


Bài viết được sự cho phép của tác giả Trần Duy Thanh
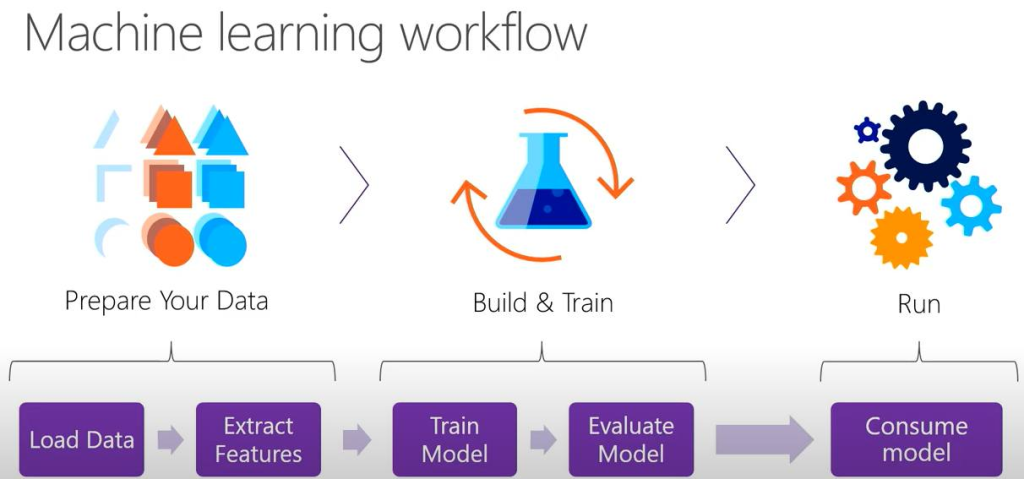
Ở bài 1 Tui đã giới thiệu về nền tảng máy học Microsoft ML.NET, các bạn chưa đọc thì chú ý đọc để nắm được sơ lược về nền tảng máy học này trước khi làm bài Dự báo giá nhà bằng mô hình hồi quy. Tui sẽ hướng dẫn từ cơ bản tới nâng cao để các bạn có thể tự tay viết được phần mềm dự báo giá nhà nên Tui chia ra làm nhiều phần, mỗi phần sẽ giúp các bạn hiểu lý thuyết cơ bản, áp dụng lý thuyết để lựa chọn các tình huống cụ thể nhằm xây dựng được phần mềm theo mục đích riêng.
Hi vọng qua mỗi phần thì nội công của các bạn sẽ thâm hậu lên, tuy nhiên đừng có chém gió quá vì các phần mềm này nó chỉ hữu ích thực sự khi chạy trong hệ thống minh bạch, nếu hệ thống không minh bạch thì nó chỉ nên là công cụ để tham khảo thôi, chứ xí xớn là Cò nó mổ cho má nhận không ra.
Mục đích của bài này sẽ giúp các bạn sẽ nắm được các kiến thức:
- Các mô hình hồi quy trong Microsoft ML.NET
- Các lớp huấn luyện được dùng trong bài toán hồi quy
- Xây dựng được phần mềm dự báo giá nhà đơn giản bằng mô hình hồi quy
- Chuẩn bị dữ liệu và mô hình hóa dữ liệu như thế nào?
- Chia bộ dữ liệu Train-Set và Test-Set ra sao
- Chọn giải thuật để train
- Train/build mô hình
- Đánh giá mô hình
- Lưu mô hình
- Tải mô hình
- Sử dụng mô hình
Các bạn lưu ý là chuỗi các bài học này Tui tập trung vào ứng dụng cách sử dụng các thư viện chứ không tập trung giải thích lý thuyết về máy học. Nên nếu bạn chưa có kiến thức cơ bản về máy học thì phải tự trang bị.
Các mô hình hồi quy trong Microsoft ML.NET
Trong máy học thì họ chia mô hình hồi quy ra làm 2 loại: Hồi quy tuyến tính và hồi quy Logistic. Microsoft cung cấp hàng loạt các giải thuật Trainning liên quan tới 2 mô hình hồi quy này:
Các Trainers hồi quy tuyến tính
- FastTreeRegressionTrainer
- FastTreeTweedieTrainer
- FastForestRegressionTrainer
- GamRegressionTrainer
- LbfgsPoissonRegressionTrainer
- LightGbmRegressionTrainer
- OlsTrainer
- OnlineGradientDescentTrainer
- SdcaRegressionTrainer
Các Trainers hồi quy Logistic:
- LbfgsLogisticRegressionBinaryTrainer
- SdcaLogisticRegressionBinaryTrainer
- SdcaNonCalibratedBinaryTrainer
- SymbolicSgdLogisticRegressionBinaryTrainer
Đây đa phần là các Extension method, và ta cũng có thể bổ sung các Trainers nếu muốn. Các lớp này được Microsoft cung cấp, và nó sẽ còn được cập nhật nhiều hơn nữa.
