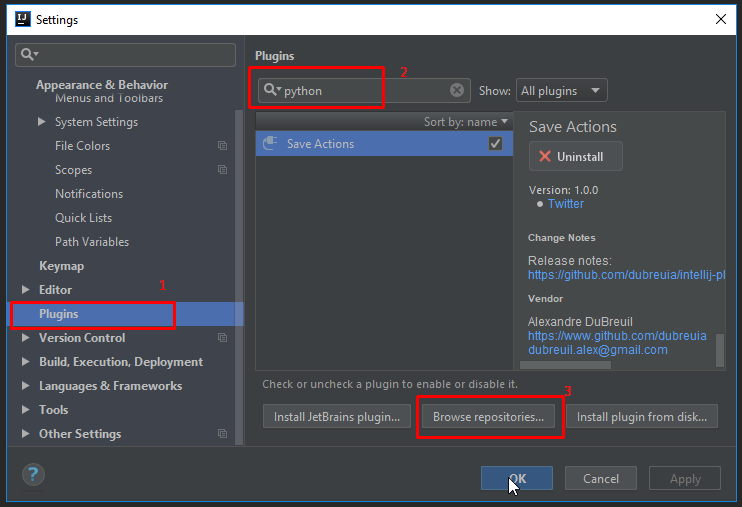
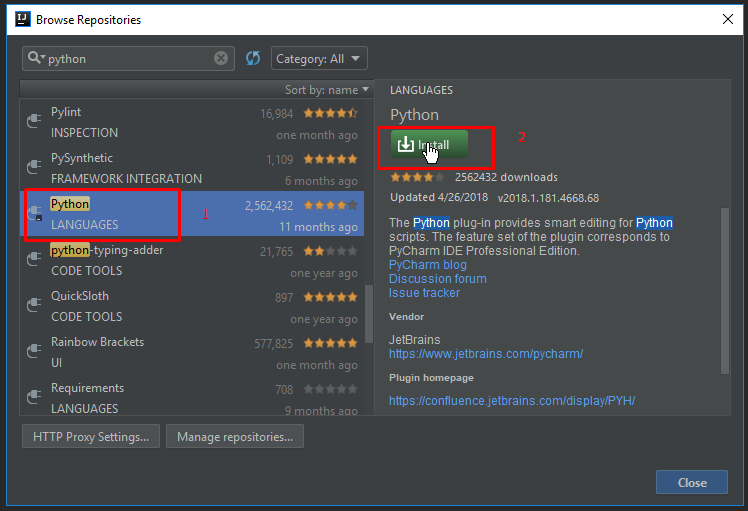
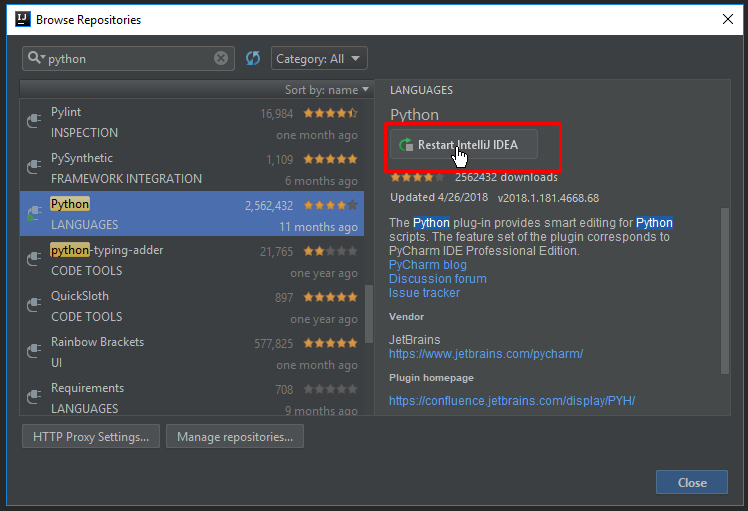
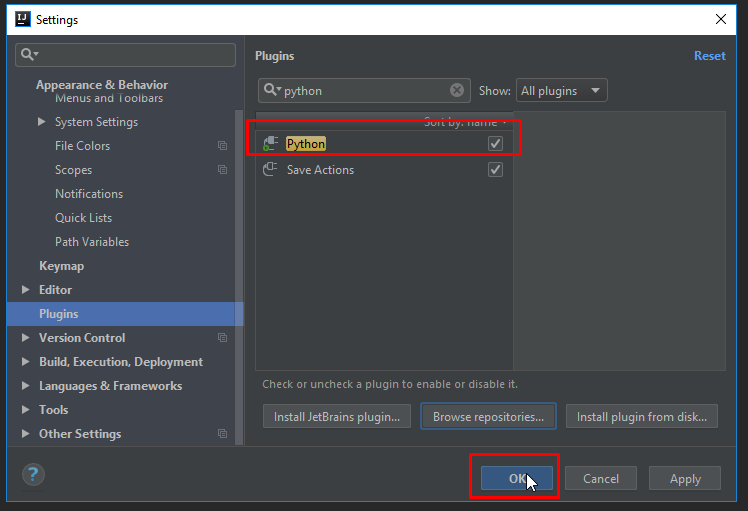
Chào các bạn, đã từ lâu hệ quản trị cơ sở dữ liệu (Database Management System – DBMS) là một phần không thể thiếu trong các hệ thống thông tin có nhu cầu quản lý và trao đổi dữ liệu. Thậm chí là việc sử dụng hệ quản trị CSDL tốt và đúng cách còn rất quan trọng trong quá trình phát triển và mở rộng hệ thống.
Vậy nên, ở trong bài viết này TopDev sẽ cùng với các bạn tìm hiểu về hệ quản trị cơ sở dữ liệu và TOP 10 HỆ QUẢN TRỊ CƠ SỞ DỮ LIỆU đang được sử dụng rộng rãi nhất tính đến thời điểm hiện tại nhé!
Hệ quản trị cơ sở dữ liệu là gì?
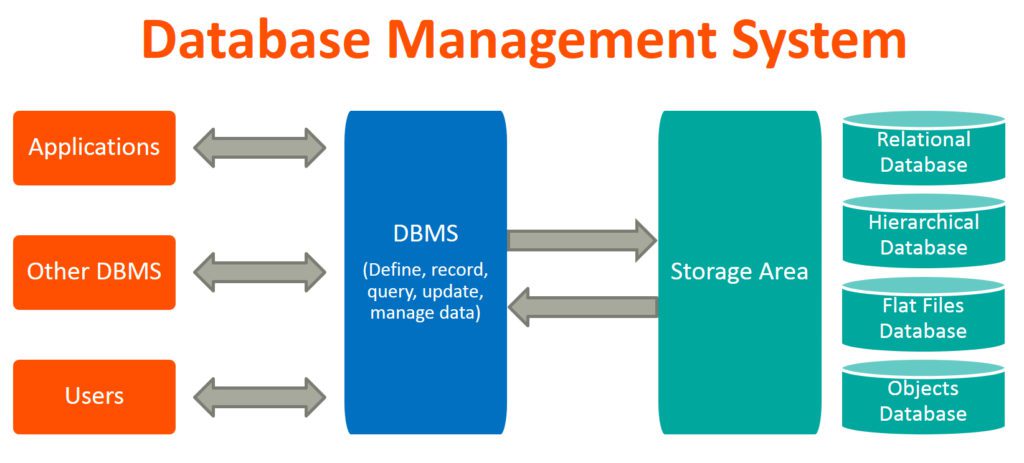
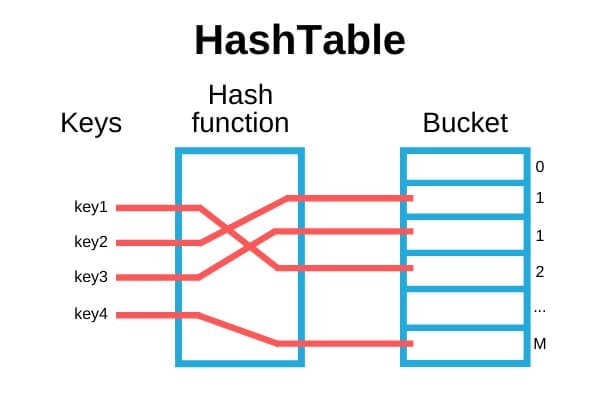
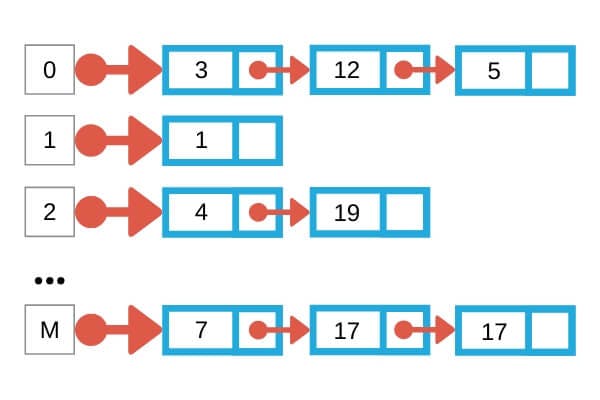
Hệ quản trị cơ sở dữ liệu – Database Management System (DBMS) là một hệ thống được sử dụng để quản lý và điều hành cơ sở dữ liệu (CSDL). Bạn có thể thao tác thêm mới, sửa, xóa và truy vấn dữ liệu một cách hiệu quả và an toàn. DBMS đảm bảo dữ liệu được tổ chức tốt và dễ dàng truy xuất, đồng thời bảo mật dữ liệu và duy trì tính nhất quán.
Một số ứng dụng thực tiễn của DBMS trong doanh nghiệp
- Quản lý Khách hàng (CRM – Customer Relationship Management): Các hệ thống CRM sử dụng DBMS để lưu trữ thông tin về khách hàng và tương tác của họ với công ty. Ví dụ như Salesforce sử dụng hệ quản trị cơ sở dữ liệu để lưu trữ thông tin khách hàng, lịch sử mua hàng, và dữ liệu liên quan để quản lý mối quan hệ khách hàng hiệu quả.
- Hệ thống Quản lý Nhân sự (HRMS – Human Resource Management System): Các hệ thống quản lý nhân sự sử dụng DBMS để lưu trữ thông tin về nhân viên, bảng lương, quản lý thời gian làm việc và các dữ liệu nhân sự khác. Ví dụ như SAP ERP HR sử dụng hệ quản trị CSDL để quản lý thông tin nhân viên và quá trình tuyển dụng.
- Hệ thống Quản lý Sản xuất và Tài nguyên (ERP – Enterprise Resource Planning): Các hệ thống ERP sử dụng DBMS để quản lý dữ liệu về quá trình sản xuất, vận hành kinh doanh, lưu trữ dữ liệu tài chính, và quản lý lô hàng. Ví dụ như Oracle ERP sử dụng hệ quản trị cơ sở dữ liệu để tích hợp các dữ liệu từ các phòng ban khác nhau của công ty.
- Hệ thống Quản lý Kho (WMS – Warehouse Management System): Các hệ thống quản lý kho sử dụng DBMS để quản lý thông tin về vị trí hàng hóa trong kho, lượng tồn kho, và quản lý điều hành các quá trình nhập xuất hàng hóa. Ví dụ như Manhattan Associates sử dụng hệ quản trị cơ sở dữ liệu để quản lý và tối ưu hóa quá trình kho hàng.
- Hệ thống Quản lý Tài chính (Financial Management System): Các hệ thống quản lý tài chính sử dụng DBMS để lưu trữ và quản lý dữ liệu tài chính, báo cáo tài chính, và quản lý chi phí. Ví dụ như QuickBooks sử dụng hệ quản trị cơ sở dữ liệu để lưu trữ thông tin tài chính và quản lý kế toán.
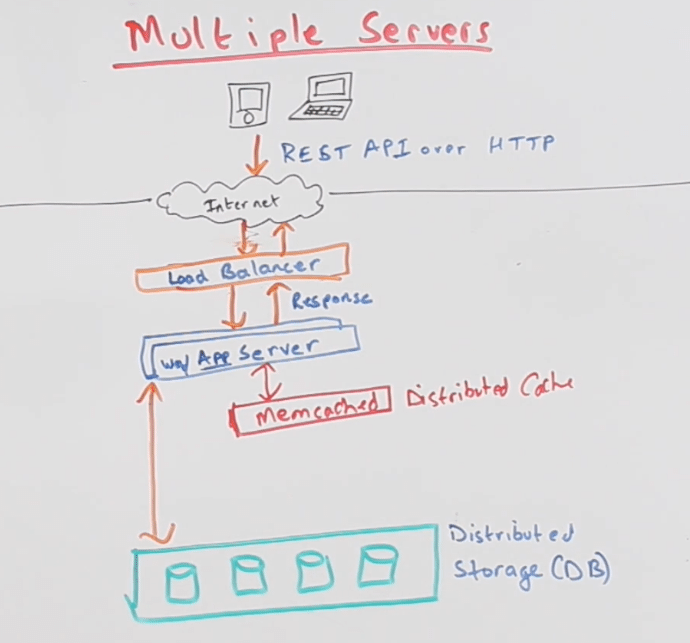
Cấu trúc của hệ quản trị cơ sở dữ liệu
Cấu trúc của một hệ quản trị CSDL bao gồm các thành phần chính sau đây:
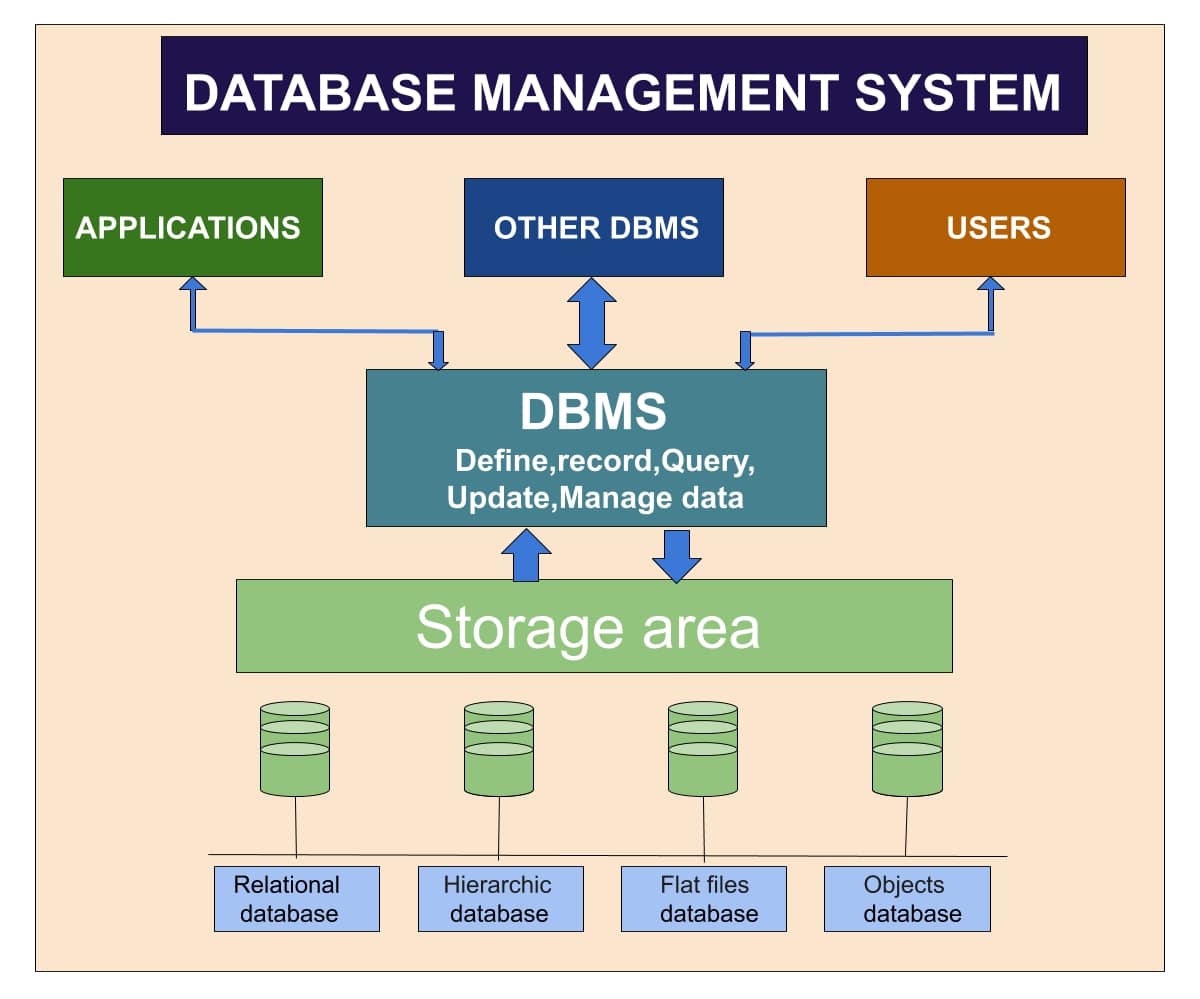
Core DBMS Engine
Là trung tâm của hệ thống DBMS, chịu trách nhiệm xử lý các yêu cầu từ người dùng và quản lý dữ liệu. Nó bao gồm các module để phân tích và thực hiện các truy vấn SQL, xử lý các giao dịch, quản lý bộ nhớ và đọc/ghi dữ liệu vào bộ nhớ hoặc ổ đĩa.
Cơ sở dữ liệu (Database)
- Bảng (Tables): Đây là thành phần chính trong cơ sở dữ liệu quan hệ (Relational Database). Mỗi bảng chứa dữ liệu có cấu trúc, được tổ chức thành các cột (fields) và hàng (rows). Mỗi cột đại diện cho một thuộc tính riêng biệt và mỗi hàng đại diện cho một bản ghi (record) cụ thể.
- Mối quan hệ (Relationships): Đây là cách mà các bảng trong cơ sở dữ liệu liên kết với nhau thông qua các khóa ngoại (foreign keys) và khóa chính (primary keys). Mối quan hệ giúp cho việc truy xuất và thao tác dữ liệu giữa các bảng trở nên hiệu quả và logic.
Hệ quản trị cơ sở dữ liệu (DBMS)
- Trình quản lý cơ sở dữ liệu (Database Manager): Là thành phần chịu trách nhiệm quản lý cơ sở dữ liệu, bao gồm các dịch vụ như lưu trữ, truy xuất, cập nhật, và bảo vệ dữ liệu. Trình quản lý cơ sở dữ liệu có thể hỗ trợ nhiều loại cơ sở dữ liệu khác nhau như quan hệ (Relational), đối tượng (Object), và các dạng khác.
- Trình quản lý bảo mật (Security Manager): Đảm bảo rằng chỉ những người được cấp quyền mới có thể truy cập vào dữ liệu và thực hiện các thao tác. Quản lý bảo mật bao gồm xác thực người dùng, kiểm soát truy cập và mã hóa dữ liệu.
- Trình quản lý dữ liệu (Data Manager): Xử lý các yêu cầu truy xuất dữ liệu từ người dùng và ứng dụng, đảm bảo rằng các truy vấn SQL được thực thi một cách hiệu quả và chính xác.
- Trình điều khiển cơ sở dữ liệu (Database Driver): Là thành phần trung gian giúp các ứng dụng kết nối và giao tiếp với cơ sở dữ liệu. Điều khiển cơ sở dữ liệu thực hiện việc chuyển đổi giữa dữ liệu được lưu trữ trong cơ sở dữ liệu và dữ liệu được xử lý bởi ứng dụng.
Vùng lưu trữ (Storage Area)
- File dữ liệu (Data Files): Đây là các tập tin vật lý hoặc phân vùng trên đĩa cứng được DBMS sử dụng để lưu trữ dữ liệu. Các bảng và dữ liệu trong cơ sở dữ liệu được lưu trữ trong các file này theo cấu trúc cụ thể của DBMS.
- File nhật ký (Log Files): Được sử dụng để ghi lại các thay đổi dữ liệu và các hoạt động quản lý của hệ thống. Log files quan trọng trong việc phục hồi dữ liệu sau khi xảy ra sự cố và đảm bảo tính toàn vẹn của dữ liệu.
Người Sử Dụng (Users)
- Người quản trị hệ thống (Database Administrators): Cài đặt và duy trì hệ thống cơ sở dữ liệu, quản lý bảo mật, và tối ưu hóa hiệu suất.
- Lập trình viên (Developers): Phát triển ứng dụng và truy xuất dữ liệu từ cơ sở dữ liệu bằng các ngôn ngữ lập trình và truy vấn SQL.
- Người dùng cuối (End Users): Truy xuất và thao tác với dữ liệu thông qua các ứng dụng được xây dựng trên nền tảng cơ sở dữ liệu.
Ứng Dụng (Applications)
- Ứng dụng kinh doanh (Business Applications): Sử dụng dữ liệu từ cơ sở dữ liệu để hỗ trợ các quyết định kinh doanh và quản lý hoạt động.
- Hệ thống phân tích dữ liệu (Analytics Systems): Phân tích và xử lý dữ liệu từ cơ sở dữ liệu để đưa ra các báo cáo, dự đoán và thống kê.
DBMS hoạt động ra sao?
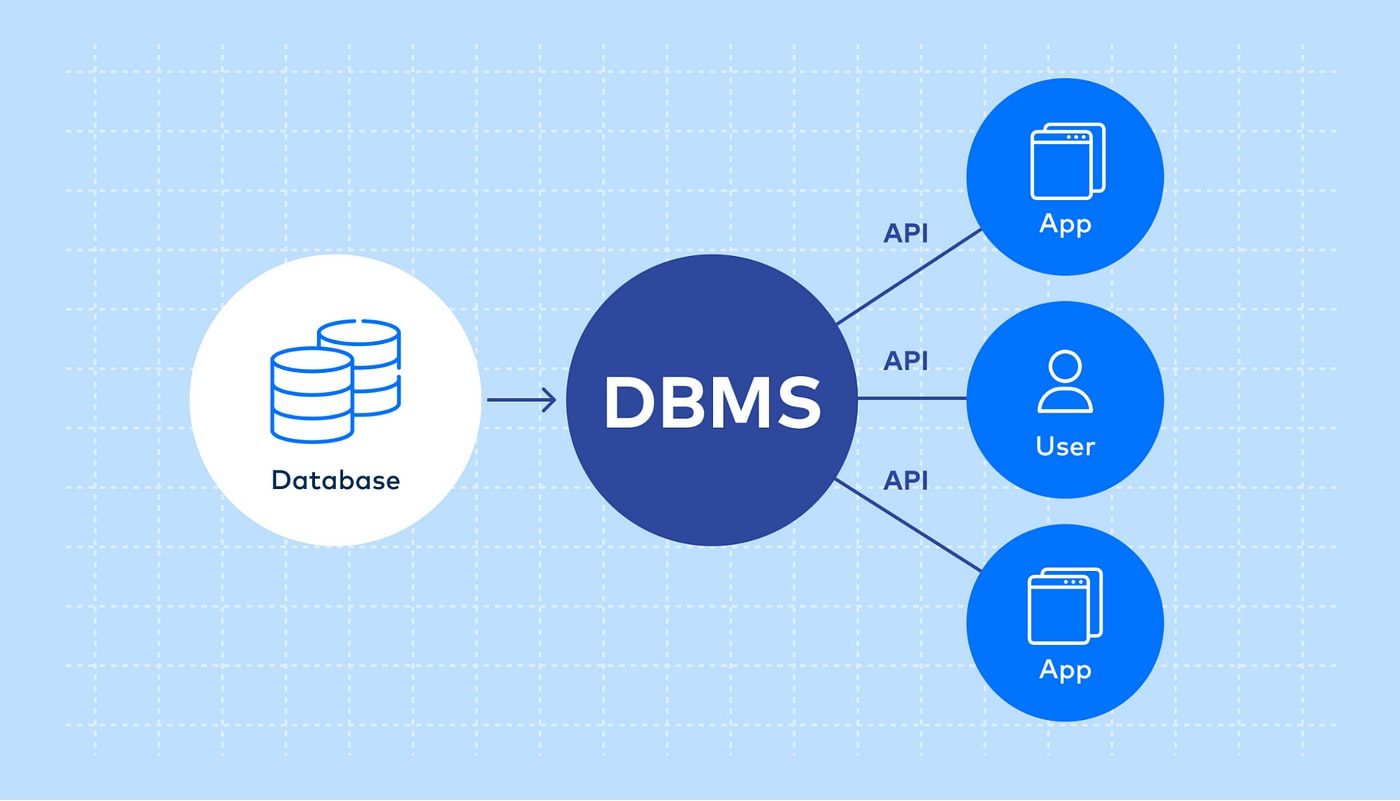
- Lưu trữ dữ liệu: DBMS quản lý cách dữ liệu được tổ chức và lưu trữ trong cơ sở dữ liệu. Dữ liệu thường được tổ chức dưới dạng bảng, trong đó mỗi bảng có các cột và hàng.
- Truy xuất dữ liệu: Người dùng có thể truy xuất dữ liệu từ cơ sở dữ liệu bằng các truy vấn SQL (Structured Query Language) để lấy thông tin cụ thể hoặc thực hiện tính toán trên dữ liệu.
- Cập nhật dữ liệu: DBMS cho phép người dùng cập nhật dữ liệu bằng cách thêm mới, sửa đổi hoặc xóa bỏ các bản ghi trong cơ sở dữ liệu.
- Quản lý bảo mật: DBMS bảo vệ dữ liệu bằng cách thiết lập quyền truy cập, mã hóa dữ liệu và xác thực người dùng.
- Quản lý hiệu suất: DBMS quản lý tối ưu hóa hiệu suất bằng cách tổ chức dữ liệu và tối ưu hóa các truy vấn để đảm bảo thời gian phản hồi nhanh nhất.
Ví dụ về hoạt động của DBMS:
Giả định: Bạn là một quản lý của một cửa hàng bán lẻ và bạn sử dụng một hệ thống quản lý cơ sở dữ liệu để lưu trữ thông tin về các sản phẩm, khách hàng và đơn đặt hàng.
1. Lưu trữ dữ liệu:
- Cơ sở dữ liệu: Hệ thống DBMS của bạn chứa các bảng dữ liệu, bao gồm bảng sản phẩm, bảng khách hàng và bảng đơn đặt hàng.
- Bảng sản phẩm: Lưu trữ thông tin về các sản phẩm như mã sản phẩm, tên sản phẩm, giá bán, số lượng tồn kho, v.v.
- Bảng khách hàng: Lưu thông tin cá nhân của khách hàng như tên, địa chỉ, email, số điện thoại, v.v.
- Bảng đơn đặt hàng: Lưu thông tin về các đơn đặt hàng bao gồm ngày đặt hàng, thông tin khách hàng, danh sách các sản phẩm được đặt hàng, v.v.
2. Truy xuất dữ liệu:
- Người dùng: Bạn, nhân viên bán hàng, muốn xem thông tin chi tiết về một sản phẩm cụ thể.
- Truy vấn SQL: Bạn sử dụng câu lệnh SQL để truy xuất dữ liệu từ bảng sản phẩm:
SELECT * FROM Products WHERE ProductID = 'P001'; - DBMS: Hệ thống DBMS phân tích và thực thi câu lệnh SQL này.
- Kết quả: Hệ thống trả về thông tin chi tiết về sản phẩm có mã
P001, bao gồm tên sản phẩm, giá bán, số lượng tồn kho, v.v.
3. Cập nhật dữ liệu:
- Người dùng: Bạn muốn cập nhật số lượng tồn kho của sản phẩm
P001sau khi bán hàng. - Câu lệnh SQL: Bạn sử dụng câu lệnh để cập nhật dữ liệu:
UPDATE Products SET StockQuantity = StockQuantity - 1 WHERE ProductID = 'P001'; - DBMS: Hệ thống DBMS xác nhận và thực hiện cập nhật dữ liệu trong bảng sản phẩm.
- Kết quả: Số lượng tồn kho của sản phẩm
P001giảm đi 1 đơn vị sau khi cập nhật thành công.
4. Bảo vệ dữ liệu:
- Quản trị viên hệ thống: Đảm bảo rằng chỉ những người có quyền truy cập được phép truy xuất và cập nhật dữ liệu trong cơ sở dữ liệu.
- DBMS: Hệ thống DBMS quản lý các quyền truy cập và đảm bảo tính bảo mật của dữ liệu bằng cách sử dụng các cơ chế xác thực và phân quyền.
5. Quản lý giao dịch:
- Người dùng: Bạn nhận được nhiều đơn đặt hàng cùng một lúc và muốn đảm bảo rằng mỗi đơn đặt hàng được xử lý một cách đáng tin cậy.
- DBMS: Hệ thống DBMS quản lý các giao dịch bằng cách thực hiện các thao tác đọc và ghi dữ liệu một cách nhất quán và đồng bộ.
- Ghi nhật ký (Log): Hệ thống DBMS lưu trữ các hoạt động ghi nhật ký để đảm bảo có thể phục hồi dữ liệu trong trường hợp có lỗi xảy ra.
6. Sao lưu và phục hồi dữ liệu:
- Quản trị viên hệ thống: Thực hiện sao lưu định kỳ của cơ sở dữ liệu để đảm bảo an toàn dữ liệu.
- DBMS: Cung cấp các công cụ để sao lưu và phục hồi dữ liệu khi cần thiết, đảm bảo tính toàn vẹn của dữ liệu.
Phân loại hệ quản trị cơ sở dữ liệu
Hệ quản trị cơ sở dữ liệu có thể được phân loại dựa trên nhiều tiêu chí khác nhau, bao gồm cấu trúc dữ liệu, kiểu mối quan hệ, và mục đích sử dụng.
1. Theo cấu trúc dữ liệu
- Hệ quản trị cơ sở dữ liệu quan hệ (Relational Database Management System – RDBMS): Lưu trữ dữ liệu trong các bảng có các mối quan hệ được xác định trước, dựa trên lý thuyết mối quan hệ. Ví dụ: MySQL, PostgreSQL, Oracle Database.
- Hệ quản trị cơ sở dữ liệu phi quan hệ (Non-relational DBMS): Lưu trữ dữ liệu theo các cấu trúc dữ liệu phi quan hệ, chẳng hạn như các tài liệu, cặp khóa-giá trị, hoặc đồ thị. Ví dụ: MongoDB (tài liệu), Redis (cặp khóa-giá trị), Neo4j (đồ thị).
2. Theo mục đích sử dụng:
- OLTP (Online Transaction Processing): Dùng để xử lý các giao dịch trực tuyến, đảm bảo hiệu suất cao và thời gian phản hồi nhanh. Ví dụ: Oracle Database, MySQL.
- OLAP (Online Analytical Processing): Dùng để phân tích và truy vấn dữ liệu phức tạp, hỗ trợ các hoạt động phân tích kinh doanh và báo cáo. Ví dụ: Microsoft SQL Server, PostgreSQL.
3. Theo phương pháp lưu trữ:
- Hệ quản trị cơ sở dữ liệu dạng dòng (Row-oriented DBMS): Lưu trữ dữ liệu dưới dạng dòng, thích hợp cho các ứng dụng thường xuyên truy cập vào toàn bộ dữ liệu của từng bản ghi. Ví dụ: PostgreSQL, Oracle Database.
- Hệ quản trị cơ sở dữ liệu dạng cột (Column-oriented DBMS): Lưu trữ dữ liệu dưới dạng cột, phù hợp cho các ứng dụng cần truy vấn dữ liệu một cách phân tích và thống kê. Ví dụ: Apache Cassandra, Google Bigtable.
4. Theo tính năng đặc biệt:
- Hệ quản trị cơ sở dữ liệu nhớ đệm (In-memory DBMS): Lưu trữ và xử lý dữ liệu trực tiếp trong bộ nhớ, giúp tăng tốc độ truy xuất dữ liệu. Ví dụ: Redis, Memcached.
- Hệ quản trị cơ sở dữ liệu đám mây (Cloud DBMS): Cung cấp dịch vụ quản trị cơ sở dữ liệu trên nền tảng đám mây, giúp giảm chi phí vận hành và quản lý cơ sở dữ liệu. Ví dụ: Amazon RDS, Microsoft Azure SQL Database.
Top 10 hệ quản trị cơ sở dữ liệu phổ biến
#1. MySQL

Được phát hành lần đầu tiên vào năm 1995 và MySQL đang được phát triển bởi tập đoàn Oracle, có thể nói MySQL là một trong những hệ quản trị cơ sở dữ liệu được sử dụng phổ biến nhất hiện nay.
MySQL được viết bởi ngôn ngữ C/C++ nên có hiệu năng cao, dễ sử dụng, có tính khả chuyển và hỗ trợ nhiều nền tảng hệ điều hành (Windows, Linux, MacOS).
MySQL cũng tương thích với nhiều ngôn ngữ lập trình phổ biến như Java, Python, NodeJS…
MySQL được xây dựng theo kiến trúc Client-Server, bao gồm một máy chủ đa luồng hỗ trợ nhiều máy khách khác nhau.
Các bạn có thể đọc thêm tài liệu về MySQL tại đây: https://www.mysql.com/ hoặc https://www.mysqltutorial.org/
#2. MariaDB

MariaDB thực chất là một nhánh được tách ra từ quá trình phát triển MySQL với mục đích phi thương mại, có nghĩa là nó sẽ hoàn toàn miễn phí cho người sử dụng.
Cũng như MySQL thì MariaDB được viết bằng ngôn ngữ C/C++, Perl nhưng được tối ưu khá nhiều về mặt hiệu năng truy vấn dữ liệu.
Hiện tại thì MariaDB cũng hỗ trợ hầu hết các hệ điều hành phổ biến như Windows, Linux và MacOS… Nên anh em lập trình không phải lo về vấn đề môi trường để sử dụng MariaDB nha.
Do hoàn toàn miễn phí nên các bạn có thể tham khảo mã nguồn mở của MariaDB tại đây: https://github.com/MariaDB/server
Ngoài ra thì các bạn cũng có thể đọc thêm về các bài viết hướng dẫn của MariaDB tại đây nữa nhé: https://www.mariadbtutorial.com/
Xem thêm: Điểm khác biệt của MariaDB và MySQL
#3. Oracle

Là một hệ quản trị cơ sở dữ liệu đa mô hình do công ty phần mềm thứ 2 thế giới là Oracle xây dựng và phát triển.
Tất nhiên là chúng ta phải trả phí để có thể sử dụng được hệ quản trị CSDL này, thậm chí là chi phí khá đắt đối với các hệ thống lớn.
Oracle được viết bằng ngôn ngữ C/C++, Assembly nên cũng cho hiệu năng rất cao. Và tất nhiên thì Oracle cũng hỗ trợ hầu hết các nền tảng hệ điều hành hiện nay như Windows, Linux, MacOS
Oracle database thường được sử dụng để chạy các công việc liên quan đến xử lý giao dịch trực tuyến (OLTP), kho dữ liệu (DW) hoặc là hỗn hợp (OLTP và DW).
Các bạn có thể mua các gói dịch vụ tại các nhà cung cấp được Oracle ủy quyền.
Về tài liệu tham khảo thì các bạn có thể xem các hướng dẫn về Oracle tại đây: https://www.oracletutorial.com/
#4. MongoDB

Ở trên thì chúng ta đã đề cập đến 3 kiểu CƠ SỞ DỮ LIỆU CÓ QUAN HỆ, tiếp theo, chúng ta sẽ đến với MongoDB – đây là một hệ quản trị cở dữ liệu phi quan hệ (NoSQL)
Hiện tại thì MongoDB cũng là một hệ quản trị cơ sở dữ liệu mã nguồn mở, tức là nó miễn phí. Các bạn có thể tham khảo mã nguồn của MongoDB tại đây: https://github.com/mongodb/mongo
MongoDB được viết bằng nhiều ngôn ngữ lập trình khác nhau như C/C++, Go, JavaScript, Python và cũng hỗ trợ trên hầu hết các nền tảng hệ điều hành (Windows, Linux, MacOS..).
Đặc điểm của HỆ QUẢN TRỊ DỮ LIỆU PHI QUAN HỆ là dữ liệu được lưu lại dưới dạng JSON (JavaScript Object Notation) và gần như là các các bản ghi không nhất thiết phải giống nhau về cấu trúc.
Các bạn có thể đọc thêm tài liệu về MongoDB tại đây: https://www.mongodb.com/3
#5. PostgreSQL

Tiếp tục với một hệ quản trị cơ sở dữ liệu có quan hệ mã nguồn mở đó là PostgreSQL.
PostgreSQL được phát triển bởi khoa điện toán của trường đại học California tại Berkeley. PostgreSQL mở đầu nhiều khái niệm quan trọng cho các hệ quản trị cơ sở dữ liệu thương mại sau này mới có.
Được viết hoàn toàn bằng ngôn ngữ lập trình C nên tốc độ cũng như hiệu năng của PostgreSQL là rất tốt.
Đồng thời thì nó cũng hỗ trợ nhiều nền tảng như Windows, Linux, MacOS nên PostgreSQL đang ngày càng trở nên phổ biến hơn.
Với ưu điểm hỗ trợ nhiều truy vấn phức tạp thì PostgreSQL cũng đang là một ứng cử viên rất tiềm năng cho các hệ thống lớn sau này.
Các bạn có thể đọc thêm tài liệu về PostgreSQL tại đây: https://www.postgresqltutorial.com/
#6. Microsoft SQL Server

Là một hệ quản trị cơ sở dữ liệu quan hệ được xây dựng và phát triển bởi Microsoft, với phiên bản đầu tiên ra đời vào năm 1989 (SQL Server 1.0) đến nay đã là phiên bản SQL Server 2019, và cũng là phiên bản ổn định nhất.
Microsoft SQL Server được viết bằng ngôn ngữ C/C++ nên hiệu năng cũng như tốc độ truy vấn rất tốt.
Ban đầu thì Microsoft SQL Server chỉ hỗ trợ hệ điều hành Windows, nhưng sau này nó đã được phát triển để hỗ trợ trên hầu hết các nền tảng hệ điều hành Linux và MacOS.
Tuy không phải là một hệ quản trị dữ liệu mã nguồn mở, song Microsoft SQL được đánh giá khá cao là “tiền nào của nấy”.
Các bạn có thể download Microsoft SQL Server tại đây https://www.microsoft.com/en-us/sql-server/sql-server-downloads
#7. Redis

Redis (viết tắt của cụm từ REmote DIctionary Server) là một mã nguồn mở được sử dụng để lưu trữ dữ liệu có cấu trúc, có thể được sử dụng như một Database, bộ nhớ cache hoặc là một Message Broker.
Redis lưu trữ dữ liệu dưới dạng Key-Value, hỗ trợ việc sắp xếp, query, backup dữ liệu lên đĩa cứng để cho phép bạn có thể khôi phục hệ thống khi gặp sự cố.
Một vài kiểu dữ liệu trong Redis như String, List, Set, Hash…
Có thể nói Redis là một sự lựa chọn tuyệt vời khi cần đến một Server lưu trữ dữ liệu đòi hỏi tính mở rộng cao, chia sẻ nhiều tiến trình, nhiều ứng dụng và nhiều server khác nhau.
#8. Elasticsearch

Chính xác thì Elasticsearch là một công cụ tìm kiếm mã nguồn mở. Elasticsearch cung cấp bộ máy tìm kiếm dạng phân tán, có đầy đủ công cụ với giao diện web HTTP hỗ trợ dữ liệu kiểu JSON.
Elasticsearch được viết bằng ngôn ngữ lập trình Java và nó được ra đời vào năm 2016. Các bạn có thể tham khảo mã nguồn của Elasticsearch tại đây: https://github.com/elastic/elasticsearch
Hiện tại thì Elasticsearch hỗ trợ hầu hết các hệ điều hành Window, Linux, MacOS
Các bạn có thể download Elasticsearch tại đây nhé: https://www.elastic.co/downloads/
#9. Firebase

Được xây dựng và phát triển bởi Google, Firebase là một dịch vụ cơ sở dữ liệu dựa trên nền tảng công nghệ điện toán đám mây.
Sự ra đời của Firebase với mục đích hỗ trợ cho các lập trình giảm thiểu thao tác với cơ sở dữ liệu, từ đó tập trung vào việc phát triển ứng dụng hơn.
Với hệ thống server mạnh mẽ, sự tiện lợi cũng như việc bảo mật cực tốt đã giúp Firebase trở thành một trong những cái tên được nhiều nhà phát triển lựa chọn để xây dựng các hệ thống lớn.
Có thể kể đến một vài ưu điểm của Firebase như sau:
- Chỉ việc tạo tài khoản và sử dụng.
- Tốc độ phát triển nhanh.
- Được hậu thuẫn bởi ông lớn Google.
- Hỗ trợ các công nghệ mới (Machine Learning (học máy), AI)
- Khả năng realtime (thời gian thực).
- Tự động sao lưu vào khôi phục…
#10. SQLite

SQLite là một hệ thống cơ sở dữ liệu quan hệ nhỏ, nó có đặc điểm là có thể tích hợp vào bên trong các trình ứng dụng khác.
SQLite được viết và phát triển bởi D. Richard Hipp sử dụng ngôn ngữ lập trình C, với mục đích không cần yêu cầu quản trị cơ sở dữ liệu mà vẫn có thể vận hành ứng dụng.
Chúng ta có thể liên kết SQLite tĩnh hoặc động tới ứng dụng, chỉ khoảng 400KB với cấu hình đầy đủ hoặc 259KB nếu bỏ qua một số tính năng tùy chọn thì SQLite thực sự rất nhẹ để tích hợp vào ứng dụng.
Các bạn có thể tham khảo các bài hướng dẫn về SQLite tại đây: https://www.sqlitetutorial.net/
Vậy là trong bài viết này mình đã cùng với các bạn điểm qua khái niệm Hệ quản trị CSDL và top 10 DBMS được sử dụng phổ biến nhất hiện nay rồi nhé.
Ngoài những hệ quản trị cơ sở dữ liệu mình đã liệt kê bên trên ra, nếu bạn còn biết thêm DBMS nào khác thì có thể comment ở phần bình luận để anh em cùng tìm hiểu nha.
Nguồn tham khảo: blogchiasekienthuc.com
Xem thêm Việc làm it cho các Developer hấp dẫn trên TopDev








 Vòng lặp không lối thoát – Nguồn ảnh / Source: geeksforgeeks.org
Vòng lặp không lối thoát – Nguồn ảnh / Source: geeksforgeeks.org Circular Wait, đợi nhau trong vòng tròn vô tận. Nguồn ảnh/ Source: The Robert C. Martin Clean Code Collection
Circular Wait, đợi nhau trong vòng tròn vô tận. Nguồn ảnh/ Source: The Robert C. Martin Clean Code Collection