Bài viết được sự cho phép bởi tác giả Vũ Thành Nam
Bài viết này mình sẽ giới thiệu cho các bạn cách kiến trúc sharding trong distributed database.
Điều đầu tiên, khi bạn đã quyết định chia nhỏ cơ sở dữ liệu với sharding, bạn cần phải hiểu rõ nó nên và sẽ làm như thế nào. Khi bạn bắt đầu chạy truy vấn dữ liệu trong các bảng được chia nhỏ, điều quan trọng là bạn phải xác định đúng phân đoạn mà bạn cần truy vấn. Nếu không nó có thể dẫn đến việc mất dữ liệu hoặc truy vấn chậm chạp một cách đáng tiếc.

Trong phần này mình sẽ cùng các bạn làm rõ kiến trúc sharding phổ biến và quy trình sử dụng nó nhằm đảm bảo việc phân phối và truy vấn dữ liệu trên cơ sở dữ liệu phân tán sao cho phù hợp nhất (mình nhấn mạnh là phù hợp nhất nhé, chứ không phải tốt nhất).
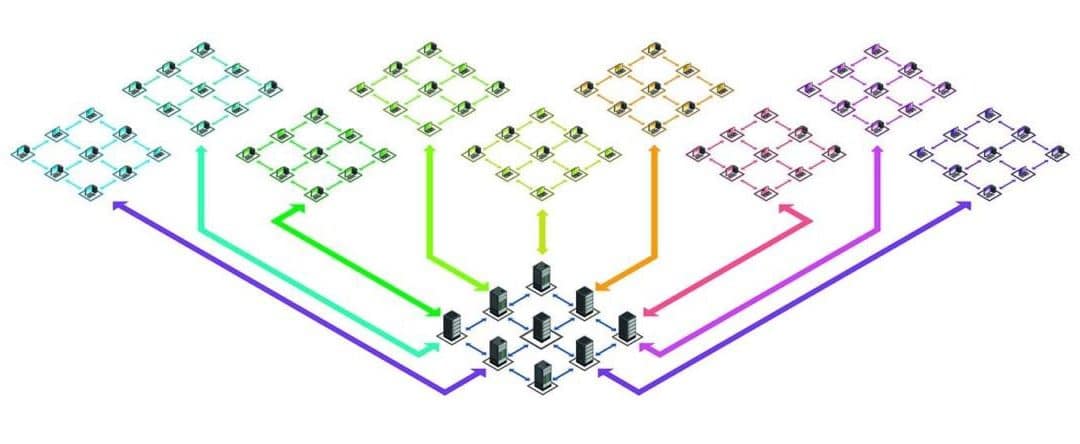
Đối với sharding, mình xin được chia nó ra thành 3 loại cơ bản: Key Based Sharding, Range Based Sharding, Directory Based Sharding. Mình sẽ đi cụ thể từng loại như sau:
Key Based Sharding
Đối với loại sharding này hay còn được biết đến là Hash Based Sharding. Đây là một loại sharding phổ biến nhất trong Citus Data. Nếu bạn từng thiết kế một cơ sở dữ liệu với các bảng liên kết với nhau theo hình thức khóa chính khóa ngoại, bảng cha bảng con thì có lẽ bạn đã từng hiểu rằng khi truy vấn tập dữ liệu bảng con theo khóa ngoại là id của bảng cha thì nó khá là đơn giản.
Một câu lênh truy vấn kèm thêm điều kiện khóa ngoại sẽ giúp bạn làm điều đó, bản chất vấn đề là cơ sở dữ liệu vấn phải duyệt qua từng bản ghi (record hay row) sau đó so sánh với điều kiện khóa ngoại có bằng với id kia không để có thể lấy ra bản ghi đó. Quá trình này khiến cơ sở dữ liệu truyền thống mất khá nhiều thời gian nếu bạn chứa rất nhiều records trong table.
Dựa trên khó khăn đó Citus có thể giải quyết vấn đề này cho bạn bằng cách sharding key, bạn chia từng phần từng phần các record theo nhóm khóa ngoại nằm trên các node khác nhau. Khi đó nếu bạn cần truy vấn dữ liệu với loại khóa ngoại đó thì Citus sẽ nhắm đúng node có khóa ngoại mà bạn sharding để tới đúng vị trí lấy đúng tập dữ liệu mà bạn cần. Khi bạn chọn một trường làm sharding key, Citus sẽ có một function hash key đó lại nhằm đánh dấu tập dữ liệu của bạn được shard trên node số mấy. Vấn đề truy vấn chỉ là lấy tập dữ liệu hash sẵn đó ra mà thôi.
Ví dụ rằng bạn có 10,000,000 record với 5 kiểu khác nhau, thì việc đánh sharding cho mỗi kiểu sẽ giúp bạn truy vấn số record trên mỗi kiểu nhanh hơn, nó sẽ quét đúng tập dữ liệu 2,000,000 records thay vì quét hết cả 10,000,000 records. Điều này dẫn tới tốc độ truy vấn sẽ nhanh hơn hẳn.
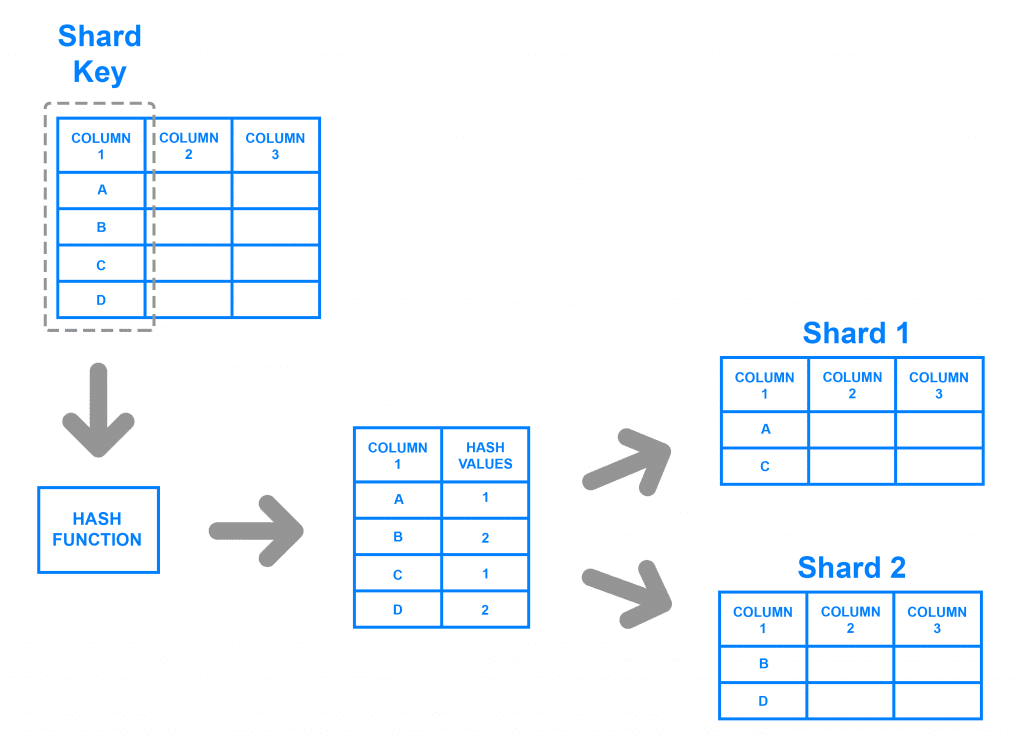
Cách sharding key này được dùng rất phổ biết và khá đơn giản với cú pháp này
SELECT create_distributed_table('tenants', 'id');
SELECT create_distributed_table('questions', 'tenant_id');Bạn có thể thấy tenant_id chính là khóa ngoại của bảng questions được liên kết tới bảng tenants. Và khi chúng ta sharding thì bạn có thể lấy chính khóa ngoại này làm trường shard key.
