Bài viết được sự cho phép của tác giả Khiêm Lê
Todo App Flutter
Todo App Flutter là một ứng dụng giúp chúng ta có thể lưu lại những công việc cần làm, tránh việc chúng ta quên đi sau một thời gian. Todo app là một ứng dụng khá đơn gian mà ai học qua lập trình di động đều biết và code khi mới bắt đầu, hôm nay chúng ta sẽ cùng thực hiện điều đó.
Trong bài này sẽ có các phần sau:
- Thiết kế giao diện ứng dụng
- Thiết lập sqlite database
- Viết code thực thi
Tạo project named Todo và bắt đầu với phần đầu tiên nào!
Thiết kế giao diện
Ý tưởng ứng dụng như sau: màn hình chính sẽ có một ListView hiện ra tất cả các task, mỗi item thì sẽ có một trailing là một button, nhấn vào sẽ hiện ra PopupMenu có hai tùy chọn là Edit và Delete. Nhấn vào Delete sẽ hiện một AlertDialog xác nhận xóa task đó. Nhấn vào Edit sẽ cho phép mình sửa task đó. Một FAB nhấn vào sẽ đưa mình đến màn hình thêm task. Màn hình thêm task đơn giản chỉ có một TextField để nhập task, một nút save phía trên thanh AppBar. Ok, bắt tay vào code nào.
Màn hình chính
Đầu tiên mình tạo một folder đặt tên là screens nằm trong folder lib. Tiếp theo, tạo một file main_screen.dart – đây chính là file màn hình chính của mình. Trong màn hình chính, mình sẽ có một ListView, một FAB, và một cái AppBar hiện tên ứng dụng. Vậy chúng ta sẽ có code sau:
import 'package:flutter/material.dart';
class MainScreen extends StatefulWidget {
static const id = 'main_screen';
@override
_MainScreenState createState() => _MainScreenState();
}
class _MainScreenState extends State<MainScreen> {
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text('Todo App'),
),
floatingActionButton: FloatingActionButton(
onPressed: () {},
child: Icon(Icons.add),
),
body: ListView.builder(
itemCount: 9,
itemBuilder: (context, index) {
return ListTile(
title: Text('Task $index'),
);
},
),
);
}
}
Mình muốn là mỗi item có trailing là một button, khi nhấn vào nó sẽ show một PopupMenu, mình sẽ chọn sử dụng Widget PopupMenuItem. Mình muốn menu có hai item là Edit và Delete, khi nhấn vào Edit sẽ đưa mình đến màn hình Edit, khi nhấn Delete thì sẽ hiển thị AlertDialog xác nhận. Code của mình như sau:
return ListTile(
title: Text('Task $index'),
trailing: PopupMenuButton(
onSelected: (i) {
if (i == 0) {
} else if (i == 1) {
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title: Text('Confirm your deletion'),
content: Text(
'This task will be deleted permanently. Do you want to do it?'),
actions: <Widget>[
FlatButton(
onPressed: () {
Navigator.pop(context);
},
child: Text('CANCEL'),
),
FlatButton(
onPressed: () {
Navigator.pop(context);
},
child: Text(
'DELETE',
style: TextStyle(color: Colors.red),
),
),
],
);
},
);
}
},
itemBuilder: (context) {
return [
PopupMenuItem(
value: 0,
child: Text('Edit'),
),
PopupMenuItem(
value: 1,
child: Text('Delete'),
),
];
},
),
);
Màn hình thêm task
Trong thư mục screens, mình tạo một file mới tên là add_task_screen.dart. Trong màn hình này, mình muốn trên AppBar có một IconButton save, nút back cũng sẽ được mình Override (mình sẽ giải thích phần này sau). Code của mình như sau:
import 'package:flutter/material.dart';
class AddTaskScreen extends StatefulWidget {
static const id = 'add_task_screen';
@override
_AddTaskScreenState createState() => _AddTaskScreenState();
}
class _AddTaskScreenState extends State<AddTaskScreen> {
final _taskController = TextEditingController();
bool _inSync = false;
String _taskError;
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text('Add task'),
backgroundColor: Colors.white,
leading: IconButton(
icon: Icon(Icons.arrow_back),
onPressed: !_inSync
? () {
Navigator.pop(context);
}
: null,
),
actions: <Widget>[
!_inSync
? IconButton(
icon: Icon(Icons.done),
onPressed: () {
},
)
: Icon(Icons.refresh),
],
elevation: 0.0,
textTheme: TextTheme(
title: Theme.of(context).textTheme.title,
),
iconTheme: IconThemeData(
color: Colors.black87,
),
),
body: WillPopScope(
onWillPop: () async {
if (!_inSync) return true;
return false;
},
child: Padding(
padding: EdgeInsets.all(16.0),
child: TextField(
controller: _taskController,
decoration: InputDecoration(
labelText: 'Task',
errorText: _taskError,
border: OutlineInputBorder(),
),
),
),
),
);
}
}
Giờ đến lượt file main.dart, chúng ta cần phải thêm các màn hình này vào để navigate giữa chúng. File main.dart như sau:
import 'package:flutter/material.dart';
import 'screens/main_screen.dart';
import 'screens/add_task_screen.dart';
void main() => runApp(MyApp());
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
initialRoute: MainScreen.id,
routes: {
MainScreen.id: (_) => MainScreen(),
AddTaskScreen.id: (_) => AddTaskScreen(),
},
);
}
}
Giờ chúng ta sẽ sửa lại file main_screen.dart, chúng ta sẽ bắt sự kiện onPress FAB thì đi sang màn hình add task. Code sửa lại như sau:
import 'package:flutter/material.dart';
import 'add_task_screen.dart';
floatingActionButton: FloatingActionButton(
onPressed: () {
Navigator.pushNamed(context, AddTaskScreen.id);
},
child: Icon(Icons.add),
),
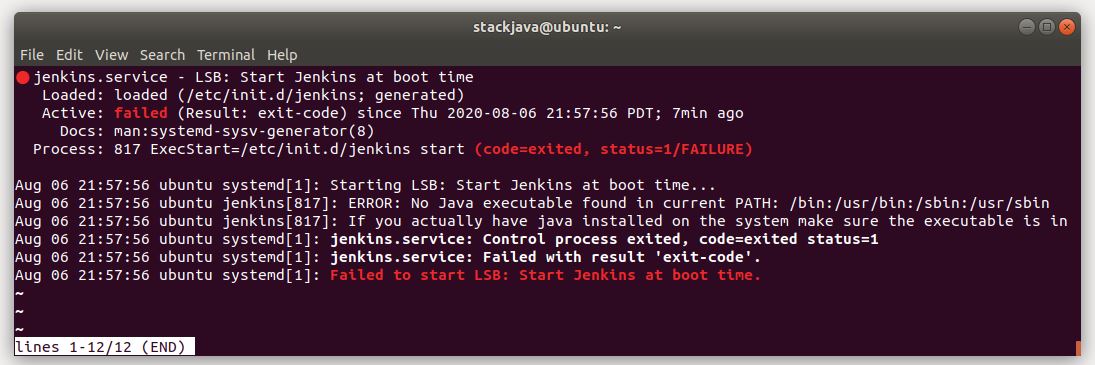
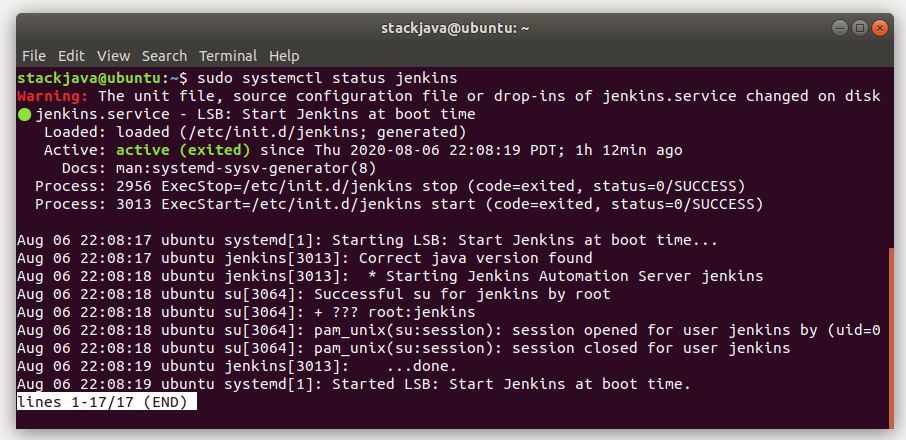
Giờ bạn có thể run app để check thử. Chúng ta sẽ chuyển sang phần tiếp theo là thiết lập sqlite database.
Thiết lập SQLite database
Đầu tiên, tạo một folder mới trong folder lib và đặt tên là models. Trong folder models, bạn tạo một file mới có tên là task.dart, đây sẽ là model data của mình. Code như sau:
class Task {
final int id;
final String task;
Task({this.id, this.task});
Map<String, dynamic> toMap() {
return {
'id': id,
'task': task,
};
}
}
Giờ chúng ta đã có model Task, tiếp theo chúng ta cần phải lưu trữ data trong database. Tạo folder có tên database trong folder lib, trong folder database tạo một file mới có tên là tasks_db.dart. Trước khi code trong file này, mình cần phải thêm 2 dependencies là path và sqflite và file pubspec.yaml:
// ...
dependencies:
flutter:
sdk: flutter
path:
sqflite:
// ...
Nhớ chạy lệnh “flutter pub get” để lấy dependencies nha. Tiếp tục với file tasks_db.dart, mình sẽ có code sau:
import 'dart:async';
import 'package:path/path.dart';
import 'package:sqflite/sqflite.dart';
import '../models/task.dart';
class TasksDB {
Database _database;
final String kTableName = 'tasks';
final String kId = 'id';
final String kTask = 'task';
Future _openDB() async {
_database = await openDatabase(
join(await getDatabasesPath(), 'tasks.db'),
onCreate: (db, version) {
return db.execute(
'CREATE TABLE $kTableName($kId INTEGER PRIMARY KEY AUTOINCREMENT, $kTask TEXT)');
},
version: 1,
);
}
Future insert(Task task) async {
await _openDB();
await _database.insert(kTableName, task.toMap());
print('Task inserted');
}
Future update(Task task) async {
await _openDB();
await _database.update(
kTableName,
task.toMap(),
where: '$kId = ?',
whereArgs: [task.id],
);
print('Task updated');
}
Future delete(int id) async {
await _openDB();
print((await _database.delete(
kTableName,
where: '$kId = ?',
whereArgs: [id],
)));
print('Task deleted');
}
Future<List<Task>> getTasks() async {
await _openDB();
List<Map<String, dynamic>> maps = await _database.query(kTableName);
return List.generate(
maps.length,
(i) => Task(
id: maps[i][kId],
task: maps[i][kTask],
));
}
}
Vậy là chúng ta đã thiết lập xong database. Giờ chúng ta sẽ thực hiện nối UI và code thực thi lại với nhau.
Viết code thực thi
Chúng ta sẽ bắt đầu với file add_task_screen.dart trước. Sẽ có một sự thay đổi lớn ở đoạn này, mình sẽ giải thích trong code. Đoạn code nào được add comment “// new” là mới thêm vào.
import 'package:flutter/material.dart';
import '../database/tasks_db.dart';
import '../models/task.dart';
class AddTaskScreen extends StatefulWidget {
static const id = 'add_task_screen';
final Task task;
AddTaskScreen(this.task);
@override
_AddTaskScreenState createState() => _AddTaskScreenState();
}
class _AddTaskScreenState extends State<AddTaskScreen> {
final _taskController = TextEditingController();
bool _inSync = false;
String _taskError;
@override
void initState() {
Task task = widget.task;
if (task != null) {
_taskController.text = task.task;
}
super.initState();
}
void addTask() async {
if (_taskController.text.isEmpty) {
setState(() {
_taskError = 'Please enter this field';
});
return null;
}
setState(() {
_taskError = null;
_inSync = true;
});
final db = TasksDB();
final task = Task(
task: _taskController.text.trim(),
);
await db.insert(task);
setState(() {
_inSync = false;
});
Navigator.pop(context, true);
}
void updateTask() async {
if (_taskController.text.isEmpty) {
setState(() {
_taskError = 'Please enter this field';
});
return null;
}
setState(() {
_taskError = null;
_inSync = true;
});
final db = TasksDB();
final task = Task(
id: widget.task.id,
task: _taskController.text.trim(),
);
await db.update(task);
setState(() {
_inSync = false;
});
Navigator.pop(context, true);
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text('Add task'),
backgroundColor: Colors.white,
leading: IconButton(
icon: Icon(Icons.arrow_back),
onPressed: !_inSync
? () {
Navigator.pop(context);
}
: null,
),
actions: <Widget>[
!_inSync
? IconButton(
icon: Icon(Icons.done),
onPressed: () {
widget.task == null ? addTask() : updateTask();
},
)
: Icon(Icons.refresh),
],
elevation: 0.0,
textTheme: TextTheme(
title: Theme.of(context).textTheme.title,
),
iconTheme: IconThemeData(
color: Colors.black87,
),
),
body: WillPopScope(
onWillPop: () async {
if (!_inSync) return true;
return false;
},
child: Padding(
padding: EdgeInsets.all(16.0),
child: TextField(
controller: _taskController,
decoration: InputDecoration(
labelText: 'Task',
errorText: _taskError,
border: OutlineInputBorder(),
),
),
),
),
);
}
}
Giờ là đến file main_screen.dart chúng ta có code như sau:
import 'package:flutter/material.dart';
import '../database/tasks_db.dart';
import '../models/task.dart';
import 'add_task_screen.dart';
class MainScreen extends StatefulWidget {
static const id = 'main_screen';
@override
_MainScreenState createState() => _MainScreenState();
}
class _MainScreenState extends State<MainScreen> {
List<Task> tasks = [];
Future getTasks() async {
final db = TasksDB();
tasks = await db.getTasks();
setState(() {});
}
Future deleteTask(int id) async {
final db = TasksDB();
await db.delete(id);
tasks = await db.getTasks();
await getTasks();
setState(() {});
}
@override
void initState() {
getTasks();
super.initState();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text('Todo App'),
),
floatingActionButton: FloatingActionButton(
onPressed: () async {
final result = await Navigator.pushNamed(context, AddTaskScreen.id);
if (result == true) getTasks();
},
child: Icon(Icons.add),
),
body: ListView.builder(
itemCount: tasks.length,
itemBuilder: (context, index) {
return ListTile(
title: Text(tasks[index].task),
trailing: PopupMenuButton(
onSelected: (i) async {
if (i == 0) {
final result = await Navigator.pushNamed(
context,
AddTaskScreen.id,
arguments: tasks[index],
);
if (result == true) getTasks();
} else if (i == 1) {
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title: Text('Confirm your deletion'),
content: Text(
'This task will be deleted permanently. Do you want to do it?'),
actions: <Widget>[
FlatButton(
onPressed: () {
Navigator.pop(context);
},
child: Text('CANCEL'),
),
FlatButton(
onPressed: () {
deleteTask(tasks[index].id);
Navigator.pop(context);
},
child: Text(
'DELETE',
style: TextStyle(color: Colors.red),
),
),
],
);
},
);
}
},
itemBuilder: (context) {
return [
PopupMenuItem(
value: 0,
child: Text('Edit'),
),
PopupMenuItem(
value: 1,
child: Text('Delete'),
),
];
},
),
);
},
),
);
}
}
Chúng ta đã xong 2 file screen rồi, nhưng nếu bạn để ý bạn sẽ thấy, mình sử dụng Constructor để nhận dữ liệu, vậy làm sao có thể dùng thuộc tính arguments để truyền dữ liệu? Chúng ta sẽ chỉnh sửa lại file main.dart để hoàn thành việc đó. Ta sẽ có code như sau:
routes: {
MainScreen.id: (_) => MainScreen(),
AddTaskScreen.id: (_) => AddTaskScreen(),
},
onGenerateRoute: (settings) {
if (settings.name == AddTaskScreen.id) {
return MaterialPageRoute(
builder: (context) {
if (settings.arguments != null) {
Task task = settings.arguments;
return AddTaskScreen(task);
}
return AddTaskScreen(null);
},
);
}
return null;
},
Tổng kết
Vậy là chúng ta đã viết được một Todo App Flutter đơn giản rồi. Mình đã upload toàn bộ Source code lên github rồi.
Vậy là trong bài này, mình đã code xong app Todo sử dụng Flutter và các plugin Flutter như path, sqflite. Hy vọng bài viết này sẽ có ích cho các bạn, nếu bạn thấy hay có thể share để mọi người cùng đọc. Cảm ơn các bạn đã đọc bài viết của mình!
Bài viết gốc được đăng tải tại khiemle.dev
Có thể bạn quan tâm:
Xem thêm Việc làm Developer hấp dẫn trên TopDev






















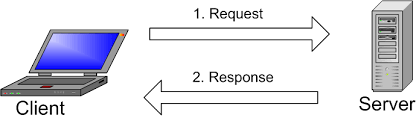
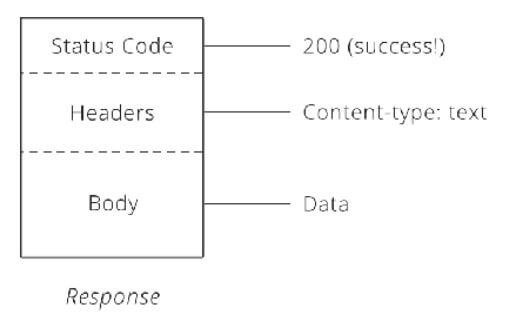
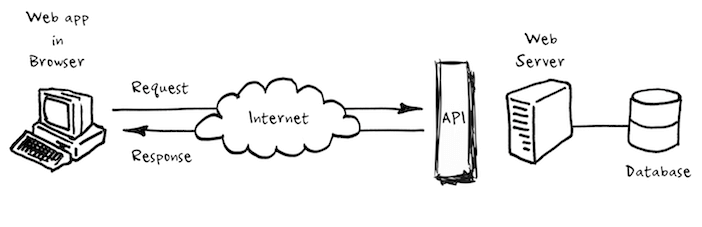 Nói đơn giản, API là cái cầu nối giữa client và server. Client ở đây có thể là máy tính, điện thoại sử dụng hệ điều hành khác nhau và được viết bằng những ngôn ngữ khác nhau. Tương tự, server back-end cũng được viết bằng các ngôn ngữ khác nhau. Để 2 thằng này có thể nói chuyện được với nhau chúng phải nói cùng 1 ngôn ngữ. Ngôn ngữ ấy chính là API.
Nói đơn giản, API là cái cầu nối giữa client và server. Client ở đây có thể là máy tính, điện thoại sử dụng hệ điều hành khác nhau và được viết bằng những ngôn ngữ khác nhau. Tương tự, server back-end cũng được viết bằng các ngôn ngữ khác nhau. Để 2 thằng này có thể nói chuyện được với nhau chúng phải nói cùng 1 ngôn ngữ. Ngôn ngữ ấy chính là API.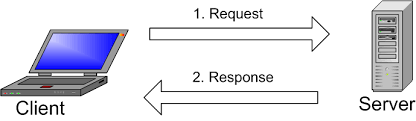

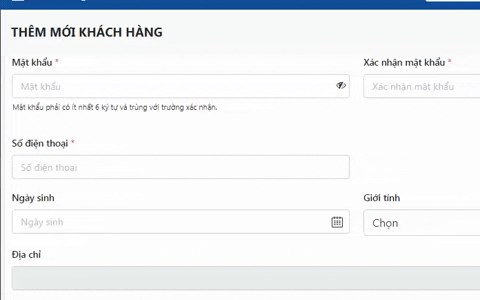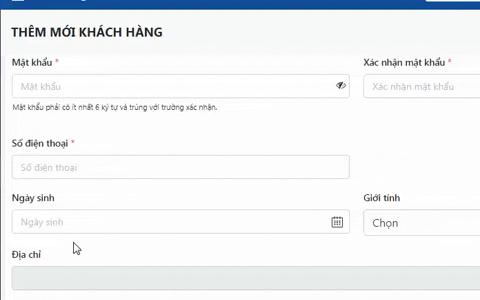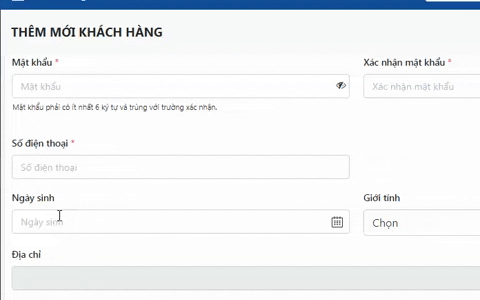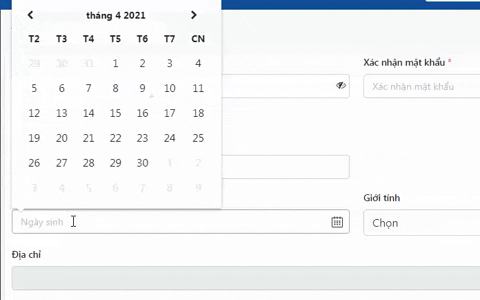
 Thông tin này nó liên quan trực tiếp đến các hoạt động trong cuộc sống hàng ngày của chúng ta như Ngày sinh, Ngày mất, Ngày đăng ký, Ngày nhập học, Ngày cấp bằng, Ngày cấp CCCD, … Bất kể thông tin nào được công nghệ hóa quản lý thì đều phải được nhập vào, do đó sự hiện diện của nó trong các ứng dụng là điều đương nhiên rồi ;))
Thông tin này nó liên quan trực tiếp đến các hoạt động trong cuộc sống hàng ngày của chúng ta như Ngày sinh, Ngày mất, Ngày đăng ký, Ngày nhập học, Ngày cấp bằng, Ngày cấp CCCD, … Bất kể thông tin nào được công nghệ hóa quản lý thì đều phải được nhập vào, do đó sự hiện diện của nó trong các ứng dụng là điều đương nhiên rồi ;))
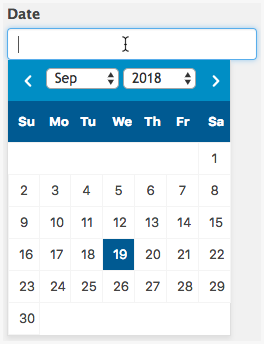
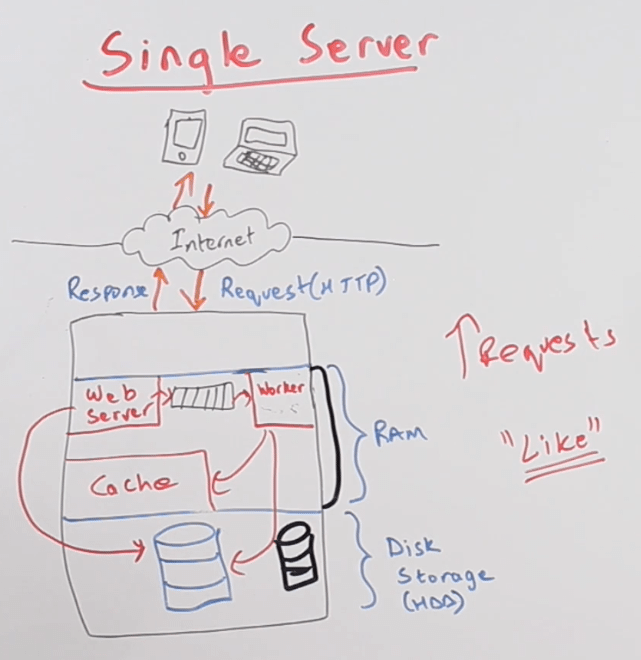
 nó kiểu như dưới này, có thể đâu đó do nhu cầu lưu trữ dữ liệu, hoặc thiết kế gì đấy mà người ta sẽ thiết kế kiểu như này:
nó kiểu như dưới này, có thể đâu đó do nhu cầu lưu trữ dữ liệu, hoặc thiết kế gì đấy mà người ta sẽ thiết kế kiểu như này:


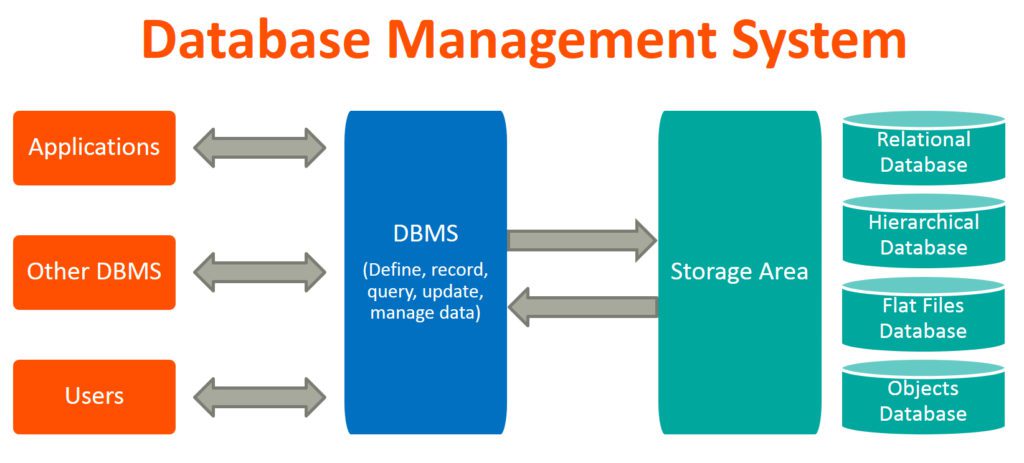

















 Vòng lặp không lối thoát – Nguồn ảnh / Source: geeksforgeeks.org
Vòng lặp không lối thoát – Nguồn ảnh / Source: geeksforgeeks.org Circular Wait, đợi nhau trong vòng tròn vô tận. Nguồn ảnh/ Source: The Robert C. Martin Clean Code Collection
Circular Wait, đợi nhau trong vòng tròn vô tận. Nguồn ảnh/ Source: The Robert C. Martin Clean Code Collection