Bài viết được sự cho phép của tác giả Võ Quang Huy
Bạn cảm thấy giao diện đăng nhập mặc định của WordPress đã quá quen thuộc. Bạn muốn tạo một trang đăng nhập theo style của riêng mình? Bài viết hôm nay, mình sẽ hướng dẫn các bạn các xây dựng một trang đăng nhập trong WordPress.
Tạo trang đăng nhập WordPress
Đầu tiên, bạn phải tạo cho mình một trang đăng nhập. Việc tạo một trang mới trong WordPress chắc mọi người cũng đã biết rồi nhỉ.
Page mình tạo mới trong trường hợp này có tiêu đề là Đăng nhập, và có đường dẫn là domain/dang-nhap.
Tiếp theo, các bạn hãy tạo một file PHP mới có cú pháp page-{slug}.php vào theme đang sử dụng. Cụ thể ở trường hợp của mình là page-dang-nhap.php.
Ngoài ra, bạn còn có thể custom page bằng phương pháp tạo Page Template. Bạn có thể xem lại video hướng dẫn tạo custom page trong wordpress này nếu chưa nắm được nhé.
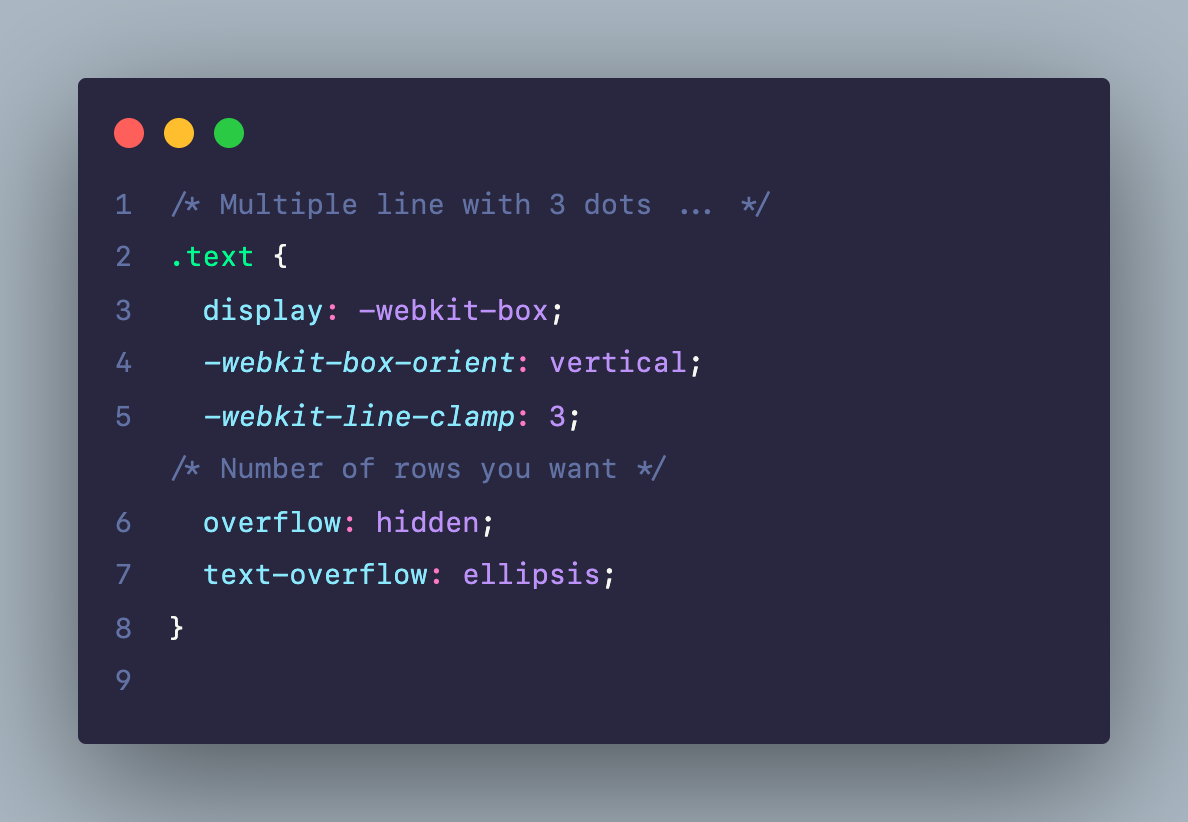
Hãy thêm đoạn code dưới này vào file PHP bạn mới vừa tạo nhé.
Đầu tiên, các bạn cần quan tâm đến một hàm đó là wp_login_form. Hàm này được WordPress cung cấp để giúp bạn tạo ra được một form đăng nhập ở bất cứ nơi nào bạn muốn.
Hàm này sẽ nhận một tham số đầu vào $args, là một array có mục đích thay đổi các giá trị của form cho phù hợp với nhu cầu của bạn. Mình sẽ giới thiệu một số option hay sử dụng nhất cho các bạn.
redirect: (string) URL chuyển hướng người dùng sau khi đăng nhập thành công. Mặc định sẽ chuyển hướng người dùng trở về trang trước.
form_id:(string) Thuộc tính ID của form. Mặc định là “loginform“.
label_username: (string) Nhãn của trường input “Tên người dùng hoặc Địa chỉ Email“.
label_password: (string) Nhãn của trường input “Mậtkhẩu“.
remember: (bool) Có hiển thị checkbox “Tự động đăng nhập” hay không?
value_remember: (bool) Checkbox “Tự động đăng nhập” có được chọn hay không? Mặc định là false (không chọn).
Bạn có thể vào document của WordPress để tìm hiểu thêm các option khác, cũng như tìm hiểu sâu hơn về code ở bên trong hàm này nhé.
Thứ hai, đó là câu lệnh điều kiện ở dòng thứ 8. Mục đích dùng để kiểm tra xem người dùng đã đăng nhập hay chưa. Nếu đăng nhập rồi thì sẽ không cho xuất hiện form đăng nhập nữa. Ở đây mình dùng hàm is_user_logged_in để xác định xem khách truy cập hiện tại có phải là người dùng đã đăng nhập hay không.
Ngoài ra, ở dòng thứ 10 mình sử dụng hàm wp_logout_url để tạo ra link đăng xuất. Hàm này nhận một tham số đầu vào là URL sau khi đăng xuất thành công. Ở đoạn code trên mình cho người dùng quay trở về trang chủ.
Kết quả đạt được
Đây là kết quả mà bạn đạt được sau khi sử dụng đoạn code trên của mình.
Vì mình đang sử dụng theme twentytwenty nên giao diện có thể khác các bạn. Hãy thay đổi cấu trúc HTML cho phù hợp với trang web của các bạn nhé.
Tổng kết
Đây là bài viết đầu tiên trong seri hướng dẫn custom tài khoản wordpress của mình. Mình sẽ tiếp tục cho ra các bài viết khác trong seri này hy vọng được sự đón nhận của các bạn.
Như vậy là mình đã hướng dẫn xong cho các bạn cách để xây dựng một trang đăng nhập trong WordPress.
Mình hy vọng với kiến thức nền tảng mà mình hướng dẫn, cộng với sự sáng tạo, các bạn sẽ tự xây dựng được một trang đăng nhập đẹp hơn, phù hợp hơn cho bản thân.
Bài viết được sự cho phép của tác giả Nguyễn Hồng Quân
Thỉnh thoảng mình có mối duyên ghé mắt qua các dự án Python, thấy cách sắp đặt vẫn còn chuệch choạc, không có lợi lắm cho việc phát triển tiếp diễn. Nên sau đây mình chia sẻ một số cách thức, công cụ, thư viện mà bạn nên chuẩn bị từ đầu, để công việc sau đó trở nên thoải mái hơn. Cách sắp đặt này có thể coi là chuẩn trong những năm 2020 này (nhưng có thể trở thành lạc hậu sau 5 năm nữa).
1. Quản lý các gói phụ thuộc
Gói phụ thuộc (dependency) là các thư viện / công cụ bên ngoài mà dự án của bạn cần. Các gói này phải được cài trước khi phần mềm của bạn có thể chạy. Ví dụ bạn làm về khoa học dữ liệu thì sẽ cần NumPy, làm web thì sẽ cần Django v.v… Việc một dự án phụ thuộc vào hàng chục gói thư viện khác là chuyện bình thường.
Thông thường các gói này sẽ được liệt kê trong file requirements.txt để khi sao chép dự án sang máy khác thì biết cần cài cái gì. Tuy nhiên, file requirements.txt chỉ là hình thức tối thiểu để quản lý gói phụ thuộc. Nó không đủ để hỗ trợ tình huống phức tạp hơn.
Ví dụ dự án của bạn sử dụng thư viện A phiên bản v1 và B phiên bản v2. Sau vài tháng, nhu cầu nảy sinh, bạn cần thêm tính năng mới, và để làm tính năng mới, bạn cần đến thư viện C. Tuy nhiên thư viện C này cũng lại phụ thuộc thư viện A, và thư viện C đang có nhiều phiên bản, v1 đến v5, mỗi phiên bản của C sẽ thương thích với một phiên bản A khác nhau. Nếu bạn nhắm mắt chọn phiên bản mới nhất của C thì nó sẽ yêu cầu A v3. Bạn không thể mù quáng nâng cấp A lên v3 vì có thể phần mềm của bạn không tương thích và đứt gãy. Nhưng trong 5 phiên bản của C mà thử từng cái một thì rất cực. Đó là lúc bạn cần một thứ nâng cao hơn file requirements.txt.
Một công cụ hiện đại mà mình hay dùng, và khuyên dùng cho tình huống này là Poetry. Khi bạn cần thêm C vào danh sách phụ thuộc, chỉ cần chạy:
$ poetry add C
thì Poetry sẽ tính toán để chọn phiên bản C phù hợp nhất.
Trước khi Poetry ra đời thì có một công cụ khác cũng khá nổi tiếng là Pipenv. Tuy nhiên cá nhân mình không thích Pipenv vì nó tạo thư viện môi trường ảo virtual environment ngay bên trong thư mục dự án. Việc đặt môi trường ảo ngay bên trong dự án này có một phiền phức là khi bạn cần chạy công cụ gì cần quét tất cả các file mã nguồn, nhiều khi nó vô tình quét trúng các file trong thư mục môi trường ảo, nhẹ nhất là làm nhiễu kết quả, nặng nhất là chạy luôn các code trong đó và bắn ra lỗi tùm lum không biết đường nào mà lần.
Việc đặt môi trường ảo ở đâu cũng là một “kinh nghiệm” đáng lưu tâm khi khởi tạo dự án.
Để sử dụng Poetry ngay từ đầu thì bạn có thể dùng các lệnh poetry new, poetry init để nó tạo ra các file cần thiết và cấu trúc thư mục mẫu.
Khi dùng Poetry, có một cái lợi khác là nó sẽ áp dụng file pyproject.toml cho dự án của bạn. Đây là một chuẩn file mới của Python, sẽ là nơi tập trung để lưu cấu hình của các công cụ bổ trợ (kiểm tra code, làm sạch code) trong quá trình phát triển dự án.
2. Ghi log
Khi ứng dụng của bạn đã đem ra triển khai, chạy thật, rồi vào một ngày đẹp trời bạn nhận được phản ánh là nó có lỗi, thậm chí có thể nó đang bị lỗi ngay trước mặt bạn. Nhưng bạn không biết chuyện gì xảy ra bên trong phần mềm, chẳng hạn nó đang đọc dữ liệu từ một nguồn nào đó nhưng gặp phải nội dung không mong muốn, không phân tích được và đổ bể. Hoặc là nó đang thực hiện phép toán chia giữa hai biến, và chẳng may biến mẫu số đang là 0, thế là sập.
Để chuẩn bị trước cho những tình huống này, bạn cần làm cho phần mềm ghi ra log, “kể lại” những diễn biến, để sau này khi có sự cố, bạn đọc lại log và có manh mối để biết phải sửa chỗ nào.
Ưu điểm của Python là nó có sẵn thư viện logging trong bộ thư viện chuẩn để các phần mềm tận dụng cho việc ghi log. Nhờ nó là “chuẩn”, các thư viện đều dùng nó nên bạn có thể tùy ý bật tắt log của các thư viện bên dưới mà ứng dụng của bạn đang sử dụng.
Ví dụ, ứng dụng của bạn đang dùng thư viện requests bên dưới, có tình huống mà log từ ứng dụng của bạn ghi ra vẫn không tiết lộ được gì về chuyện gì sai xảy ra bên trong. Bạn cần kiểm tra dữ liệu HTTP mà requests thu nhận được có đúng đắn không. Khi đó bạn chỉ cần tăng cấp độ log (log level) của requests mà không cần đụng vào code của nó, để thấy được chi tiết hơn.
Khi tham gia làm việc trên một ngôn ngữ khác không có thư viện logging chuẩn như thế này, ví dụ NodeJS, nơi mà mỗi thư viện, mỗi ứng dụng tự chế một cách ghi log riêng, bạn sẽ thấy cách làm của Python hữu ích thế nào.
Tuy nhiên, việc kèm sẵn một thư viện logging trong bộ thư viện chuẩn cũng có bất cập riêng. Đó là Python sẽ không dễ dàng nâng cấp nó, vì sợ sẽ làm đổ bể hàng loạt thư viện / ứng dụng khác. Ví dụ, để chèn nội dung biến vào log, logging trước giờ vẫn dùng cú pháp “%” như sau:
user=get_user_from_facebook()logger.debug('Got user with name %s and age %d',user.name,user.age)
Vấn đề là, format chuỗi bằng “%s” là phương pháp cũ kĩ, thời v2.5 về trước. Từ v3 (và được backport vào v2.6), Python có cách format chuỗi đơn giản hơn là “{}“. Nếu áp dụng được “{}” vào logging thì code trên sẽ trở thành:
user=get_user_from_facebook()logger.debug('Got user with name {} and age {}',user.name,user.age)
Vừa nhìn thoáng hơn mà lại không phải lăn tăn suy nghĩ chọn “%s” hay “%d“, “%f“. Tuy nhiên, thư viện logging không thể cải tiến chỗ này, vì sợ thay đổi cái là toàn bộ các thư viện có dùng logging trong hệ sinh thái sẽ sập hết.
Ghi chú:logging có cho phép cấu hình lại để sử dụng “{}“, nhưng việc thực hiện khá rườm rà và trong một dự án phức tạp thì chưa biết độ tương thích với các thư viện khác ra sao.
Ngoài vấn đề dùng “%s” ra thì logging có một điểm trừ là phong cách code với chữ hoa, ví dụ getLogger, setLevel không đồng bộ với phong cách chuẩn PEP8 của Python. Nhìn hơi ngứa mắt nên thực tế, khi làm phần mềm ở tầng “ứng dụng” (application) thì mình dùng logbook thay cho logging. Với logbook thì ngay từ đầu đã có thể dùng “{}” và có phong cách chuẩn PEP8 rồi, ví dụ:
fromlogbookimportLoggerlogger=Logger(__name__)# Some code# ...user=get_user_from_facebook()logger.debug('Got user with name {} and age {}',user.name,user.age)
Tuy nhiên, logbook không phải là thuốc tiên, nếu dùng sai liều là nó sẽ thành thuốc độc, bạn sẽ vò đầu bứt tai cả buổi mà không hiểu tại sao không thấy log đâu. Có một vài điều bạn cần lưu ý khi dùng logbook:
logbook có cách chuẩn bị rất khác với logging, với bước gọi handler.push_application(). Với một dự án đồ sộ có nhiều điểm khởi động, ví dụ Django, có các lệnh khác nhau để chạy dev server, WSGI server, job queue, nếu đặt push_application() sai chỗ, bạn sẽ thấy log hiện ra khi chạy từ lệnh này, nhưng lại không hiện khi chạy lệnh kia.
logbook được điều khiển độc lập với logging, không dùng chung cấu hình. Nghĩa là nếu bạn điều chỉnh “độ lắm lời” của module nào đó qua logging, nó sẽ không tác động gì đến logbook và ngược lại.
Bạn cần quan tâm tới nơi thu gom log cuối cùng (ví dụ ghi vào file hay gửi lên một dịch vụ online nào đấy), và trả lời câu hỏi rằng log từ logbook có cần chảy về chung đầu mối với log sinh ra từ logging hay không. Nếu không, coi chừng khi xem nơi lưu trữ cuối cùng, bạn sẽ hoang mang khi thấy log của hệ này mà không thấy hệ kia.
Nếu bạn muốn quy về một mối chung, dùng logbook.compat.LoggingHandler, bạn cần lưu ý một hạn chế của handler này là khi redirect logbook, nó không quan tâm log đó của module con nào, dồn về hết root logger của logging. Tôi đã gửi một pull request để sửa lỗi này nhưng tác giả của logbook không mặn mà nên tôi tự tạo thư viện riêng, chameleon-log để cung cấp handler đã sửa.
Lưu ý: Tôi đã thấy nhiều lập trình viên dùng log rất sai lầm, ví dụ:
user=get_user_from_facebook()logger.debug(f'Got user with name {user.name} and age {user.age}')logger.debug('Got user with name {} and age {}'.format(user.name,user.age))logger.debug('Got user with name '+user.name+' and age '+str(user.age))
Tức là bạn ấy chèn thẳng biến vào chuỗi tham số đầu tiên chứ không phải truyền gián tiếp qua tham số thứ 2, 3. Lý do là chuỗi ở tham số đầu tiên chỉ đóng vai trò “giữ chỗ”. Nếu đang bật cấp độ (log level) phù hợp thì chuỗi đó mới được format với các tham số phía sau để tạo ra message cuối cùng và xuất ra thành log. Nếu bạn chèn thẳng biến vào chuỗi, chuỗi đó sẽ được tính toán, các biến sẽ được xử lý trước khi log level được kiểm tra, làm lãng phí công sức của ứng dụng.
Thêm một “bí kíp” nữa, là việc chọn điểm thu gom log cuối cùng. Cách cổ điển là khi ra file, nhưng đó không phải là cách hay đâu. Nếu ứng dụng của bạn chạy trên Linux (server hay máy tính nhúng), nên cho nó ghi ra journald, bộ phận quy tập log của systemd. Ưu điểm của việc chuyển log cho journald là:
Journald gom log của mọi dịch vụ về một chỗ. Khi bạn đang quản lý hệ thống với nhiều phần mềm, sẽ thật nhức đầu nếu phần mềm này xem log ở chỗ này, phần mềm kia xem log ở chỗ kia. Quy về một mối thì bạn chỉ cần dùng lệnh journalctl -u ten-app là xem được log ứng dụng của bạn rồi.
Journald có nhiều phương thức để rà soát log một cách tiện lợi, ví dụ bạn muốn xem kiểu “bám đuổi”, log ghi ra tới đâu, xem ngay tới đó thì dùng lệnh journalctl -fu ten-app (-f nghĩa là “follow”).
Nếu bạn không cần bám đuổi mà muốn nó đứng một chỗ (để soi kĩ hơn), nhưng muốn “nhảy cóc” xuống dòng cuối cùng (dòng mới nhất) thì dùng lệnh journalctl -eu ten-app (-e nghĩa là “end”).
Khi bạn đang xem log bằng journalctl, bạn có thể tìm chuỗi để nhảy tới nhảy lui, bằng lệnh “/” (tìm xuôi) hoặc “?” (tìm ngược). Thực ra là bạn có thể dùng bất kì lệnh / phím tắt nào của less ở đây.
Journald cho phép chọn lọc theo ngày tháng. Chẳng hạn bạn biết rằng 9h tối hôm qua có sự cố. Bạn muốn xem log xung quanh thời điểm đó thôi, bạn có thể dùng --since, --until để cắt bớt, ví dụ journalctl -u ten-app --since '2021-08-13 21:00'.
Journalctl xác định thời gian bằng thời điểm nó nhận được log, chứ không phải ngày tháng kèm trong log, nên nó “miễn nhiễm” với sự điều chỉnh múi giờ. Chẳng hạn 9h tối qua xảy ra sự cố nhưng thời điểm đó server đang bị cấu hình nhầm múi giờ UTC+8, đến 11 giờ bạn nhận ra múi giờ sai nên vào server chỉnh lại thành UTC+7. Sáng nay bạn cần xem lại log thì không cần tính toán lại giờ theo múi giờ của tối qua.
Dưới đây là hình ảnh log được xem bằng journalctl của một ứng dụng IoT của chúng tôi. Để ý là journalctl tô màu dòng log theo độ nghiêm trọng (log level) để giúp tập trung dễ hơn.
