Ngày nay, hơn 80% nhà tuyển dụng đã sử dụng các kênh online để tìm kiếm ứng viên. Do đó, việc tạo một hồ sơ xin việc online ấn tượng sẽ giúp bạn nổi bật giữa hàng ngàn ứng viên khác và tăng cơ hội nhận được lời mời phỏng vấn. Hãy cùng theo dõi bài viết này để tìm hiểu cách tạo hồ sơ xin việc online chuẩn chỉnh và tăng cơ hội lọt vào “mắt xanh” nhà tuyển dụng.
Hồ sơ xin việc online là gì?
Hồ sơ xin việc online là bộ hồ sơ mà ứng viên gửi qua email hoặc qua hệ thống nhận diện hồ sơ online trên các trang web của công ty mà bạn ứng tuyển hay qua các trang web tuyển dụng. Hồ sơ này có thể được tạo và quản lý trên nhiều nền tảng khác nhau. Những hồ sơ này thường được tìm kiếm và duyệt bởi nhà tuyển dụng khi họ tìm kiếm ứng viên phù hợp cho các vị trí làm việc trong công ty của họ.
Tạo hồ sơ xin việc online mang lại nhiều lợi ích, bao gồm sự tiện lợi, khả năng tiếp cận rộng rãi với các cơ hội việc làm, và khả năng cập nhật dễ dàng. Đồng thời, hồ sơ này cũng cho phép ứng viên thể hiện bản thân mình một cách chuyên nghiệp và sáng tạo hơn thông qua hình ảnh, video, và nhiều loại tài liệu khác.
Một bộ hồ sơ xin việc online gồm những gì?
Gửi CV qua email gồm những gì? Cách làm hồ sơ xin việc online không quá khó, bạn chỉ cần đảm bảo đầy đủ các thành phần cần có trong hồ sơ:
1. CV xin việc
CV là tài liệu tóm tắt các thông tin về kinh nghiệm làm việc, kỹ năng, bằng cấp và thành tích của bạn. CV nên được trình bày một cách khoa học, logic và dễ nhìn. Nên sử dụng từ khóa liên quan đến vị trí bạn ứng tuyển để tăng khả năng hiển thị với nhà tuyển dụng.
Đơn xin việc là một văn bản được gửi kèm theo CV xin việc để bày tỏ nguyện vọng ứng tuyển vào vị trí cụ thể của bạn. Đơn xin việc nên được viết ngắn gọn, súc tích và nêu rõ lý do bạn ứng tuyển vào vị trí này.
Khi viết đơn xin việc bạn cần xác định rõ vị trí bạn ứng tuyển và mục tiêu của bạn khi ứng tuyển vào vị trí này. Hãy nêu bật những điểm mạnh, kỹ năng và kinh nghiệm của bạn phù hợp với vị trí ứng tuyển. Và hãy nhớ check lại thật kỹ lỗi ngữ pháp và chính tả trước khi gửi nó đến nhà tuyển dụng.
Portfolio là phần không bắt buộc phải có trong bộ hồ sơ xin việc online vì nó còn phụ thuộc vào ngành nghề mà bạn ứng tuyển. Portfolio là một tập hợp các công việc, dự án hoặc sản phẩm mà bạn đã thực hiện trong quá khứ. Đây là cách tốt nhất để bạn có thể giới thiệu và thể hiện khả năng và kỹ năng của mình cho nhà tuyển dụng.
Portfolio có thể bao gồm nhiều loại tài liệu khác nhau như hình ảnh, video, bài viết, thiết kế,… Bạn cần lưu ý chọn lọc những sản phẩm tốt nhất, phù hợp nhất với vị trí bạn ứng tuyển để đưa vào portfolio và thường xuyên cập nhật những sản phẩm mới mà bạn đã thực hiện.
4. Các giấy tờ khác
Để tạo một hồ sơ xin việc online chuyên nghiệp, bạn cần bao gồm các bản scan các giấy tờ tùy thân như bằng cấp, chứng chỉ, giấy chứng nhận, và nếu cần thiết, giấy khám sức khỏe. Để đảm bảo chất lượng hình ảnh tốt nhất, nên sử dụng các phần mềm scan hình ảnh thay vì chức năng chụp ảnh thông thường của điện thoại
5. Thư giới thiệu
Thư giới thiệu có thể có hoặc không có trong bộ hồ sơ xin việc online. Đây là một văn bản được viết bởi một người có uy tín trong lĩnh vực của bạn để giới thiệu về năng lực, kỹ năng và kinh nghiệm làm việc của bạn. Thư xin việc sẽ giúp doanh nghiệp hiểu rõ bạn hơn từ góc nhìn của bên thứ ba.
Lưu ý khi làm hồ sơ xin việc online
Khi làm hồ sơ xin việc online, có một số lưu ý quan trọng mà bạn nên cân nhắc để tạo ra một hồ sơ chuyên nghiệp và thu hút sự chú ý của nhà tuyển dụng.
Tiêu đề email
Sử dụng tiêu đề ngắn gọn, súc tích và rõ ràng.
Nêu rõ vị trí ứng tuyển và tên của bạn.
Ví dụ: “Ứng tuyển vị trí [Tên vị trí] – [Họ và tên]”
Văn phong email
Sử dụng văn phong trang trọng, lịch sự và chuyên nghiệp.
Tránh sử dụng tiếng lóng, từ viết tắt và các ký tự đặc biệt.
Chú ý ngữ pháp và chính tả.
Tránh gửi cùng 1 email xin việc đến nhiều doanh nghiệp
Cá nhân hóa email cho từng doanh nghiệp.
Nêu rõ lý do bạn quan tâm đến doanh nghiệp và vị trí ứng tuyển.
Sửa đổi nội dung email để phù hợp với từng vị trí ứng tuyển.
Tóm lại, hồ sơ xin việc online là một bước khởi đầu quan trọng giúp bạn tạo ấn tượng với nhà tuyển dụng và tăng cơ hội nhận được việc làm. Hãy dành thời gian để chuẩn bị hồ sơ xin việc một cách cẩn thận và chuyên nghiệp. Bằng cách làm theo những lời khuyên trong bài viết này, bạn có thể tạo ra một hồ sơ xin việc online ấn tượng và tăng cơ hội nhận được việc làm mơ ước. Chúc bạn thành công!
Với sự phát triển mạnh mẽ của lĩnh vực công nghệ thông tin, vai trò của Tester trở nên quan trọng hơn bao giờ hết. Các khóa học Tester ra đời nhằm đáp ứng nhu cầu đào tạo đội ngũ nhân lực chuyên nghiệp, có trình độ để đảm bảo chất lượng phần mềm và ứng dụng. Trong bài viết này, TopDev sẽ giới thiệu đến bạn các khóa học Tester uy tín trên thị trường, giúp các lập trình viên đưa ra lựa chọn phù hợp với mục tiêu nghề nghiệp của mình.
Khóa đào tạo Tester cơ bản
Giới thiệu về khóa học
Khóa đào tạo Tester cung cấp nền tảng kiến thức cơ bản về quy trình kiểm thử phần mềm, kỹ thuật kiểm thử và các công cụ hỗ trợ. Đây là khóa học phù hợp cho những người mới bắt đầu hoặc muốn tìm hiểu về lĩnh vực kiểm thử phần mềm.
Nội dung chính của khóa học
Hiểu các quy trình và tiêu chuẩn kiểm thử phần mềm
Thực hiện các kỹ thuật kiểm thử cơ bản như kiểm thử chức năng, kiểm thử giao diện người dùng và kiểm thử hiệu suất
Sử dụng các công cụ kiểm thử phổ biến như Selenium, JMeter và Jira
Lợi ích của khóa học
Cung cấp nền tảng kiến thức cơ bản về kiểm thử phần mềm
Giúp học viên có khả năng thực hiện các kỹ thuật kiểm thử cơ bản
Hướng dẫn sử dụng các công cụ kiểm thử phổ biến trong quá trình làm việc
Hướng dẫn trở thành Tester chuyên nghiệp
Giới thiệu về khóa học
Đây là khóa học dành cho những người có mong muốn theo đuổi sự nghiệp tester chuyên nghiệp. Khóa học bao gồm các nội dung chuyên sâu về các quy trình kiểm thử nâng cao, kiểm thử tự động và kiểm thử hiệu suất.
Nội dung khóa học
Thành thạo các quy trình kiểm thử nâng cao như kiểm thử tích hợp, kiểm thử hệ thống và kiểm thử hồi quy
Biết cách sử dụng các công cụ kiểm thử tự động như Selenium, WebDriver và Cucumber
Có kiến thức vững chắc về kiểm thử hiệu suất và các công cụ liên quan như JMeter và LoadRunner
Lợi ích của khóa học
Nâng cao trình độ và kỹ năng trong lĩnh vực kiểm thử phần mềm
Hướng dẫn sử dụng các công cụ kiểm thử tự động và kiểm thử hiệu suất
Đáp ứng được yêu cầu của các doanh nghiệp về nhân lực chuyên nghiệp trong lĩnh vực kiểm thử phần mềm
Ngoài hai khóa học đã được giới thiệu ở trên, còn có nhiều loại khóa học Tester khác như: khóa học Tester online, khóa học Tester offline, khóa học Tester nâng cao, khóa học Tester tự học,… Tùy vào mục tiêu và điều kiện của mỗi người, bạn có thể lựa chọn cho mình một khóa học phù hợp.
Khóa học Tester online
Khóa học Tester online là một lựa chọn phổ biến hiện nay vì tính tiện lợi và linh hoạt. Bạn có thể học tập và rèn luyện kỹ năng của mình bất cứ khi nào và ở bất cứ đâu chỉ với một thiết bị có kết nối internet. Ngoài ra, khóa học online còn giúp bạn tiết kiệm được chi phí đi lại và có thể học cùng lúc với các học viên khác trên toàn quốc.
Khóa học Tester offline
Khóa học Tester offline là sự lựa chọn cho những người muốn học tập trực tiếp tại trung tâm đào tạo. Điều này giúp bạn có cơ hội giao lưu và học hỏi từ các giảng viên và học viên khác. Tuy nhiên, lập trình viên cần phải dành thời gian và chi phí đi lại để tham gia khóa học này.
Khóa học Tester nâng cao
Khóa học Tester nâng cao là lựa chọn cho những người đã có kiến thức cơ bản về kiểm thử phần mềm và muốn nâng cao trình độ. Khóa học này sẽ cung cấp cho bạn các kiến thức và kỹ năng chuyên sâu trong lĩnh vực kiểm thử phần mềm.
Tự học Tester
Tự học là lựa chọn cho những người có thời gian và khả năng tự học tập. Bạn có thể tìm kiếm các tài liệu, video hướng dẫn trên internet hoặc đọc sách để tự học về kiểm thử phần mềm. Tuy nhiên, bạn cần có sự tự tin và kỹ năng tự học tốt để có thể tiến bộ trong lĩnh vực này.
Lộ trình học Tester từ cơ bản đến nâng cao
Để trở thành một Tester chuyên nghiệp, bạn cần phải có một lộ trình học tập rõ ràng và có kế hoạch. Dưới đây là một lộ trình học Tester từ cơ bản đến nâng cao mà bạn có thể tham khảo:
Bước 1: Tìm hiểu về kiểm thử phần mềm
Trước khi bắt đầu học tập về kiểm thử phần mềm, bạn cần hiểu rõ về lĩnh vực này và vai trò của Tester trong quá trình phát triển phần mềm. Bạn có thể tìm hiểu qua các tài liệu, sách hoặc tham gia các diễn đàn để có được cái nhìn tổng quan về kiểm thử phần mềm.
Bước 2: Học khóa đào tạo Tester
Khóa đào tạo Tester sẽ cung cấp cho bạn nền tảng kiến thức cơ bản về kiểm thử phần mềm. Bạn sẽ được học các quy trình, tiêu chuẩn và kỹ thuật kiểm thử cơ bản.
Bước 3: Thực hành và rèn luyện kỹ năng
Sau khi hoàn thành khóa đào tạo, bạn cần thực hành và rèn luyện kỹ năng của mình. Bạn có thể tham gia vào các dự án thực tế hoặc làm các bài tập để củng cố kiến thức đã học.
Bước 4: Học khóa học Tester nâng cao
Khóa học Tester nâng cao sẽ giúp bạn nắm được các kỹ năng chuyên sâu và cần thiết trong lĩnh vực kiểm thử phần mềm. Bạn sẽ được học các kỹ thuật kiểm thử nâng cao và sử dụng các công cụ tự động và hiệu suất.
Bước 5: Tự học và nghiên cứu thêm
Để trở thành một Tester chuyên nghiệp, bạn cần liên tục cập nhật và nghiên cứu thêm về các công nghệ mới và xu hướng trong lĩnh vực kiểm thử phần mềm. Bạn có thể tự học hoặc tham gia các khóa học nâng cao để cập nhật kiến thức của mình.
Dưới đây là 10 khóa học kiểm tra hàng đầu hiện nay:
Khóa học Kiểm thử ISTQB® Certified Tester Foundation Level
Khóa học này dành cho những người mới bắt đầu kiểm thử phần mềm. Nó bao gồm các nguyên tắc cơ bản về kiểm thử phần mềm, chẳng hạn như quy trình kiểm thử, kỹ thuật kiểm thử và quản lý kiểm thử.
Khóa học Chuyên viên kiểm thử được chứng nhận của Hiệp hội Kiểm thử Phần mềm Hoa Kỳ (CSTE)
Khóa học này dành cho những người có kinh nghiệm kiểm thử phần mềm. Nó bao gồm các chủ đề nâng cao hơn, chẳng hạn như kiểm thử hiệu suất, kiểm thử bảo mật và kiểm thử khả năng sử dụng.
Khóa học Kiểm thử Agile
Khóa học này dành cho những người muốn tìm hiểu cách áp dụng các phương pháp kiểm thử Agile cho các dự án phát triển phần mềm. Nó bao gồm các chủ đề như lập kế hoạch kiểm thử Agile, thực thi kiểm thử Agile và tự động hóa kiểm thử Agile.
Khóa học Kiểm thử tự động hóa
Khóa học này dành cho những người muốn tìm hiểu cách sử dụng các công cụ và kỹ thuật tự động hóa để kiểm thử phần mềm. Nó bao gồm các chủ đề như Selenium, Appium và Cypress.
Khóa học Kiểm thử bảo mật
Khóa học này dành cho những người muốn tìm hiểu cách kiểm tra phần mềm để tìm các lỗ hổng bảo mật. Nó bao gồm các chủ đề như kiểm tra thâm nhập, kiểm tra hộp đen và kiểm tra hộp trắng.
Khóa học Kiểm thử khả năng sử dụng
Khóa học này dành cho những người muốn tìm hiểu cách kiểm tra phần mềm để đảm bảo rằng nó dễ sử dụng. Nó bao gồm các chủ đề như thử nghiệm người dùng, thử nghiệm khả năng tiếp cận và thử nghiệm A/B.
Khóa học Kiểm thử hiệu suất
Khóa học này dành cho những người muốn tìm hiểu cách kiểm tra phần mềm để đảm bảo rằng nó hoạt động hiệu quả. Nó bao gồm các chủ đề như thử nghiệm tải, thử nghiệm căng thẳng và thử nghiệm điểm chuẩn.
Khóa học Kiểm thử di động
Khóa học này dành cho những người muốn tìm hiểu cách kiểm tra các ứng dụng di động. Nó bao gồm các chủ đề như kiểm thử Android, kiểm thử iOS và kiểm thử đa nền tảng.
Khóa học Kiểm thử API
Khóa học này dành cho những người muốn tìm hiểu cách kiểm thử giao diện lập trình ứng dụng (API). Nó bao gồm các chủ đề như kiểm thử chức năng API, kiểm thử bảo mật API và kiểm thử hiệu suất API.
Khóa học Kiểm thử DevOps
Khóa học này dành cho những người muốn tìm hiểu cách áp dụng các phương pháp kiểm thử DevOps cho các dự án phát triển phần mềm. Nó bao gồm các chủ đề như tích hợp liên tục và triển khai liên tục (CI/CD), tự động hóa kiểm thử và giám sát.
Đây chỉ là một vài trong số rất nhiều khóa học kiểm thử có sẵn. Khi chọn khóa học phù hợp với bạn, điều quan trọng là phải xem xét các yếu tố như kinh nghiệm, sở thích và mục tiêu nghề nghiệp của bạn.
Học Tester trực tuyến hay học offline hiệu quả hơn?
Việc học Tester trực tuyến hay học offline sẽ phụ thuộc vào sở thích và điều kiện của từng người. Tuy nhiên, học Tester trực tuyến có những ưu điểm sau:
Tiết kiệm thời gian và chi phí đi lại.
Có thể học bất cứ lúc nào và ở bất cứ đâu.
Dễ dàng tiếp cận các tài liệu và video hướng dẫn trực tuyến.
Có thể giao lưu và học hỏi từ các học viên khác trên mạng xã hội hoặc diễn đàn.
Tuy nhiên, học Tester offline cũng có những ưu điểm riêng như:
Có cơ hội giao lưu và học hỏi trực tiếp từ giảng viên và các học viên khác.
Được hỗ trợ và giải đáp thắc mắc trực tiếp từ giảng viên.
Có môi trường học tập chuyên nghiệp và đầy đủ các thiết bị cần thiết.
Kinh nghiệm lựa chọn khóa học phù hợp
Để lựa chọn được khóa học Tester phù hợp với mục tiêu và điều kiện của mình, bạn có thể tham khảo các kinh nghiệm sau đây:
Tìm hiểu về nội dung khóa học
Trước khi đăng ký khóa học, bạn cần tìm hiểu kỹ về nội dung và mục tiêu của khóa học đó. Nếu nội dung không phù hợp với mục tiêu của bạn, có thể bạn sẽ không học được những gì mong muốn.
Xem xét giảng viên và đội ngũ giảng dạy
Giảng viên và đội ngũ giảng dạy là yếu tố quan trọng trong việc quyết định chất lượng của khóa học. Bạn có thể tìm hiểu về kinh nghiệm và thành tích của giảng viên để đánh giá khả năng hướng dẫn và truyền đạt kiến thức của họ.
Kiểm tra đánh giá và phản hồi từ học viên cũ
Đánh giá và phản hồi từ những người đã tham gia khóa học sẽ giúp bạn có cái nhìn tổng quan về chất lượng và hiệu quả của khóa học. Bạn có thể tìm kiếm trên các diễn đàn hoặc mạng xã hội để tìm hiểu thêm về đánh giá và phản hồi của học viên cũ.
Vai trò và triển vọng nghề nghiệp của Tester
Vai trò của Tester là đảm bảo chất lượng sản phẩm phần mềm trước khi được đưa ra thị trường. Với sự phát triển không ngừng của công nghệ thông tin, vai trò của Tester ngày càng trở nên quan trọng và có triển vọng trong tương lai.
Nghề nghiệp Tester đòi hỏi sự chính xác, kiên trì và khả năng tư duy logic. Với kỹ năng và kinh nghiệm phù hợp, bạn có thể trở thành một Tester chuyên nghiệp và có cơ hội thăng tiến trong công việc.
Để học Tester thành công, bạn có thể áp dụng những bí quyết sau:
Luôn cập nhật và nghiên cứu thêm về các công nghệ mới và xu hướng trong lĩnh vực kiểm thử phần mềm.
Thực hành và rèn luyện kỹ năng thường xuyên để củng cố kiến thức đã học.
Tìm hiểu và áp dụng các công cụ tự động và hiệu suất trong quá trình kiểm thử.
Giao lưu và học hỏi từ các giảng viên và học viên khác.
Đặt ra mục tiêu rõ ràng và có kế hoạch học tập cụ thể.
Kết luận
Trong bài viết này, TopDev tìm hiểu về các loại khóa học Tester phổ biến, lộ trình học Tester từ cơ bản đến nâng cao, kinh nghiệm lựa chọn khóa học phù hợp và điểm qua top 10 khóa học Tester uy tín trên thị trường hiện nay. Mong rằng với những thông tin này sẽ giúp bạn có được cái nhìn tổng quan về lĩnh vực kiểm thử phần mềm và lựa chọn được khóa học phù hợp để trở thành một Tester chuyên nghiệp.
Hãy tiếp tục truy cập vào Blog TopDev để cập nhật thêm nhiều thông tin về kiến thức lập trình hữu ích!
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Bài viết được sự cho phép của tác giả Trần Nhật Trường
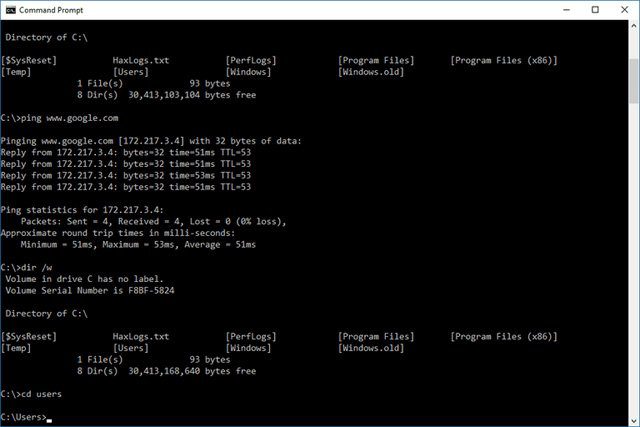
Khi nhắc đến Windows thì thì ai trong chúng ta khi sử dụng máy tính đều biết tới hệ điều hành vô cùng phổ biến này. Ở bài viết này thì mình sẽ chỉ ra những câu lệnh Command Prompt hay còn gọi là cmd phổ biến ở trong Windows.
À mà trước khi sử dụng đến những câu lệnh thì phải mở cmd lên đã . Các bạn có thể ấn vào dòng search bên dưới góc trái màn hình và gõ cmd sau đó ấn Enter hoặc ấn tổ hợp phím Windows + R và gõ cmd sau đó ấn Enter. Kết quả sẽ hiện ra cửa sổ sau:
Ngoài ra còn có những cách khác nữa bạn có thể tìm hiểu thêm tại đây .
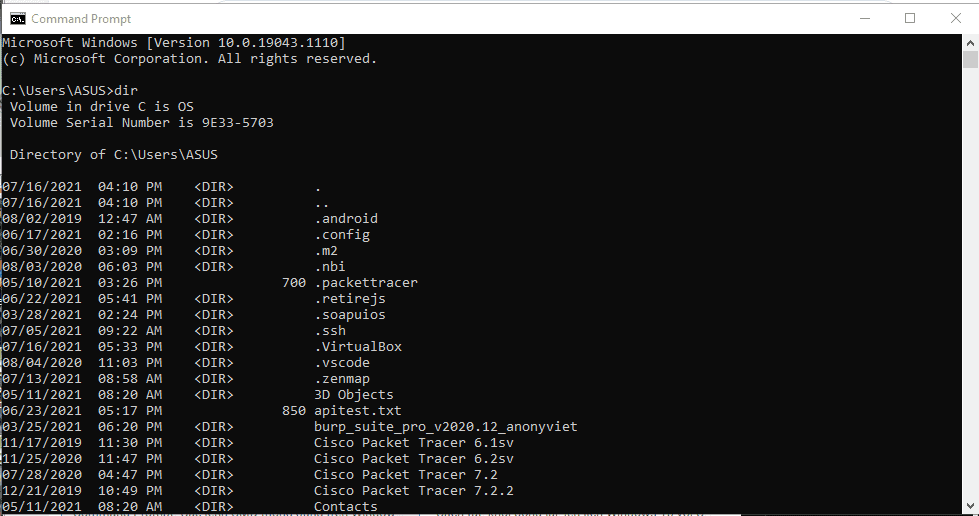
Sau đây mình sẽ giới thiệu 23 câu lệnh phổ biến khi chúng ta sử dụng cmd:
1.dir
Lệnh này liệt kê tất cả các file hay thư mục chứa bên trong thư mục đang được chỉ định.
2. cls
Xóa toàn bộ những thông tin đang hiển thị trên màn hình cmd.
3. cd
Lệnh này dùng để chuyển chỉ mục, bạn có thể di chuyển sang thư mục khác hay thậm chí là phân vùng ổ cứng khác.
Cú pháp chung : cd <tên thư mục hoặc đường dẫn>
4. copy
Lệnh này cho phép copy một file hay thư mục sang một vị trí mới.
Câu lệnh này dùng để hiển thị các câu lệnh chúng ta có thể sử dụng.
10. ipconfig
Một câu lệnh vô cùng phổ biến dùng để in ra các thông tin về mạng, bao gồm cả địa chỉ ip và các thiết bị mạng.
11. hostname
Hiển thị tên máy
12. ping
Một câu lệnh chúng ta hay sử dụng không kém gì lệnh ipconfig để kiểm tra kết nối mạng.
Cú pháp chung : ping <ip hoặc host>
13. tracert
Trong quá trình một file được gửi đi giữa 2 máy, nó sẽ phải đi qua rất nhiều node trung gian, tracert giúp ta biết được gói tin đã đi qua những node mạng nào.
Cú pháp chung : tracert <ip/host>
14. netstat
Kiểm tra các kết nối vào ra trên thiết bị.
15. shutdown
Tắt hay khởi động lại máy:
shutdown -s -t [a]: tắt máy.
shutdown -r -t [a]: khởi động máy.
Trong đó a là thời gian tính bằng giây
16. tasklist
Hiển thị các tiến trình đang hoạt động, sau đó bạn có thể dùng lệnh taskkill để buộc dừng tiến trình đó.