Việc làm Machine Learning dành cho kỹ sư ML, apply ngay!
Các lớp huấn luyện được dùng trong bài toán hồi quy
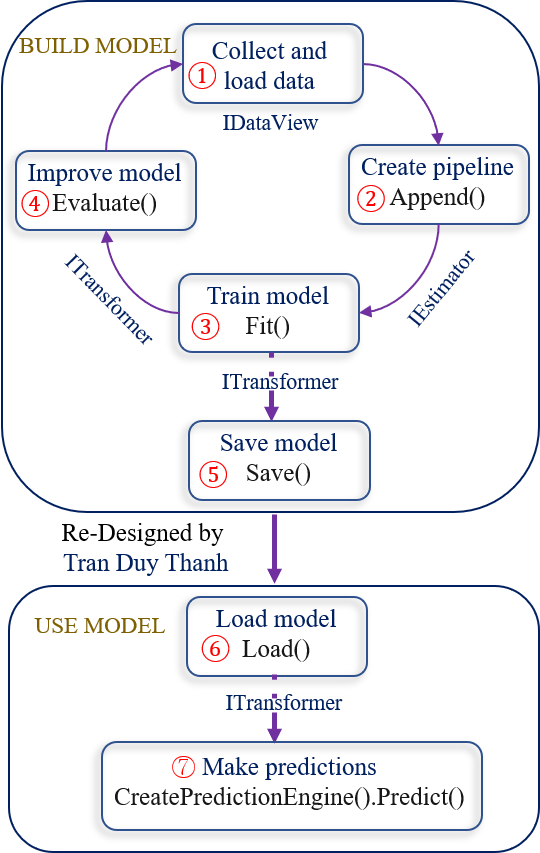
Các phần của bài dự báo giá nhà sẽ đi theo mô hình mà Tui vẽ dưới này, nó gồm 7 bước (Vui lòng trích dẫn nguồn khi dùng hình này). Tui sẽ minh họa 7 bước như trong bài 1 mà Tui đã mô tả.
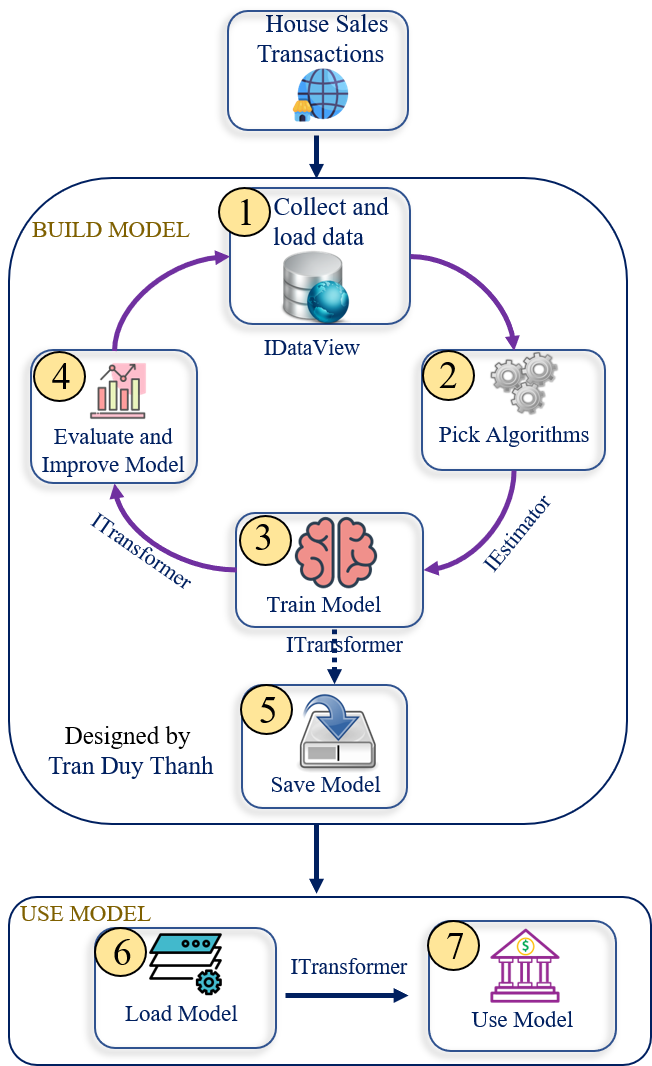
Tóm tắt 7 bước trên như sau:
Bước 1:
Collect dữ liệu và chạy tạo train – test set data
Tách dữ liệu thành 2 phần 20% cho test, 80% cho train
Bước 2:
Chọn giải thuật, rút trích đặc trưng cho tập dữ liệu
Giải thuật là lớp SdcaRegressionTrainer
Bước 3:
Tiến hành train mô hình, gọi phần Train Set (80%) để train
Bước 4:
Đánh giá mô hình, dùng độ qua R-Squared và RMSE (Root Mean Squared Error)
Nếu độ đo không thỏa yêu cầu thì quay lại bước collect dữ liệu, chọn tỉ lệ train và test phù hợp rồi build mô hình lại.
