Trong thế giới lập trình đa dạng, Ruby nổi lên như một ngôn ngữ lập trình độc đáo và đầy tiềm năng. Được ra mắt vào năm 1995 bởi Yukihiro Matsumoto, ngôn ngữ Ruby nhanh chóng thu hút sự chú ý của giới lập trình viên bởi sự linh hoạt, dễ sử dụng và khả năng hướng đối tượng mạnh mẽ.
Bài viết này sẽ giúp bạn hiểu rõ hơn về ngôn ngữ lập trình Ruby, từ khái niệm, các đặc điểm nổi bật, cho đến những ứng dụng thực tiễn và lý do tại sao Ruby là ngôn ngữ bạn nên học. Hãy cùng khám phá và tìm hiểu chi tiết về ngôn ngữ lập trình đầy tiềm năng này.
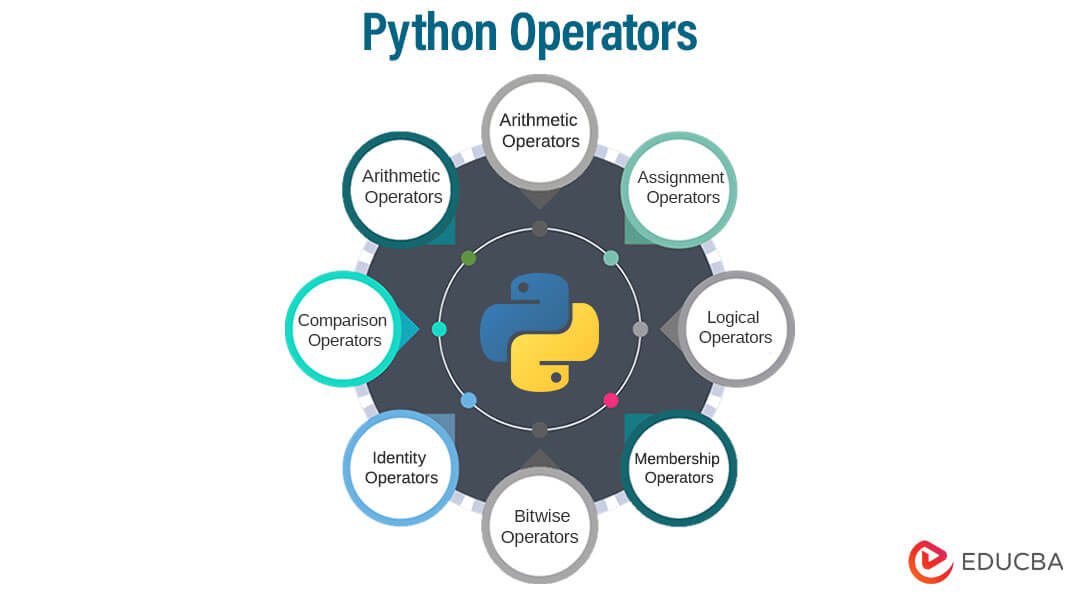
Ngôn ngữ lập trình Ruby là gì?
Ruby là một ngôn ngữ lập trình hướng đối tượng, linh hoạt và dễ đọc, được phát triển bởi Yukihiro Matsumoto vào giữa những năm 1995. Mục tiêu của Ruby là mang lại sự đơn giản và hiệu quả, giúp lập trình viên có thể viết mã một cách tự nhiên và dễ hiểu. Với cú pháp rõ ràng và gần gũi với ngôn ngữ tự nhiên, Ruby giúp giảm bớt gánh nặng lập trình và tăng cường khả năng sáng tạo của người viết mã.

Đặc biệt, Ruby nổi tiếng với framework Ruby on Rails, một công cụ mạnh mẽ giúp phát triển ứng dụng web nhanh chóng và hiệu quả. Sự kết hợp giữa tính đơn giản, mạnh mẽ và cộng đồng hỗ trợ nhiệt tình đã làm cho Ruby trở thành một lựa chọn phổ biến trong giới lập trình viên.
Ứng dụng của ngôn ngữ Ruby
Ngôn ngữ Ruby được ứng dụng rộng rãi trong nhiều lĩnh vực nhờ tính linh hoạt, dễ sử dụng và khả năng mở rộng mạnh mẽ. Dưới đây là một số ứng dụng tiêu biểu của Ruby:
1. Phát triển Web với Ruby on Rails
Ruby on Rails (RoR): Đây là framework web nổi tiếng nhất của Ruby, giúp các nhà phát triển xây dựng các ứng dụng web một cách nhanh chóng và hiệu quả. Ruby on Rails cung cấp các công cụ mạnh mẽ và thư viện phong phú, giúp giảm bớt công việc lặp đi lặp lại và tập trung vào logic kinh doanh.
