn làm một ngành khác. Sau đó bạn có thể chia phần Kinh nghiệm làm việc thành 2 phần: 1 là kinh nghiệm làm việc có liên quan trực tiếp đến ngành bạn ứng tuyển, 2 là các kinh nghiệm khác. Cuối cùng là, nếu kinh nghiệm trực tiếp bạn chưa có nhiều, thì phải chú trọng hơn nữa vào phần Skills, hãy cố gắng đưa vào những kĩ năng càng liên quan nhiều càng tốt đến vị trí mà bạn đang ứng tuyển, đừng lúc nào cũng xoay quanh mấy cái mà ai cũng có thể viết như Teamwork, MS Office, Communication nhé.
Nếu bạn để ý một tí, thì thấy những người có nhiều kinh nghiệm rồi thường CV của họ trông sẽ rất đơn giản, thậm chí là có khi thấy hơi nhàm chán nữa. Chính bởi có nhiều kinh nghiệm rồi, nên họ không cần phải CV quá màu mè làm gì. Viết như thế nào để nhà tuyển dụng dễ đọc nhất là được rồi.
Với những bạn có nhiều kinh nghiệm, thì nên có một phần Tóm tắt nghề nghiệp ở đầu CV, để nhà tuyển dụng có thể lướt qua và nắm bắt được chung chung kĩ năng và kinh nghiệm của bạn nhé. Ngoài ra các phần khác thì cũng không có thay đổi nhiều lắm, tập trung nhiều hơn vào kinh nghiệm làm việc, chứ đừng đầu tư quá vào hoạt động ngoại khoá là được.
Việc bạn biết cách sắp xếp thông tin trong CV hợp lý, sẽ giúp nhà tuyển dụng đỡ tốn thời gian hơn để tìm hiểu thông tin về bạn. Chúc bạn viết được cho bản thân một bản CV ổn nha.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Bạn đang tìm kiếm một nơi để triển khai dự án front-end của mình mà không phải trả phí? May mắn thay, có nhiều dịch vụ hosting miễn phí mà bạn có thể sử dụng để triển khai và chia sẻ ứng dụng web của mình. Dưới đây là danh sách top 5 hosting free phổ biến giúp bạn dễ dàng bắt đầu.
1. GitHub Pages
GitHub Pages là một dịch vụ hosting tuyệt vời dành cho các dự án front-end. Để triển khai ứng dụng của bạn, bạn chỉ cần tạo một nhánh có tên đặc biệt, chẳng hạn như gh-pages, và GitHub sẽ tự động tạo ra một trang web cho dự án của bạn. Bạn có thể tận dụng ngay lợi ích của việc lưu trữ mã nguồn và triển khai trên cùng một nền tảng.
2. Cloudflare Pages
Cloudflare là một nền tảng mạng phân phối nội dung (CDN) và bảo mật web phổ biến, cung cấp nhiều tính năng hữu ích cho các nhà phát triển web. Một trong những tính năng nổi bật của Cloudflare là Pages, cho phép bạn triển khai dự án web tĩnh của mình một cách nhanh chóng và dễ dàng.
Ngoài vai trò là một CDN và dịch vụ bảo mật web, Cloudflare còn cung cấp Cloudflare Pages – một nền tảng JAMstack cho phép bạn triển khai website tĩnh một cách nhanh chóng và dễ dàng. Nền tảng này được tích hợp sẵn nhiều tính năng mạnh mẽ, giúp tối ưu hóa hiệu suất, bảo mật và trải nghiệm người dùng cho website của bạn.
3. Vercel
Vercel là một dịch vụ hosting với tốc độ cao và quy trình triển khai đơn giản. Bạn có thể kết nối Vercel với nhiều loại repository khác nhau và triển khai ngay lập tức. Nền tảng này cung cấp một giao diện người dùng thân thiện, giúp bạn dễ dàng quản lý các thiết lập và theo dõi quá trình triển khai.
Firebase là một phần của nền tảng Firebase của Google. Nó cung cấp hosting nhanh chóng và tích hợp tốt với các dịch vụ khác của Firebase như Realtime Database và Authentication. Một lợi ích lớn của Firebase Hosting là khả năng cấu hình đơn giản, với hỗ trợ HTTPS và custom domain.
Netlify không chỉ là một dịch vụ hosting miễn phí mà còn là một nền tảng triển khai liên tục (CI/CD) tốt. Bạn có thể kết nối trực tiếp với repository của mình trên GitHub, GitLab hoặc Bitbucket để tự động triển khai mỗi khi có sự thay đổi trong mã nguồn. Netlify cũng hỗ trợ các tính năng như serverless functions, một ưu điểm lớn cho các dự án front-end phức tạp.
Dù bạn là một nhà phát triển mới hoặc có kinh nghiệm, lựa chọn một dịch vụ hosting free phù hợp là quan trọng để đảm bảo sự thuận tiện và hiệu quả cho dự án front-end của bạn.
Tại thị trường Việt Nam hiện nay, Salesforce Developer đang là một vị trí có nhu cầu tuyển dụng cao với nhiều mức đãi ngộ hấp dẫn do nhu cầu hiện đại hóa của các doanh nghiệp. Tuy nhiên đây là một vị trí đòi hỏi yêu cầu cao cả về kiến thức lập trình cũng như nền tảng quy trình và kinh doanh. Bài viết hôm nay chúng ta cùng nhau tìm hiểu Salesforce Developer là gì và cần học gì để trở thành một nhà phát triển Salesforce nhé.
Salesforce là gì?
Salesforce là giải pháp CRM (Customer Relationship Management) trên nền tảng điện toán đám mây dành cho các doanh nghiệp ở nhiều lĩnh vực khác nhau. Nền tảng này cung cấp một giải pháp toàn diện về quản lý, bán hàng, dịch vụ chăm sóc khách hàng, marketing, … với tính bảo mật cao, phù hợp với nhiều quy mô doanh nghiệp khác nhau và có khả năng mở rộng theo sự phát triển của doanh nghiệp.
Những tính năng nổi bật của Salesforce có thể kể đến bao gồm:
Module Chatter: tính năng cho phép nhân viên có thể cập nhật, chia sẻ thông tin tới khách hàng, các phòng ban nội bộ hoặc các bên liên quan một cách dễ dàng, nhanh chóng.
Hệ thống CRM: quản lý tập trung tất cả các thông tin khách hàng từ email, số điện thoại, lịch sử giao dịch, thu nhập,…
Theo sát hành trình của khách hàng trong suốt quá trình mua hàng và từ đó xác định cơ hội bán hàng tiềm năng
Tính năng thư viện tìm kiếm thông tin một cách thông minh
Module phân tích, báo cáo và dự đoán kết quả kinh doanh
Tích hợp với nhiều thư viện, công cụ bên thứ 3 như Google với các bộ phần mềm Gmail, Calendar, Drive,…
Có khả năng tối ưu tốt dành cho các thiết bị di động
Salesforce Developer là gì?
Salesforce Developer là những người tham gia thực hiện các công việc thiết kế, tùy chỉnh, phát triển ứng dụng và tích hợp hệ thống trên các dịch vụ nền tảng của Salesforce. Công việc cụ thể của một Salesforce Developer bao gồm:
Phân tích, làm rõ các nhu cầu của khách hàng với nền tảng Salesforce
Nghiên cứu, tìm hiểu các tính năng của Salesforce để đưa ra giải pháp cho khách hàng
Xây dựng, phát triển ứng dụng Salesforce tùy chỉnh
Quản lý, duy trì đảm bảo tính toàn vẹn, bảo mật của dữ liệu trên nền tảng Salesforce
Tích hợp các hệ thống bên thứ ba vào Salesforce
Ngôn ngữ lập trình được sử dụng cho Salesforce là Apex – một ngôn ngữ lập trình hướng đối tượng mạnh mẽ với cú pháp khá giống với Java cùng ưu điểm là thuận tiện và dễ dàng hơn trong việc viết code, viết test và tương tác với CSDL. Để tùy chỉnh giao diện người dùng, Salesforce sử dụng ngôn ngữ lập trình JavaScript. Bên cạnh đó, nền tảng này cũng cung cấp 2 ngôn ngữ truy vấn đề có thể tương tác với CSDL là SOQL (Salesforce Object Query Language) và SOSL (Salesforce Object Search Language).
Salesforce Developer có đặc thù là làm việc trên nền tảng Salesforce, không chỉ bao gồm các công việc liên quan đến lập trình, kỹ thuật mà còn cần hiểu, nắm được những quy trình cùng dịch vụ khách hàng; vì vậy vị trí này đòi hỏi những kỹ năng đặc thù liên quan như:
Hiểu biết về nền tảng CRM điện toán đám mây với các sản phẩm của Salesforce như: Sales Cloud, Service Cloud, Marketing Cloud, Commerce Cloud, Community Cloud,…
Tài liệu Salesforce hoàn toàn bằng tiếng Anh, vì vậy làm việc, giao tiếp bằng tiếng Anh là một kỹ năng vô cùng cần thiết đối với một Salesforce Developer.
Kỹ năng làm việc nhóm, làm việc với khách hàng, hợp tác với các bộ phận khác. Bạn cũng có thể cần thiết phải trao đổi trực tiếp với đội hỗ trợ từ Salesforce trong các vấn đề liên quan đến kỹ thuật của nền tảng.
Kỹ năng báo cáo và tạo báo cáo. Có khả năng mô hình hóa dữ liệu, có kinh nghiệm với bảo mật và an ninh thông tin.
Salesforce là một nền tảng lớn, được sử dụng ở rất nhiều công ty, tổ chức mang tính toàn cầu; vì vậy việc học để trở thành một Salesforce Developer là không hề dễ dàng, đòi hỏi bạn cần đi từng bước, có sự kiên trì với yêu cầu cao trong quá trình học. Các bạn có thể đi theo các bước sau nếu muốn trở thành một Salesforce Developer ngay từ bây giờ.
1. Học về lập trình phần mềm
Trước tiên bạn cần trang bị kiến thức về lập trình phần mềm, bao gồm lập trình Backend, làm việc với Database và một chút về tùy chỉnh giao diện người dùng. Nếu đã có kiến thức nền về Java, SQL thì việc học về ngôn ngữ Apex trong Salesforce sẽ trở nên dễ dàng hơn.
2. Tham gia các khóa học online trên Salesforce
Salesforce có cung cấp các khóa online dành cho các lập trình viên mong muốn trở thành Salesforce Developer và làm việc trên nền tảng này. Nền tảng đào tạo về Salesforce được gọi là Trailhead, ở đây bạn có thể tìm hiểu và học thêm về các giải pháp của Salesforce thông qua các kiến thức cơ bản, đơn giản và rất dễ hiểu.
3. Cải thiện các kỹ năng khác
Ngoài kiến thức liên quan đến nền tảng, bạn cũng cần trang bị thêm một số kỹ năng liên quan để có thể làm việc với nền tảng Salesforce bao gồm cách sử dụng các công cụ no-code hoặc low-code; có kiến thức về UI/UX cơ bản, hiểu về quy trình, nghiệp vụ được áp dụng trong Salesforce đồng thời có những kỹ năng mềm như giao tiếp, làm việc nhóm, thuyết trình để có thể thuận tiện khi hợp tác với các đội nhóm khác.
4. Thi chứng chỉ Salesforce
Salesforce cung cấp khá nhiều chứng chỉ khác nhau tùy theo nhu cầu và lĩnh vực mà bạn sẽ làm việc trên nền tảng này. Thi đạt những chứng chỉ này sẽ giúp bạn mở rộng các kỹ năng về Salesforce, đồng thời là một minh chứng giúp mở rộng cơ hội nghề nghiệp của bạn. Một số chứng chỉ các bạn có thể tìm hiểu và lựa chọn học thi:
The Salesforce Platform App Builder certification
The Salesforce Platform Developer I certification
The Salesforce Platform Developer II certification
The Salesforce JavaScript Developer I certification
The Salesforce Commerce Cloud Developer certification
Các câu hỏi thường gặp
1. Salesforce Developer có cần biết về JavaScript không?
Có, đặc biệt khi làm việc với Lightning Web Components (LWC). JavaScript là một phần quan trọng trong phát triển LWC và tích hợp với các hệ thống web khác. Hiểu biết về JavaScript giúp Salesforce Developer xây dựng các ứng dụng giao diện người dùng hiện đại và tương tác.
2. Salesforce Developer có cần kỹ năng về quản trị hệ thống không?
Có, Salesforce Developer cần có hiểu biết cơ bản về quản trị hệ thống để cấu hình và quản lý môi trường Salesforce. Điều này bao gồm việc thiết lập các đối tượng tùy chỉnh, quản lý quyền và bảo mật, và làm việc với các quy trình tự động hóa như Flow và Process Builder. Tuy nhiên, chi tiết về quản trị thường là công việc của Salesforce Administrator.
3. Sự khác biệt giữa Salesforce Developer và Salesforce Administrator là gì?
Salesforce Developer tập trung vào viết mã và phát triển các ứng dụng tùy chỉnh trên nền tảng Salesforce, bao gồm việc xây dựng các logic nghiệp vụ phức tạp và tích hợp với hệ thống bên ngoài. Ngược lại, Salesforce Administrator tập trung vào quản lý người dùng, cấu hình hệ thống, và đảm bảo các quy trình nghiệp vụ được thực thi một cách hiệu quả trong môi trường Salesforce.
Kết bài
Công nghệ điện toán đám mây đã và đang cho thấy nhiều ưu điểm cùng sự phát triển mạnh mẽ trong những năm gần đây, và Salesforce là một minh chứng thành công cho sự phát triển đó. Salesforce Developer hứa hẹn sẽ tiếp tục là một nghề hot trong nhóm ngành CNTT trong thời gian sắp tới. Hy vọng bài viết hữu ích dành cho bạn và hẹn gặp lại trong các bài viết tiếp theo của mình.
IT Helpdesk và IT Support đều là những vị trí trong tổ chức có công việc hỗ trợ các bộ phận khác hay khách hàng những vấn đề liên quan đến kỹ thuật và công nghệ. Sự tương đồng giữa nhiệm vụ, trách nhiệm của 2 vị trí này khiến nhiều bạn chưa nắm rõ được vai trò và kỹ năng cần có của từng vị trí. Bài viết hôm nay chúng ta cùng nhau phân biệt IT Helpdesk và IT Support để hiểu rõ hơn nhé.
IT Helpdesk là gì?
IT Helpdesk là một vị trí thuộc bộ phận IT của tổ chức, là cầu nối giữa người sử dụng đến bộ máy CNTT, có nhiệm vụ giải quyết các vấn đề nội bộ trong doanh nghiệp như hỏng hóc, sửa chữa các thiết bị IT, kết nối mạng, vấn đề gặp phải với dữ liệu,… Cụ thể thì công việc chính thường ngày của một IT Helpdesk là hỗ trợ người sử dụng máy tính (bao gồm nhân viên trong tổ chức hoặc khách hàng sử dụng) cài đặt, xử lý lỗi liên quan đến phần mềm, phần cứng, đường truyền hoặc các thiết bị hỗ trợ khác như máy in, máy fax,…
Nhiệm vụ của một IT Helpdesk bao gồm:
Xác định và giải quyết các vấn đề liên quan đến phần cứng, phần mềm, kết nối mạng hoặc các ứng dụng khác cho người dùng
Hỗ trợ và đảm bảo vận hành phần mềm và phần mềm cho doanh nghiệp
Đảm nhận quản lý tên miền, hệ thống server hoặc những tác vụ kỹ thuật khác của doanh nghiệp
Theo dõi, ghi log, cập nhật tình hình và báo cáo các vấn đề cần sửa chữa, khắc phục
Phụ trách bảo hành, sửa chữa máy móc và các thiết bị phần cứng liên quan
IT Support là gì?
