Thị trường logistics ngày càng phát triển mang đến cho các công ty nhiều cơ hội và dư địa cho một thị trường mới. Để đáp ứng nhu cầu của các công ty từ trong đến ngoài nước, các dịch vụ 3PL đã sớm được triển khai để phục vụ thị trường. Vậy 3PL thực chất là gì? Các công ty 3PL ở Việt Nam đang phát triển gồm những thương hiệu nào?
3PL là gì?
3PL – Third Party Logistics: hậu cần bên thứ 3, có thể hiểu một cách đơn giản là một đơn vị chuyên cung cấp các dịch vụ logistics sẽ được công ty có nhu cầu thuê để đảm nhận các nhiệm vụ liên quan đến việc vận hành một mảng nhất định trong chuỗi cung ứng của doanh nghiệp đó. Việc thuê ngoài các đơn vị 3PL giúp doanh nghiệp có thể tiết kiệm tối đa nhân lực của mình, sử dụng các dịch vụ bên ngoài với chuyên môn cao trong lĩnh vực đó sẽ giúp doanh nghiệp đạt hiệu quả công việc cao hơn.
Các dịch vụ do 3PL cung cấp rất đa dạng liên quan đến các vấn đề về logistics và chuỗi cung ứng. Có thể kể đến như lưu kho và vận chuyển hàng hóa, soạn hàng, đóng gói, giao hàng, thực hiện đơn hàng,… Tùy theo nhu cầu cụ thể của doanh nghiệp mà họ có thể thuê nhiều 3PL cùng lúc để thực hiện mỗi chức năng khác nhau.
Những lợi ích khi sử dụng 3PL đối với các doanh nghiệp
Giảm chi phí cho doanh nghiệp: Thực tế việc thuê một công ty ngoài để thực hiện 3PL sẽ tiết kiệm khá nhiều chi phí so với việc một công ty chưa có chuyên môn trong mảng này triển khai thực hiện. Dựa trên khối lượng công việc, 3PL có thể thương lượng với doanh nghiệp và đưa ra mức giá tốt nhất để hoàn thành những công việc đó.
Giúp doanh nghiệp tập trung phát triển các khía cạnh chuyên môn của mình.
Cung cấp trải nghiệm tốt hơn cho người tiêu dùng: Các doanh nghiệp thực hiện 3PL có chuyên môn sâu rộng trong lĩnh vực của mình, mạng lưới vận chuyển rộng lớn, do vậy họ hoàn toàn có thể thực hiện việc này tốt hơn so với doanh nghiệp mới bắt đầu.
Linh hoạt trong việc tăng giảm quy mô hoạt động: Nhu cầu tiêu dùng tùy theo thời điểm khác nhau mà sẽ có những biến động nhất định. Vậy nên việc sử dụng 3PL cho phép các doanh nghiệp dựa vào tình hình thực tế để tăng giảm tần suất hoạt động, mà không cần cam kết vốn khi không cần thiết.
Chủ động trong các vấn đề liên quan đến logistics quốc tế: Đối với các công ty hoạt động buôn bán trên thị trường quốc tế, 3PL sẽ giúp giải quyết hiệu quả các vấn đề liên quan đến giấy tờ, thuế, hải quan hay các vấn đề phát sinh ở biên giới,… Và giúp các công ty tránh gặp phải các rắc rối liên quan đến vấn đề giữa các quốc gia mà 3PL nắm rất rõ.
Sử dụng 3PL mang lại rất nhiều lợi ích cho các doanh nghiệp
Các công ty 3PL ở Việt Nam
1. Tập đoàn Deutsche Post DHL Group
DHL là một thương hiệu có tuổi đời lâu năm trên thế giới, chuyên về hoạt động hậu cần xuất hiện ở hơn 220 quốc gia và vùng lãnh thổ. Các hoạt động của DHL được đánh giá cao về chất lượng và tiết kiệm chi phí.
2. Tập đoàn A.P. Moller-Maersk
A.P. Mller-Maersk được đánh giá là công ty vận tải biển lớn nhất thế giới. Với hơn 100 năm kinh nghiệm trong ngành vận tải hàng hóa, Maersk Việt Nam đã trở thành công ty vận chuyển hàng đầu với các dịch vụ linh hoạt, chất lượng và đáng tin cậy.
3. Công ty Vận Tải và Logistics Viettel Post
Là doanh nghiệp Việt Nam, sau nhiều năm hoạt động, đến nay Viettel Post đã vươn lên trở thành một trong những thương hiệu chuyển phát hàng đầu cả nước, với mạng lưới bưu cục, trung tâm điều hành, mạng lưới mở rộng phủ khắp các tỉnh, thành.
4. Công Ty Vận Tải và Logistics Gemadept
Gemadept tự hào là doanh nghiệp tiên phong trong lĩnh vực khai thác cảng và hậu cần tại thị trường Việt Nam, với mạng lưới hoạt động rộng lớn trải dài ở khắp các tỉnh thành trên cả nước.
5. Công Ty Vận Tải – Logistics TRANSIMEX
TRANSIMEX cung cấp các giải pháp logistics tổng thể cho khách hàng với nhiệm vụ của một 3PL, bao gồm giao nhận hàng hóa quốc tế, kho bãi, vận tải nội địa và phân phối.
6. Dịch Vụ Vận Tải và Logistics của FedEX
Có trụ sở đặt tại Hoa Kỳ, FedEx Express đến nay đã tận dụng mạng lưới đường hàng không và đường bộ toàn cầu để xúc tiến vận chuyển nhanh chóng, hiệu quả và chất lượng các lô hàng nhận được.
7. Công Ty Vận Tải và Logistics – Indo Trans Logistics Corporation (ITL)
ITL là thương hiệu công ty 3PL nổi bật trong cả nước, nhiều nằm liền đều nằm trong top các doanh nghiệp 3PL hoạt động hiệu quả nhất.
Các công ty 3PL cung cấp những giải pháp hậu cần, vận chuyển và giao nhận hàng hóa đầy hiệu quả và tối ưu chi phí. Nếu tận dụng tốt điều này cũng như có thể tìm được công ty đáp ứng yêu cầu đề ra, các doanh nghiệp chắc chắn sẽ đạt kết quả tốt hơn trong hoạt động hậu cần. Mong rằng các công ty 3PL ở Việt Nam được đề cập trong bài viết này sẽ giúp ích cho người đọc.
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
Mức ngoài (External Level) hoặc mức khung nhìn (View Level): xác định các giao diện như những ứng dụng, tương tác và hiển thị cho người sử dụng.
Mức quan niệm (Conceptual Level) hoặc mức logic: còn gọi là mô hình quan niệm của dữ liệu (MQD) hoặc mô hình logic của dữ liệu (MLD). Nó xác định cách sắp xếp thông tin bên trong CSDL;
Mức trong (Internal Level) hoặc mức vật lý (Physical Level): xác định cách thức lưu trữ dữ liệu và các phương pháp truy cập vào đó;
Giữa ba mức này có hai ánh xạ(mapping):Ánh xạ giữa mức ngoài và mức quan niệmÁnh xạ giữa mức trong và mức quan niệmMô phỏng cho mô hình kiến trúc hệ quản trị CSDL là mô hình ANSI/SPARC ra đời năm 1975 đã xác định một kiến trúc trừu tượng phục vụ cho phân tích và thiết kế các hệ quản trị cơ sở dữ liệu (DBMS)Mô hình kiến trúc ANSI/SPARC cho phép tạo ra sự độc lập giữa bản thân dữ liệu và việc xử lý dữ liệu. Sơ đồ ở hình bên cho thấy sự triển khai kiến trúc vật lý của một hệ quản trị CSDL là như thế nào.
Nói chung một hệ quản trị CSDL có những đặc trưng ưu việt sau đây:
Tính độc lập vật lý: mức vật lý có thể thay đổi mà không bị phụ thuộc vào mức quan niệm. Điều đó có nghĩa rằng những người sử dụng không cần nhìn thấy các khía cạnh vật chất của CSDL. Nói cách khác, cấu trúc thể hiện thông tin là trong suốt đối với những người sử dụng;
Tính độc lập logic: mức quan niệm có thể được hiệu chỉnh mà không phụ thuộc vào mức vật lý, nghĩa là người quản trị CSDL có thể phát triển nó mà không làm phiền gì đến người sử dụng;
Có thể thao tác được: những người không rành về CSDL cũng có thể mô tả được các yêu cầu của họ mà không cần biết tới các thành tố kỹ thuật của CSDL;
Tốc độ truy cập nhanh: hệ thống phải có khả năng đáp ứng (trả lời) các yêu cầu một cách nhanh nhất có thể có và điều đó đòi hỏi áp dụng các giải thuật tìm kiếm nhanh;
Tính quản trị tập trung: hệ quản trị CSDL phải cho phép người quản trị có khả năng thao tác các dữ liệu, chèn vào các phần tử và xác minh tính toàn vẹn của dữ liệu theo một cách tập trung;
Hạn chế sự dư thừa: hệ quản trị CSDL phải có khả năng lưu trữ tối thiểu những thông tin dư thừa, vừa để chống lãng phí bộ nhớ vừa để tránh các lỗi;
Kiểm tra tính toàn vẹn: các dữ liệu phải nhất quán giữa chúng với nhau, hơn nữa khi các phần tử này tham chiếu đến các phần tử khác thì những phần tử khác phải có mặt;
Dữ liệu có thể chia sẻ: hệ quản trị CSDL phải cho phép nhiều người sử dụng truy cập đồng thời đến CSDL;
An ninh dữ liệu: hệ quản trị CSDL phải có các cơ chế cho phép quản lý quyền truy cập vào dữ liệu tùy theo từng người sử dụng.
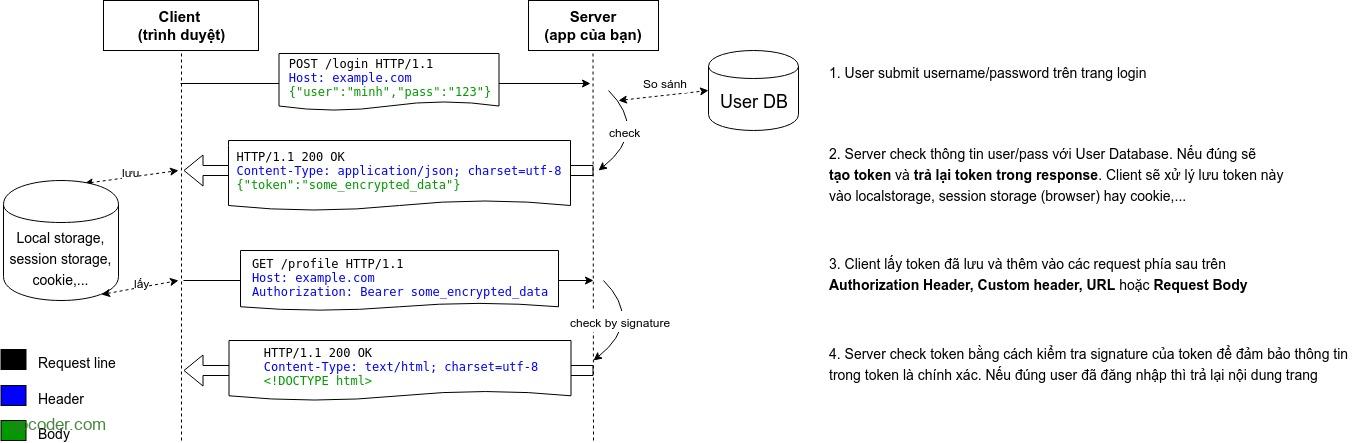
REST Web service: JWT – Token-based Authentication trong Jersey 2.x
Bài viết được sự cho phép của tác giả Giang Phan
Trong bài trước, chúng ta đã cùng tìm hiểu về xác thực và phân quyền ứng dụng sử dụng cơ chế Basic Authentication trong Jersey 2.x. Trong bài này, chúng ta cùng tìm hiểu về cơ chế Token-based Authentication sử dụng tiêu chuẩn JSON Web Token (JWT).
Giới thiệu Token-based Authentication trong Jersey REST API
JSON Web Token (JWT) là 1 tiêu chuẩn mở (RFC 7519), định nghĩa cách thức truyền tin an toàn giữa các ứng dụng bằng một đối tượng JSON. Dữ liệu truyền đi sẽ được mã hóa và chứng thực, có thể được giải mã để lấy lại thông tin và đánh dấu tin cậy nhờ vào “chữ ký” của nó. Phần chữ ký của JWT sẽ được mã hóa lại bằng HMAC hoặc RSA. Chi tiết các bạn xem lại bài viết “Giới thiệu Json Web Token (JWT)“.
Token-based Authentication là cơ chế xác thực người dùng dựa trên việc tạo ra token – một chuỗi ký tự (thường được mã hóa) mang thông tin xác định người dùng được server tạo ra và lưu ở client. Server sau đó có thể không lưu lại token này.
Tương tự như cơ chế Basic Authentication, với Token-based Authentication chúng ta cũng sẽ tạo ContainerRequestFilter để verify access của một user.
Token-based Authentication trong Jersey Server
Tạo Jersey project
Chúng ta sẽ tạo project mới tương tự project Basic Authentication ở bài viết trước.
Khai báo thư viện hỗ trợ JWT
Có nhiều thư viện Java hỗ trợ tạo JWT và verify JWT. Chúng ta có thể sử dụng một trong hai thư viện phổ biến sau:
SecurityContext : chứa thông tin chứng thực của một request. Sau khi chứng thực thành công, chúng ta cần cung cấp thông tin chứng thực user, role cho context class này. Các phương thức của SecurityContext sẽ được triệu gọi trước khi các resource method đã đánh dấu với các Annotation @RolesAllowed hoặc @PermitAll hoặc @DenyAll được thực thi.
BasicSecurityConext.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
packagecom.gpcoder.model;
importjava.security.Principal;
importjavax.ws.rs.core.SecurityContext;
/**
* The SecurityContext interface provides access to security related
* information. An instance of SecurityContext can be injected into a JAX-RS
* resource class field or method parameter using the @Context annotation.
Lưu ý: ngoài cách thêm thông tin header thủ công trong mỗi request, chúng ta có thể tạo một ClientRequestFilter để tự động thêm thông tin header như đã giới thiệu trong bài viết “Filter và Interceptor với Jersey 2.x“.
Với sự phát triển không ngừng của ngành công nghệ phần mềm và ứng dụng chu trình phát triển Agile, kiểm thử tự động (Automated Testing) đã trở thành một đề tài nóng bỏng trong giới kiểm thử và quản trị chất lượng phần mềm. Nhưng, làm thế nào để có thể tự động hoá việc kiểm thử cho một sản phẩm phần mềm thì không phải ai cũng có thể áp dụng hiệu quả. Đây chỉ là các bước mà mình, qua quá trình học tập và làm việc với kiểm thử tự động đúc kết được. Hy vọng sẽ giúp ích được phần nào cho các bạn trên con đường kiểm thử tự động này…
Bước 1: Phân tích khả năng áp dụng kiểm thử tự động.
Hiển nhiên, chúng ta không thể tự động hoá mọi việc trong kiểm thử phần mềm được. Có những phần mềm mới hay công nghệ viết ra phần mềm mà những công cụ kiểm thử tự động hiện tại chưa hỗ trợ hoặc chỉ hỗ trợ một phần. Ví dụ rõ ràng nhất là khi chúng ta kiểm thử một trang Web trên một trình duyệt mới, và lúc đó, công cụ kiểm thử tự động chưa có phiên bản mới hỗ trợ trên trình duyệt đó. Hay, một ví dụ khác về chương trình SAP, các nhà phát triển SAP đã đưa ra một lựa chọn ngăn chặn việc chạy script tự động trên nó, và để có thể kiểm thử tự động trên SAP, chúng ta cần yêu cầu các nhà phát triển chương trình SAP gỡ bỏ lựa chọn này.
Bước 2: Lựa chọn công cụ kiểm thử tự động thích hợp.
Sau khi xác định được sản phẩm hiện tại có thể làm Kiểm Thử Tự Động hay không, bước kế tiếp, chúng ta cần xác định nên sử dụng công cụ kiểm thử tự động nào. Công cụ nào hỗ trợ kiểm thử tự động cho công nghệ mà sản phẩm sử dụng? Ưu nhược điểm của từng công cụ? Ngôn ngữ kịch bản nào mà công cụ kiểm thử sử dụng? Nhân sự hiện tại có quen thuộc với công cụ đó hay không?
Bước 3: Xây dựng môi trường làm việc.
Môi trường làm việc bao gồm các khái niệm, chu trình, thủ tục và môi trường mà kịch bản kiểm thử tự động được thiết kế và viết ra. Bên cạnh đó, nó cũng nên bao gồm luôn cấu trúc thư mục, lưu trữ các kịch bản kiểm thử cũng như các mối quan hệ logic giữa các thành phần.
Bước 4: Viết kịch bản kiểm thử, thực thi và phân tích kết quả.
Dựa trên các kịch bản kiểm thử đã được tạo ra bằng kiểm thử thủ công, dựa vào ngôn ngữ kịch bản mà công cụ kiểm thử tự động hỗ trợ, chúng ta viết các đoạn mã tương tác với sản phẩm phần mềm trên các môi trường và thực thi nó. Sau khi thực thi các đoạn mã, chúng ta cần phân tích các kết quả đạt được và ghi lại các vấn đề của sản phẩm, nếu có.
TL;DR: Đừng bao giờ đánh nhau với borrow checker, nó được sinh ra để bạn phải phục tùng nó
Một trong những cơn ác mộng của lập trình viên khi làm việc với Rust đó là chuyện đập nhau với borrow checker, ví dụ như những lúc bị compiler chửi vào mặt như thế này.
fnmain() {
let a = vec![5];
let b = a;
println!("{:?}", a);
}
error[E0382]: use of moved value: `a`
--> borrowchecker.rs:4:22
|
3 | let b = a;
| - value moved here
4 | println!("{:?}", a);
| ^ value used here after move
|
= note: move occurs because `a` has type `std::vec::Vec<i32>`, which does not implement the `Copy` trait
Chỉ với một câu lệnh gán thông thường, chúng ta đã bị ăn lỗi.
Và trong hầu hết mọi trường hợp thì kẻ có lỗi chính là các lập trình viên Borrow checker cũng chưa bao giờ đập ai (nó chỉ đứng đó và chửi vô mặt người ta thôi). Lỗi ở đây chính là vì chúng ta không hiểu về mô hình quản lý bộ nhớ của Rust, và các quy tắc mà ngôn ngữ lập trình này đặt ra.
Vậy Rust kiểm soát bộ nhớ như thế nào? Và làm sao để chúng ta có thể làm vừa lòng Rust compiler trong những trường hợp như thế này?
Bài viết này sẽ giúp các bạn hiểu được chuyện đó thông qua hai vấn đề chính: Ownership (quyền sở hữu của một biến) và Borrowing (vay mượn/tham chiếu giữa các biến).
Ownership
Trong máy tính, bộ nhớ (memory) là từ dùng để chỉ các ô nằm liền kề nhau để lưu trữ thông tin.
Khi chúng ta khai báo một biến mới trong Rust, một vùng nhớ sẽ được cấp phát trong bộ nhớ, và nó sẽ mọc thêm mắt mũi chân càng như thế này:
Just kididng một biến a khi được khai báo, máy tính sẽ cấp phát một vùng nhớ trên stack, với giá trị mặc định là giá trị được truyền vào khi khai báo. Địa chỉ của vùng nhớ này sẽ được gán cho biến a.
Khi đó ta có thể coi là: vùng nhớ này thuộc về biến a, và a có quyền sở hữu (ownership) đối với vùng nhớ đó.
Một vùng nhớ tại một thời điểm chỉ có thể thuộc về duy nhất một biến. Và điều gì xảy ra nếu ta gán một biến vào một biến khác?
Quyền sở hữu vùng nhớ của biến này sẽ được chuyển sang biến khác, ở ví dụ trên ta khai báo biến a là một vector, sau đó gán biến a cho b, lúc này vùng nhớ mà biến a sở hữu đã được chuyển (move) sang cho b.
Nếu ngay sau đó chúng ta tìm cách đọc biến a thì sẽ gặp lỗi, vì không còn mang giá trị nào để có thể đọc được nữa.
error[E0382]: use of moved value: `a`
|
3 | let b = a;
| - value moved here
4 | println!("{:?}", a);
| ^ value used here after move
|
Để tránh việc giá trị của một biến bị moved sau khi thực hiện phép gán, ta có thể implement trait Copy cho kiểu dữ liệu của biến đó.
Chức năng của Copy trait đúng với tên gọi của nó, khi phép gán xảy ra, thì thay vì move giá trị của biến này sang biến khác, Rust runtime sẽ copy giá trị đó. Và sau phép gán, cả 2 biến vẫn có thể được sử dụng một cách bình thường.
Một số kiểu dữ liệu như i32 thường được implement sẵn trait này. Để biết kiểu dữ liệu mình tính xài được implement sẵn những trait nào thì bạn có thể xem trong phần Trait Implementations của kiểu dữ liệu đó.
Borrowing
Sao Rust compiler khó tánh dữ vậy? Giá trị của một biến thì thuộc quyền sở hữu của biến đó à? Vậy làm sao để truyền dữ liệu qua lại giữa các biến? Lỡ kiểu dữ liệu tui xài hổng có implement trait Copy thì làm sao?
Đến đây thì chúng ta bắt gặp một vấn đề rất là đời thường, xin nhắc lại, mặc dù Rust là một ngôn ngữ lập trình nhưng nó luôn phản ánh đúng với thực trạng của xã hội, đây là vấn đề thường ngày trong chuyện giao tiếp giữa người với người, vâng, rất nhân văn: Muốn xài đồ của người khác thì tất nhiên phải đi mượn (borrow).
Để mượn một giá trị trong Rust rất dễ, chúng ta chỉ cần đặt dấu & vào trước biến cần mượn. Ví dụ:
let b = &a;
Và tất nhiên khi đem cho mượn, giá trị của một biến vẫn thuộc quyền sở hữu của biến đó, Rust chỉ tạo một tham chiếu (references) đến vùng nhớ chứa giá trị này, chứ không move nó đi chỗ khác. Chính vì vậy, một biến có thể cho mượn bao nhiêu lần tùy ý. Nhưng với một điều kiện, đó là các tham chiếu đến giá trị của biến đó là readonly. Tức là không ai có thể thay đổi được giá trị của biến, trừ chính biến đó.
Cũng giống như khi bạn cho ai mượn ví tiền của bạn chỉ để xem cái ví như thế nào thôi, thì người ta không có quyền lấy tiền từ ví của bạn. Nhưng với vợ bạn thì sẽ khác…
Vợ bạn có thể dùng &mut để vừa mượn vừa thay đổi được số tiền trong ví của bạn.
Lưu ý: Có thể bạn biết rồi, trong Rust, mọi giá trị được khai báo đều là immutable, nghĩa là không thể thay đổi được. Vì thế một biến được khai báo theo cách thông thường thì cũng immutable nốt. Nếu ta mượn một biến immutable để ghi (mutate nó) thì sẽ bị ăn lỗi:
error[E0596]: cannot borrow immutable local variable `a` as mutable
--> borrowchecker.rs:3:18
|
2 | let a = 10;
| - consider changing this to `mut a`
3 | let b = &mut a;
| ^ cannot borrow mutably
Để không phải đau đầu với chuyện mượn/trả, moving của các biến, chúng ta có các quy tắc cần nhớ sau:
Một biến sau khi được gán thì không dùng được nữa (bị moved)
Muốn dùng một biến sau khi gán thì có thể borrow nó, hoặc implement Copy trait cho kiểu dữ liệu của nó
Một biến có thể được mượn để đọc (immutable borrow) không giới hạn số lần
Chỉ có duy nhất một lần mượn để ghi (mutable borrow) tại một thời điểm
Tạm thời viết chừng này đã, bài này nằm trong thư mục draft lâu quá rồi . Ở phần tiếp theo chúng ta sẽ tiếp tục tìm hiểu sang khái niệm còn lại, đó là Lifetime.
