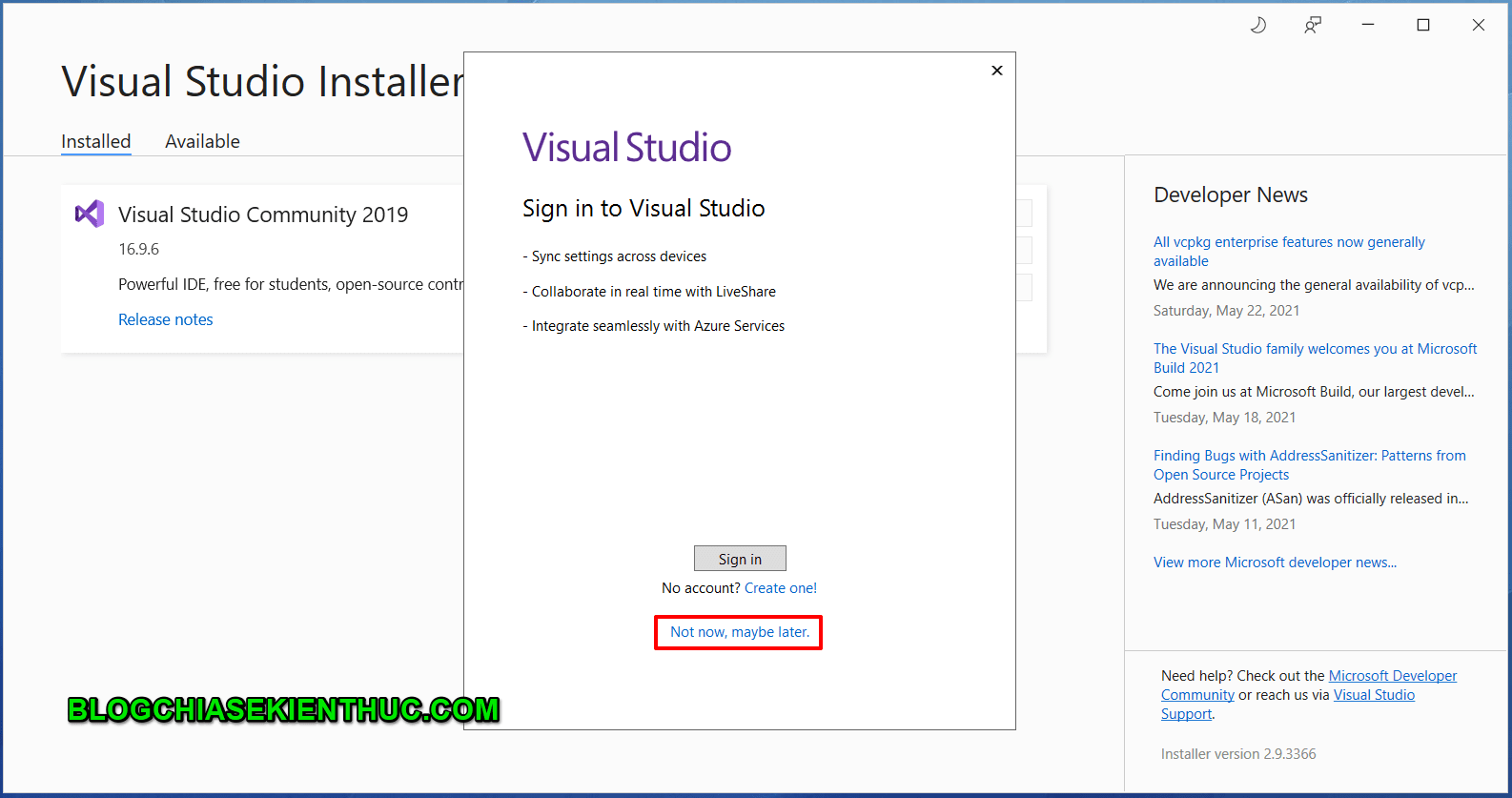
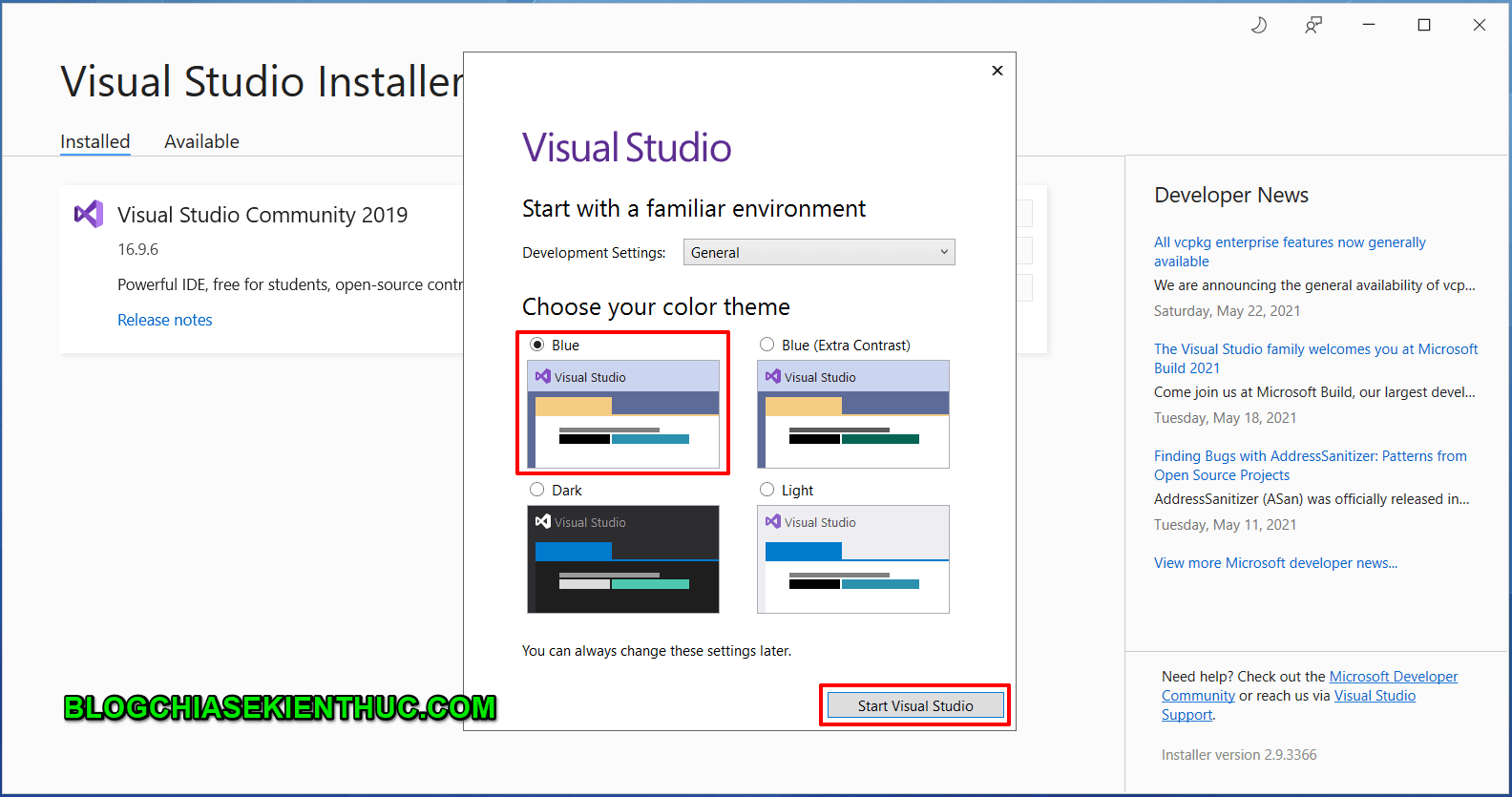
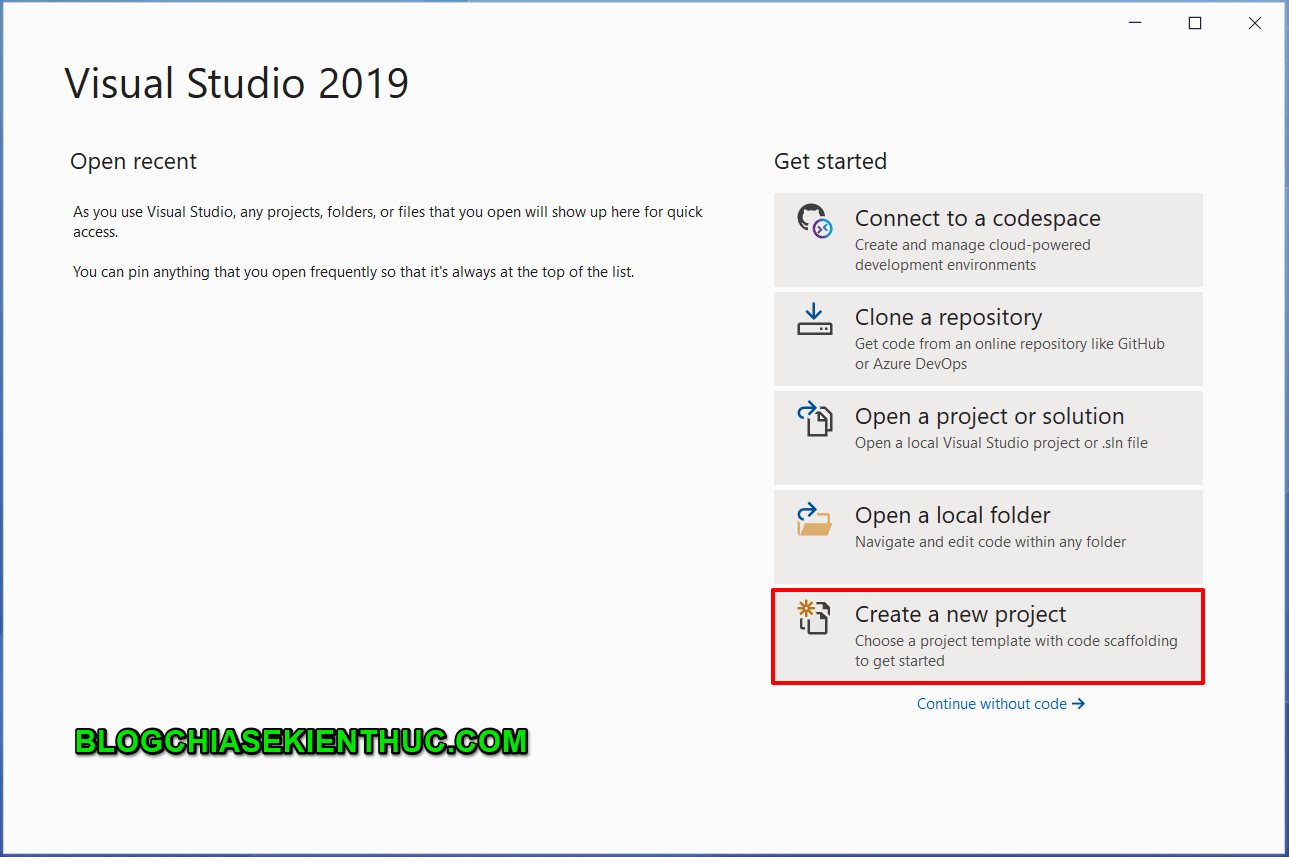
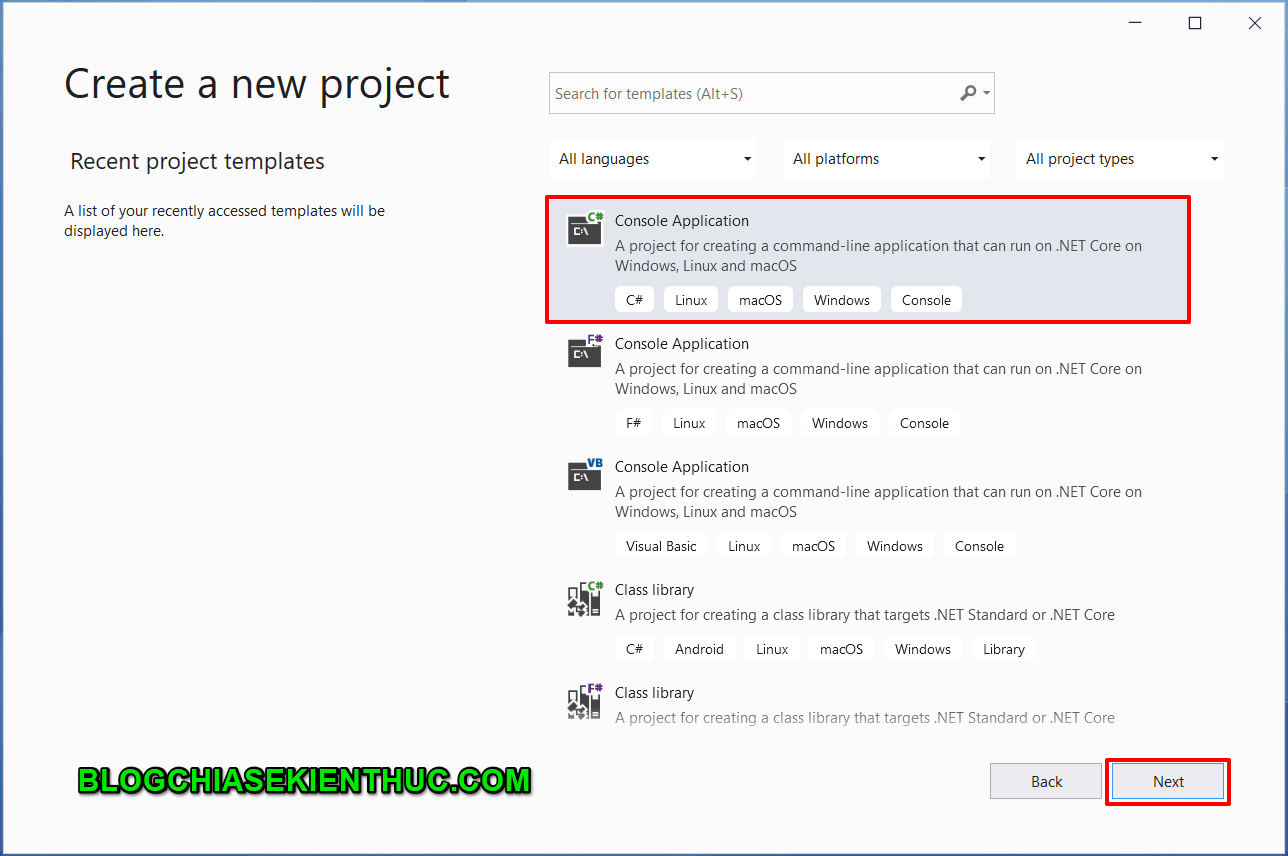
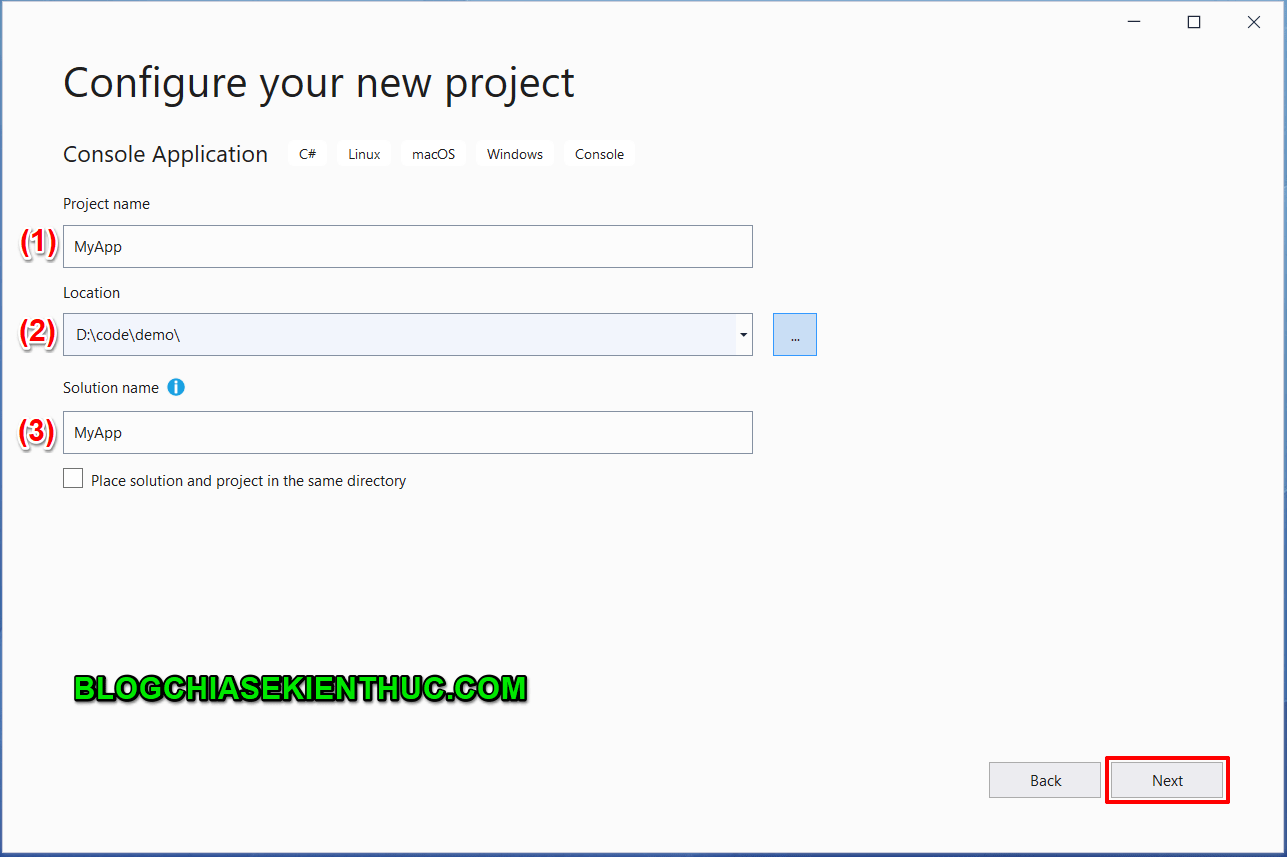
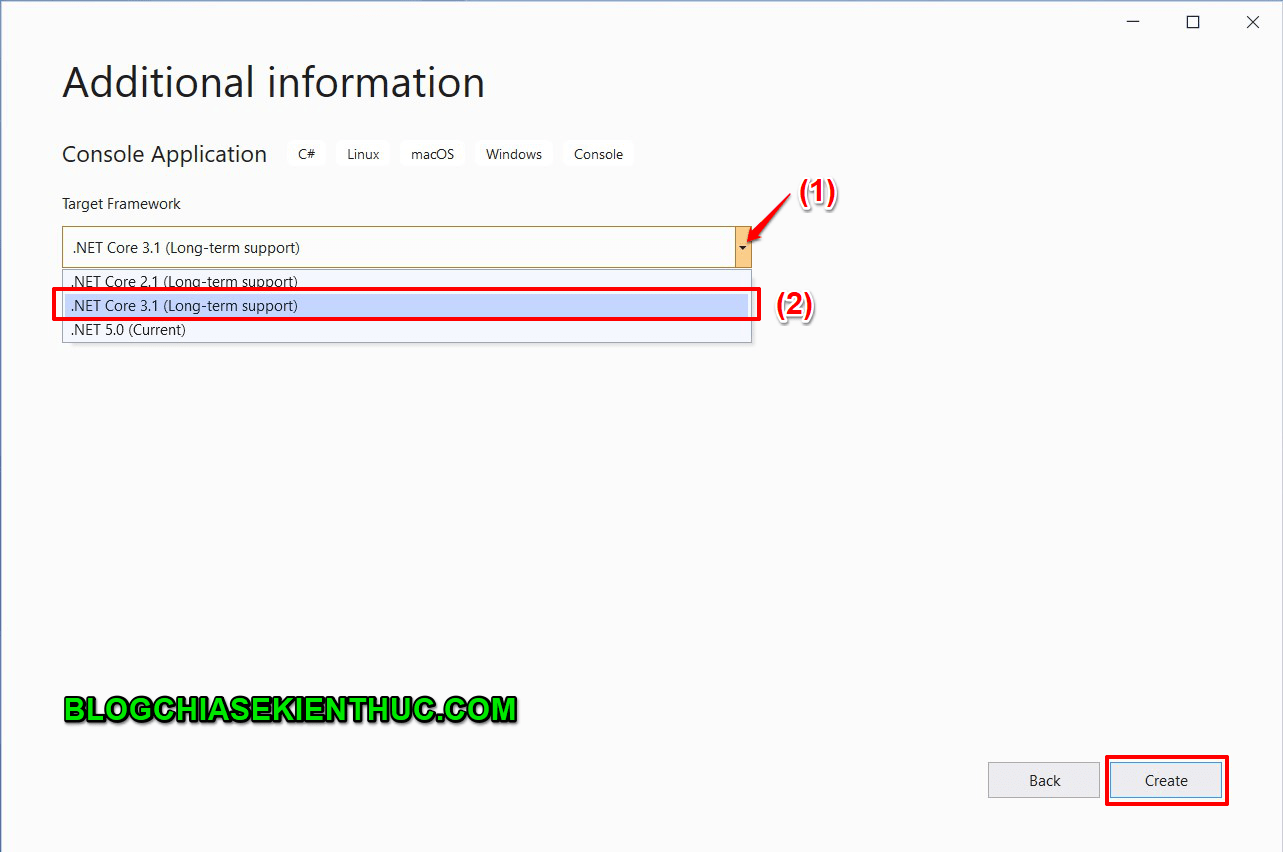
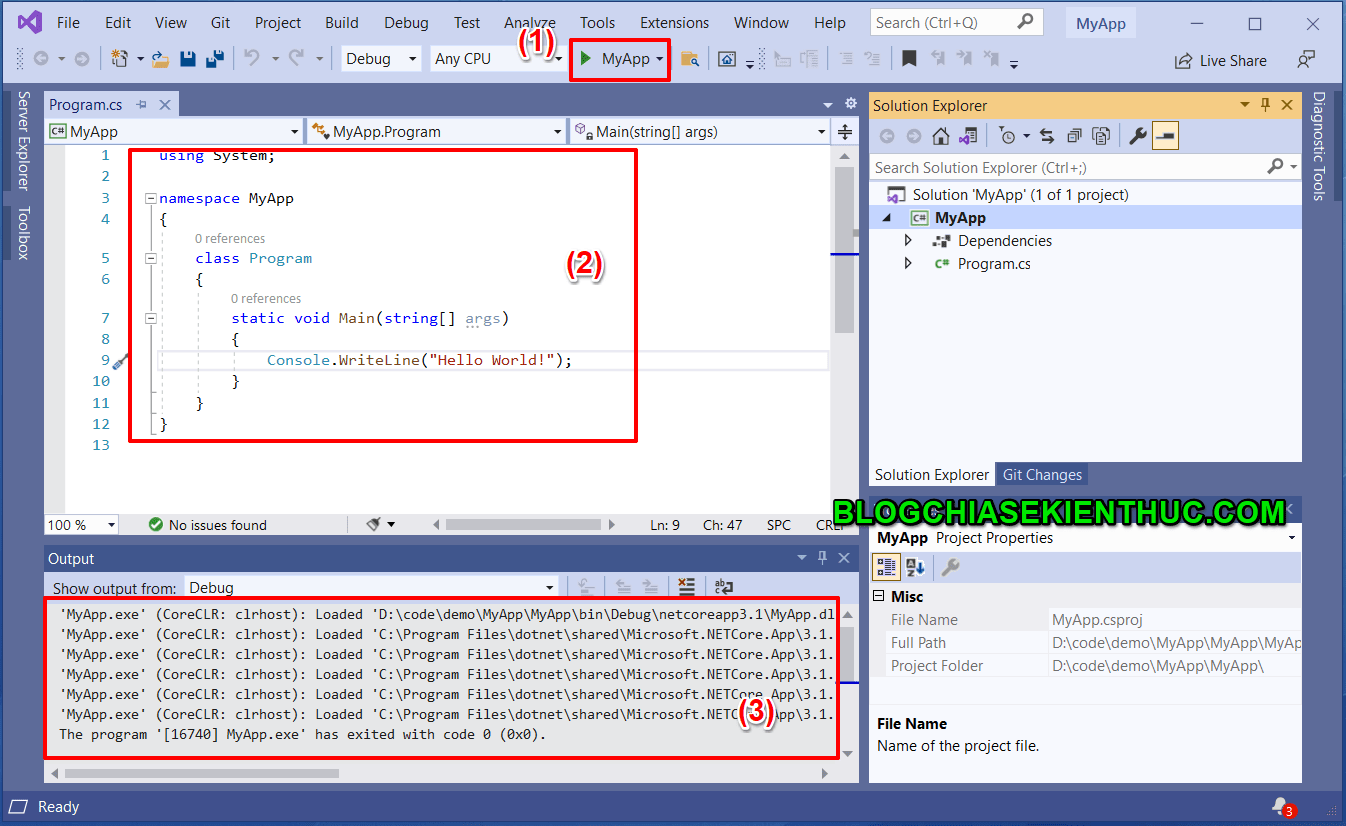
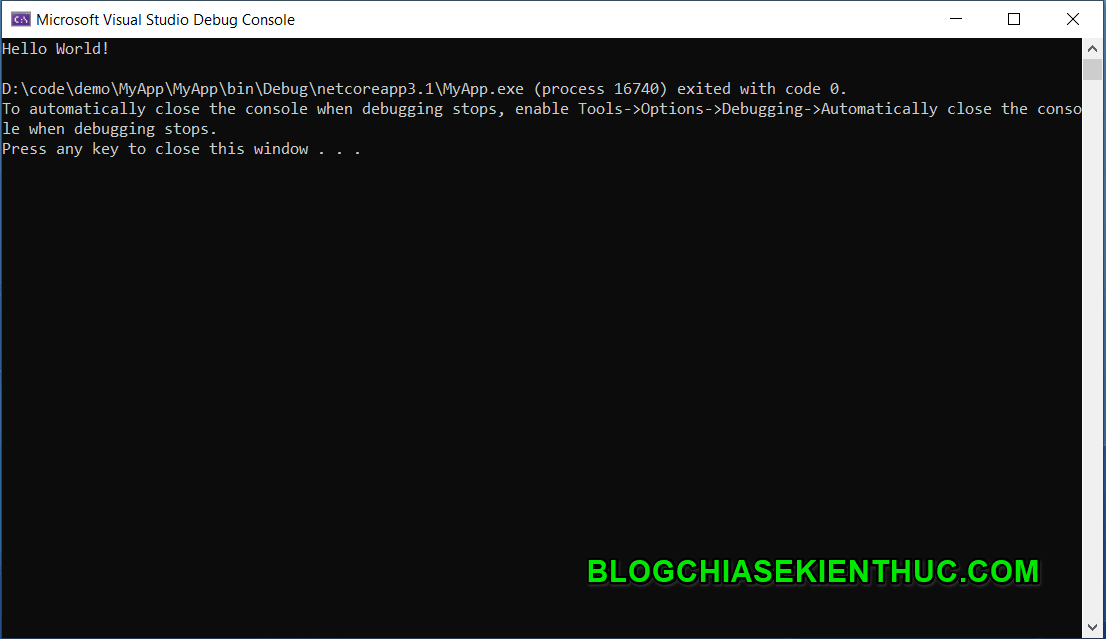
MVC được hình thành bởi các nghiên cứu của Trygve Reenskaug vào khoảng các năm 1978-1979. Sau đó nó được điều chỉnh và được cài đặt lần đầu tiên vào các lớp của thư viện Xerox PARC Smalltalk-80. Mô hình MVC cổ điển hiện tại ít được sử dụng trong môi trường lập trình desktop như trước đây nhưng hiện tại nó vẫn được sử dụng cực kì rộng rãi như là kiến trúc cơ bản trong các môi trường lập trình web.
Tổng quan mô hình MVC
MVC là gì?
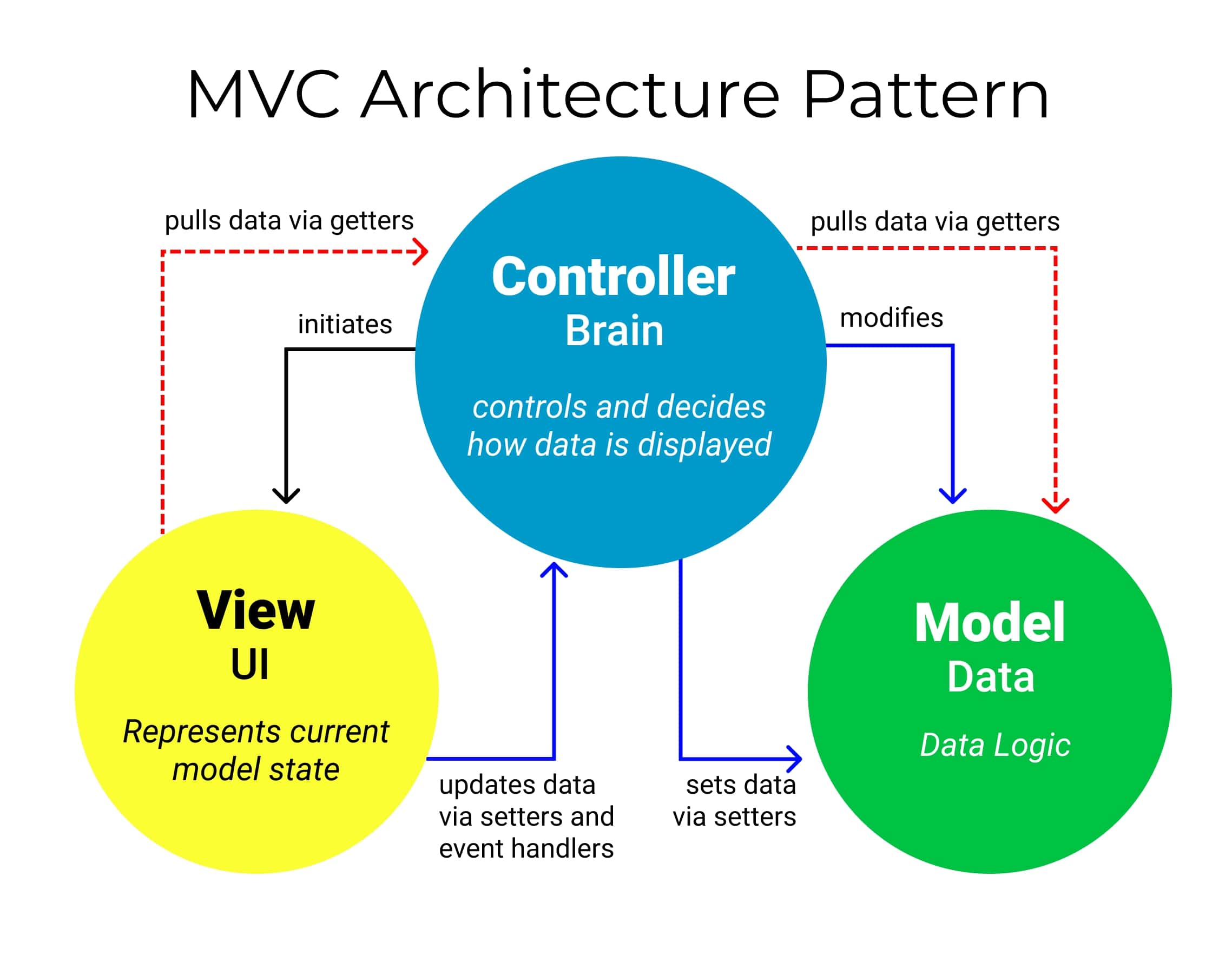
Mô hình MVC – Model-View-Controller là phương pháp chia nhỏ các các thành phần dữ liệu (data), trình bày (output) và dữ liệu nhập từ người dùng (input) thành những thành phần riêng biệt.
MVC hoạt động như thế nào?
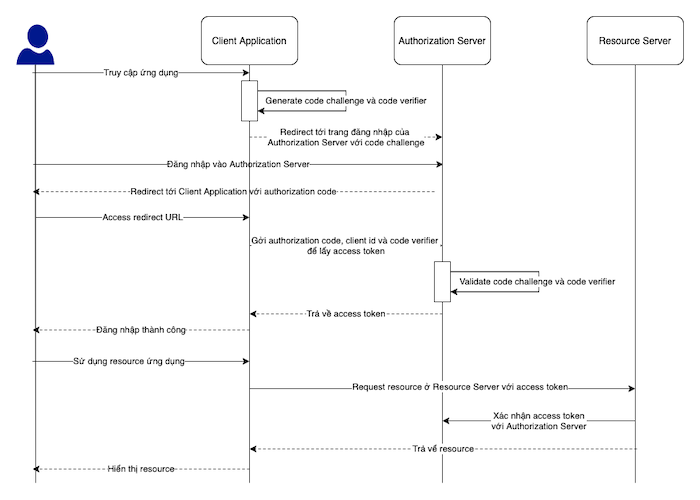
Thông thường, chúng ta biết rằng mô hình MVC gồm 3 thành phần: Model, View và Controller
- View – Nơi người dùng tương tác.
- Controller – Xử lý yêu cầu và gửi phản hồi đến view.
- Model – Middleware xử lý các thao tác cơ sở dữ liệu.
View
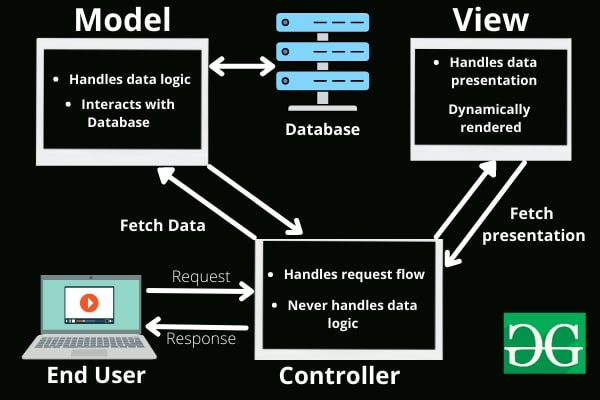
Về cơ bản, View đại diện cho cách dữ liệu được trình bày trong ứng dụng (UI). Các view được tạo ra dựa trên dữ liệu thu thập từ model. Bằng cách yêu cầu thông tin từ model, sau đó sẽ trả kết quả tới người dùng. Ngoài việc hiển thị dữ liệu từ các biểu đồ, sơ đồ và bảng, view còn hiển thị dữ liệu từ các nguồn khác. Tất cả các thành phần giao diện người dùng, chẳng hạn như hộp văn bản, menu thả xuống, v.v., sẽ xuất hiện trong bất kỳ view nào của khách hàng.
Controller
Controller là thành phần xử lý tương tác của người dùng. Dữ liệu đầu vào của người dùng được controller phân tích và xử lí, khi người dùng thao tác bất kì với hệ thống controller sẽ gửi thông tin đến model để xử lí và sau đó trả về kết quả view
Người dùng -tương tác-> Controller => Model => View (output) -trả kết quả-> Người dùng
Bằng cách giao tiếp với view liên quan của controller, người dùng có thể thay đổi giao diện của view (ví dụ: cuộn qua một tài liệu) và cập nhật trạng thái của model liên quan (ví dụ: lưu một tài liệu).
Model
Model là nơi lưu trữ dữ liệu và logic. Ví dụ, khi Controller truy xuất thông tin khách hàng từ cơ sở dữ liệu, dữ liệu được chuyển đổi giữa các thành phần controller hoặc giữa các yếu tố logic nghiệp vụ. Nó thao tác dữ liệu và gửi lại cơ sở dữ liệu, hoặc được sử dụng để hiển thị thông tin tương tự.
Ngoài ra, nó phản hồi các yêu cầu từ view và có các chỉ thị từ controller cho phép nó tự cập nhật. Nó cũng là mức thấp nhất của mô hình chịu trách nhiệm duy trì dữ liệu.
Ứng tuyển ngay các vị trí PHP tuyển dụng mới nhất trên TopDev
Ví dụ thực tiễn về mô hình MVC
Khi bạn đến quán trà đá và gọi 1 cốc trà đá. Lúc này:
- Bạn là “người dùng” và “cốc trà đá” là “yêu cầu từ phía người dùng”.
- Đối với bà chủ quán, cốc trà đá là một quy trình gồm các bước:
- Lấy cái cốc
- Cho đá vào
- Cho trà vào
- Cho thêm nước lọc cho trà loãng bớt
- Khuấy đều lên
- Đưa cốc trà cho bạn
- Thanh toán
Bộ não của bà chủ quán lúc này đóng vai trò Controller. Kể từ thời điểm bạn nói “một cốc trà đá” bằng tiếng Việt và bà chủ quán hiểu được, công việc bắt đầu. Trà đá, nước mía hay cocktail thì cũng như nhau, nhưng nguyên liệu thì hoàn toàn khác biệt. Bà chủ quán chỉ có thể sử dụng những công cụ và nguyên liệu của quán, và những công cụ đó sẽ đóng vai trò Model, bao gồm:
- Đôi tay của bà chủ
- Các nguyên liệu pha chế (trà, nước …)
- Đá lạnh
- Bia, nước ngọt, thuốc lá…
- Chanh, sấu, gừng…
- Các ly cốc để đựng đồ uống
Những nguyên liệu và công cụ này, thông qua một loạt các bước, đã trở thành cốc trà đá mát lạnh đến tay bạn. Cốc trà đá lúc này đóng vai trò View. “View” được làm nên từ những công cụ, nguyên liệu trong “Model”, được chế biến và bàn giao tới tay bạn thông qua “Controller” (chính là bộ não của bà chủ quán).
>> Xem thêm: Mô hình MVC trong php là gì? Hướng dẫn chi tiết
Ưu điểm của Kiến trúc MVC
Mô hình MVC ra đời giúp các lập trình viên giải quyết nhiều vấn đề lúc bấy giờ, cùng điểm qua các ưu điểm của MVC:
- Mã nguồn dễ bảo trì và mở rộng: Kiến trúc MVC giúp mã nguồn dễ bảo trì, có thể mở rộng và phát triển một cách dễ dàng.
- Các thành phần có thể kiểm tra độc lập: Các thành phần của nó có thể được kiểm tra riêng biệt từ các thành phần người dùng.
- Hỗ trợ các loại khách hàng mới dễ dàng hơn: Kiến trúc này hỗ trợ việc thêm các loại khách hàng mới một cách dễ dàng.
- Phát triển song song các thành phần: Có thể phân chia phát triển các thành phần khác nhau một cách song song.
- Giảm bớt độ phức tạp: Bằng cách chia ứng dụng thành ba phần, bạn có thể tránh được sự phức tạp.
- Sử dụng mô hình Front Controller: Chỉ sử dụng mô hình Front Controller, trong đó mỗi yêu cầu được xử lý bởi một bộ điều khiển duy nhất.
- Hỗ trợ phát triển theo hướng kiểm thử tối đa: Hỗ trợ phát triển theo hướng kiểm thử (TDD) một cách tối đa.
- Dễ dàng cho các nhóm phát triển lớn: Một nhóm lớn các nhà thiết kế và phát triển web có thể tạo và duy trì các ứng dụng web với nó.
- Kiểm tra từng lớp và đối tượng riêng biệt: Bạn có thể kiểm tra tất cả các lớp và đối tượng riêng lẻ vì chúng đều độc lập với nhau.
- Hành động của bộ điều khiển có thể nhóm logic: Các hành động của bộ điều khiển có thể được nhóm lại một cách logic bằng cách sử dụng các mẫu thiết kế MVC.
Nhược điểm của Kiến trúc MVC
Bên cạnh ưu điểm MVC cũng tồn tại một số nhược điểm:
- Khó đọc, thay đổi và kiểm thử đơn vị: Khó đọc, thay đổi và kiểm thử đơn vị mô hình này vì không có thành phần riêng biệt để xử lý giao diện người dùng (UI). Tất cả phải được thực hiện trên lớp view. Vì vậy, cần phải phụ thuộc vào một framework khác để làm điều đó.
- Không hỗ trợ xác thực chính thức: Kiến trúc MVC không cung cấp hỗ trợ xác thực chính thức. Vì vậy, việc xác thực cần phải được thực hiện rõ ràng.
- Xử lý dữ liệu có thể không hiệu quả: Có thể dẫn đến quá trình xử lý dữ liệu không hiệu quả vì nó làm cho logic thực thi trở nên phức tạp.
- Khó sử dụng với giao diện người dùng hiện nay: Việc sử dụng MVC khó khăn với giao diện người dùng hiện đại. Hầu hết các framework UI phổ biến hiện nay đều có kiến trúc triển khai riêng của chúng và không thể nhúng vào MVC.
- Cần duy trì nhiều mã trong bộ điều khiển: Cần duy trì nhiều mã trong các bộ điều khiển, gần như cho mỗi hành động khác nhau trên trang, chúng ta cần khai báo các phương thức Action riêng biệt.
Nhầm lẫn về MVC
Một nhầm lẫn thường gặp trong quan hệ giữa các thành phần MVC là khi xem mục đích của Controller như là thành phần trung gian để tách rời View khỏi Model. Trong khi thực tế, kiến trúc MVC tách rời dữ liệu và xử lý trung tâm khỏi phần trình bày thông qua cơ chế là Observer Pattern chứ không phải Controller. Nhiệm vụ của Controller là cần nối giữa người dùng là ứng dụng, không phải giữa View và Model.
Trong khi mục đích chính của MVC là tách rời trình bày và các xử lý bên trong. Việc phân rõ vai trò xử lý ouput (View) và input (Controller) là một hệ quả nhằm hoàn thiện cơ chế cho ý tưởng trên. Hiện nay trong nhiều môi trường lập trình hiện đại, nhiều control được cung cấp và hoàn thiện hơn (nhiều xử lý sự kiện cơ bản đã được hỗ trợ sẵn) so với trước đây nên việc khoáng tất cả các xử lý sự kiện cho một thành phần độc lập như Controller không còn là vấn đề quan trọng nữa.
Trong khi đó, những cơ chế như Observer Pattern cũng có vấn đề của riêng chúng. Trong khi được dùng như phương tiện hiệu quả để loại bỏ sự phụ thuộc của Model vào các thành phần khác, nó có một vấn đề lớn là tại một thời điểm, chúng ta khó có thể xác định điều gì sẽ xảy ra bằng cách đọc code và việc thực hiện các testing cũng khó khăn hơn. Hơn nữa, do Model chỉ liên kết gián tiếp đến View thông qua Observer Pattern, khi sự thay đổi trạng thái của Model cần đến một vài thao tác xử lý phức tạp để áp dụng lên giao diện thì với mô hình cổ điển sẽ gặp khó khăn.
Một vấn đề khác là chúng ta cần lưu trữ tình trạng hiện tại của UI (UI state), ví dụ trong danh sách sinh viên thì chúng ta cần biết sinh viên nào đang được chọn. Trong khi thành phần UI nắm giữ dữ liệu trình bày đang được chọn thì dữ liệu sinh viên thuộc về Model, như vậy dữ liệu về sinh viên được chọn sẽ được lưu trữ ở đâu khi cần truy xuất đến?
Vì những lí do trên, MVC sau này đã có những thay đổi và bổ sung nhất định (như khái niệm Application Model). Kiến trúc MVP chúng ta sẽ bàn dưới đây cũng dựa trên tư tưởng cơ bản của MVC nhưng với cách tiếp cận khác nhằm mục đích khắc phục các khuyết điểm đã có.
Tài liệu tham khảo: https://www.interviewbit.com/blog/mvc-architecture/
Có thể bạn quan tâm:
Xem thêm Việc làm IT hấp dẫn trên TopDev