Bước 5:
Lưu mô hình nếu như bước 4 thỏa yêu cầu
Bước 6:
Tải mô hình, khi sử dụng chỉ việc vào bước 6 và bước 7.
Bước 7:
Sử dụng mô hình bằng cách gọi hàm Predict để dự báo giá nhà.
Ta bắt đầu học cách sử dụng mô hình hồi quy tuyến tính, với giải thuật SdcaRegressionTrainer để làm phần 1 của dự báo giá nhà, đây là bài cơ bản để hiểu cơ chế trước, các bài sau sẽ nâng cấp dần lên.
Khởi động Visual Studio 2022, nếu chưa cài đặt thì đọc bài này.
Trong mục dự án tìm chọn Console App rồi nhấn Next
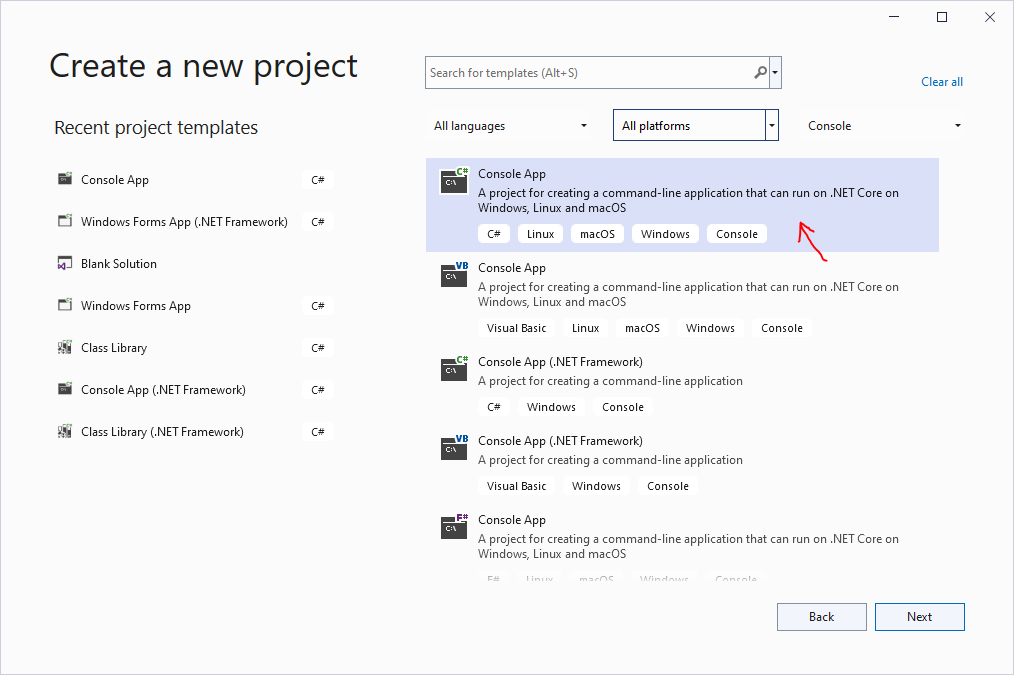
Sau khi nhấn Next:
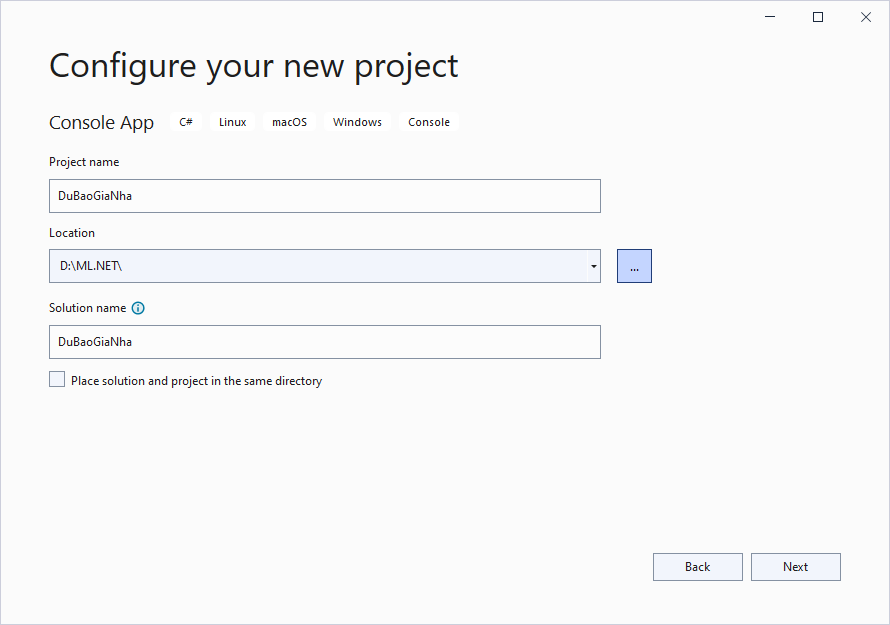
Đặt tên là “DuBaoGiaNha” rồi bấm Next

Chọn Framework .NET 6.0 (long-term support) rồi bấm Create. Dĩ nhiên khi nó ra version mới thì có thể là 7.0, 8.0….
Giao diện của dự án sẽ như hình dưới đây:
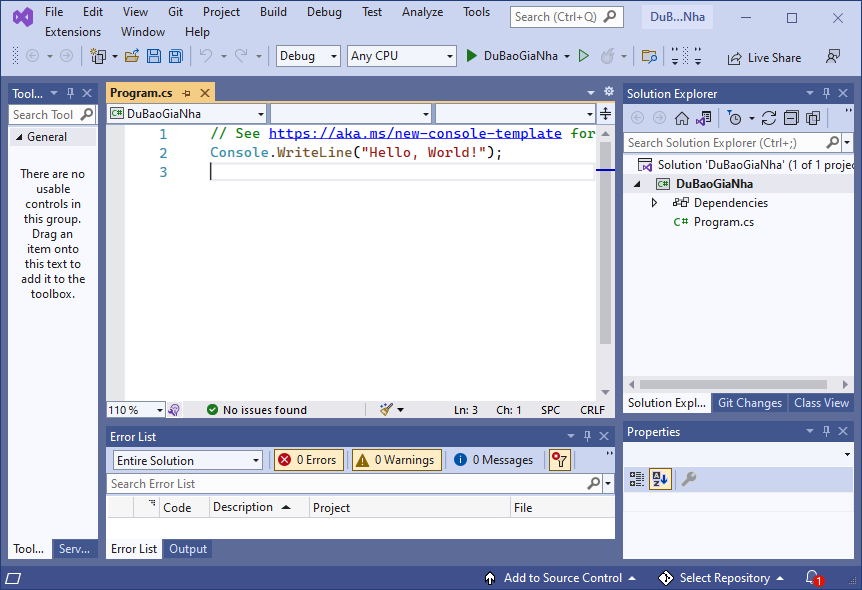
Bây giờ ta sẽ bổ sung thư viện máy học Microsoft.NET cho dự án bằng Nuget như sau:
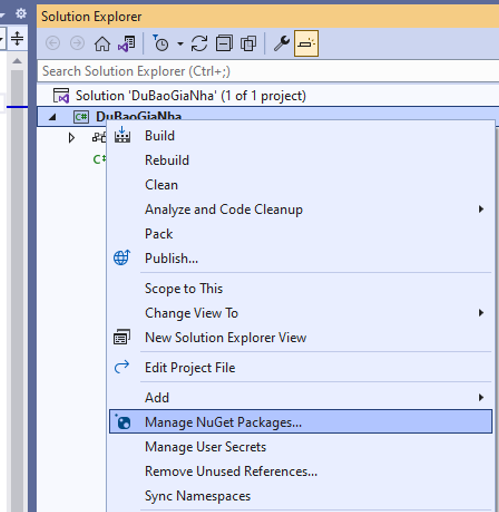
Bấm chuột phải vào dự án chọn/ Manage Nuget Packages…
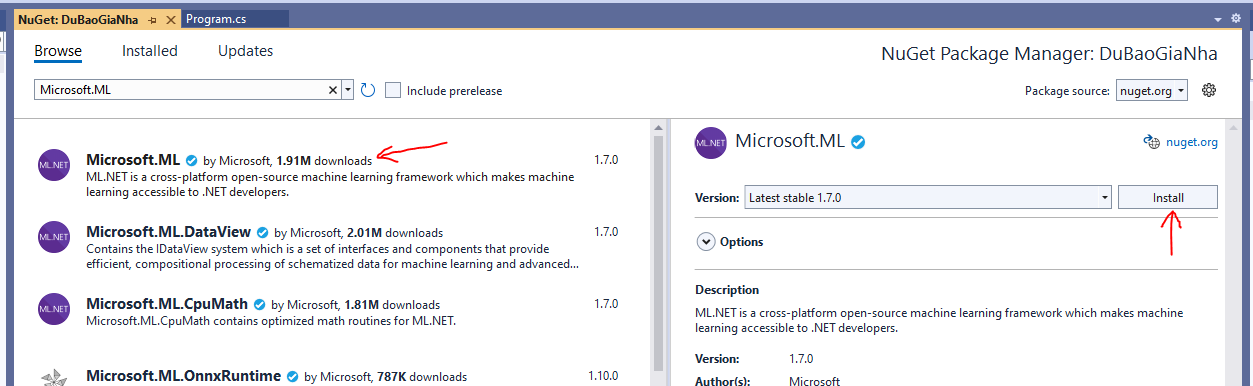
Mục Browser tìm “Microsoft.ML”, rồi bấm Install
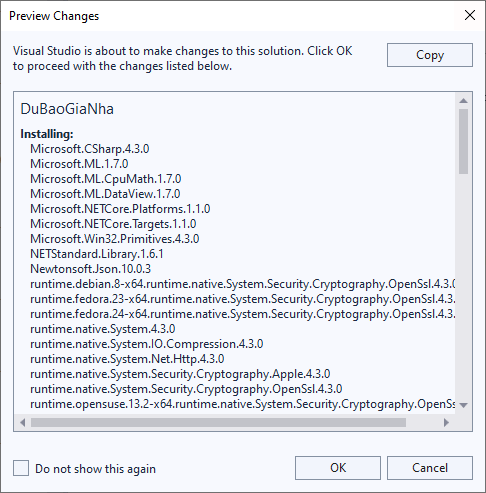
Nó hiển thị cửa sổ ở trên thì bấm OK.
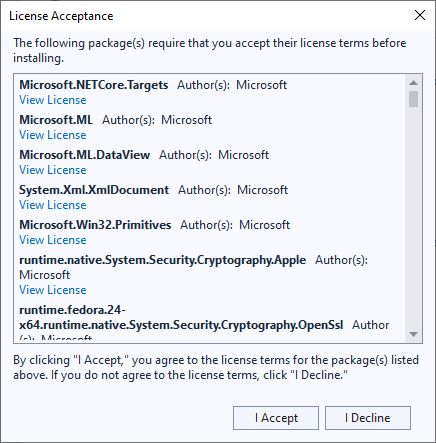
Sau đó màn hình License Acceptance cũng xuất hiện, ta nhấn “I Accept”
Nếu cài đặt thành công thì trong dự án mục Packages sẽ xuất hiện như hình trên.
Ta bắt đầu lập trình nhé
Vì đây là phần 1, phần cơ bản để hiểu được cơ chế. Nên ta giả sử rằng ta có 1 tập các các nhà có các diện tích và giá của nó (tức là chỉ có 2 thuộc tính: Diện tích và Giá), bây giờ làm sao để chương trình nó dự báo được giá của một căn nhà mới khi biết được Diện tích? (Dĩ nhiên trong thực tế không có trường hợp này, vì giá 1 căn nhà nó lệ thuộc vào: Thành phố, quận, huyện, phường, đường, diện tích, mặt tiền, hẻm, đường lộ, số tầng, số phòng ngủ, phòng khách, bếp, nhà vệ sinh…. nhiều thông số khác…. và ở nước ta chắc là lệ thuộc vào Cò.).
Một lưu ý quan trọng trong máy học là “Garbage in Garbage out” tức là dữ liệu đầu vào là rác thì kết quả đầu ra cũng là rác, vì nó build mô hình sai. Như vậy khi thu thập dữ liệu ta phải luôn luôn có bước tiền xử lý. Ví dụ ta không thể cho máy nó học Giá của một căn nhà mà chủ nhà bị phá sản bị chủ nợ tới xiết bắt bán giá rẻ bèo, hay không thể cho nó học các dữ liệu là giao dịch giả được. Điều này là hiển nhiên thôi, chúng ta đi học cũng vậy, chúng ta phải học từ những điều đúng chứ?
Bây giờ ta tạo 1 lớp là House có 2 thuộc tính Diện tích và Giá Nhà như sau:
Bấm chuột phải vào dự án / chọn Add/ Chọn Class

Đặt tên Class là “House” rồi bấm Add, tiến hành viết lệnh như dưới đây cho lớp House
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DuBaoGiaNha
{
internal class House
{
public float Size { get; set; }
public float Price { get; set; }
}
}
Tiếp tục lặp lại bước tạo lớp House, ta tạo 1 lớp mới tên là “PredictedHouse” như dưới đây
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DuBaoGiaNha
{
internal class PredictedHouse:
{
}
}
Tiến hành bổ sung mã lệnh như bên dưới:
- thư viện Microsoft.ML.Data;
- thuộc tính [ColumnName(“Score”)], đó là kết quả trả về quả Predict do giải thuật ta lựa chọn trong trường hợp hồi quy tuyến tính này. Và phải viết như vậy, nó sẽ tự động Mapping kết quả trong “Score” cho thuộc tính Price
- Lưu ý dữ liệu các thuộc tính ta khai báo là float hết nhé, thuộc tính Price ta có thể đổi tên bất kỳ
using Microsoft.ML.Data;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DuBaoGiaNha
{
internal class PredictedHouse:House
{
[ColumnName("Score")]
public float Price { get; set; }
}
}
Như vậy ta có cấu trúc lớp như hình dưới đây, đồng thời vào “Program.cs” bổ sung 5 lệnh using namespace:
using System;
using System.Text;
using DuBaoGiaNha;
using Microsoft.ML;
using Microsoft.ML.Data;
using static Microsoft.ML.DataOperationsCatalog;
Trong Máy học Microsoft ML.NET tất cả đều bắt đầu bằng đối tượng MLContext, nên ta khai báo:
using System;
using System.Text;
using DuBaoGiaNha;
using Microsoft.ML;
using Microsoft.ML.Data;
using static Microsoft.ML.DataOperationsCatalog;
//xuất dấu Tiếng Việt
Console.OutputEncoding = Encoding.UTF8;
//khai báo đối tượng MLContext
MLContext mlContext = new MLContext();
Ta tiến hành 7 bước như sau:
Ngay bên dưới dòng lệnh 10 (dòng khởi tạo đối tượng MLContext), bổ sung các lệnh cho bước 1:
//Bước 1. Chuẩn bị dữ liệu và chạy tạo train - test set data
House[] houseData = {
new House() { Size = 1.1F, Price = 1.2F },
new House() { Size = 1.9F, Price = 2.3F },
new House() { Size = 2.8F, Price = 3.0F },
new House() { Size = 3.4F, Price = 3.7F },
new House() { Size = 4.4F, Price = 7.7F },
new House() { Size = 3.2F, Price = 3.2F },
new House() { Size = 3.4F, Price = 3.8F },
new House() { Size = 5.6F, Price = 8.1F },
new House() { Size = 1.2F, Price = 1.4F },
new House() { Size = 4.0F, Price = 6.5F },
new House() { Size = 3.8F, Price = 5.9F }};
//load dữ liệu vài IDataView
IDataView alldata = mlContext.Data.LoadFromEnumerable(houseData);
//tách dữ liệu thành 2 phần 20% cho test, 80% cho train
TrainTestData splitDataView = mlContext.Data.TrainTestSplit(alldata, testFraction: 0.2);
Ở bước 1, Tui tạo khoảng 11 dữ liệu đầu vào, xem đó là lịch sử giao dịch
Hàm LoadFromEnumerable sẽ giúp chuyển dữ liệu đối tượng House thành IDataView, đây là interface quan trọng của Microsoft Machine Learning, nó giúp chuyển các dữ liệu đầu vào thành định dạng của ML.NET
Khi có dữ liệu rồi ta cần tách làm 2 nguồn, 1 nguồn để train mô hình, 1 nguồn để test mô hình.
Hàm TrainTestSplit sẽ giúp tách dữ liệu thành 2 nguồn theo tỉ lệnh testFraction, ở trên Tui để là 0.2 có nghĩa là lấy 20% cho test, 80% cho train. Nó sẽ trả về đối tượng TrainTestData, đối tượng này sẽ tự lưu phần Train-Set và Test-Set. (các bạn cứ tưởng tượng, Giảng Viên đưa 100 đề thi cho các bạn, bạn lấy ra 80 đề để ôn thi, sau đó bạn kiểm tra xem mình ôn bài có tốt không bằng cách lấy 20 đề kia làm luôn coi như nó là đề thật. Sau khi tới ngày thi thực tế thì Giảng Viên mới đưa 1 đề thật, nếu ôn luyện tốt thì đề thi thật sẽ được điểm cao),
Tiếp tục bổ sung lệnh cho bước 2 ở cuối:
// 2. Chọn giải thuật, rút trích đặc trưng cho tập dữ liệu
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
Ở bước 2 này ta cần rút trích đặc trưng cho dữ liệu, trong trường hợp này Căn nhà chỉ có đầu vào là Size (diện tích), nếu nó có nhiều thì cứ thêm vào các thuộc tính khác như là số tầng, phòng ngủ…. còn “Features” là keyword, phải viết y chang vậy.
Ở bước 2 chọn giải thuật train là Sdca (SdcaRegressionTrainer), labelColumnName được hiểu là cột mà mình cần dự báo, ở đây là cột Price (thuộc tính Price)
Nó sẽ trả về pipline (IEstimator)
Sau đó ta bổ sung lệnh cho bước 3:
// 3. Tiến hành train mô hình, gọi phần Train Set
var model = pipeline.Fit(splitDataView.TrainSet);
Ta gọi hàm Fit , truyền vào là tập dữ liệu huấn luyện , nó được lưu trong đối tượng splitDataView ở bước 1, Ta lấy phần dữ liệu huấn luyện thôi nha splitDataView.TrainSet
Kết quả của Fit nó sẽ trả về 1 model có kiểu ITransformer.
Tiếp tục bổ sung lệnh của bước 4 để đánh giá chất lượng của mô hình
//4. train mô hình xong thì phải đánh giá nó
RegressionMetrics metrics = mlContext.Regression.Evaluate(splitDataView.TestSet,
labelColumnName: "Size", scoreColumnName: "Price");
//thông số này càng nhỏ càng tốt
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError);
//thông số này càng tịnh tiến tới 100% càng tốt
//trong kinh tế lượng họ cho rằng >=50% là ổn, nhưng không có nghĩa <50% là dở
//ví dụ như chứng khoán nó sẽ nhảy búa xua
Console.WriteLine("RSquared: " + metrics.RSquared);
Ở bước 4 Ta dùng 2 độ đo, R-Squared và Root Mean Squared Error
Sau khi dựa vào các độ đo này thì ta sẽ quyết định mô hình tốt hay không, nếu không tốt thì quay lại bước dữ liệu, kiểm tra xem dữ liệu có sạch sẽ và chuẩn mực không, rồi thử các trường hợp chia dữ liệu để chạy lại mô hình.
Sau khi bước 4 hoàn tất thì tiến hành viết lệnh cho bước 5 nhằm lưu mô hình này xuống ổ cứng, lưu lại để lần sau chỉ đọc ra sử dụng thôi, chứ không phải tốn thời gian với chi phí để build lại mô hình .
//5.giả sử mô hình ngon rồi thì lưu mô hình lại
mlContext.Model.Save(model, splitDataView.TrainSet.Schema, "housemodel.zip");
Như vậy mặc định nó sẽ lưu vào nơi thực thi của dự án.
Hàm Save có 3 đối số, đối số 1 là mô hình và ta muốn lưu, đối số 2 là cấu trúc của TrainSet (Schema), đối số 3 là tên mô hình được lưu xuống file, mặc định để .zip
Tiếp tục bổ sung lệnh cho bước 6:
//6. Load mô hình lên để sài
//dĩ nhiên là bước 6,7 này nó nằm riêng chỗ khác, 1->5 lưu xong thì dẹp nó đi
//khi dùng chỉ quan tâm bước 6, và 7 thôi. Nhưng vì Tui hướng dẫn để 1 lèo 1->7 cho bạn hiểu
DataViewSchema modelSchema;
// Load trained model
var modelDaLuu = mlContext.Model.Load("housemodel.zip", out modelSchema);
Hàm Load sẽ có 2 đối số: Đối số 1 là tên file của mô hình mà ta lưu ở bước 5, đối số 2 là Schema là kết quả trả về loại cấu trúc của TrainSet mà ta lưu ở bước 5.
Sau khi load được mô hình thì ta tiến hành sử dụng như trong bước 7:
//7. Gọi predict để dùng mô hình xem dự báo
var input = new House() { Size = 2.5F };
var output = mlContext.Model.CreatePredictionEngine<House, PredictedHouse>(modelDaLuu).Predict(input);
Console.WriteLine("Nhà diện tích " + input.Size + " được dự đoán có giá =" + output.Price);
Ở bước 7 ta gọi CreatePredictionEngine với House là Input, PredictedHouse là output.
Truyền mồ hình vào rồi Gọi hàm Predict nó sẽ trả về một đối tượng PredictedHouse
Như vậy tới đây Tui đã trình bày xong 7 bước của bài máy học dùng Hồi quy tuyến tính để dự báo giá nhà.
Xem ngay tin tuyển dụng .NET tại các doanh nghiệp hàng đầu trên TopDev
Dưới đây là coding đây đủ:
using System;
using System.Text;
using DuBaoGiaNha;
using Microsoft.ML;
using Microsoft.ML.Data;
using static Microsoft.ML.DataOperationsCatalog;
//xuất dấu Tiếng Việt
Console.OutputEncoding = Encoding.UTF8;
//khai báo đối tượng MLContext
MLContext mlContext = new MLContext();
//Bước 1. Chuẩn bị dữ liệu và chạy tạo train - test set data
House[] houseData = {
new House() { Size = 1.1F, Price = 1.2F },
new House() { Size = 1.9F, Price = 2.3F },
new House() { Size = 2.8F, Price = 3.0F },
new House() { Size = 3.4F, Price = 3.7F },
new House() { Size = 4.4F, Price = 7.7F },
new House() { Size = 3.2F, Price = 3.2F },
new House() { Size = 3.4F, Price = 3.8F },
new House() { Size = 5.6F, Price = 8.1F },
new House() { Size = 1.2F, Price = 1.4F },
new House() { Size = 4.0F, Price = 6.5F },
new House() { Size = 3.8F, Price = 5.9F }};
//load dữ liệu vài IDataView
IDataView alldata = mlContext.Data.LoadFromEnumerable(houseData);
//tách dữ liệu thành 2 phần 20% cho test, 80% cho train
TrainTestData splitDataView = mlContext.Data.TrainTestSplit(alldata, testFraction: 0.2);
// 2. Chọn giải thuật, rút trích đặc trưng cho tập dữ liệu
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Tiến hành train mô hình, gọi phần Train Set
var model = pipeline.Fit(splitDataView.TrainSet);
//4. train mô hình xong thì phải đánh giá nó
RegressionMetrics metrics = mlContext.Regression.Evaluate(splitDataView.TestSet,
labelColumnName: "Size", scoreColumnName: "Price");
//thông số này càng nhỏ càng tốt
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError);
//thông số này càng tịnh tiến tới 100% càng tốt
//trong kinh tế lượng họ cho rằng >=50% là ổn, nhưng không có nghĩa <50% là dở
//ví dụ như chứng khoán nó sẽ nhảy búa xua
Console.WriteLine("RSquared: " + metrics.RSquared);
//5.giả sử mô hình ngon rồi thì lưu mô hình lại
mlContext.Model.Save(model, splitDataView.TrainSet.Schema, "housemodel.zip");
//6. Load mô hình lên để sài
//dĩ nhiên là bước 6,7 này nó nằm riêng chỗ khác, 1->5 lưu xong thì dẹp nó đi
//khi dùng chỉ quan tâm bước 6, và 7 thôi. Nhưng vì Tui hướng dẫn để 1 lèo 1->7 cho bạn hiểu
DataViewSchema modelSchema;
// Load trained model
var modelDaLuu = mlContext.Model.Load("housemodel.zip", out modelSchema);
//7. Gọi predict để dùng mô hình xem dự báo
var input = new House() { Size = 2.5F };
var output = mlContext.Model.CreatePredictionEngine<House, PredictedHouse>(modelDaLuu).Predict(input);
Console.WriteLine("Nhà diện tích " + input.Size + " được dự đoán có giá =" + output.Price);
Chạy phần mềm (nhấn F5) ta có kết quả:
Root Mean Squared Error : 0.2828426113221826
RSquared: -6.999914170176103
Nhà diện tích 2.5 được dự đoán có giá =3.3304372
Bạn thử các dữ liệu khác, thay đổi tỉ lệ của Train-set, test-set để đánh giá lại chất lượng lại mô hình cũng thử Predict để xem giá của các căn nhà có thông số khác.
