Trong thời đại công nghệ hiện nay, việc phát triển các ứng dụng web động và dịch vụ web là một nhu cầu thiết yếu của các doanh nghiệp và lập trình viên. ASP.NET, một framework mã nguồn mở được phát triển bởi Microsoft, đã nhanh chóng trở thành công cụ không thể thiếu cho việc này. Được thiết kế để đơn giản hóa quá trình phát triển ứng dụng web, ASP.NET cung cấp nhiều tính năng mạnh mẽ và linh hoạt, giúp lập trình viên dễ dàng tạo ra các ứng dụng chất lượng cao, bảo mật và hiệu quả.
Cùng TopDev tìm hiểu ASP.NET là gì? và các lợi ích tuyệt vời của ASP.NET ngay trong bài viết dưới đây!
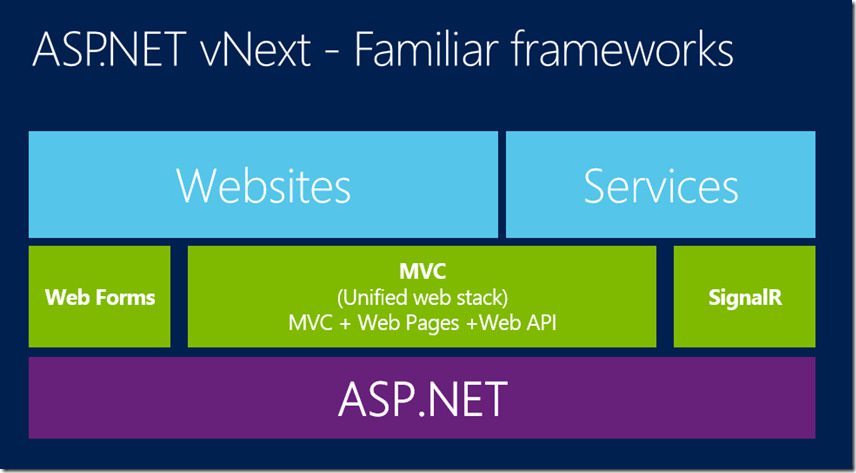
ASP.NET là gì? Phân tích thành phần và phương thức hoạt động chi tiết
ASP.NET là gì?
ASP.NET là một framework mã nguồn mở phía server được phát triển bởi Microsoft, nhằm mục đích xây dựng các ứng dụng web động và dịch vụ web. Nó cho phép các lập trình viên tạo ra các trang web và ứng dụng sử dụng HTML5, CSS, và JavaScript. Được giới thiệu lần đầu tiên vào đầu thế kỷ 21, ASP.NET đã nhanh chóng trở thành một công cụ quan trọng trong việc phát triển ứng dụng web, đặc biệt là trong môi trường doanh nghiệp.
ASP.NET được cấu thành từ ba thành phần chính, mỗi thành phần đảm nhận một vai trò cụ thể trong việc phát triển ứng dụng:
Thành phần của ASP.NET
Ngôn ngữ lập trình
C#: Ngôn ngữ lập trình hướng đối tượng, phổ biến nhất trong .NET framework, được sử dụng rộng rãi để phát triển các ứng dụng web và dịch vụ web.
VB.NET: Ngôn ngữ lập trình lâu đời của Microsoft, cũng được sử dụng để phát triển các ứng dụng web.
F#: Ngôn ngữ lập trình chức năng, hỗ trợ lập trình hướng đối tượng và hướng chức năng.
Thư viện
Thư viện .NET (CoreFX): Chứa các lớp và phương thức cần thiết để thực hiện các chức năng cơ bản như quản lý tệp tin, xử lý ngoại lệ, giao tiếp mạng và nhiều chức năng khác.
Common Language Infrastructure (CLI)
Common Language Runtime (CLR): Nền tảng thực thi các chương trình Dot Net, giúp quản lý bộ nhớ, bảo mật và xử lý ngoại lệ.
Common Intermediate Language (CIL): Mã trung gian được biên dịch từ mã nguồn, sau đó được CLR thực thi.
ASP.NET hỗ trợ nhiều mô hình phát triển ứng dụng khác nhau, tùy thuộc vào yêu cầu cụ thể của từng dự án:
Web Forms: Cho phép xây dựng các ứng dụng web với giao diện người dùng phong phú, sử dụng kéo và thả để thiết kế trang web.
ASP.NET MVC: Mô hình phát triển theo kiến trúc MVC (Model-View-Controller), tách biệt giữa logic ứng dụng, giao diện người dùng và luồng dữ liệu, giúp dễ dàng quản lý và mở rộng ứng dụng.
ASP.NET Web Pages: Đơn giản hóa việc phát triển ứng dụng web bằng cách sử dụng Razor syntax, cho phép viết mã HTML và C# trong cùng một trang.
ASP.NET Web API: Dùng để xây dựng các dịch vụ web và API RESTful, cho phép các ứng dụng khác tương tác thông qua HTTP.
ASP.NET Core: Phiên bản mới nhất và linh hoạt nhất của ASP.NET, hỗ trợ đa nền tảng và cải thiện hiệu suất, cho phép chạy trên Windows, macOS và Linux.
Đơn giản, bảo mật và hỗ trợ tốt: ASP.NET cung cấp quản lý bộ nhớ tự động, bảo mật tích hợp và xử lý ngoại lệ hiệu quả, giúp bảo vệ ứng dụng khỏi các mối đe dọa bảo mật. Nó được xây dựng trên môi trường Windows server quen thuộc, giúp tiết kiệm thời gian thiết lập và cấu hình cho các lập trình viên.
Tốc độ và hiệu suất cao: Các ứng dụng ASP.NET được biên dịch, giúp mã nguồn chạy nhanh và hiệu quả hơn so với các mã nguồn được diễn dịch như PHP và JavaScript. Quá trình biên dịch tạo ra mã đối tượng, sau đó được thực thi nhanh chóng bởi nền tảng .NET, giúp tăng tốc độ và khả năng mở rộng của ứng dụng.
Tiết kiệm chi phí: ASP.NET giúp giảm chi phí phát triển và triển khai nhờ vào việc sử dụng phần mềm miễn phí và khả năng lưu trữ trên nhiều nền tảng như Linux, macOS và Windows. Các công cụ phát triển như Visual Studio Code miễn phí cho tất cả người dùng, kể cả các công ty lớn, giúp tiết kiệm chi phí phần mềm.
Cộng đồng lớn và tài nguyên hỗ trợ phong phú: ASP.NET có một cộng đồng lập trình viên .NET lớn và nhiều tài nguyên học tập, bao gồm các khóa học, tài liệu và diễn đàn hỗ trợ. Microsoft đầu tư mạnh mẽ vào việc phát triển và duy trì ASP.NET, đảm bảo rằng nền tảng này luôn cập nhật với các tính năng và công nghệ mới nhất.
Quản lý trạng thái và bộ nhớ đệm (Caching): ASP.NET cho phép quản lý trạng thái và bộ nhớ đệm hiệu quả, giúp cải thiện hiệu suất ứng dụng. Các trang web và ứng dụng thường được truy cập có thể được lưu vào bộ nhớ đệm, giảm thiểu thời gian phản hồi và cung cấp trải nghiệm người dùng tốt hơn.
Khả năng mở rộng và tích hợp: ASP.NET dễ dàng tích hợp với các công nghệ và dịch vụ khác của Microsoft, cũng như các công cụ và nền tảng của bên thứ ba, giúp xây dựng các ứng dụng mạnh mẽ và đa chức năng.
.NET đã được phát hành và ứng dụng từ nhiều năm trước. Vào năm 2016, Microsoft giới thiệu một phiên bản mới hơn gọi là .NET Core, và ngược lại gọi phiên bản ban đầu là .NET Full Framework. Ban đầu, bạn có thể sử dụng một trong hai .NET Full Framework hoặc .NET Core. Tuy nhiên, đến hiện tại, .NET Full Framework không còn được phát triển và .NET Core hiện nay chỉ được gọi là .NET (với phiên bản .NET 5 trở đi).
ASP.NET là một framework phát triển web chạy trên nền tảng .NET. Phiên bản đầu tiên của ASP.NET hiện được biết đến là ASP.NET WebForms, thuộc phần của ASP.NET Full Framework và không còn được phát triển nữa. Sau WebForms là ASP.NET MVC, một phiên bản giống Ruby on Rails nhưng về mặt kỹ thuật nó được xây dựng trên nền tảng ASP.NET thuộc Full Framework. Khi .NET Core được phát hành, một phiên bản cập nhật của ASP.NET MVC cũng được phát hành cùng với nó và được gọi là ASP.NET Core.
Tóm lại, ta có thể phân biệt đơn giản .NET là nền tảng và ASP.NET Core là framework phát triển web chạy trên nền tảng đó.
ASP.NET là một framework mạnh mẽ và linh hoạt, lý tưởng cho việc phát triển các ứng dụng web và dịch vụ web. Với các tính năng vượt trội về hiệu suất, bảo mật và khả năng mở rộng, ASP.NET giúp các doanh nghiệp và lập trình viên tạo ra các ứng dụng web chất lượng cao, đáp ứng nhu cầu của người dùng. Hãy cân nhắc sử dụng ASP.NET cho dự án tiếp theo của bạn để tận dụng những lợi ích mà nền tảng này mang lại.
Nguồn tham khảo: www.shareitsolutions.com/blog/what-is-asp-net/
.NET là gì? .NET là nền tảng phát triển ứng dụng toàn diện của Microsoft, đã được sử dụng trong nhiều thập kỷ để xây dựng các ứng dụng web, desktop và di động, từ các startup đến các doanh nghiệp lớn. .NET không chỉ đóng vai trò trung tâm trong ngành phát triển phần mềm mà còn được ưa chuộng rộng rãi trong cộng đồng lập trình viên. Điều này thể hiện qua số lượng dự án mã nguồn mở và sự hiện diện của C# trong top năm ngôn ngữ lập trình phổ biến nhất. Với phiên bản mới nhất, .NET 5, Microsoft đã cách mạng hóa ngành công nghiệp bằng việc tiên phong khái niệm phát triển phần mềm toàn cầu.
Cùng TopDev tìm hiểu chi tiết về .NET trong bài viết dưới đây!
.NET là gì? Nền tảng phát triển ứng dụng toàn diện của Microsoft
.NET là gì?
.NET hay còn được gọi là dotnet là một nền tảng phát triển mã nguồn mở và đa nền tảng, được thiết kế để xây dựng nhiều loại ứng dụng khác nhau. Được phát triển bởi Microsoft, .NET hỗ trợ nhiều ngôn ngữ lập trình và thư viện để xây dựng các ứng dụng web, di động, desktop, IoT và nhiều hơn nữa.
Các ngôn ngữ lập trình hỗ trợ bởi .NET
C# (C sharp): Ngôn ngữ lập trình hướng đối tượng hiện đại, thuộc họ ngôn ngữ C. Cú pháp của nó quen thuộc với các lập trình viên C, C++, Java và JavaScript.
F# (F sharp): Ngôn ngữ lập trình chức năng, cũng hỗ trợ lập trình hướng đối tượng.
Visual Basic: Ngôn ngữ lập trình lịch sử của Microsoft, nay đã trở thành ngôn ngữ lập trình hướng đối tượng hoàn chỉnh trong .NET.
Ngoài các ngôn ngữ trên, .NET còn hỗ trợ nhiều ngôn ngữ khác thông qua Common Language Infrastructure (CLI), đảm bảo khả năng tương tác giữa các ngôn ngữ trên nền tảng này.
Thị trường .NET tuyển dụng như thế nào? Xem ngay việc làm .NET tại TopDev
Kiến trúc và thành phần của .NET
.NET cho phép bạn xây dựng nhiều loại ứng dụng khác nhau nhờ vào kiến trúc tối ưu và mô đun của nó. Các thành phần chính bao gồm:
CoreCLR: Đây là runtime của .NET, chịu trách nhiệm thực thi các chương trình CLI và bao gồm một trình biên dịch just-in-time.
CoreFX: API của nền tảng, cung cấp các thư viện chuẩn để thực hiện các chức năng thông dụng như quản lý hệ thống tệp, xử lý ngoại lệ, giao tiếp mạng, đa luồng, và nhiều hơn nữa.
Mô hình ứng dụng .NET
Ngoài các thành phần cốt lõi trên, .NET cung cấp các framework hỗ trợ phát triển các loại ứng dụng khác nhau:
ASP.NET: Framework cho phép xây dựng các ứng dụng web và web API.
Windows Presentation Foundation (WPF): Giao diện người dùng đồ họa cho các ứng dụng desktop Windows.
Xamarin: Framework để xây dựng các ứng dụng di động, TV và desktop đa nền tảng.
Blazor: Framework để xây dựng ứng dụng web client bằng C#, cũng cho phép tạo các ứng dụng web client bằng mã WebAssembly.
ML.NET: Framework học máy, giúp tích hợp các mô hình học máy vào ứng dụng .NET của bạn.
Ngoài ra, .NET còn hỗ trợ nhiều tác vụ lập trình thông dụng khác như quản lý tệp, giao tiếp mạng, bảo mật, truy cập cơ sở dữ liệu và nhiều hơn nữa. Các thư viện cụ thể có thể được tìm thấy trên kho lưu trữ NuGet, giúp bạn tạo, chia sẻ và sử dụng các thư viện .NET cho hầu hết mọi mục đích.
.NET không chỉ hỗ trợ nhiều ngôn ngữ lập trình mà còn khuyến khích các best practices như Dependency Injection, giúp giảm sự phụ thuộc giữa các thành phần của ứng dụng và dễ dàng kiểm thử. .NET cũng hỗ trợ kiểm thử đơn vị và tích hợp thông qua xUnit.
.NET được ra mắt vào năm 2002 với mục tiêu tạo ra một nền tảng phát triển toàn cầu cho mọi ngôn ngữ lập trình. Ban đầu, .NET chủ yếu hướng đến Windows, nhưng sau đó đã mở rộng ra nhiều nền tảng khác như Linux, hệ thống nhúng, thiết bị di động và trình duyệt.
.NET Framework: Phiên bản ban đầu của .NET, chỉ chạy trên Windows và hiện đang trong giai đoạn kết thúc vòng đời sau khi phát hành .NET 5.
Mono: Dự án mang .NET đến các máy Linux, nhưng không luôn tương thích hoàn toàn với .NET Framework.
.NET Core: Phiên bản viết lại hoàn toàn của .NET Framework với mục tiêu đa nền tảng, hỗ trợ Windows, Linux và Mac.
.NET Standard: Tiêu chuẩn hóa các API của .NET để tạo ra các thư viện đa nền tảng.
Vì vậy, chúng tôi biết mình muốn làm việc với C# và chúng tôi biết mình cần .NET. Làm cách nào để có được nền tảng .NET trên máy tính của chúng tôi?
Cài đặt .NET – cách 1
Tải xuống Visual Studio – một môi trường phát triển tích hợp (IDE) dành cho các ứng dụng .NET. Nó hoạt động như một ứng dụng, giống như trình duyệt web bạn đang sử dụng để xem bài viết này. Visual Studio đi kèm với nền tảng .NET, một trình chỉnh sửa mã, và các công cụ bổ sung để giúp bạn viết mã.
Tải xuống .NET SDK (bộ công cụ phát triển phần mềm). SDK cũng đi kèm với nền tảng .NET, nhưng không có công cụ chỉnh sửa mã. Thay vì là một ứng dụng trên máy tính của bạn, SDK được truy cập thông qua giao diện dòng lệnh (CLI) — để sử dụng SDK, bạn sẽ mở terminal trên máy tính của mình và gõ lệnh thay vì nhấp vào các nút. Trong ví dụ này, bạn có thể thấy một terminal trong đó người dùng đã chạy các lệnh như dotnet new và dotnet run để xây dựng một ứng dụng mới, sau đó chạy nó (ứng dụng chỉ in ra “Hello World!“).
Hiệu Suất Cao: .NET có hiệu suất cao nhờ vào khả năng biên dịch Just-In-Time (JIT) và tối ưu hóa mã nguồn.
Đa Nền Tảng: .NET Core và .NET 5+ hỗ trợ chạy trên nhiều hệ điều hành như Windows, macOS, và Linux, giúp phát triển ứng dụng đa nền tảng dễ dàng hơn.
Hỗ Trợ Nhiều Ngôn Ngữ Lập Trình: .NET hỗ trợ nhiều ngôn ngữ lập trình như C#, F#, Visual Basic, giúp lập trình viên lựa chọn ngôn ngữ phù hợp với nhu cầu của mình.
Bảo Mật Tốt: .NET cung cấp nhiều tính năng bảo mật như xác thực và ủy quyền, mã hóa dữ liệu, và bảo vệ chống tấn công XSS, CSRF.
Thư Viện Phong Phú: .NET có một hệ thống thư viện phong phú (CoreFX) hỗ trợ nhiều chức năng từ quản lý tệp, giao tiếp mạng, đến xử lý dữ liệu.
Phát Triển Nhanh Chóng với Visual Studio: Visual Studio là môi trường phát triển tích hợp mạnh mẽ, hỗ trợ tốt cho lập trình .NET, giúp tăng tốc quá trình phát triển và gỡ lỗi.
Cộng Đồng Lớn và Tài Nguyên Hỗ Trợ: .NET có một cộng đồng lập trình viên lớn và nhiều tài nguyên học tập, giúp dễ dàng tìm kiếm hỗ trợ và giải pháp cho các vấn đề kỹ thuật.
Hỗ Trợ Kiểm Thử: .NET hỗ trợ tốt cho việc kiểm thử đơn vị và kiểm thử tích hợp với các công cụ như xUnit, MSTest, và NUnit.
Nhược Điểm của .NET
Khó Khăn Trong Việc Học: .NET có thể khó khăn đối với người mới bắt đầu do sự phức tạp của hệ thống và yêu cầu kiến thức về nhiều ngôn ngữ và công nghệ khác nhau.
Chi Phí Cao: Một số công cụ và dịch vụ liên quan đến .NET, đặc biệt là các phiên bản cao cấp của Visual Studio và Azure, có chi phí cao.
Kích Thước Lớn: Ứng dụng .NET thường có kích thước lớn do cần bao gồm nhiều thư viện và phụ thuộc.
Tốc Độ Cập Nhật Nhanh: .NET thường xuyên cập nhật phiên bản mới, điều này đòi hỏi lập trình viên phải luôn cập nhật kiến thức và có thể gặp khó khăn trong việc duy trì tính tương thích của các ứng dụng hiện có.
Hiệu Suất Đối Với Ứng Dụng Nhẹ: Đối với một số ứng dụng nhẹ và đơn giản, việc sử dụng .NET có thể dẫn đến hiệu suất không tối ưu so với các công nghệ khác như Node.js hoặc Python.
Phụ Thuộc vào Microsoft: .NET là sản phẩm của Microsoft, do đó có sự phụ thuộc vào các quyết định và chiến lược của công ty này.
Tạo ứng dụng di động chỉ trong 1 nốt nhạc với TERAAPP.NET
.NET đã và đang là nền tảng phát triển ứng dụng toàn diện, đáp ứng mọi nhu cầu từ web, di động, desktop đến IoT. Với .NET 5, Microsoft tiếp tục củng cố vị thế của mình trong ngành phát triển phần mềm, mang lại cho các nhà phát triển một công cụ mạnh mẽ và linh hoạt để xây dựng các ứng dụng hiện đại.
Xem việc làm .NET fresher update mới nhất tại TopDev
Trong thế giới lập trình đa dạng, Ruby nổi lên như một ngôn ngữ lập trình độc đáo và đầy tiềm năng. Được ra mắt vào năm 1995 bởi Yukihiro Matsumoto, ngôn ngữ Ruby nhanh chóng thu hút sự chú ý của giới lập trình viên bởi sự linh hoạt, dễ sử dụng và khả năng hướng đối tượng mạnh mẽ.
Bài viết này sẽ giúp bạn hiểu rõ hơn về ngôn ngữ lập trình Ruby, từ khái niệm, các đặc điểm nổi bật, cho đến những ứng dụng thực tiễn và lý do tại sao Ruby là ngôn ngữ bạn nên học. Hãy cùng khám phá và tìm hiểu chi tiết về ngôn ngữ lập trình đầy tiềm năng này.
Ngôn ngữ lập trình Ruby là gì?
Ruby là một ngôn ngữ lập trình hướng đối tượng, linh hoạt và dễ đọc, được phát triển bởi Yukihiro Matsumoto vào giữa những năm 1995. Mục tiêu của Ruby là mang lại sự đơn giản và hiệu quả, giúp lập trình viên có thể viết mã một cách tự nhiên và dễ hiểu. Với cú pháp rõ ràng và gần gũi với ngôn ngữ tự nhiên, Ruby giúp giảm bớt gánh nặng lập trình và tăng cường khả năng sáng tạo của người viết mã.
Đặc biệt, Ruby nổi tiếng với framework Ruby on Rails, một công cụ mạnh mẽ giúp phát triển ứng dụng web nhanh chóng và hiệu quả. Sự kết hợp giữa tính đơn giản, mạnh mẽ và cộng đồng hỗ trợ nhiệt tình đã làm cho Ruby trở thành một lựa chọn phổ biến trong giới lập trình viên.
Ứng dụng của ngôn ngữ Ruby
Ngôn ngữ Ruby được ứng dụng rộng rãi trong nhiều lĩnh vực nhờ tính linh hoạt, dễ sử dụng và khả năng mở rộng mạnh mẽ. Dưới đây là một số ứng dụng tiêu biểu của Ruby:
1. Phát triển Web với Ruby on Rails
Ruby on Rails (RoR): Đây là framework web nổi tiếng nhất của Ruby, giúp các nhà phát triển xây dựng các ứng dụng web một cách nhanh chóng và hiệu quả. Ruby on Rails cung cấp các công cụ mạnh mẽ và thư viện phong phú, giúp giảm bớt công việc lặp đi lặp lại và tập trung vào logic kinh doanh.
Các dự án nổi bật: Nhiều ứng dụng và website lớn đã được xây dựng bằng Ruby on Rails, bao gồm GitHub, Airbnb, Shopify, và Basecamp. Những dự án này minh chứng cho khả năng mở rộng và tính ổn định của Ruby on Rails.
2. Xử lý dữ liệu và scripting
Ruby được sử dụng rộng rãi trong việc viết các script để tự động hóa các tác vụ lặp lại, xử lý dữ liệu và tạo báo cáo. Khả năng dễ đọc và viết của Ruby giúp việc xử lý dữ liệu trở nên dễ dàng hơn.
Data Processing: Ruby có thể được sử dụng để phân tích và xử lý dữ liệu, đặc biệt là với các thư viện mạnh mẽ như Nokogiri để xử lý XML và HTML, hay CSV để xử lý các tập tin CSV.
3. Automation và DevOps
Ruby được sử dụng trong các công cụ tự động hóa và quản lý cấu hình như Chef và Puppet. Những công cụ này giúp quản lý các hệ thống và cấu hình máy chủ một cách tự động, giảm thiểu sai sót và tiết kiệm thời gian.
Chef và Puppet: Đây là hai công cụ DevOps nổi tiếng được viết bằng Ruby, giúp quản trị viên hệ thống tự động hóa việc quản lý cấu hình, triển khai ứng dụng và giám sát hệ thống.
4. Phát triển ứng dụng di động
RubyMotion: Đây là một công cụ cho phép các nhà phát triển viết ứng dụng iOS và Android bằng Ruby. RubyMotion cung cấp một môi trường phát triển tích hợp, cho phép viết mã Ruby và biên dịch thành các ứng dụng di động gốc.
Nhờ vào tính linh hoạt và dễ sử dụng, Ruby đã trở thành một công cụ mạnh mẽ trong nhiều lĩnh vực khác nhau, từ phát triển web, xử lý dữ liệu, tự động hóa đến phát triển ứng dụng di động. Sự phổ biến của Ruby và Ruby on Rails minh chứng cho khả năng và tiềm năng của ngôn ngữ này trong ngành công nghệ.
Ruby là ngôn ngữ lập trình tuyệt vời với nhiều ưu điểm nổi bật. Tuy nhiên, cũng cần lưu ý đến một số nhược điểm của Ruby trước khi sử dụng. Hãy cùng TopDev điểm qua một số ưu nhược điểm nổi bật của Ruby dưới đây:
1. Ưu điểm của ngôn ngữ Ruby
Cú pháp dễ đọc và dễ viết: Ruby có cú pháp gần gũi với ngôn ngữ tự nhiên, giúp lập trình viên dễ dàng hiểu và viết mã. Điều này làm giảm bớt thời gian học tập và tăng năng suất làm việc.
Tính hướng đối tượng mạnh mẽ: Ruby là ngôn ngữ lập trình hướng đối tượng, với mọi thứ đều là đối tượng. Điều này giúp cấu trúc mã trở nên rõ ràng, dễ bảo trì và mở rộng.
Ruby on Rails: Framework Ruby on Rails là một trong những lý do chính khiến Ruby trở nên phổ biến. Rails giúp việc phát triển các ứng dụng web trở nên nhanh chóng và hiệu quả, với nhiều công cụ và thư viện hỗ trợ sẵn có.
Cộng đồng mạnh mẽ: Ruby có một cộng đồng lập trình viên rất tích cực và hỗ trợ, với nhiều tài liệu, thư viện (gems), và plugin được phát triển liên tục. Điều này tạo điều kiện thuận lợi cho việc học tập và giải quyết các vấn đề kỹ thuật.
Thư viện phong phú: Ruby có nhiều thư viện và gem hỗ trợ cho hầu hết các nhu cầu lập trình, từ web development, automation, đến data processing.
Khả năng mở rộng và tùy biến: Ruby cho phép lập trình viên mở rộng và tùy biến các thành phần của ngôn ngữ, từ các lớp cơ bản đến các thư viện và framework. Điều này giúp đáp ứng tốt các yêu cầu đặc thù của dự án.
2. Nhược điểm của ngôn ngữ Ruby
Hiệu suất: So với một số ngôn ngữ lập trình khác như C++ hay Java, Ruby có hiệu suất thấp hơn. Điều này có thể là một vấn đề khi xử lý các tác vụ yêu cầu tính toán cao hoặc xử lý nhiều dữ liệu lớn.
Tiêu thụ tài nguyên: Ruby tiêu thụ nhiều tài nguyên hệ thống hơn, đặc biệt là bộ nhớ. Điều này có thể gây ra vấn đề khi triển khai ứng dụng trên các hệ thống có tài nguyên hạn chế.
Độ phổ biến và nhu cầu thị trường: So với các ngôn ngữ phổ biến khác như JavaScript, Python, hay Java, Ruby có ít cơ hội việc làm hơn, đặc biệt là ở một số thị trường nhất định. Điều này có thể làm giảm khả năng tìm kiếm việc làm cho lập trình viên Ruby.
Khó khăn trong việc bảo trì mã nguồn: Do tính linh hoạt cao, mã Ruby có thể trở nên khó bảo trì nếu không được viết cẩn thận. Các tính năng như monkey patching có thể dẫn đến các lỗi khó phát hiện và sửa chữa.
So sánh Ruby với Python: Nên chọn ngôn ngữ lập trình nào?
Ruby và Python đều là những ngôn ngữ lập trình hướng đối tượng, dễ học và phổ biến, được sử dụng rộng rãi trong nhiều lĩnh vực như phát triển web, phân tích dữ liệu, lập trình khoa học và tự động hóa. Tuy nhiên, hai ngôn ngữ này cũng có những điểm khác biệt riêng về cú pháp, hiệu suất, cộng đồng và ứng dụng, dẫn đến những lựa chọn phù hợp cho từng đối tượng người dùng khác nhau.
Dưới đây là bảng so sánh chi tiết giữa Ruby và Python:
Ruby
Python
Cú pháp
Linh hoạt, gần gũi với ngôn ngữ tự nhiên
Rõ ràng, nhất quán, dễ đọc và dễ bảo trì
Hiệu suất
Chậm hơn so với nhiều ngôn ngữ khác, đặc biệt là trong tác vụ yêu cầu cao
Tốt hơn Ruby trong nhiều trường hợp, có thể tối ưu hóa với thư viện như NumPy
Cộng đồng
Nhiệt tình, đặc biệt xung quanh Ruby on Rails
Rất lớn và đa dạng, nhiều tài liệu học tập và tài nguyên miễn phí
Ứng dụng thực tiễn
Phát triển web (Ruby on Rails), Automation và DevOps (Chef, Puppet)
Khoa học dữ liệu, học máy (Pandas, TensorFlow, Scikit-learn), phát triển web (Django, Flask), Automation và scripting
Khả năng mở rộng và bảo trì
Linh hoạt, nhưng có thể khó bảo trì nếu không được quản lý tốt
Nhất quán và rõ ràng, dễ bảo trì và mở rộng
Tiêu thụ tài nguyên
Tiêu thụ nhiều tài nguyên hệ thống, đặc biệt là bộ nhớ
Sử dụng ít tài nguyên hơn so với Ruby, nhưng không phải ngôn ngữ tiết kiệm nhất
Framework phổ biến
Ruby on Rails
Django, Flask
Thư viện phổ biến
Nhiều gem hỗ trợ phát triển web và DevOps
Thư viện mạnh mẽ cho khoa học dữ liệu, học máy, xử lý dữ liệu
Cơ hội việc làm
Ít cơ hội hơn so với Python, nhưng vẫn phổ biến trong phát triển web
Rất nhiều cơ hội trong nhiều lĩnh vực khác nhau
Tiềm năng phát triển và mức lương của lập trình viên Ruby
Nhu cầu tuyển dụng lập trình viên Ruby tại Việt Nam đang tăng cao do sự phát triển mạnh mẽ của ngành công nghệ thông tin, đặc biệt là lĩnh vực phát triển web và ứng dụng di động. Ruby on Rails, framework web phổ biến nhất được xây dựng dựa trên Ruby, ngày càng được nhiều doanh nghiệp lựa chọn cho các dự án của mình.
Bên cạnh đó, Ruby có cộng đồng lập trình viên lớn và hoạt động tích cực tại Việt Nam, luôn sẵn sàng chia sẻ kiến thức và hỗ trợ lẫn nhau. Điều này giúp các lập trình viên Ruby dễ dàng học hỏi, nâng cao kỹ năng và tìm kiếm cơ hội việc làm.
Về mức lương, lập trình viên Ruby có mức lương cao so với mặt bằng chung của ngành lập trình. Theo BÁO CÁO THỊ TRƯỜNG IT VIỆT NAM 2023 của TopDev, mức lương của Ruby Developer cấp bậc Junior (1 – 2 năm) và Middle Level (3-4 năm) lần lượt là 888 USD và 1.590 USD.
Kết luận
Vậy là TopDev đã tổng hợp đầy đủ các thông tin chi tiết về ngôn ngữ Ruby. Hy vọng những chia sẻ này sẽ giúp bạn đưa ra lựa chọn phù hợp cho con đường lập trình của mình. Nếu có hứng thú về ngành công nghệ thông tin, hãy đón chờ thêm nhiều bài viết hấp dẫn khác từ TopDev nhé!
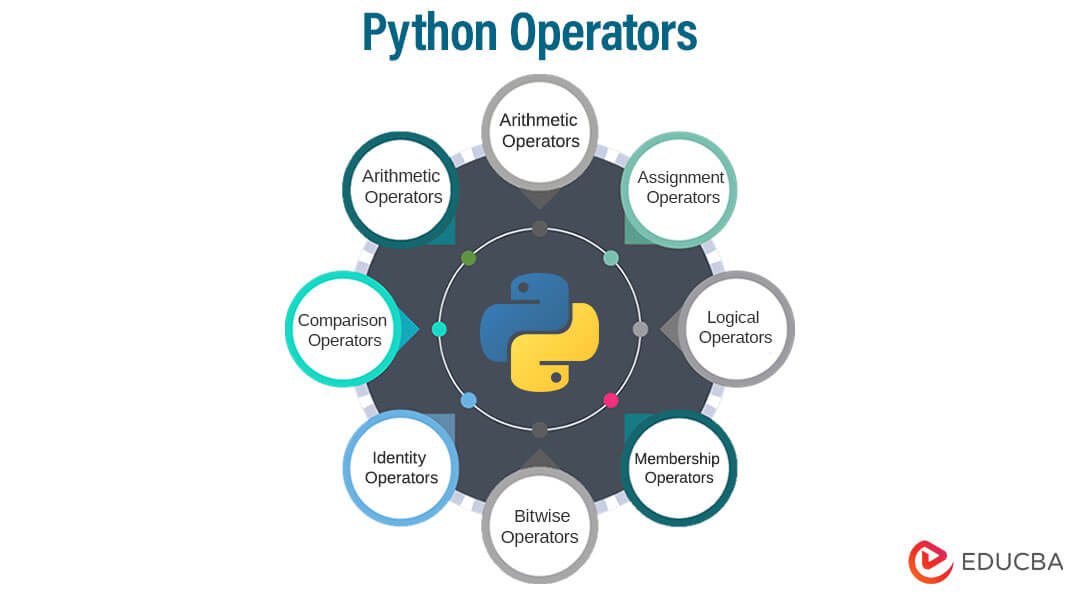
Trong lập trình, toán tử có thể hiểu là một hàm với các toán hạng là các giá trị đầu vào (input), thực hiện một số các phép toán cụ thể và trả về một giá trị đầu ra (output). Mỗi toán tử được quy định với các ký hiệu, biểu tượng riêng đặc trưng trong từng ngôn ngữ lập trình.
Hầu hết các ngôn ngữ lập trình đều sẽ hỗ trợ các loại toán tử cơ bản giống nhau. Với một ngôn ngữ mạnh về khả năng tính toán như Python, việc nắm được các loại toán tử và sử dụng chúng là điều cực kỳ quan trọng để tối ưu source code dự án. Bài viết hôm nay chúng ta cùng tìm hiểu xem Python hỗ trợ những loại toán tử nào và cách sử dụng chi tiết từng loại toán tử đó nhé.
Giới thiệu về toán tử Python
Trong Python, các toán tử được khai báo bằng các biểu tượng, từ khóa tương tự như các ký hiệu toán học giúp dễ dàng ghi nhớ và sử dụng. Các phép toán cơ bản cộng (+), trừ (-), nhân (*) hay chia (/) được sử dụng với ý nghĩa tương tự như khi chúng ta làm toán. Ngoài ra còn có các toán tử thao tác logic giúp chúng ta dễ dàng xử lý với biến được Python thêm vào để sử dụng.
Thành phần của một toán tử bao gồm các toán hạng và ký hiệu toán tử tương ứng. Trong Python, khái niệm toán tử một ngôi là phép toán hoạt động với chỉ một toán hạng, tức là chỉ có duy nhất một giá trị đầu vào. Ví dụ như phép phủ định hay thao tác đảo ngược bit. Tương tự thì toán tử hai ngôi là phép toán hoạt động với 2 toán hạng, là loại toán tử phổ biến nhất.
Python còn có khái niệm toán tử ba ngôi (ternary operator) được sử dụng trong việc viết rút gọn mã nguồn, chẳng hạn như câu điều kiện (if/ else). Tuy nhiên loại này mình sẽ không được đề cập trong bài viết này nhé.
Các loại toán tử trong Python
Dựa trên chức năng, toán tử trong Python được chia thành 7 loại bao gồm:
1. Toán tử số học – Arithmetic Operators
Toán tử số học là những phép tính gần gũi với chúng ta nhất, được sử dụng để thực hiện các phép toán số học trên các toán hạng.
Ví dụ với 2 biến a = 12 và b = 5, chúng ta có các toán tử như bảng dưới đây:
Ký hiệu
Toán tử
Mô tả
Ví dụ
+
Phép cộng
Cộng 2 toán hạng với nhau
a+b = 17
–
Phép trừ
Trừ 2 toán hạng với nhau
a-b = 7
*
Phép nhân
Nhân 2 toán hạng với nhau
a*b = 60
/
Phép chia
Chia 2 toán hạng với nhau
a/b = 2.4
%
Phần dư
Lấy phần dư còn lại sau khi thực hiện chia 2 toán hạng
a%b = 2
**
Phép mũ
Thực hiện phép tính mũ toán hạng bởi số mũ
a**b = 248832
//
Làm tròn
Thực hiện làm tròn xuống phép chia 2 toán hạng
a//b = 2
2. Toán tử quan hệ – Relational Operators
Toán tử quan hệ là những phép toán thực hiện việc so sánh giá trị của hai toán hạng; kết quả đầu ra sẽ chỉ cho ra giá trị đúng (True) hoặc sai (False).
Ví dụ với 2 biến a = 12 và b = 5, chúng ta có các toán tử như bảng dưới đây:
Lưu ý: toán tử <> (có giá trị tương tự với toán tự !=) đã bị bỏ đi ở Python 3 nên mình không liệt kê vào đây.
Ký hiệu
Toán tử
Mô tả
Ví dụ
==
So sánh bằng
Trả về True nếu 2 toán hạng bằng nhau
a==b => False
!=
So sánh khác
Trả về True nếu 2 toán hạng khác nhau
a!=b => True
<
Nhỏ hơn
Trả về True nếu toán hạng bên trái nhỏ hơn toán hạng bên phải
a<b => False
>
Lớn hơn
Trả về True nếu toán hạng bên trái lớn hơn toán hạng bên phải
a>b => True
>=
Lớn hơn hoặc bằng
Trả về True nếu toán hạng bên trái lớn hơn hoặc bằng toán hạng bên phải
a>=b => True
<=
Nhỏ hơn hoặc bằng
Trả về True nếu toán hạng bên trái nhỏ hơn hoặc bằng toán hạng bên phải
a<=b => False
3. Toán tử gán – Assignment Operators
Toán tử gán là những phép toán lấy đầu vào là giá trị ở phía bên phải của nó và gán giá trị đó cho toán hạng ở phía bên trái. Python hỗ trợ toán tử gán bằng (=) và một số toán tử gán phức hợp khác (thực hiện phép toán trước khi gán) tương tự như các ngôn ngữ lập trình khác.
Ví dụ với biến a = 12, chúng ta có các toán tử như bảng dưới đây:
Toán tử logic là những toán tử thực hiện phép toán logic trên các toán hạng. Khác với một số ngôn ngữ dùng ký tự cho phép toán logic như C, Java, JS, … thì Python sử dụng từ khóa tường minh cho toán tử logic.
Ký hiệu
Toán tử
Mô tả
Ví dụ
and
Phép và
Trả về kết quả True khi cả 2 điều kiện đều True
5>4 and 4<3 => False
or
Phép hoặc
Trả về kết quả True khi 1 trong 2 điều kiện là True
5>4 or 4<3 => True
not
Phép phủ định
Đảo ngược trạng thái logic của toán hạng
not(4<3) => True
5. Toán tử bitwise – Bitwise Operators
Toán tử bitwise là các phép toán được thực hiện trên các chuỗi bit hay số nhị phân tại cấp độ của từng bit riêng biệt. Thao tác trên từng bit được thực hiện nhanh và hỗ trợ trực tiếp bởi CPU.
Ví dụ với 2 biến a = 12 và b = 15, khi biểu diễn dưới hệ nhị phân chúng ta có: a = 00001100 và b = 00001111.
Ký hiệu
Toán tử
Mô tả
Ví dụ
&
Thao tác bit AND
Sao chép một bit tới kết quả nếu bit này tồn tại trong cả hai toán hạng
a&b = 00001100 => 12
|
Thao tác bit OR
Sao chép một bit tới kết quả nếu bit này tồn tại trong bất kỳ toán hạng nào
a|b = 00001111 => 14
^
Thao tác bit XOR
Sao chép những bit 1 chỉ tồn tại trong một toán hạng
a^b = 00000010 => 2
~
Thao tác bit NOT
Thao tác đảo ngược bit 1 thành 0 và ngược lại
~a = -00001101 => -13
<<
Dịch chuyển trái
Dịch chuyển sang trái 1 số lượng bit được xác định
a<<2 = 00110000 => 48
>>
Dịch chuyển phải
Dịch chuyển sang trải 1 số lượng bit được xác định
a>>2 = 00000011 => 3
6. Toán tử định danh – Indentity Operators
Toán tử định danh trong Python giúp so sánh vị trí ô nhớ của 2 đối tượng trong Python, bao gồm 2 toán tử:
is: Trả về True nếu như các biến ở 2 bên toán tử trỏ về cùng 1 đối tượng
is not: Trả về False nếu các biến ở 2 bên toán tử trỏ về cùng 1 đối tượng
Ví dụ: a=10; b=25; c=10;
a is b => False
a is c => True
a is not b => True
7. Toán tử membership – Membership Operators
Toán tử membership trong Python có đầu vào gồm 2 toán hạng, nó giúp kiểm tra xem một biến có nằm trong một dãy hay không. Có 2 toán tử membership bao gồm:
in: Trả về True nếu biến nằm trong dãy các biến
not in: Trả về True nếu biến không nằm trong dãy các biến
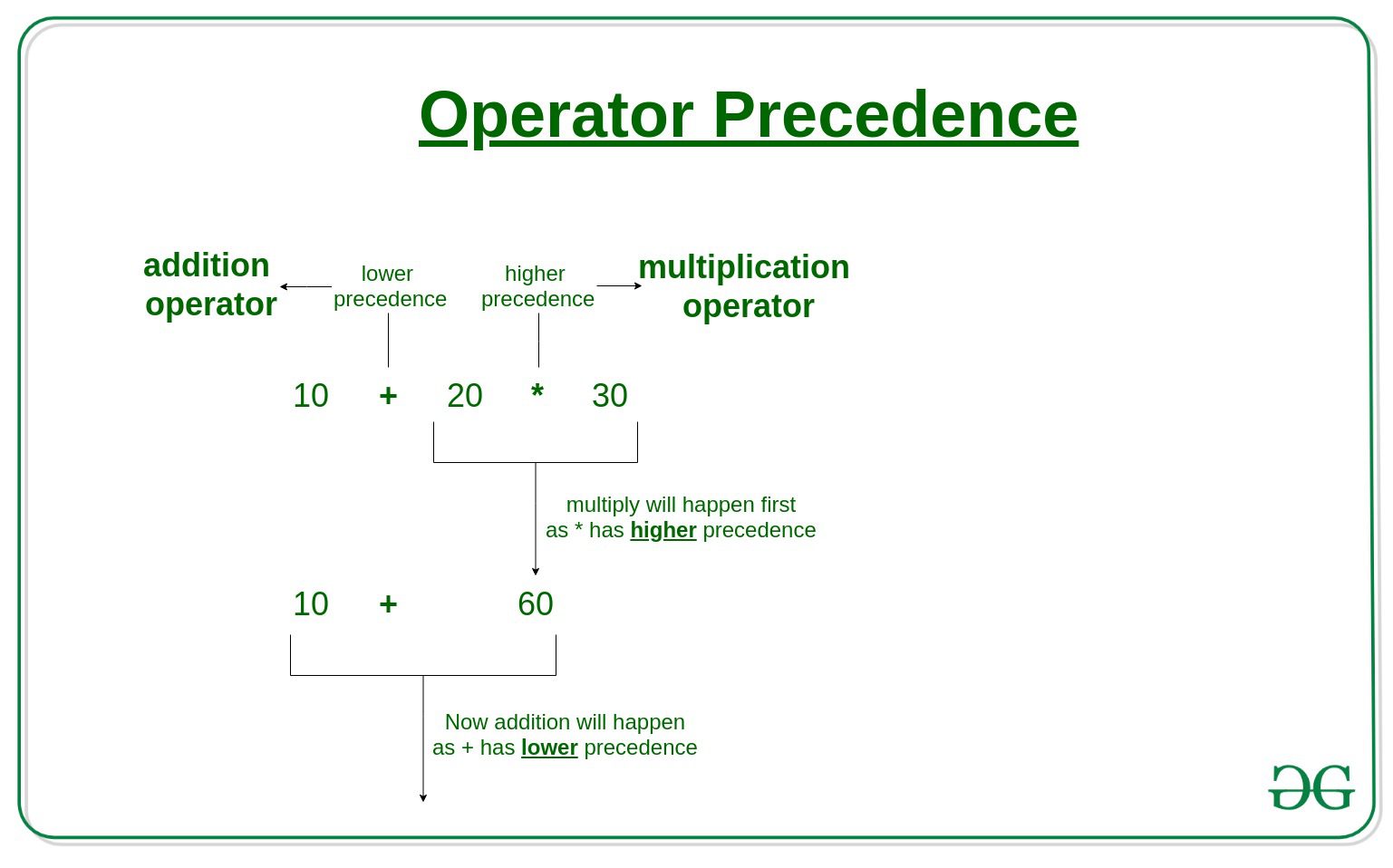
Trong một biểu thức chứa nhiều toán tử, chúng ta cần xác định được mỗi toán tử trong biểu thức đó thực hiện công việc gì và thứ tự mà chúng thực hiện. Thứ tự thực hiện các phép tính trong biểu thức đó gọi là độ ưu tiên của toán tử – Operator Precedence.
Trong Python thứ tự ưu tiên của các toán tử được thể hiện như ở bảng dưới đây, thứ tự ưu tiên từ cao xuống thấp (cao sẽ được thực hiện trước):
Toán tử
Mô tả
**
Toán tử mũ
~ + –
Phần bù,phép cộng, trừ cho toán tử một ngôi
* / % //
Phép nhân, chia, lấy phần dư, làm tròn
+ –
Phép cộng/ trừ
>> <<
Dịch bit trái/ phải
&
Phép và
^ |
Phép XOR, OR
<= < > >=
Toán tử so sánh
== !=
Toán tử so sánh bằng
= %= /= //= -= += *= **=
Toán tử gán
is is not
Toán tử định danh
in not in
Toán tử Membership
not or and
Toán tử Logic
Kết bài
Hy vọng qua bài viết này, bạn đã có thể nắm được đầy đủ các toán tử cơ bản trong Python; các ký hiệu toán học, các loại toán tử cùng thứ tự ưu tiên để thực hiện chính xác một phép toán phức tạp khi lập trình. Cảm ơn các bạn đã đọc bài và hẹn gặp lại trong các bài viết tiếp theo của mình.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Hiệu ứng văn bản với gradient text là một cách tuyệt vời để tạo điểm nhấn cho văn bản trên trang web của bạn. Sử dụng CSS, bạn có thể dễ dàng áp dụng hiệu ứng gradient text để làm cho văn bản trở nên hấp dẫn và nổi bật. Dưới đây là một ví dụ sử dụng hiệu ứng gradient text được tạo bằng CSS.
Để làm được như trên, bạn làm theo các bước hướng dẫn dưới đây:
Bước 1: Tạo HTML cơ bản
Đầu tiên, chúng ta cần tạo 1 khối HTML để chứa văn bản.
<div><p>thanhnamnguyen.dev</p></div>
Bước 2: Thêm CSS Gradient
Sử dụng CSS sau để tạo hiệu ứng chuyển màu trên văn bản (gradient text). Mình sử dụng thuộc tính background: linear-gradient để tạo dải màu sắc tương ứng. Gradient này chạy từ trái qua phải và bao gồm bốn màu: #7953cd, #00affa, #0190cd, và #764ada (các mã màu này đang áp dụng ở chế độ darkmode). Các con số (20%, 30%, 70%, 80%) xác định vị trí của màu trong gradient.
-webkit-background-clip và background-clip: Định nghĩa việc clip gradient vào văn bản.
-webkit-text-fill-color và text-fill-color: Đặt màu chữ trong suốt để hiển thị gradient.
background-size: Đặt kích thước của background gradient là 500% theo chiều ngang và tự động theo chiều dọc.
Sử dụng animation textShine với thời gian 5 giây, kiểu easing-in-out, lặp vô hạn và thay đổi đối diện.
Cùng với CSS ở trên, chúng ta cũng cần thêm hiệu ứng bằng cách sử dụng @keyframes textShine { ... }: Định nghĩa animation textShine. Nó bắt đầu với một vị trí background ở 0% theo chiều ngang và 50% theo chiều dọc, và kết thúc ở vị trí 100% theo chiều ngang và 50% theo chiều dọc, tạo hiệu ứng di chuyển gradient từ trái sang phải.
Từ trước tới nay, các bạn được học về Node.js đều được bảo là Node.js chỉ xử lý đơn luồng. Tức là tại một thời điểm, chỉ có một Thread được thực hiện.
Nói đơn giản cho dễ hiểu: bạn có CPU 8 nhân, 16 threads. Giờ bạn muốn duyệt một 1 triệu records để tìm phần tử lớn nhất. Với node.js, sẽ chỉ có 1 thread của CPU là thực hiện công việc duyệt tìm vì mặc định Node.js là single-thread. 1 thread chạy cắm đầu, 7 threads kia ngồi cười khúc khích.
Nhưng với Java, công việc được chia đều ra cho các threads, nên tốc độ sẽ xử lý trong bài toán ví dụ này sẽ nhanh hơn.
Đến đây, mình tin là bạn sẽ bật ra thắc mắc: Vậy không có cách nào để Node.js thực hiện đa luồng à?
Thế mạnh của Node.js là cơ chế none-blocking I/O, giúp ứng dụng có tốc độ rất nhanh. Tuy nhiên, có những bài toán yêu cầu phải xử lý đa luồng để tận dụng sức mạng CPU đa nhân. Tất nhiên là có thể làm được nhờ sự trợ giúp của cluster.
Bài viết này, chúng ta sẽ cùng nhau tìm hiểu về Cluster trong Node.js
Cluster trong Node.js
Khi nào nên sử dụng Cluster
Như mình đã đề cập ở trên, thế mạnh của Node.js là none-blocking I/O, điều này giúp cho ứng dụng mặc dù chỉ sử dụng 1 thread để chạy nhưng tốc độ thì không hề tồi chút nào. Đơn giản vì Node.js tận dụng được thời gian nhàn rỗi của CPU.
Tuy nhiên, điều này chỉ phù hợp với các ứng dụng mà mỗi tác vụ chỉ thực hiện trong thời gian ngắn. Kiểu như các ứng dụng chat, ứng dụng chạy Real-Time…
Còn với các ứng dụng nặng về tính toán như xử lý ảnh, crawler data,… thì đơn luồng như Node.js không phù hợp.
Nếu bạn vẫn “chày cối” chọn Node.js thì vẫn có cách. Đó là sử dụng cluster để Node.js có thể xử lý đa luồng, tận dụng các nhân CPU còn nhàn rỗi.
Cluster trong Node.js hoạt động như thế nào?
Cluster trong Node.js được tạo một cách đơn giản, bạn sử dụng một module cùng tên: Cluster module.
Cơ chế hoạt động của nó cũng khá đơn giản. Cluster module cho phép Node.js tạo số luồng nhỏ hơn hoặc bằng số lõi của CPU, tự động phân chia công việc để tận dụng sức mạnh của CPU.
Cách sử dụng Cluster
Lý thuyết thì cơ bản vậy thôi, chúng ta sẽ cùng nhau thực hành tạo cluster để xử lý đa luồng trong Node.js
Đoạn code dưới mình sẽ tạo một server lắng nghe cùng một port thông qua cluster.
/* Đoạn code demo tạo clusters*/'use strict';// Importing các Modules cần thiếtconst http = require('http'), cluster = require('cluster'), os = require('os').cpus().length;/*Chúng ta sẽ tạo số cluster tương ứng với số nhân của CPU.*/if(cluster.isMaster){ for(let i =0; i < os; i++){ cluster.fork(); console.log(`The Worker number: ${i +1}is alive`); } cluster.on('exit',(worker)=>{ console.log(`The Worker number: ${worker.id} has died`); });}else{ // Chúng ta sẽ tạo các cluster cùng lắng cùng một port http.createServer((sol, res)=>{ res.end('Hi, we are harnessing the power of clusters :)'); }).listen(3000,()=> console.log('The server is running on the port:3000')); console.log(`The Worker number: ${cluster.worker.id}is running`);}
Như đoạn code trên, cluster đầu tiên được tìm thấy sẽ là master cluster. Sau đó thì sẽ nhân bản ra các cluster từ master cluster, đó chính là cách mà chúng ta chia sẻ port. Một listener cũng được thêm vào cluster để biết được trạng thái stop/failed của một worker.
Sử dụng Cluster kết hợp với Express.js
Ở ví dụ trên, chúng ta đã biết tạo cluster với http module. Giờ chúng ta sẽ làm một ví dụ về cách sử dụng cluster khi kết hợp http và express.js
/* Creating clusters and serving an application that uses express*/'use strict';// importing the modulesconst cluster = require('cluster'), os = require('os').cpus().length, server = require('./serverHttp');/* We see if it is the master cluster in case it is, we will clone the cluster amount at the same time as the cores of the processor.*/if(cluster.isMaster){const Master = require('./work');const master =new Master({cluster:cluster});for(let i =0; i < os; i++){ master.liftWorker();} cluster.on('exit',(worker)=>{ console.log(worker) console.log(`The Worker number: ${worker.id}is dead.`); master.liftWorkerError();});}else{ // Creating a server with http and express. let app =new server(); app.initiate(); console.log(`cluster ${cluster.worker.id}is running.`)}
Bạn thấy đấy, cách viết code cũng tương tự như lúc trước. Chỉ khác là lần này chúng ta sẽ chia công việc thành nhiều module.
// Class to pick cluster workersclass Master { constructor(config){ this.config= config ||{}; this.cluster=this.config.cluster; } // Pick up a new Worker liftWorker(){ let worker =this.cluster.fork(); console.log(`The worker ${worker.id}is started.`); } // Raise a worker when one dies in case of errors liftWorkerError(){ let worker =this; setTimeout(()=>{ worker.liftWorker(); },200); } }
module.exports= Master;
Về cơ bản là chúng ta sẽ tạo riêng một file là work.js. Mục đích của module này là cung cấp các phương thức để tạo mới một hoặc nhiều workers khi một worker bị die.
Cuối cùng là chúng ta sẽ có module chính để tạo server và lắng nghe một port.
'use strict';const http = require('http'), express = require('./express');// Creating the server with httpclass Servidor{ constructor(config){ this.config= config ||{}; this.app=new express(); this.server= http.createServer(this.app.server); this.app.gets(); } // Starting the server initiate(){ this.server.listen(3000,()=> console.log('The server is running on port 3000')); }}module.exports= Servidor;
'use strict';const express = require('express');class Server { constructor(config){ this.config= config ||{}; this.server= express(); } // Serving the routes get gets(){ this.server.get('/',(sol, res, next)=>{ res.send(`This route is served by the workes`); }); this.server.get(`/hello`,(sol, res, next)=>{ res.send('This route too 🙈'); }); }}module.exports= Server;
Kết luận
Node.js là giải pháp thích hợp để xử lý các ứng dụng có lượng traffic lớn. Tuy nhiên, với các ứng dụng nặng về tính toán thì Node.js cũng có thể làm tốt.
Mình biết về cluster trong Node.js cũng khá lâu rồi. Nhưng hồi đó cluster còn chưa ổn định, và ngon lành như bây giờ. Giờ thì ngon lành rồi.
Tất nhiên, cũng như các ngôn ngữ, giải pháp khác, việc xử lý đa luồng chưa bao giờ là dễ cả, code sẽ cần nhiều logic hơn. Nhưng nhìn chung, cluster sẽ giúp bạn đơn giản hóa rất nhiều việc xử lý đa luồng trong Node.js
Cảm nhận của bạn về cluster khi sử dụng trong dự án như thế nào? Để lại bình luận bên dưới nhé.
Bài viết được sự cho phép của tác giả Tống Xuân Hoài
Vấn đề
Tôi đã có một bài viết về vấn đề blog của tôi sử dụng RediSearch làm cơ sở dữ liệu chính ở RediSearch là gì? Estacks đang sử dụng RediSearch làm cơ sở dữ liệu!, bên cạnh đó là lý do tôi dùng RediSearch vì tính năng Tìm kiếm fulltext trong RediSearch mà tôi luôn muốn tìm kiếm của blog trở nên mạnh mẽ và hữu ích hơn cho bạn đọc.
Cho đến hiện tại mọi thứ vẫn đang hoạt động rất tốt, chỉ có một điều Redis không có kiểu dữ liệu JSON trong khi tôi lại muốn thao tác với dữ liệu dạng JSON một cách thân thiện nhất. Do đó trong quá trình tìm hiểu tôi phát hiện ra Redis cung cấp một module có tên là RedisJSON đã giúp tôi làm được điều đó. Nếu như bạn đang dùng Redis hay RediSearch mà muốn thao tác với dữ liệu JSON thì đây quả là một điều tuyệt vời.
RedisJSON là gì?
RedisJSON là một module cung cấp hỗ trợ JSON cho Redis. RedisJSON cho phép bạn lưu trữ, cập nhật và truy xuất các giá trị JSON trong cơ sở dữ liệu Redis tương tự như bất kỳ kiểu dữ liệu Redis nào khác. RedisJSON cũng hoạt động với RediSearch để cho phép bạn lập chỉ mục và truy vấn các tài liệu JSON.
127.0.0.1:6379> JSON.SET obj $ '{"title": "Chào các Developer - Hôm nay uống gì và code gì?", "url": "https://2coffee.dev"}'"OK"
127.0.0.1:6379> JSON.GET obj $
[{"title":"Chào các Developer - Hôm nay uống gì và code gì?","url":"https://2coffee.dev"}]
Cách sử dụng
Để sử dụng RedisJSON trước tiên bạn cần cài đặt Redis v6.x trên server của mình. Redis cung cấp nhiều cách khác nhau để tải module RedisJSON. Hai cách phổ biến là:
Nếu đã quen làm việc với NoSQL thì RedisJSON cung cấp cho chúng ta một cách thuận tiện cho việc thao tác với các dữ liệu dạng JSON mà không lo sai sót dữ liệu. SQL cũng đã tích hợp kiểu dữ liệu JSON từ lâu giúp cho chúng ta có nhiều lựa chọn hơn trong việc tổ chức dữ liệu.
RedisJSON dễ dàng tích hợp với RediSearch để lập chỉ mục và tìm kiếm, việc này vừa mang lại tính thuận tiện trong lưu trữ, cộng với khả năng tìm kiếm fulltext mạnh mẽ của RediSearch và tốc độ của Redis. Tôi đang sử dụng bộ 3 công cụ này còn bạn có dự định gì cho dự án sắp tới chưa? 😀
IRAC (Issue – Rule – Analysis – Conclusion) là một phương pháp phổ biến và quen thuộc với sinh viên luật và dân luật nói chung. Cá nhân mình thấy phương pháp này khá hay và hoàn toàn có thể áp dụng vào bất cứ công việc hoặc ngành nghề nào.
Giới thiệu
Phương pháp IRAC (đọc là eye-rack hoặc ai rách haha) là một cái sườn giúp bạn có thể sắp xếp câu trả lời cho một vấn đề nào đó một cách chi tiết và rõ ràng. Thực ra phương pháp này bắt đầu được đưa ra và áp dụng bởi các công ty luật ở Mỹ.
Cấu trúc của một câu trả lời chuẩn IRAC bao gồm các thành phần cơ bản: Issue – Vấn đề, Rule – Quy phạm, Analysis – Phân tích và Conclusion – Kết luận.
Mình là lập trình viên, nên sẽ cố gắng giải thích một cách đơn giản và non-legal hết sức có thể ^_^
Issue: các vấn đề mà khách hàng đưa ra cho chúng ta mà chúng ta cần giải quyết và tư vấn cho họ.
Rule: các quy tắc và những thứ common sense cần tuân thủ trong quá trình thực hiện yêu cầu. Các quy tắc ở đây có thể là một vài tiêu chuẩn chung hoặc những quy định cụ thể từ phía khách hàng.
Analysis: phân tích, làm rõ ràng các yêu cầu của khách hàng. Dựa vào các Rule mà chúng ta liệt kê ra các solutions hợp lý để giải quyết Issue.
Conclusion: từ kết quả Analysis ở trên, chúng ta tổng kết lại các phương pháp tốt nhất hoặc phù hợp nhất để khách hàng có thể áp dụng.
Trong một số trường hợp, chúng ta có thể gộp chung phần Analysis và Conclusion lại với nhau mà không cần phải tách biệt chúng.
Thông thường đây là quá trình tốn nhiều thời gian nhất trong quá trình lấy yêu cầu. Chúng ta cần phải tưởng tượng ra một big picture về chức năng khách hàng mong muốn, sau đó dần xoáy sâu vào phần details.
Trong quá trình này, để tiết kiệm thời gian cũng như giúp khách hàng dễ nắm bắt ý kiến của mình, chúng ta có thể đưa ra một số bản mockup mô tả chức năng. Dựa vào các bản mockup này, khách hàng sẽ có thể giúp bạn thay đổi, hiệu chỉnh một số thứ cho phù hợp. Khách hàng khá thích làm việc với những người làm việc rõ ràng như vậy, nên các dev nào có ý muốn chuyển sang hướng manager hãy chú ý nhé ^_^.
Hãy cố gắng đặt càng nhiều câu hỏi càng tốt, khách hàng sẽ không thấy phiền lòng đâu. Bạn càng đặt nhiều câu hỏi thì điều đó càng chứng tỏ bạn đang hiểu rõ hơn về thứ mà khách hàng mong muốn. Tuy nhiên, hãy tránh hỏi những câu hỏi ngu ngốc.
Đừng quên keep track tất cả những thông tin mà bạn nhận được. Bạn sẽ cần nó để viết documents lại sau này. Mình khuyên bạn nên keep track mọi thứ qua email nếu có thể.
Conclusion
Sau quá trình phân tích thông tin và clear requirements với khách hàng, lúc này bạn cần viết một bản tổng kết nội dung, kèm theo FSD (Functional Specification Document) rồi gửi cho khách hàng. Có thể sẽ có một vài chỉnh sửa nho nhỏ nào đó.
Việc tiếp theo là ngồi rung đùi chờ khách hàng sign-off rồi bắt tay vào làm thôi. Với một số công ty nhỏ và quy trình không quá strictly thì bạn cũng có thể làm luôn được rồi.
Bài viết của mình đến đây là hết, cám ơn các bạn đã theo dõi nhé 😀
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Github không chỉ là một nơi để lưu trữ mã nguồn mở và làm việc nhóm, mà còn là một nền tảng mạng xã hội cho các nhà phát triển và chuyên gia công nghệ. Và giới thiệu mới nhất của Github chính là Github Profile README – một cách tuyệt vời để cá nhân hóa trang cá nhân của bạn và giới thiệu về bản thân mình một cách sáng tạo. Trong bài viết này, chúng ta sẽ cùng nhau khám phá tính năng mới này và làm thế nào để tận dụng tối đa.
1. Github Profile là gì?
Github Profile README là một trang README.md đặc biệt được hiển thị ngay ở phần đầu trang của trang cá nhân GitHub của bạn. Điều này cung cấp cho bạn một không gian để tạo ra một bảng tự giới thiệu động với văn bản, hình ảnh, liên kết và thậm chí là các biểu tượng đặc sắc. Nó giúp bạn nổi bật hơn trong cộng đồng GitHub và tạo ấn tượng mạnh mẽ từ những người đang xem trang cá nhân của bạn.
Github Profile README là một cách tuyệt vời để làm cho trang cá nhân của bạn nổi bật trong cộng đồng phát triển. Việc tạo ra một trang cá nhân độc đáo không chỉ giúp bạn chia sẻ thông tin về bản thân mình mà còn là cơ hội để thể hiện sự sáng tạo của bạn. Hãy bắt đầu sáng tạo ngay hôm nay và để cho trang cá nhân của bạn trở nên độc đáo và ấn tượng trên Github!
Một API cho phép giao tiếp hai chiều giữa các ứng dụng phần mềm thông qua các requests. Một Webhook là một API nhẹ, hỗ trợ chia sẻ dữ liệu một chiều được kích hoạt bởi các events.
Một API cho phép giao tiếp hai chiều giữa các ứng dụng phần mềm thông qua các requests. Một Webhook là một API nhẹ, hỗ trợ chia sẻ dữ liệu một chiều và thường được kích hoạt bởi các events.
Khi kết hợp cùng nhau, chúng cho phép các application chia sẻ dữ liệu và function, giúp cho các services đạt được kết quả to lớn hơn tổng các thành phần của chúng.
API và Webhook đều cho phép các hệ thống phần mềm khác nhau đồng bộ và chia sẻ thông tin. Khi các ứng dụng phần mềm trở nên ngày càng kết nối, điều quan trọng là các nhà phát triển hiểu rõ sự khác biệt giữa hai phương tiện này để chia sẻ dữ liệu và lựa chọn công cụ phù hợp nhất với nhu cầu của công việc đang thực hiện.
API là gì?
API là viết tắt của cụm từ Application Programming Interface.
Một API giống như một cổng thông tin mà thông qua đó thông tin và chức năng có thể được chia sẻ giữa các services. Từ interface là chìa khóa để hiểu rõ mục đích của một API. Giống như một trình duyệt web là một interface cho người sử dụng cuối để nhận, gửi và cập nhật thông tin trên web server, một API là một interface cung cấp chức năng tương tự cho các ứng dụng phần mềm.
Có nhiều loại và danh mục khác nhau của API (chúng ta sẽ khám phá sau), nhưng nói chung, API là cách phổ biến nhất để các hệ thống phần mềm khác nhau kết nối và chia sẻ thông tin.
Webhook là gì?
Một webhook có thể được coi là một loại API được kích hoạt bởi các events thay vì requests.
Thay vì một service tạo một request để nhận một phản hồi từ service khác, một webhook là một dịch vụ cho phép một service gửi dữ liệu đến một service khác ngay sau khi một event cụ thể được emit. Webhooks đôi khi được coi là “API đảo ngược,” vì giao tiếp được khởi tạo bởi service gửi dữ liệu thay vì service nhận nó.
Với sự phát triển mạnh mẽ của các distributed system (hệ thống xử lý phân tán), webhook đang trở nên phổ biến hơn khi là một giải pháp gọn nhẹ cho việc kích hoạt notification và cập nhật dữ liệu theo thời gian thực mà không cần phải phát triển một API toàn diện.
Chẳng hạn, nếu bạn muốn nhận notification trên Slack khi có tweet đề cập đến một tài khoản cụ thể và chứa một #hashtag nhất định được publish, thay vì Slack liên tục yêu cầu Twitter về bài viết mới đáp ứng các tiêu chí này, việc Twitter gửi một thông báo đến Slack chỉ khi event này xảy ra là một lựa chọn tốt hơn nhiều.
Đây chính là mục đích của một webhook – thay vì phải liên tục yêu cầu dữ liệu, service nhận dữ liệu có thể ngồi lại và xử lý những gì nó cần mà không cần gửi các request lặp đi lặp lại đến hệ thống khác.
API cho khả năng tích hợp mạnh mẽ
Một đặc điểm quan trọng của API là chúng cung cấp giao tiếp hai chiều giữa các service khác nhau thông qua một chu kỳ request – response, thường sử dụng thông qua giao thức HTTP.
Trong một trường hợp sử dụng API điển hình, một service sẽ yêu cầu một tập hợp cụ thể dữ liệu từ một service khác bằng cách sử dụng yêu cầu HTTP GET request. Miễn là yêu cầu hợp lệ, hệ thống nhận sẽ gửi về response bằng dữ liệu được yêu cầu ở định dạng có thể đọc bằng máy, thường là XML hoặc JSON. Điều này làm cho các service có thể chia sẻ dữ liệu mà không cần quan tâm đến ngôn ngữ lập trình cá nhân hoặc các đặc tả nội bộ của chúng.
Tính chất phổ quát của tương tác API có thể tạo ra vô số kịch bản, từ người dùng iPhone kiểm tra nhiệt độ địa phương thông qua API của AccuWeather đến tài xế Grab điều hướng đến vị trí đón tiếp theo thông qua API của Google Maps.
Ngoài việc nhận dữ liệu, API cũng có thể xử lý toàn bộ các hoạt động “CRUD” (Create, Read, Update và Delete) giữa hai ứng dụng. Nói cách khác, API không chỉ để hiển thị dữ liệu cho người dùng trong một interface mà còn có thể được sử dụng để thay đổi dữ liệu trong service nơi nó được lưu trữ. Đây là cách mà API cho phép các hệ thống phần mềm mở rộng dịch vụ và chức năng của chúng, cũng như tích hợp với các nền tảng khác một cách toàn diện và có ý nghĩa.
Sự linh hoạt của API khiến chúng trở thành công cụ mạnh mẽ cho developers để mở rộng khả năng của ứng dụng.
Hầu hết các dịch vụ web hiện đại bao gồm API cho phép dữ liệu và chức năng của họ được tích hợp vào các công cụ khác – thực tế, rất hiếm khi gặp một dịch vụ web doanh nghiệp nào không tận dụng một API từ ít nhất một ứng dụng khác một cách nào đó.
Nhiều người có thể nghĩ rằng vì webhook là reatime event nên chúng khó triển khai từ mặt kỹ thuật.
Trên thực tế, một ưu điểm chính của webhook là chúng dễ thiết lập hơn và tốn ít tài nguyên hơn so với API. Việc tạo một API là một quy trình phức tạp, trong một số trường hợp có thể khó khăn như việc thiết kế và xây dựng cấu trúc của service, nhưng triển khai một webhook đôi khi chỉ đơn giản là thiết lập một HTTPPOST request duy nhất ở đầu gửi, thiết lập một URL ở đầu nhận để tiếp nhận và sau đó thực hiện một số hành động trên dữ liệu đó.
Các trường hợp sử dụng phổ biến cho webhook bao gồm:
gửi danh sách email subscriptions và unsubscriptions đến một hệ thống CRM,
tự động cập nhật phần mềm kế toán khi hóa đơn được thanh toán,
hoặc thiết lập bất kỳ loại thông báo nào.
Trong mỗi loại event này, data chỉ đi theo một hướng và không cần nhận hay xử lý dữ liệu được cập nhật.
Những đặc tính giống nhau khiến cho việc triển khai webhook tương đối dễ dàng cũng là lý do tại sao chúng giới hạn hơn nhiều so với APIs.
Việc cập nhật dữ liệu mà một webhook gửi đòi hỏi việc cấu hình lại nó hoàn toàn để lắng nghe event khác, và trong hầu hết các trường hợp, việc tạo một webhook mới sẽ hiệu quả hơn.
Khác với API, webhook không cho phép hệ thống gửi thêm, cập nhật và xóa dữ liệu ở đầu nhận, điều này là lý do tại sao webhook một mình quá hạn chế để cung cấp việc tích hợp đầy đủ giữa các service.
API có thể được phân loại dựa trên các giao thức và kiến trúc xác định cách chúng gửi – nhận dữ liệu.
Lịch sử cho thấy, mẫu kiến trúc phổ biến nhất cho thiết kế API là REST (Representational State Transfer), đặc biệt là đối với các API phục vụ ứng dụng dựa trên nền tảng WEB.
REST, được đặt ra bởi Roy Fielding vào năm 2000, cho phép giao tiếp giữa hai ứng dụng qua HTTP, tương tự như cách trình duyệt tương tác với máy chủ. REST không phải là một tiêu chuẩn chính thức mà là một bộ hướng dẫn về cách thiết kế API và các web serivce khác. Một API được coi là RESTful nếu thiết kế của nó tuân theo những đề xuất sau:
Client-Server (Khách hàng-Máy chủ): Tương tự như browser yêu cầu một trang web từ server, trong một API RESTful, một ứng dụng (client) yêu cầu một URL được lưu trữ trên một service khác (server) thông qua HTTP. Máy chủ đánh giá yêu cầu và response bằng dữ liệu được yêu cầu hoặc một thông báo lỗi.
Stateless (Không lưu trạng thái): Server không cần biết gì về state của client yêu cầu để cung cấp một response thích hợp. Một request từ client cần chứa đủ thông tin để server gửi response.
Cacheability (Có thể lưu trữ vào bộ nhớ đệm): Response từ server nên chỉ ra liệu client có nên lưu trữ dữ liệu vào bộ nhớ đệm hay không.
Layered Systems (Hệ thống đa lớp): API không phụ thuộc vào một hệ thống cụ thể để thực hiện yêu cầu; nó có thể gửi phản hồi qua các lớp khác nhau. Điều này có nghĩa là hệ thống nhận có thể là một client, một proxy, hoặc bất kỳ trung gian nào khác.
Ví dụ đơn giản sau đây https://www.boredapi.com/api/activity tuân theo quy ước REST. Khi bạn truy cập URL, browser của bạn sẽ hiển thị một activity được đề xuất để tham gia nếu bạn đang rảnh đến nhức cả trứng =)), được định dạng dưới kiểu JSON:
{"activity":"Shop at support your local farmers market","type":"relaxation","participants":1,"price":0.2,"link":"","key":"8979931","accessibility":0.1}
Mặc dù REST đã được sử dụng rộng rãi và vẫn còn phổ biến, những phương pháp và kiến trúc mới đang dần xuất hiện.
Một lựa chọn đáng chú ý khác là GraphQL, được phát triển bởi Facebook.
GraphQL cung cấp một cách linh hoạt và hiệu quả hơn cho khách hàng yêu cầu dữ liệu cụ thể mà họ cần, giảm việc lấy quá nhiều hoặc quá ít dữ liệu. Nó cho phép khách hàng xác định cấu trúc của phản hồi, tạo điều kiện cho tương tác linh hoạt và cá nhân hóa hơn.
mutation{
qrAssign(connectorId:"23024"poolName:"joint-tech"qrId:"AMPJ-1120311132"useCustom:true){
id
qrId
charger {
chargerUri
}}}
Trong tương lai, chúng ta có thể mong đợi sự tiếp tục phát triển trong kiến trúc API, với sự tập trung vào khả năng mở rộng, khả năng realtime và sự thích ứng với nhu cầu đa dạng của khách hàng.
Các bài trước mình đã hướng dẫn các bạn sử dụng Sqlite và Realm database. Tuy nhiên, vẫn còn một giải pháp thao tác với database cũng rất hay ho khác. Đó chính là Room database trong Android.
Vậy Room Database là gì? Cách sử dụng Room database như thế nào?
Chúng ta sẽ cùng nhau tìm hiểu thông qua một dự án ví dụ nhé.
#Giới thiệu Room database trong Android
Room database được phát triển và cải tiến từ sqlite. Room database giúp đơn giản hoá việc code,và giảm thiểu các công đoạn liên quan đến cơ sở dữ liệu.
Bản chất Room database là abstract layer gồm cơ sở dữ liệu chuẩn SQLite được Android thông qua.
Với 3 thành phần chính là: Database, DAO (Data Access Object) và entity. Mỗi thành phần đều có nhiệm vụ và chức năng riêng.
#Xây dựng ứng dụng sử dụng Room database trong Android
1. Cài đặt thư viện
Đầu tiên các bạn import thư viện vào file build.gradle
Sau đó các bạn tạo interface để thực hiện truy vấn.
DAO là interface được chú thích với @Dao, nó đóng vai trò trung gian truy cập vào các đối tượng trong cơ sở dữ liệu và các bảng của nó.
Có bốn chú thích cụ thể cho các hoạt động cơ bản của DAO: @Insert, @Update, @Delete, and @Query.
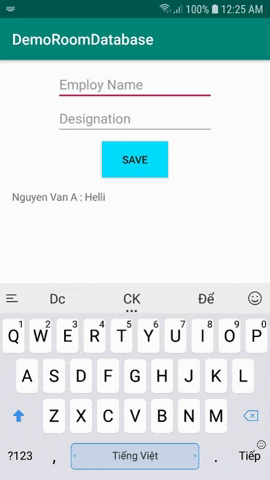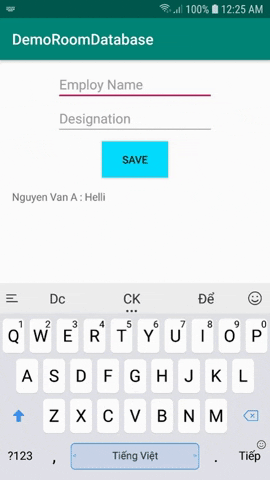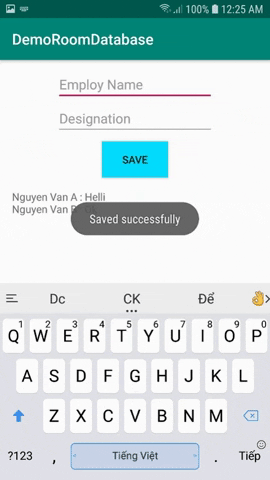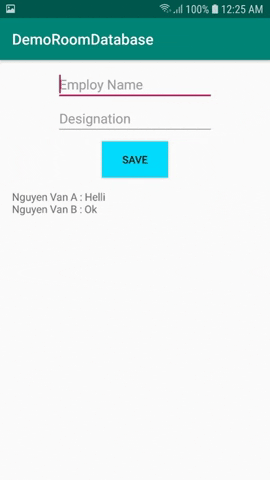
@Daopublicinterface EmployDao { @Insert(onConflict = REPLACE) voidinsertEmploy(Employee employee); @Insert(onConflict = IGNORE) voidinsertOrReplaceEmploy(Employee... employees); @Update(onConflict = REPLACE) voidupdateEmploy(Employee employee); @Query("DELETE FROM Employee") voiddeleteAll(); @Query("SELECT * FROM Employee") public List<Employee> findAllEmploySync();}
Và cuối cùng các bạn tạo AppDatabase.
Thành phần Database là một abstract class đã được chú giải bằng @Database. Nó extend RoomDatabase Class và trong đó định nghĩa một danh sách các Entities và các DAO.
@Database(entities = {Employee.class}, version = 1)publicabstractclass AppDatabase extends RoomDatabase { privatestatic AppDatabase INSTANCE; publicabstract EmployDao employDao(); publicstatic AppDatabase getInMemoryDatabase(Context context){ if(INSTANCE == null){ INSTANCE =
Room.inMemoryDatabaseBuilder(context.getApplicationContext(), AppDatabase.class) // To simplify the codelab, allow queries on the main thread. // Don't do this on a real app! See PersistenceBasicSample for an example. .allowMainThreadQueries() .build(); } return INSTANCE; } publicstaticvoiddestroyInstance(){ INSTANCE = null; }}
Như vậy, mình đã hướng dẫn các bạn từng bước sử dụng Room database trong Android. Với Room database, nhưng thao tác đọc, ghi database trở lên dễ dàng hơn bao giờ hết.
Bạn có thấy như vậy không? Toàn bộ source code của bài hướng dẫn, các bạn download ở đây nhé. Download Complete Code
Hy vọng bài viết sẽ giúp các bạn làm được và hiểu chi tiết cấu trúc và làm các dự án nâng cao hơn sau này!
Kỹ năng lập trình không phải là thứ quan trọng nhất. Ở bất cứ ngành nghề nào, giao tiếp giữa người với người luôn luôn được đánh giá cao.
Khi trò chuyện với các project manager, bạn thỉnh thoảng sẽ nghe đến vài câu chuyện khủng khiếp về các lập trình viên mà họ từng làm việc chung.
Bạn được kể về những cử chỉ thô lỗ mà các lập trình viên đối xử với khách hàng, khiến cho các project manager hiếm khi dám mang các lập trình viên tham dự các cuộc họp của họ. Bạn cũng nghe về các lí do tồi tệ mà các lập trình viên đưa ra khi không hoàn thành một thứ gì đó cũng như việc trả lời khách hàng thô lỗ qua email.
Dù cho bạn có là lập trình viên hay đảm nhận bất cứ vị trí nào khác ở bất kỳ ngành nghề nào, điều này thực sự rất tồi tệ. Nó chắc chắn sẽ giới hạn khả năng của bạn, khiến bạn rất rất khó bức phá đến một vị trí cao cấp hơn. Có một kỹ năng giao tiếp tốt luôn luôn tốt hơn là chỉ có mỗi kỹ năng nghề nghiệp xuất sắc, và nó cũng cực kỳ giúp ích cho bạn để phát triển sự nghiệp bản thân sau này.
Nếu bạn có thể trở thành một người mà mọi người yêu quý, thì họ sẽ muốn làm việc chung với bạn, thuê và giới thiệu bạn với những đồng nghiệp hay những người quen khác, hay thậm chí dành cho bạn nhiều sự ưu ái, hay bất cứ gì khác hơn mà bạn không nghĩ đến. Họ cũng sẽ sẵn sàng nói ra những điều tốt đẹp về bạn khi bạn muốn phỏng vấn ở những nơi khác.
Bạn cần phải có kiến thức tốt, nhưng đừng chỉ dừng lại ở đây. Kỹ năng giao tiếp sẽ luôn là trụ cột quan trọng thứ hai cho sự nghiệp của hầu hết mọi người.
Một chiến lược quan trọng để mọi người lắng nghe bạn – đó chính là bạn cần học cách lắng nghe họ.
Bất kể bạn có nắm giữ tất cả thông tin quan trọng và đang đứng thuyết trình giữa 20 con người khác trong một cuộc họp, nếu bạn không lắng nghe họ, họ cũng sẽ không có nghĩa vụ phải lắng nghe bạn.
Phát triển phần mềm là một dự án nhóm – team work
Các team tồi tệ nhất là team có nhiều người nóng tính và hay hờn dỗi. Họ không sẵn sàng chia sẻ suy nghĩ hay cảm xúc của họ. Họ tổ chức các cuộc họp không cấu trúc, không kế hoạch. Các thành viên lười nói chuyện, lười lắng nghe. Ai cũng có công việc riêng và không sẵn sàng chia sẻ. Không có sự lắng nghe sẽ không có sự hiểu biết. Không có sự hiểu biết sẽ không có sự hợp tác.
Ở một chiều hướng ngược lại, các team tuyệt vời luôn có những điếm nhấn cá nhân và đoàn thể riêng. Mọi người chờ mong cuộc họp, ai ai cũng chuẩn bị tốt hết sức có thể. Cuộc họp làm cho họ cảm thấy tốt, được đánh giá cao, có giá trị và có sự lắng nghe. Điều đó làm cả team có động lực, thoải mái và vui vẻ. Bạn sẽ dễ dàng tìm thấy sự hài hước của các thành viên trong các team như thế này.
Nếu bạn muốn trở nên tốt và tốt hơn khi làm việc với team, lắng nghe là kỹ năng số một mà bạn cần thành thạo. Hãy lắng nghe một cách tích cực và đưa ra những câu hỏi thông minh.
Trở thành người chủ động lắng nghe
Nếu người bạn muốn nói chuyện cảm thấy thông điệp của họ được truyền tải, họ được lắng nghe và thấu hiểu, lúc đó họ sẽ cởi mở hơn khi lắng nghe những câu chuyện của bạn.
Trở thành một người biết chủ động lắng nghe là cách để bạn có được những gì bạn muốn.
Nếu muốn nhận được từ ai đó thứ gì, thì mình cần phải sẵn sàng cho người khác thứ mà họ cần.
Nói cách khác, bạn cần lắng nghe họ nếu bạn muốn họ giúp bạn điều gì đó. Thậm chí, khi bạn biết lắng nghe, họ sẽ giới thiệu một giải pháp tốt hơn với cái bạn nghĩ đến. Điều đó luôn luôn có thể xảy ra.
Điều quan trọng không phải ai là người có cái tôi lớn hơn, hay ai sẽ là người chiến thắng. Đó chính là quá trình làm việc hiệu quả và học hỏi lẫn nhau để trở nên tốt hơn. Bạn không bao giờ đạt được chúng nếu bạn cứ khư khư nghĩ rằng mình đã có toàn bộ câu trả lời mình muốn.
Một số nghiên cứu cho thấy có khoảng 60% những người tự cho mình là đúng thường có xu hướng đạt hiệu quả kém. Sự tự tin thái quá của họ đã ngăn cản việc thấu hiểu động lực của đối tác cũng như cả sự thành công của họ.
Nếu bạn nghĩ bạn biết tất cả, bạn là người đang thua cuộc.
Tôi càng học được nhiều bao nhiêu thì tôi lại càng nhận ra được mình thiếu hiểu biết bấy nhiêu. – Albert Einstein
Cuộc trò chuyện cũng như vậy. Bạn có thể nghĩ rằng bạn hiểu đối phương đang muốn gì, hay thậm chí có thể diễn giải mọi điều họ nói như minh chứng cho sự tự tin của mình. Nhưng hành vi này người ta gọi là thành kiến xác nhận – confirmation bias.
Wikipedia định nghĩa nó như sau:
Thành kiến xác nhận là xu hướng tìm kiếm, giải thích, ủng hộ cũng như nhớ lại thông tin theo cách tiếp cận, tự củng cố hay giả thuyết của bản thân. Nó là một kiểu thành kiến nhận thức.
Không có gì đặt một mối quan hệ bên bờ vực nguy hiểm nhanh hơn sự kém cỏi trong lắng nghe đối phương. Không mất quá nhiều thời gian để người khác nhận ra được thành ý của bạn khi nghe họ nói.
Bạn có biết chỉ có 7% thông điệp là những lời bạn nói hay không? (Nghiên cứu của giáo sư tâm lý học UCLA, Albert Mehrabian, phát hiện ra rằng 7% thông điệp được lấy qua từ ngữ, 38% qua ngữ điệu và 55% qua biểu cảm khuôn mặt hoặc ngôn ngữ cơ thể.)
Rất khó để thuyết phục người khác bạn đang lắng nghe họ trong khi bản thân bạn đang bán đứng chính mình.
Có một ranh giới giữa mỏng manh giữa lắng nghe để trả lời hay thấu hiểu.
Khi chúng ta lắng nghe để trả lời, chúng ta thường sẽ chăm chú tìm kiếm những sai sót trong ngôn từ của đối phương. Ngay khi chúng ta phát hiện ra một vài điều gì đó, cuộc trò chuyện sẽ bị gián đoạn, chúng ta trở nên như những con sói vồ vập xông vào cắn xé đối phương để bảo vệ niềm tin của mình.
Chúng ta ai cũng đều có thể làm như thế, và tôi cũng vậy. Cách duy nhất để ngăn chặn điều đó là ý thức được về nó.
Bạn sẽ bỏ lỡ rất nhiều thông tin giá trị nếu bạn xem nhẹ vấn đề này.
Chúng ta có một số mẹo nhỏ để vượt qua vấn đề, và khiến bạn dần trở nên một người biết tích cực lắng nghe.
Giữ trạng thái tò mò khi lắng nghe người khác trình bày, đừng vội giả định và đưa ra kết luận
Khi người kia nói, hãy lặp lại vài từ cuối cùng của họ. Làm điều đó với một giọng điệu tò mò, và giữ im lặng. Chỉ cần lặp lại ba từ cuối cùng và im lặng. Lặp đi lặp lại nhiều từ hơn sẽ khiến đối phương nghĩ bạn không hiểu và bắt đầu giải thích điều họ đang nói.
Bắt đầu câu hỏi với “Cái gì – What” và “Như thế nào – How“. Làm cách nào để chúng ta giải quyết vấn đề này? Bạn đã áp dụng các bước như thế nào để đạt được điều đó?…
Tránh bắt đầu câu hỏi với mệnh đề “Tại sao – Why“. Bạn liệu có nhớ khi còn bé, mẹ bạn bắt đầu la hét bạn: “Tại sao con lại phá đồ của mẹ?”. Khi lớn lên, bạn quay ra hỏi đồng nghiệp của mình: “Tại sao bạn lại sử dụng kiến trúc này?”, “Tại sao bạn không học thêm về lập trình web?”… Những câu hỏi như vậy đem lại cảm giác như lời buộc tội, kể cả khi bạn có ý định tốt. Tốt hơn hết, bạn nên đặt câu hỏi nào đó như: “Thư viện mà anh chọn có gì khác với những thư viện khác không?”, hoặc “Kiến trúc ABC có đặc điểm nào tốt hơn kiến trúc XYZ mà chúng ta thảo luận trước đó không?”…
Đừng sử dụng “Tôi hiểu – I understand” khi người khác đang giải thích. Nó giống như một lối tắt kém cỏi để thuyết phục người khác rằng bạn đang hiểu đúng hướng.
Cụm từ “Tôi hiểu – I understand” hay “Tôi biết rồi – I know” thường thường sẽ đi kèm với mệnh đề “Nhưng – But”. Đại loại nó mang ý nghĩa “Tôi hiểu rồi nhưng bạn vui lòng lắng nghe những gì tôi nói sau đây…“.
Khi người khác nói với bạn “Tôi hiểu”, thì thực sự họ dường như không có khái niệm gì về những vấn đề của bạn. Họ chỉ muốn bạn ngừng nói để họ có thể cho chúng ta biết ý kiến của họ. Họ mong đợi chúng ta nghĩ rằng mình đã được lắng nghe, nhưng họ đã làm tổn hại cuộc giao tiếp hơn họ nghĩ. Chúng ta không cần thiết phải làm điều đó.
Nếu bạn muốn cho người khác biết bạn đang tập trung lắng nghe, hãy sử dụng các từ mang tính chất xác nhận ngắn hạn, như “OK”, “Uhm”, “Ah”, “Vâng/Dạ – Yes”… Hoặc sử dụng các cụm câu “Có vẻ như bạn đang muốn…”, “Hình như điều này đang khiến bạn…”, “Dường như bạn đang khá thất vọng về…”. Đây là những cụm từ mang ý nghĩa hên xui, bạn có thể đúng hoặc sai. Quan trọng nhất, nó khiến ngươi khác thoải mái, do đối tượng hướng đến ở đây là họ, không phải nói về bạn. Thử đi rồi họ sẽ đưa lượt cho bạn.
Tóm tắt, tóm tắt, và tóm tắt. Sau khi bạn đã có được một bức tranh cơ bản về vấn đề và quan điểm của họ, bước tiếp theo là lặp lại cho họ hiểu “thế giới” của họ như thế nào.
Bạn sẽ đến lượt phát biểu của mình sau khi người khác nói với bạn: “Đúng rồi đấy – That’s right!”. Khi họ nói như vậy, bạn biết rằng bạn đã chốt và hiểu được một chút. Nhưng đừng nhầm lẫn khi họ nói “Anh đúng rồi – You’re right!”. Khi họ nói vậy có nghĩa là họ đang muốn thoát khỏi cuộc trò chuyện, và họ muốn bạn để họ một mình.
Khi bạn đã thể hiện được kỹ năng lắng nghe tích cực của mình, đây là lúc bạn bắt đầu trình bày quan điểm của bạn về vấn đề này. Và khi đối phương cảm thấy được bạn đã lắng nghe và hiểu được quan điểm của họ, họ sẽ sẵn sàng lắng nghe bạn hơn.
Họ cũng sẽ cởi mở hơn để hợp tác vào cuộc trò chuyện, thậm chí nhận định rằng cách của bạn là tốt nhất. Đó là mục đích của cuộc giao tiếp khi mà thành quả mọi người đạt được sẽ là “Win – Win”.
Trong thế giới lập trình, trách nhiệm lớn nhất của chúng ta không phải chỉ làm cho code chạy được, mà còn phải đảm bảo rằng các đoạn code mà chúng ta viết có thể dễ dàng kiểm tra và bảo trì trong một khoảng thời gian dài.
Tạm biệt dirty code trong lập trình JS
Khi chúng ta bước chân vào thế giới lập trình, chúng ta có thể thấy được những điều hữu ích mà nó đem lại cho hàng triệu người. Chỉ bằng việc thao tác với các đoạn code, lập trình đã giúp cho cuộc sống của chúng ta trở nên dễ dàng hơn.
Tuy nhiên, “năng lực lớn đi đôi với trách nhiệm lớn“. Trong thế giới lập trình, trách nhiệm lớn nhất của chúng ta không phải chỉ làm cho code chạy được, mà còn phải đảm bảo rằng các đoạn code mà chúng ta viết có thể dễ dàng kiểm tra và bảo trì trong một khoảng thời gian dài.
Có một số thói quen nhỏ trong lập trình có thể gây tác động tiêu cực liên tục đến code mà chúng ta viết và sản phẩm mà chúng ta tạo ra. Mình đã trải nghiệm những vấn đề này trực tiếp.
Hôm nay mình sẽ chia sẻ những vấn đề này và lý do tại sao bạn nên tránh chúng bằng mọi giá.
1. Sử dụng var thay vì let và const
Bạn nên chỉ sử dụng let và const bởi một vài lý do sau:
Scope rõ ràng hơn.
Nó không tạo ra các đối tượng global.
Với const – nó hiển thị lỗi ngay khi chúng ta cố gắng khai báo lại một biến.
// Sử dụng var:var x =10;if(true){var x =20;}
console.log(x);// Output: 20// Khi chúng ta sử dụng var, biến có thể được khai báo lại và ghi đè giá trị của nó trong cùng phạm vi.// Sử dụng let:let y =10;if(true){let y =20;}
console.log(y);// Output: 10// Khi chúng ta sử dụng let, biến chỉ có thể được khai báo lại trong cùng khối lệnh và không ghi đè giá trị của nó ở ngoài khối lệnh đó.// Sử dụng const:const z =10;
z =20;// Error: Assignment to constant variable.// Khi chúng ta sử dụng const, biến không thể được khai báo lại và không thể được ghi đè giá trị của nó.
Kể cả khi bạn muốn code của mình hoạt động ổn định với các trình duyệt cũ như IE11 thì bạn cũng không nên vứt bỏ nó. Hãy sử dụng let/const kèm với polyfill. Tuy vậy, 2023 rồi ai mà xài IE cũ nữa đâu, cả Microsoft cũng đã có kế hoạch xoá sạch IE rồi 😀
2. Dùng comments để mô tả code
Comments (hay chú thích) là một phần cơ bản trong quá trình xây dựng phần mềm, nó giúp chúng ta hiểu rõ hơn về đoạn mã mà chúng ta đang đọc.
Tuy nhiên, chúng ta không nên mắc phải sai lầm khi giải thích từng bước mà code của chúng ta đang làm, mà chúng ta phải tạo ra code dễ đọc. Comments chỉ nên cung cấp context (bối cảnh).
Tránh sự lặp lại trong comments của bạn. Đừng viết những gì bạn đang làm, hãy viết lý do tại sao bạn làm nó.
Hãy đặt các tên biến/function/class mô tả một cách rõ ràng công việc của chúng, thay vì ngồi viết một đống comments.
Hãy cố gắng viết code rõ ràng và clean hết sức có thể. Hãy nhớ, không phải code càng ngắn càng tốt, mà code rõ ràng, sạch sẽ, dễ thay đổi, dễ quản lý mới là tốt.
Viết comments rõ ràng, tốt nhất là cùng một ngôn ngữ (tiếng Anh, tiếng Việt…). Đừng viết chỗ này tiếng Anh, chỗ kia tiếng Việt, chỗ khác lại phang tiếng Trung Quốc vô 😀
Comments nên súc tích, gọn gàng. Theo thời gian, comments thường không được bảo trì, code lại thay đổi thường xuyên.
3. Sử dụng so sánh bằng (==) thay vì so sánh bằng nghiêm ngặt (===)
Mặc dù chúng có vẻ rất giống nhau về hình thức, tuy nhiên chúng lại có những điều khác nhau về cách hoạt động.
Toán tử so sánh bằng (==) sẽ cố gắng chuyển đổi các phần tử so sánh về cùng kiểu, sau đó thực hiện so sánh xem có giống nhau hay không. Điều này có thể gây ra một vài lỗi vớ vẩn không đáng có.
So sánh bằng nghiêm ngặt (===) luôn kiểm tra xem các toán hạng có các kiểu dữ liệu và giá trị khác nhau hay không.
Nên tránh sử dụng toán tử so sánh bằng (==) vì nó có thể gây ra các kết quả không mong muốn khi các phần tử so sánh có kiểu dữ liệu khác nhau. Nếu bạn sử dụng toán tử so sánh bằng nghiêm ngặt (===), bạn sẽ có thể kiểm tra xem các phần tử so sánh có giống nhau hoàn toàn không, bao gồm cả kiểu dữ liệu của chúng.
let x =5;let y ="5";
console.log(x == y);// true
console.log(x === y);// false
console.log([]==0);// true
console.log([]===0);// false
4. Không sử dụng optional chaining
Toán tử optional chaining (?) cho phép chúng ta đọc giá trị của một thuộc tính nằm sâu trong chuỗi các đối tượng liên kết mà không cần phải kiểm tra từng tham chiếu trong chuỗi đó.
Chúng ta nên sử dụng optional chaining trong các tình huống khi chúng ta không chắc chắn rằng một thuộc tính nào đó tồn tại trong đối tượng hoặc nó có giá trị là gì.
Sử dụng optional chaining giúp chúng ta tránh được những lỗi không mong muốn khi truy cập vào một thuộc tính không tồn tại, đồng thời cũng làm cho mã của chúng ta trở nên ngắn gọn và dễ đọc hơn.
6. Truyền nhiều params vào function hay một single object chứa các params?
Việc truyền nhiều tham số hay truyền một đối tượng chứa nhiều tham số vào một hàm sẽ phụ thuộc vào từng trường hợp cụ thể và cách tiếp cận lập trình của từng người.
Tuy nhiên, khi truyền một đối tượng chứa nhiều params vào một hàm thì có thể giúp cho code dễ đọc hơn và dễ bảo trì hơn.
Ví dụ, việc truyền một đối tượng options vào hàm render() của một component có thể giúp cho việc hiểu rõ hơn những thiết lập khác nhau được truyền vào thành phần đó. Điều này thậm chí còn tốt hơn nếu chúng ta dùng kèm với Typescript.
Ngoài ra, việc truyền một object có thể giúp tránh tình trạng quên truyền params hoặc truyền params sai vị trí. Tuy nhiên, khi quá nhiều tham số được truyền vào một object, code có thể trở nên khó hiểu và khó bảo trì.
Do đó, cần cân nhắc và sử dụng phương pháp phù hợp với từng trường hợp cụ thể để có được code dễ đọc, dễ bảo trì và dễ mở rộng.
Chúng ta đã từng gặp tình huống kiểm tra xem một biến có tồn tại hay không hoặc nó có chứa giá trị khác với null hoặc undefined không. Vì thế, chúng ta thường phải thực hiện kiểm tra rất dài như thế này:
if(x !==''&& x !==null&& x !==undefined){// Do something}
Có một cách viết đơn giản và trang nhã hơn như sau:
if(!!x){// Do something}
Clean hơn nhiều đúng không 😀
Túm cái váy lại
Viết code sạch luôn là trách nhiệm của chúng ta. Mình đã học được rằng việc có một code dễ bảo trì và dễ đọc sẽ tiết kiệm được rất nhiều giờ làm việc cho bạn và team của bạn.
Hãy nhớ rằng chúng ta dành nhiều thời gian để đọc code hơn là viết code. Mình hy vọng những mẹo nhỏ này sẽ giúp cho bạn tạo ra những sản phẩm tuyệt vời và kỳ diệu.
Bài viết được sự cho phép của tác giả Lê Nhật Thanh
Target của bài viết: Những bạn muốn trở thành Senior backend developer hoặc mong muốn tìm hiểu CQRS là gì.
Một số thuật ngữ mình dùng trong bài viết các bạn có thể search thêm cụ Google để nắm hơn:
High availability: Một hệ thống website có tính sẵn sàng cao. Hoạt động liên tục 24/7 trong mọi điều kiện, kể cả khi có sự cố xảy ra.
High consistency: Tính nhất quán về dữ liệu, tất cả request của user đều thấy được dữ liệu mới nhất nếu nó được update.
Trade-off: Đánh đổi khi thiết kế hệ thống lớn
GIỚI THIỆU MỘT CHÚT TRƯỚC KHI TÌM HIỂU CQRS LÀ GÌ
Bài viết này rất dài, có thể sẽ mất của bạn vài chục phút đến vài giờ để đọc và hiểu nội dung. Nhưng nó sẽ rất đáng nếu bạn bỏ ra từng ấy thời gian vì những gì bạn sẽ thu lại được. Mình đã cố gắng viết nó ra thì bây giờ đến lượt bạn, cố gắng đọc hiểu nó và góp ý thêm cho mình nha.
Let’s go!
ĐIỂM XUẤT PHÁT: MÔ HÌNH TRUYỀN THỐNG VÀ THÁCH THỨC
Trước khi bắt đầu khám phá CQRS là gì, hãy xem xét một ứng dụng ví dụ sử dụng mô hình truyền thống (ví dụ MVC). Chúng ta sẽ sử dụng một dự án Rest API service với Java và Spring Boot framework.
MÔ HÌNH TRUYỀN THỐNG (VÍ DỤ SỬ DỤNG MVC)
Ở mức đơn giản, chúng ta thường có một cấu trúc thư mục quen thuộc với các tầng như Controller, Service, Repository và Model.
Trước khi vào bài thì mình có một yêu cầu nhỏ. Các bạn phải từng làm qua một framework backend rồi nha. Ví dụ NestJs, Laravel, .Net MVC hay gì cũng được. Hoặc các bạn đã nắm được về kiến trúc MVC. Hiểu thế nào là view, model, controller, repository, service, …
Trong bài viết này, mình sẽ lấy ví dụ với Java (Spring boot framework). Các bạn cũng đừng lo lắng. Vì nếu các bạn nắm được MVC rồi hoặc 1 trong các backend framework. Thì chúng ta cũng không cần quan tâm tới ngôn ngữ mình thể hiện trong bài viết nữa. Đừng quá phụ thuộc vào chúng, hãy cố gắng nắm được nội dung và hiểu nó.
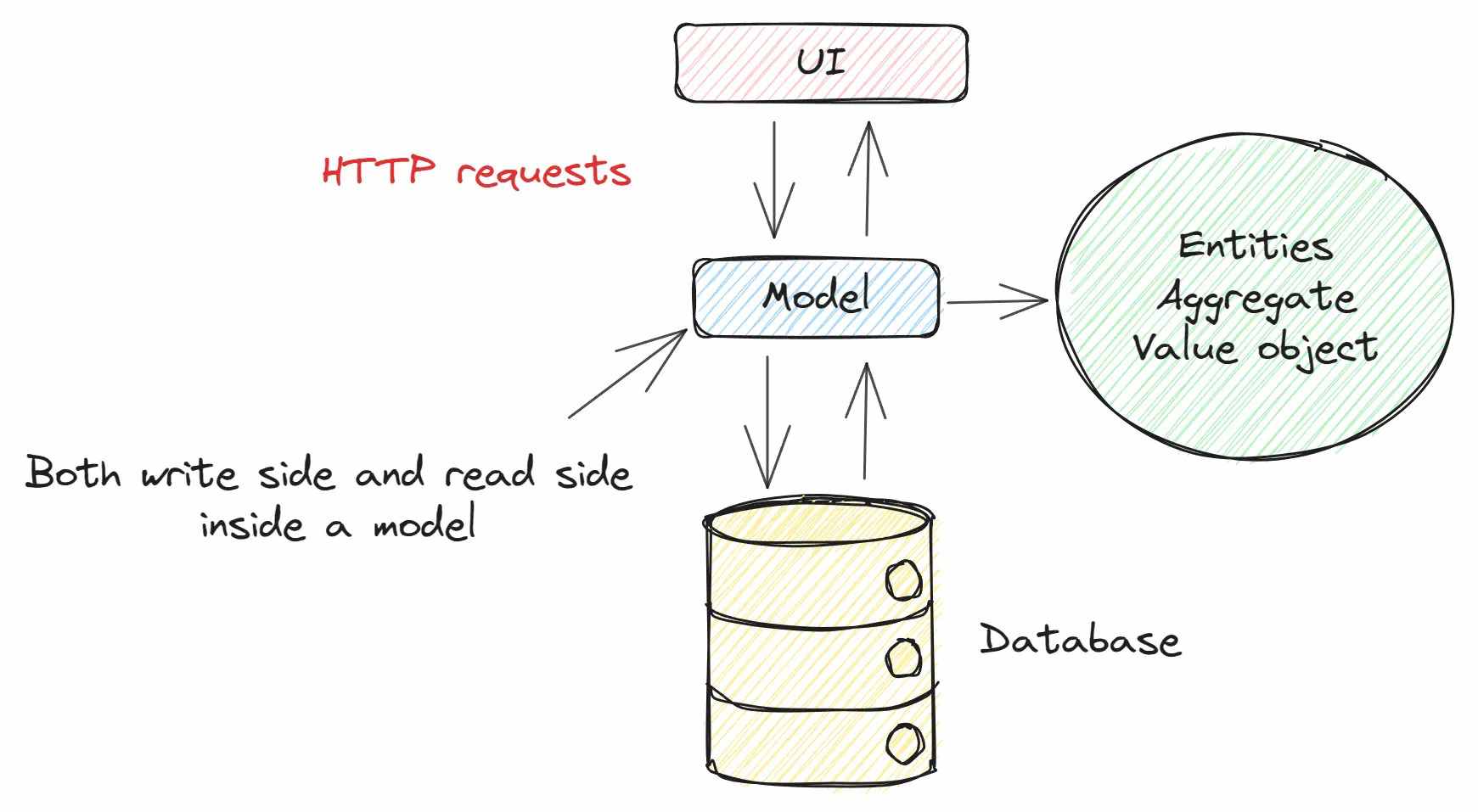
Chúng ta sẽ tập trung vào tầng Model trước! Nếu bạn đã làm việc với hệ thống Backend thì bạn cũng đã thao tác rất nhiều với các Model.
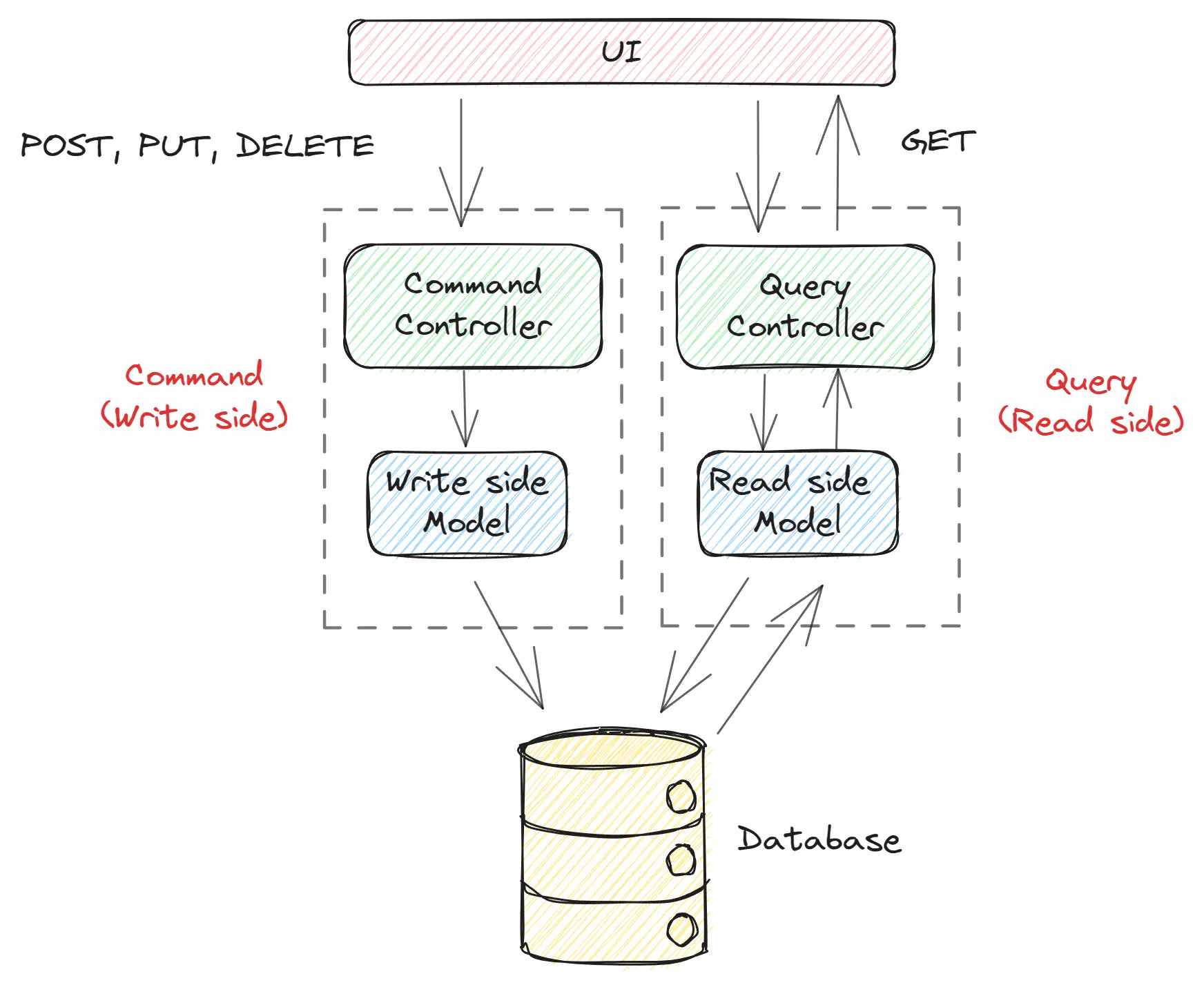
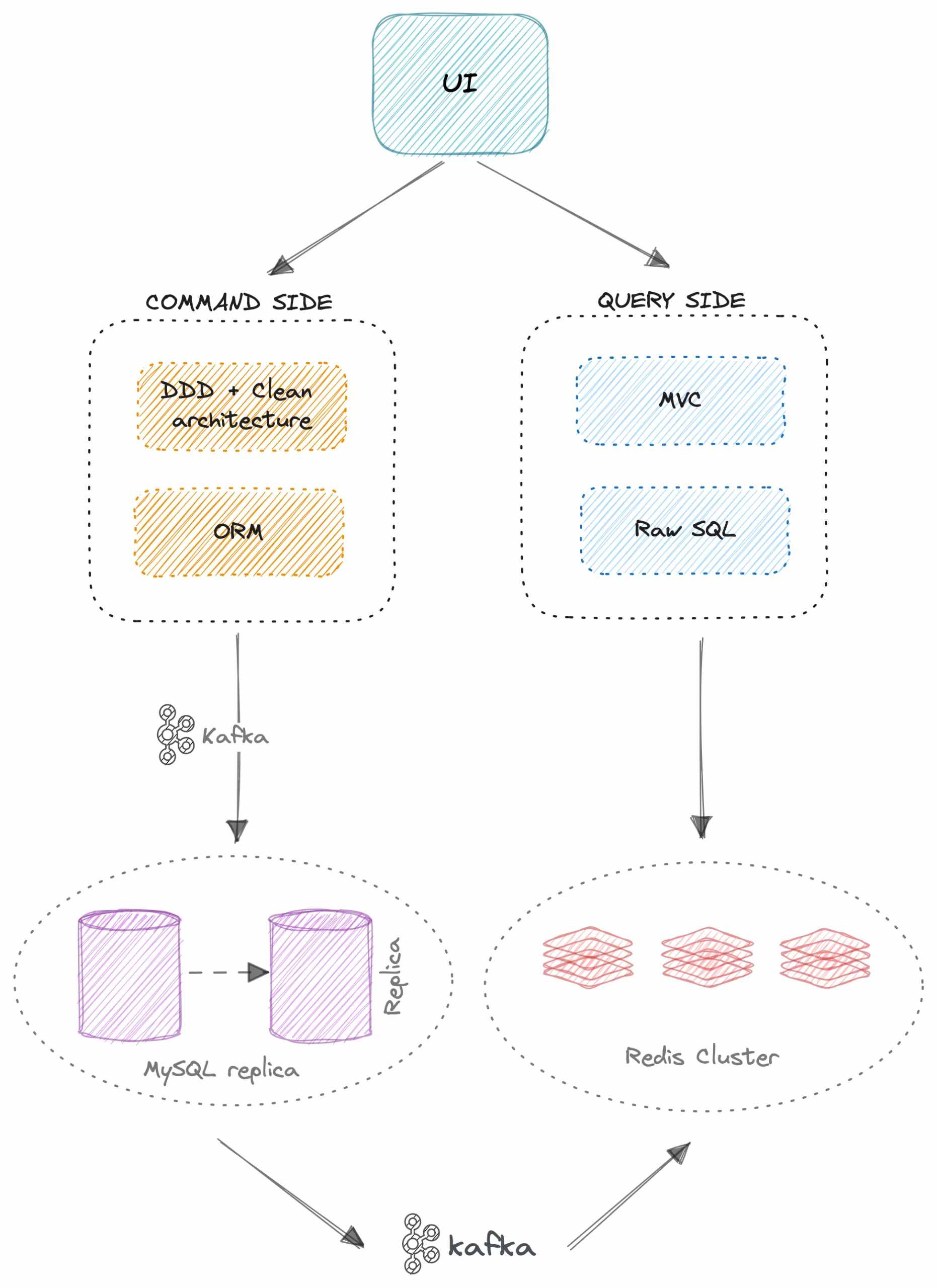
À, từ đây đến hết bài viết, mình sẽ chia các HTTP request thành 2 loại:
Write side – hay còn gọi là Command side: Bao gồm tất cả các request chỉnh sửa vào database (POST, PUT, DELETE request)
Read side – hay còn gọi là Query side: Bao gồm tất cả các request dùng để lấy dữ liệu từ database (GET request)
Lưu ý là mình sẽ sử dụng 2 từ read side và write side trong xuyên suốt bài viết.
ĐI VÀO CODE MỘT CHÚT
Ok, mình sẽ lấy ví dụ triển khai một ứng dụng web báo điện tử. Ví dụ như VnExpress hay 24h,…
Giả sử mình có một model Article. Và khi các bạn thực hiện các API như createArticle, updateArticle, deleteArticle, getArticleById, getAll, … thì bạn vẫn cứ phải thao tác với model Article.
Ví dụ vào code nha. Lưu ý là chúng ta chỉ quan tâm hàm create thôi nha.
Chúng ta có một cấu trúc thư mục cực kì quen thuộc với hầu hết các bạn.
Các bạn có thể đọc lướt qua cũng được. Vì các bạn đã quá quen thuộc với kiểu viết API backend như vậy.
// ArticleController.java@RestController@RequestMapping("/api/v1/articles")@AllArgsConstructorpublicclassArticleController{privateArticleServiceInterface articleService;@PostMapping@ResponseStatus(HttpStatus.CREATED)publicvoidcreate(@RequestBodyArticleDto article){
articleService.create(article);}// Một số API khác như update, delete, getAll, getById, getByAuthor, ....}
// ArticleService.java@AllArgsConstructor@ServicepublicclassArticleService{privateArticleRepository articleRepository;privateUserRepository userRepository;publicvoidcreate(ArticleDto articleRequest){Optional<User> user
= userRepository.findById(articleRequest.getUserId());if(user.isEmpty()){thrownewUserNotFoundException("APPLICATION-ERROR-0001");}Article article =newArticle(
UUID.randomUUID().toString(),
articleRequest.getTitle(),
articleRequest.getContent(),
user.get().getId(),
articleRequest.getSummary(),
articleRequest.getThumbnail(),
articleRequest.getSlug(),// ...);
articleRepository.save(article);}// Một số API khác như update, delete, getAll, getById, getByAuthor, ....}
Repository trong Spring Boot thì khá lạ. Vì bạn chẳng thấy các method CRUD (create, read, update, delete) đâu cả. Vì ở đây Repository đang được kế thừa JpaRepository của Spring Data JPA trong Spring Boot. Và trong interface đó đã có hết toàn bộ những method CRUD và mở rộng hơn.
Bây giờ chúng ta sẽ đi qua model chính trong ứng dụng đơn giản này.
// ArticleEntity.java@AllArgsConstructor@NoArgsConstructor@Data@Builder@Entity@Table(name="articles")publicclassArticleEntityimplementsSerializable{@Serialprivatestaticfinallong serialVersionUID =6009937215357249661L;@Id@Column(nullable =false, unique =true, length =100)privateString id;@Column(nullable =false)privateString title;@Column(columnDefinition ="TEXT", length =20000)privateString content;@ManyToOne(fetch =FetchType.LAZY)privateUserEntity user;@Column(columnDefinition ="TEXT", length =1000)privateString summary;@Column(nullable =false, unique =true)privateString thumbnail;@Column(nullable =false, unique =true, length =100)privateString slug;// Một số properties khác nữa// ...// Bên dưới là business logic// Ví dụ: Slug chỉ được phép chứa các kí tự a-z, A-Z và dấu _}
Ở trên đây, model Article của chúng ta làm tới 2 nhiệm vụ là mapping với một ORM để thao tác trực tiếp với database table. Và nhiệm vụ thứ 2 là lưu trữ state (trạng thái) của hệ thống. Ở đây là lưu trữ state của một Article trong vòng đời của một request.
Model trong một ứng dụng enterprise sẽ làm khá nhiều nhiệm vụ:
Lưu trữ trạng thái (như mình nói ở trên)
Mapping với database (cũng giống mình nói ở trên)
Cái tiếp theo là thông thường trong model sẽ chứa business logic. Mà business logic của những model lớn thường sẽ rất phức tạp. Về thuật ngữ business logic (hay domain logic, hay nghiệp vụ) thì các bạn có thể search google để biết nha. Cái này cũng khá là dễ hiểu.
Rõ ràng chúng ta chỉ có một model Article. Vì vậy các thao tác read side và write side đều phải thao tác qua model này.
Nghĩa là một model sẽ phải chứa tất cả business logic cho cả CRUD. Và khi ứng dụng càng lớn, business logic càng nhiều. Và thay đổi càng nhiều thì sẽ khiến cho model càng ngày càng phức tạp. Kể cả các tầng khác như Controller, Service, hay Repository cũng sẽ phức tạp hơn rất nhiều. Codebase lúc này sẽ phình to ra và dẫn tới việc bảo trì và mở rộng khó khăn hơn.
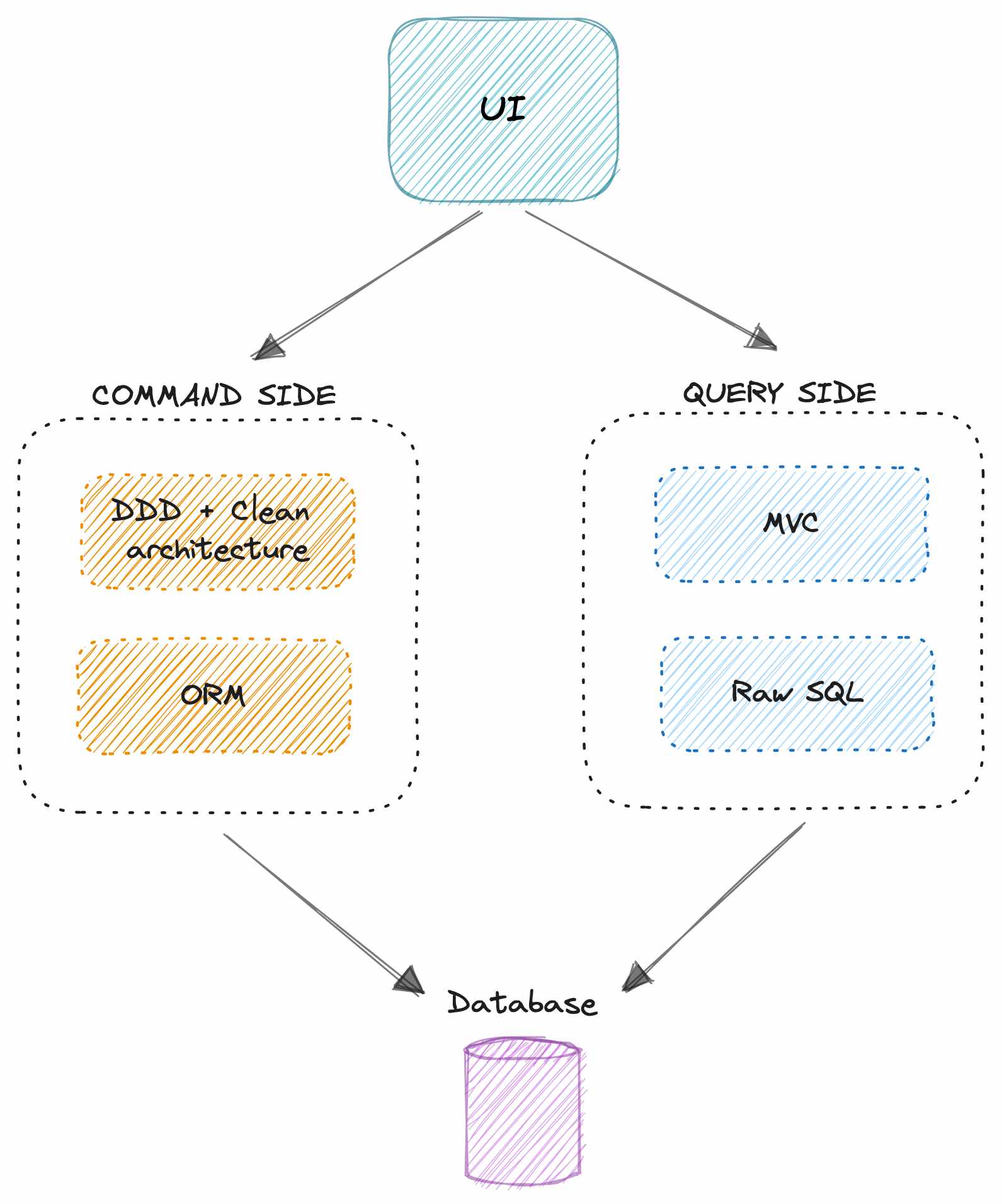
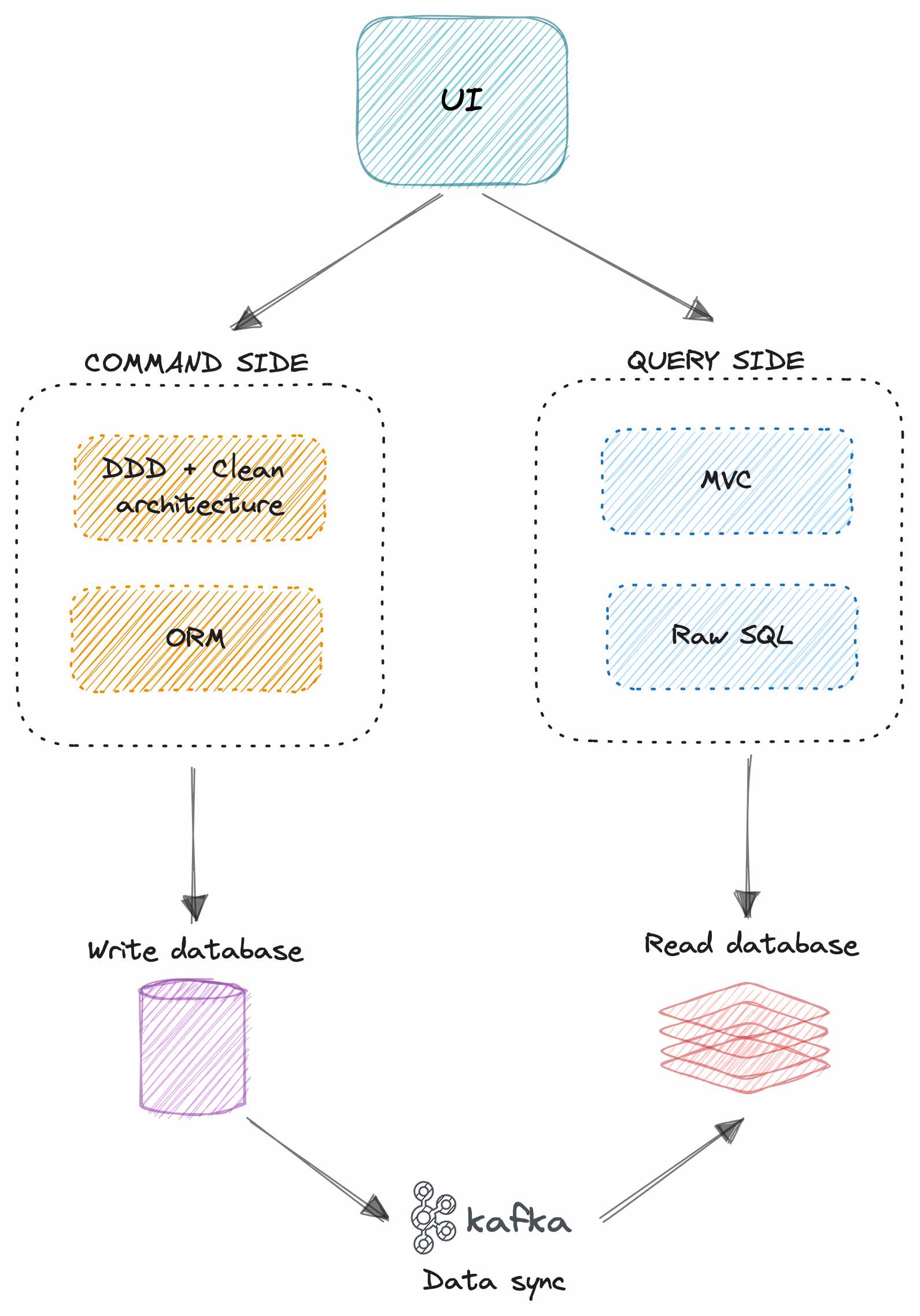
ĐẶC BIỆT LÀ KHI BẠN SỬ DỤNG ORM ĐỂ TƯƠNG TÁC VỚI DATABASE
Write side: Khi bạn thực hiện các API write side (create, update, delete) thì bạn dùng ORM để mapping database khá là đơn giản. Ví dụ create thì lưu 1 lần xuống toàn bộ thông tin của entity (ứng dụng lớn thì lưu cả cụm aggregate). Vì vậy thao tác về mặt code sẽ khá tường minh và đơn giản (cho dù có liên kết n-n hay 1-n,…).
Read side: Câu này mình sẽ nhắc nhiều trong bài viết: Ở read side thì số lượng use case (có thể coi 1 use case là 1 API đi cho dễ) sẽ vô cùng nhiều và đặc biệt khó dự đoán được. Ví dụ một số use case
Lấy danh sách bài viết cùng với summary để hiển thị ở khu vực recommend hoặc homepage (chỉ lấy title, thumbnail, summary)
Lấy danh sách bài viết của một tác giả (chỉ lấy title, thumbnail, summary)
Lấy danh sách bài viết trong tháng này.
Lấy danh sách bài viết có lượng truy cập cao trong (ngày, tuần, tháng, …)
Lấy danh sách bài viết theo category, kết hợp với ngày tháng, tác giả, …
v/v (còn rất nhiều use case khác nữa)
CHO NÊN
Khi bạn dùng ORM đối với rất nhiều use case như vậy và tương tác với chỉ một entity Article thì toang. Business logic trong model này sẽ trở nên phức tạp. Chưa nói là phải join tùm lum bảng (kết hợp nhiều entity). Và chưa nói tiếp tới vụ dư thừa dữ liệu và phức tạp khi join các bảng mà dùng ORM.
Và code base ở các file service, controller, repository cũng sẽ trở nên phức tạp theo. Vì có nhiều use case mà như mình có nói hồi nảy.
Và khi đó, đôi khi chúng ta phải thực hiện query thuần cho những API bên read side.
DƯ THỪA DỮ LIỆU
Trước khi mình nói về vấn đề dư thừa dữ liệu. Thì mình muốn nói thêm một ý khá quan trọng:
Write side chúng ta thường tao tác với hầu hết các field (trường dữ liệu) trong model (entity). Ví dụ tạo một article thì chúng ta sẽ thao tác gần như tất cả các field trong một entity. Nhưng read side thì không như vậy, đôi khi chỉ thao tác với một vài trường dữ liệu trong một entity. Hoặc kết hợp nhiều entity với nhau (join nhiều bảng một lần) – như mình nói ở các use case read site ở trên.
Ngoài ra thì hầu hết các hệ thống web application, các request read side thường chiếm phần lớn trong hệ thống. Ví dụ một trang thương mại điện tử, người bán hàng tạo một sản phầm và publish nó (write side). Và người bán chỉ tạo một lần đó thôi, còn lại hầu hết các request từ user khác đến sản phẩm đó là read side, ví dụ xem chi tiết sản phẩm, sản phẩm tương tự, search, …
Cũng vì lý do read side và write side đều được xử lý thông qua một model duy nhất. Nên đôi khi sẽ làm chúng ta bị dư thừa dữ liệu, đặc biệt ở read side.
Giả sử ArticleEntity ở trên có khoảng vài chục trường dữ liệu (ở trên thì mình chỉ lấy ví dụ có vài trường dữ liệu thôi). Thì khi chúng ta thực hiện tạo mới một article, thì rõ ràng khá bình thường, chúng ta sẽ lưu cả entity xuống database (cùng với đó là thêm thông tin userId để biết đang của tác giả nào).
Nhưng khi ở read side, giả chúng ta chỉ lấy vài trường dữ liệu để hiển thị. Nhưng chúng ta phải query hết toàn bộ dữ liệu rồi map vào entity. Và rồi loại bỏ dữ liệu dư thừa rồi trả ra view cho user. Và như mình nói thì ở read side rất đa dạng các kiểu get dữ liệu lên. Mà mỗi lần get dữ liệu lên lại phải get hết thông qua entity thì bị dư thừa (còn tạo nhiều model khác ứng với mỗi trường hợp get dữ liệu thì codebase sẽ loạn lên). Hoặc là kiểu join nhiều bảng, ráp một ít dữ liệu của entity này và một ít dữ liệu của entity khác. Tình trạng dư thừa dữ liệu khi get data lên (rồi mapping thông qua ORM) là rất nhiều.
KHẢ NĂNG CHỊU TẢI KÉM
Chúng ta chỉ thao tác với một database duy nhất nên việc khả năng chịu tải kém lá đúng. Đột nhiên một lúc nào đó, hàng triệu request read side tới hệ thống thì hệ thống sẽ tạch ngay. Cho dù bạn có scale hệ thống bằng cách như tăng cấu hình phần cứng, load balancing, … thì request cao vẫn sẽ tạch, vì database connection lúc này rất nhiều. Database lúc này sẽ trở thành điểm bottlenecks (nút thắt cổ chai).
Ở ngay đây (hơi ngoài lề một chút), nhiều bạn sẽ cho rằng, chúng ta sẽ dùng một cache server để handle.
Và thông thường các bạn chưa có kinh nghiệm sẽ triển khai một ứng dụng với Cache database như thế này.
Ở read side, khi có request tới cache, nếu không có trong cache (miss cache) thì chui xuống database để lấy thông tin. Cách này, cũng tạm được, sẽ giảm tải được khá nhiều cho database, nhưng ở ngoài hệ thống lớn, người ta không làm như vậy.
Lý do là vì: khi hàng triệu use truy xuất tới một endpoint bị miss cache và đều chui xuống database thì trường hợp này cũng sẽ tạch. Ví dụ mấy sàn thương mại điện tử vào dịp 9/9 hay 10/10 tổ chức flash sale. Thì các trường hợp hàng triệu user truy cập vào một endpoint là điều bình thường.
Cho nên triển khai như vậy sẽ không hợp lý đối với một hệ thống real world.
Nói cách dễ hiểu hơn! Thì read side và write side được tách biệt hoàn toàn không còn dính tới nhau nữa. Khác hoàn toàn với cách xử lý truyền thống ở trên.
Và bên write side người ta gọi là command, bên read side người ta gọi là query.
Biết được CQRS là gì rồi, tiếp thôi nào!
LỢI ÍCH CỦA CQRS LÀ GÌ?
Tăng khả năng mở rộng: CQRS cho phép các command và query được xử lý riêng biệt. Điều này có thể giúp tăng khả năng mở rộng của hệ thống.
Tăng hiệu suất: CQRS có thể giúp tăng hiệu suất của hệ thống bằng cách cho phép các command và query được xử lý theo cách tối ưu nhất cho từng loại.
Tăng khả năng bảo trì: CQRS có thể giúp tăng khả năng bảo trì của hệ thống bằng cách tách biệt các command và query. Điều này có thể giúp các anh dev dễ dàng sửa đổi hoặc nâng cấp hệ thống hơn.
Tăng khả năng tái sử dụng: CQRS có thể giúp tăng khả năng tái sử dụng của hệ thống bằng cách tách biệt các command và query. Điều này có thể giúp các dev dễ dàng reuse lại các thành phần trong hệ thống
Những lợi ích ở trên đây mình chỉ tóm tắt thôi.
Để biết chi tiết hơn về lợi ích của CQRS là cái gì. Thì chúng ta đi sâu hơn một chút nhé.
ĐƠN GIẢN HOÁ CODEBASE GIÚP HỆ THỐNG DỄ BẢO TRÌ VÀ MỞ RỘNG
Nếu doanh nghiệp nghèo chỉ có tiền thuê được một server database. Thì chúng ta vẫn sẽ áp dụng CQRS để đơn giản hoá codebase trước.
Bây giờ chúng ta sẽ tổ chức cấu trúc thư mục lại áp dụng CQRS nha. Tổ chức cấu trúc thư mục là hoàn toàn linh hoạt đối với từng project và từng team. Nên đối với CQRS sẽ có khá nhiều cách tổ chức cấu trúc thư mục. Mình thì muốn tách ra hoàn toàn thành 2 phần khác nhau.
Các bạn có thể tách ra thành 2 repository (github) hoàn toàn tách biệt luôn.
com.lenhatthanh.blog.query/|-- controller/||--ArticleController.java (all get requests)| `--...|-- service/||--ArticleService.java
| `--...|-- repository/||--ArticleRepository.java (ở đây có thể sử dụng query thuần)| `--...
`-- model/|--Các Model tương ứng với từng use case
`--...
Khi apply CQRS, số lượng file có thể sẽ tăng lên, nhưng đó không phải là vấn đề. Vì lúc này code base đã được tách ra thành 2 phần riêng biệt. Code base lúc này rất dễ bảo trì và mở rộng.
TỐI ƯU HÓA CODE BASE WRITE SIDE
Đương nhiên rồi! chúng ta sẽ sử dụng ORM ở write side là quá tuyệt vời (dễ code, dễ bảo trì và cực kì tường minh).
Và đối với ứng dụng enterprise, chúng ta có thể dùng Domain Driven Design để có thể tập trung toàn bộ business phức tạp lại một chổ (ở core domain). Để ứng dụng có thể dễ dàng mở rộng về mặt codebase khi business thay đổi hoặc tăng lên phức tạp. Ngoài ra chúng ta có thể kết hợp thêm Clean Architecture để có một cấu trúc code base tốt hơn. Nhưng không phải bạ đâu cũng dùng nha các bạn.
Ngoài ra ORM còn giúp chúng ta nhiều thứ hơn như về ngăn chặn các vấn đề security (như SQL injection,…).
TỐI ƯU HÓA CODE BASE READ SIDE
Như mình đã nói thì số lượng request và use case ở đây cực kì phức tạp. Nên chúng ta có thể dùng query thuần (không dùng ORM) ở phần read side (trong trường hợp ứng dụng của bạn chỉ có một database ví dụ MySQL). Khi sử dụng query thuần thì code sẽ đở phức tạp đi rất nhiều so với dùng ORM ở read side. Bạn có thể thử dùng ORM và join nhiều bảng cùng với mỗi bảng thì lấy một ít dữ liệu sẽ thấy ngay vấn đề.
Sau khi tối ưu về mặt codebase như trên thì chúng ta sẽ có một thiết kế như sau:
Nhưng trên thực tế. Nếu đã apply CQRS thì ít ai chỉ tối ưu về mặt codebase mà không tối ưu về mặt database và server. Vì tối ưu về khả năng chịu tải là một vấn đề lớn nếu apply kiến trúc ở trên.
SCALE VỀ MẶT DATABASE VÀ SERVER KHI SỬ DỤNG CQRS
Khi sử dụng CQRS pattern, chúng ta có thể tách riêng hoàn toàn ra 2 server riêng biệt là Write side server và read side server. Và ứng với mỗi side, chúng ta sẽ có database riêng biệt.
SCALE ĐỘC LẬP VỚI NHAU NẾU LƯỢNG REQUEST TĂNG LÊN ĐỘT BIẾN
Bởi vì thông thường lượng request ở Read side chiếm phần lớn, nên bạn sẽ dễ dàng scale server (phần cứng hoặc instance nếu sử dụng cloud services) ở Read side. Ví dụ tăng cấu hình server lên hay tăng số lượng server lên. Hoặc sử dụng database chuyên dụng cho read data như Redis, mongoDB
Còn bên write side thì cũng có thể scale độc lập như vậy.
TỐI ƯU HOÁ PHẦN CỨNG CHO MỖI SERVER
Chúng ta có thể lắp các loại ổ cứng, ram chuyên cho đọc hay ghi tương ứng ở mỗi server read hay write (on-premise). Còn nếu chúng ta sử dụng cloud service có thể dễ dàng lựa chọn các service phù hợp cho mỗi side của ứng dụng.
SAU KHI SCALE XONG THÌ CHÚNG TA SẼ CÓ DESIGN SAU
Ở hình trên mình đã dùng Kafka (một message queue) để có thể sync data bất đồng bộ từ write side sang read side.
Và ví dụ bên dưới sẽ cho các bạn thấy mình sẽ dễ dàng scale hệ thống như thế nào. Ở design dưới thì mình scale về database là chính.
Mình có design một message queue (mình dùng Kafka) ngay trước khi ghi dữ liệu vào write database. Bởi vì lý do là nếu chạy đồng bộ (sync) thì ngay write database sẽ dễ trở thành một nút thắt cổ chai khi lượng request write tăng đột biến.
Ở write database thì mình dùng một Replica database. Và coi như là một backup trong trường hợp server bị chết.
Một message queue để đồng bộ dữ liệu từ write database sang read database.
Ở read database nếu lượng request quá nhiều và dữ liệu quá lớn. Thì mình có thể design nó thành một hệ thống database distributed (phân tán) để chịu tải tốt hơn và high availability hơn.
Ngoài ra chúng ta cũng có thể sử dụng K8S auto scaling instance cho ứng dụng của mình đặc biệt bên read side cho hệ thống ở trên.
Tới đây thì chúng ta đã biết CQRS là cái gì rồi. CQRS hay như thế đấy! Nhưng vẫn sẽ có một vài điểm đánh đổi (trade-off). Chúng ta cùng tìm hiểu tiếp.
VẤN ĐỀ KHI ÁP DỤNG CQRS
TÍNH NHẤT QUÁN VỀ DỮ LIỆU (DATA CONSISTENCY)
Đây chính là một loại đánh đổi (trade-off) khi chúng ta triển khai các hệ thống lớn.
Đây có thể xem là vấn đề lớn nhất khi áp dụng CQRS. Hay những pattern khác mà sử dụng event driven architecture (sử dụng Kafka đó bạn). Bởi vì data được sync bất đồng bộ từ write side lên read side nên dữ liệu sẽ không nhất quán (inconsistency).
Khi dữ liệu được tạo hoặc update bên write side. Thì đôi khi phải mất một khoảng thời gian nhất định thì dữ liệu đó mới sync qua được read side. Nhất là trong những lúc cao điểm, request tăng cao dẫn tới server chịu tải nhiều hơn.
BÂY GIỜ CHÚNG TA SẼ NÓI MỘT CHÚT VỀ TRADE-OFF
Nếu chúng ta muốn dữ liệu consistency (nhất quán). Nghĩa là dữ liệu bên write side update sao thì tất cả các request bên read side luôn trả về dữ liệu mới nhất. Thì ở đây chúng ta có thể sử dụng cơ chế sync (đồng bộ) thay vì async (bất đồng bộ). Ví dụ như sử dụng Rest API để sync dữ liệu luôn. Như vậy chúng ta sẽ có dữ liệu high consistency. Nhưng chúng ta sẽ phải đánh đổi thời gian response ở write side. Và khi lượng request tăng cao có thể dẫn tới server quá tải và không thể handle request. Dẫn tới tính availability sẽ thấp xuống.
Và đương nhiên ngược lại, nếu chúng ta muốn high availability thì phải đánh đổi với consistency.
Tùy vào business của hệ thống mà chúng ta (là những engineer) lựa chọn về việc đánh đổi khi triển khai hệ thống lớn.
Đối với một số hệ thống không cần yêu cầu về tính chất consistency tuyệt đối như báo điện tử (24h, VnExpress), media,… Chúng ta có thể đặt tính availability lên trên consistency và có thể sử dụng design ở hình trên. Lúc này chúng ta sẽ có khái niệm eventual consistency (nghĩa là không hoàn toàn nhất quán).
PHỨC TẠP HOÁ VÀ CHI PHÍ CAO
Câu mình muốn nói là: Không phải lúc nào cũng apply CQRS nếu không muốn tăng độ phức tạp của project.
Các bạn có thể thấy những hình ở trên, để triển khai một hệ thống lớn áp dụng CQRS và event driven architecture (và những pattern khác). Thì mọi thứ sẽ phức tạp hơn rất nhiều từ việc nhân sự, đội ngũ, đến cách tổ chức code. Và đặc biệt là hệ thống server sẽ nhiều hơn.
Hệ thống server nhiều (service nhiều) sẽ đi kèm với độ phức tạp cũng tăng lên rất nhiều. Như khi chúng ta monitor, xử lý, khôi phục hệ thống khi lỗi, … Vâng, và đó cũng là một kiểu trade-off cho chúng ta.
Thiết kệ hệ thống lớn, chúng ta phải đưa ra lựa chọn!
TÚM CÁI VÁY LẠI!
Trong hành trình khám phá CQRS là gì này, chúng ta đã thấy những ưu và nhược điểm của mô hình này. CQRS không phải là một giải pháp đối với tất cả các ứng dụng. Nhưng nó có thể là lựa chọn mạnh mẽ cho những ứng dụng đòi hỏi hiệu suất cao và tính mở rộng.
Nhớ rằng, quá trình triển khai CQRS có thể phức tạp, nhưng nếu được thực hiện đúng cách. Nó có thể đem lại lợi ích lâu dài cho sự phát triển và bảo trì của ứng dụng. Hãy cân nhắc kỹ lưỡng và kiểm soát mỗi quyết định để đảm bảo rằng CQRS phản ánh đúng nhu cầu của dự án của bạn.
Chúc các bạn thành công trong việc xây dựng các hệ thống mạnh mẽ và linh hoạt!
À còn một ý nữa. Khi bạn search những bài viết kiểu CQRS là gì trên google. Thì nó ra khá nhiều các title như Event sourcing, Event Driven Architecture, DDD… Các bạn có thời gian thì tìm hiểu thêm nha. Mình chỉ muốn trình bày only CQRS là cái gì trong bài viết này thôi.
Ngày 31.05.2024 vừa qua, TopDev đã tổ chức thành công sự kiện Vietnam Mobile Summit với chủ đề “Mobile & Life”. Thu hút đông đảo sự quan tâm của cộng đồng công nghệ, sự kiện đã mang đến những chia sẻ chuyên sâu về các xu hướng công nghệ di động mới nhất, cũng như những giải pháp sáng tạo ứng dụng trí tuệ nhân tạo (AI) và kinh nghiệm phát triển sản phẩm từ các chuyên gia đầu ngành.
Điểm nhấn cho sự kiện lần này đến từ 2 phiên thảo luận từ các chuyên gia công nghệ đến từ nhiều công ty, doanh nghiệp nổi tiếng với chủ đề: “AI FOR FUTURE” và “Creating Harmony Between Designers, Developers and Stakeholders”. Ngoài ra, phiên pitching đặc biệt của K-Global@2024 – các startup công nghệ hàng đầu Hàn Quốc, cũng đã để lại ấn tượng mạnh mẽ trước các nhà đầu tư, chuyên gia và khán giả tham gia tại sự kiện Vietnam Mobile Summit 2024.
Khám phá tiềm năng to lớn của AI tại Việt Nam
Trí tuệ nhân tạo (AI) đang trở thành một phần không thể thiếu trong đời sống và kinh tế hiện đại. Với sự phát triển không ngừng, AI đang mở ra những cơ hội mới và đồng thời đặt ra những thách thức cần được giải quyết. Theo anh Đinh Lê Vũ – Global Senior Manager tại Qualcomm, Việt Nam sở hữu nhiều lợi thế để trở thành trung tâm phát triển AI trong khu vực nhờ sở hữu lực lượng dân số trẻ, năng động, nguồn nhân lực dồi dào và khả năng thích ứng nhanh chóng với công nghệ mới. Tuy nhiên, bên cạnh đó cũng tồn tại một số thách thức như thiếu sự đồng bộ trong phát triển, nguồn vốn đầu tư hạn chế và hệ sinh thái khởi nghiệp còn khá non trẻ.
PANEL DISCUSSION #1: AI FOR FUTURE với sự góp mặt của các diễn giả Vanessa Phan, Nguyễn Việt Phương, Quân Nguyễn, Đinh Lê Vũ, Jaymie Võ
Cũng theo anh Vũ, top 3 lĩnh vực tiềm năng nhất cho việc ứng dụng và phát triển AI tại Việt Nam là ngành bán lẻ, ngân hàng và dịch vụ lưu trú. Theo quan điểm của các chuyên gia, việc xây dựng mô hình AI không chỉ dừng lại ở tốc độ và độ chính xác mà còn phải làm cho nó thấu hiểu nhu cầu của người dùng để nâng cao trải nghiệm khách hàng. Đây chính là điểm mấu chốt giúp các doanh nghiệp thành công khi bắt tay vào đầu tư xây dựng hệ thống AI.
Bên cạnh đó, phiên thảo luận cũng đưa ra một số lời khuyên hữu ích dành cho các bạn fresher mới vào nghề cũng như các chủ doanh nghiệp, những người làm sản phẩm. Với Fresher IT cần trau dồi tiếng Anh và kỹ năng giao tiếp để hòa nhập môi trường làm việc quốc tế. Những người làm sản phẩm thì cần cân bằng giữa kỹ thuật và nhu cầu thị trường để tạo ra sản phẩm AI mang lại giá trị thực tiễn. Còn đối với doanh nghiệp, cần phải xác định rõ mục tiêu sử dụng AI trước khi tìm kiếm giải pháp phù hợp.
Hành trình từ phát triển ý tưởng đến xây dựng sản phẩm
Tại panel “Creating Harmony Between Designers, Developers and Stakeholders”, khán giả đã có cơ hội được lắng nghe các chiến lược giao tiếp và hợp tác hiệu quả, đồng thời khám phá các câu chuyện thành công từ quá trình lên ý tưởng đến thực thi sản phẩm của những diễn giả uy tín đến từ Tanca, VPBank, GEEK Up, ELSA Corp và RegenX.
PANEL DISCUSSION #2: Creating Harmony Between Designers, Developers and Stakeholders với sự góp mặt của các diễn giả Trần Viết Quân, Tony Lê, Hoàng Nguyễn, Sơn Vũ, Nguyễn Anh Tuấn
Anh Hoàng Nguyễn từ GEEK Up đã chia sẻ về quá trình phát triển sản phẩm từ việc lên ý tưởng đến cách làm việc với khách hàng và tung sản phẩm ra thị trường. Theo anh, đội ngũ Product Analytics của GEEK Up luôn bắt đầu bằng việc trao đổi và tìm hiểu kỹ lưỡng những mong muốn và ý tưởng của đối tác. Sau đó, họ tiến hành thiết kế và thử nghiệm sản phẩm ở quy mô nhỏ để đánh giá hiệu quả trước khi triển khai rộng rãi.
Anh Hoàng Nguyễn từ GEEK Up chia sẻ về quá trình phát triển sản phẩm từ việc lên ý tưởng đến cách làm việc với khách hàng và tung sản phẩm ra thị trường
Bên cạnh đó, GEEK Up áp dụng mô hình co-partner, kết hợp ưu điểm của cả công ty outsource và inhouse để tối ưu hóa hiệu quả dự án. Sự phối hợp chặt chẽ giữa đội ngũ GEEK Up và các team inhouse của khách hàng giúp dự án tiến triển nhanh chóng và đạt được kết quả tốt nhất. Khi sản phẩm được tung ra thị trường, nếu có bất đồng về tầm nhìn sản phẩm, hai bên sẽ dựa trên các insight khách hàng để thử nghiệm các giả định khác nhau, đảm bảo sản phẩm cuối cùng phù hợp nhất với nhu cầu thị trường.
K-Global@2024: Cầu nối công nghệ Việt – Hàn
Phần pitching của K-global@Vietnam 2024 là một trong những điểm nhấn tại Vietnam Mobile Summit năm nay. Được xem như một cầu nối công nghệ giữa hai quốc gia, chương trình là nơi hội tụ của những chuyên gia CNTT hàng đầu đến từ xứ sở kim chi.
Gian hàng của K-global@Vietnam 2024 tại Vietnam Mobile Summit 2024
Các startup Hàn Quốc tham gia đã mang đến một bức tranh công nghệ đa sắc màu, phản ánh sự đa dạng và sáng tạo của hệ sinh thái di động. Từ trí tuệ nhân tạo (AI) ứng dụng trong giáo dục và y tế, đến các giải pháp bảo mật tiên tiến; từ ứng dụng doanh nghiệp tối ưu hóa quy trình làm việc, đến những trải nghiệm AR/VR/XR đầy sáng tạo – mỗi bài thuyết trình đều là một lời khẳng định về năng lực và tầm nhìn của các nhà phát triển tại Hàn Quốc.
Người tham dự tham gia trải nghiệm các sản phẩm công nghệ tại các gian hàng của K-global@Vietnam
Không chỉ là nơi giới thiệu sản phẩm, K-global@Vietnam 2024 còn là một workshop học hỏi lẫn nhau. Các startup Việt Nam học được cách tiếp cận thị trường quốc tế, trong khi các đối tác Hàn Quốc có cơ hội hiểu sâu về hành vi người dùng và môi trường kinh doanh độc đáo của Việt Nam. Chương trình cung cấp nhiều chuyên đề về các xu hướng công nghệ mới nhất, giúp doanh nghiệp Việt Nam cập nhật kiến thức và nâng cao năng lực cạnh tranh.
Tổng kết
Vietnam Mobile Summit 2024 không chỉ là nơi thảo luận về công nghệ mà còn là sân chơi kết nối giữa các chuyên gia, doanh nghiệp và startup hàng đầu. Từ AI đến phát triển sản phẩm, từ thị trường nội địa đến quốc tế, sự kiện đã phác thảo một tương lai đầy hứa hẹn cho ngành di động Việt Nam. Với sự đổi mới không ngừng và tinh thần hợp tác, ngành công nghiệp này chắc chắn sẽ tiếp tục phát triển mạnh mẽ, khẳng định vị thế của Việt Nam trên bản đồ công nghệ toàn cầu.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Để giúp bạn chuẩn bị tốt nhất cho các cuộc phỏng vấn liên quan đến Docker, TopDev đã tổng hợp danh sách TOP 35 câu hỏi phỏng vấn Docker và cách trả lời hay nhất. Bỏ túi ngay để có một buổi phỏng vấn thật thành công bạn nhé.
21. Docker volume được lưu ở đâu trong docker?
Volume được tạo và quản lý bởi Docker và không thể truy cập bằng thực thể khác docker. Nó được lưu trữ trong hệ thống file host Docker ở /var/lib/docker/volumes/.
22. Lệnh docker info là gì?
Lệnh lấy thông tin chi tiết về Docker được cài đặt trên hệ thống host. Thông tin có thể giống như số lượng container hoặc image và chúng đang chạy ở trạng thái nào và các thông số kỹ thuật phần cứng như tổng bộ nhớ được cấp phát, tốc độ của bộ xử lý, phiên bản kernel,…
23. Ý nghĩa của các lệnh up, run và start của docker compose?
Sử dụng lệnh up để duy trì docker-compose (lý tưởng là mọi lúc), chúng ta có thể khởi động hoặc khởi động lại tất cả các mạng, dịch vụ và driver được liên kết với ứng dụng được chỉ định trong file docker-compos.yml. Bây giờ, nếu chúng ta đang chạy docker-compose ở chế độ “attached” thì tất cả log từ các container sẽ có thể truy cập được đối với chúng ta. Trong trường hợp docker-compose được chạy ở chế độ “detached”, thì khi các container được khởi động, nó sẽ thoát ra và không hiển thị log nào.
Sử dụng lệnh run, docker-compose có thể chạy các tác vụ một lần hoặc đột xuất dựa trên các yêu cầu nghiệp vụ. Ở đây, tên dịch vụ phải được cung cấp và docker chỉ bắt đầu dịch vụ cụ thể đó và cả các dịch vụ khác mà dịch vụ đích phụ thuộc (nếu có). Lệnh này hữu ích để kiểm tra container và cũng thực hiện các tác vụ như thêm hoặc xóa dữ liệu vào container,…
Sử dụng lệnh start, chỉ những container đó mới có thể được khởi động lại đã được tạo và sau đó dừng lại. Điều này không hữu ích cho việc tạo các container mới của riêng nó.
24. Các yêu cầu cơ bản để Docker chạy trên mọi hệ thống?
Docker có thể chạy trên cả nền tảng Linux và Windows.
Đối với nền tảng Windows, ít nhất docker cần có Windows 10 64bit với bộ nhớ RAM 2GB. Đối với các phiên bản thấp hơn, có thể cài đặt docker bằng cách sử dụng toolbox trợ giúp. Docker có thể được tải xuống từ trang web https://docs.docker.com/docker-for-windows/.
Đối với nền tảng Linux, Docker có thể chạy trên nhiều phiên bản Linux khác nhau như Ubuntu> = 12.04, Fedora> = 19, RHEL> = 6.5, CentOS> = 6, v.v.
25. Cách đăng nhập vào docker registry?
Sử dụng lệnh docker login để đăng nhập vào kho lưu trữ đám mây của riêng họ có thể được nhập và truy cập.
26. Các instructions phổ biến trong Dockerfile?
FROM: dùng cho thiết lập image cơ sở cho instruction sắp tới. File docker được xem là hợp lệ nếu nó bắt đầu bằng FROM.
LABEL: dùng cho tổ chức image dựa trên dự án, module hoặc license. Nó còn giúp tự động hoá như một cặp key-value cụ thể trong khi xác định label mà sau này có thể được truy cập và xử lý theo chương trình.
RUN: dùng cho thực thi instruction theo sau nó trên top image hiện tại trong lớp mới. Lưu ý: mỗi lần thực thi lệnh RUN, chúng ta thêm các lớp trên image và sử dụng lớp đó cho các bước tiếp theo.
CMD: dùng cho cung cấp giá trị mặc định của container thực thi. Trong trường hợp nhiều lệnh CMD, lệnh cuối cùng sẽ được xem xét.
27. Sự khác biệt giữa Daemon Logging và Container Logging?
Trong Docker, logging được hỗ trợ ở hai level là level Daemon và level Container.
Daemon: gồm 4 kiểu level
Debug có tất cả dữ liệu xuất hiện trong quá trình thực thi của tiến trình daemon.
Info quan tâm tất cả thông tin cùng với lỗi trong suốt quá trị thực thi tiến trình daemon.
Error gồm các lỗi xảy ra trong quá trình thực thi tiến trình daemon.
Fatal chức lỗi fatal trong quá trình thực thi tiến trình daemon.
Container:
Level container có thể thực hiện logging bằng lệnh: sudo docker run –it <container_name> /bin/bash.
Để kiểm tra log của level container ta có thể thực hiện: sudo docker logs <container_id>.
28. Cách thiết lập giao tiếp giữa docker host và linux host?
Điều này có thể được thực hiện bởi mạng bằng cách xác định “ipconfig” trên docker host. Lệnh này đảm bảo rằng một adapter ethernet được tạo miễn là docker có mặt trong host.
29. Cách xoá một container?
Ta có hai bước xoá container:
docker stop <container_id>
docker rm <container_id>
30. Sự khác biệt giữa CMD và ENTRYPOINT?
Lệnh CMD cung cấp các giá trị mặc định có thể thực thi cho một container đang thực thi. Trong trường hợp file thực thi phải được bỏ qua thì việc sử dụng lệnh ENTRYPOINT cùng với định dạng mảng JSON phải được kết hợp.
ENTRYPOINT chỉ định rằng lệnh bên trong nó sẽ luôn được chạy khi container khởi động. Lệnh này cung cấp một tùy chọn để cấu hình các tham số và các file thực thi. Nếu DockerFile không có lệnh này, thì nó sẽ vẫn được kế thừa từ image cơ sở được đề cập trong lệnh FROM.
ENTRYPOINT được sử dụng phổ biến nhất là /bin/sh hoặc /bin/bash cho hầu hết các image cơ sở.
Thực tế, tất cả Dockerfile nên có ít nhất một trong hai lệnh.
31. Có thể dùng JSON thay cho YAML khi phát triển docker-compose trong Docker không?
Có thể. Ta có thể chạy docker-compose trong json, như
docker-compose-f docker-compose.json up
32. Bạn có thể chạy bao nhiêu container trong docker và các yếu tố ảnh hưởng đến giới hạn này là gì?
Không có giới hạn xác định rõ ràng về số lượng container có thể chạy trong docker. Nhưng tất cả phụ thuộc vào những hạn chế – cụ thể hơn là những hạn chế về phần cứng. Kích thước của ứng dụng và tài nguyên CPU có sẵn là 2 yếu tố quan trọng ảnh hưởng đến giới hạn này. Trong trường hợp ứng dụng của bạn không quá lớn và bạn có tài nguyên CPU dồi dào, thì chúng ta có thể chạy một số lượng lớn các container.
33. Vòng đời của container trong Docker?
Các giai đoạn khác nhau của docker container từ khi bắt đầu tạo cho đến khi kết thúc được gọi là vòng đời của docker container.
Các giai đoạn quan trọng nhất là:
Created: Đây là trạng thái mà container vừa được tạo mới nhưng chưa bắt đầu.
Running: Trong trạng thái này, container sẽ chạy với tất cả các quy trình liên quan của nó.
Paused: Trạng thái này xảy ra khi container đang chạy bị tạm dừng.
Stopped: Trạng thái này xảy ra khi container đang chạy đã bị dừng.
Deleted: Trong trường hợp này, container ở trạng thái chết.
34. Làm thế nào để sử dụng docker cho nhiều môi trường ứng dụng?
Tính năng docker-compose của docker sẽ hỗ trợ bạn tại đây. Trong file docker-compose, chúng ta có thể xác định nhiều dịch vụ, mạng và container cùng với ánh xạ volume một cách rõ ràng và sau đó chúng ta chỉ cần gọi lệnh docker-compose up.
Khi có nhiều môi trường tham gia – đó có thể là máy chủ dev, staging, uat hoặc production, chúng ta muốn xác định các quy trình và phụ thuộc dành riêng cho server chủ để chạy ứng dụng. Trong trường hợp này, chúng ta có thể tiếp tục tạo file docker-compose theo môi trường cụ thể có tên là docker-compos. {environment}.yml và sau đó dựa trên môi trường, chúng ta có thể thiết lập và chạy ứng dụng.
35. Làm sao đảm bảo container1 chạy trước container2 trong khi dùng docker compose?
Docker-compose không đợi bất kỳ container nào “sẵn sàng” trước khi đến container kế tiếp. Để thực thi như vậy, ta có thể sử dụng:
Bạn có thể sử dụng depend_on đã được thêm vào phiên bản 2 của docker-compose khi được hiển thị trong file docker-compose.yml mẫu bên dưới:
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Để giúp bạn chuẩn bị tốt nhất cho các cuộc phỏng vấn liên quan đến Docker, TopDev đã tổng hợp danh sách TOP 35 câu hỏi phỏng vấn Docker và cách trả lời hay nhất. Bỏ túi ngay để có một buổi phỏng vấn thật thành công bạn nhé.
16. Sự khác biệt giữa ảo hoá (virtualization) và containerization?
virtualization
containerization
Nó giúp chạy nhiều hệ điều hành trên phần cứng của một server vật lý
Nó giúp triển khai nhiều ứng dụng trên cùng hệ điều hành trên một máy ảo hoặc server
Hypervisors cung cấp các máy ảo tổng thể cho hệ điều hành khách
Container đảm bảo cung cấp môi trường/không gian người dùng biệt lập để chạy các ứng dụng. Mọi thay đổi được thực hiện trong container không phản ánh trên server hoặc các container khác của cùng server
Các máy ảo này tạo thành một phần trừu tượng của lớp phần cứng hệ thống, điều này có nghĩa là mỗi máy ảo trên host hoạt động giống như một máy vật lý
Container tạo thành sự trừu tượng của lớp ứng dụng có nghĩa là mỗi container tạo thành một ứng dụng khác nhau
17. Sự khác biệt giữa lớp COPY và ADD trong Dockerfile?
Cả hai có chức năng giống nhau, nhưng COPY được ưa thích hơn vì mức độ minh bạch cao hơn ADD.
COPY cung cấp các hỗ trợ cơ bản cho sao chép file cục bộ trong khi ADD cung cấp tính năng bổ sung như URL từ xa và hỗ trợ xuất tar.
Có, chỉ có thể thực hiện được khi đang sử dụng một số chính sách do docker xác định trong khi sử dụng lệnh run của docker. Sau đây là các chính sách hiện có:
Off: container sẽ không được khởi động lại trong trường hợp nó bị dừng hoặc bị lỗi.
Un-failure: Ở đây, container chỉ khởi động lại khi nó gặp lỗi không liên quan đến người dùng.
Unless-stop: Sử dụng chính sách này, đảm bảo rằng container chỉ có thể khởi động lại khi người dùng thực hiện lệnh để dừng nó.
Always: Bất kể lỗi hay dừng, container luôn được khởi động lại trong loại chính sách này.
Các chính sách này có thể dùng như sau:
docker run -dit — restart [restart-policy-value][container_name]
Image: được xây dựng từ một loạt các lớp instruction. Một image tương ứng với container và được sử dụng để vận hành nhanh chóng do cơ chế lưu vào bộ nhớ đệm của mỗi bước.
Layer: Mỗi layer tương ứng với một instruction của image của Dockerfile. Nói đơn giản hơn layer còn là image nhưng nó là image của instruction.
Ví dụ:
FROM ubuntu:18.04COPY . /myappRUN make /myappCMD python /myapp/app.py
Quan trọng hơn, mỗi layer là một tập khác cảu layer trước đó.
Kết quả xây dựng file docker này là một image. Trong khi instruction hiện tại trong file thêm layer vào image.
20. Mục đích của tham số volume trong lệnh chạy docker là gì?
Cú pháp của lệnh chạy docker sử dụng volumn là: docker run -v host_path:docker_path <container_name>.
Tham số volume được dùng cho đồng bộ hoá một thư mục trong container với bất kỳ thư mục host nào. Ví dụ: docker run -v /data/app:usr/src/app myapp. Lệnh trên gắn thứ mục /data/app trong host vào thư mục usr/src/app. Ta có thể đồng bộ container với file dữ liệu từ host mà không cần khởi động lại.
Điều này đảm bảo rằng ngay cả khi container bị xóa, dữ liệu của container vẫn tồn tại trong vị trí host lưu trữ được ánh xạ theo volume, làm cho nó trở thành cách dễ dàng nhất để lưu trữ dữ liệu container.
Bài viết được sự cho phép của tác giả Tống Xuân Hoài
Vấn đề
Ngày xưa đi học không biết có ai thắc mắc tại sao lại phải học môn cấu trúc dữ liệu và giải thuật không? Môn học cho chúng ta biết một số cấu trúc dữ liệu phổ biến như là danh sách liên kết (linked list) đơn – đôi, mảng, queue, stack… Nhưng có vẻ như nó thật nhàm chán cho những ai đã biết và đang lập trình. Chưa kể hầu hết ngôn ngữ lập trình đều tự triển khai hoặc có thư viện hỗ trợ tất cả cấu trúc này, ấy vậy mà thầy cô vẫn yêu cầu chúng ta tự triển khai lại các cấu trúc này một cách thủ công.
Có lẽ mục đích thật sự đằng sau đó là muốn chúng ta hiểu về tầm quan trọng của cấu trúc dữ liệu. Thật vậy, rất nhiều ý tưởng, giải pháp được phát minh ra dựa trên chúng. Có thể kể đến là Message queue – một cấu trúc góp mặt trong thiết kế hệ thống phần mềm, nhằm tăng khả năng xử lý và giải quyết nhiều vấn đề phức tạp trong hệ thống phân tán.
Vài năm trở lại đây, khái niệm về hệ thống phân tán không còn quá xa lạ. Thay vì xử lý tất ở một nơi duy nhất thì chia nhỏ công việc ra để xử lý. Mỗi nơi xử lý một nhiệm vụ duy nhất, từ đó giúp cho hệ thống phân cấp rõ ràng hơn, năng xuất hơn và chịu lỗi tốt hơn.
Queue là hàng đợi, message queue là một hàng đợi tin nhắn. Một hàng đợi hoạt động theo kiểu vào trước ra trước (First In, First Out). Tưởng tượng như bạn có một cái ống nước đủ rộng để nhét những viên bi vào, thì cho có đổ tất cả các viên bi vào trong phễu ở một đầu, thì đầu kia vẫn chỉ lăn ra từng viên một theo thứ tự trước sau. Không thể nào có hai viên cùng lăn ra một lúc được, đó chính là một hàng đợi.
Trong hệ thống phần mềm, message queue là một cấu trúc quan trọng và được áp dụng rất nhiều bởi hệ thống phân tán. Vì thế, bài viết ngày hôm nay hãy cùng tôi đi qua một vài khái niệm cơ bản về cấu trúc này nhé.
Message queue là gì?
Message queue là một khái niệm trong lĩnh vực phân tán hệ thống và lập trình đa luồng. Nó là một cấu trúc dữ liệu dùng để lưu trữ các thông điệp (message) trong một hệ thống phân tán.
Message queue thường được sử dụng để giao tiếp giữa các thành phần của hệ thống thông tin, cho phép chúng truyền thông điệp (message) cho nhau một cách bất đồng bộ. Thay vì gửi trực tiếp thông điệp từ một thành phần đến thành phần khác, các thành phần này gửi thông điệp vào message queue và các thành phần khác có thể lấy thông điệp từ message queue để xử lý.
Tại sao lại không gửi thông điệp trực tiếp mà phải thông qua một message queue? Có nhiều lý do, trong đó nổi bất nhất là để quản lý được thông điệp. Hãy tưởng tượng nếu gửi trực tiếp thông điệp đến một điểm đích không khả dụng thì sẽ như thế nào? Thông điệp có thể bị mất và hệ thống cũng chẳng bao giờ xử lý được thông điệp nữa.
Về cơ bản, message queue là một hàng đợi tin nhắn. Ngoài ra, để đưa thông điệp được vào hàng đợi và xử lý thông điệp thì cần phải có sự tham gia của nhiều thành phần. Sự kết hợp giữa chúng tạo thành một hệ thống xử lý hàng đợi tin nhắn hoàn chỉnh.
Tùy thuộc vào dịch vụ cung cấp message queue mà chúng có nhiều thành phần khác nhau. Nhưng về cơ bản, phải có ít 3 thành phần tham gia vào quá trình xử lý là Producer, Message queue và Consumer.
Producer (nơi gửi thông điệp) gửi thông điệp vào message queue: Producer là thành phần hoặc ứng dụng tạo ra thông điệp và gửi nó vào message queue. Thông điệp có thể là bất cứ loại dữ liệu nào, ví dụ: tin nhắn, tác vụ xử lý, sự kiện, hay yêu cầu.
Message queue là nơi lưu trữ thông điệp: Message queue lưu trữ các thông điệp được gửi bởi Producer. Thông điệp có thể được lưu trữ bền vững trong bộ nhớ hoặc trên ổ đĩa tùy thuộc vào cấu hình của message queue.
Consumer (nơi nhận thông điệp) lấy thông điệp từ message queue: Consumer là thành phần hoặc ứng dụng muốn nhận và xử lý thông điệp. Consumer yêu cầu lấy thông điệp từ message queue, sau khi nhận được thông điệp, consumer tiến hành xử lý nó theo logic của ứng dụng.
Quá trình này lặp đi lặp lại mỗi khi Producer gửi thêm thông điệp vào Message queue và Consumer lấy và xử lý các thông điệp. Sự bất đồng bộ giữa Producer và Consumer cho phép hệ thống hoạt động hiệu quả và linh hoạt, đồng thời đảm bảo tính tin cậy và khả năng mở rộng.
Ứng dụng message queue như thế nào?
Message queue có rất nhiều ứng dụng trong các hệ thống phân tán và lập trình đa luồng có thể kể đến như:
Hệ thống xử lý dữ liệu theo thời gian thực: Trong các hệ thống xử lý dữ liệu theo thời gian thực, message queue được sử dụng để truyền tải dữ liệu từ các nguồn khác nhau đến các hệ thống xử lý. Các nguồn dữ liệu gửi thông điệp vào message queue và các hệ thống xử lý lấy thông điệp từ queue để xử lý dữ liệu một cách song song và bất đồng bộ.
Hệ thống đa luồng và bất đồng bộ: Message queue cho phép các thành phần trong hệ thống hoạt động độc lập và bất đồng bộ. Các thành phần có thể gửi thông điệp vào message queue và tiếp tục công việc của mình mà không cần chờ đợi phản hồi từ các thành phần khác. Điều này giúp tăng hiệu suất và khả năng mở rộng của hệ thống.
Hệ thống xử lý sự kiện: Trong các hệ thống xử lý sự kiện, message queue được sử dụng để gửi và nhận các sự kiện từ các nguồn khác nhau.
Giao tiếp giữa các dịch vụ: Trong kiến trúc dịch vụ phân tán, message queue được sử dụng để giao tiếp giữa các dịch vụ. Các dịch vụ gửi thông điệp vào message queue để yêu cầu hoặc truyền thông tin cho các dịch vụ khác.
Hàng đợi công việc: Message queue cũng được sử dụng trong các hệ thống hàng đợi công việc, nơi các công việc được gửi vào message queue, sau đó chúng được xử lý một cách lần lượt.
Hai cái tên nổi bật cung cấp cấu trúc message queue có thể kể đến RabbitMQ và Apache Kafka. Ngoài ra còn có một vài thư viện hỗ trợ triển khai message queue đơn giản dựa trên các dịch vụ khác như BullMQ, Kue, Agenda.
Một số ví dụ điển hình
Thật khó hình dung những ứng dụng của message queue nếu không có ví dụ cụ thể. Thực tế công việc hàng ngày của tôi ứng dụng cấu trúc này thường xuyên. Có thể kể đến một vài trường hợp phổ biến nhất như sau.
Trong một hệ thống thương mại điện tử, message queue có thể được sử dụng để xử lý đơn hàng. Khi khách hàng đặt hàng, thông tin đơn hàng được gửi vào message queue. Hệ thống xử lý đơn hàng lấy thông điệp từ queue và tiến hành xử lý đơn hàng, bao gồm kiểm tra hàng tồn kho, xác nhận thanh toán và gửi thông báo vận chuyển. Việc sử dụng message queue giúp tách biệt quá trình đặt hàng và xử lý đơn hàng, đồng thời đảm bảo tính tin cậy và khả năng mở rộng của hệ thống.
Trong một hệ thống gửi email hàng loạt, message queue có thể được sử dụng để xử lý và gửi email. Khi người dùng yêu cầu gửi email, thông điệp email được gửi vào message queue. Hệ thống xử lý email lấy thông điệp từ queue và thực hiện quá trình gửi email, bao gồm tạo nội dung, thêm tệp đính kèm và gửi đi. Việc sử dụng message queue giúp xử lý email một cách bất đồng bộ và đảm bảo tính tin cậy trong việc gửi email hàng loạt.
Trong một hệ thống xử lý sự kiện thời gian thực, message queue được sử dụng để truyền tải và xử lý sự kiện. Các sự kiện này liên quan nhiều đến việc tổng hợp, phân tích thông tin của một hệ thống thông tin.
Sử dụng message queue để trao đổi thông tin giữa các dịch vụ trong hệ thống phân tán nhằm tăng khả năng xử lý và chịu tải, đảm bảo không ảnh hưởng đến tốc độ xử lý thông tin luồng chính.
Đây chỉ là một số ví dụ điển hình về việc sử dụng message queue. Thực tế, message queue có thể được áp dụng trong nhiều lĩnh vực và tình huống khác nhau, tùy thuộc vào yêu cầu và mục đích sử dụng của hệ thống.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Docker đã trở thành một công cụ không thể thiếu trong việc triển khai và quản lý các ứng dụng container hóa. Với sự phổ biến ngày càng tăng của Docker, việc nắm vững kiến thức và kỹ năng về Docker không chỉ là một lợi thế mà còn là một yêu cầu quan trọng đối với các kỹ sư phần mềm, DevOps và những người làm việc trong lĩnh vực công nghệ thông tin.
Để giúp bạn chuẩn bị tốt nhất cho các cuộc phỏng vấn liên quan đến Docker, TopDev đã tổng hợp danh sách TOP 35 câu hỏi phỏng vấn Docker và cách trả lời hay nhất. Bỏ túi ngay để có một buổi phỏng vấn thật thành công bạn nhé.
Docker là một nền tảng mã nguồn mở rất phổ biến và mạnh mẽ được sử dụng để xây dựng, triển khai và chạy các ứng dụng. Docker cho phép bạn tách ứng dụng/phần mềm khỏi cơ sở hạ tầng bên dưới.
Container là một đơn vị tiêu chuẩn của phần mềm đi kèm với các phần phụ thuộc để các ứng dụng có thể được triển khai nhanh chóng và đáng tin cậy trên các nền tảng tính toán khác nhau.
Docker có thể được hình dung như một con tàu lớn (docker) chở những thùng sản phẩm (container) khổng lồ.
Docker container không yêu cầu cài đặt một hệ điều hành riêng biệt. Docker chỉ dựa vào hoặc sử dụng các tài nguyên của nhân và chức năng của nó để phân bổ chúng cho CPU và bộ nhớ, nó dựa vào chức năng của nhân và sử dụng cách ly tài nguyên cho CPU và bộ nhớ, đồng thời các namespace riêng biệt để tách biệt chế độ xem của ứng dụng đối với OS (hệ điều hành ).
Phát triển ứng dụng không chỉ đơn thuần là viết code! Chúng liên quan đến rất nhiều việc hậu trường như sử dụng nhiều framework và kiến trúc cho mọi giai đoạn trong vòng đời của nó, điều này làm cho quá trình trở nên phức tạp và đầy thử thách. Sử dụng bản chất của container hóa giúp các nhà phát triển đơn giản hóa và tăng tốc hiệu quả quy trình làm việc của ứng dụng, đồng thời cho phép họ tự do phát triển bằng cách sử dụng lựa chọn công nghệ và môi trường phát triển của riêng họ.
Tất cả những khía cạnh này tạo thành phần cốt lõi của DevOps, điều này càng trở nên quan trọng hơn đối với bất kỳ nhà phát triển nào cũng cần biết những điều này để cải thiện năng suất, thúc đẩy sự phát triển nhanh chóng cùng với việc ghi nhớ các yếu tố về khả năng mở rộng ứng dụng và quản lý tài nguyên hiệu quả hơn.
Hãy tưởng tượng container như một hộp rất nhẹ được cài đặt sẵn với tất cả các package, phần phụ thuộc, phần mềm theo yêu cầu của ứng dụng của bạn, chỉ cần triển khai production với những thay đổi cấu hình tối thiểu.
Rất nhiều tổ chức như PayPal, Spotify, Uber, v.v. sử dụng Docker để đơn giản hóa các hoạt động và đưa cơ sở hạ tầng và bảo mật đến gần hơn để tạo ra các ứng dụng an toàn hơn.
Mang tính di động, Container có thể được triển khai trên nhiều nền tảng như máy ảo, nền tảng Kubernetes, v.v. theo yêu cầu của quy mô hoặc nền tảng mong muốn.
Nói một cách đơn giản nhất, container bao gồm các ứng dụng và tất cả các phụ thuộc của chúng.
Chúng chia sẻ nhân và tài nguyên hệ thống với các container khác và chạy như các hệ thống biệt lập trong hệ điều hành chủ.
Mục đích chính của container là loại bỏ sự phụ thuộc vào cơ sở hạ tầng trong khi triển khai và chạy các ứng dụng. Điều này có nghĩa là bất kỳ ứng dụng được chứa trong container nào cũng có thể chạy trên bất kỳ nền tảng nào bất kể cơ sở hạ tầng đang được sử dụng bên dưới.
Về mặt kỹ thuật, chúng chỉ là các phiên bản runtime của docker image.
Chúng là các gói thực thi (được đóng gói với code ứng dụng và phần phụ thuộc, gói phần mềm, v.v.) nhằm mục đích tạo container. Docker image có thể được triển khai cho bất kỳ môi trường docker nào và các container có thể được xoay ở đó để chạy ứng dụng.
Hypervisor là một phần mềm giúp cho quá trình ảo hóa diễn ra vì nó đôi khi được gọi là Virtual Machine Monitor. Điều này phân chia tài nguyên của hệ thống máy chủ và phân bổ chúng cho từng môi trường khách được cài đặt.
Điều này có nghĩa là nhiều hệ điều hành có thể được cài đặt trên một hệ thống máy chủ duy nhất.
Hypervisor có 2 loại:
Native Hypervisor: Loại này còn được gọi là Bare-metal Hypervisor và chạy trực tiếp trên hệ thống máy chủ bên dưới, điều này cũng đảm bảo quyền truy cập trực tiếp vào phần cứng máy chủ, đó là lý do tại sao nó không yêu cầu hệ điều hành cơ bản.
Hosted Hypervisor: Loại này sử dụng hệ điều hành máy chủ cơ bản đã được cài đặt hệ điều hành hiện có.
Nó là một file YAML bao gồm tất cả các chi tiết liên quan đến các dịch vụ, mạng và khối lượng khác nhau cần thiết để thiết lập ứng dụng dựa trên Docker. Vì vậy, docker-compose được sử dụng để tạo nhiều container, lưu trữ chúng và thiết lập giao tiếp giữa chúng. Với mục đích giao tiếp giữa các container, các cổng được tiếp xúc bởi từng container.
Namespace về cơ bản là một tính năng của Linux đảm bảo phân vùng tài nguyên hệ điều hành theo cách loại trừ lẫn nhau. Điều này hình thành khái niệm cốt lõi đằng sau quá trình container hóa khi namespace giới thiệu một lớp cách ly giữa các container. Trong docker, namespace đảm bảo rằng các container có thể di động và chúng không ảnh hưởng đến máy chủ bên dưới. Ví dụ về các loại namespace hiện đang được Docker hỗ trợ – PID, Mount, User, Network, IPC.
7. Cách hiển thị trạng thái của tất cả docker container bằng dòng lệnh?
dockerps-a
8. Dữ liệu được lưu trữ trong container sẽ bị mất trong những trường hợp nào?
Dữ liệu của container vẫn ở trong đó cho đế khi bạn xóa container.
Theo thuật ngữ đơn giản, Docker image registry là một khu vực lưu trữ các docker image. Thay vì chuyển đổi các ứng dụng thành container mỗi lần, một nhà phát triển có thể sử dụng trực tiếp các iamge được lưu trữ trong registry. Docker image registry có thể là công khai hoặc riêng tư và DockerHub là tổ chức đăng ký công khai phổ biến và nổi tiếng nhất hiện có.
Docker Client: thành phần này sẽ thực hiện hành động “build” và “run” nhằm mục đích mở ra giao tiếp với docket host.
Docker Host: thành phần này gồm daemon chính của docker, các host container và image của chúng. Daemon thiết lập một kết nối đến docker registry.
Docker Registry: thành phần này lưu trữ docker image. Nó có thể là công khai hoặc riêng tư. Các registry công khai nổi tiếng là Docker Hub và Docker Cloud.
Bài viết được sự cho phép của tác giả Nguyễn Thành Nam
Trong quá trình phát triển phần mềm và quản lý dự án, việc bảo vệ thông tin bí mật như API key, mật khẩu, và các thông tin quan trọng khác là rất quan trọng. Một cách phổ biến để giải quyết vấn đề này là sử dụng file .env, một cách quản lý biến môi trường được nhiều lập trình viên sử dụng.
I. File .env là gì
Tệp .env là một tệp cấu hình chứa các biến môi trường cho một ứng dụng hoặc dự án phần mềm. Trong ngữ cảnh này, biến môi trường là các giá trị mà ứng dụng sử dụng để cấu hình chạy, chẳng hạn như API key, mật khẩu cơ sở dữ liệu, và các thông số cấu hình khác…
Tên .env là viết tắt của từ environment (môi trường), và tệp này thường được sử dụng để giữ các thông tin nhạy cảm mà bạn không muốn lưu trữ trực tiếp trong mã nguồn của bạn, đặc biệt là khi chia sẻ mã nguồn trên các hệ thống quản lý phiên bản như Git.
Mỗi dòng trong tệp .env thường chứa một biến môi trường và giá trị của nó, được đặt tên theo định dạng TEN_BIEN=GIATRI.
Các giá trị này sau đó có thể được đọc và sử dụng trong mã nguồn ứng dụng để cấu hình và thực hiện các tác vụ cụ thể. Thông thường, một thư viện như dotenv được sử dụng để tải các biến môi trường từ tệp .env vào quá trình chạy của ứng dụng.
II. Các đặc điểm của file .env
1. Quản lý biến môi trường một cách đơn giản
Một trong những ưu điểm lớn nhất của .env là khả năng đơn giản hóa quản lý biến môi trường. Thay vì trực tiếp nhúng thông tin bí mật vào mã nguồn, chúng ta có thể lưu trữ chúng trong tệp .env và gọi chúng trong mã nguồn khi cần thiết. Điều này giúp lập trình viên dễ dàng thay đổi cấu hình mà không cần sửa đổi mã nguồn.
2. Thông tin bí mật được an toàn
Thông tin bí mật như API key, mật khẩu và các thông tin nhạy cảm khác thường xuyên cần được bảo vệ khỏi sự truy cập trái phép. .env giúp ngăn chặn việc lộ thông tin này bằng cách giữ chúng trong một tệp không nằm trong lịch sử kiểm soát phiên bản (Git). Điều này đảm bảo rằng những thay đổi thông tin bí mật không được lưu trữ trong các commit của mã nguồn.
3. Quản lý phạm vi dự án hiệu quả
Mỗi dự án có thể có nhiều cấp độ biến môi trường tùy thuộc vào hệ điều hành, người dùng hay phiên làm việc. .env giúp quản lý phạm vi dự án một cách hiệu quả bằng cách giữ thông tin trong phạm vi chỉ của ứng dụng, tránh xung đột với các biến môi trường khác trên hệ thống.
4. Khả năng di chuyển và linh hoạt
Tệp .env có khả năng di chuyển, cho phép bạn đặt nó ở bất kỳ thư mục nào trong dự án. Điều này tăng cường an ninh bằng cách tránh hiển thị thông tin quan trọng khi có sự cố cấu hình máy chủ hoặc mã nguồn. Giống như việc lưu trữ SSH key tại một vị trí ổn định như ~/.ssh
5. Tích hợp dễ dàng trong quy trình phát triển
Sử dụng .env không chỉ giúp bảo vệ thông tin bí mật mà còn tạo ra một quy trình phát triển mạnh mẽ. Bạn có thể tích hợp .env vào công cụ CI/CD của mình để tự động hóa việc cung cấp các thông tin bí mật phù hợp với môi trường triển khai, tạo ra một quy trình triển khai an toàn và linh hoạt.
6. Tệp bị bỏ qua
Tệp .env có thể được bỏ qua khỏi hệ thống kiểm soát phiên bản, ngăn chặn thông tin bí mật bị commit vào lịch sử của mã nguồn (sử dụng git ignore). Bạn cũng có thể tạo một tệp .sample.env để hướng dẫn người sử dụng về cách thiết lập các biến môi trường mà không cần chia sẻ thông tin bí mật.
Sau khi toàn tất, bạn kiểm tra trong file .gitignore đã có .env hay chưa. Cuối cùng, khi push code hoàn tất, bạn có thể thêm các biến trong .env lên (ví dụ mình sử dụng Vercel như hình bên dưới).
IV. Kết luận
Sử dụng tệp .env không chỉ giúp bảo vệ thông tin bí mật của ứng dụng mà còn tăng cường tính di động và linh hoạt của mã nguồn. Điều này làm cho .env trở thành một công cụ quan trọng trong quá trình phát triển và bảo trì dự án. Hãy tích hợp .env vào quy trình phát triển của bạn để đảm bảo an toàn thông tin và sự thuận tiện trong quản lý biến môi trường.