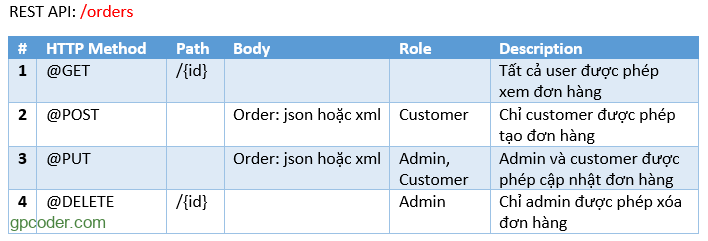
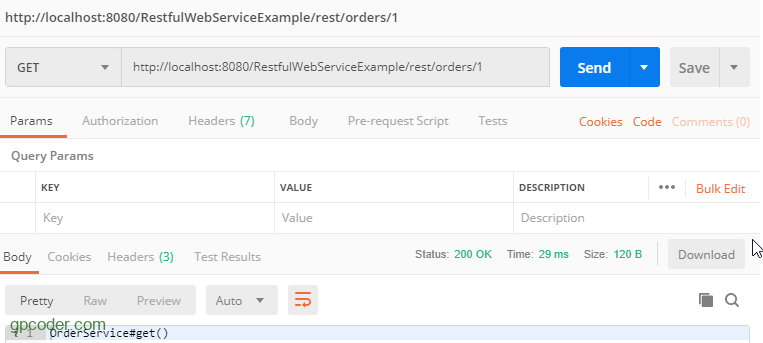
Tạo ứng dụng Java RESTful Client không sử dụng 3rd party libraries
Bài viết được sự cho phép của tác giả Giang Phan
Trong bài này tôi sẽ giới thiệu với các bạn cách gọi Restful web service sử dụng thư viện chuẩn java.net của Java, không sử dụng bất kỳ 3rd party libraries nào khác.
Các bước thực hiện
Để gọi restful web service thông qua lớp java.net chúng ta lần lượt thực hiện các bước sau:
Lưu ý: toàn bộ các API trả về kết quả là plain/text nên tôi không cần xử lý gì thêm. Nếu API các bạn nhận được là một chuỗi json, các bạn có thể sử dụng các thư viện như Gson hay Jackson để convert json về java object.
Trên đây là ví dụ đơn giản để gọi các Restful API sử dụng thư viện chuẩn java.net. Trong các dự án người ta thường ít sử dụng cách này do viết khá dài dòng và phức tạp. Trong các bài viết tiếp theo, tôi sẽ giới thiệu với các bạn các thư viện rất đơn giản và hiệu quả để tạo ứng dụng Java RESTful Client như Jersey client, OkHttp, Retrofit, Feign.
kafka_server là địa chỉ Apache Kafka server với định dạng host:port
partition_number là số lượng partitions mà chúng ta cần tạo
replication_number là số lượng replicate mà chúng ta muốn cho mỗi partition. Giá trị của tham số này sẽ phụ thuộc vào số lượng Apache Kafka server mà chúng ta đang có các bạn nhé!
Ngày 3/12, Diễn đàn Công nghệ FPT Techday 2021 diễn ra theo hình thức trực tuyến với chủ đề “Tái thiết toàn diện, bứt phá trong bình thường xanh”.
Diễn đàn đã thu hút hơn 100.000 người tham dự trực tiếp trên nhiều nền tảng khác nhau. Sự kiện một lần nữa giúp FPT khẳng định vai trò tiên phong chuyển đổi số hướng đến mục tiêu giúp các tổ chức, doanh nghiệp tái thiết toàn diện, bứt phá trong bình thường xanh, đồng thời tạo sân chơi trí tuệ cho các tài năng công nghệ trẻ.
Chia sẻ tại Diễn đàn Công nghệ FPT Techday 2021, ông Trương Gia Bình, Chủ tịch HĐQT FPT đã đặt lại bài toán chung về sứ mệnh của công nghệ trong bình thường xanh.
“COVID-19 ập đến như một tai họa. Doanh nghiệp đóng cửa, người lao động mất việc, cuộc sống đảo lộn. Chính trong thời điểm Covid-19 này chúng ta nhận ra rằng công nghệ đang mang một sứ mạng mới, công nghệ vị nhân sinh. Công nghệ vì cuộc sống của con người. Bằng công nghệ, chúng ta có thể chiến thắng COVID-19. Bằng công nghệ, các doanh nghiệp tái thiết mọi hoạt động quản trị, vận hành, kinh doanh để tăng tốc, bứt phá. Bằng công nghệ, người dân có thể thích ứng an toàn với dịch bệnh. Bằng công nghệ Việt Nam sẽ trở thành một điểm sáng phát triển kinh tế của thế giới, sẽ là một địa điểm hấp dẫn đầu tư nước ngoài và trở thành một quốc gia cường thịnh vào năm 2045” – ông Trương Gia Bình nhấn mạnh.
Tại sự kiện FPT Techday 2021, FPT đã ra mắt bộ giải pháp công nghệ gồm 6 sản phẩm giúp doanh nghiệp đảm bảo nguồn lực, vận hành linh hoạt, tăng tốc kinh doanh.
FPT eCovax nhân lực giúp doanh nghiệp đảm bảo nguồn lực dựa trên công nghệ AI và Big Data, thông qua việc số hóa toàn bộ quy trình tuyển dụng, hỗ trợ phỏng vấn sàng lọc, định hướng công việc phù hợp bằng Bot AI, lưu trữ – phân tích – dự báo nhu cầu của ứng viên.
FPT.AI Advisory Virtual Assistant – trợ lý ảo ứng dụng AI thế hệ thứ hai và giải pháp ký điện tử FPT.eContract và FPT.CA giúp doanh nghiệp tăng tốc kinh doanh ngay trong đại dịch. Còn với FPT AI Reader Flex và Ubot, mọi tài liệu văn bản với cấu trúc thông tin đa dạng, mọi nghiệp vụ trong doanh nghiệp đều được số hóa một cách dễ dàng và tự động hóa một cách trơn tru, giúp doanh nghiệp vận hành linh hoạt.
Cũng tại sự kiện, lần đầu tiên FPT trình diễn mô hình triển lãm thành phố xanh thông minh (Green Smart City) gồm 6 cấu phần chính: chính quyền xanh, doanh nghiệp xanh, giáo dục xanh, y tế xanh, cuộc sống xanh, lưu chuyển xanh. Triển lãm mang đến trải nghiệm đầy đủ về một thế giới bình thường xanh được tái thiết, vận hành, kết nối linh hoạt dựa trên nền tảng cốt lõi là công nghệ với gần 50 giải pháp, sản phẩm công nghệ của FPT, giúp vừa đảm bảo an toàn trong mọi tình huống vừa linh hoạt phát triển kinh tế.
Trong đó, chính quyền xanh – trái tim của thành phố xanh thông minh, được vận hành dựa trên các giải pháp công nghệ tiên tiến nhất giúp các nhà chức trách có được dữ liệu cập nhật theo thời gian thực về mọi hoạt động, từ đó ra quyết định kịp thời, chặt chẽ và ngay lập tức thấy được kết quả của sự thay đổi. Đặc biệt, trong bối cảnh COVID-19 diễn biến phức tạp trung tâm chỉ đạo xanh sẽ là nơi trao đổi và kết nối liên thông với các bộ chỉ huy để cùng bàn thảo và đưa ra lời giải cho các bài toán lớn mà không cần phải gặp trực tiếp.
Doanh nghiệp xanh, với sự hỗ trợ của công nghệ, có thể chủ động kiểm soát được tỷ lệ nhân sự xanh; quản trị, vận hành, làm việc từ xa. Hay khu vực y tế xanh mô phỏng một nền y tế không giấy tờ, với sự kết hợp nhịp nhàng của y bác sĩ với các hệ thống bệnh án điện tử, sổ khám bệnh điện tử… giúp công việc được thông suốt, giảm thời gian chờ đợi. Giáo dục xanh mang tới trải nghiệm học tập, giảng dạy giữa thầy và trò được kết nối thông suốt dựa trên công nghệ trí tuệ nhân tạo, phương pháp đào tạo kiến tạo xã hội giúp cho người học tích cực, chủ động và thích thú tham gia, gia tăng hiệu quả học tập.
Ông Nguyễn Văn Khoa, Tổng Giám đốc FPT chia sẻ: “COVID-19 đã khiến các doanh nghiệp nhìn nhận lại vai trò của công nghệ. Rất nhiều các doanh nghiệp đã chi hàng triệu USD để hoàn thiện khả năng quản trị và vận hành như Kim Tín, Boston Pharma, Tân Hoàng Minh, AceCook… Với hệ thống quản trị này, họ xác định rằng không để vuột mất cơ hội và bước vào kỷ nguyên số một cách vững chắc. Với năng lực về công nghệ, sự thấu hiểu và kinh nghiệm triển khai thành công rất nhiều dự án cho các chính phủ, doanh nghiệp trên thế giới và tại Việt Nam, chúng tôi tự tin và cam kết sẽ là một đối tác cùng đồng hành với các doanh nghiệp để tái thiết an toàn – linh hoạt – thần tốc trong bình thường xanh”.
Cùng với việc ra mắt các giải pháp công nghệ mới, ngay tại sự kiện, Giám đốc Công nghệ của FPT, ông Vũ Anh Tú cam kết: “Tập đoàn sẽ tiếp tục nghiên cứu và ứng dụng những công nghệ mới để giúp doanh nghiệp giải những bài toán một cách nhanh hơn, chính xác hơn và ưu việt hơn. Đồng thời tập trung vào việc kiến trúc lại các sản phẩm sẵn có để tạo ra một nền tảng mở để cộng đồng cùng tham gia phát triển, có tính tin cậy và linh hoạt, có khả năng thấu hiểu và tự học hỏi để thông minh hơn, có tính bảo mật cao”.
Trong thời gian tới, FPT sẽ tập trung và phát triển 4 nền tảng công nghệ lõi: Hyper Automation; AI; Cloud và Blockchain.
Với công nghệ Hyper Automation, các giải pháp của FPT sẽ giúp doanh nghiệp tự động hóa thông minh cho nhiều quy trình có giá trị lớn nhưng dữ liệu phi cấu trúc, phân mảnh, chẳn hạn như: phân tích tình trạng nợ công ty vay vốn; đối soát hóa đơn; tổng đài ảo gọi điện nhắc nhở tự động về khoản vay, tình trạng hồ sơ…
Với công nghệ trí tuệ nhân tạo (AI), FPT sẽ tạo ra những trợ lý ảo thế hệ mới có khả năng suy luận gần như con người trên cơ sở những thông tin tiếp nhận từ các giác quan và xây dựng hệ sinh thái giải pháp ứng dụng AI phục vụ nhiều ngành công nghiệp khác nhau.
Trong lĩnh vực Cloud, FPT sẽ đẩy mạnh mô hình cung cấp dịch vụ PaaS (cung cấp nền tảng như một dịch vụ) và đặc biệt là SaaS (cung cấp phần mềm như một dịch vụ). Qua đó, công nghệ và sản phẩm công nghệ Made by FPT không chỉ phục vụ cho việc phát triển nội tại của FPT mà còn phụng sự cho bền vững, đột phá của khách hàng.
Làm sao để cho Dev thấy màn hình của phone mình đang gặp 1 con bug? Cách đơn giản nhất là mang cái phone tới bàn làm việc của Dev. Nhưng nếu Dev không làm việc chung tòa nhà với Tester hoặc ở một quốc gia hay châu lục khác thì sao? Có một cách khá đơn giản đó là hiển thị màn hình của thiết bị trên PC và share màn hình PC với họ.
