HTTP-over-QUIC là một giao thức (protocol) thử nghiệm đã đổi tên thành HTTP/3. IETF đã ra bản draft vào 03/2020.
Có một bước tiến dài trong quá trình phát triển từ HTTP/1.1 (ra đời vào năm 1999) cho đến sự xuất hiện của HTTP/2 (chính thức vào 2015) và mọi thứ đang tiếp tục phát triển với HTTP/3 dự kiến hoàn thành vào năm 2019. Bài viết có so sánh rất nhiều giữa HTTP/2 và 3 nên nếu chưa biết HTTP/2 là gì, bạn có thể đọc trước ở đây
Đường tới QUIC
QUIC (Quich UDP Internet Connections) một giao thức truyền tải internet đem đến rất nhiều cải tiến với thiết kế để tăng tốc lưu lượng HTTP cũng như làm cho nó bảo mật hơn, kèm theo mục tiêu cuối cùng sẽ dần dần thay thế TCP và TLS trên web. Trong bài blog này, chúng ta cùng điểm qua một vài tính năng chính của QUIC và những lợi điểm của nó cũng như những thử thách gặp phải trong quá trình hỗ trợ giao thức mới này. HTTP/3 bản chất là sự tiến hoá lên từ giao thức QUIC do Google phát triển, tất cả đều bắt đầu từ gợi ý sau của Mark Nottingham.
Thực tế là có 2 giao thức cùng có tên là QUIC:
- “Google QUIC” (viết tắt là gQUIC) là giao thức gốc được thiết kế bởi các kỹ sư của Google nhiều năm trước, mà sau nhiều năm thử nghiệm đang được IETF (Internet Engineering Task Force) đưa vào thành chuẩn chung.
- “IETF QUIC” (từ giờ ta sẽ gọi đơn giản là QUIC) là giao thức dựa trên gQUIC nhưng đã thay đổi rất nhiều khiến nó có thể được xem là một giao thức hoàn toàn khác. Từ format của các gói tin cho đến handshaking và mapping của HTTP, QUIC đã cải tiến rất nhiều thiết kết gốc của gQUIC nhờ vào sự hợp tác mở của rất nhiều tổ chức và nhân, cùng chia sẻ một mục đích chung giúp Internet nhanh hơn và an toàn hơn.
Tóm lại, QUIC có thể coi là kết hợp của TCP+TLS+HTTP/2 nhưng được implement trên UDP. Bởi vì TCP đã được phát triển, xây dựng sâu vào trong nhân của hệ điều hành, vào phần cứng của middlebox nên để có thể đưa ra sự thay đổi lớn cho TCP gần như là điều không thể. Tuy nhiên, vì QUIC được xây dựng trên UDP nên nó hoàn toàn không bị giới hạn gì cả.
Vậy đâu là những cải tiến mà QUIC đem lại?
Bảo mật là sẵn sàng (và cả hiệu năng nữa)
Một trong những điểm nổi bật của QUIC so với TCP đấy là việc bảo mật mặc định ngay từ mục đích thiết kế của giao thức. QUIC đạt được điều này thông qua việc cung cấp các tính năng bảo mật như xác thực và mã hoá (việc thường được thực hiện bởi lớp giao thức cao hơn TLS) ngay từ trong bản thân của giao thức.
Quá trình bắt tay (handshake) ban đầu của QUIC bao gồm bắt tay 3 bước (three-way handshake) như của TCP và đi kèm với bắt tay TLS 1.3, cung cấp xác thực cho end-points và đàm phán (negotiation) các tham số mã hoá. Đối với những ai đã quen với giao thức TLS, QUIC thay thế lớp bản ghi TLS bằng format frame của riêng mình trong khi vẫn giữ nguyên các message bắt tay TLS.
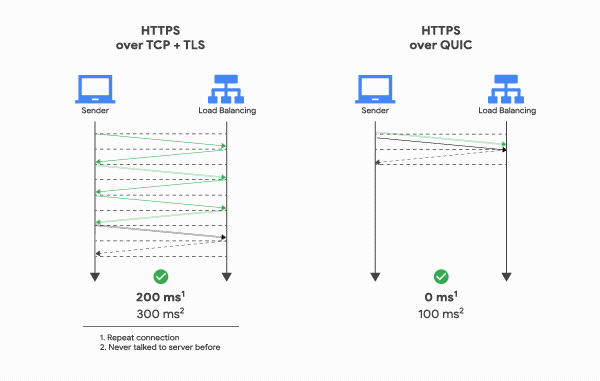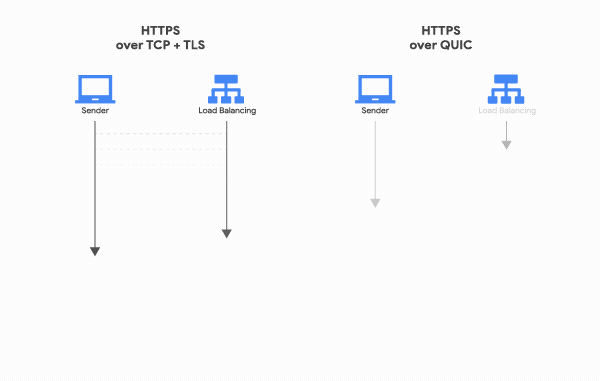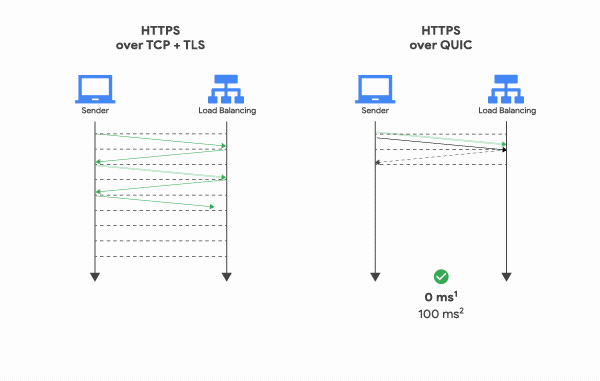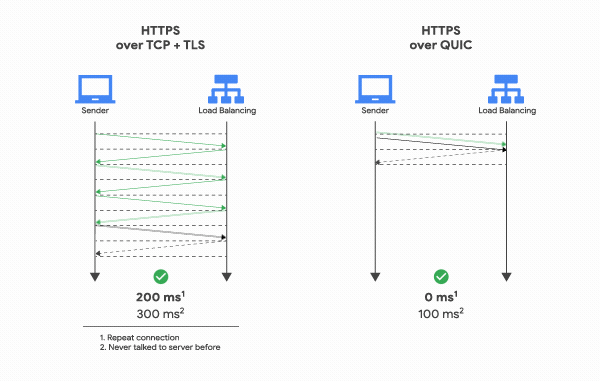
Hệ quả là không chỉ đảm bảo rằng kết nối luôn được xác thực vào bảo mật mà còn làm cho việc khởi tạo kết nối trở nên nhanh hơn: bắt tay thông qua QUIC chỉ cần 1 lần truyền tin qua lại giữa client và server là hoàn thành, thay vì phải tốn 2 lần: 1 lần cho TCP và 1 lần cho TLS 1.3 như hiện tại.
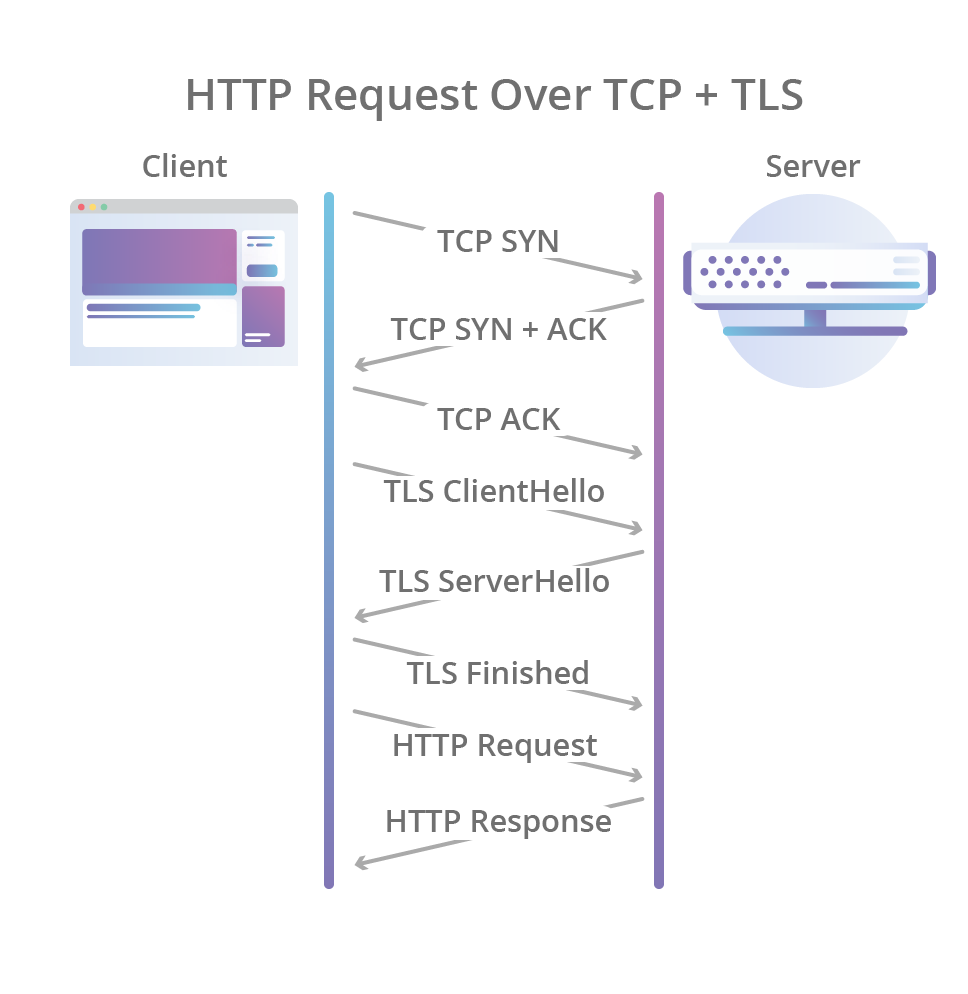
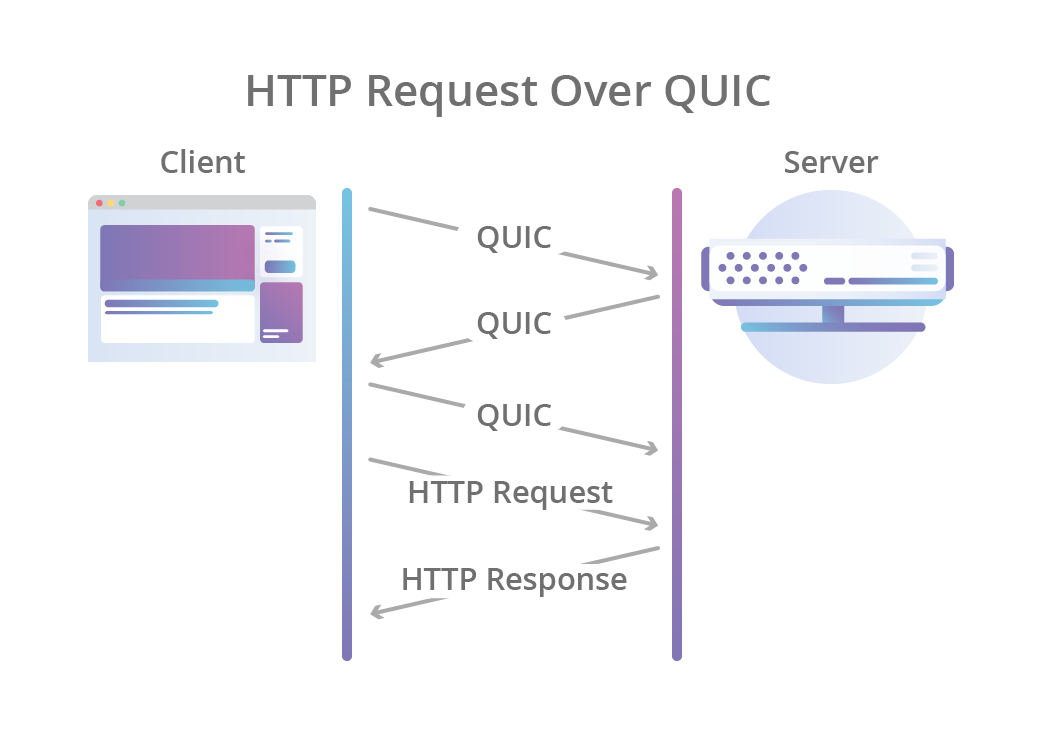
Tuy nhiên QUIC còn tiến xa hơn, mã hoá luôn cả metadata của kết nối, thứ mà có thể bị lợi dụng bởi các bên trung gian nhằm can thiệp vào kết nối. Ví dụ: số lượng gói tin (packets) có thể được sử dụng bởi kẻ tấn công trên đường truyền nhằm tìm ra mối liên quan với hoạt động của người dùng trên nhiều đường mạng khác nhau khi connection migration (xem bên dưới) diễn ra. Bằng việc mã hoá, QUIC đảm bảo rằng không ai có thể tìm ra mối liên quan với hoạt động dựa trên thông tin này ngoài end-point mà người dùng kết nối tới.
Mã hoá cũng là một thuốc chữa hiệu quả cho ossification (tạm dịch: vôi hoá, là một hiện tượng trong thiết kết giao thức, nếu bạn thiết kế giao thức có cấu trúc linh hoạt nhưng chẳng mấy khi sử dụng đặc tính đó thì khả năng có một số implement của giao thức sẽ coi phần đó là cố định. Giống như bạn có một cánh cửa mở nhưng hiếm khi mở nó, thì phần bản lề (phần di chuyển) dần dần sẽ bị oxy hoá), cho phép ta thực hiện việc đàm phán nhiều version khác nhau của cùng một giao thức. Thực tế đây ossification chính là lí do khiến việc triển khai TLS 1.3 bị trì hoãn quá lâu, và chỉ có thể được thực hiện sau rất nhiều thay đổi, được thiết kế để tránh cho các bên sản xuất thiết bị hiểu nhầm và block version mới của TLS, được đưa vào thực tế.
Head-of-line blocking
Một trong những cải tiến HTTP/2 đem đến là khả năng multiplex nhiều HTTP request trên cùng một kết nối TCP. Điều này cho phép các ứng dụng sử dụng HTTP/2 xử lý các request đồng thời và tối ưu hơn băng thông có sẵn.
Đây thực sự là cải tiến lớn so với thế hệ trước, yêu cầu app phải tạo nhiều kết nối TCP+TLS nếu app muốn xử lý đồng thời nhiều request HTTP/1.1 (VD như khi trình duyệt cần phải tải đồng thời Javascript và CSS để hiển thị trang). Tạo nhiều kết nối mới yêu cầu phải lặp đi lặp lại việc bắt tay nhiều lần, đồng thời phải trải qua quá trình khởi động (warm-up) dẫn tới việc hiển thị trang web bị chậm. Khả năng multiplex nhiều HTTP tránh được tất cả những điều này.

Tuy nhiên, vẫn có nhược điểm. Vì nhiều request/response được truyền qua cùng một kết nối TCP, tất cả đều bị ảnh hưởng bởi việc mất gói tin (packet loss), VD: do nghẽn mạng (network congestion), kể cả khi chỉ phần dữ liệu bị mất chỉ ảnh hưởng đến một kết nối. Hiện tượng này được gọi là “head-of-line blocking”.
QUIC đã tiến một bước sâu hơn và hỗ trợ việc multiplexing sao cho: các luồng (stream) HTTP khác nhau sẽ được map với các luồng QUIC transport khác nhau, nhưng tất cả vẫn chia sẻ chung một kết nối QUIC, nên không cần phải bắt tay lại. Thêm vào đó, tuy trạng thái nghẽn mạng được chia sẻ nhưng các luồng QUIC được phân phát riêng biệt nên trong phần lớn các trường hợp việc mất gói tin của một luồng không làm ảnh hưởng đến luồng khác.
Việc này có thể giảm đi trông thấy thời gian cần đển hiển thị hoàn chỉnh trang web (với CSS, Javascript, ảnh và các thể loại media khác nhau) đặc biệt trong tình huống đường mạng hay bị nghẽn và tỉ lệ rớt mạng cao.
Nghe có vẻ đơn giản, nhỉ?
Để có thể đem đến những điều hứa hẹn như vậy, QUIC cần phải phá bỏ một số giả định mà rất nhiều ứng dụng mạng vẫn tin vào, dẫn tới khả năng cài đặt QUIC và triển khai nó trở nên khó khăn hơn.
Vì vậy, QUIC được thiết kế để hoạt động dựa trên giao thức UDP để dễ dàng cho vệc triển khai và tránh vấn đề xảy ra khi các thiết bị mạng lại bỏ (drop) các gói tin từ một giao thức không rõ ràng, vì cơ bản tất cả các thiết bị mạng đều có hỗ trợ sẵn UDP. Việc này cũng cho phép QUIC nhanh chóng được đưa vào các ứng dụng ở tầng user, VD: các trình duyệt có thể cài đặt các giao thức mới và chuyển đến tay người dùng mà không cần phải chờ hệ điều hành cập nhật.
Mặc dù mục tiêu thiết kế ban đầu của QUIC là để tránh việc phải “break” những cái đang có, thì với thiết kế này cũng đưa việc chống lạm dụng và điều hướng gói tin đến đúng end-point trở nên thách thức hơn.
Chỉ cần NAT để đưa tất cả vào và âm thầm binding từ phía sau
Về cơ bản, các NAT router có thể theo dõi các kết nối TCP chạy qua bằng cách sử dụng 1 tuple gồm 4 thành phần (source IP address, source port, destination IP address, destination port) và bằng cách theo dõi các packet TCP SYN, ACK, FIN được truyền qua mạng, router có thể theo dõi được khi nào thì kết nối mới được tạo và bị huỷ. Việc này cũng cho phép router quản lý chính xác thời gian NAT binding (NAT binding: là mapping tương ứng giữa IP address và và port nội bộ với bên ngoài)
Đối với QUIC, việc này vẫn chưa khả thi do các NAT router có mặt hiện nay vẫn chưa hiểu QUIC là gì nên khi xử lý chúng sẽ fallback về mặc định, nghĩa là coi gói tin QUIC như là 1 gói tin UDP bình thường và xử lý. Việc xử lý UDP thiếu chính xác, tuỳ ý và có time-out ngắn có thể gây ảnh hưởng đến các kết nối cần giữ trong thời gian dài.
Khi bị timeout sẽ có hiện tượng NAT rebinding, lúc này end-point ở phía ngoài phạm vi của NAT sẽ thấy các gói tin đến từ một port khác với port ban đầu khi kết nối được khởi tạo, dẫn đến việc theo dấu kết nối chỉ bằng tuple gồm 4 thành phần như trên là không thể.
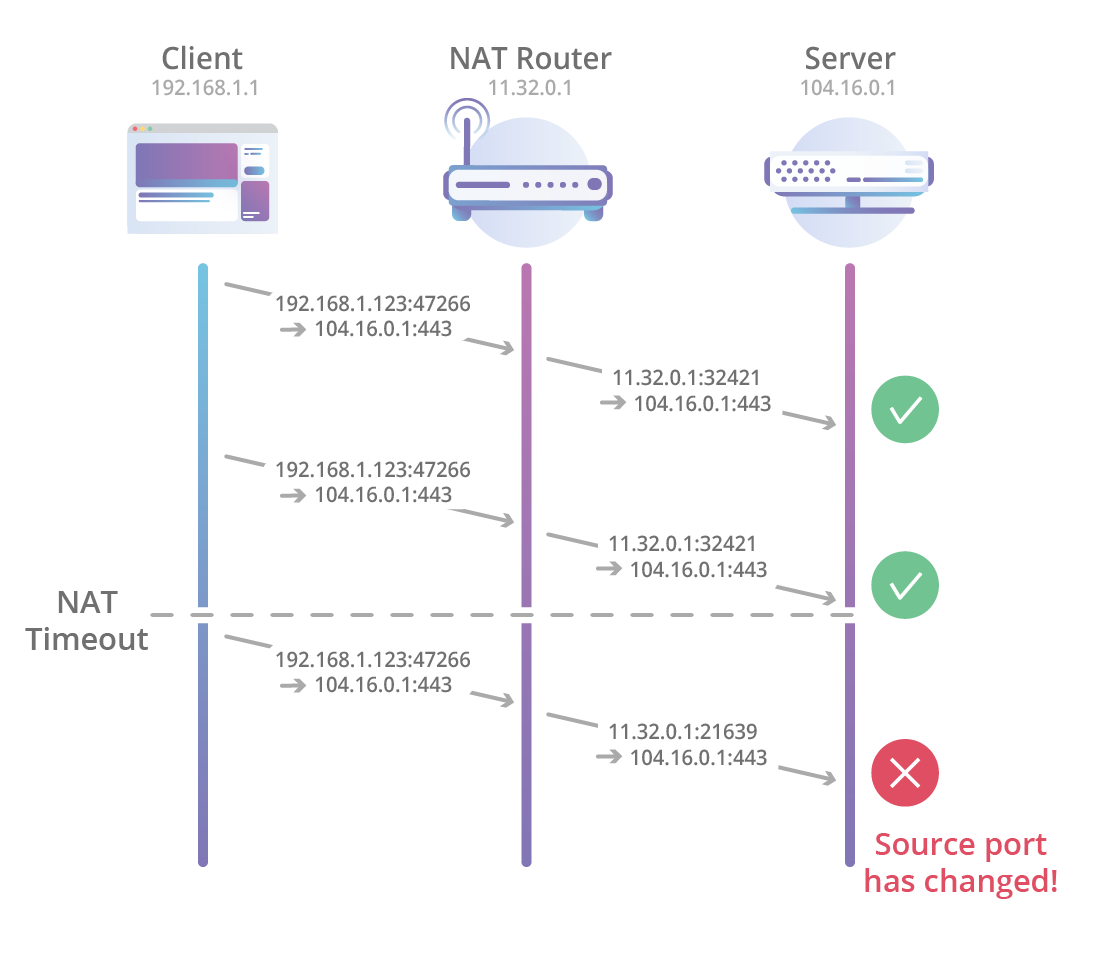
Và không chỉ mỗi NAT gặp vấn đề, một tính năng khác mà QUIC đem tới cũng gặp tình trạng tương tự. Đó là tính năng connection migration: cho phép chuyển qua lại giữa các kết nối khác nhau, VD: khi một thiết bị mobile đang kết nối thông qua mạng di động (cellular data) bắt được Wifi có chất lượng tốt hơn và chuyển sang mạng wifi này, vẫn đảm bảo kết nối dù IP và port có thể thay đổi.

QUIC giải quyết vấn đề này bằng cách đưa vào một khái niệm mới: Connection ID. Connection ID là một đoạn dữ liệu có chiều dài tự ý ở bên trong gói tin QUIC cho phép định danh một kết nối. End-point có thể dùng ID này để theo dấu kết nối cần được xử lý mà không cần phải kiểm tra tuple 4 thành phần như trên. Trên thực tế có thể có nhiều ID trong cùng một kết nối (khi có connection migration, việc này sẽ xảy ra để tránh liên kết nhầm các đường mạng khác nhau) nhưng về cơ bản việc này được quản lý bởi end-point chứ không phải thiết bị trung gian nên cũng không sao.
Tuy nhiên, đây cũng có thể là vấn đề với các nhà mạng sử dụng địa chỉ anycast và ECMP routing khi mà duy nhất một địa chỉ IP đích có thể là định danh cho rất nhiều server ở phía sau. Vì các edge router (router ngoài cùng) trong mạng cũng chưa biết phải xử lý QUIC như thế nào nên có thể xảy ra trường hợp gói tin UDP ở trong cùng một kết nối QUIC (nghĩa là cùng connection ID) nhưng có tuple 4 thành phần khác nhau (do bị NAT rebinding hoặc do connection migration) có thể bị điều hướng đến một server khác dẫn đến đứt kết nối.
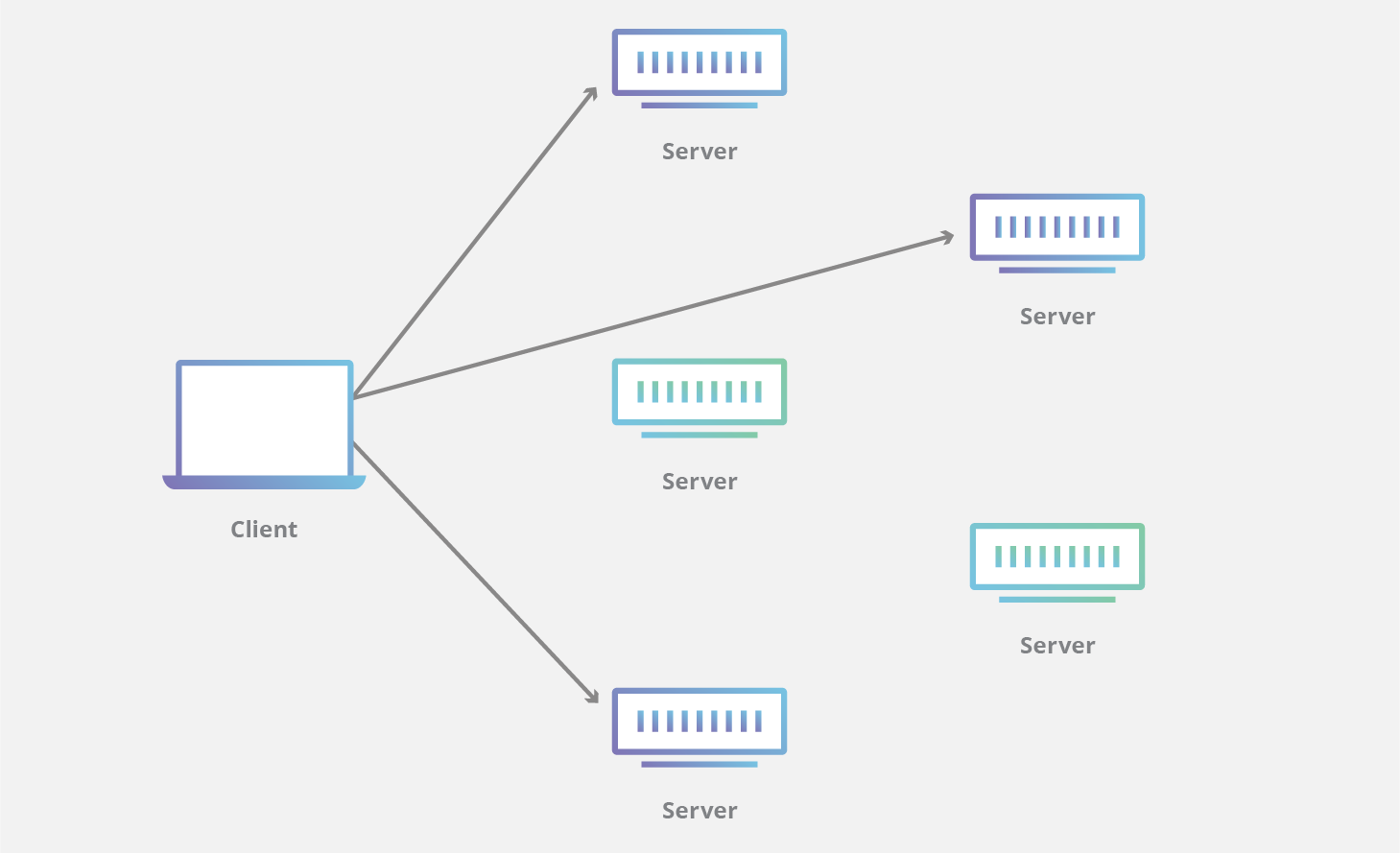
Để giải quyết vấn đề này, các nhà mạng cần phải triển khai giải pháp load balance thông minh hơn ở layer 4, có thể bằng các phần mềm mà ko cần đụng đến các router (có thể tham khảo dự án Katran của Facebook)
QPACK
Một lợi điểm khác được HTTP/2 giới thiệu là nén header (header compression (HPACK)) cho phép HTTP/2 end-point giảm lượng dữ liệu phải truyền qua mạng bằng cách loại bỏ các phần thừa trong HTTP request và response.
Cụ thể, HPACK có các bảng động (dynamic tables) chứa các header đã được gửi (hoặc được nhận) trong HTTP request (hoặc response) trước đó, cho phép các end-point tham chiếu các header trước đó với các header gặp phải ở trong request (hoặc resoponse) mới và không cần truyền lại nữa.
Các bảng động của HPACK cần phải được đồng bộ giữa bên mã hoá (phía gửi HTTP request hoặc response) và phía giải mã (nơi nhận chúng) nếu không thì phía giải mã sẽ không thể giải mã được.
Với HTTP/2 chạy trên TCP, việc đồng bộ này diễn ra rất rõ ràng vì lớp TCP đã xử lý giúp chúng ta việc truyền đi các HTTP request và response theo đúng thứ tự chúng được gửi. Khi đó, phía mã hoá có thể gửi hướng dẫn cập nhật bảng như là một phần của request (hoặc response) khiến cho việc mã hoá trở nên rất đơn giản. Nhưng đối với QUIC thì mọi chuyện lại phức tạp hơn.
QUIC có thể gửi nhiều HTTP request ( hoặc response) qua nhiều luồng đồng lập, nghĩa là nếu chỉ có một luồng, QUIC cũng sẽ cố gắng gửi theo đúng thứ tự nhưng khi nhiều luồng xuất hiện, trật tự không còn được đảm bảo nữa.
Ví dụ, nếu client gửi một HTTP request A qua luồng A, và request B qua luồng B, thì có thể xuất hiện trường hợp như sau: do việc sắp xếp lại thứ tự của gói tin mà request B được server nhận trước request A, và nếu request B được client encode và có tham chiếu đến một header từ request A thì server sẽ không thể decode được vì chưa nhận được request A ?!
Ở giao thức gQUIC, vấn đề này được giải quyết đơn giản bằng xếp thứ tự tất cả các header của HTTP request và response (chỉ header chứ không phải body) trên cùng một luồng gQUIC. Khi đó tất các header sẽ được truyền đúng thứ tự trong mọi trường hợp. Đây là một cơ chế rất đơn giản cho phép có thể sử dụng lại rất nhiều code của HTTP/2 nhưng ngược lại cũng gia tăng vấn đề head-of-line blocking, thứ mà QUIC được thiết kế để làm giảm. Do đó, nhóm IETF QUIC đã thiết kế một cách mapping mới giữa HTTP và QUIC (“HTTP/QUIC”) và một cơ chế nén header mới gọi là “QPACK”.
Trong bản draft mới nhất của phần mapping HTTP/QUIC và QPACK, mỗi trao đổi HTTP request/response sử dụng một luồng QUIC 2 chiều củả chính nó, do vậy sẽ không xuất hiện tình trạng head-of-line blocking. Thêm vào đó, để hỗ trợ QPACK, mỗi phía của kết nối sẽ tạo thêm 2 luồng QUIC một chiều, một dùng để gửi cập nhật bảng QPACK đến cho phía còn lại, một để xác nhận những cập nhật này. Theo cách này mã hoá QPACK có thể sử dụng bảng động tham chiếu chỉ sau khi nó đã được xác nhận bởi phía giải mã.
Chống lại tấn công Reflection
Một vấn đề thường gặp phải ở những giao thức dựa trên UDP (xem thêm ở đây và ở đây) đấy là chúng nhạy cảm với kiểu tấn công reflection (phản chiếu). Đây là hình thức tấn công mà kẻ tấn công lừa server gửi một lượng lớn dữ liệu đến nạn nhân bằng cách làm giả địa chỉ IP source của gói tin gửi đến server khiến chúng trông có vẻ như là được gửi từ nạn nhân. Hình thức này được sử dụng rất nhiều trong các cuộc tấn công DDoS.
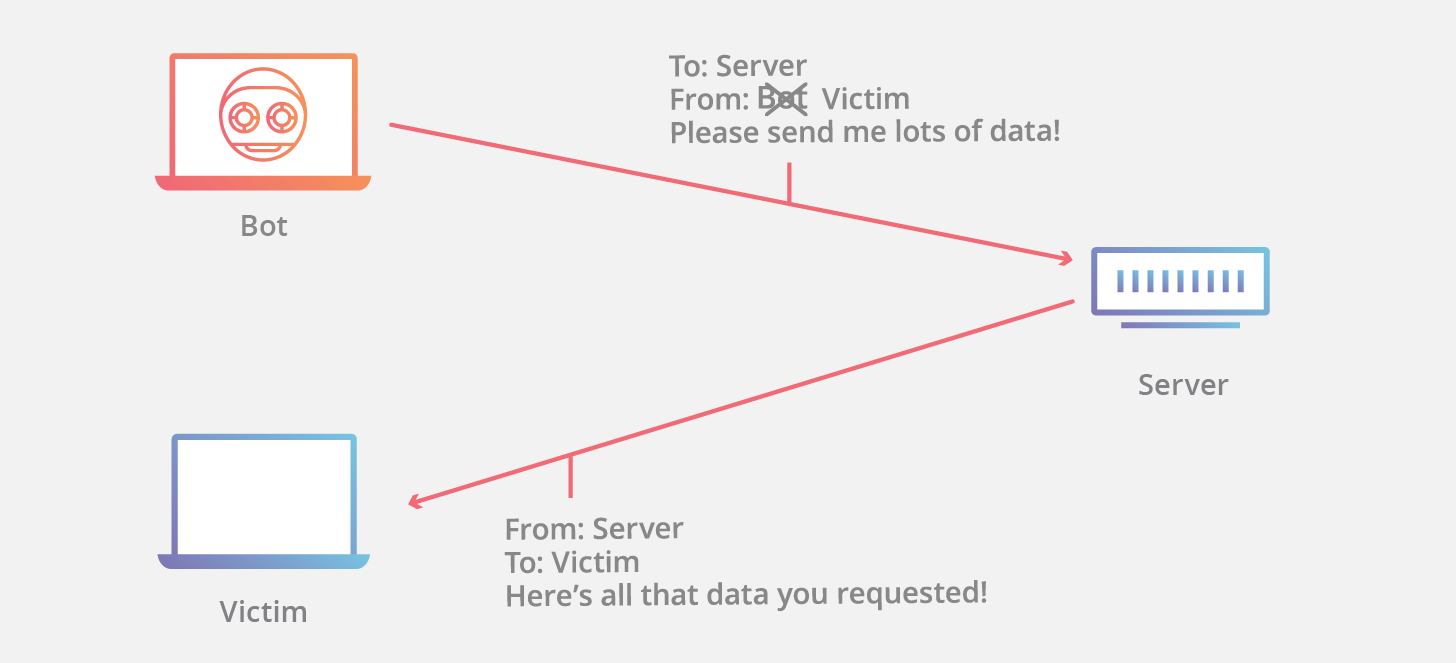
Nó còn đặc biệt hiệu quả trong trường hợp, response gửi bởi server lớn hơn rất nhiều so với request mà nó nhận được (nên còn có tên gọi là tấn công “khuếch đại”).
TCP không thường được sử dụng cho hình thức tấn công này do những gói tin được gửi trong quá trình bắt tay (SYN, SYN+ACK,…) đều có chiều dài bằng nhau nên không có tiềm năng dùng để “khuếch đại”.
Quy trình bắt tay của QUIC thì ngược lại, không được đối xứng như vậy: ví dụ với TLS, trong lần gửi đầu tiên, QUIC server thường sẽ gửi lại certificate chain của mình, có thể rất lớn, trong khi client chỉ cần gửi có vài bytes (TLS ClientHello message chứa trong gói tin QUIC). Vì lí do này, gói tin QUIC ban đầu gửi từ client cần phải pad (gắn thêm dữ liệu) đến một chiều dài tối thiểu cho dù thực tế nội dung của gói tin nhỏ hơn nhiều. Kể cả như thế đi nữa thì biện pháp này vẫn chưa đủ, vì về cơ bản, response của server thường được chia thành nhiều gói tin nên vẫn có thể lớn hơn rất nhiều gói tin đã đc padding từ client.
Giao thức QUIC cũng định nghĩa một cơ chế xác thực địa chỉ IP nguồn, khi đó server thay vì gửi lại một response dài thì chỉ gửi lại một gói tin “retry” nhỏ hơn rất nhiều chưa một token mã hoá đặc biệt mà client sẽ phải echo (gửi lại đúng ý nguyên) về phía server trong một gói tin mới. Theo cách này, server có thể chắc chắn là client không fake địa chỉ IP nguồn của chính mình (vì client đúng là có nhận được retry packet) và có thể tiếp tục hoàn thành quá trình bắt tay. Nhược điểm của biện pháp này là nó tăng thời gian bắt tay thông thường từ 1 vòng trao đổi client-server lên thành 2 vòng.
Một giải pháp khác là làm giảm kích cỡ của response từ server cho đến một lúc mà tấn công reflection trở nên không còn hiệu quả quả nữa, ví dụ sử dụng chứng chỉ ECDSA (cơ bản nhỏ hơn nhiều so với chứng chỉ RSA tương đương). Cloudflare cũng đang thử nghiệm với các cơ chế nén chứng chỉ TLS sử dụng các thuật toán nén như zlib, broti (là một tính năng được giới thiệu ban đầu bởi gQUIC nhưng hiện không khả dụng trong TLS).
Forward error correction
Là kĩ thuật sửa lỗi cho phép phát hiện và sửa một số lỗi nhất định xảy ra trong quá trình truyền dữ liệu mà không cần phải truyền lại. HTTP/3 cũng hỗ trợ kỹ thuật này, đọc thêm tại https://http3-explained.haxx.se/en/quic-v2#forward-error-correction
Hiệu năng của UDP
Một vấn đề lặp đi lặp lại với QUIC là những thiết bị phần cứng và phần mềm hiện tại chưa hiểu được giao thức mới này là gì. Ở trên, chúng ta đã xem xét cách QUIC giải quyết các vấn đề phát sinh khi gói tin đi qua các thiết bị mạng, router nhưng có một vấn đề tiềm năng khác chính là hiệu năng gửi và nhận dữ liệu qua UDP ở trên chính các end-point đang sử dụng QUIC. Qua nhiều năm, rất nhiều công sức đã được bỏ ra để tối ưu TCP nhất có thể, từ việc xây dựng khả năng off-loading vào phần mềm (hệ điều hành) và phần cứng (card mạng) nhưng đối với UDP thì hoàn toàn chưa có gì.
Tuy nhiên, chỉ còn là vấn đề thời gian cho đến khi UDP cũng được hưởng lợi từ những công sức trên. Gần đây, ta có thể thấy vài ví dụ, từ việc implement Generic Segmentation Offloading for UDP on LInux thứ cho phép các ứng dụng có thể gửi nhiều đoạn UDP giữa user-space và network stack của kernel-space với chi phí tương đương (hoặc gần như tương đương) của việc chỉ gửi 1 đoạn. Hay là việc thêm zerocopy socket support on Linux cũng cho phép ứng dụng tránh được chi phí phát sinh khi copy vùng nhớ từ user-spacve vào kernel-space.
Kết luận
Giống như HTTP/2 và TLS 1.3, QUIC đem đến rất nhiều tính năng mới để nâng cao hiệu năng và bảo mật của web site, cũng như các thành phần khác dựa trên internet. Nhóm hoạt động IETF đang đặt ra mục tiêu đưa ra version đầu tiên của spec của QUIC vào cuối năm 2018.
- Cloudflare cũng đã và đang làm việc chăm chỉ để có thể sớm đưa những lợi ích của QUIC đến với toàn bộ khách hàng. Update: Cloudflare đã hoàn thành việc hỗ trợ HTTP/3 bằng việc tạo ra quiche, phiên bản open-source của HTTP/3 được viết bằng Rust.

- Google nói rằng gần 1/2 tất cả những request từ trình duyệt Chrome tới server của Google được thực hiện qua QUIC và họ mong muốn sẽ tăng thêm lưu lượng thực hiện qua QUIC để tiến tới đưa nó thành phương thức mặc định từ kết nối client của Google, kể cả từ trình duyệt và thiết bị di động, đến server của Google.
- Hỗ trợ cho HTTP/3 đã được thêm vào Chrome (Canary build) vào 09/2019, và mặc dù HTTP/3 chưa được bật mặc định tron bất kỳ trình duyệt nào nhưng ở thời điểm năm 2020, HTTP/3 đã được hỗ trợ trong Chrome and Firefox (cần bật flag thì mới có thể dùng được). Bạn có thể thử nghiệm với HTTP/3 theo hướng dẫn tại đây.
 Chúng ta có thể mong chờ vào một tương lai tươi sáng với QUIC!
Chúng ta có thể mong chờ vào một tương lai tươi sáng với QUIC!
Bài viết được dịch và tổng hợp từ CloudFlare Blog và Medium