Bài viết được sự cho phép của tác giả Trần Ngọc Minh
Giới thiệu
Cơ sở dữ liệu vector là các cơ sở dữ liệu chuyên biệt được thiết kế cho các tình huống nơi hiểu biết về ngữ cảnh (context), độ tương đồng (similarity) hoặc các mẫu (patterns) quan trọng hơn việc khớp chính xác các giá trị. Tận dụng toán học của các vector và nguyên lý của hình học để hiểu và tổ chức dữ liệu, những khả năng này là cần thiết để tăng cường sức mạnh của trí tuệ nhân tạo phân tích và tạo sinh. Sự bùng nổ của các công nghệ trí tuệ nhân tạo (AI) và học máy (ML) là nguyên nhân chính đằng sau sự phát triển nhanh chóng của cơ sở dữ liệu vector trong hai năm qua, mang lại giá trị lớn hơn thông qua hiệu suất, linh hoạt và chi phí.
Khác với các tiến hóa khác trong cơ sở dữ liệu, cơ sở dữ liệu vector không được tạo ra để thay thế bất kỳ công nghệ nào mà là để giải quyết các trường hợp mới mà không có giải pháp với công nghệ hiện có. Mục đích chính của bài viết này là cung cấp một cái nhìn tổng quan rõ ràng và dễ tiếp cận về cơ sở dữ liệu vector, nêu bật tầm quan trọng, ứng dụng và nguyên tắc cơ bản.

Cơ Sở Dữ Liệu Vector
Cơ sở dữ liệu vectơ là cơ sở dữ liệu chuyên dụng để lưu trữ, tìm kiếm và quản lý thông tin dưới dạng vectơ, là biểu diễn số của các đối tượng trong không gian nhiều chiều (ví dụ: tài liệu, văn bản, hình ảnh, video, âm thanh) phản ánh các đặc điểm nhất định của bản thân đối tượng đó.
Biểu diễn số học này được gọi là một nhúng vector (a vector embedding), hoặc đơn giản là nhúng (embedding), mà chúng ta sẽ tìm hiểu chi tiết hơn sau này.
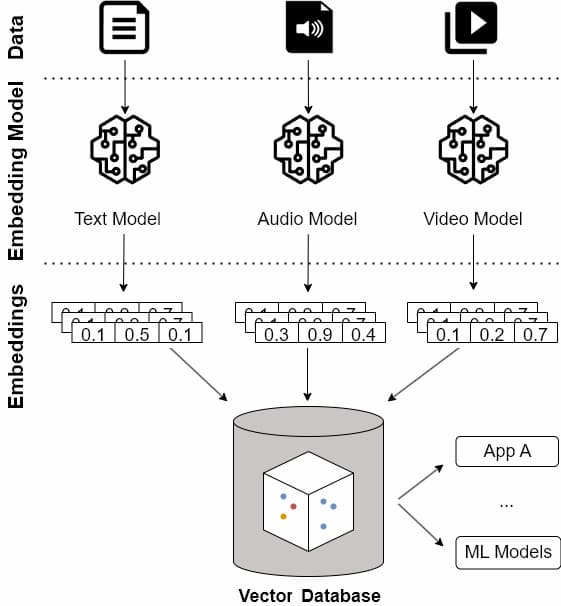
Các nhúng vector được tạo ra bằng cách sử dụng các mô hình Học Máy (ML) có khả năng chuyển đổi giá trị ngữ nghĩa và định tính của đối tượng thành một biểu diễn số học. Có nhiều mô hình ML cho mỗi loại dữ liệu, chẳng hạn như văn bản, âm thanh, hình ảnh và các mô hình nhúng khác. Việc sử dụng một cơ sở dữ liệu vector không phải là một yêu cầu bắt buộc để có thể tạo ra hoặc sử dụng các nhúng vector. Điều này bởi vì có nhiều thư viện chỉ số vector tập trung vào việc lưu trữ các nhúng với các chỉ số trong bộ nhớ trong (in-memory indexes), nhưng cơ sở dữ liệu vector được khuyến khích sử dụng cho kiến trúc doanh nghiệp, sản xuất và khi làm việc với tải cao và khối lượng dữ liệu lớn.
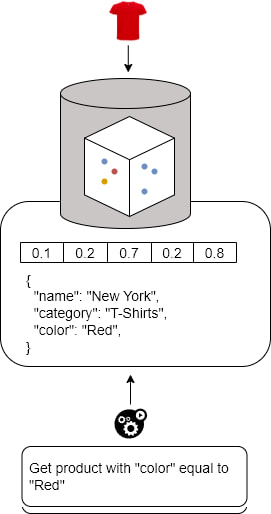
Hiện nay, các cơ sở dữ liệu vector được thiết kế để hỗ trợ việc kết hợp của nhúng đó với siêu dữ liệu (metadata) của đối tượng, có thể bao gồm nhiều thông tin như định nghĩa có cấu trúc và định nghĩa đối tượng. Việc có thông tin này cùng với các vector cho phép truy vấn, lọc và quản lý phức tạp hơn, tương tự như các truy vấn được thực hiện trong cơ sở dữ liệu truyền thống. Điều này chắc chắn làm cho cơ sở dữ liệu vector có tính tích hợp, linh hoạt và dễ hiểu hơn với người dùng cuối và trong các kiến trúc dữ liệu.
Cơ sở dữ liệu vector là một hệ thống hoàn chỉnh được thiết kế để quản lý nhúng ở quy mô lớn. Dưới đây là những điểm khác biệt chính và lợi ích của việc sử dụng cơ sở dữ liệu vector:
- Khả năng lưu trữ và bền vững: Cho phép dữ liệu được lưu trữ trên đĩa cũng như trong bộ nhớ và cung cấp các tính năng chống lỗi như sao chép dữ liệu hoặc sao lưu định kỳ.
- Sẵn có cao và đáng tin cậy: Hoạt động liên tục và cung cấp sự chịu đựng đối với các sự cố và lỗi dựa trên kiến trúc gom cụm và sao chép dữ liệu.
- Khả năng mở rộng: Mở rộng theo chiều ngang qua nhiều nút.
- Hiệu suất được tối ưu hóa và hiệu quả chi phí: Xử lý và tổ chức dữ liệu thông qua các vector có số chiều cao có thể chứa hàng nghìn chiều.
- Hỗ trợ truy vấn phức tạp và API: Cho phép các truy vấn phức tạp kết hợp giữa tìm kiếm tương đồng vector với các truy vấn cơ sở dữ liệu truyền thống.
- Bảo mật và kiểm soát truy cập: Bao gồm các tính năng bảo mật tích hợp, chẳng hạn như xác thực và ủy quyền, mã hóa dữ liệu, cách ly dữ liệu và các cơ chế kiểm soát truy cập, là yếu tố quan trọng cho các ứng dụng doanh nghiệp và tuân thủ các quy định bảo vệ dữ liệu.
- Tích hợp mượt mà và SDKs: Tích hợp một cách mượt mà với các hệ sinh thái dữ liệu hiện tại, cung cấp thư viện tích hợp cho nhiều ngôn ngữ lập trình, một loạt các API (ví dụ: GraphQL, RESTful) và tích hợp với Apache Kafka.
- Hỗ trợ cho các thao tác CRUD: Cơ sở dữ liệu vector cho phép bạn thêm, cập nhật và xóa các đối tượng cùng với các vector của chúng. Điều này giúp người dùng không cần phải tạo lại chỉ mục cho toàn bộ cơ sở dữ liệu khi có bất kỳ thay đổi dữ liệu cơ bản nào.
Cơ sở dữ liệu truyền thống (hoặc quan hệ) và cơ sở dữ liệu vector
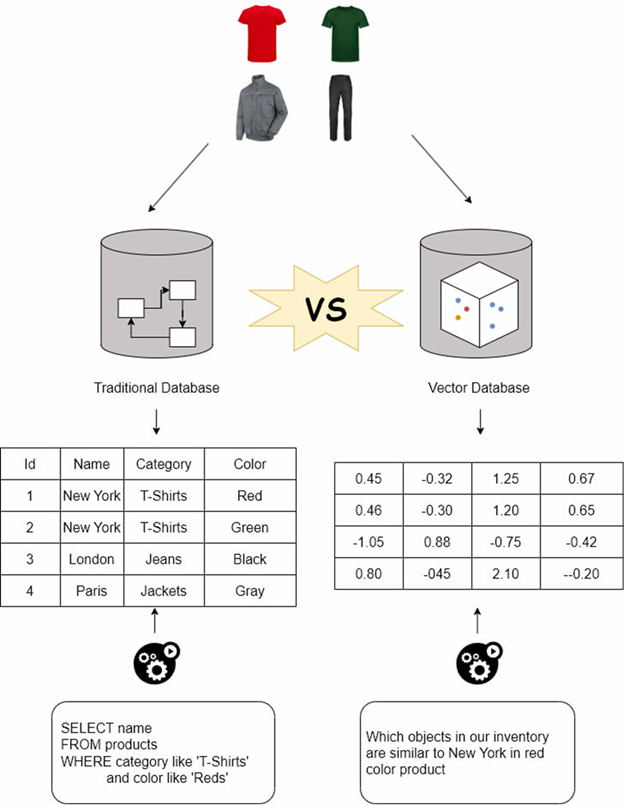
Cơ sở dữ liệu truyền thống hoặc quan hệ là không thể thiếu đối với các ứng dụng đòi hỏi dữ liệu có cấu trúc và bán cấu trúc sẽ trả về kết quả khớp chính xác với truy vấn. Những cơ sở dữ liệu này lưu trữ thông tin theo hàng hoặc tài liệu, và ở cuối mỗi hàng, có một bản ghi cung cấp thông tin có cấu trúc như thuộc tính sản phẩm, chi tiết khách hàng, v.v.
Ngược lại, cơ sở dữ liệu vector được tối ưu hóa để lưu trữ và tìm kiếm thông qua dữ liệu vector có số chiều cao sẽ trả về các mục dựa trên các phép đo tương đồng (similarity metrics) thay vì khớp chính xác.
Các khái niệm chính của cơ sở dữ liệu vector
Sử dụng cơ sở dữ liệu vector đòi hỏi hiểu các khái niệm cơ bản của chúng: nhúng (embedding), chỉ mục (indexes), khoảng cách (distance) và tương tự (similarity).
Nhúng (Embeddings) và Chiều (Dimensions)
Như đã giải thích trước đó, nhúng là các biểu diễn số hóa của các đối tượng phản ánh ý nghĩa ngữ nghĩa và mối quan hệ của chúng trong không gian đa chiều bao gồm các mối quan hệ ngữ nghĩa, cách sử dụng ngữ cảnh hoặc các đặc điểm. Biểu diễn số hóa này được tạo thành bởi một mảng số trong đó mỗi phần tử tương ứng với một chiều cụ thể.

Số chiều trong các biểu diễn nhúng rất quan trọng vì mỗi chiều tương ứng với một đặc điểm mà chúng ta thu thập từ đối tượng. Nó được biểu diễn dưới dạng một giá trị số học và lượng hóa, và nó cũng xác định bản đồ chiều trong đó mỗi đối tượng sẽ được xác định.
Hãy xem xét một ví dụ đơn giản với một biểu diễn số hóa của các từ, trong đó các từ là định nghĩa của mỗi sản phẩm bán lẻ thời trang được lưu trữ trong cơ sở dữ liệu giao dịch của chúng ta. Hãy tưởng tượng nếu chúng ta có phản ánh đặc điểm cốt lõi của những đối tượng này chỉ với hai chiều.
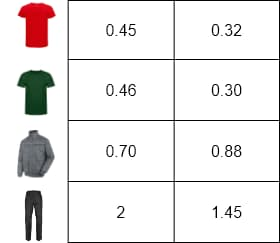
Trong Hình 6, chúng ta có thể thấy biểu diễn chiều của các đối tượng này để minh họa sự tương đồng của chúng. Áo thun gần nhau vì cả hai là cùng một sản phẩm nhưng có màu sắc khác nhau. Áo khoác gần áo thun vì chúng có các thuộc tính chung như tay áo và cổ áo. Ở phía bên phải nhất là quần jeans không chia sẻ thuộc tính với các sản phẩm khác.

Rõ ràng, với hai chiều là không đủ. Số chiều đóng vai trò quan trọng trong việc những biểu diễn nhúng này có thể nắm bắt được các đặc điểm quan trọng của các sản phẩm. Nhiều chiều có thể cung cấp độ chính xác cao hơn nhưng cũng tốn nhiều tài nguyên về tính toán, bộ nhớ, độ trễ và chi phí.
Xem thêm Việc làm database hấp dẫn trên TopDev
Tích hợp Mô hình nhúng vector (Vector Embedding Models)
Một số cơ sở dữ liệu vector cung cấp khả năng tích hợp với các mô hình nhúng, cho phép chúng ta tạo ra các biểu diễn nhúng từ dữ liệu thô và tích hợp mô hình ML vào các hoạt động của cơ sở dữ liệu một cách mượt mà. Tính năng này đơn giản hóa quá trình phát triển và ẩn đi những phức tạp liên quan đến việc tạo ra và sử dụng các biểu diễn nhúng cho cả quá trình chèn dữ liệu và truy vấn.
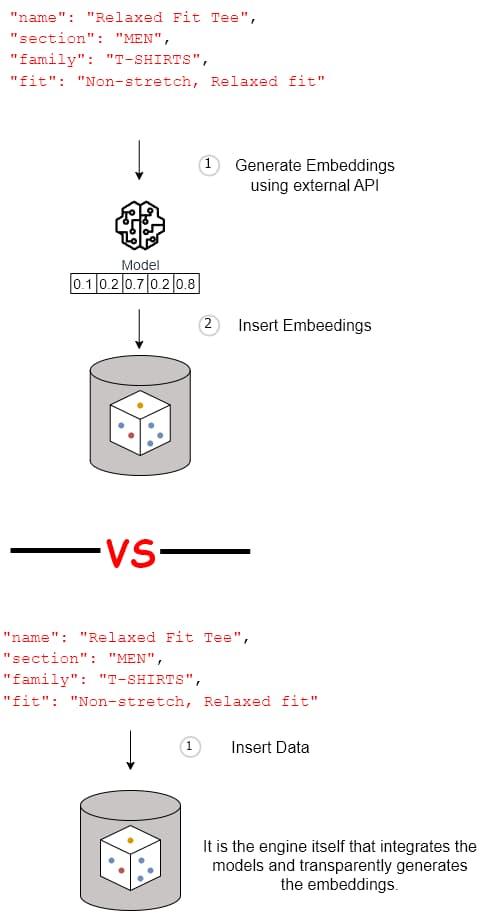
Bảng 1: So sánh mô hình sinh nhúng
| Các ví dụ | Không tích hợp | Tích hợp |
| Nhập dữ liệu | Trước khi chúng ta có thể chèn từng đối tượng, chúng ta phải gọi mô hình của chúng ta để tạo ra một biểu diễn vector nhúng. Sau đó, chúng ta có thể chèn dữ liệu của chúng ta với vector. | Chúng ta có thể chèn từng đối tượng trực tiếp vào cơ sở dữ liệu vector, ủy quyền việc biến đổi cho cơ sở dữ liệu. |
| Truy vấn | Trước khi chúng ta thực hiện một truy vấn, chúng ta phải gọi mô hình của chúng ta để tạo ra một nhúng vector từ truy vấn của chúng ta trước tiên. Sau đó, chúng ta có thể thực hiện một truy vấn với vector đó. | Chúng ta có thể thực hiện một truy vấn trực tiếp trong cơ sở dữ liệu vector, ủy quyền việc biến đổi cho cơ sở dữ liệu. |
Các Phép đo Khoảng cách (Distance Metrics) và Tương tự (Similarity)
Các phép đo khoảng cách là các đo lường và hàm toán học được sử dụng để xác định khoảng cách (tương tự) giữa hai phần tử trong không gian vector. Trong ngữ cảnh của nhúng, các phép đo khoảng cách đánh giá khoảng cách xa nhau bao nhiêu giữa hai nhúng. Một truy vấn tương tự truy vấn các nhúng tương tự với một đầu vào cụ thể dựa trên một phép đo khoảng cách; đầu vào này có thể là một nhúng vector, văn bản hoặc một đối tượng khác. Có một số phép đo khoảng cách. Các phép đo phổ biến nhất là các phép đo sau đây.
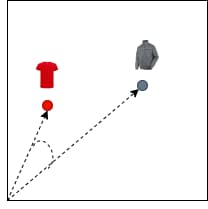
Tương tự Cosine (Cosine Similarity)
Tương tự cosine đo lường cosin của góc giữa hai nhúng vector, và thường được sử dụng như một phép đo khoảng cách trong phân tích văn bản và các lĩnh vực khác nơi độ lớn của vector ít quan trọng hơn hướng của nó.
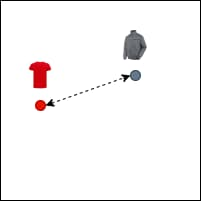
Khoảng cách Euclid (Euclidean Distance)
Khoảng cách Euclid đo độ dài đường thẳng giữa hai điểm trong không gian Euclid.
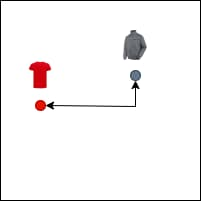
Khoảng cách Manhattan (Manhattan Distance)
Khoảng cách Manhattan (chuẩn L1) là tổng của các hiệu số tuyệt đối các tọa độ của hai điểm.
Lựa chọn phương pháp đo khoảng cách và đo độ tương tự có ảnh hưởng sâu sắc đến hành vi và hiệu suất của các mô hình Học Máy; tuy nhiên, khuyến nghị là sử dụng cùng một phương pháp đo khoảng cách như phương pháp đã được sử dụng để huấn luyện mô hình cụ thể.
Chỉ mục Vector (Vector Indexes)
Các chỉ mục vector là các cấu trúc dữ liệu chuyên biệt được thiết kế để lưu trữ, tổ chức và truy vấn các nhúng vector đa chiều một cách hiệu quả. Các chỉ mục này cung cấp các truy vấn tìm kiếm nhanh chóng một cách hiệu quả về chi phí. Có một số chiến lược chỉ mục được tối ưu hóa để xử lý sự phức tạp và quy mô của không gian vector. Một số ví dụ bao gồm:
- Gần nhất xấp xỉ (Approximate nearest neighbor – ANN)
- Chỉ mục đảo ngược (Inverted index)
- Băm nhạy cục bộ (Locality-sensitive hashing – LSH)
Thường mỗi cơ sở dữ liệu thực hiện một phần con của các chiến lược chỉ mục này, và trong một số trường hợp, chúng được tùy chỉnh để có hiệu suất tốt hơn.
Khả năng mở rộng (Scalability)
Cơ sở dữ liệu vector thường là các giải pháp có khả năng mở rộng cao hỗ trợ mở rộng theo chiều dọc và chiều ngang. Mở rộng theo chiều ngang dựa trên hai chiến lược cơ bản: phân chia và sao chép. Cả hai chiến lược đều rất quan trọng để quản lý các cơ sở dữ liệu quy mô lớn và phân tán.
Phân chia (Sharding)
Phân chia liên quan đến việc chia cơ sở dữ liệu thành các phần nhỏ hơn, dễ quản lý hơn gọi là các phân đoạn. Mỗi phân đoạn chứa một phần con của dữ liệu cơ sở dữ liệu, làm cho nó chịu trách nhiệm về một đoạn cụ thể của dữ liệu.
Bảng 2: Ưu điểm và xem xét quan trọng của phân đoạn chính
| Ưu điểm | Xem xét |
| Bằng cách phân phối dữ liệu trên nhiều máy chủ, phân đoạn có thể giảm tải trên mỗi máy chủ, dẫn đến hiệu suất cải thiện. | Triển khai phân đoạn có thể phức tạp, đặc biệt là trong việc phân phối dữ liệu, quản lý các phân đoạn và xử lý truy vấn trên các phân đoạn. |
| Phân đoạn cho phép cơ sở dữ liệu mở rộng bằng cách thêm nhiều phân đoạn trên các máy chủ bổ sung, hiệu quả xử lý nhiều dữ liệu và người dùng mà không giảm hiệu suất. | Đảm bảo phân phối đồng đều dữ liệu và tránh các điểm nóng nơi một phân đoạn nhận được nhiều truy vấn hơn so với các phân đoạn khác có thể là một thách thức. |
| Việc thêm các máy chủ có cấu hình vừa phải có thể mang lại hiệu quả về chi phí hơn là nâng cấp một máy chủ đơn lớn với cấu hình cao. | Số lượng truy vấn không tăng khi thêm nhiều nút phân đoạn. |
Sao chép (Replication)
Sao chép liên quan đến việc tạo bản sao của cơ sở dữ liệu trên nhiều nút trong cụm.
Bảng 3: Các ưu điểm và xem xét quan trọng của sao chép
| Ưu điểm | Xem xét |
| Sao chép đảm bảo rằng cơ sở dữ liệu vẫn có sẵn cho các hoạt động đọc ngay cả khi một số máy chủ bị ngừng hoạt động. | Việc duy trì tính nhất quán của dữ liệu trên các bản sao, đặc biệt là trong môi trường ghi nhiều, có thể là một thách thức và có thể yêu cầu các cơ chế đồng bộ hóa phức tạp. |
| Sao chép cung cấp một cơ chế cho việc phục hồi sau thảm họa vì dữ liệu được sao lưu ở nhiều vị trí khác nhau. | Sao chép đòi hỏi thêm tài nguyên lưu trữ và mạng, vì dữ liệu được sao chép ở nhiều máy chủ. |
| Sao chép có thể cải thiện khả năng mở rộng đọc của hệ thống cơ sở dữ liệu bằng cách cho phép các truy vấn đọc được phân phối trên nhiều bản sao. | Trong các cài đặt sao chép không đồng bộ, có thể có sự chậm trễ giữa khi dữ liệu được ghi vào chỉ mục chính và khi nó được sao chép vào các chỉ mục phụ. Sự chậm trễ này có thể ảnh hưởng đến các ứng dụng yêu cầu tính nhất quán dữ liệu gần thời gian thực hoặc gần thời gian thực trên các bản sao. |
Các Trường hợp Sử dụng
Cơ sở dữ liệu vector và nhúng là rất quan trọng đối với một số trường hợp sử dụng chính, bao gồm tìm kiếm ngữ nghĩa, dữ liệu vector trong trí tuệ nhân tạo sinh, và nhiều hơn nữa.
Tìm kiếm ngữ nghĩa
Bạn có thể truy xuất thông tin bằng cách tận dụng khả năng của các nhúng vector để hiểu và phù hợp với ngữ cảnh ngữ nghĩa của các truy vấn với nội dung liên quan. Các truy vấn được thực hiện bằng cách tính toán sự tương đồng giữa vector truy vấn và các vector tài liệu trong cơ sở dữ liệu, sử dụng một số phương pháp đo khoảng cách đã được giải thích trước đó, như tương đồng cosine. Một số ứng dụng sẽ là:
- Hệ thống gợi ý: Thực hiện các truy vấn tương tự để tìm các mục phù hợp với sở thích của người dùng, cung cấp các gợi ý chính xác và kịp thời để cải thiện trải nghiệm của người dùng.
- Hỗ trợ khách hàng: Lấy thông tin phù hợp nhất để giải quyết các thắc mắc, câu hỏi hoặc vấn đề của khách hàng.
- Quản lý kiến thức: Tìm thông tin liên quan nhanh chóng từ kiến thức của tổ chức bao gồm tài liệu, slides, video hoặc báo cáo trong các hệ thống doanh nghiệp.
Dữ liệu Vector trong Trí Tuệ Nhân Tạo Tạo Sinh (Generative AI): Tạo sinh tăng cường truy xuất (Retrieval-Augmented Generation – RAG)
Trí tuệ nhân tạo tạo sinh và các mô hình ngôn ngữ lớn (LLMs) có những hạn chế nhất định khi phải được huấn luyện với một lượng lớn dữ liệu. Các quá trình huấn luyện này đặt ra chi phí cao về thời gian, tài nguyên và tiền bạc. Do đó, những mô hình này thường được huấn luyện với các ngữ cảnh tổng quát và không thường xuyên được cập nhật với thông tin mới nhất.
Tạo sinh tăng cường truy xuất (RAG) đóng một vai trò quan trọng vì nó được phát triển để cải thiện chất lượng phản hồi trong các ngữ cảnh cụ thể bằng cách sử dụng một kỹ thuật tích hợp một nguồn thông tin ngoại vi phù hợp và được cập nhật vào quá trình tạo sinh. Một cơ sở dữ liệu vector đặc biệt thích hợp để triển khai các mô hình RAG do khả năng độc đáo của nó trong xử lý dữ liệu đa chiều, thực hiện các truy vấn tương tự hiệu quả và tích hợp một cách mượt mà với quy trình làm việc AI/ML.
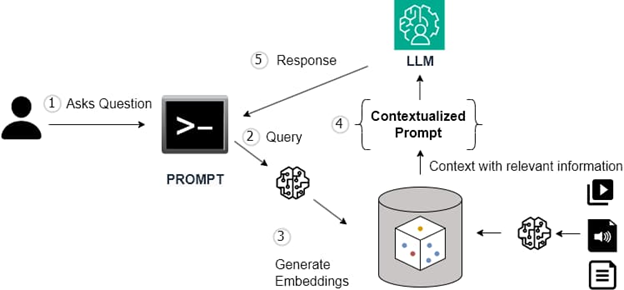
Việc sử dụng cơ sở dữ liệu vector trong mô hình tích hợp RAG có những lợi ích sau:
- Hiểu biết ngữ nghĩa: Các nhúng vector nắm bắt các mối quan hệ ngữ nghĩa tinh tế trong dữ liệu, dù là văn bản, hình ảnh hoặc âm thanh. Sự hiểu biết sâu sắc này là rất quan trọng đối với các mô hình sinh ra để tạo đầu ra chất lượng cao, thực tế và có liên quan văn bản vào ngữ cảnh hoặc đầu vào.
- Giảm chiều: Bằng cách đại diện cho dữ liệu phức tạp trong một không gian vector có số chiều thấp hơn, điều này nhằm mục đích giảm xuống các bộ dữ liệu lớn để làm cho nó có thể thực hiện được cho các mô hình AI xử lý và học hỏi từ đó.
- Chất lượng và độ chính xác: Sự chính xác của việc tìm kiếm sự tương đồng trong cơ sở dữ liệu vector đảm bảo rằng thông tin được lấy ra để tạo sinh là có liên quan và chất lượng cao.
- Tích hợp mượt mà: Cơ sở dữ liệu vector cung cấp các API, SDK và công cụ giúp việc tích hợp với các khung công cụ AI/ML khác dễ dàng. Sự linh hoạt này giúp việc phát triển và triển khai các mô hình RAG dễ dàng hơn, cho phép nhà nghiên cứu và nhà phát triển tập trung vào tối ưu hóa mô hình thay vì đối mặt với thách thức quản lý dữ liệu.
- Tạo ra ngữ cảnh: Các nhúng vector nắm bắt bản chất ngữ cảnh của văn bản, hình ảnh, video và nhiều hơn nữa, giúp các mô hình AI hiểu ngữ cảnh và tạo ra nội dung mới mà có liên quan hoặc tương tự về ngữ cảnh.
- Khả năng mở rộng: Cơ sở dữ liệu vector cung cấp một giải pháp có khả năng mở rộng có thể quản lý thông tin quy mô lớn mà không làm giảm hiệu suất truy xuất.
Cơ sở dữ liệu vector cung cấp nền tảng công nghệ cần thiết cho việc triển khai hiệu quả các mô hình RAG và biến chúng trở thành lựa chọn tối ưu cho việc tương tác với các cơ sở kiến thức quy mô lớn.
Các Trường hợp Sử dụng Cụ thể Khác
Ngoài các trường hợp sử dụng chính đã thảo luận ở trên là một số trường hợp khác, chẳng hạn như:
- Phát hiện bất thường: Các nhúng nắm bắt các mối quan hệ và mẫu tinh tế trong dữ liệu, làm cho việc phát hiện các sự bất thường, mà có thể không rõ ràng thông qua các phương pháp truyền thống, trở nên có thể.
- So sánh sản phẩm tương tự trong bán lẻ: Bằng cách chuyển đổi các đặc điểm sản phẩm thành các nhúng vector, các nhà bán lẻ có thể nhanh chóng tìm kiếm các sản phẩm có đặc điểm tương tự (ví dụ: thiết kế, chất liệu, giá cả, doanh số).
Kết Luận
Bài viết này cung cấp một cái nhìn tổng quan về các nguyên tắc cơ bản của cơ sở dữ liệu vector với minh họa một ứng dụng thực tế trong lĩnh vực bán lẻ thời trang. Bằng cách tùy chỉnh tập dữ liệu và các truy vấn, chúng ta có thể khám phá toàn bộ tiềm năng của cơ sở dữ liệu vector cho các tìm kiếm tương tự và các ứng dụng khác dựa trên trí tuệ nhân tạo. Điều này chỉ là điểm khởi đầu để bắt đầu khám phá thế giới của các vector. Các mô hình ML và vector đại diện cho các công cụ mạnh mẽ trong lĩnh vực học máy và trí tuệ nhân tạo, cung cấp một biểu diễn tinh tế và có số chiều cao của dữ liệu phức tạp.
Cơ sở dữ liệu vector không phải là một giải pháp kỳ diệu cung cấp giá trị ngay lập tức, tuy nhiên giống như rượu ngon, các nhà phát triển — cũng như các nhà máy rượu vang— phải sử dụng thử nghiệm cẩn thận, tối ưu hóa tham số và đánh giá liên tục.
Bài viết gốc được đăng tải tại ngocminhtran.com
Xem thêm:
- Database migration sử dụng Flyway
- Chạy database migration khi deploy, nên hay không?
- Todo List: Xóa dữ liệu từ database
Xem thêm tuyển dụng các vị trí IT hấp dẫn trên TopDev













 là gì? Đặc điểm và phân loại Database")