Điểm lại các khái niệm trong Flux action, dispatch, store, điều kiện tiên quyết đề đọc bài này là nên xem lại John Wick
Vấn đề
Trước tiên chúng ta cần biết Flux giải quyết vấn đề gì. Flux là một pattern để xử lý luồng dữ liệu trong ứng dụng. Flux và React được sinh ra và lớn lên dưới ngôi nhà Facebook. 2 đứa chúng nó thường đi cùng nhau, chứ không phải dính vào nhau như hình với bóng
Một trong những ví dụ phổ biến khi nói đến Flux là vòng lặp của tính năng notification. Khi đăng nhập vào Facebook, bạn thấy một thông báo mới trên icon cái chuông huyền diệu, một khi click vào cái chuông này, toàn bộ thông báo sẽ ko còn nằm trong new message nữa. Một vài phút sau, khi nhận được thông báo mới, cái chuông lại rung lên, báo bạn biết có thông báo mới, và cứ thế, vòng lặp cứ tiếp tục.
Với kiểu thiết kế Model-View
Các model sẽ nắm giữ dữ liệu và truyền dữ liệu này xuống các cục view -> nơi sẽ render, hiển thị dữ liệu này.
User tương tác thông qua view, view đôi lúc sẽ cập nhập lại dữ liệu của model, và đôi khi model này cần thay đổi dữ liệu trên model khác. Hơn nữa, nhiều khi một thay đổi của user kéo theo một chuỗi các thay đổi khác, có khi nó là một async. Tưởng tượng như đánh trái banh bàn, bạn ko thể biết được trái banh nó sẽ đập vào đâu hết.
Khi ấy bạn sẽ không biết được dữ liệu bị rơi rớt ở đâu.
Đội ngũ Facebook giải quyết bằng một kiến trúc khác, luồng dữ liệu sẽ đi một chiều duy nhất, một khi cần thêm dữ liệu mới, luồng lại đi từ điểm xuất phát. Và họ gọi kiến trúc đó là Flux
Nhìn vào cái hình trên, bạn sẽ không thể cảm được của kiến trúc này ngay và luôn, không đọc tài liệu về Flux, có thể bạn sẽ chẳng hứng thú vì với nó.
Cùng đi chi tiết từng khái niệm một. Hình dung tổ chức hội bàn đào trong John Wick, với những nhóm nhân vật khác nhau, nắm giữ những vai trò khác nhau.
Giới thiệu các vai chính
Bọn action creator
Nhiệm vụ của bọn này là tạo ra action, tất cả những thay đổi, tương tác phải tới gặp bọn này. Nó giống như bọn ngồi điều hành điện thoại trong phim John Wick, những đứa khác tới đây, phát đi 1 thông điệp, action creator sẽ “định dạng” lại thông điệp đó bằng một mật mã mà tất các những đứa khác nằm trong hệ thống hiểu được.
Thông điệp được gửi đi bao gồm: kiểu thông điệp (type) và nội dung chính của thông điệp (payload). Trong đó kiểu thông điệp là một hằng số đã được định nghĩa trước đó.
Tác dụng phụ của một hệ thống mà toàn bộ kiểu thông điệp đã được định nghĩa sẵn, lính mới vào chỉ cần mở file này ra là biết được ứng dụng đang làm, sẽ có những tình huống nào sẽ làm thay đổi trạng thái dữ liệu.
Bọn dispatcher
Trong John Wick, nói chung các bạn nên xem John Wick trước khi đọc bài này đó, bạn trực điện thoại nhận tin nhắn, format tin nhắn xong, bạn sẽ hét lên cho các bạn đứng trực chổ tổng đài điện thoại. Bạn trực điện thoại này biết danh sách các đầu cầu (store) cần gửi thông báo đến.
Quá trình này được thực hiện một cách tuần tự, không chen lấn, không xen ngang, nếu mỗi đầu cầu cần ràng buộc về thứ tự nhận thông tin, chúng ta có để anh dispatcher này quản lý.
Anh Dispatcher trong Flux sẽ khác với dispatcher trong các kiến trúc khác. Thông tin luôn được gửi đến hết các đầu cầu bất kể nó là thông tin gì. Nghĩa là mỗi đầu cầu không chỉ đăng ký một kênh thông tin nhất định, nó lắng nghe toàn bộ thông tin được gửi đi, chuyện nó quan tâm và xử lý trên từng thông tin nào là nó tự quyết định, giống như chú Bowery King nhận được yêu cầu truy sát John Wick, nhưng anh nhận tin rồi ko làm gì cả.
Bọn đầu cầu Store
Gọi là đầu cầu thì cũng chưa đầy đủ, ngoài là nơi tiếp nhận và thực thông tin, nó còn là nơi chứa toàn bộ dữ liệu của ứng dụng, nguồn tiền của 1 tổ chức, mọi luật lệ, logic của dữ liệu sẽ nằm ở đây.
Anh Store này như chú Bowery King, khi muốn anh ấy làm gì đó, chuyển tiền, nhận tiền, đóng tiền thì bạn buộc phải làm đúng quy trình từ trên xuống dưới action creator -> dispatcher
Bọn View
Nhận dữ liệu, thay đổi thông tin hiển thị, tiếp nhận dữ liệu từ user, đưa ngược lên lại tổ chức là công dụng toàn bộ của bọn này.
Tổng hợp lại chúng ta có sơ đồ vận hành của tổ chức này như sau
Trong hình minh họa trên, còn một đứa nữa đứng giữa View và Store, được gọi là controller view, một dạng của người đưa tin, nó sẽ nhận thông báo từ đầu cầu store khi có dữ liệu thay đổi, rồi mới đưa xuống view
Năm điều nhỏ nhỏ, nhưng rất hay ho cần thiết, cần biết
Nếu chưa biết Service worker API là gì, bạn hãy vào đọc lại link mình đã gắn sẵn
Đặt file service worker trong thư mục root
Đừng thấy file service worker là js mà bạn đi bỏ nào trong thư mục js hay scripts, bởi vì file service worker bỏ vào thư mục nó sẽ bị giới hạn hoạt động ở trong thư mục js đó thôi. Nghĩa là nó chỉ can thiệp được khi user truy cập www.yoursite.com/js/, tất cả request từ www.yoursite.com hay www.yoursite.com/news nó sẽ cho qua.
Nhưng thật lòng mà nói, bỏ luôn trong thư mục root có phải dễ chịu không, nó tự động handle toàn bộ request ở cả site luôn cho khỏe
Sử dụng Panel Application trên Chrome Dev Tools
Trên tab này chúng ta sẽ biết được mình đã đăng ký file service worker thành công chưa, giả lập offline, bypass cái service worker hoặc gỡ bỏ luôn.
Không sử dụng Hard Reload
Một trong những thói quen của chúng ta là dùng “Hard Reload” hay “Empty Cache and Hard Reload” trên trình duyệt để xem những thay đổi mới nhất. Tuy nhiên là khi có service worker rồi, nó sẽ tự động bypass vụ “Hard Reload” này. Tip tiếp theo sẽ chỉ bạn cách làm ngay thôi
Bật “Update on Reload”
Để đảm bảo luôn luôn lấy file mới nhất, trên tab Application check vào ô Update on Reload là xong. Như vậy thì khi thực hiện reload trang (reload bình thường luôn ấy) trình duyệt tự động update cái service worker luôn.
Còn muốn thực hiện manual, click vào link Update bên dưới màn hình này.
Inspect và manual delete cache
Cuối cùng, cũng hay, là trên tab Application cho phép chúng ta xóa chỉ định cụ thể file cache nào muốn xóa. Cột bên trái, mục Cache Storage, click nút expand, bạn sẽ thấy danh sách cache object đang được lưu trên trang này
Bài này khá căn bản và cần thiết cho bạn nào chưa biết gì về CORS, nghe ai đó nói về từ khóa ghê gớm này mà ko biết nó là gì, không để cập đến vấn đề setup làm sao để chạy CORS trên server – vì mình ko biết code phía server đâu
Cross-Origin Resource Sharing (CORS) là một cơ chế sử dụng thông tin trên HTTP header để báo với trình duyệt, cho phép ứng dụng web chạy từ nhà này, có quyền truy xuất resource từ 1 nhà khác (2 thằng gọi là khác nhà khi khác tên miền, khác port, khác giao thức http và https)
Ví dụ một request cross-origin: nhà bạn ở http://domain-a.com dùng javascript gửi request bên nhà http://api.domain-b.com/data.json
Vì lý do bảo mật, trình duyệt sẽ không cho thực hiện các request cross-origin như vậy. Nghĩa là các ứng dụng web gọi API chỉ có thể sử dụng resource từ cùng nhà (same-origin policy là từ chuẩn, nếu bạn cần research thêm), trừ khi response từ nhà khác đó cho phép gọi CORS (bằng cách thêm một số thông tin trên header)
Các request có thể dùng CORS
Gửi một network request bằng fetch
Web font, hoặc load @font-face trong CSS
WebGL texture
Image, video
Khi config thành công trên server, server sẽ trả thêm một số thông tin trên header để trình duyệt biết và cấp phép chạy
Access-Control-Allow-Origin
Chỉ định các tên miền nào được phép truy cập, ví dụ để cho phép tất cả tên miền có thể gọi tới
Access-Control-Allow-Origin: *
Cho phép 1 tên miền cụ thể
Access-Control-Allow-Origin: https://example.com
Các kiểu request CORS
Có 2 kiểu CORS request: các request đơn thuần, và các request preflight, 2 cái này sẽ do trình duyệt xác định sử dụng cái nào, là một developer chúng ta cũng thật sự không cần quan tâm.
Request đơn thuần như GET, POST, HEAD
Các request được trình duyệt xếp loại đơn thuần là GET, POST, HEAD Sử dụng CORS safe -listed header Khi sử dụng Content-Type, chỉ các giá trị sau là được cho phép application/x-www-form-urlencoded, multipart/form-data, text/plain Không có các listener nào được đăng ký trên XMLHttpRequestUpload Không sử dụng ReadableStream
Preflight request
Đơn giản là ngược lại các trường hợp ở trên thì sẽ là dạng preflight, trình duyệt sẽ gửi đi một request ở phương thức options để xác định server có hỗ trợ ko trước khi thực sự gửi đi request chính.
Đối với loại preflight request, ngoài việc chuyển phương thức sang options, nó sẽ set thêm một số thuộc tính trên header
Access-Control-Request-Method: phương thức GET hay POST nên được sử dụng Access-Control-Request-Headers: kiểu header muốn sử dụng Origin: nơi gửi request
Chúng ta có thể tạm dịch nó ra ngôn ngữ tự nhiên là “Tao muốn thực hiện một request dạng GET với content-type và Accept header từ địa chỉ localhost:3000 có được ko?”
Kết quả trả về từ server sẽ cho phép trình duyệt tiến hành tiếp, hay dừng lại ở đó. Response từ server sẽ như thế này
Khi cần loop qua một array, tìm phần tử, sắp xếp, hoặc làm gì đó trên array, khả năng rất cao là trong array đã có một phương thức sẵn để bạn xài, không cần dùng tới vòng lặp for. Chúng ta sẽ cùng điểm qua những phương thức như vậy trong bài viết này.
Các phương thức phải biết
map
Hàm được sử dụng nhiều nhất trong đám, mỗi khi cần thay đổi giá trị phần tử trong array, không thay đổi số lượng phần tử, nghĩ tới map
const numbers = [1, 2, 3, 4]
// cộng thêm một vào tất cả các phần tử
const numbersPlusOne = numbers.map(n => n + 1)
console.log(numbersPlusOne) // [2, 3, 4, 5]
Tạo một array mới, chỉ giữ lại một kiểu property mong muốn trong object
Giờ xét tới một ví dụ tương đối phức tạp hơn, giảm số chiều trong mảng xuống 1, cụ thể là [1, 2, 3, [4, [[[5, [6, 7]]]], 8]] thành [1, 2, 3, 4, 5, 6, 7, 8]
Lưu ý quan trọng, khi sử dụng spread operator luôn khắc ghi trong lòng là nó sẽ thực hiện một shallow copy, mà shallow copy nghĩa là gì, là nó sẽ copy dùng cách đỡ tốn công nhất có thể, nếu các giá trị trong mảng kiểu số, chữ (primitive types) thì không vấn đề, khi trong mảng đó chứa mảng khác, object thì nó chỉ trỏ tới cùng đối tượng gốc thôi, chứ không phải là sao i
Khá tương đồng với hàm filter, chúng ta cung cấp cho nó một hàm để kiểm tra tất cả các phần tử của mảng. Tuy nhiên nó sẽ trả về phần tử đầu tiên thỏa điều kiện chứ không chạy hết toàn bộ mảng.
Ví dụ, chúng ta muốn lấy một số đoạn chat messages từ API, 2 cách làm với vòng lặp for và slice
// The "traditional way" to do it:
// xác định số lượng muốn lấy, sử dụng vòng lặp for
const nbMessages = messages.length < 5 ? messages.length : 5
let messagesToShow = []
for (let i = 0; i < nbMessages; i++) {
messagesToShow.push(posts[i])
}
// Nếu "arr" ít hơn 5 phần tử,
// nó vẫn chạy bình thường
const messagesToShow = messages.slice(0, 5)
some
Để kiểm tra có ít nhất một phần tử trong mảng thỏa điều kiện
Tạo một array mới từ một object hoặc một đối tượng bất kỳ có thể tạo được
const nodes = document.querySelectorAll('.todo-item')//lấy danh sách NodeListconst todoItems = Array.from(nodes)// có thể sử dụng các phương thức của array trên todoItems này
todoItems.forEach(item=>{
item.addEventListener('click',function(){alert(`You clicked on ${item.innerHTML}`)})})
Hiện tại hầu hết những hệ thống lớn trên thế giới đều cung cấp Rate Liming cả. Nhưng mà ít ai để ý đến thuật toán đằng sau công nghệ đó như thế nào.
Kĩ thuật này được 69.96% các hệ thống từ lớn đến nhỏ như Google, Facebook, LinkedIn, Youtube áp dụng
Kĩ thuật này giúp chúng ta ngăn chặn DDOS, chống spam, giữ cho hệ thống hoạt động trơn tru.
Thế nhưng, chúng ta ít người biết đến “người hùng” thầm lặng này. Kĩ thuật này có tên là Rate Limiting.
Rate Limiting là cái gì cơ?
Giả sử như hệ thống của chúng ta nhận được hàng nghìn request nhưng mà trong số đó chỉ xử lí được trăm request/s chẳng hạn, và số request còn lại thì bị lỗi (do CPU hệ thống đang quá tải không thể xử lí được).
Để giải quyết được vấn đề này thì cơ chế Rate Limiting đã ra đời. Mục đích của nó chỉ cho phép nhận 1 số lượng request nhất định trong 1 đơn vị thời gian. Nếu quá sẽ trả về response lỗi.
1 số ví dụ hay gặp trong Rate Limiting như:
Mỗi người dùng chúng ta chỉ cho phép gửi 100 request/s. Nếu vượt quá thì sẽ trả về response lỗi.
Mỗi người dùng chỉ cho phép nhập sai thẻ credit 3 lần trong 1 ngày
Mỗi địa chỉ IP chỉ có thể tạo được 2 account trong 1 ngày.
Để dễ hiểu mình sẽ lấy ví dụ như khi bạn uống bia nhé 😉 Giả sử 1 chai bia là một request tới server thì tửu lượng 6 chai Tiger Nâu độ cồn 5% của bạn là thuật toán Rate Limit giúp bạn không sập quá nặng 😄.
Về cơ bản thì rate limiter sẽ cho phép gửi bao nhiêu request trong 1 khoảng thời gian nào đó. Nếu vượt quá sẽ bị block lại.
Khuyến cáo: Hình ảnh minh họa thôi nha. Mùa dịch nhìn có thèm cũng không được ra quán nhậu nha :)))
Một số thuật toán hay dùng?
Vì tên mấy thuật toán dịch ra mình thấy hơi chuối nên mình để nguyên, anh em nào biết dịch sao cho hay thì comment ở dưới nha.
Những thuật toán thường được áp dụng để rate limit bao gồm:
Bucket Algorithm
Leaky bucket: Vào một ngày bạn có bồ (giả định) và cô ấy không muốn bạn uống nhiều, nên đổ hết 8, 9 chai vào 1 cái xô rồi đục lỗ cho nó lủng. Dù bạn có mua một két để luyện thành tiên tửu nhưng đều phải đổ vào xô, mỗi ngày chỉ chảy ra tầm 1 chai. Và bạn chỉ được uống bia chảy ra từ xô.
Cách này giúp cho hệ thống không sợ bị quá tải khi có nhiều người truy cập, vì cái xô sẽ chặn bớt.
Token Bucket
Thay vì đổ bia vào xô, bồ bạn sẽ bỏ vào xô mỗi ngày 40 Token. Nếu bạn uống Tiger bạn sẽ mua được 2 chai, còn uống Corona thì chỉ được 1 chai.
Hết ngày, dù còn hay hết token, bồ bạn sẽ bỏ vào cho đủ khẩu phần 50 Token mỗi ngày. Cách này đảm bảo 1 ngày bạn chỉ mua bia tối đa 40 Token.
Trong thực tế, có nhiều request sẽ tốn nhiều tài nguyên hơn, chạy lâu hơn (tạo report, lưu nhiều dữ liệu). Nếu dùng Leaky Bucket, ta chỉ đảm bảo được số lượng request tới server. Với thuật toán này, cái gì tốn nhiều tài nguyên hơn sẽ cần nhiều token hơn, ta có thể dễ dàng kiểm soát lượng tải tới server.
Window Algorithm
Thay vì dùng xô để hạn chế lưu lượng, những thuật toán này phân chia khoảng thời gian (timing window) để hạn chế số lượng request.
Fixed window
Thấy xô dùng lâu ngày thấy nhàm chán, gấu bạn quyết định giờ 1 tuần bạn chỉ được uống tối đa 3 chai mỗi chai 20 token. Một tuần (tính từ 0h sáng thứ 2 tới 24h đêm CN) này chính là fixed window, tối đa là 3 chai.
Cách này dễ hiểu, dễ code, các hệ thống lớn khi cung cấp API cũng hay ra giới hạn như thế này. Tuy nhiên, nó có 1 điểm yếu là… có thể bị lợi dụng để burst số lượng request vượt giới hạn.
Ví dụ, gấu bạn ra mức giới hạn này vì muốn bạn uống 2 ngày 1 chai. Tuy nhiên đêm đó bạn lên cơn thèm nên đợi 11h30 tối CN uống 3 chai, sau đó 1h sáng thứ 2 bơm thêm 3 chai nữa (tiên tửu)!
Vậy là trong canh Tý bạn uống 6 chai, bạn sập như chưa từng luôn!
Do vậy, để tránh bọn ranh ma người ta đã dùng Sliding Window Log / Sliding Window để hạn chế trường hợp trên.
Sliding Window Log
Thay vì dùng fixed window, gấu bạn quyết định thay đổi thuật toán. Giờ đây, khi bạn bơm alcohol, gấu sẽ ghi log lại. Sau đó, gấu bắt đầu tính từ lần đó đến đúng một tuần sau.
Ví dụ vào một buổi trưa nóng nực 11h thứ 2 bạn khui một chai bia mát lạnh để giải nhiệt cuộc sống, gấu sẽ tra log từ 11h trưa thứ 2 tuần trước đến 11h trưa thứ 2 tuần này. Đây chính là Sliding Window.
Tuần 1 - Tuần 2
2 3 4 5 6 7 CN - 2 3 4 5 6 7 CN
Nếu gấu đếm trong khoản thời gian này, bạn uống ít hơn 3 chai thì sẽ vui vẻ khui cho bạn uống, còn không … gấu vẫn sẽ vui cười và khui nhưng là cho nó uống (còn bạn thì nhìn thèm vãi chưởng).
Cách này đảm bảo lượng cồn bạn nạp vào người trong 1 tuần không vượt quá 3 chai. Nếu bạn nốc liền 3 chai cùng lúc, bạn sẽ phải nhịn … đúng 7 ngày sau mới được liếm nhẹ được miếng sinh tố lúa mạch :))
Cách này rất chính xác, tuy nhiên, nó vẫn có 1 số khuyết điểm:
Tốn khá nhiều bộ nhớ vì phải log toàn bộ request,
Tốn tài nguyên vì phải log ở mỗi lần request
Chạy có thể sẽ chậm, vì mỗi lần có request, ta phải query đếm lượng request trong 1 khoản thời gian nhất định để xem có tiếp nhận request hay không
Hãy tưởng tượng hệ thống tầm 1 triệu người dùng, mỗi ngày họ gửi 1000 request là ta phải log gần 1 tỷ event mỗi ngày. Toang rồi ông giáo ạ!
Sliding Window (Rolling Window)
Sliding Window là sự cải tiến từ Sliding Window Log. Ta sẽ đánh đổi độ chính xác lấy tốc độ và bộ nhớ (lưu ít hơn ,query ít hơn). Ta không log trên mỗi request, mà chỉ lưu lại số lượng trên mỗi khoản thời gian.
Quay lại với cô người yêu ví dụ nào. Do gấu thấy ghi lại mỗi lần bạn uống mệt qué nên bây giờ, gấu chỉ log 1 lần vào Chủ Nhật là tuần đó bạn uống bao nhiêu chai bia.
Ví dụ ở tuần 1 bạn uống 3 chai. Vào 11h trưa thứ 2 tuần thứ 2, bạn định uống thêm 1 chai. Sliding Window sẽ là từ 11h trưa tuần thứ 2 tuần trước đến 11h thứ 2 tuần này.
Tuần 1 Tuần 2
2 3 4 5 6 7 CN - 2 3 4 5 6 7 CN
Sliding window này có 6 ngày rưỡi trong tuần thứ 1 (trưa thứ 2 đến tối CN), nửa ngày trong tuần 2 (sáng thứ 2).
Do không có log cụ thể, ta sẽ ước đoán lượng bia bạn uống trong khoảng thời gian này bằng công thức sau.
Số uống tuần 1 * (Ngày trong tuần 1 / 7) + Số uống tuần 2 * (Ngày trong tuần 2 / 7)
3 * (4.5/7) + 1 * (2.5/7) = 2.285
Tức là trong khoảng 7 ngày này bạn đã uống tầm 2.285 chai bia, chưa uống thêm được.
Có thể là không chính xác lắm, vì số lượng bia bạn uống sẽ không trải dài đều theo tuần. Tuy vậy, nó không bị khai thác lỗ hổng như fixed window, lại tốn ít tài nguyên và bộ nhớ hơn, nên được sử dụng tương đối nhiều.
Là một lập trình viên thì ta luôn chú ý đến năng suất của sản phẩm như phải an toàn, không bị lỗi và đương nhiên sẽ chạy nhanh. Và bài này mình sẽ đề cập đến vấn đề tối ưu code của PHP và làm thế nào để website chạy nhanh hơn. Vậy nâng skill lập trình PHP như thế nào?
1. Nắm được nguyên tắc hoạt động của trình biên dịch
Có lẽ phần này thì ai cũng biết nhưng tôi nghĩ cũng nên đưa ra vì nó rất là quan trọng, và hy vọng những bạn chưa hiểu nguyên tắc hoạt động sẽ nắm bắt được.
Đối với trình biên dịch một ngôn ngữ lập trình bất kỳ thì trình biên dịch luôn luôn dịch một file từ trên xuống dưới và từ trái qua phải. Giả sử bạn tạo 2 fiel a.php và b.php thì nếu bạn require b.php vào a.php thì lúc này trình biên dịch sẽ thực thi hết file b.php rồi mới dịch xuống dòng kế tiếp sau lệnh require ở file a.php.
Trường hợp bạn gọi tới một hàm nào đó. Nếu trong chương trình chạy đến một hàm nào đó thì nó sẽ thực thi hết nội dung bên trong hàm đó rồi mới chạy xuống dòng lệnh kế tiếp, và hàm đó bạn có thể đặc bất kỳ vị trí nào trong file PHP, không giống như JavaScript hay C++ là bạn phải khai báo phía trên nó mới hiểu.
2. Thuần thục các toán tử trong lập trình
Các ngôn ngữ lập trình sẽ có những cách thể hiện toán tử khác nhau nhưng về bản chất thì toán tử thuộc về toán học nên nó không thể thay đổi, tức là cho dù bạn làm việc trên ngôn ngữ nào đi nữa thì nó vẫn là nó. Và đây cũng là tiền đề về kỹ năng lập trình cho các bạn.
Tôi có một ví dụ nho nhỏ:
$a = 12;
$b = '12';
var_dump($a == $b); // kết quả true
var_dump($a === $b);// kết quả false
Trong ví dụ này kết quả thú nhất trả về true, kết quả thứ 2 trả về false, lý do là vì khi ta sử dụng toán tử so sánh ba dấu === thì nó sẽ so sánh cả giá trị và kiểu dữ liệu, còn hai dấu bằng == thì nó chỉ so sánh giá trị. Điều này thể hiện đúng trong ngôn ngữ PHP và JavaScript.
Còn rất nhiều các toán tử khác. Các bạn có thể tham khảo bài này toán tử và biểu thức hoặc lên trang php.net
Là một lập trình viên thì ai cũng muốn mình có một cái đầu logic. Nhưng vấn đề này có thành hiện thực hay không thì nó phụ thuộc vào thiên phú trời cho và sự chăm chỉ của bạn. Tôi có một ví dụ sau:
Các bạn thấy kết quả của biến $a luôn luôn là một trong hai giá trị của mệnh đề if hoặc else. Như vậy cái đoạn khai báo biến $a = ''; liệu có cần thiết không? Rõ ràng là không cần thiết vì biến $a luôn luôn tồn tại sau khi mệnh đề if else thực thi nên câu lệnh echo $a; luôn luôn không lỗi và có kết quả đúng như mong muốn. Tức là ta code lại như sau:
Kết quả tương đương nhỉ :D. Tuy nhiên điều này lại gây ra sự khó nhìn đó là không nhìn rõ biến $a bắt nguồn từ đâu.
Xét ví dụ 2 như sau:
if ($a == 12 && isset($a)){
echo 'A = 12';
}
Rõ ràng bài toán này sẽ không logic vì trường hợp biến $a không tồn tại sẽ sinh lỗi. Lỗi là vì ta đi kiểm tra $a == 12 trước rồi mới kiểm tra isset sau, nếu ta đổi ngược lại thì sẽ logic.
4. Rút ngắn code lại
Việc rút ngắn code lại không hề đơn giản với những bạn mới vào nghề lập trình (giống như mình ), và ai cũng muốn code mình ngắn gọn, dễ hiểu và chạy nhanh (tối ưu). Thông thường ta code xong một chương trình thì xem lại việc tối ưu code xem có thể giảm được phần nào hay không.
Với ví dụ này nó hơi dài dòng, vì biến $a sẽ có giá trị là 20 hoặc là 12 sau khi chương trình chạy xong. Như vậy ta có cách này code gọn hơn đó là bỏ cái else đi vì bến $a ta đã khai báo $a = 12; , tức là:
$a = 12;
$b = 20;
if ($b == 20){
$a = 20;
}
5. Kiểm tra dữ liệu trước khi đưa xử lý truy vấn database
Thông thường những bạn mới vào nghề ít khi chú ý vấn đề này, đó là khi ta lấy dữ liệu từ phía người dùng. Chẳng hạn bạn làm một form đăng ký với giới tính là nam hoặc nữ tương đương với 0 hoặc 1. Như vậy cái thẻ select của bạn sẽ có 2 options có giá trị là 0 và 1, và người dùng sẽ chọn rồi submit. Nhưng giả sử người dùng biết sử dụng firebug thì họ dễ dàng chỉnh sửa số 1 hoặc số 0 thành một số khác bất kỳ, điều này dẫn đến khi bạn update vào data không đúng quy tắc. Bởi vậy với những trường hợp như vậy nên kiểm tra cho chính xác.
6. Thiết kế database chuẩn theo ứng dụng
Đang nói về code mà lại đưa vấn đề database vào thì hơi kỳ nhưng mình nghĩ cũng nên đưa vào vì nó rất quan trọng cho một chương trình ứng dụng có sử dụng cơ sở dữ liệu. Dưới đây là một số chú ý khi sử dụng với Sql.
Sử dụng indexes cho các field nằm trong điều kiện where của các câu truy vấn.
Khi truy vấn với kiểu int sẽ nhanh hơn kiểu varchar, vì vậy những field có như cầu tìm kiếm nếu có thể nên chuyển sang hết kiểu INT và index chúng. Ví dụ như tìm kiếm theo ngày tháng.
Không sử dụng toán tử like trong các câu truy vấn vì nó rất chậm, nếu có thể hãy dùng fulltext search.
Trong các câu truy vấn càng ít điều kiện lọc càng tốt. Chẳng hạn như bạn check thông tin đăng nhập, thông thường bạn thiết lập 2 điều kiện là tên đăng nhập và mật khẩu. Nhưng có cách khác hay hơn đó là bạn chỉ lọc với điều kiện tên đăng nhập thôi, sau đó bạn lấy kết quả và so sánh với mật khẩu để đưa ra kết quả thành công hay thất bại.
Hiểu được sự logic của các toán tử và dữ liệu thực tế để đưa ra vị trí các biểu thức trong các điều kiện AND và OR. Ví dụ trong bảng tin tức bạn có status và is_featured. Trong đó status = 1 thì hiển thị và status = 0 thì ẩn. Còn is_featured = 1 thì là tin đặc đặc trưng và is_featured = 0 là không phải. bây giờ tôi muốn lấy danh sách các tin đặc trưng thì đương nhiên ta sẽ dùng 2 điều kiện đó là where status = 1 AND is_featured = 1. Nhưng giả sử ta đặc ngược lại where is_featured = 1 AND status = 1 thì câu truy vấn sẽ nhanh hơn. Tại vì đối với toán tử AND thì nếu biểu thức đầu tiên sai thì nó không cần kiểm tra biểu thức thứ 2, trong database thì is_featured chiếm số lượng ít nên ta có thể áp dụng được.
Có thể trùng lặp dữ liệu, ở trường các bạn được dạy là càng ít trùng lặp càng tốt, nhưng khi đi làm thực tế thì việc tốn dung lượng lưu trữ ko quan trọng nữa mà chỉ đòi hỏi tốc độ.
Áp dụng quy tắc “cần gì thì lấy nấy”, tức là cần field nào thì ta select field đó chứ ko nên sử dụng select *
Có thể áp dụng kỹ thuật Partition trong Mysql để phân khối ra. Vấn đề này tôi chỉ nêu ra chứ ko bàn luận về nó.
7. Sử dụng cache cho website
Kỹ thuật cache quyết định tốc độ của một website thực thụ. Hiện nay có rất nhiều kỹ thuật cache như cache file, xml, memcache, redis cache.
Kết luận
Những vấn đề trên mình chỉ đưa ra thảo luận nên nếu có gì sai sót các bạn góp ý giúp mình để mình có thể hoàn thiện bài này hơn nhé. Hy vọng anh em sẽ tạo được những website ưng ý hơn
Học cách viết một helper function để kiểm tra element nằm trong viewport
“Nằm trong viewport” nghĩa là nó đang hiển thị bên trong phần nhìn thấy được của trình duyệt, function này cần thiết khi chúng ta cần tới lazy loading, hiệu ứng này kia.
Phần quan trọng nhất của function này là dùng Element.getBoundingClientRect(), nó cho chúng ta giá trị position của element so với viewport. Nó trả về một object chứa height, width, khoảng cách đến top, right, bottom, left với viewport
// chọn element
var h1 = document.querySelector('h1');
// lấy position của element trên
var bounding = h1.getBoundingClientRect();
console.log(bounding)
// {
// height: 118,
// width: 591.359375,
// top: 137,
// bottom: 255,
// left: 40.3125,
// right: 631.671875
// }
Nếu một element nằm trong viewport được xác định như sau
top, left >= 0
right <= độ rộng của viewport
bottom <= độ cao của viewport
Để check độ rộng của viewport, chúng ta có 2 cách, một số trình duyệt hỗ trợ window.innerWidth, một số khác hỗ trợ document.documentElement.clientWidth, số còn lại thì support cả 2. Rắc rối nhở!
Hãy học sử dụng reduce, vượt qua những ví vụ căn bản bằng cộng, trừ, nhân, chia
Khi đọc tài liệu trên MDN về Array.prototype.reduce() chúng ta sẽ có cái nhìn khá tổng quát về .reduce(), những ví dụ cộng, nhân số cơ bản để chúng ta dễ nắm cách hàm .reduce() chạy. Tuy nhiên vì nó quá căn bản, nên bạn sẽ không thể thấy hết được sự lợi hại của .reduce()
function add(a, b) {
return a + b;
}
function multiply(a, b) {
return a * b;
}
const sampleArray = [1, 2, 3, 4];
const sum = sampleArray.reduce(add, 0);
console.log('Tổng:', sum);
// ⦘ Tổng: 10
const product = sampleArray.reduce(multiply, 1);
console.log('Nhân lại bằng:', product);
// ⦘ Nhân lại bằng: 24
Có thể nhiều người không để ý, biến tích lũy (accumulator = tham số đầu tiên) và giá trị hiện tại (tham số thứ 2) không nhất thiết phải giống nhau.
Chúng ta có thể khai báo một hàm reducer như sau là hoàn toàn hợp lệ
Với bài viết này chúng ta cũng xem xét những ứng dụng khác, cao cấp hơn của .reduce(), sử dụng việc thay đổi kiểu của biến tích lũy như ví dụ trên, mở ra nhiều ứng dụng bảo đảm là hay
Bình thường khi nghĩ tới .reduce() chúng ta nghĩ tới viết lấy một mảng sau đó đưa nó về 1 giá trị bằng biến tích lũy, giá trị này hoàn toàn có thể là một array khác.
Vấn đề duy nhất của cách thứ 2 này là performance không tốt.
Kết hợp map và filter cùng lúc
Lấy lại ví dụ với mảng peopleArr ở trên, chúng ta lấy người vừa đăng nhập sau cùng, không tính các user không có email. Cách thứ nhất để làm là tách ra làm 3 bước
Lọc hết các user không có email
Lấy giá trị lastSeen
Tìm giá trị lớn nhất
function notEmptyEmail(x) {
return (x.email !== null) && (x.email !== undefined);
}
function getLastSeen(x) {
return x.lastSeen;
}
function greater(a, b) {
return (a > b) ? a : b;
}
const peopleWithEmail = peopleArr.filter(notEmptyEmail);
const lastSeenDates = peopleWithEmail.map(getLastSeen);
const mostRecent = lastSeenDates.reduce(greater, '');
Một cách khác để làm với reduce
function notEmptyEmail(x) {
return (x.email !== null) && (x.email !== undefined);
}
function greater(a, b) {
return (a > b) ? a : b;
}
function notEmptyMostRecent(currentRecent, person) {
return (notEmptyEmail(person)) ? greater(currentRecent, person.lastSeen) : currentRecent;
}
const mostRecent = peopleArr.reduce(notEmptyMostRecent, '');
Chạy các phương thức async theo hàng đợi
Rất hữu ích khi cần giới hạn số lượng request API, hoặc lấy kết quả của một Promise truyền cho thằng kế tiếp. Ví dụ lấy message cho tất cả user trong mảng peopleArr
function fetchMessages(username) {
return fetch(`https://example.com/api/messages/${username}`).then(response => response.json());
}
function getUsername(person) {
return person.username;
}
async function chainedFetchMessages(p, username) {
// p là một promise
const obj = await p;
const data = await fetchMessages(username);
return { ...obj, [username]: data };
}
const msgObj = peopleArr
.map(getUsername)
.reduce(chainedFetchMessages, Promise.resolve({}))
.then(console.log)
Fluent Design sẽ là ngôn ngữ thiết kế được Microsoft áp dụng rộng rãi trong tương lai, những thay đổi đã dần xuất hiện trên Windows và hãng muốn mở rộng ngôn ngữ này trên nhiều nền tảng khác như iOS, Android cũng như thiết kế web.
Fluent Design sẽ là ngôn ngữ thiết kế được Microsoft áp dụng rộng rãi trong tương lai
Tham vọng của Microsoft về Fluent Design
Microsoft cho ra mắt hẳn một trang web để nói về Fluent Design – link. Khi nói về ngôn ngữ thiết kế này, Microsoft đang tham vọng đưa ngôn ngữ Fluent Design đến với mọi sản phẩm và dịch vụ của hãng, từ các ứng dụng trên Windows đến các ứng dụng điện toán đám mây. Không những vậy, tham vọng của Microsoft còn muốn vươn ra ngoài hệ sinh thái của mình, lan tỏa ra các nền tảng di động như Android và IOS, website.
Fluent Design – Ngôn ngữ thiết kế mới của Microsoft trên các nền tảng
Video giới thiệu Fluent Design từ Microsoft
Từ khi Windows 8 ra đời và sau đó là Windows 10 thì Flat Design với phong cách tối giản, phẳng hóa mọi thứ là ngôn ngữ thiết kế chính của các sản phẩm hệ sinh thái Microsoft. Nhưng hiện nay, sự phát triển của các thiết bị ngoại vi như kính thực tế ảo, cũng như sự nhàm chán dần dần của người dùng với thiết kế phẳng đặt ra yêu cầu về một ngôn ngữ thiết kế đổi mới. Câu trả lời của Microsoft chính là Fluent Design.
Fluent Design được áp dụng dần trên các ứng dụng Windows
Có thể nói, Fluent Design chính là sự kế thừa những điểm tốt của Material Design – Google, phát triển thêm những tối ưu cho thực tế ảo và trải nghiệm người dùng mới. Vì sao mình lại nói như vậy, chúng ta hãy đi qua một số nguyên lý cơ bản của Fluent Design nhé.
Những yếu tố chính tạo nên Fluent Design
1. Light
Ánh sáng (Light) là công cụ quan trọng để thu hút sự chú ý của người dùng. Một nút bấm phát sáng có thể hướng dẫn người dùng cách sử dụng một ứng dụng, hoặc nhấn mạnh một tính năng của chương trình mà có thể họ chưa từng để ý đến nó.
2. Depth
Chiều sâu (Depth) Hai thứ Light và Depth giúp app đẹp hơn, mượt mà hơn, cảm giác thân thiệt hơn. Cũng như cách mà Material Design đem tới cho người dùng. Ngôn ngữ thiết kế Metro phẳng, ngắn ngủi, Microsoft hầu như chỉ dựa vào các khung hình vuông vức buồn tẻ, để cung cấp cho người dùng thông tin và công cụ. Còn với Fluent Design, Microsoft đang thử thách các nhà phát triển khi loại bỏ mô hình này và thay thế nó bằng cách đưa thông tin và các đối tượng thoát khỏi khung hình 2D truyền thống.
Những yếu tố chính tạo nên Fluent Design: Ánh sáng, Chiều sâu, Chuyển động, Vật thể, Mở rộng
3. Motion
Chuyển động (Motion) – Một giao diện hình ảnh động đẹp có thể là một yếu tố hấp dẫn, nhưng các hiệu ứng Chuyển động mới là thứ giúp thu hút sự chú ý của người dùng, bằng cách cho họ thứ gì đó hoạt động để nhìn vào và tương tác với nó. Belfiore so sánh việc sử dụng chuyển động trong Fluent Design giống như việc một đạo diễn sử dụng các cử động để dẫn dắt người dùng vào câu chuyện mà họ muốn kể.
4. Material
Chất liệu (Material) – Giống như các ý tưởng cốt lõi của Fluent Design, Chất liệu dường như là một sự thay đổi đột phá cho phong cách đồ họa của Windows trong quá khứ. Các hình vuông chức năng trong giao diện truyền thống của Microsoft có thể vẫn hoạt động được, nhưng nó thiếu tính kết nối với thế giới thực. Belfiore gợi ý rằng điều quan trọng làm người dùng yêu thích thiết kế ứng dụng của Windows là nó có thể mô phỏng cảm giác “nhạy cảm và đầy sinh lực” của những chất liệu làm nên thế giới thực.
Material trong Fluent Design
Đọc tới đây, chúng ta có đã có cảm giác rất giống những gì Material Design đang làm. Nhưng khi nhìn vào concept Fluent Design bên trên, chúng ta có thể thấy sự khác biệt, Material Design tập trung vào nội dung, làm nổi khối nội dung chính trên nền phẳng, thu hút người dùng. Fluent Design không chỉ làm nổi khối nội dung mà toàn bộ giao diện đều được làm dạng vật thể, và làm hiệu ứng ánh sáng cho cả nền giao diện.
5. Scale
Khả năng mở rộng – thu hẹp (Scale) – Kích thước tương đối của các vật thể kỹ thuật số là điều mà các nhà phát triển VR đã nỗ lực làm việc trong vài năm nay – một vật thể có kích thước đúng trên màn hình nhưng có thể cực lớn hoặc cực nhỏ khi nhìn qua kính VR hoặc AR. Vì vậy, tạo ra một kích thước đúng cho các đối tượng ảo là điều tối quan trọng để có được một giao diện người dùng thứ nhất tốt.
Một trong những nhược điểm của Windows 10 so với MacOS mà người dùng thường nhắc tới là khả năng hỗ trợ độ phân giải cao. Màn hình 4K khi dùng Win 10 các icon, chữ rất nhỏ, khi scale lên lại bị mờ.
Hiện tại Fluent Design đã được triển khai trên một số ứng dụng Windows như bộ icon Office 365, ứng dụng Notepads mới. Bạn có thể tải và trải nghiệm Notepads trên Microsoft Store nhé.
Component như trên (<ListPage />), khi nhận một data mới, tất cả component con bên trong là Header và List sẽ re-render, mặc dù cái title không hề thay đổi. Nếu Header không tốn quá nhiều thời gian để render thì ko có vấn đề. Ngược lại dĩ nhiên là nếu render Header tốn rất nhiều thời gian, chúng ta phải xây lại để tối ưu hơn.
React.memo là một HOC, đọc lại bài này, nó sẽ nhớ kết quả render của component. Nếu component trả về một output giống hệt cho cùng một prop, đưa nó vào React.memo sẽ tiết kiệm tí thời gian.
Cũng tương tự nó sẽ nhớ kết quả trả về, tuy nhiên nó sẽ có thêm phần gọi là array dependencies, là một danh sách các thằng mà nó phụ thuộc, nếu giá trị phụ thuộc thay đổi nó mới rọi render lại, không thể trả thẳng kết quả lần trước
Trong ví dụ trên, 1 component nhận một danh sách các widget, các widget này trước khi truyền vào sẽ được thêm vào 2 giá trị là total price và delivery date. Nếu giá trị các widget không thay đổi khi render lại component, thì không cần thiết phải chạy qua các hàm someComplexFunction, someOtherComplexFunction. Sử dụng useMemo để ghi nhớ kết quả và bỏ qua trong trường hợp đó.
1 component như vậy sẽ re-render cả cha và con cùng lúc, thậm chí component con có là PureComponent được wrap bên trong React.memo đi nữa, bởi vì onClick sẽ khác nhau trên mỗi lần render. Sử dụng useCallback chúng ta viết lại như sau
Khi định hướng phát triển nguồn nhân lực ngày càng được cụ thể hóa, các chuyên gia nhân sự cần có cái nhìn nghiêm túc về nguồn nhân lực (tức con người nhân sự) của họ. Cho dù xã hội đang từng bước thay đổi, những sản phẩm của công nghệ ra đời để thay thế cho con người nhưng có một quy luật không bao giờ thay đổi được, đó là con người vẫn là trung tâm của mọi yếu tố.
Với lý do đó, ta nhận thấy việc tập trung vào khai thác, phân tích con người, tận dụng nguồn dữ liệu của con người để hình thành nên những chiến lược quan trọng về nhân sự từ thu hút ứng viên, giữ chân và đồng hành cùng tài năng nhân sự.
Tại sao phân tích con người là chiến lược quan trọng?
Theo báo cáo về Xu hướng vốn nguồn nhân lực của Deloitte, có đến 71% các công ty xem việc phân tích yếu tố con người là ưu tiên hàng đầu, đồng thời đánh giá cao những dữ liệu mà yếu tố này mang lại. Ngược lại, chỉ vỏn vẹn 9% trong số họ tin rằng họ thật sự hiểu rõ về khía cạnh phát triển tài năng nhân sự có thể tạo ra sự thúc đẩy hiệu suất làm việc trong công ty họ.
Jaclyn Lee, Giám đốc Nhân sự trường Đại học Công nghệ và Thiết kế chia sẻ:
Các tổ chức hiện nay nhận ra rằng đang tồn tại một thực tiễn quan trọng. Đó là việc quản trị nhân sự cần một cách tiếp cận tốt hơn. Và giải pháp hữu hiệu chính là nguồn dữ liệu từ việc phân tích và phát triển con người.
Cách tiếp cận này sẽ làm giảm thiểu sự thiên vị và chủ quan của con người vì đã nắm bắt được nguồn dữ liệu này thông qua phân tích. Và khi một người làm nhân sự có thể tạo ra sự ảnh hưởng thông qua những phân tích (tức vận dụng những dữ liệu thông minh từ phân tích con người), họ sẽ đủ tự tin để đảm nhận vai trò xây dựng và phát triển chiến lược nhân sự; tạo ra lợi thế cạnh tranh lớn.
Các khía cạnh để xây dựng chiến lược phân tích con người nhân sự và những case study thực tế
Thu hút nhân tài và phát hiện những tồn đọng
Việc phân tích con người tạo ra những dữ liệu thực có giá trị. Các chuyên gia nhân sự có thể dựa trên nguồn dữ liệu này (là những đặc tính, sự phù hợp về các yếu tố kỹ năng, phẩm chất; mức độ đồng hành lâu dài,…) để tạo ra các giải pháp nhân sự thích hợp nhằm thu hút các ứng viên tiềm năng.
Ví dụ, LinkedIn cung cấp cho các chuyên gia nhân sự một nền tảng truyền thông xã hội, trên đó là những mô tả cụ thể, chi tiết về nguồn nhân lực mà họ mong muốn. Lúc này, chính nguồn tài nguyên mà các nhà tuyển dụng, quản trị nhân sự có được từ việc phân tích yếu tố con người sẽ hợp thức hóa để lựa chọn nguồn nhân lực phù hợp. tiêu đề tuyển dụng
Một minh chứng khác chính là việc thay đổi chiến lược nhân sự của ISS để tạo ra sự khác biệt lớn. ISS có hơn 500.000 nhân viên trên toàn cầu thế nhưng có các công ty cơ sở của họ đang phát sinh nhiều vấn đề lớn. Và để giải quyết mọi vấn đề, các nhà lãnh đạo nhân sự đã tiến hành phân tích yếu tố con người, cụ thể như sau:
1. Phân tích sức mạnh liên kết giữa sự gắn kết của các nhân viên, sự hài lòng của khách hàng thông qua sự chuyển biến về cả hai mặt tích cực/tiêu cực trong lợi nhuận.
2. Phân tích dữ liệu để xác định các quy trình nhân sự có tác động lớn nhất trong việc cải thiện sự gắn kết và trải nghiệm của ứng viên; tập trung vào việc phát triển động lực, chất lượng phục vụ nhân sự, định hướng đào tạo đối với các nhân viên.
Từ những phân tích trên, các nhà quản trị nhân sự đã tìm thấy mối liên hệ chặt chẽ giữa ứng viên, nhân viên với các vấn đề phát sinh không mong muốn. Có thể thấy, việc phân tích về nguồn lực con người có thể giúp nhận ra những tồn đọng trong công tác nhân sự đồng thời đề ra những phương án giúp khắc phục tình trạng đó.
Giữ chân nhân viên
Một trong những vấn đề lớn được giải quyết triệt để thông qua việc phân tích con người chính là sự lãng phí lao động.
Một dẫn chứng từ IBM có thể giúp chúng ta có cái nhìn sâu sắc hơn. Công ty này đã áp dụng một chương trình mang tên “Chủ động duy trì”. Và họ đã thừa nhận rằng nhờ vào việc phân tích yếu tố con người, họ có thể dự đoán được nhân viên nào có khả năng sẽ rời đi. Đó là cơ sở để họ tự nhìn nhận, đánh giá lại cả quá trình phát triển nhân sự và xác định kế hoạch tốt nhất để giữ chân nhân viên của mình.
Nielsen cũng nhờ vào việc phân tích yếu tố con người để tìm ra hàng loạt mong muốn của nhân viên mình đối với tổ chức/doanh nghiệp. Nielsen cho phép nhân viên tự bày tỏ những phản hồi của bản thân về mọi khía cạnh của công ty đồng thời trao quyền cho nhân viên có thể tự quyết định về việc ra đi hay ở lại tiếp tục đồng hành cùng công ty của mình. Sau khi thực hiện những cách thức, Nielsen đã có những kê cụ thể cho thấy mức độ hài lòng của nhân viên đã có sự cải thiện lên đến 70% và hầu như chưa có trường hợp nào phải thay đổi môi trường làm việc nhân sự.
Đo lường và quản lý hiệu suất làm việc
Đây được đánh giá là lợi ích thiết thực nhất từ việc phân tích con người. Các nhà tuyển dụng nhân sự có thể nắm bắt được xu hướng chung của nhân viên mình từ đó, khuyến khích các vấn đề về năng suất làm việc ở cấp độ nhóm và cá nhân. Hiệu suất làm việc càng cao cho thấy con người và vấn đề phát triển nguồn nhân lực càng quan trọng.
Minh họa thực tế từ công ty công nghệ Cisco. Công ty đã thực hiện các cuộc khảo sát về sự tham gia của nhân viên hàng năm và số lượng phản hồi cho nghiên cứu này là hơn 73.000 nhân viên. Điều này đồng nghĩa phải mất rất nhiều thời gian để phân tích tất cả dữ liệu đó, chia sẻ nó và đề ra những giải kế hoạch hành động tương ứng.
Thông qua việc phân tích con người, HR đo lường được hiệu suất của nhóm và mức độ tương tác của nhà lãnh đạo với các nhóm của họ. Đánh giá phân tích này cho thấy tình trạng hoạt động hiện tại của từng nhóm thậm chí từng cá nhân. Vì vậy, nhà quản trị nhân sự có thể dễ dàng quan sát, theo dõi các chỉ số hiệu suất, làm cơ sở cho việc thiết lập các lộ trình cải thiện hiệu suất sau này.
Lời kết
Phân tích con người (hay quản trị và phát triển nguồn nhân lực) không phải là một giải pháp thay thế cho chiến lược hoặc tư duy mới trong lĩnh vực nhân sự. Mà thật sự nó đủ tư cách là một chiến lược quan trọng, một công cụ chuyên dụng của HR cho phép tối ưu hóa nguồn dữ liệu nhằm cải thiện và phát triển tổ chức/doanh nghiệp ở mọi cấp độ từ thu nhận tài năng đến hiệu suất.
Tuy nhiên, đây là một công cụ khác trong hộp công cụ của HR chuyên nghiệp. Với các phép đo phù hợp, các công ty có thể sử dụng dữ liệu để cải thiện và phát triển doanh nghiệp ở mọi cấp độ từ thu nhận nhân tài đến quản trị hiệu suất làm việc.
Đây là một bài viết tương đối dài dòng về useEffect, bạn cần biết và đã đọc qua tài liệu về useEffect trên trang chính thức của React trước, và nếu chỉ thực sự cần biết sử dụng useEffect ra sao, bạn không cần đọc bài viết phân tách mổ xẻ sâu kiểu này.
Mỗi lần render là một giá trị Prop và State độc lập
Trước khi bắt đầu nói về useEffect chúng ta cần nhắc lại quá trình render
Khác với Vue, nó không phải là một dạng data binding, watcher, proxy, nó chỉ là một giá trị thông thường.
const count = 42;
<p> {count} </p>;
Đầu tiên giá trị khởi tạo của count sẽ =0. Khi chúng ta gọi setCount(1), React sẽ gọi lại component một lần nữa, với giá trị count lúc này là 1. Cứ vậy
// Lần đầu render
function Counter() {
const count = 0; // trả về bởi useState() // ...
<p>You clicked {count} times</p>;
// ...
}
// sau khi click, function này được gọi lại lần nữa
function Counter() {
const count = 1; // trả về bởi `useState() // ...
<p>You clicked {count} times</p>;
// ...
}
// sau khi click, function được gọi lại lần nữa
function Counter() {
const count = 2; // trả về bởi useState() // ...
<p>You clicked {count} times</p>;
// ...
}
Khi update một state, React gọi lại component, mỗi lần render như vậy, nó sẽ thấy một giá trị count mới. Sau đó React sẽ update lại DOM tương ứng.
Vấn đề mấu chốt cần nắm là giá trị counttrong các lần render khác nhau là khác nhau.
Bấm tiếp Click me cho counter lên 5 trước khi bị gọi timeout
Câu hỏi ở đây là nó sẽ alert ra 5 – giá trị cuối cùng, hay là 3 giá trị lúc chúng ta click
Chạy thử
Bạn có thấy kết quả quá vô lý?
Như đã nói ở trên, giá trị count là hằng số trên mỗi lần render. Function của chúng ta được gọi nhiều lần, mỗi lần gọi như vậy giá trị count bên trong là một số độc lập hoàn toàn với giá trị trước đó
Không phải đặc sản của React, viết dạng function như thế này bạn sẽ dễ hình dung hơn.
Câu hỏi là useEffect đã làm cách nào để lấy được giá trị cuối cùng của count?
Lẽ nào đó có một dạng “data binding” hay “watching” ở đây để update giá trị count bên trong hàm effect? Hoặc giả React chơi chiêu dùng biến mutable bên trong component để luôn có được giá trị cuối?
Không hề!
Chúng ta đã biết: giá trị count là hằng số cho các lần render, event handle cũng độc lập trên các lần render khác nhau, effect cũng vậy luôn.
Không phải giá trị count thay đổi bên trong useEffectbất biến, mà là useEffect cũng bị thay đổi trên từng lần render.
// lần render đầu tiên
function Counter() {
// ...
useEffect(() => {
document.title = `You clicked ${0} times`;
});
// ...
}
// sau khi click
function Counter() {
// ...
useEffect(() => {
document.title = `You clicked ${1} times`;
});
// ...
}
// click thêm lần nữa
function Counter() {
// ...
useEffect(() => {
document.title = `You clicked ${2} times`;
});
// ..
}
Có thể mường tượng effect là một phần của kết quả lúc render
function Greeting({ name }) {
return <h1 className="Greeting">Hello, {name}</h1>;
}
Nếu chúng ta render <Greeting name="Dan" />, sau đó render <Greeting name="Luu" />. Cuối cùng chúng ta luôn nhận được Hello, Luu
React luôn đồng bộ cục DOM với giá trị hiện tại của prop và state. Không cần phân biệt giữa mount và update khi render. Có thể hình dung effect cũng tương tự như vậy, useEffect cho phép đồng bộ những phần không nằm trong React tree với giá trị của prop và state
function Greeting({ name }) {
useEffect(() => {
document.title = "Hello, " + name;
});
return <h1 className="Greeting">Hello, {name}</h1>;
}
Câu thần chú cho việc này là: Quan trọng là đích đến, không phải quá trình
Chạy effect trên tất cả lúc chạy render sẽ không hay lắm, đôi khi có trường hợp lặp vô tận.
Trong quá trình re-render, React chỉ cập nhập đúng phần DOM đã thay đổi.
Dịch ra ngôn ngữ con người là thế này: “Tao biết React mày không phân biệt được sự khác nhau bên trong function, nên tao hứa là tao chỉ dùng đến name bên trong function này thôi, và chỉ giá trị name này update thì mày hả gọi nó”
Một là không nói dối, 2 là không nói dối nhiều lần
Đừng bao giờ lừa gạt React bằng cách đưa dependency không đúng cho nó, hậu quả nhãn tiền. Hợp lý, nhưng nhiều lập trình viên quen sử dụng class sẽ cố tình qua mặt
function SearchResults() {
async function fetchData() {
// ...
}
useEffect(() => {
fetchData();
}, []);
// việc ntn được hôn? không phải lúc nào cũng đúng
// có cách viết tốt hơn
}
Bạn sẽ nghĩ là “Tao chỉ muốn chạy nó lúc mount thôi”. Nếu chúng ta chỉ định một dependency, tất cả giá trị bên trong component sử dụng bởi effect phải được khai báo cụ thể. Bao gồm prop, state, function
Đôi khi mà làm như vậy nó phát sinh lỗi. Thí dụ như gọi fetch data liên tục hoặc socket được tạo không cần thiết. Cách giải quyets là không xóa chúng khỏi dependency
Trước khi nói về cách giải quyết, chúng ta xem vấn đề ở đây là gì khi so sánh Dependency
Hậu quả của việc dối trá
Nếu mảng dependency chứa tất cả giá trị sử dụng trong useEffect, React biết được khi nào thì re-run nó
useEffect(() => {
document.title = "Hello, " + name;
}, []); // Sai: không được phép bỏ qua thằng name
Rõ ràng là 2 thằng dependency không khác nhau, nên nó sẽ không chạy effect
Trong tình huống này, vấn đề khá là hiển nhiên, nhưng trực giác có thể đánh lừa bạn trong các tình huống khác, lấy ví dụ, chúng ta muốn giá trị counter tăng đều sau mỗi giây. Với một class, trực giác sẽ mách bảo: “Set up cái interval một lần, rồi dứt tình vứt áo một lần”, kiểu như thế này, khi chuyển qua dùng useEffect bạn sẽ nghĩ đến dùng [] cho mảng phụ thuộc “Tao chỉ muốn tình một đêm”, đúng không?
Theo như lập luận rất hay gặp “danh sách phụ thuộc cho phép chúng ta chỉ định việc re-render effect khi nào”, và ở đây ta chỉ muốn trigger nó một lần vì nó là interval, nhưng tại sao lại có vấn đề ở đây?
Chúng ta đang muốn effect này chỉ chạy lần đầu tiên mà thôi, đưa vào dependencies là [] có vẻ hợp lý, React sẽ bỏ qua hết những lần sau, nhưng chúng ta đang lừa dối React, vì bên trong chúng ta có sử dụng giá trị count, chúng ta có giá trị phụ thuộc mà không khai báo. Thực tế setCount() sẽ gọi liên tục sau 1 giây, chứ không dừng lại sau lần gọi đầu tiên.
Ở lần render đầu tiên, count = 0, vì thế setCount(count + 1) ở lần render đầu tiên nghĩa là setCount(0+1), nhưng vì không re-run effect thêm lần nào nữa, chúng ta cứ gọi mãi setCount(0+1) ở những lần tiếp theo
// state = 0
function Counter() {
// ...
useEffect(
// lần đầu
() => {
const id = setInterval(() => {
setCount(0 + 1); // luôn là setCount(1) }, 1000);
return () => clearInterval(id);
},
[] // không re-run );
// ...
}
// state = 1
function Counter() {
// ...
useEffect(
// không bao giờ chạy () => {
const id = setInterval(() => {
setCount(1 + 1);
}, 1000);
return () => clearInterval(id);
},
[]
);
// ...
}
Những con bug như thế này sẽ rất rất khó để mò ra được, vì thế hãy luôn thành thật với React, khai báo hết dependency đang có.
2 cách để thú thật với React về dependency
Nên chọn cách một, cách 2 chỉ áp dụng khi cần thiết
Cách 1: luôn là người trung thực, chính trực đạo đức hết mực, luôn khai báo đầy đủ thông tin bạn trai, bạn gái, ba má, chú bác nào bạn đang phụ thuộc cho cơ quan thuế
Tuy nhiên thế này, khi giá trị count thay đổi, cái interval của chúng ta sẽ bị xóa và đặt lại lần nữa sau những lần render, nó không phải là cái chúng ta mong muốn nó hoạt động như vậy
Cách 2 là thay đổi tư duy, giảm bớt anh trai nuôi, em gái nuôi không cần thiết
Chúng ta không nói xạo, chúng ta giảm bớt số lượng những thứ phụ thuộc cho việc re-run effect
Để làm được việc này, chúng ta phải hỏi bản thân: chúng ta dùng count để làm gì? Có vẻ như chúng ta chỉ dùng nó cho việc gọi hàm setCount, chúng ta không thực sự cần giá trị count nếu chúng ta biết được giá trị trước đó, trường hợp trên, chúng ta có thể không cần dùng đến giá trị count mà dùng previous state
Khi nói về effect, định hướng lập trình chúng ta là đồng bộ hóa, có một khái niệm khá thú vị khi thực hiện đồng bộ hóa là chúng ta thường không đồng bộ toàn bộ nội dung. Lấy ví dụ như Google Docs, nó không thực sự truyền tải cả trang lên phía server, làm như vậy hiệu năng sẽ rất tệ, cái nó làm là gửi đi một thông tin chứa cái mà user đang muốn thực hiện.
Tốt nhất truyền đi thật ít thông tin từ effect (chỉ những thông tin cần thiết nhất) vào trong component. Hàm setCount(c => c + 1) sẽ gửi đi ít thông tin hơn so với hàm setCount(count + 1) đứng trên một khía cạnh nào đó vì nó không phụ thuộc giá trị hiện tại, sử dụng ít state nhất có thể để đạt được kết quả là một trong các nguyên lý chính của đợt cập nhập React với effect
Tuy nhiên không phải lúc nào cuộc sống cũng đơn giản với bạn như vậy, nếu chúng ta muốn tính toán giá trị của state mới dựa trên một prop, 2 giá trị state phụ thuộc lẫn nhau, setState là không đủ. Chúng ta có người chị em hàng xóm tên useReducer
function Counter({ step }) {
const [count, dispatch] = useReducer(reducer, 0);
function reducer(state, action) {
if (action.type === "tick") {
return state + step;
} else {
throw new Error();
}
}
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: "tick" });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
return <h1>{count}</h1>;
}
Cách dùng useReducer như vậy là một dạng cheat mode của hook, cho phép chúng ta bỏ qua các dependency ngầm khỏi effect, và chặn re-run không không cần thiết
Trước khi qua Singapore làm việc, mình đã có 1 khoảng thời gian khá dài là 1 freelancer chuyên nhận những dự án phần mềm trực tiếp từ khách hàng và ngoài ra mình cũng làm đầu mối đưa cho bạn bè thực hiện nhiều dự án khác nhau. Nhờ đó mình tích lũy được 1 số kinh nghiệm cũng như rút ra được những kỹ năng cần có để trở thành 1 freelancer tốt.
Kỹ năng chuyên môn
Mình nghĩ đây là yếu tố tiên quyết để bạn có thể nhận dự án. Mình thường thấy các bạn freelancer thường bắt đầu làm ở 1 cty rồi mới tách ra làm riêng khi đã tích lũy đủ kiến thức, kinh nghiệm. Cũng có bạn có khả năng kết nối công việc cho những freelancer khác thì có thể không cần chuyên môn nhưng bài viết này mình sẽ tập trung cho bạn nào làm trực tiếp với khách hàng nhé.
Kỹ năng “deal” cho dự án
1. Làm thế nào để ước tính giá trị cho 1 dự án freelancer?
Nhiều bạn mới bắt đầu làm 1 dự án riêng thường phân vân không biết định giá thế nào hay hỏi mình câu này lắm. Đa số những dự án mình đã thực hiện được ước tính dựa trên “hour rate”, nghĩa là giá tiền/giờ. Sau đó mình sẽ ước lượng tổng số giờ thực hiện xong dự án và cộng thêm khoảng 15% dành cho việc phản hồi, chỉnh sửa từ khách hàng.
Ví dụ hour rate trước đây của mình là 20USD/giờ, giả sử dự án mình ước tính phải thực hiện trong 50 giờ thì tổng chi phí của mình được tính ra như sau:
Tổng chi phí = 20 * (50 + 50 * 0.15) = 1150 USD
Ngoài ra, bạn sẽ phải gặp 1 số dạng dự án mà khách hàng đưa ra mức tiền tối đa thì lúc đó phải tính theo phương pháp khác. Đó là tính ngược lại để ra tổng số giờ, dựa trên số giờ đó để tính ra số lượng giờ thực hiện cho các chức năng, dùng thư viện, framework có sẵn hay không để giảm bớt công sức bạn phải bỏ ra.
2. Làm thế nào để ước tính thời gian cho 1 dự án freelancer?
Cái này phải dựa trên kinh nghiệm thực chiến, càng làm nhiều thì bạn sẽ dễ dàng đánh giá được từng chức năng tốn thời gian bao nhiêu, có rủi ro gì không,… hoặc nếu bạn quen ai đó có kinh nghiệm thì có thể trao đổi thử rồi đưa ra ước lượng. Kinh nghiệm của mình là bạn có thể tăng 1 số giờ cho các chức năng bạn đã xác định được lên 1 chút để có thể bù lại cho chức năng bạn vẫn chưa chắc chắn thì sẽ giảm rủi ro hơn.
3. Chốt deal với khách những chức năng cần có
Đây là 1 thao tác CỰC KỲ QUAN TRỌNG nếu như bạn không muốn ôm hận về sau. Trước khi chốt hạ với khách, bạn cần lên được 1 danh sách những chức năng sẽ làm, tốt nhất là 1 bảng báo giá cụ thể để khách xem rồi sau đó yêu cầu họ làm 1 bảng hợp đồng thỏa thuận 2 bên rõ ràng để nếu họ có yêu cầu thêm những chức năng không nằm trong đó cũng có cái để làm bằng chứng. Hầu như dự án nào cũng sẽ có phần phát sinh, bạn cũng nên cân nhắc nếu phần đó không tốn quá nhiều thời gian thì cũng nên hỗ trợ miễn phí để họ vui và biết đâu dự án tới họ sẽ tìm đến bạn.
Mình nhắc lại là PHẢI CÓ HỢP ĐỒNG, đặc biệt là lần đầu tiên làm việc với họ bởi giấy trắng mực đen là cái đem ra trao đổi dễ nhất và ngay cả khách hàng của bạn cũng sẽ cần cái đó để đảm bảo bạn có thực hiện theo cam kết hay không. Mình có 1 khách hàng làm khá nhiều dự án, đến lần thứ 4, thứ 5 mình bỏ qua bước làm hợp đồng này và cuối cùng phải chịu thiệt làm thêm 1 số cái cũng như thời gian chuyển khoản bị delay.
4. Deal với những thứ phát sinh bằng đàm phán
Mình chắc chắn dự án kiểu này luôn có phần phát sinh và bạn phải là người linh hoạt xử lý sao cho mềm mại, thuyết phục khách hàng bằng lý lẽ vì chất lượng của dự án để không làm họ khó chịu. Nhiều bạn gặp phần này thường rất khó xử, hoặc đôi khi mất bình tỉnh nhưng nên giữ cái đầu lạnh, nếu cần thiết thì lấy bản hợp đồng ra nói chuyện nhé. Có 1 số cái trao đổi miệng thì sau buổi họp bạn cần gửi 1 tin nhắn hoặc 1 email để chốt lại để có bằng chứng nhé.
Kỹ năng sắp xếp độ ưu tiên
Mình nghĩ phần này quan trọng hơn cả sắp xếp thời gian, bởi khi làm việc với khách hàng, bạn phải biết họ cần xem gì theo từng giai đoạn. Cách đây mình giao 1 dự án cho đứa em làm và bị khách phàn nàn vì sau cả tuần vẫn không thấy có gì thay đổi. Mình trao đổi với em nó thì mới biết em nó tập trung làm phần backend nhiều quá. Nên cố gắng tập trung cho khách hàng thấy sự thay đổi theo tiến độ, đừng để tư duy “tech” ảnh hưởng bởi có những khách hàng họ không cần quan tâm bên dưới thế nào đâu.
Kỹ năng giải quyết vấn đề
Do tính chất mỗi dự án mỗi khác, có nhiều vấn đề khác nhau nên đòi hỏi bạn phải có khả năng nghiên cứu, giải quyết vấn đề bằng “mọi thủ đoạn” để “get shit done”. Cần phải luôn dựa trên số thời gian đã xác định từ đầu để bạn đưa ra giải pháp hợp lý, tránh bị sa đà quá cỡ dẫn tới chịu thiệt thòi. Nhưng nếu bạn chủ động chịu thiệt thòi để học hỏi thì thoải mái nhé.
Kỹ năng giao tiếp
Phải có 1 kênh giao tiếp để giữ liên lạc thường xuyên với khách hàng để họ thấy bạn làm việc chuyên nghiệp. Có những bạn mình biết khi dự án bị trễ tiến độ hoặc có vấn đề thì thường tỏ ra sợ hãi hoặc có dấu hiệu “mất tích” không xem tin nhắn khách hàng. Đừng như vậy, lớn hết rồi, cứ thẳng thắn trao đổi với khách hàng vấn đề bạn đang gặp phải và đưa ra hướng giải quyết. Có nhiều bạn lấy lý do này nọ kiểu nhà em bị mất internet, điện thoại em hỏng, máy em hư các kiểu mà không có phương án tự giải quyết thì chỉ làm khách hàng cảm thấy khó chịu hơn thôi. Họ thuê bạn để giải quyết vấn đề cho họ chứ không phải họ giải quyết vấn đề của bạn.
Kỹ năng xây dựng thương hiệu cá nhân
Dù hiện giờ mình ở Singapore nhưng vẫn thường xuyên có bạn bè nhờ làm các dự án freelancer, ít nhất đã có 5 dự án mình đã giới thiệu lại cho mấy đứa em ở Việt Nam từ khi mình qua đây.
Và điều cuối cùng mình lưu ý đó chính là sức khỏe. Nên chia đều thời gian ra để làm, đừng để đến giai đoạn cuối mới bắt đầu bức tốc thì rất dễ cạn kiệt sức lực. Chúng ta kiếm tiền để tận hưởng cuộc sống chứ không phải kiếm tiền để mua thuốc trị bệnh. Nến hãy cố gắng cân bằng thời gian, ăn uống điều độ thì mới có đủ sức khỏe cày cuốc được nhiều dự án khác nữa nhé.
CV hay còn gọi là Curriculum Vitae, một bản sơ yếu lý lịch tóm tắt những thông tin cơ bản về mỗi ứng viên.
Theo một cuộc khảo sát về những người làm nghề nhân sự của Eric Hilden,những yếu tố được nhà tuyển tìm kiếm và đánh giá cao trong CV của ứng viên tương ứng như sau:
1. Kinh nghiệm trong những công viên liên quan: 45%
2. Kỹ năng và trình độ chuyên môn: 44%
3. Yếu tố thẩm mỹ: 25%
4. Thành tích cá nhân: 16%
5. Chính tả và ngữ pháp: 14%
6. Có mục tiêu nghề nghiệp và khao khát thành công: 11%
Với thời buổi công nghệ phát triển như hiện nay thì việc bạn tự thiết kế một CV đúng chuẩn là điều không quá khó khăn. Một bản CV ấn tượng là bước đầu tiên giúp bạn chứng tỏ năng lực để chinh phục các nhà tuyển dụng. Ngay sau đây, cùng tham khảo top 5 website giúp bạn tạo cho mình những CV thật hoàn hảo.
1. TopDev CV
Được đánh giá là một trong những chuyên trang trực tuyến miễn phí nổi bật, CV TopDev là giải pháp hiệu quả nhất giúp các ứng viên kết nối nguồn nhân lực với những tập đoàn lớn trong và ngoài nước.
Với giao diện tiện ích, TopDev cho phép bạn tự thiết kế những CV IT chuẩn Developer và đúng nội dung đồng thời phù hợp với sở thích, năng lực của mình.
Nếu bạn yêu thích những Curriculum Vitae theo phong cách chuyên nghiệp nước ngoài thì Resumedone là sự lựa chọn hoàn hảo. Website tập trung tạo những khung thiết kế nhằm đáp ứng nhu cầu tuyển dụng chất lượng cao. Resumedone cũng là nơi thích hợp để tìm kiếm các CV tiếng anh chất lượng nhất.
Đây được xem là một trong những công cụ trực tuyến tốt nhất nếu bạn muốn tạo ra một bản CV vừa chuyên nghiệp vừa ấn tượng. Tuy nhiên, điều chắc chắn là thời gian bạn đầu tư cho nó cũng sẽ tốn nhiều hơn so với các công cụ đơn giản khác.
3. EnhanCV
EnhanCV là công cụ tạo CV online với nhiều kiểu thiết kế đa dạng, độc đáo.
EnhanCV từng gây sốt trong giới tuyển dụng khi trở thành trang web được yêu thích nhất vì sự đánh giá tích cực từ các ứng viên. Tuy nhiên đối với trang web này, bạn có thể sẽ phải trả phí khi tải và tạo một CV song, vẫn có nhiều bản miễn phí để các bạn lựa chọn.
4. Resume
Resume được đánh giá là một trong những công cụ trực tuyến tốt nhất nếu bạn muốn tạo ra một bản CV vừa chuyên nghiệp vừa ấn tượng.
Khả năng về sự điều chỉnh với những giao diện thiết kế tinh tế là một trong những ưu điểm của phần mềm này. Đồng thời, một điểm cộng lớn cho Resume là bạn có thể dễ dàng định dạng CV theo cả hai dạng PDF hoặc DOC tùy vào yêu cầu của nhà tuyển dụng.
5. Resume Coach
Đây cũng là một trong những công cụ được sử dụng phổ biến vì mức độ đơn giản của nó.
Resume Coach giúp tạo ra mẫu CV theo nền tảng có sẵn và các bước để thiết kế một CV trên phần mềm này cũng không mất quá nhiều thời gian. Tuy vậy, với khả năng tùy chỉnh cao và dễ sử dụng, bạn có thể thỏa sức sáng tạo trên bản mẫu theo cá tính riêng của bạn.
Trên đây là top 5 website giúp bạn thiết kế những bộ CV chuẩn nhất. Hãy lựa chọn và tự thiết kế ngay cho mình những CV chất lượng để có thể gây ấn tượng đối với nhà tuyển dụng nhé!
Bất cứ một lập trình viên nào đều phải từng làm việc liên quan đến CSS. Tuy nhiên làm việc với CSS thuần một thời gian dài bạn sẽ thấy nó rất nhàm chán. Bạn có thể viết CSS một cách chuyên nghiệp hơn, nhanh và rõ ràng mạch lạc hơn bằng SASS/SCSS.
CSS Preprocessor là gì?
CSS Preprocessors là ngôn ngữ tiền xử lý CSS. Là một ngôn ngữ kịch bản mở rộng của CSS và được biên dịch thành cú pháp CSS giúp bạn viết CSS nhanh hơn và có cấu trúc rõ ràng hơn. CSS Preprocessor có thể giúp bạn tiết kiệm thời gian viết CSS, dễ dàng bảo trì và phát triển CSS.
SASS/SCSS là gì?
SASS/SCSS là một chương trình tiền xử lý CSS (CSS preprocessor). Nó giúp bạn viết CSS theo cách của một ngôn ngữ lập trình, có cấu trúc rõ ràng, rành mạch, dễ phát triển và bảo trì code hơn. Ngoài ra nó có rất nhiều các thư viện hỗ trợ kèm theo giúp bạn viết code CSS một cách dễ dàng vào đơn giản hơn. Có rất nhiều loại CSS Preprocessor trong đó bao gồm SASS, Stylus hay LESS.
SASS và SCSS về bản chất vấn đề là giống nhau, chỉ khác nhau ở cách viết
Sass là chữ viết tắt của Syntactically Awesome Style Sheets, chương trình tiền xử lý bằng ngôn ngữ kịch bản (Preprocessor Scripting Language ), sẽ được biên dịch thành CSS. Nghĩa là, mình sẽ làm style bằng SASS, rồi SASS sẽ render việc mình làm thành file CSS.
SASS bản thân có hai kiểu viết khác nhau, một kiểu như là HAML, Pug – Sử dụng indent (cách thụt đầu dòng) để phân tách các khối code , sử dụng xuống dòng để phân biệt rules , có phần mở rộng là .sass.
SCSS sử dụng cú pháp giống với Ruby (vì đơn giản nó được thiết kế bởi các lập trình viên Ruby). Có phần mở rộng là .scss , SCSS ra đời sau SASS và có cú pháp viết tương tự như cách viết CSS. Cú pháp này được tạo ra nhằm thu hẹp khoảng cách giữa SASS và CSS bằng cách mang lại một thứ gì đó thân thiện với CSS. Trong hình phía dưới:
Ví dụ nếu bạn chỉ muốn CSS cho thẻ ul với class menu, với CSS thuần bạn sẽ viết
.navbar ul.menu {
list-style: none;
}
Nếu bạn tiếp tục muốn CSS cho thẻ li trong thẻ ul (có class là menu) thì
.navbar ul.menu li {
padding: 3px;
}
Sau đó bạn muốn tiếp tục CSS cho thẻ a trong thẻ li… bạn sẽ phải lặp đi lặp lại tên tag (hoặc class, hoặc id) cha của thẻ muốn css thì sẽ rất mệt và nhàm chán. Thay vào đó bạn có thể dùng Nested Ruled của SASS để giúp mọi thứ trở nên đơn giản hơn một cách rõ rệt. Ví dụ:
.navbar {
ul.menu {
list-style: none;
li {
padding: 3px;
a {
text-decoration: none;
}
}
}
}
Và sau khi được đoạn SASS trên được compile ra CSS thuần sẽ như sau:
.navbar ul.menu {
list-style: none;
}
.navbar ul.menu li {
padding: 3px;
}
.navbar ul.menu li a {
text-decoration: none;
}
Thực tế mình nhận thấy rằng quy tắc xếp chồng này cũng được sử dụng rất nhiều khi vào 1 project có viết css.
Biến – variable
Sử dụng biến với SCSS vô cùng cơ bản, bạn chỉ cần đặt tên cho biến – bắt đầu bằng $. Biến chứa đựng các giá trị mà chúng ta dùng nhiều lần ví dụ như mã màu, font hay kiểu chữ.
Mixin giúp bạn tạo các hàm được sử dụng trong SCSS, bạn hoàn toàn có thể truyền các tham số vào bên trong nó để sử dụng.
Mixin là một cơ chế khá phổ biến trong SASS. Công dụng của nó là mang nhiều thuộc tính mà bạn đã quy ước trong một mix nào đó rồi @include vào một thành phần bất kỳ mà không cần phải viết lại các thuộc tính đó (Ví dụ ở trên là color vs font-style)
Khi nghe đến extends hay còn gọi là kế thừa, thì có thể bạn sẽ nghĩ ngay đến OOP (lập trình hướng đối tượng) đúng không? Cách làm sẽ là bạn định nghĩa ra 1 class, rồi những tag nào cần thì @extend nó vào là xong:
Cú pháp import của SASS rất hữu dụng và thường xuyên được sử dụng trong các project. Nó tương tự cách bạn require hay include file này vào file khác trong PHP.
Đặt trường hợp bạn có 1 trang index, bao gồm header, body, footer. Thay vì sử dụng CSS cho những cái trên vào một style.css thì với SASS bạn sẽ thực hiện như sau, nhớ có dấu _ trước tên file được import:
Tạo 1 file _header.scss để CSS riêng cho header.
_body.scss để CSS riêng cho body.
_footer.scss để CSS riêng cho footer.
Rồi ở file style.css ta chỉ cần @import 3 file trên là mượt mà ngay
_header.scss
#header {
// viết code sass ở đây
}
_body.scss
#body {
// viết code sass ở đây
}
_footer.scss
#footer {
// viết code sass ở đây
}
style.scss
@import 'header';
@import 'body';
@import 'footer';
// viết code sass ở đây
Vòng lặp
Mệnh đề điều kiện IF
Trình compile SASS
Hiện nay tồn tại tương đối nhiều trình biên dịch SASS sang CSS thuần. Trong đó có hai trình biên dịch mình xài thường xuyên, mình sẽ giới thiệu ở dưới. Ngoài ra bạn có thể tự search thêm những trình duyệt khác nhé.
Koala
Đây là một phần mềm dùng để compile CSS Preprocessor như SASS, LESS… mình hay dùng nó khi viết SASS.
Nếu bạn đang làm việc bằng Laravel thì bạn không cần đến phần mềm thứ 3 đâu vì bản thân Laravel đã tích hợp một công cụ tên là Laravel Mix rất đa năng, compile các CSS Preprocessor sang CSS thuần là một trong những tính năng xịn xò của nó.
Như những gì mình vừa trình bày ở phía trên, các bạn cũng đã có thể thấy những sức mạnh mà SASS/SCSS mang lại trong việc viết CSS, nó biến việc làm việc với SCSS như làm việc với một ngôn ngữ lập trình thực sự. Ngoài ra, với việc phải biên dịch từ SCSS ra CSS cũng cho phép chúng ta có thể sử dụng 1 số các tính năng như: tự động thêm prefix vào các thuộc tính CSS3, định dạng lại các tệp tin CSS (nén hoặc ko nén).
Atom, molecule, organism, template, và page là những khái niệm chính của phương pháp Atomic này.
Đây là một trong những cách tiếp cận để thiết kế một system. Tác giả của structure này là Brad Frost, ám ảnh bởi một thạc sĩ hóa học người Việt Nam (chắc dạy ở Mỹ), dạy môn hóa học khi anh này đang học cấp II.
Lấy ý tưởng nguyên tử hóa học, sự kết hợp giữa các nguyên tử tạo ra một phân tử, kết hợp các phân tử lại tạo thành 1 sinh vật
Những khái niệm chính của Atomic
Atom nguyên tử (nguyên tố), đơn vị nhỏ nhất
Molecule do 2 nguyên tử trở lên hợp lại tạo thành, những phân tử hóa học như H2O được cấu thành từ nguyên tử Hidro và Oxy
Organism là sự kết hợp của nhiều phân tử tạo thành
Chúng ta đã biết bảng tuần hoàn hóa học, thứ ám ảnh thời học sinh
Thì lớn lên chúng ta có bảng tuần hoàn HTML, ám ảnh thời web developer
Sự kết hợp của các element chúng ta tạo ra những trang web khác nhau (Organism)
Ngoài 3 khái niệm chính trên của hóa học, tác giả đưa thêm 2 khái niệm vào của dân web chúng ta
Template
Page
Atom
Những element nhỏ nhất trong giao diện, đó chính là các thẻ html
<input /><label /><button />
Molecule
Trong lập trình chúng ta thường gọi nó là component, thí dụ như search component sẽ bao gồm label, input, button
Organism
Một component có ô search, có thanh navigation, logo, đố bạn đó là gì? Header
Tất nhiên header cũng có thể có nhiều component khác
Một component có thể gọi là Organism có thể bao gồm nhiều component lặp lại như danh sách sản phẩm, bài viết
Template
Giờ tới khái niệm mà tất cả anh em làm web chúng ta điều biết
Template là page nhưng ở dạng skeleton, chúng ta chưa tô vẽ gì cụ thể, nó như một cái rập, chúng ta dùng để đập ra vài trăm bộ đồ.
Page
Page là một một UI hoàn chỉnh với nội dung, hình ảnh, logic có đầy đủ hết rồi
HTTP-over-QUIC là một giao thức (protocol) thử nghiệm đã đổi tên thành HTTP/3. IETF đã ra bản draft vào 03/2020.
Có một bước tiến dài trong quá trình phát triển từ HTTP/1.1 (ra đời vào năm 1999) cho đến sự xuất hiện của HTTP/2 (chính thức vào 2015) và mọi thứ đang tiếp tục phát triển với HTTP/3 dự kiến hoàn thành vào năm 2019. Bài viết có so sánh rất nhiều giữa HTTP/2 và 3 nên nếu chưa biết HTTP/2 là gì, bạn có thể đọc trước ở đây
Đường tới QUIC
QUIC (Quich UDP Internet Connections) một giao thức truyền tải internet đem đến rất nhiều cải tiến với thiết kế để tăng tốc lưu lượng HTTP cũng như làm cho nó bảo mật hơn, kèm theo mục tiêu cuối cùng sẽ dần dần thay thế TCP và TLS trên web. Trong bài blog này, chúng ta cùng điểm qua một vài tính năng chính của QUIC và những lợi điểm của nó cũng như những thử thách gặp phải trong quá trình hỗ trợ giao thức mới này. HTTP/3 bản chất là sự tiến hoá lên từ giao thức QUIC do Google phát triển, tất cả đều bắt đầu từ gợi ý sau của Mark Nottingham.
Thực tế là có 2 giao thức cùng có tên là QUIC:
“Google QUIC” (viết tắt là gQUIC) là giao thức gốc được thiết kế bởi các kỹ sư của Google nhiều năm trước, mà sau nhiều năm thử nghiệm đang được IETF (Internet Engineering Task Force) đưa vào thành chuẩn chung.
“IETF QUIC” (từ giờ ta sẽ gọi đơn giản là QUIC) là giao thức dựa trên gQUIC nhưng đã thay đổi rất nhiều khiến nó có thể được xem là một giao thức hoàn toàn khác. Từ format của các gói tin cho đến handshaking và mapping của HTTP, QUIC đã cải tiến rất nhiều thiết kết gốc của gQUIC nhờ vào sự hợp tác mở của rất nhiều tổ chức và nhân, cùng chia sẻ một mục đích chung giúp Internet nhanh hơn và an toàn hơn.
Tóm lại, QUIC có thể coi là kết hợp của TCP+TLS+HTTP/2 nhưng được implement trên UDP. Bởi vì TCP đã được phát triển, xây dựng sâu vào trong nhân của hệ điều hành, vào phần cứng của middlebox nên để có thể đưa ra sự thay đổi lớn cho TCP gần như là điều không thể. Tuy nhiên, vì QUIC được xây dựng trên UDP nên nó hoàn toàn không bị giới hạn gì cả.
Vậy đâu là những cải tiến mà QUIC đem lại?
Bảo mật là sẵn sàng (và cả hiệu năng nữa)
Một trong những điểm nổi bật của QUIC so với TCP đấy là việc bảo mật mặc định ngay từ mục đích thiết kế của giao thức. QUIC đạt được điều này thông qua việc cung cấp các tính năng bảo mật như xác thực và mã hoá (việc thường được thực hiện bởi lớp giao thức cao hơn TLS) ngay từ trong bản thân của giao thức.
Quá trình bắt tay (handshake) ban đầu của QUIC bao gồm bắt tay 3 bước (three-way handshake) như của TCP và đi kèm với bắt tay TLS 1.3, cung cấp xác thực cho end-points và đàm phán (negotiation) các tham số mã hoá. Đối với những ai đã quen với giao thức TLS, QUIC thay thế lớp bản ghi TLS bằng format frame của riêng mình trong khi vẫn giữ nguyên các message bắt tay TLS.
Hệ quả là không chỉ đảm bảo rằng kết nối luôn được xác thực vào bảo mật mà còn làm cho việc khởi tạo kết nối trở nên nhanh hơn: bắt tay thông qua QUIC chỉ cần 1 lần truyền tin qua lại giữa client và server là hoàn thành, thay vì phải tốn 2 lần: 1 lần cho TCP và 1 lần cho TLS 1.3 như hiện tại.
Tuy nhiên QUIC còn tiến xa hơn, mã hoá luôn cả metadata của kết nối, thứ mà có thể bị lợi dụng bởi các bên trung gian nhằm can thiệp vào kết nối. Ví dụ: số lượng gói tin (packets) có thể được sử dụng bởi kẻ tấn công trên đường truyền nhằm tìm ra mối liên quan với hoạt động của người dùng trên nhiều đường mạng khác nhau khi connection migration (xem bên dưới) diễn ra. Bằng việc mã hoá, QUIC đảm bảo rằng không ai có thể tìm ra mối liên quan với hoạt động dựa trên thông tin này ngoài end-point mà người dùng kết nối tới.
Mã hoá cũng là một thuốc chữa hiệu quả cho ossification (tạm dịch: vôi hoá, là một hiện tượng trong thiết kết giao thức, nếu bạn thiết kế giao thức có cấu trúc linh hoạt nhưng chẳng mấy khi sử dụng đặc tính đó thì khả năng có một số implement của giao thức sẽ coi phần đó là cố định. Giống như bạn có một cánh cửa mở nhưng hiếm khi mở nó, thì phần bản lề (phần di chuyển) dần dần sẽ bị oxy hoá), cho phép ta thực hiện việc đàm phán nhiều version khác nhau của cùng một giao thức. Thực tế đây ossification chính là lí do khiến việc triển khai TLS 1.3 bị trì hoãn quá lâu, và chỉ có thể được thực hiện sau rất nhiều thay đổi, được thiết kế để tránh cho các bên sản xuất thiết bị hiểu nhầm và block version mới của TLS, được đưa vào thực tế.
Head-of-line blocking
Một trong những cải tiến HTTP/2 đem đến là khả năng multiplex nhiều HTTP request trên cùng một kết nối TCP. Điều này cho phép các ứng dụng sử dụng HTTP/2 xử lý các request đồng thời và tối ưu hơn băng thông có sẵn.
Đây thực sự là cải tiến lớn so với thế hệ trước, yêu cầu app phải tạo nhiều kết nối TCP+TLS nếu app muốn xử lý đồng thời nhiều request HTTP/1.1 (VD như khi trình duyệt cần phải tải đồng thời Javascript và CSS để hiển thị trang). Tạo nhiều kết nối mới yêu cầu phải lặp đi lặp lại việc bắt tay nhiều lần, đồng thời phải trải qua quá trình khởi động (warm-up) dẫn tới việc hiển thị trang web bị chậm. Khả năng multiplex nhiều HTTP tránh được tất cả những điều này.
Tuy nhiên, vẫn có nhược điểm. Vì nhiều request/response được truyền qua cùng một kết nối TCP, tất cả đều bị ảnh hưởng bởi việc mất gói tin (packet loss), VD: do nghẽn mạng (network congestion), kể cả khi chỉ phần dữ liệu bị mất chỉ ảnh hưởng đến một kết nối. Hiện tượng này được gọi là “head-of-line blocking”.
QUIC đã tiến một bước sâu hơn và hỗ trợ việc multiplexing sao cho: các luồng (stream) HTTP khác nhau sẽ được map với các luồng QUIC transport khác nhau, nhưng tất cả vẫn chia sẻ chung một kết nối QUIC, nên không cần phải bắt tay lại. Thêm vào đó, tuy trạng thái nghẽn mạng được chia sẻ nhưng các luồng QUIC được phân phát riêng biệt nên trong phần lớn các trường hợp việc mất gói tin của một luồng không làm ảnh hưởng đến luồng khác.
Việc này có thể giảm đi trông thấy thời gian cần đển hiển thị hoàn chỉnh trang web (với CSS, Javascript, ảnh và các thể loại media khác nhau) đặc biệt trong tình huống đường mạng hay bị nghẽn và tỉ lệ rớt mạng cao.
Nghe có vẻ đơn giản, nhỉ?
Để có thể đem đến những điều hứa hẹn như vậy, QUIC cần phải phá bỏ một số giả định mà rất nhiều ứng dụng mạng vẫn tin vào, dẫn tới khả năng cài đặt QUIC và triển khai nó trở nên khó khăn hơn.
Vì vậy, QUIC được thiết kế để hoạt động dựa trên giao thức UDP để dễ dàng cho vệc triển khai và tránh vấn đề xảy ra khi các thiết bị mạng lại bỏ (drop) các gói tin từ một giao thức không rõ ràng, vì cơ bản tất cả các thiết bị mạng đều có hỗ trợ sẵn UDP. Việc này cũng cho phép QUIC nhanh chóng được đưa vào các ứng dụng ở tầng user, VD: các trình duyệt có thể cài đặt các giao thức mới và chuyển đến tay người dùng mà không cần phải chờ hệ điều hành cập nhật.
Mặc dù mục tiêu thiết kế ban đầu của QUIC là để tránh việc phải “break” những cái đang có, thì với thiết kế này cũng đưa việc chống lạm dụng và điều hướng gói tin đến đúng end-point trở nên thách thức hơn.
Chỉ cần NAT để đưa tất cả vào và âm thầm binding từ phía sau
Về cơ bản, các NAT router có thể theo dõi các kết nối TCP chạy qua bằng cách sử dụng 1 tuple gồm 4 thành phần (source IP address, source port, destination IP address, destination port) và bằng cách theo dõi các packet TCP SYN, ACK, FIN được truyền qua mạng, router có thể theo dõi được khi nào thì kết nối mới được tạo và bị huỷ. Việc này cũng cho phép router quản lý chính xác thời gian NAT binding (NAT binding: là mapping tương ứng giữa IP address và và port nội bộ với bên ngoài)
Đối với QUIC, việc này vẫn chưa khả thi do các NAT router có mặt hiện nay vẫn chưa hiểu QUIC là gì nên khi xử lý chúng sẽ fallback về mặc định, nghĩa là coi gói tin QUIC như là 1 gói tin UDP bình thường và xử lý. Việc xử lý UDP thiếu chính xác, tuỳ ý và có time-out ngắn có thể gây ảnh hưởng đến các kết nối cần giữ trong thời gian dài.
Khi bị timeout sẽ có hiện tượng NAT rebinding, lúc này end-point ở phía ngoài phạm vi của NAT sẽ thấy các gói tin đến từ một port khác với port ban đầu khi kết nối được khởi tạo, dẫn đến việc theo dấu kết nối chỉ bằng tuple gồm 4 thành phần như trên là không thể.
Và không chỉ mỗi NAT gặp vấn đề, một tính năng khác mà QUIC đem tới cũng gặp tình trạng tương tự. Đó là tính năng connection migration: cho phép chuyển qua lại giữa các kết nối khác nhau, VD: khi một thiết bị mobile đang kết nối thông qua mạng di động (cellular data) bắt được Wifi có chất lượng tốt hơn và chuyển sang mạng wifi này, vẫn đảm bảo kết nối dù IP và port có thể thay đổi.
QUIC giải quyết vấn đề này bằng cách đưa vào một khái niệm mới: Connection ID. Connection ID là một đoạn dữ liệu có chiều dài tự ý ở bên trong gói tin QUIC cho phép định danh một kết nối. End-point có thể dùng ID này để theo dấu kết nối cần được xử lý mà không cần phải kiểm tra tuple 4 thành phần như trên. Trên thực tế có thể có nhiều ID trong cùng một kết nối (khi có connection migration, việc này sẽ xảy ra để tránh liên kết nhầm các đường mạng khác nhau) nhưng về cơ bản việc này được quản lý bởi end-point chứ không phải thiết bị trung gian nên cũng không sao.
Tuy nhiên, đây cũng có thể là vấn đề với các nhà mạng sử dụng địa chỉ anycast và ECMP routing khi mà duy nhất một địa chỉ IP đích có thể là định danh cho rất nhiều server ở phía sau. Vì các edge router (router ngoài cùng) trong mạng cũng chưa biết phải xử lý QUIC như thế nào nên có thể xảy ra trường hợp gói tin UDP ở trong cùng một kết nối QUIC (nghĩa là cùng connection ID) nhưng có tuple 4 thành phần khác nhau (do bị NAT rebinding hoặc do connection migration) có thể bị điều hướng đến một server khác dẫn đến đứt kết nối.
Để giải quyết vấn đề này, các nhà mạng cần phải triển khai giải pháp load balance thông minh hơn ở layer 4, có thể bằng các phần mềm mà ko cần đụng đến các router (có thể tham khảo dự án Katran của Facebook)
QPACK
Một lợi điểm khác được HTTP/2 giới thiệu là nén header (header compression (HPACK)) cho phép HTTP/2 end-point giảm lượng dữ liệu phải truyền qua mạng bằng cách loại bỏ các phần thừa trong HTTP request và response.
Cụ thể, HPACK có các bảng động (dynamic tables) chứa các header đã được gửi (hoặc được nhận) trong HTTP request (hoặc response) trước đó, cho phép các end-point tham chiếu các header trước đó với các header gặp phải ở trong request (hoặc resoponse) mới và không cần truyền lại nữa.
Các bảng động của HPACK cần phải được đồng bộ giữa bên mã hoá (phía gửi HTTP request hoặc response) và phía giải mã (nơi nhận chúng) nếu không thì phía giải mã sẽ không thể giải mã được.
Với HTTP/2 chạy trên TCP, việc đồng bộ này diễn ra rất rõ ràng vì lớp TCP đã xử lý giúp chúng ta việc truyền đi các HTTP request và response theo đúng thứ tự chúng được gửi. Khi đó, phía mã hoá có thể gửi hướng dẫn cập nhật bảng như là một phần của request (hoặc response) khiến cho việc mã hoá trở nên rất đơn giản. Nhưng đối với QUIC thì mọi chuyện lại phức tạp hơn.
QUIC có thể gửi nhiều HTTP request ( hoặc response) qua nhiều luồng đồng lập, nghĩa là nếu chỉ có một luồng, QUIC cũng sẽ cố gắng gửi theo đúng thứ tự nhưng khi nhiều luồng xuất hiện, trật tự không còn được đảm bảo nữa.
Ví dụ, nếu client gửi một HTTP request A qua luồng A, và request B qua luồng B, thì có thể xuất hiện trường hợp như sau: do việc sắp xếp lại thứ tự của gói tin mà request B được server nhận trước request A, và nếu request B được client encode và có tham chiếu đến một header từ request A thì server sẽ không thể decode được vì chưa nhận được request A ?!
Ở giao thức gQUIC, vấn đề này được giải quyết đơn giản bằng xếp thứ tự tất cả các header của HTTP request và response (chỉ header chứ không phải body) trên cùng một luồng gQUIC. Khi đó tất các header sẽ được truyền đúng thứ tự trong mọi trường hợp. Đây là một cơ chế rất đơn giản cho phép có thể sử dụng lại rất nhiều code của HTTP/2 nhưng ngược lại cũng gia tăng vấn đề head-of-line blocking, thứ mà QUIC được thiết kế để làm giảm. Do đó, nhóm IETF QUIC đã thiết kế một cách mapping mới giữa HTTP và QUIC (“HTTP/QUIC”) và một cơ chế nén header mới gọi là “QPACK”.
Trong bản draft mới nhất của phần mapping HTTP/QUIC và QPACK, mỗi trao đổi HTTP request/response sử dụng một luồng QUIC 2 chiều củả chính nó, do vậy sẽ không xuất hiện tình trạng head-of-line blocking. Thêm vào đó, để hỗ trợ QPACK, mỗi phía của kết nối sẽ tạo thêm 2 luồng QUIC một chiều, một dùng để gửi cập nhật bảng QPACK đến cho phía còn lại, một để xác nhận những cập nhật này. Theo cách này mã hoá QPACK có thể sử dụng bảng động tham chiếu chỉ sau khi nó đã được xác nhận bởi phía giải mã.
Chống lại tấn công Reflection
Một vấn đề thường gặp phải ở những giao thức dựa trên UDP (xem thêm ở đây và ở đây) đấy là chúng nhạy cảm với kiểu tấn công reflection (phản chiếu). Đây là hình thức tấn công mà kẻ tấn công lừa server gửi một lượng lớn dữ liệu đến nạn nhân bằng cách làm giả địa chỉ IP source của gói tin gửi đến server khiến chúng trông có vẻ như là được gửi từ nạn nhân. Hình thức này được sử dụng rất nhiều trong các cuộc tấn công DDoS.
Nó còn đặc biệt hiệu quả trong trường hợp, response gửi bởi server lớn hơn rất nhiều so với request mà nó nhận được (nên còn có tên gọi là tấn công “khuếch đại”).
TCP không thường được sử dụng cho hình thức tấn công này do những gói tin được gửi trong quá trình bắt tay (SYN, SYN+ACK,…) đều có chiều dài bằng nhau nên không có tiềm năng dùng để “khuếch đại”.
Quy trình bắt tay của QUIC thì ngược lại, không được đối xứng như vậy: ví dụ với TLS, trong lần gửi đầu tiên, QUIC server thường sẽ gửi lại certificate chain của mình, có thể rất lớn, trong khi client chỉ cần gửi có vài bytes (TLS ClientHello message chứa trong gói tin QUIC). Vì lí do này, gói tin QUIC ban đầu gửi từ client cần phải pad (gắn thêm dữ liệu) đến một chiều dài tối thiểu cho dù thực tế nội dung của gói tin nhỏ hơn nhiều. Kể cả như thế đi nữa thì biện pháp này vẫn chưa đủ, vì về cơ bản, response của server thường được chia thành nhiều gói tin nên vẫn có thể lớn hơn rất nhiều gói tin đã đc padding từ client.
Giao thức QUIC cũng định nghĩa một cơ chế xác thực địa chỉ IP nguồn, khi đó server thay vì gửi lại một response dài thì chỉ gửi lại một gói tin “retry” nhỏ hơn rất nhiều chưa một token mã hoá đặc biệt mà client sẽ phải echo (gửi lại đúng ý nguyên) về phía server trong một gói tin mới. Theo cách này, server có thể chắc chắn là client không fake địa chỉ IP nguồn của chính mình (vì client đúng là có nhận được retry packet) và có thể tiếp tục hoàn thành quá trình bắt tay. Nhược điểm của biện pháp này là nó tăng thời gian bắt tay thông thường từ 1 vòng trao đổi client-server lên thành 2 vòng.
Một giải pháp khác là làm giảm kích cỡ của response từ server cho đến một lúc mà tấn công reflection trở nên không còn hiệu quả quả nữa, ví dụ sử dụng chứng chỉ ECDSA (cơ bản nhỏ hơn nhiều so với chứng chỉ RSA tương đương). Cloudflare cũng đang thử nghiệm với các cơ chế nén chứng chỉ TLS sử dụng các thuật toán nén như zlib, broti (là một tính năng được giới thiệu ban đầu bởi gQUIC nhưng hiện không khả dụng trong TLS).
Một vấn đề lặp đi lặp lại với QUIC là những thiết bị phần cứng và phần mềm hiện tại chưa hiểu được giao thức mới này là gì. Ở trên, chúng ta đã xem xét cách QUIC giải quyết các vấn đề phát sinh khi gói tin đi qua các thiết bị mạng, router nhưng có một vấn đề tiềm năng khác chính là hiệu năng gửi và nhận dữ liệu qua UDP ở trên chính các end-point đang sử dụng QUIC. Qua nhiều năm, rất nhiều công sức đã được bỏ ra để tối ưu TCP nhất có thể, từ việc xây dựng khả năng off-loading vào phần mềm (hệ điều hành) và phần cứng (card mạng) nhưng đối với UDP thì hoàn toàn chưa có gì.
Tuy nhiên, chỉ còn là vấn đề thời gian cho đến khi UDP cũng được hưởng lợi từ những công sức trên. Gần đây, ta có thể thấy vài ví dụ, từ việc implement Generic Segmentation Offloading for UDP on LInux thứ cho phép các ứng dụng có thể gửi nhiều đoạn UDP giữa user-space và network stack của kernel-space với chi phí tương đương (hoặc gần như tương đương) của việc chỉ gửi 1 đoạn. Hay là việc thêm zerocopy socket support on Linux cũng cho phép ứng dụng tránh được chi phí phát sinh khi copy vùng nhớ từ user-spacve vào kernel-space.
Kết luận
Giống như HTTP/2 và TLS 1.3, QUIC đem đến rất nhiều tính năng mới để nâng cao hiệu năng và bảo mật của web site, cũng như các thành phần khác dựa trên internet. Nhóm hoạt động IETF đang đặt ra mục tiêu đưa ra version đầu tiên của spec của QUIC vào cuối năm 2018.
Cloudflare cũng đã và đang làm việc chăm chỉ để có thể sớm đưa những lợi ích của QUIC đến với toàn bộ khách hàng. Update: Cloudflare đã hoàn thành việc hỗ trợ HTTP/3 bằng việc tạo ra quiche, phiên bản open-source của HTTP/3 được viết bằng Rust.
Google nói rằng gần 1/2 tất cả những request từ trình duyệt Chrome tới server của Google được thực hiện qua QUIC và họ mong muốn sẽ tăng thêm lưu lượng thực hiện qua QUIC để tiến tới đưa nó thành phương thức mặc định từ kết nối client của Google, kể cả từ trình duyệt và thiết bị di động, đến server của Google.
Hỗ trợ cho HTTP/3 đã được thêm vào Chrome (Canary build) vào 09/2019, và mặc dù HTTP/3 chưa được bật mặc định tron bất kỳ trình duyệt nào nhưng ở thời điểm năm 2020, HTTP/3 đã được hỗ trợ trong Chrome and Firefox (cần bật flag thì mới có thể dùng được). Bạn có thể thử nghiệm với HTTP/3 theo hướng dẫn tại đây. Chúng ta có thể mong chờ vào một tương lai tươi sáng với QUIC!
Để trở thành Solution Architect thì nên bắt đầu từ đâu? Đâu là những hiểu lầm và suy nghĩ sai về nghề Solution Architect? Làm sao để tiến xa hơn với vị trí Solution Architect? Hãy cùng trò chuyện và gặp gỡ “thủ lĩnh” Solution Architect tại TIKI – anh Lê Minh Nghĩa, sẽ chia sẻ tất cả những kinh nghiệm và góc nhìn lâu năm trong nghề mà bất cứ Architect nào cũng quan tâm.
Solution Architect là gì?
Theo anh một Solution Architect có vai trò như thế nào ở một công ty Thương mại điện tử (TMĐT)? Anh có thể giới thiệu một cách khái quát về công việc của mình ở thời điểm hiện tại?
Mình gia nhập team cách đây 3 năm từ hồi cuối 2016 với vai trò là Solution Architect, hiện nay mình đang là Senior Technical Architect tại TIKI. Đối với mình, công việc Architect khá thú vị, và điều mà mình thích nhất đó là trải nghiệm – mình có thể nhìn thấy toàn bộ hệ thống phát triển như thế nào, mở rộng làm sao và mình có thể có tầm nhìn đáp ứng nhu cầu phát triển của công ty bằng cách nào. Phần này khá thú vị, song cũng khá thách thức. Thách thức ở đây nằm ở chỗ làm việc vừa phải tổng thể vừaphảichi tiết.
Architect không giống như nhiều bạn nghĩ vì không nhiều người từng trải qua công việc này. Architect thực chất là người “master builder”, là người phải hiểu rõ công việc xây dựng hệ thống đến mức nhìn thấy những thành phần nhỏ nhất, và biết rõ những thành phần ấy được cấu tạo ra sao. Đó không phải là công việc đơn thuần kiểu làm từ trên xuống (top-down), mà là công việc khá chi tiết và vất vả. Vì khi bạn vừa phải nhìn tổng thể vừa phải nhìn chi tiết, đồng nghĩa với việc bạn xử lý một lượng vấn đề rất lớn, và phải ra quyết định phù hợp tại từng thời điểm với từng hoàn cảnh với nguồn lực mình đang có.
Để trở thành một Solution Architect giỏi thì chúng ta cần phải chú ý phát triển những kỹ năng gì?
Đầu tiên, bạn phải là một engineer rất giỏi. Bạn phải là một “master builder”, nghĩa là một “bậc thầy” về xây dựng hệ thống. Chỉ khi nào bạn hiểu tường tận quá trình xây dựng hệ thống, lúc đó bạn có thể xây dựng bất cứ một hệ thống nào trong lĩnh vực mình đang tham gia – bạn sẽ hiểu được từng thành phần nhỏ được vận hành thế nào, thì bạn mới có khả năng trở thành một Architect.
Tuy nhiên, đó mới chỉ là điều kiện cần.
Điều kiện đủ ở đây là bạn phải có động lực, mong muốn nhìn từ trên cao xuống từng thành phần được cấu thành ra sao. Bởi vì đôi khi những engineer rất giỏi có thể giải quyết những vấn đề nhỏ nhưng lại không có khả năng nhìn tổng thể để kết nối tất cả các vấn đề lại thành hệ thống lớn, tức là bạn chưa có tầm nhìn của một Architect.
Ngoài ra, để trở thành Architect bạn cần có khả năng về con người, tức là tố chất về leadership (tài lãnh đạo) của bạn phải rất là tốt – một yếu tố rất quan trọng. Bởi vì không phải lúc nào những giải pháp bạn đưa ra cũng gặp thuận lợi, bạn phải hiểu được rằng bạn đang có trong tay những người như thế nào, những người ấy có khả năng ra sao về mặt kỹ thuật, và làm sao có thể kết nối những con người này để đưa giải pháp trở thành hiện thực. Đó là công việc mà đòi hỏi khả năng kỹ thuật và cả khả năng con người rất tốt.
Anh có thể miêu tả một career path cụ thể cho một Solution Architect được không?
Có 2 thứ theo quan điểm mình vừa chia sẻ.
Bạn phải là một engineer thật sự đam mê – đam mê về công việc của mình và phải là một engineer rất giỏi và có background ngôn ngữ vững vàng. Bạn phải có khát khao lớn hơn nữa – khi đứng đầu của một hệ thống bạn có thể nhìn tổng thể hệ thống vận hành ra sao. Bạn có khát khao làm sao có thể kết nối những thành phần nhỏ để tạo nên những gì lớn hơn. Cái khát khao ấy sẽ thôi thúc bạn hướng tới những sự hình thành kỹ năng, năng lực của một Architect, đó là khả năng nhìn từ trên xuống (top-down).
Bạn cũng cần có động lực để vượt qua những khó khăn công việc của một Architect, đó là vừa phải nắm được tổng thể cũng như những chi tiết. Ngoài ra, bạn cũng cần có khả năng vượt qua rào cản về con người để thuyết phục mọi người rằng “Solution của tôi đúng”.
Kinh nghiệm bản thân khi công tác tại TIKI
Anh có thể chia sẻ về một kỉ niệm đáng nhớ cũng như kinh nghiệm xương máu về việc ứng dụng một công nghệ mới vào sản phẩm của công ty?
Kinh nghiệm đáng nhớ nhất của mình đó là khi bắt đầu apply những giải pháp giúp hệ thống có thể chia tách được. Tại thời điểm đó, nhiều khái niệm và thuật ngữ ngành còn rất mới với nhiều người. Khi đó những giải pháp của mình đưa ra không phải lúc nào cũng được mọi người ủng hộ ngay lập tức.
Và kỷ niệm vui khi ở Tiki là khi ở đây, không phải lúc nào đưa giải pháp mới mọi người cũng hiểu, và ủng hộ theo kiểu là “Tôi hiểu giải pháp của bạn là sao” nhưng mọi người luôn luôn tạo điều kiện để người đó thực hiện. Người đó có quyền thử nghiệm, thực hiện ngay tại chỗ. Và khi giải pháp này đúng, mọi người sẽ ủng hộ và áp dụng chúng trên diện rộng. Khi mình đưa giải pháp đó ra, có thể mọi người chưa hiểu và chưa ủng hộ, nhưng mọi người luôn tạo điều kiện tối đa để mình thực hiện giải pháp đó. Và sau khi giải pháp đó thành hiện thực thì công nghệ nhanh chóng trên quy mô toàn công ty, mọi người có thể sử dụng công nghệ ấy để có thể replicate data, chia tách hệ thống tốt hơn. Nhờ vậy, Tiki có thể scale tốt hơn rất nhiều.
Đây là kỷ niệm rất ý nghĩa. Với bản thân mình, mình đã chứng minh được: 1 là giải pháp đúng, 2 là mình đã hiểu được giá trị văn hóa của chúng tôi là gì. Khi làm việc cùng nhau, không phải lúc nào công việc cũng mượt mà như mọi người thường nghĩ, nhưng ở đây chúng tôi có một thứ văn hóa tốt, đấy là mọi người có quyền thử nghiệm và khi đúng thì nó sẽ được nhân rộng một cách nhanh chóng. Điều đấy rất quan trọng đối với một công ty trẻ!
Ngành CNTT chưa bao giờ hết nóng, tuy nhiên các doanh nghiệp vẫn gặp khó khăn trong việc tuyển dụng các lập trình viên phù hợp, theo anh đâu là vấn đề?
Nguyên nhân đầu tiên là do nhu cầu quá lớn, không chỉ ở riêng TIKI mà nói chung tại các công ty công nghệ, vì đây là kỷ nguyên số và tất cả mọi người đều muốn số hóa nhanh nhất có thể. Mọi người muốn hệ thống thông minh hơn, muốn hệ thống làm được nhiều thứ hơn. Vì vậy, nhu cầu về IT vô cùng lớn ở Việt Nam và trên toàn thế giới.
Về phía doanh nghiệp, bài toán này càng khó hơn và số lượng ứng viên chất lượng thì không nhiều. Tại TIKI, phía công ty cũng khó khăn trong việc tìm được người phù hợp với tiêu chuẩn của mình. Người có năng lực thấp thì rất nhiều nhưng các bạn ấy không sẵn sàng giải quyết các bài toán tại TIKI, và cũng không cảm thấy hạnh phúc khi giải quyết các vấn đề và TIKI cũng không thu được giá trị từ các bạn đó.
Anh có thể chia sẻ một số khó khăn về kỹ thuật khi mở rộng mô hình B2C sang mô hình marketplace?
Khi chuyển từ B2C to marketplace về phía công nghệ thì có 2 khó khăn lớn.
Thứ nhất, B2C là mô hình mình mua hàng về và bán, nhưng hiện nay mình trở thành một cái sàn để các seller vận hành trên đó và có đến hàng chục, hàng trăm ngàn seller vận hành. Như vậy, tính phức tạp nghiệp vụ cũng tăng lên gấp bội, vì vậy đòi hỏi kỹ năng thiết kế hệ thống phần mềm (software) phải linh hoạt, dễ dàng hoạt động cho các nghiệp vụ mới, phát sinh liên tục.
Khó khăn thứ hai, đương nhiên là về mặt hiệu năng. Khi bạn có một lượng lớn giao dịch diễn ra trên hệ thống trong 3 năm marketplace, TIKI tăng trưởng trung bình 2 đến 3 lần mỗi năm, thì lượng giao dịch, đơn hàng và sản phẩm đều tăng gấp bội. Từ vài trăm nghìn sản phẩm lên đến hàng triệu sản phẩm, và như vậy lượng xử lý trở nên vô cùng khó khăn và phức tạp. Hạ tầng cũng phải mở rộng lên gấp nhiều lần. Vì vậy, để có thể build hệ thống đáp ứng nhu cầu về hiệu năng là một challenge lớn về mặt kỹ thuật. Người engineer tại TIKI cùng lúc sẽ phải giải quyết 2 việc, bạn phải build nên một phần mềm thật linh hoạt, mềm dẻo, thay đổi nhanh tương ứng với tăng trưởng vài ba lần mỗi năm. Bạn phải có system rất scale để có thể handle hàng trăm ngàn transaction mỗi ngày và xử lý lượng dữ liệu lên đến hàng triệu sản phẩm.
Theo anh nền tảng Data và Devops đang đóng vai trò như thế nào cho những doanh nghiệp thương mại điện tử tại thị trường Việt Nam?
Data và Devops là 2 khái niệm khác nhau, nhưng cả 2 đều rất quan trọng. Đối với data thì quá hiển nhiên, tất cả doanh nghiệp khi mở rộng thì mọi quyết định đều dựa trên dữ liệu. Mà dữ liệu là thứ quan trọng bậc nhất để mọi cấp bậc từ người nhân viên lấy hàng cho tới một manager C-level để make decision. Vì vậy, data ở TIKI cũng như tất cả các công ty E-commerce khác là vàng và thứ quan trọng nhất để chúng tôi đưa ra quyết định kinh doanh hiệu quả.
Còn DevOps liên quan đến quá trình phát triển hệ thống, development và triển khai hệ thống. DevOps rất quan trọng với những công ty có scale quy mô lớn, như TIKI có đến hơn 400 services và ứng dụng khác nhau theo mô hình microservice và hàng ngàn backgroundworker để chạy của hàng trăm engineer để phát triển. Với lượng mã nguồn triển khai lớn như vậy mà nền tảng DevOps không tốt thì sẽ rất khó để scale và mở rộng. Vì vậy DevOps cực kỳ quan trọng khi mà bạn và quá trình phát triển phần mềm trở nên phức tạp với quy mô lớn. Bất kỳ công ty công nghệ nào muốn scale lên thì cần DevOps rất tốt, bạn không thể triển khai manual khi bạn chỉ có 1 – 2 project.
Lời khuyên từ chuyên gia
Anh có thể chia sẻ cụ thể về lộ trình học/nghiên cứu của các công nghệ hiện có để đảm bảo tối thiểu có thể làm việc cùng team với anh tại TIKI?
Phải hiểu một điều là công nghệ là thuật ngữ rộng, nó bao hàm những yếu tố nền tảng và học thuật. Để làm việc tại TIKI thì đầu tiên các bạn cần có background, nền tảng tốt, bạn tốt nghiệp Đại học hay tự trang bị kiến thức miễn vững vàng đều tốt. Đấy là những điều tối quan trọng để bạn có thể làm việc tại TIKI. Về công nghệ theo hướng ngôn ngữ lập trình, thì bạn chỉ cần thành thạo những ngôn ngữ phổ biến, như Java, PHP, NodeJS hay Python, đó đều là những ngôn ngữ chúng tôi đều đang sử dụng. Nếu như bạn có những khả năng cơ bản về những ngôn ngữ đó, bạn có thể làm việc tại Tiki. Tại Tiki, điều quan trọng nhất là bạn phải luôn chào đón việc học hỏi những cái mới.
Anh có thể chia sẻ quy trình tuyển dụng của Tiki Engineering không? Những điểm mạnh hoặc lợi ích, phát triển bản thân hoặc điều gì thú vị nhất khi trở thành thành viên của tech team nói chung và team của anh nói riêng?
Process tuyển dụng của Tiki khá chặt chẽ vì Tiki mong muốn rằng mình có những ứng viên thật sự chất lượng và họ phải hiểu rằng chúng tôi rất nghiêm túc trước tài năng của họ. Nếu không tính vòng lọc hồ sơ thì sẽ có 4 vòng phỏng vấn chính, trong đó:
2 vòng phỏng vấn về problem-solving (xử lý vấn đề) dựa trên kiến thức về cấu trúc dữ liệu và giải thuật
1 vòng về system design (thiết kế hệ thống)
1 vòng về culture fit văn hoá doanh nghiệp.
Đây là 4 vòng cơ bản, nếu 1 bạn pass được 4 vòng đó thì đủ tiêu chuẩn để làm việc tại TIKI. Phía TIKI quan tâm đến những ứng viên, đầu tiên là có background tốt (1) về những kiến thức về cấu trúc dữ liệu và giải thuật tốt – là những thứ quan trọng để có thể giải quyết những vấn đề của Tiki. Thứ hai, bạn phải có khả năng xử lý vấn đề tốt (2), tức là bạn phải có những đề xuất giải pháp nhanh chóng khi có vấn đề phát sinh. Cái thứ ba tất nhiên là bạn cần có những kỹ năng cơ bản của những engineer về lập trình và thiết kế hệ thống (3). Trong thực tiễn những điều này rất quan trọng và cũng rất hữu ích, khi bạn đối mặt với những công nghệ mới, nếu bạn học nhanh thì sẽ có nhiều thời gian để làm hơn.
Có một điều mà dưới góc nhìn và trải nghiệm của mình và những bạn đã đồng hành cùng TIKI cảm thấy là điều “hấp dẫn” nhất của TIKI. Trong vòng 1 năm qua kể từ khi ứng dụng những quy trình hoạt động mới, thì TIKI có sự tăng trưởng kinh doanh cực kỳ nhanh và vượt trội – 2 đến 3 lần mỗi năm. Thế nhưng, TIKI có một hệ thống không tốt!
Mình gọi là “hấp dẫn” là vì, đó là 2 điều kiện mà mình nghĩ rằng nó rất cần thiết đối với một bạn engineer trẻ, khao khát được học, được làm và chứng minh bản thân mình. Bởi vì khi bạn có một hệ thống không tốt mà hệ thống ấy lại tăng trưởng rất nhanh tức là bạn có cơ hội để làm rất nhiều thứ. Với mình thì đây là những điều hấp dẫn nhất đối với một bạn engineer. Và những ai đã vượt qua giai đoạn thử thách thì đều cảm thấy rất xứng đáng, vì các bạn có thể làm rất nhiều thứ, có thể cống hiến và góp sức cho những thứ mà có tầm ảnh hưởng rất lớn đến hệ thống và bộ máy TIKI.
Anh chia sẻ về một ngày làm việc của mình và team tại TIKI?
Đối với một engineer, công việc hàng ngày khá là thú vị. Thú vị ở chỗ bạn gắn với một business tăng trưởng liên tục. Bạn thường xuyên nhận được những báo cáo đòi hỏi những yêu cầu, ý tưởng kinh doanh mới. Công việc hàng ngày của engineer nói chung là phân tích những yêu cầu về business để bạn thấy được cơ hội, và có thể mang lại lợi ích cho công ty và khách hàng và làm sao để biến ý tưởng ấy trở thành hiện thực nhanh nhất có thể. Hoặc đơn giản là làm sao để bạn giải quyết những vấn đề như phải scale hệ thống gấp 2, 3 đến 10 lần trước những vấn đề về hiệu năng. Đấy là những công việc hàng ngày của bạn engineer.
Anh hay dùng công nghệ và cách thức gì để quản lý công việc của team, cũng như đo đạc hiệu quả làm việc của họ?
Về cách thức quản lý, Tiki có một mô hình tổ chức tương đối phẳng và xem trọng tính linh hoạt mà nỗ lực để giải quyết những vấn đề có thể phát sinh. Vì vậy toàn bộ bộ máy engineer của TIKI được tổ chức thành những team nhỏ, thay đổi dựa trên nhu cầu về nghiệp vụ. Các team ấy được toàn quyền quyết định với những vấn đề thuộc phạm vi mình phải giải quyết. Bạn sẽ quyết định về giải pháp, quyết định về con người, để làm sao để giải quyết nhanh nhất và hiệu quả nhất. Bởi đặc thù của E-commerce là tăng trưởng rất nhanh, vì vậy việc ra quyết định trong quá trình xây dựng sản phẩm phải làm sao nhanh chóng nhất và hiệu quả nhất có thể.
Còn về công nghệ, ở Tiki mình không nghĩ có gì quá đặc biệt. Nó vẫn tuân thủ theo những công nghệ phổ biến trong cách thức quản lý công việc, về mã nguồn cũng như là về DevOps. Mọi thứ cũng phổ biến như là Genkin, Github mọi người theo dõi những nguồn quản lý để deploy.
Nỗi sợ lớn nhất của anh trong công việc công nghệ của mình?
Tùy vị trí mà mỗi người sẽ có những nỗi sợ khác nhau. Mình nghĩ rằng đối với những bạn engineer tại Tiki, các bạn cũng có áp lực giống như nhiều công ty khác – phải làm sao để hệ thống không chết. Khi các bạn engineer submit mã nguồn thì các bạn sẽ phải thận trọng để biết rằng nó không bị ảnh hưởng tiêu cực.
Áp lực thứ hai, cụ thể hơn là với cấp quản lý, công ty tăng trưởng rất nhanh, bạn cũng cần đưa ra những giải pháp nhanh chóng để làm sao không tạo ra những tình thế buộc bụng cho doanh nghiệp, bạn phải làm sao giải quyết những vấn đề về kinh doanh tốt nhất có thể để công ty tăng trưởng và mang lại doanh thu cho khách hàng.
Công nghệ recommendation của Tiki do mình tự phát triển hay sử dụng giải pháp nào khác? Anh có thể chia sẻ thêm về công nghệ này
Thực tế thì công nghệ recommendation tại Tiki cũng là cái “bát đồng”. Cái cơ hội để hoàn thiện và phát triển là rất lớn. Điều Đáng mừng là công nghệ này do Tiki tự làm, Tiki không nói là nó đã hoàn thiện nhưng Tiki cảm thấy rằng khi làm chủ được nó, thì cơ hội để chúng tôi cải thiện là rất cao.
Tiki có ứng dụng công nghệ AI không? Nếu có anh vui lòng chia sẻ chi tiết về việc ứng dụng này
Việc ứng dụng về AI thì rất nhiều. Đối với Tiki, AI là công nghệ tiếp theo để chúng tôi có thể phát triển thị phần. Vì nhu cầu xử lý trong business đòi hỏi Tiki phải ứng dụng hoạt động này ngày càng nhiều lên. Nếu công việc xử lý bằng tay sẽ rất khó để mở rộng lên, quy mô hàng trăm nghìn khách hàng, hàng triệu seller và hàng chục triệu sản phẩm, những việc xử lý bằng tay sẽ không ra quyết định bằng cách tự mình xử lý dữ liệu. Vì vậy AI rất quan trọng trong việc scale-up và mở rộng doanh nghiệp. Tiki còn ứng dụng AI trong tự động hóa quy trình, tối ưu hóa trong Marketing, search và trải nghiệm người dùng.
Xin cảm ơn anh Nghĩa về phần chia sẻ rất chi tiết vừa rồi. Hy vọng qua bài phỏng vấn này các bạn độc giả đã học hỏi thêm về vai trò của một Solution Architect cũng như làm thế nào để trở thành master builder tại công ty. Đừng bỏ lỡ những bài phỏng vấn các chuyên gia công nghệ hàng đầu tại mục Chuyên gia nói nhé!
Là gương mặt quen thuộc với cộng đồng YouTube với dự án âm nhạc “Dân IT”, góp mặt là host của các buổi phỏng vấn chuyên sâu trên TopDev TV, Bảo Đại thật ra đang đảm nhận vị trí AI Researcher | Research Scientist tại Knorex, ngoài ra anh còn là một lecturer tại tổ chức Viet.AI. Cùng TopDev trò chuyện cùng anh chàng đa tài này và hiểu hơn về công việc cũng như học hỏi lộ trình anh Đại chọn để trở thành một AI Researcher nhé.
Chào anh, là một “nghệ sĩ” trong giới công nghệ anh hãy cho độc giả biết hơn về cơ duyên đến với nghiên cứu trí tuệ nhân tạo cũng như con đường sự nghiệp của mình
Đối với câu hỏi này thì mình nghĩ không có cơ duyên nào. Thực ra thì đó là sự lựa chọn thôi. Ví dụ như mình thích cái gì đó mình sẽ try hard vì nó. Thực ra con đường nghiên cứu về AI cũng là sự lựa chọn của mình
Mình bắt đầu nghiên cứu AI từ năm 2, khi mà mình còn ngồi trên ghế nhà trường ở trường Đại học Khoa học Tự nhiên. Hồi đó mình cũng không thích lập trình lắm, mình thích học toán và làm bài tập toán nhiều hơn. Khi mình tiếp xúc về AI, mình cảm thấy là AI phù hợp với cái mình thích hơn cho nên từ đó mình định hướng cho career path sẽ lập trình ít lại. Mình không định hướng làm dev mà mình làm research nhiều hơn là dev. Cứ như vậy cho đến cho đến lúc ra trường cho đến lúc đi làm may mắn là mình vẫn theo đuổi công việc mà mình muốn.
Hiện tại công việc của mình là nghiên cứu về AI thì nó hơi chung chung. Công việc hiện tại của mình tại ở Knorex là AI Researcher, tức là research về NLP, viết tắt của từ natural language processing, hay còn gọi là xử lý ngôn ngữ tự nhiên. Các bài toán ví dụ có thể kể đến, như google translate: nó sẽ làm cho máy có thể hiểu được ngôn ngữ con người. Mình chủ yếu làm về mảng NLP nhiều hơn so với các mảng khác của AI, như computer vision hoặc là xử lý âm thanh.
Những kinh nghiệm khi theo đuổi ngành AI Reseacher
Theo anh thì học AI có khó không và một bạn sinh viên cần chuẩn bị gì để học tốt AI?
Thực ra thì đối với mình thì không riêng gì AI, mỗi ngành đều có cái khó riêng. Đối với AI thì cần chuẩn bị kỹ càng, có nền tảng toán vững chắc. Toán ở đây cũng khá là rộng cho nên là mình có thể recommend cho các bạn những thứ toán có thể chuẩn bị cho AI đó là calculus và linear algebra: đại số tuyến tính và giải tích. Khi bạn học AI sẽ liên quan đến 2 thứ này nhiều nhất, ngoài ra các bạn cũng cần kiến thức tí xíu về lập trình nữa. Theo kinh nghiệm của mình học lập trình để học được AI, mình không cần đi quá sâu về thuật toán và mà chỉ cần biết lập trình cơ bản. Ngôn ngữ lập trình ở đây mình recommend các bạn chọn python làm ngôn ngữ lập trình các bạn bắt đầu học về AI.
Nếu đã có background là developer thì làm thế nào trở thành một AI researcher?
Mình cũng không phải là một developer đúng nghĩa. Mình thì chủ yếu tập trung vào research cho nên theo mình, để các bạn dev trở thành một AI researcher các bạn có rất là nhiều tiềm năng để có thể chuyển hướng qua ngành research hơn là những bạn khác. Tại vì các bạn đã có base lập trình sẵn cộng với tư duy logic nữa, thì điều kiện đủ để các bạn cần phải thêm vô cái kỹ năng của mình đó là các bạn cần phải có thói quen đọc nhiều. Đối với việc research, các bạn cần phải đọc nhiều, nhất là các bài báo khoa học (hay còn gọi là paper). Nếu kiên nhẫn và tích lũy kiến thức thì AI Researcher không phải là mục đích quá khó.
Đối với anh thì đâu là giải pháp tiếp thu nhanh những thuật toán trong quá trình học Machine Learning (ML)?
Đối với bản thân mình, trong giai đoạn đầu mình học về ML, Deep Learning (DL), mình cũng khá là sợ vì rất là nhiều công thức mình không hiểu gì cả. Cách mà mình để hiểu nó nhanh thì thật ra mình không có, nhưng mà mình biết cách để mà hiểu nó trước. Đôi khi một công thức trong một thuật toán bất kỳ của ML hay DL nào đó đọc qua tốn khoảng 1-2 tiếng để search về nó, để xem về nó, để hiểu tất cả các ký tự mà nó muốn nói. Thực ra các công thức này là những cái ngắn gọn nhất của một cái idea, một cái mô hình mà người ta muốn viết. Để ngắn gọn, người ta phải viết ra công thức. Từ đó khi mình đọc các công thức khó hiểu là chuyện đương nhiên và để hiểu nó thì mình phải làm cho nó phức tạp hơn.
Ví dụ như khi mình học lớp 12 thì khi mà đưa ra công thức thì các bạn không muốn nhìn nó chút nào hết. Nhưng các bạn thích làm bài tập hơn, vì khi làm bài tập mình cảm thấy mình hiểu nó. Đó là kiểu phức tạp hóa vấn đề theo hướng tích cực. Tức là tất cả các bài tập đều áp dụng 1 công thức, mục tiêu của nó là phức tạp hóa vấn đề và để cho con người có thể hiểu công thức đó dưới dạng từng trường hợp một. Khi lên đại học và học AI, các bạn nhìn vô công thức các bạn sợ thì cứ thử học AI như cách các bạn học toán cấp 3. Tức là các bạn phải lấy giấy ra, lấy viết ra và ghi lên giấy những cái mình thử tính bằng tay từng cái một thì các bạn sẽ hiểu được công thức đó sẽ trở nên nhanh chóng.
Mình có 1 câu nói của thầy mình hồi trước – thầy Lê Hoài Bắc ở ĐH KHTN “Cái mà tụi em cần nhất đó là không phải các em lập trình đc trên máy tính khi các em học về AI, về ML. Cái các em cần nhất đó là khi các em chỉ có một cây viết, một tờ giấy, các em có thể viết được mô hình, làm được mô hình, biết được máy chạy ra con số gì trên giấy thì khi đó các em sẽ thành công. chứ k hẳn là mình sẽ ngồi lập trình trên máy ra được số thì tại vì vấn đề ở đây là khi các bạn làm về AI, có rất nhiều thư viện hỗ trợ sẵn, các bạn không cần phải làm gì nhiều. Đôi khi các bạn không cần phải hiểu nó chạy cái gì bên trong. Nó hoàn toàn là một hộp đen nhưng các bạn sẽ hoàn toàn thành công. Mình nghĩ câu đó của thầy rất là đúng và nó có rất nhiều impact cho mình trong quá trình học tập cũng như làm việc về AI.
Là lecturer tại Viet.AI, anh nhận thấy những bạn học trái ngành có thể học AI (researcher) không?
Theo mình, tất cả những bạn học trái ngành đều có cơ hội trở thành 1 AI researcher, tương đồng với tất cả mọi người. Không phải là các bạn học về cơ khí sẽ có riêng về cơ khí, sẽ khó khăn hơn cho các bạn thì điều đó là không đúng. Tại vì có những ví dụ ở trong lớp Viet.AI mình đứng lớp dạy, những khóa trước mình đã gặp được những bạn đến từ những ngành khác nhau ví dụ ngành kinh tế, ngành cơ khí và hiện tại các bạn đang là bác sĩ nữa thì các bạn vẫn có base khá là ok. Đúng là dù các bạn không có thể nào lập trình hoàn toàn tốt như các bạn dev được nhưng các bạn có 1 cái kiến thức riêng về chuyên ngành các bạn thì các bạn có thể adopt AI, như là AI cho healthcare, hay AI cho cơ khí gì đó thì vì những người trái ngành như vậy làm cho cái việc học tập và phát triển AI ở Việt Nam ngày càng được đa dạng hóa hơn rất là nhiều. Mình không nghĩ các bạn đó gặp khó khăn nhiều hơn so với anh em dev khi bắt đầu học về ai.
AI là thuật ngữ rất rộng, vậy có thể chia nhỏ các lĩnh vực của AI không?
AI có thể phân chia thành nhiều lĩnh vực nhỏ khác nhau. Sơ khởi nhất các bạn có thể nghĩ đến việc AI có thể xử lý được ngôn ngữ con người – NLP. Lĩnh vực thứ 2 là xử lý ảnh Computer Vision, chủ yếu tập trung đầu vào là ảnh và đầu ra là phân lớp, ví dụ con chó con mèo cái nhà chẳng hạn thì nó thuộc về CV. Mảng thứ 3 mình nghĩ có thể nhắc đến là Sound Processing. Như các bạn biết bài toán chị Google đặt ra là Text to speech – input là chữ, output là giọng nói hoặc ngược lại là speech to text thì cái đó là lĩnh vực xử lý âm thanh. Khi mà mình chia thành những lĩnh vực nhỏ như vậy, mình đang dựa trên ứng dụng mình chia. Ngoài ra nói về mặt các dạng mô hình thì mình có thể chia AI ra thành các dạng khác. Đầu tiên mình có thể nhắc tới Supervisor learning là học cái giám sát. Tức là khi mình đưa cái dữ liệu đầu vào trong cái máy học thì mình sẽ chỉ ra rõ đâu là con chó, đâu là con mèo để máy có thể biết được đó là những cái mình cần phải học. Thứ 2 là unsupervised learning – học không có giám sát, tức là mình đưa dữ liệu vào cho máy và máy sẽ phân loại ra những cái nó cho là khác nhau. Ví dụ mình đưa vào 2 loại là bút bi và bút chì, mình đưa rất nhiều hình ảnh cho máy và mình bắt máy phải phân ra 2 bên thì mình expect là máy sẽ phân ra bút bi, bút chì mà không đưa 1 cái label nào cho máy hết. Ngoài ra còn có những lĩnh vực khác như là reinforcement learning – học tăng cường. Nó được áp dụng cho lĩnh vực xe tự động rất là nhiều.
Anh có thể chia sẻ rõ hơn về ứng dụng NLP mà anh đang nghiên cứu, anh mong muốn sẽ đạt được kết quả gì?
Đối với ứng dụng NLP thì mình sửa lỗi chính tả, dịch máy (machine translation) ví dụ như google translate, text summarization – tóm tắt văn bản, input văn bản dài và output văn bản đã được tóm tắt bởi máy.
Riêng đối với bản thân mình khi làm việc tại Knorex thì bài toán mà mình tập trung nhất đó là bài toán text classification – phân loại văn bản. Mình muốn máy có thể học được văn bản đó đang nói tới chủ đề gì (vd: sport, du lịch,…) thì đầu vào là văn bản và đầu ra là label, topic của văn bản đó đang nói về điều gì. Ngoài ra mình còn làm những bài toán khác vd language detection – đầu vào là văn bản và đầu ra biết cái ngôn ngữ đó thuộc tiếng anh, tiếng việt, tiếng TBN chẳng hạn. Đó cũng là 1 bài toán của NLP
AI và những ứng dụng trong thực tế
Vậy theo anh đâu là sự khác biệt giữa AI và ML?
Thuật ngữ AI được sử dụng nhiều hơn còn ML đôi khi một số bạn cũng không biết rõ do không học trong ngành ngày.
Sự khác nhau rất rõ rệt đó là: AI là cha của ML, ML là tập con của AI. Khi nhắc đến AI thì mọi người nghĩ ngay đến cái gì đó rất là to, thông minh. Thì AI chung lại là những cách làm cho ML có thể thông minh hơn. Mình có thể code cứng luôn. Gặp trường hợp A thì nó gọi là A gặp trường hợp B trả lời B, những cái code cứng như vậy vẫn là AI. Mình sẽ đưa những cái luật để máy hiểu đc rồi trả về mà k cần học gì thì đó vẫn là AI.
ML là tập con AI nhưng nó không phải là code luật, không phải là if-else nữa mà nó sẽ kiểu đưa dữ liệu vào cho máy và máy sẽ tự động học và sau đó nó sẽ dựa trên những dữ liệu đó và trả lời câu hỏi người dùng dựa trên dữ liệu mình đưa.
ML cần dữ liệu nhiều hơn và mình thấy cái quan trọng của ML nằm ở dữ liệu. Mình không cần phải ngồi code if-else liên tục mấy trăm mấy ngàn dòng nữa để máy có thể thông minh hơn mà mình chỉ cần huấn luyện máy dựa trên dữ liệu mình tìm được. Nó tiết kiệm rất nhiều thời gian và hiện tại nó cũng đang là xu hướng.
Trong ML lại có một cái term khác là Deep Learning. Deep learning lại là tập con của ML. Deep learning sẽ nói về những cái neural network, sẽ có rất nhiều lớp sâu thiệt sâu và hơi chuyên ngành cho nên là mình chỉ nhắc sơ qua thôi.
Theo nhận xét của mình, anh có cảm thấy AI đang bị tâng bốc quá hay không?
Mình cũng cảm thấy 1 phần AI rất trendy. Thật ra lúc học năm nhất năm hai đại học, mình cũng không nghĩ nó sẽ trở nên trendy như vậy ở thời điểm hiện tại. Mình học chỉ vì mình thích nó thôi.
Mình cũng biết 1 nhãn hàng – không tiện nói tên, họ sử dụng keyword AI trong bài Thông cáo báo chí (TCBC) thì cái TCBC của họ được share rất là nhiều. Những nhà báo tò mò và đến với họ rất là nhiều. Họ sử dụng AI như thể là một keyword chứng tỏ là họ đang đi theo cái trend hiện tại. Và mình cũng hiểu tại sao lại có trend như hiện tại vì nó đem lại rất nhiều lợi ích cho user, nó cũng khá là thú vị. Mình nghĩ sự tâng bốc này có thể giải thích được và không có gì gọi là negative impact – ảnh hưởng tiêu cực nào cho tụi mình hết vì tụi mình cũng vui khi biết ah hiện tại AI cũng rất là hot.
Tại sao một số startup lại tuyên bố là họ sử dụng AI trong sản phẩm? Liệu có phải là chiêu trò marketing?
Thực ra có rất nhiều trường hợp.
Có thể họ không cần phải build full squad một cái API của họ. Tức là họ không cần phải build từ đầu tới cuối để cho sản phẩm có AI mà có thể sử dụng nền tảng AI của bên thứ 3 để adopt cho sản phẩm của họ. Trường hợp này họ không cần làm gì cả, họ chỉ cần bỏ tiền ra để mua API của bên thứ 3 ví dụ như IBM. Điều đó không có gì sai cả, miễn là sản phẩm của họ có thể đưa ra những lợi ích nhất định cho ng dùng.
Tuy nhiên, mình vẫn muốn là khi mà nói về AI trong sản phẩm thì mình vẫn nên build full squad. Nếu như có chỉnh sửa trong quá trình phát triển sản phẩm thì mình có thể 100% làm được chuyện đó.
Quay trở lại câu hỏi trong việc họ có sử dụng AI hay không thì anh cũng không chắc là họ có sử dụng. Tuy nhiên nếu mà có thì mình vẫn có thể tin được vì họ có thể mua bên thứ 3 hoặc tạo full squad thì mình cũng không thể biết.
Khó khăn doanh nghiệp gặp khi áp dụng AI vào sản phẩm là gì?
Đầu tiên, tại sao phải sử dụng AI mà không phải những kỹ thuật khác?
Đôi khi họ muốn adopt AI vào những mặt khác của business là một chuyện khác. Tuy nhiên, cái đầu tiên mà mình nghĩ khá quan trọng là nếu doanh nghiệp có thể sử dụng những kỹ thuật khác mà vẫn có thể giải quyết bài toán thì họ nên sử dụng những kỹ thuật ấy, không nên sử dụng AI.
Thứ 2, nếu build AI từ đầu đến cuối, cái khó khăn ở đây chính là khi sản phẩm scale up, ai có hỗ trợ được không? Có đủ nhanh không?
Hiện tại, những kỹ thuật của AI rất phát triển. Họ cần rất nhiều computational resources để thực hiện những bài toán như vậy. Các bài toán về AI rất phức tạp, cần rất nhiều computational resources và các doanh nghiệp nhỏ không đủ để đáp ứng được.
Nếu doanh nghiệp nhỏ khọng đáp ứng được các resource thì câu nói “AI là cuộc chơi cho những ông lớn” liệu có đúng?
Mình nghĩ nó đúng 1 phần. Vì hiện tại, tất cả các mô hình AI đưa ra những kết quả đúng, chính xác nhất hiện tại thường được đề cử bởi những ông lớn. Những thứ gọi là “state obvious”. Việt Nam mình chưa có đủ điều kiện tự propose một cái mô hình. Bởi vì ở Google có rất nhiều computational resource, rất nhiều máy CPU để huấn luyện mô hình, rất nhiều điều kiện để phát triển nghiên cứu. Thì đối với câu “sân chơi của những ông lớn” đúng nghĩa là họ đưa ra những cái mới và mình xài những cái mới của họ. Sân chơi ở đây là sân chơi research nhưng mà nó không đúng ở phần khi áp dụng nó vào sản phẩm. Đối với việc ứng dụng những sản phẩm của Google, Facebook thì nó vẫn là sân chơi của mình. Ví dụ có những sản phẩm của Google, Facebook không thực sự adopt cho thị trường Việt. Vẫn còn những con hẻm nhỏ, sân chơi, đất diễn cho doanh nghiệp Việt, họ sẽ cố gắng lấy những mô hình propose bởi Google hay Facebook, họ đọc hiểu và ứng dụng cho bài toán ở doanh nghiệp việt. Thì đó vẫn là sân chơi của mình!
Lời khuyên để “tồn tại” trong lĩnh vực
Theo kinh nghiệm của mình, anh có thấy quá trình phỏng vấn DEV với một AI researcher có khác nhau không?
Thực sự mình chưa có cơ hội phỏng vấn ở vị trí dev, nhưng mình cũng xin chia sẻ một ít. Khi mà mình join 1 team, quá trình phỏng vấn cũng diễn ra tương tự. Bạn vẫn có bài test cho bạn. Điều khác nhau là kiến thức thôi. Đầu tiên họ sẽ check về kiến thức AI của bạn là bao nhiêu. Tiếp theo mà AI researcher phải có chính là kỹ năng nghiên cứu – research. Tức là bạn cần có kỹ năng đọc hiểu bài báo khoa học để ứng dụng kiến thức của bài báo để giải quyết bài toán của công ty. Thì đó là cái cần thiết nhất bạn cần phải có để xin việc.
Anh có thể chia sẻ lời khuyên để CV của bạn nổi bật phỏng vấn vị trí AI Researcher.
Đầu tiên bạn phải có một vài project nho nhỏ về AI để show cho nhà tuyển dụng biết bạn đã có làm việc về Ai ít nhiều rồi. Bạn sẽ show cho họ biết những thư viện nào bạn đã học rồi.
Thứ 2, bạn có thể đưa đường dẫn repository của các bạn vô. Hiện tại các nhà tuyển dụng rất quan trọng việc bạn đã có đóng góp gì cho cộng đồng, nhất là công việc AI researcher.
Thứ 3, mình nghĩ hơi khó đó là các bạn hãy làm research, viết paper gửi về các hội nghị về AI. Thì khi các bạn có một cái bài báo các bạn nhận đang tải thì đó là một điều rất tuyệt vời cho CV của bạn.
Khi làm việc về AI, anh có những kỷ niệm đáng nhớ nào?
Hiện tại, ở Knorex thì mình có một bài toán khác không liên quan NLP, may mắn mình cũng là project holder cho dự án. Đó là dự án brand safety. Cụ thể là làm sao mình biết trang web user đang connect có phải trang web 18+ không. Mục tiêu cuối cùng của việc detect là để các brand sẽ không phải đặt quảng cáo của mình trên những trang web đó.
Bài toán: input web => output có phải web 18+ không?
Để làm được chuyện đó mình phải thu thập dữ liệu về để train một cái model sao có thể detect được đâu là ảnh bình thường, đâu là ảnh 18+. Thì mình phải lấy rất nhiều ảnh 18+ về máy, sau đó gắn nhãn đâu là ảnh 18 đâu là ảnh bình thường. Đôi khi mình hay bị đồng nghiệp chọc đó là Đại vô công ty vừa được coi hình 18+ còn được trả tiền nữa thì đó là một kỷ niệm khá lạ và vui.
Nhưng mà mình không sướng như các bạn nghĩ. Đôi khi có những trang web sensitive khác 18+ liên quan máu me, những hình ảnh gore thì những thứ này mình cũng phải làm và đôi khi thì mình không ăn nổi do mình coi những hình ảnh đó nhiều quá.
Xin cảm ơn phần chia sẻ rất mới mẻ về AI cũng như về lộ trình trở thành AI Researcher từ anh. Hãy cùng đón đọc “Chuyên gia nói” tại TopDev để không bỏ lỡ bất kỳ bài phỏng vấn chuyên sâu từ các chuyên gia công nghệ nào tại Việt Nam nhé.






















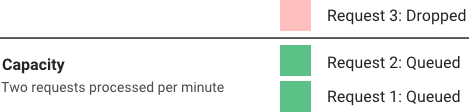

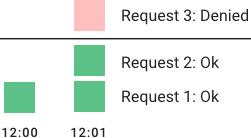
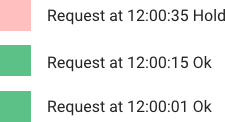
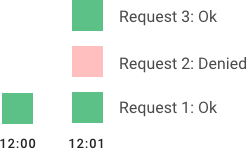

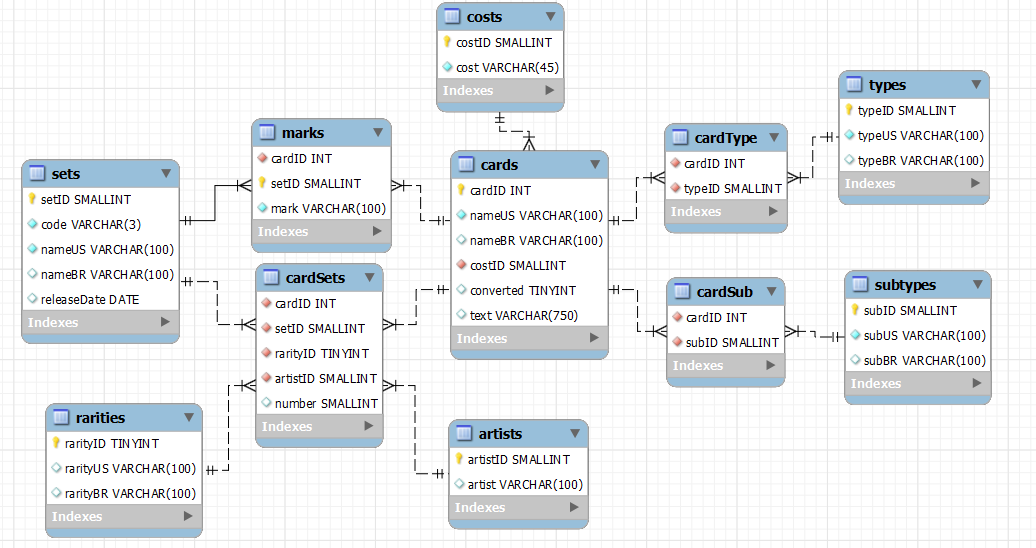















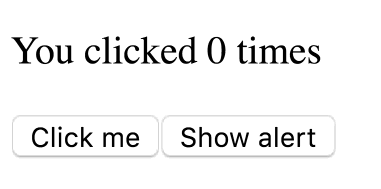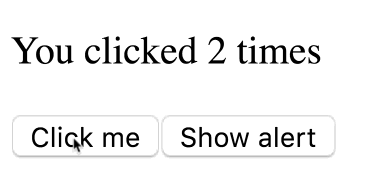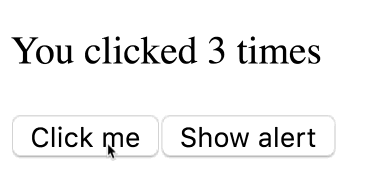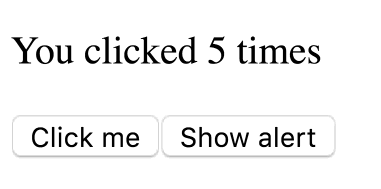
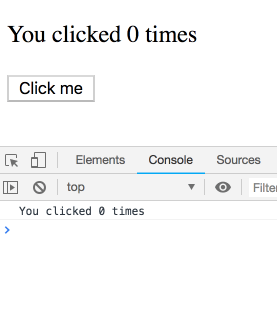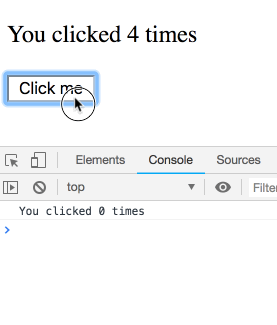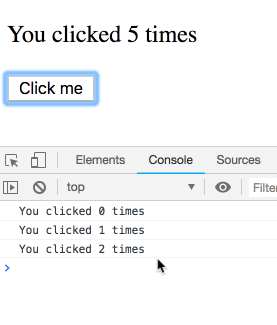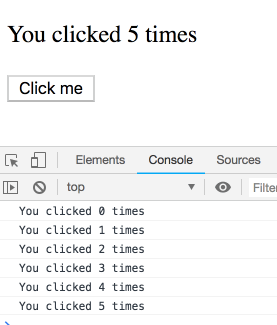
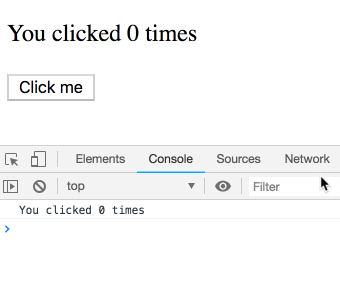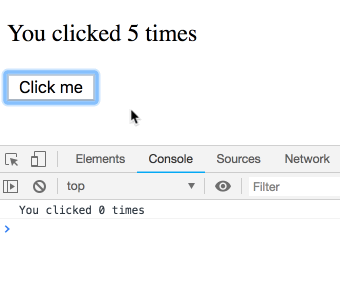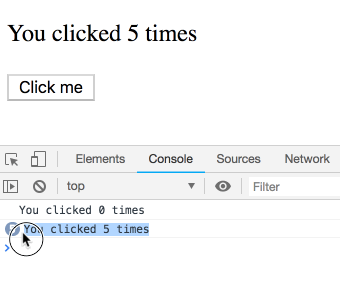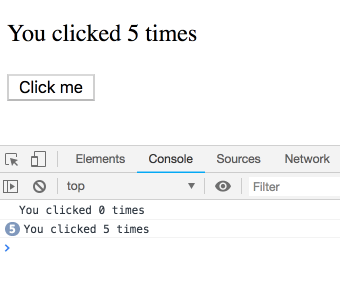
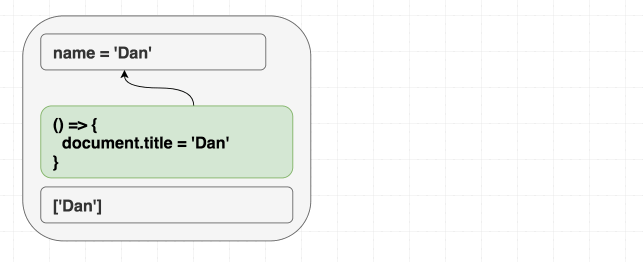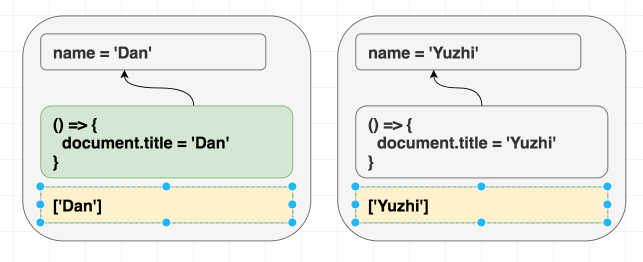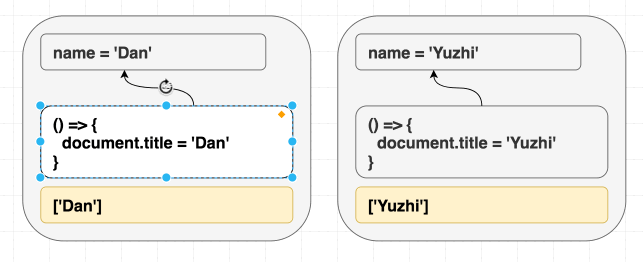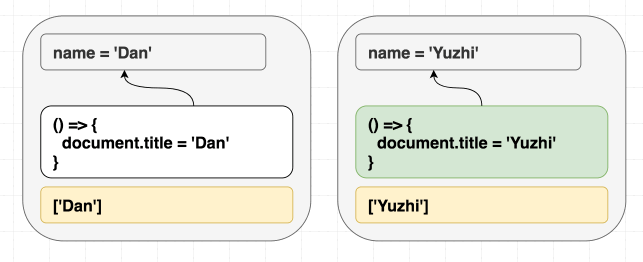
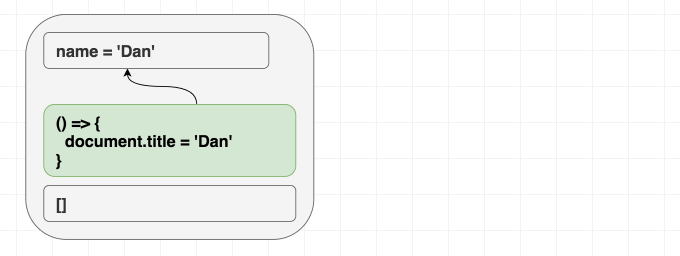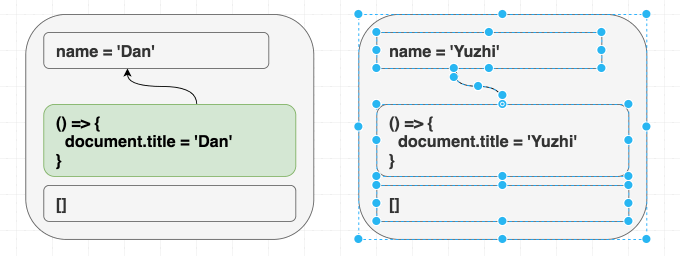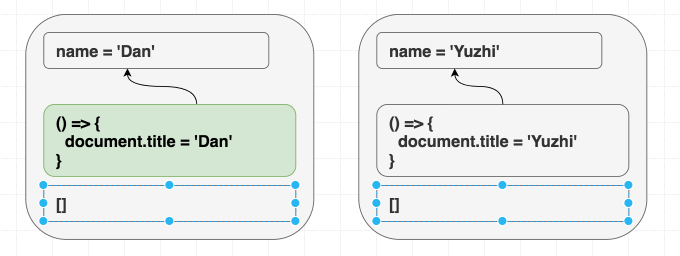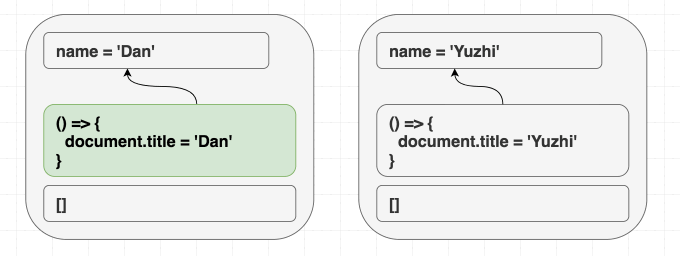
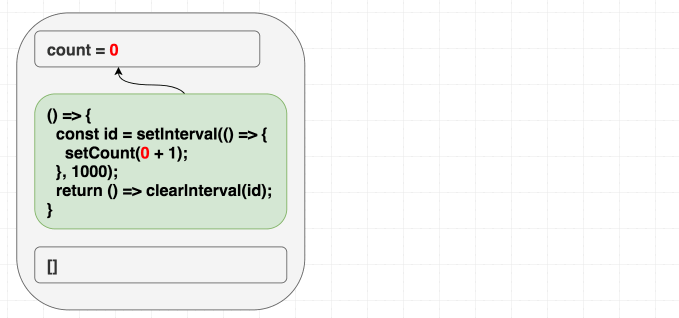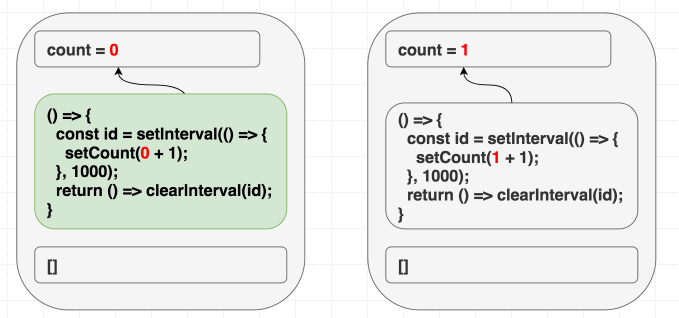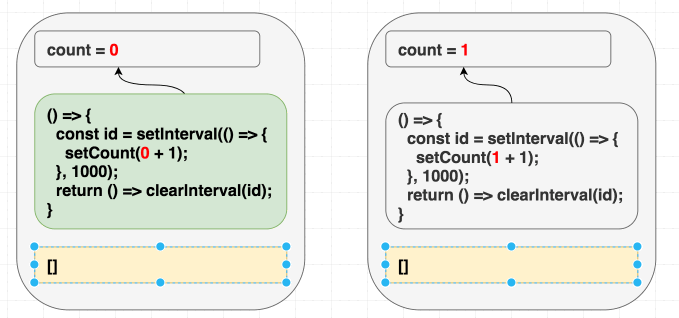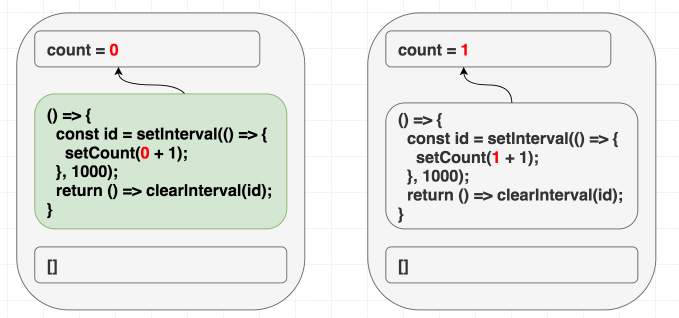
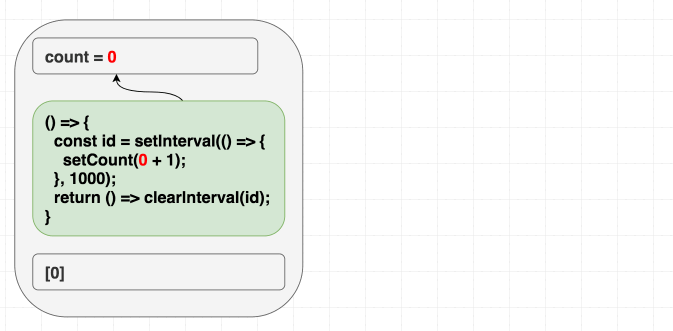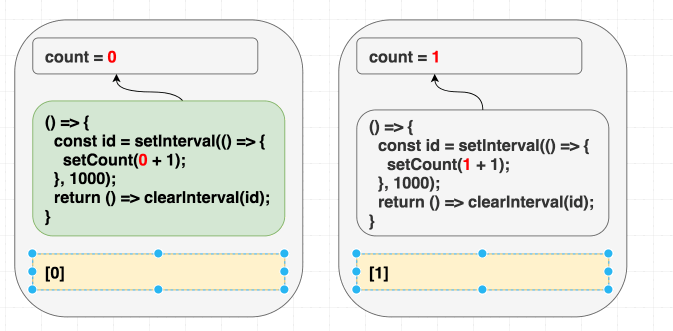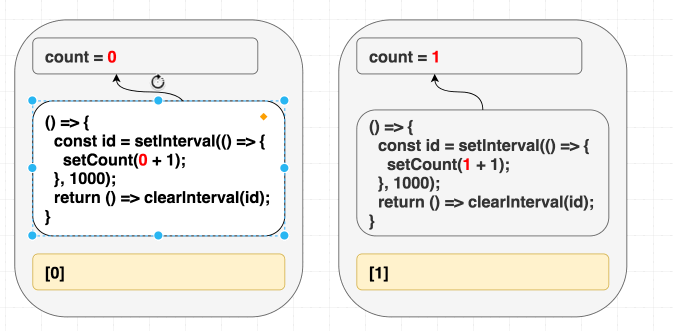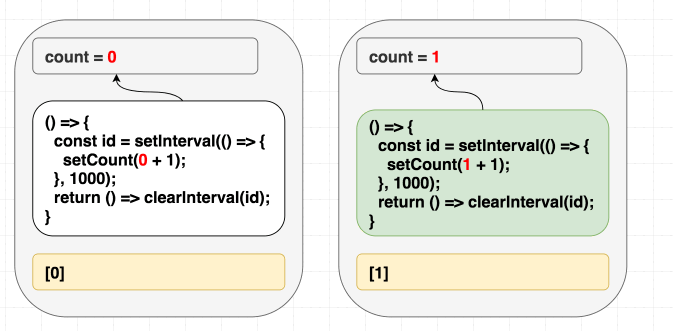
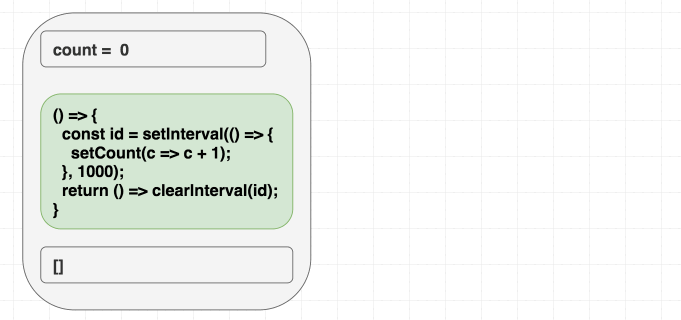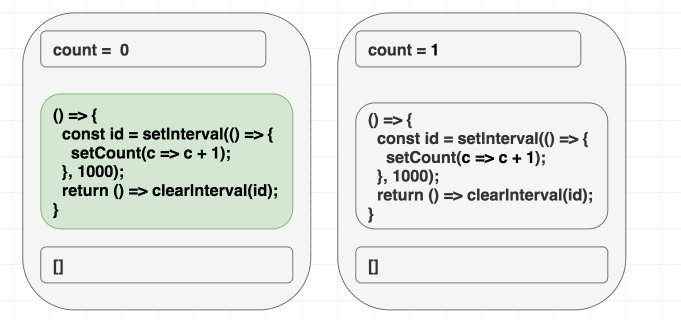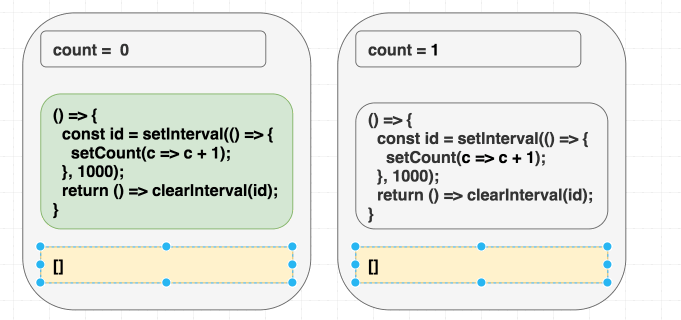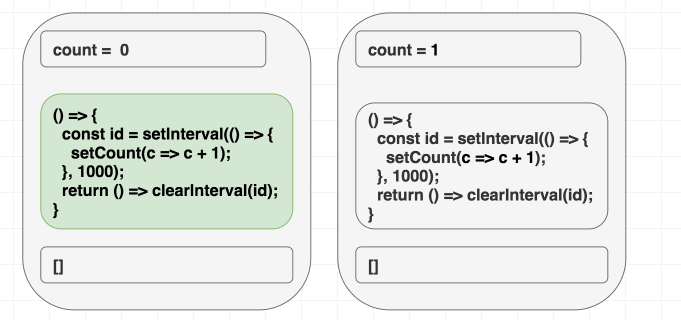


 EnhanCV từng gây sốt trong giới tuyển dụng khi trở thành trang web được yêu thích nhất vì sự đánh giá tích cực từ các ứng viên. Tuy nhiên đối với trang web này, bạn có thể sẽ phải trả phí khi tải và tạo một CV song, vẫn có nhiều bản miễn phí để các bạn lựa chọn.
EnhanCV từng gây sốt trong giới tuyển dụng khi trở thành trang web được yêu thích nhất vì sự đánh giá tích cực từ các ứng viên. Tuy nhiên đối với trang web này, bạn có thể sẽ phải trả phí khi tải và tạo một CV song, vẫn có nhiều bản miễn phí để các bạn lựa chọn.  Khả năng về sự điều chỉnh với những giao diện thiết kế tinh tế là một trong những ưu điểm của phần mềm này. Đồng thời, một điểm cộng lớn cho Resume là bạn có thể dễ dàng định dạng CV theo cả hai dạng PDF hoặc DOC tùy vào yêu cầu của nhà tuyển dụng.
Khả năng về sự điều chỉnh với những giao diện thiết kế tinh tế là một trong những ưu điểm của phần mềm này. Đồng thời, một điểm cộng lớn cho Resume là bạn có thể dễ dàng định dạng CV theo cả hai dạng PDF hoặc DOC tùy vào yêu cầu của nhà tuyển dụng.

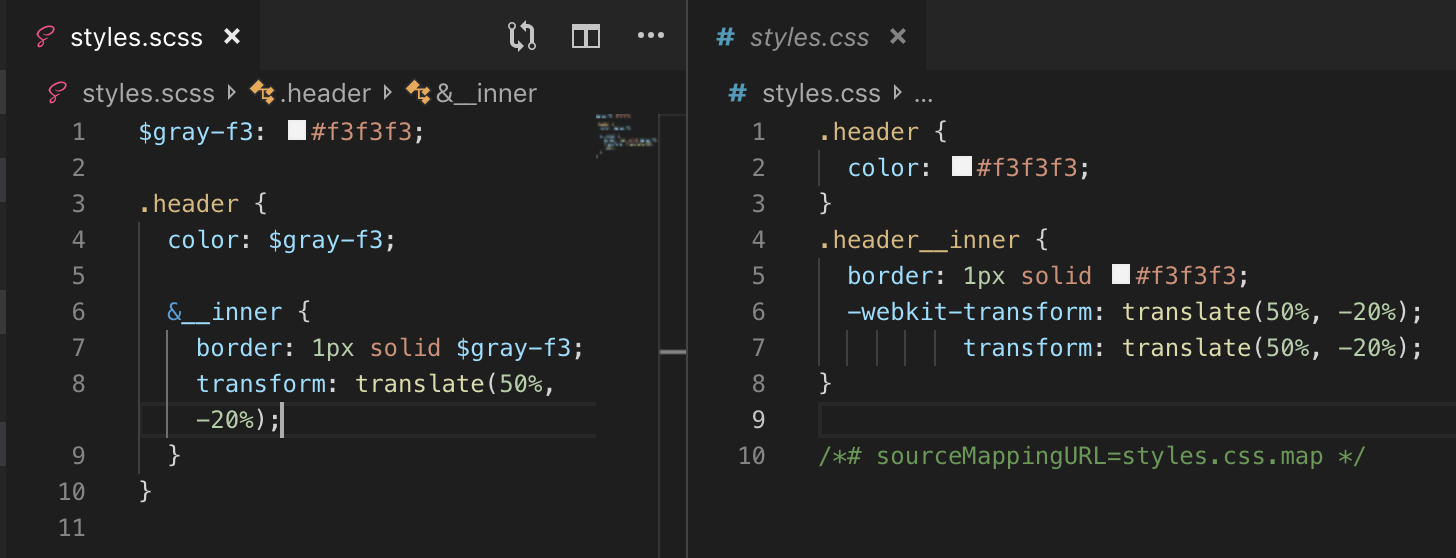
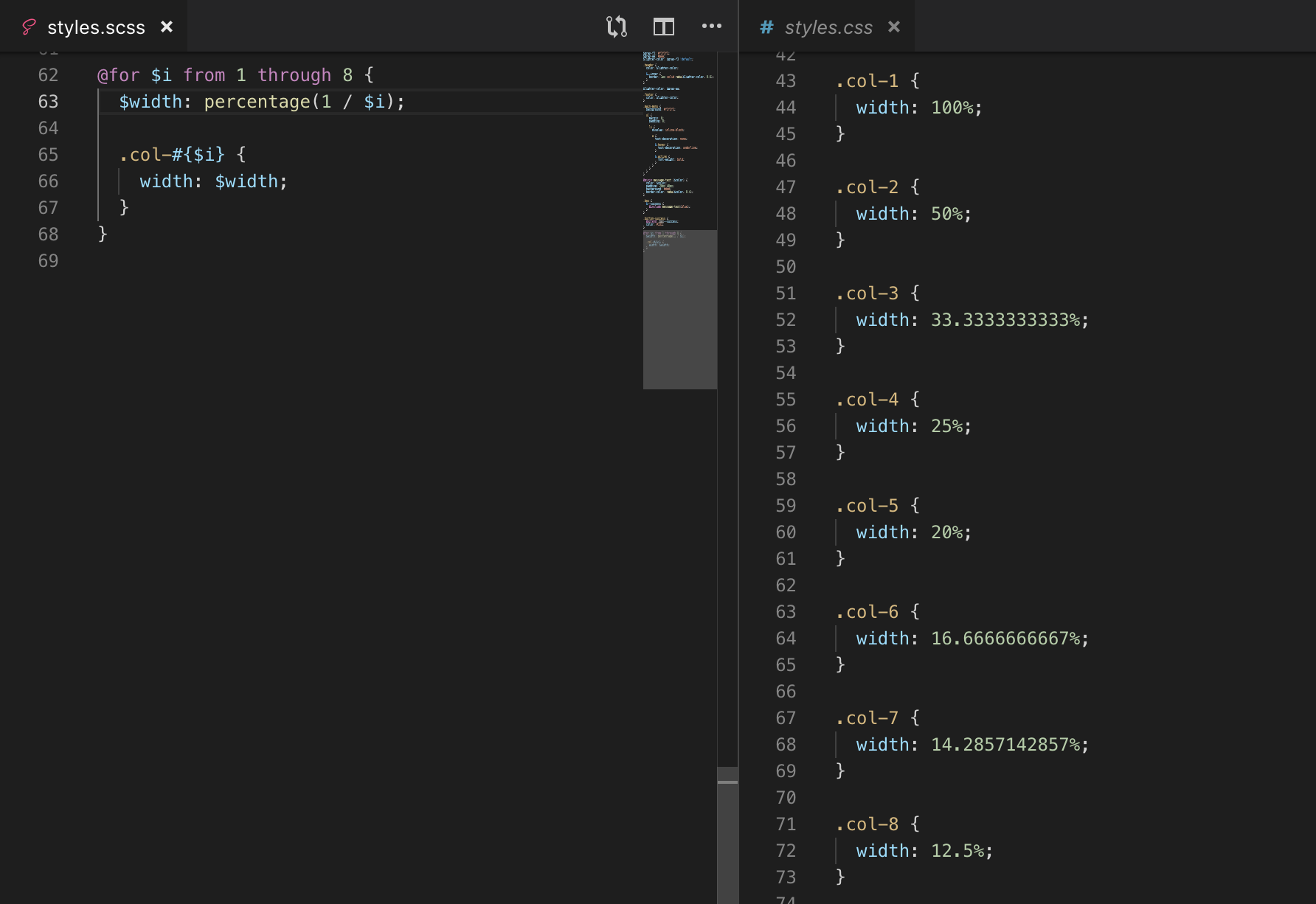
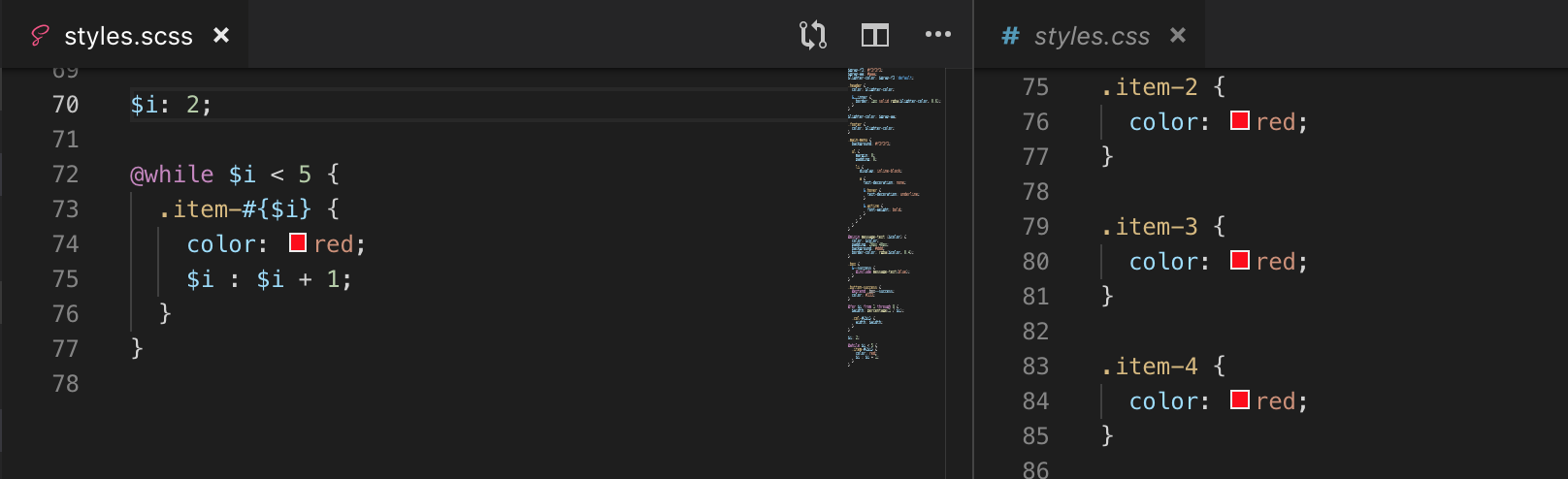
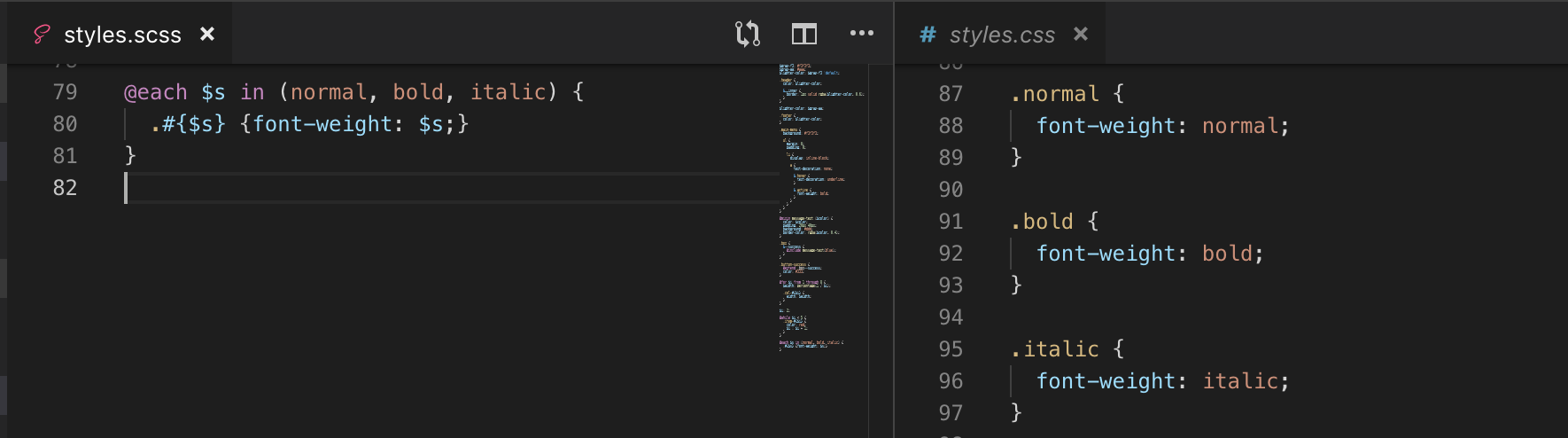
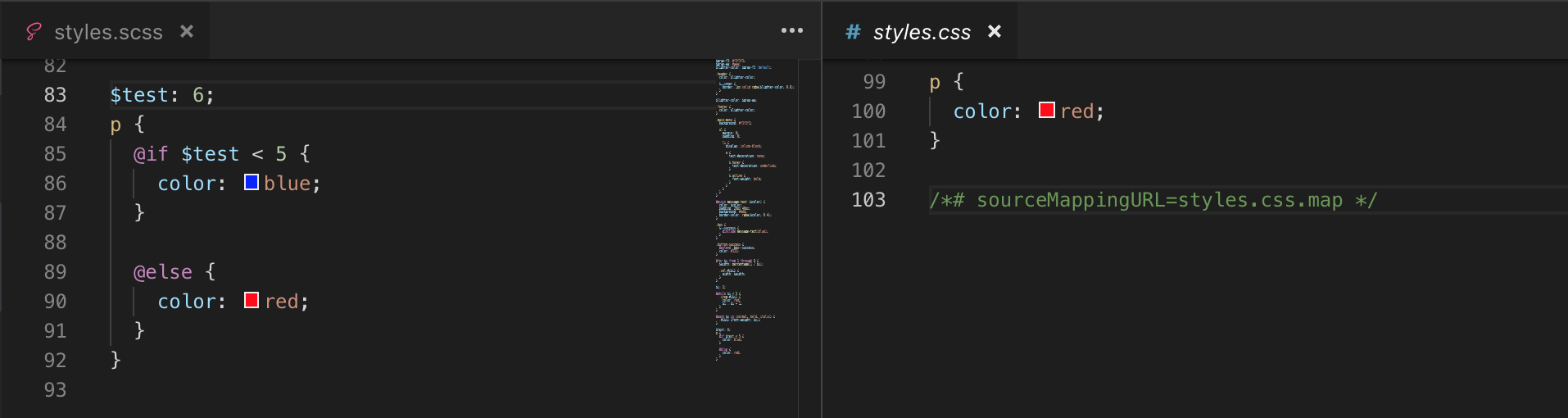
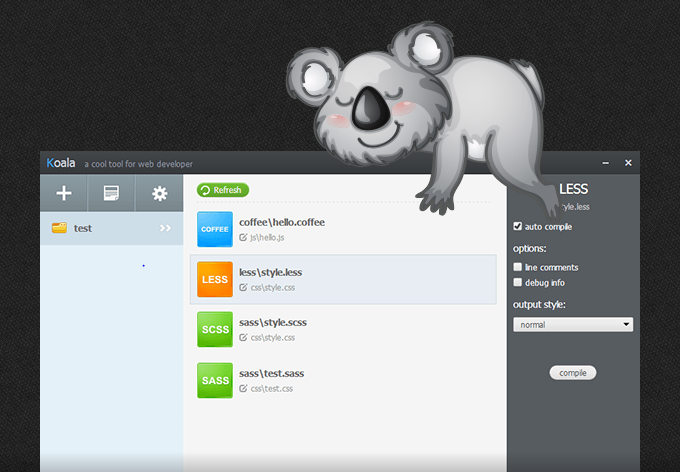

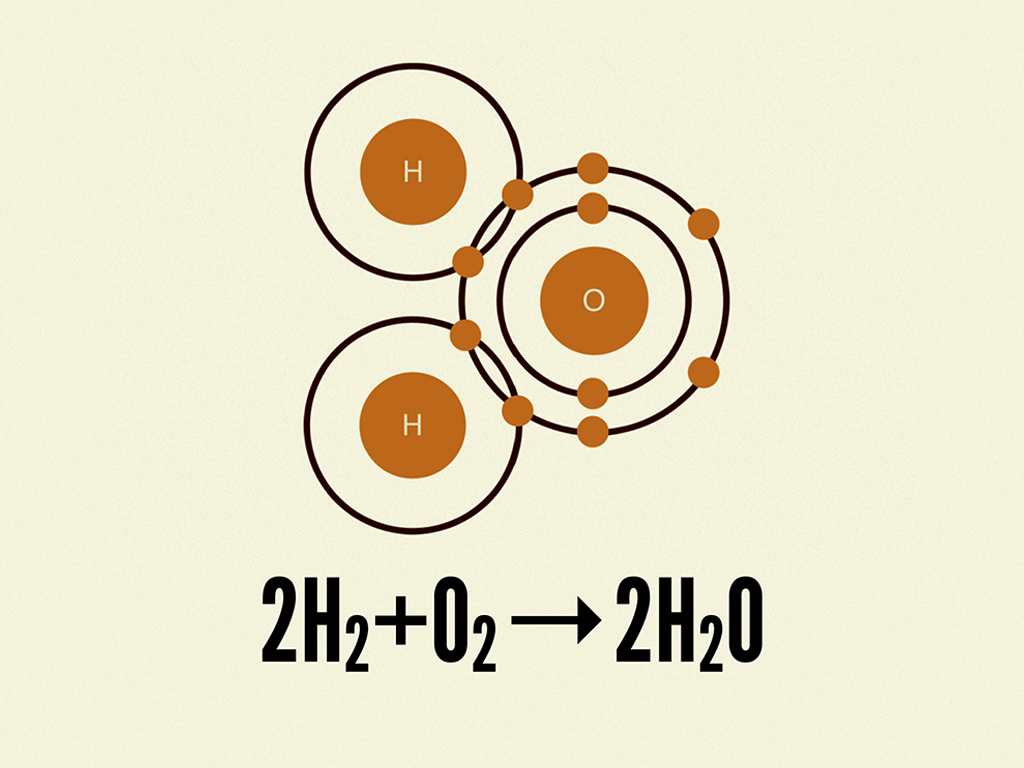

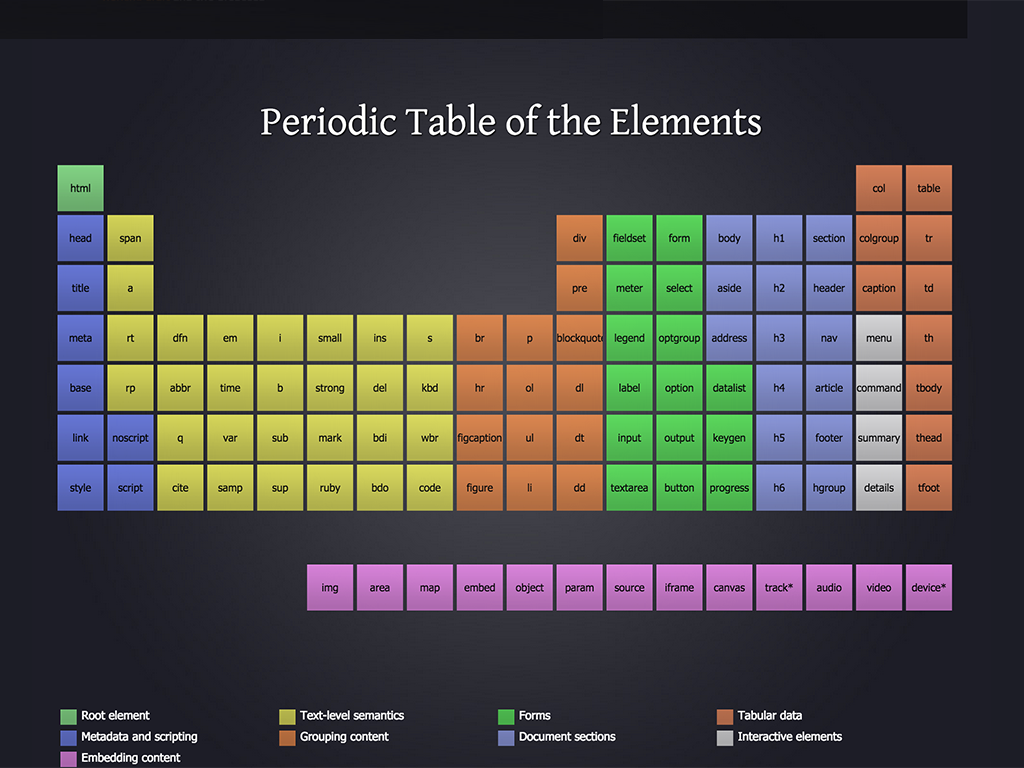

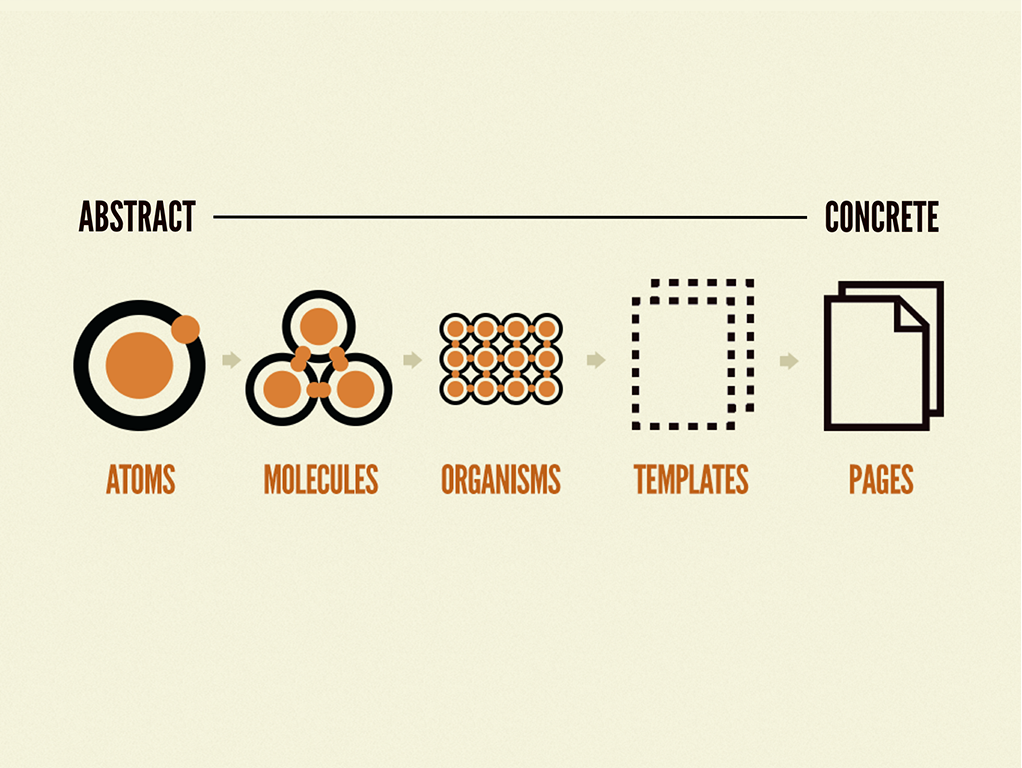

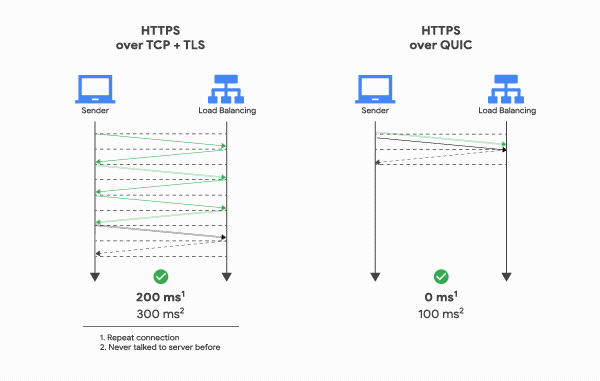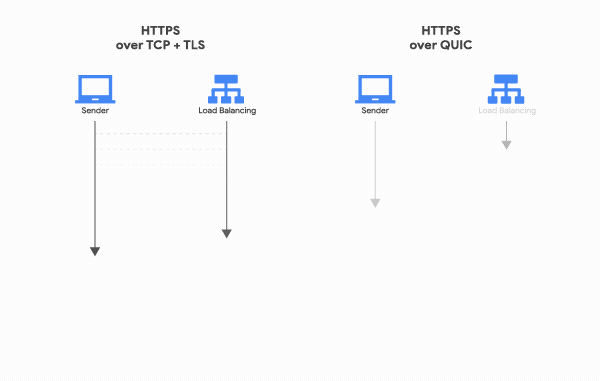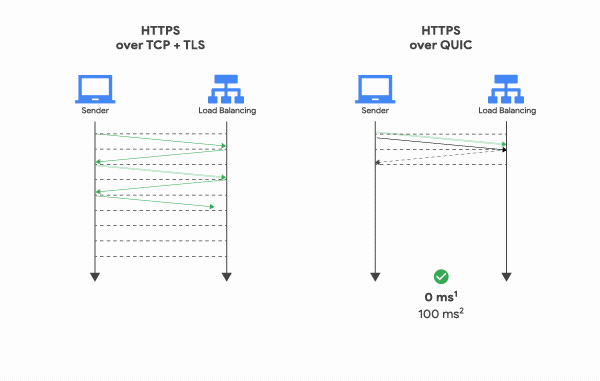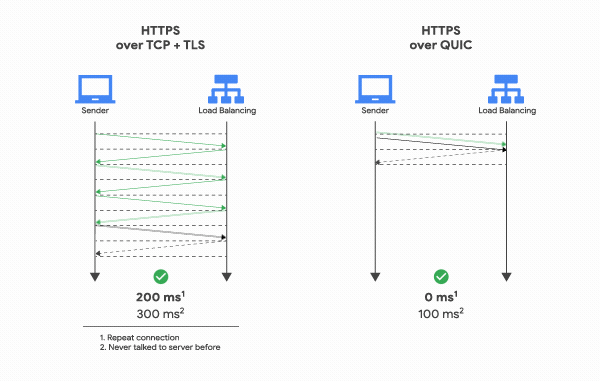
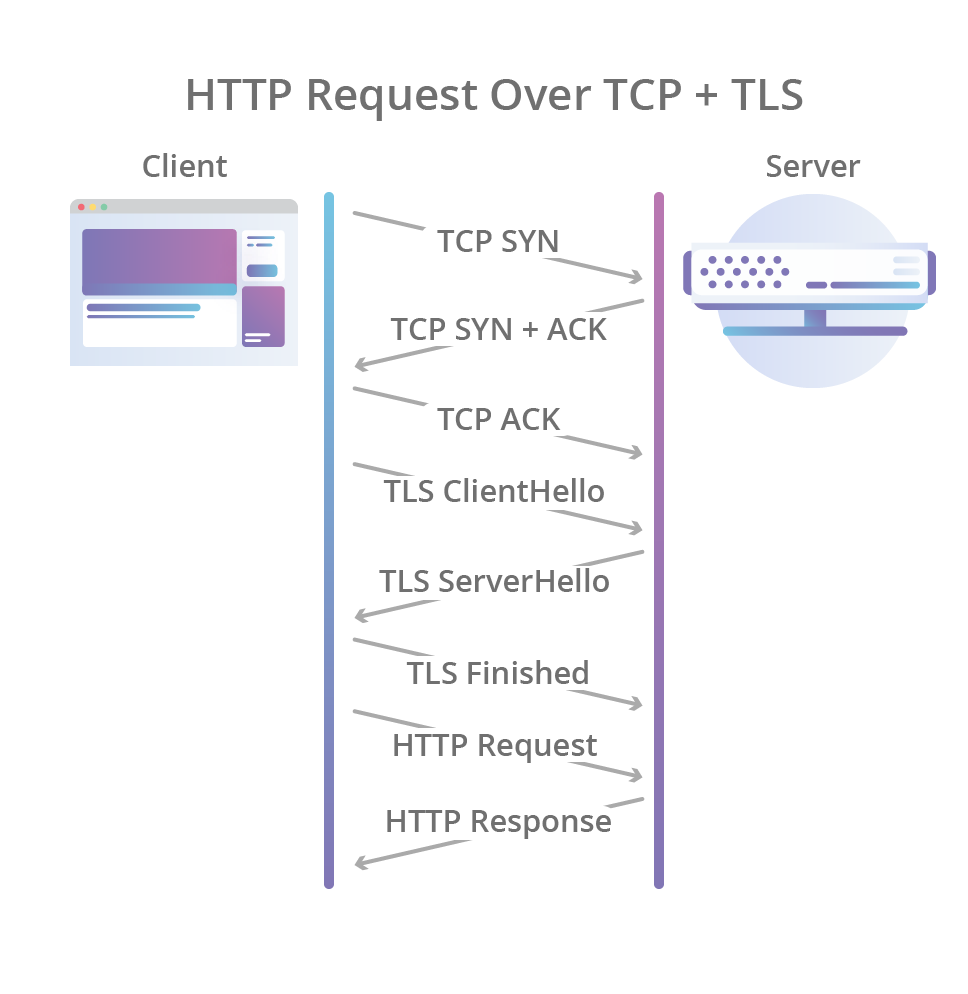
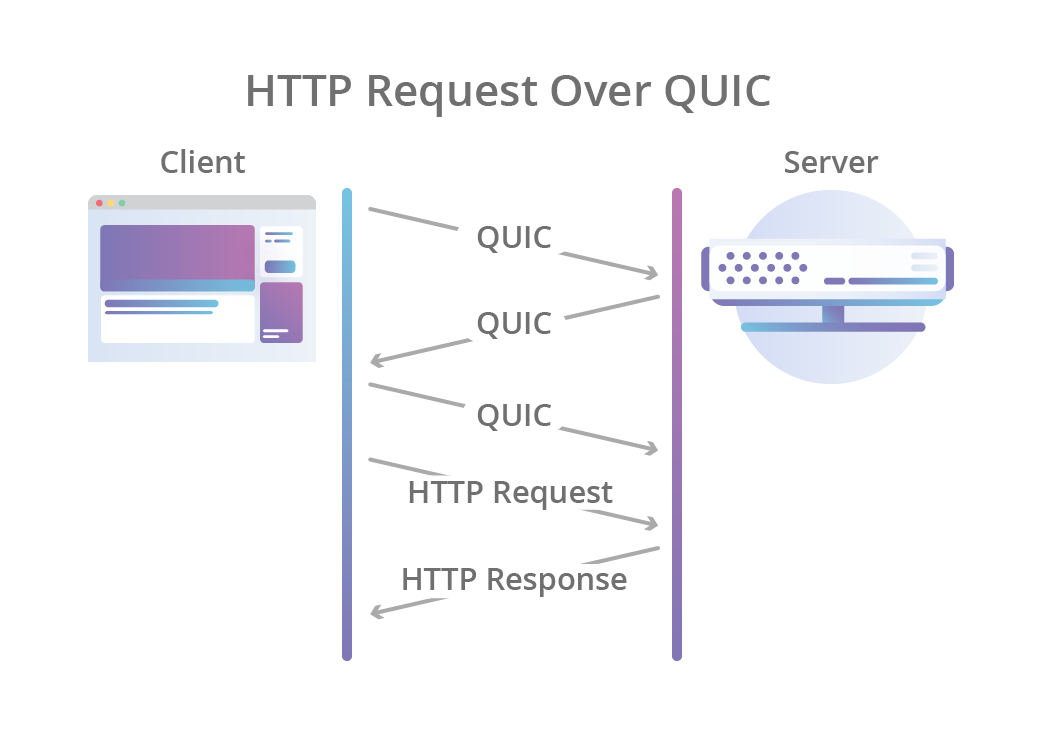

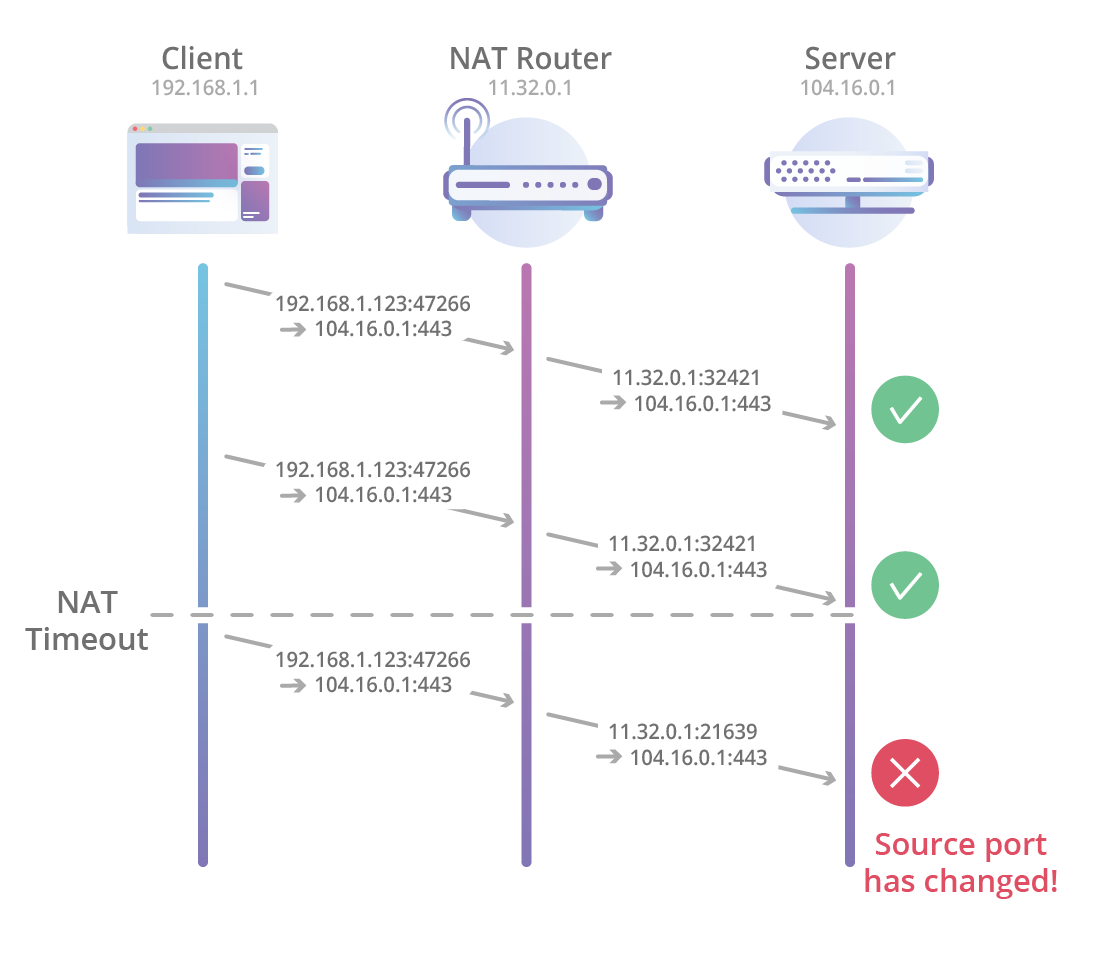


 Chúng ta có thể mong chờ vào một tương lai tươi sáng với QUIC!
Chúng ta có thể mong chờ vào một tương lai tươi sáng với QUIC!