Như vậy các bạn đã hiểu được đầy đủ cách lập trình một bài dùng máy học với mô hình hồi quy tuyến tính để dự báo giá của một căn nhà. Ráng làm lại để hiểu thêm cách gọi cũng như cách sử dụng các thông số.
Bài sau Tui sẽ tiếp tục bài dự báo giá nhà, nhưng làm trên giao diện tương tác để các bạn dễ sử dụng hơn, với lại khi đưa cho khách hàng sử dụng thì phải có giao diện tương tác chứ đúng không?
Thứ tự các bài tiếp theo gồm:
- Dự báo giá nhà dùng giao diện
- Dự báo giá nhà dùng giao diện + nạp dữ liệu từ text file
- Dự báo giá nhà dùng giao diện + nạp dữ liệu từ Json file
- Dự báo giá nhà dùng giao diện + nạp dữ liệu từ Excel
- Dự báo giá nhà dùng giao diện + nạp dữ liệu từ SQL Server
- Dự báo giá nhà với quy trình tổng hợp
Chúc các bạn thành công.
Mã nguồn của chương trình có thể tải tại đây:
https://www.mediafire.com/file/waqsthuxc97g6go/DuBaoGiaNha.rar/file
Bài viết gốc được đăng tải tại duythanhcse.wordpress.com
Bạn có thể xem thêm:
- Mát máy sau khi chuyển từ InfluxDB sang TimescaleDB
- Cách Trình Duyệt Hiển Thị Website Của Bạn
- Thành thạo kỹ năng CSS của bạn với bộ code cực chất
Đừng bỏ lỡ tin tuyển dụng IT từ các công ty hàng đầu trên TopDev nhé!










































")

 Có ba lý do chính để chúng tôi đưa ra lựa chọn này :
Có ba lý do chính để chúng tôi đưa ra lựa chọn này :








 Ngoài ra công ty cũng lắp đặt máy pha cà phê espresso và bàn chơi bida để các thành viên nhóm có thể thư giãn và còn nhiều hoạt động khác cùng công ty nữa.
Ngoài ra công ty cũng lắp đặt máy pha cà phê espresso và bàn chơi bida để các thành viên nhóm có thể thư giãn và còn nhiều hoạt động khác cùng công ty nữa.

 Điều đầu tiên chính là kỹ năng về thiết kế và viết code để phát triển các sản phẩm chất lượng cao. Vì người dùng Nhật Bản rất khắt khe đối với chất lượng sản phẩm đặc biệt là trong lĩnh vực B2B. Họ yêu cầu cao về các lỗi và cả hiệu suất sản phẩm, cho nên bạn cần phải có kỹ năng xây dựng sản phẩm thật vững để xử lý lượng lớn dữ liệu mà không xảy ra lỗi. Và kĩ năng làm việc cùng đội nhóm, tất nhiên cũng là một trong những điều quan trọng để xây dựng văn hóa doanh nghiệp nữa.
Điều đầu tiên chính là kỹ năng về thiết kế và viết code để phát triển các sản phẩm chất lượng cao. Vì người dùng Nhật Bản rất khắt khe đối với chất lượng sản phẩm đặc biệt là trong lĩnh vực B2B. Họ yêu cầu cao về các lỗi và cả hiệu suất sản phẩm, cho nên bạn cần phải có kỹ năng xây dựng sản phẩm thật vững để xử lý lượng lớn dữ liệu mà không xảy ra lỗi. Và kĩ năng làm việc cùng đội nhóm, tất nhiên cũng là một trong những điều quan trọng để xây dựng văn hóa doanh nghiệp nữa.