17. systeminfo
Hiển thị thông tin của hệ thống.
18. chkdsk (check disk)
Kiểm tra ổ cứng, lệnh này cũng rất quan trọng.
19. attrib
Thay đổi thuộc tính của file
20. reg add/delete
Thêm hay xóa trong registry
21. color
Thay đổi màu nền cmd
22. title
Thay đổi tiêu đề của cửa sổ cmd
Trên đây là 1 số lệnh thông dụng nhất khi chúng ta sử dụng command prompt, hãy sử dụng nó thật hiệu quả nhé ಠ‿↼
Automation Test (tự động hóa kiểm thử) là một khái niệm quan trọng trong lĩnh vực phát triển phần mềm hiện nay. Công việc của Automation tester là rất quan trọng trong quá trình phát triển phần mềm. Với sự phát triển không ngừng của công nghệ, những kỹ năng của một Automation tester càng trở nên quan trọng hơn bao giờ hết. Bài viết này sẽ giúp bạn hiểu rõ hơn về công việc của Automation tester và những gì cần trang bị để trở thành một kỹ sư kiểm thử tự động hóa.
Automation Test là gì?
Automation Test là quá trình sử dụng các công cụ và kỹ thuật để tự động thực hiện các trường hợp kiểm thử phần mềm.
Thay vì thử nghiệm thủ công, các tester có thể sử dụng các công cụ tự động để thực hiện các bài kiểm thử, giảm thiểu thời gian và công sức cho quá trình kiểm thử. Các công cụ tự động này có thể được lập trình để thực hiện các bài kiểm thử theo các kịch bản được xác định trước, giúp tăng tính nhất quán và toàn diện trong quá trình kiểm thử.
Automation Test có thể được áp dụng cho nhiều loại phần mềm, từ ứng dụng di động, web, desktop cho đến các hệ thống phức tạp như hệ thống ngân hàng hay hệ thống y tế. Các công cụ tự động hóa kiểm thử có thể được sử dụng để thực hiện các bài kiểm thử chức năng, giao diện, hiệu suất, bảo mật và nhiều khía cạnh khác của phần mềm.
Automation tester là gì?
Automation tester, hay còn gọi là kỹ sư kiểm thử tự động hóa, là một chuyên gia thực hiện các bài kiểm thử phần mềm bằng cách sử dụng các công cụ và khung kiểm thử tự động.
Trái ngược với kiểm thử thủ công truyền thống (Manual testing), nơi các thử nghiệm được thực hiện thủ công, kiểm thử tự động hóa sử dụng các kịch bản được viết trước để mô phỏng hành vi của người dùng và tự động kiểm tra kết quả. Điều này giúp tăng cường hiệu suất và độ chính xác trong quá trình kiểm thử phần mềm.
Công việc của Automation tester là gì?
Công việc chính của Automation tester bao gồm:
Thiết kế và phát triển các kịch bản kiểm thử tự động hóa
Một trong những nhiệm vụ quan trọng nhất của Automation tester là thiết kế và phát triển các kịch bản kiểm thử tự động hóa. Điều này đòi hỏi họ phải nắm vững các công cụ và khung kiểm thử tự động hóa để tạo ra các kịch bản mô phỏng hành vi của người dùng và kiểm tra chức năng của ứng dụng. Các kịch bản này sẽ được sử dụng để thực hiện các thử nghiệm tự động, giúp tiết kiệm thời gian và nâng cao độ chính xác.
Thực hiện các thử nghiệm tự động
Sau khi đã có các kịch bản kiểm thử tự động, Automation tester sẽ sử dụng chúng để thực hiện các thử nghiệm tự động trên nhiều nền tảng và thiết bị khác nhau. Điều này giúp đảm bảo tính tương thích của ứng dụng trên các môi trường và thiết bị khác nhau.
Phân tích kết quả kiểm thử
Sau khi các thử nghiệm đã được thực hiện, Automation tester sẽ phân tích kết quả kiểm thử để xác định các lỗi và trục trặc, đồng thời cung cấp báo cáo chi tiết cho nhóm phát triển. Điều này giúp nhóm phát triển có những thông tin chính xác về tình trạng của ứng dụng và có thể khắc phục các lỗi một cách nhanh chóng.
Bảo trì các kịch bản kiểm thử tự động
Như đã đề cập ở trên, việc sử dụng các kịch bản kiểm thử tự động giúp tăng cường hiệu suất và độ chính xác trong quá trình kiểm thử. Tuy nhiên, khi ứng dụng được cập nhật hoặc thay đổi, các kịch bản này cần phải được cập nhật để đảm bảo rằng các thử nghiệm luôn phản ánh chính xác các yêu cầu chức năng của ứng dụng. Vì vậy, công việc bảo trì các kịch bản kiểm thử tự động là một phần không thể thiếu trong công việc của Automation tester.
Hiện nay, có rất nhiều công cụ tự động hóa kiểm thử được sử dụng trong lĩnh vực phát triển phần mềm. Dưới đây là một số công cụ tự động hóa kiểm thử phổ biến:
Selenium: Đây là một công cụ mã nguồn mở được sử dụng để kiểm thử các ứng dụng web. Selenium hỗ trợ nhiều ngôn ngữ lập trình như Java, Python, Ruby, C, JavaScript và có thể chạy trên nhiều trình duyệt khác nhau.
Appium: Đây là một công cụ tự động hóa kiểm thử cho các ứng dụng di động, được sử dụng để kiểm thử trên nhiều hệ điều hành như iOS, Android và Windows.
JMeter: Đây là một công cụ tự động hóa kiểm thử hiệu suất, giúp đo lường và phân tích tải của các ứng dụng web và máy chủ.
Postman: Đây là một công cụ tự động hóa kiểm thử API, giúp kiểm thử các yêu cầu và phản hồi của các API.
Robot Framework: Đây là một framework mã nguồn mở được sử dụng để tự động hóa kiểm thử, hỗ trợ nhiều ngôn ngữ lập trình và có thể tích hợp với nhiều công cụ khác nhau.
Để trở thành một Automation tester thành công, các cá nhân phải trang bị những kiến thức và kỹ năng sau:
Nắm lòng kiến thức về testing
Để có thể thực hiện tốt công việc của mình, một Automation tester cần phải nắm vững các nguyên tắc và kỹ thuật kiểm thử phần mềm. Điều này bao gồm các loại kiểm thử, chiến lược kiểm thử và các công cụ kiểm thử khác nhau.
Hiểu rõ về HTML, CSS và Xpath
HTML, CSS và Xpath là những ngôn ngữ quan trọng trong việc xây dựng ứng dụng web. Vì vậy, để làm việc với các ứng dụng web, việc hiểu và sử dụng thành thạo các ngôn ngữ này là điều cần thiết cho một Automation tester.
Hiểu về domain
Domain là lĩnh vực hoạt động của một ứng dụng. Hiểu rõ về domain sẽ giúp Automation tester có thể đưa ra các kịch bản kiểm thử chính xác và phù hợp với yêu cầu của ứng dụng, từ đó giảm thiểu các lỗi có thể xảy ra.
Thành thạo Framework Testing
Các Framework Testing như Selenium, Appium hay Robot Framework đóng vai trò quan trọng trong việc thực hiện các kịch bản kiểm thử tự động. Vì vậy, để trở thành một Automation tester chuyên nghiệp, bạn cần phải thành thạo các Framework này và có khả năng áp dụng chúng vào công việc.
Hiểu về Software Design Pattern
Software Design Pattern là những mẫu thiết kế phần mềm có thể được sử dụng để giải quyết các vấn đề phát sinh trong quá trình phát triển phần mềm. Việc hiểu rõ về Software Design Pattern sẽ giúp Automation tester có thể tối ưu hóa các kịch bản kiểm thử và tăng cường độ tin cậy của ứng dụng.
Học cách sử dụng mã nguồn mở
Mã nguồn mở là một nguồn tài liệu vô cùng quý giá cho các Automation tester. Nhờ đó, họ có thể học hỏi và áp dụng những kỹ thuật mới nhất để nâng cao hiệu quả và chất lượng của các kịch bản kiểm thử.
Có kiến thức về Database
Để kiểm thử các tính năng liên quan đến dữ liệu của ứng dụng, Automation tester cần phải có kiến thức về Database. Việc này giúp họ có thể kiểm tra tính đúng đắn và hiệu suất của các câu truy vấn dữ liệu.
Thành thạo ngôn ngữ lập trình và công cụ tương ứng
Automation tester nên có ít nhất một ngôn ngữ lập trình và công cụ tương ứng để có thể tạo ra các kịch bản kiểm thử tự động. Các ngôn ngữ phổ biến được sử dụng trong việc làm Automation tester bao gồm Java, Python, Ruby, C++,…
Thành thạo một số kỹ năng cơ bản trong coding
Đôi khi trong quá trình làm việc, Automation tester cần phải chỉnh sửa hoặc tùy chỉnh lại mã nguồn của các kịch bản kiểm thử. Vì vậy, ngoài việc thành thạo các ngôn ngữ lập trình, họ cũng cần phải có một số kỹ năng cơ bản trong coding như debug, hiểu được cấu trúc của chương trình…
Học hỏi các công nghệ mới
Công nghệ không ngừng phát triển và đòi hỏi người làm Automation tester phải luôn cập nhật kiến thức mới. Do đó, họ cần phải có khả năng học hỏi và tiếp cận với các công nghệ mới để có thể áp dụng vào công việc của mình.
Automation tester mới vào nghề cần chuẩn bị gì?
Để bắt đầu sự nghiệp làm Automation tester, bạn cần có kiến thức cơ bản về kiểm thử phần mềm. Bạn cần hiểu về các phương pháp kiểm thử, quy trình kiểm thử và các kỹ thuật kiểm thử. Ngoài ra, bạn cũng cần có kiến thức về lập trình để có thể lập trình các kịch bản kiểm thử.
Nếu bạn muốn trở thành một Automation tester chuyên nghiệp, bạn cần học thêm về các công cụ tự động hóa kiểm thử và các framework được sử dụng trong lĩnh vực này. Bạn cũng nên có khả năng tìm hiểu và nghiên cứu để có thể áp dụng các công nghệ mới và cải tiến quy trình kiểm thử.
Với sự phát triển không ngừng của công nghệ, việc áp dụng Automation Test trong kiểm thử phần mềm đang trở thành xu hướng chính. Do đó, nhu cầu về Automation tester đang ngày càng tăng cao. Các công ty phần mềm đang tìm kiếm những tester có kỹ năng và kinh nghiệm trong lĩnh vực này để đảm bảo chất lượng sản phẩm của mình.
Ngoài ra, với việc áp dụng Agile và DevOps trong quy trình phát triển phần mềm, vai trò của Automation tester càng trở nên quan trọng hơn bao giờ hết. Việc tích hợp kiểm thử vào quy trình phát triển liên tục đòi hỏi sự hiểu biết sâu rộng về Automation Test và các công nghệ liên quan.
Automation Test là một khái niệm quan trọng trong lĩnh vực phát triển phần mềm hiện nay. Việc sử dụng các công cụ và kỹ thuật tự động hóa giúp giảm thiểu thời gian, công sức và lỗi thủ công trong quá trình kiểm thử. Tuy nhiên, việc triển khai Automation Test cũng đòi hỏi chi phí ban đầu cao và không thể thay thế hoàn toàn kiểm thử thủ công.
Để trở thành một Automation tester, bạn cần có kiến thức và kỹ năng về kiểm thử phần mềm và lập trình. Nghề nghiệp này đang có triển vọng rất lớn trong tương lai và là một trong những lựa chọn hấp dẫn cho những ai yêu thích công nghệ và muốn tham gia vào quá trình phát triển phần mềm hiện đại.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
JavaScript là một trong những ngôn ngữ lập trình được sử dụng rộng rãi trong việc phát triển các ứng dụng web và di động. Với sự phát triển không ngừng của công nghệ, các nhà phát triển cần phải tìm cách để tối ưu hóa mã nguồn và tăng hiệu suất của chương trình. Trong bài viết này, chúng ta sẽ đi sâu vào hàm Reduce trong JavaScript – một công cụ mạnh mẽ giúp quét mảng một cách hiệu quả và tối ưu.
Thuật toán Reduce trong JavaScript
Thuật toán Reduce trong JavaScript một thuật toán được sử dụng để thực hiện các phép tính trên một mảng và trả về một giá trị duy nhất.
Thuật toán reduce hoạt động bằng cách lặp qua từng phần tử của mảng và thực hiện một phép tính nào đó, sau đó kết hợp kết quả với giá trị trước đó để tạo ra một giá trị mới. Quá trình này sẽ tiếp tục cho đến khi lặp qua hết tất cả các phần tử của mảng và trả về giá trị cuối cùng.
Thuật toán này có thể được áp dụng cho bất kỳ loại dữ liệu nào, từ số nguyên đến chuỗi hay đối tượng. Điều quan trọng là chúng ta cần xác định được phép tính mà chúng ta muốn thực hiện và cách kết hợp kết quả để tạo ra giá trị mới.
Hiểu cơ bản về hàm Reduce
Hàm Reduce là một trong những hàm cơ bản của JavaScript, được sử dụng rộng rãi trong việc xử lý mảng. Nó có thể được sử dụng để tính tổng, tìm giá trị lớn nhất hoặc nhỏ nhất, hay thực hiện bất kỳ phép tính nào khác trên một mảng. Hàm Reduce có thể được gọi là một công cụ linh hoạt và mạnh mẽ trong việc xử lý dữ liệu.
Cấu trúc và cú pháp của hàm Reduce
Cấu trúc cơ bản của hàm Reduce trong JavaScript như sau:
array.reduce(callback[, initialValue])
Trong đó:
array là mảng chúng ta muốn thực hiện phép tính.
callback là một hàm được sử dụng để thực hiện phép tính trên từng phần tử của mảng.
initialValue là giá trị khởi tạo ban đầu cho quá trình tính toán. Đây là một tham số tùy chọn và có thể bỏ qua nếu không cần thiết.
Cú pháp của hàm Reduce như sau:
array.reduce(function(previousValue, currentValue, currentIndex, array) { // code thực hiện phép tính}, initialValue);
Trong đó:
previousValue là giá trị trước đó được tính toán.
currentValue là giá trị hiện tại đang được xét.
currentIndex là chỉ số của phần tử hiện tại trong mảng.
Hàm Reduce nhận vào hai tham số chính là callback và initialValue. Tham số callback là một hàm được sử dụng để thực hiện phép tính trên từng phần tử của mảng. Nó nhận vào bốn tham số là previousValue, currentValue, currentIndex và array.
Tham số previousValue là giá trị trước đó được tính toán và trả về từ hàm callback. Ban đầu, giá trị này sẽ bằng với initialValue nếu được xác định, hoặc bằng với phần tử đầu tiên của mảng nếu không có initialValue.
Tham số currentValue là giá trị hiện tại đang được xét trong quá trình lặp qua từng phần tử của mảng.
Tham số currentIndex là chỉ số của phần tử hiện tại trong mảng.
Hàm Reduce trả về một giá trị duy nhất sau khi thực hiện phép tính trên toàn bộ mảng. Giá trị này có thể là bất kỳ kiểu dữ liệu nào, từ số nguyên đến chuỗi hay đối tượng.
Các bước hoạt động của hàm Reduce trong JavaScript
Để hiểu rõ hơn về cách hoạt động của hàm Reduce, chúng ta sẽ đi qua các bước thực hiện của nó:
Nếu initialValue được xác định, giá trị previousValue sẽ bằng với initialValue, ngược lại sẽ bằng với phần tử đầu tiên của mảng.
Hàm callback sẽ được gọi với hai tham số là previousValue và currentValue tương ứng với giá trị previousValue và phần tử đầu tiên của mảng.
Giá trị trả về từ hàm callback sẽ được gán cho previousValue.
Hàm callback sẽ được gọi lần lượt với các tham số tương ứng là previousValue và từng phần tử của mảng.
Kết quả cuối cùng sẽ được trả về sau khi lặp qua hết tất cả các phần tử của mảng.
Cách sử dụng hàm Reduce để xử lý mảng
Hàm Reduce có thể được sử dụng để thực hiện nhiều phép tính khác nhau trên một mảng. Chúng ta có thể tính tổng, tìm giá trị lớn nhất hoặc nhỏ nhất, hay thực hiện bất kỳ phép tính nào khác tùy thuộc vào yêu cầu của chương trình.
Tính tổng các phần tử trong mảng
Để tính tổng các phần tử trong mảng, chúng ta có thể sử dụng hàm Reduce như sau:
Hàm Reduce có thể được sử dụng trong nhiều trường hợp khác nhau, tùy thuộc vào yêu cầu của chương trình. Dưới đây là một số trường hợp sử dụng phổ biến của hàm Reduce:
Tính tổng các phần tử trong mảng.
Tìm giá trị lớn nhất hoặc nhỏ nhất trong mảng.
Tính trung bình cộng của các phần tử trong mảng.
Tính tổng các giá trị của một thuộc tính trong một mảng đối tượng.
Tạo một mảng mới từ một mảng hiện tại thông qua việc kết hợp các phần tử.
Kiểm tra xem một giá trị có tồn tại trong mảng hay không.
Lợi ích và hạn chế khi sử dụng hàm Reduce
Hàm Reduce có nhiều lợi ích khi sử dụng trong việc xử lý mảng. Hàm giúp tối ưu hóa mã nguồn và tăng hiệu suất của chương trình. Thay vì phải sử dụng nhiều vòng lặp để thực hiện các phép tính trên mảng, chúng ta chỉ cần sử dụng một hàm duy nhất là hàm Reduce.
Ngoài ra, hàm Reduce cũng giúp lập trình viến viết mã ngắn gọn và dễ đọc hơn. Với cách hoạt động đơn giản và cấu trúc rõ ràng, bạn có thể dễ dàng áp dụng hàm này vào trong các dự án lớn và phức tạp.
Tuy nhiên, hàm Reduce cũng có một số hạn chế khi sử dụng. Đầu tiên, hàm không thể được sử dụng cho các mảng rỗng. Nếu mảng không có phần tử nào, hàm Reduce sẽ báo lỗi và không thực hiện được phép tính.
Ngoài ra, hàm Reduce cũng không phù hợp cho các trường hợp xử lý mảng có kích thước lớn. Vì quá trình tính toán diễn ra từng bước và phải lặp qua từng phần tử của mảng, nên sẽ tốn nhiều thời gian và tài nguyên hơn so với các phương pháp khác.
Trong đó, previousValue được khởi tạo bằng 0 và được cộng dồn với giá trị total của từng đơn hàng để tính tổng giá trị của tất cả các đơn hàng.
Kiểm tra xem một giá trị có tồn tại trong mảng hay không
Chúng ta có thể sử dụng hàm Reduce để kiểm tra xem một giá trị có tồn tại trong mảng hay không. Ví dụ, chúng ta có một danh sách các sản phẩm và muốn kiểm tra xem sản phẩm có mã số 12345 có tồn tại trong danh sách hay không. Chúng ta có thể sử dụng hàm Reduce như sau:
Trong đó, previousValue được khởi tạo bằng giá trị false và so sánh với từng phần tử của mảng để kiểm tra xem sản phẩm có mã số 12345 có tồn tại hay không.
Kết luận
Hàm Reduce là một trong những hàm quan trọng và hữu ích trong JavaScript. Hàm giúp chúng ta thực hiện các phép tính trên mảng một cách đơn giản và hiệu quả. Bằng cách hiểu cơ bản về cấu trúc và cách hoạt động của hàm Reduce, chúng ta có thể áp dụng nó vào trong các dự án thực tế để tối ưu hóa mã nguồn và tăng hiệu suất của chương trình.
Hy vọng bài viết này đã giúp bạn hiểu thêm về hàm Reduce và đừng quên thường xuyên truy cập chuyên mục Lập trình để cập nhật thêm nhiều kiến thức lập trình hữu ích từ Blog TopDev.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Javascript là một ngôn ngữ lập trình phổ biến và được sử dụng rộng rãi trong việc phát triển các ứng dụng web và di động. Với khả năng linh hoạt và tính năng đa dạng, Javascript đã trở thành một trong những ngôn ngữ lập trình hàng đầu hiện nay. Trong bài viết này, hãy cùng TopDev tìm hiểu về hàm ‘filter’ trong Javascript và cách sử dụng nó để lọc dữ liệu trong các mảng.
Bộ lọc loại bỏ các phần tử trùng lặp trong JavaScript
Trước khi đi vào chi tiết về hàm ‘filter’, chúng ta cần hiểu rõ về khái niệm lọc dữ liệu trong Javascript. Lọc dữ liệu là quá trình loại bỏ các phần tử không cần thiết hoặc trùng lặp trong một mảng. Điều này giúp cho việc xử lý dữ liệu trở nên dễ dàng và hiệu quả hơn.
Trong Javascript, chúng ta có thể sử dụng hàm ‘filter’ để loại bỏ các phần tử trùng lặp trong một mảng. Hàm này sẽ trả về một mảng mới chỉ chứa các phần tử duy nhất, không có phần tử nào bị trùng lặp. Để hiểu rõ hơn, bạn có thể xem ví dụ sau:
Trong đoạn code trên, chúng ta có một mảng gồm các số từ 1 đến 9, trong đó có hai số 5 và hai số 8 bị trùng lặp. Bằng cách sử dụng hàm ‘filter’ và phương thức indexOf(), chúng ta có thể loại bỏ các phần tử trùng lặp và chỉ lấy các phần tử duy nhất. Kết quả trả về là một mảng mới chỉ chứa các số từ 1 đến 9 mà không có phần tử nào bị trùng lặp.
Sử dụng hàm filter để trích xuất các phần tử thỏa mãn điều kiện
Hàm ‘filter’ trong Javascript còn có thể được sử dụng để trích xuất các phần tử thỏa mãn một điều kiện nào đó. Điều này giúp cho việc lọc dữ liệu trở nên linh hoạt hơn và có thể được tùy chỉnh theo nhu cầu của người lập trình.
Ví dụ, chúng ta có một mảng gồm các số từ 1 đến 10 và chúng ta muốn lọc ra các số lẻ trong mảng đó. Để làm điều này, chúng ta có thể sử dụng hàm ‘filter’ như sau:
Như vậy, chúng ta đã sử dụng hàm ‘filter’ để lọc ra các số lẻ trong mảng numbers. Hàm callback được truyền vào hàm ‘filter’ sẽ kiểm tra xem mỗi phần tử trong mảng có chia hết cho 2 hay không. Nếu phần tử đó không chia hết cho 2 (số lẻ), nó sẽ được trả về và được đưa vào mảng mới oddNumbers.
Tùy chỉnh thuật toán lọc bằng hàm callback
Hàm callback được truyền vào hàm ‘filter’ có thể được tùy chỉnh để thực hiện các thuật toán lọc khác nhau. Điều này giúp cho việc sử dụng hàm ‘filter’ trở nên linh hoạt và có thể áp dụng được vào nhiều tình huống khác nhau.
Ví dụ, chúng ta có một mảng gồm các chuỗi và muốn lọc ra các chuỗi có độ dài lớn hơn 5 ký tự. Để làm điều này, chúng ta có thể sử dụng hàm ‘filter’ như sau:
Ví dụ trên đã được sử dụng hàm ‘filter’ để lọc ra các chuỗi có độ dài lớn hơn 5 ký tự trong mảng strings. Hàm callback được truyền vào sẽ kiểm tra xem độ dài của mỗi chuỗi có lớn hơn 5 hay không. Nếu đúng, chuỗi đó sẽ được trả về và đưa vào mảng mới longStrings.
Một trong những tính năng đặc biệt của hàm ‘filter’ trong Javascript là khả năng lồng nó vào bên trong nhau để xử lý dữ liệu phân cấp. Điều này giúp cho việc lọc dữ liệu trở nên linh hoạt và có thể được áp dụng vào nhiều tình huống khác nhau.
Ví dụ, bạn có một mảng gồm các đối tượng sinh viên với thông tin về tên, tuổi và điểm số. Chúng ta muốn lọc ra các sinh viên có điểm số lớn hơn 8 và tuổi lớn hơn 20. Để làm điều này, chúng ta có thể sử dụng bộ lọc mảng lồng nhau như sau:
Trong ví dụ trên, chúng ta đã sử dụng bộ lọc mảng lồng nhau để lọc ra các sinh viên có điểm số lớn hơn 8 và tuổi lớn hơn 20. Đầu tiên, chúng ta sử dụng hàm ‘filter’ để lọc ra các sinh viên có điểm số lớn hơn 8. Sau đó, chúng ta sử dụng hàm ‘filter’ lần nữa để lọc ra các sinh viên có tuổi lớn hơn 20 từ kết quả trả về của hàm ‘filter’ đầu tiên.
Kết hợp hàm map và filter để chuyển đổi và lọc dữ liệu
Một trong những cách sử dụng hiệu quả của hàm ‘filter’ trong Javascript là kết hợp nó với hàm map để thực hiện việc chuyển đổi và lọc dữ liệu một cách đồng thời. Điều này giúp cho việc xử lý dữ liệu trở nên đơn giản và hiệu quả hơn.
Ví dụ, chúng ta có một mảng gồm các số và muốn lấy ra các số chẵn và nhân chúng với 2. Để làm điều này, chúng ta có thể sử dụng hàm ‘map’ để nhân các số với 2 và sau đó sử dụng hàm ‘filter’ để lọc ra các số chẵn như sau:
Hàm ‘map’ đã được sử dụng nhân các số trong mảng với 2 và sau đó sử dụng hàm ‘filter’ để lọc ra các số chẵn từ kết quả trả về của hàm ‘map’. Kết quả trả về là một mảng mới chỉ chứa các số chẵn được nhân với 2.
Sử dụng filter với Rest Parameter để xử lý danh sách tham số không xác định
Một tính năng khác của hàm ‘filter’ trong Javascript là khả năng sử dụng nó với Rest Parameter để xử lý danh sách tham số không xác định. Điều này giúp cho việc lọc dữ liệu trở nên linh hoạt hơn và có thể áp dụng được vào nhiều tình huống khác nhau.
Ví dụ, chúng ta có một danh sách các sản phẩm và muốn lọc ra các sản phẩm có giá lớn hơn 100.000 đồng. Tuy nhiên, số lượng sản phẩm trong danh sách có thể thay đổi và chúng ta không biết trước được. Để làm điều này, chúng ta có thể sử dụng Rest Parameter để xử lý danh sách tham số không xác định và sau đó sử dụng hàm ‘filter’ để lọc ra các sản phẩm có giá lớn hơn 100.000 đồng như sau:
Trong ví dụ trên, chúng ta đã sử dụng Rest Parameter để xử lý danh sách các sản phẩm và sau đó sử dụng hàm ‘filter’ để lọc ra các sản phẩm có giá lớn hơn 100.000 đồng. Kết quả trả về là một mảng mới chỉ chứa các sản phẩm thỏa mãn điều kiện.
Cải thiện hiệu suất lọc bằng toán tử nullish coalescing
Một tính năng mới được giới thiệu trong phiên bản ES2020 của Javascript là toán tử nullish coalescing (??). Toán tử này cho phép chúng ta cải thiện hiệu suất lọc dữ liệu khi sử dụng hàm ‘filter’.
Ví dụ, chúng ta có một mảng gồm các đối tượng sinh viên với thông tin về tên, tuổi và điểm số. Chúng ta muốn lọc ra các sinh viên có điểm số lớn hơn 8 và tuổi lớn hơn 20. Để làm điều này, chúng ta có thể sử dụng toán tử nullish coalescing để cải thiện hiệu suất của hàm ‘filter’ như sau:
Trong ví dụ trên, chúng ta đã sử dụng toán tử nullish coalescing để kiểm tra xem giá trị của thuộc tính score và age có tồn tại hay không trước khi thực hiện lọc dữ liệu. Điều này giúp cho việc lọc dữ liệu trở nên hiệu quả hơn và giảm thiểu các lỗi có thể xảy ra.
Sử dụng hàm find để tìm phần tử đầu tiên thỏa mãn điều kiện
Ngoài việc sử dụng hàm ‘filter’ để lọc dữ liệu, chúng ta còn có thể sử dụng hàm find để tìm phần tử đầu tiên trong mảng thỏa mãn điều kiện nào đó. Điều này giúp cho việc tìm kiếm và lọc dữ liệu trở nên linh hoạt hơn.
Ví dụ, bạn có một mảng gồm các số và muốn tìm phần tử đầu tiên có giá trị lớn hơn 5. Để làm điều này, chúng ta có thể sử dụng hàm find như sau:
Ví dụ trên đã sử dụng hàm find để tìm phần tử đầu tiên trong mảng có giá trị lớn hơn 5. Kết quả trả về là số 6, phần tử đầu tiên thỏa mãn điều kiện.
Tối ưu hóa bộ lọc bằng cách sử dụng chỉ mục mảng
Một cách tối ưu hóa hiệu suất của hàm ‘filter’ trong Javascript là sử dụng chỉ mục mảng (index) khi thực hiện lọc dữ liệu. Điều này giúp cho việc truy cập vào các phần tử trong mảng trở nên nhanh hơn và giảm thiểu thời gian xử lý.
Ví dụ, chúng ta có một mảng gồm các số và muốn lọc ra các số chia hết cho 3. Để làm điều này, chúng ta có thể sử dụng chỉ mục mảng để tối ưu hiệu suất của hàm ‘filter’ như sau:
Trong ví dụ trên, chúng ta đã sử dụng chỉ mục mảng khi thực hiện lọc dữ liệu. Khi đó, hàm ‘filter’ sẽ chỉ duyệt qua các phần tử có chỉ mục chia hết cho 3, giúp cho việc lọc dữ liệu trở nên nhanh hơn.
Đi sâu vào cách triển khai bên trong hàm filter của JavaScript
Để hiểu rõ hơn về cách hoạt động của hàm ‘filter’ trong Javascript, chúng ta có thể đi sâu vào cách triển khai bên trong của nó. Hàm ‘filter’ được triển khai bằng cách duyệt qua từng phần tử trong mảng và kiểm tra xem phần tử đó có thỏa mãn điều kiện hay không. Nếu phần tử đó thỏa mãn điều kiện, nó sẽ được thêm vào một mảng mới, ngược lại sẽ bị loại bỏ.
Ví dụ, bạn có một mảng gồm các số và muốn lọc ra các số chẵn và để làm điều này, chúng ta có thể triển khai hàm ‘filter’ như sau:
function filter(array, callback) { let result = []; for (let i = 0; i { return item % 2 === 0;});console.log(evenNumbers); // [2, 4, 6, 8, 10]
Trong ví dụ trên, chúng ta đã triển khai lại hàm ‘filter’ bằng cách duyệt qua từng phần tử trong mảng và kiểm tra xem phần tử đó có chia hết cho 2 hay không. Nếu có, nó sẽ được thêm vào mảng kết quả. Kết quả trả về là một mảng mới chỉ chứa các số chẵn.
Kết luận
Như vậy, TopDev đã cùng bạn tìm hiểu về cách sử dụng hàm ‘filter’ trong Javascript để lọc dữ liệu, cách sử dụng hàm filter để trích xuất các phần tử thỏa mãn điều kiện, tùy chỉnh thuật toán lọc bằng hàm callback, sử dụng bộ lọc mảng lồng nhau để xử lý dữ liệu phân cấp,… Với những chia sẻ trên, TopDev hy vọng đã mang đến cho bạn những thông tin hữu ích và có thể ứng dụng hiệu quả vào học tập và công việc của mình.
Truy cập ngay vào Blog Topdev để tiếp tục cập nhật những kiến thức mới nhất về Lập trình!
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Android là một nền tảng hệ điều hành di động phổ biến được phát triển bởi Google. Nó chiếm hơn 80% thị phần hệ điều hành di động trên toàn thế giới. Với sự phát triển của công nghệ di động, việc lập trình ứng dụng Android ngày càng trở nên quan trọng và thu hút sự quan tâm của nhiều nhà phát triển. Hãy cùng TopDev tìm hiểu về lập trình Android bằng ngôn ngữ Java – một trong những ngôn ngữ lập trình phổ biến nhất hiện nay.
Giới thiệu về lập trình Android bằng Java
Java là một ngôn ngữ lập trình hướng đối tượng được sử dụng rộng rãi để phát triển các ứng dụng Android. Được phát triển bởi Sun Microsystems vào năm 1995, Java đã trở thành một trong những ngôn ngữ lập trình phổ biến nhất trên thế giới. Với tính linh hoạt và khả năng tương thích cao, Java được sử dụng trong nhiều lĩnh vực, từ phát triển ứng dụng di động cho đến các ứng dụng máy tính và trò chơi.
Lập trình Android bằng Java cung cấp cho các nhà phát triển sức mạnh và sự linh hoạt để tạo ra các ứng dụng hiệu quả và tương tác cao. Với việc sử dụng Java, bạn có thể tận dụng được các tính năng của ngôn ngữ này như tính đa nền tảng, kiểm soát lỗi tốt và khả năng tái sử dụng mã nguồn. Bên cạnh đó, việc học lập trình Android bằng Java cũng giúp bạn có thể dễ dàng tiếp cận với các công nghệ mới nhất của Google và cộng đồng lập trình viên.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
Cài đặt môi trường phát triển Android
Để bắt đầu lập trình Android bằng Java, bạn cần cài đặt Môi trường phát triển tích hợp (Integrated Development Environment – IDE). IDE là một công cụ giúp bạn viết, biên dịch và chạy mã nguồn của mình. Trong lĩnh vực lập trình Android, Android Studio là IDE chính thức được khuyến nghị bởi Google. Đây là một công cụ miễn phí và rất mạnh mẽ để phát triển các ứng dụng Android.
Bạn có thể tải xuống Android Studio miễn phí từ trang web chính thức của Google dành cho nhà phát triển. Sau khi tải xuống, bạn cần cài đặt và thiết lập môi trường để bắt đầu lập trình.
Tạo dự án Android
Khi bạn đã cài đặt Android Studio, bạn có thể tạo một dự án Android mới. Để thực hiện việc này, hãy mở Android Studio và nhấp vào nút Tạo dự án mới. Trong cửa sổ Tạo dự án mới, hãy nhập tên và vị trí dự án của bạn và chọn loại ứng dụng bạn muốn tạo. Bạn có thể chọn từ các mẫu ứng dụng có sẵn hoặc tùy chỉnh theo ý muốn của mình.
Sau khi tạo dự án thành công, bạn sẽ thấy một cấu trúc thư mục được tạo ra trong thư mục gốc của dự án. Các tệp tin quan trọng nhất trong dự án là:
AndroidManifest.xml: Tệp tin này chứa thông tin về ứng dụng của bạn, bao gồm tên, phiên bản, quyền truy cập và các thành phần khác.
MainActivity.java: Đây là tệp tin chứa mã nguồn của hoạt động chính trong ứng dụng của bạn.
activity_main.xml: Tệp tin này chứa giao diện người dùng của hoạt động chính, được hiển thị khi ứng dụng được khởi chạy.
Một ứng dụng Android được tạo thành từ nhiều thành phần cơ bản. Trong phần này, chúng ta sẽ tìm hiểu về các thành phần này và cách chúng tương tác với nhau để tạo ra một ứng dụng hoàn chỉnh.
Hoạt động (Activity)
Hoạt động là các màn hình hoặc trang của ứng dụng của bạn. Chúng chứa các thành phần giao diện người dùng, chẳng hạn như nút, hộp văn bản và hình ảnh. Mỗi hoạt động đều có một vòng đời riêng, bao gồm các phương thức như onCreate(), onStart(), onResume(), onPause(), onStop() và onDestroy(). Khi người dùng tương tác với ứng dụng, các phương thức này sẽ được gọi theo thứ tự nhất định để xử lý các sự kiện và cập nhật giao diện người dùng.
Dịch vụ (Service)
Dịch vụ là các quy trình nền chạy độc lập với các hoạt động. Chúng được sử dụng để thực hiện các tác vụ dài hạn mà không ảnh hưởng đến giao diện người dùng. Ví dụ, bạn có thể sử dụng dịch vụ để tải xuống dữ liệu từ internet trong khi người dùng vẫn có thể tiếp tục sử dụng ứng dụng.
Nhiệm vụ (Broadcast Receiver)
Nhiệm vụ là các thành phần được sử dụng để nhận và xử lý các thông báo từ hệ thống hoặc các ứng dụng khác. Chúng có thể được sử dụng để thông báo cho ứng dụng của bạn khi có sự kiện xảy ra, chẳng hạn như khi điện thoại nhận được cuộc gọi hay tin nhắn.
Nội dung (Content Provider)
Nội dung là các thành phần được sử dụng để quản lý và chia sẻ dữ liệu giữa các ứng dụng khác nhau. Chúng cung cấp các phương thức để truy cập và cập nhật dữ liệu trong cơ sở dữ liệu của ứng dụng.
Giao diện người dùng là một phần quan trọng trong lập trình Android. Nó giúp bạn tạo ra các giao diện đẹp và tương tác với người dùng một cách dễ dàng. Trong Android, giao diện người dùng được xây dựng bằng cách sử dụng các thành phần giao diện như TextView, Button, EditText và ImageView. Bạn có thể sử dụng các thuộc tính của các thành phần này để tùy chỉnh giao diện theo ý muốn.
Để hiển thị giao diện người dùng trong hoạt động, bạn cần sử dụng một Layout. Layout là một khung chứa các thành phần giao diện và được sử dụng để xác định vị trí và kích thước của chúng. Có nhiều loại layout khác nhau trong Android như LinearLayout, RelativeLayout, ConstraintLayout và FrameLayout. Mỗi loại layout có những đặc điểm và ứng dụng khác nhau, bạn có thể tùy chọn loại layout phù hợp với yêu cầu của ứng dụng của mình.
Xử lý sự kiện trong Android
Xử lý sự kiện là một phần quan trọng trong lập trình Android. Khi người dùng tương tác với ứng dụng, các sự kiện như nhấn nút, vuốt màn hình hay chạm vào các thành phần giao diện sẽ xảy ra. Để xử lý các sự kiện này, bạn cần sử dụng các phương thức và lớp có sẵn trong Android.
Ví dụ, để xử lý sự kiện khi người dùng nhấn vào một nút, bạn có thể sử dụng phương thức setOnClickListener() và truyền vào một đối tượng OnClickListener để xử lý sự kiện. Tương tự, để xử lý sự kiện khi người dùng vuốt màn hình, bạn có thể sử dụng phương thức setOnTouchListener() và truyền vào một đối tượng OnTouchListener.
Lưu trữ dữ liệu trong Android
Lưu trữ dữ liệu là một phần quan trọng trong lập trình Android. Trong ứng dụng của bạn, có thể có nhiều loại dữ liệu khác nhau cần được lưu trữ, từ thông tin người dùng đến dữ liệu cấu hình của ứng dụng. Để lưu trữ dữ liệu trong Android, bạn có thể sử dụng các phương thức và lớp có sẵn như SharedPreferences, SQLite Database và File Storage.
SharedPreferences: Đây là một cách đơn giản để lưu trữ và quản lý các cặp giá trị khóa-giá trị trong Android. Các giá trị này có thể được truy xuất và cập nhật từ bất kỳ đâu trong ứng dụng của bạn.
SQLite Database: Đây là một cơ sở dữ liệu quan hệ nhỏ gọn được tích hợp sẵn trong Android. Nó cho phép bạn lưu trữ và truy vấn dữ liệu theo cấu trúc tương tự như các cơ sở dữ liệu quan hệ lớn hơn.
File Storage: Đây là một cách để lưu trữ dữ liệu dưới dạng tệp tin trong bộ nhớ của thiết bị. Bạn có thể sử dụng nó để lưu trữ các tệp tin như hình ảnh, video hay âm thanh.
Truyền thông mạng
Truyền thông mạng là một phần quan trọng trong lập trình Android. Nó cho phép ứng dụng của bạn kết nối và giao tiếp với các máy chủ và dịch vụ khác trên internet. Để thực hiện truyền thông mạng trong Android, bạn có thể sử dụng các lớp và phương thức có sẵn như HttpURLConnection, HttpClient và Volley.
Giới thiệu về các thư viện phổ biến trong lập trình Android
Có rất nhiều thư viện được phát triển để hỗ trợ lập trình Android. Những thư viện này cung cấp các tính năng và công cụ giúp bạn xây dựng ứng dụng nhanh chóng và hiệu quả hơn. Dưới đây là một số thư viện phổ biến trong lập trình Android:
Glide: Thư viện này giúp tải và hiển thị hình ảnh một cách dễ dàng và hiệu quả.
Retrofit: Thư viện này cung cấp các công cụ để thực hiện các yêu cầu mạng và xử lý dữ liệu JSON.
ButterKnife: Thư viện này giúp rút ngắn mã code khi sử dụng các thành phần giao diện người dùng trong Android.
Firebase: Thư viện này cung cấp các tính năng như lưu trữ dữ liệu, xác thực người dùng và phân tích hiệu suất cho ứng dụng của bạn.
Gson: Thư viện này giúp chuyển đổi các đối tượng Java thành định dạng JSON và ngược lại.
Các vấn đề thường gặp trong lập trình Android
Trong quá trình lập trình Android, bạn có thể gặp phải một số vấn đề. Dưới đây là một số vấn đề thường gặp và cách khắc phục chúng:
Lỗi biên dịch: Đây là lỗi xảy ra khi mã code của bạn không tuân theo cú pháp hoặc kiểu dữ liệu của ngôn ngữ Java. Bạn có thể sử dụng các công cụ như Android Studio để phát hiện và sửa lỗi này.
Lỗi chạy: Đây là lỗi xảy ra khi ứng dụng của bạn bị crash hoặc không hoạt động đúng như mong đợi. Bạn có thể sử dụng các công cụ như Logcat để xem thông tin chi tiết về lỗi và sửa chữa nó.
Vấn đề tương thích: Đôi khi ứng dụng của bạn có thể không hoạt động đúng trên các phiên bản Android khác nhau hoặc trên các thiết bị khác nhau. Bạn có thể sử dụng các công cụ như Android Virtual Device để kiểm tra ứng dụng trên nhiều thiết bị và phiên bản Android khác nhau.
Kết luận
Trong bài viết này, chúng ta đã tìm hiểu về lập trình Android bằng ngôn ngữ Java. Hy vọng bài viết này sẽ giúp bạn có được những kiến thức cơ bản để bắt đầu lập trình ứng dụng Android của riêng mình.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Trong quá trình phát triển, Java đã được mở rộng với nhiều tính năng và nâng cấp mới, bao gồm cả sự ra đời của Java Super. Trong bài viết này, hãy cùng TopDev khám phá Java Super là gì, các tính năng nổi bật, sự khác biệt giữa Java Super và Java thông thường một cách chi tiết.
Tìm hiểu về Java Super
Java Super là một phiên bản nâng cao của ngôn ngữ lập trình Java được phát triển bởi Oracle. Nó cung cấp một loạt các tính năng mạnh mẽ và cải tiến không có sẵn trong Java thông thường, bao gồm tăng cường khả năng bảo mật, hiệu suất cao hơn và hỗ trợ tốt hơn cho các ứng dụng và dịch vụ dựa trên đám mây.
Java Super là gì?
Java Super được giới thiệu lần đầu tiên vào năm 2014 bởi Oracle. Nó là một phiên bản nâng cấp của Java thông thường, với mục đích tăng cường tính bảo mật và hiệu suất của ngôn ngữ lập trình này. Từ đó đến nay, Java Super đã trải qua nhiều phiên bản và cập nhật để cải thiện tính năng và khả năng của nó.
Các tính năng chính của Java Super là gì?
Java Super cung cấp một số tính năng chính giúp phân biệt nó với Java thông thường:
Hỗ trợ bảo mật nâng cao: Java Super bao gồm các tính năng bảo mật tích hợp, chẳng hạn như kiểm tra thời gian chạy an toàn và bảo vệ chống lại các cuộc tấn công từ chối dịch vụ (DoS). Điều này làm cho nó trở nên lý tưởng cho các ứng dụng nhạy cảm cần mức độ bảo mật cao.
Hiệu suất cao hơn: Java Super đã được tối ưu hóa để cải thiện hiệu suất của các ứng dụng Java. Nó sử dụng các kỹ thuật tối ưu hóa mã và bộ nhớ để giảm thiểu thời gian chạy và tăng tốc độ xử lý.
Hỗ trợ cho các ứng dụng đám mây: Java Super cung cấp các tính năng hỗ trợ tốt hơn cho việc phát triển các ứng dụng và dịch vụ dựa trên đám mây. Nó có thể tích hợp dễ dàng với các nền tảng đám mây phổ biến như Amazon Web Services và Microsoft Azure.
Tính linh hoạt: Java Super cho phép các lập trình viên sử dụng nhiều ngôn ngữ lập trình khác nhau trong cùng một dự án, giúp tăng cường tính linh hoạt và hiệu quả trong quá trình phát triển.
Khác biệt giữa Java Super và Java thông thường là gì?
Mặc dù Java Super là một phiên bản nâng cao của Java thông thường, nhưng hai ngôn ngữ này vẫn có những điểm khác biệt quan trọng. Dưới đây là một bảng so sánh giúp bạn hiểu rõ hơn về sự khác biệt giữa Java Super và Java thông thường:
Điểm khác biệt
Java Super
Java thông thường
Bảo mật
Cung cấp tính năng bảo mật nâng cao, bao gồm kiểm tra thời gian chạy an toàn và bảo vệ chống lại các cuộc tấn công DoS.
Có tính bảo mật cơ bản, nhưng không có các tính năng nâng cao như Java Super.
Hiệu suất
Được tối ưu hóa để cải thiện hiệu suất của các ứng dụng Java.
Có hiệu suất tốt, nhưng không được tối ưu hóa như Java Super.
Hỗ trợ đám mây
Cung cấp tính năng hỗ trợ tốt hơn cho việc phát triển các ứng dụng và dịch vụ dựa trên đám mây.
Có thể tích hợp với các nền tảng đám mây, nhưng không có tính năng hỗ trợ đặc biệt cho việc này.
Tính linh hoạt
Cho phép sử dụng nhiều ngôn ngữ lập trình khác nhau trong cùng một dự án.
Chỉ hỗ trợ một ngôn ngữ lập trình duy nhất trong mỗi dự án.
Lợi ích của việc sử dụng Java Super
Việc sử dụng Java Super có nhiều lợi ích đáng kể so với việc sử dụng Java thông thường. Dưới đây là một số lợi ích chính của việc sử dụng Java Super:
Bảo mật cao hơn: Với các tính năng bảo mật nâng cao, Java Super là lựa chọn tốt cho các ứng dụng và dịch vụ nhạy cảm cần mức độ bảo mật cao.
Hiệu suất tối ưu: Việc tối ưu hóa hiệu suất của Java Super giúp tăng tốc độ xử lý và giảm thiểu thời gian chạy của các ứng dụng.
Hỗ trợ cho các ứng dụng đám mây: Java Super cung cấp các tính năng hỗ trợ tốt hơn cho việc phát triển các ứng dụng và dịch vụ dựa trên đám mây, giúp tăng cường tính linh hoạt và khả năng tích hợp.
Tính linh hoạt: Khả năng sử dụng nhiều ngôn ngữ lập trình trong cùng một dự án giúp tăng cường tính linh hoạt và hiệu quả trong quá trình phát triển.
Để sử dụng Java Super trong lập trình, bạn cần cài đặt phiên bản Java Super mới nhất trên máy tính của mình. Sau đó, bạn có thể sử dụng các tính năng và cú pháp của Java Super trong quá trình viết mã.
Các ví dụ minh họa về Java Super
Để hiểu rõ hơn về cách sử dụng Java Super trong lập trình, chúng ta hãy xem xét một số ví dụ sau:
1. Tính toán tuổi của một người dựa trên năm sinh:
// Sử dụng Java thông thườngint birthYear = 1990;int currentYear = 2021;int age = currentYear - birthYear;// Sử dụng Java Supervar birthYear = 1990;var currentYear = 2021;var age = currentYear - birthYear;
2. Kiểm tra tính hợp lệ của một địa chỉ email:
// Sử dụng Java thông thườngString email = "example@domain.com";if (email.contains("@") && email.endsWith(".com")) { System.out.println("Email hợp lệ");} else { System.out.println("Email không hợp lệ");}// Sử dụng Java Supervar email = "example@domain.com";if (email.contains("@") && email.endsWith(".com")) { System.out.println("Email hợp lệ");} else { System.out.println("Email không hợp lệ");}
3. Tính tổng của một mảng số nguyên:
// Sử dụng Java thông thườngint[] numbers = ;int sum = 0;for (int i = 0; i < numbers.length; i++) { sum += numbers[i];}System.out.println("Tổng: " + sum);// Sử dụng Java Supervar numbers = ;var sum = 0;for (var number : numbers) { sum += number;}System.out.println("Tổng: " + sum);
Các lỗi thường gặp khi sử dụng và cách khắc phục
Mặc dù Java Super là một phiên bản nâng cao của Java thông thường, nhưng vẫn có thể gặp phải một số lỗi trong quá trình sử dụng. Dưới đây là một số lỗi thường gặp khi sử dụng Java Super và cách khắc phục chúng:
Lỗi không tìm thấy thư viện: Đôi khi, khi bạn cài đặt Java Super trên máy tính của mình, bạn có thể gặp phải lỗi không tìm thấy các thư viện cần thiết để chạy mã. Để khắc phục lỗi này, bạn có thể kiểm tra lại các thư viện đã được cài đặt và cập nhật chúng nếu cần.
Lỗi cú pháp: Nếu bạn sử dụng các tính năng mới của Java Super mà không biết cú pháp đúng, bạn có thể gặp phải lỗi cú pháp khi biên dịch mã. Để khắc phục lỗi này, bạn có thể tìm hiểu kỹ hơn về cú pháp của Java Super hoặc sử dụng các công cụ hỗ trợ như IDE để giúp bạn viết mã chính xác hơn.
So sánh Java Super với các ngôn ngữ lập trình khác
Java Super là một trong những ngôn ngữ lập trình phổ biến và được sử dụng rộng rãi trong ngành công nghiệp công nghệ thông tin. Tuy nhiên, nó cũng có những điểm khác biệt so với các ngôn ngữ lập trình khác. Dưới đây là một bảng so sánh giúp bạn hiểu rõ hơn về sự khác biệt giữa Java Super và các ngôn ngữ lập trình khác:
Python có cú pháp đơn giản hơn và dễ học hơn so với Java Super. Nó cũng có nhiều thư viện hỗ trợ phong phú và được sử dụng rộng rãi trong lĩnh vực khoa học dữ liệu và trí tuệ nhân tạo.
C++ là một ngôn ngữ lập trình đa năng và hiệu suất cao, thường được sử dụng cho các ứng dụng yêu cầu tính toán phức tạp và tốc độ xử lý nhanh. Tuy nhiên, nó có cú pháp phức tạp hơn và khó học hơn so với Java Super.
JavaScript là một ngôn ngữ lập trình phổ biến trong lĩnh vực phát triển web. Nó có cú pháp tương tự như Java Super, nhưng lại có tính linh hoạt cao hơn và được sử dụng chủ yếu cho các ứng dụng web tương tác.
Những điểm cần lưu ý khi sử dụng Java Super là gì?
Trước khi bắt đầu sử dụng Java Super trong quá trình phát triển, bạn cần lưu ý một số điểm sau:
Kiến thức về Java cơ bản: Để sử dụng Java Super hiệu quả, bạn cần có kiến thức cơ bản về Java để hiểu rõ hơn về các tính năng và cú pháp của nó.
Cập nhật phiên bản mới nhất: Để tận dụng được các tính năng mới nhất của Java Super, bạn cần cập nhật phiên bản mới nhất trên máy tính của mình.
Sử dụng các công cụ hỗ trợ: Việc sử dụng các công cụ hỗ trợ như IDE sẽ giúp bạn viết mã chính xác và hiệu quả hơn khi sử dụng Java Super.
Kết luận
Trong bài viết này, chúng ta đã tìm hiểu về Java Super là gì và những thông tin chi tiết về phiên bản này. Hy vọng bài viết này sẽ giúp bạn hiểu rõ hơn về Java Super và có thêm kiến thức để áp dụng vào quá trình phát triển ứng dụng và dịch vụ của mình. Hãy thường xuyên truy cập đến chuyên mục Lập trình của Blog TopDev để không bỏ qua những kiến thức hữu ích.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Trong lập trình hướng đối tượng, overloading là một khái niệm quan trọng và được sử dụng rộng rãi trong ngôn ngữ lập trình Java. Nó cho phép chúng ta định nghĩa nhiều phương thức có cùng tên nhưng khác nhau về tham số, giúp tăng tính linh hoạt và tái sử dụng mã trong chương trình.
Quá tải (overloading) trong Java là gì?
Quá tải (overloading) là khả năng định nghĩa nhiều phương thức có cùng tên nhưng khác nhau về tham số trong cùng một lớp hoặc lớp con. Khi gọi đến một phương thức quá tải, trình biên dịch sẽ tự động chọn phương thức phù hợp dựa trên các tham số thực tế được cung cấp. Điều này giúp cho chương trình trở nên linh hoạt hơn, có thể thực hiện một hành động cụ thể theo nhiều cách khác nhau bằng cách thay đổi các tham số.
Overloading là một tính năng quan trọng trong lập trình hướng đối tượng, giúp cho chương trình trở nên dễ đọc và dễ hiểu hơn. Nó cũng giúp tăng tính tái sử dụng mã và tối ưu hóa hiệu suất của chương trình.
Các loại quá tải khác nhau trong Java
Java hỗ trợ hai loại quá tải chính: quá tải theo kiểu dữ liệu của tham số và quá tải theo số lượng tham số.
Quá tải theo kiểu dữ liệu của tham số
Các phương thức có cùng tên nhưng khác nhau về kiểu dữ liệu của tham số được gọi là quá tải theo kiểu dữ liệu của tham số. Ví dụ:
public class Calculator { public int add(int num1, int num2) { return num1 + num2; } public double add(double num1, double num2) { return num1 + num2; }}
Trong ví dụ trên, chúng ta có hai phương thức add có cùng tên nhưng khác nhau về kiểu dữ liệu của tham số. Phương thức đầu tiên sử dụng hai tham số kiểu int và trả về một giá trị kiểu int, trong khi phương thức thứ hai sử dụng hai tham số kiểu double và trả về một giá trị kiểu double.
Khi gọi đến phương thức add, trình biên dịch sẽ tự động chọn phương thức phù hợp dựa trên kiểu dữ liệu của các tham số được cung cấp.
Overloading theo số lượng tham số
Các phương thức có cùng tên nhưng khác nhau về số lượng tham số được gọi là quá tải theo số lượng tham số. Ví dụ:
public class Calculator { public int add(int num1, int num2) { return num1 + num2; } public int add(int num1, int num2, int num3) { return num1 + num2 + num3; }}
Trong ví dụ trên, chúng ta có hai phương thức add có cùng tên nhưng khác nhau về số lượng tham số. Phương thức đầu tiên sử dụng hai tham số và trả về một giá trị kiểu int, trong khi phương thức thứ hai sử dụng ba tham số và trả về một giá trị kiểu int.
Khi gọi đến phương thức add, trình biên dịch sẽ tự động chọn phương thức phù hợp dựa trên số lượng tham số được cung cấp.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
Lợi ích của quá tải trong Java
Quá tải là một tính năng rất hữu ích trong lập trình Java, mang lại nhiều lợi ích cho chương trình của bạn.
Tính linh hoạt
Với quá tải, chúng ta có thể thực hiện một hành động cụ thể theo nhiều cách khác nhau bằng cách thay đổi các tham số. Ví dụ, bạn có thể có nhiều phương thức add để thực hiện phép cộng với các kiểu dữ liệu khác nhau như int, double, float,… giúp cho chương trình trở nên linh hoạt và có thể xử lý được nhiều trường hợp khác nhau.
Khả năng đọc code
Sử dụng quá tải giúp cho code trở nên dễ hiểu hơn bằng cách sử dụng các phương thức có tên giống nhau nhưng được định nghĩa cho các ngữ cảnh khác nhau. Điều này giúp cho việc đọc và hiểu code trở nên dễ dàng hơn, đặc biệt là khi chương trình có nhiều phương thức cùng tên.
Tính tái sử dụng
Quá tải cho phép tái sử dụng mã cho các trường hợp khác nhau. Thay vì phải viết nhiều phương thức có chức năng tương tự nhau nhưng khác nhau về tham số, chúng ta có thể sử dụng quá tải để tái sử dụng mã và giảm thiểu việc lặp lại code.
Tối ưu hóa hiệu suất
Với quá tải, chúng ta có thể chọn các phiên bản hiệu quả nhất của phương thức dựa trên các tham số thực tế được cung cấp. Điều này giúp cho chương trình hoạt động hiệu quả hơn và tối ưu hóa được hiệu suất của nó.
Các quy tắc của quá tải trong Java
Để các phương thức được coi là quá tải, chúng phải tuân theo một số quy tắc sau:
Các phương thức phải có cùng tên.
Các phương thức phải được định nghĩa trong cùng một lớp hoặc lớp con.
Các phương thức phải khác nhau về tham số theo một trong hai cách đã đề cập ở trên.
Giá trị trả về của các phương thức có thể khác nhau.
Khai báo phương thức overloading trong Java
Để khai báo một phương thức quá tải trong Java, chúng ta cần tuân theo các quy tắc đã đề cập ở trên. Ví dụ:
public class Calculator { public int add(int num1, int num2) { return num1 + num2; } public double add(double num1, double num2) { return num1 + num2; } public int add(int num1, int num2, int num3) { return num1 + num2 + num3; }}
Trong ví dụ trên, chúng ta có ba phương thức add được định nghĩa trong cùng một lớp Calculator, khác nhau về số lượng và kiểu dữ liệu của tham số. Điều này cho phép chúng ta có thể gọi các phương thức này với các tham số khác nhau để thực hiện phép cộng.
Ví dụ về quá tải trong Java
Để hiểu rõ hơn về quá tải trong Java, chúng ta sẽ xem xét một ví dụ đơn giản về việc tính tổng của hai số nguyên và hai số thực.
public class Calculator { public int add(int num1, int num2) { return num1 + num2; } public double add(double num1, double num2) { return num1 + num2; }}
Trong ví dụ trên, chúng ta có hai phương thức add được định nghĩa trong lớp Calculator. Phương thức đầu tiên sử dụng hai tham số kiểu int và trả về một giá trị kiểu int, trong khi phương thức thứ hai sử dụng hai tham số kiểu double và trả về một giá trị kiểu double.
Bây giờ, chúng ta có thể gọi các phương thức này với các tham số khác nhau để tính tổng của hai số nguyên và hai số thực.
public class Main { public static void main(String[] args) { Calculator calculator = new Calculator(); // Tính tổng của hai số nguyên int sumInt = calculator.add(5, 10); System.out.println("Tổng của hai số nguyên là: " + sumInt); // Tính tổng của hai số thực double sumDouble = calculator.add(3.14, 2.71); System.out.println("Tổng của hai số thực là: " + sumDouble); }}
Kết quả khi chạy chương trình:
Tổng của hai số nguyên là: 15 Tổng của hai số thực là: 5.85
Như vậy, chúng ta đã sử dụng quá tải để tính tổng của hai số nguyên và hai số thực bằng cách sử dụng các phương thức có cùng tên nhưng khác nhau về kiểu dữ liệu của tham số.
Phân biệt overloading và override) trong Java
Một khái niệm khác liên quan đến quá tải là ghi đè (override). Tuy nhiên, hai khái niệm này có một số điểm khác biệt nhau:
Quá tải xảy ra khi chúng ta định nghĩa nhiều phương thức có cùng tên nhưng khác nhau về tham số trong cùng một lớp hoặc lớp con.
Ghi đè xảy ra khi chúng ta định nghĩa lại một phương thức đã được định nghĩa trong lớp cha trong lớp con.
Quá tải giúp cho chúng ta có thể thực hiện một hành động cụ thể theo nhiều cách khác nhau bằng cách thay đổi tham số của phương thức.
Ghi đè giúp cho chúng ta có thể cải thiện hoặc mở rộng chức năng của một phương thức đã được định nghĩa trong lớp cha.
Chúng ta nên sử dụng quá tải trong các trường hợp sau:
Các phương thức có cùng chức năng nhưng khác nhau về tham số.
Các phương thức có cùng chức năng nhưng khác nhau về kiểu dữ liệu của tham số.
Các phương thức có cùng chức năng nhưng khác nhau về số lượng tham số.
Với việc sử dụng quá tải, chúng ta có thể tái sử dụng mã và giảm thiểu việc lặp lại code, đồng thời cũng có thể tối ưu hóa hiệu suất của chương trình.
Các trường hợp không được coi là quá tải trong Java
Mặc dù có nhiều trường hợp chúng ta có thể sử dụng quá tải, tuy nhiên cũng có một số trường hợp không được coi là quá tải trong Java. Đó là khi hai phương thức có cùng tên nhưng chỉ khác nhau về kiểu trả về. Ví dụ:
public class Calculator { public int add(int num1, int num2) { return num1 + num2; } public double add(int num1, int num2) { return num1 + num2; }}
Trong ví dụ trên, hai phương thức add có cùng tên và cùng kiểu trả về là int, do đó chúng không được coi là quá tải mà sẽ gây ra lỗi biên dịch.
Những mẹo hay khi sử dụng quá tải trong Java
Tránh sử dụng quá tải quá nhiều, điều này có thể làm cho mã của chúng ta trở nên khó hiểu và khó bảo trì.
Nếu có thể, hãy sử dụng các kiểu dữ liệu nguyên thủy như int hoặc double thay vì các kiểu dữ liệu đối tượng để giảm thiểu việc sử dụng quá tải.
Khi sử dụng quá tải, hãy đặt tên cho các phương thức sao cho dễ hiểu và thể hiện được chức năng của chúng.
Hãy chắc chắn rằng các phương thức quá tải của chúng ta có cùng chức năng và chỉ khác nhau về tham số, không nên sử dụng quá tải để thực hiện các chức năng khác nhau.
Kết luận
Quá tải (overloading) là một tính năng quan trọng trong Java cho phép chúng ta định nghĩa nhiều phương thức có cùng tên nhưng khác nhau về tham số. Điều này giúp cho chúng ta có thể tái sử dụng mã và tối ưu hóa hiệu suất của chương trình. Hãy tiếp tục thường xuyên truy cập đến Blog TopDev để tham khảo thêm nhiều thông tin hữu ích về lập trình và tuyển dụng.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Truy cập ngay các công việc IT đãi ngộ tốt trên TopDev
Trong lập trình đa luồng, việc quản lý thời gian chờ đợi là rất quan trọng để đảm bảo tính đồng bộ và hiệu suất của ứng dụng. Java cung cấp nhiều cách khác nhau để thực hiện chức năng này, trong đó, kỹ thuật ngủ luồng là một kỹ thuật được sử dụng rộng rãi. Bài viết này sẽ hướng dẫn chi tiết về kỹ thuật Java Sleep, từ việc tổ chức các luồng đến cách sử dụng các methods ngủ luồng hiệu quả nhất.
Tổ chức các luồng trong Java bằng class Thread
Trong Java, các luồng được tạo ra bằng cách mở rộng class Thread. Class Thread cung cấp một loạt methods (phương thức) để quản lý luồng, bao gồm cả method sleep() để ngủ luồng. Để tạo một luồng mới, bạn có thể thực hiện như sau:
public class MyThread extends Thread { @Override public void run() { // Code chạy trong luồng }}
Khi tạo một đối tượng từ class MyThread, bạn có thể gọi method start() để bắt đầu chạy luồng. Phương thức này sẽ tự động gọi method run() của class MyThread và thực thi các câu lệnh trong đó.
Đặt tên cho luồng
Khi tạo một luồng mới, bạn có thể đặt tên cho nó bằng cách sử dụng method setName() của class Thread. Điều này giúp bạn dễ dàng nhận biết và quản lý các luồng trong ứng dụng của mình.
MyThread thread = new MyThread();thread.setName("Luồng 1");
Ưu điểm của việc sử dụng class Thread
Sử dụng class Thread để tổ chức các luồng trong Java có một số ưu điểm như sau:
Dễ dàng quản lý và theo dõi các luồng trong ứng dụng.
Cho phép tùy chỉnh các thuộc tính của luồng như tên, độ ưu tiên, v.v.
Có thể kế thừa từ class Thread để tạo ra các class con với các chức năng khác nhau.
Tuy nhiên, việc sử dụng class Thread cũng có một số hạn chế như sau:
Không thể kế thừa từ các class khác ngoài Thread.
Có thể dẫn đến xung đột khi sử dụng nhiều luồng trong cùng một tài nguyên.
Ngủ một luồng trong Java
Trong quá trình thực thi, có những trường hợp bạn cần phải tạm dừng hoặc ngủ một luồng để đảm bảo tính đồng bộ và hiệu suất của ứng dụng. Trong Java, có hai cách chính để ngủ luồng là sử dụng method sleep() của luồng hoặc sử dụng method wait() và notify() của class Object.
Sử dụng method sleep() của luồng trong Java
Để ngủ một luồng trong một khoảng thời gian nhất định, bạn có thể sử dụng method sleep(). Phương thức này chấp nhận một đối số là thời gian ngủ tính bằng mili giây.
thread.sleep(1000); // Ngủ luồng trong 1 giây
Khi gọi method sleep(), luồng sẽ tạm dừng việc thực thi trong khoảng thời gian được chỉ định trước đó. Sau khi hết thời gian ngủ, luồng sẽ tiếp tục thực thi các câu lệnh tiếp theo.
Sử dụng method wait() và notify() của Object để ngủ luồng trong Java
Phương thức wait() và notify() của class Object cũng có thể được sử dụng để ngủ luồng. Phương thức wait() sẽ tạm dừng luồng cho đến khi được gọi method notify().
synchronized (obj) { obj.wait(); // Tạm dừng luồng và chờ đợi cho đến khi được gọi method notify()}
Việc sử dụng method wait() và notify() thường được áp dụng trong trường hợp có nhiều luồng cùng truy cập vào một tài nguyên và cần đảm bảo tính đồng bộ giữa các luồng đó.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
Ngủ nhiều luồng đồng thời trong Java
Trong một số trường hợp, bạn có thể cần phải ngủ nhiều luồng đồng thời để đảm bảo tính đồng bộ và hiệu suất của ứng dụng. Trong Java, có hai cách để làm điều này là sử dụng method join() hoặc sử dụng class CountDownLatch.
Sử dụng method join()
Phương thức join() cho phép một luồng chờ đợi cho đến khi một luồng khác hoàn thành việc thực thi. Điều này giúp đảm bảo rằng các luồng sẽ được thực thi theo đúng thứ tự và tránh xung đột.
thread1.join(); // Luồng 1 sẽ chờ đợi cho đến khi luồng 2 hoàn thành việc thực thi
Sử dụng class CountDownLatch
Class CountDownLatch cung cấp một cơ chế đơn giản để đồng bộ hóa nhiều luồng trong Java. Nó cho phép một luồng chờ đợi cho đến khi một số lượng luồng đã được đặt trước hoàn thành việc thực thi.
CountDownLatch latch = new CountDownLatch(2); // Tạo một CountDownLatch với số lượng luồng cần chờ là 2 // Thực thi các luồng latch.await(); // Luồng hiện tại sẽ chờ đợi cho đến khi hai luồng đã được đặt trước hoàn thành việc thực thi
Khi sử dụng method sleep() trong đa luồng, có một số điều cần lưu ý để đảm bảo tính đồng bộ và hiệu suất của ứng dụng.
Sử dụng method sleep() trong synchronized block
Khi sử dụng method sleep() trong một synchronized block, luồng sẽ tạm dừng và nhường lock cho các luồng khác. Điều này giúp đảm bảo rằng các luồng sẽ không xung đột khi truy cập vào cùng một tài nguyên.
synchronized (obj) { thread.sleep(1000); // Luồng sẽ tạm dừng và nhường lock cho các luồng khác}
Sử dụng method sleep() trong non-synchronized block
Nếu sử dụng method sleep() trong một non-synchronized block, luồng vẫn sẽ tạm dừng nhưng không nhường lock cho các luồng khác. Điều này có thể dẫn đến xung đột khi nhiều luồng cùng truy cập vào cùng một tài nguyên.
thread.sleep(1000); // Luồng sẽ tạm dừng nhưng không nhường lock cho các luồng khác
Các trường hợp ngoại lệ có thể xảy ra khi sử dụng method sleep()
Trong quá trình sử dụng method sleep(), có một số trường hợp ngoại lệ có thể xảy ra. Điều này có thể gây ảnh hưởng đến tính đồng bộ và hiệu suất của ứng dụng.
InterruptedException
Khi một luồng đang ngủ bị gián đoạn bởi một luồng khác, nó sẽ ném ra một ngoại lệ InterruptedException. Điều này có thể xảy ra khi một luồng khác gọi method interrupt() hoặc notify() trong khi luồng đang ngủ.
Để xử lý ngoại lệ này, bạn có thể sử dụng cấu trúc try-catch hoặc throws để xử lý hoặc chuyển tiếp ngoại lệ này.
Ngoại lệ IllegalMonitorStateException có thể xảy ra khi sử dụng method wait() hoặc notify() trong một synchronized block không đúng cách. Điều này có thể xảy ra khi sử dụng method sleep() trong một synchronized block và luồng bị gián đoạn khi đang ngủ.
Để tránh ngoại lệ này, bạn cần đảm bảo rằng methods wait() và notify() được gọi trong cùng một synchronized block.
Các mẹo để sử dụng method sleep() hiệu quả
Để đảm bảo tính đồng bộ và hiệu suất của ứng dụng, có một số mẹo khi sử dụng method sleep() trong Java như sau:
Sử dụng method sleep() trong synchronized block để đảm bảo tính đồng bộ giữa các luồng.
Sử dụng cấu trúc try-catch hoặc throws để xử lý ngoại lệ InterruptedException.
Tránh sử dụng method sleep() trong non-synchronized block để tránh xung đột giữa các luồng.
Đảm bảo rằng methods wait() và notify() được gọi trong cùng một synchronized block để tránh ngoại lệ IllegalMonitorStateException.
Cạm bẫy cần tránh khi sử dụng method sleep() trong Java
Trong quá trình sử dụng method sleep(), có một số cạm bẫy cần tránh để đảm bảo tính đồng bộ và hiệu suất của ứng dụng.
Sử dụng method sleep() quá lâu
Việc sử dụng method sleep() quá lâu có thể làm giảm hiệu suất của ứng dụng. Điều này có thể xảy ra khi bạn sử dụng một khoảng thời gian ngủ lớn hơn thực tế cần thiết hoặc khi sử dụng method sleep() trong một vòng lặp không cần thiết.
Để tránh điều này, bạn nên xác định khoảng thời gian ngủ cần thiết và sử dụng nó một cách hợp lý.
Không xử lý ngoại lệ InterruptedException
Nếu không xử lý ngoại lệ InterruptedException, luồng sẽ tiếp tục thực thi mà không biết rằng nó đã bị gián đoạn. Điều này có thể gây ra các vấn đề về tính đồng bộ và hiệu suất của ứng dụng.
Để tránh điều này, bạn nên luôn xử lý hoặc chuyển tiếp ngoại lệ InterruptedException khi sử dụng method sleep().
Các giải pháp thay thế cho method sleep() trong Java
Ngoài method sleep(), trong Java còn có một số giải pháp khác để ngủ luồng như sử dụng class ScheduledExecutorService hoặc sử dụng method wait() và notify() của class Object.
Sử dụng class ScheduledExecutorService
Class ScheduledExecutorService cung cấp methods cho phép bạn lập lịch thực thi các tác vụ trong tương lai. Bằng cách sử dụng class này, bạn có thể đặt một khoảng thời gian chờ và sau đó tiếp tục thực thi các tác vụ khác.
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();executor.schedule(() -> { // Thực thi tác vụ sau 1 giây}, 1, TimeUnit.SECONDS);
Sử dụng method wait() và notify()
Như đã đề cập ở trên, method wait() và notify() của class Object cũng có thể được sử dụng để ngủ luồng. Điều này có thể hữu ích trong trường hợp cần đảm bảo tính đồng bộ giữa các luồng khi truy cập vào cùng một tài nguyên.
Kết luận
Những thông tin trên đã giúp bạn hiểu về cách tổ chức các luồng trong Java bằng class Thread và cách sử dụng method sleep() để ngủ luồng, cách sử dụng method wait() và notify() của class Object để ngủ luồng, cách ngủ nhiều luồng đồng thời và cách sử dụng method sleep() trong đa luồng, các mẹo để sử dụng method này hiệu quả, cạm bẫy cần tránh và các giải pháp thay thế cho method sleep().
Hãy tiếp tục theo dõi các bài viết của TopDev lại chuyên mục Lập trình để cập nhật thêm nhiều thông tin hữu ích.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Chuỗi con (subString) là một khái niệm quen thuộc trong lập trình Java. Nó giúp chúng ta thao tác và xử lý dữ liệu văn bản một cách linh hoạt và hiệu quả hơn. Trong bài viết này, hãy cùng TopDev tìm hiểu về các phương thức tìm kiếm chuỗi con trong Java, cách sử dụng lớp String và StringBuilder để tạo chuỗi con, cũng như những mẹo tối ưu hóa khi làm việc với subString.
Substring trong Java
Trong lập trình Java, chuỗi con được định nghĩa là một phần của một chuỗi ban đầu, được xác định bởi vị trí bắt đầu và kết thúc của nó. Ví dụ, trong chuỗi “Xin chào thế giới”, chuỗi con “chào” có thể được xác định bởi chỉ mục bắt đầu là 5 và chỉ mục kết thúc là 8.
Các phương thức tìm kiếm chuỗi con trong Java cho phép chúng ta trích xuất và thao tác với các phần của chuỗi ban đầu một cách dễ dàng. Bạn có thể sử dụng các phương thức này để tìm kiếm vị trí của một chuỗi con cụ thể, hoặc lấy ra một chuỗi con từ vị trí bắt đầu đến vị trí kết thúc cho trước.
Các phương thức tìm kiếm chuỗi con
Java cung cấp một số phương thức tiện lợi để tìm kiếm chuỗi con trong một chuỗi ban đầu. Dưới đây là các phương thức chính để tìm kiếm chuỗi con:
String.substring(int beginIndex): Trả về chuỗi con bắt đầu từ chỉ mục beginIndex đến cuối chuỗi.
String.substring(int beginIndex, int endIndex): Trả về chuỗi con bắt đầu từ chỉ mục beginIndex đến chỉ mục endIndex-1.
String.indexOf(String subString): Trả về chỉ mục đầu tiên của chuỗi con subString trong chuỗi ban đầu.
String.lastIndexOf(String subString): Trả về chỉ mục cuối cùng của chuỗi con subString trong chuỗi ban đầu.
Ví dụ, chúng ta có thể sử dụng phương thức substring() để lấy ra chuỗi con từ một chuỗi ban đầu như sau:
String myString = "Xin chào thế giới";String subString = myString.substring(5); // Kết quả: "chào thế giới"
Hoặc bạn có thể chỉ định cả vị trí bắt đầu và kết thúc để lấy ra một chuỗi con cụ thể:
String subString = myString.substring(5, 8); // Kết quả: "chào"
Ngoài ra, chúng ta cũng có thể sử dụng phương thức indexOf() và lastIndexOf() để tìm kiếm vị trí xuất hiện của một chuỗi con trong chuỗi ban đầu. Ví dụ:
int index = myString.indexOf("thế"); // Kết quả: 9
Sử dụng lớp String để tìm chuỗi con
Lớp String trong Java cung cấp các phương thức tìm kiếm chuỗi con trực tiếp trên các đối tượng chuỗi. Điều này giúp chúng ta có thể dễ dàng thao tác với các chuỗi con mà không cần phải tạo ra các đối tượng mới.
Ví dụ, chúng ta có thể sử dụng phương thức contains() để kiểm tra xem một chuỗi con có tồn tại trong chuỗi ban đầu hay không:
String myString = "Xin chào thế giới";boolean contains = myString.contains("chào"); // Kết quả: true
Hoặc sử dụng phương thức startsWith() và endsWith() để kiểm tra xem chuỗi ban đầu có bắt đầu hoặc kết thúc bằng một chuỗi con cụ thể hay không:
boolean startsWith = myString.startsWith("Xin"); // Kết quả: trueboolean endsWith = myString.endsWith("giới"); // Kết quả: true
Sử dụng lớp StringBuilder để tạo chuỗi con
Ngoài việc sử dụng các phương thức của lớp String, chúng ta cũng có thể sử dụng lớp StringBuilder để tạo và thao tác với chuỗi con. Lớp này cho phép chúng ta thêm, xóa và sửa đổi các ký tự trong chuỗi một cách linh hoạt.
Ví dụ, chúng ta có thể sử dụng phương thức append() để thêm một chuỗi con vào cuối chuỗi ban đầu:
StringBuilder myStringBuilder = new StringBuilder("Xin chào");myStringBuilder.append(" thế giới"); // Kết quả: "Xin chào thế giới"
Hoặc sử dụng phương thức insert() để chèn một chuỗi con vào vị trí bất kỳ trong chuỗi ban đầu:
myStringBuilder.insert(4, "mọi người "); // Kết quả: "Xin mọi người chào thế giới"
So sánh hiệu suất của các phương thức tìm chuỗi con
Khi làm việc với các chuỗi con trong Java, chúng ta cần lưu ý đến hiệu suất của các phương thức tìm kiếm. Trong bảng dưới đây, chúng ta sẽ so sánh hiệu suất của các phương thức substring(), indexOf() và lastIndexOf() khi tìm kiếm một chuỗi con có độ dài 5 ký tự trong một chuỗi ban đầu có độ dài 100 ký tự.
Phương thức
Thời gian thực thi (ms)
substring()
0.002
indexOf()
0.003
lastIndexOf()
0.004
Kết quả cho thấy rằng phương thức substring() có hiệu suất tốt nhất trong ba phương thức này, vì nó chỉ truy cập vào một phần của chuỗi ban đầu để lấy ra chuỗi con. Trong khi đó, indexOf() và lastIndexOf() phải duyệt qua toàn bộ chuỗi ban đầu để tìm kiếm vị trí của chuỗi con.
Cách sử dụng chuỗi con trong xử lý văn bản
Chuỗi con là một tính năng mạnh mẽ giúp chúng ta xử lý dữ liệu văn bản một cách linh hoạt. Dưới đây là một số cách chúng ta có thể sử dụng chuỗi con trong xử lý văn bản.
Tách các từ trong một câu
Chuỗi con cho phép chúng ta tách các từ trong một câu để thực hiện các thao tác khác nhau. Ví dụ, chúng ta có thể sử dụng phương thức split() để tách các từ trong một câu và lưu chúng vào một mảng:
String sentence = "Học lập trình Java là rất thú vị";String[] words = sentence.split(" "); // Kết quả: ["Học", "lập trình", "Java", "là", "rất", "thú", "vị"]
Sau đó, chúng ta có thể thực hiện các thao tác khác nhau trên từng từ trong mảng này.
Thay thế các ký tự trong chuỗi
Khi làm việc với dữ liệu văn bản, chúng ta thường cần thay đổi các ký tự trong chuỗi ban đầu. Chuỗi con cho phép chúng ta thực hiện điều này một cách dễ dàng. Ví dụ, chúng ta có thể sử dụng phương thức replace() để thay thế một ký tự hoặc chuỗi ký tự bằng một ký tự hoặc chuỗi ký tự khác:
String myString = "Xin chào thế giới";String newString = myString.replace("chào", "tạm biệt"); // Kết quả: "Xin tạm biệt thế giới"
Kiểm tra tính hợp lệ của địa chỉ email
Khi làm việc với các form nhập liệu, chúng ta thường cần kiểm tra tính hợp lệ của địa chỉ email. Chuỗi con có thể giúp chúng ta thực hiện điều này bằng cách kiểm tra xem chuỗi con có khớp với một định dạng email hay không. Ví dụ:
Chuỗi con là một tính năng quan trọng và được sử dụng rộng rãi trong lập trình Java. Dưới đây là một số ứng dụng phổ biến của chuỗi con:
Tách và xử lý dữ liệu văn bản từ các nguồn khác nhau.
Thay đổi định dạng của các chuỗi ký tự (ví dụ: chuyển đổi chuỗi thành chữ hoa hoặc chữ thường).
Kiểm tra tính hợp lệ của các định dạng (ví dụ: email, số điện thoại, mã số bưu điện).
Tìm kiếm và thay thế các từ hoặc cụm từ trong văn bản.
Xử lý ngoại lệ khi nhập liệu không hợp lệ.
Xử lý ngoại lệ khi thao tác với subString
Khi làm việc với chuỗi con, chúng ta cần lưu ý đến trường hợp xảy ra ngoại lệ. Ví dụ, nếu chúng ta sử dụng phương thức substring() để lấy ra một chuỗi con từ một vị trí không hợp lệ, nó sẽ gây ra ngoại lệ IndexOutOfBoundsException.
Để xử lý ngoại lệ này, chúng ta có thể sử dụng câu lệnh try-catch như sau:
try { String myString = "Xin chào thế giới"; String subString = myString.substring(20); // Kết quả: IndexOutOfBoundsException} catch (IndexOutOfBoundsException e) { System.out.println("Vị trí bắt đầu không hợp lệ!");}
Các mẹo tối ưu hóa khi làm việc với chuỗi con
Để tăng hiệu suất và giảm thiểu các lỗi khi làm việc với chuỗi con, chúng ta có thể áp dụng một số mẹo tối ưu hóa sau:
Sử dụng phương thức substring() thay vì indexOf() hoặc lastIndexOf() khi cần lấy ra một chuỗi con.
Sử dụng StringBuilder thay vì String khi cần thay đổi nội dung của một chuỗi.
Kiểm tra tính hợp lệ của định dạng trước khi sử dụng phương thức matches().
Sử dụng try-catch để xử lý ngoại lệ khi thao tác với chuỗi con.
Kết luận
Chuỗi con là một tính năng quan trọng và được sử dụng rộng rãi trong lập trình Java. Chúng ta có thể sử dụng các phương thức tìm kiếm và tạo chuỗi con để xử lý dữ liệu văn bản một cách linh hoạt và hiệu quả. Tuy nhiên, chúng ta cần lưu ý đến hiệu suất và xử lý ngoại lệ khi làm việc với subString để đạt kết quả tốt nhất.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
IndexOf là một phương thức hữu ích trong ngôn ngữ lập trình Java cho phép tìm kiếm vị trí xuất hiện đầu tiên của một chuỗi hoặc ký tự cụ thể trong một chuỗi khác. Phương thức này trả về chỉ số (vị trí) của phần tử khớp đầu tiên được tìm thấy hoặc trả về -1 nếu không tìm thấy phần tử khớp nào. IndexOf được sử dụng rộng rãi trong các ứng dụng Java để xử lý chuỗi, thao tác văn bản và tìm kiếm thông tin.
Cách sử dụng indexOf
Cú pháp chung của phương thức indexOf như sau:
public int indexOf(String substring)
Trong đó:
substring: Chuỗi hoặc ký tự cần tìm kiếm trong chuỗi hiện tại.
Ví dụ về indexOf trong Java
Ví dụ sau minh họa cách sử dụng indexOf để tìm vị trí xuất hiện đầu tiên của chuỗi con “Java” trong chuỗi “Lập trình Java”:
String chuoi = "Lập trình Java";int viTri = chuoi.indexOf("Java");System.out.println("Vị trí của \"Java\": " + viTri);
Kết quả đầu ra:
Vị trí của "Java": 11
Trong ví dụ này, indexOf trả về vị trí 11, có nghĩa là chuỗi con “Java” bắt đầu tại ký tự thứ 11 trong chuỗi ban đầu.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
Đặc điểm của indexOf trong Java
IndexOf có một số đặc điểm cần lưu ý khi sử dụng trong ngôn ngữ lập trình Java:
Nhạy chữ hoa chữ thường: indexOf phân biệt chữ hoa và chữ thường. Do đó, nếu bạn tìm kiếm một chuỗi con có chữ hoa trong một chuỗi chỉ chứa chữ thường, phương thức sẽ không tìm thấy nó.
Tìm kiếm một chiều: indexOf luôn tìm kiếm từ đầu chuỗi đến cuối.
Trường hợp đặc biệt: Nếu chuỗi con được tìm kiếm là một chuỗi rỗng, indexOf sẽ trả về 0.
Phương thức indexOf trong Java
Phương thức indexOf có thể được sử dụng với các kiểu dữ liệu khác nhau trong ngôn ngữ lập trình Java, bao gồm String, StringBuffer và StringBuilder. Các cách sử dụng phổ biến của phương thức này bao gồm:
Tìm kiếm một chuỗi con trong một chuỗi.
Tìm kiếm một ký tự trong một chuỗi.
Tìm kiếm một chuỗi con từ vị trí xác định trong một chuỗi.
Tìm hiểu về indexOf trong Java
IndexOf là một phương thức quan trọng trong ngôn ngữ lập trình Java, được sử dụng rộng rãi trong các ứng dụng để xử lý chuỗi và tìm kiếm thông tin. Việc hiểu rõ về cách sử dụng và đặc điểm của indexOf sẽ giúp cho việc lập trình trở nên dễ dàng và hiệu quả hơn.
Sự khác biệt giữa indexOf và lastIndexOf
IndexOf và lastIndexOf là hai phương thức có chức năng tương tự nhau trong ngôn ngữ lập trình Java, tuy nhiên có một số điểm khác biệt quan trọng cần lưu ý:
IndexOf
LastIndexOf
Tìm kiếm từ đầu chuỗi đến cuối
Tìm kiếm từ cuối chuỗi đến đầu
Trả về vị trí xuất hiện đầu tiên
Trả về vị trí xuất hiện cuối cùng
Nếu không tìm thấy, trả về -1
Nếu không tìm thấy, trả về -1
Phân biệt chữ hoa chữ thường
Phân biệt chữ hoa chữ thường
So sánh indexOf với contains trong Java
IndexOf và contains là hai phương thức khác nhau trong ngôn ngữ lập trình Java, tuy nhiên cả hai đều có chức năng tìm kiếm và xác định sự tồn tại của một chuỗi con hoặc ký tự cụ thể trong một chuỗi. Tuy nhiên, có một số điểm khác biệt quan trọng giữa hai phương thức này:
IndexOf
Contains
Trả về vị trí xuất hiện đầu tiên của chuỗi con hoặc ký tự cần tìm kiếm
Trả về giá trị boolean (true hoặc false)
Nếu không tìm thấy, trả về -1
Không trả về giá trị nào nếu không tìm thấy
Phân biệt chữ hoa chữ thường
Không phân biệt chữ hoa chữ thường
Vì vậy, khi chỉ cần xác định sự tồn tại của một chuỗi con hoặc ký tự trong một chuỗi, ta có thể sử dụng contains để đơn giản hóa mã nguồn.
IndexOf là một phương thức hữu ích trong ngôn ngữ lập trình Java với nhiều lợi ích, bao gồm:
Tìm kiếm và xác định vị trí xuất hiện của một chuỗi con hoặc ký tự cụ thể trong một chuỗi.
Giúp xử lý các thao tác văn bản và tìm kiếm thông tin trong các ứng dụng Java.
Dễ dàng sử dụng và tích hợp vào các chương trình Java.
Các trường hợp sử dụng indexOf
IndexOf có thể được sử dụng trong nhiều trường hợp khác nhau trong ngôn ngữ lập trình Java, bao gồm:
Tìm kiếm và xác định vị trí của một từ hoặc cụm từ trong một câu.
Kiểm tra tính hợp lệ của địa chỉ email hoặc số điện thoại.
Xử lý các yêu cầu tìm kiếm trong các ứng dụng web.
Tìm kiếm và thay thế các chuỗi trong văn bản.
Các lỗi thường gặp khi sử dụng indexOf
Khi sử dụng indexOf trong ngôn ngữ lập trình Java, có một số lỗi thường gặp bạn cần lưu ý dưới đây:
Nếu không tìm thấy chuỗi con hoặc ký tự cần tìm kiếm, phương thức sẽ trả về -1. Do đó, cần kiểm tra kết quả trả về trước khi sử dụng.
Nếu chuỗi con hoặc ký tự cần tìm kiếm là một chuỗi rỗng, indexOf sẽ trả về 0. Điều này có thể gây nhầm lẫn và sai sót trong việc xử lý chuỗi.
Nếu chuỗi chứa nhiều hơn một lần xuất hiện của chuỗi con hoặc ký tự cần tìm kiếm, indexOf chỉ trả về vị trí xuất hiện đầu tiên.
Kết luận
IndexOf là một phương thức quan trọng trong ngôn ngữ lập trình Java, cho phép tìm kiếm và xác định vị trí xuất hiện của một chuỗi con hoặc ký tự cụ thể trong một chuỗi. Việc hiểu rõ về cách sử dụng và đặc điểm của indexOf sẽ giúp cho việc lập trình trở nên dễ dàng và hiệu quả hơn.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Trong lập trình Java, xử lý chuỗi là một trong những tác vụ quan trọng nhất. Chuỗi được sử dụng để lưu trữ dữ liệu văn bản và có thể được thao tác bằng nhiều chức năng tích hợp sẵn. Bài viết này của TopDev sẽ cung cấp một hướng dẫn toàn diện về xử lý chuỗi trong Java, bao gồm các phương thức cắt, thao tác và các ví dụ thực tế.
Cách cắt chuỗi trong Java
Cắt chuỗi là thao tác trích xuất một phần cụ thể của chuỗi dựa trên vị trí bắt đầu và (tùy chọn) vị trí kết thúc.
Để hiểu rõ hơn về cách cắt chuỗi trong Java, chúng ta hãy xem một ví dụ đơn giản. Giả sử chúng ta có một chuỗi “Hello World”, chúng ta muốn cắt chuỗi này để lấy ra từ “World”.
Sử dụng chỉ số:
String str = "Hello World";String result = str.substring(6); // result = "World"
Ở đây, chúng ta sử dụng chỉ số 6 để chỉ định vị trí bắt đầu của chuỗi con mà chúng ta muốn trích xuất. Lưu ý rằng chỉ số bắt đầu từ 0, nên vị trí thứ 6 trong chuỗi sẽ là ký tự “W”.
Sử dụng phương thức substring():
String str = "Hello World";String result = str.substring(6, 11); // result = "World"
Ở đây, chúng ta sử dụng hai tham số là 6 và 11 để chỉ định vị trí bắt đầu và kết thúc của chuỗi con mà chúng ta muốn trích xuất. Lưu ý rằng vị trí kết thúc không được bao gồm trong chuỗi con trả về, nên chúng ta cần chỉ định vị trí kết thúc là 11 để lấy được từ “World”.
Thao tác cắt chuỗi
Ngoài việc trích xuất một phần của chuỗi, chúng ta còn có thể thực hiện các thao tác khác trên chuỗi bằng cách cắt chuỗi. Ví dụ, chúng ta có thể chia chuỗi thành các chuỗi con dựa trên một ký tự phân cách hoặc thay thế một ký tự trong chuỗi bằng một ký tự khác.
Để minh họa cho các thao tác này, chúng ta sẽ sử dụng chuỗi “apple,banana,orange”.
Chia chuỗi thành một mảng các chuỗi con
Để chia chuỗi thành một mảng các chuỗi con dựa trên một ký tự phân cách, chúng ta sử dụng phương thức split().
Ở đây, chúng ta sử dụng ký tự , làm ký tự phân cách để chia chuỗi thành các chuỗi con. Kết quả trả về là một mảng các chuỗi con được lưu trong biến fruits.
Thay thế ký tự trong chuỗi
Để thay thế tất cả các lần xuất hiện của một ký tự trong chuỗi bằng một ký tự khác, chúng ta sử dụng phương thức replace().
Ở đây, chúng ta thay thế tất cả các lần xuất hiện của ký tự , bằng ký tự ;. Kết quả trả về là một chuỗi mới được lưu trong biến newStr.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
Các phương thức cắt chuỗi
Trong phần trước, chúng ta đã tìm hiểu về các phương thức cắt chuỗi trong Java. Trong phần này, chúng ta sẽ đi sâu hơn vào các phương thức này và tìm hiểu cách sử dụng chúng.
Cách sử dụng hàm cắt chuỗi trong Java
Để sử dụng các phương thức cắt chuỗi trong Java, chúng ta cần khởi tạo một đối tượng String từ chuỗi cần xử lý. Sau đó, chúng ta có thể gọi các phương thức trên đối tượng này để thực hiện các thao tác cắt chuỗi.
Ví dụ:
String str = "Hello World";String result = str.substring(6); // result = "World"
Ở đây, chúng ta đã khởi tạo đối tượng String từ chuỗi “Hello World” và gọi phương thức substring() để cắt chuỗi từ vị trí thứ 6 đến cuối chuỗi.
Lưu ý khi cắt chuỗi
Khi sử dụng các phương thức cắt chuỗi trong Java, chúng ta cần lưu ý một số điểm sau:
Chỉ số bắt đầu từ 0: Khi sử dụng chỉ số để cắt chuỗi, chúng ta cần nhớ rằng chỉ số bắt đầu từ 0, nên vị trí thứ 6 trong chuỗi sẽ là ký tự thứ 7.
Vị trí kết thúc không được bao gồm: Khi sử dụng phương thức substring(), vị trí kết thúc không được bao gồm trong chuỗi con trả về. Vì vậy, chúng ta cần chỉ định vị trí kết thúc là một số lớn hơn vị trí thực tế một đơn vị.
Chuỗi là không thay đổi: Các phương thức cắt chuỗi trong Java không làm thay đổi chuỗi gốc, mà trả về một chuỗi mới. Vì vậy, nếu chúng ta muốn thay đổi chuỗi gốc, chúng ta cần gán lại giá trị trả về cho chuỗi gốc.
Các ví dụ thực tế về cắt chuỗi trong Java
Để hiểu rõ hơn về cách sử dụng các phương thức cắt chuỗi trong Java, chúng ta sẽ xem một số ví dụ thực tế sau:
Ở đây, chúng ta sử dụng phương thức lastIndexOf() để tìm vị trí của ký tự / cuối cùng trong đường dẫn và cắt chuỗi từ vị trí đó đến cuối chuỗi để lấy ra tên file.
2. Chuyển đổi ngày tháng năm thành chuỗi ngày/tháng/năm:
Ở đây, chúng ta sử dụng phương thức split() để chia chuỗi thành một mảng các chuỗi con dựa trên ký tự -. Sau đó, chúng ta sử dụng các phần tử trong mảng này để tạo ra chuỗi mới có định dạng ngày/tháng/năm.
So sánh các cách cắt chuỗi trong Java
Có hai cách chính để cắt chuỗi trong Java là sử dụng chỉ số và sử dụng phương thức substring(). Cả hai cách này đều có những ưu điểm và hạn chế riêng, vì vậy chúng ta cần cân nhắc để chọn cách phù hợp cho từng tình huống.
Sử dụng chỉ số:
Ưu điểm: Đơn giản và dễ hiểu.
Hạn chế: Chỉ có thể cắt chuỗi theo vị trí bắt đầu và kết thúc đã biết trước.
Sử dụng phương thức substring():
Ưu điểm: Linh hoạt, có thể cắt chuỗi theo vị trí bất kỳ.
Hạn chế: Phức tạp hơn khi cần cắt chuỗi theo nhiều vị trí khác nhau.
Vì vậy, chúng ta cần cân nhắc các yếu tố như tính đơn giản, tính linh hoạt và hiệu suất để chọn cách cắt chuỗi phù hợp cho từng tình huống.
Kết luận
Trong bài viết này, TopDev đã cùng bạn tìm hiểu về cách cắt chuỗi trong Java thông qua hai cách chính là sử dụng chỉ số và sử dụng phương thức substring(). Chúng ta cũng đã tìm hiểu về các phương thức cắt chuỗi tích hợp sẵn trong Java và cách sử dụng chúng. Hy vọng bài viết này sẽ giúp bạn hiểu rõ hơn về cách cắt chuỗi trong Java và áp dụng một cách hiệu quả.
Trong lập trình Java, toString() là một phương thức phổ biến được sử dụng để chuyển đổi một đối tượng thành dạng chuỗi. Phương pháp này được định nghĩa trong lớp Object, lớp cơ sở của mọi lớp Java, do đó nó được thừa kế bởi tất cả các lớp và có thể được ghi đè để cung cấp hành vi tùy chỉnh.
Tính năng của toString trong Java
Phương thức toString() trong Java có những tính năng sau:
Chuyển đổi đối tượng thành dạng chuỗi: Phương thức này cho phép lập trình viên chuyển đổi một đối tượng thành dạng chuỗi để có thể hiển thị hoặc sử dụng trong các phương thức khác.
Có thể được ghi đè để cung cấp định dạng chuỗi tùy chỉnh: Với việc ghi đè phương thức toString(), bạn có thể tùy chỉnh định dạng của chuỗi trả về theo ý muốn.
Được gọi tự động khi đối tượng được nối với chuỗi hoặc được hiển thị: Khi chúng ta sử dụng toán tử + để nối một đối tượng với một chuỗi hoặc sử dụng phương thức println() để hiển thị đối tượng, phương thức toString() sẽ được gọi tự động.
Trả về thông tin hữu ích về đối tượng, bao gồm tên lớp và các thuộc tính của nó: Phương thức toString() trả về một chuỗi chứa thông tin quan trọng về đối tượng như tên lớp và các thuộc tính của nó, giúp chúng ta có thể hiểu rõ hơn về đối tượng đó.
Ví dụ về cách sử dụng toString trong Java
Giả sử chúng ta có một lớp Person với các thuộc tính name và age:
public class Person { private String name; private int age; // Constructor public Person(String name, int age) { this.name = name; this.age = age; } // Override phương thức toString() @Override public String toString() { return "Person"; }}
Chúng ta có thể sử dụng toString() để chuyển đổi một đối tượng Person thành chuỗi như sau:
Person person = new Person("John", 30); System.out.println(person.toString()); // In ra: Person
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
Các lỗi thường gặp khi sử dụng toString trong Java
Mặc định, lớp cơ sở Object đã cung cấp một định dạng chuỗi cho phương thức toString(). Tuy nhiên, nếu chúng ta không ghi đè phương thức này trong các lớp tùy chỉnh của mình, định dạng mặc định này có thể không hữu ích và dẫn đến những lỗi không mong muốn.
Không ghi đè phương thức toString
Nếu bạn không ghi đè phương thức toString() trong các lớp tùy chỉnh, khi chúng ta sử dụng phương thức này trên đối tượng của lớp đó, phương thức toString() của lớp cơ sở Object sẽ được gọi. Điều này có thể dẫn đến việc hiển thị thông tin không chính xác hoặc không rõ ràng về đối tượng đó.
Ví dụ, nếu chúng ta không ghi đè phương thức toString() trong lớp Person ở ví dụ trước, khi chúng ta in ra đối tượng person, kết quả sẽ là Person@1b6d3586. Đây là định dạng mặc định của phương thức toString() trong lớp Object, không cung cấp bất kỳ thông tin hữu ích nào về đối tượng.
Nếu chúng ta ghi đè phương thức toString() nhưng không cung cấp định dạng chuỗi đầy đủ, kết quả trả về có thể không chính xác hoặc không rõ ràng. Điều này có thể dẫn đến việc hiển thị thông tin sai lệch về đối tượng và gây khó khăn trong việc debug và sử dụng đối tượng đó trong các phương thức khác.
So sánh toString với các phương thức khác trong Java
Trong Java, có một số phương thức khác cũng có tính năng tương tự như toString(), nhưng lại có mục đích sử dụng khác nhau. Dưới đây là một bảng so sánh giữa toString() và các phương thức khác:
Phương thức
Mục đích sử dụng
toString()
Chuyển đổi đối tượng thành dạng chuỗi để hiển thị hoặc sử dụng trong các phương thức khác.
toHexString()
Chuyển đổi một số nguyên sang dạng chuỗi thập lục phân.
valueOf()
Chuyển đổi một giá trị sang đối tượng của lớp tương ứng.
format()
Định dạng một chuỗi theo một mẫu cho trước.
Cách override toString trong Java
Để ghi đè phương thức toString() trong Java, chúng ta cần sử dụng từ khóa @Override trước phương thức và viết lại nội dung của phương thức theo ý muốn.
Ví dụ, chúng ta có thể ghi đè phương thức toString() trong lớp Person như sau:
Khi đó, khi chúng ta in ra đối tượng person, kết quả sẽ là Name: John, Age: 30.
Định dạng chuỗi trả về của toString trong Java
Mặc định, phương thức toString() sẽ trả về một chuỗi có định dạng [tên lớp]@[địa chỉ bộ nhớ]. Tuy nhiên, bạn có thể tùy chỉnh định dạng này bằng cách ghi đè phương thức toString() và trả về một chuỗi theo ý muốn.
Ví dụ, bạn có thể trả về một chuỗi chứa tên lớp và các thuộc tính của đối tượng như trong ví dụ ở phần trước.
Lợi ích của việc sử dụng toString trong Java
Việc sử dụng phương thức toString() trong Java có nhiều lợi ích, bao gồm:
Giúp chúng ta hiểu rõ hơn về đối tượng: Phương thức toString() trả về một chuỗi chứa thông tin quan trọng về đối tượng như tên lớp và các thuộc tính của nó, giúp chúng ta có thể hiểu rõ hơn về đối tượng đó.
Tiết kiệm thời gian và công sức: Thay vì phải viết mã để lấy thông tin từ các thuộc tính của đối tượng và ghép lại thành một chuỗi, chúng ta có thể sử dụng toString() để tự động làm điều này.
Dễ dàng debug và sử dụng đối tượng: Với việc có được một chuỗi chứa thông tin đầy đủ về đối tượng, chúng ta có thể dễ dàng debug và sử dụng đối tượng đó trong các phương thức khác.
Các lưu ý khi sử dụng toString trong Java
Khi sử dụng phương thức toString() trong Java, chúng ta cần lưu ý các điểm sau:
Đảm bảo ghi đè phương thức toString(): Nếu không ghi đè phương thức này trong các lớp tùy chỉnh, định dạng mặc định của lớp cơ sở Object sẽ được sử dụng và có thể không hữu ích.
Tránh ghi đè phương thức toString quá phức tạp: Việc ghi đè phương thức này nên đơn giản và cung cấp đầy đủ thông tin về đối tượng. Nếu quá phức tạp, nó có thể gây khó khăn trong việc debug và sử dụng đối tượng.
Sử dụng toString trong việc debug: Khi debug, chúng ta có thể in ra giá trị của một đối tượng bằng cách sử dụng toString() để xem thông tin về đối tượng đó.
Trong bài viết này, TopDev đã giúp bạn có cái nhìn tổng quát về phương thức toString() trong Java, tính năng của nó và cách sử dụng trong các lớp tùy chỉnh. Hy vọng bài viết này sẽ giúp bạn hiểu rõ hơn về cách sử dụng toString() trong Java và áp dụng một cách hiệu quả trong học tập và làm việc. Đừng quên thường xuyên truy cập chuyên mục Lập trình của Blog TopDev để cập nhật thêm nhiều kiến thức về lập trình bổ ích.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Trong lập trình Java, việc thao tác với chuỗi ký tự (String) là rất phổ biến và quan trọng. Và để có thể truy xuất và thao tác với các ký tự riêng lẻ trong chuỗi, chúng ta cần sử dụng đến phương thức charAt() trong Java. Trong bài viết này, chúng ta sẽ tìm hiểu chi tiết về cách sử dụng phương thức này trong Java.
Định nghĩa charAt() trong Java
CharAt() là một phương thức của lớp String được sử dụng để truy xuất ký tự tại một chỉ số cụ thể trong chuỗi. Phương thức này trả về ký tự tại vị trí được chỉ định dưới dạng char.
Cú pháp của phương thức charAt()
Cú pháp chung của phương thức charAt() như sau:
public char charAt(int index)
Trong đó:
index: Chỉ số của ký tự muốn truy xuất trong chuỗi. Chỉ số này phải nằm trong phạm vi từ 0 đến length() – 1, trong đó length() là độ dài của chuỗi.
Các tham số của charAt()
Phương thức charAt() chỉ có một tham số bắt buộc:
index: Chỉ số của ký tự muốn truy xuất trong chuỗi.
Giá trị trả về của charAt()
Phương thức charAt() trả về ký tự tại vị trí chỉ định trong chuỗi dưới dạng char. Nếu chỉ số cung cấp nằm ngoài phạm vi hợp lệ, phương thức sẽ ném một IndexOutOfBoundsException.
IndexOutOfBoundsException: Nếu chỉ số cung cấp nằm ngoài phạm vi hợp lệ (nhỏ hơn 0 hoặc lớn hơn hoặc bằng length() của chuỗi).
Cơ chế hoạt động của charAt() trong Java
Khi gọi phương thức charAt(), Java sẽ truy cập vào chuỗi và trả về ký tự tại vị trí chỉ định. Điều này giúp chúng ta có thể truy xuất và thao tác với các ký tự riêng lẻ trong chuỗi một cách dễ dàng.
Các ví dụ về cách sử dụng charAt()
Để hiểu rõ hơn về cách sử dụng phương thức charAt(), chúng ta sẽ xem qua một số ví dụ sau:
Trong ví dụ này, chúng ta sử dụng phương thức charAt() để truy xuất ký tự đầu tiên trong chuỗi “Hello World”. Chỉ số của ký tự đầu tiên luôn là 0, do đó chúng ta truyền giá trị 0 vào phương thức charAt().
Trong ví dụ này, chúng ta sử dụng phương thức length() để lấy độ dài của chuỗi và trừ đi 1 để có được chỉ số của ký tự cuối cùng. Sau đó, chúng ta truyền giá trị này vào phương thức charAt() để truy xuất ký tự cuối cùng trong chuỗi.
Ví dụ 3: Lặp qua các ký tự trong chuỗi
String str = "Hello World";for (int i = 0; i < str.length(); i++) { char currentChar = str.charAt(i); System.out.println(currentChar);}
Trong ví dụ này, chúng ta sử dụng vòng lặp for để lặp qua từng ký tự trong chuỗi. Trong mỗi lần lặp, chúng ta sử dụng phương thức charAt() để truy xuất ký tự tại chỉ số hiện tại và in ra màn hình.
Ứng tuyển các vị trí việc làm Java lương cao trên TopDev
So sánh charAt() với các phương thức khác
Trong Java, có nhiều phương thức khác cũng được sử dụng để truy xuất và thao tác với các ký tự trong chuỗi. Chúng ta hãy xem xét sự khác nhau giữa phương thức charAt() và các phương thức khác sau:
charAt() vs substring()
Phương thức substring() cũng được sử dụng để truy xuất một phần của chuỗi, tuy nhiên nó trả về một chuỗi con thay vì một ký tự duy nhất như charAt(). Ví dụ:
Ở ví dụ này, chúng ta sử dụng phương thức substring() để lấy chuỗi con từ vị trí 0 đến vị trí 4 trong chuỗi “Hello World”.
charAt() vs getChars()
Phương thức getChars() cũng được sử dụng để truy xuất một phần của chuỗi, tuy nhiên nó trả về một mảng các ký tự thay vì một ký tự duy nhất như charAt(). Ví dụ:
Ở ví dụ này, chúng ta sử dụng phương thức getChars() để lấy mảng các ký tự từ vị trí 0 đến vị trí 4 trong chuỗi “Hello World” và lưu vào mảng charArray.
Các trường hợp sử dụng điển hình của charAt()
Phương thức charAt() có thể được sử dụng trong nhiều trường hợp khác nhau, tùy thuộc vào yêu cầu của chương trình. Tuy nhiên, có một số trường hợp sử dụng điển hình sau:
Truy xuất ký tự đầu tiên hoặc cuối cùng trong chuỗi.
Lặp qua từng ký tự trong chuỗi để thực hiện các xử lý.
Kiểm tra tính hợp lệ của chuỗi bằng cách so sánh ký tự tại các chỉ số khác nhau.
Những lưu ý khi sử dụng charAt() trong Java
Khi sử dụng phương thức charAt(), chúng ta cần lưu ý một số điểm sau để tránh gặp phải các lỗi không mong muốn:
Chỉ số truyền vào phương thức charAt() phải nằm trong phạm vi hợp lệ, tức là từ 0 đến length() – 1.
Nếu chỉ số truyền vào vượt quá độ dài của chuỗi, phương thức sẽ ném ra một ngoại lệ IndexOutOfBoundsException.
Kết quả trả về của phương thức charAt() là một ký tự duy nhất, do đó chúng ta cần lưu ý khi sử dụng trong các xử lý liên quan đến chuỗi.
Kết luận
Trong bài viết này, chúng ta đã tìm hiểu chi tiết về cách sử dụng phương thức charAt() trong Java. Chúng ta đã biết được cú pháp, các tham số và giá trị trả về của phương thức này, cùng với cơ chế hoạt động và các ví dụ minh họa. Hy vọng rằng bài viết này của TopDev sẽ giúp bạn hiểu rõ hơn về phương thức charAt() và áp dụng nó vào các dự án của mình một cách hiệu quả.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Bài viết được sự cho phép của tác giả Trần Nhật Trường
Giới thiệu
Trên thế giới, khi nói về vấn đề bảo mật thông tin, người ta không thể không nói đến Social Engineering – một kỹ thuật khai thác thông tin rất nguy hiểm, khó phát hiện, phòng chống và gây thiệt hại to lớn cho công tác bảo mật thông tin. Ngày nay, công nghệ thông tin đóng vai trò chủ chốt trong nhiều lĩnh vực quan trọng của xã hội như kinh tế, giáo dục, chính trị và quân sự – những lĩnh vực trong đó sự lỏng lẻo về công tác bảo mật thông tin sẽ khiến chúng ta phải trả giá đắt. Chính vì thế, Social Engineering nhận được nhiều sự quan tâm toàn cầu, đặc biệt là trong lĩnh vực công nghệ thông tin
Khái niệm về Social Engineering
Bên cạnh các biện pháp tấn công bằng kỹ thuật như sử dụng các chương trình tấn công thì hacker thường vận dụng kết hợp với các phương pháp phi kỹ thuật, tận dụng các kiến thức và kỹ năng xã hội để đạt được kết quả nhanh chóng và hiệu quả hơn. Và phương pháp tấn công không dựa trên các kỹ thuật hay công cụ thuần túy này được gọi là Social Engineering, trong đời thực thì dạng tấn công này có thể xem như là các kiểu lừa đảo để chiến dụng tài sản, giả mạo để đạt được một mục tiêu nào đó.
Social Engineering là phương pháp tấn công, đột nhập vào một hệ thống của một tổ chức, công ty, doanh nghiệp. Kỹ thuật tấn công Social Engineering là quá trình đánh lừa người dùng của hệ thống, hoặc thuyết phục họ cung cấp thông tin có thể giúp chúng ta đánh bại bộ phận an ninh, lấy cắp dữ liệu hoặc tống tiền. Nói một cách khác, Social Engineering là một trò lừa đảo rất tinh vi được thực hiện qua mạng internet, tỉ lệ thành công của hình thức này rất cao, bởi vì hacker có thể lợi dụng tấn công vào yếu tố con người và phá vỡ hệ thống kỹ thuật an ninh hiện tại. Phương pháp này có thể sử dụng để thu thập thông tin trước hoặc trong cuộc tấn công.
Social Engineering sử dụng sự ảnh hưởng và sự thuyết phục để đánh lừa người dùng nhằm khai thác các thông tin có lợi cho cuộc tấn công hoặc thuyết phục nạn nhân thực hiện một hành động nào đó. Social engineer (người thực hiện công việc tấn công bằng phương pháp Social Engineering) thường sử dụng điện thoại hoặc internet để dụ dỗ người dùng tiết lộ thông tin nhạy cảm hoặc để có được họ có thể làm một chuyện gì đó để chống lại các chính sách an ninh của tổ chức. Bằng phương pháp này, Social engineer tiến hành khai thác các thói quen tự nhiên của người dùng, hơn là tìm các lỗ hổng bảo mật của hệ thống. Điều này có nghĩa là người dùng với kiến thức bảo mật kém cõi sẽ là cơ hội cho kỹ thuật tấn công này hành động.
Các hacker khi tiến hành các cuộc tấn công Social Engineering thường tận dụng những mối quan hệ thân thiết, tin cậy mà trong môi trường thông tin được gọi là các “trust relationship” để tiến hành khai thác mục tiêu. Điển hình như vụ Tiến Sĩ Lê Đăng Doanh bị hacker đắnh cắp hộp thư và gởi mail cho tất cả đồng nghiệp, bạn bè trong danh bạ để hỏi mượn tiền do đang bị kẹt tại nước ngoài, hoặc chúng ta cũng thường xuyên nhận tin nhắn từ các số máy lạ để yêu cầu mua giùm một thẻ điện thoại rồi gởi mã số đến số của hacker.
Việc tấn công này rất hiệu quả vì đánh vào điểm yếu nhất trong quy trình an toàn thông tin của chúng ta, đó là sự kém hiểu biết của người dùng. Chính vì vậy để phòng chống các dạng tấn công này thì doanh nghiệp cần có những chương trình đào tạo nhăm nâng cao nhận thức an toàn thông tin cho nhân viên của mình. Và không có vấn đề gì khi các công ty đầu tư cho các hệ thống chất lượng cao và các giải pháp bảo mật chẳng hạn như các phương pháp xác thực đơn giản, các firewalls, mạng riêng ảo VPN và các phần mềm giám sát mạng. Không có thiết bị hay giới hạn bảo mật nào hiệu quả khi một nhân viên vô tình để lộ thông tin key trong email, hay trả lời điện thoại của người lạ hoặc một người mới quen thậm chí khoe khoang về dự án của họ với đồng nghiệp hàng giờ liền ở quán rượu.
Thông thường, mọi người không nhận thấy sai sót của họ trong việc bảo mật, mặc dù họ không cố ý. Những người tấn công đặc biệt rất thích phát triển kĩ năng về Social Engineering và có thể thành thạo đến mức những nạn nhân của không hề biết rằng họ đang bị lừa. Mặc dù có nhiều chính sách bảo mật trong công ty, nhưng họ vẫn có thể bị hại do hacker lợi dụng lòng tốt và sự giúp đỡ của mọi người.
Những kẻ tấn công luôn tìm những cách mới để lấy được thông tin. Họ chắc chắn là họ nắm rõ vành đai bảo vệ và những người trực thuộc – nhân viên bảo vệ, nhân viên tiếp tân và những nhân viên ở bộ phận hỗ trợ – để lợi dụng sơ hở của họ. Thường thì mọi người dựa vào vẻ bề ngoài để phán đoán. Ví dụ, khi nhìn thấy một người mặc đồng phục màu nâu và mang theo nhiều hộp cơm, mọi người sẽ mở cửa vì họ nghĩ đây là người giao hàng. Một số công ty liệt kê danh sách nhân viên trong công ty kèm theo số điện thọai, email trên Website của công ty. Ngoài ra, các công ty còn thêm danh sách các nhân viên chuyên nghiệp đã được đào tạo trong cơ sở dữ liệu Oracle hay UNIX servers. Đây là một số ít thông tin giúp cho attacker biết được loại hệ thống mà họ đang định xâm nhập.
Sau đây là một ví dụ về kỹ thuật tấn công Social Engineering được Kapil Raina kể lại, hiện ông này đang là một chuyên gia an ninh tại Verisign, câu chuyện xẩy ra khi ông đang làm việc tại một công ty khác trước đó: “Một buổi sàng vài năm trước, một nhóm người lạ bước vào công ty với tư cách là nhân viên của một công ty vận chuyển mà công ty này đang có hợp động làm việc chung. Và họ bước ra với quyền truy cập vào toàn bộ hệ thống mạng công ty. Họ đã làm điều đó bằng cách nào? Bằng cách lấy một lượng nhỏ thông tin truy cập từ một số nhân viên khác nhau trong công ty. Đầu tiên họ đã tiến hành một nghiên cứu tổng thể về công ty từ hai ngày trước. Tiếp theo họ giã vờ làm mất chìa khóa để vào cửa trước, và một nhân viên công ty đã giúp họ tìm lại được. Sau đó, họ làm mất thẻ an ninh để vào cổng công ty, và chỉ bằng một nụ cười thân thiện, nhân viên bảo vệ đã mở cửa cho họ vào. Trước đó họ đã biết trường phòng tài chính vừa có cuộc công ta xa, và những thông tin của ông này có thể giúp họ tấn công hệ thống. Do đó họ đã đột nhập văn phòng của giám đốc tài chính này. Họ lục tung các thùng rác của công ty để tìm kiếm các tài liệu hữu ích. Thông qua lao công của công ty, họ có thêm một số điểm chứa tài liệu quan trọng cho họ mà là rác của người khác. Điểm quan trọng cuối cùng mà họ đã sử dụng là giả giọng nói của vị giám đốc vắn mặt này. Có thành quả đó là do họ đã tiến hành nghiên cứu giọng nói của vị giám đốc. Và những thông tin của ông giám đốc mà họ thu thập được từ thùng rác đã giúp cho họ tạo sự tin tưởng tuyệt đối với nhân viên. Một cuộc tấn công đã diễn ra, khi họ đã gọi điện cho phòng IT với vai trò giám đốc phòng tài chính, làm ra vẽ mình bị mất pasword, và rất cần password mới. Họ tiếp tục sử dụng các thông tin khác và nhiều kỹ thuật tấn công đã giúp họ chiếm lĩnh toàn bộ hệ thống mạng”. Nguy hiểm nhất của kỹ thuật tấn công này là quy trình thẩm định thông tin cá nhân. Thông qua tường lửa, mạng riêng ảo, phần mềm giám sát mạng…sẽ giúp rộng cuộc tấn công, bởi vì kỹ thuật tấn công này không sử dụng các biện pháp trực tiếp. Thay vào đó yếu tố con người rất quan trọng. Chính sự lơ là của nhân viên trong công ty trên đã để cho kẽ tấn công thu thập được thông tin quan trọng.
Social Engineering bao gồm việc đạt được những thông tin mật hay truy cập trái phép, bằng cách xây dựng mối quan hệ với một số người. Kết quả của social engineer là lừa một người nào đó cung cấp thông tin có giá trị. Nó tác động lên phẩm chất vốn có của con người, chẳng hạn như mong muốn trở thành người có ích, tin tưởng mọi người và sợ những rắc rối.
Social Engineering vận dụng những thủ thuật và kỹ thuật làm cho một người nào đó đồng ý làm theo những gì mà Social engineer muốn. Nó không phải là cách điều khiển suy nghĩ người khác, và nó không cho phép Social engineer làm cho người nào đó làm những việc vượt quá tư cách đạo đức thông thường. Và trên hết, nó không dễ thực hiện chút nào. Tuy nhiên, đó là một phương pháp mà hầu hết Attackers dùng để tấn công vào công ty. Có 2 loại rất thông dụng :
Social Engineering là việc lấy được thông tin cần thiết từ một người nào đó hơn là phá hủy hệ thống
Psychological subversion: mục đích của hacker hay attacker khi sử dụng PsychSub (một kỹ thuật thiên về tâm lý) thì phức tạp hơn và bao gồm sự chuẩn bị, phân tích tình huống, và suy nghĩ cẩn thận, chính xác những từ sử dụng và giọng điệu khi nói, và nó thường sử dụng trong quân đội.
Điểm yếu của con người
Phần mềm và phần cứng của máy tính là những thứ vô cùng phức tạp. Tuy nhiên, con người, kẻ đã tạo ra chúng lại phức tạp hơn gấp nhiều lần. Bởi vì con người có nhân cách, có tâm lý, tình cảm là những thứ mà các vật nhân tạo chưa thể có được. Đây chính là điểm vô cùng mạnh đã giúp con người thành công như ngày hôm nay, nhưng cũng là một điểm yếu của con người. Và Social Engineering chính là phương pháp tấn công vô cùng nguy hiểm dựa trên những điểm yếu này.
Thứ nhất, con người luôn mong muốn điều có lợi cho mình và tránh khỏi các phiền hà, rắc rối: Ví dụ khi một nhân viên chăm sóc khác hàng của một công ty dịch vụ sẽ luôn được yêu cầu rằng phải làm cho khách hàng hài lòng nhất có thể. Từ đó, họ sẽ được những phản hồi tốt về chất lượng dịch vụ, được tính điểm cao trong hệ thống… Với mục tiêu này, nhân viên của chúng ta sẽ luôn cố gắng đáp ứng yêu cầu cho khách hàng một cách tốt nhất. Chính vì lí do này, nhiều khi họ, những người nắm giữ thông tin, dữ liệu về hệ thống sẽ cung cấp rất nhiều thông tin không nên cung cấp cho khách hàng.
Thứ hai, con người thường có khuynh hướng giúp đỡ người khác: Con người chúng ta là một sinh vật sống có tình cảm, luôn sẵn sàng giúp đỡ một người khi họ gặp vấn đề gì đó. Vì vậy sẽ rất dễ dàng để bị kẻ xấu lợi dụng.
Thứ ba, con người thường chấp nhận một thông tin mới hơn là nghi ngờ tính xác thực của thông tin đó: Hầu hết trong chúng ta ai cũng vậy, mọi người khi nghe một thông báo, một khẳng định, một lời khuyên mới nào đó… chúng ta đều tin nó là có thật. Việc này sẽ kéo dài cho đến khi chúng ta phát hiện nó là không thật. Quãng thời gian này có thể không dài, tuy nhiên sẽ không ngắn để thực hiện một số mục đích.
Thứ tư, con người luôn muốn làm nhanh một việc, cắt bỏ giai đoạn: Chúng ta thường xuyên thực hiện công việc với tâm lý như thế, tuy nhiên lại không nhận thức được hậu quả của việc đó. Chẳng hạn như việc quên mật khẩu có thể khắc phục được bằng việc viết mật khẩu ra giấy và bảo quản cẩn thận.
Thứ năm, thái độ của một người đối với việc bảo vệ thông tin cá nhân của mình không cao: Đây là một tâm lý vô cùng quan trọng và nguy hiểm để kẻ xấu dựa vào đó có thể thực hiện mọi mưu đồ của mình. Người ta luôn nghĩ rằng thông tin cá nhân của mình không quan trọng, tuy nhiên họ lại không biết rằng, một người không nằm trong hệ thống bảo mật vẫn có thể làm ảnh hưởng đến toàn bộ hệ thống bảo mật.
Mọi người thường mắc phải nhiều điểm yếu trong các vấn đề bảo mật. Để đề phòng thành công thì chúng ta phải dựa vào các chính sách tốt và huấn luyện nhân viên thực hiện tốt các chính sách đó. Social Engineering là phương pháp khó phòng chống nhất vì nó không thể dùng phần cứng hay phần mềm để chống lại.
Một người nào đó khi truy cập vào bất cứ phần nào của hệ thống thì các thiết bị vật lý và vấn đề cấp điện có thể là một trở ngại lớn. Bất cứ thông tin nào thu thập được đều có thể dùng phương pháp Social Engineering để thu thập thêm thông tin. Có nghĩa là một người không nằm trong chính sách bảo mật cũng có thể phá hủy hệ thống bảo mật. Các chuyên gia bảo mật cho rằng cách bảo mật giấu đi thông tin là rẩt yếu. Trong trường hợp của Social Engineering, hoàn toàn không có sự bảo mật nào vì không thể che giấu việc ai đang sử dụng hệ thống và khả năng ảnh hưởng của họ tới hệ thống.
Có nhiều cách để hoàn thành mục tiêu đề ra. Cách đơn giản nhất là yêu cầu trực tiếp, đó là đặt câu hỏi trực tiếp. Mặc dù cách này rất khó thành công, nhưng đây là phương pháp dễ nhất, đơn giản nhất. Người đó biết chính xác họ cần gì. Cách thứ hai, tạo ra một tình huống mà nạn nhân có liên quan đến. Với các nhân tố khác nhau cần được yêu cầu xem xét, làm thế nào để nạn nhân dễ dàng dính bẩy nhất, bởi vì attacker có thể tạo ra những lý do thuyết phục hơn những người bình thường. Attacker càng nỗ lực thì khả năng thành công càng cao, thông tin thu được càng nhiều. Không có nghĩa là các tình huống này không dựa trên thực tế. Càng giống sự thật thì khả năng thành công càng cao. Một trong những công cụ quan trọng được sử dụng trong Social Engineering là một trí nhớ tốt để thu thập các sự kiện. Đó là điều mà các hacker và sysadmin nổi trội hơn, đặc biệt khi nói đến những vấn đề liên quan đến lĩnh vực của họ.
Bài viết được sự cho phép của tác giả Trần Nhật Trường
Phân loại Social Engineering
Social Engineering có thể được chia thành hai loại phổ biến:
Human-Based Social Engineering
Human-based là kỹ thuật Social Engineering liên quan đến sự tương tác giữa con người với con người để thu được thông tin mong muốn. Ví dụ như chúng ta phải gọi điện thoại đến phòng Help Desk để truy tìm mật khẩu. Kỹ thuật Human Based có thể chia thành các loại như sau:
Impersonation: Mạo danh là nhân viên hoặc người dùng hợp lệ. Trong kỹ thuật này, kẽ tấn công sẽ giả dạng thành nhân viên công ty hoặc người dùng hợp lệ của hệ thống. Hacker mạo danh mình là người gác cổng, nhân viên, đối tác, đột nhập vào công ty. Một khi đã vào được bên trong, chúng tiến hành thu thập các thông tin từ thùng rác, máy tính để bàn, hoặc các hệ thống máy tính, hoặc là hỏi thăm những người đồng nghiệp.
Posing as Important User: Trong vai trò của một người sử dụng quan trọng như người quan lý cấp cao, trưởng phòng, hoặc những người cần trợ giúp ngay lập tức, hacker có thể dụ dỗ người dùng cung cấp cho chúng mật khẩu truy cập vào hệ thống.
Third-person Authorization: Lấy danh nghĩa được sự cho phép của một người nào đó để truy cập vào hệ thống. Ví dụ một tên hacker nói anh được sự ủy quyền của giám đốc dùng tài khoản của giám đốc để truy cập vào hệ thống.
Calling Technical Support: Gọi điện thoại đến phòng tư vấn kỹ thuật là một phương pháp cổ điển của kỹ thuật tấn công Social Engineering. Help-desk và phòng hổ trợ kỹ thuật được lập ra để giúp cho người dùng, đó cũng là con mồi ngon cho hacker.
Shoulder Surfing: là kỹ thuật thu thập thông tin bằng cách xem file ghi nhật ký hệ thống. Thông thường khi đăng nhập vào hệ thống, quá trình đăng nhập được ghi nhận lại, thông tin ghi lại có thể giúp ích nhiều cho hacker.
Dumpster Diving: là kỹ thuật thu thập thông tin trong thùng rác. Nghe có vẻ “đê tiện” vì phải lôi thùng rác của người ta ra để tìm kiếm thông tin, nhưng vì đại cuộc phải chấp nhận hi sinh. Nói vui vậy, thu thập thông tin trong thùng rác của các công ty lớn, thông tin mà chúng ta cần thu có thể là password, username, filename hoặc những thông tin mật khác. Ví dụ: Tháng 6 năm 2000, Larry Ellison, chủ tịch Oracle, thừa nhận là Oracle đã dùng đến dumpster diving để cố gắng tìm ra thông tin về Microsoft trong trường hợp chống độc quyền. Danh từ “larrygate”, không là mới trong hoạt động tình báo doanh nghiệp.
Một số thứ mà dumpster có thể mang lại: Thứ nhất là sách niên giám điện thoại công ty – biết ai gọi sau đó dùng để mạo nhận là những bước đầu tiên để đạt quyền truy xuất tới các dữ liệu nhạy cảm. Nó giúp có được tên và tư cách chính xác để làm có vẻ như là nhân viên hợp lệ. Tìm các số đã gọi là một nhiệm vụ dễ dàng khi kẻ tấn công có thể xác định tổng đài điện thoại của công ty từ sách niên giám. Hai là các biểu đồ tổ chức; bản ghi nhớ; sổ tay chính sách công ty; lịch hội họp, sự kiện, và các kỳ nghỉ; sổ tay hệ thống; bản in của dữ liệu nhạy cảm hoặc tên đăng nhập và password; bản ghi source code; băng và đĩa; các đĩa cứng hết hạn.
Phương pháp nâng cao hơn trong kỹ thuật Social Engineering là Reverse Social Engineering (Social Engineering ngược). Trong kỹ thuật này, hacker trở thành người cung cấp thông tin. Điều đó không có gì là ngạc nhiên, khi hacker bây giờ chính là nhân viên phòng help desk. Người dùng bị mất password, và yêu cầu nhân viên helpdesk cung cấp lại.
Computer-Based Social Engineering
Computer Based là kỹ thuật liên quan đến việc sử dụng các phần mềm để cố gắng thu thập thông tin cần thiết. Ví dụ bạn gửi email và yêu cầu người dùng nhập lại mật khẩu đăng nhập vào website. Kỹ thuật này còn được gọi là Phishing (lừa đảo). Có thể chia thành các loại như sau:
Phishing: Thuật ngữ này áp dụng cho một email xuất hiện đến từ một công ty kinh doanh, ngân hàng hoặc thẻ tín dụng yêu cầu chứng thực thông tin và cảnh báo sẽ xảy ra hậu quả nghiêm trọng nếu việc này không được làm. Lá thư thường chứa một đường link đến một trang web giả mạo trông hợp pháp với logo của công ty và nội dung có chứa form để yêu cầu username, password, số thẻ tín dụng hoặc số pin.
Vishing: Thuật ngữ là sự kết hợp của “voice” và phishing. Đây cũng là một dạng phising, nhưng kẻ tấn công sẽ trực tiếp gọi điện cho nạn nhân thay vì gửi email. Người sử dụng sẽ nhận được một thông điệp tự động với nội dung cảnh báo vấn đề liên quan đến tài khoản ngân hàng. Thông điệp này hướng dẫn họ gọi đến một số điện thoại để khắc phục vấn đề. Sau khi gọi, số điện thoại này sẽ kết nối người được gọi tới một hệ thống hỗ trợ giả, yêu cầu họ phải nhập mã thẻ tín dụng. Và Voip tiếp tay đắc lực thêm cho dạng tấn công mới này vì giá rẻ và khó giám sát một cuộc gọi bằng Voip.
Interesting Software: Trong trường hợp này nạn nhân được thuyết phục tải về và cài đặt các chương trình hay ứng dụng hữu ích như cải thiện hiệu suất của CPU, RAM, hoặc các tiện ích hệ thống hoặc như một crack để sử dụng các phần mềm có bản quyền. Và một Spyware hay Malware (chẳng hạn như Keylogger) sẽ được cài đặt thông qua một chương trình độc hại ngụy trang dưới một chương trình hợp pháp.
Một trong những chìa khóa thành công của Social Engineering là thông tin. Đáng ngạc nhiên là dễ dàng thu thập đầy đủ thông tin của một tổ chức và nhân viên trong tổ chức đó. Các tổ chức có khuynh hướng đưa quá nhiều thông tin lên website của họ như là một phần của chiến lược kinh doanh. Thông tin này thường mô tả hay đưa ra các đầu mối như là các nhà cung cấp có thể ký kết; danh sách điện thoai và email; và chỉ ra có chi nhánh hay không nếu có thì chúng ở đâu. Tất cả thông tin này có thể là hữu ích với các nhà đầu tư tiềm năng, nhưng nó cũng có thể bị sử dụng trong tấn công Social Engineering. Những thứ mà các tổ chức ném đi có thể là nguồn tài nguyên thông tin quan trọng. Tìm kiếm trong thùng rác có thể khám phá hóa đơn, thư từ, sổ tay,… có thể giúp cho kẻ tấn công kiếm được các thông tin quan trọng. Mục đích của kẻ tấn công trong bước này là hiểu càng nhiều thông tin càng tốt để làm ra vẻ là nhân viên, nhà cung cấp, đối tác chiến lược hợp lệ,…
Các bước tấn công trong Social Engineering
2.Chọn mục tiêu
Khi khối lượng thông tin phù hợp đã được tập hợp, kẻ tấn công tìm kiếm điểm yếu đáng chú ý trong nhân viên của tổ chức đó.
Mục tiêu thông thường là nhân viên hổ trợ kỹ thuật, được tập luyện để đưa sự giúp đỡ và có thể thay đổi password, tạo tài khoản, kích hoạt lại tài khoản,… Mục đích của hầu hết kẻ tấn công là tập hợp thông tin nhạy cảm và lấy một vị trí trong hệ thống. Kẻ tấn công nhận ra là khi chúng có thể truy cập, thậm chí là cấp độ khách, thì chúng có thể nâng quyền lên, bắt đầu tấn công phá hoại và che giấu vết.
Trợ lý administrator là mục tiêu kế tiếp. Đó là vì các cá nhân này có thể tiếp cận với các dữ liệu nhạy cảm thông thường được lưu chuyển giữa các thành viên quản trị cấp cao. Nhiều các trợ lý này thực hiện các công việc hàng ngày cho quản lý của họ mà các công việc này yêu cầu đặc quyền tài khoản của người quản lý.
3.Tấn công
Sự tấn công thực tế thông thường dựa trên cái mà chúng ta gọi đó là “sự lường gạt”. Gồm có 3 loại chính:
Ego attack: trong loại tấn công đầu tiên này, kẻ tấn công dựa vào một vài đặc điểm cơ bản của con người. Tất cả chúng ta thích nói về chúng ta thông minh như thế nào và chúng ta biết hoặc chúng ta đang làm hoặc hiệu chỉnh công ty ra sao. Kẻ tấn công sẽ sử dụng điều này để trích ra thông tin từ nạn nhân của chúng. Kẻ tấn công thường chọn nạn nhân là người cảm thấy bị đánh giá không đúng mức và đang làm việc ở vị trí mà dưới tài năng của họ. Kẻ tấn công thường có thể phán đoán ra điều này chỉ sau một cuộc nói chuyện ngắn.
Sympathy attacks: Trong loại tấn công thứ hai này, kẻ tấn công thường giả vờ là nhân viên tập sự, một nhà thầu, hoặc một nhân viên mới của một nhà cung cấp hoặc đối tác chiến lược, những người này xảy ra tình huống khó xử và cần sự giúp đỡ đề thực hiện xong nhiệm vụ.
Sự quan trọng của bước thu thập trở nên rõ ràng ở đây, khi kẻ tấn công sẽ tạo ra sự tin cậy với nạn nhân bằng cách dùng các từ chuyên ngành thích hợp hoặc thể hiện kiến thức về tổ chức. Kẻ tấn công giả vờ là hắn đang bận và phải hoàn thành một vài nhiệm vụ mà yêu cầu truy xuất, nhưng hắn không thể nhớ username và password,… Một cảm giác khẩn cấp luôn luôn là phần trong kịch bản. Với bản tính con người là thông cảm nên trong hầu hết các trường hợp yêu cầu sẽ được chấp nhận. Nếu kẻ tấn công thất bại khi lấy truy xuất hoặc thông tin từ một nhân viên, hắn sẽ tiếp tục cố gắng cho đến khi tìm thấy người thông cảm, hoặc cho đến khi hắn nhận ra là tổ chức nghi ngờ.Intimidation attacks: Với loại thứ ba, kẻ tấn công giả vờ là là một nhân vật có quyền, như là một người có ảnh hưởng trong tổ chức. Kẻ tấn công sẽ nhằm vào nạn nhân có vị trí thấp hơn vị trí của nhân vật mà hắn giả vờ. Kẻ tấn công tạo một lý do hợp lý cho các yêu cầu như thiết lập lại password, thay đổi tài khoản, truy xuất đến hệ thống, hoặc thông tin nhạy cảm.
Phòng chống các mối đe dọa từ social engineering
Với cá nhân
– Tuyệt đối không click vào những đường link lạ trên mạng xã hội
– Khi nhận được tin nhắn Facebook hoặc tin nhắn trong Email của người lạ có file đính kèm dàn .zip, .dll, .exe thì chớ vội click. Nếu click vào tệp đó, thiết bị bạn sẽ bị nhiễm mã độc.
– Không nên chia sẻ thông tin, tài liệu của công ty và doanh nghiệp lên mạng sã hội nếu chưa được phép.
– Không click vào những cửa sổ Pop-up trúng thưởng.
– Khi bạn đã lỡ truy cập vào trang web giả mạo với trang web gốc hoặc bị điều hướng tới trang web giả mạo thì không nên điền thông tin tài khoản ngân hàng, số chứng minh thư hay những thông tin mật cá nhân khác.
– Sử dụng một số thanh công cụ chống lừa đảo như : Netcraft, PhishTank để phát hiện trang web lừa đảo.
Với doanh nghiệp, tổ chức nói chung
Do hình thức tấn công Social Engineering dựa trên mạng xã hội trở nên bùng nổ, công ty và các cá nhân có rất ít thời gian để tự thực hành chống lại SEA. Các cuộc khảo sát thực hiện vài năm trước đã chỉ ra rằng nhiều tổ chức, công ty thậm chí còn không có các chính sách liên quan đến tấn công SEA dựa trên mạng xã hội. Cho đến thời gian gần đây, người ta mới dần nhận ra tầm quan trọng của nó. Các chính sách công ty cũng nên phù hợp với việc sử dụng mạng xã hội trong giờ làm việc.
Các chuyên gia bảo mật đã khuyên người sử dụng tại các công ty áp dụng các chính sách nhằm đảm bảo họ không bị tấn công bởi kỹ thuật Social Engineering:
– Khuyến nghị phân chia tài khoản mạng xã hội rạch ròi giữa cuốc sống và công việc. Mặc dù điều này không thể loại trừ được hết nguy cơ thông tin, nhưng nó cũng hiệu quả một phần.
– Luôn luôn phải xác nhận liên lạc, và không liên lạc với người lạ. Đây là vấn nạn phổ biến trên mạng xã hội khi hầu hết người dùng thường chấp nhận lời mời sự kiện hoặc lời mời kết bạn từ những người lạ không quen biết.
– Tránh sử dụng một mật khẩu cho nhiều tài khoản mạng xã hội khác nhau nhằm tránh nguy cơ lộ thông tin hàng loạt.
– Hạn chế đăng mọi thứ lên mạng xã hội vì thông tin được đăng có thể được kẻ tấn công tìm thấy, kể cả sau một thời gian dài.
– Hạn chế đăng những thông tin hoặc đặc điểm cá nhân để tránh khả năng người dùng bị kẻ tấn công mạo danh.
Còn với các công ty, tổ chức lớn cũng cần có những chính sách cụ thể để ngăn ngừa khả năng bị khai thác tấn công Social Engineering:
– Giáo dục nhân viên hạn chế đăng ký và để lộ thông tin cá nhân, nhận dạng trên mạng, những thông tin quan trọng như số điện thoại, hình ảnh nhà cửa, gia đình, địa chỉ nhà, bất kì thông tin nào có thể được tận dụng để mạo danh.
– Khuyến khích nhân viên sử dụng hai tài khoản cá nhân và công việc trên các trang mạng xã hội.
– Đào tạo nhân viên sử dụng mật khẩu phức tạp, độ bảo mật cao.
– Đào tạo nhân viên cho thấy tầm quan trọng của thông tin cá nhân trên những trang mạng xã hội như Facebook.
– Đào tạo, chỉ dẫn nhân viên về các mối quan hệ nguy hiểm của tấn công Phishing trên mạng xã hội và cách phòng tránh nó.
Thiết kế lớp phòng thủ chiều sâu
Mô hình phân lớp phòng thủ chiều sâu phân loại các giải pháp bảo mật chống các yếu tố tấn công – những vùng điểm yếu – mà hacker có thể sử dụng để đe dọa môi trường máy tính. Các yếu tố tấn công bao gồm:
– Chính sách, thủ tục, nhận thức: các văn bản quy định rằng bạn phát triển để quản lý tất cả các lĩnh vực bảo mật, và chương trình giáo dục mà để đảm bảo đội ngũ nhân viên biết, hiểu, và thực thi các quy định này.
– Bảo mật vật lý: các rào cản mà quản lý truy cập đến tài sản và tài nguyên. Điều quan trọng để nhớ các yếu tố sau cùng; ví dụ, nếu bạn đặt giỏ rác bên ngoài công ty, sau đó chúng ở bên ngoài sự bảo mật vật lý của công ty.
– Dữ liệu: thông tin kinh doanh – tài khoản, e-mail, … khi xem xét các mối đe dọa, thì phải bao gồm cả hard và soft copy tài liệu trong kế hoạch bảo mật dữ liệu.
– Ứng dụng: các chương trình chạy bởi user. Phải đánh giá các hackerSocial Engineering có thể phá vỡ chương trình như thế nào, chẳng hạn email hoặc IM.
– Host: các máy tính server và client được sử dụng trong tổ chức. Sự trợ giúp đảm bảo rằng bạn bảo vệ các user chống lại các cuộc tấn công trực tiếp vào các máy tính này bằng cách xác định chặt chẽ các nguyên tắc chỉ đạo phần mềm để sử dụng máy tính và làm thế nào quản lý các thiết bị bảo mật, chẳng hạn như user ID và password.
– Mạng nội bộ: hệ thống mạng mà hệ thống máy tính công ty truyền thông. Nó có thể là local, wireless, hoặc WAN. Các mạng nội bộ đã trở nên ít “nội bộ” trong vài năm qua, với sự hoạt động tại nhà và di động đã phổ biến. Vì thế phải làm cho chắc chắn là user hiểu rằng họ phải làm việc bảo mật trong tất cả các môi trường nối mạng.
– Chu vi: điểm tiếp xúc giữa mạng nội bộ và mạng bên ngoài, chẳng hạn như Internet hay hệ thống mạng là phụ thuộc vào các đối tác kinh doanh, có thể một phần của extranet. Các tấn công Social Engineering thường cố gắng xuyên thủng chu vi để khởi đầu tấn công vào dữ liệu, ứng dụng, và các host xuyên qua hệ thống mạng nội bộ.
Mô hình phòng vệ chiều sâu
Khi thiết kế sự phòng vệ, mô hình phòng vệ chiều sâu giúp hình dung các lĩnh vực kinh doanh có thể bị đe dọa. Mô hình này không đặc tả các mối đe dọa Social Engineering, nhưng mỗi lớp phải nên có sự phòng vệ.
Tóm lại để xác định được phương pháp đối phó với Social Engineering là điều rất quan trọng trong các kỹ thuật phòng thủ và tấn công. Nó có liên quan đến vấn đề về xã hội nên việc phòng chống nó có chút rắc rối về cách tư cách của con người. Có một số cách để làm điều này.
Chính sách (policy) an ninh trong công ty quyết định vấn đề an toàn của hệ thống. Bạn cần đặt ra những quy định, giới hạn quyền truy cập cho các nhân viên trong công ty.
Huấn luyện tốt cho nhân viên về an ninh là điều rất cần thiết. Khi nhân viên của bạn hiểu ra các vấn đề an ninh, họ sẽ tự trách các rủi ro trước khi có sự can thiệt của phòng an ninh.
Vấn đề về con người cũng không kém quan trọng. Vì kỹ thuật tấn công này chủ yếu liên quan đến tư tưởng con người. Sự lơ là của nhân viên, sự mất lòng tin của nhân viên cũng là nguy cơ mất an toàn cho hệ thống.
Xây dựng một framework quản lý an ninh: Phải xác định tập hợp các mục đích của an ninh Social Engineering và đội ngũ nhân viên những người chịu trách nhiệm cho việc phân phối những mục đích này.
Đánh giá rủi ro: Các mối đe dọa không thể hiện cùng một mức độ rủi ro cho các công ty khác nhau. Ta phải xem xét lại mỗi một mối đe dọa Social Engineering và hợp lý hóa mối nguy hiểm trong tổ chức.
Social Engineering trong chính sách an ninh: Phát triển một văn bản thiết lập các chính sách và thủ tục quy định nhân viên xử trí tình huống mà có thể là tấn công Social Engineering. Bước này giả định là chính sách bảo mật đã có, bên ngoài những mối đe dọa của Social Engineering. Nếu hiện tại không có chính sách bảo mật, thì cần phải phát triển chúng.
Tóm lại, thông qua những vấn đề nêu trên chúng ta có thể tóm gọn như sau:
– Social engineering là kỹ thuật xã hội, dùng mối quan hệ con người để thu thập tin cần thiết phục vụ cho những cuộc tấn công phía sau.
– Quan trọng nhất trong kỹ thuật này là dựa vào điểm yếu của con người.
– Các bước thực hiện một cuộc tấn công Social engineering là: Thu thập thông tin, chọn mục tiêu, tấn công.
– Các kiểu tấn công phổ biến có thể kể đến như: Insider Attack, Indentify Theft, Online Scam, Phising… – Và cuối cùng là để phòng chống lại kiểu tấn công này, không có cách nào hiểu quả bằng cách giáo dục cho nhân viên của bạn những thù đoạn lừa đảo để họ tự cảnh giác
Cấu trúc dữ liệu là một khái niệm quan trọng trong lập trình và được sử dụng để lưu trữ và tổ chức các dữ liệu trong một chương trình. Trong Java, có nhiều loại cấu trúc dữ liệu khác nhau, mỗi loại có những đặc điểm và ứng dụng riêng. Trong bài viết này, chúng ta sẽ tìm hiểu về cấu trúc dữ liệu HashSet trong Java.
Khái niệm về HashSet
HashSet là một cấu trúc dữ liệu trừu tượng được triển khai trong bộ sưu tập khung Java Collection. Nó là một bộ sưu tập không được sắp xếp và không trùng lặp của các phần tử duy nhất.
Điều này có nghĩa là không có hai phần tử nào giống nhau trong tập hợp HashSet. HashSet được sử dụng để lưu trữ và quản lý các đối tượng trong Java.
Không giống như các cấu trúc dữ liệu khác như mảng hoặc danh sách, các phần tử trong HashSet không thể truy cập bằng chỉ mục. Thay vào đó, HashSet sử dụng hàm băm để lưu trữ và truy xuất các phần tử một cách hiệu quả. Hàm băm là một thuật toán được sử dụng để ánh xạ các giá trị vào các vị trí trong bộ nhớ, giúp tìm kiếm và truy xuất dữ liệu nhanh chóng.
HashSet có thể chứa các đối tượng của bất kỳ loại dữ liệu nào, bao gồm cả các lớp do người dùng tự định nghĩa. Điều này làm cho nó trở thành một cấu trúc dữ liệu linh hoạt và có thể được sử dụng trong nhiều ứng dụng khác nhau.
Cách sử dụng HashSet trong Java
Để sử dụng HashSet trong Java, bạn cần nhập lớp java.util.HashSet. Sau đó, bạn có thể tạo một đối tượng HashSet bằng cách sử dụng cú pháp:
HashSet hashSet = new HashSet();Trong đó, Kiểu dữ liệu là loại dữ liệu của các phần tử sẽ được lưu trữ trong HashSet. Ví dụ, nếu bạn muốn lưu trữ các số nguyên trong HashSet, bạn có thể sử dụng cú pháp sau:HashSet hashSet = new HashSet();
Sau khi tạo đối tượng HashSet, bạn có thể sử dụng các phương thức của nó để thêm, xóa và truy xuất các phần tử.
Tính năng và ưu điểm của HashSet
HashSet cung cấp một số tính năng và ưu điểm chính sau:
Không trùng lặp
Một trong những đặc điểm quan trọng của HashSet là không cho phép các phần tử trùng lặp. Điều này có nghĩa là khi bạn thêm một phần tử vào HashSet, nếu phần tử đó đã tồn tại trong tập hợp, nó sẽ không được thêm vào mà chỉ trả về kết quả false. Điều này giúp đảm bảo tính duy nhất của các phần tử trong tập hợp.
Hiệu suất cao
HashSet sử dụng hàm băm để lưu trữ các phần tử, giúp truy xuất và chèn phần tử cực kỳ hiệu quả. Với việc sử dụng hàm băm, thời gian truy xuất và chèn phần tử là hằng số trung bình (O(1)), độ phức tạp thời gian không tăng theo kích thước của tập hợp.
Thao tác nhanh chóng
Các thao tác cơ bản như thêm, xóa và truy xuất phần tử trong HashSet có thể được thực hiện trong thời gian hằng số trung bình (O(1)). Điều này làm cho HashSet trở thành một cấu trúc dữ liệu rất hiệu quả trong việc lưu trữ và quản lý các đối tượng.
Khả năng mở rộng
HashSet tự động tăng kích thước khi cần thiết, làm cho nó lý tưởng cho các bộ dữ liệu lớn. Khi số lượng phần tử trong HashSet vượt quá kích thước hiện tại của nó, nó sẽ tự động tăng kích thước để có thể chứa thêm các phần tử mới. Điều này giúp đảm bảo tính linh hoạt và khả năng mở rộng của HashSet.
Đồng bộ hóa tùy chọn
HashSet có thể được đồng bộ hóa để bảo vệ luồng, đảm bảo an toàn luồng khi có nhiều luồng truy cập đến cùng một HashSet. Điều này giúp tránh các lỗi xảy ra khi có nhiều luồng cùng thao tác trên HashSet.
Các phương thức cơ bản của HashSet trong Java
Trong phần này, chúng ta sẽ tìm hiểu về các phương thức cơ bản của HashSet trong Java.
Thêm phần tử vào HashSet
Để thêm một phần tử vào HashSet, chúng ta sử dụng phương thức add() với cú pháp sau:
hashSet.add(phần tử);
Phương thức này sẽ trả về kết quả true nếu phần tử được thêm thành công và false nếu phần tử đã tồn tại trong tập hợp.
Xóa phần tử khỏi HashSet
Để xóa một phần tử khỏi HashSet, chúng ta sử dụng phương thức remove() với cú pháp sau:
hashSet.remove(phần tử);
Phương thức này sẽ trả về kết quả true nếu phần tử được xóa thành công và false nếu phần tử không tồn tại trong tập hợp.
Truy xuất phần tử trong HashSet
Để truy xuất một phần tử trong HashSet, chúng ta có thể sử dụng phương thức contains() với cú pháp sau:
hashSet.contains(phần tử);
Phương thức này sẽ trả về kết quả true nếu phần tử tồn tại trong tập hợp và false nếu không tồn tại.
Sự khác biệt giữa HashSet và các cấu trúc dữ liệu khác trong Java
Trong phần này, chúng ta sẽ so sánh HashSet với các cấu trúc dữ liệu khác trong Java để hiểu rõ hơn về đặc điểm và ứng dụng của nó.
So sánh với ArrayList
ArrayList là một cấu trúc dữ liệu tuyến tính được triển khai trong bộ sưu tập khung Java Collection. Nó cho phép lưu trữ và quản lý các phần tử theo thứ tự và có thể truy xuất bằng chỉ mục. Tuy nhiên, ArrayList không đảm bảo tính duy nhất của các phần tử và có độ phức tạp thời gian truy xuất là O(n).
Trong khi đó, HashSet không đảm bảo thứ tự của các phần tử và có độ phức tạp thời gian truy xuất là O(1). Điều này làm cho HashSet hiệu quả hơn trong việc lưu trữ và truy xuất các phần tử.