Mặc dù bây giờ cũng có phương án là gửi lên các dịch vụ cloud (như StackDriver của Google, CloudWatch của AWS), nhưng tôi không thích dùng chúng, vì thao tác tìm kiếm / nhảy cóc trên journalctl nhanh ra kết quả hơn. Các dịch vụ kia là giao điện web nên mỗi lần tìm kiếm bạn phải chờ trang web tải, rồi bấm vào link này link nọ, rồi lại chờ. Các dịch vụ đó chỉ có giá trị cho việc cài đặt cảnh báo, thống kê . Vì vậy khi cấu hình logging, tôi sẽ dùng hai “handler”, một ghi xuống journald, một để gửi log lên dịch vụ cloud.
Trên đây là một số kinh nghiệm khi tạo dựng từ đầu một dự án Python, nhưng chắc nó cũng đáng giá với các ngôn ngữ khác nữa (chỉ thay đổi phần mềm tương ứng). Kinh nghiệm còn nhiều nhưng hôm nay chỉ ghi ra tới đây thôi. Mốt nhớ ra kể tiếp.
Trái với sự phổ biến trong quá khứ, hiện nay ngôn ngữ lập trình Cobol được khá ít người biết đến. Tuy nhiên, có thể nói Cobol là một ngôn ngữ lập trình mang tính khả dụng và hữu ích cao. Để hiểu rõ Cobol là gì, bạn hãy theo dõi nội dung bên dưới.
1. Cobol là gì?
Cobol (Common Business-Oriented Language) là một ngôn ngữ lập trình máy tính thế hệ thứ ba, chủ yếu tập trung vào giải quyết một vấn đề kinh doanh. Ngôn ngữ này thường được sử dụng trong hệ thống kinh doanh, tài chính và hành chính của các công ty và cả chính phủ.
Cobol được phát triển bởi Hội nghị Ngôn ngữ Hệ thống Dữ liệu (Conference of Data System Languages – CODASYL). Ban đầu, Cobol là lập trình hướng thủ tục (Procedural), nhưng kể từ năm 2002, nó trở thành lập trình hướng đối tượng (Object-oriented).
Cơ bản bạn đã hiểu được Cobol là gì, ứng dụng trong môi trường nào. Vậy, Cobol có những đặc điểm hay ưu nhược điểm gì mà lại được sử dụng phổ biến trong những môi trường như vậy?
2. Đặc điểm ngôn ngữ lập trình Cobol
Những đặc điểm nổi bật của Cobol có thể kể đến như:
Tính đơn giản và tiêu chuẩn hóa: Cobol là một ngôn ngữ chuẩn, dễ học. Nó có thể được biên dịch và thực thi trên nhiều loại máy tính. Bên cạnh đó, Cobol còn hỗ trợ lượng lớn từ vựng cấu trúc và có một phong cách mã hóa logic.
Khả năng định hướng kinh doanh: Khả năng xử lý tệp nâng cao của Cobol cho phép nó xử lý lượng dữ liệu khổng lồ. Cobol xử lý hơn 70% giao dịch kinh doanh trên thế giới. Từ những báo cáo đơn giản đến các giao dịch phức tạp, việc sử dụng Cobol đều phù hợp và mang lại hiệu quả.
Tính phổ quát: Cobol đã thích nghi với sự thay đổi và hoạt động kinh doanh trên nhiều nền tảng và thiết bị. Ngôn ngữ này cung cấp các công cụ gỡ lỗi và kiểm tra cho hầu hết các nền tảng máy tính.
Cấu trúc và khả năng mở rộng: Các cấu trúc điều khiển logic có sẵn trong Cobol giúp bạn dễ dàng đọc, sửa đổi và gỡ lỗi. Cobol cũng có khả năng mở rộng, đáng tin cậy và khả năng di động trên các nền tảng.
Không có một ngôn ngữ lập trình nào hoàn hảo tính đến thời điểm hiện tại. Bên cạnh những ưu điểm vượt trội, Cobol cũng có những hạn chế cần phải xem xét:
Vì có Source Code lớn nên khi maintain hay chỉnh sửa đọc code sẽ tiêu tốn khá nhiều thời gian và công sức.
Hiện Cobol đang dần bị lãng quên do ít người dùng và dường như không còn được phát triển, cải tiến.
Một chương trình Cobol được tổ chức phân cấp theo thứ bậc. Không nhất thiết phải bao gồm tất cả các thành phần trong một chương trình. Mỗi thành phần sẽ bao gồm một hệ hay nhiều thành phần con khác nhau cùng hoạt động như:
Division: là phân vùng chính có khối mã lệnh bao gồm một hay nhiều vùng. Trong đó, vị trí bắt đầu là vị trí sau tên gọi phân vùng và vị trí kết thúc là điểm bắt đầu một phân vùng tiếp theo hoặc kết thúc chương trình.
Section: một vùng cũng là một khối mã lệnh (nhưng nhỏ hơn phân vùng) thường bao gồm một hoặc nhiều đoạn khác nhau.
Paragraph: là một đoạn lệnh của chương trình chính bao gồm một hoặc nhiều câu lệnh.
Sentence, Statement: câu lệnh bao gồm một hoặc nhiều mệnh đề khác nhau và kết thúc bằng dấu chấm. Trong đó, một mệnh đề bao gồm một động từ / lệnh Cobol và một hoặc nhiều operand.
Cấu trúc một chương trình Cobol sẽ bao gồm 4 phân vùng (division). Ta có thể lược bỏ một số phân vùng, tuy nhiên phải tuân theo thứ tự như sau:
Identification Division: cung cấp thông tin về chương trình cho lập trình viên và trình biên dịch.
Environment Division: giúp xác định các tệp đầu vào và đầu ra cho chương trình.
Data Division: bao gồm các thông tin khai báo biến dữ liệu
Procedure Division: bao gồm các mã lệnh sử dụng dùng để thao tác trên các thành phần dữ liệu đã được khai báo trong Data Division.
4. Ví dụ với chương trình “Hello World”
Một ví dụ quen thuộc với tất cả các lập trình viên khi bắt đầu học một ngôn ngữ mới – “Hello World”. Mã chương trình Cobol hiển thị “Hello World” như sau:
Dòng 000100 và 000200: phân vùng Identification Division dùng để nhận diện những thông tin cơ bản về chương trình, ở đây nó chỉ bao gồm PROGRAM-ID, HELLO.
Dòng 000300: vùng Environment Division dùng để nhận diện môi trường khi chương trình được thực thi. Cobol có thể chạy được trên nhiều nền tảng, nhiều loại máy khác nhau, và vùng này thường dùng để điều khiển và kiểm soát sự khác nhau giữa những loại máy đó. Trong ví dụ này, chương trình không chỉ ra yêu cầu của một loại máy cụ thể, do đó vùng Environment Division được bỏ trống.
Dòng 000400 là vùng dữ liệu Data Division bao gồm những dữ liệu của chương trình. Chương trình này không có dữ liệu nêu vùng Data Division được bỏ trống.
Dòng 000500 đến dòng 001100 là các dòng trong vùng Procedure Division. Vùng Procedure Division bao gồm hai đoạn (paragraph) từ dòng 000700 (PROGRAM-BEGIN) và từ dòng 001000 (PROGRAM-DONE). Thuật ngữ paragraph trong Cobol gần như là một hàm hay chương trình con trong một số ngôn ngữ lập trình khác. Tất các những công việc thực sự của chương trình là thực hiện câu lệnh ở dòng 000800.
Một số lưu ý về cách trình bày Code khi lập trình Cobol
Mỗi chương trình Cobol có 80 ký tự mỗi dòng
Vùng đánh số dòng (line numbers area) : gồm 6 ký tự (cột) đầu tiên của mỗi dòng trong chương trình được sử dụng để đánh số thứ tự các dòng code của chương trình.
Vùng chỉ thị (indicator area) : nằm ở ký tự thứ 7, mô tả phần tiếp theo bằng dấu ‘- hoặc một nhận xét bằng dấu ‘* hoặc dấu ‘/.
Vùng A (Area A) : 4 ký tự tiếp theo (8-11) chứa các phân vùng (Division) và các đoạn (Sections). Thông thường vị trí bắt đầu tốt cho phân vùng này là bắt đầu từ cột thứ 8 thay vì các vị trí khác trong vùng A.
Vùng B (Area B): gồm các ký tự có vị trí từ 12 đến 72. Các câu lệnh phải bắt đầu và kết thúc trong vùng B này.
Vùng không chỉ định: bao gồm các ký tự từ vị trí 73. Những ký tự này sẽ không được xét trong chương trình.
Trên đây là những kiến thức tổng quan xoay quanh khái niệm Cobol là gì. Cobol không phải là một ngôn ngữ lập trình hợp thời như Python nhưng nó là một ngôn ngữ quan trọng. Hi vọng những thông tin trên sẽ giúp ích cho bạn trong việc đưa ra quyết định có nên học Cobol.
Bài viết được sự cho phép của tác giả Trần Anh Tuấn
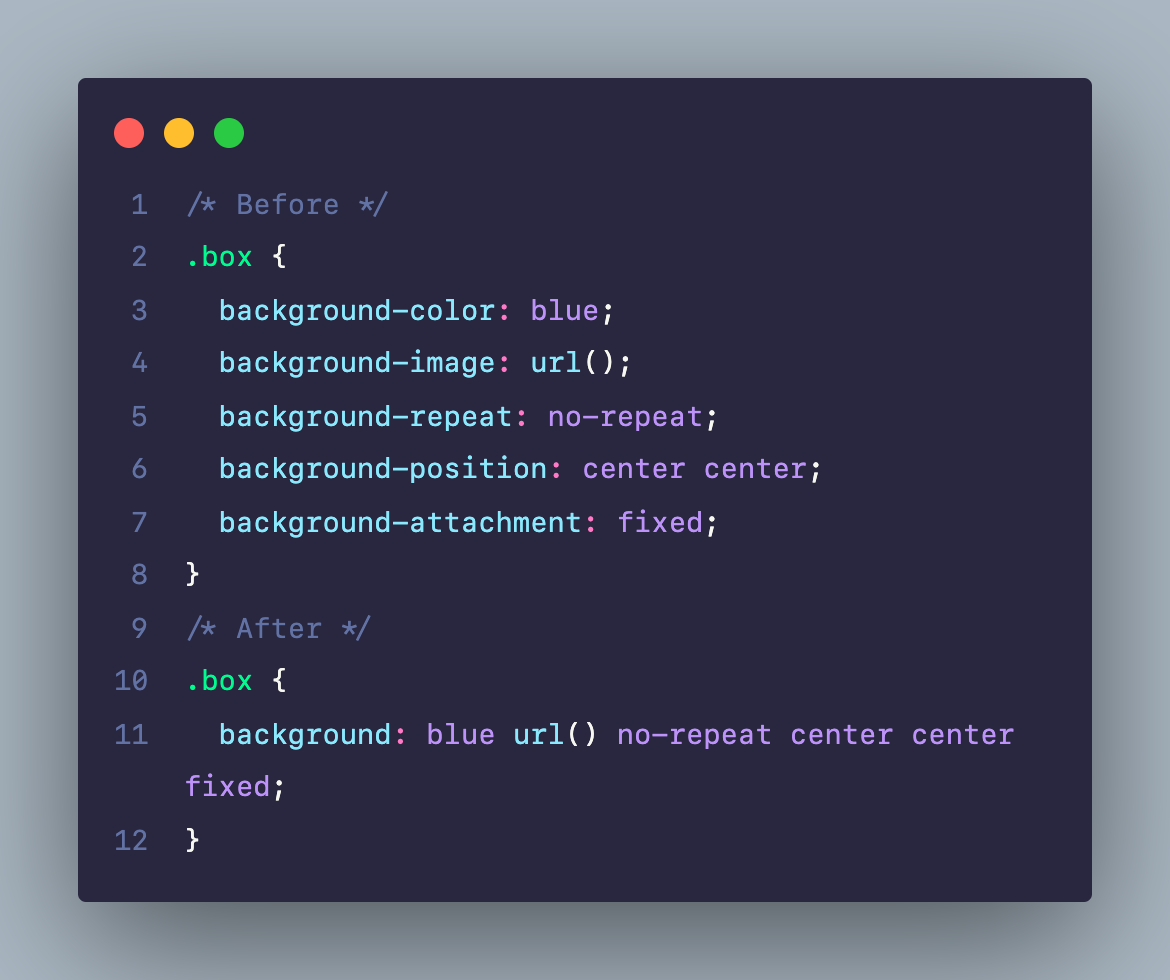
Ở bài viết này mình sẽ chia sẻ cho các bạn 3 cách code border gradient trong CSS, không giới thiệu dài dòng, mình đi thẳng vào từng cách một luôn nhé ⚡️
Với cách này thì chúng ta sẽ sử dụng 2 thuộc tính trong CSS đó chính là border-image-slice và border-image-source, cách này nhanh gọn lẹ nhất, tuy nhiên có một nhược điểm đó chính là không dùng được với border-radius(khi làm bo góc)
Trường hợp này thì chúng ta sẽ dùng một trick đó chính là tạo background gradient cho .boxed bình thường, sau đó thêm padding tương ứng cho độ dày của border, và bên trong tạo thêm 1 thẻ html ví dụ là .boxed-child chẳng hạn và cho nó màu nền trùng với màu nền của body
background-image: linear-gradient(to right bottom, #6a5af9, #f62682);
padding: 10px;
border-radius: 10px;
}
.boxed-child{
width: 100%;
height: 100%;
background-color: #191a28;
border-radius: inherit;
}
Chúng ta sẽ có kết quả như dưới đây kèm bo góc luôn, tuy nhiên cách làm này không hay, vì đôi khi chúng ta không được phép thêm HTML vào bên trong thì sao, vì thế sẽ có cách số 3 đó chính là sử dụng lớp giả :before hoặc :after để xử lý.
Sử dụng thêm thẻ html để tạo border gradient
Sử dụng before hoặc after
Nếu buộc phải có bo góc thì mình nghĩ dùng cách này là ổn áp nhất và chúng ta sẽ có code CSS như sau, các bạn chú ý những thuộc tính quan trọng đó chính là background-clip: padding-box và chỗ margin: -10px nó sẽ tương ứng cho border: 10px ví dụ border 20px thì margin sẽ là -20px nhé.
Là công ty IT outsourcing năng động với nhiều dự án đa ngành mang tầm quốc tế, việc quản lý hiệu quả các dự án của khách hàng và tăng tính kết nối, làm việc nhóm giữa các lập trình viên luôn là ưu tiên hàng đầu tại SHIFT ASIA. Nhằm mang đến sự hiệu quả và thuận tiện trong việc quản lý dự án, SHIFT ASIA đã và đang sử dụng GitLab như một công cụ cần thiết khi phát triển phần mềm. Ngoài ra, các lập trình viên tại SHIFT ASIA còn sử dụng GitLab như một kỹ năng không thể thiếu trong công việc của mình. Hãy tìm hiểu xem tại sao GitLab có vai trò quan trọng như vậy và SHIFT ASIA đang sử dụng GitLab hiệu quả như thế nào với bài chia sẻ từ anh OTIS HỒ – Senior Software Developer tại SHIFT ASIA nhé.
Anh OTIS – Senior Software Developer từ SHIFT ASIA với nhiều năm kinh nghiệm về lập trình qua nhiều môi trường làm việc khác nhau.
GitLab là gì?
GitLab là một hệ thống quản lý phát triển và triển khai phần mềm tự động. Lõi của GitLab là phần mềm Git, một phần mềm giúp quản lý phiên bản mã nguồn và lịch sử thay đổi mã nguồn. GitLab còn cung cấp công cụ quản lý yêu cầu kết hợp chặt chẽ với công cụ Git để giúp nhà phát triển dễ dàng theo dõi mã nguồn được phát triển tương ứng với yêu cầu nào. Với GitLab, mọi thành viên trong dự án có một công cụ chung để theo dõi tiến độ, review code và triển khai môi trường. GitLab giúp mọi thành viên trong dự án có thể tập trung vào chuyên môn của mình.
Các tính năng nổi bật của GitLab
Issues Management
GitLab cung cấp tính năng quản lý yêu cầu/công việc, các yêu cầu có thể được viết dưới định dạng Markdown, thuận tiện cho các lập trình viên và người quản lý dự án có thể đọc hiểu nội dung của dự án. Tính năng quản lý yêu cầu có bảng phân công công việc theo chuẩn quy trình Scrum Master, giúp dễ dàng quản lý, phân phối công việc, hoàn thành dự án lập trình chất lượng hơn. Các yêu cầu có thể liên kết với nhau (Linked issues), giúp cho quản lý có thể dễ dàng nhận ra blocker issues, duplicated issues. Mỗi một yêu cầu sẽ được tương ứng với một nhánh (Branch) do lập trình viên thực thi, và thời gian lập trình viên thực thi trên branch đó có thể được lưu lại dễ dàng với command-line được cung cấp bởi GitLab.
Code Review – Teamwork
GitLab cung cấp giao diện thân thiện giúp trưởng nhóm kỹ thuật (Technical Leader) có thể đánh giá mã nguồn của các thành viên một cách dễ dàng và nhanh chóng. Việc đánh giá mã nguồn và xử lý các phản hồi diễn ra nhanh chóng và được lưu lại cho việc truy hồi trong tương lai.
GitLab CI/CD
Là công cụ giúp phần mềm được triển khai (Continuous Development) và tích hợp (Continuous Integration) một cách liên tục. Trước đây, bạn phải có một công cụ CI/CD riêng lẻ (Jenkins, Circle CI, TravisCI), thì với GitLab CI/CD bạn dễ dàng cập nhật liên tục phiên bản mới nhất của phần mềm. Ngoài ra, công cụ GitLab CI/CD còn giúp bạn có thể chạy nhiều tác vụ xử lý tuần tự (Pipeline), bao gồm xây dựng (Build), kiểm tra tự động (Automation Test) và triển khai (Deployment) phần mềm lên môi trường production.
Minh họa quy trình CI/CD trên GitLab
Code Analytics
GitLab CI/CD còn cung cấp công cụ phân tích mã nguồn giúp nhà phát triển có thể phát hiện những mã nguồn thiếu chất lượng, có thể tạo ra lỗi tiềm tàng trong tương lai.
Tại SHIFT ASIA GitLab đang được sử dụng như thế nào?
Hiện tại SHIFT ASIA đang sử dụng GitLab cho hầu hết các dự án của mình.
SHIFT ASIA xây dựng một phiên bản GitLab trên hệ thống máy chủ nội bộ của SHIFT ASIA và chỉ có những thành viên của dự án mới có thể truy cập vào mã nguồn của dự án.
GitLab tích hợp các tính năng cần thiết cho bất kỳ yêu cầu dự án nào:
CI/CD: tự động xây dựng và chạy kiểm thử đơn vị (Unit Test) khi có yêu cầu tổng hợp mã nguồn từ một nhánh đang phát triển vào nhánh chính (master branch). Việc này giúp cho mã nguồn được đảm bảo về mặt chất lượng trước khi được bàn giao.
Issues Management: GitLab hỗ trợ việc quản lý yêu cầu/công việc của dự án với các tính năng vượt trội như liên kết các thay đổi trên mã nguồn với lại công việc tương ứng, thông báo trạng thái mã nguồn đã được tổng hợp vào nhánh chính giúp việc theo dõi và quản lý task được thuận tiện hơn.
Với việc sử dụng GitLab trong hầu hết các dự án của mình, SHIFT ASIA mang đến những dịch vụ phát triển phần mềm với chất lượng tốt nhất. GitLab giúp SHIFT ASIA có “SHIFT LEFT” một cách hiệu quả trong việc phát triển phần mềm. Với việc ưu tiên “SHIFT LEFT”, công ty luôn tạo cơ hội cho các lập trình viên được học hỏi và trao dồi thêm các kiến thức không chỉ liên quan đến phát triển phần mềm mà còn liên quan đến kiểm thử (Testing), triển khai liên tục (CI/CD) và hạ tầng (Infrastructure). Chính việc này một lần nữa khẳng định slogan của công ty: Crazy For Quality!
Bài viết được sự cho phép của tác giả Nguyễn Văn Trọng
Mindset là gì thì chắc ai cũng nghe tới, nhưng có thực sự hiểu rõ về nó không thì cũng cần phải đào sâu một chút. Trong bài viết này mình sẽ đi vào các tình huống thường gặp trong công việc để các bạn có cái nhìn gần hơn về tác động tốt-xấu của nó.
Vì Sao Mindset Lại Cần Thiết
Hãy cùng xem ví dụ về mindset tệ. Có thể mọi người sẽ cười nhưng trong thực tế thì không hiếm đâu, thậm chí nhiều là đằng khác. Ai cũng nói về đam mê, nhưng ít khi nào thành công tách rời với trách nhiệm. Một người có mindset sai, thiếu tinh thần trách nhiệm sẽ để lại hậu quả cực kỳ nghiêm trọng không chỉ cho bản thân mà còn “đào hố” đồng đội.
Riêng trường hợp ngồi chơi 4 ngày làm 1 ngày thì đôi khi lại do tính chủ quan, tự tin thái quá. Đúng ra nếu tự tin làm trong 1 ngày thì nên nói với PM/Team Lead là “task này dễ quá, cho em thêm vài cái nữa làm cho vui”. Sợ bị bốc lột? kệ chứ, còn trẻ ai muốn bốc gì bốc. Cứ cắm đầu làm chả lo thiệt thân đâu. Với leader giỏi thì họ nhìn là biết ngay ai chăm chỉ, tất nhiên là được việc nữa chứ chỉ chăm thôi thì chưa đủ. Còn gặp leader tệ quá, họ không thấy bản thân ưu tú thì bảo họ nhường chỗ cho mình lên thay muahaaaa … giỡn chứ đôi lúc người ta nhiều cái để lo nên không để ý, mình nhắc khéo, không được mới tìm phương án khác như … nhảy việc.
Đây mới gọi là tốt. Thực ra trong ví dụ này mình chỉ đưa ra có vài ý tiêu biểu, đằng sau đó còn nhiều nữa các bạn cứ tự suy nghĩ cách đối ứng sao cho phù hợp. Trong các ý trên thì nên làm lần lượt, đầu tiên là phân tích – tự ước lượng công việc (estimate), kỹ năng này sẽ giúp ích rất nhiều cho công việc BrSE sau này khi phải estimate dự án lớn. Vì có lớn cỡ nào mình cũng bẻ nhỏ ra được, ước lượng từng cái một rồi ghép lại là xong, ai bảo estimate khó thì chắc họ chỉ tỏ ra nguy hiểm thôi.
Như trên là tình huống trong công việc, còn to tát hơn như sự nghiệp thì phải làm sao ?
Dạo trước có nói chuyện với một cậu DEV, em nó bảo ước mơ sau này sẽ trở thành kỹ sư công nghệ hàng đầu, tạo ra một sản phẩm thật hoành tráng. Nhưng khi mình hỏi lại một số câu cơ bản thì câu trả lời hầu như là không/chưa.
C1. Em có chắc chắn với hướng đi của mình là đúng không ? CÓ
C2. Em đã có kế hoạch gì với việc đó chưa ? CHƯA
C3. Em hiểu thế nào là kỹ sư công nghệ hàng đầu, họ là người như thế nào, mỗi ngày họ làm gì/học gì, bằng cách nào họ trở thành số 1 (từ số 0) chưa ? CHƯA
C4. Thế theo em một sản phẩm hoành tráng là như thế nào ? và làm sao/mất bao lâu để tạo ra nó ? ẤP ÚNG
C5. Em có đang làm tốt những thứ cơ bản của lập trình như đặt tên biến, comment mô tả xử lý, optimize source, commit source hàng ngày lên GIT … cũng như những thứ cao cấp hơn xíu xíu như SOLID/Design Patterns chưa ? cái cơ bản thì có nhưng vụ khai báo biến hơi loạn, còn SOLID là cái gì thì em chưa nghe qua.
C6. Ngoài công việc ra em có code thêm gì để luyện tay hoặc tham gia khoá học nào để nâng cao không ? Việc làm không hết thời gian đâu mà luyện với học thêm anh.
Cách làm đúng như hình bên dưới.
Việc hiểu sở trường – sở đoản của bản thân nói thì dễ, thực tế không nhiều người nhận ra được, thậm chí ngộ nhận. Biết là ai sinh ra cũng có điểm mạnh yếu riêng, các “diễn giả” dạy làm giàu nói hoài. Bởi vậy nên chúng ta cần kiểm chứng bằng cách thử – sai – thử lại – sửa … cho tới lúc cảm nhận được mình muốn gì, mình cần gì và mình mạnh yếu chỗ nào. Khi đã hiểu rõ (có thể mất vài năm thậm chí hàng chục năm) thì già cmn rồi :))) , giỡn chứ lúc ấy mình quyết tâm đi theo nó tới cùng ắt sẽ để lại thành tựu gì đấy.
Định Nghĩa – Phân Loại
Mindset đơn giản là tư duy. Đối với mỗi tình huống cụ thể, mỗi người sẽ có một cách xử lý khác nhau, có tốt có xấu. Và điểm khác nhau được tạo ra bởi mindset. Ví dụ thì như trên, còn nếu các bạn chưa hiểu rõ lắm thì mình đưa ra thêm tình huống này cho dễ hình dung:
Bạn A được giao cho làm module login trong 3 ngày, bạn cắm đầu làm rất chăm chỉ nhưng tới gần lúc giao hàng thì báo lại là “anh ơi ! em làm không kịp”, chắc phải thêm 3 ngày nữa mới xong, ông PM B mắng mỏ làm bạn bỏ luôn không làm nữa.
Các bạn nghĩ mình đang nói tới bạn A hả, nhầm rồi :))) đang muốn nhắm tới ông PM B. Việc đầu tiên không phải là mắng mem của mình, mà tìm cách khắc phục, đầu tiên là tìm nguyên nhân chậm, sau đó check lại coi thêm 3 ngày nữa có kịp không hay là 4-5 ngày. Check các dữ kiện cần thiết và báo lại cho các bên liên quan, sau khi xử lý sự cố ổn thoả thì mới quay lại khiển trách và bảo bạn A rút kinh nghiệm, lần sau nhớ báo sớm để anh còn xử lý. Hình như đọc ví dụ xong không hình dung được thêm gì, mà thôi kệ.
Tiếp theo là phân loại, theo sách vở thì có 2 loại như bên dưới.
Nhìn hình cũng hiểu rồi đúng không ? Growth và Fixed. Cái khó ở đây là phần đông mỗi người rơi vào trạng thái lấp lửng, chả biết mình thuộc loại nào, đôi khi tự nhận là Growth mà thực tế hay bị Fixed (Xin lỗi mình dùng tiếng anh đoạn này vì là thuật ngữ). Và việc loại bỏ cảm giác tự ti về xuất phát điểm là cực khó, nó ăn sâu thành nếp rồi nên không thể bảo bỏ là bỏ ngay được, cần thời gian.
Cách tốt nhất để thay đổi tư duy là tiếp xúc với những người đẳng cấp, có cơ hội gặp gỡ, nói chuyện hỏi han với họ là bắt lấy, đừng có ngại, lớn rồi ai chơi trò ngại ngùng. Sau mỗi lần như vậy ta sẽ thay đổi vì muốn được như họ, và những người đó thường có nguồn năng lượng (nội công) rất mạnh mẽ có thể truyền sang bản thân mình (kể cả online) <= Đoạn này nói xạo đấy, đừng tin.
Các Bước Nâng Cao Mindset
Phần 1 và 2 mình đã phân tích thông qua các vị dụ, mặc dù hơi xạo xíu xíu nhưng nhìn chung cũng giúp các bạn tới gần hơn bản chất và tác động của mindset lớn như thế nào. Bây giờ vấn đề là làm sao để nâng cao nó.
Việc tiếp xúc với người đẳng cấp – hào hoa phong nhã xinh đẹp ngời ngời (mình chỉ được duy nhất cái đẹp trai, buồn!) thì khó, và có gặp cũng chỉ 1 vài lần nó chả thấm vào đâu. Vậy nên quay về với thực tại với 2 đối tượng : 1 là bản thân, 2 là “những người sống quanh tôi”.
“Bất kể tuổi tác”, nói thì dễ, mấy ông lớn lớn tuổi chút là coi mấy đứa em không ra gì, chuyên áp đặt suy nghĩ và còn khinh thường vì người ta ít trải nghiệm. Thực tế là vậy. Hiếm người nào 30 40 mà lại đi học hỏi cậu em 20 – 25.
Nhìn nhận sự việc theo hướng đa chiều – tích cực. Ví dụ như này : làm việc với ông khách khó tính suốt ngày soi mói chửi rủa. Vậy điểm sáng ở đây là gì : Tại ông khó quá nên mình sẽ có trải nghiệm làm với khách khó, sau này gặp người khác bớt khó hơn thì coi như là dễ. Nghĩ theo cách đấy đời tươi sáng hẳn.
Tiếp theo là nhìn nhận bản thân, đánh giá định kỳ mỗi 6 tháng – 1 năm – 2 năm, chu kỳ anh em tự đặt tuỳ mục tiêu lớn hay nhỏ. Rồi tự đặt ra thật nhiều câu hỏi, tự trả lời không được thì mang đi hỏi. Nhớ hay hỏi câu nào cho có giá trị tí chứ mấy câu mà google 1 phát đầy ra thì khỏi cần.
Và bước cuối cùng, củng cố – nâng cao tư duy thông qua học tập – hành động. Học thì có nhiều cách, học qua công việc – qua cuộc sống, thậm chí tham gia khoá học kỹ năng cũng không phải lựa chọn tồi. Mình không có ác cảm gì với các ông thầy dạy làm giàu cả, chỉ trêu cho vui, nhiều cái họ nói không sai (cũng có cái bốc phét), nghe và kiểm chứng rồi kết luận. Rồi qua hành động, chính là công việc thường ngày, sau mỗi quyết định thì chờ kết quả nó “nổ” ra rồi rút kinh nghiệm sâu sắc, lần sau làm khác đi. Có thể tiếng “nổ” sẽ to hoặc nhỏ hơn, nếu to quá thì lại tìm cách khác cho tới khi hài lòng. Đó chính là việc nâng cấp bản thân thông qua trải nghiệm : thử – sai – sửa …
Kết
Lâu ngày không viết cứng tay quá. Tính ra cũng cả năm trời rồi chứ có ít đâu, từ ngày ra sách cái vênh mặt lên bỏ luôn blog, tội lỗi. Mình sai thì nhận, và tìm cách sửa sai bằng việc hàng tháng 1 bài blog ra đều đặn.
Nói về mindset thì còn nhiều lắm, ví dụ đưa ra cả ngày không hết. Trong mỗi tình huống đều có nhiều đáp án, không có cái nào đúng hoàn toàn và sai hoàn toàn cả, ở mức tương đối. Điều quan trọng nhất là mình cần phải dẹp bỏ ngay thái độ tự ti về xuất phát điểm (địa vị, kỹ năng, hoàn cảnh gia đình), phải luôn nghĩ rằng dù đang đứng ở đâu đi chăng nữa thì nếu muốn tới đích hãy nhấc chân lên và đi. Cho dù khó khăn cỡ nào cũng không dừng lại (dừng nghỉ chút thì được). Cho tới 1 ngày nhìn lại mình đã cách xa đích hơn, nhầm… mình càng tới gần đích hơn, và lấy đó làm động lực để đi tiếp. Thành công = 10% Đam mê + 90% trách nhiệm = 10% năng khiếu + 90% khổ luyện, cái này cũng là của mấy ông thầy dạy làm giàu nè. Vậy nhé, khi nào nghĩ ra cái gì hay thì mình lại viết tiếp.
Bài viết được sự cho phép của tác giả Phạm Minh Khoa
Middleware là những đoạn mã trung gian nằm giữa các request và response, nó nhận các request, thi hành các mệnh lệnh tương ứng trên request đó. sau khi hoàn thành nó sẽ response (phản hồi) hoặc chuyển kết quả ủy thác cho 1 Middleware khác trong hàng đợi.
Trong NextJS, middle mới chỉ được thêm vào từ version 12.0.0 (cho bản beta), tài liệu chính thức của nó được mô tả trên trang chủ của NextJS tại link: https://nextjs.org/docs/middleware
Bài viết này mình sẽ giải thích qua cách sử dụng của nó và tạo thử 1 ví dụ cho các bạn dễ hình dung.
Cách sử dụng
Để sử dụng middleware thì chúng ta tạo file _middleware.ts nằm trong thư mục pages của dự án.
Sau khi tạo xong chúng ta sẽ copy đoạn code typescript như dưới đây vào:
// pages/_middleware.ts
import type { NextFetchEvent, NextRequest } from 'next/server'
export function middleware(req: NextRequest, ev: NextFetchEvent) {
return new Response('Hello, world!')
}
Nếu bạn thích viết bằng javascript thì dùng đoạn code dưới đây
Các bạn nên quan tâm đến thằng NextResponse, nó cung cấp cho chúng ta 4 phương thức trong middleware:
redirect(): chuyển hướng request từ route này đến 1 route khác
rewrite(): viết lại response của bạn
next(): tiếp tục sang 1 middleware khác trong chuỗi (middleware chain)
json(): trả về JSON response hoặc dữ liệu
import { NextResponse } from 'next/server'
import type { NextRequest } from 'next/server'
export function middleware(req: NextRequest) {
// if the request is coming from New York, redirect to the home page
if (req.geo.city === 'New York') {
return NextResponse.redirect('/home')
// if the request is coming from London, rewrite to a special page
} else if (req.geo.city === 'London') {
return NextResponse.rewrite('/not-home')
}
return NextResponse.json({ message: 'Hello World!' })
}
Chi tiết các bạn có thể xem thêm doc của NextJS dưới đây:
Giả sử chúng ta muốn xây dựng 1 trang thông báo với user rằng trang web hiện tại đang trong quá trình xây dựng (hoặc đang bảo trì, .. coming soon).
Để giải quyết bài toán, chúng ta sẽ tìm cách điều hướng tất cả các request đến website sang 1 trang thông báo trang đang xây dựng.
Trước hết chúng ta tạo 1 pages là underConstraction.js. Source code các bạn tự tùy biến theo ý bạn thích nhé (đơn giản là hiển thị thôi mà)
Tiếp đó chúng ta sẽ thực hiện logic điều hướng trong middleware
import type { NextFetchEvent, NextRequest } from "next/server";
import { NextResponse } from "next/server";
// In rewrite method you pass a page folder name(as a string). which // you create to handle underConstraction functionalty.
export function middleware(req: NextRequest, ev: NextFetchEvent) {
return NextResponse.rewrite("/underConstraction");
}
Ở đây các bạn cũng có thể dùng phương thức redirect, khác nhau ở chỗ nó sẽ thay đổi path (đường dẫn) hiển thị trên trình duyệt thôi.
Khi nào các bạn đã hoàn thiện website, không cần thông báo cho user nữa thì chỉ cần chỉnh sửa lại middleware của mình chút là được.
// you just call next() method to contious middlerware chain or call nextjs default middleware. your blog website file.
export function middleware(req: NextRequest, ev: NextFetchEvent) {
return NextResponse.next();
}
Đơn giản và tiện dụng đúng không ạ. Ngoài ví dụ đơn giản trên thì các bạn có thể xem thêm các ví dụ sử dụng middleware trong NextJS từ examples trên trang chủ:
Bài viết được sự cho phép của tác giả Trần Văn Dem
Khi lập trình backend bằng ngôn ngữ Java, nếu muốn chương trình chạy nhanh hơn chúng ta sẽ sử dụng khái niệm multithreading để tăng hiệu năng tổng thể của chương trình. Tuy nhiên khi sử dụng multithreading cũng sẽ gây ra các sai lầm về mặt dữ liệu nên chúng ta sẽ sử dụng các kỹ thuật như lock , synchronized để đảm bảo việc đó. Nhưng sử dụng các cơ chế này sẽ gây giảm hiệu năng chương trình của bạn xuống.
Các CPU hiện nay hỗ trợ rất tốt cho lập trình đa luồng nhưng hiểu rõ cách hoạt động của CPU sẽ giúp chương trình của bạn sẽ nhanh và chính xác hơn. Việc hiểu cách hoạt động của CPU để viết phần mềm tận dụng hết khả năng của phần cứng được biết đến với tên mechanical-sympathy. Bài này sẽ giúp mọi người hiểu rõ hơn về CPU, cách lập trình đa luồng tốt hơn.
Cách CPU xử lý dữ liệu
Sau đây là kiến trúc cơ bản của một CPU
Tại đây chúng ta thấy một CPU sẽ sử dụng chung một bộ nhớ cache L3. Các bộ nhớ L1,L2 sẽ là của riêng các core trong cpu. Tốc độ cpu truy cập các bộ nhớ L1,L2,L3 sẽ giảm dần và độ lớn của bộ nhớ cache L1,L2,L3 sẽ tăng dần. CPU sẽ không Load dữ liệu trực tiếp từ RAM để xử lý vì hành động này sẽ rất tốn thời gian. Khi cần thao tác với 1 biến thì CPU sẽ tìm tại bộ nhớ L1, L2, L3 nếu không có thì mới load từ RAM vào các bộ nhớ cache trên.
CPU sẽ không load dữ liệu cơ bản mà sẽ load theo dạng Cache line. Cache line này thường sẽ là 64b
Lý do CPU load dữ liệu theo Cache line bởi vì nó có thể tận dụng được 1 lần load được nhiều dữ liệu hơn và nếu các phép tính toán cần sử dụng các loại dữ liệu này thì sẽ không được load lại.
Ví dụ khi chúng ta duyệt giá trị trong 1 Array thì các phần tử Array sẽ được xếp cạnh nhau trong memory nên khi load vào để tính toán sẽ được load theo Cache line điều đó sẽ tăng performance của CPU. Với Java khi chúng ta khai báo biến nguyên thủy trong 1 Object thì các biến đó sẽ được xếp cạnh nhau trên RAM, với các biến Object thì chỉ chứa Reference chứ nội dung của nó sẽ được lưu ở chỗ khác tại memory*.
Nếu 2 biến X,Y cùng nằm trên 1 Cache line , Thread 0 sử dụng và thay đổi giá trị của biến X và xảy ra trước khi Thread 1 sử dụng biến Y. Điều này sẽ khiến Cache line bị CPU sẽ đánh dấu là Invalid và điều đó sẽ khiến Core 2 bắt buộc phải Load lại Cache line trước khi sử dụng biến Y. Điều trên được gọi là False Sharing.
False Sharing thực sự sẽ ảnh hưởng đến hiệu suất chương trình của bạn vì nó khiến Core load lại CacheLine nhiều lần điều đó sẽ càng phức tạp nếu nhiều hơn 2 luồng và mỗi luồng sẽ lại thay đổi 1 biến trên cache line. Vậy nên trước khi tăng tài nguyên thì hãy chắc chắn rằng chương trình bạn viết không bị False Sharing. Các bộ profile của intel sẽ cho bạn biết chương trình có đang bị False Sharing hay không nhưng có 1 cách đơn giản hơn khi lập trình MultiThread là hãy cố thiết kế hệ thống sao cho các Thread của bạn không sử dụng chung các object. Mỗi luồng sẽ có 1 bộ dữ liệu riêng để truy cập thay vì chia sẻ chung 1 Array, Map, Object,…
Tham khảo tại link dưới dây để đo hiệu năng khi chương trình bị False Sharing :
mechanical-sympathy.blogspot.com/2011/07/fa..
mechanical-sympathy.blogspot.com/2011/08/fa..
Race condition
Khái niệm race condition thì chắc hẳn ai code multi threading cũng biết và biết các cách chống lại điều này. Nhưng chắc cũng không ít anh em đọc đến False Sharing sẽ thấy lú là sao đã có False Sharing rồi nhưng lại có thể race condition được. Các CPU của intel, amd sẽ có 1 giao thức để thực hiện invalidcacheline. MESI Protocol tham khảo tại:
cs.utexas.edu/~pingali/CS377P/2018sp/lectur…
people.cs.pitt.edu/~melhem/courses/2410p/ch..
Protocol này được mô tả rất kỹ trong 2 link trên hoặc mọi người hãy search google để tìm đọc thêm về protocol này. Tóm tắt lại Protocol này sẽ đánh dấu cache line có 4 state sau :
Invalid (uncached)
Shared
Exclusive
Modified
Đây là mô tả chương trình của chúng ta khi bị race condition
CORE1 load counter vào bộ nhớ cache. Đánh dấu Cacheline là Exclusive
1 reg = reg + 1; reg = load(&counter);
CORE1 tăng biến reg. CORE2 load biến counter vào cache. Tại thời điểm này cả 2 Cacheline là Shared
2 store(&counter, reg); reg = reg + 1;
CORE1 lưu giá trị mới cho biến counter. CORE2 thực hiện tính toán. Tại thời điểm này CORE1 đánh dấu cache line là Modified, ngay sau đó CORE 2 sẽ nhận được cacheline đã bị thay đổi và đánh dấu cho Cache line là Invalid.
3 store(&counter, reg); Vì Cache line đã bị invalid nên CORE2 thực hiện load lại biến counter trước khi thực hiện hành động store. Và biến counter đã được CORE1 lưu lại trước đó nên tại đây CORE2 sẽ thực hiện lưu lại giá trị của CORE1 đã lưu.
Sau cùng cacheline của CORE1 sẽ là Invalid và CORE2 sẽ là Modified. Vì CORE1 đã thực hiện xong hành động nên khi được mark là Invalid lần tính toán sau CORE1 sẽ load lại cacheline này.
Vậy khi sảy ra trường hợp race condition chương trình chúng ta sẽ đưa ra một kết quả sai và tệ hơn nữa nó lại gây cho CORE thực hiện load lại nhiều lần cacheline vào trong bộ nhớ cache của mình.
Happens-before relationship Java
Trong Lập trình đa luồng của Java cung cấp cho chúng ta khái niệm happens-before relationship.
Trước khi tìm hiểu Happens-before relationship ta sẽ tìm hiểu về cách CPU thực hiện Instruction Reordering.
Các CPU hiện nay có khả năng sắp xếp thứ tự thực hiện các instruction để có thể thực thi chúng song song(parallel).
Ví dụ:
a = b + c
d = a + e
l = m + n
y = x + z
Sau khi CPU thực hiện Instruction Reordering
a = b + c
l = m + n
y = x + z
d = a + e
Với các instruction trên được sắp xếp lại, CPU có thể thực hiện 3 instruction đầu tiên song song vì chúng không phụ thuộc lẫn nhau trước khi thực thi instruction thứ 4 -> tăng performance.
Tuy nhiên trong vài trường hợp khi thực hiện thì Instruction Reordering sẽ dẫn đến việc chương trình thực hiện không đúng trên nhiều luồng như ví dụ sau đây:
Nếu CPU sắp xếp lại thứ tự thực hiện instruction (2) trước (1) thì ở Thread2 có thể xảy ra trường hợp điều kiện (3) đúng nhưng giá trị balance chưa được update -> chương trình sẽ không hoạt động đúng, vẫn lấy ra giá trị balance cũ. Ở đây Happens-before relationship sẽ giải quyết vấn đề đó, nó đảm bảo thứ tự thực hiện được giữ nguyên. Tất cả thay đổi xảy ra ở Thread1 trước khi ghi isDepositSuccess sẽ được nhìn thấy và cập nhật ở Thread2 khi đọc isDepositSuccess.
Trong Java, Happens-before relationship được đảm bảo khi sử dụng volatite, synchronized và java.util.concurrent.atomic.
Tham khảo link này về cách volatite, synchronized đảm bảo Happens-before relationship.
Nếu hành động X, Y được thực hiện trên 2 luồng khác nhau nhưng hành động X xảy ra trước khi hành động Y thì mọi thay đổi của X sẽ được luồng thực hiện hành động Y nhìn thấy và cập nhật. Theo cơ chế này chúng ta không cần nhất thiết phải sử dụng lock, synchronized để chia sẻ dữ liệu giữa các luồng chỉ cần đảm bảo một một quan hệ Happens-before-relationship thì dữ liệu sẽ được đồng bộ(sử dụng volatile trong trường hợp chỉ có duy nhất 1 luồng ghi).
Trong trường hợp có nhiều hơn 1 luồng sửa đổi dữ liệu chúng ta sẽ sử dụng các cơ chế lock, synchronized . Trong Java thì các hoạt động này cũng sẽ là happens-before relationship.
Concurrent is hard and lock is bad
Lập trình đa luồng là rất khó đối với tất cả developer để tránh race condition chúng ta thường sử dụng cơ chế lock. Đây là một cách dễ dàng nhất nhưng nó lại mang lại hiệu năng thấp nhất.
Lý do lock mang lại hiệu năng thấp hơn các thuật toán chia sẻ tài nguyên khác là khi sử dụng lock sẽ gây lên context switching trong CPU.
Khi CPU chuyển từ thực hiện logic của luồng hiện tại sang thực hiện logic của luồng khác, CPU cần phải lưu lại dữ liệu cục bộ, trạng thái,… của luồng hiện tại và load dữ liệu, con trỏ,… của luồng khác để thực hiện logic. Quá trình chuyển đổi này được gọi là context switching, quá trình này thực sự không hề rẻ nên bạn cần tìm cách tránh nó khi lập trình.
Bạn có thể thay thế bằng cách sử dụng cơ chế CAS trong Java đại diện là các lớp Atomic. Trên thực tế cũng có các thuật toán lock free xây dựng trên cơ chế CAS khi sử dụng các thuật toán này mọi người lưu ý code tránh bị trường hợp False Sharing. Có một thư viện xây dựng queue rất nổi tiếng dựa trên cơ chế CAS có hiệu năng cực cao trên Java là LMAX Disruptor. Nếu bạn đọc được code Java bạn nên đọc qua mã nguồn của thư viện này. Sau khi hiểu được cơ chế cũng như cách hoạt động của LMAX Disruptor thì khẳng định bạn sẽ dùng nó để tăng chương trình Multithreading của mình.
Kết Luận
Khi lập trình concurrency chúng ta cần cố gắng thiết kế các luồng đọc các dữ liệu khác nhau, hạn chế sử dụng lock vì sẽ gây context switching ảnh hưởng đến hiệu năng của hệ thống. Nếu làm được như vậy thì hệ thống của bạn đã làm theo một khái niệm mechanical-sympathy phần cứng sẽ giúp chương trình của bạn chạy nhanh nhất có thể. Lập trình concurrency là rất khó và để lập trình concurrency hiệu quả nhất thì lại càng khó hy vọng sau bài viết này các bạn sẽ có những keyword để phục vụ trong quá trình làm việc.
Ngay lúc này, hãy theo chân TopDev để gặp gỡ và trò chuyện cùng anh Takenaka Kazumasa – Hà Nội Branch Director và nghe anh chia sẻ về tầm nhìn, định hướng phát triển và cả những điều tuyệt vời tại chi nhánh mới này nhé!
Có ba lý do chính để chúng tôi đưa ra lựa chọn này :
Điều thứ hai nằm ở sự tương đồng về văn hóa. Chúng tôi tìm thấy ở người Việt Nam nhiều nét tính cách tương đồng hơn so với một số khu vực khác. Và hơn thế nữa, trụ sở Money Forward Nhật Bản hiện đang có khá nhiều thành viên đến từ Việt Nam.
Về việc lựa chọn mở rộng chi nhánh tại Hà Nội, một phần là vì chúng tôi muốn thử sức với nhiều thị trường khác nhau tại Việt Nam để mở rộng quy mô cho tập đoàn Money Forward. Và ở thời điểm hiện tại thì tốc độ phát triển của Money Forward đang rất nhanh và điều đó đòi hỏi chúng tôi phải mở rộng thêm chi nhánh. Vì thế chúng tôi quyết định “cập bến” tại Hà Nội – một trong những thị trường CNTT lớn nhất Việt Nam.
Đây là một mảnh đất màu mỡ, rất tiềm năng và có nhiều cơ hội để phát triển. Về mặt vĩ mô, nền kinh tế Việt Nam đang trên đà phát triển mạnh mẽ, đây chính là môi trường lý tưởng cho sự vươn lên của các doanh nghiệp Fintech. Ngoài ra, như đã đề cập thì Việt Nam là quốc gia sở hữu nguồn lực tuyệt vời về Developer, vậy nên cả môi trường và năng lực đều phù hợp cho lĩnh vực Fintech. Đó cũng là lý do mà nhiều công ty nước ngoài và start-up Việt Nam hướng tới phát triển lĩnh vực Fintech tại đây. Tôi cũng có một người bạn Nhật Bản đang kinh doanh mảng Fintech tại Việt Nam nữa đấy!
Và hơn hết, chúng tôi, Money Forward Việt Nam, đang hướng tới phát triển các sản phẩm Fintech tại thị trường Việt Nam trong tương lai chứ không chỉ riêng ở Nhật Bản.
Điểm tôi đặc biệt chú ý về các Lập trình viên Việt Nam là họ vô cùng tâm huyết với nghề. Nhiều người đã có thể vạch ra được kế hoạch và có tầm nhìn riêng về sự nghiệp của chính mình. Vì thế mà họ có động lực phát triển mạnh mẽ và có vốn kinh nghiệm hoặc kỹ năng khá vững.
Chúng tôi mong muốn trở thành lợi thế cạnh tranh của tập đoàn Money Forward và cung cấp nhiều giá trị hơn nữa đến cho người dùng. Cá nhân tôi hi vọng có thể xây dựng Money Forward Vietnam tại Hà Nội trở thành chi nhánh công nghệ hàng đầu của tập đoàn có thể cung cấp các giải pháp cho bất kì hệ thống phức tạp nào. Và đồng thời, chúng tôi muốn nhân rộng những văn hóa trong đội ngũ ở Hà Nội đến các đội nhóm của Money Forward trên khắp thế giới.
Hình ảnh khai trương tại chi nhánh Money Forward Vietnam tại Hà Nội
Money Forward Việt Nam là công ty Product, chúng tôi không chỉ tập trung vào công nghệ mà còn quan tâm đến các giá trị cho người dùng. Với quan hệ hợp tác PdM, các Lập trình viên có thể thoải mái đề xuất ý tưởng để làm cho mỗi sản phẩm ngày càng hoàn thiện hơn. Chúng tôi tạo điều kiện để họ xem những thành phẩm ấy như thể sản phẩm của chính mình. Sau khi nhận được sự tin tưởng từ Money Forward Nhật Bản, các dự án của chúng tôi sẽ ngày càng nhiều thách thức hơn.
Văn phòng đang được hoàn thiện từng ngày nhưng chắc chắn sẽ là điểm đến lý tưởng cho các Lập trình viên đấy! Văn phòng sẽ được đặt trong điều kiện ánh sáng phù hợp, không gian rộng mở với thiết kế tương tự như trụ sở chính và chi nhánh Hồ Chí Minh.
Ngoài ra công ty cũng lắp đặt máy pha cà phê espresso và bàn chơi bida để các thành viên nhóm có thể thư giãn và còn nhiều hoạt động khác cùng công ty nữa.
Điều đầu tiên chính là kỹ năng về thiết kế và viết code để phát triển các sản phẩm chất lượng cao. Vì người dùng Nhật Bản rất khắt khe đối với chất lượng sản phẩm đặc biệt là trong lĩnh vực B2B. Họ yêu cầu cao về các lỗi và cả hiệu suất sản phẩm, cho nên bạn cần phải có kỹ năng xây dựng sản phẩm thật vững để xử lý lượng lớn dữ liệu mà không xảy ra lỗi. Và kĩ năng làm việc cùng đội nhóm, tất nhiên cũng là một trong những điều quan trọng để xây dựng văn hóa doanh nghiệp nữa.
Đây hẳn là một câu hỏi khó nhằn đấy! Nhưng cũng có vài điều tôi muốn chia sẻ. Thứ nhất là về kỹ năng chuyên môn, chúng tôi không chỉ tập trung vào những công nghệ mới nhất, bởi với Money Forward thì mang lại giá trị cho người dùng thông qua việc phát triển sản phẩm chính là mục tiêu quan trọng. Ngoài ra, để phát triển một sản phẩm tốt, kỹ năng đối với các công nghệ mới nhất là chưa đủ, lập trình cũng cần quan tâm đến cả quá trình thực hiện, teamwork nữa. Chưa hết, việc học các kiến thức nền như DB, storage,… cũng cực kì quan trọng, giúp ích rất nhiều trong việc sử dụng công nghệ một cách chính xác. Và chúng ta cũng cần xem xét về điều gì phù hợp với bản thân chứ không nên bị ảnh hưởng bởi các xu hướng mới.
Cảm ơn những chia sẻ hữu ích từ anh Takenaka Kazumasa về những điều tuyệt vời tại Money Forward Việt Nam. Hi vọng Money Forward Việt Nam chi nhánh Hà Nội sẽ đạt được những khát vọng của mình và ngày càng phát triển vững mạnh hơn nữa. Rất mong nhận được những chia sẻ thú vị hơn nữa từ anh trong thời gian tiếp theo.
Đừng quên tham khảo thêm một số việc làm IT lương cao HOT nhất tại Money Forward Việt Nam nhé:
Bài viết được sự cho phép của tác giả Phạm Minh Khoa
Anh em làm frontend web thường xuyên làm việc với HTML CSS, khi các bạn viết xong code và thực hiện chạy nó trên browsers (trình duyệt), chúng sẽ được xử lý qua 1 chuỗi các bước để xây dựng và hiển thị trang web đó lên. Các bạn có bao giờ lăn tăn xem trình duyệt cụ thể là làm những gì đối với file .html của chúng ta không? Bài viết này sẽ giới thiệu với các bạn các bước xử lý của trình duyệt. Trước tiên thì chúng ta sẽ sử dụng file html sau (có chứa có css và script)
Khi trình duyệt nhận được file HTML, nó sẽ thực hiện luồng các bước xử lý như sau:
Sử dụng file HTML để tạo DOM (Document Object Model)
Sử dụng CSS để tạo CSSOM (CSS Object Model)
Chạy Script xử lý DOM và CSSOM kết hợp để tạo thành Render Tree
Sử dụng Render Tree để Layout (xác định size và position của toàn bộ phần tử trên trang web)
Paint tất cả các pixel (hiển thị lên màn hình)
Cụ thể chúng ta sẽ đi vào từng bước nhé:
Bước 1: HTML
Trình duyệt đọc file HTML từ trên xuống dưới và sử dụng nó để tạo ra các node từ file HTML. Như file HTML đầu bài, các node sẽ được sinh ra như hình trên, từ đó sẽ tạo thành cây DOM.
Lưu ý: từ việc tạo DOM trên thì chúng ta nên đặt style ở ngay trên đầu và script ở cuối file vì style luôn cần được load sớm, còn script thì ngược lại càng muộn càng tốt (vì phải có HTML với CSS thì script mới chạy).
Ở đây chúng ta thấy rằng Trình duyệt sẽ chỉ Render Tree được khi DOM và CSSOM được tạo hoàn chỉnh, vì thế CSSOM sẽ chặn quá trình render trang web và chúng ta có 1 khái niệm gọi là “Render Blocking” để chỉ những node liên quan đến style dùng để tạo CSSOM. Cũng vì thế mà chúng ta nên giảm kích thước style và load chúng càng sớm càng tốt, ngược lại những style dư thừa (hoặc chưa cần thiết) thì nên cắt bớt hoặc trì hoãn tải tối đa có thể.
Nếu trình duyệt tìm thấy những javascript node (external hoặc internal) như dưới đây
// An external script
<script src="app.js"></script>
// An internal script
<script>
alert("Oh, hello");
</script>
lúc đó việc parse file HTML và tạo DOM/CSSDOM node sẽ bị dừng lại để chờ xử lý. Từ đó chúng ta lại có thêm 1 thuật ngữ là “Parser blocking” để chỉ những đoạn JavaScript trên. Ví dụ ta có 1 đoạn script như sau:
var button = document.querySelector("button");
button.style.fontWeight = "bold";
button.addEventListener("click", function () {
alert("Well done.");
});
Nó sẽ ảnh hưởng đến DOM và CSSOM như sau:
Vì những script có thể cần đến HTML hoặc style để xử lý, do vậy chúng ta nên chạy script khi những phần tử đó đã sẵn sàng. Nếu có nhiều external script thì trình duyệt sẽ tải về và chạy lần lượt theo thứ tự trước sau.
Lưu ý: chúng ta có thể sử dụng attribute “async” để tải script về 1 cách không đồng bộ trên 1 thread khác và tiếp tục parse trang, khi nào việc tải về hoàn tất thì nó sẽ được chạy.
<script src="async-script.js" async></script>
<script src="defer-script.js" defer></script>
async và defer đều là trì hoàn việc tải script về để không chặn việc load trang; điểm khác nhau là defer sẽ chỉ chạy khi HTML parse xong và chạy theo thứ tự, còn async thì có thể chạy ở bất kỳ thời điểm nào khi nó load xong. Các bạn có thể xem hình dưới để dễ hình dung:
Từ đó ta thấy async sẽ hữu ích với những script không tác động gì đến DOM/CSSOM, không ảnh hưởng gì đến UX, ví dụ như analytics hoặc tracking. Còn defer thì sẽ hữu ích với những script tác động đến Render Tree nhưng không liên quan gì đến việc hiển thị phần above the fold (phần trên nếp gấp) của trang web hoặc cần những script khác chạy trước nó.
Bước 4: Render Tree
Khi tất cả các node đã được đọc, DOM và CSSOM đã sẵn sàng thì trình duyệt sẽ ghép chúng lại và dựng Render Tree.
Bước 5: Layout
Ở bước này, trình duyệt sẽ xác định size và position của tất cả các phần tử trên trang web.
Bước 6: Paint
Bước cuối cùng là vẽ và hiển thị trang trên màn hình.
Nhìn thì nhiều bước thế thôi nhưng toàn bộ quá trình này thưởng chỉ diễn ra trong vài giây hoặc vài chục giây. Tối ưu tốc độ load trang là 1 việc không dễ cho các frontend developer. Hy vọng bài viết sẽ cho các bạn cái nhìn tổng quan về quá trình 1 website được tạo ra.
Hàng ngày, cá nhân hoặc doanh nghiệp đều tiếp nhận và xử lý một lượng dữ liệu nhất định. Theo năm tháng, lượng dữ liệu này trở nên khổng lồ và đòi hỏi một nơi lưu trữ đầy đủ nhằm đảm bảo hiệu quả cho những bước phân tích tiếp theo, cũng như giúp nâng cao tốc độ cho các kết quả trả về của hệ thống. Data warehouse đảm nhận nhiệm vụ này. Để hiểu rõ hơn Data Warehouse là gì, bạn hãy theo dõi bài viết bên dưới.
1. Data Warehouse là gì?
Data warehouse (DW) hay kho dữ liệu là một hệ thống lưu trữ dữ liệu từ nhiều nguồn, nhiều môi trường khác nhau như: phần mềm bán hàng, kế toán, nhân sự hay hệ thống lõi ngân hàng,… giúp tăng cường hiệu suất của các truy vấn cho báo cáo và phân tích.
Data Warehouse hoạt động như một kho lưu trữ trung tâm. Dữ liệu đi vào kho dữ liệu từ hệ thống giao dịch và các cơ sở dữ liệu liên quan khác. Sau đó, dữ liệu được xử lý, chuyển đổi để người dùng có thể truy cập những dữ liệu này thông qua công cụ Business Intelligence, SQL client hay bảng tính.
Một Data Warehouse thường bao gồm các yếu tố như:
Một cơ sở dữ liệu quan hệ để lưu trữ và quản lý dữ liệu.
Giải pháp trích xuất, tải và biến đổi ELT để chuẩn bị dữ liệu cho phân tích.
Khả năng phân tích thống kê, báo cáo và khai thác dữ liệu.
Các công cụ phân tích khách hàng để trực quan hóa và trình bày dữ liệu cho người dùng doanh nghiệp.
Các ứng dụng phân tích khác, phức tạp hơn tạo ra thông tin có thể hành động bằng cách áp dụng khoa học dữ liệu và thuật toán trí tuệ nhân tạo AI hoặc các tính năng đồ thị và không gian cho phép nhiều loại phân tích dữ liệu hơn trên quy mô lớn.
Sau khi hiểu được Data Warehouse là gì và cách thức hoạt động của nó, chúng ta tiếp tục tìm hiểu về những đặc tính cũng như lợi ích mà kho dữ liệu này mang lại cho cá nhân cũng như doanh nghiệp
2. Những đặc tính của Data Warehouse
2.1. Hướng chủ đề (subject-oriented)
Hướng chủ đề tức thông tin trong Data Warehouse sẽ được tổ chức và sắp xếp theo một chủ đề nhất định. Ví dụ, chủ đề phân tích bệnh án bệnh nhân, bệnh liên quan đến tim, thì bác sỹ cần quan tâm không chỉ một mà còn phải có các chỉ số liên quan đến máu, chỉ số về huyết áp, nhịp tim, điện tâm đồ. Ngoài ra còn cần theo dõi theo thời gian để xem xét sự thay đổi mà có phương pháp điều trị kịp thời. Trong trường hợp này thời gian được gọi là chiều phân tích.
Mục đích của Kho dữ liệu là phục vụ các yêu cầu phân tích, hoặc khai phá cụ thể được gọi là chủ đề.
2.2. Được tích hợp (integrated)
Mở rộng cho ví dụ trên, các khoa khác nhau tại bệnh viện sẽ thực hiện nhiều xét nghiệm khác nhau. Tương tự với doanh nghiệp, dữ liệu cần phân tích nằm rải rác tại những phòng ban khác nhau và cần tích hợp lại. Từ đó, tổng hợp dữ liệu từ nhiều nguồn vào một kho dữ liệu cho phép chúng ta có thể xem đồng thời nhiều nhóm chỉ tiêu khác nhau. Quá trình tích hợp này sẽ được thực hiện trong quá trình ETL.
2.3. Có gán nhãn thời gian (time variant)
Vì dữ liệu thay đổi liên tục nên chúng sẽ được gán 1 nhãn thời gian tương ứng tại thời điểm nhập liệu. Việc gắn thời gian này giúp ta dễ dàng so sánh dữ liệu với nhau để biết được các thay đổi đang đi theo chiều hướng tích cực hay tiêu cực.
Ví dụ, so sánh độ đo doanh thu của một mặt hàng của tháng hiện tại với tháng trước, tháng này năm trước thì sẽ có nhiều thông tin hơn để đánh giá doanh thu của mặt hàng đó là tốt hay không, trên cơ sở đó sẽ có các quyết định phù hợp. Ngoài ra, dữ liệu lịch sử còn cho phép dự báo được tương lai khi ứng dụng khai phá dữ liệu.
Dữ liệu trong Kho dữ liệu có chức năng báo cáo lại các chỉ số về hoạt động kinh doanh thực tế đã xảy ra do đó không thể cập nhật, thay đổi vì nó sẽ không phản ánh đúng thực tế. Vì vậy, với kho dữ liệu chỉ có 2 thao tác chính là tải dữ liệu vào kho và truy cập (đọc) dữ liệu từ kho.
3. Data warehouse mang lại lợi ích gì?
Sự xuất hiện của kho dữ liệu nhằm mục đích đáp ứng lượng dữ liệu ngày càng tăng cần được xử lý. Nhu cầu lưu trữ dữ liệu tăng lên đi kèm với đó là sự phức tạp của hệ thống máy tính. Từ đó, ta thấy được những lợi ích mà kho dữ liệu mang lại cho doanh nghiệp như:
Tích hợp dữ liệu vào một nguồn, ở cùng một định dạng, giải quyết sự phân mảnh và mất cân bằng dữ liệu để đáp ứng nhu cầu thông tin của tất cả người dùng.
Tiết kiệm thời gian và hiệu quả trong việc tìm kiếm dữ liệu cần thiết.
Thông qua xử lý và phân tích dữ liệu Data Warehouse giúp cho dữ liệu của doanh nghiệp hiệu quả hơn.
Giúp người dùng đưa ra các quyết định hợp lý, nhanh chóng và hiệu quả, đem lại nhiều lợi nhuận hơn,…
Giúp tổ chức, xác định, quản lý và thực hiện các dự án/hoạt động một cách hiệu quả và chính xác.
Tăng đáng kể lượng dữ liệu cần được tổng hợp, lưu trữ và xử lý.
Trên đây là bài viết mang cái nhìn tổng quan về Data Warehouse là gì, định nghĩa và những khái niệm liên quan. Để hiểu sâu hơn các bạn có thể tìm hiểu về cách thức hoạt động chuyên sâu cũng như cấu trúc của Data Warehouse, các khái niệm liên quan như OLTP, OLAP,…
Trong nội dung bài này, mình sẽ giải thích vì sao lại có hiện tượng tràn bộ nhớ Stack, và đặc biệt hay xảy ra khi gọi đệ quy.
Một số khái niệm
Bộ nhớ Stack: bộ nhớ dành riêng cho việc lưu trữ các biến cục bộ, tham số, kết quả trả về, và ghi nhớ các thanh ghi. Bộ nhớ này có giới hạn về kích thước.
Push: thao tác push và stack
Pop: thao tác lấy ra từ stack.
RBP – register base pointer – thanh ghi chứa địa chỉ bắt đầu của stack được sử dụng trong chương trình con hiện tại.
RSP – register stack pointer – đỉnh của stack hiện tại. Giá trị địa chỉ của stack sẽ giảm dần khi mình tăng kích thước của stack.
Vào bài thôi
Xét một hàm đơn giản như sau:
int add(int a, int b) { return a + b;}
Ta thấy trong hàm này có 2 tham số là a và b. Khi biên dịch hàm này trên chip Intel 64bit ta có kết quả như sau:
_add: pushq %rbp # đẩy giá trị của rbp vào bộ nhớ stack movq %rsp, %rbp # gán địa chỉ bắt đầu bằng đỉnh của stack. movl %edi, -4(%rbp) # chuyển giá trị của tham số thứ nhất từ thanh ghi %edi vào ô nhớ có địa chỉ %rbp - 4 (số int có kích thước 4 byte) movl %esi, -8(%rbp) # chuyển giá trị của tham số thứ hai (b) từ thanh ghi %esi vào ô nhớ có địa chỉ %rbp - 8 movl -4(%rbp), %eax # gán a cho thanh ghi %eax - thanh ghi %eax sẽ chứa giá trị trả về của hàm addl -8(%rbp) %eax # cộng b cho thanh ghi %eax popq %rbp # phục hồi lại địa chỉ bắt đầu stack cho %rbp retq # trở lại
Ta thấy hàm này này sử dụng tổng cộng 16 bytes trên stack (8 bytes để lưu %rbp và 8 bytes để lưu tham số a, b), khi gọi hàm này thì đỉnh của stack giảm đi 16 bytes. Sau khi kết thúc lời gọi hàm này thì bộ nhớ stack được giải phóng (tăng lên lại 16 bytes), đơn giản chưa mọi người?
Bây giờ ta sẽ xét tiếp trường hợp một hàm đệ quy:
Xét đoạn code sau:
int factorial(int n) { if (n == 0) { return 1; } return n * factorial(n - 1);}
Đoạn này sẽ được dịch ra Assembly như sau:
_factorial: pushq %rbp # tương tự, đẩy giá trị của rbp vào bộ nhớ stack movq %rsp, %rbp # gán địa chỉ bắt đầu bằng đỉnh của stack. subq $16, %rsp # trừ bộ nhớ stack đi thêm 16 bytes …. callq _factorial # gọi đệ quy … addq $16, %rsp # cộng đỉnh stack lại 16 bytes popq %rbp # phục hồi địa chỉ bắt đầu của stack retq # trả về
Khi trong hàm chúng ta có lời gọi hàm thì chương trình sẽ tính lại đỉnh của stack (trong trường hợp này là -16 bytes, để dành 16 bytes để lưu các giá trị tính toán trung gian trong hàm). Trong hàm này, tổng cộng bộ nhớ stack được sử dụng là 24 bytes (16 bytes + 8 bytes để lưu con trỏ %rbp). Sau khi gọi hàm thì 24 bytes này sẽ được phục hồi và trả về lại trên hệ thống.
Nếu chúng ta gọi đệ quy thì bộ nhớ stack sẽ tăng liên tục sau mỗi lời gọi hàm, do bộ nhớ STACK có giới hạn, nên sẽ bị TRÀN STACK!!
Tada!! quá dễ sao nói rườm rà vậy?? Hy vọng lời giải thích rườm rà này sẽ giúp các bạn hiểu ra bản chất của vấn đề.
Tái bút:
Thêm 1 lí do để viết Assembly vì hàm add trên trình duyệt làm hơi rườm rà, không cần xài stack luôn.
_add: movl %edi, %eax addl %esi, %eax retq
Gọi là “Tràn Stack” có vẻ hơi sai vì địa chỉ stack được đánh giá ngược nên nó giảm cho đến khi bị tràn, chắc phải gọi là hụt stack mới đúng.
Bộ nhớ stack không tự động bị xoá đi sau khi kết thúc lời gọi hàm, nên password, key, không nên lưu trữ dạng raw trong bộ nhớ để tránh bị quét bộ nhớ. Sau khi xử lí nhớ dọn dẹp.
Bài viết được sự cho phép của tác giả Lại Đình Cường
Chạy debug WordPress là cách tốt nhất để kiểm tra lỗi trong quá trình bạn viết code. Bài viết này sẽ dành cho các bạn đang phát triển giao diện hoặc plugin cho WordPress. Nội dung bài này sẽ hướng dẫn cho bạn cách bật debug, kiểm tra lỗi phát sinh trong quá trình viết code nhằm giúp sản phẩm của bạn được hoàn thiện hơn.
Hướng dẫn chạy debug WordPress
Chạy debug PHP là một phần quan trọng của mọi dự án lập trình web dựa trên mã nguồn mở PHP. Đối với WordPress thì hệ thống debug được thiết kế để bạn có thể sử dụng một cách dễ dàng nhằm kiểm tra lỗi trong quá trình viết code. Nó có thể kiểm tra được code trong nhân của WordPress cũng như kiểm tra code của giao diện và plugin.
WP_DEBUG
Biến WP_DEBUG là một hằng số được khai báo trong tập tin wp-config.php. Hằng này có chức năng cho phép bạn bật hoặc tắt debug trong WordPress. WP_DEBUG là hằng số có giá trị là kiểu bool (đúng hoặc sai). Bạn có thể khai báo trong tập tin wp-config.php, nếu bạn đặt giá trị là true thì có nghĩa là chức năng debug được bật, ngược lại nếu bạn đặt là false thì chức năng debug được đặt trong trạng thái tắt.
Chú ý: Giá trị của hằng số WP_DEBUG là thuộc kiểu boolean (true/false), do vậy bạn chỉ cần gõ vào giá trị là true hoặc false, bạn không cần phải để dấu nháy đơn hoặc nháy kép hoặc bất kỳ thứ gì khác vào đây. Nếu bạn điền giá trị là ‘false’ thì hằng này được coi như là có giá trị true vì chữ false được bỏ trong dấu nháy đơn nên nó được coi là một chuỗi.
Và bạn chỉ cần bật debug để kiểm tra lỗi phát sinh trong quá trình thực hiện code thử nghiệm, còn đối với các trang hoạt động chính thức thì bạn nên tắt chức năng này đi.
PHP Errors, Warnings và Notices
Đây là những dạng bạn hay thấy trong khi lập trình PHP, nếu bạn bật chức năng chạy debug thì hệ thống sẽ theo dõi các dòng code mà phát sinh ra lỗi, hoặc cảnh báo hoặc là chú ý.
Tùy vào cấu hình của bạn mà các thông báo này được xuất ra ngoài trang web hoặc không. Nếu bạn không cho xuất ra bên ngoài thì hệ thống sẽ sao lưu lại thông báo lỗi trong một tập tin log để bạn có thể xem và khắc phục.
Thật khó để bạn có thể tìm ra lỗi ở một dự án lớn nếu như không có chức năng debug này. Đối với WordPress cũng vậy, nếu bạn bật debug lên thì mọi lỗi trong dự án của bạn đều có thể được tìm thấy dễ dàng.
Deprecated là thông báo các hàm hoặc các tham số đầu vào được thay thế bởi các hàm hoặc tham số đầu vào khác. Nếu bạn bật chức năng chạy debug thì tất cả các hàm và tham số được đánh dấu là deprecated sẽ được hệ thống cảnh báo.
Deprecated có nghĩa là bạn phải sử dụng hàm mới hoặc tham số mới để thay thế, vì các hàm cũ sẽ không còn tương thích đối với phiên bản mới hoặc các hàm này có thể bị xóa bỏ trong tương lai.
WP_DEBUG_LOG
WP_DEBUG_LOG là một hằng số có giá trị là kiểu bool như mình nói ở bên trên. Nếu như bạn khai báo hằng số này có giá trị là true thì các thông báo lỗi sẽ được lưu lại vào tập tin debug.log.
define('WP_DEBUG_LOG', true);
Bạn có thể tìm thấy tập tin sao debug.log trong thư mục wp-content của WordPress, trong này sẽ chứa các thông báo lỗi cũng như nội dung khác bạn ghi vào trong quá trình kiểm tra debug WordPress.
WP_DEBUG_DISPLAY
WP_DEBUG_DISPLAY là một hằng số có giá trị là kiểu bool, bạn có thể bật hoặc tắt chức năng cho phép hiển thị thông báo lỗi ra ngoài màn hình hoặc là ẩn tất cả thông báo lỗi.
Bật debug trong tập tin wp-config.php
Bên dưới là ví dụ cơ bản nhất về cách bật chức năng debug WordPress để kiểm tra lỗi. Bạn có thể thêm vào các dòng khai báo bên dưới vào trong tập tin wp-config.php. Nhớ là phải thay lại hằng số WP_DEBUG có sẵn trong tập tin config đi nhé.
// Bật chức năng chạy debug define('WP_DEBUG', true); // Bật chức năng sao lưu thông báo lỗi vào tập tin /wp-content/debug.log define('WP_DEBUG_LOG', true); // Ẩn các thông báo lỗi và cảnh báo ra bên ngoài màn hình define('WP_DEBUG_DISPLAY', false); @ini_set('display_errors', 0);
Nếu bạn muốn chạy debug WordPress một cách đầy đủ hơn thì bạn làm như sau. Bạn hãy thay thế nguyên đoạn chú thích trước khi khai báo hằng số WP_DEBUG và cả dòng khai báo hằng số này thành đoạn code như bên dưới:
define('WP_DEBUG', true); /* Add any custom values between this line and the "stop editing" line. */ /** * Auto detect domain */ $protocol = (isset($_SERVER['HTTPS']) && strtolower($_SERVER['HTTPS']) != 'off') ? 'https://' : 'http://'; $url = $protocol . $_SERVER['SERVER_NAME']; $folder = basename(dirname(__FILE__)); if ( ! empty($folder) && false === strpos($url,$folder)){ $url .= '/'; $url .= $folder; } define('WP_HOME', $url); define('WP_SITEURL', WP_HOME ); /** * Change defaults value for better performance */ define('WP_MEMORY_LIMIT', '256M'); define('WP_MAX_MEMORY_LIMIT', '256M'); define('EMPTY_TRASH_DAYS', 3 ); define('AUTOSAVE_INTERVAL', 300 ); define('WP_POST_REVISIONS', 1 ); define('WP_DEBUG_LOG', WP_DEBUG ); define('SAVEQUERIES', false); define('WP_DEBUG_DISPLAY', false); @ini_set('log_errors', 'On'); @ini_set('display_errors', 'Off'); /* That's all, stop editing! Happy publishing. */
Trong trường hợp bạn muốn áp dụng cho trang chính của bạn đang hoạt động trên mạng, bạn chỉ cần tắt debug đi là được nhé. Bạn chỉ cần khai báo dòng define( 'WP_DEBUG', true ); thành define( 'WP_DEBUG', false);.
Bài viết được sự cho phép của tác giả Lê Xuân Quỳnh
Qua 1 vòng Google để tìm hiểu về JWT thì không thấy ông Việt Nam nào nói cho tử tế và đầy đủ để 1 thằng newbie như mình hiểu. Sau đó vô tình mình tìm kiếm một bài viết mình cho là ổn nhất về JWT, nên mạo phép vừa dịch vừa sử dụng theo ý mình, những ai đọc được tiếng Anh có thể xem ở đây cho chuẩn: https://medium.com/swlh/building-a-user-auth-system-with-jwt-using-golang-30892659cc0
Vậy JWT là gì?
Chúng ta đều biết rằng, để nâng cao tính bảo mật khi làm các ứng dụng client-server thì cần có các cơ chế sinh token nhằm xác định request hợp lệ, tránh tình huống bị tấn công bởi các hacker vào hệ thống.
JWT = JSON Web Token, hiểu nôm na là xác thực người dùng từ phía máy chủ bằng JSON.
Theo cách tiếp cận truyền thống, chúng ta có các sessions để xác thực người dùng, khi mà người dùng đăng nhập thành công thì sẽ tạo ra 1 token lưu trên máy chủ để xác thực cho các request tiếp theo. Server sẽ gửi sessions ID cho client, và client sẽ gửi ID này kèm với các request sau đó, để server query trên database nhằm kiểm tra xem có đúng đó là request hợp lệ không.
Tuy nhiên, phương pháp này gặp nhiều khó khăn khi hệ thống cần scale lớn, xây dựng theo dạng Microservice với data lưu ở mỗi service khác nhau. Ví dụ bạn có n cụm máy chủ, thì để xác thực thành công, bạn phải truy vấn token lưu ở n máy chủ rồi so sánh, rất mất thời gian, cũng như dễ bị tấn công nếu như 1 máy chủ nào đó bị tấn công chiếm token. Tốt nhất là không lưu token trên máy chủ.
JWT ra đời nhằm giải quyết bài toán đó. Nó là phương pháp xác thực cho MSA(microservice architecture). Với cách tiếp cận này, thông tin xác thực chỉ lưu ở client-side. JWT đơn giản là 1 JSON payload để lưu định danh user đó. Nó đơn giản là 1 token chứa thông tin xác thực dạng Message Authentication Code(MAC), gồm 3 thành phần chính: header, payload và signature ngăn cách nhau bởi dấu chấm.
Chúng ta thấy rất nhiều ký tự loạn xị ngậu lên, bản chất là đoạn string đã encode sang base64, ngăn cách nhau bởi các dấu chấm. Chúng ta vào trang jwt.io và copy cái token trên dán vào như sau:
Chúng ta thấy 1 token có 3 thành phần sau khi decoded như sau:
Phần header chứa metadata, bao gồm kiểu mã hóa của token, ở trên là HS256, dạng JWT. Để hiểu hơn các dạng mã hóa vui lòng tìm kiếm thêm từ khóa mã hóa công khai trên Google bạn nhé.
Phần Payload chứa thông tin xác định thằng user đó, ở trên là tên, sub, iat.
Phần còn lại là chữ ký. Chữ ký này là chữ ký điện tử các bạn nha, không phải là chữ ký khi bạn ký đơn kết hôn với vợ đâu, nhưng về mặt ý nghĩa thì nó cũng tương tự, là 1 khi đã ký thì bạn không thể thay đổi được nữa, bút sa gà chết.
hmacsha256 chính là 1 hàm băm sha 256, bạn hiểu nôm na là băm xong thì không chuyển ngược lại giữ liệu ban đầu, hay nói cách khác là 1 hàm 1 chiều, giống như bạn cho 1 con bò vào máy và tạo ra 1 cây xúc xích còn điều ngược lại thì không thể vậy đó. Hàm này băm header, encoded payload và khóa bí mật của server. Khái niệm băm cũng y chang bạn băm thịt vậy, cho xương, thịt.. mọi thứ và băm nhuyễn đến khi nào bạn lấy 1 mẩu trong đó ra thì nó có tính chất tương tự mọi nơi ở cục thịt sau khi băm.
Do vậy, khi chúng ta gửi 1 request gồm header và payload sau khi encoded trên thì phía server sẽ tiến hành băm chúng với khóa bí mật của server và tạo ra 1 chữ ký, rồi gửi lại cho client. Các lần request tiếp theo, nó cũng làm tương tự và tiến hành so sánh chữ ký mới nhất với chữ ký đã có trước đó, nếu như nó trùng nhau nghĩa là matches, request là hợp lệ. Luồng hoạt động của nó như sau:
Client gửi thông tin đăng nhập gồm username và password.
Server kiểm tra thông tin đó có tồn tại trong database không và tính hợp lệ của request.
Nếu hợp lệ, JWT sẽ tạo 1 payload chứa thông tin định danh user và thời gian hiệu lực – expiration timestamp(chúng ta sẽ nói sau).
Server sẽ tạo ra signature gồm 2 thành phần như đã nói ở trên. JWT đã hoàn thành xong 1 token gồm 3 thành phần header + payload + signature.
Server sẽ gửi lại cho client thông tin token này để lưu lại, nhằm để client xác thực trong các request sau này.
Với các request tiếp theo, server sẽ xác thực token bằng việc kiểm tra thời gian hiệu lực của token và tạo ra 1 chữ ký mới, sau đó so sánh với chữ ký đã sẵn có trong token.
Sơ đồ hoạt động của JWT.
Vậy rõ ràng server không hề lưu token mà nó chỉ lưu duy nhất mỗi secret key để tạo ra chữ ký mà thôi. Cho nên nếu giả sử như chúng ta bị lộ khóa tới tay hacker thì server rất dễ bị tấn công. Do vậy chúng ta phải bảo mật khóa này. Có nhiều trường hợp commit cả khóa lên source code, dẫn đến lộ thông tin khóa mà server bị tấn công. Về phần này, các bạn có thể đọc thêm về cơ chế gitignore các file .env để không commit các thông tin nhạy cảm như khóa.
Cho đến thời điểm này khi nói về JWT thì chúng ta chỉ nói 1 khái niệm token chung. Nhưng thực tế chúng ta có 2 loại token, đó là AccessToken và RefreshToken.
Bản chất 2 thằng trên đều là JSON Web Token, vậy tại sao lại cần tới 2 cái lận? Như bạn đã biết, JWT chứa đầy đủ thông tin cần thiết để xác thực, và hãy thử tượng tượng xem điều gì sẽ ra khì token này lọt vào 1 tay hacker nào đó. Hắn có thể sẽ giả mạo người dùng và bắt đầu làm chuyện tầm bậy với server của chúng ta như ăn cắp dữ liệu, tệ hơn là phá hỏng database. Do vậy người ta đẻ ra 1 cái gọi là access token, nhằm valid mỗi request của chúng ta, nó có đặc điểm là sẽ hết hạn sau 1 khoảng thời gian ngắn. Điều này nhằm hạn chế rủi ro khi hacker có được access token của bạn, họ cũng không phá hoại được nhiều.
Vậy thì khi access token này hết hạn, đồng nghĩa với việc user này cũng sẽ hết quyền truy vấn, do vậy chúng ta cần loại token thứ 2 để refresh lại token này, gọi là refresh token. Ở đây chúng ta cũng có thể check time expried của token, tuy nhiên giả sử như token hết hạn thì ta phải yêu cầu người dùng đăng nhập lại nhiều lần, làm cho người dùng khó chịu mà bỏ app, thì không ai muốn đúng không?
Refresh token này sẽ không bao giờ hết hạn hoặc hết hạn trong khoảng thời gian dài(ví dụ Google, github và Facebook thường là 90 ngày) và có nhiệm vụ tạo 1 access token mới từ Server. Tất nhiên, nếu bạn cũng để lộ refresh token này thì coi như toi, hacker lại có thể tấn công bạn được. Nhưng rõ ràng access token thì sử dụng với tuần suất lớn, còn refresh token thì chỉ khi nào access token hết hạn mới dùng đến thôi. Do vậy tăng tính bảo mật hơn đúng không nào?
Sơ đồ hoạt động của access token và refresh token.
Một ví dụ thực tế mà các hacker tấn công vào facebook, khi tạo ra các ứng dụng giả mạo hoặc các tool hỗ trợ facebook như xóa bạn bè, tự động like hay share. Họ yêu cầu người dùng cấp rất nhiều quyền, sau đó server facebook sẽ sinh ra 1 refresh token để có thể cấp quyền cho user. Khi họ có được nó, ai mà biết được họ đã làm những gì ngoài những tiện ích mà người dùng có được. Ví dụ như chạy quảng cáo chùa, tạo ra các tool để kiếm tiền trên facebook. Xem thêm tại đây:
Quay lại bài viết, sau khi user gửi thông tin username và password lên, server sẽ tạo ra 2 token gồm access token và refresh token và gửi trả lại cho client. Client gửi access token lên server để xác thực. Access token sẽ hết hạn trong thời gian ngắn, và client dùng refresh token để lấy 1 access token mới.
Hi vọng là bạn đã hiểu được ý nghĩa của JWT rồi. Trong phần tiếp theo chúng ta sẽ nghiên cứu cách triển khai JWT trong Golang.
Đến hẹn lại lên, cũng tròn 2 năm kể từ bài Coffee Talk lần trước, hôm nay mình mời được anh Trần Thiện Khiêm, một nhân vật cũng khá nổi tiếng và sôi nổi để cùng trò chuyện về chủ đề mà rất nhiều bạn quan tâm: Đó là sống và làm việc ở nước ngoài.
# Hành trình xuất ngoại làm việc
Huy: Hello a Khiêm, cảm ơn anh đã dành thời gian để ngồi chém gió với em hôm nay. A với e thì nhẵn mặt nhau rồi, trên mạng thì a cũng khá là nổi rồi, nhưng cho bạn nào chưa biết, thì a có thể giới thiệu một tí về mình được ko?
Khiêm: Chào Huy và các bạn, anh là Khiêm, một lập trình viên đến từ Đà Nẵng, hiện tại đang làm việc tại Canada. Mình đã làm khá nhiều công ty ở nhiều lĩnh vực khác nhau: Gameloft, Clearpath, Visa, Amazon và hiện tại đang làm việc tại Facebook được vài tháng rồi. Rất vui được nói chuyện trao đổi với Huy. 😃
Huy: Hình như đến thời điểm này, Gameloft là công ty anh gắn bó lâu nhất. Sau đó thì xuất ngoại vào Visa luôn. Có vẻ là một bước thay đổi khá lớn cả về công việc lẫn cuộc sống, anh có thể chia sẻ một chút về quyết định này không?
Khiêm: Trước khi sang VISA Singapore thì mình có làm cho công ty thiên đường Clear Path 2 năm ở vị trí .NET Architect. Mình chưa từng nghĩ sẽ ra nước ngoài làm việc, nhưng khi mấy đứa như Huy Trần đi Mỹ làm mình cũng sốt ruột lắm. Quyết định đi qua Singapore của mình khá bất ngờ và cũng là thay đổi khá lớn vì tại thời điểm đó mình vừa có em bé được 3 tháng tuổi. Cũng khá tình cờ, vì mình nhận được thư mời tham gia sự kiện tuyển dụng của Grab ở trong Sài Gòn, mình thử sức và có offer luôn. Khi có offer của Grab rồi mình cũng tham gia phỏng vấn thử mấy chỗ và có thêm 2 offer nữa, 1 ở Florida và 1 của VISA. Cuối cùng mình chọn VISA vì duyên. Tại thời điểm đó nếu mình chọn Mỹ thì khá rủi ro do việc xin visa H1B rất hên xui. Còn offer ở Grab thì không tốt bằng offer của VISA.
Huy: Ồ, thật ra thì em nhìn thấy anh và bạn bè quanh mình toàn là vô làm big firm thì em cũng sốt ruột y vậy đó. :v Đùa vui tí, thế từ khi đi ra ngoài thì góc nhìn về cuộc sống, công việc, hay career path của anh có thay đổi gì không?
Khiêm: Lúc mình xác định sang Singapore làm việc thì mình rất lo lắng, nên mình định hướng lại là phải “sống sót” trước đã chứ không có tham vọng nhiều như hồi ở VN, mình coi như là một khởi đầu mới, bắt đầu lại từ đầu. Sau một thời gian làm việc thì mình mới bắt đầu tự tin hơn và đặt mục tiêu cao hơn.
Còn về cuộc sống thì rõ ràng đi một ngày đàng học một sàng khôn, ở nhiều nơi, biết nhiều thứ mà nếu ở VN thì mình sẽ không biết được, nhưng nhiều lúc cũng nhớ VN kinh khủng.
Huy: Anh mất bao lâu để “sống sót” trước khi chuyển qua chế độ đặt mục tiêu cao hơn? Anh thấy môi trường làm việc ở Sing có gì khác so với ở Việt Nam không? Và so với môi trường Canada/Mỹ sau này thì như thế nào?
Khiêm: Cũng phải vài tháng để mình làm quen với môi trường làm việc ở Singapore. Vấn đề của mình không phải là cách làm việc hay kỹ thuật, mà do mình bị thiếu tự tin. Mình cảm thấy tự ti vì xuất phát điểm của mình so với đồng nghiệp, khả năng tiếng Anh và giao tiếp không bằng họ, và cứ có cảm giác sợ hãi rằng mình không được giỏi bằng người khác, sợ bị đánh giá, sợ nói sai, v.v..
Sau khi mình vào dự án và đóng góp nhiều thì mình mới cảm thấy tự tin hơn và cảm giác mình sẽ làm được nhiều hơn.
Môi trường làm việc ở Singapore khá trẻ trung, năng động, thoải mái, công việc cũng không quá căng thẳng, công ty tập trung vào việc cân bằng đời sống cho anh em. Lương khá cao và thuế thấp so với Mỹ và Canada. Lần đầu tiên nhận lương ở Canada mình bị shock mất 1 tuần mới tỉnh lại 🙁
Ở Canada thì đời sống khá thoải mái, gần gũi với thiên nhiên, có điều kiện đi ô tô, đi chơi xả láng mà không lo lắng gì. Ngoài ra thời tiết ở Canada rất tuyệt vời nữa. Môi trường làm việc thì cũng giống ở Singapore.
Huy: Khi quyết định “tiến thêm bước nữa” sang Canada thì anh có phải đối mặt với đắn đo suy nghĩ gì không? Hay là nghĩ đã đi được rồi thì cứ đi thêm thôi? Trong suốt thời gian ở Sing thì có khi nào anh nghĩ sẽ về lại Việt Nam để làm không? Giờ làm ở Canada thì anh có định về không?
Khiêm: Lúc đó mình nghĩ đơn giản có cơ hội thì đi thôi. Vì nếu về lại Singapore thì cũng khá đơn giản, nhưng cơ hội sang bên này thì khó hơn, nên đúng là cứ nghĩ đã đi thì đi. Thêm một lý do nữa là ở Singapore không có điều kiện để định cư do Singapore không có chính sách cho nhập tịch. Lúc mình làm ở Singapore thì mình cũng có nhiều đề nghị về lại VN làm và mình thỉnh thoảng cũng nghĩ tới chuyện sau này sẽ về VN. Nhưng trước mắt thì mình không có dự định gì quá xa, ở Canada cũng khá thích và bây giờ mình cũng đã ổn định nhà cửa rồi, di chuyển cả gia đình cũng khó lắm.
# Benefit khi làm việc tại big firm
Huy: Uhm cái này thì cũng công nhận. Thôi giờ chuyển chủ đề một tí nhé. Nói về chuyện đi làm ở big firm đi. Giờ mà hỏi lương thì chắc anh ko nói đâu, nhưng anh có thể nói qua một tí về một gói benefit + lương thưởng điển hình ở mấy công ty kiểu này được không? Ví dụ như là lương tháng nhiêu chế độ bảo hiểm, stock này kia?
Khiêm: Mình thấy thích nhất là việc được hỗ trợ chuyển vùng (từ VN sang Singapore và từ Singapore sang Canada). Mình được bao từ vé máy bay, khách sạn, giới thiệu cuộc sống ở thành phố mới và cả container chuyển đồ đi nữa (có thể chuyển tất cả các đồ đạc trong nhà qua chỗ mới luôn).
Thu nhập hàng năm thì bao gồm lương cơ bản, cổ phiếu và thưởng (thường được tính theo mục tiêu bao nhiêu phần trăm, ví dụ 15% của lương cơ bản, nếu năm đó làm tốt có thể đạt được 200% mục tiêu đó).
Riêng phần cổ phiếu sẽ được chia ra trong nhiều năm, và đây là phần thu nhập lâu dài giúp mình gắn bó với công ty.
Về các chế độ khác thì tuỳ công ty, ví dụ có công ty cho tiền mua đồ tập thể thao hàng năm (vài nghìn đô), tiền tập Gym, tiền đi học những thứ mình thích, nói chung cũng rất hấp dẫn.
Ngoài ra lúc nhận offer còn thêm có phần thưởng lúc vào công ty (sign on bonus) khoảng vài chục nghìn để tiêu xài ăn chơi mừng công việc mới nữa.
Huy: Anh có thể cho con số cụ thể để các bạn dễ hình dung về việc cổ phiếu được chia ra trong nhiều năm được không? Lấy ví dụ một bạn dev ở Amazon làm lương tầm $300k hay $400k (một năm) thì break down ra như thế nào?
Khiêm: Ví dụ một bạn nhận offer với total compensation $300k ở Amazon, thường có thể chia ra như sau:
Lương căn bản $200k.
Cổ phiếu được chia ra làm 4 năm theo tỉ lệ 5% cho năm đầu tiên, 15% cho năm thứ 2, và 40% cho năm thứ 3 và 40% cho năm thứ 4. Với cổ phiếu hiện tại giá 3.5k, bạn đó sẽ nhận được tầm 70 cổ phiếu để đảm bảo năm 3, và năm 4 các bạn nhận được khoảng 28 cổ phiếu (để đủ 300k).
2 năm đầu tiên bạn đó sẽ nhận được sign on bonus để đảm bảo nhận được tổng $300k mỗi năm.
Ví dụ năm đầu tiên bạn đó nhận được lương cơ bản là 200k, 3 cổ phiếu (5% của 70), và 90k sign on bonus. Ở Amazon thì không có thưởng hằng năm, bạn sẽ được tăng lương hằng năm.
Ngoài ra do cổ phiếu biến động nên khả năng bạn được tăng thu nhập rất lớn.
Ví dụ sau 2 năm cổ phiếu amazon tăng lên 5 lần, thì thay vì nhận được 100k, bạn sẽ nhận được 500k (nếu điều đó xảy ra)
Huy: Uhm nhìn con số cũng khá là hấp dẫn, vậy còn những năm sau đó thì sao nhỉ? Sau khi đã vested hết 4 năm? Công ty có cho mình gói stock khác không?
Khiêm: Thường thì năm thứ 2 trở đi mình sẽ được top up stock cho năm thứ 5, tương tự vậy… Ngoài ra sau 4 năm thì mình cũng sẽ có nhiều cơ hội thăng chức để cải thiện thu nhập và lương của bạn cũng được tăng hằng năm.
Tuy nhiên do cổ phiếu biến động nhiều nên cũng có nhiều bạn sau 4 năm bị giảm thu nhập. Tất nhiên làm việc ở một công ty nhiều năm thì bạn có nhiều thứ khác ngoài lương, ví dụ ảnh hưởng của bạn với team, kinh nghiệm làm việc, khả năng được lên vị trí cao hơn, v.v…
# Career path và kỹ năng làm việc tại các công ty lớn
Huy: Nói đến đây thì em nhớ ra có một topic nữa cũng rất muốn hỏi. Anh nghĩ sao về career path và những đòi hỏi về kĩ năng ở các công ty lớn như Amazon, Facebook? Em có nghe một số người bạn hay than rằng công việc ở những cồng ty lớn thường ít thú vị, điều này có thật không? Thêm nữa, dân làm IT thường chỉ focus vào nâng cao tay nghề kĩ thuật, theo anh thì nếu chỉ thuần túy tập trung vào kĩ thuật thì có đủ để thành công ở những môi trường này không?
Khiêm: Về mặt kỹ năng, lúc phỏng vấn các công ty lớn cũng rất chú trọng về giải thuật và thiết kế, lúc vào làm thì cũng áp dụng nhiều. Ngoài kỹ thuật ra, thì mình nghĩ để tiến được xa thì người lập trình viên phải có tư duy về sản phẩm, xem sản phẩm của công ty là sản phẩm của mình và đóng góp nhiều ý kiến vào cách phát triển sản phẩm, cách cải thiện và giúp đỡ các thành viên khác trong team, … Các kỹ năng mềm như làm việc nhóm, trình bày, v.v.. cũng rất quan trọng.
Về career path thì ở cách công ty lớn cũng có các tiêu chí rất rõ ràng, và hằng quý mình sẽ xem xét lại tiêu chí đó để định hướng cho công việc của mình.
Công việc có thú vị hay không thì tuỳ vào team và tuỳ vào thái độ của mình đối với công việc. Như thời gian làm ở Amazon thì mình cũng có những lúc có rất nhiều việc thú vị nhưng cũng có lúc gần như ngồi không, lúc đó mình lại nghĩ ra những thứ khác để làm.
Ngoài kỹ thuật ra thì như mình nói ở trên, tầm nhìn, tư duy về sản phẩm, cách giải quyết vấn đề, kỹ năng mềm … và nếu chém gió tốt hoặc làm cây hài của team được nữa thì càng tốt.
Nhưng nếu chỉ giỏi về kỹ thuật và không muốn động vào những lĩnh vực khác thì nếu biết cách phát huy thế mạnh của mình bạn cũng có thể thành công theo hướng kỹ thuật.
Huy: Nhiều bạn rất quan tâm đến việc đi ra nước ngoài làm việc, nhưng không biết phải bắt đầu như thế nào, là một người từng đánh đông dẹp tây từ Châu Á tới Châu Mỹ thì anh có thể chia sẻ cho mọi người biết cần chuẩn bị hành trang như thế nào được không? Assuming là người ta không có quá khứ đi thi olympic tin học như a nhé, cho nó khách quan.
Khiêm: Mình thấy trong ngành mình có khá nhiều cơ hội đi nước ngoài
Đi Singapore làm cho các start up nhỏ, thường các start up này tuyển người ở Việt Nam qua các trang online như Angelist, job streets.
Đi Nhật Bản theo dạng onsite cũng là một lựa chọn nhưng các bạn cần biết tiếng Nhật.
Đi làm cho các công ty, tập đoàn lớn ở Singapore, Canada, Úc: Các bạn cần luyện tập leetcode, khả năng giải quyết vấn đề và thiết kế hướng đối tượng.
Tiếng Anh là một kỹ năng không thể thiếu, các bạn cần giao tiếp được, hiểu và có thể trả lời phỏng vấn, sử dụng trong công việc.
Nhu cầu tuyển lập trình viên khá nhiều tại thời điểm này, nên các bạn cần nắm bắt cơ hội. Như riêng team cũ của mình ở Amazon cũng đang tuyển 7 bạn lập trình viên và cũng đang khó khăn trong việc tìm ra người phù hợp. Các bạn có thể ứng tuyển online và phỏng vấn online luôn.
Huy: Ngoài ra thì về CV hay kinh nghiệm cá nhân, có cần chuẩn bị gì không? Và anh nghĩ ở giai đoạn nào thì nên đặt mục tiêu đi nước ngoài? Nhiều ý kiến cho rằng mới ra trường thì chưa nên đi vội mà nên dành ra vài năm tích lũy kinh nghiệm, anh nghĩ sao về quan điểm này?
Khiêm: Theo mình nghĩ thì nên chuẩn bị một cái CV ấn tượng, không cần dài dòng nhưng nêu bật lên được những thành quả mình đã làm được trong quá trình làm việc. Mình thường chuẩn bị CV 1 trang đơn giản nhất có thể. Về thời điểm ra nước ngoài làm việc, mình nghĩ thường các công ty ở nước ngoài sẽ ít khi tuyển fresher trừ khi người đó thật xuất sắc, vì các công ty phải lo chi phí và thủ tục giấy tờ để tuyển một nhân viên ở nước khác, nên họ thường chỉ tuyển các bạn có kinh nghiệm hơn là những bạn mới ra trường.
# Hỏi vu vơ thôi
Huy: Giờ đổi chủ đề tí cho vui nhỉ? Lúc nãy a có nói là cuộc sống ở Canada khá thoải mái, gần gũi với thiên nhiên, vậy ngoài công việc và gia đình ra, anh có dành thời gian cho việc gì khác không? Có ý định quay về làm game không?
Khiêm: Ngoài công việc và gia đình ra thì mình thường chơi Dota 2 sau khi cả nhà đi ngủ, hoặc code thêm những gì mình thích và cả xem phim nữa. Mình cũng thử bỏ Dota 2 mấy lần và mỗi lần bỏ đều thấy rất tự hào về bản thân 😂 hy vọng sang năm mình có thể tiếp tục bỏ tiếp. Mình còn rất thích đi cắm trại, dã ngoại với gia đình, bạn bè, tụ tập ăn uống, hội hè.
Hiện tại thì mình chưa có ý định quay lại làm Game trừ phi có ý tưởng đột phá.
Huy: Chúc anh sớm có ý tưởng đột phá :)) Và rất cảm ơn những chia sẽ của anh trong buổi nói chuyện ngày hôm nay. Chúc anh và gia đình sức khỏe và tiếp tục gặt hái thêm nhiều thành công ở Facebook.
Bài viết được sự cho phép của tác giả Trần Anh Tuấn
Xin chào các bạn hôm nay ngồi code rồi thấy có nhiều đoạn code được dùng đi dùng lại thường xuyên trong quá trình làm từ trước đến giờ, thấy khá là hữu ích cho nên mình quyết định chia sẻ lên blog này để cho các bạn có thể vào tham khảo và lấy về dùng luôn. Những đoạn code này khá cơ bản nhưng thực sự cần thiết trong nhiều trường hợp lắm đây. Chúng ta cùng khám phá dưới đây 20 tấm ảnh kèm ghi chú đi theo cực kỳ chi tiết nhé.
# Center với Flexbox
Đoạn code này khi các bạn muốn làm các phần tử hiển thị chính giữa khi sử dụng với CSS Flexbox nhé.
# Center với CSS Grid
Đoạn này chức năng tương tự đoạn trên nhưng mà sử dụng CSS Grid nhé các bạn. Place-items tương ứng là align-items và justify-content áp dụng với CSS Grid.
# Center theo chiều ngang với absolute
Đoạn code này khi các bạn muốn một phần tử canh giữa theo chiều ngang với thuộc tính position: absolute nhé. Rất hay dùng khi làm việc với thuộc tính position khi căn chỉnh phần tử á.
# Center theo chiều dọc với absolute
Đoạn code này khi các bạn muốn một phần tử canh giữa theo chiều dọc với thuộc tính position: absolute nhé.
# Center theo 2 chiều với absolute
Đoạn code này khi các bạn muốn một phần tử canh giữa theo chiều ngang và chiều dọc luôn cũng với thuộc tính position: absolute nhé.
# Viết rút gọn code CSS cho thuộc tính border
# Viết rút gọn code CSS cho thuộc tính background
# Viết rút gọn code CSS cho giá trị về màu sắc
Nếu mã màu trùng nhau 6 ký tự thì các bạn chỉ cần điền vào 3 là đủ hoặc theo cấu trúc aabbcc thì có thể viết thành abc là được.
Đoạn code này giúp các bạn hiển thị chữ trên 1 hàng mà thôi nếu chữ quá dài thì sẽ xuất hiện dấu 3 chấm… nhe.
# CSS cho placeholder của input, textarea
# CSS cho selection
Khi các bạn vào một trang web các bạn muốn copy nội dung nào đó thì các bạn sẽ bôi đen nó, đoạn code này giúp CSS cho đoạn bôi đen đó đấy nhé. Khá là hay ho.
# Ẩn icon mũi tên ở input có type là number
# Box-sizing
Đoạn code này sẽ được toàn bộ selectors về box-sizing: border-box để hiển thị kích thước cho đúng nhé. Quan trọng lắm nha các bạn.
# Sử dụng đơn vị rem
Nếu các bạn không thích code với đơn vị px cố định thì các bạn có thể sử dụng đơn vị rem nhé, đoạn code này giúp đưa font-size về cơ số 10 cho dễ tính toán. Lúc này 1rem = 10px.
# Responsive media
Nếu các bạn muốn hiển thị video, hình ảnh theo tỉ lệ như 16:9 hay 4:3 thì các bạn có thể dùng biến trong CSS như mình để lưu lại, sau đó dùng CSS để tính toán như dưới đây để video hay hình ảnh có thể hiển thị responsive nhé. HTML của nó trông như thế này:
Đây không đơn thuần là làm background gradient thông thường, mà là các bạn muốn sử dụng 2 lớp nền, lớp ở trên là gradient mờ mờ, còn ở dưới là một hình nền thì các bạn có thể sử dụng đoạn code dưới đây nha. Các bạn sẽ thay mã màu tương ứng cho phù hợp với thiết kế của các bạn và hình nền nhé.
# Hiển thị dấu 3 chấm cho nhiều dòng
Ở mục phía trên mình có nói tới vấn đề hiển thị dấu 3 chấm trên một hàng, còn đoạn code này sẽ giúp các bạn hiển thị dấu 3 chấm… cho nhiều hàng, ví dụ bạn muốn nếu chữ nhiều quá thì tới dòng thứ 5 sẽ hiển thị dấu 3 chấm thì các bạn thay giá trị ở đoạn code -webkit-line-clamp thành 5 chẳng hạn nhé.
# Gradient cho chữ
# Tuỳ chỉnh thanh scroll
Mặc định thanh scrollbar không được đẹp cho lắm thì các bạn có thể dùng đoạn code dưới đây để làm cho nó hiển thị theo ý các bạn nhé. Tuy nhiên việc custom này không hỗ trợ trên Firefox nhé.
# Tạm kết
Bài này mình sẽ cập nhật thường xuyên nếu có những đoạn code mới hay ho và bổ ích cho các bạn nhé. Mình không để code sẵn để các bạn copy vì mình nghĩ nếu các bạn tự gõ lại thì sẽ mau nhớ và mau giỏi hơn cũng như hiểu được bản chất của các thuộc tính trong CSS. Cuối cùng chúc các bạn học tập thật tốt nhé..
Với tổng giá trị lên đến 1.6 tỷ đồng, RMIT Việt Nam sẽ trao học bổng cho 4 ứng viên xuất sắc nhất theo học Thạc sĩ Trí tuệ Nhân tạo và Thạc sĩ An toàn Thông tin, hai chương trình mới của nhà trường, trong kỳ học tháng 6/2022.
Theo thông tin từ phía nhà trường, mỗi suất học bổng được trao có giá trị 400 triệu đồng, tương ứng với 50% học phí của chương trình. Qua đó, học bổng tạo điều kiện cho những tài năng có đam mê hoặc đang công tác ở lĩnh vực AI hoặc an toàn thông tin được phát triển bản thân trở thành những chuyên gia hàng đầu trong ngành.
Nuôi dưỡng tài năng, đào tạo nhân lực cho đất nước
Nền khoa học và công nghệ thông tin của Việt Nam luôn cần đội ngũ nhân lực chất lượng cao giữa bối cảnh bùng nổ số nhiều năm gần đây. Trong đó không thể thiếu hai lĩnh vực AI và an toàn thông tin.
Trên thế giới, AI đang phát triển với tốc độ chóng mặt ở các phương diện về lập trình, dữ liệu và thuật toán. AI có mặt ở khắp nơi, từ đời sống hằng ngày đến công việc và các hoạt động vui chơi, giải trí. Tuy nhiên, theo thống kê, số lượng chuyên gia ở Việt Nam lại chưa đủ để đáp ứng nhu cầu ngày càng tăng. Một trong những thách thức lớn được ghi nhận là sự thiếu hụt các tổ chức đào tạo có khả năng gia nhập hàng ngũ quốc tế.
Bên cạnh đó, khái niệm an toàn thông tin đã không còn xa lạ với hầu hết mọi ngành nghề khi mọi doanh nghiệp, tổ chức đều đang trên đà dịch chuyển số, với nhiều cơ hội nhưng cũng không ít rủi ro. Theo báo cáo của Bkav, thiệt hại do virus máy tính gây ra đối với người dùng Việt Nam năm 2021 tiếp tục ở mức rất cao, lên tới 24,4 nghìn tỷ VNĐ (tương đương 1,06 tỷ USD). Nhu cầu xây dựng đội ngũ chuyên gia hàng đầu để thiết kế, bảo vệ hệ thống an toàn thông tin của các cơ quan nhà nước lẫn tư nhân đều ở mức rất cao.
Với 2 chương trình mới cùng 4 suất học bổng đầy giá trị cho học kỳ tháng 6 sắp tới, RMIT mong muốn nuôi dưỡng, đào tạo nên những chuyên gia ở lĩnh vực AI và an toàn thông tin để có thể đương đầu với những thay đổi, những cơ hội và cả những rủi ro.
Học tập và làm việc trong môi trường chuẩn quốc tế
Ở cả hai chương trình, học viên sẽ được học tập với các chuyên gia đầu ngành từ RMIT Melbourne & RMIT Việt Nam trong môi trường giáo dục linh hoạt, tôn trọng sự đa dạng. Ngoài ra, những học viên có sẵn kiến thức nền về công nghệ thông tin, máy tính hoặc các lĩnh vực liên quan đều có thể được xem xét miễn giảm môn học để tăng tốc cho lộ trình sự nghiệp của bản thân.
Đặc biệt, ở những học kỳ cuối cùng, mỗi chương trình đều có những môn học hoặc những hướng phát triển đặc thù được thiết kế theo mô hình học tập kết hợp thực tiễn (WIL- work integrated learning) – mô hình đã làm nên danh tiếng của đại học RMIT trong nhiều năm qua.
Ở chương trình Thạc sĩ An toàn Thông tin, học viên sẽ phải hoàn thành hai môn học nhận thức ngành và kết nối ngành với các bài tập dự án trực tiếp với doanh nghiệp. Còn với Thạc sĩ Trí tuệ Nhân tạo, học viên có hai lựa chọn: hoặc thực hiện một dự án AI với doanh nghiệp đối tác; hoặc nghiên cứu chuyên sâu về AI để hoàn thành một luận án làm tiền đề vững chắc cho những ai muốn theo đuổi học vị Tiến sĩ.
Ngoài những điểm hấp dẫn trên, cả hai chương trình còn nhiều điều thú vị khác dành cho học viên như cơ hội học tập và làm việc ở nước ngoài, cơ hội được gặp gỡ các chuyên gia đầu ngành cũng như được là một phần của mạng lưới cựu sinh viên RMIT khắp nơi trên thế giới, mở rộng các mối quan hệ trong công việc và lĩnh vực nghiên cứu.
Với một suất học bổng từ đại học RMIT Việt Nam, những trải nghiệm trên sẽ không còn quá xa với những ai có đam mê với AI và an toàn thông tin, cũng như khát khao được đào sâu chuyên môn, theo đuổi những kiến thức phổ cập nhất của thế giới và trở thành nhà lãnh đạo của tương lai.
Thông tin chi tiết về học bổng của Hai chương trình Thạc sĩ Trí tuệ Nhân tạo (AI) và Thạc sĩ An toàn Thông tin (Cyber Security) sẽ được giới thiệu vào ngày 26/3/2022 tại sự kiện ra mắt ngành học của RMIT Việt Nam. Để tham gia sự kiện, bạn có thể đăng ký tại đây: https://bit.ly/3wrCFy7
.NET là nền tảng lập trình được phát triển bởi Microsoft, được chạy trên hệ điều hành Microsoft Window bao gồm nhiều công nghệ khác nhau. Vốn được xếp trong top các công nghệ được sử dụng nhiều nhất hiện nay với mức lương vô cùng hậu hĩnh, vì vậy trở thành lập trình viên .NET là lựa chọn hàng đầu của nhiều bạn trẻ đam mê lập trình. Để trở thành một lập trình viên .NET giỏi cần trang bị những gì? Hãy cùng lắng nghe 5 chia sẻ từ anh Nguyễn Thành Công – Head of Development của Pixelz ngay dưới đây.
Một vài nét về anh Nguyễn Thành Công:
Cựu sinh viên của Đại học Bách Khoa Hà Nội và từng công tác tại các tập đoàn lớn: Panasonic R&D Center, Niteco,…
Hơn 10 năm kinh nghiệm trong ngành phát triển phần mềm và hơn 7 năm ở vị trí quản lý (Team Leader, Tech Lead, Manager).
Hiện đang giữ vị trí Head of Development tại Pixelz Vietnam – Công ty Platform As a Service của Đan Mạch, chuyên cung cấp nền tảng công nghệ kết hợp giữa AI và người để đáp ứng nhu cầu chỉnh sửa ảnh cho các hãng thời trang hàng đầu trên thế giới.
“Kiến thức nền tảng về lập trình hướng đối tượng rất quan trọng”
Theo mình, kiến thức về lập trình hướng đối tượng được xem là một trong những kỹ năng lập trình quan trọng không chỉ dành cho mỗi lập trình viên .NET mà rất cần thiết với hầu hết các lập trình viên. Việc trang bị kiến thức nền tảng về lập trình hướng đối tượng sẽ giúp bạn thiết kế và xử lý vấn đề được tốt hơn. Bên cạnh đó còn có những lợi ích khác của lập trình hướng đối tượng mang lại:
Mô hình hóa được bài toán theo hướng đối tượng (thực thể) giúp bạn viết code rõ ràng, dễ đọc và bảo trì;
Tuân thủ những tính chất chặt chẽ của lập trình hướng đối tượng;
Dễ dàng hơn khi tiếp cận với Design Pattern.
Xem ngay tin tuyển dụng .NET tại các doanh nghiệp hàng đầu trên TopDev
“Design Pattern: Hãy áp dụng vào trong công việc thường ngày của bạn”
Nói một cách dễ hiểu, Design Pattern là các mẫu thiết kế được chắt lọc thông qua quá trình tích lũy kinh nghiệm khi phát triển phần mềm của các chuyên gia lập trình trên thế giới. Đây được xem giải pháp chung để giải quyết các vấn đề phổ biến khi thiết kế phần mềm trong lập trình hướng đối tượng OOP. Việc am hiểu và áp dụng Design Pattern sẽ giúp bạn giải quyết được bài toán của mình tốt nhất, đồng thời đảm bảo dễ dàng mở rộng, hạn chế lỗi, dễ phát triển và bảo trì, vì mỗi mẫu thiết kế đã tuân theo nguyên tắc của SOLID Design.
Thế nên, nếu bạn muốn nâng cao tay nghề và chinh phục con đường trở thành lập trình viên .NET giỏi, thì ngay từ bây giờ, hãy áp dụng Design Pattern vào trong công việc thường ngày cũng như các dự án thực tiễn của mình.
“Sách là người thầy vĩ đại và thông thái nhất”
Công nghệ phát triển kéo theo thói quen thu nạp kiến thức của con người thay đổi. Tuy nhiên, sách vẫn người thầy vĩ đại và thông thái nhất của chúng ta. Theo quan điểm cá nhân mình, việc đọc sách là vô cùng quan trọng, vì đây là phương pháp giúp mở mang kiến thức hiệu quả nhất. Vì vậy, hãy dành một ít thời gian trong ngày để đọc và chắt lọc những kiến thức về lập trình và công nghệ mà sách mang lại. Ngoài ra, các bạn có thể tìm đọc một số tựa sách hay về lập trình mà mình tâm đắc: Head First Design Pattern, Patterns of Enterprise Application Architecture, Domain Driven Design, Naked Object,…
“Hãy tìm hiểu và cập nhật công nghệ, kiến thức mới thường xuyên”
Không thể phủ nhận công nghệ hiện đang phát triển với tốc độ chóng mặt, điều này đòi hỏi các bạn lập trình viên phải thường xuyên theo dõi, cập nhật các công nghệ lẫn các kiến thức mới để phù hợp với hiện tại. Đặc biệt, trong giai đoạn COVID-19 vừa qua đã cho thấy tầm quan trọng của công nghệ cho việc phát triển doanh nghiệp, từ đó vai trò của các lập trình viên CNTT cũng có phần thay đổi so với thời kỳ tiền COVID-19.
Hiện nay, Pixelz đã áp dụng công nghệ AI/ ML kết hợp với Computer Vision truyền thống với mong muốn mang đến chất lượng tuyệt vời cho sản phẩm. Điều này là cơ hội cũng như thách thức của bản thân mình và team. Thách thức ở chỗ mình và team phải xử lý lượng dữ liệu khổng lồ, nhưng vẫn phải đảm bảo hệ thống được vận hành trơn tru 24/7. Nhưng đây cũng chính là cơ hội để mọi người được học hỏi, tiếp xúc và ứng dụng công nghệ mới, đồng thời giúp nâng cao kỹ năng của từng cá nhân.
Việc tìm hiểu và cập nhật công nghệ, kiến thức mới thường xuyên là điều không thể thiếu, vì vậy mình khuyên các bạn hãy dành thời gian để đọc một số blog công nghệ như: Martin Fowler, Uber Engineering hoặc cài 1 số ứng dụng như Medium hoặc Feedly,…
“Cuối cùng, hãy yêu thích con đường mà bạn đã chọn”
Việc chinh phục ước mơ không bao giờ là dễ dàng, nếu bạn đã chọn được con đường mình yêu thích, hãy nỗ lực không ngừng và không từ bỏ. Việc học đi đôi với hành cũng cần thiết hơn bao giờ hết, vì chỉ có sai bạn mới biết sửa chữa và tiến bộ hơn mỗi ngày. Hãy chọn một môi trường tốt để học hỏi và phát triển sự nghiệp, nơi khiến bạn có thể bùng nổ năng lực và khám phá thêm nhiều điều mới mẻ hơn về công nghệ.
Với mình, Pixelz là “ngôi nhà” chung mà mình và mọi người có thể cùng nhau xây dựng mối quan hệ trung thực, thẳng thắn, chân thành và cùng nhau phát triển. Sở hữu văn hoá đổi mới sáng tạo và mô hình phẳng, tại đây, mọi người được trao quyền và khuyến khích tự chủ trong công việc, không ngại đương đầu với thách thức hay nắm bắt lấy cơ hội để có được những bước nhảy vọt cho sự nghiệp.
KẾT
Đây là những kinh nghiệm mà mình mong muốn được gửi đến các bạn đã và đang trên con đường chinh phục sự nghiệp là một lập trình viên .NET. Dù bạn là Fresher mới ra trường hay Senior dày dặn kinh nghiệm, việc học hỏi mỗi ngày là một điều cần thiết để bản thân được tiến bộ hơn. Bên cạnh đó, một môi trường làm việc tốt sẽ góp phần tạo bước đệm cho sự nghiệp của bạn. Hiện Pixelz đang rộng mở nhiều cơ hội cho các bạn đam mê lập trình gia nhập. Nếu bạn mong muốn được về chung “một nhà” và cùng chinh phục các dự án sắp tới thì có thể tham khảo ngay các vị trí đang tuyển tại đây nhé!
Đây cũng là lần đầu tiên nhà trường ra mắt hai chương trình Thạc sĩ chuẩn quốc tế cho khối ngành STEM (Khoa học, Công nghệ, Kỹ thuật và Toán học). Không chỉ được công nhận toàn cầu, mỗi chương trình đều mang những dấu ấn và những đặc thù riêng, đáng để tìm hiểu trước khi chọn lựa hướng đi cho tương lai.
Chương trình Thạc sĩ Trí tuệ Nhân tạo được thiết kế cho những ai có mong muốn tập trung và đào sâu vào những ứng dụng của AI nhằm thúc đẩy sự phát triển của công nghệ. Chương trình có 3 khối kiến thức chính: thiết kế và phát triển AI, học máy/ học sâu và khoa học dữ liệu.
Trong bối cảnh tăng trưởng chóng mặt của lĩnh vực này, đại học RMIT tự hào được Hội đồng Nghiên cứu Úc vinh danh là cơ sở có những nghiên cứu AI “vượt chuẩn thế giới”. Học viên sẽ được phổ cập những kiến thức nâng cao và cấp tiến nhất về điện toán, phát triển và lắp đặt các hệ thống AI trong môi trường nghiên cứu lẫn môi trường hành nghề chuyên nghiệp, cũng như luôn luôn trau dồi kỹ năng và ý thức đạo đức nghề. Sau khi tốt nghiệp, học viên có thể theo đuổi các vị trí như kỹ sư AI, chuyên gia phân tích dữ liệu hoặc nhà nghiên cứu về khoa học dữ liệu, thuật toán hay những tích hợp của AI.
Với chương trình Thạc sĩ An toàn Thông tin, cũng là chương trình lâu đời nhất của Úc ở lĩnh vực này, học viên sẽ học cách kiến tạo một không gian mạng an toàn, giảm thiểu rủi ro cho người dùng, doanh nghiệp và tổ chức giữa bối cảnh bùng nổ kỹ thuật số.
Chương trình cho học viên tiếp cận những nhánh chuyên môn nhỏ hơn, bao gồm bảo mật internet và hệ thống LAN, các dạng thức khác nhau của mật mã học, và mật mã học cải tiến để giải quyết các rủi ro trong tương lai. Trên hết, không chỉ được học về yếu tố khoa học và kỹ thuật, học viên còn được học sâu về yếu tố con người và doanh nghiệp, trở thành những chuyên gia toàn diện, đáp ứng được nhu cầu của thị trường ngày nay khi các tổ chức và công ty đang không ngừng săn đón những nhà quản lý cấp cao, những kỹ sư thiết kế – hệ thống an toàn thông tin.
Vì cả hai chương trình đều đến từ RMIT Melbourne, học viên sẽ được học tập với các chuyên gia đầu ngành từ RMIT Melbourne & RMIT Việt Nam trong môi trường giáo dục linh hoạt, song hành giữa những kiến thức chuyên ngành bắt buộc và những môn tự chọn hấp dẫn để để đa dạng hoá kiến thức, hướng theo chuyên môn mong muốn. Ngoài ra, những học viên có sẵn kiến thức nền về công nghệ thông tin, máy tính hoặc các lĩnh vực liên quan đều có thể được xem xét miễn giảm môn học.