Đối với Android, việc này khá đơn giản vì có hằng tá các công cụ hỗ trợ, đặc biệt là AndroidScreenCast (hàng chính hãng & miễn phí luôn nhá.)
Coi như các bước chuẩn bị đã xong, các bạn gắn thiết bị iOS như iPhone, iPad vào PC thông qua cable
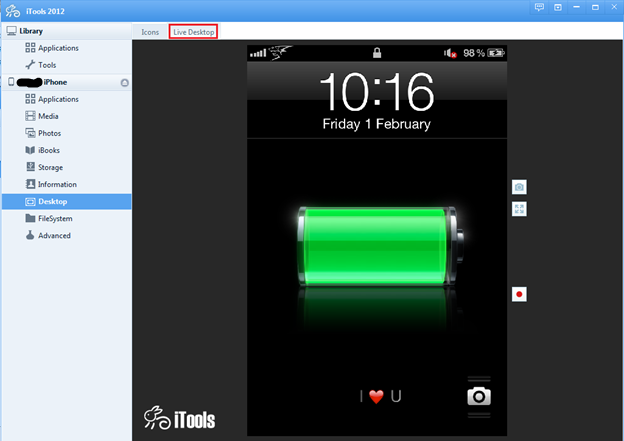
Mở iTools & chọn Desktop, tiếp theo chọn “Live Desktop” và thế là bạn có thể thấy màn hình iOS trên PC.
Bạn biết những cách khác hoặc tool khác, hãy chia sẻ tiếng nói của mình :). Mình rất mong nhận được những đóng góp, gợi ý cũng như những lời đề nghị để nội dung của các bài viết trên VNTesters ngày càng phong phú và hữu ích cho mọi người, đặc biệt là các bạn Tester (kỹ sư kiểm thử phần mềm) chuyên nghiệp.
Như đã có lần mình đề cập, việc đọc paper cũng khá là quan trọng, vì bên cạnh việc được đọc từ những nguồn kiến thức “sạch”, và chất lượng, chúng ta còn sẽ xây dựng được cho mình một kĩ năng khác, là kĩ năng đọc sâu và kĩ năng nghiên cứu, khá là quan trọng trong thời đại thông tin tràn lan trên Internet, khi mà chúng ta tiếp xúc với một lượng lớn thông tin nhưng không có thời gian để lãnh hội hết, dẫn tới một thói quen hết sức tai hại đó là đọc một cách hời hợt (shallow reading).
Nằm trong hoạt động nghiên cứu của nhóm rbvn/algorithm, tuần này mình đọc một paper khá thú vị đó là Why Functional Programming Matters của John Hughes. Dưới đây là một vài ghi chép của mình trong quá trình đọc, share lên để giúp cho các bạn có cái nhìn toàn cảnh về nội dung của paper, giúp cho việc đọc trở nên dễ dàng hơn, và hoàn toàn không có mục đích tổng hợp, tóm tắt.
■ Trong paper này cũng có vài đoạn đọc vào khá là thú vị, mình sẽ không ghi ra đây mà để cho các bạn tự đọc và tự thấy. Ông tác giả cũng khá là hài hước mà không kém phần nghiêm túc.
Đây là một trong số những paper mà bất cứ ai quan tâm đến computer science đều phải đọc ít nhất một lần trong đời, và khá là dễ đọc, trừ vụ code minh họa được viết bằng Miranda (a.k.a daed lang ), trông khá giống với Haskell.
Quan điểm mà tác giả John Hughes đưa ra trong bài là: Một dự án phần mềm cần phải được tổ chức một cách tốt nhất có thể, để dễ viết hơn, dễ debug hơn, reuse code tốt hơn. Và yếu tố quan trọng nhất để có một cấu trúc project tốt là Modularity (chia project thành nhiều module nhỏ).
Tác giả viết:
Modular design brings with it great productivity improvements. First of all, small modules can be coded quickly and easily. Secondly, general purpose modules can be re-used, leading to faster development of subsequent programs. Thirdly, the modules of a program can be tested independently, helping to reduce the time spent debugging.
Vậy modularize là làm gì? Là chia nhỏ nó ra thành nhiều bài toán con, giải từng bài con đó rồi tổng hợp chúng lại:
When writing a modular program to solve a problem, one first divides the problem into sub- problems, then solves the sub-problems and combines the solutions.
Và các functional programming languages cung cấp cho chúng ta 2 features quan trọng để phục vụ cho việc modularize, đó là:
Higher-order Function
Lazy Evaluation
Đối với higher-order function, tác giả đưa ra một loạt ví dụ minh họa, như là xây dựng một hàm reduce, nhận vào một hàm bất kỳ (thể hiện đặc tính của higher-order function) để thực hiện tính toán trên một list, từ đó thực hiện việc tính toán các phép toán bất kỳ chỉ bằng việc kết hợp (compose) các chương trình nhỏ hơn (module) với hàm reduce:
reduce :: (a -> a -> a) -> a -> [a] -> a
reduce f a [] = a
reduce f a (x:xs) = f x (reduce f a xs)
-- tính tổng một listadd a b = a + b
sum = reduce add 0sum [1, 2, 3, 4] == 10-- tính tích một listmultiply a b = a * b
product = reduce multiply 1product [1, 2, 3, 4] == 24
Về lazy evaluation, tác giả giải thích bằng cách đưa ra một ví dụ hết sức đơn giản nhưng mà đọc lâu thiệt lâu mới hiểu: Giả sử có hai chương trình con (hoặc là hàm) f và g, chúng ta có thể compose chúng như sau:
(g . f) input
-- tương đương vớig (f input)
Có nghĩa là, ta sẽ gọi hàm f với tham số là input, đồng thời lấy kết quả trả về để làm tham số cho câu lệnh gọi hàm g.
Đặc tính laziness của Haskell và các functional programming languages nằm ở chỗ, việc thực thi f và g diễn ra một cách đồng bộ và chặt chẽ (ai dịch chữ strict synchronisation cho tui với), f chỉ được thực thi và trả về giá trị khi g thực hiện đọc tham số đầu vào của nó, và f cũng sẽ bị dừng khi g dừng lại.
The two programs f and g are run together in strict synchronisation. F is only started once g tries to read some input, and only runs for long enough to deliver the output g is trying to read. Then f is suspended and g is run until it tries to read another input. As an added bonus, if g terminates without reading all of f’s output then f is aborted.
Và trong trường hợp f là một hàm sinh ra một tập giá trị có số lượng cực kì lớn, nếu implement trên các ngôn ngữ thông thường (thực thi xong f, lấy kết quả, truyền vào g) thì có thể sẽ cần một lượng bộ nhớ cực kì lớn, mà có khi là không đủ, ví dụ:
-- trả về danh sách các số từ input đến +∞f input = [input..]
Như thế, nhờ vào đặc tính lazy evaluation, chúng ta có thể dễ dàng phân tách chương trình thành nhiều module nhỏ mà không cần quá bận tâm đến time và space complexity. Có thể thấy rõ qua ví dụ tính căn bậc 2 dùng phương pháp Newton-Raphson.
■ Trước khi đọc tiếp, các bạn nên dừng lại và tìm đọc về thuật toán tìm căn bậc hai theo phương pháp Newton-Raphson trước nhé.
import Prelude hiding (sqrt)
nextN x = (x + N/x)/2within eps (a:b:rest) =
if abs (a - b) <= eps then
b
else
within eps (b:rest)
sqrtN = within 0.0001 (iterate (next N) 1.0)
■ Đoạn code đã được convert sang Haskell để dễ chạy, không kiếm ra cái Miranda compiler nào cả, lệnh repeat chính là iterate trong Haskell.
Ở đây, output của câu lệnh iterate (next N) 1.0 là một list dài vô hạn, nhưng trong câu lệnh within 0.0001 (iterate (next N) 1.0), nó sẽ dừng lại ngay khi chúng ta tìm được hai giá trị xấp xỉ nhau. Thế mới thấy được ưu điểm của lazy evaluation.
Tác giả kết thúc phần kĩ thuật bằng ví dụ ở mục 5: thuật toán Alpha-beta để implement trò chơi tic-tac-toe, minh họa một cách đầy đủ cả hai ứng dụng của higher-order function và lazy evaluation để định nghĩa gametree và sinh ra các nước đi cho cây trò chơi (vốn là một thao tác cực kì tốn kém).
Thông qua paper này, tác giả đã khẳng định được tầm quan trọng của functional programming, cũng như trả lời được câu hỏi mà có lẽ nhiều người cũng hay hỏi: “Why Functional Programming?”, thông qua việc làm rõ 3 vấn đề sau:
Modularity là yếu tố quan trọng để phát triển một phần mềm tốt.
Higher-order function và lazy evaluation là hai feature quan trọng của các functional programming languages giúp cho việc modularize hiệu quả hơn, giúp cho việc phát triển được productive hơn.
Suy ra Functional Programming đóng vai trò quan trọng trong việc bảo đảm chất lượng và productivity của các dự án phần mềm.
Hy vọng những ghi chép trên sẽ có ích cho các bạn nào đang có ý định tự mình đọc paper này. Hoặc giúp các bạn phần nào trả lời cho câu hỏi liệu mình có nên dấn thân vào tìm hiểu FP hay không.
Còn bây giờ thì mình phải tạm gác khoa học sang một bên, vợ bắt đi ngủ rồi, hẹn gặp lại các bạn trong các bài review paper sắp tới.
Các công ty phần mềm nước ngoài tại Việt Nam đóng góp rất nhiều cho việc tạo ra những sản phẩm công nghệ hiện đại và đáp ứng nhu cầu sử dụng của người dùng. Tìm hiểu thêm top các công ty IT đang phát triển tại Việt Nam sẽ giúp bạn đọc có thêm cái nhìn tổng quan về ngành công nghệ thông tin ở nước ta hiện nay.
*Số thứ tự trong bài viết chỉ nhằm liệt kê các công ty, không nhằm mục đích xếp hạng hay đánh giá
Trực thuộc tập đoàn FPT, FPT Software hiện là công ty xuất khẩu dịch vụ phần mềm lớn nhất nhì ở Việt Nam và đang hiện diện tại 11 quốc gia trên thế giới và lớn nhất Đông Nam Á.
2. KMS Technology
KMS Technology Việt Nam là nhà cung cấp hàng đầu về dịch vụ kiểm thử và tư vấn, dịch vụ thiết kế app cũng như các dịch vụ outsourcing khác.
3. Vinova
Trụ sở đặt tại Singapore, Vinova chuyên cung cấp các dịch vụ phát triển ứng dụng web và thiết bị di động sáng tạo, đẳng cấp.
4. Harvey Nash
Harvey Nash được đánh giá rất cao trong dịch vụ thuê ngoài công nghệ thông tin/ dịch vụ nghiệp vụ doanh nghiệp, lĩnh vực tìm kiếm nhân sự cấp cao.
5. Global CyberSoft
Công ty lập trình app GCS được đánh giá là công ty hàng đầu về thiết kế app tại Việt Nam sau hơn 13 năm chính thức gia nhập thị trường. Chất lượng sản phẩm và hoạt động kinh doanh hiệu quả của công ty đã được ghi nhận qua thời gian.
6. Fujinet Systems JSC
Công ty hoạt động chủ yếu cho các khách hàng đến từ Nhật Bản và đã nhiều năm liên tiếp giành được các giải thưởng là công ty hàng đầu trong lĩnh vực IT outsourcing.
7. Netcompany
Với các chi nhánh đặt tại 10 quốc gia, Netcompany cung cấp các giải pháp CNTT quan trọng đối với doanh nghiệp để hỗ trợ phát triển một xã hội bền vững, các doanh nghiệp thành công và cạnh tranh tốt hơn trong thời đại chuyển đổi công nghệ số hiện nay.
8. E.V.O.L.A.B.L.E Asia (Evolable Châu Á tại Việt Nam)
Công ty hoạt động với hình thức “các phòng Lab” – một hình thức mới mẻ của ngành các công ty IT. Evolable định hướng công ty trở thành nhà cung cấp dịch vụ hàng đầu Châu Á.
9. ASUS Việt Nam
Là một trong những thương hiệu IT luôn đạt doanh thu hàng đầu tại Đài Loạn, ở Việt Nam, ASUS khá phổ biến với các dòng sản phẩm là các thiết bị thông minh, máy tính bảng, điện thoại, máy tính…
10. NashTech Vietnam
NashTech Vietnam là công ty thành viên của tập đoàn Harvey Nash đến từ vương quốc Anh. Đây được xem là nơi tập hợp những chuyên gia trong lĩnh vực công nghệ, cung cấp giải pháp thông minh nhằm tạo dựng giá trị thực tiễn cho khách hàng.
11. HANSEN TECHNOLOGIES
Hansen là nhà cung cấp phần mềm và dịch vụ toàn cầu cho ngành năng lượng, nước và truyền thông. Đến nay đã tiếp cận được hơn 600 khách hàng đến từ 80 quốc gia khác nhau.
12. Techbase Vietnam
Công ty Techbase Việt Nam có 100% vốn đầu tư từ Tập đoàn Yahoo Nhật Bản. Hoạt động chính của công ty là phát triển phần mềm cho các sản phẩm của Tập đoàn Yahoo Nhật Bản (hơn 20 dịch vụ).
13. Bosch Việt Nam
Bosch là một trong những công ty hàng đầu trong mảng IT – Consultant trên thế giới. Bosch Việt Nam bắt đầu hoạt động tại Việt Nam từ năm 1994, từ đó đến nay liên tục là công ty đi đầu trong các hoạt động về tăng trưởng doanh thu và môi trường làm việc phát triển.
14. Axon Active Vietnam
Axon Active Việt Nam là một công ty phát triển phần mềm quốc tế có trụ sở chính tại Thụy Sĩ. Tại Việt Nam, Axon Active không chỉ chú trọng đến chất lượng sản phẩm mà cũng rất để tâm đến phát triển môi trường làm việc cho nhân viên.
15. Absolute Software (Vietnam) Ltd
Có trụ sở đặt tại Vancouver, Canada, hoạt động chính của Absolute Software là cung cấp các giải pháp quản lý rủi ro dữ liệu và bảo mật bền vững cho hàng nghìn khách hàng trên toàn cầu.
16. Nexus Frontier Tech
Với các văn phòng đặt tại London, Tokyo, Singapore, Boston và Hà Nội, Nexus Frontier Tech tập trung vào việc phát triển các giải pháp AI cụ thể, hiệu quả nhất cho khách hàng.
Các công ty phần mềm nước ngoài tại Việt Nam sẽ liên tục được cập nhật để người đọc có thêm các thông tin hữu ích. Đón đọc thêm nhiều bài viết khác tại topdev.vn/blog
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products
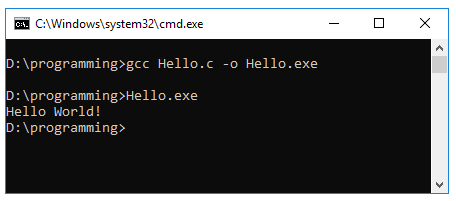
Xét ví dụ chương trình Hello World (in ra dòng chữ Hello World) sau:
Hello.c
/*
* Hello.c
* Created on: Mar 24, 2019
* Author: stackjava
* Description: Writes the words "Hello World!" on the screen
*/
#include
int main() {
// print 'Hello World' to console
printf("Hello World");
return 0;
}
/* hello.c ...*/ phần mô tả file. Cho biết tác giả, ngày tạo và mục đích của file. Phần này cũng có thể coi là một chú thích.
#include <stdio.h> là lệnh tiền xử lý thực hiện khai báo thư viện stdio.h. Thư viện này cho phép chúng ta sử dụng hàm printf()
int main() {...} là một hàm với tên là main, có kiểu giá trị trả về là int
// print 'Hello Worl' to console là một chú thích, dùng để giải thích code cho người đọc, nó sẽ được trình biên dịch bỏ qua khi biên dịch
printf("Hello World \n"); Thực hiện in ra dòng chữ ‘Hello World‘. Chi tiết việc in ra màn hình của hàm printf() được định nghĩa trong file stdio.h
return 0; kết thúc hàm main và trả về kết quả là 0
Phần mô tả file và phần chút thích không gây ảnh hưởng tới chương trình (có cũng được mà không có cũng không sao)
Khi dùng Google Calendar hoặc Reminder.app của macOS, mình rất thích chức năng tạo nhanh một event bằng cách nhập vào nội dung một cách tự nhiên như khi đang nói, ví dụ:
get hair cut at 10am every Sunday
hoặc là
doctor appointment at 1pm on Monday
Khi nhận được input như này, một event mới sẽ được tạo ra với ngày và giờ tương ứng, còn nội dung của event sẽ là phần text mở đầu, ví dụ “get hair cut”, hoặc “doctor appointment”.
Thường thì cái gì mình thích, mình sẽ tìm cách clone lại, chức năng này cũng ko ngoại lệ.
Vì bài viết này là phần tiếp theo của bài viết trước, chúng ta sẽ tiếp tục dùng Rust và Nom. Recommend các bạn đọc kĩ phần trước, và chuẩn bị những kiến thức cơ bản của Rust, nhất là về Result, Option, cargo test, trước khi đọc tiếp bài này.
Đây không phải là cú pháp mà Google Calendar hay Reminder.app sử dụng, nhưng đây sẽ là cú pháp chúng ta sẽ dùng trong bài viết này, đơn giản là vì nó… đơn giản
Cấu trúc của một event input là một tổ hợp của nhiều token như sau:
Trong đó:
<event-text> là nội dung của event cần tạo.
<time> là thời gian diễn ra event, có thể nhập thời gian ở 2 dạng: at 10pm hoặc 11:32. Từ khóa “at” có thể được bỏ đi, phần meridiem indicator (“am” hoặc “pm”) cũng là optional.Một token <time> sẽ có dạng:
Nếu chỉ có giá trị giờ (hour) mà không có phút (minutes) thì mặc định sẽ là 00 phút.
<repeat> và <date>: Hai token này đi chung với nhau vì đôi lúc, những event sẽ lặp lại định kỳ (ví dụ nhắc trả bill hàng tháng, ví dụ every 15th), cũng có thể chỉ diễn ra một lần (on Monday), giá trị on hoặc every sẽ được dùng để xác định token <repeat>.
date = ?("on"|"every") + date
Để cho đơn giản thì chúng ta sẽ tạm bỏ qua việc xác thực nội dung nhập vào, nên những case như thế này vẫn sẽ được chấp nhận:
32:42pmhoặc
24:59
Trên thực tế, validation cũng không phải là nhiệm vụ của parser.
Thuật toán parse event
Vậy ta sẽ parse nội dung như thế nào sau khi đã xác định được 3 thành phần trên?
Thuật toán parse của chúng ta sẽ duyệt từng kí tự từ đầu đến cuối string, và tìm cách parse ra từng token.
Chạy từ đầu input cho đến trước khi ta gặp phần tử đầu tiên của một <time> token, lưu tất cả kí tự đã gặp lại:
Tiếp theo, khi bắt gặp phần tử đầu tiên của <time> token (là chữ “at”), cho đến cuối (là khi đọc được phần meridiem indicator “am” hoặc “pm”) ta sẽ bắt đầu quá tình parse <time> token.
Sau khi xác định xong <time> token, đi tiếp và nếu gặp “on” hoặc “every”, ta sẽ bắt đầu parse <date> token.
Sau khi đã xác định được <time> token và <date> token, thì phần nội dung chúng ta đã lưu lại từ đầu chính là <event-text>. Đến lúc này ta hoàn tất quá trình parse.
Implementation
Xác định xong cú pháp và thuật toán là coi như giải quyết xong 75% bài toán rồi, 95% còn lại nằm ở việc đánh nhau với Rust bây giờ ta implement thôi.
Việc đầu tiên là define ra cấu trúc dữ liệu cho kết quả sau khi parse, ta sẽ gọi nó là ReminderEvent:
Một ReminderDate sẽ chứa content là một chuỗi thô chưa qua xử lý, ví dụ như “Tuesday”, “14/12”. Bao giờ cần xài thì parse tiếp sau, trong bài viết này mình sẽ lưu raw. Nếu đây là một event diễn ra định kì (có chữ “every” khi parse date), thì trường repeated sẽ là true.
Một ReminderTime chứa các giá trị giờ / phút dưới dạng chuỗi thô, giá trị meridiem indicator sẽ được lưu trong trường meridiem, vì nó có thể có, có thể không tồn tại trong input, mặc định sẽ là true cho “am”, và false cho “pm”.
Vì các giá trị raw được lưu dưới dạng string slice &str, tham chiếu trực tiếp từ input, bản thân Rust compiler không tự suy ra được lifetime cho các giá trị này, nên ta phải tự annotate bằng <'a>.
Tiếp theo, kế hoạch thực hiện sẽ là:
Viết hàm parse ReminderTime
Viết hàm parse ReminderDate
Sau đó kết hợp 2 hàm này để viết hàm parse ReminderEvent
Hàm parse ReminderTime
Ở bài trước ta đã biết, một parser dùng Nom sẽ có dạng fn(&str) -> IResult, hàm parse_time của chúng ta cũng sẽ có dạng như thế:
Trước khi bắt tay vào code, mình có thói quen viết trước một vài test case, để khi implement chúng ta sẽ biết được mình có đi đúng hướng hay không. “Má, chém gió vl! ” — Bình luận từ đồng nghiệp của tác giảĐây là một thói quen tốt, các bạn cũng nên làm như vậy, tốn time chút nhưng hiệu quả.
Trong hàm test_parse_time() ở trên, ta tạo một mảng test_times chứa tập các tuple dạng (input, expected_result). Trong đó, các input là các string mà trên thực tế sẽ được nhập vào từ phía user, expected_result là một giá trị kiểu Result, nếu nó là giá trị Ok(...) có nghĩa là input này parse được, còn giá trị Err() là trường hợp lỗi. Mỗi giá trị Ok(...) sẽ có dạng (hour, minute, meridiem). Trong vòng lặp tiếp theo của hàm test, ta duyệt qua từng test case, lấy ra giá trị thực tế actual từ parser (kiểu ReminderTime) và so sánh nó với từng giá trị trong tuple test.
Có test rồi thì ta có thể implement được rồi, quay lại hàm parse_time, việc đầu tiên là dùng các combinator của nom để đọc input, nhắc lại cú pháp của <time> token:
Trước khi đi vào giải thích, đây là hàm parse_time hoàn chỉnh:
fnparse_time(input: &str) -> IResult<&str, ReminderTime> {
let (remain, (_, _, hour, opt_min, _, am)) = tuple((
opt(tag("at")),
multispace0,
digit1,
opt(tuple((tag(":"), digit1))),
multispace0,
opt(alt((tag("am"), tag("pm")))),
))
.parse(input)?;
let (_, minute) = opt_min.unwrap_or(("", "00"));
let meridiem = am == Some("am") || am == None;
Ok((remain, ReminderTime { hour, minute, meridiem }))
}
Để đọc chuỗi “at”, ta có thể dùng hàm tag() của nom, vì “at” có thể có hoặc không xuất hiện trong input, ta dùng hàm opt() để cho nom biết nó là một giá trị optional.
opt(tag("at"))
Tiếp sau “at” là một hoặc nhiều kí tự space, ta dùng multispace0 để xác định nó. Sau đó là hour, cấu thành từ một hoặc nhiều kí tự số, ta dùng digit1 để parse.
Phần giá trị phút minute, thường sẽ đi sau hour, cách nhau bằng một kí tự ':', nó cũng là optional.
opt(tuple(tag(":"), digit1))
Tiếp theo lại là một mớ khoảng trắng nếu có, tiếp tục dùng multispace0.
Cuối cùng là phần meridiem indicator, có thể có hoặc không, ta dùng hàm alt() để parse lấy một trong 2 giá trị tag("am") và tag("pm").
opt(alt((tag("am"), tag("pm"))))
Các giá trị sau khi parse được lưu vào một tuple, mỗi phần tử của tuple sẽ được gán với một biến, lần lượt là remain, hour, opt_min, am. Trong đó remain là phần chuỗi còn sót lại sau quá trình parse.
Vì phần minute là một giá trị optional, kiểu Option, ta cần một bước hậu xử lý để nếu nó là None thì mặc định nó thành giá trị "00".
let (_, minute) = opt_min.unwrap_or(("", "00"));
Tương tự, giá trị am cũng là optional, nhưng ta sẽ có 2 trường hợp: Hoặc nó là Some("am"), hoặc nó là None, nếu đúng thì giá trị meridiem của kết quả trả về sẽ là true, ngược lại nó là false.
let meridiem = am == Some("am") || am == None;
Cuối cùng, nếu mọi thứ ok hết, ta tạo ra một object ReminderTime từ các giá trị đã được xử lý ở trên, và trả về kết quả.
Chạy thử hàm test, ta sẽ thấy mọi thứ đều pass hết, lý do không phải vì test lụi, mà là vì chúng ta code xịn, chả có mấy khi, cứ tự tin lên.
running 1 test
test test_parse_time ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Hàm parse ReminderDate
Tiếp theo là hàm parse parse_date, như trên, ta cũng bắt đầu bằng:
Khá đơn giản, vì phần <date> nằm sau phần <time> token, hai phần này ngăn cách với nhau bằng một hoặc nhiều khoảng trắng, ta dùng multispace0 để parse các khoảng trắng này.
Tiếp theo, để vì nội dung mở đầu của <date> là “on” hoặc “every”, thay vì lấy luôn giá trị raw của chúng dưới dạng string, ta có thể map các giá trị này thành một giá trị kiểu boolean, và dùng luôn giá trị đó để xác định thuộc tính repeated của <date> token. Ta dùng hàm value() để map giá trị “on” thành false, và “every” thành true. Vì phần “on” || “every” là optional, ta wrap biểu thức trên bằng opt().
Sau đó là bước hậu xử lý, giá trị repeat sau khi parse sẽ có 2 trường hợp: Some(true|false) hoặc None, nếu giá trị trả về là None, ta có thể mặc định nó thành false.
Phần còn lại của input sẽ là phần ReminderDate.content, chúng ta chỉ việc lấy ra dưới dạng raw string, xài rest combinator để lấy toàn bộ ra. Nếu phần content là một chuỗi rỗng (empty), thì ta sẽ mặc định nó thành “today”.
Cuối cùng là khởi tạo object ReminderDate rồi trả về kết quả.
Lại tiếp tục chạy test để thấy khả năng code thần sầu của tác giả:
running 1 test
test test_parse_date ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Như vậy, chúng ta đã hoàn thành 2 building block quan trọng đó là parse_time() và parse_date() để xác định được <time> và <date> token. Bước cuối cùng là kết hợp 2 parser này và parse nội dung input hoàn chỉnh.
Hàm parse ReminderEvent
Xem lại cú pháp của một input event hoàn chỉnh:
<event-text> <time> <repeat> <date>
Đến đây hẳn các bạn cũng đoán được logic của hàm parse_event(), nhưng mà khoan đã, việc đầu tiên là define ra cái hàm:
#[test]fntest_parse_event() {
let test_events: [(&str, Result<(&str, &str, &str, bool, &str, bool), ()>); 10] = [
("go feed the fish at 10am", Ok(("go feed the fish", "10", "00", true, "today", false))),
("feed the fish at 10:00am", Ok(("feed the fish", "10", "00", true, "today", false))),
("walk the dog 10:00am today", Ok(("walk the dog", "10", "00", true, "today", false))),
("feed the cat at 4 tomorrow", Ok(("feed the cat", "4", "00", true, "tomorrow", false))),
("get haircut at 14:24 pm", Ok(("get haircut", "14", "24", false, "today", false))),
("credit card pay at 8am", Ok(("credit card pay", "8", "00", true, "today", false))),
("credit card pay at 8:00 every 20th", Ok(("credit card pay", "8", "00", true, "20th", true))),
("cafe with Justin at Ginza at 6 on 08/23", Ok(("cafe with Justin at Ginza", "6", "00", true, "08/23", false))),
("pick up books at library at 10am every Sunday", Ok(("pick up books at library", "10", "00", true, "Sunday", true))),
("lorem ipsum doro tata", Err(()))
];
for test_case in test_events {
let result = parse_event(test_case.0);
if test_case.1.is_ok() {
let (_, actual) = result.unwrap();
let expected = test_case.1.unwrap();
assert_eq!(actual.text, expected.0);
assert_eq!(actual.time.hour, expected.1);
assert_eq!(actual.time.minute, expected.2);
assert_eq!(actual.time.meridiem, expected.3);
assert_eq!(actual.date.content, expected.4);
assert_eq!(actual.date.repeated, expected.5);
} else {
assert!(result.is_err());
}
}
}
Trong đó input là nội dung event input sẽ được nhập vào từ user, và các field trong Result sẽ là các field tương ứng của object ReminderEvent, ReminderTime và ReminderDate.
Bằng việc kết hợp các hàm parse_time() và parse_date(), ta có thể implement hàm parse_event() một cách rất đơn giản:
fnparse_event(input: &str) -> IResult<&str, ReminderEvent> {
let (input, (vtask, (time, date))) =
many_till(anychar, pair(parse_time, parse_date)).parse(input)?;
let text = vtask
.iter()
.map(|c| c.to_string())
.collect::<Vec<String>>()
.join("")
.trim()
.to_string();
Ok((input, ReminderEvent { text, time, date }))
}
Ta dùng combinator tên là many_till(anychar, ...) để lấy tất cả các kí tự xuất hiện trong input, cho đến khi parse được <time> hay <date> token.
Giá trị trả về của many_till là một vector chứa nhiều kí tự Vec<char>, việc còn lại chỉ là join() chúng lại để thu về một giá trị kiểu String.
Cuối cùng, chạy lại toàn bộ test:
running 3 tests
test test_parse_date ... ok
test test_parse_time ... ok
test test_parse_event ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Như vậy chúng ta đã hoàn thành việc build một parser hết sức đơn giản, để parse một input event dưới dạng ngôn ngữ tự nhiên thành một data struct hoàn chỉnh. Từ đây ta có thể xây dựng được những ứng dụng triệu đô, dư sức cạnh tranh với Google Calendar hay Reminder.app (tự tin không ai đánh thuế mà).
Input:
"write new blog post at 9am every 14th Dec"
Output:
ReminderEvent{ text:"write new blog post", date:ReminderDate{ content:"14th Dec", repeated:true}, time:ReminderTime{ hour:"9", minute:"00", meridiem:true}}
Hy vọng vẫn có bạn đọc xuống được đến tận đây mà không drop giữa chừng và hy vọng bài viết này giúp các bạn hiểu rõ hơn về Nom Parser, cũng như kĩ thuật Parser Combination. Lần tới, khi cần parse một nội dung gì đó, thay vì đâm đầu vào sử dụng RegEx, hãy thử chậm lại một tí và sử dụng Nom hay một thư viện Parser Combination nào đó để build, mình nghĩ ngoài đồng nghiệp ra, thì chính bạn trong tương lai sẽ rất cảm kích cái quyết định đó của bản thân. Chúc các bạn may mắn
Trong các bài viết trước chúng ta sử dụng thư viện Jersey client để gọi các RESTful API. Trong bài này, tôi sẽ giới thiệu với các bạn thư viện khác, rất mạnh mẽ để gọi các RESTful API là OkHttp.
Giới thiệu OkHttp
OkHttp là một thư viện Java mã nguồn mở, được thiết kế để trở thành một HTTP Client hiệu quả với tốc độ tải nhanh và giảm băng thông đường truyền.
Một số đặc điểm nỗi bật của OkHttp:
Hỗ trợ Http/2 protocol.
Connection pooling : giúp giảm độ trợ của các request.
GZIP compression : hỗ trợ nén dữ liệu khi truyền tải.
Interceptor là một tính năng rất hữu ích nó giúp chúng ta có thể chỉnh sửa request/response, retry call, monitor ứng dụng.
OkHttp hỗ trợ 2 loại Interceptor:
Application Interceptor : loại interceptor này thường được sử dụng để thay đổi headers/query cho cả request/ response. Loại interceptor này chắc chắn được gọi 1 lần ngay cả khi nó được truy xuất từ bộ nhớ đệm (Cache).
Network Interceptor : được sử dụng để giám sát yêu cầu giống như được truyền qua mạng. Nó rất hữu ích để theo dõi chuyển hướng (redirect) , thử lại (retry) và cung cấp quyền truy cập vào các resource của request. Loại interceptor này sẽ KHÔNG được gọi nếu nó được truy xuất từ bộ nhớ đệm (Cache).
Bây giờ chúng ta sẽ sử dụng Interceptor để tự động thêm Token vào mỗi request, chúng ta không cần thêm nó một cách thủ công trong từng request. Ví dụ bên dưới sử dụng 2 Interceptor:
AuthInterceptor : thêm Token vào mỗi request.
LoggingInterceptor : log trước khi gửi request và sau khi nhận response.
String.format("Sending request %s on %s%n%s", request.url(), chain.connection(), request.headers()));
Response response = chain.proceed(request);
longt2 = System.nanoTime();
System.out.println(String.format("Received response for %s in %.1fms%n%s", response.request().url(),
(t2 - t1) / 1e6d, response.headers()));
returnresponse;
}
}
Để sử dụng Interceptor, chúng ta cần đăng ký với Client thông qua phương thức addInterceptor() hoặc addNetworkInterceptor(). Chương trình bên dưới, tôi đăng ký AuthInterceptor ở mức Application và LoggingInterceptor cho cả 2 mức Application và Network.
Chạy ứng dụng, các bạn sẽ thấy nó có cùng kết quả với ví dụ đầu tiên. Tuy nhiên, chúng ta không cần quan tâm đến token nữa. Mọi thứ đã được handle trong AuthInterceptor.
Trên đây là những thông tin cơ bản về OkHttp, ngoài ra chúng ta có thể upload, download file khi sử dụng retrofit. Trong java thường nếu xử lý trên web thì ít khi dùng đến thư viện OkHttp, thư viện này được sử dụng chủ yếu trong các ứng dụng Android để thao tác từ client đến server. Hy vọng bài viết giúp ích cho các bạn, hẹn gặp lại ở các bài viết tiếp theo.
Xét một tình huống thường gặp trong lập trình: Giả sử ta có một interface kiểu Shape, và 2 class là Rectangle, Circle cùng implement interface Shape, sau đó ta tạo một danh sách tên là shapes để chứa tất cả các đối tượng có implement Shape.
pubtraitShape {}
pubstructRectangle {}
impl Shape for Rectangle {}
pubstructCircle {}
impl Shape for Circle {}
fnmain() {
let shapes: Vec<Box<dyn Shape>> = vec![
Box::new(Rectangle {}),
Box::new(Circle {}),
];
}
Trong quá trình làm việc với mảng shapes, có lúc chúng ta muốn lấy một giá trị ra và cast nó về kiểu Rectangle hoặc Circle để sử dụng, thường thì chúng ta sẽ làm như này:
let rect: &Rectangle = shapes.get(0).unwrap().as_ref();
Xong rồi sẽ bị Rust chửi vào mặt:
error[E0308]: mismatched types
--> src/main.rs:15:28
|
15 | let rect: &Rectangle = shapes.get(0).unwrap().as_ref();
| ---------- ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected struct `Rectangle`, found trait object `dyn Shape`
| |
| expected due to this
|
= note: expected reference `&Rectangle`
found reference `&dyn Shape`
Lỗi vì shapes là một vector chứa các object kiểu dyn Shape, nên khi dùng hàm get() để lấy một phần tử ra, phần tử đó sẽ mang kiểu dyn Shape.
Để có thể chuyển một object kiểu dyn Shape thành Rectangle, chúng ta có thể implement trait std::any::Any cho kiểu Rectangle.
Kiểm thử phần mềm đang ngày càng phát triển ở Việt Nam và được nhiều người quan tâm biết đến. Trong quá trình tìm hiểu và phát triển nghề nghiệp, mình thấy có những ngộ nhận về kiểm thử phần mềm mà nhiều người (bao gồm kỹ sư kiểm thử phần mềm, lập trình viên, nhà quản lý) thường mắc phải. Dưới đây là 5 ngộ nhận phổ biến đúc kết từ việc nghiên cứu tìm hiểu và kinh nghiệm cá nhân của một kỹ sư kiểm thử phần mềm được coi như “có chút kinh nghiệm” (7 năm).
Ngộ nhận 1: “Không làm lập trình được thì đi làm kiểm thử”
Đây là một trong những ngộ nhận phổ biến nhất về công việc kiểm thử phần mềm. Rất nhiều ứng viên đã chia sẻ như vậy trong những buổi phỏng vấn vào vị trí kỹ sư kiểm thử phần mềm. Họ chia sẻ rằng họ được đào tạo để trở thành lập trình viên nhưng vẫn chưa tìm được việc cho nên họ muốn chuyển qua công việc kiểm thử. Hoặc một dạng câu trả lời khác là tạm thời làm kiểm thử sao đó để chuyển qua làm lập trình viên. Sở dĩ có sự ngộ nhận này là do mọi người ngầm hiểu công việc kiểm thử là rất dễ làm và không cần kiến thức lập trình hoặc kiểm thử là những bước đầu tiên của lập trình.
Thực ra kiểm thử và lập trình là 2 công việc khác nhau và đòi hỏi những kỹ năng chuyên môn khác nhau. Không có gì đảm bảo một lập trình viên giỏi sẽ làm công việc kiểm thử tốt hơn một lập trình viên bình thường hoặc không phải là lập trình viên
Ngộ nhận 2: “Kiểm thử phần mềm ai làm chẳng được…”
Nhiều người quan niệm làm kiểm thử phần mềm rất dễ, chẳng cần biết lập trình, chỉ cần biết sơ sơ về kiến thức tin học và chút tỉ mỉ. Nếu ai đó có quan niệm như vậy thì cần phải nhìn nhận lại. Không có công việc nào là dễ dàng nếu như mình không có đủ kỹ năng cần thiết để làm nó hoặc chưa bao giờ làm nó. Nhiều người sau một thời gian làm công việc kiểm thử cũng nhận định công việc kiểm thử “cũng dễ thiệt”. Tuy nhiên, họ không nhận ra rằng làm được việc và làm xuất sắc là khác nhau. Kiểm thử phần mềm đòi hỏi những kỹ năng chuyên môn mà không phải ai cũng có sẵn như sự đam mê, tò mò, khả năng sáng tạo, khả năng quan sát, phân tích, trình bày, tranh luận, vv…và cả kiến thức lập trình. Kiểm thử phần mềm là một nghệ thuật mà đã là nghệ thuật thì không phải ai cũng có thể đam mê và làm được.
Ngộ nhận 3: “Cái gì…thời buổi này còn kiểm thử thủ công?”
Trong vài năm trở lại đây, mọi người đã được biết đến nhiều hơn về kiểm thử tự động. “Người người nhà nhà” làm kiểm thử tự động. Đi một vòng mấy website về tuyển dụng, số lượng tuyển dụng cho vị trí kiểm thử tự động tăng cao. Điều đó tạo nên một trào lưu làm kiểm thử tự động khiến cho nhiều người ngộ nhận là đây là thời đại của kiểm thử tự động và kiểm thử thủ công được gọi là “kiểm thử chân tay” mang hàm ý mỉa mai.
Kiểm thử tự động và kiểm thử thủ công thực ra là 2 cách tiếp cận việc kiểm thử hoàn toàn khác nhau. Kiểm thử tự động có thể thích hợp cho việc kiểm thử đệ quy, unit test nhưng kiểm thử tự động không thể giúp tìm được nhiều lỗi sản phẩm hơn. Một điều mà nhiều người vẫn hay quên rằng ngay cả công cụ kiểm thử tự động cũng có lỗi (dĩ nhiên là có rồi, con người phát triển mà) và chắc chắn là ít ra vẫn sẽ cần kỹ sư kiểm thử phần mềm để tìm lỗi cho nó.
Ngộ nhận 4: “Kiểm thử làm chi cho tốn kém”
Rất nhiều người nghĩ kiểm thử là công việc tốn kém không cần thiết. Tại sao phải kiểm thử khi mình đã có những lập trình viên “pro”/”xuất sắc”/“siêu”. Thứ nhất, “pro”, “xuất sắc”, “siêu” hay những mỹ từ nào để nói về năng lực của lập trình viên là những từ ngữ mang tính tương đối. Thứ hai, đã là người là có sai sót.
Những người có quan niệm “kiểm thử là tốn kém” thì họ sẽ nhận ra thế nào tốn kém đúng nghĩa khi sản phảm đưa ra thị trường và bị phàn nàn về chất lượng sản phẩm. Chi phí để vá lỗi thì có thể cân đo đong đếm được còn chi phí để lấy lại niềm tin đã mất của khách hàng thì không biết đo làm sao. Lúc đó nhiều người sẽ nói “ Giá như, giá như có đội kiểm thử thì tốt biết bao…”
Một quan niệm khác cũng nguy hiểm không kém là để lập trình viên kiểm thử luôn sản phẩm. Tại sao không chứ? Không ai hiểu sản phẩm tốt hơn người đã làm ra nó. Có thể đúng nhưng không phải ai cũng có thể nhận ra lỗi của mình hoặc đủ dũng cảm và sự khách quan để thừa nhận lỗi của mình (Ở đây mình đang giả định là lập trình viên có đầy đủ kỹ năng của một kỹ sư kiểm thử phần mềm chuyên nghiệp, có thể làm 16 tiếng/1 ngày và chỉ nhận lương bằng với một lập trình viên chuyên code và làm 8 tiếng/1 ngày).
Ngộ nhận 5: “Kiểm thử rồi mà sao ứng dụng vẫn còn lỗi vậy?”
Oh, mấy sếp hay hỏi câu này. Bất cứ sản phẩm nào cũng sẽ có lỗi cho dù đội kiểm thử có chuyên nghiệp bao nhiêu. Muốn kiểm thử và tìm ra tất cả lỗi thì phải có điều kiện cần và đủ. Cần là kiểm thử hết tất cả mọi thứ liên quan đến công việc kiểm thử như các loại kiểm thử, kỹ thuật kiểm thử, phương pháp tiếp cận, cấp độ kiểm thử (xem thêm https://en.wikipedia.org/wiki/Software_testing). Cho dù có được điều kiện cần thì vẫn phải cần điều kiện đủ là có đủ thời gian để kiểm thử. Ngày nay, dưới áp lực của việc đưa sản phẩm ra thị trường càng sớm càng tốt để tăng tính cạnh tranh cho sản phẩm cho nên nhiều người đã chọn giải pháp là rút ngắn giai đoạn kiểm thử hoặc chấp nhận sản phẩm ra thị trường với những lỗi “chấp nhận được”. Dĩ nhiên, nói như thế không có nghĩa là kỹ sư kiểm thử phần mềm có quyền thở phào nhẹ nhõm và thờ ơ với công việc kiểm thử của mình. Trách nhiệm vẫn sẽ thuộc về kỹ sư kiểm thử phần mềm nếu như những lỗi đó nằm trong phạm vi kiểm thử.
Mình vừa chia sẻ 5 ngộ nhận phổ biến về công việc kiểm thử phần mềm. Những ngộ nhận trên cũng chính là những quan sát nhận định của chính mình trong thời gian làm công việc kiểm thử ở vị trí kỹ sư kiểm thử phần mềm hoặc trưởng nhóm kiểm thử. Những nhận định trên là mang tính chủ quan và có thể chỉ có giá trị tại thời điểm khi viết bài này và không loại trừ khả năng chính mình cũng đang ngộ nhận. Sự ngộ nhận tuy không xấu nhưng đừng để sự ngộ nhận cản trở bạn trở thành một kỹ sư kiểm thử phần mềm chuyên nghiệp hoặc con đường phát triển của công việc kiểm thử phần mềm. Một công việc đầy thử thách nhưng cũng không kém phần thú vị.
Tạo ứng dụng Java RESTful Client với thư viện Retrofit
Bài viết được sự cho phép của tác giả Giang Phan
Trong các bài viết trước chúng ta sử dụng thư viện Jersey client, OkHttp để gọi các RESTful API. Trong bài này, tôi sẽ giới thiệu với các bạn thư viện khác là Retrofit.
Giới thiệu Retrofit
Retrofit là một type-safe HTTP client cho Java và Android được phát triển bởi Square. Retrofit giúp dễ dàng kết nối đến một dịch vụ REST trên web bằng cách chuyển đổi API thành Java Interface.
Tương tự với các thư viện khác, Retrofit giúp bạn dễ dàng xử lý dữ liệu JSON hoặc XML sau đó phân tích cú pháp thành Plain Old Java Objects (POJOs). Tất cả các yêu cầu GET, POST, PUT, và DELETE đều có thể được thực thi.
Retrofit được xây dựng dựa trên một số thư viện mạnh mẽ và công cụ khác. Đằng sau nó, Retrofit làm cho việc sử dụng OkHttp để xử lý các request/ response trên mạng. Ngoài ra, từ Retrofit2 không tích hợp bất kỳ một bộ chuyển đổi JSON nào để phân tích từ JSON thành các đối tượng Java. Thay vào đó nó đi kèm với các thư viện chuyển đổi JSON sau đây:
Một đối tượng có thể được chỉ định để sử dụng làm phần thân yêu cầu HTTP với Annotation @Body.
@POST("/api/v1/users")
Call createUser(@Body User user);
Form encoded and Multipart
Các phương thức cũng có thể được khai báo để gửi dữ liệu được mã hóa và dữ liệu multipart. Dữ liệu được mã hóa theo form được gửi khi @FormUrlEncoded được chỉ định trên phương thức. Mỗi cặp key-value được chú thích bằng @Field chứa tên và đối tượng cung cấp giá trị.
Các yêu cầu multipart được sử dụng khi @Multipart xuất hiện trên phương thức. Các phần được khai báo bằng cách sử dụng @Part. @Multipart thường được sử dụng để truyền tải file.
Các method của chúng ta sử dụng Call để nhận kết quả trả về.
Call : là một invocation của các method trong Retrofit được sử gửi request lên server và nhận kết quả trả về.
ResponseBody : là kiểu dữ liệu của response về từ server. Do tất cả API của Server trả về là String nên chúng ta sẻ sử dụng ResponseBody. Nếu response trả về là json Order, các bạn có thể sử dụng trực tiếp Call<User>.
Để sử dụng các method này, chúng ta sẽ tạo một Retrofit client:
Trong ví dụ này, tôi sử dụng phương thức call.execute() để gửi request lên server và nhận kết quả trả về. Phương thức này được thực thi đồng bộ (Synchronous). Nếu bạn muốn gửi request bất đồng bộ, có thể sử dụng phương thức call.enqueue(callback).
Sử dụng Interceptor với OkHttp
Trong ví dụ trên, ở mỗi phương thức chúng ta đều phải thêm một tham số authentication để gửi lên server. Cách làm này khá là phiền phức. Để giải quyết vấn đề này, chúng ta có thể sử dụng Interceptor, một tính năng đã được hỗ trợ trong OkHttp. Với Retrofit chúng ta cũng có thể sử dụng Interceptor, do nó sử dụng toàn bộ OkHttp như một phần implement của nó.
Bây giờ chúng ta sẽ sử dụng Interceptor để tự động thêm Token vào mỗi request, chúng ta không cần thêm nó một cách thủ công trong từng request. Ví dụ bên dưới sử dụng 2 Interceptor:
AuthInterceptor : thêm Token vào mỗi request.
LoggingInterceptor : log trước khi gửi request và sau khi nhận response.
String.format("Sending request %s on %s%n%s", request.url(), chain.connection(), request.headers()));
Response response = chain.proceed(request);
longt2 = System.nanoTime();
System.out.println(String.format("Received response for %s in %.1fms%n%s", response.request().url(),
(t2 - t1) / 1e6d, response.headers()));
returnresponse;
}
}
Để sử dụng Interceptor, chúng ta cần đăng ký với Client thông qua phương thức addInterceptor() hoặc addNetworkInterceptor(). Chương trình bên dưới, tôi đăng ký AuthInterceptor ở mức Application và LoggingInterceptor cho cả 2 mức Application và Network.
Chạy ứng dụng, các bạn sẽ thấy nó có cùng kết quả với ví dụ đầu tiên. Tuy nhiên, chúng ta không cần quan tâm đến token nữa. Mọi thứ đã được handle trong AuthInterceptor.
Trên đây là những thông tin cơ bản về Retrofit, ngoài ra chúng ta có thể upload, download file khi sử dụng retrofit. Tương tự OkHttp, Retrofit được sử dụng chủ yếu trong các ứng dụng Android để thao tác từ client đến server. Tuy nhiên, chúng ta hoàn toàn có thể sử dụng nó một cách dễ dàng với Rest Client trong ứng dụng java web.
ps – hiện những tiến trình đang hoạt động tích cực
top – hiện tất cả các tiến trình đang hoạt động
kill pid – ép thoát tiến trình có mã pid
killall proc – ép thoát các tiến trình tên proc *
bg – hiện các công việc đã kết thúc hoặc đang chạy nền; tiếp tục một công việc đã tạm ngừng
fg – ngừng chạy nền (chuyển sang foreground) với công việc gần đây nhất
fg n – ngừng chạy nền với công việc n
Quyền sử dụng tập tin
chmod octal file – thay đổi quyền sử dụng của tập tin file thành octal. Mỗi chữ số ứng với từng tài khoản có được bằng cách cộng các số sau:
4 – đọc (r)
2 – ghi (w)
1 – thực thi (x)
Ví dụ:
chmod 777 – tất cả đều có đủ 3 quyền
chmod 755 – rwx cho người sở hữu, rx cho nhóm sở hữu và các tài khoản khác
Xem man chmod để biết thêm chi tiết.
SSH
ssh user@host – kết nối đến máy host với tài khoản user
ssh -p port user@host – kết nối đến máy host qua cổng port với tài khoản user
ssh-copy-id user@host – thêm khóa công cộng của tài khoản user vào máy host để thiết lập đăng nhập không cần mật khẩu (đăng nhập có khóa) Tìm kiếm
grep pattern files – tìm mẫu lặp pattern trong các tập tin files grep -r pattern dir – tìm mẫu lặp pattern trong thư mục dir và tất cả các thư mục con (recursive)
command | grep pattern – tìm mẫu lặp pattern trong đầu ra của lệnh command
locate file – tìm tất cả các tập tin có tên file
Thông tin hệ thống
date – hiện ngày giờ hiện tại
cal – hiện lịch tháng này
uptime – hiện thời gian từ lúc bật máy
w – hiện những người đang đăng nhập
whoami – hiện tên tài khoản của bạn
finger user – hiện thông tin về tài khoản user
uname -a – hiện thông tin về nhân HĐH
cat /proc/cpuinfo – hiện thông tin về CPU
cat /proc/meminfo – hiện thông tin về bộ nhớ
man command – hiện hướng dẫn cho lệnh command
df – hiện mức sử dụng đĩa
du – hiện dung lượng thư mục
* Hiện top 10 file dung lượng lớn trong thư mục /var: du -a /var | sort -n -r | head -n 10
free – hiện dung lượng bộ nhớ trống và lượng bộ nhớ tráo đổi (swap) đã dùng
whereis app – hiện đường dẫn của ứng dụng
app which app – cho biết lệnh nào sẽ được chạy mặc định thay cho app
Nén
tar cf file.tar files – tạo một tập tar có tên file.tar chứa các tập tin khác
tar xf file.tar – giải phóng các tập tin từ file.tar
tar czf file.tar.gz files – tạo một tập tar có nén bằng Gzip
tar xzf file.tar.gz – giải nén một tập tar bằng Gzip
tar cjf file.tar.bz2 – tạo một tập tar có nén bằng Bzip2
tar xjf file.tar.bz2 – giải nén một tập tar bằng Bzip2
gzip file – nén file và đổi tên thành file.gz
gzip -d file.gz – giải nén file.gz
Mạng
ping host – gửi lệnh ping đến máy host và hiện kết quả
whois domain – kiểm tra thông tin whois của tên miền domain
dig domain – kiểm tra thông tin DNS của tên miền domain
dig -x host – tìm ngược tên miền của máy host
wget file – tải tập tin file
wget -c file – tiếp tục tải tập tin đang dở
Cài đặt
Cài đặt từ mã nguồn:
./configure
make
make install
dpkg -i pkg.deb – cài gói phần mềm (Debian)
rpm -Uvh pkg.rpm – cài gói phần mềm (RPM)
Phím tắt
Ctrl+C – dừng hoàn toàn lệnh đang chạy
Ctrl+Z – tạm dừng lệnh hiện tại, tiếp tục chạy nền bằng lệnh bg hoặc chạy chính với lệnh fg
Ctrl+D – thoát khỏi phiên làm việc hiện tại, giống với exit
Ctrl+W – xóa một từ trong dòng hiện tại
Ctrl+U – xóa cả dòng
Ctrl+R – hiện danh sách các lệnh gần đây !! – lặp lại lệnh gần đây nhất exit – thoát khỏi phiên làm việc hiện tại
Storyboard đồng thời đảm nhiệm việc kết nối các màn hình với nhau.
Mỗi màn hình được quản lý bởi một View Controller và chứa các View để thể hiện giao diện.
Các màn hình được kết nối với nhau bởi các đối tượng segue. Segue giúp bạn tạo hiệu ứng chuyển cảnh và truyền dữ liệu qua lại giữa các màn hình.
Storyboard sẽ thể hiện cho bạn một bức tranh toàn cảnh về các màn hình và mối quan hệ giữa các chúng. Do đó bạn có thể sử dụng Storyboard để thiết kế và quản lý giao diện các màn hình cho ứng dụng của bạn.
II.Cách làm việc với Storyboard
Cách tạo storyboard mới các bạn click vào File –> New –>File –>Storyboard
Và giờ các bạn chọn nơi lưu
Một project chúng ta có thể tạo một hoặc nhiều storyboard để quản lý các màn hình.
Khi làm việc với các tập tin storyboard thì Xcode sẽ sử dụng một công cụ đặc biệt là Interface Builder.
Interface builder cung cấp một môi trường kéo thả giúp lập trình viên có thể dễ dàng thêm, chỉnh sửa và xoá các thành phần UI tham gia vào ứng dụng.
Mỗi một màn hình trong ứng dụng sẽ tương ứng với một scene trong storyboard.
Khi tạo 1 project mới chúng ta chỉ có 1 scene tương ứng với 1 màn hình trống trong ứng dụng.
Mũi tên ở phía tay trái trong cửa sổ interface builder chỉ vào scene này được gọi là điểm bắt đầu của storyboard.
Scene ứng với điểm đầu tiên sẽ được chạy đầu tiên khi ứng dụng bắt đầu chạy.
Hy vọng bài hôm nay sẽ giúp các bạn hiểu rõ về storyboard trong Xcode
Lương là một trong những thước đo quan trọng được nhiều người dùng để lựa chọn công việc cho bản thân. Một công ty có thu nhập tốt luôn là yếu tố thu hút đông đảo các ứng viên ứng tuyển. Vậy ở Việt Nam hiện tại có những công ty nào đang trả lương cao nhất? Bài viết dưới đây sẽ tổng hợp top những công ty trả lương cao nhất Việt Nam cho người đọc có cái nhìn tổng quan hơn về thị trường lao động.
Top các công ty trả lương cao nhất Việt Nam
*Số thứ tự trong bài viết chỉ nhằm liệt kê các công ty, không nhằm mục đích xếp hạng hay đánh giá
1. Hãng hàng không Quốc gia Việt Nam – Vietnam Airlines
Thu nhập bình quân của các nhân viên đang làm việc tại Vietnam Airlines hiện nằm trong khoảng từ 25 – 40 triệu đồng/tháng.
Thu nhập bình quân của nhân viên ngân hàng Vietcombank trong năm 2018 là 35,47 triệu đồng/người/tháng. Ngoài ra, chế độ đãi ngộ hấp dẫn mới tiền thưởng cao là một trong những lý do giúp Vietcombank luôn thu hút nhiều nhân tài.
3. Tổng công ty đầu tư và kinh doanh vốn nhà nước SCIC
Thu nhập trung bình của người lao động tại SCIC là 30,4 triệu đồng/tháng.
Mức lương Samsung trả cho người mới vào làm, không có kinh nghiệm thường ở mức khoảng 15 triệu đồng/tháng. Số năm và chất lượng công việc tăng thì tiền lương cũng theo đó tăng lên.
8. Công ty Tân Cảng Sài Gòn SNP
Thu nhập bình quân của người lao động tại SNP rơi vào khoảng 23 triệu đồng/tháng.
Thu nhập bình quân của người lao động tại MB Bank cũng nằm trong top lương cao của các ngân hàng khi nhân viên nhận trên 18 triệu đồng/tháng.
10. Tập đoàn dầu khí Việt Nam PVN
Thu nhập bình quân của người lao động trên 16 triệu đồng/tháng.
11. Công Ty Cổ Phần Ô Tô Trường Hải
Mức lương cứng nhân viên tại Ô Tô Trường Hải nhận được hàng tháng rơi vào khoảng 10 – 12 triệu đồng/tháng chưa kể hoa hồng.
12. Công Ty Cổ Phần Sữa Việt Nam Vinamilk
Mức lương tại Vinamilk luôn là con số hấp dẫn với các ứng viên, tùy thuộc vào vị trí cũng như năng lực làm việc mà nhân viên tại đây sẽ nhận những mức lương khác nhau, trung bình đều trên 10 triệu đồng/tháng.
Thu nhập trung bình tại FPT Software là trên 20 triệu đồng/tháng, khá cao so với mặt bằng chung mức lương trong ngành IT.
(Tiếp tục update)
Tuyển Dụng Nhân Tài IT Cùng TopDev Đăng ký nhận ưu đãi & tư vấn về các giải pháp Tuyển dụng IT & Xây dựng Thương hiệu tuyển dụng ngay!
Hotline: 028.6273.3496 – Email: contact@topdev.vn
Dịch vụ: https://topdev.vn/page/products








")

 Mô hình kiến trúc ANSI/SPARC cho phép tạo ra sự độc lập giữa bản thân dữ liệu và việc xử lý dữ liệu. Sơ đồ ở hình bên cho thấy sự triển khai kiến trúc vật lý của một hệ quản trị CSDL là như thế nào.
Mô hình kiến trúc ANSI/SPARC cho phép tạo ra sự độc lập giữa bản thân dữ liệu và việc xử lý dữ liệu. Sơ đồ ở hình bên cho thấy sự triển khai kiến trúc vật lý của một hệ quản trị CSDL là như thế nào.


















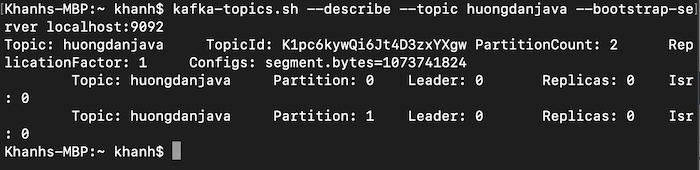 Như các bạn thấy, topic huongdanjava của mình có 2 partitions và số lượng ReplicationFactor là 1 như câu lệnh mình đã chạy ở trên.
Như các bạn thấy, topic huongdanjava của mình có 2 partitions và số lượng ReplicationFactor là 1 như câu lệnh mình đã chạy ở trên.