IT Support cũng thuộc bộ phận IT và có vai trò rộng hơn so với IT Helpdesk. Nhiệm vụ của IT Support là tư vấn, hỗ trợ kỹ thuật cũng như bảo trì phần cứng, phần mềm cho hệ thống doanh nghiệp và khách hàng, đối tác mà doanh nghiệp cung cấp sản phẩm.
Nhiệm vụ của một IT Support thường có thể đảm nhận cả các đầu việc của một IT Helpdesk, tổng quan được chia thành 3 nhiệm vụ chính bao gồm:
Tư vấn, thiết kế và quản lý hệ thống server, mạng nội bộ, mạng Internet cho công ty, doanh nghiệp hoặc các khách hàng, đối tác có sử dụng dịch vụ, sản phẩm
Xử lý chung các sự cố liên quan đến máy tính bao gồm cả phần cứng, phần mềm, hay các thiết bị mạng, đường truyền,…
Hỗ trợ thu thập thông tin, phản hồi từ khách hàng về sản phẩm, dịch vụ mà doanh nghiệp cung cấp; chăm sóc khách hàng giải quyết các vấn đề một cách nhanh nhất
Như đã đề cập ở trên, cả IT Helpdesk và IT Support đều thuộc bộ phận IT của tổ chức. Tùy thuộc vào quy mô của tổ chức, doanh nghiệp mà có thể chia ra vai trò cụ thể của từng vị trí; hoặc cũng có thể đóng vai trò và đảm nhận công việc tương tự nhau. Nhìn chung thì vai trò của IT Support là rộng hơn, đòi hỏi nhiều kỹ năng liên quan đến tư vấn, thiết kế hệ thống và quản lý chung để vận hành cả cơ sở hạ tầng IT.
Chúng ta cùng so sánh một số yếu tố cụ thể hơn giữa 2 vị trí này nhé:
Về mức độ hỗ trợ: IT Helpdesk tập trung hỗ trợ các vấn đề cụ thể, thông thường sẽ xử lý, giải quyết khi các vấn đề đã xảy ra ví dụ như hỏng hóc thiết bị, phần cứng hay lỗi phần mềm cần cài đặt lại. IT Support sẽ tập trung chủ yếu ở quy mô tổ chức, đưa ra nhiều biện pháp nhằm cải thiện hệ thống, có phương án dự án nhằm ngăn chặn hay hạn chế sự cố xảy ra.
Về quy mô tổ chức: ở các doanh nghiệp lớn, bộ phận IT Support sẽ được thành lập và có nhiệm vụ duy trì hoạt động của toàn bộ hệ thống; lúc này nhiệm vụ của IT Support là bao gồm việc đảm bảo an ninh thông tin, quản lý dữ liệu đồng thời đảm bảo hiệu suất và khả năng mở rộng trong tương lai. Trong khi đó IT Helpdesk có thể được chia nhỏ về sát các phòng ban để nhanh chóng hỗ trợ trực tiếp người dùng một cách nhanh nhất.
Về kỹ năng chuyên môn: IT Support yêu cầu có kinh nghiệm nhất định về hệ thống cũng như có khả năng quản trị server cùng kiến thức về bảo mật, an ninh thông tin. IT Helpdesk tập trung vào kỹ năng xử lý sự cố để chẩn đoán, hỗ trợ người dùng một cách nhanh nhất.
Có thể xem IT Helpdesk cũng là một vị trí trong bộ phận IT Support, vì vậy công việc nào cũng đều phục vụ cho các hoạt động vận hành hệ thống CNTT của một doanh nghiệp và tổ chức.
Việc trở thành một IT Support đòi hỏi các bạn có quá trình học hỏi chuyên môn sâu hơn về các kiến thức liên quan đến hệ thống; thông thường một IT Support ở level senior sẽ tập trung vào một lĩnh vực chuyên môn cụ thể, có hiểu biết và kinh nghiệm về một ngành nghề, loại hình dịch vụ hay hệ thống nhất định. Vì vậy quá trình trở thành một chuyên gia trong lĩnh vực IT Support không hề dễ dàng. Ngược lại, đặc thù của một IT Helpdesk đòi hỏi bạn cần tương tác nhiều hơn với người dùng, có sự linh hoạt trong các xử lý sự cố, đưa ra phương án giải quyết tối ưu để phản hồi lại người dùng.
Tùy thuộc vào quy mô tổ chức, loại hình dịch vụ/ sản phẩm mà doanh nghiệp cung cấp thì quy mô của bộ phận IT sẽ khác nhau. Có nhiều tổ chức sẽ xem 2 vị trí IT Helpdesk và IT Support là một vì nhiệm vụ tương đồng. Vì vậy việc lựa chọn vị trí nào trong 2 vị trí trên hoàn toàn do mong muốn cũng như yêu cầu công việc của bạn. Nếu đang bắt đầu học và tìm hiểu để có được công việc ở 1 trong 2 vị trí trên thì bạn hoàn toàn có thể tự tin apply vào cả hai mà không có quá nhiều sự khác biệt.
Kết bài
Qua bài viết này hy vọng các bạn đã có cái nhìn rõ hơn và có thể phân biệt được giữa IT Helpdesk và IT Support. Vị trí hay công việc nào cũng đều đòi hỏi sự học hỏi, yêu thích nghề nghiệp và mong muốn xây dựng, đóng góp công sức vào các hoạt động của tổ chức, doanh nghiệp. Hy vọng bài viết hữu ích dành cho bạn và hẹn gặp lại trong các bài viết tiếp theo của mình.
Theo thống kê từ hãng nghiên cứu thị trường Statista năm 2023, Oracle Database là hệ quản trị cơ sở dữ liệu phổ biến nhất thế giới hiện nay. Oracle cũng là tên của tập đoàn công nghệ sở hữu sản phẩm này cũng nhiều công nghệ nổi bật khác được sử dụng rộng rãi trên toàn cầu. Bài viết hôm nay chúng ta cùng nhau trả lời cho câu hỏi Oracle là gì và tìm hiểu về hệ thống quản trị CSDL này nhé.
Oracle là gì?
Oracle là một thương hiệu nổi tiếng toàn cầu được biết đến là một trong những nhà cung cấp công nghệ lớn nhất trên thị trường hiện nay. Thành lập từ năm 1977, Oracle đã xây dựng và phát triển nhiều công nghệ liên quan đến thiết kế, phát triển cơ sở dữ liệu cùng nhiều phần mềm sử dụng trong quản trị doanh nghiệp.
Nhắc đến Oracle, chúng ta thường nghĩ đến đầu tiên và cũng là sản phẩm chủ đạo của tập đoàn này chính là hệ thống quản trị cơ sở dữ liệu được sử dụng rộng rãi trong các ứng dụng doanh nghiệp, hệ thống ngân hàng hay thương mại điện tử. Ngoài ra, tập đoàn này cũng phát triển và xây dựng các hệ thống khác như phần mềm cấp trung, phần mềm hoạch định nguồn lực doanh nghiệp (ERP), quản lý nguồn nhân lực (HCM), quản lý quan hệ khách hàng (CRM) hay quản lý chuỗi cung ứng (SCM). Năm 2019, Oracle được xếp hạng là công ty phần mềm ở vị trí thứ hai toàn cầu theo doanh thu và vốn hóa thị trường.
Hệ quản trị CSDL Oracle
Oracle là một hệ thống quản trị CSDL (RDBMS – Relational Database Management System) lớn nhất hiện nay, được sử dụng phổ biến trong nhiều hệ thống lớn nhờ vào sự ổn định, hiệu suất cao, tính bảo mật vượt trội và khả năng mở rộng dễ dàng.
Kiến trúc của Oracle Database
Kiến trúc của CSDL Oracle bao gồm 3 lớp: File Systems – Lớp dữ liệu, Background Processes – Lớp xử lý và Memory – Lớp bộ nhớ.
1. Lớp dữ liệu – File systems
Bao gồm các file dữ liệu được tổ chức lưu trữ trên các ổ đĩa của server. Khi có yêu cầu truy xuất dữ liệu được gửi đến, dữ liệu sẽ được đọc từ ổ đĩa vào bên trong bộ nhớ của máy chủ nhằm nâng cao tốc độ đọc ghi. Một CSDL Oracle lưu trữ nhiều loại file khác nhau bao gồm:
Init file: thông tin cơ sở liên quan
Control file: thông tin cấu hình
Database file: dữ liệu
Redo Log file: ghi nhật ký chỉnh sửa
2. Lớp xử lý – Background processes
Chứa các công cụ đảm bảo sự ăn khớp của mối quan hệ giữa phần CSDL vật lý (lớp dữ liệu) và phần hiển thị trong bộ nhớ (lớp bộ nhớ). 2 công cụ chính được sử dụng ở lớp này bao gồm:
Database writer: xử lý ghi vào CSDL
Log writer: xử lý ghi nhật ký
3. Lớp bộ nhớ – Memory
Lớp bộ nhớ được lưu trên vùng đệm bộ nhớ máy tính nhằm cải thiện tốc độ xử lý trong CSDL Oracle, được phân chia thành 2 khu vực:
SGA – System Global Area: khu vực bộ nhớ chia sẻ
PGA – Program Global Area: khu vực bộ nhớ riêng tư
Oracle Database có 4 phiên bản chính phục vụ cho các bài toán và đối tượng khách hàng khác nhau, bao gồm:
Oracle Database Enterprise Edition: cung cấp phần mềm chạy các ứng dụng xử lý giao dịch, lưu trữ dữ liệu, phân tích hoạt động, … thích hợp cho các tổ chức, doanh nghiệp lớn
Oracle Database Standard Edition: cung cấp bộ tính năng hạn chế hơn phù hợp cho các nhóm và phòng ban
Oracle Database Personal Edition: phiên bản sử dụng dành cho cá nhân
Oracle Database Express Edition: phiên bản miễn phí thiết kế dành cho môi trường phát triển, thử nghiệm hoặc triển khai ở quy mô nhỏ
Ưu điểm của Oracle Database
CSDL Oracle cung cấp nhiều tính năng hữu ích cho người dùng để quản lý dữ liệu với tính khả dụng cao, ưu tiên bảo mật hàng đầu cùng khả năng mở rộng một cách nhất quán mà vẫn giữ được hiệu suất ứng dụng. Ưu điểm có thể kể đến của Oracle Database gồm:
Cung cấp CSDL với hiệu suất cao nhờ có phương pháp luận và nguyên tắc riêng
Hỗ trợ quản lý đa người dùng trên cùng một CSDL/ Server duy nhất
Cung cấp nhiều phiên bản lựa chọn phù hợp với nhiều đối tượng người dùng trả phí/ có phí hay kèm theo các tính năng cao cấp
Xử lý linh hoạt với cân bằng tải, khả năng dự phòng dữ liệu tốt và mở rộng CSDL dễ dàng. Oracle cũng cung cấp các tính năng backup và phục hồi online cho người dùng dễ dàng thao tác
Hỗ trợ PL/SQL cho các phần mở rộng lập trình
Định hướng phát triển của Oracle
Những năm trở lại đây, Oracle đang dần chuyển dịch cơ cấu để hướng tới trở thành một nhà cung cấp các dịch vụ điện toán đám mây. Trước đó trong quá trình phát triển hơn 30 năm, tập đoàn Oracle đã bổ sung nhiều công nghệ CSDL khác từ việc mua lại như:
Năm 2005: Oracle mua lại CSDL bộ nhớ TimesTen trở thành sản phẩm Oracle TimesTen In-Memory Database
Năm 2007: Oracle mua lại Essbase từ Hyperion Solutions – trở thành một hệ quản trị CSDL đa chiều (MDBMS – Multidimensional Database Management System)
Năm 2010: Oracle mua lại Sun Microsystems với CSDL MySQL – trở thành hệ quản trị CSDL mã nguồn mở phổ biến nhất hiện nay
Năm 2011: Oracle cho ra mắt Oracle NoSQL Database – một giải pháp lưu trữ dữ liệu dạng key-value
Với việc được trang bị đầy đủ các công nghệ liên quan đến CSDL, cùng với việc đẩy mạnh tập trung vào phần cứng trong những năm gần đây, Oracle Database có thể dễ dàng đáp ứng được hầu hết các nhu cầu của các dự án công nghệ hay quản lý thông tin theo quy mô từ nhỏ đến lớn.
Các bạn cũng có thể tìm hiểu thêm về các sản phẩm công nghệ khác từ tập đoàn Oracle phục vụ cho đa dạng các lĩnh vực khác nhau từ quản lý tài chính, nhân sự, chuỗi cung ứng hay hoạch định doanh nghiệp:
Oracle E-Business Suite: hệ thống quản trị doanh nghiệp
Oracle Fusion Applications: bộ ứng dụng điện toán đám mây quản lý doanh nghiệp
Oracle Enterprise Manager: ứng dụng Web quản lý tập trung các hệ thống CNTT của tổ chức, doanh nghiệp
Oracle Big Data Discovery: ứng dụng trực quan hóa Big Data (dữ liệu lớn) phục vụ phân tích dữ liệu cho doanh nghiệp
Kết bài
Hy vọng với những chia sẻ trong bài viết trên đã giúp các bạn giải đáp được câu hỏi Oracle là gì cũng như có được những kiến thức về hệ thống quản trị CSDL Oracle. Với sự đầu tư mạnh mẽ vào công nghệ trong thời gian gần đây, chắc chắn Oracle vẫn sẽ tiếp tục duy trì là một hệ quản trị CSDL tối ưu, phù hợp với nhiều loại dự án hay quy mô doanh nghiệp khác nhau trong tương lai sắp tới. Cảm ơn các bạn đã đọc bài và hẹn gặp lại trong các bài viết tiếp theo của mình.
Data hay Dữ liệu là một thuật ngữ quen thuộc nhưng mang ý nghĩa vô cùng quan trọng. Trong bài viết này, cùng TopDev khám phá khái niệm cơ bản về data và tầm quan trọng của nó trong cuộc sống hàng ngày.
Data là gì?
Data (hay Dữ liệu), có thể được định nghĩa đơn giản là các thông tin, số liệu hoặc sự kiện được ghi lại hoặc thu thập. Từ những dữ liệu thô như tên, địa chỉ, tuổi tác, đến những dữ liệu phức tạp hơn như hành vi người dùng trên các nền tảng trực tuyến, lượng người xem một video, hay thậm chí là các mẫu âm thanh và hình ảnh – tất cả đều có thể được coi là dữ liệu.
Sự ra đời của Big Data
Trong kỷ nguyên số hiện nay, với sự phát triển không ngừng của công nghệ, chúng ta đang tạo ra một khối lượng khổng lồ dữ liệu mỗi ngày. Sự ra đời của Big Data được thúc đẩy bởi nhiều yếu tố khác nhau, bao gồm:
Sự phổ biến của các thiết bị di động và Internet of Things (IoT):
Với sự gia tăng số lượng thiết bị di động và các thiết bị IoT kết nối internet, lượng dữ liệu được tạo ra từ các thiết bị này ngày càng lớn.
Sự phát triển của các nền tảng trực tuyến và mạng xã hội:
Các nền tảng trực tuyến như mạng xã hội, thương mại điện tử, và các dịch vụ web khác đang tạo ra một lượng lớn dữ liệu về hành vi người dùng, giao dịch, và dữ liệu khác.
Tăng cường sử dụng cảm biến và thiết bị thu thập dữ liệu:
Các cảm biến và thiết bị thu thập dữ liệu đang được sử dụng ngày càng nhiều trong các lĩnh vực khác nhau như y tế, sản xuất, và logistics, tạo ra một lượng lớn dữ liệu về các quá trình và sự kiện.
Sự phát triển của công nghệ lưu trữ và xử lý dữ liệu:
Các công nghệ lưu trữ và xử lý dữ liệu mới như đám mây, big data analytics, và trí tuệ nhân tạo đã giúp chúng ta có khả năng quản lý và khai thác những khối lượng dữ liệu khổng lồ này.
Các loại Data cơ bản
Mặc dù Data có thể xuất hiện dưới nhiều hình thức khác nhau, nhưng chúng có thể được chia thành ba loại cơ bản sau:
Data cấu trúc (Structured Data):
Đây là dữ liệu được tổ chức và lưu trữ trong các cơ sở dữ liệu theo một cấu trúc xác định, thường là dạng hàng và cột giống như một bảng tính. Các ví dụ về Data cấu trúc bao gồm:
Bảng dữ liệu trong Excel hoặc các bảng trong cơ sở dữ liệu quan hệ (RDBMS)
Dữ liệu giao dịch trong các hệ thống ERP hoặc CRM
Dữ liệu mô tả sản phẩm trong một cơ sở dữ liệu của một trang web thương mại điện tử
Data bán cấu trúc (Semi-structured Data): Đây là dữ liệu không hoàn toàn cấu trúc theo một định dạng chuẩn nhưng vẫn có một số định dạng nhất định. Data bán cấu trúc thường được lưu trữ dưới dạng tệp văn bản có một số thẻ hoặc trường được xác định. Các ví dụ về Data bán cấu trúc bao gồm:
Tệp XML và JSON
Dữ liệu từ các nguồn web (HTML, RSS feeds)
Dữ liệu từ email, tin nhắn văn bản hoặc tài liệu Word, PDF
Data không cấu trúc (Unstructured Data): Đây là dữ liệu thô chưa được tổ chức theo bất kỳ cấu trúc nào và không tuân theo bất kỳ mô hình dữ liệu cụ thể nào. Data không cấu trúc thường có định dạng nhị phân và bao gồm:
Dữ liệu đa phương tiện như hình ảnh, video, âm thanh
Dữ liệu văn bản tự do như email, tin tức, bài viết blog
Việc khai thác và sử dụng data hiệu quả có thể mang lại lợi thế lớn cho các doanh nghiệp trong một thị trường ngày càng cạnh tranh. Dưới đây là một số lý do chính minh họa tầm quan trọng của data đối với doanh nghiệp:
Hiểu khách hàng sâu sắc hơn:
Data giúp doanh nghiệp hiểu rõ hơn về hành vi, sở thích và nhu cầu của khách hàng, từ đó giúp thiết kế và cung cấp các sản phẩm và dịch vụ phù hợp hơn.
Ra quyết định kinh doanh dựa trên dữ liệu:
Thông qua phân tích dữ liệu, doanh nghiệp có thể đưa ra những quyết định kinh doanh sáng suốt dựa trên bằng chứng và thông tin chính xác, giúp giảm thiểu rủi ro và tối ưu hóa hiệu quả hoạt động.
Dự đoán nhu cầu và xu hướng thị trường:
Bằng cách phân tích dữ liệu về nhu cầu khách hàng, doanh số bán hàng và các yếu tố khác, doanh nghiệp có thể dự đoán chính xác xu hướng thị trường và điều chỉnh chiến lược kinh doanh phù hợp.
Cải thiện hiệu quả hoạt động:
Data giúp doanh nghiệp nhận diện và loại bỏ các quy trình không hiệu quả, tối ưu hóa hoạt động và cải thiện năng suất lao động.
Phát triển sản phẩm và dịch vụ mới:
Thông qua phân tích dữ liệu, doanh nghiệp có thể nhận ra những nhu cầu chưa được đáp ứng và phát triển các sản phẩm hoặc dịch vụ mới đáp ứng nhu cầu đó.
Tăng cường quan hệ khách hàng:
Bằng cách sử dụng dữ liệu để hiểu rõ hơn về khách hàng, doanh nghiệp có thể cung cấp trải nghiệm khách hàng tốt hơn, từ đó xây dựng và duy trì mối quan hệ lâu dài với khách hàng.
Cạnh tranh hiệu quả hơn:
Khai thác data một cách hiệu quả giúp doanh nghiệp có được lợi thế cạnh tranh trên thị trường, đáp ứng nhanh hơn và chính xác hơn các nhu cầu của khách hàng.
Data có thể được tạo ra từ nhiều nguồn khác nhau như các thiết bị kỹ thuật số, cảm biến, giao dịch trực tuyến, mạng xã hội, thiết bị di động, và nhiều nguồn khác.
Câu 2. Làm thế nào để khai thác giá trị từ Data?
Để khai thác giá trị từ dữ liệu, chúng ta cần áp dụng các kỹ thuật phân tích dữ liệu (Data Analytics) và trí tuệ nhân tạo (AI) để xử lý, phân tích và rút ra những hiểu biết sâu sắc từ dữ liệu.
Câu 3. Ai là người sử dụng Data?
Dữ liệu được sử dụng bởi nhiều đối tượng khác nhau như doanh nghiệp, chính phủ, tổ chức nghiên cứu, các nhà khoa học, và cả người tiêu dùng.
Kết luận
Data là nguồn sống của kỷ nguyên số hiện đại. Nó là tài nguyên quý giá giúp các doanh nghiệp và tổ chức đưa ra những quyết định đúng đắn, cải thiện sản phẩm và dịch vụ, và giành được lợi thế cạnh tranh trên thị trường. TopDev hy vọng rằng bài viết này đã cung cấp cho bạn nhiều thông tin hữu ích xoay quanh thuật ngữ này. Hãy tiếp tục theo dõi Blog TopDev để cập nhật thêm nhiều kiến thức hữu ích về lập trình và các tips tuyển dụng hiệu quả.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
JavaScript (JS) đã trở thành một trong những ngôn ngữ lập trình quan trọng nhất và phổ biến nhất trên thế giới. Khi bạn bắt đầu làm việc với JS, có một số mẹo và kỹ thuật quan trọng có thể giúp bạn tối ưu hiệu suất và hiểu rõ hơn về ngôn ngữ này. Trong bài viết này, chúng ta sẽ khám phá những mẹo quan trọng khi làm việc với JavaScript.
1. Sử dụng ‘const’ và ‘let’ thay vì ‘var’
Một cải tiến quan trọng trong ECMAScript 6 là sự giới thiệu của const và let. Thay vì sử dụng var, const sẽ giữ giá trị không thay đổi, trong khi let cho phép thay đổi giá trị của biến. Điều này giúp kiểm soát phạm vi biến và giảm khả năng xảy ra lỗi do sự thay đổi bất ngờ của giá trị biến.
// Sử dụng const cho giá trị không thay đổiconst PI = 3.14;
// Sử dụng let khi cần thay đổi giá trịlet counter = 0;
counter += 1;
2. Hiểu rõ về scope và closures
Phạm vi (scope) và closures là hai khái niệm quan trọng trong JavaScript. Scope xác định đâu là nơi biến có thể truy cập được, trong khi closures là khả năng truy cập biến từ các hàm bên ngoài. Hiểu rõ về chúng giúp tránh được nhiều lỗi phổ biến và tối ưu hóa mã nguồn.
// ScopefunctionexampleScope() {
if (true) {
var insideIf = 'I am accessible inside the function';
}
console.log(insideIf); // accessible
}
// ClosuresfunctionouterFunction() {
let outerVariable = 'I am outer';
functioninnerFunction() {
console.log(outerVariable);
}
return innerFunction;
}
const closureExample = outerFunction();
closureExample(); // I am outer
3. Tận dụng arrow functions
Arrow functions giúp làm ngắn gọn mã nguồn và giữ nguyên giá trị của this. Điều này rất hữu ích trong các tình huống như xử lý sự kiện và callbacks. Sử dụng chúng để làm mã nguồn của bạn trở nên sáng tạo và dễ đọc hơn.
// Arrow functionconst add = (a, b) => a + b;
// Sử dụng arrow function trong array methodconst numbers = [1, 2, 3, 4];
const squaredNumbers = numbers.map((num) => num * num);
4. Xử lý mảng và đối tượng một cách thông minh
JavaScript cung cấp nhiều phương thức mạnh mẽ như map(), filter(), và reduce() để thao tác mảng. Sử dụng chúng để giảm thiểu việc sử dụng vòng lặp và làm cho mã nguồn của bạn trở nên rõ ràng hơn. Đối với đối tượng, hãy sử dụng destructuring để truy cập dữ liệu dễ dàng.
// Sử dụng array methodconst numbers = [1, 2, 3, 4];
const sum = numbers.reduce((acc, num) => acc + num, 0);
// Sử dụng destructuring cho đối tượngconst person = { name: 'John', age: 30 };
const { name, age } = person;
5. Async/Await thay vì Callbacks
Xử lý bất đồng bộ trở nên dễ đọc hơn với sự giới thiệu của async/await. Thay vì sử dụng callbacks, bạn có thể sử dụng cú pháp tuần tự, làm cho mã nguồn trở nên sạch sẽ và dễ theo dõi.
// Sử dụng async/awaitasyncfunctionfetchData() {
try {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
console.log(data);
} catch (error) {
console.error('Error fetching data:', error);
}
}
Hiệu suất của ứng dụng JavaScript là yếu tố quan trọng. Tránh sử dụng vòng lặp vô hạn và sử dụng requestAnimationFrame để thực hiện các tác vụ liên quan đến đồ họa mà không làm chậm trình duyệt.
// Sử dụng requestAnimationFramefunctionanimate() {
// Your animation logic here
requestAnimationFrame(animate);
}
7. Quản lý lỗi một cách hiệu quả
Sử dụng try/catch để bắt lỗi và xử lý chúng một cách chính xác. Điều này giúp tránh tình trạng crash và đảm bảo ứng dụng của bạn chạy mượt mà hơn.
// Sử dụng try/catchfunctiondivide(a, b) {
try {
if (b === 0) {
thrownewError('Cannot divide by zero');
}
return a / b;
} catch (error) {
console.error('Error:', error.message);
}
}
8. Sử dụng thư viện một cách thông minh
Có nhiều thư viện như lodash, Underscore giúp giảm bớt việc xây dựng hàm và tăng tốc quá trình code. Hãy sử dụng chúng một cách hợp lý để không làm nặng mã nguồn của bạn không cần thiết.
// Sử dụng lodash để thao tác mảngconst numbers = [1, 2, 3, 4];
const sum = _.sum(numbers);
Việc kiểm thử là quan trọng để đảm bảo tính ổn định của mã nguồn. Sử dụng các framework kiểm thử như Jest hoặc Mocha để giúp bạn đảm bảo rằng ứng dụng của bạn hoạt động đúng như mong đợi.
// Sử dụng Jest framework cho kiểm thử
test('adds 1 + 2 to equal 3', () => {
expect(add(1, 2)).toBe(3);
});
10. Mã nguồn đơn giản là mã nguồn hiệu quả
Tránh sự phức tạp không cần thiết trong mã nguồn của bạn. Mã nguồn đơn giản là mã nguồn dễ đọc và bảo trì. Luôn giữ tư duy sáng tạo và duy trì mã nguồn của mình với sự rõ ràng và hiệu quả.
// Mã nguồn đơn giản và dễ đọcfunctioncalculateSum(a, b) {
return a + b;
}
Với sự phát triển của ứng dụng web, việc làm việc hiệu quả với JavaScript trở nên quan trọng hơn bao giờ hết. Bằng cách áp dụng những mẹo hay, bạn sẽ có thể tận dụng sức mạnh của JavaScript một cách hiệu quả và tối ưu.
Cấu trúc dữ liệu được sử dụng trong các chương trình để dễ dàng hơn trong việc định vị thông tin và lấy thông tin. Cấu trúc dữ liệu là cách các ngôn ngữ lập trình thể hiện các giá trị cơ bản, chúng chứa các kiểu dữ liệu cơ bản như số, chuỗi, boolean…, nó đưa ra cách thức lưu trữ nhiều giá trị trong một biến số. Cấu trúc dữ liệu cũng được sử dụng để phân nhóm và tổ chức cho các cấu trúc khác.
Để làm rõ hơn sự cần thiết các cấu trúc dữ liệu cơ bản, chúng ta có một ví dụ như sau:
Một chương trình rất đơn giản với 3 biến chứa tên 3 người bạn, chúng ta in ra tên 3 người này. Tưởng tượng khi số lượng bạn gia tăng, bạn phải thêm vào hàng trăm biến và hàng trăm câu lệnh in ra màn hình. Quả là một thảm họa!
List (danh sách) là một kiểu dữ liệu cơ bản trong Python, cho phép bạn lưu trữ và quản lý một tập hợp các phần tử trong một thứ tự nhất định. Trong bài viết này, chúng ta sẽ cùng tìm hiểu chi tiết về cấu trúc dữ liệu List trong Python, cách nó hoạt động, và cách sử dụng nó một cách hiệu quả.
Cấu trúc dữ liệu List trong Python là gì?
List trong Python là một cấu trúc dữ liệu dùng để lưu trữ và quản lý một tập hợp các phần tử theo một thứ tự nhất định. List có thể chứa nhiều giá trị khác nhau, bao gồm cả số nguyên, chuỗi, và thậm chí là các List khác.
Điểm nổi bật của List là nó có khả năng thay đổi (mutable), nghĩa là bạn có thể thêm, sửa, hoặc xóa các phần tử sau khi List đã được tạo.
List có thể được coi là một cấu trúc dữ liệu dạng mảng tuần tự (tương tụ như vector trong C++ và ArrayList trong Java).
Một List được biểu diễn bằng cặp ngoặc vuông [] và các phần tử trong List được ngăn cách nhau bởi dấu phẩy ,. Tên của list được gán bằng cách sử dụng dấu =.
friends =["Rolf","Bob","Anne"]
ages =[35,28,37]
Để hiển thị nội dung List chúng ta có thể dùng hàm print(). List này có thể rất dài, bạn thấy đấy, chương trình ở phần trên với 3 biến có thể viết ngắn gọn hơn.
Chú ý, một danh sách có thể chứa nhiều loại dữ liệu khác nhau nếu bạn thấy cần thiết, tuy nhiên khuyến cáo nên dừng một loại dữ liệu thống nhất cho các phần tử trong danh sách.
friends =["Rolf",2,"Anne"]
Định nghĩa danh sách này có cả số 2 bên trong danh sách friends, nó rất tối nghĩa, không có người bạn nào tên là 2 cả.
Các phần tử trong List được lưu trữ theo thứ tự mà chúng được thêm vào và sẽ không thay đổi. Nếu thêm phần tử mới vào list thì phần tử đó sẽ xuất hiện ở cuối danh sách. Bạn có thể truy cập các phần tử bằng cách sử dụng chỉ số (index) của chúng, với chỉ số đầu tiên là 0.
List được sắp xếp nhất định, các phần tử sẽ có một thứ tự xác định và sẽ không thay đổi. Nếu thêm phần tử mới vào list thì phần tử đó sẽ xuất hiện ở cuối danh sách.
Không giống như chuỗi (string) trong Python, List có thể thay đổi, nghĩa là bạn có thể sửa đổi, thêm, hoặc xóa các phần tử trong List sau khi nó đã được tạo.
Chứa các phần tử có kiểu dữ liệu khác nhau: Một List có thể chứa các phần tử với các kiểu dữ liệu khác nhau, chẳng hạn như số nguyên, chuỗi, và thậm chí là các List khác.
List cho phép các phần tử trùng lặp, có nghĩa là một giá trị có thể xuất hiện nhiều lần trong list.
Các thao tác với List trong Python
Khởi tạo List
Trong Python, việc khởi tạo một List rất đơn giản và có thể được thực hiện bằng cách sử dụng cặp ngoặc vuông []. Bạn có thể tạo một List chứa các phần tử với nhiều kiểu dữ liệu khác nhau, chẳng hạn như số nguyên, chuỗi, số thực, hoặc thậm chí là một List khác.
# Khởi tạo một List rỗng
empty_list = []
# Khởi tạo List với các phần tử
numbers = [1, 2, 3, 4, 5]
fruits = ["apple", "banana", "cherry"]
mixed = [1, "hello", 3.14, True]
Xác định độ dài của List
Bạn có thể dễ dàng lấy độ dài (số phần tử) của một List bằng cách sử dụng hàm tích hợp len() trong Python. Đây là một thao tác cơ bản và rất hữu ích khi bạn cần biết số lượng phần tử trong List.
Python cung cấp phương thức sort() và hàm sorted() để sắp xếp các phần tử trong List. Phương thức sort() sẽ sắp xếp List tại chỗ (thay đổi List ban đầu), trong khi sorted() sẽ trả về một List mới đã được sắp xếp mà không thay đổi List ban đầu.
Trong Python, bạn có thể trích lọc một phần của List bằng cách sử dụng cú pháp slicing (cắt lát). Cú pháp này sử dụng dấu hai chấm : để xác định phạm vi chỉ số mà bạn muốn trích lọc.
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Trích lọc từ phần tử thứ 2 đến thứ 5 (không bao gồm phần tử thứ 5)
sublist = numbers[2:5]
print(sublist) # Output: [2, 3, 4]# Trích lọc từ phần tử thứ 3 đến hết List
sublist = numbers[3:]
print(sublist) # Output: [3, 4, 5, 6, 7, 8, 9]
Truy xuất phần tử trong List
list_name[element_position]
Bạn có thể truy cập các phần tử trong List bằng cách sử dụng index của chúng. Chỉ số trong List bắt đầu từ 0 cho phần tử đầu tiên.
fruits = ["apple", "banana", "cherry"]
print(fruits[0]) # Output: appleprint(fruits[1]) # Output: bananaprint(fruits[2]) # Output: cherry# Truy cập phần tử từ cuối List bằng chỉ số âmprint(fruits[-1]) # Output: cherryprint(fruits[-2]) # Output: banana
Thay đổi giá trị phần tử trong List
Vì List trong Python là có thể thay đổi (mutable), bạn có thể thay đổi giá trị của bất kỳ phần tử nào bằng cách truy cập vào phần tử đó thông qua chỉ số và gán cho nó một giá trị mới.
fruits = ["apple", "banana", "cherry"]
# Thay đổi giá trị của phần tử thứ hai
fruits[1] = "mango"print(fruits) # Output: ["apple", "mango", "cherry"]
Chú ý, nếu bạn truy xuất đến một phần tử không có trong danh sách, một lỗi sẽ xuất hiện có dạng “index out of range”. Ví dụ như các phần tử trong danh sách fruits có vị trí tương ứng là 0, 1, 2. Nếu bạn truy xuất đến phần tử có vị trí lớn hơn 2 sẽ gặp lỗi “index out of range”.
Thêm phần tử vào List
Có nhiều cách để thêm phần tử vào List trong Python, chẳng hạn như sử dụng các phương thức append(), insert(), và extend().
Dưới đây là một số hàm và phương thức phổ biến của List trong Python, giúp bạn thao tác với danh sách một cách hiệu quả:
Hàm thao tác với list trong Python
len(): Trả về số lượng phần tử trong List.
min(): Trả về phần tử nhỏ nhất trong List.
max(): Trả về phần tử lớn nhất trong List.
sum(): Tính tổng các phần tử trong List (dành cho List chứa các số).
sorted(): Trả về một List mới đã được sắp xếp mà không thay đổi List ban đầu.
Phương thức thao tác trên List
append(): Thêm một phần tử vào cuối List.
extend(): Thêm nhiều phần tử từ một List khác vào cuối List hiện tại.
insert(): Thêm một phần tử vào vị trí cụ thể trong List.
remove(): Xóa phần tử đầu tiên khớp với giá trị được chỉ định.
pop(): Xóa và trả về phần tử tại một vị trí xác định (hoặc phần tử cuối).
clear(): Xóa toàn bộ phần tử trong List.
index(): Trả về chỉ số của phần tử đầu tiên khớp với giá trị được chỉ định.
count(): Đếm số lần một phần tử xuất hiện trong List.
reverse(): Đảo ngược thứ tự các phần tử trong List.
copy(): Trả về một bản sao của List.
sort(): Sắp xếp các phần tử trong List tại chỗ.
Các hàm toán học và logic với List
any(): Trả về True nếu có bất kỳ phần tử nào trong List là True.
all(): Trả về True nếu tất cả các phần tử trong List đều là True.
Qua bài viết này, TopDev đã cung cấp khái niệm List trong Python và các tính chất cũng như các thao tác sử dụng. List cung cấp nhiều tính năng mạnh mẽ để lưu trữ, quản lý và thao tác với dữ liệu. Từ việc khởi tạo, truy cập, sắp xếp, đến các thao tác phức tạp như thêm, xóa, trích lọc và tìm kiếm, Python cung cấp rất nhiều công cụ hữu ích giúp bạn làm việc với List một cách hiệu quả.
Xem thêm một số kiểu dữ liệu khác như Tuple và Set trong Python:
Javascript là một thành phần không thể thiếu đối với frontend developers. Tuy nhiên, ngay từ lúc ra đời, nó đã tồn tại khá nhiều vấn đề cần khắc phục. Đó là lý do tại sao từ 2015 (ES6) tới 2021 (ES12) ra đời nhằm giúp Javascript trở nên tốt hơn.
ECMAScript
Là một bản đặc tả kỹ thuật (specification) cung cấp các quy tắc, chi tiết, hướng dẫn mà một ngôn ngữ kịch bản (scripting language) phải tuân theo cho một vài mục đích chung.
Nói thì hơi khó hiểu, nhưng bạn có thể hiểu nôm na là: một nhóm các ông lớn trong lĩnh vực phần mềm (bao gồm nhưng không giới hạn các nhà cung cấp trình duyệt web) ngồi lại với nhau, sau đó đưa ra một concept rồi mọi người làm theo.
Cụ thể thì bản đặc tả này giúp chúng ta có một cách viết chung cho Javascript, quên đi cái thời mỗi trình duyệt chạy Javascript mỗi kiểu.
ES6 (hay ES2015)
Bản ES6 này đem đến cho chúng ta rất nhiều tính năng hữu ích, một trong số quan trọng nhất có thể kể đến như: classes, arrow functions, template string, destructuring, promises…
Đây cũng là phiên bản mang đến rất nhiều sự thay đổi, ảnh hưởng tới sự phát triển rực rỡ của Javascript tới sau này.
1. Classes
Javascript vốn dĩ là một ngôn ngữ xây dựng trên concept Prototype. Tất nhiên, nó support OOP tạm bợ kèm theo cách viết phức tạp.
Bản ES6 này cuối cùng đã đưa ra định nghĩa Class (khá quen thuộc trong các ngôn ngữ lập trình khác như PHP, .NET, Java…).
classAnimal{constructor(name, color){this.name = name;this.color = color;}// Đây là một property trong prototypytoString(){
console.log(`name ${this.name}, color ${this.color}`);}}var animal =newAnimal('myDog','yellow');// khởi tạo class
animal.toString();// name myDog, color yellow
console.log(animal.hasOwnProperty('name'));//true
console.log(animal.hasOwnProperty('toString'));// false
console.log(animal.__proto__.hasOwnProperty('toString'));// trueclassCatextendsAnimal{constructor(action){// Class này kế thừa Animal, do đó cần gọi super function trong constructor.super('cat','white');this.action = action;}toString(){
console.log(`${super.toString()}, action ${this.action}`);}}var cat =newCat('catch')
cat.toString();// name cat, color white, action catch
console.log(cat instanceofCat);// true
console.log(cat instanceofAnimal);// true
2. Arrow functions
Là một cách viết function nhanh chóng mà không phải khai báo từ khóa function.
Khác với cách khai báo function thông thường, arrow function chia sẻ this context (cũng như arguments) giống phần code bên ngoài của chúng.
constadd=(a, b)=>{return a + b
}// Nếu nội dung trong function body đơn giản, bạn có thể rút gọn luôn 2 dấu ngoặc {}constadd=(a, b)=> a + b
// Sử dụng chung this context với object bên ngoài.const someone ={
_name:"John Doe",
_friends:["Jane Doe"],printFriends(){this._friends.forEach(f=>
console.log(`${this._name} knows ${f}`))}}// Sử dụng chung arguments với function bên ngoàifunctionsquare(){letdoSquare=()=>{let numbers =[]for(let number of arguments){
numbers.push(number * number)}return numbers
}returndoSquare()}
Quên đi các kiểu viết như vầy đi nha 😀
const _self =this;const that =this;
3. Template string
Template string cung cấp giải pháp tốt hơn thay thế việc cộng từng chuỗi nhỏ theo cách truyền thống.
Người ta nói nó giúp hạn chế các kiểu tấn công như injection attacks, nhưng cá nhân mình thì thấy nó giúp code dễ đọc hơn thôi :D.
// Template string cơ bản, không có tham biến`This is a pretty little template string.`// Chuỗi với nhiều dòng`In ES5 this is
not legal.`// Thêm vào các tham biếnconst name ="Bob", time ="today"`Hello ${name}, how are you ${time}?`
Ngoài ra, có một tính năng nữa khá hay với template string, đó là Tagged templates.
functiontagged(strings, person, age){const str0 = strings[0];// "That "const str1 = strings[1];// " is a "const str2 = strings[2];// "."const ageStr = age >99?"centenarian":"youngster"return`${str0}${person}${str1}${ageStr}${str2}`}const output = tagged`That ${'Mike'} is a ${age}.`// That Mike is a youngster.
React có một package styled-components khá nổi tiếng cũng sử dụng tagged templates.
4. Destructuring
Destructuring giúp chúng ta xử lý nội dung của Array và Object dễ dàng hơn.
// Gán biến theo thứ tự thành phần trong Arrayconst[a, b, c]=[1,2,3]
a ===1// true
b ===2// true
c ===3// true// Bạn cũng có thể bỏ qua vài tham số nếu không cần thiếtconst[a,, c]=[1,2,3]
c ===3// true// Thực hiện điều tương tự với Objectconst student ={
name:'John Doe',
age:31,
country:'Vietnam'}const{ name, age, country }= student
name ==='John Doe'// true
age ===31// true
country ==='Vietnam'// true
5. Default value cho tham số
Nếu bạn không nhập tham số, nó sẽ tự động lấy giá trị mặc định.
functionf(x, y =12){return x + y
}f(3)===15// true
6. Rest syntax
functionrestSample(x,...rest){// rest là một Arrayreturn x * rest.length
}restSample(3,"hello","John Doe","Vietnam")===9// trueconst student ={
name:'John Doe',
age:31,
country:'Vietnam'}const{ name,...rest }= student
name ==='John Doe'// true
rest.age ===31// true
rest.country ==='Vietnam'// true
rest.name ===undefined// true
# Cú pháp spead
functionspreadSample(x, y, z){return x + y + z;}// Do function spreadSample chỉ nhận 3 tham số// Khi bạn pass 6 tham số nó cũng chỉ thao tác trên 3 tham số đầu 1,2,3spreadSample(...[1,2,3,4,5,6])===6// true
# Sử dụng với Array
const students =['Brian','Ronnie']const people =['Ken',...students,'Tom','Justin']// ['Ken', 'Brian', 'Ronnie', 'Tom', 'Justin']
# Sử dụng với Object
const student ={
name:'John Doe',
age:31,
country:'Vietnam'}const studentB ={...student,
name:'Jane Doe'}
studentB.age ===31// true
studentB.country ==='Vietnam'// true
studentB.name ==='Jane Doe'// true
8. Khai báo object nâng cao
Hỗ trợ các kiểu viết nhanh (shorthand) khi khai báo property, method cũng như thực hiện gọi hàm super.
const ageField ='age'const address ='290 An Duong Vuong, HCMC, Vietnam'const student ={// Khai báo field mặc định, giống ES5
name:'John Doe',// Khai báo field dynamic[ageField]:18,// Viết tắt, thay vì phải viết `address: address`
address,// Khai báo nhanh phương thức trong object// Thay vì phải viết `toString: () {...}`toString(){// Super callreturn'Student '+super.toString()}}
9. Sử dụng let/const thay thế cho var
let: biến chung trong một scope cụ thể, có thể bị ghi đè.
const: không thể ghi đè. Tuy nhiên, đối với các đối tượng indicators sau:
Array: không thể ghi đè, nhưng có thể thêm vào hoặc xóa bớt các elements của nó.
Object: cũng không thể ghi đè, nhưng có thể thay đổi nội dung của các properties.
Cả let/const đều chỉ hoạt động trong một scope cụ thể. Tham khảo ví dụ sau đây:
functionscope(){{let x
{// Đoạn code này ok vì lúc này chúng ta đã ở trong một block scoped mớiconst x ='John Doe'// Lỗi rồi nha, x đã được khai báo trong cùng block với từ khóa `const` ở trên
x ='Jane Doe'{// Đoạn code này ok vì lúc này chúng ta đã ở trong một block scoped mớilet x ='Justin'}}// x đã được khai báo trước đo với let, nên bạn có thể assign nó tùy ý
x ='Ronnie'// Lỗi rồi nha, x đã được khai báo trong cùng block với từ khóa `let` ở trênlet x ="inner"}}
10. Iterators và for … of …
Câu lệnh for … of … thực hiện vòng lặp trên một danh sách các giá trị theo thứ tự từ một interable object.
Mặc định, Javascript tích hợp sẵn các iterable objects như Array, String, TypedArray, Map, Set, NodeList, các DOM collections, đối tượng arguments.
Ngoài ra, chúng ta cũng có thể tự define các iterable objects giống như ví dụ dưới đây.
interfaceIteratorResult{
done:boolean
value:any}interfaceIterator{next(): IteratorResult
}interfaceIterable{[Symbol.iterator](): Iterator
}let fibonacci: Iterable ={[Symbol.iterator](){let pre =0,
cur =1return{next(){[pre, cur]=[cur, pre + cur]return{ done:false, value: cur }},}},}for(const n of fibonacci){// Break loop khi value lớn hơn 1000000, không thì toangif(n >1_000_000)break;console.log(n);}
11. Generators
Generators đơn giản hóa quá trình tạo ra các iterators thông qua từ khóa function* và yield. Một function được khai báo với function* sẽ trả về một Generator instance.
Generator là một kiểu con (subtype) của iterators, bao gồm next và throw.
Từ khóa yield là một expression trả về giá trị (giống như return vậy đó). Bạn cũng có thể throw exception nếu muốn.
const fibonacci:{[Symbol.iterator]:()=> Generator<number>}={[Symbol.iterator]:function*(){let pre =0, cur =1for(;;){[pre, cur]=[cur, pre + cur]yield cur
}},}for(const n of fibonacci){// Break loop khi value lớn hơn 1000000if(n >1_000_000)break
console.log(n)}
12. Modules
Bạn có thể viết code ở nhiều file khác nhau để dễ quản lý, mỗi file sẽ được xem như một module. Bạn chỉ cần export chúng, sau đó import vào nơi bạn cần sử dụng.
// lib/math.jsexportfunctionsum(x, y){return x + y
}exportconst pi =3.141593// app.jsimport*as math from"lib/math"
console.log("2π = "+ math.sum(math.pi, math.pi))// otherApp.jsimport{sum, pi}from"lib/math"
console.log("2π = "+sum(pi, pi))
Ngoài ra, ES6 còn cung cấp thêm 2 biểu thức đặc biệt là export default và export *.
Map – WeakMap – Set – WeakSet là các kiểu dữ liệu mới được ra đời để xử lý Collection – hay dữ liệu có cấu trúc, giúp giải quyết những thiếu sót mà các kiểu dữ liệu thông thường (như Object, Array) gặp phải, đồng thời mang lại tốc độ xử lý tốt hơn.
Set
Set là một collection các phần tử khác nhau và không có key. Dữ liệu trong Set luôn luôn là duy nhất (unique).
// Khởi tạo Setconst blankSet =newSet()// Khởi tạo Set có khai báo giá trịconstset: Set<string|number>=newSet(['a','b','c','d',1,2,3])// Thêm phần tửconst s: Set<string>=newSet()
s.add('hello').add('goodbye').add('hello')// Đếm số phần tử
s.size ===2// true// Kiểm tra một phần tử có tồn tại hay không
s.has('hello')// true// Xóa phần tửconst char =newSet(['a','b','c'])
char.delete('c')// char = Set(2) {"a", "b"}// Loop qua các phần tử// Do Set là kiểu dữ liệu iterators, do đó chúng ta cần dùng for...ofconst chars =newSet(['a','b','c'])for(const char of chars){console.log(char)}// Convert một Set sang Arrayconst char =newSet(['a','b','c'])const arrChar =[...char]// ['a', 'b', 'c']
WeakSet
Tương tự như Set, tuy nhiên có một vài khác biệt lớn:
dữ liệu truyền vào WeakSet phải là object, class hoặc function.
không có thuộc tính size, nên chỉ có loop từ từ.
nó cũng không có các methods như clear, keys, values, entries, forEach như Set.
do đó, nó cũng không thuộc kiểu iterators.
// Khởi tạo WeakSetconst ws =newWeakSet()const value ={ data:42}
ws.add(value)
Một điểm quan trọng nữa là bạn cần tạo biến cho từng element trước khi add vào WeakSet, nếu không Javascript sẽ coi như đó là dữ liệu rác và thực hiện garbage collected.
// Khởi tạo WeakSetconst ws =newWeakSet()const value ={ data:42}
ws.add(value)// [{ data: 42 }]// Do element truyền vào không có references ở đâu cả// Nên hệ thống tự động thực hiện garbage collected.
ws.add({ data:43})// [{ data: 42 }]
Thực ra mình cũng chưa có dịp xài thằng này bao giờ.
Map
Thằng này thì nó cũng tương tự như Set, nhưng Map sẽ có cấu trúc dạng key => value, trong khi Set chỉ có value.
key của Map có thể là bất cứ thứ gì (string, number, symbol, NaN, class, function,…)
Đây cũng là thứ mà NestJS lưu trữ các Provider để thực hiện dependency injection.
const m =newMap()
m.set('hello',42)
m.get('hello')===42// true// Key có thể là bất cứ cái gì bạn muốnconstset=newSet()
m.set(set,34)
m.get(set)===34// true
WeakMap
Thằng này cũng tương tự WeakSet, tuy nhiên WeakSet thì dựa trên value, còn WeakMap dựa trên key nha mọi người.
Thằng này mình cũng chưa xài bao giờ luôn 😀
14. Proxy
Đây là một tính năng cực kỳ cực kỳ hay ho mà ES6 cung cấp. Nó giúp chúng ta thực hiện những thứ tương tự như Magic Methods trong PHP.
Bạn có thể hiểu nó wrap lại một variable, khi bạn thao tác một hành động nào đó, nó sẽ chặn lại và thực hiện một vài xử lý cụ thể mà bạn muốn.
const proxy =newProxy(target, handler)
target: đối tượng bạn cần wrap
handler: nó được gọi là proxy configuration – hoặc trap.
// Thực hiện proxy một object thườngconst target ={}const handler ={get:function(receiver, name){return`Hello, ${name}!`}}const p =newProxy(target, handler)
p.world ==="Hello, world!"// true// Thực hiện proxy một functionconsttarget=function(){return'I am the target'}const handler ={apply:function(receiver,...args){return'I am the proxy'},}const p =newProxy(target, handler)p()==='I am the proxy'// true
Sau đây là danh sách các trap mà proxy hiện tại đang hỗ trợ:
const handler ={// target.prop
get:...,// target.prop = value
set:...,// 'prop' in target
has:...,// delete target.prop
deleteProperty:...,// target(...args)
apply:...,// new target(...args)
construct:...,// Object.getOwnPropertyDescriptor(target, 'prop')
getOwnPropertyDescriptor:...,// Object.defineProperty(target, 'prop', descriptor)
defineProperty:...,// Object.getPrototypeOf(target), Reflect.getPrototypeOf(target),// target.__proto__, object.isPrototypeOf(target), object instanceof target
getPrototypeOf:...,// Object.setPrototypeOf(target), Reflect.setPrototypeOf(target)
setPrototypeOf:...,// for (let i in target) {}
enumerate:...,// Object.keys(target)
ownKeys:...,// Object.preventExtensions(target)
preventExtensions:...,// Object.isExtensible(target)
isExtensible :...}
15. Symbol
Symbol là một kiểu dữ liệu nguyên thủy (primitive data types). Khi bạn tạo một symbol, giá trị của nó được giữ kín và chỉ sử dụng nội bộ.
Mỗi một symbol đều là duy nhất, có nghĩa là chúng không bao giờ có giá trị giống nhau, mặc dù nhìn trông giống nhau.
Bạn cũng có thể khởi tạo symbol bằng expression Symbol.for. Lúc này chúng sẽ hoạt động như một singleton – nếu đã tồn tại thì trả về symbol đã tạo, nếu chưa có thì tạo mới.
Lưu ý: sử dụng Symbol.for khi bạn muốn tạo một symbol ở chỗ này nhưng lại sử dụng ở chỗ khác, tuy nhiên nó sẽ khiến symbol mất đi tính duy nhất. Cho nên, tốt nhất bạn nên export ra rồi sử dụng thay vì khai báo kiểu singleton này.
Promise là một giải pháp xử lý bất đồng bộ, với cách viết trang nhã, dễ đọc hơn so với callback truyền thống.
Trước đó, Promise đã được implement trong một vài thư viện của JS như Q, When, Bluebird… Từ bản ES6, nó đã được hỗ trợ trong JS core.
Một Promise đại diện cho một value có thể chưa tồn tại ở thời điểm hiện tại, nhưng sẽ được xử lý và có value cụ thể vào một thời gian nào đó trong tương lai.
functiontimeout(duration =0){returnnewPromise((resolve, reject)=>{setTimeout(resolve, duration)})}const p =timeout(1000).then(()=>{returntimeout(2000)}).then(()=>{thrownewError('hmm')}).catch((err)=>{return Promise.all([timeout(100),timeout(200)])})
18. Reflect API
Ở ES5, nó tồn tại dưới dạng static method của Object. Lên ES6 thì nó được tách ra thành Reflect class.
Reflect không có constructor, do đó bạn không thể khởi tạo một new instance. Mọi phương thức của nó đều là static.
Các phương thức của Reflect tương ứng với các traps của proxy và kết quả trả về của nó cũng chính là kết quả trap cần trả về.
constO={ a:1}
Object.defineProperty(O,'b',{ value:2})O[Symbol('c')]=3
Reflect.ownKeys(O)// ['a', 'b', Symbol(c)]functionC(a, b){this.c = a + b
}const instance = Reflect.construct(C,[20,22])
instance.c // 42
ES7 (hay ES2016)
TC39 giới thiệu rất nhiều features, nhưng release có vài cái thôi 😀
Rất may async – await đã được sinh ra để giải quyết vấn đề này
const database =awaitconnectToDatabase()const user =awaitgetUser(database)const settings =awaitgetUserSettings(database)awaitenableAccess(user, settings)
Lúc này code trông clean hẳn rồi phải không 😀
2. Object.values()
Trả về toàn bộ values của một object dưới dạng array.
const countries: Record<string,string>={BR:'Brazil',DE:'Germany',RO:'Romania',US:'United States of America'}const values:string[]= Object.values(countries)// ['Brazil', 'Germany', 'Romania', 'United States of America']
3. Object.entries()
Trả về một array các pairs (mỗi pair là một array có 2 phần tử, phần tử đầu tiên là key, phần tử thứ hai là value).
interfaceString{padStart(maxLength:number, fillString?:string):stringpadEnd(maxLength:number, fillString?:string):string}// Trả về một string mới có độ dài bằng 10// Có thêm 6 space phía trước, do độ dài ban đầu là 4 ký tự'0.10'.padStart(10)// ' 0.10''0.10'.padStart(12)// ' 0.10''23.10'.padStart(12)// ' 23.10''12,330.10'.padStart(12)// ' 12,330.10''hi'.padStart(1)// 'hi''hi'.padStart(5)// ' hi''hi'.padStart(5,'abcd')// 'abchi''hi'.padStart(10,'abcd')// 'abcdabcdhi''loading'.padEnd(10,'.')// 'loading...'
6. Trailing commas
Cho phép tồn tại dấu phẩy ở sau tham số cuối cùng của một khi khai báo hoặc gọi một function.
getDescription(name, age,){...}
ES8 có một vài thay đổi tuy nhỏ nhưng tác động rất lớn, nhưng đối với mình quan trọng nhất vẫn là các toán tử bất đồng bộ async – await.
ES9 (hay ES2018)
Thay đổi bự nhất chắc là cho phép thực hiện await trong vòng loop.
1. await khi loop
Đôi khi chúng ta có nhu cầu thực hiện gọi một function async trong vòng lặp for.
asyncfunctiondoSomething(item){returnPromise.resolve(item)}asyncfunctionprocess(array){for(const i of array){awaitdoSomething(i)}}asyncfunctionprocess(array){
array.forEach(async i =>{awaitdoSomething(i)})}
Code như vầy là tèo cmnr nha 😀
Do bản thân vòng lặp for là đồng bộ nên nó sẽ thực hiện xong toàn bộ vòng lặp trước khi các biểu thức bất đồng bộ bên trong được xử lý xong.
ES9 giới thiệu một cách giúp thực hiện điều này.
asyncfunctionprocess(array){forawait(const i of array){doSomething(i)}}
2. Promise.finally()
finally() sẽ đuợc gọi sau khi một Promise hoàn thành, bất kể là fails (.catch()) hay success (.then()).
functionprocess(){process1().then(process2).then(process3).catch(console.log).finally(()=>{console.log(`it must execut no matter success or fail`)})}
3. Cải thiện rest – spead syntax
Thực ra mình lỡ giới thiệu hết trong phần ES6 rồi 😀 do quên mất là một số tính năng chỉ xuất hiện sau bản ES9.
Thôi kéo lên coi lại giúp mình nha 😀
4. RegExp groups
RegExp lúc này có thể trả về các packets thỏa điều kiện.
const regExpDate =/([0-9]{4})-([0-9]{2})-([0-9]{2})/const match = regExpDate.exec('2020-06-25')const year = match[1]// 2020const month = match[2]// 06const day = match[3]// 25
5. Regexp dotAll
. đại diện cho bất kỳ ký hiệu ngoại trừ \n – hay xuống dòng – enter.
Cũng không có quá nhiều sự thay đổi, tuy nhiên cũng khá thú vị.
1. JSON.stringify() hoạt động thân thiện hơn
Trước đó, JSON.stringify() sẽ trả về một chuỗi string không đúng định dạng Unicode nếu đầu vào là một Unicode nhưng nằm ngoài vùng hỗ trợ.
Bây giờ thì nó sẽ trả ra một chuỗi Unicode hợp lệ dưới dạng UTF-8.
2. Kiểu dữ liệu bigint
BigInt – bigint là một kiểu dữ liệu nguyên thủy mới được sử dụng để biểu diễn các số nguyên có giá trị lớn hơn 2^53. Đây cũng là định dạng số lớn nhất mà Javascript có thể biểu diễn.
const x = Number.MAX_SAFE_INTEGER;// 9007199254740991 - nó chính là (2^53 - 1)const y = x +1;// 9007199254740992 - nó chính là (2^53)const z = x +2// 9007199254740992 - vẫn là 2^53
Một số BigInt được tạo bằng cách thêm n vào cuối chữ số hoặc có thể gọi hàm tạo như ví dụ bên dưới
Còn Array.flatMap() là sự kết hợp của 2 phương thức map() và flat() với depth=1. Hay nói cách khác là mỗi giá trị của mảng sẽ được map sang một mảng mới và flat với depth=1.
Promise hỗ trợ hai loại combinators, đó là hai phương thức tĩnh Promise.all() và Promise.race(). Nhưng với ES11 thì bạn có thêm phương thức Promise.allSettled().
Nếu Promise.all() và Promise.race() sẽ dừng lại khi có bất kì một Promise nào bị rejected thì Promise.allSettled() sẽ tiếp tục chạy hết các Promise còn lại.
Trong quá trình làm việc, chắc hẳn bạn cũng đã quá quen thuộc với các câu lệnh kiểm tra giá trị có tồn tại hay không trước khi xử lý tiếp:
interfaceCar{
id:string
info:{
name:string}}const car: Car |undefined=awaitgetCar()const isCarExist = car && car.info
if(isCarExist){
carName = car.info.name
}// Đoạn code sau sẽ báo lỗi khi car không tồn tạiconst carInfo = car.info
Với ES11, chúng ta có thể kiểm tra một property của Object hoặc element của Array có tồn tại hay chưa bằng toán tử ?
carName = car?.info?.name
const carInfo = car?.info
// Hoặc kết hợp giá trị default nếu chưa tồn tại
carName = car?.info?.name ||'Default Name'// Tương tự với Arrayconst arr:{ name:string}[]=[{ name:'John'},{ name:'Jane'},{ name:'James'}]const name4 = arr[4]?.name ||'Default Name'
Code clean hơn nhiều rồi phải không 😀
3. Toán tử check null ??
Trong Javascript, 3 giá trị 0, null và undefined đều đại diện giá trị false.
!!0// false!!undefined// false!!null// false
Nhưng đôi lúc, 0 là một giá trị bình thường, chúng ta không muốn nó là false.
const user ={
level:0,}const level = user.level ||'no level'// 0 đại diện cho false, nên ở đây JS sẽ hiển thị 'no level'// Nếu bạn muốn hiển thị 0const level =
user.level !==undefined&& user.level !==null? user.level :'no level'
ES11 cung cấp cách thức khác clean hơn
const username = user.level ??'no level'// 0
4. Dynamic import
Như tên gọi, chúng ta có thể import một thư viện ở bất kỳ đâu trong đoạn code.
Để cải thiện khả năng đọc, bổ sung mới này cho phép sử dụng _ làm dấu phân cách trong các ký tự số.
// A decimal integer literal with its digits grouped per thousand:1_000_000_000_000// A decimal literal with its digits grouped per thousand:1_000_000.220_720// A binary integer literal with its bits grouped per octet:0b01010110_00111000// A binary integer literal with its bits grouped per nibble:0b0101_0110_0011_1000// A hexadecimal integer literal with its digits grouped by byte:0x40_76_38_6A_73// A BigInt literal with its digits grouped per thousand:4_642_473_943_484_686_707n
Lưu ý là nó không ảnh hưởng tới giá trị, chỉ là giúp chúng ta đọc code dễ hơn mà thôi.
3. String.replaceAll()
Một cách viết khác cho phương thức String.replace() giúp replace toàn bộ string mà không cần sử dụng RegExp.
const str ='macOS is way better than windows. I love macOS.'const newStr = str.replace('macOS','Linux')
console.log(newStr)// Linux is way better than windows. I love macOS.const newStr2 = str.replace(/macOS/g,'Linux')
console.log(newStr2)// Linux is way better than windows. I love Linux.const str ='macOS is way better than windows. I love macOS.'const newStr = str.replaceAll('macOS','Linux')
console.log(newStr)// Linux is way better than windows. I love Linux.
4. Toán tử gán có điều kiện &&=, ||=, ??=
Các toán tử gán logic mới được đề xuất &&=, ||=, ??= giúp chúng ta có thể gán một giá trị cho một biến dựa trên một phép toán logic. Nó kết hợp phép toán logic với biểu thức gán.
let x =10let y =15
x &&= y
// Tương đương if(x) x = y
x ||= y
// Tương đương if(!x) { x = y }
x ??= y
// Tương đương if(x === null || x === undefined) { x = y }
Kết
Bài dài quá rồi. Mình sẽ tổng hợp về ES2022 vào phần tới nhé.
Bài viết được sự cho phép bởi tác giả Vũ Thành Nam
Các anh chị em ngoài ngành hay nghe anh em chúng tôi nói bugs bugs, chúng tôi sợ gì k sợ sợ bugs, chẳng biết nó là gì thì bài viết này mình sẽ giúp mọi người hiểu hơn về con sâu bọ mà không chỉ riêng mùng 5 tháng 5 anh em chúng tôi mới đi giết sâu bọ nhé!
Ngày xưa ở quê mọi người thường nói tắt đèn để tránh rầy nâu ngoài ruộng lúa bay vào, giờ lớn lên thì chuyển chế độ dark mode để có niềm tin hi vọng rằng code mình sạch bug.
Sợ quá! sợ quá đi thôi!
Bug là gì?
Bug là những lỗi phần mềm trong chương trình hoặc hệ thống máy tính khiến cho kết quả trả về không được chính xác hoặc không đạt hiệu quả như mong muốn. Hiểu một cách đơn giản hơn, bug là lỗi xuất hiện trong quá trình viết code mà bất cứ người lập trình viên nào cũng khó tránh khỏi.
Có rất nhiều nguyên nhân gây ra một bug như:
– Có nhiều câu lệnh if lồng nhau và đặt lệnh else ở sai nhánh.
– Đưa ra các giả định không chính xác như truy xuất một thuộc tính nào đó không tồn tại.
– Khách hàng sử dụng phần mềm theo cách khác cũng có thể dính bug.
Các loại Bug điển hình
Bug tí hon
Bug tí hon được coi như một loại “bọ” bởi chúng có kích thước vô cùng nhỏ, tuy nhiên để tiêu diệt được chúng thì không hề dễ dàng. Để loại bỏ bug tí hon, bạn cần phải tốn rất nhiều thời gian để tìm cho ra đoạn code có vấn đề. Bug tí hon thường xuất hiện do bạn quên dấu chấm phẩy, dấu 2 ngoặc, thụt lề sai,… Mặc dù là loại bug gây ra nhiều khó chịu nhất nhưng bạn có thể phát hiện chúng bằng việc sử dụng IDE phù hợp.
Bug không tồn tại
Bug không tồn tại rất khó xác định bởi Compile Error nhảy lung tung, nhưng bạn không thể xác định được lỗi nào đã xảy ra dù đã review code rất nhiều lần. Nguyên nhân xảy ra bug không tồn tại là do bạn đã sử dụng sai hoặc do trình biên dịch bị lỗi. Cách để xử lý tốt nhất đó là bạn nên chọn phần trình biên dịch sao cho phù hợp để tránh không hỗ trợ các tính năng mới mang tính hiện hành.
Bug khủng
Nguyên nhân gây ra bug khủng đó là do dòng code bị sai chính tả hoặc sai cú pháp. Bạn cần thực sự am hiểu về nhiều loại ngôn ngữ lập trình để tránh lặp lại lỗi sai cú pháp, đồng thời bạn nên sử dụng đúng các loại dữ liệu để tránh xảy ra sai phạm truy cập dưới dạng lỗi tài nguyên.
Bug ẩn thân
Bug ẩn thân là những lỗi không hiển thị trong quá trình bạn đang biên dịch. Những lỗi này chỉ xuất hiện sau khi bạn đã cài đặt hoàn tất và đang trong quá trình sử dụng phần mềm. Bug ẩn thân cũng là nguyên nhân khiến cho phần mềm không còn được an toàn và dễ bị hack.
Bug bất ngờ
Đúng như cái tên của nó, bug bất ngờ sẽ đột nhiên xuất hiện và báo lỗi trong khi bạn đã chạy thử đoạn code cực kỳ hoàn hảo trước đó. Bug bất ngờ có thể dễ hoặc khó sửa tùy từng trường hợp. Trong quá trình sửa lỗi, bạn không nên động chạm tới những dòng code đang hoạt động tốt để tránh phát sinh thêm bug.
Những loại bug thường gặp
Gặp bug và có thể sửa lỗi bug không đơn thuần chỉ là công việc phải làm mà còn là cơ hội cho lập trình viên sáng tạo, khai phá năng lực của bản thân. Từ đây có thể nghiên cứu và phát triển bản thân hơn nữa trong tương lai. Hiện nay, có rất nhiều loại bug khác nhau ứng với những cách fix và xử lý khác nhau. Một số loại bug thường gặp phải kể đến là: Bug tí hon, Bug khủng, Bug không tồn tại, Bug bất ngờ và Bug ẩn thân.
Những sản phẩm càng có yêu cầu cao cùng quy trình thực hiện phức tạp thì càng có khả năng xuất hiện bug. Trong quá trình design và coding có thể vô tình gây ra bug. Ngoài ra, bug có thể xuất hiện bởi nhiều nguyên nhân khác như: quy trình kiểm thử không cẩn thận, logic design rời rạc, code kém, build version không được kiểm soát cẩn thận,… Dù là bất cứ lý do gì thì việc sửa bug cũng tốn khá nhiều thời gian của các lập trình viên.
Debug là quá trình tìm kiếm lỗi hay tìm ra nguyên nhân gây ra lỗi để có phương pháp sửa lỗi (fix bug) phù hợp. Việc kiểm soát lỗi này là công đoạn quan trọng nhưng không hề đơn giản với những người lập trình viên chưa có nhiều kinh nghiệm.
Fix bug là gì?
Fix bug là công việc sửa lỗi sau khi debug. Kỹ năng debug và kỹ năng fix bug có tầm quan trọng như nhau. Một người lập trình viên giỏi và tài năng là người có thể debug và fix bug tốt, từ đó tạo ra những sản phẩm chất lượng, có giá trị sử dụng.
Tầm quan trọng của debug
Với bất kỳ người làm lập trình nào, việc xảy ra lỗi trong hàng nghìn dòng lệnh là chuyện khá bình thường. Điều này dẫn tới việc chương trình sẽ chạy sai chức năng nó được quy định và bị đánh giá kém chất lượng. Chính vì vậy, khi gặp những lỗi như vậy, các lập trình viên phải debug để fix bug để chương trình có thể hoạt động tốt.
Debug đóng vai trò cực kỳ quan trọng đối với các lập trình viên. Chúng không chỉ loại bỏ lỗi ra khỏi chương trình mà còn có thể giúp lập trình viên hiểu rõ hơn quá trình thực thi của chương trình. Nếu lập trình viên không có khả năng debug thì không thể nào xây dựng một chương trình trọn vẹn.
Các phương pháp debug hiệu quả bạn nên tham khảo
Có nhiều phương pháp để tiến hành quá trình tìm kiếm, kiểm soát lỗi cho các lập trình viên. Dưới đây là những phương pháp bạn nên tham khảo để sử dụng cho quá trình debug của mình:
– Debugging Tool: Đây là phương pháp sử dụng công cụ để tiến hành tìm kiếm, kiểm soát lỗi. Phương pháp này sẽ đi sâu vào source code nhất. Những Debugging Tool phần mềm thông dụng là Microsoft Visual Studio Debugger, GNU Debugger. Ngoài ra, bạn cũng có thể sử dụng những Debugging Tool phần cứng đặc thù được thiết kế chuyên biệt để phục vụ một ứng dụng nào đó.
– Print Line: Đây đơn giản là phương pháp thêm vào source code của bạn những dòng lệnh. Những dòng lệnh này sẽ in ra những thông tin mà bạn cần theo dõi trong quá trình chương trình thực thi. Chẳng hạn, nếu đang dùng Arduino IDE, bạn sẽ không tìm được debugging tool phù hợp nên cách debug phù hợp nhất là dùng Serial.print().
– Logging: Đây là phương pháp tạo ra một biểu mẫu để ghi lại thông tin sau khi chương trình thực thi. Từ những thông tin này, bạn sẽ phân tích nguyên nhân lỗi phát sinh là do đâu.
– Nhờ người khác thực hiện debug: Đây là phương pháp cũng khá hiệu quả nếu như bạn thấy mình chưa thực sự hiểu sâu về quá trình tìm kiếm và kiểm soát lỗi này.
Để có thể debug nhanh, hiệu quả, bạn cần nắm rõ 1 vài mẹo như sau:
– Sử dụng comment để đánh dấu các code đã hoàn thiện để dễ tìm và sửa sau này
– Đặt tên các hàm có ý nghĩa để debug dễ dàng hơn
– Dùng Breakpoints để rà tiến độ chạy của code xem chính xác chưa
– Chú ý tới Error Message để tìm ra số dòng code sẽ giúp bạn debug nhanh hơn
Lợi ích của việc gặp bug và fix bug
Gặp bug không hề “đen” như bạn vẫn tưởng tượng. Thực tế thì fix lỗi bug có thể mang lại cho bạn những bài học kinh nghiệm quý báu nếu biết tận dụng cơ hội học hỏi.
Một vài lợi ích khi gặp bug phải nhắc đến là:
– Tăng kiến thức lập trình: Khi dành thời gian để sửa bug, các lập trình viên có thể trau dồi thêm rất nhiều kiến thức mới chưa từng được học trước đó. Với mỗi lỗi bug khác nhau sẽ có những bài học kinh nghiệm khác nhau. Sửa lỗi bug vừa là cơ hội ôn lại kiến thức cũ vừa là lúc thực hành sau những lý thuyết khô khan.
– Code dễ debug hơn: Khi tự sửa bug, bạn có thể biết cách viết code dễ debug hơn. Tìm ra bug và sửa bug sẽ giúp bạn tăng kinh nghiệm, dễ dàng xử lý các tình huống phát sinh
– Tạo niềm vui cho cả khách hàng và người lập trình: Khi về tay những bug đã được fix lỗi cẩn thận chắc chắn khách hàng sẽ hài lòng và đánh giá tốt về dịch vụ của bạn. Tương tự như vậy, người lập trình sẽ hài lòng với thành quả mình tạo ra.
Theo thống kế thì thời gian mà các lập trình viên dùng để fix bug nhiều hơn thời gian viết code cho chương trình mới. Vậy nên, hoàn toàn có thể khẳng định fix bug là công việc quan trọng và cần sự tỉ mỉ.
Đó là những chia sẻ về lỗi bug và lý do tại sao cần phải sửa bug. Hy vọng rằng thông qua những thông tin trên, bạn có thể nắm được những thông tin chi tiết về bug và cách fix bug hiệu quả nhất.



