Ngày 7/4 vừa qua, Meta đã cho ra mắt một công cụ AI mới có tên là Segment Anything Model (SAM) với khả năng giúp máy tính xác định từng chi tiết cụ thể trong một bức ảnh thuộc về đối tượng nào. Khả năng của SAM kèm theo việc có thể thực thi theo thời gian thực giúp nó trở thành một trong những cải tiến đáng quan tâm nhất hiện nay trong cộng đồng AI. Bài viết hôm nay chúng ta cùng tìm hiểu về Segment Anything Model và những ứng dụng thực tiễn của nó nhé.
Image Segmentation
Thị giác máy tính (Computer Vision) là 1 lĩnh vực của Trí tuệ nhân tạo (AI – Artificial Intelligence) với bài toán đặt ra là sao chép được khả năng thị giác con người bởi sự nhận diện và hiểu biết một hình ảnh mang tính điện tử. Nó bao gồm các phương pháp thu nhận, xử lý ảnh kỹ thuật số, phân tích và nhận dạng các hình ảnh để cho ra các thông tin dạng số.
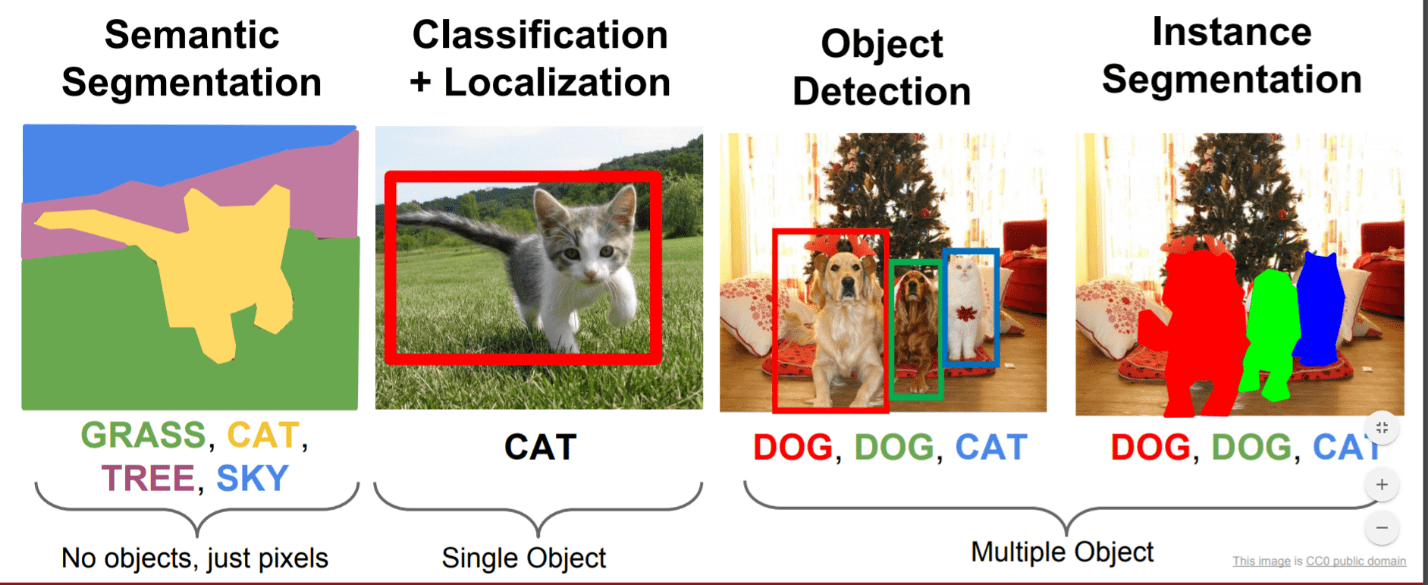 Image Segmentation – Phân vùng ảnh là một bài toán nằm trong Thị giác máy tính với nhiệm vụ là phân chia một hình ảnh thành nhiều vùng ảnh khác nhau, đồng thời cũng phát hiện ra vùng ảnh chứa vật thể và gán nhãn phù hợp cho chúng. Xác định pixel hình ảnh nào thuộc về một đối tượng là nhiệm vụ cốt lõi trong thị giác máy tính và được sử dụng trong nhiều ứng dụng, từ phân tích hình ảnh khoa học đến chỉnh sửa ảnh.
Image Segmentation – Phân vùng ảnh là một bài toán nằm trong Thị giác máy tính với nhiệm vụ là phân chia một hình ảnh thành nhiều vùng ảnh khác nhau, đồng thời cũng phát hiện ra vùng ảnh chứa vật thể và gán nhãn phù hợp cho chúng. Xác định pixel hình ảnh nào thuộc về một đối tượng là nhiệm vụ cốt lõi trong thị giác máy tính và được sử dụng trong nhiều ứng dụng, từ phân tích hình ảnh khoa học đến chỉnh sửa ảnh.
Segment Anything Model
Segment Anything Model (SAM) là một mô hình AI nằm trong dự án Segment Anything của Meta với vai trò là một Foundation Model (Mô hình nền tảng) có thể segment (phân vùng) vật thể trong ảnh sử dụng prompt (thao tác gợi ý).


Cụ thể thì với một ảnh đầu vào, người dùng có thể click chọn một vài điểm bất kỳ của vật thể trong bức ảnh thì mô hình AI sẽ có thể trả về một mask sát với vật thể; hoặc cách khác; người dùng sẽ một bounding box (vùng biên) quanh vật thể hay thậm chí là sử dụng đoạn văn bản mô tả vật thể cần phân vùng trong ảnh thì cũng cho ra kết quả tương tự. Việc xử lý này có thể thực hiện với Input (đầu vào) bao gồm cả ảnh và video mà vẫn có thể cho ra kết quả với thời gian thực thi theo thời gian thực. Bạn có thể trải nghiệm các demo ngay trên website của Segment Anything Model ở link dưới đây: https://segment-anything.com/
Mô hình phân vùng chung của SAM
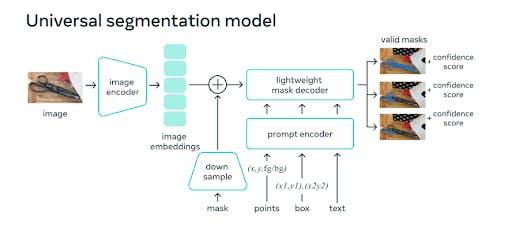
SAM gồm 3 thành phần chính:
- Image Encoder: chuyển đổi ảnh về dạng embeddings bằng cách sử dụng bộ dữ liệu mặt nạ Segment Anything 1-Billion (SA-1B) – một trong những bộ dữ liệu phân đoạn lớn nhất từng được tạo ra. Bộ dữ liệu được đào tạo trên 11 triệu hình ảnh và xác định được hơn 1 tỷ mặt nạ.
- Prompt Encoder: sử dụng encode points, bounding boxes dưới dạng positional encodings và encode texts thông qua convolutions(tích chập) và rồi cộng từng phần tử trên với embedding của ảnh.
- Mask Decoder: dựa vào embedding của ảnh, embedding của prompt và một output token để trả về mask tương ứng.
Để huấn luyện SAM cũng như tạo ra được bộ dữ liệu SA-1B trong quá trình gán nhãn dữ liệu, một Data Engine được tạo ra với 3 giai đoạn:
- Assisted-manual (Thủ công): tương tự như các model truyền thống khác, SAM sẽ được huấn luyện trên tập dữ liệu công khai với nhóm các chuyên gia đã gán nhãn từ trước
- Semi-automatic (Bán tự động): lúc này SAM có thể tự động tạo ra mask cho một tập con các đối tượng bằng cách nhắc (gợi ý) cho nó các vị trí đối tượng có khả năng xảy ra
- Fully automatic (Tự động hoàn toàn): ở giai đoạn này thì một mạng lưới các điểm kích thước 32×32 dùng làm prompt cho SAM, từ đó mang lại trung bình 100 masks chất lượng cao cho mỗi hình ảnh.
So sánh SAM và các mô hình khác
So với các mô hình tương tự trước đó, SAM được xem là một bước tiến lớn đối với AI vì nó được xây dựng trên nền tảng đã được thiết lập bởi các mô hình trước đó. SAM có thể nhận những gợi ý đầu vào (prompt) từ các hệ thống khác, chẳng hạn như trong tương lai với công nghệ AR/VR (thực tế tăng cường/ thực tế ảo), prompt sẽ là được truyền vào với cử chỉ ánh mắt của người dùng.
Một lý do khác giúp những kết quả thu được từ SAM mang tính đột phá là nhờ các kỹ thuật áp dụng trong mô hình SAM cho thấy sự tốt hơn so với các giải thuật áp dụng trong mô hình khác. Dưới đây là so sánh SAM với mô hình ViTDet.

Tiềm năng của SAM
Hiện tại bạn có thể trải nghiệm SAM trong trình duyệt của Meta với hình ảnh của riêng bạn. Theo các nhà nghiên cứu từ Meta thì SAM cũng có thể nhận lệnh phân tích văn bản, mặc dù vậy thì tính năng này chưa được hãng phát hành. Tiềm năng của SAM AI rõ ràng là rất lớn, nó có thể trở thành một công cụ hữu ích trong các ngành công nghiệp công nghệ cao và trong các lĩnh vực nghiên cứu. SAM cũng có thể góp mặt trong nhiều ứng dụng chỉnh sửa ảnh hay phân tích hình ảnh khoa học và là một phần trong các hệ thống AI lớn hơn.
Hy vọng bài viết này đã mang lại cho các bạn cái nhìn tổng quan về mô hình mới này. Cùng chờ đợi những cập nhật tiếp theo đến từ Segment Anything Model của Meta trong thời gian gần sắp tới cũng như các ứng dụng của nó vào thực tiễn cuộc sống. Hẹn gặp lại các bạn trong các bài viết tiếp theo của mình.
Tác giả: Phạm Minh Khoa
Xem thêm:
- Tình hình hiện tại và tương lai của IoT năm 2022
- “Con người là nhân tố quyết định để chuyển đổi số thành công”
- Lộ trình từng bước trở thành Machine Learning Engineer
Xem thêm tuyển dụng IT mới nhất tại TopDev





")
")
")


 là gì? – Xu hướng của thời đại mới")


