

Bài viết được sự cho phép của tác giả Huy Hoàng
Khi tìm hiểu và làm việc với Distributed Systems, chúng ta có thể sẽ hay bắt gặp những cụm từ như: Replicated State machine, Log replication hay Event-driven, Event-sourcing. Về bản chất, những khái niệm này đều được xây dựng xung quanh mô hình “Máy trạng thái” (State machine). Bài viết này sẽ mô tả mô hình này và lý do tại sao State machine lại được áp dụng rộng rãi trong Distributed Systems.
Nhắc lại sơ qua một vài khái niệm
- Trạng thái (state) của một process có thể hiểu là tập hợp các giá trị của các biến (variable) trong process đó. VD, nếu process
p1có thể có stateS1 = {x=1, y=2}. Thường trong thực tế, một process sẽ có cả dữ liệu trong RAM lẫn trên đĩa cứng, chúng ta coi tất cả các dữ liệu này là state của process đó. - State machine trong tin học là một mô hình tính toán, trong đó một máy tính (machine) thay đổi trạng thái (state) dựa theo chuỗi input mà nó được cung cấp. Ta hãy lấy ví dụ một bài toán: xác định xem trong một dãy số nhị phân (VD:
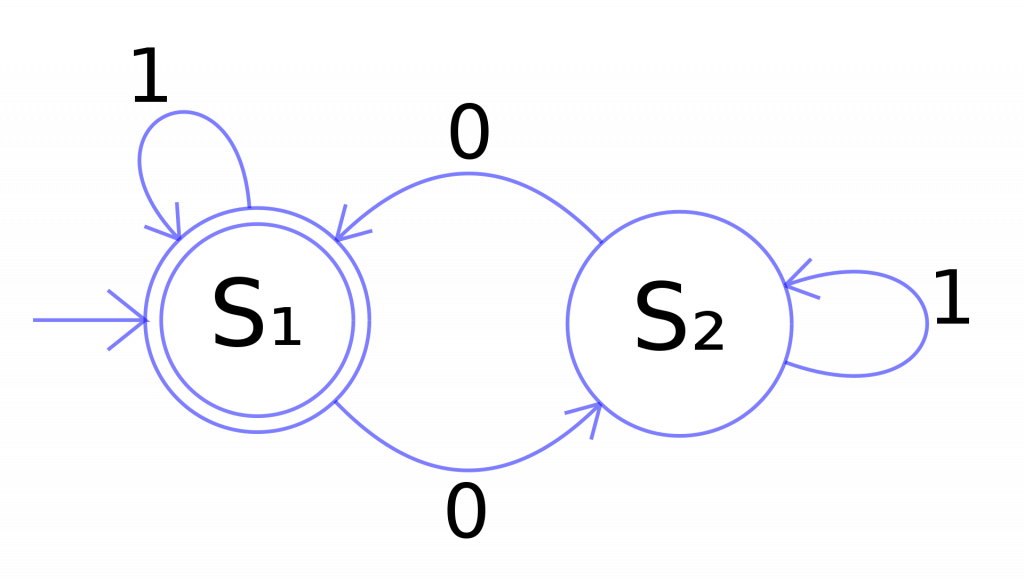
110100101), số chữ số0là chẵn hay lẻ. Bài toán này có thể giải bằng cấu trúc State machine, trong đó chuỗi input là chuỗi các chữ số nhị phân, và “state” có thể là “chẵn” (S1) hay “lẻ” (S2). State machine này bắt đầu từ trạng thái S1 (có 0 chữ số0), và với mỗi giá trị chữ số, nó thay đổi trạng thái theo như hình minh họa bên dưới. Trạng thái cuối cùng cũng là kết quả (output) của bài toán. - Về thứ tự của các phần tử trong một tật hợp. Giả sử ta có một tập hợp
S={x1,x2,x3,x4}. Nếu tất cả các phần tử của tập hợp này có thể được sắp xếp theo một thứ tự cố định (VD:x1 < x2 < x3 < x4), bao gồm cả tính bắc cầu (x1 < x2, x2 < x3 => x1 < x3) và phản đối xứng (x1 <= x2 & x2 <= x1 => x1 = x2), thì tập hợp này được gọi là có thứ tự toàn phần (total order). Nếu không thỏa mãn điều kiện trên thì tập hợp này có thứ tự một phần (partial order). Khái niệm này quan trọng trong việc xác định thứ tự các sự kiện trong Distributed Systems. Bạn có thể tham khảo kĩ hơn về lý thuyết thứ tự của tập hợp tại đây.

Bắt đầu từ một cấu trúc quen thuộc: log
Hầu như ai làm dev cũng đều phải quen làm việc với log. Nói đơn giản thì log là một chuỗi các dữ kiện giúp lưu lại thông tin về những sự kiện đã xảy ra trong quá trình phần mềm vận hành. Mỗi dữ kiện được gọi là một entry. Ví dụ, đây là một đoạn log của dpkg trên Ubuntu:
$ tail -f /var/log/dpkg.log
2020-09-21 01:51:20 status installed man-db:amd64 2.9.1-1
2020-09-21 01:51:21 trigproc dbus:amd64 1.12.16-2ubuntu2.1 <none>
2020-09-21 01:51:22 status half-configured dbus:amd64 1.12.16-2ubuntu2.1
2020-09-21 01:51:23 status installed dbus:amd64 1.12.16-2ubuntu2.1
2020-09-21 01:51:24 trigproc mime-support:all 3.64ubuntu1 <none>
2020-09-21 01:51:25 status half-configured mime-support:all 3.64ubuntu1
2020-09-21 01:51:26 status installed mime-support:all 3.64ubuntu1
2020-09-21 01:51:27 trigproc initramfs-tools:all 0.136ubuntu6.3 <none>
2020-09-21 01:51:28 status half-configured initramfs-tools:all 0.136ubuntu6.3
2020-09-21 01:51:29 status installed initramfs-tools:all 0.136ubuntu6.3
Một log entry trong ví dụ trên bao gồm hai thông tin: một là mô tả về sự kiện, hai là thời điểm (timestamp) xảy ra của sự kiện. Loại log quen thuộc này thường được gọi là Application log, mục đích chính của nó là giúp chúng ta truy tìm thông tin khi cần thiết (ví dụ như để truy vết bug chẳng hạn). Lưu ý là, các entry trong log luôn có thứ tự toàn phần (total order). Đối với log kể trên thì giá trị của timestamp là yếu tố xác định thứ tự của các entry. Log entry chỉ có thể được thêm vào log, chứ không thể bị xóa đi hay thay đổi. Thuật ngữ mô tả quy tắc này là “append-only”.
Trong lý thuyết về Distributed Systems, hai thành phần thông tin kể trên của log (nội dung và thứ tự của sự kiện) đóng vai trò quan trọng. Các hệ thống Distributed Systems hiện nay đều được xây dựng xung quanh việc đồng thuận về nội dung của chuỗi log. Hệ quả này dựa trên nguyên lý (tạm gọi là nguyên lý nhân bản trạng thái) như sau:
Nếu ta có hai process tất định (deterministic) như nhau và chúng xử lý cùng chuỗi dữ liệu đầu vào (input) như nhau, thì chúng sẽ có đầu ra (output) và trạng thái cuối cùng (state) như nhau.
Deterministic process ở đây được hiểu là process chỉ vận hành dựa trên việc xử lý input chứ không phụ thuộc vào các yếu tố bên ngoài (VD như yếu tố thời gian, yếu tố ngẫu nhiên…). Hiển nhiên là hai hệ thống deterministic như nhau nếu cùng nhận một chuỗi input sẽ cho ra kết quả như nhau. Do đó, chúng ta có thể lưu trữ hoàn toàn lịch sử trạng thái của một hệ thống bằng việc lưu trữ chuỗi input dưới dạng log.
Đến đây thì chúng ta có thể nhận thấy được sự liên quan giữa “log” và “State machine”. Nếu ta có một deterministic process được cấu trúc theo dạng State machine và một log lưu lại các input của process này, ta có được toàn bộ thông tin về quá trình hoạt động của process. Lấy ví dụ, một hệ thống ngân hàng cần lưu trữ thông tin tài khoản của khách hàng. Ta có thể lưu những yêu cầu xử lý của khách hàng dưới dạng input log như sau:
1. Tài khoản X được khởi tạo.
2. Tài khoản X nạp 100.000 VND.
3. Tài khoản Y được khởi tạo.
4. Tài khoản X chuyển cho tài khoản Y 50.000 VND.
5. Tài khoản Y rút ra 20.000 VND.
Từ log trên ta có thể dễ dàng tính ra trạng thái cuối cùng của hệ thống này (sau sự kiện 5) là {X=50.000, Y=30.000}. Tuy nhiên, ngoài ra, cấu trúc input log này có một vài ưu điểm như sau:
- Thứ nhất, cấu trúc này lưu trữ được nhiều thông tin hơn là việc lưu trạng thái thông thường. Ở đây ta mặc nhiên có được một lịch sử giao dịch cho tài khoản X và Y. Điều này cho phép ta có thể xác định được trạng thái của hệ thống trong bất kì thời điểm nào.
- Thứ hai, cấu trúc này hỗ trợ khả năng đối phó sự cố (fault tolerant) của hệ thống. Nếu như một server bị crash trong quá trình hoạt động, thì khi phục hồi, ta có thể tái thiết lại trạng thái cho server đó bằng cách “chạy” lại input log này (đây còn được gọi là ‘log replay’).
- Kết cấu này cũng mang tính đàn hồi (scalable) cao. Dữ liệu log kể trên có thể được nhân bản hay chuyển hóa thành các dạng dữ liệu khác nhằm phục vụ cho các mục đích khác nhau. Ta sẽ bàn về điều này nhiều hơn trong phần Event sourcing.
Log replication và Replicated State machine.
Ở phần 2, chúng ta đã nói sơ qua về tầm quan trọng của bài toán đồng thuận (consensus) trong DS. Bài toán này thực ra là phiên bản đơn giản hóa, vì yêu cầu đặt ra chỉ là giúp các server đồng thuận 1 giá trị. Trên thực tế, các hệ thống khi vận hành phải tiếp nhận yêu cầu của người dùng và thay đổi trạng thái liên tục, do đó bài toán ở đây là các server phải đồng thuận một chuỗi giá trị thay đổi theo thời gian. Các server cũng có thể bị mất kết nối hoặc crash, khiến cho việc đồng bộ thông tin giữa các máy càng trở nên phức tạp. Lấy ví dụ, nếu một server crash và sau đó phục hồi, khi đó trạng thái của server này đã khác biệt so với các server khác. Làm thế nào để ta biết được trạng thái nào mới là trạng thái đúng?
Mô hình Replicated State machine (các máy trạng thái nhân bản), hay Log replication, được phát triển nhằm giải quyết vấn đề này. Trong mô hình này, mỗi server trong hệ thống được cấu trúc dưới dạng State machine, tương đồng với Deterministic process được nêu ở phần trên. Log trong trường hợp này là chuỗi các input mà hệ thống nhận được từ người dùng (client), sắp xếp theo thứ tự thời gian (total order). State machine và log này được nhân bản ra tất cả các server trong hệ thống nhằm giúp các máy đồng thuận với nhau. Có nhiều cơ chế để thực hiện thao tác nhân bản này, ví dụ như leader/follower (thuật toán Raft), hay atomic broadcast (thuật toán ZAB). Chúng ta sẽ tìm hiểu sâu hơn về các thuật toán này trong các bài sau.
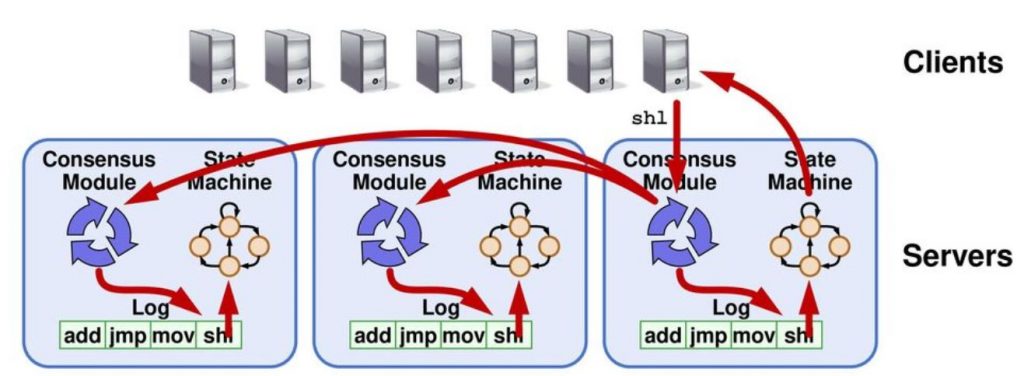
Điểm ưu việt của cơ chế này là, trong trường hợp một server nào đó fail, server này có thể phục hồi trạng thái bằng cách replay lại log. Các server cũng có thể so sánh phiên bản log của mình và xác định được phiên bản nào là phiên bản được cập nhật mới nhất (dựa trên thứ tự các entry trong log). Ngoài ra, nếu một server mới được thêm vào hệ thống, server này cũng có thể đồng thuận với các server còn lại thông qua cơ chế tương tự.
Mối liên hệ đến Event-sourcing
Replicated State machine (RSM) và Event-sourcing (ES) là hai khái niệm khác nhau. RSM chỉ về mô hình consensus trong Distributed Systems nói chung, trong khi đó ES nói về cách tổ chức và sắp đặt dữ liệu của một ứng dụng cụ thể. Tuy nhiên, hai khái niệm này dựa trên cùng một nguyên lý nhân bản trạng thái nêu trên, nên ta hãy bàn sơ qua về ES ở đây một chút.
Event-sourcing hoạt động dựa trên việc lưu lại dữ liệu của một hệ thống dưới dạng một chuỗi các sự kiện (event) theo thứ tự thời gian trong một cấu trúc Event Log. Event log này là dữ liệu duy nhất mô tả trạng thái của hệ thống, tại thời điểm hiện tại cũng như trong quá khứ. Kiến trúc ES hoạt động khác biệt so với kiểu trên trúc phổ thông thêm-sửa-xóa (CRUD). Thử ví dụ về hệ thống ngân hàng ở phần trước: một hệ thống theo kiểu CRUD có thể lưu mỗi tài khoản ở một dòng trong bảng SQL, trong khi đó, với ES, ta lưu tất cả các sự kiện trong hệ thống trong một chuỗi event duy nhất (xem VD ở trên). Cũng giống như input log, Event log cho phép tái tạo lại dữ liệu của hệ thống ở bất kì thời điểm nào.
Điểm cộng lớn nhất của cách bố trí dữ liệu kiểu này nằm ở sự đơn giản: một chuỗi sự kiện duy nhất chứa đầy đủ các thông tin của hệ thống, từ số tiền hiện tại đến lịch sử giao dịch của một tài khoản. Theo kiểu CRUD, ta sẽ phải có một bảng riêng biệt để lưu lịch sử các giao dịch của các tài khoản, và sử dụng JOIN khi cần truy cập dữ liệu ở nhiều bảng khác nhau. Với ES, ta chỉ có một chuỗi duy nhất (thường được gọi là single source of truth).
Sự đơn giản này giúp các hệ thống ES có tính đàn hồi (scalability) cao. Với kiểu CRUD, thường thì ta sẽ phải thiết kế Database nhằm tối ưu cho cả việc đọc và ghi dữ liệu. Tuy nhiên không phải dữ liệu nào cũng có thể tối ưu được một cách tuyệt đối. Hầu hết các hệ thống đều phải hy sinh hiệu năng cho việc đọc (hoặc ghi) để tối ưu cho hoạt động còn lại. Hơn nữa, các ứng dụng trên thực tế đều phải thay đổi theo thời gian để liên tục đáp ứng yêu cầu mới, do đó, việc tối ưu database ngay từ đầu gần như là bất khả thi.
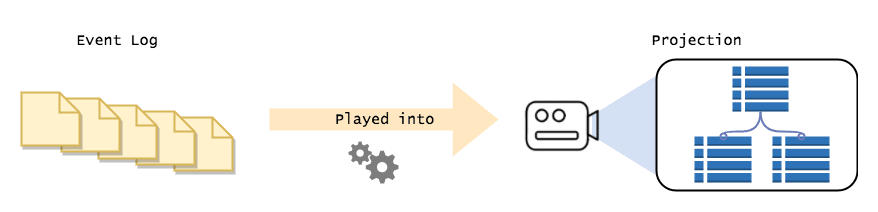
Với ES thì dữ liệu được tổ chức theo kiểu hoàn toàn khác biệt. Tất cả tiến trình ghi (write) đều có hiệu năng cao, do chỉ phải thêm (append) event (do event không được phép sửa/xóa). Các event này sau đó được chuyển hóa thành các dạng dữ liệu được tối ưu cho việc đọc (có thể là trong một bảng SQL hoặc các database khác). Quy trình này được gọi là projection (Xem hình minh họa ở trên), trong đó Event log tại từng thời điểm nhất định được chuyển hóa thành các snapshot nhằm tối ưu việc truy cập dữ liệu. Điều này giúp cho hệ thống không bị bó buộc bởi cấu trúc quan hệ – thực thể (entity-relationship) trong các kiểu dữ liệu truyền thống.
Bài viết gốc được đăng tải tại dhhoang.github.io
Có thể bạn quan tâm:
- [P1] Tổng quan về Distributed Systems
- Bài toán đồng thuận trong Distributed Systems
- Stateless là gì? Stateful là gì?
Xem thêm Việc làm Developer hấp dẫn trên TopDev






")
")