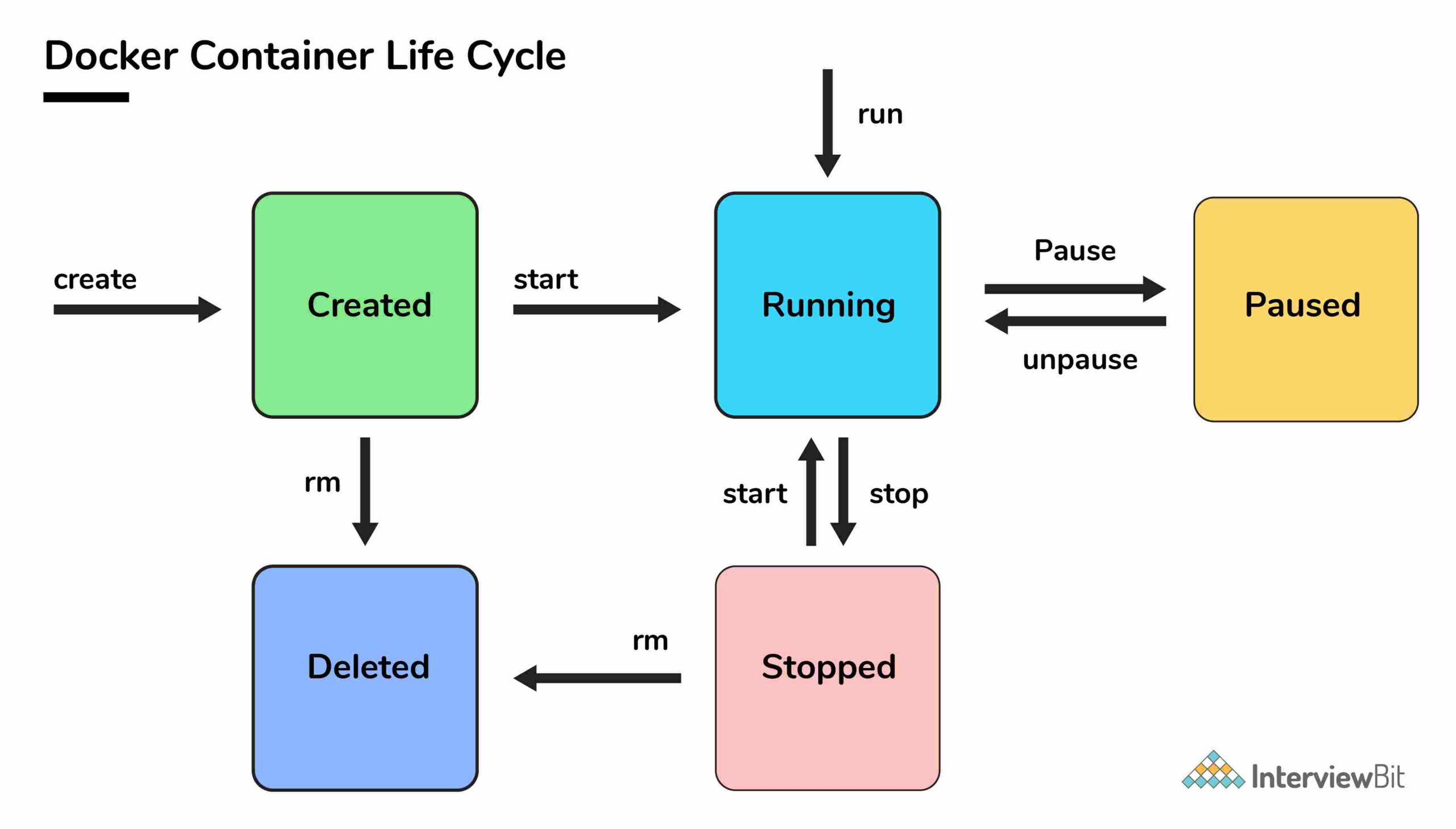



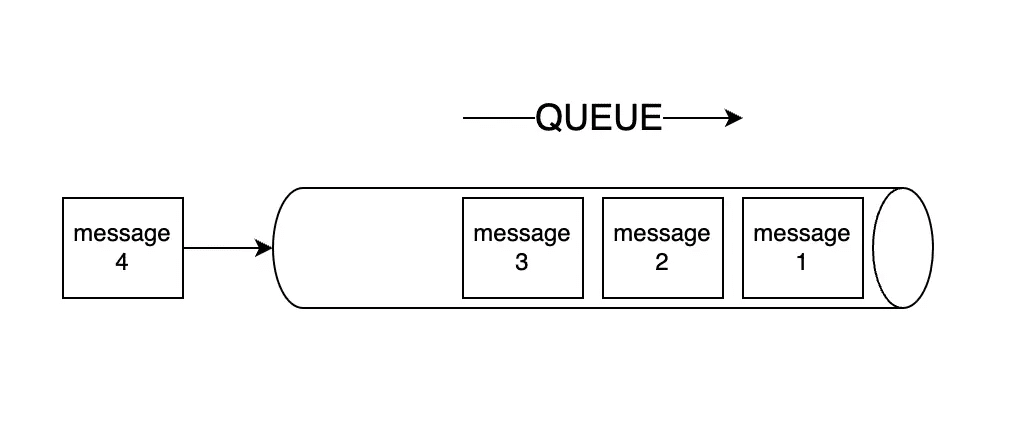
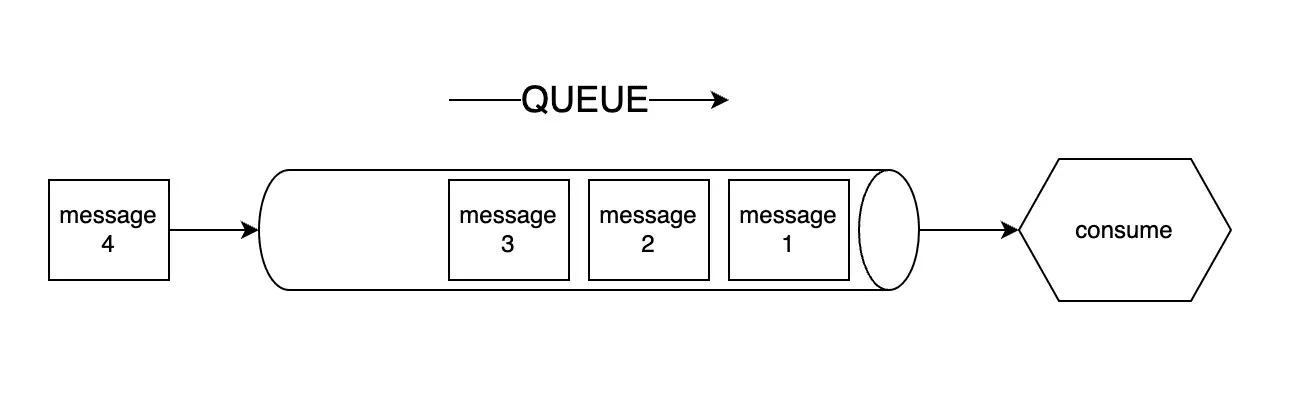
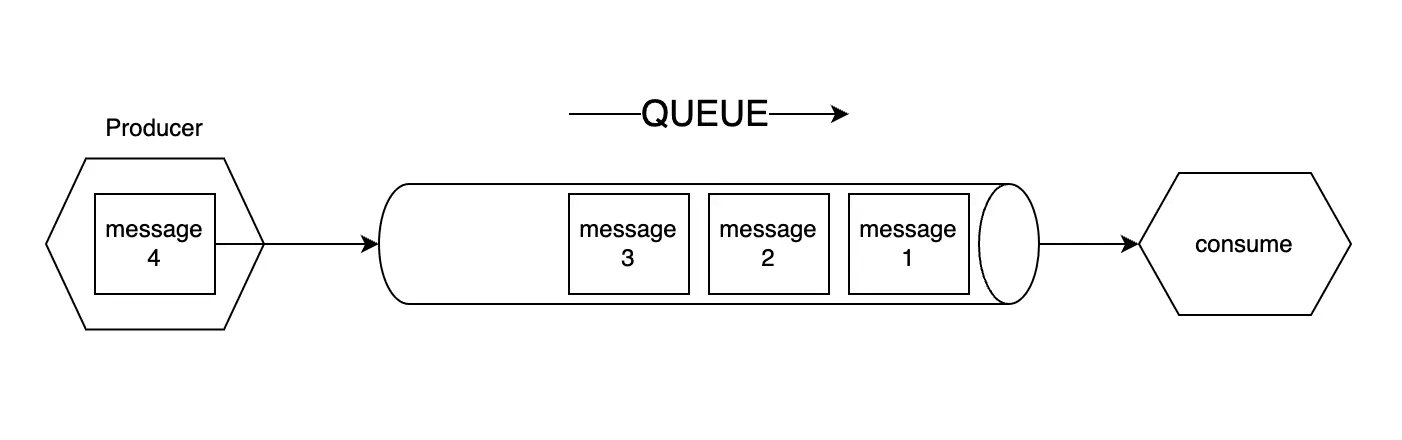


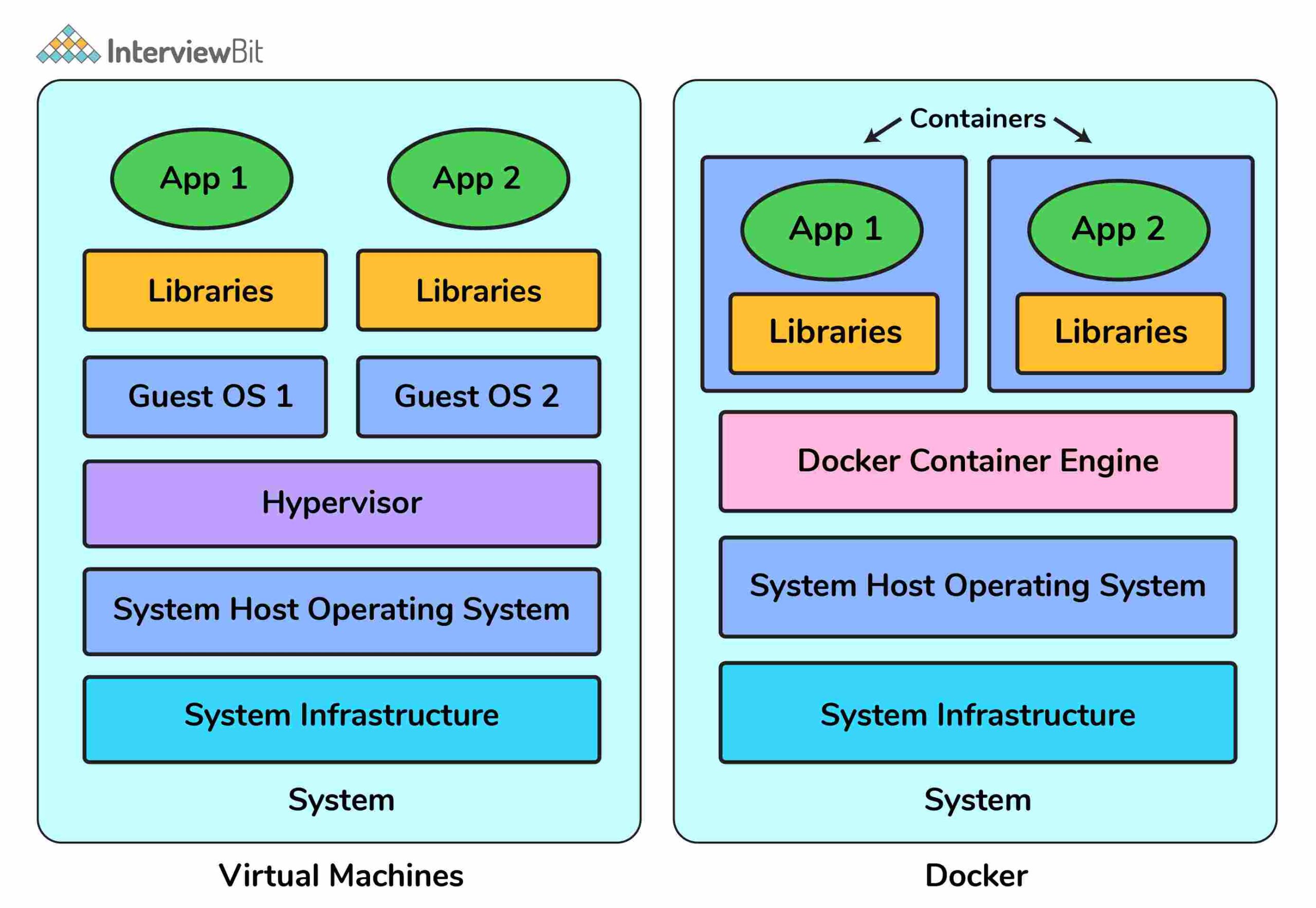
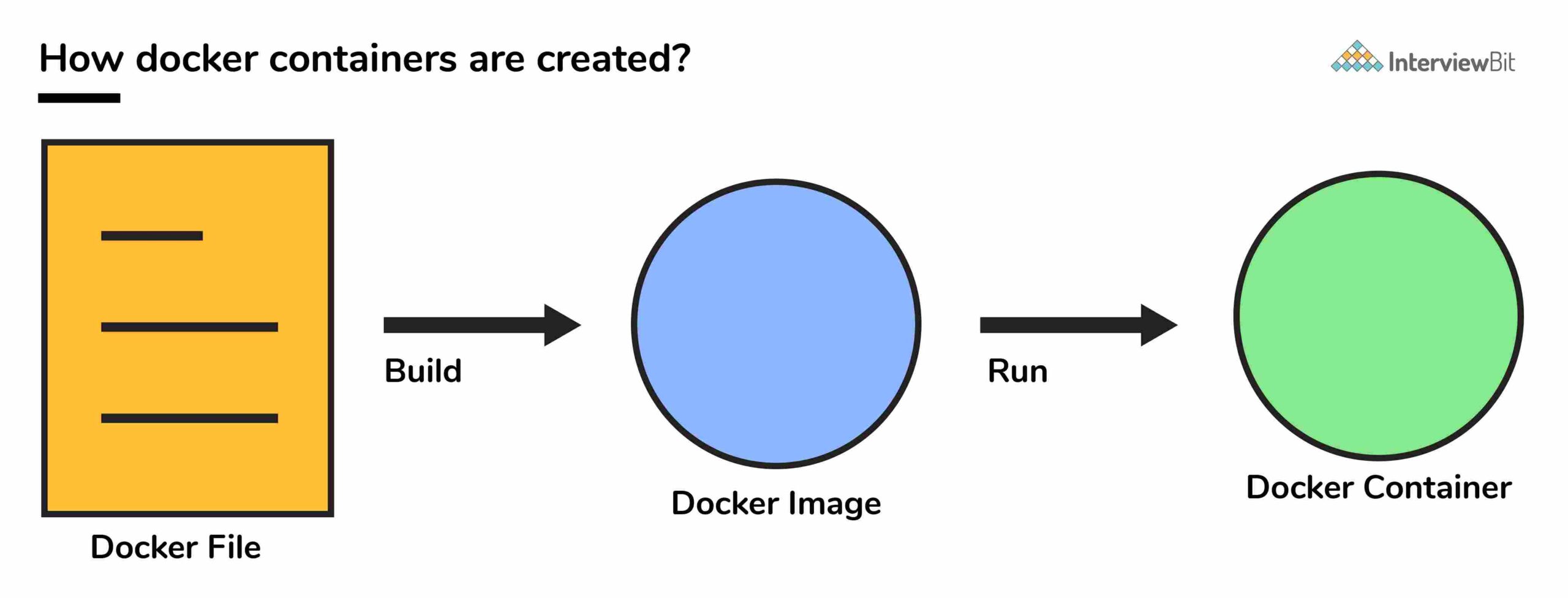