Tuy nhiên không phải chúng ta chỉ được lấy khóa ngoại làm trường shard key đâu nhé. Tùy thuộc vào dữ liệu của bạn có sự gom nhóm phù hợp mà bạn chọn trường nhóm đó làm sharding. Chỉ cần trường đó của bạn là duy nhất và ít thay đổi, chính xác hơn là không được thay đổi, nếu thay đổi bạn cần sharding lại để Citus có thể hiểu được và sắp xếp hash values lại sao cho phù hợp với lần truy vấn tiếp theo. Cách truy vấn thì cũng đơn gian thôi, chỉ cần bạn thêm điều kiện where với trường shard key, còn lại citus sẽ lo hết giúp bạn. Nó sẽ dựa trên hash value để tìm đúng địa chỉ node và truy vấn tập dữ liệu mà bạn cần.
Range Based Sharding
Khác với Key Based Sharding, đối với Range Based Sharding thì Citus sẽ gom nhóm các khoảng giá trị của bạn định nghĩa theo từng nhóm khoảng giá trị thay vì theo key. Ví dụ bạn có khoảng 10,000,000 record thì citus sẽ giúp bạn sharding chia thành từng khoảng giá trị với trường định nghĩa, từ 1 đến 1000, từ 1001 đến 2000,… cứ như thế các nhóm giá trị được hình thành và được phân bổ vào các node. Tương tự thì cách truy vấn citus giúp bạn tìm kiếm tập giá trị thuộc nhóm range nào để trỏ đúng nodes cần tìm và lấy giá trị đó lên
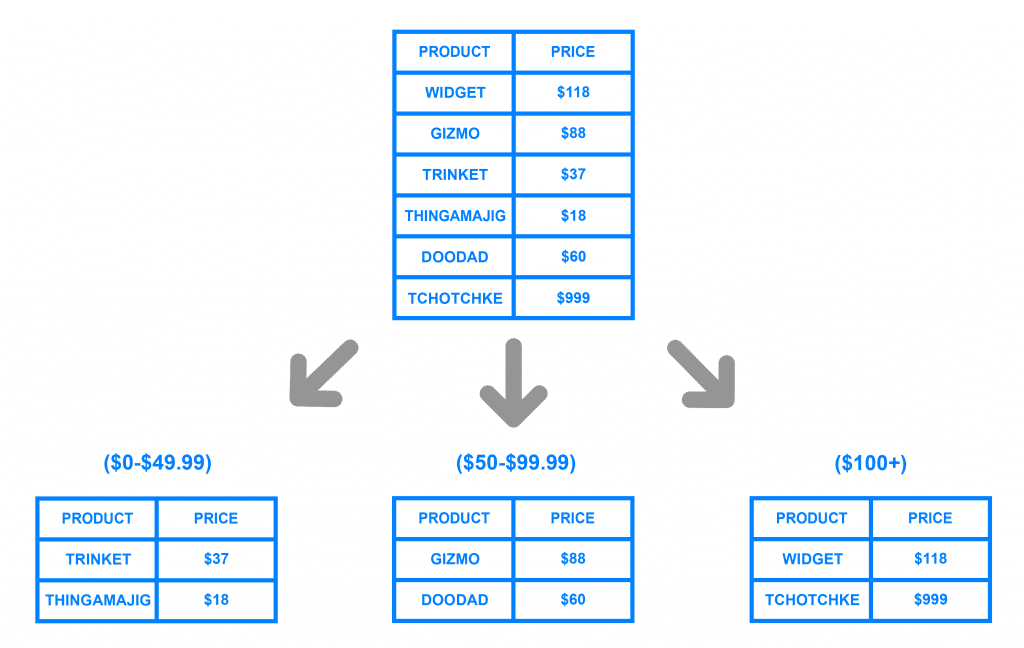
Điểm khó khăn của cách phân bổ này là khoảng dữ liệu sẽ bị mất cân bằng khi yêu cầu truy vấn bị lệch về một khoảng giá trị nào đó, và có những khoảng giá trị thì không bao giờ được truy vấn. Như hình minh họa trên, do mình chia khoảng giá thành 3 phần nhưng nghiệp vụ của mình chỉ toàn truy vấn trong khoảng từ 0 đến 49.99$ mà thôi. Vậy là tự nhiên sự phân bổ này bị mất cân bằng và làm cho ý nghĩa của việc sharding không còn phát huy đúng hiệu quả của mình nữa.
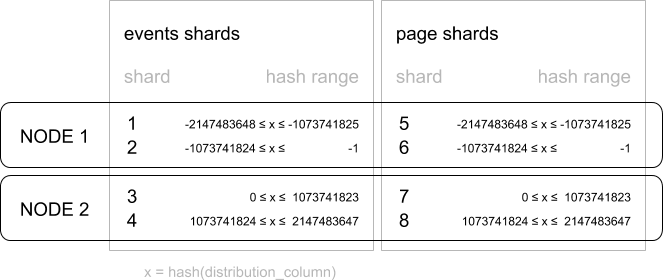
Directory Based Sharding
Tương tự như Key Based Sharding, Directory Based Sharding chia các nhóm cơ sở dữ liệu có điểm chung vào thành những nhóm và shard key chúng, nhưng thay vì sử dụng hash values thì loại sharding này lại sử dụng delivery zone. Bạn hình dung Key Based Sharding như việc chia những dữ liệu thành nhiều file, còn Directory Based Sharding lại chia dữ liệu ra thành nhiều folder, mỗi folder sẽ có chứa nhiều file, và trong file mới thực sự là dữ liệu bạn cần.
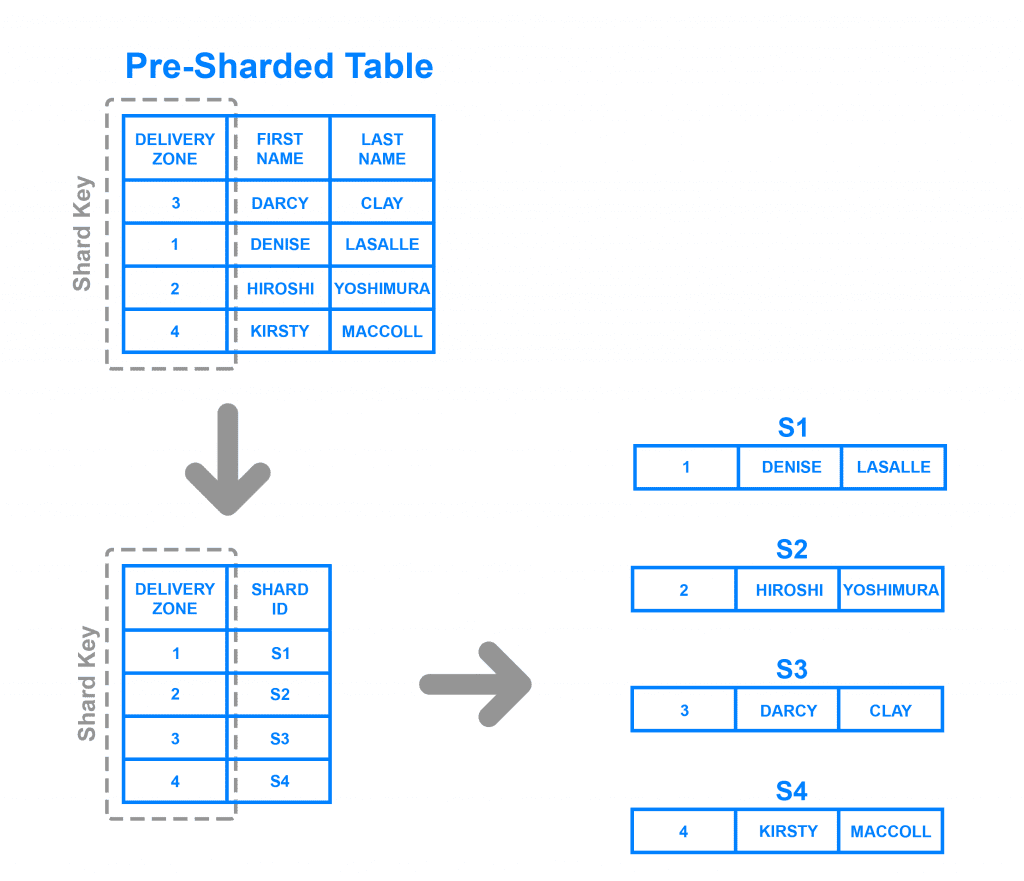
Loại sharding này còn có thêm một bảng tra cứu giống như mục lục vậy, shard key nào thuộc zone nào, từ đó giúp cho việc phân loại và truy vấn được dễ dàng hơn. Mặt khác, phân đoạn dựa trên thư mục cho phép bạn sử dụng bất kỳ hệ thống hoặc thuật toán nào bạn muốn để gán các mục nhập dữ liệu cho các phân đoạn và việc thêm động các phân đoạn bằng cách sử dụng phương pháp này tương đối dễ dàng.