Đặc biệt, ở những học kỳ cuối cùng, mỗi chương trình đều có những môn học hoặc những hướng phát triển đặc thù được thiết kế theo mô hình học tập kết hợp thực tiễn (WIL- work integrated learning) – mô hình đã làm nên danh tiếng của đại học RMIT trong nhiều năm qua. Với Thạc sĩ An toàn Thông tin, học viên sẽ phải hoàn thành hai môn học nhận thức ngành và kết nối ngành để sẵn sàng cho công việc ngay sau khi tốt nghiệp. Còn với Thạc sĩ Trí tuệ Nhân tạo, học viên có hai lựa chọn: hoặc thực hiện một dự án AI với doanh nghiệp đối tác; hoặc nghiên cứu chuyên sâu về AI để hoàn thành một luận án làm tiền đề vững chắc cho những ai muốn theo đuổi học vị Tiến sĩ.
Tại Việt Nam, đại học RMIT không còn xa lạ với những ai muốn theo đuổi học vị Thạc sĩ. Những chương trình bậc cao học về Quản trị Kinh doanh hay Kinh doanh Quốc tế đã và đang thu hút nhiều học viên. Với hai chương trình Thạc sĩ mới này, RMIT mong muốn đáp ứng được nhu cầu tuyển dụng của thị trường khoa học – công nghệ để không ngừng đào tạo thêm những nhà lãnh đạo cho tổ chức, doanh nghiệp trong và ngoài nước.
Hai chương trình Thạc sĩ Trí tuệ Nhân tạo (AI) và Thạc sĩ An toàn Thông tin (Cyber Security) sẽ ra mắt vào ngày 26/3/2022, chính thức tuyển sinh cho kỳ nhập học tháng 6 ngay sau đó. Để đăng ký tham gia sự kiện ra mắt chương trình và tìm hiểu thêm về những cơ hội học bổng lên tới 400 triệu/ suất, bạn có thể đăng ký tại đây.
Hai lớp học thử về AI và An toàn Thông tin tại sự kiện ra mắt ngày 26/3
Để có được trải nghiệm thực tiễn nhất, người tham gia có thể tham gia một trong 2 lớp học thử khi dự sự kiện.
Lớp học thử “Dạy máy học tóm tắt văn bản bằng phương pháp “trừu tượng hóa” kinh điển” sẽ dạy người tham gia cách phát triển một giải pháp AI để giải bài toán tóm tắt văn bản hiệu quả cho một sản phẩm hay dịch vụ dựa trên các review trên mạng.
Lớp học thử “Các cuộc tấn công tống tiền (ransomware) bắt đầu như thế nào?” sẽ mô phỏng bước đầu trong một cuộc tấn công tống tiền của tin tặc nhắm vào các doanh nghiệp, tổ chức.
Cả hai lớp học được điều phối bởi chính các tiến sĩ của RMIT và sẽ được giảng dạy hoàn toàn bằng tiếng Anh.
Team Leader là gì? Những kỹ năng nào mà một Team Leader cần có?
Team Leader là một thuật ngữ quen thuộc trong công việc ở các công ty hiện nay. Team Leader được xem như người nắm quyền điều hành và chi phối các nhiệm vụ trong một nhóm, cũng như tạo ra tính gắn kết giữa các thành viên trong nhóm. Vậy cụ thể công việc của các Team Leader là gì? Và những kỹ năng của team leader nào cần có để làm tốt công việc của mình?
Team Leader là gì?
Team Leader có thể hiểu một cách đơn giản là người lãnh đạo và chịu trách nhiệm cao nhất trong một đội nhóm, một phòng làm việc. Công việc chính của team leader là phân bố công việc và đánh giá hiệu suất làm việc của các thành viên trong team. Team leader sẽ là người chịu trách nhiệm trong việc đào tạo nhân lực, hướng dẫn thành viên trong nhóm mình cách làm việc để tạo được kết quả chung đúng như những gì mà team đã đặt ra.
Vậy leadership là gì? Leadership chính là kỹ năng cần có của một người làm lãnh đạo. Với team leader, các kỹ năng liên quan đến việc gắn bó tổ chức, vận hành đội nhóm và thiết lập công việc thật sự rất quan trọng. Người lãnh đạo cần biết cách để tạo ra mục tiêu phấn đấu cho cả team, biết cách truyền động lực và đề ra những phương pháp để cả nhóm cùng đạt được kết quả đó.
Bên cạnh đó, team leader phải là người có tầm nhìn và có khả năng quan sát, đánh giá vấn đề một cách nhạy bén và kịp thời để có được những đề xuất phù hợp. Và đương nhiên, một team leader cần có khả năng huấn luyện đội, nhóm để mọi người trong nhóm đều có thể làm tốt công việc mà họ đang được giao phó. Đó chính là những kỹ năng mà một team leader cần có.
Đây có thể khẳng định là một trong những công việc quan trọng nhất của team leader. Công việc của team có hiệu quả hay không, có đạt đúng những KPIs được đặt ra lúc đầu hay không hoàn toàn phụ thuộc vào khả năng phối hợp và phân chia nhiệm vụ của team leader.
Team leader phải là người nắm rõ khả năng của từng thành viên, thế mạnh và điểm yếu của họ để có thể giao những công việc phù hợp, và đảm bảo hoàn thành công việc một cách trơn tru nhất. Khi một nhân viên được giao những công việc sở trường chắc chắn họ có thể làm việc và tạo ra kết quả xuất sắc nhất. Vậy nên một team leader có khả năng phát hiện ra năng lực thật sự của một team-member là điều rất cần thiết.
2. Tìm kiếm và tập hợp những thành viên xuất sắc
Những thành viên có năng lực sẽ đóng góp cho việc gia tăng năng suất làm việc và mang lại kết quả làm việc tốt nhất cho cả team. Điều đó không có nghĩa là đội nhóm của bạn bắt buộc phải có tất cả các thành viên đều xuất sắc. Chỉ cần một số trong các thành viên là những người có khả năng sáng tạo tốt, và quan trọng là họ có thể phối hợp ăn ý với các thành viên khác và cùng nâng đỡ nhau để phát triển.
Để làm được điều này, team leader cần cố gắng khai thác tính cách, động cơ công việc cũng như năng lực chuyên môn của từng ứng viên để có thể nắm được chính xác nhất cách nhân viên triển khai vấn đề. Từ đó, đưa ra những phương pháp làm việc làm việc phù hợp với khả năng của từng thành viên trong nhóm.
3. Kiểm soát được công việc và đưa ra những điều chỉnh kịp thời
Là một team leader, bạn có thể không cần phải làm hết tất cả mọi việc nhưng bắt buộc phải nắm được tiến độ hoàn thành của các nhiệm vụ. Vì trách nhiệm chính của một team leader là quản lý và giám sát. Bạn phải là người đầu tiên nhìn thấy được các vấn đề trong nội bộ, vấn đề với công việc để đưa ra hướng giải quyết kịp thời, tránh làm ảnh hưởng đến tiến độ chung của cả nhóm.
Tuy nhiên, điều đó không đồng nghĩa với việc chỉ có duy nhất trưởng nhóm là người được quyền giám sát mà tất cả các thành viên đều có thể tham gia vào quá trình đấy. Các thành viên cũng có thể theo dõi tiến độ và tự điều chỉnh, đóng góp ý kiến trong quá trình làm việc. Điều quan trọng nhất là cần tạo sự đoàn kết với cả team để luôn đạt được hiệu quả cao trong công việc.
Điều đầu tiên cần có ở một team leader là luôn sẵn sàng hỗ trợ người trong team của mình. Không chỉ có vai trò phân phối công việc cho các thành viên, leader cũng phải giám sát công việc và kịp thời hỗ trợ mọi người. Nếu bạn là leader, bạn luôn sẵn sàng tham gia vào công việc của cấp dưới sẽ khiến họ nể trọng bạn hơn, và khi tham gia vào công việc bạn sẽ đánh giá được cấp dưới có tận tâm với công việc họ đang làm không để kịp thời đưa ra góp ý.
Bên cạnh đó, hãy cố gắng trau dồi kỹ năng quản lý công việc của bạn nhiều hơn nữa. Vì khi đã trở thành một leader, bạn không chỉ quản lý mỗi công việc của mình mà còn là công việc của cả nhóm, của rất nhiều người. Cần học cách để sắp xếp công việc hợp lí cũng như đảm bảo không bị chậm tiến độ hay bỏ qua tasks vì không thể quản lý đầy đủ.
Đồng thời, hãy tìm hiểu thêm về kỹ năng quản lý dự án để lead một dự án bất kì được giao. Đây là yếu tố then chốt giúp team leader thực sự tỏa sáng trong vai trò dẫn dắt một team từ lập kế hoạch dự án, cho đến thực thi dự án, đo lường hiệu quả và kết thúc dự án.
Cùng với đó là bồi dưỡng khả năng leadership của bản thân, như khả năng xây dựng và duy trì 1 đội ngũ chất lượng ngay từ đầu, giao việc uỷ quyền đúng người đúng việc, tạo động lực hay giải quyết xung đột nội bộ và quản lý rủi ro hiệu quả.
Là một team leader, bạn không chỉ là người giúp cả team đạt được kết quả tốt mà còn phải luôn sẵn sàng để gánh chịu trách nhiệm khi không đạt kết quả như mong đợi. Tùy thuộc vào thái độ và sự sẵn sàng của bạn mà công việc làm leader có thể đạt được thành công hay không. Hy vọng các thông tin về kỹ năng làm việc của team leader trong bài viết sẽ giúp bạn trau dồi thêm cho bản thân mình.



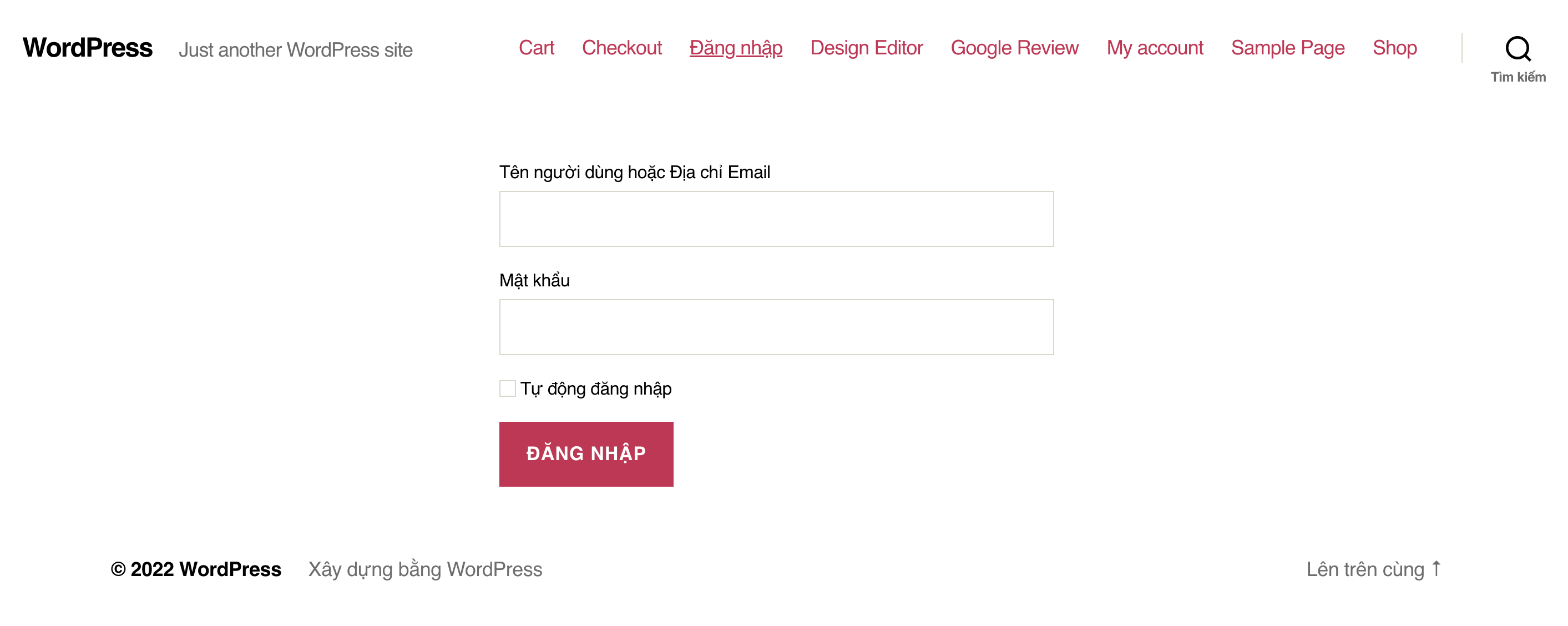












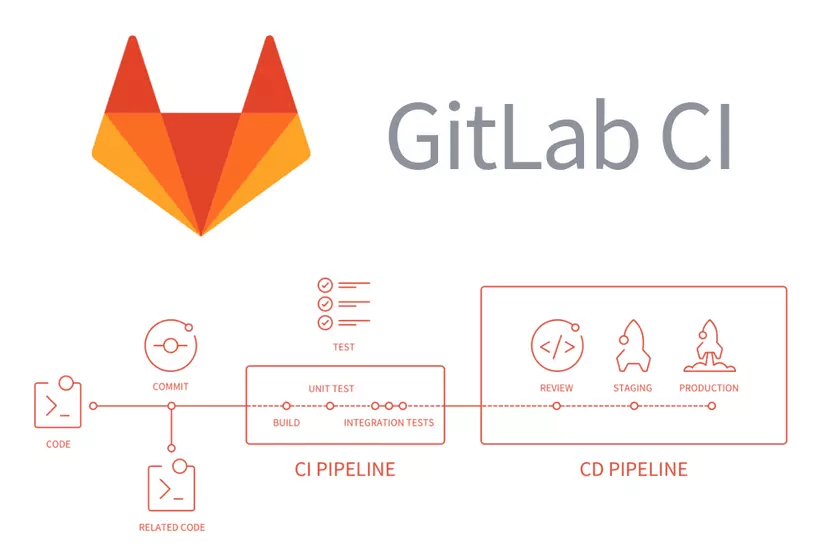









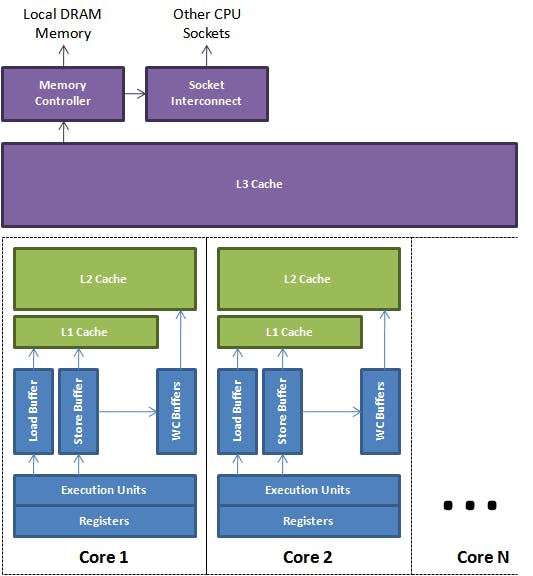
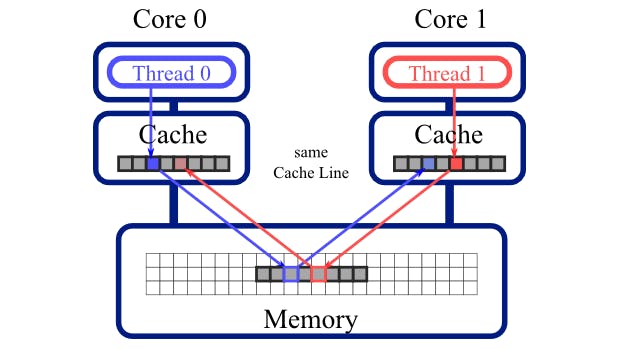
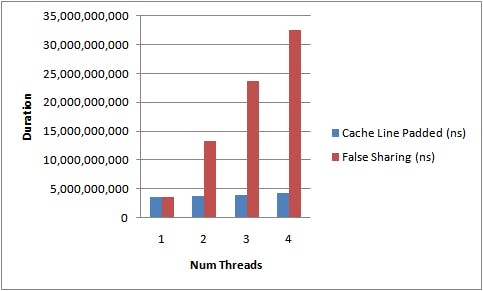
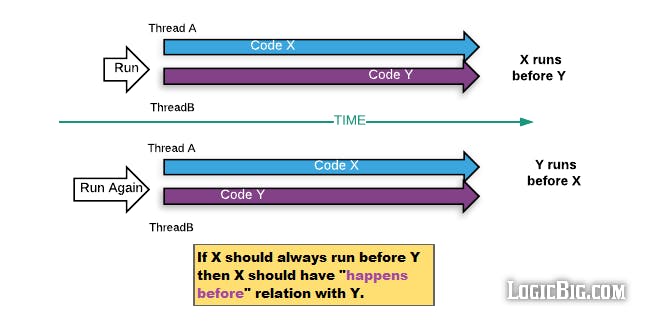
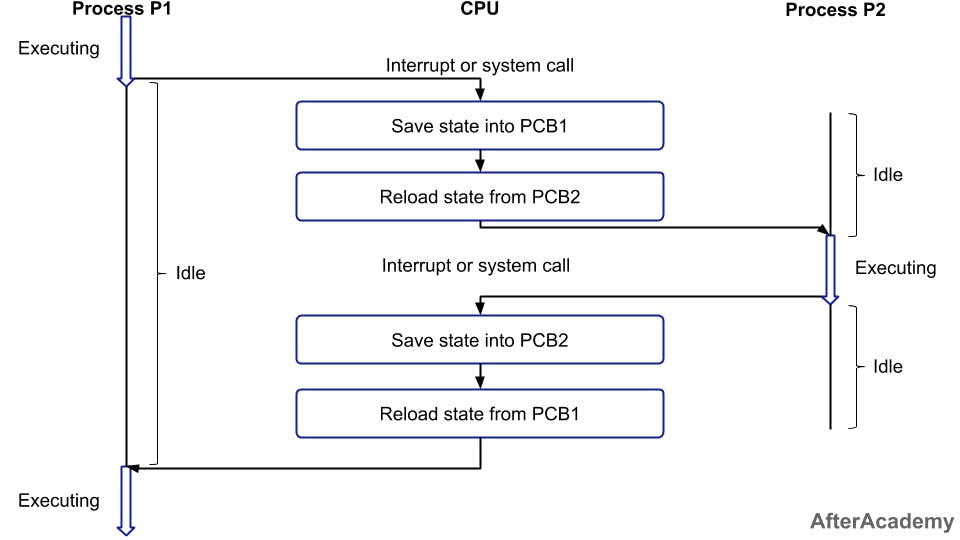
")

 Có ba lý do chính để chúng tôi đưa ra lựa chọn này :
Có ba lý do chính để chúng tôi đưa ra lựa chọn này :








 Ngoài ra công ty cũng lắp đặt máy pha cà phê espresso và bàn chơi bida để các thành viên nhóm có thể thư giãn và còn nhiều hoạt động khác cùng công ty nữa.
Ngoài ra công ty cũng lắp đặt máy pha cà phê espresso và bàn chơi bida để các thành viên nhóm có thể thư giãn và còn nhiều hoạt động khác cùng công ty nữa.

 Điều đầu tiên chính là kỹ năng về thiết kế và viết code để phát triển các sản phẩm chất lượng cao. Vì người dùng Nhật Bản rất khắt khe đối với chất lượng sản phẩm đặc biệt là trong lĩnh vực B2B. Họ yêu cầu cao về các lỗi và cả hiệu suất sản phẩm, cho nên bạn cần phải có kỹ năng xây dựng sản phẩm thật vững để xử lý lượng lớn dữ liệu mà không xảy ra lỗi. Và kĩ năng làm việc cùng đội nhóm, tất nhiên cũng là một trong những điều quan trọng để xây dựng văn hóa doanh nghiệp nữa.
Điều đầu tiên chính là kỹ năng về thiết kế và viết code để phát triển các sản phẩm chất lượng cao. Vì người dùng Nhật Bản rất khắt khe đối với chất lượng sản phẩm đặc biệt là trong lĩnh vực B2B. Họ yêu cầu cao về các lỗi và cả hiệu suất sản phẩm, cho nên bạn cần phải có kỹ năng xây dựng sản phẩm thật vững để xử lý lượng lớn dữ liệu mà không xảy ra lỗi. Và kĩ năng làm việc cùng đội nhóm, tất nhiên cũng là một trong những điều quan trọng để xây dựng văn hóa doanh nghiệp nữa.







")