Các dự án nổi bật: Nhiều ứng dụng và website lớn đã được xây dựng bằng Ruby on Rails, bao gồm GitHub, Airbnb, Shopify, và Basecamp. Những dự án này minh chứng cho khả năng mở rộng và tính ổn định của Ruby on Rails.
2. Xử lý dữ liệu và scripting
Ruby được sử dụng rộng rãi trong việc viết các script để tự động hóa các tác vụ lặp lại, xử lý dữ liệu và tạo báo cáo. Khả năng dễ đọc và viết của Ruby giúp việc xử lý dữ liệu trở nên dễ dàng hơn.
Data Processing: Ruby có thể được sử dụng để phân tích và xử lý dữ liệu, đặc biệt là với các thư viện mạnh mẽ như Nokogiri để xử lý XML và HTML, hay CSV để xử lý các tập tin CSV.
3. Automation và DevOps
Ruby được sử dụng trong các công cụ tự động hóa và quản lý cấu hình như Chef và Puppet. Những công cụ này giúp quản lý các hệ thống và cấu hình máy chủ một cách tự động, giảm thiểu sai sót và tiết kiệm thời gian.
Chef và Puppet: Đây là hai công cụ DevOps nổi tiếng được viết bằng Ruby, giúp quản trị viên hệ thống tự động hóa việc quản lý cấu hình, triển khai ứng dụng và giám sát hệ thống.
4. Phát triển ứng dụng di động
RubyMotion: Đây là một công cụ cho phép các nhà phát triển viết ứng dụng iOS và Android bằng Ruby. RubyMotion cung cấp một môi trường phát triển tích hợp, cho phép viết mã Ruby và biên dịch thành các ứng dụng di động gốc.
Nhờ vào tính linh hoạt và dễ sử dụng, Ruby đã trở thành một công cụ mạnh mẽ trong nhiều lĩnh vực khác nhau, từ phát triển web, xử lý dữ liệu, tự động hóa đến phát triển ứng dụng di động. Sự phổ biến của Ruby và Ruby on Rails minh chứng cho khả năng và tiềm năng của ngôn ngữ này trong ngành công nghệ.
Ưu và nhược điểm của ngôn ngữ lập trình Ruby
Ruby là ngôn ngữ lập trình tuyệt vời với nhiều ưu điểm nổi bật. Tuy nhiên, cũng cần lưu ý đến một số nhược điểm của Ruby trước khi sử dụng. Hãy cùng TopDev điểm qua một số ưu nhược điểm nổi bật của Ruby dưới đây:
1. Ưu điểm của ngôn ngữ Ruby
- Cú pháp dễ đọc và dễ viết: Ruby có cú pháp gần gũi với ngôn ngữ tự nhiên, giúp lập trình viên dễ dàng hiểu và viết mã. Điều này làm giảm bớt thời gian học tập và tăng năng suất làm việc.
- Tính hướng đối tượng mạnh mẽ: Ruby là ngôn ngữ lập trình hướng đối tượng, với mọi thứ đều là đối tượng. Điều này giúp cấu trúc mã trở nên rõ ràng, dễ bảo trì và mở rộng.
- Ruby on Rails: Framework Ruby on Rails là một trong những lý do chính khiến Ruby trở nên phổ biến. Rails giúp việc phát triển các ứng dụng web trở nên nhanh chóng và hiệu quả, với nhiều công cụ và thư viện hỗ trợ sẵn có.
- Cộng đồng mạnh mẽ: Ruby có một cộng đồng lập trình viên rất tích cực và hỗ trợ, với nhiều tài liệu, thư viện (gems), và plugin được phát triển liên tục. Điều này tạo điều kiện thuận lợi cho việc học tập và giải quyết các vấn đề kỹ thuật.
- Thư viện phong phú: Ruby có nhiều thư viện và gem hỗ trợ cho hầu hết các nhu cầu lập trình, từ web development, automation, đến data processing.
- Khả năng mở rộng và tùy biến: Ruby cho phép lập trình viên mở rộng và tùy biến các thành phần của ngôn ngữ, từ các lớp cơ bản đến các thư viện và framework. Điều này giúp đáp ứng tốt các yêu cầu đặc thù của dự án.

2. Nhược điểm của ngôn ngữ Ruby
- Hiệu suất: So với một số ngôn ngữ lập trình khác như C++ hay Java, Ruby có hiệu suất thấp hơn. Điều này có thể là một vấn đề khi xử lý các tác vụ yêu cầu tính toán cao hoặc xử lý nhiều dữ liệu lớn.
- Tiêu thụ tài nguyên: Ruby tiêu thụ nhiều tài nguyên hệ thống hơn, đặc biệt là bộ nhớ. Điều này có thể gây ra vấn đề khi triển khai ứng dụng trên các hệ thống có tài nguyên hạn chế.