Mặc dù Directory Based Sharding là phương pháp linh hoạt nhất trong số các phương pháp sharding được thảo luận ở đây, nhưng nhu cầu kết nối với bảng tra cứu trước mọi truy vấn hoặc ghi có thể có tác động bất lợi đến hiệu suất của ứng dụng. Hơn nữa, bảng tra cứu có thể trở thành một điểm lỗi, một điểm chí mạng: nếu nó bị hỏng hoặc không thành công, nó có thể ảnh hưởng đến khả năng ghi dữ liệu mới hoặc truy cập dữ liệu hiện có.
Vì vậy việc gom nhóm này thường chỉ sử dụng cho các cơ sở dữ liệu có độ phức tạp cao, cấu trúc phân nhóm nhiều, để có thể dễ dàng phân loại chúng. Còn nếu bạn có cơ sở dữ liệu đơn giản thì có lẽ Key Based Sharding là đủ cho bạn.
Việc có hay không nên triển khai sharded database architecture vẫn còn là một chủ đề tranh cái của nhiều lập trình viên. Đa số các lập trình viên coi sharding là một kết quả không thể tránh khỏi trước sự bùng nổ dữ liệu lớn quá nhanh và mạnh mẽ và khi chúng đạt đến một kích thước nhất định, nhưng có một số lập trình viên thì lại coi đó là một vấn đề nên tránh do nó rất phức tạp và đau đầu để xử lý những thứ liên quan trừ khi nó thực sự cần thiết và bất đắc dĩ. Cũng dễ hiểu thôi, sharding thực sự phức tạp hơn bạn nghĩ trong cách hoặt động và việc thêm bớt các node shard.
Do sự phức tạp tăng thêm này, nên sharding thường chỉ được thực hiện khi xử lý lượng dữ liệu rất lớn. Dưới đây là một số tình huống phổ biến trong đó việc chia nhỏ cơ sở dữ liệu có thể có lợi:
– Số lượng dữ liệu của ứng dụng tăng lên vượt quá khả năng lưu trữ của một node cơ sở dữ liệu duy nhất.
– Khối lượng ghi hoặc đọc vào cơ sở dữ liệu vượt quá những gì mà một node đơn hay cluster có thể xử lý, dẫn đến thời gian phản hồi hoặc thời gian chờ bị chậm lại.
– Băng thông đường truyền mạng mà ứng dụng yêu cầu lớn hơn băng thông có sẵn cho một node database.