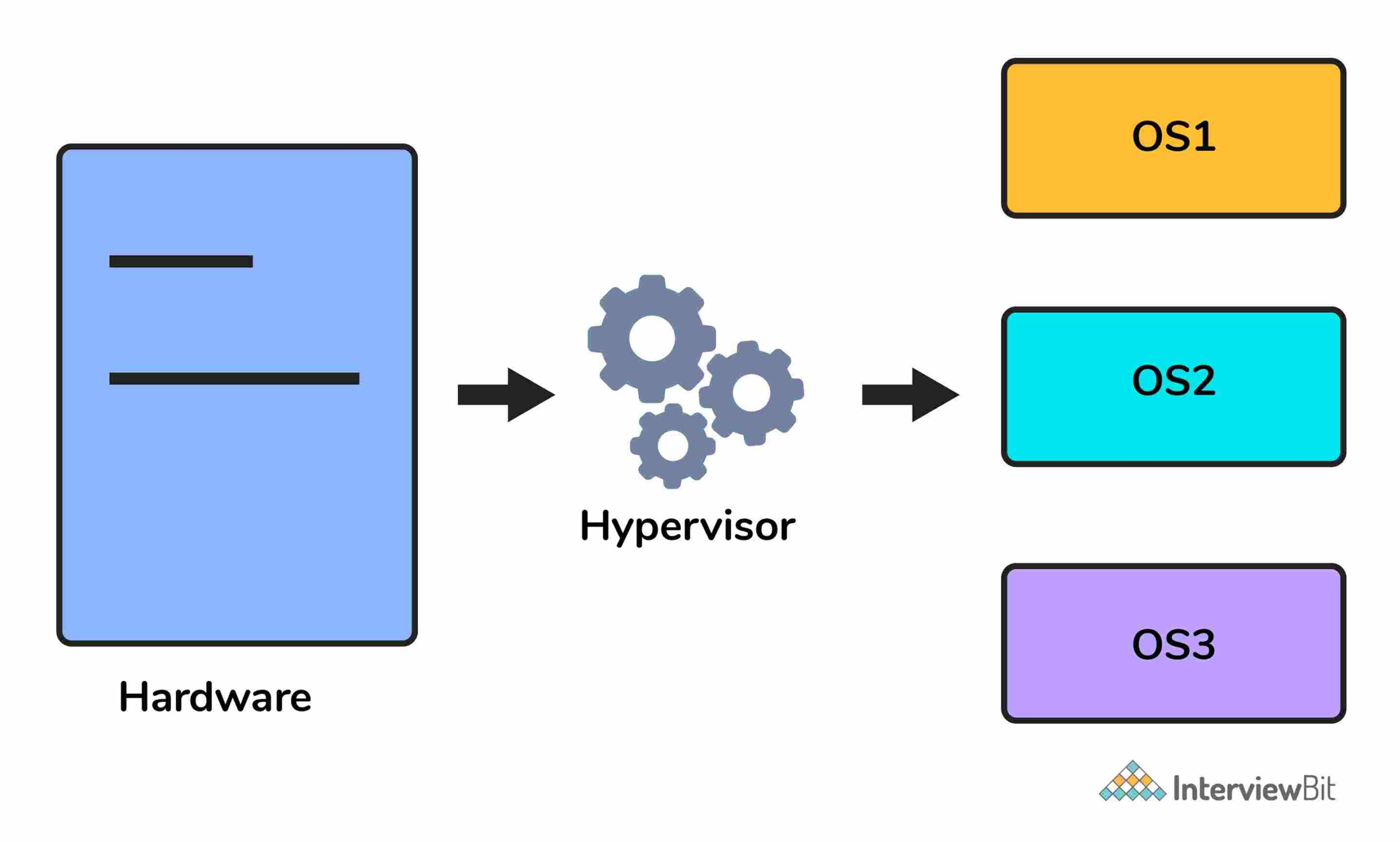
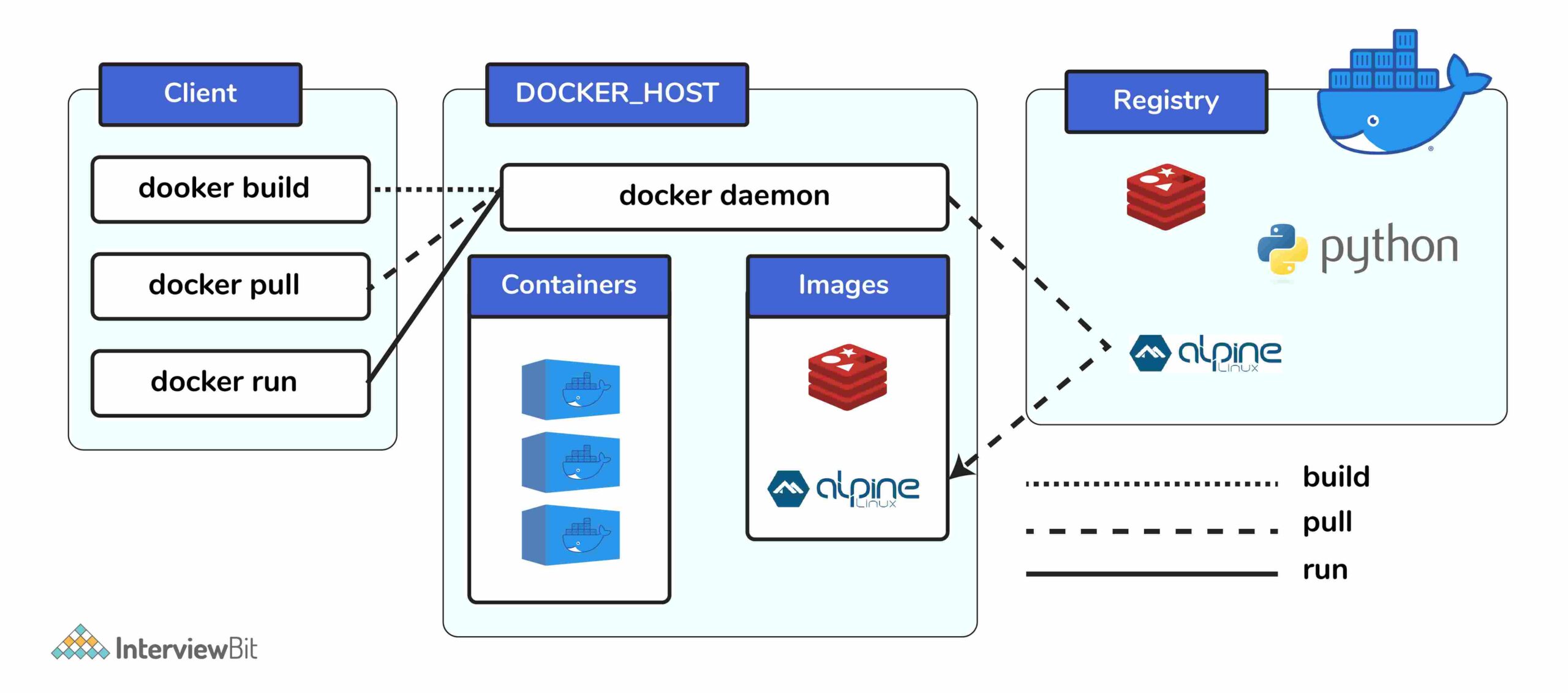









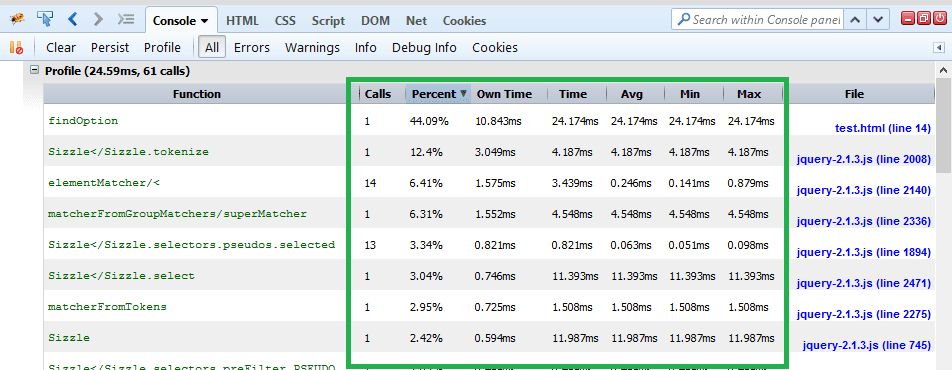



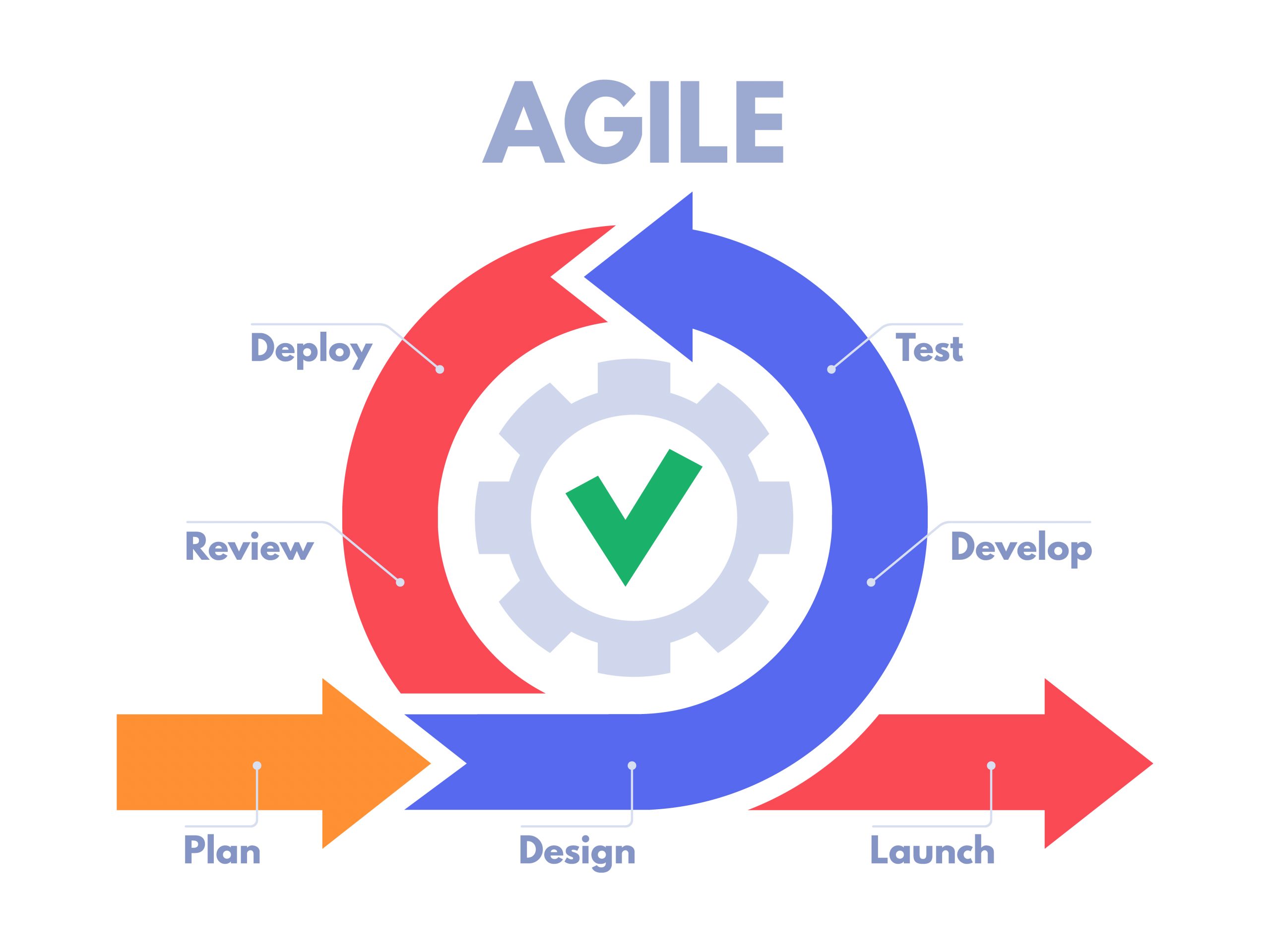








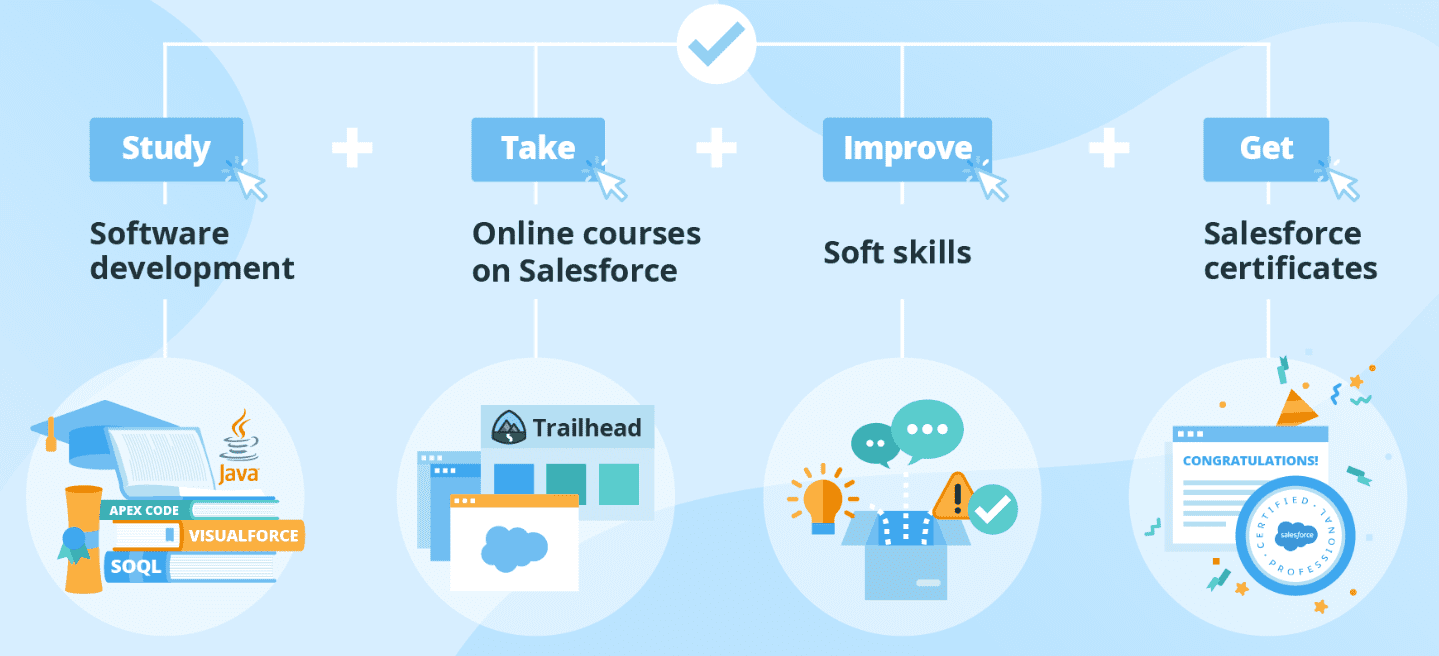




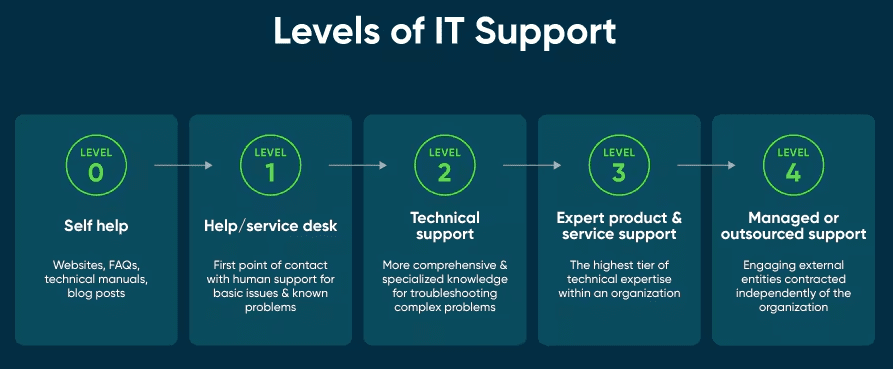



")