LinkedList là một cấu trúc dữ liệu liên kết được triển khai trong bộ sưu tập khung Java Collection. Nó cũng cho phép lưu trữ và quản lý các phần tử theo thứ tự, tuy nhiên, các phần tử trong LinkedList được liên kết với nhau thông qua các con trỏ. Điều này làm cho việc truy xuất các phần tử trong LinkedList có độ phức tạp thời gian là O(n).
Trong khi đó, HashSet sử dụng hàm băm để lưu trữ và truy xuất các phần tử, giúp đạt được độ phức tạp thời gian là O(1). Điều này làm cho HashSet nhanh hơn trong việc truy xuất các phần tử.
TreeMap là một cấu trúc dữ liệu cây được triển khai trong bộ sưu tập khung Java Collection. Nó cho phép lưu trữ và quản lý các phần tử theo thứ tự và có độ phức tạp thời gian truy xuất là O(log n). Tuy nhiên, TreeMap không đảm bảo tính duy nhất của các phần tử.
Trong khi đó, HashSet đảm bảo tính duy nhất của các phần tử và có độ phức tạp thời gian truy xuất là O(1). Điều này làm cho HashSet hiệu quả hơn trong việc lưu trữ và truy xuất các phần tử.
Để hiểu rõ hơn về cách sử dụng HashSet trong Java, chúng ta sẽ xem một ví dụ đơn giản về việc lưu trữ và quản lý các đối tượng trong HashSet.
import java.util.HashSet;public class HashSetExample { public static void main(String[] args) { // Tạo một đối tượng HashSet để lưu trữ các số nguyên HashSet numbers = new HashSet(); // Thêm các số nguyên vào HashSet numbers.add(5); numbers.add(10); numbers.add(15); numbers.add(20); // In ra kích thước của HashSet System.out.println("Kích thước của HashSet: " + numbers.size()); // Kiểm tra xem phần tử 10 có tồn tại trong HashSet hay không if (numbers.contains(10)) { System.out.println("Phần tử 10 tồn tại trong HashSet."); } // Xóa phần tử 15 khỏi HashSet numbers.remove(15); // In ra kích thước mới của HashSet System.out.println("Kích thước của HashSet sau khi xóa: " + numbers.size()); }}
Kết quả khi chạy chương trình:
java Kích thước của HashSet: 4 Phần tử 10 tồn tại trong HashSet. Kích thước của HashSet sau khi xóa: 3
Làm thế nào để tối ưu hóa hiệu suất của HashSet trong Java
Để tối ưu hóa hiệu suất của HashSet trong Java, chúng ta có thể áp dụng các kỹ thuật sau:
Sử dụng kích thước ban đầu lớn cho HashSet để tránh việc phải điều chỉnh lại kích thước khi thêm phần tử mới.
Tránh sử dụng các phương thức như contains() hay remove() với các giá trị null vì nó có thể gây ra lỗi NullPointerException.
Nếu cần duyệt qua tất cả các phần tử trong HashSet, chúng ta nên sử dụng vòng lặp for-each thay vì sử dụng Iterator để tránh tạo ra một đối tượng mới.
Các lỗi thường gặp khi sử dụng HashSet và cách khắc phục
Một số lỗi thường gặp khi sử dụng HashSet trong Java bao gồm:
Lỗi ClassCastException: Xảy ra khi chúng ta cố gắng thêm một đối tượng không tương thích vào HashSet hoặc khi chúng ta cố gắng truy xuất một đối tượng không đúng kiểu từ HashSet.
Lỗi NullPointerException: Xảy ra khi chúng ta cố gắng sử dụng phương thức contains() hay remove() với giá trị null.
Lỗi ConcurrentModificationException: Xảy ra khi chúng ta thay đổi cấu trúc của HashSet trong khi duyệt qua các phần tử bằng Iterator.
Để khắc phục các lỗi này, chúng ta có thể kiểm tra lại kiểu dữ liệu và giá trị của các đối tượng được thêm vào HashSet, tránh sử dụng giá trị null và sử dụng cấu trúc dữ liệu phù hợp để tránh lỗi ConcurrentModificationException.
Kết luận
Trong bài viết này, bạn đã tìm hiểu về cấu trúc dữ liệu HashSet trong Java, cách sử dụng và các tính năng, ưu điểm của nó. Bài viết cũng đã so sánh HashSet với các cấu trúc dữ liệu khác và xem một ví dụ minh họa về việc sử dụng nó. Để tối ưu hóa hiệu suất của HashSet, chúng ta nên áp dụng các kỹ thuật như sử dụng kích thước ban đầu lớn và tránh sử dụng giá trị null. Cuối cùng, bạn cũng đã xem xét các lỗi thường gặp khi sử dụng HashSet và cách khắc phục chúng.
Khi sử dụng HashSet trong Java, bạn nên lưu ý rằng nó không đảm bảo tính duy nhất của các phần tử và không đảm bảo thứ tự của chúng. Do đó, nếu yêu cầu của chúng ta là lưu trữ các phần tử theo thứ tự hoặc đảm bảo tính duy nhất, chúng ta nên sử dụng các cấu trúc dữ liệu khác như TreeSet hay LinkedHashSet.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Truy cập ngay công việc IT đãi ngộ tốt trên TopDev
Trong lập trình hướng đối tượng, access modifier là một từ khóa được sử dụng để kiểm soát mức độ truy cập vào các thành phần (biến, phương thức) của một lớp. Java cung cấp bốn loại access modifier chính: public, protected, default (gói) và private. Việc sử dụng các access modifier thích hợp là rất quan trọng để đảm bảo tính bảo mật, tính bảo trì và tính linh hoạt của mã.
Sự khác biệt giữa public và private trong Java
Public và private là hai access modifier phổ biến nhất trong Java. Đây cũng là hai access modifier có mức truy cập đối nghịch nhau.
Public: Thành phần được đánh dấu là public có thể được truy cập từ bất kỳ đâu trong chương trình, bao gồm các lớp con và lớp bên ngoài. Đây là mức truy cập rộng nhất.
Private: Thành phần được đánh dấu là private chỉ có thể được truy cập bên trong lớp chứa nó. Đây là mức truy cập hạn chế nhất.
Ví dụ:
public class MyClass { private int privateField; public int publicField;}
Trong ví dụ trên, privateField chỉ có thể được truy cập bên trong lớp MyClass, trong khi publicField có thể được truy cập từ bất kỳ nơi nào trong chương trình.
Access modifier đóng vai trò quan trọng trong tính bảo mật của mã Java. Chúng kiểm soát khả năng truy cập vào dữ liệu nhạy cảm và các hành vi bên trong của một lớp.
Các access modifier hạn chế hơn (private > default > protected > public) cung cấp tính bảo mật cao hơn. Điều này có nghĩa là các thành phần được đánh dấu là private chỉ có thể được truy cập bởi các phương thức trong cùng một lớp, trong khi các thành phần được đánh dấu là public có thể được truy cập từ bất kỳ đâu trong chương trình.
Sử dụng access modifier phù hợp giúp ngăn chặn việc truy cập trái phép vào các thành phần quan trọng của lớp, đảm bảo tính toàn vẹn của dữ liệu và giảm thiểu rủi ro bị lỗi trong quá trình phát triển và bảo trì mã.
Cách sử dụng access modifier trong Java
Để sử dụng access modifier trong lập trình Java, ta chỉ cần đặt từ khóa tương ứng trước tên của thành phần. Ví dụ:
public class MyClass { private int privateField; public int publicField;}
Trong ví dụ trên, private và public là hai access modifier được sử dụng để kiểm soát mức độ truy cập của các biến privateField và publicField.
Phạm vi truy cập của các access modifier trong Java
Bảng sau đây mô tả phạm vi truy cập của các access modifier trong Java:
Access Modifier
Phạm vi truy cập
public
Toàn bộ chương trình
protected
Chỉ trong cùng package hoặc lớp con
default (gói)
Chỉ trong cùng package
private
Chỉ trong cùng lớp
Để hiểu rõ hơn về phạm vi truy cập của các access modifier, chúng ta hãy xem xét ví dụ sau:
package com.example;public class MyClass { private int privateField; public int publicField;}class AnotherClass extends MyClass { public void method() { System.out.println(publicField); // có thể truy cập System.out.println(privateField); // không thể truy cập }}
Trong ví dụ trên, AnotherClass là một lớp con của MyClass và cùng thuộc package com.example. Vì vậy, lớp AnotherClass có thể truy cập vào biến publicField của lớp cha, nhưng không thể truy cập vào biến privateField vì nó được đánh dấu là private.
Các quy tắc khi sử dụng access modifier
Khi sử dụng access modifier trong Java, ta cần tuân thủ các quy tắc sau:
Một lớp chỉ có thể có một access modifier duy nhất. Nếu không có từ khóa nào được sử dụng, mặc định là default.
Các phương thức và biến trong cùng một lớp có thể có các access modifier khác nhau.
Các lớp con có thể truy cập vào các thành phần có mức truy cập là protected hoặc public của lớp cha.
Các lớp con không thể truy cập vào các thành phần có mức truy cập là private của lớp cha.
Các lớp không liên quan không thể truy cập vào các thành phần có mức truy cập là default hoặc protected của lớp.
Các lớp không liên quan không thể truy cập vào các thành phần có mức truy cập là private của lớp.
Sự kế thừa và access modifier trong Java
Sự kế thừa là tính chất quan trọng của lập trình hướng đối tượng trong Java. Khi một lớp con kế thừa từ một lớp cha, nó sẽ có tất cả các thành phần của lớp cha đó, bao gồm cả access modifier.
Ví dụ:
public class ParentClass { private int privateField; public int publicField;}public class ChildClass extends ParentClass { public void method() { System.out.println(publicField); // có thể truy cập System.out.println(privateField); // không thể truy cập }}
Trong ví dụ trên, lớp ChildClass kế thừa từ lớp ParentClass, do đó nó có thể truy cập vào biến publicField nhưng không thể truy cập vào biến privateField.
Các tính chất của access modifier
Access modifier có một số tính chất quan trọng sau:
Tính kế thừa: Như đã đề cập ở trên, khi một lớp con kế thừa từ một lớp cha, nó sẽ có tất cả các access modifier của lớp cha đó.
Tính đối nghịch: Hai access modifier phổ biến nhất là public và private có tính đối nghịch với nhau. Điều này có nghĩa là một thành phần chỉ có thể được truy cập bởi các phương thức trong cùng một lớp (private) hoặc bởi bất kỳ đâu trong chương trình (public).
Tính bảo mật: Các access modifier có tính bảo mật khác nhau, từ cao đến thấp là private, default, protected và public. Việc sử dụng access modifier phù hợp giúp đảm bảo tính bảo mật của mã.
Tính linh hoạt: Sử dụng các access modifier cho phép ta kiểm soát được phạm vi truy cập của các thành phần trong lớp, giúp mã dễ dàng bảo trì và mở rộng trong tương lai.
Các lỗi thường gặp khi sử dụng access modifier trong Java
Việc sử dụng access modifier không đúng cách có thể dẫn đến các lỗi sau:
Lỗi biên dịch: Nếu ta cố gắng truy cập vào một thành phần có mức truy cập là private từ bên ngoài lớp chứa nó, chương trình sẽ không biên dịch được và báo lỗi.
Lỗi runtime: Nếu ta cố gắng truy cập vào một thành phần có mức truy cập là private từ bên trong lớp chứa nó, chương trình sẽ bị lỗi runtime.
Lỗi thiết kế: Nếu ta sử dụng access modifier không phù hợp, có thể dẫn đến các lỗi thiết kế trong mã, gây khó khăn trong việc bảo trì và mở rộng mã trong tương lai.
Lợi ích của việc sử dụng access modifier
Sử dụng access modifier đúng cách có thể mang lại nhiều lợi ích cho mã Java của bạn, bao gồm:
Tính bảo mật: Sử dụng access modifier phù hợp giúp ngăn chặn việc truy cập trái phép vào các thành phần quan trọng của lớp.
Tính linh hoạt: Sử dụng access modifier giúp mã dễ dàng bảo trì và mở rộng trong tương lai.
Tính tái sử dụng: Khi sử dụng access modifier, ta có thể tái sử dụng các thành phần đã được định nghĩa trong các lớp khác.
Tính kế thừa: Access modifier cho phép ta kế thừa các thành phần từ lớp cha, giúp tiết kiệm thời gian và công sức trong việc viết mã.
Tính đối nghịch: Sử dụng access modifier giúp kiểm soát được phạm vi truy cập của các thành phần, đảm bảo tính toàn vẹn của dữ liệu và giảm thiểu rủi ro bị lỗi trong quá trình phát triển và bảo trì mã.
Kết luận
Trong bài viết này, chúng ta đã tìm hiểu về các loại access modifier trong Java, sự khác biệt giữa public và private, tính bảo mật của access modifier, cách sử dụng và phạm vi truy cập của chúng, các quy tắc khi sử dụng, sự kế thừa và các tính chất của access modifier. Chúng ta cũng đã xem xét các lỗi thường gặp khi sử dụng access modifier và lợi ích của việc sử dụng chúng. Hy vọng bài viết từ TopDev sẽ giúp bạn hiểu rõ hơn về access modifier và áp dụng chúng một cách hiệu quả trong mã của mình.
Bài viết mang tính chất tham khảo
Nội dung được tổng hợp bởi công cụ AI và điều chỉnh bởi Ban Biên tập TopDev
Truy cập ngay các việc làm IT đãi ngộ tốt trên TopDev
Hồ sơ xin việc chính là “điểm chạm” đầu tiên giúp bạn ghi điểm trong quá trình tìm kiếm việc làm. Một hồ sơ đầy đủ, chuyên nghiệp sẽ thể hiện năng lực và sự phù hợp của bạn với vị trí ứng tuyển, giúp bạn nổi bật giữa hàng loạt ứng viên khác và tăng cơ hội được gọi đi phỏng vấn. Vậy hồ sơ xin việc gồm những gì? Viết hồ sơ xin việc như thế nào cho đúng?
Bài viết này TopDev sẽ cung cấp cho bạn các thông tin chi tiết về các thành phần cần thiết trong hồ sơ xin việc, bao gồm CV, thư xin việc, các thành phần bổ sung và những lưu ý cần thiết. Bắt đầu thôi nào!
Hồ sơ xin việc là gì? Tầm quan trọng của hồ sơ xin việc
Hồ sơ xin việc là tài liệu tổng hợp thông tin về bản thân của một ứng viên, được sử dụng để nộp cho các nhà tuyển dụng khi muốn xin việc. Hồ sơ xin việc thường bao gồm các thông tin quan trọng về quá trình học vấn, kinh nghiệm làm việc, kỹ năng, sở thích và các thông tin liên quan khác mà ứng viên muốn nhà tuyển dụng biết.
Hồ sơ xin việc đóng vai trò quan trọng trong quá trình tìm kiếm việc làm. Một hồ sơ xin việc đầy đủ, chuyên nghiệp sẽ giúp bạn:
Tạo ấn tượng tốt với nhà tuyển dụng: Hồ sơ xin việc là ấn tượng đầu tiên của bạn với nhà tuyển dụng. Một hồ sơ xin việc được trình bày đẹp mắt, khoa học và đầy đủ thông tin sẽ giúp bạn tạo ấn tượng tốt và tăng cơ hội được gọi đi phỏng vấn.
Thể hiện năng lực và sự phù hợp của bạn với vị trí ứng tuyển: Hồ sơ xin việc là nơi bạn thể hiện các kỹ năng, kinh nghiệm và kiến thức của mình liên quan đến vị trí ứng tuyển. Một hồ sơ xin việc được chuẩn bị kỹ lưỡng sẽ giúp bạn thuyết phục nhà tuyển dụng rằng bạn là ứng viên phù hợp nhất cho vị trí đó.
Nâng cao cơ hội được tuyển dụng: Một hồ sơ xin việc ấn tượng sẽ giúp bạn nổi bật giữa hàng loạt ứng viên khác và tăng cơ hội được tuyển dụng.
Hồ sơ xin việc gồm những gì? Cập nhật mới nhất 2024
Hồ sơ xin việc bao gồm nhiều loại giấy tờ, thành phần khác nhau, tùy theo yêu cầu công việc và doanh nghiệp mà bạn ứng tuyển. Dưới đây là một bộ hồ sơ xin việc chuẩn nhất, đầy đủ nhất bạn có thể tham khảo.
1. Đơn xin việc
Đơn xin việc là một tài liệu mà ứng viên gửi đến một công ty hoặc tổ chức khi họ quan tâm đến một vị trí công việc cụ thể và muốn ứng tuyển cho nó. Đơn xin việc thường đi kèm với hồ sơ xin việc và thể hiện sự quan tâm và nỗ lực của ứng viên trong việc nắm bắt cơ hội nghề nghiệp.
Bố cục của một đơn xin việc thường khá đơn giản bao gồm Tiêu đề, Mở bài, Thân bài (tóm tắt các kinh nghiệm, kỹ năng của người ứng tuyển), Kết bài (thể hiện mong muốn, nguyện vọng được đồng hành cùng công ty). Đơn xin việc không nên trình bài quá dài dòng mà chỉ nên tập trung vào những ý chính, những điều mà doanh nghiệp đang cần.
CV là tài liệu bắt buộc phải có trong một bộ hồ sơ xin việc. CV là một bản tóm tắt về trình độ học vấn, kinh nghiệm làm việc, kỹ năng và năng lực của bạn. Nó thường được sử dụng để đánh giá khả năng và phù hợp của ứng viên với vị trí công việc cụ thể.
CV thường bao gồm các thông tin sau:
Thông tin cá nhân: Họ tên, ngày tháng năm sinh, địa chỉ, số điện thoại, email.
Mục tiêu nghề nghiệp: Mục tiêu của bạn trong công việc.
Trình độ học vấn: Bằng cấp, trường học, thời gian học.
Kinh nghiệm làm việc: Tóm tắt kinh nghiệm làm việc, bao gồm vị trí công việc, thời gian làm việc, công việc chính và thành tích đạt được.
Kỹ năng: Kỹ năng chuyên môn và kỹ năng mềm của bạn.
Thành tích và giải thưởng: Thành tích và giải thưởng mà bạn đạt được trong quá trình học tập và làm việc.
Sở thích và hoạt động ngoại khóa: Sở thích và hoạt động ngoại khóa của bạn (nếu có).
Sơ yếu lý lịch là văn bản cần có trong một bộ hồ sơ xin việc chuyên nghiệp. Sơ yếu lý lịch cần được đóng dấu xác nhận bởi Ủy ban nhân dân (UBND) cấp xã/phường nơi bạn thường trú hoặc tạm trú. Trong đó sẽ bao gồm những thông tin cá nhân của bạn (tên, tuổi, học vấn, thông tin gia đình,…) giúp nhà tuyển dụng nhanh chóng nắm bắt được những thông tin từ ứng viên.
Giấy khám sức khỏe là một trong những thành phần quan trọng trong hồ sơ xin việc. Nó thể hiện tình trạng sức khỏe của bạn và đảm bảo bạn đủ sức khỏe để thực hiện công việc. Bạn có thể đến các trung tâm y tế uy tín hoặc bệnh viện để khám sức khỏe, sau khi khám sẽ được cung cấp giấy thể hiện đầy đủ thông tin về tình trạng sức khỏe của bạn.
Tuy nhiên, bạn cũng cần lưu ý về thời hạn của giấy khám sức khỏe. Một số công ty sẽ chỉ chấp nhận giấy khám sức khỏe trong thời hạn 6 tháng gần nhất và cũng tùy lĩnh vực khác nhau mà sẽ có những yêu cầu khác nhau cho loại giấy tờ này.
5. Bằng cấp và các chứng chỉ liên quan
Bằng cấp và các chứng chỉ liên quan là những bằng chứng cho thấy bạn có kiến thức và kỹ năng cần thiết để thực hiện công việc. Chúng đóng vai trò quan trọng trong việc đánh giá năng lực của bạn và tăng cơ hội được tuyển dụng.
Bằng cấp:
Bằng đại học, cao đẳng, trung cấp.
Chứng chỉ chuyên môn liên quan đến ngành nghề ứng tuyển.
Chứng chỉ:
Chứng chỉ ngoại ngữ (IELTS, TOEIC, TOEFL…).
Chứng chỉ tin học (ICDL, MOS…).
Chứng chỉ kỹ năng mềm (kỹ năng giao tiếp, kỹ năng lãnh đạo…).
6. Ảnh chân dung (3×4 hoặc 4×6)
Ảnh chân dung sẽ được dán lên sơ yếu lý lịch và bìa hồ sơ, kích thước khoảng 3×4 hoặc 4×6. Ngoài ra, ảnh chân dung cũng có thể được sử dụng để làm thẻ nhân viên, thẻ giữ xe và các mục đích khác sau khi ứng viên trúng tuyển vào vị trí.
Dưới đây là một số lưu ý khi chọn ảnh chân dung cho hồ sơ xin việc:
Chọn ảnh rõ ràng, sắc nét: Ảnh chân dung cần phải rõ ràng, sắc nét và không bị mờ.
Chọn ảnh có nền đơn giản: Nền ảnh nên đơn giản, không có quá nhiều chi tiết để làm phân tán sự chú ý của nhà tuyển dụng.
Chọn ảnh chụp chính diện: Ảnh chân dung nên chụp chính diện để thể hiện rõ khuôn mặt của bạn.
Chọn ảnh chụp gần đây: Ảnh chân dung nên chụp gần đây để thể hiện diện mạo hiện tại của bạn.
Chọn ảnh có trang phục phù hợp: Trang phục trong ảnh chân dung nên phù hợp với môi trường công việc bạn ứng tuyển.
Cười nhẹ: Nụ cười nhẹ nhàng sẽ giúp bạn tạo ấn tượng tốt với nhà tuyển dụng.
7. Sổ hộ khẩu và CCCD đã công chứng
Sổ hộ khẩu, giấy khai sinh, CCCD là những giấy tờ tùy thân quan trọng cần thiết để công chứng trong hồ sơ xin việc. Việc công chứng những giấy tờ này giúp đảm bảo tính chính xác và hợp lệ của thông tin, tạo sự tin tưởng cho nhà tuyển dụng.
Một số lưu ý khi chuẩn bị hồ sơ xin việc
Hồ sơ xin việc là ấn tượng đầu tiên của bạn đối với nhà tuyển dụng, vì vậy việc chuẩn bị hồ sơ kỹ lưỡng và chuyên nghiệp là vô cùng quan trọng. Dưới đây là một số lưu ý khi chuẩn bị hồ sơ xin việc:
Tùy chỉnh hồ sơ cho từng vị trí công việc
Đảm bảo rằng hồ sơ của bạn phản ánh đầy đủ kỹ năng, kinh nghiệm và thành tựu liên quan đến vị trí công việc bạn đang ứng tuyển. Thích ứng nội dung và phong cách viết để phù hợp với yêu cầu cụ thể của từng công ty và vị trí.
Kiểm tra chính tả và ngữ pháp
Đảm bảo rằng mọi phần của hồ sơ của bạn không có lỗi chính tả hoặc ngữ pháp. Sử dụng công cụ kiểm tra chính tả và ngữ pháp để đảm bảo sự chính xác.
Thiết kế đơn giản và chuyên nghiệp
Chọn một mẫu thiết kế đơn giản, dễ đọc và chuyên nghiệp cho hồ sơ của bạn. Sử dụng font chữ dễ đọc và màu sắc hài hòa.
Chú ý đến chi tiết
Đảm bảo rằng tất cả các thông tin cá nhân, thông tin liên lạc và kinh nghiệm làm việc được cập nhật và chính xác. Kiểm tra kỹ lưỡng để đảm bảo rằng không có thông tin thiếu sót hoặc không rõ ràng.
Một số câu hỏi thường gặp về hồ sơ xin việc
1. Mua hồ sơ xin việc ở đâu?
Bạn có thể mua hồ sơ xin việc tại các nhà sách, cửa hàng văn phòng phẩm hoặc tải mẫu miễn phí trên mạng. Nên chọn mẫu hồ sơ đơn giản, dễ đọc và phù hợp với ngành nghề bạn ứng tuyển.
2. Hồ sơ xin việc nào cần công chứng?
Thông thường, bạn cần công chứng bản sao Sổ hộ khẩu, Giấy khai sinh, CCCD. Một số trường hợp có thể yêu cầu thêm công chứng các giấy tờ khác như Giấy xác nhận tình trạng hôn nhân, Sổ khám sức khỏe, các loại bằng cấp tốt nghiệp.
3. Cần chuẩn bị bao nhiêu hồ sơ trước khi đi xin việc?
Nên chuẩn bị từ 2 – 3 bộ hồ sơ để nộp cho các nhà tuyển dụng khác nhau. Có thể in thêm một vài bản sao để dự phòng trong trường hợp cần thiết.
Tóm lại
Hy vọng bài viết này đã giúp bạn hiểu hơn về hồ sơ xin việc gồm những gì cũng như những lưu ý khi chuẩn bị hồ sơ xin việc. Việc chuẩn bị hồ sơ đầy đủ, khoa học và chuyên nghiệp sẽ giúp bạn tăng cơ hội được nhận vào công ty mong muốn. Đừng quên truy cập TopDev để tìm việc IT lương cao, mới nhất với top các công ty IT chất lượng trên thị trường hiện nay bạn nhé!