Trước khi nghĩ đến sharding, có lẽ bạn nên nghĩ đến một số sự lựa chọn khác để tối ưu hóa cơ sở dữ liệu của mình, do sharding là một giải pháp đáng cân nhắc lại. Dưới đây là một số giải pháp tối ưu hóa khác mà bạn có thể xem xét trước khi sử dụng sharding:
– Setting up a remote database:
Nếu bạn đang làm việc với ứng dụng monolithic trong đó tất cả các thành phần nằm trên cùng một máy chủ, bạn có thể cải thiện hiệu suất cơ sở dữ hiệu bằng cách chuyển server cơ sở dữ liệu sang chính máy khởi chạy ứng dụng. Điều này không làm phức tạp thêm nhiều như sharding vì các bảng của cơ sở dữ liệu vẫn còn nguyên vẹn. Tuy nhiên, nó vẫn cho phép bạn chia tỷ lệ cơ sở dữ liệu của mình theo chiều dọc so với phần còn lại của cơ sở hạ tầng. Hơn nữa đường truyền dữ liệu sẽ tốt hơn do chúng nằm trên cùng một máy chủ.
– Implementing caching:
Nếu hiệu suất đọc của ứng dụng là nguyên nhân khiến bạn gặp rắc rối, thì bộ nhớ đệm là một chiến lược có thể giúp cải thiện điều đó. Bộ nhớ đệm bao gồm việc lưu trữ tạm thời dữ liệu đã được yêu cầu trong bộ nhớ trước đó cho phép bạn truy cập dữ liệu đó nhanh hơn nhiều sau này.
– Creating one or more read replicas:
Một chiến lược khác có thể giúp cải thiện hiệu suất đọc, điều này liên quan đến việc sao chép dữ liệu từ một máy chủ cơ sở dữ liệu (máy chủ chính) sang một hoặc nhiều máy chủ phụ.
Sau đó, mọi bản ghi mới sẽ được chuyển đến bản chính trước khi được sao chép sang bản thứ hai, trong khi các lần đọc được thực hiện riêng cho các máy chủ thứ cấp. Việc phân phối các lần đọc và ghi như thế này giúp cho bất kỳ máy nào không phải chịu quá nhiều tải, giúp tránh bị chậm và treo máy.
Giải pháp này thường sử dụng trong các mạng xã hội, họ lợi dụng điểm mạnh của no-sql là truy vấn nhanh để lưu một cơ sở dữ liệu phụ và đồng bộ chúng về cơ sở dữ liệu chính dưới background chạy nền ngay sau đó.
Lưu ý rằng việc tạo bản sao đọc liên quan đến nhiều tài nguyên máy tính hơn và do đó tốn nhiều chi phí tiền bạc hơn, đây có thể là một hạn chế đáng kể đối với một số người.
– Upgrading to a larger server:
Trong hầu hết các trường hợp, việc mở rộng máy chủ cơ sở dữ liệu của một người thành một máy có nhiều tài nguyên hơn đòi hỏi ít nỗ lực hơn so với sharding.
Giống như việc tạo bản sao đọc, một máy chủ được nâng cấp với nhiều tài nguyên hơn có thể sẽ tốn nhiều tiền hơn. Do đó, bạn chỉ nên thực hiện việc thay đổi kích thước nếu nó thực sự trở thành lựa chọn tốt nhất của bạn.
Cái gì giải quyết được bằng tiền thì luôn dễ dàng hơn đúng không ạ 😀
Hãy nhớ rằng nếu ứng dụng hoặc trang web của bạn phát triển vượt qua một thời điểm nhất định, không có chiến lược nào trong số này sẽ đủ để tự cải thiện hiệu suất của chúng. Trong những trường hợp như vậy, sharding thực sự có thể là lựa chọn tốt nhất cho bạn.
Tóm lại Sharding có thể là một giải pháp tuyệt vời cho những người muốn mở rộng cơ sở dữ liệu của họ theo chiều ngang. Tuy nhiên, nó cũng thêm nhiều phức tạp và tạo ra nhiều điểm thất bại tiềm ẩn cho ứng dụng của bạn. Sharding có thể là cần thiết đối với một số người, nhưng thời gian và nguồn lực cần thiết để tạo và duy trì một kiến trúc phân đoạn có thể lớn hơn lợi ích cho những người khác.
Hi vọng bài viết này có thể giúp bạn hiểu rõ hơn nữa về sharding, nên và không nên sử dụng hướng tới giải pháp sharding này.
Bài viết gốc được đăng tải tại ntechdevelopers.com
Xem thêm:


