Quanh mình đâu đâu cũng thấy việc marketing, thông tin về ngành nghề marketing. Cứ mỗi 10 bạn mình tư vấn CV, cũng có ít nhất 6-7 bạn mong muốn làm hoặc đã từng làm một số công việc nhỏ liên quan đến ngành này. Thiết nghĩ marketing nhiều như vậy, mình nên viết một bài chia sẻ ngắn ngắn của mình về lĩnh vực này.
Bài viết này mình sẽ không viết về ngành marketing đâu, mà mình muốn đề cập đến việc mình có thể dùng ‘các kĩ thuật marketing’ nào để quảng bá CV của mình. Để quảng bá được hàng tốt, thì phải quảng báo được bản thân tốt trước đã chứ nhỉ? Các kĩ thuật này có thể dùng cho CV ở mọi ngành nghề, không riêng gì marketing đâu nhé.
1) Làm SEO cho CV
Chắc nhiều bạn cũng có nghe về khái niệm SEO rồi, nhưng cũng có thể chưa biết kĩ lắm. SEO tức là search engine optimization ấy, nôm na là viết nội dung website sử dụng các từ khoá sao cho website của mình lúc search ra phát là xuất hiện ngay trên Google.
Tương tự như làm SEO cho website vậy, CV của chúng mình cũng cần được SEO để được nhà tuyển dụng chú ý hơn, đọc lướt mà vẫn chú ý giữa hàng ngàn CV khác bên cạnh. Có 2 kĩ thuật mình thường áp dụng để giúp cho content của CV tốt hơn, đó là:
1.1 – Dùng ‘key words’ phù hợp
Nôm na kĩ thuật này là phải làm sao để biến cho CV của mình có một chút na ná và những ngôn từ kĩ thuật giống như trong tin tuyển dụng của nhà tuyển dụng đăng lên ấy. Một ví dụ cụ thể, dưới đây là tin tuyển dụng cho vị trí International Marketing Executive cho một công ty giáo dục ở HCMC:
Nếu nhìn nhanh, mình sẽ thấy một số từ khoá đặc thù của công việc này – tức việc marketing đó là ‘exhibitions’, ‘events’, ‘newsletters’, ‘direct mail’, ‘press releases’. Khi đã tìm ra từ khoá rồi, thì nhiệm vụ của chúng mình là phải edit/ sửa lại cho nội dung CV sao cho xuất hiện những từ giống như thế này. Ví dụ thay vì viết:
Manage the promotional activities of the ABC company.
Mình có thể viết lại:
Prepare promotional tasks for ABC company including writing 2 newsletters and 1 press release monthly, sending direct mail through MailChimp system to a database of 1000+ clients.
Vì tiếng Anh không phải ngôn ngữ mẹ đẻ của chúng mình, nên mình hiểu tại sao khi đọc CV, các từ như ‘support’, ‘manage’, ‘help’, ‘do’, etc. lại xuất hiện vô cùng nhiều. Chính mình đến tận bây giờ để mà viết CV, cũng rất bế tắc nếu muốn tìm những động từ khác hay ho hơn để có thể thay thế.
Tuy nhiên nhờ sự xuất hiện của Google, mình bớt bế tắc hơn một chút. Bạn có thể click vào link này, để xem 185 động từ có thể dùng thay thế cho các động từ nhàm chán trên.
Một ví dụ đơn giản, thay cho việc dùng từ increased, mình sẽ có một vài cách dùng khác như “rocketed sales by 30%,” “slashed sales cycle by 20%,” hoặc là “supercharged sales staff performance.”
2) Chèn link vào CV
Bây giờ không như xưa nữa rồi, công nghệ ngày càng phát triển hơn, CV ngày càng đa dạng. Đơn giản nhất bây giờ vẫn là viết ra Word và nộp qua email. Một số cách sáng tạo hơn có thể là viết trên Powerpoint theo dạng portfolio (mình thấy có bạn viết cả trên Excel @@), bạn nào giỏi thiết kế thì dùng Photoshop, Illustrator, bạn nào giỏi web thì làm hẳn một website portfolio cá nhân luôn.
Vậy nên khi viết CV, chúng mình cũng có thể chèn link vào CV để giới thiệu thêm về website cá nhân, dự án video, bài viết đã làm, đã viết để quảng bá thêm bản thân. Tốt nhất là bạn Ctrl + K thôi chứ đừng copy paste cả cái link dài ngoằng vào CV nhé. Đây là ví dụ trực tiếp từ CV cũ của mình:
Mạng xã hội đang ngày càng phát triển nhanh chóng, ở Việt Nam hiện tại dùng nhiều nhất là Facebook, rồi đến Instagram, LinkedIn, Twitter, Tumblr, etc.
Một số nhà tuyển dụng tọc mạch, ví dụ giống mình, sẽ hay lên Google và tìm các trang mạng cá nhân của ứng viên, để tìm hiểu thêm những thông tin bên lề. Vậy nên theo mình để tiết kiệm thời gian cho nhà tuyển dụng, bạn nên để luôn một vài thông tin các trang mạng xã hội bạn đang dùng lên CV để NTD xem. Ấy nhưng mà khoan?
Đừng vội vàng hấp tấp kẻo nó sẽ thành con dao 2 lưỡi. Mình chỉ khuyên các bạn cho link mạng xã hội vào CV nếu bạn thực sự thấy trang của bạn chuyên nghiệp và có ích cho NTD khi họ tìm kiếm thông tin. Tốt nhất và thời điểm này là bạn nên tạo một tài khoản LinkedIn, cập nhật thông tin cá nhân của mình vào đó – là cách chuyên nghiệp nhất hiện tại.
Bài viết được sự cho phép bởi tác giả Vũ Thành Nam
Bài viết này mình sẽ giới thiệu cho các bạn cách kiến trúc sharding trong distributed database.
Điều đầu tiên, khi bạn đã quyết định chia nhỏ cơ sở dữ liệu với sharding, bạn cần phải hiểu rõ nó nên và sẽ làm như thế nào. Khi bạn bắt đầu chạy truy vấn dữ liệu trong các bảng được chia nhỏ, điều quan trọng là bạn phải xác định đúng phân đoạn mà bạn cần truy vấn. Nếu không nó có thể dẫn đến việc mất dữ liệu hoặc truy vấn chậm chạp một cách đáng tiếc.
Trong phần này mình sẽ cùng các bạn làm rõ kiến trúc sharding phổ biến và quy trình sử dụng nó nhằm đảm bảo việc phân phối và truy vấn dữ liệu trên cơ sở dữ liệu phân tán sao cho phù hợp nhất (mình nhấn mạnh là phù hợp nhất nhé, chứ không phải tốt nhất).
Đối với sharding, mình xin được chia nó ra thành 3 loại cơ bản: Key Based Sharding, Range Based Sharding, Directory Based Sharding. Mình sẽ đi cụ thể từng loại như sau:
Key Based Sharding
Đối với loại sharding này hay còn được biết đến là Hash Based Sharding. Đây là một loại sharding phổ biến nhất trong Citus Data. Nếu bạn từng thiết kế một cơ sở dữ liệu với các bảng liên kết với nhau theo hình thức khóa chính khóa ngoại, bảng cha bảng con thì có lẽ bạn đã từng hiểu rằng khi truy vấn tập dữ liệu bảng con theo khóa ngoại là id của bảng cha thì nó khá là đơn giản.
Một câu lênh truy vấn kèm thêm điều kiện khóa ngoại sẽ giúp bạn làm điều đó, bản chất vấn đề là cơ sở dữ liệu vấn phải duyệt qua từng bản ghi (record hay row) sau đó so sánh với điều kiện khóa ngoại có bằng với id kia không để có thể lấy ra bản ghi đó. Quá trình này khiến cơ sở dữ liệu truyền thống mất khá nhiều thời gian nếu bạn chứa rất nhiều records trong table.
Dựa trên khó khăn đó Citus có thể giải quyết vấn đề này cho bạn bằng cách sharding key, bạn chia từng phần từng phần các record theo nhóm khóa ngoại nằm trên các node khác nhau. Khi đó nếu bạn cần truy vấn dữ liệu với loại khóa ngoại đó thì Citus sẽ nhắm đúng node có khóa ngoại mà bạn sharding để tới đúng vị trí lấy đúng tập dữ liệu mà bạn cần. Khi bạn chọn một trường làm sharding key, Citus sẽ có một function hash key đó lại nhằm đánh dấu tập dữ liệu của bạn được shard trên node số mấy. Vấn đề truy vấn chỉ là lấy tập dữ liệu hash sẵn đó ra mà thôi.
Ví dụ rằng bạn có 10,000,000 record với 5 kiểu khác nhau, thì việc đánh sharding cho mỗi kiểu sẽ giúp bạn truy vấn số record trên mỗi kiểu nhanh hơn, nó sẽ quét đúng tập dữ liệu 2,000,000 records thay vì quét hết cả 10,000,000 records. Điều này dẫn tới tốc độ truy vấn sẽ nhanh hơn hẳn.
Cách sharding key này được dùng rất phổ biết và khá đơn giản với cú pháp này
Bạn có thể thấy tenant_id chính là khóa ngoại của bảng questions được liên kết tới bảng tenants. Và khi chúng ta sharding thì bạn có thể lấy chính khóa ngoại này làm trường shard key.
Tuy nhiên không phải chúng ta chỉ được lấy khóa ngoại làm trường shard key đâu nhé. Tùy thuộc vào dữ liệu của bạn có sự gom nhóm phù hợp mà bạn chọn trường nhóm đó làm sharding. Chỉ cần trường đó của bạn là duy nhất và ít thay đổi, chính xác hơn là không được thay đổi, nếu thay đổi bạn cần sharding lại để Citus có thể hiểu được và sắp xếp hash values lại sao cho phù hợp với lần truy vấn tiếp theo. Cách truy vấn thì cũng đơn gian thôi, chỉ cần bạn thêm điều kiện where với trường shard key, còn lại citus sẽ lo hết giúp bạn. Nó sẽ dựa trên hash value để tìm đúng địa chỉ node và truy vấn tập dữ liệu mà bạn cần.
Range Based Sharding
Khác với Key Based Sharding, đối với Range Based Sharding thì Citus sẽ gom nhóm các khoảng giá trị của bạn định nghĩa theo từng nhóm khoảng giá trị thay vì theo key. Ví dụ bạn có khoảng 10,000,000 record thì citus sẽ giúp bạn sharding chia thành từng khoảng giá trị với trường định nghĩa, từ 1 đến 1000, từ 1001 đến 2000,… cứ như thế các nhóm giá trị được hình thành và được phân bổ vào các node. Tương tự thì cách truy vấn citus giúp bạn tìm kiếm tập giá trị thuộc nhóm range nào để trỏ đúng nodes cần tìm và lấy giá trị đó lên
Điểm khó khăn của cách phân bổ này là khoảng dữ liệu sẽ bị mất cân bằng khi yêu cầu truy vấn bị lệch về một khoảng giá trị nào đó, và có những khoảng giá trị thì không bao giờ được truy vấn. Như hình minh họa trên, do mình chia khoảng giá thành 3 phần nhưng nghiệp vụ của mình chỉ toàn truy vấn trong khoảng từ 0 đến 49.99$ mà thôi. Vậy là tự nhiên sự phân bổ này bị mất cân bằng và làm cho ý nghĩa của việc sharding không còn phát huy đúng hiệu quả của mình nữa.
Directory Based Sharding
Tương tự như Key Based Sharding, Directory Based Sharding chia các nhóm cơ sở dữ liệu có điểm chung vào thành những nhóm và shard key chúng, nhưng thay vì sử dụng hash values thì loại sharding này lại sử dụng delivery zone. Bạn hình dung Key Based Sharding như việc chia những dữ liệu thành nhiều file, còn Directory Based Sharding lại chia dữ liệu ra thành nhiều folder, mỗi folder sẽ có chứa nhiều file, và trong file mới thực sự là dữ liệu bạn cần.
Loại sharding này còn có thêm một bảng tra cứu giống như mục lục vậy, shard key nào thuộc zone nào, từ đó giúp cho việc phân loại và truy vấn được dễ dàng hơn. Mặt khác, phân đoạn dựa trên thư mục cho phép bạn sử dụng bất kỳ hệ thống hoặc thuật toán nào bạn muốn để gán các mục nhập dữ liệu cho các phân đoạn và việc thêm động các phân đoạn bằng cách sử dụng phương pháp này tương đối dễ dàng.
Mặc dù Directory Based Sharding là phương pháp linh hoạt nhất trong số các phương pháp sharding được thảo luận ở đây, nhưng nhu cầu kết nối với bảng tra cứu trước mọi truy vấn hoặc ghi có thể có tác động bất lợi đến hiệu suất của ứng dụng. Hơn nữa, bảng tra cứu có thể trở thành một điểm lỗi, một điểm chí mạng: nếu nó bị hỏng hoặc không thành công, nó có thể ảnh hưởng đến khả năng ghi dữ liệu mới hoặc truy cập dữ liệu hiện có.
Vì vậy việc gom nhóm này thường chỉ sử dụng cho các cơ sở dữ liệu có độ phức tạp cao, cấu trúc phân nhóm nhiều, để có thể dễ dàng phân loại chúng. Còn nếu bạn có cơ sở dữ liệu đơn giản thì có lẽ Key Based Sharding là đủ cho bạn.
Việc có hay không nên triển khai sharded database architecture vẫn còn là một chủ đề tranh cái của nhiều lập trình viên. Đa số các lập trình viên coi sharding là một kết quả không thể tránh khỏi trước sự bùng nổ dữ liệu lớn quá nhanh và mạnh mẽ và khi chúng đạt đến một kích thước nhất định, nhưng có một số lập trình viên thì lại coi đó là một vấn đề nên tránh do nó rất phức tạp và đau đầu để xử lý những thứ liên quan trừ khi nó thực sự cần thiết và bất đắc dĩ. Cũng dễ hiểu thôi, sharding thực sự phức tạp hơn bạn nghĩ trong cách hoặt động và việc thêm bớt các node shard.
Do sự phức tạp tăng thêm này, nên sharding thường chỉ được thực hiện khi xử lý lượng dữ liệu rất lớn. Dưới đây là một số tình huống phổ biến trong đó việc chia nhỏ cơ sở dữ liệu có thể có lợi:
– Số lượng dữ liệu của ứng dụng tăng lên vượt quá khả năng lưu trữ của một node cơ sở dữ liệu duy nhất.
– Khối lượng ghi hoặc đọc vào cơ sở dữ liệu vượt quá những gì mà một node đơn hay cluster có thể xử lý, dẫn đến thời gian phản hồi hoặc thời gian chờ bị chậm lại.
– Băng thông đường truyền mạng mà ứng dụng yêu cầu lớn hơn băng thông có sẵn cho một node database.
Trước khi nghĩ đến sharding, có lẽ bạn nên nghĩ đến một số sự lựa chọn khác để tối ưu hóa cơ sở dữ liệu của mình, do sharding là một giải pháp đáng cân nhắc lại. Dưới đây là một số giải pháp tối ưu hóa khác mà bạn có thể xem xét trước khi sử dụng sharding:
– Setting up a remote database:
Nếu bạn đang làm việc với ứng dụng monolithic trong đó tất cả các thành phần nằm trên cùng một máy chủ, bạn có thể cải thiện hiệu suất cơ sở dữ hiệu bằng cách chuyển server cơ sở dữ liệu sang chính máy khởi chạy ứng dụng. Điều này không làm phức tạp thêm nhiều như sharding vì các bảng của cơ sở dữ liệu vẫn còn nguyên vẹn. Tuy nhiên, nó vẫn cho phép bạn chia tỷ lệ cơ sở dữ liệu của mình theo chiều dọc so với phần còn lại của cơ sở hạ tầng. Hơn nữa đường truyền dữ liệu sẽ tốt hơn do chúng nằm trên cùng một máy chủ.
– Implementing caching:
Nếu hiệu suất đọc của ứng dụng là nguyên nhân khiến bạn gặp rắc rối, thì bộ nhớ đệm là một chiến lược có thể giúp cải thiện điều đó. Bộ nhớ đệm bao gồm việc lưu trữ tạm thời dữ liệu đã được yêu cầu trong bộ nhớ trước đó cho phép bạn truy cập dữ liệu đó nhanh hơn nhiều sau này.
– Creating one or more read replicas:
Một chiến lược khác có thể giúp cải thiện hiệu suất đọc, điều này liên quan đến việc sao chép dữ liệu từ một máy chủ cơ sở dữ liệu (máy chủ chính) sang một hoặc nhiều máy chủ phụ.
Sau đó, mọi bản ghi mới sẽ được chuyển đến bản chính trước khi được sao chép sang bản thứ hai, trong khi các lần đọc được thực hiện riêng cho các máy chủ thứ cấp. Việc phân phối các lần đọc và ghi như thế này giúp cho bất kỳ máy nào không phải chịu quá nhiều tải, giúp tránh bị chậm và treo máy.
Giải pháp này thường sử dụng trong các mạng xã hội, họ lợi dụng điểm mạnh của no-sql là truy vấn nhanh để lưu một cơ sở dữ liệu phụ và đồng bộ chúng về cơ sở dữ liệu chính dưới background chạy nền ngay sau đó.
Lưu ý rằng việc tạo bản sao đọc liên quan đến nhiều tài nguyên máy tính hơn và do đó tốn nhiều chi phí tiền bạc hơn, đây có thể là một hạn chế đáng kể đối với một số người.
– Upgrading to a larger server:
Trong hầu hết các trường hợp, việc mở rộng máy chủ cơ sở dữ liệu của một người thành một máy có nhiều tài nguyên hơn đòi hỏi ít nỗ lực hơn so với sharding.
Giống như việc tạo bản sao đọc, một máy chủ được nâng cấp với nhiều tài nguyên hơn có thể sẽ tốn nhiều tiền hơn. Do đó, bạn chỉ nên thực hiện việc thay đổi kích thước nếu nó thực sự trở thành lựa chọn tốt nhất của bạn.
Cái gì giải quyết được bằng tiền thì luôn dễ dàng hơn đúng không ạ 😀
Hãy nhớ rằng nếu ứng dụng hoặc trang web của bạn phát triển vượt qua một thời điểm nhất định, không có chiến lược nào trong số này sẽ đủ để tự cải thiện hiệu suất của chúng. Trong những trường hợp như vậy, sharding thực sự có thể là lựa chọn tốt nhất cho bạn.
Tóm lại Sharding có thể là một giải pháp tuyệt vời cho những người muốn mở rộng cơ sở dữ liệu của họ theo chiều ngang. Tuy nhiên, nó cũng thêm nhiều phức tạp và tạo ra nhiều điểm thất bại tiềm ẩn cho ứng dụng của bạn. Sharding có thể là cần thiết đối với một số người, nhưng thời gian và nguồn lực cần thiết để tạo và duy trì một kiến trúc phân đoạn có thể lớn hơn lợi ích cho những người khác.
Hi vọng bài viết này có thể giúp bạn hiểu rõ hơn nữa về sharding, nên và không nên sử dụng hướng tới giải pháp sharding này.
Bài viết được sự cho phép của tác giả Nguyễn Hoàng Phú Thịnh
Bài này mình sẽ đi sơ lược cho anh em: BPMN là gì, tại sao nó ra đời, dành cho đối tượng nào. Và quan trọng hơn hết, BPMN được dùng cho mục đích gì?
Okay, let’s gooooo!!!
1. BPMN là gì?
BPMN là viết tắt của Business Process Modeling Notation. “Notation” nghĩa là ký hiệu. Tức BPMN là tập hợp các ký hiệu chuẩn để mô tả quy trình của doanh nghiệp. Hay để mô hình hóa quy trình của doanh nghiệp.
Để hiểu chi tiết hơn thì anh em bấm vào hình dưới đây để xem ví dụ.
À nhầm, không phải hình đó, hình dưới này nha anh em ?
Quy trình từ lúc khách hàng đặt bánh pizza đến khi ăn bánh pizza. (Nguồn ảnh: BusinessProcessIncubator.com)
2. Tại sao nó quan trọng?
BPMN là một trong những vũ khí tối quan trọng của anh em nào làm BA. Vì sao? Vì trong công việc, mình phải tiếp cận và lắng nghe rất nhiều quy trình nghiệp vụ của khách hàng.
Lắng nghe xong, nhiệm vụ của anh em là phải document lại. Mà mỗi khách hàng mỗi khác nhau, mỗi quy trình mỗi phức tạp. Document sao cho gọn, cho dễ đọc mà vẫn đảm bảo được nội dung gốc ban đầu? BPMN chính là câu trả lời.
Chỉ khi anh em thật sự hiểu được khách hàng, hiểu được quy trình họ làm hằng ngày. Thì mình mới nhìn nhận ra được, đâu là điểm chưa tối ưu trong quy trình của họ.
Và không chỉ có một mình mình cần hiểu, BA phải truyền đạt lại những “hiện trạng” và yêu cầu của khách hàng cho cả team cùng hiểu. Khi đó, BPMN là phương pháp tối ưu nhất để truyền đạt lại mớ bồng bông các quy trình này.
Có lần mình làm dự án cho khách hàng là 1 công ty nhà nước. Phải nói quy trình của khách hàng này là mother of lộn xộn, tuầy huầy, tùm lum tùm la hết. Một mớ công văn, một mớ giấy tờ. Mà bản nào cũng 5-6 trang A4.
Quy trình của họ thể hiện bằng chữ trong văn bản. Đọc thì cũng hiểu thôi. Nhưng khi số lượng quy trình ngày một tăng thì càng đọc càng rối ?
Chưa kể các quy trình không bao giờ đứng riêng lẻ, mà luôn kết nối với nhau. Output của thằng này sẽ luôn là input của thằng tiếp theo.
Một khi quy trình thể hiện bằng văn bản, thì phải nói là rất khó cho team để mapping các quy trình lại với nhau. Vì đọc chữ sẽ tốn sức hơn nhiều so với xem hình ảnh. Chưa kể đọc xong phải mường tượng luồng đi của quy trình, rồi từ đó mới mapping được.
Thế là team mất gần cả tháng trời để tổng hợp, phân loại và sắp xếp nó cho ra hồn, rồi mới modeling bằng BPMN được. Giờ nghĩ lại vẫn còn thấy ớn ớn…
Nói theo kiểu ba láp ba xàm thì già trẻ, lớn bé, đẹp chai, đẹp gái gì cũng dùng BPMN được hết, vì nó khá là dễ. Còn nói theo kiểu đàng quàng thì BPMN dành cho cả người dùng high level lẫn lower level đọc.
High level là sao? Họ là những người quản lý tầng trên, họ chỉ cần care đến bức tranh tổng quan, và nắm được trong đó có những quy trình nào là chủ yếu.
High Level chỉ cần quan tâm, để ra được báo giá thì cần có mấy bước, tương tác với những đối tượng nào, hoặc có những document nào liên quan…
Còn lower level là những người dùng trực tiếp, họ follow theo quy trình để làm. Do đó, BPMN cho những đối tượng này thường rất chi tiết và cover được toàn bộ các trường hợp có thể xảy ra.
4. Bà con với UML?
Mình thấy có nhiều anh em hay nhầm BPMN với UML. Hồi xưa mình cũng hay nhầm, nhưng giờ chịu khó google nên cũng phân biệt được hai anh này.
UML là Unified Modeling Language – ngôn ngữ mô hình thống nhất. Tên tiếng Việt dịch ra nghe hơi chuối, nên thôi anh em cứ đọc là UML cho chắc. Nôm na, UML là tập hợp các diagram và các ký hiệu để mô tảphần mềm. Nôm na là như vậy.
Anh em nghe có thấy nó giống với BPMN hông. Cơ bản cũng là mấy cái hình vẽ thôi, nhưng mục đích của nó lại khác nhau.
Trong khi BPMN hướng tới quy trình nghiệp vụ,
thì UML hướng tới việc xây dựng phần mềm.
Cụ thể, BPMN tiếp cận theo hướng process-oriented, còn UML thì tiếp cận theo hướng object-oriented.
Process-oriented là tập trung trả lời cho câu hỏi: khách hàng phải làm bao nhiêu bước, đó là những bước gì, trong thời gian bao lâu để hoàn thành được công việc, mục tiêu.
Còn Object-oriented tập trung cho việc mổ xẻ một đối tượng theo nhiều góc nhìn, chiều kích khác nhau để rõ ràng hơn cho việc thiết kế và xây dựng hệ thống.
Do đó, để có nhiều góc nhìn khác nhau, thì UML có hẳn một bộ các diagram khác nhau. Mỗi diagram có một chức năng riêng. Ví dụ lấy đối tượng Customer ra mổ xẻ. Anh em có thể mô hình hóa được đối tượng Customer này (bằng UML) ở nhiều khía cạnh khác nhau:
Customer có những thuộc tính gì, mối quan hệ giữa đối tượng Customer và các đối tượng khác ra sao (Class Diagram).
Customer có thể làm được những tính năng gì, tương tác với hệ thống và các đối tượng khác ra sao (Use Case Diagram).
Hoạt động của Customer theo trình tự thời gian là như thế nào (Sequence Diagram).
Và còn rất nhiều khía cạnh với nhiều diagram khác nữa, mình sẽ nói ở bài sau nhé anh em.
Còn BPMN, như anh em thấy chỉ có 1 diagram duy nhất. Bởi vì nó chỉ có 1 mục đích duy nhất: thể hiện được quy trình nghiệp vụ.
Tóm lại, UML và BPMN là hai khái niệm hoàn toàn khác nhau. Nó không tương phản mà lại ăn nhậu rất hợp rơ với nhau. Trong dự án, anh em vừa phải dùng UML, vừa phải dùng BPMN thì document mới đầy đủ, và cover hết các khía cạnh được 🙂
Kể cho anh em chuyện này nghe mất hồn chơi.
Hồi xưa mình làm 1 dự án theo kiểu Agile… hơi nửa vời chút xíu :v Document làm toàn BPMN, và mình thề là nguyên bộ Solution Design không quá… 100 chữ. Vì chỉ toàn hình là hình. Nghĩ thế là khỏe, vì document quá tiện và gọn nhẹ.
Tuy nhiên vấn đề bắt đầu xuất hiện khi có change request, mà toàn liên quan tới những cái vặt vặt mới ghê. Ví dụ như message thông báo, nội dung email template, status của record…
Mà BPMN thì không thần thánh tới mức… cover được hết những tiểu tiết này. Nên hồi đó mình phải note chi chít các chi tiết nhỏ này vào quy trình BPMN. Khiến cho nó rối, sai quy tắc notation, và đặc biệt là rất… oải để đọc nó.
Và khi có change request, thì rất khó để anh em trace lại được những sự thay đổi. Những sự thay đổi mà BPMN không ghi nhận được, như những chi tiết nhỏ mình nói ở trên. Do đó, không phải cứ dùng BPMN là hay, cái gì lạm dụng quá cũng sẽ bị phản dam. Cũng may dự án đã Go-Live thành công, chứ không cả đám ăn cám hết.
Thường thì software implementation ít dùng UML nhiều như software development. Nhưng khi nảy sinh một yêu cầu mới cần phải build từ đầu, thì lấy UML ra dùng cũng là một sự lựa chọn không tồi. Đừng khư khư mãi vào BPMN nhé anh em.
BPMN tập trung vào quy trình, còn UML tập trung vào từng đối tượng cụ thể để phục vụ cho việc build phần mềm (Nguồn ảnh: bonkersworld.net)
5. BPMN cứu rỗi đời mình như thế nào?
Trước khi kết thúc bài này thì mình sẽ kể cho anh em nghe một câu chuyện hư cấu có thật.
Đó là lần team dự án mình gặp phải một kèo chua cay như gói mì hảo hảo.
Đây là một khách hàng B2B, vừa sản xuất vừa bán B2B luôn. Mà bán B2B thì quy trình duyệt giá cho một đơn hàng khá phức tạp. Vì giá trị đơn hàng là rất lớn, và phải luôn đảm bảo giá tốt nhất cho khách mua hàng.
Lần đó team mình qua phải 3, 4 lần gì mới lấy được requirement cụ thể cho quy trình làm báo giá này. Nó qua rất nhiều bước.
Từ lúc Salesperson nhận một yêu cầu hỏi hàng, sau đó sẽ làm báo giá cho khách hàng. Đa phần các báo giá đều sẽ được áp các mức chiết khấu mặc định, phụ thuộc vào khách hàng và số lượng sản phẩm khác nhau.
Nếu Salesperson không muốn giảm giá gì thêm thì họ sẽ gửi báo giá cho khách hàng duyệt. Nếu khách hàng đồng ý thì nhập ngày giao hàng (mà khách yêu cầu), rồi kiểm tồn kho (check on hand), và cuối cùng là làm Order. Nếu không đồng ý thì Salesperson phải deal lại ngày giao hàng.
Còn nếu Salesperson muốn có một mức giá tốt hơn mức giá chuẩn (tức là discount nhiều hơn mức discount chuẩn cho phép), thì Salesperson phải xin giá. Mà để xin giá thì phải raise yêu cầu cho Team Leader.
Tức là Salesperson sẽ nhập mức discount họ mong muốn. Sau đó chuyển qua Team Leader để duyệt giá chặng một. Team Leader sẽ dựa vào mức discount mà Salesperson đề xuất để duyệt giá.
Nếu mức discount làm cho giá trị của từng line sản phẩm vẫn cao hơn hoặc bằng giá vốn hàng bán (COGS), Team Leader sẽ tự cân đối revenue trong quý mà duyệt hoặc không.
Nếu mức discount mà Salesperson yêu cầu cao quá, làm cho giá trị của từng line sản phẩm thấp hơn cả giá vốn hàng bán (tức là bán chịu lỗ, không để mất khách) thì Team Leader không có quyền duyệt, mà phải đẩy lên Sales Manager để duyệt giá chặng hai. Anh sếp ảnh cho thì bán, không thì phải xin giá lại từ đầu.
Đó chỉ mới là bán hàng OBL (Own Brand Labelling), tức là hàng chuẩn, hàng mình tự sản xuất rồi bán. Còn bán hàng OEM thì phức tạp hơn. OEM là Orginal Equipment Manufacturing, tức là mình sản xuất theo thiết kế, yêu cầu đặc thù của khách hàng.
Ví dụ sản xuất 5000 cái bô dài 50 cm, rộng 40 cm, cao 30 cm, có in hình mặt cười nham nhở chẳng hạn.
Đối với hàng OEM thì phải đưa yêu cầu thiết kế qua bên R&D, rã ra BOM (bill of materials), rồi chạy Pilot (làm hàng mẫu). Nếu fail ở bước nào, thì quy trình trả về Salesperson, yêu cầu trao đổi lại với khách hàng.
Chạy Pilot xong mà khách hàng ok mẫu mã này nọ xong xuôi, thì tiếp tục tới phần giá như ở trên. Nhưng đâu dễ ăn của ngoại.
Vì là hàng OEM, nên cần phải phân rã BOM ra và đưa qua bộ kế toán để xin giá vốn hàng bán (vì là sản phẩm mới toanh nên đâu biết giá gốc bao nhiêu đâu mà bán).
Tức là cái bô có thành bô, miệng bô, thân bô. Mỗi bộ phân bao nhiêu tiền, ghép lại thành một cái bô, sẽ ra được giá gốc là bao nhiêu tiền. Rồi gom góp các loại chi phí sản xuất, môi trường, nhân công, điện nước này nọ. Ra được một mức giá, gọi là giá vốn hàng bán (COGS). Rồi mới đưa cái cục giá đó cho ông Salesperson, ổng sẽ lấy mức giá này để bắt đầu deal với khách hàng. Rồi đoạn deal phía sau, sẽ tiếp tục quy trình báo giá cho sản phẩm OBL như phía trên.
Đó là tóm tắt quy trình của khách hàng, bằng chữ. Anh em thấy quá mệt đúng không. Đưa một mớ này vô document chắc chả ai thèm đọc hết.
Khi đó, BPMN xuất hiện như một vị cứu tinh. Những notation của BPMN đều cover được hết quy trình bên trên.
Bấm hình dưới đây xem chi tiết nhé anh em.
Anh em thông cảm, hình hơi mờ. Chờ xíu cho nó load đủ >> bấm vào nút View Full Size để xem full HD.
Do đó, không có BPMN, mình cũng chả biết transfer lại quy trình này cho team như thế nào cho hiệu quả. Mặc dù mình vẫn có thể chế ra các ký hiệu để vẽ vời, miễn đáp ứng được yêu cầu trên.
Nhưng khi deliver tài liệu cho bất kỳ một stakeholders nào khác, chẳng lẽ lại phải mất công giải thích: cái ô vuông nghĩa là A, cái hình chữ nhật nghĩa là B. Như vậy rất tốn thời gian. Trong khi BPMN đã là một cái chuẩn, vẽ con mèo là mọi người hiểu ngay con mèo, không thể nào hiểu ra con chó được.
Do đó, in BPMN, we trust ?
6. Tạm kết
Mình sẽ tạm dừng bài 1 về BPMN ở đây. Qua bài này hi vọng anh em nắm được:
BPMN là gì? (Business Process Modeling Notation)
Tại sao nó lại quan trọng? (giúp BA document và transfer thông tin hiệu quả hơn)
Dành cho đối tượng nào? (hầu hết là mọi người)
BPMN khác với UML ra sao? (một ông làm về process, còn một ông làm về software)
Ở bài sau chúng ta sẽ đi chi tiết vào “BPMN in action”. BPMN gồm những thành phần gì và các nguyên tắc khi vẽ BPMN.
Nếu cảm thấy “con hàng” BPMN này có thể giúp ích nhiều được cho mình trong công việc, thì anh em có thể mạnh dạn tham khảo các khoá học BPMN ngắn hạn nhé.
Bài viết được sự cho phép của tác giả Nguyễn Hoàng Phú Thịnh
Hế lôôôôô anh em. Hôm nay mình sẽ note về một đề tài khá “muôn thuở”. Đó là chuyện yêu cầu kinh nghiệm khi đi phỏng vấn làm Business Analyst.
Bài này mình muốn chia sẻ chủ yếu cho hai đối tượng.
Một là những anh em còn đang ngồi giảng đường, mong muốn làm BA, nhưng đang lo lắng, bồn chồn. Không biết chưa có kinh nghiệm thì có ứng tuyển BA ổn không.
Hai là những anh em đã đi làm, nhưng không phải làm BA. Giờ muốn chuyển sang làm BA, nhưng lại sợ kinh nghiệm không phù hợp.
Anh em nào không thuộc hai nhóm trên, vẫn có thể đọc tiếp. Vì đơn giản, đây là blog của mình nên mình thích nói gì thì nói thôi, hố hố.
Bài này mình chia sẻ cho anh em với tư cách: từng là một chàng sinh ziên đẹp chai thanh lịch zô địch khắp vũ trụ, chân ướt chân ráo mới ra trường ăn may sao được nhận vào làm BA.
Ngoài ra, hồi đại học mình cũng được làm một job BA internship. Và đặc biệt là mình cũng từng bị rớt phỏng vấn BA lúc mới ra trường. Do đó, mình rất hiểu những gì sinh viên có, và không có, để phù hợp với vị trí BA.
Bài này mình sẽ gom góp, sắp xếp lại mọi thứ theo góc nhìn của mình. Để từ đó, anh em có sự chuẩn bị tốt hơn khi ra trường, cũng như khi apply vị trí BA.
Okay, let’s goooooo!!!
1. Ý đồ thật sự của chữ “kinh nghiệm”
1.1. Công thức chung
Tất cả đều bắt đầu từ Job Description.
Nhà tuyển dụng viết JD không chỉ để anh em đọc vào rồi xem thử: à cái này tui đã từng làm chưa, à cái kia tui chưa làm bao giờ hết, hay cái này khó quá nên chắc không phù hợp.
Hổng phải zậy!!!
Nhà tuyển dụng viết JD là để anh em dòm vào đó, một cách cẩn thận. Rồi từ từ suy xét xem: Kinh nghiệm của mình có làm được những việc này hay không? Chứ hổng phải: Mình đã từng làm những việc này hay chưa?
Do đó, để làm BA (hoặc bất kỳ công việc nào khác), đầu tiên anh em phải hiểu công việc đó làm gì cái đã. Cái này đơn giản, bỏ qua.
Sau khi biết được công việc đó làm gì, anh em phải ngồi chiêm nghiệm lại các kinh nghiệm mình có. Sau đó, phân tích và mapping kinh nghiệm của mình vào công việc trong Job Description. Cuối cùng là rút ra kết luận, mình có thực sự phù hợp hay không. Vậy là ok!
Ngâm cứu Job Description >> Chiêm nghiệm >> Phân tích >> Kết luận
Sẽ không ai tuyển một thợ Nail đi làm BA, và cũng không ai tuyển một BA đi làm thợ Nail cả. Tuyển thợ điện đi làm thợ sửa ống nước, thợ sửa xe máy thì được. Chứ tuyển thợ điện đi làm kỹ sư cầu đường thì quả thật rất khó.
Giữa kinh nghiệm và yêu cầu công việc, nó phải có gì đó ăn nhậu với nhau. Chứ trớt quớt quá thì fail là cái chắc. Do đó, biết mình biết ta, trăm trận không thua. Khi đó anh em mới dám mạnh dạn tự tin mà đi phỏng vấn được.
1.2. Yêu cầu công việc của BA
Hiểu được điều cơ bản trên, anh em sẽ tự vạch ra cho mình những nước đi đúng đắn nhất từ thời sinh viên. Cái mình cần ở đây là kinh-nghiệm-liên-quan-tới-yêu-cầu-công-việc của BA.
Thành thạo tiếng Anh, nói được tiếng Nhật và đọc được tài liệu tiếng Pháp.
Có domain knowledge về ngành sản xuất, y tế, giáo dục, nhân sự, tài chính, ngân hàng,…nói chung là biết tuốt.
Hiểu tường tận về blockchain là một lợi thế.
Thuần thục Agile/ Scrum.
Có khả năng multitask, như vừa lấy yêu cầu, vừa document ngay tại chỗ luôn.
Yêu cầu năng suất làm việc cao, có thể làm việc liên tù tì từ 9 giờ sáng tới 9 giờ tối mà không lèm bèm, càm ràm gì hết.
…
Đó, ví dụ về một Job Description. Mặc dù nghe giống tuyển siêu nhân hơn là tuyển BA. Nhưng không sao, anh em chỉ cần để ý tới phần mô tả công việc thôi.
Đó là những công việc mà một người BA sẽ làm. Do đó, mình cần phải build up những kinh nghiệm liên quan tới các đầu việc này. Phân tích một tí về các công việc đặc trưng của BA thì gồm 2 nhóm kỹ năng.
Thu thập yêu cầu từ khách hàng ==> Kỹ năng giao tiếp, thuyết phục, thuyết trình, đặt câu hỏi, lắng nghe, thấu hiểu…
Viết tài liệu dự án ==> Kỹ năng và kiến thức về Word, Excel, Power Point, kỹ năng đánh máy, tối ưu công việc, làm sao cho nhanh, cho hiệu quả.
Làm việc với các stakeholders (khách hàng, Dev, PM, QA, QC…) ==> Kỹ năng làm việc nhóm, xử lý xung đột, kiểm soát cảm xúc, tư duy logic…
Lên kế hoạch công việc ==> Kỹ năng planning, time management.
Kỹ năng cứng
Viết tài liệu dự án ==> Kiến thức và thực hành về UML, BPMN và các loại document có trong dự án.
Hiểu nghiệp vụ ==> Hiểu các nghiệp vụ về Sales, Kế toán, Sản xuất, Marketing, Customer Service, Field Service, Supply Chain…
Domain Knowledge ==> Hiểu về đặc thù các ngành nghề như Banking, Finance, Insurance, Manufacture, Horeca (hotel-restaurant-cafe), Retail, Human Resource, Real Estate, Education…
Thiết kế database ==> Kiến thức và thực hành về database, hiểu về SQL…
Có kiến thức về công nghệ ==> Hiểu cách một application, web app hay mobile app hoạt động. Đối với làm triển khai thì hiểu công nghệ của các hãng (như Microsoft, SAP, Oracle…). Hoặc hiểu về các khái niệm như API, Web Service…
Thiết kế mockup, prototype ==> Kiến thức căn bản về UX/UI và thực hành trên các tool như Visio, Balsamiq Mockup, Axure…
Hiểu quy trình làm việc ==> Kiến thức về Agile/Scrum, Waterpark, à nhầm, Waterfall, hoặc các development management tool như TFS, GitHub, SVN, Jira…
Thường thì dưới phần Mô tả công việc, sẽ luôn có phần Yêu cầu kỹ năng/ kinh nghiệm cụ thể. Tuy nhiên theo mình thì anh em vẫn nên tự phân tích các đầu mục công việc này. Để xem mình có thực sự hiểu những gì người ta đang cần hay không.
Okay, vậy là coi như anh em đã hiểu được Job Description một cách cụ thể.
Tiếp theo, mình sẽ nói về những hành động cụ thể mà anh em có thể làm ngay, để đáp ứng được với các yêu cầu công việc này.
2. Your next step
Khi còn ngồi ghế giảng đường thì có khá nhiều con đường để anh em lựa chọn, cụ thể gồm 6 con đường cơ bản sau:
Tham gia các CLB trong trường
Tham gia các hoạt động tình nguyện
Đi làm thêm, đi làm “pặc-tham”
Xung phong thuyết trình
Học theo nhóm, làm đồ án, làm bài tập theo nhóm
Và cuối cùng là đi thực tập.
Mình chưa thấy ai thời đại học, không làm những việc trên (chí ít là một việc) mà ra trường kiếm được việc ngay cả.
Mình cực kỳ recommend anh em thời đại học nên quẩy những thứ trên. Tệ nhất cũng phải được 2/6 các mục trên. Thì khi đó, ra trường mới có thể tìm được việc ưng ý.
2.1. Chiêm nghiệm
Mình có thằng bạn, hồi năm nhất đại học nó toàn chơi game rồi ngủ. Sang năm hai thấy chán quá nên nó mới quyết định “try something new” bằng cách tham gia điên dại vào các CLB sinh viên trong trường lúc đó.
Mà các CLB này thì hoạt động phải nói là muôn màu phong phú. Từ tổ chức sự kiện, đến đi thiện nguyện, tham gia các cuộc thi, tổ chức training, bán hàng…, nói chung là tùm lum tùm la hết.
Còn trên lớp thì thằng này được cái rất chịu khó làm việc nhóm. Đối tượng thuyết trình chính luôn là nó. Không đẩy nó lên, thì cũng tự nó xung phong, nên anh em trong team đỡ vả lắm.
Ngoài ra, nó cũng chịu khó tham gia các cuộc thi, kiếm tiền đi phượt. Mà được cái nó biết chọn lọc, không phải cuộc thi nào cũng tham gia. Nó chỉ tham gia những cuộc thi liên quan đến ngành nó học thôi, may sao cũng ruồi ruồi được 1-2 giải nhỏ.
Nó cũng chịu khó tham gia mấy tổ chức lợi nhuận phi giáo dục, ủa lộn, mấy tổ chức giáo dục phi lợi nhuận.
Đi dạy mấy đứa nhỏ cấp 1 ở mấy trường dưới Bình Triệu. Nhờ đó mà kỹ năng chém gió của nó cũng lên được kha khá.
Mình để ý là thằng này cũng khá tốt trong việc giao cấu với bạn bè, đồng bọn mới. Kèo đá banh đá bóng gì là đều do nó cầm đầu hết.
Sơ bộ thì thằng bạn mình cũng có đủ các kỹ năng mềm để làm BA chứ hả anh em. Nhưng đó chỉ là một nửa câu chuyện. Nửa còn lại là kỹ năng cứng thì để mình ngó xem nó có gì ?
Vì thằng này là một thằng hay quan sát nên lâu lâu nó hay ba láp ba xàm về mấy thứ xung quanh nó. Như cái máy quẹt thẻ giữ xe nó hoạt động ra sao chẳng hạn.
Nó cũng chịu khó đọc sách. Mà sách nó đọc thì cũng nhiều loại, xàm cũng có, mà cực xàm cũng có.
Nói về chuyện thực tập thì nghe kể đâu nó apply tới tận mười mấy công ty. Mà có đúng 2-3 công ty gì đó là chịu nhận nó.
Chưa kể lúc thực tập về, nó còn làm khóa luận nữa. Hồi đó nghe nói nó làm đề tài về thiết kế hệ thống vận hành dữ liệu đầu vào gì đó cho công ty nghiên cứu thị trường.
Lăn lê bò trường với khóa luận khoảng hơn 3 tháng, nó cũng thu hoạch được khá nhiều vốn liếng. Từ kiến thức nền tảng chung về IT, đến các kiến thức về phân tích, thiết kế hệ thống thực tế.
Chưa kể vì nhiều lần đau thương với Microsoft Word nên nó cũng rút kinh nghiệm nhiều khi làm Word. Nó còn kể lúc thực tập, vì được làm Vlookup nhiều nên Excel nó tự tin lắm.
2.3. Kết luận
Cuối cùng, gom góp lại những gì nó từng trải, từng làm, ngồi chiêm nghiệm một hồi. Thấy kỹ năng mềm của nó quá hợp với BA đi chứ. Kỹ năng cứng là thứ nó không tự tin, nhưng đó là những gì nó có thể làm để chuẩn bị cho một buổi phỏng vấn BA. ==> Mức độ tự tin khoảng 85%.
Note một ý nhỏ với anh em, kỹ năng cứng với anh em sinh viên mới ra trường thực ra cũng không cần yêu cầu quá nhiều. Quan trọng nhất vẫn là thái độ và kỹ năng mềm của mình thôi. Vì hai cái đó sinh viên hoàn toàn có được, từ rèn được.
Còn về kỹ năng cứng thì đa phần là ở mức độ tự tìm hiểu. Rồi cố gắng ứng dụng được nhiều nhất có thể khi đi thực tập mà thôi 🙂
Thời buổi giờ có quá nhiều resource cho anh em ngâm cứu. Từ free tới tính phí. Quan trọng là anh em có chịu bỏ thời gian ra học hay không thôi.
Rảnh rảnh cứ lên Udemy, Pluralsight hoặc chỉ cần Youtube là có nhiều clip hay để học rồi. Hoặc nếu máu hơn thì cứ để dành một ít vốn liếng đi học khóa học BA. Cũng hết sảy con bà bảy.
Mẹo nhỏ đọc nghe hú hồn chơi
Muốn chuẩn bị kiến thức về nghiệp vụ, chỉ cần đăng ký TRIAL các hệ thống rồi vào vọc là ô kê.
Cách đăng ký cũng dễ ẹc, chỉ cần đọc hướng dẫn là trong vòng 3 nốt nhạc, anh em đã có ngay một hệ thống, tha hồ vào vọc.
Có các hãng nổi tiếng sau anh em có thể chọn (bấm vào các link sau rồi làm theo hướng dẫn)
Nói vòng vòng nãy giờ túm cái váy lại, là anh em phải làm.
Làm những thứ liên quan đến công việc BA như mình nói ở trên.
Làm MC, quá good
Làm quản trò, quá good
Làm gia sư, quá good
Làm tình nguyện viên, quá good
Làm sales, quá good
Làm biếng, quá bad, cái này thì là quá bad.
Những cái “bad” khác mà anh em có thể dễ dàng nhận ra như: làm biếng, làm biếng, hoặc làm biếng. Tức là làm gì cũng tốt, miễn có làm là được, nhưng đừng làm biếng.
Nhưng bên cạnh cái làm biếng, còn một cái làm khác, cũng “bad” không kém.
Đó là làm không liên quan.
Ví dụ làm bồi bàn quán ăn, quán cà phê. Cũng tốt thôi, nhưng thật sự nó không liên quan lắm đến những thứ mình có nói ở trên. Anh em có thể có kỹ năng giao tiếp, kỹ năng xử lý tình huống. Nhưng bù lại công việc chỉ gói gọn chừng đó, không mở rộng ra được. Mà không mở rộng, thì sẽ không tự phát triển lên được. Làm dưới 3 tháng thì ô kê, trên 3 tháng thì nên cân nhắc.
Sẽ có anh em hỏi: “Làm part time ở tiệm photocopy ổn không anh?” Cái này thì mình lại nghĩ là quá good đi chứ. Như anh sếp của mình, thời đi học cũng từng làm partime ở tiệm photocopy.
Nói về Word thì ổng trùm lắm. Nhắm mắt vẫn dùng phím tắt múa như thường. Heading, căn lề, font chữ, size chữ, theme, paragraph các kiểu làm rẹc rẹc.
Hồi đó làm document, mình cứ đinh ninh là ổn, đưa qua ảnh review một cái thì thôi rồi, y như rằng phải làm lại… bản mới.
3. Túm cái váy
Phải thử rồi mới biết.
Đừng ngại chuyện không có kinh nghiệm. Giờ không chỉ BA, mà các ngành nghề khác cũng vậy, cũng không quá yêu cầu kinh nghiệm như trước nữa.
Mà dù có yêu cầu kinh nghiệm nhiều thì anh em cũng chả việc gì phải ngại. Như mình chia sẻ ở trên, có kinh nghiệm liên quan đến công việc BA thì cứ tự tin, mạnh dạn mà phỏng vấn.
Quay lại trường hợp của mình: mình bị rớt phỏng vấn BA là vì mình chưa thể hiện được mức độ phù hợp của mình với công việc. Mình chưa thật sự show cho họ thấy được: “à, tui đã hiểu, đã sẵn sàng làm cái này, cái kia, làm công việc của một BA thật sự”.
Đó là lý do mà mình, và nhiều anh em khác bị rớt phỏng vấn, do cả hai (cả người phỏng vấn và người được phỏng vấn) chưa tìm được nhu cầu của nhau.
Đừng nghĩ làm BA là một công việc gì đó cần kinh nghiệm ghê gớm. Cứ mạnh mẽ, tự tin mà apply, phải manh động lên.
Sẽ không ai nghĩ một con voi biết bơi, cho đến khi người ta thấy nó dưới nước.
Hãy cho nhà tuyển dụng thấy những gì bạn đã làm. Hãy thuyết phục công ty chọn bạn làm BA. Và họ sẽ không hối hận khi thấy những gì bạn làm.
…hoặc ngược lại ?
That’s all! Hẹn gặp anh em ở những bài sau. Có gì cần trao đổi, chém gió thêm thì anh em cứ comment bên dưới nhé.
Mình mới gắn nút like cho blog. Anh em nào thấy thích bài này thì cứ like mạnh tay nhé ? See yaaaa!!!
Bài viết được sự cho phép của tác giả Trần Nhật Trường
I. GIỚI THIỆU
Thay vì sử dụng Service Account keys, Workload Identity cho phép các workload xác thực bằng cách sử dụng danh tính của chúng mà không cần lưu trữ các khóa bí mật.
Workload Identity là một tính năng của Google Cloud cho phép bạn quản lý và cấp phát danh tính cho các workload (ứng dụng, dịch vụ) chạy trên Google Cloud hoặc trên các môi trường khác như Kubernetes hay các cloud khác. Workload Identity giúp giảm thiểu việc quản lý và sử dụng các khóa dịch vụ (Service Account keys), thay vào đó, nó sử dụng danh tính liên kết để ủy quyền và truy cập tài nguyên.
II. HƯỚNG DẪN
1. Cấu hình trên GCP
Để chuyển đổi Service Account (SA) key sang Workload Identity trên Google Cloud, bạn cần làm theo các bước sau:
Bước 1: Tạo một Workload Identity Pool
– Mở Google Cloud Console.
– Điều hướng tới “IAM & Admin” > “Workload Identity Federation”.
– Nhấp vào “Create Pool” và cung cấp các thông tin cần thiết như tên pool, ID, và mô tả.
Cập nhật ứng dụng của bạn để sử dụng chứng chỉ của provider thay vì sử dụng SA key.
Tùy thuộc vào ngôn ngữ lập trình và môi trường, cấu hình có thể khác nhau, ta sẽ cần cung cấp đường dẫn tới file cấu hình hoặc thiết lập các biến môi trường.
Bước 4: Cấu hình ứng dụng để sử dụng Workload Identity
Ví dụ 1: Sử dụng Google Cloud Storage trong Spring Boot:
Ta không cần thêm cấu hình đặc biệt nào trong ứng dụng Spring Boot vì thư viện Google Cloud Client Library sẽ tự động phát hiện các chứng chỉ từ môi trường khi chạy trên GKE với Workload Identity.
Lưu ý:
Đảm bảo rằng ta đã cài đặt và cấu hình gcloud, kubectl. Kiểm tra và thay thế tất cả các biến PROJECT_ID, SERVICE_ACCOUNT_NAME, K8S_NAMESPACE, KSA_NAME, POD_NAME, CONTAINER_NAME, IMAGE
Sử dụng thư viện trong ứng dụng Golang: Trong ví dụ này, storage.NewClient(ctx) tự động phát hiện các chứng chỉ từ môi trường của GKE, nhờ cấu hình Workload Identity.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
package main
import (
"context"
"log"
"cloud.google.com/go/storage"
)
func main() {
ctx := context.Background()
// Tạo client mới cho Google Cloud Storage
client, err := storage.NewClient(ctx)
if err != nil {
log.Fatalf("Failed to create client: %v", err)
}
// Sử dụng client để tương tác với Google Cloud Storage
Thay vì sử dụng option.WithCredentialsFile(“path/to/your/credentials/file.json”) (case sử dụng SA key), ta có thể cấu hình ứng dụng sử dụng chứng chỉ được tự động phát hiện từ môi trường khi chạy trên GKE với Workload Identity.
BONUS
Vậy với GCE (Compute engine) a.k.a VM thì có phương pháp nào không phải sử dụng SA key không? Câu trả lời là có.
Để một ứng dụng chạy trên VM của Google Cloud Platform (GCP) sử dụng service account của VM đó mà không cần sử dụng Service Account key (SA key), bạn có thể cấu hình VM để sử dụng Application Default Credentials (ADC). Đây là phương pháp được khuyến nghị vì nó đơn giản hơn và an toàn hơn so với việc quản lý và sử dụng SA key thủ công. Đọc thêm bài viết này để hiểu ADC hoạt động như nào https://cloud.google.com/docs/authentication/application-default-credentials.
Vậy ADC có thể apply cho cả GKE, vậy sao không dùng luôn ADC mà lại dùng Workload Identity? Lý do là:
– ADC thiếu Pod-level Identity: ADC không hỗ trợ việc ánh xạ danh tính tới mức pod. Tất cả các pod trên cùng một node sẽ chia sẻ cùng một service account, dẫn đến quyền truy cập rộng hơn và khó kiểm soát chi tiết.
– ADC không Hỗ trợ Kubernetes RBAC: ADC không tích hợp với hệ thống Role-based Access Control (RBAC) của Kubernetes, dẫn đến khó khăn trong việc quản lý và gán quyền truy cập chi tiết.
– Workload Identity có khả năng liên kết với các nhà cung cấp danh tính bên ngoài như AWS, Azure, hoặc hệ thống OIDC, giúp mở rộng khả năng xác thực và quản lý danh tính cho các workload đa đám mây. ADC không cung cấp khả năng này.
Trong lập trình Java việc hiểu rõ về các từ khóa như final, static, và static final là rất cần thiết. Ở bài viết trước ta đã tìm hiểu về static, trong bài viết này, chúng ta sẽ tiếp tục tìm hiểu chi tiết về ý nghĩa và cách sử dụng của từ khóa final trong Java.
Từ khóa final trong Java
Trong Java, từ khóa final được sử dụng để tạo ra các hằng số hoặc ngăn chặn sự thay đổi, kế thừa, hoặc ghi đè trong một số trường hợp cụ thể. Final có thể được áp dụng cho biến, phương thức, và lớp, và mỗi trường hợp sử dụng final đều có ý nghĩa riêng.
Các trường hợp sử dụng:
Biến final: khi một biến được khai báo với từ khoá final, nó chỉ chứa một giá trị duy nhất trong toàn bộ chương trình (hay dễ hiểu hơn gọi là biến hằng).
Phương thức final: khi một phương thức được khai báo với từ khoá final, các class con kế thừa sẽ không thể ghi đè (override) phương thức này.
Lớp final: khi từ khoá final sử dụng cho một lớp, lớp này sẽ không thể được kế thừa.
Biến static final trống: Một biến final mà không được khởi tạo tại thời điểm khai báo được gọi là biến final trống.
Từ khóa final có thể được áp dụng với các biến, một biến final mà không có giá trị nào được gọi là biến final trống hoặc biến final không được khởi tạo. Nó chỉ có thể được khởi tạo trong constructor. Biến final trống cũng có thể là static mà sẽ chỉ được khởi tạo trong khối static. Chúng ta sẽ tìm hiểu chi tiết về những điều này.
Khi một biến được khai báo với từ khóa final, giá trị của nó không thể thay đổi sau khi đã được khởi tạo. Nói cách khác, biến đó trở thành một hằng số.
Ví dụ: Trình biên dịch sẽ thông báo lỗi khi bạn cố ý thay đổi giá trị của biến này, bởi vì biến final một khi được gán giá trị thì không bao giờ thay đổi được.
Bạn sẽ nhận được thông báo lỗi khi cố tình thay đổi giá trị của biến final: The final field UsingFinalExample.WEBSITE cannot be assigned.
Ví dụ: Có thể thay đổi giá trị của thuộc tính của một object là final, nhưng bạn không thể khởi tạo lại object đó một lần nữa.
Phương thức final (Final method) trong Java
Khi một phương thức được khai báo là final, nó không thể bị ghi đè (override) trong các lớp con. Điều này đảm bảo rằng phương thức này không thể thay đổi hành vi bởi bất kỳ lớp nào kế thừa nó.
Ví dụ về không thể ghi đè phương thức final.
Bạn sẽ nhận được thông báo lỗi khi cố tình ghi đè phương thức final: Cannot override the final method from Parent.
Lớp final (Final class) trong Java
Khi một lớp được khai báo là final, lớp đó không thể bị kế thừa. Điều này có nghĩa là không thể tạo ra bất kỳ lớp con nào từ lớp final.
Ví dụ về không thể kế thừa lớp final.
Bạn sẽ nhận được thông báo lỗi khi cố tình kế thừa từ lớp final: The type Child cannot subclass the final class Parent.
Biến static final trống trong Java
Một biến static final mà không được khởi tạo tại thời điểm khai báo thì đó là biến static final trống. Nó chỉ có thể được khởi tạo trong khối static và một khi nó đã được khởi tạo thì không thể bị thay đổi.
Một số câu hỏi thường gặp khi đi phỏng vấn liên quan đến từ khóa final
Phương thức final có được kế thừa không?
Trả lời: Có, phương thức final được kế thừa nhưng bạn không thể ghi đè nó.
Biến final trống hoặc không được khởi tạo là gì?
Trả lời: Một biến final mà không được khởi tạo tại thời điểm khai báo được gọi là biến final trống. Biến được khởi tạo tại thời điểm tạo đối tượng và một khi nó đã được khởi tạo thì không thể bị thay đổi.
Ví dụ:
Bạn sẽ nhận được thông báo lỗi khi cố tình thay đổi giá trị của biến final: The final field WEBSITE may already have been assigned.
Tham số final là gì?
Nếu bạn khai báo bất cứ tham số nào là final, thì bạn không thể thay đổi giá trị của nó.
Bạn sẽ nhận được thông báo lỗi khi cố tình thay đổi giá trị của tham số final: The final local variable website cannot be assigned. It must be blank and not using a compound assignment.
Trên đây là những lý thuyết cơ bản về từ khóa final trong Java. Khi tham gia vào các dự án thực tế sẽ có nhiều trường hợp áp dụng khác nhau. Cám ơn các bạn đã theo dõi bài viết. Hẹn gặp lại ở bài viết tiếp theo.
Bài viết được sự cho phép của tác giả Nguyễn Hoàng Phú Thịnh
Bản thân mình thời gian đầu dùng Use Case cũng gặp rất nhiều khó khăn. Một mớ bồng bông câu hỏi cứ lởn quởn trong đầu: bản chất của Use Case là gì, dùng cho mục đích nào, vẽ vậy đúng hay chưa, có chi tiết quá không, hoặc thậm chí vẽ Use Case xong cũng chẳng biết để làm gì???
Do đó bài này mình sẽ note về những thứ mình học được, làm được và dĩ nhiên quan trọng nhất là những sai lầm mà mình từng mắc phải khi làm Use Case.
Use Case là kỹ thuật dùng để mô tả sự tương tác giữa người dùng và hệ thống với nhau, trong một môi trường cụ thể và vì một mục đích cụ thể.
Sự tương tác ở đây có thể là:
Người dùng tương tác với hệ thống như thế nào?
Hoặc, hệ thống tương tác với các hệ thống khác như thế nào?
Và dĩ nhiên, sự tương tác này phải nằm trong một môi trường cụ thể, tức là nằm trong một bối cảnh, phạm vi chức năng cụ thể, hoặc rộng hơn là trong một hệ thống/ phần mềm cụ thể.
Sau cùng, việc mô tả sự tương tác này phải nhằm diễn đạt một mục đích cụ thể nào đó. Use Case phải diễn rả được Requirement theo góc nhìn cụ thể từ phía người dùng.
Ví dụ sơ đồ Use Case diễn tả sự tương tác giữa người dùng là độc giả với trang blog Thinhnotes chẳng hạn.
Ví dụ đơn giản về Use Case
Tương tác ở đây là gì?
Độc giả đọc bài notes
Độc giả yêu thích bài notes
Độc giả chia sẻ bài notes
Độc giả nhận xét bài notes
Độc giả gửi bài notes cho độc giả khác qua email
Môi trường cụ thể? Quá đơn giản, đó là trang blog Thinhnotes.com (không phải trang Admin).
Mục đích cụ thể?
Người dùng có thể đọc được bài notes trên blog (đơn giản bỏ qua)
Người dùng có thể bày tỏ được sự yêu thích bài notes
Người dùng có thể chia sẻ bài notes này trên các nền tảng khác để nhiều người khác có thể đọc được
Người dùng có thể viết nhận xét khen chê gạch đá các kiểu cho tác giả
Người dùng có thể gửi bài notes này qua email cho một người bất kỳ.
Đó là tất tần tật những nội dung mà một Use Case sẽ thể hiện.
Về hình thức thì Use Case tồn tại ở 2 dạng:
Hình vẽ Use Case (Use Case Diagram)
Đặc tả Use Case (Use Case Specification).
Ở bài sau mình sẽ nói Use Case Specification sau nhé anh em. Bài này mình sẽ tập trung nói về Use Case Diagram.
Use Case Diagram là một thành viên trong họ UML (Unified Modeling Language).
Use Case thuộc họ Behavior trong bộ UML
Mỗi Diagram trong bộ UML này đều có những mục đích khác nhau. Tùy trường hợp, tùy dự án mà anh em sẽ “rút hàng” ra chiến như thế nào cho hợp lý.
Hiểu sơ bộ Use Case là gì và mục đích của nó, chúng ta cùng tìm hiểu chi tiết Use Case Diagram và cách vẽ nhé anh em 😎
2. Các thành phần của Use Case Diagram
2.1. Actor, Use Case, Communication Link và Boundary
Cũng không có gì quá phức tạp, Use Case Diagram gồm 5 thành phần chính:
Actor
Use Case
Communication Link
Boundary of System
Và, Relationships.
Các thành phần có trong một Use Case Diagram
Actor thì có thể là Người dùng, hoặc một System nào đó. Vì UML quy định Actor là hình thằng người nên có thể anh em sẽ nhầm lẫn chỗ đó phải là người dùng nhưng hổng phải.
Một số câu hỏi anh em có thể tự lẩm bẩm trong đầu để xác định Actor như sau:
Ai là người sử dụng hệ thống?
Ai sẽ là người Admin của hệ thống (tức người cài đặt, quản lý, bảo trì… hệ thống)?
Hệ thống này có được sử dụng bởi bất kỳ một hệ thống nào khác không? (*)
Hệ thống lưu trữ dữ liệu, vậy ai là người input dữ liệu vào hệ thống?
Hệ thống lưu trữ dữ liệu, vậy ai là người cần những dữ liệu output?
Ở mục (*), mình muốn highlight cho anh em chỗ này. Không phải giải pháp/ phần mềm nào làm ra đều được sử dụng bởi con người. Có những phần mềm làm ra, để cho… phần mềm khác sử dụng.
Chẳng hạn như làm các services. Mình có một anh bạn làm BA, giải pháp mà ảnh cùng đồng bọn làm ra là 1 services không được dùng bởi con người, mà được dùng bởi một hệ thống khác để xác thực người dùng.
Ký hiệu của Actor chủ yếu là hình thằng người, nhưng để Diagram thêm phong phú, đa dạng thì anh em có thể sử dụng các hình dưới đây, miễn có ghi chú rõ ràng là được.
Các ký hiệu thể hiện Actor.
Còn Use Case là anh em sẽ thể hiện dưới dạng hình Oval, thể hiện sự tương tác giữa các Actor và hệ thống.
Communication Link thể hiện sự tương tác giữa Actor nào với System. Nối giữa Actor với Use Case.
Boundary of System là phạm vi mà Use Case xảy ra. Ví dụ trong hệ thống CRM, phạm vi có thể là từng cụm tính năng lớn như Quản lý khách hàng, Quản lý đơn hàng, hoặc cả một module lớn như Quản lý bán hàng.
…
Ô kê nãy giờ dễ ẹc, mấy cái này nhìn sơ qua là anh em biết ngay cái một.
Cái cuối cùng mới chính là cái mà mình tin là nhiều anh em vẫn còn rất dễ lộn, đó là Relationship.
Relationship gồm 3 loại: Include, Extend, và Generalization.
a) Include
Include nghĩa là mối quan hệ bắt buộc phải có giữa các Use Case với nhau.
Xét về nghĩa, Include nghĩa là bao gồm, tức nếu Use Case A có mối quan hệ include Use Case B, thì nghĩa là: Use Case A bao gồm Use Case B.Để Use Case A xảy ra, thì Use Case B phải đạt được.
Ví dụ về Include trong Use Case
Xét ví dụ trên, chúng ta có Use Case: Nhận xét bài notes. Use Case này include 2 Use Case khác là: Đăng nhập WordPress và Soạn thảo nhận xét.
Rõ ràng anh em thấy: để nhận xét được một bài viết, anh em cần phải đăng nhập vào 1 tài khoản nào đó, để blog nhận diện anh em là ai, tên gì, quê quán, giai gái ra sao.
Ví dụ ở blog mình là anh em sẽ cần đăng nhập vào tài khoản WordPress. Sau khi đăng nhập xong, anh em phải soạn thảo nhận xét, tức là gõ nhận xét, chỉnh sửa, xóa tới xóa lui. Sau khi viết xong nhận xét, anh em sẽ bấm nút Submit để hoàn thành chẳng hạn.
Chỉ khi nào xong 2 bước trên (đăng nhập và soạn thảo nhận xét), thì anh em mới có thể xong bước Nhận xét bài notes được.
Hay nói cách khác để Use Case: Nhận xét bài notes xảy ra, thì Use Case: Đăng nhập WordPress và Use Case: Soạn thảo nhận xét phải bắt buộc hoàn thành trước tiên.
Đó chính là mối quan hệ Include. Anh em xem tiếp 1 số ví dụ dưới cho dễ hình dung nhé.
Muốn rút được tiền thì đầu tiên khách hàng phải xác thực tài khoản đi cái đãMuốn đặt được xe thì phải hoàn thành được 3 bước này rồi hệ thống mới cho đặtHoặc khách hàng muốn đánh giá được chuyến đi thì trước đó họ phải đặt xe cái đãHoặc tương tự là Use Case thể hiện tính năng Theo dõi tiến độ giao hàng trên một trang e-Commerce bất kỳ
Một số điểm cần chú ý khi vẽ Include cho Use Case
Thực sự không có quy tắc nào rõ ràng cho việc khi nào cần tách Use Case ra thành các Use Case nhỏ và cho nó một mối quan hệ Include cả.
Việc tách hay không tách phụ thuộc duy nhất vào người vẽ. Và lý do lớn nhất để mối quan hệ Include ra đời là giúp cho các Use Case của chúng ta DỄ QUẢN LÝ hơn; làm cho Use Case Diagram trông có vẻ nguy hiểm hơn mà thôi 😎
Và anh em chỉ nên tách Use Case khi nó có độ phức tạp lớn và những thứ tách ra được có thể được tận dụng ở các Use Case sau này.
Độ phức tạp lớn thì khi tách ra mình mới có được những Use Case vừa phải, đủ để diễn đạt dễ hiểu cho các stakeholders. Còn tận dụng được ở các Use Case sau là sao?
Sử dụng Include như thế nào cho hợp lý?
Ví dụ Use Case A gồm 2 Use Case nhỏ bên trong là X và Y. Do đó Use Case A được tách thành Use Case X và Use Case Y.
Tương tự, Use Case B gồm Use Case Y bên trong, nên được tách thành Use Case Y.
Nhưng, Use Case C gồm Use Case X và Use Case Z bên trong, nhưng chỉ có Use Case X là được tách ra cho mối quan hệ Include. Vì có thể Use Case Z “không đáng” để tách ra thành một Use Case nhỏ hơn.
Chúng ta tách Use Case X từ Use Case A để Use Case C có thể tận dụng được mà không cần vẽ lại. Tương tự, tách Use Cas Y từ Use Case B để Use Case A có thể tận dụng mà cũng không cần vẽ lại.
Điều này giúp Use Case Diagram của chúng ta trở nên chặt chẽ, logic và gọn nhẹ hơn rất nhiều.
Còn Use Case Z, vì nó không được “dùng lại” ở một Use Case bất kỳ nào sau đó, nên người vẽ có thể cân nhắc có tách nó ra hay không!
Nếu Use Case đó đủ lớn và khá là high-level, thì có lẽ chúng ta nên tách. Còn nếu ngược lại, Use Case đã rõ ràng, là một requirement từ phía User cụ thể thì không đáng để anh em tách nó ra thành một Use Case nhỏ, chỉ làm hình thêm thêm rối mà thôi.
Khi tách Use Case ra thành các Use Case nhỏ để tận dụng mối quan hệ Include, anh em hãy nhớ 2 thứ: độ lớn của Use Case và khả năng tái sử dụng lại của nó
Còn cách vẽ thì anh em cứ nhớ là include tới thằng nào thì dấu mũi tên hướng tới thằng đó nhé anh em. Nhớ để qua phần Extend cho khỏi lộn.
b) Extend
Extend là mối quan hệ mở rộng giữa các Use Case với nhau.
Nếu Include là mối quan hệ bắt buộc, thì Extend là một mối quan hệ không bắt buộc. Nó thể hiện mối quan hệ có thể có hoặc có thể không giữa các Use Case với nhau.
Một Use Case B là extend của Use Case A thì có nghĩa Use Case B chỉ là một thứ optional, và chỉ xảy ra trong một hoàn cảnh cụ thể nào đó.
Lấy ví dụ Grab phía trên, anh em sẽ dễ dàng có được một mối quan hệ Extend như sau.
Ví dụ về mối quan hệ Extend giữa các Use Case
Trong trường hợp này, Use Case: Gửi tiền tip cho lái xe là một Use Case có mối quan hệ Extend với Use Case: Đánh giá chuyến đi. Tức, Use Case: Gửi tiền tip cho lái xe chỉ là một Use Case có thể xảy ra, hoặc không; và nó liên quan đếnUse Case: Đánh giá chuyến đi, chứ không phải bất kỳ một Use Case nào khác.
À…à…Nhắc tới lúc có lúc không, tức là nhắc tới điều kiện xảy ra.
Anh em có thể thể hiện rõ ý chỗ này bằng một thứ luôn đi kèm với Extend, đó là Extension Point 😎
Extension Point nôm na là điều kiện mà Use Case có mối quan hệ Extend sẽ xảy ra. Còn để sát nghĩa thì anh em có thể hiểu chữ Point ở đây nghĩa là điểm dữ liệu thể hiện sự khác biệt.
Tức nếu dữ liệu này là A thì Use Case không xảy ra, nhưng nếu dữ liệu này là B thì Use Case sẽ xảy ra.
//Theo mình nhớ là hình như anh em chỉ có thể gửi tiền tip cho tài xế, nếu cuốc xe đó anh em chấm họ maximum là 5 sao.//
Vậy thì anh em sẽ vẽ Use Case Diagram chỗ đó như sau.
Use Case Diagram có thể hiện rõ khi nào thì mối quan hệ Extend diễn ra
Extension Point ở đây là dữ liệu Driver Rating. Nếu Driver Rating đạt giá trị 5 sao, thì Use Case: Gửi tiền tip cho lái xe sẽ xảy ra, và hoàn toàn optional, tùy thuộc vào khách hàng.
Và nó liên quan mật thiết đến Use Case: Đánh giá chuyến đi, là một phần mở rộng của Use Case: Đánh giá chuyến đi.
Extension Point không nhất thiết phải là một dữ liệu nào đó trên hệ thống, mà có thể là một “điều kiện” bất kỳ, miễn là nó thể hiện được trường hợp cụ thể mà Use Case sẽ xảy ra.
Ở một ví dụ khác.
Mối quan hệ Extend trong Use Case Diagram của A kia rồi chấm côm
Còn nếu Use Case có quá nhiều mối quan hệ Extend, làm cho Diagram nhìn rối bời quá, anh em có thể bỏ luôn phần comment của Extension Point luôn cũng được.
Vẽ vầy cũng hông sao
c) Generalization
Generalization đơn giản là quan hệ cha con giữa các Use Case với nhau. Nhưng khác biệt với Include và Extend là nó còn được dùng để thể hiện mối quan hệ giữa các… Actor với nhau.
Đầu tiên là mối quan hệ cha-con giữa các Use Case. Ví dụ:
Đăng nhập thì có thể đăng nhập qua số điện thoại, hoặc đăng nhập qua email.
Đặt hàng thì có đặt hàng qua điện thoại, hoặc đặt hàng qua website.
Thanh toán thì thanh toán qua thẻ ATM, qua thẻ thanh toán quốc tế, hoặc qua ví điện tử.
Hoặc tìm kiếm thì có thể tìm kiếm bằng từ khóa, hoặc tìm kiếm theo nhóm sản phẩm.
Hoặc mối quan hệ cha-con giữa các Actor. Ví dụ:
Khách hàng gồm khách hàng cũ và khách hàng mới
Hoặc Vendor thì có thể gồm Retailers và Wholesalers.
Ví dụ về quan hệ cha-con (Generalization) trong Use Case
Nhìn chung, Generalization giúp anh em thể hiện rõ hơn các yêu cầu bằng việc gom nhóm các Use Case lại theo quan hệ cha-con. Cá nhân mình thì rất ít khi vẽ relationship này, chủ yếu chỉ dùng Include và Extend là chính.
Còn một điểm nữa là Generalization có tính kế thừa. Tức thằng cha có gì thì thằng con có cái đó, kể cả Use Case hay Actor.
Ví dụ Use Case A có include đến Use Case B và C. Thì Use Case A’ là con của Use Case A cũng sẽ có mối quan hệ Include đến Use Case B và C, mặc dù không được thể hiện trên hình.
…
Ô kê, vậy là xong phần Relationship – một trong những phần chuối nhất, dễ lộn nhất trong Use Case. Hi vọng những ví dụ trên giúp anh em hiểu được cụ thể như thế nào là Include, Extend và Generalization trong một Use Case Diagram 😎
3. Một số sai lầm phổ biến khi vẽ Use Case
Use Case Diagram là thứ để anh thể hiện được requirement của khách hàng.
Vẽ sao mà khách hàng nhìn vô một phát là thấy khoái liền. Khách hàng mà chân nhịp nhịp, miệng lẩm bẩm: “Đúng rồi…đúng rồi…, tính năng này có,… tính năng kia có luôn, à… tích hợp lấy dữ liệu này có, ô kê ô kê,… vầy là đủ rồi!”, thì coi như anh em đã vẽ khá good 🙂
Chém nãy giờ mạnh vậy chứ mình vẽ chẳng bao giờ là ổn cả. PM cứ phải duyệt đi duyệt lại cả chục lần. Nhờ đó mới có những sai lầm phổ biến mà mình hay gặp khi vẽ Use Case Diagram cho anh em tham khảo dưới đây, hehe.
3.1. Chuyện đặt tên
Trong mô hình hóa, chuyện đặt tên là rất-rất-rất quan trọng.
Vì đã nói “mô-hình-hóa” tức là chúng ta dùng hình ảnh để nói chuyện, thì khi đó hàm lượng chữ chiếm rất ít. Và chính vì nó ít, nên những gì chúng ta ghi trên diagram phải rất súc tích, cô đọng và có giá trị ngay tức thì.
Chỉ cần người đọc họ nhìn vô diagram mà thấy ngay 1 dòng chữ khó hiểu, thì ngay lập tức tụt bà nó hết mood, hết muốn xem tiếp rồi.
Nói về Use Case thì có 1 vài lưu ý sau cho anh em:
Actor thì phải đặt tên bằng danh từ, không dùng động từ, và cũng không mệnh đề quan hệ gì hết.
Tên Use Case thì phải ghi rõ ràng, rành mạch, đẹp nhất là dưới format: Verb + Noun.
Ví dụ: Đổi điểm thành viên, Chuyển tiền nội địa, Chuyển tiền quốc tế, Duyệt nhận xét bài viết.
BA chúng ta vẽ Use Case nhằm mục đích diễn tả yêu cầu cho stakeholders hiểu, do đó anh em không được dùng những từ kỹ thuật trong đây, không thể hiện sự nguy hiểm ở đây, người ta đọc zô hông hiểu gì hết là trớt quớt.
Và đặc biệt là tránh đặt tên quá dài và không nên dùng kiểu bị động.
Ví dụ về quan hệ cha-con (Generalization) trong Use Case
3.2. Vẽ Use Case mà thành phân rã chức năng
Đây chính xác là lỗi mà mình hay gặp nhất, rất thường xuyên gặp khi vẽ Use Case.
Sai lầm 2: không phân biệt được phân rã chức năng và Use Case
Dấu hiệu nhận biết rõ ràng nhất là khi Use Case Diagram của anh em đầy rẫy chữ “manage”, manage cái này, manage cái kia…
Đầu tiên là chữ Manage rất rộng nghĩa. Yêu cầu quản lý A gồm 5 việc, thì không có nghĩa yêu cầu quản lý B cũng gồm 5 việc. Use Case là diagram thể hiện yêu cầu của End-Users, nhằm đạt được một mục đích nào đó.
Ở ví dụ trên, nếu nói Manage Gears, Manage Brakes, hay Manage Air Conditioner thì quá tối nghĩa, chả ai hiểu nhằm mục đích sau cùng là để làm gì.
Thứ hai, hình minh họa trên vẽ Use Case nhưng lại chưa mang được góc nhìn của End-Users, tức chưa cho thấy được End-Users muốn đạt được gì sau ngần ấy Use Case được liệt kê ra.
Nguyên nhân có thể do người vẽ chưa nắm đủ thông tin về yêu cầu của End-Users, ảnh chưa hiểu rõ rốt cuộc thì người dùng họ muốn làm gì trên hệ thống, hay hệ thống phải tương tác những gì với hệ thống khác.
Từ đó mới có chuyện anh em nhìn vô Use Case Diagram ở trên mà cảm thấy mông lung như một trò đùa. Do đó, chúng ta chỉ vẽ Use Case khi đã có đủ thông tin cần thiết:
End-users muốn làm gì? Nhằm mục đích gì? ==> tương tác giữa end-users và hệ thống
Hệ thống phải nhận/ lấy data từ những nguồn nào? ==> tương tác giữa hệ thống với những hệ thống bên ngoài khác.
Ngoài ra, khi đã có đủ thông tin nhưng Use Case mình vẽ vẫn bị confuse. Lý do có thể do các Use Case mình vẽ bị lệch các cấp độ Requirement với nhau.
Ví dụ Use Case A thì thể hiện Business Requirement, tức là rất high level. Nhưng sang Use Case B và C thì lại nói rất detail tới mức Solution Requirement như.
3 Use Case này bị lệch cấp độ với nhau, gây “rối bời” cho người xem
Để sửa lại Use Case trên, đơn giản mình chỉ cần bỏ Use Case A: Quản lý học viên ra, vì nó là thứ rất chung chung, không thể hiện được mục đích cụ thể, so với 2 Use Case còn lại.
Tuy nhiên, chữ “Manage” trong Use Case lại rất công dụng, công dụng đến mức không thể không dùng trong các document mình làm, nó sẽ giúp mình giải quyết vấn đề ở mục số 3.4 phía dưới, đọc tiếp nhé anh em.
3.3. Rối nùi Use Case
Anh em tham khảo một số hình sau sẽ rõ.
Sai lầm 3: Rối nùi Use Case
Vấn đề của hình này là ôm đồm quá nhiều. Dẫn đến quá nhiều Use Case xuất hiện trong cùng một Diagram, đã vậy cũng không có Boundary of System rõ ràng.
Như anh em thấy, Use Case này vẽ rất sai ở những điểm như sau:
Xác định sai Use Case (nên mới nhiều UC như vậy): những thứ như single, double, num of guest… rõ ràng đâu phải là một Use Case, đâu phải là một sự tương tác.
Đặt tên Use Case sai: quá nhiều cụm danh từ cho Use Case.
Không có Boundary of System.
Những Use Case có extend không ghi chú cụ thể điều kiện khi nào thì UC extend xảy ra.
Một note nhỏ quan trọng cho anh em, Use Case Diagram sạch đẹp là chỉ nên có trên dưới 10 Use Case trong đó. Các Use Case còn lại anh em hãy dùng Boundary of System để phân chia theo phân hệ một cách hợp lý nhất có thể.
Hình này rõ ràng là quá thứ dữ. Thật ra trường hợp này cũng khá phổ biến, mình trước kia bị hoài. Mấu chốt đến từ một số điều sau:
Một số Use Case đặt tên sai
Chưa tận dụng các Relationship để thể hiện, khiến cho các Use Case quá rời rạc nhau, và trông rất không hợp logic.
Người vẽ không dùng Boundary of System để phân nhóm, giới hạn các Use Case.
Và đặc biệt, người vẽ quá chú trọng đến các chức năng cơ bản nhất, đó là: CRUD – Create/Read/Update/Delete.
3.4. Quá chi tiết các chức năng CRUD
Như ví dụ trên, mỗi thực thể là một lần CRUD. Như vậy quá tốn effort, trong khi 96,69% là ở phân hệ nào, hay dữ liệu nào, anh em cũng đều cần phải CRUD dữ liệu hết.
Điều này tạo ra một sự lặp đi lặp lại ở các Use Case Diagram, nhưng không thể hiện được gì nhiều cho người xem. Để giải quyết vấn đề này, anh em có thể có làm 1 trong 2 cách sau.
Cách 1
Thêm một dòng note trước đoạn mô tả Use Case trong tài liệu: “Toàn bộ dữ liệu đều có chức năng Thêm/ Đọc/ Sửa/ Xóa và chịu tác động bởi sự phân quyền từ phía Quản trị hệ thống” hoặc đại loại vậy. Để cho các stakeholder biết được rằng hệ thống có chức năng CRUD các dữ liệu này.
Nhưng nên nhớ CRUD ở đây là đứng từ góc nhìn End-Users: hệ thống có cho phép End-Users CRUD dữ liệu hay không?
Ví dụ hệ thống CRM lấy dữ liệu khuyến mãi từ hệ thống ERP. Thì về bản chất CRM phải có khả năng Create dữ liệu khuyến mãi, thì mới lấy dữ liệu khuyến mãi từ ERP về được.
Nhưng theo góc nhìn của End-Users, thì không một người dùng nào (kể cả System Admin) có thể tạo thủ công dữ liệu khuyến mãi trên CRM, mà End-Users họ chỉ Đọc/ Sửa/ Xóa dữ liệu được lấy về này thôi.
Do đó ở đây anh em cần mô tả rõ là có phải tất cả dữ liệu đều cho phép End-Users CRUD được hay không (không tính phân quyền).
Cách 2
Tạo hẳn một Use Case với tên là: Manage “X”, với X là một đối tượng bất kỳ.
Thay vì vẽ như bên trái, thì hãy vẽ như bên phải
Nếu không đầy đủ 4 tính năng CRUD, thì anh em có thể làm 1 cái note nhỏ bên trên, nói rõ Manage là có những tính năng gì, không có những tính năng gì.
3.5. Thẩm mỹ
Cuối cùng vẫn quay về vấn đề thẩm mỹ. Nguyên nhân việc Use Case mất thẩm mỹ đến từ 2 lý do:
Mắt thẩm mỹ kém: chiếm 0,00000000000069%
Ẩu, cẩu thả: chiếm 99,00000000000000069%
Làm gì cũng vậy, đặc biệt là mô hình hóa để làm document. Ẩu là thứ mình nên cố gắng hạn chế nó nhất. Vì làm đúng 1 lần, đẹp 1 lần, sau này đỡ mắc công làm lại chứ hông có gì hết.
Một số điểm anh em cần chú ý sau:
Kích cỡ các Use Case trong Diagram là phải như nhau, kể cả cha-con, lẫn các mối quan hệ Include. Tuy nhiên, Use Case có Extend sẽ được vẽ to hơn một chút.
Nhớ phải đánh dấu Use Case ID trong hình vẽ.
Các mối quan hệ không được chồng chéo lẫn nhau. Anh em có thể vẽ 1 Actor ở 2 vị trí khác nhau để tránh các đường nối bắt chéo lên nhau.
Khi vẽ Use Case Diagram, tập trung vào câu hỏi What để tìm ra Use Case, tránh câu hỏi How, vì khi đó anh em rất dễ đi vào detail.
Và nếu được, hãy tô màu lên Use Case để nhìn Diagram được rõ ràng, sáng sủa và mạch lạc 🙂
Hi vọng qua bài này anh em đã hiểu rõ bản chất của Use Case, và biết cách vẽ Use Case Diagram. À mà không những biết cách vẽ, mà còn vẽ đúng, vẽ đẹp và tránh được những lỗi sai thường gặp nữa.
Bài sau mình sẽ note lại cách viết Use Case Specification sau cho nhanh gọn và đơn giản nhất. Nếu có gì thắc mắc cứ thả còm men bên dưới hoặc email cho mình nhé.
Nếu bạn là một lập trình viên thích viết clean code, cố gắng viết code một cách ngắn gọn nhất có thể thì việc tối ưu hóa các khối lệnh điều kiện là điều cơ bản quan trọng trong JavaScript. Bằng cách thay đổi điều kiện check, bạn có thể giản lược rất nhiều đoạn code của mình cũng như giúp source code của bạn trở nên rõ ràng hơn. Bài viết dưới đây, mình sẽ chia sẻ một vài kinh nghiệm nhỏ giúp bạn cấu trúc lại những đoạn câu lệnh if/ else trong JavaScript một cách hiệu quả nhé.
Không nên sử dụng các điều kiện phủ định
Bạn không nên sử dụng điều kiện phủ định (giá trị false) cho các câu lệnh if của mình; điều này đơn giản giúp cho việc đọc lại source code của bạn sẽ trở nên tự nhiên hơn. Thêm vào đó, với các biến boolean, không cần thiết phải viết điều kiện check với giá trị true/ false, sử dụng toán tử phủ định sẽ giúp ngắn gọn cho dòng code của bạn.
Không nên viết code thế này:
constisEmailNotVerified= (email) => {// implementation}if (!isEmailNotVerified(email)) {// do something...}if (isVerified===true) {// do something...}
Mà hãy chuyển sang cách viết như dưới đây:
constisEmailVerified= (email) => {// implementation};if (isEmailVerified(email)) {// do something...}if (isVerified) {// do something...}
Hãy sử dụng Array.includes để gộp nhiều điều kiện
Giả sử chúng ta muốn kiểm tra xem mẫu xe đầu vào là renault hay peugeot, điều kiện if có thể xử lý đơn giản như sau:
Trong trường hợp nếu chúng ta cần check trong 1 tập hợp nhiều mẫu xe khác nhau, lúc này cách viết trên sẽ khiến code của bạn trở nên dài và cồng kềnh hơn. Để giải quyết vấn đề này, chúng ta sử dụng Array.includes để kiểm tra xem trong mảng đầu vào có giá trị cần tìm hay không.
Tinh chỉnh thêm đoạn code một chút nữa, ta có thể tách biệt phần khai báo dữ liệu và phần xử lý logic (kiểm tra điều kiện), code sẽ trở nên sáng sủa hơn rất nhiều.
Hãy sử dụng Array.every hoặc Array.find để bắt điều kiện khớp tất cả tiêu chí
Ở ví dụ dưới đây, chúng ta cần kiểm tra xem danh sách các xe đầu vào (cars) có đều thuộc về cùng một hãng xe (model) được nhập vào hay không. Để thực hiện việc kiểm tra, đoạn code dưới đây sử dụng một vòng lặp for để duyệt qua tất cả các phần tử trong mảng; biến isValid được dùng làm biến để trả về giá trị cho hàm check.
Để viết code một cách gọn gàng hơn, chúng ta có thể sử dụng phương every có sẵn trong lớp Array. Hàm này trả về true nếu như tất cả các phần tử trong mảng đều thỏa mãn điều kiện truyền vào.
Bạn cũng có thể sử dụng phương thức find để kiểm tra xem có tồn tại phần tử nào mà giá trị model không giống với giá trị đầu vào hay không. Kết quả trả về có ý nghĩa tương tự.
Về mặt hiệu năng, cả 3 cách trên đều cho kết quả như nhau vì cả hai hàm every và find đều thực hiện vòng lặp gọi từng phần tử của mảng, cũng đều trả về false ngay lập tức nếu tìm thấy giá trị điều kiện sai.
Sử dụng Array.some để check điều kiện tồn tại
Tương tự như cách sử dụng Array.every, chúng ta có thể sử dụng Array.some cho việc kiểm tra xem có tồn tại phần tử nào trong mảng thỏa mãn điều kiện truyền vào hay không. Ví dụ dưới đây kiểm tra xem có mẫu xe “renault” (giá trị đầu vào) nào trong danh sách xe (cars) ban đầu hay không.
Nhiều bạn có thói quen khi viết một function sẽ tạo biến giữ giá trị trả về của hàm, sau đó lần lượt qua các câu lệnh if khác nhau, biến đó sẽ được thay đổi, gán giá trị và cuối cùng trả về qua câu lệnh return ở cuối hàm.
constcheckModel= (car) => {letresult; // first, we need to define a result value// check if car existsif (car) {// check if car model existsif (car.model) {// check if car year existsif (car.year) {result=`Car model: ${car.model}; Manufacturing year: ${car.year};`; } else {result="No car year"; } } else {result="No car model"; } } else {result="No car"; }returnresult; // our single return statement};console.log(checkModel()); // outputs 'No car'console.log(checkModel({ year:1988 })); // outputs 'No car model'console.log(checkModel({ model:"ford" })); // outputs 'No car year'console.log(checkModel({ model:"ford", year:1988 })); // outputs 'Car model: ford; Manufacturing year: 1988;'
Bạn có thể thấy rằng cách viết trên khiến đoạn code của chúng ta trở nên rất dài và khó đọc. Các điều kiện if lồng nhau khiến việc debug luồng chạy của chương trình trở nên khó khăn hơn. Để giải quyết vấn đề này, bạn nên dùng kết hợp việc return sớm theo từng điều kiện, kết hợp sử dụng toán tử ba ngôi (if/ else rút gọn) để giúp code của bạn clear hơn.
constcheckModel= ({ model, year } = {}) => {if (!model&&!year) return"No car";if (!model) return"No car model";if (!year) return"No car year";// here we are free to do whatever we want with the model or year// we made sure that they exist// no more checks required// doSomething(model);// doSomethingElse(year);return`Car model: ${model}; Manufacturing year: ${year};`;};console.log(checkModel()); // outputs 'No car'console.log(checkModel({ year:1988 })); // outputs 'No car model'console.log(checkModel({ model:"ford" })); // outputs 'No car year'console.log(checkModel({ model:"ford", year:1988 })); // outputs 'Car model: ford; Manufacturing year: 1988;'
Sử dụng Indexing hoặc Maps thay thế cho câu lệnh Switch
Ví dụ dưới đây, hàm getCarsByState trả về các hãng xe theo giá trị quốc gia truyền vào, trong đó giá trị trả về dưới dạng một mảng các tên hãng xe. Sử dụng cấu trúc switch là một cách giải quyết tự nhiên cho bài toán này.
Vấn đề vẫn là bài toán khi dữ liệu tăng lên và logic code của bạn sẽ không tách biệt khỏi phần khai báo dữ liệu. Hãy sử dụng Indexing hoặc Map để tái cấu trúc đoạn code trên, các bạn sẽ được đoạn code như dưới đây:
Dễ thấy sự thay đổi trong 2 đoạn code dưới so với sử dụng khối switch/ case; vừa ngắn gọn hơn và tách biệt được khai báo dữ liệu ra khỏi logic code. Bạn sẽ dễ dàng bổ sung phần dữ liệu vào chương trình mà không làm thay đổi nội dung hàm.
Kết bài
Hy vọng bài viết này mang lại những kinh nghiệm hữu ích dành cho bạn trong việc xử lý các khối lệnh điều kiện trong JavaScript. Việc tận dụng được đặc trưng, các phương thức có sẵn của ngôn ngữ lập trình sẽ giúp bạn tối ưu hóa được source code mà bạn viết ra. Cảm ơn các bạn đã đọc bài và hẹn gặp lại trong các bài viết tiếp theo của mình.
Dart là một ngôn ngữ lập trình mới, được phát triển bởi Google dành cho việc phát triển các ứng dụng đa nền tảng. Dart thường được gắn liền với Flutter framework, một lựa chọn cho việc xây dựng mobile app. Tuy nhiên, Dart không chỉ dùng cho việc xây dựng ứng dụng di động, ngôn ngữ này còn được áp dụng cho nhiều dự án phát triển phần mềm đa lĩnh vực khác. Bài viết hôm nay chúng ta cùng nhau tìm hiểu Dart là gì và ứng dụng của ngôn ngữ lập trình Dart trong thực tế nhé.
Dart là gì?
Dart là một ngôn ngữ lập trình mã nguồn mở được Google phát triển và ra mắt lần đầu tiên vào năm 2011. Dart có cú pháp viết mã đặc trưng kiểu C nên dễ học, dễ đọc và dễ viết nhất là với những bạn đã có kinh nghiệm với lập trình C hay Java trước đó thì việc tiếp cận Dart sẽ nhanh hơn. Google phát triển Dart dành cho sự phát triển ứng dụng đa nền tảng bao gồm ứng dụng Web, di động, máy chủ và cả máy tính để bàn.
Trải qua hơn 10 năm phát triển, hiện nay phiên bản mới nhất của Dart là version 3.5.2 trên stable channel ra mắt vào 28/8/2024. Qua từng phiên bản cập nhật lớn, Dart đã có sự thay đổi khá nhiều so với định hướng của ngôn ngữ này từ ban đầu, có thể kể đến các cột mốc cập nhật lớn như:
Version 1.0: phát hành tháng 11/2013 với các công cụ hỗ trợ mạnh mẽ như trình biên dịch Dart-to-JavaScript, Dart Virtual Machine và Dart Editor. Mục tiêu ban đầu của Dart là thay thế JavaScript như một ngôn ngữ lập trình Web.
Version 2.0: công bố vào năm 2017, Dart chuyển hướng tập trung vào việc phát triển ứng dụng di động. Cùng với sự ra mắt của bộ công cụ phát triển ứng dụng di động Flutter của Google, Dart (ngôn ngữ chính của Flutter) giúp chúng ta phát triển ứng dụng cross-platform cho cả Android và iOS.
Version 3.0: ra mắt vào năm 2023, Dart có sự bổ sung nhiều tính năng mới quan trọng như Patterns, Records và Class modifiers tập trung nâng cao khả năng kiểm soát chương trình của ngôn ngữ này.
Tính năng của ngôn ngữ Dart
Dart là một ngôn ngữ mới, được sự đầu tư phát triển bởi đội ngũ từ Google nên có nhiều tính năng của một ngôn ngữ lập trình hiện đại. Chúng ta cùng điểm qua một số tính năng nổi bật của ngôn ngữ lập trình Dart nhé:
Object-Oriented
Dart là một ngôn ngữ lập trình hướng đối tượng (OOP) thuần túy với mọi giá trị là một đối tượng, nó hỗ trợ đầy đủ các đặc điểm của OOP như class-based, tính kế thừa, tính đa hình. Lập trình hướng đối tượng giúp chúng ta tổ chức mã nguồn một cách rõ ràng và dễ quản lý cũng như có khả năng tái sử dụng mã một cách hiệu quả. Bạn cũng sẽ thấy quen thuộc khi viết code vì các khái niệm trong Dart sẽ giống đến 80% như trong Java – một ngôn ngữ lập trình hướng đối tượng phổ biến.
Strong Typing
Ngôn ngữ Dart là một ngôn ngữ strongly typed, nghĩa là nó đảm bảo rằng kiểu của một object không bị thay đổi đột ngột trong chương trình. Dart có các quy tắc và những hạn chế để đảm bảo rằng giá trị của một biến luôn khớp với static type của biến đó.
Garbage Collection
Dart có 1 bộ gom rác tương tự như Java; Garbage Collection trong Dart là chương trình chạy nền, theo dõi toàn bộ trạng thái hoạt động của các Object, tìm ra những Object không được dùng đến và xóa nó đi. Điều này giúp tối ưu khả năng sử dụng bộ nhớ của thiết bị với các ứng dụng viết bằng Dart.
JIT & AOT Compilation
Dart hỗ trợ cả hai phương pháp biên dịch là Ahead-Of-Time (AOT) và Just-In-Time (JIT) giúp tối ưu hóa quy trình phát triển ứng dụng. AOT cho phép biên dịch mã nguồn thành mã máy gốc trước khi ứng dụng được khởi chạy, giúp cải thiện tốc độ và hiệu suất của ứng dụng. JIT là kỹ thuật biên dịch thời gian thực, nó cho phép hot reloading nhờ biên dịch ngay sau khi code được lưu; từ đó tăng tốc độ viết code của lập trình viên.
Asynchronous Programming
Lập trình bất đồng bộ (Asynchronous) giúp bạn thực hiện các action (hành động) trong cùng một lúc mà không cần theo tuần tự; ví dụ như các hành động lấy dữ liệu từ phía Backend thông qua API. Ngôn ngữ Dart hỗ trợ lập trình bất đồng bộ thông qua lớp Future (giống với Promise trong JavaScript) hay sử dụng async/ await tương tự trong nhiều ngôn ngữ lập trình khác.
Nhắc đến ứng dụng của Dart thì điều đầu tiên chúng ta phải nhắc đến công cụ Flutter – một framework dành cho việc phát triển ứng dụng di động đa nền tảng (Android và iOS) sử dụng Dart làm ngôn ngữ lập trình. Ngoài Flutter ra, Dart còn được Google sử dụng làm ngôn ngữ cho nhiều lĩnh vực phát triển khác nhau bao gồm cả Web, Server side và các ứng dụng desktop.
Xây dựng ứng dụng di động
Xây dựng ứng dụng di động bằng Flutter framework là ứng dụng phổ biến và nổi bật nhất của ngôn ngữ lập trình Dart. Flutter cho phép lập trình viên viết code một lần bằng ngôn ngữ Dart và build ứng dụng ra để chạy được trên cả nền tảng Android lẫn iOS. Điều này giúp tiết kiệm thời gian, chi phí cũng như tăng tính đồng nhất giữa các ứng dụng khi phát triển bằng Flutter.
Xây dựng ứng dụng Web
Ngôn ngữ Dart ban đầu được thiết kế nhằm mục đích thay thế cho JavaScript trong phát triển Web. Trải qua những lần cập nhật lên phiên bản mới, ý định này đã không còn là hướng đi chính của đội ngũ phát triển Dart. Mặc dù vậy, với bộ công cụ như DartPad hay các thư viện như AngularDart (nếu bạn chưa biết thì Angular cũng là một sản phẩm của Google) thì Dart hoàn toàn có khả năng xây dựng các ứng dụng Web tương tác với người dùng một cách hiệu quả. Ngoài ra, bạn cũng có thể sử dụng Dart để biên dịch thành JavaScript để tái sử dụng source code một cách hữu ích.
Xây dựng ứng dụng server-side
Google cung cấp sẵn cho chúng ta thư viện dart:io cùng các gói mở rộng Aqueduct trong Dart giúp ngôn ngữ này có khả năng xây dựng các ứng dụng service-side một cách hiệu quả. Aqueduct là một framework HTTP mở rộng dùng để xây dựng các REST API trên Dart VM (máy ảo Dart), trong đó tích hợp sẵn một ORM (Object-Relational Mapping – ánh xạ đến CSDL) kiểu tĩnh. Sử dụng Dart cho ứng dụng server-side có thể giúp bạn tận dụng được một số ưu điểm về hiệu năng của ngôn ngữ này.
Framework Flutter không chỉ cho phép bạn build ứng dụng ra các nền tảng mobile mà còn có thể build ra ứng dụng dành cho Desktop. Flutter for Desktop cho phép lập trình viên xây dựng ứng dụng chạy được trên nền tảng Windows, macOS và Linux từ cùng một source code ban đầu viết bằng Dart.
Xây dựng công cụ dòng lệnh
Dart còn được nhiều nhà phát triển sử dụng để tạo ra các công cụ hoặc tiện ích dòng lệnh (CLI – Command Line Interface) giúp tự động hóa các tác vụ liên quan đến quản lý dự án hay các công việc khác một cách hiệu quả. Khi bạn đã quen với Dart thì việc sử dụng ngôn ngữ này cho nhiều mục đích khác nhau sẽ dễ dàng hơn so với việc dùng một ngôn ngữ hoàn toàn độc lập.
Kết bài
Dart là một ngôn ngữ lập trình mạnh mẽ và đa năng, với sự hậu thuẫn của team phát triển đến từ Google, hứa hẹn tương lai tươi sáng cho cho ngôn ngữ lập trình này. Vì thế nếu bạn đang có ý định học và sử dụng ngôn ngữ này cho dự án, công việc của mình; hãy bắt đầu ngay từ bây giờ. Cảm ơn các bạn đã đọc bài và hẹn gặp lại trong các bài viết tiếp theo của mình.
Hãy để CV của bạn tỏa sáng trong mắt nhà tuyển dụng bằng cách khai thác tối đa các công cụ Tạo CV Online và Chuẩn hóa CV từ TopDev. Không chỉ dừng lại ở đó, khi trải nghiệm các tính năng độc đáo này, bạn sẽ có cơ hội tham gia chương trình “Chuẩn hóa CV, Chốt ngay phím chất” với nhiều phần quà giá trị đang chờ đón. Đừng bỏ lỡ cơ hội quý giá để định hình tương lai sự nghiệp của bạn. Hãy đăng ký ngay và khám phá những tính năng ưu việt của TopDev!
MySQL và MongoDB là hai hệ thống quản lý cơ sở dữ liệu phổ biến được sử dụng rộng rãi hiện nay, đều có khả năng mang lại hiệu năng và khả năng quản trị tốt. Tuy nhiên mỗi hệ thống sẽ có những đặc điểm khác nhau và phụ thuộc vào trường hợp bài toán thực tế để sử dụng một cách hiệu quả. Để xác định xem dự án sắp tới của bạn cần sử dụng hệ thống nào thì trong bài viết này chúng ta cùng so sánh giữa MySQL và MongoDB nhé.
MySQL là gì?
MySQL là một hệ thống quản trị cơ sở dữ liệu (CSDL) quan hệ mã nguồn mở (RDBMS) đầy đủ tính năng thuộc sở hữu của Oracle. Dữ liệu trong MySQL được lưu trữ dưới dạng các bảng và sử dụng ngôn ngữ truy vấn có cấu trúc (SQL) để thực hiện việc truy cập đến CSDL. MySQL được sử dụng cho việc lưu trữ các thông tin trên trang Web, tương thích với gần như tất cả các hệ điều hành (Windows, Linux, Unix,…) và hỗ trợ hầu hết các ngôn ngữ lập trình phổ biến (PHP, C, Java, JS,…).
MongoDB là gì?
MongoDB là một hệ thống CSDL phi quan hệ (NoSQL) mã nguồn mở được phát hành từ năm 2009. Dữ liệu trong MongoDB được lưu trữ dưới dạng tài liệu (document) JSON cho phép các ứng dụng lưu trữ và truy vấn một cách linh hoạt (không ràng buộc theo một ngôn ngữ truy vấn nào). MongoDB hiện nay cũng hỗ trợ hầu hết các ngôn ngữ lập trình phổ biến và được nhiều công ty lớn sử dụng như Facebook, Google hay Adobe,…
Điểm giống nhau giữa MySQL và MongoDB
Cả MySQL và MongoDB đều là các hệ thống quản trị CSDL phổ biến được sử dụng rộng rãi; chúng đều có sẵn các tính năng giúp người dùng thao tác và phân tích dữ liệu. Các tính năng, đặc điểm giống nhau mà cả 2 hệ thống này đều có hỗ trợ như:
Giấy phép mã nguồn mở: MySQL và MongoDB đều có giấy phép mã nguồn mở, chúng ta có thể tải xuống miễn phí để sử dụng, đồng thời có thể sửa đổi source code tùy theo nhu cầu sử dụng
Hỗ trợ lập chỉ mục (index): MySQL và MongoDB đều sử dụng lập chỉ mục để cải thiện tốc độ truy vấn và hiệu năng truy cập dữ liệu thường xuyên.
Hỗ trợ hầu hết các ngôn ngữ lập trình phổ biến: cả 2 nền tảng này đều tương thích với nhiều ngôn ngữ lập trình: Java, Python, PHP, C,…
Tính bảo mật cao: cả MySQL và MongoDB đều cho phép bạn thiết lập các cấp độ khác nhau cho quyền truy cập của người dùng. Để bảo vệ việc lưu trữ và thao tác với dữ liệu, mã hóa TLS/SSL được cả 2 hệ thống tích hợp sẵn.
Sự hỗ trợ lớn từ cộng đồng: MySQl với lịch sử phát triển gần 30 năm tạo ra một cộng đồng lập trình viên sử dụng vô cùng lớn, đứng sau là hãng Oracle uy tín. MongoDB mặc dù ra mắt sau nhưng sự tích cực và sẵn sàng lắng nghe của đội ngũ support cũng được đánh giá rất cao. Bạn có thể dễ dàng tìm được sự trợ giúp trong quá trình sử dụng 2 hệ thống này.
Chúng ta cùng xem xét sự khác biệt giữa 2 hệ thống này qua từng tiêu chí chính nhé:
Mô hình dữ liệu
MongoDB biểu thị dữ liệu dưới dạng tài liệu JSON, trong khi đó MySQL sử dụng các bảng bao gồm các hàng và cột để lưu trữ dữ liệu. Điều này dẫn đến sự khác nhau cơ bản giữa 2 nền tảng này khi bạn bắt đầu: với MySQL, bạn bắt buộc phải xác định lược đồ, cấu trúc, mô hình dữ liệu trước; ngược lại thì MongoDB không yêu cầu bạn xác định từ trước, có thể linh hoạt trong việc lưu trữ dữ liệu.
Các khái niệm giữa 2 hệ thống này gọi tên khác nhau nhưng cũng có sự tương đồng dựa theo mục đích sử dụng. Bạn có thể theo dõi hình trên để hiểu hơn các khái niệm trên nền tảng CSDL tương ứng.
Cả 2 hệ thống này đều cung cấp nhiều tính năng và chức năng từ đơn giản đến phức tạp. MongoDB được đánh giá cao hơn với nhiều tính năng liên quan đến việc phân tích dữ liệu, xử lý tìm kiếm nhiều mặt trên nhiều loại dữ liệu đa dạng. MongoDB cũng hỗ trợ mở rộng quy mô hệ thống dữ liệu theo chiều ngang thông qua Sharding (lưu trữ các bản ghi dữ liệu qua nhiều thiết bị) hay tính năng data locality giúp sắp xếp dữ liệu cho hệ thống phân tán một cách hiệu quả.
Ngôn ngữ truy vấn
Cả MySQL và MongoDB đều có một ngôn ngữ truy vấn riêng: MySQL sử dụng ngôn ngữ truy vấn có cấu trúc SQL; MongoDB sử dụng MQL- mặc dù là NoSQL nhưng nó cũng có đầy đủ các tính năng thao tác với dữ liệu như SQL. Một vài ví dụ sử dụng tương đương của 2 ngôn ngữ truy vấn này:
Thao tác truy cập dữ liệu:
MySQL: SELECT * FROM products
MongoDB: db.products.find()
Thao tác chèn, thêm mới:
MySQL: INSERT INTO products(id, name, amount)VALUES (‘001’, ‘Iphone 12’, 20)
MySQL được thiết kế giúp thực hiện các thao tác ghép nối, làm việc giữa các bảng dữ liệu với hiệu năng cao; tuy nhiên điều này cũng phần nào ảnh hưởng đến hiệu năng khi chèn, thêm mới, cập nhật dữ liệu. Ngược lại, MongoDB được thiết kế với mô hình dữ liệu phân cấp, thông tin được lưu trữ hầu hết ở một tài liệu duy nhất; điều này giúp hiệu suất chèn, thêm mới, thao tác với dữ liệu đơn trở nên nhanh vượt trội; nhưng lại không được tối ưu hóa cho các phép ghép nối dữ liệu từ nhiều tài liệu khác nhau.
Nên sử dụng MySQL hay MongoDB
MongoDB ra mắt sau nhưng thu hút được người dùng hiện nay với triết lý đơn giản và cởi mở và linh hoạt hơn. Cộng đồng lập trình viên cũng như đội ngũ hỗ trợ của MongoDB tỏ ra tích cực hơn so với tình trạng bế tắc trong việc cập nhật của MySQL. Mặc dù vậy, MySQL vẫn là một giải pháp tỏ ra phù hợp cho nhiều công ty trên toàn thế giới với bề dày lịch sử phát triển của mình.
Hãy lựa chọn MongoDB nếu bạn cần làm việc với lượng dữ liệu lớn và không có cấu trúc; hoặc bạn chưa thể xác định được cấu trúc dữ liệu của bạn và có định hướng cho các mục tiêu xa hơn trong tương lai. Ngược lại thì MySQL sẽ nên lựa chọn nếu quy mô dữ liệu của bạn không quá lớn, có tính cấu trúc rõ ràng; sử dụng MySQL có thể mang lại khả năng bảo vệ dữ liệu đáng tin cậy, dễ quản lý và tính sẵn sàng cao hơn.
Kết bài
Qua bài viết trên, hy vọng bạn đã có cái nhìn chi tiết hơn về 2 hệ thống quản trị CSDL phổ biến này. So sánh giữa MySQL và MongoDB trong từng trường hợp sử dụng cụ thể sẽ giúp bạn lựa chọn được công cụ phù hợp cho bài toán sắp tới của bản thân. Cảm ơn các bạn đã đọc bài và hẹn gặp lại trong các bài viết tiếp theo của mình.
Bài viết được sự cho phép của tác giả Nguyễn Hoàng Phú Thịnh
Chắc hẳn 500 anh em thường rất hay nghe tới “thuyết”: “Làm BA, là á hả, phải rành kỹ thuật dữ lắm, phải biết công nghệ này, công nghệ kia, thậm chí á hả, phải đọc hiểu được code đó nha, đâu zỡn chơi được, không là không mần được khỉ khô gì đâu, bla…bla….”
Thoạt nhìn thì câu trên có vẻ sai, nhưng thực tế thì nó… không đúng tí nào hết anh em.
Mình thấy xung quanh mình hầu như ai cũng nghĩ zậy (rất nhiều người nghĩ zậy). Và đặc biệt là các bạn chẻ trên mạng đang ấp ủ ý định làm BA.
Nó sẽ gây ra một cục hoang mang siêu to khổng lồ và ảnh hưởng ghê gớm đến sự tự tin của anh em…
Mình không biết tí gì về IT, sao làm BA bây giờ *icon run lẩy bẩy*
Kỹ thuật là đụng tới lập trình đúng hônggg, em học dở toán với tin lắm, a hu hu.
Trước giờ em chả biết gì về phần mềm các kiểu hết, giờ làm BA nổi hông…
Bài này mình sẽ note về những gì mình đã từng trải, và về thứ gọi là “kỹ thuật” đối với một người làm BA.
Mình tin là hỏi 10 người thì hết 10 ngàn người trả lời: “kỹ thuật” nghĩa là coding, là lập trình. Tức là phải hiểu, thậm chí phải rành về thuật toán các kiểu… Để nói chuyện với dev người ta còn hiểu nữa, “BA là cầu nối mà”.
Nhưng không, “kỹ thuật” ở đây hoàn toàn không phải là cốt-kiếc gì hết. Mà là: kỹ thuật của công việc BA. Tức là sao?
Bất cứ công việc nào cũng đều có kỹ thuật của nó hết.
Nghề viết có các kỹ thuật riêng, như: viết lách, viết ký sự, phóng sự…
Nghề sư phạm cũng có các kỹ thuật riêng của nó, áp dụng cho từng đối tượng
Chụp ảnh cũng phải có kỹ thuật thì chụp mới ra hồn được
Thậm chí… chích xì ke cũng phải có “kỹ thuật chích” thì chích mới… phê được. Đâu phải dễ ăn mà bay zô, cầm kim tiêm chích phát một là được.
Do đó, nghề BA cũng phải có các kỹ thuật của nó. Bên cạnh bộ kiến thức chuyên môn và bộ kỹ năng cũng rất quan trọng cho công việc BA này.
Theo từ điển Cambridge (không phải cứ từ điển là đúng, nhưng ít nhiều cũng có cái cho anh em mình tham khảo 😀 )
Technical (adj) = relating to practical skills and methods that are used in a particular activity. Còn theo tiếng Việt mình một cách đơn giản: “Kỹ thuật” là phương pháp được sử dụng để đạt được một kết quả nhất định.
Ví dụ muốn moi móc yêu cầu => sẽ có 11 kỹ thuật thường được áp dụng.
Do đó, mệnh đề trên là mình thấy hoàn toàn sai.
BA cần kỹ thuật không? Cần? Nhưng “kỹ thuật” ở đây không phải liên quan tới lập trình. Mà “kỹ thuật” ở đây là các kỹ thuật trong công việc của BA.
2. “Loại BA” nào thì cần kỹ thuật?
Trên thị trường hiện nay có hằng hà loại BA.
Có người thì chuyên làm về tối ưu quy trình. Có người thì chuyên hẳn về một platform công nghệ. Có người thì tập trung làm product. Hoặc cũng có người chỉ chuyên giải quyết các vấn đề tích hợp…
Nhưng dù có làm gì đi nữa, hễ ai mà làm một loạt các chuỗi công việc: Xác định Business Objective >> Làm việc với Stakeholders >> Đề xuất Solution >> Tiến hành Transition để đưa vào thực tế, thì người đó đều đang làm công việc BA. Bất kể giải pháp có là IT, hay non IT đi chăng nữa.
Bài note này mình nói về: yêu cầu “kỹ thuật” đối với BA. Và khái niệm “kỹ thuật” như nãy giờ anh em mình làm rõ, được áp dụng cho hầu hết các loại BA nhé anh em, bao gồm cả IT BA lẫn Non-IT BA.
Use Case, thứ có vẻ… “không đụng tới là không được” trong công việc BA.
Vì sao nó lợi hại như vậy? Vì nó giúp anh em mô tả sự tương tác giữa người dùng và hệ thống với nhau.
Một cách trực quan, nó thể hiện được các actor tương tác những gì, với những ai, trong một môi trường cụ thể – thông qua Use Case Diagram.
Và cũng một cách rất chi tiết, nó giúp anh em thể hiện được mọi ngóc ngách của sự tương tác đó, như: actor là ai, trigger point là gì, pre-condition ra sao, post-condition thế nào…. thông qua Use Case Specification.
Và đặc biệt là thể hiện được sự tương tác này diễn ra step-by-step như thế nào (Basic Flow)? Hoặc có thể có những cách làm nào khác không (Alternative Flow)? Và cũng thể hiện được luôn: các bước làm nào khiến cho sự tương tác này diễn ra thất bại (Exception Flow)?
…
Xưa giờ anh em hay gói gọn Use Case trong ngữ cảnh “software development”. Giờ thử áp dụng Use Case để phân tích một thứ gì đó trong cuộc sống nhé.
Giả dụ: Mình mở một nhà hàng bán đặc sản Lào ngon nhất Vịnh Bắc Bộ. Và để thu hút 500 anh em tới ăn đông đảo, mình muốn các khâu trong nhà hàng phải thật chỉn chu và kỹ lưỡng. Đặc biệt là khâu tiếp đón khách tới quán ăn.
Vì là BA mà, nên mình muốn phân tích xem thử khâu tiếp đón khách vô quán cụ thể nó ra sao, bao gồm:
Thực tế nó được bắt đầu khi nào?
Khi nào thì quán sẵn sàng đón khách?
Khi nào thì xem như khâu đón khách diễn ra thành công?
Các bước đón khách diễn ra như thế nào?
Hoặc có cách nào khác đổi mới để đón khách ngầu lòi hơn hay không?
Hoặc những thứ cấm kỵ nhân viên làm khi đón khách vào quán?
Và hàng trăm thứ khác nữa mà mình muốn biết (vì mình muốn làm khâu này thật kỹ) mà giờ chưa nghĩ ra!!!
Ánh xạ qua kỹ thuật Use Case, nó sẽ như thế này (ví dụ nhé anh em):
Thực tế nó được bắt đầu khi nào? – Trigger
Khi khách gửi xe xong và… bước vào quán
Hoặc xe taxi/ grab car chở khách tới ngay trước sảnh.
Khi nào quán sẵn sàng đón khách – Pre-Condition(s)
Khi đầu bếp báo đồ ăn đã sẵn sàng
Và phục vụ báo bàn ghế đã được dọn dẹp.
Khi nào thì xem như khâu tiếp đón khách diễn ra thành công – Post-Condition(s)
Khi khách đã vô tới bàn của mình
Và quay sang cảm ơn hoặc cười với nhân viên (vì service khủng mà, nên điều này là bắt buộc)
Các bước đón khách diễn ra như thế nào – Basic Flow
Chào anh/ chị >> hỏi xem có đặt bàn trước chưa >> hỏi xem có bạn chưa >> hỏi đi mấy người >> dẫn vô đến tận bàn >> cảm ơn anh/ chị. (Về lý thuyết, anh em có thể mô tả rõ: tương tác giữa nhân viên và khách thế nào. Ví dụ nếu nhân viên hỏi mà khách trả lời A thì sao, trả lời B thì làm gì…. Phân tích chi tiết sẽ giúp anh em cover đủ được các trường hợp hơn nữa ở bước sau)
Hoặc có cách nào khác đổi mới để đón khách ngầu lòi hơn hay không?– Alternative Flow
Ví dụ:
Mô tả các bước đón khách từ xe taxi/ grab car khi xe dừng ở trước sảnh
Hoặc đổi mới cách đón khách: Nếu ngày lễ halloween thì khách vô sẽ cho kẹo, hoặc ngày valentine thì khách vô sẽ tặng sô cô la…
Hoặc những thứ cấm kỵ nhân viên làm khi đón khách vào quán? – Exception Flow
Khi khách vào tới trước cửa quán mà nhân viên còn nói chuyện riêng >> failed
Khi hỏi khách mà không cười và nhìn khách >> failed
Khi dẫn khách vào mà trang phục lôi thôi, đầu tóc không đúng quy định >> failed.
Trên là ví dụ cho việc áp dụng Use Case để phân tích một thứ gì đó ngoài phạm vi phần mềm.
Khi phân tích ra chi tiết như vầy, mình sẽ có cái nhìn đầy đủ hơn để dễ dàng: training cho nhân viên, hoặc cải thiện các khâu chưa đạt, hoặc cũng có thể tối ưu lại nhân sự…..vâng vâng và mây mây.
Nếu anh em muốn phân tích gì đó thật kỹ lưỡng và chi tiết, hãy thử sử dụng kỹ thuật Use Case này. Nó sẽ giúp anh em nhìn được hầu hết mọi ngóc ngách của vấn đề. Để từ đó tính trước những việc cần làm nếu chẳng may gặp sự cố 🙂
UML là Unified Modeling Language, còn BPMN là Business Process Model and Notation. Nôm na UML và BPMN sẽ giúp anh em chuyển thể quy trình và hàng tá thứ khác sang dạng hình vẽ.
Hay nói sang hơn, UML và BPMN là các kỹ thuật dùng để “mô hình hóa”.
Mô hình hóa cái gì? Mô hình hóa những thứ phức tạp, rối rắm như:
Quy trình chẳng hạn (dùng BPMN, hoặc UML Activity Diagram)
Hoặc để mô tả các bảng dữ liệu quan hệ với nhau ra sao (UML ERD)
Hoặc để mô tả luồng tương tác giữa người dùng với hệ thống (UML Sequence Diagram)
Hoặc mô tả luồng dữ liệu đi như thế nào (UML DFD)
Và còn rất nhiều thứ phức tạp khác, mà anh em sẽ cần chuyển hóa nó thành hình vẽ để có thể “tiêu hóa” dễ dàng hơn.
Nói về UML/ BPMN thì sẽ có 2 thứ:
Tools để vẽ
Và cách vẽ.
Đa phần mọi người sẽ rất rành về các tools để vẽ, tools nào cũng biết, cũng đã từng xài. Nhưng để “vẽ không sai” và thể hiện đúng ý đồ thì không phải ai cũng làm được. Nó nằm ở cách vẽ.
Vẽ một diagram chuẩn là 5 người nhìn vào diagram, là cả 5 người cùng hiểu chung một ý. Chứ không phải mỗi người hiểu mỗi ý khác nhau. Nhưng thực tế thì anh em biết đó, thường sẽ là… mỗi người hiểu một ý khác nhau. Vụ này mình bị miết nên rành lắm.
Mấu chốt là diagram mình vẽ, nó còn có những cách đọc, cách nhìn khác nữa, mà mình “chưa nhìn ra”. À háaaa, kiểu như bị hở chỗ này, hở chỗ kia.
Giống như hình mình vẽ theo cách hiểu A của mình, nhưng thực tế hình này còn có cách hiểu B, C, và thậm chí cách hiểu D nữa. Người khác nhìn vào, chẳng may họ không nhìn theo cách hiểu A của mình, mà lại đi hiểu theo cách B, C, D của họ là toang ngay.
Lúc đó, mô hình hóa không giúp cho vấn đề dễ tiêu hóa hơn, mà còn làm “tan chảy” độ nguyên bản của nó, làm “tam sao thất bản”, làm cho vấn đề trở nên rối rắm hơn khi mỗi người hiểu một ý.
Đó là lý do mà thế giới có các: bộ quy chuẩn để vẽ UML hay BPMN.
Tình huống nào thì dùng cái gì? Dùng diagram này thì có những ký hiệu chuẩn nào, quy tắc dùng ra sao, khi dùng thì chú ý điểm gì…..? Có những chuẩn này, anh em sẽ dễ dàng align cách diễn đạt và cách hiểu với nhau hơn.
Anh em đọc thêm seri mình viết về BPMN tại đây nhé.
Tóm gọn, kỹ thuật UML/ BPMN không chỉ là biết dùng tools để vẽ, mà phải vẽ sao cho đúng và thể hiện được trọn vẹn ý đồ của mình.
3.3. Data Modeling
Ở kỹ thuật này, chủ yếu anh em BA làm phần mềm sẽ dùng nhiều.
Vì Data Modeling sẽ giúp anh em đi sâu vào cách dữ liệu được lưu như thế nào dưới database của một giải pháp phần mềm. Rộng hơn một chút dưới góc nhìn của BA, Data Modeling sẽ giúp anh em nắm được:
Những đối tượng nào được “ghi lại” dưới database, mức độ chi tiết của từng đối tượng?
Quan hệ giữa các đối tượng ra sao => phần nào sẽ giúp anh em mường tượng được function liên quan đến những đối tượng đó
Những business rules nằm sau các bảng dữ liệu là gì?
Data Modeling có thể được sử dụng để anh em tiếp cận vấn đề => phân tích xem thử có những đối tượng nào cần mổ xẻ >> lưu trữ >> phân tích. Hoặc cũng có thể là phương tiện để anh em catch up một system nào đó.
“BA giải quyết vấn đề”, giả sử nếu cần một giải pháp công nghệ để giải quyết một bài toán bất kỳ đi chẳng hạn.
Giả dụ: bạn mình đang gặp vấn đề trong việc quản lý hồ sơ ứng viên. Có một số “pain points” như sau:
Trung bình một bộ hồ sơ có quá nhiều thông tin. Trong đó có những thông tin bắt buộc lẫn những thông tin không bắt buộc.
Bộ hồ sơ có những “rules” liên quan ăn nhậu với nhau rất chặt chẽ, ví dụ:
Ứng viên nữ thì không quá 30 tuổi, ứng viên nam thì phải dưới 35
Ứng viên nữ cho bộ phận Admin thì tối thiểu phải IELTS 7.0, kinh nghiệm tối thiểu 4 năm, và chưa có gia đình
Ứng viên cho bộ phận Purchasing thì không được có kinh nghiệm làm ở các công ty: ABC và XYZ.
Ngoài ra còn phải check trùng thông tin ứng viên theo một bộ thông tin định danh, bao gồm: Họ và tên, CMND, Giới tính và DOB.
Và đặc biệt là: vì quản lý hồ sơ giấy nên mỗi lần check thông tin là mất cả buổi và rất dễ sai sót.
Nắm được một mớ pain points trên, chiếu qua lăng kính Biz Analyst, mình sẽ rõ được Business Objectives ở đây là phải có “một cái gì đó” giúp giải quyết gọn lẹ những yêu cầu trên.
“Một cái gì đó” ở đây sẽ là: Excel.
Đầu tiên mình sẽ xem bộ hồ sơ sẽ có những thông tin nào, tức bao gồm những đối tượng nào? Ví dụ có 5 đối tượng cần lưu trữ: Ứng viên, Kinh nghiệm làm việc, Học vấn, Sơ yếu lý lịch, và Lịch sử trao đổi.
5 đối tượng này sẽ tương đương với 5 sheets trong file excel.
Tiếp theo, 5 đối tượng này quan hệ với nhau như thế nào? Ví dụ ứng viên sẽ có nhiều kinh nghiệm làm việc, nhiều học vấn và nhiều lịch sử trao đổi công việc với nhau… Nếu quan hệ như vậy thì record giữa các sheet sẽ “link” với nhau như thế nào?
Chưa hết, mỗi thông tin trong bộ hồ sơ có quy định gì đặc biệt không, hay có dây mơ rễ má tới các thông tin khác như thế nào không? Mình sẽ liệt kê ra hết, thành một bộ validation rules cho từng dữ liệu.
Và sau cùng mình sẽ build một file Excel, sử dụng VBA để làm một cái form. Bạn mình sẽ nhập hồ sơ qua form, và validate thông tin ngay trên form nhập liệu này.
Kỹ thuật Data Modeling sẽ giúp anh em tóm gọn một mớ thứ rối rắm bên trên dưới góc nhìn data. Nó có thể thông qua Entity Relationship Diagram, Data Flow Diagram, hoặc Data Dictionaries.
Hoặc ở một ví dụ khác, khách hàng cần quản lý quy trình: Bước A >> Bước B >> Bước C >> Bước D.
Cơ bản anh em có 2 cách để thiết kế dữ liệu chỗ này:
Cách 1: Làm 4 tables, tượng trưng cho 4 objects: A, B, C, D. 4 đối tượng này link với nhau (quan hệ với nhau) theo một rules nhất định.
Cách 2: Chỉ cần 1 table, tượng trưng cho cả 4 objects: A, B, C, D. Và phân biệt từng chặng trong quy trình dựa vào 1 field status của table này. Status = A là đang ở bước A. Status = B là đang ở bước B, tượng tự cho C, và D.
Nếu requirement chỉ cần quản lý quy trình này thôi thì cả 2 cách đều ổn.
Nhưng nếu sau này khách hàng cần phân tích dữ liệu theo dạng Pipeline Chart thì có vẻ: cách 2 sẽ… khó hơn một tí so với cách 1. Vì rõ ràng, tổ chức dữ liệu như cách 1 sẽ tự nhiên hơn cách 2, nhưng lại tốn nhiều effort để thực hiện hơn cách 2.
Do đó, anh em cần phải hiểu và làm được Data Modeling để nhìn nhận những vấn đề tương tự như vầy.
Khi đã hiểu về data, hiểu về thứ nhỏ nhất xây nên một giải pháp phần mềm, hiểu về từng viên gạch nhỏ nhất để xây nên một ngôi nhà. Anh em mới có cơ hội làm đúng được khái niệm “phân tích và thiết kế”trong công việc BA của mình 🙂
3.4. Wireframe
Kỹ thuật cuối cùng là thiết kế Wireframe cho giao diện phần mềm. Cũng giống Data Modeling, kỹ thuật này áp dụng cho anh em IT BA là nhiều.
Nôm na thì Wireframe sẽ giúp anh em thể hiện được CẤU TRÚC và NHÓM THÔNG TIN có trên UI của phần mềm. Điều này giúp anh em truyền tải được yêu cầu người dùng đến Development Team, một cách chính xác và rõ ràng hơn bao giờ hết.
Vì kỹ thuật này cũng không quá đặc biệt. Và theo mình cũng không quá khó.
Với những thứ chưa biết, chưa rõ nó có thể chạy ra sao, behaviour như thế nào, anh em có thể xem thêm các framework hoặc các thư viện sẵn có về UI như Ant Design, hoặc Semantic-UI để tham khảo các components sẵn có của họ cũng rất hay.
Mình có note một bài về: Sketch – Wireframe – Mockup – Prototypeở đây. Anh xem thêm nhé.
4. Tạm kết
Nói về “kỹ thuật”, nhưng bài này không nói về lập trình, hay cách một application hoạt động.
Thực tế mình quan sát, đa phần những BA chính hiệu xung quanh mình thường ít khi quan tâm đến những thứ sâu xa về kỹ thuật, lập trình. Nếu có thì cũng đâu đó tìm hiểu thêm, chứ hiếm khi chủ động tìm hiểu vì phạm vi công việc.
Vì đơn giản, ai trong team cũng có vai trò riêng của mình.
Họ nhận thức rõ được phạm vi công việc của họ, họ không care (không thể và cũng không muốn care) đến những chuyện thuần về giải pháp kỹ thuật. Đó là nhiệm vụ nên làm và sẽ được làm tốt nhất bởi Solution Architect và các anh em Developer.
Nếu ai cũng rõ nhiệm vụ của mình, và tập trung hoàn thành tốt nhiệm vụ, sản phẩm làm ra sẽ trơn tru và hoàn thiện hơn rất nhiều.
Tuy vậy, mình không phủ định hoàn toàn chuyện kiến thức về lập trình có ảnh hưởng tích cực đến công việc của BA.
Như đầu bài, note này hy vọng sẽ giúp anh em đỡ lo lắng, và căng thẳng hơn khi nhắc đến 2 chữ “kỹ thuật” đối với BA. Thay vào đó, hãy cứ nắm vững 4 “kỹ thuật” trên là mình tin anh em có thể làm tốt được vai trò BA của mình trong bất kỳ công ty nào.
Hi vọng bài note này sẽ có ích với anh em. Tương tác và chia sẻ góc nhìn của anh em bên dưới nhé.
CSS là một trong ba kiến thức nền tảng của lập trình viên Frontend bên cạnh HTML và JavaScript, giúp bạn tạo ra phong cách cho trang Web. Để có thể khai báo và áp dụng CSS style đúng cho từng phần tử HTML trên DOM, chúng ta cần đến các CSS Selector. Vậy CSS Selector là gì? Bài viết hôm nay chúng ta cùng nhau tìm hiểu về nó và cách sử dụng các loại CSS Selector phổ biến hiện nay nhé.
CSS Selector là gì?
CSS Selector là một mẫu (template) hoặc quy tắc (rules) được sử dụng để xác định các phần tử HTML cụ thể trên trang, từ đó áp dụng các thuộc tính CSS lên chúng.
Như chúng ta đã biết, có 3 cách để khai báo CSS bao gồm: inline (viết trực tiếp vào thẻ HTML thông qua thuộc tính style), internal (viết tại file HTML và nằm trong cặp <style></style>) và external (viết thành file css riêng và import vào thông qua các thẻ <link></link>). Ngoại trừ cách khai báo inline, gắn trực tiếp CSS vào phần tử được chỉ định thì cách viết internal và external đều khai báo CSS tách biệt với HTML; từ đó yêu cầu cần có cách để xác định được rằng đoạn CSS này sẽ áp dụng cho phần tử (hay nhóm phần tử) HTML nào. Và đấy chính là công việc của CSS Selector.
Cú pháp khai báo CSS Selector
Lợi ích khi sử dụng CSS Selector
CSS Selector giúp bạn chỉ định chính xác và nhanh chóng nhiều phần tử HTML trên trang để áp dụng các thuộc tính CSS, lợi ích khi sử dụng CSS Selector bao gồm:
Tách biệt phần HTML và CSS giúp cho source code của trang Web trở nên dễ đọc hiểu và dễ quản lý
Tăng tính nhất quán trong thiết kế và bố cục (layout) cho trang Web
Có khả năng xây dựng nhiều mẫu CSS khác nhau (các themes) và áp dụng một cách thống nhất trên toàn trang Web
Tăng tính linh hoạt trong việc định dạng phần tử HTML và có khả năng tái sử dụng CSS giúp tiết kiệm thời gian cũng như giảm rủi ro lỗi
CSS Selector có thể xem là không thể thiếu trong việc phát triển, xây dựng Website hiện nay, vì vậy việc nắm được cách sử dụng các loại CSS Selector để áp dụng vào thực tế là điều vô cùng quan trọng. Chúng ta cùng tìm hiểu những CSS phổ biến cùng cách sử dụng chúng nhé.
Có 5 loại CSS selector chính thường xuyên được sử dụng giúp bạn có thể chọn các nhóm phần tử khác nhau trên một trang Web. Chúng ta cùng đi lần lượt từng loại nhé.
Id Selector
Id selector sử dụng thuộc tính id để chọn một element trên DOM. Thông thường giá trị id của element trên DOM là duy nhất, vì vậy khi sử dụng id selector, kỳ vọng trả về là sẽ áp dụng css cho một phần tử cụ thể. Lưu ý rằng selector này chỉ hoạt động được khi giá trị id khai báo phải khớp với thuộc tính id của element.
Cú pháp của Id selector:
#id_name { style: properties; }
Trong đó:
ký tự # (dấu thăng) thể hiện cho việc sử dụng loại Id selector
id_name: giá trị id khai báo để áp dụng css
Class Selector
Class selector sử dụng thuộc tính class để chọn các elements trên DOM. Giá trị class thường sẽ được tái sử dụng ở nhiều phần tử, vì thế class selector sẽ chọn ra được nhiều elements và gán các css cho các thành phần đó. Sử dụng class selector giúp bạn linh hoạt, đồng thời có khả năng tái sử dụng cao trong việc khai báo CSS. Selector này cũng là loại được sử dụng nhiều nhất trong thực tế.
Cú pháp của class selector:
.class_name { style: properties; }
Trong đó:
ký tự . (dấu chấm) thể hiện cho việc sử dụng loại class selector
class_name: giá trị class khai báo để áp dụng css
Class selector cũng là nền tảng cho nhiều bộ CSS Framework/ Library như Bootstrap, Tailwind,… sử dụng thông qua classname để quy định các CSS cho phần tử.
Element Selector sử dụng thẻ tên (HTML Tags) cho việc chọn các phần tử trên DOM. Việc sử dụng element selector sẽ có thể làm ảnh hưởng đến rất nhiều phần tử cùng thẻ tên, vì thế thông thường loại selector này dùng cho một số css chung trên trang (như font family) hoặc style toàn trang (như themes).
Cú pháp của element selector:
tag_name { style: properties; }
Trong đó:
tag_name: giá trị thẻ tên khai báo để áp dụng css
lưu ý trước tagname không chứa ký tự nào khác
Universal Selector
Universal Selector sử dụng cho việc chọn tất cả các phần tử trên trang. Bạn cũng có thể sử dụng universal selector bên trong một thẻ, một classname, một id để áp dụng css cho tất cả các phần tử con bên trong đối tượng tương ứng.
Cú pháp của universal selector:
* { style: properties; }
Trong đó:
ký tự * (hoa thị) thể hiện cho việc sử dụng loại universal selector
lưu ý universal selector áp dụng cho tất cả phần tử con, cháu, … trong đối tượng khai báo
Pseudo Classes
Pseudo class là tên được thêm vào css selector để cho biết mã CSS sẽ được áp dụng vào phần tử khi phần tử ở trạng thái nào đó cụ thể. Ví dụ khi một phần tử đang được focus, hoặc đang được hover, hay một ô input đang ở trạng thái disabled, …
Cú pháp của pseudo class:
selector:pseudo { style: properties; }
Trong đó:
selector: phần tử được sử dụng khai báo CSS thông qua các CSS selector
ký tự : đánh dấu việc khai báo trạng thái của phần tử
pseudo: thuộc tính trạng thái của phần tử, ví dụ hover, focus, active, …
Lưu ý rằng mỗi phần tử (HTML tag) sẽ có những thuộc tính trạng thái khác nhau. Bạn có thể tham khảo thêm danh sách các trạng thái của từng loại phần tử như dưới đây:
Kết bài
Qua bài viết này, hy vọng các bạn đã hiểu rõ hơn về CSS Selector và cách sử dụng của một số loại CSS Selector phổ biến. Sử dụng đúng và hiệu quả các CSS Selector sẽ giúp bạn áp dụng CSS vào trang Web của mình một cách linh hoạt và chính xác. Cảm ơn các bạn đã đọc bài và hẹn gặp lại trong các bài viết tiếp theo của mình.
Bài viết được sự cho phép của tác giả Nguyễn Hoàng Phú Thịnh
Hế lô 500 anh emmmm 🙂
Hằng ngày đi làm, chắc hẳn anh em hay nghe những thứ như Wireframe, Mockup, hay Prototype.
Mình tin là ai cũng biết mấy thứ này nói về gì. Nhưng để hiểu rõ từng loại một, đặc tính và mục đích sử dụng của từng loại thì không phải anh em nào cũng nắm.
Bài note này mình sẽ chém gió một số thứ về UI, hi vọng giúp anh em phân biệt rõ: Như thế nào là Sketch, Wireframe, Mockup và Prototype? 😎
1. Khác biệt cơ bản
Thật ra lúc đầu mình cũng thấy hơi rối ở mấy khái niệm này. Gì mà tùm lum tùm la, ông nào cũng như ông nào, chả thấy khác gì nhao.
Nhưng để đơn-giản cu-te hột-me hơn thì anh em cứ hình dung như sau.
Có ông kiến trúc sư, người ta thuê ổng thiết kế một ngôi nhà. Ổng sẽ nghiên cứu, vẽ vời các kiểu để ra được một thứ, gọi là: BẢN THIẾT KẾ.
Bản thiết kế nhà (Nguồn: xaynhasaigon.vn)
Vẽ xong, ổng mới đưa bản thiết kế này cho mấy anh kỹ thuật 3D, phác thảo ngôi nhà ra hình – ra dáng, để đưa cho khách hàng xem và duyệt..
Đây, bản phác thảo nhà 3D (Nguồn: baophat.com)
Rõ ràng cả 2 bản: Bản thiết kế và Bản phác thảo khác nhau quá đúng không anh em?
Một cái là thiết kế sơ khởi, chỉ gồm những phần chính, và thể hiện tổng quan ngôi nhà.
Còn một cái thì lên màu, nội thất, chi tiết 3D đẹp đẽ các kiểu.
Đó là đi từ “thiết kế sơ bộ >> thiết kế chi tiết”.
Mỗi loại đều thể hiện một nội dung khác nhau, và truyền tải một thông điệp khác nhau.
Bản thiết kế vs. Bản phác thảo
Sketch, Wireframe, Mockup, hay Prototype trong phần mềm cũng vậy.
Về cơ bản, để xây một phần mềm thì anh em cũng phải đi từ thiết kế sơ bộ >> thiết kế chi tiết.
Và khoảng cách giữa “thiết kế sơ bộ >> thiết kế chi tiết” chính là nằm gói gọn trong 4 chữ: Sketch >> Wireframe >> Mockup >> Prototype, với mức độ chi tiết tăng dần theo từng loại.
Khoảng cách từ Sketch đến Prototype
Phần dưới đây anh em mình sẽ cùng tìm hiểu từng loại và mỗi loại nó khác gì nhau? Lét sờ gâuuuu!
2. Sketch
SKETCH đơn giản là PHÁC HỌA. Phác họa nghĩa là vẽ nhanh, phác thảo nhanh một hình ảnh nào đó. Keyword ở đây là nhanh, rất nhanh nhé anh em. Hoàn toàn không thể hiện tiểu tiết.
Vì sao lại vẽ nhanh?
Mục đích của Sketch là để capture nhanh những ý tưởng lúc anh em ngồi tư duy một mình hoặc đang brainstorm với nhau.
Đó là những lúc anh em ngồi trao đổi với nhau theo kiểu:
“Thế này, chỗ này có cái lưới, gồm n dòng ở đây, được chưa…
Chắc nút X để chỗ này, bấm vào cái bặccccc, là ra popup như thế này;
Đây đây, popup sẽ hiện chỗ này, một cục ngay đây nha…, cạnh lưới hình ảnh lúc nãy, ở đây nè, sao, ổn chưa…”
(đại loại vậy)
Thường mình hay dùng bút lông vẽ lên bảng trắng để trao đổi với đồng bọn. Ít khi dùng giấy bút như mấy hình Sketch đẹp đẹp trên mạng.
Vì khi anh em dùng giấy bút, lúc vẽ nhầm thì khó bôi lắm >> mà không bôi được thì xóa tới xóa lui >> xấu.
Mà không xóa tới xóa lui >> vẽ lại cái khác >> tốn thời gian >> đứt mạch suy nghĩ
Do đó, best nhất là cứ dùng bút lông vẽ lên bảng trắng. Sai tới đâu, vẽ lại tới đó. Nếu lỡ có sai thì quẹt một phát vẽ là trắng trơn ngay, cứ đà đó mà vẽ tiếp.
Và thường thì mình hay dùng Sketch để trao đổi về những tính năng enhancement. Tức system hiện tại đã có, khách hàng muốn làm thêm cái này, cái kia. Giờ bê cái đó lên hệ thống thì nó sẽ chạy ra sao?
Phương pháp Sketch không chỉ giúp anh em “hườm hườm” được màn hình của chức năng đó ngay tức thì, mà còn giúp cả team cùng suy nghĩ đúng-thứ-mình-đang-nói*.
*Tức, thay vì mình chỉ nói: “à à, cái nút đó ở trên, cái lưới ở dưới. Bấm vô cái nút thì popup hiện lên, cạnh cái lưới zậy nè….”. Thì rất có thể, mỗi người sẽ hiểu một kiểu khác nhau. Tới lúc confirm, ông thì hiểu A, bà thì hiểu Á >> lộn xì ngầu lên hết.
Nên, tóm gọn ở mục này:
SKETCH là bản phác thảo nhanh UI của phần mềm, nhằm ghi nhận nhanh ý tưởng về một chức năng nào đó.
Ô kê, sang cấp độ thứ 2, đó là Wireframeeeeeeee!!!
Wireframe thì chi tiết hơn Sketch đôi chút. Và sự “chi tiết hơn” ở đây thể hiện rõ được cấu trúc của giao diện phần mềm.
Cấu trúc là sao? Tức Wireframe sẽ giúp anh em thể hiện được:
Luồng đi cơ bản của user (User Flows)
Và cấu trúc nhóm thông tin gồm những gì?
Thường khi vẽ wireframe cho website hay web apps, mình sẽ luôn cấu trúc các phần consistent như sau:
Header: gồm nhóm thông tin tổng quan như: Name, Owner, và Status.
Body: gồm “X” section (các phần dữ liệu => thể hiện thông tin của wireframe này muốn mô tả về cái gì)
Footer: thường mình sẽ để các trường thông tin cơ bản như: Created By, Created On, Modified By, và Modified On.
Ví dụ Wireframe của một dự án mình làm
Theo mình, Wireframe là bước quan trọng nhất, vì nó chính xác là bộ khung của UI. Không cần quan tâm đến màu sắc, font chữ, to nhỏ, hiệu ứng thế nào; cái quan trọng nhất của Wireframe là ở cấu trúc và nhóm thông tin mà nó thể hiện.
Wireframe là bố cục của UI, mặc dù không quá chi tiết nhưng nó thể hiện rõ được luồng thao tác của người dùng và cấu trúc các nhóm thông tin có trên UI đó.
Một trong những công cụ tốt nhất để anh em vẽ Wireframe là Balsamiq. Trực quan, dễ học, dễ xài, tính năng đơn giản, thao tác nhanh gọn. Đủ để capture nhanh cấu trúc của một màn hình.
Wireframe phải luôn được design ở mức Low Fidelity và thường là output của các UX Designer. Đôi khi có thể là BA, do họ hiểu expectation của người dùng về User Flows. Nhưng nếu áp dụng đúng chuyên môn và trách nhiệm thì người làm Wireframe ngay từ đầu phải là UX Team.
Như mình nói ở trên, Wireframe phải thể hiện được: luồng thao tác của người dùng, và cấu trúc các nhóm thông tin ra sao. Nên phần nào nó sẽ định hình bộ khung cho tất cả màn hình có trong sản phẩm.
Do đó để làm tốt Wireframe, đòi hỏi anh em phải thật sự hiểu User và vấn đề mình giải quyết ở đây là gì. Thường chúng ta sẽ phải làm User Research rất kỹ để ra được các bộ User Personas. Để từ đó ra các quyết định về luồng thao tác và các component có trên UI của mình.
Sau khi chốt được bộ khung, anh em sẽ qua một thứ nhiều chi tiết hơn, đó là…
4. Mockup
Nhiều anh em hay đánh đồng Wireframe với Mockup là một về độ chi tiết của nó. Nhưng không, Mockup chi tiết hơn Wireframe rất, rất, và rất nhiều.
Chi tiết hơn, cả về: màu sắc, vị trí field, kích cỡ, font chữ, hình ảnh, đường kẻ, phân lô, phân luồng. Thậm chí là cả validationcủa các trường dữ liệu.
Tức trường nào thì được input, trường nào thì bị disable. Các trường phụ thuộc với nhau như thế nào. Khi trường A có giá trị 1, thì trường B có giá trị gì… đại loại vậy.
So với Wireframe chỉ thể hiện bố cục, cấu trúc của màn hình là chủ yếu. Thì Mockup lại thể hiện rõ màn hình nó có gì ở trỏng, chi tiết đến từng field, dấu chấm, dấu phẩy.
Mockup chính là Wireframe, nhưng ĐẦY ĐỦ thông tin và thể hiện được NHIỀU CHI TIẾT HƠN
Trong 4 loại: Sketch, Wireframe, Mockup và Prototype, độ chi tiết trên màn hình của Mockup và Prototype là cao nhất. Do đó khi làm Mockup, anh em đã phải rất rõ User Requirement.
“Rất rõ” là sao, là phải nắm được:
Màn hình này thuộc chức năng/ nhóm chức năng nào?
Màn hình này có nằm trong Business Process Flow nào không?
Màn hình này thể hiện nội dung gì?
Input/ Output trên màn hình này là gì?
Những validation có trên màn hình này?
Thì chỉ khi nắm được những thông tin này, anh em mới đủ dữ kiện để làm Mockup khớp với requirement được. Chính khách hàng sẽ dựa vào các Mockup này để sign-off cho anh em làm tiếp. Để đảm bảo rằng: khách hàng sẽ nhận được đúng cái họ cần.
Hoặc ngầu lòi hơn, họ có thể yêu cầu không chỉ Mockup. Không chỉ là những màn hình tĩnh, vô tri vô giác – đơn điệu – nhạt nhẽo – chán òm này.
Mà họ cần một thứ gì đó: sống động hơn, linh hoạt hơn, thực tế hơn, và thể hiện một cách chính xác – chân thật đến từng mi-li-mét, thứ mà khách hàng muốn.
Khi đó, thứ anh em cần làm chính là… 😎
5. Prototype
Dòm bên ngoài thì Prototype không khác Mockup là mấy. Nhưng thứ làm Prototype trở nên vi diệu hơn đó là khả năng tương tác của nó.
Tức thay vì những màn hình tĩnh, thì với Prototype, người dùng hoàn toàn có thể tương tác trực tiếp với nó. Tức sờ mó, à nhầm… tức nhấn nút, kéo thả, trượt lên, trượt xuống, bung mở popup… các kiểu đều được.
Điều này sẽ giúp khách hàng mường tượng rõ hơn về sản phẩm họ sẽ nhận được.
Prototype là “mẫu thử đầu tiên” của phần mềm/ hoặc một chức năng của phần mềm, và người dùng có thể tương tác được ngay trên màn hình của chức năng/ phần mềm đó.
Thay vì Mockup chỉ thể hiện góc nhìn không gian: có những element nào trên màn hình.
Thì Prototype thể hiện luôn được góc nhìn theo thời gian: hiện tại màn hình như vầy, sau khi nhấn A, màn hình sẽ như vầy, sau khi kéo B, màn hình sẽ chuyển qua như vầy, hoặc nhấn nút C, 5 giây sau, thông báo này sẽ hiện ra…
Tức là rất có thể, khách hàng dòm vô cũng không biết cái nào hàng thật, cái nào hàng giả 😆
Nếu dịch ra tiếng Việt thì Prototype nghĩa là “mẫu thử đầu tiên”. Nghe hơi thô nhưng khá sát nghĩa.
Nghĩa là thay vì làm nguyên 1 phần mềm từ đầu tới cuối, anh em chỉ cần chọn ra 1-2 tính năng nổi trội nhất để làm Prototype mà thôi.
Nổi trội có thể là thứ quan trọng nhất. Hoặc thứ khó nhất, tức là làm để chứng minh năng lực. Chứng minh rằng: tụi tui hoàn toàn có thể làm được theo đúng như những gì mấy anh muốn, thậm chí… ngon lành hơn!!!
Thường Prototype được làm trong giai đoạn pitching dự án. Hoặc cũng có thể làm để làm rõ requirement với khách hàng. Thường áp dụng cho những requirement phức tạp, cần thể hiện một cách trực quan.
Một điểm nữa mình muốn nói, đó là: Prototype hoàn toàn khác với khái niệm “phiên bản beta”.
Bản beta là bản đầy đủ chức năng, đã có thể được sử dụng của một sản phẩm. Còn prototype chỉ là “phần mặt tiền trông có vẻ là hàng thiệt” của một sản phẩm nào đó thôi. Hoàn toàn không có code front-end và back-end phía sau.
Khác với Wireframe, Mockup hay Prototype sẽ do các anh em UI Designer lãnh đạn, à nhầm, lãnh trách nhiệm. Tức nhiệm vụ này sẽ do UI Team làm.
Họ sẽ dùng các chuyên môn riêng biệt của mình về: Interaction Design, Visual Design, hay bộ Design System của công ty… để cụ thể hóa wireframe bên trên do team UX thiết kế.
Còn đứng ở khía cạnh BA, chúng ta cũng có thể deliver những bản thiết kế này. Tùy vào cấu trúc team, budget, hoàn cảnh, hoặc cả kỹ năng và khả năng của anh em.
Nhưng anh em cũng nên lưu ý, thường trong dự án thì Prototype là thứ làm tốnnhiềueffort, và tốnnhiều tiền nhất. Nên nếu sử dụng đúng lúc sẽ hiệu quả. Còn nếu làm dụng thì sẽ rất dễ bị “ô-vờ”, từ over budget, over time, overexpectation của khách hàng, không đáng!!!
Hiện thị trường có rất nhiều tool để làm Prototype. Nhưng một trong những món “powerful” nhất mình từng xài đó là AxureRP. Một trong những tool khủng mà anh em có thể configure điều kiện if else để mô tả những luồng tương tác phức tạp.
Anh em có tool gì ngon ngon thì còm men bên dưới để mình bắt chước nhé.
6. Tạm kết
Mình sẽ note vài gạch đầu dòng để anh em dễ lưu tâm như sau:
Sketch: là bản phác thảo nhanh UI của phần mềm, nhằm ghi nhận nhanh ý tưởng về một chức năng nào đó.
Wireframe: là bố cục của UI, mặc dù không quá chi tiết nhưng nó thể hiện rõ được luồng thao tác và cấu trúcnhóm thông tin có trên UI đó.
Mockup: chính là Wireframe, nhưng ĐẦY ĐỦ thông tin và thể hiện được NHIỀU CHI TIẾT HƠN
Prototype: là “mẫu thử đầu tiên” của phần mềm/ hoặc một chức năng của phần mềm, và người dùng có thể tương tác được trên màn hình của chức năng/ phần mềm đó.
Nói về độ “tốn effort để làm” thì: Sketch >> Wireframe >> Mockup >> Prototype. Theo đó thì Prototype là thứ tốn tiền nhất để làm, giảm dần xuống Mockup, và Wireframe.
Nên nếu ai đó đặt hàng anh em làm Mockup hay Prototype thì phải clear rõ nhu cầu và chi phí của từng loại ngay từ đầu nhé.
ChatGPT và Google Search được coi là hai phương tiện tra cứu thông tin mạnh nhất hiện nay. Mỗi phương thức đều có ưu và nhược điểm riêng, liệu có thể kết hợp cả hai không? Câu trả lời là có, việc tích hợp ChatGPT vào Google Search là một bước tiến quan trọng, mang đến cho người dùng khả năng tìm kiếm thông minh hơn, nhanh chóng hơn và chính xác hơn. Cùng TopDev tìm hiểu cách để tích hợp ChatGPT vào Google Search dễ dàng và nhanh chóng trong bài viết dưới đây bạn nhé!
Nhắc lại về Chat GPT và Google Search
ChatGPT là một mô hình ngôn ngữ AI do OpenAI phát triển, được thiết kế để tương tác với con người qua ngôn ngữ tự nhiên. Nó có khả năng hiểu và tạo ra các câu trả lời dựa trên các truy vấn mà người dùng đưa ra, giúp cung cấp thông tin một cách nhanh chóng và chính xác. ChatGPT không chỉ dừng lại ở việc cung cấp thông tin đơn thuần mà còn có thể trả lời các câu hỏi phức tạp, giải thích chi tiết và thậm chí tham gia vào các cuộc trò chuyện tương tác.
Google Search, ngược lại, là công cụ tìm kiếm phổ biến nhất thế giới, chủ yếu hoạt động bằng cách quét và liệt kê các trang web có liên quan đến truy vấn của người dùng. Khi tìm kiếm keyword nào đó, Google sẽ trả về một danh sách kết quả là nhưng bài viết liên quan nhất đến keyword trên, và người dùng tự lựa chọn và tìm hiểu thêm từ các nguồn đó. Kết quả tìm kiếm của Google thường là danh sách các trang web, video, hình ảnh và các tài liệu khác có thể giúp người dùng tìm kiếm thông tin mà họ cần.
Điểm khác biệt chính của chatGPT và Google Search đó là:
ChatGPT trả lời trực tiếp trong ngữ cảnh, cá nhân hóa và có khả năng tham gia cuộc trò chuyện, có sự tương tác giữa chatbot và con người.
Google Search cung cấp các liên kết web liên quan nhưng không có khả năng tương tác và cá nhân hóa sâu như ChatGPT.
Ưu điểm của việc tích hợp ChatGPT vào Google Search
Việc tích hợp chat GPT – tìm trên Google mang lại một số ưu điểm sau đây:
Trải nghiệm tìm kiếm tốt hơn với AI
Tích hợp ChatGPT vào Google Search giúp cung cấp thông tin do AI tạo ra mà bạn không thể có được chỉ từ tìm kiếm Google thông thường. Điều này mang đến một lớp thông tin bổ sung, giúp người dùng tiếp cận với kiến thức phong phú hơn và chi tiết hơn.
Tóm tắt kết quả tìm kiếm
Khi tích hợp, bạn sẽ vừa có danh sách các bài viết trả về từ Google, đồng thời có kết quả trả lời trực tiếp cho câu hỏi từ chatGPT. Câu trả lời tóm tắt này giúp tiết kiệm tối đa thời gian và tăng tính hiệu quả lên cao nhất trong công việc hàng ngày và các hoạt động học tập.
Giao diện thân thiện và linh hoạt
Ứng dụng tích hợp này rất dễ sử dụng, cho phép người dùng chuyển đổi giữa các phiên bản ChatGPT, bật tắt tính năng khi cần thiết, và sao chép phản hồi vào clipboard một cách dễ dàng. Điều này mang lại sự tiện lợi và linh hoạt cao hơn khi tìm kiếm và thu thập thông tin trực tuyến.
Đầu tiên, bạn vào Chrome Web Store để tải và cài đặt tiện ích ChatGPT for Google. Bạn có thể tìm kiếm tiện ích này bằng cách sử dụng từ khóa hoặc truy cập trực tiếp qua đường link này.
Khi đã tìm thấy, hãy nhấn vào nút “Add to Chrome” hoặc “Thêm vào Chrome” ở góc trên bên phải của trang để bắt đầu quá trình cài đặt.
Sau khi nhấn “Thêm vào Chrome”, một hộp thoại xác nhận sẽ xuất hiện, yêu cầu bạn xác nhận việc cài đặt tiện ích này vào trình duyệt. Hãy nhấp vào nút “Thêm tiện ích” để hoàn tất quá trình cài đặt. Tiện ích ChatGPT for Google sẽ tự động được tải xuống và cài đặt vào trình duyệt của bạn.
Bước 2: Đăng Nhập Vào Tài Khoản ChatGPT
Sau khi cài đặt tiện ích, bạn cần truy cập vào trang web chính thức của ChatGPT và đăng nhập vào tài khoản của mình. Nếu bạn chưa có tài khoản, hãy tạo mới một tài khoản để tiếp tục. Việc đăng nhập này sẽ kết nối tài khoản ChatGPT của bạn với Google Search.
Lưu ý: Nếu không có tài khoản chat GPT thì sẽ không tích hợp được.
Bước 3: Sử Dụng ChatGPT Trong Google Search
Sau khi đã đăng nhập thành công, bạn có thể sử dụng công cụ ChatGPT trực tiếp trên Google Search. Khi bạn tìm kiếm thông tin trên Google, phản hồi từ ChatGPT sẽ hiển thị ở bên phải của trang kết quả, giúp bạn có thêm thông tin chi tiết và chính xác hơn. Bạn cũng có thể sử dụng biểu tượng ChatGPT for Google để truy cập nhanh vào các tính năng thông minh của ChatGPT.
Và đây là kết quả khi bạn tìm kiếm trên Google, phần bên phải sẽ kết hợp hiển thị câu trả lời của chatGPT:
Với những bước đơn giản này, bạn sẽ tích hợp thành công ChatGPT vào Google Search, giúp nâng cao hiệu quả tìm kiếm và tiếp cận thông tin một cách toàn diện hơn.
Việc tích hợp ChatGPT vào Google Search không chỉ mang đến trải nghiệm tìm kiếm thông minh hơn mà còn giúp bạn tiết kiệm thời gian và nâng cao hiệu quả công việc. Với các bước cài đặt đơn giản và những tiện ích mạnh mẽ, việc sử dụng ChatGPT trở nên dễ dàng hơn bao giờ hết. Hãy thử tích hợp ChatGPT vào Google Search và khám phá những lợi ích mà nó mang lại cho trải nghiệm tìm kiếm của bạn.
Trong thời đại công nghệ phát triển vượt bậc, việc tương tác với trí tuệ nhân tạo (AI) đang ngày càng trở nên phổ biến và dễ dàng hơn. VoiceGPT là một trong những ứng dụng tiên tiến nhất hiện nay, mang đến khả năng tương tác với ChatGPT thông qua giọng nói, giúp bạn tiết kiệm thời gian và nâng cao trải nghiệm người dùng. VoiceGPT không chỉ đơn thuần là một công cụ hỗ trợ giao tiếp, mà còn mở ra một kỷ nguyên mới của sự tương tác tự nhiên giữa con người và máy tính.
VoiceGPT là gì?
VoiceGPT là một ứng dụng tích hợp với nền tảng chatGPT của OpenAI, cho phép người dùng tương tác với ChatGPT thông qua giọng nói. Thay vì phải gõ văn bản, người dùng có thể trực tiếp trò chuyện với AI bằng cách sử dụng giọng nói tự nhiên của mình.
VoiceGPT ra đời nhằm phục vụ cho những người gặp khó khăn trong việc sử dụng bàn phím để nhập prompt. VoiceGPT không chỉ hỗ trợ việc giao tiếp tiện lợi hơn mà còn nâng cao trải nghiệm người dùng nhờ khả năng phản hồi nhanh chóng và chính xác.
Đặc biệt, VoiceGPT hoàn toàn miễn phí tại Việt Nam, bạn có thể dễ dàng tạo tài khoản và sử dụng.
VoiceGPT hoạt động ra sao?
VoiceGPT là một ứng dụng trí tuệ nhân tạo sử dụng công nghệ xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) và nhận diện giọng nói tiên tiến để cho phép người dùng giao tiếp với máy tính thông qua giọng nói. Đây là cách mà VoiceGPT hoạt động:
Nhận dạng giọng nói
VoiceGPT bắt đầu bằng việc sử dụng công nghệ nhận dạng giọng nói (Speech Recognition) để chuyển đổi lời nói của người dùng thành văn bản. Khi người dùng nói vào microphone, hệ thống sẽ thu âm và xử lý âm thanh này để xác định các từ ngữ mà người dùng đã nói. Công nghệ này thường dựa trên các mô hình học máy sâu (Deep Learning) để nhận diện và phiên âm giọng nói một cách chính xác.
Xử lý ngôn ngữ tự nhiên (NLP)
Sau khi chuyển đổi lời nói thành văn bản, VoiceGPT sử dụng mô hình GPT để xử lý ngôn ngữ tự nhiên. Đây là bước quan trọng, trong đó mô hình sẽ phân tích văn bản để hiểu ngữ cảnh, xác định ý nghĩa của câu hỏi hoặc yêu cầu, và từ đó tạo ra phản hồi thích hợp. GPT đã được huấn luyện trên một lượng dữ liệu văn bản khổng lồ, giúp nó có khả năng hiểu biết và phản hồi tự nhiên giống như con người.
Phản hồi bằng giọng nói
Sau khi tạo ra văn bản phản hồi, VoiceGPT chuyển đổi văn bản này trở lại thành giọng nói thông qua công nghệ chuyển đổi văn bản thành giọng nói (Text-to-Speech – TTS). Công nghệ này cho phép tạo ra giọng nói tự nhiên, rõ ràng và có thể điều chỉnh để phù hợp với ngôn ngữ và phong cách mà người dùng mong muốn. Cuối cùng, phản hồi giọng nói này sẽ được phát qua loa hoặc tai nghe của người dùng.
Học hỏi và cải thiện
Một trong những điểm mạnh của VoiceGPT là khả năng học hỏi và cải thiện liên tục. Với mỗi lần tương tác, hệ thống có thể thu thập thêm dữ liệu và cải thiện độ chính xác của việc nhận diện giọng nói, xử lý ngôn ngữ tự nhiên và phản hồi. Điều này giúp VoiceGPT trở nên ngày càng thông minh hơn và mang lại trải nghiệm người dùng tốt hơn qua thời gian.
Các tính năng nổi bật của Voice Chat GPT
Nhập liệu và phản hồi bằng giọng nói cho các cuộc trò chuyện tự nhiên
VoiceGPT cho phép bạn tương tác với ChatGPT bằng giọng nói thay vì phải gõ văn bản. Bạn có thể đưa ra câu hỏi hoặc lệnh bằng giọng nói của mình, và ChatGPT sẽ phản hồi lại cũng bằng giọng nói. Điều này mang lại một trải nghiệm giao tiếp tự nhiên và trực quan hơn, giúp bạn dễ dàng hơn trong việc trò chuyện với AI.
Hỗ trợ đa dạng ngôn ngữ
Voice Chat GPT hiện đang hỗ trợ 67 ngôn ngữ khác nhau, trong đó có tiếng Việt, giúp người dùng trên toàn thế giới có thể tương tác với AI bằng ngôn ngữ mẹ đẻ của mình. Điều này không chỉ tạo sự thuận tiện mà còn mở rộng khả năng sử dụng ứng dụng trong môi trường đa ngôn ngữ, hỗ trợ người dùng trong việc học tập, làm việc hoặc đơn giản là giao tiếp hàng ngày.
Giao diện thân thiện, dễ dùng
Voice GPT được thiết kế với giao diện thân thiện và trực quan, dễ dàng sử dụng cho mọi đối tượng người dùng. Từ việc chọn ngôn ngữ, kích hoạt microphone, đến việc điều hướng các chức năng chính, mọi thứ đều được sắp xếp hợp lý để người dùng có thể bắt đầu trò chuyện với AI một cách nhanh chóng và hiệu quả.
Chia sẻ và xuất câu chuyện
Một tính năng đặc biệt của Voice Chat GPT là khả năng chia sẻ và xuất câu chuyện hoặc cuộc trò chuyện. Người dùng có thể lưu lại những cuộc trò chuyện đáng nhớ, xuất chúng dưới dạng văn bản hoặc âm thanh, và chia sẻ với bạn bè, gia đình hoặc đồng nghiệp thông qua các nền tảng mạng xã hội, email, hoặc ứng dụng tin nhắn.
Nhận dạng và phân tích giọng nói cực chuẩn
Voice GPT sử dụng công nghệ nhận dạng giọng nói tiên tiến, cho phép nó nhận diện và phân tích giọng nói của người dùng một cách chính xác. Điều này giúp cải thiện chất lượng phản hồi của AI, đảm bảo rằng các câu trả lời luôn đúng ngữ cảnh và phù hợp với câu hỏi hay yêu cầu của người dùng.
Tích hợp dễ dàng với các ứng dụng khác
Voice Chat GPT có thể được tích hợp dễ dàng với các ứng dụng và dịch vụ khác, giúp người dùng tận dụng tối đa sức mạnh của AI trong nhiều lĩnh vực khác nhau, từ chăm sóc khách hàng, giáo dục, đến giải trí và truyền thông.
Công nghệ OCR để trích xuất văn bản từ hình ảnh
Nếu bạn có một hình ảnh chứa văn bản và muốn ChatGPT xử lý nó, VoiceGPT đã tích hợp công nghệ OCR (Optical Character Recognition) để trích xuất văn bản từ hình ảnh một cách dễ dàng. Tính năng này rất hữu ích khi bạn cần trích xuất thông tin từ tài liệu, hình ảnh hoặc bảng trắng.
Cách tải và sử dụng VoiceGPT trên Android
Trước tiên, bạn cần tải ứng dụng VoiceGPT về thiết bị của mình.
Bước 3: Quá trình tải sẽ mất khoảng vài giây để tải. Khi hoàn thành, bạn ấn vào Mở để bắt đầu sử dụng ứng dụng nhé.
Bước 4: Đăng nhập hoặc tạo tài khoản
Sau khi cài đặt xong, mở ứng dụng VoiceGPT.
Đăng nhập bằng tài khoản OpenAI của bạn. Nếu bạn chưa có tài khoản, bạn có thể đăng ký mới ngay trên ứng dụng.
Bước 5: Cấp quyền truy cập giọng nói. Nhấn “Cho phép” để ứng dụng có thể nghe và nhận diện giọng nói của bạn.
Bước 4: Bắt đầu sử dụng
Sau khi hoàn tất các bước cài đặt, bạn chỉ cần nhấn vào biểu tượng microphone và bắt đầu nói chuyện với VoiceGPT.
VoiceGPT sẽ lắng nghe và trả lời bạn ngay lập tức.
VoiceGPT đã chứng minh được tiềm năng vượt trội trong việc cung cấp một trải nghiệm giao tiếp tự nhiên và hiệu quả với AI. Với những tính năng nổi bật như nhận dạng giọng nói chính xác, hỗ trợ nhiều ngôn ngữ, và khả năng trích xuất văn bản từ hình ảnh, VoiceGPT đang thay đổi cách chúng ta tương tác với công nghệ hàng ngày. Hơn nữa, voice GPT hoàn toàn miễn phí và rất dễ sử dụng, nhờ vậy ngày càng có nhiều người tiếp cận với công nghệ AI. Hãy tải và trải nghiệm ngay để khám phá những tiện ích mà VoiceGPT mang lại!
Bài viết được sự cho phép của tác giả Tống Xuân Hoài
Vấn đề
Khi mới tiếp xúc với Node.js và cũng là lần đầu học cách sử dụng Linux, nodemon là một thư viện mà tôi thường hay sử dụng để phát triển ứng dụng, vì chỉ cần lưu mã thì ngay lập tức nó sẽ “nạp” lại mã mới mà không cần phải “kill” đi bật lại ứng dụng một cách thủ công nữa, tính năng này ngày nay còn được gọi là “hot reload”.
Sau bước phát triển là bước triển khai. Trong lúc thực hành chạy ứng dụng ở trên máy chủ, loay hoay mãi không biết làm sao để chạy được nó. Nếu dùng cách thông thường là gõ “node index.js” hoặc thậm chí dùng cả nodemon thì cứ mỗi khi thoát khỏi terminal, thoát khỏi máy chủ, thì ứng dụng cũng “bay màu” theo mất. Tôi hiểu rằng ứng dụng sẽ bị thoát nếu như không giữ được kết nối đến máy chủ. Thế là sao?
Mãi sau mới biết thì ra để giữ cho ứng dụng được chạy mãi, chúng ta cần phải có một công cụ quản lý tiến trình. Không chỉ cho riêng Node mà hầu hết các ngôn ngữ khác cũng cần phải có. Đối với Node thì cái tên được nhắc đến nhiều nhất có lẽ là pm2.
Từ khi biết đến pm2, tôi đã có thể dễ dàng triển khai các ứng dụng của mình. Cứ thế cho đến một thời gian sau, được làm nhiều dự án và tiếp xúc với nhiều công nghệ khác như Docker, Kubernetes… thì pm2 dần trở nên không còn cần thiết nữa, vì về bản chất các công cụ đó đã tích hợp sẵn công cụ dành cho quản lý.
Gần đây, khi đang bảo trì nhiều dự án, mà hầu hết chúng đều dùng pm2 thì tôi phải dành thời gian đọc lại tài liệu về cách sử dụng vì đã lâu rồi chưa đụng đến. Lúc đó chợt nhận ra đã có quá nhiều thay đổi trong khoảng thời gian đó. Nhiều tính năng mới được thêm vào hoặc cũng có thể là những tính năng mà mình chưa được biết đến.
Nhưng phải thành thật mà nói rằng pm2 vẫn là công cụ quản lý ứng dụng Node.js rất mạnh mẽ. Bất kỳ ai làm việc với Node cũng nên dành thời gian để tìm hiểu về nó. Vì thế bài viết ngày hôm nay tôi sẽ điểm lại một vài tính năng chính của công cụ này.
PM2 là gì?
pm2 là trình quản lý tiến trình daemon giúp bạn quản lý và duy trì ứng dụng luôn luôn trực tuyến.
Cài đặt pm2 rất đơn giản, thông qua npm tích hợp sẵn trong Node.
$ npm install pm2@latest -g
Sau đó bạn đã có thể khởi động ứng dụng Node của mình:
$ pm2 start app.js
Ứng dụng được chạy trong nền, để xem tất cả ứng dụng đang chạy:
$ pm2 list
Điều hữu ích nhất ở pm2 là nó giữ được ứng dụng chạy ở dưới nền, nghĩa là bạn có thoát khỏi máy chủ thì ứng dụng của bạn vẫn chạy.
Hầu hết mọi người đều biết khi chạy một ứng dụng Node, nó chỉ chạy trên một lõi của CPU. Nếu máy tính đa nhân thì Cluster mode sẽ giúp dàn trải tất cả tiến trình đến các lõi còn lại. Ví dụ CPU có 4 lõi, bạn muốn chạy trên cả 4 thì rất đơn giản.
$ pm2 start app.js -i max
max là chỉ định tất cả nhân đều tham gia, ngoài ra nếu muốn chính xác bao nhiêu thì thay max bằng một con số.
pm2 có cơ chế ghi logs vào tệp để truy xuất thông tin sau này. Các thông tin đó bao gồm các lệnh in vào console như console.log. Để xem lại logs:
$ pm2 logs 0
Với 0 là id của tiến trình hoặc thay nó bằng tên của tiến trình.
Để dừng một tiến trình:
$ pm2 stop 0
Chạy lại sau khi dừng:
$ pm2 start 0
Hoặc khởi động lại:
$ pm2 restart 0
Hoặc xoá hẳn ứng dụng với điều kiện nó phải được cho dừng từ trước:
$ pm2 delete 0
Các lệnh pm2 start là rời rạc và đơn lẻ. Tưởng tượng thay vì có một mà là có nhiều tiến trình Node cần khởi động cùng một lúc thì sao? Đó là lúc ecosystem trở nên hữu ích. ecosystem là cơ chế gom tất cả ứng dụng vào một tệp cấu hình và khởi động trong một lệnh duy nhất.
Để tạo một tệp cấu hình, sử dụng lệnh pm2 ecosystem, pm2 tạo ra một tệp ecosystem.config.js giống như sau:
Hãy sửa lại cấu hình cho phù hợp với dự án rồi khởi động nó bằng cách:
$ pm2 start ecosystem.config.js
Trong trường hợp máy chủ khởi động lại, pm2 không tự động khởi động theo khiến cho tất cả ứng dụng không hoạt động. Để giải quyết vấn đề này, sử dụng lệnh:
$ pm2 startup
Nhưng trước đó, bạn cần “commit” các tiến trình sẽ khởi động theo startup bằng lệnh:
$ pm2 save
pm2 save tạo ra một “snapshot” các tiến trình đang chạy tại thời điểm hiện tại để phục hồi lại tất cả sau này.
Sau đó nếu muốn kích hoạt hàm countActive thì chỉ cần:
pm2 trigger rpc countActive
Pm2 cũng cung cấp một API để quản lý pm2 thông qua RESTFul API. Hiểu đơn giản tức là bạn có thể tạo ra một máy chủ để thêm/sửa/xoá các ứng dụng khác dùng pm2, thực hiện qua việc gọi API. Bạn đọc có thể xem chi tiết tại PM2 API.
Và một vài tính năng nâng cao khác nữa.
Gần đây, pm2 còn ra thêm dịch vụ pm2 plus cho phép giám sát ứng dụng một cách toàn diện như giao diện giám sát thời gian thực, báo cáo, nhật ký, và cả notifications… Có thể thấy nó khá tương đồng với các ứng dụng APM (Application Performance Monitoring). Nhưng vì không có gói miễn phí nên tôi chưa có dịp trải nghiệm dịch vụ này. Nếu bạn đã hoặc đang sử dụng, hãy để lại bình luận ở phía dưới bài viết nhé!
Với sự phát triển không ngừng của trí tuệ nhân tạo (AI), OpenAI đã tiếp tục đẩy mạnh việc mở rộng các mô hình ngôn ngữ lớn (LLM) với việc ra mắt GPT-4o Mini vào tháng 7 năm 2024. Đây là phiên bản thu nhỏ của GPT-4o, nhưng vẫn giữ được những tính năng mạnh mẽ và cải tiến đáng kể so với các mô hình trước đó. Bài viết này sẽ cung cấp một cái nhìn chi tiết về GPT-4o Mini, từ tính năng nổi bật đến ứng dụng thực tiễn, cũng như cách mà phiên bản này đang định hình tương lai của AI.
GPT-4o Mini là gì?
GPT-4o Mini là phiên bản nhỏ gọn và tiết kiệm chi phí nhất trong dòng mô hình GPT-4o của OpenAI. Mặc dù có kích thước nhỏ hơn so với GPT-4o, GPT-4o Mini vẫn giữ được nhiều tính năng mạnh mẽ và cải tiến đáng kể. Mô hình này được thiết kế để mang lại hiệu suất cao với chi phí thấp, phù hợp cho nhiều ứng dụng AI khác nhau, từ hỗ trợ khách hàng, phân tích dữ liệu, đến tạo nội dung tự động.
GPT-4o Mini vượt trội hơn các mô hình nhỏ trước đó nhờ khả năng xử lý văn bản và hình ảnh, đồng thời cung cấp sự linh hoạt và hiệu quả chi phí vượt trội, giúp mở rộng khả năng áp dụng trí tuệ nhân tạo trong nhiều lĩnh vực. Mô hình này cũng tích hợp các biện pháp an toàn tiên tiến, giúp giảm thiểu các phản hồi không phù hợp và nâng cao độ tin cậy.
Theo OpenAI, GPT-4o mini là “mô hình nhỏ có khả năng và hiệu quả về chi phí nhất hiện nay”
Một trong những cải tiến đáng kể nhất của GPT-4o Mini là khả năng xử lý nhanh hơn và hiệu quả hơn so với các mô hình trước. Được tối ưu hóa để giảm thời gian chờ và cải thiện khả năng phản hồi, GPT-4o Mini rất phù hợp cho các ứng dụng yêu cầu tương tác thời gian thực như chatbot hỗ trợ khách hàng hay trợ lý ảo. Khả năng tính toán được cải thiện giúp mô hình này xử lý khối lượng lớn yêu cầu cùng lúc mà không làm giảm chất lượng.
GPT-4o Mini thể hiện khả năng lý luận vượt trội hơn các mô hình nhỏ khác trong cả văn bản và hình ảnh, với điểm số 82.0% trên MMLU (một tiêu chuẩn đánh giá trí tuệ văn bản và lý luận), so với 77.9% của Gemini Flash và 73.8% của Claude Haiku.
Khả Năng Quan Sát Và Xử Lý Đa Phương Tiện
GPT-4o Mini vượt trội hơn hẳn so với các phiên bản trước trong việc xử lý và phân tích dữ liệu đa phương tiện. Khả năng nhận diện và phân tích hình ảnh, văn bản và âm thanh một cách liền mạch cho phép mô hình này xử lý các tình huống phức tạp và đưa ra những nhận xét chính xác, tăng cường khả năng hiểu biết và phản hồi ngữ cảnh của AI.
Dịch Song Ngữ Nhanh Chóng
Với sự tối ưu hóa trong khả năng dịch ngôn ngữ, GPT-4o Mini có thể dịch các đoạn văn bản dài và phức tạp với độ chính xác cao. Điều này đặc biệt hữu ích trong các ứng dụng quốc tế, nơi mà việc xử lý ngôn ngữ đa dạng và chính xác là điều cần thiết.
Hiểu Và Biểu Đạt Cảm Xúc
GPT-4o Mini được cải tiến với khả năng nhận diện và biểu đạt cảm xúc trong các phản hồi, tạo ra sự tương tác chân thực hơn giữa người dùng và AI. Khả năng này giúp GPT-4o Mini trở thành công cụ lý tưởng cho các ứng dụng yêu cầu giao tiếp nhạy bén và sâu sắc, như trong dịch vụ chăm sóc khách hàng hoặc các nền tảng giáo dục.
Xử Lý Liền Mạch Và Tính Năng An Toàn
Việc xử lý các tác vụ liên tiếp trong GPT-4o Mini trở nên mượt mà hơn, giảm thiểu độ trễ và nâng cao trải nghiệm người dùng. Ngoài ra, GPT-4o Mini được tích hợp các biện pháp an toàn nâng cao, giúp giảm thiểu các phản hồi không phù hợp hoặc gây hại, đảm bảo an toàn và độ tin cậy cao hơn cho người dùng.
So Sánh GPT-4o Mini Với GPT-4 Và GPT-4 Turbo
Mặc dù GPT-4o Mini có kích thước nhỏ hơn, nhưng nó vẫn có nhiều điểm vượt trội so với GPT-4 và GPT-4 Turbo, đặc biệt là về hiệu suất và chi phí:
Tính năng/Model
GPT-4
GPT-4 Turbo
GPT-4o Mini
Ngày phát hành
Tháng 3/2023
Tháng 11/2023
Tháng 7/2024
Số token
8,192 tokens
128,000 tokens
128,000 tokens
Cập nhật kiến thức
Tháng 9/2021
Tháng 4/2023
Tháng 10/2023
Khả năng đa phương tiện
Cơ bản
Nâng cao
Đầy đủ
Chi phí (trên triệu tokens)
$30
$15
$0.15
Mô hình GPT-4o mini được cải tiến, không chỉ mang lại hoạt động nhanh chóng mà còn tiết kiệm chi phí hơn so với các mô hình ngôn ngữ lớn khác như GPT-4o hay GPT-4 Turbo. Đối với một số nhà phát triển sử dụng API của OpenAI, chỉ cần chi trả 0,15 USD cho mỗi triệu mã đầu vào và 0,6 USD cho mỗi triệu mã đầu ra.
GPT-4o Mini đánh dấu một bước tiến quan trọng trong việc cung cấp trí tuệ nhân tạo cho các ứng dụng thực tiễn với chi phí thấp và hiệu quả cao. Với những cải tiến vượt bậc trong hiệu suất và khả năng tích hợp, GPT-4o Mini hứa hẹn sẽ trở thành một công cụ quan trọng trong việc phát triển các ứng dụng AI thông minh và đáng tin cậy.
Phiên bản Chat GPT-4o là bản cập nhật mới nhất năm 2024 của OpenAI, mang đến nhiều cải tiến và tính năng nổi bật so với phiên bản trước đó là ChatGPT-4. Vậy ChatGPT-4o có gì mới và khác biệt gì so với ChatGPT-4? Hãy cùng khám phá chi tiết dưới đây.
ChatGPT-4o là gì?
Chat GPT-4o là mô hình ngôn ngữ hàng đầu của OpenAI trong danh mục công nghệ LLM (Large Language Model), phát hành vào ngày 13/05/2024. Trong đó, chữ “o” trong ChatGPT-4o là chữ viết tắt của GPT-4 Omni (toàn năng). GPT-4o có khả năng xử lý đa phương thức đối với đầu vào bất kỳ sự kết hợp nào giữa văn bản, âm thanh và hình ảnh.
Chat GPT-4o giới hạn kiến thức được cập nhật đến 10/2023
GPT-4o đánh dấu một bước tiến mới trong sự phát triển của mô hình ngôn ngữ GPT-4, đây không phải là bản cập nhật đầu tiên của GPT-4, vì trước đó mô hình này đã nhận được sự nâng cấp vào tháng 11 năm 2023 với phiên bản GPT-4 Turbo. Vào tháng 7 năm 2024, OpenAI tiếp tục cho ra mắt phiên bản nhỏ hơn của GPT-4o là GPT-4o mini.
Chat GPT-4o có gì mới?
ChatGPT-4o mang đến nhiều cải tiến vượt trội so với phiên bản GPT-4 Turbo trước đó, cả về khả năng và hiệu suất. Tương tự như các phiên bản trước của GPT-4, GPT-4o có thể được sử dụng trong nhiều trường hợp, như tạo văn bản, tóm tắt nội dung, và trả lời câu hỏi dựa trên kiến thức. Ngoài ra, mô hình này còn có khả năng lý luận, giải quyết các bài toán toán học phức tạp và lập trình.
Một điểm nổi bật mới của GPT-4o là khả năng phản hồi đầu vào âm thanh với tốc độ nhanh, chỉ mất trung bình khoảng 320 mili giây, tương đương với phản xạ của con người. Mô hình này cũng có thể tạo ra giọng nói nhân tạo với âm thanh tự nhiên giống con người.
Thay vì sử dụng nhiều mô hình riêng biệt để xử lý âm thanh, hình ảnh và văn bản, GPT-4o kết hợp tất cả các phương thức này thành một mô hình duy nhất. Điều này cho phép GPT-4o hiểu và xử lý mọi sự kết hợp của đầu vào văn bản, hình ảnh và âm thanh, đồng thời tạo ra phản hồi dưới dạng tương ứng.
Sự kết hợp giữa khả năng xử lý âm thanh đa phương thức với tốc độ cao và tính trực quan trong tương tác giúp GPT-4o mang lại trải nghiệm tương tác tự nhiên hơn với người dùng.
ChatGPT-4o được nâng cấp với một loạt các tính năng mới nhằm cải thiện trải nghiệm người dùng và tăng cường hiệu suất của mô hình AI. Những tính năng mới của GPT-4o so với chat GPT-4
Khả năng xử lý đa phương tiện (Multimodality)
Cả GPT-4o và GPT-4 đều là các mô hình AI đa phương tiện có khả năng xử lý nhiều loại dữ liệu như văn bản, hình ảnh và âm thanh. Tuy nhiên, cách mà hai mô hình này tiếp cận đa phương tiện lại rất khác nhau và đây là một trong những điểm khác biệt lớn nhất giữa GPT-4o và GPT-4.
GPT-4 chủ yếu được thiết kế để xử lý văn bản, do đó, khi cần xử lý hình ảnh, âm thanh hoặc video, GPT-4 phải sử dụng các mô hình khác của OpenAI như DALL-E (cho hình ảnh) hoặc Whisper (cho nhận diện giọng nói). Trong khi đó, GPT-4o được thiết kế với mục đích xử lý đa phương tiện từ đầu, điều này có nghĩa là GPT-4o có thể xử lý và phản hồi mọi loại dữ liệu (văn bản, hình ảnh, âm thanh) mà không cần phải thông qua chatbot khác.
Nhờ khả năng đa phương tiện nguyên bản này, GPT-4o có thể thực hiện các tác vụ liên quan đến nhiều loại dữ liệu như phân tích hình ảnh nhanh hơn so với GPT-4. Trong buổi giới thiệu GPT-4o vào ngày 13 tháng 5 năm 2024, OpenAI đã trình diễn việc GPT-4o phân tích video trực tiếp của một người dùng giải bài toán và cung cấp phản hồi bằng giọng nói trong thời gian thực.
Performance and Efficiency
GPT-4o cũng được thiết kế để nhanh hơn và hiệu quả hơn GPT-4 trên mọi phương diện, không chỉ riêng cho các truy vấn đa phương tiện. Theo OpenAI, GPT-4o nhanh gấp đôi so với phiên bản mới nhất của GPT-4.
Trong các thử nghiệm, GPT-4o thực sự đã cho thấy thời gian phản hồi nhanh hơn GPT-4, mặc dù không hoàn toàn đạt gấp đôi tốc độ, và chất lượng phản hồi tương đương. OpenAI cũng cho biết GPT-4o có khả năng hiểu ngữ cảnh mạnh hơn so với GPT-4, giúp nó nắm bắt tốt hơn các thành ngữ, ẩn dụ và tham chiếu văn hóa.
Nguồn ảnh: techtarget.com
Giá cả (Pricing)
Một trong những lợi thế của GPT-4o nhờ hiệu quả tính toán được cải thiện là chi phí sử dụng thấp hơn so với GPT-4. Đối với các nhà phát triển sử dụng API của OpenAI, GPT-4o là lựa chọn tiết kiệm hơn rất nhiều với mức giá 5 USD cho mỗi triệu token đầu vào và 15 USD cho mỗi triệu token đầu ra, trong khi GPT-4 có giá 30 USD cho mỗi triệu token đầu vào và 60 USD cho mỗi triệu token đầu ra.
Đối với người dùng ứng dụng web, sự khác biệt về giá cả còn lớn hơn. GPT-4o sẽ được sử dụng cho phiên bản miễn phí của ChatGPT, thay thế GPT-3.5 hiện tại. Điều này giúp người dùng miễn phí có thể truy cập vào tính năng đa phương tiện, phản hồi văn bản chất lượng cao hơn, trò chuyện bằng giọng nói và các GPT tùy chỉnh mà trước đây chỉ dành cho khách hàng trả phí. GPT-4 sẽ chỉ còn dành cho những người dùng trả phí, bao gồm các gói ChatGPT Plus, Team và Enterprise, với mức giá khởi điểm từ 20 USD mỗi tháng.
Tuy nhiên, việc triển khai này vẫn đang diễn ra, và một số người dùng có thể chưa có quyền truy cập vào GPT-4o hoặc GPT-4o mini. Tính đến ngày 23 tháng 7 năm 2024, GPT-3.5 vẫn là mặc định cho người dùng miễn phí không có tài khoản ChatGPT.
Ngoài ra, người dùng miễn phí và trả phí sẽ có mức độ truy cập khác nhau đối với từng mô hình. Người dùng miễn phí sẽ bị giới hạn số lượng tin nhắn với GPT-4o, và sau khi đạt giới hạn, họ sẽ được chuyển sang sử dụng GPT-4o mini. Người dùng ChatGPT Plus sẽ có giới hạn tin nhắn cao hơn so với người dùng miễn phí, và những người dùng trên các gói Team và Enterprise sẽ có ít hạn chế hơn nữa.
Hỗ trợ ngôn ngữ (Language Support)
GPT-4o cũng cung cấp hỗ trợ ngôn ngữ tốt hơn đáng kể so với GPT-4, đặc biệt là đối với các ngôn ngữ không sử dụng bảng chữ cái phương Tây như Hindi, tiếng Trung và tiếng Hàn. OpenAI đã cải thiện quy trình tokenization cho các ngôn ngữ này, giúp nén văn bản hiệu quả hơn, xử lý các ngôn ngữ phi Tây phương một cách nhanh chóng và rẻ hơn.
Sự cải thiện này giúp GPT-4o trở nên hiệu quả hơn cho các ứng dụng toàn cầu và mở rộng khả năng tiếp cận tới những nhóm người dùng có thể chưa từng tương tác đầy đủ với các mô hình AI trước đây. Tuy nhiên, không phải không có thách thức. Chỉ vài ngày sau khi GPT-4o được phát hành, các nhà nghiên cứu đã nhận thấy rằng nhiều token tiếng Trung trong mô hình này chứa các cụm từ không phù hợp liên quan đến nội dung khiêu dâm và cờ bạc. Điều này có thể là do quá trình làm sạch dữ liệu không đầy đủ, gây ra các vấn đề về hiểu biết và tiềm ẩn nguy cơ bảo mật.
Dưới đây là bảng so sánh tóm tắt giữa ChatGPT-4o và GPT-4:
Tiêu chí
ChatGPT-4o
GPT-4
Ngày ra mắt
Tháng 5 năm 2024
Tháng 3 năm 2023
Token
128,000 tokens
128,000 tokens
Hạn chế kiến thức
Tháng 10 năm 2023
Tháng 09 năm 2021
Khả năng đa phương tiện
Xử lý văn bản, hình ảnh, âm thanh trong cùng một mô hình
Văn bản, hình ảnh (cải thiện) nhưng cần gọi các mô hình khác như DALL-E, Whisper
Hiệu năng
Nhanh gấp đôi so với GPT-4, tối ưu hóa cho đa phương tiện
Chậm hơn so với GPT-4o
Khả năng xử lý ngôn ngữ
Hỗ trợ tốt hơn cho các ngôn ngữ không dùng bảng chữ cái phương Tây, bao gồm tiếng Trung, tiếng Hàn, tiếng Hindi
Hỗ trợ tốt nhưng không bằng GPT-4o trong việc nén và xử lý văn bản phi tiếng Anh
Tính năng bảo mật
Được cải thiện với các biện pháp bảo vệ nâng cao
Có các tính năng bảo mật, nhưng không mạnh mẽ bằng GPT-4o
GPT-4o có miễn phí không?
GPT-4o có phiên bản miễn phí cho người dùng, nhưng sẽ bị giới hạn số lượng request mỗi ngày. Sau khi đạt đến giới hạn này, người dùng sẽ được chuyển sang sử dụng GPT-4o mini, một phiên bản nhỏ hơn và rẻ hơn của GPT-4o hoặc GPT-3.5 (là model được miễn phí hoàn toàn của chatGPT).
Để truy cập vào GPT-4o, bạn cần thực hiện các bước sau:
Bước 1: Truy cập trang web OpenAI: Mở trình duyệt web và truy cập vào trang web chính thức của OpenAI tại https://www.openai.com/.
Bước 2: Đăng ký tài khoản OpenAI: Nếu chưa có tài khoản, bạn cần đăng ký một tài khoản mới bằng cách cung cấp địa chỉ email và mật khẩu.
Bước 3: Nâng cấp lên ChatGPT Plus: Sau khi đăng nhập, bạn cần nâng cấp tài khoản của mình lên gói ChatGPT Plus bằng cách chọn gói dịch vụ phù hợp và hoàn tất thanh toán.
Bước 4: Truy cập vào ChatGPT-4o: Sau khi nâng cấp, bạn có thể bắt đầu sử dụng GPT-4o bằng cách truy cập vào trang ChatGPT và vào Menu, chọn phiên bản GPT-4o để sử dụng các tính năng nâng cao.
Tóm lại, GPT-4o là sản phẩm mới nhất và “omni” nhất của OpenAI cho tới hiện tại. Nó vượt trội hơn GPT-4 trong nhiều khía cạnh, từ hiệu năng, khả năng xử lý đa phương tiện, cho đến hỗ trợ ngôn ngữ và chi phí sử dụng. Bài viết trên đã giới thiệu chi tiết về chat GPT-4o và hướng dẫn cách sử dụng trên website. Theo dõi TopDev để cập nhật liên tục các kiến thức về AI bạn nhé!
Trong thời đại công nghệ số hiện nay, các công cụ trí tuệ nhân tạo ngày càng phát triển mạnh mẽ và được ứng dụng rộng rãi trong nhiều lĩnh vực. Một trong những công nghệ nổi bật chính là Chat GPT, một sản phẩm của OpenAI. Phiên bản Chat GPT 4.0 được ra mắt vào tháng 3/2023, đã mang đến nhiều cải tiến vượt bậc so với các phiên bản trước đó, cùng khám phá những tính năng mới của chat GPT-4 trong bài viết dưới đây.
Chat GPT-4 là gì?
Chat GPT-4 (còn được biết đến là chatGPT 4.0) là phiên bản mới nhất hiện nay do OpenAI phát triển, ra mắt vào 14/03/2023. GPT-4 được thiết kế để tiếp tục cải tiến các khả năng của các phiên bản trước, bằng cách cung cấp khả năng xử lý ngôn ngữ tự nhiên mạnh mẽ hơn, hiểu sâu hơn về ngữ cảnh, và tạo ra các phản hồi văn bản giống con người hơn.
Với GPT-4, OpenAI đã tăng cường khả năng của mô hình trong việc xử lý các tác vụ ngôn ngữ phức tạp hơn, bao gồm phân tích, tạo nội dung, dịch thuật và thậm chí là phân tích hình ảnh.
Hiện tại, GPT-4 có nhiều phiên bản khác nhau như GPT-4 Turbo và phiên bản mới nhất GPT-4o, còn được gọi là GPT-4 Omni.
Nhưng GPT-4 có gì khác biệt so với mô hình GPT-3 và GPT-3.5? Hãy cùng tìm hiểu sự khác biệt này trong những phần tiếp theo của bài viết.
Ưu điểm mới vượt trội của Chat GPT-4 so với chatGPT
Chat GPT-4 đã giới thiệu một loạt các tính năng mới nổi bật, nhằm cải thiện đáng kể khả năng xử lý và tương tác của mô hình với người dùng. Dưới đây là những điểm mới nổi bật của chatGPT 4.0 so với chat GPT phiên bản cũ (GPT-3.5):
Độ chính xác và độ tin cậy cao hơn
Chat GPT-4 được đào tạo trên một tập dữ liệu lớn hơn nhiều so với các phiên bản trước, giúp tăng cường độ chính xác và giảm thiểu các lỗi không chính xác. Điều này đồng nghĩa với việc mô hình có thể xử lý các nhiệm vụ phức tạp một cách đáng tin cậy và sáng tạo hơn.
Tăng số lượng kí tự Input và Output
Chat GPT-4 có giới hạn số từ cao hơn gấp 8 lần so với phiên bản trước, cho phép mô hình xử lý các đầu vào phức tạp và đa dạng hơn, từ đó tạo ra các đầu ra chi tiết và toàn diện hơn.
Input được dưới dạng văn bản và hình ảnh
Một trong những tính năng nổi bật nhất của GPT-4 là khả năng xử lý đầu vào dưới dạng cả văn bản và hình ảnh. Đây là bước tiến lớn trong khả năng “đa phương thức” (multimodal) của AI.
Trong một ví dụ mà OpenAI đã trình diễn, một bản phác thảo trên giấy của một trang web đã được tải lên GPT-4 cùng với các hướng dẫn đơn giản, và mô hình đã tự động tạo ra mã HTML cho trang web đó. Khả năng này cho phép GPT-4 không chỉ xử lý văn bản mà còn có thể phân tích và tạo ra thông tin dựa trên hình ảnh, mở ra nhiều ứng dụng mới trong việc tạo nội dung và thiết kế.
Thời gian trả lời nhanh hơn
Một trong những cải tiến đáng chú ý của GPT 4.0 là khả năng xử lý yêu cầu nhanh hơn nhiều so với các phiên bản trước. Điều này giúp giảm thiểu thời gian chờ đợi và cải thiện hiệu quả trong việc giao tiếp với người dùng.
Xử lý các nhiệm vụ phức tạp hiệu quả hơn
Sự khác biệt giữa GPT-3.5 và GPT-4 trở nên rõ ràng khi xử lý các nhiệm vụ phức tạp. Trong các thử nghiệm mô phỏng kỳ thi, GPT-4 đạt kết quả cao hơn đáng kể so với phiên bản trước. Ví dụ, trong kỳ thi luật, GPT-3.5 chỉ đạt điểm trong 10% cuối cùng, trong khi GPT-4 lại nằm trong top 10% người có điểm cao nhất.
Đa ngôn ngữ
GPT 4.0 đã mở rộng khả năng hỗ trợ ngôn ngữ, giúp người dùng từ nhiều quốc gia và khu vực khác nhau có thể sử dụng mô hình này mà không gặp rào cản về ngôn ngữ. Điều này làm cho GPT 4.0 trở thành một công cụ toàn cầu thực sự.
Nhược điểm của Chat GPT 4.0
Yêu cầu tài nguyên cao: GPT-4.0 yêu cầu nhiều tài nguyên máy tính hơn so với các phiên bản trước, bao gồm phần cứng mạnh mẽ và dung lượng bộ nhớ lớn. Điều này có thể làm hạn chế khả năng tiếp cận của một số người dùng.
Vẫn có khả năng sinh ra thông tin sai lệch: Mặc dù đã được cải thiện, GPT-4.0 vẫn có thể cung cấp thông tin sai lệch hoặc không chính xác trong một số tình huống, đặc biệt khi xử lý các thông tin không rõ ràng hoặc mơ hồ.
Chi phí cao: Với phiên bản chat GPT 4.0, bạn cần trả 20 đô mỗi tháng để có thể sử dụng
Giới hạn số yêu cầu mỗi giờ: Chat GPT 4.0 giới hạn tối đa 100 request/h, điều này hạn chế khả năng sử dụng khi bạn muốn tương tác lâu dài hoặc trải nghiệm nhiều tính năng mới.
Chưa update được thông tin mới nhất: Khả năng cập nhật thông tin của chat GPT 4.0 cũng chỉ dừng lại ở năm 2021 do đó, các thông tin, sự kiện mới sau thời gian này sẽ không có trên ChatGPT-4.
Đọc thêm: Bạn muốn dùng chatGPT miễn phí? Không thể bỏ qua GPT-4o mini
Chat GPT 4 có miễn phí không?
Chat GPT-4 không hoàn toàn miễn phí. OpenAI cung cấp GPT-4 thông qua dịch vụ trả phí, như ChatGPT Plus. Để sử dụng GPT-4, người dùng cần đăng ký gói ChatGPT Plus với mức phí là $20 mỗi tháng (giá có thể thay đổi tùy theo chính sách của OpenAI). Gói này cung cấp quyền truy cập ưu tiên vào GPT-4, với tốc độ phản hồi nhanh hơn và hiệu suất cao hơn so với các phiên bản miễn phí trước đó như GPT-3.5.
Tuy nhiên, OpenAI vẫn cung cấp phiên bản miễn phí của ChatGPT, nhưng phiên bản miễn phí này sử dụng GPT-3.5 thay vì GPT-4. Điều này có nghĩa là người dùng không trả phí vẫn có thể sử dụng dịch vụ ChatGPT, nhưng sẽ không có quyền truy cập vào các tính năng và cải tiến của GPT-4.
Hướng dẫn đăng kí và sử dụng Chat GPT 4.0
Bước 1: Truy cập vào trang web OpenAI
Mở trình duyệt web và truy cập vào trang web chính thức của OpenAI tại https://www.openai.com/.
Tìm đến phần ChatGPT hoặc có thể trực tiếp truy cập vào trang ChatGPT tại https://chat.openai.com/.
Bước 2: Đăng ký tài khoản
Nếu bạn chưa có tài khoản OpenAI, bạn cần đăng ký một tài khoản mới. Nhấn vào nút “Sign Up” để bắt đầu quá trình đăng ký.
Bạn có thể đăng ký bằng địa chỉ email của mình hoặc sử dụng tài khoản Google hoặc Microsoft để đăng ký nhanh chóng.
Sau khi nhập thông tin cần thiết, xác nhận email của bạn bằng cách nhấp vào liên kết xác nhận được gửi đến hộp thư điện tử của bạn.
Bước 3: Chọn gói ChatGPT Plus
Để sử dụng ChatGPT 4.0, bạn cần nâng cấp lên gói ChatGPT Plus. Để làm điều này, đăng nhập vào tài khoản của bạn và tìm đến phần “Upgrade to Plus”.
Nhấn vào “Upgrade” để bắt đầu quá trình nâng cấp.
Bước 4: Thanh toán
Sau khi chọn gói ChatGPT Plus, bạn sẽ được yêu cầu nhập thông tin thanh toán. Mức phí hiện tại cho ChatGPT Plus là $20 mỗi tháng (có thể thay đổi tùy theo chính sách của OpenAI).
Nhập thông tin thẻ tín dụng hoặc phương thức thanh toán khác và xác nhận thanh toán của bạn.
Bước 5: Truy cập và sử dụng ChatGPT 4.0
Sau khi hoàn tất thanh toán, bạn sẽ có quyền truy cập vào ChatGPT 4.0. Đăng nhập vào tài khoản OpenAI của bạn.
Bắt đầu nhập câu hỏi hoặc yêu cầu của bạn trong hộp thoại và ChatGPT 4.0 sẽ phản hồi theo yêu cầu của bạn.
Chat GPT 4.0 đã mang đến nhiều cải tiến đáng kể so với các phiên bản trước đó, từ tốc độ phản hồi nhanh hơn, chất lượng câu trả lời tốt hơn, cho đến khả năng phân tích hình ảnh và hỗ trợ đa ngôn ngữ. Với những tính năng này, GPT 4.0 không chỉ giúp nâng cao trải nghiệm người dùng mà còn mở ra nhiều cơ hội ứng dụng mới trong nhiều lĩnh vực khác nhau.
Bạn đang tìm việc làm IT? Truy cập ngay TopDev – nền tảng việc làm IT hàng đầu







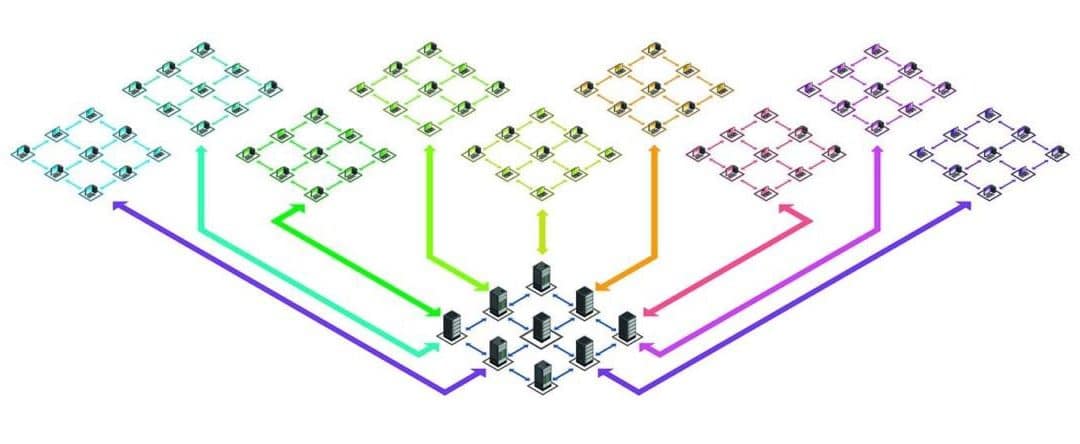
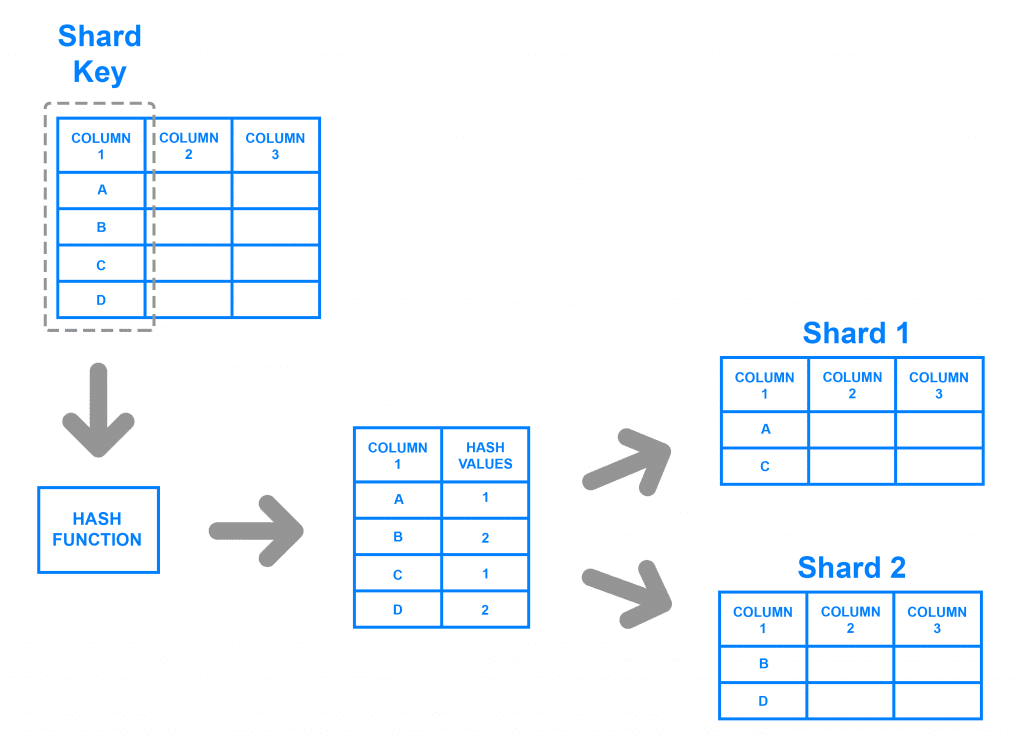
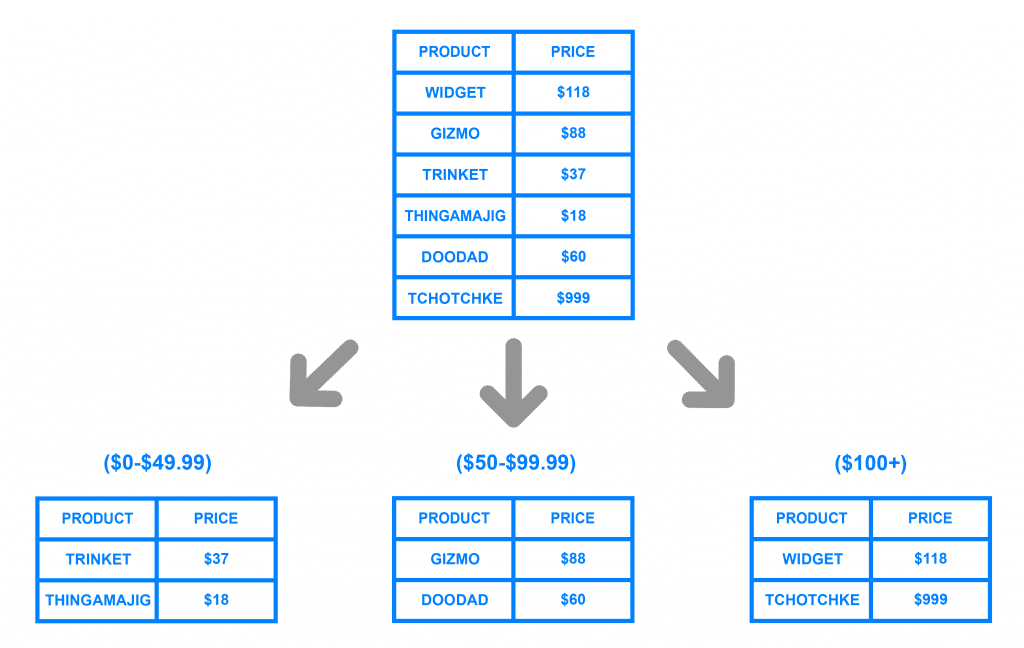
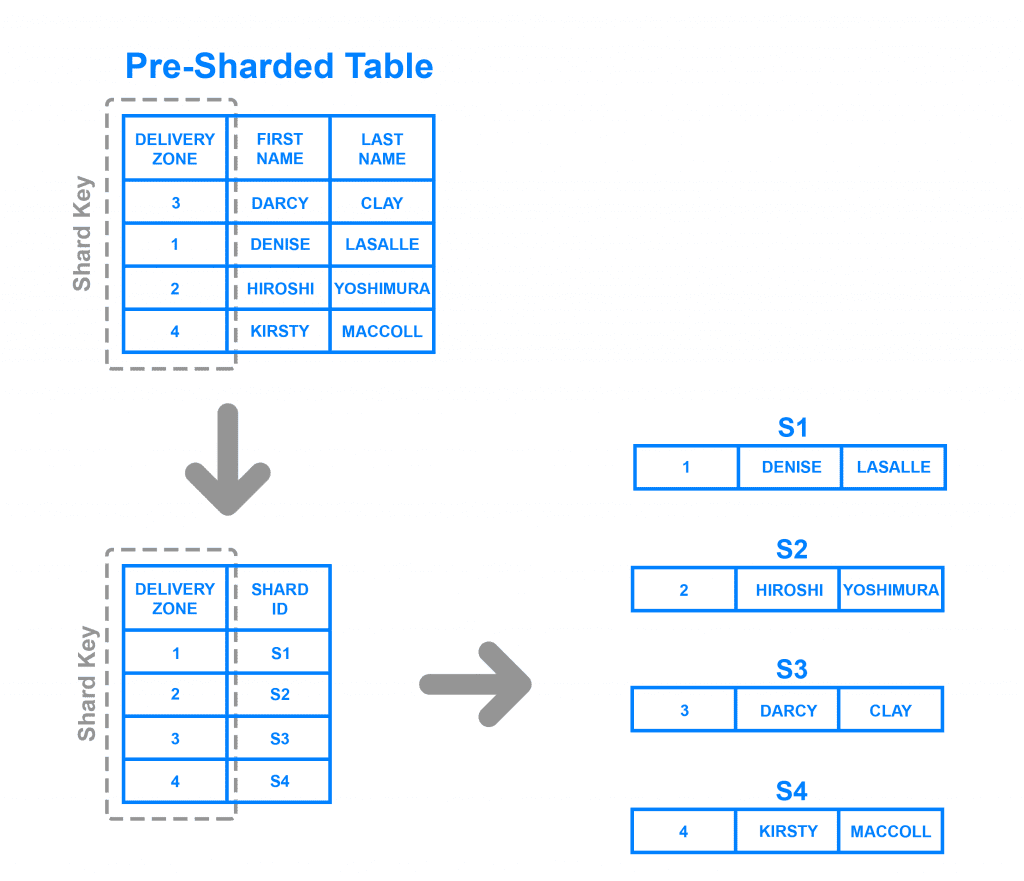

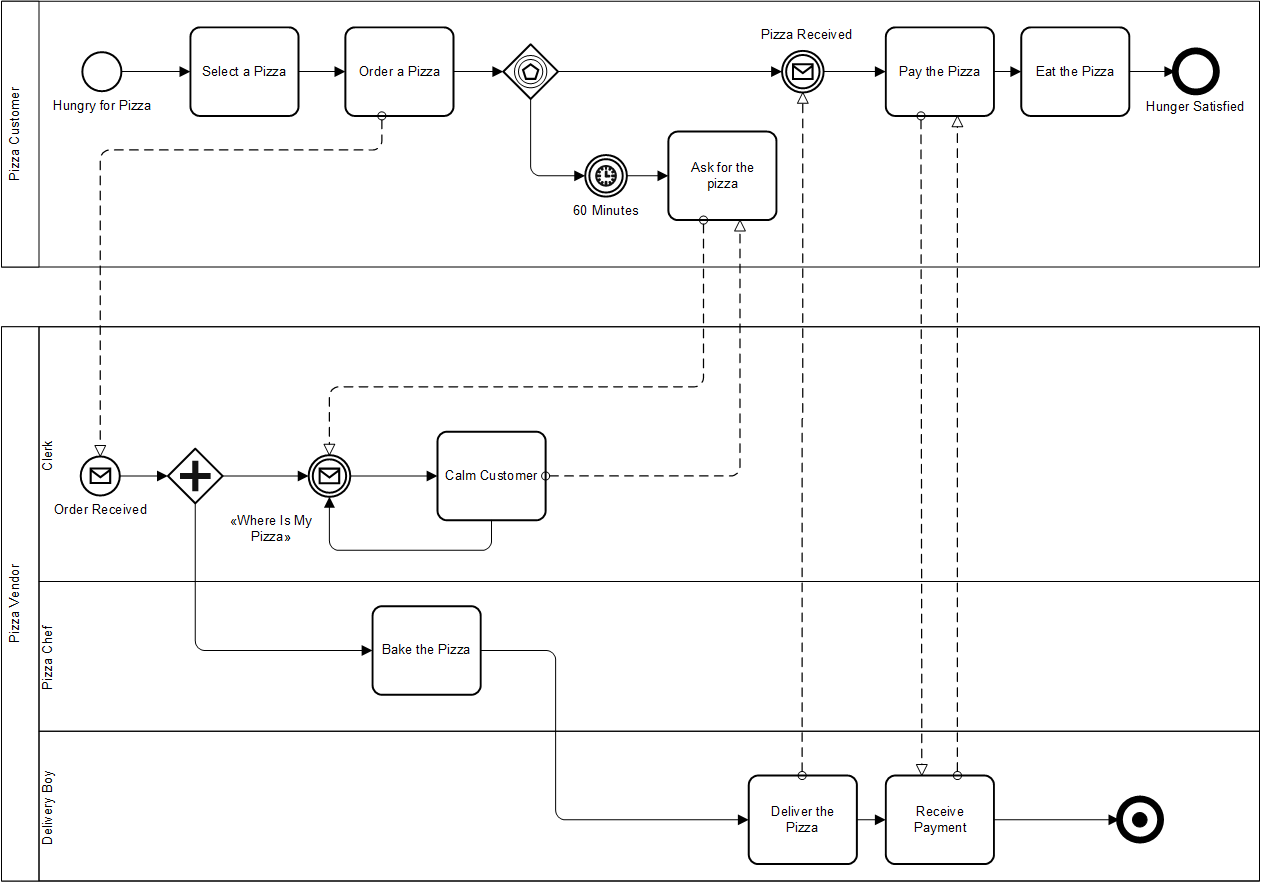

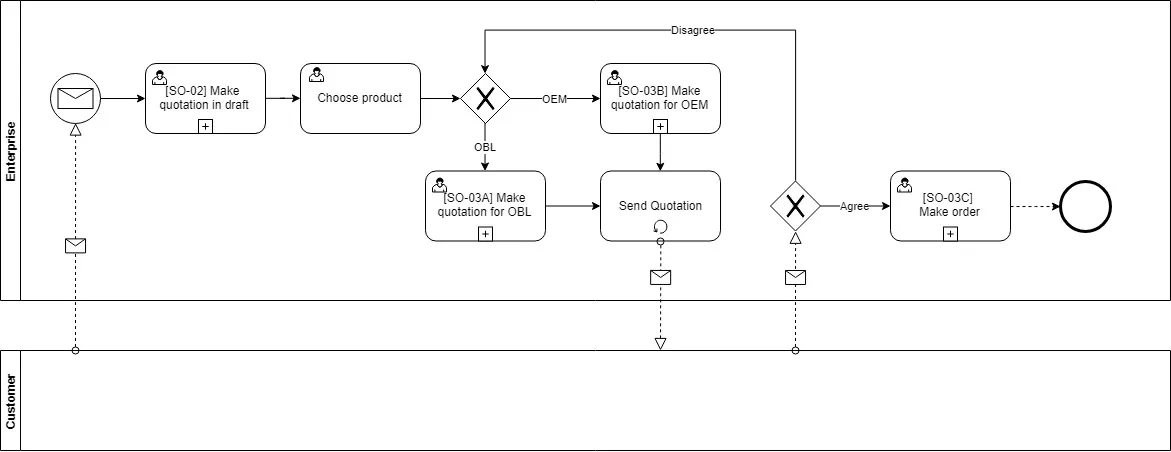





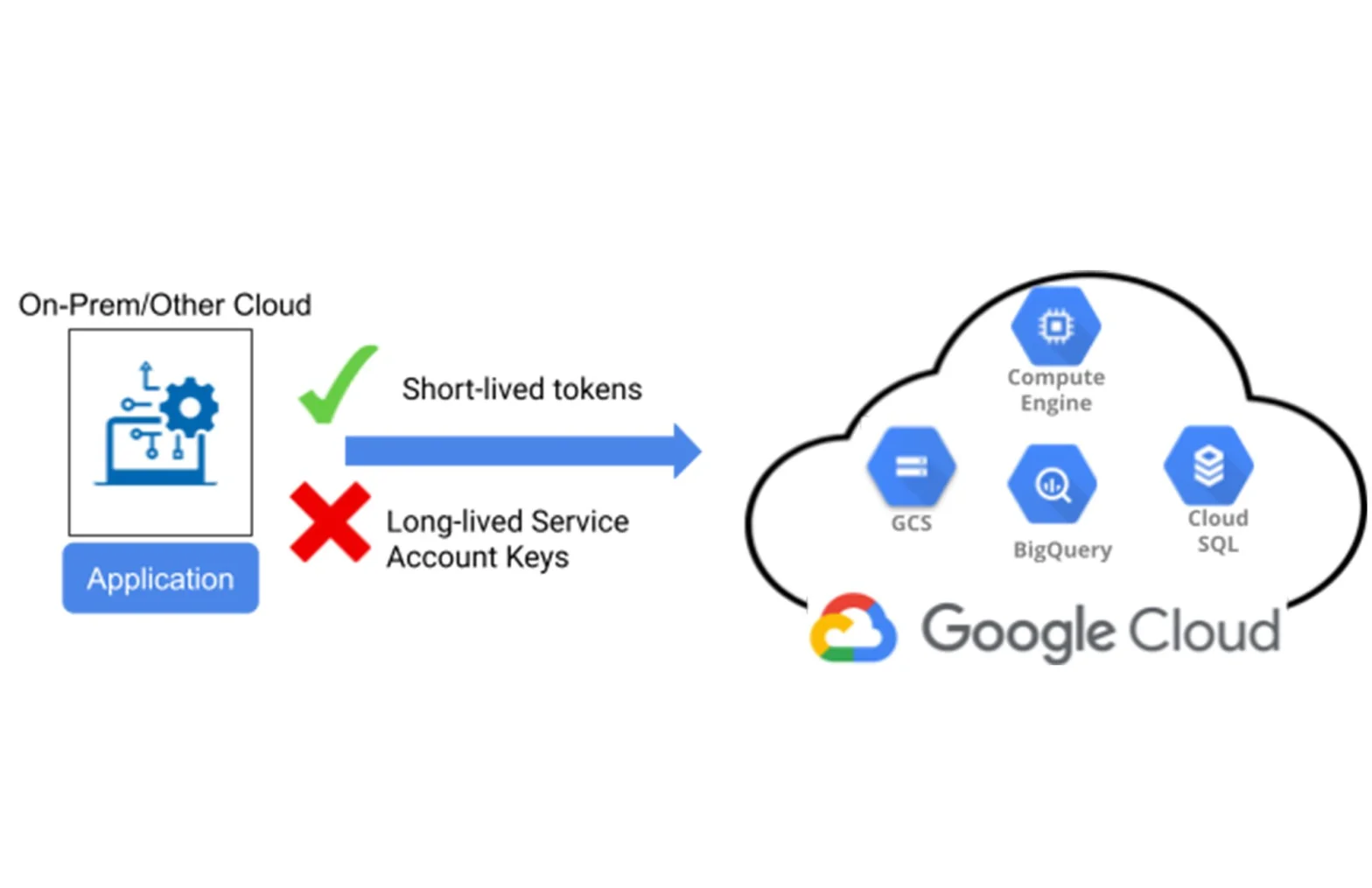

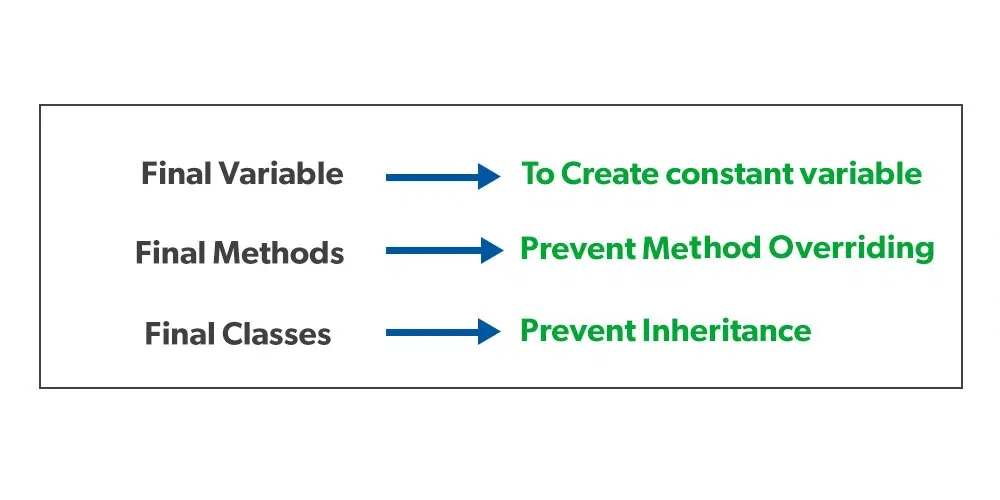
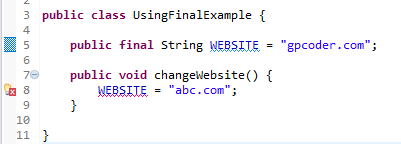
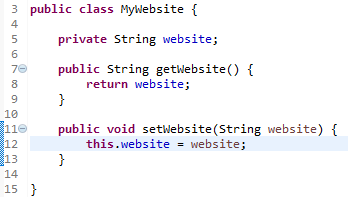
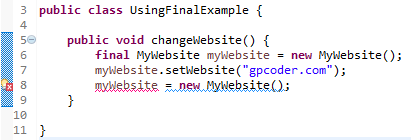

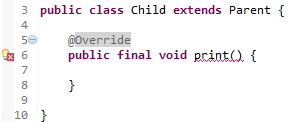
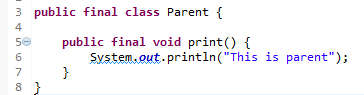

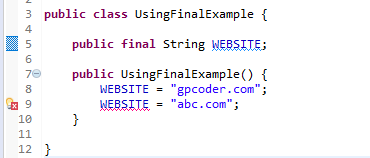
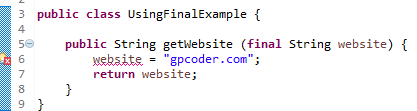


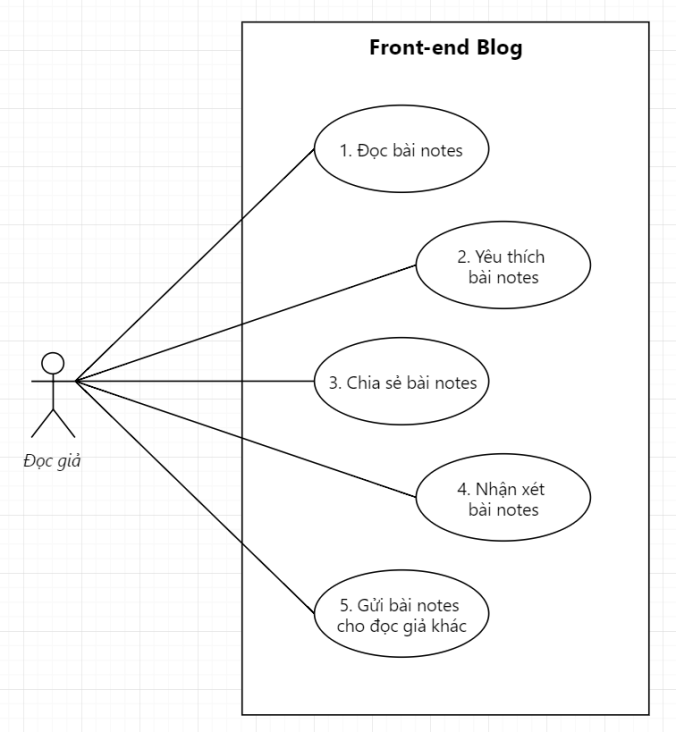
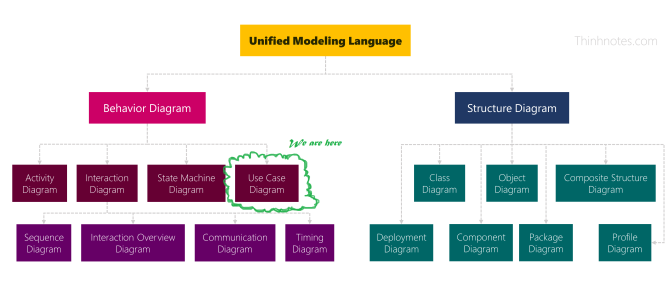
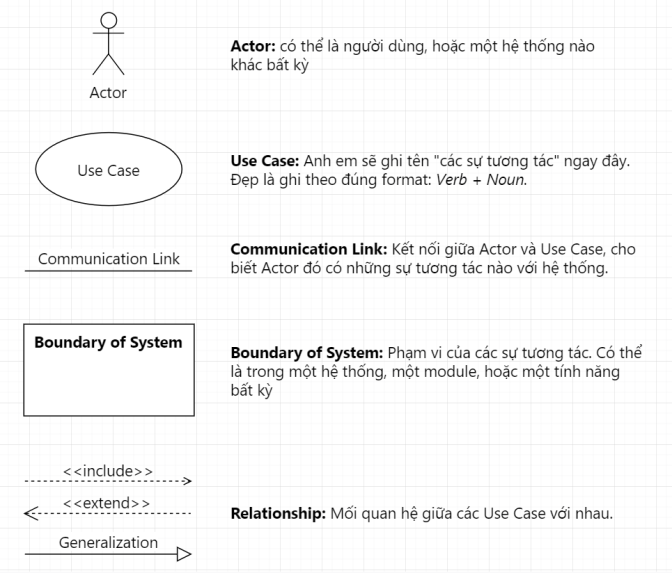
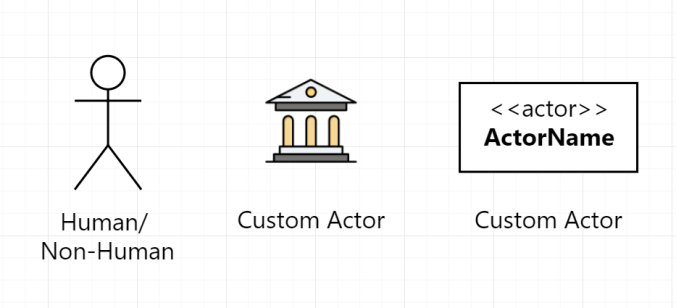
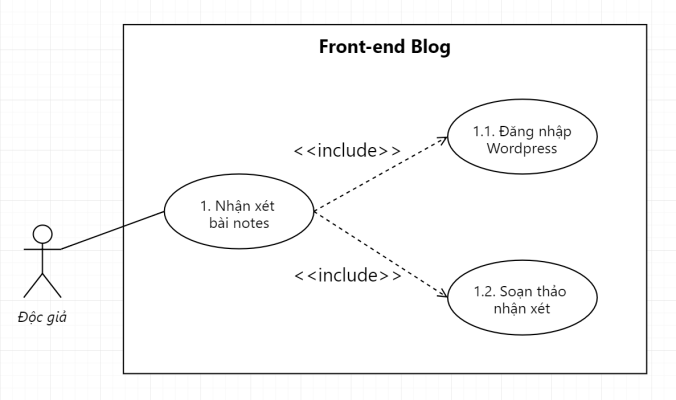
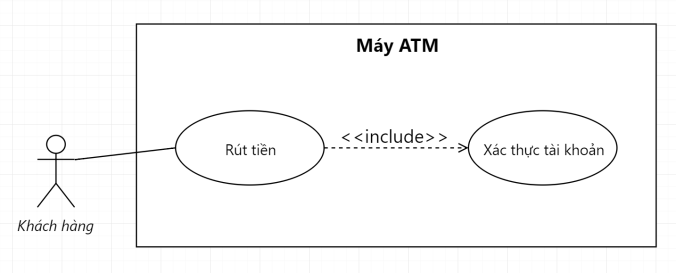
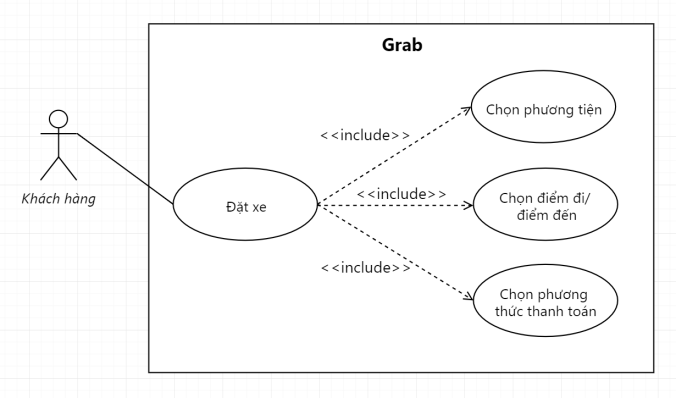
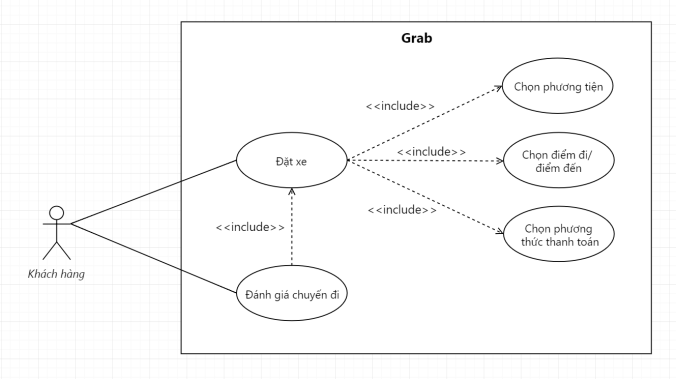
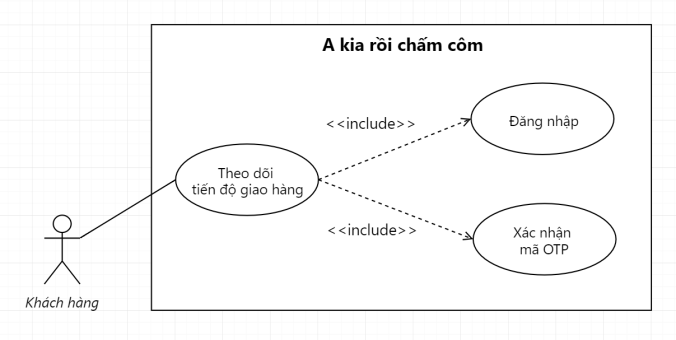
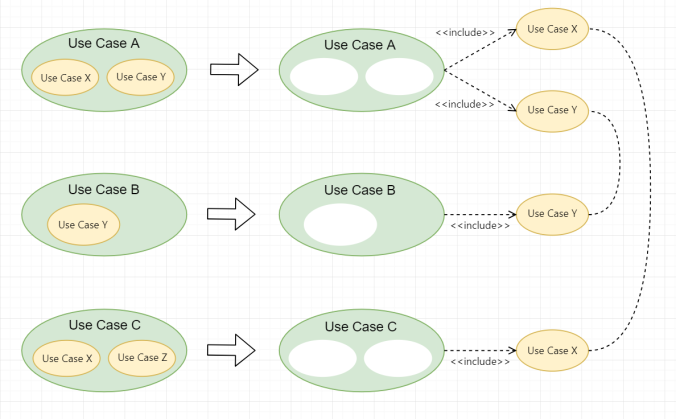
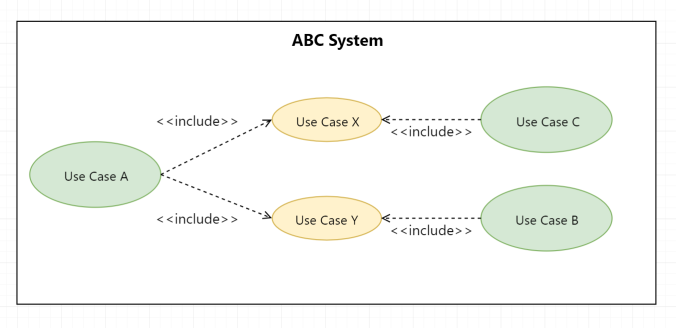
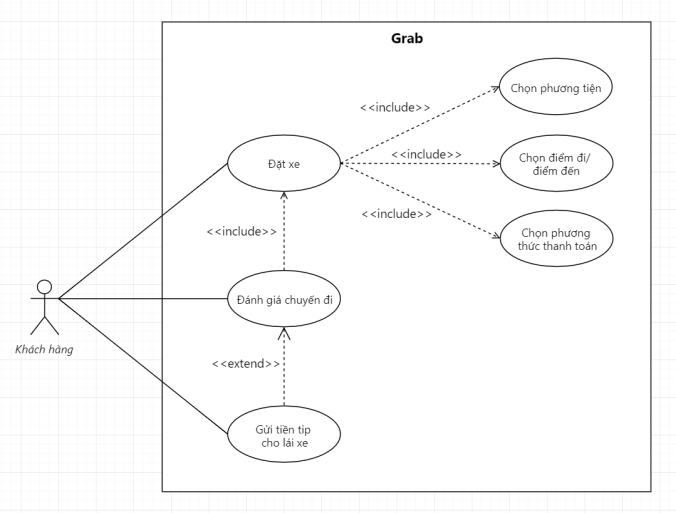
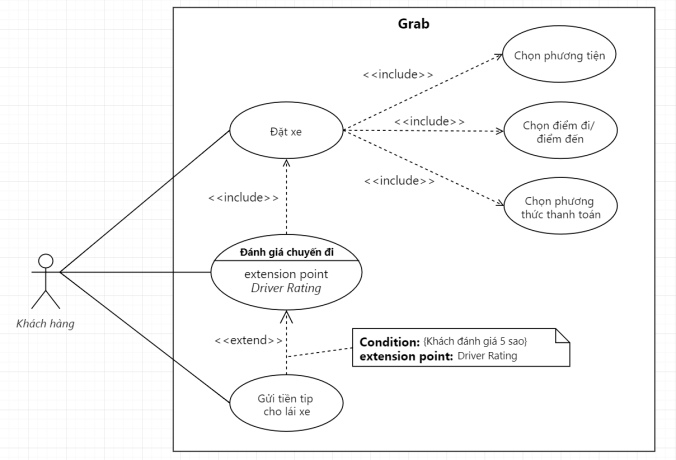
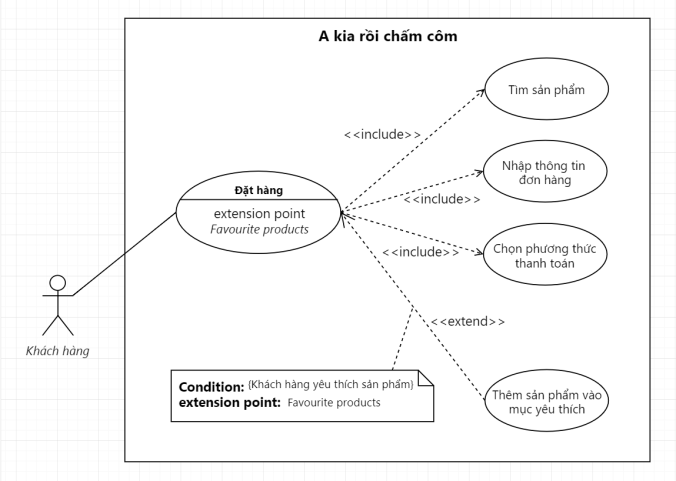
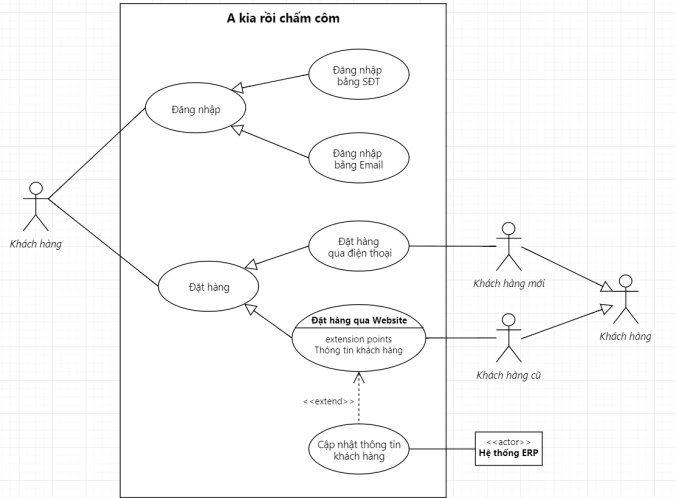
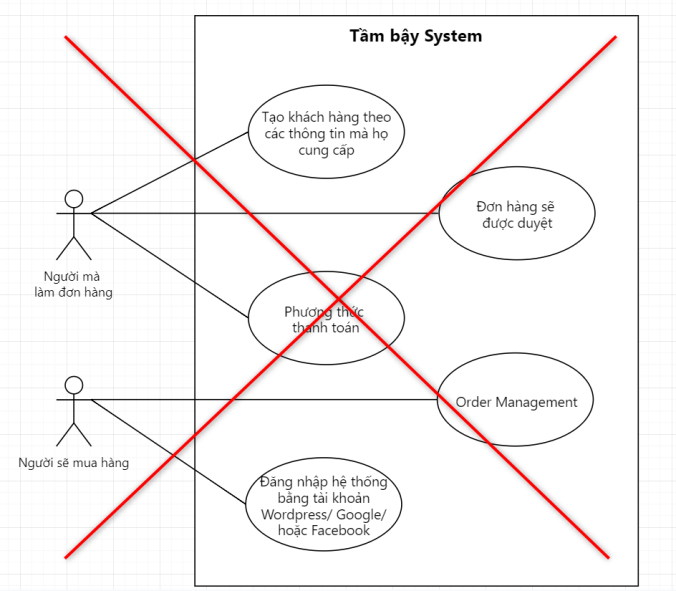
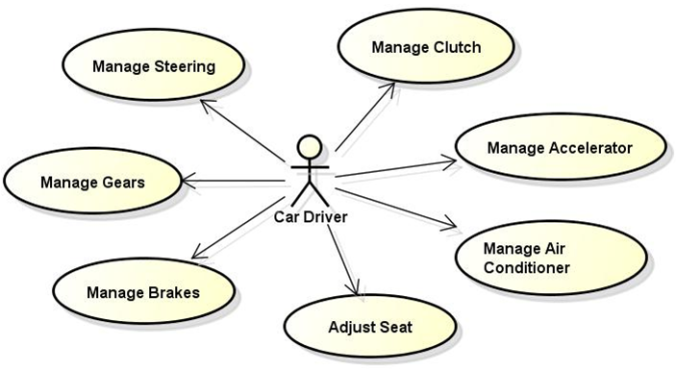
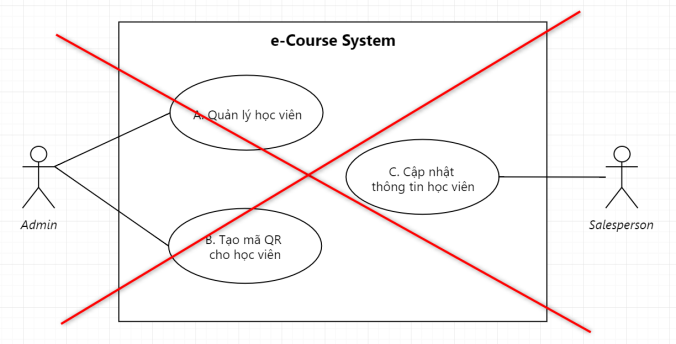
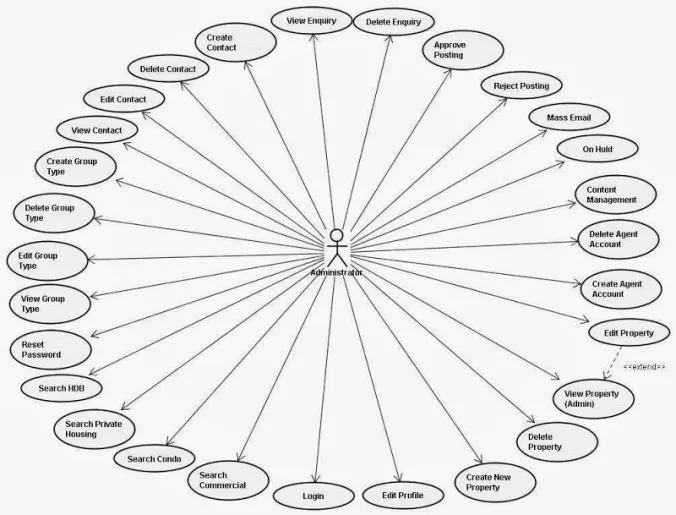
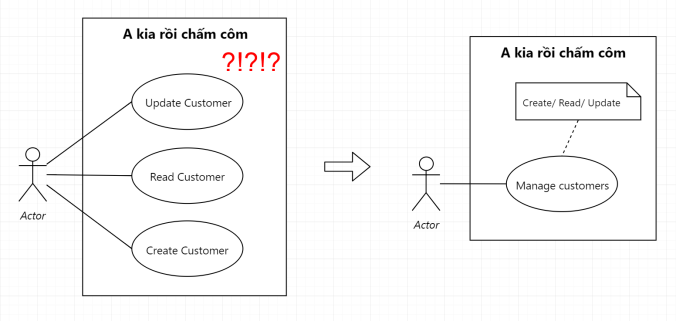



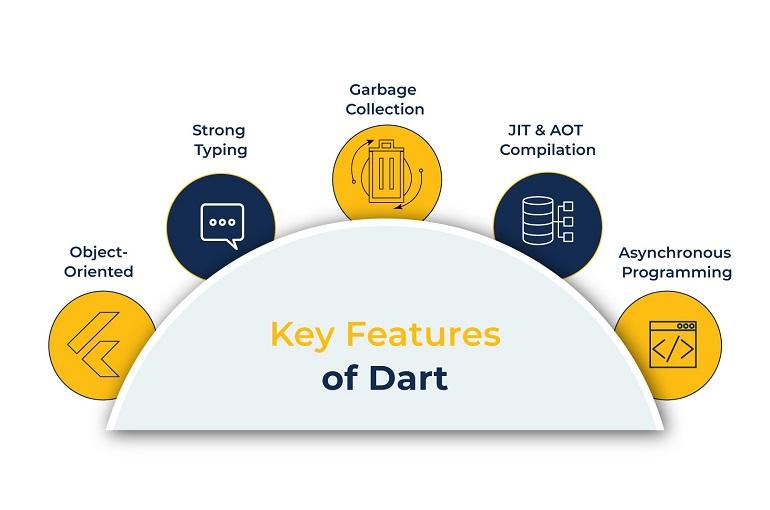




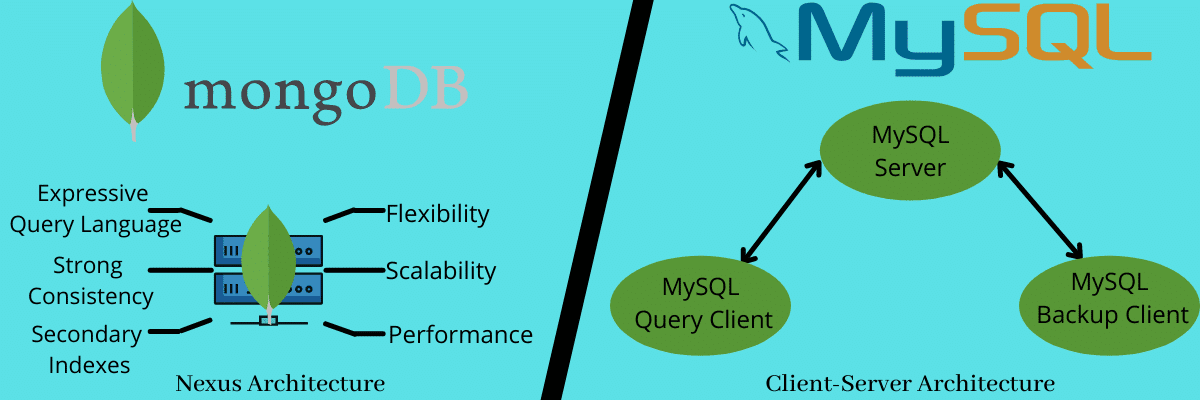
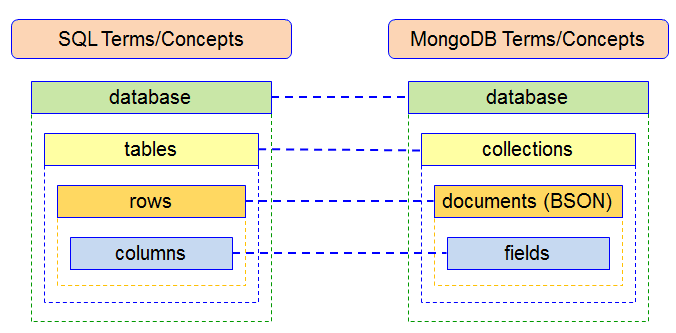
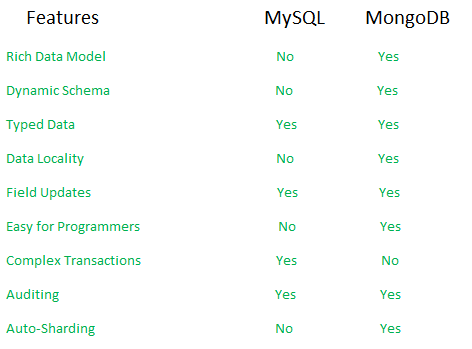



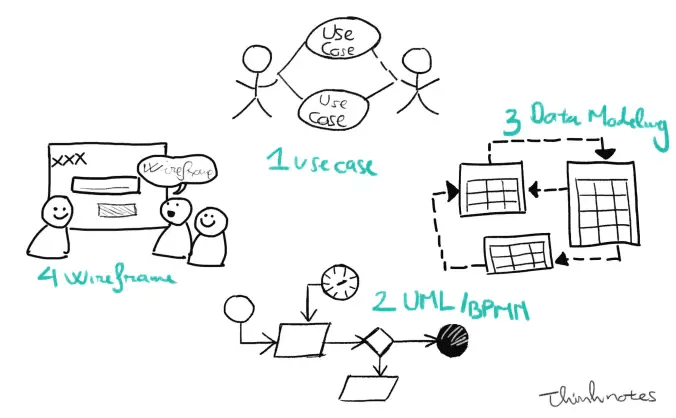



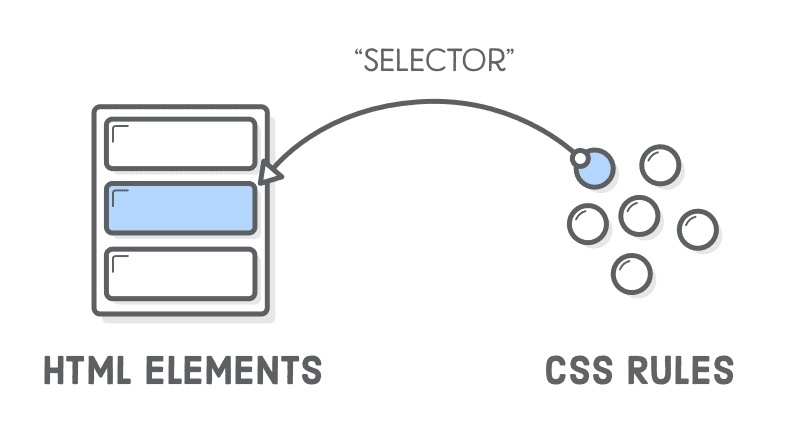
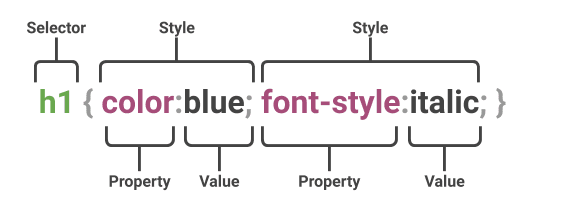
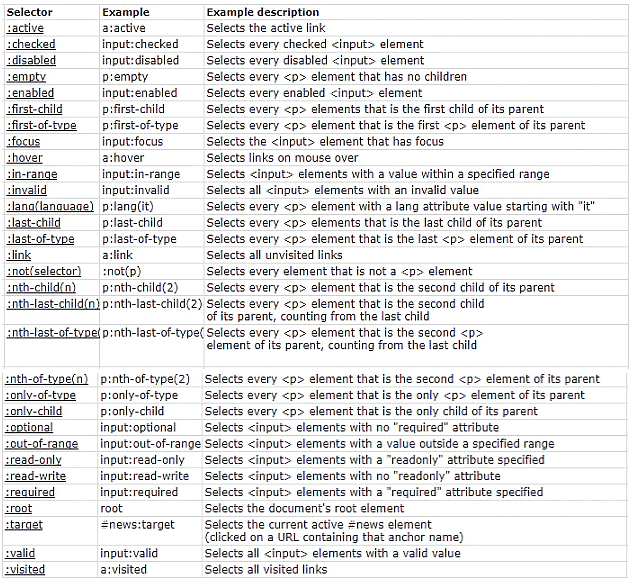


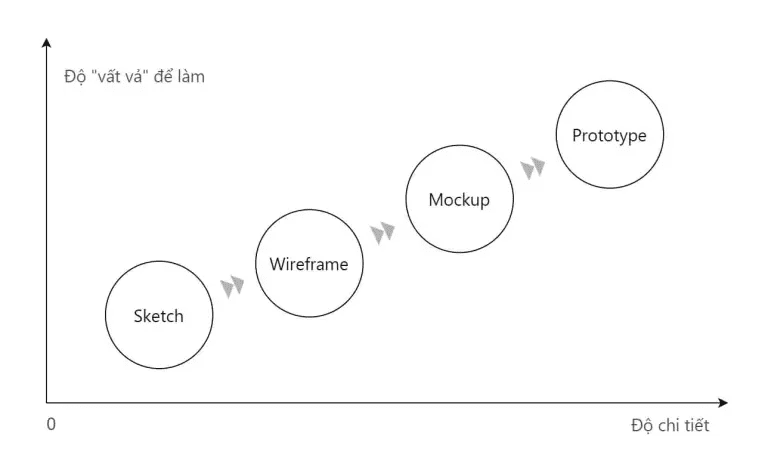
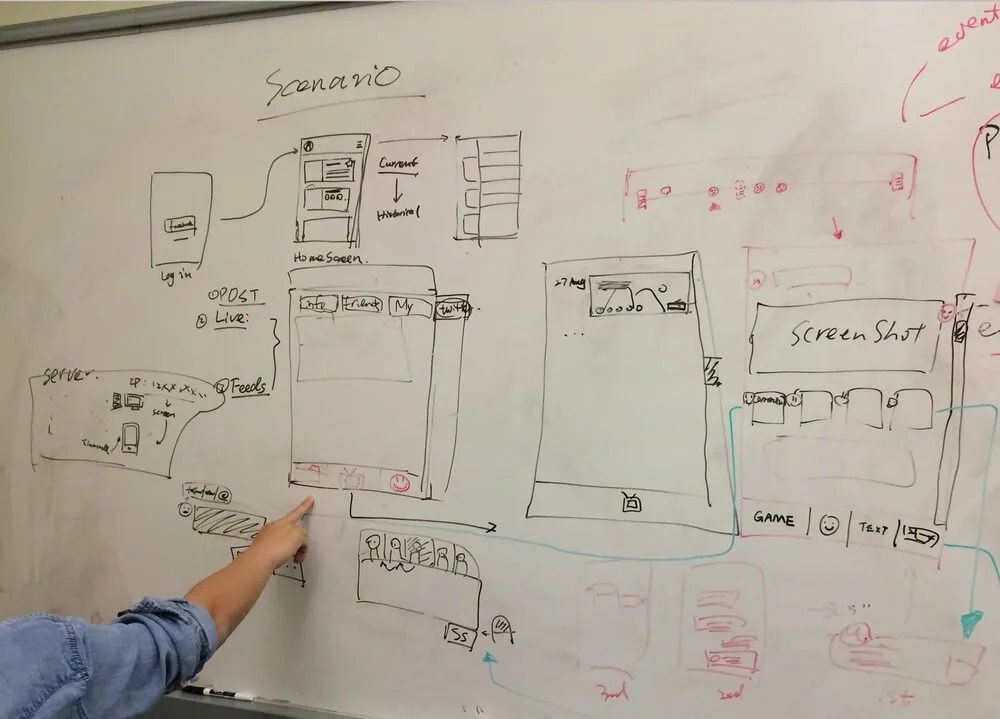








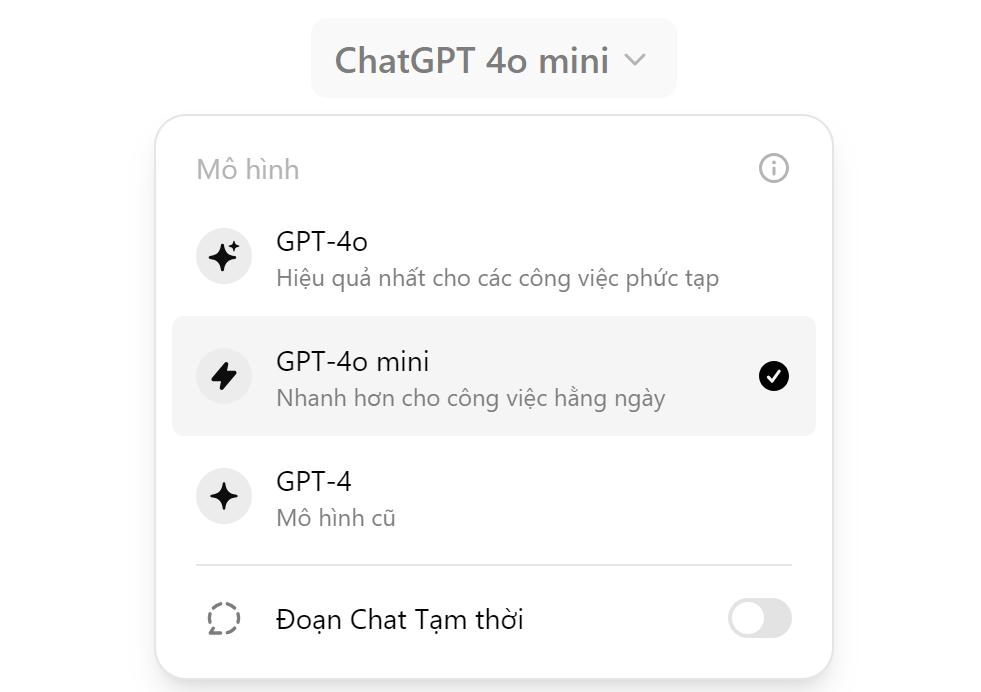


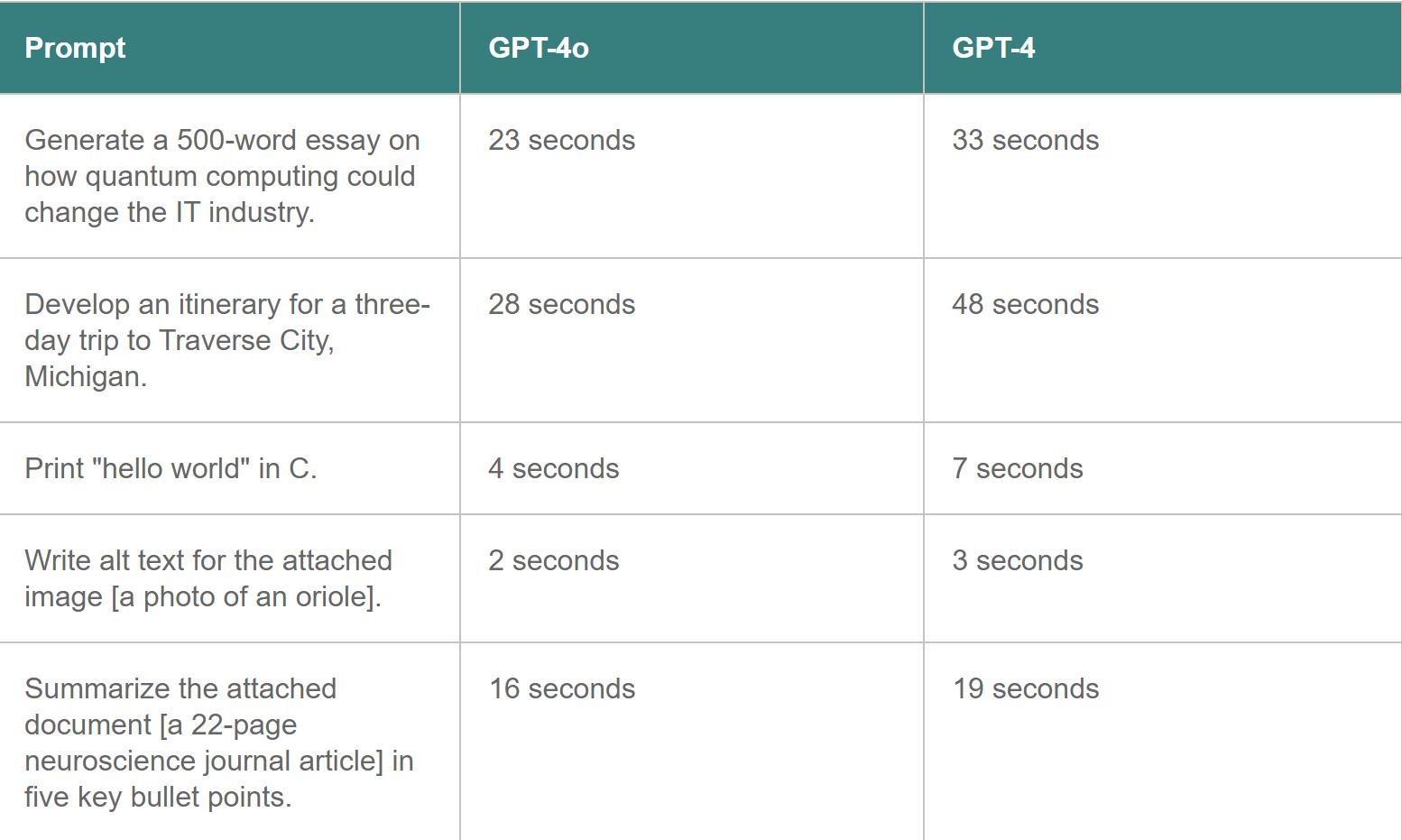
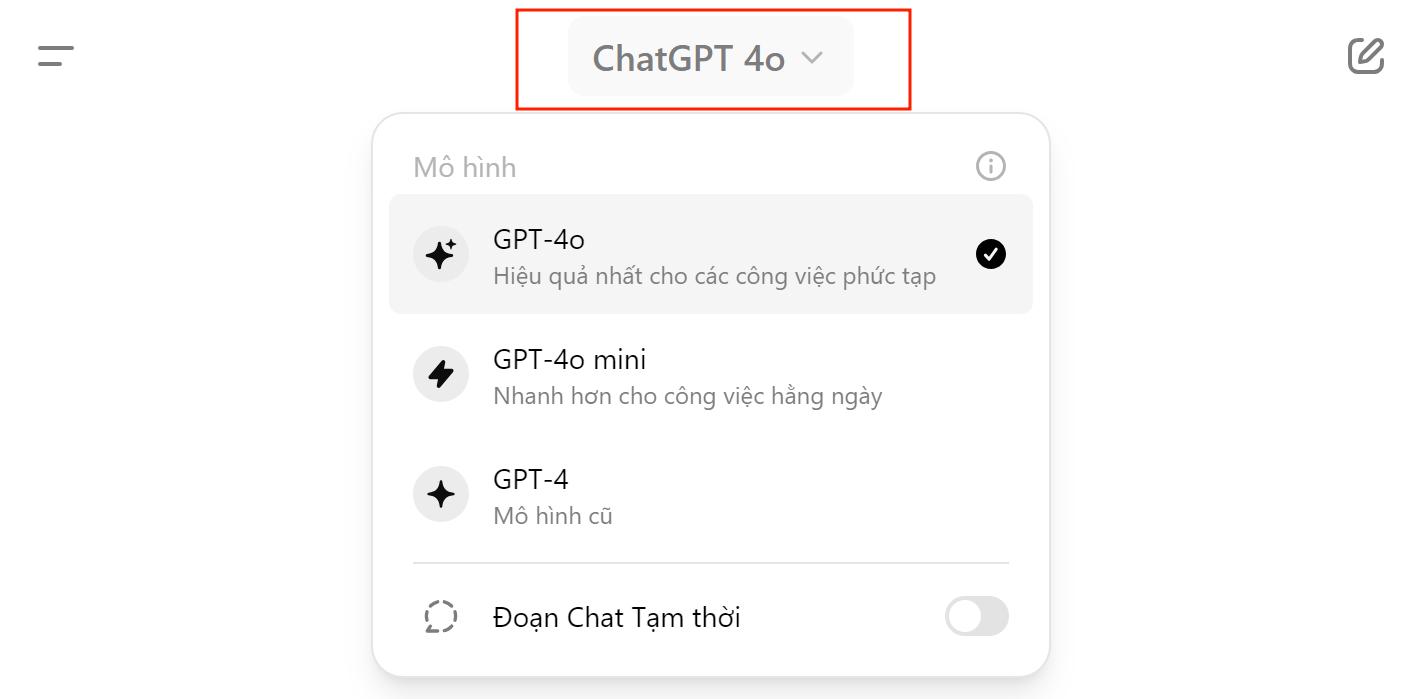

 Chat GPT-4 (còn được biết đến là chatGPT 4.0) là phiên bản mới nhất hiện nay do OpenAI phát triển, ra mắt vào 14/03/2023. GPT-4 được thiết kế để tiếp tục cải tiến các khả năng của các phiên bản trước, bằng cách cung cấp khả năng xử lý ngôn ngữ tự nhiên mạnh mẽ hơn, hiểu sâu hơn về ngữ cảnh, và tạo ra các phản hồi văn bản giống con người hơn.
Chat GPT-4 (còn được biết đến là chatGPT 4.0) là phiên bản mới nhất hiện nay do OpenAI phát triển, ra mắt vào 14/03/2023. GPT-4 được thiết kế để tiếp tục cải tiến các khả năng của các phiên bản trước, bằng cách cung cấp khả năng xử lý ngôn ngữ tự nhiên mạnh mẽ hơn, hiểu sâu hơn về ngữ cảnh, và tạo ra các phản hồi văn bản giống con người hơn.