- Độ phổ biến và nhu cầu thị trường: So với các ngôn ngữ phổ biến khác như JavaScript, Python, hay Java, Ruby có ít cơ hội việc làm hơn, đặc biệt là ở một số thị trường nhất định. Điều này có thể làm giảm khả năng tìm kiếm việc làm cho lập trình viên Ruby.
- Khó khăn trong việc bảo trì mã nguồn: Do tính linh hoạt cao, mã Ruby có thể trở nên khó bảo trì nếu không được viết cẩn thận. Các tính năng như monkey patching có thể dẫn đến các lỗi khó phát hiện và sửa chữa.
Tham khảo tuyển dụng Ruby on rails lương cao trên TopDev
So sánh Ruby với Python: Nên chọn ngôn ngữ lập trình nào?
Ruby và Python đều là những ngôn ngữ lập trình hướng đối tượng, dễ học và phổ biến, được sử dụng rộng rãi trong nhiều lĩnh vực như phát triển web, phân tích dữ liệu, lập trình khoa học và tự động hóa. Tuy nhiên, hai ngôn ngữ này cũng có những điểm khác biệt riêng về cú pháp, hiệu suất, cộng đồng và ứng dụng, dẫn đến những lựa chọn phù hợp cho từng đối tượng người dùng khác nhau.
Dưới đây là bảng so sánh chi tiết giữa Ruby và Python:
| Ruby | Python | |
| Cú pháp | Linh hoạt, gần gũi với ngôn ngữ tự nhiên | Rõ ràng, nhất quán, dễ đọc và dễ bảo trì |
| Hiệu suất | Chậm hơn so với nhiều ngôn ngữ khác, đặc biệt là trong tác vụ yêu cầu cao | Tốt hơn Ruby trong nhiều trường hợp, có thể tối ưu hóa với thư viện như NumPy |
| Cộng đồng | Nhiệt tình, đặc biệt xung quanh Ruby on Rails | Rất lớn và đa dạng, nhiều tài liệu học tập và tài nguyên miễn phí |
| Ứng dụng thực tiễn | Phát triển web (Ruby on Rails), Automation và DevOps (Chef, Puppet) | Khoa học dữ liệu, học máy (Pandas, TensorFlow, Scikit-learn), phát triển web (Django, Flask), Automation và scripting |
| Khả năng mở rộng và bảo trì | Linh hoạt, nhưng có thể khó bảo trì nếu không được quản lý tốt | Nhất quán và rõ ràng, dễ bảo trì và mở rộng |
| Tiêu thụ tài nguyên | Tiêu thụ nhiều tài nguyên hệ thống, đặc biệt là bộ nhớ | Sử dụng ít tài nguyên hơn so với Ruby, nhưng không phải ngôn ngữ tiết kiệm nhất |
| Framework phổ biến | Ruby on Rails | Django, Flask |
| Thư viện phổ biến | Nhiều gem hỗ trợ phát triển web và DevOps | Thư viện mạnh mẽ cho khoa học dữ liệu, học máy, xử lý dữ liệu |
| Cơ hội việc làm | Ít cơ hội hơn so với Python, nhưng vẫn phổ biến trong phát triển web | Rất nhiều cơ hội trong nhiều lĩnh vực khác nhau |
Tiềm năng phát triển và mức lương của lập trình viên Ruby
Nhu cầu tuyển dụng lập trình viên Ruby tại Việt Nam đang tăng cao do sự phát triển mạnh mẽ của ngành công nghệ thông tin, đặc biệt là lĩnh vực phát triển web và ứng dụng di động. Ruby on Rails, framework web phổ biến nhất được xây dựng dựa trên Ruby, ngày càng được nhiều doanh nghiệp lựa chọn cho các dự án của mình.
Bên cạnh đó, Ruby có cộng đồng lập trình viên lớn và hoạt động tích cực tại Việt Nam, luôn sẵn sàng chia sẻ kiến thức và hỗ trợ lẫn nhau. Điều này giúp các lập trình viên Ruby dễ dàng học hỏi, nâng cao kỹ năng và tìm kiếm cơ hội việc làm.
Về mức lương, lập trình viên Ruby có mức lương cao so với mặt bằng chung của ngành lập trình. Theo BÁO CÁO THỊ TRƯỜNG IT VIỆT NAM 2023 của TopDev, mức lương của Ruby Developer cấp bậc Junior (1 – 2 năm) và Middle Level (3-4 năm) lần lượt là 888 USD và 1.590 USD.
Kết luận
Vậy là TopDev đã tổng hợp đầy đủ các thông tin chi tiết về ngôn ngữ Ruby. Hy vọng những chia sẻ này sẽ giúp bạn đưa ra lựa chọn phù hợp cho con đường lập trình của mình. Nếu có hứng thú về ngành công nghệ thông tin, hãy đón chờ thêm nhiều bài viết hấp dẫn khác từ TopDev nhé!
Xem thêm: