Bài viết được sự cho phép của tác giả Nguyễn Văn Minh
Pattern thứ hai mà mình muốn giới thiệu chính là Abstract Factory. Nó có thể được hình dung như một nhà máy lớn, bên trong có các nhà máy nhỏ hơn sản xuất ra những loạt sản phẩm liên quan đến nhau.
Hãy lấy một hãng sản xuất ô tô làm ví dụ, chẳng hạn Hyundai. Họ có nhà máy, hoặc xưởng, chế tạo bánh xe: bánh của Azera, bánh của Sonata, bánh của Veloster, v.v… Đến lượt cửa xe, cũng có nhà máy chế tạo cửa Azera, cửa Sonata, cửa Veloster. Thân xe, động cơ, đèn, và các thành phần khác có những nhà máy chế tạo chúng.
Vậy phải tổ chức việc sản xuất ấy như thế nào? Cùng theo dõi tiếp nhé!
Nếu mới làm quen với Design Pattern, có thể bạn sẽ muốn đọc bài tổng quan của mình tại đây hoặc bài về Singleton tại đây.
ABSTRACT FACTORY
Giống như ở bài trước về Singleton, bài này gồm 5 phần:
Ý tưởng chính
Vấn đề cần giải quyết
Cấu trúc
Code ví dụ
Lưu ý
Vài lời bình luận
Ý tưởng chính
Khai báo một interface với các phương thức tạo các đối tượng abstract.
Một hệ thống phân cấp với các “dòng xe” và các “bộ phận xe”.
Tránh sử dụng từ khoá new.
Vấn đề cần giải quyết
Khi bạn muốn phần mềm của mình có thể được triển khai trên nhiều nền tảng khác nhau, bạn phải tìm cách xử lý việc khởi tạo các đối tượng trên các nền tảng đó. “Nền tảng” ở đây có thể hiểu là hệ điều hành, cơ sở dữ liệu,… Trong ví dụ ở phần mở đầu, Azera, Sonata và Veloster chính là các nền tảng.
Tuy nhiên, nếu bạn xử lý chuyện này bằng những câu if ... else thì chẳng mấy chốc code của bạn sẽ thành một mớ bòng bong vì phần mềm sẽ dần nở to. Và đó là lý do mà Abstract Factory ra đời.
Cấu trúc
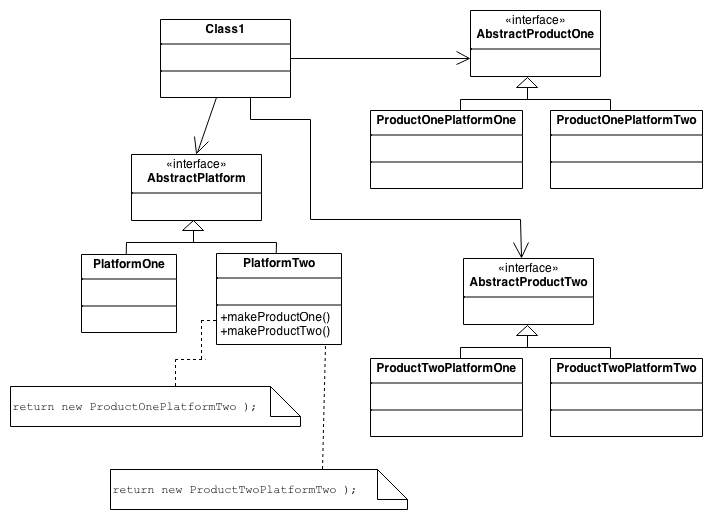
Ta cần có năm thành phần, đó là:
Abstract Platform: interface hoặc abstract class với các phương thức tạo ra các “sản phẩm”
Concrete Platforms: Khai báo cụ thể các “nền tảng” (PlatformOne, PlatformTwo trong hình)
Abstract Products: interface hoặc abstract class định nghĩa các loại “sản phẩm” (AbstractProductOne, AbstractProductTwo trong hình)
Concrete Products: Khai báo cụ thể các “sản phẩm” (ProductOnePlatformOne, ProductOnePlatformTwo, ProductTwoPlatformOne, ProductTwoPlatformTwo trong hình)
Client: Đối tượng sử dụng Abstract Platform và Abstract Product
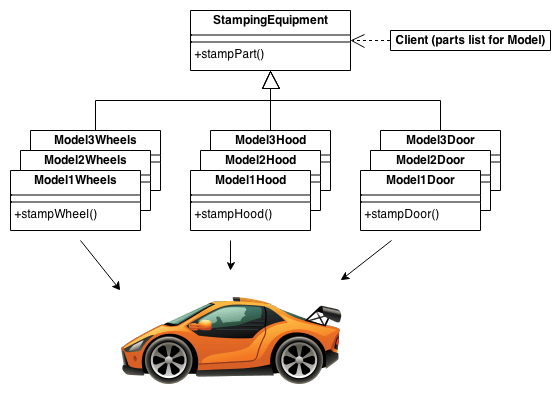
Với ví dụ về việc sản xuất xe, biểu đồ có thể trở thành như sau.
Bạn cũng cần kiểm tra các tiêu chí dưới đây.
Hãy xem xét liệu việc độc lập với các “nền tảng” và việc khởi tạo các đối tượng có phải là vấn đề của hệ thống hiện tại hay không.
Làm rõ đâu là “nền tảng”, đâu là “sản phẩm”, và mối quan hệ giữa chúng.
Định nghĩa một factory (interface) với đầy đủ các phương thức khởi tạo từng sản phẩm.
Định nghĩa các lớp dẫn xuất của interface trên, đảm bảo đã “bao gói” các phương thức khởi tạo (ứng với việc gọi new).
Client không được dùng new mà phải dùng các phương thức mà bạn đã khai báo ở interface.
Code ví dụ
Dưới đây là code ví dụ về việc khởi tạo các loại CPU, MMU, viết bằng ngôn ngữ Java.
Các “sản phẩm” (CPU, MMU)
// class CPU
abstract class CPU {}
// class EmberCPU
class EmberCPU extends CPU {}
// class EnginolaCPU
class EnginolaCPU extends CPU {}
// class MMU
abstract class MMU {}
// class EmberMMU
class EmberMMU extends MMU {}
// class EnginolaMMU
class EnginolaMMU extends MMU {}
enumArchitecture {
ENGINOLA, EMBER
}
abstractclassAbstractFactory {
privatestaticfinal EmberToolkit EMBER_TOOLKIT = new EmberToolkit();
privatestaticfinal EnginolaToolkit ENGINOLA_TOOLKIT = new EnginolaToolkit();
// Returns a concrete factory object that is an instance of the
// concrete factory class appropriate for the given architecture.
static AbstractFactory getFactory(Architecture architecture) {
AbstractFactory factory = null;
switch (architecture) {
case ENGINOLA:
factory = ENGINOLA_TOOLKIT;
break;
case EMBER:
factory = EMBER_TOOLKIT;
break;
}
return factory;
}
publicabstract CPU createCPU();
publicabstract MMU createMMU();
}
Client
publicclassClient { publicstaticvoid main(String[] args) { AbstractFactory factory = AbstractFactory.getFactory(Architecture.EMBER); CPU cpu = factory.createCPU(); } }
Lưu ý
Creational patterns có thể kết hợp với nhau hoặc thay thế cho nhau. Và để quyết định dùng pattern nào hoặc kết hợp như thế nào, bạn phải xem xét trường hợp của mình.
Abstract Factory thường được kết hợp với Factory Method, đôi khi là cả Protoype nữa.
Abstract Factory có thể thay thế cho Facade để che giấu những lớp được đặc tả riêng cho từng “nền tảng”.
Phân biệt Abstract Factory và Builder. Trong khi Abstract Factory chú trọng việc khởi tạo những nhóm đối tượng có liên quan đến nhau (chiều ngang); thì Builder chú trọng vào việc tạo ra một đối tượng qua nhiều bước nối tiếp nhau, giống như một dây chuyền vậy (chiều dọc). Trường hợp của Abstract Factory, đối tượng được trả về ngay; còn trong trường hợp của Builder, đối tượng là kết quả của cả quá trình.
Thông thường, việc thiết kế hệ thống sẽ đi từ Factory Method (dễ hiểu, dễ tuỳ biến) thành Abstract Factory, Prototype, hoặc Builder (mềm dẻo hơn, phức tạp hơn) nếu như người thiết kế cảm thấy tính mềm dẻo là cần thiết.
Vài lời bình luận
Như đã nói ở trên, các creational pattern có thể thay thế cho nhau hoặc kết hợp với nhau tuỳ hoàn cảnh, và việc thiết kế có thể đi từ Factory Method đến Abstract Factory. Tức là bạn phải xem xét thật kỹ càng bài toán của mình để biết cần lựa chọn giải pháp nào, thay vì vội vàng lựa chọn.
Các pattern được đưa ra rõ ràng là đem lại cái lợi lớn cho các lập trình viên nhưng bạn không nên lệ thuộc vào chúng. Theo tôi, đừng bao giờ nên giả định rằng: “Chắc tương lai hệ thống sẽ phải thế này, thế kia” hay “Có lẽ sau này hệ thống cần phải mềm dẻo hơn, flexible hơn nên phải chọn Abstract Factory”. Code ít hơn bao giờ cũng tốt hơn.
Bài viết này chia sẻ một số cách sử dụng Xpath và CSS selector để tìm một phần tử nào đó trong Selenium. Bài này khá là hữu ích đối với mình, và mình cũng hi vọng sẽ giúp ích một phần nào đó cho các bạn.
Bên cạnh bài viết này các bạn cũng có thể tham khảo bài biết về các cách xác định locator của một phần tử web ở bài viết này nhé.
ID của một phần tử được định nghĩa viết theo cú pháp Xpath là “[@id=’idName’]” nhưng theo cú pháp CSS thì nó là “#idName”/
Ví dụ phần tử div có id là ‘panel’ sẽ được diễn tả như sau:
Xpath: //div[@id=’panel’]
Theo CSS selector: css = div#panel
2. Theo Class:
Class của một phần tử được định nghĩa theo cú pháp Xpath là “[@class=’className’]” nhưng theo cú pháp CSS nó được định nghĩa là “.className”.
Ví dụ một phần tử div với class là ‘panelClass’ sẽ được diễn tả như sau:
Theo Xpath locator: //div[@class=’panelClass’]
Theo CSS selector: css=div.panelClass
Đối với những phần tử có nhiều class thì cần tách riêng những class đó bằng cách sử dụng dấu cách (“ “) trong Xpath, và sử dụng dấu chấm (“.”) trong CSS. Các bạn xem ví dụ phía dưới này nhé:
Theo Xpath locator: //div[@class=’panelClass1 panelClass2′]
Theo CSS selector: css=div.panelClass1.panelClass2
3. Một số thuộc tính khác
Để lựa chọn một phần tử theo một số thuộc tính bất kì nào đó của nó, (ví dụ: một phần tử div có thuộc tính name, hay thuộc tính type của một phần tử input) ta có như sau:
Với Xpath locator: //div[@name=’continue’] và //input[@type=’button’]
Với CSS selector: css=div[name=’continue’] và css=input[type=’button’]
4. Phần tử con liền kề (direct child)
Một phần tử con liền kề của một phần tử được biểu thị bằng hai dấu gạch chéo xuôi “//” trong Xpath và dấu ngoặc lớn hơn (“>“) trong Css selector. Xem ví dụ dưới đây về phần tử “ul” có phần tử con liền kề là “li”
Với Xpath locator: //ul/li
Với CSS selector: css=ul > li
5. Child / subchild
Phần tử con hoặc phần tử “cháu” (phần tử con của phần tử con) được biểu thị bằng hai dấu gạch phải “//” trong Xpath, và dấu cách (“ “) trong CSS Selector. Dưới dây là ví dụ về một child/subchild “li” của phần tử cha “ul”
Với Xpath locator: //ul//li
Với CSS selector: css=ul li
Các bạn lưu ý tránh nhầm lẫn giữa cách biểu diễn “ul li” và “ul > li” nhé!
6. nth Child:
Để tìm phần tử con thứ nth, theo cú pháp Xpath ta sẽ sử dụng “[n]”, theo CSS chúng ta sẽ biểu thị theo cú pháp “:nth-of-type(n)”. Các bạn tham khảo ví dụ phía dưới nhé:
Ta có phần tử có id =’drinks’ chứa 1 danh sách các loại đồ uống:
Coffee
Tea
Milk
Soup
Soft Drinks
Để lấy ra đồ uống số 5 trong danh sách trên:
Theo Xpath: //ul[@id=’drinks’]/li[5]
Theo CSS: css=ul#drinks li:nth-of-type(5), cũng có thể sử dụng cú pháp khác là li:nth-child(5).
7. Cha của 1 phần tử – Parent of an element
Cha của một phần tử có thể được biểu diễn thông qua ký tự “/..” trong Xpath và “:parent” trong CSS. Ví dụ dưới dây nếu bạn muốn tìm cha của danh sách các mục của class ‘blue’ thì:
first
second
third
fourth
fifth
Theo Xpath: //li[@class=’blue’]/..
Theo CSS: css=li.blue:parent
8. Tìm anh em cùng cha(Next Sibling)
Next Sibling chính là những phần tử anh em cùng cấp với nhau thuộc cùng một phần tử cha nào đó. Tìm phần tử next sibling tức là lấy ra 1 phần tử tiếp theo sau một phần tử cụ thể nào đó khác, điều kiện là nằm trong cùng 1 cha.
Ví dụ bạn muốn chọn ra anh em của phần tử “li” ở vị trí thứ 2 trong danh sách có class “blue”:
Trong Xpath: //li[@class=’blue’]/../li[2]
Trong CSS selector: css=li.blue + li
Tương tự nếu ban jmuoons lấy phần tử thứ 3 trong danh sách ta có các biểu diễn theo cú pháp lần lượt như sau:
In Xpath locator: //li[@class=’blue’]/../li[3]
In CSS selector: css=li.blue + li + li
9. Tìm phần tử theo Text tương ứng với Text trong phần tử đó (Innertext)
Ta sẽ sử dụng một phương thức Javascript là methodcontains() để kiểm tra đoạn văn bản “text” bên trong một phần tử web. Ví dụ với một link có text là “Sign in”
Theo Xpath locator: //a[contains(text(), ‘Sign in’)] hoặc a//[contains(string(), ‘Sign in’)]
Theo CSS selector: css=a:contains(‘Sign in’)
10. Tìm phần tử dựa theo Sub-string tương ứng có trong phần tử đó (Match by Sub-string)
Đây là một cách khá là thú vị nhé! Với cách này ta sẽ kết hợp các chuỗi dựa vào một phần của chuỗi đó. Ví dụ như dựa vào tiền tố (Prefix), hậu tố (suffix) hoặc một dạng mẫu (sub-string) nào đó.
(*) Tìm theo sub-string (bộ mẫu) – Substring (partern)
Ví dụ về 1 phần tử ‘div’ với một ‘id’ và chứa đoạn text là “partern”
Với Xpath locator chúng ta sẽ cần sử dụng hàm contains() để kết hợp 1 sub-string:
//div[contains(@id,’pattern’)]
Với CSS selector ta sẽ sử dụng “*=” để kết hợp 1 sub-string:
css=div[id*=’pattern’]
(*) Tìm theo tiền tố – prefix
Với ví dụ 1 phần tử ‘div’ với một ‘id’ và đoạn text bắt đầu với đoạn text “prefixString”:
Theo Xpath locator ta cần sử dụng từ khóa “starts-with” để tìm prefix tương ứng:
//div[starts-with(@id,”prefixString”)]
Theo CSS selector ta sẽ sử dụng “^=”:
Css=div[id^=’prefixSring’]
(*) Tìm theo hậu tố
Tương tự với ví dụ bên trên, tìm phần tử div có id và đoạn text kết thúc là “suffixString”:
Theo Xpath locator, chúng ta sẽ sử dụng “ends-with” để tìm hậu tố tương ứng. Lưu ý một chút là method “ends-with()” là một chuẩn chỉ được sử dụng trong Xpath2.0, nó sẽ không chạy với Xpath1.0 (phân biệt hai phiên bản này các bạn tìm GG để rõ hơn nhé).
//div[ends-with(@id,”suffixString”)]
Theo CSS selector, ta sẽ cần sử dụng “$=”:
css=div[id$=’suffixString’]
Ta có thể tóm tắt thành một bảng tổng hợp thu gọn như này nha:
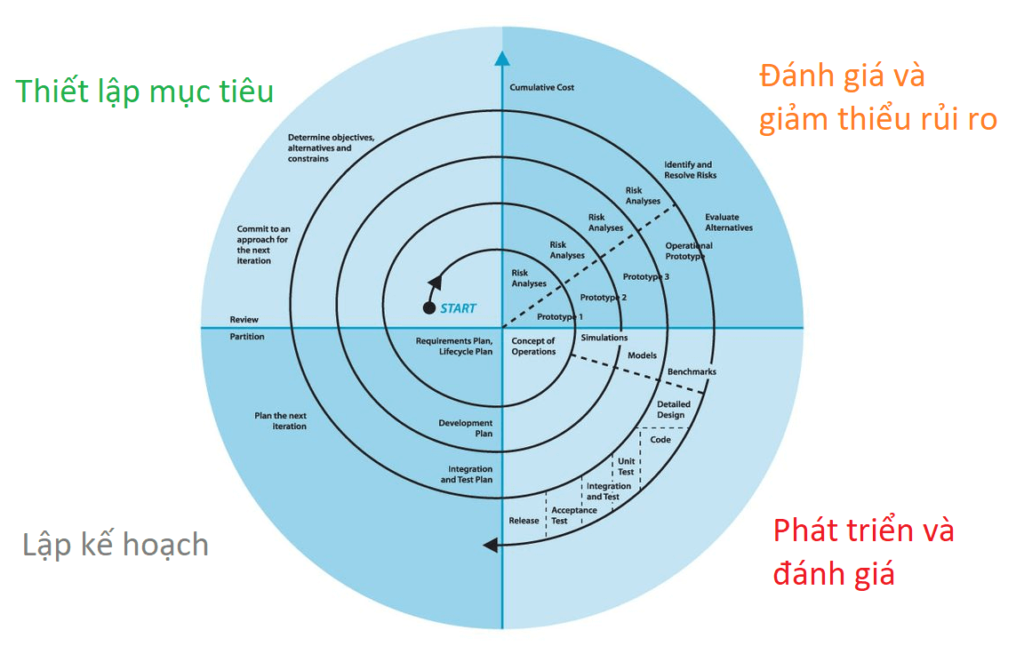
Mô hình xoắn ốc (Spiral model) có thể được xem là sự kết hợp giữa mô hình thác nước (Waterfall model) và mô hình mẫu (Prototype model) và đồng thời thêm phân tích rủi ro (Risk assessment).
Vâng, và trong phần tiếp theo này mình sẽ chia sẻ với các bạn những back-end framework được dựa trên các ngôn ngữ lập trình khác và cũng đang rất “hot” hiện nay.
#5. Laravel
Laravel là một back-end framework ra mắt vào năm 2011, nó được viết dựa trên ngôn ngữ lập trình PHP.
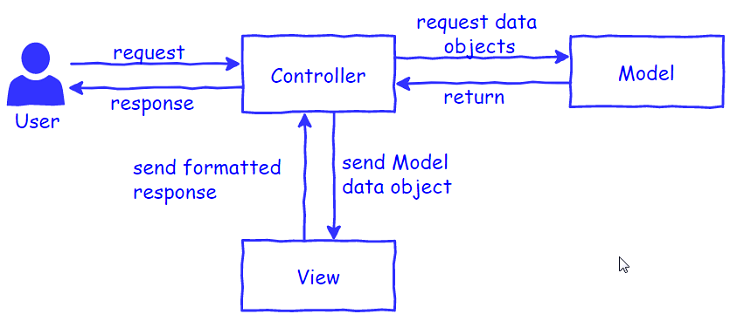
Về cấu trúc Laravel được thiết kế theo mô hình MVC (Model – View – Controller). Laravel cũng là một open source với mục đích giúp cho việc viết code đơn giản, dễ dàng và bảo mật hơn.
Cho bạn nào chưa biết về kiến trúc MVC thì mình chia sẻ luôn vì nhiều framework được xây dựng dựa trên kiến trúc này.
M là Model: Cấu trúc dữ liệu theo cách tin cậy và chuẩn bị dữ liệu theo lệnh của controller (Các lớp thực thể được viết bằng các ngôn ngữ lập trình như PHP, Java, Python…)
V là View: Hiển thị dữ liệu cho người dùng theo cách dễ hiểu dựa trên hành động của người dùng (HTML, CSS, JavaScript…)
C là Controller: Nhận lệnh từ người dùng, gửi lệnh đến cho Model để cập nhập dữ liệu, truyền lệnh đến View để cập nhập giao diện hiển thị.
Laravel sẽ phù hợp với dự án nào?
Chúng ta có thể sử dụng Laravel cho tất cả các dự án từ nhỏ tới lớn. Nhưng thường là các dựa án liên quan đến các trang thương mại điện tử.
Laravel được đánh giá là một trong những framework được cộng động lập trình viên PHP yêu thích nhất. Các bạn có thể tìm hiểu thêm về Laravel tại đây: https://laravel.com/
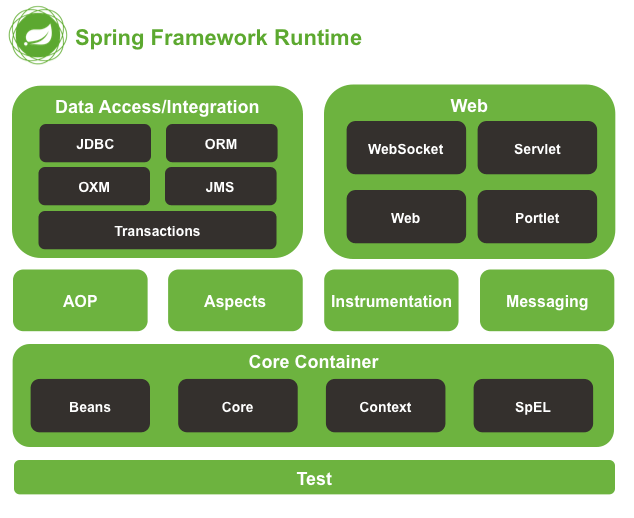
#6. Spring Framework
Các bạn lập trình viên Java chắc không còn xa lạ gì với những cái tên như SpringMVC, Spring Boot…
Có thể nói Spring là một hệ sinh thái chứ không đơn thuần là một framework nữa, vì Spring cung cấp một bộ công cụ để bạn có thể giải quyết vấn đề mà không phải dùng thêm các công cụ khác.
Spring được xây dựng và phát triển dựa trên 2 nguyên tắc chính đó là: Dependency Injection và Aspect Oriented Programming.
Như mình đã nói Spring rất lớn, nó được chia thành nhiều modul khác nhau. Chúng ta có thể sử dụng một trong số các modul đó tùy thuộc vào dự án.
Một số dự án nổi bật của Spring có thể kể đến như:
Spring MVC được thiết kế dành cho việc xây dựng các ứng dụng nền tảng web.
Spring Security: Cung cấp các cơ chế xác thực (authentication) và phân quyền (authorization) cho ứng dụng của bạn.
Spring Boot là một framework giúp chúng ta phát triển cũng như chạy ứng dụng một cách nhanh chóng.
Spring Batch giúp chúng ta dễ dàng tạo các lịch trình (scheduling) và tiến trình (processing) cho các công việc xử lý theo mẻ (batch job).
Spring Social kết nối ứng dụng của bạn với các API bên thứ ba của Facebook, Twitter, Linkedin … (ví dụ đăng nhập bằng facebook, Google+ …).
Chúng ta đã đề cập đến các thư viện, framework liên quan đến JavaScript, Java, PHP và sẽ thật thiếu sót nếu không đề cập đến framework của Python.
Django được viết hoàn toàn dựa trên Python, có đầy đủ các thư viện hỗ trợ việc lập trình trình web.
Django được thiết kế theo mô hình MVC và được phát triển bởi Django Software Foundation đồng thời cũng là một open-source framework.
Đây chính là những tiêu chí mà Django hướng đến. Nếu bạn đã có kiến thức về Python và muốn đi theo hướng lập trình viên web thì Django là một lựa chọn hoàn hảo.
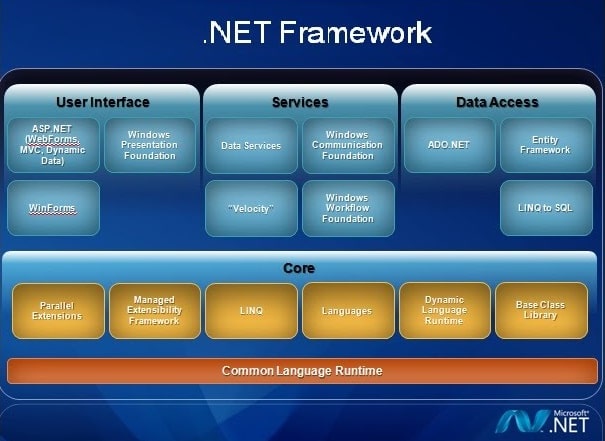
Tiếp theo, chúng ta sẽ cùng điểm qua một gương mặt được xây dựng và phát triển bởi Microsoft đó chính là ASP.net
ASP.NET trong đó: ASP là Active Server Pages và .NET là Network Enabled Technologies.
Các ứng dụng ASP.Net cũng có thể được viết bằng nhiều ngôn ngữ .Net như C#, VB.Net và J#
Và đây chính là kiến trúc của công nghệ .NET nói chung và ASP.NET nói riêng.
Hiện nay, ngôn ngữ lập trình C# do Microsoft phát triển cũng đang rất được giới lập trình viên yêu thích. Nếu bạn có kiến thức về C# thì có thể tìm hiểu về các công nghệ .NET để phát triển các ứng dụng web.
Quay lại với framework Ruby on Rails của chúng ta là một web framework mã nguồn mở, được thiết kế để phát triển các ứng dụng Ruby và cho phép chúng chạy như một trang web thực sự. Rails là cách gọi tắt của Ruby on Rails.
Cuối cùng mình muốn đề cập đến một framework nữa liên quan đến PHP, nhưng có lẽ nhiều bạn mới học có thể chưa biết đến.
Cũng vì PHP vẫn là một trong những ngôn ngữ khá là phổ biến hiện này. Trên các trang tuyển dụng hoặc các page tuyển dụng bạn sẽ không khó để tìm các vị trí liên quan đến PHP.
Cake PHP cũng được thiết kế theo mô hình MVC giống như đối thử Laravel của nó, có thể kể đến một vài điểm nổi bật của CakePHP như sau:
Kiến trúc MVC tiểu chuẩn giúp việc phát triển ứng dụng web dễ dàng
Tích hợp các thao tác thêm, sửa, xóa, cập nhật (CRUD) tương tác với cơ sở dữ liệu
Vậy là qua hai phần của bài viết thì mình đã cùng các bạn điểm mặt 10 web framework tốt nhất hiện nay (từ front-end cho đến back-end) rồi nhé.
Việc sử dụng framework để phát triển các ứng dụng trong thực tế là một yêu cầu gần như bắt buộc vì tính an toàn, tái sử dụng cũng như tốc độ phát triển và triển khai dự án.
Nếu bạn quan tâm đến mảng lập trình thì có thể chuẩn bị cơ bản thật vững ở một ngôn ngữ nào đó rồi học lên sử dụng các framework để hiểu được và biến đổi chúng linh hoạt.
Chúc các bạn học tốt và hẹn gặp lại các bạn trong các bài viết tiếp theo !
Bắt đầu một dự án mới, một kế hoạch mới với các Software Developers luôn là việc thú vị và hấp dẫn. Tuy nhiên khi overload cũng là lúc chúng ta cảm thấy mệt mỏi và không thể hoàn thành công việc một cách tốt nhất. Chính vì thế, biết thêm một số mẹo hay ho khi làm việc giúp công việc mỗi ngày của các Software Developers trơn tru hơn.
Nắm bắt những cách làm việc hợp lí để nâng cao hiệu quả công việc
Những mẹo hay ho cho các Software Developers
Tìm cho mình một cố vấn phù hợp cho bản thân
Một trong những mẹo cho Software Developer hay ho nhất. Đây được xem là điều tốt nhất bạn có thể làm để trở thành một dev giỏi nhất là tìm cho mình một người cố vấn xuất sắc và phù hợp với bản thân. Một người cố vấn giỏi sẽ đưa ra lời khuyên hữu ích về mọi thứ, từ kiến trúc đến thiết kế, và thậm chí cả cách cải thiện con đường sự nghiệp của bạn.
Một người không ở cùng công ty hoặc làm cùng vị trí có thể sẽ là người cố vấn tốt nhất cho bạn. Bạn có thể nói chuyện với họ và nhận lời khuyên của họ qua điện thoại, qua email hoặc chat. Một người cố vấn không nhất thiết phải làm việc tại công ty của bạn cũng như không phải là một dev sành sõi mà đơn giản chỉ là họ có thể giúp bạn đưa ra những ý kiến sáng suốt hơn.
Tìm một người hiểu về Software Developing và đã thành công trong sự nghiệp của họ mà bạn tôn trọng để nhờ sự giúp đỡ khi cần thiết là việc làm hữu ích.
Trở thành một lập trình viên giỏi có nghĩa là bạn có thể giao tiếp hiệu quả với users và các dev khác. Trên thực tế, phần lớn những lập trình viên giỏi đều là những người có thể chia sẻ ý tưởng một cách hiệu quả và tốt nhất. Nếu bạn có thể trình bày ý tưởng của mình một cách rõ ràng và ngắn gọn, người khác sẽ muốn lắng nghe những gì bạn nói hơn. Vậy nên đây là mẹo cho Software Developer trở nên chuyên nghiệp hơn.
Nhưng giao tiếp không chỉ là nói chuyện. Đó cũng là việc lắng nghe những gì người khác nói. Các nghiên cứu chỉ ra rằng những người biết lắng nghe tốt sẽ thành công hơn trong sự nghiệp của họ so với những người nói tốt.
Vì vậy, bạn đừng bao giờ đánh giá thấp sức mạnh của một người biết lắng nghe, đặc biệt là khi làm việc với khách hàng hoặc các dev khác trong nhóm của bạn. Học cách lắng nghe có thể là vô giá, đặc biệt nếu bạn đang có kế hoạch làm việc với người khác.
Khi tôi bắt đầu làm việc với tư cách là một Software Developers, tôi nhớ rằng các đồng nghiệp của tôi luôn có thể chỉ cho tôi đúng hướng khi giải quyết vấn đề hoặc triển khai các tính năng. Đó là khi tôi bắt đầu sử dụng mọi thứ trên Google, tìm hiểu các công cụ và kỹ thuật mới.
Việc biết cách sử dụng Google hiệu quả không khiến bạn trở thành một lập trình viên mà nó sẽ giúp bạn có hiệu suất cao hơn với công việc mình đang làm. Hãy dành thời gian để tìm hiểu về tất cả các loại công cụ khác nhau để nếu một vấn đề xuất hiện đòi hỏi điều gì đó nằm ngoài phạm vi kinh nghiệm của bạn, bạn có thể nhanh chóng xác định xem nó có đáng để dành thời gian tìm hiểu hay không.
Ngay sau khi bạn đọc xong bài viết này, hãy bắt đầu coding đi nhé! Nghe có vẻ hiển nhiên, nhưng bạn phải bắt đầu viết code mỗi ngày. Đây có thể được xem là giải pháp hiệu quả nhất để bạn có thể làm việc tốt hơn và nâng cao kỹ năng của mình. Coding không chỉ là mẹo cho Software Developer mà là việc bắt buộc để nâng cao tay nghề và chuyên môn của bạn.
Coding mỗi ngày giúp các kỹ năng của bạn luôn nhạy bén, giúp bạn học ngôn ngữ và công nghệ mới, đồng thời cho phép bạn làm việc trên những thứ mà bạn quan tâm. Nếu nó không làm bạn hứng thú, hãy chuyển đổi nó bằng cách thay đổi ngôn ngữ hoặc dự án ít nhất một lần một tháng. Điều này sẽ giúp mọi thứ trở nên thú vị hơn và đảm bảo rằng bạn không bị mắc kẹt trong một cuộc chạy đua trong nhiều tháng liên tục.
Điều này có thể nói dễ hơn làm, bởi vì việc tìm kiếm thời gian để thực hiện việc này có thể khá khó khăn trừ khi bạn là người cực kỳ kỷ luật hoặc có nhiều thời gian rảnh rỗi trong tuần. Dù thế nào đi nữa, nếu bạn muốn trở thành một Software Developers tài ba, thực hành sẽ giúp ích rất nhiều vì nó là mẹo cho Software Developer. Cách tốt nhất để làm điều này là có một số mục tiêu cho mỗi tuần tập trung vào việc cải thiện kỹ năng của tôi trong một số thứ mà tôi hiện đang gặp khó khăn. Có hai lợi ích chính cho việc này:
Bạn thấy mình đang tích cực làm việc để trở nên giỏi hơn những gì bạn làm, thay vì chỉ chăm chăm thực hiện những thay đổi nhỏ ở chỗ này và chỗ khác.
Nó cung cấp cho bạn một số mục tiêu và chỉ tiêu cụ thể dễ đo lường. Điều này giúp bạn xem tiến trình của mình và nhanh chóng cho bạn biết loại kỹ năng, công cụ hay công nghệ nào còn thiếu trong hộp công cụ của bạn. Rồi sau này, khi họ trở nên có liên quan trong một dự án trong thế giới thực, họ sẽ không còn xa lạ như mọi thứ xung quanh nữa!
Không ai đạt được thành công ngay trong lần thử đầu tiên, vì vậy đừng cảm thấy tồi tệ khi bạn đang bị rối tung lên. Những người khác vẫn đang học hỏi! Điều cần thiết là học hỏi từ những sai lầm của bạn để bạn có thể tránh tái phạm trong tương lai và để bạn cũng có thể giúp những người khác học hỏi từ chúng.
Trên thực tế, nếu bạn mắc lỗi và sau đó sửa nó trước khi mọi người nhận ra, bạn đã học được gì? Nếu ai đó chỉ ra rằng có vấn đề với code bạn đã viết hoặc cho bạn biết cách cải thiện một lựa chọn thiết kế cụ thể, hãy cảm ơn họ vì đã phát hiện ra nó. Họ đang giúp đỡ bạn bằng cách chỉ ra điều gì đó cần cải thiện hoặc làm rõ.
Ngay cả khi họ sai về những gì cần sửa chữa, hãy đặt câu hỏi và thảo luận vấn đề với họ để làm rõ lý do tại sao họ nghĩ đó là một vấn đề. Hãy nhớ rằng chỉ vì ai đó không đồng ý với giải pháp của bạn không có nghĩa là nó sai – nó chỉ có nghĩa là họ có nhu cầu hoặc mong đợi khác với bạn.
Bài học kinh nghiệm chính ở đây là: cởi mở và sẵn sàng học hỏi!
Kết luận
Nắm bắt những mẹo và những kỹ năng này sẽ giúp bạn làm việc hiệu quả hơn với vai trò là một Software Developer. Hãy luôn khiêm tốn và sẵn sàng học hỏi để có thể trở thành một lập trình viên giỏi nhất trong lĩnh vực của mình.
Bài viết được sự cho phép của tác giả Kien Dang Chung
Trong phần trước Làm việc với cơ sở dữ liệu trong Laravel bạn đã bắt đầu làm quen với việc thực hiện các câu truy vấn SQL dạng thô (raw SQL query), một khó khăn trong việc sử dụng các câu truy vấn này là việc truyền giá trị vào câu truy vấn. Các ứng dụng thực tế thường có các câu truy vấn rất phức tạp, nếu sử dụng raw SQL query sẽ rất khó khăn. Để giải quyết vấn đề này, Laravel đưa ra Laravel Query Builder giúp bạn có thể xây dựng bất kỳ câu truy vấn nào dù nó phức tạp đến đâu. Laravel Query Builder sử dụng PDO (PHP Data Object, hệ thống API có sẵn của PHP để kết nối đến các CSDL thông dụng), bản thân API PDO đã bảo vệ bạn trước các tấn công SQL Injection, do đó khi xử dụng Query Builder bạn không cần lo lắng xử lý dữ liệu trước khi chèn vào database.
Truy xuất dữ liệu từ database
Lấy toàn bộ các bản ghi từ một bảng
$users=DB::table('users')->get();
Sử dụng phương thức table() để trả về một instance query builder của một bảng, khi đó muốn lấy tất cả các bản ghi sử dụng phương thức get(). Phương thức get() trả về Illuminate\Support\Collection với mỗi bản ghi là một đối tượng StdClass trong PHP.
Điều kiện trong một câu truy vấn có thể rất phức tạp khi kết hợp các mệnh đề where khác như: orWhere, whereBetween, whereNotBetween, whereIn, whereNotIn, whereNull, whereNotNull, whereDate, whereMonth, whereDay, whereYear, whereColumn, whereExist. Các ví dụ cho từng kiểu mệnh đề where như sau:
// Ví dụ về orWhere
$users=DB::table('users')->where('vote','>',50)->orWhere('comment','>',50)->get();
// Ví dụ về whereBetween
$users=DB::table('users')->whereBetween('age',[18,35])->get();
// Ví dụ về whereIn
$users=DB::table('users')->whereIn('id',[1,2,3])->get();
// Ví dụ về whereNull
$users=DB::table('users')->whereNull('vote')->get();
// Ví dụ về whereDate
$users=DB::table('users')->whereDate('join_date','2017-03-27')->get();
//Ví dụ về whereDay
$users=DB::table('users')->whereDay('join_date','27')->get();
// Ví dụ về whereMonth
$users=DB::table('users')->whereMonth('join_date','03')->get();
//Ví dụ về whereYear
$users=DB::table('users')->whereYear('join_date','2017')->get();
//Ví dụ về whereColumn
$users=DB::table('account')->whereColumn([['working_balance','=','last_balance'],['updated_at','>','created_at']])->get();
// Ví dụ về whereExist
DB::table('users')->whereExists(function($query){$query->select(DB::raw(1))->from('orders')->whereRaw('orders.user_id = users.id');})->get();
// Ví dụ nhóm các điều kiện trong mệnh đề điều kiện
DB::table('users')->where('name','=','FirebirD')->orWhere(function($query){$query->where('vote','>',50)->where('role','<>','superadmin');})->get();
Thao tác với kết quả trả về
Sắp xếp kết quả trả về của truy vấn bằng phương thức orderBy()
// Insert một bản ghi
DB::table('users')->insert(['name'=>'Nguyễn Văn A','email'=>'anv@gmail.com','votes'=>0]);
// Insert nhiều bản ghi
DB::table('users')->insert([['name'=>'Nguyễn Văn A','email'=>'anv@gmail.com','votes'=>0],['name'=>'Nguyễn Văn B','email'=>'bnv@gmail.com','votes'=>0],['name'=>'Nguyễn Văn C','email'=>'cnv@gmail.com','votes'=>0],['name'=>'Nguyễn Văn D','email'=>'dnv@gmail.com','votes'=>0],]);
Có những trường hợp khi insert vào CSDL bạn cần lấy lại ID bản ghi để làm tham số cho các thao tác tiếp theo, sử dụng insertGetId
$user_id=DB::table('users')->insertGetId(['name'=>'Nguyễn Văn A','email'=>'anv@gmail.com','votes'=>0]);echo'User vừa đăng ký có id là'.$user_id;
Xây dựng một số trang phục vụ các việc sau nhập thông tin sản phẩm, quản lý danh sách sản phẩm: xóa sản phẩm, sửa sản phẩm… Chúng ta cùng bắt đầu thực hiện nào!
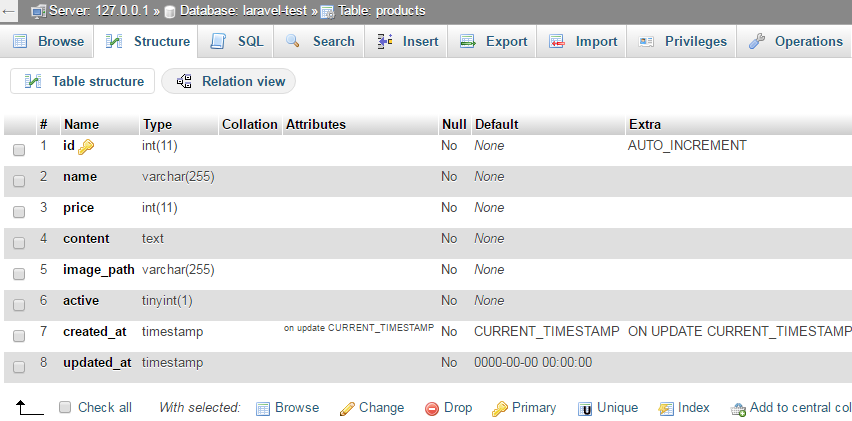
Bước 1: Tạo bảng products trong database laravel-test đã tạo trong bài Làm việc với cơ sở dữ liệu trong Laravel.
Bước 2: Tạo một controller tên là ProductController, sử dụng Restful Resource Controller.
c:\xampp\htdocs\laravel-test>php artisan make:controller ProductController --res
ource
Controller created successfully.
Bước 4: Xử lý từng hành động trên sản phẩm Bảng route tương ứng cho từng hành động như sau:
Verb
URI
Action
Route Name
GET
/product
index
product.index
GET
/product/create
create
product.create
POST
/product
store
product.store
GET
/product/{product_id}
show
product.show
GET
/product/{product_id}/edit
edit
product.edit
PUT/PATCH
/product/{product_id}
update
product.update
DELETE
/product/{product_id}
destroy
product.destroy
Tạo mới sản phẩm:
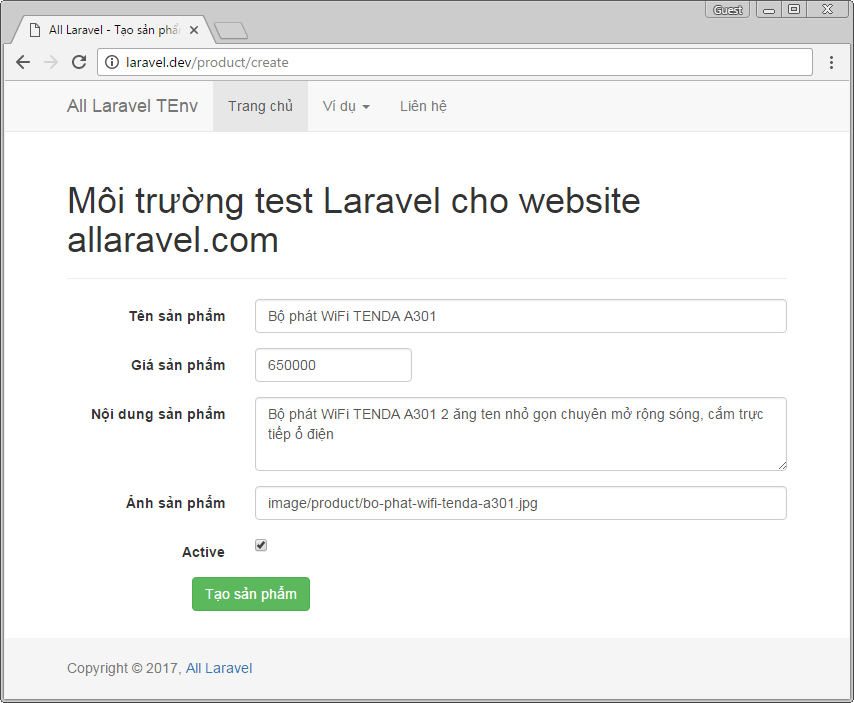
Tạo view create.blade.php trong resources/views/fontend/product
@extends('layouts.default')
@section('title','Tạo sản phẩm')
@section('content')
@if(isset($success))<div class="alert alert-success"role="alert">{{$success}}</div>
@endif
@if(isset($fail))<div class="alert alert-danger"role="alert">{{$fail}}</div>
@endif{!!Form::open(array('url'=>'/product','class'=>'form-horizontal'))!!}<div class="form-group">{!!Form::label('name','Tên sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-9">{!!Form::text('name','',array('class'=>'form-control'))!!}</div></div><div class="form-group">{!!Form::label('price','Giá sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-3">{!!Form::text('price','',array('class'=>'form-control'))!!}</div></div><div class="form-group">{!!Form::label('content','Nội dung sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-9">{!!Form::textarea('content','',array('class'=>'form-control','rows'=>3))!!}</div></div><div class="form-group">{!!Form::label('image_path','Ảnh sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-9">{!!Form::text('content','',array('class'=>'form-control'))!!}</div></div><div class="form-group">{!!Form::label('active','Active',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-3">{!!Form::checkbox('active','',true)!!}</div></div><div class="form-group"><div class="col-sm-offset-2 col-sm-10">{!!Form::submit('Tạo sản phẩm',array('class'=>'btn btn-success'))!!}</div></div>{!!Form::close()!!}
@endsection
Thêm nội dung phương thức create trong ProductController
/**
* Show the form for creating a new resource.
*
* @return \Illuminate\Http\Response
*/publicfunctioncreate(){returnview('fontend.product.create');}
Tiếp đến chúng ta xử lý insert sản phẩm vào CSDL, nó sẽ nằm trong phương thức store của ProductController (xem bảng các route của product)
/**
* Store a newly created resource in storage.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/publicfunctionstore(Request $request){$validator=Validator::make($request->all(),['name'=>'required|max:255','price'=>'required|number','content'=>'required','image_path'=>'required']);if($validator->fails()){returnredirect('product/create')->withErrors($validator)->withInput();}else{ // Lưu thông tin vào database, phần này sẽ giới thiệu ở bài về database
$active=$request->has('active')?1:0;$product_id=DB::table('product')->insertGetId('name'=>$request->input('name'),'price'=>$request->input('price'),'content'=>$request->input('content'),'image_path'=>$request->input('image_path'),'active'=>$active);returnredirect('product/create')->with('message','Sản phẩm được tạo thành công với ID: '.$product_id);}}
Để nhập sản phẩm ta vào đường dẫn http://laravel.dev/product/create
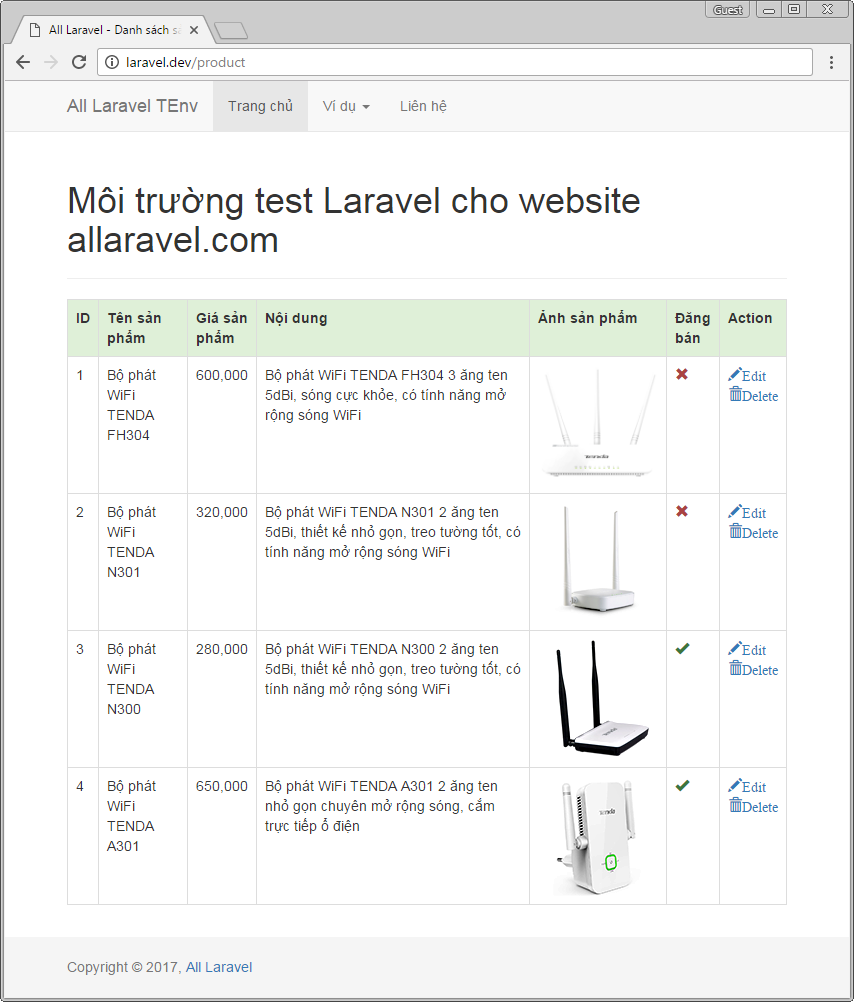
Danh sách sản phẩm:
Danh sách sản phẩm sẽ được xử lý trong phương thức index của ProductController, chúng ta thêm nội dung cho phương thức này như sau:
/**
* Display a listing of the resource.
*
* @return \Illuminate\Http\Response
*/publicfunctionindex(){$products=DB::table('products')->get();returnview('fontend.product.list')->with($products);}
Tiếp đến chúng ta tạo một view để hiển thị danh sách sản phẩm tên là list.blade.php nằm trong thư mục resources/views/fontend/product
Kết quả khi chạy http://laravel.dev/product ta có danh sách các sản phẩm
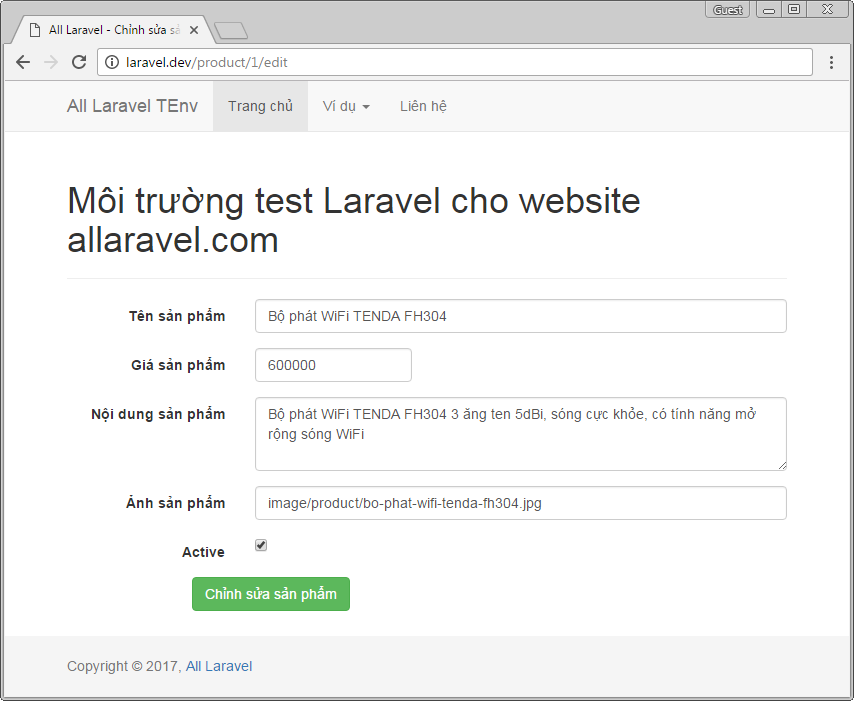
Chỉnh sửa sản phẩm
Chúng ta sử dụng phương thức edit() trong ProductController để chỉnh sửa sản phẩm, nội dung phương thức này như sau:
/**
* Show the form for editing the specified resource.
*
* @param int $id
* @return \Illuminate\Http\Response
*/publicfunctionedit($id){$product=DB::table('products')->find($id);returnview('fontend.product.edit')->with(compact('product'));}
Tạo một view để chỉnh sửa sản phẩm resources/views/fontend/product/edit.blade.php với nội dung như sau:
@extends('layouts.default')
@section('title','Chỉnh sửa sản phẩm')
@section('content')
@if(isset($success))<div class="alert alert-success"role="alert">{{$success}}</div>
@endif
@if(count($errors)>0)<div class="alert alert-danger"><ul>
@foreach($errors->all()as$error)<li>{{$error}}</li>
@endforeach</ul></div>
@endif{!!Form::open(array('url'=>'/product/'.$product->id,'class'=>'form-horizontal','method'=>'put'))!!}<div class="form-group">{!!Form::label('name','Tên sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-9">{!!Form::text('name',$product->name,array('class'=>'form-control'))!!}</div></div><div class="form-group">{!!Form::label('price','Giá sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-3">{!!Form::text('price',$product->price,array('class'=>'form-control'))!!}</div></div><div class="form-group">{!!Form::label('content','Nội dung sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-9">{!!Form::textarea('content',$product->content,array('class'=>'form-control','rows'=>3))!!}</div></div><div class="form-group">{!!Form::label('image_path','Ảnh sản phẩm',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-9">{!!Form::text('image_path',$product->image_path,array('class'=>'form-control'))!!}</div></div><div class="form-group">{!!Form::label('active','Active',array('class'=>'col-sm-3 control-label'))!!}<div class="col-sm-3">{!!Form::checkbox('active',$product->active,true)!!}</div></div><div class="form-group"><div class="col-sm-offset-2 col-sm-10">{!!Form::submit('Chỉnh sửa sản phẩm',array('class'=>'btn btn-success'))!!}</div></div>{!!Form::close()!!}
@endsection
Phương thức update() của ProductController đảm nhận phần cập nhật nội dung sản phẩm, thêm code vào phương thức này như sau:
/**
* Update the specified resource in storage.
*
* @param \Illuminate\Http\Request $request
* @param int $id
* @return \Illuminate\Http\Response
*/publicfunctionupdate(Request $request,$id){$active=$request->has('active')?1:0;$updated=DB::table('products')->where('id','=',$id)->update(['name'=>$request->input('name'),'price'=>$request->input('price'),'content'=>$request->input('content'),'image_path'=>$request->input('image_path'),'active'=>$active,'updated_at'=> \Carbon\Carbon::now()]);returnRedirect::back()->with('message','Cập nhật sản phẩm thành công')->withInput();}
OK, giờ chúng ta click vào Edit sản phẩm bất kỳ trong danh sách sản phẩm nó sẽ xuất hiện cửa sổ chỉnh sửa sản phẩm
Thay đổi thông tin và click Chỉnh sửa sản phẩm, sau đó vào lại trang danh sách sản phẩm http://laravel.dev/product chúng ta sẽ thấy nội dung đã thay đổi. Xóa một sản phẩm Thông thường các sản phẩm khi đã nhập vào hệ thống chúng ta sẽ không xóa đi mà chỉ cần không active nó lên là ok, do vậy phần này mình bỏ qua nhé, với lại cũng hơi lười tí.
Laravel Query Builder giúp chúng ta xây dựng ứng dụng thật nhanh chóng cho dù các câu truy vấn có phức tạp đến đâu chúng ta cũng xử lý rất dễ dàng. Trong ví dụ phần ảnh sản phẩm tôi tạm thời để theo kiểu copy bằng tay đường dẫn ảnh sản phẩm. Trong thời gian tới, khi nào rảnh tôi sẽ hướng dẫn bạn tích hợp CKEditor và CKFinder vào hệ thống giúp đưa vào nội dung phong phú vào và quản lý lựa chọn tài nguyên như ảnh, file dễ dàng hơn.
Vì đây là mã nguồn mở nên người phát triển có thể custom về bộ core CI/CD theo ý muốn. Và Concourse được xây dựng trên cơ chế đơn giản về resources, tasks và jobs. Việc sử dụng Concourse là một cách tiếp cận về CI/CD tuyệt vời.
Bạn có thể hiểu pipeline như một Makefile phân tán, cấp cao hơn, chạy liên tục.
Mỗi mục trong resource là một phụ thuộc và mỗi mục trong các job mô tả một plan để chạy khi công việc được kích hoạt (bằng tay hoặc bằng một step có được).
Việc làm có thể phụ thuộc vào các nguồn lực đã passed các công việc trước đó. Chuỗi kết quả của công việc và tài nguyên là một biểu đồ phụ thuộc liên tục thúc đẩy dự án của bạn tiến lên, từ source code đến production.
HIển thị hoạt động
Cấu hình pipeline của bạn sau đó được hiển thị trong giao diện người dùng web, chỉ cần một cú nhấp chuột để nhận được từ hộp màu đỏ (thất bại) để xem tại sao nó thất bại.
Hiển thị hoạt động cũng cung cấp một vòng phản hồi “gut check” – nếu nó có vẻ sai, có lẽ nó đã sai.
Tất cả quản trị được thực hiện bằng cách sử dụng Fly CLI. Lệnh fly set-pipeline đẩy cấu hình lên tới Concourse. Khi nó trông ổn, bạn có thể kiểm tra file để kiểm soát nguồn. Điều này giúp dễ dàng khôi phục nếu máy chủ Concourse của bạn bị down.
Reproducible, Debuggable Builds
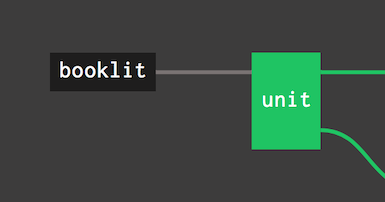
$ fly -t ci intercept -j booklit/unit -s unit
root@2c15ff11:/tmp/build/0df9eea0# ps
PID TTY TIME CMD
171 pts/1 00:00:00 bash
1876 pts/1 00:00:00 ps
root@2c15ff11:/tmp/build/0df9eea0# ls
depspath gopath
root@2c15ff11:/tmp/build/0df9eea0# █
Tất cả mọi thứ chạy trong container, đảm bảo một môi trường sạch sẽ trên mỗi lần chạy. Mỗi task chỉ định image riêng của nó, cho nó toàn quyền kiểm soát các dependencies, thay vì quản lý chúng trên các workers.
fly intercept sẽ đưa bạn vào một trong các build của các containers, có thể hữu ích cho việc debugging.
The fly execute command executes a task as a one-off build, with your local changes. This will run your code in exactly the same way it would run in your pipeline, without you having to repeatedly push broken commits until it works. Achieve the fabled green build #1!
When a job fails, you can also use fly execute with -jflag to run with the same inputs as the failed job. You can then replace an input with your local changes with -i to test if your fix is valid.
Lệnh fly execute thực thi một task như một bản dựng một lần, với các thay đổi cục bộ của bạn. Điều này sẽ chạy code của bạn theo cách chính xác giống như cách nó sẽ chạy trong pipeline của bạn, mà bạn không phải liên tục đẩy các commit bị hỏng cho đến khi nó hoạt động. Đạt được huyền thoại build màu xanh #1!
Khi một job thất bại, bạn cũng có thể sử dụng fly execute với cờ-j để chạy với cùng các inputs như failed job. Bạn có thể thay thế một input bằng các thay đổi local của bạn bằng -i để kiểm tra xem bản sửa lỗi của bạn có hợp lệ không.
Concourse không có một hệ thống plugin phức tạp. Thay vào đó, nó có một sự trừu tượng mạnh mẽ duy nhất.
Phần resources của một pipeline liệt kê các Resources , là các vị trí bên ngoài trừu tượng nơi pipeline của bạn sẽ theo dõi các thay đổi, tìm nạp từng chút từ và đẩy từng chút đến.
Ví dụ, một resource với kiểu git tham chiếu đến git repository, resource này sẽ được clone trong một get step và push đến trong put step. Đằng sau hậu trường, Concourse sẽ liên tục run git fetch để tìm kiếm các commit mới mà các jobs có thể muốn trigger.
Về cốt lõi, Concourse không biết gì về Git. Nó đi kèm với một loại resource git ra khỏi hộp, nhưng bạn có thể dễ dàng đưa chính bạn vào pipeline của bạn. Các loại resource được triển khai dưới dạng image chứa các scripts – sử dụng docker-image, chúng có thể được tìm nạp từ Docker registry.
Bài viết được sự cho phép của tác giả Edward Thien Hoang
Robert C. Martin (hay còn gọi là Uncle Bob) cho ra đời ý tưởng của mình về Clean Architecture vào năm 2012, trong một bài viết trên blog của mình, và giảng dạy về nó tại một vài hội nghị, và gần đây nhất là cuốn sách Clean Architecture: A Craftsman’s Guide to Software Structure and Design xuất bản năm 2017.
Clean Architecture dựa trên các khái niệm, quy tắc, và mô hình nổi tiếng, giải thích làm thế nào để kết hợp chúng với nhau, để đề xuất cách xây dựng các ứng dụng chuẩn.
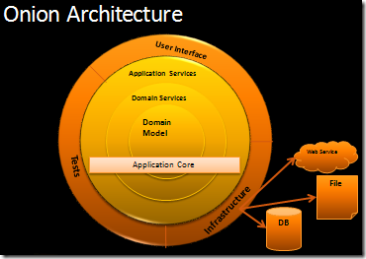
Đứng trên vai những gã khổng lồ: EBI, Hexagonal and Onion Architectures
Các mục tiêu cốt lõi của Clean Architecture cũng giống với đối với Ports & Adapters (Hexagonal) và Onion Architectures:
Độc lập các công cụ;
Sự độc lập của các cơ chế phân phối;
Khả năng cô lập kiểm thử.
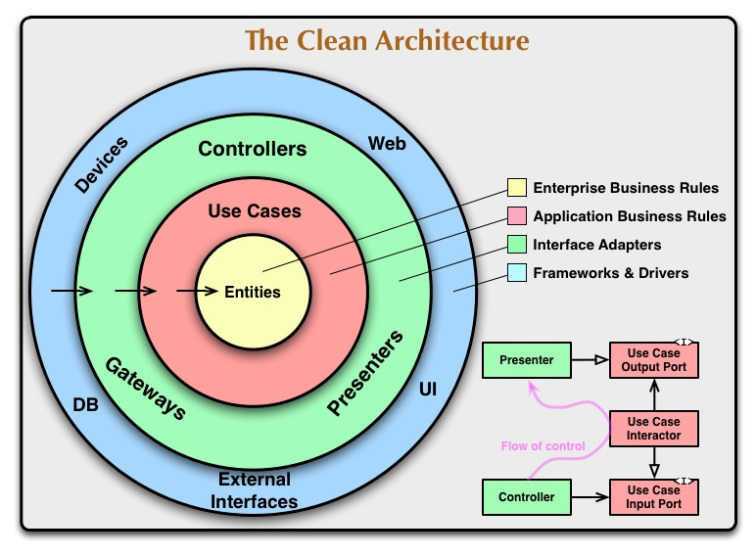
Trong bài viết về Clean Architecture đã được xuất bản, đây là sơ đồ được sử dụng để giải thích ý tưởng tổng quát:
Robert C. Martin 2012, The Clean Architecture
Như ông Bob nói trong bài của mình, sơ đồ trên là một nỗ lực để tích hợp các ý tưởng kiến trúc gần đây vào một ý tưởng có thể thực hiện được.
Hãy so sánh sơ đồ Clean Architecture với các sơ đồ được sử dụng để giải thích Hexagonal Architecture và Onion Architecture, và xem chúng trùng nhau ở đâu:
CÁC CÔNG CỤ BÊN NGOÀI VÀ CƠ CHẾ PHÂN PHỐI
(Externalisation of tools and delivery mechanisms)
Hexagonal Architecture tập trung vào việc mở rộng các công cụ và cơ chế phân phối từ ứng dụng, sử dụng interfaces (Port) và Adapter. Đây cũng là một trong những nền tảng cốt lõi của Onion Architecture, như chúng ta có thể thấy qua biểu đồ của nó, UI, cơ sở hạ tầng và các testing đều nằm trong layer ngoài cùng của sơ đồ. Clean Architecture cũng có đặc điểm giống như vậy, có giao diện người dùng, web, DB, v.v … ở layer ngoài cùng. Trong cùng là tất cả mã lõi ứng dụng độc lập với framework / libraries.
CHIỀU CỦA SỰ PHỤ THUỘC
(Dependencies direction)
Trong Hexagonal Architecture, chúng ta không có bất cứ điều gì rõ ràng cho chúng ta biết hướng của các phụ thuộc. Tuy nhiên, chúng ta có thể dễ dàng suy luận nó: Ứng dụng có một Port (interface) phải được implement hoặc sử dụng bởi Adapter. Vì vậy Adapter phụ thuộc vào giao diện, nó phụ thuộc vào ứng dụng nằm ở trung tâm. Bên ngoài phụ thuộc vào bên trong, hướng của các phụ thuộc là về phía trung tâm. Trong Onion Architecture, chúng ta cũng không có bất cứ điều gì rõ ràng cho chúng ta biết hướng phụ thuộc, tuy nhiên, trong bài thứ hai của mình, Jeffrey Palermo cho biết rõ ràng rằng tất cả các phụ thuộc đều hướng đến trung tâm. Clean Architecture, lần lượt, nó khá rõ ràng trong chỉ ra rằng sự phụ thuộc hướng là hướng về trung tâm. Tất cả đều đưa ra Nguyên tắc đảo ngược phụ thuộc (Dependency Inversion Principle) ở cấp kiến trúc. Vòng tròn bên trong không hề biết gì về các vòng tròn bên ngoài. Hơn nữa, khi chúng ta truyền dữ liệu qua một ranh giới (Boundary), nó luôn ở dạng thuận tiện nhất cho vòng tròn phía trong.
CÁC LAYERS
Sơ đồ Kiến trúc Hexagonal Architecture chỉ hiển thị cho chúng ta hai layer: Bên trong ứng dụng và bên ngoài của ứng dụng. Mặt khác, Onion Architecture mang đến sự kết hợp các layer ứng dụng được xác định bởi DDD: Entities, Value Objects, Application Services chứa các use-case logic; Domain Services đóng gói domain logic không thuộc về các Entities hoặc Value Objects… Khi so sánh với Onion Architecture, Clean Architecture sẽ duy trì Application Services layer (Use Cases) và Entities layer nhưng dường như nó quên mất Domain Services layer. Tuy nhiên, đọc bài của Bác Bob chúng ta nhận ra rằng ông coi một thực thể không chỉ là và Entity theo ý nghĩa của DDD mà bất cứ Domain object nào: “Một entity có thể là một đối tượng với các phương thức, hoặc nó có thể là một tập hợp các cấu trúc dữ liệu và các hàm. “. Trong thực tế, ông đã sáp nhập hai layer bên trong để đơn giản hóa sơ đồ.
KHẢ NĂNG CÔ LẬP KIỂM THỬ
(Testability in isolation)
Trong cả ba kiểu Kiến trúc, chúng đều tuân theo các nguyên tắc phân tách domain logic với các thành phần bên ngoài. Điều này có nghĩa là trong mọi trường hợp chúng ta chỉ có thể mô phỏng các công cụ bên ngoài và các cơ chế phân phối và thực hiện kiểm thử ứng dụng mà không sử dụng bất kỳ DB hay HTTP request nào.
Như chúng ta có thể thấy, Clean Architecture sẽ kết hợp các quy tắc của Hexagonal Architecture và Onion Architecture. Cho đến nay, kiến trúc sạch sẽ không thêm bất cứ điều gì mới cho phương trình. Tuy nhiên, ở góc dưới cùng bên phải của Clean Architecture diagram, chúng ta có thể thấy thêm một biểu đồ nhỏ …
ĐỨNG TRÊN VAI NHỮNG GÃ KHỔNG LỒ: MVC VÀ EBI
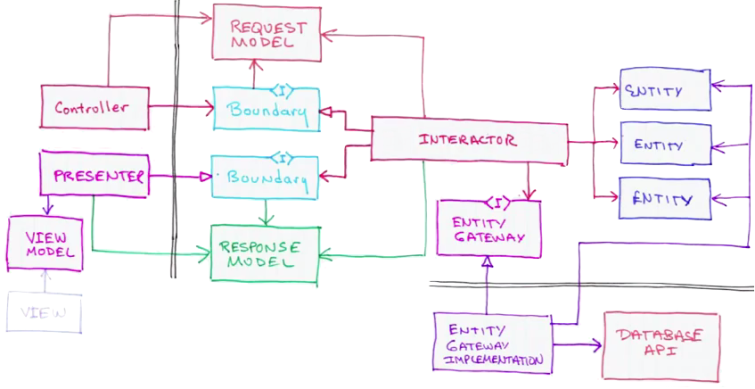
Biểu đồ phụ nhỏ ở góc dưới cùng bên phải của Clean Architecture diagram sẽ giải thích về sơ đồ luồng tương tác (flow of control) giữa các component. Biểu đồ nhỏ này không cung cấp cho chúng ta nhiều thông tin, nhưng lời giải thích về bài đăng trên blog và các bài giảng của hội thảo được đưa ra bởi Robert C. Martin mở rộng về đề tài này.
Trong sơ đồ ở trên, ở phía bên trái, chúng ta có View và Controller của MVC. Mọi thứ bên trong / giữa các đường kẻ đôi màu đen đại diện cho Model trong MVC. Mô hình này cũng đại diện cho kiến trúc EBI (với “Boundary”, Interactor và the Entities”), “Application” trong Hexagonal Architecture, “Application Core” trong Onion Architecture, “Entities” và “Use Cases” layer trong Clean Architecture.
Theo biểu đồ luồng tương tác, chúng ta có một yêu cầu HTTP đến các Controller. Controller sau đó sẽ:
Phân tích Request;
Tạo một Request Model với các dữ liệu có liên quan;
Execute một method trong Interactor (đã được đưa (inject) vào Controller bằng cách sử dụng interface của Interactor là Boundary), chuyển nó cho Request Model;
Interactor sẽ:
Sử dụng implementation của Entity Gateway (được đưa vào Interactor bằng cách sử dụng Entity Gateway Interface) để tìm các Entities liên quan;
Phối hợp các tương tác giữa các Entities;
Tạo Response Model với kết quả dữ liệu trả về;
Tạo ra Presenter chứa Response Model;
Trả lại Presenter cho Controller;
Dùng Presenter để tạo ra một ViewModel;
Bind ViewModel với View;
Trả View về cho Client.
KẾT LUẬN
Tôi không nói rằng Clean Architecture là cuộc cách mạng bởi vì nó không thực sự mang lại một khái niệm hoặc mô hình đột phá mới. Tuy nhiên, tôi xin nói rằng đó là một công trình có tầm quan trọng lớn, bởi vì:
Nó khôi phục các khái niệm, quy tắc và khuôn mẫu bị quên lãng;
Nó làm rõ các khái niệm và quy tắc hữu ích và quan trọng;
Nó cho chúng ta biết tất cả các khái niệm, quy tắc và mẫu này phù hợp với nhau để cung cấp cho chúng ta một cách chuẩn hóa để xây dựng các ứng dụng phức tạp với sự bảo trì trong đầu.
Khi tôi nghĩ về Bác Bob làm việc với Clean Architecture, nó làm cho tôi nghĩ về Isaac Newton. Trọng lực luôn ở đó, mọi người đều biết rằng nếu chúng ta thả quả táo cách mặt đất một mét, nó sẽ di chuyển xuống mặt đất. “Điều duy nhất” mà Newton đã làm là xuất bản một bài báo đưa ra sự thật đó *. Đó là một điều “đơn giản” phải làm, nhưng nó cho phép mọi người lý giải về nó và sử dụng ý tưởng cụ thể làm nền tảng cho những ý tưởng khác.
Nói cách khác, tôi thấy Robert C. Martin là Isaac Newton trong phát triển phần mềm!
Đây là bài viết trong loạt bài viết về “Tổng quan về sự phát triển của kiến trúc phần mềm“. Đây là loạt bài viết chủ yếu giới thiệu về một số mô hình kiến trúc phần mềm hay nói đúng hơn là sự phát triển của chúng qua từng giai đoạn, qua đó giúp chúng ta có cái nhìn tổng quát, up-to-date và là roadmap để bắt đầu hành trình chinh phục (đào sâu) thế giới của những bản thiết kế với vai trò là những kỹ sư và kiến trúc sư phần mềm đam mê với nghề.
Trong kiểm thử phần mềm thì hai khái niệm Độ ưu tiên (Priority) và Độ nghiêm trọng (Severity) cũng không quá xa lạ, đặc biệt là trong quản lý bug. Hai khái niệm trên đã trở nên quá quen thuộc và phổ biến đến nỗi chúng ta hầu như không phân biệt được ý nghĩa cũng như sự khác nhau giữa hai khái niệm đó. Mặc dù hai yếu tố này không phải là yếu tố sống còn trong quản lý bug nhưng việc hiểu đúng sẽ giúp chúng ta tiết kiệm thời gian cũng như làm công việc hiệu quả hơn.
Mức độ nghiêm trọng của một con bug thường chỉ mức độ tác động của con bug đó đến sản phẩm/ người dùng. Mỗi dự án hay sản phẩm có tiêu chí đánh giá độ nghiêm trọng khác nhau nhưng thông thường sẽ có 4-5 mức độ khác nhau từ nghiêm trọng nhất đến ít nghiêm trọng hơn:
Mức độ 1: Hệ thống sập, dữ liệu bị mất, ứng dụng không cài đặt được v.v.
Mức độ 2: Chức năng chính của sản phẩm không hoạt động
Mức độ 3: Chức năng phụ của sản phẩm không hoạt động
Mức độ 4: Bug nhỏ, không quan trọng
(Mức độ 5): Yêu cầu cải tiến sản phẩm, thêm chức năng
Cũng nên lưu ý việc định nghĩa mức độ nghiêm trọng phụ thuộc vào sản phẩm khác nhau, mang tính tham khảo và tương đối.
Việc xác định được độ nghiêm trọng của con bug giúp nhà quản lí dự án, chủ sản phẩm có cái nhìn tốt hơn và thuận lợi hơn về tình hình chất lượng của sản phẩm. Số lượng bug là chưa đủ để đánh giá tình hình. Việc đội kiểm thử tìm được 50 con bug trong 1 tháng cũng không nói lên nhiều về tình hình chất lượng của sản phẩm. Tuy nhiên, nếu biết được trong 50 con bug đó có đến hơn 1 nửa là bug với độ nghiêm trọng ở cấp độ 1 và 2 sẽ hữu ích hơn nhiều. Ngoài ra, với góc độ của kỹ sư kiểm thử, độ nghiêm trọng cũng giúp “quảng cáo” cho con bug của mình từ đó sẽ gây được sự chú ý của mọi người và tăng cơ hội con bug đó được sửa.
Có một thực tế không lấy gì vui vẻ là việc xác định độ nghiêm trọng của con bug không hẳn lúc nào cũng mang tính chất trắng-đen và tuyệt đối. Sẽ không có gì ngạc nhiên nếu chúng ta cho rằng vấn đề này là nghiêm trọng trong khi chủ sản phẩm, nhà quản lý dự án lại không nghĩ như vậy. Không hẳn là họ đang cố tình “dìm hàng” chúng ta mà cũng có thể cách chúng ta cung cấp thông tin không thể hiện được đầy đủ mức độ nghiêm trọng của vấn đề. Hãy phân tích và cung cấp thêm thông tin để cho thấy tác động nghiêm trọng của con bug đối với sản phẩm cũng như người dùng cuối như thế nào như xảy ra trên nhiều môi trường; lặp đi lặp lại; có khả năng ảnh hưởng đến các thành phần, chức năng khác; hình ảnh thương mại của công ty v.v. Và dĩ nhiên, nếu vấn đề không thực sự nghiêm trọng, chúng ta cũng không có lí do gì để làm cho lớn chuyện. Việc hiểu rõ sản phẩm, người dùng cùng khả năng phân tích, suy luận sẽ giúp chúng ta làm tốt khâu này.
Độ ưu tiên
Như chúng ta đã biết nếu đã là bug thì sẽ phải sửa. Tuy nhiên, có một thực tế là đội phát triển khó có thể sửa hết tất cả bug một lượt cũng như không đáng để sửa hết tất cả các bug. Do đó, đội phát triển sẽ phải cần đến độ ưu tiên của con bug để biết được bug nào cần được sửa trước bug nào sau. Độ ưu tiên của con bug cũng thường được chia thành 3-4 cấp độ:
Mức độ 1: Cao – Bug sẽ phải sửa ngay lập tức
Mức độ 2: Trung bình – Bug sẽ sửa trong bản cập nhật lần tới
Mức độ 3: Thấp – Bug không cần sửa trong bản cập nhật lần tới, có thể sửa nếu có thời gian
Tương tự mức độ nghiêm trọng, mức độ ưu tiên cũng như ý nghĩa của chúng có thể sẽ khác nhau ở những sản phẩm, dự án khác nhau.
Thế chúng ta sẽ dựa vào đâu để xác định độ ưu tiên? Bug nào sửa trước bug nào sửa sau (hoặc không sửa)? Quá dễ, dựa vào độ nghiêm trọng của bug. Bug nào nghiêm trọng nhất, tác động đến người dùng nhiều nhất thì sẽ được ưu tiên sửa trước. Bug nào ít nghiêm trọng hơn sẽ được sửa sau. Đúng…nhưng không phải lúc nào cũng đúng. Giả sử chúng ta tìm được một bug làm sập hệ thống. Quá tuyệt đúng không nào. Chúng ta đánh giá mức độ nghiêm trọng ở Mức độ 1 (rất là nghiêm trọng) và độ ưu tiên 1 (cần được sửa gấp). Nhưng hôm sau, độ ưu tiên của bug đó được điều chỉnh xuống thấp trong khi con bug bắt lỗi chính tả của thằng bạn lại được đánh giá có độ ưu tiên cao để sửa. Chúng ta buồn rầu, thất vọng, khó chịu và quyết phải hỏi cho ra lẽ và được giải thích rằng “Mặc dù bug đó làm sập hệ thống nhưng khả năng người dùng bị lỗi đó là rất thấp do để làm ra bug đó bạn phải trải qua vài chục bước hay bug đó chỉ xảy ra trên một môi trường cụ thể cũng như rất ít người dùng chạy sản phẩm trên môi trường đó”. Suy cho cùng đó là một quyết định liên quan đến kinh doanh và hầu như chúng ta không thể thay đổi được quyết định đó. Có một thực tế phải thừa nhận là kỹ sư kiểm thử chúng ta biết rất ít hay thậm chí không thể biết được khối lượng công việc của đội phát triển, chi phí của dự án cũng như những quyết định kinh doanh mang tính chiến lược của nhà đầu tư, quản lý dự án hay chủ sản phẩm. Điều đó cũng không có gì là quá tệ đối với một kỹ sư kiểm thử. Nó chỉ liên quan đến vai trò và trách nhiệm công việc của kỹ sư kiểm thử. Xác định độ ưu tiên được khuyến khích đối với kỹ sư kiểm thử nhưng không phải bắt buộc. Đó là lí do tại sao ở một số dự án thậm chí kỹ sư kiểm thử được yêu cầu không xác định độ ưu tiên cho con bug và độ ưu tiên chỉ được xác định sau buổi họp đánh giá bug. Điều này cũng không có gì là vô lí.
Lời kết
Trách nhiệm và vai trò của kỹ sư kiểm thử là cung cấp thông tin về chất lượng sản phẩm càng nhiều càng chi tiết càng tốt cho các nhà quản lí dự án, cho chủ sản phẩm những người sau đó sẽ đưa ra những quyết định kinh doanh cho sản phẩm dựa vào những thông tin đó. Độ ưu tiên và độ nghiêm trọng chỉ là hai trong số rất nhiều thông tin quan trọng khác chúng ta cần phải cung cấp như môi trường của con bug, mức độ lặp đi lặp lại, các bước mô tả con bug, phạm vi của con bug v.v. Tuy nhiên, việc hiểu đúng về mức độ nghiêm trọng, độ ưu tiên của sản phẩm cho thấy chúng ta thực sự hiểu rõ và quan tâm đến chất lượng sản phẩm cũng như thể hiện sự chuyên nghiệp của một kỹ sư kiểm thử.
Bài viết được sự cho phép của tác giả Edward Thiên Hoàng
Technical debt – tạm dịch là “Khoản nợ kỹ thuật” được dùng nhiều trong Software Engineering. Theo Henrik Kniberg, những khoản nợ kỹ thuật là bất cứ thứ gì trong việc viết mã khiến bạn chậm lại về lâu dài. Ví dụ như là mã khó đọc, thiếu (hoặc không có) kiểm thử tự động, mã trùng lặp, hoặc sự liên kết lằng nhằng giữa lớp, mô-đun… (Think of technical debt as anything about your code that slows you down over the long term. Hard-to-read code, lack of test automation, duplication, tangled dependencies, etc. Henrik Kniberg).
Cũng giống như những khoản nợ về tài chính: có vay mới có nợ, có nợ ắt sẽ sinh lãi. Technical debt sinh ra vì nhiều lý do: áp lực kinh doanh, thiếu kỹ năng trong phân tích thiết kế cũng như kỹ năng lập trình, không có các bộ mã kiểm thử dẫn đến việc trì hoãn (hoặc không thể) tái cấu trúc lại mã nguồn… Nếu không được trả, theo thời gian, nợ sẽ đẻ lãi, dẫn đến việc chậm tiến độ, những đoạn mã mới được thêm vào sẽ mất nhiều thời gian và chi phí hơn, mà đa phần trong số đó là chi phí cho việc gỡ rối (debugging) và kiểm thử hồi quy (regression testing).
Nếu bạn đang làm việc với 1 legacy system (có rất nhiều định nghĩa về legacy code, nhưng mình thích nhất định nghĩa của Robert C. Martin: legacy code = code without test) nghĩa là bạn đang mang trên mình món nợ về kỹ thuật. Một đoạn mã được viết cách đây 10 năm cũng gọi là legacy code, một đoạn mã được viết ngày hôm qua cũng gọi là legacy code nếu chúng đều không được “chống lưng” bằng mã kiểm thử. Và nếu bạn vẫn tiếp tục tạo ra những đoạn mã “without test”, cũng tức là bạn đang tự đẻ thêm nợ cho chính system của mình. Điều đó cũng giống như việc bạn thêm vào những đoạn mã khó đọc, mã trùng lặp, hoặc sự kiên kết lằng nhằng giữa lớp, mô-đun… (Có phải mình cũng vừa lặp lại những gì đã nói ở trên?).
Vậy bạn sẽ trả nợ bằng cách nào? Hay thõa hiệp trước món nợ + lãi đang ngày một tăng khi mã mới được thêm vào?
Có hàng tá lý do để biện minh cho việc thõa hiệp, có thể kể ra như: đừng phá vỡ những đoạn mã đã chạy ổn định, hệ thống chúng ta quá phức tạp, do đó cần thêm thời gian để (tìm hiểu) thêm mới hoặc sữa chữa một đoạn mã nào đó (và đảm bảo không phá vỡ những đoạn mã hiện tại). Có một câu ví von khá hay về vấn đề này. “The code may not be pretty, but damnit, it works!” dùng để nói về Duct Tap Programmer – người viết mã chỉ để “chạy được”.
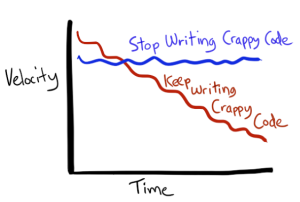
Nếu chọn cách trả nợ, những việc bạn sẽ làm là đừng (hoặc hạn chế) để lại nợ nần cho những thế hệ (mã) phía sau. Và điều đầu tiên đó là Hãy ngừng việc tạo ra những đoạn mã xấu (Stop writing crappy code).
TDD đã khó, TDD cho legacy system còn khó gấp bội. Bài viết dưới đây của Mark Levison bàn về việc những vấn đề gặp phải khi áp dụng TDD trong Legacy System, qua đó trích dẫn 1 số phương pháp của Keith Ray – XP Coach để làm việc với legacy code nhằm giảm (paying down) những khoản technical debt, dựa trên nền tảng cốt lõi là viết mã sạch, tái cấu trúc mã nguồn và bỏ túi SOLID principles.
Allan Baljeu was trying to TDD with a legacy C++ code base, he was running into trouble because:
we end up with classes that don’t fully implement the functionality that’s eventually needed, and when others come around to use those classes, and eventually fuller implementations are required, then it turns out that the original design is not adequate, a new design is required, some expectations (tests) need to change and previous uses of the class need to be updated.
He wondered if Big Design Up Front would help solve the problem. George Dinwiddie, Agile Coach, suggested that Alan’s design was trying to tell him something. You have to pay attention to the fundamentals of clean code. You can look at basic coupling and cohesion (i.e. SOLID).
Mike “Geepaw” Hill, Agile Coach, says that in his years of coaching agile teams, one of the following has been at the root of these problems:
team is not yet up to speed on refactoring, so your classes aren’t really
minimal
team is not yet skilled at simplicity, so ditto
team is not yet doing aggressive & rapid microtesting (aka unit testing), so changes break tests too often
team doesn’t know how to handle cross-team or company-to-public dependencies, e.g. shipping api’s
team neither pairing nor open workspacing, dramatically slowing team-wide understanding.
team likely has no jiggle-less build
team could be using tools from the ’40s
Keith Ray, XP Coach, suggests that with legacy code (i.e. systems with high technical debt) the cost of repaying technical debt dominates the cost of implementing a story. He goes on to offer an approach:
To make the code more well-factored (paying down the technical debt), whenever you need to integrate a new feature into it, you should pay close attention to code smells in both the new code and the old code and consider refactoring to deal with each smell as you recognize it.
You can do refactorings in small safe steps (even in C++) manually. Very closely follow the instructions in Fowler’s book on Refactoring until you learn them by heart. Eclipse with gcc has a few refactorings that actually work: Extract Method and Rename. Rename understands scope, so it is safer than search-and-replace. Extract Method and the other refactorings in Ecipse might be buggy, so be careful when you use them. For things like changing a function signature, “lean on the compiler” to show where changes have to be made.
You also need tests to make sure the refactorings are not damaging the existing features. Feather’s book on working with legacy code has lots of techniques for adding tests to legacy code. On a higher level, code smells are violations of good design principles. For example, the Single Responsibility Principle (SRP) says there should one purpose for every class / method / module. There are principles about coupling and cohesion and managing dependencies, etc. It’s often easier to detect a code smell than it is to apply these abstract principles. “Large Class” and “Large Method” are remedied by “Extract Class” and “Extract Method/Move Method”, though knowing SRP helps in deciding what parts of a class or method should be extracted.
Perhaps the most important design principle is “Tell, don’t ask”: keep functionality and data together…. bad code often has the functionality in one place, and gets the data it needs from other places, creating problems with dependencies and lack of locality — symptomized by “adding a new feature requires changing lots of code”. The code smells “Shotgun Surgery”, “Feature Envy”, “Long Parameter List” are applicable here.
Getting fast feedback will allow more refactoring, which will (eventually) allow faster development of new features. Try to get parallel builds happening (distributed compilation). Try to get smaller source files and smaller header files. Reduce the complexity of header files – use forward declarations, avoid inline code, try to keep only one class per header file / source file. Using the “pimpl” idiom widely can decrease compile time by 10%, but it can also disguise the “Large Class” and “Feature Envy” code smells.
The advantage of refactoring instead of rewriting, is that you always have working code. If your manual and automated tests are good, then you should be able to ship the code, even if it is a half-way state between a bad design and a good design.
Stateless là design không lưu dữ liệu của client trên server. Có nghĩa là sau khi client gửi dữ liệu lên server, server thực thi xong, trả kết quả thì “quan hệ” giữa client và server bị “cắt đứt” – server không lưu bất cứ dữ liệu gì của client.
Stateful là một design ngược với stateless, server cần lưu dữ liệu của client, điều đó đồng nghĩa với việc ràng buộc giữa client và server vẫn được giữ sau mỗi request (yêu cầu) của client. Data được lưu lại phía server có thể làm đầu vào (input parameters) cho lần kế tiếp, hoặc là dữ kiện dùng trong quá trình xử lý hay phục vụ cho bất cứ nhu cầu nào phụ thuộc vào bussiness (nghiệp vụ) cài đặt.
Hai mô hình tương tác cơ bản của thiết kế client-server là cơ sở để hình thành nên các application protocol, framework, technology,… Ví dụ, HTTP là một Application Protocol (giao thức ứng dụng) dạng stateless, nghĩa là tương tác client-server theo HTTP thì phần server sẽ không lưu lại dữ liệu của client.
HTTP ban đầu được dùng cho web, đơn thuần chỉ là Web Site. Phần client gửi request (yêu cầu) truy vấn tới các Web Page (trang web – là các trang HTML), server nhận yêu cầu, đáp trả nội dung của Web Page và sau đó cắt đứt mọi liên hệ với client (không lưu data của client).
Khi sự đơn giản của Web Site hấp dẫn nhà phát triển phần mềm, người ta nảy sinh ý tưởng xây dựng phần mềm dưới dạng web. Nghĩa là HTML dùng vào làm User Interface (giao diện người dùng) cho một application (ứng dụng phần mềm) và phần mềm được thiết kế dưới dạng client-server, khi đó HTTP đóng vai trò protocol cho tương tác chủ – khách. Nhưng phần mềm viết ra để xử lý dữ liệu của người dùng, nghĩa là trong rất nhiều tương tác, server cần phải lưu data hoặc kết quả trả về làm đầu vào cho lần xử lý kế tiếp, đặc biệt những nghiệp vụ được đặt trong transaction. Như vậy, về căn bản HTTP không đáp ứng được sự phức tạp trong yêu cầu phát triển phần mềm.
Tuy nhiên, người ta có nhiều mánh khóe để khắc phục yếu điểm đó. Dù là một stateless design nhưng nếu kết hợp với HTML chúng ta vẫn có thể biến một Web Site làm được những gì tương tự như stateful. Có 4 cách lưu data của client khi xây dựng Web Application.
Sử dụng URL Rewriter: HTML là ngôn ngữ định dạng tài liệu, nó không phải là ngôn ngữ lập trình nên không thể sử dụng các biến để lưu dữ liệu. Tuy nhiên, dữ liệu có thể được viết vào các link (liên kết) và như thế khi người dùng click vào link thì dữ liệu sẽ được gửi lên server. Phần lớn dữ liệu được viết vào phần query dưới các cặp parameters gồm key=value (cặp khóa/giá trị), một vài cài đặt có thể đưa dữ liệu vào phần path hay trong các biến của javascript,…
Hidden Form: Thay vì lưu dữ liệu vào đường link, ta sẽ lưu dữ liệu vào các thành phần của form và type (kiểu) của các element này là hidden – ẩn. Như vậy, mọi action (hành xử) của người dùng sẽ gọi đến hành động post (gửi) form đó lên server và như thế dữ liệu cần lưu ở lần trước đó sẽ được gửi lại. HTTP method được dùng ở đây là Post chứ không phải Get trong URL Rewriter. Get là một dạng truy vấn cho phép đọc (read) trong khi Post là một truy vấn cho phép ghi (write). Khi đó dữ liệu của client gửi lên server sẽ nằm trong phần body của một HTTP Message chứ không phải trong phần Header như việc dùng link (liên kết) ở trên.
Sử dụng Cookie: Trình duyệt cho phép mỗi Web Application lưu khoảng 4kb dữ liệu dưới dạng key/value. Như vậy, nếu ta lưu data của lần truy vấn trước đó vào cookie thì giá trị này sẽ được gửi lên server trong mỗi request. Cookie là 1 phần trong header của HTTP Message.
Sử dụng HTTP Session: Ngược với cookie, các Web Server có thể cho phép mỗi client lưu một dung lượng nhỏ data trên đó. Dữ liệu được lưu dưới dạng key/value và sẽ bị expire nếu bị timeout (sau khoảng thời gian tính từ lúc client gửi truy vấn cuối cùng đến server nếu vượt quá giới hạn thì sẽ bị hủy).
Web Application là một ví dụ minh họa cho stateless design với vài kỹ thuật nhỏ khắc phục yếu điểm của nó trong xây dựng phần mềm. Ở tầng bussiness, ta cũng có thể thiết kế tương tác dạng client-server. Hệ thống phần mềm khi đó có architecture (kiến trúc) là distributed (phân tán). EJB là một ví dụ với việc session bean được thiết kế hỗ trợ cả stateless và stateful.
Bài viết được sự cho phép của tác giả Nguyễn Hữu Khanh
Chúng ta thường nghe nói về các thuật toán nhanh và hiệu quả khi thực hiện một tác vụ nào đó, nhưng nhanh và hiệu quả ở đây được hiểu như thế nào? Có phải nó được đo bằng thời gian thực hiện xong tác vụ đó trong vài giây hay vài phút hay không? Câu trả lời là không các bạn ạ!
Chương trình trên máy tính của mình chạy chậm hơn trên máy tính của các bạn bởi vì mình đang sử dụng một máy tính cũ hoặc bởi vì trong lúc chạy chương trình này mình còn chạy rất nhiều chương trình khác nữa,… Vì thế, khi chương trình trên máy tính của mình chạy chậm hơn trên máy tính của bạn không có nghĩa là bạn đang sử dụng một thuật toán hiệu quả hơn của mình. Do đó, khi so sánh hai thuật toán bất kỳ thực hiện cho một tác vụ nào đó, chúng ta không thể dựa vào thời gian thực thi tác vụ đó.
Để giải quyết vấn đề này, khái niệm Big O Notation đã được đưa ra để định nghĩa, đo lường tính hiệu quả của một thuật toán. Nó dựa vào số bước cần thực hiện của một thuật toán cho một tác vụ nào đó để đo lường tính hiệu quả của thuật toán đó. Cụ thể nó như thế nào, chúng ta hãy cùng xem xét các ví dụ sau nhé:
Ví dụ thứ nhất:
private int getLastElement(int[] numbers) {
return numbers[numbers.length - 1];
}
Các bước thực hiện trong phương thức trên là:
Lấy thuộc tính length của mảng numbers (1)
Thực hiện phép tính numbers.length – 1 (2)
Sau khi có kết quả ở bước (2) thì lấy giá trị tại index này trong mảng numbers. (3)
Và cuối cùng là return lại kết quả. (4)
Như vậy, phương thức trên, thuật toán của chúng ta sẽ trải qua tất cả 4 bước cho dù số lượng dữ liệu trong mảng numbers có lớn như thế nào!
Nếu quy về dạng hàm số mà các bạn đã được học ở phổ thông thì chúng ta có thể biểu diễn thuật toán trên như sau:
f(n)=4
với n là số lượng dữ liệu trong mảng của chúng ta.
Nào, hãy xem xét ví dụ thứ hai nhé các bạn:
public static int sum(int[] numbers) {
int sum = 0;
for (int i = 0; i < numbers.length; i++) {
sum = sum + numbers[i];
}
return sum;
}
Với ví dụ này, chúng ta có thể xác định số bước cần thực hiện của thuật toán này như sau:
Ở ngoài vòng lặp for, chúng ta có 3 bước bao gồm:
Khởi tạo biến sum với giá trị 0
Khởi tạo biến i với giá trị 0
Return lại giá trị của biến sum
Trong vòng lặp for, với mỗi phần tử trong mảng numbers thì chúng ta lại có các bước như sau:
Như vậy, trong vòng lặp for, với mỗi phần tử trong mảng numbers, chúng ta có 6 bước cần thực hiện. n là số phần tử trong mảng numbers thì chúng ta có 6n bước cần thực hiện.
Tổng cộng, chúng ta có 6n + 3 bước cần thực hiện cho thuật toán trong phương thức này. Dưới dạng hàm số, chúng ta có thể biểu diễn như sau:
f(n)=6n+3
Như vậy, như các bạn thấy, với ví dụ thứ nhất, rõ ràng số bước cần thực hiện không phụ thuộc vào số lượng dữ liệu mà chúng ta đưa vào. Còn ở ví dụ thứ hai, dữ liệu đưa vào của chúng ta càng lớn thì số bước cần thực hiện của chúng ta lại tăng theo.
Và ở đây, các bạn sẽ thấy, chúng ta sẽ có một hàm g(n) khác sao cho kể từ một giá trị n >= n0, giá trị của hàm g(n) nhân với một hằng số nào đó c0 luôn luôn lớn hơn giá trị của hàm f(n). Khi đó, hàm g(n) gọi là cận trên của hàm f(n) và hàm f(n) gọi là Big O của hàm g(n), viết là f(n) = O(g(n)).
Trong ví dụ thứ hai, chúng ta có thể gọi hàm g(n) = n là Big O của hàm f(n) = 6n + 3. Bởi vì ở đây, khi giá trị của n0 >= 3, c0 = 7 thì: f(n) = 21 c0 * g(n) = 21
giá trị của hàm f(n) luôn nhỏ hơn hoặc bằng giá trị của hàm g(n) nhân với một hằng số c0.
Chúng ta có thể định nghĩa của Big O Notation như sau:
Trong ví dụ thứ nhất, thì f(n) là một Big O của một hằng số, gọi là O(1).
Ở ví dụ thứ hai thì f(n) là một Big O của n, gọi là O(n).
Như vậy, Big O Notation là một khái niệm để xác định khả năng mở rộng của một thuật toán dựa vào số bước thực hiện của thuật toán đó. Chúng ta có thể dự đoán được thuật toán đó với dữ liệu ngày càng lớn thì sẽ như thế nào. Và cho phép chúng ta ước lượng được trường hợp xấu nhất dựa vào cận trên của thuật toán này.
Bài viết được sự cho phép của tác giả Nguyễn Trần Chung
Khi bạn viết xong website đưa lên môi trường production cho user truy cập vào. Ok thôi, bạn sẽ gõ domain trang web bạn trên browser và enter … 💨💨💨 vèo vèo vèo chưa đầy nửa giây web đã load xong. Nhưng thật không may, không phải ai cũng sở hữu một mạng network tốc độ bàn thờ như bạn, có người sử dụng 4G, 3G, 2G hay lưu lượng tốc độ cao đã hết và bị bóp băng thông mạng đến nghẹt thở.
Bạn ngay lập tức nhận được những lời phiền toái từ người dùng mà bạn chả hiểu vì sao (nếu trang web bạn có giá trị), hoặc còn không thì họ sẽ không quay lại trang web nào nữa mà bạn sẽ không biết điều đó.
Bạn có biết?
47% khách hàng rời bỏ website vì tốc độ load trang quá chậm.
Cứ 0.1s load web chậm, bạn sẽ mất 1% doanh thu
Vậy để giả lập tốc độ network của người dùng như thế nào, hãy cùng mình đi tiếp nhé 😉
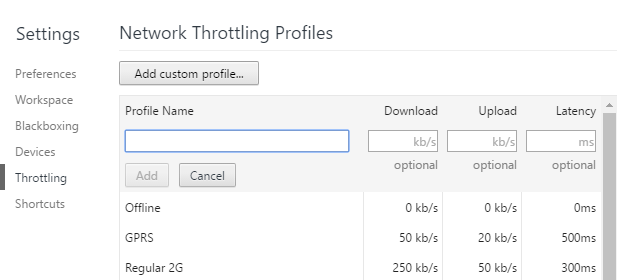
Mô phỏng kết nối chậm bằng Chrome
Đầu tiên cần phải có trình duyệt Chrome rồi, bạn hãy cài đặt ngay nếu chưa nhé.
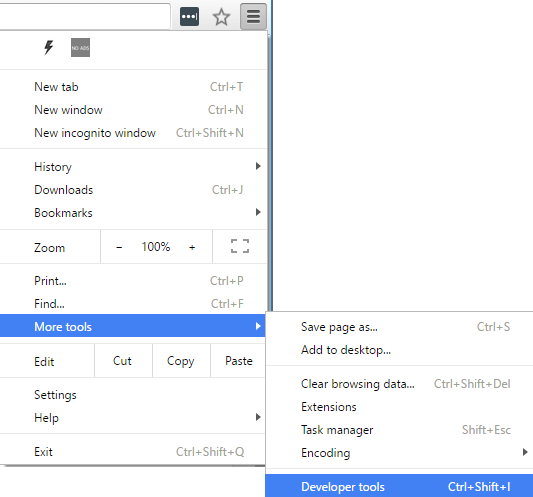
Mở tab mới và mở công cụ dành cho nhà phát triển bằng cách ấn phím F12 hoặc Ctrl + Shift + I hoặc có thể làm như ảnh dưới đây nhé
Thông thường khi lần đầu bạn mở, docker side sẽ nằm bên phải, bạn có thể chỉnh để nó nằm ở dưới cuối để dễ thao tác nhé
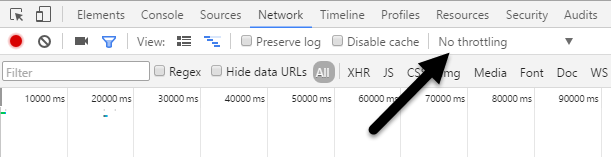
Bây giờ hãy tiếp tục và nhấp vào tab Network. Ở bên phải, bạn sẽ thấy một nhãn gọi là No Throttling.
Nếu bạn nhấp vào đó, bạn sẽ nhận được danh sách các tốc độ được cấu hình trước mà bạn có thể sử dụng để mô phỏng kết nối chậm.
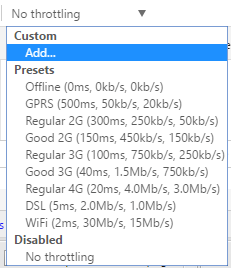
Từ trên xuống dưới tương ứng với tốc độ từ chậm đến nhanh, bạn có thể thử nhiều trường hợp để biết chính xác website mình nhanh cỡ nào nhé.
Mục custom ⇒ add cho phép bạn tùy chỉnh băng thông bao gồm: tốc độ upload, download và độ trễ
Lại một năm nữa đã đi qua, và một năm mới lại đến, hôm nay đã là tuần thứ hai của năm mới rồi mà chưa có thời gian nhìn lại một năm đã qua. Nói là “không có thời gian” thì mọi người nghe thấy cũng hơi ngờ vực, nên mình cũng sẽ phải xem lại các kế hoạch và công việc của mình, tại sao mà không có lấy nổi ít nhất hai tiếng liền mạch để viết một bài, một chủ đề cho nghiêm túc?! Lý do thì ai cũng có lý do chính đáng của mình cả, cơ bản là mình có thực sự muốn dành thời gian cho nó hay không thôi!
Hehe, trên lý thuyết là như thế, nhưng mà tất nhiên là mình muốn dành thời gian cho nó, vậy nên để khắc phục (có thể là tạm thời thôi, lâu dài thì chưa biết :)) ) mình tranh thủ thời gian đi làm (khá) sớm, lúc mà công ty còn chưa có mấy người đến và cộng với thời gian đứng chờ thang máy, mới nghĩ là khoảng thời gian này khá là phù hợp để suy nghĩ và viết về những kiến thức cơ bản. Trước đó thì thời gian đến sớm mình hay ngồi đọc sách (đọc khoảng nửa tiếng thì mọi người trong công ty bắt đầu đến nhiều, ồn ào hơn thì mình cất sách đi và chuẩn bị các thứ để bắt đầu làm việc, thế nhưng cũng có những hôm đọc được tầm nửa tiếng thì mình lại buồn ngủ, trong lúc ồn ào đó mình cũng tranh thủ được 10 -15 phút haha).
Thôi lan man quá, vào chủ đề thôi, thời gian tranh thủ này thì mình đọc và ôn lại các lý thuyết về kiểm thử phần mềm, dù có thể là nó không được sử dụng trực tiếp nhiều trong công việc hàng ngày mình vẫn làm, nhưng mình nghĩ ít nhiều nó cũng có ích cho sau này, thứ nhất là kiến thức không bị mai một, tiếp nữa là khi nào cần đến thì bỏ ra xem lại sẽ nhanh hơn, và nhất là có thể sẽ giúp ích cho ai đó đang cần tìm thì sao!
Hôm nay chúng ta sẽ cùng thảo luận về Static testing và Dynamic testing (Kiểm thử tĩnh và kiểm thử động). Để cho dễ hiểu và dễ hình dung hơn, mình sẽ kết hợp lý thuyết với một ví dụ cụ thể, như phía dưới đây.
Ví dụ: Ta có một mô tả yêu cầu – khá là đơn giản như sau:
Cửa sổ sẽ thực hiện mở khi người dùng bấm vào nút Mở và sẽ thực hiện đóng lại khi ấn vào nút Đóng.
1. Static testing
1.1. Static testing – Được thực hiện mà không phải thực thi code
Từ yêu cầu phía bên trên, thì các coder của chúng ta sẽ phải viết code để làm sao đáp ứng được yêu cầu của người dùng là bấm vào nút mở thì cửa mở và bấm vào nút đóng thì cửa đóng, ví dụ một giả lập như sau:
buttonPressed(){
if ( Button ==up)
UpMovement
else
DownMovement
}
Static testing sẽ làm gì ở đây, thì đó chính là kiểm tra xem đoạn code mà các coder viết có đúng, có đáp ứng được yêu cầu đó hay không, hoặc có bao phủ được một số các trường hợp cơ bản cần phải có hay không… Static testing sẽ kiểm tra đến từng dòng code, kiểm tra tính logic cũng như việc thực thi được yêu cầu đặt ra. Ở ví dụ trên là ví dụ đơn giản và dòng code mô phỏng thì khá là dễ hình dung cũng như kiểm tra, còn đối với các bài toán thực tế thì nó sẽ rắc rối hơn, yêu cầu kết hợp rất nhiều các điều kiện và các cách xử lý khác nhau, có những hàm, function dài đến cả mấy chục dòng thì việc kiểm tra không phải là đơn giản như ví dụ trên nữa :))
1.2. Static testing – Được thực hiện ở giai đoạn Verification (Giai đoạn xác minh)
Giả sử một quy trình sơ bộ để xây dựng sản phẩm như sau:
Từ User Requirement >> System requirement >> Global design >> Detail design >> Implementation
Ở giai đoạn đầu, khi mà ta mới chỉ có các tài liệu yêu cầu, thiết kế mà chưa tiến hành viết code hay thực thi thì việc kiểm thử động là chưa khả thi, vì vậy mà việc sử dụng Static testing trên các tài liệu yêu cầu, hay các bản thiết kế ở giai đoạn này sẽ là phương án phù hợp và hiệu quả.
1.3. Góp phần tiết kiệm chi phí cho sản phẩm
Nói Static testing góp phần tiết kiệm chi phí cho sản phẩm là như thế nào? Có nghĩa là những lỗi được tìm ra ở static testing sẽ mất ít chi phí và sửa chữa hơn. Ví dụ như ở trên, tại giai đoạn Verification, từ tài liệu mô tả yêu cầu người dùng, ta có tài liệu mô tả hệ thống, rồi đến các bản thiết kế tổng thể, chi tiết nếu thực hiện tốt static testing sẽ tìm ra được những vấn đề, lỗi (nếu có) được mô tả hoặc thiết kế chưa đúng với yêu cầu của người dùng thì việc sửa chữa cập nhật tài liệu ngay từ những bước đầu này sẽ mất ít chi phí hơn là việc mãi đến giai đoạn Validation mới tìm được ra vấn đề thì sẽ tốn nhiều chi phí không đáng có hơn. Do đó giúp tiết kiệm chi phí cho sản phẩm.
1.4. Static testing thực hiện trên các luồng nghiệp vụ, và hoạt động review code.
2. Dynamic tesing:
2.1. Được thực hiện khi thực thi code
Cũng đối với ví dụ trên, static testing ngắn gọn là sẽ soi vào code còn dynamic testing thì sẽ thực hiện dựng code đó lên rồi thực thi việc test trên môi trường và thiết bị tương tự như môi trường thực tế mà phần mềm/hệ thống sẽ được sử dụng. Ta sẽ thực hiện kiểm tra hoạt động của hệ thống đúng theo luồng hoạt động và mô tả của yêu cầu, đó là nhấn vào nút mở, kiểm tra xem có đúng là cửa sổ được mở hay không? Và nhấn lại vào nút đóng thì có đúng là nó được đóng hay không? Đảm bảo việc hoạt động của các nút và chức năng tương ứng đáp ứng được yêu cầu đưa ra là được, ta sẽ không quan tâm phía dưới nó được xây dựng và chạy như thế nào, hay coder code nó như thế nào….
2.2. Được thực hiện ở giai đoạn Validation
Validation được thực hiện sau khi hệ thống đã được code dựa trên các tài liệu yêu cầu, thiết kế, vì dynamic testing được thực hiện khi run code. Tức là lúc này phải có một bản build rồi thì mới thực hiện được.
2.3. Tốn nhiều chi phí để sửa chữa cập nhật hơn
Với dynamic testing, việc kiểm thử được thực hiện sau khi đã có code, và đã được build, với những lỗi phát sinh trong quá trình code thì nó là điều không tránh khỏi thì sẽ không nói đến ở đây. Tuy nhiên những vấn đề liên quan đến lỗi tài liệu mô tả, hay lỗi thiết kế từ giai đoạn trước đó để lọt, thì sẽ mất nhiều thời gian và chi phí để sửa chữa hơn. Đối với những chức năng đơn lẻ độc lập thì chi phí đôi khi có thể là chấp nhận được, rất là hiếm khi nhưng nếu vì sơ suất trong lúc phân tích yêu cầu, ở những phần chức năng có liên quan, phụ thuộc nhau (Ví dụ như: sửa cái này thì ảnh hưởng đến hoạt động của nhiều phần khác) thì chi phí lúc này có thể tăng lên rất nhiều lần.
2.4. Dynamic testing thực hiện kiểm thử chức năng và phi chức năng.
Tạm kết
Kiến thức cơ bản liên quan đến Static và Dynamic mình tạm dừng ở đây đã, tài liệu tiếng Việt cũng có khá nhiều rồi, chi tiết cụ thể của từng cái khi mà tìm cũng không hề ít, nên mình không nói thêm, nói lại nữa :))) Lẽ ra để cột so sánh thì sẽ trực quan hơn nhưng mà vì nội dung từng mục hơi dài, và phần hiển thị của theme wordpress này cũng nhỏ nên cứ viết tràn kiểu này vậy. Hi vọng bài viết đã cung cấp một lượng thông tin hữu ích cho các bạn. Nếu có chỗ nào còn thắc mắc hay chưa rõ ý, muốn trao đổi và góp ý các bạn thoải mái để lại bình luận phía dưới nhé!
Nếu bạn là một lập trình viên web, đặc biệt là một lập trình viên front-end thì có lẽ bạn đã từng “ngộ độc” vì có quá nhiều web framework mới ra đời.
Điều đó dẫn đến hai câu hỏi đó là: “Tại sao ngày càng có nhiều web framework như vậy?” và “Giữa muôn vàn web framework như vậy thì chúng ta nên học cái nào?”
Với câu hỏi đầu tiên thì mình sẽ trả lời cho các bạn là tại sao. Còn câu hỏi thứ hai mình sẽ không trả lời là nên chọn cái nào, mà chỉ gợi ý với bạn về một số lựa chọn, vì bản chất rất khó để lựa chọn một cái.
I. Tại sao lại ngày càng có nhiều web framework như vậy?
Các bạn cứ tưởng tượng đơn giản như thế này, ngày trước khi lắp ráp một chiếc xe ô tô thì người ta làm thủ công từng giai đoạn.
Điều này có lợi gì? Nó giúp cho việc lắp ráp được can thiệp sâu hơn. Có nghĩa là bạn có thể đi sâu vào từng khâu, kiểm soát và hoàn thành một cách theo mong muốn. Dẫn đến sản phẩm làm ra thường sẽ rất đặc biệt, rất hoàn thiện.
Nhưng nhược điểm là bạn sẽ không thể làm như vậy với một số lượng lớn xe được. Thực ra thì vẫn có thể nhưng sẽ rất tốn công và tốn tiền.
Và thế là các dây chuyền sản xuất ra đời, chuyên môn hóa từng khâu bằng robot, tiết kiệm được nhân công và thời gian sản xuất hơn rất nhiều.
Sự ra đời của các web framework cũng y như vậy. Chúng ta phải giải quyết một bài toán lặp đi lặp lại. Framework giúp chúng ta đơn giản nó bằng cách gọi hàm truyền tham số chẳng hạn.
Chúng ta gặp một dự án với cấu trúc tương tự các dự án trước, framework sẽ giúp chúng ta tận dụng mã nguồn…
Nói tóm lại, framework ra đời để giúp cho việc phát triển ứng dụng thuận lợi hơn, dễ dàng hơn, chuẩn hóa các khâu trong phát triển phần mềm, hỗ trợ giải quyết các bài toán lặp đi lặp lại.
II. Giữa muôn vàn web framework như vậy chúng ta nên học cái nào?
Như mình đã trình bày bên trên, bạn sẽ phải lựa chọn và linh động trong việc học các framework nên mình sẽ không thể recommend bất cứ một framework nào. Nó tùy thuộc vào dự án và vị trí của bạn (front-end dev hay back-end dev).
Sau đây là 10 web framework (cả font-end lẫn back-end) mà mình thấy bạn có thể xem xét học khi bắt đầu.
Bất cứ framework nào thì cũng base trên một ngôn ngữ lập trình. Vì vậy các bạn nên học thật chắc ngôn ngữ lập trình mà framework đó được xây dựng.
#1. ReactJS (front-end)
Chính xác thì ReactJS là một thư viện (Library) chứ không phải là một framework (framework khác gì Library thì mình sẽ chia sẻ trong một bài khác nha).
ReactJS được viết dựa trên JavaScript, được phát triển và duy trì bởi một trong những gã khổng lồ công nghệ đó là Facebook.
Được ra đời năm 2013 và tất nhiên là ReactJS cũng là open-source – tức là các bạn có thể sử dụng ReactJS miễn phí.
ReactJS sử dụng cấu trúc component-based – tức là mọi thứ trong ReactJS đều thuộc vào các component. Sau này nhiều framework cũng ra đời và có kiến trúc component.
Để tìm hiểu về ReactJS bạn có thể tham khảo tài liệu trên trang của ReactJS: https://reactjs.org/
Ưu điểm:
ReactJS được áp dụng trong các single-page applications để tối ưu trải nghiệm người dùng, bằng cách chỉ tải các thành phần cần thiết (không load lại trang).
Các ứng dụng viết bằng ReactJS dễ mở rộng do ReactJS được viết theo kiến trúc Component.
Khi học ReactJS, bạn sẽ dễ dàng tiếp cận với ReactNative là một framework dùng để xây dựng ứng dụng di động đa nền tảng, cũng do Facebook phát triển và đang rất “hot”
ReactJS được nhiều công ty lơn sử dụng như: Netflix, Facebook, Airbnb, Reddit…
Nhược điểm:
Được viết bằng javascript nên nếu bạn nào nhảy vào học ReactJS luôn sẽ gặp khó khăn vì vốn dĩ JavaScript nó đã “dị” rồi.
Tài liệu về ReactJS theo như cộng đồng chia sẻ thì khó và ít tài liệu hay.
#2. Angular (front-end)
Là một front-end web framework được phát triển bởi Google và phát hành vào năm 2016 (hàng Google nghe thôi đã thấy “ngon” rồi).
Trước khi nhắc đến Angular thì chúng ta phải nhắc đến AngularJS. Đây chính là tiền thân của Angular (ra đời năm 2010). Nhưng do hiệu năng không tốt nên đã được cải tiến để trở thành các phiên bản Angular sau này.
Angular được viết dựa trên TypeScript (cũng kiểu như JavaScript nhưng chặt chẽ hơn, hướng đối tượng).
Tất nhiên là Angular cũng là một framework open-source nên bạn có thể sử dụng miễn phí framework này. Để tìm hiểu về framework này bạn có thể tham khảo tài liệu tại đây: https://angular.io/tutorial
Ưu điểm:
Angular phù hợp với các ứng dụng lớn, tức là nếu bạn có ý tưởng về việc phát triển ứng dụng trên nền tảng web và cả di động thì Angular là lựa chọn phù hợp.
Angular hỗ trợ binding dữ liệu hai chiều – có nghĩa rằng dữ liệu được đồng bộ hóa giữa tầng View và Model.
Nhược điểm:
Cộng đồng front-dev đều phải công nhận học Angular khá là khó. Nếu đem so sánh với ReactJS và VueJS thì Angular khó học hơn.
Với lại Angular không phù hợp với các ứng dụng nhỏ cần thời gian phát triển ngắn.
#3. VueJS
Nếu như vài năm trước cộng đồng web front-end có ReactJS và Angular xưng bá thì những năm trở lại đây có thêm VueJS chen chân vào cuộc đua này.
VueJS được ra đời năm 2014 bởi một kỹ sư người Trung Quốc. Có thể nói VueJS kết hợp được những nét hay ho của của ReactJS và AngularJS.
Cách viết template của VueJS khá giống với AngularJS, nhưng cách tổ chức file lại khá giống với ReactJS.
VueJS cũng là một open-source framework, được cộng đồng Trung Quốc và open-source chống lưng phát triển. Các bạn có thể đọc thêm về VueJS tại đây: https://vuejs.org/
Ưu điểm:
Có thể nói VueJS là một trong những framework nhẹ nhất hiện nay (chỉ khoảng 20KB)
VueJS được đánh giá là dễ học, phù hợp cho cả người mới học nhưng cũng linh hoạt cho cả những người sử dụng nâng cao.
Nhược điểm:
Ở Việt Nam thì VueJS còn khá mới nên số lượng job không nhiều, các dự án lớn cũng không thích hợp với VueJS
Cộng đồng người dùng còn hạn chế so với ReactJS và Angular.
#4. ExpressJS (back-end)
Trước khi nói về Express thì chúng ta phải nói về NodeJS, vì đây chính là base của Express. Nói cách khác Express được viết bằng nodejs.
Chúng ta biết rằng JavaScript chỉ có thể chạy được ở phía client (trên trình duyệt người dùng), nhưng về sau nodejs ra đời đã giúp chúng ta có thể viết code javascript ở cả phía back-end.
Express chính là một framework được viết dựa trên nodejs. Nó cung cấp cho chúng ta rất nhiều tính năng mạnh mẽ trên nền tảng web cũng như trên các ứng dụng di động.
Một số tính năng của ExpressJS có thể kể đến như:
Thiết lập các lớp trung gian để trả về các HTTP request
Định nghĩa router cho phép sử dụng với các hành động khác nhau dựa trên phương thức HTTP và URL
Cho phép trả về các trang HTML dựa vào các tham số.
Ở Việt Nam, nodejs nói chung và express nói riêng đang ngày càng được sử dụng nhiều, đặc biệt là trong các dự án không quá lớn. Học nodejs và Express là một lựa chọn khá là phù hợp tại thời điểm hiện tại.
III. Lời Kết
Vậy là trong phần 1 của bài viết này mình đã chia sẻ với các bạn 4 web framework của các ông lớn công nghệ để các bạn có thể tham khảo, học hỏi, cũng như tìm hiểu thêm rồi ha.
Tất cả đều được xây dựng một cách gián tiếp hoặc trực tiếp từ JavaScript. Vì vậy nếu mới học mình khuyên các bạn hãy bắt đầu từ việc học JavaScript thật chắc trước nha. Hẹn gặp các bạn trong phần 2 !
Không có một định nghĩa chung nào cho mô hình microservice. Nhưng về cơ bản, microservice là cách thức phát triển phần mềm như một bộ các service có thể triển khai độc lập được [1].
Sơ đồ trên là một thể hiện của mô hình microservice. Trên thực tế mô hình microservice được áp dụng vào các sản phẩm có rất nhiều biến thể, sẽ rất khó để có một mô hình phù hợp và chính xác cho từng bài toán.
Theo kiến trúc trên, một ứng dụng được chia thành một bộ các microservice, mỗi microservice thực chất là một service có thể được triển khai và chạy độc lập. Chúng tách biệt về mặt mã nguồn, về hoạt động và dữ liệu. Mỗi microservice có nơi chứa dữ liệu của riêng của nó và chỉ có nó có quyền truy cập vào vùng dữ liệu này. Do các microservice là độc lập, chúng không giao tiếp trực tiếp với nhau mà qua một thành phần trung gian được gọi là API gateway. Có thể thấy vai trò của API gateway rất quan trọng trong mô hình microservice. Nó là điểm đến và đi của mọi yêu cầu hay phản hồi.
2. Các đặc trưng của mô hình Microservice
1. Micro-service
Đặc trưng này được thể hiện ngay từ tên của kiến trúc. Nó là microservice chứ không phải là miniservice hay nanoservice. Trên thực tế không tồn tại mô hình kiến trúc cho miniservice hay nanoservice. Từ microservice được sử dụng để giúp người thiết kế có cách tiếp cận đúng đắn. Một ứng dụng lớn cần được chia nhỏ ra thành nhiều thành phần, các thành phần đó cần tách biệt về mặt dữ liệu (database) và phải đủ nhỏ cả về mặt kích cỡ và độ ảnh hưởng của nó trong hệ thống, khi thêm một microservice vào hệ thống cũng nên đảm bảo rằng nó đủ nhỏ để dễ dàng tháo gỡ, xóa bỏ khỏi hệ thống mà không ảnh hưởng nhiều tới các thành phần khác.
2. Tính độc lập
Các microservice hoạt động tách biệt nhau trong hệ thống, do vậy việc build một microservice cũng độc lập với việc build các microservice khác. Thông thường, để tiện cho việc phát triển và duy trì các microservice, người phát triển nên viết các built script khác nhau cho mỗi microservice.
Do tính tách biệt này mà mỗi microservice đều dễ dàng thay thế và mở rộng. Hơn thế nữa, nó còn giúp việc phát triển các microservice linh động hơn, các microservice có thể được phát triển bởi các team khác nhau, dùng các ngôn ngữ khác nhau và tiến độ phát triển dự án cũng nhanh hơn do không có sự phụ thuộc giữa các team, mỗi team có thể chủ động quản lý phần việc riêng của mình.
3. Tính chuyên biệt
Mỗi microservice là một dịch vụ chuyên biệt, có thể hoạt động độc lập, thông thường mỗi microservice đại diện cho một tính năng mà các công ty/ doanh nghiệp muốn cung cấp tới người dùng, do vậy người thiết kế hệ thống microservice cần hiểu rõ về hoạt động kinh doanh của công ty. Các đầu vào đầu ra và chức năng của mỗi microservice cần được định nghĩa rõ ràng.
4. Phòng chống lỗi
Kiến trúc microservice sinh ra là để dành cho các hệ thống từ lớn đến vô cùng lớn. Nó áp dụng phương pháp chia để trị, phương pháp này giúp việc áp dụng các công cụ, kỹ thuật cho việc giám sát,phòng chống lỗi phần mềm, lỗi hệ thống hiệu quả.
Khi một thành phần trong hệ thống bị lỗi, nó có thể được thay thế bằng các thành phần dự phòng một cách dễ dàng, trong quá trình thay thế thành phần bị lỗi, các thành phần khác vẫn hoạt động bình thường, do vậy hoạt động của toàn bộ hệ thống sẽ không hoặc ít bị gián đoạn.
3. Các ưu và nhược điểm của Microservice
1. Kiến trúc ứng dụng nguyên khối (Monolithic application)
Các ứng dụng phần mềm được phát triển theo kiến trúc nguyên khối rất phổ biến.
Với kiến trúc nguyên khối toàn bộ ứng dụng là một khối lớn, trong khối lớn ấy có chia thành các mô đun nhỏ, mỗi mô đun thực hiện một nhiệm vụ riêng và các mô đun thường gọi nhau qua function call. Việc phát triển và triển khai ứng dụng với kiến trúc này khá đơn giản khi mà các IDE hỗ trợ rất tốt việc kiểm tra và chạy ứng dụng với chỉ một cú click chuột hay một phím tắt. Kiến trúc này cũng đặc biệt phù hợp với các công ty outsource, họ có thể tạo ra một mẫu ứng dụng(template) và khi nhận được dự án với khách hàng mới họ chỉ việc bê mẫu này ra và chỉnh sửa, thêm thắt một vài phần khác biệt mà khách hàng yêu cầu.
Kiến trúc nguyên khối có thể mở rộng bằng cách thêm một load balancer (thiết bị cân bằng tải) và triển khai thêm các khối ứng dụng nữa nếu cần.
Tuy nhiên khi ứng dụng trở lên ngày càng lớn thì mô hình kiến trúc này bộc lộ càng nhiều điểm yếu.
Trong ứng dụng nguyên khối, sự chặt chẽ là vừa là ưu điểm vừa là nhược điểm. Với một khối ứng dụng lớn, người ta phải định nghĩa ra các tiêu chuẩn và các mẫu thiết kế, các mẫu đầu vào, đầu ra để đảm bảo cho code có chất lượng cao và nhất quán. Sự chặt chẽ và nhất quán này đôi khi là rào cản cho một số lập trình viên khác, họ không quen hoặc họ thích dùng các chuẩn viết code khác hơn, những lập trình viên mới cũng phải mất một thời gian dài ban đầu để làm quen với điều này.
Khi ứng dụng nguyên khối ngày một lớn thì quá trình maintain (duy trì) và sửa lỗi ứng dụng cũng trở thành ác mộng vì thời gian build và khởi động lại ứng dụng rất lớn. Đôi khi chỉ sửa một dòng code mà phải khởi động lại cả một chương trình to mất tới cả nửa tiếng.
Khi một ứng dụng thành công, ngày càng nhiều người biết tới và sử dụng, việc mở rộng ứng dụng để đáp ứng được nhiều người dùng là điều cần làm.
Giả sử bạn xây dựng một trang mạng xã hội theo kiến trúc nguyên khối có các thành phần chính là upload ảnh để chia sẻ, gợi ý kết bạn, hiển thị quảng cáo và hộp tin nhắn. Lượng người dùng trên trang của bạn tăng lên rất nhiều lần nhưng lưu lượng chủ yếu lại đổ vào phần hộp tin nhắn. Lúc này để mở rộng năng lực của website bạn phải triển khai thêm toàn bộ khối ứng dụng trên các server khác bao gồm tất cả các thành phần: upload ảnh, gợi ý kết bạn, hiển thị quảng cáo và hộp tin nhắn. Rõ ràng việc này gây lãng phí tài nguyên vì các thành phần upload ảnh, gợi ý kết bạn, hiển thị quảng cáo cũng được triển khai và chiếm dụng tài nguyên dù rằng việc mở rộng chúng là điều không cần thiết. Hơn nữa việc nhiều thành phần khác nhau thực hiện các business logic khác nhau được triển khai trên cùng server có thể cũng gây ảnh hưởng và đụng độ lẫn nhau.
Như vậy khi ứng dụng lớn dần lên, đến một lúc nào đó, kiến trúc nguyên khối sẽ không còn thực sự phù hợp nữa. Sự gia đời của kiến trúc Microservice là để khắc phục điều này.
2. Kiến trúc Microservice
Ưu điểm
Nhược điểm
– Cho phép lập trình viên linh động hơn trong việc lựa chọn ngôn ngữ, công cụ và nền tảng để phát triển và triển khai các microservice (tuy nhiên trong một hệ thống, việc lựa chọn các ngôn ngữ khác nhau để phát triển các microservice không được khuyến khích)
– Một microservice có thể được phát triển bởi một team nhỏ. Do vậy việc quản lý sẽ dễ dàng hơn.
– Dễ dàng thực hiện tự động tích hợp và tự động triển khai (CI-CD) bằng cách sử dụng một số công cụ như Jenkins, Hudson …
– Mỗi microservice có kích thước nhỏ, giúp cho các lập trình viên dễ tiếp cận, đọc hiểu source code. Do vậy các thành viên mới tham gia team sẽ hòa nhập và đóng góp cho team nhanh hơn.
– Các microservice khởi động nhanh giúp quá trình phát triển, kiểm thử cũng nhanh hơn.
– Dễ dàng mở rộng và tích hợp với các dịch vụ của bên thứ ba.
– Cô lập lỗi tốt hơn, khi một microservice bị lỗi và ngừng hoạt động thì các microservice khác vẫn có thể hoạt động bình thường. Với mô hình nguyên khối, một lỗi nhỏ có thể làm cả hệ thống ngừng hoạt động.
– Khi cần thay đổi một thành phần, thì chỉ cần sửa đổi, cập nhật và triển khai lại thành phần đó chứ không cần triển khai lại toàn bộ hệ thống.
– Nhược điểm của kiến trúc microservice đến từ bản chất của hệ thống phân tán.
– Việc triển khai hệ thống microservice phức tạp hơn nhiều so với việc triển khai hệ thống nguyên khối.
– Các lập trình viên phải tốn nhiều công sức hơn để thực hiện phần giao tiếp giữa các microservice, với kiến trúc nguyên khối có khi họ chỉ cần gọi hàm để thực hiện việc này.
– Các microservice thường (nên) được triển khai bên trong docker container và giao tiếp với nhau qua REST API. Việc này làm hiệu năng của toàn bộ chương trình ứng dụng giảm xuống đáng kể do giới hạn tốc độ truyền tải của các giao thức và tốc độ mạng. Hơn nữa việc giao tiếp giữa các microservice có thể bị lỗi khi các kết nối bị lỗi.
– Cần tính toán kích cỡ của một microservice. Nếu một microservice quá lớn, bản thân nó trở thành một ứng dụng theo kiến trúc nguyên khối. Nếu một microservice quá nhỏ thì độ phức tạp của hệ thống tăng lên rất nhiều, làm cho hệ thống trở lên khó hiểu, lúc này việc quản lý giám sát và triển khai hệ thống sẽ khó khăn hơn.
– Khi ứng dụng ngày càng lớn lên, số lượng microservice ngày càng nhiều, các lập trình viên thường có xu hướng sử dụng sự hỗ trợ từ các công cụ mã nguồn mở, hoặc của bên thứ 3, việc sử dụng, tích hợp các công cụ này làm cho hệ thống khó kiểm soát và có thể bị dính các mã độc làm cho hệ thống kém an toàn.
Cách này tồn tại một hạn chế là khi database schema cần thay đổi cho microservice1 thì nó sẽ làm ảnh hưởng và gây lỗi cho các microservice khác sử dụng chung database này. Để sửa lỗi, ta cần sửa đổi, cập nhật toàn bộ microservice còn lại để chúng có thể hoạt động với schema mới.
Có một cách tiếp cận khác, giúp tránh được hạn chế trên.
Sơ đồ trên, microservice2 không truy cập trực tiếp vào database, thay vào đó nó truy cập database thông qua microservice1. Do đó việc thay đổi schema của database sẽ không ảnh hưởng tới microservice2. Tuy nhiên với cách tiếp cận này thì microservice2 phụ thuộc vào microservice1, khi microservice1 có lỗi thì microservice2 cũng bị lỗi theo.
Việc chọn cách tiếp cận nào phụ thuộc rất nhiều vào tình hình thực tế của dự án. Cần cân nhắc thiệt hơn của mỗi phương án để đưa ra lựa chọn cuối cùng.
2. Giữ source code của microservice ở mức hợp lý
Như đã đề cập ở phần ưu và nhược điểm của microservice. Kích thước source code của một microservice không nên quá nhỏ hoặc quá lớn. Tuy nhiên cái khó ở đây là không có một con số định lượng cho kích thước của một microservice, nên thông thường việc quyết định kích thước của một microservice là do kinh nghiệm, cảm tính.
3. Tạo build script cho mỗi microservice
Build script có thể là một file bash hoặc Dockerfile để đóng gói microservice vào bên trong một docker image.
4. Triển khai mỗi microservice bên trong một app (docker container)
Việc triển khai mỗi microservice trong một docker container đem lại rất nhiều lợi ích cho việc triển khai và mở rộng ứng dụng cũng như việc phân chia tài nguyên phần cứng cho mỗi microservice. Hiện nay có rất nhiều công cụ hỗ trợ cho việc liên tục tích hợp, liên tục triển khai hệ thống microservice. Các công cụ này giúp tăng hiệu quả làm việc cho các lập trình viên, giảm thời gian phôi phối sản phẩm phần mềm, và các công cụ này đòi hỏi mỗi microservice được đóng gói trong một docker image và triển khai trên app.
5. Stateless server
Khi một yêu cầu được gửi đến server thì một phiên làm việc (session) được mở ra, kèm theo đó là các thông tin của phiên. Stateless server là server không lưu thông tin của phiên. Mà thông tin về phiên được lưu ở một nơi khác, như caching server chẳng hạn.
Việc này rất quan trọng, bởi vì mỗi microservice thường được đóng gói thành một docker image. Khi muốn cập nhật một microservice, ta cập nhật docker image của nó, và khi chạy docker image mới (xóa bỏ container cũ và tạo container mới dựa trên image mới) thì toàn bộ thông tin của các phiên hoạt động trên container cũ sẽ bị mất, thông tin phiên thường bao gồm thông tin mà client gửi tới server, mất thông tin này là một lỗi vô cùng nghiêm trọng. Nếu container là stateless thì nó không lưu thông tin của các phiên nên không có gì để mất cả.
Kết luận
Kiến trúc microservice không nhỏ như cái tên của nó. Mà nó là một kiến trúc dành cho các ứng dụng lớn. Nếu ứng dụng của bạn chưa đủ lớn và cũng không có ý định mở rộng trong tương lai thì hướng phát triển theo kiến trúc nguyên khối vẫn là một lựa chọn hợp lý.
Kiến trúc microservice giải quyết được rất nhiều vấn đề của kiến trúc nguyên khối, nó tỏ ra vượt trội kiến trúc nguyên khối ở nhiều khía cạnh. Tuy nhiên kiến trúc này cũng có không ít những hạn chế.
Tấn công mạng hiện đang rất phổ biến, nó không chỉ xảy ra với các tổ chức hay doanh nghiệp lớn, mà nó còn tập trung vào các cá nhân ít hiểu biết về công nghệ, về kiến thức sử dụng máy tính và có tính chủ quan trong phòng chống rò rỉ dữ liệu cá nhân, dẫn đến những hậu quả không đáng có.
Chính vì vậy mà trong bài viết này, mình sẽ chia sẻ một vài điều mà bạn cần lưu ý để có thể an toàn trước các nguy cơ tấn công mạng trên Internet.
Ngoài những cách bên dưới mình đề xuất ra, nếu bạn còn có thêm phương pháp nào hay và hiệu quả khác nữa thì đừng ngần ngại chia sẻ phía bên dưới phần comment nha.
#1. SỬ DỤNG PASSWORD KHÓ ĐOÁN
Khi bạn sử dụng các dịch vụ trên Internet, bạn phải sử dụng các mật khẩu mạnh đủ mạnh, bao gồm: các chữ cái viết thường, viết HOA, xen kẽ là các chữ số và các kí tự đặc biệt như @#$%&… thì mới tạo nên những mật khẩu mạnh được.
Bạn cũng nên tạo thói quen thay đổi mật khẩu sau một khoảng thời gian để nếu vì một sự cố nào đó mà mật khẩu cũ bị lộ ra thì tài khoản của bạn vẫn còn được an toàn.
Đặc biệt, bạn không nên dùng một mật khẩu cho nhiều loại tài khoản khác nhau, nếu bạn hay quên mật khẩu của mình thì có thể sử dụng các dịch vụ bên thứ ba để quản lý mật khẩu như 1Password, Swifty, Dashlane, LastPass…
Nhưng sẽ tốn một khoản phí hàng tháng đó, hoặc cách rẻ nhất mà bạn có thể làm là ghi vào giấy hoặc đâu đó rồi bảo quản nó thật tốt :))
#2. SỬ DỤNG BẢO MẬT HAI LỚP
Bảo mật hai lớp đúng như tên gọi của nó, là bạn phải vượt qua hai lớp mật khẩu thì mới truy cập được vào tài khoản được.
Một lớp là mật khẩu mà bạn đã thiết lập lúc mới tạo tài khoản, còn một lớp thì bạn phải nhập mã OTP (One Time Password) được gửi qua tin nhắn SMS hoặc qua các ứng dụng như Google Authenticator, Microsoft Authenticator,…
Với cách này ngay cả khi hacker có đoán được mật khẩu của bạn rồi thì hắn cũng không thể đăng nhập vào tài khoản ngay được, mà phải cần thêm mã OTP từ thiết bị của bạn nữa. Nên có ai đó yêu cầu bạn cung cấp mã OTP thì cũng đừng có dại mà đưa nhé, nhiều vụ bị lừa lắm rồi.
Hiện tại hầu hết các dịch vụ lớn trên Internet đều hỗ trợ bảo mật hai lớp như Gmail, Facebook, DropBox, OneDrive,… bạn có thể mở kích hoạt nó trong phần cài đặt của tài khoản ha.
Mã OTP cũng không quá phiền đâu, chỉ khi bạn đăng nhập trên một thiết bị mới thì nó mới yêu cầu nhập mã OTP, còn nếu bạn vẫn sử dụng trên một thiết bị thì bạn chỉ cần nhập mật khẩu thôi.
#3. THƯỜNG XUYÊN CẬP NHẬT HỆ ĐIỀU HÀNH VÀ CÁC PHẦN MỀM DIỆT VIRUS, ỨNG DỤNG..
Bạn không nên tắt các bản cập nhật của Windows vì nếu có các lỗ hổng nghiêm trọng thì Microsoft sẽ vá chúng qua các bản cập nhật, và nếu bạn tắt UPDATE Windows thì bạn sẽ không nhận được bản vá kịp thời được nữa.
Dù biết là các bản cập nhật Windows gần đây có khá là nhiều lỗi, nhưng đành phải sống chung với lũ thôi các bạn ạ (┬┬﹏┬┬)
Bạn cũng nên thường xuyên cập nhật các phần mềm, đặc biệt là phần mềm diệt Virus, bình thường thì các phần mềm sẽ tự động update nên bạn không cần phải làm gì thêm đâu.
Nhưng nếu không an tâm thì bạn có thể tự kiểm tra trên trang chủ của các phần mềm đó.
#4. SAO LƯU TẤT CẢ DỮ LIỆU QUAN TRỌNG LÊN CLOUD
Các mối nguy hiểm không chỉ đến từ tấn công mạng, mà có khi nó nằm ngay chính cái ổ cứng “đến tháng” của bạn.
Bạn không thể đảm bảo được ổ cứng của bạn ngày mai có thể chạy bình thường hay không, nên việc sao lưu dữ liệu là cực kỳ quan trọng.
Nếu chẳng may bị dính Virus mã hóa dữ liệu thì bạn chỉ cần cài lại Windows rồi tải dữ liệu trên cloud về và làm việc tiếp thôi.
Các dịch vụ cloud phổ biến hiện nay như Google Drive, OneDrive, Dropbox, iCloud,… cụ thể hơn thì bạn có thể tham khảo bài viết các dịch vụ lưu trữ đám mây tốt nhất hiện nay nhé !
Nếu bạn vẫn chưa thật sự an tâm với các dịch vụ lưu trữ này thì bạn cũng có thể mua thêm ổ cứng ngoài để lưu trữ cho an tâm hơn.
#5. SỬ DỤNG VPN KHI ĐANG DUYỆT WEB
Bạn nên đầu tư cho mình một VPN để khi duyệt web nó có thể bảo vệ các thông tin của bạn được an toàn hơn. VPN trên thị trường có rất nhiều loại từ miễn phí đến trả phí bạn có thể tự tìm hiểu nhé.
Đặc biệt là khi sử dụng WiFi công cộng thì bạn nên dùng thêm VPN, vì bạn có thể để lộ rất nhiều thông tin nhạy cảm khi truy cập các trang web không sử dụng giao thức https.
Tốt nhất là bạn không nên đăng nhập vào tài khoản ngân hàng, hay các tài khoản quan trọng khác khi đang sử dụng wifi công cộng.
Nếu gấp quá thì bạn có thể đăng ký các gói Data của nhà mạng để sử dụng chứ không nên đánh liều để rồi mất tiền thì chẳng biết kêu ai nhé. (T_T)
#6. LỜI KẾT
Vâng, trên đây là những lưu ý mà bạn cần phải đặc biệt quan tâm trên môi trường Internet. Và cũng đừng quên đọc lại bài viết này của Admin để tránh bị hack, bị chiếm đoạt tài khoản…: 13 lưu ý bạn PHẢI BIẾT để luôn được AN TOÀN TRÊN INTERNET
Okay. Vậy là mình đã giới thiệu với bạn một vài thứ mà bạn cần phải lưu ý để có thể an toàn trước những hacker nguy hiểm ngoài kia, hãy chia sẻ để nhiều người cũng được an toàn như bạn nhé. Chúc bạn thành công !
Bắt đầu với chuỗi bài học liên quan đến Selenium, mình muốn ôn lại một chút về lý thuyết, định nghĩa và một số các ưu nhược điểm của Selenium. Mấy kiến thức này có thể có trong bài test vòng sơ tuyển của một số công ty muốn tuyển vị trí automation test (ahihi cái này là mình đoán thế nhé). Mà dù có hay không thì cũng đâu quan trọng, vì dù gì thì trước khi sử dụng cái gì đó thì mình cũng nên biết một ít về lai lịch của nó, coi như là làm quen bước đầu để dễ làm việc với nhau ấy mà. Giống như quảng cáo bao giờ chả có câu “đọc kỹ hướng dẫn sử dụng trước khi dùng” đó.
Không lan man mất thì giờ nữa, trong lĩnh vực phần mềm nói chung và riêng mảng test nói riêng, thì khi nhắc đến Selenium người ta thường nghĩ ngay đến nó như là một tool đi liền với automation. Vậy thì Selenium là gì?
Selenium là gì?
Selenium là một bộ công cụ kiểm thử tự động open source (open source test automation tool), dành cho các ứng dụng web, hỗ trợ hoạt động trên nhiều trình duyệt và nền tảng khác nhau như Windows, Mac, Linus… Với Selenium, bạn có thể viết các testscript bằng các ngôn ngữ lập trình khác nhau như Java, PHP, C#, Ruby hay Python hay thậm chí là Perl…
Selenium được sử dụng để automate các thao tác với trình duyệt, hay dễ hiểu hơn là nó giúp giả lập lại các tương tác trên trình duyệt như một người dùng thực sự. Ví dụ bạn có thể lập trình để tự động bật trình duyệt, open một link, input dữ liệu, hay get infor page, upload, download dữ liệu từ trên web page. Với selenium bạn có thể làm đc rất nhiều thứ. Hơn thế nữa, bạn có thể sử dụng, tùy biến để tận dụng tối đa sức mạnh của nó. Ngoài mục đích sử dụng trong kiểm thử, bạn có thể tự xây dựng một project để automate những công việc nhàm chán, lặp đi lặp lại của bạn.
Định nghĩa Selenium là gì khá dài, với Selenium ta có thể mô phỏng hầu hết những thao tác người dùng với trình duyệt (nhấp – click, cuộn – scroll, đóng tab, click check box, …)
Selenium được phát triển bởi ThoughtWorks từ năm 2004 với tên ban đầu là JavaScriptTestRunner. Đến năm 2007, tác giả Jason Huggins rời ThoughtWorks và gia nhập Selenium team, một phần của Google và phát triển thành Selenium như hiện nay.
Selenium là một khái niệm chung về một bộ phần mềm được sử dụng trong automation, mỗi loại trong đó đáp ứng một yêu cầu testing khác nhau. Về cơ bản thì Selenium Suite có 4 thành phần:
Selenium IDE: Selenium Integreted Development Environment (IDE), là một plug-in trên trình duyệt Fire-Fox, ta có thể sử dụng để record và play back lại các thao tác đó theo một quy trình hay một test case nào đó.
Selenium RC: Selenium Remote Control (RC), Selenium server khởi chạy và tương tác với trình duyệt web.
WebDriver: Selenium WebDriver gửi lệnh khởi chạy và tương tác trực tiếp tới các trình duyệt mà không cần thông qua một server như Selenium RC.
Selenium Grid: Selenium Hub dùng để khởi chay nhiều các test thông qua các máy và các trình duyệt khác nhau tại cùng một thời điểm.
Năm 2008, Selenium team đã quyết định gộp Selenium RC và WebDriver để tạo ra Selenium 2 với nhiều tính năng mạnh mẽ hơn, mà hiện nay phần lớn các project Selenium đều sử dụng. Selenium 1 được gọi là Selenium RC.
Cùng tìm hiểu chi tiết một chút về các thành phần này:
Selenium IDE
Selenium Integrated Development Environment (IDE), là framework đơn giản nhất và dễ học nhất trong bộ Selenium. Nó là một plug-in chỉ dành cho trình duyệt FireFox – bạn chỉ có thể sử dụng Selenium IDE với trình duyệt FireFox mà thôi. Bạn có thể kết hợp Selenium IDE với các plug-in khác để tận dụng được nhiều tính năng hơn với IDE.
Tuy nhiên, vì nó đơn giản nên bạn cũng chỉ thực hiện được những case đơn giản mà thôi. Với những case phức tạp hơn, thì bạn phải sử dụng WebDriver.
Ưu điểm:
Dễ dàng cài đặt và sử dụng
Không yêu cầu người dùng phải có kỹ năng lập trình, chỉ cần bạn có hiểu biết một chút về HTML và DOM là đã có thể sử dụng được tool rồi.
Có thể export các test đã tạo để sử dụng trong Webdriver hoặc Selenium RC
Có cung cấp chức năng để bạn có thể report kết quả hoặc các hỗ trợ khi sử dụng
Bạn có thể sử dụng tích hợp với các extension khác nữa.
Nhược điểm:
Là 1 extension mà bạn chỉ có thể cài đặt trên trình duyệt Fire Fox
Nó được thiết kể để tạo các test đơn giản hoặc prototype test
Với IDE thì bạn không thể thực hiện được các tính toán, câu lệnh phức tạp, hay có điều kiện.
Hiệu năng hoạt động thì chậm hơn nhiều so với Webdriver và Selenium RC
Selenium Webdriver
Selenium Webdriver được đánh giá là tốt hơn Selenium IDE và Selenium RC trên rất nhiều các khía cạnh. Selenium Webdriver thực hiện automate tương tác với trình duyệt với hướng tiếp cận hiện đại và ổn định hơn. Các tương tác với trình duyệt được gửi trực tiếp từ Selenium driver mà không thông qua Javascript như selenium RC.
Selenium Webdriver hỗ trợ nhiều các ngôn ngữ lập trình như: Java, C#, PHP, Python, Perl và Ruby.
Ưu điểm:
Communicate trực tiếp với trình duyệt
Tương tác với trình duyệt giống như thao tác của một người dùng thật
Tốc độ nhanh hơn so với Selenium IDE
Thao tác dễ dàng hơn với các phép tính toán logic hay các điều kiện phức tạp
Nhược điểm:
Cài đặt phức tạp hơn so với Selenium IDE
Đòi hỏi người dùng phải có kĩ năng lập trình
Selenium Grid
Về lý thuyết ta có thể hiểu đây là ta xây dựng một Selenium hub dùng để khởi chay nhiều các test thông qua các máy và các trình duyệt khác nhau tại cùng một thời điểm. Có thể hiểu đơn giản thông qua hình dưới đây:
Bằng cách chạy các kiểm thử song song, Grid giúp giảm đáng kể thời gian kiểm thử tổng thể.
Mã nguồn mở: Phải nói điểm này là điểm mạnh nhất của Selenium khi so sánh với các test tool khác. Vì là mã nguồn mở nên chúng ta có thể sử dụng mà không phải lo lắng về phí bản quyền hay thời hạn sử dụng.
Cộng đồng hỗ trợ: Vì là mã nguồn mở nên Selenium có một cộng đồng hỗ trợ khá mạnh mẽ. Bên cạnh đó, Google là nơi phát triển Selenium nên chúng ta hoàn toàn có thể yên tâm về sự hổ trợ miễn phí khi có vấn đề về Selenium. Tuy nhiên, đây cũng là một điểm yếu của Selenium. Cơ bản vì là hàng miễn phí, cộng đồng lại đông nên một vấn đề có thể nhiều giải pháp, và có thể một số giải pháp là không hữu ích. Mặc khác, chúng ta không thể hối thúc hay ra deadline cho sự hỗ trợ.
Selenium hỗ trợ chạy trên nhiều OS khác nhau với mức độ chỉnh sửa script hầu như là không có. Thực sự thì điều này phụ thuộc phần lớn vào khả năng viết script của chúng ta.
Chạy test case ở backround: Khi chúng ta thực thi một test scrpit, chúng ta hoàn toàn có thể làm việc khác trên cùng một PC. Điều này hỗ trợ chúng ta không cần tốn quá nhiều tài nguyên máy móc khi chạy test script.
Không hỗ trợ Win app: Selenium thực sự chỉ hỗ trợ chúng ta tương tác với Browser mà không hỗ trợ chúng ta làm việc với các Win app, kể cả Win dialog như Download/Upload – ngoại trừ Browser Alarm. Vậy nên, để xử lý các trường hợp cần tương tác với hệ thống hay một app thứ ba, chúng ta cần một hay nhiều thư viện khác như AutoIt hay Coded UI.
Ưu điểm của Selenium
Hiện tại, danh sách Top 10 Automation Testing Tools đã bao gồm nhiều cái tên (mabl, randorex). Tuy nhiên, Selenium vẫn là một cái gì đó khó thay thế, vẫn nổi bật và có nhiều giá trị.
Hỗ trợ nhiều ngôn ngữ lập trình
Bản thân mình, trong quá trình làm việc cho công ty cũng được tiếp xúc với selenium một vài lần. Cụ thể là với Webdriver Java, Javascript và Python.
Hiện tại hỗ trợ tới 6 ngôn ngữ lập trình: Java, Python, C#, Ruby, JavaScript và Kotlin. So far, so good.
Miễn phí – free
Khỏi phải nói, ưu điểm này thật sự là đáng tiền nhất của Selenium, so với các đối thủ khác như Ranorex hoặc Mabl, Selenium hoàn toàn miễn phí. Chính vì vậy, nó thường được các doanh nghiệp IT Nhật Bản tin dùng.
Tất nhiên với Java, ta có ngay slogan quen thuộc: “Viết một lần – Chạy khắp nơi“, làm gì chả thích. “Run once time, run everywhere”.
Hỗ trợ đa trình duyệt với Webdriver
Selenium hỗ trợ test tự động trên nhiều browser. Hỗ trợ tốt khi khách hàng cần test trên nhiều phiên bản, nhiều loại browser khác nhau (thường thì chắc chắn sẽ yêu cầu như vậy).
Đối với môt số khách hàng từ Nhật hay cơ quan chính phủ, yêu cần website hoạt động tốt trên IE 9,10,11,. Việc viết test case một lần và chạy trên nhiều trình duyệt là vô cùng tiện lợi và nhanh chóng.
Hỗ trợ Internet Explorer, tin vui cho mấy anh em phát triển phần mềm chính phủ
Dễ dàng take evidence khi chạy
Thực tế khi làm việc, khách hàng lúc nào cũng yêu cầu evidence khi thực hiện chạy testcase.
Khi một website đã hoàn thiện để chạy automation test, nếu có lỗi xảy ra, ngoài ghi log hoặc báo file, yêu cầu cần thiết nhất luôn là chụp evidence (bằng chứng) ngay lúc đó.
Selenium hỗ trợ rất tốt cho những trường hợp muốn chụp lại màn hình. Kể cả trong trường hợp page ở website là scroll. Xem thêm video hướng dẫn take screenshots trong Selenium:
Một số nhược điểm của Selenium
Mặc dù có nhiều ưu điểm không phải automation test tools nào cũng có. Selenium vẫn tồn tại một số yếu điểm dưới đây:
Muốn chạy ổn, hãy cố handle timeout
Một nhược điểm cố hữu có các Automation test tools (không ngoại trừ Selenium) là timeout. Trường hợp sử dụng để kiểm thử cho website, tốc độ mạng có thể khác nhau giữa những lần chạy testcase. Chắc chắn là không giống nhau giữa các lần chạy.
Việc chạy automation test vào lúc mạng chậm, traffic đang stuck có thể làm fail một số testcase. Trong những trường hợp như vậy, cần xử lí tốt các trường hợp timeout.
Thực tế, trong quá trình làm việc, mình thấy các Exception Timeout thường do:
Mình đang test ở page 1 -> nhấn button A -> di chuyển tới page 2 -> tìm kiếm button B. Các hàm tìm kiếm có thể là (getElementById(), getElementByTag(), …).
Nuột nà là thế, nhưng do mạng chậm, nên lúc tới page 2 vẫn không tìm được button B -> văng Exception.
Nếu không kiểm soát tốt, hết ram, chết đứng
Thông thường, mỗi testcase sẽ khởi chạy với một new instance của browser ta muốn chạy. Tuy nhiên, nếu có vấn đề, hoặc ta không thể handle các trường hợp cần đóng browser. Rất có thể có các trường hợp sau:
Không thể tìm đúng đối tượng trên browser do instance của browser cũ chưa tắt (close)
Quá tải ram do nhiều trình duyệt mở (nhất là chrome)
Có rất nhiều nguyên nhân dẫn tới trường hợp này. Nếu trước đó đã có exception không được catch or throws, sẽ không thể close instance browser đã mở.
Như vậy, bài viết của TopDev đã cung cấp định nghĩa về Selenium là gì, các thành phần chính trong Selenium và ưu nhược điểm của công cụ này trong việc tự động hóa kiểm thử web, ứng dụng. Hy vọng những thông tin trên sẽ giúp bạn áp dụng Selenium hiệu quả vào công việc của mình.
Một phần của trang web bạn đang test, cho phép người dùng tương tác với hệ thống, thu thập thông tin: form đăng nhập/ đăng kí/ mua hàng/ bình luận/..
Cách thức hoạt động:
User mở form nhập liệu
Điền thông tin vào form sau đó submit dữ liệu lên máy chủ – trong step này dữ liệu được nhập vào có thể được kiểm tra tại browser của người dùng thông qua các đoạn mã Javascript
Server sau khi nhận được thông tin sẽ xử lý thông qua các ngôn ngữ kịch bản máy chủ và thực hiện kiểm tra dữ liệu trong form, logic, ghi dữ liệu vào DB
Sau khi xử lý xong thông tin sẽ gửi lại hồi đáp thành công hay không về trình duyệt và kết thúc một chu trình khép kín xử lý form nhập liệu
Thuộc tính ‘required’ của thẻ <input>:
‘required’ là thuộc tính mới trong HTML5 dành cho thẻ input. Tác dụng của required là buộc người dùng phải nhập dữ liệu thì mới gửi được (submit)
Giờ bạn không điền gì vào trường NAME > nhấn nút Submit> bạn sẽ nhận được thông báo kiểu như “Vui lòng điền vào trường này” = “Please fill out this field.”
Thuộc tính required hỗ trợ hầu hết các trình duyệt thông dụng hiện tại
Những thẻ input type dùng required attribute: text, checkbox, radio, email, password, search, url, telephone, date time picker, number, file
Required là thuộc tính kiểu boolean, nghĩa là nó chỉ nhận 2 giá trị có hoặc không có. Nếu không có requried trong thẻ input nghĩa là không yêu cầu phải nhập đủ dữ liệu, ngược lại nếu có thì phải nhập đủ mới được Submit
Vậy có phải chỉ cần verify thuộc tính required có xuất hiện tại field cần check là đủ hay ko?
WebElement nameTextbox = driver.findElement(By.xpath(“//input[@id=’fname’ and @required]”));
Assert.assertTrue(nameTextbox.isDisplayed);
Cách check trên (verify field name textbox có thuộc tính required) có thể đúng nhưng chưa đủ – nếu như field đó chỉ cần verify là field required, ko yêu cầu các message cụ thể cần hiển thị cho nhiều trường hợp. Nhưng 1 field có thể có nhiều validation message khác thì nên check cụ thể các message cho từng case:
Email invalid/incorrect:
Please enter an email address.
Please match the requested format.
…
Làm sao để verify HTML5 message khi Selenium ko support:
Selenium ko tương tác được với các html5 message, nếu để ý sẽ thấy các javascript message này được browser hiển thị chứ ko hề được tìm thấy trong DOM – vì thế ko nên sử dụng Inspector/ Firebug để find các message này
Giải pháp là dùng chính javascript để get các message này và verify với các case cụ thể
Hiểu đơn giản là nền tảng về đường truyền dữ liệu phân tán.
Apache Kafka là distributed event streaming platform có khả năng xử lý hàng nghìn tỷ sự kiện mỗi ngày. Ban đầu được hình thành như một hàng đợi nhắn tin, Kafka dựa trên sự trừu tượng của nhật ký cam kết phân tán. Kể từ khi được tạo và mở bởi LinkedIn vào năm 2011, Kafka đã nhanh chóng phát triển từ hàng đợi nhắn tin đến một nền tảng phát trực tuyến sự kiện đầy đủ.
Một stream platform sẽ có 3 khả năng chính:
Publish và subscribe vào các stream của các bản ghi, tương tự như một hàng chờ tin nhắn.
Các stream của các bản ghi được lưu trữ bằng phương pháp chịu lỗi cao cũng như khả năng chịu tải.
Xử lý các stream của các bản ghi mỗi khi có bản ghi mới.
Kafka thường được sử dụng cho 2 mục đích chính sau:
Xây dựng các pipeline stream dữ liệu theo thời gian thực để nhận dữ liệu giữa các hệ thống hoặc ứng dụng một cách đáng tin cậy.
Xây dựng các ứng dụng stream theo thời gian thực để biến đổi hoặc ánh xạ đến các stream của dữ liệu.
Để khái quát được các tính năng của kafka, bạn có thể xem ảnh dưới.
Tại sao Apache Kafka được sử dụng?
Kafka là dự án mã nguồn mở, đã được đóng gói hoàn chỉnh, khả năng chịu lỗi cao và là hệ thống nhắn tin nhanh. Vì tính đáng tin cậy của nó, kafka đang dần được thay thế cho hệ thống nhắn tin truyền thống. Nó được sử dụng cho các hệ thống nhắn tin thông thường trong các ngữ cảnh khác nhau. Đây là hệ quả khi khả năng mở rộng ngang và chuyển giao dữ liệu đáng tin cậy là những yêu cầu quan trọng nhất. Một vài use case cho kafka:
Website Activity Monitoring: theo dõi hoạt động của website
Stream Processing: xử lý stream
Log Aggregation: tổng hợp log
Metrics Collection: thu thập dữ liệu
Để rõ hơn về lợi ích của kafka, hãy tưởng tượng một hệ thống thương mại điện tử có nhiều máy chủ thực hiện các công việc khác nhau, tất cả các máy chủ này đều muốn giao tiếp với database server, vì vậy chúng ta sẽ có nhiều data pipeline kết nối các server khác đến database server này, hình ảnh minh họa như sau:
Nhưng trong thực tế, hệ thống thương mại điện tử sẽ còn phải kết nối đến một vài server khác nữa như là
Như bạn thấy ở ảnh trên, data pipeline đang trở nên phức tạp theo sự gia tăng của số lượng hệ thống. Để giải quyết vấn đề này thì kafka ra đời. Kafka tách rời các data pipeline giữa các hệ thống để làm cho việc communicate giữa các hệ thống trở nên đơn giản hơn và dễ quản lý hơn.
Cấu trúc của Apache Kafka
Một mô hình cấu trúc kafka đơn giản
Một mô hình cấu trúc kafka chi tiết
Như bạn thấy ở 2 ảnh trên, cấu trúc của kafka bao gồm các thành phần chính sau:
Producer: Một producer có thể là bất kì ứng dụng nào có chức năng publish message vào một topic.
Messages: Messages đơn thuần là byte array và developer có thể sử dụng chúng để lưu bất kì object với bất kì format nào – thông thường là String, JSON và Avro
Topic: Một topic là một category hoặc feed name nơi mà record được publish.
Partitions: Các topic được chia nhỏ vào các đoạn khác nhau, các đoạn này được gọi là partition
Consumer: Một consumer có thể là bất kì ứng dụng nào có chức năng subscribe vào một topic và tiêu thụ các tin nhắn.
Broker: Kafka cluster là một set các server, mỗi một set này được gọi là 1 broker
Zookeeper: được dùng để quản lý và bố trí các broker.
Kết
Bài viết này chỉ giới thiệu về kafka chứ không đào sâu vào cách hoạt động hoặc cách implement kafka. Để sử dụng kafka, bạn đọc có thể tải kafka ở đây và làm theo hướng dẫn.