

Chào mọi người, nối tiếp bài trước là tận dụng caching ở trình duyệt để tăng tốc cho microservices. Ở bài này mình sẽ chia sẻ một case study khá thông dụng trong các dự án “vừa vừa”, đó là nhu cầu export dữ liệu ra file excel. Nếu như các bạn thường xuyên làm việc liên quan đến các hệ thống quản lý dữ liệu thì data table / grid sẽ xuất hiện khá nhiều, kéo theo tính năng thường xuyên được yêu cầu là export dữ liệu (ra file Excel).
Có thể bạn quan tâm:
Phương pháp export dữ liệu “cổ điển”
Trước khi đi sâu vào cách Teamcrop export dữ liệu, chúng ta cùng nhau bàn về cách tiếp cận “cổ điển” mà có lẽ bạn nào cũng đã từng triển khai. Để export dữ liệu, công đoạn khó nhất là lấy dữ liệu, code của bạn sẽ phải fetch data thông qua các câu truy vấn (thường là SELECT..) vào database, và cũng tránh mỗi lần query vào database quá nhiều record nên thường có lấy từng khúc (thông qua LIMIT..) và tất nhiên bạn sẽ phải có một vòng lặp vô hạn để đảm bảo lấy hết dữ liệu cần xuất.

Sau khi có được dữ liệu, bạn thường sẽ dùng một thư viện liên quan đến xử lý Excel để xây dựng file excel, thêm dòng, thêm cột và response data về cho client (trình duyệt), và người dùng sẽ tải được file này.

Dù theo kiến trúc nào (monolithic hay microservices), thì phương pháp này cũng có một vấn đề lớn là nếu lượng dữ liệu cần xuất quá nhiều, thì dẫn đến request của bạn sẽ xử lý lâu (IO), memory sẽ lớn vì lưu trữ dữ liệu chờ xuất, giữ kết nối tới DB lâu, thậm chí table có thể bị lock, cái gì cũng lâu, kéo theo làm giảm performance của hệ thống, nếu có nhiều người cùng export một lúc, mỗi request chờ 2, 3 phút thì đúng là thảm họa, vô tình bị rơi vào tình trạng tự mình DoS.
Ngoài những vấn đề nêu trên, thì phương pháp export “cổ điển” này phải triển khai theo dạng case-by-case, tức là bạn cần xuất dữ liệu gì, thế nào thì phía backend phải có xử lý tương ứng để lấy dữ liệu và export. Và các script export này cũng phải hỗ trợ các vấn đề liên quan đến kiếm tra quyền truy cập (được export hay không), cũng phải kiểm tra bộ lọc dữ liệu để người dùng có thể tùy biến dữ liệu cần xuất.
Vấn đề còn lớn hơn khi ở kiến trúc Microservices, vì dữ liệu lấy từ database của 1 service chỉ chứa khóa ngoại của service khác. Ví dụ trường hợp muốn xuất danh sách đơn hàng, để một file excel có thông tin cửa hàng, sản phẩm, nhân viên…thì đều phải dùng service khác để lấy dữ liệu từ phía service. Như vậy, trong kiến trúc microservices, ngoài việc bị delay do IO, còn phải delay do request đến các service liên quan để lấy đủ dữ liệu. Do đặc thù của export nên lượng dữ liệu sẽ lớn, kéo theo lượng request để lấy data của các service khác cũng sẽ tịnh tiến.
Phương pháp “cổ điển” cải tiến
Phương pháp cổ điển thường không có progress bar (%), nên nếu vô tình người dùng export những tính năng nhiều dữ liệu, xử lý lâu thì cảm giác chờ nhiều khi là…vô tận.
Để giảm cảm giác “chờ đợi” của người dùng khi export dữ liệu, có một phương pháp “xoa diệu” gọi là async export, tức là tất cả quy trình export diễn ra bất đồng bộ. Người dùng chỉ cần nhấn nút export và giao diện sẽ báo những thông báo dạng “chúng tôi sẽ email / thông báo / gọi điện cho bạn khi export xong”. Triển khai theo phương pháp này sẽ làm cho vấn đề phức tạp hơn vì với mỗi tính năng cần export, phải triển khai theo cơ chế lưu trữ kết quả export (thường là ghi file), rồi cơ chế thông báo (email, notification), rồi cơ chế xóa file (chẳng lẽ giữ file export này suốt trên server ^^!).
Do tính chất đặc thù của phương pháp async export này nên một hệ thống chỉ có 1 vài tính năng “bự” làm theo cách này mà thôi, hầu hết vẫn là nhấn-chờ-tải.
Phương pháp export của Teamcrop
Cropcom là hệ thống với hàng trăm tính năng liên quan đến bán hàng, nhân sự, logistic… nên tính năng export dữ liệu ra excel là rất nhiều. Lúc trước mình cũng tiếp cận theo phương pháp “cổ điển”, tuy nhiên khi các vấn đề mình nêu ra ngày càng lớn thì buộc phải “tìm” một phương pháp đơn giản, an toàn và hiệu quả hơn. Và sau một thời gian tìm hiểu thì hệ thống export của crop đã đạt được một số ý sau:
- Phối hợp với bộ lọc của giao diện, người dùng đang xem / lọc / tìm kiếm gì thì có thể export bảng dữ liệu đó.
- Tối ưu quá trình lấy dữ liệu từ các service khác trong kiến trúc microservices.
- Có progress bar, người dùng biết được tiến trình download.
- Trong trường hợp mạng bị lỗi (lag, rớt) giữa chừng thì có thể resume download.
- Không cần case-by-case ở phía service, là một giải pháp general và chỉ cần định nghĩa template (cột) của file sẽ export.
- Không tạo ra những request lâu hoặc truy cập nhiều dữ liệu một lúc.
- Không tạo ra các file tạm trên server.
Để đạt được những yêu cầu như trên thì bên mình đã mang hoàn toàn tính năng export dữ liệu về phía client (JS) và tận dụng được tất cả cơ chế của client đã xây dựng.
Frontend đã viết 1 component (ExportDataComponent), component này thường được đặt chung với bảng dữ liệu và dùng chung với các tham số bộ lọc tìm kiếm, đường dẫn truy vấn lẫn dữ liệu. Khi người dùng tìm kiếm hay lọc dữ liệu thì component này cũng sẽ cập nhật được thông tin tìm kiếm mới để hỗ trợ cho việc thấy cái gì là export được cái đó.
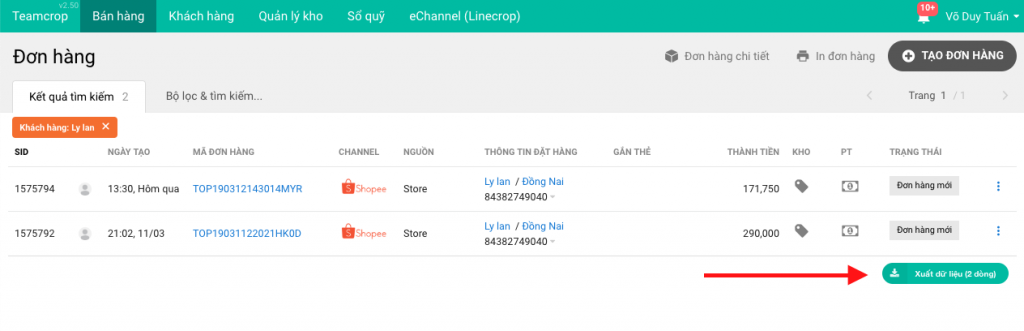
Về phần dữ liệu thì do matching với cơ chế lọc dữ liệu nên tận dụng được API lấy danh sách. Ví dụ export đơn hàng thì sẽ gọi service lấy danh sách đơn hàng, và tất nhiên khi đi theo cơ chế này thì cũng sẽ được “phân trang tự nhiên”. Mỗi lần lấy dữ liệu thì lấy với số lượng recordPerPage như danh sách đang coi, và cũng như khi xem bảng dữ liệu người dùng nhấn trang tiếp theo, component này sẽ tự lặp và request cho đến hết các trang. Lợi thế của việc này là mỗi request lấy dữ liệu không làm treo hệ thống vì nó là request lấy dữ liệu (JSON) bình thường và có giới hạn mỗi lần lấy. Lợi thế thứ hai là trên giao diện sẽ thể hiện được progressbar, vì đã xác định được sẽ lấy bao nhiêu dữ liệu nên vẽ 1 cái progressbar rất đơn giản.
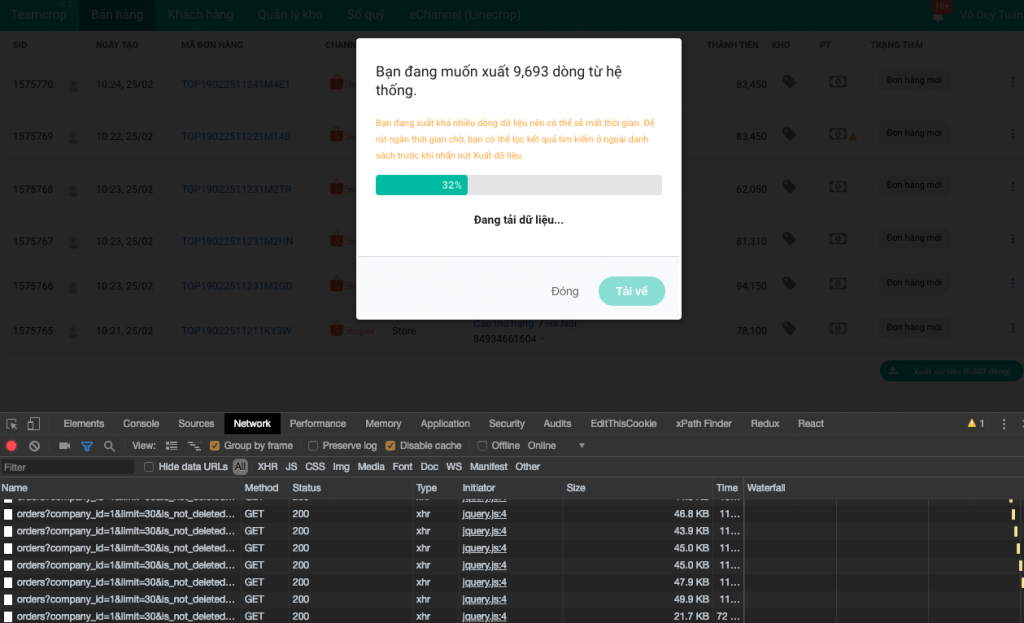
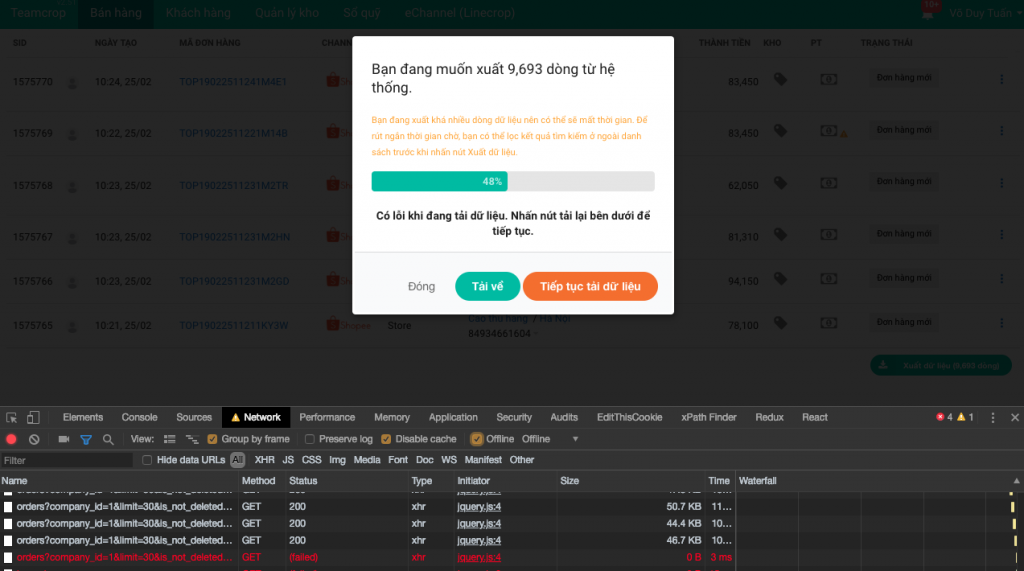
Việc lấy từng trang ở giao diện cũng hỗ trợ tính năng resume khi có lỗi. Khi một request lấy dữ liệu bị fail (ajax error) thì giao diện sẽ phản ứng, hiện thông báo và người dùng có thể nhấn nút resume để tiếp tục download từ trang bị lỗi.
Trong trường hợp kiến trúc Microservices, cũng giống như bài trước nói về caching của trình duyệt, mình có thể nhanh chóng lấy dữ liệu từ các nguồn đã cache ở client. Ví dụ cửa hàng, nhân viên, sản phẩm..
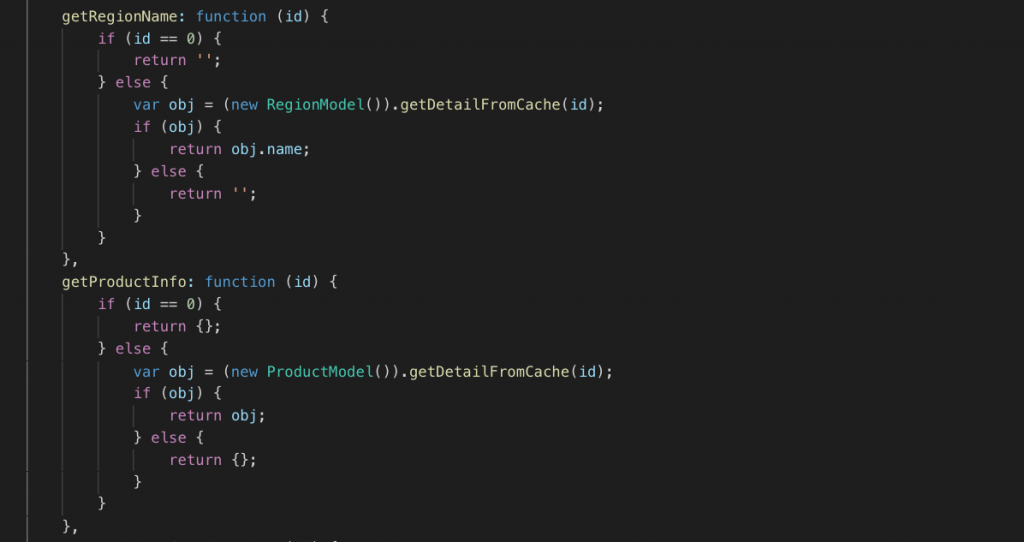
Đối với dữ liệu không cache (thường là transaction data, ví dụ khách hàng, phiếu thu chi, nhập xuất…), thì sẽ lấy theo idlist. Ví dụ thông tin khách hàng, mình sẽ làm 1 request bao gồm các ID của khách hàng, rồi làm 1 request lên service khách hàng để lấy dữ liệu. Phương pháp idlist này cũng được sử dụng ở lấy danh sách, chứ không dành riêng cho phần export.
Là một component thiết kế theo hướng generalize, mapping với tính năng lấy danh sách ở giao diện nên phía server không cần triển khai thêm code export, client vẫn lấy hết được dữ liệu mà không cần làm thêm gì cả. Công việc chính của việc export là định nghĩa cấu trúc cột & kiểu dữ liệu của file excel.
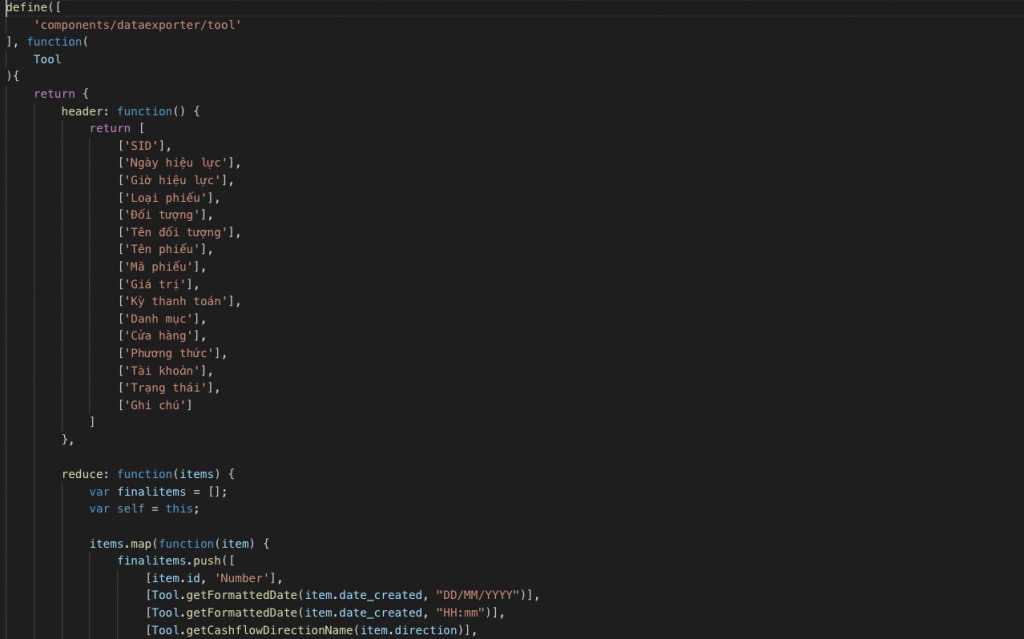
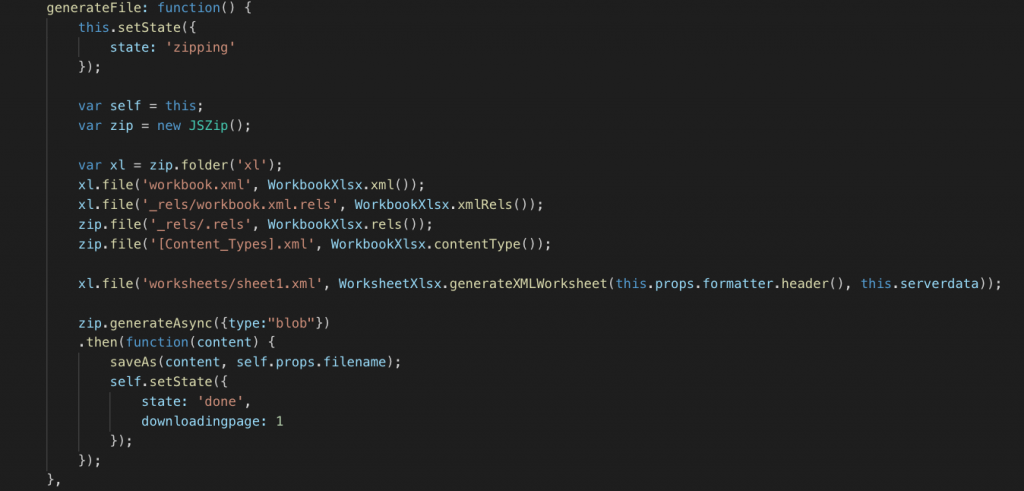
Sau khi đã có dữ liệu đầy đủ thì tiến hành dùng Javascript (của trình duyệt) để tạo một file excel. Excel thực chất là một file zip, trong đó có các file xml chứa format và dữ liệu (sheet) nên sử dụng thư viện JSZip để tạo file zip chứa các file xml và FileSaver để người dùng download trực tiếp file về máy.
Như vậy, với một vài thay đổi và cách tiếp cận mới thì tính năng export đã cải tiến khá nhiều và mang lại trải nghiệm người dùng tốt hơn cũng như phía service ít bị ảnh hưởng bởi các request export nhiều dữ liệu. Một lợi thế khác là code rất dễ maintain và cải tiến.
Hy vọng bài viết này sẽ giúp nhiều bạn trong việc tiếp cận hệ thống Microservices và tận dụng kiến trúc Single Page App ở Frontend để tối ưu trải nghiệm export dữ liệu.
Nguồn: Bloghoctap













