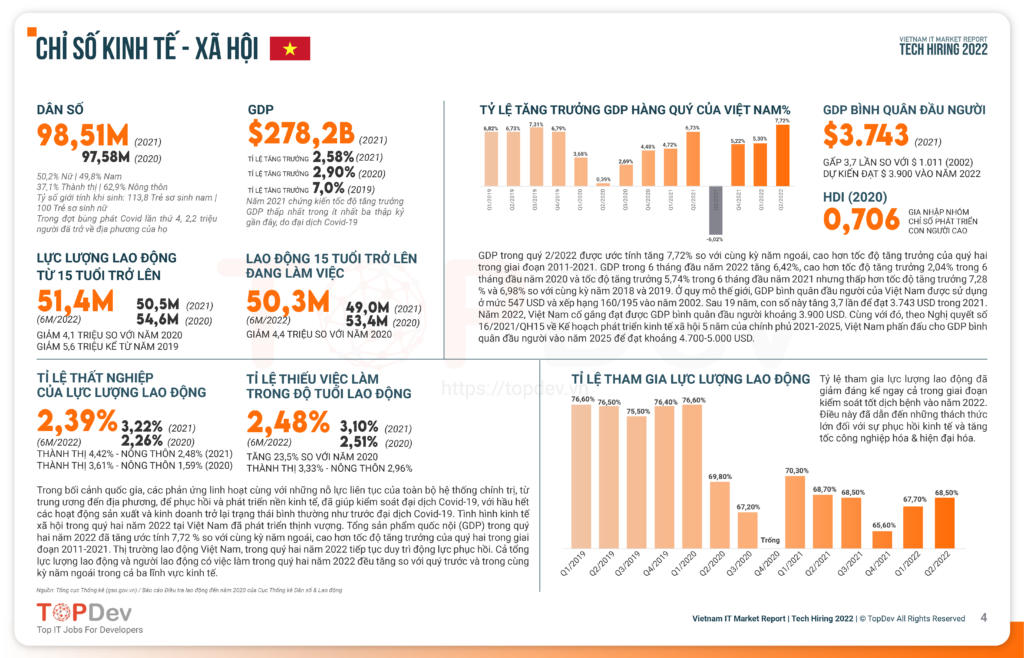
React hiện nay là thư viện rất được ưa chuộng bởi các lập trình viên khi xây dựng những ứng dụng web dạng một trang (Single Page Application) nhờ việc dễ học, dễ viết và nhiều công cụ hỗ trợ. Tuy nhiên khi ứng dụng của bạn ngày càng trở nên lớn hơn thì các vấn đề cũng xuất hiện nhiều hơn, nhất là việc liên quan tới tối ưu hiệu năng cho ứng dụng. Trong bài viết này, mình sẽ cùng các bạn tìm hiểu về Code-Splitting – một kỹ thuật để giúp “giảm” dung lượng file bundle nhằm cải thiện thời gian load website và nâng cao hiệu năng ứng dụng của bạn.
Bundle JS Files là gì?
Trước tiên bạn cần hiểu khái niệm bundle file trong React là gì. Thông thường khi tạo ra một ứng dụng thì chúng ta sẽ viết source code của mình vào nhiều files khác nhau, trong đó có chứa nhiều các modules và thư viện bên thứ 3 (3rd-party libs). Khi tiến hành build ứng dụng của bạn, React sẽ thực hiện việc chuyển đổi rất nhiều file source code mà bạn viết trở thành 1 file lớn hơn để sử dụng nó đưa cho các trình duyệt web khi load ứng dụng. Những file đó được gọi là bundle.
