

Phỏng vấn Data Scientist liệu có phải chỉ là những câu hỏi liên quan tới giải thuật và phân tích dữ liệu?
Lựa chọn bước đi trên con đường làm Data Scientist, mong rằng bộ câu hỏi dưới đây có thể giúp đỡ bạn phần nào trong quá trình phỏng vấn và ứng tuyển vị trí Data Scientist.


1. Những library nào thường được bạn sử dụng?
Khởi động với câu hỏi phỏng vấn Data Scientist đầu tiên, luôn là câu hỏi nhẹ nhàng nhưng không kém phần tinh tế.
Nhưng library nào bạn thường sử dụng ở vị trí Data Scientist? Việc sử dụng library nào tuỳ thuộc vào kinh nghiệm của bản thân ứng viên, tuy nhiên có một số library thường được sử dụng nhiều.
-
- Pandas
-
- NumPy
-
- SciPy
-
- Scrapy
-
- Librosa
-
- MatPlotLib

Tensor Flow và Pandas anh em chắc không còn xa lạ gì. Tuỳ vào kinh nghiệm thực tế cũng như quá trình làm việc. Ứng viên có thể nêu ra các libraries thân thuộc hoặc có kinh nghiệm nhiều hơn. Ngoài ra người phỏng vấn cũng sẽ hỏi các câu hỏi sâu hơn liên quan tới kinh nghiệm sử dụng thực tế của từng library.
Một số câu hỏi khác có thể chuẩn bị thêm:
-
- Thuật toán pruning trong cây quyết định (decision tree)
-
- k-fold cross-validation là gì?
-
- Eigenvalue và eigenvector là gì?
2. RNN (recurrent neural network) là gì?
Câu hỏi thứ hai phỏng vấn Data Scientist liên quan tới khái niệm cơ bản của Recurrent Neural Network.
RNN là một thuật toán sử dụng dữ liệu tuần tự. RNN được sử dụng trong dịch ngôn ngữ, nhận dạng giọng nói, chụp ảnh, v.v. Có nhiều loại mạng RNN khác nhau như một-một, một-nhiều, nhiều-một và nhiều-nhiều. RNN được sử dụng trong tìm kiếm bằng giọng nói của Google và Siri của Apple.
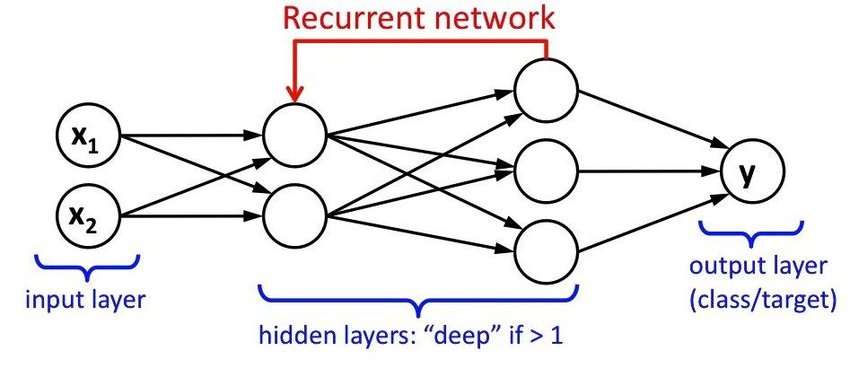
RNN là thuật toán khá phổ biến trong giới khoa học dữ liệu, chính vì vậy nó có rất nhiều ứng dụng trong thực tế. Để chuẩn bị tốt cho buổi phỏng vấn, anh em có thể ôn lại các khái niệm cơ bản về RNN.
Một số câu hỏi có thể chuẩn bị thêm cho phần khái niệm này:
-
- Feature vectors là gì?
-
- Các bước để tạo ra cây quyết định (decision tree)
-
- Logistic regression là gì?
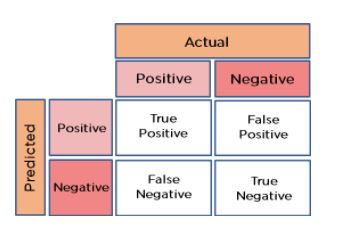
3. Tính toán độ chính xác với confusion matrix như thế nào?
Câu hỏi phỏng vấn Data Scientist tập trung vào thực tế tính toán độ chính xác của dữ liệu với confusion matrix. Câu hỏi này đòi hỏi ứng viên phải có hiểu biết cụ thể với Confusion Matrix.
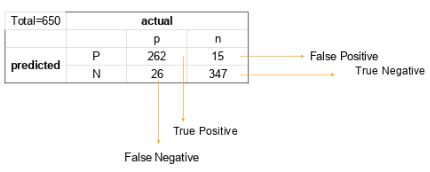
Đối với hình ảnh dưới đây ta có dữ liệu của tổng dữ liệu, giá trị thực và giá trị dự đoán. Công thức tính toạn độ chính xác ở đây sẽ là:
Accuracy = (True Positive + True Negative) / Total Observations
Theo như công thức này, ta có thể tính toán được giá trị
-
- = (262 + 347) / 650
-
- = 609 / 650
-
- = 0.93
Vậy độ chính xác cuối cùng được tính ra ở đây là 93%.
Một số câu hỏi khác có thể chuẩn bị thêm:
-
- Phương trình và tính toán độ chính xác và tỷ lệ thu hồi cho hình ảnh sau
4. Tại sao R lại được sử dụng trong Data Visualization?
Câu hỏi thứ 4 phỏng vấn Data Scientist tập trung vào ngôn ngữ và các điểm mạnh giúp ngôn ngữ có thể đáp ứng được các nhu cầu cụ thể.
Trong trường hợp này là Data Visualization, đã là Data Scientist chắc chắn bạn đã một lần trực quan hoá dữ liệu. Việc trực quan hoá dữ liệu và việc rất quan trọng và thường xuyên được làm bởi các nhà khoa học dữ liệu.
Ngôn ngữ R được sử dụng nhiều trong việc trực quan hoá dữ liệu thường bởi một số lý do sau đây:
-
- Hầu hết các loại biểu đồ đều có thể được tạo ra bởi R
-
- R có nhiều loại thư viện lattice, ggplot2, leaflet, hỗ trợ rất tốt khi custom
-
- So với Python, R cho phép chỉnh sửa hoặc custom lại các loại biểu đồ
Một số câu hỏi có thể chuẩn bị thêm cho phần này:
-
- Sự khác biệt giữa box plot và histogram?
-
- Bias-variance trade-off là gì?
Việc làm Data Analytics HOT tại TP. Hồ Chí Minh
5. Sự khác biệt giữa Normalisation và Standardization là gì?
Câu hỏi thứ 5 phỏng vấn Data Scientist tập trung vào phân tích sự khác biệt giữa Normalisation và Standardization
Để trả lời câu hỏi này, ta sẽ tập trung đi vào phân tích sự khác biệt giữa kỹ thuật convert data (technique of converting data), formula của từng loại này. Chi tiết được viết ra ở bảng dưới đây
| Standardization | Normalization |
| Kỹ thuật chuyển đổi dữ liệu theo cách được phân phối bình thường và có độ lệch chuẩn là 1 và giá trị trung bình là 0. | Kỹ thuật chuyển đổi tất cả các giá trị dữ liệu nằm trong khoảng từ 1 đến 0 được gọi là Chuẩn hóa. Điều này còn được gọi là tỷ lệ tối thiểu-tối đa. |
| Quá trình tiêu chuẩn hóa đảm bảo rằng dữ liệu tuân theo phân phối chuẩn chuẩn. (theo normal standard) | Dữ liệu trở về phạm vi từ 0 đến 1 được xử lý bằng Chuẩn hóa. (Normalization) |
| Standardization formula X’ = (X – ) / | Normalization formula Công thức sử dụng: X’ = (X – Xmin) / (Xmax – Xmin) |
Một số câu hỏi có thể chuẩn bị thêm cho phần so sánh này:
-
- Nêu sự khác biệt giữa error và residual error?
-
- Sự khác biệt giữa Point Estimates và Confidence Interval?
6. Tham khảo về phỏng vấn Data Scientist
Cảm ơn anh em đã đọc bài – Thank you for your time – Happy coding!
Tác giả: Kiên Nguyễn
Xem thêm:
- Tuyển tập câu hỏi phỏng vấn Data Engineer mới nhất
- Top 10 thư viện Python tốt nhất cho Data Scientist nửa đầu năm 2023
- Top những thuật toán machine learning mà bất cứ Data Scientist nào cũng cần phải biết
Xem thêm Việc làm IT hấp dẫn trên TopDev



")
")
")
")
")
")
")