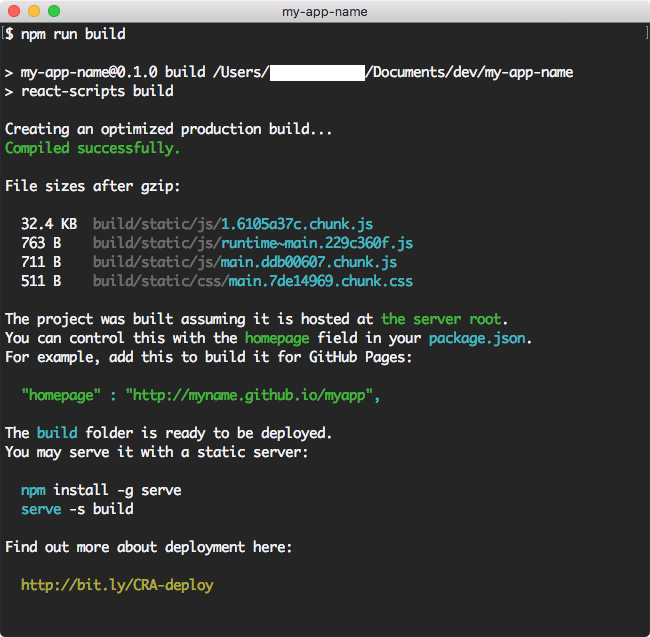
Nguồn: telerik.com
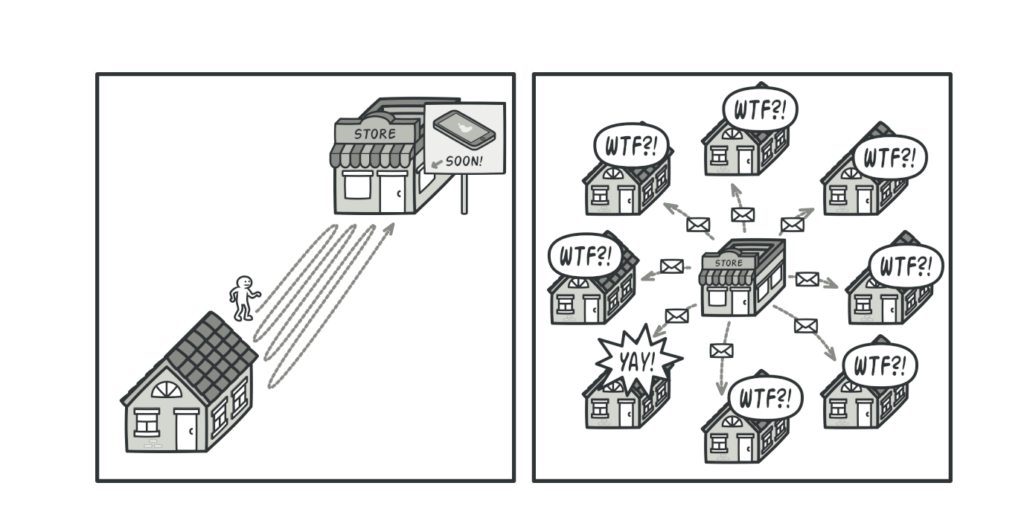
Ban đầu ứng dụng của bạn tạo ra những file bundle nhỏ, và việc trình duyệt load chúng lên không thành vấn đề; sau một thời gian phát triển, với việc import và sử dụng ngày càng nhiều các thư viện và module thì các files bundle của bạn cũng ngày càng nặng thêm. Nếu không thực hiện tối ưu, kích thước các file bundle có thể lên tới 40-50Mb là chuyện bình thường, điều đó cũng đồng nghĩa với việc ứng dụng của bạn trở nên nặng nề khi load, user sẽ cần chờ 1 khoảng thời gian khá lâu để có thể tương tác được với các phần tử trên màn hình.
Vậy cách giải quyết cho vấn đề này là gì?
Code-Splitting là gì?
Rõ ràng để load một ứng dụng hay một màn hình cụ thể, ứng dụng của bạn không cần phải “nạp” hết các module hay thư viện được import vào; vì thế để giải quyết cho vấn đề bundle file size lớn, chúng ta cần một kỹ thuật để tách nó ra thành 2 phần: phần cần thiết load để khởi động ứng dụng (hay màn hình) và phần có thể load nạp vào sau khi ứng dụng đã được chạy. Và khi cần cần thiết load để có thể khởi động ứng dụng càng nhỏ, thì thời gian tải ứng dụng của chúng ta càng nhanh hơn. React đã cung cấp cho chúng ta tính năng này và gọi nó là Code-Splitting.
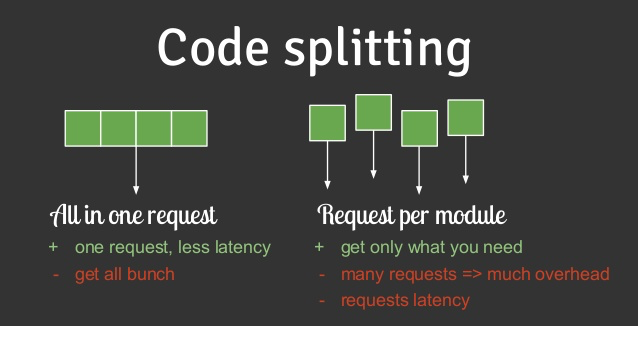 Nguồn: wiki.tino.org
Nguồn: wiki.tino.org
Có 3 kỹ thuật xử lý trong Code-Splitting thường được sử dụng, chúng ta cùng lần lượt tìm hiểu và xem cách triển khai của chúng nhé.
Dynamic Import
Thông thường khi chúng ta cần import 1 module nào để sử dụng, câu lệnh import sẽ được thực hiện như dưới đây:
import { add } from './math';
console.log(add(16, 26));Đoạn khai báo trên sẽ import module math một cách đồng bộ – tức là sẽ import vào luôn file bundle từ khởi tạo. Với Dynamic Import, chúng ta sẽ xử lý lại đoạn code trên để chỉ import khi ứng dụng cần gọi đến phương thức add của module math. Code sẽ được viết lại như sau:
import("./math").then(math => {
console.log(math.add(16, 26));
});Phương thức dynamic import giúp việc import module, file một cách bất đồng bộ bằng việc trả về 1 Promise. Nó hoạt động được cả ở server-side và client-side giúp bạn có thể sử dụng trong các trường hợp load file, assets hay những module, 3rd-party libs không cần thiết cho việc hiển thị ứng dụng, màn hình lần đầu tiên.
Sử dụng React.lazy và Suspense
Phương thức React.lazy giúp bạn tạo ra 1 component ở dạng lazy-loading, nghĩa là sẽ chỉ tạo ra component đó khi nó thực sự được gọi đến và cần hiển thị ra. Hãy xem ví dụ dưới đây:
import React, { useState } from 'react';
import ProjectIntro from './projectIntro';
import ProjectDetails from './projectDetails';
export default function App() {
const [showDetails, setShowDetails] = useState(false);
return (
<>
<h1>Project List</h1>
<ProjectIntro />
<button onClick={() => setShowDetails(true)}>Show Details</button>
{showDetails ? <ProjectDetails /> : null }
</>
);
};Ở đoạn code trên, component ProjectDetails mặc định sẽ không hiển thị, tuy nhiên nó vẫn sẽ được load vào trong bundle file vì đã được import ngay trên đầu. React.lazy giúp bạn dynamic import 1 component, kết hợp với Suspense bọc bên ngoài cho phép chúng ta thêm xử lý hiệu loading component đó mà không làm tăng đáng kể bundle file size. Source code cho việc triển khai React.lazy và Suspense như sau:
import React, { useState, Suspense } from 'react';
import ProjectIntro from './projectIntro';
const ProjectDetails = React.lazy(() => import("./projectDetails"));
export default function App() {
const [showDetails, setShowDetails] = useState(false);
return (
<>
<h1>Project List</h1>
<ProjectIntro />
<button onClick={() => setShowDetails(true)}>Show Details</button>
<Suspense fallback={<div>Loading...</div>}>
{showDetails ? <ProjectDetails /> : null }
</Suspense>
</>
);
};Có một lưu ý ở đây là React.lazy sẽ không thực hiện được khi render app ở server-side. Các bạn có thể tham khảo cách sử dụng 1 thư viện lazy load khác dành cho React như Loadable-components.
Tham khảo tin tuyển dụng lập trình viên React mới nhất tại đây!
Route-based code splitting
Ở hai kỹ thuật trên, chúng ta đã tìm cách giảm kích thước bundle file bằng cách giảm những thành phần cần thiết để load ứng dụng trong 1 component. Với phạm vi một ứng dụng, chúng ta có chứa nhiều màn hình, tại mỗi thời điểm sử dụng thì người dùng sẽ chỉ tương tác với một hoặc một vài màn hình nhất định. Vì thế việc code splitting hoàn toàn cần thiết để thực hiện trên phạm vi ứng dụng.
Khi 1 ứng dụng React chạy, tương ứng với mỗi route sẽ có 1 component đảm nhiệm việc hiển thị và tương tác với người dùng, điều đó cũng có nghĩa các component khác không cần thiết phải được load lên ngay lúc đó. Chúng ta vẫn sẽ sử dụng lazy load cho trường hợp này, code thực hiện sẽ như sau:
import React, { Suspense, lazy } from 'react';
import { BrowserRouter as Router, Routes, Route } from 'react-router-dom';
import Home from "./home";
const Profile = lazy(() => import('./profile'));
const ContactUs = lazy(() => import('./contact'));
const App = () => (
<Router>
<Suspense fallback={<div>Loading...</div>}>
<Routes>
<Route path="/" element={<Home />} />
<Route path="/profile" element={<Profile />} />
<Route path="/contact" element={<ContactUs />} />
</Routes>
</Suspense>
</Router>
);Ở đoạn code trên, 2 components Profile và ContactUs được xử lý lazy loading, chúng sẽ chỉ được load khi user đi đến route tương ứng. Điều đó giúp cho ứng dụng của bạn không cần phải chờ load hết tất cả các component trong Router, giảm kích thước bundle file ban đầu.
Lời kết
Như vậy chúng ta đã đi qua được các kỹ thuật Code-Splitting giúp tối ưu ứng dụng React thông qua việc giảm bundle file size. Trong thực tế các project React hiện nay, việc sử dụng lazy load là hết sức cần thiết khi có quá nhiều component, các module, thư viện được sử dụng trên cùng 1 màn hình. Hãy cố gắng tối ưu source code của bạn nhất có thể ngay từ ban đầu để tránh phải giải quyết các vấn đề về hiệu năng cho việc mở rộng sau này. Hy vọng bài viết cung cấp cho bạn kiến thức hữu ích cho các dự án React sắp tới, hẹn gặp lại mọi người trong các biết tiếp theo của mình.
Tác giả: Phạm Minh Khoa
Xem thêm: